
本文仅考虑我和我的团队解决业务问题的方法之一。 它不是一个非常技术性的帖子,所以我不会详细介绍具体的编码细节,但我会指出一些有用的参考资料和库。
在数据处理成为一个越来越庞大的主题的世界中,能够快速有效地提取信息可以成为一项重要的业务优势。 信息提取的最大挑战之一是来源和文档格式的多样性。
例如,在金融领域,有大量的扫描文件,如工资单、银行对账单、贷款协议等。 这些文档可以在没有一致结构的情况下呈现信息,因此提取重要信息可能很耗时。
出于这个原因,我们利用涉及计算机视觉和 NLP 技术的不同解决方案来开发一种能够识别问题:答案格式中的信息并自动提取它的方法。 例如,如果有一个员工姓名为“姓名:Juan”的文档字段,我们的模型需要能够将该信息提取为 {Question: “Name”, Answer: “Juan”}
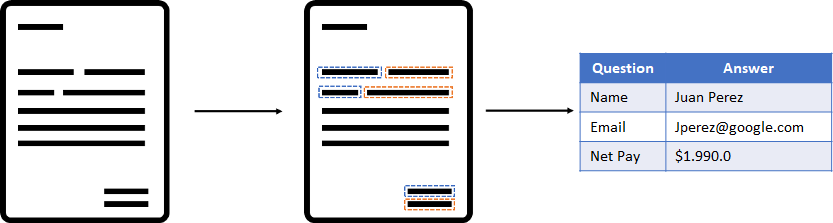
在本文中,我想展示我们为实现模型而执行的不同步骤:
- 构建数据集
- 微调预训练的文本和布局模型
- 定义问题:答案关系算法
构建数据集
为了测试我们的方法,我们编译了一组从互联网下载的 32 张工资单图像。 工资单是一份文件,其中包含有关工资的详细清单和特定工作的详细信息。 它们具有员工姓名、日期和支付金额等值。 该模型使用在互联网上找到的 32 种不同的工资单文件(jpg 格式)进行训练。
光学字符识别(OCR)
建立模型的第一步是能够以计算机可以理解的格式提取每张工资单的内容。 为此,我们使用 OCR(光学字符识别)。 OCR 软件允许将扫描文档或图片中的数据捕获为文本。 有许多 OCR 工具。 对于这个项目,我们使用了 Cloud Vision API。 此工具接收图像并返回文本元素列表及其与图像的相对坐标(通常称为“边界框”)。
标签工作室(Label-Studio)
提取所有字段和边界框后,需要对每个字段进行标注,为此我们使用了一个名为 Label-Studio 的注释工具,您可以在此处查看文档和网站,OCR 返回的每个框都被手动分类为 以下选项:标题、问题、答案。

微调布局LM(LayoutLM)模型
类 BERT 模型已被证明是各种 NLP 任务中最先进的技术,并且在尝试使用文档布局和视觉信息提取文本信息时它们并不落后。
LayoutLM 是一种简单但有效的文本和布局预训练方法,用于文档图像理解和信息提取任务。您可以在此处查看更多信息:
LayoutLM:用于文档图像理解的文本和布局的预训练https://arxiv.org/abs/1912.13318
近年来,预训练技术已在各种 NLP 任务中得到成功验证。尽管…
arxiv.org
我们的模型将是使用我们已经描述的数据集的该模型的微调版本,您可以在 hugginface.co 存储库中找到预训练的模型。
多模式 的文档 AI(文本+布局/格式+图像)预训练 Microsoft Document AI | GitHub LayoutLMv2 是一个…
https://huggingface.co/microsoft/layoutlmv2-base-uncased
模型的输入是:
- 标记 id:由 OCR 工具检测并由模型标记器嵌入的文本
- Box:包含文本项在框形上的相对坐标的列表(x0,y0,width,height)
- 标签:(“标题”,“问题”,“答案”)
结果
训练模型后,我们得到以下分数:
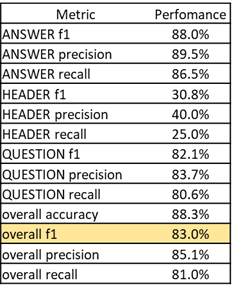
我们得到了 83% 的总体 f1 分数,这可能会更好,但考虑到我们训练数据集的大小,结果还不错,我们可以看到标题标签的性能较低,这可能是由于注释不佳或 只是缺少常规标题。
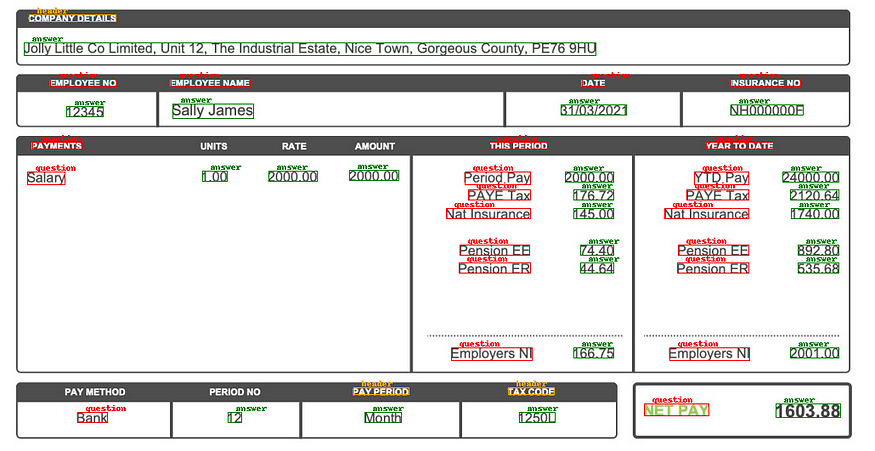
LayoutLM模型分类
定义问题:答案关系算法
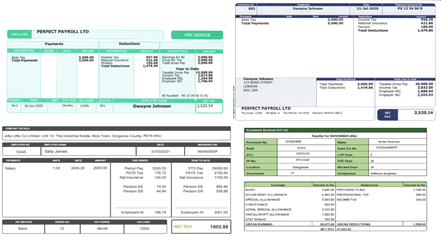
一旦定义了每个框的类别,下一个任务就是将每个问题与其各自的答案相关联,例如,在上图中,有一个问题:“员工编号”。 和答案:“12345”,但模型还没有连接这两个项目的东西。
为了连接这些项目,我们采用迭代方法,遍历答案,然后根据框之间的距离及其垂直/水平对齐的组合,我们对问题和答案之间的所有潜在关系进行排序。

运行算法找到键值项后,我们得到下表:

结论
我们能够使用 OCR 从扫描的文档中提取文本,然后使用 LayoutLM 模型对其进行标记,并将其转换为结构化格式。 总的来说,结果是可以接受的,如果我们使用更大的训练集,性能可能会更好,文档的质量和 OCR 工具的性能也会影响最终结果。
接下来要尝试什么
- 获取更大的数据集
- 尝试不同的 OCR 工具
- 改进键值算法
原文:https://medium.com/@simsagues/document-information-extraction-using-ocr…
最新内容
- 6 days 8 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago