
category
当大多数人想到API时,他们想到的是分布式应用程序中客户端-服务器交互的后端访问点。在许多情况下,这确实是其目的。但是,API可以不仅仅是服务器端逻辑和该逻辑的公共消费者之间的接口。例如,完全可以使API层作为计算域内外发生的所有活动的主控制中心。换言之,API层可以是一个环来管理它们,这就是Kubernetes所采用的方法。
Kubernetes是由谷歌创建的工作负载和容器编排技术,但现在由云原生计算基金会(CNCF)维护,它有一个名为API服务器的组件,控制Kubernete安装内外的大部分活动。使用API作为一个环来管理整个Kubernetes安装是一种有趣的系统设计方法,也是一种值得研究的方法。
在这篇文章中,我们将做到这一点。我们将研究Kubernetes体系结构的基础,然后我们将研究API服务器如何控制该体系结构中的组件。最后,我们将研究如何使Kubernetes安装的API服务器具有容错性。
理解Kubernetes体系结构
Kubernetes最初在谷歌是一个名为博格系统的内部工具。Kubernetes的第一个版本于2015年向公众发布。它在2016年被移交给CNCF,并在今天得到维护。(CNCF是谷歌和Linux基金会合作的结果。)Kubernetes的整个源代码都可以在GitHub上免费获得,考虑到技术的复杂性和开发它所需的数百万美元,这是一个很大的赠品。
如上所述,Kubernetes是一种工作负载和容器编排技术。Kubernetes之所以如此强大,是因为它旨在管理大规模运行的大型应用程序。通常,这些应用程序由数十、数百甚至数千个松散耦合的组件组成,这些组件在一组机器上运行。
运行受控Kubernetes的机器集合称为集群。Kubernetes集群可以由数十台、数百台甚至数千台机器组成。一个集群可以有真实机器或虚拟机器的任何组合
集群作为计算单元
开发人员可以将集群概念化为单个计算单元。一个Kubernetes集群可能由一百台机器组成,但开发人员对底层集群的组成几乎一无所知。所有的工作都是以Kubernetes集群为抽象进行的。隐藏集群动态的内部非常重要,因为Kubernetes集群是短暂的。Kubernetes的设计使得集群的组成可以在一瞬间发生变化,但这种变化确实会干扰集群上运行的应用程序的操作。将机器添加到Kubernetes不会影响集群上运行的应用程序。从集群中删除机器时也是如此。
正如Kubernetes集群可以按需上下扩展机器一样,在集群上运行的应用程序也可以。所有这些活动都是完全不透明的。集群中的应用程序以及使用集群的服务和其他应用程序都对集群的内部一无所知。无论出于何种目的,Kubernetes集群都可以表现得像一台非常非常大的计算机。
Kubernetes的短暂性使其成为一种非常强大的计算范式。但是,伴随着这种力量而来的是巨大的复杂性。Kubernetes有很多需要管理的活动部件。这就是我们稍后将要讨论的API服务器发挥作用的地方。但是,首先让我们来看看组成Kubernetes集群的组件。
容器和吊舱(Containers and Pods)
Kubernetes中计算逻辑的基本单元是Linux容器。您可以将容器视为一个抽象层,它提供了一种在计算机上运行进程的方式,从而将进程与所有其他进程隔离开来。
例如,通过在容器中运行每个Nginx实例,可以在一台机器上以隔离的方式同时运行多个Nginx web服务器。每个容器都可以有自己的CPU、内存和存储分配。尽管容器将“共享”主机操作系统中的资源,但该容器与主机操作系统并没有紧密地交织在一起。容器认为它有自己的文件系统和网络资源。因此,如果出现问题,您需要重新启动或销毁其中一个Nginx服务器,只需重新启动或摧毁容器,在某些情况下只需几秒钟。如果您在没有容器技术的情况下直接在主机上运行这些Nginx服务器,那么删除和重新安装主机可能需要几秒钟甚至几分钟的时间。而且,如果主机文件系统中存在损坏,管理修复程序并重新启动主机可能会超过一两分钟。
隔离和易于管理只是容器如此受欢迎的两个原因,也是它们是Kubernetes的基础。
开发人员对托管在容器中的一段逻辑进行编程。例如,逻辑可以是用GoLang编写的某种人工智能算法。或者,逻辑可以是Node.js代码,该代码访问数据库中的数据并将其转换为返回给调用者的JSON。可以托管在容器中的逻辑的可能性是无限的。
Kubernetes将一个或多个容器组织成一个称为pod的抽象单元。pod这个名字对Kubernetes来说很特别。pod将其容器呈现给Kubernetes集群。访问pod中的逻辑的方式是通过Kubernetes服务。(见图1。)
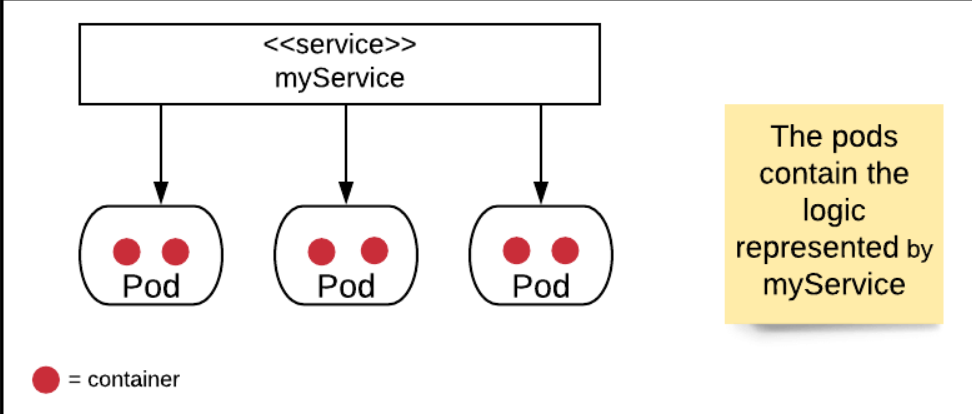
图1:在Kubernetes中,pod包含由关联服务表示的逻辑
服务表示pod到网络的逻辑。让我们看看如何促进这种表示。
了解Services and Pods
开发人员或Kubernetes管理员配置服务,将其绑定到具有相关逻辑的pod。出于所有意图和目的,服务代表Kubernetes集群内部的其他服务以及Kubernete集群外部的用户和程序的“pod逻辑”。
Kubernetes使用标签将服务绑定到一个或多个pod。标签是Kubernetes中描述服务和pod的基础。
有两种方法可以在Kubernetes中创建服务或pod。一种方法是使用名为kubectl的Kubernetes客户端直接在命令行调用pod或服务的创建。下面的清单1显示了一个使用kubectl创建pod的示例。
清单1:创建一个名为pinger的pod,该pod使用Docker容器映像reselbob/pinger
清单2展示了如何在命令行中使用kubectl来创建一个使用清单1中创建的pod的服务。
清单2:创建一个名为myservice的服务,该服务在端口8001上侦听,并绑定到名为pinger的pod
在命令行中使用kubectl来创建pod和服务被称为命令式方法。虽然命令式方法对于Kubernetes的实验很有用,但在专业级别上,手动向集群中添加pod和服务是不可取的。相反,首选的方法是使用更具程序性的声明性方法。
声明性方法是开发人员或管理员创建一个名为清单文件的配置,该文件描述给定的pod或服务。(通常,清单文件是用YAML编写的,但也可以使用JSON。)然后,开发人员、管理员或某种类型的自动化脚本使用kubectl子命令apply将清单文件中的配置设置应用到集群。下面的清单3显示了一个具有任意名称my_pod.yaml的清单文件,该文件将创建前面使用命令式方法创建的ping er pod。

清单3:用于创建包含容器pinger的pod的清单文件
一旦定义了清单文件,我们就可以这样声明地创建pod:
创建pod后,我们将创建一个具有任意名称pinger_service.yaml的清单文件,如下面的清单4所示:
清单4:清单文件定义了一个服务,该服务绑定到具有标签app:pinger和purpose:demo的pod

清单4:清单文件定义了一个服务,该服务绑定到具有标签app:pinger和purpose:demo的pod
为了在Kubernetes集群中创建服务pinger_service,我们应用清单文件,如下所示:
然而,悬而未决的问题是,服务pinger_service实际上是如何绑定到pod pinger_pod的。这就是标签的作用所在。
请注意清单3中描述pod清单文件的第5行到第7行。您将看到以下条目:
这些行表示pod已经配置了两个标签作为键值对。一个标签是应用程序,其值为pinger。另一个标签是有价值的目的,demo。术语“标签”是Kubernetes的保留词。然而,标签app:pinger和purpose:demo完全是任意的。
Kubernetes标签很重要,因为它们是识别集群中pod的方式。事实上,服务将使用这些标签作为其绑定机制。
看看清单4中描述服务清单文件的第5行到第8行。您将看到以下条目:
术语“选择器”是一个Kubernetes保留字,表示服务将绑定到组成pod的标签。请记住,上面的清单文件my_pod.yaml发布了两个标签,app:pinger和purpose:demo。my_service.yaml中定义的选择器使服务发挥作用,如果它说:“我被配置为进入集群,寻找任何带有标签app:pinger和目的:demo的pod。我会将进入我的任何流量路由到这些pod上。”
诚然,上述服务所做的类比查找语句过于简单。在发现pod的IP地址和与pod副本集合进行负载平衡以使服务到pod的路由工作方面,有很多工作要做。仍然使用标签是Kubernetes将pod绑定到服务的方式。它可能很简单,但即使在网络规模上也能工作!
Kubernetes的短暂性
了解容器、pod和服务之间的关系对于使用Kubernetes至关重要,但还有更多。请记住,Kubernetes是一个短暂的环境。这意味着,不仅可以根据需要从集群中添加和删除机器,容器、pod和服务也可以。正如您可能想象的那样,保持集群的正常运行需要大量的状态管理,当我们在即将到来的场景中描述Kubernetes的短暂方面时,您会看到这一点。(在这种情况下,我们将创建多个pod,这些pod由Kubernetes保证始终运行,即使主机或pod本身出现问题。)
除了容器、Pods和服务,还有许多其他资源——实际的、虚拟的和逻辑的——可以在Kubernetes集群中运行。例如,有ConfigMaps、Secrets、ReplicaSets、Deployments和Namespaces等。(请阅读Kubernetes API资源的完整文档。)
需要理解的重要一点是,在任何给定的时间,任何Kubernetes集群上都可能有数百甚至数千个资源在发挥作用。资源协同作用,状态不断变化。
以下是资源更改状态的一个实例。当Kubernetes部署创建的pod失败时,它将由Kubernete自动补充。(您将在下一节中阅读有关Kubernetes部署的详细信息。)新的pod可能会在与出现故障的pod相同的虚拟机(也称为“节点”)上进行补充,也可能会在新配置的虚拟机上进行补充。Kubernetes将跟踪补货的所有细节——主机的IP地址、pod本身的IP地址以及控制pod的Kubernete部署,仅举几个被跟踪的细节。与pod相关的所有细节、部署、使用pod的服务以及托管pod的节点都被视为集群状态的一部分。
正如您所看到的,将pod从一个节点移动到另一个节点是集群中的一个重要状态变化。这只是在任何给定时间可能发生的数百种状态变化之一。然而,Kubernetes知道集群中一直在运行的整个网络上发生的一切。问题是,怎么做?答案就在控制平面上。
理解Kubernetes控制平面
如上所述,Kubernetes旨在支持分布在许多机器上的分布式应用程序,无论是真实的还是虚拟的。这些机器可能位于同一个数据中心。同样有可能的是,组成集群的机器集合可能分布在全国计算区域甚至全球范围内。Kubernetes旨在支持这种级别的分发。
用Kubernetes的说法,机器被称为节点。在Kubernetes集群中,有两种类型的节点。有控制器节点,也有工作节点。控制器节点顾名思义。它控制集群中的活动,并协调工作节点之间的活动。工作节点顾名思义;它们完成了运行容器、pod和服务的实际工作。
控制器节点包含保持集群运行以及管理集群不断变化的状态所需的许多组件。这些组件组成了所谓的“控制平面”(见图2)
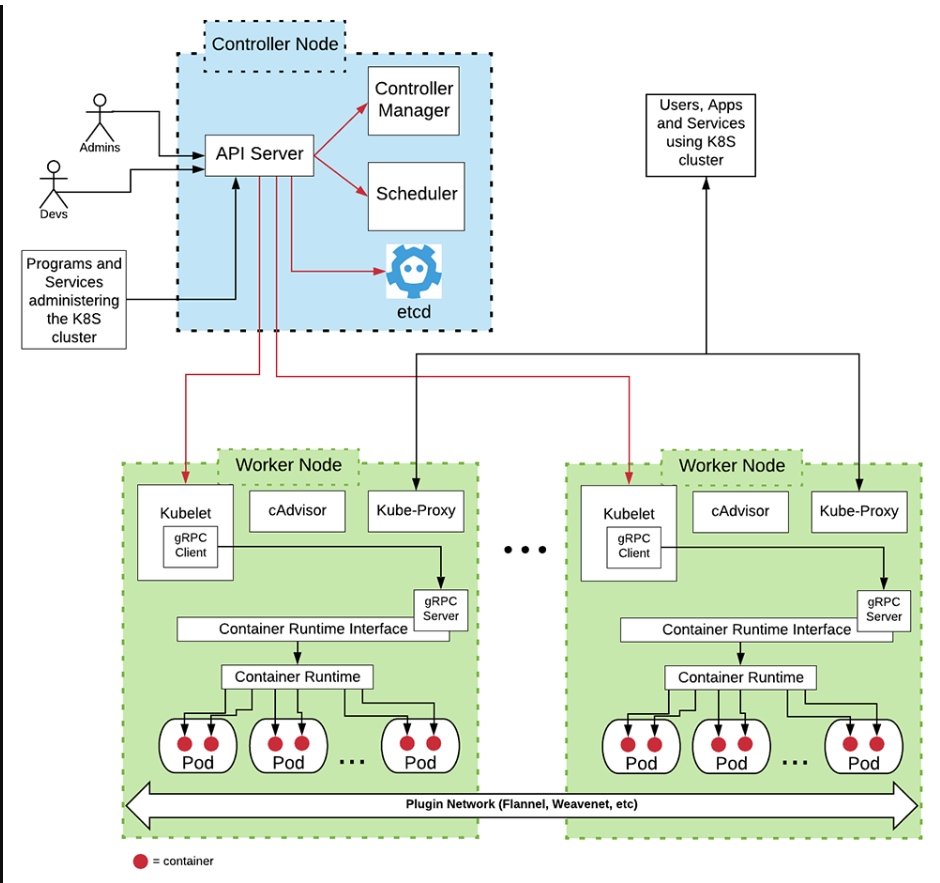
图2:Kubernetes集群的基本架构
下面的表1描述了控制节点和工作节点中的组件。为了进行更深入的讨论,您可以在这里阅读Kubernetes文档,该文档描述了控制平面和安装在每个工作节点上的组件。
| Component | Location | Purpose |
|---|---|---|
| API Server | Controller Node | The API Server is the primary interface into a Kubernetes cluster and for components within the given Kubernetes cluster. It's a set of REST operations for creating, updating and deleting Kubernetes resources within the cluster. Also, the API publishes a set of endpoints that allow components, services, and administrators to "watch" cluster activities asynchronously. |
| etcd | Controller Node | etcd is the internal database technology used by Kubernetes to store information about all resources and components that are operational within the cluster. |
| Scheduler | Controller Node | The Scheduler is the Kubernetes component that identifies a node to be the host location where a pod will be created and run within the cluster. Scheduler does NOT create the container's associated with a pod. Scheduler notifies the API Server that a host node has been identified. The kubelet component on the identified worker node does the work of creating the given pod's container(s). |
| Controller Manager | Controller Node | The Controller Manager is a high-level component that controls the constituent controller resources that are operational in a Kubernetes cluster. Examples of controllers that are subordinate to the Controller Manager are replication controller, endpoints controller which binds services to pods, namespace controller, and the serviceaccounts controller. |
| kubelet | Worker Node | kubelet interacts with the API Server in the controller node to create and maintain the state of pods on the node in which it is installed. Every node in a Kubernetes cluster runs an instance of kubelet. |
| Kube-Proxy | Worker Node | Kube-proxy does Kubernetes network management activity on the node upon which it is installed. Every node in a Kubernetes cluster runs an instance of Kube-proxy. Kube-proxy provides service discovery, routing, and load balancing between network requests and container endpoints. |
| Container Runtime Interface | Worker Node | The Container Runtime Interface (CRI) works with kubelet to create and destroy containers on the node. Kubernetes is agnostic in terms of the technology used to realize containers. The CRI provides the abstraction layer required to allow kubelet to work with any container runtime operational within the node. |
| Container Runtime | Worker Node | The Container Runtime is the actual container daemon technology in force in the node. The Container Runtime does the work of creating and destroying containers on a node. Examples of Container Runtime technologies are Docker, containerd, and CRI-O, to name the most popular. |
作为命令中心的API服务器
如上所述,Kubernetes采用“一个环来管理所有”的集群管理方法,而“一个环形”是一个API服务器。一般来说,管理Kubernetes集群的所有组件仅与API服务器通信。他们彼此不交流。让我们来看看这是如何工作的。
想象一下,一个Kubernetes管理员想要在一个集群中提供3个相同的pod,以实现故障安全冗余。管理员创建一个清单文件,用于定义Kubernetes部署的配置。部署是一个Kubernetes资源,它代表一个由相同pod组成的ReplicSet,这些pod由Kubernete保证始终运行。ReplicaSet中的pod数量是在创建Deployment时定义的。清单5中显示了定义这样一个部署的清单文件的示例。请注意,Deployment有3个pod,其中每个pod都有一个运行Nginx web服务器的容器。
--
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
清单5:一个清单文件,它创建了3个pod,每个pod托管一个Nginx容器。
Kubernetes管理员为部署创建清单文件后,管理员通过调用Kubernetes-client-CLI工具kubectl将其提交给API服务器,如下所示:
哪里
- kubectl是用于与API服务器交互的Kubernetes命令行工具
- apply是用于将清单文件的内容提交到API服务器的子命令\
- -f是选项,表示配置信息根据以下文件名存储在文件中
- mydeployment.yaml是用于示例目的的虚构文件名,其中包含与正在创建的Kubernetes资源相关的配置信息
kubectl通过HTTP将清单文件中的信息发送到API服务器上。API服务器然后通知完成配置所需的组件。这才是真正行动的开始。
Kubernetes Pod创建剖析
下面的图3演示了管理员使用kubectl命令行工具创建Kubernetes资源时所做的工作。(在这种情况下,管理员正在创建一个Kubernetes部署。让我们来看看细节。
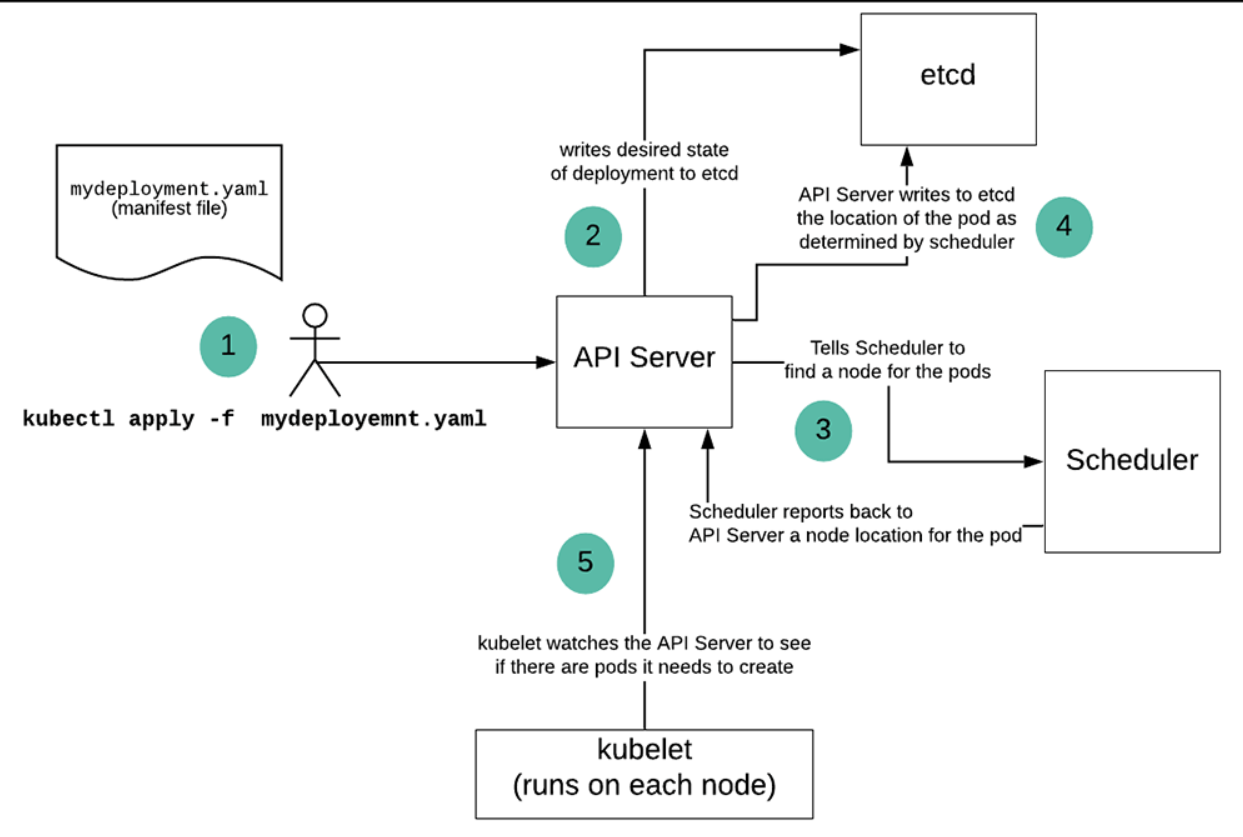
图3:使用kubectl在Kubernetes部署中创建pod的过程
在图3 Callout(1)中的场景中,Kubernetes管理员通过在命令提示符下输入kubectl apply-f mydeployment.yaml,将清单文件的内容提交给运行在Kubernete集群上的API服务器。(清单文件的内容显示在上面的清单5中。)API服务器将有关部署的配置信息输入到etcd中(Callout 2)。etcd是内部数据库,用于存储集群中所有事物的所有状态信息。在这种情况下,有关部署和所需pod副本数量的信息存储在etcd中。此外,还存储了用于配置部署中的pod的模板信息。
部署信息存储在etcd中后,API服务器通知调度程序查找节点来承载部署定义的pods。(标注3)调度器将找到符合pod要求的节点。例如,pod可能需要一个具有特殊类型CPU或特定内存配置的节点。调度器知道集群中所有节点的详细信息,并将找到满足pod要求的节点。(请记住,集群中每个节点的信息都存储在etcd中。)
计划程序识别用于部署的主机节点,并将该信息发送回API服务器。(标注4)调度器不会在节点上创建任何pod或容器。这是库贝莱的作品。
除了发布典型的RESTHTTP接口外,API服务器还具有异步端点,这些端点充当PubSub消息代理中的队列。Kubernetes集群中的每个节点都运行一个kubelet实例。kubelet的每个实例都“监听”API服务器。API服务器将发送一条消息,通知请求在特定的Kubernetes节点上创建和配置pod容器。运行在相关节点上的kubelet实例从API服务器的消息队列中获取该消息,并根据提供的规范创建容器。(标注5)kubelet通过与上面表1中描述的容器运行时接口(CRI)交互来创建容器。CRI绑定到节点上安装的特定容器运行时引擎。
kubelet向API服务器发送容器已创建的状态信息以及有关容器配置的信息。此时,kubelet将保持容器的健康,并在出现问题时通知API服务器。
正如您所看到的,API服务器实际上是一个环,它在Kubernetes集群中管理所有这些环。然而,让API服务器成为集群上发生的许多关键处理活动的中心会产生单点故障风险。如果API服务器出现故障,会发生什么情况?如果你是像Netflix这样的公司,这不是一个微不足道的问题。这是灾难性的。幸运的是,使用控制器节点副本解决了这个问题。
确保API服务器始终可用
如上所述,Kubernetes通过使用控制器节点副本来确保API服务器的高可用性。这类似于在Kubernetes部署中创建pod副本。只是,不是复制pod,而是复制控制器节点。所有控制器节点都位于负载均衡器后面,因此,流量会相应地进行路由。
设置一组控制器节点副本需要一些工作。首先,您将在集群中的每个节点上安装kubelet、kubectl和kube proxy以及容器运行时,无论该节点是控制器节点还是工作节点。然后,您需要设置一个负载均衡器来将流量路由到各个控制器节点,但之后,您可以使用Kubernetes命令行工具kubeadm将节点配置为相应的控制器和工作节点。要确保命令行中的所有配置设置都是正确的,还有一些工作要做。这需要注意,但不是过于详细的工作。
就状态存储而言,etcd仍然是集群状态的唯一权威。在多控制器节点配置中,本地机器上的每个etcd实例将读取和写入请求转发到在仲裁配置中设置的etcd服务器的共享集群上。在quorum配置中,当集群中的大多数etcd服务器批准更改时,就会对数据库进行写入。
在遍布网络的仲裁配置中设置etcd是否会在读写性能方面产生延迟问题?是的,确实如此。然而,根据Kubernetes的维护人员的说法,同一谷歌计算引擎区域内的机器之间的延迟时间不到10毫秒。尽管如此,在执行对时间极为敏感的操作时,明智的做法是使群集中的所有机器至少位于同一数据中心,最好位于数据中心的同一排服务器机架内。在时间极其敏感的情况下,机器之间的物理距离很重要!
把它放在一起
API正在成为现代应用程序体系结构中的关键。它们可以使应用程序易于扩展和维护。然而,API可以做的不仅仅是向客户端消费者公开表示应用程序逻辑。正如我们从本文的分析中看到的,Kubernetes API Server是使用API控制软件系统所有操作方面的一个主要示例。Kubernetes API服务器所做的远不止提供数据。它管理系统状态、资源创建、更改通知以及对系统的访问。事实上,正是这一环主宰了他们所有人。
毫无疑问,Kubernetes API服务器是一项复杂的技术。但事实上,Kubernetes在整个行业中被广泛使用,这为使用API作为系统控制中心的体系结构风格提供了证据。使用API作为实现软件系统的一种从环到规则的方法是一种巧妙的设计敏感性,也是一种值得考虑的方法。
- 登录 发表评论
- 101 次浏览
Tags
最新内容
- 1 week ago
- 2 weeks 1 day ago
- 2 weeks 5 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago