
这是一个关于我们如何设法克服搜索和相关性堆栈的稳定性和性能问题的简短故事。
语境
在过去的 10 个月里,我很高兴与个性化和相关性团队合作。我们负责根据排名和机器学习向用户提供“个性化和相关的内容”。我们通过一组提供三个公共端点的微服务来做到这一点,即 Home Feed、Search 和 Related items API。我记得加入团队几个月后,下一个挑战是能够为更大的关键国家提供优质服务。目标是保持我们在较小国家/地区已经拥有的完美性能和稳定性。
我们使用 Zookeeper 在 Openshift 上的 AWS 中使用 SolrCloud (v 7.7)。在撰写本文时,我们很自豪地提到,该 API 每分钟服务约 15 万个请求,并每小时向我们最大区域的 Solr 发送约 21 万个更新。
基线
在我们最大的市场中部署 Solr 后,我们必须对其进行测试。我们使用内部工具进行压力测试,我们可以大致获得所需的流量。我们相信 Solr 配置良好,因此团队致力于提高客户端的性能并针对 Solr 设置更高的超时时间。最后我们同意我们可以稍微松散地处理交通。
迁移后
服务以可接受的响应时间进行响应,Solr 客户端表现非常好,直到由于超时而开始打开一些断路器。超时是由 Solr 副本响应时间过长的明显随机问题产生的,这些问题在没有信息显示的情况下更频繁地影响前端客户端。以下是我们遇到的一些问题:
- 高比例的副本进入恢复并且需要很长时间才能恢复
- 副本中的错误无法到达领导者,因为它们太忙了
- 领导者承受过多的负载(来自索引、查询和副本同步),这导致它们无法正常运行并导致分片崩溃
- 对“索引/更新服务”的怀疑,因为减少其到 Solr 的流量会阻止副本停止或进入恢复模式
- 完整的垃圾收集器经常运行(老年代和年轻代)。
- 运行在 CPU 之上的 SearchExecutor 线程,以及垃圾收集器
- SearchExecutor 线程在缓存预热时抛出异常 (LRUCache.warm)
- 响应时间从 ~30 ms 增加到 ~1500 ms
- 发现某些 Solr EBS 卷上的 IOPS 达到 100%
处理问题
分析
作为分析的一部分,我们提出了以下主题
Lucene 设置
Apache Solr 是一个广泛使用的搜索和排名引擎,经过深思熟虑并在后台使用 Lucene 进行设计(也与 ElasticSearch 共享)。 Lucene 是所有计算背后的引擎,并为排名和 Faceting 创造了魔力。是否可以对 Lucene 进行数学运算并检查设置?我可以根据大量文档和论坛阅读资料分享一个近似结果,但是它的配置不如 Solr 的数学那么重。
调整 Lucene 是可能的,前提是您愿意牺牲文档的结构。真的值得努力吗?不,当您进一步阅读时,您会发现更多信息。
文档与磁盘大小
假设我们有大约 1000 万个文档。假设平均文档大小为 2 kb。最初,您的磁盘空间将至少占用以下空间:

分片
一个集合拥有多个分片并不一定会产生更具弹性的 Solr。当一个分片出现问题而其他分片无论如何都可以响应时,时间响应或阻塞器将是最慢的分片。
当我们有多个分片时,我们将文档总数除以分片数。这减少了缓存和磁盘大小并改进了索引过程。
索引/更新过程
是否有可能我们有一个过度杀伤的索引/更新过程?鉴于我们的经验,这并不过分。我将把这个问题的分析留给另一篇文章。否则,这将过于广泛。在我们的主要市场,我们已经达到每小时 21 万次更新(高峰流量)。
Zookeeper
Apache Zookeeper 在此环境中的唯一工作是尽可能准确地保持所有节点的集群状态可用。如果副本恢复过于频繁,一个常见问题是集群状态可能与 Zookeeper 不同步。这将在正在运行的副本之间产生不一致的状态,并且尝试恢复的副本最终会进入一个可能持续数小时的长循环。 Zookeeper 非常稳定,它可能仅由于网络资源而失败,或者更好地说是缺少它。
我们有足够的内存吗?
理论
Solr 性能最重要的驱动因素之一是 RAM。 Solr 需要足够的内存用于 Java 堆,并需要可用内存用于 OS 磁盘缓存。
强烈建议 Solr 在 64 位 Java 上运行,因为 32 位 Java 被限制为 2GB 堆,这可能会导致更大的堆不存在的人为限制(在本文后面部分讨论) .
让我们快速了解一下 Solr 是如何使用内存的。首先,Solr 使用两种类型的内存:堆内存和直接内存。直接内存用于缓存从文件系统读取的块(类似于 Linux 中的文件系统缓存)。 Solr 使用直接内存来缓存从磁盘读取的数据,主要是索引,以提高性能。
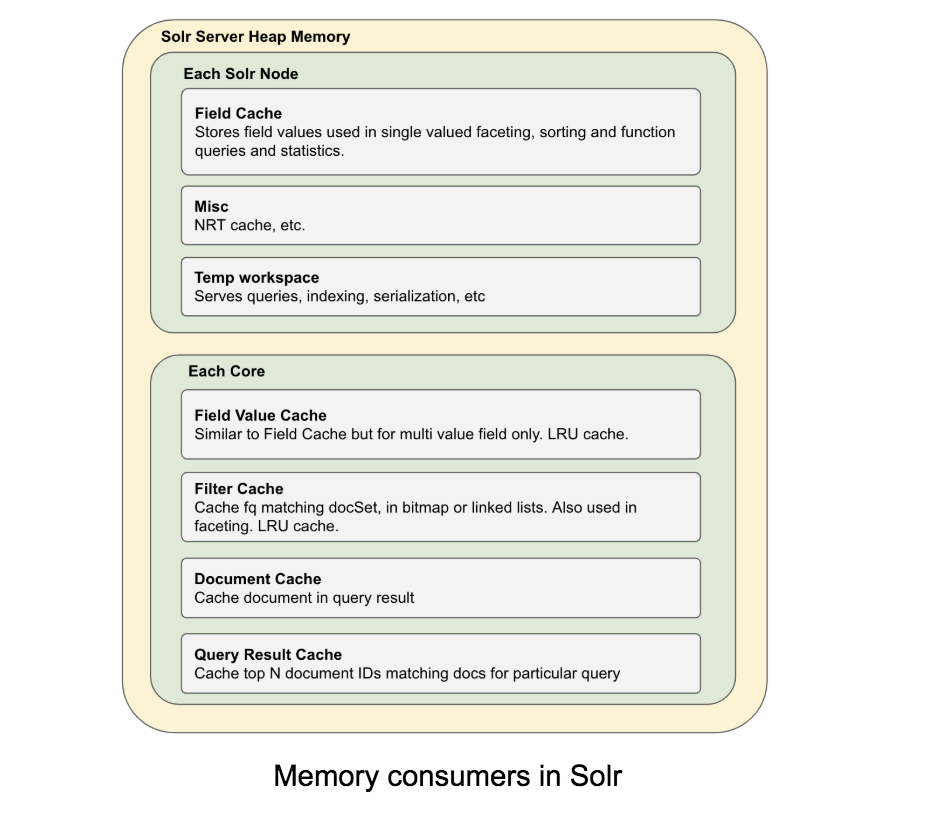
当它被暴露时,大部分堆内存被多个缓存使用。
JVM 堆大小需要与 Solr 堆需求估计相匹配,以及更多用于缓冲目的。 堆和操作系统内存设置的这种差异为环境提供了一些空间来适应零星的内存使用高峰,例如后台合并或昂贵的查询,并允许 JVM 有效地执行 GC。 例如,在 28Gb RAM 计算机中设置 18Gb 堆。
让我们记住我们一直在为 Solr 改进的方程式,与内存调整最相关的领域如下:

虽然下面的解释很长而且很复杂,但是为了建立另一个帖子,我仍然想分享我们一直在研究的数学。 我们在解决问题之初就使用了自己的计算器,只是为了实现后来在线社区共享的类似问题。
此外,我们确保在启动 Solr 时在 JVM Args 中正确启用垃圾收集器。

缓存证据
我们根据 Solr 管理面板中的证据调整缓存,如下所示:
- queryResultCache 的命中率为 0.01
- filterCache 的命中率为 0.43
- documentCache 的命中率为 0.01
垃圾收集器和堆
使用 New Relic,我们可以检查实例上的内存和 GC 活动,并注意到 NR 代理由于内存阈值而频繁打开其断路器(浅红色竖线):20%; 垃圾收集 CPU 阈值:10%。 此行为是实例上可用内存问题的明确证据。
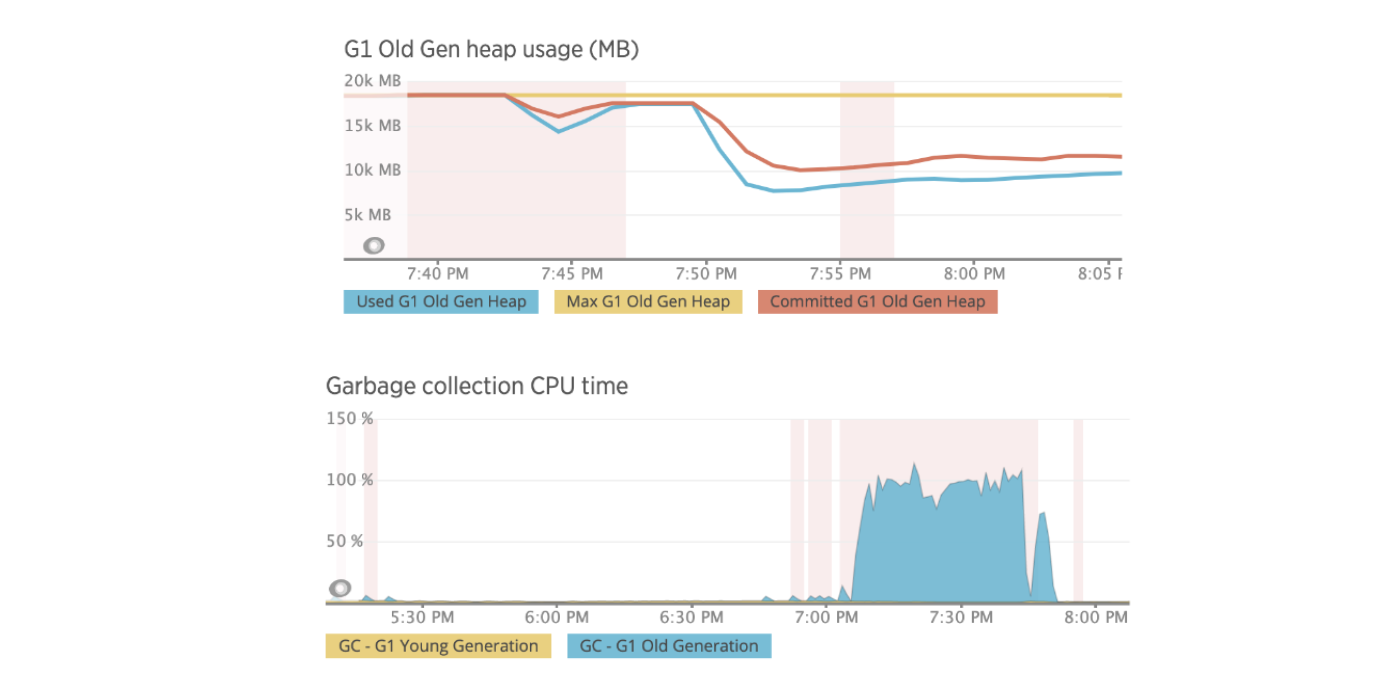
我们还可以监控一些高 CPU 实例进程,发现在 searcherExecutor 线程使用 100% 的 CPU 时占用了大约 99% 的堆。 使用 JMX 和 JConsole,我们遇到了包含以下内容的异常:
…org.apache.solr.search.LRUCache.warm(LRUCache.java:299) …作为堆栈跟踪的一部分。 上述异常与缓存设置大小和预热有关。
磁盘活动 — AWS IOPS
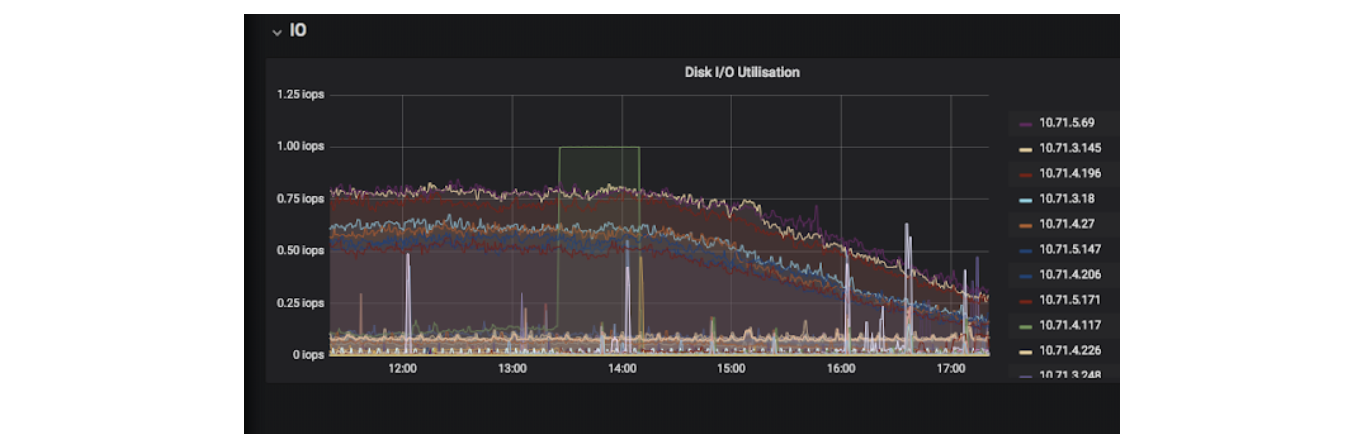
开始解决问题
搜索结果容错
为前端客户端提供搜索结果的第一个想法是始终让 Solr 副本仍然存在以响应查询,以防集群由于副本处于恢复甚至消失状态而变得不稳定。 Solr 7 引入了在领导者及其副本之间同步数据的新方法:
- NRT 副本:在 SolrCloud 中处理复制的旧方法。
- TLOG replicas:它使用事务日志和二进制复制。
- PULL 副本:仅从领导者复制并使用二进制复制。
长话短说,NRT 副本可以执行三个最重要的任务,索引、搜索和引导。另一方面,TLOG 副本将以稍微不同的方式处理索引,搜索和引导。差异因素在于 PULL 副本,它只为带有搜索的查询提供服务。
通过应用这种配置,我们可以保证只要分片有领导者,PULL 副本就会响应,从而大大提高可靠性。此外,这种副本不会像处理索引过程的副本那样频繁地进行恢复。
当索引服务满负荷时,我们仍然面临问题,导致 TLog 副本进入恢复。
调整 Solr 内存
基于这个问题我们是否有足够的 RAM 来存储文档数量?,我们决定进行实验。最初的担忧是为什么我们在文档的“单位”中配置这些值,如下所示:

根据之前共享的公式,考虑到我们有 700 万份文档,估计的 RAM 约为 3800 Gb。 但是,假设我们有 5 个分片,那么每个分片将处理大约 140 万个直接影响副本的文档。 我们可以估计,使用该分片配置,所需的 RAM 约为 3420 Gb。 这不会产生根本性的变化,所以我们继续前进。
缓存结果
从缓存证据中,我们可以看到只有一个缓存被使用得最好,即 filterCache。 测试的解决方案如下:

通过之前的缓存配置,我们获得了以下结果:
- queryResultCache 的命中率为 0.01
- filterCache 的命中率为 0.99
- documentCache 的命中率为 0.02
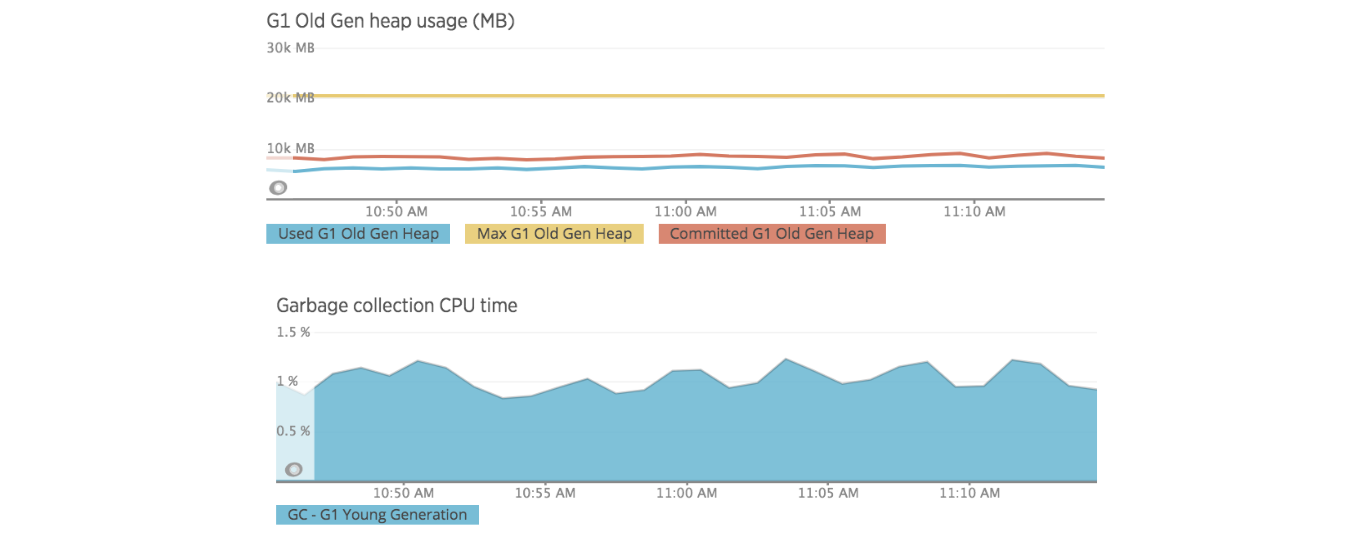
垃圾收集器结果
在本节中,我们可以看到 New Relic 提供的垃圾收集器指标。 我们没有老年代活动,通常会导致 New Relic 代理打开它的断路器(内存耗尽)。
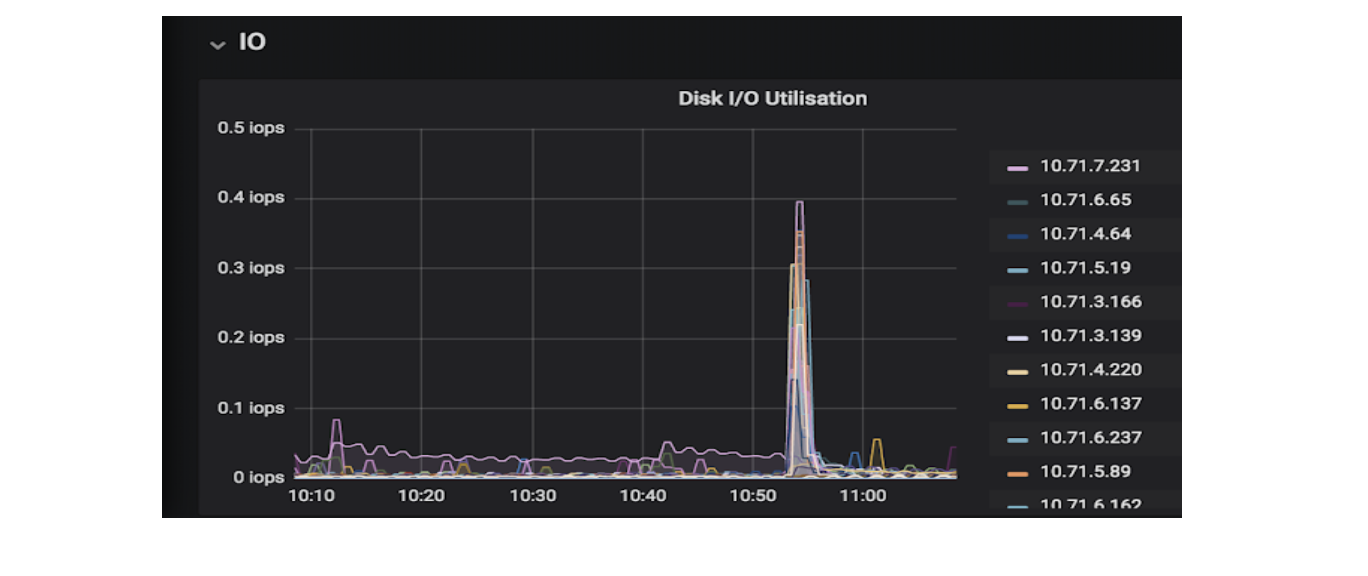
磁盘活动结果
我们在磁盘活动方面也取得了惊人的成果,索引也大幅下降。
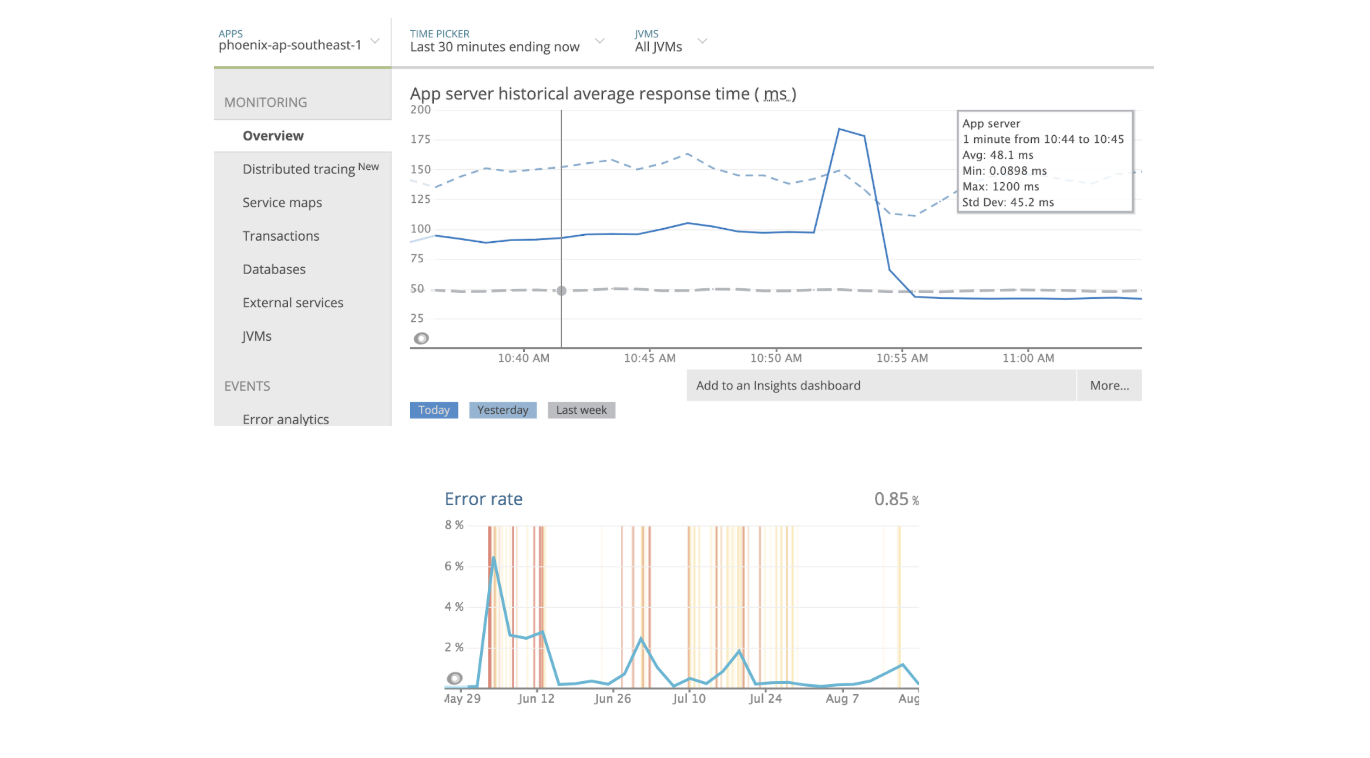
外部服务结果
其中一项访问 Solr 的服务在 New Relic 中的响应时间和错误率显着下降。
调整 Solr 集群
多分片模式的一个缺点是,如果任何副本被破坏,分片领导者将比其对等节点花费更多的时间来回答。这导致分片中最差的时间响应,因为 Solr 会在提供最终响应之前等待所有分片回答。
为了缓解上述问题并考虑到前面描述的结果,我们决定开始逐渐减少节点和分片的数量,这对降低内部复制因子有影响。
结论
经过数周的调查、测试和调优,我们不仅摆脱了最初暴露的问题,而且通过减少延迟提高了性能,通过设置更少的分片和更少的副本降低了管理复杂性,获得了对索引/更新的信任服务满负荷工作,并通过使用几乎一半的 AWS EC2 实例帮助公司减少开支。
我要特别感谢使这成为可能的团队,以及 SRE 和 AWS TAM 的指导和支持。
原文:https://tech.olx.com/improving-solr-performance-f4202d28b72d
本文:https://tech.olx.com/improving-solr-performance-f4202d28b72d