
DVC跟踪ML模型和数据集
DVC的建立是为了使ML模型具有可共享性和可复制性。它设计用于处理大型文件、数据集、机器学习模型、度量以及代码。
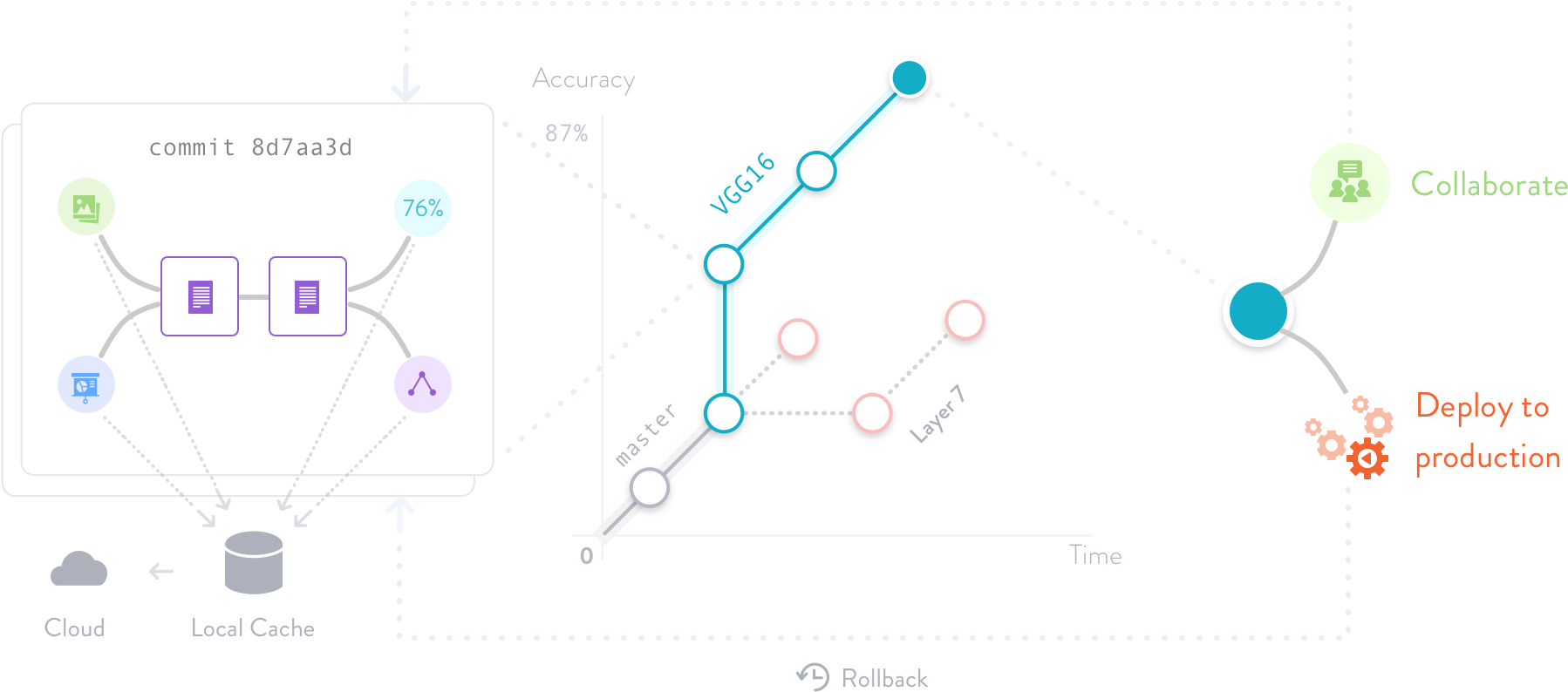
ML项目版本控制
版本控制机器学习模型,数据集和中间文件。DVC通过代码将它们连接起来,并使用Amazon S3、Microsoft Azure Blob存储、Google Drive、Google云存储、Aliyun OSS、SSH/SFTP、HDFS、HTTP、网络连接存储或光盘来存储文件内容。
完整的代码和数据来源有助于跟踪每个ML模型的完整演化。这保证了再现性,并使其易于在实验之间来回切换。
ML实验管理
利用Git分支的全部功能尝试不同的想法,而不是代码中草率的文件后缀和注释。使用自动度量跟踪来导航,而不是使用纸张和铅笔。
DVC被设计成保持分支像Git一样简单和快速-无论数据文件大小如何。除了一流的市民指标和ML管道,这意味着一个项目有更干净的结构。比较想法和挑选最好的很容易。中间工件缓存可以加快迭代速度。
部署与协作
使用push/pull命令将一致的ML模型、数据和代码包移动到生产、远程机器或同事的计算机中,而不是临时脚本。
DVC在Git中引入了轻量级管道作为一级公民机制。它们与语言无关,并将多个步骤连接到一个DAG中。这些管道用于消除代码进入生产过程中的摩擦。
特性:
Git兼容
DVC运行在任何Git存储库之上,并与任何标准Git服务器或提供者(GitHub、GitLab等)兼容。数据文件内容可以由网络可访问存储或任何支持的云解决方案共享。DVC提供了分布式版本控制系统的所有优点—无锁、本地分支和版本控制。
存储不可知
使用Amazon S3、Microsoft Azure Blob存储、Google Drive、Google云存储、Aliyun OSS、SSH/SFTP、HDFS、HTTP、网络连接存储或光盘存储数据。支持的远程存储列表在不断扩展。
再现性
可复制的
单个“dvc repro”命令端到端地再现实验。DVC通过始终如一地维护输入数据、配置和最初用于运行实验的代码的组合来保证再现性。
低摩擦分支
DVC完全支持即时Git分支,即使是大文件也是如此。分支漂亮地反映了ML过程的非线性结构和高度迭代的性质。数据是不重复的-一个文件版本可以属于几十个实验。创建尽可能多的实验,瞬间来回切换,并保存所有尝试的历史记录。
度量跟踪
指标是DVC的一等公民。DVC包含一个命令,用于列出所有分支以及度量值,以跟踪进度或选择最佳版本。
ML管道框架
DVC有一种内置的方式,可以将ML步骤连接到DAG中,并端到端地运行整个管道。DVC处理中间结果的缓存,如果输入数据或代码相同,则不会再次运行步骤。
语言与框架不可知论
不可知语言框架
无论使用哪种编程语言或库,或者代码是如何构造的,可再现性和管道都基于输入和输出文件或目录。Python、R、Julia、Scala Spark、custom binary、Notebooks、flatfiles/TensorFlow、PyTorch等都支持。
HDFS、Hive和Apache Spark
HDFS、Hive和Apache Spark
在DVC数据版本控制周期中包括Spark和Hive作业以及本地ML建模步骤,或者使用DVC端到端管理Spark和Hive作业。通过将繁重的集群作业分解为更小的DVC管道步骤,可以大大减少反馈循环。独立于依赖项迭代这些步骤。
故障跟踪
追踪故障
坏主意有时比成功的主意能在同事间激发更多的想法。保留失败尝试的知识可以节省将来的时间。DVC是建立在一个可复制和易于访问的方式跟踪一切。
用例
保存并复制你的实验
在任何时候,获取你或你的同事所做实验的全部内容。DVC保证所有的文件和度量都是一致的,并且在正确的位置复制实验或者将其用作新迭代的基线。
版本控制模型和数据
DVC将元文件保存在Git中,而不是Google文档中,用于描述和控制数据集和模型的版本。DVC支持多种外部存储类型,作为大型文件的远程缓存。
为部署和协作建立工作流
DVC定义了作为一个团队高效一致地工作的规则和流程。它用作协作、共享结果以及在生产环境中获取和运行完成的模型的协议。
本文:
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】或者QQ群【11107777】
最新内容
- 1 week 2 days ago
- 2 weeks 3 days ago
- 3 weeks ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago