
category
生成型人工智能使我们能够在更短的时间内完成更多的工作。文本到SQL使人们能够使用自然语言探索数据并得出见解,而不需要专门的数据库知识。Amazon Web Services(AWS)已帮助许多客户使用自己的数据将此文本连接到SQL功能,这意味着更多的员工可以生成见解。在这个过程中,我们发现在有100多个表的企业环境中需要一种不同的方法,每个表都有几十列。我们还了解到,当基于用户问题生成的SQL查询中出现错误时,稳健的错误处理至关重要。
本文演示了企业如何使用Amazon Bedrock代理实现可扩展的代理文本到SQL解决方案,并使用高级错误处理工具和自动模式发现来提高数据库查询效率。我们基于代理的解决方案提供了两个关键优势:
自动可扩展的模式发现——当执行查询的初始尝试失败时,可以动态更新模式和表元数据以生成SQL。这对于拥有大量表和列以及许多查询模式的企业客户来说非常重要。
- 自动错误处理——错误消息直接反馈给代理,以提高运行查询的成功率。
- 您会发现,这些功能可以帮助您应对企业级数据库挑战,同时使您的文本到SQL体验更加健壮和高效。
用例
代理文本到SQL解决方案可以使具有复杂数据结构的企业受益。在这篇文章中,要了解代理文本到SQL解决方案在复杂企业环境中的机制和优势,想象一下你是一家银行风险管理团队的业务分析师。您需要回答以下问题:“查找在美国发生的所有被标记为欺诈的交易,以及用于这些交易的设备信息”,或“检索2023年1月1日至2023年12月31日期间John Doe的所有交易,包括欺诈标志和商家详细信息”。为此,您不仅需要了解数十个(有时是数百个)表,还需要处理复杂的JOIN查询。下图说明了欺诈调查可能需要的示例表模式。

The key pain points of implementing a text-to-SQL solution in this complex environment include the following, but aren’t limited to:
- The amount of table information and schema will get excessive, which will entail manual updates on the prompts and limit its scale.
- As a result, the solution might require additional validation, impacting the quality and performance of generating SQL.
Now, consider our solution and how it addresses these problems.
Solution overview
Amazon Bedrock Agents seamlessly manages the entire process from question interpretation to query execution and result interpretation, without manual intervention. It seamlessly incorporates multiple tools, and the agent analyzes and responds to unexpected results. When queries fail, the agent autonomously analyzes error messages, modifies queries, and retries—a key benefit over static systems.
As of December 2024, the Amazon Bedrock with structured data feature provides built-in support for Amazon Redshift, offering seamless text-to-SQL capabilities without custom implementation. This is recommended as the primary solution for Amazon Redshift users.
Here are the capabilities that this solution offers:
- Executing text-to-SQL with autonomous troubleshooting:
- The agent can interpret natural language questions and convert them into SQL queries. It then executes these queries against an Amazon Athena database and returns the results.
- If a query execution fails, the agent can analyze the error messages returned by AWS Lambda and automatically retries the modified query when appropriate.
- Dynamic schema discovery
- Listing tables – The agent can provide a comprehensive list of the tables in the fraud detection database. This helps users understand the available data structures.
- Describing table schemas – Users can request detailed information about the schema of specific tables. The agent will provide column names, data types, and associated comments, giving users a clear understanding of the data structure.
The solution uses direct database tools for schema discovery instead of vector store–based retrieval or static schema definitions. This approach provides complete accuracy with lower operational overhead because it doesn’t require a synchronization mechanism and continually reflects the current database structure. Direct schema access through tools is more maintainable than hardcoded approaches that require manual updates, and it provides better performance and cost-efficiency through real-time database interaction.
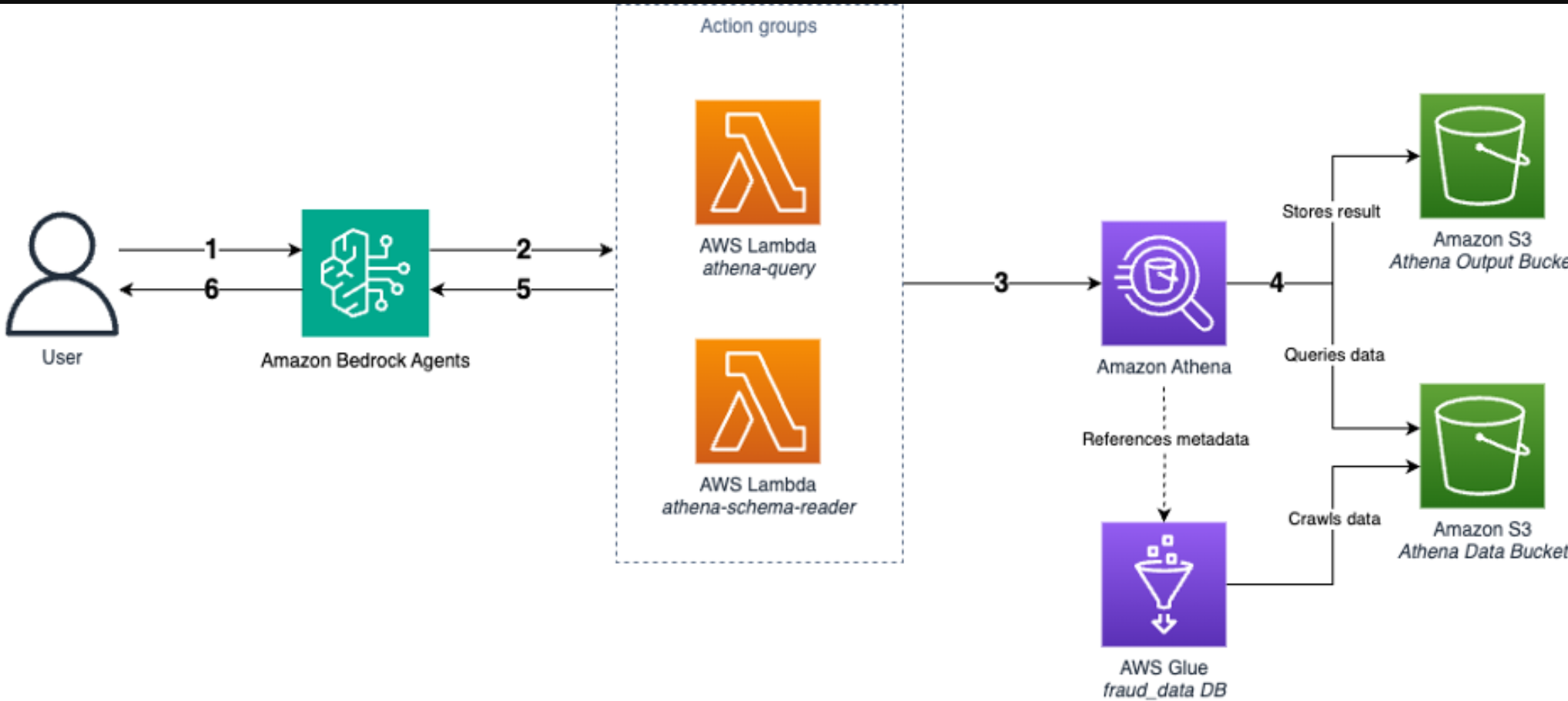
The workflow is as follows:
- A user asks questions to Amazon Bedrock Agents.
- To serve the user’s questions, the agent determines the appropriate action to invoke:
- To execute the generated query with confidence, the agent will invoke the athena-query
- To confirm the database schema first, the agent will invoke the athena-schema-reader tool:
- Retrieve a list of available tables using its
/list_tablesendpoint. - Obtain the specific schema of a certain table using its
/describe_tableendpoint.
- Retrieve a list of available tables using its
- The Lambda function sends the query to Athena to execute.
- Athena queries the data from the Amazon Simple Storage Service (Amazon S3) data bucket and stores the query results in the S3 output bucket.
- The Lambda function retrieves and processes the results. If an error occurs:
- The Lambda function captures and formats the error message for the agent to understand.
- The error message is returned to Amazon Bedrock Agents.
- The agent analyzes the error message and tries to resolve it. To retry with the modified query, the agent may repeat steps 2–5.
- The agent formats and presents the final responses to the user.
The following architecture diagram shows this workflow.
Implementation walkthrough
To implement the solution, use the instructions in the following sections.
Intelligent error handling
Our agentic text-to-SQL solution implements practical error handling that helps agents understand and recover from issues. By structuring errors with consistent elements, returning nonbreaking errors where possible, and providing contextual hints, the system enables agents to self-correct and continue their reasoning process.
Agent instructions
Consider the key prompt components that make this solution unique. Intelligent error handling helps automate troubleshooting and refine the query by letting the agent understand the type of errors and what to do when error happens:
The prompt gives guidance on how to approach the errors. It also states that the error types and hints will be provided by Lambda. In the next section, we explain how Lambda processes the errors and passes them to the agent.
Implementation details
Here are some key examples from our error handling system:
These error types cover the main scenarios in text-to-SQL interactions:
- Query execution failures – Handles syntax errors and table reference issues, guiding the agent to use the correct table names and SQL syntax
- Result retrieval issues – Addresses permission problems and invalid column references, helping the agent verify the schema and access rights
- API validation – Verifies that basic requirements are met before query execution, minimizing unnecessary API calls
Each error type includes both an explanatory message and an actionable hint, enabling the agent to take appropriate corrective steps. This implementation shows how straightforward it can be to enable intelligent error handling; instead of handling errors traditionally within Lambda, we return structured error messages that the agent can understand and act upon.
Dynamic schema discovery
The schema discovery is pivotal to keeping Amazon Bedrock Agents consuming the most recent and relevant schema information.
Agent instructions
Instead of hardcoded database schema information, we allow the agent to discover the database schema dynamically. We’ve created two API endpoints for this purpose:
Implementation details
Based on the agent instructions, the agent will invoke the appropriate API endpoint.
The /list_tables endpoint lists the tables in a specified database. This is particularly useful when you have multiple databases or frequently add new tables:
The /describe_table endpoint reads a specific table’s schema with details. We use the “DESCRIBE” command, which includes column comments along with other schema details. These comments help the agent better understand the meaning of the individual columns:
When implementing a dynamic schema reader, consider including comprehensive column descriptions to enhance the agent’s understanding of the data model.
These endpoints enable the agent to maintain an up-to-date understanding of the database structure, improving its ability to generate accurate queries and adapt to changes in the schema.
Demonstration
You might not experience the exact same response with the presented screenshot due to the indeterministic nature of large language models (LLMs).
The solution is available for you to deploy in your environment with sample data. Clone the repository from this GitHub link and follow the README guidance. After you deploy the two stacks—AwsText2Sql-DbStack and AwsText2Sql-AgentStack—follow these steps to put the solution in action:
- Go to Amazon Bedrock and select Agents.
- Select AwsText-to-SQL-AgentStack-DynamicAgent and test by asking questions in the Test window on the right.
- Example interactions:
- Which demographic groups or industries are most frequently targeted by fraudsters? Present aggregated data.
- What specific methods or techniques are commonly used by perpetrators in the reported fraud cases?
- What patterns or trends can we identify in the timing and location of fraud incidents?
- Show the details of customers who have made transactions with merchants located in Denver.
- Provide a list of all merchants along with the total number of transactions they’ve processed and the number of those transactions that were flagged as fraudulent.
- List the top five customers based on the highest transaction amounts they’ve made.

- Choose Show trace and examine each step to understand what tools are used and the agent’s rationale for approaching your question, as shown in the following screenshot.

- (Optional) You can test the Amazon Bedrock Agents code interpreter by enabling it in Agent settings. Follow the instructions at Enable code interpretation in Amazon Bedrock and ask the agent “Create a bar chart showing the top three cities that have the most fraud cases.”

最佳实践
基于我们对动态模式发现和智能错误处理的讨论,以下是优化代理文本到SQL解决方案的关键实践:
- 使用动态模式发现和错误处理——使用/list_tables和/descripte_table等端点,允许代理动态适应您的数据库结构。如前所述,实施全面的错误处理,使代理能够有效地解释和响应各种错误类型。
- 平衡静态和动态信息——尽管动态发现功能强大,但考虑在提示中包含关键、稳定的信息。这可能包括数据库名称、键表关系或很少更改的常用表。达到这种平衡可以在不牺牲灵活性的情况下提高性能。
- 根据您的环境进行定制——我们设计的示例始终调用/list_tables和/descripte_table,您的实现可能需要调整。考虑您的特定数据库引擎的功能和限制。您可能需要提供除列注释之外的其他上下文。考虑包括数据库描述、表关系或常见查询模式。关键是通过扩展元数据、自定义端点或详细说明,为您的代理提供尽可能多的有关数据模型和业务上下文的相关信息。
- 实施强大的数据保护——尽管我们的解决方案使用Athena,它本身不支持写操作,但在您的特定环境中考虑数据保护至关重要。从提示中的明确说明开始(例如,“仅限只读操作”),并考虑其他层,如亚马逊基岩护栏或基于LLM的审查系统,以确保生成的查询与您的安全策略保持一致。
- 实施分层授权——为了在使用Amazon Bedrock代理时增强数据隐私,您可以在代理处理敏感数据之前使用Amazon Verified Permissions等服务来验证用户访问权限。将用户身份信息(如JWT令牌)传递给代理及其关联的Lambda函数,从而对预构建的策略进行细粒度的授权检查。通过基于“已验证权限”决策在应用程序级别实施访问控制,您可以减轻意外的数据泄露,并保持强大的数据隔离。要了解更多信息,请参阅AWS安全博客中的Amazon Bedrock Agent分层授权增强数据隐私。
- 为您的代理确定最佳编排策略——Amazon Bedrock为您提供了一个定制代理编排策略的选项。自定义编排使您可以完全控制希望代理如何处理多步骤任务、做出决策和执行工作流。
通过实施这些实践,您可以创建一个文本到SQL的解决方案,该解决方案不仅可以充分利用AI代理的潜力,还可以维护数据系统的安全性和完整性。
结论
总之,使用AWS服务实现可扩展的代理文本到SQL解决方案为企业工作负载提供了显著的优势。通过使用自动模式发现和强大的错误处理,组织可以有效地管理具有大量表和列的复杂数据库。基于代理的方法促进了动态查询生成和细化,从而提高了数据查询的成功率。我们想邀请您今天尝试这个解决方案!访问GitHub深入了解解决方案的细节,并按照部署指南在您的AWS帐户中进行测试。
- 登录 发表评论
- 23 次浏览
最新内容
- 1 month 2 weeks ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago