
category
Evidently是开源ML和LLM可观察性框架。评估、测试和监控任何AI驱动的系统或数据管道。从表格数据到Gen AI。100+指标。
Evidently一个用于评估、测试和监控ML和LLM驱动系统的开源框架。
什么是Evidently?
显然,这是一个开源Python库,用于评估、测试和监控ML和LLM系统——从实验到生产。
🔡 适用于表格和文本数据。
✨ 支持从分类到RAG的预测性和生成性任务的评估。
📚 从数据漂移检测到LLM判断,有100多个内置指标。
🛠️ 用于自定义指标的Python接口。
🚦 离线评估和实时监控。
💻 开放式架构:轻松导出数据并与现有工具集成。
显然,它非常模块化。您可以从一次性评估开始,也可以提供全面的监控服务。
1.报告和测试套件
报告计算和总结各种数据,ML和LLM质量评估。
- 从预设和内置指标开始,或进行自定义。
- 最适合实验、探索性分析和调试。
- 在Python中查看交互式报告,或导出为JSON、Python字典、HTML,或在监控UI中查看。
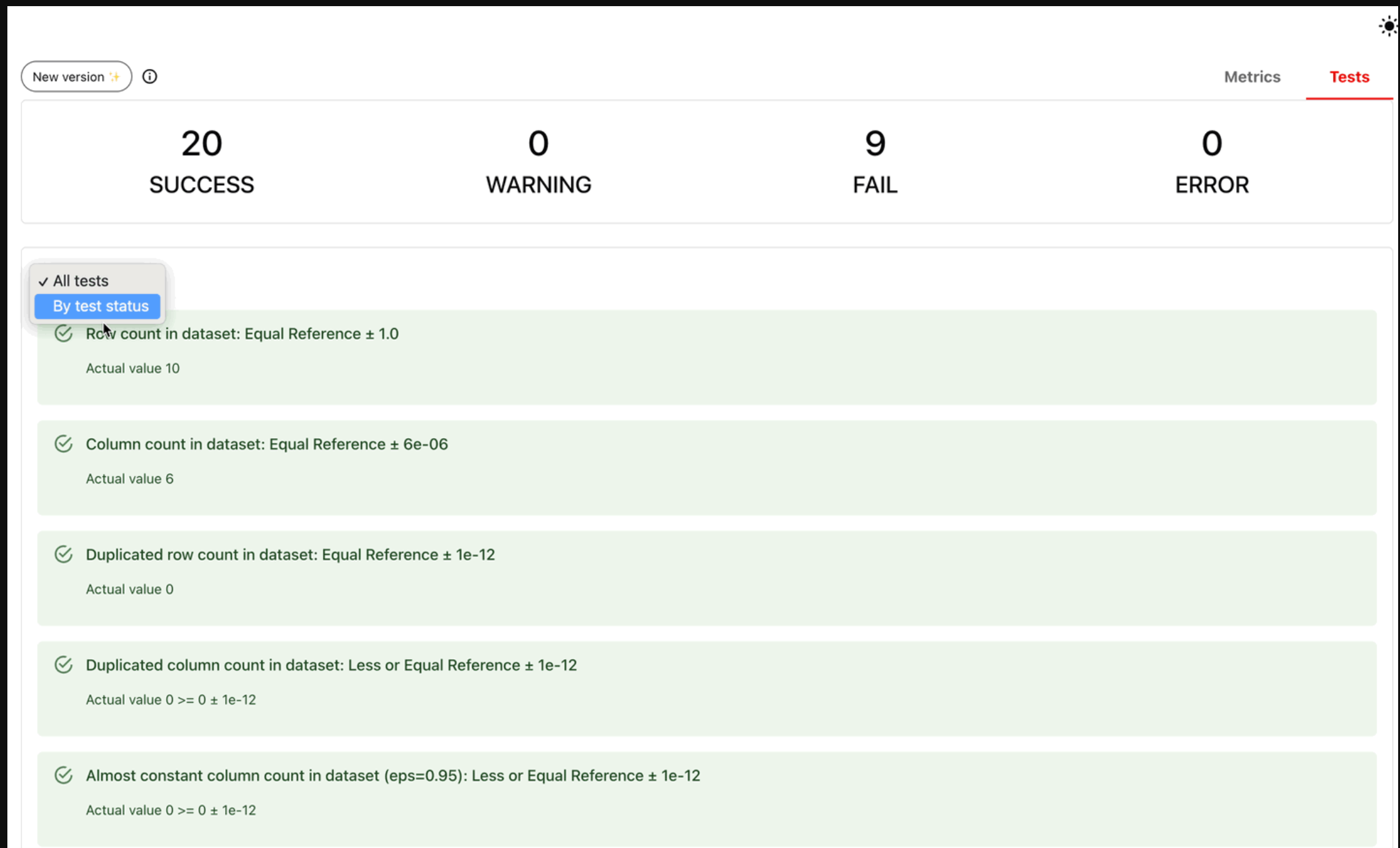
通过添加通过/失败条件,将任何报告转换为测试套件。
- 最适合回归测试、CI/CD检查或数据验证。
- 零设置选项:从参考数据集中自动生成测试条件。
- 将测试条件设置为gt(大于)、lt(小于)等的简单语法。

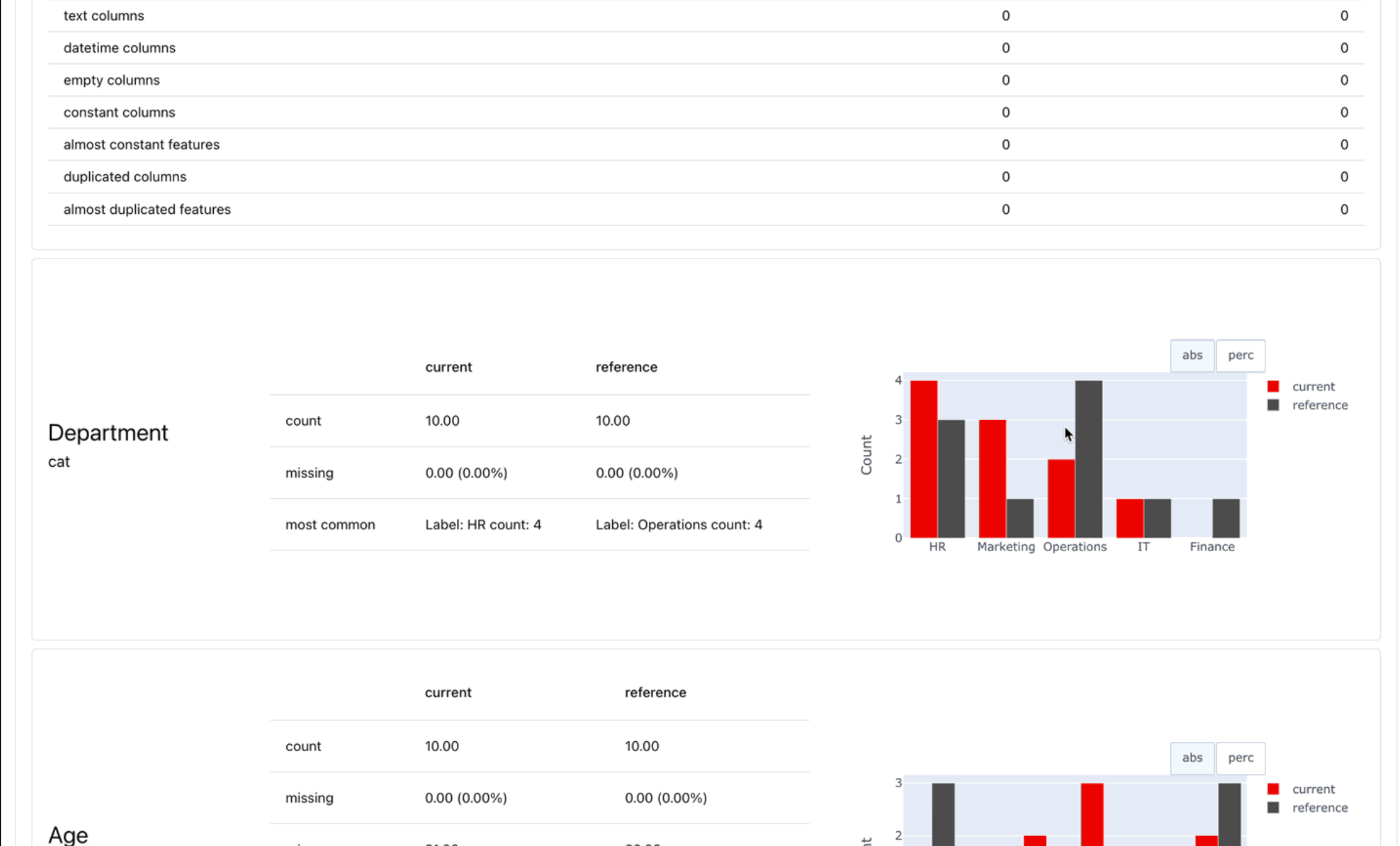
报告示例
2.监控仪表板
监控UI服务有助于随着时间的推移可视化指标和测试结果。
您可以选择:
- 自托管开源版本。现场演示。
- 注册Evidently Cloud(推荐)。
显然,Cloud提供了一个慷慨的免费层和额外的功能,如数据集和用户管理、警报和无代码评估。比较OSS与云。
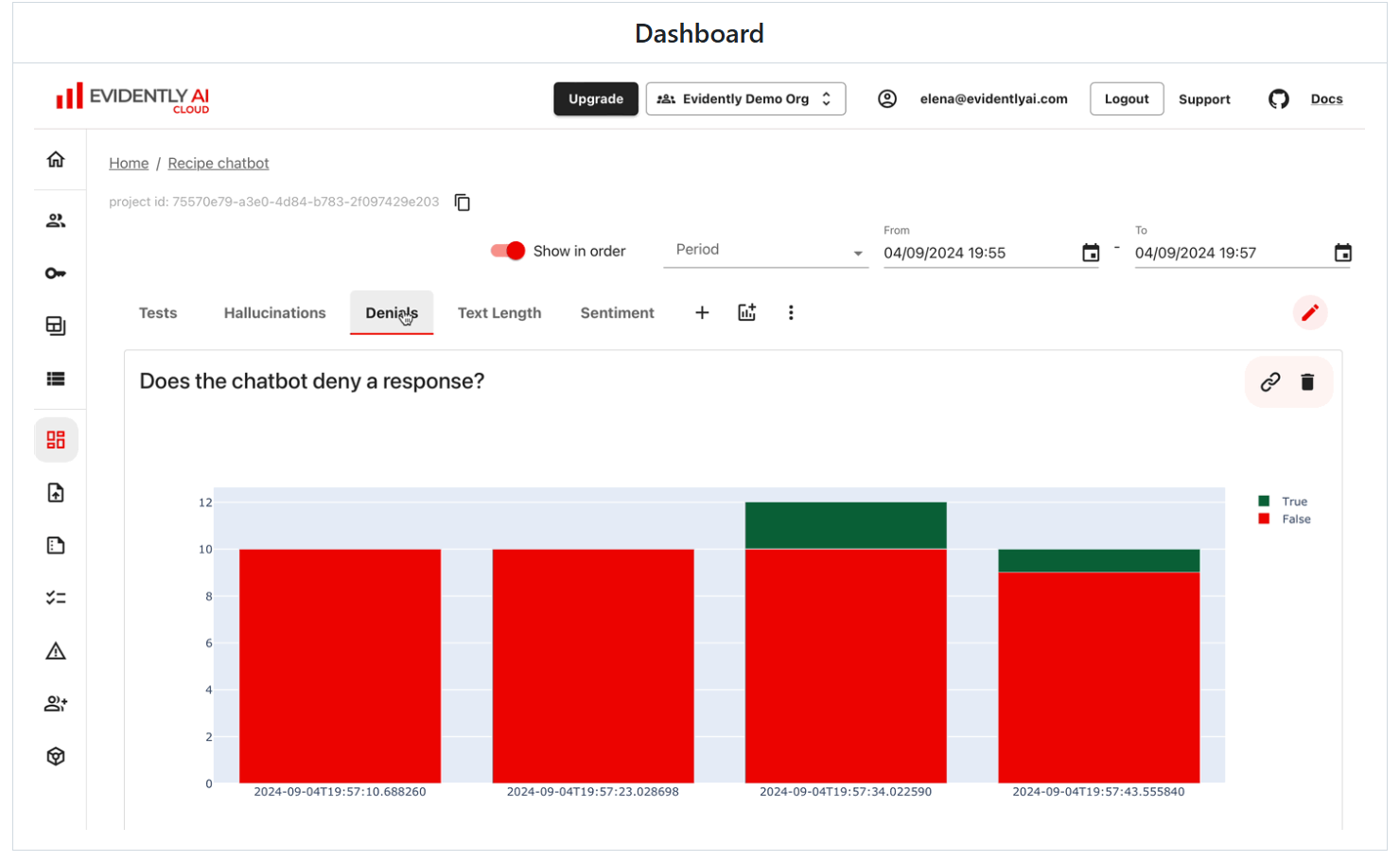
仪表板示例
👩💻 明显安装
要从PyPI安装:
pip install evidently
要使用conda安装程序安装Evidently,请运行:
conda install -c conda-forge evidently
▶️ 入门
报告
LLM评估
这是一个简单的Hello World。查看教程了解更多信息:LLM评估。
导入必要的组件:
import pandas as pd
from evidently import Report
from evidently import Dataset, DataDefinition
from evidently.descriptors import Sentiment, TextLength, Contains
from evidently.presets import TextEvals
创建一个包含问题和答案的玩具数据集。
eval_df = pd.DataFrame([
["What is the capital of Japan?", "The capital of Japan is Tokyo."],
["Who painted the Mona Lisa?", "Leonardo da Vinci."],
["Can you write an essay?", "I'm sorry, but I can't assist with homework."]],
columns=["question", "answer"])
创建一个明显的数据集对象并添加描述符:行级评估器。我们将检查每个回复的情绪、长度以及是否包含表示否认的单词。
eval_dataset = Dataset.from_pandas(pd.DataFrame(eval_df),
data_definition=DataDefinition(),
descriptors=[
Sentiment("answer", alias="Sentiment"),
TextLength("answer", alias="Length"),
Contains("answer", items=['sorry', 'apologize'], mode="any", alias="Denials")
])
您可以查看添加了分数的数据帧:
eval_dataset.as_dataframe()
要获取总结报告以查看分数分布:
report = Report([
TextEvals()
])
my_eval = report.run(eval_dataset)
my_eval
# my_eval.json()
# my_eval.dict()
您还可以选择其他评估者,包括LLM作为评判者,并配置通过/失败条件。
数据和ML评估
这是一个简单的Hello World。有关更多信息,请查看教程:表格数据。
导入报告、评估预设和玩具表格数据集。
import pandas as pd
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset
iris_data = datasets.load_iris(as_frame=True)
iris_frame = iris_data.frame
运行数据漂移评估预设,该预设将测试列分布的偏移。将数据帧的前60行作为“当前”数据,并将以下数据作为参考。在Jupyter记事本中获取输出:
report = Report([ DataDriftPreset(method="psi") ], include_tests="True") my_eval = report.run(iris_frame.iloc[:60], iris_frame.iloc[60:]) my_eval
您还可以保存HTML文件。您需要从目标文件夹打开它。
my_eval.save_html("file.html")
要获取JSON或Python字典的输出:
my_eval.json()
# my_eval.dict()
您可以选择其他预设,从个人指标创建报告,并配置通过/失败条件。
监控仪表板
这将在本地托管的Evidently UI中启动一个演示项目。注册Evidently Cloud,立即获得具有其他功能的托管版本。
如果你有uv,你可以用一个命令运行Evidently UI。
uv run --with evidently evidently ui --demo-projects all
如果没有,请使用标准方法创建虚拟环境。
pip install virtualenv
virtualenv venv
source venv/bin/activate
安装Evidently(pip install clearly)后,使用演示项目运行Evidently UI:
evidently ui --demo-projects all
访问localhost:8000以访问UI。
🚦 你能评估什么?
显然有100多个内置的疏散通道。您还可以添加自定义。
以下是您可以查看的示例:
| 🔡 Text descriptors | 📝 LLM outputs |
| Length, sentiment, toxicity, language, special symbols, regular expression matches, etc. | Semantic similarity, retrieval relevance, summarization quality, etc. with model- and LLM-based evals. |
| 🛢 Data quality | 📊 Data distribution drift |
| Missing values, duplicates, min-max ranges, new categorical values, correlations, etc. | 20+ statistical tests and distance metrics to compare shifts in data distribution. |
| 🎯 Classification | 📈 Regression |
| Accuracy, precision, recall, ROC AUC, confusion matrix, bias, etc. | MAE, ME, RMSE, error distribution, error normality, error bias, etc. |
| 🗂 Ranking (inc. RAG) | 🛒 Recommendations |
| NDCG, MAP, MRR, Hit Rate, etc. | Serendipity, novelty, diversity, popularity bias, etc. |
🔡 文本描述符📝 LLM输出
长度、情感、毒性、语言、特殊符号、正则表达式匹配等。基于模型和LLM的评估具有语义相似性、检索相关性、摘要质量等。
🛢 数据质量📊 数据分布漂移
缺失值、重复值、最小-最大范围、新的分类值、相关性等。20多种统计测试和距离度量,用于比较数据分布的变化。
🎯 分类📈 回归
准确度、精密度、召回率、ROC AUC、混淆矩阵、偏差等。MAE、ME、RMSE、误差分布、误差正态性、误差偏差等。
🗂 排名(股份有限公司RAG)🛒 建议
NDCG、MAP、MRR、命中率等。偶然性、新颖性、多样性、流行偏见等。
- 登录 发表评论
- 46 次浏览
最新内容
- 6 days 23 hours ago
- 1 week 3 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago