
category
通过自动化复杂任务、增强决策和简化操作,人工智能代理正迅速成为跨行业客户工作流程中不可或缺的一部分。然而,在生产系统中采用人工智能代理需要可扩展的评估管道。强大的代理评估使您能够衡量代理执行某些操作的程度,并获得对这些操作的关键见解,从而增强AI代理的安全性、控制、信任、透明度和性能优化。
Amazon Bedrock Agents使用Amazon Bedrocks上可用的基础模型(FM)、API和数据的推理来分解用户请求、收集相关信息并高效完成任务,使团队能够专注于高价值的工作。您可以通过与公司系统、API和数据源无缝连接,使生成式AI应用程序能够自动化多步任务。
Ragas是一个开源库,用于测试和评估各种LLM用例中的大型语言模型(LLM)应用程序,包括检索增强生成(RAG)。该框架能够定量衡量RAG实施的有效性。在这篇文章中,我们使用Ragas库来评估亚马逊基岩代理的RAG能力。
LLM-as-year是一种评估方法,它使用LLM来评估AI生成输出的质量。该方法采用LLM作为公正的评估者,对输出进行分析和评分。在这篇文章中,我们采用LLM作为判断技术来评估亚马逊基岩代理的文本到SQL和思维链能力。
Langfuse是一个开源的LLM工程平台,它提供了跟踪、评估、提示管理和指标等功能,用于调试和改进您的LLM应用程序。
在《亚马逊Bedrock Agents加速癌症生物标志物的分析和发现》一文中,我们展示了制药公司癌症生物标志物发现的研究代理。在这篇文章中,我们扩展了之前的工作,并展示了具有以下功能的开源基岩试剂评估:
- 评估亚马逊基岩代理的能力(RAG、文本到SQL、自定义工具使用)和整体思路
- 综合评估结果和跟踪数据通过内置的可视化仪表板发送到Langfuse
- 各种Amazon Bedrock Agent配置选项的跟踪解析和评估
首先,我们对各种不同的亚马逊基岩代理进行评估。其中包括样本RAG代理、样本文本到SQL代理,以及使用多代理协作发现癌症生物标志物的药物研究代理。然后,对于每个代理,我们展示如何导航Langfuse仪表板以查看跟踪和评估结果。
技术挑战
如今,人工智能代理开发人员通常面临以下技术挑战:
- 端到端代理评估——尽管Amazon Bedrock为LLM模型和RAG检索提供了内置的评估功能,但它缺乏专门为Amazon Bedrock代理设计的指标。需要评估整体代理目标,以及特定任务和工具调用的单个代理跟踪步骤。还需要支持单代理和多代理,以及单轮和多轮数据集。
- 具有挑战性的实验管理——亚马逊基岩代理提供了许多配置选项,包括LLM模型选择、代理说明、工具配置和多代理设置。然而,由于缺乏系统的方法来跟踪、比较和衡量不同代理版本之间配置更改的影响,因此对这些参数进行快速实验在技术上具有挑战性。这使得通过迭代测试有效优化代理性能变得困难。
解决方案概述
下图说明了开源基岩剂评估是如何在高层次上工作的。该框架运行一个评估作业,该作业将调用您在Amazon Bedrock中的代理并评估其响应。
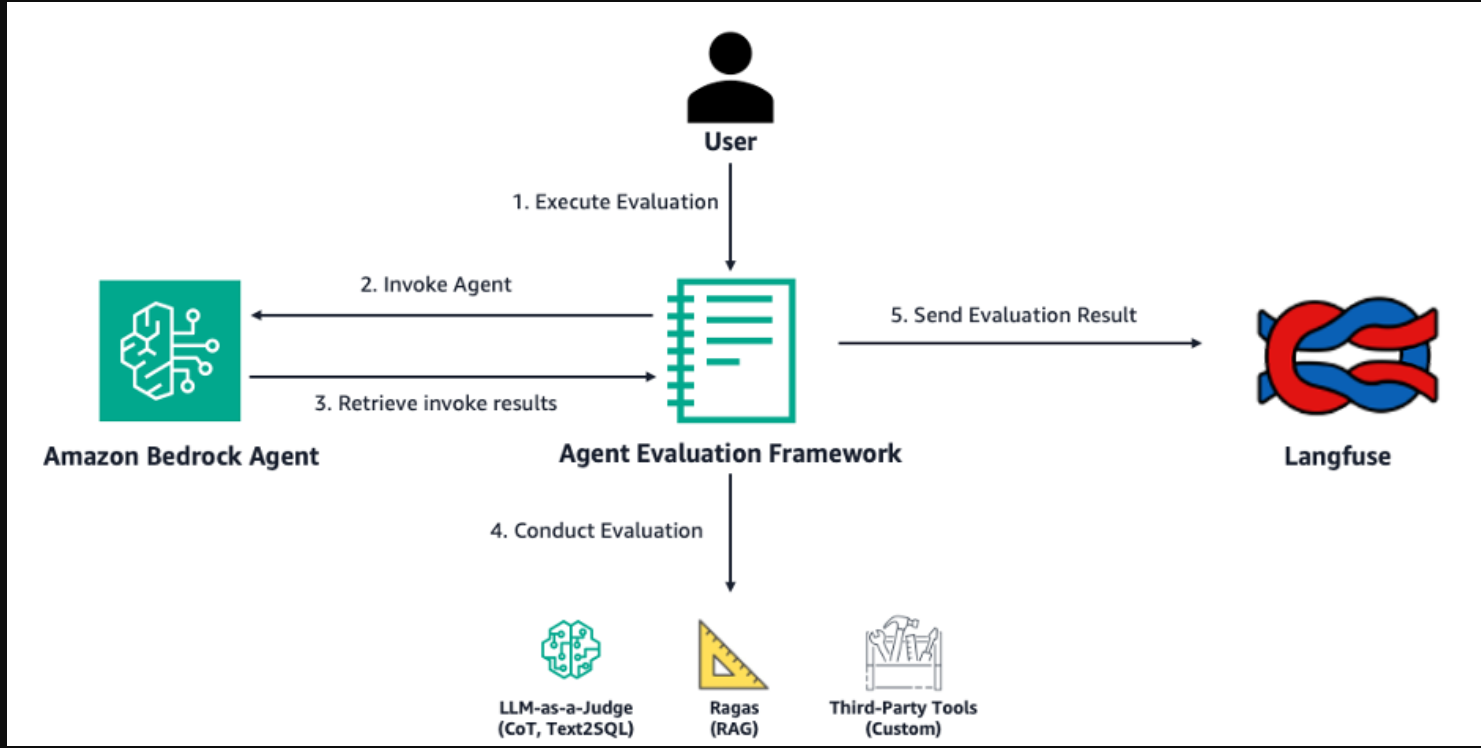
工作流程包括以下步骤:
- 用户指定代理ID、别名、评估模型以及包含问题和基本事实对的数据集。
- 用户执行评估作业,该作业将调用指定的Amazon Bedrock代理。
- 检索到的代理调用跟踪通过框架中的自定义解析逻辑运行。
- 该框架根据代理调用结果和问题类型进行评估:
- 思维链——LLM作为评委,亚马逊基岩LLM电话(针对不同类型问题的每次评估运行进行)
- RAG–Ragas评估库
- 文本到SQL-LLM作为法官与亚马逊Bedrock LLM通话
- 收集评估结果和解析的痕迹,并将其发送给Langfuse以获取评估见解。
Prerequisites
To deploy the sample RAG and text-to-SQL agents and follow along with evaluating them using Open Source Bedrock Agent Evaluation, follow the instructions in Deploying Sample Agents for Evaluation.
To bring your own agent to evaluate with this framework, refer to the following README and follow the detailed instructions to deploy the Open Source Bedrock Agent Evaluation framework.
Overview of evaluation metrics and input data
First, we create sample Amazon Bedrock agents to demonstrate the capabilities of Open Source Bedrock Agent Evaluation. The text-to-SQL agent uses the BirdSQL Mini-Dev dataset, and the RAG agent uses the Hugging Face rag-mini-wikpedia dataset.
Evaluation metrics
The Open Source Bedrock Agent Evaluation framework conducts evaluations on two broad types of metrics:
- Agent goal – Chain-of-thought (run on every question)
- Task accuracy – RAG, text-to-SQL (run only when the specific tool is used to answer question)
Agent goal metrics measure how well an agent identifies and achieves the goals of the user. There are two main types: reference-based evaluation and no reference evaluation. Examples can be found in Agent Goal accuracy as defined by Ragas:
- Reference-based evaluation – The user provides a reference that will be used as the ideal outcome. The metric is computed by comparing the reference with the goal achieved by the end of the workflow.
- Evaluation without reference – The metric evaluates the performance of the LLM in identifying and achieving the goals of the user without reference.
We will showcase evaluation without reference using chain-of-thought evaluation. We conduct evaluations by comparing the agent’s reasoning and the agent’s instruction. For this evaluation, we use some metrics from the evaluator prompts for Amazon Bedrock LLM-as-a-judge. In this framework, the chain-of-thought evaluations are run on every question that the agent is evaluated against.
Task accuracy metrics measure how well an agent calls the required tools to complete a given task. For the two task accuracy metrics, RAG and text-to-SQL, evaluations are conducted based on comparing the actual agent answer against the ground truth dataset that must be provided in the input dataset. The task accuracy metrics are only evaluated when the corresponding tool is used to answer the question.
The following is a breakdown of the key metrics used in each evaluation type included in the framework:
- RAG:
- Faithfulness – How factually consistent a response is with the retrieved context
- Answer relevancy – How directly and appropriately the original question is addressed
- Context recall – How many of the relevant pieces of information were successfully retrieved
- Semantic similarity – The assessment of the semantic resemblance between the generated answer and the ground truth
- Text-to-SQL:
- SQL query semantic equivalence – The equivalence of response query with the reference query
- Answer correctness – How well the generated answer correctly represents the query results and matches ground truth
- Chain-of-thought:
- Helpfulness – How well the agent satisfies explicit and implicit expectations
- Faithfulness – How well the agent sticks to available information and context
- Instruction following – How well the agent respects all explicit directions
User-agent trajectories
The input dataset is in the form of trajectories, where each trajectory consists of one or more questions to be answered by the agent. The trajectories are meant to simulate how a user might interact with the agent. Each trajectory consists of a unique question_id, question_type, question, and ground_truth information. The following are examples of actual trajectories used to evaluate each type of agent in this post.
For more simple agent setups like the RAG and text-to-SQL sample agent, we created trajectories consisting of a single question, as shown in the following examples.
The following is an example of a RAG sample agent trajectory:
The following is an example of a text-to-SQL sample agent trajectory:
Pharmaceutical research agent use case example
In this section, we demonstrate how you can use the Open Source Bedrock Agent Evaluation framework to evaluate pharmaceutical research agents discussed in the post Accelerate analysis and discovery of cancer biomarkers with Amazon Bedrock Agents . It showcases a variety of specialized agents, including a biomarker database analyst, statistician, clinical evidence researcher, and medical imaging expert in collaboration with a supervisor agent.
The pharmaceutical research agent was built using the multi-agent collaboration feature of Amazon Bedrock. The following diagram shows the multi-agent setup that was evaluated using this framework.

如图所示,RAG评估将在临床证据研究人员子代理上进行。同样,文本到SQL的评估将在生物标志物数据库分析师子代理上运行。思维链评估评估主管代理的最终答案,以检查它是否正确地编排了子代理并回答了用户的问题。
研究代理轨迹
对于像药物研究代理这样更复杂的设置,我们使用了一组与行业相关的预先生成的测试问题。通过根据主题创建问题组,而不管可能调用哪些子代理来回答问题,我们创建了包括跨越多种工具使用类型的多个问题的轨迹。由于已经产生了相关问题,与评估框架的整合只需要将地面实况数据正确地格式化为轨迹。
我们将根据包含RAG问题和文本到SQL问题的轨迹来评估此代理:
Chain-of-thought evaluations are conducted for every question, regardless of tool use. This will be illustrated through a set of images of agent trace and evaluations on the Langfuse dashboard.
After running the agent against the trajectory, the results are sent to Langfuse to view the metrics. The following screenshot shows the trace of the RAG question (question ID 3) evaluation on Langfuse.

屏幕截图显示以下信息:
- 跟踪信息(代理调用的输入和输出)
- 跟踪步骤(代理生成和相应的子步骤)
- 跟踪元数据(输入和输出令牌、成本、模型、代理类型)
- 评估指标(RAG和思维链指标)
以下屏幕截图显示了Langfuse上文本到SQL问题(问题ID 4)评估的跟踪,该评估评估了生物标志物数据库分析代理,该代理生成SQL查询,以在包含生物标志物信息的Amazon Redshift数据库上运行。

屏幕截图显示了以下信息:
- 跟踪信息(代理调用的输入和输出)
- 跟踪步骤(代理生成和相应的子步骤)
- 跟踪元数据(输入和输出令牌、成本、模型、代理类型)
- 评估指标(文本到SQL和思维链指标)
思维链评价是两个问题评价轨迹的一部分。对于这两种痕迹,LLM作为法官被用来围绕亚马逊基岩特工对给定问题的推理生成分数和解释。
总的来说,我们针对代理运行了56个问题,分为21个轨迹。跟踪、模型成本和分数显示在以下屏幕截图中。

The following table contains the average evaluation scores across 56 evaluation traces.
| Metric Category | Metric Type | Metric Name | Number of Traces | Metric Avg. Value |
| Agent Goal | COT | Helpfulness | 50 | 0.77 |
| Agent Goal | COT | Faithfulness | 50 | 0.87 |
| Agent Goal | COT | Instruction following | 50 | 0.69 |
| Agent Goal | COT | Overall (average of all metrics) | 50 | 0.77 |
| Task Accuracy | TEXT2SQL | Answer correctness | 26 | 0.83 |
| Task Accuracy | TEXT2SQL | SQL semantic equivalence | 26 | 0.81 |
| Task Accuracy | RAG | Semantic similarity | 20 | 0.66 |
| Task Accuracy | RAG | Faithfulness | 20 | 0.5 |
| Task Accuracy | RAG | Answer relevancy | 20 | 0.68 |
| Task Accuracy | RAG | Context recall | 20 | 0.53 |
安全注意事项
考虑以下安全措施:
- 启用Amazon Bedrock代理日志记录-为了使用Amazon Bedrocks代理的安全最佳实践,请启用Amazon Bedrock模型调用日志记录,以便在您的帐户中安全地捕获提示和响应。
- 检查合规性要求——在您的生产环境中实施Amazon Bedrock Agent之前,请确保Amazon Bedrock合规性认证和标准符合您的监管要求。有关满足合规要求的更多信息和资源,请参阅Amazon Bedrock的合规性验证。
清理
如果部署了示例代理,请运行以下笔记本以删除创建的资源。
如果您选择了自托管的Langfuse选项,请按照以下步骤清理您的AWS自托管Langfuse设置。
结论
在这篇文章中,我们介绍了开源基岩代理评估框架,这是一个简化代理开发过程的Langfuse集成解决方案。该框架配备了用于RAG的内置评估逻辑、文本到SQL、思维链推理,并与Langfuse集成以查看评估指标。使用开源基岩试剂评估试剂,开发人员可以快速评估他们的试剂,并快速尝试不同的配置,加快开发周期并提高试剂性能。
我们展示了如何将该评估框架与药物研究代理相结合。我们使用它来评估生物标志物问题的代理性能,并将跟踪信息发送给Langfuse,以查看不同问题类型的评估指标。
开源基岩代理评估框架使您能够使用Amazon基岩代理加速生成AI应用程序的构建过程。要在您的AWS帐户中自托管Langfuse,请参阅使用CDK Python在Amazon ECS上使用Fargate托管Langfus。要探索如何简化您的亚马逊基岩代理评估过程,请开始使用开源基岩代理评估。
请参阅亚马逊基岩团队的《迈向有效的GenAI多代理协作:企业应用程序的设计和评估》,以了解更多关于多代理协作和端到端代理评估的信息。
- 登录 发表评论
- 48 次浏览
最新内容
- 1 month 1 week ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago