
category
PostgreSQL不仅仅是一个简单的关系数据库;它是一个数据管理框架,有可能吞噬整个数据库领域。“一切皆用Postgres”的趋势不再局限于少数精英团队,而是正在成为主流的最佳实践。
OLAP的新挑战者
在2016年的一次数据库会议上,我认为PostgreSQL生态系统中的一个重大差距是缺乏一个足够好的用于OLAP工作负载的柱状存储引擎。虽然PostgreSQL本身提供了许多分析功能,但它在大型数据集上进行全面分析的性能并不能完全满足专用实时数据仓库的要求。
以ClickBench为例,它是一个分析性能基准,我们在其中记录了PostgreSQL、其生态系统扩展和衍生数据库的性能。未经编辑的PostgreSQL表现不佳(x1050),但经过优化可以达到(x47)。此外,还有三个与分析相关的扩展:柱状存储Hydra(x42)、时间序列TimescaleDB(x103)和分布式Citus(x262)。

Clickbench c6a.4xlarge, 500gb gp2 results in relative time
这种性能并不算差,尤其是与MySQL和MariaDB(x3065,x19700)等纯OLTP数据库相比;然而,它的第三层性能还不够“好”,落后于第一层OLAP组件,如Umbra、ClickHouse、Databend、SelectDB(x3~x4)一个数量级。这是一个棘手的问题——使用起来不够令人满意,但又太好了,无法丢弃。
然而,ParadeDB和DuckDB的到来改变了游戏!
ParadeDB的原生PG扩展PG_analytics实现了第二级性能(x10),将与顶级的差距缩小到仅3–4倍。考虑到额外的好处,这种级别的性能差异通常是可以接受的——ACID、新鲜度和实时数据无需ETL,无需额外的学习曲线,无需维护单独的服务,更不用说其ElasticSearch级全文搜索功能了。
DuckDB专注于纯OLAP,将分析性能推向极致(x3.2)——不包括专注于学术的闭源数据库Umbra,DuckDB可以说是实用OLAP性能最快的。它不是PG扩展,但PostgreSQL可以通过DuckDB FDW和PG_gak等项目,充分利用DuckDB作为嵌入式文件数据库的分析性能提升。
ParadeDB和DuckDB的出现将PostgreSQL的分析能力推向了OLAP的顶级,填补了其分析性能的最后一个关键缺口。
数据库领域的钟摆
OLTP和OLAP之间的区别在数据库诞生之初并不存在。OLAP数据仓库与数据库的分离出现在20世纪90年代,原因是传统的OLTP数据库难以支持分析场景的查询模式和性能需求。
长期以来,数据处理的最佳实践包括将MySQL/PostgreSQL用于OLTP工作负载,并通过ETL过程将数据同步到专门的OLAP系统,如Greenplum、ClickHouse、Doris、Snowflake等。
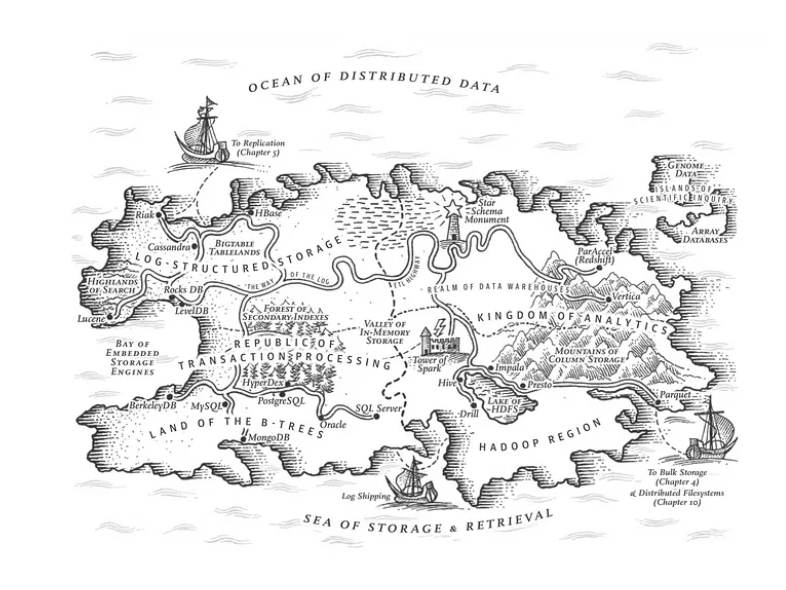
DDIA ch3: Republic of OLTP & Kingdom of Analytics
与许多“专用数据库”一样,专用OLAP系统的优势往往在于性能——比原生PostgreSQL或MySQL提高了1-3个数量级。然而,成本是冗余数据、过度的数据移动、分布式组件之间对数据值缺乏一致性、专业技能的额外人工费用、额外的许可成本、有限的查询语言能力、可编程性和可扩展性、有限的工具集成、与完整的DMBS相比数据完整性和可用性较差。
然而,俗话说,“来龙去脉”。在摩尔定律之后的三十多年里,随着硬件的改进,性能呈指数级增长,而成本却直线下降。2024年,单个x86服务器可以拥有数百个内核(512 vCPU,EPYC 9754 x2)、几个TB的RAM,单个NVMe SSD可以容纳高达64TB/3M 4K rand IOPS/14GB/s,单个全闪存机架可以达到几个PB;像S3这样的对象存储提供了几乎无限的存储。
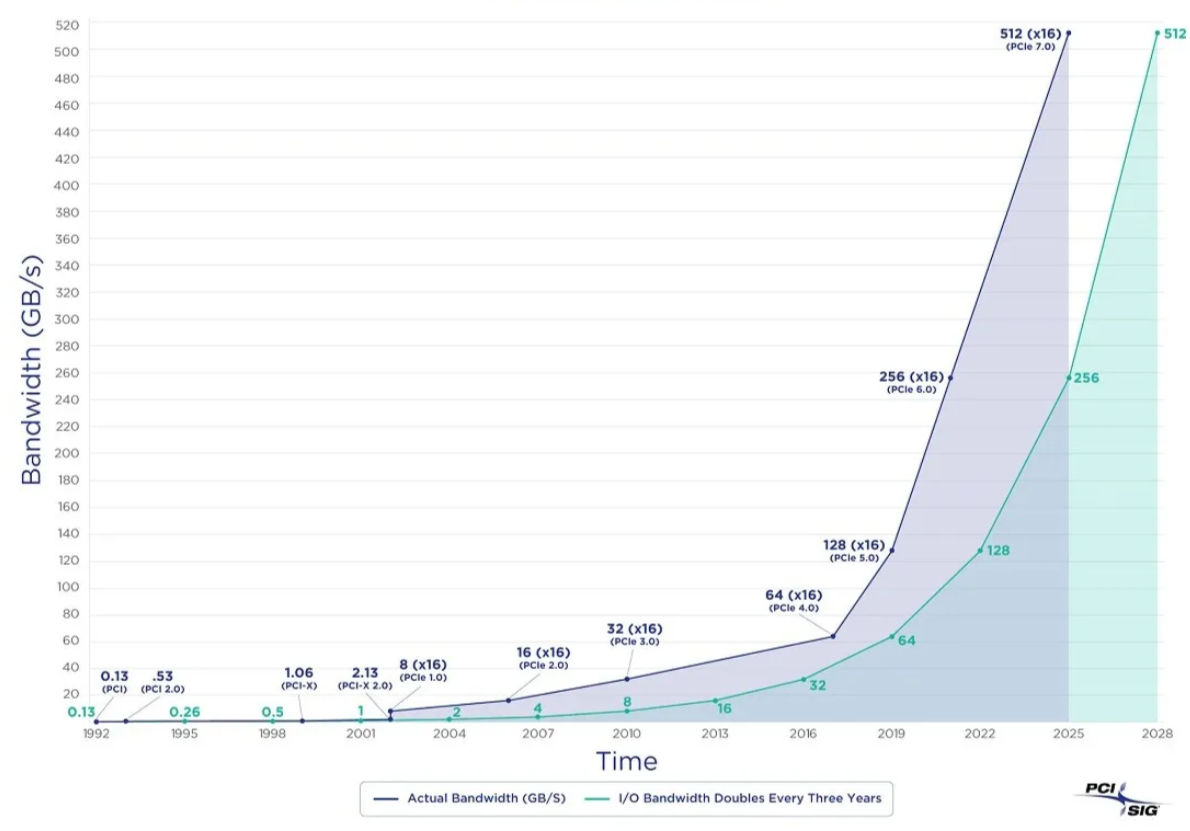
I/O Bandwidth doubles every 3 years
硬件的进步解决了数据量和性能问题,而数据库软件开发(PostgreSQL、ParadeDB、DuckDB)解决了访问方法的挑战。这使得分析行业(即所谓的“大数据”行业)的基本假设受到审查。
正如DuckDB的宣言“大数据已死”所暗示的那样,大数据时代已经结束。大多数人没有那么多数据,而且大多数数据很少被查询。随着硬件和软件的发展,大数据的前沿正在消退,99%的场景都不需要“大数据”。
如果99%的用例现在可以在具有独立PostgreSQL/DackDB(及其副本)的单机上处理,那么使用专用分析组件有什么意义?如果每部智能手机都可以自由发送和接收文本,那么寻呼机又有什么意义呢?(需要注意的是,北美医院仍在使用寻呼机,这表明可能只有不到1%的情况真正需要“大数据”。)
基本假设的转变正在引导数据库世界从多样化阶段回到趋同阶段,从大爆炸到大灭绝。在这个过程中,一个统一的、多模型的、超级融合的数据库的新时代将出现,OLTP和OLAP将重新结合起来。但是,谁将领导这项重新整合数据库领域的重大任务呢?
PostgreSQL:数据库世界的食客
数据库领域有很多利基:时间序列、地理空间、文档、搜索、图形、矢量数据库、消息队列和对象数据库。PostgreSQL让所有这些领域都能感受到它的存在。
PostGIS扩展就是一个很好的例子,它为地理空间数据库设定了事实上的标准;TimescaleDB扩展笨拙地定位了“通用”时间序列数据库;矢量扩展PGVector将专用的矢量数据库利基变成了一条笑点。
这已经不是第一次了;我们在最古老、最大的子域OLAP分析中再次见证了这一点。但PostgreSQL的雄心并没有止步于OLAP;它正在关注整个数据库世界!

PostgreSQL Ecosystem
是什么让PostgreSQL如此强大?当然,它是先进的,但甲骨文也是如此;它是开源的,MySQL也是。PostgreSQL的优势来自于其先进性和开源性,使其能够与Oracle/MySQL竞争。但其真正的独特之处在于其极端的可扩展性和蓬勃发展的扩展生态系统。
极限可扩展性的魔力
PostgreSQL不仅仅是一个关系数据库;这是一个能够吞噬整个数据库星系的数据管理框架。其核心竞争力除了源代码和先进性外,还源于可扩展性,即基础设施的可重用性和可扩展性的可组合性。
PostgreSQL允许用户开发扩展,利用数据库的公共基础设施以最低成本提供功能。例如,矢量数据库扩展pgvector只有几千行代码,与PostgreSQL的数百万行代码相比,其复杂性可以忽略不计。然而,这种“微不足道”的扩展实现了完整的矢量数据类型和索引功能,优于许多专门的矢量数据库。
为什么?因为pgvector的创建者不需要担心数据库的一般附加复杂性:ACID、恢复、备份和PITR、高可用性、访问控制、监控、部署、第三方生态系统工具、客户端驱动程序等,这些都需要数百万行代码才能很好地解决。他们只关注问题的本质复杂性。
例如,ElasticSearch是在Lucene搜索库的基础上开发的,而Rust生态系统有一个改进的下一代全文搜索库Tantivy,作为Lucene的替代方案。ParadeDB只需要将其封装并连接到PostgreSQL的接口,就可以提供与ElasticSearch相当的搜索服务。更重要的是,它可以站在PostgreSQL的肩膀上,利用整个PG生态系统的联合力量(例如,与pgvector的混合搜索)与另一个专用数据库进行“不公平”的竞争。

Pigsty & PGDG has 234 extensions available. And there are 1000+ more in the ecosystem
可扩展性带来了另一个巨大的优势:扩展的可组合性,允许不同的扩展协同工作,在1+1»2的情况下产生协同效应。例如,TimescaleDB可以与PostGIS相结合,用于时空数据支持;用于全文搜索的BM25扩展可以与PGVector扩展组合,从而提供混合搜索功能。
此外,分布式扩展Citus可以透明地将独立集群转换为水平分区的分布式数据库集群。该功能可以与其他功能正交组合,使PostGIS成为分布式地理空间数据库,PGVector成为分布式矢量数据库,ParadeDB成为分布式全文搜索数据库,等等。
更强大的是,扩展是独立发展的,而不需要繁琐的主分支合并和协调。这允许扩展——PG的可扩展性允许许多团队并行探索数据库的可能性,所有扩展都是可选的,不会影响核心功能的可靠性。那些成熟和健壮的特性有机会稳定地集成到主分支中。
PostgreSQL通过极端可扩展性的魔力实现了基本的可靠性和敏捷功能,使其成为数据库世界中的异类,并改变了数据库格局的游戏规则。
DB竞技场的游戏改变者
PostgreSQL的出现改变了数据库领域的范式:致力于打造“新数据库内核”的团队现在面临着一场艰巨的考验——如何在开源、功能丰富的Postgres中脱颖而出。他们独特的价值主张是什么?
除非出现革命性的硬件突破,否则实用的、新的、通用的数据库内核似乎不太可能出现。没有一个单一的数据库能与PG的整体实力相媲美,因为PG有着开源和免费的王牌,即使是Oracle也无法与之匹敌;-)
如果一个利基数据库产品在特定方面(通常是性能)能比PostgreSQL好一个数量级,那么它可能会为自己开辟空间。然而,PostgreSQL生态系统通常不需要很长时间就可以产生开源扩展替代方案。选择开发一个PG扩展而不是一个全新的数据库,可以让球队在追赶中获得压倒性的速度优势!
遵循这一逻辑,PostgreSQL生态系统将像滚雪球一样越滚越大,积累优势,不可避免地走向垄断,在几年内反映出Linux内核在服务器操作系统中的地位。开发人员调查和数据库趋势报告证实了这一轨迹。

StackOverflow 2023调查:十项全能运动员PostgreSQL

StackOverflow过去7年的数据库趋势
PostgreSQL一直是HackerNews和StackOverflow最喜欢的数据库。许多新的开源项目默认PostgreSQL作为他们的主要(如果不是唯一的)数据库选择。许多新一代公司都在PostgreSQL中运行。
正如“Radical Simplicity:Just Use Postgres”所说,“Just Use Postgres”可以实现简化技术堆栈、减少组件、加速开发、降低风险和添加更多功能。Postgres可以取代许多后端技术,包括MySQL、Kafka、RabbitMQ、ElasticSearch、Mongo和Redis,毫不费力地为数百万用户服务。Just Use Postgres不再局限于少数精英团队,而是成为主流的最佳实践。
还能做什么?
数据库域的结局似乎是可以预测的。但是我们能做什么,我们应该做什么?
对于绝大多数场景,PostgreSQL已经是一个近乎完美的数据库内核,这使得内核“瓶颈”的想法变得荒谬。PostgreSQL和MySQL将内核修改标榜为卖点的分支基本上没有进展。
这与今天Linux操作系统内核的情况类似;尽管Linux发行版过多,但每个人都选择相同的内核。Linux内核的分叉被视为制造了不必要的困难,业界对此表示反对。
因此,主要的冲突不再是数据库内核本身,而是两个方向——数据库扩展和服务!前者涉及内部可扩展性,而后者涉及外部可组合性。与操作系统生态系统非常相似,竞争格局将集中在数据库分发上。在数据库领域,只有那些以扩展和服务为中心的分布才有可能获得最终的成功。
内核仍然不温不火,MySQL母公司的分支MariaDB即将退市,而AWS则从免费内核之上提供服务和扩展中获利,蓬勃发展。投资已流入众多PG生态系统扩展和服务分发:Citus、TimescaleDB、Hydra、PostgresML、ParadeDB、FerretDB、StackGres、Aiven、Neon、Suabase、Tembo、PostgresAI,以及我们自己的PG分发版--Pigsty。
PostgreSQL生态系统中的一个困境是许多扩展和工具的独立进化,缺乏统一的协同机制。例如,Hydra发布了自己的包和Docker映像,PostgresML也是如此,每个映像都使用自己的扩展分发PostgreSQL映像,而且只有自己的扩展。这些图片和包与AWS RDS等全面的数据库服务相去甚远。
即使是像AWS这样的服务提供商和生态系统集成商,在众多扩展面前也存在不足,由于各种原因(AGPLv3许可证、多租户的安全挑战),无法包括许多扩展,从而无法利用PostgreSQL生态系统扩展的协同放大潜力。

云RDS(PG 162024-02-29)上没有许多重要的扩展,请查看完整的扩展列表了解详细信息:Pigsty RDS&PGDG/AWS RDS PG/Aliyun RDS PG
扩展是PostgreSQL的灵魂。一个没有使用扩展自由的Postgres就像无盐烹饪,一个巨大的约束。
解决这一问题是我们的主要目标之一。
我们的决心:Pigsty
尽管我之前接触过MySQL和MSSQL,但当我在2015年第一次使用PostgreSQL时,我确信它未来在数据库领域的主导地位。近十年后,我从用户和管理员转变为贡献者和开发人员,见证了PG朝着这个目标前进。
与不同用户的交互表明,数据库领域的缺点不再是内核——PostgreSQL已经足够了。真正的问题是利用内核的功能,这也是RDS蓬勃发展的原因。
然而,我认为这种功能应该像免费软件一样可访问,就像PostgreSQL内核本身一样——每个用户都可以使用,而不仅仅是从网络封建领主那里租用。
因此,我创建了Pigsty,这是一个包含电池的本地第一个PostgreSQL发行版,作为一个开源的RDS替代品,旨在利用PostgreSQL生态系统扩展的集体力量,并使生产级数据库服务的访问民主化。

Pigsty stands for PostgreSQL in Great STYle
我们定义了六个核心命题来解决PostgreSQL数据库服务中的核心问题:可扩展Postgres、可靠基础设施、可观察图形、可用服务、可维护工具箱和可组合模块。
这些价值主张的首字母缩写提供了Pigsty的另一个缩写:
Postgres,基础设施,图形,服务,工具箱,你的。
Postgres, Infras, Graphics, Service, Toolbox, Yours.
您的图形化Postgres基础设施服务工具箱。
可扩展的PostgreSQL是这个发行版的关键。在最近推出的Pigsty v2.6中,我们集成了DuckdbFDW和ParadeDB扩展,极大地增强了PostgreSQL的分析能力,并确保每个用户都能轻松利用这种能力。
我们的目标是整合PostgreSQL生态系统中的优势,创造一种类似于数据库世界Ubuntu的协同力量。我相信核心争论已经解决,真正的竞争前沿就在这里。

开发人员,您的选择将决定数据库世界的未来。我希望我的工作能帮助你更好地利用世界上最先进的开源数据库内核:PostgreSQL。
Tags
最新内容
- 1 hour ago
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago