
category
知识库是Azure人工智能搜索中由技能集创建的人工智能丰富内容的二级存储。在Azure AI搜索中,索引作业总是将输出发送到搜索索引,但如果您将技能集附加到索引器,您也可以选择将富含AI的输出发送到Azure存储中的容器或表。知识库可以用于非搜索场景(如知识挖掘)中的独立分析或下游处理。
索引的两个输出,搜索索引和知识存储,是同一管道的互斥产品。它们源自相同的输入,包含相同的数据,但它们的内容是结构化的、存储的,并在不同的应用程序中使用。

带技能的管道
从物理上讲,知识存储是Azure存储、Azure表存储或Azure Blob存储,或者两者兼而有之。任何可以连接到Azure存储的工具或进程都可以使用知识库的内容。Azure AI搜索中不支持从知识库中检索内容的查询。
当通过Azure门户查看时,知识库看起来像任何其他表、对象或文件的集合。下面的屏幕截图显示了一个由三个表组成的知识库。您可以采用命名约定,例如kstore前缀,以将内容保持在一起。
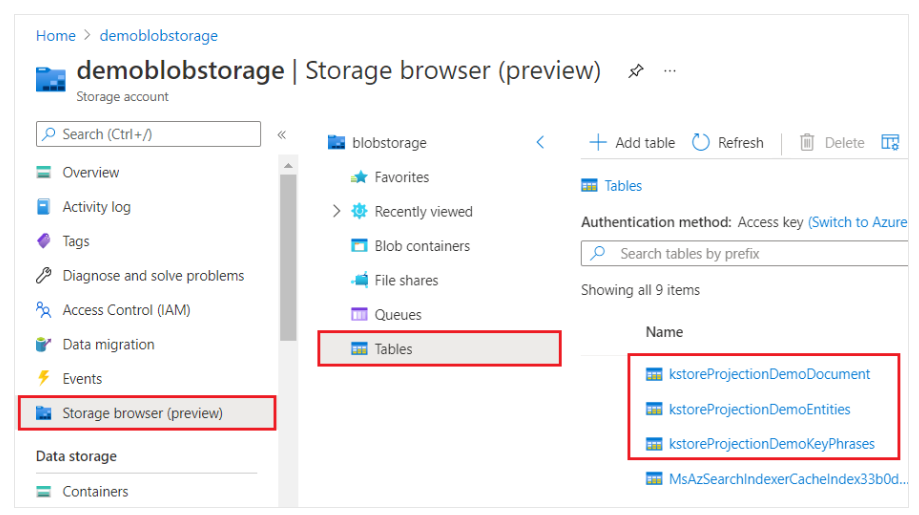
从丰富树读写技能
知识库的好处
知识库的主要好处有两方面:对内容的灵活访问和形成数据的能力。
与只能通过Azure AI搜索中的查询访问的搜索索引不同,任何支持连接到Azure存储的工具、应用程序或流程都可以访问知识库。这种灵活性为消费由丰富管道生成的经过分析和丰富的内容开辟了新的场景。
丰富数据的相同技能集也可以用于塑造数据。像Power BI这样的一些工具可以更好地处理表,而数据科学工作负载可能需要blob格式的复杂数据结构。将Shaper技能添加到技能集中可以控制数据的形状。然后,您可以将这些形状传递给投影,无论是表还是Blob,以创建与数据的预期用途一致的物理数据结构。
下面的视频介绍了这两个好处以及更多内容。
知识库定义
知识库是在技能集定义中定义的,它有两个组成部分:
- 到Azure存储的连接字符串
- 确定知识库是由表、对象还是文件组成的投影。projects元素是一个数组。可以在一个知识库中创建多组表对象文件组合。
JSON
"knowledgeStore": {
"storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>",
"projections":[
{
"tables":[ ],
"objects":[ ],
"files":[ ]
}
]
}
在此结构中指定的投影类型决定了知识库使用的存储类型,但不决定其结构。如果以编程方式创建知识库,则表、对象和文件中的字段由Shaper技能输出确定,如果使用门户,则由导入数据向导确定。
- tables将丰富的内容投影到表存储中。当您需要将表格报告结构用于分析工具的输入或作为数据框架导出到其他数据存储时,请定义表格投影。您可以在同一投影组中指定多个表,以获得丰富文档的子集或横截面。在同一投影组中,表关系被保留,以便您可以处理所有这些关系。
投影内容未聚合或规范化。下面的屏幕截图显示了一个按关键字排序的表,父文档显示在相邻列中。与索引过程中的数据摄取相比,没有对内容进行语言分析或聚合。套管的多种形式和差异被认为是独特的例子。
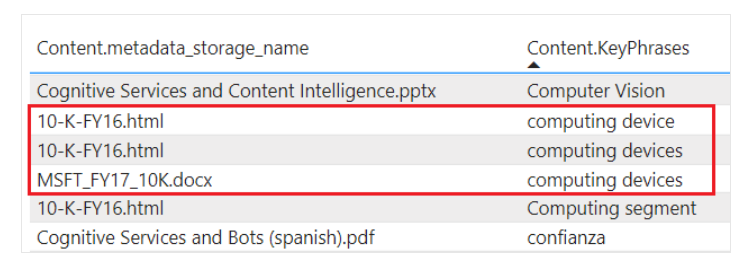 表中关键短语和文档的屏幕截图
表中关键短语和文档的屏幕截图
- 对象将JSON文档投影到Blob存储中。对象的物理表示是一个层次结构的JSON结构,表示一个丰富的文档。
- files将图像文件投影到Blob存储中。文件是从文档中提取的图像,完整地传输到Blob存储中。虽然它被命名为“文件”,但它显示在Blob存储中,而不是文件存储中。
创建知识库
若要创建知识库,请使用门户网站或API。
你需要Azure存储、一套技能和一个索引器。因为索引器需要搜索索引,所以还需要提供索引定义。
采用门户方法,以最快的方式访问已完成的知识库。或者,选择RESTneneneba API来更深入地理解对象是如何定义和关联的。
Azure门户
使用“导入数据”向导分四个步骤创建您的第一个知识库。
- 定义包含要丰富的数据的数据源。
- 定义一套技能。技能集指定了丰富步骤和知识库。
- 定义索引架构。您可能不需要,但索引器需要它。向导可以推断索引。
- 完成向导。数据提取、丰富和知识库创建都发生在最后一步中。
该向导自动执行多项任务。具体来说,整形和投影(Azure存储中物理数据结构的定义)都是为您创建的。
与应用程序连接
一旦存储中存在丰富的内容,任何连接到Azure存储的工具或技术都可以用于探索、分析或使用这些内容。以下列表是一个开始:
- Azure门户中的存储资源管理器或存储浏览器(预览),以查看丰富的文档结构和内容。将其视为查看知识库内容的基准工具。
- Power BI用于报告和分析。
- 用于进一步操作的Azure数据工厂。
内容生命周期
每次运行索引器和技能集时,如果技能集或基础源数据发生了更改,就会更新知识库。索引器获取的任何更改都会通过丰富过程传播到知识库中的投影,确保投影数据是原始数据源中内容的当前表示形式。
笔记
虽然您可以编辑投影中的数据,但假设源数据中的文档已更新,则在下一次管道调用时,任何编辑都将被覆盖。
源数据的更改
对于支持更改跟踪的数据源,索引器将处理新的和更改的文档,并绕过已经处理的现有文档。时间戳信息因数据源而异,但在blob容器中,索引器会查看上次修改的日期,以确定需要摄入哪些blob。
技能设置的更改
如果您正在对技能集进行更改,则应启用富集文档的缓存,以便在可能的情况下重用现有的富集。
如果没有增量缓存,索引器将始终按照高水位线的顺序处理文档,而不会倒退。对于Blob,索引器将处理按lastModified排序的Blob,而不考虑索引器设置或技能集的任何更改。如果您更改了技能集,则先前处理的文档不会更新以反映新的技能集。技能集更改后处理的文档将使用新的技能集,导致索引文档是新旧技能集的混合。
使用增量缓存,在技能集更新后,索引器将重用不受技能集更改影响的任何富集。上游的强化是从缓存中提取的,任何独立于更改技能的强化也是如此。
删除
尽管索引器在Azure存储中创建和更新结构和内容,但它不会删除它们。即使索引器或技能集被删除,投影仍然存在。作为存储帐户的所有者,如果不再需要投影,则应删除该投影。
接下来的步骤
知识库提供了丰富文档的持久性,在设计技能集或创建新的结构和内容以供能够访问Azure存储帐户的任何客户端应用程序使用时非常有用。
创建丰富文档的最简单方法是通过门户,但REST客户端和RESTAPI可以更深入地了解如何以编程方式创建和引用对象。
- 登录 发表评论
- 79 次浏览
Tags
最新内容
- 5 days 10 hours ago
- 1 week 2 days ago
- 1 month 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago