
category
机器学习(ML)已经从实验阶段发展成为业务运营中不可或缺的一部分。组织现在积极部署机器学习模型,用于精确的销售预测、客户细分和流失预测。在传统机器学习继续改变业务流程的同时,生成式人工智能已经成为一股革命性的力量,引入了强大且可访问的工具,重塑了客户体验。
尽管生成式人工智能很突出,但传统的机器学习解决方案对于特定的预测任务仍然至关重要。销售预测依赖于历史数据和趋势分析,最有效的方法是使用已建立的机器学习算法,包括随机森林、梯度增强机(如XGBoost)、自回归综合移动平均(ARIMA)模型、长短期记忆(LSTM)网络和线性回归技术。传统的机器学习模型,如K-means和分层聚类,在客户细分和流失预测应用中也表现出色。尽管生成式人工智能在内容生成、产品设计和个性化客户互动等创造性任务中表现出了卓越的能力,但传统的机器学习模型在数据驱动的预测中仍然保持着优势。组织可以通过同时使用这两种方法来实现最佳结果,创建在保持成本效益的同时提供准确预测的解决方案。
为了实现这一目标,我们在这篇文章中展示了客户如何通过在Amazon SageMaker AI上集成预测性ML模型和模型上下文协议(MCP)来扩展AI代理的功能,MCP是一种开放协议,规范了应用程序如何向大型语言模型(LLM)提供上下文。我们展示了一个全面的工作流程,使AI代理能够通过使用SageMaker托管的ML模型做出数据驱动的业务决策。通过使用Strands Agents SDK(一种开源SDK,采用模型驱动的方法,仅需几行代码即可构建和运行AI代理)和灵活的集成选项,包括直接端点访问和MCP,我们向您展示了如何构建智能、可扩展的AI应用程序,将对话式AI的强大功能与预测分析相结合。
解决方案概述
该解决方案通过将部署在Amazon SageMaker AI端点上的ML模型与AI代理集成来增强AI代理,使其能够通过ML预测做出数据驱动的业务决策。人工智能代理是一种基于LLM的应用程序,它使用LLM作为其核心“大脑”,以最少的人为输入自主观察其环境、计划行动和执行任务。它集成了推理、记忆和工具使用,通过动态创建和修改计划、与外部系统交互以及从过去的交互中学习来优化结果,从而执行复杂的多步骤问题解决。这使得人工智能代理能够超越简单的文本生成,成为能够在各种现实世界和企业场景中进行决策和目标导向行动的独立实体。对于这个解决方案,AI代理是使用Strands Agents SDK开发的,它允许从简单的助手快速开发到复杂的工作流程。预测性ML模型托管在Amazon SageMaker AI上,并将被AI代理用作工具。这可以通过两种方式实现:代理可以直接调用SageMaker端点以更直接地访问模型推理功能,或者使用MCP协议来促进AI代理和ML模型之间的交互。这两种选择都是有效的:通过将工具调用直接嵌入代理代码本身,直接工具调用不需要额外的基础设施,而MCP通过引入额外的架构组件,即MCP服务器本身,实现了工具的动态发现以及代理和工具执行的解耦。为了可扩展和安全地实现工具调用逻辑,我们建议使用MCP方法。尽管我们推荐MCP,但我们也讨论并实现了直接端点访问,让读者可以自由选择他们喜欢的方法。
Amazon SageMaker AI提供了两种在单个端点后面托管多个模型的方法:推理组件和多模型端点。这种整合的托管方法能够在一个环境中高效部署多个模型,从而优化计算资源并最大限度地减少模型预测的响应时间。出于演示目的,本文仅在一个端点上部署一个模型。如果您想了解更多关于推理组件的信息,请参阅Amazon SageMaker AI文档“多模型共享资源利用率”。要了解有关多模型端点的更多信息,请参阅Amazon SageMaker AI文档多模型端点。
架构
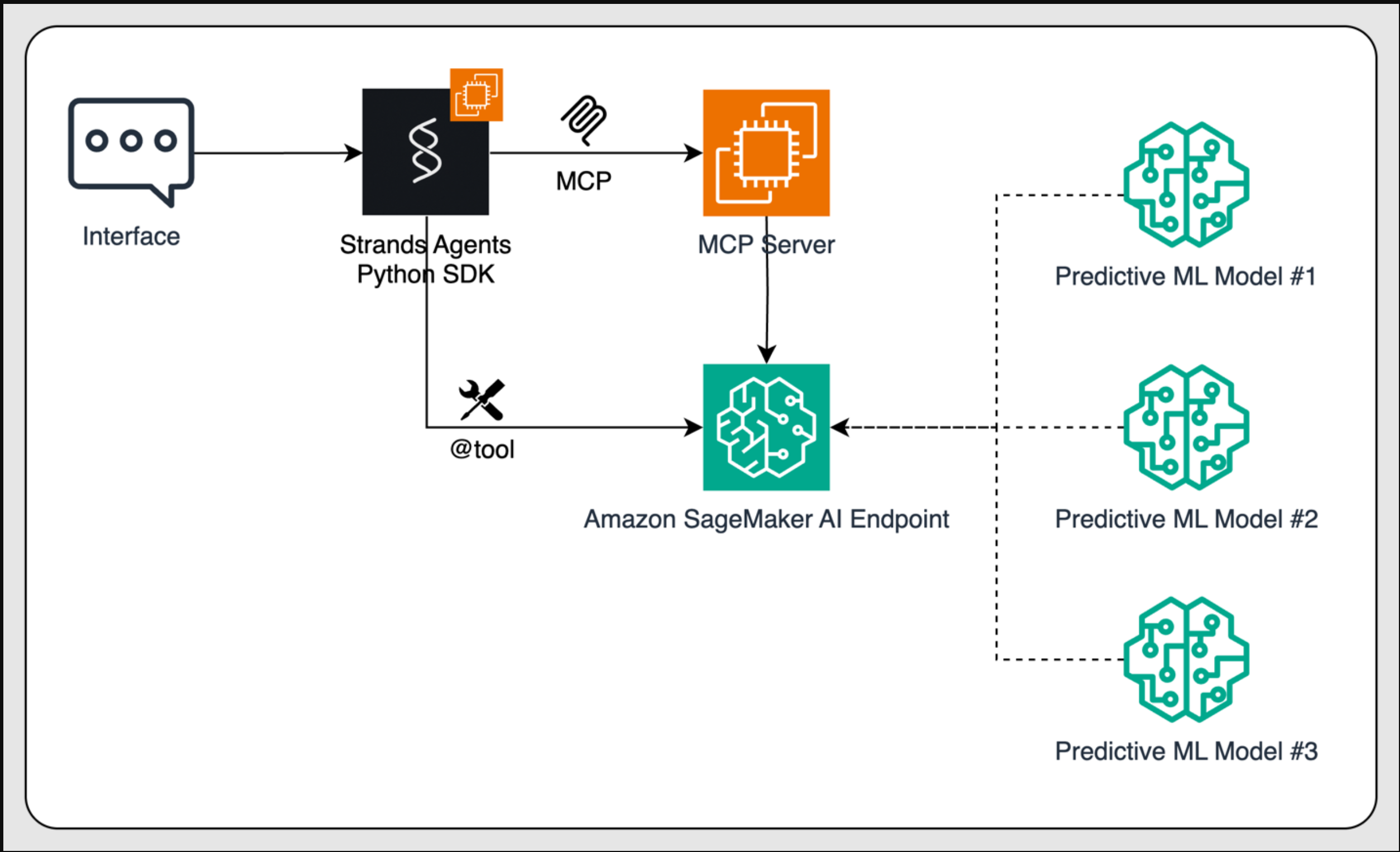
在这篇文章中,我们定义了一个工作流程,通过使用Amazon SageMaker AI调用预测性ML模型,使AI代理能够做出数据驱动的业务决策。该过程始于用户通过界面(如基于聊天的助手或应用程序)进行交互。此输入由使用开源Strands Agents SDK开发的AI代理管理。Strands Agent采用模型驱动的方法,这意味着开发人员只需一个提示和一系列工具即可定义代理,从而促进从简单助手到复杂自主工作流的快速开发。
当代理收到需要预测的请求(例如,“2025年下半年的销售额是多少?”)时,为代理提供动力的LLM决定与托管ML模型的Amazon SageMaker AI端点进行交互。这可以通过两种方式实现:直接将端点用作Strands Agents Python SDK的自定义工具,或通过MCP调用该工具。使用MCP,客户端应用程序可以发现MCP服务器公开的工具,获取所需参数的列表,并将请求格式化到Amazon SageMaker推理端点。或者,代理可以使用工具注释(如@tool)直接调用SageMaker端点,绕过MCP服务器,更直接地访问模型推理功能。
最后,SageMaker托管模型生成的预测通过代理路由回,并最终传递到用户界面,从而实现实时、智能的响应。
下图说明了这一过程。此解决方案的完整代码可在GitHub上获得。
Prerequisites
To get started with this solution, make sure you have:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker AI. To learn more about how IAM works with SageMaker AI, refer to AWS Identity and Access Management for Amazon SageMaker AI.
- Access to Amazon SageMaker Studio and a SageMaker AI notebook instance or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
- Access to accelerated instances (GPUs) for hosting the LLMs.
Solution implementation
In this solution, we implement a complete workflow that demonstrates how to use ML models deployed on Amazon SageMaker AI as specialized tools for AI agents. This approach enables agents to access and use ML capabilities for enhanced decision-making without requiring deep ML expertise. We play the role of a data scientist tasked with building an agent that can predict demand for one product. To achieve this, we train a time-series forecasting model, deploy it, and expose it to an AI agent.
The first phase involves training a model using Amazon SageMaker AI. This begins with preparing training data by generating synthetic time series data that incorporates trend, seasonality, and noise components to simulate realistic demand patterns. Following data preparation, feature engineering is performed to extract relevant features from the time series data, including temporal features such as day of week, month, and quarter to effectively capture seasonality patterns. In our example, we train an XGBoost model using the XGBoost container available as 1P container in Amazon SageMaker AI to create a regression model capable of predicting future demand values based on historical patterns. Although we use XGBoost for this example because it’s a well-known model used in many use cases, you can use your preferred container and model, according to the problem you’re trying to solve. For the sake of this post, we won’t detail an end-to-end example of training a model using XGBoost. To learn more about this, we suggest checking out the documentation Use XGBoost with the SageMaker Python SDK. Use the following code:
Then, the trained model is packaged and deployed to a SageMaker AI endpoint, making it accessible for real-time inference through API calls:
After the model is deployed and ready for inferences, you need to learn how to invoke the endpoint. To invoke the endpoint, write a function like this:
Note that the function invoke_endpoint() has been written with proper docstring. This is key to making sure that it can be used as a tool by LLMs because the description is what allows them to choose the right tool for the right task. YOu can turn this function into a Strands Agents tool thanks to the @tool decorator:
And to use it, pass it to a Strands agent:
As you run this code, you can confirm the output from the agent, which correctly identifies the need to call the tool and executes the function calling loop:
As the agent receives the prediction result from the endpoint tool, it can then use this as an input for other processes. For example, the agent could write the code to create a plot based on these predictions and show it to the user in the conversational UX. It could send these values directly to business intelligence (BI) tools such as Amazon QuickSight or Tableau and automatically update enterprise resource planning (ERP) or customer relationship management (CRM) tools such as SAP or Salesforce.
Connecting to the endpoint through MCP
You can further evolve this pattern by having an MCP server invoke the endpoint rather than the agent itself. This allows for the decoupling of agent and tool logic and an improved security pattern because the MCP server will be the one with the permission to invoke the endpoint. To achieve this, implement an MCP server using the FastMCP framework that wraps the SageMaker endpoint and exposes it as a tool with a well-defined interface. A tool schema must be specified that clearly defines the input parameters and return values for the tool, facilitating straightforward understanding and usage by AI agents. Writing the proper docstring when defining the function achieves this. Additionally, the server must be configured to handle authentication securely, allowing it to access the SageMaker endpoint using AWS credentials or AWS roles. In this example, we run the server on the same compute as the agent and use stdio as communication protocol. For production workloads, we recommend running the MCP server on its own AWS compute and using transport protocols based on HTTPS (for example, Streamable HTTP). If you want to learn how to deploy MCP servers in a serverless fashion, refer to this official AWS GitHub repository. Here’s an example MCP server:
Finally, integrate the ML model with the agent framework. This begins with setting up Strands Agents to establish communication with the MCP server and incorporate the ML model as a tool. A comprehensive workflow must be created to determine when and how the agent should use the ML model to enhance its capabilities. The implementation includes programming decision logic that enables the agent to make informed decisions based on the predictions received from the ML model. The phase concludes with testing and evaluation, where the end-to-end workflow is validated by having the agent generate predictions for test scenarios and take appropriate actions based on those predictions.
Clean up
When you’re done experimenting with the Strands Agents Python SDK and models on Amazon SageMaker AI, you can delete the endpoint you’ve created to stop incurring unwanted charges. To do that, you can use either the AWS Management Console, the SageMaker Python SDK, or the AWS SDK for Python (boto3):
Conclusion
In this post, we demonstrated how to enhance AI agents’ capabilities by integrating predictive ML models using Amazon SageMaker AI and the MCP. By using the open source Strands Agents SDK and the flexible deployment options of SageMaker AI, developers can create sophisticated AI applications that combine conversational AI with powerful predictive analytics capabilities. The solution we presented offers two integration paths: direct endpoint access through tool annotations and MCP-based integration, giving developers the flexibility to choose the most suitable approach for their specific use cases. Whether you’re building customer service chat assistants that need predictive capabilities or developing complex autonomous workflows, this architecture provides a secure, scalable, and modular foundation for your AI applications. As organizations continue to seek ways to make their AI agents more intelligent and data-driven, the combination of Amazon SageMaker AI, MCP, and the Strands Agents SDK offers a powerful solution for building the next generation of AI-powered applications.
For readers unfamiliar with connecting MCP servers to workloads running on Amazon SageMaker AI, we suggest Extend large language models powered by Amazon SageMaker AI using Model Context Protocol in the AWS Artificial Intelligence Blog, which details the flow and the steps required to build agentic AI solutions with Amazon SageMaker AI.
To learn more about AWS commitment to the MCP standard, we recommend reading Open Protocols for Agent Interoperability Part 1: Inter-Agent Communication on MCP in the AWS Open Source Blog, where we announced that AWS is joining the steering committee for MCP to make sure developers can build breakthrough agentic applications without being tied to one standard. To learn more about how to use MCP with other technologies from AWS, such as Amazon Bedrock Agents, we recommend reading Harness the power of MCP servers with Amazon Bedrock Agents in the AWS Artificial Intelligence Blog. Finally, a great way to securely deploy and scale MCP servers on AWS is provided in the AWS Solutions Library at Guidance for Deploying Model Context Protocol Servers on AWS.
- 登录 发表评论
- 44 次浏览
最新内容
- 1 month 1 week ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago