
Chinese, Simplified
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
多模式RAG
- 许多文档包含混合的内容类型,包括文本和图像。然而,在大多数RAG应用程序中,图像中捕获的信息都会丢失。随着多模式LLM(如GPT-4V)的出现,如何在RAG中利用图像是值得考虑的。
- 以下是使用LangChain在RAG中使用图像的三种方法:
- 选项1:
- 使用多模式嵌入(如CLIP)来嵌入图像和文本。
- 使用相似性搜索检索两者。
- 将原始图像和文本块传递到多模式LLM以进行答案合成。
- 选项2:
- 使用多模式LLM(如GPT-4V、LLaVA或FUYU-8b)从图像中生成文本摘要。
- 嵌入和检索文本。
- 将文本块传递给LLM进行答案合成。
- 选项1:
- 选项3:
- 使用多模式LLM(如GPT-4V、LLaVA或FUYU-8b)从图像中生成文本摘要。
- 嵌入和检索带有原始图像参考的图像摘要。您可以使用带有矢量数据库(如Chroma)的多矢量检索器来存储原始文本和图像及其摘要以供检索。
- 将原始图像和文本块传递到多模式LLM以进行答案合成。
- 选项2适用于多模态LLM不能用于答案合成的情况(例如,成本等)。
下图(来源)概述了上述三种选项。
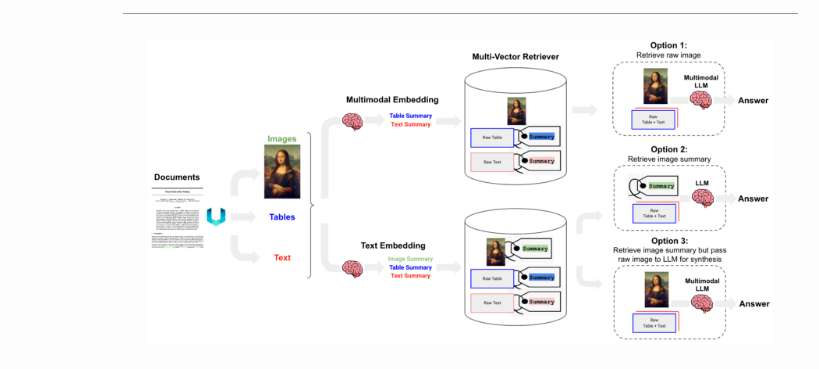
- LangChain提供选项1和选项3的食谱。
- 以下信息图(来源)还提供了多式联运RAG的顶级概述:
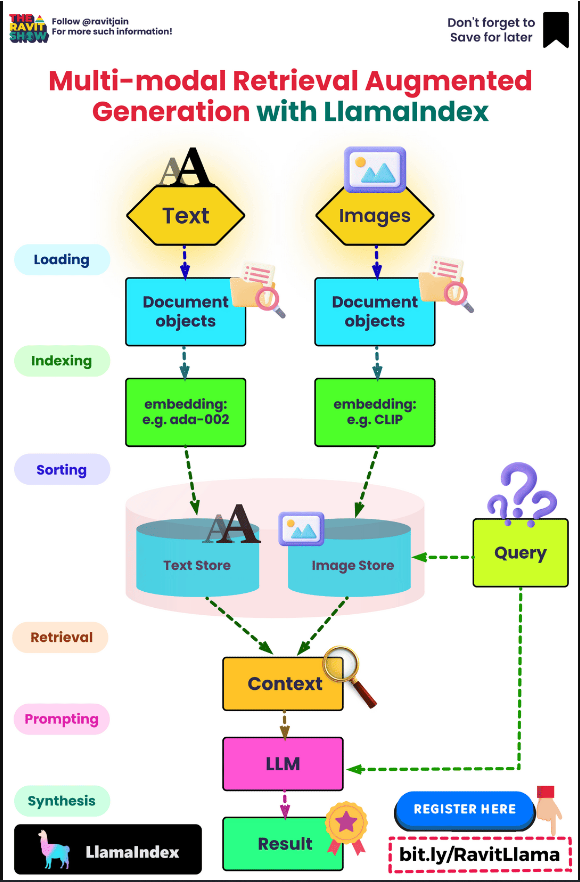
改进RAG系统
- 为了增强和完善RAG系统,请考虑以下三种结构化方法,每种方法都附有全面的指南和实际实施:
- 重新排序检索结果:一种基本而有效的方法是使用重新排序模型来细化通过初始检索获得的结果。这种方法优先考虑更相关的结果,从而提高生成内容的整体质量。MonoT5、MonoBERT、DuoBERT等都是可以用作重新排序的深度模型的示例。有关此技术的详细探索,请参阅Mahesh Deshwal提供的指南和代码示例。
- FLARE技术:在重新排序之后,应该探索FLARE方法。每当生成的内容的片段的置信水平低于指定阈值时,该技术就动态地查询互联网(也可以是本地知识库)。这克服了传统RAG系统的一个显著限制,传统RAG通常只在一开始查询知识库,然后产生最终输出。Akash Desai的指南和代码演练提供了对该技术的深刻理解和实际应用。有关FLARE技术的更多信息,请参阅Active Retrieval Augmented Generation一节。
- HyDE方法:最后,HyDE技术引入了一个创新概念,即响应查询生成假设文档。然后将该文档转换为嵌入向量。该方法的唯一性在于使用向量来识别语料库嵌入空间内的相似邻域,从而基于向量相似度来检索相似的真实文档。要深入研究这种方法,请参阅Akash Desai的指南和代码实现。在没有相关标签的精确零样本密集检索部分中,更多关于HyDE技术。
- 这些方法中的每一种都提供了一种独特的方法来完善RAG系统,有助于获得更准确和与上下文相关的结果。
相关论文
知识密集型NLP任务的检索增强生成

- 来自Facebook人工智能研究、伦敦大学学院和纽约大学的Lewis等人的论文介绍了将预先训练的参数记忆和非参数记忆相结合的检索增强生成(RAG)模型,用于语言生成任务。
- 针对大型预训练语言模型的局限性,如访问和精确操作知识的困难,RAG模型将预训练的序列到序列(seq2seq)模型与维基百科的密集向量索引合并,由神经检索器访问。
- RAG框架包括两个模型:RAG序列,对整个序列使用相同的检索文档;RAG令牌,允许每个令牌有不同的段落。
- 检索组件Dense Passage Retriever(DPR)使用双编码器架构以及基于BERT的文档和查询编码器。发电机组件采用BART大型、经过预训练的seq2seq变压器,参数为400M。
- RAG模型在检索器和生成器组件上联合训练,而无需直接监督要检索的文档,使用Adam的随机梯度下降。培训使用维基百科转储作为非参数知识源,分为2100万个100个单词块。
- 用于查询/文档嵌入和检索的方法和模型以及RAG框架的端到端结构概述如下:
- 查询/文档嵌入:
- 检索组件Dense Passage Retriever(DPR)遵循双编码器架构。
- DPR使用BERTBASE作为文档和查询编码器的基础。
- 对于文档z,稠密表示d(z)由文档编码器BERTd生成.
- 对于查询x,一个查询表示q(x)由查询编码器BERTq产生.
- 创建嵌入使得给定查询的相关文档在嵌入空间中接近,从而允许有效检索。
- 检索过程:
- 检索过程包括计算前k
- 这本质上是最大内积搜索(MIPS)问题。
- MIPS问题在亚线性时间内近似求解,以有效地检索相关文档。
- 端到端结构:
- RAG模型使用输入序列x来检索文本文档z,然后将其用作生成目标序列y的附加上下文。
- 发电机组件使用BART大型预训练seq2seq变压器进行建模,该变压器具有400M参数。BART-large将输入x与检索到的内容z组合以用于生成。
- RAG序列模型使用相同的检索文档来生成完整的序列,而RAG令牌模型可以使用每个令牌的不同段落。
- 培训过程包括联合培训检索器和生成器组件,而无需直接监督应检索的文档。训练使用Adam的随机梯度下降来最小化每个目标的负边缘对数似然。
- 值得注意的是,文档编码器BERTd在训练期间保持固定,避免了文档索引的定期更新。
- 该文件的下图概述了所提出的方法。他们将预先训练的检索器(查询编码器+文档索引)与预先训练的seq2seq模型(生成器)相结合,并对端到端进行微调。对于查询x
,他们使用最大内积搜索(MIPS)来查找前K个文档zi.对于最终预测y,他们对待z作为一个潜在变量,并在给定不同文献的seq2seq预测上边缘化
- 在开放域QA任务中,RAG建立了新的最先进的结果,优于参数seq2seq模型和特定任务的检索和提取架构。RAG模型显示,即使在任何检索到的文档中都没有正确的答案,也能够生成正确的答案。
- RAG序列在Open MS-MARCO NLG中超过了BART,表明更少的幻觉和更真实的文本生成。RAG代币在《危险边缘》问题生成中的表现优于RAG序列,显示出更高的真实性和特异性。
- 在FEVER事实验证任务中,RAG模型取得了接近最先进模型的结果,这些模型需要更复杂的体系结构和中间检索监督。
- 这项研究展示了混合生成模型的有效性,将参数记忆和非参数记忆相结合,为一系列NLP任务组合这些组件提供了新的方向。
- 密码交互式演示。
主动检索增强生成
- 尽管大型语言模型(LLM)具有非凡的理解和生成语言的能力,但它们往往会产生幻觉,并产生事实上不准确的输出。
- 通过从外部知识资源中检索信息来增强LLM是一个很有前途的解决方案。大多数现有的检索增强LLM都采用了仅基于输入检索一次信息的检索和生成设置。然而,在涉及长文本生成的更一般的场景中,这是有限的,在整个生成过程中不断收集信息是至关重要的。在过去的一些工作中,在生成输出的同时多次检索信息,这些输出大多使用以前的上下文作为查询以固定的间隔检索文档。
- 江等人在CMU、Sea AI Lab和EMNLP 2023中的Meta AI发表的这篇论文提出了前瞻性主动三元增强生成(FLARE),这是一种解决大型语言模型(LLM)产生事实上不准确内容的趋势的方法。
- FLARE迭代地使用对即将出现的语句的预测来主动决定在整个生成过程中何时检索以及检索什么,从而通过动态、多阶段的外部信息检索增强LLM。
- 与使用固定间隔或基于输入的检索的传统检索和生成模型不同,FLARE的目标是持续收集信息以生成长文本,从而减少幻觉和事实不准确。
- 当生成由概率阈值确定的低置信度令牌时,系统触发检索。这可以预测未来的内容,形成查询以检索相关文档以进行重新生成。
- 下图显示了FLARE。从用户输入x开始和初始检索结果Dx,FLARE迭代生成一个临时的下一句话(以灰色斜体显示),并检查它是否包含低概率标记(以下划线表示)。如果是(步骤2和3),则系统检索相关文档并重新生成句子。

- FLARE在四个长格式、知识密集型生成任务/数据集上进行了测试,显示出卓越或有竞争力的性能,证明了它在解决现有检索增强LLM的局限性方面的有效性。
- 该模型适用于现有的LLM,如GPT-3.5上的实现所示,并使用现成的检索器和Bing搜索引擎。
- 代码
多模式检索增强生成器
- 这篇由Google Research的Chen等人撰写的论文提出了多模式检索增强变换器(MuRAG),它旨在将检索过程扩展到文本之外,包括图像或结构化数据等其他模式,然后可以与文本信息一起使用,为生成过程提供信息。
- MuRAG的神奇之处在于它的两阶段训练方法:预训练和微调,每一个都经过精心设计,以建立模型利用大量多模态知识的能力。
- MuRAG的主要目标是将视觉和文本知识结合到语言模型中,以提高其多模式问答的能力。
- MuRAG的独特之处在于它能够访问外部非参数多模式记忆(图像和文本)来增强语言生成,解决了以前模型中纯文本检索的局限性。
- MuRAG具有双编码器架构,将预训练的视觉转换器(ViT)和文本编码器(T5)模型相结合,以创建骨干编码器,从而能够将图像-文本对、仅图像和仅文本输入编码为统一/联合多模式表示。
- MuRAG是在图像文本数据(LAION,概念字幕)和纯文本数据(PAQ,VQA)的混合上预训练的。它使用对比损失来检索相关知识,使用生成损失来预测答案。它采用了一个两阶段的训练管道:先用小的批内内存进行初始训练,然后用大的全局内存进行训练。
- 在检索器阶段,MuRAG将任何模态的查询q作为输入,并从图像-文本对的存储器M中检索。具体来说,我们应用骨干编码器fθ来编码查询q,并在所有候选存储器m∈m上使用最大内积搜索(MIPS)来找到前k个最近邻居TopK(mÜq)=[m1,…,mk]。形式上,我们定义TopK(MŞq)如下所示:
TopK(M∣q)=Topm∈Mfθ(q)[CLS]⋅fθ(m)[CLS]
- 在读取器阶段,检索(原始图像块)与查询q组合,作为增强输入[m1,……,mk,q],将其馈送到骨干编码器fθ,以产生检索增强编码。解码器模型gθ使用对该表示的关注来逐个标记地生成文本输出y=y1,…,yn。
p(yiŞyi−1)=gθ(yiÜfθ)(TopK(MÜq);qy1:i−1)
- 其中y从给定的词汇表V中解码.
- 下图来自原始论文(来源),显示了模型如何利用外部存储库来检索图像和文本片段中封装的各种知识。然后利用这种多模式信息来增强生成过程。上半部分概述了预训练阶段的设置,而下半部分指定了微调阶段的框架。

- 该过程总结如下:
- 对于检索,MuRAG使用最大内积搜索来找到前k个
- 记忆中最相关的图像-文本对给出了一个问题。这里的“内存”是指模型可以从中检索信息的外部知识库。具体地说,存储器包含大量的图像-文本对集合,这些对在训练之前由骨干编码器离线编码。
- 在训练和推理过程中,给定一个问题,MuRAG的检索器模块将使用最大内积搜索来搜索该内存,以找到最相关的图像-文本对。
- 存储器充当知识源,可以包含各种类型的多模式数据,如与下游任务相关的带标题的图像、文本段落、表格等。
- 例如,当对WebQA数据集进行微调时,内存中包含从维基百科中提取的110万个图像文本对,模型可以从中检索这些图像文本对来回答问题。
- 因此,总之,记忆是编码在多模式空间中的大型非参数外部知识库,MuRAG通过学习从给定的问题中检索相关知识,以增强其语言生成能力。内存提供了世界知识,以补充隐含存储在模型参数中的内容。
- 为了阅读,检索到的多模式上下文与问题嵌入相结合,并输入解码器以生成答案。
- MuRAG在WebQA和MultimodalQA这两个多模式QA数据集上实现了最先进的结果,比纯文本方法的准确率高出10-20%。它展示了结合视觉和文本知识的价值。
- 关键的局限性是对大规模预训练数据的依赖、计算成本以及视觉推理(如计数对象)中的问题。但总的来说,MuRAG代表了在构建基于视觉的语言模型方面的一个重要进展。
假设文档嵌入(HyDE)
- 来自CMU和滑铁卢大学的Gao等人发表在《无相关性标签的精确零样本密集检索》中,提出了一种创新方法,称为假设文档嵌入(HyDE),用于在无相关性标签情况下进行有效的零样本密集检索。HyDE利用指令遵循的语言模型(如InstructionGPT)来生成一个捕获相关性模式的假设文档,尽管它可能包含事实上的不准确之处。然后,像Contriever这样的无监督对比编码器将该文档编码为嵌入向量,以在语料库嵌入空间中识别相似的真实文档,有效地过滤掉不正确的细节。
- HyDE的实现结合了InstructGPT(GPT-3模型)和Contriever模型,利用OpenAI操场的默认温度设置进行生成。对于英语检索任务,使用纯英语的Contriever模型,而对于非英语任务,使用多语言的mContriever。
- 以下图片说明了HyDE模型。将显示文档片段。HyDE在不更改底层GPT-3和Contriever/mContriever模型的情况下为所有类型的查询提供服务。

- 实验使用Pyserini工具包进行。结果表明,HyDE比最先进的无监督密集检索器Contriever有了显著的改进,在各种任务和语言中具有与微调检索器相当的强大性能。具体而言,在网络搜索和低资源任务中,HyDE在精度和面向回忆的指标方面表现出了相当大的改进。即使与微调后的车型相比,它仍然具有竞争力,尤其是在召回方面。在多语言检索中,HyDE改进了mContriever模型,并优于在MS-MARCO上微调的非Contriever模式。然而,经过微调的mContrieverFT在性能上存在一些差距,这可能是由于非英语语言培训不足。
- 进一步的分析探讨了使用HyDE的不同生成模型和微调编码器的效果。更大的语言模型带来了更大的改进,HyDE使用微调编码器表明,功能较弱的指令语言模型可能会影响微调检索器的性能。
- HyDE的一个可能的缺陷是,它可能会产生潜在的“幻觉”,因为它生成的假设文件可能包含虚构或不准确的细节。之所以出现这种现象,是因为HyDE使用指令遵循的语言模型(如InstructionGPT)来基于查询生成文档。生成的文档旨在捕捉查询的相关性模式,但由于它是在没有直接引用真实世界数据的情况下创建的,因此可能包含虚假或虚构的信息。HyDE的这一方面是对其在零样本检索场景中操作的能力的权衡,在该场景中,它创建了上下文相关但不一定是事实准确的文档来指导检索过程。
- 最后,本文介绍了语言模型和密集编码器/检索器之间交互的新范式,表明强大而灵活的语言模型可以有效地处理相关性建模和指令理解。这种方法消除了对相关性标签的需求,在搜索系统生命的初始阶段提供了实用性,并为多跳检索/QA和会话搜索等任务的进一步进步铺平了道路。
RAGAS:检索增强生成的自动评估
- 本文由卡迪夫大学爆炸梯度的Es等人和AMPLYFI介绍了RAGAS,这是一个用于检索增强生成(RAG)系统的无参考评估框架。
- RAGAS专注于评估RAG系统的性能,如检索系统在提供相关上下文方面的有效性、LLM利用该上下文的能力以及生成的总体质量。
- 该框架提出了一套指标来评估这些维度,而不依赖于基本事实人类注释。
- RAGAS侧重于三个质量方面:忠实性、答案相关性和上下文相关性。
- 忠实:定义为生成的答案在多大程度上基于所提供的上下文。它是使用公式来测量的:F=|V||s|其中,|V|是上下文支持的语句数,|s|是从答案中提取的语句总数。
- 答案相关性:该指标评估答案在多大程度上解决了给定的问题。它是通过从答案中生成潜在问题并使用公式测量它们与原始问题的相似性来计算的:AR=1n∑ni=1sim(q,qi),其中q是原始问题,qi是生成的问题,sim表示它们嵌入之间的余弦相似性。
- 上下文相关性:衡量检索到的上下文仅包含回答问题所需信息的程度。它是使用提取的相关句子占上下文中总句子的比例来量化的:CR=提取的句子数量与c(q)中的句子总数之比
- 本文使用WikiEval数据集验证了RAGAS,证明了其在评估这些方面时与人类判断的一致性。
- 作者认为,RAGAS有助于RAG系统更快、更高效的评估周期,由于LLM的快速采用,这一点至关重要。
- RAGAS是使用WikiEval数据集进行验证的,该数据集包括问题-上下文-答案三元组,用人类对忠实性、答案相关性和上下文相关性的判断进行注释。
- 评估表明,RAGAS与人类判断密切一致,尤其是在评估忠诚度和答案相关性方面。
- 代码
微调还是检索?LLM中知识注入的比较
- 这篇由微软的Ovadia等人撰写的论文对大型语言模型(LLM)中的知识注入方法进行了深入的比较。所解决的核心问题是,在提高知识密集型任务的LLM性能方面,无监督微调(USFT)是否比检索增强生成(RAG)更有效。
- 研究人员使用从维基百科上刮来的知识库和GPT-4创建的时事问题数据集,重点研究LLM记忆、理解和检索事实数据的能力。该研究采用了Llama2-7B、Mistral-7B和Orca2-7B等模型,根据大规模多任务语言理解评估(MMLU)基准和当前事件数据集对它们进行任务评估。
- 探索了两种知识注入方法:微调,它使用特定任务的数据继续模型的预训练过程,以及检索增强生成(RAG),它使用外部知识源来增强LLM的响应。本文还深入研究了基于监督、无监督和强化学习的微调方法。
- 关键发现是,RAG在知识注入方面优于无监督微调。使用外部知识源的RAG在知识注入方面明显比单独的USFT更有效,甚至比RAG和微调的组合更有效,特别是在问题直接对应于辅助数据集的情况下。这表明,USFT在将新知识嵌入模型参数方面可能没有那么有效。
- 下图显示了知识注入框架的可视化。
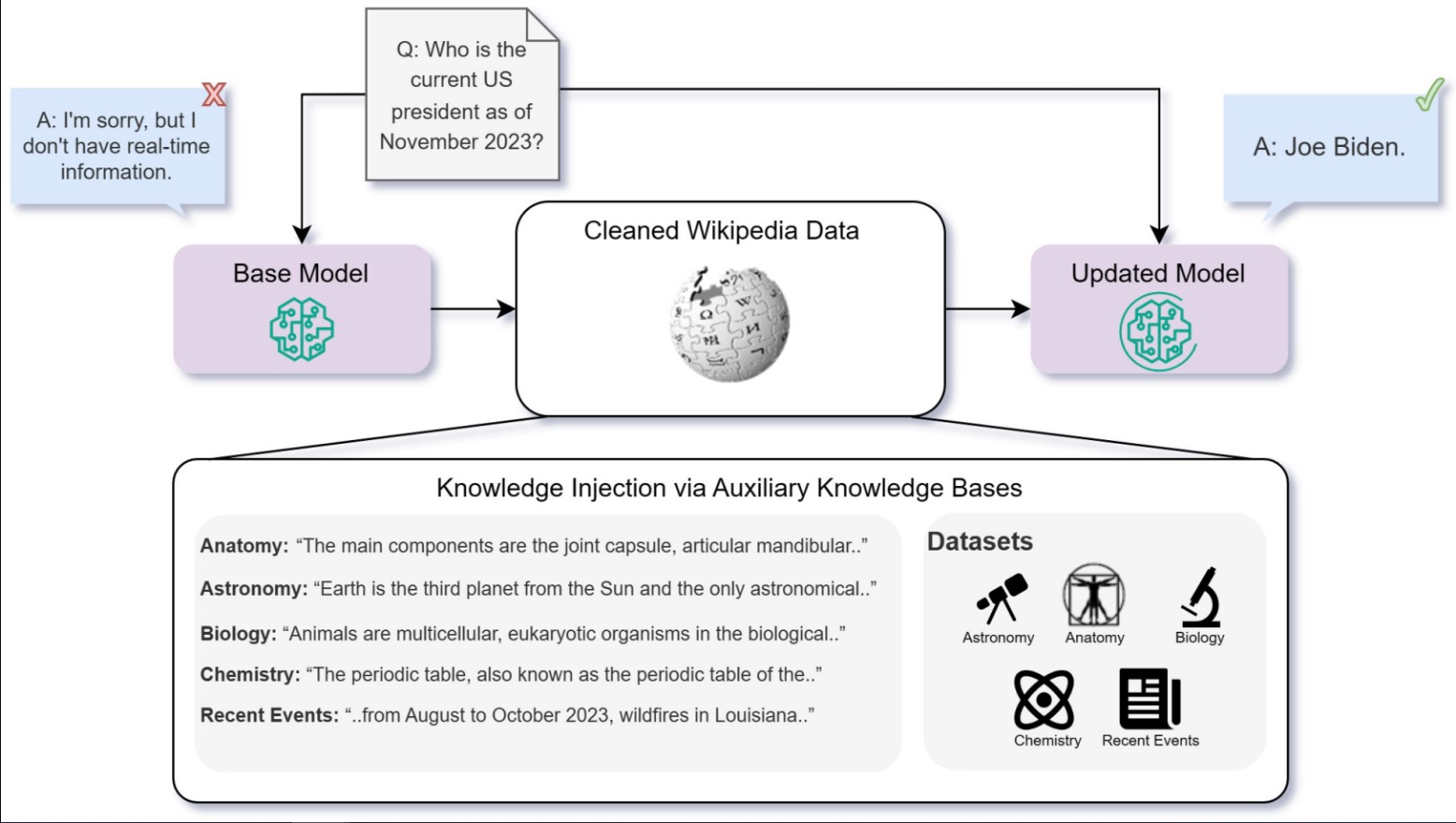
- 请注意,在这种情况下,USFT是预训练的直接延续(因此在文献中也称为连续预训练),预测数据集上的下一个令牌。有趣的是,对同一事实进行多次转述的微调显著提高了基线表现,表明了信息的重复和多样化呈现对有效知识同化的重要性。
- 作者通过抓取维基百科上与各种主题相关的文章创建了一个知识库,用于微调和RAG。此外,使用GPT-4生成了一个关于时事的多项选择题数据集,并创建了转述来扩充该数据集。
- 该研究的局限性包括只关注无监督微调,而没有探索有监督微调或从人类反馈中强化学习(RLHF)。该研究还注意到,各实验的准确性表现差异很大,因此很难确定结果的统计显著性。
- 这篇论文还质疑了为什么基线模型在有四个选项的多项选择题中没有达到25%的准确率,这表明这些任务可能不能代表真正的“看不见”的知识。此外,这项研究主要评估简单的知识或事实任务,而没有深入研究推理能力。
- 总之,虽然微调可能是有益的,但RAG被认为是LLM中知识注入的一种优越方法,尤其是对于涉及新信息的任务。研究结果突出了使用各种微调技术和辅助知识库进行该领域进一步研究的潜力。
密集X检索:我们应该使用什么检索粒度?
- RAG管道设计中的一个关键选择是分块:它应该是句子级、段落级还是章节级?此选择会显著影响您的检索和响应生成性能。
- 来自华盛顿大学、腾讯人工智能实验室、宾夕法尼亚大学、卡内基梅隆大学的Chen等人的这篇论文介绍了一种在开放域NLP任务中使用“命题”作为检索单元,而不是传统的文档段落或句子进行密集检索的新方法。命题被定义为文本中的原子表达式,以简洁、自包含的自然语言格式封装不同的事实。检索粒度的这种变化对检索和下游任务性能都有显著影响。
- 命题遵循三个关键原则:
- 每个命题都包含了不同的含义,共同代表了整个文本的语义。
- 它们是最小的、不可分割的,确保了准确性和清晰度。
- 每一个命题都是语境化的和自成一体的,包括所有必要的文本语境(如引用),以便于充分理解。
- 作者开发了一个名为“命题器”的文本生成模型,将维基百科页面划分为命题。该模型分两步进行了微调,首先提示GPT-4生成段落到命题对,然后微调Flan-T5大型模型。
- 命题作为检索单元的有效性使用FACTOIDWIKI数据集进行评估,该数据集是一个经过处理的英语维基百科转储,分为段落、句子和命题。实验在五个开放域QA数据集上进行:自然问题(NQ)、TriviaQA(TQA)、网络问题(WebQ)、SQuAD和实体问题(EQ)。比较了六种不同的密集寻回器模型:SimCSE、Contriever、DPR、ANCE、TAS-B和GTR。
- 下图说明了这样一个事实,即在命题层面上对检索语料库进行分割和索引是一种简单而有效的策略,可以提高密集检索器在推理时的泛化性能(a,B)。我们实证比较了当密集检索器与维基百科在100个单词的段落、句子或命题(C,D)水平上进行索引时,检索和下游开放域QA任务的性能
.

- 后果
- 段落检索性能:在所有数据集和模型中,基于命题的检索始终优于句子和段落级别的检索。这一点在SimCSE和Contriever等无监督寻回器中尤为明显,它们显示出平均值Recall@5分别提高12.0%和9.3%。
- 跨任务泛化:命题检索的优势在跨任务泛化设置中最为明显,尤其是对于不太常见的实体的查询。与检索器模型训练期间未发现的数据集中的其他粒度相比,它显示出显著的改进。
- 下游QA性能:在先检索后读取的设置中,基于命题的检索导致更强的下游QA性能。这对于无监督和有监督的寻回犬来说都是如此,精确匹配(EM)得分显著提高。
- 问题相关信息密度:命题被证明提供了更高密度的相关信息,导致正确答案更频繁地出现在前l个检索词中。与句子和段落检索相比,这是一个显著的优势,尤其是在100-200个单词的范围内。
- 错误分析:该研究还强调了每个检索粒度的典型错误类型。例如,段落级检索经常遇到实体模糊的问题,而命题检索在多跳推理任务中面临挑战。
- 该论文的图表显示,在段落检索任务和下游开放域QA任务中,通过命题进行检索都能产生最佳的检索性能,例如,以Contriever或GTR作为骨干检索器。
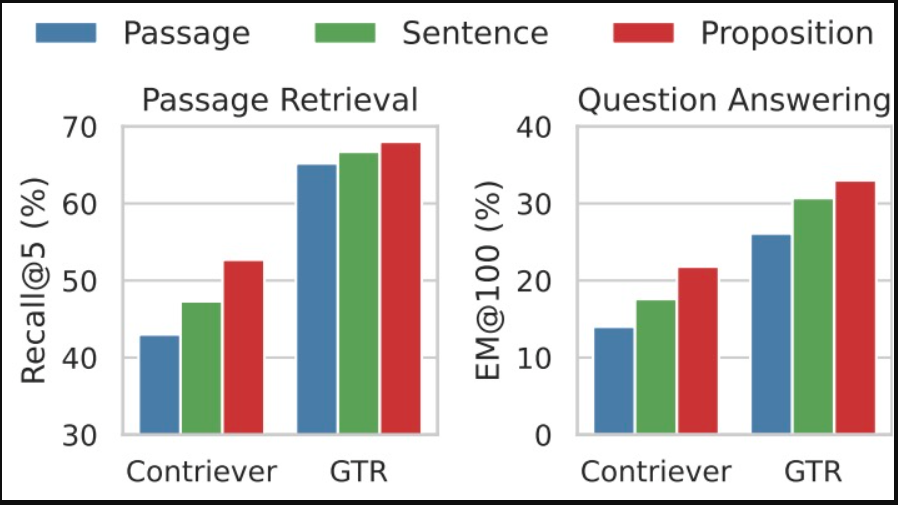
- 研究表明,使用命题作为检索单元显著提高了密集检索性能和下游QA任务的准确性,优于传统的基于段落和句子的方法。FACTOIDWIKI及其2.5亿个命题的引入有望促进未来信息检索的研究。
ARES:一种用于检索增强生成系统的自动评估框架
- 本文由斯坦福大学和加州大学伯克利分校的Saad Falcon等人介绍了ARES(自动RAG评估系统),用于从上下文相关性、答案忠实性和答案相关性的角度评估检索增强生成(RAG)系统。
- ARES使用语言模型生成合成训练数据,并微调轻量级LM判断,以评估单个RAG组件。它利用一小组人工注释的数据点进行预测推理(PPI),为其预测提供统计保证。
- 该框架分为三个阶段:
- LLM生成合成数据集:ARES使用生成LLM(如FLAN-T5 XXL)来创建从目标语料库段落中导出的问答对的合成数据集。这一阶段包括积极和消极的培训例子。
- 准备LLM评委:使用合成数据集,针对三个分类任务——上下文相关性、答案忠实性和答案相关性——对单独的轻量级LM模型进行微调。这些模型是使用对比学习目标进行调整的。
- 使用置信区间对RAG系统进行排名:
- 在准备好LLM评委后,下一步包括使用他们对各种RAG系统进行评分和排名。这个过程从每个RAG方法的域查询文档答案三元组中的ARES采样开始。然后,评委们给每个三元组贴上标签,评估上下文相关性、答案忠实度和答案相关性。对每个域内三元组的这些标签进行平均,以评估RAG系统在三个度量中的性能。
- 虽然平均得分可以被报告为每个RAG系统的质量指标,但这些得分是基于未标记的数据和来自综合训练的LLM法官的预测,这可能会引入噪声。另一种选择是仅依靠一个小的人类偏好验证集进行评估,检查每个RAG系统与人类注释的一致程度。然而,这种方法需要分别标记每个RAG系统的输出,这可能耗时且昂贵。
- 为了提高评估的精度,ARES采用了预测推理(PPI)。PPI是一种统计方法,通过利用对较大的未注释数据集的预测,缩小对较小注释数据集预测的置信区间。它结合了标记数据点和ARES对非注释数据点的判断预测,为RAG系统性能构建了更严格的置信区间。
- PPI涉及在人类偏好验证集上使用LLM判断来学习整流函数。该函数构建了ML模型性能的置信集,考虑了较大的无注释数据集中的每个ML预测。置信集有助于为ML模型的平均性能(例如,其上下文相关性、答案忠实性或答案相关性准确性)创建更精确的置信区间。通过将人类偏好验证集与更大的数据点集与ML预测相集成,PPI为ML模型性能开发了可靠的置信区间,优于传统的推理方法。
- PPI整流器功能解决LLM法官所犯的错误,并为RAG系统的成功率和失败率生成置信界限。它估计在上下文相关性、答案忠实性和答案相关性方面的表现。PPI还允许以指定的概率水平来估计置信区间;在这些实验中,使用了标准的95%α。
- 最后,确定RAG的每个分量的精度置信区间,并使用这些区间的中点对RAG系统进行排序。这种排名能够比较同一系统内的不同RAG系统和配置,有助于确定特定领域的最佳方法。
- 总之,ARES使用PPI对RAG系统进行评分和排序,使用人类偏好验证集来计算置信区间。PPI的工作原理是首先生成大样本数据点的预测,然后人工注释小子集。这些注释用于计算整个数据集的置信区间,确保系统评估能力的准确性。
- 为了实现对RAG系统进行评分并与其他RAG配置进行比较的ARES,需要三个组件:
- 评估标准(例如上下文相关性、答案忠实性和/或答案相关性)的注释查询、文档和答案三元组的人类偏好验证集。应该至少有50个例子,但几百个例子是理想的。
- 一组为数不多的示例,用于在系统中对上下文相关性、答案忠实度和/或答案相关性进行评分。
- RAG系统输出的一组更大的未标记查询文档答案三元组用于评分。
- 论文中的下图显示了ARES的概述:作为输入,ARES管道需要一个域内通道集、一个由150个或更多注释数据点组成的人类偏好验证集,以及五个域内查询和答案的少数镜头示例,这些示例用于在合成数据生成中提示LLM。为了让LLM评委做好评估准备,我们首先从语料库段落中生成综合查询和答案。使用我们生成的训练三元组和对比学习框架,我们对LLM进行微调,以根据三个标准对查询-段落-答案三元组进行分类:上下文相关性、答案忠实性和答案相关性。最后,我们使用LLM判断来评估RAG系统,并使用PPI和人类偏好验证集生成排名的置信界限。

- 在KILT和SuperGLUE的数据集上进行的实验证明了ARES在评估RAG系统方面的准确性,优于现有的自动评估方法,如RAGAS。ARES在各个领域都很有效,即使在查询和文档发生领域变化的情况下也能保持准确性。
- 本文强调了ARES在跨领域应用中的优势及其局限性,例如它无法在剧烈的领域变化(例如,语言变化、文本到代码)中进行概括。它还探索了使用GPT-4生成标签作为PPI过程中人工注释的替代品的潜力。
- ARES代码和数据集可在GitHub上进行复制和部署。
发布日期
星期二, 二月 13, 2024 - 13:29
最后修改
星期二, 二月 13, 2024 - 14:52
Article
最新内容
- 18 hours ago
- 4 days 18 hours ago
- 1 month 3 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago