

今天,即使是小型初创公司也可能不得不处理数 TB 的数据或构建支持每分钟(甚至一秒钟!)数十万个事件的服务。所谓“规模”,通常是指系统应在短时间内处理的大量请求/数据/事件。尝试以幼稚的方式实现需要处理大规模的服务,在最坏的情况下注定要失败,或者在最好的情况下代价高昂。
本文将描述一些使系统能够处理大规模的原则和设计模式。当我们讨论大型(而且大多是分布式)系统时,我们通常通过查看三个属性来判断它们的好坏和稳定性:
- 可用性:系统应该尽可能地可用。正常运行时间百分比是客户体验的关键,更不用说如果没有人可以使用应用程序就没有用。可用性用“9”来衡量。
- 性能:即使在重负载下,系统也应该继续运行并执行其任务。此外,速度对于客户体验至关重要:实验表明,它是防止客户流失的最重要因素之一!
- 可靠性:系统应该准确地处理数据并返回正确的结果。一个可靠的系统不会静默失败或返回不正确的结果或创建损坏的数据。一个可靠的系统以一种努力避免故障的方式构建,当它不可能时,它会检测、报告,甚至可能尝试自动修复它们。
我们可以通过两种方式扩展系统:
- 垂直扩展(纵向扩展):将系统部署在更强大的服务器上,这意味着一台具有更强 CPU、更多 RAM 或两者兼有的机器
- 横向扩展(横向扩展):将系统部署在更多服务器上,这意味着启动更多实例或容器,使系统能够服务更多流量或处理更多数据/事件
纵向扩展规模通常不太可取,主要是因为两个原因:
- 它通常需要一些停机时间
- 有限制(我们不能“永远”扩大规模)
另一方面,为了能够扩展系统,它必须具有允许这种扩展的某些特性。例如,为了能够水平扩展,系统必须是无状态的(例如,大多数数据库不能横向扩展)。
本文的目的是让您体验许多不同的设计模式和原则,这些模式和原则使系统能够横向扩展,同时保持可靠性和弹性。 由于这种性质,我无法深入研究每个主题,而只是提供一个概述。 也就是说,在每个主题中,我都尝试添加有用的链接,指向关于该主题的更全面的资源。
所以让我们深入研究吧!
幂等性
这个术语是从数学中借来的,它被定义为:
f(f(x)) = f(x)
这乍一看可能有点吓人,但背后的想法很简单:无论我们调用函数 f on x 多少次,我们都会得到相同的结果。 此属性为系统提供了极大的稳定性,因为它允许我们简化代码,也使我们的操作生活更轻松:可以重试失败的 HTTP 请求,并且可以重新启动崩溃的进程而无需担心副作用。
此外,一个长时间运行的作业可以被分成多个部分,每个部分都可以是自己幂等的,这意味着当作业崩溃并重新启动时,所有已经执行的部分都将被跳过(可恢复性)。
拥抱异步

当我们进行同步调用时,执行路径会被阻塞,直到返回响应。 这种阻塞有资源开销,主要是内存和上下文切换的成本。 我们不能总是只使用异步调用来设计我们的系统,但是当我们可以让我们的系统更高效时。 一个展示异步如何提供良好效率/性能的示例是 Nodejs,它具有单线程事件循环,但它正在与许多其他并发语言和框架进行斗争。
健康检查
这种模式特定于微服务:每个服务都应该实现一个 /health 路由,该路由应该在系统快速运行后很快返回。 假设一切正常,它应该返回 HTTP 代码 200,如果服务出现故障,它应该返回 500 错误。 现在,我们知道一些错误不会被健康检查发现,但假设处于压力下的系统会运行不佳并成为潜在的,它也会被健康检查反映出来,这也会变得更加潜在,这也可以帮助我们识别 存在问题并自动生成待命人员可以接听的警报。 我们也可以选择暂时将节点从队列中移除(参见下面的服务发现),直到它再次稳定为止。
断路器

断路器是从电力领域借用的术语:当电路闭合时,电流正在流动,当电路打开时,电流停止。
当一个依赖不可达时,所有对它的请求都会失败。 根据 Fail Fast 原则,当我们尝试调用时,我们希望我们的系统快速失败,而不是等到超时。 这是断路器设计模式的一个很好的用例:通过使用断路器包装对函数的调用,断路器将识别对特定目的地(例如特定 IP)的调用何时失败,并开始失败 调用而没有真正进行调用,从而使系统快速失败。
断路器将保持一个状态(打开/关闭),并通过每隔一段时间重试一次实际调用来刷新其状态。
Netflix 的 Hystrix 库中引入并广泛采用了断路器的实现,如今在其他库中也很常见。
终止开关/功能标志

今天的另一种常见做法是对新功能执行“静默部署”。 它是通过使用 if 检查功能标志是否已启用(或者,通过检查相关的 kill-switch 标志是否已禁用)的条件来控制功能来实现的。 这种做法并不能 100% 保证我们的代码没有错误,但它确实可以降低将新错误部署到生产环境的风险。 此外,如果我们启用了功能标志并且我们在系统中看到了新错误,则很容易禁用该标志并“恢复正常”,这从操作的角度来看是一个巨大的胜利。
舱壁(Bulkhead)
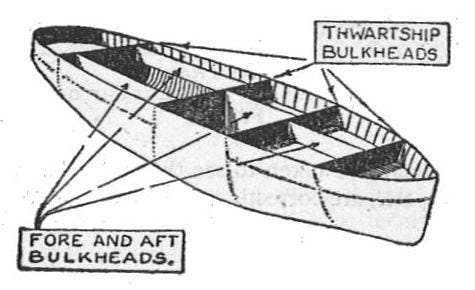
隔板是船底隔间之间的分隔墙或屏障。 它的工作是隔离一个区域,以防底部有洞——以防止水淹没整个船(它只会淹没有洞的隔间)。
通过在考虑模块化和隔离的情况下构建软件,可以将相同的原则应用于软件。 一个例子可以是线程池:当我们为不同的组件创建不同的线程池以确保耗尽其中一个中的所有线程的错误时 - 不会影响其他组件。
另一个很好的例子是确保不同的微服务不会共享同一个数据库。 我们还避免共享配置:不同的服务应该有自己的配置设置,即使它需要某种重复,以避免一个服务中的配置错误影响不同服务的情况。
服务发现

在动态的微服务世界中,实例/容器来来去去,我们需要一种方法来了解新节点何时加入/离开队列。 服务发现(也称为服务注册)是一种通过允许节点在中央位置(如黄页)注册来解决此问题的机制。 这样,当服务 B 想要调用服务 A 时,它会首先调用服务发现来请求可用节点 (IP) 的列表,它将缓存并使用一段时间。
超时、睡眠和重试
任何网络都可能遭受瞬时错误、延迟和拥塞问题。 当服务 A 调用服务 B 时,请求可能会失败,如果发起重试,则第二个请求可能会成功通过。 也就是说,重要的是不要以简单的方式(循环)实现重试,而不是“烘焙”到重试之间的延迟机制(也称为“睡眠”)。 原因是我们应该意识到被调用的服务:可能有多个其他服务同时调用服务B,如果它们都继续重试,结果将是“重试风暴”:服务B会 被请求轰炸,这可能会使它不堪重负并使其崩溃。 为了避免“重试风暴”,通常的做法是使用指数退避重试机制,该机制会在重试之间引入指数增长的延迟,并最终导致“超时”,这将停止任何额外的重试。
后备

有时我们只需要一个“B计划”。 假设我们正在使用推荐服务,以便为客户获得最佳和最准确的推荐。 但是,当服务出现故障或暂时无法访问时,我们能做些什么呢?
我们可以有另一个服务作为后备:其他服务可能会保留我们所有客户的推荐的快照,每周刷新自己,当它被调用时,它需要做的就是返回该特定客户的相关记录。 这种信息是静态的,易于缓存和服务。 这些后备建议确实有点陈旧,但是拥有不是完全最新的建议总比没有任何建议要好得多。
优秀的工程师在构建系统时会考虑这些选项!
请注意,断路器实现可能包括提供后备服务的选项!
指标、监控和警报
在运行大规模系统时,不是系统是否会失败的问题,而是系统何时会失败的问题:由于规模大,即使是百万分之一的罕见事件也会发生。最终发生。
既然我们理解并接受错误是“生活的一部分”,我们就必须找出处理它们的最佳方法。
为了拥有一个可靠的可用系统,我们需要能够快速检测(MTTD)和修复(MTTR)错误,为此,我们需要获得对系统的可观察性。这可以通过发布指标、监控这些指标并在我们的监控系统检测到“关闭”的指标时发出警报来实现。
Google 将 4 个指标定义为黄金信号,但这并不意味着我们不应该发布其他指标。我们可以将指标分为 3 个桶:
- 业务指标:源自业务上下文的指标,例如,我们可能会在每次下订单、批准或取消订单时发布指标
- 基础设施指标:衡量我们部分基础设施的大小/使用情况的指标,例如,我们可以监控我们的应用程序使用的 CPU 使用率、内存和磁盘空间
- 功能指标:发布有关我们系统中特定功能的信息的指标。一个示例可以是在我们正在运行的 A/B 测试中发布的指标,以提供有关分配到实验不同单元的用户的见解
小轶事:在我为 Netflix 工作的日子里,我和我的团队所做的一件事是开发 Watson,使团队能够通过创建程序化运行手册从已知场景中自动修复他们的服务!
限速
速率限制或节流是另一种有助于减轻系统压力的有用模式。
节流有 3 种类型:
- 用户限速(客户端)
- 服务器限速和
- 地理限速
背压

背压是一种用于处理来自上游服务的请求负载高于处理能力的情况的技术。 处理背压的一种方法是向上游服务发出信号,告知它应该对自身进行速率限制。
有一个专用的 HTTP 响应代码 429“请求过多”,旨在向客户端发出信号,表明服务器尚未准备好以当前速率接受更多请求。 这样的响应通常会返回一个 Retry-After 标头,以指示客户端在重试之前应该等待多少秒。
处理背压的另外两种方法是限制(也称为“在地板上抛出请求”)和缓冲。
可以在此处找到有关背压的其他推荐阅读。
金丝雀发布

金丝雀测试是一种用于将更改逐步推广到生产环境的技术。当监控系统发现问题时——金丝雀会自动回滚,对生产流量的损害最小。
请记住,为了启用金丝雀发布,我们需要能够与“正常”节点分开监控金丝雀集群,然后我们可以使用“常规”节点舰队作为基线,并将其与我们收到的指标进行比较从金丝雀。例如,我们可以比较我们在两者中收到的 500 个错误率,如果金丝雀产生更高的错误率,我们可以回滚它。
还有一种更保守的方法是使用生产中的影子流量来做金丝雀。
我以前的一位同事 Chris Sanden 与人合着了一篇关于 Kayenta 的好文章:一种在 Netflix 中开发的用于自动金丝雀分析的工具。
今天的内容就到这里了,希望大家能学到新东西!
如果你认为我错过了一个重要的模式/原则——请写评论,我会添加它。
最新内容
- 1 week ago
- 2 weeks 1 day ago
- 2 weeks 5 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago