
category
LLM体系结构不仅仅是关于层和神经元。支持大型语言模型的更广泛的系统——从数据接收到缓存、推理和成本——发挥着至关重要的作用。在本博客中,我们回顾了我们最近关于LLM应用程序新兴架构的网络研讨会,涵盖了支持LLM在现实应用程序中有效部署它们的架构和系统。
与我们一起深入了解LLM的局限性和功能,以及旨在优化其性能和克服固有挑战的各种技术和系统。在坚实、全面的系统方法的支持下,您将了解上下文、数据接收和编排的重要性,以及LLM的变革潜力。
LLM限制
LLM以其前所未有的规模改变了生成型人工智能,使其能够直接从自然语言执行各种任务。它们的大规模——通过参数的数量和训练数据的大小来捕捉——使它们能够学习更丰富的语言表示。这通常会在准确性和生成文本的质量方面带来更好的性能,尤其是与较小的特定任务模型相比。但是,就像任何新技术一样,它们也有几个局限性。
标记限制
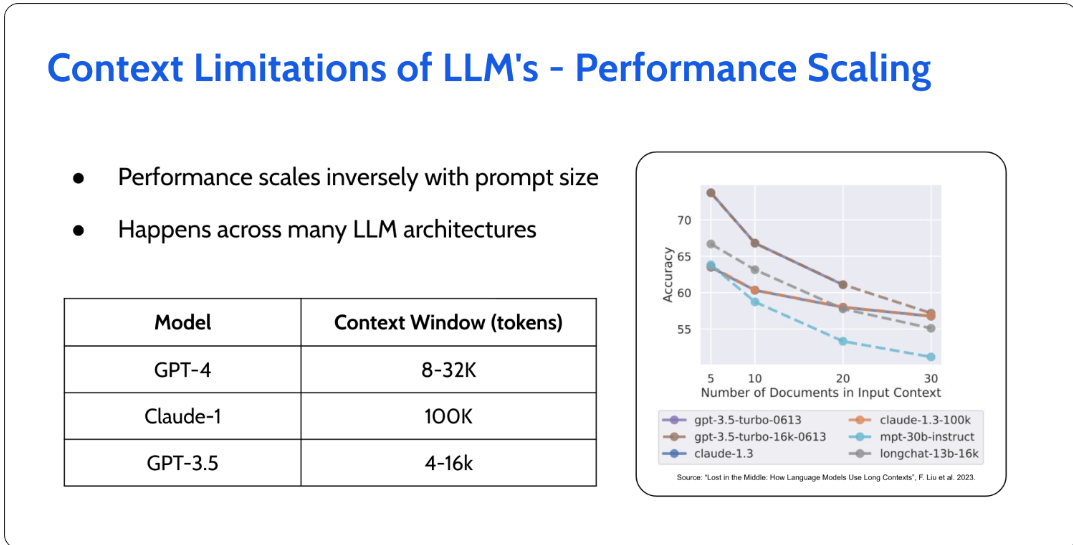
LLM模型的技术挑战之一是固有的令牌限制。标记可以被描述为文本块的最小可理解单元,包括标点符号、表情符号、单词或单词的一部分。例如,对于GPT模型,标准令牌限制徘徊在8000个令牌左右。从长远来看,一个有8000个标记的文本块大致相当于一篇长文或几页密集的文本。虽然这看起来很重要,但对于需要考虑大量模型内容的应用程序来说,这种令牌限制可能会对模型能够准确有效地服务的请求的广度或复杂性造成限制。
与上下文相关的性能降低
随着LLM上下文长度的增长,保持连贯和上下文相关的叙事变得具有挑战性。这就像一个人试图记住并与几个小时前开始的对话建立联系,而不遗漏细节。这使得找出如何有效地检索相关内容,同时避免性能螺旋式下降变得至关重要。
偏见
尽管LLM的外表看起来很客观,但它们可能会受到训练数据中的偏见的影响。在一个常见的LLM基准中,模型被要求在输出A和B之间进行选择,这取决于哪个选项更准确。不幸的是,研究人员发现,LLM模型倾向于对第一个输入a表现出偏见,因为它是第一个出现的选项。另一种常见的表现形式是所谓的“近因偏见”,它反过来起作用。当被要求执行任务时,模型将优先考虑最近给出的任务描述,而不是较旧的、可能更相关的数据。

幻觉
在一种通常被称为“幻觉”的现象中,该模型对输出响应做出了“最佳猜测”假设,基本上填补了它不知道的部分。LLM有一种固有的倾向,即不惜一切代价产生响应,即使这是以发明来源或编造细节为代价的。结果可能是事实上不正确的,有时甚至毫无意义。这个问题仍然是当今LLM面临的主要问题之一。
进入检索增强生成(RAG)
LLM还为时尚早,而且这些工具正在迅速扩散。但争论的焦点之一仍然是:如何提高这些LLM的准确性和上下文,以及需要什么样的模型协调才能实现这一点?像检索增强生成(RAG)这样的体系结构设计已经开始发挥作用,以解决这些限制和约束。在之前关于LLM培训的网络研讨会上(以下是录音、幻灯片和文章),我们讨论了即时工程作为部署前微调的一个例子,以及它通过向模型提供所需相关输出的例子来指导模型响应的能力。RAG通过允许我们将即时工程与上下文检索相结合,成为LLM设计模式中的灯塔。当模型可能缺少特定信息时,它会通过利用外部来源(通常是矢量数据库)来补充其知识进行干预。RAG不只是依靠其内部权重,而是查询这些数据库,为用户提供上下文感知的精确信息。这种双重性——同时使用模型的内部知识和外部数据——动态地拓宽了LLM所能实现的目标,使其更加准确和情境感知。
这些扩展的RAG模型通过允许LLM交叉检查和补充来自外部来源的知识,在限制幻觉方面做得很好,从而抑制了未来产生幻觉的机会。此外,通过拓宽数据来源,RAG可以帮助提供更平衡的视角,减轻固有的偏见。
实施RAG
实现RAG系统包括将相关数据或文档拆分为离散块,然后将其存储在矢量数据库中。当接收到用户请求时,LLM扫描数据库以找到那些与查询最相关的片段,并且可以用于通过丰富其上下文信息来增强响应。
需要问的问题是:在最大限度地提高结果质量的同时,将数据分解成小块的最佳方法是什么?管理大型文档的一种策略让人想起map reduce模式(想想几年前我们刚开始使用ML模型时的Hadoop)。这里,文档根据预先确定的规则进行拆分,并迭代合并结果,直到最终产品符合指定的上下文窗口。
RAG的潜力在于它能够组合不同的管弦乐队。因为RAG本质上是一个与LLM一起运行的检索系统,这里有一些编排和预处理可以帮助解决我们一直在讨论的挑战。
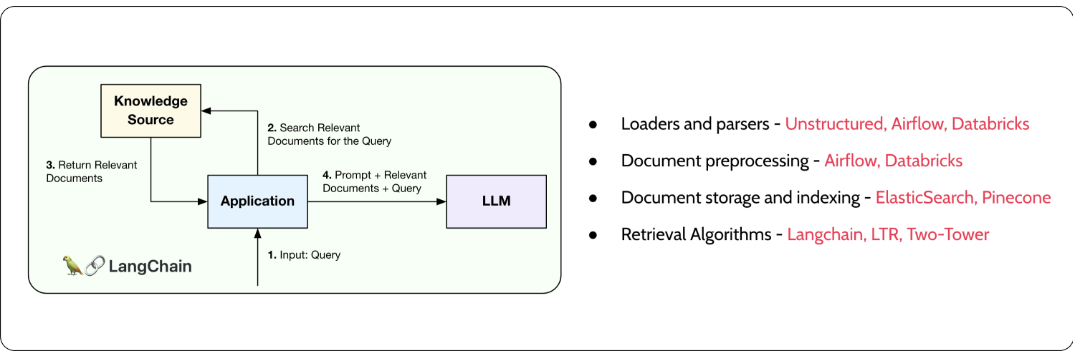
描述:可与RAG一起使用的编排和预处理示例
这些技术经常与矢量数据库一起使用。矢量数据库有助于精确定位与给定查询相关的特定数据块,而不是搜索原始数据。这些数据库用于将LLM的应用问题转化为信息检索挑战。但这里也有局限性。例如,假设你正在存储关于一家足球俱乐部的新闻,你想让模特给你俱乐部的当前状态。好吧,如果你有20年的新闻,并且数据库使用嵌入相似性,你很有可能检索到20年前关于俱乐部状态的新闻。如果你的数据库中有关于Windows 11和Windows 10漏洞的文档,也会有同样的风险。因为信息非常相似,所以你很可能会得到交叉引用的信息,这些信息在一种情况下是真实的,但在另一种情况中不是。
这正是我们需要高级RAG架构的原因,它可以以显著提高准确性的方式对检索到的文档进行后处理。以下是一些我们喜欢的管弦乐队。
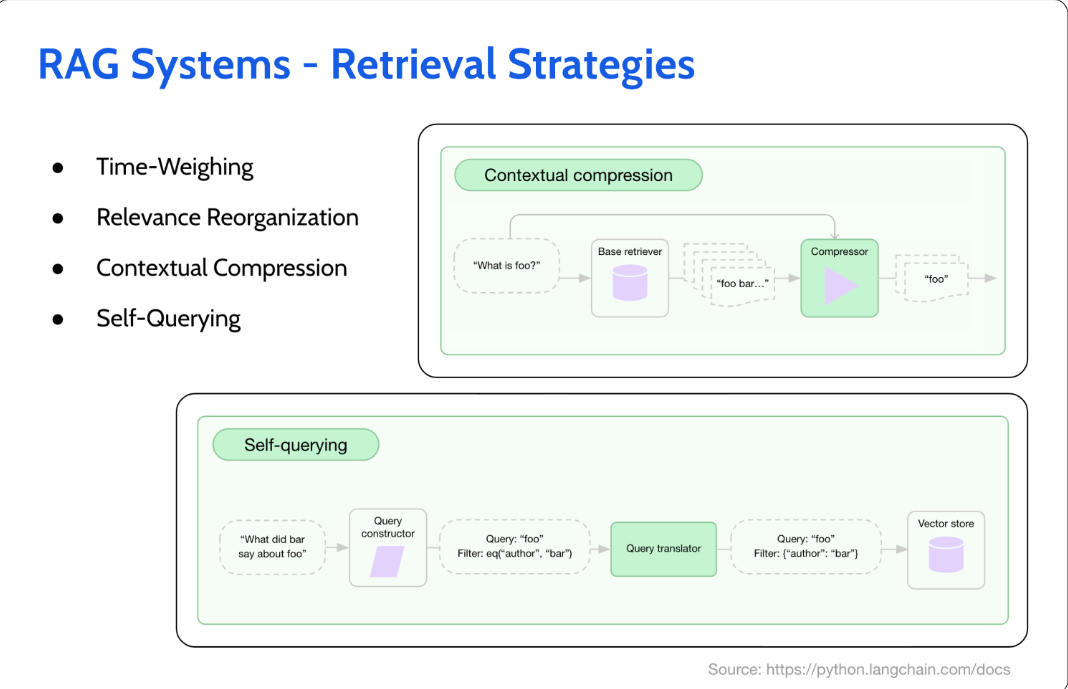
添加时间分量——例如,在上面的足球新闻示例中,我们可以在向量数据库中的相似性搜索中添加时间分量,从而防止检索机制过于深入过去。
后期处理
另一个解决方案涉及利用第二个更灵活的LLM来改进文档检索。这种“策展人”LLM在检索后对文档进行重新排序,以便首先检索到最重要或最相关的文档。
上下文压缩
这项技术包含了一个LLM,经过微调,可以从检索到的文档中去除不相关的绒毛。剩下的是高效精简、更相关、总结的内容。
自我查询
另一种策略使用单独的LLM来获取用户查询,并将其转换为可以与SQL数据库等外部组件交互的结构化查询。事实上,就在几个月前,谷歌发布了SQLPalm,它可以接受自然语言查询并将其转换为SQL查询。这甚至可以用来用老式SQL替换矢量数据库——所有这些都是通过使用LLM实现的。Langchain中的SQLDatabaseChain是使用自然语言提示运行SQL查询的另一种方式。
前瞻性主动检索(FLARE)

FLARE 是一种基于现代LLM迭代性质的技术。FLARE鼓励不断改进,而不是停留在第一个生成的输出上。通过迭代,模型强化其响应,确保准确性和相关性。例如,如果要基于查询检索文档,FLARE将预测下一句话;如果生成的内容的不确定性很高,则会提示LLM检索更多文档。FLARE通过细分流程并专注于不断改进,确保LLM体系结构保持强健和响应能力。
LLM工具、代理和插件
在大型语言模型(LLM)不断发展的环境中,最显著的进步之一是在模型体系结构中部署了代理和工具。正如网络研讨会中所讨论的,代理充当着复杂的协调人,熟练地决定何时部署特定的工具或资源以实现期望的结果。他们通过分解复杂任务并利用模型的语言能力进行任务分解和结果表示来简化流程。
作为对代理的补充,工具充当外部资源,从Python解释器到Selenium等web获取服务。它们的复杂性不仅在于它们各自的功能,还在于它们的协同作用。例如,插件比工具更广泛,使LLM能够与外部API或工具无缝集成,从而进一步模糊了模型内部固有内容和外部访问内容之间的界限。
这种由代理体系结构带来的范式转变为LLM创造了巨大的机会。例如,ReAct框架通过行动、观察和思考不断循环,以确保模型以更高的信心得出结论。随后在ReAct之上添加的Reflexion框架促使模型检查其输出,使其与用户规范和期望更紧密地保持一致。使用这种类型的“思想链”提示,而不是提出孤立的个人问题,可以使模型在整个交互过程中保持某种上下文线索。每一个问题都建立在之前的回答之上,以便对主题进行更深入、更细致的探索。
这种代理、工具和创新框架的结合正在彻底改变我们对LLM的理解和实施方式,确保它们不仅在知识上具有扩展性,而且在应用上具有适应性和洞察力。
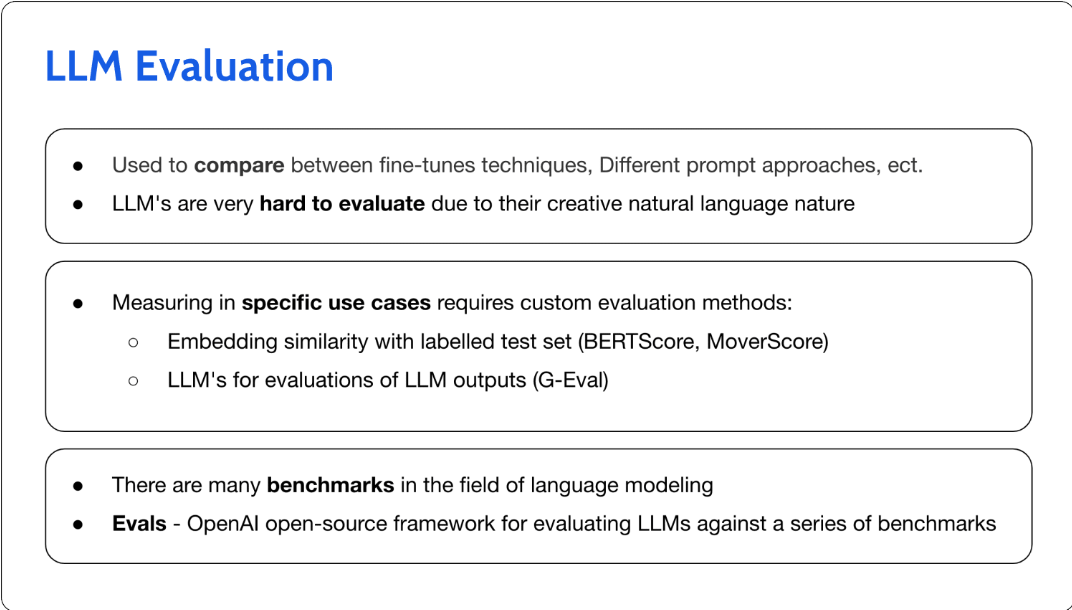
评估LLM
首先,让我们区分LLM评估和LLM监控。一天结束时的LLM评估的目的是帮助我们选择大型语言模型。在上下文和通用模型智能方面,这里有很多潜在的度量标准,选择适合您的用例的度量标准至关重要,就像使用更传统的ML监控度量标准一样。
监测LLM
LLM的监控与传统的ML模型监控大不相同。以漂移为例。即使假设我们知道LLM训练的所有数据,漂移在如此大的背景下会产生什么影响?当在LLM的背景下进行检查时,这只是潜在的问题指标之一。
另一半是,如果我们发现了一个问题,我们怎么可能解决这个问题?在传统的ML中,我们通常会寻求重新培训或功能工程。对于LLM,传统的解析流不仅是一项不应掉以轻心的巨大任务,而且我们还可以利用其他更上游的解析机制,如即时工程、检索调优和微调。

使用LLM,监视和可观察性转移到涵盖用户查询、上下文、模型响应和用户反馈的功能链上——所有这些都是为了改进检索过程和微调。换句话说,可观察性从模型转移到模型的周围环境。
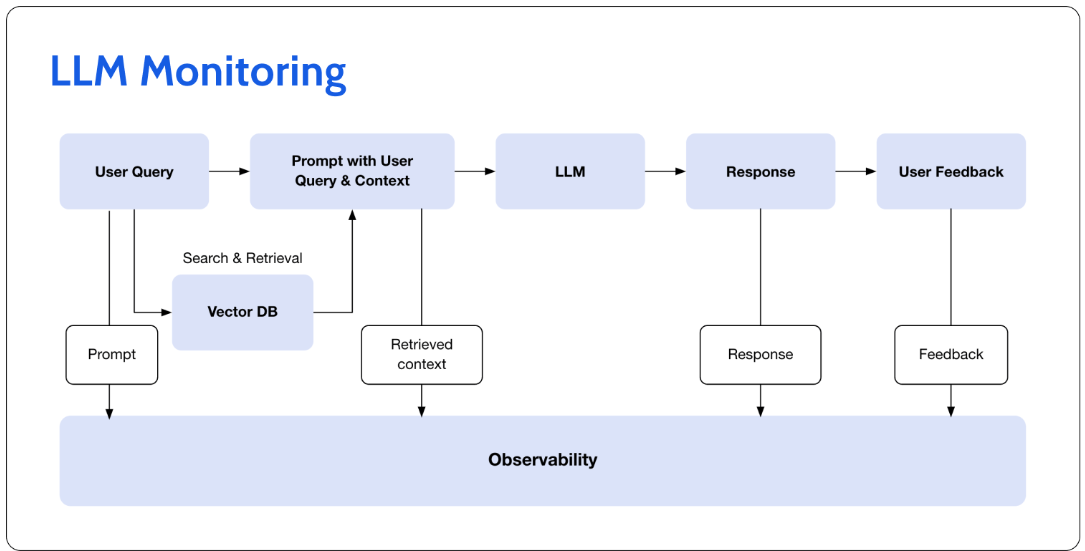
有关LLM度量与周围上下文相关的示例,请跳到32:02,查看附带的Elemeta开源和Superwise LLM监控。
速度、安全和前方道路
无论LLM的知识多么渊博,他们都有界限。其中包括他们产生幻觉或编造信息的倾向、无法管理大块数据、固有偏见和数据隐私。在这篇文章中,我们研究了旨在解决这些限制的新兴体系结构。
正如本博客及其合作伙伴关于LLM调优的网络研讨会所揭示的那样,如何实施LLM不仅关乎模型,还关乎支持它的复杂架构和系统。随着我们深入LLM领域,了解这些细微差别对于发挥其真正潜力至关重要。
如果你和我们一样对LLM着迷,请加入我们下一次网络研讨会的讨论!
- 登录 发表评论
- 157 次浏览
最新内容
- 1 week 5 days ago
- 2 weeks 6 days ago
- 3 weeks 3 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago