
category
在这篇文章中,我们将演示如何在Amazon cAgents中使用多代理协作构建多代理系统,以解决生物制药行业的复杂业务问题。我们展示了研发(R&D)、法律和金融领域的专业代理如何通过分析来自多个来源的数据,共同提供全面的商业见解。
亚马逊Bedrock 代理和多代理协作
商业智能和市场研究使大小企业能够通过数据捕捉行业趋势、竞争格局,并影响关键业务战略。例如,生物制药公司通过分析专利和法律简报来制定投资策略,利用数据了解药物市场规模、临床试验、副作用的普遍性以及创新和陷阱。在此过程中,组织面临着访问和分析分散在多个数据源中的信息的挑战。整合和查询这些不同的数据集可能是一项复杂而耗时的任务,需要开发人员浏览不同的数据格式、查询语言和访问机制。此外,要全面了解一个组织的运营情况,通常需要结合法律、财务和研发等各个部门的数据见解。
生成式人工智能代理系统已成为一种有前景的解决方案,使组织能够使用生成式人工智慧进行自主推理和基于行动的任务。然而,迄今为止,许多代理系统都是使用单个代理设置构建的,这在复杂的业务环境中带来了挑战。除了管理多个数据源的挑战外,对多个业务领域的信息和指导进行编码可能会导致代理的大型语言模型(LLM)增长到“忘记中间”的程度。因此,对于可以在代理中有效编码的每个领域,知识的广度和深度之间存在权衡。此外,使用带有代理的单个LLM限制了所选模型的成本、延迟和准确性优化。
Amazon Bedrock Agents及其多代理协作功能为应对这些挑战和构建智能自动化代理系统提供了强大的企业级解决方案。作为AWS生态系统中的托管服务,Amazon Bedrock Agents提供与AWS数据源的无缝集成、内置安全控制和企业级可扩展性。它包含对其他亚马逊基岩功能的内置支持,如亚马逊基岩护栏和亚马逊基岩知识库。该服务显著降低了部署开销,使开发人员能够通过API驱动的熟悉的AWS云环境和控制台来关注代理逻辑。具有专用子代理的监督代理模型实现了高效的分布式问题解决,通过智能路由分解复杂的任务。
在这篇文章中,我们讨论了如何使用多代理协作构建一个多代理系统,以解决虚构的生物制药公司面临的复杂业务问题,该公司需要来自三个专业领域的专业知识和数据:研发、法律和金融。我们展示了如何智能地组合不同来源的数据来支持复杂的推理,以及代理协作如何促进开放式问答,例如“与治疗产品X的副作用相关的潜在法律和财务风险是什么,它们可能会如何影响公司的长期股票表现?”
(下图描述了我们的制药示例中使用的监督代理和3个子代理的角色,以及使用多代理协作的好处。)

解决方案概述
我们的用例围绕PharmaCorp展开,这是一家虚构的制药公司,面临着管理其制药研发、法律和财务部门大量数据的挑战。每个部门都处理结构化数据,如股票价格,以及非结构化数据,例如临床试验报告。每个部门的数据位于不同的数据存储中,这使得团队难以获得跨职能的见解,并减缓了决策过程。
为了解决这个问题,我们在亚马逊基岩代理中使用多代理协作,为每个部门构建了一个具有特定领域子代理的多代理系统。这些子代理有效地处理数据查询和信息检索,主代理在子代理之间传递必要的上下文,并跨部门综合见解。多代理设置使PharmaCorp能够在几分钟内访问专业知识和信息,否则需要数小时的人工编译。这种方法打破了数据孤岛,加强了组织协作。
以下架构图说明了解决方案设置。
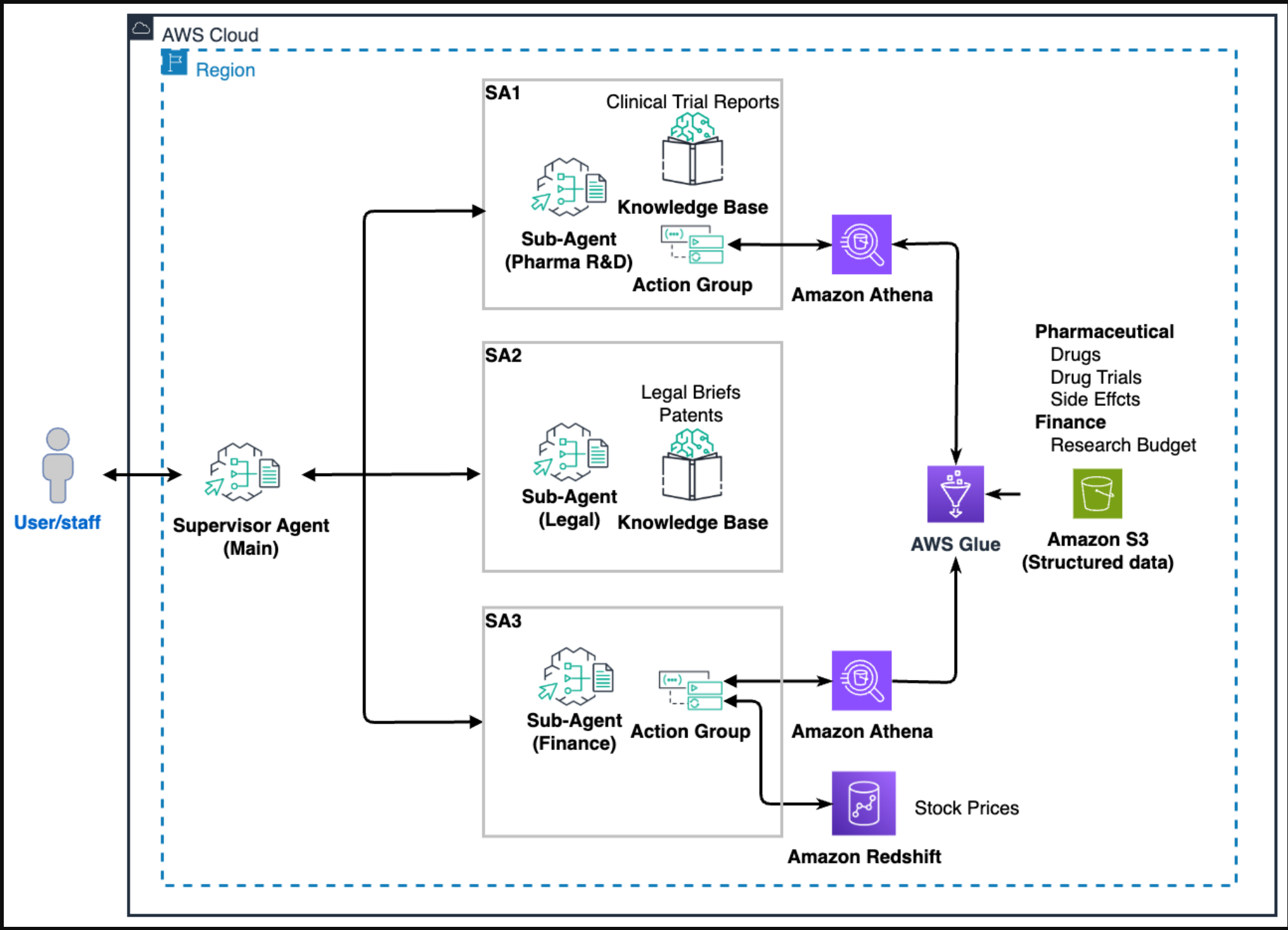
主代理充当编排器,向多个子代理提问并合成检索到的数据:
- 研发子代理可以通过Amazon Athena和非结构化临床试验报告访问临床试验数据
- 法定分代理人可以访问非结构化专利和诉讼法律简报
- 财务子代理可以通过Athena访问研究预算数据和存储在Amazon Redshift中的历史股价数据
每个子代理都有细粒度权限,只能访问其域中的数据。以下部分详细描述了所使用的数据和模型以及主要代理交互。
Dataset
We generated synthetic data using Anthropic’s Claude 3.5 Sonnet model, comprised of three domains: Pharma R&D, Legal, and Finance. The domains contain structured data stored in SQL tables and unstructured data that is used in domain knowledge bases. The data can be accessed through the following files: R&D, Legal, Finance.
Efforts have been made to align synthetic data within and across domains. For example, clinical trial reports map to each trial and side effects in related tables. Rises and dips in stock prices tend to correlate with patents and lawsuits. However, there might still be minor inconsistencies between data.
Pharma R&D domain
The Pharma R&D domain has three tables: Drugs, Drug Trials, and Side Effects. Each table is queried from Amazon Simple Storage Service (Amazon S3) through Athena. The Drugs table contains information on the company’s available products, therapeutic areas, target conditions, mechanisms of action, development phase, discovery year, and lead scientist. The Drug Trials table contains information on specific trials for each drug such as phase, dates, number of participations, and outcomes. The Side Effects table contains side effects, frequency, and severity reported from each trial.
The unstructured data for the Pharma R&D domain consists of synthetic clinical trial reports for each trial, which contain more detailed information about the trial design, outcomes, and recommendations.
Legal domain
The Legal domain has unstructured data consisting of patents and lawsuit legal briefs. The patents contain information about invention background, description, and experimental results. The legal briefs contain information about lawsuit court proceedings, outcomes, and analysis.
Finance domain
The Finance domain has two tables: Stock Price and Research Budgets. The Stock Price table is stored in Amazon Redshift and contains PharmaCorp’s historical monthly stock prices and volume. Amazon Redshift is a database optimized for online analytical processing (OLAP), which generally entails analyzing large amounts of data and performing complex analysis, as might be done by analysts looking at historical stock prices. The Research Budgets table is accessed from Amazon S3 through Athena and contains annual budgets for each department.
The data setup showcases how a multi-agent framework can synthesize data from multiple data sources and databases. In practice, data could also be stored in other databases such as Amazon Relational Database Service (Amazon RDS).
Models used
Anthropic’s Claude 3 Sonnet, which has a good balance of intelligence and speed, is used in this multi-agent demonstration. With the multi-agent setup, you can also employ a more intelligent or a smaller, faster model depending on the use case and requirements such as accuracy and latency.
Prerequisites
To deploy this solution, you need the following prerequisites:
- An active AWS account.
- Access to Amazon Titan Embeddings G1 – Text, Anthropic’s Claude 3 Sonnet, and Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock. For instructions, refer to Add or remove access to Amazon Bedrock foundation models.
Deploy the solution
To deploy the solution resources, we use AWS CloudFormation. The CloudFormation template creates two S3 buckets, two AWS Lambda functions, an Amazon Bedrock agent, an Amazon Bedrock knowledge base, and an Amazon Elastic Compute Cloud (Amazon EC2) instance.
Download the provided CloudFormation template, then complete the following steps to deploy the stack:
- Open the AWS CloudFormation console (the preferred AWS Regions are
us-west-2orus-east-1for the solution). - Choose Stacks in the navigation pane.
- Choose Create stack and With new resources (standard).
- Select Choose existing template and upload the provided CloudFormation template file.
- Enter a stack name, then choose Next.
- Leave the stack settings as default and choose Next.
- Select the acknowledgement check box and create the stack.
After the stack is complete, you can view the new supervisor agent on the Amazon Bedrock console.
An example of agent collaboration
After you deploy the solution, you can test the communication among agents that help answer complex questions across PharmaCorp’s three divisions. For example, we ask the main agent “How did the results of NeuroClear’s Phase 2 trials affect PharmaCorp’s stock price, patent filings, and potential legal risks?”
This question requires a comprehensive understanding of the relationships between NeuroClear’s clinical trial results, financial impacts, and legal outcomes for PharmaCorp. Let’s see how the multi-agent system addresses this complex query.
The main agent identifies that it needs input from three specialized sub-agents to fully assess how NeuroClear’s clinical trial results might impact PharmaCorp’s legal and financial performance. It breaks down the user’s question into key components and develops a plan to gather detailed insights from each expert. The following is its chain-of-thought reasoning, task breakdown, and sub-agent routing:
Then, the main agent asks a question to the R&D sub-agent:
The R&D sub-agent correctly plans and executes its own sequence of steps, which include performing queries and searching its own knowledge base. It responds with the following:
The main agent takes this information and determines its next step:
It asks the finance sub-agent the following:
Through this example, we can see how multi-agent collaboration enables a comprehensive analysis of complex business questions by using specialized knowledge from different domains. The main agent effectively orchestrates the interaction between sub-agents, synthesizing their insights to provide a holistic answer that considers R&D, financial, and legal aspects of the NeuroClear clinical trials and their potential impacts on PharmaCorp.
Clean up
When you’re done testing the agent, complete the following steps to clean up your AWS environment and avoid unnecessary charges:
- Delete the S3 buckets:
- On the Amazon S3 console, empty the buckets
structured-data-${AWS::AccountId}-${AWS::Region}andunstructured-data-${AWS::AccountId}-${AWS::Region}. Make sure that both of these buckets are empty by deleting the files. - Select each file, choose Delete, and confirm by entering the bucket name.
- On the Amazon S3 console, empty the buckets
- Delete the Lambda functions:
- On the Lambda console, select the
CopyDataLambdafunction. - Choose Delete and confirm the action.
- Repeat these steps for the
CopyUnstructuredDataLambdafunction.
- On the Lambda console, select the
- Delete the Amazon Bedrock agent:
- On the Amazon Bedrock console, choose Agents in the navigation pane.
- Select the agent, then choose Delete.
- Delete the Amazon Bedrock knowledge base in Bedrock:
- On the Amazon Bedrock console, choose Knowledge bases under Builder tools in the navigation pane.
- Select the knowledge base and choose Delete.
- Delete the EC2 instance:
- On the Amazon EC2 console, choose Instances in the navigation pane.
- Select the EC2 instance you created, then choose Delete.
业务影响
使用Amazon Bedrock Agents实施这个多代理系统可以为制药公司带来巨大的好处。通过跨领域自动化数据检索和分析,公司可以减少研究时间,实现更快的数据驱动决策,特别是当领域专家分布在不同的组织单位,直接互动有限时。该系统在几分钟内提供全面、跨职能见解的能力可以改善风险缓解,因为通过连接不同的数据点,可以更早地发现潜在的法律和财务问题。这种自动化还允许更有效地分配人力资源,使专家能够专注于高价值的任务,而不是常规的数据分析。
我们的例子展示了多智能体系统在药物研发中的力量,但这项技术的应用远远超出了单个用例。例如,生物技术公司可以通过让专业人员从Amazon Redshift中提取基因组信号,进行Kaplan-Meier生存分析,并并行解释CT扫描,来加速癌症生物标志物的发现。大型卫生系统可以自动汇总患者记录、实验室结果和试验数据,以简化护理协调并标记紧急病例。旅行社可以编排端到端的行程,公司可以管理个性化的客户沟通。有关潜在应用程序的更多信息,请参阅以下帖子:
- Accelerate analysis and discovery of cancer biomarkers with Amazon Bedrock Agents
- How agentic AI systems can solve the three most pressing problems in healthcare today
- Unlocking complex problem-solving with multi-agent collaboration on Amazon Bedrock
- Enabling complex generative AI applications with Amazon Bedrock Agents
尽管多智能体系统的潜力在这些不同的应用中是引人注目的,但了解实现此类系统的实际考虑因素非常重要。复杂的编排工作流会通过多个模型调用提高推理成本,增加端到端延迟,放大测试和维护要求,并在速率限制、重试和代理间或数据连接协议方面引入操作开销。然而,最新技术正在迅速发展。新一代更快、更便宜的模型可以帮助降低每次通话的费用和延迟,而更强大的模型可以在更少的时间内完成任务。观察性工具为多代理管道提供端到端跟踪和仪表板。最后,像Anthropic的模型上下文协议这样的协议开始标准化代理访问数据的方式,为强大的多代理生态系统铺平了道路。
结论
在这篇文章中,我们探讨了使用Amazon Bedrock Agents使用多代理协作实现的多代理生成人工智能系统如何解决多个业务领域的数据访问和分析挑战。通过一个虚构的制药公司管理其不同部门数据的演示用例,我们展示了为每个领域量身定制的专业子代理如何简化信息检索和合成。每个子代理都使用领域优化的模型并安全地访问相关数据源,使组织能够生成跨职能的见解。
通过这种多代理架构,组织可以克服数据孤岛,增强协作,实现高效的数据驱动决策,同时优化成本、延迟和安全性。具有多代理协作的Amazon Bedrock代理通过提供一个安全、可扩展的框架来管理代理之间的协作、通信和任务委托,从而促进了这种设置。在以下资源中探索有关Amazon Bedrock中多代理协作的其他演示和研讨会:
- 登录 发表评论
- 16 次浏览
最新内容
- 1 month 1 week ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago