
category
https://youtu.be/BPYOsDCZbno?list=PL1T8fO7ArWleMMI8KPJ_5D5XSlovTW_Ur
1-简介
ML开发的梦想是,给定一个项目规范和一些样本数据,您可以得到一个不断改进的大规模部署的预测系统。
现实情况截然不同:
- 您必须对数据进行收集、聚合、处理、清理、标记和版本设置。
- 您必须找到模型体系结构及其预先训练的权重,然后编写和调试模型代码。
- 您运行训练实验并审查结果,这些结果将反馈到尝试新架构和调试更多代码的过程中。
- 现在可以部署模型了。
- 在模型部署之后,您必须监视模型预测并关闭数据飞轮循环。基本上,您的用户会为您生成新的数据,这些数据需要添加到训练集中。

这个现实大约有三个组成部分:数据、开发和部署。对他们来说,工具基础设施的前景是巨大的,所以我们将有三场讲座来涵盖这一切。本次讲座的重点是开发部分。
2-软件工程

语言
对于编程语言的选择,Python是科学和数据计算领域的明显赢家,因为已经开发了所有的库。有一些竞争者,比如Julia和C/C++,但Python确实赢了。
编辑
要编写Python代码,您需要一个编辑器。您有许多选项,如Vim、Emacs、Jupyter Notebook/Lab、VS Code、PyCharm等。
- 我们推荐VS Code,因为它有一些不错的功能,比如内置的git版本控制、文档窥视、远程项目打开、linters和类型提示来捕捉bug等等。
- 许多从业者使用Jupyter笔记本进行开发,这是数据科学项目的“初稿”。在开始编码并看到即时输出之前,您必须稍微考虑一下。然而,笔记本电脑有各种各样的问题:原始编辑器、无序的执行工件,以及对它们进行版本和测试的挑战。与这些问题相对应的是nbdev包,它允许您在一个笔记本环境中编写和测试所有代码。
- 我们建议您使用对笔记本电脑具有内置支持的VS Code,您可以在导入笔记本电脑的模块中编写代码。它还可以进行出色的调试。
如果你想构建更具互动性的东西,Streamlight是一个很好的选择。它可以装饰Python代码,获得交互式小程序,并将它们发布在网络上与世界共享。

对于设置Python环境,我们建议您看看我们是如何在实验室中完成的。
3-深度学习框架

深度学习并不是像Numpy那样使用矩阵数学库的大量代码。但是,当你必须将代码部署到CUDA上进行GPU驱动的深度学习时,你需要考虑深度学习框架,因为你可能正在编写奇怪的层类型、优化器、数据接口等。
框架
有各种各样的框架,如PyTorch、TensorFlow和Jax。它们都很相似,首先通过运行Python代码来定义模型,然后收集不同部署模式(CPU、GPU、TPU、移动)的优化执行图。
- 我们更喜欢PyTorch,因为它在模型数量、论文数量和竞赛获胜者数量等方面绝对占主导地位。例如,在2021年ML竞赛的获胜者中,约77%使用PyTorch。
- 使用TensorFlow,您可以使用TensorFlow.js(可以在浏览器中运行深度学习模型)和Keras(为轻松的模型开发提供无与伦比的开发体验)。
- Jax是一个用于深度学习的元框架。
PyTorch拥有出色的开发经验,并且已经做好了生产准备,使用TorchScript的速度甚至更快。有一个很棒的分布式培训生态系统。有用于视觉、音频等的库。还有移动部署目标。
PyTorch Lightning为组织训练代码、优化器代码、评估代码、数据加载器等提供了一个很好的结构。有了这个结构,您可以在任何硬件上运行代码。有一些不错的功能,如性能和瓶颈探查器、模型检查点、16位精度和分布式训练库。
另一种可能性是FastAI软件,它是与fast.ai课程一起开发的。它提供了许多高级技巧,如数据增强、更好的初始化、学习速率调度器等。它具有模块化结构,具有低级API、中级API、高级API和特定应用程序。FastAI的主要问题是它的代码风格与主流Python截然不同。
在FSDL,我们更喜欢PyTorch,因为它有强大的生态系统,但TensorFlow仍然非常好。如果你有特定的理由更喜欢它,你仍然会玩得很开心。
Jax是谷歌最近的一个项目,并不是专门针对深度学习的。它提供通用的矢量化、自动区分和GPU/TPU代码的编译。对于深度学习,有单独的框架,如Flax和Haiku。您应该只针对特定需要使用Jax。
元框架和模型Zoos
大多数时候,您将至少从某人开发或发布的模型体系结构开始。您将在模型中枢上使用特定的体系结构(使用预先训练的权重对特定数据进行训练)。
- ONNX是一个用于保存深度学习模型的开放标准,允许您从一种类型的格式转换到另一种类型。它可以很好地工作,但也可能遇到一些边缘情况。
- HuggingFace已经成为一个绝对一流的模型库。它从NLP任务开始,但后来扩展到各种任务(音频分类、图像分类、对象检测等)。所有这些任务都有60000个预先训练的模型。有一个Transformers库,可以与PyTorch、TensorFlow和Jax一起使用。人们上传了7500个数据集。它还有一个社区方面,有一个问答论坛。
- TIMM是最先进的计算机视觉模型和相关代码的集合,看起来很酷。
4-分布式培训

假设我们有多台由上面的小方块表示的机器(每台机器中有多个GPU)。您正在发送要由带有参数的模型处理的数据批。数据批处理可以适合单个GPU,也可以不适合。模型参数可以适合单个GPU,也可以不适合。
最好的情况是,您的数据批处理和模型参数都适用于单个GPU。这就是所谓的琐碎并行。您可以在其他GPU/机器上启动更多独立的实验,也可以增加批量大小,直到它不再适合一个GPU。
数据并行性
如果你的模型仍然适合一个GPU,但你的数据不再适合,你必须尝试数据并行性——这可以让你在GPU之间分布一批数据,并在GPU之间分配模型计算的平均梯度。很多模型开发工作都是跨GPU的,所以您需要确保GPU具有快速的互连。
如果你使用的是服务器卡,那么在训练时间上要有线性的加速。如果您使用的是消费卡,请期待次线性加速。
数据并行是在PyTorch中使用强大的DistributedDataParallel库实现的。Horovod是另一个第三方图书馆选项。PyTorch Lightning使使用这两个库中的任何一个都变得非常简单——其中的加速似乎是相同的。
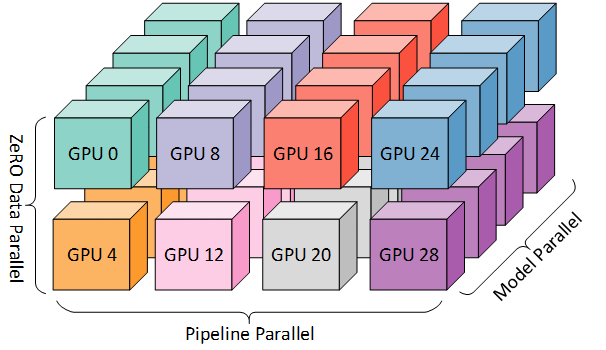
一个更高级的场景是,你甚至不能在一个GPU上安装你的模型。您必须将模型分布在多个GPU上。对此有三种解决方案。
碎片数据并行性
碎片数据并行性从一个问题开始:究竟是什么占用了GPU内存?
- 模型参数包括组成模型层的浮动。
- 需要梯度来进行反向传播。
- 优化器状态包括有关梯度的统计信息
- 最后,您必须发送一批用于模型开发的数据。
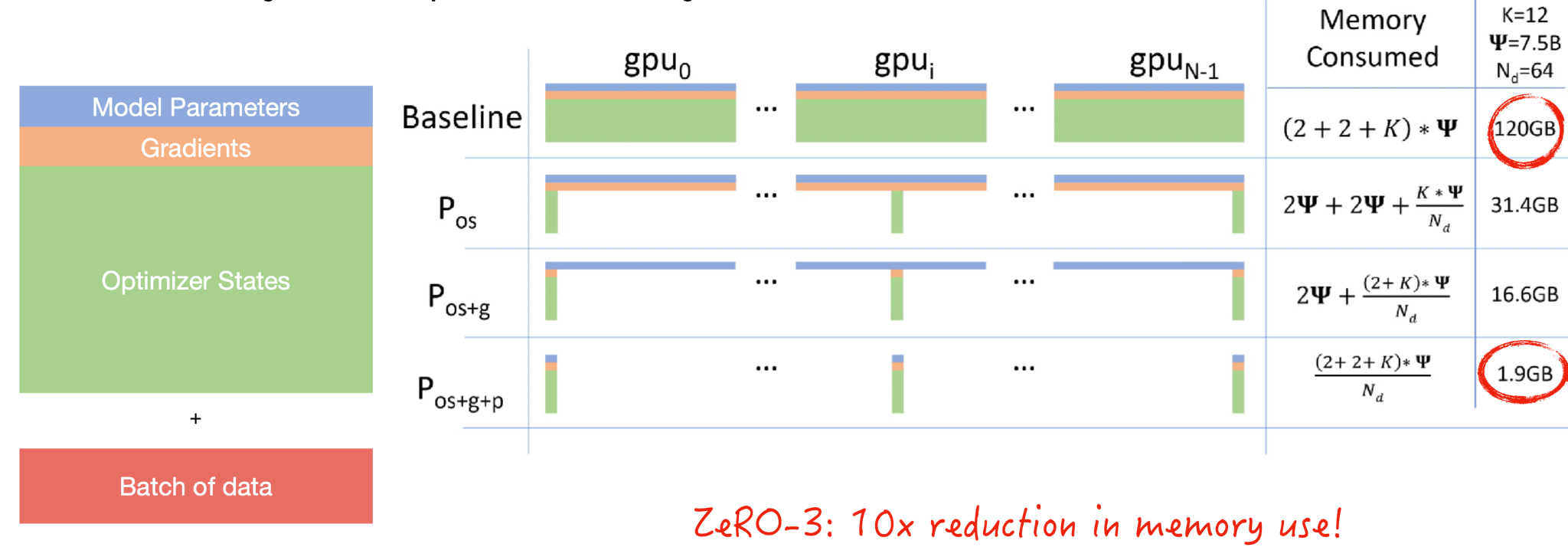
共享是一个来自数据库的概念,如果你有一个数据源,你实际上可以将其分解为分布在分布式系统中的数据碎片。微软实现了一种称为ZeRO的方法,该方法对优化器状态、梯度和模型参数进行分片。这导致内存使用量减少了一个疯狂的数量级,这意味着你的批量大小可能会大10倍。您应该观看本文中的视频,了解随着计算的进行,模型参数是如何在GPU之间传递的。
共享数据并行由微软的DeepSpeed库和脸书的FairScale库实现,也由PyTorch原生实现。在PyTorch中,它被称为完全共享的DataParallel。使用PyTorch Lightning,您可以尝试在不更改模型代码的情况下大幅减少内存。
同样的ZeRO原理也可以应用于单个GPU。您可以在单个V100(32GB)GPU上训练13B参数模型。Fairscale实现了这一点(称为CPU卸载)。
流水线模型并行性
模型并行性意味着您可以将模型的每一层放在每个GPU上。本机实现很简单,但一次只能有一个GPU处于活动状态。像DeepSpeed和FairScale这样的库通过流水线计算使其更好,从而充分利用GPU。您需要将批量大小上的流水线数量调整到如何在GPU上拆分模型的确切程度。
张量平行度
张量并行是另一种方法,它观察到矩阵乘法没有什么特别之处,它需要整个矩阵在一个GPU上。您可以将矩阵分布在多个GPU上。NVIDIA发布了威震天LM回购,该回购针对Transformer型号进行。
如果你真的想扩展一个巨大的模型(比如GPT-3大小的语言模型),你实际上可以使用上面提到的所有三种技术。阅读这篇关于BLOOM培训背后的技术的文章,感受一下。
总结:
- 如果你的模型和数据适合一个GPU,那就太棒了。
- 如果他们没有,并且您想加快培训速度,请尝试DistributedDataParallel。
- 如果模型仍然不适合,请尝试ZeRO-3或Full Sharded Data Parallel。
- 有关加快模型训练的更多资源,请查看DeepSpeed、MosaicML和FFCV编制的列表。
5-计算

计算是开发机器学习模型和产品的下一个重要组成部分。
正如OpenAI和HuggingFace的下图所示,在过去十年中,模型的计算强度急剧增长。

最近的发展,包括GPT-3等模型,加速了这一趋势。这些模型非常大,需要大量的PB级运算才能进行训练。
GPU
为了有效地训练深度学习模型,需要GPU。NVIDIA一直是GPU供应商的首选,尽管谷歌推出了TPU(张量处理单元),这些TPU是有效的,但只能通过谷歌云提供。选择GPU时有三个主要考虑因素:
- GPU能容纳多少数据?
- GPU处理数据的速度有多快?要评估这一点,您的数据是16位还是32位?后者的资源更加密集。
- CPU和GPU之间以及GPU之间的通信速度有多快?
看看最近的NVIDIA GPU,很明显每隔几年就会推出一种新的高性能架构。这些芯片之间有区别,它们被许可用于个人用途,而不是公司用途;企业应该只使用服务器卡。
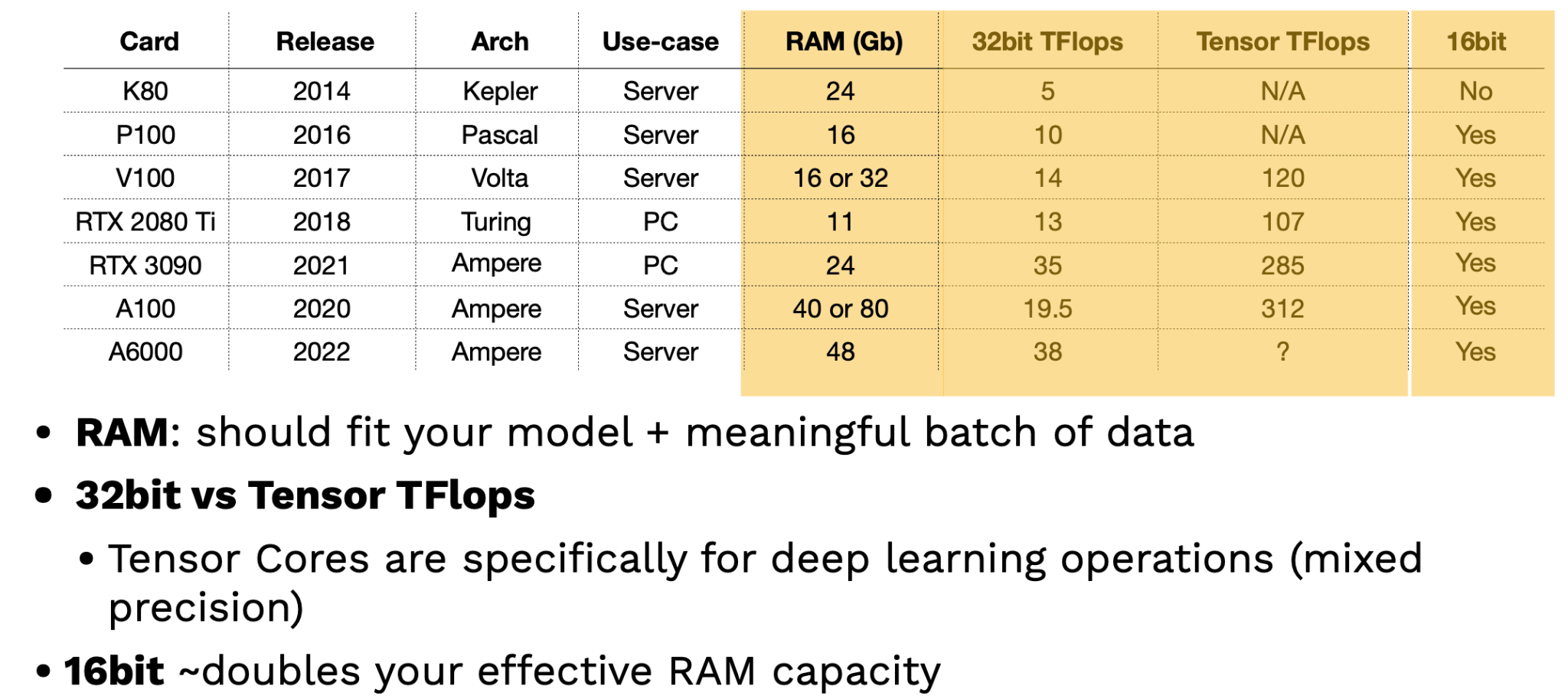
评估GPU的两个关键因素是RAM和张量TFlops。RAM越多,GPU包含的大型模型和数据集就越好。张量TFlops是NVIDIA专门为深度学习操作提供的特殊张量核心,可以处理更密集的混合精度操作。提示:利用16位训练可以有效地使您的RAM容量翻倍!
虽然这些理论基准很有用,但GPU在实际中是如何执行的?Lambda实验室在这里提供了最好的基准测试。他们的研究结果表明,最新的服务器级NVIDIA GPU(A100)比经典的V100 GPU快2.5倍以上。RTX芯片的性能也优于V100。AIME也是GPU基准测试的另一个来源。
微软Azure、谷歌云平台和亚马逊网络服务等云服务是购买GPU访问权限的默认场所。Paperspace、CoreWeave和Lambda Labs等初创云提供商也提供此类服务。
TPU
让我们简单讨论一下TPU。有四代TPU,最新的v4是深度学习最快的加速器。V4 TPU目前还不普遍,但TPU通常擅长扩展到更大的尺寸和模型尺寸。下图将TPU与速度最快的A100 NVIDIA芯片进行了比较。
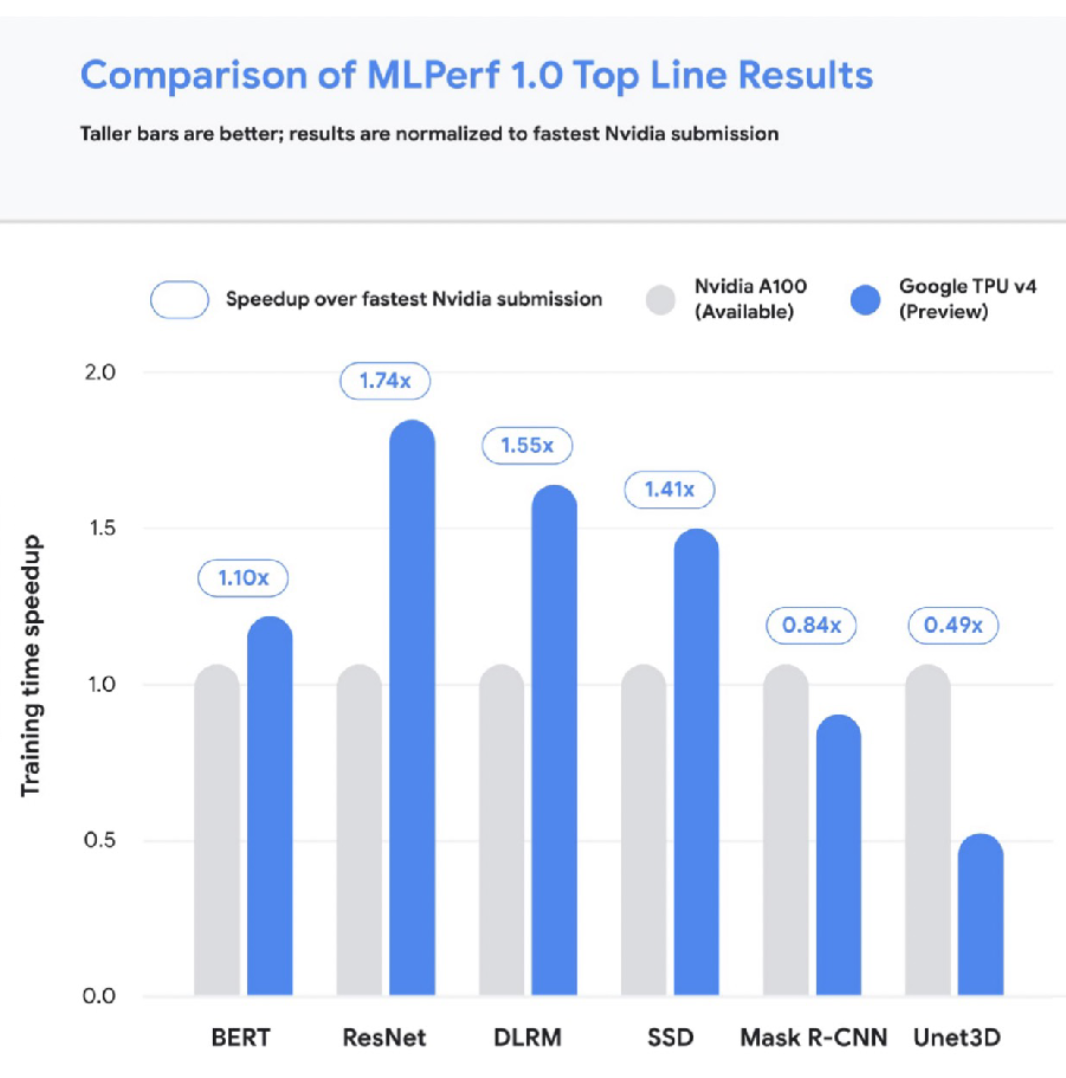
将云访问的成本与GPU进行比较可能会让人不知所措,所以我们制作了一个解决这个问题的工具!请随时为我们的云GPU成本指标库做出贡献。该工具具有各种漂亮的功能,如仅为最新的芯片型号启用过滤器等。
如果我们将成本指标与性能指标相结合,我们会发现每小时最昂贵的芯片并不是每次实验最昂贵的!举个例子:在4个V100上运行相同的变形金刚实验在72小时内花费1750美元,而在4个A100上运行同样的实验仅在8小时内花费250美元。根据你试图训练的模型仔细考虑成本和性能。
这里有一些有用的启发式方法:
- 在最便宜的云中使用每小时最昂贵的GPU。
- 初创企业(例如Paperspace)往往比主要的云提供商更便宜。
On-Prem与Cloud
对于预构建用例,您可以很容易地构建自己的计算机,也可以选择NVIDIA等公司的预构建计算机。你可以花大约7000美元打造一台拥有128 GB RAM和2个RTX 3909的安静PC,并在一天内完成安装。超越这一点可能会变得更加昂贵和复杂。Lambda Labs提供一台售价60000美元的机器,配有8个A100(超级快!)。Tim Dettmers提供了一个关于在这里建造机器的很好的(稍微过时的)视角。
关于prem与云使用的一些提示:
- 拥有自己的GPU机器可以将您的心态从最小化成本转变为最大化效用,这可能很有用。
- 要想真正扩大实验规模,你可能只需要在最便宜的云中使用最昂贵的机器。
- 考虑到TPU的性能,它值得在大规模训练中进行试验。
- Lambda Labs是赞助商,我们非常鼓励on-prem和云GPU上使用它们!
6-资源管理

既然我们已经讨论了原始计算,那么让我们讨论一下如何管理计算资源的选项。假设我们想要管理一组实验。从广义上讲,我们需要GPU形式的硬件、软件需求(例如PyTorch版本)和数据来进行训练。
解决
利用指定依赖关系的最佳实践(例如Poetry、conda、pip工具),可以在一台机器上快速轻松地进行此类实验。
然而,如果您有一组机器可以在上面运行实验,那么SLURM是一种行之有效的工作负载管理解决方案,目前仍在广泛使用。
为了更具可移植性,Docker是一种将整个依赖堆栈打包为轻量级虚拟机包的方法。Kubernetes是在集群上运行许多Docker容器的最流行方式。OSS Kubeflow项目帮助管理依赖Kubernetes的ML项目。
这些项目很有用,但可能不是最简单或最好的选择。如果您已经建立并运行了集群,那么它们就很好了,但您实际上是如何建立集群或计算平台的呢?
在继续之前,FSDL更喜欢开源和/或价格透明的产品。我们讨论的是属于这些类别的工具,而不是定价不透明的SaaS。
工具
对于AWS的从业者来说,AWS Sagemaker为构建机器学习模型提供了一个方便的端到端解决方案,从标记数据到部署模型。Sagemaker有大量特定于AWS的配置,这可能会让人反感,但它带来了许多易于使用的老式算法进行训练,并允许您使用BYO算法。他们也在增加对PyTorch的支持,尽管PyTorch价格上涨了15-20%。
Anyscale是一家由伯克利OSS项目Ray的制造商创建的公司。Anyscale最近推出了Ray Train,他们声称它比具有类似价值主张的Sagemaker更快。Anyscale使提供计算集群变得非常容易,但它比其他选择要昂贵得多。
Grid.ai是由PyTorch Lightning的创建者创建的。网格允许您通过“网格运行”指定要轻松使用的计算参数,然后指定所需的计算类型和选项。您可以在后台使用它们的实例或AWS。电网的未来并不确定,因为其未来与Lightning的兼容性(考虑到其品牌重塑)尚未明确。
还有几个非ML选项可用于启动计算!编写自己的脚本,使用各种库,甚至Kubernetes都是可以选择的。这条路线比较难。
Determined.AI是一个用于管理预处理和云集群的OSS解决方案。它们提供集群管理、分布式培训等。它非常易于使用,并且正在积极开发中。
尽管如此,在许多云提供商上启动培训的易用性仍有提高的空间。
7-实验和模型管理
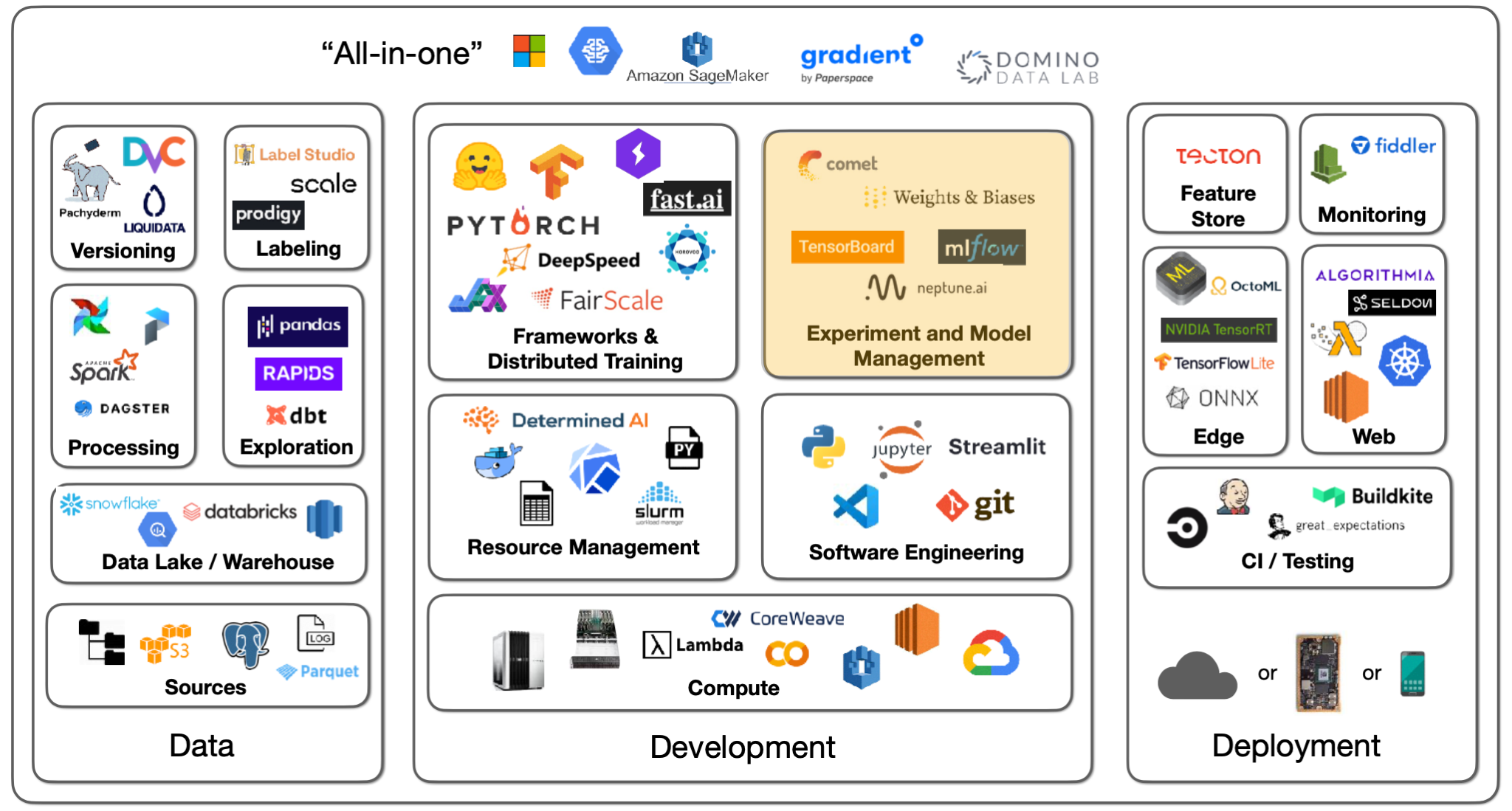
与计算相比,实验管理几乎要解决了。实验管理是指帮助我们跟踪在模型开发生命周期中迭代的代码、模型参数和数据集的工具和过程。这些工具对于有效的模型开发至关重要。这里有几种解决方案:
- TensorBoard:一个非独占的谷歌解决方案,可有效进行一次性实验跟踪。管理许多实验是困难的。
- MLflow:一个非排他性的Databricks项目,除了实验管理之外,还包括模型封装等。它必须是自托管的。
- Weights and Biases::一个易于使用的解决方案,对个人和学术项目免费!日志记录只需简单地从一个“实验配置”命令开始。
- 其他选项包括 Neptune AI, Comet ML, and Determined AI,,所有这些都有可靠的实验跟踪选项。
其中许多平台还提供智能超参数优化,这使我们能够控制为模型搜索正确参数的成本。例如,Weights and Biases有一个名为Sweep的产品,可以帮助进行超参数优化。最好将其作为常规ML培训工具的一部分;不需要专用工具。
8-“一体化”
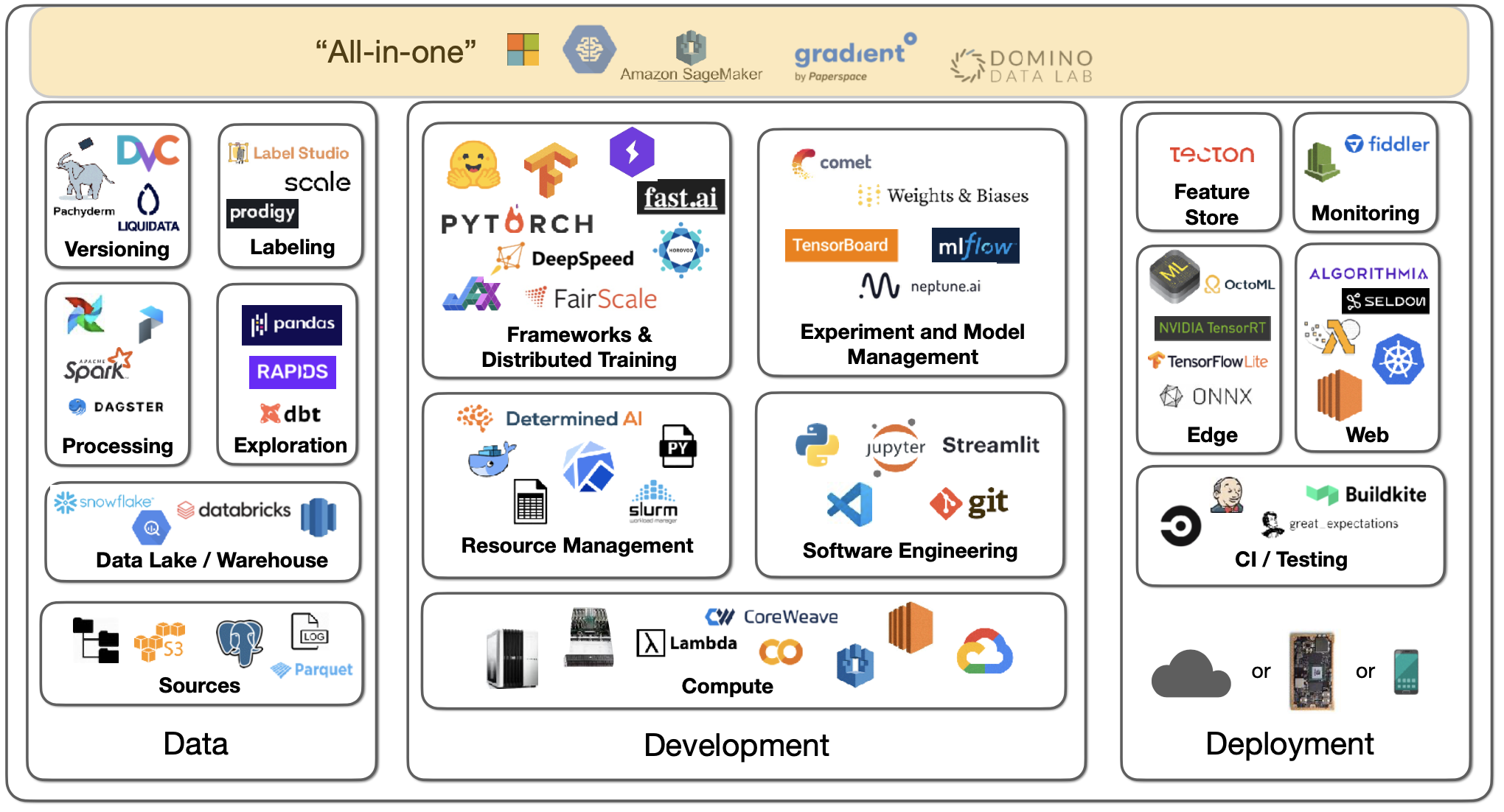
有机器学习基础设施解决方案可以提供一切——培训、实验跟踪、扩展、部署等。这些“一体式”平台简化了事情,但价格不便宜!示例包括 Gradient by Paperspace, Domino Data Lab, AWS Sagemaker,等。
最新内容
- 1 day 9 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 2 weeks ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago