
category
企业聊天应用程序可以通过会话交互增强员工的能力。由于语言模型的不断进步,例如OpenAI的GPT模型和Meta的LLaMA模型,这一点尤其正确。这些聊天应用程序包括聊天用户界面(UI)、包含与用户查询相关的领域特定信息的数据存储库、对领域特定数据进行推理以产生相关响应的语言模型,以及监督这些组件之间交互的协调器。
本文提供了一个基线架构,用于构建和部署使用Azure OpenAI服务语言模型的企业聊天应用程序。该体系结构使用Azure机器学习提示流来创建可执行流。这些可执行流协调了从传入提示到数据存储的工作流,以获取语言模型的基础数据,以及其他所需的Python逻辑。可执行流被部署到托管在线端点后面的机器学习计算集群。
自定义聊天用户界面(UI)的托管遵循基线应用程序服务web应用程序指南,用于在Azure应用程序服务上部署安全、区域冗余和高可用的web应用程序。在该架构中,应用服务通过私有端点上的虚拟网络集成与Azure平台即服务(PaaS)解决方案进行通信。聊天UI应用程序服务通过专用端点与流的托管在线端点进行通信。禁用了对机器学习工作区的公共访问。
重要的
本文没有讨论基线应用服务web应用程序的组件或架构决策。阅读这篇文章,了解有关如何托管聊天UI的体系结构指南。
机器学习工作区配置有托管虚拟网络隔离,需要批准所有出站连接。使用此配置,将创建托管虚拟网络,以及允许连接到私有资源(如工作场所Azure存储、Azure容器注册表和Azure OpenAI)的托管私有端点。这些专用连接在流创作和测试期间使用,并由部署到机器学习计算的流使用。
提示
GitHub标志。本文由一个参考实现支持,该实现展示了Azure上的基线端到端聊天实现。您可以在迈向生产的第一步中将此实现用作自定义解决方案开发的基础。
架构

图显示了OpenAI的基线端到端聊天架构。
该图显示了具有专用端点的应用服务基线架构,该端点连接到机器学习托管虚拟网络中的托管在线端点。托管在线端点位于机器学习计算集群的前面。该图显示了机器学习工作空间,其中虚线指向计算集群。此箭头表示可执行流已部署到计算集群。托管虚拟网络使用托管专用端点,这些端点为可执行流所需的资源(如容器注册表和存储)提供专用连接。该图进一步显示了用户定义的专用端点,这些端点为Azure OpenAI服务和Azure AI搜索提供了专用连接。
下载此体系结构的Visio文件。
组件
该体系结构的许多组件与基线应用程序服务web应用程序体系结构中的资源相同,因为在这两种体系结构中,用于托管聊天UI的方法是相同的。本节中重点介绍的组件侧重于用于构建和编排聊天流、数据服务以及公开语言模型的服务的组件。
- 机器学习是一种托管云服务,您可以使用它来训练、部署和管理机器学习模型。该架构使用了机器学习的其他几个功能,用于为由语言模型提供支持的人工智能应用程序开发和部署可执行流:
- 机器学习提示流是一种开发工具,您可以使用它来构建、评估和部署将用户提示、通过Python代码执行的操作以及对语言学习模型的调用链接起来的流。提示流在该体系结构中用作协调提示、不同数据存储和语言模型之间的流的层。
- 通过托管在线端点,您可以部署流进行实时推理。在这个体系结构中,它们被用作聊天UI的PaaS端点,以调用机器学习托管的提示流。
- 存储用于持久化提示流源文件,以进行提示流开发。
- Container Registry允许您在专用注册表中为所有类型的容器部署构建、存储和管理容器映像和工件。在这个体系结构中,流被打包为容器映像并存储在ContainerRegistry中。
- Azure OpenAI是一个完全托管的服务,提供对Azure OpenAI语言模型的REST API访问,包括GPT-4、GPT-3.5-Turbo和嵌入模型集。在该体系结构中,除了模型访问之外,它还用于添加常见的企业功能,如虚拟网络和专用链接、托管身份支持和内容过滤。
- Azure AI搜索是一种云搜索服务,支持全文搜索、语义搜索、矢量搜索和混合搜索。AI搜索之所以包含在架构中,是因为它是聊天应用程序背后流程中使用的常见服务。AI搜索可用于检索和索引与用户查询相关的数据。提示流实现RAG检索增强生成模式,从提示中提取适当的查询,查询AI搜索,并将结果用作Azure OpenAI模型的基础数据。
机器学习提示流程
企业聊天应用程序的后端通常遵循类似于以下流程的模式:
- 用户在自定义聊天用户界面(UI)中输入提示。
- 该提示由接口代码发送到后端。
- 用户意图,无论是问题还是指令,都是由后端从提示中提取的。
- 可选地,后端确定保存与用户提示相关的数据的数据存储
- 后端查询相关的数据存储。
- 后端将意图、相关基础数据和提示中提供的任何历史记录发送到语言模型。
- 后端返回结果,以便将其显示在UI上。
- 后端可以用任何数量的语言实现,并部署到各种Azure服务。该体系结构使用机器学习提示流,因为它提供了一种简化的体验来构建、测试和部署在提示、后端数据存储和语言模型之间协调的流。
提示流运行时
机器学习可以直接托管两种类型的提示流运行时。
- 自动运行时:一个无服务器计算选项,用于管理计算的生命周期和性能特征,并允许对环境进行流驱动的自定义。
- 计算实例运行时:一个始终运行的计算选项,工作负载团队必须在其中选择性能特征。此运行时提供了对环境的更多自定义和控制。
提示流也可以托管在主机容器主机平台上的机器学习计算外部。此体系结构使用应用程序服务来演示外部托管。
网络
与基于身份的访问一样,网络安全也是使用OpenAI的基线端到端聊天架构的核心。从高层来看,网络体系结构确保:
- 只有一个单一的、安全的聊天UI流量入口点。
- 网络流量已过滤。
- 传输中的数据使用传输层安全性(TLS)进行端到端加密。
- 通过使用私有链接来保持Azure中的流量,可以最大限度地减少数据泄露。
- 网络资源通过网络分割在逻辑上进行分组并相互隔离。
网络流量

图表显示了OpenAI的基线端到端聊天架构和流量数字。
该图类似于具有三个编号网络流的Azure OpenAI架构的基线端到端聊天架构。入站流和从应用服务到Azure PaaS服务的流是从基线应用服务web架构复制的。机器学习托管在线端点流显示了从客户端UI虚拟网络中的计算实例专用端点指向托管在线端点的箭头。第二个数字显示了从托管在线端点指向计算集群的箭头。第三个显示了从计算集群到专用端点的箭头,这些端点指向容器注册表、存储、Azure OpenAI服务和AI搜索。
该图中的两个流包含在基线应用程序服务web应用程序架构中:从最终用户到聊天UI的入站流(1)和从应用程序服务到Azure PaaS服务的流(2)。本节重点介绍机器学习在线端点流。以下流程从基线应用程序服务web应用程序中运行的聊天UI到部署到机器学习计算的流程:
- 来自应用程序服务托管的聊天UI的呼叫通过专用端点路由到机器学习在线端点。
- 联机端点将调用路由到运行已部署流的服务器。在线端点同时充当负载均衡器和路由器。
- 部署流所需的对Azure PaaS服务的调用通过托管的专用端点进行路由。
机器学习入门
在此体系结构中,禁用对机器学习工作区的公共访问。用户可以通过私有访问访问工作空间,因为该体系结构遵循机器学习工作空间配置的私有端点。事实上,在整个体系结构中使用私有端点来补充基于身份的安全性。例如,您的应用程序服务托管的聊天UI可以连接到不暴露在公共互联网上的PaaS服务,包括机器学习端点。
连接到用于流创作的机器学习工作空间还需要专用端点访问。
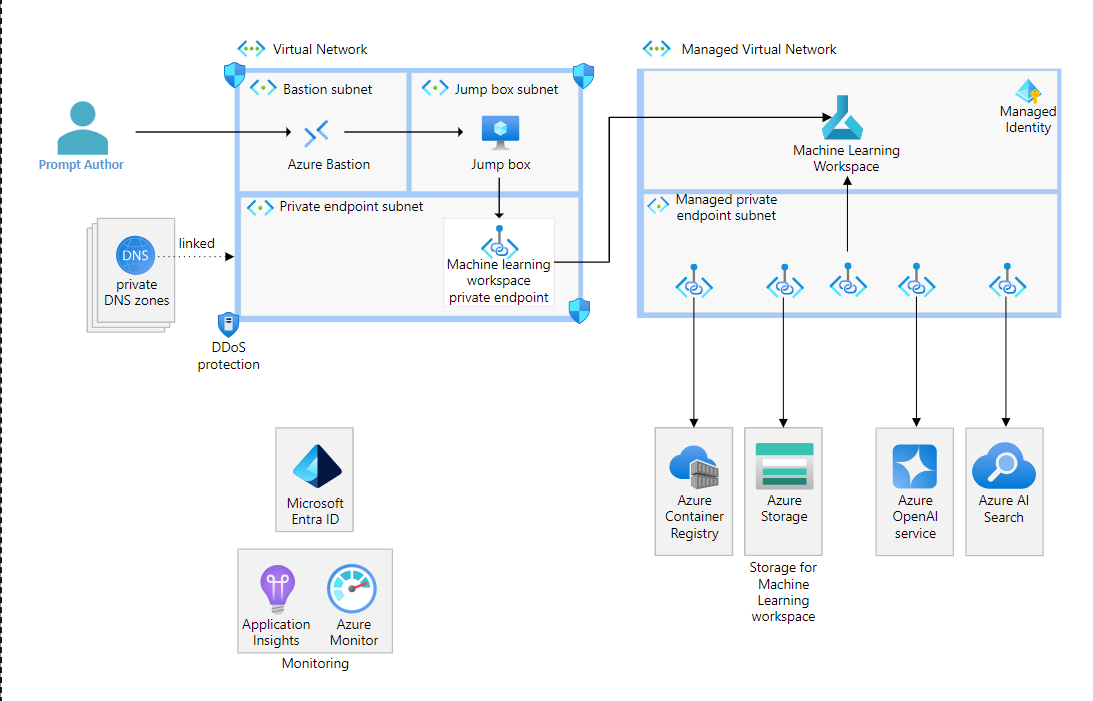
该图显示用户通过跳转框连接到机器学习工作区,以编写具有流号的流OpenAI。
该图显示了一个用户通过Azure Bastion连接到跳转框虚拟机。有一个从跳转框到机器学习工作区专用端点的箭头。从专用端点到机器学习工作区还有另一个箭头。在工作区中,有四个箭头指向四个专用端点,这些端点连接到Container Registry、Storage、Azure OpenAI Service和AI Search。
该图显示了一个提示流作者通过Azure Bastion连接到虚拟机跳转框。从该跳转框中,作者可以通过与跳转框位于同一网络中的专用端点连接到机器学习工作区。与虚拟网络的连接也可以通过ExpressRoute或VPN网关和虚拟网络对等实现。
从机器学习管理的虚拟网络到Azure PaaS服务的流程
我们建议您将机器学习工作区配置为需要批准所有出站连接的托管虚拟网络隔离。该体系结构遵循该建议。有两种类型的已批准出站规则。所需的出站规则是指解决方案工作所需的资源,如容器注册表和存储。用户定义的出站规则是指您的工作流将要使用的自定义资源,如Azure OpenAI或AI搜索。您必须配置用户定义的出站规则。创建托管虚拟网络时会配置所需的出站规则。
出站规则可以是私有终结点、服务标签或外部公共终结点的完全限定域名(FQDN)。在该架构中,到Azure服务的连接,如容器注册表、存储、Azure密钥库、Azure OpenAI和AI搜索,都是通过私有链接连接的。尽管不在此体系结构中,但一些可能需要配置FQDN出站规则的常见操作是下载pip包、克隆GitHub repo或从外部存储库下载基本容器映像。
虚拟网络分割与安全
此体系结构中的网络具有独立的子网,用于以下目的:
- 应用程序网关
- 应用程序服务集成组件
- 专用终结点
- Azure堡垒【Bastion】
- 跳转框【Jump box 】虚拟机
- 训练-不用于此体系结构中的模型训练
- 评分
每个子网都有一个网络安全组(NSG),该组将这些子网的入站和出站流量限制为所需流量。下表显示了基线添加到每个子网的NSG规则的简化视图。该表提供了规则名称和函数。
| Subnet | Inbound | Outbound |
|---|---|---|
| snet-appGateway | Allowances for our chat UI users source IPs (such as public internet), plus required items for the service. | Access to the App Service private endpoint, plus required items for the service. |
| snet-PrivateEndpoints | Allow only traffic from the virtual network. | Allow only traffic to the virtual network. |
| snet-AppService | Allow only traffic from the virtual network. | Allow access to the private endpoints and Azure Monitor. |
| AzureBastionSubnet | See guidance in Working with NSG access and Azure Bastion. | See guidance in Working with NSG access and Azure Bastion. |
| snet-jumpbox | Allow inbound Remote Desktop Protocol (RDP) and SSH from the Azure Bastion host subnet. | Allow access to the private endpoints |
| snet-agents | Allow only traffic from the virtual network. | Allow only traffic to the virtual network. |
| snet-training | Allow only traffic from the virtual network. | Allow only traffic to the virtual network. |
| snet-scoring | Allow only traffic from the virtual network. | Allow only traffic to the virtual network. |
所有其他流量都被明确拒绝。
在实现虚拟网络分段和安全性时,请考虑以下几点。
- 为具有子网的虚拟网络启用DDoS保护,该子网是具有公共IP地址的应用程序网关的一部分。
- 尽可能在每个子网中添加一个NSG。使用最严格的规则来启用完整的解决方案功能。
- 使用应用程序安全组对NSG进行分组。对NSG进行分组可以使复杂环境中的规则创建更加容易。
内容过滤和滥用监控
Azure OpenAI包括一个内容过滤系统,该系统使用一系列分类模型来检测和防止输入提示和输出完成中特定类别的潜在有害内容。这种潜在有害内容的类别包括仇恨、性、自残、暴力、脏话和越狱(旨在绕过语言模型约束的内容)。您可以为每个类别配置过滤内容的严格程度,选项有低、中或高。此参考体系结构采用了严格的方法。根据您的要求调整设置。
除了内容过滤,Azure OpenAI还实现了滥用监控功能。滥用监控是一种异步操作,旨在检测和减轻重复出现的内容或行为的实例,这些内容或行为表明使用服务的方式可能违反Azure OpenAI行为准则。如果您的数据高度敏感,或者有内部政策或适用的法律法规阻止处理用于滥用检测的数据,您可以申请豁免滥用监测和人为审查。
可靠性
基线应用服务web应用程序架构侧重于关键区域服务的区域冗余。可用性区域是一个区域内物理上独立的位置。当跨区域部署两个或多个实例时,它们在区域内为支持服务提供冗余。当一个区域出现停机时,该区域内的其他区域可能仍然不受影响。该体系结构还确保有足够的Azure服务实例和这些服务的配置分布在可用性区域中。有关更多信息,请参阅审查该指南的基线。
本节从应用程序服务基线中未提及的该架构中组件的角度讨论可靠性,包括机器学习、Azure OpenAI和AI搜索。
流部署的区域冗余
企业部署通常需要区域冗余。要在Azure中实现区域冗余,资源必须支持可用性区域,并且您必须部署至少三个资源实例,或者在实例控制不可用时启用平台支持。目前,机器学习计算不支持可用性区域。为了减轻数据中心级灾难对机器学习组件的潜在影响,有必要在各个区域建立集群,同时部署负载均衡器在这些集群之间分配调用。您可以使用运行状况检查来帮助确保呼叫只路由到运行正常的集群。
部署提示流并不局限于机器学习计算集群。可执行流是一个容器化的应用程序,可以部署到与容器兼容的任何Azure服务。这些选项包括Azure Kubernetes服务(AKS)、Azure功能、Azure容器应用程序和应用程序服务等服务。这些服务中的每一项都支持可用性区域。为了在不增加多区域部署复杂性的情况下实现区域冗余以快速执行流,您应该将流部署到其中一个服务。
下图显示了将提示流部署到应用程序服务的替代体系结构。在这种架构中使用应用程序服务是因为工作负载已经将其用于聊天UI,并且不会从将新技术引入工作负载中获益。具有AKS经验的工作负载团队应考虑在该环境中进行部署,尤其是当AKS用于工作负载中的其他组件时。
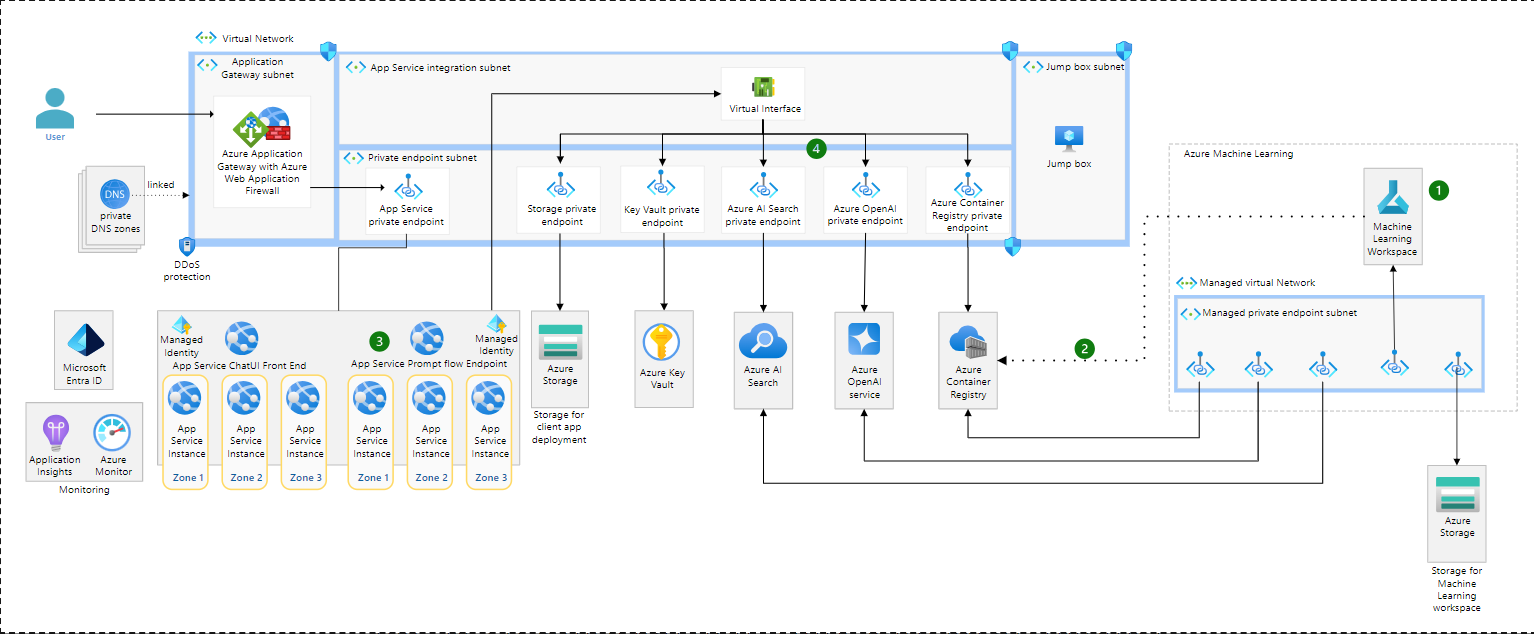
该图显示了OpenAI的基线端到端聊天架构,并将提示流部署到应用程序服务。
该图显示了应用程序服务基线架构,其中包括三个客户端应用程序服务实例和三个提示流应用程序服务示例。除了应用程序服务基线架构中的内容外,该架构还包括容器注册、人工智能搜索和Azure OpenAI的私有端点。该体系结构还显示了在托管虚拟网络中运行的用于创作流的机器学习工作区。托管虚拟网络使用托管专用端点,该端点为可执行流所需的资源(如存储)提供专用连接。该图进一步显示了用户定义的专用端点,提供与Azure OpenAI和AI搜索的专用连接。最后,从机器学习工作区到容器注册表有一条虚线,表示可执行流部署到容器注册表,提示流应用程序服务可以在那里加载它。
该图针对该体系结构中的显著区域进行了编号:
- 流仍然在机器学习提示流中编写,并且机器学习网络架构没有变化。流作者仍然通过专用端点连接到工作区创作体验,并且托管的专用端点用于在测试流时连接到Azure服务。
- 此虚线表示容器化的可执行流被推送到Container Registry。图中未显示将流容器化并推送到Container Registry的管道。
- 在同一应用服务计划中部署了另一个web应用程序,该应用程序已经托管了聊天UI。新的web应用程序承载了容器化的提示流,位于同一应用程序服务计划上,该计划已经在至少三个实例上运行,分布在可用性区域中。当加载提示流容器映像时,这些应用程序服务实例通过专用端点连接到容器注册表。
- 提示流容器需要连接到所有相关服务以执行流。在该架构中,提示流容器连接到AI搜索和Azure OpenAI。只暴露在机器学习管理的专用端点子网中的PaaS服务现在也需要暴露在虚拟网络中,以便从应用程序服务建立视线。
Azure OpenAI-可靠性
Azure OpenAI目前不支持可用性区域。为了减轻数据中心级灾难对Azure OpenAI中模型部署的潜在影响,有必要将Azure OpenAI部署到各个区域,同时部署负载均衡器以在区域之间分配调用。您可以使用运行状况检查来帮助确保呼叫只路由到运行正常的集群。
为了有效地支持多个实例,我们建议您将微调文件外部化,例如到地理冗余存储帐户。这种方法最大限度地减少了每个区域存储在Azure OpenAI中的状态。您仍然必须对每个实例的文件进行微调,以承载模型部署。
根据每分钟令牌(TPM)和每分钟请求(RPM)来监控所需的吞吐量是很重要的。确保从您的配额中分配了足够的TPM,以满足您的部署需求,并防止对已部署模型的调用被抑制。Azure API管理等网关可以部署在您的一个或多个OpenAI服务之前,并且可以配置为在出现暂时错误和节流时重试。API管理也可以用作断路器,以防止服务被呼叫淹没,超过其配额。
AI搜索-可靠性
在支持可用性区域的区域中部署具有标准或更高定价层的AI搜索,并部署三个或更多副本。复制副本自动均匀分布在可用性区域中。
请考虑以下指南来确定适当数量的副本和分区:
- 监控AI搜索。
- 使用监控指标、日志和性能分析来确定适当数量的副本,以避免基于查询的限制和分区,并避免基于索引的限制。
机器学习-可靠性
如果您部署到机器学习管理的在线端点后面的计算集群,请考虑以下关于扩展的指导:
- 自动扩展您的在线端点,以确保有足够的容量来满足需求。如果由于突发使用而导致使用信号不够及时,请考虑过度规划,以防止可用实例过少对可靠性造成影响。
- 考虑根据部署指标(如CPU负载)和端点指标(如请求延迟)创建扩展规则。
- 对于一个活动的生产部署,应部署不少于三个实例。
- 避免针对正在使用的实例进行部署。而是部署到新的部署,并在部署准备好接收流量后转移流量。
笔记
如果您将流部署到应用程序服务,则基线架构中的应用程序服务可扩展性指南也适用。
安全
该体系结构实现了网络和身份安全边界。从网络的角度来看,唯一可以从互联网访问的是通过应用程序网关的聊天UI。从身份的角度来看,聊天UI应该对请求进行身份验证和授权。在可能的情况下,使用托管身份对Azure服务的应用程序进行身份验证。
本节介绍密钥轮换和Azure OpenAI模型微调的身份和访问管理以及安全注意事项。
身份和访问管理
以下指南扩展了应用程序服务基线中的身份和访问管理指南:
- 为以下机器学习资源创建单独的托管标识(如适用):
- 用于流创作和管理的工作空间
- 计算测试流的实例
- 已部署流中的联机端点(如果流已部署到托管联机端点)
- 使用Microsoft Entra ID实现聊天UI的身份访问控制
机器学习基于角色的访问角色
有五个默认角色可用于管理对机器学习工作区的访问:AzureML数据科学家、AzureML计算操作员、读者、贡献者和所有者。除了这些默认角色外,还有一个AzureML学习工作区连接机密读取器和一个Azure ML注册表用户,可以授予对工作区资源(如工作区机密和注册表)的访问权限。
该体系结构遵循最小特权原则,只在需要的地方将角色分配给前面的身份。考虑以下角色分配。
| Managed identity | Scope | Role assignments |
|---|---|---|
| Workspace managed identity | Resource group | Contributor |
| Workspace managed identity | Workspace Storage Account | Storage Blob Data Contributor |
| Workspace managed identity | Workspace Storage Account | Storage File Data Privileged Contributor |
| Workspace managed identity | Workspace Key Vault | Key Vault Administrator |
| Workspace managed identity | Workspace Container Registry | AcrPush |
| Online endpoint managed identity | Workspace Container Registry | AcrPull |
| Online endpoint managed identity | Workspace Storage Account | Storage Blob Data Reader |
| Online endpoint managed identity | Machine Learning workspace | AzureML Workspace Connection Secrets Reader |
| Compute instance managed identity | Workspace Container Registry | AcrPull |
| Compute instance managed identity | Workspace Storage Account | Storage Blob Data Reader |
Key旋转
该架构中有两种服务使用基于密钥的身份验证:Azure OpenAI和机器学习管理的在线端点。因为您对这些服务使用基于密钥的身份验证,所以重要的是:
- 将密钥存储在安全存储中,如密钥保管库,以供授权客户端(如托管提示流容器的Azure Web App)按需访问。
- 实施关键轮换战略。如果手动轮换密钥,请创建密钥过期策略,并使用Azure策略监视密钥是否已轮换。
OpenAI模型微调
如果您在实现中微调OpenAI模型,请考虑以下指导:
- 如果您上传培训数据以进行微调,请考虑使用客户管理的密钥来加密这些数据。
- 如果您将培训数据存储在Azure Blob Storage等存储中,请考虑使用客户管理的密钥进行数据加密,使用管理的身份控制对数据的访问,并使用专用端点连接到数据。
通过政策进行治理
为了帮助确保与安全性保持一致,请考虑使用Azure策略和网络策略,以便部署与工作负载的要求保持一致。通过策略使用平台自动化减少了手动验证步骤的负担,并确保了即使绕过管道也能进行治理。请考虑以下安全策略:
在Azure AI服务和密钥库等服务中禁用密钥或其他本地身份验证访问。
要求具体配置网络访问规则或NSG。
需要加密,例如使用客户管理的密钥。
成本优化
成本优化是指寻找减少不必要费用和提高运营效率的方法。有关更多信息,请参阅成本优化的设计审查检查表。
若要查看此场景的定价示例,请使用Azure定价计算器。您需要自定义示例以匹配您的使用情况,因为此示例仅包括体系结构中包含的组件。该场景中最昂贵的组件是聊天UI、提示流计算和AI搜索。优化这些资源以节省最大成本。
计算
机器学习提示流支持多种选项来托管可执行流。这些选项包括机器学习、AKS、应用程序服务和Azure Kubernetes服务中的托管在线端点。每个选项都有自己的计费模型。计算的选择会影响解决方案的总体成本。
Azure OpenAI
Azure OpenAI是一种基于消费的服务,与任何基于消耗的服务一样,控制需求与供应是主要的成本控制。要在Azure OpenAI中具体做到这一点,您需要使用以下方法的组合:
- 控制客户端。客户端请求是消费模型中成本的主要来源,因此控制客户端行为至关重要。所有客户应:
- 获得批准。避免以支持免费访问的方式公开服务。通过网络和身份控制来限制访问,例如密钥或基于角色的访问控制(RBAC)。
- 自我控制。要求客户端使用API调用提供的令牌限制约束,例如max_tokens和max_completions。
- 在可行的情况下,使用分批。检查客户端以确保它们正确地对提示进行批处理。
- 优化提示输入和响应长度。较长的提示会消耗更多的令牌,从而提高成本,但缺少足够上下文的提示并不能帮助模型产生良好的结果。创建简洁的提示,提供足够的上下文,使模型能够生成有用的响应。同样,确保优化响应长度的限制。
- Azure OpenAI游乐场的使用应该是必要的,并且在预生产实例中使用,这样这些活动就不会产生生产成本。
- 选择正确的人工智能模型。模型选择在Azure OpenAI的总体成本中也起着很大作用。所有型号都有优点和缺点,并单独定价。在用例中使用正确的模型,以确保当较低成本的模型产生可接受的结果时,您不会在较高成本的模型上超支。在这个聊天参考实现中,选择GPT 3.5-turbo而不是GPT-4,以节省大约一个数量级的模型部署成本,同时获得足够的结果。
- 了解计费断点。微调每小时收费。为了提高效率,您希望尽可能多地利用每小时的可用时间来改善微调结果,同时避免滑入下一个计费周期。同样,来自图像生成的100个图像的成本与一个图像的费用相同。最大限度地提高价格突破点,为您带来优势。
- 了解计费模型。Azure OpenAI也可以通过提供的吞吐量以基于承诺的计费模式提供。在您有了可预测的使用模式后,如果在您的使用量下更具成本效益,请考虑切换到这种预购买计费模式。
- 设置资源调配限制。确保所有资源调配配额仅按每个模型分配给预期将成为工作负载一部分的模型。在启用动态配额的情况下,对已部署模型的吞吐量不限于此配置的配额。配额并不直接与成本对应,成本可能会有所不同。
- 监控现收现付的使用情况。如果您使用现收现付定价,请监控TPM和RPM的使用情况。使用这些信息为体系结构设计决策提供信息,例如要使用什么模型,并优化提示大小。
- 监控供应的吞吐量使用情况。如果您使用调配的吞吐量,请监控调配管理的使用情况,以确保您不会未充分利用您购买的调配吞吐量。
- 成本管理。遵循关于使用OpenAI的成本管理功能来监控成本、设置预算以管理成本以及创建警报以通知利益相关者风险或异常情况的指导。
卓越运营
卓越运营概述了部署应用程序并使其在生产中运行的运营过程。有关更多信息,请参阅卓越运营的设计审查清单。
机器学习-内置提示流运行时
为了最大限度地减少操作负担,自动运行时是机器学习中的一个无服务器计算选项,它简化了计算管理,并将大部分提示流配置委托给正在运行的应用程序的requirements.txt文件和flow.dag.yaml配置。这使得这种选择具有低维护性、短暂性和应用程序驱动性。使用计算实例运行时或外部化计算(如在该体系结构中)需要更由工作负载团队管理的计算生命周期,并且应在工作负载要求超过自动运行时选项的配置功能时进行选择。
监控
为所有服务配置诊断。除机器学习和应用程序服务外的所有服务都配置为捕获所有日志。机器学习诊断被配置为捕获审计日志,这些日志都是记录客户与数据或服务设置交互的资源日志。应用程序服务配置为捕获AppServiceHTTPLogs、AppServiceConsoleLogs、AppServicesAppLogs和AppServicePlatformLogs。
评估为此体系结构中的资源(如Azure Monitor基线警报中的资源)生成自定义警报。例如
- 容器注册表警报
- 机器学习和Azure OpenAI警报
- Azure Web应用程序警报
语言模型操作
像这样的基于Azure OpenAI的聊天解决方案的部署应该遵循LLMOps中的指导,并与Azure DevOps和GitHub进行即时流。此外,它必须考虑持续集成和持续交付(CI/CD)以及网络安全体系结构的最佳实践。以下指南介绍了基于LLMOps建议的流程及其相关基础设施的实施。此部署指南不包括前端应用程序元素,这些元素与基线中的高可用区域冗余web应用程序架构相比没有变化。
开发
机器学习提示流在机器学习工作室或通过Visual studio代码扩展提供基于浏览器的创作体验。这两个选项都将流代码存储为文件。当您使用机器学习工作室时,文件存储在存储帐户中。使用Microsoft Visual Studio代码时,文件存储在本地文件系统中。
为了遵循协作开发的最佳实践,源文件应保存在GitHub等在线源代码存储库中。这种方法有助于跟踪所有代码更改、流作者之间的协作以及与测试和验证所有代码更改的部署流的集成。
对于企业开发,请使用Microsoft Visual Studio代码扩展和提示流SDK/CLI进行开发。提示流作者可以从Microsoft Visual Studio代码构建和测试他们的流,并将本地存储的文件与在线源代码管理系统和管道集成。虽然基于浏览器的体验非常适合探索性开发,但通过一些工作,它可以与源代码管理系统集成。流文件夹可以从“文件”面板中的流页面下载、解压缩并推送到源代码管理系统。
评价
测试聊天应用程序中使用的流,就像测试其他软件工件一样。为语言模型输出指定和断言一个“正确”答案是很有挑战性的,但您可以使用语言模型本身来评估响应。考虑对语言模型流实现以下自动化评估:
- 分类准确性:评估语言模型给出的分数是“正确”还是“不正确”,并汇总结果以产生准确性等级。
- 连贯性:评估模型预测答案中的句子写得有多好,以及它们之间的连贯性。
- 流利度:评估模型的预测答案的语法和语言准确性。
- 基于上下文的基础性:评估模型的预测答案基于预先配置的上下文的效果。即使语言模型的回答是正确的,如果它们不能根据给定的上下文进行验证,那么这些回答就没有根据。
- 相关性:评估模型的预测答案与所问问题的一致性。
在实施自动化评估时,请考虑以下指导:
- 从评估中得出分数,并根据预定义的成功阈值进行测量。使用这些分数来报告管道中的测试通过/不通过。
- 其中一些测试需要预先配置的问题、上下文和基本事实的数据输入。
- 包括足够的问答对,以确保测试结果可靠,建议至少100-150对。这些问答对被称为“黄金数据集”。根据数据集的大小和领域,可能需要更大的群体。
- 避免使用语言模型生成黄金数据集中的任何数据。
部署流程
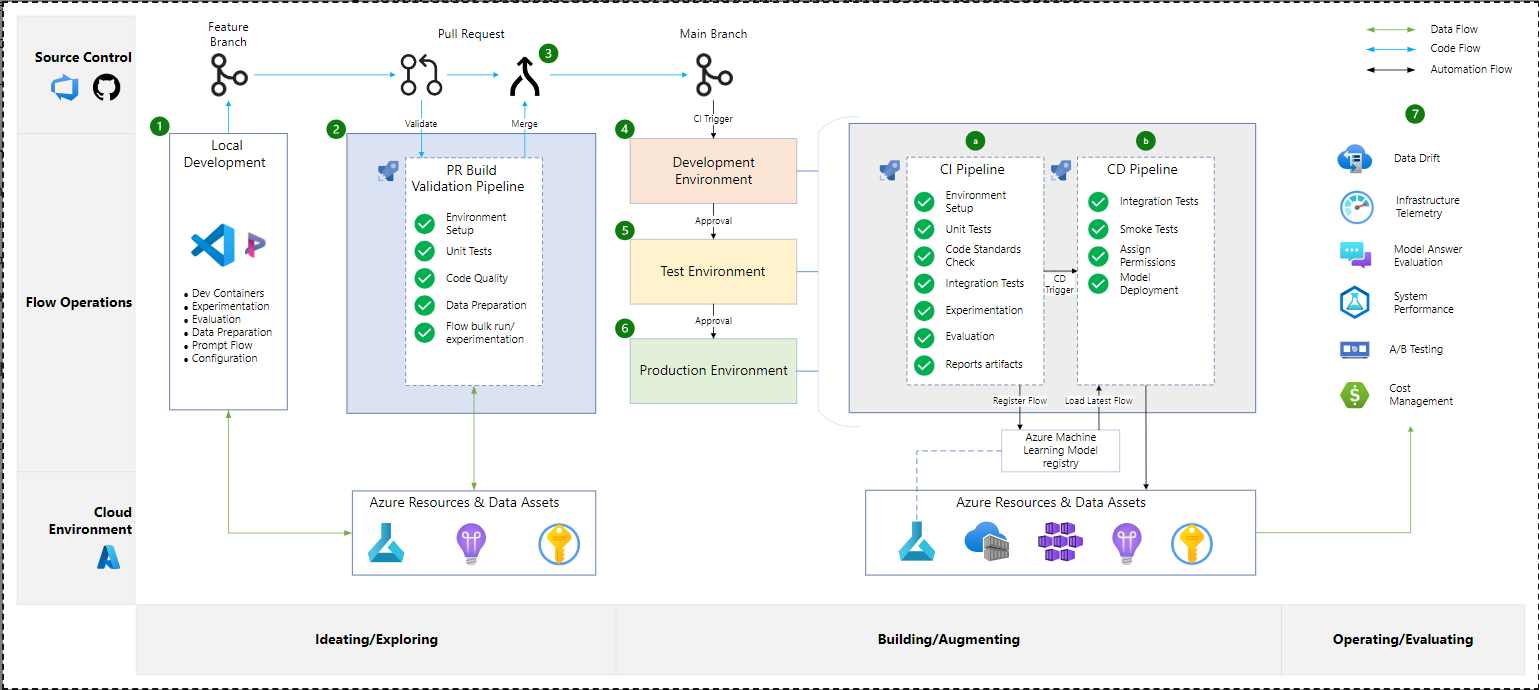
显示提示流的部署流的图。
该图显示了提示流的部署流程。以下用数字标注:1。本地开发步骤,2。一个包含拉取请求(PR)管道的框,3。手动批准,4。发展环境,5。测试环境,6。生产环境,7。监视任务的列表以及CI管道和b.CD管道。
- 提示工程师/数据科学家打开一个功能分支,他们在其中处理特定任务或功能。提示工程师/数据科学家使用Microsoft Visual Studio代码的提示流迭代流,定期提交更改并将这些更改推送到功能分支。
- 一旦本地开发和实验完成,快速的工程师/数据科学家就会打开一个从Feature分支到Main分支的pull请求。拉取请求(PR)触发PR管道。此管道运行快速质量检查,应包括:
- 实验流程的执行
- 执行配置的单元测试
- 代码库的编译
- 静态代码分析
- 管道可以包含一个步骤,该步骤要求至少一名团队成员在合并前手动批准PR。审批者不能是提交者,他们必须具备快速流动的专业知识和对项目需求的熟悉程度。如果PR未被批准,则合并将被阻止。如果PR已批准,或者没有批准步骤,则功能分支将合并到主分支中。
- 合并到Main将触发开发环境的构建和发布过程。明确地
- CI管道是从合并到主管道触发的。CI管道执行PR管道中完成的所有步骤,以及以下步骤:
- 实验流程
- 评估流程
- 当检测到更改时,在机器学习注册表中注册流
- CD管道是在CI管道完成后触发的。此流程执行以下步骤:
- 将流从机器学习注册表部署到机器学习在线端点
- 运行针对在线端点的集成测试
- 针对在线端点运行烟雾测试
- CI管道是从合并到主管道触发的。CI管道执行PR管道中完成的所有步骤,以及以下步骤:
- 批准流程被构建在发布促进流程中——批准后,重复步骤4.a和4.b中描述的CI&CD流程,以测试环境为目标。步骤a.和b.是相同的,只是用户验收测试是在测试环境中的烟雾测试之后运行的。
- 在测试环境得到验证和批准后,运行步骤4.a和4.b中描述的CI&CD过程,以促进向生产环境的发布。
- 在发布到实时环境中后,将执行监视性能指标和评估部署的语言模型的操作任务。这包括但不限于:
- 检测数据漂移
- 观察基础设施
- 管理成本
- 将模型的性能传达给利益相关者
部署指南
您可以使用机器学习端点来部署模型,从而在发布到生产环境时实现灵活性。考虑以下策略以确保最佳的模型性能和质量:
- 蓝/绿部署:使用此策略,您可以将新版本的web服务安全地部署到有限的一组用户或请求,然后再将所有流量引导到新部署。
- A/B测试:蓝色/绿色部署不仅可以有效地安全地推出更改,还可以用于部署新的行为,允许一部分用户评估更改的影响。
- 包括Python文件的linting,这些文件是管道中提示流的一部分。Linting检查是否符合样式标准、错误、代码复杂性、未使用的导入和变量命名。
- 当您将流部署到与网络隔离的机器学习工作区时,请使用自托管代理将工件部署到Azure资源。
- 只有当模型发生更改时,才应更新机器学习模型注册表。
- 语言模型、流和客户端UI应该是松散耦合的。可以而且应该能够在不影响模型的情况下更新流和客户端UI,反之亦然。
- 当您开发和部署多个流时,每个流都应该有自己的生命周期,这允许在将流从实验推广到生产时获得松散耦合的体验。
基础设施
当你部署基线Azure OpenAI端到端聊天组件时,提供的一些服务是架构中的基础和永久性服务,而其他组件本质上更为短暂,它们的存在与部署有关。
基础组件
该体系结构中的某些组件的生命周期超出了任何单个提示流或任何模型部署。这些资源通常由工作负载团队作为基础部署的一部分部署一次,并与提示流或模型部署的新的、删除的或更新分开进行维护。
- 机器学习工作区
- 机器学习工作区的存储帐户
- 容器注册表
- AI搜索
- Azure OpenAI
- Azure应用程序见解
- Azure堡垒
- 用于跳转框的Azure虚拟机
短期组件
一些Azure资源与特定提示流的设计结合得更紧密。这种方法允许这些资源绑定到组件的生命周期,并在该体系结构中变得短暂。当工作负载发展时,如添加或删除流或引入新模型时,Azure资源会受到影响。这些资源将被重新创建并删除以前的实例。这些资源中的一些是直接的Azure资源,一些是其包含服务中的数据平面表现。
- 如果更改了机器学习模型注册表中的模型,则应将其作为CD管道的一部分进行更新。
- 容器映像应作为CD管道的一部分在容器注册表中更新。
- 如果部署引用了不存在的端点,则在部署提示流时会创建机器学习端点。需要更新该端点以关闭公共访问。
- 当部署或删除流时,会更新机器学习端点的部署。
- 创建新终结点时,必须使用终结点的密钥更新客户端UI的密钥保管库。
性能效率
性能效率是指您的工作负载能够有效扩展以满足用户对其提出的要求。有关更多信息,请参阅性能效率的设计审查检查表。
本节从Azure搜索、Azure OpenAI和机器学习的角度描述性能效率。
Azure搜索-性能效率
按照指南分析AI搜索中的性能。
Azure OpenAI-性能效率
确定您的应用程序是否需要提供吞吐量或共享主机或消耗模型。提供的吞吐量确保为您的OpenAI模型部署保留处理能力,从而为您的模型提供可预测的性能和吞吐量。这种计费模式不同于共享托管或消费模式。这种消费模式是尽力而为的,可能会受到邻居吵闹或平台上其他压力的影响。- 监控供应吞吐量的供应管理利用率。
机器学习-性能效率
如果您部署到机器学习在线端点:
- 遵循有关如何自动缩放联机端点的指导。这样做可以保持与需求的紧密一致,而不会过度规划,尤其是在使用率较低的时期。
- 为在线端点选择适当的虚拟机SKU,以满足您的性能目标。测试较低实例数和较大SKU与较大实例数和较小SKU的性能,以找到最佳配置。
部署此场景
要部署和运行参考实现,请遵循OpenAI端到端基线参考实现中的步骤。
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
- Rob Bagby | Patterns & Practices - Microsoft
- Freddy Ayala | Cloud Solution Architect - Microsoft
- Prabal Deb | Senior Software Engineer - Microsoft
- Raouf Aliouat | Software Engineer II - Microsoft
- Ritesh Modi | Principal Software Engineer - Microsoft
- Ryan Pfalz | Senior Solution Architect - Microsoft
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next step
Related resources
- 登录 发表评论
- 63 次浏览
Tags
最新内容
- 10 hours ago
- 1 week 1 day ago
- 1 week 5 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago