
如果你正在考虑是否卡夫卡RabbitMQ最适合你的用例,请继续阅读,了解这些工具背后的不同的架构和方法,如何处理信息不同,和他们的性能优缺点。我们将讨论的最佳用例的每个工具,当它可能比依赖于一个完整的端到端流处理的解决方案。
在这个页面:
- 什么是Apache Kafka和RabbitMQ?
- Kafkavs RabbitMQ -有什么区别?
- 他们如何处理信息
- 他们的表现如何
- 他们最好的用例
- 流处理的端到端平台
什么是Apache Kafka和RabbitMQ?
Apache Kafka和RabbitMQ是两个开源的、有商业支持的发布/订阅系统,很容易被企业采用。RabbitMQ是2007年发布的一个较老的工具,是消息传递和SOA系统中的主要组件。今天,它还被用于流用例。Kafka是一个较新的工具,发布于2011年,它从一开始就是为流媒体场景设计的。
RabbitMQ是一种通用消息代理,支持协议包括MQTT、AMQP和STOMP。它可以处理高吞吐量用例,比如在线支付处理。它可以处理后台作业或充当微服务之间的消息代理。
Kafka是为高接入数据重放和流开发的消息总线。Kafka是一个持久的消息代理,它使应用程序能够处理、持久化和重新处理流数据。Kafka有一个直接的路由方法,它使用一个路由密钥将消息发送到一个主题。
Kafka vs RabbitMQ -架构上的差异
RabbitMQ架构
- 通用消息代理—使用请求/应答、点到点和发布-子通信模式的变体。
- 智能代理/哑消费者模型——以与代理监视消费者状态相同的速度向消费者交付消息。
- 成熟的平台——良好的支持,可用于Java、客户机库、。net、Ruby、node.js。提供几十个插件。
- 通信——可以是同步的或异步的。
- 部署场景——提供分布式部署场景。
- 多节点集群到集群联合——不依赖于外部服务,但是,特定的集群形成插件可以使用DNS、api、领事等。
Apache Kafka架构
- 高容量的发布-订阅消息和流平台——持久、快速和可伸缩。
- 持久消息存储——类似于日志,运行在服务器集群中,它在主题(类别)中保存记录流。
- 消息——由值、键和时间戳组成。
- 愚蠢的代理/聪明的消费者模型——不试图跟踪哪些消息被消费者读了,只保留未读的消息。卡夫卡在一段时间内保存所有消息。
- 需要外部服务运行在某些情况下Apache Zookeeper。
拉vs推
Apache Kafka:基于拉的方法
Kafka使用了拉模型。使用者请求来自特定偏移量的成批消息。Kafka允许 long-pooling, ,这可以防止在没有消息超过偏移量时出现紧循环。
由于它的分区,拉式模型对Kafka来说是合乎逻辑的。Kafka在没有竞争消费者的分区中提供消息顺序。这允许用户利用消息批处理来实现有效的消息传递和更高的吞吐量。
RabbitMQ:基于推的方法
RabbitMQ使用了一个推模型,并通过在使用者上定义的预取限制来阻止过多的使用者。这可以用于低延迟的消息传递。
推模型的目的是快速地独立地分发消息,确保工作均匀地并行化,并按照消息到达队列的大致顺序处理消息。
他们如何处理消息?
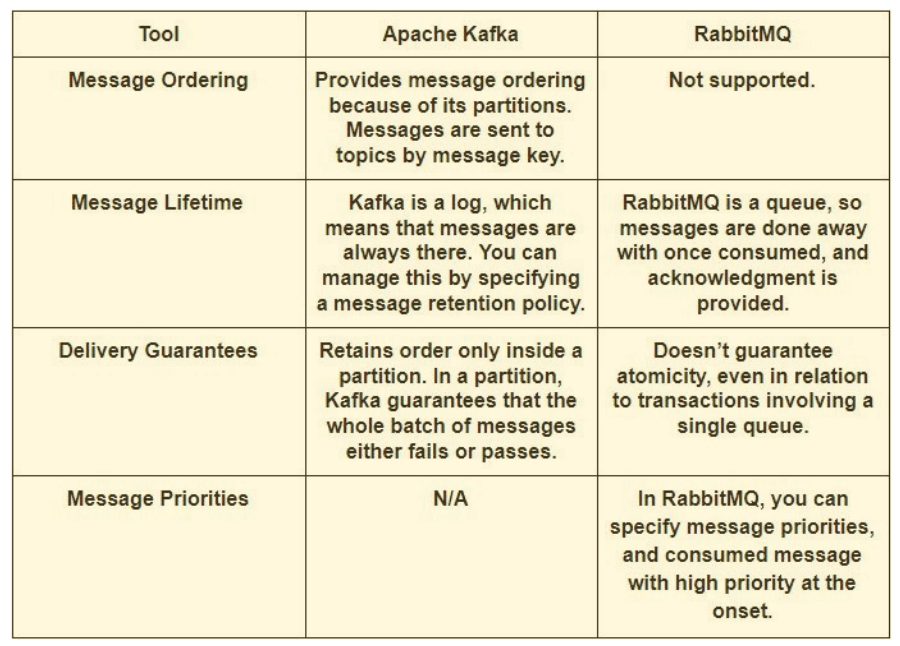
Kafka vs RabbitMQ性能
Apache Kafka:
Kafka提供了比RabbitMQ等消息代理更高的性能。它使用顺序磁盘I/O来提高性能,使其成为实现队列的合适选项。它可以在有限的资源下实现高吞吐量(每秒数百万条消息),这是大数据用例所必需的。
RabbitMQ:
RabbitMQ也可以每秒处理100万条消息,但是需要更多的资源(大约30个节点)。您可以使用RabbitMQ实现与Kafka相同的许多用例,但是您需要将它与其他工具(如Apache Cassandra)结合使用。
最好的用例是什么?
Apache Kafka用例
Apache Kafka提供了代理本身,并针对流处理场景设计。最近,它增加了Kafka Streams,一个用于构建应用程序和微服务的客户端库。Apache Kafka支持诸如度量、活动跟踪、日志聚合、流处理、提交日志和事件来源等用例。
下面的消息传递场景特别适合Kafka:
- 具有复杂路由的流,事件吞吐量为100K/sec或更多,“至少一次”分区排序
- 需要流历史记录的应用程序,以“至少一次”分区顺序交付。客户端可以看到事件流的“重播”。
- 事件溯源,将系统建模为事件序列。
- 在多级管道中进行数据流处理。管道生成实时数据流的图形。
RabbitMQ的用例
当web服务器需要快速响应请求时,可以使用RabbitMQ。这消除了在用户等待结果时执行资源密集型活动的需要。RabbitMQ还用于向不同的接收者传递消息,以供使用或在高负载(每秒20K+消息)下在工作人员之间共享负载。
场景,RabbitMQ可以用于:
- 需要支持遗留协议的应用程序,如STOMP、MQTT、AMQP、0-9-1。
- 对每条消息的一致性/保证集的粒度控制
- 到消费者的复杂路由
- 需要各种发布/订阅、点对点请求/应答消息传递功能的应用程序。
Kafka和RabbitMQ:总结
本指南涵盖了Apache Kafka和RabbitMQ之间的主要区别和相似之处。虽然它们的架构不同,但它们每秒都可以消耗数百万条消息,而且在某些环境中性能更好。RabbitMQ几乎在内存中控制它的消息,使用大集群(30多个节点)。相比之下,Kafka利用顺序磁盘I/O操作,因此需要较少的硬件。
原文:https://www.upsolver.com/blog/kafka-versus-rabbitmq-architecture-performance-use-case
本文:http://jiagoushi.pro/node/1124
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
最新内容
- 8 hours ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago