
category
概述
本文讨论了示例零售集市应用程序的安全规划。它显示了示例应用程序的架构和数据流图。随着架构和代码库的发展,工件可能会发生变化。下图中的每个标记实体都附有元信息,描述了以下项目:
- 威胁
- 范围内的数据
- 安全控制建议
谨慎和弹性是人工智能模型有效应对复杂和敏感任务的基本素质,确保它们能够在具有挑战性的环境中做出明智的决策并保持性能。更多细节可以在下面的自由裁量权标题下找到。除了本计划中推荐的安全控制措施外,强烈建议您使用SIEM和SOC工具实施强大的防御机制。
应用概述
Retail-mart是一家虚构的零售公司,是零售业创新、以客户为中心和市场领导地位的象征。Retail-mart拥有数十年的丰富历史,始终树立卓越标准,已成为家喻户晓的品牌,是质量和便利的代名词。
Retail-mart经营着各种各样的零售产品,以满足客户的不同需求。无论是杂货、服装、珠宝还是DIY建筑产品,便利店电子商务平台都能提供无缝的购物体验。零售市场存在于零售业的各个方面。
该公司致力于提供以下产品,这表明了其对客户满意度的承诺:
- 顶级产品。
- 卓越的服务。
- 多种选择,满足各行各业购物者的需求。
Retail-mart希望通过使用数据驱动的分析和人工智能驱动的推荐来拥抱尖端技术,以增强购物体验,并确保客户找到他们真正需要的东西。
该安全规划将突出与拟议架构相关的安全风险,以及将降低安全风险可能性和严重性的安全控制措施。
图表
架构图
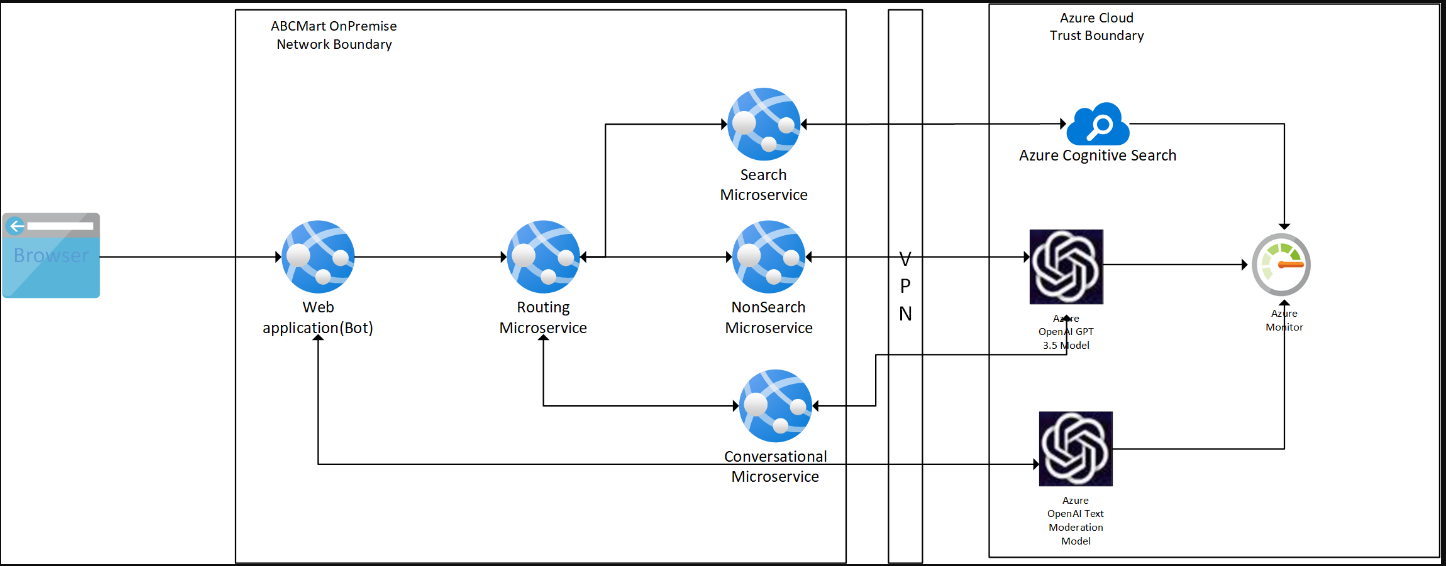
Data Flow Diagram
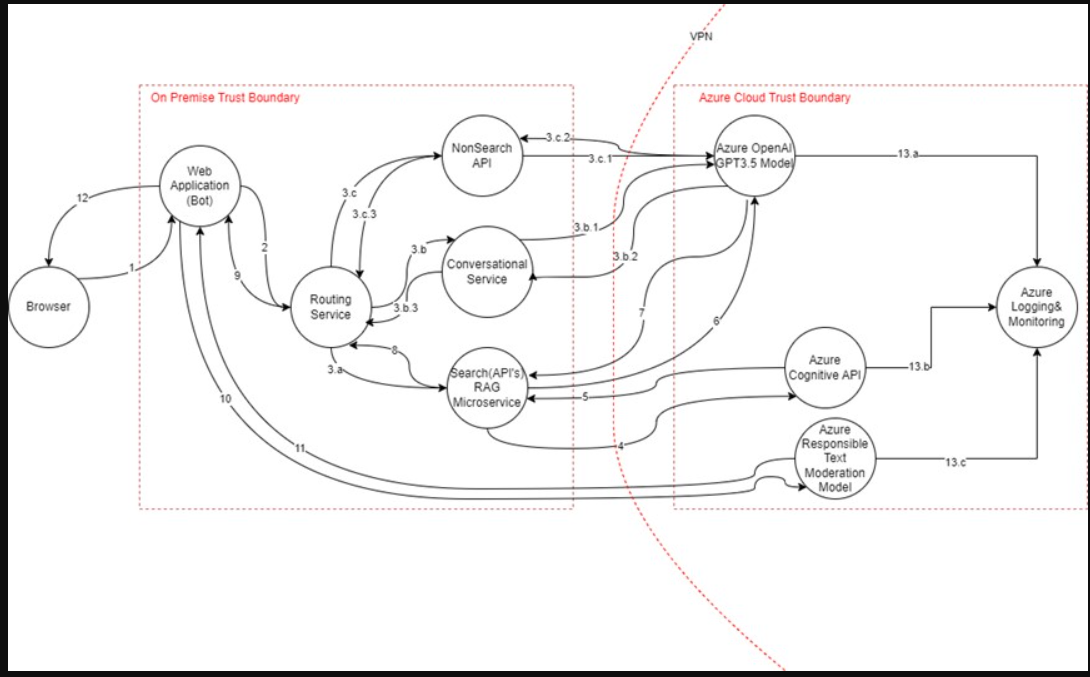
使用案例
需要搜索的提示流/提示输入/RAG模式数据流序列-1、2、3.a、4、5、6、7、8、9、10、11、12
数据流属性
| # | Transport Protocol | Data Classification | Authentication | Authorization | Notes |
|---|---|---|---|---|---|
| 1 | HTTPS | Confidential | Entra ID | Entra Scopes | User is authenticated to web application. User launches chatbot and enters prompt. |
| 2 | HTTPS | Confidential | Entra ID | Entra Application permissions | Request is enhanced and sent to routing service. |
| 3.a | HTTPS | Confidential | Entra ID | Entra Application permissions | If request is related to search, then it's sent to Search RAG (Retrieval Augmented Generation) microservice |
| 3.b | HTTPS | Confidential | Entra ID | Entra Application permissions | If the request is conversational, it is sent to Conversational Microservice. |
| 3.b.1 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Conversational Prompt Input is sent to GPT model |
| 3.b.2 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Conversational prompt response from GPT model. |
| 3.b.3 | HTTPS | Confidential | Entra ID | Entra Application permissions | Response from Conversational Service to Routing Service |
| 3.c | HTTPS | Confidential | Entra ID | Entra Application permissions | If the request is not a search, it is sent to Non-Search Microservice. |
| 3.c.1 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Non-Search Request sent to GPT model |
| 3.c.2 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Non-Search response from GPT model |
| 3.c.3 | HTTPS | Confidential | Entra ID | Entra Application permissions | Response from Non-Search API service to Routing Service |
| 4 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Search API calls AI search API to fetch top 10 products. |
| 5 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Response from AI search API with details about top 10 products matching search input. |
| 6 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Product details output from AI search is sent to GPT model to summarize the content. |
| 7 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Response of GPT model to summarize the output |
| 8 | HTTPS | Confidential | Entra ID | Entra Application permissions | Response from Search Service |
| 9 | HTTPS | Confidential | Entra ID | Entra Application permissions | Response from routing service to Web application |
| 10 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Request sent to content moderation service to filter out harmful content provided by user. Content moderation service used at both user input and output response. |
| 11 | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Output response of content moderation service. |
| 12 | HTTPS | Confidential | Entra ID | Entra Application permissions | Response from web application to client browser |
| 13.a, 13.b, 13.c | HTTPS | Confidential | Entra ID | Azure RBAC(Azure AI Services OpenAI User) | Logs sent to Azure Monitor. |
Threat map
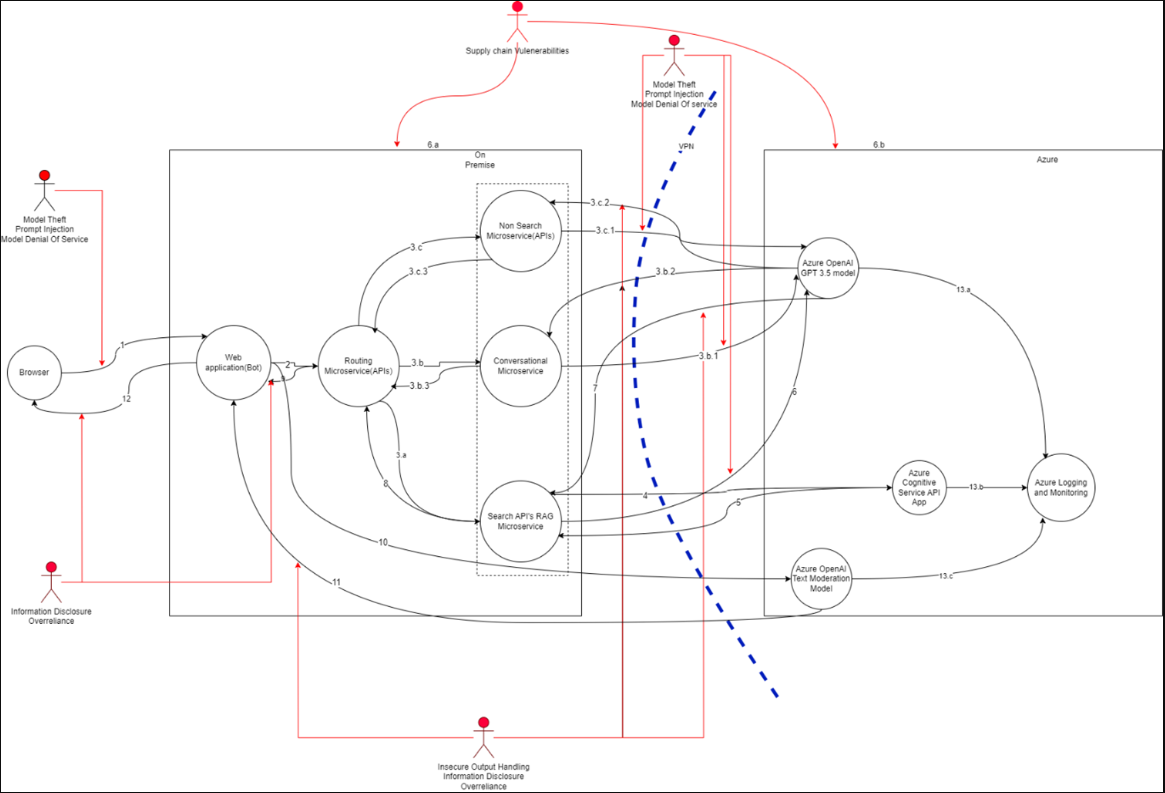
威胁属性
威胁#1:提示注入
原则:保密、完整、可用、隐私
威胁:用户可以修改系统级提示限制,以“越狱”LLM并覆盖之前的控件。
由于该漏洞,攻击者可以创建恶意输入,操纵LLM在不知不觉中执行意外操作。有直接和间接两种快速注射方式。直接提示注入,也称为越狱,发生在攻击者覆盖或暴露底层系统提示时。越狱允许攻击者利用后端系统。
当LLM接受来自网站或文件等外部来源的输入时,会发生间接提示注入。攻击者可能会在外部内容中嵌入提示注入。
受影响资产聊天机器人服务、路由微服务、会话微服务、Azure OpenAI GPT3.5模型、搜索API RAG微服务。
缓解措施:
- 对后端系统的LLM访问实施权限控制。
- 将外部内容与用户提示隔离开来,并在使用不受信任的内容时限制其影响。
- 定期手动监控输入和输出,以按预期进行检查。
- 通过LLM保持用户对决策能力的精细控制。
- 所有产品和服务都必须使用批准的加密协议和算法对传输中的数据进行加密。
- 使用Azure AI内容安全过滤器进行提示输入及其响应。
- 使用TLS加密所有基于HTTP的网络流量。使用其他机制,如IPSec,对包含客户或机密数据的非HTTP网络流量进行加密。
- 仅使用TLS 1.2或TLS 1.3。使用基于ECDHE的密码套件和NIST曲线。使用强键。启用HTTP严格传输安全。关闭TLS压缩,不要使用基于票证的会话恢复。
威胁#2:模型盗窃
原则:保密
威胁: 用户可以修改系统级提示限制,以“越狱”LLM并覆盖之前的控件。
当专有LLM模型发生以下行为之一时,就会出现这种威胁:
- 妥协的。
- 物理被盗。
- 复制。
- 提取权重和参数以创建等效函数。
受影响的资产聊天机器人服务、路由微服务、对话微服务、Azure OpenAI GPT3.5模型、搜索API RAG微服务
缓解措施:
- 实施强有力的访问控制和强有力的身份验证机制,以限制对LLM模型存储库和培训环境的未经授权的访问。
- 限制LLM访问网络资源、内部服务和API。
- 定期监控和审计与LLM模型存储库相关的访问日志和活动,以检测和应对任何可疑活动。
- 通过治理、跟踪和审批工作流自动化MLOps部署。
- 速率限制API调用(如适用)。
- 所有客户或机密数据在写入非易失性存储介质之前必须加密(静态加密)。
- 使用批准的算法,包括AES-256、AES-192或AES-128。
威胁#3:模型拒绝服务
原则:可用性
威胁:
- 攻击者以一种消耗大量资源的方法与LLM交互,从而导致他们和其他用户的服务质量下降。被攻击的一个可能会产生高昂的资源成本。这种攻击也可能是由于供应链中的漏洞造成的。
- 受影响的资产聊天机器人服务、路由微服务、对话微服务、Azure OpenAI GPT3.5模型、搜索API RAG微服务
缓解措施:
- 实施输入验证和净化,以确保用户输入符合定义的限制,并过滤掉任何恶意内容。
- 限制每个请求或步骤的资源使用,使涉及复杂部分的请求执行得更慢。
- 强制执行API速率限制,以限制单个用户或IP地址在特定时间范围内可以发出的请求数。
- 限制以下计数:
- 排队的操作数。
- 系统中对LLM响应做出反应的总操作数。
- 持续监控LLM的资源利用率,以识别可能指示DoS攻击的异常尖峰或模式。
- 根据LLM上下文窗口设置严格的输入限制,以防止过载和资源耗尽。
- 提高开发人员对LLM中潜在DoS漏洞的认识,并为安全的LLM实施提供指导方针。
- Azure信任边界内的所有服务都必须对所有传入请求进行身份验证,包括来自同一网络的请求。还应应用适当的授权以防止不必要的权限。
- 只要可用,就使用Azure托管身份对服务进行身份验证。如果不支持托管标识,则可以使用服务主体。
- 外部用户或服务可以使用用户名+密码、令牌或证书进行身份验证,前提是这些凭据存储在密钥库或任何其他库解决方案中。
- 对于授权,请使用Azure RBAC和条件访问策略来分离职责。只授予最少量的访问权限,以在特定范围内执行操作。
威胁#4:输出处理不安全
原则:保密
威胁:对LLM输出的审查不足,对LLM输出来的未经过滤的接受可能会导致意外的代码执行。
- 当LLM输出的验证、净化和处理不足时,就会发生不安全的输出处理,这些输出会被传递到下游的其他组件和系统。由于LLM生成的内容可以通过提示输入进行控制,因此这种行为就像为用户提供间接访问更多功能的机会。
- 受影响的资产Web应用程序、非搜索微服务、搜索API RAG微服务、对话微服务、浏览器。
缓解措施:
- 将模型视为任何其他用户。采取零信任策略。对从模型到后端函数的响应应用适当的输入验证。
- 遵循最佳实践,以确保有效的输入验证和净化。
- 将模型输出编码回用户,以减少JavaScript或Markdown的不必要代码执行。
- 使用Azure AI内容安全过滤器进行提示输入及其响应。
威胁#5:供应链漏洞
原则:保密性、完整性和可用性
威胁:用于开发的开源/第三方软件包中的漏洞可能导致攻击者利用这些漏洞。
- 这种威胁是由于软件组件、训练数据、机器学习模型或部署平台中的漏洞造成的。
- 受影响的资产Web应用程序、非搜索微服务、搜索API RAG微服务、对话微服务、Azure OpenAI GPT 3.5模型、Azure Open人工智能文本审核工具、Azure人工智能服务API APP
缓解措施:
- 使用Azure Artifacts发布和控制提要,这将降低供应链漏洞的风险。
- 仔细审查数据源和供应商,包括条款和条件及其隐私政策,只使用值得信赖的供应商。确保有足够的、经过独立审计的安全措施。验证模型操作员策略是否与您的数据保护策略一致。也就是说,你的数据不会用于训练他们的模型。同样,寻求模型维护者对使用受版权保护的材料的保证和法律缓解。
只使用信誉良好的插件,并确保它们已经过测试,符合您的应用程序要求。LLM不安全插件设计提供了有关不安全插件的LLM方面的信息,您应该对其进行测试,以降低使用第三方插件的风险。 - 使用软件物料清单(SBOM)维护最新的组件库存,以确保您拥有最新、准确和签名的库存,防止篡改已部署的软件包。SBOM可用于快速检测和警报新的零日漏洞。
- 在撰写本文时,SBOM不包括模型、其工件和数据集。如果你的LLM应用程序使用自己的模型,你应该使用MLOps最佳实践。使用提供具有数据、模型和实验跟踪的安全模型存储库的平台。
- 在使用外部模型和供应商时,您还应该使用模型和代码签名。
- 对提供的模型和数据进行异常检测和对抗鲁棒性测试可以帮助检测篡改和中毒。
- 实施充分的监控,以涵盖组件和环境漏洞扫描、未经授权插件的使用以及过时的组件,包括模型及其工件。
- 实施修补策略以减轻易受攻击或过时的组件。确保应用程序依赖于API和底层模型的维护版本。
- 定期审查和审核供应商的安全和访问,确保其安全态势或T&C没有变化。
威胁6:过度依赖
原则:诚信
威胁:当法学硕士产生错误信息并以权威的方式提供时,可能会出现过度依赖。
- 受影响的资产Web应用程序、非搜索微服务、搜索API RAG微服务、对话微服务、浏览器
缓解措施:
- 定期监控和审查LLM输出。使用自洽性或投票技术来过滤不一致的文本。比较单个提示的多个模型响应可以更好地判断输出的质量和一致性。
- 用可信的外部源交叉检查LLM输出。这一额外的验证层可以帮助确保模型提供的信息准确可靠。
- 通过微调或嵌入来增强模型,以提高输出质量。与特定领域中的调优模型相比,通用预训练模型更有可能产生不准确的信息。为此,可以采用快速工程、参数高效调谐(PET)、全模型调谐和思维链提示等技术。
- 实现自动验证机制,可以根据已知事实或数据交叉验证生成的输出。这种交叉验证可以提供额外的安全层,并降低与幻觉相关的风险。
- 将复杂任务分解为可管理的子任务,并将其分配给不同的代理。这种分解不仅有助于管理复杂性,还可以减少产生幻觉的机会。每个代理都可以对一个较小的任务负责。
- 传达与使用LLM相关的风险和限制。这些风险包括信息不准确的可能性。有效的风险沟通可以让用户为潜在问题做好准备,并帮助他们做出明智的决策。
- 构建API和用户界面,鼓励负责任和安全地使用LLM。使用内容过滤器、用户对潜在不准确的警告以及人工智能生成内容的清晰标签等措施。
- 在开发环境中使用LLM时,建立安全的编码实践和指导方针,以防止可能的漏洞集成。
- 教育用户,使他们了解直接使用LLM输出而无需任何验证的影响。
威胁#7:信息泄露
原则:保密、隐私
威胁:
- LLM应用程序有可能通过其输出揭示敏感信息、专有算法或其他机密细节。这一发现可以产生以下结果:
- 未经授权访问敏感数据。
- 未经授权评估知识产权。
- 侵犯隐私。
- 其他安全漏洞。
- 受影响的资产Web应用程序、非搜索微服务、搜索API RAG微服务、对话微服务、浏览器
缓解措施:
- 整合足够的数据净化和清理技术,以防止用户数据进入训练模型数据。
- 实施稳健的输入验证和净化方法,以识别和过滤潜在的恶意输入。这些方法将防止在用数据丰富模型和微调模型时模型被毒害。
在微调数据中被视为敏感的任何内容都有可能被泄露给用户。因此,应用最小特权规则,不要根据最高特权用户可以访问的信息来训练模型,这些信息可能会 - 示给较低特权用户。
- 应限制对外部数据源的访问(运行时的数据编排)。
- 对外部数据源应用严格的访问控制方法,并采用严格的方法来维护安全的供应链。
秘密清单
一个理想的架构应该不包含任何秘密。应尽可能使用托管身份等无凭据选项。在需要秘密的地方,通过维护秘密清单来跟踪它们以用于操作目的非常重要。
附录
自由裁量权(Discretion)
人工智能应该是它可以访问的任何信息的负责任和值得信赖的保管人。作为人类,我们无疑会对我们的人工智能关系给予一定程度的信任。在某些时候,这些代理将代表我们与其他代理或其他人类进行对话。
设计限制数据访问并确保用户/系统能够访问授权数据的控制措施,对于建立对人工智能的信任比以往任何时候都更重要。与这一思维过程相一致,LLM输出符合负责任的人工智能标准也同样重要。
韧性
该系统应能够识别异常行为,并防止在与人工智能系统和特定任务相关的可接受行为的正常边界之外进行操纵或胁迫。这些行为是由AI/ML领域特有的新型攻击引起的。
系统的设计应能抵制与当地法律、道德和社区及其创造者所持有的价值观相冲突的投入。这意味着为人工智能提供了确定交互何时“脱离脚本”的能力。完整性。
因此,重要的是要完善早期检测异常的防御机制,以便基于人工智能的应用程序可以在保持业务连续性的同时安全地发生故障。
安全原则
- 保密是指将数据保密或保密的目的。在实践中,这是关于控制对数据的访问,以防止未经授权的披露。
- 完整性是指确保数据没有被篡改,因此可以被信任。它是正确的、真实的、可靠的。
- 可用性意味着网络、系统和应用程序已启动并正在运行。它确保授权用户在需要时能够及时可靠地访问资源。
- 隐私涉及关注个人用户权利的活动。
微软零信任原则
明确验证。始终根据所有可用数据点进行身份验证和授权,包括用户身份、位置、设备健康状况、服务或工作负载、数据分类和异常。- 使用最低权限访问。通过及时和适量访问(JIT/JEA)、基于风险的自适应策略和数据保护来限制用户访问,以帮助保护数据和生产力。
- 假设违约。尽量减少爆破半径和分段通道。验证端到端加密,并使用分析来获得可见性、推动威胁检测和改进防御。
Microsoft数据分类指南
| **Classification | Description |
|---|---|
| Sensitive | Data that is to have the most limited access and requires a high degree of integrity. Typically, it is data that will do the most damage to the organization should it be disclosed. Personal data (including PII) falls into this category and includes any identifier, such as name, identification number, location data, online identifier. It also includes data related to one or more of the following factors specific to the identity of the individual: physical, psychological, genetic, mental, economic, cultural, social. |
| Confidential | Data that might be less restrictive within the company but might cause damage if disclosed. |
| Private | Private data is compartmental data that might not do the company damage. This data must be kept private for other reasons. Human resources data is one example of data that can be classified as private. |
| Proprietary | Proprietary data is data that is disclosed outside the company on a limited basis or contains information that could reduce the company's competitive advantage, such as the technical specifications of a new product. |
| Public | Public data is the least sensitive data used by the company and would cause the least harm if disclosed. This data could be anything from data used for marketing to the number of employees in the company. |
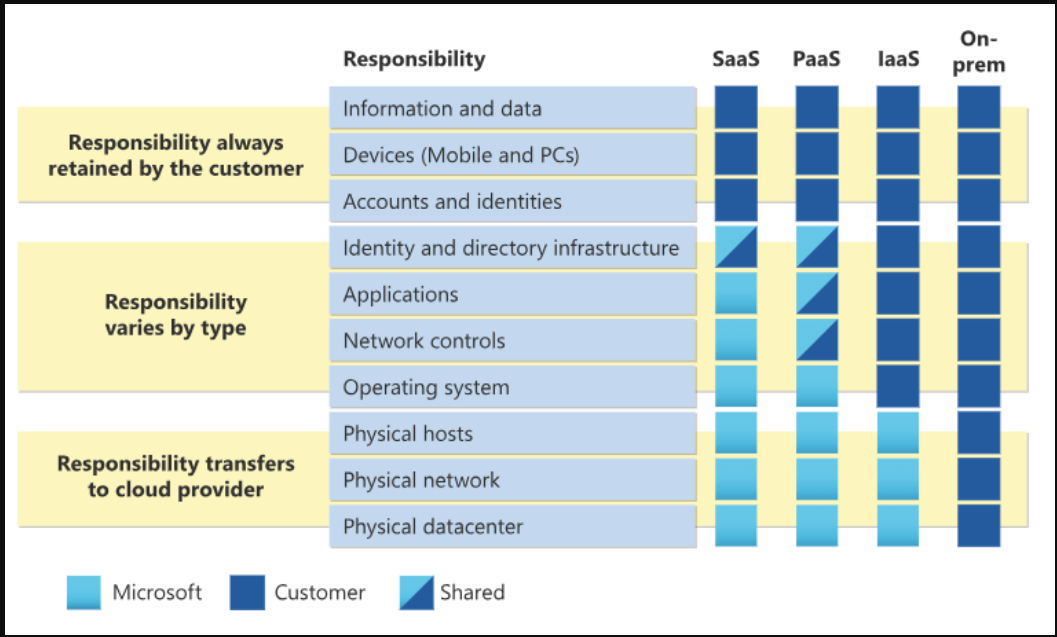
Azure云中的共享责任模型
对于所有云部署类型,客户都拥有自己的数据和身份。他们负责保护其数据和身份、本地资源以及他们控制的云组件的安全。客户控制的云组件因服务类型而异。
无论部署类型如何,客户始终保留以下责任:
- 数据
- 端点
- 账户
- 访问管理
For more information
- 登录 发表评论
- 78 次浏览
最新内容
- 9 hours 24 minutes ago
- 1 week 1 day ago
- 1 week 5 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago