
您的灾难恢复计划应该是组织业务连续性计划(BCP)的一个子集,而不应该是一个独立的文档。如果由于灾难对除工作负载之外的业务要素的影响而无法实现工作负载的业务目标,那么维护用于恢复工作负载的积极灾难恢复目标是没有意义的。例如,地震可能会阻止您运输在电子商务应用程序上购买的产品–即使有效的灾难恢复使您的工作负载正常运行,您的BCP也需要满足运输需求。您的灾难恢复战略应基于业务需求、优先级和环境。
业务影响分析和风险评估
业务影响分析应量化工作负载中断的业务影响。它应该确定无法使用您的工作负载对内部和外部客户的影响以及对业务的影响。分析应有助于确定工作负载需要多长时间可用,以及可以容忍多少数据丢失。然而,重要的是要注意,不应孤立地制定恢复目标;中断概率和恢复成本是有助于为工作负载提供灾难恢复的业务价值的关键因素。
业务影响可能取决于时间。您可能需要考虑将其纳入灾难恢复计划中。例如,在每个人都拿到工资之前,工资系统的中断可能会对业务产生非常大的影响,但在每个人已经拿到工资之后,可能会产生很小的影响。
对灾害类型和地理影响的风险评估,以及工作负载的技术实施概述,将确定每种灾害发生中断的概率。
对于高度关键的工作负载,您可以考虑在多个区域部署基础架构,并在适当的位置进行数据复制和连续备份,以将业务影响降至最低。对于不太关键的工作负载,一个有效的策略可能是根本不进行任何灾难恢复。对于某些灾难场景,根据灾难发生的概率低,不制定任何灾难恢复策略作为明智的决策也是有效的。请记住,AWS区域内的可用性区域已经设计好了它们之间的距离,并仔细规划了位置,这样,最常见的灾难应该只影响一个区域,而不会影响其他区域。因此,AWS区域内的多AZ架构可能已经满足了您的许多风险缓解需求。
应评估灾难恢复选项的成本,以确保灾难恢复策略在考虑到业务影响和风险的情况下提供正确的业务价值水平。
利用所有这些信息,您可以记录不同灾难场景和相关恢复选项的威胁、风险、影响和成本。这些信息应用于确定每个工作负载的恢复目标。
恢复目标(RTO和RPO)
在创建灾难恢复(DR)战略时,组织通常会规划恢复时间目标(RTO)和恢复点目标(RPO)。
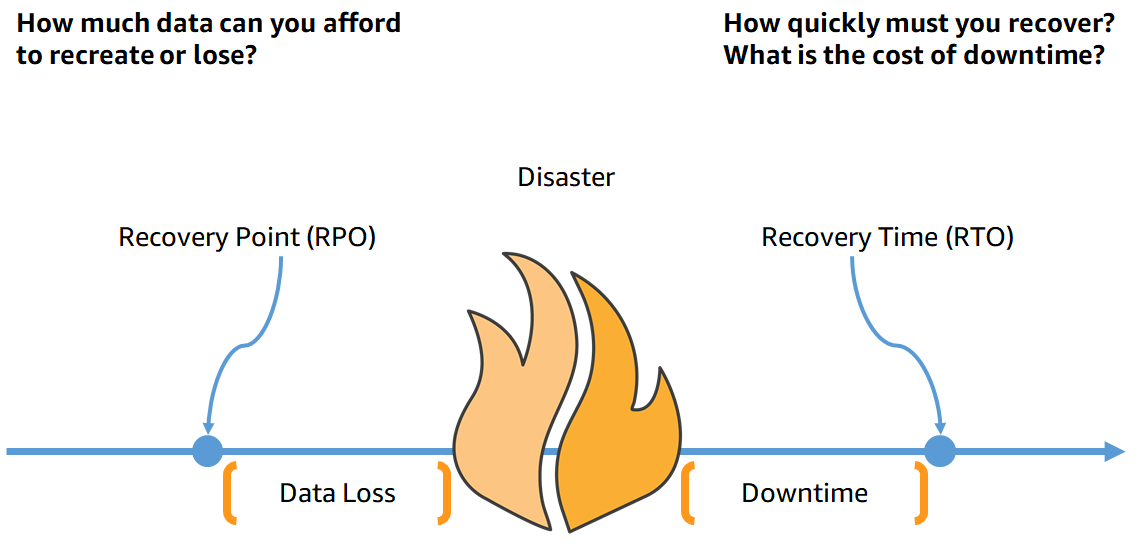
图3-恢复目标
恢复时间目标(RTO)是服务中断和恢复服务之间的最大可接受延迟。该目标确定了服务不可用时的可接受时间窗口,并由组织定义。
本文大致讨论了四种灾难恢复策略:备份和恢复、引导灯( pilot light)、热备用(warm standby)和多站点活动/活动(multi-site active/active)(请参阅云中的灾难恢复选项)。在下图中,业务部门已经确定了其最大允许RTO以及在服务恢复策略上可以花费的金额限制。考虑到业务目标,灾难恢复策略Pilot Light或Warm Standby将同时满足RTO和成本标准。
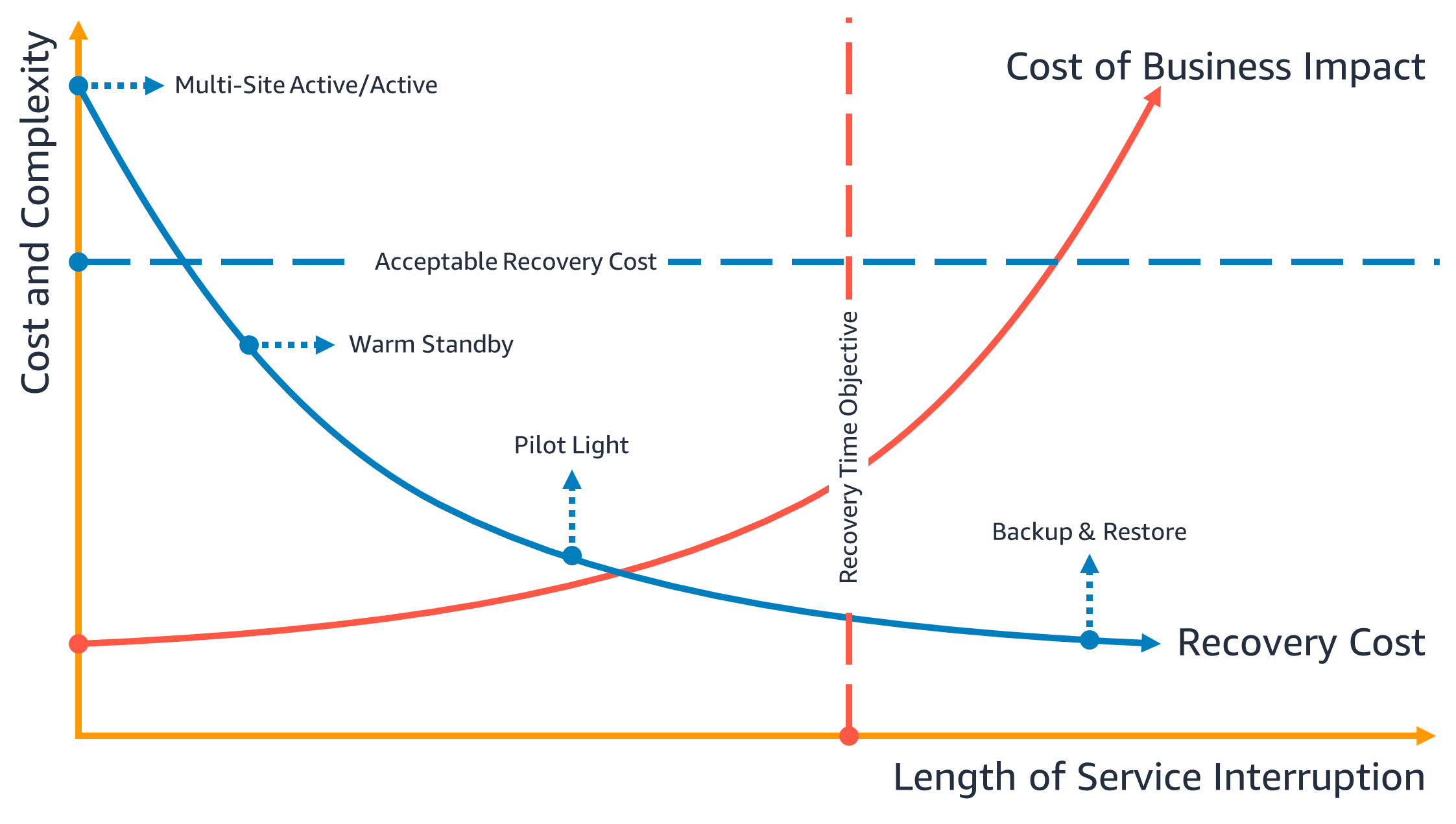
图4-恢复时间目标
恢复点目标(RPO)是自上一个数据恢复点以来可接受的最长时间。该目标确定了在最后一个恢复点和服务中断之间的数据可接受损失,并由组织定义。
在下图中,业务部门确定了其允许的最大RPO,以及他们在数据恢复策略上可以花费的资金限制。在这四种灾难恢复策略中,“引燃光”或“热备用”灾难恢复策略都符合RPO和成本标准。
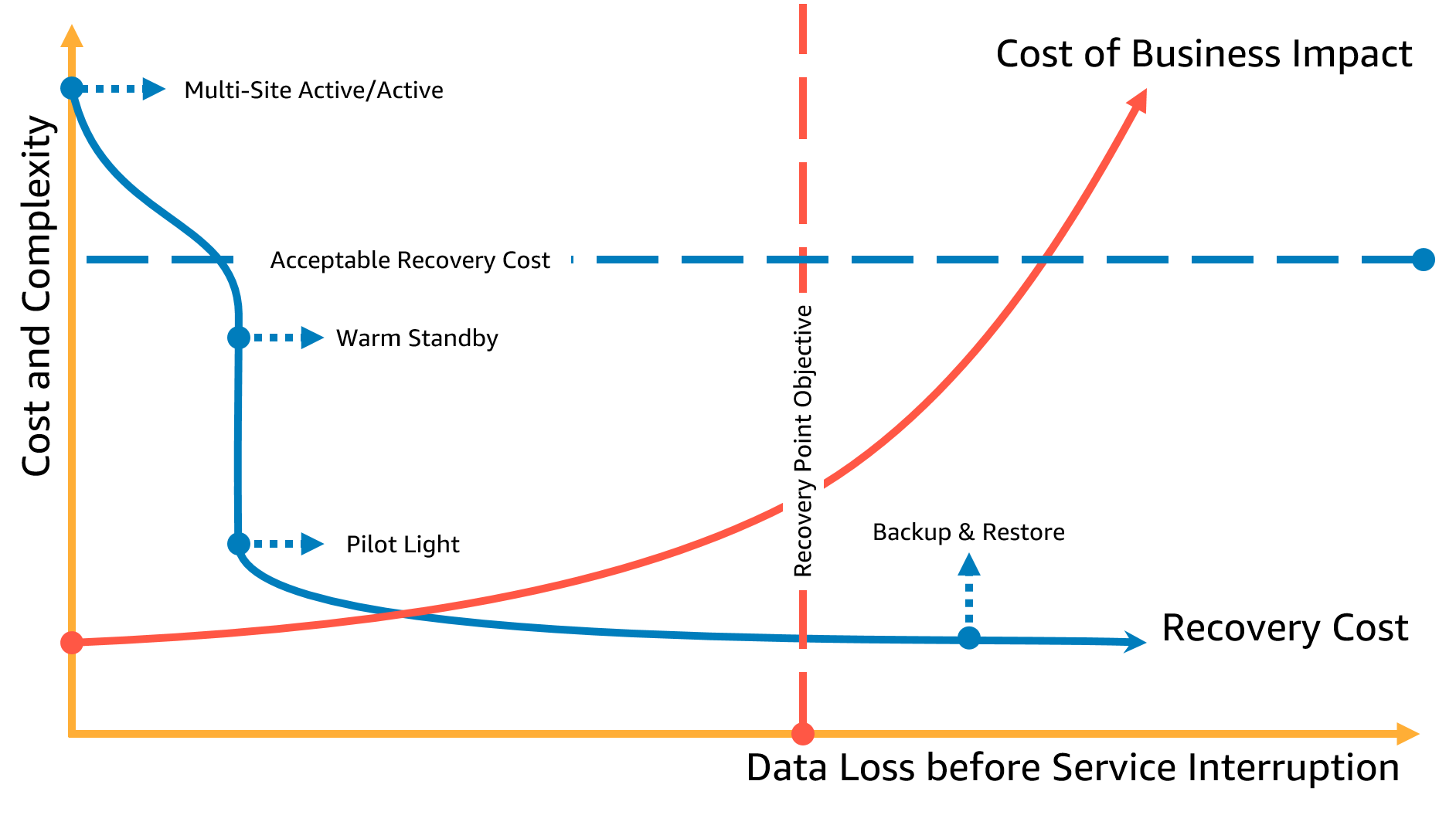
图5-恢复点目标
笔记
如果恢复策略的成本高于故障或损失的成本,则除非存在第二驱动因素(如监管要求),否则不应实施恢复选项。在进行评估时,考虑不同成本的恢复策略。
最新内容
- 1 day 12 hours ago
- 1 day 12 hours ago
- 1 day 12 hours ago
- 1 day 12 hours ago
- 1 day 12 hours ago
- 1 day 13 hours ago
- 1 day 13 hours ago
- 1 day 13 hours ago
- 1 day 13 hours ago
- 1 day 13 hours ago