
逐步从单一数据湖转移到分散的 21 世纪数据网格。
(另请查看后续文章:三种数据网格)
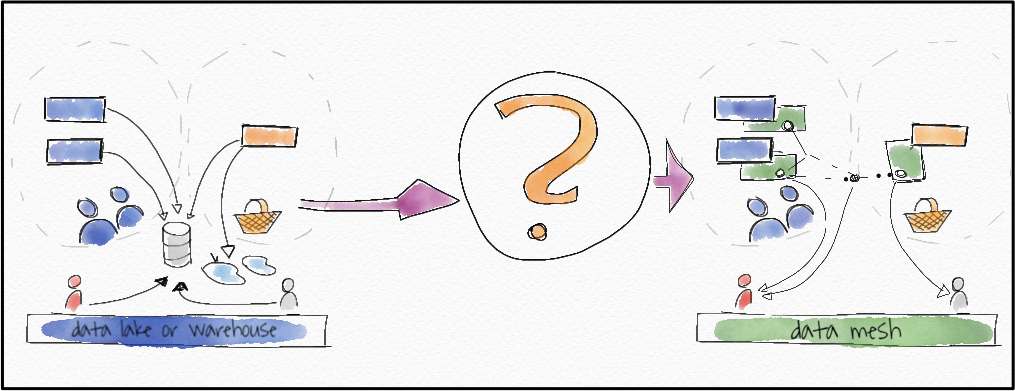
Left: data lakes with central access, on the right: user accessing data from teams domain teams providing a great data product. (all images by the author)
21 世纪的数据格局如何? ThoughtWorks 的 Zhamak Deghani 给出了一个漂亮的、对我来说令人惊讶的答案:它是去中心化的,与我们目前在几乎所有公司中看到的都非常不同。答案被称为“数据网格”。
如果您像我一样感受到公司当前数据架构的痛苦,那么您想迁移到数据网格。但是怎么做?这就是我在本文中探索的内容。
但首先,简要回顾一下数据网格。
Twitter 数据网格总结
现代软件开发需要一种分散的数据方法。数据必须被其生成团队视为产品;他们需要为它服务;分析团队和软件团队需要改变!
更长的总结
DDD、微服务和 DevOps 在过去十年改变了我们开发软件的方式。然而,分析部门的数据并没有赶上这一点。为了在采用现代开发方法的公司中加快基于数据的决策,分析和软件团队需要改变。
- (1) 软件团队必须将数据视为他们服务于其他所有人(包括分析团队)的产品
- (2) 分析团队必须以此为基础,停止囤积数据,而是按需提取数据
- (3) 分析团队必须开始将他们的数据湖/数据仓库也视为数据产品。
如果简短的摘要对您有吸引力,让我带您了解如何从您当前的起点实际进入数据网格。我们将通过一个示例,在途中经过遗留的单体、数据湖和数据仓库。我们一步一步地从我们的“旧”系统转移到这个新系统。
旁注:将数据湖称为“旧”对您来说可能看起来很奇怪,对我来说也是如此。时任 Pentaho 的首席技术官/创始人的 James Dixon 仅在 10 年前就设想了数据湖的概念。然而,围绕数据湖的核心转变,即软件、DevOps、DDD、微服务也是在过去十年才出现的。因此,我们确实需要迎头赶上,因为在这些趋势完全改变我们开发软件的方式之前,中央全能数据湖是一个老问题的答案。此外,一个全能的数据湖并不是 Dixon 最初想象的那样。
我们从一个典型的电子商务业务微服务架构示例开始。
- 我们展示了这个示例在数据湖/数据仓库架构中的样子(A 点),
- 然后与数据网格架构进行比较(C 点)
- 然后举这个例子,但是添加一个“数据湖作为数据节点”(B),因为这实际上是我们从 A 到 C 的方式。
- 我们考虑应该启动我们从 A 到 C 的转变的痛点。
- 我们从 A -> B -> C 一步一步来。
- 我们会考虑首先移动哪些部件的细节。
- 我们考虑可能的问题以及如何处理它们。
- 我们考虑另一种解决问题的方法。
具有数据网格架构的电子商务微服务架构

E-commerce business modeled with three operational microservices.
这是一个基本的微服务体系结构,有两个域,一个“客户域”和一个客户API,一个CRM系统,“订单域”和一个订单API。这些服务是运营服务,它们运营着电子商务网站。这些API允许您在order API中创建订单,在CRM系统中的customer API中创建客户,检查信用额度等等。它们可能是REST API,再加上一些事件流、一些发布子系统,具体的实现并不重要。
旁注:对我们来说,订单和客户是不同的领域。这意味着这些领域的语言可能会有所不同。从团队2,即订单团队中看到的“客户”只有一个意思,即通过客户id识别的人,他们刚刚在网站上买了东西。在团队1中,含义可能有所不同。他们可能会考虑客户从CRM系统中的实体,它可以将状态从仅仅“领先”改变为“购买”客户,只有第二个在团队2方知道。
团队1拥有客户域。他们对这个领域了如指掌。他们知道什么是潜在客户,从潜在客户到实际客户的过渡状态如何等等。另一方面,团队2知道关于订单域的一切。他们知道被取消的订单是否可以恢复,网站上的订单漏斗是什么样子,等等。团队可能对另一个领域略知一二,但不是所有的细节。它们不是自己的。
这两个域都会生成大量数据作为副产品。组织中的很多人都需要这些数据。让我们看看其中的一些:
- 数据工程师:需要订单和客户数据进行转换,以生成OLAP多维数据集基础数据、模块化数据;在开始进行转换之前,他还需要数据来测试和理解它。
- 营销人员:需要按商品类别对订单进行概述,以便每天动态地扩展他们的活动。
- 数据科学家:正在构建推荐系统,因此需要所有订单数据始终保持最新,以训练他的系统。
- 管理层:希望对整体增长进行总体概述。
针对这些需求的数据湖/数据仓库解决方案将以类似的形式出现。
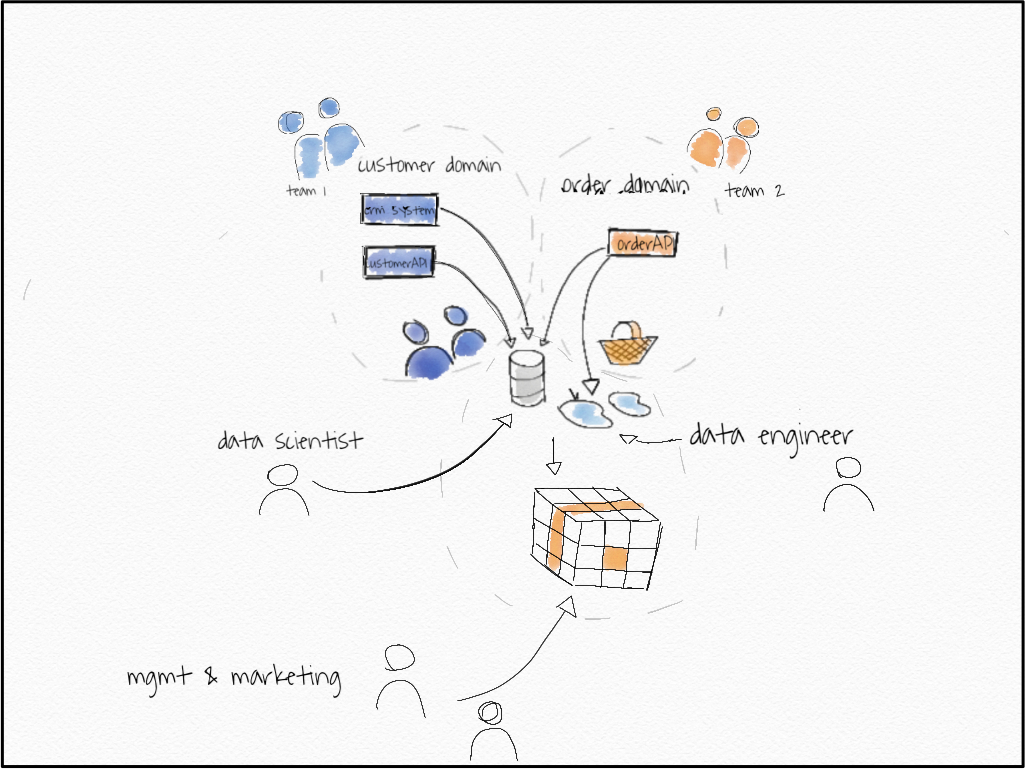
一个由数据工程师组成的中央团队很可能会通过 ETL 工具或流解决方案提供所有数据。 他们将拥有一个中央数据湖或数据仓库,以及一个用于营销和管理的 BI 前端。
数据科学家可能会直接从数据湖中获取数据,这可能是他们访问数据的最简单方式。
我们看到这种架构有哪些可能的问题?
- 这种架构在数据工程团队中造成了中心瓶颈
- 它可能会导致领域知识在通过其中心枢纽的途中丢失,
- 并对所有这些不同的、异构的需求进行优先排序。
到目前为止这么好。 那么数据网格方法呢?
这是具有数据网格架构的同一个电子商务网站。

Green: new data-APIs. Bottom: Mgmt with straight BI tool access, marketing with data form data-API, left: data scientist with data from data-API
发生了什么变化?首先,数据科学家和营销人员可以访问源域中的数据!但还有更多。
旁注:数据网格架构的关键是获取数据 DATSIS。可发现的、可寻址的、可信赖的、自描述的、可互操作的和安全的。
我会提到以下几点。
让我们逐步了解要点
- 客户域:客户域有两个新的只读“数据 API”。对于示例而言,可能只有一个或两个 API 并不重要。在这两种情况下,客户域都将确保将 CRM 系统和客户 API 中的“客户”概念联系起来。
- 订单域:订单域获得了一个新的数据API,即订单数据API。
- 客户数据 API 数据示例:客户数据 API 可能有多个端点:
allCustomers/:每行为一个“客户”提供数据。
stats/ :使用诸如“Num customers: 1,000, Num Lead: 4,000;客户电话:1,500,中小企业客户联系:500,中小企业客户:600”
更多端点。
- order-data-API 数据示例: order-data-API 可能有多个端点:
allOrderItems/:每行提供一个订单行项目。
allBuckets/:每行提供一个存储桶,它是订单项的集合。
stats/:提供数据,如“订单:1,000,000,2019 年订单:600,000 平均桶容量:30 美元”; stats 端点可能采用日期范围、年份等参数。
- 数据 API 是只读的。其他人不是。 * Data API 将 DATA 作为他们的产品,非常完美。您可以将 SLA 固定到它们,检查它们的使用情况。 API 被建模为它们自己的 API,我们不会滥用 Order API 作为数据 API。因此,我们可以分别关注不同的用户。
- *-data-APIs 可以以任何合理的形式实现,例如:
- 作为位于 AWS S3 存储桶中的 CSV/parquet 文件(端点由子文件夹分隔,API 由顶级文件夹分隔)(可寻址)
- 作为通过 JSON/JSON 行的 REST API
- 通过中央数据库和模式。(是的,我知道“中央”不是“去中心化”)
- Schemata 位于数据旁边。 (自我描述)。
- CRM 系统可以同时被视为操作 API 和数据 API,但您确实希望将其包装为符合您设置的标准。否则,您将失去数据网格架构的任何好处。
- 所有数据 API 应具有相同的格式。这让消费变得非常容易! (可互操作且安全)
- 数据 API 可以通过 Confluence 页面或任何更高级的表单或数据目录发现,我们知道哪个团队拥有该数据并可以在下游使用它。 (可发现)
- 有一个新域。数据工程师刚刚获得了自己的商业智能建模数据域。他知道他正在为一个利益相关者服务。该域被包装为服务,仅服务于一个利益相关者。通过这种方式,数据工程师可以将管理需求集中在建模数据上并适当地确定其优先级。
- 营销团队可以直接从源头访问他们的“按类别订购数据”,因为它是特定领域的。
- BI 系统来自数据库,我们将其包装为数据服务。为什么?因为我们只为管理提供服务,他们只想要我们无法从 API 获得的建模和连接数据,这很好。整体增长听起来像是一个与某个领域无关但跨领域的实体。
让我们来看看数据用户的需求以及发生了什么变化
- 数据工程师:数据工程师已经从数据 API 接收到大部分建模数据。这意味着,不会丢失任何领域知识。他有 SLA 可以查看并确切知道他得到了什么。他可以轻松地使用用于两种 data-* API 的一种标准 API 以任何方式组合数据并将其放入他自己的数据服务中。他确切地知道向谁索取特定数据,并且所有数据都记录在同一个地方。
- 营销人员:可以直接从订单源中提取他们需要的数据,即使数据工程师数据服务(还没有?)提供该信息。因此,如果他们想要更改该数据,他们可以直接去找具有领域知识的人。如果他们想合并“漏斗数据”,他们可以询问真正知道那是什么的团队!
- 数据科学家:可以直接使用经过测试并具有 SLA 的 order-data-API,以应对他将一直进行的大量阅读。数据在一秒钟内就在那里,不需要破解数据库,这是我见过的不止一次。它已经投入生产,可以立即纳入推荐系统。数据科学家很容易实现他们的 CD4ML 版本。
- 管理层:仍然通过他们的商业智能系统获得他们的总体观点。但是,根据领域的不同,可能的更改可以在三个地方实现,而不仅仅是一个。中央数据团队不再是瓶颈。
数据团队仍然在那里,但可能的负载被适当地分配给分散的参与者,无论如何这些参与者更适合这项工作。但是,数据团队也有自己的服务。怎么可能看起来完全一样?让我们看看数据湖如何仍然适合数据网格以及可能的痛点。如果你从一个开始,就会有一个重要的过渡状态。
我们的数据湖,只是另一个节点
在三种情况下,现在不一定是中央数据湖或仓库仍然有意义:
如果我们想结合两个数据域来建模中间的东西,这不能发生在一个域中,而应该发生在一个新的域中。
如果我们想整合市场数据等外部数据。外部数据通常不符合我们的标准,因此我们需要以某种方式包装它们。
如果我们从 A -> C 点过渡,我们不仅会丢弃我们的数据湖,还会降低它的复杂性。
痛点
什么时候应该考虑迁移到数据网格?首先,如果您对自己的结构感到满意,如果您对公司使用数据做出决策的方式感到满意,那么不要这样做。但是,如果您感到以下任何痛苦,则解决方案是数据网格。
- 如果您将域复杂性与微服务/域驱动设计相结合,您可能会觉得事情过于“复杂”,以至于中央团队无法立即正确地提供数据。
- 如果确实如此,您认为将数据导入数据仓库的成本很高,因此您忽略了要导入的对个人用户有价值的数据源。这些应该单独提供服务,并且是“作为数据网格节点剥离”的完美候选者。
- 你还没有关闭数据 -> 信息 -> 洞察力 -> 决策 -> 行动回到数据的循环。
- 您是数据 -> 连续智能周期中的数据速度以周和月为单位,而不是几天或几小时。
- 您已经在“将数据转换尽可能靠近数据用户”;这是我们目前正在做的事情,通常这是数据 -> 信息 -> 洞察力 -> 决策 -> 行动 -> 数据管道中出现瓶颈的迹象。这可以被认为是一个中间阶段,有关更多信息,请参见最后一段。
从单一数据湖到数据网格
让我们面对现实吧。数据仓库或数据湖,以及负责导入和建模数据的中央分析团队。这是一个遗留的整体,团队从中导入数据时没有API,可能有直接的数据库访问和大量的ETL作业、表格等。也许我们在新的领域中获得了一些新的微服务……让我们保持简单但通用的方式。
旁注:我喜欢Michael Feathers对遗留代码的定义:没有测试的代码。这就是我的意思,大的,丑陋的,不快乐的代码,没有人喜欢使用。
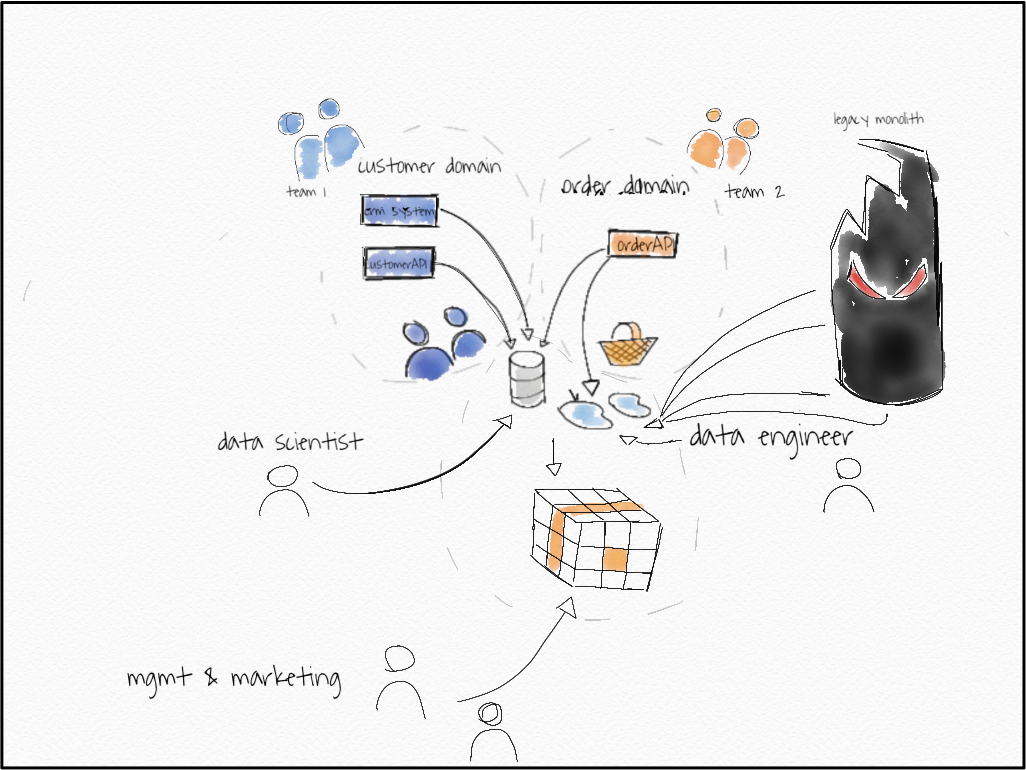
请记住,目标是逐步获取所有数据 DATSIS。
- 第 1 步:(可寻址数据)重新路由数据湖数据并更改 BI 工具访问权限。
所有数据当前都通过数据湖消费和服务。如果我们想改变这一点,我们首先需要在那里打开大开关,同时为未来的迁移修复可寻址性的标准化。
为此,让我们尝试使用 S3 存储桶。因此,我们将标准化固定为:
示例:可以通过以下方式访问 {name}-data-service:
- - s3://samethinghere/data-services/{name}
详细地说,所有服务都至少有一个端点,即默认数据端点。其他端点是子文件夹,例如:
- s3://samethinghere/data-services/{name}/default
- s3://samethinghere/data-services/{name}/{endpoint1}
- s3://samethinghere/data-services/{name}/{endpoint2}
架构版本位于:
- s3://samethinghere/data-services/{name}/schemata/v1.1.1.datetoS.???
我们使用格式为“vX.Y.Z”的语义版本,日期为秒。
数据文件以“vX.Y.Z.datapart01.???”的形式表示,每个文件限制为 1000 行,以便于使用。
我们将数据湖重新路由到它的新“地址”并更改 BI 工具访问权限。
s3://samethinghere/data-services/data-lake/default
s3://samethinghere/data-services/data-lake/growthdata
s3://samethinghere/data-services/data-lake/modelleddata
???
这对组织的其他人来说还没有改变,我们需要给他们访问权限。
- 第 2 步:(可发现性)创建一个空间来查找我们的新 data-* 源。
我们可以通过在我们的知识管理系统中创建一个页面来实现最简单的可发现性形式(即 confluence/您的内部 wiki,...)。
好的,所以现在除了当前使用数据湖的人之外的新人可以找到数据。现在我们可以开始将节点添加到我们的数据网格中,我们可以采取任何一种方式,通过打破一个闪亮的新微服务或打破那些令人讨厌的旧旧片段之一。
让我们首先考虑微服务案例。
- 第 3 步:开发一个新的微服务。
拆分服务的重点是将所有权交给创建数据的领域团队,例如,您可以让分析团队中的某个人加入负责的领域团队。现在,让我们以“订单团队”为例。
我们创建新的订单数据 API。修复一组基本的 SLA,并确保遵守您为数据湖设置的标准。我们现在有两个数据服务:
s3://samethinghere/data-services/data-lake/default
s3://samethinghere/data-services/data-lake/growthdata
s3://samethinghere/data-services/data-lake/modelleddata
s3://samethinghere/data-services/order-data/default
s3://samethinghere/data-services/order-data/allorderitems
s3://samethinghere/data-services/order-data/stats
将新服务放入可发现性工具中。
第二种选择是让中央分析团队创建这个数据服务,在这种情况下,所有权仍然存在。但至少我们分离了服务。
- 第 4 步:打破传统作品。
遗留系统通常不像闪亮的新微服务那样好用。通常,您将拥有某种数据库表,您甚至不知道从其中获取数据,从某些服务器或任何其他形式的遗留数据中获取一些 CSV,没有良好记录和标准化的接口。
没关系。你现在可以保持这种状态。您已经有了某种方式将该数据导入您的数据仓库或数据湖,因此将其拆分出来并将其表示为数据服务。
例如,您可以从:
源数据库 — ETL 工具 → 数据湖中的原始数据 → 数据湖中的转换数据
围绕前两个阶段进行总结,并使用标准化:
(源数据库 - ETL 工具 → 数据湖中的原始数据 → S3 存储桶)= 新数据服务
(新数据服务的S3 Bucket)——ETL工具→将数据导入数据湖→数据湖转换数据
这样,当你转移服务时,域团队只需要切换主干,依赖用户就可以切换到新的数据消费方式,甚至在域团队获得所有权之前。
- 第 5 步:(可发现性)切换可发现性和 BI 工具源。
现在开始将您的数据服务推送给普通受众以获得快速反馈,让营销团队找到您已经突破的来源。然后将 BI 工具切换到现在的两个数据服务,而不仅仅是一个。
然后,您可以考虑关闭对数据湖服务中订单数据的支持。
- 第 6 步:迁移所有权。
如果你在这里,恭喜,你已经打破了中央数据湖的第一部分,现在你需要确保在这些服务的新功能请求流入之前,所有权也已经转移。你可以这样做:
- 通过迁移一些人,连同服务到域团队
- 也许通过为新服务创建一个新团队
- 只需将服务迁移到域团队
- 第 7 步:继续。
包装,包装,包装,打破越来越多的服务。优雅地推出旧部分并用新的 API 替换它们。开始收集分布式服务的新功能请求。
到目前为止,您的中央数据湖将变得非常小,仅包含已连接和建模的数据,如果您开始转移人员,您的数据团队也会如此。
- 第 8 步:(TSIS)使其值得信赖、自我描述、可互操作且安全。
构建通用数据平台。这可能意味着每个人都可以使用库将文件放置在正确的位置或任何其他更复杂的工具集中。无论团队中有什么重复,您都可以将大部分内容掌握在中央手中。例如,如果您很快注意到营销和销售人员不容易访问 AWS S3 文件,您可能会决定从 S3 切换到可通过 EXCEL 访问的中央数据库等。
在这种情况下,您需要一个库来通过简单的升级进行切换,而不会给团队带来太多麻烦。例如,在 AWS 设置中,您可以使用通用的“data-service-shipper”创建一个 lambda 函数,该函数负责:
- 获取版本化模式并将它们映射到中央数据库中的数据库模式。
- 将数据传送到数据库中的适当模式中。
这样,域团队除了升级他们的“库”之外几乎没有任何努力。其他选项可能包括创建一个通用 REST API,您可以用它发出数据及其位置的信号,并让 API 处理其余部分,例如将 CSV、parquet 等转换为单一格式。
我首先选择哪部分数据进行突破?
因此,与微服务一样,从单体应用开始的最佳方法是在您感到某种“痛苦”时分解部分。但是我们先突破哪一部分呢?这是基于三个考虑的判断电话:
- 成本:分解数据有多难?
- 好处:数据多久更改一次?
- 好处:数据对您的业务有多重要?
这些好处间接表明,您将能够收集多少真实数据服务的用例,因为不断变化的数据意味着数据服务的变化,而数据的重要性意味着许多人希望从该数据服务中获得洞察力.
如果你权衡这些事情,你可能会得出不同的结论。例如,在我们的示例中,客户域可能是一个很好的起点,因为此类数据很可能经常更改。但是,有时它不如订单数据重要,另一方面,订单数据可能难以突破,这取决于您已经在其上放置了多少 1000 个 ETL 作业。
如果您有一个起点,那么您的道路上仍有垫脚石。
垫脚石
目前,作为副产品提供数据的团队没有适当关注该数据的动机,主要是因为该数据的潜在“利益相关者/消费者”没有直接反馈。
这是必须改变的,你必须把它作为一个核心部分来处理。这可能就是为什么Zhamak Deghani建议您使用特定的用例,识别用户,并组建一个新团队,只关心特定的用户。一、 另一方面,我不明白为什么当前的订单团队不能担任这个角色。诚然,这种转变有点困难,但公司必须花费的资源要容易得多,而且可能更容易销售。
如果你无法让数据生成团队跳上这列火车,你有两个选择:
- 创建一个新团队并接受一个用例
- 利用现有的中心团队担任该角色,并收集数据。检查数据服务的需求及其创造的价值,然后决定将其推广到哪里。
最后,让我们探讨一下这种体系结构的可能替代方案。
还有其他选择吗?
我试图想出一个替代方案,但意识到这更像是一个由不同实现组成的矩阵。
数据网格的关键概念是分散所有权,我们可以这样说,因为域团队通常认为他们的数据是他们真正拥有的副产品。因此,数据湖是原始数据的集中所有权。
如果我们现在区分原始数据和转换数据,我们可以看到四种不同的数据架构。我们还可以看到从数据湖到数据网格的2-3种不同方式。
Ownership of raw & transformed data can both be central or decentralized. This produces four quadrants with a variety of solutions.
如果从“数据湖”移动到“B 点”,然后再到完整的数据网格,我们在上面所描述的内容。
然而,第二种选择是首先实现去中心化的“转换数据所有权”,然后可能考虑转向完整的数据网格。
去中心化转换后的数据所有权如何?
- 数据湖仍然可以导入所有“原始数据”
- 然后,靠近决策者的数据知识丰富的用户可以访问原始数据,并在本地桌面 ETL 解决方案中进行转换。
- 原始数据也可以被推送到分散的数据仓库中,在那里,离用户更近的“某人”可以对该数据进行基本的 ETL。
- 当然,每个部门都可以有自己的小型数据团队为该部门做 ETL。
区别在哪里?在这种情况下,您可以收集大量需求,并锐化部门对数据的确切用例。像市场营销这样的部门通常更接近领域,然后是中间数据团队,所以你会在“领域语言”问题上获得一些优势,但不是全部。您仍然会在原始数据消耗方面保持中心瓶颈,而不是将“数据作为产品”推入领域团队。我认为这两者在未来的某个地方都是必要的。
结束
我试图写一篇比 Zhamak Deghani 更短的文章,但这似乎行不通。以下是我能找到有关数据网格架构信息的仅有的四个地方:
- Zhamak Deghanis 文章位于 Martin Fowlers 网站
- Zhamak 出现在 ThoughtWorks 播客第 30 集中,他们还提到了“将转型推向最终用户”的概念
- 数据工程播客第 90 集以数据网格为特色
- 以数据网格为特色的软件工程周刊播客
原文:https://towardsdatascience.com/data-mesh-applied-21bed87876f2
本文:
最新内容
- 1 day 17 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 2 weeks ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago