
十多年前,“软件正在吞噬世界”这句话描述了软件是如何迅速成为科技行业以外许多行业的中心的。主要的图书零售商、视频服务提供商、音乐公司、娱乐公司,甚至电影制作公司基本上都是软件公司。
这一趋势仍在持续。
将人工智能视为软件的延伸,赋予它新的和改进的功能,这通常是有用的。从这个意义上说,人工智能的发展可能会加速软件的激增速度。同样显而易见的是,它允许访问以前不可能的新功能。
随着新的软件功能为新产品让路,有理由问:这是如何改变价值游戏的?如果软件的激增使规模从巴诺到亚马逊,从百视达到网飞,那么人工智能在市场上会做什么?模型有价值吗?它在数据中吗?这个新政权的护城河在哪里?
本系列的第一篇文章,Generative AI有什么大不了的?是未来还是现在?(包含第1-4点),讨论了关于生成人工智能的有用观点的要点。在本文中,我们分享了对人工智能技术堆栈价值的观察,并重点讨论了一些技术护城河可能在哪里。
5) 人工智能技术和价值堆栈的地图和景观
到目前为止,不同的分析师和投资者已经发布了许多生成性人工智能景观数据。这些通常有助于了解一个新兴行业的现状以及不同参与者之间的比较。

Generative AI Landscape plots from Antler, Sequoia Capital, and NfX that contextualize Generative AI startups and capabilities
就我个人而言,我发现在技术堆栈(例如,应用程序/基础设施)中分解公司比在数据模式(例如,文本/图像)中分解更有价值。这些堆栈图区分了直接向用户销售的公司(应用程序级别)和他们所依赖的平台。因此,一个自然的起点是这三层的人工智能技术堆栈:
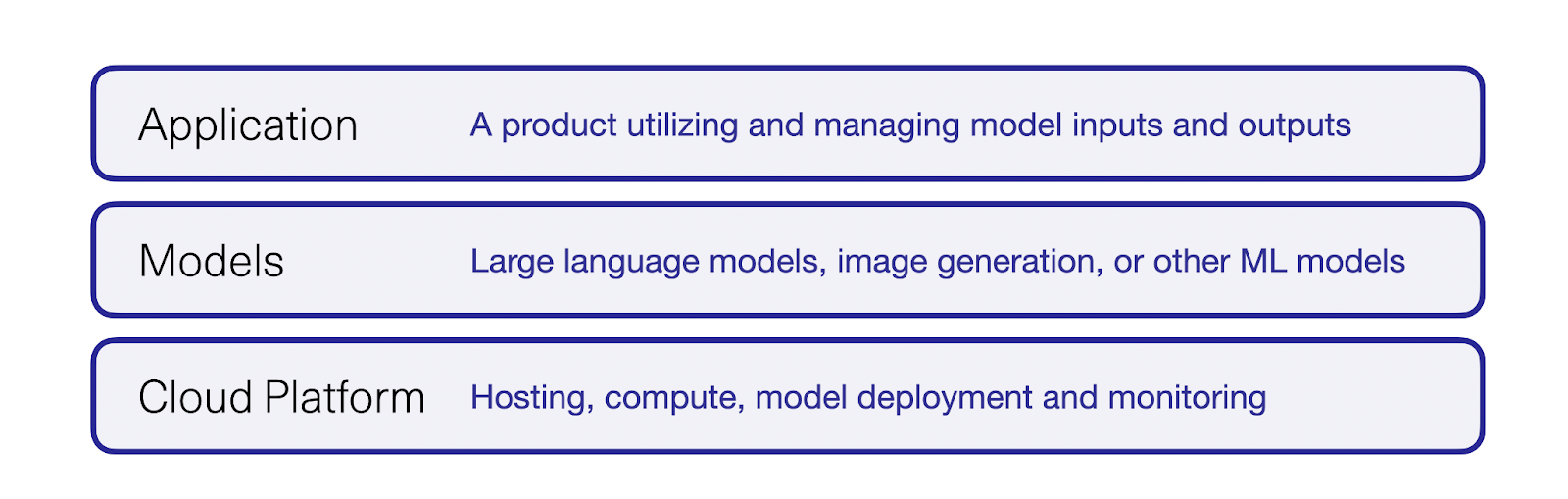
The three layers of Application, Models, and Cloud Platform are a reasonable starting point for tech stacks of AI product
应用程序、模型和云平台这三层是人工智能产品技术堆栈的合理起点
通过拆分模型层来区分专有模型和开源模型(考虑到Midtrivel没有开发人员可以用来在其上构建应用程序的API),你可以通过a16z获得生成性AI技术堆栈。
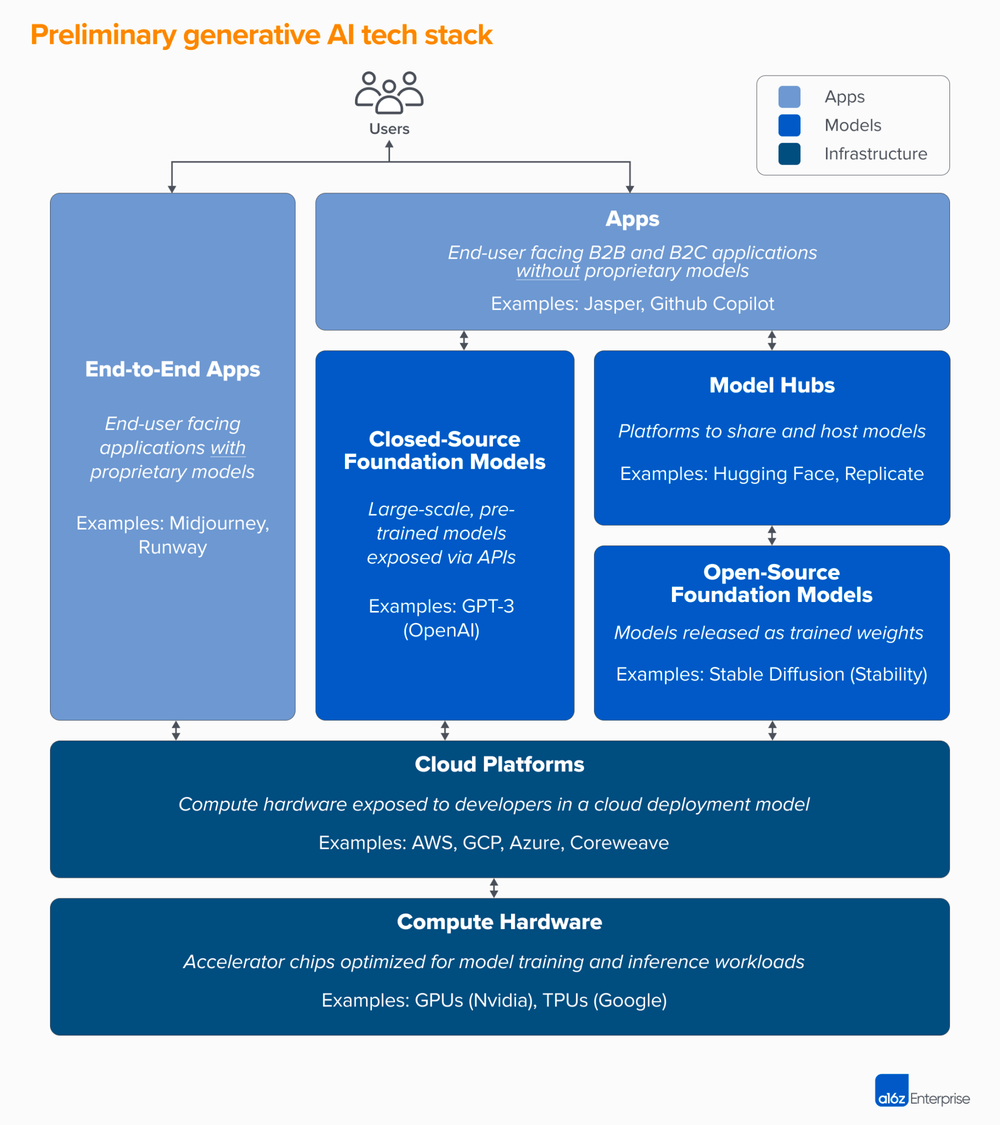
《谁拥有Generative AI平台?》中的Generative AI技术堆栈图?提供了不同类型车型以及如何提供这些车型的更多细节
在这个图中再添加几个组件是很有用的。
首先,模型从训练的数据中获得价值。因此,需要将数据和机器学习操作(MLOps)作为支持模型的一层。有关这两个领域及其参与者的详细信息,请参阅此数据和MLOps景观图。

Models layer relies on Data and MLOps technologies
模型层依赖于数据和MLOps技术,这些技术有自己新兴和不断发展的业务模型
这一增加使景观包含了Scale、Surge和Snorkel等公司。数据层也是Shutterstock作为训练DALL-E的数据提供商(并随后成为分发DALL-E创建的图像的应用程序)的地方。
别忘了商业魔咒
虽然我们的数据现在涵盖了主要的软件部分,但重要的是要考虑业务因素,这些因素可以帮助区分或促进产品的采用,而不仅仅是软件组件。一个很好的例子是Lensa AI现有的分销基础(以及吸引人的影响者)如何帮助使用量激增,据报道,2022年12月的收入为800万美元。在文本方面,Jasper的增长引擎成功推动其2022年的收入达到7500万美元。Writer指出,其在风格指南和品牌语调方面的专业知识是与许多人工智能写作助理的区别。

在考虑竞争护城河时,我们不应该只考虑技术护城河。商业因素仍然是一个产品可以拥有的巨大杠杆。
6) 企业:不是为一个,而是为你的系统中的数千个人工智能触点做计划
如果你正在为一家公司构建ML战略,那么值得考虑的是“模型”层不局限于一个或几个模型。就像软件如何在公司的所有功能中使用一样(例如,IT、人力资源、销售、营销等),依靠人工智能为使用软件的大多数功能提供价值。
加速采用的一个很好的例子是2018年谷歌演示中的这条曲线。它显示,使用深度学习模型的谷歌内部项目数量不断增加,截至2017年底,已达到约7000个项目。
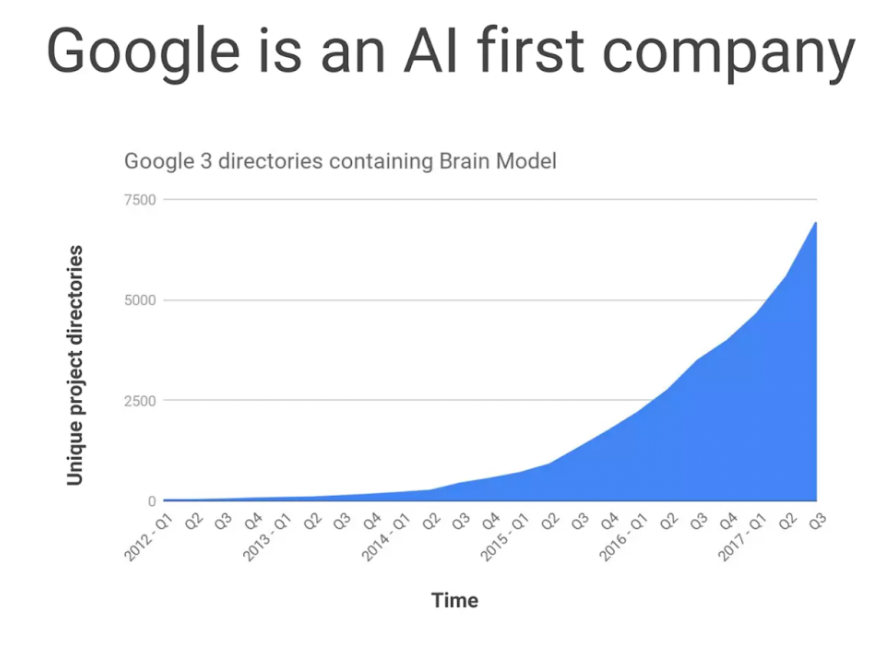
在人工智能第一的公司,人工智能的使用可以在几年内迅速激增到数千个用例。[来源]
今天这一趋势如何?据彭博社报道,在谷歌的《抓住聊天GPT的计划是将人工智能融入一切》中:“一项新的内部指令要求在几个月内将“生成性人工智能”纳入其所有最大的产品中。”
有几种力量推动这样的期望,例如:
虽然我们倾向于将人工智能视为一个独立的组件,但更有用的观点是将其视为软件的简单扩展,使其能够解决更复杂的问题。因此,无论软件生活在哪里,我们都将继续寻找人工智能可以改进这些系统的领域。
你的第一个模型很少能完全解决问题。总是需要在多个模型之间进行迭代,直到一个模型能够在生产中正确使用。
请注意,这里的人工智能接触点并不一定意味着模型。一个模型可以为多个用例赋能。例如,文本生成模型可以通过更改文本提示来处理不同的用例。例如,文本嵌入模型可以实现神经搜索,以及文本分类和情感分析。
如果一家公司的目标是使用十种型号和一千种型号,那么它的技术组合将完全不同。因此,在价值等式中,我们需要考虑当前推动生成人工智能的深度学习革命的主要组成部分之一:微调的自定义模型。
7) 对基础模型的多个子项和迭代的说明
进入微调模型
如果你要在十年前建立一个文本生成模型,你很可能需要在几个月的时间里从头开始训练它。人工智能的核心发展之一是,我们现在有了预训练的基础模型,这些模型在大量任务(比如语言任务)中表现出色,然后可以在更小的数据集上再训练一点(这一过程被称为微调),使其在一项任务中表现出色。

“基础/基础模型”和“微调模型”是理解人工智能模型潜在动力学的关键概念
微调对经济价值图很重要,因为它允许企业建立专有的自定义模型,即使原始模型是公开的,甚至是开源的。
如果你在应用层,考虑用微调模型在模型层中下沉你的爪子
如果您在应用程序层中构建产品,那么经过微调的自定义模型可以在模型层中使您的产品与众不同。当使用托管语言模型提供程序时,可以在这里实现快速提升,这使得微调模型就像上传单个文件一样容易。这种设置可以方便地对数十个或数百个自定义模型进行实验。

应用层中的产品在模型层中获得某种护城河的一种方法是保留他们自己的微调模型,这些模型使用他们的专有数据在特定任务上进行了高度优化
当你考虑到像Lensa AI这样的产品可能会为每个付费用户微调一个基本的稳定扩散模型时,将因子微调到生成人工智能的价值方程中(推测)。另一个例子是,当使用人工智能编写《星际之门》科幻系列的一集剧本时,需要十二个经过微调的模型来捕捉每个角色的语气和风格。
生成、使用和反馈数据对模型的未来版本很有价值
部署人工智能产品并不是最后一步。相反,这只是一个新的重要过程的第一步:收集新的数据来改进模型和改善用户体验。在名为“让用户给出反馈”的People+AI指南模式中阅读更多关于这方面的信息。在用户界面中,它的一个简单版本可以看起来像Grammarly的反馈选项,附在每个模型建议上。

Grammarly的写作助理征求您对其建议的反馈意见。这些反馈是改善服务的重要数据。
收集反馈数据将增加专有数据池,从而使您的产品与众不同。

反馈和产品使用数据指出了模型可以改进的地方,使产品/服务更加符合用户的期望
另一种形式的反馈是收集人类偏好数据,以在现在通常被称为RLHF(从人类反馈中强化学习)的过程中优化模型。
在用户和数据注释器的帮助下,您的产品的使用数据可以生成有价值的培训数据。下图描述了一个这样的过程。这是这个模型(和数据)迭代周期的一个版本:
发布原型并研究其用途
- 1) 将您的应用程序放在用户面前。可选地,应用程序可以由一个自定义模型提供动力,该模型已使用v1专有数据进行了微调。
- 2) 收集用户与应用程序的交互。
- 3) 检查用户提示并为这些提示寻找高质量的生成。

数据改进周期的三个第一步:发布早期版本,观察使用情况,然后收集和标记可以改进模型的数据
寻找高质量的世代是一个完整的主题。人工贴标机和模型都可以在管道中使用,以提供这些完井。但暂时掩盖这个过程,得到这些数据后会发生什么?
运用所学知识,将其提升到一个新的水平
以下两个步骤是:
- 4.将这些新提示和生成添加到数据集中,以创建数据集的v2。
- 5.使用这个新的数据集创建一个新的模型。

在前一步中收集的数据是对专有数据的关键补充,可以用来为您的用例创建更好的模型
部署模型的另一个有用的副产品是收集模型的代,并将其公开以帮助其他用户。
8) 模型使用数据集允许对模型的生成空间进行集体探索

在图像生成中,模型很重要,但展示其他用户在实际提示的同时生成的内容的公共画廊也很重要
虽然这可能不是每个人都在寻找的一条生成性人工智能护城河,但模型前几代的公共画廊正在成为图像生成模型经济价值的重要组成部分。

MidJourney和Lexica.ai提供非常有用的公共世代画廊
中途旅行就是一个很好的例子。免费试用可以让用户有一定数量的世代,对公司来说非常成功。这些用户生成的所有图像都可以在公共Discord聊天室和midtravel.com上查看。但是,即使你为服务付费,基本和标准计划仍然会在网站上公开你生成的图像。只有Pro Plan才允许该公司所谓的隐形模式。
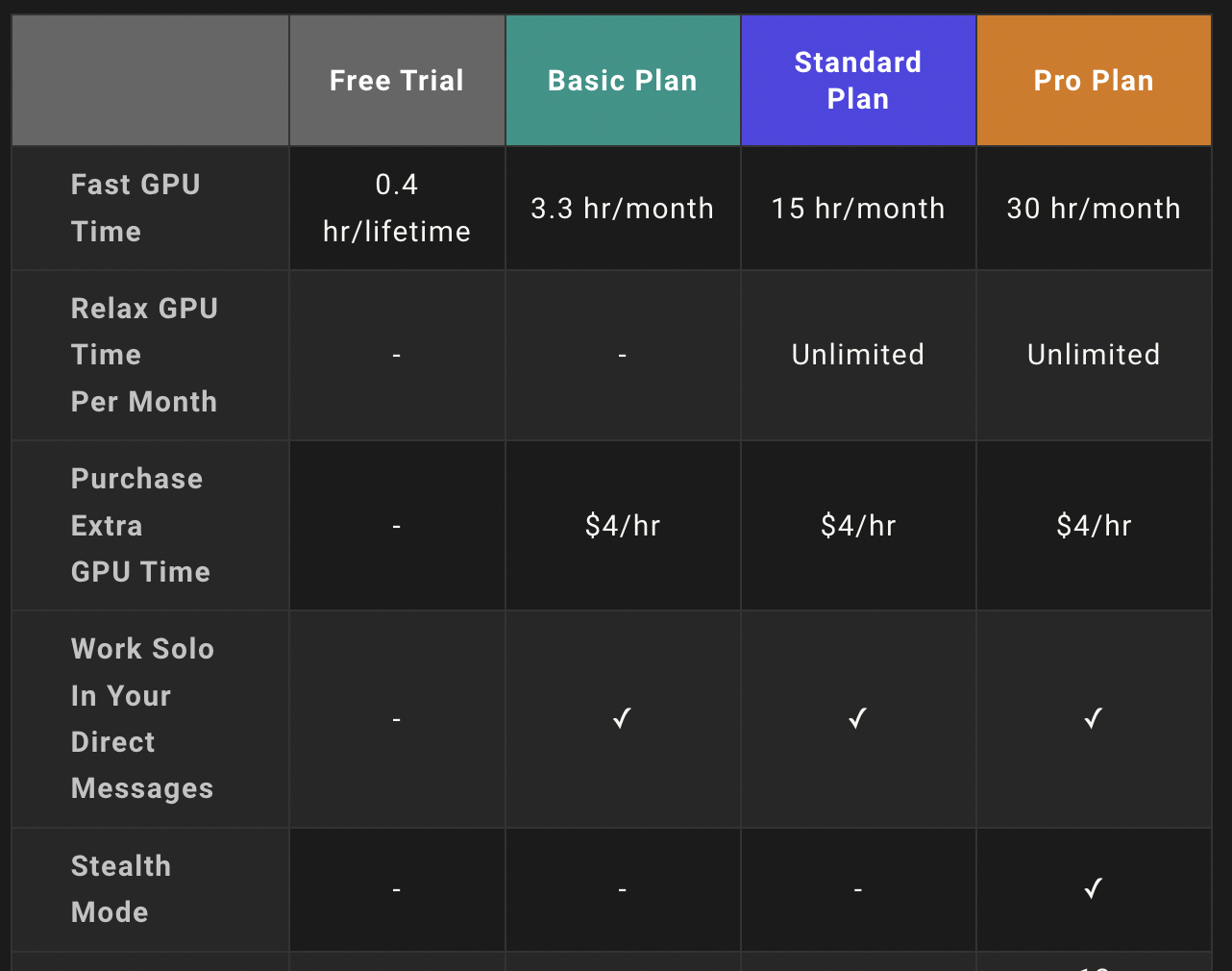
在Midtravel上,即使是付费用户也会在公众席上分享他们的世代(Pro Plan除外)
一个庞大而多样的生成图像库通过允许用户快速放大他们想要的结果,极大地改善了这些服务的用户体验。很多时候,它们会让你接触到一些你可能会发现比你脑海中的想法更好的想法,因此它们可以让你通过寻找不同的灵感来源来快速发展某种概念。
另一个将模型生成的公共库用于产品的例子是Lexica.art,它很快成为稳定扩散模型生成的图像和用于创建图像的提示的主要库之一。

Lexica主页展示了他们几代人的Aperture模型
应用层玩家的Moats口袋
现在,让我们把所有这些点放在一起,最后看一看应用层上的玩家可能会有哪些竞争优势。

创业公司可以在不同的领域为其人工智能产品积累竞争优势。
这些口袋对人工智能业务来说是最重要的吗?不一定。商业护城河往往比技术护城河更重要。
你怎么认为?我们很想听听你对这个话题的看法,因为这是一个快速发展的领域
Tags
最新内容
- 1 month 2 weeks ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago