
category
开发强大的文本到SQL功能是自然语言处理(NLP)和数据库管理领域的一个关键挑战。NLP和数据库管理的复杂性在这个领域增加了,特别是在处理复杂的查询和数据库结构时。在这篇文章中,我们介绍了一个简单而强大的解决方案,其中包含使用自定义代理实现以及Amazon Bedrock和Converse API的文本到SQL的附带代码。
将自然语言查询转换为SQL语句的能力将改变企业和组织的游戏规则,因为用户现在可以以更直观和更易访问的方式与数据库进行交互。然而,数据库模式的复杂性、表之间的关系以及自然语言的细微差别往往会导致不准确或不完整的SQL查询。这不仅损害了数据的完整性,还阻碍了整体用户体验。通过一个简单而强大的架构,代理可以理解您的查询,制定执行计划,创建SQL语句,在出现SQL错误时进行自我纠正,并从执行中学习以在未来进行改进。随着时间的推移,代理可以对该做什么和不该做什么形成连贯的理解,从而有效地回答用户的查询。
解决方案概述
该解决方案由AWS Lambda函数和亚马逊关系数据库服务(Amazon RDS)组成,该函数包含代理的逻辑,该代理与Amazon DynamoDB通信以保持长期内存,通过Converse API调用Amazon Bedrock中Anthropic的Claude Sonnet,使用AWS Secrets Manager检索数据库连接详细信息和凭据,该服务包含名为HR database的示例Postgres数据库。Lambda函数连接到虚拟私有云(VPC),并通过AWS PrivateLink VPC端点与DynamoDB、Amazon Bedrock和Secrets Manager通信,以便Lambda可以与RDS数据库通信,同时通过AWS网络保持流量私有。
在演示中,您可以通过Lambda函数与代理进行交互。您可以为其提供自然语言查询,例如“每个地区的每个部门有多少员工?”或“每个地区按性别划分的员工组合是什么”。以下是解决方案架构。
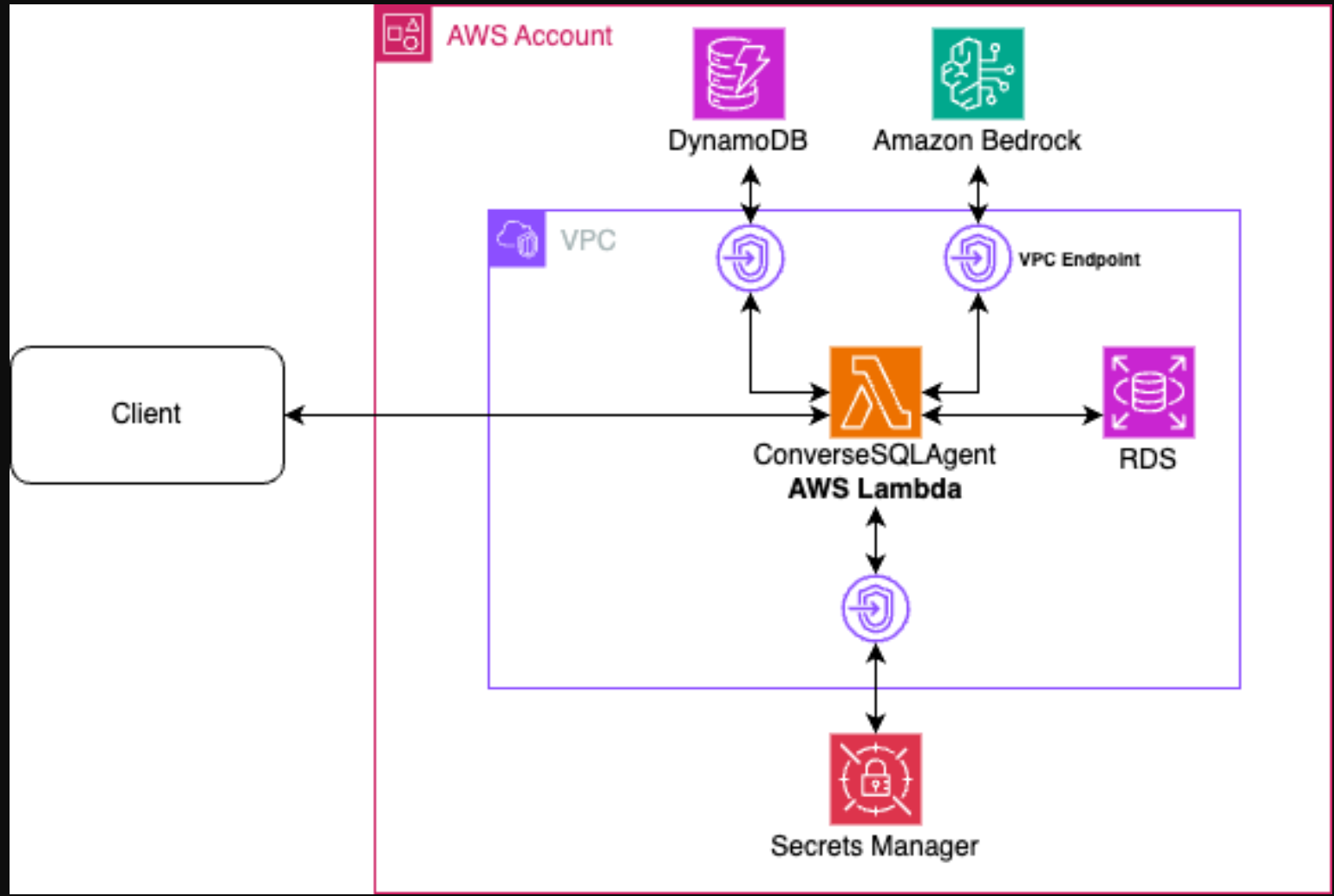
A custom agent build using Converse API
Converse API is provided by Amazon Bedrock for you to be able to create conversational applications. It enables powerful features such as tool use. Tool use is the ability for a large language model (LLM) to choose from a list of tools, such as running SQL queries against a database, and decide which tool to use depending on the context of the conversation. Using Converse API also means you can maintain a series of messages between User and Assistant roles to carry out a chat with an LLM such as Anthropic’s Claude 3.5 Sonnet. In this post, a custom agent called ConverseSQLAgent was created specifically for long-running agent executions and to follow a plan of execution.
The Agent loop: Agent planning, self-correction, and long-term learning
The agent contains several key features: planning and carry-over, execution and tool use, SQLAlchemy and self-correction, reflection and long-term learning using memory.
Planning and carry-over
The first step that the agent takes is to create a plan of execution to perform the text-to-SQL task. It first thinks through what the user is asking and develops a plan on how it will fulfill the request of the user. This behavior is controlled using a system prompt, which defines how the agent should behave. After the agent thinks through what it should do, it outputs the plan.
One of the challenges with long-running agent execution is that sometimes the agent will forget the plan that it was supposed to execute as the context becomes longer and longer as it conducts its steps. One of the primary ways to deal with this is by “carrying over” the initial plan by injecting it back into a section in the system prompt. The system prompt is part of every converse API call, and it improves the ability of the agent to follow its plan. Because the agent may revise its plan as it progresses through the execution, the plan in the system prompt is updated as new plans emerge. Refer to the following figure on how the carry over works.
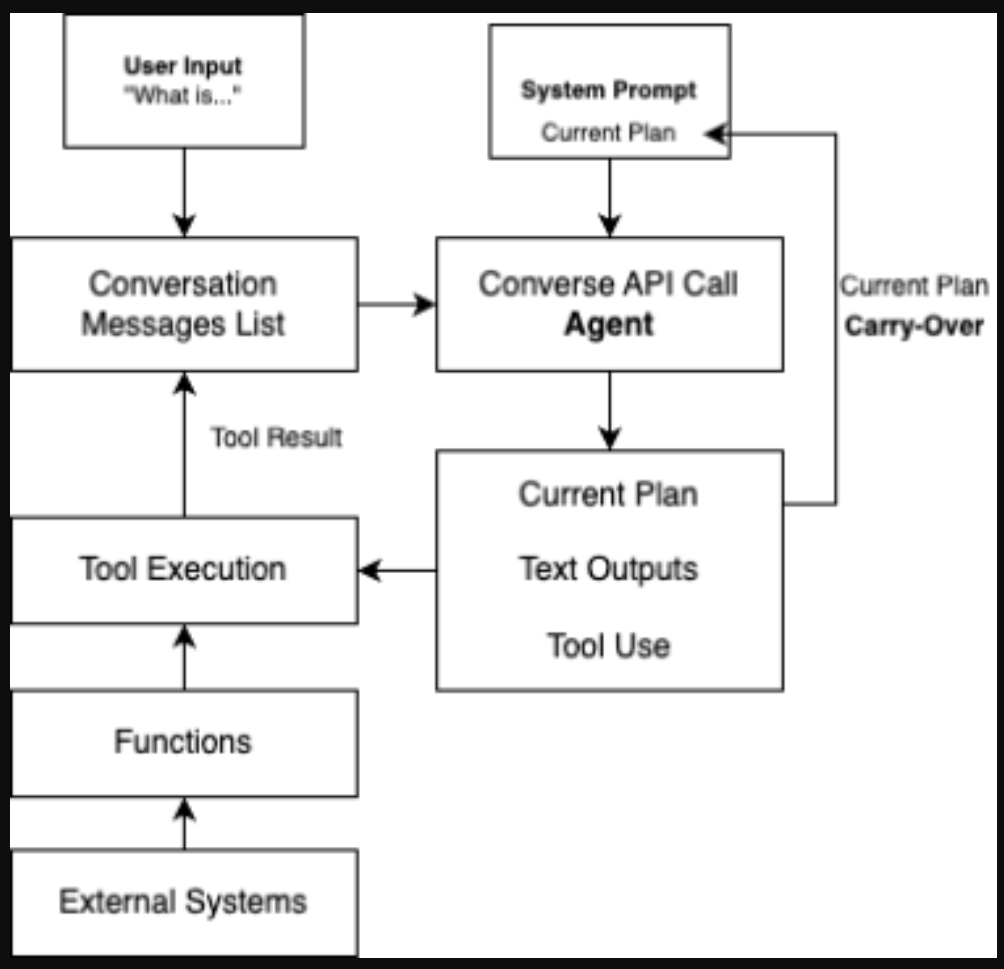
Execution and tool use
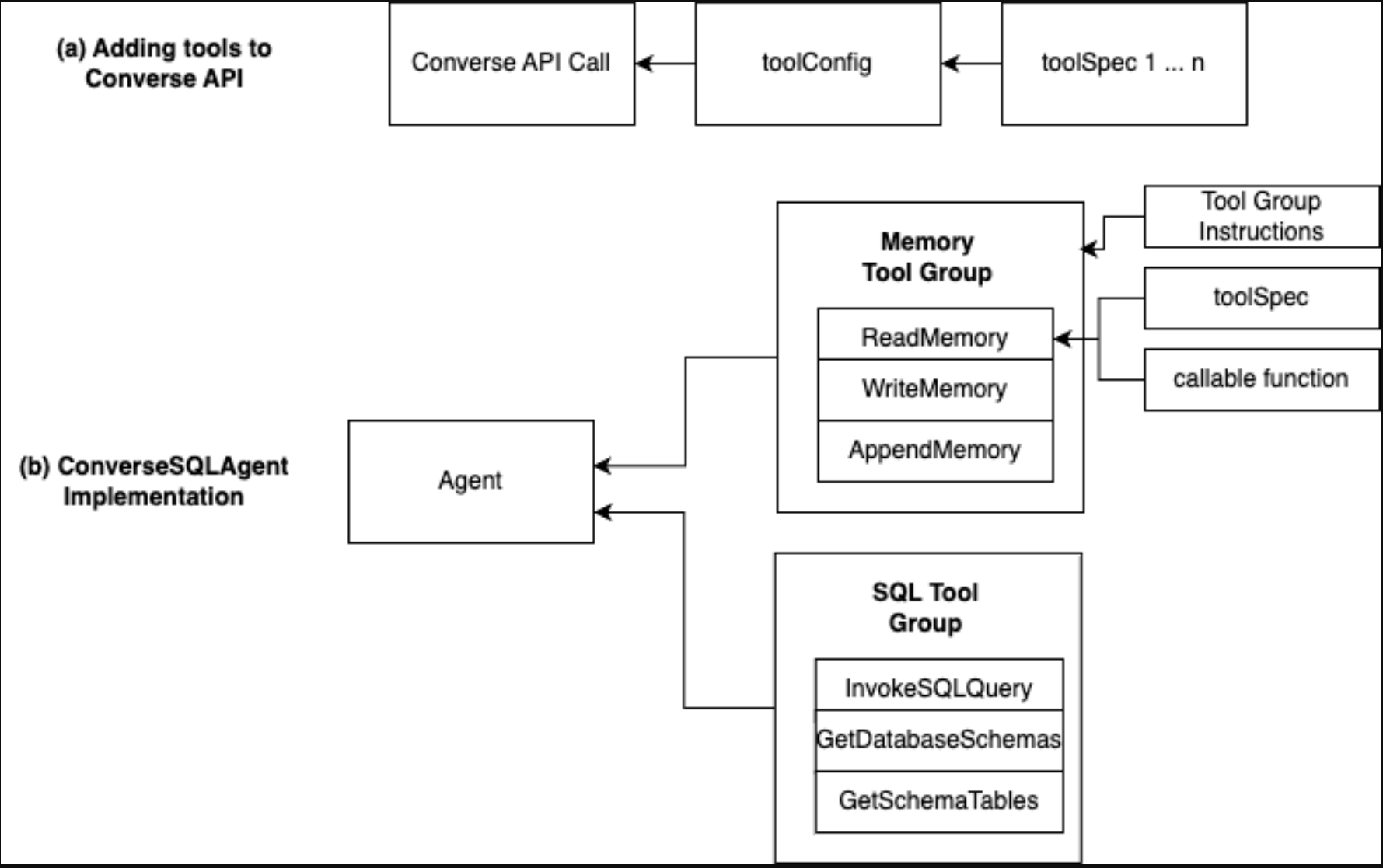
After the plan has been created, the agent will execute its plan one step at a time. It might decide to call on one or more tools it has access to. With Converse API, you can pass in a toolConfig that contains the toolSpec for each tool it has access to. The toolSpec defines what the tool is, a description of the tool, and the parameters that the tool requires. When the LLM decides to use a tool, it outputs a tool use block as part of its response. The application, in this case the Lambda code, needs to identify that tool use block, execute the corresponding tool, append the tool result response to the message list, and call the Converse API again. As shown at (a) in the following figure, you can add tools for the LLM to choose from by adding in a toolConfig along with toolSpecs. Part (b) shows that in the implementation of ConverseSQLAgent, tool groups contain a collection of tools, and each tool contains the toolSpec and the callable function. The tool groups are added to the agent, which in turn adds it to the Converse API call. Tool group instructions are additional instructions on how to use the tool group that get injected into the system prompt. Although you can add descriptions to each individual tool, having tool group–wide instructions enable more effective usage of the group.
SQLAlchemy and self-correction
The SQL tool group (these tools are part of the demo code provided), as shown in the preceding figure, is implemented using SQLAlchemy, which is a Python SQL toolkit you can use to interface with different databases without having to worry about database-specific SQL syntax. You can connect to Postgres, MySQL, and more without having to change your code every time.
In this post, there is an InvokeSQLQuery tool that allows the agent to execute arbitrary SQL statements. Although almost all database specific tasks, such as looking up schemas and tables, can be accomplished through InvokeSQLQuery, it’s better to provide SQLAlchemy implementations for specific tasks, such as GetDatabaseSchemas, which gets every schema in the database, greatly reducing the time it takes for the agent to generate the correct query. Think of it as giving the agent a shortcut to getting the information it needs. The agents can make errors in querying the database through the InvokeSQLQuery tool. The InvokeSQLQuery tool will respond with the error that it encountered back to the agent, and the agent can perform self-correction to correct the query. This flow is shown in the following diagram.
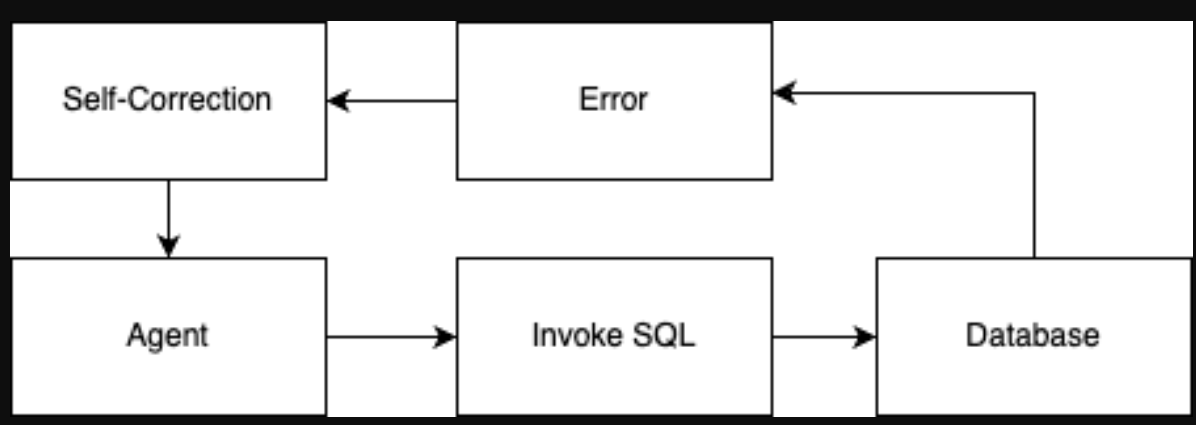
Reflection and long-term learning using memory
Although self-correction is an important feature of the agent, the agent must be able to learn through its mistakes to avoid the same mistake in the future. Otherwise, the agent will continue to make the mistake, greatly reducing effectiveness and efficiency. The agent maintains a hierarchical memory structure, as shown in the following figure. The agent decides how to structure its memory. Here is an example on how it may structure it.
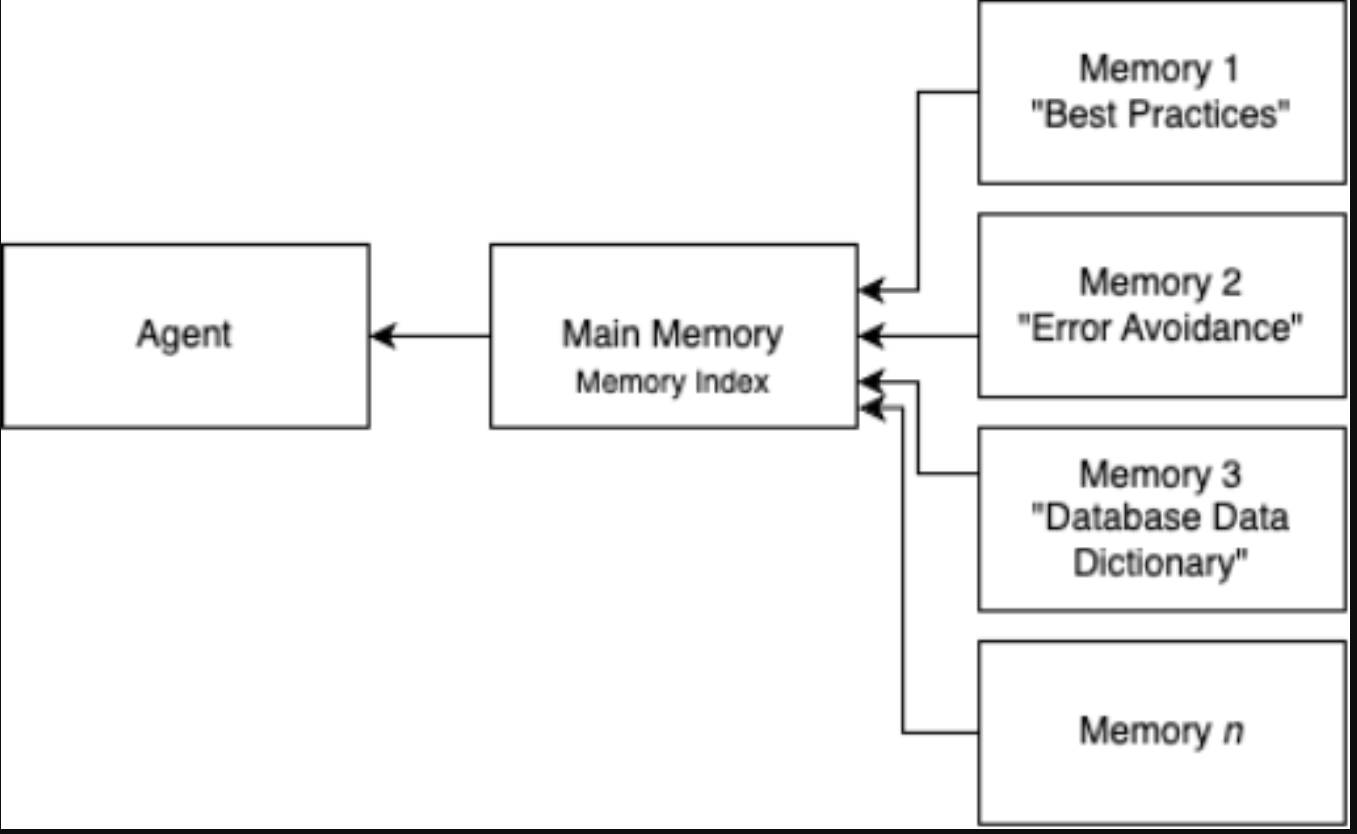
The agent can reflect on its execution, learn best practices and error avoidance, and save it into long-term memory. Long-term memory is implemented through a hierarchical memory structure with Amazon DynamoDB. The agent maintains a main memory that has pointers to other memories it has. Each memory is represented as a record in a DynamoDB table. As the agent learns through its execution and encounters errors, it can update its main memory and create new memories by maintaining an index of memories in the main memory. It can then tap onto this memory in the future to avoid errors and even improve the efficiency of queries by caching facts.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- An AWS account with an AWS Identity and Access Management (IAM) user with permissions to deploy the CloudFormation template
- The AWS Command Line Interface (AWS CLI) installed and configured for use
- Python 3.11 or later
- Amazon Bedrock model access to Anthropic’s Claude 3.5 Sonnet
Deploy the solution
The full code and instructions are available in GitHub in the Readme file.
- Clone the code to your working environment:
git clone https://github.com/aws-samples/aws-field-samples.git
- Move to
ConverseSqlAgentfolder - Follow the steps in the Readme file in the GitHub repo
Cleanup
To dispose of the stack afterwards, invoke the following command:
cdk destroy
结论
开发健壮的文本到SQL功能是自然语言处理和数据库管理中的一个关键挑战。尽管目前的方法取得了进展,但仍有改进的空间,特别是在复杂的查询和数据库结构方面。ConverseSQLAgent的引入,一个使用Amazon Bedrock和Converse API的定制代理实现,为这个问题提供了一个很有前途的解决方案。该代理的架构具有规划和遗留、执行和工具使用、通过SQLAlchemy进行自我纠正以及基于反射的长期学习等特点,展示了其理解自然语言查询、开发和执行SQL计划以及不断提高其能力的能力。随着企业寻求更直观的方式来访问和管理数据,ConverseSQLAgent等解决方案有可能弥合自然语言和结构化数据库查询之间的差距,释放出新的生产力和数据驱动的决策水平。要更深入地了解生成式人工智能,请查看以下附加资源:
- 登录 发表评论
- 22 次浏览
最新内容
- 1 day 3 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago