
category
在这篇文章中,将解释OpenAI的ChatGPT架构及其大型语言模型GPT-3、InstructGPT、ChatGPT和GPT-4。

目录
- GPT-3:引入大型语言模型
- InstructionGPT:利用人类反馈强化学习
- ChatGPT:利用率为王
- GPT-4:引入人工生成智能(AGI)
- OpenAI时间表和常见问题解答
1.GPT-3:引入大型语言模型
变压器型号于2017年推出。此后,OpenAI分别在2018年和2019年基于transformer模型推出了GPT-1和GPT-2。
从PLM到LLM
GPT-2是一种预训练语言模型(PLM),用于在大规模语料库上预训练转换器模型。PLM在解决各种自然语言处理(NLP)任务方面表现出强大的能力。
快进到2020年,transformer 语言模型的容量大幅增加,从1亿个参数增加到1750亿个参数。OpenAI将具有175B参数的模型命名为“GPT-3”。研究界为大型PLM创造了术语“大型语言模型”(LLM),例如,包含数百亿或数千亿个参数的大型PLM是在大量文本数据上训练的。
GPT-3在许多NLP任务上都取得了强大的性能,包括翻译、问答、阅读理解、文本隐含和许多其他任务。
规模定律
研究人员发现,模型缩放可以提高性能。当参数尺度超过一定水平时,它们表现出小规模语言模型所不具备的特殊能力。
缩放定律是指缩放PLM(模型大小和数据大小)通常会提高下游任务的模型容量。这些大型PLM表现出与小型PLM不同的行为,并在解决一系列复杂任务时表现出令人惊讶的能力(称为“涌现能力”【emergent abilities】)。
LLM的涌现能力被正式定义为“不存在于小模型中但出现于大模型中的能力”,这是LLM与以前的PLM区别开来的最显著特征之一。当涌现能力出现时,它还引入了一个显著的特征:当规模达到一定水平时,表现显著高于随机。
尽管取得了进展并产生了影响,但LLM的基本原则仍然没有得到很好的探索。为什么涌现能力会出现在LLM中,而不是较小的PLM中,这仍然是个谜。根据比例定律,某些能力,例如上下文学习,是不可预测的。
数据集集合
通过对来自不同来源的文本数据的混合进行预训练,LLM可以获得广泛的知识范围,并可能表现出强大的泛化能力。当混合不同的来源时,需要仔细设置预训练数据的分布,因为这也可能影响LLM的性能。

根据GPT-3论文,GPT-3的数据集包括CommonCrawl、WebText2、Books1、Books2和维基百科。CommonCrawl是最大的开源网络爬行数据库之一,包含PB级的数据量,已被广泛用作现有LLM的训练数据。维基百科的纯英语过滤版本在大多数LLM中广泛使用。至于Books1和Books2,它们比GPT-1和GPT-2中使用的BookCorpus大得多。
尽管它没有显示在GPT-3数据集中,但代码也是作为数据集的一部分添加的。代码数据来自现有的从互联网上抓取开源许可代码的工作。两个主要来源是开源许可证下的公共代码库,如GitHub,以及与代码相关的问答平台,如StackOverflow。
在知识库更加多样化的情况下,模型显示出执行更广泛任务的能力。
架构
一般来说,现有的LLM可以分为编码器-解码器架构(encoder-decoder)和新的仅解码器架构(decoder-only)。
原始的Transformer模型建立在编码器-解码器架构上,该架构由两堆Transformer块组成,分别作为编码器和解码器。编码器采用堆叠的多头自注意层对输入序列进行编码,以生成其潜在表示,而解码器对这些表示进行交叉注意,并自回归生成目标序列。
由于大多数语言任务都可以被视为基于输入的预测问题,因此仅解码器的LLM对于隐含地学习如何以统一的方式完成任务具有潜在的优势。GPT-2和GPT-3使用随意解码器架构【casual decoder architecture 】(见下图)。在GPT-3中,有96个层变换器解码器。当提到“仅解码器架构”时,它通常指的是随意的解码器架构。
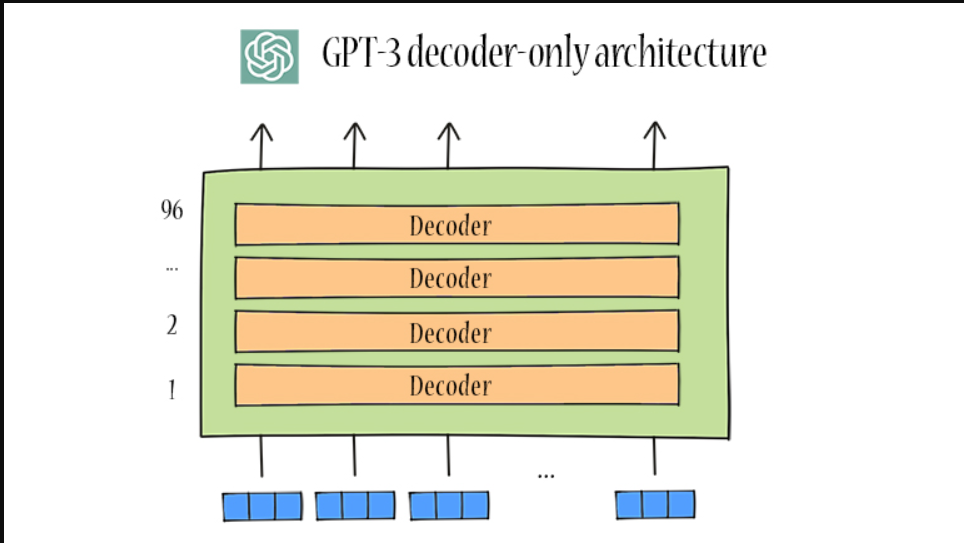
这种规模的模型通常需要数千个GPU或TPU来训练。为了支持分布式训练,已经发布了几个优化框架,以促进并行算法的实现和部署。
- 数据并行性
- 管道平行度
- 张量平行度
- 混合专家

2.指导GPT:利用人类反馈进行强化学习
LLM在广泛的NLP任务中表现出了非凡的能力。然而,这些模型有时可能表现出意想不到的行为,例如编造虚假信息、追求不准确的目标以及产生有害、误导和有偏见的表达。对于LLM,语言建模目标通过单词预测重新训练模型参数,同时缺乏对人类价值观(有益、诚实、无害)或偏好的考虑。为了避免这些意想不到的行为,人们提出了人类结盟,以使LLM的行为符合人类的期望。
RLHF概述
2022年初,为了解决上述问题,引入了InstructGPT。OpenAI设计了一种有效的调整方法,使LLM能够遵循预期的指令,该方法利用了人工反馈强化学习(RLHF)技术。这是为了通过精心设计的标签策略将人类纳入训练循环。
这项技术使用人类偏好作为奖励信号来微调LLM。OpenAI雇佣了一个由40名承包商组成的团队,根据他们在筛选测试中的表现对数据进行标记。然后在这个数据集上训练一个奖励模型(RM),以预测输出标注者更喜欢哪个模型。最后,将该RM用作奖励函数,并使用近端策略优化(PPO)算法对监督学习基线进行微调,以最大化该奖励。
InstructionGPT生成更合适的输出,并更可靠地遵循指令中的显式约束。1.3B参数InstructGPT的输出优先于175B GPT-3的输出,尽管参数少了100倍。此外,InstructionGPT显示了真实性的提高和有毒输出生成的减少,同时在公共NLP数据集上具有最小的性能回归。
RLHF步骤
RLHF系统包括三个关键组件:要对齐的预训练LM、从人类反馈中学习的奖励模型和训练LM的强化语言算法。

由OpenAI提供
RLHF有三个步骤:
步骤1:监督微调(SFT)
收集示范数据,并制定有监督的政策。贴标机提供了输入提示分布上所需行为的演示。然后,该团队使用监督学习在这些数据上微调预训练的GPT-3模型。
步骤2:重新编排模型训练(RM)
收集比较数据,并训练奖励模型。该团队收集了一个模型输出之间的比较数据集,其中标注器指示他们对给定输入更喜欢哪个输出。然后训练一个奖励模型来预测人类偏好的输出。
步骤3:强化学习微调(RL)
使用PPO针对奖励模型优化策略。团队使用RM的输出作为标量奖励。然后使用近端策略优化PPO算法对监督策略进行微调以优化该奖励。
步骤2和步骤3是连续迭代的;收集关于当前最佳策略的更多比较数据,该当前最佳策略用于训练新RM,然后训练新策略。在实践中,大多数比较数据来自监督政策,有些来自PPO政策。
3.ChatGPT:利用率为王
2022年末,ChatGPT的推出引起了社会的广泛关注。ChatGPT是一款基于LLM开发的强大人工智能聊天机器人,具有与人类惊人的对话能力。
ChatGPT是先前LLM(例如GPT-3和InstructGPT)不断演变的结果。这是一种实际上对人类有帮助的产品。
提示
提示已成为使用LLM的突出方法。上下文学习(ICL)是与GPT-3一起首次提出的一种特殊的提示形式。ICL使用格式化的自然语言提示,包括任务描述和一些任务示例作为演示。由于ICL的性能在很大程度上依赖于演示,因此作为GPT-3开发的一部分,正确地设计它们是一个重要问题。
ChatGPT应用交互式提示机制,例如通过自然语言对话来解决复杂任务。这些已经被证明是非常有用的。
NLP任务
ChatGPT展示了广泛应用程序中的功能,如对话系统、文本摘要、机器翻译、代码生成等。以下是ChatGPT中NLP任务的一些主要功能。
- 问题和答案
- 翻译
- 生成代码
- 写诗
- 写文章
- 文本摘要
-
情感分析
ChatGPT还展示了一种从现有LLM中学习的可行方法,用于增量开发或实验研究。增量任务包括撰写文本摘要、回答事实问题、根据给定的押韵方案写诗,或按照标准程序解决数学问题。
良好的包装
得益于其前身InstructGPT的RLHF,ChatGPT在产生高质量、无害的回答方面表现出强大的协调能力,例如拒绝回答侮辱性问题。有时,这会给人一种你正在与训练有素的客户服务代表交谈的印象。
你可能还注意到,ChatGPT的用户界面比其他类似产品更具吸引力,如Bing的聊天、谷歌的Bard和Meta的Blender Box 3。
与Meta的Blender box3或微软的Bing聊天不同,ChatGPT不使用消息、左右对话框的格式。相反,ChatGPT被格式化为问答字段。在这种格式中,用户可以得到更长、更正式的答案。
与谷歌的Bard一次显示答案不同,ChatGPT使用动画逐词显示。它给人一种错觉,以为有人在思考和打字。

所有这些细节使ChatGPT成为一款出色且广受好评的产品。
ChatGPT还支持使用插件,这可以为LLM提供超出语言建模范围的更广泛的能力。例如,web浏览器插件使ChatGPT能够访问新信息。通过将提取的相关信息融入上下文,LLM可以获得新的事实知识,并更好地执行相关任务。
4.GPT-4:引入人工生成智能(AGI)
OpenAI的最新型号是GPT-4。GPT-4是一个大规模的多模式模型,可以接受图像和文本输入,并产生文本输出。GPT-4在各种专业和学术基准上表现出人类水平的表现。
OpenAI没有给出GPT-4的架构细节,包括模型大小、硬件、训练计算、数据集构建、训练方法等。然而,GPT-4肯定是使用前所未有的计算和数据规模进行训练的。
GPT-4优于ChatGPT
GPT-4在各种领域和任务中表现出非凡的能力,包括抽象、理解、视觉、编码、数学、医学、法律、对人类动机和情绪的理解等等。它还能够将多个领域的技能和概念与流动性相结合,显示出对复杂想法的深刻理解。
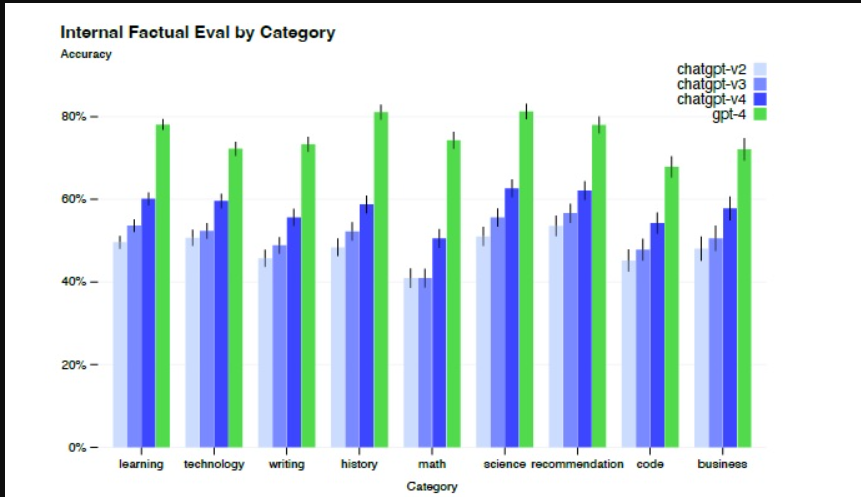
GPT在考试中的表现往往大大超过以前的模型ChatGPT。同时,为了提高模型的安全性,RLHF在GPT-4中持续进行。与之前的ChatGPT相比,GPT-4显著减少了幻觉,而ChatGPT本身随着不断迭代而不断改进。
GPT-4还引入了一种基于深度学习堆栈的新机制,称为可预测缩放,可以用更小的模型预测大型模型的性能,这可能对开发LLM非常有用。
GPT-4存档AGI
GPT-4比以前的人工智能模型显示出更多的通用智能。GPT-4在各个领域的各种具有挑战性的任务中接近人的表现,被认为是“通用人工智能系统的早期版本”。这是迈向一系列日益普遍的智能系统的第一步。
还有更多的工作要做
GPT-4仍有许多局限性。在某些领域,GPT-4表现不佳。特别是,它仍然存在LLM的一些有据可查的缺点,例如幻觉或犯基本算术错误的问题。
LLM也可能产生有毒、虚构或有害的内容。它需要有效和高效的控制方法来消除LLM使用的潜在风险,如偏见、虚假信息、过度依赖、隐私、网络安全、扩散等。
由于下一个单词预测范式的局限性,表现为模型缺乏规划、工作记忆、回溯能力和推理能力。该模型依赖于生成下一个单词的局部贪婪过程,而对任务或输出没有任何全局或深入的理解。因此,该模型善于产生流畅连贯的文本,但在解决无法按顺序处理的复杂或创造性问题方面存在局限性。
要创建一个符合完整AGI条件的系统,还有很多工作要做,包括可能需要追求一种超越下一个单词预测的新范式。
OpenAI邀请了许多与AI风险相关领域的专家来评估和改进GPT-4在遇到风险内容时的行为。
5.OpenAI时间表
| 2018 | GPT-1, A Generative Pre-trained Transformer (GPT) |
| 2019 | GPT-2, A Pre-trained language model (PLM) |
| 2020 | GPT-3, A Large language model (LLM) |
| Nov 2021 | WebGPT, A browser-assisted question-answering with human feedback |
| Mar 2022 | InstructGPT, Reinforcement learning with human feedback(RLHF) |
| Nov 2022 | ChatGPT, A well received product |
| Mar 2023 | GPT-4, First step to Artificial General Intelligence (AGI) capabilities |
How ChatGPT works (YouTube)
How Google Translate works
What are in ChatGPT’s datasets?
ChatGPT’s datasets are a mixture of text data from diverse sources, including CommonCrawl, WebText2, Books1, Books2, Wikipedia, and code from GitHub and StackOverflow.
What algorithm is used in ChatGPT’s Reinforcement Learning?
ChatGPT’s Reinforcement Learning with Human Feedback(RLHF) has 3 steps: Supervised fine-tuning, Rewording model training, and Reinforcement Learning fine-tuning. The first two steps have humans involved. The last step uses the Proximal Policy Optimization (PPO) algorithm in reinforcement learning.
What is ChatGPT’s architecture?
ChatGPT’s architecture is built on the Transformer model, which is an encoder-decoder architecture. Since most language tasks can be cast as the prediction problem based on the input, ChatGPT (GPT-2, GPT-3) changes to decoder-only architecture with many more layers.
Why is ChatGPT more attractive than Google Bard?
Unlike Google’s Bard, which displays the answer all at once, ChatGPT uses animation to display words by words. It gives an illusion that somebody is thinking and typing. People like this kind of “thinking and action” mode.
The transformer model mug

- 登录 发表评论
- 152 次浏览
Tags
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago