
category
语音人工智能正在改变我们与技术的互动方式,使对话互动比以往任何时候都更加自然和直观。与此同时,人工智能代理变得越来越复杂,能够理解复杂的查询并代表我们采取自主行动。随着这些趋势的融合,你会看到智能人工智能语音代理的出现,它们可以在执行各种任务的同时进行类似人类的对话。
在本系列文章中,您将学习如何使用Pipecat构建智能AI语音代理,Pipecat是一个用于语音和多模式会话AI代理的开源框架,其基础模型位于Amazon Bedrock上。它包括高级参考架构、最佳实践和代码示例,以指导您的实现。
构建人工智能语音代理的方法
构建会话式AI代理有两种常见方法:
- 使用级联模型:在这篇文章(第1部分)中,您将了解级联模型方法,深入了解会话式AI代理的各个组件。通过这种方法,语音输入在将语音响应发送回用户之前会经过一系列架构组件。这种方法有时也被称为流水线或组件模型语音架构。
- 在单一架构中使用语音到语音基础模型:在第2部分中,您将学习Amazon Nova Sonic,一种最先进的统一语音到语音的基础模型,如何通过在单一架构中将语音理解和生成结合起来,实现实时、类人的语音对话。
常见用例
AI语音代理可以处理多种用例,包括但不限于:
- 客户支持:人工智能语音代理可以全天候处理客户查询,提供即时响应,并在必要时将复杂问题路由给人工代理。
- 出站呼叫:人工智能代理可以进行个性化的外展活动,安排预约或通过自然对话跟进潜在客户。
- 虚拟助理:语音AI可以为个人助理提供动力,帮助用户管理任务、回答问题。
架构:使用级联模型构建AI语音代理
要使用级联模型方法构建代理语音AI应用程序,您需要编排涉及多个机器学习和基础模型的多个架构组件。
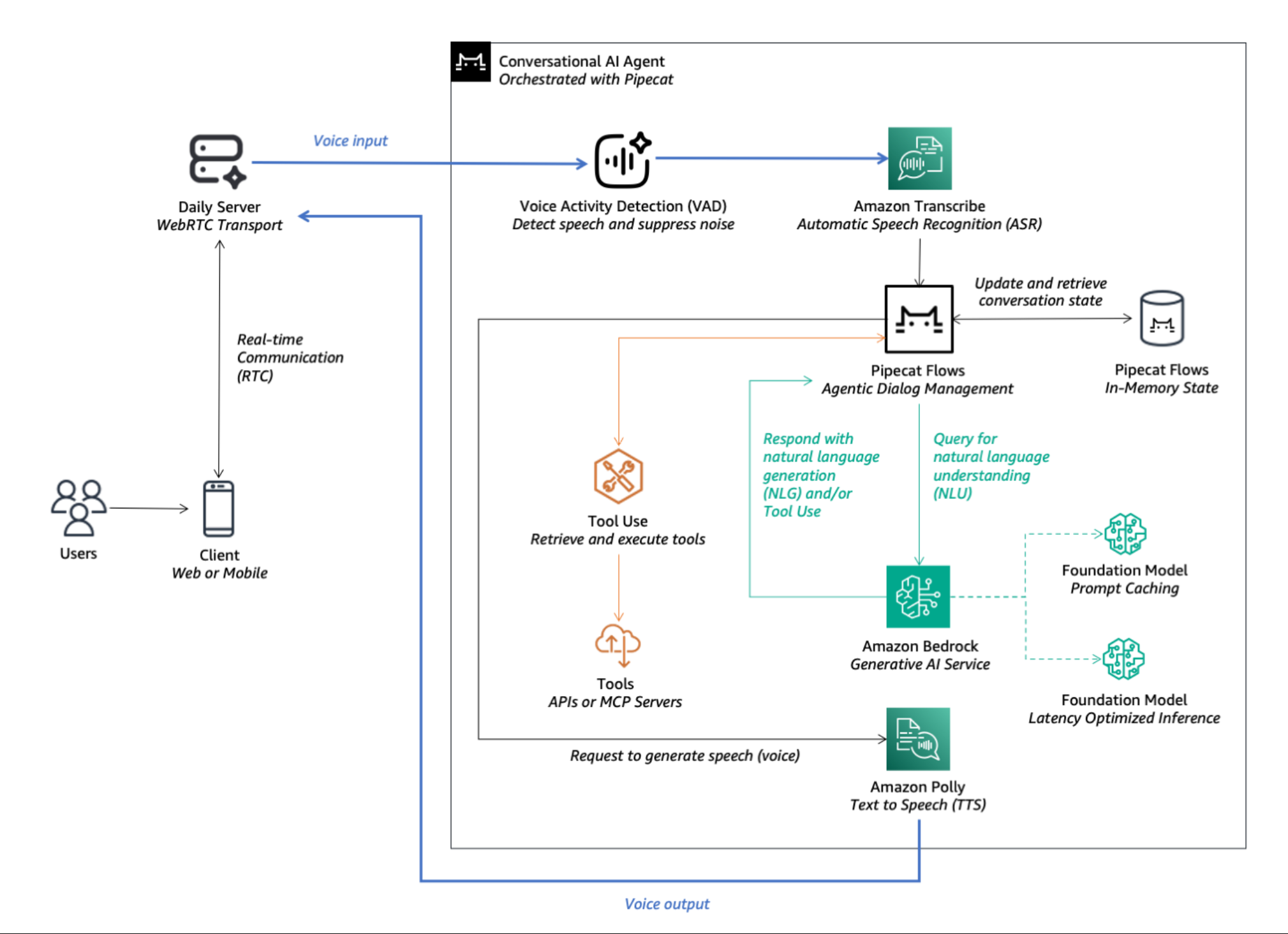
Figure 1: Architecture overview of a Voice AI Agent using Pipecat
These components include:
WebRTC Transport: Enables real-time audio streaming between client devices and the application server.
Voice Activity Detection (VAD): Detects speech using Silero VAD with configurable speech start and speech end times, and noise suppression capabilities to remove background noise and enhance audio quality.
Automatic Speech Recognition (ASR): Uses Amazon Transcribe for accurate, real-time speech-to-text conversion.
Natural Language Understanding (NLU): Interprets user intent using latency-optimized inference on Bedrock with models like Amazon Nova Pro optionally enabling prompt caching to optimize for speed and cost efficiency in Retrieval Augmented Generation (RAG) use cases.
Tools Execution and API Integration: Executes actions or retrieves information for RAG by integrating backend services and data sources via Pipecat Flows and leveraging the tool use capabilities of foundation models.
Natural Language Generation (NLG): Generates coherent responses using Amazon Nova Pro on Bedrock, offering the right balance of quality and latency.
Text-to-Speech (TTS): Converts text responses back into lifelike speech using Amazon Polly with generative voices.
Orchestration Framework: Pipecat orchestrates these components, offering a modular Python-based framework for real-time, multimodal AI agent applications.
Best practices for building effective AI voice agents
Developing responsive AI voice agents requires focus on latency and efficiency. While best practices continue to emerge, consider the following implementation strategies to achieve natural, human-like interactions:
Minimize conversation latency: Use latency-optimized inference for foundation models (FMs) like Amazon Nova Pro to maintain natural conversation flow.
Select efficient foundation models: Prioritize smaller, faster foundation models (FMs) that can deliver quick responses while maintaining quality.
Implement prompt caching: Utilize prompt caching to optimize for both speed and cost efficiency, especially in complex scenarios requiring knowledge retrieval.
Deploy text-to-speech (TTS) fillers: Use natural filler phrases (such as “Let me look that up for you”) before intensive operations to maintain user engagement while the system makes tool calls or long-running calls to your foundation models.
Build a robust audio input pipeline: Integrate components like noise to support clear audio quality for better speech recognition results.
Start simple and iterate: Begin with basic conversational flows before progressing to complex agentic systems that can handle multiple use cases.
Region availability: Low-latency and prompt caching features may only be available in certain regions. Evaluate the trade-off between these advanced capabilities and selecting a region that is geographically closer to your end-users.
Example implementation: Build your own AI voice agent in minutes
This post provides a sample application on Github that demonstrates the concepts discussed. It uses Pipecat and and its accompanying state management framework, Pipecat Flows with Amazon Bedrock, along with Web Real-time Communication (WebRTC) capabilities from Daily to create a working voice agent you can try in minutes.
Prerequisites
To setup the sample application, you should have the following prerequisites:
- Python 3.10+
- An AWS account with appropriate Identity and Access Management (IAM) permissions for Amazon Bedrock, Amazon Transcribe, and Amazon Polly
- Access to foundation models on Amazon Bedrock
- Access to an API key for Daily
- Modern web browser (such as Google Chrome or Mozilla Firefox) with WebRTC support
Implementation Steps
After you complete the prerequisites, you can start setting up your sample voice agent:
-
Clone the repository:
-
Set up the environment:
-
Configure API key in
.env: -
Start the server:
- Connect via browser at
http://localhost:7860and grant microphone access - Start the conversation with your AI voice agent
Customizing your voice AI agent
To customize, you can start by:
- Modifying
flow.pyto change conversation logic - Adjusting model selection in
bot.pyfor your latency and quality needs
To learn more, see documentation for Pipecat Flows and review the README of our code sample on Github.
Cleanup
The instructions above are for setting up the application in your local environment. The local application will leverage AWS services and Daily through AWS IAM and API credentials. For security and to avoid unanticipated costs, when you are finished, delete these credentials to make sure that they can no longer be accessed.
Accelerating voice AI implementations
To accelerate AI voice agent implementations, AWS Generative AI Innovation Center (GAIIC) partners with customers to identify high-value use cases and develop proof-of-concept (PoC) solutions that can quickly move to production.
Customer Testimonial: InDebted
InDebted, a global fintech transforming the consumer debt industry, collaborates with AWS to develop their voice AI prototype.
“We believe AI-powered voice agents represent a pivotal opportunity to enhance the human touch in financial services customer engagement. By integrating AI-enabled voice technology into our operations, our goals are to provide customers with faster, more intuitive access to support that adapts to their needs, as well as improving the quality of their experience and the performance of our contact centre operations”
says Mike Zhou, Chief Data Officer at InDebted.
By collaborating with AWS and leveraging Amazon Bedrock, organizations like InDebted can create secure, adaptive voice AI experiences that meet regulatory standards while delivering real, human-centric impact in even the most challenging financial conversations.
结论
通过将Pipecat等开源框架与Amazon Bedrock上具有延迟优化推理和快速缓存的强大基础模型相结合,构建智能AI语音代理现在比以往任何时候都更容易访问。
在这篇文章中,您学习了如何构建AI语音代理的两种常见方法,深入研究了级联模型方法及其关键组件。这些基本组件协同工作,创建了一个能够自然理解、处理和响应人类语音的智能系统。通过利用生成式人工智能的这些快速进步,您可以创建复杂、响应迅速的语音代理,为您的用户和客户提供真正的价值。
要开始自己的语音AI项目,请在Github上尝试我们的代码示例,或联系您的AWS客户团队,探索与AWS生成AI创新中心(GAIIC)的合作。
您还可以在第2部分中学习使用统一的语音到语音基础模型Amazon Nova Sonic构建AI语音代理。
- 登录 发表评论
- 49 次浏览
最新内容
- 6 days 23 hours ago
- 1 week 3 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago