
企业数据库系统要求高可用性——系统应能容忍故障并始终稳定运行。同样重要的是可扩展性,以便随着系统的发展可以添加服务器。即使数据量或访问量增加,也需要保持响应速度和处理能力。
在本文中,我们讨论了使用pgpool II(PostgreSQL开源扩展之一)的高可用性系统设置。它是我们的解决方案之一,可以满足这两个要求:高可用性和可扩展性。
什么是pgpool II?
pgpool II是一个中间件,可以在Linux和Solaris上运行,在应用程序和数据库之间运行。其主要特点包括:
| Feature | Classification | 解释 |
| Load balancing | 高效地将只读查询分发到多个数据库服务器,以便可以处理更多查询。 | 性能改进 |
| Connection pooling | 保留/重用与数据库的连接,以减少连接开销,并在重新连接时提高性能。 | |
| Replication | 在任何给定时间点将数据复制到多个数据库服务器,以实现数据库冗余。† | 数据库的高可用性 |
| Automatic failover | 如果主数据库服务器发生故障,将自动切换到备用服务器以继续操作。 | |
| Online recovery | 在不停止操作的情况下还原或添加数据库服务器。 | |
| Watchdog | 链接pgpool II的多个实例,执行心跳监测,并共享服务器信息。当发生故障时,开关自动导通。 | pgpool II的高可用性 |
pgpool II可以使用自己的复制功能或其他软件提供的复制功能,但通常建议使用PostgreSQL的流式复制。流复制是一种通过将PostgreSQL(主)的事务日志(WAL)传送到PostgreSQL的多个实例(备用)来复制数据库的功能。这一功能在文章“什么是流式复制,以及如何设置它?”中进行了解释。

Diagram illustrating streaming replication
负载平衡和连接池
横向扩展是通过添加服务器来提高整个数据库系统处理能力的一种方法。PostgreSQL允许您使用流复制进行扩展。在此场景中,将查询从应用程序高效地分发到数据库服务器至关重要。PostgreSQL本身没有分发功能,但您可以利用pgpoolII的负载平衡,它可以高效地分发只读查询,以平衡工作负载。
另一个很棒的pgpool II功能是连接池。通过使用pgpool II的连接池,可以保留和重用连接,从而减少连接到数据库服务器时发生的开销。
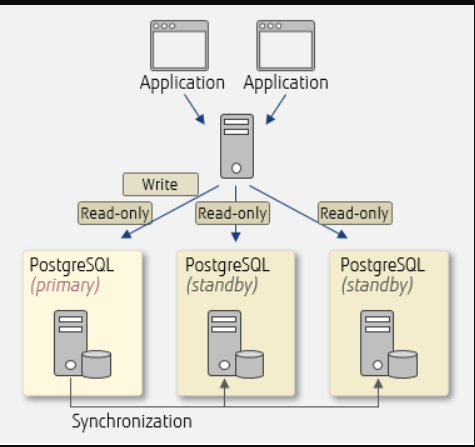
要使用这些功能,需要在pgpool.conf中设置相关参数。
自动故障切换和在线恢复
本节介绍使用pgpool II的自动故障切换和在线恢复。解释假设使用PostgreSQL的流复制。
下图说明了pgpool II在PostgreSQL(主)中检测到错误时如何执行自动故障切换。

- 1.分离出现故障的主服务器并停止pgpool II的查询分发
- 2.将备用服务器升级为新的主服务器
- 3.更改每个PostgreSQL的复制同步位置
注意,您需要事先为2和3创建脚本,并在pgpool II中设置它们。
在线恢复功能执行来自pgpool II的在线恢复命令,并将分离的旧PostgreSQL(主)恢复为PostgreQL(备用)。命令操作如下所述。
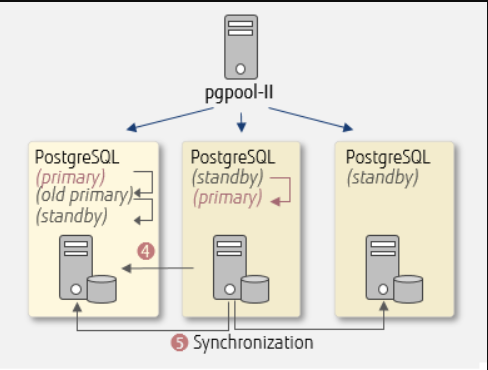
- 4.根据新PostgreSQL(主)的数据重建旧的PostgreSQL,并将其恢复为PostgreSQL
- 5.更改每个PostgreSQL的复制同步位置
您需要预先为这些进程创建脚本,并将它们存储在数据库服务器端。
笔记
pgpool II的在线恢复功能必须作为PostgreSQL的扩展功能安装在数据库服务器端。
监控狗(Watchdog)
为了实现整个系统的高可用性,pgpool II本身也需要冗余。此冗余的此功能称为看门狗。
下面是它的工作原理。看门狗在活动/备用设置中链接pgpool II的多个实例。然后,链接的pgpool II实例执行相互监听并共享服务器信息(主机名、端口号、pgpoolⅡ状态、虚拟IP信息、启动时间)。如果提供服务的pgpool II(活动)发生故障,pgpoolⅡ(备用)会自动检测并执行故障切换。执行此操作时,新的pgpool II(活动)启动一个虚拟IP接口,而旧的pgpool-II(活动的)停止其虚拟IP接口。这允许应用程序端使用具有相同IP地址的pgpool II,即使在服务器切换之后也是如此。通过使用Watchdog,pgpool II的所有实例协同工作,以执行数据库服务器监视和故障切换操作-pgpoolⅡ(活动)充当协调器。

在冗余配置中,我们还需要考虑pgpool II和数据库(PostgreSQL)大脑分裂的可能后果。分裂大脑是存在多个活动服务器的情况。在此状态下更新数据将导致数据不一致,恢复将变得繁重。为了避免大脑分裂,建议将pgpool II配置为3个或更多服务器,并且服务器数量为奇数。以下是大脑分裂可能发生的例子:
- pgpool II的裂脑
- 当设置了2个pgpool II实例并且仅在连接这些pgpoolⅡ实例的网络中发生错误时,将不会发生故障切换,但pgpool II的协调将停止。
- 数据库的分割大脑(PostgreSQL)
- 当设置了2个pgpool II实例并且连接pgpoolⅡ(活动)和PostgreSQL(主要)的网络中发生错误时。在两站式设置中,将不进行投票以判断故障转移(稍后描述)。
现在,让我们看一个例子,当有3个pgpool II实例时,看门狗可以避免数据库中出现分裂的大脑:
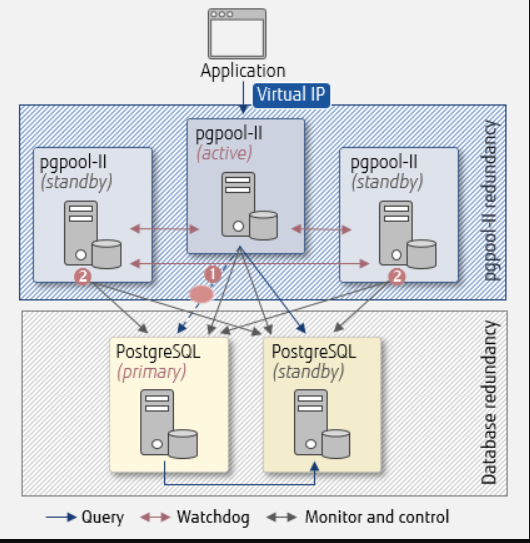
对pgpool II使用看门狗-网络故障
- 1.pgpool II(活动)检测到由于自身和PostgreSQL(主)之间的网络断开而导致的故障,但无法确定PostgreQL(主)是否正在运行。
- 2.pgpool II(备用)的其他实例投票判断故障切换
之后,pgpool II的实例决定采取行动:
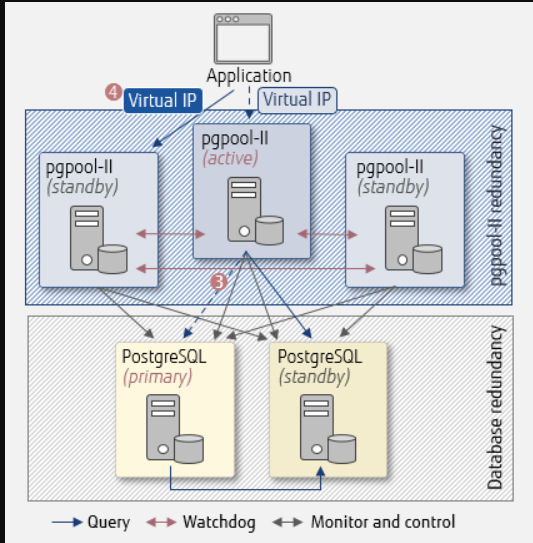
将看门狗与pgpool II一起使用
- 3.没有故障转移,因为它不是多数票。在这里,避免了大脑分裂。pgpool II(活动)阻止PostgreSQL(主要)停止查询分发
- 4.如果在pgpool II(活动)上检测到故障,则将连接切换到pgpoolⅡ(备用)
因此,应用程序端的更新查询可以继续运行。
使用pgpool II进行系统设置
在这里,我们介绍了一个基于真实业务的系统设置,并执行了一个简单的操作检查。
系统设置
我们将设计一个满足以下要求的示例系统设置,假设使用pgpool II的实际业务场景:
- 考虑到大脑分裂的高可用性设置
- 未来扩展
- 负载平衡和连接池以提高性能
通常,为了选择硬件和软件,我们会分析性价比,并以简单高效的设置为目标。这样做的第一个因素是pgpool II的分配。下表总结了可能的位置及其对系统的影响:
| 位置 | Server load | Network | Server cost (quantity) |
| 专用服务器 | 不受其他软件影响。 |
受网络影响:
|
需要额外的服务器来运行pgpool II。 我们建议准备奇数个服务器,从3开始。 |
| 数据库服务器(共存) |
受共存数据库的性能影响。 需要考虑服务器的冗余和可扩展性。 |
网络影响小。 pgpool II和数据库之间的部分连接可以是本地的。 |
我们建议使用3个或更多共存的pgpool II服务器。 根据可用数据库服务器的数量,还需要更多的服务器。 |
| 应用服务器或web服务器(共存) |
受共存软件性能的影响。 需要考虑服务器的冗余和可扩展性。 |
无网络影响。 应用程序(web服务器)和pgpool II可以本地连接。 |
我们建议使用3个或更多共存的pgpool II服务器。 此外,还需要更多的服务器,具体取决于可用应用程序服务器或web服务器的数量。 |
pgpool II在数据库服务器上共存
首先,让我们来看看pgpool II在数据库服务器上共存的配置设置。
我们假设一个实际的系统设置可以在实际的业务案例中使用。如下图所示,来自客户端的请求由负载平衡器分发,应用程序在3个应用程序服务器上并行运行。
pgpool II的多个实例将与看门狗一起工作。将PostgreSQL(备用)添加到数据库服务器3以进行扩展,然后根据需要添加更多服务器。
在此设置中,请注意,工作负载集中在运行pgpool II(活动)的数据库服务器上。在计算负载平衡时要考虑到这一点。

pgpool II配置示例
pgpool II在应用程序服务器上共存
接下来,让我们看一个pgpool II在应用程序服务器上共存的示例设置。pgpool II现在以多主机配置运行,因此分配了固定IP。好处如下。
- pgpool II的负载平衡
- 在pgpool II(活动)和pgpoolⅡ(备用)上接受更新和只读查询
- 减少应用程序和pgpool II之间的网络开销
注意,即使在多主机配置中,pgpool II(活动)仍然是控制数据库的协调器。添加第三个数据库服务器以及更多的扩展。

pgpool II配置示例
操作检查
让我们检查应用程序服务器上同时存在pgpool II的设置中的自动故障切换和在线恢复。假设PostgreSQL和pgpool II已经安装、配置和启动。该示例使用以下内容:
- host0:数据库服务器1的主机
- host1:数据库服务器2的主机
- host5:运行pgpool II(活动)的应用程序服务器1的主机
1连接到应用程序服务器1上的pgpool II(活动),并检查数据库服务器的状态。
$ psql -h host5 -p 9999 -U postgres postgres=# SHOW pool_nodes; node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change ---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+--------------------- 0 | host0 | 5432 | up | 0.500000 | primary | 2 | false | 0 | 2020-08-27 14:43:54 1 | host1 | 5432 | up | 0.500000 | standby | 2 | true | 0 | 2020-08-27 14:43:54 (2 rows)
2强制停止数据库服务器1(主机0)上的PostgreSQL(主)。
$ pg_ctl -m immediate stop
3从应用程序服务器1再次检查数据库服务器状态。
第一个连接将失败,但第二个连接将成功,因为重置后将恢复到数据库的连接。
请注意,host0的状态已更改为“关闭”,角色已交换。我们刚刚确认,到主机1的故障切换是自动完成的,并且已升级到主服务器。
postgres=# SHOW pool_nodes;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | down | 0.500000 | standby | 2 | false | 0 | 2020-08-27 14:47:20
1 | host1 | 5432 | up | 0.500000 | primary | 2 | true | 0 | 2020-08-27 14:47:20
(2 rows)4从应用程序服务器1执行数据库服务器1(主机0)的联机恢复命令。
确认已正常完成。
$ pcp_recovery_node -h host5 -p 9898 -U postgres -n 0 Password: (yourPassword) pcp_recovery_node -- Command Successful
5从应用程序服务器1再次检查数据库服务器状态。
在线恢复后,将在第一次连接到数据库时重置连接,第二次连接将成功。由于host0的状态已更改为“up”,您可以看到它已恢复并处于待机状态。
postgres=# SHOW pool_nodes;
ERROR: connection terminated due to online recovery
DETAIL: child connection forced to terminate due to client_idle_limitis:-1
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | up | 0.500000 | standby | 2 | true | 0 | 2020-08-27 14:50:13
1 | host1 | 5432 | up | 0.500000 | primary | 2 | false | 0 | 2020-08-27 14:47:20
(2 rows)笔记
我们已经看到,pgpool II是PostgreSQL的一个有效的开源扩展,用于企业使用。它适用于具有大量同时连接并需要扩展的中大型系统。
在采用pgpool II时,请务必注意以下事项:
- 构建环境需要许多配置设置,用户必须创建所需的脚本。
- 彻底检查和验证设计和环境设置。
- 负载平衡中只分发只读查询。
- 在处理许多更新查询的系统中看不到性能改进。类似地,只读性能随着数据库服务器数量的增加而提高,但更新性能可能会降低。
Tags
最新内容
- 6 days 12 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago