
Chinese, Simplified
category
大型语言模型(LLM)微调涉及使预训练模型适应特定任务。此过程通过更新新数据集上的参数来实现。具体来说,LLM使用<输入,输出>对所需行为的代表性示例进行部分再训练。因此,它涉及更新模型权重。
微调的数据要求
在微调LLM之前,了解数据要求以支持培训和验证至关重要。
以下是一些指导方针:
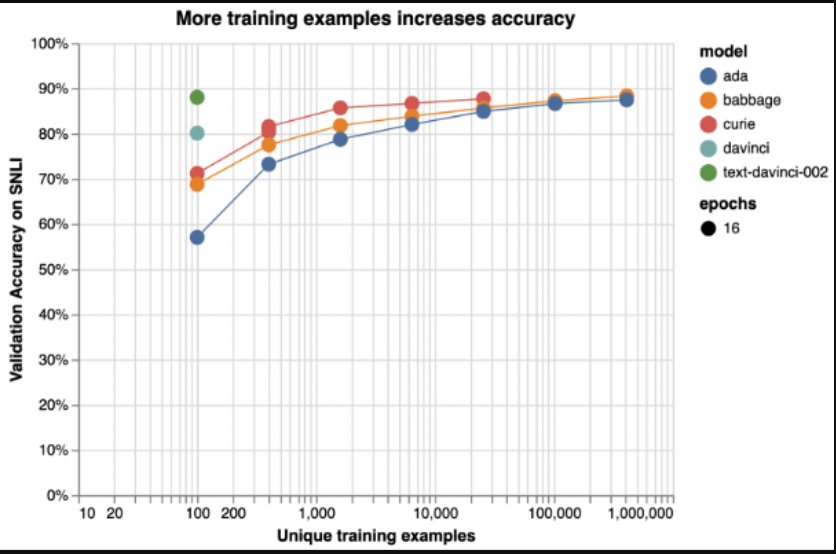
- 使用大型数据集:训练和验证数据集所需的大小取决于任务的复杂性和正在微调的模型。一般来说,您希望有数千或数万个示例。如下图中的示例所示,较大的模型用较少的数据学习更多。他们仍然需要足够的数据来避免过度拟合或忘记他们在预训练阶段学到的东西。
- 使用高质量的数据集:数据集应保持一致的格式,并清除不完整或不正确的示例。
- 使用代表性数据集:微调数据集的内容和格式应代表将使用模型的数据。例如,如果你正在微调一个用于情绪分析的模型,你希望有来自不同来源、流派和领域的数据。这些数据还应反映人类情感的多样性和细微差别。您还希望正、负和中性示例的分布均衡,以避免模型的预测出现偏差。
- 使用足够指定的数据集:数据集应在输入中包含足够的信息,以生成您希望在输出中看到的内容。例如,如果您正在对电子邮件生成模型进行微调,您希望提供清晰具体的提示,以指导模型的创造力和相关性。您还需要定义电子邮件的预期长度、样式和语气。
微调
此图显示了斯坦福自然语言推理(SNLI)语料库上文本分类性能的说明性示例。有序的句子对按其逻辑关系分类:矛盾的、隐含的或中性的。如果没有另行指定,则使用默认微调参数。
如何格式化数据以微调OpenAI
要使用Azure OpenAI(或OpenAI)微调模型,您需要一组具有特定格式的训练示例。有关更多信息,请参阅使用微调自定义Azure OpenAI模型。
以下是一些附加指南:
- 使用JSON:训练示例应以JSON格式提供,其中每个示例由一对<prompt,completion>组成。提示是一个文本片段,您希望模型继续。完成是模型应该学会产生的一种可能的延续。例如,如果你想微调LLM以生成故事,提示可以是故事的开头,完成可以是下一个句子或段落。
- 使用分隔符和停止顺序:要通知模型提示何时结束、完成何时开始以及完成何时结束,请使用固定分隔符和结束顺序。分隔符是在提示末尾插入的特殊标记或符号。停止序列是您在结束时插入的特殊标记或符号。例如,您可以使用\n###作为分隔符,\n###\n作为停止序列,如下所示:
文本
{"prompt": "Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do.\n##\n",
"completion": "She wondered if they should just go back home.\n###\n"}- 不要混淆模型:确保分隔符和停止序列不包含在提示文本或训练数据中。模型应该只将它们视为分隔符和停止序列。
- 使用一致的风格和语气:你还应该确保你的提示和完成在风格、语气和长度方面是一致的。它们应该与您要微调模型的任务或域相匹配。
- 保持训练和推理提示的一致性:确保使用模型进行推理时使用的提示的格式和措辞与训练模型的方式相同,包括使用相同的分隔符。
微调超参数
在微调GPT-3等LLM时,调整超参数以优化模型在特定任务或域上的性能非常重要。用户在微调模型时可以调整许多超参数。下表列出了其中一些参数,并为每个参数提供了一些建议。(来源:微调GPT-3以对文本进行分类的最佳实践)
| Parameter | Description | Recommendation |
|---|---|---|
| n_epochs | Controls the number of epochs to train the model for. An epoch refers to one full cycle through the training dataset. | • Start from 2-4 • Small datasets may need more epochs and large datasets may need fewer epochs. • If you see low training accuracy (under-fitting), try increasing n_epochs. If you see high training accuracy but low validation accuracy (over-fitting), try lowering n_epochs. |
| batch_size | Controls the batch size, which is the number of examples used in a single training pass. | • Recommendation is set the batch size in the range of 0.01% to 4% of training set size. • In general, larger batch sizes tend to work better for larger datasets. |
| learning_rate_multiplier | Controls learning rate at which the model weights are updated. The fine-tuning learning rate is the original learning rate used for pre-training, multiplied by this value. | • Recommendation is experiment with values in the range 0.02 to 0.2 to see what produces the best results. • Larger learning rates often perform better with larger batch sizes. • learning_rate_multiplier has minor effect compared to n_epochs and batch_size. |
| prompt_loss_weight | Controls how much the model learns from prompt tokens vs completion tokens. | • If prompts are long (relative to completions), try reducing this weight (default is 0.1) to avoid over-prioritizing learning the prompt. • prompt_loss_weight has minor effect compared to n_epochs and batch_size. |
微调的挑战和局限性
微调大型语言模型可能是一种强大的技术,可以使它们适应特定的领域和任务。然而,在将微调应用于实际问题之前,还需要考虑一些挑战和缺点。以下是其中一些挑战和缺点。
- 微调需要与目标域和任务匹配的高质量、足够大且具有代表性的训练数据。高质量的数据具有相关性、准确性、一致性和多样性,足以覆盖模型在现实世界中可能遇到的场景和变化。质量差或不具代表性的数据会导致微调模型中的过度拟合、欠拟合或偏差,从而损害其泛化能力和鲁棒性。
- 微调大型语言模型意味着与培训和托管自定义模型相关的额外成本。
- 格式化用于微调大型语言模型的输入/输出对对其性能和可用性至关重要。
- 每当数据更新或发布更新的基础模型时,可能需要重复微调。这涉及定期监测和更新。
- 微调是一项重复性的任务(反复试验),因此需要仔细设置超参数。微调需要大量的实验和测试来找到超参数和设置的最佳组合,以实现所需的性能和质量。
- 登录 发表评论
- 133 次浏览
发布日期
星期日, 十月 6, 2024 - 11:24
最后修改
星期日, 十月 6, 2024 - 11:24
Tags
Article
最新内容
- 3 days 8 hours ago
- 1 week 4 days ago
- 2 weeks 1 day ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago