
建造无头湖屋的设计注意事项
在过去的几十年里,我们看到了向消费者提供(大规模)数据的演变,从数据仓库(Azure Synapse、Redshift、Big Query、Snowflake或ClickHouse),到数据湖(ADLS Gen2、S3或GCS),再到最新的迭代,即数据湖仓(Delta Lake、Apache Hudi或Iceberg)。
数据仓库模式现在在行业中占主导地位,通常与特定的供应商(例如Databricks)、计算引擎(例如Synapse Spark)、存储(例如ADLS Gen2)和开放表格式(例如Delta Lake)有关。虽然单个计算引擎可以与不同的查询引擎、表格式、存储和元数据存储很好地集成,但由于继承的依赖性,切换到另一个计算引擎可能非常复杂。
在今天的lakehouse架构中,主计算引擎(head)可以确定架构和能力决策,从而导致集中式数据湖和数据网格拓扑中的问题。此外,每个数据角色(数据工程师、数据科学家等)与数据和工具有着不同的关系,具有不同的需求和期望的结果,这使得单个主管往往不理想。这导致了三个主要问题:
- 有限的数据和元数据互操作性:并非总是可以从辅助计算引擎访问数据和元数据。这是对数据访问的倒退,也是对互操作性的倒退。例如,跨Spark和配置单元查询Delta还不可能——从Spark(例如Azure Databricks)创建的Delta表无法从配置单元(例如HDInsight)读取,反之亦然。此外,OSS HMS和HDInsight HMS并不完全兼容,需要更改模式才能使其工作。
- 数据访问和管理:用户希望跨系统查看表所有权元数据。例如,从Azure Databricks创建的增量表元数据在Synapse上可用吗?同样,用户如何在不同计算引擎创建的表和数据集之间实现统一的数据访问和治理?Unity Catalog适用于Databricks,Purview适用于Synapse,或Apache Ranger适用于HDInsight。
- 安全、监控和集成:除了数据访问和治理支持外,当转移到辅助引擎时,安全(例如RLS、CLS或动态数据屏蔽)、监控(例如工具和遥测/警报奇偶校验)和ETL的集成程度如何?这种新的计算是如何与现有的报告(Power BI)或数据科学工具(AzureML)集成的?
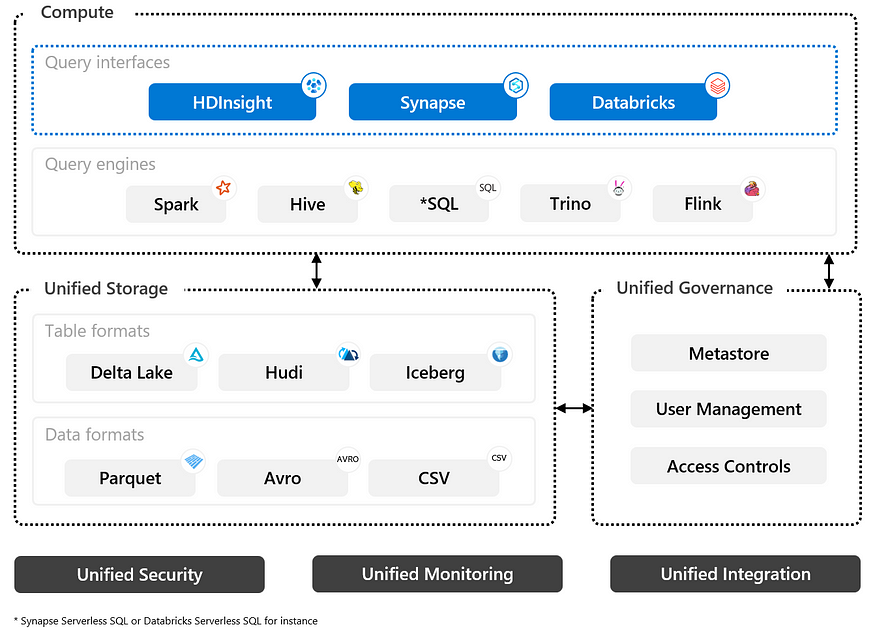
什么是无头湖屋?
无头lakehouse(又名可配置计算)可以定义为一种统一的数据架构,它提供了一种无缝的方式来访问和管理不同计算系统、存储位置和格式的数据。它使不同的系统和用户能够轻松地访问、分析和使用数据,提高了数据管理和分析的灵活性和可扩展性。这样,寻找可互操作计算引擎的用户将能够快速、顺畅地访问数据,并拥有自己的计算引擎。其他功能包括:
用户不希望数据被锁定在特定的存储和/或元存储中,无法用于其他引擎,或者在数据传输和格式转换上花费额外的时间和计算成本。
- 支持通过多个查询引擎和工作负载进行数据访问的多种计算功能。这可以是无服务器的,也可以是已配置的。
- 统一的数据和元数据存储,避免冗余存储、元数据和跨系统ETL。
- 统一的管理和治理,包括用户管理、访问控制、数据沿袭和质量、模式演变等。
- 数据存储和所有计算引擎中的统一安全性将其统一用于查询和作业。
- 统一协作和数据共享促进了基于API的不同团队之间的协作和数据分享。
- 对日志、度量和警报进行统一监控,包括平台可观察性。
- 统一集成和ETL将来自各种来源的数据集成到统一的数据存储中,并使其可供消费者使用。
多种计算功能
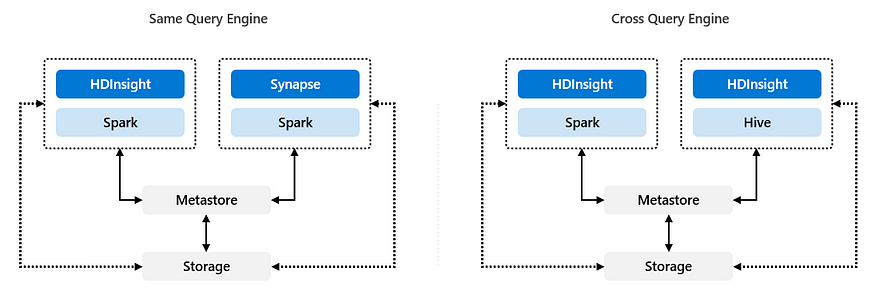
在无头湖屋模式中,多个计算引擎可以导致两种不同的拓扑结构。在这两种拓扑中,关注引擎、元存储和数据格式的版本对于确保互操作性至关重要:
- 相同查询引擎:第一个拓扑是“相同查询引擎”。在这个模型中(见下图),不同的计算引擎(如HDInsight和Synapse)使用相同的查询引擎(如Spark)。每个计算引擎都可以访问底层数据和元存储。
- 交叉查询引擎:“交叉查询引擎”拓扑涉及使用多个查询引擎(如Spark和Hive)访问同一存储和元存储。这允许不同的计算系统(例如HDInsight和Databricks)使用相同的数据和元存储。
统一的数据和元数据存储
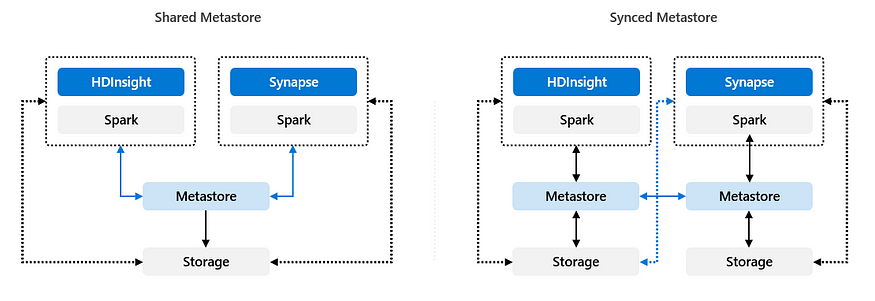
用户可以使用德尔塔表将数据保存在ADLS Gen2中,并从不同的计算引擎读取数据。这允许从一个平台切换到另一个平台,使数据在不同的计算引擎之间具有互操作性。在无头湖屋模式中,从多个系统访问这样的统一数据存储至关重要。例如,Synapse、HDInsight和Azure Databricks与ADLS Gen2配合良好。
类似地,元数据也可以存储在单独的外部元存储中。通过共享HMS或同步机制,可以跨多个计算引擎访问此类元数据,而无需迁移元数据或从外部表重建元存储。
- 共享Metastore:共享HMS方法的一个关键优势是得到所选计算引擎(+供应商)的充分支持,因此不需要构建任何定制的东西。这降低了实现和支持方面的风险,但它确实限制了供应商偏离元存储方法的一些功能兼容性,就像Databricks Unity Catalog的情况一样。有关更多详细信息,请参阅此。
- 同步Metastore:如果有人希望进行一些定制开发,那么同步元商店的方法可能更合适。在同步模型中,将有一系列元存储来掌握数据产业的不同引擎。然后,这些不同的元商店将通过定制的流程进行同步,以提供所有引擎的可见性和互操作性。例如,这可以在外部HMS上使用Azure SQL数据同步来实现。
如有任何建议或问题,请随时联系:)
参考文献:
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics (cidrdb.org)
- Data lakes — Azure Architecture Center | Microsoft Learn
- Data Mesh topologies. Design considerations for building a… | by Piethein Strengholt | Towards Data Science
- Using a Shared Hive Metastore Across Azure Synapse, HDInsight, and Databricks | by Aitor Murguzur | Mar, 2023 | Medium
- Building a Data Lakehouse Using Azure HDInsight | by Aitor Murguzur | Apr, 2023 | Medium
最新内容
- 4 hours ago
- 1 week 1 day ago
- 1 week 5 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago