
内部数据治理:第 2 部分 │数据治理模型
在本系列的第一部分中,我们定义了数据治理并研究了导致大规模清理项目的失误。 在这篇文章中,我们将研究常见的数据治理模型,哪些模型最适合不同类型的组织。
没有单一的数据治理模型适合所有组织。 在当今的业务中通常会使用各种模型,其中一些模型更适合较小或较大的组织,而另一些模型更适合各种结构或业务需求。 让我们看一下四种最常见的数据治理模型:
1. 去中心化执行——单一业务单元
这种数据治理模型的特点是各个业务用户维护自己的主数据。 该模型确保数据由本地用户创建,这些用户通常是该主数据的消费者。

用户、好处和注意事项:
- 最适合小型组织,例如单个工厂或单个公司
- 提供更简单的数据维护
- 需要很大的敏捷性才能设置主数据
- 不与其他业务部门共享主数据
- 缩短主数据的生命周期
虽然这个模型更简单,并且可以更快地设置主数据,但除非管理得当,否则用户也会看到数据中的巨大不一致。以下策略和策略有助于确保该模型有效运行:
- 明确定义数据所有权并将其限制为组织内的少数专家
- 确保清楚地记录每个字段的填充方式以及每个字段的每个值的含义
- 如果预算允许,自动化工具可以控制数据的一致性
- 设置控制和审计以快速修复任何不一致
- 将数据治理组织的角色限制为构建流程和程序以及执行定期数据审计
2. 去中心化执行——多个业务单元
这种数据治理模型的特点是各个业务用户维护自己的主数据。在这种情况下,我们有多个业务部门与共享的客户、材料和供应商合作。

用户、好处和注意事项:
- 最适合涉及多个工厂和/或多个公司的中小型组织
- 提供更简单的数据维护
- 需要很大的敏捷性才能设置主数据
- 允许与其他业务部门共享主数据
- 缩短主数据的生命周期
如前所述,虽然这种数据治理模型更简单,并且可以更快地设置主数据,但它也可能导致数据不一致,在涉及多方时产生深远的影响。确实需要控制此模型,因为非常常见的副作用,如重复的主数据和不一致的数据导致不一致或无意义的报告可能会变得很麻烦。为了使该模型有效地工作,关键是:
- 利用可以确保数据一致性的自动化工具——与谁创建主数据无关
- 限制维护的字段数量,让其余字段根据各种自定义配置文件派生
- 确保清楚地记录每个字段的填充方式以及每个字段的每个值的含义
- 设置控制和审计以快速修复任何不一致
- 确定对部门和业务单位有影响的受控字段,然后对维护这些字段的人员实施严格控制,并明确定义每个字段的含义
- 数据治理组织的角色不应仅限于构建流程和程序以及执行定期数据审计,还应包括拥有自动化工具并使其适应业务需求
3. 集中治理——单个或多个业务单元
第三种数据治理模型的特点是单个或多个业务部门集中维护主数据。在此模型中,一个中央组织负责根据来自主数据消费者的请求设置主数据。
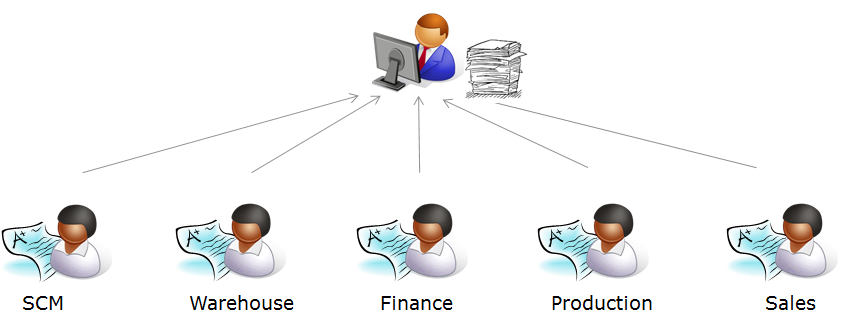
用户、好处和注意事项:
- 最适合拥有多个工厂和/或多家公司的大中型组织
- 带来复杂的数据需求
- 支持更长的主数据生命周期、更长的产品生命周期以及与客户和供应商的长期关系
- 涉及很多法律问题,必须根据政府法规等外部因素保持最新
- 允许与其他业务部门共享主数据
- 需要更大的系统环境,并需要将主数据分发到各种系统
这种数据治理模型可以确保对主数据的高度控制,但它的特点往往是建立主数据的延迟,需要一个正式的和更大的数据治理组织。同样,在此模型中,创建的主数据很可能是一致的,并且由于设置主数据的用户数量有限,因此引入更改和流程改进的速度更快。为了改进模型,组织应该:
- 构建自动化流程,为主数据维护流程提供透明度和可见性
- 为不同的主数据请求建立KPI,确保数据治理组织的规模根据需求进行扩展
- 确认业务和主数据团队之间进行有效沟通,以确保主数据规则适应业务和产品的变化
- 数据治理组织的作用不应仅限于流程和程序,还应包括维护主数据,包括调整流程以满足业务需求
4. 集中数据治理和分散执行
最后一种数据治理模型的特点是由一个集中的治理机构定义控制框架,各个企业创建其各自的主数据部分。
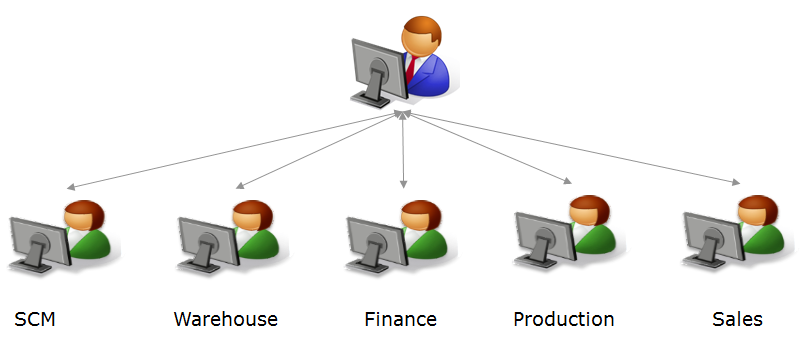
用户、好处和注意事项:
- 最适合拥有多家工厂和/或多家公司的大中型组织
- 带来复杂的数据需求,但需要灵活地创建主数据
- 支持更长的主数据生命周期、更长的产品生命周期以及与客户和供应商的长期关系
- 涉及很多法律问题,必须根据政府法规等外部因素保持最新
- 允许与其他业务部门共享主数据
- 需要更大的系统环境,并需要将主数据分发到各种系统
这种数据治理模型可以确保敏捷性,但同时组织必须确保在需要时实施适当的控制。在此模型中,数据治理组织和业务之间存在共同责任。
为了有效利用这种模式,组织必须:
- 识别影响跨部门和业务单位的受控字段,然后分配所有权以集中维护
- 构建自动化工具以避免源头重复数据删除
- 当发生冲突时,确保一个中央组织在各个部门和业务单位之间进行调解
- 自动化请求流程并利用自动化工具帮助本地企业持续管理数据
- 设置控制和审计以快速修复任何不一致
- 数据治理组织的作用不应仅限于流程和程序,还应包括维护部分主数据,包括进行流程调整以满足业务需求。在这里,主数据团队还对业务起到指导作用,以确保一致性
只要有适当的控制框架,无论是手动还是自动,所有四种数据治理模型都可以工作。所需的自动化水平取决于多种因素,包括:
- 公司规模
- 公司架构
- 公司主数据的复杂性
- 创建和更新的主数据记录数
- 主数据生命周期长度
- 从报告和法律角度看主数据的影响
了解有关数据治理的更多信息
想了解更多关于如何管理您的主数据? 有关 it.mds 的更多信息,请访问 NTT DATA Business Solutions Addstore。 您将深入了解 it.mds 如何使您的主数据面向业务,在整个业务中提供更好的治理,并通过业务驱动的工作流提供更高的合规性。
在本系列的第三部分中,我们将介绍数据治理的七个关键步骤。
原文:https://nttdata-solutions.com/us/local-blog/grc-and-security-local-blog…
最新内容
- 2 days 6 hours ago
- 1 week 3 days ago
- 2 weeks ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago