
NLP技术的商业应用

介绍
机器学习 (ML) 应用程序已经无处不在。每天都有关于自动驾驶汽车人工智能、在线客户支持、虚拟个人助理等的新闻。然而,如何将现有的商业实践与所有这些惊人的创新联系起来可能并不明显。一个经常被忽视的领域是应用自然语言处理 (NLP) 和深度学习来帮助快速有效地处理大量业务文档,从而在大海捞针。
允许机器学习有机应用的领域之一是金融机构和保险公司的风险管理。组织在如何应用机器学习来改善风险管理方面面临许多问题。这里只是其中的几个:
- · 如何识别可以从使用人工智能中受益的有影响力的用例?
- · 如何弥合主题专家的直觉期望和技术能力之间的差距?
- · 如何将 ML 集成到现有的企业信息系统中?
- · 如何在生产环境中控制机器学习模型的行为?
本文旨在分享 IBM Data Science and AI Elite (DSE) 和 IBM Expert Labs 团队的经验,基于风险控制领域的多个客户参与。 IBM DSE 构建了各种加速器,可以帮助组织快速开始采用 ML。在这里,我们将介绍风险管理领域的用例,介绍认知风险控制加速器,并讨论机器学习如何改变该领域的企业业务实践。
风险管理草图
2020年,多家金融机构被罚款超过数亿美元/个。罚款的原因是风险控制状态不充分。
这引发了对金融公司的呼吁,以确保他们必须使用的大量风险控制的高质量。这包括明确识别风险、实施风险控制以防止风险发展,以及最终建立测试程序。
对于非专业人士来说,风险控制有点令人困惑。这是关于什么的?一个简单的定义是实施风险控制以监控公司业务运营的风险。例如,安全风险可能是入侵者猜测密码并因此访问某人的帐户。可能的风险控制可以设计为建立一个策略,该策略需要通过组织的系统强制执行长且重要的密码。作为萨班斯-奥克斯利法案 (SOX) 的结果,上市公司需要有效管理此类风险的方法,并作为建立风险控制和评估这些控制质量的努力的一部分。
风险管理人员的一个重要因素是控制是否定义良好。对此的评估可以通过回答诸如谁监控风险、应该做什么来识别或预防风险、在组织的生命周期中应该多久执行一次控制程序等问题来完成。所有这些问题都应该得到回答。现在我们需要意识到,企业中此类控件的数量从数千到数十万不等,人工对控件语料库进行评估是非常困难的。这就是当代人工智能技术能够提供帮助的地方。
当然,这种类型的挑战只是一个例子,试图在一篇文章中涵盖广泛的风险管理领域是不切实际的,因此我们专注于从业者在日常实践中面临的一些具体挑战和已经使用认知风险控制加速器实施。
可用的公共风险控制数据库并不多,因此加速器中的解决方案基于 NIST 特别出版物 800-53 的安全控制,可在 https://nvd.nist.gov/800-53 获得。这个安全控制数据库很小,但它允许我们展示可以扩展到大量和不同风险控制领域的方法。
使用文本分析和深度学习进行风险控制
关键用例类别之一是使现有风险控制合理化:挑战在于现有风险控制的开发方式可能存在许多历史方面。例如,一些风险控制可以通过复制其他现有控制并进行最少的修改来构建。再比如,一些风险控制可以通过将多种风险控制合二为一来形成。这种方法的常见后果是重复的控制以及与业务不再相关的控制的存在。最困难的挑战之一是评估现有风险控制的总体质量状态。因此,从业务角度来看,第一个目标是建立质量评估:自动评估控制描述的质量,通过只关注那些真正需要审查和改进的内容,从而节省大量的日常阅读描述时间。一个很好的问题是人工智能是如何出现在这里的。基于 NLP 的 ML 模型在常见的语言相关任务中变得非常有效,特别是在回答问题等挑战中。此处可以引用的一种模型是基于 Transformer 架构的(更多详细信息,请参阅 https://medium.com/inside-machine-learning/what-is-a-transformer- 上有关 Transformer 架构的文章d07dd1fbec04)。
在风险管理草图中,回答有关风险控制描述的问题的能力是评估控制描述质量的关键。 从鸟瞰的角度来看,未回答问题的数量是控制描述质量的一个很好的指标。 最好的消息是,借助 Transformers 等当代 AI 模型的功能以及附加的实用规则,这种提出正确问题的技术成为一种有效机制,可以在 AI 的帮助下由一个小团队控制大量控制描述。
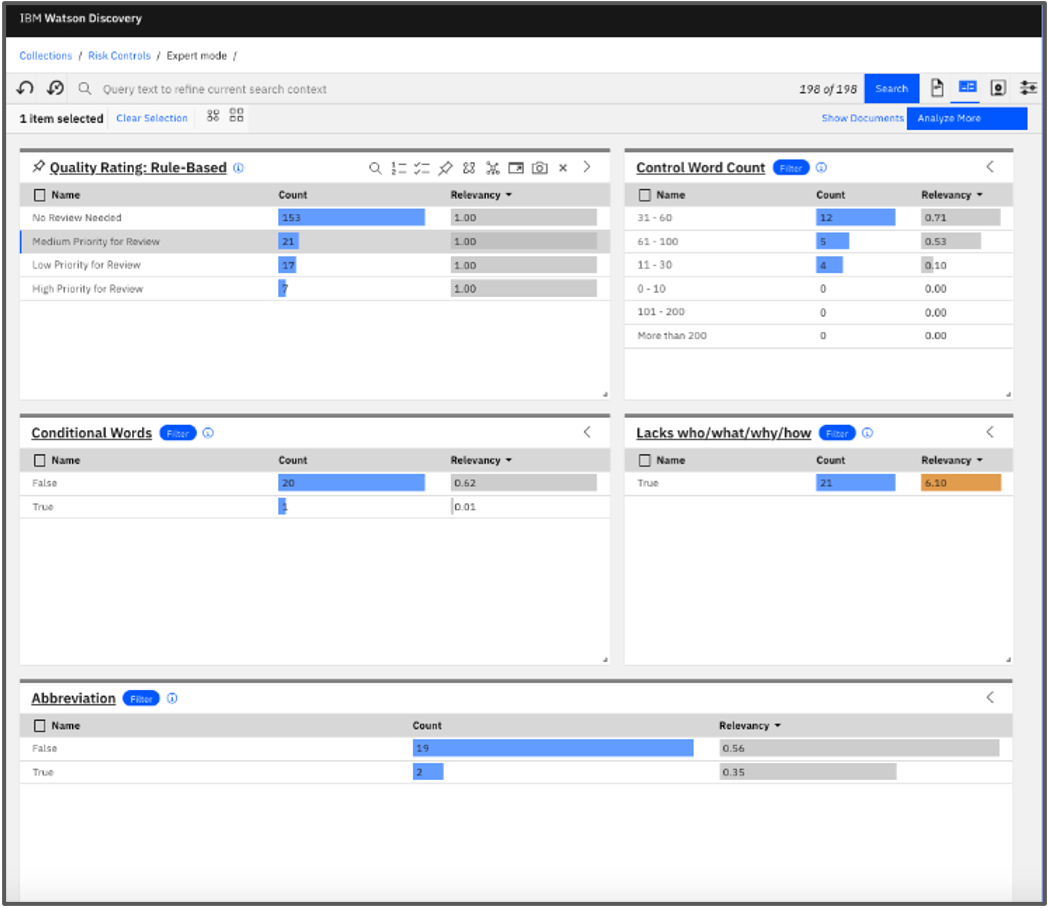
- Controls Quality Assessment (image by authors)
通常,在文档中查找重复项被认为是一项简单的任务,Levenshtein Distance 可以帮助查找用相似措辞表达的项目。 但是,如果我们想找到语义相似的描述,这将成为一项更具挑战性的任务。 这是当代人工智能可以提供帮助的另一个领域——使用大型神经网络(例如自动编码器、语言模型等)构建的嵌入可以捕获语义相似性。 从实际结果的角度来看,我们的经验是重复和重叠的识别可能导致控制量减少多达 30%。
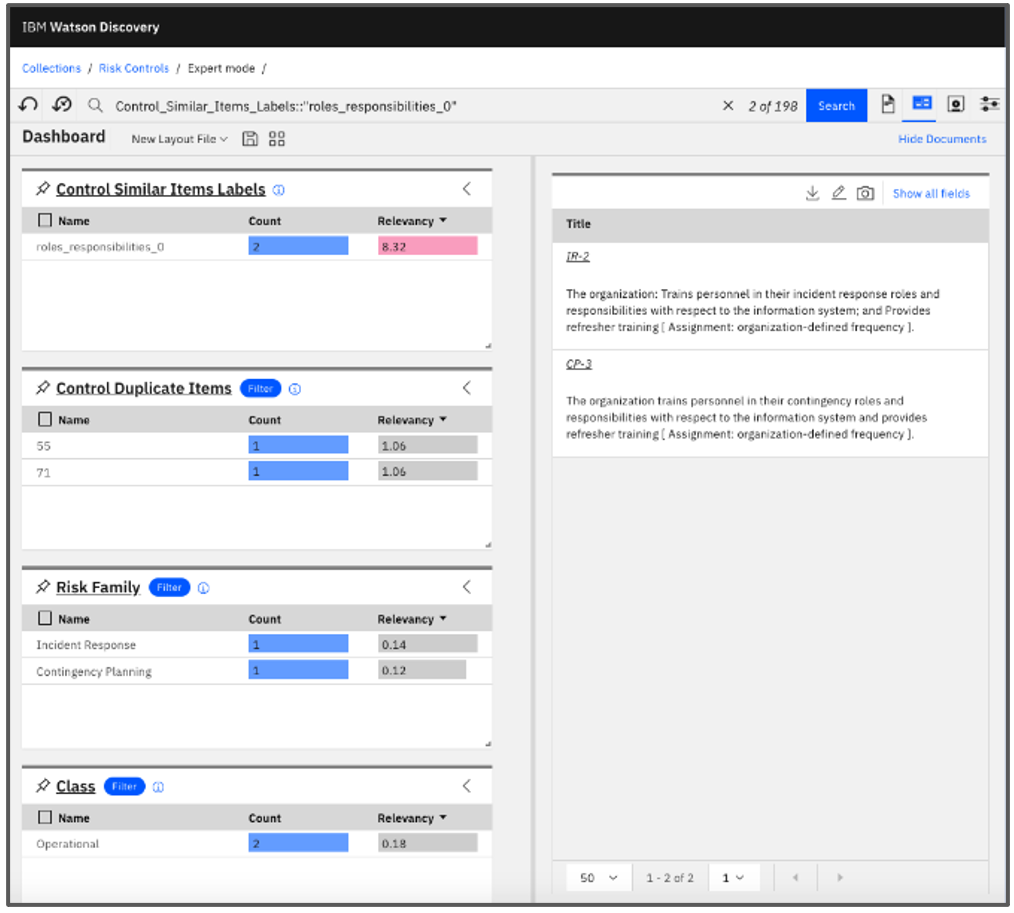
- Analysis of Overlaps (image by authors)
此外,通过聚类等机器学习技术分析信息的内部结构已成为一种常见的做法。 这使业务从业者能够更好地理解更大规模的控制内容,并查看现有的风险和控制分类是否与内容保持一致,或者两者中可能缺少什么。
- Clustering Example (image by authors)
以前的用例主要集中在现有控件的分析上。另一个用例侧重于帮助风险经理创建新的风险控制。使用语义相似性为给定风险推荐控制可以显着减少人工工作并为构建控制提供灵活的模板。机器学习可以帮助分析风险描述并找出正确的控制集来解决每个风险。
在大型组织中,团队通常致力于其他团队可能使用的解决方案和最佳实践。在整个组织中采用最佳实践需要广泛的培训。机器学习在这种情况下非常有用。一个例子可能是将控制分类为预防性或检测性。在这个用例中,我们使用监督机器学习通过使用来自特定团队的现有标记集将控件分类扩展到整个控件集,即使用机器学习完成知识转移,而不是耗时的人员培训。
IBM DSE 风险控制加速器中的认知技术使我们能够构建风险控制、推荐以自然语言表述的风险控制、识别控制中的重叠以及分析控制的质量。
该加速器提供了一个认知控制分析应用程序,该应用程序集成了已开发的模型并将其应用于非结构化风险控制内容。
使用 IBM Cloud Pak for Data 实施认知风险控制
从逻辑上讲,认知风险控制加速器包含几个组件:
- 第一个是所谓的认知助手——它是一个应用 ML 模型来促进内容处理的应用程序,例如,通过识别风险控制优先级、类别和评估控制描述的质量。作为产品化的一部分,认知助理成为企业信息系统的一部分。

- 第二个组件是内容分析:当通过机器学习模型丰富数据时,Watson Discovery 内容挖掘可用于在丰富的内容中找到洞察力
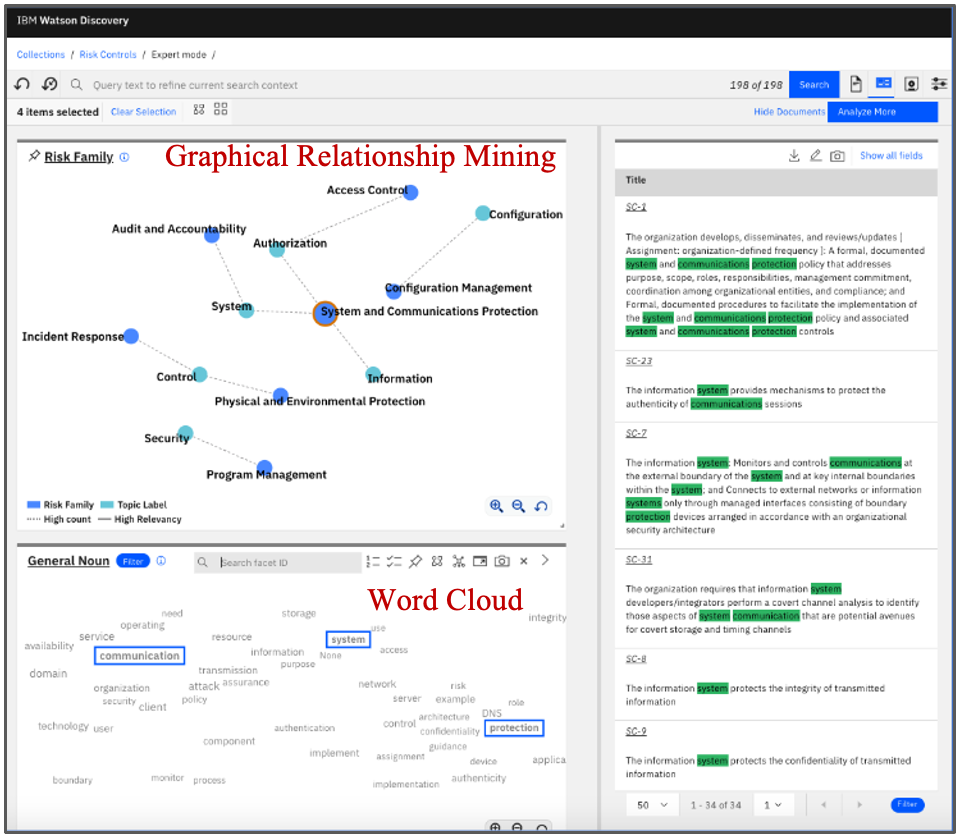
Content Analysis with Watson Discovery (image by authors)
- 另一个组件是一组支持数据科学模型的 Jupyter 笔记本
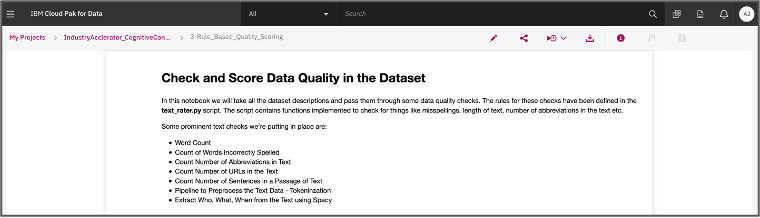
- Jupyter Notebook in Watson Studio (image by authors)
让我们看看使用 IBM Cloud Pak for Data 的基于加速器的实现的底层。
在我们这样做之前,让我们简要回顾一下 IBM 平台和方法。 IBM 有一种用于 AI 之旅的规范方法,称为 AI 阶梯。在他的“AI 阶梯:揭开 AI 挑战的神秘面纱”中,Rob Thomas(IBM 云和认知软件高级副总裁)证实,要将您的数据转化为洞察力,您的组织应遵循以下列出的阶段:
- 收集 — 轻松访问数据的能力,包括数据虚拟化
- 组织 — 对数据进行编目、构建数据字典以及确保访问数据的规则和政策的方法
- 分析——这包括交付机器学习模型,使用数据科学来识别使用认知工具和人工智能技术的洞察力。这自然需要构建、部署和管理您的机器学习模型
- 注入——从很多角度来看,这是一个关键阶段。这是指以允许业务信任结果的方式操作 AI 模型的能力,即在生产模式下在企业系统中使用您的机器学习模型,同时能够确保这些模型的持续性能及其可解释性.
Cloud Pak for Data 是 IBM 的多云数据和 AI 平台,提供信息架构并提供所有概述的功能。下图捕获了在 AI Ladder 上下文中开发实现的详细信息。
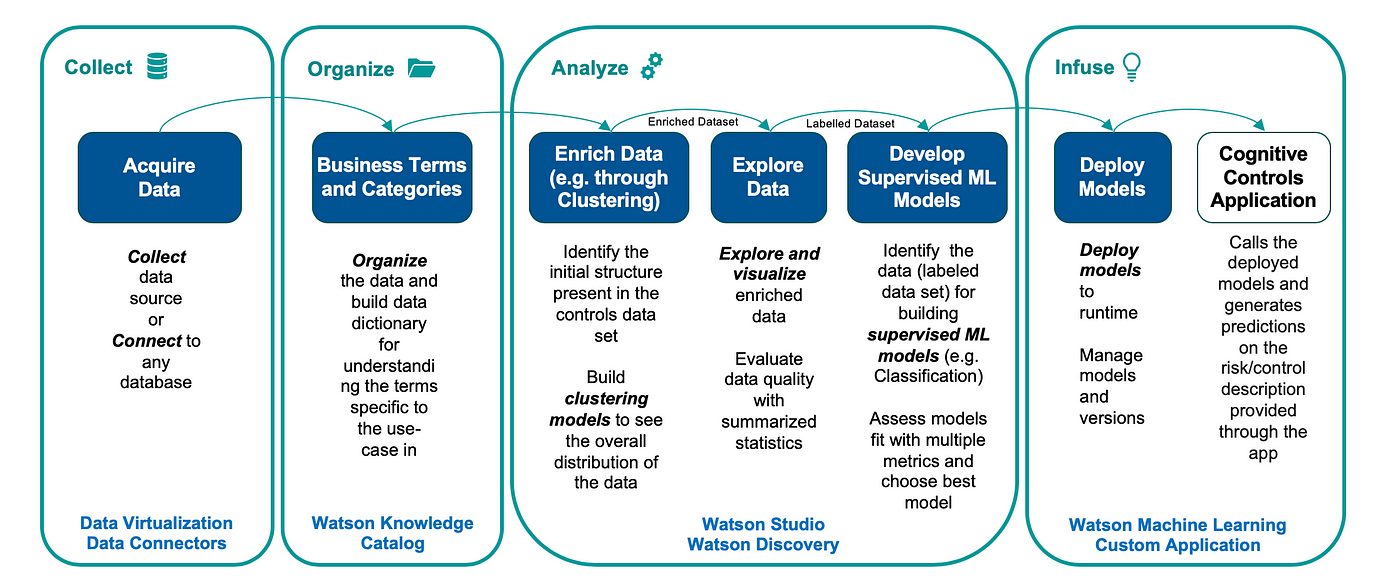
- Phases (image by authors)
它捕获了基于 DSE 加速器实施认知风险控制项目的各个阶段:
- 实施风险控制项目的前两个阶段是获取和编目数据集——例如,在加速器中,我们使用 NIST 控制数据集。此处的控件表示为自由文本描述。
- 下一阶段是在 Watson Studio 中丰富获取的非结构化数据:聚类被用作理解内容内部结构的一种方式。风险控制叙述可能很长,可能会讨论多个主题,因此可能需要一些机制来跟踪随着描述的进展而变化的主题。在我们的聚类实践中,我们在嵌入和潜在狄利克雷分配 (LDA) 之上使用了 K-means。它确实需要数据科学家和主题专家的仔细协调,因为数学可能与中小企业的期望不符。这里也可以进行更广泛的丰富——一个很好的例子是对描述的质量进行分类。
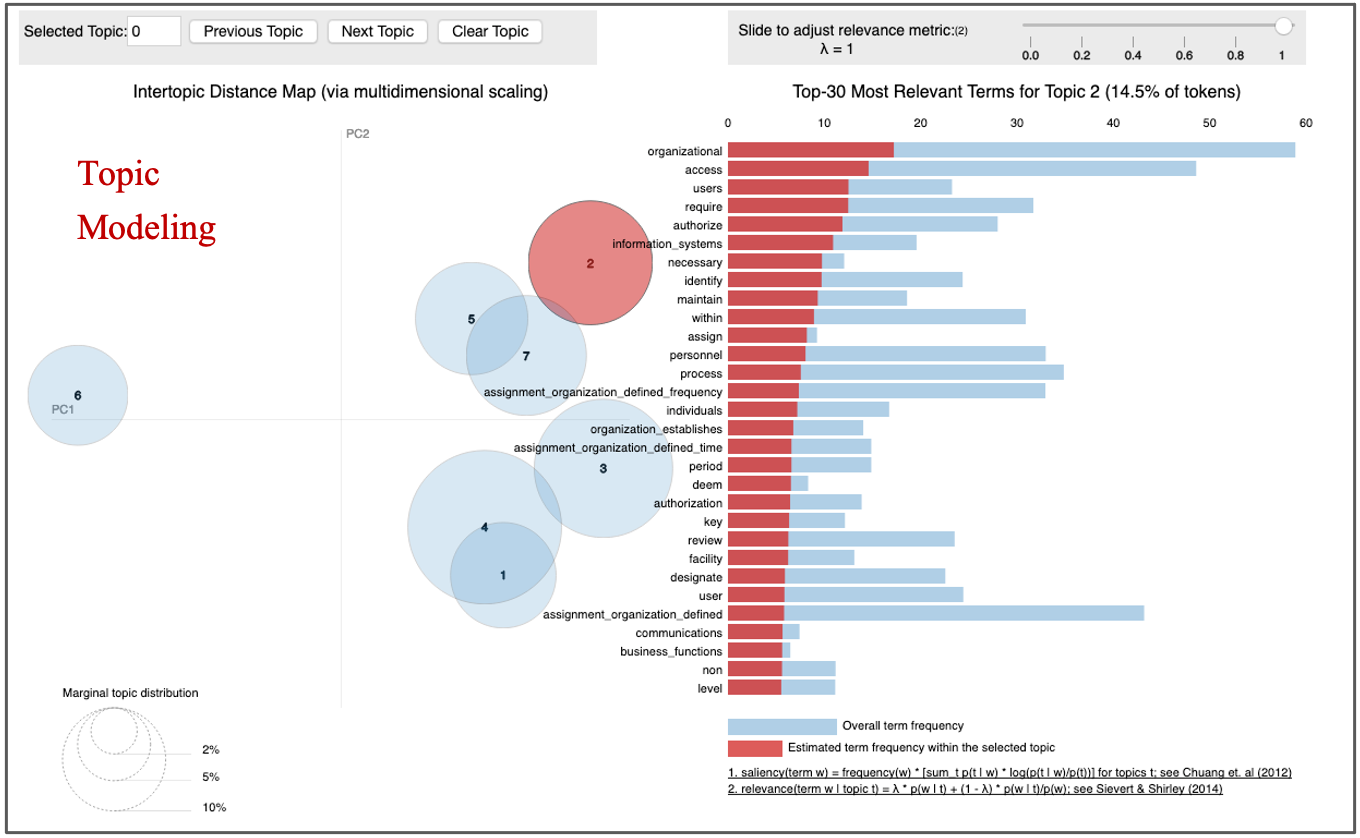
Topic Modeling (image by authors)
- 扩充完成后,我们需要了解生成的数据集。这导致我们进入探索阶段。在实践中,挑战在于数量。内容审查是最耗时的过程之一,因为它需要仔细阅读大量文本。我们如何探索海量的非结构化信息? Watson Discovery 内容挖掘是使这成为可能并大大减少工作量的工具。
- 内容经过中小企业审查后,构成了构建监督机器学习模型的基础。 IBM 平台提供了部署模型、监控偏差以及获得复杂模型决策的可解释性的方法。所有这些都包含在机器学习的操作化中,并由 IBM Cloud Pak For Data 提供支持。
结论
本文介绍了机器学习在当代商业中不断增长的应用领域之一——认知风险控制。访问我们的加速器目录,了解有关认知控制加速器的更多信息。如果您有兴趣了解有关认知风险控制和 AI 技术的更多信息,请随时与 IBM Data Science and AI Elite Team 联系。此外,如果您发现您的用例与所提供的用例相似,或者如果您的业务和技术挑战可以通过上述方法或工具解决,请联系 IBM。
致谢
作者(IBM DSE 和专家实验室)感谢他们的同事在认知控制业务和技术方法方面的持续合作和开发:Stephen Mills(IBM Promontory 董事总经理)、Miles Ravitz(IBM Promontory 高级负责人)、 Rodney Rideout(IBM 全球企业咨询服务部交付主管)、Vinay Rao Dandin(数据科学家)、Aishwarya Srinivasan(数据科学家,IBM DSE)和 Rakshith Dasenahalli Lingaraju(数据科学家,IBM DSE)。
原文:https://towardsdatascience.com/cognitive-risk-management-7c7bcfe84219
最新内容
- 1 week 2 days ago
- 2 weeks 3 days ago
- 3 weeks ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago