软件架构
软件架构 intelligentxInfoQ 架构和设计趋势 2019
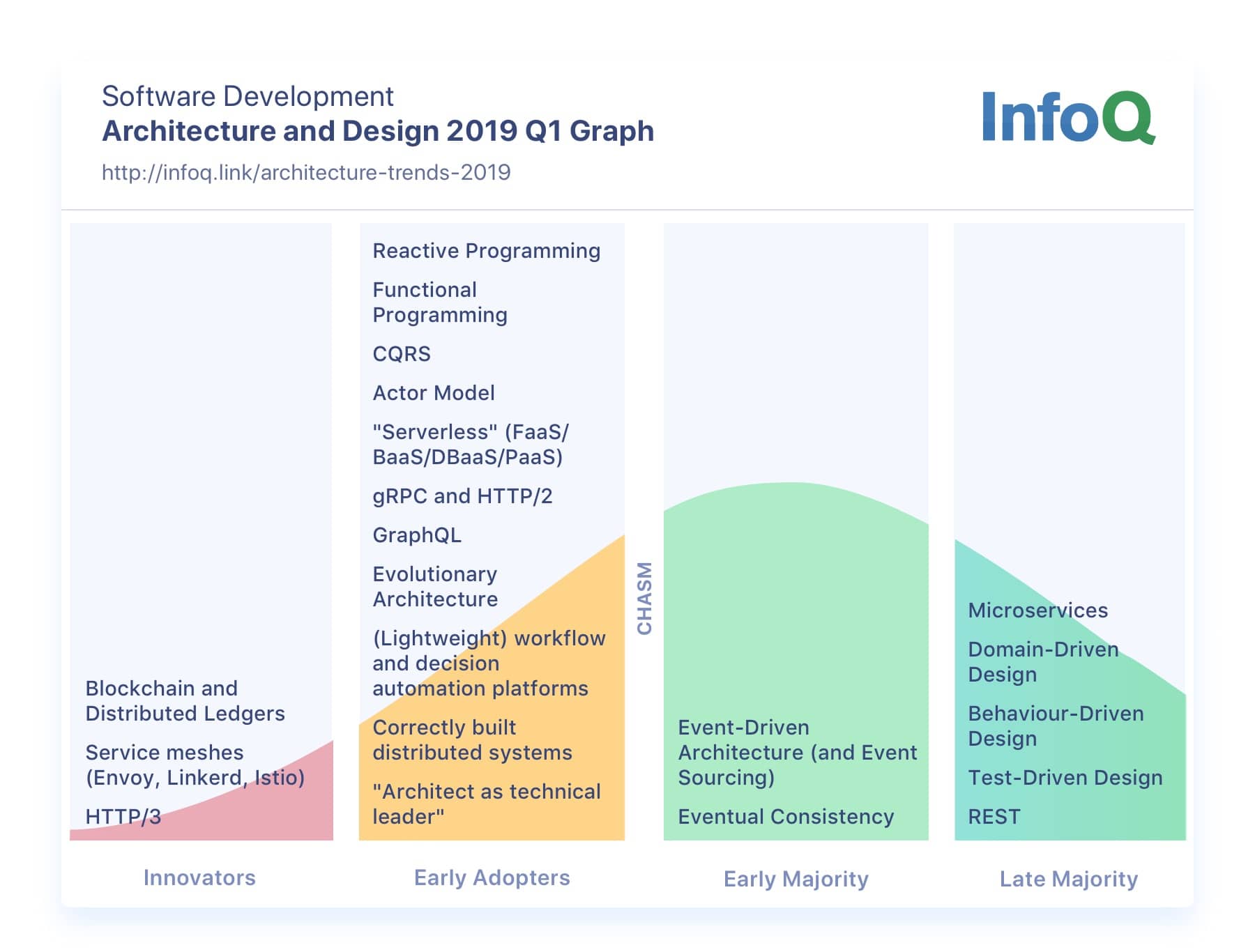
InfoQ 架构和设计趋势 2024
Gantner 架构趋势
- 1175 次浏览
API架构
- 234 次浏览
【API设计】API架构 - 为 REST API 设计最佳实践
一般来说,只要 HTTP 协议存在,Web 服务就已经存在。但是,自从云计算出现以来,它们已成为实现客户端与服务和数据交互的无处不在的方法。
作为一名开发人员,我很幸运能够使用一些仍然围绕@work 的 SOAP 服务。但是,我主要使用 REST,这是一种用于开发 API 和 Web 服务的基于资源的架构风格。
在我职业生涯的大部分时间里,我都参与了构建、设计和使用 API 的项目。
我见过的大多数 API 都“声称”是“RESTful” —— 意思是符合 REST 架构的原则和约束。
然而,我与少数几个合作过的人给 REST 一个非常非常糟糕的代表。
HTTP 状态代码的不准确使用、纯文本响应、不一致的模式、插入端点的动词……我觉得我已经看到了这一切(或者至少,很多)。
因此,我决定写一篇文章来描述我个人认为设计 REST API 时的一些最佳实践。
只是为了让我们清楚……
我并不声称自己是权威,也不打算推断以下实践与任何“神圣的 REST 原则”100% 同步(如果存在这样的事情)。 我从我自己在整个职业生涯中构建和使用不同 API 的经验中拼凑出这些想法。
另外,我也不会假装精通 REST API 设计! 我相信这是一门艺术/运动——你练习得越多,你得到的就越好。
我将列出一些代码片段作为“糟糕设计的例子”。 如果它们看起来像你会写的东西,那很好! 🙂 唯一重要的是我们一起学习。
这里有一些技巧、建议和指导,可以帮助您设计出色的 REST API,让您的消费者(和开发人员)满意。
1. 学习HTTP的基础知识
如果您渴望构建一个设计良好的 REST API,您必须了解 HTTP 协议的基础知识。我坚信这将帮助您做出好的设计选择。
我发现 Mozilla 开发人员网络文档上的 HTTP 概述是有关此主题的非常全面的参考。
虽然,就 REST API 设计而言,这是一个适用于 RESTful 设计的 HTTP TLDR:
HTTP 有动词(动作或方法):GET、POST、PUT、PATCH 和 DELETE 是最常见的。
REST 是面向资源的,资源由 URI 表示:/library/
端点是动词和 URI 的组合,例如:GET: /books/
端点可以解释为对资源执行的操作。示例: POST: /books/ 可能意味着“创建一本新书”。
概括地说,动词映射到 CRUD 操作:GET 表示读取,POST 表示创建,PUT 和 PATCH 表示更新,DELETE 表示删除
响应的状态由其状态代码指定:1xx 表示信息,2xx 表示成功,3xx 表示重定向,4xx 表示客户端错误和 5xx 表示服务器错误
当然,您可以使用 HTTP 协议为 REST API 设计提供的其他内容,但我相信您必须牢记这些基本内容。
2.不返回纯文本
尽管这不是任何 REST 架构风格强加或强制的,但大多数 REST API 按照惯例使用 JSON 作为数据格式。
但是,仅返回包含 JSON 格式字符串的响应正文还不够好。 您仍应指定 Content-Type 标头。 它必须设置为值 application/json。
这在处理应用程序/编程客户端时尤为重要(例如,另一个服务/API 通过 Python 中的请求库与您的 API 交互) — 其中一些依赖此标头来准确解码响应。
💡专业提示:您可以使用 Firefox 轻松验证响应的内容类型。 它具有内置的漂亮显示内容类型:application/json 的响应。 🔥
在 Firefox 中,“Content-Type: text/plain”看起来……很简单。
“Content-Type: application/json” 不错,这是多么漂亮和实用。🕺
3. 不要在 URI 中使用动词
到目前为止,如果您已经了解了基础知识,您就会开始意识到将动词放在 URI 中不是 RESTful。
这是因为 HTTP 动词应该足以准确描述对资源执行的操作。
示例:假设您正在提供一个端点来生成和检索一本书的封面。 我会注意到 :param 是 URI 参数的占位符(如 ID 或 slug)。 您的第一个想法可能是创建一个与此类似的端点:
GET: /books/:slug/generateBookCover/
但是,GET 方法在语法上足以说明我们正在检索(“GETting”)一本书的封面。 所以,让我们使用:
GET: /books/:slug/bookCover/
同样,对于创建新书的端点:
# Don’t do this POST: /books/createNewBook/ # Do this POST: /books/
4.资源使用复数名词
这可能很难确定,是否应该对资源名词使用复数形式或单数形式。
我们应该使用 /book/:id/ (单数)还是 /books/:id/ (复数)?
我个人的建议是使用复数形式。
为什么? 因为它非常适合所有类型的端点。
我可以看到 GET /book/2/ 很好。 但是 GET /book/ 呢? 我们是要拿到图书馆里唯一的一本书,还是两本书,还是全部?
为了防止这种歧义,让我们保持一致(💡软件职业建议!)并在任何地方使用复数:
GET: /books/2/ POST: /books/ ...
5.在响应正文中返回错误详细信息
当 API 服务器处理错误时,在 JSON 正文中返回错误详细信息很方便(*并且推荐*)以帮助消费者进行调试。 如果您包含受错误影响的字段,那就更好了!
{
"error": "Invalid payload.",
"detail": {
"name": "This field is required."
}
}
6. 特别注意 HTTP 状态码
我觉得这个很重要。如果您需要从本文中记住一件事,那可能就是它。
您的 API 可能做的最糟糕的事情是返回带有 200 OK 状态代码的错误响应。
这只是糟糕的语义。相反,返回一个准确描述错误类型的有意义的 HTTP 状态代码。
不过,您可能想知道,“但我按照您的建议在响应正文中发送了错误详细信息,那有什么问题呢?”
让我给你讲一个故事。 🙂
我曾经不得不集成一个 API,它为每个响应返回 200 OK 并通过状态字段指示请求是否成功:
{
"status": "success",
"data": {}
}
尽管 HTTP 状态代码返回 200 OK,但我不能绝对确定它没有无法处理我的请求。
事实上,API 可以像这样返回响应:
HTTP/1.1 200 OK
Content-Type: text/html
{
"status": "failure",
"data": {
"error": "Expected at least three items in the list."
}
}
(是的——它也返回了 HTML 内容。因为,为什么不呢?)
因此,在读取数据之前,我必须检查状态代码和临时状态字段以确保一切正常。
太烦人了! 🤦♂️
这种设计是真正的禁忌,因为它破坏了 API 与其消费者之间的信任。您开始担心 API 可能会骗您。
所有这些都非常非 RESTful。 你应该怎么做?
使用 HTTP 状态代码,仅使用响应正文提供错误详细信息。
HTTP/1.1 400 错误请求
HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"error": "Expected at least three items in the list."
}
7. 你应该一致地使用 HTTP 状态码
一旦您掌握了 HTTP 状态代码,您应该致力于始终如一地使用它们。
例如,如果您选择 POST 端点在某处返回 201 Created,则对每个 POST 端点使用相同的 HTTP 状态代码。
为什么? 因为消费者不必担心在哪种情况下哪个端点上的哪个方法将返回哪个状态代码。
所以,要可预测(一致)。 如果您必须偏离惯例,请将其记录在带有大标志的地方。
通常,我坚持以下模式:
GET: 200 OK PUT: 200 OK POST: 201 Created PATCH: 200 OK DELETE: 204 No Content
8.不要嵌套资源
您现在可能已经注意到 REST API 处理资源。检索列表或资源的单个实例很简单。但是,当您处理相关资源时会发生什么?
例如,假设我们要检索特定作者的书籍列表 - name=Cagan 的作者。基本上有两种选择。
第一个选项是将书籍资源嵌套在作者资源下,例如:
GET: /authors/Cagan/books/
一些架构师推荐这种约定,因为它确实代表了作者与其书籍之间的一对多关系。
但是,现在还不清楚您请求的是什么类型的资源。是作者吗?是书吗? …
同样扁平比嵌套更好,所以必须有更好的方法......而且有! :)
我个人的建议是直接使用查询字符串参数过滤书籍资源:
GET: /books?author=Cagan
这显然意味着:“获取作者姓名 Cagan 的所有书籍”,对吗? 🙂
9. 优雅地处理尾部斜杠
URIs 是否应该有一个斜杠/ 并不是一个真正的争论。您应该简单地选择一种方式或另一种方式(即带有或不带有尾部斜杠),坚持使用它并在客户端使用错误的约定时优雅地重定向客户端。
(我承认,我自己不止一次犯过这个罪。🙈)
讲故事的时间! 📙 有一天,当我将 REST API 集成到我的一个项目中时,我在每次调用时不断收到 HTTP 500 内部错误。我使用的端点看起来像这样:
POST: /buckets
我很生气,我终其一生都无法弄清楚我到底做错了什么。 🤪
最后,结果是服务器出现故障,因为我缺少尾部斜杠!所以,我开始使用:
POST: /buckets/
Aaaand 之后一切顺利。 🤦♂️
API 尚未修复,但希望您可以为您的消费者避免此类问题。
💡专业提示:大多数基于 Web 的框架(Angular、React 等)都有一个选项可以优雅地重定向到 URL 的尾随或非尾随版本。找到该选项并尽早激活它。
10.利用查询字符串进行过滤和分页
大多数时候,一个简单的端点不足以满足各种复杂的业务案例。
您的消费者可能希望检索满足特定条件的项目,或一次少量检索它们以提高性能。
这正是过滤和分页的目的。
通过过滤,消费者可以指定返回的项目应该具有的参数(或属性)。
分页允许消费者检索数据集的一部分。最简单的一种分页是页码分页,它由一个page和一个page_size决定。
现在,问题是:您如何在 REST API 中合并这些功能?
我的回答是:使用查询字符串。
我会说为什么你应该使用查询字符串进行分页是很明显的。它看起来像这样:
GET: /books?page=1&page_size=10
但是,过滤可能不太明显。起初,您可能会想到做这样的事情来检索仅已出版书籍的列表:
GET: /books/published/
设计问题:已发布不是资源!相反,它是您正在检索的数据的特征。那种事情应该放在查询字符串中。
所以最后,用户可以像这样检索“包含 20 个项目的已出版书籍的第二页”:
GET: /books?published=true&page=2&page_size=10
非常明确,不是吗?
11、了解401 Unauthorized和403 Forbidden的区别
如果我每次看到开发人员甚至一些有经验的架构师都把它搞砸的话,我有一个季度的时间……
在处理 REST API 中的安全错误时,很容易混淆错误是与身份验证还是授权(也称为权限)有关 — 过去一直发生在我身上。
这是我的备忘单,用于了解我正在处理的内容,具体取决于情况:
- 消费者是否未提供身份验证凭据?他们的 SSO 令牌是否无效/超时? 👉 401 未经授权。
- 消费者是否通过了正确的身份验证,但他们没有访问资源所需的权限/适当的许可? 👉 403 禁止。
12.善用HTTP 202 Accepted
我发现 202 Accepted 是 201 Created 的一个非常方便的替代品。它基本上意味着:
我,服务器,已理解您的请求。我还没有创建资源(还),但这很好。
我发现 202 Accepted 特别适用于两种主要情况:
- 如果资源将作为未来处理的结果创建 - 例如:在作业/进程完成后。
- 如果资源已经以某种方式存在,但这不应被解释为错误。
13. 使用专门用于 REST API 的 Web 框架
作为最后一个最佳实践,让我们讨论这个问题:您实际上如何在您的 API 中实施最佳实践?
大多数情况下,您希望创建一个快速的 API,以便一些服务可以相互交互。
Python 开发者会使用 Flask,JavaScript 开发者会使用 Node(Express),他们会实现一些简单的路由来处理 HTTP 请求。
这种方法的问题在于,该框架通常不针对构建 REST API 服务器。
例如,Flask 和 Express 都是两个非常通用的框架,但它们并不是专门用来帮助您构建 REST API 的。
因此,您必须采取额外的步骤在 API 中实施最佳实践。大多数时候,懒惰或缺乏时间意味着你不会付出努力——并且会给你的消费者留下一个古怪的 API。
解决方案很简单:为工作使用正确的工具。
新框架已经出现在各种语言中,专门用于构建 REST API。它们可帮助您轻松遵循最佳实践,而不会牺牲生产力。
在 Python 中,我发现的最好的 API 框架之一是 Falcon。它就像 Flask 一样简单易用,非常快速且非常适合在几分钟内构建 REST API。
Falcon:减轻我们 0.0564 多个世纪以来 API 的负担。
如果你更喜欢 Django 类型的人,那么首选是 Django REST 框架。 它不是那么直观,但非常强大。
在 Node 中,Restify 似乎也是一个不错的选择,尽管我还没有开始尝试。
我强烈建议您试一试这些框架。 它们将帮助您构建美观、优雅且设计良好的 REST API。
结束语
我们都应该努力使 API 使用起来很愉快。 两者都是为了消费者和我们自己的开发人员。
我希望本文能帮助您学习一些技巧,并启发您构建更好的 REST API 的技术。 对我来说,它归结为良好的语义、简单性和常识。
REST API 设计是一门艺术,比什么都重要。
如果您对我上面分享的任何提示有不同的方法,请分享。 我很想听听。
与此同时,让他们的 API 不断涌现!
原文:https://abdulrwahab.medium.com/api-architecture-best-practices-for-desi…
- 178 次浏览
【API 架构】 REST API 的性能最佳实践
在我之前的部分中,我分享了一些关于如何设计有效的 REST API 的最佳实践。
一个深思熟虑的设计还必须考虑 API 的性能方面。 如果 API 不能满足不断增长的请求以及不断变化的业务和/或客户需求,那么好的设计就毫无意义。
那么……什么是 API 性能?
就像任何性能一样,API 性能很大程度上取决于 API 如何响应和运行,以响应它收到的不同类型的请求。
示例:假设我们有一个面向客户的应用程序,用于显示客户的当前订单。 我们的应用程序从 API 获取订单详细信息。 但是现在,客户表示他们希望在一个地方查看所有订单(过去和当前)。 因此,我们构建了一个我的订单页面来显示客户的所有订单。 这意味着,我们的 API 现在将返回比以前更多的数据和更大的有效载荷。
我们如何确保我们的 API 能够将所有数据返回给我们的客户,而不会出现诸如延迟、服务器端错误和过多请求之类的问题?
性能提升技巧
1- 减少和限制有效载荷大小
响应数据的超大负载会减慢请求完成、其他服务调用的速度,并影响性能下降。 如您所知,现在我们正在为客户退回所有订单,而不仅仅是他们当前的订单,我们将不得不处理一些性能下降问题。
我们可以使用 GZip 压缩来减少我们的有效载荷大小。
这减少了我们在 Web 应用程序(客户端)上响应的下载大小,并提高了上传速度或某些实体(订单)的创建。
我们可以在 Web API 上使用 Deflate 压缩。
或者,我们可以将 Accept-Encodingrequest 标头更新为 gzip 。
2- 启用缓存
缓存是提高 API 性能的最简单方法之一。 如果我们有频繁返回相同响应的请求,那么该响应的缓存版本有助于避免额外的服务调用/数据库查询。
您需要确保在使用缓存定期使缓存中的数据无效时,尤其是在发生新数据更新时。
示例:假设我们的客户想要订购汽车零件,我们的应用调用一些汽车零件 API 来获取零件价格。 由于响应(部分价格)每周仅更改一次(@ 12:00am),因此我们可以在此之前的剩余时间内缓存响应。 这使我们不必每次都重新调用以返回相同的零件价格。
3-提供足够的网速
即使是设计最稳健的 API,缓慢的网络也会降低其性能。 不可靠的网络可能会导致停机,从而导致您的组织违反 SLA、服务条款和您可能对客户做出的承诺。 投资合适的网络基础设施很重要,这样我们才能保持所需的性能水平。
这可以通过利用和购买足够的云资源和基础设施来实现(例如:在 AWS 中,分配适当数量的 EC2 实例,使用网络负载均衡器)。
此外,如果您有大量后台进程,请在单独的线程上运行这些进程以避免阻塞请求。 您还可以使用镜像和内容交付网络 (CDN)(例如 CloudFront)来更快地处理全球不同地区的请求。
4- 防止意外调用、减速和滥用
您可能会遇到这样的情况,即您的 API 遭受 DDoS 攻击,这种攻击可能是恶意的、有意的,也可能是工程师调用 API 以从某个本地应用程序循环执行时无意的。
您可以通过测量交易并监控每个 IP 地址或每个 SSO/JWT 令牌(如果客户/调用应用程序在调用 API 之前获得授权)发生的交易数量来避免这种情况。
这种速率限制方法有助于减少会减慢 API 速度的过多请求,有助于处理意外调用/执行,并主动监控和识别可能的恶意活动。
5- 尝试在 PUT 上使用 PATCH
PUT 和 PATCH 操作会产生相同的结果,这是工程师之间的一个普遍误解。
它们在更新资源方面相似,但它们各自执行更新的方式不同。
PUT 操作通过向整个资源发送更新来更新资源。
PATCH 操作仅对需要更新的资源应用部分更新。 产生的 PATCH 调用产生更小的有效载荷,并大规模提高性能。
💡专业提示:尽管PATCH调用可以限制请求大小,但您应该注意它不是幂等的。 这意味着,PATCH 可能会通过一系列多次调用产生不同的结果。 因此,您应该仔细考虑使用 PATCH 请求的应用程序,并确保在需要时以幂等方式实现它们。 如果没有,请使用 PUT 请求。

6- 启用日志记录、监控和警报
这可能是您将在此处阅读的最重要的提示之一。 如果你应该从这篇文章中学到一件事,那就应该是这个! 没有就这一点进行谈判。
拥有日志、监控和警报可帮助工程师在问题成为问题之前对其进行诊断和修复。 许多 API(基于 Express/Node 的、Java、Go)都有用于评估以下内容的预定义端点:
/health/metrics
如果您没有启用日志记录,并且存在潜在问题,您将无法跟踪源,或特定请求中出现问题的位置。
如果您没有启用监控,您将无法从分析的角度了解某些问题或错误发生的频率。 这将阻止您考虑可能的解决方案。
而且……如果您没有启用警报,您将不知道是否存在问题,直到客户(或更糟的是,客户)报告它。 害怕!
7- 启用分页
分页有助于从多个响应中创建内容桶。 这种优化有助于改进响应,同时保留传输/显示给客户的数据。
您可以标准化、细分和限制响应,这有助于降低结果的复杂性,并通过仅提供客户要求的响应/结果来改善整体客户体验。
结束语
我们知道 API 非常棒,如果针对性能进行适当的优化和增强,它可以非常强大地为企业和客户提供出色的体验。
业务需求和客户期望总是随着时间的推移而发展。 作为负责任的工程师,我们可以决定如何以高性能的方式构建 API,这可以帮助我们实现并超越我们的目标。
这些技巧只是冰山一角,适用于一般设置中的所有 API。 根据您的特定 API 和用例、它与哪些服务交互、调用它的频率、调用它的位置等,您可能需要以不同的方式实现这些技巧。
原文:https://abdulrwahab.medium.com/api-architecture-performance-best-practi…
- 145 次浏览
Comments
【API】什么是 API 管理,为什么它很重要?
当今复杂的数字生态系统由许多相互关联的部分组成。 API 作为看门人和连接器在其中发挥着关键作用——提供了许多最终用户甚至没有注意到的自动化机会和效率。
企业密切关注 API。它们对于应用程序、数据和各种客户交互的功能至关重要。
这使得 API 管理成为几乎每个部门的组织的重要主题。根据 Zion Market Research 的数据,2017 年至 2022 年间,全球 API 管理市场预计将以 33.4% 的复合年增长率增长,到 2022 年将达到 34.3616 亿。
阅读本文以了解 API 管理是什么、它为组织带来的好处以及如何为您的业务获取正确的 API 管理解决方案。
什么是 API 管理?
API 管理是一组流程,用于分发、控制和分析组织用来跨云连接应用程序和数据并与外部世界连接的 API。
API 管理的主要目标是使创建自己的 API 或使用外部 API 的组织能够监控其活动并满足使用 API 的开发和应用程序的需求。这就是他们如何确保所有 API 的使用均符合公司政策并以适当的安全级别进行管理。
通过在您的组织和外部世界的边缘部署 API 管理,您可以获得从安全性和可追溯性到通信效率的重要功能。
API 管理由许多移动块组成,这些块通常合并到一个整体解决方案中。在 BlueSoft,我们采取了不同的方法。我们的解决方案 Agama API 在开发时考虑到了微服务模式,以使组织能够充分利用其 API 生态系统。许多企业现在转向微服务架构,因为它有助于加速软件开发。我们已经预料到了这一点,并准备了一个解决方案来帮助他们完成他们的旅程。
API 管理对 IT 世界的影响
API的功能究竟是什么?它们公开组织的数据并通过应用程序提供其资产。 API 还用于向客户、员工和合作伙伴交互添加数字层。
这就是 API 管理如此重要的原因。它为开发人员和企业提供了用于保护、扩展、管理、分析和货币化 API 程序的工具。
一项详细研究 API 采用在数字化转型计划中的作用的研究表明,API 是关键推动因素。结果显示,71% 的受访组织预计到 2022 年 API 调用量将增加。
API 管理的好处

改善客户体验
API 推动新应用程序的快速发展,并在各种渠道中创造无缝体验,满足客户的需求。由于连接性的提高,不同行业的组织可以在全新的水平上提供响应性和便利性。例如,API 带来了您必须自己构建的个性化和增值服务。
可扩展性
企业正在处理比以往更多的应用程序和数据。他们需要不断扩大规模,同时培养创新文化——通常是通过创建和发布新的 API。通过在整个 API 生命周期中简化访问并减少技术负担,API 管理支持可扩展性。
更严格的安全性
当多方(从内部开发人员到合作组织和客户)都可以访问 API 时,安全性成为关键焦点。当您的应用程序是分布式和断开连接时,管理数据访问可能会很棘手。
您需要采取一切可能的措施来保护敏感数据,并确保正确分配和管理权限。如果没有 API 管理解决方案,很难实现这一目标,因为您无法利用其可见性和一致性。
避免关键系统的变化
API 管理解决方案可以利用现有系统,并允许您避免对公司每天使用的关键系统进行任何更改。
变得更加敏捷和响应迅速
能够实时快速创建和发布任何端点有助于企业保持敏捷并变得更具适应性。
数据驱动的决策
API 管理解决方案收集和分析数据,让您深入了解使用模式、设备和地理位置——所有这些都旨在推动更明智的决策。
最大化开发人员性能
您的开发人员可以使用集中式生命周期管理解决方案来了解和分析整套 API 和 Web 服务。他们在一个集中的面板中获得出色的服务可见性和可追溯性,从而提高团队的工作效率。
由于专用的开发人员门户,开发人员还可以享受更轻松和自动化的文档管理。借助 Sandbox 等模块,API 管理工具还支持与外部开发团队进行测试。
API管理是如何实现的?
API 管理解决方案旨在使 API 创建、部署、发布和维护更容易和更精简。
不可否认,每个单独的 API 管理工具都带有一组独特的功能。大多数都提供安全、文档、沙盒环境和高可用性等核心功能。
如今,组织内部构建 API 管理解决方案或从第三方提供商处购买作为服务。在 Facebook、Google 和 Twitter 等科技巨头的推动下,开放 API 运动促进了 API 对轻量级 JSON 和 REST 服务的依赖,而不是传统的面向服务架构 (SOA)。现代工具经常使用这些格式。
API 管理软件必须包含哪些内容
以下是您在为您的业务选择正确的 API 管理工具时应该寻找的必备功能:
- 提供 API 文档以及开发人员入职流程(例如注册和帐户管理)的开发人员门户。
- 自动化和控制您的 API 和使用它们的应用程序之间的连接。
- 一个 API 网关,作为所有客户端的单一入口点,并确定它们如何通过策略与 API 交互。
- API 生命周期管理涵盖从设计、实施到退役的整个周期。
- 通过使用合同实现 API 货币化。您可以通过基于 API 调用次数等指标定义的合约,通过访问 API 背后的微服务获利。
- 能够监控来自单个应用程序的 API 流量,因此您可以了解您的 API 发生了什么——例如,哪个消费者或应用程序调用了哪个 API,以及失败的频率或多少 API(以及原因)。
- 多个 API 实现和版本之间的一致性。
- 提高应用程序性能的内存管理和缓存机制。
- 保护 API 不被滥用并确保将正确权限授予正确人员的安全程序和策略。
- 一个清晰的状态流来帮助 API 管理员——负责管理生产中可见的内容并负责哪个 API 在哪里工作的人。
如何知道您找到了正确的工具?
通过考虑可靠性、灵活性、API 行为质量、速度和成本等因素来衡量 API 管理的成功与否。
使用 Agama API 管理您的 API
我们的解决方案 Agama API 包括核心功能,例如 API 设计、发布分析、监控、安全和货币化。此外,它非常灵活,可以轻松与您的监控系统连接。
它的架构适用于两种替代方案:
- API管理解决方案负责数据转换的地方,
- 并且它是一个代理层,通过添加机制来保护通信,以启用缓存,这要归功于缓存。
我们可以在本地基础设施(数据中心)、公共云或混合环境中部署 Agama API。
在 BlueSoft,我们不遵循“黑盒方法”,可以根据您的独特需求轻松定制我们的 API 管理平台。我们知道,真正的价值与您的想法的独特性以及我们带来的不可或缺的标准化有关。
我们的专家可以帮助您部署、更改、支持和创建部署环境。我们经常建议我们的客户如何以务实的方式引入正确的机制。
最好的部分?您不必处理许可限制,例如用户限制、交易或处理能力。 Agama API 中没有这样的限制。
API 已经在塑造我们的数字生态系统方面发挥着关键作用。通过使用可靠的 API 管理解决方案(如 Agama API)来充分利用它们。
原文:https://bluesoft.com/what-is-api-management-and-why-is-it-important/
- 141 次浏览
【API架构】REST API 行业辩论:OData vs GraphQL vs ORDS
本文比较了标准 API 和服务,以通过 Internet 查询数据以进行分析、集成和数据管理。
Progress 的高级软件工程师 Jeff Leinbach 和 Progress 的开发布道者 Saikrishna Teja Bobba 进行了这项研究,以帮助您决定在您的应用程序或分析/数据管理工具中考虑采用哪种标准 API。我们对比了 OData、GraphQL 和 ORDS 之间的区别,它们是用于通过 Internet 查询和更新数据的标准 API 和服务。重点是实现跨 API 的互操作性,以进行分析、集成和数据管理。
我们一直在根据 AWS re:Invent、Oracle OpenWorld、Dreamforce、API World 等行业活动中的大量讨论跟踪这些主题。 Progress 在数据访问标准(包括 ODBC、JDBC、ADO.NET 和现在的 OData (REST))的开发和贡献方面也拥有丰富的传统,并且是第一个加入 OData 技术委员会的成员。
什么是 REST?
REST(表示状态传输)或 RESTful Web 服务是在 Internet 上的计算机系统之间提供互操作性的一种方式。符合 REST 的 Web 服务允许请求系统使用一组统一且预定义的无状态操作来访问和操作 Web 资源的文本表示。 RESTful 实现使用 HTTP、URI、JSON 和 XML 等标准。
重要的是要注意 REST 是一种架构风格,而不是标准。
通过 Internet 查询数据的标准 API
OData
OData 最初由 Microsoft 于 2007 年开发,是一种 OASIS 标准 REST API,建立在 Microsoft、SAP、CA、IBM 和 Salesforce 等公司之间。它允许以简单和标准的方式创建和使用可查询和可互操作的 RESTful API。 OData 为您提供了一组丰富的查询功能,并因其开源方法以及出色的可扩展性而迅速获得支持。
GraphQL
GraphQL 于 2012 年在 Facebook 内部开发,在 2015 年公开发布之前,是一种部署在 Facebook、Shopify 和 Intuit 等公司的数据查询语言。 GraphQL 为您的 API 中的数据提供了完整且易于理解的描述,使客户能够准确地询问他们需要什么,使 API 更容易随着时间的推移而发展,并支持强大的开发人员工具。
ORDS
ORDS(Oracle REST 数据服务)是 Oracle REST 服务,它为以 Oracle 为中心的应用程序提供类似的标准化。它使具有 SQL 和其他数据库技能的开发人员能够构建对 Oracle 数据库的企业级数据访问 API,当今的现代、最先进的应用程序开发人员希望使用这些 API,并且确实越来越需要使用这些 API 来构建应用程序。 Oracle 的 60 个小组使用 ORDS,包括 Oracle Database、Times Ten 和 NoSQL。
对比标准 API
图 1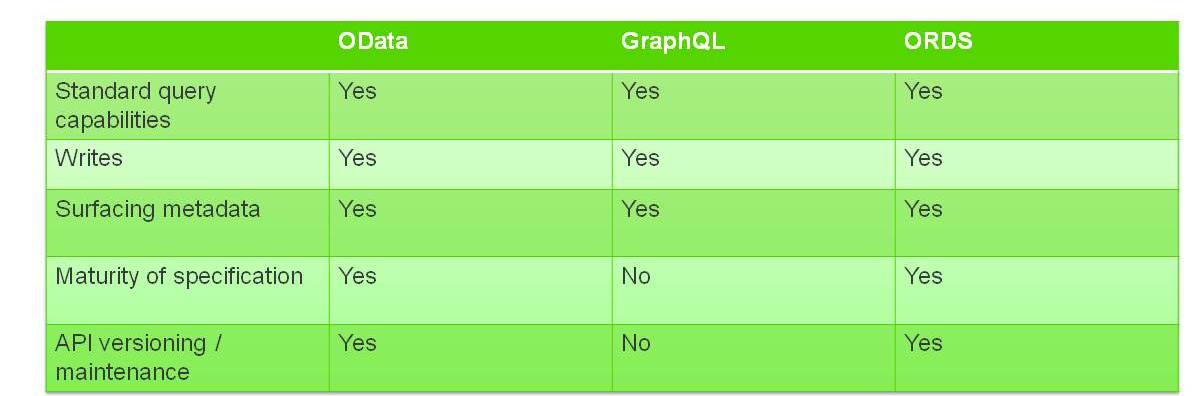
对比图 1 中的标准 API 的标准是基于实现与多个数据源的互操作性。 关于这种比较需要注意的一点是规范的成熟度。 尽管 GraphQL 越来越受欢迎,但在广泛采用、最佳实践和工具方面的成熟度仍然存在问题。
在 API 版本控制/维护下,您会认为“否”是不好的,但实际上是好的。 这是 GraphQL 的优势之一,我稍后会介绍。
图 2
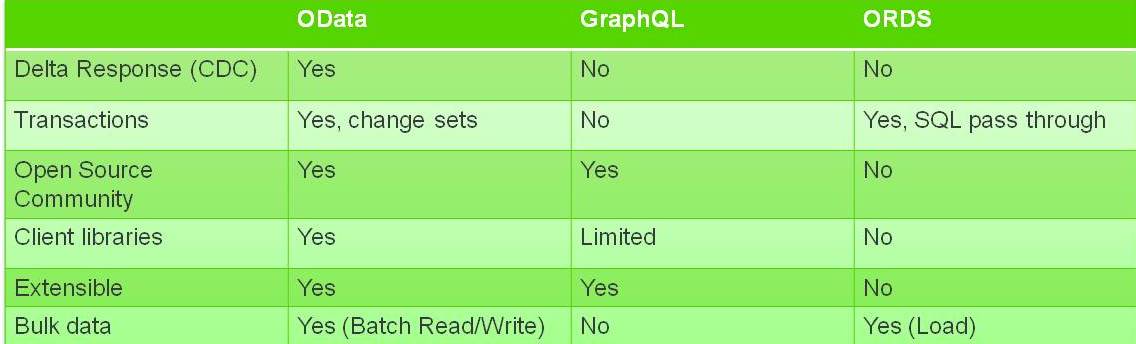
在图 2 中,我们完成了对要考虑的其他标准的初步分析,并将在以后的文章中扩展这些领域。
标准查询能力
图 3
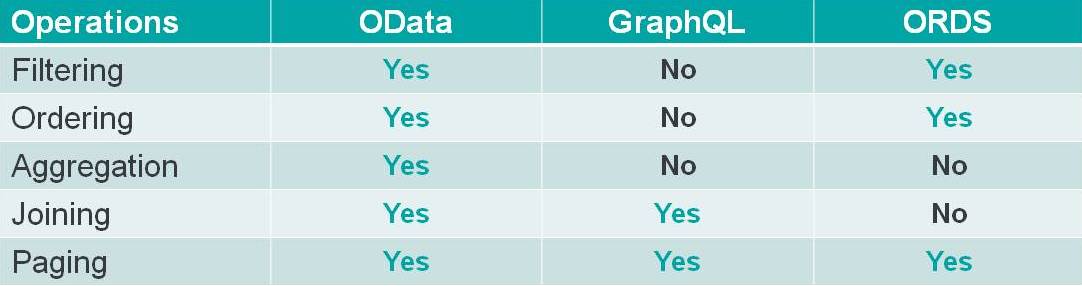
图 3 突出显示了通过开放标准接口访问数据的通用标准。 OData 全面支持所有这些查询功能。您可以使用 GraphQL 和 ORDS 执行其中一些操作,但它们没有标准化或以实现互操作性的方式记录。
GraphQL 与 REST 非常相似,因为它定义了与 Web 服务交互的方式,但它并没有告诉你服务的作用。因此,您可以通过创建可以调用的函数来进行过滤、排序和连接等操作,但应用程序开发人员必须了解它们在语义上的工作方式才能知道它们的行为是什么。
使用 ORDS,您可以进行聚合和连接,但这是通过创建您可以调用的自定义函数来完成的。但是应用程序必须知道这些函数做了什么才能理解如何解释结果。没有元数据或标准行为定义可以告诉应用程序会发生什么。
呈现元数据
图 4
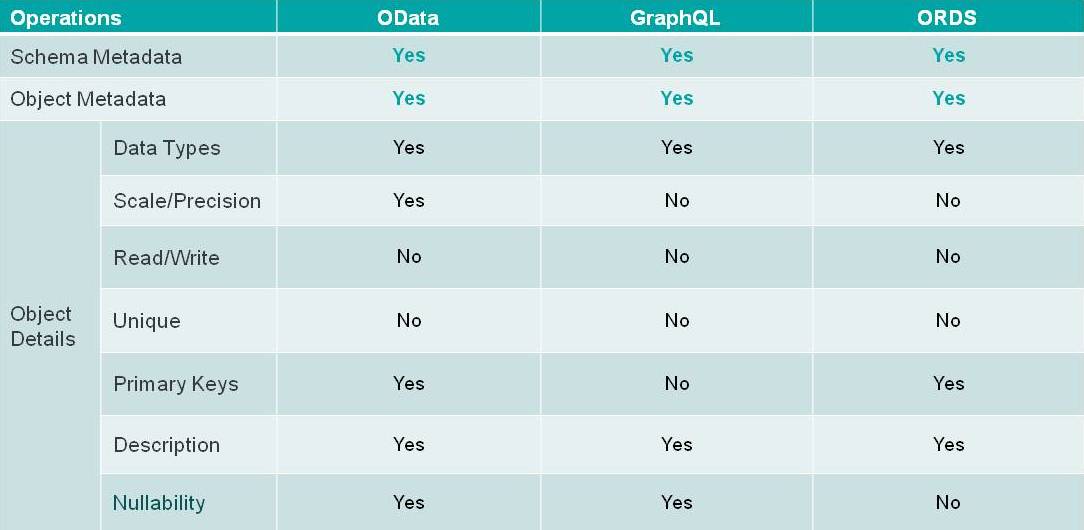
图 4 比较了表面元数据,这是分析和数据管理应用程序的核心,需要以可互操作的方式以编程方式对模式进行逆向工程。
这些 API 中的每一个都在努力解决这个问题,但是 GraphQL 和 ORDS 不会告诉您数据的规模和精度,而 OData 会。 GraphQL 也不会告诉您主键,ORDS 也不会告诉您可空性。此信息对于应用程序能够知道它可以对每个特定字段做什么和不能做什么很重要。
API 版本控制和维护
一个令人头疼的问题是在 API 更改时处理应用程序的更新,同时还要维护旧版本。导致 REST API 令人头疼的最大问题是,当您查询端点时会返回所有字段。 API 开发人员无法了解客户是否依赖特定领域的信息。客户端开发人员必须处理所有返回的字段,即使他们不需要这些信息。
GraphQL 通过强制客户端准确指定他们需要哪些字段来解决 API 版本控制和维护问题。 API 开发人员可以主动联系已知的字段使用者,以迁移已弃用的字段。响应包括有关哪些字段已弃用的信息。
OData 通过提供一个选择列表来将返回的字段数限制为应用程序所需的字段数,从而提供类似的功能。这减少了应用程序中的响应大小和处理。但是,它没有提供一种机制来指示字段已被弃用。
OData 更加灵活,因为可以轻松编写查询以返回所有字段。 OData 正在将模式版本控制添加到规范中以解决此问题。
例子
为了直观地说明使用这些 API 的差异,以下两个代码示例展示了如何在 GraphQL 和 OData 中执行“排序依据”。

在 All Opportunities 函数调用的 GraphQL 示例中,从名称上可以看出它的作用。 但是,GraphQL 中没有任何内容可以告诉您可以为这些参数传递什么以及指定为参数的值如何导致函数运行。 并且这种行为在不同实现的基础上可能会有所不同。

相比之下,当您使用 orderBy 查询参数时,OData 会准确地告诉您它的行为方式,因为它的行为被定义为规范的一部分。
建议

GraphQL 几乎就像一种编程语言,这使得它非常灵活。它功能强大,但使用它意味着您的应用程序与特定 GraphQL 服务的实现方式紧密耦合。没有办法笼统地描述它是如何工作的。
对于习惯于处理 Web 服务的人来说,GraphQL 也可能有点尴尬,因为为了查询数据,您不需要执行 GET 操作,这就是您从普通 REST Web 服务获取结果的方式。您执行 POST,准确定义要包含在响应中的字段和函数。
因此,尽管 GraphQL 使您能够从元数据中确定哪些字段和函数可用,但您仍然不知道它们在语义上的含义。
消除进入障碍
本文主要关注 API 使用者,但 GraphQL 开发 API 的门槛要低得多。如果你正在做一个快速的项目,GraphQL 可能是要走的路。但是你仍然有你的应用程序与你的实现紧密耦合的问题。
OData 确实很强大,但是伴随着很多繁重的工作,因为您必须遵守标准的所有行为。您必须符合 OData 的最低行为级别。这为服务开发人员设置了更大的进入壁垒。
但是,您可以利用我们的混合技术来生成标准
REST API (OData)。 我们利用我们的混合技术完成所有繁重的工作,以生成标准的 REST API (OData)。 我们使用 OData 完成所有繁重的工作,因此您不必担心遵守标准。 我们为您降低了进入门槛。
此外,还有许多 OData 客户端可以帮助您快速轻松地启动和运行 OData 服务。 如果您正在开发一个新的应用程序,有很多已经支持 OData 的应用程序,以及可以为您提供帮助的 OData 客户端库。
如果您想了解如何嵌入我们的混合技术以使用 OData 通过 REST 公开数据,请立即与我们的一位数据连接专家交谈。
原文:https://www.progress.com/blogs/rest-api-industry-debate-odata-vs-graphq…
- 146 次浏览
【API架构】REST API 设计的原则和最佳实践
这篇最佳实践文章面向对创建 RESTful Web 服务感兴趣的开发人员,这些服务提供跨多个服务套件的高可靠性和一致性; 遵循这些准则; 服务定位于内部和外部客户快速、广泛、公开采用。
这是一个完整的图表,可以轻松理解 REST API 的原理、方法和最佳实践。
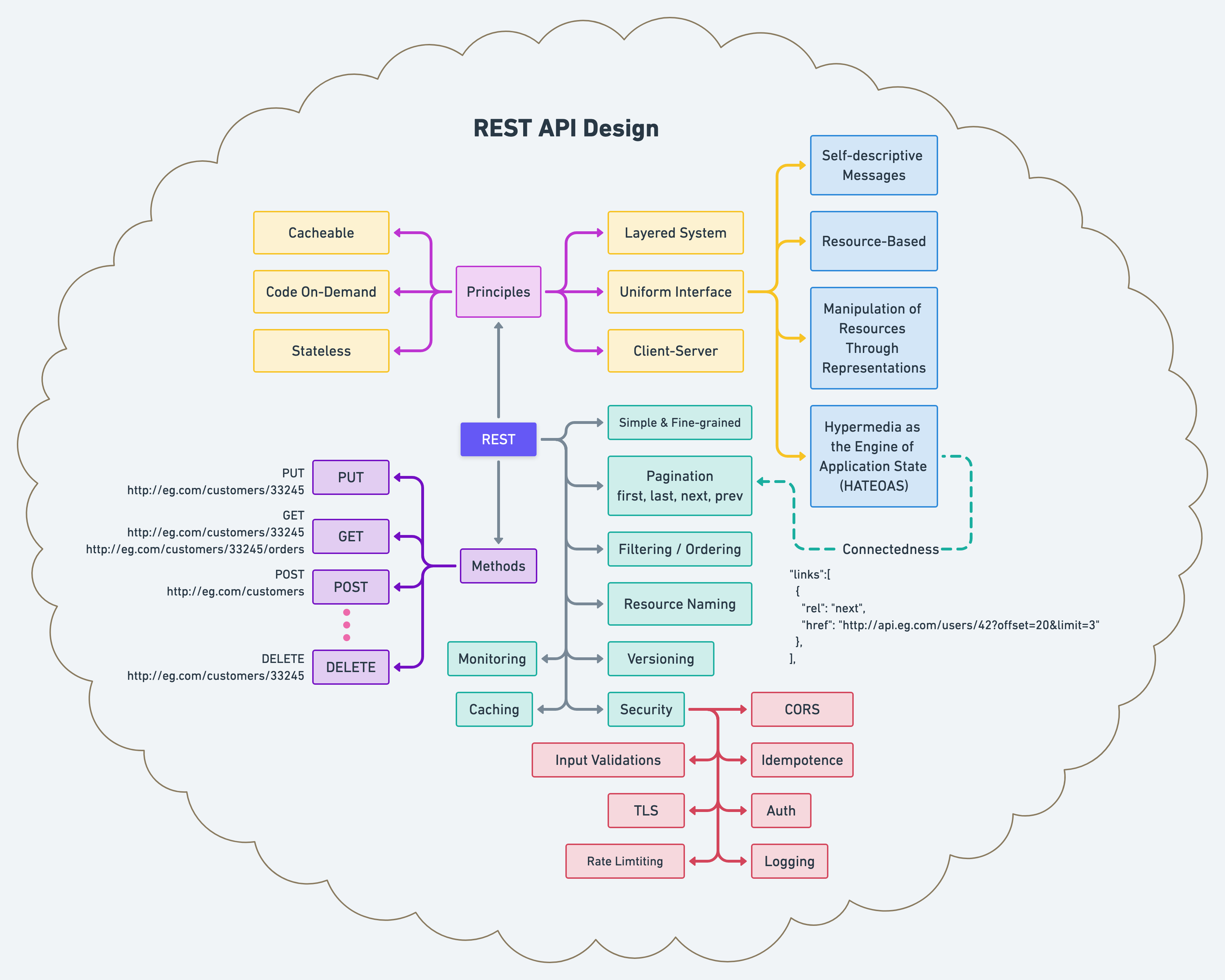 现在,让我们从每个盒子的原理开始详细说明它。
现在,让我们从每个盒子的原理开始详细说明它。
六项原则/约束
- 客户端-服务器:关注点分离是客户端-服务器约束背后的原则。通过将用户界面问题与数据存储问题分开,我们提高了用户界面跨多个平台的可移植性,并通过简化服务器组件提高了可扩展性。
- 无状态:通信必须是无状态的,如客户端-无状态-服务器 (CSS) 风格。从客户端到服务器的每个请求都必须包含理解请求所需的所有信息。因此,会话状态完全保留在客户端上。
- 可缓存:为了提高网络效率,我们添加了缓存约束以形成客户端-缓存-无状态-服务器风格。缓存约束要求数据响应带有隐式或显式标签为可缓存或不可缓存的请求。如果响应是可缓存的,则客户端缓存有权为以后的等效请求重用该响应数据。
- 分层系统:客户端通常无法判断它是直接连接到终端服务器还是沿途的中介。中间服务器可以通过启用负载平衡和提供共享缓存来提高系统可扩展性。层也可以强制执行安全策略。
- 按需代码:REST 允许通过下载和执行小程序或脚本形式的代码来扩展客户端功能。通过减少需要预先实现的功能数量来简化客户端。它允许在部署后下载功能,提高了系统的可扩展性。
- 统一接口:通过将通用性的软件工程原理应用于组件接口,简化了整个系统架构,提高了交互的可见性。实现与它们提供的服务分离,这鼓励了独立的可进化性。 REST 定义了四个接口约束:资源的识别、通过表示的资源操作、自描述消息和作为应用程序状态引擎的超媒体。
- 自描述消息:每条消息都包含足够的信息来描述如何处理消息。
- 基于资源:在请求中使用 URI 作为资源标识符来标识单个资源。资源本身在概念上与返回给客户端的表示分开。
- 通过表示操作资源:当客户端表示资源(包括附加的任何元数据)时,它有足够的信息来修改或删除服务器上的资源,前提是它有这样做的权限。
- 超媒体作为应用程序状态引擎 (HATEOAS):客户端通过正文内容、查询字符串参数、请求标头和请求的 URI(资源名称)传递状态。服务通过正文内容、响应代码和响应头向客户端提供状态。
最佳实践
现在,让我们换个角度来了解 REST 的基本最佳实践,这是每个工程师都应该知道的。
- 保持简单和细粒度:创建模拟系统底层应用程序域或系统数据库架构的 API。最终,您将需要聚合服务——利用多种底层资源来减少闲聊的服务。
- 过滤和排序:对于大型数据集,从带宽的角度来看,限制返回的数据量至关重要。此外,我们可能希望指定要包含在响应中的资源的字段或属性,从而限制返回的数据量。我们最终想要查询特定值并对返回的数据进行排序。
- 版本控制:有很多方法可以破坏合同并对 API 开发中的客户产生负面影响。如果您不确定更改的后果,最好谨慎行事并考虑版本控制。在决定新版本是否合适或对现有表示的修改是否充分和可接受时,需要考虑几个因素。由于维护多个版本变得繁琐、复杂、容易出错且成本高昂,因此对于任何给定资源,您应该支持不超过两个版本。
- 缓存:缓存通过启用系统中的层来消除检索请求数据的远程调用来增强可扩展性。服务通过在响应(如 Cache-Control、Expires、Pragma、Last-Modified 等)上设置标头来提高缓存能力
- 分页:REST 的原则之一是连通性——通过超媒体链接。同时,没有它们,服务仍然有用。当链接在响应中返回时,API 变得更具自我描述性。对于支持分页的响应中返回的集合,“first”、“last”、“next”和“prev”链接至少是有益的。
- 资源命名:当资源命名正确时,API 是直观且易于使用的。做得不好,同样的 API 会让人感觉很笨拙,并且难以使用和理解。 RESTful API 适用于消费者。 URI 的名称和结构应该向这些消费者传达含义。通常很难知道数据边界应该是什么,但是通过了解您的数据,您很可能有能力进行尝试,并将什么作为代表返回给您的客户是有意义的。为您的客户设计,而不是为您的数据设计。
- - 复数:普遍接受的做法是始终在节点名称中使用复数形式,以保持您的 API URI 在所有 HTTP 方法中保持一致。原因是“客户”是服务套件中的一个集合,而 ID(例如 33245)指的是集合中的这些客户之一。
- 监控:确保添加各种监控以提高 API 的质量或性能。数据点可以是响应时间(P50、p90、P99)、状态代码(5XX、4XX 等)、网络带宽等等。
- 安全:
- - 授权/认证:对服务的授权与对任何应用程序的授权没有什么不同。问这个问题,“这个主体对给定资源是否有请求的权限?”
- - CORS:在服务器上实现 CORS 就像在响应中发送额外的 HTTP 标头一样简单,例如 Access-Control-Allow-Origin、Access-Control-Allow-Credentials 等
- - TLS:所有身份验证都应使用 SSL。 OAuth2 需要授权服务器和访问令牌凭据才能使用 TLS。
- - 幂等性:如果执行一次或多次,将产生相同结果的操作。根据其适用的上下文,它可能具有不同的含义。例如,在具有副作用的方法或子程序调用的情况下,这意味着修改后的状态在第一次调用后保持不变。
- - 输入验证:验证服务器上的所有输入。接受“已知”好的输入并拒绝错误的输入,防止 SQL 和 NoSQL 注入,将消息大小限制为字段的确切长度,服务应仅显示一般错误消息等等。
- - 限速:是一种限制网络流量的策略。它限制了某人在特定时间范围内重复操作的频率 - 例如,尝试登录帐户。
- - 记录:确保您不会意外记录任何个人身份信息 (PII)。
至此,我结束了这次学习,我希望你今天学到了一些新东西。请分享给更多的同事或朋友。最后,考虑成为Medium会员,谢谢!
参考:
原文:https://blog.devgenius.io/best-practice-and-cheat-sheet-for-rest-api-de…
- 325 次浏览
【API架构】什么是 REST
REST 是 REpresentational State Transfer 的首字母缩写词,是分布式超媒体系统的一种架构风格。罗伊菲尔丁于 2000 年在他的著名论文中首次提出了它。
与其他架构风格一样,REST 有其指导原则和约束。如果需要将服务接口称为 RESTful,则必须满足这些原则。
符合 REST 架构风格的 Web API(或 Web 服务)是 REST API。
1. REST 的指导原则
RESTful 架构的六个指导原则或约束是:
1.1 统一接口
通过将通用性原则应用于组件接口,我们可以简化整个系统架构并提高交互的可见性。
多个架构约束有助于获得统一的接口并指导组件的行为。
以下四个约束可以实现统一的 REST 接口:
- 资源标识——接口必须唯一标识客户端和服务器之间交互中涉及的每个资源。
- 通过表示(REpresentation)操作资源——资源在服务器响应中应该有统一的表示。 API 使用者应该使用这些表示来修改服务器中的资源状态。
- 自描述消息——每个资源表示应该携带足够的信息来描述如何处理消息。它还应该提供客户端可以对资源执行的附加操作的信息。
- 超媒体作为应用程序状态的引擎——客户端应该只有应用程序的初始 URI。客户端应用程序应该使用超链接动态驱动所有其他资源和交互。
1.2.客户端-服务器
客户端-服务器设计模式强制关注点分离,这有助于客户端和服务器组件独立发展。
通过将用户界面关注点(客户端)与数据存储关注点(服务器)分离,我们提高了用户界面跨多个平台的可移植性,并通过简化服务器组件来提高可扩展性。
在客户端和服务器发展的同时,我们必须确保客户端和服务器之间的接口/契约不会中断。
1.3.无状态
无状态要求从客户端到服务器的每个请求都必须包含理解和完成请求所需的所有信息。
服务器无法利用服务器上任何先前存储的上下文信息。
因此,客户端应用程序必须完全保持会话状态。
1.4.可缓存
可缓存约束要求响应应隐式或显式地将自身标记为可缓存或不可缓存。
如果响应是可缓存的,则客户端应用程序有权在稍后为等效请求和指定时间段重用响应数据。
1.5 分层系统
分层系统样式允许通过约束组件行为来由分层层组成架构。
例如,在分层系统中,每个组件都无法看到它们正在与之交互的直接层之外。
1.6 按需编码(可选)
REST 还允许通过以小程序或脚本的形式下载和执行代码来扩展客户端功能。
下载的代码通过减少需要预先实现的功能数量来简化客户端。服务器可以将部分功能以代码的形式交付给客户端,客户端只需要执行代码即可。
2. 什么是资源?
REST 中信息的关键抽象是资源。我们可以命名的任何信息都可以是资源。例如,REST 资源可以是文档或图像、临时服务、其他资源的集合或非虚拟对象(例如,人)。
资源在任何特定时间的状态称为资源表示。
资源表示包括:
- 数据
- 描述数据的元数据
- 以及可以帮助客户过渡到下一个所需状态的超媒体链接。
一个 REST API 由一组相互关联的资源组成。这组资源称为 REST API 的资源模型。
2.1资源标识符
REST 使用资源标识符来识别客户端和服务器组件之间交互中涉及的每个资源。
2.2.超媒体
表示的数据格式称为媒体类型。媒体类型标识了一个规范,该规范定义了如何处理表示。
RESTful API 看起来像超文本。每个可寻址的信息单元都带有一个地址,可以是显式的(例如,链接和 id 属性),也可以是隐式的(例如,源自媒体类型定义和表示结构)。
超文本(或超媒体)意味着信息和控制的同时呈现,使得信息成为用户(或 automaton)获得选择和选择动作的可供性。
请记住,超文本在浏览器上不需要是 HTML(或 XML 或 JSON)。当机器了解数据格式和关系类型时,它们可以跟踪链接。
— Roy Fielding
2.3.自我描述
此外,资源表示应该是自描述的:客户端不需要知道资源是员工还是设备。它应该根据与资源相关联的媒体类型进行操作。
所以在实践中,我们将创建许多自定义媒体类型——通常是一种媒体类型与一种资源相关联。
每种媒体类型都定义了一个默认处理模型。例如,HTML 定义了超文本的呈现过程以及每个元素周围的浏览器行为。
媒体类型与资源方法没有关系,得到/ put / post / delete / ......除了某些媒体类型元素将定义像href属性的锚元素的进程模型的事实之外,veroct方法,在对应于 CDATA 编码的 href 属性的 URI 上调用检索请求 (GET)。”
3. 资源方法
与 REST 相关的另一件重要事情是资源方法。这些资源方法用于在任何资源的两种状态之间执行所需的转换。
很多人错误地将资源方法与 HTTP 方法(即 GET/PUT/POST/DELETE)相关联。 Roy Fielding 从未提及任何关于在何种条件下使用哪种方法的建议。他所强调的只是它应该是一个统一的界面。
例如,如果我们决定应用程序 API 将使用 HTTP POST 来更新资源——而不是大多数人推荐的 HTTP PUT——那没关系。尽管如此,应用程序界面仍将是 RESTful。
理想情况下,转换资源状态所需的一切都应该是资源表示的一部分——包括所有支持的方法以及它们将以何种形式离开表示。
我们应该输入一个 REST API,除了初始 URI(书签)和一组适合目标受众的标准化媒体类型(即任何可能使用该 API 的客户端都可以理解)之外,没有任何先验知识。
从那时起,所有应用程序状态转换都必须由客户端选择服务器提供的选项来驱动,这些选项存在于接收到的表示中,或者由用户对这些表示的操作暗示。
转换可能由客户对媒体类型和资源通信机制的了解确定(或限制),这两者都可以即时改进(例如,按需编码)。 [这里的失败意味着带外信息正在推动交互而不是超文本。]
4. REST和HTTP不一样
许多人更喜欢将 HTTP 与 REST 进行比较。 REST 和 HTTP 不一样。
REST != HTTP
尽管 REST 还打算使 Web(互联网)更加精简和标准,但 Roy fielding 提倡更严格地使用 REST 原则。这就是人们尝试将 REST 与 Web 进行比较的地方。
Roy fielding 在他的论文中没有提到任何实现方向——包括任何协议偏好甚至 HTTP。到目前为止,我们都在遵守 REST 的六项指导原则,我们可以将其称为我们的接口——RESTful。
五、总结
简而言之,在 REST 架构风格中,数据和功能被视为资源,并使用统一资源标识符 (URI) 进行访问。
通过使用一组简单的、定义明确的操作对资源进行操作。此外,资源必须与其表示分离,以便客户端可以访问各种格式的内容,例如 HTML、XML、纯文本、PDF、JPEG、JSON 等。
客户端和服务器通过使用标准化的接口和协议来交换资源的表示。通常 HTTP 是最常用的协议,但 REST 并不强制要求它。
有关资源的元数据可用并用于控制缓存、检测传输错误、协商适当的表示格式以及执行身份验证或访问控制。
最重要的是,与服务器的每次交互都必须是无状态的。
所有这些原则都有助于 RESTful 应用程序变得简单、轻量和快速。
参考:
- 50 次浏览
【API架构】使用 JSON API 的好处
在 API 工艺的世界里,没有比设计更受热议的领域了。 从 REST、gRPC 到 GraphQL,有许多方法可以设计和标准化 Web API 交互。 今天,我们将注意力转向另一种方法,JSON API,JSONAPI.org 上详细介绍的用于构建 API 的规范。
JSONAPI.org 中描述的 JSON API 非常适合使您的 JSON 响应格式更加一致。 以提高生产力和效率为目标,JSON API 因其可以消除多余的服务器请求的高效缓存功能而受到吹捧。
在这篇文章中,我们将定义 JSON API 是什么,并了解如何使用它来构建高效的 API。 我们将介绍 JSON API 的一些主要优点,并通过 FitBit 的案例研究了解该规范在实践中的应用情况。 希望本概述将介绍 JSON API 的新手,并帮助您判断它是否适合您的 API 场景。
什么是 JSON API (JSONAPI.org)?
JSON API 是一种适用于 HTTP 的格式。它描述了客户端应如何从服务器请求或编辑数据,以及服务器应如何响应所述请求。该规范的一个主要目标(现在是稳定的 v1.0)是优化 HTTP 请求;在请求数量和客户端和服务器之间交换的数据包大小方面。
“JSON API 是一种有线(Wire)协议,用于通过 HTTP 增量获取和更新图形”
——耶胡达·卡茨
在 JSON API 中,客户端和服务器都在请求文档中发送 JSON API 数据,带有以下标头,而不指定媒体类型参数:
Content-Type: application/vnd.api+json
JSON API 表示如何调用资源以及如何共享相关链接。 JSON 对象位于请求的根部,它必须包含资源数据、错误或元信息。数据以及与数据的关系可以通过 GET 调用来获取,如下所示:
GET /articles HTTP/1.1
Accept: application/vnd.api+json
以下是资源类型 `articles` 在 JSON API 响应中的显示方式:
// ...
{
"type": "articles",
"id": "1",
"attributes": {
"title": "Rails is Omakase"
},
"relationships": {
"author": {
"links": {
"self": "/articles/1/relationships/author",
"related": "/articles/1/author"
},
"data": { "type": "people", "id": "9" }
}
}
}
// ...到目前为止,相当标准的东西。 JSON API 支持创建、更新和删除资源的典型 CRUD 流程。 JSON API 将始终向后兼容,它是一个社区驱动的计划,在 Github 上接受拉取请求。
使用 JSON API 的好处
既然我们对 JSON API 是什么有了基本的了解,那么有哪些独特的优势使它脱颖而出?
复合文档
复合文档是 JSON API 中的一项独特功能,允许服务器将相关资源与请求的主要资源一起发送——如果实施得当,这可以减少必要的 HTTP 请求的数量。复合文档使用 include 参数工作,如下所示:
GET https://api.example.com/posts?include=author
这使您能够在初始请求中包含其他资源。
稀疏字段集
如果您使用复合文档来包含相关资源,您可能会遇到回复量大的问题。再一次,JSON API 有一个解决方案。
JSON API 的另一个独特方面是稀疏字段集,它使客户端只能从特定字段请求数据。它通过将要检索的字段添加到具有资源名称和所需字段的 URI 参数来工作。这提供了额外的定制,可以减少臃肿。它看起来像:
GET /articles?include=author&;fields[articles]=title,body&;fields[people]=name HTTP/1.1
Accept: application/vnd.api+json
稀疏字段集是一种标准化方法,它允许客户端仅指定他们希望从对象中包含在响应中的属性。 使用稀疏字段集,您只能获得所需的字段,提供独特的定制潜力,这对精益数据共享环境很有吸引力。
可选性
JSONAPI.org 中的许多功能都是可选的;您可以关闭或打开它们。这些功能使客户能够决定接受哪些资源,从而很好地适应精益的移动环境。让客户就如何检索和处理数据达成一致是有帮助的,因为它消除了冗余和优化以减少膨胀。
优化功能
JSON API 配备了许多功能来优化 API 返回包。 JSON API 中的特殊服务器端操作包括排序和分页;将返回资源的数量限制为子集的能力,包括 first、last、next 和 prev 链接。
缓存
在他的演讲中,Lee 强调了定义良好的资源如何提高缓存能力,从而提高最终用户的“感知速度”。
“因为数据变化影响的资源更少,所以数据变化时失效的资源更少”
在 JSON API 用例中,缓存本质上是内置在 HTTP 中的。由于使用 JSON API 的客户端以相同的方式访问数据,因此他们不需要将数据存储在不同的位置。这种设计可能需要转变思想,但如果使用得当,可以带来显着的优化优势。
JSON API 如何在实践中使用:FitBit 案例研究
让我们看看 JSON API 如何在实践中实现以设计高效的 API,使用 FitBit 作为现实生活中的案例研究。
Jeremiah Lee 在 FitBit 领导 API 开发 4 年,在此期间他参与了他们的 JSON API 采用。健身可穿戴公司 FitBit 拥有蓬勃发展的 API 程序;在每年 40 亿次请求中,有 1/4 是通过第三方应用程序完成的,收入可观。
符合 API 风格有助于标准化客户端
一个常见的问题是当不同的客户端类型偏好不同的方法来从服务器检索数据时。围绕功能区域形成的工程团队通常一次一个平台地逐步实施新功能,并在每个客户端中找到相反的约束。
Lee 描述了 FitBit 团队如何拥有四个主要客户:Android、iOS、Windows 和 Web。一个主要问题是 Android 和 iOS 对 API 应该如何运行有非常不同的想法。 iOS 更喜欢较少的网络请求和较大的 API 响应,而 Android 更喜欢更多的网络请求和较小的 API 响应。
为了将这些约束规范化为一致的数据模型,团队必须首先解决请求数量和请求大小之间的争论。 FitBit 团队在具有敌对数据网络的移动环境中工作,无法依赖理想的客户端连接。
相信 HTTP/2、TLS 1.3 和改进的 LTE 网络的日益普及,FitBit 团队决定他们可以减少请求的开销、发出并发请求并减少安全延迟问题,同时相信更多弹性连接。这将导致他们采用更小的资源和许多轻量级的 HTTP 请求。
JSON API 帮助创建一致的数据模型
“如果没有明确的指导,数据模型可能会变得混乱。”
——耶利米·李
Lee 描述了在 FitBit,他们的 API 如何开始类似于“视图模型”;现有端点变得超载,数据相关性松散,而不是范围广泛。团队正在根据用户体验视图重载端点。
随着客户体验随着时间的推移而发展,团队正在以任意方式拆分数据。由于没有权威或风格可以遵循,这造成了很多不一致。客户端和服务器数据模型之间的错位造成了问题。团队需要就如何检索数据和处理数据达成一致,并且需要能够以很少的开销检查数据更改。
他们倾向于使用 JSON API 来规范化他们的数据。使用 JSON API 定义数据之间关系的能力,他们能够建立客户端-服务器通信期望。
JSON API 有助于保持同步
FitBit 案例中的另一个问题是与服务器保持同步。他们的设备需要经常与服务器同步,并且这些数据也可以被第三方应用程序修改。
这些更改必须非常快速地反映在所有 API 客户端中。 JSON API 利用的 HTTP 缓存使他们能够防止召回过时的数据,从而减少冗余并提高最终用户的感知速度。根据 Lee 的说法,这真的开始在一个应用程序中叠加多种体验。
比较 JSON API 和 GraphQL
既然我们本质上是在讨论使用图形,为什么不使用 GraphQL 呢?虽然您可以使用 GraphQL 实现许多相同的功能,但 Lee 看到了采用 JSON API 的两个主要好处:分页和可缓存性。
分页是 GraphQL 没有专门解决的一个领域。或者,当客户端请求它们时,JSON API 会向客户端提供诸如 next 和 prev 之类的链接。由于 GraphQL 中的分页完全由客户端处理,Lee 认为这很不幸,因为客户端可能会在不知不觉中进行昂贵、耗时的数据库查询。
GraphQL 也没有利用 HTTP 缓存功能,因为它与协议无关。由于没有建议的通用方法,这意味着每个 GraphQL API 处理缓存的方式都会略有不同。
“我个人认为缓存对于客户端性能考虑来说太重要了,不能事后考虑”
——耶利米·李
Lee 还指出,使用 JSON API 意味着开发人员不必采用像 GraphQL 这样的另一个工具链,而是可以继续使用他们很可能已经熟悉的技术。
GraphQL 的许多好处,例如查询效率和减少往返调用,都可以在 JSON API 中使用稀疏字段集和复合文档进行匹配。 JSON API 因此可以提供与 GraphQL 相同的功能。
考虑将 JSON API 用于“实用”的 API 设计
JSON API LogoJeremiah Lee 称其为“务实”,我们必须同意。如上所述,让客户端和服务器共享一个通用数据模型(如 JSON API)有很多优点。
“JSONAPI.org 规范应该是您的智能默认设置”
——耶利米·李
虽然 JSON API 并不适合所有情况,但许多人声称它是客户端和服务器通过 HTTP 共享通用数据接口的一种很好的默认方式。凭借上面列出的优势,以及它的健康采用,JSON API 似乎是 API 风格的有力竞争者。
我们鼓励您自己阅读规范。您如何看待 JSONAPI.org?您使用什么规范来定义您的 API 和数据模型?
资源
- Jeremiah Lee Slides with commentary
- Introduction to the JSON:API spec: Presentation by Marco Otte-Witte
- JSON API Homepage
- JSON API Specification
- JSON API Twitter
- JSON API Github
- JSON Patch: Can be used for incremental udpates
原文:https://nordicapis.com/the-benefits-of-using-json-api/
本文:
- 79 次浏览
【Open API】eBay为其所有RESTful公共api提供了OpenAPI规范(OAS)
今天,eBay宣布他们正在利用OpenAPI规范(OAS)来实现它所有的RESTful公共api。使用OpenAPI,开发人员可以下载一个eBay OpenAPI契约,生成代码并在几分钟内成功调用一个eBay API。api在eBay的开发者生态系统中扮演着重要的角色,帮助公司建立并向买家和卖家提供最好的体验。
“考虑到我们对OpenAPI周围的开发者生态系统的需求和了解,使用OpenAPI规范是一个一致的选择,”eBay Portland的总经理盖尔·弗雷德里克(Gail Frederick)和eBay副总裁开发生态系统说。“OpenAPI规范实际上是描述api的标准,在eBay基于微服务的新体系结构中扮演着关键角色。”
作为OpenAPI计划的成员和主席,我看到越来越多的公司转向基于分布式和微服务的体系结构,因为为用户构建高质量的体验并更快地将产品或服务推向市场是任何企业成功的关键。为支持这种转换而创建的技术和工具主要是由开放协作构建的,跨越了像Node这样的应用程序开发技术。像Kubernetes这样的容器编排。由于api是分布式组件之间的“粘合剂”,因此OAS标准在这一转换中扮演了中心角色。
易趣就是这样。随着eBay从单一的、集中的体系结构过渡到分布式的微服务体系结构,公司需要改进服务契约的开发、测试、发布以及与API规范集成的方式。
该公司对这种转变有一系列需求:
API契约需要满足跨不同技术堆栈的无缝探索和集成的需求,成为行业标准,并具有丰富的特性,以补充我们的技术标准和治理模型,因此需要探索新的规范。
主要的标准是人类和机器可读的规范、语言无关性的规范、厂商中立的规范和开源的规范。
Shekhar Banerjee, MTS高级架构师,eBay
由于其工具支持、完全可定制的堆栈、代码优先和契约优先的API开发方法,以及最重要的是,OpenAPI作为由OpenAPI首创的开放协作所领导的标准继续发展,OAS成为了一致的选择。迁移到OAS进一步推进了eBay对其开发者生态系统的使命,即通过不再使用sdk和花费更多时间编写API客户端代码来提高开发者的效率和生产力。
自2017年8月以来,eBay一直是OpenAPI计划的成员之一,也是业内最早发布基于OpenAPI 3.0规范的合同的公司之一。我们很高兴看到eBay继续支持我们的联盟以及其他开放合作项目,包括云本地计算基金会(CNCF)。
- 139 次浏览
【REST架构】OData、JsonAPI、GraphQL 有什么区别?
问题:
我在职业生涯中使用过很多 OData,现在我来自不同团队的同事中很少有人建议我们迁移到 JsonAPI 和 GraphQL,因为它与 Microsoft 无关。 我对这两种查询语言都没有太多经验。 据我所知,OData 是 Salesforce、IBM、Microsoft 使用的标准,并且非常成熟。 为什么要切换到 JsonAPI 和/或 GraphQL? 有真正的好处吗? JsonAPI 和 GraphQL 是新标准吗? 根据受欢迎程度更改公共 api 实现似乎没有用,尤其是在没有太大好处的情况下。
有人可以启发我吗?
答案:
OData 是与 JSON API 类似的规范。它们都描述了用于创建和使用 RESTful API 的标准协议。 GraphQL 是一种完全不同的 API 设计方法,并指定了一种查询 API 资源的不同方式。
OData:
自 2007 年以来在 Microsoft 设计和开发,由 OASIS 联盟标准化。最新版本 V4 已提交给 ISO/IEC JTC 1 以作为国际标准获得批准。技术委员会 (TC) 中的公司包括 CA Technologies、Citrix、IBM、Microsoft、Progress、Red Hat、SAP 和 SDL。
有许多用于流行编程语言的库 - .NET、Java、JavaScript、PHP 和 Ruby。该规范允许动态资源,并且有一个服务文档列出了所有 API 端点供客户端发现。此外,还有一个描述架构的元数据文档。
JSON API:
JSON API 最初由 Yehuda Katz 于 2013 年 5 月起草。这个初稿是从 Ember Data 的 REST 适配器隐式定义的 JSON 传输中提取的。该规范的当前稳定版本是 1.0。 JSON API 规范适用于大多数编程语言,包括客户端和服务器端。
JSON API 通过 JSON 文档中的链接属性支持 HATEOAS。其他功能包括分页、排序、过滤和关系。 JSON API 服务器生成的 JSON 文档非常冗长,带有许多嵌套属性。
GraphQL:
自 2015 年以来在 Facebook 开发。该规范仍是工作草案。它在 React 爱好者中很受欢迎,主要与 React 或 Vue.js 结合使用。与 GraphQL 类似的是 Falcor,它也相对较新。
虽然 GraphQL 使用 HTTP,但它不被视为 REST,而是 REST 的替代品。相反,它在单个(虚拟)JSON 文档中使用查询/响应模型。这种新模型更适合开发人员使用,但它相对于 REST 的优势是值得商榷的。鉴于其年轻,生态系统尚未成熟。
为了清楚和完整起见,我将 OpenAPI 包括在列表中,尽管它并不完全是 API 规范。这可能会让一些人感到困惑。 OpenAPI 标准是一种与语言无关的标准,用于描述和定义 API。例如,您的 API 可以遵循上述标准之一(不包括 GraphQL),也可以使用 OpenAPI 3 进行记录。
OpenAPI(又名 Swagger):
作为 OpenAPI Initiative 和 Linux 基金会的一部分开发。得到 Google、Microsoft、IBM、SAP、Oracle、Ebay 和 PayPal 等大型科技公司的支持。该规范的当前版本是 3.1.0。大多数编程语言都有实现,以及许多其他工具,如 Web UI 生成器等。
使用 OpenAPI 等规范获得的最好的东西是围绕它们的工具——API 文档页面的生成器、客户端 SDK 代码的生成器等。
这个标准可能是当今最常用于 API 声明、文档和代码生成的标准。它还受到云提供商(如 Amazon Web Services)在其 API 网关中的支持。
总之,OData 和 JSON API 都是 JSON 数据格式,它们在数据周围添加上下文和特征(例如链接),GraphQL 是一种完全不同的查询和变异 JSON 数据的新方法,而 OpenAPI 是声明和记录任何数据的标准方法RESTful API。
我个人的看法:
如您所见,有很多 RESTful 规范,而不是单一的通用标准。我同意 xumix 的观点——他们似乎都患有“这里没有发明”综合症。选择上述任何一项的好处都很小,特别是如果您的项目是中小型项目。您的 API 实现的规范是否重要?应该不多吧。只需专注于构建一致且记录良好的 API。
原文:https://stackoverflow.com/questions/44711161/what-is-the-difference-bet…
本文:
- 99 次浏览
【应用架构】有原则GraphQL
视频号

微信公众号

知识星球

尽管名为GraphQL,但它并不是一种简单的查询语言。这是一个全面解决现代应用与云服务之间连接问题的方案。因此,它构成了现代应用程序开发堆栈中一个新的重要层的基础:数据图。这个新层将公司的所有应用程序数据和服务集中在一个地方,具有一致的、安全的、易用的界面,这样任何人都可以在最小的摩擦下使用它。
在Apollo,我们从2015年就开始构建行业领先的数据图技术,我们估计我们的软件现在在超过90%的GraphQL实现中使用。多年来,我们与各种规模的公司中实现GraphQL的开发人员进行了数千次对话。我们希望分享我们所学到的知识,因此我们将他们的经验提炼为一组创建、维护和操作数据图的最佳实践。我们在这里将它们以10个GraphQL原则的形式呈现,分为三类,其格式受到了Twelve Factor应用程序的启发。
完整性原则
确保图定义良好、稳定且一致
1. 一个图
您的公司应该有一个统一的图表,而不是由每个团队创建的多个图表。
通过一个图形,你可以最大化GraphQL的价值:
- 可以通过一个查询访问更多的数据和服务
- 代码、查询、技能和经验可以跨团队移植
- 所有图形用户都可以查看的所有可用数据的中心目录
- 实现成本最小化,因为图形实现工作不重复
- 图的中央管理——例如,统一的访问控制策略——成为可能
当团队在没有协调工作的情况下创建他们自己的图表时,他们的图表几乎不可避免地会开始重叠,以不兼容的方式向图表添加相同的数据。在最好的情况下,这是昂贵的返工;在最坏的情况下,它会造成混乱。在公司的数据图采用过程中,应该尽可能早地遵循这一原则。
2. 联合实施
尽管只有一个图,但该图的实现应该跨多个团队联合。
如果没有高度专门化的基础设施,单片架构很难扩展,数据图也不例外。与在单个代码库中实现组织的整个数据图层不同,定义和实现图的责任应该划分到多个团队中。每个团队都应该负责维护公开他们的数据和服务的模式部分,同时拥有独立开发和在他们自己的发布周期上操作的灵活性。
这维护了图的单一、统一视图的价值,同时保持了整个公司的开发工作的分离。
3.跟踪注册表中的模式
应该有一个单一的事实来源来记录和跟踪图表。
就像在版本控制系统中跟踪源代码很重要一样,在模式注册表中跟踪图形的定义也很重要。您的公司应该有一个模式注册表,它是图形的权威定义,而不是依赖于当前正在运行的进程或在开发人员的笔记本上检入的任何代码。像一个源代码控制系统,注册表的模式存储修改图,谁让他们的历史,它应该理解图像的多个版本的概念(例如,登台和生产,或不同的开发分支)的方式相似的软件开发过程。
模式注册中心应该成为系统的中心,为开发人员工具、工作流或任何业务流程提供支持,这些业务流程将受益于对数据图的感知,以及对数据图的任何实际或建议的更改。
敏捷原则
快速展开图形并不断调整它以适应不断变化的需求
4. 抽象的,需求模式法
模式应该作为一个抽象层,为使用者提供灵活性,同时隐藏服务实现细节。
GraphQL的很大一部分价值在于提供了服务和使用者之间的抽象,因此该模式不应该与特定的服务实现或特定的使用者紧密耦合,因为它们现在已经存在了。通过将实现细节排除在模式之外,应该可以重构实现图的服务——例如,从一个整体转换到微服务,或者改变服务实现的语言——而不影响该领域的应用程序。同样,模式不应该与特定应用程序获取数据的方式紧密耦合。如果新应用程序的功能与现有的应用程序类似,那么应该可以编写新应用程序,而对图形的修改应该最小。
要实现这一点,可以使用面向需求的模式的标准:该模式侧重于为应用程序开发人员提供良好的开发体验,并根据现有图构建新功能。以这个标准为目标将有助于防止图与将来可能更改的服务实现耦合,并有助于增加添加到图中的每个字段的重用价值。
5. 使用敏捷方法进行模式开发
模式应该根据实际需求逐步构建,并随着时间的推移平稳地演进。
提前定义组织所有数据的“完美模式”可能很有诱惑力。相反,真正使模式有价值的是它遵循实际用户需求的程度,而这些需求从来都不是预先完全知道的,并且是不断变化的。实现“完美模式”的真正途径是使图易于根据实际需要进行演化。
不应该推测性地将字段添加到模式中。理想情况下,每个字段应该只在响应消费者对附加功能的具体需求时添加,而设计的目的是最大限度地让其他有类似需求的消费者重用。
更新图形应该是一个连续的过程。与其每隔6个月或12个月发布一个新的图形“版本”,不如在必要时每天多次更改图形。可以随时添加新字段。要删除字段,首先要弃用它,然后在没有使用者使用它时删除它。模式注册表支持图形的这种敏捷演化,以及使每个人都知道可能影响他们的更改的流程和工具。这确保了只有完全审查过的变更才能投入生产。
6. 迭代地提高性能
性能管理应该是一个连续的、数据驱动的过程,能够平稳地适应不断变化的查询负载和服务实现。
数据图层是讨论服务团队和使用其服务的应用程序开发人员之间的性能和容量的最佳位置。这个对话应该是一个持续的过程,它使服务开发人员能够持续地、主动地了解消费者打算用他们的服务做什么。
与其优化图形的每一种可能的用法,不如将重点放在支持生产中所需的实际查询形状上。工具应该提取提议的新查询形状,并在它们投入生产之前将它们呈现给所有受影响的服务团队,这些团队具有延迟需求和预计的查询量。一旦查询进入生产环境,就应该持续监视它的性能。如果遵循这一原则,那么很容易将问题追溯到行为不符合预期的服务。
7. 使用图形元数据来增强开发人员的能力
开发人员应该在整个开发过程中对图形有丰富的认识。
GraphQL的主要价值在于它为开发人员提供了巨大的生产力提升。为了最大限度地提高性能,开发人员的工具应该让他们对数据图有普遍的认识,并贯穿于他们在整个开发生命周期中使用的所有工具。
每当开发人员进行与管理数据或连接到服务相关的工作时,他们的工具应该将关于图的实时信息放在手边。这些信息应该是最新的,工具应该是高度智能的,以有用和强大的方式将图形感知应用到当前的情况。如果处理得当,不仅会提高开发人员的工作效率和幸福感,而且GraphQL还会成为连接前端和后端团队的纽带,在整个开发生命周期中实现无缝对话。
一些数据图形感知工具的功能的实际例子包括:
- 开发人员可以在他们的编辑器中享受所有可用图形数据和服务的实时文档,而且总是最新的。
- 有关废弃字段的信息可以传播到使用这些字段的开发人员的编辑器中,并提供建议的替代方案
- 根据实时生产数据,在开发人员输入查询时,可以向他们显示查询的估计成本(以延迟或服务器资源计算)。
- 运维团队可以跟踪后端服务的负载,将其追溯到特定的应用程序、版本、功能,甚至代码行,从而全面了解开发人员如何使用其服务。
- 当服务开发人员对其模式进行更改时,可以作为持续集成过程的一部分自动确定更改的影响。如果更改会破坏现有的客户机(根据重播最近的生产使用情况确定),那么服务开发人员可以确定将受到影响的精确客户机、版本和开发人员。
- 当应用程序开发人员构建特性时,可以从他们的代码中提取支持这些特性的新查询,并与操作团队共享。有了这种认识,操作团队就可以提前提供所需的能力,并在开发过程的早期介入,如果查询不能在预期的范围内得到批准的话。
- 当应用程序是用类型化语言(如TypeScript、Java或Swift)开发的时候,类型信息可以从服务类型声明一直传播到应用程序的每一行代码,从而确保全堆栈类型的正确性和对错误的即时反馈。
操作原则
安全地将图部署到大规模生产环境中
8. 存取和需求控制
在每个客户端基础上授予对图形的访问权,并管理客户端可以访问什么以及如何访问它。
数据图中的授权具有两个同样重要的方面:访问控制和需求控制,前者表示允许用户访问哪些对象和字段,后者表示允许用户如何(以及多少)访问这些资源。虽然经常讨论访问控制,但也需要注意需求控制,因为它在GraphQL的任何生产部署中都是至关重要的。允许用户不考虑成本执行任何可能的查询是错误的,因为用户没有能力管理它对生产系统的影响。访问和需求控制都必须在充分了解数据图的语义和性能的情况下执行。在不分析实际发送的查询的情况下,仅将用户限制在每分钟特定的查询数量是不够的,因为查询可以访问大量的服务,而且查询的成本可以在多个数量级上变化。
验证在数据图也有两个方面:请求操作的应用程序,并使用这个应用程序的人。虽然访问控制中心的人使用应用程序,适当的需求控制至少取决于每个应用控制人均控制,应用程序的开发人员,而不是应用程序的用户负责应用程序所使用的特定查询的形状做它的工作。
控制需求的最佳方法包括:
- 当不受信任的用户访问生产系统时,他们应该只发送由经过验证的应用程序开发人员预先注册的查询,而不是允许他们使用应用程序的凭据发送任意查询。对于只分发给可信用户的内部应用程序来说,这有时并不严格。
- 对于预计将发送大量查询的应用程序,团队应该设计一个与更广泛的软件开发周期相一致的查询审批工作流,以便在查询进入生产之前对其进行审查。这可以确保它们不会获取不必要的数据,并且服务器的容量可以支持它们。
- 作为第二道防线,在执行查询之前估计它的成本,并为每个用户和每个应用程序制定查询成本预算,可以防止过度使用预先注册的操作,或者在无法进行预先注册的操作的情况下。
- 开发人员应该能够禁用特定应用程序在生产环境中发送特定查询的能力,无论是作为紧急情况下的安全网,还是发现第三方应用程序以不可接受的方式使用数据图。
9. 结构化的日志
捕获所有图形操作的结构化日志,并利用它们作为了解图形用法的主要工具。
可以捕获关于在图上执行的每个操作(读或写)的大量信息:哪些用户和应用程序执行了该操作、访问了哪些字段、实际执行操作的方式、如何执行操作,等等。这些资料非常宝贵,应当有系统地加以收集,供以后使用。它应该以结构化的、机器可读的格式捕获,而不是文本日志,这样就可以为尽可能多的目的利用它。
图形操作的记录称为跟踪。跟踪应该召集所有相关信息关于一个操作在一个地方,包括业务信息(谁做了手术,访问或改变,哪些功能的应用程序由哪些开发人员,是否成功,如何执行)和纯技术信息(后端服务联系,每个服务如何导致延迟,是否使用缓存)。
因为跟踪真正地捕获了一个图是如何被使用的,它们可以被用于广泛的用途:
- 了解是否可以删除废弃字段,或者是否可以删除仍在访问它的特定客户端,以及它们的重要性
- 根据实时的生产数据,实时地预测一个查询需要多长时间执行,因为开发人员正在他们的IDE中输入查询
- 自动检测生产中的问题(如增加的延迟或错误率)并诊断其根本原因
- 提供权威的审计跟踪,显示哪些用户访问了特定的记录
- 为商业智能查询提供支持(当天气炎热时,人们会在自己所在的地方更频繁地搜索冰激凌吗?)
- 根据API使用情况为合作伙伴生成发票,可以根据访问的特定字段或消耗的资源创建详细的成本模型
所有图形操作的跟踪应该集中在一个中心位置,这样就有了一个权威的跟踪流。然后,这个流可以通过管道进入其他可观察性系统(可能在对不支持graphql的现有系统进行简单转换之后),或者存储在一个或多个数据仓库中供以后使用(根据预算、用例和规模的需要进行汇总和取样)。
10. 将GraphQL层与服务层分离
采用分层架构,将数据图功能分解为单独的层,而不是整合到每个服务中。
在大多数API技术中,客户机不直接与服务器通信,除非在开发中。取而代之的是一种分层的方法,其中将一些问题(如负载平衡、缓存、服务位置或API密钥管理)分解为单独的一层。然后,可以将此层与后端服务分开设计、操作和伸缩。
GraphQL也不例外。与其将一个完整的数据图系统所需的所有功能都放到每个服务中,不如将大多数数据图功能分解成位于客户端和服务之间的独立层,让每个服务专注于服务于实际的客户端请求。这一层可以由多个进程组成,执行访问和需求控制、联合、跟踪收集和潜在的缓存等功能。这一层的某些部分是特定于graphql的,需要深入了解数据图,而负载平衡和客户端身份验证等其他功能可能由现有系统来执行。
即使在只有一个应用程序和一个服务的简单场景中,这个单独的层也是有价值的;否则,属于中间层的功能必须在服务器中实现。在复杂的应用程序中,这一层可能开始看起来像一个地理上分布的系统:通过多个入口点接收传入的查询,处理其中一些在网络的边缘边缘缓存的好处,路由子组件查询多个数据中心的公共云,民营,或由合作伙伴,最后这些组件组装成一个查询结果,同时记录跟踪,这是纪念整个操作。
在某些情况下,此数据图层将使用GraphQL与后端服务通信。但是,最常见的情况是,后端服务保持不变,并继续被它们现有的api(如REST、SOAP、gRPC、Thrift甚至SQL)访问,这些api与数据图对象之间的映射由构成数据图层一部分的服务器完成。
原文:https://principledgraphql.com
讨论:请加入知识星球【首席架构师圈】
- 60 次浏览
Web应用架构
- 338 次浏览
【web应用架构】web 框架那个更快
ℹ️ Updated on 2020-07-18 ℹ️
Benchmarking with wrk
- Threads : 8
- Timeout : 8
- Duration : 15s (seconds)
ℹ️ Sorted by max req/s on concurrency 64 ℹ️
| Language | Framework | Speed (64) | Speed (256) | Speed (512) | |
|---|---|---|---|---|---|
| 1 | php (7.4) | mark (1.1) | 167 900 | 172 088 | 173 349 |
| 2 | nim (1.2) | httpbeast (0.2) | 165 808 | 197 548 | 200 123 |
| 3 | javascript (13.14) | nanoexpress-pro (2.2) | 159 374 | 203 682 | 209 592 |
| 4 | go (1.14) | fasthttp (1.15) | 158 244 | 170 931 | 174 931 |
| 5 | nim (1.2) | whip (0.2) | 157 852 | 185 577 | 186 965 |
| 6 | go (1.14) | atreugo (11.4) | 153 402 | 165 386 | 169 576 |
| 7 | go (1.14) | router (1.2) | 152 854 | 164 684 | 169 379 |
| 8 | go (1.14) | fasthttprouter (0.1) | 152 460 | 164 763 | 168 679 |
| 9 | javascript (13.14) | sifrr (0.0) | 151 082 | 193 326 | 196 249 |
| 10 | go (1.14) | gorouter-fasthttp (4.4) | 150 957 | 162 632 | 166 975 |
| 11 | go (1.14) | gearbox (1.0) | 149 964 | 161 740 | 165 613 |
| 12 | java (11) | rapidoid (5.5) | 148 731 | 176 813 | 177 967 |
| 13 | java (11) | jooby (2.8) | 144 563 | 187 072 | 191 087 |
| 14 | kotlin (1.3) | kooby (2.8) | 143 410 | 184 223 | 188 305 |
| 15 | c (11) | agoo-c (0.7) | 143 179 | 189 183 | 191 403 |
| 16 | java (11) | light-4j (2.0) | 141 210 | 176 879 | 181 302 |
| 17 | crystal (0.35) | router.cr (0.2) | 139 828 | 167 278 | 166 448 |
| 18 | crystal (0.35) | toro (0.4) | 139 397 | 169 974 | 169 052 |
| 19 | crystal (0.35) | spider-gazelle (3.3) | 138 223 | 165 592 | 164 228 |
| 20 | php (7.4) | workerman (4.0) | 137 200 | 167 944 | 170 403 |
| 21 | crystal (0.35) | kemal (0.26) | 132 422 | 156 420 | 154 940 |
| 22 | crystal (0.35) | grip (0.28) | 130 657 | 156 505 | 154 662 |
| 23 | nim (1.2) | jester (0.4) | 130 311 | 152 825 | 154 276 |
| 24 | rust (1.45) | actix (2.0) | 125 383 | 136 847 | 133 849 |
| 25 | crystal (0.35) | amber (0.35) | 125 178 | 144 644 | 143 136 |
| 26 | php (7.4) | simps (1.0) | 106 139 | 161 415 | 178 670 |
| 27 | go (1.14) | clevergo (0.3) | 104 631 | 106 188 | 110 306 |
| 28 | go (1.14) | rte (0.0) | 104 620 | 106 149 | 110 679 |
| 29 | java (11) | act (1.9) | 104 185 | 134 428 | 135 251 |
| 30 | go (1.14) | echo (4.1) | 103 125 | 105 277 | 109 307 |
| 31 | go (1.14) | httprouter (1.3) | 103 050 | 104 779 | 108 820 |
| 32 | go (1.14) | fiber (1.12) | 102 607 | 147 858 | 158 998 |
| 33 | go (1.14) | gin (1.6) | 101 067 | 106 832 | 110 609 |
| 34 | go (1.14) | chi (4.1) | 98 634 | 99 431 | 103 165 |
| 35 | go (1.14) | gorouter (4.4) | 98 633 | 103 964 | 107 547 |
| 36 | go (1.14) | aero (1.3) | 97 903 | 99 607 | 103 562 |
| 37 | go (1.14) | violetear (7.0) | 96 608 | 97 463 | 101 120 |
| 38 | go (1.14) | webgo (4.1) | 95 193 | 96 077 | 99 893 |
| 39 | csharp (8.0) | aspnetcore (3.1) | 94 733 | 108 017 | 110 905 |
| 40 | go (1.14) | goroute (0.0) | 94 052 | 93 621 | 97 834 |
| 41 | go (1.14) | kami (2.2) | 93 292 | 100 148 | 102 552 |
| 42 | fsharp (4.7) | falco (1.2) | 92 339 | 106 072 | 108 406 |
| 43 | go (1.14) | gorilla-mux (1.7) | 92 088 | 90 908 | 95 179 |
| 44 | fsharp (4.7) | frank (6.1) | 91 990 | 104 069 | 106 111 |
| 45 | go (1.14) | beego (1.12) | 91 186 | 96 653 | 100 384 |
| 46 | javascript (13.14) | polkadot (1.0) | 90 657 | 102 551 | 103 376 |
| 47 | crystal (0.35) | athena (0.9) | 86 509 | 105 308 | 104 455 |
| 48 | c (99) | kore (3.3) | 85 960 | 119 082 | 141 485 |
| 49 | javascript (13.14) | 0http (2.5) | 85 365 | 98 058 | 99 126 |
| 50 | javascript (13.14) | restana (4.6) | 81 941 | 91 578 | 91 555 |
| 51 | cpp (14/17) | drogon (1.0) | 81 662 | 87 368 | 90 524 |
| 52 | javascript (13.14) | polka (0.5) | 80 601 | 88 104 | 87 295 |
| 53 | go (1.14) | air (0.19) | 80 321 | 81 983 | 85 383 |
| 54 | javascript (13.14) | rayo (1.3) | 78 392 | 85 836 | 84 595 |
| 55 | javascript (13.14) | fastify (3.1) | 77 280 | 86 412 | 85 020 |
| 56 | elixir (1.1) | cowboy_stream (2.8) | 77 117 | 79 037 | 77 251 |
| 57 | php (7.4) | one (2.0) | 76 042 | 91 735 | 96 299 |
| 58 | ruby (2.7) | agoo (2.13) | 74 106 | 110 573 | 123 845 |
| 59 | go (1.14) | gf (1.13) | 73 254 | 80 074 | 81 884 |
| 60 | scala (2.13) | akkahttp (10.1) | 73 141 | 85 596 | 82 421 |
| 61 | csharp (8.0) | carter (5.1) | 73 130 | 74 246 | 66 783 |
| 62 | swift (5.2) | perfect (3.1) | 72 461 | 82 137 | 87 742 |
| 63 | php (7.4) | hyperf (2.0) | 71 889 | 90 300 | 94 927 |
| 64 | java (11) | javalin (3.9) | 71 495 | 79 141 | 78 295 |
| 65 | javascript (13.14) | muneem (2.4) | 70 256 | 77 801 | 76 235 |
| 66 | python (3.8) | falcon (2.0) | 68 617 | 75 668 | 76 314 |
| 67 | kotlin (1.3) | ktor (1.2) | 67 121 | 88 190 | 88 361 |
| 68 | fsharp (4.7) | saturn (0.14) | 66 497 | 62 731 | 55 831 |
| 69 | java (11) | spring-boot (2.3) | 65 455 | 71 623 | 71 444 |
| 70 | javascript (13.14) | foxify (0.1) | 64 148 | 70 024 | 69 199 |
| 71 | php (7.4) | comet (0.8) | 62 612 | 67 405 | 67 497 |
| 72 | go (1.14) | mars (1.0) | 59 797 | 60 607 | 64 349 |
| 73 | javascript (13.14) | koa (2.13) | 59 674 | 65 111 | 63 278 |
| 74 | java (11) | micronaut (1.2) | 57 662 | 66 616 | 65 711 |
| 75 | fsharp (4.7) | websharper (4.6) | 56 923 | 58 362 | 54 924 |
| 76 | javascript (13.14) | iotjs-express (0.0) | 56 004 | 58 967 | 59 745 |
| 77 | haskell (8.8) | scotty (0.12) | 55 879 | 62 428 | 66 645 |
| 78 | python (3.8) | bottle (0.12) | 55 116 | 60 823 | 60 007 |
| 79 | clojure (1.1) | coast (1.0) | 53 021 | 54 762 | 54 992 |
| 80 | javascript (13.14) | feathersjs (4.5) | 53 012 | 56 219 | 55 119 |
| 81 | javascript (13.14) | express (4.17) | 52 902 | 56 723 | 55 330 |
| 82 | rust (1.45) | nickel (0.11) | 52 618 | 48 793 | 51 696 |
| 83 | python (3.8) | apidaora (0.27) | 51 515 | 59 053 | 59 192 |
| 84 | java (11) | spring-framework (5.2) | 51 296 | 59 316 | 59 156 |
| 85 | javascript (13.14) | nestjs-fastify (7.3) | 50 931 | 60 892 | 59 478 |
| 86 | swift (5.2) | kitura (2.9) | 50 405 | 50 872 | 50 863 |
| 87 | swift (5.2) | kitura-nio (2.9) | 49 712 | 51 150 | 51 070 |
| 88 | javascript (13.14) | moleculer (0.14) | 49 456 | 52 663 | 51 879 |
| 89 | elixir (1.1) | cowboy (2.8) | 47 798 | 48 484 | 48 750 |
| 90 | python (3.8) | pyramid (1.1) | 47 764 | 50 253 | 50 442 |
| 91 | python (3.8) | asgineer (0.7) | 47 627 | 54 254 | 54 501 |
| 92 | rust (1.45) | gotham (0.4) | 46 373 | 52 337 | 54 878 |
| 93 | php (7.4) | siler-swoole (1.7) | 45 565 | 68 053 | 74 899 |
| 94 | swift (5.2) | vapor (4.23) | 45 341 | 48 039 | 47 892 |
| 95 | python (3.8) | blacksheep (0.2) | 44 967 | 50 418 | 50 507 |
| 96 | cpp (11) | evhtp (1.2) | 43 647 | 44 683 | 44 202 |
| 97 | scala (2.13) | http4s (0.21) | 42 326 | 48 277 | 47 692 |
| 98 | javascript (13.14) | hapi (19.1) | 42 248 | 45 758 | 44 916 |
| 99 | python (3.8) | hug (2.6) | 42 168 | 44 293 | 44 976 |
| 100 | javascript (13.14) | nestjs-express (7.3) | 41 140 | 43 789 | 42 970 |
| 101 | php (7.4) | imi (1.2) | 41 017 | 47 086 | 47 684 |
| 102 | python (3.8) | sanic (20.6) | 40 439 | 48 110 | 47 946 |
| 103 | python (3.8) | starlette (0.13) | 40 394 | 44 210 | 44 588 |
| 104 | javascript (13.14) | restify (8.5) | 39 954 | 43 417 | 42 549 |
| 105 | elixir (1.1) | plug (1.10) | 39 654 | 40 583 | 40 747 |
| 106 | csharp (8.0) | simplify.web (4.1) | 36 547 | 37 086 | 35 917 |
| 107 | python (3.8) | emmett (2.0) | 35 263 | 39 568 | 39 663 |
| 108 | crystal (0.35) | orion (3.0) | 34 914 | 33 918 | 29 528 |
| 109 | scala (2.13) | play (2.8) | 34 647 | 37 040 | 37 025 |
| 110 | elixir (1.1) | phoenix (1.5) | 33 992 | 35 518 | 35 721 |
| 111 | clojure (1.1) | luminus (1.0) | 31 689 | 32 569 | 32 417 |
| 112 | crystal (0.35) | shivneri (0.15) | 30 797 | 30 161 | 27 481 |
| 113 | haskell (8.8) | servant (0.17) | 30 434 | 29 284 | 28 323 |
| 114 | fsharp (4.7) | giraffe (4.1) | 30 235 | 28 822 | 28 120 |
| 115 | dart (2.8) | aqueduct (3.3) | 29 971 | 30 096 | 29 962 |
| 116 | fsharp (4.7) | suave (2.5) | 29 197 | 29 977 | 31 845 |
| 117 | nim (1.2) | rosencrantz (0.4) | 27 634 | 23 877 | 21 571 |
| 118 | php (7.4) | swoft (2.0) | 27 634 | 33 470 | 34 678 |
| 119 | python (3.8) | fastapi (0.59) | 26 912 | 29 394 | 29 387 |
| 120 | nim (1.2) | akane (0.1) | 26 627 | 22 183 | 19 714 |
| 121 | php (7.4) | yii-swoole (2.0) | 26 277 | 31 291 | 32 132 |
| 122 | ruby (2.7) | syro (3.2) | 25 741 | 29 593 | 28 479 |
| 123 | php (7.4) | sw-fw-less (preview) | 25 667 | 31 452 | 31 917 |
| 124 | ruby (2.7) | hanami-api (0.1) | 25 632 | 28 830 | 27 512 |
| 125 | ruby (2.7) | roda (3.34) | 24 920 | 28 354 | 27 291 |
| 126 | python (3.8) | molten (1.0) | 24 593 | 25 860 | 25 732 |
| 127 | python (3.8) | responder (2.0) | 24 299 | 26 653 | 26 415 |
| 128 | php (7.4) | chubbyphp-swoole (3.1) | 24 293 | 29 108 | 29 633 |
| 129 | rust (1.45) | iron (0.6) | 24 175 | 24 341 | 24 340 |
| 130 | python (3.8) | aiohttp (3.6) | 23 664 | 26 132 | 26 490 |
| 131 | python (3.8) | clastic (19.9) | 23 404 | 25 203 | 25 107 |
| 132 | javascript (13.14) | turbo_polka (0.3) | 23 248 | 22 736 | 21 330 |
| 133 | ruby (2.7) | cuba (3.9) | 23 016 | 25 621 | 25 030 |
| 134 | python (3.8) | masonite (2.3) | 22 134 | 23 324 | 23 179 |
| 135 | python (3.8) | flask (1.1) | 22 075 | 23 192 | 23 136 |
| 136 | go (1.14) | macaron (1.3) | 20 151 | 22 685 | 22 867 |
| 137 | ruby (2.7) | rack-routing (0.0) | 19 946 | 21 276 | 21 418 |
| 138 | ruby (2.7) | rack_app (7.6) | 19 540 | 20 793 | 20 692 |
| 139 | ruby (2.7) | camping (2.1) | 18 954 | 19 060 | 18 964 |
| 140 | java (11) | blade (2.0) | 15 292 | 17 610 | 17 259 |
| 141 | dart (2.8) | start (0.4) | 14 224 | 13 842 | 12 911 |
| 142 | go (1.14) | tango (0.6) | 14 146 | 14 645 | 14 701 |
| 143 | php (7.4) | spiral (2.4) | 13 078 | 13 360 | 13 230 |
| 144 | crystal (0.35) | runcobo (0.2) | 13 002 | 12 826 | 11 896 |
| 145 | ruby (2.7) | sinatra (2.0) | 12 825 | 12 867 | 12 936 |
| 146 | go (1.14) | gramework (1.7) | 12 526 | 12 784 | 12 771 |
| 147 | java (11) | struts2 (2.5) | 12 128 | 13 157 | 12 915 |
| 148 | javascript (13.14) | sails (1.2) | 12 108 | 12 938 | 12 548 |
| 149 | ruby (2.7) | grape (1.4) | 11 869 | 11 833 | 11 831 |
| 150 | python (3.8) | quart (0.13) | 11 074 | 11 607 | 10 829 |
| 151 | php (7.4) | chubbyphp-roadrunner (3.1) | 10 004 | 10 777 | 10 760 |
| 152 | swift (5.2) | swifter (1.4) | 9 942 | 10 134 | 10 016 |
| 153 | php (7.4) | sunrise-router-roadrunner (2.4) | 9 743 | 9 456 | 9 244 |
| 154 | python (3.8) | django (3.0) | 9 480 | 9 487 | 9 184 |
| 155 | python (3.8) | tornado (6.0) | 9 092 | 9 871 | 9 402 |
| 156 | python (3.8) | cherrypy (18.6) | 8 804 | 8 765 | 8 703 |
| 157 | pony (0.35) | jennet (0.1) | 8 516 | 16 636 | 15 585 |
| 158 | ruby (2.7) | flame (4.18) | 8 030 | 8 004 | 8 002 |
| 159 | php (7.4) | fastsitephp (1.3) | 7 981 | 7 896 | 7 748 |
| 160 | ruby (2.7) | hanami (1.3) | 7 803 | 7 920 | 7 958 |
| 161 | python (3.8) | tonberry (0.2) | 6 888 | 6 603 | 6 290 |
| 162 | php (7.4) | ubiquity (2.3) | 6 787 | 6 679 | 6 670 |
| 163 | php (7.4) | one-fpm (2.0) | 6 071 | 5 943 | 5 990 |
| 164 | php (7.4) | phalcon (4.0) | 5 792 | 5 717 | 5 735 |
| 165 | php (7.4) | hamlet (3.2) | 5 773 | 5 687 | 5 708 |
| 166 | php (7.4) | siler (1.7) | 5 685 | 5 636 | 5 658 |
| 167 | php (7.4) | bearframework (1.2) | 5 142 | 5 097 | 5 129 |
| 168 | php (7.4) | ice (1.5) | 5 006 | 4 976 | 5 016 |
| 169 | php (7.4) | sunrise-router (2.4) | 4 945 | 4 913 | 4 946 |
| 170 | php (7.4) | chubbyphp (3.1) | 4 568 | 4 555 | 4 613 |
| 171 | php (7.4) | slim (4.5) | 3 819 | 3 843 | 3 895 |
| 172 | v (0.1) | vape (0.3) | 3 692 | 1 734 | 2 287 |
| 173 | ruby (2.7) | rails (6.0) | 3 683 | 3 452 | 3 438 |
| 174 | php (7.4) | nette (3.0) | 3 654 | 3 696 | 3 744 |
| 175 | php (7.4) | lumen (7.2) | 3 506 | 3 534 | 3 637 |
| 176 | php (7.4) | yii (2.0) | 3 444 | 3 487 | 3 543 |
| 177 | julia (1.5) | merly (0.2) | 3 392 | 8 155 | 6 444 |
| 178 | perl (5.32) | dancer2 (2.0) | 3 235 | 2 528 | 1 359 |
| 179 | php (7.4) | sunrise-router-annotations (2.4) | 3 130 | 3 177 | 3 226 |
| 180 | php (7.4) | symfony (5.1) | 2 770 | 2 801 | 2 846 |
| 181 | php (7.4) | mezzio (3.2) | 2 488 | 2 525 | 2 546 |
| 182 | python (3.8) | cyclone (1.3) | 2 416 | 2 416 | 2 412 |
| 183 | ruby (2.7) | pakyow (1.0) | 2 286 | 2 275 | 2 293 |
| 184 | python (3.8) | klein (20.6) | 1 588 | 1 609 | 1 600 |
| 185 | python (3.8) | nameko (2.12) | 1 523 | 1 487 | 1 468 |
| 186 | php (7.4) | laminas (3.1) | 1 339 | 1 358 | 1 380 |
| 187 | php (7.4) | codeigniter4 (4.0) | 1 039 | 1 059 | 1 122 |
| 188 | php (7.4) | basicphp (0.9) | 586 | 465 | 548 |
| 189 | php (7.4) | laravel (7.2) | 320 | 159 | 3 655 |
| 190 | crystal (0.35) | lucky (0.23) | 306 | 332 | 323 |
原文:https://github.com/the-benchmarker/web-frameworks
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 123 次浏览
【Web3】什么是Web3?一个新的去中心化网络,或是最新的营销流行语
Web3已成为一种将区块链、智能合约和去中心化应用程序结合在一起的尝试,但其真正的功效难以确定。
Web3,如Web3基金会设想的那样,将是一个公共互联网,数据和内容被注册在块链上,在对等分布式网络上进行令牌化或管理和访问。
Web3有望成为一个去中心化的、不可变的web版本,不存在中间人,并具有与加密货币、不可替代代币(NFT)和以分布式账本(DAPP)为基础的新型去中心化应用程序相同的加密可验证性。
如果所有这些听起来都很复杂,那是因为它是复杂的。就目前而言,Web3是一个有点模糊的概念,它仍然被定义为一个更理想的web外观,而不是一个可供开发人员构建的有形且可访问的技术堆栈。
这种模糊性导致了整个行业在这个术语上的某种程度的分歧,有人称赞Web3是一种革命性的方式,可以让互联网回归自由主义的根基,而著名的怀疑论者,如密码乐观主义者埃隆·马斯克(Elon Musk),则认为Web3是一个“营销时髦词”
Web3的起源
Web3首先由以太坊区块链的创建者之一Gavin Wood描述。在2014年的一篇博文中,伍德设想“Web3.0”是一个加密的在线空间,以应对爱德华·斯诺登(Edward Snowden)2013年披露的全球监控事件所引发的隐私问题。
他写道,在Web3中,“我们假设是公开的信息,我们发布。我们假设是一致同意的信息,我们放在共识账上。我们假设是私人的信息,我们保守秘密,从不泄露。”。
该模型将通过加密技术“在数学上强制实施”,在加密技术中,交易将被验证并添加到区块链中,以实现普遍的透明性和不可撤销性。
在2021年11月的有线采访中,伍德进一步细化了这个定义,以“少信任,多真相”。
Web3这个词直到2021才真正开始流行,然而,当像Andreessen Horowitz合作伙伴Chris Dixon这样的风险资本家开始把Web3作为一个“由建造者和用户拥有的互联网,用令牌编排的时候”。
作为这一领域的大投资者,Andreessen Horowitz在Web3游戏中有着丰富的经验,因此有必要采取一些有益的措施,Twitter联合创始人杰克·多尔西(Jack Dorsey)等批评者非常乐意将Web3称为“一个有着不同标签的中央集权实体”
Web 1.0和Web 2.0
如果Web3是internet的下一个迭代,那么它与Web1.0和Web2.0到底有什么不同?
从1990年到2004年左右,Web1.0是现代互联网的第一次迭代。在Web1.0时代,用户通常使用静态网页,其中只读内容由雅虎和AOL等一小群看门人创建和分发。
Web2.0是一种动态的、交互式的Web,在这种Web中,静态网页由应用程序和用户生成的内容连接在一起。Web2.0由一系列占主导地位的平台统治,比如FAANG公司Facebook(现在的Meta)、亚马逊、苹果、Netflix和谷歌的市场力量,所有这些公司都在一定程度上为个人数据交换服务。
Web3与Web2.0的不同之处在于,它消除了这些强大的把关人,增强了互联网的平等性。在互联网上,用户通过各种代币的所有权获得回报,同时在共享、分布式、防篡改的账本上保持其数据的私密性和安全性。
“本质上,这意味着我个人可以像世界上任何人一样轻松地成为这项整体服务的提供者或共同提供者,”伍德告诉《连线》。
这反映在Web3基金会的任务声明中,通过“去中心化和公平的互联网,用户控制自己的数据、身份和命运”来“培育去中心化式Web软件协议的尖端应用”。
这种想法自然产生了去中心化的自治组织或DAO,它们是高度民主的互联网社区,有着共同的目标,没有领导结构。当然,一个人的平等主义网络可能是另一个人不受管制的野蛮西方。
Web3与Tim Berners Lee早在1999年就将其描述为Web3.0或语义网(semantic Web),后者专注于使互联网机器可读,但这一愿景在很大程度上尚未实现。
Web3堆栈
一些工程师已经尝试定义Web3堆栈,因为它目前存在,但这不是一个简单的练习。
Nader Dabit,前AWS高级开发人员倡导者,现为Web3公司Edge&Node的开发人员关系工程师,试图从高层次概述Web3堆栈,包括:
- 区块链
- 区块链开发环境
- 文件存储
- P2P数据库
- API(索引和查询)
- 身份
- 客户端(框架和库)
- 其他议定书
这显然与当今常用的web开发三层体系结构有很大的不同,三层体系结构包括:
- 前端web服务器
- 中间层应用服务器
- 后端数据库或数据存储
Preethi Kasireddy拥有在风险投资公司Andreessen Horowitz和加密交换Coinbase工作的独特地位。她在Web3体系结构上的博客文章展示了一个开发模型,“您可以编写智能合约,定义应用程序的逻辑,并将其部署到去中心化的状态机[即以太坊区块链]。”
智能合约的编写本身可能需要学习新的编程语言,如Solidity、Vyper,或者越来越多的Rust。然后,您需要了解如何部署到以太坊虚拟机,或您选择的区块链的类似执行机制。
开发人员还需要掌握向区块链“签署”交易的机制,MetaMask将自己确立为这一过程的早期行业标准工具。
接下来,Kasireddy讨论了在以太坊上构建应用程序的扩展问题。她写道:“任何在以太坊上构建应用程序的人都知道,在区块链上存储所有东西会变得非常昂贵,速度非常快。”。这就需要“一个去中心化的链外存储解决方案,如IPFS[星际文件系统]或Swarm。”
随着越来越多的开发人员涌入该领域,以及工具的成熟,这些问题可能会得到解决。像Polygon这样的项目已经在研究区块链缩放问题的解决方案。但就目前而言,在新生的Web3堆栈上开发应用程序看起来很有挑战性。
正如Kasireddy自己所写,“如果所有这些都让你头晕目眩,那么你并不孤单。拼凑所有这些工具是复杂的,可能会带来痛苦的开发体验。但不要担心,我们开始看到新的开发框架,它们真的改善了开发人员的体验。”
Web3应用程序
Web3怀疑论者经常提出的一个问题是,应用程序在哪里?正如上面所概述的那样,随着一个新的、复杂的应用程序栈的出现,我们还没有看到大量杀手级Web3应用程序进入市场也就不足为奇了。
虽然Web3承诺将NFT和加密货币所有权的基础技术带入web的潜在新领域,但这一承诺尚未兑现。
早期的Web3项目往往由它们的不易访问性和微妙的用户体验来定义。要访问大多数Web3应用程序,用户需要一个加密钱包,很可能需要一个新的浏览器,了解全新的术语世界,并愿意支付在以太坊区块链上执行操作所需的不稳定“气体”费用。这些都是普通互联网用户进入互联网的重大障碍。
虽然去中心化的社交网络Mastodon和GitHub clone Radicle是基于一些Web3原则构建的,就像勇敢的浏览器一样,大多数现有的Web3应用程序都是为了交易加密资产或在赌场游戏上下注加密货币。
“如果Web3将成为身份识别或社交媒体的未来,我们需要问问自己,有什么证据表明采用Web3真的比前几代互联网技术更好吗?”Tim O'Reilly问道,他创造了Web2.0这个术语。
Web3基金会在其网站上列出了几个项目,但这些项目主要集中在构建互操作Web3所需的底层协议上。
正如区块链和信任新架构的作者凯文·沃巴赫(Kevin Werbach)对TechCrunch所说:“许多所谓的Web3解决方案并不像看上去那样去中心化,而其他解决方案还没有显示出它们的可扩展性、安全性和可访问性足以满足大众市场的需要。”
Web3入门
准备好开始了吗?您可以在许多地方了解有关Web3核心原则和技术的更多信息。
Edge&Node的Dabit建议从流行的以太坊区块链和用于编写智能合同的Solidity编程语言的文档开始。然后,您可以开始探索Web3工具、库和API的全新世界。你还需要一个加密钱包,比如MetaMask,来管理你的Web3资产。
随着人们对这个术语兴趣的增长,也出现了一些Web3教程,包括Udemy、Coursera、Web3大学、Buildspace等网站上出现的教程,以及通过以太坊网站本身出现的教程。
原文:https://www.infoworld.com/article/3646597/what-is-web3-a-new-decentrali…
本文:
- 95 次浏览
【Web3】我把我的创业公司卖给了 Airbnb,并全力开发 web3——这就是为什么
当我们谈论 web3 时,我怀疑大多数技术人员会立即想到 NFT、加密货币或 DeFi。 我不能责怪他们:从 Twitter 的活动来看,这主要是事实。
但作为开发人员,我真正感兴趣的并不是 NFT、加密货币或 DeFi。事实上,我估计这些项目中有 95% 充其量是高风险的,最坏的情况是骗局——而且绝对没有准备好 供消费者采用。
同时,我也觉得剩下的5%是值得提倡的。 我说作为一个应该成为 Web 2.0 助推器的人:几年前,我的专注于开发人员的初创公司被 Airbnb 收购,如果我选择去,我在传统硅谷框架内的职业选择非常好 那样。
相反,在过去的 6 个月里,我将我的创意和专业精力投入到为 web3 开发人员创建免费的开源工具上:Studio 721
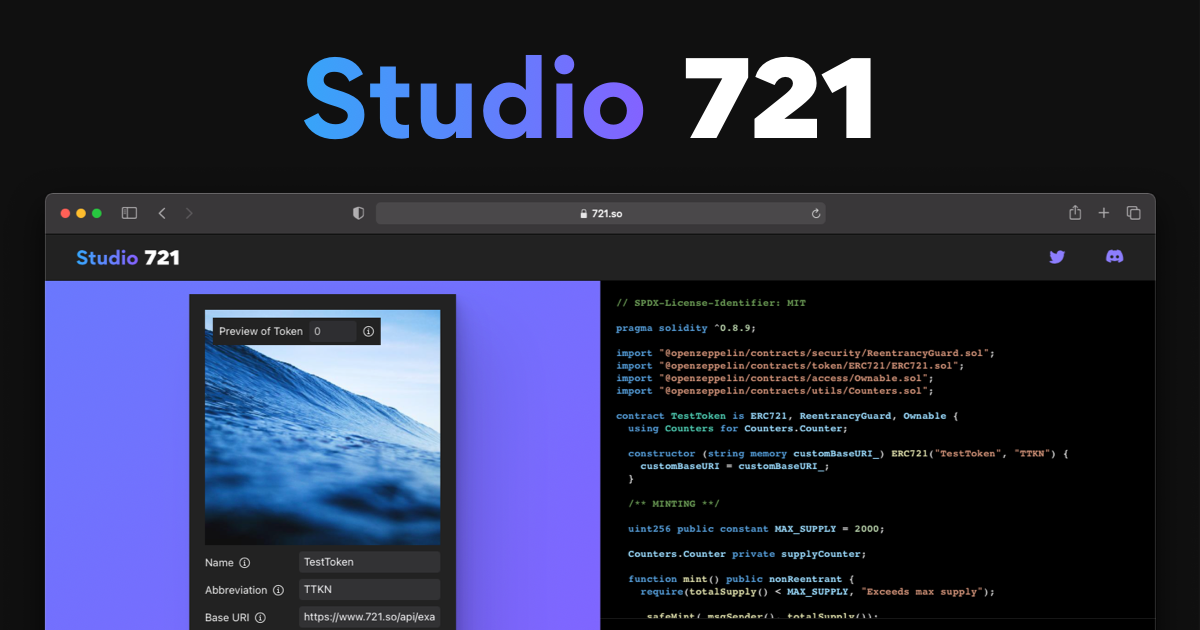
- Studio 721, an open source website for creating and uploading metadata and artwork to IPFS (web3 file hosting), and deploying NFT smart contracts to the Ethereum and Polygon blockchains
我对 web3 作为开发者平台的未来持乐观态度。因为尽管整个平台存在许多缺点,但一些 web3 功能已经令人震惊,对开发人员来说非常好用。以下是其中三个特别适用于基于以太坊的项目的功能:
使用以太坊登录
在以太坊区块链上为应用程序创建注册过程就像添加钱包连接选项一样简单和即时。该系统的构建使登录成为其架构的核心。从隐私和安全的角度来看,泄露个人数据的想法并不存在,因为应用程序只能访问消费者自己已经公开的数据。
将此与创建一个将 Facebook 作为登录选项结合的应用程序进行对比。对于开发人员来说,这是一个耗时的麻烦。你首先需要设置一个开发者账号,同意 Facebook 的服务条款,然后集成官方 SDK。这个过程至少需要几天时间,实际上,您还想为 Apple、Google、Twitter 等添加登录选项。毕竟,如果 Facebook 或其他平台巨头不批准您的应用程序 - 并且围绕它的规则非常模糊——他们可以立即将其关闭。
尽管如此,我们实际上别无选择,只能使用 Facebook 和其他社交网络。实际上,他们已经是我们在现代社会中的许多活动的守门人。尽管 Facebook 不仅“拥有”你的所有数据,而且可以(而且经常拥有!)意外泄露它而几乎没有追索权。以太坊为这一切提供了一个可行的替代方案。
这让我想到了下一点:
全球测试网络
Web 2.0 的另一个挫折是缺乏简单、安全和可互操作的测试网络。假设您正在开展在线零售业务,并且您想制作一个推特应用程序来发布当天的热门商品。您可能希望在构建应用程序时对其进行测试。但是,无法创建虚拟 Twitter 帐户或虚假推文。而且,如果您的应用程序存在错误,则很容易开始使用可能敏感的业务数据向垃圾推文发送垃圾邮件。此示例中的风险很低,因为您的新业务可能没有任何 Twitter 关注者。但是,一旦您的企业收集个人数据或与支付处理器相关联,风险就会变得非常严重;那么一个错误就会威胁到人们的财务或隐私。
即使在 Facebook 和其他科技巨头,这类数据泄露已经经常发生,以至于许多人认为这只是软件开发中不可避免的一部分。一些平台确实支持测试账户,尤其是在风险很高的情况下。但是很多人没有,或者即使他们这样做了,他们也经常受到限制,阻止(例如)Facebook 测试账户和 Stripe 测试账户之间的完全互操作性。
相比之下,以太坊再次闪耀,提供了一个单一的全球网络,区块链上的所有软件都可以无缝通信。作为这种架构的自然结果,可以启动整个网络的测试版本,包括其上的每个应用程序。现在所有结果(包括由错误引起的任何外部性)都可以进行模拟和安全测试。这种力量根本不存在于 web3 之外。它使无畏的发展成为可能。
内置支付处理
最后,支付:作为开发商,收取 IAP 和其他收入一直是一个关键的摩擦点。从理论上讲,集成像 Stripe 这样的处理器应该很容易,但这也意味着设置帐户、签署平台的服务条款、学习其 API 并处理其合规性要求。作为跳过这些障碍的交换,您作为开发人员必须等待付款被处理——但前提是平台首先削减了您的收入。
相比之下,以太坊仍然存在交易费用,但作为开发人员,您通常会在一分钟内收到付款。虽然许多支付处理器并不支持每个国家,但以太坊在全球范围内自动得到支持。是的,交易费用目前可能相当高。但作为开发者,我相信这个可扩展性问题是可以解决的,而不是 web3 的根本缺陷。现实的解决方案正在开发中,就 L2s 而言,已经成为他们自己的创新平台。
—
出于所有这些原因以及更多原因,作为一名开发人员,从 Web 2.0 堆栈转变并尝试这个新环境是非常令人兴奋的。我可以从从事 web3 工作的开发人员那里感受到同样的能量;我会在推特上发布我在业余时间制作的一个有趣的小应用程序,第二天,我的 Discord 中就有 800 人兴奋地谈论它。
这并不是说 web3 是完美的——远非如此。普通消费者还没有为用户体验做好准备,对 NFT 和加密货币的投机炒作只会加剧这个问题,对消费者的采用产生不切实际的期望。
归根结底,对我来说,真正重要的是开发人员的 web3 基础设施。
可以这样想:在 Web 2.0 期间,几乎没有任何消费者将 Linux 作为自己直接个人使用的操作系统。但是对于消费者网络的后台架构和我们现在都认为理所当然的开发人员工具来说,Linux 仍然是不可或缺的。这就是为什么我在未来几年的职业生涯中投资于相信 web3 将沿着类似的路径发展的原因。
原文:https://medium.com/@devinabbott/i-sold-my-startup-to-airbnb-and-went-al…
- 72 次浏览
【Web后端架构】2022年10个最佳Web开发后端框架
这些都是2022年在Java、Ruby、Python、JavaScript、PHP、Scala和Golang中进行web开发的最佳后端开发框架
大家好,如果您是一名应用程序编程人员,正在寻找2022年要学习的最佳后端框架,那么您来对地方了。在前面,我已经分享了最好的全栈开发课程,在本文中,我将与您分享创建web应用程序的10个最好的后端框架。
Web开发通常分为两类:前端开发和后端开发。后端开发人员负责构建web应用程序的服务器端。
当前端部分与用户交互时,后端部分负责内部工作。如果没有后端,前端可能会工作,也可能无法工作,但要创建一个功能齐全的web应用程序,必须有一个与前端连接的适当后端。
后端开发人员的角色不同于前端开发人员。前端开发人员更关注应用程序的外观,而后端开发人员则关注服务器、数据库以及两端的连接和交互方式。
后端开发人员应该具备许多必要的技能。理解后端框架就是其中之一。有几种后端框架,本文将讨论目前使用的顶级后端框架。
该列表包括基于编程语言和技术堆栈的最佳后端框架。这意味着您不需要学习所有这些,而是选择与您选择的编程语言和技术堆栈相匹配的一种。
2022年10个最佳Web开发后端框架
在不浪费任何时间的情况下,这里列出了程序员可以为web开发学习的10个最佳后端框架。虽然在特定的技术堆栈或编程语言(如Java开发人员)中有很多选择,但也有MicroNaut, Quarkus, Vert.X,、 和其他框架,但我只根据受欢迎程度、成熟度和功能选择了最好的框架,比如Spring Boot。
1.面向Java开发人员的Spring框架+Spring Boot
Java被认为是一种常青的编程语言。它的一个常见用途是在后端开发中。Spring框架是最好的Java框架之一。
它于2002年发布,今天,它是最流行的后端框架之一,用于创建基于spring的生产级独立应用程序。
使用Spring boot很容易,因为它省略了Spring框架所具有的各种配置开销。当您使用Spring框架项目(如Spring Boot、Spring Cloud、Spring security等)时,您可以获得许多有用的功能,如缓存、事务管理、配置管理、监控、安全蚀刻。
如果你想在2022年学习Spring框架和Spring Boot,并且需要资源,那么我强烈建议你加入Udemy上的Spring和Hibernate(包括Spring Boot)课程。超过200000名Java开发人员参加了这门课程,学习Spring、Hibernate和Spring Boot,这是Java中最重要的三种后端框架。
2.面向Python开发人员的Django
Django是web开发中最流行的Python框架。Django基于Don't Repeat Yourself(DRY)原则,注重代码重用,从而提高了开发速度。它也是一个非常安全的框架。
作为一个Python框架,Django非常用户友好,易于学习。它也是最流行的全堆栈框架之一,提供了很多现成的功能,比如REST API支持。
如果你想在2022年学习Django,那么我建议你参加由Jose Portilla在Udemy上开设的Python和Django全栈Web开发者训练营课程。
Jose是一位很棒的讲师,这门32小时的Django课程是在线学习Django最全面的资源之一。
3.面向JavaScript开发人员的Express.js
JavaScript是世界上最流行的编程语言。随着节点的出现。js,JavaScript在后端开发社区的受欢迎程度迅速增加,在过去十年中,Node。js已经成为顶级品牌之一。
这就是为什么Express在2010年为节点开发者发布的原因。它是一个极小的节点。js框架用于开发高度灵活的应用程序。
考虑到JavaScript是最流行的web开发语言,而且可能是唯一一种提供从前端到后端到移动学习的全堆栈开发的语言,Expressjs可能是程序员的最佳选择。
如果你想学习表达。2022年的js需要一个资源,我推荐MERN堆栈从前到后:完整堆栈React、Redux和Node。js课程由我最喜欢的Udemy讲师Brad Traversy编写,这门课程非常适合任何想学习使用MERN stack进行全栈web开发的人,MERN stack包括React和Express。js。
4.面向.Net 开发者的ASP.NET core
ASP。NET内核是ASP的继承者。网它是一个开源的、独立于平台的框架,用于在平台上构建web应用程序。NET平台。它被认为是性能最好的后端框架之一。
它基本上是ASP的统一版本。NET MVC和ASP。NET Web API转换为编程模块,从而使其功能更加强大。
如果你想学习ASP。NET核心,并需要一个资源,然后我建议你加入完整的ASP。网络MVC 5课程由Mosh Hamedani在Udemy上完成。这门7.5小时的课程最适合C#and。NET开发人员谁想要学习ASP。网
C#开发者的最佳后端框架
5.面向PHP程序员的Laravel
PHP是后端开发中使用最多的编程语言之一。Larvel是一个基于MVC架构的PHP框架。它是一个初学者友好的框架,具有用户友好的界面、广泛的库和出色的API支持。
使用Laravel可以简化后端开发,同时构建现代安全的web应用程序。如果您正在处理非平凡的应用程序,这一点尤其正确。
如果你想学习幼虫,并为PHP开发者寻找学习Laravel的最佳在线课程,那么你也可以通过Laravel为初学者查看PHP——成为Udemy上Laravel课程的大师。这门43小时的课程是在线学习拉拉瓦尔的最佳课程之一。
6.面向Ruby程序员的Ruby on Rails
Ruby on rails,俗称rails,是一个基于MVC架构的服务器端框架。这是一个初学者友好的框架,易于理解和学习。
然而,它的优点和缺点仍然存在争议,但它因其用户友好而受到世界各地后端开发人员的喜爱。
如果你想在2022年学习Ruby on Rails并需要资源,那么Rob Percival在Udemy上的完整Ruby on Rails开发人员课程是一个很好的课程。它有超过46小时的内容和157篇文章,8个编码练习和1个可下载资源。
Ruby开发者的最佳后端框架
7.面向Golang开发者的Fiber 框架
Fiber是Golang程序员的web开发框架。它构建在Fasthttp之上,Fasthttp是Go最快的HTTP引擎。它的设计目的是在考虑到零内存分配和性能的情况下简化快速开发
Fiber是一个精简但功能极其强大的框架。由于极度精简,很容易将第三方库与马提尼酒整合在一起。该框架提供了更多的可伸缩性和更少的开销问题。
它类似于Express。js和js对路由、服务静态文件、构建restapi、灵活的中间件支持、模板引擎和低内存占用有很好的支持。
如果你想了解更多关于使用Golang和Fiber构建web应用程序的知识,我建议你加入Rob Percival和CodeStars在Udemy上的完整React&Golang课程。这是一门基于项目的课程,你将使用React和Golang Fiber从头开始构建一个管理应用程序。
8.面向PHP开发人员的CakePHP框架
CakePHP是另一个PHP框架,它基于另一个流行的后端框架Ruby on rails的概念。
它遵循MVC体系结构,并提供了一些有用的功能,如模型视图控制器、前端控制器、活动记录、数据映射和配置约定。
如果你想从头开始学习CakePHP,并且需要一个资源,我建议你在Udemy上查看CakePHP for初学者,以完成项目课程。这门6小时的课程是Udemy上评分最高的CakePHP课程,适合初学者和经验丰富的PHP程序员。
最佳PHP后端框架
9.Python开发人员的Flask框架
Flask是另一个可用于后端开发的python框架。它被认为是一个微框架,因为它省略了特定工具和库的使用。此外,没有数据库抽象层、表单验证或外部源依赖。
它是一个简单、高度灵活、高性能的web框架。作为一个轻量级的框架或微框架,它很容易学习和理解。此外,作为一个Python框架,它非常用户友好。
如果你想从头开始学习Flask,并且需要一个资源,那么你也可以在Udemy上通过Flask和Python课程查看REST API。由Jose Salvatierra创建,这门17小时的课程非常适合学习web开发。
最佳Python后端框架
10.Scala开发人员的Play框架
PLAY是用Scala和Java编写的,是最强大的后端web框架之一。它基于MVC架构,提供各种功能,如热代码重新加载、显示程序错误,以及专注于提高开发人员的盈利能力。
此外,它是RESTfull和非阻塞的。
如果你想学习Scala并开始使用Play Framework进行web开发,并且需要一个资源来开始在线学习,那么我建议你加入Scala&Functional Programming for初学者|在Udemy上学习JVM课程。
这是一门在线学习Scala的好课程,是Play框架所必需的,已经有超过3万名学生加入了这门课程。
用于web开发的最佳Scala后端框架
这就是程序员在2022年能学到的最好的后端框架。正如我所说,如果你想成为一名完整的堆栈工程师或后端工程师,学习后端开发是值得的。如今,后端开发依赖于后端框架。
有几种后端框架,有些流行,有些不流行。在本文中,我们讨论了顶级后端框架。所有这些框架在后端社区都非常流行,在就业市场上对它们有巨大的需求。
大多数框架都是用流行的编程语言编写的,比如Java、Python和JavaScript。如果您是初学者,可以从Ruby on rails等对初学者友好的框架或Flask等轻量级框架开始。如果你热衷于学习最受欢迎的,那么你可以选择Spring Boot、Django或Express。
原文:https://medium.com/javarevisited/10-best-backend-frameworks-for-web-dev…
- 651 次浏览
【Web应用】2023年主导的Web开发趋势💥[更新]
视频号
微信公众号
知识星球
“弄清楚下一个大趋势是什么,告诉我们应该关注什么。”-马克·扎克伯格
多年来,Web开发已被证明是任何组织/企业成功的不可或缺的因素。它是您业务的窗口,有助于您在全球范围内发展业务。
现在,Web开发世界在不断变化,趋势也在不断变化。有时,这些趋势的变化速度远远超过了它们的使用速度。为了保持领先,有必要关注正在流行的最新趋势、更新、技术和方法。此外,了解趋势并控制周围发生的事情对于web开发来说是非常重要的。
在分析了2023年网络发展趋势列表中各行业的趋势后,我们收集了一些趋势。在接下来的一年里,您将了解值得您关注的顶级网络技术堆栈。
我们列出这个列表是为了节省时间,并帮助您在即将到来的时代发展业务。所以,让我们开始吧。
1.单页应用程序
都在一个地方。无需切换。无需等待。。!!
嗯,当一次点击就可以从服务器上下载一个网页时,这有点令人恼火。它还会消耗你的时间,也会给用户留下不好的影响。这种情况导致了SPA的趋势。
SPA是近年来的趋势之一,有助于避免与服务器的长时间通信。它提供了更好的页面性能,并提供了高级别的数据保护。
因此,单页应用程序是一种在浏览器内工作的应用程序,在使用过程中不需要重新加载页面。您每天都在使用这种类型的应用程序。例如,Gmail、谷歌地图、Facebook或GitHub。
图片来源:Pinterest
随着2023年JavaScript框架的兴起,SPA将使用这种语言进行内容加载,这种趋势不会很快消失。此外,这些应用程序不需要额外的等待时间,为用户提供即时反馈。此外,它还提供了一些惊人的优势。
优点:
- 原生浏览器环境中出色的UX/UI
- 节省的带宽
- 使用Chrome工具更轻松地设置和调试
- 对API的关注
- 缓存过程的效率
单页应用示例:
例如,您可以查看Sneat Bootstrap 5 HTML管理模板。它是最新的对开发人员最友好的🤘🏻 & 高度可定制✨ 基于Bootstrap 5的管理面板模板。
此外,最高的行业标准被认为会为您带来最好的引导程序管理模板,不仅速度快🚀易于使用,但具有高度可扩展性。
此外,Sneat Bootstrap 5管理模板功能强大,还允许您构建任何类型的web应用程序。例如,您可以创建:
- SaaS平台
- 项目管理应用程序
- 电子商务后端
- CRM系统
- 分析应用程序
- 银行应用程序
- 教育应用程序
- 健身应用程序及更多…。
此外,您可以使用这个最好的创新Bootstrap管理员来创建引人注目、高质量和高性能的Web应用程序。此外,您的应用程序将完全响应,确保它们在台式机、平板电脑和移动设备上看起来令人惊叹,功能完美。
特点:
- 基于Bootstrap 5
- 垂直和水平布局
- 默认、带边框和半暗主题
- 支持明暗模式
- 国际化/i18n和RTL就绪
- 布局生成器
- 主题配置:轻松定制我们的模板。
- SASS供电
- 全响应布局
- 清除注释代码(&C)
- 记录良好
- 享受无忧支持
也可在React Dashboard版本中获得。
2. Progressive Web Apps (PWA)

Image credit: Pinterest
你拇指上的一切…!!我们知道这个概念,对吧?导航方便,工作平稳,装载量少,速度快。是的,这就是PWA,即Progressive Web App的意义。。!!快速、可靠、流畅的用户友好体验。
毫无疑问,PWA并不是什么新鲜事。尽管如此,自从它来到这里以来,它一直是这个小镇的话题,而且它也将在2023年占据主导地位。现代开发商和投资者之所以瞄准它,是因为它能够提供高质量的用户体验。由于它们对移动非常友好,毫无疑问,对PWA的需求将增加。
好吧,Progressive Web Apps(PWA)是用现代API构建和增强的,以提供增强的功能、可靠性和可安装性,同时使用单个代码库访问任何设备上的任何人、任何地方。这使得它适合跨设备兼容性。
它们不仅快速、即时加载,还允许用户离线使用服务,同时执行本地应用程序的所有功能。
优点
- PWA有助于提供流畅且用户友好的网络体验。
- 有助于降低反弹率
- 脱机工作,因为它独立于连接
- 使您的应用程序可靠、功能强大且可安装
使用PWA的一些服务示例:
3. 人工智能开发

根据报告“2019年人工智能市场的价值将达到399亿美元,到2025年可能达到1906.1亿美元,预测期内的复合年增长率为42.2%。”这是一个相当大的数字…!!不是吗?😮
现在,如果网站的内容或布局不吸引人,大约38%的人会跳过网站。超过75%的客户根据网站设计来决定企业的信誉。用户只需0.5秒就可以形成对网站的看法。从那时起,技术介入网络开发的世界是至关重要的。在这里,人工智能进入了2023年的网络发展趋势。
将人工智能应用于网络开发可以帮助您预测客户的选择,从而塑造网站的整体外观。AI让你知道,
- 你的客户下一步打算买什么?
- 客户决定购买产品的理想时间范围。
- 什么样的产品最吸引顾客?
- 哪些产品不受客户欢迎?
- 谁都有兴趣购买你们的产品?
我们生活在一个数字时代,众所周知,即将到来的时代将在各个领域采用更智能的方法。这意味着更少的手动操作。例如聊天机器人、增强现实/虚拟现实。说到这里,许多初创企业、中小企业和大型组织已经在寻求为其业务雇佣人工智能开发人员,以通过人工智能应用程序、软件和工具满足最终用户的未来需求。
Sketch2Code是一种基于web的解决方案,最近推出。它依靠人工智能将手写UI设计从图像转换为有效的HTML标记代码。
许多用户甚至对人工智能在某种程度上参与大多数网站并不感到惊讶。它在网络开发领域创造了一个新的维度。
4. WebAssembly

在开发web应用程序时,首先不能忽视的是性能。现在,JavaScript的限制使繁重的计算变得缓慢。这大大恶化了用户体验。
这是WebAssembly日益流行的主要原因之一。有了这项技术,任何编程语言中的代码都可以编译成在浏览器中运行的字节码。
WebAssembly是一个开放标准,它为可执行程序定义了一种可移植的二进制代码格式,以及相应的文本汇编语言,以及用于促进此类程序与其宿主环境之间交互的接口。
优点:
- 它独立于编程语言和平台
- 独立于硬件
- 快速执行代码
- 提供高级别的安全性。
这一切都归结为三角关系——占地面积小、跨平台脚本和速度。这三个组件都是现代web开发中的关键组件。这就是为什么今天大部分的web开发案例都没有WebAssembly的原因。
For more info check Webassembly concepts
5. 语音搜索和导航

Credit Giphy
嘿Siri…。今天的趋势是什么?
我们人类一天比一天懒…不是吗。。!!?😂 首先,我们制造了手机,然后开发了智能手机来减少体力劳动,现在我们正朝着“语音免提”的方向发展。面向命令的服务是当今的热门话题。
语音搜索和导航将成为2023年最主要的网络发展趋势之一。它们已经成为我们日常生活的一部分。它们非常棒,因为它们让我们搜索信息、做笔记等等的方式变得很简单。
苹果、安卓和谷歌等品牌在其用户界面/用户体验设计过程中实现了这一趋势。因此,这种迅速出现的趋势不容忽视…!!
谷歌报告称,全球27%的在线人口在手机上使用语音搜索。
Voicebot.ai报告称,超过一半的成年人使用过语音搜索,2019年初,33%的人每月使用语音搜索,高于2018年的25%。
通过在web开发中实现语音搜索和导航,您可以确保您的服务提供令人惊叹的用户体验。
- 语音用户界面根据以下算法工作:
- 语音识别软件将输入的模拟波转换为数字格式
- 音频输入被分解为单独的声音、音素
- 该软件分析每一个单词,并将它们与字典中的单词进行比较
- 语音转换为屏幕文本或计算机命令
优点:
- 易用性
- 允许徒手交互
- 任务执行速度快
- 出色的用户体验
- 直观方便
人们喜欢花更少的时间键入命令。这就是他们越来越多地使用语音搜索的原因。因此,网络开发将与此类功能的实现密切相关。
6. 本地应用程序将主导市场

如果你正在工作,突然出现网络问题怎么办。。!!一直依赖互联网有点烦人。这就是Native应用程序的用武之地。它还允许您离线工作。
原生移动应用程序是直接安装在智能手机上的应用程序,在大多数情况下,根据应用程序的性质,它可以在没有互联网连接的情况下工作。
好吧,原生应用程序开发已经很有需求了,未来,软件开发人员可以预计这一趋势将主导2023年的网络开发趋势。
由于它们是为特定平台专门设计的,与混合应用程序相比,它们通常提供更好的用户体验和更强大的性能。这就是为什么,越来越多的企业正在投资于iOS和Android的多个本地应用程序,以使他们能够为用户提供更好的体验。
优点:
- 由于使用了底层设备的功能,因此具有广泛的功能
- 更好地与操作系统的用户体验相匹配的UI
- 响应迅速
- 提醒推送
- 通过应用商店中的评级进行质量保证。
随着智能手机在市场上越来越受欢迎,iOS和Android操作系统在市场上的主导地位越来越大,对本地应用程序开发的投资似乎不会很快减少,事实上,在2023年或可预见的未来都不会减少。
7. Motion design UI

Credit: Vuexy By Anand Patel on Dribbble
运动设计是2023年网页设计和网页发展的主要趋势之一。极简主义的设计加上复杂的互动,给人一种引人入胜的互动外观,吸引了用户的注意力。
顾名思义,动作设计就是设计动作。然而,它远远超出了在构思后简单地为屏幕元素设置动画的范围。
必须在UI/UX设计阶段就已经考虑到动作设计。这背后的原因是,仅仅拥有一个包含动画的屏幕就有点达不到预期目标:添加的动作必须有意义和目的。
由于运动设计,这些元素将被实现:
- 页眉转换;
- 图表
- 弹出窗口
- 下拉菜单
- 滚动
所有这些都将帮助你展示你的独特风格,娱乐用户,改善行为因素,并帮助你的网络应用程序在搜索结果中排名更高。
在AMP的帮助下,可以在不损失下载速度的情况下实现动作设计。因此,如果你想让用户停留在你的页面上,那么不要忽略这个…!!
优点:
- 定义你的结构和互动
- 简化导航
- 减缓加载时间
- 增加会话长度,从而降低反弹率
- 为了提高参与度并为网络应用程序的用户提供更好的UI/UX,请尝试使用动作UI技术进行升级。
通过动画引导用户浏览您的应用程序,演示下一步要采取的步骤;
通过朗朗上口的动画对用户的手势做出反应;
演示应用程序不同组件之间的关系等。
8. 无服务器架构

Credit: Runcloud
运动设计是2023年网页设计和网页发展的主要趋势之一。极简主义的设计加上复杂的互动,给人一种引人入胜的互动外观,吸引了用户的注意力。
顾名思义,动作设计就是设计动作。然而,它远远超出了在构思后简单地为屏幕元素设置动画的范围。
必须在UI/UX设计阶段就已经考虑到动作设计。这背后的原因是,仅仅拥有一个包含动画的屏幕就有点达不到预期目标:添加的动作必须有意义和目的。
由于运动设计,这些元素将被实现:
- 页眉转换;
- 图表
- 弹出窗口
- 下拉菜单
- 滚动
所有这些都将帮助你展示你的独特风格,娱乐用户,改善行为因素,并帮助你的网络应用程序在搜索结果中排名更高。
在AMP的帮助下,可以在不损失下载速度的情况下实现动作设计。因此,如果你想让用户停留在你的页面上,那么不要忽略这个…!!
优点:
- 定义你的结构和互动
- 简化导航
- 减缓加载时间
- 增加会话长度,从而降低反弹率
为了提高参与度并为网络应用程序的用户提供更好的UI/UX,请尝试使用动作UI技术进行升级。
- 通过动画引导用户浏览您的应用程序,演示下一步要采取的步骤;
- 通过朗朗上口的动画对用户的手势做出反应;
- 演示应用程序不同组件之间的关系等。
9. 持续集成和部署

我们生活在一个数字时代,在这个时代,速度和连续性在任何行业和业务中都扮演着残酷的角色,网络开发世界也不例外。事实上,在网络开发的世界里,提供快速、流畅和更新的服务是最重要的。
定期修复、更新、改进UI/UX等错误的频率使您的web服务负责任,成为用户的最爱。此外,大多数现代应用程序都需要在不同的平台和工具中开发代码,团队需要一种机制来集成和验证其更改。它会影响您的整体业务。因此,持续集成和部署在网络世界中至关重要。🧐
好吧,持续集成是指尽早自动测试对代码库所做的每一项更改的过程。Continuous Deployment遵循Continuous Integration过程中发生的测试,并将更改推送到暂存或生产系统。而持续交付意味着应用程序进入生产环境进行彻底测试,并且持续部署会自动更新它们。
优点:
- 较小的代码更改更简单(更原子化)
- 故障隔离更简单、更快。
- 产品通过快速功能介绍快速改进
- 平均解决时间(MTTR)更短,因为代码更改更小,故障隔离更快。
- 可测试性由于较小的、特定的更改而提高。这些较小的变化允许更准确的阳性和阴性检测。
- 检测和纠正生产逃逸所花费的时间更短,发布速度更快。
有了这样的优势,难怪会有更多的软件开发公司在他们的工作中采用这种方法。因为它是网络开发世界中最关键的方面。
10. 云技术将继续存在

Created by Taras Ivanytskyi on dribbble
你知道吗,2020年,云服务行业创造了近400亿美元的收入,使其市值从2019年的2278亿美元增至2664亿美元,在短短一年内增长了17%?
有了这些数字,有一点是肯定的;在web开发服务中,云技术是王者。2023年,由于云技术,预计谷歌、微软和亚马逊等云供应商将继续赚得盆满钵满。
这一热门趋势背后的原因是,云上有几家公司,预计还会有更多的公司搬到那里。从小型创业公司或跨国公司,到多个行业的企业,从医疗保健到情报机构,甚至政府组织,各种规模的企业都将转向数据存储的云提供商。

Credit: Cloudopedia
Following are some cloud services.
- AWS Lambda
- Google Cloud Functions
- Azure Functions
- IBM OpenWhisk
- Alibaba Function Compute
- Iron Functions
- Auth0 Webtask
- Oracle Fn Project
- Kubeless
云技术在数据存储方面提供了强大的安全性、可扩展性和灵活性,考虑到可能导致安全漏洞的黑客威胁一直存在,组织将希望确保采取可衡量的措施来保护其敏感数据,避免数据泄露和其他可能损害数据隐私的活动。
11. 5G技术将无与伦比

Credit: Rpc senate
5G是第五代蜂窝网络,它带来了新的功能,将为人们、企业和社会创造机会。即使在网络开发领域,5G也占据主导地位。由于需要增强服务,因此必须加快连接速度。
2023年,软件开发商可以预计5G技术将作为一种趋势回归,但这一次的理由是正确的。随着新射频的使用和速度达到100 Gbps,5G技术的速度大约是4G网络的100倍,软件开发行业的专家预测,未来五年,它将引领全球14亿台设备的标准数据传输。
优点:
- 变速箱速度更高
- 减少延迟
- 连接的设备数量更多
- 网络切片
- 增强的容量
- 可用性和覆盖范围

Credit: By Kate mangostar on Freepik
5G技术是为增强现实、虚拟现实和4K视频流等计算密集型应用程序设计的。对创建能够提高业务性能的设计和功能感兴趣的软件开发人员会发现这项技术特别有用。
随着更好的数据传输和更快的网络的承诺,5G技术无疑是2023年最佳网络发展趋势之一的有力竞争者。
12. Mixed Reality (MR)

AR/VR市场(即混合现实)将从2017年的10.54亿美元增长到2024年的99.82亿美元,2018-2023年的复合年增长率将达到73.2%。
混合现实(MR)是增强现实(AR)和虚拟现实(VR)的结合。它在企业应用程序中发挥着关键作用。AR将数字内容与用户的物理环境相结合,而VR则为用户创造了身临其境的体验。
在这项技术的帮助下,Web应用程序开发、国防、旅游、建筑、建筑、游戏、医疗保健等许多领域的组织正在实现关键的商业价值。
MR如何扭转局面:
- 企业、政府组织,甚至非营利组织都可以使用AR和VR来培训员工从事复杂的工作。
- 在物理环境上实时覆盖数字信息的能力为增强现实在商业中创造了许多可能性。
- 媒体和娱乐企业正在以一种重要的方式使用AR和VR,为消费者提供引人入胜的内容。
- 企业可以使用AR和VR让潜在客户虚拟地“试用”他们的产品,这增加了他们的销售努力。
MR在网站上的体验将在未来几年不断增加。想想宜家这样的家具网站,展示你房间里的家具。。!!
13. Blockchain: 增强企业解决方案的透明度、效率和安全性

比特币问世时有点革命性…!!它在某种程度上震撼了市场,也为网络开发世界打开了一扇新的大门。Cision PR Newswire的一份报告估计,2025年区块链技术市场将达到576.41亿美元,2019年至2025年的复合年增长率将达到69.4%。
比特币和以太币等加密货币让我们注意到了区块链,这项技术对企业系统有着广泛的影响。基本上,区块链是一个对等(P2P)网络,它提供去中心化、分布式账本、透明和安全功能。
在区块链网络上运行的智能合约是不可篡改和透明的,因此,它们是安全和值得信赖的。此外,它们的执行是不可逆转的,这使得合同管理更容易。
优点:
- 权力下放
- 不可变性
- 安全
- 透明度
- 保护物联网(IoT)
Check “Benefits of blockchain for identity management” for more information
几个区块链用例示例:
- 改善供应链管理
- 身份管理:区块链可以通过其防篡改数据和分布式账本来改进“身份和访问管理”(IAM)流程。
- 更好的分析:区块链提供了不变性和审计跟踪,从而确保了正确的数据质量。这可以帮助所有行业的企业,因为他们可以根据可靠的数据运行分析工具。
- 去中心化颠覆:以太坊和NEO等区块链平台使企业家能够构建“去中心化应用程序”(DApp),因此,他们可以颠覆现有的中心化商业模式。
- 保护物联网(IoT):物联网具有巨大的潜力,因为它可以从数十亿个传感器和设备中获得见解。尽管如此,物联网仍面临风险,因为设备之间的整个通信都是通过互联网进行的。区块链可以通过其强大的安全功能来保护这种通信。
14. IoT: 物联网
Credit: By vectorpouch on Freepik
根据研究,“到2020年,将有超过200亿台物联网设备活跃并连接到互联网”。真是令人印象深刻…!!😎
我们希望一切都更智能。无论是智能手机还是灯泡。。!!你看,对智能设备的需求与日俱增,而且不会停止。而且,多亏了互联网,智能生活正在成为现实。你所要做的就是命令…!!是的,这就是我们喜欢的东西。😁
嗯,没有互联网的生活是不可能想象的,因为现在世界的每一个方面都被连接起来,使一切变得方便、简单和智能。因此,为了让世界更加互联,物联网的出现是一件幸事。
物联网是指能够与其他设备和网络通信的广泛的互联网连接设备。它们可以执行各种功能,但最常用于收集信息和执行特定操作。你会惊讶地发现,每秒钟都有127台设备连接到互联网。
优点:
- 改进监控
- 预测和行动的新能力
- 增加客户对话
- 微调服务和产品
- 改进对操作过程的控制
如今,互联网让生活变得更加轻松,但也让世界变得越来越小。由于不断增强的功能,互联网现在已经成为我们丰富生活的系统和日常生活的一部分。
Iot肯定会在很长一段时间内统治网络开发世界…!!
15. MEAN-React-Vue-Flutter
如果没有一定的技术堆栈,上面列出的大多数趋势都无法实现。但现在有数百个框架和库。它们中的哪一个最常使用?
MEAN是一个免费的开源JavaScript软件栈,用于构建动态网站和web应用程序。由于MEAN堆栈支持程序的所有组件都是用JavaScript编写的,因此MEAN应用程序可以用一种语言编写,用于服务器端和客户端执行环境
MEAN堆栈是最受欢迎的堆栈之一。它包括:
- MongoDB——一个数据库
- React.js——一个web框架
- Vue.js——一个前端框架
- Angular——一个前端框架
- Flutter for web
React库起着重要作用。它经常被用作MEAN堆栈中Angular的替代品。它能够更快、更容易地实现更改,因此越来越多的开发人员选择它而不是Angular。
- React是一个开源的前端JavaScript库,用于构建用户界面或UI组件。它由Facebook和一个由个人开发者和公司组成的社区维护。
您可以查看Sneat MUI React NextJS管理模板和Vuexy React管理模板。这些是最好的React管理模板,用于构建强大而令人敬畏的web应用程序。
您可以查看ReactJS开发人员路线图,了解如何使用ReactJS的详细概述。除此之外,还有一篇关于最佳ReactJS UI框架和组件库的文章会很有帮助。
在小米和阿里巴巴等巨头转向Vue后,Vue已经在全球市场上站稳了脚跟。这是一个非常紧凑的前端解决方案。
您可以查看使用VueJS制作的Materio Vuetify VueJS管理模板。
- Vue.js是一个开源的模型-视图-视图模型前端JavaScript框架,用于构建用户界面和单页应用程序。
此外,还有一篇关于Trending VueJS UI组件库和框架的详细文章,您会发现这些文章很有用。
- Angular是一个基于TypeScript的开源web应用程序框架,由谷歌的Angular团队以及个人和企业社区领导。
为了获得更好的外观,请查看使用Angular制作的Apex Angular Admin Template
最后一个流行的解决方案是Flutter for Web。Flutter是一个开源的用户界面软件开发工具包,由谷歌创建。它用于从单个代码库为Android、iOS、Linux、Mac、Windows、Google Fuchsia和web开发应用程序。它有助于在任何设备上提供高质量的网络应用程序,因此在网络开发人员的评分中名列前茅。
16. API-First Development

Credit: Freepik
API-first方法意味着对于任何给定的开发项目,您的API都被视为“一流公民”。它满足用户的需求。使用这种方法,开发人员可以在用户访问网站时同时执行任务和推送代码。
它还降低了开发费用并提高了交付速度。此外,这种方法还允许新网站成为内容传递源。这种互连性允许开发人员将外部产品添加到他们的应用程序中,以帮助增强他们的功能和性能。
新的物联网设备、软件工具和网络接口都包含API,允许它们相互连接,并为用户提供无缝的数字体验。
以前,许多开发人员可能首先关注该产品,然后将其需要连接到其他设备的事实视为事后考虑。现在,API成为焦点,并成为公司寻找增加与用户互连性的方法的中心。
优点:
- 开发团队可以并行工作
- 更快的上市时间
- 降低开发应用程序的成本
- 良好的客户体验
- 降低故障风险
17. Accelerated Mobile Pages (AMP)

AMP类似于PWA,是web开发中的新兴技术之一。随着互联网越来越以用户为中心,这是一种新的网络发展趋势。因此,许多品牌选择创建本地应用程序来改善用户体验。此外,AMP插件还可以帮助企业节省用户体验费用并接触目标用户。
AMP背后的目的是为用户提供无缝的页面体验,让他们沉迷于网站。不同的功能是谷歌和推特最近开发的开源插件。
AMP是经过优化的页面,可快速加载和操作。此外,它们有一个方便但基本的设计,不同于全范围的网络产品。页面变得便于移动,并增加了内容的可读性。AMP等插件允许不同网速的用户访问页面,并使互联网更加用户友好。
它使公司能够节省用户体验的成本,同时提高其可达性。此外,以下是AMP带来的一些优势。
优点:
- 提高网站参与度
- 提高排名和流量
- 较低的反弹率
- 增加了广告浏览量
- 点击率更高
18. Dark mode:
Credit: Materio Vuetify VueJS Admin Template
嗯,暗模式、夜班和其他弱光用户界面选项是一种趋势,主要是因为它们为用户提供了一个低对比度的网站或应用程序,在弱光环境中更容易查看。
此外,黑色是一种特别强烈的颜色,它会打击人们的强烈情绪,如果使用过量,很容易压倒个人。当您想要突出显示特定类型的内容时,暗模式特别有用。
此外,Spotify、Netflix和Steam都是在黑暗模式下设计的。与此同时,谷歌开始提供暗模式,Instagram、Twitter、苹果和安卓是提供暗模式的一些最受欢迎的应用程序和服务。
根据安卓管理局的评估,81.9%的受访者接受在设备上使用暗模式,9.9%的受访者在亮模式和暗模式之间切换。Polar的另一项调查显示,95%的用户喜欢使用暗模式而不是亮模式。
这一趋势的主要原因如下:
- 它给人一种超现代、酷炫的外观
- 它节省了设备电池电量(在OLED/AMOLED屏幕的情况下)
- 它允许弹出和突出显示其他设计元素
- 它可以减少弱光条件下的眼睛疲劳。
尽管如此,我们不应该忽视这样一个事实:任何过量的东西都是有害的。所以,小心使用它…!!
19. Cybersecurity

这是2023年以及未来最重要的趋势之一。随着新兴技术和对技术的依赖,网络安全威胁的风险正在增加。2020年10月,黑客用恶意软件攻击了德国第二大软件供应商software AG,要求赔偿近2000万美元。
根据Cloudflare的数据,2020年分布式拒绝服务(DDoS)攻击的数量每个季度都翻了一番。在DDoS攻击中,黑客会用大量恶意互联网流量淹没目标服务器。这可能会导致数小时的停机时间,也可能导致收入损失。
客户已经认识到这一新出现的威胁,并希望公司采取强有力的安全措施,确保其个人信息的安全。这就是为什么,保护您的公司和客户信息将是2023年的优先事项,尤其是在网络攻击持续增加的时候。
以下是您可以采取的一些步骤:
- 进行脆弱性评估
- 保护您的远程访问
- 引入角色、权限和多因素身份验证
20. Push Notifications

推送通知是由移动应用程序发送到用户设备的小型弹出消息,即使在应用程序未打开时也会出现。这些通知旨在吸引注意力,并可以传达提醒、更新、促销等信息。
它们可以提供实时更新,或通过必要的细节和推送通知来吸引用户的注意力,例如提醒用户重新访问最近查看的项目或新的博客文章。
推送通知是与受众沟通的好方法。根据Localytics的一项研究,52%的智能手机用户在他们的设备上启用了推送功能,这些通知可以通过以下方式为企业带来好处:
- 引导用户访问您的社交媒体渠道
- 推广产品和服务(特别是特惠)
- 通过提供有价值的内容建立信任和品牌声誉
- 吸引当前不在您网站上的用户
- 恢复电子商务应用程序的废弃购物车
以下应用程序使用此技术来提高销售额:
21. No-Code/Low-Code Apps

无代码/低代码的平台使web开发更加容易。这些工具使用户能够利用预先制作的代码块和管理模板创建软件解决方案。
简言之,它们是可视化的软件开发环境,使开发人员能够拖放软件组件,连接它们,并创建移动或web应用程序。这些平台经常与它们所代表的开发方法互换使用。
因此,它减少了编码所需的时间和精力。此外,无论技术经验如何,任何人都可以开发软件和高需求应用程序。这些工具还使公民开发人员更容易构建有用的应用程序,而无需编写复杂的代码。
以下是您可以使用的一些无代码开发工具。
For more such, No code tools refer to the collection: Best No Code Development Tools
22. Personalization

根据访问者的需求和特点,不同版本的网页会显示给不同的访问者。可以对登录页进行个性化设置,以共享专为特定访问者量身定制的信息。事实上,客户渴望个性化。这就是让他们保持投入和忠诚的原因…!!
因此,个性化正在为2023年的网络开发设定基准。您可以通过多种交互方式向您的网站访问者提供个性化权限。例如,您可以允许用户手动或通过他们的反馈设置他们的首选项。除此之外,你还可以授权他们根据他们的意愿更改你的网站外观,这样他们会感觉更紧密。
机器学习的内容个性化,也称为预测性内容个性化,是一种先进的人工智能驱动方法,可以向每个用户动态显示最相关的内容。
23. CRM Integration

客户关系管理(CRM)系统帮助企业管理与当前和潜在客户的关系和互动。在其潜力中,许多企业没有将其纳入其网络解决方案,从而错过了好处。
通过连接您的网站和CRM,您将能够增强客户体验。通过这种方式,您将能够在客户消费旅程的每个阶段为其提供帮助。此外,您将通过消除手动复制和粘贴或导出和导入的需要来节省管理费用。这会提高你的工作效率,让你的日程安排更加专注于其他目标。
以下是提供CRM集成的一些服务和应用程序:
24. AI & Machine Learning

几年来,人工智能一直在渗透我们的数字生活,但随着越来越多的公司投资于技术,我们可以期待在可能的方面取得重大进展。特别是自然语言处理(NLP)和机器学习(ML)已经从理论概念发展到了成熟的应用。
例如,“YouTube使用NLP从视频音频中自动创建字幕,或者谷歌分析使用ML更好地了解网站用户的行为,或者Alexa使用VR和ML,这样我们就可以与机器进行完整的对话。”
机器学习(ML)用于网络开发,为用户提供改进的体验。开发人员使用ML使软件能够分析传入数据、检测模式和个性化内容。许多领先的公司都使用这项技术来增强用户体验。例如,Airbnb和Netflix使用ML为用户定制搜索结果。
结论
好吧,正如这里谈到的2023年的网络发展趋势一样,很难追逐它们,因为它们变化如此之快。但是,我们必须控制住它们,并尝试它们。。!!
通过跟踪网络开发的最新趋势,您可以用世界级的用户体验来安抚用户,提高您的网络应用排名,并为您的服务打开新市场…!!
通过使用这些趋势,您将能够为您的网络应用程序的用户提供令人惊叹的体验。此外,你将增加成为他们首选的机会!
一般来说,每一个网络发展趋势都值得你关注。其中一些可能会持续到未来十年,例如物联网、语音机器人、MR、ETC。而其中一些将在几个月内成为常态。
所以,不要犹豫,尽快在下一个项目中开始实施它们。
一定要告诉我们你最喜欢的一个,如果我们在这里错过了,我们很乐意听到。发展快乐。🤩
- 105 次浏览
【Web应用技术】GraphQL性能提示:从数据库请求中选择字段
GraphQL的真正威力…从客户端请求一直到数据库指定所请求的字段。

问题
GraphQL最强大的特性之一是客户端可以指定从响应返回的字段,从而减少通过网络传输的数据,从而避免过度获取数据。
然而,我们真的做了更少的工作吗?后端服务器和数据库仍然必须执行查询数据库的所有工作,获取被请求对象的所有字段,然后仅通过GraphQL/Network层返回被请求的字段。
因此,通过发送较小的响应大小,我们只是节省了网络时间,但我们的后端服务器和数据库仍然在做额外的不必要的工作,以获取所请求对象的所有字段。这基本上是浪费了很多时间,我们可以优化。
解决方案
如果有一种方法可以确定客户机请求哪些字段,并且只从数据库层返回这些字段,那该怎么办?
大多数现代数据库都提供了“投影”或“选择”特性,其中数据库驱动程序允许使用者指定应该从与数据库查询匹配的文档中返回哪些字段,以避免返回所有不必要的字段,并加快对数据库的查询。
这对数据库查询性能有相当大的影响,因为它避免了不必要的工作,如果您想知道潜在的节省是什么样子的,可以看看我之前写的这篇文章,它展示了在MongoDB中使用/不使用投影的一些性能指标。
Apollo-Server解析器函数
因此,我们可以从网络层和数据库层实现这一点,唯一缺少的是在我们的服务器/解析器中解决它。
用apollo-server编写的graphQL解析器函数通常接受四个输入参数。根,args,上下文和信息。如果我们要写一个解析器,返回所有用户从数据库举例,它会像这样:
resolvers = {
getUsers: function (root, args, context, info) {
const User = mongoose.model('User')
return User.find({})
}
}根对象通常是Schema中请求的操作/字段的父对象。args是可以传递给该操作的任何参数,而上下文包括传递到上下文对象的任何参数(通常用于身份验证)。但是info对象呢?它似乎包括一些关于传入请求的信息。
所以我在apollographql.com上查阅了它的文档,这是我找到的
Info:这个参数只应该在高级情况下使用,但是它包含关于查询执行状态的信息,包括字段名、从根到字段的路径等等。它只在GraphQL.js源代码中有文档说明。
不是很有用,但我认为它可能包含有关传入请求和请求字段的必要信息,在查看了可能能够执行我想要的操作的在线库之后,我发现了graphql-fields。
graphql-fields
我遇到了graphql-fields,它可以根据info参数返回被请求的字段,它还可以处理高级情况,如联合类型、片段、子字段( union types, fragments, sub-fields)等。
下面是它所能做的,对于这样一个返回所有用户姓名和电子邮件的查询
{
users {
name
}
}
结果就是:[' name ', ' email ']
用法:
const graphqlFields = require(‘graphql-fields’);
function userResolver(root, args, context, info) {
const topLevelFields = Object.keys(graphqlFields(info));
console.log(topLevelFields)
// prints [‘name’, ‘email’]
}
很好,现在我们可以使用这个结果从数据库中只选择这些字段,而不是为每个用户从数据库中请求整个用户文档。
使用结果
在我的例子中,我使用MongoDB和Mongoose作为数据库驱动程序,所以Mongoose投影所需的语法与我从graphql-fields得到的结果有一点不同。
我想实现的等价查询如下所示:
User.find({}).select({name: 1, email: 1}).lean()
将来自graphql-fields的结果转换为猫鼬需要的选择对象的helper函数如下:
export function getMongooseSelectionFromSelectedFields (info, fieldPath = null) {
const selections = graphqlFields(info)
const mongooseSelection = Object
.keys(fieldPath ? selections[fieldPath] : selections)
.reduce((a, b) => ({ …a, [b]: 1 }), {})
return mongooseSelection
}
好了,现在客户端请求的字段就是数据库请求和返回的字段,这使我们的解析器更快了!
这在自动持久化查询(APQ)和缓存中完美地工作。另外两个表现容易获胜。
我添加了一个fieldPath参数来支持响应中的一层嵌套,以防从数据库请求数据的操作不是顶层操作。
这是新的解析器的样子:
resolvers = {
getUsers: function (root, args, context, info) {
const mongooseSelection = getMongooseSelectionFromRequest(info)
return User.find({}).select(mongooseSelection).lean()
}
}
结论
GraphQL是相当强大的,它不仅优化性能的客户端应用,但也可以用于优化后端性能,毕竟我们得到的特定请求字段在我们的解析器免费。
原文:https://itnext.io/graphql-performance-tip-database-projection-82795e434b44
本文:http://jiagoushi.pro/node/1176
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】
- 63 次浏览
【Web应用架构】WebSocket 协议介绍
由HyBi工作组开发的WebSocket有线协议(RFC 6455)由两个高级组件组成:用于协商连接参数的开放HTTP握手和二进制消息帧机制,以实现低开销、基于消息的文本和二进制数据传输。
WebSocket协议试图在现有HTTP基础架构的上下文中解决现有双向HTTP技术的目标;因此,它被设计为在HTTP端口80和443上工作……然而,这种设计并没有将WebSocket限制为HTTP,而且未来的实现可以在专用端口上使用更简单的握手,而无需重新发明整个协议。
----WebSocket协议RFC 6455
WebSocket协议是一个功能完整的独立协议,可以在浏览器之外使用。尽管如此,它的主要应用程序是作为基于浏览器的应用程序的双向传输。
二进制框架层
客户端和服务器端WebSocket应用程序通过一个面向消息的API进行通信:发送方提供一个任意的UTF-8或二进制有效负载,当整个消息可用时,接收方被通知它的传递。为了实现这一点,WebSocket使用了自定义的二进制帧格式(图17-1),它将每个应用程序消息分解成一个或多个帧,将它们传输到目的地,重新组装它们,并在收到整个消息后通知接收者。

Figure 17-1. WebSocket frame: 2–14 bytes + payload
Frame
通信的最小单位,每个单位包含一个可变长度的帧头和一个可携带全部或部分应用程序消息的有效负载。
Message
映射到逻辑应用程序消息的完整帧序列。
决定将应用程序消息分割成多个框架是由客户机和服务器框架代码的底层实现做出的。因此,应用程序仍然很高兴地不知道各个WebSocket帧或者帧是如何执行的。话虽如此,理解每个WebSocket帧在连线上是如何表示的要点仍然是有用的:
- 每个帧(FIN)的第一个比特表示该帧是否为消息的最后一个片段。一条消息可能只包含一帧。
- 操作码(4位)表示传输帧的类型:用于传输应用程序数据的文本(1)或二进制(2)或用于连接活性检查的控制帧,如连接关闭(8)、ping(9)和pong(10)。
- 掩码位指示负载是否被掩码(仅针对从客户机发送到服务器的消息)。
- 有效载荷长度用可变长度字段表示:
- 如果0-125,那么这就是有效载荷长度。
- 如果是126,那么下面的两个字节表示一个16位无符号整数,表示帧长度。
- 如果是127,那么下面的8个字节表示一个64位无符号整数,表示帧长度。
- 屏蔽键包含一个用于屏蔽有效负载的32位值。
- 有效负载包含应用程序数据和自定义扩展数据(如果客户端和服务器在建立连接时协商了扩展)。
所有客户端发起的帧的有效负载都使用帧头中指定的值来隐藏:这可以防止恶意脚本在客户端执行缓存中毒攻击,攻击那些可能不理解WebSocket协议的中介。有关这次攻击的详细信息,请参考2011年W2SP上的 "Talking to Yourself for Fun and Profit"。
因此,每个服务器发送的WebSocket帧都会产生2-10字节的帧开销。客户端还必须发送一个屏蔽密钥,这将在头文件中增加额外的4个字节,导致开销增加6-14个字节。没有其他元数据可用,例如头字段或关于有效负载的其他信息:所有WebSocket通信都是通过交换帧来执行的,这些帧将有效负载视为应用程序数据的不透明blob。
WebSocket多路复用和堆头阻塞( Head-of-Line Blocking)
WebSocket易受行头阻塞的影响:消息可以被分割成一个或多个帧,但是来自不同消息的帧不能交叉,因为在HTTP/2帧机制中没有等效的“流ID”;参见流、消息和帧)。
因此,一个大消息,即使被分割成多个WebSocket帧,也会阻止与其他消息相关联的帧的传递。如果您的应用程序交付的是对延迟敏感的数据,请注意每个消息的有效负载大小,并考虑将大消息拆分为多个应用程序消息!
核心WebSocket规范中缺乏多路复用也意味着每个WebSocket连接都需要一个专用的TCP连接,这可能成为HTTP/1的一个潜在问题。由于浏览器维护的每个源的连接数量有限而进行的部署;请参阅耗尽客户机和服务器资源。
从好的方面来看,由HyBi工作组开发的“WebSockets多路复用扩展”解决了后一个限制:
有了这个扩展,一个TCP连接可以通过封装带有通道ID标签的帧来提供多个虚拟WebSocket连接……这个多路复用扩展维护独立的逻辑通道,每个逻辑通道提供独立WebSocket连接的完全等价逻辑,包括单独的握手头。
--------------WebSocket多路复用(草案10)
有了这个扩展,多个WebSocket连接(通道)可以在同一个TCP连接上多路复用。然而,每个单独的通道仍然很容易被线头阻塞!因此,一种可能的解决方案是使用不同的通道或专用的TCP连接并行地多路传输多个消息。
最后,注意前面的扩展仅对HTTP/1是必要的。x连接。虽然目前还没有官方规范可以使用HTTP/2传输WebSocket帧,但是这样做会容易得多:HTTP/2有内置的流多路复用,通过在HTTP/2帧机制中封装WebSocket帧,可以在一个会话中传输多个WebSocket连接。
协议的扩展
WebSocket规范允许协议扩展:WebSocket协议的有线格式和语义可以通过新的操作码和数据字段进行扩展。虽然有些不寻常,但这是一个非常强大的特性,因为它允许客户端和服务器在基本的WebSocket框架层之上实现额外的功能,而不需要任何来自应用程序代码的干预或合作。
有一些WebSocket协议扩展的例子吗?负责WebSocket规范开发的HyBi工作组列出了两个正在开发中的官方扩展:
“WebSockets的多路复用扩展”
这个扩展为单独的逻辑WebSocket连接提供了一种共享底层传输连接的方法。
“WebSocket的压缩扩展”
一个用于创建WebSocket扩展的框架,为WebSocket协议添加压缩功能。
如前所述,每个WebSocket连接都需要一个专用的TCP连接,这是低效的。多路复用扩展通过为每个WebSocket帧增加一个额外的“通道ID”来允许多个虚拟的WebSocket通道共享一个TCP连接来解决这个问题。
类似地,基本的WebSocket规范没有为传输数据的压缩提供任何机制或规定:每一帧都携带由应用程序提供的有效负载数据。因此,虽然这对于优化的二进制数据结构来说不是问题,但这可能会导致高字节传输开销,除非应用程序实现了自己的数据压缩和解压缩逻辑。实际上,压缩扩展支持HTTP提供的等效传输编码协商。
要启用一个或多个扩展,客户机必须在初始升级握手时公布它们,服务器必须选择并确认在协商的连接的生命周期中将使用的扩展。作为一个实际的示例,现在让我们仔细看看升级顺序。
WebSocket多路复用和压缩在野外
到2013年中期,WebSocket多路复用还没有被任何流行的浏览器支持。类似地,对压缩的支持也很有限:谷歌Chrome和最新的WebKit浏览器可能会在服务器上发布一个“x-webkit-deflate-frame”扩展。然而,deflate-frame是基于一个过时的修订标准,并将在未来过时。
顾名思义,每帧都是逐帧压缩有效负载内容,这对于可能在多个帧之间分割的大消息不是最优的。因此,压缩扩展的最新版本已经切换到每消息压缩——这是一个好消息。坏消息是每条消息的压缩还处于试验阶段,目前还不能在任何流行的浏览器中使用。
因此,应用程序应该密切关注传输数据的内容类型,并在适用的情况下应用自己的压缩。也就是说,至少要等到本地WebSocket压缩支持在所有流行的浏览器上广泛可用。这对于移动应用程序尤其重要,因为在移动应用程序中,每个不必要的字节都会给用户带来很高的代价。
HTTP升级协商
WebSocket协议提供了很多强大的特性:面向消息的通信、它自己的二进制帧层、子协议协商、可选协议扩展等等。因此,在交换任何消息之前,客户机和服务器必须协商建立连接所需的适当参数。
利用HTTP执行握手提供了几个优点。首先,它使WebSocket与现有的HTTP基础设施兼容:WebSocket服务器可以在端口80和443上运行,这两个端口通常是客户端唯一开放的端口。其次,它允许我们重用和扩展HTTP升级流自定义WebSocket头执行协商:
- Sec-WebSocket-Version
- 由客户端发送来指示它想要使用的WebSocket协议的版本(对于RFC6455“13”)。如果服务器不支持客户端版本,则必须使用支持版本列表进行响应。
- Sec-WebSocket-Key
- 客户端发送的自动生成的密钥,它充当服务器的“质询”,以证明服务器支持所请求的协议版本。
- Sec-WebSocket-Accept
- 包含Sec-WebSocket-Key签名值的服务器响应,证明它理解所请求的协议版本。
- Sec-WebSocket-Protocol
- 用于协商应用程序子协议:客户端发布支持协议列表;服务器必须使用单个协议名进行应答。
- Sec-WebSocket-Extensions
- 用于协商用于此连接的WebSocket扩展:客户端声明支持的扩展,服务器通过返回相同的头来确认一个或多个扩展。
有了这些,我们现在就有了执行HTTP升级和协商客户端和服务器之间新的WebSocket连接的所有必要的部分:
GET /socket HTTP/1.1 Host: thirdparty.com Origin: http://example.com Connection: Upgrade Upgrade: websocket Sec-WebSocket-Version: 13 Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Sec-WebSocket-Protocol: appProtocol, appProtocol-v2 Sec-WebSocket-Extensions: x-webkit-deflate-message, x-custom-extension
- 请求执行WebSocket协议升级
- 客户端使用的WebSocket协议版本
- 自动生成密钥来验证服务器协议支持
- 应用程序指定的子协议的可选列表
- 客户端支持的可选协议扩展列表
就像浏览器中任何其他客户端发起的连接一样,WebSocket请求遵循同源策略:浏览器自动在升级握手中附加源头,远程服务器可以使用CORS来接受或拒绝跨源请求;参见跨源资源共享(CORS)。要完成握手,服务器必须返回一个成功的“交换协议”响应,并确认客户端公布的选择:
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Access-Control-Allow-Origin: http://example.com Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo= Sec-WebSocket-Protocol: appProtocol-v2 Sec-WebSocket-Extensions: x-custom-extension
- 确认WebSocket升级的响应代码
- CORS头指示选择进入跨源连接
- 签名键值证明协议支持
- 由服务器选择的应用程序子协议
- 由服务器选择的WebSocket扩展的列表
所有RFC6455-compatible WebSocket服务器使用相同的算法来计算客户挑战的答案:Sec-WebSocket-Key的内容与独特的GUID连接字符串中定义的标准,SHA1哈希计算,生成的字符串是base - 64编码,并返回给客户端。
一次成功的WebSocket握手至少必须包含协议版本和客户端发送的自动生成的质询值,以及来自服务器的101 HTTP响应代码(交换协议)和一个哈希的质询-响应来确认所选协议版本:
- 客户端必须发送Sec-WebSocket-Version和Sec-WebSocket-Key。
- 服务器必须通过返回Sec-WebSocket-Accept来确认协议。
- 客户端可以通过Sec-WebSocket-Protocol发送应用程序子协议列表。
- 服务器必须选择一个子协议并通过Sec-WebSocket-Protocol返回。如果服务器不支持任何连接,则连接将中止。
- 客户端可以发送一个协议扩展列表在Sec-WebSocket-Extensions。
- 服务器可以确认一个或多个选定的扩展通过Sec-WebSocket-Extensions。如果没有提供扩展,则连接在不提供扩展的情况下继续运行。
最后,一旦前面的握手完成,如果握手成功,连接现在就可以用作交换WebSocket消息的双向通信通道。从这里开始,客户端和服务器之间不再有其他明确的HTTP通信,由WebSocket协议接管。
代理、中介和WebSockets
在实践中,由于安全和策略的原因,许多用户拥有一组受限的开放端口——具体来说端口80 (HTTP)和端口443 (HTTPS)。因此,WebSocket协商是通过HTTP升级流执行的,以确保与现有网络策略和基础设施的最佳兼容性。
然而,正如我们前面提到的代理中介,TLS,和新协议在网络上,许多现有HTTP中介可能不理解新WebSocket协议,从而导致各种各样的失败案例:盲目连接升级,意想不到的WebSocket帧缓冲,内容修改协议的不了解,误分类的WebSocket信息流作为妥协的HTTP连接,等等。
WebSocket密钥和接受握手解决了一些问题:它是一个安全策略,可以防止服务器和中介在没有真正理解WebSocket协议的情况下盲目地“升级”连接。然而,尽管这种预防措施解决了显式代理的一些部署问题,但它对于“透明代理”是不够的,“透明代理”可以在没有通知的情况下分析和修改网络上的数据。
解决方法?建立一个安全的端到端隧道。,用WSS !通过在执行HTTP升级握手之前协商一个TLS会话,客户机和服务器建立一个加密隧道,从而解决前面列出的所有问题。对于移动客户端来说尤其如此,它的流量经常要通过各种代理服务,而这些代理服务在WebSocket中可能不能很好地发挥作用。
本文:http://jiagoushi.pro/node/1111
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】
- 71 次浏览
【Web应用架构】WebSocket介绍和WebSocket API
WebSocket支持在客户端和服务器之间双向的、面向消息的文本和二进制数据流。它是浏览器中最接近原始网络套接字的API。除了WebSocket连接也不仅仅是一个网络套接字,因为浏览器在一个简单的API背后抽象了所有的复杂性,并提供了一些额外的服务:
- 连接协商和同源策略的实施
- 与现有HTTP基础设施的互操作性
- 面向消息的通信和有效的消息框架
- 子协议协商和可扩展性
WebSocket是浏览器中最通用、最灵活的传输方式之一。简单和最小的API使我们能够以流方式在客户机和服务器之间分层和交付任意的应用程序协议——从简单的JSON有效负载到定制的二进制消息格式的任何内容——其中任何一方都可以随时发送数据。
但是,定制协议的代价是它们是定制的。应用程序必须考虑到缺少状态管理、压缩、缓存和其他由浏览器提供的服务。设计约束和性能权衡总是存在的,利用WebSocket也不例外。简而言之,WebSocket不是HTTP、XHR或SSE的替代品,为了获得最佳性能,充分利用每种传输的优势至关重要。
WebSocket是由多个标准组成的:WebSocket API由W3C定义,WebSocket协议(RFC 6455)及其扩展由HyBi工作组(IETF)定义。
WebSocket API
浏览器提供的WebSocket API非常小和简单。同样,连接管理和消息处理的所有低级细节都由浏览器处理。为了启动一个新的连接,我们需要一个WebSocket资源的URL和一些应用程序回调:
var ws = new WebSocket('wss://example.com/socket');
ws.onerror = function (error) { ... }
ws.onclose = function () { ... }
ws.onopen = function () {
ws.send("Connection established. Hello server!");
}
ws.onmessage = function(msg) {
if(msg.data instanceof Blob) {
processBlob(msg.data);
} else {
processText(msg.data);
}
}- 打开一个新的安全WebSocket连接(wss)
- 可选回调,在发生连接错误时调用
- 可选回调,在连接终止时调用
- 可选回调,在建立WebSocket连接时调用
- 客户端发起的消息到服务器
- 为来自服务器的每个新消息调用的回调函数
- 为接收到的消息调用二进制或文本处理逻辑
API不言自明。实际上,它应该与我们在前一章看到的EventSource API非常相似。这是有意为之,因为WebSocket提供了类似的扩展功能。话虽如此,两者之间也有一些重要的区别。让我们一个一个来看看。
效仿WebSocket
WebSocket协议已经经历了许多修订、实现回滚和安全调查。然而,好消息是RFC6455定义的最新版本(v13)现在被所有现代浏览器支持。唯一值得注意的遗漏是Android浏览器。有关最新状态,请参阅http://caniuse.com/websockets。
类似于SSE的polyfill策略(用定制的JavaScript模拟EventSource), WebSocket浏览器API可以通过一个可选的JavaScript库来模拟。然而,模拟WebSockets的难点不是API,而是传输!因此,polyfill库及其回退传输(XHR轮询、EventSource、iframe轮询等)的选择将对模拟WebSocket会话的性能产生重大影响。
为了简化跨浏览器的部署,流行的库(如SockJS)在浏览器中提供了类似WebSocket的对象的实现,而且更进一步地提供了一个定制服务器来实现对WebSocket的支持和各种替代传输。定制服务器和客户机的结合能够实现“无缝回退”:性能下降,但应用程序API保持不变。
其他库,比如Socket。除了多传输回退功能外,IO还实现了其他特性,如心跳、超时、支持自动重新连接等。
当考虑一个polyfill 库或“实时框架”,Socket.IO,密切关注客户端和服务器的底层实现和配置:始终利用本地WebSocket接口获得最佳性能,并确保回退传输满足您的性能目标。
WS和WSS URL方案
WebSocket资源URL使用自己的定制方案:ws用于明文通信(例如,ws://example.com/socket), wss用于需要加密通道(TCP+TLS)。为什么使用自定义模式,而不是熟悉的http?
WebSocket协议的主要用例是在浏览器和服务器上运行的应用程序之间提供一个优化的双向通信通道。然而,WebSocket有线协议可以在浏览器之外使用,并且可以通过非http交换进行协商。因此,HyBi工作组选择采用自定义URL方案。
尽管自定义方案启用了非http协商选项,但在实践中,还没有用于建立WebSocket会话的替代握手机制的现有标准。
接收文本和二进制数据
WebSocket通信由消息和应用程序代码组成,不需要担心缓冲、解析和重构接收到的数据。例如,如果服务器发送了1 MB的有效负载,应用程序的onmessage回调将只在客户机上整个消息可用时被调用。
此外,WebSocket协议对应用程序的有效负载没有任何假设和限制:文本和二进制数据都是公平的。在内部,该协议只跟踪关于消息的两部分信息:作为可变长度字段的有效负载的长度和区分UTF-8和二进制传输的有效负载类型。
当浏览器接收到新消息时,它会自动转换为DOMString对象(用于基于文本的数据)或Blob对象(用于二进制数据),然后直接传递给应用程序。唯一的另一个选项,作为性能提示和优化客户端,是告诉浏览器转换接收到的二进制数据到ArrayBuffer,而不是Blob:
var ws = new WebSocket('wss://example.com/socket');
ws.binaryType = "arraybuffer";
ws.onmessage = function(msg) {
if(msg.data instanceof ArrayBuffer) {
processArrayBuffer(msg.data);
} else {
processText(msg.data);
}
}- 当收到二进制消息时,强制进行ArrayBuffer转换
用户代理可以将此作为如何处理传入的二进制数据的提示:如果属性设置为“blob”,则将其缓冲到磁盘是安全的,如果属性设置为“arraybuffer”,则可能更有效地将数据保存在内存中。自然,用户代理被鼓励使用更微妙的启发式来决定是否将传入数据保存在内存中……
WebSocket API, W3C候选推荐
Blob对象表示不变的原始数据的类文件对象。如果您不需要修改数据,也不需要将其分割成更小的块,那么它就是最佳格式——例如。,您可以将整个Blob对象传递给图像标记(请参阅使用XHR下载数据中的示例)。另一方面,如果需要对二进制数据执行额外的处理,那么ArrayBuffer可能更适合。
用JavaScript解码二进制数据
ArrayBuffer是一种通用的、固定长度的二进制数据缓冲区。但是,ArrayBuffer可以用来创建一个或多个ArrayBufferView对象,每个对象可以以特定的格式显示缓冲区的内容。例如,假设我们有以下类似c的二进制数据结构:
structsomeStruct{charusername[16];unsignedshortid;floatscores[32];};给定这种类型的ArrayBuffer对象,我们可以在同一个缓冲区中创建多个视图,每个视图都有自己的偏移量和数据类型:
varbuffer=msg.data;varusernameView=newUint8Array(buffer,0,16);varidView=newUint16Array(buffer,16,1);varscoresView=newFloat32Array(buffer,18,32);console.log("ID: "+idView[0]+" username: "+usernameView[0]);for(varj=0;j<32;j++){console.log(scoresView[j])}每个视图接受父缓冲区、起始字节偏移量和要处理的元素数量——偏移量是根据前面字段的大小计算的。因此,ArrayBuffer和WebSocket为我们的应用程序提供了所有必要的工具来在浏览器中流处理二进制数据。
发送文本和二进制数据
一旦WebSocket连接建立,客户端就可以随意发送和接收UTF-8和二进制消息。WebSocket提供了一个双向通信通道,它允许在相同的TCP连接上双向传递消息:
var ws = new WebSocket('wss://example.com/socket');
ws.onopen = function () {
socket.send("Hello server!");
socket.send(JSON.stringify({'msg': 'payload'}));
var buffer = new ArrayBuffer(128);
socket.send(buffer);
var intview = new Uint32Array(buffer);
socket.send(intview);
var blob = new Blob([buffer]);
socket.send(blob);
}- 发送UTF-8编码的文本消息
- 发送一个UTF-8编码的JSON有效负载
- 将ArrayBuffer内容作为二进制有效负载发送
- 将ArrayBufferView内容作为二进制有效负载发送
- 将Blob内容作为二进制有效负载发送
WebSocket API接受一个DOMString对象,该对象在网络上被编码为UTF-8,或者一个用于二进制传输的ArrayBuffer、ArrayBufferView或Blob对象。但是,请注意,后面的二进制选项只是为了API的方便:在网络上,WebSocket框架通过单个位标记为二进制或文本。因此,如果应用程序或服务器需要关于负载的其他内容类型信息,那么它们必须使用额外的机制来通信该数据。
send()方法是异步的:提供的数据由客户机排队,然后函数立即返回。因此,特别是在传输大的有效负载时,不要将快速返回误认为数据已经发送的信号!要监视浏览器排队的数据量,应用程序可以查询套接字上的bufferedAmount属性:
var ws = new WebSocket('wss://example.com/socket');
ws.onopen = function () {
subscribeToApplicationUpdates(function(evt) {
if (ws.bufferedAmount == 0)
ws.send(evt.data);
});
};- 订阅应用程序更新(例如,游戏状态更改)
- 检查客户机上缓冲的数据量
- 如果缓冲区为空,则发送下一个更新
前面的示例尝试将应用程序更新发送到服务器,但前提是前面的消息已从客户机的缓冲区中抽取。为什么要费心去做这样的检查呢?所有WebSocket消息都是按照客户端排队的确切顺序传递的。结果,队列消息的大量积压,甚至单个大消息,都将延迟在it后排队的消息的传递——线头阻塞!
为了解决这个问题,应用程序可以将大消息分割成更小的块,仔细监视bufferedAmount值以避免在行头阻塞,甚至为挂起的消息实现自己的优先级队列,而不是盲目地将它们全部排在套接字上。
许多应用程序生成多种类型的消息:高优先级更新,如控制流量;低优先级更新,如后台传输。为了优化传递,应用程序应该密切关注每种类型的消息如何以及何时在套接字上排队!
Subprotocol谈判
WebSocket协议对每个消息的格式不做任何假设:一个位跟踪消息是否包含文本或二进制数据,这样它可以被客户端和服务器有效地解码,但其他消息的内容是不透明的。
此外,与HTTP或XHR请求不同的是,它们通过每个请求和响应的HTTP头来通信额外的元数据,对于WebSocket消息没有这种等效的机制。因此,如果需要关于消息的额外元数据,那么客户端和服务器必须同意实现它们自己的子协议来通信这些数据:
- 客户端和服务器可以预先就固定的消息格式达成一致。,所有通信都将通过json编码的消息或自定义二进制格式完成,必要的消息元数据将成为编码结构的一部分。
- 如果客户机和服务器需要传输不同的数据类型,那么它们可以就一致的消息头达成一致,该消息头可用于通信指令来解码剩余的有效负载。
- 可以使用文本和二进制消息的混合来传递有效负载和元数据信息。时,文本消息可以与等效的HTTP头通信,然后与应用程序有效负载通信二进制消息。
这个列表只是一个可能的策略的小样本。WebSocket消息的灵活性和低开销是以额外的应用逻辑为代价的。但是,消息序列化和元数据管理只是问题的一部分!一旦我们确定了消息的序列化格式,我们如何确保客户机和服务器相互理解,以及如何保持它们同步?
幸运的是,WebSocket提供了一个简单而方便的子协议协商API来解决第二个问题。作为初始连接握手的一部分,客户端可以向服务器发布它支持的协议:
var ws = new WebSocket('wss://example.com/socket',
['appProtocol', 'appProtocol-v2']);
ws.onopen = function () {
if (ws.protocol == 'appProtocol-v2') {
...
} else {
...
}
}- 在WebSocket握手期间发布的子协议数组
- 检查服务器选择的子协议
如前面的示例所示,WebSocket构造函数接受子协议名称的可选数组,它允许客户端发布它理解或愿意为这个连接使用的协议列表。指定的列表被发送到服务器,服务器被允许选择一个由客户机发布的协议。
如果子协议协商成功,那么onopen回调在客户端上被触发,并且应用程序可以查询WebSocket对象上的协议属性来确定所选择的协议。另一方面,如果服务器不支持任何客户端发布的客户端协议,那么WebSocket握手是不完整的:onerror回调被调用,连接被终止。
子协议名称由应用程序定义,并在初始HTTP握手期间按指定的方式发送到服务器。除此之外,指定的子协议对核心WebSocket API没有影响。
本文:http://jiagoushi.pro/node/1110
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 109 次浏览
【Web应用架构】WebSocket用例,性能和性能检查列表
WebSocket API为客户机和服务器之间的文本和二进制数据的双向、面向消息流提供了一个简单的接口:向构造函数传递一个WebSocket URL,设置几个JavaScript回调函数,然后我们就启动并运行了——其余的由浏览器处理。再加上WebSocket协议,它提供了二进制帧、可扩展性和子协议协商,WebSocket成为在浏览器中交付定制应用协议的完美工具。
然而,就像任何关于性能的讨论一样,尽管WebSocket协议的实现复杂性对应用程序是隐藏的,但它仍然对如何以及何时使用WebSocket有重要的性能暗示。WebSocket不是XHR或SSE的替代品,为了获得最佳性能,我们必须充分利用每种传输的优势!
要查看每个传输的性能特征,请参考XHR用例和性能以及SSE用例和性能。
请求和响应流
WebSocket是唯一允许在同一个TCP连接上进行双向通信的传输(图17-2):客户端和服务器可以随意交换消息。因此,WebSocket在两个方向上都提供了文本和二进制应用程序数据的低延迟交付。

图17-2。XHR, SSE, WebSocket的通信流程
- XHR为“事务性”请求-响应通信进行了优化:客户机向服务器发送完整的、格式良好的HTTP请求,服务器以完整的响应响应。不支持请求流,在Streams API可用之前,没有可靠的跨浏览器响应流API。
- SSE实现了基于文本数据的高效、低延迟的服务器到客户端的流化:客户端启动SSE连接,服务器使用事件源协议将更新流化到客户端。在初始握手之后,客户端不能向服务器发送任何数据。
传播和排队延迟
交换从XHR到SSE或WebSocket的传输不会减少客户端和服务器之间的往返!无论传输方式如何,数据包的传播延迟都是相同的。然而,除了传播延迟之外,还有排队延迟:消息在被路由到另一方之前必须在客户机或服务器上等待的时间。
在XHR轮询的情况下,排队延迟是客户端轮询间隔的函数:消息可能在服务器上可用,但直到下一个客户端XHR请求才能发送;请参阅XHR轮询的建模性能。相比之下,SSE和WebSocket都使用一个持久连接,这允许服务器在消息可用的时候就发送消息(以及客户端,在WebSocket的情况下)。
因此,对于SSE和WebSocket来说,“低延迟交付”是指消除消息排队延迟。我们还没有想出如何让WebSocket数据包的传输速度超过光速!
消息开销
一旦WebSocket连接建立,客户端和服务器通过WebSocket协议交换数据:应用消息被分成一个或多个帧,每个帧增加2到14字节的开销。而且,由于框架是通过自定义二进制格式完成的,因此UTF-8和二进制应用程序数据都可以通过相同的机制进行有效编码。与XHR和SSE相比如何?
- SSE只增加了5字节的每条消息,但仅限于UTF-8内容;参见事件流协议。
- HTTP / 1。x请求(XHR或其他)将携带额外的500-800字节HTTP元数据,加上cookie;参见测量和控制协议开销。
- HTTP/2压缩HTTP元数据,这大大降低了开销;看到标题压缩。事实上,如果头在请求之间不改变,开销可以低至8字节!
请记住,这些开销数字不包括IP、TCP和TLS帧的开销,这些开销会增加每条消息60-100字节的综合开销,而与应用程序协议无关;参见优化TLS记录大小。
数据效率和压缩
每个XHR请求可以通过定期的HTTP协商来协商最佳的传输编码格式(例如,基于文本的数据的gzip)。类似地,由于SSE仅限于utf -8传输,所以可以通过在整个会话中应用gzip有效地压缩事件流数据。
使用WebSocket,情况会更加复杂:WebSocket可以传输文本和二进制数据,因此压缩整个会话没有意义。二进制有效负载可能已经被压缩了!因此,WebSocket必须实现自己的压缩机制,并有选择地将其应用于每个消息。
好消息是HyBi工作组正在为WebSocket协议开发每消息压缩扩展。然而,它还没有在任何浏览器中可用。因此,除非应用程序通过仔细优化其二进制有效负载(参见用JavaScript解码二进制数据)来实现自己的压缩逻辑,并为基于文本的消息实现自己的压缩逻辑,否则它可能会对传输的数据产生较高的字节开销!
Chrome和一些基于webkit的浏览器支持WebSocket协议压缩扩展的旧版本(每帧压缩);参见WebSocket多路复用和压缩。
自定义应用程序协议
浏览器针对HTTP数据传输进行了优化:它理解该协议,并提供广泛的服务,如身份验证、缓存、压缩等等。因此,XHR请求免费继承所有这些功能。
相比之下,流允许我们提供定制的客户端和服务器之间的协议,但代价的绕过许多浏览器提供的服务:最初的HTTP握手可以执行一些协商参数的连接,但是一旦建立了会话,所有进一步的客户端和服务器之间的数据流是不透明到浏览器。因此,交付自定义协议的灵活性也有其缺点,应用程序可能必须实现自己的逻辑来填补缺失的空白:缓存、状态管理、消息元数据的交付,等等!
初始的HTTP升级握手允许服务器利用现有的HTTP cookie机制来验证用户。如果验证失败,服务器可以拒绝WebSocket升级。
利用浏览器和中间缓存
使用常规HTTP具有显著的优势。问您自己一个简单的问题:客户机会从缓存接收到的数据中获益吗?或者,如果中介可以缓存资产,它是否可以优化资产的交付?
例如,WebSocket支持二进制传输,这允许应用程序流任意的图像格式而没有开销——好漂亮!然而,图像是在自定义协议中交付的这一事实意味着它不会被浏览器缓存或任何中介(例如CDN)缓存。因此,您可能需要向客户机进行不必要的传输,并向源服务器传输更多的流量。同样的逻辑也适用于所有其他数据格式:视频、文本等等。
因此,确保你为工作选择了合适的交通工具!解决这些问题的一个简单而有效的策略是使用WebSocket会话来传递非缓存数据,比如实时更新和应用“控制”消息,这可以触发XHR请求来通过HTTP协议获取其他资产。
部署WebSocket基础设施
HTTP为短时间和突发传输进行了优化。因此,许多服务器、代理和其他中介经常被配置为主动超时空闲HTTP连接,当然,这正是我们不希望看到的长时间WebSocket会话。为了解决这个问题,有三方面需要考虑:
- 路由器,负载平衡器,和代理在自己的网络
- 外部网络中的透明和显式代理(如ISP和运营商代理)
- 客户网络中的路由器、防火墙和代理
我们无法控制客户端网络的策略。事实上,一些网络可能会完全阻止WebSocket流量,这就是为什么您可能需要一个备用策略。类似地,我们无法控制外部网络上的代理。然而,这正是TLS可以帮助的地方!通过在安全的端到端连接上使用隧道,WebSocket通信可以绕过所有的中间代理。
使用TLS并不会阻止中间层对空闲TCP连接计时。然而,在实践中,它极大地提高了协商WebSocket会话的成功率,并且通常还有助于扩展连接超时间隔。
最后,还有我们自己部署和管理的基础设施,这通常也需要关注和调优。尽管责怪客户端或外部网络很容易,但问题往往是在家里。服务路径中的每个负载均衡器、路由器、代理和web服务器都必须进行调优,以允许长时间连接。
例如,Nginx 1.3.13+可以代理WebSocket流量,但默认为60秒超时!为了增加限制,我们必须明确地定义较长的超时:
location /websocket {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 3600;
proxy_send_timeout 3600;
}- 设置读取间隔60分钟的超时时间
- 在写之间设置60分钟的超时时间
类似地,在一个或多个Nginx服务器前安装一个负载均衡器也很常见,比如HAProxy。毫不奇怪,我们在这里也需要应用类似的显式配置。HAProxy,因为:
defaults http timeout connect 30s timeout client 30s timeout server 30s timeout tunnel 1h
- 隧道的60分钟不活动超时
前面示例的问题是额外的“隧道”超时。在HAProxy中,连接、客户端和服务器的超时只适用于初始的HTTP升级握手,但是一旦升级完成,超时由隧道值控制。
Nginx和HAProxy只是在我们的数据中心运行的数百个不同的服务器、代理和负载平衡器中的两个。我们不能列举这些页面中所有的配置可能性。前面的示例只是说明了大多数基础设施需要自定义配置来处理长期存在的会话。因此,在实现应用程序保持生命值之前,首先要仔细检查基础设施。
长期会话和空闲会话占用所有中间服务器上的内存和套接字资源。因此,短超时通常被认为是安全、资源和操作方面的预防措施。部署WebSocket、SSE和HTTP/2(它们都依赖于长寿命会话)带来了各自的新操作挑战。
性能检查表
部署高性能WebSocket服务需要在客户端和服务器端进行仔细的调优和考虑。列入议程的标准的简短清单:
- 使用安全的WebSocket (WSS over TLS)进行可靠的部署。
- 密切关注polyfill 的性能(如有必要)。
- 利用子协议协商来确定应用程序协议。
- 优化二进制有效载荷以最小化传输大小。
- 考虑压缩UTF-8内容以最小化传输大小。
- 为接收到的二进制有效负载设置正确的二进制类型。
- 监视客户机上缓冲的数据量。
- 分割大型应用程序消息以避免线头阻塞。
- 在适用的情况下利用其他传输。
最后,但绝对不是最不重要的,优化移动!在手机上,实时推送可能是一个代价高昂的性能反模式,因为电池寿命总是非常宝贵。这并不是说WebSocket不应该在移动设备上使用。相反,它可以是一种高效的交通工具,但一定要考虑到它的要求:
本文:http://jiagoushi.pro/node/1112
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 226 次浏览
【Web应用架构】Web框架基准测试 2020-05-2 8第19轮 按吞吐量排序
Best fortunes responses per second, Dell R440 Xeon Gold + 10 GbE(424 tests)
| Rnk | Framework | Best performance (higher is better) | Errors | Cls | Lng | Plt | FE | Aos | DB | Dos | Orm | IA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | drogon-core | 678,278 | 100.0% | 0 | Ful | C++ | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 2 | actix-core | 651,144 | 96.0% | 0 | Plt | Rus | Non | act | Lin | Pg | Lin | Raw | Rea |
| 3 | actix-pg | 607,052 | 89.5% | 0 | Mcr | Rus | Non | act | Lin | Pg | Lin | Raw | Rea |
| 4 | drogon | 553,366 | 81.6% | 0 | Ful | C++ | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 5 | may-minihttp | 476,965 | 70.3% | 0 | Mcr | Rus | Rus | may | Lin | Pg | Lin | Raw | Rea |
| 6 | h2o | 411,176 | 60.6% | 0 | Plt | C | Non | h2o | Lin | Pg | Lin | Raw | Rea |
| 7 | lithium-postgres | 401,783 | 59.2% | 0 | Mcr | C++ | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 8 | fasthttp-prefork-quicktemplate | 363,587 | 53.6% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 9 | atreugo-prefork-quicktemplate | 362,342 | 53.4% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 10 | hyper-db | 358,511 | 52.9% | 0 | Mcr | Rus | Rus | Hyp | Lin | Pg | Lin | Raw | Rea |
| 11 | php-ngx-pgsql | 356,507 | 52.6% | 0 | Plt | PHP | ngx | ngx | Lin | Pg | Lin | Raw | Rea |
| 12 | workerman-pgsql | 352,508 | 52.0% | 0 | Plt | PHP | wor | Non | Lin | Pg | Lin | Raw | Rea |
| 13 | vertx-postgres | 347,356 | 51.2% | 0 | Plt | Jav | ver | Non | Lin | Pg | Lin | Raw | Rea |
| 14 | ulib-postgres | 344,634 | 50.8% | 0 | Plt | C++ | Non | ULi | Lin | Pg | Lin | Mcr | Rea |
| 15 | fasthttp-quicktemplate | 319,764 | 47.1% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 16 | atreugo-quicktemplate | 319,390 | 47.1% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 17 | greenlightning | 318,601 | 47.0% | 0 | Mcr | Jav | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 18 | jooby-pgclient | 312,439 | 46.1% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 19 | fiber-prefork | 301,604 | 44.5% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 20 | go-pgx-prefork-quicktemplate | 298,935 | 44.1% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 21 | lithium | 296,750 | 43.8% | 0 | Mcr | C++ | Non | Non | Lin | My | Lin | Ful | Rea |
| 22 | workerman | 291,339 | 43.0% | 0 | Plt | PHP | wor | Non | Lin | My | Lin | Raw | Rea |
| 23 | php-ngx-mysql | 290,312 | 42.8% | 0 | Plt | PHP | ngx | ngx | Lin | My | Lin | Raw | Rea |
| 24 | aspcore-rhtx-pg | 285,398 | 42.1% | 0 | Plt | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 25 | swoole | 283,728 | 41.8% | 0 | Plt | PHP | swo | Non | Lin | My | Lin | Raw | Rea |
| 26 | aspcore-ado-pg | 273,121 | 40.3% | 0 | Plt | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 27 | proteus | 264,265 | 39.0% | 0 | Mcr | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 28 | kooby | 258,382 | 38.1% | 0 | Ful | Kot | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 29 | gemini-postgres | 258,129 | 38.1% | 0 | Ful | Jav | Svt | Res | Lin | Pg | Lin | Mcr | Rea |
| 30 | zysocket-v | 257,268 | 37.9% | 0 | Ful | C# | .NE | zys | Lin | Pg | Lin | Raw | Rea |
| 31 | jooby-jaxrs | 254,398 | 37.5% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 32 | jooby | 252,239 | 37.2% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 33 | kumbiaphp-workerman | 249,309 | 36.8% | 0 | Ful | PHP | wor | Non | Lin | Pg | Lin | Raw | Rea |
| 34 | light-4j | 243,211 | 35.9% | 0 | Plt | Jav | lig | Non | Lin | Pg | Lin | Raw | Rea |
| 35 | cpoll_cppsp-raw | 242,929 | 35.8% | 0 | Plt | C++ | Non | Non | Lin | My | Lin | Raw | Rea |
| 36 | beetlex | 241,339 | 35.6% | 0 | Ful | C# | .NE | bee | Lin | Pg | Lin | Raw | Rea |
| 37 | es4x | 237,751 | 35.1% | 0 | Mcr | JS | ver | Non | Lin | Pg | Lin | Raw | Rea |
| 38 | ulib-postgres_fit | 235,845 | 34.8% | 0 | Plt | C++ | Non | ULi | Lin | Pg | Lin | Mcr | Rea |
| 39 | jooby-jetty | 235,161 | 34.7% | 0 | Ful | Jav | Jty | Non | Lin | Pg | Lin | Raw | Rea |
| 40 | aspcore-mw-ado-pg | 234,321 | 34.5% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 41 | aspcore-vb-mw-ado-pg | 227,638 | 33.6% | 0 | Mcr | vb | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 42 | go-pgx-quicktemplate | 225,782 | 33.3% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 43 | jlhttp-postgres | 222,691 | 32.8% | 0 | Plt | Jav | JLH | Non | Lin | Pg | Lin | Raw | Rea |
| 44 | undertow-postgresql | 222,598 | 32.8% | 0 | Plt | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 45 | jooby-netty | 222,565 | 32.8% | 0 | Ful | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 46 | vertx-web-scala | 214,768 | 31.7% | 0 | Mcr | Sca | ver | Non | Lin | Pg | Lin | Raw | Rea |
| 47 | fiber | 210,127 | 31.0% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 48 | revenj-jvm | 210,121 | 31.0% | 0 | Ful | Jav | Svt | Res | Lin | Pg | Lin | Ful | Rea |
| 49 | kemal | 208,775 | 30.8% | 0 | Ful | Cry | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 50 | rapidoid-postgres | 208,499 | 30.7% | 0 | Plt | Jav | Rap | Non | Lin | Pg | Lin | Mcr | Rea |
| 51 | crystal | 207,551 | 30.6% | 0 | Plt | Cry | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 52 | grip | 207,490 | 30.6% | 0 | Mcr | Cry | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 53 | crystal-radix | 204,596 | 30.2% | 0 | Plt | Cry | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 54 | raze | 202,714 | 29.9% | 0 | Ful | Cry | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 55 | http4k-apache | 202,537 | 29.9% | 0 | Mcr | Kot | apa | Non | Lin | Pg | Lin | Raw | Rea |
| 56 | kumbiaphp-workerman-mysql | 201,807 | 29.8% | 0 | Ful | PHP | wor | Non | Lin | My | Lin | Mcr | Rea |
| 57 | aspcore-mw-dap-pg | 198,450 | 29.3% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Mcr | Rea |
| 58 | openresty | 198,054 | 29.2% | 0 | Plt | Lua | OpR | ngx | Lin | My | Lin | Raw | Rea |
| 59 | act-eclipselink-pgsql | 196,017 | 28.9% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 60 | ubiquity-workerman | 190,634 | 28.1% | 0 | Ful | PHP | wor | Non | Lin | Pg | Lin | Ful | Rea |
| 61 | zebra | 188,840 | 27.8% | 0 | Ful | f# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 62 | hexagon-resin-postgresql | 188,288 | 27.8% | 0 | Mcr | Kot | Svt | Non | Lin | Pg | Lin | Raw | Rea |
| 63 | http4k-undertow | 188,273 | 27.8% | 0 | Mcr | Kot | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 64 | aspcore-ado-my | 187,309 | 27.6% | 0 | Plt | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 65 | cutelyst-thread-pg | 186,461 | 27.5% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 66 | cutelyst-pf-pg-nodelay | 186,376 | 27.5% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 67 | cutelyst-thread-pg-nodelay | 185,641 | 27.4% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 68 | simps | 182,191 | 26.9% | 0 | Mcr | PHP | swo | Non | Lin | My | Lin | Raw | Rea |
| 69 | cutelyst-pf-pg | 179,972 | 26.5% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 70 | ulib-mysql | 179,425 | 26.5% | 0 | Plt | C++ | Non | ULi | Lin | My | Lin | Mcr | Rea |
| 71 | vertx-web-postgres | 176,093 | 26.0% | 0 | Mcr | Jav | ver | Non | Lin | Pg | Lin | Raw | Rea |
| 72 | act-hibernate-pgsql | 175,656 | 25.9% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 73 | helidon | 173,306 | 25.6% | 0 | Mcr | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 74 | aspcore-mw-ado-my | 170,573 | 25.1% | 0 | Mcr | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 75 | aspcore-vb-mw-ado-my | 169,856 | 25.0% | 0 | Mcr | vb | .NE | kes | Lin | My | Lin | Raw | Rea |
| 76 | chi-gojay-prefork | 165,126 | 24.3% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 77 | http4k | 164,684 | 24.3% | 0 | Mcr | Kot | Svt | Non | Lin | Pg | Lin | Raw | Rea |
| 78 | fasthttp-prefork | 163,706 | 24.1% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 79 | actix-diesel | 161,892 | 23.9% | 0 | Mcr | Rus | Non | act | Lin | Pg | Lin | Ful | Rea |
| 80 | atreugo-prefork | 161,479 | 23.8% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 81 | giraffe | 161,005 | 23.7% | 0 | Ful | f# | .NE | kes | Lin | Pg | Lin | Mcr | Rea |
| 82 | chi-prefork | 160,869 | 23.7% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 83 | act-hibernate-pgsql-rythm | 159,866 | 23.6% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 84 | chi-sjson-prefork | 159,292 | 23.5% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 85 | aspcore-mw-ef-pg | 157,931 | 23.3% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 86 | aspcore-mw-dap-my | 155,853 | 23.0% | 0 | Mcr | C# | .NE | kes | Lin | My | Lin | Mcr | Rea |
| 87 | warp-mysql-haskell | 155,711 | 23.0% | 0 | Mcr | Hkl | Wai | wai | Lin | My | Lin | Raw | Rea |
| 88 | act-hibernate-mysql | 154,441 | 22.8% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 89 | act-eclipselink-pgsql-rythm | 153,060 | 22.6% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 90 | warp | 152,392 | 22.5% | 0 | Mcr | Hkl | Wai | wai | Lin | Pg | Lin | Raw | Rea |
| 91 | php-ngx-async | 151,834 | 22.4% | 0 | Plt | PHP | ngx | ngx | Lin | My | Lin | Raw | Rea |
| 92 | swoole-no-async | 151,102 | 22.3% | 0 | Plt | PHP | swo | Non | Lin | My | Lin | Raw | Rea |
| 93 | proteus-mysql | 150,380 | 22.2% | 0 | Mcr | Jav | Utw | Non | Lin | My | Lin | Raw | Rea |
| 94 | act-hibernate-mysql-rythm | 147,057 | 21.7% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 95 | fasthttp | 146,882 | 21.7% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 96 | act-eclipselink-mysql | 146,534 | 21.6% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 97 | atreugo | 144,987 | 21.4% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 98 | go-my-prefork | 144,289 | 21.3% | 0 | Plt | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 99 | hexagon-jetty-postgresql | 141,759 | 20.9% | 0 | Mcr | Kot | Svt | Non | Lin | Pg | Lin | Raw | Rea |
| 100 | ulib-mongodb | 141,657 | 20.9% | 0 | Plt | C++ | Non | ULi | Lin | Mo | Lin | Mcr | Rea |
| 101 | gemini-mysql | 140,793 | 20.8% | 0 | Ful | Jav | Svt | Res | Lin | My | Lin | Mcr | Rea |
| 102 | ubiquity-swoole | 140,604 | 20.7% | 0 | Ful | PHP | swo | Non | Lin | Pg | Lin | Ful | Rea |
| 103 | act-eclipselink-mysql-rythm | 136,914 | 20.2% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 104 | go-pgx-prefork | 134,727 | 19.9% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 105 | ratpack-jdbc | 134,690 | 19.9% | 0 | Mcr | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 106 | rapidoid-mysql | 133,362 | 19.7% | 0 | Plt | Jav | Rap | Non | Lin | My | Lin | Mcr | Rea |
| 107 | polkadot-postgres | 131,783 | 19.4% | 0 | Plt | JS | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 108 | ratpack-pgclient | 131,066 | 19.3% | 0 | Mcr | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 109 | cutelyst-nginx-pg | 128,097 | 18.9% | 0 | Ful | C++ | uWS | ngx | Lin | Pg | Lin | Raw | Rea |
| 110 | fasthttp-mongo-prefork | 124,521 | 18.4% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 111 | aspcore-mvc-ado-pg | 124,455 | 18.3% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 112 | warp-hasql | 122,305 | 18.0% | 0 | Mcr | Hkl | Wai | wai | Lin | Pg | Lin | Raw | Rea |
| 113 | atreugo-mongo-prefork | 122,256 | 18.0% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 114 | imi-raw | 121,648 | 17.9% | 0 | Mcr | PHP | swo | Non | Lin | My | Lin | Raw | Rea |
| 115 | workerman-async | 118,772 | 17.5% | 0 | Plt | PHP | wor | Non | Lin | My | Lin | Raw | Rea |
| 116 | nodejs-mongodb-raw | 115,477 | 17.0% | 0 | Plt | JS | njs | Non | Lin | Mo | Lin | Raw | Rea |
| 117 | aspcore-mvc-dap-pg | 115,329 | 17.0% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Mcr | Rea |
| 118 | ubiquity-swoole-mysql-async | 115,321 | 17.0% | 0 | Ful | PHP | swo | Non | Lin | My | Lin | Ful | Rea |
| 119 | lwan | 114,729 | 16.9% | 0 | Mcr | C | Lwa | lwa | Lin | My | Lin | Raw | Rea |
| 120 | vertx-web-susom-postgres | 114,654 | 16.9% | 0 | Mcr | Jav | ver | Non | Lin | Pg | Lin | Raw | Rea |
| 121 | go-mgo-prefork | 111,343 | 16.4% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 122 | polkadot-mongodb | 111,286 | 16.4% | 0 | Plt | JS | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 123 | go-pgx | 111,168 | 16.4% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 124 | fintrospect | 110,211 | 16.2% | 0 | Mcr | Sca | Nty | Non | Lin | My | Lin | Raw | Rea |
| 125 | servlet-postgresql | 109,125 | 16.1% | 0 | Plt | Jav | Svt | Res | Lin | Pg | Lin | Raw | Rea |
| 126 | cutelyst-thread-my | 107,101 | 15.8% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 127 | cutelyst-thread-my-nodelay | 106,740 | 15.7% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 128 | php-unit | 106,582 | 15.7% | 0 | Plt | PHP | uni | Non | Lin | My | Lin | Raw | Rea |
| 129 | cutelyst-thread-pg-grantlee | 105,911 | 15.6% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 130 | php-pgsql-raw | 104,730 | 15.4% | 0 | Plt | PHP | fpm | ngx | Lin | Pg | Lin | Raw | Rea |
| 131 | aspcore-mvc-ado-my | 104,075 | 15.3% | 0 | Ful | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 132 | polkadot-mysql | 103,016 | 15.2% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 133 | cutelyst-pf-my-nodelay | 101,653 | 15.0% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 134 | cutelyst-pf-my | 101,536 | 15.0% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 135 | toro | 101,088 | 14.9% | 282 | Mcr | Cry | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 136 | chi-gojay | 99,528 | 14.7% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 137 | aspcore-mvc-dap-my | 99,238 | 14.6% | 0 | Ful | C# | .NE | kes | Lin | My | Lin | Mcr | Rea |
| 138 | akka-http | 99,237 | 14.6% | 0 | Mcr | Sca | Akk | Non | Lin | My | Lin | Raw | Rea |
| 139 | chi | 98,889 | 14.6% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 140 | hexagon-resin-mongodb | 98,017 | 14.5% | 0 | Mcr | Kot | Svt | Non | Lin | Mo | Lin | Raw | Rea |
| 141 | php | 97,727 | 14.4% | 0 | Plt | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 142 | chi-sjson | 96,765 | 14.3% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 143 | aah-postgresql | 96,699 | 14.3% | 0 | Ful | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 144 | php-h2o | 96,667 | 14.3% | 0 | Plt | PHP | fpm | h2o | Lin | My | Lin | Raw | Rea |
| 145 | php-pools | 96,572 | 14.2% | 0 | Plt | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 146 | treefrog-mongodb | 96,231 | 14.2% | 0 | Ful | C++ | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 147 | chi-scratch | 95,476 | 14.1% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 148 | fastify-postgres | 95,088 | 14.0% | 0 | Mcr | JS | njs | Non | Lin | Pg | Lin | Raw | Rea |
| 149 | aspcore-mvc-ef-pg | 94,107 | 13.9% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 150 | fastify-mysql | 93,665 | 13.8% | 0 | Mcr | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 151 | servlet-mysql | 92,967 | 13.7% | 0 | Plt | Jav | Svt | Res | Lin | My | Lin | Raw | Rea |
| 152 | nodejs | 91,799 | 13.5% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 153 | nodejs-chakra | 91,778 | 13.5% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 154 | fastify | 91,769 | 13.5% | 0 | Mcr | JS | njs | Non | Lin | Mo | Lin | Raw | Rea |
| 155 | wt | 90,647 | 13.4% | 0 | Ful | C++ | Non | Non | Lin | My | Lin | Ful | Rea |
| 156 | micronaut | 90,601 | 13.4% | 0 | Mcr | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 157 | act-morphia-mongo | 89,840 | 13.2% | 0 | Ful | Jav | Utw | Non | Lin | Mo | Lin | Ful | Rea |
| 158 | redkale-postgres | 89,236 | 13.2% | 0 | Ful | Jav | red | Non | Lin | Pg | Lin | Raw | Rea |
| 159 | act-morphia-mongo-rythm | 89,013 | 13.1% | 0 | Ful | Jav | Utw | Non | Lin | Mo | Lin | Ful | Rea |
| 160 | servant-psql-simple | 88,759 | 13.1% | 0 | Mcr | Hkl | Wai | Wrp | Lin | Pg | Lin | Raw | Rea |
| 161 | pedestal | 88,252 | 13.0% | 0 | Mcr | Clj | Jty | Non | Lin | My | Lin | Mcr | Rea |
| 162 | go-my | 87,930 | 13.0% | 2 | Plt | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 163 | hexagon | 87,718 | 12.9% | 0 | Mcr | Kot | Svt | Non | Lin | Mo | Lin | Raw | Rea |
| 164 | play2-java-jpa-hikaricp-netty | 85,449 | 12.6% | 0 | Ful | Jav | Nty | Non | Lin | My | Lin | Ful | Rea |
| 165 | minijax | 85,399 | 12.6% | 0 | Ful | Jav | JAX | Utw | Lin | My | Lin | Ful | Rea |
| 166 | fasthttp-mongo | 83,915 | 12.4% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 167 | cutelyst-nginx-my | 83,551 | 12.3% | 0 | Ful | C++ | uWS | ngx | Lin | My | Lin | Raw | Rea |
| 168 | atreugo-mongo | 81,040 | 11.9% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 169 | treefrog-postgres | 79,580 | 11.7% | 8 | Ful | C++ | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 170 | duct | 79,059 | 11.7% | 0 | Mcr | Clj | Rin | Non | Lin | Pg | Lin | Raw | Rea |
| 171 | vertx-web-mongodb | 78,538 | 11.6% | 0 | Mcr | Jav | ver | Non | Lin | Mo | Lin | Raw | Rea |
| 172 | hamlet-workerman | 78,214 | 11.5% | 0 | Ful | PHP | wor | Non | Lin | My | Lin | Mcr | Rea |
| 173 | compojure-raw | 76,832 | 11.3% | 0 | Mcr | Clj | Svt | Res | Lin | My | Lin | Raw | Rea |
| 174 | cutelyst-thread-my-grantlee | 75,816 | 11.2% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 175 | http-kit-raw | 75,309 | 11.1% | 0 | Plt | Clj | Rin | Non | Lin | My | Lin | Raw | Rea |
| 176 | kumbiaphp | 74,171 | 10.9% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Mcr | Rea |
| 177 | kumbiaphp-raw | 73,714 | 10.9% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 178 | duct-mongodb | 73,630 | 10.9% | 0 | Mcr | Clj | Rin | Non | Lin | Mo | Lin | Raw | Rea |
| 179 | echo | 73,300 | 10.8% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 180 | uvicorn | 72,929 | 10.8% | 0 | Plt | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 181 | ubiquity | 72,844 | 10.7% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 182 | play2-java-jooq-hikaricp-netty | 72,685 | 10.7% | 0 | Ful | Jav | Nty | Non | Lin | My | Lin | Ful | Rea |
| 183 | hamlet-swoole | 70,964 | 10.5% | 0 | Ful | PHP | swo | Non | Lin | My | Lin | Mcr | Rea |
| 184 | treefrog | 70,769 | 10.4% | 10 | Ful | C++ | Non | Non | Lin | My | Lin | Mcr | Rea |
| 185 | apidaora-core | 70,659 | 10.4% | 0 | Mcr | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 186 | duct-aleph | 70,285 | 10.4% | 0 | Mcr | Clj | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 187 | aah-mysql | 69,752 | 10.3% | 0 | Ful | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 188 | roa-diesel | 68,129 | 10.0% | 0 | Mcr | Rus | Non | Hyp | Lin | Pg | Lin | Ful | Rea |
| 189 | nestjs-fastify-mysql | 67,920 | 10.0% | 0 | Mcr | typ | Non | Non | Lin | My | Lin | Ful | Rea |
| 190 | play2-java-jpa-hikaricp | 67,361 | 9.9% | 0 | Ful | Jav | Akk | Non | Lin | My | Lin | Ful | Rea |
| 191 | nestjs-fastify | 67,331 | 9.9% | 0 | Mcr | typ | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 192 | blacksheep | 67,321 | 9.9% | 0 | Plt | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 193 | gin-scratch | 67,227 | 9.9% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 194 | play2-java-ebean-hikaricp-netty | 66,647 | 9.8% | 0 | Ful | Jav | Nty | Non | Lin | My | Lin | Ful | Rea |
| 195 | luminus | 66,471 | 9.8% | 0 | Mcr | Clj | Rin | Non | Lin | Pg | Lin | Raw | Rea |
| 196 | ubiquity-roadrunner | 66,418 | 9.8% | 0 | Ful | PHP | roa | Non | Lin | Pg | Lin | Ful | Rea |
| 197 | ubiquity-roadrunner-mysql | 65,948 | 9.7% | 0 | Ful | PHP | roa | Non | Lin | My | Lin | Ful | Rea |
| 198 | undertow-jersey-hikaricp | 65,485 | 9.7% | 0 | Plt | Jav | JAX | Non | Lin | My | Lin | Ful | Rea |
| 199 | sanic | 65,039 | 9.6% | 0 | Mcr | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 200 | lapis | 64,724 | 9.5% | 0 | Ful | Lua | OpR | ngx | Lin | Pg | Lin | Ful | Rea |
| 201 | nestjs-fastify-mongo | 64,206 | 9.5% | 0 | Mcr | typ | Non | Non | Lin | Mo | Lin | Ful | Rea |
| 202 | grizzly-jersey | 63,557 | 9.4% | 0 | Mcr | Jav | JAX | Grz | Lin | My | Lin | Ful | Rea |
| 203 | apidaora | 63,489 | 9.4% | 0 | Mcr | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 204 | chubbajs | 63,215 | 9.3% | 0 | Mcr | JS | njs | Non | Lin | Pg | Lin | Mcr | Rea |
| 205 | starlette | 62,707 | 9.2% | 0 | Mcr | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 206 | jawn | 62,631 | 9.2% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 207 | dropwizard-postgres | 62,354 | 9.2% | 0 | Ful | Jav | JAX | Jty | Lin | Pg | Lin | Ful | Rea |
| 208 | php-raw7-tcp | 60,871 | 9.0% | 21,542 | Plt | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 209 | play2-scala-anorm-netty | 60,767 | 9.0% | 0 | Ful | Sca | Nty | Non | Lin | My | Lin | Ful | Rea |
| 210 | quarkus-hibernate | 60,752 | 9.0% | 0 | Ful | Jav | JAX | Non | Lin | Pg | Lin | Ful | Rea |
| 211 | play2-java-jooq-hikaricp | 59,473 | 8.8% | 0 | Ful | Jav | Akk | Non | Lin | My | Lin | Ful | Rea |
| 212 | vibed-ldc-pgsql | 59,436 | 8.8% | 0 | Plt | D | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 213 | gin | 58,974 | 8.7% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 214 | vibed-dmd-pgsql | 58,795 | 8.7% | 0 | Plt | D | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 215 | vibed-ldc | 56,526 | 8.3% | 0 | Plt | D | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 216 | play2-scala-slick-netty | 56,293 | 8.3% | 0 | Ful | Sca | Nty | Non | Lin | My | Lin | Ful | Rea |
| 217 | nodejs-postgres | 55,925 | 8.2% | 0 | Plt | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 218 | play2-java-ebean-hikaricp | 55,653 | 8.2% | 0 | Ful | Jav | Akk | Non | Lin | My | Lin | Ful | Rea |
| 219 | ktor | 54,879 | 8.1% | 0 | Mcr | Kot | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 220 | roa-pg | 54,664 | 8.1% | 0 | Mcr | Rus | Non | Hyp | Lin | Pg | Lin | Raw | Rea |
| 221 | nestjs | 53,905 | 7.9% | 0 | Mcr | typ | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 222 | dropwizard | 53,256 | 7.9% | 0 | Ful | Jav | JAX | Jty | Lin | My | Lin | Ful | Rea |
| 223 | vibed | 52,780 | 7.8% | 0 | Mcr | D | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 224 | lithium-postgres-1t | 52,667 | 7.8% | 0 | Mcr | C++ | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 225 | play2-scala-anorm | 52,585 | 7.8% | 0 | Ful | Sca | Akk | Non | Lin | My | Lin | Ful | Rea |
| 226 | fastapi-orjson | 52,080 | 7.7% | 0 | Mcr | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 227 | officefloor-tpr | 52,053 | 7.7% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Raw | Rea |
| 228 | fastapi | 51,981 | 7.7% | 0 | Mcr | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 229 | officefloor-thread_affinity | 51,936 | 7.7% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Raw | Rea |
| 230 | officefloor-micro | 51,760 | 7.6% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Raw | Rea |
| 231 | roda-sequel-postgres | 50,981 | 7.5% | 0 | Mcr | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 232 | nestjs-mysql | 50,712 | 7.5% | 0 | Mcr | typ | Non | Non | Lin | My | Lin | Ful | Rea |
| 233 | nodejs-mysql | 50,692 | 7.5% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Ful | Rea |
| 234 | lithium-mysql-1t | 50,460 | 7.4% | 0 | Mcr | C++ | Non | Non | Lin | My | Lin | Ful | Rea |
| 235 | revenj | 50,341 | 7.4% | 0 | Ful | C# | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 236 | sw-fw-less | 49,667 | 7.3% | 2,861 | Mcr | PHP | swo | Non | Lin | My | Lin | Ful | Rea |
| 237 | phoenix | 49,186 | 7.3% | 0 | Ful | Eli | Cow | Non | Lin | Pg | Lin | Ful | Rea |
| 238 | roda-sequel | 49,140 | 7.2% | 0 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 239 | http-kit | 49,067 | 7.2% | 0 | Plt | Clj | Rin | Non | Lin | My | Lin | Mcr | Rea |
| 240 | symfony-swoole | 48,130 | 7.1% | 0 | Ful | PHP | swo | Non | Lin | My | Lin | Ful | Rea |
| 241 | blade | 47,774 | 7.0% | 0 | Ful | Jav | Non | Non | Lin | My | Lin | Ful | Rea |
| 242 | nestjs-mongo | 47,518 | 7.0% | 0 | Mcr | typ | Non | Non | Lin | Mo | Lin | Ful | Rea |
| 243 | redstone | 46,969 | 6.9% | 0 | Mcr | Dar | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 244 | koa-postgres | 46,451 | 6.8% | 0 | Mcr | JS | njs | Non | Lin | Pg | Lin | Raw | Rea |
| 245 | compojure | 45,881 | 6.8% | 0 | Mcr | Clj | Svt | Res | Lin | My | Lin | Mcr | Rea |
| 246 | koa-mysql | 45,846 | 6.8% | 0 | Mcr | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 247 | play2-scala-slick | 45,521 | 6.7% | 0 | Ful | Sca | Akk | Non | Lin | My | Lin | Ful | Rea |
| 248 | roa-sqlx | 44,869 | 6.6% | 0 | Mcr | Rus | Non | Hyp | Lin | Pg | Lin | Raw | Rea |
| 249 | express-mysql | 44,166 | 6.5% | 0 | Mcr | JS | njs | Non | Lin | My | Lin | Ful | Rea |
| 250 | responder | 43,647 | 6.4% | 0 | Plt | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 251 | tapestry | 42,982 | 6.3% | 0 | Ful | Jav | Svt | Res | Lin | My | Lin | Ful | Rea |
| 252 | officefloor-netty | 42,591 | 6.3% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Ful | Rea |
| 253 | undertow-jersey | 42,567 | 6.3% | 0 | Plt | Jav | JAX | Non | Lin | My | Lin | Ful | Rea |
| 254 | wicket | 41,489 | 6.1% | 0 | Ful | Jav | Svt | Res | Lin | My | Lin | Ful | Rea |
| 255 | officefloor | 40,849 | 6.0% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Ful | Rea |
| 256 | start | 40,689 | 6.0% | 0 | Mcr | Dar | Non | ngx | Lin | Mo | Lin | Raw | Rea |
| 257 | roda-sequel-postgres-passenger-mri | 40,281 | 5.9% | 0 | Mcr | Rby | Rac | Pas | Lin | Pg | Lin | Ful | Rea |
| 258 | roda-sequel-passenger-mri | 39,824 | 5.9% | 0 | Mcr | Rby | Rac | Pas | Lin | My | Lin | Ful | Rea |
| 259 | spark | 39,411 | 5.8% | 0 | Mcr | Jav | Svt | Jty | Lin | My | Lin | Ful | Rea |
| 260 | redstone-mongodb | 38,873 | 5.7% | 0 | Mcr | Dar | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 261 | http4k-ktorcio | 38,385 | 5.7% | 0 | Mcr | Kot | kto | Non | Lin | Pg | Lin | Raw | Rea |
| 262 | aiohttp-pg-raw | 36,432 | 5.4% | 0 | Mcr | Py | asy | Gun | Lin | Pg | Lin | Raw | Rea |
| 263 | ktor-reactivepg | 36,141 | 5.3% | 0 | Ful | Kot | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 264 | ffead-cpp-nginx-mongo | 35,466 | 5.2% | 0 | Ful | C++ | ffe | ngx | Lin | Mo | Lin | Ful | Rea |
| 265 | stream | 35,416 | 5.2% | 0 | Mcr | Dar | Non | ngx | Lin | Mo | Lin | Raw | Rea |
| 266 | bottle-raw | 35,031 | 5.2% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Raw | Rea |
| 267 | spiral | 34,641 | 5.1% | 0 | Ful | PHP | roa | Non | Lin | My | Lin | Ful | Rea |
| 268 | roda-sequel-postgres-torquebox-jruby | 34,601 | 5.1% | 0 | Mcr | Rby | Rac | Tor | Lin | Pg | Lin | Ful | Rea |
| 269 | sinatra-sequel-postgres | 34,114 | 5.0% | 0 | Mcr | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 270 | imi | 33,593 | 5.0% | 0 | Ful | PHP | swo | Non | Lin | My | Lin | Ful | Rea |
| 271 | sinatra-sequel | 32,998 | 4.9% | 0 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 272 | ktor-cio | 32,514 | 4.8% | 0 | Mcr | Kot | kto | Non | Lin | Pg | Lin | Raw | Rea |
| 273 | ktor-jasync | 31,618 | 4.7% | 0 | Ful | Kot | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 274 | slim | 31,441 | 4.6% | 0 | Mcr | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 275 | http4s | 31,328 | 4.6% | 0 | Mcr | Sca | NIO | bla | Lin | Pg | Lin | Raw | Rea |
| 276 | iron | 30,908 | 4.6% | 0 | Mcr | Rus | Rus | Hyp | Lin | Pg | Lin | Raw | Rea |
| 277 | roda-sequel-torquebox-jruby | 29,168 | 4.3% | 0 | Mcr | Rby | Rac | Tor | Lin | My | Lin | Ful | Rea |
| 278 | hot-mysql | 28,409 | 4.2% | 75 | Plt | Grv | Jty | Jty | Lin | My | Lin | Raw | Rea |
| 279 | rocket | 28,343 | 4.2% | 0 | Ful | Rus | Rus | Hyp | Lin | Pg | Lin | Ful | Rea |
| 280 | sinatra-sequel-postgres-passenger-mri | 28,289 | 4.2% | 0 | Mcr | Rby | Rac | Pas | Lin | Pg | Lin | Ful | Rea |
| 281 | ffead-cpp-nginx-mysql | 28,035 | 4.1% | 0 | Ful | C++ | ffe | ngx | Lin | My | Lin | Ful | Rea |
| 282 | sinatra-sequel-passenger-mri | 27,834 | 4.1% | 0 | Mcr | Rby | Rac | Pas | Lin | My | Lin | Ful | Rea |
| 283 | aqueduct | 27,525 | 4.1% | 0 | Mcr | Dar | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 284 | spring | 27,339 | 4.0% | 0 | Ful | Jav | tom | Non | Lin | Pg | Lin | Mcr | Rea |
| 285 | elixir-plug-ecto | 27,062 | 4.0% | 0 | Mcr | Eli | bea | cow | Lin | Pg | Lin | Ful | Rea |
| 286 | api_hour | 26,718 | 3.9% | 0 | Mcr | Py | asy | Gun | Lin | Pg | Lin | Raw | Rea |
| 287 | yii2-raw | 26,652 | 3.9% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 288 | spring-mongo | 26,424 | 3.9% | 0 | Ful | Jav | tom | Non | Lin | Mo | Lin | Ful | Rea |
| 289 | aspcore-mono-pg | 26,280 | 3.9% | 0 | Plt | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 290 | quart-uvicorn | 26,082 | 3.8% | 0 | Mcr | Py | Non | uvi | Lin | Pg | Lin | Raw | Rea |
| 291 | quarkus-pgclient | 25,956 | 3.8% | 0 | Ful | Jav | JAX | Non | Lin | Pg | Lin | Mcr | Rea |
| 292 | sinatra-sequel-postgres-torquebox-jruby | 25,953 | 3.8% | 0 | Mcr | Rby | Rac | Tor | Lin | Pg | Lin | Ful | Rea |
| 293 | cppcms-postgres | 25,706 | 3.8% | 0 | Plt | C++ | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 294 | roda-sequel-postgres-unicorn-mri | 25,407 | 3.7% | 0 | Mcr | Rby | Rac | Uni | Lin | Pg | Lin | Ful | Rea |
| 295 | lumen-swoole | 25,147 | 3.7% | 0 | Mcr | PHP | swo | Non | Lin | My | Lin | Ful | Rea |
| 296 | hamlet | 24,781 | 3.7% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Mcr | Rea |
| 297 | cppcms | 24,372 | 3.6% | 0 | Plt | C++ | Non | Non | Lin | My | Lin | Raw | Rea |
| 298 | duct-httpkit | 24,358 | 3.6% | 0 | Mcr | Clj | Rin | Non | Lin | Pg | Lin | Raw | Rea |
| 299 | codeigniter | 24,135 | 3.6% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 300 | wildfly-ee | 23,881 | 3.5% | 0 | Ful | Jav | Svt | Wil | Lin | My | Lin | Ful | Rea |
| 301 | aspcore-mono-my | 23,793 | 3.5% | 0 | Plt | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 302 | fat-free-raw | 23,751 | 3.5% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 303 | flask-raw | 23,136 | 3.4% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Raw | Rea |
| 304 | aiohttp | 22,972 | 3.4% | 0 | Mcr | Py | asy | Gun | Lin | Pg | Lin | Ful | Rea |
| 305 | spring-webflux-pgclient | 22,607 | 3.3% | 0 | Ful | Jav | Nty | Non | Lin | Pg | Lin | Mcr | Rea |
| 306 | spring-webflux-jdbc | 22,528 | 3.3% | 0 | Ful | Jav | Nty | Non | Lin | Pg | Lin | Mcr | Rea |
| 307 | sinatra-sequel-postgres-unicorn-mri | 22,308 | 3.3% | 0 | Mcr | Rby | Rac | Uni | Lin | Pg | Lin | Ful | Rea |
| 308 | sinatra-sequel-unicorn-mri | 22,238 | 3.3% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 309 | aspcore-mono-mw-my | 21,561 | 3.2% | 0 | Mcr | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 310 | sinatra-sequel-torquebox-jruby | 21,509 | 3.2% | 0 | Mcr | Rby | Rac | Tor | Lin | My | Lin | Ful | Rea |
| 311 | spring-webflux-mongo | 21,503 | 3.2% | 0 | Ful | Jav | Nty | Non | Lin | Mo | Lin | Ful | Rea |
| 312 | php-eloquent | 21,482 | 3.2% | 0 | Plt | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 313 | go-mgo | 21,469 | 3.2% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 314 | pyramid-py2 | 21,461 | 3.2% | 0 | Ful | Py | Non | Mei | Lin | Pg | Lin | Ful | Rea |
| 315 | ninja-standalone | 21,454 | 3.2% | 0 | Ful | Jav | Jty | Non | Lin | My | Lin | Ful | Rea |
| 316 | laravel-swoole | 20,935 | 3.1% | 0 | Ful | PHP | swo | Non | Lin | My | Lin | Ful | Rea |
| 317 | tornado-py3-uvloop | 20,728 | 3.1% | 0 | Plt | Py | Non | Tor | Lin | Pg | Lin | Raw | Rea |
| 318 | flask-pypy2-raw | 20,654 | 3.0% | 0 | Mcr | Py | Tor | Non | Lin | My | Lin | Raw | Rea |
| 319 | api_hour-mysql | 20,054 | 3.0% | 0 | Mcr | Py | asy | Gun | Lin | My | Lin | Raw | Rea |
| 320 | aspcore-mono-mw-pg | 19,321 | 2.8% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 321 | pyramid | 18,538 | 2.7% | 0 | Ful | Py | Non | Mei | Lin | Pg | Lin | Ful | Rea |
| 322 | dropwizard-mongodb | 18,221 | 2.7% | 0 | Ful | Jav | JAX | Jty | Lin | Mo | Lin | Ful | Rea |
| 323 | fat-free | 18,048 | 2.7% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 324 | aspcore-mono-mw-ef-pg | 18,022 | 2.7% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 325 | roda-sequel-unicorn-mri | 17,780 | 2.6% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 326 | aspcore-mono-mvc-pg | 17,679 | 2.6% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 327 | morepath | 17,502 | 2.6% | 0 | Mcr | Py | Mei | Gun | Lin | Pg | Lin | Ful | Rea |
| 328 | activeweb | 17,470 | 2.6% | 0 | Ful | Jav | Svt | Non | Lin | My | Lin | Mcr | Rea |
| 329 | weppy-pypy2 | 17,463 | 2.6% | 0 | Ful | Py | Tor | Non | Lin | Pg | Lin | Ful | Rea |
| 330 | play2-scala-reactivemongo-netty | 16,736 | 2.5% | 0 | Ful | Sca | Nty | Non | Lin | Mo | Lin | Ful | Rea |
| 331 | sinatra-unicorn-mri | 16,445 | 2.4% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 332 | yii2 | 16,415 | 2.4% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 333 | weppy-py3 | 16,005 | 2.4% | 0 | Ful | Py | Mei | Non | Lin | Pg | Lin | Ful | Rea |
| 334 | tornado-pypy2 | 15,986 | 2.4% | 0 | Plt | Py | Non | Tor | Lin | Mo | Lin | Raw | Rea |
| 335 | sinatra-postgres-unicorn-mri | 15,806 | 2.3% | 0 | Mcr | Rby | Rac | Uni | Lin | Pg | Lin | Ful | Rea |
| 336 | ffead-cpp | 15,622 | 2.3% | 0 | Ful | C++ | ffe | ffe | Lin | Mo | Lin | Ful | Rea |
| 337 | emmett | 15,547 | 2.3% | 0 | Ful | Py | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 338 | ktor-jetty | 15,439 | 2.3% | 0 | Mcr | Kot | Jty | Non | Lin | Pg | Lin | Raw | Rea |
| 339 | hapi-postgres | 15,127 | 2.2% | 0 | Mcr | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 340 | play2-scala-reactivemongo | 15,100 | 2.2% | 0 | Ful | Sca | Akk | Non | Lin | Mo | Lin | Ful | Rea |
| 341 | django-postgresql | 15,085 | 2.2% | 0 | Ful | Py | Non | Mei | Lin | Pg | Lin | Ful | Rea |
| 342 | sinatra-postgres-passenger-mri | 15,015 | 2.2% | 0 | Mcr | Rby | Rac | Pas | Lin | Pg | Lin | Ful | Rea |
| 343 | sinatra-passenger-mri | 14,920 | 2.2% | 0 | Mcr | Rby | Rac | Pas | Lin | My | Lin | Ful | Rea |
| 344 | weppy-nginx-uwsgi | 14,751 | 2.2% | 0 | Ful | Py | uWS | ngx | Lin | Pg | Lin | Ful | Rea |
| 345 | django | 14,699 | 2.2% | 0 | Ful | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 346 | hapi-mysql | 14,678 | 2.2% | 0 | Mcr | JS | njs | Non | Lin | My | Lin | Ful | Rea |
| 347 | aspcore-mono-mvc-ef-pg | 14,407 | 2.1% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 348 | ringojs-convenient | 14,033 | 2.1% | 0 | Mcr | JS | Rin | Non | Lin | My | Lin | Mcr | Rea |
| 349 | aspcore-mono-mvc-my | 13,904 | 2.0% | 0 | Ful | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 350 | bottle-pypy2 | 13,727 | 2.0% | 0 | Mcr | Py | Tor | Non | Lin | My | Lin | Ful | Rea |
| 351 | macchiato | 13,493 | 2.0% | 0 | Mcr | Clj | njs | Non | Lin | Pg | Lin | Raw | Rea |
| 352 | mojolicious | 12,464 | 1.8% | 0 | Ful | Prl | Non | Hyp | Lin | Pg | Lin | Raw | Rea |
| 353 | tornado-py3 | 12,328 | 1.8% | 0 | Plt | Py | Non | Tor | Lin | Mo | Lin | Raw | Rea |
| 354 | phalcon | 12,253 | 1.8% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 355 | turbogears | 11,931 | 1.8% | 0 | Mcr | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 356 | bottle | 11,880 | 1.8% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 357 | fuel | 11,759 | 1.7% | 0 | Mcr | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 358 | grails | 11,287 | 1.7% | 0 | Ful | Grv | Svt | Non | Lin | My | Lin | Ful | Rea |
| 359 | web2py-optimized | 11,074 | 1.6% | 0 | Ful | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 360 | flask | 10,101 | 1.5% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 361 | goframe | 9,869 | 1.5% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 362 | flask-pypy2 | 9,008 | 1.3% | 0 | Mcr | Py | Non | Tor | Lin | My | Lin | Ful | Rea |
| 363 | rails | 8,764 | 1.3% | 0 | Ful | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 364 | tornado | 8,702 | 1.3% | 0 | Plt | Py | Non | Tor | Lin | Mo | Lin | Raw | Rea |
| 365 | hapi-nginx | 8,624 | 1.3% | 0 | Mcr | JS | njs | ngx | Lin | Pg | Lin | Ful | Rea |
| 366 | rails-unicorn | 8,528 | 1.3% | 0 | Ful | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 367 | lumen | 8,435 | 1.2% | 0 | Mcr | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 368 | rails-postgresql | 8,434 | 1.2% | 0 | Ful | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 369 | cakephp | 7,418 | 1.1% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 370 | symfony | 7,137 | 1.1% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 371 | bottle-nginx-uwsgi | 6,640 | 1.0% | 0 | Mcr | Py | uWS | ngx | Lin | My | Lin | Ful | Rea |
| 372 | flask-nginx-uwsgi | 6,597 | 1.0% | 0 | Mcr | Py | Non | ngx | Lin | My | Lin | Ful | Rea |
| 373 | web2py | 6,014 | 0.9% | 0 | Ful | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 374 | kitura-postgres | 5,682 | 0.8% | 0 | Ful | Swi | kit | kit | Lin | Pg | Lin | Raw | Rea |
| 375 | kitura-gcd-postgres | 5,605 | 0.8% | 0 | Ful | Swi | kit | kit | Lin | Pg | Lin | Raw | Rea |
| 376 | express-mongodb | 5,588 | 0.8% | 0 | Mcr | JS | njs | Non | Lin | Mo | Lin | Ful | Rea |
| 377 | laravel | 5,563 | 0.8% | 0 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 378 | kitura-nio-postgres | 5,465 | 0.8% | 0 | Ful | Swi | kit | kit | Lin | Pg | Lin | Raw | Rea |
| 379 | httpserver-postgres | 5,421 | 0.8% | 363,929 | Plt | Jav | htt | Non | Lin | Pg | Lin | Raw | Rea |
| 380 | kitura-postgres-orm | 5,420 | 0.8% | 0 | Ful | Swi | kit | kit | Lin | Pg | Lin | Ful | Rea |
| 381 | kitura-gcd-postgres-orm | 5,350 | 0.8% | 0 | Ful | Swi | kit | kit | Lin | Pg | Lin | Ful | Rea |
| 382 | kitura-nio-postgres-orm | 5,228 | 0.8% | 0 | Ful | Swi | kit | kit | Lin | Pg | Lin | Ful | Rea |
| 383 | kitura-mongodb | 4,657 | 0.7% | 0 | Ful | Swi | kit | kit | Lin | Mo | Lin | Raw | Rea |
| 384 | urweb-mysql | 4,600 | 0.7% | 0 | Ful | Ur | Ur/ | Non | Lin | My | Lin | Mcr | Rea |
| 385 | koa | 4,528 | 0.7% | 0 | Mcr | JS | njs | Non | Lin | Mo | Lin | Raw | Rea |
| 386 | hapi | 4,341 | 0.6% | 0 | Mcr | JS | njs | Non | Lin | Mo | Lin | Ful | Rea |
| 387 | padrino-unicorn | 3,275 | 0.5% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 388 | padrino | 3,201 | 0.5% | 0 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 389 | urweb | 2,939 | 0.4% | 0 | Ful | Ur | Ur/ | Non | Lin | Pg | Lin | Mcr | Rea |
| 390 | express-graphql-mysql | 2,817 | 0.4% | 0 | Mcr | JS | njs | Non | Lin | My | Lin | Ful | Rea |
| 391 | officefloor-spring_data | 2,622 | 0.4% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Ful | Rea |
| 392 | ffead-cpp-nginx-postgresql | 2,403 | 0.4% | 0 | Ful | C++ | ffe | ngx | Lin | Pg | Lin | Ful | Rea |
| 393 | spyne-nginx-uwsgi | 2,279 | 0.3% | 0 | Mcr | Py | Non | ngx | Lin | Pg | Lin | Ful | Rea |
| 394 | spyne-raw | 1,892 | 0.3% | 28 | Mcr | Py | spy | Non | Lin | Pg | Lin | Raw | Rea |
| 395 | phalcon-micro | 1,886 | 0.3% | 53,048 | Mcr | PHP | fpm | ngx | Lin | My | Lin | Raw | Rea |
| 396 | akka-http-slick-postgres | 1,796 | 0.3% | 0 | Mcr | Sca | Akk | Non | Lin | Pg | Lin | Ful | Rea |
| 397 | aspnet-mono-ngx-my | 1,545 | 0.2% | 0 | Plt | C# | .NE | ngx | Lin | My | Lin | Raw | Rea |
| 398 | phpixie | 1,375 | 0.2% | 53,987 | Ful | PHP | fpm | ngx | Lin | My | Lin | Ful | Rea |
| 399 | express-graphql-postgres | 1,087 | 0.2% | 0 | Mcr | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 400 | racket | 883 | 0.1% | 0 | Mcr | rac | rac | rac | Lin | Pg | Lin | Raw | Rea |
| 401 | express-postgres | 718 | 0.1% | 0 | Mcr | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 402 | klein | 578 | 0.1% | 0 | Mcr | Py | Non | Twi | Lin | My | Lin | Ful | Rea |
| 403 | express-graphql-mongodb | 492 | 0.1% | 0 | Mcr | JS | njs | Non | Lin | Mo | Lin | Ful | Rea |
| 404 | sailsjs | 443 | 0.1% | 0 | Ful | JS | njs | Non | Lin | My | Lin | Mcr | Rea |
| 405 | http4k-netty | 1 | 0.0% | 657,083 | Mcr | Kot | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 406 | amber | — | Did not complete | — | Ful | Cry | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 407 | beetlex-core | — | Did not complete | — | Plt | C# | .NE | bee | Lin | Pg | Lin | Raw | Rea |
| 408 | falcore | — | Did not complete | — | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 409 | ffead-cpp-mysql | — | Did not complete | — | Ful | C++ | ffe | ffe | Lin | My | Lin | Ful | Rea |
| 410 | ffead-cpp-postgresql | — | Did not complete | — | Ful | C++ | ffe | ffe | Lin | Pg | Lin | Ful | Rea |
| 411 | goji | — | Did not complete | — | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 412 | hanami | — | Did not complete | — | Ful | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 413 | hanami-unicorn | — | Did not complete | — | Ful | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 414 | kami | — | Did not complete | — | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 415 | cherrypy | — | Did not complete | — | Mcr | Py | Non | Non | Lin | My | Lin | Ful | Rea |
| 416 | cherrypy-py3 | — | Did not complete | — | Mcr | Py | Non | Non | Lin | My | Lin | Ful | Rea |
| 417 | pronghorn | — | Did not complete | — | Plt | Kot | pro | Non | Lin | Mo | Lin | Raw | Rea |
| 418 | sailsjs-postgres | — | Did not complete | — | Ful | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 419 | quart | — | Did not complete | — | Mcr | Py | Non | hyp | Lin | Pg | Lin | Raw | Rea |
| 420 | sinatra | — | Did not complete | — | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 421 | sinatra-postgres | — | Did not complete | — | Mcr | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 422 | spider-gazelle | — | Did not complete | — | Ful | Cry | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 423 | spring-webflux-rxjdbc | — | Did not complete | — | Ful | Jav | Nty | Non | Lin | Pg | Lin | Mcr | Rea |
| 424 | spyne | — | Did not complete | — | Mcr | Py | spy | Non | Lin | Pg | Lin | Ful | Rea |
原文:https://www.techempower.com/benchmarks/
本文:http://jiagoushi.pro/node/1118
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 161 次浏览
【Web应用架构】Web框架基准测试 2020-05-2 8第19轮 框架比较
Framework overhead of fortunes responses, Dell R440 Xeon Gold + 10 GbE
| Framework best | vs | Platform best | Ratio (higher is better) | ||
|---|---|---|---|---|---|
| drogon-core | 678,278 | vs | nodejs | 91,799 | 738.9% |
| roda-sequel-postgres-passenger-mri | 40,281 | vs | rack-sequel-postgres-passenger-mri | 5,644 | 713.7% |
| drogon | 553,366 | vs | nodejs | 91,799 | 602.8% |
| roda-sequel-passenger-mri | 39,824 | vs | rack-sequel-passenger-mri | 6,774 | 587.9% |
| sinatra-sequel-postgres-passenger-mri | 28,289 | vs | rack-sequel-postgres-passenger-mri | 5,644 | 501.2% |
| lithium-postgres | 401,783 | vs | nodejs | 91,799 | 437.7% |
| sinatra-sequel-passenger-mri | 27,834 | vs | rack-sequel-passenger-mri | 6,774 | 410.9% |
| php-ngx-pgsql | 356,507 | vs | php | 97,727 | 364.8% |
| workerman-pgsql | 352,508 | vs | php | 97,727 | 360.7% |
| greenlightning | 318,601 | vs | nodejs | 91,799 | 347.1% |
| lithium | 296,750 | vs | nodejs | 91,799 | 323.3% |
| workerman | 291,339 | vs | php | 97,727 | 298.1% |
| php-ngx-mysql | 290,312 | vs | php | 97,727 | 297.1% |
| swoole | 283,728 | vs | php | 97,727 | 290.3% |
| es4x | 237,751 | vs | nodejs | 91,799 | 259.0% |
| tornado-py3-uvloop | 20,728 | vs | tornado | 8,702 | 238.2% |
| grip | 207,490 | vs | nodejs | 91,799 | 226.0% |
| tornado-pypy2 | 15,986 | vs | tornado | 8,702 | 183.7% |
| php-ngx-async | 151,834 | vs | php | 97,727 | 155.4% |
| swoole-no-async | 151,102 | vs | php | 97,727 | 154.6% |
| undertow-jersey-hikaricp | 65,485 | vs | undertow-jersey | 42,567 | 153.8% |
| http-kit-raw | 75,309 | vs | http-kit | 49,067 | 153.5% |
| polkadot-postgres | 131,783 | vs | nodejs | 91,799 | 143.6% |
| tornado-py3 | 12,328 | vs | tornado | 8,702 | 141.7% |
| treefrog-mongodb | 96,231 | vs | treefrog | 70,769 | 136.0% |
| nodejs-mongodb-raw | 115,477 | vs | nodejs | 91,799 | 125.8% |
| lwan | 114,729 | vs | nodejs | 91,799 | 125.0% |
| vertx-web-scala | 214,768 | vs | vertx-web-postgres | 176,093 | 122.0% |
| workerman-async | 118,772 | vs | php | 97,727 | 121.5% |
| polkadot-mongodb | 111,286 | vs | nodejs | 91,799 | 121.2% |
| http4k-ktorcio | 38,385 | vs | ktor-cio | 32,514 | 118.1% |
| vibed-ldc-pgsql | 59,436 | vs | vibed | 52,780 | 112.6% |
| polkadot-mysql | 103,016 | vs | nodejs | 91,799 | 112.2% |
| vibed-dmd-pgsql | 58,795 | vs | vibed | 52,780 | 111.4% |
| php-unit | 106,582 | vs | php | 97,727 | 109.1% |
| php-pgsql-raw | 104,730 | vs | php | 97,727 | 107.2% |
| vibed-ldc | 56,526 | vs | vibed | 52,780 | 107.1% |
| aspcore-rhtx-pg | 285,398 | vs | aspcore-ado-pg | 273,121 | 104.5% |
| roda-sequel-torquebox-jruby | 29,168 | vs | rack-sequel-torquebox-jruby | 28,046 | 104.0% |
| fastify-postgres | 95,088 | vs | nodejs | 91,799 | 103.6% |
| fastify-mysql | 93,665 | vs | nodejs | 91,799 | 102.0% |
| kemal | 208,775 | vs | crystal | 207,551 | 100.6% |
| nodejs-chakra | 91,778 | vs | nodejs | 91,799 | 100.0% |
| fastify | 91,769 | vs | nodejs | 91,799 | 100.0% |
| php-h2o | 96,667 | vs | php | 97,727 | 98.9% |
| php-pools | 96,572 | vs | php | 97,727 | 98.8% |
| micronaut | 90,601 | vs | nodejs | 91,799 | 98.7% |
| crystal-radix | 204,596 | vs | crystal | 207,551 | 98.6% |
| raze | 202,714 | vs | crystal | 207,551 | 97.7% |
| spring-mongo | 26,424 | vs | spring | 27,339 | 96.7% |
| roda-sequel-postgres-torquebox-jruby | 34,601 | vs | rack-sequel-postgres-torquebox-jruby | 36,847 | 93.9% |
| aspcore-mw-ado-my | 170,573 | vs | aspcore-ado-my | 187,309 | 91.1% |
| aspcore-vb-mw-ado-my | 169,856 | vs | aspcore-ado-my | 187,309 | 90.7% |
| aspcore-mono-mw-my | 21,561 | vs | aspcore-mono-my | 23,793 | 90.6% |
| act-eclipselink-pgsql | 196,017 | vs | undertow-postgresql | 222,598 | 88.1% |
| duct | 79,059 | vs | nodejs | 91,799 | 86.1% |
| aspcore-mw-ado-pg | 234,321 | vs | aspcore-ado-pg | 273,121 | 85.8% |
| kumbiaphp-workerman | 249,309 | vs | workerman | 291,339 | 85.6% |
| aspcore-vb-mw-ado-pg | 227,638 | vs | aspcore-ado-pg | 273,121 | 83.3% |
| aspcore-mw-dap-my | 155,853 | vs | aspcore-ado-my | 187,309 | 83.2% |
| spring-webflux-pgclient | 22,607 | vs | spring | 27,339 | 82.7% |
| spring-webflux-jdbc | 22,528 | vs | spring | 27,339 | 82.4% |
| duct-mongodb | 73,630 | vs | nodejs | 91,799 | 80.2% |
| officefloor | 40,849 | vs | officefloor-micro | 51,760 | 78.9% |
| act-hibernate-pgsql | 175,656 | vs | undertow-postgresql | 222,598 | 78.9% |
| spring-webflux-mongo | 21,503 | vs | spring | 27,339 | 78.7% |
| apidaora-core | 70,659 | vs | nodejs | 91,799 | 77.0% |
| sinatra-sequel-torquebox-jruby | 21,509 | vs | rack-sequel-torquebox-jruby | 28,046 | 76.7% |
| duct-aleph | 70,285 | vs | nodejs | 91,799 | 76.6% |
| kumbiaphp | 74,171 | vs | php | 97,727 | 75.9% |
| kumbiaphp-raw | 73,714 | vs | php | 97,727 | 75.4% |
| ubiquity | 72,844 | vs | php | 97,727 | 74.5% |
| nestjs-fastify-mysql | 67,920 | vs | nodejs | 91,799 | 74.0% |
| aspcore-mono-mw-pg | 19,321 | vs | aspcore-mono-pg | 26,280 | 73.5% |
| nestjs-fastify | 67,331 | vs | nodejs | 91,799 | 73.3% |
| aspcore-mw-dap-pg | 198,450 | vs | aspcore-ado-pg | 273,121 | 72.7% |
| act-hibernate-pgsql-rythm | 159,866 | vs | undertow-postgresql | 222,598 | 71.8% |
| sanic | 65,039 | vs | nodejs | 91,799 | 70.8% |
| sinatra-sequel-postgres-torquebox-jruby | 25,953 | vs | rack-sequel-postgres-torquebox-jruby | 36,847 | 70.4% |
| nestjs-fastify-mongo | 64,206 | vs | nodejs | 91,799 | 69.9% |
| kumbiaphp-workerman-mysql | 201,807 | vs | workerman | 291,339 | 69.3% |
| apidaora | 63,489 | vs | nodejs | 91,799 | 69.2% |
| act-eclipselink-pgsql-rythm | 153,060 | vs | undertow-postgresql | 222,598 | 68.8% |
| aspcore-mono-mw-ef-pg | 18,022 | vs | aspcore-mono-pg | 26,280 | 68.6% |
| ubiquity-roadrunner | 66,418 | vs | php | 97,727 | 68.0% |
| play2-java-jpa-hikaricp | 67,361 | vs | akka-http | 99,237 | 67.9% |
| ubiquity-roadrunner-mysql | 65,948 | vs | php | 97,727 | 67.5% |
| aspcore-mono-mvc-pg | 17,679 | vs | aspcore-mono-pg | 26,280 | 67.3% |
| roda-sequel-postgres-unicorn-mri | 25,407 | vs | rack-sequel-postgres-unicorn-mri | 38,628 | 65.8% |
| ubiquity-workerman | 190,634 | vs | workerman | 291,339 | 65.4% |
| simps | 182,191 | vs | swoole | 283,728 | 64.2% |
| php-raw7-tcp | 60,871 | vs | php | 97,727 | 62.3% |
| nodejs-postgres | 55,925 | vs | nodejs | 91,799 | 60.9% |
| sinatra-sequel-unicorn-mri | 22,238 | vs | rack-sequel-unicorn-mri | 36,980 | 60.1% |
| play2-java-jooq-hikaricp | 59,473 | vs | akka-http | 99,237 | 59.9% |
| nestjs | 53,905 | vs | nodejs | 91,799 | 58.7% |
| aspcore-mono-mvc-my | 13,904 | vs | aspcore-mono-my | 23,793 | 58.4% |
| servant-psql-simple | 88,759 | vs | warp | 152,392 | 58.2% |
| aspcore-mw-ef-pg | 157,931 | vs | aspcore-ado-pg | 273,121 | 57.8% |
| sinatra-sequel-postgres-unicorn-mri | 22,308 | vs | rack-sequel-postgres-unicorn-mri | 38,628 | 57.8% |
| lithium-postgres-1t | 52,667 | vs | nodejs | 91,799 | 57.4% |
| fastapi-orjson | 52,080 | vs | nodejs | 91,799 | 56.7% |
| fastapi | 51,981 | vs | nodejs | 91,799 | 56.6% |
| play2-java-ebean-hikaricp | 55,653 | vs | akka-http | 99,237 | 56.1% |
| aspcore-mvc-ado-my | 104,075 | vs | aspcore-ado-my | 187,309 | 55.6% |
| nestjs-mysql | 50,712 | vs | nodejs | 91,799 | 55.2% |
| nodejs-mysql | 50,692 | vs | nodejs | 91,799 | 55.2% |
| lithium-mysql-1t | 50,460 | vs | nodejs | 91,799 | 55.0% |
| aspcore-mono-mvc-ef-pg | 14,407 | vs | aspcore-mono-pg | 26,280 | 54.8% |
| play2-scala-anorm | 52,585 | vs | akka-http | 99,237 | 53.0% |
| aspcore-mvc-dap-my | 99,238 | vs | aspcore-ado-my | 187,309 | 53.0% |
| redstone | 46,969 | vs | dart | 89,867 | 52.3% |
| nestjs-mongo | 47,518 | vs | nodejs | 91,799 | 51.8% |
| koa-postgres | 46,451 | vs | nodejs | 91,799 | 50.6% |
| koa-mysql | 45,846 | vs | nodejs | 91,799 | 49.9% |
| ubiquity-swoole | 140,604 | vs | swoole | 283,728 | 49.6% |
| toro | 101,088 | vs | crystal | 207,551 | 48.7% |
| express-mysql | 44,166 | vs | nodejs | 91,799 | 48.1% |
| roda-sequel-unicorn-mri | 17,780 | vs | rack-sequel-unicorn-mri | 36,980 | 48.1% |
| play2-scala-slick | 45,521 | vs | akka-http | 99,237 | 45.9% |
| aspcore-mvc-ado-pg | 124,455 | vs | aspcore-ado-pg | 273,121 | 45.6% |
| start | 40,689 | vs | dart | 89,867 | 45.3% |
| redstone-mongodb | 38,873 | vs | dart | 89,867 | 43.3% |
| imi-raw | 121,648 | vs | swoole | 283,728 | 42.9% |
| aspcore-mvc-dap-pg | 115,329 | vs | aspcore-ado-pg | 273,121 | 42.2% |
| ubiquity-swoole-mysql-async | 115,321 | vs | swoole | 283,728 | 40.6% |
| stream | 35,416 | vs | dart | 89,867 | 39.4% |
| quart-uvicorn | 26,082 | vs | uvicorn | 72,929 | 35.8% |
| spiral | 34,641 | vs | php | 97,727 | 35.4% |
| aspcore-mvc-ef-pg | 94,107 | vs | aspcore-ado-pg | 273,121 | 34.5% |
| lapis | 64,724 | vs | openresty | 198,054 | 32.7% |
| slim | 31,441 | vs | php | 97,727 | 32.2% |
| rocket | 28,343 | vs | nodejs | 91,799 | 30.9% |
| aqueduct | 27,525 | vs | dart | 89,867 | 30.6% |
| elixir-plug-ecto | 27,062 | vs | nodejs | 91,799 | 29.5% |
| yii2-raw | 26,652 | vs | php | 97,727 | 27.3% |
| hamlet-workerman | 78,214 | vs | workerman | 291,339 | 26.8% |
| duct-httpkit | 24,358 | vs | nodejs | 91,799 | 26.5% |
| hamlet | 24,781 | vs | php | 97,727 | 25.4% |
| hamlet-swoole | 70,964 | vs | swoole | 283,728 | 25.0% |
| codeigniter | 24,135 | vs | php | 97,727 | 24.7% |
| fat-free-raw | 23,751 | vs | php | 97,727 | 24.3% |
| php-eloquent | 21,482 | vs | php | 97,727 | 22.0% |
| emmett | 15,547 | vs | uvicorn | 72,929 | 21.3% |
| fat-free | 18,048 | vs | php | 97,727 | 18.5% |
| sw-fw-less | 49,667 | vs | swoole | 283,728 | 17.5% |
| symfony-swoole | 48,130 | vs | swoole | 283,728 | 17.0% |
| yii2 | 16,415 | vs | php | 97,727 | 16.8% |
| hapi-postgres | 15,127 | vs | nodejs | 91,799 | 16.5% |
| hapi-mysql | 14,678 | vs | nodejs | 91,799 | 16.0% |
| play2-scala-reactivemongo | 15,100 | vs | akka-http | 99,237 | 15.2% |
| macchiato | 13,493 | vs | nodejs | 91,799 | 14.7% |
| aspcore-mono-my | 23,793 | vs | aspcore-ado-my | 187,309 | 12.7% |
| phalcon | 12,253 | vs | php | 97,727 | 12.5% |
| fuel | 11,759 | vs | php | 97,727 | 12.0% |
| imi | 33,593 | vs | swoole | 283,728 | 11.8% |
| aspcore-mono-pg | 26,280 | vs | aspcore-ado-pg | 273,121 | 9.6% |
| hapi-nginx | 8,624 | vs | nodejs | 91,799 | 9.4% |
| lumen-swoole | 25,147 | vs | swoole | 283,728 | 8.9% |
| lumen | 8,435 | vs | php | 97,727 | 8.6% |
| cakephp | 7,418 | vs | php | 97,727 | 7.6% |
| laravel-swoole | 20,935 | vs | swoole | 283,728 | 7.4% |
| symfony | 7,137 | vs | php | 97,727 | 7.3% |
| officefloor-spring_data | 2,622 | vs | officefloor | 40,849 | 6.4% |
| express-mongodb | 5,588 | vs | nodejs | 91,799 | 6.1% |
| laravel | 5,563 | vs | php | 97,727 | 5.7% |
| koa | 4,528 | vs | nodejs | 91,799 | 4.9% |
| hapi | 4,341 | vs | nodejs | 91,799 | 4.7% |
| express-graphql-mysql | 2,817 | vs | nodejs | 91,799 | 3.1% |
| phalcon-micro | 1,886 | vs | php | 97,727 | 1.9% |
| akka-http-slick-postgres | 1,796 | vs | akka-http | 99,237 | 1.8% |
| phpixie | 1,375 | vs | php | 97,727 | 1.4% |
| express-graphql-postgres | 1,087 | vs | nodejs | 91,799 | 1.2% |
| express-postgres | 718 | vs | nodejs | 91,799 | 0.8% |
| express-graphql-mongodb | 492 | vs | nodejs | 91,799 | 0.5% |
| sailsjs | 443 | vs | nodejs | 91,799 | 0.5% |
| spring-webflux-rxjdbc | 0 | vs | spring | 27,339 | 0.0% |
原文:https://www.techempower.com/benchmarks/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 88 次浏览
【Web应用架构】使用WebSocket构建交互式web应用程序
本指南引导您完成创建“Hello, world”应用程序的过程,该应用程序在浏览器和服务器之间来回发送消息。WebSocket是TCP之上的一个轻薄的层。这使得它适合使用“子协议”来嵌入消息。在本指南中,我们使用STOMP消息传递和Spring创建交互式web应用程序。
你将建立什么
您将构建一个接收带有用户名称的消息的服务器。作为响应,服务器将把问候语推送到客户机订阅的队列中。
你需要的东西
- 大约15分钟
- 最喜欢的文本编辑器或IDE
- JDK 1.8或更高版本
- Gradle 4+或Maven 3.2+
- 你也可以直接导入代码到你的IDE:
- Spring Tool Suite(STS)
- IntelliJ IDEA
如何完成本指南
与大多数Spring入门指南一样,您可以从头开始并完成每个步骤,或者可以绕过您已经熟悉的基本设置步骤。无论哪种方式,您最终都会得到工作代码。
要从头开始,先从 Starting with Spring Initializr开始。
要跳过基本步骤,请做以下步骤:
下载并解压缩本指南的源存储库,或者使用Git克隆它:
- Git clone https://github.com/springing-guides/gs-messaging-stomp-websocket.git
- cd到 gs-messaging-stomp-websocket/initial
- 向前跳转Create a Resource Representation Class.
- 完成后,可以对照gs-messaging-stomp-websocket/complete中的代码检查结果。
从Spring Initializr开始
对于所有Spring应用程序,都应该从Spring Initializr开始。Initializr提供了一种快速获取应用程序所需的所有依赖项的方法,并为您进行了大量设置。这个例子只需要Websocket依赖。下图显示了为这个示例项目设置的Initializr:

前面的图像显示了选择Maven作为构建工具的Initializr。你也可以使用Gradle。它还显示了com的值。示例和消息传递-stomp-websocket分别作为组和工件。您将在本示例的其余部分使用这些值。
下面的清单显示了当你选择Maven时创建的pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>messaging-stomp-websocket</artifactId> <version>0.0.1-SNAPSHOT</version> <name>messaging-stomp-websocket</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
下面的清单显示了构建过程。gradle文件是创建时,你选择gradle:
plugins {
id 'org.springframework.boot' version '2.2.2.RELEASE'
id 'io.spring.dependency-management' version '1.0.8.RELEASE'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-websocket'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
test {
useJUnitPlatform()
}
添加依赖关系
在这种情况下,Spring Initializr并没有提供您需要的一切。对于Maven,您需要添加以下依赖项:
<dependency> <groupId>org.webjars</groupId> <artifactId>webjars-locator-core</artifactId> </dependency> <dependency> <groupId>org.webjars</groupId> <artifactId>sockjs-client</artifactId> <version>1.0.2</version> </dependency> <dependency> <groupId>org.webjars</groupId> <artifactId>stomp-websocket</artifactId> <version>2.3.3</version> </dependency> <dependency> <groupId>org.webjars</groupId> <artifactId>bootstrap</artifactId> <version>3.3.7</version> </dependency> <dependency> <groupId>org.webjars</groupId> <artifactId>jquery</artifactId> <version>3.1.1-1</version> </dependency>
下面的清单显示了完成的pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.2.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>messaging-stomp-websocket</artifactId> <version>0.0.1-SNAPSHOT</version> <name>messaging-stomp-websocket</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
如果你使用Gradle,你需要添加以下依赖:
implementation 'org.webjars:webjars-locator-core' implementation 'org.webjars:sockjs-client:1.0.2' implementation 'org.webjars:stomp-websocket:2.3.3' implementation 'org.webjars:bootstrap:3.3.7' implementation 'org.webjars:jquery:3.1.1-1'
下面的清单显示了完成的构建。gradle文件:
plugins {
id 'org.springframework.boot' version '2.2.2.RELEASE'
id 'io.spring.dependency-management' version '1.0.8.RELEASE'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-websocket'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
test {
useJUnitPlatform()
}
创建资源表示类
现在已经设置了项目和构建系统,可以创建STOMP消息服务了。
通过考虑服务交互来开始流程。
服务将接受主体为JSON对象的STOMP消息中包含名称的消息。如果名称是Fred,则消息可能类似于以下内容:
{
"name": "Fred"
}
要对带有名称的消息进行建模,您可以创建一个普通的旧Java对象,该对象带有name属性和相应的getName()方法,如下所示(来自src/main/ Java /com/example/messagingstompwebsocket/HelloMessage.java):
package com.example.messagingstompwebsocket;
public class HelloMessage {
private String name;
public HelloMessage() {
}
public HelloMessage(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}在接收到消息并提取名称后,服务将通过创建一个问候语并将该问候语发布到客户机订阅的单独队列中来处理它。问候语也是一个JSON对象,如下所示:
{
"content": "Hello, Fred!"
}要对问候表示建模,添加另一个具有内容属性和相应getContent()方法的普通Java对象,如下所示(来自src/main/ Java /com/example/messagingstompwebsocket/Greeting.java):
package com.example.messagingstompwebsocket;
public class Greeting {
private String content;
public Greeting() {
}
public Greeting(String content) {
this.content = content;
}
public String getContent() {
return content;
}
}Spring将使用Jackson JSON库自动将Greeting类型的实例编组为JSON。
接下来,您将创建一个控制器来接收hello消息并发送问候消息。
创建一个消息处理控制器
在Spring处理STOMP消息传递的方法中,可以将STOMP消息路由到@Controller类。例如,GreetingController(来自src/main/java/com/example/messagingstompwebsocket/GreetingController.java)被映射为处理/hello目的地的消息,如下所示:
package com.example.messagingstompwebsocket;
import org.springframework.messaging.handler.annotation.MessageMapping;
import org.springframework.messaging.handler.annotation.SendTo;
import org.springframework.stereotype.Controller;
import org.springframework.web.util.HtmlUtils;
@Controller
public class GreetingController {
@MessageMapping("/hello")
@SendTo("/topic/greetings")
public Greeting greeting(HelloMessage message) throws Exception {
Thread.sleep(1000); // simulated delay
return new Greeting("Hello, " + HtmlUtils.htmlEscape(message.getName()) + "!");
}
}这个控制器是简洁和简单的,但是还有很多工作要做。我们一步一步地把它分解。
@MessageMapping注释确保,如果消息被发送到/hello目的地,则调用greeting()方法。
消息的有效负载被绑定到HelloMessage对象,该对象被传递到greeting()。
在内部,该方法的实现通过导致线程休眠一秒来模拟处理延迟。这是为了演示,在客户机发送消息后,服务器可以按照需要花费多长时间来异步处理消息。客户机可以继续执行它需要执行的任何工作,而无需等待响应。
延迟一秒之后,greeting()方法创建一个greeting对象并返回该对象。返回值广播给/topic/greetings的所有订阅者,如@SendTo注释中指定的那样。注意,来自输入消息的名称是经过清理的,因为在本例中,它将回显并在客户端浏览器DOM中重新呈现。
为STOMP消息传递配置Spring
现在已经创建了服务的基本组件,您可以配置Spring来启用WebSocket和STOMP消息传递。
创建一个名为WebSocketConfig的Java类,它类似于下面的清单(来自src/main/ Java /com/example/messagingstompwebsocket/WebSocketConfig.java):
package com.example.messagingstompwebsocket;
import org.springframework.context.annotation.Configuration;
import org.springframework.messaging.simp.config.MessageBrokerRegistry;
import org.springframework.web.socket.config.annotation.EnableWebSocketMessageBroker;
import org.springframework.web.socket.config.annotation.StompEndpointRegistry;
import org.springframework.web.socket.config.annotation.WebSocketMessageBrokerConfigurer;
@Configuration
@EnableWebSocketMessageBroker
public class WebSocketConfig implements WebSocketMessageBrokerConfigurer {
@Override
public void configureMessageBroker(MessageBrokerRegistry config) {
config.enableSimpleBroker("/topic");
config.setApplicationDestinationPrefixes("/app");
}
@Override
public void registerStompEndpoints(StompEndpointRegistry registry) {
registry.addEndpoint("/gs-guide-websocket").withSockJS();
}
}WebSocketConfig带有@Configuration注释,表示它是一个Spring配置类。它还使用@EnableWebSocketMessageBroker进行了注释。顾名思义,@EnableWebSocketMessageBroker支持由消息代理支持的WebSocket消息处理。
configureMessageBroker()方法实现了WebSocketMessageBrokerConfigurer中的默认方法来配置消息代理。它首先调用enableSimpleBroker(),使一个简单的基于内存的消息代理能够将问候消息带回以/topic为前缀的目的地上的客户机。它还为绑定带有@MessageMapping注释的方法的消息指定/app前缀。这个前缀将用于定义所有的消息映射。例如,/app/hello是GreetingController.greeting()方法映射要处理的端点。
registerStompEndpoints()方法注册/gs-guide-websocket端点,启用SockJS回退选项,以便在WebSocket不可用的情况下使用替代传输。SockJS客户机将尝试连接到/gs-guide-websocket,并使用最好的传输(websocket、xhr-streaming、xhr-polling,等等)。
创建浏览器客户端
有了服务器端部分,您就可以将注意力转向将消息发送到服务器端和从服务器端接收消息的JavaScript客户机了。
创建一个类似如下清单的index.html文件(来自src/main/resources/static/index.html):
<!DOCTYPE html>
<html>
<head>
<title>Hello WebSocket</title>
<link href="/webjars/bootstrap/css/bootstrap.min.css" rel="stylesheet">
<link href="/main.css" rel="stylesheet">
<script src="/webjars/jquery/jquery.min.js"></script>
<script src="/webjars/sockjs-client/sockjs.min.js"></script>
<script src="/webjars/stomp-websocket/stomp.min.js"></script>
<script src="/app.js"></script>
</head>
<body>
<noscript><h2 style="color: #ff0000">Seems your browser doesn't support Javascript! Websocket relies on Javascript being
enabled. Please enable
Javascript and reload this page!</h2></noscript>
<div id="main-content" class="container">
<div class="row">
<div class="col-md-6">
<form class="form-inline">
<div class="form-group">
<label for="connect">WebSocket connection:</label>
<button id="connect" class="btn btn-default" type="submit">Connect</button>
<button id="disconnect" class="btn btn-default" type="submit" disabled="disabled">Disconnect
</button>
</div>
</form>
</div>
<div class="col-md-6">
<form class="form-inline">
<div class="form-group">
<label for="name">What is your name?</label>
<input type="text" id="name" class="form-control" placeholder="Your name here...">
</div>
<button id="send" class="btn btn-default" type="submit">Send</button>
</form>
</div>
</div>
<div class="row">
<div class="col-md-12">
<table id="conversation" class="table table-striped">
<thead>
<tr>
<th>Greetings</th>
</tr>
</thead>
<tbody id="greetings">
</tbody>
</table>
</div>
</div>
</div>
</body>
</html>这个HTML文件导入了SockJS和STOMP javascript库,这些库将用于通过STOMP over websocket与我们的服务器通信。我们还导入app.js,它包含客户端应用程序的逻辑。下面的清单(来自src/main/resources/static/app.js)显示了该文件:
var stompClient = null;
function setConnected(connected) {
$("#connect").prop("disabled", connected);
$("#disconnect").prop("disabled", !connected);
if (connected) {
$("#conversation").show();
}
else {
$("#conversation").hide();
}
$("#greetings").html("");
}
function connect() {
var socket = new SockJS('/gs-guide-websocket');
stompClient = Stomp.over(socket);
stompClient.connect({}, function (frame) {
setConnected(true);
console.log('Connected: ' + frame);
stompClient.subscribe('/topic/greetings', function (greeting) {
showGreeting(JSON.parse(greeting.body).content);
});
});
}
function disconnect() {
if (stompClient !== null) {
stompClient.disconnect();
}
setConnected(false);
console.log("Disconnected");
}
function sendName() {
stompClient.send("/app/hello", {}, JSON.stringify({'name': $("#name").val()}));
}
function showGreeting(message) {
$("#greetings").append("<tr><td>" + message + "</td></tr>");
}
$(function () {
$("form").on('submit', function (e) {
e.preventDefault();
});
$( "#connect" ).click(function() { connect(); });
$( "#disconnect" ).click(function() { disconnect(); });
$( "#send" ).click(function() { sendName(); });
});这个JavaScript文件需要理解的主要部分是connect()和sendName()函数。
connect()函数使用SockJS和stomp.js打开到/gs-guide-websocket的连接,这是我们的SockJS服务器等待连接的地方。成功连接后,客户端订阅/topic/greetings目的地,服务器将在其中发布问候消息。当目的地接收到问候语时,它将向DOM追加一个段落元素以显示问候语消息。
sendName()函数检索用户输入的名称,并使用STOMP客户机将其发送到/app/hello目的地(在那里GreetingController.greeting()将接收它)。
使应用程序可执行
Spring Boot为您创建一个应用程序类。在这种情况下,它不需要进一步修改。您可以使用它来运行此应用程序。下面的清单(来自src/main/java/com/example/messagingstompwebsocket/MessagingStompWebsocketApplication.java)显示了应用程序类:
package com.example.messagingstompwebsocket;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MessagingStompWebsocketApplication {
public static void main(String[] args) {
SpringApplication.run(MessagingStompWebsocketApplication.class, args);
}
}@SpringBootApplication是一个方便的注释,添加了以下所有内容:
- @Configuration:标记类作为应用程序上下文bean定义的源。
- @EnableAutoConfiguration:告诉Spring Boot根据类路径设置、其他bean和各种属性设置开始添加bean。例如,如果spring-webmvc在类路径中,这个注释将应用程序标记为web应用程序并激活关键行为,比如设置一个DispatcherServlet。
- 告诉Spring在com - example包中寻找其他组件、配置和服务,让它找到控制器。
main()方法使用Spring引导的Spring application. run()方法来启动应用程序。您注意到没有一行XML吗?也没有web.xml文件。这个web应用程序是100%纯Java的,您不必配置任何管道或基础设施。
构建一个可执行JAR
您可以使用Gradle或Maven从命令行运行该应用程序。您还可以构建一个包含所有必要的依赖项、类和资源的可执行JAR文件并运行它。构建可执行jar使得在整个开发生命周期中,跨不同环境,等等,将服务作为应用程序进行发布、版本和部署变得更加容易。
如果你使用Gradle,你可以使用./gradlew bootRun来运行这个应用程序。或者,您可以使用./gradlew build构建JAR文件,然后运行JAR文件,如下所示:
java -jar build/libs/gs-messaging-stomp-websocket-0.1.0.jar
如果使用Maven,可以使用./mvnw spring-boot:run来运行应用程序。或者,您可以使用./mvnw clean包构建JAR文件,然后运行JAR文件,如下所示:
java -jar target/gs-messaging-stomp-websocket-0.1.0.jar
这里描述的步骤创建了一个可运行的JAR。您还可以构建一个经典的WAR文件。
将显示日志输出。服务应该在几秒钟内启动并运行。
测试服务
现在服务已经运行,将浏览器指向http://localhost:8080并单击Connect按钮。
在打开连接时,会询问您的姓名。输入您的姓名并单击Send。您的名字将通过STOMP以JSON消息的形式发送到服务器。经过一秒钟的模拟延迟后,服务器返回一条消息,其中包含在页面上显示的“Hello”问候语。此时,您可以发送另一个名称,或者单击Disconnect按钮关闭连接。
总结
恭喜你!您刚刚用Spring开发了一个基于stomp的消息传递服务。
原文:https://spring.io/guides/gs/messaging-stomp-websocket/
本文:http://jiagoushi.pro/node/1122
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 49 次浏览
【Web应用架构】如何扩展WebSockets
当与那些还没有使用过WebSockets的开发人员交谈时,他们通常会有同样的担忧:如何将它扩展到多个服务器上?
发布到一台服务器上的通道是可以的,前提是所有订阅者都连接到那台服务器。一旦您有多个服务器,您就需要添加一些其他的东西。这就是这篇文章试图解决的问题。
缩放HTTP vs WebSockets
要了解为什么扩展WebSockets似乎令人生畏,让我们将其与HTTP进行对比,因为大多数人都很了解它。
使用HTTP,您有一个once off请求/应答模式,您不期望客户机的下一个请求返回到相同的服务器。至少您不应该这样做,因为这意味着您有一个棘手的会话问题,并且您不能轻易地向外扩展以获得性能或冗余。
使用HTTP,您可以在负载均衡器后运行几乎无限数量的web服务器实例。当请求进入时,负载平衡器将请求传递给健康的web服务器实例,并且在web服务器计算完响应后将其传递回客户机。HTTP连接的生命周期通常很短,它们只存在到给出响应为止。这是一种很容易理解的、普遍存在的方法,而且扩展性很好。在长轮询中有一个例外,但它并不常见,对本文也不重要。
另一方面,WebSockets与HTTP请求的区别在于它们是持久的。WebSocket客户端打开一个到服务器的连接并重用它。在这个长时间运行的连接上,服务器和客户机都可以发布和响应事件。这个概念称为双工连接。可以通过负载均衡器打开连接,但一旦打开连接,它就会一直与同一服务器在一起,直到关闭或中断。
这意味着交互是有状态的;对于每个打开的客户端连接,您最终将至少在WebSocket服务器的内存中存储一些数据。例如,您可能知道哪个用户位于套接字的客户端,以及用户感兴趣的是什么类型的数据。
WebSocket连接的持久性使得它在实时应用中如此强大,但这也使得它难以扩展。
一个WebSocket应用程序示例
让我们来讨论一个示例应用程序,这样我们就可以在更具体的上下文中讨论问题和方法。
以我们为例,让我们确定一个协作白板应用程序。在这个应用程序中,有多个白板,这意味着人们可以协作绘制多个草图。当一个用户在一个特定的白板上作画时,它通过一个WebSocket连接发布坐标,并通过WebSocket连接发布到打开相同白板的所有其他用户。换句话说,我们在WebSockets上公开了一个pub/sub模式。
在本例中,这意味着应用程序的每个用户的套接字连接的服务器端至少需要知道用户打开了什么白板。
Web套接字实现,如套接字。io有通道的概念。可以将其视为客户端订阅的地址,服务或其他客户端发布到该地址。
它可能容易认为所有我们需要构建协作白板应用是采用渠道(每个白板都有它自己的通道),然后坐下来放松一下,但你将会看到在这篇文章中,你仍然有问题扩展和容错。
您需要一个发布/订阅代理
首先,我说的“pub/sub broker”是什么意思?有各种各样的技术在相当大的规模上支持发布/订阅模式。
当你需要在套接字上扩展发布/订阅架构时,你需要找到一个好的发布/订阅技术来作为你的解决方案的核心。
我们不需要为这篇文章确定一个特定的选项,但这里有一些不错的选择:Redis, RabbitMQ, Kafka,和RethinkDB。
为了了解为什么我们需要添加一个pub/sub代理来帮助你扩展你的WebSockets,让我们先以一个服务器为背景来考虑我们的例子。
对于一个服务器来说,用WebSockets构建一个发布/订阅服务其实很容易。这是因为在一台服务器上,服务器将知道所有客户机以及客户机感兴趣的数据。
考虑一下我们的示例应用程序。当客户端发送绘图的坐标时,我们只需找到绘图的正确通道,并将对绘图所做的更新发布到该通道。所有的客户端都连接到一台服务器上,因此它们都会得到更改的通知。这有点像内存中的pub/sub。
但在现实中,我们希望跨多个服务器扩展,我们这么做有两个原因:1)共享处理能力,2)冗余。
那么我们怎样才能确保我们的应用扩展?嗯,我们需要一些方法让其他与连接的客户端服务知道数据已经改变。
在构建这样一个应用程序时,你可能已经有了一个数据库,甚至在你开始考虑扩展之前。你不会仅仅信任连接的客户来存储所有图纸的数据。不,您将希望在绘图数据从客户端传入时持久保存它,以便在用户打开绘图时随时提供绘图数据。
但问题来了。如果服务器a上的WebSocket写入一些数据到数据库,服务器B上的WebSocket如何知道去获取数据库的最新数据以便通知它的客户端新的数据?
让我们谈谈在解决方案的中心使用Redis的过程。尽管您的集群中可能有数百个WebSocket服务器,让我们假设您只有3个服务器,这样可以使事情更简单一些。我们将把这些服务器称为WS1、WS2和WS3。有时我会用我的创意名字来给自己取个惊喜!
好,假设你有9个人打开了一幅特定的画,画的是一只狗骑着一匹小马驹骑着一只恐龙,id为abc123保存在你的数据库中。假设有3个人连接到集群中的每个服务器(WS1、WS2、WS3)。
一个连接到WS1的用户在白板上画一些东西。在您的WebSocket服务器逻辑中,您写入数据库,以确保更改已经被持久化,然后根据与绘图相关联的唯一标识符(很可能是基于绘图的数据库id)发布到一个通道。在这个例子中,我们假设通道名是drawing_abc123。
在这一点上,你已经把数据安全地写入数据库,并且你已经发布了一个事件到你的pub/sub代理(Redis频道),通知其他有新数据的相关方。
因为你有用户连接到其他WebSocket服务器(WS2, WS3),对同一个绘图感兴趣,他们将在drawing_abc123通道上开放订阅Redis。他们得到事件的通知,并且每个服务器查询DB更新,并在你的WebSocket层使用的WebSocket通道上发出它。
您可以看到,发布/订阅代理用于允许您通过扩展的WebSocket集群公开发布/订阅模型。
处理故障转移
使用pub/sub代理来协调WebSockets的另一个好处是,现在可以轻松处理故障转移。
当一个客户端连接到一个WebSocket服务器时,该服务器崩溃了,客户端可以通过负载平衡器打开一个连接到另一个WebSocket服务器。新的WebSocket服务器将确保对WebSocket客户端感兴趣的数据的发布/订阅代理有一个订阅,并在WebSocket发生变化时通过管道传输。
使用增量
当客户端重新连接时,需要考虑的一件事是使客户端足够智能,通过某种数据同步偏移量(可能以时间戳的形式)发送,以便服务器不会再次发送所有数据。
如果对图纸的每次更新都打上了时间戳,那么客户端可以很容易地存储他们收到的最新时间戳。当客户端失去了连接到一个特定的服务器,它可以连接到你的websocket集群(通过你的负载平衡器)通过在过去的时间戳,收到这样的查询DB只能建立,这样它会返回更新后出现客户端最后成功收到更新。
在应用程序的负载中,担心副本传到客户机可能并不重要。但即便如此,使用时间戳方法来节省资源和用户的带宽也是一个好主意。
结论
构建运行在一台服务器上的发布/订阅服务相对简单。挑战在于构建一个可以水平伸缩以实现负载共享和容错的服务。
当您向外扩展时,您需要一种方法让web套接字服务订阅已更改的数据,因为对所述数据的更改也将来自其他服务器而不是自身。支持实时查询的数据库非常适合用于此目的,例如RethinkDB。这样你只有WebSockets和你的DB。也就是说,你可能已经在你的环境中使用了支持pub/sub的技术(Redis, RabbitMQ, Kafka),这将比在混合中引入一种新的DB技术更容易销售。
感谢你的阅读!:)如果你喜欢它,请转发,点赞加关注。
原文:https://hackernoon.com/scaling-websockets-9a31497af051
本文:http://jiagoushi.pro/node/1115
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 57 次浏览
【Web应用架构】模式:前端的后端(BFF)
面向用户界面和外部方的单用途边缘服务
介绍
随着web的出现和成功,交付用户界面的实际方式已经从厚客户端应用程序转变为通过web交付的界面,这一趋势也使基于SAAS的解决方案总体上得以发展。通过web提供用户界面的好处是巨大的——主要是因为发布新功能的成本大大降低了,因为客户端安装的成本(在大多数情况下)被完全消除了。
然而,这个简单的世界并没有持续太久,不久之后,手机时代就到来了。现在我们有麻烦了。我们有服务器端功能,我们希望通过桌面web UI和一个或多个移动UI公开这些功能。考虑到最初开发的系统是以桌面web UI为基础的,我们在适应这些新类型的用户界面时经常会遇到问题,因为桌面web UI和我们支持的服务之间已经有了紧密的耦合。
通用API后端
容纳多种类型的UI的第一步通常是提供单一的服务器端API,并根据需要随时间增加更多功能以支持新类型的移动交互:
通用API后端
如果这些不同的ui想要进行相同或非常相似的调用,那么这种通用API很容易成功。然而,移动体验的本质往往与桌面web体验截然不同。首先,移动设备的价格非常不同。我们有更少的屏幕房地产,这意味着我们可以显示更少的数据。打开与服务器端资源的大量连接可能会耗尽电池寿命和有限的数据计划。其次,我们希望在移动设备上提供的交互的性质可能有很大的不同。想想一个典型的实体零售商吧。在桌面应用程序中,我可能允许您查看要出售的商品、在线订购或在商店中预订。不过,在移动设备上,我可能希望允许您扫描条形码进行价格比较,或者在商店中为您提供基于上下文的优惠。随着我们构建了越来越多的移动应用程序,我们逐渐意识到人们使用它们的方式非常不同,因此我们需要公开的功能也会有所不同。
因此,在实践中,我们的移动设备将要进行不同的呼叫,更少的呼叫,并将要显示不同的(可能更少)数据比他们的桌面对应。这意味着我们需要在我们的API后端添加额外的功能来支持我们的移动接口。
通用API后端的另一个问题是,根据定义,它们为多个面向用户的应用程序提供功能。这意味着,当推出新的交付时,单个API后端可能会成为瓶颈,因为许多更改都试图对同一个可部署工件进行。
通用API后端承担多个职责的趋势,因此需要大量工作,通常会导致专门创建一个团队来处理这个代码库。这会使问题变得更糟,因为现在前端团队必须与一个单独的团队进行交互以获得所做的更改—一个团队必须平衡不同客户团队的优先级,并且还必须与多个下游团队合作,在新的API可用时使用它们。可以说,在这一点上,我们刚刚在我们的体系结构中创建了一个智能的中间件,它并不关注任何特定的业务领域,这与许多人对明智的面向服务的体系结构应该是什么的看法背道而驰。
介绍前端的后端
对于这个问题,我在REA和SoundCloud中看到的一个解决方案是,不是有一个通用的API后端,而是每个用户都有一个后端,或者(前SoundClouder)Phil Calçado称之为前端后端(BFF)。从概念上讲,您应该将面向用户的应用程序视为两个组件:位于外围的客户端应用程序和位于外围的服务器端组件(BFF)。
BFF与特定的用户体验紧密耦合,通常由与用户界面相同的团队维护,从而使定义和调整API更容易满足UI的需要,同时也简化了对客户机和服务器组件的发布进行排队的过程。
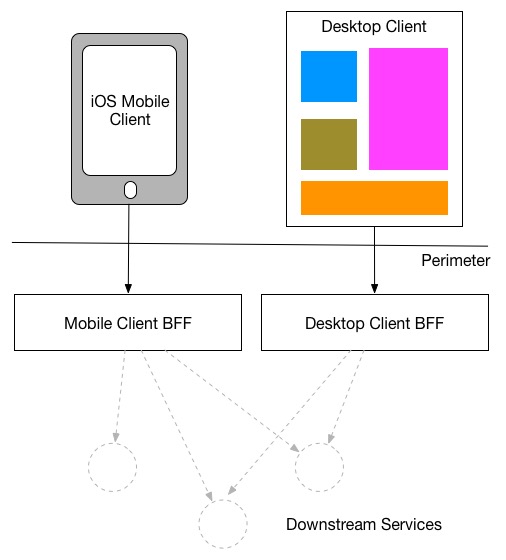
每个用户界面使用一个服务器端BFF
BFF紧紧地关注于一个UI,而仅仅是那个UI。这使得它能够集中注意力,因此会更小。
有多少BFF?
当谈到在不同平台上提供相同(或相似)的用户体验时,我看到了两种不同的方法。我更喜欢的模式是严格地为每种不同类型的客户提供一个BFF——这是我在REA看到的一个模式:
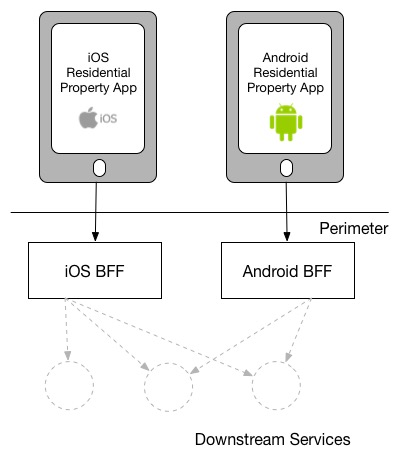
不同的移动平台,不同的BFF,用于REA
另一个模型,我在SoundCloud上看到过,每种用户界面使用一个BFF。因此,本机应用程序的Android和iOS版本都使用相同的BFF:
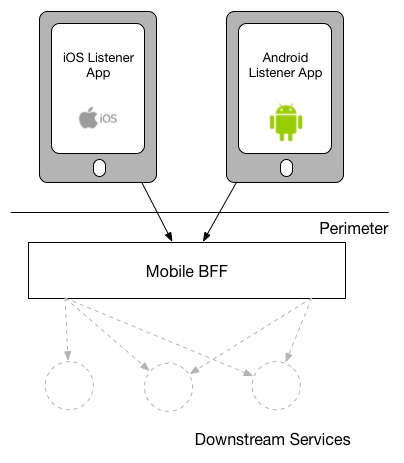
有一个用于不同移动后端的BFF,如在SoundCloud中使用的
我对第二种模式的主要担心是,使用一个BFF的客户类型越多,它就越容易因处理多个关注点而变得臃肿。不过,这里需要理解的关键是,即使是在共享BFF时,它也是针对同一类用户界面的——因此,虽然SoundCloud针对iOS和Android的侦听器本机应用程序使用相同的BFF,但其他本机应用程序将使用不同的BFF(例如,新的Creator应用程序Pulse使用不同的BFF)。如果同一个团队同时拥有Android和iOS应用程序,并且也拥有BFF,我也会更轻松地使用这个模型——如果这些应用程序是由不同的团队维护的,我更倾向于推荐更严格的模型。因此,你可以将你的组织结构看作是模型最有意义的主要驱动因素之一(康威定律再次获胜)。值得注意的是,我采访过的SoundCloud工程师建议,如果今天再次做出决定,他们可能会重新考虑为Android和iOS监听器应用程序提供一个BFF。
我真的很喜欢Stewart Gleadow的一个指导方针(他反过来称赞了Phil Calçado和Mustafa Sezgin)是“一次经历,一次朋友”。因此,如果iOS和Android的体验非常相似,那么更容易证明拥有一个BFF是合理的。然而,如果它们相差很大,那么拥有单独的bff就更有意义了。
皮特·霍奇森观察到,当围绕团队边界对齐时,bff最有效,因此团队结构应该决定你拥有多少bff。所以如果你有一个移动团队,你应该有一个BFF,但是如果你有独立的iOS和Android团队,你会有独立的BFF。我担心的是团队结构往往比我们的系统设计更灵活。因此,如果你有一个移动的BFF,然后将团队分成iOS和Android专业,那么你是否也必须将BFF分开?如果bff已经是独立的,那么拆分团队会更容易,因为您可以重新分配已经独立的资产的所有权。但是,BFF和团队结构的相互作用是很重要的,我们稍后将对此进行探讨。
通常,实现少量bff的驱动因素是重用服务器端功能以避免过多的重复,但是还有其他方法可以处理这个问题,我们将很快介绍。
以及多个下游服务(微服务!)
对于有少量后端服务的体系结构,BFFs可能是一种有用的模式。然而,对于使用大量服务的组织来说,它们是必不可少的,因为聚合多个下游调用以提供用户功能的需求急剧增加。在这种情况下,一个对BFF的调用通常会导致多个对微服务的下游调用。例如,设想一个电子商务公司的应用程序。我们要在用户的愿望列表中提取一个项目列表,显示库存水平和价格:
| The Brakes - Give Blood | In Stock! (14 items remaining) | $5.99 | Order Now |
| Blue Juice - Retrospectable | Out Of Stock | $17.50 | Pre Order |
| Hot Chip - Why Make Sense? | Going fast (2 items left) | $9.99 | Order Now |
多个服务保存我们想要的信息。Wishlist服务存储关于列表的信息,以及每个项目的id。目录服务存储每个项目的名称和价格,库存水平存储在我们的库存服务中。因此在我们的BFF中,我们将公开一个检索完整播放列表的方法,该方法至少包含3个调用:
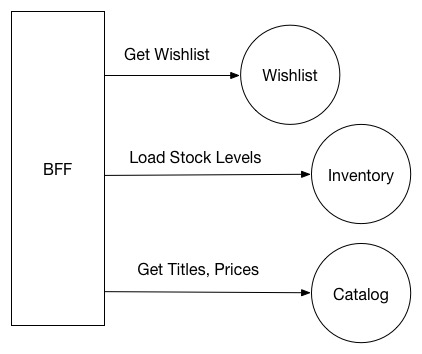
进行多个下游调用以构建愿望列表的视图
从效率的角度来看,尽可能多地并行运行调用会更明智。一旦对Wishlist服务的初始调用完成,理想情况下,我们希望同时运行对其他服务的调用,以减少总的调用时间。这种需要将我们希望并行运行的调用与按顺序运行的调用混合起来的情况很快就会变得难以管理,特别是对于更复杂的场景。当多个调用的组合变得更容易管理时,这是一个反应式编程风格可以帮助的领域(例如RxJava或Finagle的futures系统提供的)。
但故障模式变得很重要。在上面的示例中,我们可以坚持所有下游调用都必须返回,以便我们将负载返回给客户机。然而,这是否明智?显然,如果Wishlist服务关闭了,我们不能做任何事情,但是如果只有Inventory服务关闭了,那么最好是降低我们传递给客户端的功能,也许只是删除stock level指示符?首先,这些问题必须由BFF自己管理,但我们还需要确保调用BFF的客户机能够解释部分响应并正确地呈现它。
再利用
每个用户界面都有一个BFF的一个关注点是,在BFF本身之间可能会有很多重复。例如,它们可能最终执行相同类型的聚合,具有用于与下游服务交互的相同或相似代码等。一些人对此作出反应,希望将这些代码合并在一起,从而拥有通用的聚合边缘API服务。这个模型一次又一次地证明了它会导致高度膨胀的代码,同时多个关注点挤在一起。
正如我之前多次说过的,我对跨服务的重复代码相当放心。这就是说,虽然在单个流程边界中,我通常会尽我所能将复制重构为适当的抽象,但当遇到跨服务的复制时,我没有相同的反应。这主要是因为我通常更担心提取共享代码导致服务之间紧密耦合的可能性——这比一般的复制更让我担心。也就是说,在某些情况下,这是有道理的。
我的同事皮特·霍奇森(Pete Hodgson)指出,如果你没有朋友,那么通常“共同”的逻辑最终会被烘焙到不同的客户身上。由于这些客户机使用非常不同的技术堆栈,因此很难确定发生这种重复的事实。随着组织倾向于为服务器端组件建立一个通用的技术堆栈,拥有多个重复的bff可能更容易被发现和排除。
当需要提取共享代码时,有两个明显的选项。第一种方法是提取某种共享库,这种方法通常最便宜,但更令人担忧。这可能有问题的原因是,共享库是耦合的主要来源,尤其是用于生成客户端库以调用下游服务时。尽管如此,有些情况下这感觉是对的——特别是当被抽象的代码纯粹是服务内部的一个关注点时。
另一种选择是在一个新服务中提取出共享功能,如果您能够概念化新服务具有围绕所讨论的域建模的某些内容,则该服务可以很好地工作。
这种方法的一个变体可能是将聚合责任推到更下游的服务上。以上面的例子为例,我们讨论了愿望列表的呈现。假设我们在两个地方呈现一个愿望列表-在Android上,iOS Web上。我们的每一个朋友都在打同样的三个电话:
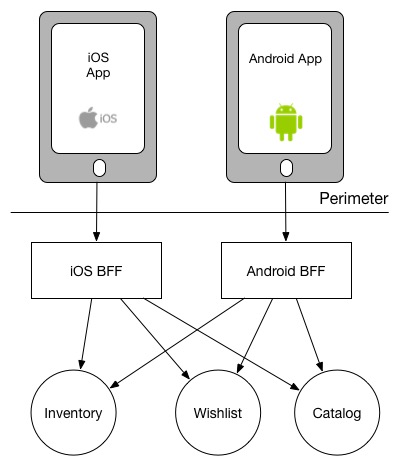
多个BFF执行相同的任务
相反,我们可以更改Wishlist服务来为我们进行下游调用,从而简化呼叫者的工作:
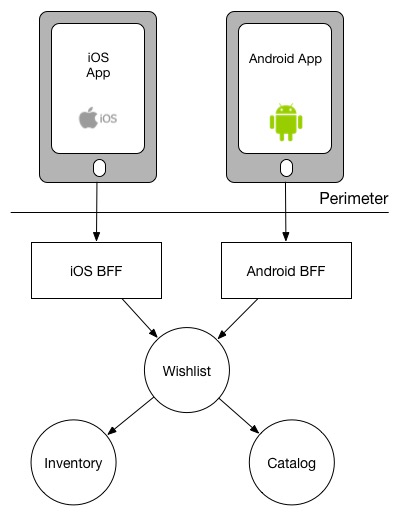
进一步向下游推进集合关税,以消除bff中的重复
我不得不说,在两个地方使用相同的代码不一定会导致我想以这种方式提取服务,但如果创建新服务的事务成本足够低,或者我在多个地方(例如,在桌面web上)使用它,我肯定会考虑。我认为,即使在服务级别,当您将要第三次实现某个东西时创建一个抽象仍然是一个很好的经验法则。
桌面Web及其他领域的BFFs
你可以认为BFFs只是在解决移动设备的限制方面有用处。桌面web体验通常在更强大的设备上提供,具有更好的连接性,在这些设备上进行多个下游呼叫的成本是可控的。这允许您的web应用程序直接对下游服务进行多个调用,而无需BFF。
我也看到过在网络上使用BFF也很有用的情况。当您在服务器端生成大部分web UI(例如使用服务器端模板)时,BFF显然是可以做到这一点的地方。它还可以在一定程度上简化缓存,因为您可以在BFF前面放置一个反向代理,允许您缓存聚合调用的结果(尽管您必须确保相应地设置缓存控件,以确保聚合内容的过期时间与聚合中最新的内容所需的时间一样短)。事实上,我见过它多次使用,但没有称之为BFF——事实上,通用API后端常常是从这样一个野兽身上长出来的。
我看到至少有一个组织为其他需要打电话的外部团体使用了bff。回到我多年的音乐商店例子,我可能会公开一个BFF,允许第三方提取版税支付信息,提供Facebook集成或允许流媒体到一系列机顶盒设备:
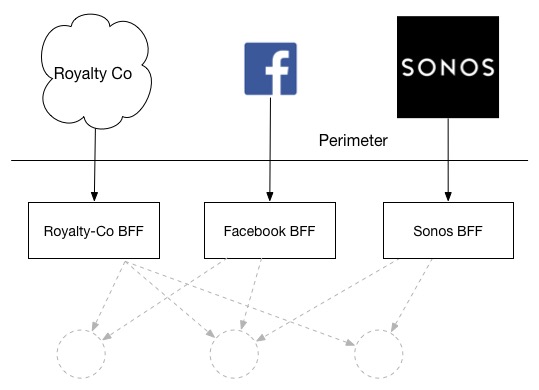
使用BFF向第三方公开api
这种方法特别有效,因为第三方通常没有能力(或愿望)使用或更改它们发出的API调用。对于一个通用的API后端,您可能不得不保留API的旧版本,以满足您无法进行更改的外部方的一小部分-使用BFF,这个问题大大减少了。
和自主性
我们经常看到这样的情况:一个团队正在前端工作,另一个团队正在创建后端服务。一般来说,我们试图通过移动到围绕业务垂直线的微服务来避免这一点,但即使如此,也存在难以避免的情况。首先,在一定规模或复杂程度上,需要多个团队参与。其次,执行良好的Android或iOS体验所需的技术技能的深度往往需要专门的团队。
因此,构建用户界面的团队面临这样一种情况:他们正在调用另一个团队正在驱动的API,而且在开发用户界面时,API往往在不断发展。BFF可以在这里提供帮助,特别是如果它是由创建用户界面的团队拥有的话。他们在创建前端的同时改进了BFF的API。它们可以很快地重复这两个过程。BFF本身仍然需要调用其他下游服务,但这可以在不中断用户界面开发的情况下完成。
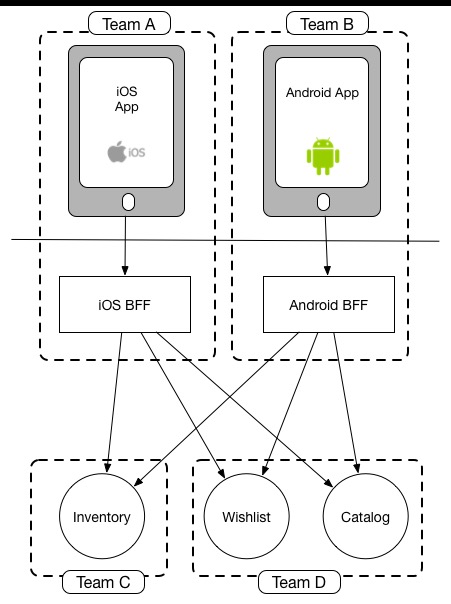
使用bff时的团队所有权边界示例
使用与团队边界一致的BFF的另一个好处是,创建界面的团队可以更灵活地考虑功能所在的位置。例如,他们可以决定将功能推送到服务器端,以促进将来的重用并简化本机移动应用程序,或者允许更快地发布新功能(因为您可以绕过应用商店审查流程)。如果团队同时拥有移动应用程序和BFF,这个决定可以由团队单独做出——这不需要任何跨团队的协调。
一般周边问题
有些人使用bff来实现一般的外围关注点,例如身份验证/授权或请求日志记录。我对这事很恼火。一方面,这个功能的大部分都是通用的,所以我倾向于使用另一个位于上游的层来实现它,可能使用类似Nginx或Apache服务器的层。另一方面,这样一个额外的层也会增加延迟。在微服务环境中经常使用BFFs,在微服务环境中,我们已经对延迟非常敏感,因为正在进行的网络调用的数量很多。此外,要构建类似于生产的堆栈,需要部署的层越多,开发和测试就越复杂—将所有这些关注点都放在BFF中作为一个更独立的解决方案可能会很有吸引力:
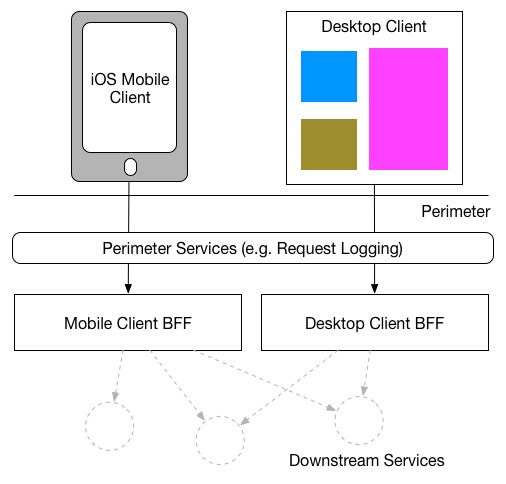
使用网络设备实现一般外围关注点
如前所述,消除这种重复的另一种方法是使用共享库。假设您的bff使用的是相同的技术,这应该不会太困难,尽管通常关于microservice体系结构中的共享库的警告是适用的。
何时使用
对于只提供web UI的应用程序,我怀疑只有在服务器端需要大量聚合时,BFF才有意义。否则,我认为其他UI组合技术也同样可以工作,而不需要额外的服务器端组件(我希望很快会讨论这些)。
不过,当您需要为移动用户界面或第三方提供特定功能时,我会从一开始就强烈考虑为每一方使用bff。如果部署额外服务的成本很高,我可能会重新考虑,但是在大多数情况下,BFF可以带来的关注分离使它成为一个相当有说服力的提议。基于上述原因,如果构建UI的人员和下游服务之间存在显著的分离,那么我更倾向于使用BFF。
进一步阅读(和观看)
自从我写这篇文章以来,ThoughtWorks的Lukasz Plotnicki发表了一篇关于SoundCloud使用BFF模式的伟大文章
卢卡斯在最近一期的软件工程播客中接受了关于模式(和其他事情)的采访。
来自SoundCloud的Bora Tunca在2016年microxchg的一次演讲中也谈到了更多细节。
结论
前端后端解决了使用微服务时移动开发的一个紧迫问题。此外,它们提供了通用API后端的令人信服的替代方案,许多团队将它们用于移动开发之外的其他用途。限制他们所支持的消费者数量的简单行为使他们更容易处理和更改,并帮助开发面向客户的应用程序的团队保留更多的自主权。
本文:http://jiagoushi.pro/pattern-backends-frontends
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 207 次浏览
【Web架构】Web3.0——第三代互联网的开端
你可能听说过Web3.0,但你知道吗,这到底是什么意思?如果你仍然不知道这意味着什么,那么别担心,你并不孤单。
Web 1.0 vs 2.0 vs 3.0
要理解什么是Web3.0,我们首先必须了解Internet的早期版本。
Web 1.0
互联网在20世纪80年代左右开始发展。在90年代得到了很好的宣传,因为企业开始在高水平上使用互联网。由于这正是风暴来临前的平静时刻,商家们正利用它来推销自己的产品,而不是收音机和杂志。
从1994年到2004年,这十年属于Web1.0。Web1.0是关于阅读而不是写作的。它是静态的,而不是动态的。有了这些缺点,它诞生了Web2.0。
Web 2.0
现在,这就是2004年时代开始的地方。互联网的下一个主要阶段是互动和用户。随着新兴技术的出现,Web2.0获得了如此多的基准,许多科技公司对此感到满意。用户在Facebook、YouTube、Instagram、Twitter等平台上创建了大部分内容,当然,谁会忘记TikTok呢。
现在的问题是,当大多数平台都是免费的时候,他们怎么能在上面赚到数十亿美元呢。问题就这样开始了!
在这个世界上,没有什么是免费的!
如果您不是为产品付费,那么您就是产品。
通过Web2.0,用户还可以向控制这些平台的公司提供个人信息和数据。
看到这一点,用户必须想办法应对世界最大科技公司的过度行为和市场支配地位。一种新的基本方式已经被开发出来,让个人在不放弃隐私和宝贵数据的情况下使用互联网,Web3!互联网的下一步。
Web 3.0
在区块链技术的推动下,Web3.0提出了一个让整个互联网去中心化的想法。这些网络的关键创新在于创建没有单一实体控制的平台,但每个人仍然可以信任。这是因为这些网络的每个用户和运营商都必须遵循同一套硬编码规则,即共识协议。
集中与分散
当我们说集中式时,这纯粹表明其中隐藏着客户机和服务器的概念。这意味着数据将存储在单个中央服务器上,该服务器将由个人或公司所有。
另一方面,分散表示数据将存储在单个节点上,而不是存储在中央服务器上。得益于区块链,数据是不可变和安全的。
整个去中心化互联网被称为 Web 3.0。
您如何使用 Web 3.0?
在 Web 3.0 中,网络是去中心化的,因此没有任何实体可以控制它。随着加密、以太坊和区块链等新兴 Web 3 技术的出现,最近出现了一个新术语,即 DApps(去中心化应用程序)。任何人都可以在未经中央公司许可的情况下构建和连接不同的 dapp。
有许多可用的 Web 3.0 dapp。目前,我正在探索这两个;
未来
网络是一个未完成的项目。 Web 的未来即将增加连接性、隐私性和可扩展性。可以肯定的是,我们将在 2022 年从 Web 2.0 迁移到 Web 3.0。我们可以说我们已经处于 Web 3.0 时代的入口,因为 Crypto 和 NFT 近来声名鹊起
是的,它需要一些时间才能完全成型,但我们很快就会每天使用所有去中心化的服务。
没有你的帮助,改变不可能发生:
拍拍手,分享这篇文章。
语文:https://shritam.medium.com/web-3-0-the-beginning-of-third-generation-in…
本文:
- 120 次浏览
【Web架构】静态站点生成器概述 Gatsby ,Hugo 和Jekyll对比
在本文中,您将看到三种最好的静态站点生成器的比较,它们的优点、缺点以及您应该使用它们的原因。
网站统治着网络,无论是静态的还是动态的。虽然现在很多网站都是动态的,但是静态的仍然很受欢迎。事实上,静态网站的使用在增加。
在本文中,您将看到三种最好的静态站点生成器的比较,它们的优点、缺点以及您应该使用它们的原因。
静态站点生成器使构建静态站点轻而易举。想象一下,只要做很少或没有复杂的工作,仍然有网站:
- 与动态的对手相比,它们的速度快得惊人。
- 需要更少的维护。
- 具有高水平的安全性。
- 非常适合简单的网站,如作品集。

虽然您可以手动创建静态站点,但这样做有很多缺点。这可能是一个困难的过程,当您打算进行更改时,许多问题会浮出水面,而扩展不是您所期待的。
Gatsby、Hugo和Jekyll是最受欢迎的静态站点生成器中的三种,它们受欢迎的原因有很多。让我们看看他们能提供什么。
盖茨比(Gatsby)
由节点。盖茨比是这三款中最新的静态网站生成器。然而,它发展得相当快,并且现在被大量使用。盖茨比受益于庞大的JavaScript开发者社区,并将继续改进。
除了使用Node之外,Gatsby还对客户端使用了response .js。使用反应物.js使Gatsby能够受益于框架呈现DOM的方法,因为组件成为焦点。
Gatsby还支持GraphQL,这意味着数据查询变得更加容易。由于有了GraphQL, Gatsby可以生成能够访问和利用来自不同来源的数据的站点。
您将在使用Gatsby时看到,生成的站点是进步的Web应用程序。PWAs提供了很好的用户体验,它们是web和移动应用程序的完美结合——从两方面挑选特性。
PWA是下一个重要的东西,所以你可以从中受益当使用Gatsby生成静态网站。
优点
- 盖茨比生成Progressive Web Apps——这样您的站点就可以享受这些应用程序带来的好处。
- 它支持GraphQL。
- 大量的插件都是可用的——谈谈庞大的用户社区的好处吧。
- 解释性教程不难找到,文档也很棒。
缺点
- 使用Gatsby需要大量的JavaScript、React和GraphQL知识。
- 网站生成速度可以更快,盖茨比有点慢。
雨果(Hugo)
开发人员称之为“世界上最快的网站构建框架”(Hugo),这绝非偶然。
《雨果》是用Golang 写成的,于2014年发行。毫无疑问,Golang是一种快速的语言,它的效果体现在雨果的速度上。Hugo是专门用来解决提高速度的需要的,它可以在你说jack之前建立巨大的网站。
毫无疑问,Hugo是最快的静态网站生成器可用,它产生网站在毫秒和不可战胜。
Hugo还使用了基于Go模板的模板,并附带了一个轻量级HTTP服务器——您可以将其视为一个完整的包。
虽然这听起来好得令人难以置信,但Hugo消除了所有配置或依赖的麻烦,使其使用起来很愉快。
由于其速度快和各种内置功能,您会发现Hugo被用于生成博客和文档。它得到了广泛的应用,并继续得到改善。
优点
- 它的速度非常快,任何东西都无法与之匹敌。
- 有很多内置的功能,你几乎不需要第三方插件。
- 雨果很容易搞定,没有麻烦。
- 它有适当的文档。
- 它的模板语言并不难学。
缺点
- 学习Golang 可能是困难的。
- 不支持XML作为数据文件类型。但是,支持YAML、JSON和CSV。
变身怪医(Jekyll)
Jekyll由Tom Preston-Werner在2009年发布,是这个列表中最老的静态站点生成器。
Jekyll是用Ruby编写的,全世界都在使用。由于加入了GitHub——Tom Preston-Werner是GitHub的联合创始人——Jekyll获得了开源社区的大量关注和贡献。
与Hugo一样,Jekyll也附带一个HTTP服务器,通常用于生成博客。它也经常用于生成投资组合。
虽然Jekyll对页面内容使用Markdown,但它也使用液体模板语言来处理页面。Jekyll也使用Sass,这对于喜欢CSS预处理器的开发人员来说非常重要。
由于Jekyll有许多开发人员为其做出贡献,所以您可以找到一个插件来实现几乎任何您想要实现的功能。
优点
- 设置和部署Jekyll是一个简单的过程。
- 它有一个巨大的开发者社区——你可以找到帮助你的人。
- 这里有教程和全面的文档。
- 它使用了易于学习的液态模板语言。
- Jekyll是伟大的搜索引擎优化(SEO)。
- 大量的插件可用。
缺点
- 为Windows用户设置可能很困难——Jekyll需要一个Ruby环境。
- 杰基尔在建筑工地的时候速度很慢。
选择静态站点生成器
尝试从这三种静态站点生成器中挑选可能是一项困难的任务。它们本身都是伟大的工具。让我们来看看为什么你可能想要选择一个在其余的原因。
结论
静态站点生成器有助于使静态站点易于构建、修改和扩展。在本文中,您已经看到了三种最好的静态站点生成器。您应该能够更好地决定下一个静态站点项目使用哪种工具。
有什么问题吗?你认为还有什么静态网站生成器可以与这三种匹敌?你可以在评论区分享你的想法。
原文:https://dzone.com/articles/static-site-generators-overview-gatsby-vs-hugo-vs
本文:http://jiagoushi.pro/node/1377
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 424 次浏览
【应用架构】轮询vs SSE vs WebSocket —如何选择合适的 ?
构建实时Web应用程序有点挑战,我们需要考虑如何将数据从服务器发送到客户端。 能够“主动”实现这一功能的技术已经存在了很长时间,并且仅限于两种通用方法:客户端请求或服务器请求。
实现这些的几种方法:
- 长/短轮询(客户端拉动)
- WebSockets(服务器推送)
- 服务器发送的事件(服务器推送)
- 客户端拉取-客户端以一定的定期间隔向服务器请求更新
- 服务器推送-服务器正在主动将更新推送到客户端(客户端拉取的反向操作)
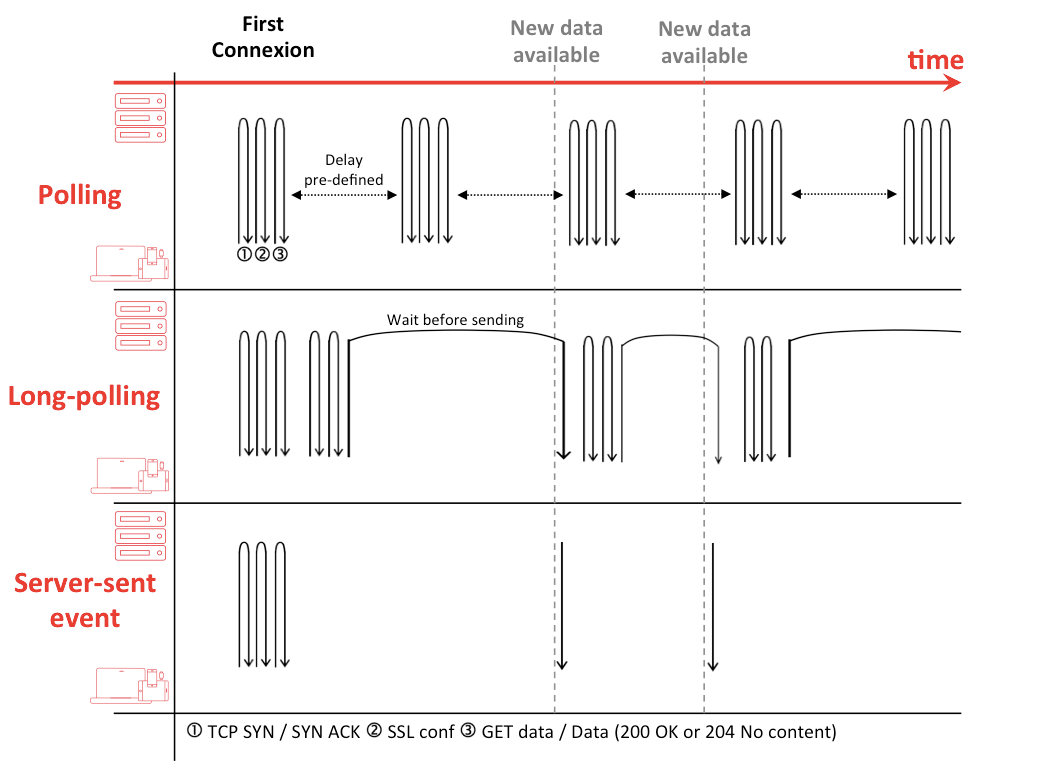
让我们以一个简单的用例来比较以上技术,然后选择合适的技术。
范例:
我们的示例用例非常简单。 我们需要开发一个仪表板Web应用程序,该应用程序可以流转来自(GitHub / Twitter / .. etc)等网站的活动列表。 这个应用程序的目的是从上面列出的各种方法中选择合适的一种。
1.使用轮询:
轮询是一种技术,客户端通过该技术定期向服务器请求新数据。 我们可以通过两种方式进行轮询:短轮询和长轮询。 简单来说,短轮询是基于AJAX的计时器,它以固定的延迟进行调用,而长轮询则基于Comet(即,当服务器事件发生时,服务器将无延迟地将数据发送到客户端)。 两者都有优点和缺点,并根据用例进行调整。 有关深入的详细信息,请阅读StackOverflow社区给出的答案。
让我们看看一个简单的客户端长轮询代码段的外观:
/* Client - subscribing to the github events */
subscribe: (callback) => {
const pollUserEvents = () => {
$.ajax({
method: 'GET',
url: 'http://localhost:8080/githubEvents',
success: (data) => {
callback(data) // process the data
},
complete: () => {
pollUserEvents();
},
timeout: 30000
})
}
pollUserEvents()
}
这基本上是一个长轮询功能,它像往常一样第一次运行,但是它设置了三十(30)秒的超时,并且在每次对服务器进行Async Ajax调用之后,回调都会再次调用Ajax。
AJAX调用可在HTTP协议上运行,这意味着默认情况下,对同一域的请求应进行多路复用。我们发现这种方法存在一些陷阱。
多路复用(轮询响应实际上无法同步)
轮询需要3次往返(TCP SIN,SSL和数据)
超时(如果连接保持空闲时间太长,代理服务器将关闭连接)
您可以在这里阅读更多关于现实世界的挑战。
2.使用WebSockets:
WebSocket只是客户端和服务器之间的持久连接。这是一种通过单个TCP连接提供全双工通信通道的通信协议。
RFC 6455声明WebSocket“旨在在HTTP端口80和443上工作,并支持HTTP代理和中介”,从而使其与HTTP协议兼容。为了实现兼容性,WebSocket握手使用HTTP升级标头将HTTP协议更改为WebSocket协议。 HTTP和WebSocket都位于OSI模型的应用程序层,因此依赖于第4层的TCP。
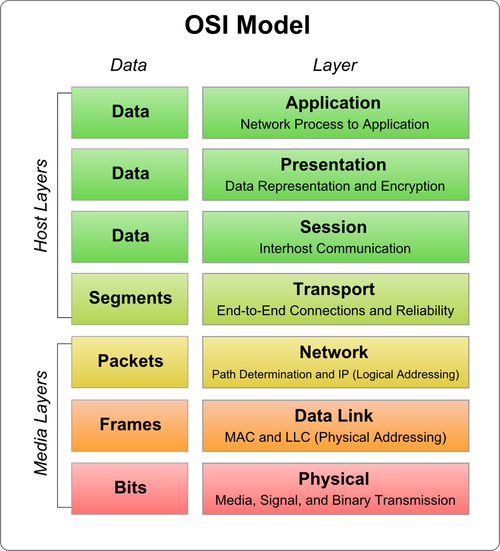
有一个MDN文档详细解释了WebSocket,我也建议您阅读它。
让我们看看一个非常简单的WebSocket客户端实现的样子:
$(function () {
// if user is running mozilla then use it's built-in WebSocket
window.WebSocket = window.WebSocket || window.MozWebSocket;const connection = new WebSocket('ws://localhost:8080/githubEvents');
connection.onopen = function () {
// connection is opened and ready to use
};connection.onerror = function (error) {
// an error occurred when sending/receiving data
};connection.onmessage = function (message) {
// try to decode json (I assume that each message
// from server is json)
try {
const githubEvent = JSON.parse(message.data); // display to the user appropriately
} catch (e) {
console.log('This doesn\'t look like a valid JSON: '+ message.data);
return;
}
// handle incoming message
};
});
如果服务器支持WebSocket协议,它将同意升级,并将通过响应中的Upgrade标头传达此信息。
让我们看看如何在Node.JS(服务器)中实现:
const express = require('express');
const events = require('./events');
const path = require('path');const app = express();
const port = process.env.PORT || 5001;
const expressWs = require('express-ws')(app);
app.get('/', function(req, res) {
res.sendFile(path.join(__dirname + '/static/index.html'));
});app.ws('/', function(ws, req) {
const githubEvent = {}; // sample github Event from Github event API https://api.github.com/events
ws.send('message', githubEvent);
});app.listen(port, function() {
console.log('Listening on', port);
});
一旦我们从GitHub事件API获得数据,就可以在建立连接后将其流式传输到客户端。 对于我们的场景,这种方法也有一些陷阱。
- 使用WebSockets,我们需要自己处理许多由HTTP处理的问题。
- WebSocket是用于传输数据的另一种协议,它不会通过HTTP / 2连接自动多路复用。 在服务器和客户端上实现自定义多路复用有点复杂。
- WebSocket是基于帧的,而不是基于流的。 当我们打开网络标签。 您可以看到WebSocket消息在frame中列出。
有关WebSocket的详细信息,请查看这篇很棒的文章,在这里您可以阅读有关碎片以及如何在后台进行处理的更多信息。
3.使用SSE:
SSE是一种机制,一旦建立了客户端-服务器连接,服务器就可以将数据异步推送到客户端。 然后,只要有新的“大块”数据可用,服务器就可以决定发送数据。 可以将其视为单向发布-订阅模型。
它还提供了一个标准的JavaScript客户端API,称为EventSource,已在大多数现代浏览器中实现,作为W3C的HTML5标准的一部分。 Polyfills可用于不支持EventSource API的浏览器。

我们可以看到Edge和Opera Mini落后于此实现,对于SSE而言,最重要的案例是针对移动浏览器设备,因为这些浏览器没有可行的市场份额。 Yaffle是事件源的众所周知的pollyfill。
由于SSE是基于HTTP的,因此它很自然地与HTTP / 2相适应,并且可以结合使用以实现两者的最佳选择:HTTP / 2处理基于多路复用流的有效传输层,而SSE为应用程序提供API以实现 推。 因此,开箱即用地通过HTTP / 2实现多路复用。 连接断开时会通知客户端和服务器。 通过使用消息维护唯一的ID,服务器可以看到客户端错过了n条消息,并在重新连接时发送了未完成消息的积压。
让我们看看示例客户端实现的外观:
const evtSource = new EventSource('/events');
evtSource.addEventListener('event', function(evt) {
const data = JSON.parse(evt.data);
// Use data here
},false);
此代码段非常简单。 它连接到我们的源并等待接收消息。 现在,示例NodeJS服务器将如下所示。
// events.js
const EventEmitter = require('eventemitter3');
const emitter = new EventEmitter();function subscribe(req, res) {
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
Connection: 'keep-alive'
});// Heartbeat
const nln = function() {
res.write('\n');
};
const hbt = setInterval(nln, 15000);const onEvent = function(data) {
res.write('retry: 500\n');
res.write(`event: event\n`);
res.write(`data: ${JSON.stringify(data)}\n\n`);
};emitter.on('event', onEvent);
// Clear heartbeat and listener
req.on('close', function() {
clearInterval(hbt);
emitter.removeListener('event', onEvent);
});
}function publish(eventData) {
// Emit events here recieved from Github/Twitter APIs
emitter.emit('event', eventData);
}module.exports = {
subscribe, // Sending event data to the clients
publish // Emiting events from streaming servers
};// App.js
const express = require('express');
const events = require('./events');
const port = process.env.PORT || 5001;
const app = express();app.get('/events', cors(), events.subscribe);
app.listen(port, function() {
console.log('Listening on', port);
});
我们从这种方法中获得的主要好处是:
- 实施更简单,数据效率更高
- 开箱即用地通过HTTP / 2自动多路复用
- 将客户端上数据的连接数限制为一个
如何在SSE,WebSocket和Polling中进行选择?
经过漫长而详尽的客户端和服务器实施之后,SSE似乎是我们解决数据交付问题的最终答案。也有一些问题,但是可以解决。
可以利用服务器发送事件的应用程序的一些简单示例:
- 实时股价流图
- 重要事件的实时新闻报道(发布链接,推文和图片)
- 由Twitter的流API提供的实时Github / Twitter仪表板墙
- 监视服务器统计信息(如正常运行时间,运行状况和正在运行的进程)的监视器。
但是,SSE不仅是其他提供快速更新的方法的可行替代方案。在某些特定情况下,例如在SSE被证明是理想解决方案的情况下,每个人都可以胜过其他人。考虑一个像MMO(大型多人在线)游戏这样的场景,该场景需要来自连接两端的大量消息。在这种情况下,WebSockets将压制SSE。
如果您的用例需要显示实时的市场新闻,市场数据,聊天应用程序等,例如在我们的案例中,依靠HTTP / 2 + SSE将为您提供有效的双向通信渠道,同时又能获得留在其中的好处HTTP世界。
如果您想为我们的用例获取示例客户端-服务器实现,请签出GitHub代码。
资源
- “caniuse.com”
- “使用服务器发送的事件进行流更新”,HTML5 Rocks的Eric Bidelman
- “使用HTML5 SSE的数据推送应用”,O’Reilly Media的Darren Cook
感谢您阅读。如果您认为这篇文章很有用,请在您的圈子中分享。
原文:https://codeburst.io/polling-vs-sse-vs-websocket-how-to-choose-the-right-one-1859e4e13bd9
本文:https://pub.intelligentx.net/polling-vs-sse-vs-websocket-how-choose-right-one
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 450 次浏览
【通讯协议】HTTP/2和GRPC:微服务通信的事实标准
视频号
微信公众号
知识星球
HTTP/2和gRPC允许微服务之间更快、更简单、更健壮的通信。但你有没有想过,我们为什么要使用这种技术堆栈,他们为什么要发明HTTP/2和gRPC?
在本文中,让我们看看HTTP/2与HTTP/1.x的主要区别是什么,它解决了什么问题,以及gRPC如何在后台利用HTTP/2并利用HTTP/2的所有效率。
HTTP协议背景
应用层是开放系统互连(OSI)模型中的最顶层,即第7层。应用层有许多网络协议,HTTP就是其中之一。
HTTP/1.1
HTTP/1.1是1989年作为万维网的通信标准开发的。HTTP使用类似GET POST或DELETE的方法来指定客户端希望对资源执行的操作。
例如,假设您正在访问www.example.com网站。当您导航到此URL时,web浏览器会以基于文本的消息的形式发送HTTP请求。
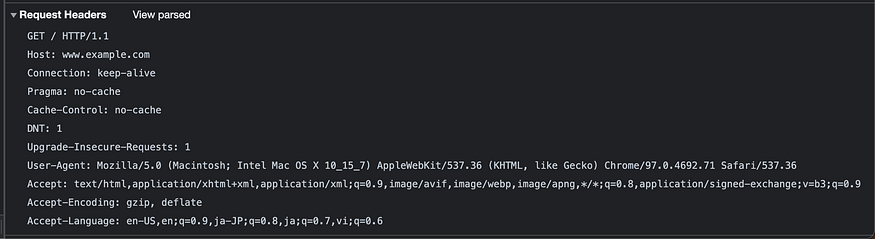
响应此请求,除了HTML中调用的任何图像、样式表或其他资源外,Web服务器还会向请求客户端返回一个HTML页面。请注意,在第一次数据调用中,并不是所有的资源都返回给客户端。请求和响应将在服务器和客户端之间来回发送,直到web浏览器收到在屏幕上呈现HTML页面内容所需的所有资源。
HTTP/2
HTTP/2于2015年5月发布。从技术角度来看,区分HTTP/1.1和HTTP/2的最重要特征之一是二进制成帧层。与将所有请求和响应保持为纯文本格式的HTTP/1.1不同,HTTP/2使用二进制框架层以二进制格式封装所有消息,同时仍然保持HTTP语义,如谓词、方法和标头。应用程序级API仍会以传统HTTP格式创建消息,但底层会将这些消息转换为二进制。这确保了在HTTP/2之前创建的web应用程序在与新协议交互时可以继续正常运行。
因此,HTTP/1.1和HTTP/2共享语义,确保在这两种协议中服务器和客户端之间传输的请求和响应以具有头和体的传统格式化消息的形式到达目的地,使用GET和POST等熟悉的方法。在下一节中,让我们看看HTTP/1.1如何尝试通过其交付模型优化效率,以及由此产生的问题,然后是HTTP/2的二进制帧层的优势,以及它如何对请求进行优先级排序的描述。
HTTP/1.1问题
Pipelining和线路堵塞头
客户端在HTTPGET请求上收到的第一个响应通常不是完全呈现的页面。相反,它包含指向请求页面所需的其他资源的链接。客户端发现,只有在下载页面后,页面的完整呈现才需要服务器提供这些额外资源。因此,客户端将不得不发出额外的请求来检索这些资源。在HTTP/1.0中,客户端必须断开并重新建立每一个新请求的TCP连接,这在时间和资源方面都是一件代价高昂的事情。
HTTP/1.1通过引入持久连接和流水线来解决这个问题。对于持久连接,HTTP/1.1假设TCP连接应该保持打开,除非直接通知关闭,这大大提高了重新建立TCP连接的成本。通过流水线,客户端可以沿着同一连接一个接一个地发送请求,而无需等待对每个请求的响应。

但是,服务器仍然需要按照传入请求的顺序发送响应。因此HTTP/1.1仍然是一个FIFO队列,在某些情况下,位于队列头部的请求无法检索其所需的资源,将阻塞其后面的所有请求。这被称为行头(HOL)阻塞。添加单独的并行TCP连接可能有助于解决此问题,但客户端和服务器之间可能存在的并发TCP连接数量有限,并且每个新连接都需要大量资源,这与HTTP/1.0的问题相同。
HTTP/2的创建就是为了解决这些问题。让我们看看使用二进制帧层可以如何解决这些问题。
HTTP/2和HTTP/1.x之间的主要区别
二进制成帧层
在HTTP/2连接中,存在多个数据流。每个流都由熟悉的请求/响应格式的多条消息组成。
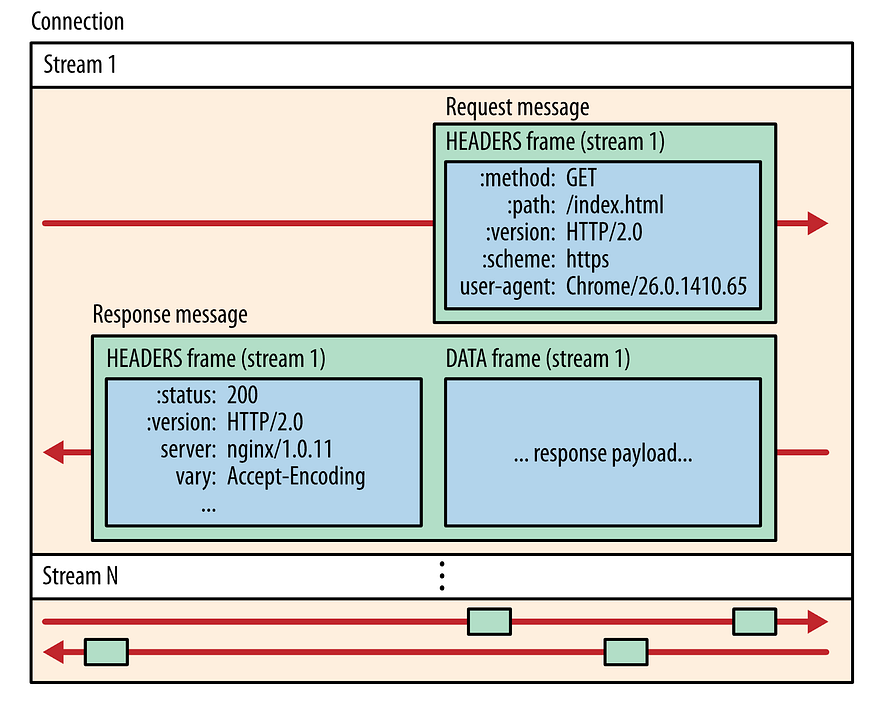
这些消息中的每一条都被拆分为称为帧的较小单元。
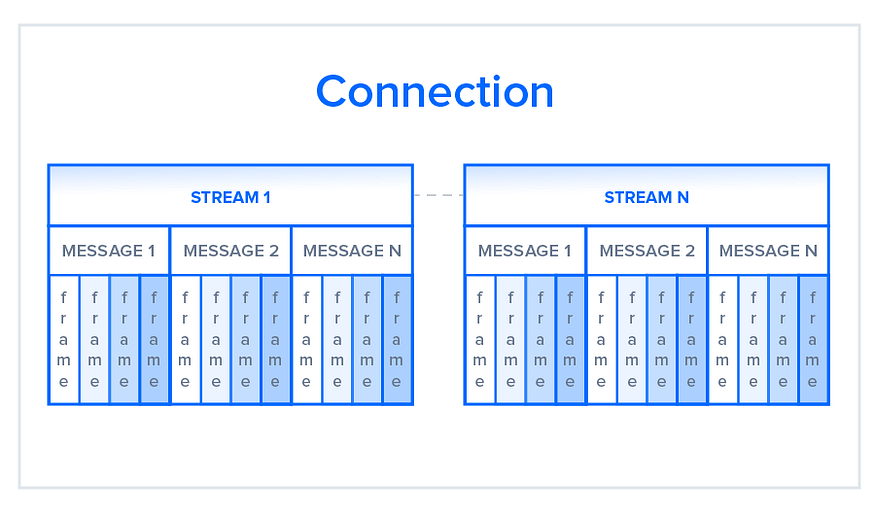
在最细粒度的层面上,通信信道由一堆二进制编码的帧组成,每个帧都标记到一个特定的流。识别标签允许连接在传输期间交错这些帧,并在另一端重新组装它们。交错的请求和响应可以并行运行,而不会阻塞它们后面的消息,这一过程称为多路复用。多路复用通过确保没有消息需要等待另一个消息完成,解决了HTTP/1.1中的行头阻塞问题。这也意味着服务器和客户端可以发送并发请求和响应,从而实现更大的控制和更高效的连接管理。
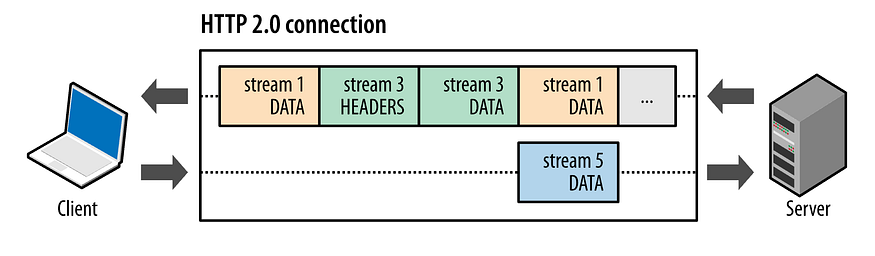
由于多路复用允许客户端并行构建多个流,因此这些流只需要使用单个TCP连接。通过减少整个网络的内存和处理占用,每个源拥有一个持久连接改进了HTTP/1.1。这导致了更好的网络和带宽利用率,从而降低了总体运营成本。
头压缩
每个HTTP传输都携带一组头,这些头描述了传输的资源及其属性。在HTTP/1.x中,此元数据始终以纯文本形式发送,每次传输会增加500-800字节的开销,如果使用HTTP cookie,则有时会增加千字节。为了减少这种开销并提高性能,HTTP/2使用HPACK压缩格式压缩请求和响应标头元数据。
除了压缩之外,客户端和服务器还维护一个常见字段及其压缩值的列表。因此,当这些字段被重复时,它们只是包括对压缩值的引用。
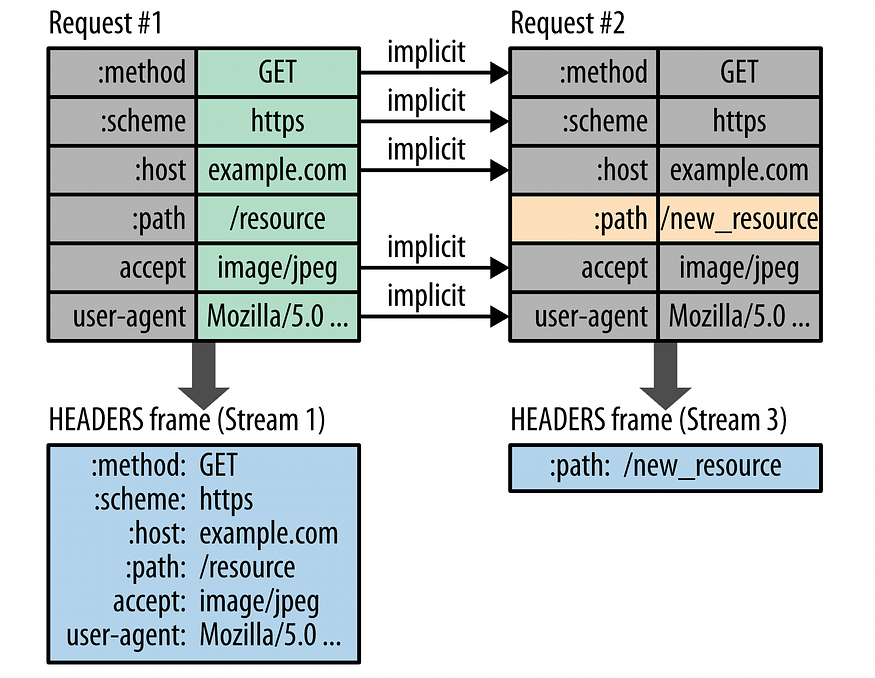
服务器推送
除了对原始请求的响应之外,服务器还可以向客户端推送额外的资源,而客户端不必显式地请求每个资源。

例如,当浏览器请求页面时,服务器会在响应中发送HTML,然后需要等待浏览器解析HTML并发出对所有嵌入资产的请求,然后才能开始发送JavaScript、图像和CSS。
服务器推送可能允许服务器通过将其认为客户端需要的响应“推送”到其缓存中来避免这种往返延迟。
然而,推动反应并不是“神奇的”——如果使用不当,可能会损害表现。正确使用服务器推送是一个正在进行的实验和研究领域。
总之,与HTTP/1.1相比,HTTP/2:
- 是二进制的,而不是文本的
- 完全多路复用,而不是有序和阻塞
- 因此可以使用一个连接进行并行
- 使用标头压缩来减少开销
- 允许服务器主动将响应“推送”到客户端缓存中
有关HTTP/2的更多详细信息,请访问HTTP2Spec和O'Reilly高性能浏览器网络。
现在您可能想知道HTTP/2和gRPC之间的关系是什么。gRPC使用HTTP/2作为其消息传递协议,因此它固有了HTTP/2的所有效率。在下一节中,让我们更详细地了解gRPC提供了哪些功能,并将其与其他通信类型进行比较。
微服务之间的通信
服务通过消息以同步或异步的方式相互通信。让我们看看服务间通信是如何发展的。
SOAP-简单对象访问协议
- 客户端和服务器以XML的形式交换数据
- 由于它的XML,它可以在完全独立于语言和平台的平台上实现。
- 可以通过HTTP、SMTP、TCP、UDP等任何协议进行操作。
- 至今仍存在于许多遗留服务中。
- 很难处理,有一套严格的编码规则。
- 协议的冗长、XML的解析速度慢以及缺乏标准化的交互模型,导致了更直接地使用HTTP协议的服务占主导地位。例如REST。
REST-重新呈现状态传输
- 交互(创建-读取-更新-删除)资源的标准方式。
- 公开API(URL)作为资源的访问点。
- 只能使用HTTP。
- 仅公开HTTP方法(POST、GET、PUT、PATCH和DELETE)上的CRUD行为。如果我们的需求与这些定义良好的规则稍有不同,我们需要调整这组名称以公开我们的API。
- 没有定义严格的接口类型。即使我们有OpenAPI或Swagger规范,它也没有与带下划线的体系结构或消息协议进行类型绑定。
gRPC-Google远程过程调用
- 由谷歌设计的开源RPC框架。
- 公开要远程调用的其他服务的过程。
- 最大的优点是它可以与HTTP/2协议一起工作,并且因此受益于HTTP/2的许多上述效率。
- 实现协议缓冲区或Protobuf,一种gRPC中的IDL(接口描述语言)。
- 现在,我们了解了几种流行的相互通信协议的背景和总体思想。让我们看看优缺点,以及为什么我们应该选择gRPC而不是REST来进行微服务通信。
gRPC vs REST
HTTP/1.1与HTTP/2
RESTAPI遵循通常基于HTTP1.1构建的请求-响应通信模型。不幸的是,这意味着,如果微服务从客户端接收到多个请求,则模型必须一次处理每个请求,从而降低整个系统的速度。然而,RESTAPI也可以建立在HTTP/2上,但通信的请求-响应模型保持不变,这使得RESTAPI无法充分利用HTTP2的优势,例如流通信和双向支持。
gRPC没有面临类似的障碍。它基于HTTP2构建,支持双向通信和流式通信。gRPC可以通过不断地流式传输信息来同时处理请求,同时也可以处理类似于基于HTTP1.1构建的“一元”交互。
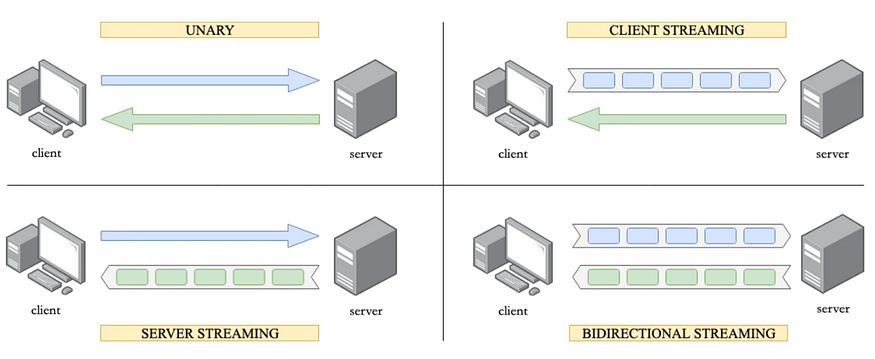
有效载荷数据结构
如前所述,gRPC默认情况下使用协议缓冲区来序列化有效负载数据。此解决方案更轻,因为它启用了高度压缩的格式并减小了消息的大小。此外,Protobuf(或协议缓冲区)是二进制的;因此,它对结构化数据进行序列化和反序列化,以便进行通信和传输。换句话说,强类型消息可以自动从Protobuf转换为客户端和服务器的编程语言。
这可以减少从字符串转换为类型的许多错误,例如,客户端发送一个int64字段类型,该字段类型被转换为JSON字符串并发送到服务器,但服务器期望int32字段类型和各种错误都可能发生。
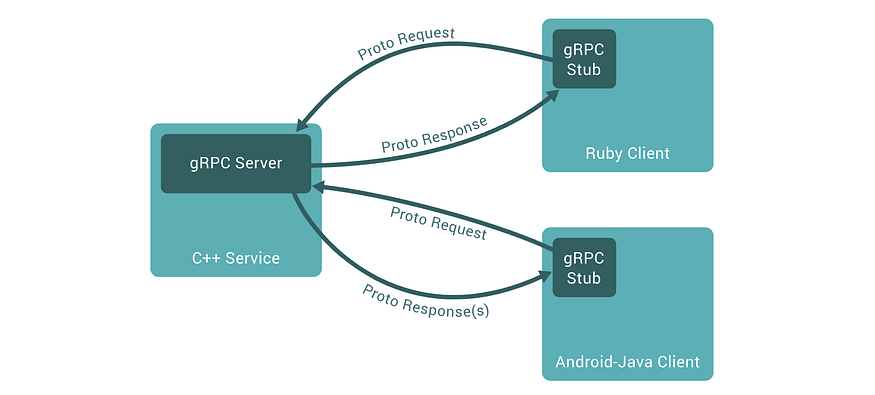
REST主要依靠JSON或XML格式来发送和接收数据。事实上,尽管JSON没有强制要求任何结构,但它是最流行的格式,因为它具有灵活性和发送动态数据的能力,而不必遵循严格的结构。使用JSON的另一个显著好处是它的可读性级别,Protobuf还无法与之竞争。
尽管如此,JSON在数据传输方面并没有那么轻量级或快速。原因在于,在使用REST时,JSON(或其他格式)必须序列化,并转换为客户端和服务器端使用的编程语言。这给传输数据的过程增加了额外的步骤和开销,从而可能损害性能并导致错误。
生成代码功能
与gRPC不同,REST API不提供内置代码生成功能,这意味着开发人员必须使用Swagger或Postman等第三方工具来为API请求生成代码。

相比之下,gRPC具有原生代码生成功能,因为它的协议编译器与几种编程语言兼容。这对于集成以不同语言和平台开发的各种服务的微服务系统尤其有益。
结论
在本文中,我们了解了HTTP/2,它为什么诞生,它解决了什么问题,与HTTP/1.x相比的关键差异,以及gRPC如何在后台利用HTTP/2并利用HTTP/2的所有效率。我们还比较了REST和gRPC,发现gRPC在性能、有效负载数据结构和本地生成代码的能力方面比REST有很多优势。这些原因使得HTTP/2和gRPC完全适合高性能、可靠性和健壮的微服务通信。
参考文献
- HTTP/1.1 vs HTTP/2: What’s the Difference? (digitalocean.com)
- HTTP/2 and gRPC — The Next Generation of Microservices Interactions (blog.netsil.com)
- Introduction to HTTP/2 (developers.google.com)
- HTTP/2 Frequently Asked Questions (http2.github.io)
- GRPC VS REST: COMPARING APIS ARCHITECTURAL STYLES (www.imaginarycloud.com)
- 196 次浏览
Web框架基准
在以下测试中,我们测量了几个Web应用程序平台,全栈框架和微框架(统称为“框架”)的性能。 有关更多信息,请阅读介绍,动机和最新环境详细信息。
令人难以置信的高性能
打破慢速Web应用程序的诅咒。 清理过早复杂系统架构的吸血鬼排水管。 轻易超过蹒跚的僵尸。 高性能是万圣节所需要的。
Best fortunes responses per second, Dell R440 Xeon Gold + 10 GbE(330 tests)
| Rnk | Framework | Best performance (higher is better) | Errors | Cls | Lng | Plt | FE | Aos | DB | Dos | Orm | IA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | h2o | 423,298 | 100.0% | 0 | Plt | C | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 2 | vertx-postgres | 336,138 | 79.4% | 0 | Plt | Jav | ver | Non | Lin | Pg | Lin | Raw | Rea |
| 3 | fasthttp-postgresql | 329,433 | 77.8% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 4 | swoole | 303,514 | 71.7% | 0 | Plt | PHP | Non | swo | Lin | My | Lin | Raw | Rea |
| 5 | revenj-jvm | 298,539 | 70.5% | 0 | Ful | Jav | Svt | Res | Lin | Pg | Lin | Ful | Rea |
| 6 | aspcore-ado-pg | 294,285 | 69.5% | 1 | Plt | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 7 | proteus | 293,550 | 69.3% | 0 | Mcr | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 8 | cpoll_cppsp-raw | 270,826 | 64.0% | 0 | Plt | C++ | Non | Non | Lin | My | Lin | Raw | Rea |
| 9 | jlhttp-postgres | 252,441 | 59.6% | 0 | Plt | Jav | JLH | Non | Lin | Pg | Lin | Raw | Rea |
| 10 | actix-raw | 251,204 | 59.3% | 0 | Plt | Rus | Non | act | Lin | Pg | Lin | Raw | Rea |
| 11 | aspcore-vb-mw-ado-pg | 251,116 | 59.3% | 0 | Mcr | vb | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 12 | aspcore-mw-ado-pg | 241,173 | 57.0% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 13 | rapidoid-postgres | 231,402 | 54.7% | 0 | Plt | Jav | Rap | Non | Lin | Pg | Lin | Mcr | Rea |
| 14 | actix-pg | 228,889 | 54.1% | 0 | Mcr | Rus | Non | act | Lin | Pg | Lin | Raw | Rea |
| 15 | http4k-apache | 224,845 | 53.1% | 0 | Mcr | Kot | apa | Non | Lin | Pg | Lin | Raw | Rea |
| 16 | actix-diesel | 223,999 | 52.9% | 0 | Mcr | Rus | Non | act | Lin | Pg | Lin | Ful | Rea |
| 17 | jooby | 221,535 | 52.3% | 0 | Ful | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 18 | gemini-postgres | 217,759 | 51.4% | 0 | Ful | Jav | Svt | Res | Lin | Pg | Lin | Mcr | Rea |
| 19 | aspcore-mw-dap-pg | 212,723 | 50.3% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Mcr | Rea |
| 20 | zebra | 204,276 | 48.3% | 0 | Ful | F# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 21 | proteus-mysql | 202,941 | 47.9% | 0 | Mcr | Jav | Utw | Non | Lin | My | Lin | Raw | Rea |
| 22 | undertow-postgresql | 202,206 | 47.8% | 0 | Plt | Jav | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 23 | chi-sjson-prefork | 191,958 | 45.3% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 24 | aspcore-ado-my | 191,664 | 45.3% | 0 | Plt | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 25 | chi-gojay-prefork | 191,408 | 45.2% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 26 | cutelyst-thread-pg | 187,179 | 44.2% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 27 | cutelyst-thread-pg-nodelay | 186,547 | 44.1% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 28 | ulib-mysql | 186,295 | 44.0% | 0 | Plt | C++ | Non | ULi | Lin | My | Lin | Mcr | Rea |
| 29 | cutelyst-pf-pg | 185,985 | 43.9% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 30 | cutelyst-pf-pg-nodelay | 185,532 | 43.8% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 31 | vertx-web-postgres | 184,656 | 43.6% | 0 | Mcr | Jav | vtx | Non | Lin | Pg | Lin | Raw | Rea |
| 32 | chi | 182,456 | 43.1% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 33 | chi-prefork | 182,446 | 43.1% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 34 | chi-gojay | 181,786 | 42.9% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 35 | chi-sjson | 181,538 | 42.9% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 36 | http4k-undertow | 180,451 | 42.6% | 0 | Mcr | Kot | Utw | Non | Lin | Pg | Lin | Raw | Rea |
| 37 | http4k | 176,462 | 41.7% | 0 | Mcr | Kot | Svt | Non | Lin | Pg | Lin | Raw | Rea |
| 38 | aspcore-vb-mw-ado-my | 171,405 | 40.5% | 0 | Mcr | vb | .NE | kes | Lin | My | Lin | Raw | Rea |
| 39 | aspcore-mw-ado-my | 169,994 | 40.2% | 0 | Mcr | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 40 | act-eclipselink-pgsql-rythm | 167,668 | 39.6% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 41 | aspcore-mw-ef-pg | 165,264 | 39.0% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 42 | act-hibernate-pgsql-rythm | 162,968 | 38.5% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 43 | openresty | 162,585 | 38.4% | 0 | Plt | Lua | OpR | ngx | Lin | My | Lin | Raw | Rea |
| 44 | rapidoid-mysql | 162,159 | 38.3% | 0 | Plt | Jav | Rap | Non | Lin | My | Lin | Mcr | Rea |
| 45 | aspcore-mw-dap-my | 161,075 | 38.1% | 0 | Mcr | C# | .NE | kes | Lin | My | Lin | Mcr | Rea |
| 46 | act-hibernate-mysql-rythm | 157,278 | 37.2% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 47 | silicon | 156,932 | 37.1% | 0 | Mcr | C++ | Non | mic | Lin | My | Lin | Ful | Rea |
| 48 | fasthttp | 151,740 | 35.8% | 0 | Plt | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 49 | ulib-mongodb | 148,175 | 35.0% | 0 | Plt | C++ | Non | ULi | Lin | Mo | Lin | Mcr | Rea |
| 50 | act-eclipselink-mysql-rythm | 145,028 | 34.3% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 51 | nodejs-mongodb-raw | 132,260 | 31.2% | 0 | Plt | JS | njs | Non | Lin | Mo | Lin | Raw | Rea |
| 52 | go-prefork | 129,744 | 30.7% | 0 | Plt | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 53 | cutelyst-nginx-pg | 129,311 | 30.5% | 0 | Ful | C++ | uWS | ngx | Lin | Pg | Lin | Raw | Rea |
| 54 | cutelyst-thread-my-nodelay | 123,381 | 29.1% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 55 | act-eclipselink-pgsql | 123,329 | 29.1% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 56 | cutelyst-pf-my-nodelay | 123,320 | 29.1% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 57 | cutelyst-pf-my | 123,234 | 29.1% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 58 | wt-postgres | 122,970 | 29.1% | 0 | Ful | C++ | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 59 | cutelyst-thread-my | 122,740 | 29.0% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 60 | gemini-mysql | 120,380 | 28.4% | 0 | Ful | Jav | Svt | Res | Lin | My | Lin | Mcr | Rea |
| 61 | servlet-postgresql | 119,548 | 28.2% | 0 | Plt | Jav | Svt | Res | Lin | Pg | Lin | Raw | Rea |
| 62 | act-eclipselink-mysql | 116,675 | 27.6% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 63 | act-hibernate-pgsql | 115,726 | 27.3% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 64 | servlet-mysql | 113,226 | 26.7% | 0 | Plt | Jav | Svt | Res | Lin | My | Lin | Raw | Rea |
| 65 | act-hibernate-mysql | 112,524 | 26.6% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 66 | light-4j | 112,145 | 26.5% | 0 | Plt | Jav | lig | Non | Lin | Pg | Lin | Raw | Rea |
| 67 | php-php5-raw | 110,992 | 26.2% | 0 | Plt | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 68 | aspcore-mvc-ado-pg | 109,223 | 25.8% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 69 | minijax | 107,888 | 25.5% | 0 | Ful | Jav | JAX | Utw | Lin | My | Lin | Ful | Rea |
| 70 | fintrospect | 105,386 | 24.9% | 0 | Mcr | Sca | Nty | Non | Lin | My | Lin | Raw | Rea |
| 71 | pedestal | 101,967 | 24.1% | 0 | Mcr | Clj | Jty | Non | Lin | My | Lin | Mcr | Rea |
| 72 | redkale-postgres | 101,378 | 23.9% | 0 | Ful | Jav | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 73 | cutelyst-thread-pg-grantlee | 101,308 | 23.9% | 0 | Ful | C++ | cut | Non | Lin | Pg | Lin | Raw | Rea |
| 74 | php-raw7 | 100,583 | 23.8% | 0 | Plt | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 75 | aspcore-mvc-dap-pg | 100,572 | 23.8% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Mcr | Rea |
| 76 | cutelyst-nginx-my | 98,017 | 23.2% | 0 | Ful | C++ | uWS | ngx | Lin | My | Lin | Raw | Rea |
| 77 | php-raw7-tcp | 97,737 | 23.1% | 0 | Plt | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 78 | wt | 97,099 | 22.9% | 0 | Ful | C++ | Non | Non | Lin | My | Lin | Ful | Rea |
| 79 | ratpack | 96,266 | 22.7% | 0 | Mcr | Jav | Nty | Non | Lin | My | Lin | Raw | Rea |
| 80 | aspcore-mvc-ado-my | 95,924 | 22.7% | 0 | Ful | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 81 | officefloor-tpr | 93,689 | 22.1% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Raw | Rea |
| 82 | aspcore-mvc-dap-my | 93,174 | 22.0% | 0 | Ful | C# | .NE | kes | Lin | My | Lin | Mcr | Rea |
| 83 | nodejs-mysql | 91,940 | 21.7% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Ful | Rea |
| 84 | nodejs | 91,928 | 21.7% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 85 | compojure-raw | 90,976 | 21.5% | 0 | Mcr | Clj | Svt | Res | Lin | My | Lin | Raw | Rea |
| 86 | aspcore-mvc-ef-pg | 87,822 | 20.7% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 87 | go-postgres | 87,424 | 20.7% | 0 | Plt | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 88 | crystal-radix | 87,019 | 20.6% | 558 | Plt | Cry | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 89 | http-kit-raw | 87,008 | 20.6% | 0 | Plt | Clj | Rin | Non | Lin | My | Lin | Raw | Rea |
| 90 | officefloor-micro | 86,218 | 20.4% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Raw | Rea |
| 91 | act-morphia-mongo-rythm | 86,100 | 20.3% | 0 | Ful | Jav | Utw | Non | Lin | Mo | Lin | Ful | Rea |
| 92 | amber | 84,035 | 19.9% | 194 | Ful | Cry | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 93 | raze | 83,707 | 19.8% | 101 | Ful | Cry | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 94 | kemal | 82,979 | 19.6% | 316 | Ful | Cry | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 95 | cutelyst-thread-my-grantlee | 82,129 | 19.4% | 0 | Ful | C++ | cut | Non | Lin | My | Lin | Raw | Rea |
| 96 | ktor | 82,089 | 19.4% | 0 | Mcr | Kot | Nty | Non | Lin | My | Lin | Raw | Rea |
| 97 | vertx-web-mongodb | 81,641 | 19.3% | 0 | Mcr | Jav | vtx | Non | Lin | Mo | Lin | Raw | Rea |
| 98 | grizzly-jersey | 79,060 | 18.7% | 0 | Mcr | Jav | JAX | Grz | Lin | My | Lin | Ful | Rea |
| 99 | crystal | 77,932 | 18.4% | 0 | Plt | Cry | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 100 | duct | 77,705 | 18.4% | 0 | Mcr | Clj | Rin | Non | Lin | Pg | Lin | Raw | Rea |
| 101 | aah-postgresql | 76,899 | 18.2% | 0 | Ful | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 102 | gin | 76,014 | 18.0% | 0 | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 103 | php-pgsql-raw | 75,607 | 17.9% | 13,713 | Plt | PHP | Non | ngx | Lin | Pg | Lin | Raw | Rea |
| 104 | act-morphia-mongo | 74,563 | 17.6% | 0 | Ful | Jav | Utw | Non | Lin | Mo | Lin | Ful | Rea |
| 105 | duct-mongodb | 72,119 | 17.0% | 0 | Mcr | Clj | Rin | Non | Lin | Mo | Lin | Raw | Rea |
| 106 | http4s | 71,950 | 17.0% | 0 | Mcr | Sca | NIO | bla | Lin | Pg | Lin | Raw | Rea |
| 107 | uvicorn | 71,763 | 17.0% | 0 | Plt | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 108 | treefrog-mongodb | 70,173 | 16.6% | 0 | Ful | C++ | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 109 | jawn | 69,938 | 16.5% | 36,137 | Ful | Jav | Svt | Utw | Lin | Pg | Lin | Raw | Rea |
| 110 | aah-mysql | 69,579 | 16.4% | 0 | Ful | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 111 | kumbiaphp-raw | 68,916 | 16.3% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 112 | duct-aleph | 68,263 | 16.1% | 0 | Mcr | Clj | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 113 | tapestry | 66,481 | 15.7% | 0 | Ful | Jav | Svt | Res | Lin | My | Lin | Ful | Rea |
| 114 | dropwizard-jdbi-postgres | 66,229 | 15.6% | 0 | Ful | Jav | JAX | Jty | Lin | Pg | Lin | Mcr | Rea |
| 115 | echo | 65,602 | 15.5% | 0 | Mcr | Go | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 116 | starlette | 65,396 | 15.4% | 0 | Plt | Py | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 117 | wicket | 65,390 | 15.4% | 0 | Ful | Jav | Svt | Res | Lin | My | Lin | Ful | Rea |
| 118 | ktor-cio | 64,841 | 15.3% | 0 | Mcr | Kot | kto | Non | Lin | My | Lin | Raw | Rea |
| 119 | act-ebean-mysql-rythm | 64,645 | 15.3% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 120 | nodejs-postgres | 62,848 | 14.8% | 0 | Plt | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 121 | revenj | 62,519 | 14.8% | 0 | Ful | C# | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 122 | act-ebean-pgsql-rythm | 62,045 | 14.7% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 123 | fastify-postgres | 61,580 | 14.5% | 0 | Mcr | JS | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 124 | officefloor-netty | 60,823 | 14.4% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Ful | Rea |
| 125 | kumbiaphp | 60,730 | 14.3% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Mcr | Rea |
| 126 | play2-java-jpa-hikaricp-netty | 60,620 | 14.3% | 0 | Ful | Jav | Nty | Non | Lin | My | Lin | Ful | Rea |
| 127 | treefrog-postgres | 59,849 | 14.1% | 0 | Ful | C++ | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 128 | micronaut | 59,054 | 14.0% | 0 | Mcr | Jav | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 129 | lapis | 58,147 | 13.7% | 0 | Ful | Lua | OpR | ngx | Lin | Pg | Lin | Ful | Rea |
| 130 | treefrog | 58,130 | 13.7% | 0 | Ful | C++ | Non | Non | Lin | My | Lin | Mcr | Rea |
| 131 | act-ebean-mysql | 56,696 | 13.4% | 0 | Ful | Jav | Utw | Non | Lin | My | Lin | Ful | Rea |
| 132 | officefloor | 56,666 | 13.4% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Ful | Rea |
| 133 | act-ebean-pgsql | 56,218 | 13.3% | 0 | Ful | Jav | Utw | Non | Lin | Pg | Lin | Ful | Rea |
| 134 | play2-java-jpa-hikaricp | 54,612 | 12.9% | 0 | Ful | Jav | Akk | Non | Lin | My | Lin | Ful | Rea |
| 135 | koa-postgres | 54,171 | 12.8% | 0 | Mcr | JS | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 136 | phoenix | 53,968 | 12.7% | 0 | Ful | Eli | Cow | Non | Lin | Pg | Lin | Ful | Rea |
| 137 | vibed-dmd-pgsql | 52,211 | 12.3% | 0 | Plt | D | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 138 | officefloor-rapidoid | 51,890 | 12.3% | 0 | Ful | Jav | off | woo | Lin | Pg | Lin | Ful | Rea |
| 139 | play2-java-jooq-hikaricp-netty | 51,766 | 12.2% | 0 | Ful | Jav | Nty | Non | Lin | My | Lin | Ful | Rea |
| 140 | roda-sequel-postgres | 51,473 | 12.2% | 0 | Mcr | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 141 | play2-scala-slick | 51,314 | 12.1% | 0 | Ful | Sca | Akk | Non | Lin | My | Lin | Ful | Rea |
| 142 | vibed-ldc-pgsql | 50,803 | 12.0% | 0 | Plt | D | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 143 | servant | 50,237 | 11.9% | 0 | Mcr | Hkl | Wai | Wrp | Lin | Pg | Lin | Raw | Rea |
| 144 | roda-sequel | 50,180 | 11.9% | 0 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 145 | nodejs-chakra | 50,130 | 11.8% | 0 | Plt | JS | njs | Non | Lin | My | Lin | Raw | Rea |
| 146 | fastify-mysql | 50,075 | 11.8% | 0 | Mcr | JS | Non | Non | Lin | My | Lin | Raw | Rea |
| 147 | fastify | 49,645 | 11.7% | 0 | Mcr | JS | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 148 | play2-scala-slick-netty | 49,641 | 11.7% | 0 | Ful | Sca | Nty | Non | Lin | My | Lin | Ful | Rea |
| 149 | compojure | 49,374 | 11.7% | 0 | Mcr | Clj | Svt | Res | Lin | My | Lin | Mcr | Rea |
| 150 | redstone | 49,320 | 11.7% | 0 | Mcr | Dar | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 151 | express-mysql | 49,092 | 11.6% | 0 | Mcr | JS | Non | Non | Lin | My | Lin | Ful | Rea |
| 152 | roda-sequel-postgres-unicorn-mri | 48,712 | 11.5% | 0 | Mcr | Rby | Rac | Uni | Lin | Pg | Lin | Ful | Rea |
| 153 | http-kit | 48,710 | 11.5% | 0 | Plt | Clj | Rin | Non | Lin | My | Lin | Mcr | Rea |
| 154 | http4k-netty | 48,454 | 11.4% | 726,800 | Mcr | Kot | Nty | Non | Lin | Pg | Lin | Raw | Rea |
| 155 | play2-java-jooq-hikaricp | 47,495 | 11.2% | 0 | Ful | Jav | Akk | Non | Lin | My | Lin | Ful | Rea |
| 156 | roda-sequel-unicorn-mri | 47,047 | 11.1% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 157 | dropwizard-postgres | 46,349 | 10.9% | 0 | Ful | Jav | JAX | Jty | Lin | Pg | Lin | Ful | Rea |
| 158 | hexagon-jetty-postgresql | 46,203 | 10.9% | 0 | Mcr | Kot | Svt | Non | Lin | Pg | Lin | Raw | Rea |
| 159 | koa-mysql | 44,719 | 10.6% | 0 | Mcr | JS | Non | Non | Lin | My | Lin | Raw | Rea |
| 160 | dropwizard | 44,342 | 10.5% | 0 | Ful | Jav | JAX | Jty | Lin | My | Lin | Ful | Rea |
| 161 | angel-postgres | 44,316 | 10.5% | 0 | Ful | Dar | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 162 | yesod | 43,866 | 10.4% | 0 | Ful | Hkl | Wai | Wrp | Lin | My | Lin | Raw | Rea |
| 163 | play2-scala-anorm-netty | 42,924 | 10.1% | 0 | Ful | Sca | Nty | Non | Lin | My | Lin | Ful | Rea |
| 164 | hexagon | 41,930 | 9.9% | 0 | Mcr | Kot | Svt | Non | Lin | Mo | Lin | Raw | Rea |
| 165 | phalcon-micro | 41,745 | 9.9% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 166 | rocket | 41,627 | 9.8% | 0 | Ful | Rus | Rus | Hyp | Lin | Pg | Lin | Ful | Rea |
| 167 | start | 41,593 | 9.8% | 0 | Mcr | Dar | Non | ngx | Lin | Mo | Lin | Raw | Rea |
| 168 | play2-java-ebean-hikaricp-netty | 41,356 | 9.8% | 0 | Ful | Jav | Nty | Non | Lin | My | Lin | Ful | Rea |
| 169 | angel | 41,283 | 9.8% | 0 | Ful | Dar | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 170 | giraffe | 39,497 | 9.3% | 0 | Ful | F# | .NE | kes | Lin | Pg | Lin | Mcr | Rea |
| 171 | redstone-mongodb | 39,390 | 9.3% | 0 | Mcr | Dar | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 172 | vibed-ldc | 39,031 | 9.2% | 0 | Plt | D | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 173 | vibed | 38,924 | 9.2% | 0 | Mcr | D | Non | Non | Lin | Mo | Lin | Mcr | Rea |
| 174 | play2-java-ebean-hikaricp | 38,829 | 9.2% | 0 | Ful | Jav | Akk | Non | Lin | My | Lin | Ful | Rea |
| 175 | play2-scala-anorm | 38,320 | 9.1% | 0 | Ful | Sca | Akk | Non | Lin | My | Lin | Ful | Rea |
| 176 | stream | 37,425 | 8.8% | 0 | Mcr | Dar | Non | ngx | Lin | Mo | Lin | Raw | Rea |
| 177 | sinatra-sequel-postgres | 37,307 | 8.8% | 0 | Mcr | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 178 | sinatra-sequel | 36,701 | 8.7% | 0 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 179 | roda-sequel-postgres-passenger-mri | 36,587 | 8.6% | 0 | Mcr | Rby | Rac | Pas | Lin | Pg | Lin | Ful | Rea |
| 180 | bottle-raw | 35,793 | 8.5% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Raw | Rea |
| 181 | onion | 35,717 | 8.4% | 0 | Plt | C | Non | Non | Lin | My | Lin | Raw | Rea |
| 182 | iron | 35,304 | 8.3% | 0 | Mcr | Rus | Rus | Hyp | Lin | Pg | Lin | Raw | Rea |
| 183 | sinatra-sequel-postgres-unicorn-mri | 35,142 | 8.3% | 0 | Mcr | Rby | Rac | Uni | Lin | Pg | Lin | Ful | Rea |
| 184 | roda-sequel-passenger-mri | 35,044 | 8.3% | 0 | Mcr | Rby | Rac | Pas | Lin | My | Lin | Ful | Rea |
| 185 | vertx-web-susom-postgres | 34,633 | 8.2% | 0 | Mcr | Jav | vtx | Non | Lin | Pg | Lin | Raw | Rea |
| 186 | undertow-jersey-hikaricp | 34,359 | 8.1% | 0 | Plt | Jav | JAX | Non | Lin | My | Lin | Ful | Rea |
| 187 | aiohttp-pg-raw | 34,037 | 8.0% | 0 | Mcr | Py | asy | Gun | Lin | Pg | Lin | Raw | Rea |
| 188 | sinatra-sequel-unicorn-mri | 33,537 | 7.9% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 189 | aqueduct | 31,352 | 7.4% | 0 | Mcr | Dar | Non | Non | Lin | Pg | Lin | Mcr | Rea |
| 190 | spring | 30,990 | 7.3% | 0 | Ful | Jav | tom | Non | Lin | Pg | Lin | Mcr | Rea |
| 191 | roda-sequel-postgres-torquebox-jruby | 30,410 | 7.2% | 0 | Mcr | Rby | Rac | Tor | Lin | Pg | Lin | Ful | Rea |
| 192 | treefrog-hybrid | 30,386 | 7.2% | 3 | Ful | C++ | Non | Non | Lin | My | Lin | Mcr | Rea |
| 193 | roda-sequel-torquebox-jruby | 30,241 | 7.1% | 0 | Mcr | Rby | Rac | Tor | Lin | My | Lin | Ful | Rea |
| 194 | undertow-jersey | 28,809 | 6.8% | 0 | Plt | Jav | JAX | Non | Lin | My | Lin | Ful | Rea |
| 195 | cppcms-postgres | 27,816 | 6.6% | 0 | Plt | C++ | Non | Non | Lin | Pg | Lin | Raw | Rea |
| 196 | hhvm | 27,774 | 6.6% | 0 | Plt | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 197 | api_hour | 27,747 | 6.6% | 0 | Mcr | Py | asy | Gun | Lin | Pg | Lin | Raw | Rea |
| 198 | sinatra-sequel-postgres-passenger-mri | 27,052 | 6.4% | 0 | Mcr | Rby | Rac | Pas | Lin | Pg | Lin | Ful | Rea |
| 199 | play2-scala-reactivemongo | 26,969 | 6.4% | 0 | Ful | Sca | Akk | Non | Lin | Mo | Lin | Ful | Rea |
| 200 | sinatra-sequel-passenger-mri | 26,790 | 6.3% | 0 | Mcr | Rby | Rac | Pas | Lin | My | Lin | Ful | Rea |
| 201 | play2-scala-reactivemongo-netty | 26,565 | 6.3% | 0 | Ful | Sca | Nty | Non | Lin | Mo | Lin | Ful | Rea |
| 202 | phalcon-mongodb | 26,155 | 6.2% | 0 | Ful | PHP | Non | ngx | Lin | Mo | Lin | Raw | Rea |
| 203 | cppcms | 25,956 | 6.1% | 0 | Plt | C++ | Non | Non | Lin | My | Lin | Raw | Rea |
| 204 | slim | 25,311 | 6.0% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 205 | wildfly-ee7 | 24,496 | 5.8% | 0 | Ful | Jav | Svt | Wil | Lin | My | Lin | Ful | Rea |
| 206 | sinatra-sequel-torquebox-jruby | 24,232 | 5.7% | 0 | Mcr | Rby | Rac | Tor | Lin | My | Lin | Ful | Rea |
| 207 | duct-httpkit | 24,156 | 5.7% | 0 | Mcr | Clj | Rin | Non | Lin | Pg | Lin | Raw | Rea |
| 208 | sinatra-sequel-postgres-torquebox-jruby | 24,100 | 5.7% | 0 | Mcr | Rby | Rac | Tor | Lin | Pg | Lin | Ful | Rea |
| 209 | ktor-jetty | 23,873 | 5.6% | 0 | Mcr | Kot | Jty | Non | Lin | My | Lin | Raw | Rea |
| 210 | flask-raw | 23,078 | 5.5% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Raw | Rea |
| 211 | ninja-standalone | 22,773 | 5.4% | 0 | Ful | Jav | Jty | Non | Lin | My | Lin | Ful | Rea |
| 212 | go-mongo | 21,702 | 5.1% | 0 | Plt | Go | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 213 | yii2 | 21,663 | 5.1% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 214 | fat-free-raw | 21,558 | 5.1% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 215 | kohana | 21,379 | 5.1% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 216 | kelp-mongodb | 21,369 | 5.0% | 0 | Ful | Prl | Plk | Sta | Lin | Mo | Lin | Raw | Rea |
| 217 | api_hour-mysql | 21,304 | 5.0% | 0 | Mcr | Py | asy | Gun | Lin | My | Lin | Raw | Rea |
| 218 | flask-pypy2-raw | 20,929 | 4.9% | 0 | Mcr | Py | Tor | Non | Lin | My | Lin | Raw | Rea |
| 219 | wheezyweb | 20,475 | 4.8% | 0 | Mcr | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 220 | phalcon | 20,437 | 4.8% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 221 | akka-http | 20,406 | 4.8% | 0 | Mcr | Sca | Akk | Non | Lin | My | Lin | Raw | Rea |
| 222 | aspcore-mono-mw-pg | 19,583 | 4.6% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 223 | aiohttp | 19,528 | 4.6% | 0 | Mcr | Py | asy | Gun | Lin | Pg | Lin | Ful | Rea |
| 224 | wheezyweb-py3 | 19,283 | 4.6% | 0 | Mcr | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 225 | aspcore-mono-my | 19,100 | 4.5% | 0 | Plt | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 226 | aspcore-mono-pg | 19,060 | 4.5% | 0 | Plt | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 227 | silex-raw | 18,666 | 4.4% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 228 | hapi-postgres | 18,660 | 4.4% | 0 | Mcr | JS | Non | Non | Lin | Pg | Lin | Ful | Rea |
| 229 | aspcore-mono-mw-my | 18,626 | 4.4% | 0 | Mcr | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 230 | hapi-mysql | 18,529 | 4.4% | 0 | Mcr | JS | Non | Non | Lin | My | Lin | Ful | Rea |
| 231 | weppy-pypy2 | 18,396 | 4.3% | 0 | Ful | Py | Tor | Non | Lin | Pg | Lin | Ful | Rea |
| 232 | morepath | 18,041 | 4.3% | 0 | Mcr | Py | Mei | Gun | Lin | Pg | Lin | Ful | Rea |
| 233 | sinatra-postgres | 17,914 | 4.2% | 122 | Mcr | Rby | Rac | Pum | Lin | Pg | Lin | Ful | Rea |
| 234 | spock | 17,582 | 4.2% | 0 | Mcr | Hkl | Wai | Wrp | Lin | Pg | Lin | Raw | Rea |
| 235 | ffead-cpp-nginx-mongo | 17,465 | 4.1% | 0 | Ful | C++ | ffe | ngx | Lin | Mo | Lin | Ful | Rea |
| 236 | sinatra-postgres-unicorn-mri | 17,299 | 4.1% | 0 | Mcr | Rby | Rac | Uni | Lin | Pg | Lin | Ful | Rea |
| 237 | sinatra | 17,239 | 4.1% | 118 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 238 | aspcore-mono-mw-ef-pg | 17,238 | 4.1% | 0 | Mcr | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 239 | sinatra-unicorn-mri | 17,068 | 4.0% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 240 | tornado-pypy2 | 16,804 | 4.0% | 0 | Plt | Py | Non | Tor | Lin | Mo | Lin | Raw | Rea |
| 241 | weppy-py3 | 16,533 | 3.9% | 0 | Ful | Py | Mei | Non | Lin | Pg | Lin | Ful | Rea |
| 242 | weppy | 16,524 | 3.9% | 0 | Ful | Py | Mei | Non | Lin | Pg | Lin | Ful | Rea |
| 243 | weppy-nginx-uwsgi | 16,283 | 3.8% | 0 | Ful | Py | uWS | ngx | Lin | Pg | Lin | Ful | Rea |
| 244 | pyramid-py2 | 16,253 | 3.8% | 0 | Ful | Py | Non | Mei | Lin | Pg | Lin | Ful | Rea |
| 245 | activeweb | 16,081 | 3.8% | 0 | Ful | Jav | Svt | Non | Lin | My | Lin | Mcr | Rea |
| 246 | pyramid | 15,284 | 3.6% | 0 | Ful | Py | Non | Mei | Lin | Pg | Lin | Ful | Rea |
| 247 | aspcore-mono-mvc-my | 14,852 | 3.5% | 0 | Ful | C# | .NE | kes | Lin | My | Lin | Raw | Rea |
| 248 | aspcore-mono-mvc-ef-pg | 14,723 | 3.5% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Ful | Rea |
| 249 | yii2-hhvm | 14,609 | 3.5% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 250 | sinatra-passenger-mri | 14,563 | 3.4% | 0 | Mcr | Rby | Rac | Pas | Lin | My | Lin | Ful | Rea |
| 251 | aspcore-mono-mvc-pg | 14,451 | 3.4% | 0 | Ful | C# | .NE | kes | Lin | Pg | Lin | Raw | Rea |
| 252 | sinatra-postgres-passenger-mri | 14,367 | 3.4% | 0 | Mcr | Rby | Rac | Pas | Lin | Pg | Lin | Ful | Rea |
| 253 | django-py3 | 14,348 | 3.4% | 0 | Ful | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 254 | hot-mongodb | 14,092 | 3.3% | 0 | Plt | Grv | Jty | Jty | Lin | Mo | Lin | Raw | Rea |
| 255 | ringojs-convenient | 13,917 | 3.3% | 0 | Mcr | JS | Rin | Non | Lin | My | Lin | Mcr | Rea |
| 256 | bottle-pypy2 | 13,670 | 3.2% | 0 | Mcr | Py | Tor | Non | Lin | My | Lin | Ful | Rea |
| 257 | zend1 | 13,074 | 3.1% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 258 | mojolicious | 12,803 | 3.0% | 0 | Ful | Prl | Non | Hyp | Lin | Pg | Lin | Raw | Rea |
| 259 | hamlet | 12,776 | 3.0% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Mcr | Rea |
| 260 | spark | 12,557 | 3.0% | 0 | Mcr | Jav | Svt | Res | Lin | My | Lin | Ful | Rea |
| 261 | limonade | 12,443 | 2.9% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Ful | Rea |
| 262 | grails | 12,401 | 2.9% | 0 | Ful | Grv | Svt | Non | Lin | My | Lin | Ful | Rea |
| 263 | slim-php5 | 12,293 | 2.9% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 264 | ffead-cpp-nginx-mysql | 12,129 | 2.9% | 0 | Ful | C++ | ffe | ngx | Lin | My | Lin | Ful | Rea |
| 265 | django-postgresql | 12,059 | 2.8% | 0 | Ful | Py | Non | Mei | Lin | Pg | Lin | Ful | Rea |
| 266 | bottle | 11,857 | 2.8% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 267 | turbogears | 11,798 | 2.8% | 0 | Mcr | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 268 | ffead-cpp-nginx-postgresql | 11,580 | 2.7% | 0 | Ful | C++ | ffe | ngx | Lin | Pg | Lin | Ful | Rea |
| 269 | tornado-py3 | 11,293 | 2.7% | 0 | Plt | Py | Non | Tor | Lin | Mo | Lin | Raw | Rea |
| 270 | web2py-optimized | 10,815 | 2.6% | 0 | Ful | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 271 | django | 10,687 | 2.5% | 0 | Ful | Py | Non | Mei | Lin | My | Lin | Ful | Rea |
| 272 | ffead-cpp-apache-mongo | 10,619 | 2.5% | 148,057 | Ful | C++ | ffe | Apc | Lin | Mo | Lin | Ful | Rea |
| 273 | ffead-cpp | 10,524 | 2.5% | 0 | Ful | C++ | ffe | ffe | Lin | Mo | Lin | Ful | Rea |
| 274 | flask | 10,376 | 2.5% | 0 | Mcr | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 275 | tornado | 9,992 | 2.4% | 0 | Plt | Py | Non | Tor | Lin | Mo | Lin | Raw | Rea |
| 276 | flask-pypy2 | 9,417 | 2.2% | 0 | Mcr | Py | Non | Tor | Lin | My | Lin | Ful | Rea |
| 277 | ffead-cpp-apache-mysql | 8,320 | 2.0% | 8,089 | Ful | C++ | ffe | Apc | Lin | My | Lin | Ful | Rea |
| 278 | cygnite | 7,999 | 1.9% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 279 | rails | 7,923 | 1.9% | 0 | Ful | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 280 | ffead-cpp-apache-postgresql | 7,919 | 1.9% | 2,909 | Ful | C++ | ffe | Apc | Lin | Pg | Lin | Ful | Rea |
| 281 | rails-unicorn | 7,899 | 1.9% | 0 | Ful | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 282 | slim-hhvm | 7,081 | 1.7% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 283 | bottle-nginx-uwsgi | 6,566 | 1.6% | 0 | Mcr | Py | uWS | ngx | Lin | My | Lin | Ful | Rea |
| 284 | flask-nginx-uwsgi | 6,423 | 1.5% | 0 | Mcr | Py | Non | ngx | Lin | My | Lin | Ful | Rea |
| 285 | ffead-cpp-mysql | 5,853 | 1.4% | 0 | Ful | C++ | ffe | ffe | Lin | My | Lin | Ful | Rea |
| 286 | express-mongodb | 5,641 | 1.3% | 0 | Mcr | JS | Non | Non | Lin | Mo | Lin | Ful | Rea |
| 287 | web2py | 5,597 | 1.3% | 0 | Ful | Py | Mei | Non | Lin | My | Lin | Ful | Rea |
| 288 | codeigniter | 5,301 | 1.3% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 289 | laravel | 5,298 | 1.3% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Ful | Rea |
| 290 | workerman | 5,078 | 1.2% | 0 | Plt | PHP | Non | wor | Lin | My | Lin | Raw | Rea |
| 291 | kitura | 5,072 | 1.2% | 0 | Mcr | Swi | kit | kit | Lin | Pg | Lin | Raw | Rea |
| 292 | kitura-gcd | 5,052 | 1.2% | 0 | Mcr | Swi | kit | kit | Lin | Pg | Lin | Raw | Rea |
| 293 | koa | 4,829 | 1.1% | 0 | Mcr | JS | Non | Non | Lin | Mo | Lin | Raw | Rea |
| 294 | hapi | 4,812 | 1.1% | 0 | Mcr | JS | Non | Non | Lin | Mo | Lin | Ful | Rea |
| 295 | fuel | 4,771 | 1.1% | 0 | Mcr | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 296 | ffead-cpp-postgresql | 4,534 | 1.1% | 0 | Ful | C++ | ffe | ffe | Lin | Pg | Lin | Ful | Rea |
| 297 | cakephp | 4,234 | 1.0% | 0 | Ful | PHP | Non | ngx | Lin | My | Lin | Ful | Rea |
| 298 | kitura-mongodb | 4,098 | 1.0% | 0 | Mcr | Swi | kit | kit | Lin | Mo | Lin | Raw | Rea |
| 299 | urweb-mysql | 4,024 | 1.0% | 0 | Ful | Ur | Ur/ | Non | Lin | My | Lin | Mcr | Rea |
| 300 | kitura-gcd-mongodb | 3,862 | 0.9% | 0 | Mcr | Swi | kit | kit | Lin | Mo | Lin | Raw | Rea |
| 301 | aspnet-mono-ngx-my | 3,840 | 0.9% | 1 | Plt | C# | .NE | ngx | Lin | My | Lin | Raw | Rea |
| 302 | padrino-unicorn | 3,606 | 0.9% | 0 | Mcr | Rby | Rac | Uni | Lin | My | Lin | Ful | Rea |
| 303 | padrino | 3,373 | 0.8% | 0 | Mcr | Rby | Rac | Pum | Lin | My | Lin | Ful | Rea |
| 304 | aspnet-mono-ngx-my-ef | 3,358 | 0.8% | 0 | Ful | C# | .NE | ngx | Lin | My | Lin | Ful | Rea |
| 305 | urweb | 2,544 | 0.6% | 0 | Ful | Ur | Ur/ | Non | Lin | Pg | Lin | Mcr | Rea |
| 306 | phreeze | 1,885 | 0.4% | 32,033 | Mcr | PHP | Non | ngx | Lin | My | Lin | Mcr | Rea |
| 307 | codeigniter-hhvm | 1,751 | 0.4% | 40,672 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 308 | phpixie | 1,627 | 0.4% | 51,719 | Ful | PHP | Non | ngx | Lin | My | Lin | Ful | Rea |
| 309 | clancats | 1,520 | 0.4% | 26,891 | Ful | PHP | Non | ngx | Lin | My | Lin | Raw | Rea |
| 310 | symfony | 1,295 | 0.3% | 1,540 | Ful | PHP | Non | ngx | Lin | My | Lin | Ful | Rea |
| 311 | octopus | 866 | 0.2% | 31,593 | Ful | Lua | OpR | ngx | Lin | My | Lin | Ful | Rea |
| 312 | klein | 602 | 0.1% | 0 | Mcr | Py | Non | Twi | Lin | My | Lin | Ful | Rea |
| 313 | cherrypy-py3 | 471 | 0.1% | 0 | Mcr | Py | Non | Non | Lin | My | Lin | Ful | Rea |
| 314 | cherrypy | 359 | 0.1% | 0 | Mcr | Py | Non | Non | Lin | My | Lin | Ful | Rea |
| 315 | dropwizard-mongodb | — | Did not complete | — | Ful | Jav | JAX | Jty | Lin | Mo | Lin | Ful | Rea |
| 316 | falcore | — | Did not complete | — | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 317 | goji | — | Did not complete | — | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 318 | hexagon-undertow-mongodb | — | Did not complete | — | Mcr | Kot | Svt | Non | Lin | Mo | Lin | Raw | Rea |
| 319 | hexagon-undertow-postgresql | — | Did not complete | — | Mcr | Kot | Svt | Non | Lin | Pg | Lin | Raw | Rea |
| 320 | http4k-sunhttp | — | Did not complete | — | Mcr | Kot | sun | Non | Lin | Pg | Lin | Raw | Rea |
| 321 | kami | — | Did not complete | — | Mcr | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 322 | kelp | — | Did not complete | — | Ful | Prl | Plk | Sta | Lin | My | Lin | Raw | Rea |
| 323 | go | — | Did not complete | — | Plt | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 324 | go-interpolate | — | Did not complete | — | Plt | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 325 | revel-jet | — | Did not complete | — | Ful | Go | Non | Non | Lin | My | Lin | Mcr | Rea |
| 326 | revel-qbs | — | Did not complete | — | Ful | Go | Non | Non | Lin | My | Lin | Mcr | Rea |
| 327 | revel-raw | — | Did not complete | — | Ful | Go | Non | Non | Lin | My | Lin | Raw | Rea |
| 328 | sailsjs | — | Did not complete | — | Ful | JS | njs | Non | Lin | My | Lin | Mcr | Rea |
| 329 | sailsjs-postgres | — | Did not complete | — | Ful | JS | njs | Non | Lin | Pg | Lin | Ful | Rea |
| 330 | webware | — | Did not complete | — | Mcr | Py | Non | Non | Lin | My | Lin | Ful | Rea |
要求摘要
在此测试中,框架的ORM用于从包含未知数量的Unix幸运cookie消息的数据库表中获取所有行(该表有12行,但代码无法预先知道表的大小)。 在运行时将额外的幸运cookie消息插入到列表中,然后按消息文本对列表进行排序。 最后,使用服务器端HTML模板将列表传递给客户端。 必须将消息文本视为不可信并正确转义,并且必须正确呈现UTF-8转发消息。
空白是可选的,可能符合框架的最佳实践。
原文:
- 229 次浏览
事件驱动架构
「事件驱动架构」事件驱动2.0 事件,存储和处理统一到一个平台
将来,数据将像现在的基础设施一样自动化和自助服务。您将打开一个控制台,列出贵公司可用的数据;定义您需要的部分,您想要的格式以及您希望它们如何结合在一起;启动一个新的端点:一个数据库,缓存,微服务或无服务器功能,你就可以了。
这些是现代时代的事件驱动架构 - 但消息传递不仅仅是将系统连接在一起的简单管道。部件消息传递系统,部分分布式数据库,流式系统允许您在公司内部存储,Join,聚合和改造数据,然后在需要的地方推送数据,无论是笨重的数据仓库还是微小的无服务器功能。
与公共云和私有云结合使用时,可以动态配置基础架构,从而使数据完全自助服务。许多公司已经实施了这个未来的某些版本。
他们采取的不同方法可分为四大类,我们看到的公司和项目通常一次采用一种:
- 1.全球事件流媒体平台
- 2.中央活动商店
- 3.事件优先和事件流应用程序
- 4.自动数据配置
我们所知道的任何一家公司都没有掌握它们,但所有这些类别都以某种形式存在于生产中。
1.全局事件流平台
这是最容易理解的,因为它类似于旧的企业消息传递模式。组织采用事件驱动的方法,使用流经ApacheKafka®等事件流平台的核心数据集(应用程序之间共享的数据集,如订单,客户,支付,账户,交易等)。
这些通过单一基础架构取代了传统的点对点通信,使应用程序可以在不同地理位置或云提供商中大规模,实时地运行。
因此,一家公司可能在旧金山运行旧式大型机,在开普敦和伦敦设有区域办事处,并且在AWS和GCP上运行高度可用的微服务,所有这些都与相同的事件主干相连。更极端的用例包括通过卫星或汽车通过移动连接船只。
公司几乎在每个行业都实施这种模式。例如Netflix,Audi,Salesforce,HomeAway,ING和RBC,仅举几例。
2.中央事件存储
流平台可以在一段定义的时间段内缓存事件或无限期地存储它们,从而创建一个类型或组织分类帐或事件存储。
一些公司使用这种模式来推动回顾性分析,例如,训练在一级方程式赛后分析中用于欺诈检测或倒带时间的机器学习模型。其他人将模式应用于许多团队。
这样就可以构建新的应用程序,而无需源系统重新发布先前的事件,这一特性对于难以从其原始源重放的数据集非常有用,例如大型机,外部或遗留系统。
一些组织将所有数据保存在Kafka中。该模式被称为前向事件缓存,事件流作为事实的来源,kappa架构或简单事件溯源。
最后,有状态流处理需要事件存储,这通常用于从许多不同的数据源创建丰富的,自给自足的事件。例如,这可能是通过客户或帐户信息丰富订单。
丰富的事件更容易从微服务或FaaS实现中消费,因为它们提供了服务所需的所有数据。它们还可用于为数据库提供非规范化输入。执行这些丰富的流处理器需要事件存储来保存支持表格操作的数据(Join客户,帐户等)。
3.事件优先和事件流应用
大多数传统应用程序通过将来自不同位置的数据集导入其数据库(例如,ETL)来工作,在数据库中可以对其进行清理,连接,过滤和聚合。
对于创建报告,仪表板,在线服务等的应用程序,这仍然是最佳选择,但对于业务处理,通过将实时事件直接推送到微服务或无服务器功能来跳过数据库步骤通常更有效。
在这种方法中,像Kafka Streams或KSQL这样的流处理器通过在将事件流推入微服务或FaaS之前清理,Join,过滤和聚合事件流来执行数据库在传统方法中所执行的数据操作。
例如,考虑使用像KSQL这样的流处理器将订单和付款连接在一起的限制检查服务,提取相关的记录/字段并将它们传递到微服务或作为检查限制的服务的功能 - 没有数据库的工作流程完全使用。
由于它们的事件驱动性质,这样的系统响应更快。它们通常也更简单,构建速度更快,因为维护的基础架构和数据更少,工具集自然可以处理异步连接的环境。
更丰富的示例直接包含流分析,例如检测信用卡支付中的异常行为或优化智能电网中的能量输送。这样的系统通常作为链存在,其中阶段分离有状态和无状态操作,可以独立地扩展并利用事务保证来保证正确性。
我们看到这种类型的应用程序出现在许多行业中:金融,游戏,零售,物联网等,跨越离线和在线用例。
4.自动数据分配
最终模式是其他模式的结晶,与PaaS /无服务器实现相结合,使数据配置完全自助服务。
用户定义他们需要的数据(实时或历史),应采取的形式以及应该在何处落地,无论是在数据库,分布式缓存,微服务,FaaS还是在任何地方。 (通常,这与可发现的模式的中央存储库结合使用。)
系统配置基础架构,在必要时预先填充它并管理事件流。流处理器过滤,操作和缓冲各种共享数据流,并根据用户的规范进行模拟。
因此,进行风险分析的财务用户可能会启动一个新的Elasticsearch实例,该实例预先填充了三个月的交易,风险结果和账簿。或者,零售公司可能会关联实时订单,付款和客户数据,并将其推送到微服务或FaaS,向客户发送付款确认。
随着组织转向公共云和私有云,基于云的基础架构的动态特性使这种模式越来越实用,从而带来系统性好处。可以快速启动新项目,环境或实验。
由于数据集被缓存或存储在消息传递系统中,因此鼓励用户仅在某个时间点获取他们需要的数据(与传统消息传递不同,传统消息传递倾向于消耗和保留整个数据集以防以后再次需要)。这可以最大限度地减少团队之间的摩擦,并使应用程序接近单一,共享的真实来源。
我们所知道的组织很少能够完全达到这种自动化水平,但这种模式的核心要素被用于金融,零售和互联网领域的几个客户的生产中,无论是在内部还是在云中。
事件驱动2.0:一个进化和一个新的开始
多年来,事件驱动的架构自然发展。最初,他们只进行了消息传递:通过传统消息系统应用的通知和状态转移。
后来,企业服务总线通过更丰富的开箱即用连接和更好的集中控制来点缀它们。集中控制变成了喜忧参半,因为它提供的标准化经常使团队进步更加困难。
最近,像事件溯源(Event Sourcing)和CQRS这样的存储模式已经变得很流行,正如Martin Fowler在他的文章中所讨论的“事件驱动”是什么意思?
我所描述的四种模式都建立在这个基础上,但今天的现代事件流系统使我们能够通过将事件,存储和处理统一到一个平台中来进一步发展。这种统一很重要,因为这些系统不是将数据锁定在一个地方的数据库;它们不是消息传递系统,数据是短暂的和短暂的。他们坐在两者之间。
通过在这两个传统类别之间取得平衡,公司已经能够跨地区和跨云实现全球连接,数据 - 他们最宝贵的商品 - 作为服务提供,无论是否意味着将其推入数据库,缓存,机器学习模型,微服务或无服务器功能。
所以,总结一下:
- 广播事件
- 缓存日志中的共享数据集并使其可被发现。
- 让用户直接操纵事件流(例如,使用像KSQL这样的流媒体引擎)
- 驱动简单的微服务或FaaS,或在您选择的数据库中创建特定于用例的视图
- 234 次浏览
【事件驱动架构】Apache Kafka云平衡协议:静态成员
静态会员是对当前再平衡协议的一种增强,旨在减少由一般Apache Kafka®客户实现的过度和不必要的再平衡造成的停机时间。这适用于Kafka消费者、Kafka Connect和Kafka流。为了更好地理解再平衡协议,我们将深入研究这个概念并解释它的含义。如果你已经知道卡夫卡平衡是什么,请直接跳到下面的章节来节省时间:我们什么时候触发不必要的平衡?
对于Kafka来说,“再平衡”意味着什么?
Kafka再平衡是一种分布式协议,用于客户端应用程序在一个动态组中处理一组公共资源。本议定书的两个主要目标是:
- 组织资源分配
- 会员更改捕获
以卡夫卡消费者为例。一组Kafka使用者通过订阅从Kafka读取输入数据,主题分区是他们的共享任务单元。三个消费者(C1、C2和C3)、两个主题(T1和T2),每个主题有三个分区,订阅如下所示:
C1: T1, T2 C2: T2 C3: T1
重新平衡协议确保C1和C2从主题T2*获得不重叠的分配,对于T1的C1和C3也是如此。一个有效的赋值是这样的:
C1: t1-p1, t2-p1 C2: t2-p2, t2-p3 C3: t1-p2, t1-p3
*注意,消费者不会检查转让人返回的赋值是否遵守这些规则。如果您的自定义的assignor将分区分配给多个所有者,它仍然会被静默地接受并导致双重抓取。严格地说,只有内置的再平衡分配程序才遵守此资源隔离规则
但是,下面的分配是不允许的,因为它引入了重叠分配:
C1: t1-p1, t2-p1 C2: t2-p1, t2-p2, t2-p3 C3: t1-p2, t1-p3
再平衡协议还需要妥善处理成员国变化。对于上述情况,如果新成员C4订阅T2加入,再平衡协议将尝试调整组内负载:
C1: t1-p1, t2-p1 C2: t2-p3 C3: t1-p2, t1-p3 C4: t2-p2
总之,再平衡协议需要在扩展时“平衡”客户机组中的负载,同时保证任务所有权的安全。与大多数分布式共识算法相似,Kafka采用了两阶段的方法。为了简单起见,我们将坚持使用卡夫卡消费者。
消费者调整演示
使用者提交进度的端点称为组协调器,它托管在指定的代理上。它还作为集团再平衡的中央管理者。当组开始再平衡时,组协调器首先将其状态切换为再平衡,以便通知所有交互的使用者重新加入组。在所有成员重新加入或协调器等待足够长的时间并达到再平衡超时之前,组继续进入另一个称为sync的阶段,该阶段正式宣布有效使用者组的形成。为了区分在此过程中退出组的成员,每个成功的再平衡都会增加一个名为generation ID的计数器,并将其值传播给所有加入的成员,以便可以隔离下一代成员。
在同步阶段,组协调器用最新的生成信息答复所有成员。具体地说,它指定其中一个成员作为leader,并用已编码的成员资格和订阅元数据对leader进行应答。
领导根据成员和主题元数据信息完成任务,并将任务信息回复协调员。在此期间,所有追随者都需要发送一个同步组请求,以获得他们的实际任务,并进入一个等待池,直到leader完成对协调器的任务传输。在接收到分配后,协调器将组从同步转换到稳定。所有未决的和即将到来的追随者同步请求将回答与个人分配。
这里,我们描述两个演示用例:一个是实际的再平衡演练,另一个是高级状态机。注意,在同步阶段,如果触发了再平衡条件,比如添加新成员、主题分区扩展等,我们总是可以切换到再平衡模式。

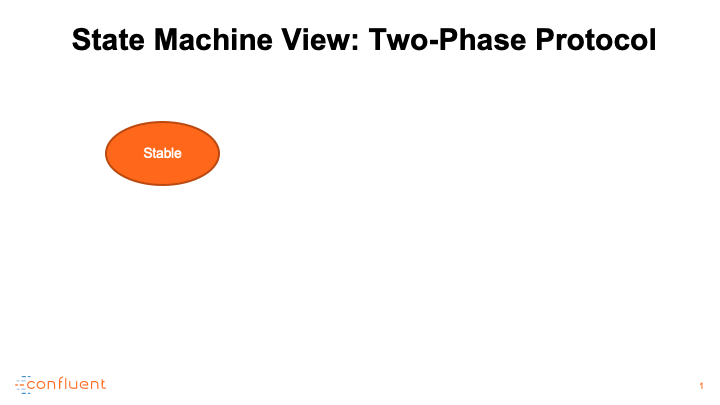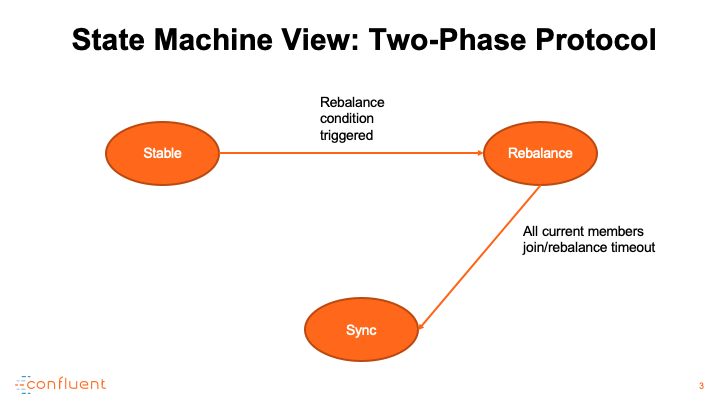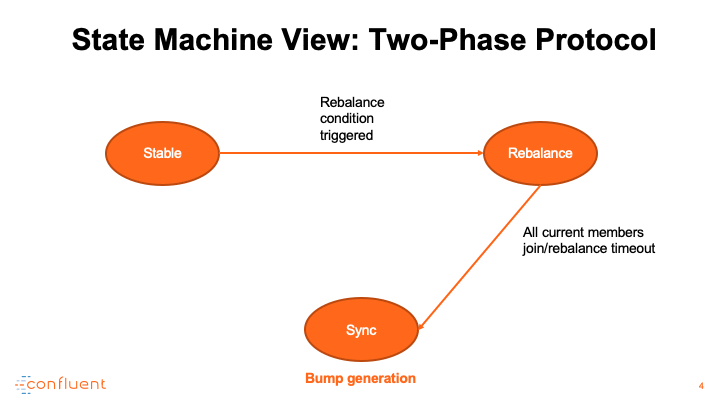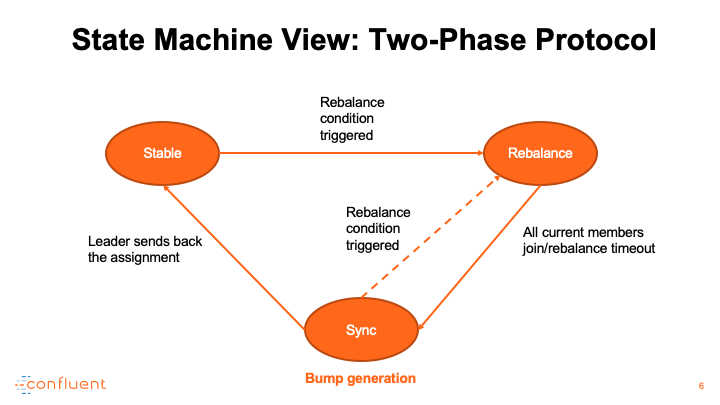
再平衡协议在实时平衡任务处理负载和允许用户自由伸缩应用程序方面非常有效,但它也是一个相当重的操作,需要整个消费组暂时停止工作。成员被期望撤销正在进行的任务,并在每次重新平衡开始和结束时初始化新的任务。这样的操作会带来开销,特别是对于有状态的操作,其中任务需要在提供服务之前首先从其备份主题恢复本地状态。
从本质上讲,当满足以下条件时,再平衡就开始了:
- 组成员变更,例如新成员加入
- 成员订阅更改,例如一个使用者更改订阅的主题
- 资源更改,例如向订阅主题添加更多分区
我们什么时候触发不必要的再平衡?
在现实世界中,有许多场景中,组协调器会触发不必要的重新平衡,这对应用程序性能有害。第一种情况是临时成员超时。要理解这一点,我们需要首先介绍两个概念:使用者心跳和会话超时。
消费者心跳和会话超时
Kafka使用者维护一个后台线程,定期向协调器发送心跳请求,以表明它的活性。使用者配置称为session.timeout。ms定义了协调器在成员最后一次心跳之后等待多长时间,然后才假定该成员失败。当此值设置得过低时,网络抖动或长时间垃圾收集(GC)可能会导致活性检查失败,从而导致组协调器删除此成员并开始重新平衡。解决方案很简单:与其使用缺省的10秒会话超时,不如将其设置为更大的值,以极大地减少由故障引起的暂态重平衡。
注意,会话超时设置的时间越长,用户实际失败时部分不可用的时间就越长。我们将在后面关于如何选择静态成员关系的部分中解释如何选择此值。
滚动反弹过程
有时,我们需要重新启动应用程序、部署新代码或执行回滚等。在最坏的情况下,这些操作可能导致大量的重新平衡。当一个使用者实例关闭时,它向组协调器发送一个请假组请求,让它自己从组中删除,然后触发另一次再平衡。当这个消费者在一次反弹后恢复时,它会向组协调器发送一个加入组请求,从而触发另一次再平衡。
在滚动弹跳过程中,连续的重新平衡被触发,实例被关闭和恢复,分区被来回重新分配。最终的赋值结果是完全随机的,并且会为任务变换和重新初始化付出很大代价。
让成员选择不离开小组怎么样?也不是一个选择。要理解其中的原因,我们需要先讨论一下成员ID。
消费者会员ID
当新成员加入组时,请求不包含成员信息。组协调器将为该成员分配一个统一惟一标识符(UUID),作为其成员ID,将该ID放入缓存中,并将该信息嵌入到对该成员的响应中。在这个使用者的生命周期内,它可以重用相同的成员ID,而不需要协调器在重新加入时触发再平衡,除非在诸如leader重新加入这样的边缘情况下。
回到滚动反弹的情况下,重新启动成员将删除内存中的会员信息和加入该组织成员ID或生成ID。自从加入消费者会被认为是一个全新的组的成员,该组织协调并不能保证其旧任务分配方案。如您所见,成员离开组并不是造成不必要任务变换的根本原因—丢失身份才是。
什么是静态会员?
与动态成员关系不同,静态成员关系旨在跨组的多个代保持成员身份。这里的目标是重用相同的订阅信息,并使协调器“可识别”旧成员。静态成员关系引入了一个名为group.instance的新的使用者配置。id,由用户配置,以惟一地标识其使用者实例。尽管在重启过程中丢失了协调器分配的成员ID,但是协调器仍然将根据join请求中提供的组实例ID识别该成员。因此,保证了相同的赋值。
静态成员关系对于云应用程序的设置非常友好,因为现在Kubernetes等部署技术对于管理应用程序的运行状况非常自包含。为了修复死去的或性能不佳的用户,Kubernetes可以很容易地关闭相关实例,然后使用相同的实例ID启动一个新的实例。
下面是静态成员关系如何工作的快速演示。

如何选择成为静态会员
自从Apache Kafka 2.3发布以来,静态成员已经成为社区的普遍可用性。如果你想成为一个阿尔法用户,这里有说明:
- 将您的代理升级到2.3或更高。具体来说,您需要升级inter.broker.protocol。版本升级到2.3或更高,以启用此特性。
- 在客户端:
- 将客户端库升级到2.3或更高版本。
- 定义较长且合理的会话超时。如前所述,紧张的会话超时值可能会使组不稳定,因为成员会由于缺少单个心跳而被逐出组。您应该根据部分不可用的业务容忍度将会话超时设置为合理的值。例如,对于能够容忍15分钟不可用的业务,将会话超时设置为10分钟是合理的,而将其设置为5秒则不合理。
- 设置group.instance。id配置为用户的惟一id。如果你是Kafka流的用户,对你的流实例使用相同的配置。
- 将新代码部署到应用程序中。静态会员将在您的下一次滚动反弹中生效。
静态成员只有在遵循这些指令的情况下才能正常工作。尽管如此,我们还是采取了一些预防措施,以减少人为失误的潜在风险。
错误处理
有时用户可能会忘记升级代理。当使用者首次启动时,它获得指定代理的API版本。如果客户端配置了组实例ID,并且代理是旧版本的,那么应用程序将立即崩溃,因为代理还不支持静态成员关系。
如果用户未能惟一地配置组实例ID,这意味着有两个或多个成员使用相同的实例ID配置,则需要使用隔离逻辑。当一个已知的静态成员没有一个成员ID,协调器生成一个新的UUID回复这个成员作为其新成员ID。与此同时,该组织协调维护映射实例ID的最新成员分配ID。如果一个已知的静态成员和一个有效的成员ID不匹配的缓存ID,它会立即被协调坚固的回应。这消除了重复静态成员并发处理的风险。
在第一个版本中,我们预计会出现一些错误,这些错误可能会使处理语义失效或阻碍防护逻辑。其中一些问题已经在主干中得到了解决,比如KAFKA-8715,我们仍在积极寻找更多问题。
原文:https://www.confluent.io/blog/kafka-rebalance-protocol-static-membership/
本文:http://jiagoushi.pro/node/1116
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 88 次浏览
【事件驱动架构】Apache Kafka再平衡协议:再平衡协议101
自从Apache Kafka 2.3.0以来,Kafka Connect和消费者特别使用的内部再平衡协议经历了几次重大变化。
再平衡协议不是一件简单的事情,有时看起来像魔术。在这篇文章中,我建议回到这个协议的基础,也就是Apache Kafka消费机制的核心。然后,我们将讨论其局限性和目前的改进。
Kafka和再平衡协议101
让我们回到一些基本的东西
Apache Kafka是一个基于分布式发布/订阅模式的流媒体平台。首先,称为生产者的流程将消息发送到主题中,主题由代理集群管理和存储。然后,称为消费者的流程订阅这些主题,以获取和处理发布的消息。
主题分布在许多代理中,以便每个代理管理每个主题的消息子集——这些子集称为分区。分区的数量是在创建主题时定义的,可以随着时间的推移而增加(但是要小心操作)。
要理解的重要一点是,对于Kafka的生产者和消费者来说,分区实际上是并行的单位。
在生成器端,分区允许并行地写入消息。如果使用密钥发布消息,那么在默认情况下,生成器将散列给定的密钥以确定目标分区。这保证了具有相同密钥的所有消息都将被发送到相同的分区。此外,使用者将保证按照该分区的顺序获得消息传递。
在使用者方面,主题的分区数量限制了使用者组中活动使用者的最大数量。使用者组是Kafka提供的一种机制,用于将多个使用者客户机分组为一个逻辑组,以便负载平衡分区的使用。Kafka保证一个主题分区只分配给组中的一个使用者。
例如,下图描述了一个名为a的消费者组,其中有三个消费者。用户已经订阅了主题A,分区分配为:P0到C1、P1到C2、P2到C3和P1。
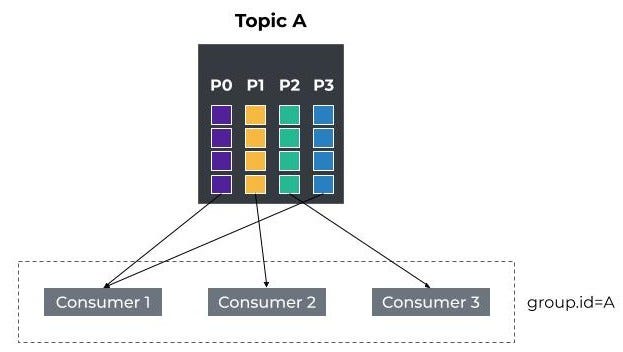
Apache Kafka -消费者组
如果一个使用者在有控制的关闭或崩溃后离开组,那么它的所有分区将在其他使用者之间自动重新分配。同样,如果一个使用者(重新)加入一个现有组,那么所有分区也将在组成员之间重新平衡。
消费者和客户在一个动态群体中合作的能力是通过使用所谓的Kafka再平衡协议而实现的。
让我们深入研究这个协议,了解它是如何工作的。
再平衡协议简述
首先,让我们给出一个术语“再平衡”在Apache Kafka上下文中含义的定义。
再平衡/再平衡:一系列使用Kafka客户端和/或Kafka协调器的分布式进程组成一个公共组,并在组的成员之间分配一组资源的过程(来源:增量合作再平衡:支持和政策)。
上面的定义实际上没有引用消费者或分区的概念。相反,它使用成员和资源的概念。造成这种情况的主要原因是,rebalance协议不仅限于管理使用者,还可以用于协调任何一组流程。
以下是一些协议再平衡的用法:
- Confluent模式注册表依赖重新平衡来选择leader节点。
- Kafka Connect使用它在工人(workers)之间分配任务和连接器。
- Kafka Streams使用它为应用程序流实例分配任务和分区。
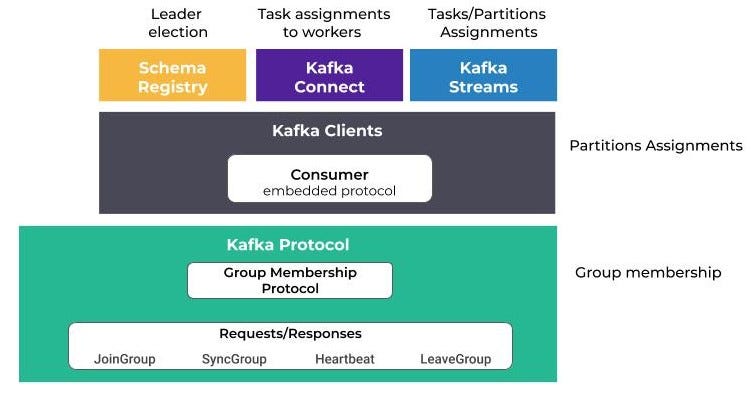
Apache Kafka重新平衡协议和组件
另外,真正需要理解的是,再平衡机制实际上是围绕两种协议构建的:组成员协议和嵌入客户端协议。
组成员协议,顾名思义,负责组成员之间的协调。参与组的客户机将使用充当协调器的Kafka代理执行一系列请求/响应。
第二个协议在客户端执行,允许通过嵌入第一个协议来扩展第一个协议。例如,使用者使用的协议将把主题分区分配给成员。
现在我们对什么是再平衡协议有了更好的理解,让我们来演示它在消费者组中分配分区的实现。
JoinGroup
当使用者启动时,它发送第一个FindCoordinator请求,以获得负责其组的Kafka代理协调器。然后,它通过发送一个JoinGroup请求来启动再平衡协议。
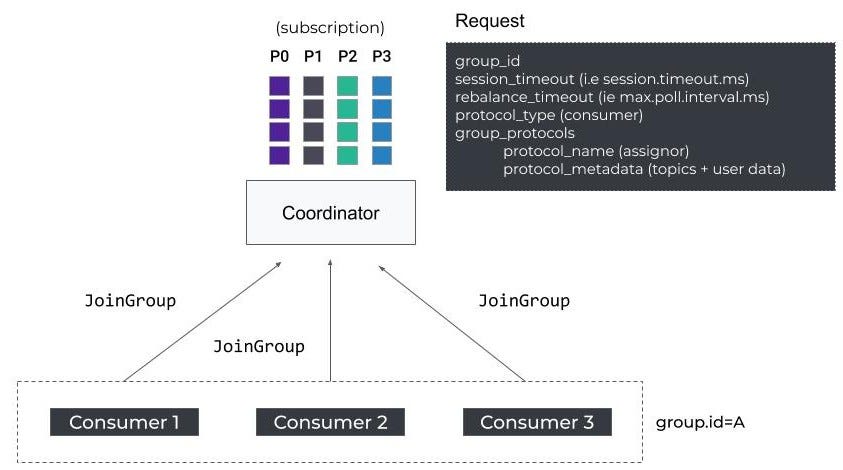
用户-再平衡协议-同步组请求
可以看到,JoinGroup包含一些客户端配置,比如session.timeout。和最大值。max.poll.interval.ms。如果成员不响应,协调器将使用这些属性将其踢出组。
此外,该请求还包含两个非常重要的字段:成员支持的客户端协议列表,以及用于执行嵌入式客户端协议之一的元数据。在我们的示例中,客户机协议是为使用者(i)配置的分区分配程序列表。i.e : partition.assignment.strategy)。元数据包含使用者订阅的主题列表。
请注意,如果您不知道这些属性是干什么用的,我建议您阅读官方文档。
JoinGroup充当屏障,意味着只要没有接收到所有消费者请求,协调器就不会发送响应(i.e group.initial.rebalance.delay.ms)或达到重新平衡超时。
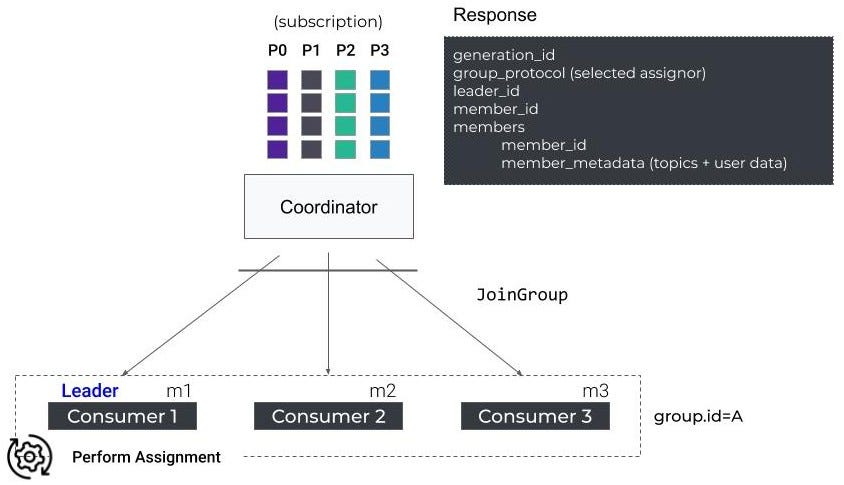
用户-再平衡协议-同步组请求
组中的第一个使用者接收活动成员列表和所选的分配策略,并充当组长,而其他使用者接收空响应。组长负责在本地执行分区分配。
SyncGroup
接下来,所有成员向协调器发送一个SyncGroup请求。组长附加了计算后的分配,而其他人只是响应一个空请求。
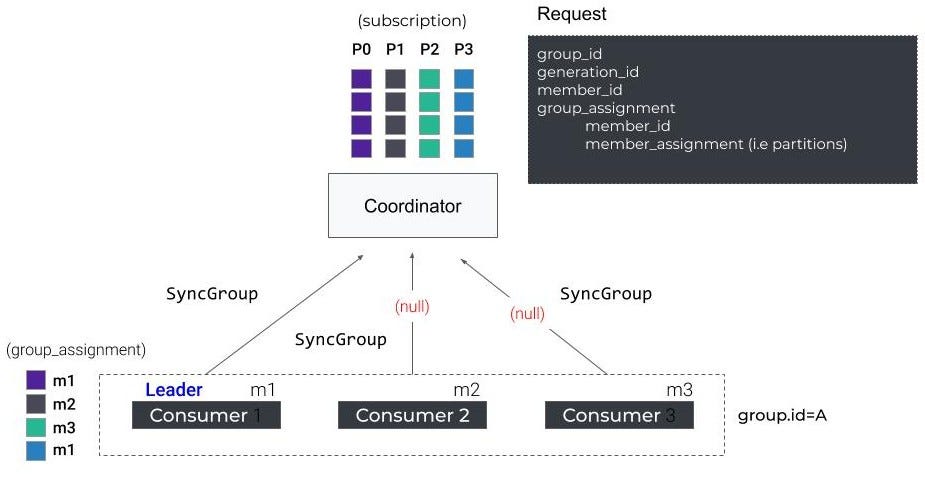
一旦协调器响应allsyncgrouprequest,每个使用者就会接收到他们分配的分区,调用配置的侦听器上的theonPartitionsAssignedMethod,然后开始获取消息。
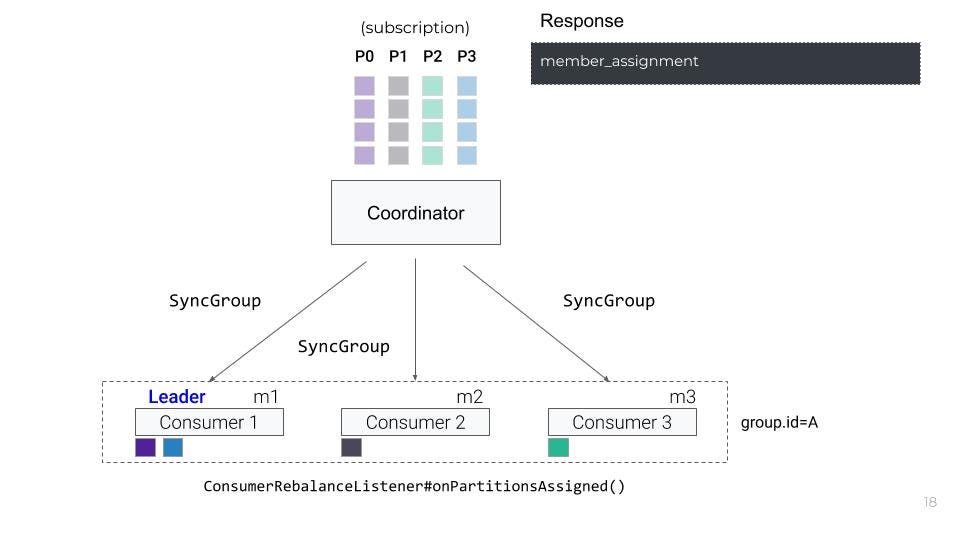
消费者-再平衡协议-同步集团反应
心跳
最后但并非最不重要的是,每个使用者定期向代理协调器发送一个Heatbeat请求,以使其会话保持活动状态(参见:heartbeat.interval.ms)。
如果再平衡正在进行,协调者使用Heatbeat响应来指示消费者,他们需要重新加入该组织。
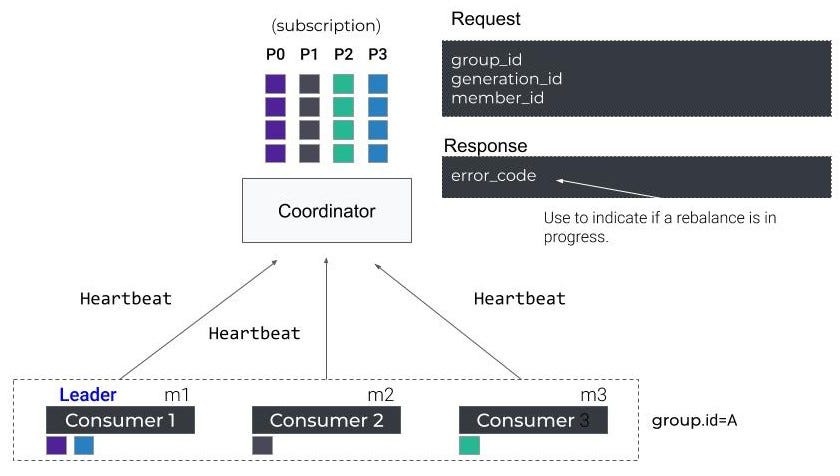
消费者-再平衡协议-心跳
到目前为止一切都很好,但是正如您应该知道的那样,在实际情况中,尤其是在分布式系统中,会发生故障。硬件可以失败。网络或用户可能会出现瞬态故障。不幸的是,对于所有这些情况,再平衡也可能被触发。
一些警告
再平衡协议的第一个限制是,我们不能简单地再平衡一个成员而不停止整个集团(停止世界效应)。
例如,让我们正确地停止一个实例。在第一个重新平衡场景中,使用者将在停止之前向协调器发送一个LeaveGroup请求。
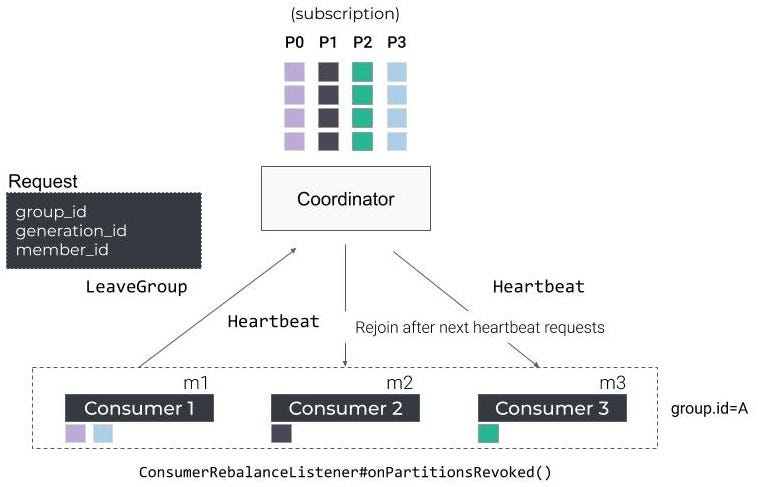
消费者-再平衡协议-离开集团
剩余的使用者将被通知必须在下一个心跳上执行再平衡,并将启动一个新的JoinGroup/SyncGroup往返,以便重新分配分区。
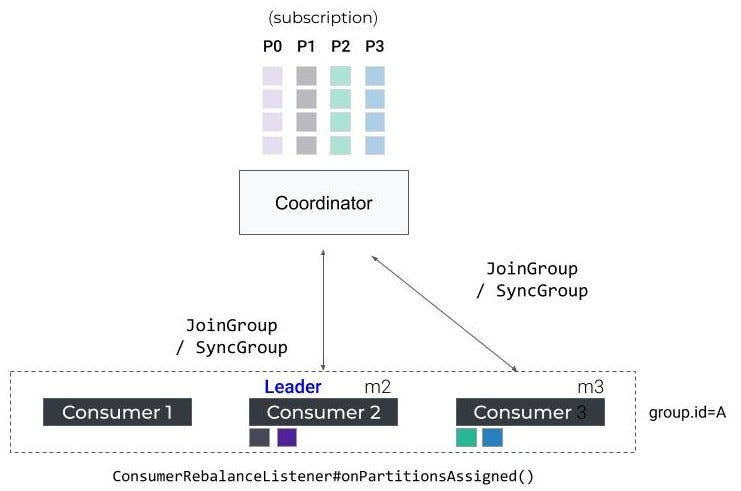
消费者-再平衡协议-重新加入
在整个重新平衡过程中,即只要没有重新分配分区,消费者就不再处理任何数据。默认情况下,重新平衡超时固定为5分钟,这可能是一段很长的时间,在此期间不断增加的用户延迟可能会成为一个问题。
但是,如果使用者只是在短暂故障后重新启动,会发生什么呢?嗯,消费者在重新加入这个群体的同时,将触发一种新的再平衡,导致所有消费者(再一次)停止消费。
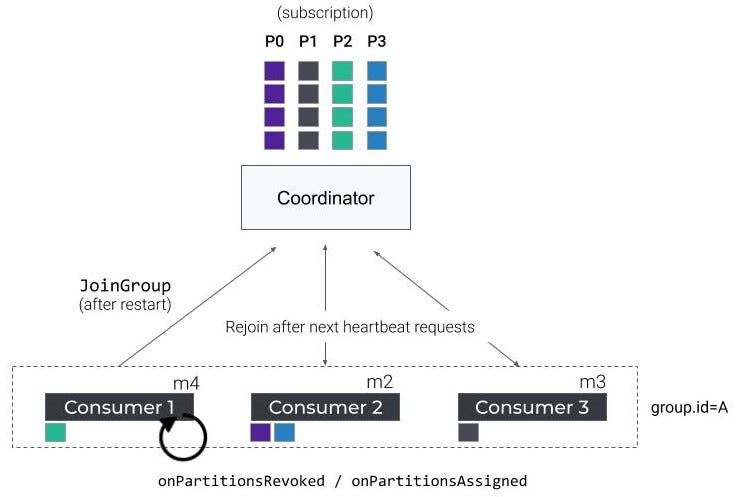
消费者-再平衡协议-重启
另一个可能导致消费者重启的原因是集团的滚动升级。不幸的是,这种情况对消费组来说是灾难性的。实际上,对于一组三个使用者,这样的操作将触发6个重新平衡,这可能对消息处理产生重大影响。
最后,在Java中运行Kafka使用者时的一个常见问题是,由于网络中断或长时间GC暂停而丢失一个心跳请求,或者由于处理时间过长而没有定期调用KafkaConsumer#poll()方法。在第一种情况下,协调器不会接收到超过session.timeout的心跳。认为消费者已经死了。在第二个示例中,处理轮询记录所需的时间优于max.poll.inteval.ms。
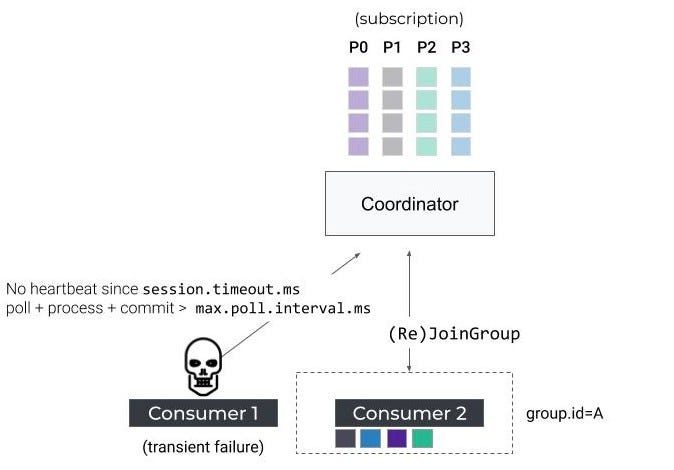
消费者-再平衡协议-超时
本文:http://jiagoushi.pro/node/1113
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 82 次浏览
【事件驱动架构】EMQX MQTT 和 Kafka 对比
视频号
微信公众号
知识星球

MQTT与Kafka完全不同。MQTT是由OASIS技术委员会的成员(大多数是IBM和Microsoft的高级工程师)开发的协议和技术标准。Kafka是LinkedIn首次实现的开源流平台。2011年开放源码后被Apache孵化器孵化,成为Apache软件基金会的顶级项目。
两者之间唯一的联系是它们都与发布/订阅模式相关。MQTT是基于发布/订阅模式的消息传递协议,而ApacheKafka的生产和消费过程也是发布/订阅模式的一部分。如果我们实现基于MQTT协议的消息代理,从发布/订阅模式的角度来看,这个MQTT代理是否等同于Kafka?答案仍然是否定的。
虽然Kafka也是一个基于发布/订阅模式的消息传递系统,但它也被称为“分布式提交日志”或“分布式流平台”。它的主要功能是实现分布式持久数据保存。Kafka的数据单元可以理解为数据库中的一行“数据”或一条“记录”。Kafka按主题分类。当Kafka的制作者发布特定主题的消息时,消费者就消费该特定主题的消息。事实上,生产者和消费者可以理解为发布者和订阅者,主题就像数据库中的一个表。每个主题包含多个分区,分区可以分布在不同的服务器上。也就是说,通过这种方式存储和读取分布式数据。Kafka的分布式体系结构有助于读写系统的扩展和维护(例如,通过备份服务器实现冗余备份,通过构建多个服务器节点实现性能改进)。在许多有大数据分析需求的大型企业中,Kafka将被用作数据流处理平台。
MQTT最初是为物联网设备的网络访问而设计的。大多数物联网设备都是低性能、低功耗的计算机设备,网络连接质量不可靠。因此,在设计协议时需要考虑以下几个关键点:
- 该协议应该足够轻量级,以允许嵌入式设备快速解析和响应。
- 足够灵活,以支持物联网设备和服务的多样化。
- 它应该被设计成异步消息协议而不是异步协议。这是因为大多数物联网设备的网络延迟很可能非常不稳定。如果使用同步消息协议,IoT设备需要等待来自服务器的响应。为大量物联网设备提供服务显然是非常不现实的。
- 必须是双向通信,并且服务器和客户端应该能够互相发送消息。
MQTT协议完美地满足了上述要求,最新版本的MQTT v5.0协议已经过优化,使其比之前的v3.1.1版本更灵活,占用的带宽更少。
对于基于mqtt的消息代理和Kafka的区别,EMQ先生认为这是因为他们的关注点不同。Kafka专注于数据的存储和读取,针对高实时性能的流式数据处理场景,而MQTT Broker则侧重于客户端和服务器之间的通信。
MQTT broker和Kafka采用的消息交换模式非常相似,因此将它们结合起来显然是个好主意。事实上,一些MQTT代理,例如EMQ X MQTT broker, 已经实现了MQTT-broker和Kafka之间的桥接。MQTT-broker用于快速接收和处理来自大量物联网设备的消息,Kafka收集并存储这些大量数据并将其发送给数据分析员来分析和处理消息。
本文:https://jiagoushi.pro/node/1098
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 1524 次浏览
【事件驱动架构】Kafka vs. RabbitMQ:架构、性能和用例
如果你正在考虑是否卡夫卡RabbitMQ最适合你的用例,请继续阅读,了解这些工具背后的不同的架构和方法,如何处理信息不同,和他们的性能优缺点。我们将讨论的最佳用例的每个工具,当它可能比依赖于一个完整的端到端流处理的解决方案。
在这个页面:
- 什么是Apache Kafka和RabbitMQ?
- Kafkavs RabbitMQ -有什么区别?
- 他们如何处理信息
- 他们的表现如何
- 他们最好的用例
- 流处理的端到端平台
什么是Apache Kafka和RabbitMQ?
Apache Kafka和RabbitMQ是两个开源的、有商业支持的发布/订阅系统,很容易被企业采用。RabbitMQ是2007年发布的一个较老的工具,是消息传递和SOA系统中的主要组件。今天,它还被用于流用例。Kafka是一个较新的工具,发布于2011年,它从一开始就是为流媒体场景设计的。
RabbitMQ是一种通用消息代理,支持协议包括MQTT、AMQP和STOMP。它可以处理高吞吐量用例,比如在线支付处理。它可以处理后台作业或充当微服务之间的消息代理。
Kafka是为高接入数据重放和流开发的消息总线。Kafka是一个持久的消息代理,它使应用程序能够处理、持久化和重新处理流数据。Kafka有一个直接的路由方法,它使用一个路由密钥将消息发送到一个主题。
Kafka vs RabbitMQ -架构上的差异
RabbitMQ架构
- 通用消息代理—使用请求/应答、点到点和发布-子通信模式的变体。
- 智能代理/哑消费者模型——以与代理监视消费者状态相同的速度向消费者交付消息。
- 成熟的平台——良好的支持,可用于Java、客户机库、。net、Ruby、node.js。提供几十个插件。
- 通信——可以是同步的或异步的。
- 部署场景——提供分布式部署场景。
- 多节点集群到集群联合——不依赖于外部服务,但是,特定的集群形成插件可以使用DNS、api、领事等。
Apache Kafka架构
- 高容量的发布-订阅消息和流平台——持久、快速和可伸缩。
- 持久消息存储——类似于日志,运行在服务器集群中,它在主题(类别)中保存记录流。
- 消息——由值、键和时间戳组成。
- 愚蠢的代理/聪明的消费者模型——不试图跟踪哪些消息被消费者读了,只保留未读的消息。卡夫卡在一段时间内保存所有消息。
- 需要外部服务运行在某些情况下Apache Zookeeper。
拉vs推
Apache Kafka:基于拉的方法
Kafka使用了拉模型。使用者请求来自特定偏移量的成批消息。Kafka允许 long-pooling, ,这可以防止在没有消息超过偏移量时出现紧循环。
由于它的分区,拉式模型对Kafka来说是合乎逻辑的。Kafka在没有竞争消费者的分区中提供消息顺序。这允许用户利用消息批处理来实现有效的消息传递和更高的吞吐量。
RabbitMQ:基于推的方法
RabbitMQ使用了一个推模型,并通过在使用者上定义的预取限制来阻止过多的使用者。这可以用于低延迟的消息传递。
推模型的目的是快速地独立地分发消息,确保工作均匀地并行化,并按照消息到达队列的大致顺序处理消息。
他们如何处理消息?
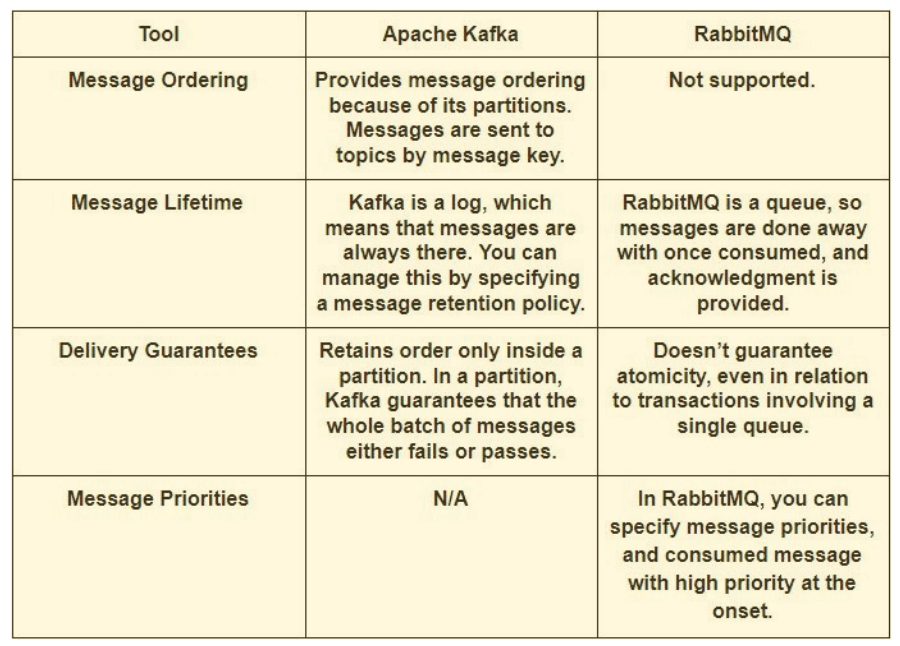
Kafka vs RabbitMQ性能
Apache Kafka:
Kafka提供了比RabbitMQ等消息代理更高的性能。它使用顺序磁盘I/O来提高性能,使其成为实现队列的合适选项。它可以在有限的资源下实现高吞吐量(每秒数百万条消息),这是大数据用例所必需的。
RabbitMQ:
RabbitMQ也可以每秒处理100万条消息,但是需要更多的资源(大约30个节点)。您可以使用RabbitMQ实现与Kafka相同的许多用例,但是您需要将它与其他工具(如Apache Cassandra)结合使用。
最好的用例是什么?
Apache Kafka用例
Apache Kafka提供了代理本身,并针对流处理场景设计。最近,它增加了Kafka Streams,一个用于构建应用程序和微服务的客户端库。Apache Kafka支持诸如度量、活动跟踪、日志聚合、流处理、提交日志和事件来源等用例。
下面的消息传递场景特别适合Kafka:
- 具有复杂路由的流,事件吞吐量为100K/sec或更多,“至少一次”分区排序
- 需要流历史记录的应用程序,以“至少一次”分区顺序交付。客户端可以看到事件流的“重播”。
- 事件溯源,将系统建模为事件序列。
- 在多级管道中进行数据流处理。管道生成实时数据流的图形。
RabbitMQ的用例
当web服务器需要快速响应请求时,可以使用RabbitMQ。这消除了在用户等待结果时执行资源密集型活动的需要。RabbitMQ还用于向不同的接收者传递消息,以供使用或在高负载(每秒20K+消息)下在工作人员之间共享负载。
场景,RabbitMQ可以用于:
- 需要支持遗留协议的应用程序,如STOMP、MQTT、AMQP、0-9-1。
- 对每条消息的一致性/保证集的粒度控制
- 到消费者的复杂路由
- 需要各种发布/订阅、点对点请求/应答消息传递功能的应用程序。
Kafka和RabbitMQ:总结
本指南涵盖了Apache Kafka和RabbitMQ之间的主要区别和相似之处。虽然它们的架构不同,但它们每秒都可以消耗数百万条消息,而且在某些环境中性能更好。RabbitMQ几乎在内存中控制它的消息,使用大集群(30多个节点)。相比之下,Kafka利用顺序磁盘I/O操作,因此需要较少的硬件。
原文:https://www.upsolver.com/blog/kafka-versus-rabbitmq-architecture-performance-use-case
本文:http://jiagoushi.pro/node/1124
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 172 次浏览
【事件驱动架构】Kafka中的模式注册表和模式演化

在这篇文章中,我们将通过Kafka模式注册表来研究Kafka中的模式演化和兼容性类型。通过对兼容性类型的良好理解,我们可以安全地随着时间的推移对模式进行更改,而不会无意中破坏生产者或消费者的利益。
数据集
在我们的“真实世界中的Hadoop开发者”课程中,有一章专门讨论Kafka。在这一章中,我们从Meetup.com直播RSVP数据到Kafka编写我们自己的产品质量,部署就绪,生产者和消费者与Spring Kafka集成。我们将使用来自Meetup.com的RSVP数据流来解释Kafka模式注册表的模式演化和兼容类型。
用例和项目设置
假设Meetup.com决定使用Kafka来分发RSVPs。在这种情况下,producer程序将由Meetup.com管理,如果我想使用Meetup.com生成的RSVPs,我必须连接到Kakfa集群并使用RSVPs。对于我来说,作为一个消费消息的消费者,我首先需要知道的是模式,即RSVP消息的结构。Kafka中消息的典型模式是这样的。
{
"namespace": "com.hirw.kafkaschemaregistry.producer",
"type": "record",
"name": "Rsvp",
"fields": [
{
"name": "rsvp_id",
"type": "long"
},
{
"name": "group_name",
"type": "string"
},
{
"name": "event_id",
"type": "string"
},
{
"name": "event_name",
"type": "string"
},
{
"name": "member_id",
"type": "int"
},
{
"name": "member_name",
"type": "string"
}
]
}
该模式列出了消息中的字段以及数据类型。您可以将模式想象为生产者和消费者之间的契约。当producer生成消息时,它将使用此模式来生成消息。因此,在本例中,每个RSVP消息将具有rsvp_id、group_name、event_id、event_name、member_id和member_name。
Producer是一个Spring Kafka项目,使用上述模式向Kafka编写Rsvp消息。因此,所有发送到Kafka主题的消息都将使用上述模式编写,并使用Avro序列化。我们假设producer代码是由meetup.com维护的。Consumer也是Spring Kafka项目,消费写给Kafka的消息。消费者还将使用上面的模式并使用Avro反序列化Rsvp消息。我们维护消费者项目。
问题
Meetup.com采用了这种分发回函的新方式——通过Kafka。生产者和消费者都同意这个模式,一切都很好。认为模式会永远这样是愚蠢的。假设meetup.com觉得提供member_id字段没有价值并删除了它。你认为会发生什么?这会影响到消费者吗?
member_id字段没有默认值,它被认为是必需的列,因此此更改将影响用户。当生产者删除一个必需的字段时,消费者将看到如下错误
导致:org.apache. kafaca .common. Error . serializationexception:反序列化id为63的Avro消息错误
引起的:org.apache.avro。AvroTypeException:发现com.hirw.kafkaschemaregistry.producer.Rsvp,
期待com.hirw.kafkaschemaregistry.producer.Rsvp,缺少必需字段member_id
如果消费者付钱给消费者,他们会很生气,这将是一个代价非常高昂的错误。有办法避免这样的错误吗?幸运的是,有一些方法可以避免Kafka模式注册表和兼容性类型的错误。Kafka模式注册表为我们提供了检查我们对提议的新模式所做更改的方法,并确保我们对模式所做的更改与现有模式兼容。对于我们的模式,哪些更改是允许的,哪些更改是不允许的,这取决于在主题级别定义的兼容性类型。
在Kafka中有几种兼容性类型。现在让我们逐个研究一下。
落后的(BACKWARD)
如果能够使用新模式生成的数据的使用者也能够使用当前模式生成的数据,则认为模式是向后兼容的。
如果没有显式指定兼容性类型,则向后兼容性类型是架构注册表的默认兼容性类型。现在让我们尝试理解当我们从新模式中删除member_id字段时发生了什么。新的模式向后兼容吗?
在新的模式中,我们删除了member_id。假设消费者已经在使用新模式生成的数据—我们需要询问他是否可以使用旧模式生成的数据。答案是肯定的。在新的模式中,member_id不存在,所以如果向消费者提供了member_id数据,也就是在当前模式中,他读取数据没有问题,因为额外的字段是可以的。所以我们可以说新模式是向后兼容的,Kafka模式注册表将允许这个新模式。
但不幸的是,正如我们在演示中看到的那样,这个变化将影响现有的客户。因此,在向后兼容模式中,使用者应该首先进行更改以适应新模式。这意味着,我们需要首先对消费者进行模式更改,然后才能对生产者进行更改。
如果您对使用者有控制权,或者使用者正在驱动对模式的更改,那么这是可以的。在某些情况下,消费者不会乐意为自己做出改变,尤其是如果他们是付费消费者的话。在这种情况下,向后兼容并不是最好的选择。
如果消费者受到更改的影响,为什么架构注册表首先允许更改?
兼容性类型并不保证所有的更改对所有人都是透明的。它为我们提供了一个指导原则,帮助我们理解对于给定的兼容性类型,哪些更改是允许的,哪些更改是不允许的。当允许对兼容类型进行更改时,通过对兼容类型的良好理解,我们将能够更好地了解谁将受到影响,从而能够采取适当的措施。
在我们的当前实例中,允许根据向后兼容类型在新模式中删除member_id。因为根据向后兼容性,能够使用带有新模式的out member_id的RSVP的使用者将能够使用带有member_id的旧模式的RSVP。因此,根据向后兼容性允许进行更改,但这并不意味着如果处理不当,更改不会造成破坏。
在向后兼容模式下,最好在更改模式之前先通知使用者。在我们的例子中,meetup.com应该通知消费者member_id将被删除,并让消费者先删除对member_id的引用,然后改变生产者来删除member_id。这是处理这种特定模式更改的最合适的方法。
在向后兼容模式下,我可以在新模式中添加一个没有默认值的字段吗?
这里,我们试图添加一个名为response的新字段,它实际上是用户的RSVP响应,并且没有默认值。在向后兼容类型中,这种模式更改是否可以接受?你觉得呢?
让我们来看看。通过向后兼容模式,能够使用新模式生成的数据的使用者也能够使用当前模式生成的数据。
因此,假设消费者已经在使用没有默认值的response数据,这意味着它是必需的字段。现在,他可以使用没有响应的当前模式生成的数据吗?答案是否定的,因为使用者希望在数据中得到响应,因为它是必需的字段。因此,建议的模式更改不是向后兼容的,而且模式注册表一开始就不允许这种更改。
这个错误非常清楚,说明“正在注册的模式与以前的模式不兼容”
因此,如果模式与设置的兼容性类型不兼容,模式注册表将拒绝更改,这是为了防止意外更改。
如果我们用默认值更改字段响应会怎样?这种更改是否被认为是向后兼容的?
回答这个问题——“已经在使用响应默认值为“无响应”的数据的消费者是否可以使用当前模式生成的没有响应的数据?”
答案是肯定的,因为当缺少响应字段时,使用带有response的新模式生成的数据的消费者将替换默认值,这是使用当前模式生成数据时的情况。
为了总结,向后兼容性允许删除和添加具有默认值的字段到模式中。与使用默认值添加字段不同,删除字段将影响用户,因此最好首先使用向后兼容类型更新用户。
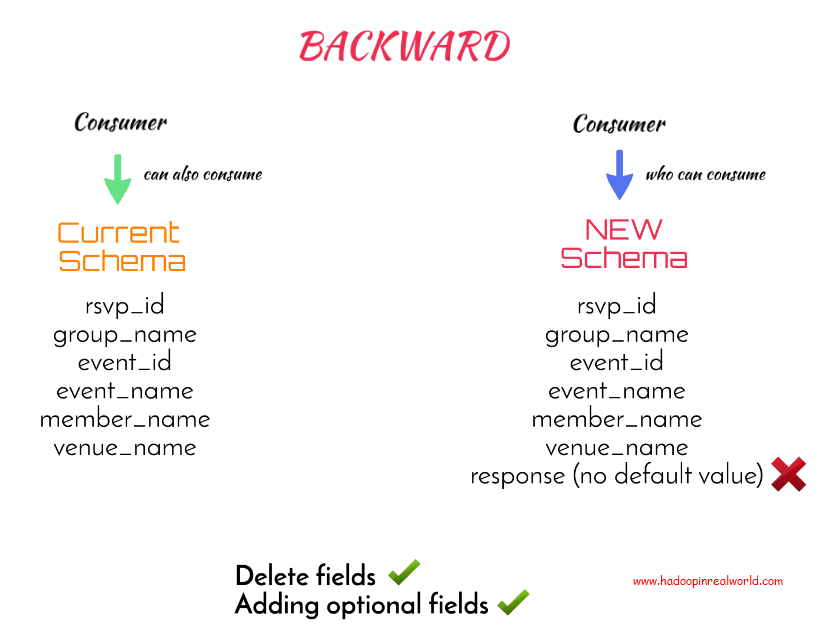
BACKWARD_TRANSITIVE
向后兼容性类型检查新版本和当前版本,如果需要对所有注册版本进行此检查,则需要使用向后兼容性类型。

向前(FORWARD)
好的,到目前为止,我们已经看到了向后和向后传递兼容性类型。
但是,如果我们不希望模式改变影响当前的消费者呢?也就是说,我们希望避免在从模式中删除member_id时发生的情况。当我们删除member_id时,它突然影响了我们的消费者。如果消费者是付费客户,他们会很生气,这会对你的声誉造成打击。那么,我们如何避免这种情况呢?
我们可以使用向前兼容类型,而不是向后使用默认兼容类型。如果使用当前模式生成的数据的消费者也能够使用新模式生成的数据,则认为模式是转发兼容的。
使用此规则,我们将不能删除新模式中没有默认值的列,因为这会影响使用当前模式的消费者。所以添加字段是可以的,删除可选字段也可以。
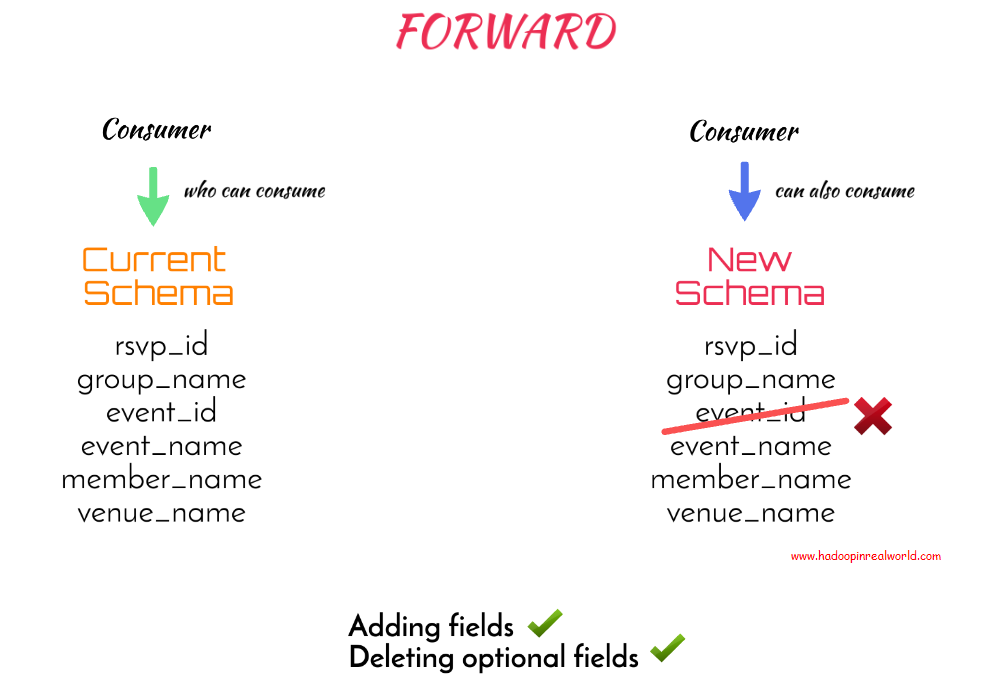
如何改变一个主题的兼容性类型?
在指定主题名称的配置上发出PUT请求,并在请求的主体中将兼容性指定为FORWARD。就是这样。让我们发出请求。
现在,当我们检查主题上的配置时,我们会看到兼容性类型现在被设置为FORWARD。既然主题的兼容性类型已更改为FORWARD,我们就不允许删除必需的字段,即没有默认值的列。让我们确认。为什么我们不尝试删除event_id字段,这是一个必需字段。
让我们通过发出REST命令来更新主题的模式。要更新模式,我们将发布一个包含新模式主体的POST。在这个模式中,我们删除了字段event_id。
{“schema”:”{\”type\”:\”record\”,\”name\”:\”Rsvp\”,\”namespace\”:\”com.hirw.kafkaschemaregistry.producer\”,\”fields\”:[{\”name\”:\”rsvp_id\”,\”type\”:\”long\”},{\”name\”:\”group_name\”,\”type\”:\”string\”},{\”name\”:\”event_name\”,\”type\”:\”string\”},{\”name\”:\”member_name\”,\”type\”:\”string\”},{\”name\”:\”venue_name\”,\”type\”:\”string\”,\”default\”:\”Not Available\”}]}”}
请参阅将兼容性类型设置为转发更新实际失败。即使更改了代码、更新了模式并推出了RSVPs,也会收到相同的响应。使用前向兼容性类型,可以保证使用当前模式的消费者能够使用新模式。
FORWARD_TRANSITIVE
仅FORWARD检查带有当前模式的新模式,如果您想检查所有注册的模式,需要将兼容性类型更改为,您猜对了——FORWARD_TRANSITIVE。

完整和没有(FULL & NONE)
还有另外3种兼容性类型。如果希望模式向前兼容和向后兼容,那么可以使用FULL。对于完全兼容类型,只允许添加或删除具有默认值的可选字段。使用当前模式完全检查新模式。如果希望根据所有注册的模式检查新模式,可以使用FULL_TRANSITIVE。与其他类型相比,完全和完全传递兼容性类型具有更多的限制性。
最后一种兼容类型是NONE。NONE表示禁用所有兼容类型。这意味着所有更改都是可能的,这是有风险的,通常不会在生产中使用。
原文:https://www.hadoopinrealworld.com/schema-registry-schema-evolution-in-kafka/
本文:http://jiagoushi.pro/node/1107
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 96 次浏览
【事件驱动架构】专家组:事件驱动的大规模架构
赖斯:欢迎来到我们关于架构的专题小组,你们一直想知道轨道。该专题小组称为事件驱动的大规模架构。当您思考事件驱动架构时,您会想到什么?这是规模、性能和灵活性的好处吗?也许你想到了一个你可能经历过的特殊问题。也许你从技术的角度来考虑,比如说无服务器,或者流处理,比如Kafka?不管您如何看待事件驱动的架构,您可能有一些问题。我们将深入探讨事件驱动系统的主题,我们将与一个专家小组进行讨论,他们一直在大规模地操作这些系统,并且拥有丰富的经验。
我和三位软件领域的杰出领导者一起工作。他们来自操作当今软件中一些最大和最知名系统的地方。
背景
我叫韦斯·赖斯。我是VMware的平台架构师,在Tanzu上工作。我主持QCON旧金山软件会议。我很幸运能成为InfoQ播客的共同主持人之一。
格温,我想让你做的是自我介绍,也许可以谈谈你建立的系统。那么,您是如何在事件驱动上着陆的?什么风把你吹来了?
沙皮拉:基本上,我是一名软件工程师,是Confluent的首席工程师。我领导云端本地Kafka团队。我们将Kafka作为一项面向客户的大规模服务。在那之前,我是一名工程师,是阿帕奇·Kafka的提交人。
Confluent是如何在事件驱动架构上实现的
基本上,在我们尝试了所有其他方法之后,我们以事件驱动的方式着陆。不是那样的。我花了很多时间与已经在使用Kafka进行事件驱动的客户在一起。我必须与我的客户一起学习模式,以及他们如何解决问题。它解决了什么问题。它创造了什么。然后当我开始管理云中的Kafka时,我们发现自己有一块巨石(monolith),我们知道我们必须解决它。你总是从一块巨石开始。他们写得很快。我们知道我们想要更好的东西,我们有很多不同的选择。真正让我们成为事件驱动型的是,它让我们避免了团队之间的指责,因为一切都是通过事件进行的。它永远被记录下来。如果需要,您可以在登台环境中查看发送了哪些消息,并重构系统的整个逻辑流。如果您在生产中看到了一些东西,而不是您所期望的,那么您实际上可以了解整个事件主题,并了解在另一个系统中发生了什么。对我们来说,这是巨大的。这不是我的责任,你的责任。我们必须非常明确,这是你拥有的。这些是你对事件的反应,我们可以从中吸取教训。
赖斯:不过,这也带来了很多其他问题,比如事情对所有这些事件的实际反应以及它们是如何编排的。伊恩,你呢?
背景,以及PokerStars sports是如何在事件驱动架构上实现的
托马斯:我是一名高级首席工程师,在弗利特(Flutter )国际公司工作,这是我七年前开始的一份工作的化身,在天空投注公司工作。我从事博彩业。这些年来,我一直致力于天空投注,投注,现在横向扑克明星体育。从事件驱动的角度来看,我有几个不同的角度。我很有兴趣了解更多关于我自己的一个方面是PokerStars多年来的发展,因为这是最大的实时事件驱动系统之一,我认为可能存在于这个地方。
我在2014年加入了天空赌局(Sky Bet back)。当时我们采用的主要方式是从一个单片系统(一个庞大的Informix数据库)中提取数据,并将其分发给组织内的工程团队,以允许他们控制数据,然后他们可以构建可扩展的前端。从那以后,我一直致力于各种其他系统的化身,包括一些由Kafka支持的系统,这些系统非常成功。看看我们如何实际使用它来管理自己的状态,这是一个非常有趣的旅程。有很多不同的角度。我最近一直在做的一件事是研究我们如何在前端使用实时事件,并将扑克传统应用到体育博彩和游戏中。
背景,以及BBC是如何在事件驱动架构上着陆的
克拉克:我是马修。我是英国广播公司的架构主管。我相信大家都知道BBC。我们有几十个网站和应用程序,有了这些,我们就有了数百项服务。这是一个相当广泛的事情。保持领先是很有趣的,但是有很多微服务思维和基于云的思维,所以基于事件的架构必须属于这一类。这不是教条式的事情。并不是说我们在任何地方都使用它。基于大量时间请求的系统是更好的解决方案。一直以来都有这些优点和缺点。基于事件的方法必须在它有很多优势的地方发挥作用。从根本上说,如果你有一个搜索引擎或推荐引擎之类的东西,它不会自己填满。您需要这些事件进入并填充它,因此它成为一个好的服务。
使用事件驱动系统时了解域模型的重要性
Reisz:我首先想问的问题之一,可能只是一些你进入事件驱动系统时没有想到的事情,一些让你大吃一惊的事情。这是你旅程的早期。我将从我自己的角度给你举一个例子。我发现当我使用事件驱动系统时,它有点难。在我参与之前,我必须非常了解这个领域,才能真正理解正在发生的舞蹈编排。格温,你谈了一些舞蹈和编曲。例如,当您使用事件驱动系统时,真正了解域模型的重要性是什么?
夏皮拉:尤其是作为一个试图为其他团队提供建议的架构师,你还必须知道你不知道的东西。你的很多工作就是划清这件事的界限,然后说,这是你所拥有的,不要走出去。如果你想在你发送的信息之外做点什么,别人会拥有它。相信他们做正确的事情,他们拥有自己的领域。文化和架构是如何协同工作的,这很有趣,因为如果你试图编写一个协调的系统而不是编舞,你实际上必须了解每个人的逻辑。你就是那个,我会打电话给你,这会发生的。然后我们再叫另一件事。如果这失败了,我就不得不称之为另一件事。我觉得,在很多方面,舞蹈文化意味着你是你领域的专家,你定义了界限。那么你就不必担心其他领域了。还有其他专家,你可以相信他们。我认为这是一种良好的公司文化。
事件驱动系统带来的惊喜
Reisz:Ian,当你从一个更经典的单片系统开始使用事件驱动系统时,有哪些事情让你感到惊讶?
托马斯:我认为大的一次似乎一次又一次地出现,从这个同步的东西到有时间轴的东西也要考虑。特别是当您有可能不同的数据源,或不同的数据生产者,并且思考,这是否真的发生在这之前?我该怎么处理?然后,从这一点开始思考,如果我看到这个事件两次会发生什么?如果我从未见过它会发生什么?我如何协调时间过后的一致性?如果你仅仅从人们从同步编程模型到异步编程模型的角度来看待它,你可以看到到处都是这种情况,就在一个整体中。你也有类似的情况。当这些数据也分布在不同的系统中时,您需要了解,我如何去检查这些数据,或者如何在另一个系统中看到这些数据,或者如何回放日志?这很有挑战性。我会说是的,可能是时间因素。
瑞兹:马修,有什么想法吗?
克拉克:是的,我同意你所说的。是的,了解事物的状态,你是否失去了什么,你是否有比赛条件,这些事情变得非常困难,非常坚毅,绝对。我们谈论无状态是一个多么美妙的范例。您可以通过无服务器功能实现这一点。你需要关心,你只需要担心当下的时刻。然而在一个事件驱动的世界里,你有你的微服务,它有很多状态。它收到了很多活动。如果你失去了一些,你就有麻烦了。它可能不得不把它传给其他东西。如果失败了,或者需要重新部署或其他什么,会发生什么?突然间,你看了看,这不是一个小问题。这不是梦想。当我从我非常满意的经典restapi转移过来时,它非常简单,突然间这不是灵丹妙药,是吗?它有各种各样的挑战。
如何处理无序事件
Reisz:人们想学习的一个问题是如何处理那些无序事件。伊恩,你说了一点关于必须处理不同时间发生的不同事件。您如何处理这样一种想法,即该事件可能不一定以这种同步事件顺序出现?你怎么处理这样的事情?
托马斯:对我们来说,当我们看到这一点时,最重要的地方是下注的位置,也就是说,有人真的在你身上花了一些钱。被抛来抛去的关键词是幂等性,确保你的事件可以在没有严重后果的情况下重演,特别是财务方面。这是一个真正的教育案例,所以要理解这是一种可能性,并在设计系统时牢记这一点,就像大多数事情一样。我们有很多事情需要考虑,如果我们多次遇到这个事件,我们如何丢弃这些东西?如果我们没有看到它,我们如何回放或将新事件推送到系统中,以尝试获得正确的一致性?然后,我们的一些运营人员对我们最大的一个阻碍是,在生产中这样做是对还是错,或者你做了什么。你自己决定吧。如果您有一个数据库,并且您的数据不一致,那么您至少有能力进入并调整它。您可以运行一些SQL命令。“我可以解决这个问题。”当你依靠回放的事件日志时,你必须考虑控制平面是什么样的?我用什么方法使自己恢复良好状态?
回到一个好的,已知的状态
瑞兹:格温,你有什么建议让人们考虑让自己回到一个众所周知的状态?
沙皮拉:我非常相信确保一切都是幂等的。你再往回走一点,相信如果你重播,它不会让你陷入更糟糕的状态。在我看来,真正做异步事件的最大障碍,并不是异步事件真的那么难,而是人们在内心深处没有接受这是唯一的方法。做一些同步的事情,做一些可扩展的事情,做一些性能好的事情,基本上你不会得到这三个。它可以是同步的、高性能的,但不能扩展。您可以同步并尝试扩展,但您将拥有非常大的队列。它不会有太多的表现。如果您想要性能和可扩展的东西,您必须是异步的。一旦你开始走,我就得走了。那么,真的,有一个幂等事件有那么难吗?通常没那么难。只是你必须,我在一个新的世界里,我不想用新的工具创造我的旧世界。事实上,我现在身处一个新世界。
编舞与精心编曲(Choreography vs well-defined orchestration)
Reisz:Nandip问了一个关于定义良好的业务流程的问题。当我看到这篇文章时,我读到的是编舞与配器,回到我们之前讨论的内容。是否总是有这样一种情况,即一切都应该是编舞,或者是否有这样一种情况,即我们需要有单独步骤的定义良好的编排?马太福音?
克拉克:从来没有一个正确的答案。我们有两种方法。有时您可以使用编排设置来操作它,有时则不能。我们之前说过的是,假设您在某个时候会被重放,无论您使用什么,您都会在事件驱动的消息中发现bug,例如,您需要重放内容的地方。即使您的技术非常擅长在正确的位置发布正确的内容,并保证至少一次一致性,您也必须在某个时候处理内容的重复,因为这只是您工作的一部分。
瑞兹:伊恩,格温,有什么想法吗?
托马斯:我真的很喜欢燕翠,他在这一点上做出了妥协,这是在一个有界的背景下,编曲可能是正确的选择。当你观察不同环境之间的交流时,事件驱动的编舞才真正开始发挥作用,而且它很强大。当然,这还不是一个完全的扣篮。我认为这可能是一个很好的定义起点。
赖斯:那是个好主意。燕翠,这也正是我的想法。他有一篇很好的博文,如果你想更多地了解这两者之间的区别的话,可以深入探讨这一点。
在Kafka架构上分离事件和创建主题
格温,这里有一个问题是关于分离事件,以及你如何真正开始思考你的话题。当有人走到你面前,问你关于分离事件和创建Kafka架构主题的问题时,你如何与他们谈论这一点?你让他们想些什么?你告诉他们要考虑什么?
夏皮拉:这很有趣,因为我过去常常回答数据库的问题,这个积分应该是什么,什么应该是分离维度。感觉就像是同样的事情不断重演。首先,就像得到一本关于数据建模的好的、非常古老的书一样,基本上不会有什么伤害,就像建模就是建模一样。你有一本领域驱动的设计书。另一方面,您有一个老式的数据仓库建模或数据建模系统。在Kafka中,您需要考虑的是一些规模要求。这就是它所做的稍微不同的事情。如果某个事件非常常见,那么您可能希望将主要度量和度量主题与稍微不常见的内容分开。因为它们可能会被单独处理,你会希望在不同的时间内对它们做出反应。另一件重要的事情是排序保证,这在数据库中是不会发生的。如果内容在不同的主题中,那么您将无法控制它们的顺序。它们可以按任何顺序处理,你需要对此表示同意。如果你想让事情有一个顺序,你把它们放在同一个分区的同一个主题上,你就有了这个完整的顺序,它就在那里。那么很多只是业务逻辑。我看到一个关于一个事件应该有多大的问题经过。这就像一个函数应该有多大。如果它变得过大,可能是一种气味。一天结束时,你的模型有好的边界吗?在您的企业中,事件是真实世界的事件吗?它是否与正在进行的某项业务保持一致?这是主要考虑因素。你不想用不同的方式人为地把东西切碎吗?
托马斯:我们曾经与工程师们进行过很多对话,他们专门关注Kafka和Kafka流,了解主题设计如何影响他们的流,因为有很多长期影响。特别是,如果您使用它来存储状态和压缩主题。人们从一开始就设置了错误数量的分区。
Shapira:有一件事我要提醒周围的人,也要提醒内部和我的云管理者,你们不想把暂时的限制变成一种宗教。如果你认为某件事是正确的商业行为,但你必须做出妥协,因为技术迫使妥协,你想非常清楚地记录我们想要做X,但实际上这是不可能的。因为那时你不知道,也许一年后X将成为可能,你可以回到它。例如,Kafka过去的分区数量是有限的。它早就消失了,而且正在变得更加消失。人们围绕它设计了整个世界的意识形态,很难说,你这样做是因为它是正确的,还是因为你相信事实上已经不存在的局限性。
赖斯:伊恩,我想让你双击一下。你说你的主题设计的长期影响,比如什么?再多描述一下?
Thomas:有时候,考虑到根据事实改变事情是多么容易,并考虑到您可能需要的吞吐量,这有点幼稚。对于Gwen在那里提到的事件大小,如果您的事件太大,那么您想要的复制模型以及在代理之间要发送的通信量就会出现问题。对我们来说,最主要的是,如果我们把状态保存在一个压缩的主题中,然后你突然意识到,等等,我们没有足够的分区来支持我们现在所拥有的吞吐量,因为这已经增加了。如果您尝试扩展,则所有这些以前的事件都将位于错误的分区上。你必须和这样的人一起玩,如果你将来需要的话,你打算如何扩大规模?您知道您现在选择的约束条件是什么吗?
我们倾向于尝试在Amazon 1型和2型框架中建模。比如,这是你现在就可以做而不用担心的事情吗?它在未来很容易改变吗?我认为,如果你不一定对系统的工作原理或者你正在使用的实际技术有足够的了解,你就不可能在没有真正意义的情况下很容易地把一个2型的东西变成一个1型的东西。它可以确保人们意识到这是一个限制,在设计系统以及如何通过这项技术放置数据时,请记住这一点。
克拉克:事实上,我发现即使是伟大的1型,2型,这个想法,这是一个可逆的决定吗?这是我在事件驱动架构中遇到的挑战之一。它会把你锁在以后很难改变的事情里。一旦有多个客户机正在接受您的事件,更改事件格式就变得非常棘手了。您希望可以在客户不关心的情况下向JSON或其他任何内容添加新字段,但这样做总是让人感到非常紧张。我想我们还没弄清楚你是怎么处理的。
夏皮拉:这方面有一整本书。格雷格·杨的书。
瑞兹:让我们谈谈这个,格温,因为有一些问题出现了。你如何解决这样的问题?
格温,你说的是一本书?
夏皮拉:是的。这是格雷格·杨的作品。他写了一整本关于事件版本控制的书,这表明这不是一个容易的问题,我现在不打算在五分钟内为你们解决它。Kafka以其对稳定的狂热而闻名于世。你可以像一个0.8的经纪人、一个3.0的制作人和一个1.0的消费者那样,让一切都运转起来。它的代价是你进化的速度极其缓慢。如果每个客户端和每个应用程序都有一个大的,如果你得到版本1的事件,如果你得到版本2的事件,这是非常不神奇的。
第2天,与事件驱动系统相关的问题
Reisz:今天早上,Katharina Probst在她的主旨演讲中提到了一系列针对微服务的第二天操作。她列举了一些事情,比如负载测试、混沌工程、AIOps监控。当我们谈论事件驱动系统时,您需要考虑哪些第二天的问题?例如,您谈到了版本控制。什么是你需要思考的事情,也许你真的没有考虑过?
克拉克:我想到的是一对夫妇,斯凯尔绝对是其中之一。如果大量事件已重新发布,会发生什么情况?通常,你会发现,如果你是一个微服务所有者,你可能会发现你的一个攻击性玩家突然出于任何原因选择发布东西。也许他们有个臭虫什么的。你需要有能力处理这件事。或者,至少,您前面可能有一个队列,您可以从中处理积压工作。您不希望积压工作持续很长时间。你有一个有趣的规模挑战,从任何地方,所有的交通可以来自所有这些事件。事实上,你正在存储状态,你是如何存储状态的?如果你重新部署自己会怎么样?你确定在这些时刻你没有掉东西吗?
赖斯:伊恩,你的想法是什么?
托马斯:我完全同意这两个观点。也许随着时间的推移,我注意到的其中一个问题是第二天过去了,但更像是第600天,当构建系统的人继续前进时,人们害怕新的人进来,试图弄清楚这件事是如何运作的,无法改变事情,并且感到担忧。很多都像你在开始时提到的,领域,以及它是如何记录的?人们是如何改变事情的?实际上,冷淡地尝试采用这个系统,并使其适应公司当前的需求是什么样的?
瑞兹:格温,你有什么想法吗?
夏皮拉:是的,我觉得我的第二天活动,我们应该在第0天完成,诸如此类的事情。测试框架,您拥有所有这些微服务,您将独立升级它们。人们都在谈论建立信心,所以你真的要做一个改变,你想有一个测试框架,运行时间不会太长,也许一两个小时,但不会太长。B、 大多数情况下都会通过。它每天应该很少有绿色建筑。第三,相当容易使用、发展和诊断。我在第二天发现,实际上升级和发布都很困难,因为我们没有一个很好的测试框架,现在我们必须基本上停止一系列生产项目,重新开始。我们有50,60个服务,我们甚至没有那么大,我们如何实际测试不断发展的场景,所有这些场景,以确信我们没有破坏其他任何东西?
事件驱动系统的监测和可观测性
赖斯:这里有一大堆关于可观察性、监控和诸如此类的问题。我想换个话题,给你们每个人一个机会谈谈可观察性、监控事件驱动系统和任何工具的重要性。我想,伊恩,当我们交换一些电子邮件时,你谈到了第二天的想法,实际上是在你正在使用的东西中加入一些监控类型的工具。我很想知道,你们每个人关于监控事件驱动系统的一些提示、技巧和想法。
托马斯:其中一些给我们带来最大价值的东西是添加跟踪,以便在消息和记录通过系统的各个部分时能够看到它们的生命周期。再加上Kibana这样的工具,可以非常强大地准确地理解事物是如何在X应用程序上移动的。我们经常被问到的一个问题是,我们看到了吗?有一件事你并不总是有奢侈的是,你是制片人,这是事件的来源。对于我们来说,我们从第三方供应商那里获取了大量数据,这些供应商在足球比赛中有球探并发布更新,我们只是不太知道,这种情况发生了吗?我们应该看到这场足球赛的比分达到了3-0,或者别的什么,但是我们没有那种状态,所以我们看到了什么比赛,什么顺序?我们构建了一些工具,使我们能够真正快速地进入生产箱并回放一些事件。
在我们花时间围绕这一点构建内部工具之前,总是让我们绊倒的事情是,我们希望在代理和客户之间建立TLS。这是Kafka特有的。这强制了我们的ACL,所以您可能没有查看特定主题的权限,您必须考虑一下,您在那里做什么。如果您确实有一些调试工具,请确保您不会干扰实际的生产客户,这样他们就不会到处乱打,并且确保您正在考虑它实际上会如何影响工作系统。然后,如果我们需要提取数据,通常情况下,我不知道每个人的系统是否都不同,因此我们有多个级别的跳转帖子来联系实际的Kafka经纪人。然后你会想,我如何从中提取有用的信息,然后把它拿走,在PIR中分类,或者类似的东西?归根结底是这样的,直到你需要它们,你才真正发现你的需求,这就是确保你已经把时间放在一边,把精力放在构建你需要的东西上。
赖斯:你的里程数可能会有所不同。绝对地Matthew,你们在可观察性方面学到的任何东西都可能是对其他人的好建议。
克拉克:正如伊恩所说,追踪真的很好,不是吗?我们在Amazon X-Ray上做了很多工作,效果非常好。然后,在每一个微服务级别上,您都能正确地记录日志,以便能够诊断哪里存在问题。只要你在每一个微服务之间都有一些经纪人,不管是Kafka,还是动情,或者其他什么,那么你就有希望发现并分离出让你失望的微服务,并尽快解决它。
瑞兹:格温,你有什么消息吗?
沙皮拉:我要补充的唯一一件事可能是采样的想法,你可以有一个外部系统来对一些事件进行采样,特别是如果正在进行的一切都是非常大规模的。然后,在后台仔细检查是否存在异常值,并确保没有任何意外情况,比如事物不会过大。伊恩刚刚对它说,你知道你的数据的形状应该是什么样的。这就是你如何检测我们是否应该看到它,而它不在这里,诸如此类的事情。我们也知道,我们不应该期望一秒钟内有许多授权尝试。如果我们明白了,可能是出了严重的问题。我们已经建立了这个系统,它在后台运行,并对样本的一些规则进行了双重检查。我认为这对我们很有帮助。
从战争故事中吸取的教训
瑞兹:格温,我要从你开始谈这件事,因为我想你已经提到了一件。对于不同的战争故事有很多要求,这让你学到了一些不同的课程。你从一些战争故事中学到了什么教训?告诉我们关于战争的故事,也许还有教训?
Shapira:我认为这与前面的版本控制讨论有关。我们基本上想升级很多东西。我们有大约1000个单一服务类型的实例,我们只想升级它们。这是一个无状态的服务,这使它变得简单。我们刚刚通过我们的管道推送了大约1000个升级事件,希望所有事件都能得到处理,其中997个能够随着时间的推移自行升级,而3个不会。我们甚至不知道为什么。活动即将开始,一切看起来都很好。我们有痕迹。我们到处都有原木。最终,我们发现这是我们最古老的三项服务,基本上就像我们拥有的前三个客户一样,可以追溯到2017年。他们有一些不同的授权密钥,阻止他们下载这些他们需要下载的东西来升级自己。甚至没有人确切记得钥匙是怎么到那里的。显然,这是一个不同类型的事件。才三点。我们最终野蛮地强迫他们。这类事情,即使你对进化非常小心,比如一步一步地进化成一个系统,它将与2017年发生的任何事情完全不兼容,甚至没有人记得。我认为这里的主要教训就是不要有任何悬而未决的东西。每三个月、六个月都要升级一次,如果你在做什么项目时没有太多的变动,那么可能还要再升级一点。
瑞兹:伊恩,你呢,告诉我们一些战争故事?
托马斯:当你问这个问题时,我突然想到了一对夫妇。他们都是几年前的人,所以我不认为我说这些话伤害了任何人的感情。其中一个是关于事件的大小,或者更确切地说是与事件相关的事物的大小。在Sky Bet上,构建页面的方法之一是,从Informix流出的信息流经过各种rabbitmq,然后由节点处理,最终存储在Mongo文档中。由于更新发生的方式,我们倾向于从Mongo读取文档,找出这对文档意味着什么,然后将其写回。这种逻辑中存在一个缺陷,这意味着我们从未真正从Mongo文档中删除过内容。因为它是一个主页,我想它是网站上的赛马主页,它只是逐渐变大了。虽然这并不明显,但不幸的是,当该网站在节礼日(在英国,这是一个体育博彩的大日子)宕机时,所有这些事情都出了问题。我们不知道为什么。这基本上是因为我们频繁地从Mongo中提取文档,从而使我们的网络饱和,以至于我们无法再实际处理它。那是非常有趣的一天。
我能想到的另一个问题是,很难解决,可能涉及到与Kafka合作的最佳实践,那就是我们有两个制作人的情况非常奇怪,所以这很简单。我们有两个制作人编写一个主题,但具有相同密钥的记录最终出现在不同的分区上。其中一个基本上是一个节点应用程序,另一个是用Kotlin编写的。密钥的使用方式和用于生成实际分区散列的数据类型意味着整数在Kotlin中使用,因此溢出。它实际上是在生成与Node.js不同的散列。那是一个相当不错的一天,寻找它。
夏皮拉:你是怎么发现的?
托马斯:我不记得了。那是几年前的事了。我们只是在这些节目中逐行播放,有什么不同?我们最后得出的唯一结论是这一个是节点,而那一个基本上就是JVM。实现中可能有什么不同?这只是一个数字。
我能想到的另一个问题是,很难解决,可能涉及到与Kafka合作的最佳实践,那就是我们有两个制作人的情况非常奇怪,所以这很简单。我们有两个制作人编写一个主题,但具有相同密钥的记录最终出现在不同的分区上。其中一个基本上是一个节点应用程序,另一个是用Kotlin编写的。密钥的使用方式和用于生成实际分区散列的数据类型意味着整数在Kotlin中使用,因此溢出。它实际上是在生成与Node.js不同的散列。那是一个相当不错的一天,寻找它。
夏皮拉:你是怎么发现的?
托马斯:我不记得了。那是几年前的事了。我们只是在这些节目中逐行播放,有什么不同?我们最后得出的唯一结论是这一个是节点,而那一个基本上就是JVM。实现中可能有什么不同?这只是一个数字。
第二天,关于操作事件驱动系统的建议
Reisz:我想把重点放在第二天,如果你能和某人坐下来,就第二天或事件驱动系统的长期运行给他们一点建议。我们一直在谈论Kafka。你有什么建议?不一定非要和Kafka在一起?你有什么建议吗?
克拉克:尽你最大的努力让事情尽可能简单,因为这些事情变得如此复杂真是不可思议。如果我们有时间的话,我会说的故事是,我们如何有一个时刻,所有这些不同的系统在做所有这些不同的事件,如果我们将这些事件标准化,并将它们放在一起,并将所有事件作为一个超级主题,这不是很好吗?当然,那是个糟糕的主意。因为它们都有不同的属性,以不同的方式扩展,以不同的方式需要。就像微服务的概念一样,让事情分开,让事情简单。不要以为事件驱动就是答案,因为它是一个很好的解决方案,但并不总是正确的解决方案。请注意,它可能不像最初看起来那么简单。
不是事件驱动系统的最佳系统
Reisz:对于事件驱动系统,哪些系统可能不是最好的?你有什么想法吗,马修?
克拉克:从根本上说,如果你是一个面向用户的东西,它会以一个请求结束,不是吗?一个用户出现了,给我一个东西。在某个时刻,您的事件必须转变为请求。这一切都是为了找出它在哪里。在英国广播公司,我们更喜欢有它,所以实际上我们会根据用户的到来做很多请求,这样我们就可以回应他们是谁。我们希望在这方面充满活力。这是一个例子。你不能现实地提前准备,因为你想对当下做出反应。
对于事件驱动系统和第二天推荐来说,不太好的事情
赖斯:伊恩,哪些东西不是伟大的事件驱动系统?那么,第二天你对某人的建议是什么?
托马斯:不好的事情?我认为考虑它的一个好方法是,如果我有一个工作流,你希望能够识别该工作流中的所有步骤,并将其作为一个深思熟虑的实体加以关注。这是一种很好的编排方式,而不是事件驱动。我的建议与此类似,不要强制在不需要的地方安装它,但在设计数据时也要非常慎重,以允许其不断发展。请记住,您选择的实现方式。你需要SNS、SQS还是运动?考虑一下您正在使用和设计的实际代理和系统的约束,而不是针对它们。
什么时候不使用事件驱动?我几乎可以这样说,从节点开始,寻找需要这种可靠性水平或重放能力的地方,以及真正强大的大规模解耦。基本上,请注意什么时候需要事件驱动而不是启动程序,因为我确实觉得它增加了一层复杂性,可能你永远都无法实现,谁知道呢?也许你的创业不会那么成功。
就第二天而言,我会稍微为自己着想,并说你确实可以选择不以自己的身份排名。它只是消除了一系列的痛苦,然后把它交给一个实际上相当兴奋和乐意照顾它的人。我认为这在总体上是正确的,就像我们不做自己的监控一样。我们有一群第三方提供商为我们进行监控。我们不经营我们自己的Kubernetes,我们用AKS,EKS,GKE来做这些。是的,基本上,偶尔有一些你不必担心的事情是很好的。
- 98 次浏览
【事件驱动架构】事件溯源,CQRS,流处理和Apache Kafka:关联是什么?
事件源作为一种应用程序体系结构模式越来越流行。事件源涉及将应用程序进行的状态更改建模为事件的不可变序列或“日志”。事件源不是在现场修改应用程序的状态,而是将触发状态更改的事件存储在不可变的日志中,并将状态更改建模为对日志中事件的响应。我们之前曾写过有关事件源,Apache Kafka及其相关性的文章。在本文中,我将进一步探讨这些想法,并展示流处理(尤其是Kafka Streams)如何帮助将事件源和CQRS付诸实践。
让我们举个例子。考虑一个类似于Facebook的社交网络应用程序(尽管完全是假设的),当用户更新其Facebook个人资料时会更新个人资料数据库。当用户更新其个人资料时,需要通知多个应用程序-搜索应用程序,以便可以将用户的个人资料重新编制索引以便可以在更改的属性上进行搜索;新闻订阅源应用程序,以便用户的联系可以找到有关个人资料更新的信息;数据仓库ETL应用程序将最新的概要文件数据加载到支持各种分析查询等的中央数据仓库中。

基于事件源的架构
事件来源涉及更改配置文件Web应用程序,以将配置文件更新建模为事件(发生的重要事件),并将其写入中央日志(例如Kafka主题)。在这种情况下,所有需要响应配置文件更新事件的应用程序,只需订阅Kafka主题并创建各自的物化视图-可以写缓存,在Elasticsearch中为事件建立索引或简单地计算in -内存聚合。个人档案Web应用程序本身也订阅了相同的Kafka主题,并将更新内容写入个人档案数据库。
事件溯源:一些权衡
使用事件源对应用程序进行建模有许多优点-它提供了对对象进行的每个状态更改的完整日志;因此故障排除更加容易。通过将用户意图表示为不可变事件的有序日志,事件源为企业提供了审核和合规性日志,这还具有提供数据源的额外好处。它支持弹性应用程序;回滚应用程序等于倒退事件日志和重新处理数据。具有较好的性能特点;写入和读取可以独立缩放。它实现了松散耦合的应用程序体系结构。它使向基于微服务的体系结构过渡变得更容易。但最重要的是:
事件源支持构建前向兼容的应用程序体系结构,即将来可以添加更多需要处理同一事件但创建不同实例化视图的应用程序的能力。
对于上述优点,也有一些缺点。事件源具有更高的学习曲线;这是一个陌生的新编程模型。事件日志可能涉及更多的查询工作,因为它需要将事件转换为适合查询的所需物化状态。
那是对事件源和一些权衡的快速介绍。本文无意探讨事件源的细节或提倡其用途。您可以在此处阅读有关事件来源和各种折衷方法的更多信息。
Kafka作为事件溯源的支柱
事件源与Apache Kafka相关。这是如何进行的-事件来源涉及维护多个应用程序可以订阅的不可变事件序列。 Kafka是一种高性能,低延迟,可扩展和持久的日志,已被全球数千家公司使用,并经过了大规模的实战测试。因此,Kafka是存储事件的自然支柱,同时向基于事件源的应用程序体系结构发展。
事件溯源和CQRS
此外,事件源和CQRS应用程序体系结构模式也相关。命令查询责任隔离(CQRS)是最常用于事件源的应用程序体系结构模式。 CQRS涉及在内部将应用程序分为两部分-命令端命令系统更新状态,而查询端则在不更改状态的情况下获取信息。 CQRS提供了关注点分离–命令或写端与业务有关;它不关心查询,数据上的不同实例化视图,针对性能的实例化视图的最佳存储等。另一方面,查询或读取端全部与读取访问权限有关。其主要目的是使查询快速高效。

Refactoring an application using event sourcing and CQRS
事件源与CQRS一起工作的方式是使应用程序的一部分在对事件日志或Kafka主题的写入过程中对更新进行建模。这与事件处理程序配对,该事件处理程序订阅Kafka主题,根据需要转换事件,并将实例化视图写入读取存储。最后,应用程序的读取部分针对读取存储发出查询。
CQRS具有一些优点-它使负载与写入和读取分离,从而可以分别缩放。各种读取路径本身可以独立缩放。此外,可以针对应用程序的查询模式优化读取存储;图形应用程序可以将Neo4j用作其读取存储,搜索应用程序可以使用Lucene索引,而简单的内容服务Web应用程序可以使用嵌入式缓存。除了技术优势之外,CQRS还具有组织上的优势-通过将写入和读取路径分离,您可以使负责写入和读取路径的业务逻辑的团队脱钩。
本文仅涉及CQRS细微差别的表面。如果您想了解更多信息,建议阅读Martin Fowler和Udi Dahan关于该主题的文章。
到目前为止,我已经对事件源和CQRS进行了介绍,并描述了Kafka如何自然地将这些应用程序架构模式付诸实践。但是,流处理在何处以及如何进入画面?
CQRS和Kafka的Streams API
这是流处理,尤其是Kafka Streams如何启用CQRS的方法。事件处理程序订阅事件日志(Kafka主题),使用事件,处理这些事件,并将结果更新应用于读取存储。对事件流进行低延迟转换的过程称为流处理。在Apache Kafka的0.10版本中,社区发布了Kafka Streams。一个强大的流处理引擎,用于对Kafka主题上的转换进行建模。
Kafka Streams非常适合在应用程序内部构建事件处理程序组件,该应用程序旨在使用CQRS进行事件来源。它是一个库,因此可以将其嵌入任何标准Java应用程序中,以对事件流进行转换建模。例如,这是一个使用Kafka Streams进行字数统计的代码片段;您可以在Confluent示例github存储库中访问整个程序的代码。
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream(stringSerde, stringSerde,"TextLinesTopic");
Pattern pattern = Pattern.compile("\\W+", Pattern.UNICODE_CHARACTER_CLASS);
KStream<String, Long> wordCounts = textLines
.flatMapValues(value-> Arrays.asList(pattern.split(value.toLowerCase())))
.map((key, word) -> new KeyValue<>(word, word))
.countByKey("Counts")
.toStream();
wordCounts.to(stringSerde, longSerde, "WordsWithCountsTopic");
KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration);
streams.start();
因此,可以轻松地将应用程序内的事件处理程序表示为Kafka Streams拓扑,但更进一步,有两个不同的选项可用于将事件处理程序的输出建模为对应用程序状态进行建模的数据存储的更新。
采取1:将应用程序状态建模为外部数据存储
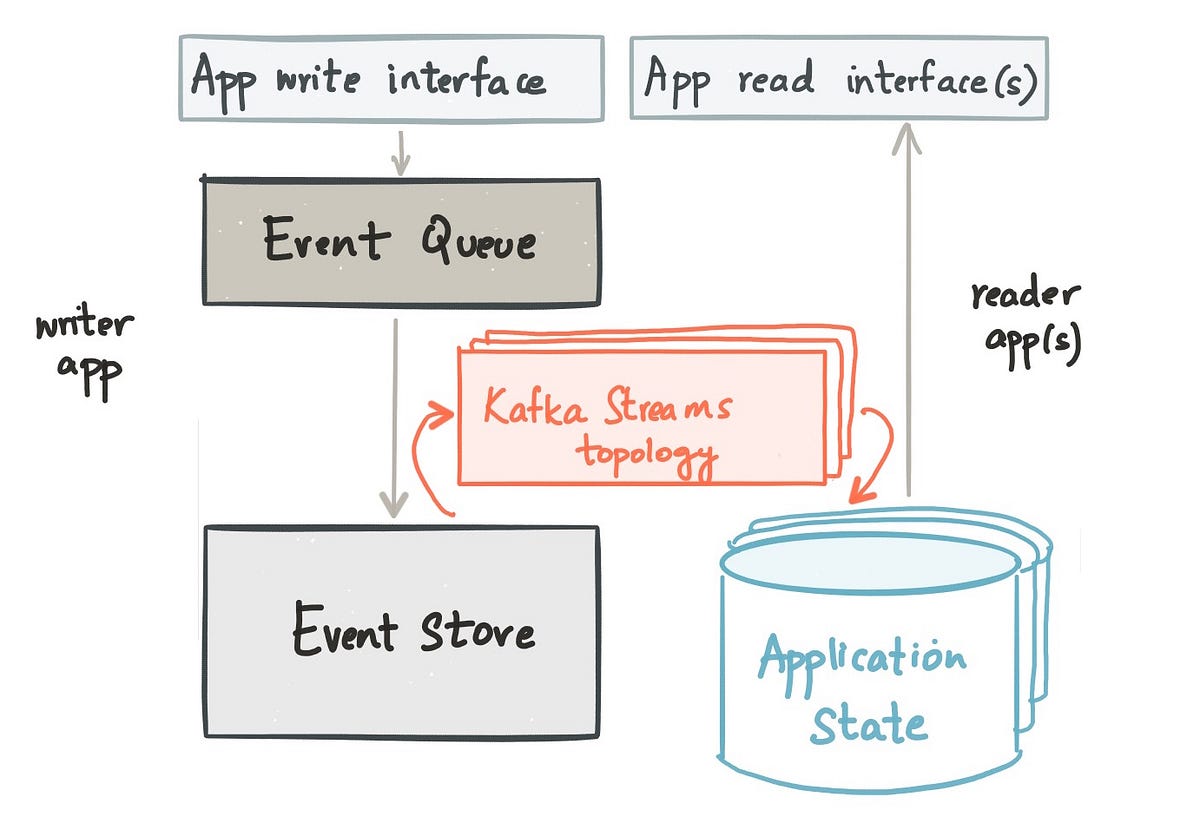
Kafka Streams拓扑的输出可以是Kafka主题(如上例所示),也可以写入外部数据存储(如关系数据库)。 从世界的角度来看,事件处理程序建模为Kafka Streams拓扑,而应用程序状态建模为用户信任和操作的外部数据存储。 执行CQRS的此选项主张使用Kafka Streams仅对事件处理程序建模,而将应用程序状态保留在外部数据存储中,该外部数据存储是Kafka Streams拓扑的最终输出。
以2:在Kafka Streams中将应用程序状态建模为本地状态
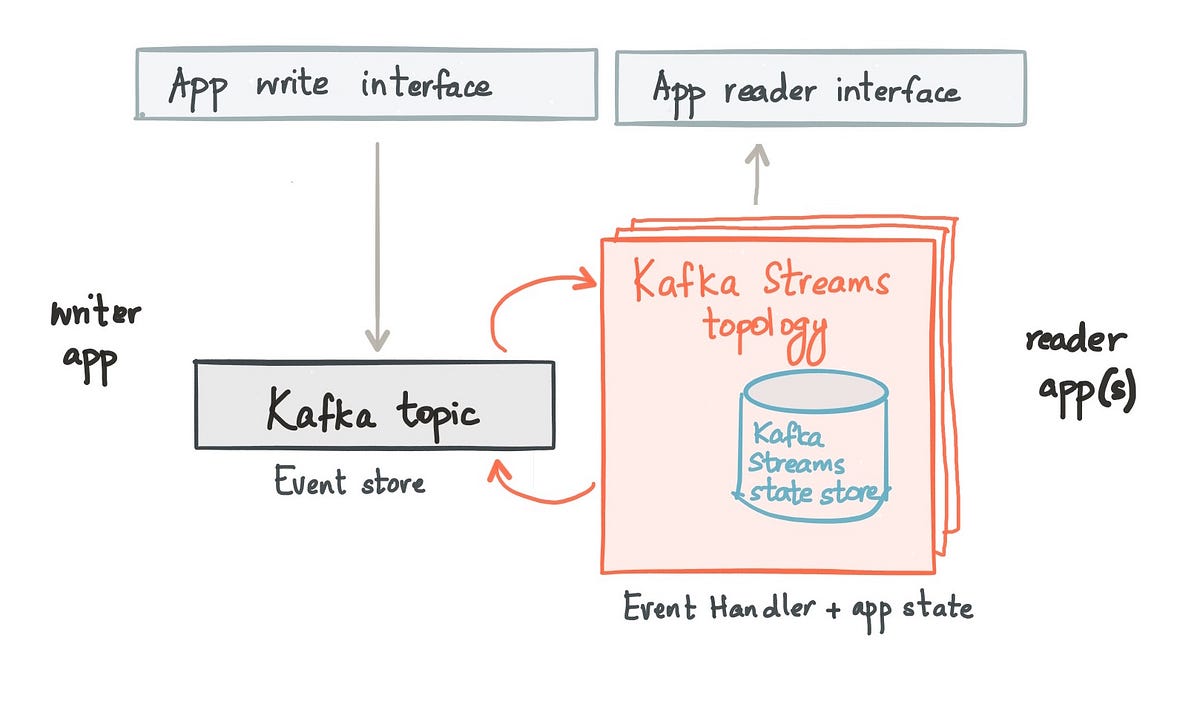
作为一种替代方法,除了对事件处理程序进行建模之外,Kafka Streams还提供了一种对应用程序状态进行建模的有效方法-它支持开箱即用的本地,分区和持久状态。此本地状态可以是RocksDB存储,也可以是内存中的哈希映射。
运作方式是,将嵌入Kafka Streams库以进行有状态流处理的应用程序的每个实例都托管应用程序状态的子集,建模为状态存储的碎片或分区。状态存储区的分区方式与应用程序的密钥空间相同。结果,服务于到达特定应用程序实例的查询所需的所有数据在状态存储碎片中本地可用。 Kafka Streams通过透明地将对状态存储所做的所有更新记录到高度可用且持久的Kafka主题中,来提供对该本地状态存储的容错功能。因此,如果应用程序实例死亡,并且托管的本地状态存储碎片丢失,则Kafka Streams只需读取高度可用的Kafka主题并将状态数据重新填充即可重新创建状态存储碎片。
实际上,Kafka Streams将Kafka用作其本地嵌入式数据库的提交日志。这正是在封面下设计传统数据库的方式-事务或重做日志是事实的源头,而表只是对存储在事务日志中的数据的物化视图。
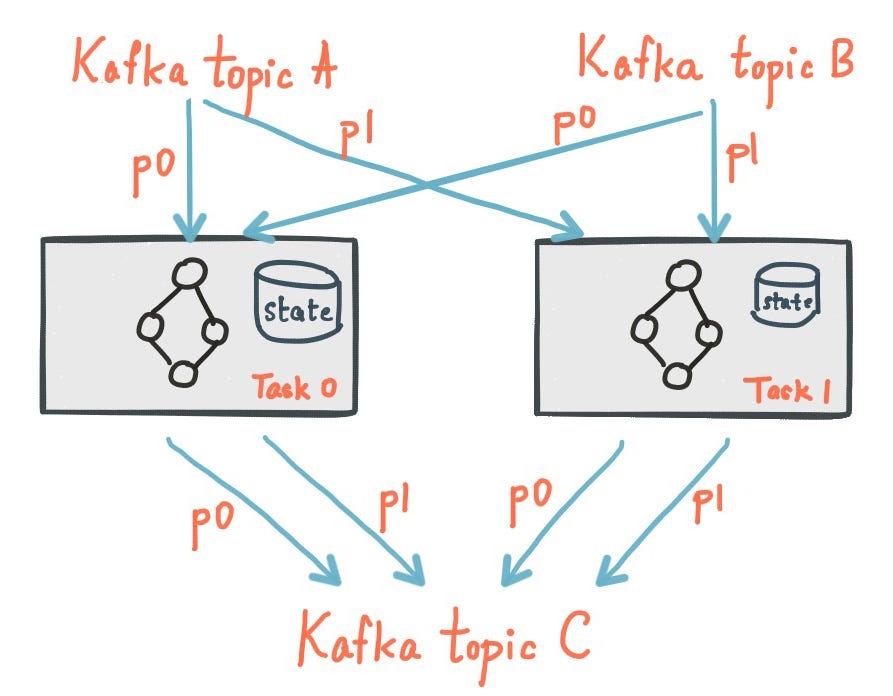
Kafka Streams中的本地,分区,持久状态
将Kafka Streams用于使用CQRS构建的有状态应用程序还具有更多优势– Kafka Streams还内置了负载平衡和故障转移功能。如果一个应用程序实例失败,则Kafka Streams会自动在其余应用程序实例之间重新分配Kafka主题的分区以及内部状态存储碎片。同样,Kafka Streams允许弹性缩放。如果启动了使用Kafka Streams执行CQRS的应用程序的新实例,它将自动在新启动的应用程序实例之间平均移动状态存储的现有碎片以及Kafka主题的分区。所有这些功能都以透明的方式提供给Kafka Streams用户。
需要使用Kafka Streams转换为基于CQRS的模式的应用程序不必担心应用程序及其状态的容错性,可用性和可伸缩性。
该嵌入式,分区且持久的状态存储通过Kafka Streams独有的一流抽象-KTable向用户公开。
Kafka流中的交互式查询
在即将发布的Apache Kafka版本中,Kafka Streams将允许其嵌入式状态存储可查询。
Kafka Streams中的这一独特功能-交互式查询(以前被Kafka社区称为Queryable State)-也使其适合将CQRS设计模式应用于应用程序。事件处理程序被建模为Kafka Streams拓扑,该拓扑将数据生成到读取存储,该存储不过是Kafka Streams内部的嵌入式状态存储。应用程序的读取部分将StateStore API用于状态存储,并基于其get()API来提供读取服务。
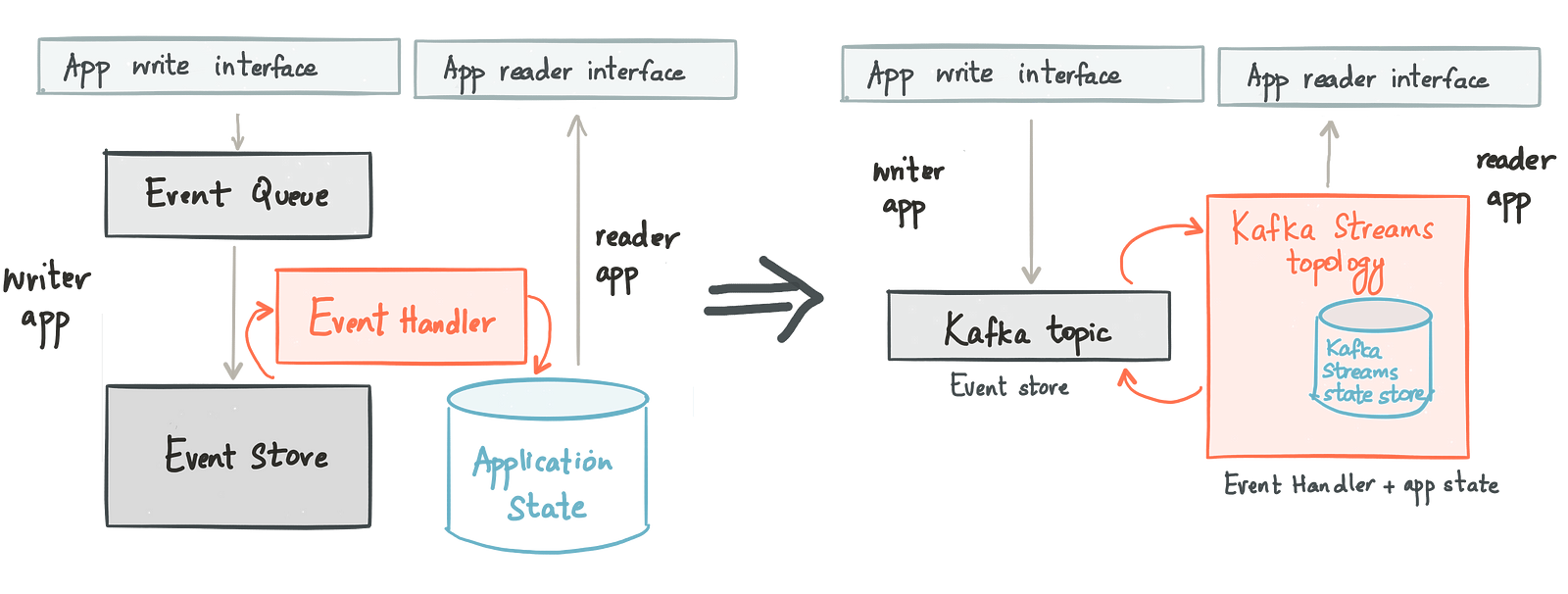
使用Kafka和Kafka Streams的事件源和基于CQRS的应用程序
Kafka Streams中的交互式查询的情况
请注意,使用交互式查询功能在Kafka Streams中使用嵌入式状态存储纯粹是可选的,并非对所有应用程序都有意义。有时,您只想使用您知道并信任的外部数据库。或者,在使用Kafka Streams时,您也可以将数据发送到外部数据库(例如Cassandra),并让应用程序的读取部分查询该数据。
但是,何时使用像这样的本地嵌入式应用程序状态才有意义?这里有一些利弊考虑-
缺点
- 现在生成的应用程序是有状态的,需要多加注意才能进行管理。
- 它涉及远离您知道和信任的数据存储。
优点
- 移动的零件更少;只是您的应用程序和Kafka集群。您不必部署,维护和操作外部数据库即可存储应用程序所需的状态。
- 它可以更快,更有效地使用应用程序状态。数据对于您的应用程序是本地的(在内存中或可能在SSD上);您可以快速访问它。这对于需要访问大量应用程序状态的应用程序特别有用。而且,在进行聚合以进行流处理的商店和商店应答查询之间没有数据重复。
- 它提供了更好的隔离;状态在应用程序内。一个恶意应用程序无法淹没其他有状态应用程序共享的中央数据存储。
- 它具有灵活性。内部应用程序状态可以针对应用程序所需的查询模式进行优化。
使用Kafka做事件溯源和CQRS:大赢家
我上面列出的利弊体现了所涉及的各种折衷,但是,我认为,朝着此应用程序体系结构迈进的最重要的胜利就是应用程序升级变得更加简单。处理应用程序的非停机升级的传统模型(依赖于外部数据库来确定其应用程序状态)相当复杂。无需停机升级就不需要同时运行新版本和旧版本的应用程序。升级几个实例后,如果发现错误,则需要能够透明地将负载切换回同一应用程序的旧实例。鉴于新实例和旧实例将需要更新外部数据库中的相同表,因此需要格外小心,以在不破坏状态存储中数据的情况下进行此类无停机升级。
现在,对于依赖于本地嵌入式状态的有状态应用程序,考虑相同的无停机升级问题。通过此模型,您可以与旧版本一起推出新版本的应用程序(在Kafka Streams中具有不同的应用程序ID)。每个人都拥有按照其应用程序业务逻辑版本指示的方式处理的应用程序状态副本。您可以逐步将流量从旧的引导到新的。如果新版本的某个错误会在应用程序状态存储区中产生意外结果,那么您始终可以将其丢弃,修复该错误,重新部署该应用程序并让其从日志中重建其状态。
放在一起:零售库存应用
现在让我们以一个例子来说明如何将本文介绍的概念付诸实践-如何使用Kafka和Kafka Streams为应用程序启用事件源和CQRS。
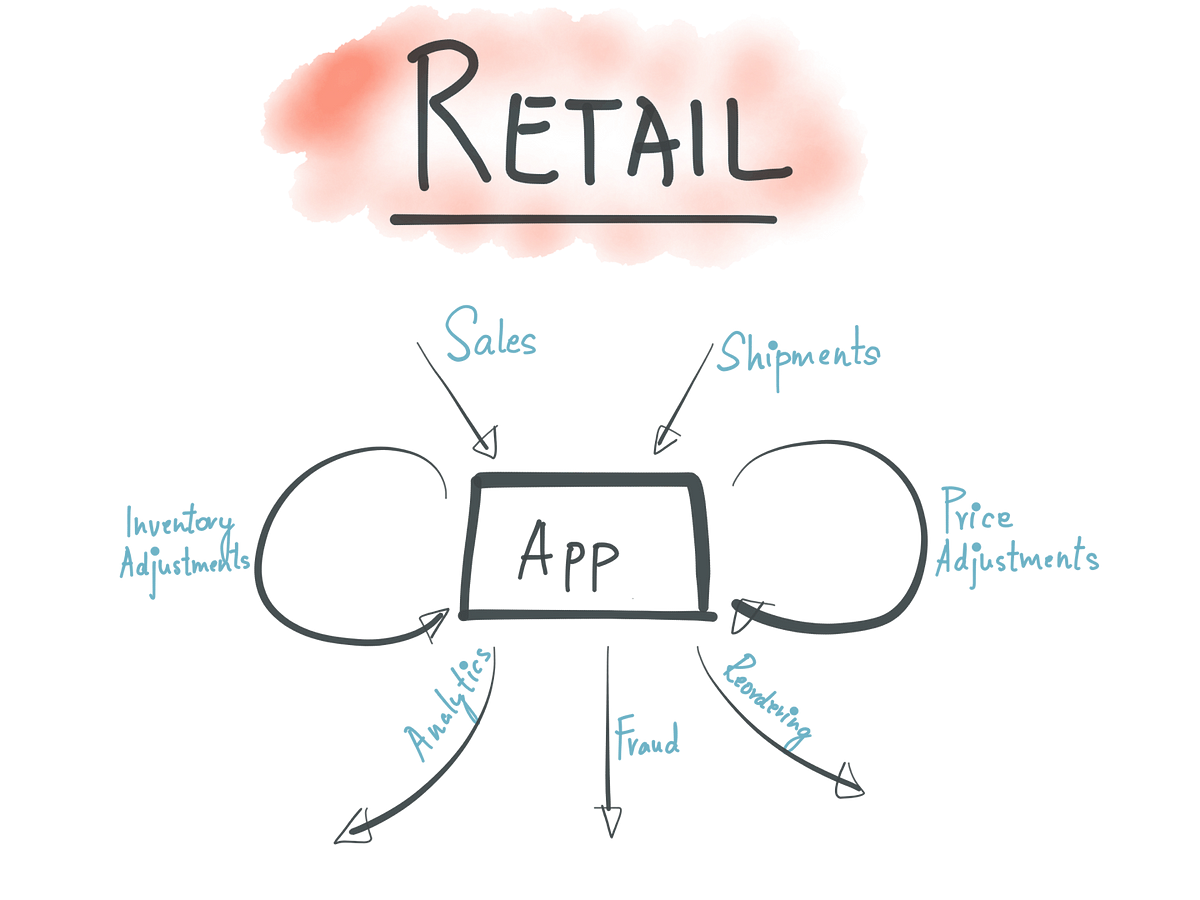
样本零售应用程序体系结构
考虑一个实体零售商的应用程序,该应用程序管理所有商店的库存; 当新货到达或发生新销售时,它会更新库存表,并且要知道商店库存的当前状态,它会查询库存表。
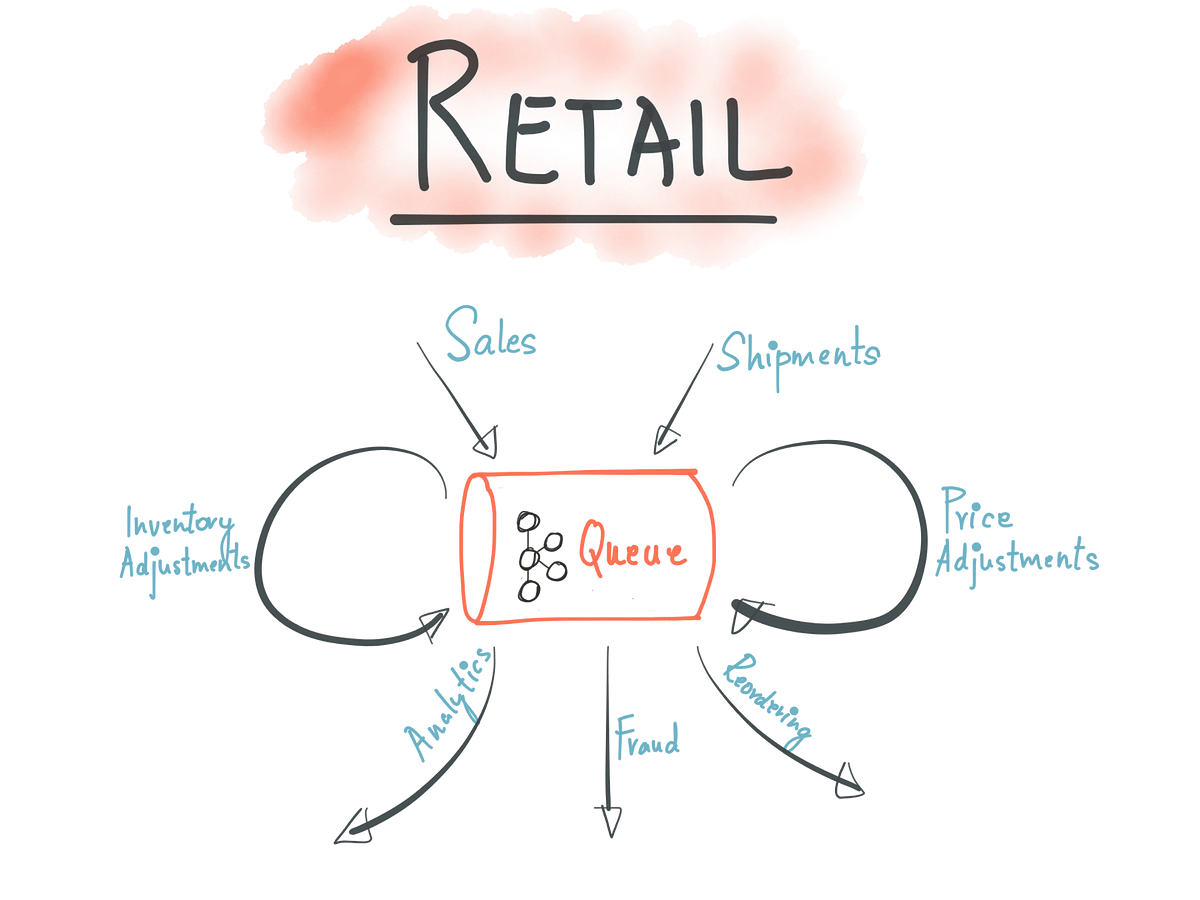
具有事件源的零售应用程序架构—由Kafka提供支持
如果我们将事件采购体系结构模式应用于此Inventory应用,则新的货件将在Shipments Kafka主题中表示为事件。 同样,新销售将以Sales Kafka主题(可能由Sales应用程序编写)中的事件表示。 为简单起见,我们假设“销售”和“发货”主题中的Kafka消息的关键字是{商店ID,商品ID},而值是商店中商品数量的计数。
Inventory应用程序内的事件处理程序被建模为Kafka Streams拓扑,该拓扑连接了Sales和Shipments Kafka主题。 联接操作创建并更新状态存储库InventoryTable,该状态存储库表示以连续方式更新的清单的当前状态。

连接操作的内部结构以构建库存表
可以将这样的应用程序部署在不同计算机上的多个实例中(如下图所示)。而且,InventoryApp的每个实例都承载InventoryTable的分片的子集,其中包含此联接操作的结果。当用户查询InventoryApp来了解商店中某商品的当前库存数量时,
- 运行InventoryApp的随机服务器收到一个请求:GET / inventory / stores / {store id} / items / {item id} / count
- 它使用Kafka Streams实例上的metadataForKey()API来获取商店的StreamsMetadata和密钥。 StreamsMetadata保存Kafka Streams拓扑中每个商店的主机和端口信息。应用程序使用StreamsMetadata检查该实例是否具有包含关键字{store id,item id}的InventoryTable分区。如果是这样,它将使用本地Kafka Streams实例上的store(“ InventoryTable”)api来获取该商店并对其进行查询。
- 如果不是,它将为当前持有包含{store id,item id}的Kafka分区的实例找到主机/端口,并转发GET请求到/ inventory / stores / {store id} / items / {item id} / count到在该主机上运行的InventoryApp实例。
- 向用户返回库存盘点
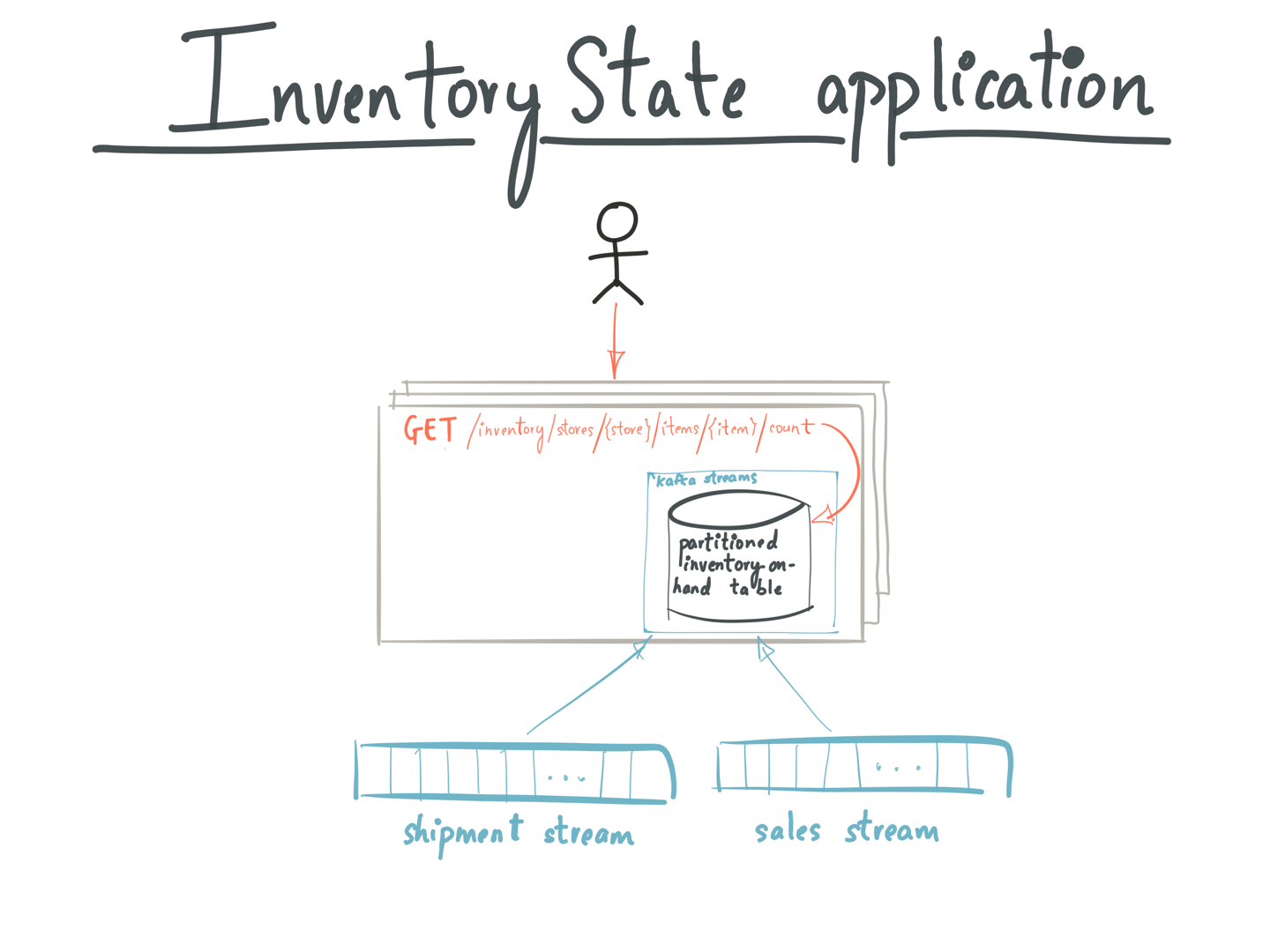
在Kafka Streams中使用交互式查询的InventoryState应用程序
要了解有关“交互式查询”功能的更多信息,请阅读其文档。除了这些资源之外,请参阅Capital One的演示文稿,该演示文稿将在实践中应用本文中介绍的一些思想,并概述使用Kafka Streams的基于REST,事件源,CQRS和响应流处理的应用程序体系结构。
如上例所示,存储和查询本地状态对于某些有状态应用程序可能没有意义。有时,您想将状态存储在您知道并信任的外部数据库中。例如,在上面的示例中,您可以使用Kafka Streams通过join操作来计算库存数量,但选择将结果写入外部数据库并查询。
但是,值得注意的是,构建具有查询本地状态的有状态应用程序有许多优点,如本文前面所述。
结论性思想
事件寻源为应用程序使用零损失协议记录其固有的不可避免的状态变化提供了一种有效的方法。这意味着恢复既简单又高效,因为它完全基于日记或像Kafka这样的有序日志。 CQRS更进一步,将原始事件变成可查询的视图;精心形成的与其他业务流程相关的视图。 Kafka的Streams API提供了以流方式创建这些视图所需的声明性功能,以及可扩展的查询层,因此用户可以直接与此视图进行交互。结果是在Apache Kafka上构建了适用的基于事件源和CQRS的应用程序体系结构;允许此类应用程序还利用Kafka的核心竞争力-性能,可伸缩性,安全性,可靠性和大规模采用。
最重要的是,以这种方式构建有状态的应用程序可使组织最终获得松散耦合的应用程序体系结构-一种具有弹性和可伸缩性,更易于故障排除和升级的应用程序体系结构,最重要的是,该体系结构具有前向兼容性。
对更多感兴趣?
如果您喜欢本文,则可能需要继续使用以下资源,以了解有关Apache Kafka上流处理的更多信息:
- 使用Apache Kafka的流SQL引擎KSQL入门,并遵循Stream Processing Cookbook中的各种教程和示例快速入门。
- 开始使用Kafka Streams API来构建自己的实时应用程序和微服务。
- 观看我们的分为三部分的在线讲座系列,了解KSQL如何工作的来龙去脉,并学习如何有效地使用它来执行监视,安全性和异常检测,在线数据集成,应用程序开发,流ETL等。
- 通过Docker浏览有关Kafka Streams API的Confluent教程,并使用我们的Confluent演示应用程序。
原文:https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
本文:https://pub.intelligentx.net/node/788
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 265 次浏览
【事件驱动架构】事件管理状态
虽然事件驱动架构的主要关注点是处理事件,但在某些情况下,您需要将事件保留用于后处理和其他应用程序的查询。事件主干具有内置事件日志,可用于存储和回复发布到主干的事件。但是,考虑到事件驱动解决方案的全部范围,可以支持其他用例和商店类型:
- 针对分析进行了优化的事件存储
- 事件源作为记录跨分布式系统的状态更改和更新的模式
- 命令查询响应分离(CQRS)作为一种优化,可以跨不同的存储区分更新和读取
当系统状态发生变化时,应用程序会发出有关状态更改的通知事件。任何有兴趣的人士都可以成为活动的消费者并采取必要的行动。状态更改事件按时间顺序存储在事件日志或事件存储中。事件日志或商店成为事实的主要来源。通过在将来的任何时间重新处理事件,可以将系统状态重新创建到某个时间点。状态变化的历史成为业务的审计记录,并且通常是数据科学家获取业务洞察力的有用数据来源。

在某些情况下,事件源模式通过使用事件日志和Kafka流完全在事件主干内实现。但是,您还可以考虑使用外部事件存储来实现模式,该存储提供了如何访问和使用数据的优化。例如,IBM®Db2®EventStore可以提供连接到主干的处理程序和事件存储,并为数据的下游分析处理提供优化。
在操作中,事件存储将按时间顺序保留具有时间戳的对象的所有状态更改事件,从而为对象创建时间序列的更改。您可以通过重播时间系列中的事件来派生对象的当前状态。事件存储只需要存储三条信息:
- 事件或聚合的类型
- 事件的序列号
- 数据作为序列化blob
您可以添加更多数据来帮助进行诊断和审计,但核心功能只需要一组很小的字段。这种方法导致数据设计可以大大优化,以便附加和检索记录序列。
命令查询责任分离(CQRS)
事件日志会导致更多工作来支持业务查询,因为它需要将事件转换为适合查询的应用程序状态。
CQRS应用模式经常与事件源有关。在此模式中,您将命令操作与查询/读取操作分开。使用事件源模式和CQRS,您通常会得到一种模式,其中更新作为状态通知事件(状态更改)完成。这些事件将保留在事件日志或存储中。在读取方面,您可以将状态保留在针对其他应用程序可能查询或读取数据的方式进行优化的不同存储中。

事件溯源,CQRS和微服务
随着微服务的采用,你有一个明确分离的状态,以便微服务与自己的状态有关。此外,通过使用事件源,您可以创建难以查询的历史记录日志。当您需要实现需要从多个服务加入数据的查询时,就会遇到挑战。要解决服务编排问题,您可以使用API组合或CQRS模式。
对于API组合,查询由与所有其他微服务集成的操作支持,并且可能转换数据以组合结果。使用此模式,您需要评估聚合要求,因为它们可以显着影响性能。您可能需要评估此API组合组件的放置位置。该组件可以是API网关,后端前端(BFF)的一部分,甚至是它自己的微服务。
另一个答案是实现CQRS模式,其中状态更改由相关业务对象作为事件发布。每个更改都保留在事件日志或事件存储中,更高级别的操作将订阅每个事件,并将数据保留在可查询数据存储中。
下一步是什么
阅读有关CQRS模式的更多信息。
讨论;加入知识星球【首席架构师圈】
- 53 次浏览
【事件驱动架构】事件驱动的云原生应用程序
事件驱动的体系结构必须跨越您的应用程序平台。开发人员构建与事件交互的应用程序,并且应用程序是事件驱动的。也就是说,它们都通过使用事件主干来生成和使用事件。在这种情况下,将事件主干视为微服务网格的一部分,提供微服务之间的发布和订阅通信,并支持松散耦合的事件驱动的微服务。
微服务是云原生平台上的首选应用程序架构。随着企业成为事件驱动,事件驱动模式需要扩展到您的微服务应用程序中。您的微服务仍在对着名的微服务进行REST调用。但是,他们必须回应并发送事件。在事件驱动的条件下,他们需要成为事件生产者和消费者来强制解耦。
事件主干:微服务的发布和订阅通信和数据共享
随着微服务的采用,对服务之间同步通信的关注正在增加。服务网格包(如Istio)可帮助您管理此同步通信环境中的通信,服务发现,负载平衡和可见性。
利用事件驱动的微服务,通信点成为事件主干的发布 - 订阅层。通过采用基于事件的方法实现微服务之间的相互通信,微服务应用程序自然响应(事件驱动)。这种方法增强了微服务的松散耦合性质,因为它使生产者和消费者脱钩。它还可以通过事件日志跨微服务共享数据。
在开发微服务应用程序时,这些事件类型特征是越来越重要的考虑因素。实际上,微服务应用程序是同步API驱动和异步事件驱动通信方式的组合。从实现视图中,使用一组已建立的模式,例如每服务数据库,事件源,命令查询责任分离(CQRS)和Saga。

带容器的事件驱动应用程序
虽然使用IBM®CloudFunctions的无服务器方法提供了简化的基于事件的编程模型,但大多数微服务应用程序是为基于容器的云原生堆栈开发和部署的。在云原生景观中,Kubernetes是容器编排的标准平台,也是事件驱动架构中容器平台的基础。
事件主干是用于微服务的共享数据的发布 - 订阅通信提供者和事件日志。在这种情况下,微服务是通过使用主题开发为骨干事件的直接消费者和生产者。此环境中的额外工作是管理消费者实例以响应事件流的需求。您必须确定需要运行多少消费者微服务实例才能跟上或始终可用于运行微服务以响应到达事件。
事件驱动的微服务模式
采用发布和订阅作为微服务通信骨干至少涉及以下模式:
- 通过子域分解:事件驱动的微服务仍然是微服务,因此您需要找到它们。域驱动子域的使用是识别和分类业务功能的一种好方法,因此也就是微服务。使用事件风暴方法,聚合有助于找到那些负责的子域。
- 每个服务一个数据库:此模式强制每个服务私有地保留数据,并且只能通过其API访问。
- Saga模式:微服务在其控制范围内发生某些事件时发布事件,例如他们负责的业务实体中的更新。对其他业务实体感兴趣的微服务订阅这些事件,并且当微服务接收到这样的事件时可以更新其自己的状态和业务实体。业务实体密钥必须是唯一且不可变的。
- 事件溯源:此模式将业务实体的状态保持为一系列状态改变事件。
- CQRS有助于将查询与命令分开,并解决具有跨微服务边界的查询。
其他考虑因素
- 业务事务跨越服务,并且是一系列步骤。每个步骤都由微服务支持,微服务负责更新自己的实体,从而最终实现数据的一致性。
- 事件主干必须保证事件至少传递一次。微服务负责管理它们与流源的偏移量,并通过检测重复事件来处理不一致性。
- 在微服务级别,更新数据和发出事件需要是原子操作,以避免在更新数据源之后和事件发出之前服务失败时的不一致。此操作可以通过向微服务数据源添加eventTable并使事件发布者定期读取此表并在发布时更改事件的状态来完成。另一种解决方案是让数据库事务日志读取器或挖掘器负责在日志中的新行上发布事件。
- 另一种避免两阶段提交和不一致的方法是使用事件存储或事件源模式来跟踪业务实体上的操作,并使用足够的数据来重建数据。事件正在成为描述业务实体状态变化的事实。
下一步是什么
-
Take the Deploy a microservices app on IBM Cloud by using Kubernetes tutorial.
-
Get answers to your questions about IBM Cloud Kubernetes Service: Manage apps in containers and clusters on cloud.
讨论:加入知识星球【首席架构师圈】
- 90 次浏览
【事件驱动架构】事件驱动的参考架构
云原生事件驱动架构必须至少支持以下功能:
- 通讯和持久化事件
- 对事件采取直接行动
- 处理事件流以获得洞察力和智能
- 提供事件驱动的微服务和功能之间的通信
在事件驱动的参考架构中,事件主干提供组件之间的连接:

原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture/reference-architecture
讨论: 加入右边知识星球【首席架构师圈】
- 147 次浏览
【事件驱动架构】事件骨干
事件主干是事件驱动架构的中心。骨干为事件通信和持久层提供了以下功能:
- 事件生成者和使用者之间的发布和订阅事件通信
- 用于在特定时间段内保留事件的事件日志
- 重播事件
- 来自消费者的订阅
事件主干是事件驱动架构中的通信层。它提供事件驱动功能之间的连接。在云原生架构中,它成为事件驱动的微服务的发布 - 订阅通信层。
事件主干可以使用两种类型的相关技术:消息代理和事件日志。您可以使用两种技术类型通过使用发布和订阅模型来实现事件通信样式。但是,请考虑事件驱动解决方案中经常使用的其他功能:
- 事件记录为时间顺序“事件发生”记录事件(事实来源)
- 直接重播事件
- 事件源作为记录分布式系统中状态变化的一种方式
- 以编程方式访问连续事件流
基于事件日志的技术可以提供支持所有这些更广泛功能的中央组件,而消息代理必须与其他组件一起扩展。

定义事件主干
这些功能对事件主干至关重要:
- 提供发布和订阅通信
- 支持许多消费者,作为共享的中心真理来源
- 存储事件一段时间(事件日志)
- 为历史演变应用程序实例提供历史事件的重播
- 提供对连续事件流数据的编程访问
- 具有高度可扩展性和对云部署级别的弹性
鉴于可用技术以及围绕这些技术的采用量和社区活动,Kafka可以成为事件主干的有效开源技术基础。 有关更多信息,请参阅Apache Kafka项目。
下一步是什么
Learn how to deploy real-time event processing and analytics on IBM Cloud Private by using a Kafka open source distribution or IBM Event Streams.
原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture/event-driven-event-backbone
讨论:加入知识星球【首席架构师圈】
- 57 次浏览
【事件驱动架构】从Apache Kafka消费者再平衡的渴望到更聪明
每个人都希望他们的基础设施具有高可用性,ksqlDB也不例外。但是,像高可用性这样的关键特性,必须经过深思熟虑和严格的设计才能实现。我们认真考虑了如何在保证最少一次和精确一次处理的同时实现这一点。要了解我们是如何做到这一点的,现在是时候剥开ksqlDB下面的层,用Apache Kafka®再平衡协议来动手了。
消费者团体和再平衡协议
Kafka消费者组协议允许独立的资源管理和负载平衡,这是任何分布式系统对于应用程序开发人员和操作人员都必须具备的。通过指定一个代理(Broker)作为组的联络点,可以在组协调器中隔离所有组管理,并允许每个使用者只关注使用消息的应用程序级工作。
组协调器最终负责跟踪两件事:订阅主题的分区和组中的成员。对这些内容的任何更改都要求该组作出反应,以确保所有主题分区都是由其使用的,并且所有成员都是积极使用的。因此,当它检测到这些变化时,组织协调者就会拿出它唯一的工具:消费者组再平衡。
再平衡的前提简单而自我描述。所有成员被告知重新加入组,当前资源被刷新并“平均地”重新分配。当然,每个应用程序都是不同的,这意味着每个消费群体也是不同的。“均匀”平衡的负载可能意味着不同的事情,甚至对于共享相同代理的两个使用者组的组协调器也是如此。认识到这一点,再平衡协议早就被推到客户端,并完全从组协调器中抽象化了。这意味着不同的Kafka客户端可以插入不同的再平衡协议。
这篇博客文章主要关注消费者客户端和构建在消费者客户端的Kafka Streams。Konstantine Karantasis在他的博客文章《Apache Kafka中的增量合作再平衡:当你可以改变世界时,为什么要停止它》中详细讨论了Kafka Connect的协议。
为了让客户指定一组没有通信用户所遵循的协议,将选择一个成员作为重新平衡的组长,然后再平衡将分两个阶段进行。在第一阶段,组协调器等待每个成员加入组。这需要发送一个恰当命名的JoinGroup请求,其中每个成员编码一个订阅,包括任何感兴趣的主题和客户端定义的用户数据。订阅由代理合并,并在JoinGroup响应中发送给组长。
leader解码订阅,然后计算并编码分配给每个使用者的分区。然后在leader的SyncGroup请求中发送给组协调器。这是重新平衡的第二阶段:所有成员必须向代理发送一个SyncGroup请求,然后代理在SyncGroup响应中向它们发送分区分配。在整个再平衡阶段,成员之间从不直接交流。它们只能通过与经纪端组协调器对话来相互传播信息。
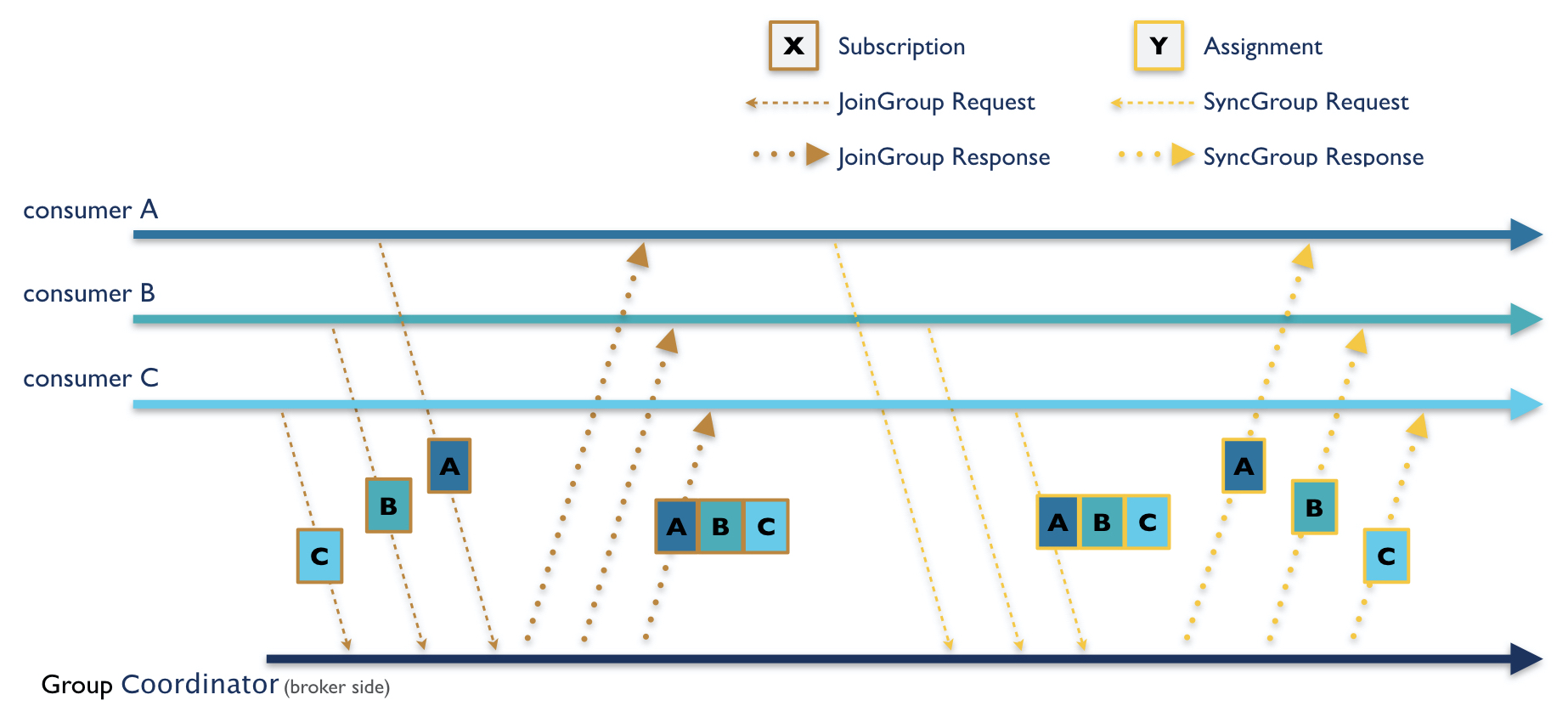
图1所示。有三个消费者的两阶段再平衡协议。在这种情况下,消费者C是组长。
使用者客户端进一步将给使用者的分区分配抽象为一个可插入的接口,称为ConsumerPartitionAssignor。如果分区转让者满足其消费者到所有分区的一对多映射契约,那么再平衡协议将负责其余的工作。这包括管理分区所有权从一个使用者到另一个使用者的转移,同时保证一个组中没有一个分区同时属于多个使用者。
这条规则听起来很简单,但在分布式系统中可能很难满足:“在同一时间”这个短语可能会在您的头脑中引起警报。
因此,为了使协议尽可能简单,迫切重新平衡协议诞生了:每个成员都需要在发送JoinGroup请求并参与重新平衡之前撤销其所有的分区。因此,该协议强制执行同步屏障;当JoinGroup响应被发送到leader时,所有的分区都是无主的,并且分区分配者可以自由地按照自己的意愿分配它们。
就安全性而言,这一切都是好的,但这个“停止世界”协议有严重的缺点:
- 在再平衡期间,该集团的任何成员都不能做任何工作
- 重新平衡持续时间随着分区计数的变化而变化,因为每个成员必须撤销并恢复分配的每个分区
每一个问题本身就已经够糟糕的了。综合起来,它们给消费者组协议的用户带来了一个严重的问题:在整个再平衡期间,所有分区和组的所有成员都将停机。这意味着从发送JoinGroup请求到接收SyncGroup响应,每个使用者都无所事事,如图2所示。
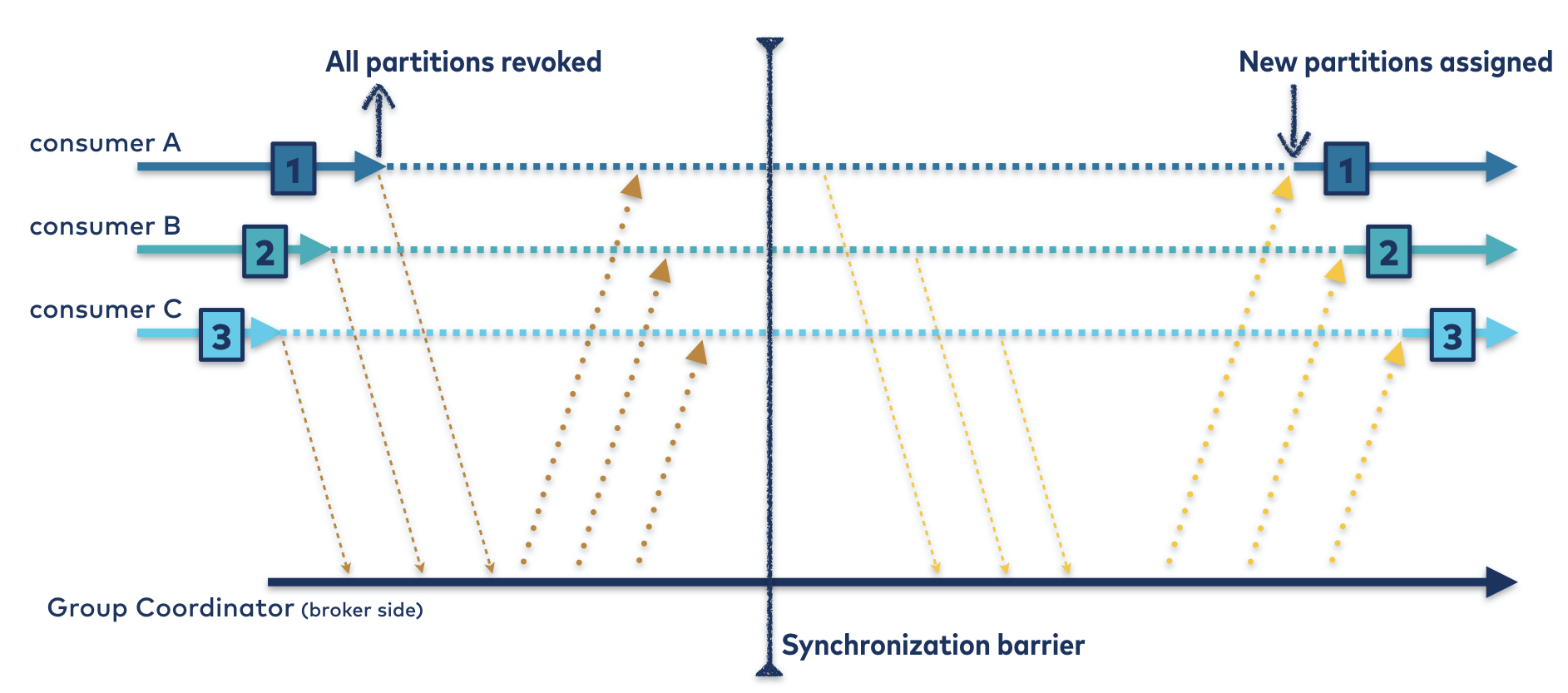
图2。迫切的再平衡协议。即使每个分区被重新分配给它的原始所有者,所有三个使用者都无法在虚线所指示的持续时间内使用分区。
虽然这在不经常重新平衡和资源很少的环境中是可以接受的,但大多数应用程序不属于这一类。我们已经做出了重大改进,减少了不稳定环境中不必要的再平衡。但只要有资源可管理,就需要重新平衡。也许我们可以通过更智能的客户端协议来减轻再平衡的痛苦。
理想的再平衡协议
要解决这个问题,请后退一步,问问在理想世界中最优的再平衡协议是什么样子的。设想一个没有节点故障、网络分区和竞争条件的世界——很好,对吗?现在考虑一下当组成员来来往往时重新分配分区的最简单方法。以这个特定的向外扩展的例子为例:
消费者A和B使用一个三分区主题。两个分区分配给A,一个分配给b。注意到负载不均匀,您决定添加第三个使用者。消费者C加入了这个群体。你希望这种再平衡如何发挥作用?
您所要做的就是将一个分区从消费者A移动到消费者c。所有三个消费者都必须重新加入组以确认它们的活动成员身份,但是对于消费者B来说,应该停止参与。在这个理想的世界中,使用者B没有理由停止处理它的分区,更不用说撤销和/或恢复它了。这意味着消费者B不会停机,如图3所示。
当然,消费者A必须撤销一个分区,但只有一个分区。一旦它放弃了它的第二个分区,它就可以愉快地返回来处理它的剩余分区。在整个重新平衡过程中,用户A并没有处于闲置状态,相反,它的停机时间只会持续到撤销一个分区所需的时间。
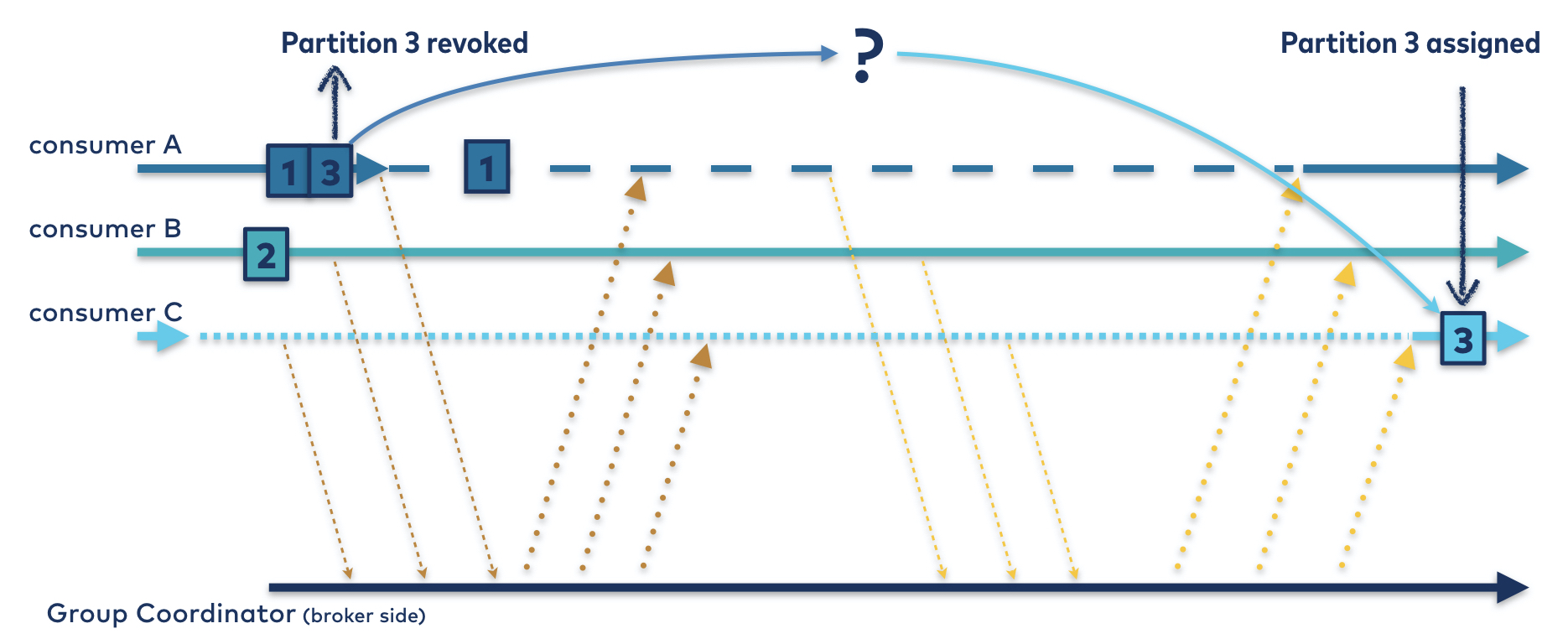
图3。你想要的再平衡协议。分区1和分区2被持续使用,分区3仅在将所有权从使用者A转移到C时停止工作。
总而言之,最佳再平衡只涉及那些需要移动以创建平衡分配的分区。您可以从最初的分配开始,并逐步移动分区以到达新的分配,而不是完全清除旧的分配以重新开始。
在理想世界和这里之间
不幸的是,回到现实世界的时候到了。消费者崩溃,不同步,拒绝合作。在这个美好的愿景完全消失之前,你所能希望的就是有一天能回来的具体计划。所以为什么不掸去旧地图绘制工具的灰尘,试着从你现在使用的渴望协议映射到一个更合作的协议呢?
要规划这一进程,你首先需要了解阻碍你前进的是什么。这又回到了上面介绍的规则:任何时候都不能有两个使用者声明同一分区的所有权。任何时候,只要放下同步屏障,就会面临风险。请记住,当前维护屏障的方法是强制所有成员在重新加入组之前撤销所有分区。
是不是太严格了?你大概可以猜到答案是肯定的。毕竟,这个障碍只需要对正在转移所有权的分区实施。重新分配给同一使用者的分区很容易满足该规则。其他分区则带来了挑战,因为使用者事先不知道他们的哪些分区将被重新分配到其他地方。显然,它们必须等待分区转让者确定分区到使用者的新映射。但是,一旦新的分配被发送到组的所有成员,同步就结束了。
如果要将一个分区从使用者a迁移到使用者B,那么B必须等待a放弃所有权后,B才能获得该分区。但是B无法知道A何时撤销了分区。请记住,吊销可以像从内存列表中删除分区那样简单,也可以像提交偏移量、刷新磁盘和清除所有相关资源那样复杂。例如,Kafka Streams用户启动状态严重的应用程序时非常清楚撤销一个分区需要多长时间。
显然,您需要某种方法让使用者指示何时重新分配其旧分区是安全的。但消费者只能在再平衡期间进行沟通,而最近一次再平衡刚刚结束。
当然,没有法律说你不能连续进行两次再平衡。如果你能让每次再平衡都不那么痛苦,那么第二次再平衡听起来就没那么糟糕了。这能以某种方式杠杆化到你想去的地方吗?渴望实现再平衡的隧道尽头是否有一线光明?
增量合作再平衡协议
好消息!您已经拥有了形成安全可靠的再平衡协议所需的所有组件。让我们退后一步,看看这种新的合作再平衡。
与前面一样,所有成员必须先发送一个JoinGroup请求。但这次,每个人都可以保留自己所有的分区。每个使用者并不撤销它们,而是在其订阅中对它们进行编码并将其发送给组协调器。
组协调器组装所有订阅并将它们发回给组组长,与前面一样。leader按照自己的意愿将分区分配给使用者,但是它必须从分配中删除所有正在转移所有权的分区。转让人可以利用每个订阅中编码的拥有分区来实施该规则。
从那里,新的分配—减去当前拥有的任何将要撤消的分区—传递给每个成员。使用者接受当前分配的差异,然后撤销新分配中没有出现的分区。同样地,他们将在分配中添加任何新的分区。对于出现在新旧分配中的每个分区,它们不需要做任何事情。很少有再平衡需要在用户之间进行分区迁移,因此在大多数情况下,几乎不需要做任何事情。
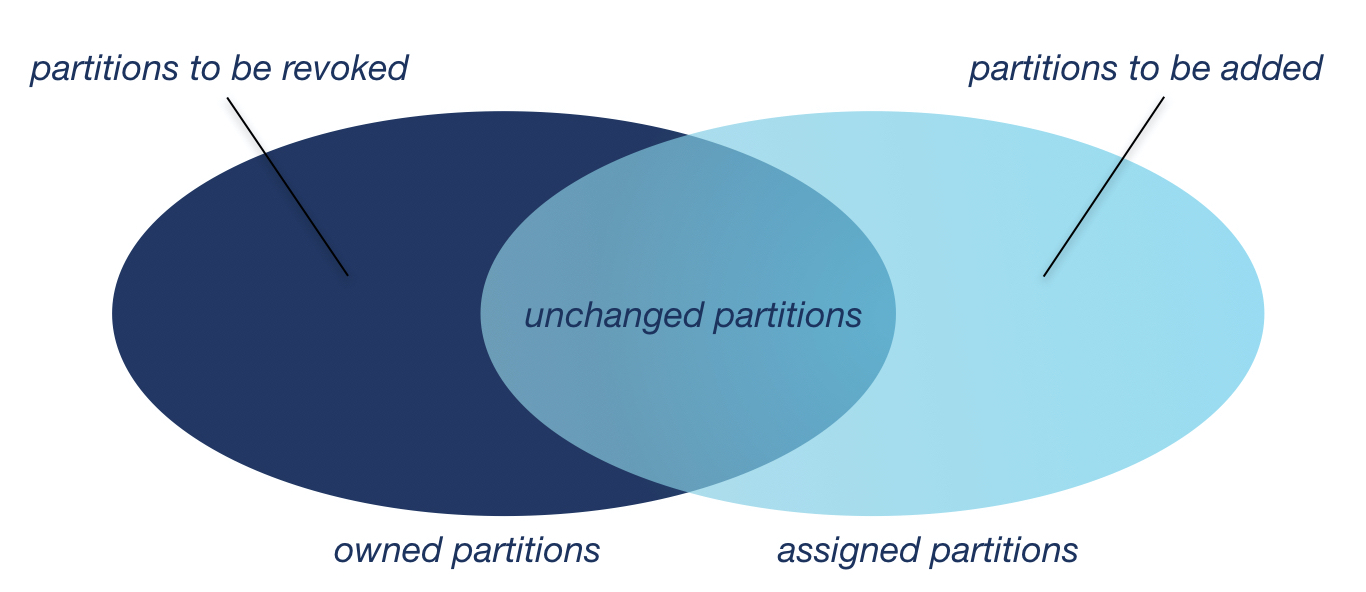
图4。分区的维恩图。既然可以撤销需要撤销的,为什么要撤销一切?
然后,被撤销分区的任何成员重新加入组,触发第二次再平衡,以便可以分配被撤销的分区。在此之前,这些分区是无主的和未分配的。同步障碍根本没有被消除;结果是,它只需要被移动。
在进行后续的再平衡时,所有已成功撤销的分区根据定义将不在已编码的拥有分区中。分割转让人可以自由地将它们分配给其合法的所有者。
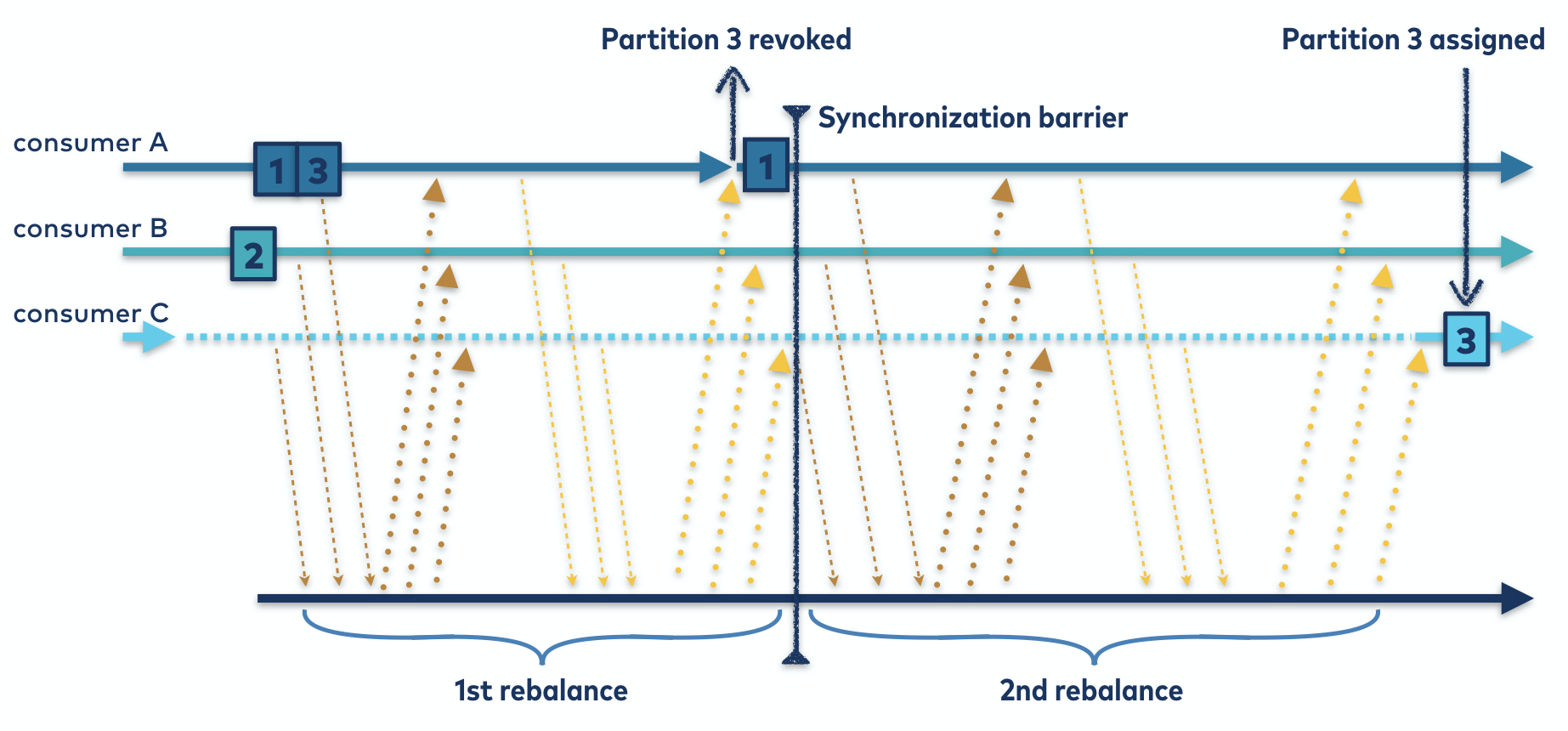
图5。合作再平衡协议。通过进行第二次再平衡以强制同步障碍,可以避免撤销所有使用者的所有分区。
DIY合作再平衡
您可能已经猜到,这取决于分区转让人来完成这项工作。不太明显的是,这只取决于分区转让者——您可以通过简单地插入一个协作转让者来开启协作再平衡。
幸运的是,工具箱中已经添加了一个新的开箱即用分区转让者:CooperativeStickyAssignor。你可能对现有的粘性分派很熟悉——CooperativeStickyAssignor更进一步,它既粘性又具有协作性。
我们引入这个assignor是为了使Apache Kafka中的协作再平衡像设置配置一样简单,而不需要引入另一个客户端配置。但更微妙的动机在于把它包装成一个粘性转让者。通过这样做,我们可以保证让与人很好地遵守合作协议。
这意味着什么?为什么它如此重要?以RoundRobinAssignor为例,它不能很好地发挥合作再平衡。每次组成员关系或主题元数据更改时,轮询调度转让者生成的分配都会更改。它不试图粘贴返回分区到它们以前的所有者。但请记住,这是一个渐进的合作再平衡协议。整个算法通过一个分区一个分区地让分配增量地从旧的分配到新的分配来工作。如果新的赋值与之前的完全不同,那么增量变化就是整个赋值。你只会回到你开始的那个热切的协议,但是有更多的重新平衡。
所以粘性和合作在新转让人中同样重要。而且,由于订阅中编码了拥有的分区,粘贴就像以前一样容易。
除了具有粘性外,CooperativeStickyAssignor还必须确保从分配中删除所有必须撤销的分区。任何声称支持合作协议的转让人都必须履行该合同。所以,如果你想自己动手做一个定制的合作转让人,你可以从零开始写一个,甚至改编一个老的渴望转让人;只要确保它符合新规定就行了。
对于那些希望通过实时升级或转让者交换切换到新协议的人,最后要警告的是:遵循推荐的升级路径。滚动升级将触发重新平衡,你不希望陷入一半人遵循旧协议,另一半人遵循新协议的中间。有关如何安全升级到协作再平衡的更多细节,请参阅发布说明。
你能在Kafka流DIY吗?
如果你是一个Kafka流用户并且已经做到了这一步,你可能会想知道这一切是如何影响你的。当您不能选择使用哪个分区转让人时,您如何使用这个新协议?
幸运的是,你不必这么做。重新平衡协议的管理和选择嵌入到StreamsPartitionAssignor中,现在在默认情况下打开协作重新平衡。您只需要启动应用程序并观察它的运行。事实上,你甚至不需要去看它——但是监控你的应用程序始终是一个很好的练习。
那么这对流意味着什么呢?为了理解什么发生了改变,什么没有,让我们跟随一个虚构的卡夫卡流开发者的冒险——叫他弗朗茨。Franz正在运行一个使用Kafka流2.3版本的应用程序。他的拓扑使用了许多本地状态存储,他的输入主题有数百个分区,并且他的应用程序依赖于交互查询(IQ)特性在处理期间查询这些状态存储中的数据。
事情似乎进展顺利,但由于负责任的监控,Franz注意到他的实例正在以最大容量运行。是时候扩大规模了。不幸的是,添加新实例需要整个组重新平衡。Franz很沮丧地看到,每个实例已经停止处理每个分区,并且在重新平衡期间交互查询被禁用。此外,再平衡需要很长时间,考虑到需要关闭和重新打开许多州商店和分区,这一点也不奇怪。但是,他们真的需要吗?
幸运的是,他看到Kafka 2.4引入了一个新的再平衡协议,他希望这将有所帮助。Franz升级了他的Streams应用程序,小心地遵循发布说明中列出的特定升级路径,以确保安全滚动升级到合作协议。一旦群体稳定下来,它就试图再次扩大规模。
这一次,情况好多了。并不是每个商店都关闭并重新开业,只有在新实例上的少数分区被撤销。Franz还发现IQ在所有运行的实例上都是可用的,并且那些仍然在恢复数据到其状态存储的实例能够在整个再平衡过程中继续这样做。备用副本还会继续使用其存储的changelog主题,这使它们有时间赶上活动副本,并在发生故障时用很少的恢复时间接管。
更妙的是,当Franz升级到Kafka的最新版本时,他发现即使是正在运行的活动任务也可以在整个平衡过程中继续处理新记录,并且整个应用程序一直保持运行。他不再被迫在扩展和避免应用程序范围内停机之间做出选择。
渴望与合作:谁赢了?
尽管合作进行再平衡有明显的优势,但具体数字总是有最后发言权。因此,我们运行了一个基准来定量地比较两种再平衡协议并确定赢家。
我们用10个实例运行了一个简单的有状态Kafka流应用程序的基准测试。为了模拟一个常见的重新平衡触发场景,我们在组达到稳定运行状态后执行滚动反弹。应用程序在一段时间内的总吞吐量如下所示。这里的吞吐量是用每秒处理的记录数来度量的,通过误差条对10个实例进行汇总,以反映它们的方差。单从吞吐量的下降就可以很明显地看出滚动反弹的开始和结束。
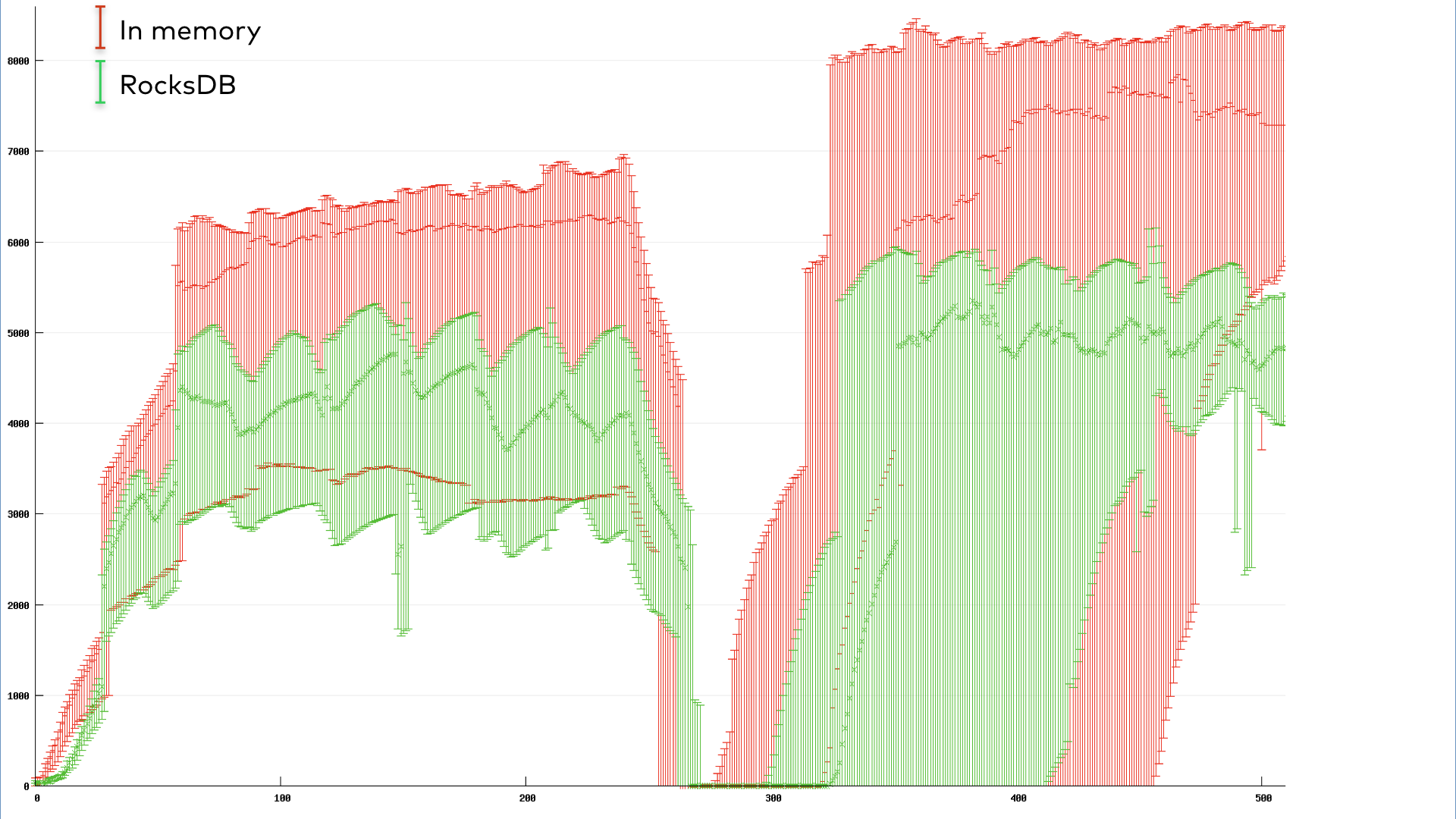
图6。吞吐量(记录/秒)与时间(秒)对于经历滚动反弹的10个实例的迫切再平衡流应用程序。
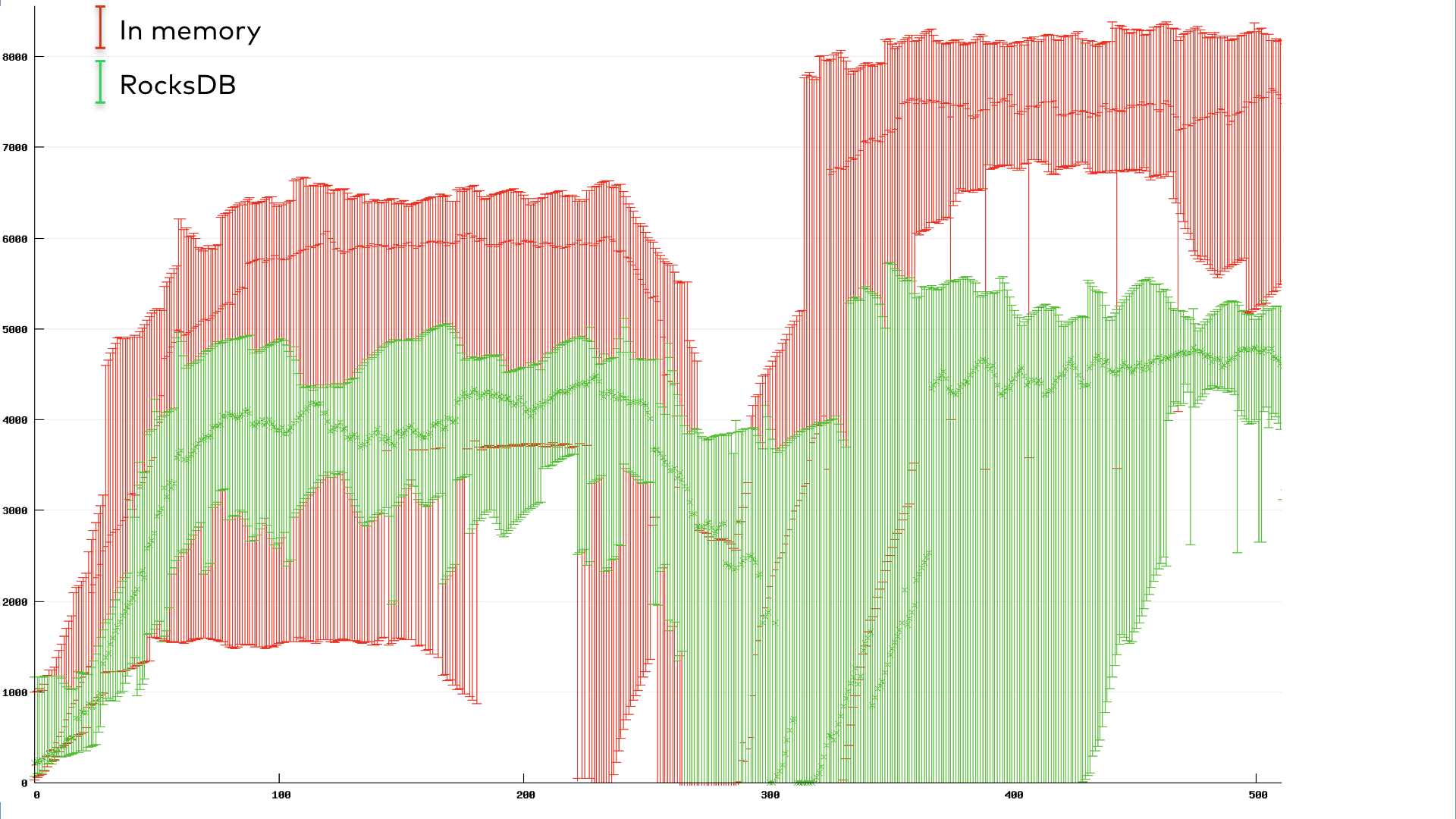
图7。吞吐量(记录/秒)与时间(秒)对一个10个实例的协作再平衡应用程序进行滚动反弹。
绿色对应使用默认rocksdb支持的状态存储的应用程序,而红色对应内存中存储。由于重新平衡开销,协作RocksDB应用程序在弹跳期间的吞吐量只有轻微下降。有趣的是,协作内存中的应用程序似乎在吞吐量上仍然受到很大的影响,尽管它的恢复速度确实比急切的情况要快。这反映了在选择备份状态存储时的一种内在权衡:内存中的存储在稳定状态下速度更快,但在重启时遭受更大的挫折,因为它必须将所有临时数据从changelog主题恢复到内存中。
图6和图7中的图形为合作协议提供了一个视觉上引人注目的情况。但数据同样惊人:eager协议的暂停时间为37138毫秒,而cooperative协议的暂停时间仅为3522毫秒。当然,数字会因情况而异。我们鼓励您在您的应用程序中尝试合作再平衡,并自己衡量差异。
结论
从一开始,停止世界的再平衡协议就困扰着Kafka客户端的用户,包括Kafka Streams和堆栈上的ksqlDB。但是,重新平衡对于有效、均匀地分配资源是至关重要的,随着越来越多的应用程序迁移到云上并需要动态伸缩,这种情况只会越来越普遍。在渐进式的合作再平衡中,这未必会造成伤害。
基本的协作再平衡协议是在Apache Kafka 2.4版本中引入的。在版本2.5中添加了轮询新数据和释放增量协作再平衡的全部力量的能力。如果您一直生活在频繁重新平衡的阴影下,或者担心向外扩展会导致停机,那么请下载Confluent平台,它构建在Kafka的最新版本之上。
改善Kafka流和管理大量状态的ksqlDB应用程序可用性的进一步工作即将到来。使用KIP-441,在切换新实例之前,我们将开始在新实例上预热任务,从而缩小另一个随状态量而增大的可用性差距。与增量的协作再平衡相结合,它将允许您启动真正可伸缩和高可用性的应用程序——即使在再平衡期间也是如此。
无论您是从头开始构建一个普通的消费者应用程序,还是使用Kafka流进行一些复杂的流处理,还是使用ksqlDB解锁新的强大用例,消费者组协议都是应用程序的核心。这使得ksqlDB应用程序能够伸缩并平稳地处理故障。偷窥背后的真相是很有趣的,但是再平衡协议最好的部分是你不必这样做。作为用户,您所需要知道的是,您的ksqlDB应用程序可以在不牺牲高可用性的情况下容错。
原文:https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/
本文:http://jiagoushi.pro/node/1117
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 106 次浏览
【事件驱动架构】何时使用RabbitMQ或Apache Kafka
如果你问自己是否Apache Kafka比RabbitMQ更好或RabbitMQ是否比Apache Kafka更可靠,我想在这里阻止你。本文将从更广泛的角度讨论这两种情况。它关注的是这两个系统提供的功能,并将指导您做出正确的决定,决定何时使用哪个系统。
web上的一些文章让Apache Kafka在RabbitMQ面前大出风头,而另一些文章则恰恰相反。我们中的很多人可能会因为听了大肆宣传,跟着人群跑而认罪。我觉得重要的是要知道是使用RabbitMQ还是Kafka取决于您项目的需求,只有当您在合适的场景中使用了正确的设置,才能进行真正的比较。
我和84codes在业界工作了很长时间,通过服务CloudAMQP为RabbitMQ提供托管解决方案,通过服务CloudKarafka为Apache Kafka提供托管解决方案。由于我已经看到了CloudAMQP和CloudKarafka用户的许多用例和不同的应用程序设置,我觉得我可以根据我的经验,在RabbitMQ和Apache Kafka上权威地回答用例问题。
在本文中,我的任务是根据多年来开发人员与开发人员之间的许多交谈来分享自己的见解,并试图传达他们关于为什么选择特定的message broker服务而不是其他服务的想法。
本文中使用的术语包括:
消息队列在RabbitMQ中是一个队列,而这个“队列”在Kafka中被称为日志,但是为了简化本文中的信息,我将一直使用队列而不是切换到“日志”。
卡夫卡的信息通常被称为记录,但是,为了简化这里的信息,我将再次提到信息。
当我在Kafka中撰写一个主题时,您可以把它看作是消息队列中的一个分类。卡夫卡主题被分成若干分区,这些分区以不变的顺序包含记录。
这两个系统都通过队列或主题在生产者和消费者之间传递消息。消息可以包含任何类型的信息。例如,它可以包含网站上发生的事件的信息,也可以是触发另一个应用程序上的事件的简单文本消息。
这种系统非常适合于连接不同的组件、构建微服务、实时数据流或将工作传递给远程工作者。
根据Confluent的数据,超过三分之一的财富500强公司使用Apache Kafka。各种大型行业也依赖于RabbitMQ,如Zalando、WeWork、Wunderlist和Bloomberg。
最大的问题;什么时候使用Kafka,什么时候使用RabbitMQ?
不久前,我在Stackoverflow上写了一个答案来回答这个问题,“有任何理由使用RabbitMQ而不是Kafka吗?”答案只有几行字,但它已经被证明是一个许多人发现有用的答案。
我将试着把答案分解成子答案,并试着解释每一部分。首先,我写道——“RabbitMQ是一个可靠的、成熟的、通用的消息代理,它支持一些协议,如AMQP、MQTT、STOMP等。RabbitMQ可以处理高吞吐量。它的一个常见用例是处理后台作业或充当微服务之间的消息代理。Kafka是一个消息总线优化的高接入数据流和重放。Kafka可以看作是一个持久的消息代理,应用程序可以在其中处理和重新处理磁盘上的流数据。
关于“成熟”一词;RabbitMQ在市场上出现的时间比Kafka(分别是2007年和2011年)要长。RabbitMQ和Kafka都是“成熟的”,这意味着它们都被认为是可靠的、可扩展的消息传递系统。
消息处理(消息重放)
这是他们之间的主要区别;与大多数消息传递系统不同,Kafka中的消息队列是持久的。发送的数据将一直存储到经过指定的保留期(一段时间或一个大小限制)为止。消息将一直停留在队列中,直到超过保留期/大小限制,这意味着消息被使用后不会被删除。相反,它可以被重放或多次使用,这是一个可以调整的设置。
在RabbitMQ中,消息被存储起来,直到接收应用程序连接并接收到队列外的消息。客户端可以在接收到消息或在完全处理完消息后ack(确认)消息。在任何一种情况下,一旦消息被处理,它就会从队列中删除。
如果您在Kafka中使用重播,请确保您使用它的方式和原因是正确的。将一个事件重复播放多次,而这个事件应该只发生一次;例如,如果您碰巧多次保存客户订单,在大多数使用场景中并不理想。当用户中存在需要部署新版本的bug,并且需要重新处理部分或全部消息时,重播就会派上用场了。
协议
我还提到了“RabbitMQ支持一些标准化协议,如AMQP, MQTT, STOMP等”,其中它本机实现AMQP 0.9.1。使用标准化消息协议允许您将RabbitMQ代理替换为任何基于AMQP的代理。
Kafka在TCP/IP之上使用自定义协议在应用程序和集群之间进行通信。Kafka不能被简单地移除和替换,因为它是唯一实现这个协议的软件。
RabbitMQ支持不同协议的能力意味着它可以在许多不同的场景中使用。
AMQP的最新版本与官方支持的0.9.1版本有很大不同。RabbitMQ不太可能偏离AMQP 0.9.1。该协议的1.0版本于2011年10月30日发布,但尚未获得开发人员的广泛支持。AMQP 1.0可通过插件使用。
路由
答案的下一部分是关于路由的,我写道:“Kafka有一个非常简单的路由方法。如果你需要以复杂的方式将消息传递给用户,RabbitMQ有更好的选择。”
RabbitMQ的主要优点是能够灵活地路由消息。直接或基于正则表达式的路由允许消息到达特定队列,而无需附加代码。RabbitMQ有四种不同的路由选择:直接、主题、扇出和头交换。直接交换路由消息到所有队列,这些队列与所谓的路由密钥完全匹配。扇形交换器可以向绑定到该交换器的每个队列广播一条消息。topics方法类似于direct,因为它使用一个路由键,但是允许通配符匹配和精确匹配。有关不同交换类型的更多信息可以在这里找到。
Kafka不支持路由;Kafka主题被划分为多个分区,这些分区以不变的顺序包含消息。您可以使用消费者组和持久主题来替代RabbitMQ中的路由,在该路由中,您将所有消息发送到一个主题,但让您的消费者组从不同的偏移量订阅。
您可以在Kafka streams的帮助下自己创建动态路由,即动态地将事件路由到主题,但这不是默认特性。
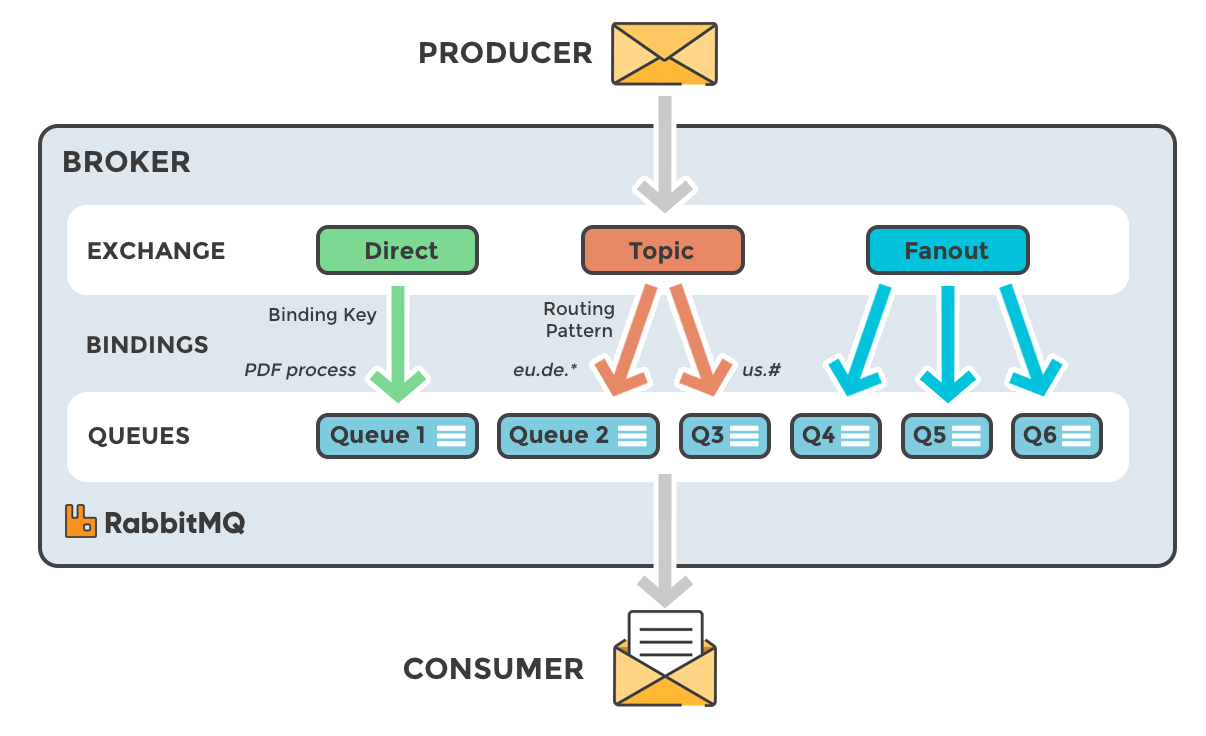
消息优先级
RabbitMQ支持所谓的优先队列,这意味着队列可以被设置为具有一系列优先级。可以在发布消息时设置每个消息的优先级。根据消息的优先级,它被放置在适当的优先级队列中。那么,什么时候可以使用优先队列呢?下面是一个简单的示例:我们每天都在为托管的数据库服务ElephantSQL运行数据库备份。数以千计的备份事件被无序地添加到RabbitMQ中。客户还可以按需触发备份,如果发生这种情况,我将一个新的备份事件添加到队列中,但具有更高的优先级。
在卡夫卡中,消息不能以优先级发送,也不能按优先级顺序发送。无论客户端有多忙,Kafka中的所有消息都按照接收它们的顺序存储和发送。
确认(提交或确认)
“确认”是在通信进程之间传递的信号,表示确认。,接收发送或处理的信息。
Kafka和RabbitMQ都支持生产者确认(RabbitMQ中的发布者确认),以确保发布的消息已安全到达代理。
当节点向使用者传递消息时,它必须决定是否应将该消息视为由使用者处理(或至少是接收)。客户端可以在接收到消息时或在客户端完全处理完消息后进行ack。
RabbitMQ可以考虑发送出去的消息,也可以等待使用者在收到消息后手动确认。
Kafka为分区中的每条消息维护一个偏移量。提交的位置是保存的最后一个偏移量。如果进程失败并重新启动,这是它将恢复到的偏移量吗?Kafka中的使用者既可以定期地自动提交偏移量,也可以选择手动控制提交的位置。
在不同版本的Apache Kafka中,Kafka是如何记录哪些被使用了,哪些没有被使用的。在早期版本中,使用者跟踪偏移量。
当RabbitMQ客户端不能处理消息时,它也可以nack(否定确认)消息。消息将被返回到它来自的队列中,就像它是一个新消息一样;这在客户端出现临时故障时非常有用。
如何处理队列?
RabbitMQ的队列在空的时候是最快的,而Kafka被设计用来保存和分发大量的消息。Kafka用很少的开销保留大量的数据。
尝试RabbitMQ的人可能没有意识到惰性队列的特性。惰性队列是将消息自动存储到磁盘的队列,从而最大限度地减少RAM的使用,但延长了吞吐量时间。根据我们的经验,惰性队列创建了更稳定的集群,具有更好的预测性能。如果你要一次发送很多消息(例如处理批处理任务),或者你认为你的用户跟不上发布者的速度,我们建议你启用惰性队列。
扩展
扩展是指增加或减少系统容量的过程。RabbitMQ和Kafka可以以不同的方式伸缩,你可以调整消费者的数量,代理的能力或者向系统中添加更多的节点。
消费者扩展
如果发布速度更快,那么就可以使用RabbitMQ,那么队列将开始增长,最终可能会产生数百万条消息,最终导致RabbitMQ耗尽内存。在这种情况下,您可以扩展处理(消费)您的消息的消费者数量。RabbitMQ中的每个队列可以有许多使用者,而这些使用者都可以“竞争”使用来自队列的消息。消息处理分布在所有活动的使用者中,因此在RabbitMQ中通过简单地添加和删除使用者就可以实现上下伸缩。
在Kafka中,分配使用者的方法是使用主题分区,其中组中的每个使用者专用于一个或多个分区。您可以使用分区机制按业务键(例如,按用户id、位置等)向每个分区发送不同的消息集。
扩展代理
我在stackoverflow的回答中写道;“Kafka是基于水平扩展(添加更多机器)的想法而建立的,而RabbitMQ主要是为垂直扩展(添加更多功能)而设计的。”答案的这一部分是提供有关运行Kafka或RabbitMQ的机器的信息。
在RabbitMQ中,水平伸缩并不总是提供更好的性能。通过垂直扩展(添加更多Power)可以获得最佳性能级别。在RabbitMQ中可以进行水平伸缩,但这意味着必须在节点之间建立集群,这可能会降低设置的速度。
在Kafka中,您可以通过向集群添加更多节点或向主题添加更多分区来扩展。这有时比像在RabbitMQ中那样在现有的机器中添加CPU或内存更容易。
许多人和博客,包括Confluent,都在谈论Kafka在缩放方面有多棒。当然,卡夫卡可以比RabbitMQ扩展得更远,因为对于你能买到的机器的强度总是有限制的。但是,在这种情况下,我们需要记住使用代理的原因。你可能有一个Kafka和RabbitMQ都可以支持的消息量,而没有任何问题,我们大多数人不会处理RabbitMQ耗尽空间的规模。
日志压缩
值得一提的是,在Apache Kafka中,RabbitMQ中不存在的一个特性是日志压缩策略。日志压缩确保Kafka始终保留单个主题分区队列中每个消息键的最后已知值。Kafka只是简单地保留消息的最新版本,并用相同的密钥删除旧版本。
日志压缩可以看作是使用Kafka作为数据库的一种方式。您可以将保留期设置为“永久”,或者对某个主题启用日志压缩,这样数据就会永久存储。
使用日志压缩的一个示例是,在数千个正在运行的集群中显示一个集群的最新状态。我们存储最终状态,而不是存储集群是否一直在响应。可以立即获得最新信息,比如队列中当前有多少条消息。
监控
RabbitMQ有一个用户友好的界面,让你监控和处理你的RabbitMQ服务器从一个网络浏览器。除了其他功能外,队列、连接、通道、交换器、用户和用户权限可以在浏览器中处理(创建、删除和列出),并且可以手动监控消息率和发送/接收消息。
对于Kafka,我们有很多用于监控的开源工具,也有一些商业工具,提供管理和监控功能。有关Kafka的不同监视工具的信息可以在这里找到。
推或拉
消息从RabbitMQ推送到使用者。配置预取限制以防止令使用者不堪重负(如果消息到达队列的速度比使用者处理它们的速度快)是很重要的。消费者也可以从RabbitMQ获取消息,但不推荐这样做。另一方面,Kafka使用拉取模型,如前所述,消费者从给定的偏移量请求一批消息。
许可证
RabbitMQ最初由Rabbit Technologies Ltd公司创建。该项目于2013年5月成为Pivotal Software的一部分。RabbitMQ的源代码是在Mozilla公共许可下发布的。牌照从未更改(截至2019年11月)。
Kafka最初是由LinkedIn创建的。2011年,它被授予开源地位,并移交给了Apache基金会。Apache Kafka受Apache 2.0许可证的保护。一些经常与Kafka组合使用的组件由另一个名为Confluent Community许可证所涵盖,例如Rest Proxy、Schema Registry和KSL。这个许可证仍然允许人们免费下载、修改和重新分发代码(非常像Apache 2.0所做的),但是它不允许任何人以SaaS的形式提供软件。
这两个许可证都是免费和开源软件许可证。如果Kafka再一次将许可证更改为更严格的东西,这就是RabbitMQ的优势所在,因为它可以很容易地被另一个AMQP经纪人取代,而Kafka不能。
复杂性
就我个人而言,我认为开始使用RabbitMQ更容易,并且发现它很容易使用。正如我们的一位客户所说;
“我们没有花任何时间学习RabbitMQ,它工作了很多年。在DoorDash的高速增长期间,它无疑降低了大量的运营成本。”Zhaobang Liu Doordash
在我看来,Kafka的架构带来了更多的复杂性,因为它从一开始就包含了更多的概念,比如主题/分区/消息偏移量等等。你必须熟悉消费者群体以及如何处理抵消。
作为Kafka和RabbitMQ操作符,我们觉得在Kafka中处理失败有点复杂。恢复或修复某些东西的过程通常更耗费时间,也更麻烦一些。
卡夫卡的生态系统
Kafka不仅仅是一个经纪人,它是一个流媒体平台,还有很多工具可以在主发行版之外很容易地与Kafka集成。Kafka生态系统由Kafka核心、Kafka流、Kafka连接、Kafka REST代理和模式注册表组成。请注意,Kafka生态系统的大多数附加工具都来自于Confluent,而不是Apache的一部分。
所有这些工具的好处是,您可以在需要编写一行代码之前配置一个巨大的系统。
Kafka Connect让您集成其他系统与Kafka。您可以添加一个数据源,允许您使用来自该数据源的数据并将其存储在Kafka中,或者相反,将主题中的所有数据发送到另一个系统进行处理或存储。使用Kafka Connect有很多可能性,而且很容易上手,因为已经有很多可用的连接器。
Kafka REST代理让您有机会从集群接收元数据,并通过简单的REST API生成和使用消息。可以从集群的控制面板轻松启用该特性。
常见用例——RabbitMQ vs Apache Kafka
关于一个系统能做什么或不能做什么,有很多信息。下面是两个主要用例,描述了我和我们的许多客户是如何考虑和决定使用哪个系统的。当然,我们也看到过这样的情况:客户在构建一个系统时,应该使用一个系统,而不是另一个系统。
RabbitMQ的用例
一般来说,如果您想要一个简单/传统的发布-订阅消息代理,那么RabbitMQ是一个明显的选择,因为它的规模很可能比您所需要的更大。如果我的需求足够简单,可以通过通道/队列来处理系统通信,并且不需要保留和流,我就会选择RabbitMQ。
我选择RabbitMQ主要有两种情况;对于长时间运行的任务,当我需要运行可靠的后台作业时。以及应用程序内部和应用程序之间的通信和集成。e作为微服务之间的中间人,系统只需通知系统的另一部分开始处理一项任务,比如在网上商店的订单处理(下订单、更新订单状态、发送订单、付款等)。
长时间运行的任务
消息队列支持异步处理,这意味着它们允许您在不立即处理消息的情况下将消息放入队列。RabbitMQ非常适合长时间运行的任务。
在我们的RabbitMQ初学者指南中可以找到一个例子,它遵循一个经典的场景,即一个web应用程序允许用户上传信息到一个web站点。该网站将处理这些信息,生成PDF,并通过电子邮件发送给用户。完成本例中的任务需要几秒钟,这就是为什么要使用消息队列的原因之一。
我们的许多客户让RabbitMQ队列充当事件总线,使web服务器能够快速响应请求,而不是被迫当场执行计算密集型任务。
以Softonic为例,他们https://www.cloudamqp.com/blog/2019-01-18 softonic-userstoryy-rabbitmq-eventbasedcommunication.html在一个每月支持1亿用户的基于事件的微服务体系结构中使用了RabbitMQ。
微服务架构中的中间人
RabbitMQ也被许多客户用于微服务体系结构,作为应用程序之间通信的一种方式,避免了传递消息的瓶颈。
例如,您可以阅读Parkster(一个数字停车服务)如何使用RabbitMQ将一个系统分解为多个微服务。
MapQuest是一个大方向服务,每月支持2310万独立移动用户。地图更新被发布到组织和公司的个人设备和软件上。这里,RabbitMQ主题分布在适当数量的队列上。数千万用户通过该框架接收到准确的企业级地图信息。
Apache Kafka的用例
通常,如果您需要一个用于存储、读取(重复读取)和分析流数据的框架,请使用Apache Kafka。它非常适合被审计的系统或需要永久存储消息的系统。这些也可以分解为两个主要用例,用于分析数据(跟踪、摄取、日志记录、安全等)或实时处理。
数据分析:跟踪、摄入、日志记录、安全
在所有这些情况下,需要收集、存储和处理大量的数据。需要洞察数据、提供搜索功能、审计或分析大量数据的公司证明使用Kafka是合理的。
据Apache Kafka的创建者说,Kafka最初的用例是跟踪网站活动,包括页面浏览、搜索、上传或用户可能采取的其他行动。这种类型的活动跟踪通常需要非常高的吞吐量,因为会为每个操作和每个用户生成消息。许多这些活动——实际上是所有的系统活动——都可以存储在Kafka中并根据需要进行处理。
数据生产者只需要将数据发送到单个位置,而后端服务主机可以根据需要使用数据。主要的分析、搜索和存储系统都与Kafka集成。
Kafka可以用来将大量的信息流传输到存储系统中,而且这些天硬盘空间的花费并不大。
实时处理
Kafka作为一个高吞吐量分布式系统;源服务将数据流推入目标服务,目标服务实时拉出数据流。
卡夫卡可以在系统处理许多生产者实时与少数消费者;例如,财务IT系统监控股票数据。
从Spotify到荷兰合作银行的流媒体服务通过Kafka实时发布信息。实时处理高吞吐量的能力增强了应用程序的能力。,使得这些应用程序比以往任何时候都更强大。
CloudAMQP在服务器设置的自动化过程中使用了RabbitMQ,但我们在发布日志和指标时使用了Kafka。
| RabbitMQ | Apache Kafka | |
|---|---|---|
| 是什么 | RabbitMQ是一种可靠、成熟、通用的消息代理 | Apache Kafka是一种为高接入数据流和重放而优化的消息总线 |
| 主要用途 | 用于应用程序内部和应用程序之间通信和集成的消息队列。用于长时间运行的任务,或需要运行可靠的后台作业时。 | 用于存储、读取(重复读取)和分析流数据的框架。 |
| 许可证 | 开放源码:Mozilla公共许可证 | 开放源码:Apache License 2.0 |
| Written in | Erlang | Scala (JVM) |
|
第一个版 本发布 |
2007 | 2011 |
| 持久性 | 持久化消息,直到在确认接收时丢弃它们为止 | 在保留期结束后保留带有要删除选项的消息 |
| 重播 | No | Yes |
| 路由 | 支持可将信息返回到使用者节点的灵活路由 | 不支持灵活的路由,必须通过单独的主题来完成 |
| 消息优先级 | Supported | Not supported |
| 监控 | 可通过内置UI使用 | 可以通过第三方工具使用,比如部署在CloudKarafka或通过Confluent |
| 语言支持 | 支持大多数语言 | 支持大多数语言 |
| 安全认证 | 支持标准认证和OAuth2 | 支持Kerberos、OAuth2和标准身份验证 |
原文:https://www.cloudamqp.com/blog/2019-12-12-when-to-use-rabbitmq-or-apache-kafka.html
本文:http://jiagoushi.pro/node/1187
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 141 次浏览
【事件驱动架构】使用GoldenGate创建从Oracle数据库到Kafka的CDC事件流
我们通过GoldenGate技术在Oracle DB和Kafka代理之间创建集成,该技术实时发布Kafka中的CDC事件流。
Oracle在其Oracle GoldenGate for Big Data套件中提供了一个Kafka连接处理程序,用于将CDC(更改数据捕获)事件流推送到Apache Kafka集群。
因此,对于给定的Oracle数据库,成功完成的业务事务中的任何DML操作(插入、更新、删除)都将转换为实时发布的Kafka消息。
这种集成对于这类用例非常有趣和有用:
- 如果遗留的单片应用程序使用Oracle数据库作为单一数据源,那么应该可以通过监视相关表的更改来创建实时更新事件流。换句话说,我们可以实现来自遗留应用程序的数据管道,而无需更改它们。
- 我们需要承认只有在数据库事务成功完成时才会发布Kafka消息。为了赋予这个特性,我们可以(始终以事务的方式)在一个由GoldenGate特别监视的表中编写Kafka消息,通过它的Kafka连接处理程序,将发布一个“插入”事件来存储原始的Kafka消息。
在本文中,我们将逐步说明如何通过GoldenGate技术实现PoC(概念验证)来测试Oracle数据库与Kafka之间的集成。
PoC的先决条件
我们将安装所有的东西在一个本地虚拟机,所以你需要:
- 安装Oracle VirtualBox(我在Oracle VirtualBox 5.2.20上测试过)
- 16 gb的RAM。
- 大约75GB的磁盘空间空闲。
- 最后但并非最不重要的是:了解vi。
PoC架构
本指南将创建一个单一的虚拟机有:
- Oracle数据库12c:要监视的表存储在其中。
- Oracle GoldenGate 12c(经典版本):将应用于监视表的业务事务实时提取,以中间日志格式(trail log)存储,并将其输送到另一个GoldenGate(用于大数据)实例管理的远程日志。
- Oracle GoldenGate for Big Data 12c:pumped的业务事务并将其复制到Kafka消息中。
- Apache Zookeeper/Apache Kafka实例:在这里发布Kafka消息中转换的业务事务。
换句话说,在某些Oracle表上应用的任何插入、更新和删除操作都将生成Kafka消息的CDC事件流,该事件流将在单个Kafka主题中发布。
下面是我们将要创建的架构和实时数据流:
步骤1/12:启动Oracle数据库
您可以自由地安装Oracle数据库和Oracle GoldenGate手动。但幸运的是……)Oracle共享了一些虚拟机,这些虚拟机已经安装了所有的东西,可以随时进行开发。
Oracle虚拟机可以在这里下载,你需要一个免费的Oracle帐户来获得它们。
我使用了Oracle Big Data Lite虚拟机(ver)。4.11),它包含了很多Oracle产品,包括:
- Oracle数据库12c第一版企业版(12.1.0.2)
- Oracle GoldenGate 12c (12.3.0.1.2)
从上述下载页面获取所有7-zip文件(约22GB),提取VM映像文件BigDataLite411。在Oracle VirtualBox中双击文件,打开导入向导。完成导入过程后,一个名为BigDataLite-4.11的VM将可用。
启动BigDataLite-4.11并使用以下凭证登录:
- 用户:oracle
- 密码:welcome1
一个舒适的Linux桌面环境将会出现。
双击桌面上的“开始/停止服务”图标,然后:
- 检查第一项ORCL (Oracle数据库12c)。
- 不要检查所有其他的东西(对PoC无用且有害)。
- 按回车确认选择。
最后,Oracle数据库将启动。
当您重新启动虚拟机时,Oracle数据库将自动启动。
与下载的虚拟机有关的其他有用信息:
- Oracle主文件夹($ORACLE_HOME)是/u01/app/ Oracle /product/12.1.0.2/dbhome_1
- GoldenGate (classic)安装在/u01/ogg中
- SQL Developer安装在/u01/sqldeveloper中。您可以从上面工具栏中的图标启动SQL Developer。
- Oracle数据库是作为多租户容器数据库(CDB)安装的。
- Oracle数据库监听端口是1521
- 根容器的Oracle SID是cdb
- PDB(可插拔数据库)的Oracle SID是orcl
- 所有Oracle数据库用户(SYS、SYSTEM等)的密码都是welcome1
- 连接到PDB数据库的tnsname别名是ORCL(参见$ORACLE_HOME/network/admin/tnsnames)。ora文件内容)。
- Java主文件夹($JAVA_HOME)是/usr/java/latest
- $JAVA_HOME中安装的Java开发工具包是JDK8更新151。
步骤2/12:在Oracle中启用归档日志
我们需要在Oracle中启用归档日志来使用GoldenGate (classic)。
从VM的Linux shell中启动SQL Plus作为SYS:
sqlplus sys/welcome1 as sysdba
然后从SQL + shell运行这个命令列表(我建议一次启动一个):
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;ALTER DATABASE FORCE LOGGING;ALTER SYSTEM SWITCH LOGFILE;ALTER SYSTEM SET ENABLE_GOLDENGATE_REPLICATION=TRUE;SHUTDOWN IMMEDIATE;STARTUP MOUNT;ALTER DATABASE ARCHIVELOG;ALTER DATABASE OPEN;
然后检查存档日志是否成功启用:
ARCHIVE LOG LIST;
输出应该是这样的:
Database log mode Archive ModeAutomatic archival EnabledArchive destination USE_DB_RECOVERY_FILE_DESTOldest online log sequence 527Next log sequence to archive 529Current log sequence 529
步骤3/12:创建一个ggadmin用户
需要为GoldenGate (classic)创建一个特殊的Oracle管理员用户。
同样,从VM的Linux shell中打开SQL Plus:
sqlplus sys/welcome1作为sysdba
并通过运行这个脚本创建ggadmin用户:
ALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;CREATE USER ggadmin IDENTIFIED BY ggadmin;GRANT CREATE SESSION, CONNECT, RESOURCE, ALTER SYSTEM TO ggadmin;EXEC DBMS_GOLDENGATE_AUTH.GRANT_ADMIN_PRIVILEGE(grantee=>'ggadmin', privilege_type=>'CAPTURE', grant_optional_privileges=>'*');GRANT SELECT ANY DICTIONARY TO ggadmin;GRANT UNLIMITED TABLESPACE TO ggadmin;
步骤4/12 -创建ESHOP模式
我们将创建一个模式(ESHOP),其中只有两个表(CUSTOMER_ORDER和CUSTOMER_ORDER_ITEM),用于生成要推送到Kafka中的CDC事件流。
使用SQL Plus(或者,如果您愿意,也可以使用SQL Developer)连接orcl作为SID的Oracle PDB:
sqlplus sys/welcome1@ORCL as sysdba
运行这个脚本:
-- init sessionALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;-- create tablespace for eshopCREATE TABLESPACE eshop_tbs DATAFILE 'eshop_tbs.dat' SIZE 10M AUTOEXTEND ON;CREATE TEMPORARY TABLESPACE eshop_tbs_temp TEMPFILE 'eshop_tbs_temp.dat' SIZE 5M AUTOEXTEND ON;-- create user schema eshop, please note that the password is eshopCREATE USER ESHOP IDENTIFIED BY eshop DEFAULT TABLESPACE eshop_tbs TEMPORARY TABLESPACE eshop_tbs_temp;-- grant eshop user permissionsGRANT CREATE SESSION TO ESHOP;GRANT CREATE TABLE TO ESHOP;GRANT UNLIMITED TABLESPACE TO ESHOP;GRANT RESOURCE TO ESHOP;GRANT CONNECT TO ESHOP;GRANT CREATE VIEW TO ESHOP;-- create eshop sequencesCREATE SEQUENCE ESHOP.CUSTOMER_ORDER_SEQ START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE;CREATE SEQUENCE ESHOP.CUSTOMER_ORDER_ITEM_SEQ START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE;-- create eshop tablesCREATE TABLE ESHOP.CUSTOMER_ORDER (ID NUMBER(19) PRIMARY KEY,CODE VARCHAR2(10),CREATED DATE,STATUS VARCHAR2(32),UPDATE_TIME TIMESTAMP);CREATE TABLE ESHOP.CUSTOMER_ORDER_ITEM (ID NUMBER(19) PRIMARY KEY,ID_CUSTOMER_ORDER NUMBER(19),DESCRIPTION VARCHAR2(255),QUANTITY NUMBER(3),CONSTRAINT FK_CUSTOMER_ORDER FOREIGN KEY (ID_CUSTOMER_ORDER) REFERENCES ESHOP.CUSTOMER_ORDER (ID));
步骤5/12:初始化GoldenGate Classic
现在是时候在BigDataListe-4.11虚拟机中安装GoldenGate (classic)实例了。
从Linux shell运行:
cd /u01/ogg./ggsci
GoldenGate CLI(命令行界面)将启动:
Oracle GoldenGate Command Interpreter for OracleVersion 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2_FBOLinux, x64, 64bit (optimized), Oracle 12c on Nov 11 2015 03:53:23Operating system character set identified as UTF-8.Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.GGSCI (bigdatalite.localdomain) 1>
从GoldenGate CLI启动经理与以下命令:
start mgr
它将引导GoldenGate的主控制器进程(监听端口7810)。
现在创建一个凭据库来存储ggadmin用户凭据(并使用具有相同名称的别名来引用它们):
add credentialstorealter credentialstore add user ggadmin password ggadmin alias ggadmin
现在,通过使用刚才创建的ggadmin别名连接到Oracle数据库,并启用对存储在名为orcl的PDB中的eshop模式的附加日志:
dblogin useridalias ggadminadd schematrandata orcl.eshop
步骤6/12:制作金门果提取物
在此步骤中,我们将创建一个GoldenGate摘要,此过程将监视Oracle archive重做日志,以捕获与ESHOP表相关的数据库事务,并将此SQL修改流写入另一个名为trail log的日志文件中。
从GoldenGate CLI运行:
edit params exteshop
该命令将打开一个引用新空文件的vi实例。在vi编辑器中放入以下内容:
EXTRACT exteshopUSERIDALIAS ggadminEXTTRAIL ./dirdat/aaTABLE orcl.eshop.*;
保存内容并退出vi,以便返回GoldenGate CLI。
保存的内容将存储在/u01/ogg/dirprm/exteshop中。人口、难民和移民事务局文件。您也可以在外部编辑它的内容,而不需要再次从GoldenGate CLI运行“edit params exteshop”命令。
现在在Oracle中注册提取过程,从GoldenGate CLI运行以下命令:
dblogin useridalias ggadminregister extract exteshop database container (orcl)
最后一个命令的输出应该是这样的:
OGG-02003 Extract EXTESHOP successfully registered with database at SCN 13624423.
使用所示的SCN号来完成提取配置。从GoldenGate CLI:
add extract exteshop, integrated tranlog, scn 13624423add exttrail ./dirdat/aa, extract exteshop
现在我们可以启动名为exteshop的GoldenGate提取过程:
start exteshop
你可以使用以下命令中的on来检查进程的状态:
info exteshopview report exteshop
验证提取过程是否正常工作以完成此步骤。从Linux shell运行以下命令,用SQL Plus(或SQL Developer)连接到ESHOP模式:
sqlplus eshop / eshop@ORCL
创建一个模拟客户订单:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA01', SYSDATE, 'DRAFT', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Toy Story', 1);COMMIT;
最后,从GoldenGate CLI跑出来:
stats exteshop
并验证前面的插入操作是否已计算在内。下面是stats命令输出的一个小示例:
Extracting from ORCL.ESHOP.CUSTOMER_ORDER to ORCL.ESHOP.CUSTOMER_ORDER:*** Total statistics since 2019-05-29 09:18:12 ***Total inserts 1.00Total updates 0.00Total deletes 0.00Total discards 0.00Total operations 1.00
检查提取过程是否正常工作的另一种方法是检查GoldenGate跟踪日志文件的时间戳。在Linux shell中运行“ls -l /u01/ogg/dirdat/”,并验证以“aa”开头的文件的时间戳已经更改。
步骤7/12:安装并运行Apache Kafka
从VM的桌面环境中打开Firefox并下载Apache Kafka(我使用的是kafka_2.11-2.1.1.tgz)。
现在,打开一个Linux shell并重置CLASSPATH环境变量(在BigDataLite-4.11虚拟机中设置的当前值会在Kafka中产生冲突):
declare -x CLASSPATH=""
从同一个Linux shell中,解压缩压缩包,启动ZooKeeper和Kafka:
cdtar zxvf Downloads/kafka_2.11-2.1.1.tgzcd kafka_2.11-2.1.1./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties./bin/kafka-server-start.sh -daemon config/server.properties
你可以通过启动“echo stats | nc localhost 2181”来检查ZooKeeper是否正常:
[oracle@bigdatalite ~]$ echo stats | nc localhost 2181Zookeeper version: 3.4.5-cdh5.13.1--1, built on 11/09/2017 16:28 GMTClients:/127.0.0.1:34997[1](queued=0,recved=7663,sent=7664)/0:0:0:0:0:0:0:1:17701[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/25Received: 8186Sent: 8194Connections: 2Outstanding: 0Zxid: 0x3fMode: standaloneNode count: 25
您可以检查Kafka是否与“echo dump | nc localhost 2181 | grep代理”(一个字符串/brokers/ids/0应该出现)
[oracle@bigdatalite ~]$ echo dump | nc localhost 2181 | grep brokers/brokers/ids/0
用于PoC的BigDataLite-4.11虚拟机已经在启动虚拟机时启动了一个较老的ZooKeeper实例。因此,请确保禁用了步骤1中描述的所有服务。
此外,当您打开一个新的Linux shell时,请注意在启动ZooKeeper和Kafka之前总是要重置CLASSPATH环境变量,这一点在步骤开始时已经解释过了。
步骤8/12:为大数据安装GoldenGate
同样,从这个页面下载Oracle GoldenGate for Big Data 12c只需要使用VM中安装的Firefox浏览器(我在Linux x86-64上使用Oracle GoldenGate for Big Data 12.3.2.1.1)。请注意,您需要一个(免费)Oracle帐户来获得它。
安装很容易,只是爆炸压缩包内的下载:
cd ~/Downloadsunzip OGG_BigData_Linux_x64_12.3.2.1.1.zipcd ..mkdir ogg-bd-poccd ogg-bd-poctar xvf ../Downloads/OGG_BigData_Linux_x64_12.3.2.1.1.tar
就这样,GoldenGate for Big Data 12c被安装在/home/oracle/ogg-bd-poc文件夹中。
同样,BigDataLite-4.11虚拟机已经在/u01/ogg-bd文件夹中安装了用于大数据的GoldenGate。但它是一个较旧的版本,连接Kafka的选项较少。
步骤9/12:启动GoldenGate for Big Data Manager
打开大数据大门
cd ~/ogg-bd-poc./ggsci
需要更改管理器端口,否则之前启动的与GoldenGate (classic)管理器的冲突将被引发。
因此,从大数据的GoldenGate来看,CLI运行:
create subdirsedit params mgr
一个vi实例将开始,只是写这个内容:
PORT 27801
然后保存内容,退出vi,返回CLI,我们终于可以启动GoldenGate for Big Data manager监听端口27081:
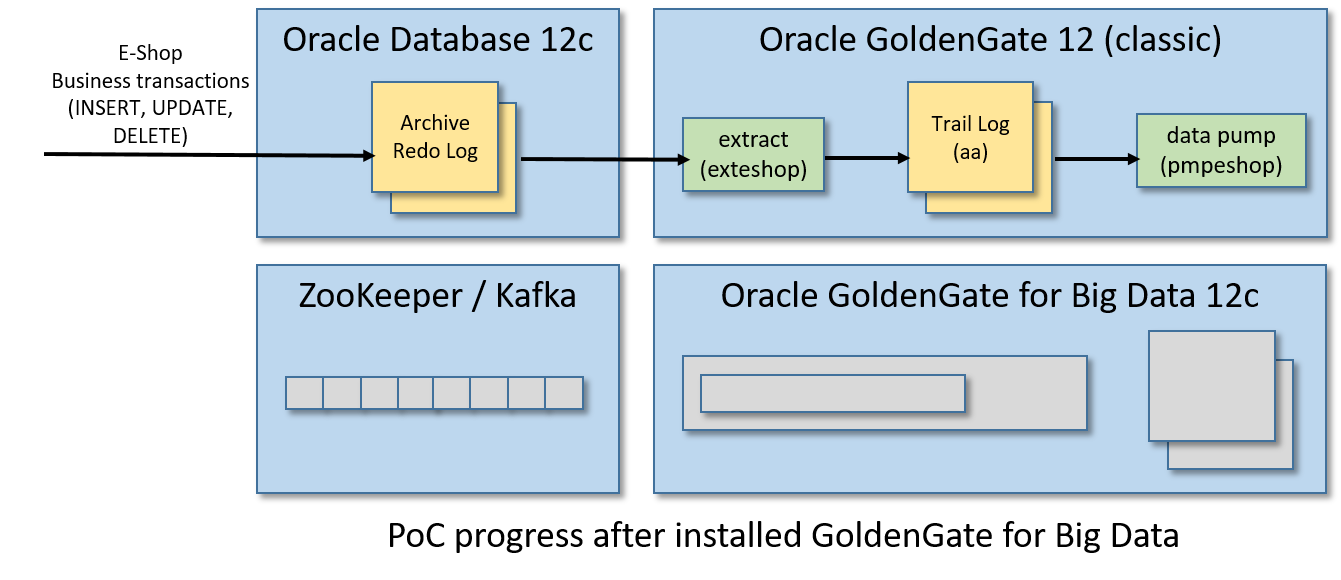
步骤10/12:创建数据泵(Data Pump)
现在,我们需要创建在GoldenGate世界中被称为数据泵的东西。数据泵是一个提取过程,它监视一个跟踪日志,并(实时地)将任何更改推到另一个由不同的(通常是远程的)GoldenGate实例管理的跟踪日志。
对于这个PoC,由GoldenGate (classic)管理的trail log aa将被泵送至GoldenGate管理的trail log bb进行大数据处理。
因此,如果您关闭它,请回到来自Linux shell的GoldenGate(经典)CLI:
cd /u01/ogg./ggsci
来自GoldenGate(经典)CLI:
edit params pmpeshop
并在vi中加入以下内容:
EXTRACT pmpeshopUSERIDALIAS ggadminSETENV (ORACLE_SID='orcl')-- GoldenGate for Big Data address/port:RMTHOST localhost, MGRPORT 27801RMTTRAIL ./dirdat/bbPASSTHRU-- The "tokens" part it is useful for writing in the Kafka messages-- the Transaction ID and the database Change Serial NumberTABLE orcl.eshop.*, tokens(txid = @GETENV('TRANSACTION', 'XID'), csn = @GETENV('TRANSACTION', 'CSN'));
保存内容并退出vi。
正如已经解释的提取器,保存的内容将存储在/u01/ogg/dirprm/pmpeshop中。人口、难民和移民事务局文件。
现在我们要注册并启动数据泵,从GoldenGate CLI:
dblogin useridalias ggadminadd extract pmpeshop, exttrailsource ./dirdat/aa begin nowadd rmttrail ./dirdat/bb extract pmpeshopstart pmpeshop
通过从CLI运行以下命令之一来检查数据泵的状态:
info pmpeshopview report pmpeshop
你甚至可以在金门大数据的dirdat文件夹中查看trail log bb是否已经创建:
[oracle@bigdatalite dirdat]$ ls -l ~/ogg-bd-poc/dirdattotal 0-rw-r-----. 1 oracle oinstall 0 May 30 13:22 bb000000000[oracle@bigdatalite dirdat]$
那检查泵送过程呢?来自Linux shell:
sqlplus eshop/eshop@ORCL
执行这个SQL脚本创建一个新的模拟客户订单:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA02', SYSDATE, 'SHIPPING', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Inside Out', 1);COMMIT;
现在从GoldenGate(经典)CLI运行:
stats pmpeshop
用于检查插入操作是否正确计数(在输出的一部分下面):
GGSCI (bigdatalite.localdomain as ggadmin@cdb/CDB$ROOT) 11> stats pmpeshopSending STATS request to EXTRACT PMPESHOP ...Start of Statistics at 2019-05-30 14:49:00.Output to ./dirdat/bb:Extracting from ORCL.ESHOP.CUSTOMER_ORDER to ORCL.ESHOP.CUSTOMER_ORDER:*** Total statistics since 2019-05-30 14:01:56 ***Total inserts 1.00Total updates 0.00Total deletes 0.00Total discards 0.00Total operations 1.00
此外,您还可以验证GoldenGate中存储的用于测试泵过程的大数据的跟踪日志的时间戳。事务提交后,从Linux shell运行:“ln -l ~/og -bd-poc/dirdat”,并检查最后一个以“bb”作为前缀的文件的时间戳。
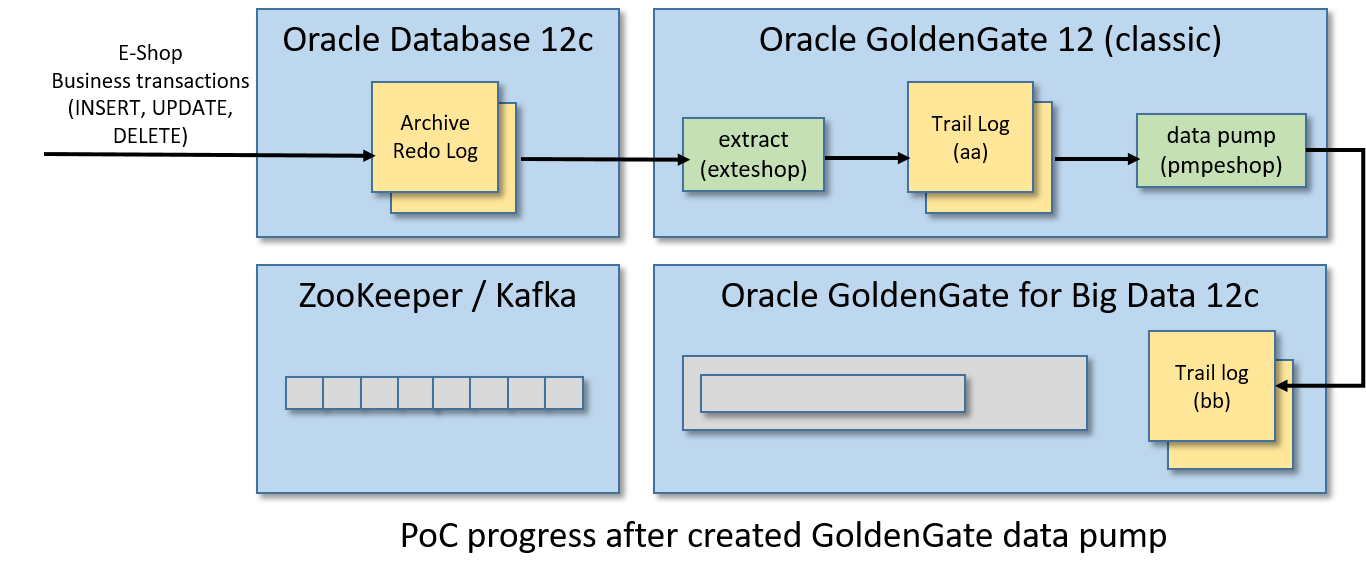
步骤11/12:将事务发布到Kafka
最后,我们将在GoldenGate中为BigData创建一个副本流程,以便在Kafka主题中发布泵出的业务事务。replicat将从trail日志bb读取事务中的插入、更新和删除操作,并将它们转换为JSON编码的Kafka消息。
因此,创建一个名为eshop_kafkaconnect的文件。文件夹/home/oracle/ogg-bd- pocd /dirprm中的属性包含以下内容:
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kafkaconnect.properties# -----------------------------------------------------------# address/port of the Kafka brokerbootstrap.servers=localhost:9092acks=1#JSON Converter Settingskey.converter=org.apache.kafka.connect.json.JsonConverterkey.converter.schemas.enable=falsevalue.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable=false#Adjust for performancebuffer.memory=33554432batch.size=16384linger.ms=0# This property fix a start-up error as explained by Oracle Support here:# https://support.oracle.com/knowledge/Middleware/2455697_1.htmlconverter.type=key
在同一个文件夹中,创建一个名为eshop_kc的文件。具有以下内容的道具:
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kc.props# ---------------------------------------------------gg.handlerlist=kafkaconnect#The handler propertiesgg.handler.kafkaconnect.type=kafkaconnectgg.handler.kafkaconnect.kafkaProducerConfigFile=eshop_kafkaconnect.propertiesgg.handler.kafkaconnect.mode=tx#The following selects the topic name based only on the schema namegg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}#The following selects the message key using the concatenated primary keysgg.handler.kafkaconnect.keyMappingTemplate=${primaryKeys}#The formatter propertiesgg.handler.kafkaconnect.messageFormatting=opgg.handler.kafkaconnect.insertOpKey=Igg.handler.kafkaconnect.updateOpKey=Ugg.handler.kafkaconnect.deleteOpKey=Dgg.handler.kafkaconnect.truncateOpKey=Tgg.handler.kafkaconnect.treatAllColumnsAsStrings=falsegg.handler.kafkaconnect.iso8601Format=falsegg.handler.kafkaconnect.pkUpdateHandling=abendgg.handler.kafkaconnect.includeTableName=truegg.handler.kafkaconnect.includeOpType=truegg.handler.kafkaconnect.includeOpTimestamp=truegg.handler.kafkaconnect.includeCurrentTimestamp=truegg.handler.kafkaconnect.includePosition=truegg.handler.kafkaconnect.includePrimaryKeys=truegg.handler.kafkaconnect.includeTokens=truegoldengate.userexit.writers=javawriterjavawriter.stats.display=TRUEjavawriter.stats.full=TRUEgg.log=log4jgg.log.level=INFOgg.report.time=30sec# Apache Kafka Classpath# Put the path of the "libs" folder inside the Kafka home pathgg.classpath=/home/oracle/kafka_2.11-2.1.1/libs/*javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=.:ggjava/ggjava.jar:./dirprm
如果关闭,重启大数据CLI的GoldenGate:
cd ~/ogg-bd-poc./ggsci
and start to create a replicat from the CLI with:
edit params repeshop
in vi put this content:
REPLICAT repeshopTARGETDB LIBFILE libggjava.so SET property=dirprm/eshop_kc.propsGROUPTRANSOPS 1000MAP orcl.eshop.*, TARGET orcl.eshop.*;
然后保存内容并退出vi。现在将replicat与trail log bb关联,并使用以下命令启动replicat进程,以便从GoldenGate启动大数据CLI:
add replicat repeshop, exttrail ./dirdat/bbstart repeshop
Check that the replicat is live and kicking with one of these commands:
info repeshopview report repeshop
Now, connect to the ESHOP schema from another Linux shell:
sqlplus eshop/eshop@ORCL
and commit something:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA03', SYSDATE, 'DELIVERED', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Cars 3', 2);COMMIT;
From the GoldenGate for Big Data CLI, check that the INSERT operation was counted for the replicat process by running:
stats repeshop
And (hurrah!) we can have a look inside Kafka, as the Linux shell checks that the topic named CDC-ESHOP was created:
cd ~/kafka_2.11-2.1.1/bin./kafka-topics.sh --list --zookeeper localhost:2181
and from the same folder run the following command for showing the CDC events stored in the topic:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning
You should see something like:
[oracle@bigdatalite kafka_2.11-2.1.1]$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning{"table":"ORCL.ESHOP.CUSTOMER_ORDER","op_type":"I","op_ts":"2019-05-31 04:24:34.000327","current_ts":"2019-05-31 04:24:39.637000","pos":"00000000020000003830","primary_keys":["ID"],"tokens":{"txid":"9.32.6726","csn":"13906131"},"before":null,"after":{"ID":11.0,"CODE":"AAAA03","CREATED":"2019-05-31 04:24:34","STATUS":"DELIVERED","UPDATE_TIME":"2019-05-31 04:24:34.929950000"}}{"table":"ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type":"I","op_ts":"2019-05-31 04:24:34.000327","current_ts":"2019-05-31 04:24:39.650000","pos":"00000000020000004074","primary_keys":["ID"],"tokens":{"txid":"9.32.6726","csn":"13906131"},"before":null,"after":{"ID":11.0,"ID_CUSTOMER_ORDER":11.0,"DESCRIPTION":"Cars 3","QUANTITY":2}}
For a better output, install jq:
sudo yum -y install jq./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning | jq .
and here is how will appear the JSON events:
{"table": "ORCL.ESHOP.CUSTOMER_ORDER","op_type": "I","op_ts": "2019-05-31 04:24:34.000327","current_ts": "2019-05-31 04:24:39.637000","pos": "00000000020000003830","primary_keys": ["ID"],"tokens": {"txid": "9.32.6726","csn": "13906131"},"before": null,"after": {"ID": 11,"CODE": "AAAA03","CREATED": "2019-05-31 04:24:34","STATUS": "DELIVERED","UPDATE_TIME": "2019-05-31 04:24:34.929950000"}}{"table": "ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type": "I","op_ts": "2019-05-31 04:24:34.000327","current_ts": "2019-05-31 04:24:39.650000","pos": "00000000020000004074","primary_keys": ["ID"],"tokens": {"txid": "9.32.6726","csn": "13906131"},"before": null,"after": {"ID": 11,"ID_CUSTOMER_ORDER": 11,"DESCRIPTION": "Cars 3","QUANTITY": 2}}
现在打开Kafka -console-consumer.sh进程,并在ESHOP上执行其他一些数据库事务,以便实时打印发送给Kafka的CDC事件流。
以下是一些用于更新和删除操作的JSON事件示例:
// Generated with: UPDATE CUSTOMER_ORDER SET STATUS='DELIVERED' WHERE ID=8;{"table": "ORCL.ESHOP.CUSTOMER_ORDER","op_type": "U","op_ts": "2019-05-31 06:22:07.000245","current_ts": "2019-05-31 06:22:11.233000","pos": "00000000020000004234","primary_keys": ["ID"],"tokens": {"txid": "14.6.2656","csn": "13913689"},"before": {"ID": 8,"CODE": null,"CREATED": null,"STATUS": "SHIPPING","UPDATE_TIME": null},"after": {"ID": 8,"CODE": null,"CREATED": null,"STATUS": "DELIVERED","UPDATE_TIME": null}}// Generated with: DELETE CUSTOMER_ORDER_ITEM WHERE ID=3;{"table": "ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type": "D","op_ts": "2019-05-31 06:25:59.000916","current_ts": "2019-05-31 06:26:04.910000","pos": "00000000020000004432","primary_keys": ["ID"],"tokens": {"txid": "14.24.2651","csn": "13913846"},"before": {"ID": 3,"ID_CUSTOMER_ORDER": 1,"DESCRIPTION": "Toy Story","QUANTITY": 1},"after": null}
恭喜你!你完成了PoC:
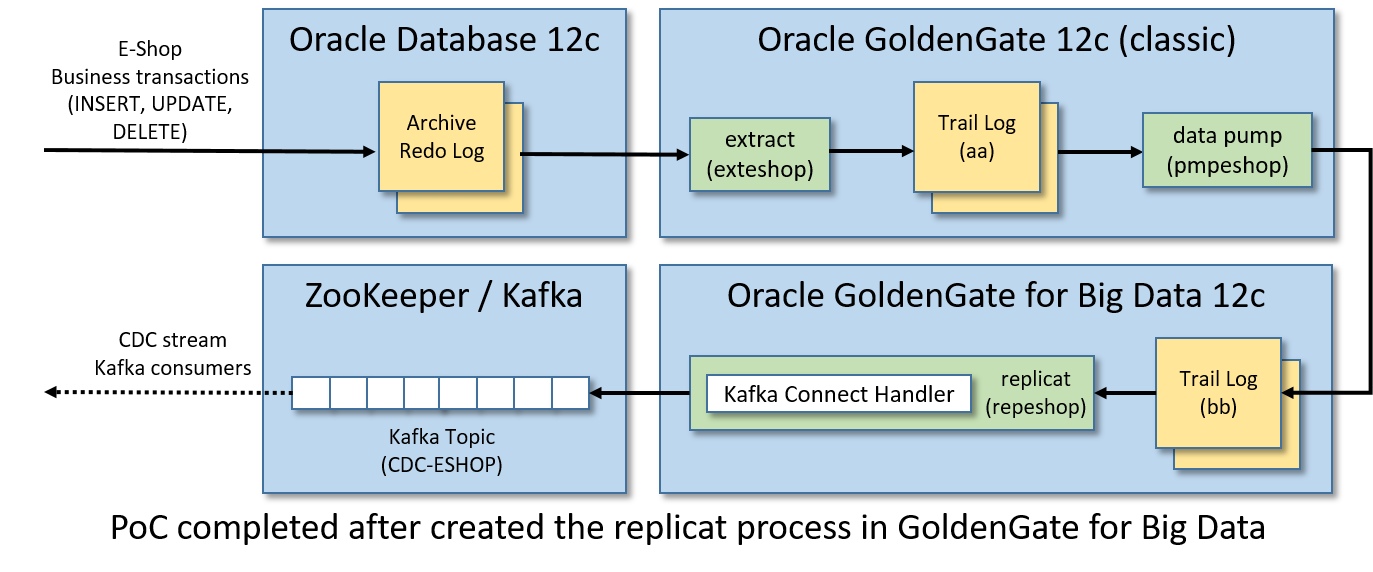
步骤12/12:使用PoC
GoldenGate中提供的Kafka Connect处理程序有很多有用的选项,可以根据需要定制集成。点击这里查看官方文件。
例如,您可以选择为CDC流中涉及的每个表创建不同的主题,只需在eshop_kc.props中编辑此属性:
gg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}-${tableName}更改后重新启动replicat,从GoldenGate for Big Data CLI:
stop repeshopstart repeshop
您可以在“~/og -bd-poc/AdapterExamples/big-data/kafka_connect”文件夹中找到其他配置示例。
结论
在本文中,我们通过GoldenGate技术在Oracle数据库和Kafka代理之间创建了一个完整的集成。CDC事件流以Kafka实时发布。
为了简单起见,我们使用了一个已经全部安装的虚拟机,但是您可以在不同的主机上免费安装用于大数据的GoldenGate和Kafka。
请在评论中告诉我您对这种集成的潜力(或限制)的看法。
原文:https://dzone.com/articles/creates-a-cdc-stream-from-oracle-database-to-kafka
本文:https://pub.intelligentx.net/node/839
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 132 次浏览
【事件驱动架构】理解何时使用RabbitMQ或Apache Kafka
人类如何做决定?在日常生活中,情感往往是触发一个复杂或压倒性决定的断路器因素。但是,专家们做出的复杂决定会带来长期后果,这不能纯粹是一时冲动。高绩效者通常只有在他们的专家、潜意识已经吸收了做决定所需的所有事实之后,才会使用“本能”、“直觉”或其他情感的断路器。
今天,市场上有几十种消息传递技术、无数esb和将近100家iPaaS供应商。自然,这就产生了如何根据您的需要选择正确的消息传递技术的问题——特别是对于那些已经在特定选择上进行了投资的技术。我们是否要大规模地转换?只是用合适的工具做合适的工作?我们是否正确地为业务需求制定了手头的工作?考虑到这一点,什么才是适合我的工具呢?更糟糕的是,详尽的市场分析可能永远不会结束,但考虑到集成代码的平均寿命,尽职调查至关重要。
这篇文章让那些无意识的专家们开始考虑一些治疗方法,从最现代、最流行的选择开始:RabbitMQ和Apache Kafka。每个都有自己的起源故事、设计意图、使用案例、集成能力和开发经验。起源揭示了任何一款软件的总体设计意图,是一个很好的起点。但是需要注意的是,在本文中,我的目标是围绕message broker重叠的用例比较这两个用例,而不是Kafka现在擅长的“事件存储/事件来源”用例。
起源
RabbitMQ是一种实现各种消息传递协议的“传统”消息代理。它是第一批实现合理级别的特性、客户机库、开发工具和高质量文档的开放源码消息代理之一。RabbitMQ最初是为了实现AMQP而开发的,AMQP是一种具有强大路由特性的消息传递开放线协议。虽然Java有JMS这样的消息传递标准,但它对需要分布式消息传递的非Java应用程序没有帮助,因为分布式消息传递严重限制了任何集成场景(微服务或单片集成)。随着AMQP的出现,对于开源消息代理来说,跨语言的灵活性变得真实了。
Apache Kafka是用Scala开发的,最初是在LinkedIn作为连接不同内部系统的一种方式。当时,LinkedIn正在转向一个更加分布式的架构,需要重新设想数据集成和实时流处理等功能,摆脱以前解决这些问题的单一方法。Kafka今天在Apache软件基金会的产品生态系统中得到了很好的采用,并且在事件驱动的架构中特别有用。
架构和设计
RabbitMQ被设计成一个通用消息代理,它采用了点对点、请求/应答和发布-子通信样式模式的几种变体。它使用智能代理/哑消费者模型,专注于以与代理跟踪消费者状态大致相同的速度向消费者交付消息。它很成熟,在正确配置的情况下性能很好,得到了很好的支持(客户端库Java、. net、node)。js, Ruby, PHP和更多的语言),并且有几十个插件可以扩展到更多的用例和集成场景。
图1 -简化的RabbitMQ整体架构来源:http://kth.diva-portal.org/smash/get/diva2:813137 FULLTEXT01.pdf
根据需要,RabbitMQ中的通信可以是同步的,也可以是异步的。发布者向交换器发送消息,使用者从队列中检索消息。通过交换器将生产者从队列中解耦,可以确保生产者不必为硬编码的路由决策所累。RabbitMQ还提供了许多分布式部署场景(并要求所有节点都能够解析主机名)。可以将多节点集群设置为集群联合,并且不依赖于外部服务(但是一些集群形成插件可以使用AWS api、DNS、领事、etcd)。
Apache Kafka是为高容量发布-订阅消息和流而设计的,这意味着它是持久的、快速的和可伸缩的。从本质上讲,Kafka提供了一种持久的消息存储,类似于日志,运行在服务器集群中,以称为主题的类别存储记录流。
图2 -全局Apache Kafka架构(1个主题,1个分区,复制因子4)
每个消息由一个键、一个值和一个时间戳组成。与RabbitMQ几乎相反的是,Kafka雇佣了一个愚蠢的经纪人,并使用聪明的消费者来读取它的缓冲区。Kafka不尝试跟踪每个消费者读了哪些消息,只保留未读的消息;相反,Kafka将所有消息保留一段时间,使用者负责跟踪它们在每个日志中的位置(使用者状态)。因此,有了合适的开发人才来创建消费者代码,Kafka就可以支持大量的消费者,并以很少的开销保留大量的数据。正如上面的图表所示,Kafka确实需要外部服务来运行——在这个例子中是Apache Zookeeper,通常认为理解、设置和操作这些服务并不简单。
需求和用例
许多开发人员开始研究消息传递,是因为他们意识到必须将许多东西连接在一起,而共享数据库等其他集成模式不可行或太危险。
Apache Kafka包含了代理本身,这实际上是其中最著名和最流行的部分,并针对流处理场景进行了设计和营销。除此之外,Apache Kafka最近还添加了Kafka Streams,它将自己定位为流媒体平台的替代品,如Apache Spark、Apache Flink、Apache Beam/谷歌云数据流和Spring云数据流。文档很好地讨论了流行的用例,如网站活动跟踪、度量、日志聚合、流处理、事件来源和提交日志。它描述的其中一个用例是消息传递,这可能会产生一些混乱。因此,让我们来解包一点,得到一些明确的消息传递场景是最适合Kafka的,例如:
- 流从A流到B流,无需复杂的路由,最大吞吐量(100k/sec+),至少按分区顺序发送一次。
- 当您的应用程序需要访问流历史记录时,至少按分区顺序交付一次。Kafka是一个持久的消息存储,客户端可以根据需要获得事件流的“重播”,这与更传统的消息代理不同,后者一旦消息被发送,就会从队列中删除。
- 流处理
- 事件溯源
RabbitMQ是一种通用的消息传递解决方案,通常用于允许web服务器快速响应请求,而不是在用户等待结果时被迫执行大量资源的过程。它还适合将消息分发给多个收件人,以便在高负载(20k+/秒)情况下在工作人员之间平衡负载。当您的需求超出吞吐量时,RabbitMQ可以提供很多功能:可靠交付、路由、联合、HA、安全、管理工具和其他功能。让我们检查一些场景最好的RabbitMQ,如:
- 您的应用程序需要使用现有协议的任何组合,如AMQP 0-9-1、STOMP、MQTT、AMQP 1.0。
- 您需要对每条消息(死信队列等)进行更细粒度的一致性控制/保证。然而,Kafka最近为事务添加了更好的支持。
- 您的应用程序需要点到点、请求/应答和发布/订阅消息传递方面的多样性
- 对消费者的复杂路由,集成多个具有重要路由逻辑的服务/应用程序
RabbitMQ也可以有效地解决卡夫卡的几个强大的使用案例,但在附加软件的帮助下。当应用程序需要访问流历史记录时,RabbitMQ通常与Apache Cassandra一起使用,或者与LevelDB插件一起用于需要“无限”队列的应用,但这两个特性都不是与RabbitMQ一起发布的。
想要更深入地了解微服务——Kafka和RabbitMQ的特定用例,请访问关键博客并阅读Fred Melo的这篇短文。
开发人员的经验
RabbitMQ正式支持Java, Spring,。net, PHP, Python, Ruby, JavaScript, Go, Elixir, Objective-C, Swift -通过社区插件与许多其他客户端和devtools。RabbitMQ客户端库是成熟的,并且有良好的文档记录。
Apache Kafka在这个领域已经取得了很大的进步,虽然它只提供Java客户端,但是社区开源客户端、生态系统项目以及适配器SDK都在不断增长,允许您构建自己的系统集成。大部分配置都是通过.properties文件或编程方式完成的。
这两种选择的流行对许多其他软件供应商有强烈的影响,他们确保RabbitMQ和Kafka与他们的技术很好地工作。
至于开发者的体验…值得一提的是我们在Spring Kafka、Spring Cloud Stream等中提供的支持。
安全与操作
这两者都是RabbitMQ的优势。RabbitMQ管理插件提供了一个HTTP API,一个基于浏览器的管理和监控UI,以及针对操作人员的CLI工具。长期监视数据存储需要像CollectD、Datadog或New Relic这样的外部工具。RabbitMQ还提供了用于监控、审计和应用程序故障排除的API和工具。除了支持TLS之外,RabbitMQ附带了由内置数据存储、LDAP或外部基于http的提供者支持的RBAC,并支持使用x509证书而不是用户名/密码对进行身份验证。使用插件可以相当直接地开发其他身份验证方法。
这些领域对Apache Kafka提出了挑战。在安全方面,最近的Kafka 0.9版本增加了TLS、基于JAAS角色的访问控制和kerberos/plain/scram认证,使用CLI来管理安全策略。这对以前的版本有很大的改进,以前的版本只能在网络级别锁定访问,这在共享或多租户方面不太好用。
Kafka使用由shell脚本、属性文件和特定格式的JSON文件组成的管理CLI。Kafka经纪人、生产者和消费者通过Yammer/JMX发布指标,但不维护任何历史,这实际上意味着使用第三方监控系统。使用这些工具,操作能够管理分区和主题,检查消费者偏移位置,并使用Apache Zookeeper为Kafka提供的HA和FT功能。虽然许多人对Zookeeper的需求持高度怀疑态度,但它确实为Kafka用户带来了集群的好处。
例如,一个3节点的Kafka集群即使在出现2次故障后仍然可以正常工作。然而,如果你想在Zookeeper中支持同样多的失败,你需要额外的5个Zookeeper节点,因为Zookeeper是基于quorum的系统,只能容忍N/2+1个失败。这些显然不应该与Kafka节点位于同一位置——所以要建立一个3节点的Kafka系统,你需要~ 8台服务器。在考虑Kafka系统的可用性时,操作人员必须考虑ZK集群的属性,包括资源消耗和设计。
性能
Kafka在这里的亮点在于设计:100k/秒的性能通常是人们选择Apache Kafka的关键驱动因素。
当然,要描述和量化每秒消息率是很棘手的,因为它们很大程度上取决于您的环境和硬件、工作负载的性质、使用哪种交付保证(例如,持久的代价是昂贵的,镜像的代价更大),等等。
每秒发送20K条消息很容易通过单只RabbitMQ,实际上,超过20K条消息并不难,因为保证的要求并不多。队列是由一个Erlang轻量级线程获得合作计划在一个本地操作系统线程池,所以它变成了一个自然瓶颈或瓶颈作为一个单独的队列是永远不会做更多的工作比CPU周期工作。
提高每秒的消息量通常要合理利用环境中的并行性,比如通过巧妙的路由来中断跨多个队列的流量(以便不同队列可以并发运行)。当RabbitMQ达到每秒100万条消息时,这个用例基本上是完全明智地做到这一点——但是实现时使用了大量资源,大约30个RabbitMQ节点。大多数RabbitMQ用户在使用由3到7个RabbitMQ节点组成的集群时都可以享受卓越的性能。
原文:https://tanzu.vmware.com/content/blog/understanding-when-to-use-rabbitmq-or-apache-kafka
本文:http://jiagoushi.pro/node/1188
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 113 次浏览
【事件驱动架构】走向事件驱动的微服务之旅
许多组织正在采用微服务架构,以减少系统组件之间的依赖关系,并允许更频繁的发布周期和更灵活的可伸缩性。但是,除非他们清楚地了解底层交互模式,否则团队可能会构建紧密耦合的分布式单体。
本文介绍了支持微服务交互的模式,并解释了事件流如何使事件驱动架构(EDA)支持松散耦合的微服务原则。
成熟的微服务景观
通常,团队通过一小组微服务和他们之间的有限数量的交互开始旅程。随着微服务数量的增长,它们之间的相互作用也在增长。了解这些交互对于维护松散耦合的微服务至关重要。
作为架构师,我们需要更加关注区域内发生的事情而不是区域之间发生的事情 - 构建微服务(Sam Newman)
推理这些交互的一步是将它们分类为命令,查询和事件。
| 命令 | 事件 | 查询 | |
| 定义 | 命令是我们想要发生的事情 | 事件是发生了什么事情 | 查询是查找内容的请求 |
| 生产 - 消费者关系 | 生产者(发送命令)和消费者(接受并执行命令)之间的一对一连接 | 它由发布者发送,该发布者不知道并且不关心该事件的(0-N)订阅者 | 请求者(提交查询)和响应者(用查询结果响应)之间的一对一交互 |
| 对系统状态的影响 | 命令改变系统状态。 通常,发送人对结果感兴趣 | 事件是系统中状态更改的通知。 订阅者对此信息感兴趣。 | 查询不会更改系统的可观察状态(没有副作用)。 请求者对结果感兴趣 |
| 交互模式 | 非常适合请求 - 响应模式 | 非常适合发布 - 订阅模式 | 非常适合请求 - 响应模式 |
虽然许多组织已经熟练使用现代API实现命令和查询,但大多数组织尚未充分利用事件驱动架构的优势。
在不断发展的生态系统中,服务需要独立发展,命令和查询会增加很多耦合,在运行时将服务捆绑在一起。事件有助于缓解这种紧密耦合,同时仍然促进服务之间的协作。
同步呼叫被认为是有害的 - 微服务(Martin Fowler)
HTTP API需要一个伴侣
HTTP是一种同步的请求 - 响应协议,客户端向已知服务器发送请求并期望来自服务器的响应;它假设服务器可用并且能够响应。此交互样式非常适合实现命令和查询,但不适合基于事件的通信。使用发布 - 订阅模式可以最好地实现基于事件的通信。
事件代表了通知和状态分布的宝贵组合。
事件=通知+状态
事件为应用程序提供了一个选择:继续执行命令和查询或包含事件以触发其进程并引用事件以提取数据供其私人使用。
随着服务生态系统的发展,架构师建议将事件建模为一等公民,并考虑服务需要与外界分享的重要商业事实。
组织经常难以识别其业务流程中的重要事件。 Event Storming研讨会可以帮助克服这个最初的障碍,因为它们是有趣的,自由流动的研讨会,将开发人员和领域专家聚集在一起,目的是将业务流程表达为一系列重要事件。
并非所有事件都是平等的,有些事件不会引起反应;然而,最重要的事件引起反应,这些事件应该在我们的软件系统中建模。
拥抱事件减少了对命令和查询的依赖。事件在服务之间传输状态,减少了它们之间的查询需求。他们还通知服务更广泛的生态系统中发生的重大事件,使服务能够做出适当的反应,从而为触发业务流程提供命令式交互的替代方案。
事件通知状态变化。命令导致状态改变。
持久化你的事件流
即使事件跨服务传输状态,订阅者也需要存储事件流的表示以避免远程查询。随着新事件的发布以及数据存储数量的增加,这些本地数据存储必须保持同步,因此数据漂移的可能性也会增加。
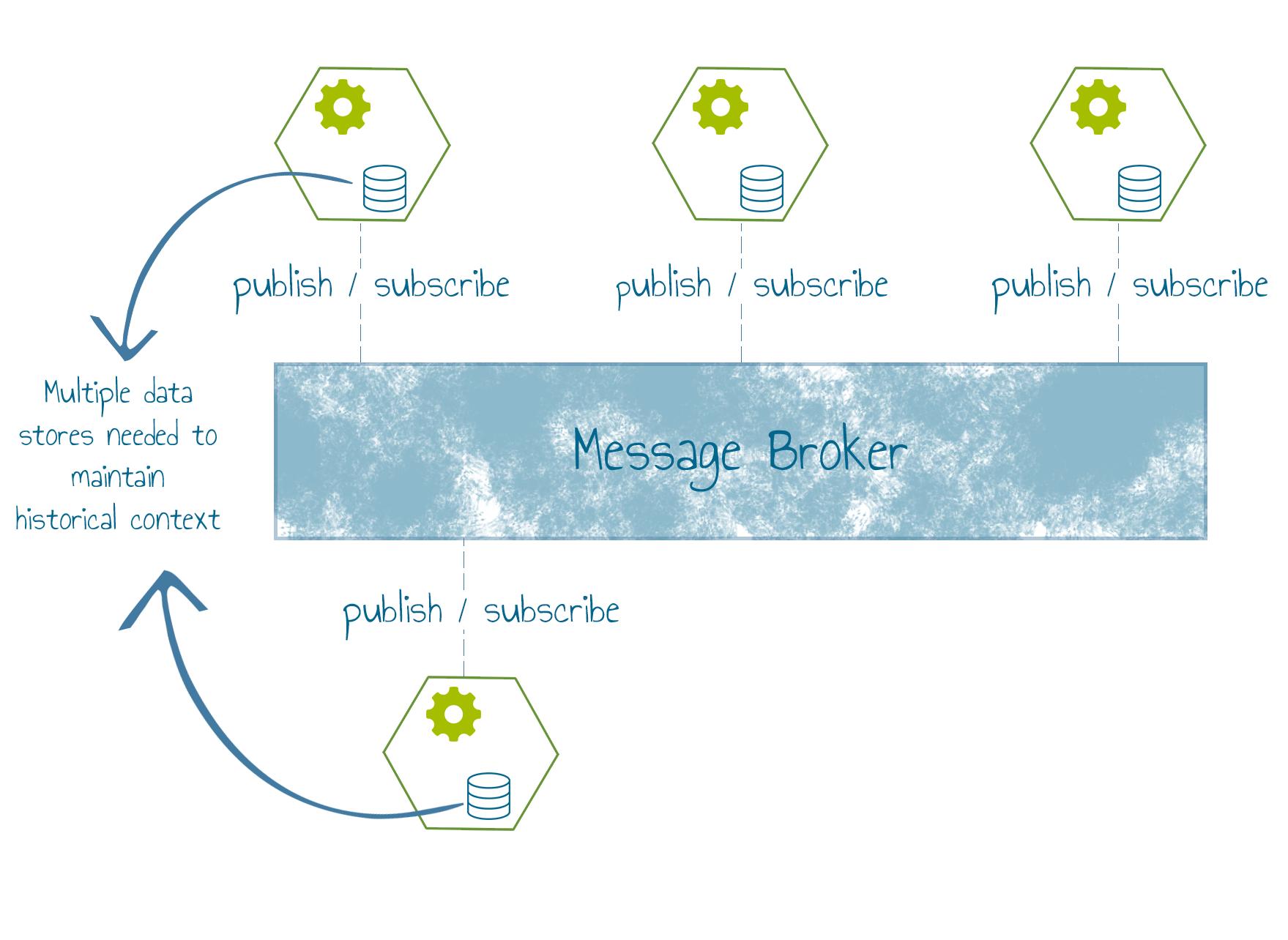
持久化事件流使服务能够直接引用共享事件流并从中创建自己的私有视图。 他们不再需要在本地存储事件的副本。
除了缓解一些复杂性之外,事件流开始提供新的机会。 由此产生的历史参考是新服务可以插入的内容,并且是一个强大的引导工具,可以将体系结构打开到扩展。
服务可以参考的事实的中央记录必然会带来很高的回报。
这种类型的持久性事件流可以实现为分布式提交日志。
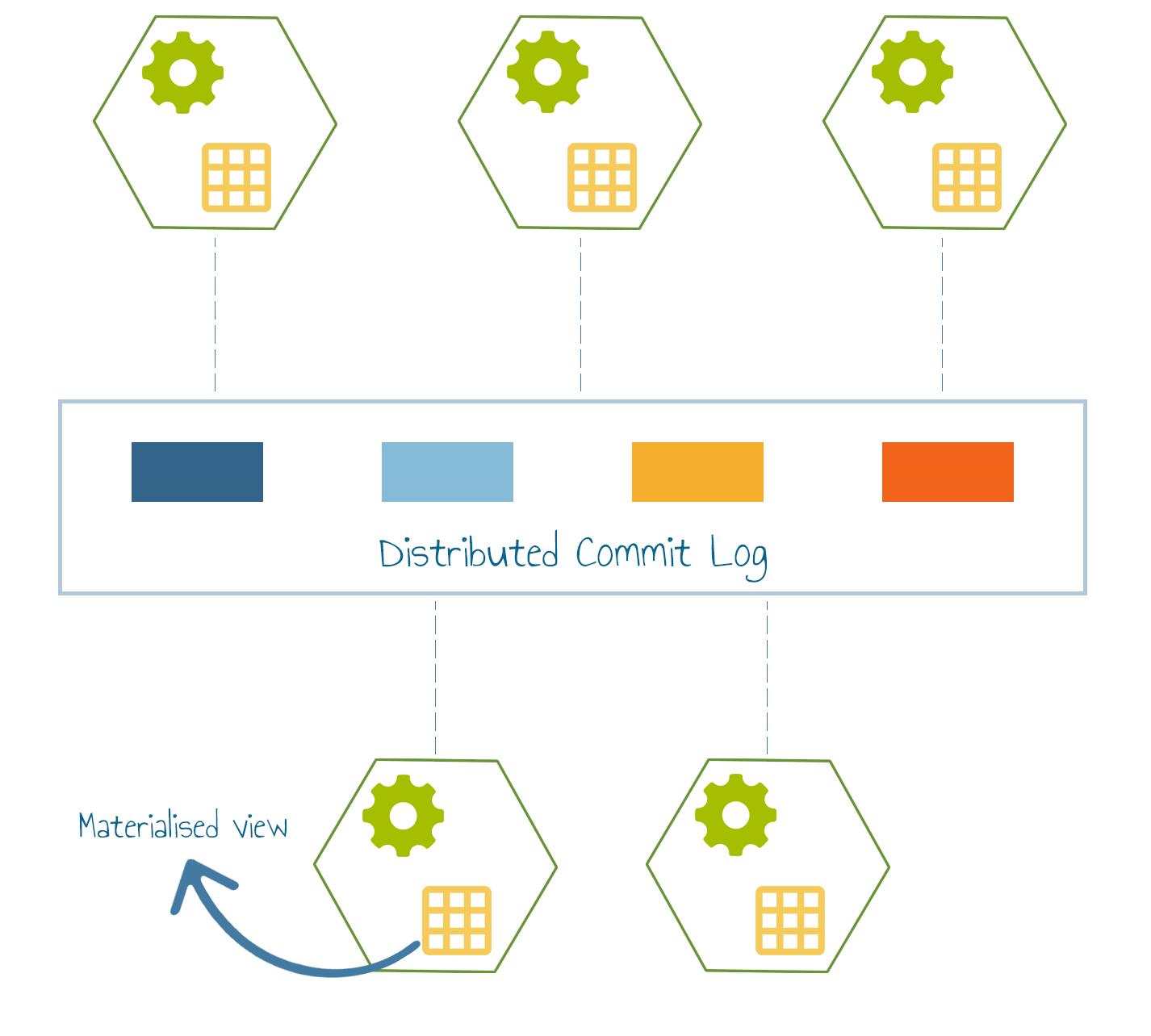
不可否认,事件驱动架构的承诺已经存在了很长时间,但它是分布式提交日志基础,这次使事情变得与众不同,并释放其真正的潜力。
分布式提交日志在概念上类似于数据库事务日志,有时称为预写日志或提交日志,其是由数据库管理系统执行的动作的历史。
分布式提交日志将消息的消耗与消息的存储分离。这种解耦提供了许多好处,与事件驱动架构最相关的三个好处是
- 事实来源:日志可以成为事实的来源。事件永久存储在日志中,订阅者可以随时引用。
- 事件重播和审计跟踪:由于事件是不可变的并且永久存储,因此默认情况下您将获得审计,监视和事件重播。除了允许现有订户重放事件历史记录外,它还允许新订户插入事件流并消耗过去的事件。
- 流处理:即使在数据进入分析引擎之前,处理提交日志中的数据也可以实现实时业务洞察。
基于分布式提交日志的事件驱动架构(EDA)使组织能够扩展其微服务架构,并从服务之间交换的数据中获得实时洞察。
EDA是微服务架构发展的下一个阶段,毫不奇怪,Google,Azure,Hortonworks等所有主要供应商都拥有支持这种发展的工具。
Apache Kafka是一种广泛采用的实现,还有像AWS Kinesis这样的云原生解决方案。
最后的想法
微服务在组织中越来越重要,这些服务之间交换的数据非常宝贵,利用这些数据进行架构可以为组织提供竞争优势,并且是微服务发展的下一个合乎逻辑的步骤。
原文:https://platform.deloitte.com.au/articles/2018/event-driven-microservices
- 90 次浏览
【事件驱动架构】连续流式事件处理
现代事件驱动解决方案的基本要素之一是能够处理连续事件流以获得洞察力和智能。您可以使用专门的流分析引擎跨事件流运行状态分析和复杂事件处理工作负载,同时保持低延迟处理时间。
通过将这些引擎作为事件驱动架构的一部分,您可以启用以下功能:
分析和理解事件流
从流中提取事件数据,以便数据科学家可以理解并推导出机器学习模型
针对事件流运行分析过程和机器学习模型
跨流和时间窗匹配复杂事件模式以做出决策并采取行动
流分析
流分析提供了查看和理解流经无界事件流的事件的功能。流应用程序处理事件流,并允许将数据和分析功能应用于流中的信息。这些应用程序被编写为跨这些功能的多步流程:
- 摄取许多事件来源
- 通过转换,过滤,关联和聚合某些指标以及使用其他数据源进行数据丰富来准备数据
- 使用评分和分类检测和预测事件模式
- 通过应用业务规则和业务逻辑来决定
- 直接运行操作,或者在事件驱动的系统中,发布事件通知或命令

流分析的基本功能
为了支持无界事件流的分析处理,这些功能对于事件流处理组件至关重要:
- 连续事件摄取和分析处理
- 跨事件流处理
- 低延迟处理,不需要存储数据
- 处理高容量和高速数据流
- 持续查询和分析Feed
- 事件和流之间的相关性
- 窗口化和有状态处理
- 查询和分析存储的数据
- 开发和运行数据管道
- 开发和运行分析管道
- 在事件流处理中对机器学习模型进行评分
支持分析和决策
除了基本的流功能之外,还可以考虑在事件流处理组件中支持其他常见的事件流类型和处理功能。通过在流应用程序代码中为这些流类型和流程创建函数,您可以简化问题并缩短开发时间。此列表包含其他事件流类型和进程的示例:
- 地理空间
- 基于位置的分析
- 地理围栏和地图匹配
- 时空聚会检测
- 时间序列分析
- 带时间戳的数据分析
- 异常检测和预测
- 文本分析
- 自然语言处理(NLP)和自然语言理解(NLU)
- 情感分析和实体提取
- 视频和音频
- 语音到文本转换
- 图像识别
- 规则:被描述为业务逻辑的决策
- 复杂事件处理(CEP):时间模式检测
- 实体分析
- 实体之间的关系
- 概率匹配
应用程序编程语言和标准
事件流应用程序和语言几乎没有标准。通常,流引擎提供与特定平台相关的特定于语言的编程模型。常用语言如下:
- Python支持数据处理,深受数据科学家和数据工程师的欢迎。
- Java™是一种普遍的应用程序开发语言。
- Scala将函数式编程和不可变对象添加到Java中。
其他平台特定的语言出现,因为实时处理需要更严格的性能要求。例如,Google启动了Apache Beam项目,为流分析应用程序提供统一的编程模型。 Beam是一种更高级别的统一编程模型,它提供了使用许多支持语言(包括Java,Python,Go和SQL)编写流分析应用程序的标准方法。流分析引擎通常通过Beam运行器支持此统一编程模型,该运行器获取代码并将其转换为特定引擎的平台本地可执行代码。
有关更多信息,请参阅支持引擎和功能的详细信息。领先的引擎包括Google Cloud Dataflow,Apache Flink,Apache Spark,Apache Apex和IBM®Streams。
运行时特性
在运营方面,流式分析引擎必须持续接收和分析到达的数据:
- Feed从不结束:
- 该系列无限制。
- 该模型不基于请求响应集。
- 消防水带不停止:
- 继续喝酒,保持健康。
- 处理速率大于或等于进给速率。
- 分析引擎必须具有弹性和自我修复能力。
许多其他信息处理环境中没有这些专门的需求和关注点。这些问题导致高度优化的运行时和引擎,用于跨事件流对分析工作负载进行状态,并行处理。
原文: https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture/event-driven-event-streams
讨论:加入知识星球【首席架构师圈】
- 204 次浏览
【事件驱动架构】针对云原生架构的事件驱动解决方案
现代数字业务实时运作。当它们发生时,它会向感兴趣的各方通报感兴趣的事物。它可以从越来越多的资源中获取并获得洞察力。它学习,预测并且聪明。从本质上讲,它是事件驱动的。
事件是捕获事实陈述的一种方式。事件发生时,事件会连续发生。通过利用这种连续流,应用程序可以根据过去发生的事情对未来作出反应和推理。
对于企业IT团队而言,采用事件驱动的开发是下一代数字业务应用程序的基础。 IT团队必须以云原生样式设计,开发,部署和运营事件驱动的解决方案。
事件驱动的体系结构和反应式编程模型不是新概念。但是,当您迁移到具有微服务,基于容器的工作负载和无服务器计算的云原生架构时,您可以在云原生环境中重新访问事件驱动的方法。将事件驱动的体系结构视为将云原生体系结构的弹性,敏捷性和可扩展特性扩展为具有响应性和响应性。
云原生架构的两个方面对于开发事件驱动架构至关重要:
- 微服务提供松散耦合的应用程序体系结构,支持以高度分布的模式进行部署,以实现弹性,灵活性和扩展性。
- 具有容器和无服务器部署的云原生平台提供了实现微服务架构的弹性,灵活性和可伸缩性的应用程序平台和工具。
事件驱动架构(EDA)是一种应用程序部署模式,至少在20年前创建并被许多公司使用。 通过混合云本机实现和微服务采用,EDA通过帮助解决微服务的松散耦合需求并避免复杂的通信集成而获得了新的关注点。 采用发布/订阅通信模型,事件源,命令查询责任隔离(CQRS)和Saga模式有助于实现支持云部署的高可扩展性和弹性的微服务。 EDA正在成为敏捷架构的强制方法,并为开发事件和处理事件流以添加人工智能服务提供机会,从而获得分析。
Jerome Boyer, STSM, Cloud Architecture Solution Engineering
事件
事件是状态变化的通知。发布或发布通知,感兴趣的各方可以订阅并采取行动。通常,通知的发布者不知道采取了什么动作,并且没有收到通知被处理的相应反馈。
通常,事件代表业务感兴趣的事物的状态变化。事件是发生的事情的记录。它们无法改变。你无法改变过去发生的事情。
事件流
事件流是一系列连续无限的事件。在开始处理流之前,可能会启动流的开始。流的结尾在未来的某个未知点。
事件按每个事件发生的时间排序。在开发事件驱动的解决方案时,通常会看到以下两种类型的事件流:
- 其事件被定义并作为解决方案的一部分发布到流中的流。
- 连接到事件流的流。示例包括来自物联网(IoT)设备的事件流,来自电话系统的语音流,视频流,或来自全球定位系统的船或平面位置。
命令
命令是做某事的指令。通常,命令指向特定的消费者。消费者运行所需的命令或过程并将确认传递回发行者。确认表明该命令已被处理。
事件和消息
消息传递在IT系统中有着悠久的历史。您可以在消息传递系统和消息的上下文中看到事件驱动的解决方案和事件。但是,这些特性值得考虑:
- 消息传输有效负载并持续存在直到它们被消耗。消息使用者通常直接被定位并且与关心消息被传递和处理的制作者相关。
- 事件将作为可重播的流历史记录保留。事件消费者与生产者无关。事件是发生事件的记录,因此无法更改。

松耦合
松耦合是事件驱动处理的主要优点之一。它允许事件生成器发出事件,而不知道谁将使用这些事件。同样,事件使用者不需要知道事件发射器。由于松耦合,事件消耗模块和事件生成器模块可以用不同语言实现,或者使用不同且适合特定作业的技术。
松散耦合的模块更适合独立发展。当它们正确实现时,松散耦合的模块会导致系统复杂性显着降低。
然而,松耦合并不意味着“没有耦合”。事件使用者使用有助于实现其目标的事件,并且这样做可以确定所需的数据以及该数据的类型和格式。事件生产者发布它希望被消费者理解和使用的事件,与潜在消费者建立隐含的合同。
例如,XML格式的事件通知必须符合消费者和生产者必须知道的某个模式。在事件驱动的系统中减少耦合可以做的最重要的事情之一是减少在模块之间流动的不同事件类型的数量。要减少事件类型的数量,请注意这些模块的内聚性。
凝聚
内聚是相关事物封装在同一软件模块中的程度。出于本讨论的目的,模块是具有高内聚性的可独立部署的软件单元。 Cohesion与耦合有关,因为高度内聚的模块与其他模块的通信较少,减少了系统中事件和事件类型的数量。
模块之间相互作用的频率越低,它们的耦合就越少。在优化模块尺寸以实现灵活性和适应性的同时实现软件的凝聚力是困难的,但是需要努力。设计凝聚力始于理解问题领域和良好的分析工作。有时,您还必须考虑支持软件环境的约束。避免使用过于细粒度的单片实现和实现。
下一步是什么
既然您已了解事件驱动解决方案的概念和价值,那么请学习如何在事件驱动的参考架构中构建一个。
原文 : https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture
讨论: 知识星球【首席架构师圈】
- 73 次浏览
【事件驱动架构】针对云原生架构的事件驱动解决方案
现代数字业务实时运作。当它们发生时,它会向感兴趣的各方通报感兴趣的事物。它可以从越来越多的资源中获取并获得洞察力。它学习,预测并且聪明。从本质上讲,它是事件驱动的。
事件是捕获事实陈述的一种方式。事件发生时,事件会连续发生。通过利用这种连续流,应用程序可以根据过去发生的事情对未来作出反应和推理。
对于企业IT团队而言,采用事件驱动的开发是下一代数字业务应用程序的基础。 IT团队必须以云原生样式设计,开发,部署和运营事件驱动的解决方案。
事件驱动的体系结构和反应式编程模型不是新概念。但是,当您迁移到具有微服务,基于容器的工作负载和无服务器计算的云原生架构时,您可以在云原生环境中重新访问事件驱动的方法。将事件驱动的体系结构视为将云原生体系结构的弹性,敏捷性和可扩展特性扩展为具有响应性和响应性。
云原生架构的两个方面对于开发事件驱动架构至关重要:
- 微服务提供松散耦合的应用程序体系结构,支持以高度分布的模式进行部署,以实现弹性,灵活性和扩展性。
- 具有容器和无服务器部署的云原生平台提供了实现微服务架构的弹性,灵活性和可伸缩性的应用程序平台和工具。
事件驱动架构(EDA)是一种应用程序部署模式,至少在20年前创建并被许多公司使用。 通过混合云本机实现和微服务采用,EDA通过帮助解决微服务的松散耦合需求并避免复杂的通信集成而获得了新的关注点。 采用发布/订阅通信模型,事件源,命令查询责任隔离(CQRS)和Saga模式有助于实现支持云部署的高可扩展性和弹性的微服务。 EDA正在成为敏捷架构的强制方法,并为开发事件和处理事件流以添加人工智能服务提供机会,从而获得分析。 ----- Jerome Boyer,STSM,云架构解决方案工程
事件
事件是状态变化的通知。发布或发布通知,感兴趣的各方可以订阅并采取行动。通常,通知的发布者不知道采取了什么动作,并且没有收到通知被处理的相应反馈。
通常,事件代表业务感兴趣的事物的状态变化。事件是发生的事情的记录。它们无法改变。你无法改变过去发生的事情。
事件流
事件流是一系列连续无限的事件。在开始处理流之前,可能会启动流的开始。流的结尾在未来的某个未知点。
事件按每个事件发生的时间排序。在开发事件驱动的解决方案时,通常会看到以下两种类型的事件流:
- 其事件被定义并作为解决方案的一部分发布到流中的流。
- 连接到事件流的流。示例包括来自物联网(IoT)设备的事件流,来自电话系统的语音流,视频流,或来自全球定位系统的船或平面位置。
命令
命令是做某事的指令。通常,命令指向特定的消费者。消费者运行所需的命令或过程并将确认传递回发行者。确认表明该命令已被处理。
事件和消息
消息传递在IT系统中有着悠久的历史。您可以在消息传递系统和消息的上下文中看到事件驱动的解决方案和事件。但是,这些特性值得考虑:
- 消息传输有效负载并持续存在直到它们被消耗。消息使用者通常直接被定位并且与关心消息被传递和处理的制作者相关。
- 事件将作为可重播的流历史记录保留。事件消费者与生产者无关。事件是发生事件的记录,因此无法更改。
松耦合
松耦合是事件驱动处理的主要优点之一。它允许事件生成器发出事件,而不知道谁将使用这些事件。同样,事件使用者不需要知道事件发射器。由于松耦合,事件消耗模块和事件生成器模块可以用不同语言实现,或者使用不同且适合特定作业的技术。
松散耦合的模块更适合独立发展。当它们正确实现时,松散耦合的模块会导致系统复杂性显着降低。
然而,松耦合并不意味着“没有耦合”。事件使用者使用有助于实现其目标的事件,并且这样做可以确定所需的数据以及该数据的类型和格式。事件生产者发布它希望被消费者理解和使用的事件,与潜在消费者建立隐含的合同。
例如,XML格式的事件通知必须符合消费者和生产者必须知道的某个模式。在事件驱动的系统中减少耦合可以做的最重要的事情之一是减少在模块之间流动的不同事件类型的数量。要减少事件类型的数量,请注意这些模块的内聚性。
凝聚
内聚是相关事物封装在同一软件模块中的程度。出于本讨论的目的,模块是具有高内聚性的可独立部署的软件单元。 Cohesion与耦合有关,因为高度内聚的模块与其他模块的通信较少,减少了系统中事件和事件类型的数量。
模块之间相互作用的频率越低,它们的耦合就越少。在优化模块尺寸以实现灵活性和适应性的同时实现软件的凝聚力是困难的,但是需要努力。设计凝聚力始于理解问题领域和良好的分析工作。有时,您还必须考虑支持软件环境的约束。避免使用过于细粒度的单片实现和实现。
下一步是什么
既然您已了解事件驱动解决方案的概念和价值,那么请学习如何在事件驱动的参考架构中构建一个。
原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 84 次浏览
【日志架构】ELK Stack + Kafka 端到端练习
在前一章中,我们已经学习了如何从头到尾地配置ELK堆栈。这样的配置能够支持大多数用例。然而,对于一个无限扩展的生产环境,瓶颈仍然存在:
- Logstash需要使用管道和过滤器处理日志,这需要花费大量的时间,如果日志爆发,可能会成为瓶颈;
- 弹性搜索需要对日志进行索引,这也消耗了时间,当日志爆发时,它就成为了一个瓶颈。
上面提到的瓶颈可以通过添加更多的Logstash部署和缩放Elasticsearch集群来平滑,当然,也可以通过在中间引入缓存层来平滑,就像所有其他的IT解决方案一样(比如在数据库访问路径的中间引入Redis)。利用缓存层最流行的解决方案之一是将Kafka集成到ELK堆栈中。我们将在本章讨论如何建立这样的环境。
架构
当Kafka被用作ELK栈中的缓存层时,将使用如下架构:
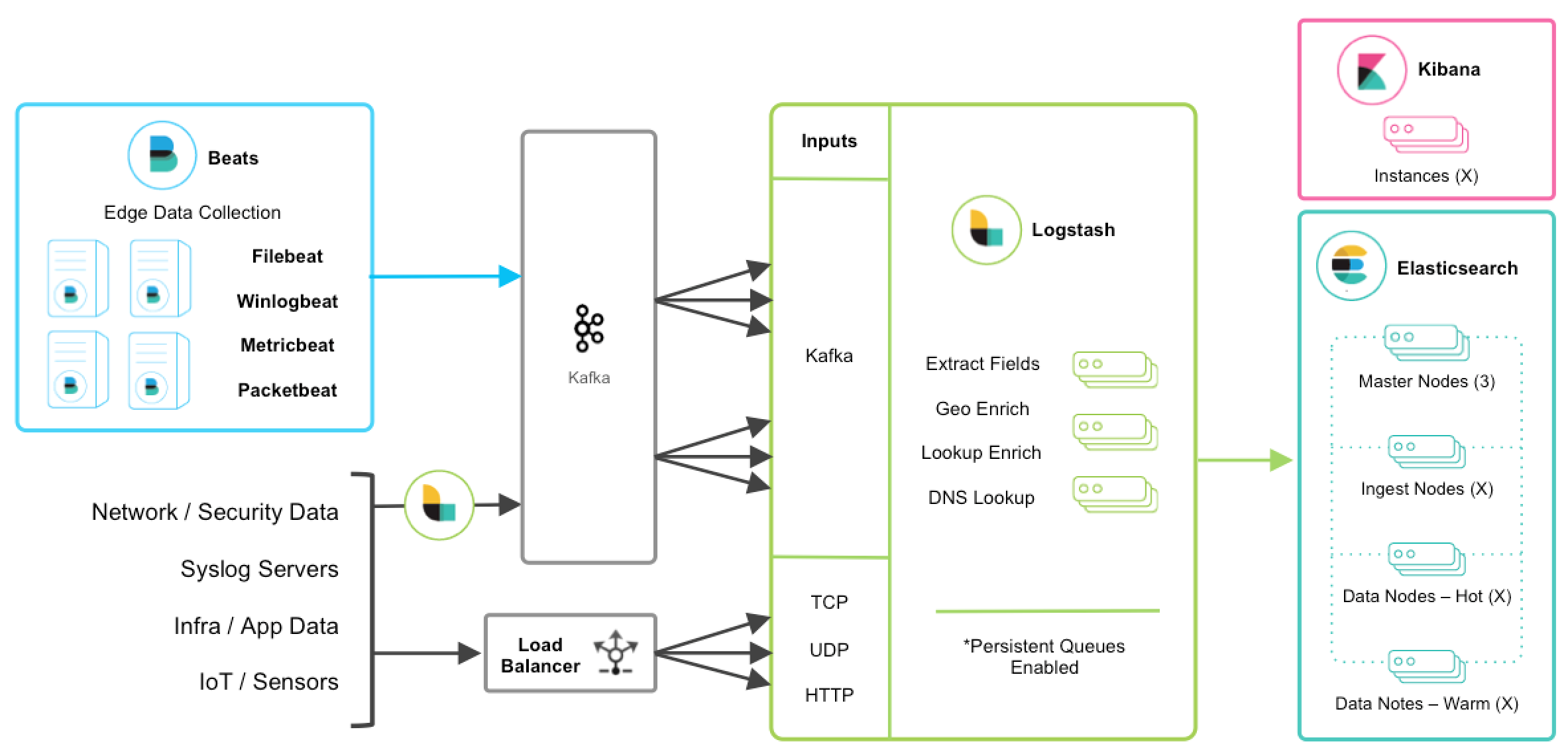
这方面的细节可以从部署和扩展Logstash中找到
演示环境
基于以上介绍的知识,我们的演示环境将构建如下:
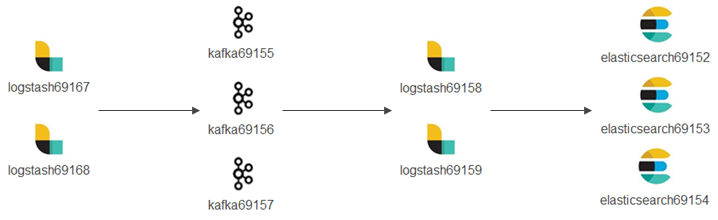
The detailed enviroment is as below:
- logstash69167/69168 (hostnames: e2e-l4-0690-167/168): receive logs from syslog, filebeat, etc. and forward/produce logs to Kafka topics;
- kafka69155/156/157 (hostnames: e2e-l4-0690-155/156/157): kafka cluster
- zookeeper will also be installed on these 3 x nodes;
- kafka manager will be installed on kafka69155;
- logstash69158/69159 (hostnames: e2e-l4-0690-158/159): consume logs from kafka topics, process logs with pipelines, and send logs to Elasticsearch;
- elasticsearch69152/69153/69154 (hostnames: e2e-l4-0690-152/153/154): Elasticsearch cluster
- Kibana will be installed on elasticsearch69152
- Data sources such as syslog, filebeat, etc. follow the same configuration as when Kafka is not used, hence we ignore their configuration in this chapter.
部署
Elasticsearch部署
安装过程已经由本文档记录,请参阅前面的章节。在本节中,我们将只列出配置和命令。
-
Install Elasticsearch on elasticsearch69152/69153/69154;
-
Configs on each node (/etc/elasticsearch/elasticsearch.yml):
-
elasticsearch69152
cluster.name: edc-elasticsearch node.name: e2e-l4-0690-152 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"] cluster.initial_master_nodes: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"]
-
elasticsearch69153
cluster.name: edc-elasticsearch node.name: e2e-l4-0690-153 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"] cluster.initial_master_nodes: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"]
-
elasticsearch69154
cluster.name: edc-elasticsearch node.name: e2e-l4-0690-154 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"] cluster.initial_master_nodes: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"]
-
-
Start Elasticsearch service on each node:
systemctl disable firewalld systemctl enable elasticsearch systemctl start elasticsearch
-
Verify (on any node): 3 x alive nodes should exist and one master node is elected successfully
[root@e2e-l4-0690-152]# curl -XGET 'http://localhost:9200/_cluster/state?pretty'
Kibana部署
安装过程已经由本文档记录,请参阅前面的章节。在本节中,我们将只列出配置和命令。
-
Install Kibana on elasticsearch69152;
-
Configure Kibana(/etc/kibana/kibana.yml):
server.host: "0.0.0.0" server.name: "e2e-l4-0690-152" elasticsearch.hosts: ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"]
-
Start the service on each node:
systemctl enable kibana systemctl start kibana
-
Verify: access http://10.226.69.152:5601 to verify that Kibana is up and running.
Zookeeper 部署
Zookeeper is a must before running a Kafka cluster. For demonstration purpose, we deploy a Zookeeper cluster on the same nodes as the Kafka cluster, A.K.A kafka69155/69156/69157.
-
There is no need to do any installation, decompressing the package is enough;
-
Configure zookeeper on each node(conf/zoo.cfg):
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/var/lib/zookeeper clientPort=2181 server.1=10.226.69.155:2888:3888 server.2=10.226.69.156:2888:3888 server.3=10.226.69.157:2888:3888
-
Create file /var/lib/zookeeper/myid with content 1/2/3 on each node:
echo 1 > /var/lib/zookeeper/myid # kafka69155 echo 2 > /var/lib/zookeeper/myid # kafka69156 echo 3 > /var/lib/zookeeper/myid # kafka69157
-
Start Zookeeper on all nodes:
./bin/zkServer.sh start ./bin/zkServer.sh status
-
Connect to Zooper for verification:
./bin/zkCli.sh -server 10.226.69.155:2181,10.226.69.156:2181,10.226.69.157:2181
Kafka 部署
A Kafka cluster will be deployed on kafka69155/69156/69157.
-
Kafka does not need any installation, downloading and decompressing a tarball is enough. Please refer to Kafka Quickstart for reference;
-
The Kafka cluster will run on kafka69155/156/157 where a Zookeeper cluster is already running. To enable the Kafka cluster, configure each node as below(config/server.properties):
-
kafka69155:
broker.id=0 listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://10.226.69.155:9092 zookeeper.connect=10.226.69.155:2181,10.226.69.156:2181:10.226.69.157:2181
-
kafka69156:
broker.id=1 listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://10.226.69.156:9092 zookeeper.connect=10.226.69.155:2181,10.226.69.156:2181:10.226.69.157:2181
-
kafka69157:
broker.id=1 listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://10.226.69.157:9092 zookeeper.connect=10.226.69.155:2181,10.226.69.156:2181:10.226.69.157:2181
-
-
Start Kafka on all nodes:
./bin/kafka-server-start.sh -daemon config/server.properties
Once the Kafka cluster is running, we can go ahead configuring Logstash. When it is required to make changes to the Kafka cluster, we should shut down the cluster gracefully as below, then make changes and start the cluster again:
./bin/kafka-server-stop.sh
Kafka Manager 部署
可以使用CLI命令管理Kafka集群。然而,它并不是非常方便。Kafka Manager是一个基于web的工具,它使基本的Kafka管理任务变得简单明了。该工具目前由雅虎维护,并已被重新命名为CMAK (Apache Kafka的集群管理)。无论如何,我们更喜欢称之为Kafka经理。
The Kafka manager will be deployed on kafka69155.
-
Download the application from its github repo;
-
After decompressing the package, change the zookeeper option as below in conf/application.conf:
kafka-manager.zkhosts="e2e-l4-0690-155:2181,e2e-l4-0690-156:2181,e2e-l4-0690-157:2181"
-
Create the app deployment(a zip file will be created):
./sbt clean dist
-
Unzip the newly created zip file (kafka-manager-2.0.0.2.zip in this demo) and start the service:
unzip kafka-manager-2.0.0.2.zip cd kafka-manager-2.0.0.2 bin/kafka-manager
-
The Kafka manager can be accessed from http://10.226.69.155:9000/ after a while;
-
Click Cluster->Add Cluster and enter below information to manage our Kafka cluster:
- Cluster Name: assign a meaningful name for this cluster
- Cluster Zookeeper Hosts: 10.226.69.155:2181,10.226.69.156:2181,10.226.69.157:2181
- Enable JMX Polling: yes
-
Done.
Logstash部署
基于我们对演示环境的介绍,我们有两套Logstash部署:
-
Log Producers: logstash69167/69168
Collect logs from data sources (such as syslog, filebeat, etc.) and forward log entries to corresponding Kafka topics. The num. of such Logstash instances can be determined based on the amount of data generated by data sources.
Actually, such Logstash instances are separated from each other. In other words, they work as standalone instances and have no knowledge on others.
-
Log Consumers: logstash69158/69159
Consume logs from Kafka topics, modify logs based on pipeline definitions and ship modified logs to Elasticsearch.
Such Logstash instances have the identical pipeline configurations (except for client_id) and belong to the same Kafka consumer group which load balance each other.
The installation of Logstash has been covered in previous chapters, we won’t cover them again in this chapter, instead, we will focus our effort on the clarification of pipeline definitions when Kafka is leveraged in the middle.
Logstash产生日志到Kafka
每个Logstash实例负责合并某些指定数据源的日志。
- logstash69167: consolidate logs for storage arrays and application solutions based on Linux;
- logstash69168: consolidate logs for ethernet switches and application solutions based on Windows.
-
Define pipelines(/etc/logstash/conf.d)
-
logstash69167
# /etc/logstash/conf.d/ps_rhel.conf input { beats { port => 5045 tags => ["server", "filebeat", "ps", "rhel"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "ps-rhel" topic_id => "ps-rhel" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/sc_sles.conf input { beats { port => 5044 tags => ["server", "filebeat", "sc", "sles"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "sc-sles" topic_id => "sc-sles" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/pssc.conf input { udp { port => 514 tags => ["array", "syslog", "sc", "ps"] } } output { kafka { id => "pssc" topic_id => "pssc" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/unity.conf input { udp { port => 5000 tags => ["array", "syslog", "unity"] } } output { kafka { id => "unity" topic_id => "unity" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/xio.conf input { udp { port => 5002 tags => ["array", "syslog", "xio"] } } output { kafka { id => "xio" topic_id => "xio" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } -
logstash69168
# /etc/logstash/conf.d/ethernet_switch.conf input { udp { port => 514 tags => ["switch", "syslog", "network", "ethernet"] } } output { kafka { id => "ether-switch" topic_id => "ether-switch" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/vnx_exchange.conf input { beats { port => 5044 tags => ["server", "winlogbeat", "vnx", "windows", "exchange"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "vnx-exchange" topic_id => "vnx-exchange" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/vnx_mssql.conf input { beats { port => 5045 tags => ["server", "winlogbeat", "vnx", "windows", "mssql"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "vnx-mssql" topic_id => "vnx-mssql" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } }
-
-
Enable pipelines (/etc/logstash/pipelines.yml):
-
logstash69167:
- pipeline.id: ps_rhel path.config: "/etc/logstash/conf.d/ps_rhel.conf" - pipeline.id: sc_sles path.config: "/etc/logstash/conf.d/sc_sles.conf" - pipeline.id: pssc path.config: "/etc/logstash/conf.d/pssc.conf" - pipeline.id: unity path.config: "/etc/logstash/conf.d/unity.conf" - pipeline.id: xio path.config: "/etc/logstash/conf.d/xio.conf"
-
logstash69168:
- pipeline.id: ethernet_switch path.config: "/etc/logstash/conf.d/ethernet_switch.conf" - pipeline.id: vnx_exchange path.config: "/etc/logstash/conf.d/vnx_exchange.conf" - pipeline.id: vnx_mssql path.config: "/etc/logstash/conf.d/vnx_mssql.conf"
-
-
Start Logstash servers on all nodes:
systemctl start logstash
-
Verify topics are successfully created on Kafka:
ssh root@kafka69155/156/157 ./bin/kafka-topics.sh -bootstrap-server "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" --list
-
Verify logs are sent to Kafka successfully:
ssh root@kafka69155/156/157 ./bin/kafka-console-consumer.sh -bootstrap-server "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" --topic <topic name>
现在,我们已经将Logstash实例配置为Kafka producer。在继续之前,有必要介绍一些关于使用Kafka作为输出插件时的管道配置的技巧。
不要为这类Logstash实例的管道定义复杂的过滤器,因为它们可能增加延迟;
- 在输入部分添加标签,以简化Kibana的日志搜索/分类工作;
- 为不同的管道指定不同的id和有意义的名称;
- 如果syslog也是设置中的数据源,则将主机字段重命名为其他有意义的名称。关于这个问题的解释,请参考tips章节。
Logstash,它消耗来自Kafka的日志
我们将为logstash69158/69159配置管道。这两个Logstash实例具有相同的管道定义(除了client_id之外),并通过利用Kafka的消费者组特性均匀地使用来自Kafka主题的消息。
由于日志被安全地缓存在Kafka中,所以在将日志实体发送到Elasticsearch之前,使用管道定义复杂的过滤器来修改日志实体是正确的。这不会导致瓶颈,因为Kafka中已经有日志了,唯一的影响是您可能需要等待一段时间才能看到Elasticsearch/Kibana中的日志。如果查看来自Elasticsearch/Kibana的日志对时间很敏感,那么可以添加属于同一使用者组的更多Logstash实例来平衡处理的负载。
-
Define pipelines(/etc/logstash/conf.d): client_id should always be set with different values
# /etc/logstash/conf.d/kafka_array.conf input { kafka { client_id => "logstash69158-array" # client_id => "logstash69159-array" group_id => "logstash-array" topics => ["unity", "vnx", "xio", "pssc", "powerstore"] codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } output { elasticsearch { hosts => ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"] index => "edc-storage-%{+YYYY.MM.dd}" } } # /etc/logstash/conf.d/kafka_server.conf input { kafka { client_id => "logstash69158-server" # client_id => "logstash69159-server" group_id => "logstash-server" topics => ["sc-sles", "ps-rhel", "vnx-exchange", "vnx-mssql"] codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } output { elasticsearch { hosts => ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"] index => "edc-server-%{+YYYY.MM.dd}" } } # /etc/logstash/conf.d/kafka_switch.conf input { kafka { client_id => "logstash69158-switch" # client_id => "logstash69159-switch" group_id => "logstash-switch" topics => ["ether-switch"] codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } output { elasticsearch { hosts => ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"] index => "edc-ethernet-%{+YYYY.MM.dd}" } } -
Enable pipelines on all nodes(/etc/logstash/pipelines.yml):
- pipeline.id: kafka_array path.config: "/etc/logstash/conf.d/kafka_array.conf" - pipeline.id: kafka_server path.config: "/etc/logstash/conf.d/kafka_server.conf" - pipeline.id: kafka_switch path.config: "/etc/logstash/conf.d/kafka_switch.conf"
-
Start logstash on all nodes:
systemctl start logstash
配置并启动Logstash之后,日志应该能够发送到Elasticsearch,并可以从Kibana检查。
现在,我们已经将Logstash实例配置为Kafka使用者。在继续之前,有必要介绍一些在使用Kafka作为输入插件时的管道配置技巧。
- 对于不同Logstash实例上的每个管道,应该始终使用不同的值设置client_id。该字段用于识别Kafka上的消费者;
- 对于不同Logstsh实例上的相同管道,group_id应该设置恒等值。这个字段用于标识Kafka上的消费者组,如果值不同,负载平衡就无法工作。
数据源配置
数据源是服务器、交换机、阵列等,它们通过beat、syslog等将日志发送到Logstash。配置它们的步骤与没有Kafka集成时相同,请参照前一章。
结论
我们已经配置了一个集成了Kafka和ELK堆栈的演示环境。通过集成Kafka,可以提高日志处理性能(添加缓存层),还可以集成更多潜在的应用程序(使用来自Kafka的日志消息并执行一些特殊操作,如ML)。
原文:https://elastic-stack.readthedocs.io/en/latest/e2e_kafkapractices.html
本文:http://jiagoushi.pro/node/1135
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 417 次浏览
【首席看事件溯源】Oracle中事件溯源的想法 Log Miner 或有其他选择?
使用微服务,架构师希望拆除单片数据库并复制数据,而不是共享数据。然后,需要对修改完成的地方(如CQRS中的C)进行审计。为了恢复,Oracle数据库已经这样做了,在修改数据块之前构建重做记录,但这是一个物理变化矢量。我们需要一些有更多可能性的逻辑来过滤和转换。有多种可能的方法。但不幸的是,自从Oracle收购了Golden GAte并将其单独出售后,数据库中构建的那些就慢慢被删除了。
- 流在12c中被弃用
- 在12c中不赞成高级复制
- 更改数据捕获在12c中是不赞成的
- LogMiner连续矿在12c就被废弃了
deprecated变成了desupport,甚至在以后的版本中被移除,比如19c的Continuous Mine——12cR2的最终路径集:
ORA-44609: CONTINOUS_MINE is desupported for use with DBMS_LOGMNR.START_LOGMNR
文档表示,替代产品是“Golden Gate”,但那是另一种需要购买的产品,功能强大但价格昂贵(而且没有标准版)。
Debezium dbz - 137
Debezium是一个用于更改数据捕获的开源分布式平台,它正在开发一个Oracle数据库连接器。许多想法在https://issues.jboss.org/browse/DBZ-137中被提及,在这篇文章中我给出了我的想法。
甲骨文xstream
完美的解决方案,因为它对源代码的开销最小,而且非常高效。但是它需要获得Golden Gate许可,因此可能不是开源产品的最佳解决方案。
甲骨文LogMiner
LogMiner包含在所有版本中,读取重做流(归档和在线重做日志)并提取所有信息。在启用补充日志记录时,我们有足够的信息来构建逻辑更改信息。许多解决方案已经基于此。但我认为它有两个问题。
LogMiner限制:
基本上,LogMiner不是用于复制的。这个想法更多的是提供一个故障排除工具来理解数据上发生了什么:什么导致了太多的重做?谁删除了一些数据?哪些会话锁定了行?有一些限制,比如不支持的数据类型。它的设计不是为了提高效率。但也有可能在另一个系统上进行开采。但是,我认为这些限制对于简单数据库上的开放源码解决方案来说是可以接受的,因为它的更改率很低。
LogMiner的未来:
更让人好奇的是,Oracle是如何去掉那些可能会替代Golden Gate的特性的。在19世纪,持续的 CONTINUOUS_MINE 被移除。这意味着我们需要不断地打开和读取整个重做日志。当甲骨文在未来的版本中看到一个与Golden Gate竞争的健壮的开源产品时,我们知道甲骨文会删除什么吗?
在DBZ-137上有一些关于RAC的注释,因为有许多重做线程,所以RAC更加复杂。我不认为RAC在这个范围内。RAC是一个昂贵的选项,只有在负载非常高的大型数据库上才需要它。这更符合Golden Gate的范围。
注意,我们可以解析V$LOGMINER_CONTENTS中的SQL_REDO和SQL_UNDO,但是也可以从dbms_logmnr.mine_value中获取它们
挖掘二进制日志流
有人尝试挖掘二进制重做日志。一些众所周知的商业产品和一些开源尝试。这非常复杂,但对于开放源码社区来说也很有趣。重做日志结构是私有的,但是Oracle不会经常更改它,因为所有可用性特性(恢复、备用……)都基于它。然而,由于这种挖掘暴露了重做的专有格式,因此可能存在一个开放源代码的法律问题。Oracle许可证明确禁止反向工程。
连续查询的通知
我研究了dbms_change_notification作为CDC备选方案的用法:https://blog.dbi-services.com/event-sourcing-cqn-is-not-a-replace -for- CDC。该特性针对几乎静态的数据,以便使缓存失效并刷新。它不是为高变化率而设计的,在这方面一点效率都没有。
客户端结果缓存
与从不经常更改的数据中刷新缓存相同,可以考虑使用客户端结果缓存进行查询,因为当修改发生时,它有一种机制可以使缓存失效。但是,这里的粒度很差,因为对表的任何更改都会使其上的所有查询无效。
物化视图日志
所有更改都可以记录在物化视图日志中。该功能是为物化视图快速刷新而建立的,是一种复制。这与LogMiner使用的重做日志无关。对于物化视图日志,更改存储在表中,必须在使用时删除。但是这个特性存在了很长时间,并且得到了广泛的应用。但是,如果需要重复写入、读取和删除,只是为了将相同的数据放到另一个地方,那么我将严肃地质疑这种体系结构。
触发器
使用触发器,我们可以像使用物化视图日志一样记录更改。它提供了更多的可能性,比如发送更改而不是将其存储在数据库中(但是我们必须管理事务的可见性)。Connor McDonald发布了一个存储经过审计的更改的优化示例:
https://blogs.oracle.com/oraclemagazine/a-fresh-look-at-auditing-row-ch…
但是这仍然是很大的开销,需要在添加或删除列时进行调整。
ORA_ROWSCN
当启用行依赖项时,ORA_ROWSCN伪列可以帮助筛选最近更新的行。然而,这种方法有两个问题。
完全读:如果我们想要一个接近实时的复制,我们可能会频繁地为更改池。如果被索引,ORA_ROWSCN会很好,但事实并非如此。它只读取存储在表块中的信息。这意味着要找到在过去5分钟内完成的更改,我们需要完全扫描表,然后ORA_ROWSCN将帮助识别那些被更改的行。它是“最后更新”列时间戳的透明替代方案,但无助于快速访问这些行。
提交时间:任何读取“更改”时间戳的内容都存在一个普遍问题。假设我每5分钟收集一次变化。我有一个很长的事务,它在12:39更新一行,并在12:42提交。在12:40运行的池,查找12:35以后的更改,由于还没有提交,所以看不到更改。在12:45运行的池可以看到它,但是当它过滤自上次运行(即12:20)以来发生的更改时,就看不到它了。这意味着每次运行都必须查看更大的窗口,包括最长的事务启动时间。然后它必须处理重复项,因为前一次运行已经捕获了一些更改。当没有可用的“提交SCN”时,这是一个普遍的问题。
Userenv (“commitscn”)
在讨论可见性时间(提交SCN)与更改时,有一种没有文档记录的方法可以获得它。使用userenv(' commitscn ')进行插入或更新,这将在事务结束时神奇地返回到表行,以设置提交SCN。它不受支持,而且它只能在事务中调用一次,然后不能在触发器中自动添加。
甲骨文闪回查询
如果我们不想在DML上添加额外的审计,那么重做日志并不是惟一的内部日志记录。Oracle还会记录一致读取的撤消信息(MVCC),并且在不增加修改开销的情况下,可以显示表中发生的所有更改。基本上,我们可以选择…从…版本之间的SCN…和…所有的变化都将是可见的与新的和旧的值和附加的信息有关的操作和事务。
但是,它没有被索引。就像使用ORA_ROWSCN一样,我们需要对表进行全扫描,由于撤消操作,一致的读操作将构建以前版本的块。
闪回数据档案
闪回查询可以重构最近的更改,这些更改受到撤消保留和最近发生的DDL的限制。Flashback数据存档(称为完全回忆)可以更进一步。该特性在企业版中可用,不需要额外的选项。它可以超越撤销保留并允许一些DDL。但是,再次强调,它没有经过优化以获得自特定时间点以来的所有更改。其思想是,当您知道要读取的行时,它就可以转到以前的版本。
最小触发+闪回查询
其中一些解决方案可以组合使用。例如,触发器只能记录更改行的ROWID,而复制过程将通过flashback查询获得关于这些行的更多信息。这降低了更改的开销,同时仍然避免了对复制进行全面扫描。或者,您可以直接从定制挖掘重做日志中获得这些ROWID,这比试图从中获取所有信息要简单得多。
DDL触发器
SQL是敏捷的,允许结构更改。如果添加一个列破坏了整个复制,那么就有问题了。上述所有解决方案都需要处理这些更改。重做日志包含字典中的更改,但是解码起来可能很复杂。所有其他解决方案都必须适应这些更改,这意味着要有DDL触发器并处理不同类型的更改。
不容易…
总结一下,没有简单的解决方案,最简单的方案已经被Oracle移除,以推动金门的销售。当有人想要复制更改并从另一个地方查询它时,我的第一个建议是:不要这样做。关系数据库用于获取新的数据和修改,并能够查询不同的目的。我们有以不同格式显示数据的视图。我们有索引来快速访问不同的用例。甲骨文并不像它的许多竞争对手。从第一个版本开始,它就针对混合工作负载进行了优化。您可以查询发生更改的同一个数据库,因为SELECT不会锁定任何内容。您有一个资源管理器来确保失控的查询不会减慢事务活动。如果正确地调优,这些查询的CPU使用率很少会高于将更改流到另一个数据库所需实现的复制活动。
那么,事件源应该建立在哪种技术上呢?LogMiner看起来很适合基本使用的小型数据库。而且该项目应该适应Oracle将来删除的特性。
混合触发器/闪回查询
当只涉及到几个表时,生成DML触发器可能是最简单的,特别是当它们只记录最小值时,比如ROWID。只有在提交事务时,ROWID才可见。然后复制过程必须使用闪回查询,只从ROWID中读取那些块。这里的好处是,flashback查询显示的是更改何时可见(提交时间),而不是更改时间,这使得过滤上次运行时已经处理的更改变得更容易。
这是一个想法,当一个触发器日志的ROWID变成了一个DEMO_CDC表,我们查询:
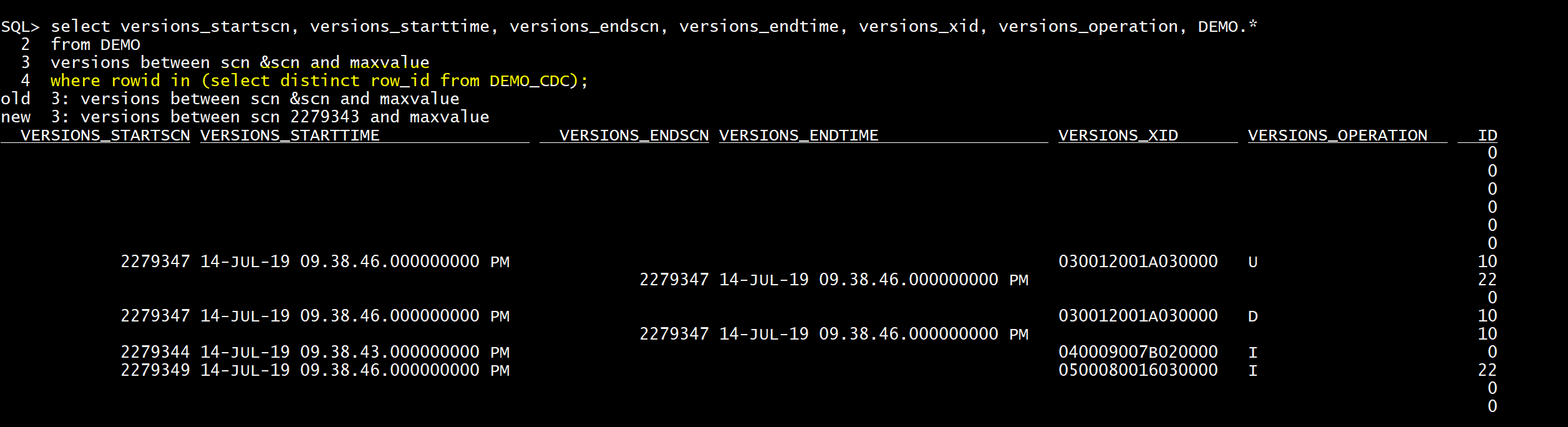
执行计划显示最佳访问与ROWID:
Explain Plan ------------------------------------------------ PLAN_TABLE_OUTPUT Plan hash value: 3039832324------------------------------------------------ | Id | Operation | Name | ------------------------------------------------ | 0 | SELECT STATEMENT | | | 1 | NESTED LOOPS | | | 2 | SORT UNIQUE | | | 3 | TABLE ACCESS FULL | DEMO_CDC | | 4 | TABLE ACCESS BY USER ROWID| DEMO | ------------------------------------------------
这里重要的一点是,查询成本与更改成比例,而不是与表的完整大小成比例。触发器开销仅限于ROWID。不需要将已经存储在基表和撤消段中的值存储在表中。如果频繁地读取这个数据,那么所涉及的所有块(ROWID列表、UNDO记录和表块)很可能仍然在缓冲区缓存中。
原文:https://medium.com/@FranckPachot/ideas-for-event-sourcing-in-oracle-d4e016e90af6
本文:https://pub.intelligentx.net/ideas-event-sourcing-oraclelog-miner-or-are-there-other-alternatives
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 205 次浏览
云原生架构
- 94 次浏览
【云原生架构】库(Library ) vs 服务(Service ) vs Sidecar(边车)
所有软件应用程序都由可重用的元素组成。 这些可重用元素的目标和功能从基础设施级别到安全级别到业务能力各不相同。
本文的目的是比较用于构建和部署这些可重用元素的不同方法。
1. 库
这是重用代码的最广泛使用的方法。 可重用代码作为库开发和发布。 在这种方法中,客户端应用程序将库定义为直接依赖项,使用提供的 API 并将其代码与主应用程序逻辑一起发送。 库和主应用程序逻辑的代码作为同一进程/容器的一部分执行。

优点
- 延迟:库中的代码与主应用程序在同一进程中执行,因此没有网络延迟。
- 可用性:整体可用性很高,因为没有网络分区(CAP 定理)。
- 易于使用:使用非常简单。
- 环境上下文:库可以访问环境上下文(内存、CPU 等),因为它们是同一容器的一部分。
缺点
- 资源:内存、CPU 等资源与主应用程序共享。这意味着库的性能会对主应用程序产生副作用。
- 技术:库中使用的库与主要应用程序的库相同,因此,如果组织有不同的应用程序集,则每种语言都需要多个实现。
- 可维护性:库中的任何错误修复都需要对所有客户端应用程序进行代码更改和测试。
服务
下一个最广泛使用的模式是为可重用功能定义服务。在这种方法中,应用程序使用请求-响应机制进行网络调用以调用另一个服务。服务和主要应用程序逻辑的代码在不同的 Pod/服务器实例中执行。
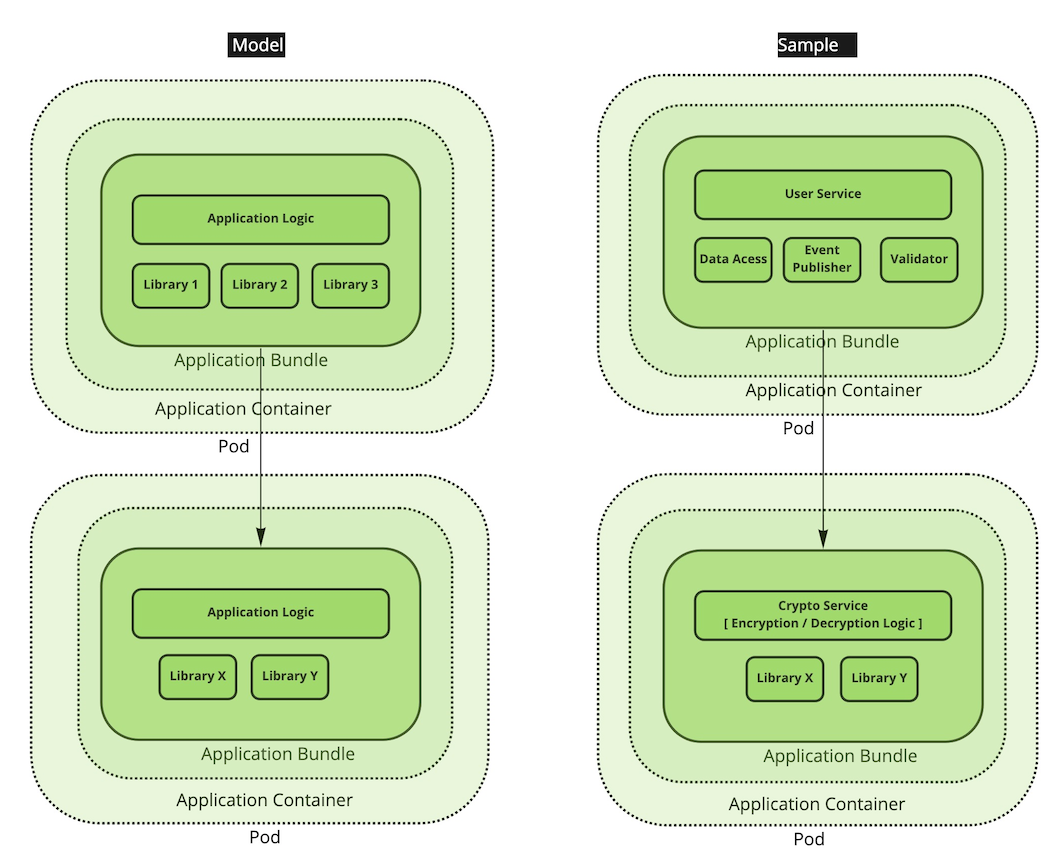
优点
- 资源:应用程序和服务分开部署,因此资源不共享。资源可以独立地针对应用程序和服务进行优化。
- 可维护性:当涉及到错误修复时,服务可以独立发布。不需要版本升级。
- 技术:可以使用适合其目的的任何技术选择来开发服务。
缺点
- 易用性:与库相比,服务的易用性相对较低。
- 延迟:由于应用程序和服务是分布式的,并且调用需要网络调用,因此延迟明显更高。
- 环境上下文:服务无法访问主应用程序的环境上下文(内存、CPU 等),因为两者都在不同的实例中独立运行。
- 可用性:由于网络分区,总体可用性将低于库。
边车
Sidecar 模式是由两个容器组成的单节点模式。 side car 和主应用程序逻辑的代码作为不同进程/容器的一部分执行,但一起部署在同一个 pod/server 实例中。
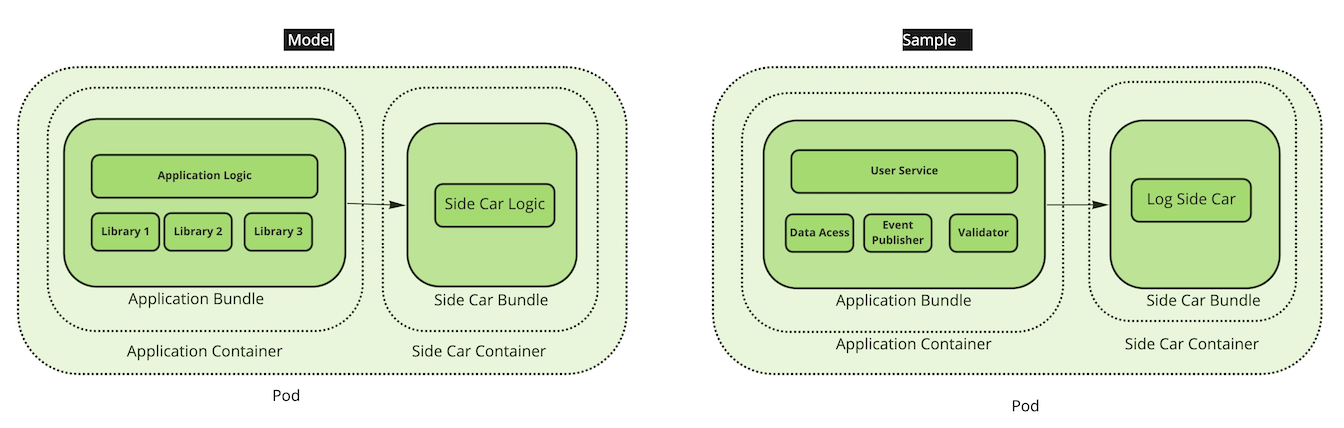
优点缺点
- 可维护性:当涉及到错误修复时,Sidecar 可以独立发布。
- 技术:Sidecar 可以使用适合其目的的任何技术进行开发。
- 延迟:与服务相比,延迟较低,但高于库。这种方法的反模式是使所有可重用的组件边车,因为这将导致显着的影响性能影响。
- 资源:应用程序和 Sidecar 部署为集合,因此资源共享,但可以为 Sidecar 单独设置资源限制,以防止 Sidecar 过度使用。这种方法的反模式是让所有可重用的组件使用边车,因为它会导致资源配置管理的巨大开销。
- 易用性:与库相比,Sidecar 的易用性相对较低,如果 CI/CD 管道支持开箱即用,则与服务相比使用起来更简单。
- 环境上下文:sidecar 可以访问环境上下文(内存、CPU 等),因为它是同一个 pod/server 实例的一部分。这允许边车进行应用程序性能监控等。
- 可用性:与服务相比,可用性会更高,因为没有真正的网络分区。一般来说,可用性主要取决于主应用程序和边车之间的通信协议。例如。如果协议被触发并忘记,那么边车中的失败不会对主应用程序产生级联副作用。
概括
上面提到的方法 — Library、Service 和 Sidecar 都可以一起用于应用程序以达到预期的结果。应用程序可以使用库进行数据库调用,使用边车进行分布式日志记录,以及提供身份验证功能的服务。开发团队需要权衡利弊,然后选择正确的解决方案。
原文:https://atul-agrawal.medium.com/library-vs-service-vs-sidecar-ff5a20b50…
- 120 次浏览
分部式架构
- 293 次浏览
【分布式】资源与事务:可观测性的基本二重性
西格曼:我叫本·西格曼。我是Lightstep的联合创始人兼首席执行官。我在这里讨论的是资源和事务,这是可观察性的一个基本的二元性。我职业生涯的大部分时间都在研究可观察性。在我职业生涯之初,我在谷歌工作了九年,致力于谷歌的分布式跟踪系统Dapper,以及他们的高可用性监控和度量系统Monar。然后,Lightstep当然也专注于可观察性。我花了很长时间才到这里。我想出了一种与过去不同的思考可观察性的方法,这就是这次演讲的内容。
事务
什么是事务?在右边,您可以看到某个系统的示意图。我们将从这个银行账户服务的角度来讨论一些事情,它处于一些更大的微服务架构,一些云原生架构中。本演示文稿中的事务不一定像银行事务。它只是指从系统的一部分传播到另一部分的任何请求,而不是整个请求。这是它所做的所有工作,直到它回来并完成它试图完成的一切。事务是应用程序中实际上“为最终用户做点什么”的东西,不管最终用户是人,或者在某些情况下,如果是Twilio,或者类似的东西。也许Twilio的最终用户实际上只是另一个运行脚本的程序。事务为用户或客户提供价值。
现在,特别是对于原生云,事务是分布式的。它们不一定非得如此,但通常是这样。它们可以用许多不同的粒度来描述。我的意思是,同一个事务可以用非常粗的粒度来描述,就像整个最终用户工作流一样。比如,如果你是一个像Lyft、Uber之类的乘车共享应用程序,那么整个请求乘车的流程可能会被视为一个事务。这是您仅有的粒度级别。您可能希望更细粒度地考虑服务之间的单个请求,比如HTTP请求。您可能会认为这是您想要用来描述事物的粒度,或者您想要更详细地了解一些甚至所有本地函数调用。然后我假设,从理论上讲,您可以根据整个系统中为完成一个事务而发生的每个CPU指令来查看一个事务。这些都是建模事务的有效方法。当然,当我们记下这个列表时,在这个粒度级别记录东西的成本会越来越高。事实上,它可能会变得如此之高,以至于会产生大量的开销,并开始影响事务。理论上,这些是不同的粒度。用于描述事务的遥测通常是跟踪和结构化日志。结构化日志类似于文本日志语句,但具有明确的键值属性。这些事情在这里有说明。您可以看到银行帐户请求有一个请求大小属性、一些HTTP路径、状态代码、延迟等等。这些是此模型中事务片段的理论属性。
我还认为,跟踪最终将取代日志记录。这需要时间,但对于事务来说,跟踪将取代日志记录。现在,我将通过向您展示跟踪模型比简单的单进程日志记录灵活得多来激发这一点。这里我不谈论2021,但这更像是放大了可观测性。这是一个日志记录语句。第22行有一些伪代码。这些日志语句中的每一条都定义了自己的表。这里的结构定义了一系列键,请求大小、路径、状态、延迟都在这里反映出来。这些列将成为此表的列。然后是从本地状态或其他地方提取的值。这组值将成为表中的行。
跟踪只是跨事务的连接
为了阐明这一点并使之清楚,您有这个日志语句,因为生产中运行的代码填充了这个理论表。当然,我并不是建议我们将这些数据全部插入MySQL或类似的东西,甚至不一定要将其插入到Elastic、Splunk或类似的东西中。只是有一个由日志语句本身描述的理论表,您可以这样建模。在某些情况下,您可以使用工具对这些表运行查询。跟踪的酷之处在于,这些日志记录系统执行灵活连接非常困难或不可能,或者非常昂贵或不可能。分布式跟踪在整个系统中进行连接。同样,如果这是您的系统架构,我们将要做的是实现所有结构化事件的连接,无论您将它们称为日志还是跟踪范围,这其实并不重要。您仍在描述事务。我们将使用跟踪上下文将所有这些服务中的结构化事件连接到一个更大的表中。其中有一个表,其中包含来自这些不同服务的列,在这里用颜色编码,服务A、B和D也在其中连接。然后,每个分布式事务表示该表中的一行。
这是非常强大的,因为如果您能够在这个概念模型中思考问题,就可以运行各种分析来找出跨服务边界的列之间的相关性。这反过来允许您了解一个服务中的行为如何影响另一个服务中的某些行为。具体来说,您可能会在服务a中的堆栈顶部有一个customer ID字段,并且您可能会发现,当银行帐户服务的延迟较高时,某些客户参与的时间比例较高。然后这就给了你一些东西,比如,那个客户是如何改变他们的工作量的,或者你做了什么?这些类型的连接实际上是理解跨服务边界的因果关系的一种非常重要的机制。如果您一直想知道分布式跟踪的所有麻烦是什么,那么在这个模型中,分布式跟踪实际上是结构化日志语句的一个连接。然后是一系列语义和查询功能。这就是事务。
资源是什么?
接下来,我们将讨论资源。什么是资源?资源是事务为完成其工作而消耗的东西。这个定义的一个副作用是,根据定义,资源是有限的。你的亚马逊账单是一种资源。同样,许多不同的颗粒。通过Kafka主题的吞吐量,Kafka集群只能支持这么多负载。当你到了负载的末尾,并且你已经消耗了所有的负载,事情会很快变得非常糟糕。你最终会遇到很多推回,很高的延迟,请求被丢弃,诸如此类的事情。类似地,CPU使用率也完全正常,直到不正常为止。如果您使服务中的CPU饱和,所有您认为理所当然的事情都会中断。更糟糕的是,进程的内存使用率直接崩溃。例如,您还可以非常精细地讨论单个互斥锁。如果你在一个锁上有很多争用,你最终会得到一个读锁,这个读锁应该是180纳秒,如果一个锁有很多争用,可能需要一百万倍的时间。这也会带来问题。这些都是资源类型。资源之所以成为一种资源,是因为它们能够跨事务生存,并且能够跨事务共享。共享资源是非常重要的,因为如果你不共享资源,你的系统将非常昂贵。在多租户、多请求环境中运行的全部好处在于,您可以更好地利用资源,并在事务中共享资源。这就是资源。
为了让它更直观一点,我为一个微服务、一个Kafka集群和一个互斥锁绘制了这些框。这完全是说明问题的。我相信有更好的方法来衡量这些东西的健康状况。对于一种资源,您要考虑的是该资源在某种程度上的剩余量。它是资源消耗量的指标。您可以看到CPU使用率会急剧上升,RAM使用率会急剧上升。您可以看到,使用者延迟或生产者延迟是Kafka集群运行状况的指标,或者您必须等待获取互斥锁的时间是互斥锁运行状况的指标。任何资源都有一些健康指标。我想在这里强调的是,这些都不是单个事务成功或失败的指标。当然,当CPU和内存使用率达到峰值时,事务会出现问题。这意味着表明资源的健康状况。我会谈谈为什么这是相关的。然后资源也有一堆标签。这其实很重要。
在我看来,这些标签或属性的用途是多方面的。当然,你只是想理解和分解。如果您看到这样的峰值,您可能希望按区域分组,或按集群ID分组,或类似的方式。那很好。您应该能够在时间序列数据库中执行此操作。更重要的是,这些标签是沟通资源和事务的通用语言。理想情况下,当事务跨越资源时,该事务会以某种方式对该资源进行注释。它可以作为从事务数据连接到资源数据的一种方式,反之亦然。这是一个非常强大的东西。稍后,当我们进入一个实际的例子时,我将讨论这个问题。
资源也是一个层次结构
我说过有不同的粒度,也有层次结构。这对于事务来说是正确的,但我认为更重要的是在这里强调这一点。您可能有一个Kafka集群,它本身有许多微服务。在这些虚拟机中,有一堆虚拟机。在这些锁中,有一堆互斥锁。这些东西也会上下波动。在资源环境中有层次结构,以及这些健康指标。
相互依存
我们已经谈过事务了。它们是客户真正关心的工作。我们已经讨论过资源,它们是使事务做一些事情并在事务之间共享的东西。这些是相互依存的。下面是这些资源的图表。这些绿色的曲线旨在说明流入或流出这些资源并执行其工作的事务。您可以看到,在本例中,事务将转到不同的HTTP端点。在这种情况下,我们将讨论不同的Kafka主题。在本例中,读卡器和写卡器试图对互斥锁执行锁定。有不同类型的事务,我们希望当事务跨越资源时,使用该资源的标识符对其进行注释。如果这个主题是Y请求,那么根据不同粒度级别的模式进行事务,如果您想要了解资源和事务是如何交互的,那么对于使用Kafka实例状态的区域和集群ID对事务进行注释是非常有价值的。或者,对于这个端点,对于要在跟踪中用诸如主机名或容器ID、服务名称、版本之类的东西注释的事务。同样,您可以使用资源中的标记清空事务,并充当这两个世界之间的映射。这就是一个例子。绿色的东西基本上是痕迹。然后在资源中,您通常使用度量遥测、时间序列统计来表示这些资源的运行状况。不总是,但通常是。
资源和事务是完全、完全相互依赖的。这是一个非常重要的问题。也就是说,如果您的资源不健康,那么事务将受到很大影响。如果事务数量过多,资源就会受到很大影响。事实上,作为一个主题,持续集成最让我感到困扰的一点是,在不知道工作负载的情况下,代码甚至可以是正确的或不正确的。我认为那完全是海市蜃楼。我觉得CI很棒。当然,我们在Lightstep中使用CI。至少对于系统软件或后端软件来说,您可以知道代码是否正确的唯一方法是在实际工作负载下运行代码。因为工作负载实际上是语义的一部分,所有关于资源如何配置,甚至资源如何设计和实现的调优都在很大程度上取决于事务的实际工作负载。这不仅仅是你可能需要更多的东西,而是你可能真的想要一个不同的东西。我不喜欢人们太讨厌MySQL。我之前有点讨厌某些类型的数据,但是如果你的数据可以很容易地放在一台机器上,而且你只需要关系语义,那就太完美了。除了一些复制问题之外,它其实没有什么错。类似地,如果你想要一个真正的行星规模和便宜的东西,你必须离开这个模型,做一些其他的事情。从设计的角度来看,或者从代码的角度来看,直到您考虑事务性工作负载时,资源也不能被认为是正确的或不正确的。可观察性是理解工作负载如何影响资源健康的最简单方法之一,反之亦然。
说到相互依赖,应用程序的客户只关心事务。我的意思是,如果你有一次停电,有人试图写一份报告,特别是为一个非技术性的最终用户写的,他们真的一点也不关心你的资源耗尽这一事实。这不是他们的问题。这是你的问题,不是他们的问题。他们只关心自己的事务是否正确,并在合理的时间内回来。正确性,也意味着这不是一个错误。正确性和延迟是客户或最终用户关心的两件事,而不是其他。如何做到这一点取决于你自己。对于运营者(operator)来说,你唯一能控制的就是你的资源。按运营者,包括DevOps、SRE。软件的全部意义在于,我们不是坐在那里从客户那里获取事实,然后填写一些东西,然后作为一个人做一些工作。我们正在编写自动化软件。那个软件是靠资源运行的。
总体而言,运营者主要关注资源,因为这实际上是他们拥有的控制点。最终用户只关心事务。最终用户和运营者也以这种方式相互依赖。如果最终用户改变行为太快,可能会给运营者带来资源问题。显然,如果运营者最终做了一些损害资源健康的事情,那么最终用户就会受到影响。最终用户、运营者、事务、资源都以这种方式相互依赖。他们之间有这种关系。最终用户和开发人员,或者开发人员或运营者也完全相互依赖。我认为这是一件非常有趣的事情,对我来说,无论如何,这是一件深刻的事情。最终用户和事务、运营者和资源,这是他们倾向于思考的,因为这是他们可以控制和处理的。它们实际上是在工作负载本身中相交的完全不同的平面。
DevOps工程师/SRE要做什么?
我们到底在做什么?这听起来像个问题。有必要能够在这两个方面之间进行转换,跨越遥测类型、度量和跟踪,通过标记进行聚合,并自动进行转换。这是一种方法,您可以通过资源和轴心来了解资源的稀缺性或健康问题,以了解事务是如何变化的。或者,您可以从事务非常慢或返回错误开始,找出与此相关的资源,因为高延迟几乎总是处于争用状态的资源,无论是您的数据库,还是Kafka队列,或者其他什么。然后,要想理解为什么会出现这种情况,就要弄清楚一些工作负载是如何变化的,比如有人推出了新代码,使数据库调用的数量增加了100倍,这就是为什么我们的数据库变得缓慢。这是一件有趣的事。您经常会在事务处理速度缓慢、找到处于争用状态的资源,然后意识到有人将负载增加了100倍的情况下切换。同样,从事务到资源再到资源,或者从事务到资源再到资源。这真的很难,因为现在人们在前端集成度量和跟踪,但实际上需要在数据层集成它们才能实现这一点。这是一个非常困难的数据工程问题,因为数据实际上看起来非常不同。度量通常表示为时间序列统计数据,跟踪通常表示为结构化事件,不管它是否跨越日志,不管怎样,它基本上是一组结构化事件数据,而不是统计数据。很难在它们之间转换。标签就是我们这样做的方式。
最后,我做这件事已经15年了,我一直在想这件事。没有人应该是这方面的专家才能使用它。它需要某种直观的东西,并在日常工作流程中为人们带来这些见解。如果我们不能做到这一点,那么我们基本上没有成功地解决相互依赖问题。
服务级别目标(SLOs)
SLOs是一个有用的工具。我只想在资源和事务的上下文中简要介绍一下SLO。SLO是一个热门话题。我认为SLO就是目标。它们是关于一组范围限定为一组资源的事务的目标。资源和事务是思考SLO的一种非常好的方式。我认为“服务水平目标”一词,人们通常认为,服务意味着微服务。不是真的。如果你像我一样老了,你拿起电话,听到拨号音,服务水平是99.99%的时间都是这样,或者别的什么。它不一定是一个微型服务。服务级别只是说,事务有多可靠?这是否意味着他们不会经常出错,或者他们很快,或者你做了什么。您希望在某组资源的上下文中检查该服务级别。这实际上就是微服务的用武之地。你也可以为其他事情设置SLO,同样,Kafka队列,数据库,诸如此类的东西。通过这种方式,SLO可以表示这两种双重性之间的契约,一方是事务和资源,另一方是运营者和最终用户。我认为这是一种优雅的方式来思考为什么SLO在连接这两个不同世界方面如此重要和重要。
这在实践中是什么样子的?
我知道我到目前为止所说的都是理论上的。我决定用这些术语展示一个生产系统中真实事件的工作示例。它确实显示了一些产品截图的东西,但这不是演示或类似的东西。这只是为了帮助从概念上说明这在实践中是如何发挥作用的,特别是在Kafka停机期间。
下面是仪表板中的一张图表,显示消费者对Kafka队列的延迟,实际上是在Lightstep自己的内部系统中。这不像是一次需要发生事故或对客户有明显影响的停机,但这肯定是人们争先恐后地想弄清楚到底发生了什么。你可以看到,10点45分,一切都很好。然后他们变得不好了。经典的情况是,Kafka本身就是一个分布式系统。它是一种资源,显然出了问题,因为作为消费者,它做任何事情都变得非常缓慢。您必须等待很长时间才能从Kafka队列中获取任何数据。你想做什么?我认为一种选择是尝试分组,并以各种方式对其进行过滤。我们真正想做的就是说,这个资源发生了什么变化?这个资源有很多事务要处理,很多事务实际上就在这里。另外,一笔事务就在这里进行。本期与本期之间的事务发生了哪些变化?这就是我作为一个操作员想要知道的,因为这可能会给我一个线索,因为Kafka的代码没有改变。工作量发生了变化。怎样你应该可以点击这个东西。在这里,您可以看到查询。
您应该能够单击此更改,然后说,是什么导致了此更改?然后进入一个UI,我们说,好吧,这里是队列不满意的异常情况。这是它正常工作的基线。再次,我们只是放大看看这两个时期是什么样子。那么我们真正想做的是,从统计学上理解,这里的事务和那里的事务有什么不同?我们试图理解的不仅仅是Kafka不开心,还有这里和这里的工作量有什么不同。美妙之处在于有标签。Kafka队列有一个名称。有关的主持人都有名字。通过Kafka队列的跟踪也使用这些标记进行注释。我们实际上可以从这个资源加入到工作负载中,并回答这个问题。回到我刚才提到的那些大型SQL表,我们可以说,让我们看看通过这个特定Kafka队列的跟踪,因为这是大型表中的一列。让我们看看在这两个不同的时间窗口中通过特定队列的跟踪,并了解与此回归相关的其他因素。
我们看到的是,在这个拥有许多不同客户的多租户系统中,有一个客户的产品ID为1753,从占所有跟踪的0.8%增加到几乎占所有跟踪的16%。这在基线和回归之间大约增加了20倍。这真的很有趣。一些客户显著地改变了他们的工作量,而这正是我想要的。问题是,客户标签的位置太高了。Kafka队列中甚至没有。只有通过从资源转向分布式事务跟踪,我们才能自动理解在这个回归中涉及到一个特定的客户ID。我们通过扩展得到更多的细节,比如说,好的,我们又增加了大约20倍。然后,如果您愿意,我们可以查看样本跟踪,以明确了解该客户正在做什么。
我想说明的是,不需要写任何查询,就可以从这种感觉转到这种感觉。您不需要成为专家就可以从资源转向事务。现在,实际上很难做到这一点。总之,总的来说。我认为我对可观察性的看法是,我们不再将度量、日志和跟踪作为可观察性的重点。这只是原始数据。相反,我们允许运营者了解其应用程序在SLO方面的运行状况,了解其资源的运行状况,就像他们今天所做的那样。然后自然地在这两件事之间切换,而不必编写查询。了解事务工作负载如何影响资源,以及资源健康状况如何影响事务工作负载,而无需举手或做任何实际工作。
总结
事务遍历系统,使用资源。用户不关心您的资源。类似地,DevOps不能对单个事务做任何事情。他们只能对自己的资源进行操作,至少不能手动操作。我们必须能够使用自然连接资源和事务的系统和提供者,以解决可观察性中最重要的问题,即是什么导致了这种变化?无论是我事务的变化,还是我资源的变化。在这个资源和事务的框架内,这就是我认为可观察性的真正方向。
问答
但是,你提到了存储数据的成本。我认为,对于人们来说,这总是一次非常棘手的谈话。你在进行这些对话时有什么一般性的建议,这样你可以最小化成本,同时最大限度地提高观察力?
西格曼:现在肯定是个问题。关于这个话题,我有很多话要说。首先,我们想到的是,我们谈论的是事务还是资源?也就是说,我们是在谈论跟踪和日志之类的东西,还是更像是统计时间序列数据,比如度量?因为我认为这两类遥测的对话是不同的。我们发现,至少在我在谷歌工作的时候,还有Lightstep,它不仅仅是一个二进制的东西。你保存数据还是不保存?这就像,你一开始就做样品吗?你能把它从主机上取下来吗?您是否将其集中在广域网上?你储存多长时间?您存储它的粒度是多少?在精度方面,它是如何随时间降低的?当你看到组织在这方面变得非常成熟时,他们实际上在整个遥测生命周期中有不同的答案。我认为这是一个非常具有挑战性的问题,因为它取决于您所谈论的粒度。
我想说的主要一点是,如果一个组织没有能力在整个生命周期(包括网络)中分析其遥测成本,而网络实际上是生命周期成本中最大的组成部分之一,那么发送数据就是了。就像任何优化问题一样,你必须从这里开始。坦率地说,我认为很多组织都无法对其进行分析。您不能说应用程序的哪一部分导致了最长期的遥测成本。在你做到这一点之前,没有办法优化它。我从那里开始。那么对于已经这样做的人来说,我认为主要的事情是能够控制单个开发人员的成本,比如添加一行代码会给度量增加太多的基数。如果你做错了,每年可能要花费数十万美元。能够在中心位置纠正这一点,我认为是下一个重点。确保单个仪表线不能为平台团队带来无限的成本。
但是,我真的很喜欢你最后的例子,你经历了一个已经发生的事件,并在屏幕上分享。Ben提到了Lightstep,所以你可以看到它是如何工作的。我自己也用过。我觉得你能以如此快的速度找到一个真正的特定客户做某个动作并引发一个事件,这真是太令人惊讶了。我自己也知道,在我从事生产系统的职业生涯中,这种情况已经发生过很多次了,能够以极快的速度达到非常小的粒度级别是非常有效的。
在给定的两个时间间隔内,能够输出重要差异的web界面是什么?你想谈谈这个吗?你对此的想法,比如不同的界面如何帮助人们做得更好?这是件大事。
西格曼:这是一篇社论。我犹豫了一下,不想表现出来。我不知道还有什么其他的方式来表现它。如果我不展示一些东西,我觉得这太抽象了。要回答字面上的问题,那是Lightstep的产品。如果可以在数据层进行集成,那么就没有理由不能在其他地方进行集成。我认为在实践中很难做到的是,资源度量数据和事务跟踪数据之间的集成必须在数据层完成。你不能仅仅通过超链接来实现。我所描述的连接实际上是一个连接。您必须能够从度量中的标记连接到数千条记录道组上的标记。要做到这一点,需要在平台级别进行一些数据工程。事实上,我很想看到开源世界中有更多的解决方案朝着这个方向发展。事件解决的最短路径当然是能够通过时间序列数据和事务数据之间的标记进行透视。如果您必须从一个筒仓式度量解决方案和一个筒仓式跟踪解决方案(如web UI)开始,那么这实际上是一个困难的问题,因为集成必须在数据层进行。从产品的角度来看,这就是为什么它如此棘手的原因。
但是,我看到一些平台是在我工作过的地方内部创建的,但是要让它正常工作需要很多年和大量的迭代,所以一点也不容易。还有一件有趣的事,比如说,当你访问到这样的系统时,比如说,你有一个客户突然改变了他们的模式,但也许这很好。也许他们已经接触了所有这些新用户,并且正在进行一系列令人惊叹的工作,这意味着你可以对其他团队,比如公司的业务部门说,“看起来这个客户的工作真的很棒。你应该知道。你知道我们正在这样做吗?”它使工程团队能够更好地与真正有趣和有洞察力的数据进行对话,我认为这也很好。建议使用哪些工具进行跟踪?它始终是一个服务网格或类似的东西,还是在系统内部单独执行更好?
西格曼:是的。事实上,我在2017年在KubeCon做了一次关于服务网格和跟踪的演讲。服务网格是有帮助的,但它绝对不能解决问题。服务网格真正做的就是为您提供服务之间调用的遥测。跟踪最困难的部分始终是成功地将此跟踪ID上下文从服务的入口通过函数调用传播到该服务的出口。服务网格与此无关。服务网格只处理服务之间的调用。它在服务中,是跟踪中最困难的部分。这真的没用。您最终会得到一组带有服务网格的点对点数据,但要真正成功地解决上下文传播问题,我唯一的建议是转向OpenTelemetry。这实际上是试图以一种相当全面的方式解决这个问题,并使上下文传播成为一种内置功能。OpenTelemetry还将与服务网格集成。服务网格的部分优势在于它解决了跟踪问题,但事实并非如此。它添加了用于跟踪的数据,但没有解决上下文传播问题,而上下文传播问题实际上是分布式跟踪的核心。
但是,我看到一些平台是在我工作过的地方内部创建的,但是要让它正常工作需要很多年和大量的迭代,所以一点也不容易。还有一件有趣的事,比如说,当你访问到这样的系统时,比如说,你有一个客户突然改变了他们的模式,但也许这很好。也许他们已经接触了所有这些新用户,并且正在进行一系列令人惊叹的工作,这意味着你可以对其他团队,比如公司的业务部门说,“看起来这个客户的工作真的很棒。你应该知道。你知道我们正在这样做吗?”它使工程团队能够更好地与真正有趣和有洞察力的数据进行对话,我认为这也很好。建议使用哪些工具进行跟踪?它始终是一个服务网格或类似的东西,还是在系统内部单独执行更好?
西格曼:是的。事实上,我在2017年在KubeCon做了一次关于服务网格和跟踪的演讲。服务网格是有帮助的,但它绝对不能解决问题。服务网格真正做的就是为您提供服务之间调用的遥测。跟踪最困难的部分始终是成功地将此跟踪ID上下文从服务的入口通过函数调用传播到该服务的出口。服务网格与此无关。服务网格只处理服务之间的调用。它在服务中,是跟踪中最困难的部分。这真的没用。您最终会得到一组带有服务网格的点对点数据,但要真正成功地解决上下文传播问题,我唯一的建议是转向OpenTelemetry。这实际上是试图以一种相当全面的方式解决这个问题,并使上下文传播成为一种内置功能。OpenTelemetry还将与服务网格集成。服务网格的部分优势在于它解决了跟踪问题,但事实并非如此。它添加了用于跟踪的数据,但没有解决上下文传播问题,而上下文传播问题实际上是分布式跟踪的核心。
但是,关于OpenTelemetry还有一个问题。你的想法是什么?
西格曼:我是管理委员会的成员,是这个项目的共同创立者,我对此极有偏见。从拥有众多贡献者的角度来看,这确实是一个非常成功的项目。我认为仅在上个月我们就有1000名投稿人。每个主要的供应商和云提供商都已经购买了该项目,并且正在为该项目配备人员等等。OpenTelemetry的唯一问题是它有太多的活动,以至于我们在维护项目时遇到了一些困难。我认为它之所以如此成功,是因为它使许多方面受益。对于主要的基础设施提供商、云提供商、可观测性供应商,尤其是最终用户来说,这是一个双赢的局面,因为您最终可以获得高质量的遥测,而无需与任何特定的供应商或提供商绑定。这种便携性是一件非常吸引人的事情。我认为,长期以来,可观测性解决方案一直受到它们所能收集的遥测数据质量的限制。OpenTelemetry真的将掀起这股浪潮,然后您将看到解决方案的改进。OpenTelemetry,是的,这是一个非常激动人心的项目。我认为我们唯一真正需要的就是能够在项目中说一点不,这样我们就能达到我们的里程碑。在某种程度上,它是自身成功的牺牲品。它肯定有一个光明的未来。
但是,对于今年刚刚结束的OpenTelemetry的路线图,你有什么要分享的吗?有什么让你兴奋的事情吗?
西格曼:跟踪、度量和日志这三大支柱对于可观察性来说没有任何意义。我会坚持我的观点。它们对遥测技术来说绝对有意义,所以这三个方面。我们从追踪开始。到目前为止基本上都是这样。指标很快就要出来了。然后日志记录将在稍后出现。我认为从标准和API集成的角度来看,这实际上是OpenTelemetry要解决的三个问题中最不重要的一个。我很高兴指标能够超过这一点。我们还与普罗米修斯社区进行了大量的合作,以确保普罗米修斯和OpenTelemetry之间的互操作,这样您就不会被迫做出选择。我认为这也是一件非常好的事情,看到今年夏天稳定下来。
但是,关于分布式跟踪的性能成本,还有一个常见的问题。你的想法是什么?
Sigelman:从延迟的角度来看,分布式跟踪不需要任何开销。在占用资源的意义上,存在一些最小的边际吞吐量开销。通常,人们可以采取一些抽样来解决这个问题。我在谷歌帮助撰写的这篇短小精悍的论文详细描述了我们对绩效的衡量。从统计噪音的角度看,这是难以察觉的,Dapper 100%的时间都在运行100%的谷歌服务,并且已经运行了15年。如果做得正确,这绝对不是一件高开销的事情。这就是它的魅力之一。
原文:https://www.infoq.com/presentations/observability-resources-transaction…
- 64 次浏览
【分布式架构】Apache Helix vs YARN
原文:https://stackoverflow.com/questions/16401412/apache-helix-vs-yarn
Apache Helix和Hadoop YARN(MRv2)有什么区别。 有没有人有这两种技术的经验? 有人能解释一下Helix对YARN的优缺点,以及LinkedIn为什么开发自己的集群管理而不是使用YARN?
虽然Helix和YARN都提供了管理分布式应用程序的功能,但两者之间存在重要差异。
YARN主要提供跨机器群集的资源管理功能,同时要求应用程序编写其自定义逻辑以从资源管理器协商资源。另一方面,Helix提供了一种声明性地管理分布式应用程序状态的方法,从而使应用程序不必进行自定义实现。目前,Helix不像YARN那样提供资源管理功能。因此,这两个系统是相辅相成的。
作为一个例子,假设您有一组节点,并且您想要在它们上启动一些容器。
- 根据资源利用率在节点之间分配容器
- 启动容器,
- 监视容器,如果他们死了重启容器
YARN提供了执行上述操作的框架/机制。拥有容器后,必须实现以下功能:
- 分区和复制:您需要将任务分配给容器,可能会为每个容器分配多个任务。为了实现冗余,您可以选择将任务分配给多个容器。
- 状态管理:管理任务的状态
- 容错:当容器出现故障时,您可以选择在剩余容器中重新分配工作,也可以根据SLA要求重新启动容器。
- 群集扩展:您可以启动新容器来处理工作负载,然后您希望重新分配任务。
- 限制:在所有这些操作中,您可能希望限制某些操作,如数据移动
Helix可以轻松实现上述功能。在YARN中,需要编写应用程序主机来实现这些(这种实现的一个例子是hadoop map reduce作业的Application master)。
Helix是在LinkedIn开发的,用于管理在线/近线空间中的分布式数据系统。在这个空间中,一旦容器被启动,它就会一直运行直到它崩溃。当容器发生故障时,可能会在剩余的容器中重新分配任务。
YARN附带资源调度算法,可以灵活高效地利用可用硬件来完成短暂的任务,例如地图缩减作业。
- 176 次浏览
【分布式架构】Apache Spark vs Apache Ignite
原文:https://stackoverflow.com/questions/36036910/apache-spark-vs-apache-ignite
目前我正在研究Apache spark和Apache点燃框架。
本文描述了它们之间的一些原理差异点燃火花但我意识到我仍然不理解它们的目的。
我的意思是哪个问题比点燃更可取,反之亦然?
答案1:
我想说Spark是交互式分析的好产品,而Ignite更适合实时分析和高性能事务处理。 Ignite通过提供高效且可扩展的内存中键值存储以及索引,查询数据和运行计算的丰富功能来实现这一目标。
Ignite的另一个常见用途是分布式缓存,它通常用于提高与关系数据库或任何其他数据源交互的应用程序的性能。
答案2
Apache Ignite是一个高性能,集成和分布式内存平台,用于实时计算和处理大规模数据集.Ignite是一个与数据源无关的平台,可以在RAM中的多个服务器之间分发和缓存数据提供前所未有的处理速度和海量应用程序可扩展性
Apache Spark(集群计算框架)是一种快速的内存数据处理引擎,具有富有表现力的开发API,允许数据工作者有效地执行需要快速迭代访问数据集的流,机器学习或SQL工作负载。通过允许用户程序将数据加载到集群的内存中并重复查询,Spark非常适合高性能计算和机器学习算法。
一些概念差异:
Spark不存储数据,它从其他存储(通常是基于磁盘)加载数据以进行处理,然后在处理完成时丢弃数据。另一方面,Ignite提供具有ACID事务和SQL查询功能的分布式内存中键值存储(分布式缓存或数据网格)。
Spark用于非事务性的只读数据(RDD不支持就地突变),而Ignite支持非事务性(OLAP)有效负载以及完全符合ACID的事务(OLTP)
Ignite完全支持可以“无数据”的纯计算有效载荷(HPC / MPP)。 Spark基于RDD,仅适用于数据驱动的有效负载。
结论:
Ignite和Spark都是内存计算解决方案,但它们针对不同的用例。
在许多情况下,它们一起使用以获得优异的结果:
- Ignite可以提供共享存储,因此状态可以从一个Spark应用程序或作业传递到另一个。
- Ignite可以为SQL提供索引,因此Spark SQL可以加速超过1,000x(spark不会索引数据)
- 使用文件而不是RDD时,Apache Ignite内存文件系统(IGFS)也可以在Spark作业和应用程序之间共享状态
- 162 次浏览
【分布式架构】何时使用Apache Helix以及何时使用Apache Mesos
Apache Mesos是一个集群管理器,可跨分布式应用程序或框架提供有效的资源隔离和共享。 它可以在动态共享节点池上运行Hadoop,MPI,Hypertable,Spark和其他框架。
Apache Helix是一种通用的集群管理框架,用于自动管理托管在节点集群上的分区,复制和分布式资源。 Helix在面对节点故障和恢复,集群扩展和重新配置时自动重新分配资源。
两者都是集群管理者,可以选择哪一个,为什么?
这是我在Apache Helix vs YARN上编写的适用于Mesos v / s Helix的内容。 YARN / Mesos和Helix相互补充。
您可以使用Helix构建系统并管理系统的内部状态。 系统构建完成后,可以单独部署,也可以使用YARN / Mesos进行部署。
@janisz,Helix被广泛使用并积极开发。
原文:https://stackoverflow.com/questions/42154354/when-to-use-apache-helix-and-when-to-use-apache-mesos
- 166 次浏览
【分布式架构】最终一致性:暗示的切换队列(Hinted Handoff Queue)
在这个博客系列中,我们将探讨最终的一致性,如果没有合适的词汇表,这个术语很难定义。这是许多分布式系统使用的一致性模型,包括XDB Enterprise Edition。为了理解最终的一致性,我们需要知道两个概念:暗示切换队列和反熵,这两个概念都需要特别注意。
第一部分
什么是暗示的切换队列?
尽管有一个很酷的名字,暗示切换(HH)队列并没有得到很多关注。HH队列有一项非常重要的工作,但是除非您是系统管理员,否则很少直接与它交互。让我们深入研究一下暗示的切换队列到底是什么,以及为什么它对您很重要。
为了讨论HH队列,我们必须稍微讨论一下分布式计算。像XDB Enterprise这样的系统作为分布式系统存在的一个原因是消除单点故障。InfluxDB Enterprise使用复制因子(Replication Factor,RF)来确定任何一组数据应该存在多少个副本。将RF设置为1以上意味着系统有更高的机会成功地为请求提供服务,并且在数据节点中断期间不会返回错误,这意味着我们不再只有一个可能丢失或不可用的数据副本。分布式系统也提出了独特的挑战:我们如何知道数据在整个系统中是一致的,尤其是在存储多个数据副本时?
首先,我们必须理解最终一致性所作的一些承诺。扰流板警报:系统中的数据最终必须一致。当我们从分布式系统请求信息时,有时我们收到的答案可能不会一致地返回。当数据在整个系统中存储和复制时,我们收到的答案有一些“漂移”,但随着时间的推移,这种“漂移”应该被消除。在实践中,这意味着最近的时间范围可能在其结果中具有最大的变化,但是这种变化被消除,因为系统通过确保在任何地方都可以获得相同信息的机制工作。

如果我们保证系统最终是一致的,我们如何解释失败的写入?数据节点离线的原因有很多,从磁盘空间耗尽到普通的旧硬件故障。如果一个节点在离线时丢失了数据点,它就永远不可能是一致的,因此,我们对最终一致性的承诺将变成谎言。
失败的写入也会影响整个系统的复制系数。维护指定的RF是我们必须遵守的另一个承诺,如果数据节点脱机,这也是写入的另一个可能的失败点。
例子
让我们研究一下最简单的示例:具有2个数据节点和一个RF=2的数据库的XDB Enterprise。数据通过某个收集代理(例如Telegraf)到达您喜爱的负载平衡器,负载平衡器将写操作(也读取,但在本例中我们将使用写操作)分发到底层数据节点。通常,负载平衡器以循环方式分发写操作。接收数据的数据节点存储并复制数据(将其发送到另一个数据节点),瞧:RF达到2。
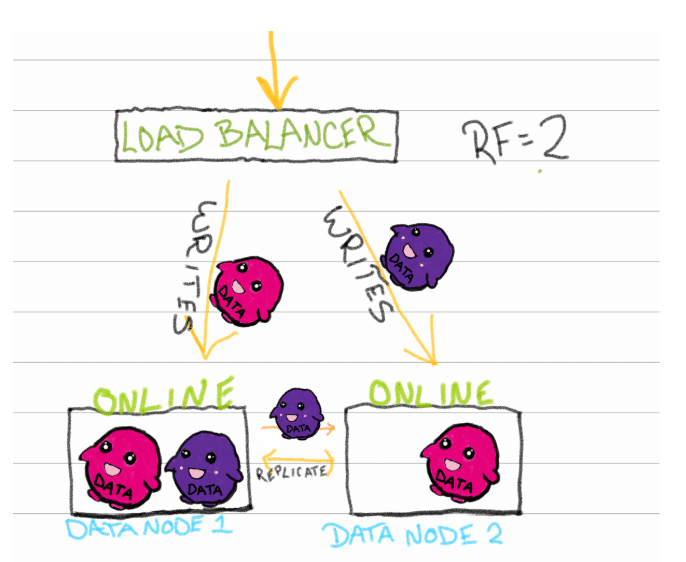
注意:图中未显示的是元节点,您可以在这里阅读。
我们仍然需要一个失败或延迟写入的解决方案。假设系统中的一个节点在物理上过热并离线。如果没有备份,任何不成功的写入都会被完全删除,再也看不到。
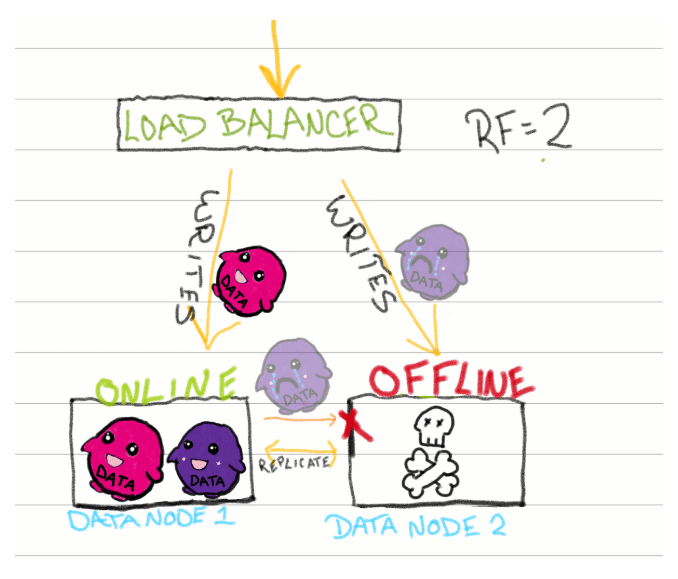
进入HH队列。
HH队列是一个持久的、基于磁盘的队列。它是XDB企业的一个基本部分,它试图确保最终的一致性,这是一种机制,确保所有的数据节点最终在它们之间拥有一组一致的数据。对于xdbenterprise,HH队列是实现最终一致性和确保最终实现每个数据库的数据复制因子的一个重要部分。
现在,让我们重温一下集群中的一个数据节点离线的场景。节点脱机的原因有很多:硬件缺陷、磁盘空间限制,甚至是定期维护。如果没有暗示的切换队列,不成功的写操作在存储之前就死了,但是现在我们有了一个安全的地方让它们着陆。
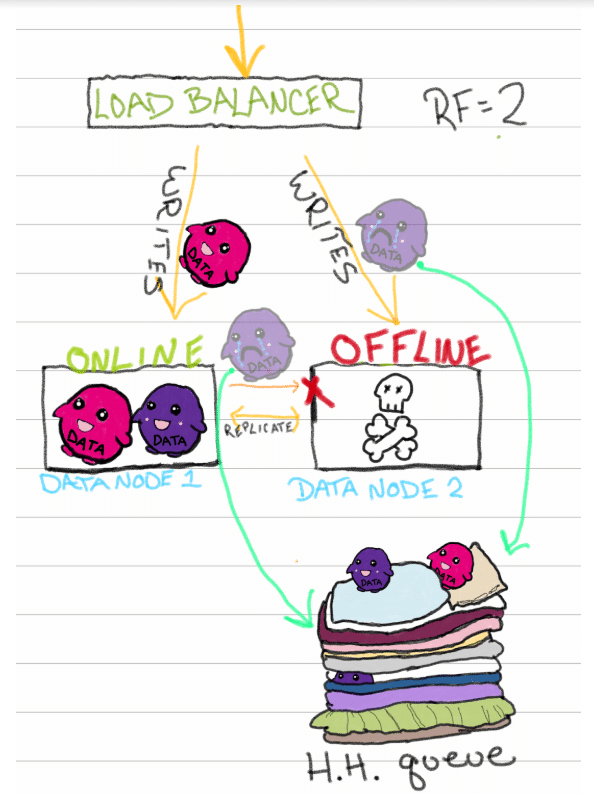
任何不成功的写入都会被定向到HH队列,当节点恢复联机时,它会检查HH队列中是否有挂起的写入。然后节点可以完成写操作,直到队列耗尽。Bam最终实现了一致性。
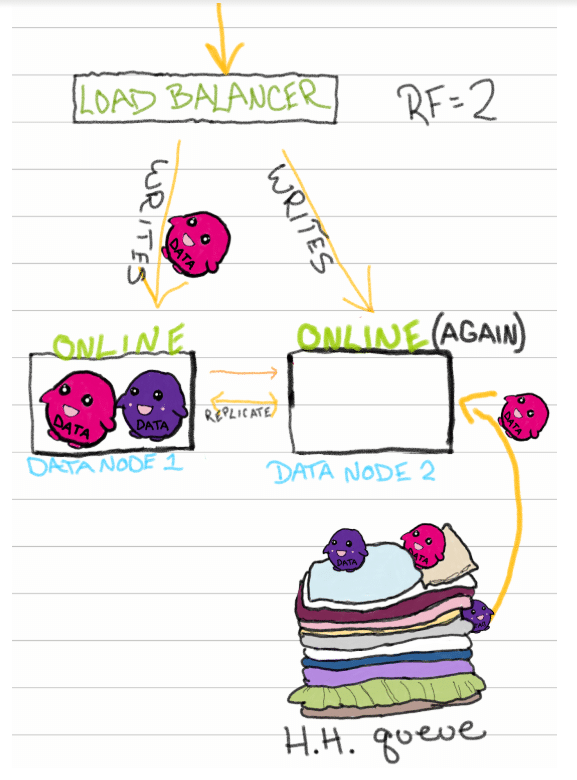
摘要
这是一个最终一致的集群内部发生的情况,但是外部有一些考虑因素:当数据成功写入一个节点,但无法正确复制时,用户看到成功还是失败?HH队列中的健康模式是什么样的?如果HH队列不断地充满和耗尽,对整个系统健康意味着什么?在下一篇文章中,我们将讨论如何解决和识别XDB企业集群中的问题模式。
原文:https://www.influxdata.com/blog/eventual-consistency-hhq/
本文:http://jiagoushi.pro/node/1454
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】或者QQ群【11107777】
- 192 次浏览
【分部署架构】allthingsdistributed 说最终一致性
大约一年前,我在一致性模型上写了这篇文章的第一个版本,但我从来没有对它感到满意,因为它写得很匆忙,而且这个主题足够重要,需要得到更彻底的处理。ACM Queue要求我修改它以便在他们的杂志中使用,我利用这个机会改进了这篇文章。这是那个新版本。
最终的一致性——在全球范围内构建可靠的分布式系统需要在一致性和可用性之间进行权衡。
亚马逊云计算的基础是基础设施服务,如Amazon的S3(简单存储服务)、SimpleDB和EC2(弹性计算云),它们为构建互联网规模的计算平台和各种应用程序提供了资源。对这些基础设施服务的要求非常严格;他们需要在安全性、可伸缩性、可用性、性能和成本效益方面取得高分,并且他们需要在满足这些需求的同时,持续地为全球各地的数百万客户服务。
在这些服务的背后是在全球范围内运行的大规模分布式系统。这种规模带来了额外的挑战,因为当系统处理数万亿、数万亿的请求时,通常发生概率很低的事件现在保证会发生,需要在系统的设计和体系结构中预先考虑。考虑到这些系统的全球范围,我们广泛地使用复制技术来保证一致的性能和高可用性。尽管复制使我们更接近我们的目标,但它不能以完全透明的方式实现它们;在许多情况下,这些服务的客户将面临在服务内部使用复制技术的后果。
其表现方式之一是所提供的数据一致性类型,特别是当底层分布式系统为数据复制提供最终一致性模型时。在Amazon设计这些大规模系统时,我们使用一组与大规模数据复制相关的指导原则和抽象,并关注高可用性和数据一致性之间的权衡。在本文中,我将介绍一些相关的背景知识,这些背景知识为我们提供了交付需要在全球范围内运行的可靠分布式系统的方法。这篇文章的早期版本出现在2007年12月的All Things Distributed weblog上,并在读者的帮助下得到了极大的改进。
历史的角度
在理想的世界中,只有一个一致性模型:当进行更新时,所有观察者都将看到该更新。第一次出现这种难以实现的情况是在70年代末的数据库系统中。关于这个主题最好的“时期文章”是Bruce Lindsay等人写的“分布式数据库的注释”5。它列出了数据库复制的基本原则,并讨论了实现一致性的许多技术。这些技术中的许多都试图实现分布透明性—也就是说,对于系统的用户来说,看起来好像只有一个系统,而不是有许多协作系统。这一时期的许多系统采取的方法是,与其破坏这种透明度,不如让整个系统失灵
在90年代中期,随着大型互联网系统的兴起,这些做法被重新审视。那时,人们开始考虑可用性可能是这些系统最重要的属性,但他们也在为它应该与什么进行交换而挣扎。系统教授Eric Brewer的加州大学伯克利分校,当时Inktomi,带来了不同的交换在主题演讲PODC 2000.1(分布式计算的原则)会议上他提出上限定理,即三个属性的数据共享系统数据一致性、系统可用性和公差网络partition-only两个可以实现在任何给定的时间。Seth Gilbert和Nancy lynch在2002年的一篇论文中给出了更正式的确认
不能容忍网络分区的系统可以实现数据一致性和可用性,通常是通过使用事务协议实现的。要做到这一点,客户端和存储系统必须是同一个环境的一部分;在某些场景下,它们作为一个整体失败,因此,客户端无法观察分区。一个重要的观察结果是,在较大的分布式系统中,网络分区是给定的;因此,一致性和可用性不能同时实现。这意味着对于放弃什么有两种选择:放松一致性将允许系统在可分区条件下保持高可用性,而将一致性作为优先级意味着在某些条件下系统将不可用。
这两个选项都要求客户端开发人员知道系统提供了什么。如果系统强调一致性,开发人员就必须处理这样一个事实,即系统可能无法进行写入操作。如果由于系统不可用而导致写入失败,那么开发人员将不得不处理如何处理要写入的数据。如果系统强调可用性,它可能总是接受写操作,但在某些条件下,读操作不会反映最近完成的写操作的结果。然后开发人员必须决定客户端是否一直需要访问绝对最新的更新。有一系列应用程序可以处理稍微陈旧的数据,它们在此模型下得到了很好的服务。
原则上,ACID属性(原子性、一致性、隔离性、持久性)中定义的事务系统的一致性属性是一种不同类型的一致性保证。在ACID中,一致性指的是保证事务完成时数据库处于一致状态;例如,当从一个账户向另一个账户转账时,两个账户中的总金额不应改变。在基于acid的系统中,这种一致性通常是编写事务的开发人员的责任,但是数据库管理完整性约束可以帮助实现这种一致性。
一致性:客户端和服务器
有两种观察一致性的方法。一个是从开发人员/客户的角度:他们如何观察数据更新。第二种方法来自服务器端:更新如何流经系统,以及系统对更新可以提供哪些保证。
客户端一致性
客户端有以下组件:
- 一个存储系统。目前,我们将把它看作一个黑盒,但是我们应该假设它是一个大规模的、高度分布式的东西,并且构建它是为了保证持久性和可用性。
- 进程a。这是一个读写存储系统的进程。
- 进程B和进程c是独立于进程A的两个进程,它们对存储系统进行读写。它们是同一个进程中的进程还是线程无关紧要;重要的是,他们是独立的,需要交流来共享信息。
- 客户端一致性与观察者(在本例中是进程A、B或C)如何以及何时看到存储系统中数据对象的更新有关。在下面演示不同类型一致性的例子中,进程A对数据对象进行了更新:
- 强烈的一致性。更新完成后,任何后续访问(A、B或C)都将返回更新后的值。
- 弱一致性。系统不保证后续访问将返回更新后的值。在返回值之前,需要满足许多条件。从更新到保证任何观察者都能看到更新值这段时间被称为不一致窗口。
- 最终一致性。这是弱一致性的一种特殊形式;存储系统保证,如果没有对对象进行新的更新,最终所有访问都将返回最后更新的值。如果没有发生故障,可以根据通信延迟、系统负载和复制方案中涉及的副本数量等因素确定不一致窗口的最大大小。实现最终一致性的最普遍的系统是DNS(域名系统)。对名称的更新根据配置的模式进行分发,并与时间控制的缓存相结合;最终,所有客户端都将看到更新。
最终一致性模型有许多重要的变化需要考虑:
- 因果一致性。如果进程A通知进程B它已经更新了一个数据项,那么进程B的后续访问将返回更新后的值,并且保证一次写操作将取代之前的写操作。进程C的访问与进程A没有因果关系,遵循通常的最终一致性规则。
- “读己之所写”一致性。这是一个重要的模型,流程A在更新了数据项之后,总是访问更新后的值,永远不会看到旧的值。这是因果一致性模型的一个特例。
- 会话一致性。这是前一个模型的实际版本,其中进程在会话上下文中访问存储系统。只要会话存在,系统就保证“读己之所写”一致性。如果会话因为某种失败场景而终止,则需要创建一个新的会话,并且保证会话不会重叠。
- 单调读一致性。如果进程已经看到了该对象的特定值,那么任何后续访问都不会返回任何以前的值。
- 单调写一致性。在这种情况下,系统保证序列化同一个进程的写操作。不能保证这种级别一致性的系统是出了名的难以编程。
这些属性中有许多是可以组合的。例如,可以结合会话级别一致性获得单调的读取。从实际的角度来看,这两个属性(单调读取和read-your-write)在最终的一致性系统中是最理想的,但并不总是必需的。这两个属性使开发人员更容易构建应用程序,同时允许存储系统放松一致性并提供高可用性。
正如您可以从这些变化中看到的,相当多的不同场景是可能的。能否处理这些后果取决于特定的应用程序。
最终一致性并不是极端分布式系统的神秘属性。许多提供主备份可靠性的现代rdbms(关系数据库管理系统)同时以同步和异步模式实现它们的复制技术。在同步模式下,副本更新是事务的一部分。在异步模式下,更新以延迟的方式到达备份,通常通过日志传送。在后一种模式中,如果主备份在发送日志之前发生故障,从提升后的备份读取数据将产生旧的、不一致的值。另外,为了支持更好的可伸缩读性能,rdbms已经开始提供从备份中读取数据的能力,这是提供最终一致性保证的经典案例,在这种情况下,不一致性窗口取决于日志传送的周期。
服务器端一致性
在服务器端,我们需要更深入地研究更新如何流经系统,以理解是什么驱动了使用系统的开发人员可以体验不同的模式。在开始之前,让我们先建立一些定义:
N =存储数据副本的节点数
W =在更新完成之前需要确认已收到更新的副本的数量
R =通过读操作访问数据对象时所接触的副本数
如果W+R > N,那么写集和读集总是重叠的,可以保证强一致性。在实现同步复制的主备份RDBMS场景中,N=2、W=2和R=1。无论客户端从哪个副本读取数据,它都将得到一致的答案。在启用了从备份读取数据的异步复制中,N=2, W=1, R=1。在这种情况下,R+W=N,一致性无法保证。
这些配置是基本的quorum协议,它们的问题在于,当系统由于故障而无法写入W个节点时,写入操作必须失败,标志着系统不可用。当N=3 W=3且只有两个节点可用时,系统将不得不失败写操作。
在需要提供高性能和高可用性的分布式存储系统中,副本的数量通常大于两个。只关注容错的系统通常使用N=3 (W=2和R=2配置)。需要提供非常高读负载的系统经常复制超出容错要求的数据;N可以是数十个甚至数百个节点,R配置为1,这样一次读取就会返回一个结果。关注一致性的系统被设置为W=N进行更新,这可能会降低写入成功的可能性。这些系统关注容错性但不具有一致性,它们的一种常见配置是使用W=1运行以获得最小的更新持久性,然后依赖一种惰性(流行)技术来更新其他副本。
如何配置N、W和R取决于常见情况是什么,以及需要优化哪些性能路径。在R=1和N=W的情况下,我们优化读的情况,而在W=1和R=N的情况下,我们优化写的非常快。当然,在后一种情况下,在存在故障的情况下,持久性不能得到保证,如果W < (N+1)/2,那么当写集不重叠时,就有可能出现写冲突。
当W+R <= N时出现弱/最终一致性,这意味着读写集有可能不重叠。如果这是一个有意的配置,并且不是基于失败的情况,那么将R设为1以外的任何值都没有意义。这种情况通常发生在两种情况中:第一种是前面提到的为了读扩展而进行的大规模复制;第二个问题是数据访问更加复杂。在简单的键-值模型中,比较不同版本以确定写入系统的最新值很容易,但是在返回对象集的系统中,确定正确的最新值集就比较困难了。在大多数写集小于副本集的系统中,会有一种机制以一种惰性的方式将更新应用到副本集的其余节点。直到所有副本都被更新为止的时间段是前面讨论过的不一致窗口。如果W+R <= N,则系统容易从尚未接收到更新的节点读取数据。
“读你的写”、会话和单调一致性是否可以实现,通常取决于客户机对执行它们的分布式协议的服务器的“粘性”。如果每次都是相同的服务器,则相对容易保证“读己之所写”和单调的读取。这使得管理负载平衡和容错稍微困难一些,但这是一个简单的解决方案。使用会话,这是粘性的,使这一点显式,并提供了一个客户端可以推理的公开级别。
有时客户端实现read-your-write和单调读取。通过在写操作上添加版本,客户端将丢弃对版本在最后一个版本之前的值的读取。
当系统中的一些节点无法到达其他节点时,就会发生分区,但两个节点集都可以被客户端组访问。如果您使用传统的多数仲裁方法,那么具有W个副本集节点的分区可以继续进行更新,而另一个分区变得不可用。对于读集也是如此。给定这两个集重叠,根据定义,少数集变得不可用。分区并不经常发生,但确实会发生在数据中心之间以及数据中心内部。
在某些应用程序中,任何分区的不可用性都是不可接受的,重要的是能够到达该分区的客户机能够取得进展。在这种情况下,双方分配一组新的存储节点来接收数据,并在分区愈合时执行合并操作。例如,在Amazon中购物车使用这样的write-always系统;在分区的情况下,客户可以继续将商品放入购物车,即使原来的购物车存在于其他分区上。一旦分区恢复,cart应用程序将帮助存储系统合并购物车。
亚马逊的Dynamo
Amazon的Dynamo系统将所有这些属性置于应用程序体系结构的显式控制之下,这是一个键值存储系统,在组成Amazon电子商务平台的许多服务以及Amazon的Web服务内部使用该系统。Dynamo的设计目标之一是允许创建Dynamo存储系统实例(通常跨越多个数据中心)的应用程序服务所有者在一致性、持久性、可用性和性能之间以一定的成本进行权衡
总结
在大规模可靠分布式系统中,必须容忍数据不一致性,原因有二:提高高并发条件下的读写性能;以及处理大多数模型会导致部分系统不可用的分区情况,即使节点已经启动并运行。
不一致是否可以接受取决于客户机应用程序。在所有情况下,开发人员都需要意识到,存储系统提供了一致性保证,并且在开发应用程序时需要考虑到这一点。对于最终一致性模型有许多实际的改进,比如会话级一致性和单调读取,它们为开发人员提供了更好的工具。很多时候,应用程序都能够毫无问题地处理存储系统的最终一致性保证。一个特定的流行案例是一个网站,在其中我们可以有用户感知一致性的概念。在此场景中,不一致性窗口需要小于客户返回下一页加载的预期时间。这允许更新在预期下一次读取之前在系统中传播。
本文的目标是提高对工程系统复杂性的认识,这些系统需要在全球范围内运行,并且需要仔细调优,以确保它们能够交付应用程序所需的持久性、可用性和性能。系统设计者拥有的工具之一是一致性窗口的长度,在此期间,系统的客户可能暴露在大规模系统工程的现实中。
原文:https://www.allthingsdistributed.com/2008/12/eventually_consistent.html
本文:http://jiagoushi.pro/node/1387
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 66 次浏览
【微服务架构】多运行时微服务架构
视频号
微信公众号
知识星球
主要收获
- 创建分布式系统并非易事。围绕“微服务”架构和“12因素应用程序”设计出现了最佳实践。这些提供了与交付生命周期、网络、状态管理以及与外部依赖关系的绑定相关的指导方针。
- 然而,以可扩展和可维护的方法一致地实现这些原则是具有挑战性的。
- 解决这些原则的传统技术方法包括企业服务总线(ESB)和面向消息中间件(MOM)。虽然这些解决方案提供了一个很好的功能集,但主要的挑战是业务逻辑和平台之间的整体架构和紧密的技术耦合。
- 随着云、容器和容器编排器(Kubernetes)的流行,解决这些原则的新解决方案也出现了。例如,Knative用于交付,服务网格用于联网,Camel-K用于绑定和集成。
- 使用这种方法,业务逻辑(称为“微逻辑”)形成了应用程序的核心,可以创建sidecar“meca”组件,这些组件提供强大的开箱即用分布式原语。
- 这种微逻辑和Mecha组件的解耦可能会改善第二天的操作,如修补和升级,并有助于维持业务逻辑的内聚单元的长期可维护性。
创建良好的分布式应用程序并非易事:此类系统通常遵循12因素应用程序和微服务原则。它们必须是无状态的、可扩展的、可配置的、独立发布的、容器化的、自动化的,有时是事件驱动的和无服务器的。一旦创建,它们应该易于升级,并且可以长期维护。在这些相互竞争的需求与当今的技术之间找到良好的平衡仍然是一项艰巨的努力。
在本文中,我将探讨分布式平台是如何发展以实现这种平衡的,更重要的是,在分布式系统的发展过程中还需要做些什么来简化可维护的分布式架构的创建。如果你想看到我现场谈论这个话题,请加入我三月在伦敦的QCon。
分布式应用程序需求
在这次讨论中,我将把现代分布式应用程序的需求分为四类——生命周期、网络、状态、绑定——并简要分析它们近年来的发展情况。
/filters:no_upscale()/articles/multi-runtime-microservice-architecture/en/resources/1Multi-Runtime-Microservices-Architecture-1-1582629228248.jpg)
Distributed application needs
生命周期
让我们从基础开始。当我们编写一个功能时,编程语言规定了生态系统中可用的库、打包格式和运行时。例如,Java使用.jar格式,所有Maven依赖项作为一个生态系统,JVM作为运行时。如今,随着发布周期的加快,生命周期中更重要的是能够以自动化的方式部署、从错误中恢复和扩展服务。这组功能广泛代表了我们的应用程序生命周期需求。
网络
在某种意义上,今天几乎每个应用程序都是分布式应用程序,因此需要联网。但现代分布式系统需要从更广泛的角度来掌握网络。从服务发现和错误恢复开始,实现现代软件发布技术以及各种跟踪和遥测。出于我们的目的,我们甚至将在这一类别中包括不同的消息交换模式、点对点和发布/订阅方法以及智能路由机制。
状态
当我们谈论状态时,通常是关于服务状态以及为什么最好是无状态。但管理我们服务的平台本身需要状态。这是进行可靠的服务编排和工作流、分布式单例、临时调度(cron作业)、幂等性、有状态错误恢复、缓存等所必需的。这里列出的所有功能都依赖于隐藏状态。虽然实际的状态管理不是本文的范围,但分布式原语及其依赖于状态的抽象是令人感兴趣的。
结合(绑定)
分布式系统的组件不仅要相互通信,还要与现代或遗留的外部系统集成。这需要连接器能够转换各种协议,支持不同的消息交换模式,如轮询、事件驱动、请求/回复、转换消息格式,甚至能够执行自定义的错误恢复过程和安全机制。
在不涉及一次性用例的情况下,以上内容代表了创建良好分布式系统所需的公共原语的良好集合。如今,许多平台都提供了这样的功能,但我们在本文中要寻找的是,我们使用这些功能的方式在过去十年中发生了怎样的变化,以及下一个十年的情况。为了进行比较,让我们看看过去十年,看看基于Java的中间件是如何满足这些需求的。
传统中间件的局限性
满足上述老一代需求的著名传统解决方案之一是企业服务总线(ESB)及其变体,如面向消息的中间件、较轻的集成框架等。ESB是一种中间件,使用面向服务的架构(即经典SOA)实现异构环境之间的互操作性。
虽然ESB可以为您提供一个很好的功能集,但ESB的主要挑战是业务逻辑和平台之间的整体架构和紧密的技术耦合,这导致了技术和组织的集中化。当一个服务被开发并部署到这样的系统中时,它与分布式系统框架深度耦合,这反过来限制了服务的发展。这通常只有在软件生命的后期才变得明显。
以下是每一类需求的一些问题和限制,这些问题和限制使ESB在现代没有用处。
生命周期
在传统中间件中,通常有一个受支持的语言运行时(如Java),它规定了软件的打包方式、可用的库、修补的频率等。业务服务必须使用这些库,这些库将其与用同一语言编写的平台紧密耦合。在实践中,这导致了协调服务和平台升级,从而阻止了独立和定期的服务和平台发布。
网络
虽然传统的中间件有一个高级功能集,主要集中在与其他内部和外部服务的交互上,但它也有一些主要缺点。网络功能以一种主要语言及其相关技术为中心。对于Java语言,即JMS、JDBC、JTA等。更重要的是,网络问题和语义也深深地刻在了业务服务中。有些库使用抽象来处理网络问题(例如曾经流行的Hystrix项目),但库的抽象“泄漏”到服务中——它的编程模型、交换模式和错误处理语义,以及库本身。虽然在一个位置编码和阅读混合了网络方面的整个业务逻辑很方便,但这将两个问题紧密地耦合到一个单独的实现中,并最终形成一个联合的进化路径。
状态
为了进行可靠的服务编排、业务流程管理和实现模式,如Saga模式和其他缓慢运行的流程,平台需要在后台保持持久状态。类似地,临时操作(如启动计时器和cron作业)是建立在状态之上的,需要数据库在分布式环境中集群化并具有弹性。这里的主要约束是,与状态交互的库和接口没有完全抽象,也没有与服务运行时解耦。通常,这些库必须使用数据库详细信息进行配置,并且它们位于将语义和依赖关系泄漏到应用程序域的服务中。
结合
使用集成中间件的主要驱动因素之一是能够使用不同的协议、数据格式和消息交换模式连接到各种其他系统。然而,这些连接器必须与应用程序一起使用,这意味着依赖关系必须与业务逻辑一起更新和修补。这意味着数据类型和数据格式必须在服务中来回转换。这意味着代码必须根据消息交换模式进行结构化和流设计。以下是一些示例,说明了即使是抽象端点也会如何影响传统中间件中的服务实现。
云原生趋势
传统的中间件功能强大。它具有所有必要的技术特征,但缺乏快速变化和扩展的能力,这是现代数字业务需求所要求的。这就是微服务架构及其设计现代分布式应用程序的指导原则正在解决的问题。
微服务背后的思想及其技术要求促成了容器和Kubernetes的普及和广泛使用。这开启了一种新的创新方式,将在未来几年影响我们处理分布式应用程序的方式。让我们看看Kubernetes和相关技术如何影响每一组需求。
生命周期
容器和Kubernetes将我们打包、分发和部署应用程序的方式发展为独立于语言的格式。有很多关于Kubernetes模式和Kubernete对开发人员的影响的文章,我将在这里简短地介绍一下。不过,请注意,对于Kubernetes来说,要管理的最小原语是容器,它专注于在容器级别和流程模型上交付分布式原语。这意味着它在管理应用程序的生命周期、健康检查、恢复、部署和扩展方面做得很好,但在容器内的分布式应用程序的其他方面(如灵活的网络、状态管理和绑定)改进得不太好。
您可能会指出,Kubernetes具有有状态工作负载、服务发现、cron作业和其他功能。的确如此,但所有这些基元都在容器级别,在容器内部,开发人员仍然必须使用特定于语言的库来访问我们在本文开头列出的更细粒度的功能。这就是Envoy、Linkerd、Consul、Knative、Dapr、Camel-K等项目的驱动力。
网络
事实证明,Kubernetes提供的围绕服务发现的基本网络功能是一个很好的基础,但对于现代应用程序来说还不够。随着微服务数量的增加和部署速度的加快,对更先进的发布策略的需求变得越来越有吸引力,这些策略包括在不接触服务的情况下管理安全、度量、跟踪、从错误中恢复、模拟错误等,并创造了一种新的软件类别,称为服务网格。
这里更令人兴奋的是,将与网络相关的关注点从包含业务逻辑的服务转移到外部,并转移到单独的运行时,无论是sidecar还是节点级代理。如今,服务网格可以进行高级路由、帮助测试、处理某些方面的安全,甚至可以使用特定于应用程序的协议(例如Envoy支持Kafka、MongoDB、Redis、MySQL等)。虽然服务网格作为一种解决方案可能还没有被广泛采用,但它触及了分布式系统中的一个真正的痛点,我相信它会找到自己的存在形式。
除了典型的服务机制外,还有其他项目,如Skupper,证实了将网络功能放入外部运行时代理的趋势。Skupper通过第7层虚拟网络解决了多集群通信挑战,并提供了高级路由和连接功能。但是,它并没有将Skupper嵌入到业务服务运行时,而是在每个Kubernetes命名空间中运行一个实例,该实例充当共享的sidecar。
总之,容器和Kubernetes在应用程序的生命周期管理方面迈出了重要的一步。服务网格和相关技术触及了真正的痛点,并为将应用程序之外的更多职责转移到代理中奠定了基础。让我们看看接下来会发生什么。
状态
我们前面列出了依赖于状态的主要集成原语。管理状态很困难,应该委托给专门的存储软件和托管服务。这不是这里的主题,但在语言无关的抽象中使用状态来帮助集成用例才是。今天,许多努力试图在语言无关抽象背后提供有状态的原语。有状态工作流管理是基于云的服务中的一项强制性功能,例如AWS Step Functions、Azure Durable Functions等。在基于容器的部署中,CloudState和Dapr都依赖于sidecar模型来更好地解耦分布式应用程序中的有状态抽象。
我所期待的也是将上面列出的所有有状态特性抽象到一个单独的运行时中。这意味着工作流管理、单重、幂等性、事务管理、cron作业触发器和有状态错误处理都可靠地发生在sidecar(或主机级代理)中,而不是生活在服务中。业务逻辑不需要在应用程序中包括这样的依赖关系和语义,并且它可以声明性地从绑定环境请求这样的行为。例如,sidecar可以充当cron作业触发器、幂等消费者和工作流管理器,自定义业务逻辑可以作为回调调用,也可以在工作流、错误处理、临时调用或唯一幂等请求的某些阶段插入。
另一个有状态的用例是缓存。无论是由服务网格层执行的请求缓存,还是使用Infinispan、Redis、Hazelcast等进行的数据缓存,都有将缓存功能推出应用程序运行时的例子。
结合
虽然我们讨论的主题是将所有分布式需求与应用程序运行时解耦,但绑定的趋势也在继续。连接器、协议转换、消息转换、错误处理和安全中介都可能移出服务运行时。我们还没有达到目标,但Knative和Dapr等项目正在朝着这个方向进行尝试。将所有这些职责从应用程序运行时中移出将导致更小的、以业务逻辑为中心的代码。这样的代码将生活在一个独立于分布式系统需求的运行时中,这些需求可以作为预打包功能来使用。
Apache Camel-K项目采用了另一种有趣的方法。该项目不是使用代理运行时来伴随主应用程序,而是依赖于一个智能的Kubernetes Operator,该Operator使用Kubernete和Knative的额外平台功能构建应用程序运行时。这里,单个代理是负责包含应用程序所需的分布式系统原语的操作员。不同之处在于,一些分布式原语被添加到应用程序运行时,而一些则在平台中启用(平台也可能包括sidecar)。
未来架构趋势
从广义上看,我们可以得出结论,通过将功能转移到平台级别,分布式应用程序的商品化达到了新的前沿。除了生命周期之外,现在我们还可以观察到网络、状态抽象、声明性事件和端点绑定,这些都是现成的,EIP是下一个。有趣的是,商品化是使用进程外模型(sidecars)进行功能扩展,而不是运行库或纯平台功能(如新的Kubernetes功能)。
我们现在正通过将所有传统中间件功能(也称为ESB)转移到其他运行时来接近完整的循环,很快,我们在服务中所要做的就是编写业务逻辑。
/filters:no_upscale()/articles/multi-runtime-microservice-architecture/en/resources/1Multi-Runtime-Microservices-Architecture-2-1582629228912.jpg)
传统中间件平台和云原生平台概述
与传统的ESB时代相比,这种架构更好地将业务逻辑与平台解耦,但尚未完全解耦。许多分布式原语,如经典的企业集成模式(EIP):拆分器、聚合器、过滤器、基于内容的路由器;以及流处理模式:映射、过滤、折叠、连接、合并、滑动窗口;仍然必须包含在业务逻辑运行时中,并且许多其他依赖于多个不同且重叠的平台附加组件。
如果我们把在不同领域创新的各种云原生项目叠加起来,我们最终会得到如下图片:
/filters:no_upscale()/articles/multi-runtime-microservice-architecture/en/resources/1Multi-Runtime-Microservices-Architecture-3-1582629227447.jpg)
多运行时微服务
这里的图表仅用于说明目的,它有目的地选择有代表性的项目,并将它们映射到一类分布式原语中。在实践中,您不会同时使用所有这些项目,因为其中一些项目是重叠的且不兼容的工作负载模型。如何解释这个图表?
Kubernetes和容器在多语言应用程序的生命周期管理方面实现了巨大的飞跃,并为未来的创新奠定了基础。
服务网格技术在Kubernetes上进行了改进,具有先进的网络功能,并开始利用应用程序问题。
虽然Knative主要通过快速扩展专注于无服务器工作负载,但它也解决了服务编排和事件驱动的绑定需求。
Dapr以Kubernetes、Knative和Service Mesh的思想为基础,深入应用程序运行时,以解决有状态工作负载、绑定和集成需求,充当现代分布式中间件。
这个图表可以帮助您直观地看到,在未来,我们很可能会使用多个运行时来实现分布式系统。多个运行时,不是因为多个微服务,而是因为每个微服务都将由多个运行时间组成,很可能是两个——自定义业务逻辑运行时间和分布式原语运行时间。
引入多运行时微服务
以下是开始形成的多运行时微服务架构的简要描述。
你还记得电影《阿凡达》和科学家们为探索潘多拉而开发的“机械套装”吗?这种多运行时架构类似于这些赋予人形驾驶员超能力的机械套装。在电影中,人类穿上西装以获得力量并获得破坏性武器。在这个软件架构中,您的业务逻辑(称为微逻辑)构成了应用程序的核心,sidecar meca组件提供了强大的开箱即用分布式原语。微逻辑与机械功能相结合,形成了一个多运行时微服务,该服务使用进程外功能来满足其分布式系统的需求。最棒的是,《阿凡达2》即将问世,以帮助推广这一架构。我们终于可以在所有软件会议上用令人敬畏的机甲图片取代老式的边车摩托车了;-)。接下来让我们看一下这个软件架构的细节。
这是一个类似于客户端-服务器架构的双组件模型,其中每个组件都是独立的运行时。它与纯客户端-服务器架构的不同之处在于,在这里,两个组件都位于同一台主机上,它们之间有可靠的网络连接,这不是一个问题。这两个组件的重要性相同,它们可以在任一方向启动操作,并充当客户端或服务器。其中一个组件被称为Micrologic,它包含了几乎所有分布式系统关注的最小业务逻辑。另一个附带的组件是Mecha,它提供了我们在文章中讨论的所有分布式系统功能(除了作为平台功能的生命周期)。
/filters:no_upscale()/articles/multi-runtime-microservice-architecture/en/resources/1Multi-Runtime-Microservices-Architecture-4-1582629229172.jpg)
多运行时(进程外)微服务架构
Micrologic和Mecha可能有一对一的部署(称为侧车模型),也可以是一个共享的Mecha和几个Micrologic运行时。第一种模型最适用于环境,如Kubernetes,后者适用于边缘部署。
Micrologic运行时特性
让我们简要探讨一下Micrologic运行时的一些特性:
- Micrologic组件本身并不是一个微服务。它包含微服务所具有的业务逻辑,但该逻辑只能与Mecha组件结合使用。另一方面,微服务是自包含的,不具有分散到其他运行时的整体功能或部分处理流。Micrologic和它的机械对应物的结合形成了一个微服务。
- 这也不是一个功能或无服务器架构。无服务器主要以其管理式快速扩展和零扩展功能而闻名。在无服务器架构中,函数实现单个操作,因为这是可伸缩性的单位。在这方面,函数不同于实现多个操作的Micrologic,但实现不是端到端的。最重要的是,操作的实现分布在Mecha和Micrologic运行时。
- 这是客户端-服务器架构的一种特殊形式,针对众所周知的分布式原语的使用进行了优化,而无需编码。此外,如果我们假设Mecha扮演服务器角色,那么必须将每个实例专门配置为与单个客户端一起工作。它不是一个通用的服务器实例,旨在与典型的客户端-服务器架构同时支持多个客户端。
- 微逻辑中的用户代码不与其他系统直接交互,也不实现任何分布式系统原语。它通过事实上的标准(如HTTP/gRPC、CloudEvents规范)与Mecha进行交互,Mecha使用丰富的功能并在配置的步骤和机制的指导下与其他系统进行通信。
- 虽然Micrologic只负责实现从分布式系统中剥离出来的业务逻辑,但它仍然必须至少实现一些API。它必须允许Mecha和平台通过预定义的API和协议与其交互(例如,通过遵循Kubernetes部署的云原生设计原则)。
Mecha运行时特性
以下是Mecha运行时的一些特性:
- Mecha是一种通用的、高度可配置的、可重复使用的组件,提供分布式原语作为现成的功能。
- Mecha的每个实例都必须配置为与一个Micrologic组件(侧车模型)一起工作,或者配置为与几个组件共享。
- Mecha没有对Micrologic运行时做出任何假设。它使用开放协议和格式(如HTTP/gRPC、JSON、Protobuf、CloudEvents)与多语言微服务甚至单片系统协同工作。
- Mecha是用简单的文本格式(如YAML、JSON)以声明方式配置的,这些格式规定了要启用哪些功能以及如何将它们绑定到Micrologic端点。对于专门的API交互,Mechan可以额外提供规范,如OpenAPI、AsyncAPI、ANSI-SQL等。对于由多个处理步骤组成的有状态工作流,可以使用规范,如Amazon State Language。对于无状态集成,企业集成模式(EIP)可以与类似于Camel-K YAML DSL的方法一起使用。这里的关键点是,所有这些都是简单的、基于文本的、声明性的、多语言的定义,Meca可以在不编码的情况下完成这些定义。请注意,这些都是未来的预测,目前还没有用于有状态编排或EIP的机制,但我预计现有的机制(Envoy、Dapr、Cloudstate等)很快就会开始添加此类功能。Mecha是一个应用级分布式原语抽象层。
- 与其依赖多个代理用于不同的目的,例如网络代理、缓存代理、绑定代理,不如由一个Mecha提供所有这些功能。一些功能的实现,如存储、消息持久性、缓存等,将由其他云或内部部署服务插入并支持。
- 一些围绕生命周期管理的分布式系统关注点由管理平台(如Kubernetes或其他云服务)提供,而不是由使用通用开放规范(如开放应用程序模型)的Mecha运行时提供。
这种架构的主要优点是什么?
好处是业务逻辑和日益增多的分布式系统关注点之间的松散耦合。软件系统的这两个元素具有完全不同的动态特性。业务逻辑始终是唯一的、自定义的代码,由内部编写。它经常变化,这取决于您的组织优先级和执行能力。另一方面,分布式原语是解决本文中列出的问题的原语,它们是众所周知的。这些由软件供应商开发,并作为库、容器或服务使用。这些代码会根据供应商的优先级、发布周期、安全补丁、开源管理规则等而变化。这两个组对彼此几乎没有可见性和控制权。
/filters:no_upscale()/articles/multi-runtime-microservice-architecture/en/resources/1Multi-Runtime-Microservices-Architecture-5-1582629228612.jpg)
业务逻辑和分布式系统关注不同架构中的耦合
微服务原则有助于通过有限的上下文将不同的业务领域解耦,在有限的上下文中,每个微服务都可以独立发展。但微服务架构并没有解决将业务逻辑与中间件问题耦合所带来的困难。对于某些轻集成用例的微服务来说,这可能不是一个大因素。但是,如果您的领域涉及复杂的集成(这对每个人来说都越来越普遍),遵循微服务原则将无法帮助您避免与中间件耦合。即使中间件被表示为包含在微服务中的库,当您开始迁移和更改这些库时,这种耦合也会变得明显。您需要的分布式原语越多,就越能耦合到集成平台中。将中间件作为预定义API上的单独运行时/进程而不是库使用有助于松耦合,并支持每个组件的独立演化。
这也是为供应商分发和维护复杂中间件软件的更好方法。只要与中间件的交互是通过涉及开放API和标准的进程间通信进行的,软件供应商就可以按照自己的速度免费发布补丁和升级。消费者可以自由使用他们喜欢的语言、库、运行时、部署方法和流程。
这种架构的主要缺点是什么?
进程间通信。分布式系统的业务逻辑和中间件机制(您可以看到名称的来源)处于不同的运行时,这需要HTTP或gRPC调用,而不是进程内方法调用。不过,请注意,这不是一个应该转到不同机器或数据中心的网络呼叫。Micrologic运行时和Mecha应该位于同一台主机上,具有低延迟和最小的网络问题可能性。
复杂性下一个问题是,它是否值得开发的复杂性,以及为了获得的利益而维护这样的系统。我认为答案会越来越倾向于肯定。分布式系统的需求和发布周期的速度都在增加。这个架构为此进行了优化。我前段时间写道,未来的开发人员必须具备混合开发技能。这种架构进一步证实并强化了这一趋势。应用程序的一部分将用更高级的编程语言编写,部分功能将由必须声明配置的现成组件提供。这两个部分不是在编译时相互连接,也不是在启动时通过进程内依赖注入相互连接,而是在部署时通过进程间通信相互连接。该模型实现了更高的软件重用率和更快的变化速度。
微服务之后不是服务(FaaS)
微服务架构有一个明确的目标。它针对变化进行优化。通过将应用程序划分为业务域,该架构通过解耦、由独立团队管理并以独立的速度发布的服务,为软件进化和可维护性提供了最佳的服务边界。
如果我们看一下无服务器架构的编程模型,它主要是基于函数的。功能针对可扩展性进行了优化。通过功能,我们将每个操作拆分为一个独立的组件,以便它能够快速、独立和按需扩展。在这个模型中,部署粒度是一个函数。选择该函数是因为它是具有输入的代码结构,其速率与缩放行为直接相关。这是一种针对极端可扩展性而优化的架构,而不是复杂系统的长期可维护性。
Serverless的另一个方面是什么?这源于AWS Lambda的流行及其完全管理的操作性质?在这方面,“AWS Serverless”以缺乏控制和锁定为代价,优化了供应速度。但完全管理的方面不是应用程序架构,而是软件消费模型。它是一个正交的功能,类似于消费一个基于SaaS的平台,在理想的世界中,该平台应该适用于任何类型的架构,无论是单片、微服务、机制还是功能。在许多方面,AWS Lambda类似于一个完全管理的Mecha架构,但有一个很大的区别:Mecha不强制执行功能模型,而是允许围绕业务领域构建更具凝聚力的代码,与所有中间件无关。
/filters:no_upscale()/articles/multi-runtime-microservice-architecture/en/resources/1Multi-Runtime-Microservices-Architecture-6-1582629229441.jpg)
架构优化
另一方面,Mecha架构优化了微服务以实现中间件的独立性。虽然微服务是相互独立的,但它们在很大程度上依赖于嵌入式分布式原语。Mecha架构将这两个关注点划分为单独的运行时,允许独立团队独立发布。这种解耦改进了第二天的操作(如修补和升级)以及业务逻辑的内聚单元的长期可维护性。在这方面,Mecha架构是微服务架构的自然发展,基于引起最大摩擦的边界拆分软件。与功能模型相比,这种优化以软件重用和进化的形式提供了更多的好处,功能模型以过度分发代码为代价,优化了极大的可扩展性。
结论
分布式应用程序有许多要求。创建有效的分布式系统需要多种技术和良好的集成方法。虽然传统的单片中间件提供了分布式系统所需的所有必要技术功能,但它缺乏业务所需的快速更改、调整和扩展能力。这就是为什么基于微服务的架构背后的思想促成了容器和Kubernetes的快速普及;随着云原生空间的最新发展,我们现在正通过将所有传统中间件功能转移到平台和现成的辅助运行时中来实现完整的循环。
这种应用程序特性的商品化主要是使用进程外模型进行特性扩展,而不是使用运行库或纯平台特性。这意味着在未来,我们很可能会使用多个运行时来实现分布式系统。多个运行时,不是因为多个微服务,而是因为每个微服务都会由多个运行时间组成;用于自定义微业务逻辑的运行时,以及用于分布式原语的现成的可配置运行时。
- 151 次浏览
【数据一致性】理解分布式系统中的一致性
首先,什么是一致性?
一致性是指分布式系统中多个节点为达到某一数值而达成的协议。
具体来说,可以分为强一致性和弱一致性。
- 强一致性:所有节点的数据在任何时候都是相同的。同时,您应该得到节点A中的key1值和节点B中的key1值。
- 弱一致性:无法保证所有节点在任何时候都拥有相同的数据,并且存在许多不同的实现。最广泛实现的是最终的一致性。所谓最终一致性,是指任何节点上的相同数据在任何时间都是相同的,但随着时间的推移,不同节点上的相同数据总是朝着收敛的方向变化。也可以简单理解为,经过一段时间后,节点之间的数据最终会达到一致状态。
分布式和一致的应用场景:
多节点提供读写服务,确保高可用性和可扩展性(ZooKeeper, DNS, redis集群)
分布式系统面临的问题:
- 消息异步(asynchronous):真实的网络不是一个可靠的通道,存在消息延迟、丢失,以及节点间消息不能同步(synchronous)
- node-fail-stop:节点继续崩溃并且无法恢复
- 节点宕机恢复(fail- recovery):节点经过一段时间后恢复,在分布式系统中最为常见
- 网络分区:网络链接有问题,将N个节点分成多个部分
- 拜占庭故障(拜占庭故障)[2]:节点或宕机或逻辑故障,即使没有卡抛出干扰分辨信息
需要满足一致性的分布式系统设计的一般前提是不存在拜占庭一般问题(内部网可信)
本文介绍了分布式系统的基本理论FLP定理,即当只有节点宕机时,系统的可用性和强一致性不能同时满足。另一种观点是CAP理论,即强一致性、可用性和分区容错,其中只有两种可以保证。
有许多协议确保一致性,包括2PC, 3PC, Paxos, raft和PacificA。
2PC:
两阶段锁提交协议,保证多个数据片上操作的原子性。(分布式事务)
将节点分为协调者和参与者(participat),并将执行分为两个阶段。
- 阶段1:协调器发起一个建议,询问是否接受每个参与者。参与执行事务操作,将撤销和重做信息写入事务日志,并向协调器回复是或否。
- 阶段2:协调器根据参与者的反馈提交或终止事务。如果参与者的回答都是yes,则提交,只要参与者的回答是no。根据协调器的提交/回滚信息正式提交或终止事务,释放占用的资源并返回ack。
- 优点:原理简单,易于实现
- 缺点:同步阻塞,单点问题,数据不一致(协调员崩溃之前发送提交请求或网络原因共识不收到提交的一部分,那么参与者不能提交事务的一部分),过于保守(如果参与者在协调)如果有失败在沟通、协调器只能依靠超时机制来确定事务需要打断。
3PC:
3级锁提交协议,保证多个数据片上操作的原子性。(分布式事务)
相对于2PC,分为查询、预提交、提交3个阶段(解决阻塞,但仍有数据不一致的可能)
流程:在收到参与者的反馈(投票)后,协调器进入阶段2,并向每个参与者发送准备提交命令。参与者可以在收到提交指令后锁定资源,但要求回滚相关操作。在收到应答(ACK)后,协调器进入第三阶段并提交/中止。3PC的第三阶段与2PC的第二阶段没有什么不同。3PC也采用协调看门狗和状态记录。
Paxos算法(求解单点问题)
Paxos算法是目前最重要的一致性算法,所有的一致性算法都是Paxos或Paxos的简化版本。
Paxos算法会解析相同数据的多个值,以达成一个值的一致。证明正确性的理论基础:任何两个合法集合(包含超过一半节点的集合)的交集都不是空的。
性格:
在投票过程的提案中有三个作用:
- Proposer:可能有多于一个提案人,并负责提出建议。
- Acceptor:必须有多个收件人。他们对特定的提案进行投票,同意接受提案,或不同意。
- Learner:学习者,收集各Acceptor接受的提案,按照少数多数的原则形成最终提案。
事实上,分布式系统中的一个组件可以对应一个或多个角色。
算法描述:
*第一阶段(准备阶段)
申请人:
- 选择提案编号n,向大多数接受人发送编号n的准备请求。
受体:
- 如果提案号n大于已经收到的提案号,提案人承诺不接受编号小于n的提案号。如果之前已经接受过提案号,则以已接受提案号中编号最高的提案号为已发送提案号。
- 如果收到的提案号n小于它收到的提案号的最大数目。
*第二阶段(接受阶段)
申请人:
- 首先,依次接收响应:
- 如果收到拒绝,将不处理。
- 如果你收到了“同意”,同时也收到了“接受人”已经接受的建议书,记下建议书和编号。
- 处理完回应后,计算拒绝和同意的数量:
- 如果大多数人拒绝,为下一个提案做准备。
- 如果大多数人同意,从这些Acceptors接受的提案中选择提案号最大的提案作为提案,不使用自己的提案,逐个向Acceptor发送Accept消息。
受体:
- 如果收到的提案编号n小于它收到的最大提案编号。
- 如果收到的提案编号n等于它收到的最大提案编号,该提案将被接受。
- 如果接收到的提案号n大于它接收到的最大提案号。
- 形成共识(与准备和接受阶段平行)
受体:
- 每当一个提案被接受,提案和编号就会被发送给学习者。
学习者:
- 记录每个接受人当前接受的提案。如果Acceptor连续发送多个提案,则保留数量最大的提案。
- 计算接受每个提案的接受人数。如果有一半以上的人被接受,就会形成共识。
原文:https://medium.com/@mena.meseha/understanding-of-consistency-in-distributed-systems-27da174cc05a
本文:http://jiagoushi.pro/node/1385
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 124 次浏览
【软件架构】支持大规模系统的设计模式和原则

今天,即使是小型初创公司也可能不得不处理数 TB 的数据或构建支持每分钟(甚至一秒钟!)数十万个事件的服务。所谓“规模”,通常是指系统应在短时间内处理的大量请求/数据/事件。尝试以幼稚的方式实现需要处理大规模的服务,在最坏的情况下注定要失败,或者在最好的情况下代价高昂。
本文将描述一些使系统能够处理大规模的原则和设计模式。当我们讨论大型(而且大多是分布式)系统时,我们通常通过查看三个属性来判断它们的好坏和稳定性:
- 可用性:系统应该尽可能地可用。正常运行时间百分比是客户体验的关键,更不用说如果没有人可以使用应用程序就没有用。可用性用“9”来衡量。
- 性能:即使在重负载下,系统也应该继续运行并执行其任务。此外,速度对于客户体验至关重要:实验表明,它是防止客户流失的最重要因素之一!
- 可靠性:系统应该准确地处理数据并返回正确的结果。一个可靠的系统不会静默失败或返回不正确的结果或创建损坏的数据。一个可靠的系统以一种努力避免故障的方式构建,当它不可能时,它会检测、报告,甚至可能尝试自动修复它们。
我们可以通过两种方式扩展系统:
- 垂直扩展(纵向扩展):将系统部署在更强大的服务器上,这意味着一台具有更强 CPU、更多 RAM 或两者兼有的机器
- 横向扩展(横向扩展):将系统部署在更多服务器上,这意味着启动更多实例或容器,使系统能够服务更多流量或处理更多数据/事件
纵向扩展规模通常不太可取,主要是因为两个原因:
- 它通常需要一些停机时间
- 有限制(我们不能“永远”扩大规模)
另一方面,为了能够扩展系统,它必须具有允许这种扩展的某些特性。例如,为了能够水平扩展,系统必须是无状态的(例如,大多数数据库不能横向扩展)。
本文的目的是让您体验许多不同的设计模式和原则,这些模式和原则使系统能够横向扩展,同时保持可靠性和弹性。 由于这种性质,我无法深入研究每个主题,而只是提供一个概述。 也就是说,在每个主题中,我都尝试添加有用的链接,指向关于该主题的更全面的资源。
所以让我们深入研究吧!
幂等性
这个术语是从数学中借来的,它被定义为:
f(f(x)) = f(x)
这乍一看可能有点吓人,但背后的想法很简单:无论我们调用函数 f on x 多少次,我们都会得到相同的结果。 此属性为系统提供了极大的稳定性,因为它允许我们简化代码,也使我们的操作生活更轻松:可以重试失败的 HTTP 请求,并且可以重新启动崩溃的进程而无需担心副作用。
此外,一个长时间运行的作业可以被分成多个部分,每个部分都可以是自己幂等的,这意味着当作业崩溃并重新启动时,所有已经执行的部分都将被跳过(可恢复性)。
拥抱异步

当我们进行同步调用时,执行路径会被阻塞,直到返回响应。 这种阻塞有资源开销,主要是内存和上下文切换的成本。 我们不能总是只使用异步调用来设计我们的系统,但是当我们可以让我们的系统更高效时。 一个展示异步如何提供良好效率/性能的示例是 Nodejs,它具有单线程事件循环,但它正在与许多其他并发语言和框架进行斗争。
健康检查
这种模式特定于微服务:每个服务都应该实现一个 /health 路由,该路由应该在系统快速运行后很快返回。 假设一切正常,它应该返回 HTTP 代码 200,如果服务出现故障,它应该返回 500 错误。 现在,我们知道一些错误不会被健康检查发现,但假设处于压力下的系统会运行不佳并成为潜在的,它也会被健康检查反映出来,这也会变得更加潜在,这也可以帮助我们识别 存在问题并自动生成待命人员可以接听的警报。 我们也可以选择暂时将节点从队列中移除(参见下面的服务发现),直到它再次稳定为止。
断路器

断路器是从电力领域借用的术语:当电路闭合时,电流正在流动,当电路打开时,电流停止。
当一个依赖不可达时,所有对它的请求都会失败。 根据 Fail Fast 原则,当我们尝试调用时,我们希望我们的系统快速失败,而不是等到超时。 这是断路器设计模式的一个很好的用例:通过使用断路器包装对函数的调用,断路器将识别对特定目的地(例如特定 IP)的调用何时失败,并开始失败 调用而没有真正进行调用,从而使系统快速失败。
断路器将保持一个状态(打开/关闭),并通过每隔一段时间重试一次实际调用来刷新其状态。
Netflix 的 Hystrix 库中引入并广泛采用了断路器的实现,如今在其他库中也很常见。
终止开关/功能标志

今天的另一种常见做法是对新功能执行“静默部署”。 它是通过使用 if 检查功能标志是否已启用(或者,通过检查相关的 kill-switch 标志是否已禁用)的条件来控制功能来实现的。 这种做法并不能 100% 保证我们的代码没有错误,但它确实可以降低将新错误部署到生产环境的风险。 此外,如果我们启用了功能标志并且我们在系统中看到了新错误,则很容易禁用该标志并“恢复正常”,这从操作的角度来看是一个巨大的胜利。
舱壁(Bulkhead)
隔板是船底隔间之间的分隔墙或屏障。 它的工作是隔离一个区域,以防底部有洞——以防止水淹没整个船(它只会淹没有洞的隔间)。
通过在考虑模块化和隔离的情况下构建软件,可以将相同的原则应用于软件。 一个例子可以是线程池:当我们为不同的组件创建不同的线程池以确保耗尽其中一个中的所有线程的错误时 - 不会影响其他组件。
另一个很好的例子是确保不同的微服务不会共享同一个数据库。 我们还避免共享配置:不同的服务应该有自己的配置设置,即使它需要某种重复,以避免一个服务中的配置错误影响不同服务的情况。
服务发现

在动态的微服务世界中,实例/容器来来去去,我们需要一种方法来了解新节点何时加入/离开队列。 服务发现(也称为服务注册)是一种通过允许节点在中央位置(如黄页)注册来解决此问题的机制。 这样,当服务 B 想要调用服务 A 时,它会首先调用服务发现来请求可用节点 (IP) 的列表,它将缓存并使用一段时间。
超时、睡眠和重试
任何网络都可能遭受瞬时错误、延迟和拥塞问题。 当服务 A 调用服务 B 时,请求可能会失败,如果发起重试,则第二个请求可能会成功通过。 也就是说,重要的是不要以简单的方式(循环)实现重试,而不是“烘焙”到重试之间的延迟机制(也称为“睡眠”)。 原因是我们应该意识到被调用的服务:可能有多个其他服务同时调用服务B,如果它们都继续重试,结果将是“重试风暴”:服务B会 被请求轰炸,这可能会使它不堪重负并使其崩溃。 为了避免“重试风暴”,通常的做法是使用指数退避重试机制,该机制会在重试之间引入指数增长的延迟,并最终导致“超时”,这将停止任何额外的重试。
后备

有时我们只需要一个“B计划”。 假设我们正在使用推荐服务,以便为客户获得最佳和最准确的推荐。 但是,当服务出现故障或暂时无法访问时,我们能做些什么呢?
我们可以有另一个服务作为后备:其他服务可能会保留我们所有客户的推荐的快照,每周刷新自己,当它被调用时,它需要做的就是返回该特定客户的相关记录。 这种信息是静态的,易于缓存和服务。 这些后备建议确实有点陈旧,但是拥有不是完全最新的建议总比没有任何建议要好得多。
优秀的工程师在构建系统时会考虑这些选项!
请注意,断路器实现可能包括提供后备服务的选项!
指标、监控和警报
在运行大规模系统时,不是系统是否会失败的问题,而是系统何时会失败的问题:由于规模大,即使是百万分之一的罕见事件也会发生。最终发生。
既然我们理解并接受错误是“生活的一部分”,我们就必须找出处理它们的最佳方法。
为了拥有一个可靠的可用系统,我们需要能够快速检测(MTTD)和修复(MTTR)错误,为此,我们需要获得对系统的可观察性。这可以通过发布指标、监控这些指标并在我们的监控系统检测到“关闭”的指标时发出警报来实现。
Google 将 4 个指标定义为黄金信号,但这并不意味着我们不应该发布其他指标。我们可以将指标分为 3 个桶:
- 业务指标:源自业务上下文的指标,例如,我们可能会在每次下订单、批准或取消订单时发布指标
- 基础设施指标:衡量我们部分基础设施的大小/使用情况的指标,例如,我们可以监控我们的应用程序使用的 CPU 使用率、内存和磁盘空间
- 功能指标:发布有关我们系统中特定功能的信息的指标。一个示例可以是在我们正在运行的 A/B 测试中发布的指标,以提供有关分配到实验不同单元的用户的见解
小轶事:在我为 Netflix 工作的日子里,我和我的团队所做的一件事是开发 Watson,使团队能够通过创建程序化运行手册从已知场景中自动修复他们的服务!
限速
速率限制或节流是另一种有助于减轻系统压力的有用模式。
节流有 3 种类型:
- 用户限速(客户端)
- 服务器限速和
- 地理限速
背压

背压是一种用于处理来自上游服务的请求负载高于处理能力的情况的技术。 处理背压的一种方法是向上游服务发出信号,告知它应该对自身进行速率限制。
有一个专用的 HTTP 响应代码 429“请求过多”,旨在向客户端发出信号,表明服务器尚未准备好以当前速率接受更多请求。 这样的响应通常会返回一个 Retry-After 标头,以指示客户端在重试之前应该等待多少秒。
处理背压的另外两种方法是限制(也称为“在地板上抛出请求”)和缓冲。
可以在此处找到有关背压的其他推荐阅读。
金丝雀发布

金丝雀测试是一种用于将更改逐步推广到生产环境的技术。当监控系统发现问题时——金丝雀会自动回滚,对生产流量的损害最小。
请记住,为了启用金丝雀发布,我们需要能够与“正常”节点分开监控金丝雀集群,然后我们可以使用“常规”节点舰队作为基线,并将其与我们收到的指标进行比较从金丝雀。例如,我们可以比较我们在两者中收到的 500 个错误率,如果金丝雀产生更高的错误率,我们可以回滚它。
还有一种更保守的方法是使用生产中的影子流量来做金丝雀。
我以前的一位同事 Chris Sanden 与人合着了一篇关于 Kayenta 的好文章:一种在 Netflix 中开发的用于自动金丝雀分析的工具。
今天的内容就到这里了,希望大家能学到新东西!
如果你认为我错过了一个重要的模式/原则——请写评论,我会添加它。
- 103 次浏览
【软件设计】系统设计面试基础:CAP 与 PACELC
什么是 CAP 定理以及 PACELC 如何扩展它?

在分布式系统中,可能会发生不同类型的故障,例如,服务器可能会崩溃或永久故障,磁盘可能会损坏导致数据丢失,或者网络连接可能会丢失,导致系统的一部分无法访问。分布式系统如何对自身进行建模以从不同的可用资源中获得最大收益?帮助分布式系统在各种分布式特性之间选择理想平衡的指导原则是什么?
检查 Grokking the System Design Interview 以了解重要的分布式系统概念。
CAP 定理
CAP 定理指出,分布式系统不可能同时提供以下所有三个理想属性:
- 一致性(C):所有节点同时看到相同的数据。这意味着用户可以读取或写入系统中的任何节点并接收相同的数据。它相当于拥有一个最新的数据副本。
- 可用性(A):可用性是指系统中非故障节点收到的每个请求都必须产生响应。即使发生严重的网络故障,每个请求也必须终止。简单来说,可用性是指即使系统中的一个或多个节点出现故障,系统仍保持可访问性的能力。
- 分区容差(P):分区是系统中任意两个节点之间的通信中断(或网络故障),即两个节点都已启动但无法相互通信。即使系统中有分区,分区容错系统也会继续运行。这样的系统可以承受任何不会导致整个网络故障的网络故障。数据在节点和网络的组合之间得到充分复制,以使系统在间歇性中断时保持正常运行。
根据 CAP 定理,任何分布式系统都需要从三个属性中选择两个。三个选项是 CA、CP 和 AP。但是,CA 并不是一个真正的连贯选项,因为在网络分区的情况下,不能容忍分区的系统将被迫放弃一致性或可用性。因此,该定理实际上可以表述为:在存在网络分区的情况下,分布式系统必须选择一致性或可用性。
CAP 定理的证明
我们无法构建一个持续可用、顺序一致且能容忍任何分区故障的通用数据存储。我们只能构建具有这三个属性中的任意两个的系统。因为,为了保持一致,所有节点都应该以相同的顺序看到相同的更新集。但是,如果网络丢失了一个分区,则一个分区中的更新可能无法在客户端读取最新分区后从过期分区读取之前到达其他分区。应对这种可能性的唯一方法是停止为来自过期分区的请求提供服务,但随后该服务不再 100% 可用。
CAP 定理缺少什么?
我们无法避免分布式系统中的分区;因此,如上所述,根据 CAP 定理,分布式系统应该在一致性或可用性之间进行选择。 ACID(原子性、一致性、隔离性、持久性)数据库,例如 MySQL、Oracle 和 Microsoft SQL Server 等 RDBMS,选择一致性(如果无法与对等方检查,则拒绝响应)。相比之下,BASE(基本可用、软状态、最终一致)数据库,例如 MongoDB、Cassandra 和 Redis 等 NoSQL 数据库,选择了可用性(响应本地数据,但不确保它是最新的)。
CAP 定理沉默的一个地方是当没有网络分区时会发生什么?在没有分区的情况下,分布式系统有哪些选择?
救援 PACELC 定理
PACELC 定理指出,在复制数据的系统中:
如果存在分区(“P”),分布式系统可以在可用性和一致性(即“A”和“C”)之间进行权衡;
else(‘E’),当系统在没有分区的情况下正常运行时,系统可以在延迟(‘L’)和一致性(‘C’)之间进行权衡。
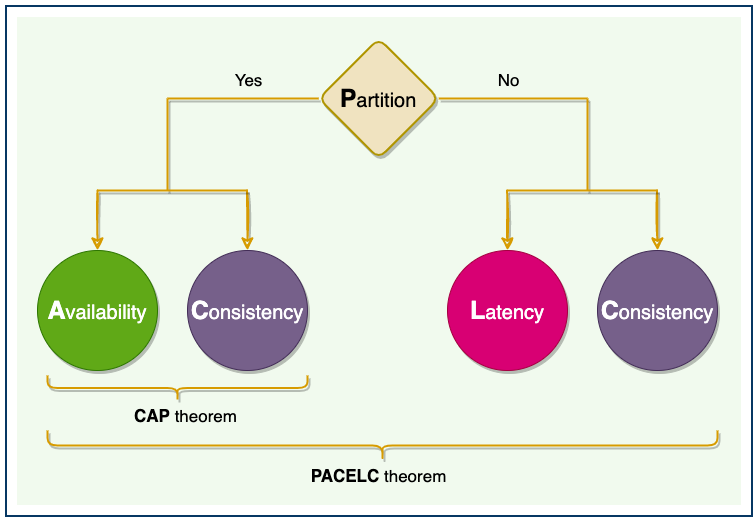
定理的第一部分(PAC)与CAP定理相同,ELC是扩展。整篇论文假设我们通过复制来保持高可用性。因此,当出现故障时,CAP 定理占上风。但如果不是,我们仍然需要考虑复制系统的一致性和延迟之间的权衡。
例子
- Dynamo 和 Cassandra 是 PA/EL 系统:它们在发生分区时选择可用性而不是一致性;否则,他们会选择较低的延迟。
- BigTable 和 HBase 是 PC/EC 系统:它们总是会选择一致性,放弃可用性和更低的延迟。
- MongoDB 可以被认为是 PA/EC(默认配置):MongoDB 在主要/次要配置中工作。在默认配置中,所有写入和读取都在主节点上执行。由于所有复制都是异步完成的(从主节点到辅助节点),当存在主节点丢失或在少数节点上被隔离的网络分区时,可能会丢失未复制到辅助节点的数据,因此会丢失分区期间的一致性。因此,可以得出结论,在网络分区的情况下,MongoDB 选择可用性但其他方面保证一致性。或者,当 MongoDB 配置为在多数副本上写入并从主副本上读取时,它可以归类为 PC/EC。
结论
CAP 和 PACELC 定理帮助分布式系统在各种分布式特性(如一致性、可用性、分区容限和延迟)之间选择理想的平衡。请查看 Grokking the System Design Interview 和 Grokking the Advanced System Design Interview 以获得一些系统设计基础知识的好例子。
原文:https://medium.com/interviewnoodle/system-design-interview-basics-cap-v…
- 132 次浏览
分布式计算框架
分布式计算框架的目标是为开发人员提供抽象,允许他们在将它们视为统一池时使用大量资源。该框架将提供一个协议来处理节点上的数据和任务分布,以及容错问题,例如重新启动失败的任务(无论是来自任务还是来自节点)。该框架不了解底层拓扑,必须应对基础架构演变。诸如MapReduce和Spark之类的流行框架还提供了一种编程模型,该模型允许将大型数据集推理为统一部分(位置透明性),并将其逻辑地分割为由群集节点独立处理的多个组件。数据集本身通常存储在分布式文件系统上,在处理任务的同一节点上;开发人员可以控制其分区,并创建一个应用于每个部分的计算管道。
MPI
消息传递接口是一种独立于语言的标准,允许程序与系统中的其他元素进行通信。 MPI在分布式计算系统中提供基本构建块,即允许程序访问计算机或远程机器中的分布式存储器的消息传递协议。但是,它需要用户在她的代码中实现消息传递,其中更高级别的框架(如Spark和Hadoop)可以透明地处理。结果是用户必须更多地了解底层基础架构,从而分散他们对程序的注意力。 MPI通常被归类为高性能计算(HPC)框架,而不是分布式计算框架,但它与后者共享许多属性。
Hadoop
Apache Hadoop是MapReduce论文的开源实现[1],该论文于2004年首次在OSDI上发布。该项目由Doug Cutting和Mike Cafarella于2006年开始,受雇于雅虎!当时。 Apache发行版的第一个正式版本于2011年发布。
Hadoop由三个主要构建块组成:分布式文件系统,HDFS(Google File System的开源实现[2]),MapReduce API和YARN [3],即调度程序。
MapReduce编程模型来自函数式编程:用户可以将函数应用(映射)到一组独立的数据段,然后聚合中间结果(reduce)。一个典型的例子是WordCount的实现,其中用户想要知道语料库中每个单词的出现次数。首先,文本被分成一定数量的分区,每个分区被映射到一个功能,该功能在其分配的分区中操作本地字数。然后,一旦完成map(),所有单独的中间结果将在reduce()阶段中连接和合并。
通常,Hadoop的Map Reduce实现将数据存储在HDFS中,这可确保有足够数量的块可用并传播到整个群集中。 YARN实现了一种称为延迟调度的技术[4],它试图通过降低网络I / O的成本来最大化数据局部性以增强性能。我们将在本章后面讨论进一步的数据局部性和延迟调度。
HDFS体系结构是主/从范例,其中主服务器保存有关数据放置和授权的所有信息,而从服务器存储数据块并定期向主服务器报告状态。为了确保容错和可用性,每个从站都有指定数量的副本(默认为3个),这些副本位于不同的物理位置,以增强其对物理故障的恢复能力。为了确保一致性,每组副本都有一个主副本,它验证(或拒绝)一段数据上的一系列突变。执行一组突变会使数据定义,这意味着该版本被确认为最终版本。
Spark
Apache Spark [5]属于新一代分布式计算框架。 Spark背后的一个关键动机是通过在内存计算中执行来增强迭代工作负载性能。原始Hadoop实现对于那些工作负载来说是非常低效的,主要是由于对将应用程序运送到其末端所需的大量磁盘访问。 Spark做了两个主要的贡献来解决这个问题:首先它引入了一种新型的数据结构,称为Resilient Distributed Dataset [6],它在内存计算中起着重要作用;第二,它提出了一个丰富的软件架构,可以轻松创建适用于各种类别的分布式计算程序,例如图形处理,机器学习和流媒体。
RDD是不可变的数据集合,用户可以从初始存储(HDFS,远程对象存储,本地文件等)创建数据,并通过转换进行修改。在某些时候,用户可以通过收集方法收集由这种转换生成的新数据。 RDD允许实现MapReduce模型的精炼版本,丰富各种可能的用户定义函数,并允许它们在数据集上创建真实的计算管道。 RDD是懒惰计算的,这意味着只有当用户想要收集数据时,才会应用转换。每个RDD都有一个谱系,这意味着应用于数据集初始切片的操作序列是已知和记录的。 Spark中的任务是对RDD的操作。每个操作在RDD的分区上,并且任务之间的关系是并发的或依赖的。任务(转换或集合)的本质定义了两种类型的依赖:narrow和wide。窄依赖性通常是RDD上两个连续map()函数的结果。广泛的依赖性通常会导致混乱,这意味着中间数据必须通过集群移动才能减少()。
在编译时,Spark分析应用于程序中RDD的操作,并生成有向非循环图。它试图在一个阶段中包含尽可能多的窄依赖关系,并且通常将广泛依赖关系的两端放入不同的阶段。优选地,通过称为延迟调度的技术将任务分配给持有所需数据的工作人员。它允许任务在不保存所需数据的情况下拒绝工人的报价。配置了不同的位置级别,节点,机架和群集位置,允许Spark逐渐增加任务对非位置的容忍度。即使在发生离散故障的情况下,通过重放RDD的谱系,框架也可以进行计算。
RDD可以在专用类型中实例化,具体取决于它们存储数据的计算类型。例如,存在图RDD,文件RDD和列存储RDD。
- 106 次浏览
【BPM架构】BPM 平台:独立还是微服务实现
介绍
BPM 是一个描述、建模和管理复杂业务流程的概念。使用 BPMN,我们可以轻松定义流程中的顺序,编排多个任务、决策和事件。有许多 IT 平台可以将 BPMN 设计变成工作代码。事实证明,协调服务、系统和业务任务的 BPM 模型和支持 IT 平台是实现业务流程的可靠来源。
那就是微服务出现的时候。也就是说,松散耦合的、基于事件的服务,旨在实现特定的业务功能,通过事件进行通信,并实现编排消息传递模型。微服务是否意味着 BPM 平台的终结?或者恰恰相反——像 Camunda 这样的 BPM 平台能否在复杂业务流程的微服务整合中发挥关键作用?
BPM 实施模型
当公司准备好启动 BPM 计划时,第一个决定是选择合适的实施模型和合适的 BPM 平台。
首先,让我们讨论该模型,它将定义整个 BPM 倡议方法本身。这是一个关键决策,需要深思熟虑,因为它将定义整个组织将如何创建和实现业务流程。有两种最流行的建模方法:
- BPM 平台可以是一个单一的 IT 系统,它将在一个地方为业务流程编排和配置规则。
- BPM 引擎可以是微服务的一部分,包含特定的子流程。这些微服务及其子流程将使用编排通信模式整合到业务流程中。
Camunda BPM Platform 可以从技术和业务角度实现这两种方法。这就是在 BlueSoft 中我们推荐该软件作为我们项目中主要 BPM 工具的主要原因之一,我们将使用它作为进一步概念的示例。
Camunda BPM 作为业务流程管理单体
自第一个 BPM 平台出现以来,这种方法已在许多组织中实施。它通常用于将集成层中的 ESB 服务编排成流程引擎层中定义良好的业务流程。我们可以从两个角度看待这种架构——业务和功能以及技术。
业务与功能视角
从业务和功能的角度来看,最重要的是业务流程本身。 Camunda 作为业务流程实现的核心,是业务定义规则和监控流程的第一层。每个业务流程都有其负责人负责业务成果和流程执行的可靠性。在流程引擎的顶部,作为最终用户的网关,通常有多个前端和门户,用户决定业务流程的实现。对于业务视角,集成层 API 就像负责数据供应和请求履行的“黑盒”,业务流程所有者不对其行为和数据管理负责。
正如我们所见,IT 团队和业务团队之间的合作主要集中在流程引擎上——而业务流程负责人定义需求和流程模型,而工程师则致力于他们的技术实现。集成和数据治理团队支持流程团队,但他们不负责业务流程和业务功能。

技术视角
从技术的角度来看,有一个多层的、集成的 IT 架构,它提供了实现业务流程实现的功能。 最重要的是,有可以使用多种不同技术(Javascript、PHP、Angular、React 等)交付的前端。 在较低级别,有 Camunda,它是业务流程定义的中心。 它存储业务规则、决策图表并在前端编排后端集成层功能和 UI 表单。 集成层是技术服务供应的中心。 在实践中,像 MuleSoft、WebMethods、Oracle ESB 等 ESB 平台通常是集成层。 他们的目标是为流程引擎提供具有标准化数据模型的 API。 该层负责公开多个系统功能、集成数据、统一协议、管理服务治理和编排简单的技术处理。
优点与挑战
| 优点 | 挑战 |
| 这种方法的重要好处是在一个地方定义和监控整个业务流程的简单性。 Camunda BPM Engine 可以轻松跟踪流程,即使是复杂的流程。 | 变更管理——在变更流程时,可能需要协调前端和集成层中的多项调整。 这些层通常由不同的技术(甚至业务)团队负责,从而使此类更改成为多个团队之间的多层计划。 |
| 决策规则、任务和业务流程定义在一个平台上处理,业务团队可以使用 Camunda Modeler 设计流程和 Camunda Task List 来完成处理。 | 数据所有权和治理。 业务流程所有者只负责流程实现和结果,而系统所有者和集成架构师只关心数据治理和一致性以及从技术角度来看 IT 系统的可靠性。 它可以围绕稳定、可靠的平台引发利益冲突,并推动业务流程调整。 |
| IT 工程师也从他们的编码过程开始使用相同的 Camunda Modeler,因此团队之间在整个过程设计和实施方面的误解空间有限。 | 由于技术故障和安全方面的原因,拥有一个定义所有业务规则和流程的地方可能会带来潜在的风险。 |
微服务架构中的 Camunda BPM
微服务架构引入了一种不同的 IT 系统设计方法,其中具有大量业务功能的大型单一单体被专为业务目的设计的较小的自主服务所取代。这样的设计会对业务流程的实施方式产生影响。我们也可以从业务&功能和技术角度来看架构设计,但它们在一个微服务中密切相关,为一个业务领域提供业务功能。
业务与功能视角
从业务和功能的角度来看,将业务流程分解为更小的子流程非常重要,这些子流程专注于在一个业务对象中提供价值和决策。由于没有集中的业务流程引擎,这些子流程对事件流层中的事件做出反应。然后,他们启用自己的业务逻辑并为其他子流程生成结果事件。与 Camunda Monolith BPM Platform 不同,跟踪业务流程实现是在两个层面上完成的:在 Camunda Engine 中的微服务层面提供特定功能,以及在事件流层中跟踪子流程之间的事件。这种流程管理导致不同的组织模型——我们仍然有业务流程所有者,但他们在管理和监控整个流程本身方面的责任较少。相反,他们像乐高积木一样构建他们的流程,使用为组合提供小型子流程的微服务。微服务团队有负责端到端数据管理、与遗留系统和外部系统集成、业务子流程实现甚至最终用户 UI 的领导——无论是从技术角度还是业务角度。这种方法导致小型、敏捷、独立的团队与业务专家和 IT 工程师相结合。
这个概念比经典的分层架构具有更大的灵活性——但也让提供每个业务功能的团队承担更多责任。它可以选择适当的技术、语言、数据库和框架来有效地满足需求。团队全权负责完成业务服务,并与技术和业务专家结合,密切合作——从数据定义开始,到业务处理,最后到最终用户的 UI 表示。
技术视角
从技术的角度来看,任何分解的子流程都会成为一组在微服务的业务层中实现的功能——在我们的示例中,一个用于客户数据更新,另一个用于风险计算更新。每个微服务都有自己的数据存储和结构,自己的集成 API 层,自己的 Camunda 引擎来实现子流程,甚至自己的 UI 表示。每一层都可以用不同的技术编写——但是在业务层中坚持使用 Camunda 对于构建跟踪和监控整个业务流程的外部架构很有用。子流程通信是通过在一个地方发布事件来完成的,其他子流程也在事件流层中发布和消费事件。在这个架构中至关重要的是,Event Streaming Layer 只是事件共享的管道,不包含任何消息编排逻辑。用于此目的的最常用技术是分布式流和队列平台,如 Kafka、Pulsar 或 Rabbit MQ。
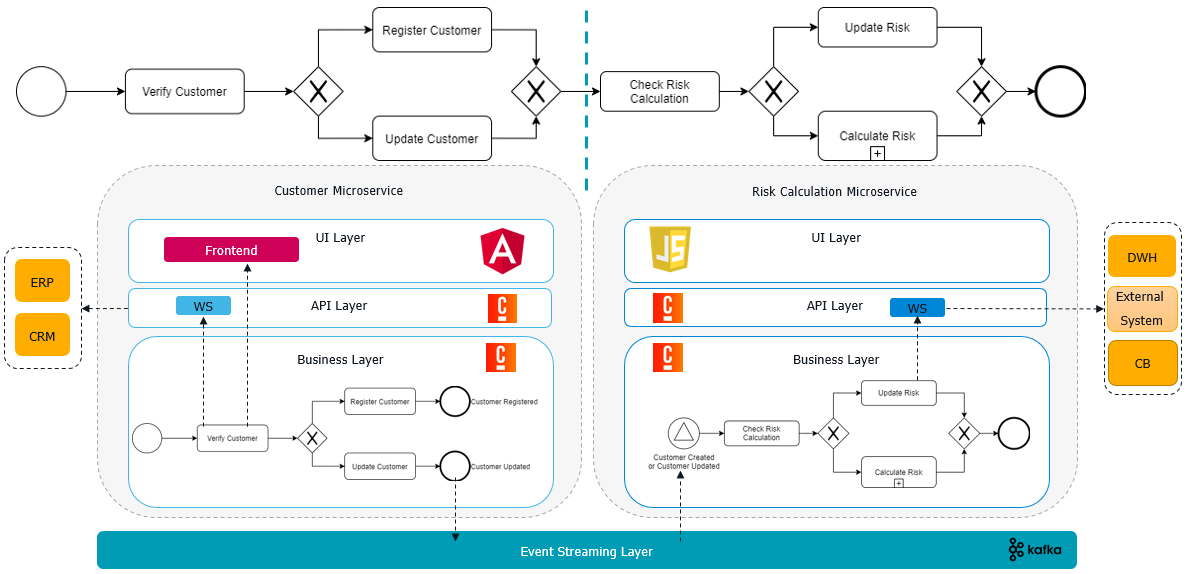
优点与挑战
| 优点 | 挑战 |
| 业务流程和技术组合变化的灵活性。 业务流程实现被分成小的、独立的、功能性的元素,当新的需求出现时更容易调整。 关注这些功能服务的专家团队有责任、知识和权力不断改进它们,从而消除分层架构中单独的技术和业务组之间潜在的利益冲突。 工程师和业务部门在 Camunda BPM 上一起工作的好处更加明显,因为在这种模式下,这些专家专注于业务流程的一小部分,因此他们之间可以更有效地共享技术和业务观点。 | 由松散耦合的子流程组成的业务流程并不容易跟踪和监控。 使用一个技术堆栈——Camunda BPM——构建业务处理可以简化这部分,但它仍然不如在 BPM Monolith IT Platform 中跟踪那么简单。 |
| 技术的灵活性。 在 BPM Monolith Platform 中,当当前的解决方案从技术角度来看已经过时或难以在特定业务需求中使用时,有一个很大的举措是重新编写在那里实现的整个业务流程。 借助微服务和分布式子流程,我们可以逐步规划这样的举措,甚至可以尝试多种技术以选择最佳技术。 | 业务服务组合管理。 借助集成平台,所有外部系统功能都具有代表性的 ESB 服务,易于通过标准化合同使用。 对于微服务,每一个都暴露了功能性 API,因此制定治理规则至关重要,不仅要规定如何构建和使用它们,还要规定在哪里可以找到它们。 |
| 错误的技术决策或重新实施整个业务流程中的人为错误的风险非常低。 使用这种方法,即使您认为 Camunda BPM 不再满足所有需求,也可以轻松地以小功能块迁移到其他解决方案。
|
遗留系统与微服务共存的情况可能具有挑战性。 微服务团队和遗留系统业务团队应该围绕数据一致性和数据所有权展开合作。 事实上,拥有微服务迟早会导致遗留系统分解,这对整个组织和 IT 系统管理都是一个挑战。 |
结论
重要的是要记住,并非每个 BPM 平台都可以实现微服务和独立实现模式。使用无代码平台,可能很难在微服务内部实现完整的业务逻辑,因此它们将作为业务流程管理的单一平台更好地工作。使用低代码平台,我们失去了 BPMN 图驱动的开发,只依赖于工程师和业务专家之间的密切理解。这种理解只发生在微服务团队中。 BPM 平台在这里是最灵活的。它们将这两个好处结合在一起:业务分析师的 BPM 图表建模工具,感谢 IT 工程师,它变成了工作代码。 Camunda BPM 是一个平台,可用于两种实现模型。
在 BlueSoft 中,我们设法将 Camunda BPM 合并到两种实施模型中:
- BPM & Microservices 并以 Trans.eu 架构为例:https://bluesoft.com/project/microservices-based-integration-platform-f…。
- BPM 作为一个简单的业务流程管理工具集,以支持在线商店和 Polarbulk 架构为例:https://bluesoft.com/project/innovative-one-click-purchase-robot-for-po…
您想知道使用 BPM 解决方案是什么样的吗?阅读这篇文章,了解有助于充分利用 Camunda BPM 并避免常见陷阱的关键最佳实践:https://bluesoft.com/camunda-bpm-best-practices/
原文:https://bluesoft.com/bpm-platforms-standalone-microservices-implementat…
- 146 次浏览
【BPM架构】Camunda BPM 最佳实践
介绍
BPM 平台是 BPMN 图成为工作代码的引擎。有许多产品实现了这些概念。其中一些被宣传为低代码,无需任何程序员帮助即可供企业使用。其中一些只是 Java 库,支持软件开发人员级别的业务流程实现。他们中的许多人都在努力获得简单性和 BPMN 驱动的代码,以实现复杂的、特定的要求和量身定制的解决方案。在众多平台中,Camunda BPM 作为一个平台脱颖而出,它是无代码简单性和低代码能力之间的诚实折衷。无论您选择哪种实施模型(在此处了解有关实施模型的更多信息:BPM 平台:独立和微服务实施),业务分析师和 BPM 平台程序员都可以在同一个 Camunda 项目上一起工作。
BPM 平台“圣杯”:无代码概念
我什么时候需要程序员?
现在,您可能想知道:“如果存在无代码 BPM 平台——我为什么还需要程序员?有许多工具被宣传为无代码概念,其中业务流程专家是设计和实施端到端流程的人。”答案很简单:您不需要程序员,如果您的 BPM 平台仅用于一个业务单元中非常简单的流程实现,无需数据集成。如果您想在组织级别实施业务流程,这对业务至关重要并且需要数据集成,那么没有无代码 BPM 平台可以满足您的需求。
在 BlueSoft 中,我们推荐 Camunda BPM 作为简单的、UI 驱动的业务流程设计(从无代码平台已知)和在 IT 工程师的帮助下实施数据集成和复杂业务规则的能力之间的最佳权衡。 Camunda BPM 的巨大优势在于,由业务专家完成的流程设计是 IT 工程师也在处理的代码的一部分。
实施 Camunda BPM 流程时的最佳最佳实践
现在,当我们知道如何建立在 Camunda BPM 中工作的团队时,让我们专注于业务专家和 IT 工程师在建模流程方面的最佳实践和工具。
当我们考虑流程建模时,我们有很多方法和工具来表达自己。它们由 BPMN 2.0 标准提供:流程应该如何工作以及它应该如何与其他微服务或遗留系统进行通信。不幸的是,在技术实现方面,标准方法是“少即是多”。作为程序员,我们习惯于遵守这条规则,但即便如此——这也不是不争的事实。
Camunda Modeler 的建模过程也是如此。常见的方法是仅使用主路径中的部分。但是,就从项目的其他贡献者的角度对过程的理解而言,我们需要在分析部分给他们一点帮助。在这种情况下,通道和外部系统调用就派上用场了。我们添加这些注释而不影响 Camunda 引擎处理流程 .bpmn 文件的方式。
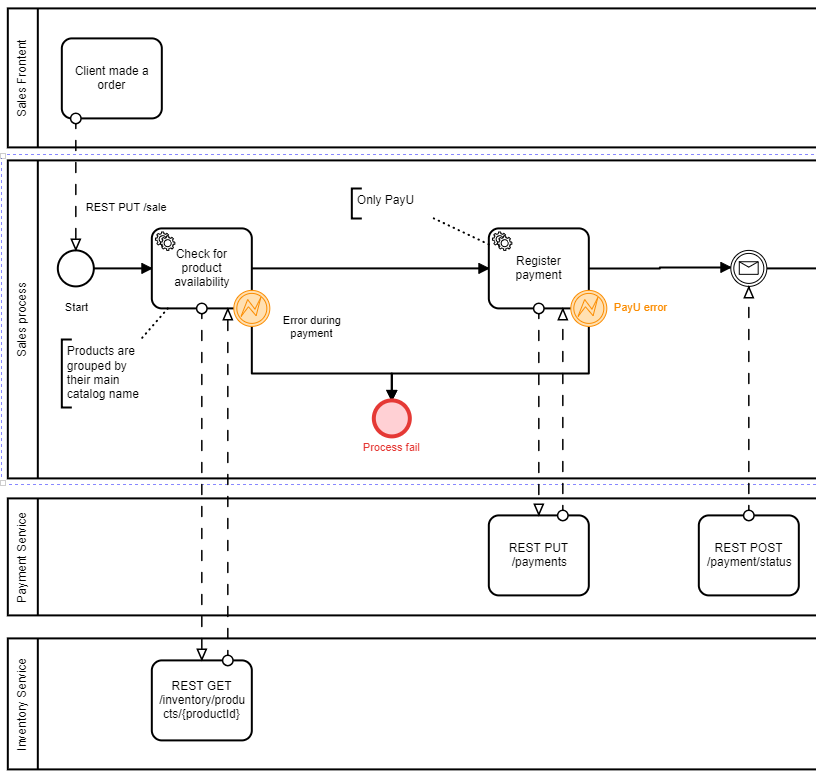
现在,让我们试着设身处地为业务分析师着想。当试图仅使用主通道(示例图中的销售流程)来理解流程时,我们根本不知道这两个服务任务究竟做了什么。可以有一个逻辑调用内部数据库,或者从缓存中访问数据,或者从初始过程数据中计算一些东西。但是当所有部分都存在时,我们清楚地看到这些步骤调用了外部系统。我们甚至知道他们对外部系统使用了哪些特定的 REST 请求!
在对流程进行整体分析时,公司从上述方法中受益。这种方法可以作为设计高级业务流程时的第一个表达工具。然后可以将 .bpmn 文件发送给开发团队,作为开始使用的输入文件。
活动实施原则
当谈到 BPMN 流程编程的可读性时,原则就派上用场了。最常见的反模式是打破 SOLID 原则的第一条规则——“单一责任模式”。这是当今编程世界最重要的原则之一。它指出单个类或包应该只负责解决一个问题。它影响从低级类实现到高级架构设计的所有概念决策。就过程的长期开发和维护而言,步骤应尽可能简单。它应该只负责调用外部系统、为最终用户提供表单或计算收集的数据。
一起实现多个外部调用或在一个步骤中计算流程的所有数据是最常见的错误。即使该流程最初是由业务分析师以这种方式设计的,开发团队也有责任将这一业务步骤拆分为多个技术步骤,并保留原始业务描述。
最好的防线是坚持总体流程——当然,这只是总体思路的基本可视化:
- 第 1 步:从外部系统调用中获取数据
- 第 2 步:计算此数据,对其进行转换等。
- 第 3 步:使用已处理数据中的手动任务为最终用户提供表单。重要提示——不要试图在这部分中包含一种计算形式!对于字典等,尝试对表单进行建模以使用前端-后端 API。
- 第 4 步:保存用户表单中的数据并将其转换为流程模型(如果保存表单数据是唯一的选项,则从附加流程返回第 3 步)
- 重复一般的想法
请记住将可配置性带到步骤中
在 Camunda 中实施流程过程中的另一个重要事项是 SOLID 的“开闭”原则。有些步骤与流程非常相关,没有理由使外部配置成为可能。但其中许多步骤,即使涉及与其他系统的集成,也可以在流程的不同部分或流程的不同部分重复使用。为了实现这一点,我们应该使用元素模板(https://github.com/camunda/camunda-modeler/tree/develop/docs/element-te…)。 Modeler 的用户可以更灵活地重用流程步骤。当然,它需要为每个活动实现一点可配置性。在访问常见的产品数据、发送电子邮件或推送到客户的移动应用程序时,如果您为该步骤提供更多可配置性,那么游戏可能是得不偿失的。
异常处理和超时
在实施之前,我们可能需要更多的时间来分析和设计所有流程的所有出口点。特别是识别来自外部系统调用的所有异常或错误代码起着至关重要的作用。我们建议为每个流程制作一个专用矩阵。最后但同样重要的是,我们需要设计流程应该如何响应这些异常。有两种常见的方法:
- 第一个是将所有步骤回滚到前一个事务点。通常,这些将是人工手动任务或事件处理程序。这种行为很容易实现,但需要在下一次重试流程中覆盖对外部系统的所有数据更改。当然,这些更改不会影响相应系统中的任何业务相关流程)。
- 第二种是使用默认的 Camunda 的“重试和等待”机制。当 Camunda 尝试重复该步骤(默认 3 次)然后抛出异常等待管理员的操作时。当由于某些业务案例(例如,客户已经为产品付款,因此没有回头路)而难以实施甚至不可能回滚时,这是一种合适的方法。在这种情况下,必须考虑外部作业或 API 调用,以便在修复错误或系统重新联机时自动执行重试过程。这通常是指补偿流量。
- 最后,我们应该考虑进程超时的问题。在实际的行业案例中,大多数流程都应该有一个计时器,当客户没有反应时,它会结束它们。没有它,未完成流程的数量可能会不断增长,并扩展到数十万个。在大多数示例中,计时器仅分配给人工任务。这是一种有效且常见的方法,但是当我们需要在每一步都升级时怎么办?或者计时器应该是全局的?在这种情况下,全局处理程序或升级处理程序应该使用 BPMN 流程而不是纯粹的编程方法来建模,以便为业务分析师提供更清晰的信息。
避免冗长的流程
避免冗长的流程说起来很容易,但在实施时却很难获得。有时我们被迫设计流程,而人工手动任务可能需要几个月的时间。这与前面提到的微服务方法——短期流程相反。防止长期流程发生的最佳方法是将流程拆分为较小的流程,仅在当事方做出决定/输入有效数据时创建。但是,当您被迫设计和维护那些长期存在的流程时,请记住在对流程进行任何更改之前必须解决的关键问题:
- 每一条数据都可以处于任何状态并且是变化的一部分。有时不可能列出流程中的所有变量并创建升级矩阵。创建新版本流程的最佳方法是强制将所有流程移动到所需状态,并将这种方法传达给企业。
- 默认情况下,进程是版本化的。但复杂的前端表单和代码不是。当然,您可以使用 OSGi 插件系统 (https://www.osgi.org/) 和已维护的代码的几个版本,但在实际情况下,就成本而言,这是一种非常罕见的方法经过考虑的。很少有框架使用 OSGi 的所有功能(其中之一是我们的开源 BPMN 项目 - Aperte Worklow https://github.com/bluesoft-rnd/aperte-workflow-core),但即便如此,它的成本也很高为每个现有流程版本维护相同代码的多个版本。
- BPMN 系统不是面向表单的门户。它们强制特定的数据状态提供验证和流动。但正因为如此,当这个流程和数据发生变化时,它们很难维护。最简单的方法是在新版本的生产发布之前强制完成所有流程。在某些情况下,更改与可以使用单个脚本转换的其他步骤和数据有关。但是在这些情况下,当流程必须保持当前状态时,分析人员必须创建“数据矩阵”,即数据作为一个维度呈现,当前状态作为另一个维度呈现。并且您应该始终分析在引入使用历史数据状态的代码的新版本时该过程将如何进行。
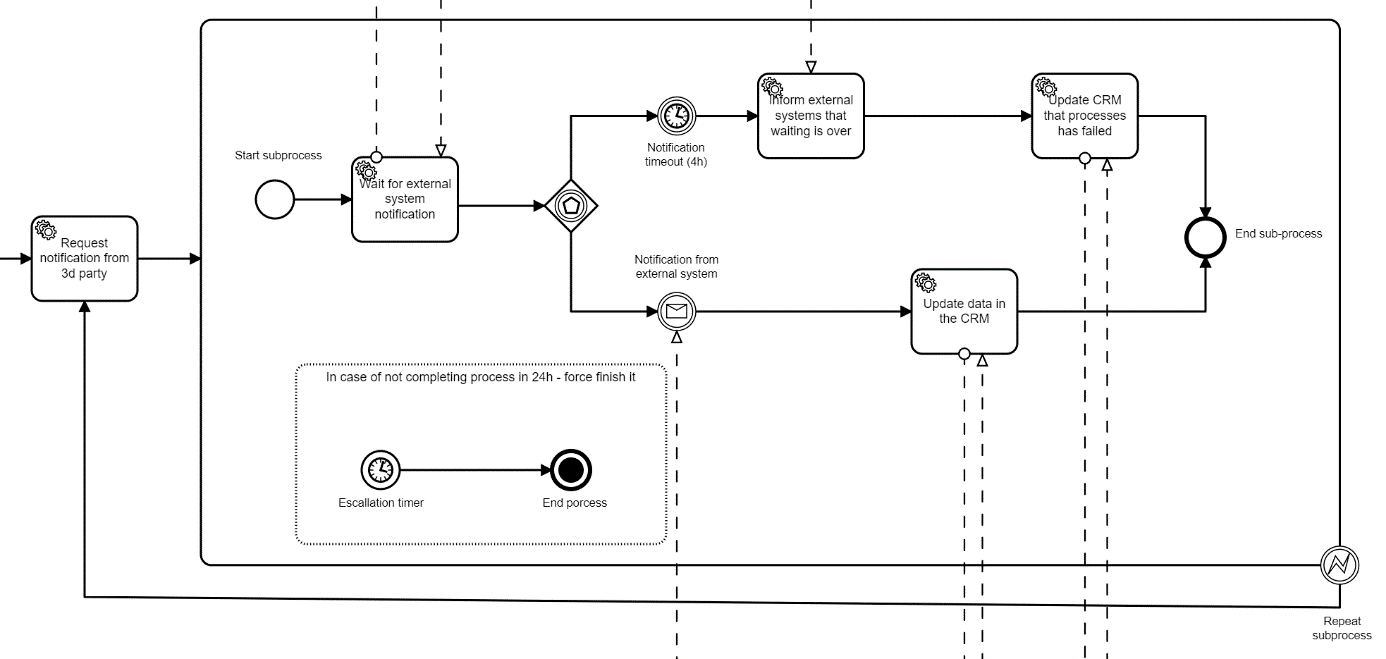
更多最佳实践。
Camunda 的官方文档是最佳实践的重要资源,我们强烈建议参与设计流程或开发团队成员的每个人仔细阅读 - https://camunda.com/best-practices/using- 我们的最佳实践/。 在这篇特别的文章中,我们想总结我们参与的许多项目的经验,以突出最常见的错误以及如何避免它们。 根据我们的经验,BPMN 设计过程并非易事,大部分知识都是在犯错时收集的,这些错误在长期使用这些过程时会发生。 我们认为,这些突出显示的要点是设计至少适当流程的关键。 对于那些与 Camunda 一起开始冒险的人来说,这样做是巨大的成功。
- 308 次浏览
前端架构
视频号
微信公众号
知识星球
- 223 次浏览
【Web趋势】JavaScript和Web开发InfoQ趋势报告
视频号
微信公众号
知识星球
关键的买点
- 新的JavaScript、CSS、HTML和WebAssembly标准的速度正在加快,以覆盖现代应用程序开发的所有方面。
- TypeScript的受欢迎程度急剧上升,现在已经进入了GitHub上最受欢迎的10种编程语言,InfoQ今年对很多框架和库进行了调整。
- WebVR/WebXR和机器学习,推动更好的3D渲染和数据可视化
- React的采用已经大大增加,但新一波的框架正在获得大量使用,其中包括Vue.js
- 应用程序的广泛选择,从先进的Web应用程序,到Electron, Ionic和Cordova等混合应用程序,再到React native和NativeScript等完整的本地编译器,为使用Web技术创建有竞争力的应用程序提供了越来越多的灵活性。
在InfoQ上,我们定期更新我们的主题图,以显示我们认为不同的主题在技术采用曲线中的位置。当我们这样做的时候,我们会考虑实践的状态,新兴的想法和我们在网络中听到的事情,以及在聚会、会议、分析师活动等等。我们还考虑了网站的流量模式和出席QCon和其他行业会议的人数。
如果话题是在右手图的一部分,你可能会发现很多现有InfoQ上的内容,我们覆盖了它当它是新的,和经验教训的创新者和早期采用者可以帮助引导个人、团队和组织,因为他们采用这些想法和做法。
曲线的主题左边是我们认为新兴的现在,使用的创新者和早期采用者,我们重点报告和内容将这些想法对我们的读者的注意力,这样他们就可以自己决定他们是否应该探索现在,或者等着看他们如何展开。
这个月我们将讨论JavaScript和Web开发,因为这个快速变化的行业每年需要进行一次以上的更新。这是我们在2018年第一季度回顾的图表。

这是2018年第四季度的修订版

web开发领域对我们来说总是一个有趣的领域,几乎每天都有新的JavaScript框架发布。试图决定哪些是需要关注的,哪些是需要忽略的尤其具有挑战性。开发人员可以从有趣的方法中学习和收集灵感,即使他们目前在日常开发工作中不使用它们。
创新者
从过去几个月的趋势来看,随着浏览器厂商超越最小可行版本,努力提高性能并填补空白,人们对WebAssembly的兴趣持续增长。
CSS Houdini在CSS领域掀起了一场热潮,PostCSS等工具正在挑战SASS、LESS和Stylus等现有的CSS预处理程序。CSS Houdini是我们继续关注的一个领域。
Deno是Node最初的创建者开发的一个新项目。在TypeScript中编写,试图解决Node.js的挑战。这是一个非常早期的项目,但显示了重大的前景。
Dojo是最早的JavaScript工具包之一,可追溯到2004年,今年发布了版本2(以及随后的版本3和4!)这代表了一个使用TypeScript的主要重写,它将Dojo变成了一个现代的、响应式的、标准一致的、基于虚拟dom的框架。新版本在性能和开发人员人机工程学方面比同类产品有了显著的改进,但它还处于采用周期的早期。
js已经成为基于javascript的机器学习的基础库。我们跟踪这个库以及利用它推进JavaScript机器学习状态的项目。
早期采用者
看看我们早期的采用者,我们继续跟踪Flow(用于JavaScript的静态类型检查器)和Elm(用于生成基于JavaScript的web应用程序的替代JavaScript语言)。
自从我们的上一份报告以来,我们已经提升了一些技术到这一类别,由于增加了行业的吸收:
- GraphQL仍然是我们遵循的一个趋势,已经建立了几个库,包括Apollo、Vulcan.js和urql。
- ECMAScript 2018现在是最终版,2019版的工作正在顺利进行。
- WebVR及其未来的替代者WebXR通过HTML、CSS和JavaScript提供了虚拟、增强和混合现实功能。随着标准从VR扩展到XR,目前出现了很大的波动,但是浏览器和JavaScript对这个领域有很大的兴趣。像A-Frame和React 360这样的库通过使用Three.js而流行起来。
我们也增加了一些早期的采用者:
与Elm一样,Reason也是JavaScript的另一种替代方案,它还提供了类型安全性和对JavaScript的流线型转换。
WICG是W3C的Web平台孵化器社区小组,它一直致力于将各种各样的有用标准转化为成果,从交集观察器和调整大小观察器等最终标准,到picture-in-picture和WebUSB等更具实验性的技术。
Web组件在过去几年里不断发展,现在Chrome和Firefox都支持本地组件,Safari也提供部分支持,Edge也在努力。许多框架和库本身也支持web组件,包括Angular、Dojo、ion、Stencil、Svelte和Vue.js。
CSS Next包含了一系列在标准过程中不断改进的CSS,其中许多可能会与PostCSS或CSS Houdini一起使用。
ion4目前处于beta测试阶段,已经经历了重大的变化,将自己从Angular等特定框架中分离出来,并专注于与现代标准保持一致。
NativeScript为Angular和Vue.js用户提供了本地编译选项,用于部署使用web技术编写的移动应用程序。
最后,net .js是一个很有前途的服务器端框架,用TypeScript编写,运行在Node.js之上
早期的多数
在我们的“早期多数”类别中,Vue.js继续发展并获得支持,我们认为它已经跨越了“早期多数”状态的鸿沟。我们看到中国对Vue.js特别浓厚的兴趣,而最近重新设计的InfoQ也利用了这个框架,目前处于测试阶段。Vue.js 3正在积极开发中,包括使用TypeScript重写。
Angular的第7版最近发布了,并在不断改进。
构建和绑定工具通常对于优化生产应用程序非常有用。几乎每个框架都利用一些工具组合来优化性能。
我们已将electronic和TypeScript 提升至早期多数地位。electronic是一个被广泛采用的桌面应用程序外壳,它结合了Node.js和Chromium,为使用web技术的应用程序提供基础设施。
TypeScript是最广泛采用的JavaScript变体,在过去几年中取得了长足的进步,现在大多数JavaScript框架都利用了它的工具和基础结构。根据GitHub最近的一份10年报告,TypeScript本身是十大语言之一,JS的状态调查将TypeScript列为目前使用最广泛的JavaScript变体。
我们在早期多数人类别中直接增加了三个项目:
React Native是一个使用JavaScript和React构建本地移动应用的框架,并迅速成为构建跨平台移动应用的流行方式。
同样,函数式和反应式编程模式主导了关于如何最有效地构建JavaScript应用程序的讨论。像lodash这样的库帮助推广了这些模式。
晚期大众
随着JavaScript生态系统的成熟,现在有一些属于后主流类别的基础技术没有被取代的迹象,但是几乎每个JavaScript开发人员都在使用它们。
我们已经提升了几个项目到我们的后期多数地位。
ide和编辑器通常被广泛使用。在桌面上,VS代码似乎已经在Atom、Sublime Text、WebStorm、甚至vim或emacs上取得了实质性的领先。像CodeSandbox这样的基于浏览器的ide为web浏览器带来了大量的VS代码体验,用于快速开发、试验和共享开发成果。
Babel version 7最近发布了,它在新出现的JavaScript版本和开发人员需要根据需要支持的版本之间提供了默认的转换。
Babel,用于将源代码从JavaScript的新兴版本转换为生产环境中支持的语言特性集的JavaScript转换工具。
React是自jQuery以来应用最广泛的框架,并在不断发展;支持React的新项目几乎每天都会发布。
Node.js 是一个被广泛采用的JavaScript服务器端和命令行环境,NPM是最常用的Node.js包管理器。几乎每个JavaScript项目的命令行和构建工具都使用Node.js,而Node.js在服务器端开发和嵌入式系统中都得到了广泛采用。
Express也在我们的列表中,是使用最广泛的节点。js-based服务器端框架。Webpack也在我们的列表中,它是事实上的构建和绑定工具,也是基于Node.js的。
我们加入HTML5和ES6/2015作为后期的主流,因为几乎所有的web应用程序都使用这些特性作为最低基线。
落后者
我们用落后者来结束我们的报告,虽然它仍然在许多应用程序中使用,但是对于新的开发工作并没有引起很大的兴趣。更新的版本已经取代了ES5和HTML4。Dojo 1。x和角1。x虽然仍在广泛部署,但处于维护模式。jQuery虽然得到了一些改进,但大部分已经被新的HTML和JavaScript特性或更成熟的框架所取代。
结论
JavaScript生态系统正在蓬勃发展,尽管跟上变化的速度可能很有挑战性,但我们相信这个领域中的许多基础部分已经变得稳定,这为创新创造了额外的领域。InfoQ的团队将为您提供JavaScript领域的专家报道,我们欢迎您的反馈、评论和外部文章贡献。
本文:https://pub.intelligentx.net/node/810
讨论:请加入知识星球【首席架构师圈】
- 62 次浏览
【前端架构】2019年最佳3个JavaScript框架

介绍javascript框架
毫无疑问,JavaScript(JS)在开发者社区中的受欢迎程度多年来呈指数级增长。 原因是它能够允许开发人员以多种方式设计和修改网页,甚至可以为实时网络应用程序添加功能。 JavaScript不仅因其简单性和易用性而受到关注,而且还因其带来的效果 - 效率,安全性和低成本结果而受到关注。
与此同时,先进技术正在推动技术人员为JS的存储库添加新技能。 毫无疑问,JavaScript库/框架市场今天有点乱。 在可用选项方面存在很多噪音,开发人员通常需要通过学习多个库/框架来测试水域,以确定最佳选择。
考虑2018年流行的JS状态调查,其中给出了开发人员当前使用的库的数量:
尽管今天有许多库,但调查结果证明Vue,React和Angular仍然是市场领导者。
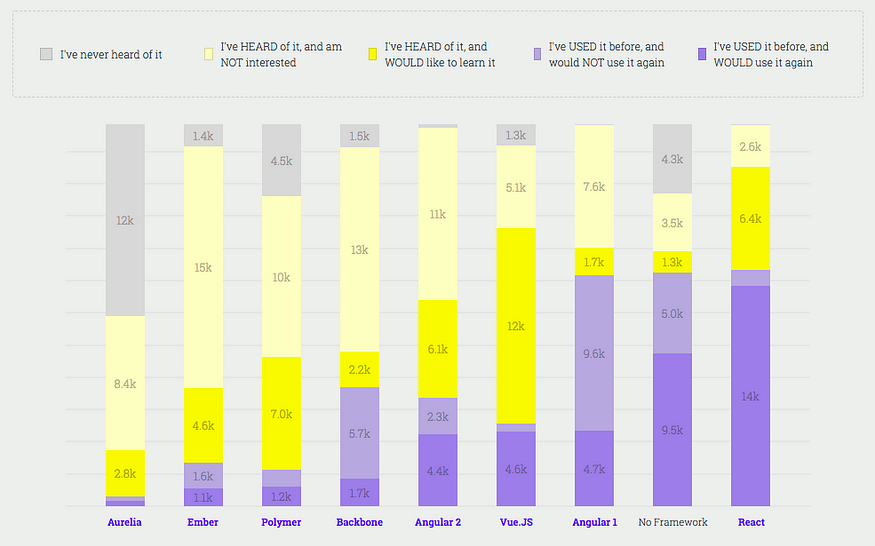
1. Vue.js
Vue成为2018年最受欢迎的前端GitHub项目,这一壮举在2018年跟随着117k星和超过29k叉的框架(在撰写本文时)。 Vue.js由他在Google期间参与过许多Angular.js项目的Evan You创建,是Angular.js的轻量级副本,并且也被证明是一种有吸引力的替代品。
开发人员喜欢Vue的主要原因之一是因为它是一个渐进的框架。这意味着它可以优雅地适应开发人员的需求,从3行开始到管理整个视图层。 VueJS可以通过“脚本”标签快速集成到应用程序中,逐渐开始探索空间。
但是Vue特别有效,因为它为Angularjs,Reactjs和Knockout等框架提供了最佳选择和可能性。这使得它成为所有框架的最佳版本,整合在一个干净整洁的软件包中。
让我们来看看使用Vue.js开发的优点和缺点
Vue.js的优点
- 尺寸:这是Vue的最佳亮点之一。 Vue的生产就绪结构令人惊讶地轻巧 - 拉链后只需18kb。与其他主要框架相比,这为其提供了急需的速度和准确性。同时,即使是Vue周围的生态系统也很小而且速度快,因为它允许用户将模板到虚拟DOM编译器以及运行时间分开。
- 集成能力:Vue提供了最佳的集成功能之一,因为它可用于构建单页面应用程序和复杂的Web应用程序。框架的小型交互式部分可以轻松地与其他框架/库集成,例如Django,Laravel和WordPress。
- 可扩展性和多功能性:您可以将Vue用作库或完全成熟的框架。由于结构简单,Vue可以很容易地用于开发大型和可重复使用的模板,而且操作简单。
- 适应性:大多数适应Vue的开发人员都从其他主要框架转向它。由于Vue与React和Angular的相似性,切换周期经常变得很快。
- 可读性:Vue非常易于阅读和理解,因为功能非常容易访问。此外,可以使用不同的组件来优化HTML块处理。
Vue.js的缺点
- 缺乏资源:由于目前市场份额较小,Vue仍有很长的路要走。相对年龄也增加了常见插件的困境,这使得使用外部工具有点困难。
- 快速进化:虽然快速开发阶段对于框架来说是好的,但在功能方面却很好,学习曲线也在不断变化。因此,在线资源可能最终过时,文档有时可能是开发人员的唯一资源。
- 反应性注意事项:文档清楚地说明了一些反应性警告,例如直接从数组中设置项目。这可以通过使用items [key] = value或添加新的data属性来完成。因此,这需要在开发过程中得到有效处理。
2. React.JS
React是另一个流行的JavaScript库,为Facebook提供支持。它于2013年由Facebook开发和开源,很快就开始涉及动态数据处理的大型Web应用程序的开发。
在2019年1月,Facebook通过将创建反应应用程序(用于帮助创建React应用程序的CLI工具)从孵化移动到官方Facebook存储库,扩展了对该库的支持。
React广泛使用的主要情况之一是开发人员需要分解复杂代码并在无错误的环境中重用它们,这些环境能够处理实时数据。与生命周期挂钩相关的元素(如装饰器)有助于增强用户体验。
React利用虚拟DOM帮助它与任何应用程序集成。与其他JS库/框架相比,它还采用JSX来构建组件并有助于开发更多SEO友好的Web页面。
为了帮助您选择最适合您需求的库/框架,让我们来看看React.js开发的优缺点:
React.js的优点
- 易于学习:React在语法方面展示了简单性,涉及大量HTML编写技巧。与Angular不同,它需要精通TypeScript的陡峭学习曲线,因此React对HTML的依赖使其成为最容易学习的JavaScript库之一。
- 库,而不是框架:React是一个JavaScript库而不是框架。这意味着它提供了一种定义UI组件的声明方法。它还可以与其他库轻松集成。例如,React-Redux库提供了React和Redux库之间的必要粘合。
- 数据和表示:React提供数据和表示层的完全分离。虽然它确实具有“状态”的概念,但它最好用于存储持续很短时间的存储。
- DOM绑定:开发人员不必经历将DOM元素绑定到功能的痛苦。 React通过在代码的多个区域中仅使用职责分割绑定来处理此问题。
- 可重用组件:Facebook开发的React方式使其能够随时重用任何级别的代码组件。这在开发过程中节省了大量时间。这种能力主要增加了设计效率,使开发人员可以轻松处理升级,因为对一个组件所做的任何更改都不会影响另一个组件。
- 单向数据流:React利用向下数据绑定。这有助于确保对子结构所做的任何更改不会最终影响其父级。这使得代码更加稳定,并且开发人员需要做的就是更改对象,修改其状态并应用更新。
React.js的缺点
- 高度发展的步伐:React的环境非常动态,不断变化。这增加了开发人员不断刷新和学习新技能的责任。这对刚开始的开发人员来说可能是一个令人头痛的问题。
- JSX作为障碍:React积极利用JSX,这是一种语法扩展,允许将HTML与JavaScript混合。尽管JSX可以保护代码免受注入(以及其他好处),但它确实涉及高度复杂性和陡峭的学习曲线。
- 搜索引擎优化问题:用户报告了有关搜索引擎优化的问题,因为搜索引擎使用客户端渲染很难索引动态网页。虽然意见主要是推测性的,但专家建议开发人员了解Google和其他搜索引擎的抓取工具是如何体验它们的。
3. Angular.JS
Angular被认为是最强大的开源框架之一。它是一种“一体化”解决方案,旨在为开发人员提供开箱即用的各种选择。从路由到HTTP请求处理和采用TypeScript,一切都已设置完毕。
虽然Angular的学习曲线在早期版本中非常陡峭,但它已在最新版本的Angular 5和6中得到了平滑。通过强大的CLI可以实现这一点,这已经消除了了解低级细节的需要。适用于简单应用。
由Google开发和维护,Angular遵循每6个月发布新版本的计划。最新版本主要集中在增加新功能和提高性能。
以下是Angular.JS开发的优缺点:
Angular 5的优点
- 文档:Angular 5附带详细的文档。与早期版本的Angular相比,这使新开发人员更容易掌握框架并理解其他项目的代码。
- 更简单的PWA:渐进式Web应用程序越来越受欢迎,Angular团队已迅速将该功能集成到框架中。 Angular 5也可以获得本机移动应用程序的功能。
- 构建优化器:Angular 5中的构建优化器删除了所有不必要的运行时代码。这使得应用程序更轻,更快,因为应用程序中JavaScript的大小减少了。
- 通用状态转移API和DOM:Angular 5已经引入了Universal State Transfer API和DOM支持。这有助于在服务器和客户端版本的应用程序之间共享代码。这有助于提高应用程序的感知性能。
- 路由器挂钩:现在可以从正在运行的防护装置开始跟踪路由器周期,直到激活完成。
- 数据绑定和MVVM:Angular 5允许双向数据绑定。这可以最大限度地降低可能出错的风险,并实现应用程序的单一行为。另一方面,模型视图视图模型功能允许开发人员在具有相同数据集的同一应用程序部分上单独工作。
Angular 5的缺点
- 复杂语法:就像Angular的第一个版本一样,Angular 5也涉及一组复杂的语法错误。尽管如此,它使用的是TypeScript 2.4,与其他Angular版本相比,它更难学习。
- 迁移:从旧版本的Angular迁移应用程序可能是一个问题,尤其是对于大型应用程序。
- 高流失:尽管Angular在使用方面非常受欢迎,但它也可以用来计算最大程度的流失率。这可能是由于与当今其他流行的替代方案相比,学习曲线更加陡峭。
比较表 - Angular 5 Vs React.js Vs Vue
以下是对2019年最受欢迎的3个JavaScript框架/库的比较的综合外观,让您可以鸟瞰当前的情况:
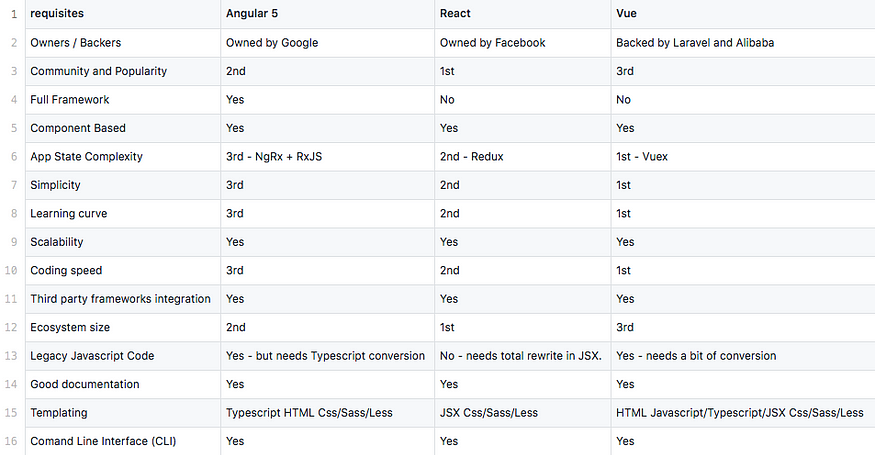
结论
所有3个框架/库今天都非常流行,并得到健康的生态系统和开发团队的支持。 没有正确的答案,这完全取决于您的个人选择和编程风格,因为每个框架都涉及不同的开发理念。 无论如何,React,Vue和Angular继续主宰JavaScript世界。
另请阅读:Angular vs. React vs. Vue:2018年比较(更新)
您认为哪个JavaScript框架/库最好? 在评论中与我们分享您的观点!
原文:https://medium.com/cuelogic-technologies/top-3-best-javascript-frameworks-for-2019-3e6d21eff3d0
本文:http://pub.intelligentx.net/node/519
讨论:请加入知识星球或者小红圈【首席架构师圈
- 57 次浏览
【前端架构】2022 年 Angular 与 React

在过去十年中,JavaScript 框架的数量急剧增加。 Angular 和 React 已成为顶级 JavaScript 框架中的流行选择。 它们允许开发人员在比以往任何时候都更少的时间和更少的代码中创建高质量的 Web 应用程序和移动应用程序。
Angular 被认为是创建单页快速执行应用程序的理想选择。 另一方面,对于需要闪电渲染服务的 Web 和移动应用程序开发项目,React 是一个令人信服的选择。 在好框架和差框架之间进行选择总是更容易。
但是,有两种理想的选择可供选择,很难确定哪一种最适合您的需求。 看看下表,就 Angular 与 React 做出明智的决定。
在本文中,我们将比较 Angular 与 React 2022。让我们探索以下内容:
- 好处
- 缺点, &
- 这些框架之间的差异。
它将帮助您做出明智的决定,决定将哪一个用于您的下一个项目。
Angular-确保更快的 SPA 开发
由 Google 创建的 Angular 是一个强大的前端框架,可以轻松构建具有基于 HTML 的用户界面的应用程序。 Angular 还提高了 Web 应用程序的速度并减少了代码大小。 Angular 被 NASA、强生、Capital One、沃尔玛等公司使用。
由于它能够从基于 DOM 操作的模板生成干净的 JavaScript 代码——并且由于它是用 JavaScript 本身编写的——与其他框架相比,Angular 拥有卓越的开发性能。
此外,前端开发人员在使用 Angular 2 编写模块时使用 TypeScript 而不是普通的 JavaScript。他们在单元测试中对变量和对象有完整的类型支持。它最终提高了测试质量和生产力。
使用 Angular 的优点
- 使用 Angular 的主要好处是它的速度。 Angular 背后的编译器创建高效的代码,这意味着您可以更快地加载您的网站,
- Angular 非常适合 SEO。这也意味着更少的错误,从而节省调试时间。
- 由于更好的错误消息和更详尽的文档,Angularjs 开发人员几乎不需要其他团队成员的帮助(这降低了成本)。
- 此外,由于 Google 是在内部创建的,因此您将获得一个设计精良且安全性高的平台。
- 最后,因为它是一个开源平台,所以如果需要,您可以随时寻求帮助。
使用 Angular 的缺点
- Angular 使用双向数据绑定,这在某些情况下可能会出现问题。例如,如果算法输出无意义的值(例如 blargle Fargo),那么您的输出也将没有意义。
- 您有时会发现自己在这样的情况下调试了几个小时,却不知道为什么某些东西不能正常工作。
React - 为应用程序提供高渲染性能
React 是一个用于设计有吸引力的用户界面的 JavaScript 库。与您可能使用过的其他 UI 库不同,React 将您的 UI 视为您可以在应用程序中使用的另一个组件。您不会在代码中编写 HTML;相反,您使用 HTML/JavaScript 构建功能并以您认为合适的方式呈现它们。
这种灵活性还允许组件重用——而不是一遍又一遍地编写(和重写)几个非常相似的 HTML 片段,使用 React,您可以在任何其他需要的地方重用每个组件。因此,当您尝试在有限的时间内完成项目时,您应该聘请 React Native 开发人员。
使用 React 的优点
- React 易于学习并使复杂的事情变得简单。
- 它是开源的。
- 您可以将它与任何技术堆栈一起使用,如果您不喜欢现有的技术堆栈,甚至可以将其构建到您的堆栈中。
- 有大量围绕 React 的开发工具可以为开发人员(和最终用户)提供出色、稳定的体验。
- 它被 Facebook、Instagram、Netflix 等公司使用。
使用 React 的缺点
- 对于许多库,您必须等待开发人员的更新才能获得错误修复或新功能。作为开发人员,这可能很麻烦并且会降低您的工作效率,因为您可能需要在每次更新时进行调整。
- 它的文档很差,因此很难将新团队成员加入开发团队。
介绍了这两种技术的优缺点后,让我们来探讨这两种技术之间的区别。
学习曲线:分析最简单的应用程序
与其最著名的竞争对手 React 相比,Angular 的学习曲线相对陡峭。虽然使用这两个框架都需要对 HTML 和 JavaScript 有基本的了解,但 Angular 还需要 Typescript 和 RXJS 的知识。
与 Angular 相比,你会更快地使用 React,因为它使用更直接的语法并且主要坚持构建组件来创建应用程序。
但是,假设您熟悉 Java 或 C++ 等面向对象的编程语言,或者之前曾在其他语言或平台上广泛使用过 OOP 概念。在这种情况下,您可能会发现开始使用 Angular 比使用 React 更容易。
所以,赢家是:真正的赢家取决于你的编码能力。
框架大小:选择较轻的框架以提高应用程序性能
随着时间的推移,JavaScript 框架的规模不断扩大。已知最早的 JavaScript 框架是 Dojo,它于 2001 年左右推出,总下载大小为 9MB。如今,流行的图书馆要大得多。 Angular 2 + Rx 的下载大小为 766K。相比之下,React 0.14.5 + React DOM + Redux 的大小为 139K。
选择框架时,请记住它需要由用户下载并安装在客户端计算机上。除了下载之外,考虑用户需要多久更新他们的库也很重要。当给定的更新涵盖安全补丁或错误修复时尤其如此。
那么,谁是赢家:React 无疑是这里的赢家。
DOM 模型:确保更快的开发速度
在 Angular 中,元素是活动的,它们不会创建任何 HTML DOM 副本。在 React 中,Virtual DOM 用于使用树差异进行快速渲染。这意味着每次对 UI 进行更新时,它都会检查已更改的内容并仅更新需要更新的内容。
这种方法适用于处理小的数据更改,例如从元素按顺序出现的列表或表格中添加/删除项目。这就是为什么重要品牌更喜欢在他们的用户界面 (UI) 开发中使用 React,因为与 Angular JS 相比,它使用更少的带宽使应用程序加载更快。
那么,谁是赢家:React
可扩展性:通过不断增长的 LCB 获得出色的性能
您可以使用这些框架中的任何一个。如果您期待制作可以处理大量数据的应用程序,您可以获得完美的性能。
例如,聊天应用程序或电子邮件应用程序必须选择 Angular。其背后的原因是 Angular 使用多种形式的数据绑定系统,这可以防止不必要的开销,以跟上所有更改。
React 遵循基于组件的架构,允许您使用小块代码构建应用程序。如果应用程序将发生重大变化,那么只更新该块而不是整个应用程序是毫不费力的。
那么,谁是赢家:Angular。
开发人员可用性:提供负担得起的项目开发
资料来源:Stack Overflow 开发者调查
与主要竞争对手 Angular 相比,React 最显着的优势之一是更多的开发人员知道如何使用它。 根据 2021 年 7 月的 Stack Overflow 调查,36.8% 的受访者表示他们在项目中使用过 React,而 Angular 的这一比例仅为 26.5%。
它使您可以接触到更多有使用 React 经验的开发人员,如果您决定使用它,可以加快开发速度。 随之而来的是,如果你可以聘请一位对 React 了如指掌的经验丰富的开发人员,而不仅仅是一个知道的足以应付的人。
这将比使用其他技术的经验不足但同样熟练的开发人员花费更多。 因此,Angular 开发人员的费用比 React 开发人员的费用更实惠。 背后的原因是一个简单的事实,即 Angular 比 React 早三年推出。
那么,谁是赢家:Angular。
顶级品牌的使用:看看全球企业更喜欢什么
作为其主要目标之一,React 是帮助团队构建大型应用程序,而不会因复杂的工具集和陡峭的学习曲线而感到不知所措。 Facebook 的开源库允许您使用组件而不是经典的 Web 视图来构建应用程序。
它有助于防止功能和视觉复杂性的臃肿,有时感觉就像永远爬山一样。如果您决定将来扩展到移动或原生应用程序开发,更轻的组件还可以更轻松地在平台之间迁移。
一些使用 React 构建的世界级应用程序包括 Facebook、Netflix、Instagram 等。
另一方面,Angular 旨在帮助我们创建和维护大型 Web 应用程序。它可以处理从简单的数据视图到复杂的单页应用程序 (SPA) 的所有内容。由于它的特性和易用性,开发人员喜欢在几乎所有可能的平台上使用 Angular!
Gmail、福布斯和 PayPal 是一些信任 Angular 的顶级品牌。
最后的要点
- React 的体积比 Angular 小得多,占用空间更轻。
- React 遵循虚拟 DOM 模型。
- Angular 确保创建可扩展的应用程序。
- Angular 开发人员的小时费率相对较低。
在阅读了我所有的比较数据之后,您现在可以决定哪个框架更适合您的项目或公司。对于这两个框架中的哪一个会获胜,没有答案。 Angular 和 React 各有利弊。
由您和您的团队决定哪一个将使您的项目更易于访问和舒适。我希望我的帖子能帮助您了解这些框架是如何相互叠加的。
原文:https://enlear.academy/angular-vs-react-in-2022-83a2ac15230c
- 103 次浏览
【前端架构】2022年的React状态管理-返回Redux
今年年初,如果你告诉我我会发布使用 Redux 的推荐,我会当着你的面笑。 然而我们来了。
状态
状态是确定应用程序将如何呈现的持久信息。
我们将讨论以下类型的状态:
- 本地状态:指的是在 React 组件中持久化的状态。
- 全局状态:指的是所有组件都可以访问的全局存储中持久化的状态。
- 服务器状态:指在服务器上持久化的状态。 (为了这个对话 - 在客户端缓存中自动管理,使用像 React Query 这样的工具。)
Redux
Redux 由 Dan Abramov 和 Andrew Clark 于 2015 年创建,作为跨整个 React 应用程序管理和提供状态的解决方案。 Redux 创建一个名为 Store 的全局状态,并允许您将组件连接到 Store 以访问全局状态。 Redux 有助于防止 prop 钻取,并使跨多个组件的状态管理变得更加容易。
但是经典的 Redux 有很多痛点,包括:
- 陡峭的学习曲线
- 一个臭名昭著的样板问题
- 缺乏标准架构——没有 2 个 Redux 实现是相同的; 很少有人是好的
- 糟糕的 TypeScript 支持
Redux 工具包
2019 年 10 月,Redux Toolkit 1.0 发布。
“Redux Toolkit 是我们官方的、固执的、包含电池的工具集,用于高效的 Redux 开发。 它旨在成为编写 Redux 逻辑的标准方式,我们强烈建议您使用它。”— Redux 团队
Mark Erikson 的 RTK 愿景旨在解决上述问题,并最终取得了成功。
在我看来,让 RTK 有价值的两大特性是 createSlice 和固执己见的 Style Guide。
切片是您在配置store时定义最终传递给 combineReducers 的功能状态的地方。
import { createSlice } from '@reduxjs/toolkit';
const initialState: {
mode: 'light' | 'dark';
} = {
mode: 'light',
};
export const themeSlice = createSlice({
name: 'theme',
initialState,
reducers: {
toggleThemeMode: (state) => {
state.mode = state.mode === 'light' ? 'dark' : 'light';
},
},
});
export const { toggleThemeMode } = themeSlice.actions;
export default themeSlice.reducer;但即使有了RTK,我仍然没有被卖掉。 这在很大程度上是因为在 RTK 发布前后,服务器状态工具也是如此。
服务器状态工具
2019 年,SWR 和 React Query 被引入 React 社区。 Vercel 创建的 SWR 和 Tanner Linsley 创建的 React Query 都解决了相同的问题:获取、缓存、同步和更新服务器状态。
服务器状态旨在保持服务器上的单一事实来源,可能会持久保存在数据库中,并消除维护和同步服务器派生状态与全局状态的需要。

由于将服务器状态抽象为查询工具时保留的全局状态很少,因此几乎没有理由使用 Redux。剩余的全局状态(如果有)可以通过上下文轻松管理。此时此刻,我强烈主张避免使用 Redux,支持使用 Server State 工具 + Context。
但随后 RTK 做出了回应。
RTK查询
2021 年 6 月,Redux Toolkit 添加了一个非常强大的工具,使 Redux 成为一个更可行的解决方案:RTK 查询。
与 SWR & React Query 类似,RTK Query 是一种管理服务器状态的数据获取和缓存工具。
使用 RTKQ 的一大好处是它可以与您的 Redux Store 集成。与 RTKQ 的每次交互都会调度一个 Redux Action。这允许所有 Redux Reducers 甚至 Redux DevTools 都可以看到每个交互。对于任何与 Redux 集成的工具(如 Sentry)来说,这都非常强大。
所以现在 RTK 有一个服务器状态解决方案,决定因素归结为您希望如何管理应用程序中剩余的全局状态。此时,您可以创建 Redux Slice,也可以使用 Context。两种解决方案的样板数量大致相同。然而,Redux 确实有一些好处。
- 首先是开箱即用的性能。如果您曾经阅读过任何关于 Context 的文章,您就会知道它作为状态管理解决方案通常不被鼓励。这是因为如果您没有正确使用 Context,很容易在您的应用中产生性能问题
- 。
- 第二个是拥有单个 Provider 的想法——而不是使用 Context,在这种情况下,每个功能都需要一个 Provider,所有这些都可以出现在组件树中的任何位置。
结论
我不敢相信我会这么说,但我现在喜欢 Redux。多亏了 Redux Toolkit 和新发布的 RTK Query,实现 Redux 实际上是非常愉快的,使用它你会收获很多,尤其是在企业环境中。
原文:https://engineering.udacity.com/react-state-management-in-2022-return-o…
- 181 次浏览
【前端架构】2022年要学习的五大前端框架
你好,开发者。 如果您是初学者并且不知道您必须学习哪个前端框架,那么您来对地方了。 今天,我将告诉你 2022 年你可以学习的 5 大前端框架。
在软件行业,有很多前端框架,但我选择了 5 个框架来学习以记住未来的范围。
在开始之前,我们必须了解一些我将在本文中使用的定义 -
MVC架构——
模型-视图-控制器是一种软件设计模式,通常用于开发用户界面,将相关的程序逻辑划分为三个相互关联的元素。 这样做是为了将信息的内部表示与信息呈现给用户和被用户接受的方式分开。
Single Page Application (单页面应用)
单页应用程序是一个web应用程序或网站,它通过使用web服务器的新数据动态重写当前网页来与用户交互,而不是web浏览器加载整个新网页的默认方法。
Two-way data binding (双向绑定)
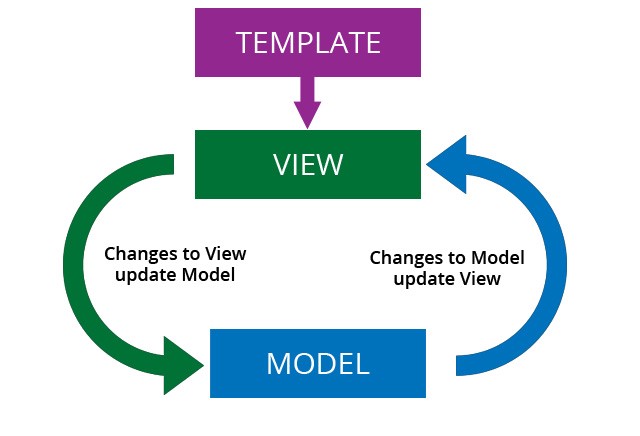
双向绑定为应用程序中的组件提供了共享数据的方法。使用双向绑定在父组件和子组件之间同时侦听事件和更新值。
TypeScript -
TypeScript是一种由Microsoft开发和维护的编程语言。它是JavaScript的严格语法超集,并向语言中添加可选的静态类型。TypeScript是为开发大型应用程序和JavaScript的跨组件而设计的。
让我们从“2022年要学习的五大前端框架”开始。
5. Backbone.js
它是最容易学习的框架之一。如果您是初学者,那么您可以很容易地学习这个框架。在骨干的帮助下。js,我们可以轻松构建单页应用程序。该框架还遵循MVC(模型、视图和控制器)体系结构。
Backbone.js 的优点和缺点:
- 它是最快的JavaScript框架之一,而且非常轻量级。
- 没有现成的结构可用, `create react app`。
4. Ember.js
Ember.js于2011年开发。它是一个基于组件的框架,支持双向数据绑定。它具有非常高效的体系结构。这是一个组织良好的框架。
Ember.js的利弊
- 它是一个非常快速、组织良好的JavaScript框架,具有良好的文档。
- Ember.js有一个小社区,语法理解起来很复杂,更新速度也很慢。
3. Vue.js
Vue.js是一个简单的基于组件的单页应用程序开发框架。它消除了Angular开发者面临的所有复杂性。你可以这么说vue.js是Angular和React的混合体(但这并不完全正确)。
Vue的优点和缺点。
- 它的两个主要优点是体积小、重量轻,并且还提供了可视DOM。它支持双向数据绑定。在Vue的帮助下,我们可以构建web应用程序、移动应用程序和PWA(渐进式web应用程序)。js。它还支持TypeScript(JavaScript的超集)。该框架还以优化应用程序性能而闻名。它还提供了设计应用程序结构的灵活性。
- 组件不稳定,它有一个较小的社区。
2. Angular
每当我们谈论前端框架时,我们都必须提到Angular。这是谷歌在2016年开发的一个非常著名的框架。它是一个完全基于类型脚本的框架,支持双向数据绑定。它的体系结构基于MVC,双向数据绑定提供了模型和视图之间更好的数据同步。
Angular的优点和缺点:
- Angular作为构建单页应用程序的框架很容易学习。借助它,我们可以构建web应用程序、移动应用程序和PWA应用程序。宝马、XBOX和Fobos等大公司都使用它。Angular拥有一个庞大而优秀的社区。
- 这是一个完全动态的解决方案,这意味着有许多解决方案可以完成一个简单的任务,从而产生一个较长的学习曲线。这就是为什么我把它放在这个列表的第二位。在非常大规模的应用中,我们有时可能会遇到优化问题。
1. React
如果你是初学者,想学习前端框架,我会推荐 React。 React 是 2022 年最流行的框架之一,也是最容易学习的框架之一。 React 由 Facebook 开发,现在是开源的。 React 支持虚拟 DOM 功能,这是所有前端框架中独一无二的。当你想要构建一个高流量的应用程序并且想要一个稳定的性能时,它会是最好的框架。
React 的优缺点:
- 它是基于组件的框架,我们可以通过它与团队协作,也可以重用组件。 React 提供了一个开发工具,我们可以通过它轻松调试和查找错误。
- React 以恒定的速度更新,这就是为什么它的文档不太好。如果您是初学者,您也可能会遇到一些问题。它使用一些人不理解的 JSX,并将其视为骗局。
感谢您阅读本文,不要忘记关注我以阅读更多此类文章。如果您觉得这个故事对您有帮助并认为对其他人也一样,您也可以与您的朋友分享这个故事。
原文:https://javascript.plainenglish.io/top-5-frontend-frameworks-to-learn-i…
- 283 次浏览
【前端架构】Angular vs React vs Vue:哪一个是2021年的最佳选择
当开始一个新的web开发项目时,许多开发人员都有一个问题:“什么工具是最合适的?”
显然,JavaScript是骨干,因为今天它提供了创建前端的广泛功能。但是人们在选择框架时面临着两难,因为JS中有很多框架,而且每个框架都有突出的特性。
通常,争论都是基于三个框架——Angular。js,反应。js和Vue.js。所以现在,我们将考虑它们的优缺点以及它们在开发者中的受欢迎程度。
开发人员的选择
Stackoverflow
首先,我们分析了主题调查,即JavaScript和Stackoverflow的状态。他们每年提供关于各种框架的流行程度和发展状况的最准确的信息。

Most popular web frameworks. Source of the image
尽管Vue.js发展迅速,该框架在评级中仅排名第七(在所有受访者和专业人士中)。React.js和Angular.js分别位居第二和第三。
值得注意的是,从总体结果来看,React.js赶上了第二的位置,而专业开发人员分别把angle .js放在了第二的位置。

Most loved frameworks. Source of the image
然而,开发人员喜欢使用React.js和Vue.js,,同时,Angular.js实际上是在列表的最后。React.js恰好是那些以前从未在这些框架的帮助下开发应用程序的人最希望学习的。紧随其后的是Vue.js和Angular.js。
NPMtrends
技术栈或框架的重要开发指标之一是下载的数量。NPM trends提供了每个工具最精确的统计数据,不仅包括下载数量,还包括Github的数据。

Downloads of Angular.js, React.js, and Vue.js. Source of the image
如您所见,React.js在这方面远远领先于它的竞争对手。与2018年相比,Angular.js的下载量减少了很多。从2019年年中开始,这一数字仍未突破100万大关。Vue.js的势头正在逐渐增强。具体来说,在2019年初,这个数字不超过500 thous。现在这个指标一直都在超过100万。

Frameworks rating on Github. Source of the image
这些指标反映了Stackoverflow的调查结果。Vue。js和反应。js的评分显著高于Angular.js。这就是下载的巨大差异的原因。
JavaScript的状态
这份年度报告是JavaScript和所有相关工具最重要的开发指标。

Frameworks rankings according to State of JavaScript 2019. Source of the image
开发人员主要满足于react.js和vue.js的工作过程。 Angular.js只有38%满足了他们的需求。同样,只有23%的开发人员对Angular有特殊的兴趣。与此同时,Vue.js和React.js的该指标分别为64%和61%。

Opinions on frameworks. Source of the image
关于框架的结果是相似的。大多数受访者要么对Angular.js不感兴趣,要么以前用过,但不想再用它工作了。React.js非常流行,大多数被调查者继续使用这个框架来解决他们的任务。

Stats of frameworks usage by company size. Source of the image
值得注意的是,相对较小的公司更喜欢React.js和Vue。而主要的开发人员(超过100名和1000名员工)更可能使用Angular.js。尽管如此,这些指标大致相等。
优点,缺点,特殊方面
现在让我们分别考虑每个框架:
- 在什么情况下,选择是不明显的?
- 为什么开发者更喜欢React.js?
- 使用每个框架时会遇到什么问题?
为什么React.js ?
React.js已经连续三年蝉联所有收视率第一。一些开发人员对这个框架毫无怨言,因为它发展迅速,而且越来越可持续。

React.js is the most used tool of JavaScript. Source of the image
事实上,值得注意的是,React.js不是一个框架,而是一个库。但是它具有广泛的功能,因此可以经常使用该工具,而不需要进行额外的集成。前端的效果不会因此而降低。
React.js是Facebook在2013年发布的,其目的是将用户界面划分为一组组件,以简化开发过程。

React.js是一个非常饱和的框架。在大多数情况下,开发人员对它只会说些恭维的话。
然而,Facebook最近发布了太多的更新,这使得一些工具过时了。许多开发人员喜欢这个过程。但在大多数情况下,社区抱怨这是因为他们必须不断掌握新技术。
值得注意的是,React.js专家在当今美国是最受欢迎的。2020年5月est. LinkedIn上活跃的query response .js有超过30000个职位空缺,实际上有4000个。
React.js受欢迎的一个关键原因是有信誉的公司Facebook的支持。Instagram、Whatsapp和Twitter等服务目前都在这个框架的基础上工作。他们都是非常快,有一个迷人的外表。这确保了对React.js的高度信任。
尽管有多个好处,只有少数情况下,当这个框架将是最合适的:
- 快速开发小型企业级应用;
- 创建SPA或跨平台应用程序;
- 扩展现有应用程序的功能。
这并不意味着React.js在其他情况下是坏的。这更像是选择性选择会更可取。
为什么Vue.js ?
Vue.js是近年来的一个发现。它突然从一个普通的框架变成了一个最受专业人士喜爱的框架。

The popularity of Vue.js over time. Source of the image
值得注意的是,它的普及是在没有大公司支持的情况下发展起来的。市场巨头们只是在Vue.js暴涨之后才开始关注它。这就是为什么它成为了React.js和angle .js长期对立的第三个框架。

Vue.js因为拥有大量的特殊方面而脱颖而出。有些甚至会出现缺点,例如,vue.js非常灵活。然而,在一个大团队中从事一个大项目的情况下,它可能会引发大量的错误。
在Vue.js开始展示其独特的特性后,许多市场巨头如Gitlab, WizzAir, EuroNews都关注了它。Grammarly完全是在Vue的基础上创建的,阿里巴巴和小米在2018年宣布完全过渡到Vue.js。
此外,这种框架在今天的亚洲市场需求很大。因此,更多的讨论和使用技巧都是中文的。你不懂那门语言?你必须把自己限制在用英语写文档和推荐。
尽管这个框架突然流行起来,但对开发人员的需求并没有增加到同样的程度。具体来说,LinkedIn上的Vue.js查询只有8000个职位空缺,实际上大约有4000个。
在什么情况下,vuei .js会是更好的选择?
- 开发“智能”和高性能应用程序;
- app的早期进入市场;
- 创建像Grammarly这样的小型轻量级应用程序。
为什么Angular.js ?
Angular.js 一直是开发用户界面的最佳选择。所以它成为了流行的stack MEAN的一部分。

Interest in Angular.js over time. Source of the image
尽管如此,在过去的几年里,开发人员一直在抱怨这个框架与竞争对手相比存在不足。因此,许多公司逐渐放弃使用Angular.js。

在很大程度上,由于新的web开发趋势的出现,这种框架失去了它的流行。Angular.js的团队没有在新版本的框架中实现所需的功能。这就是为什么我们看到Vue.js和React.js在今天变得越来越受欢迎的原因。如果超出了这三种框架的范围,那么Angular.js有时就不如其他工具(例如,Svelte)。
然而,Angular.js仍然被用来支持许多流行的网站和web应用程序。它们包括《卫报》、UpWork、PayPal和索尼。他们都是主要的网站,Angular.js证明了自己很好。
最有趣的是对Angular.js专家的需求。尽管受欢迎程度和估计的下降,需求实际上是在同一水平上的反应。js。具体来说,LinkedIn上有30000个职位空缺,Indeed上有超过5000个。
在什么情况下需要注意Angular.js?
- 创建大规模应用程序;
- 需要非常可伸缩的架构;
- 创建信使和其他应用程序«实时»;
- 使用TypeScript编写代码。
结论
根据统计数据、调查结果和各种报告,我们可以得出结论,2021年的最佳选择是React.js。第二名是Vue.js和Angular.js以较大的优势位居第三。
但是如果你从统计数据中抽象化,只考虑上下文的使用,那么就目前而言,没有最好的框架。无论如何,每种框架都有其优点和缺点,同样,每种框架都有很多的崇拜者和反对者。
选择权在你。
原文:https://merehead.com/blog/angular-vs-react-vs-vue-best-choice-2021/
本文:http://jiagoushi.pro/node/1267
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 776 次浏览
【前端架构】Angular vs React vs Vue:2019年应该选择哪种框架
大约一年前,开发人员主要讨论是否应该将Angular或React用于他们的项目。 但是在2018年的过程中,我们看到了对第三个名为Vue.js的玩家的兴趣增长。 期待2019年,这篇文章是一个全面的指南,也许是适合你的解决方案:Angular vs React vs Vue。
如果您是开发项目的开发人员而无法决定使用哪个JavaScript框架,那么本指南应该可以帮助您做出决定。
我们将介绍Angular,Vue和React的各个方面,以了解它们如何满足您的需求。 这篇文章不仅仅是Angular vs React vs Vue的指南,而是旨在提供一个结构来帮助判断前端JavaScript框架。 如果新框架明年到来,您将确切知道要查看的参数!
*在这篇文章中,我们假设您具有JavaScript的基本知识,并且也使用了JavaScript框架。
第1部分:Vue vs React与Angular的简史
在我们进入技术细节之前,让我们先谈谈这些框架背后的历史 - 只是为了更好地理解他们的哲学及其随时间的演变。
…
How it all started ?
![]()
由Google开发的Angular于2010年首次发布,使其成为最古老的。 它是基于TypeScript的JavaScript框架。 2016年Angular 2的发布发生了重大转变(以及原来名称中的“JS”的丢弃 - AngularJS)。 Angular 2+被称为Angular。 虽然AngularJS(版本1)仍然有更新,但我们将重点讨论Angular。 最新的稳定版本是Angular 7,于2018年10月发布。
![]()
Vue,也称为Vue.js,是该组中最年轻的成员。 它是由前谷歌员工Evan You在2014年开发的。在过去两年中,Vue的受欢迎程度大幅下降,尽管它没有大公司的支持。 目前的稳定版本是2.17,于2018年8月发布.Vue的贡献者得到了Patreon的支持。 目前处于原型设计阶段的Vue 3计划转向TypeScript。
![]()
由Facebook开发的React最初于2013年发布.Facebook在其产品(Facebook,Instagram和WhatsApp)中广泛使用React。 目前在16.X的稳定版本,于2018年11月发布。
以下是Angular vs React vs Vue的简短摘要,包括它们的状态和历史:
Angular vs React vs Vue的历史
| Angular | React | Vue | |
|---|---|---|---|
| Initial release | 2010 | 2013 | 2014 |
| Official site | angular.io | reactjs.org | vuejs.org |
| Approx. size (KB) | 500 | 100 | 80 |
| Current version | 7 | 16.6.3 | 2.17 |
| Used by | Google, Wix | Facebook, Uber | Alibaba, GitLab |
许可证?♂️
在使用开源框架之前,请确保通过其许可证。 有趣的是,所有三个框架都使用MIT许可证,即使在专有软件中,也会对重用提供有限的限制。 在使用任何框架或软件之前,请确保您了解许可证的含义。
以下简单的英文术语是MIT许可证的快速摘要。
...
人气?
由于“有角度”和“反应”是常用词,因此很难从Google趋势中了解它们的受欢迎程度。 虽然,他们受欢迎的一个很好的代表是他们的GitHub存储库获得的明星数量。 Vue的明星数量突然发生变化发生在2016年中期,最近,Vue一直在那里,React是最受欢迎的框架。

Angular,React和Vue的GitHub项目中的星数
让我们来看看Angular vs React vs Vue的就业市场情况,这也是衡量人气的一个很好的指标:
...
Angular vs React与Vue?♂️的就业市场
表明就业市场趋势的最佳数据来源是各种工作委员会。
从2018年末的趋势可以看出,需要Angular或React技能的工作数量大致相同,而Vue的工作数量仍然只是这个数字的一小部分(约20%)。这份清单绝对不是详尽无遗的,但可以很好地描述整个科技行业。
如果您从目前的就业市场的角度严格看待,最好的办法是学习Angular或React。但是,鉴于Vue在过去两年中越来越受欢迎,项目可能需要一些时间才能使用Vue,或者采用Vue的新项目达到成熟度级别,这些项目需要更多的开发人员。
第2部分:社区和发展
现在您已熟悉每个框架的历史和趋势,我们将查看社区以评估这些框架的开发。我们已经看到,对于所有框架,过去四个月都发布了一个主要版本,这表明开发正在全面展开。
让我们看看Angular vs React vs Vue关于GitHub存储库的统计信息:
| Angular | React | Vue | |
|---|---|---|---|
| # Watchers | 3.3k | 3.7k | 5.7k |
| # Stars | 43k | 71k | 122k |
| # Forks | 11k | 16k | 17k |
| # Commits in last month | 446 | 339 | 81 |
| # Contributors | 798 | 1.8k | 240 |
Vue拥有大量的观察者,明星和分叉。这表明它在用户中的受欢迎程度及其在比较Vue与React时的价值。但是,Vue的提交和贡献者数量低于Angular和React。
一种可能的解释是,Vue完全由开源社区驱动,而Angular和React在Google和Facebook员工中占有很大比例,为存储库做出了贡献。
从统计数据来看,这三个项目都显示出重要的开发活动,这在将来肯定会继续下去 - 只是这些统计数据不能成为不决定使用其中任何一项的基础。
第3部分:迁移
当您使用您选择的框架时,您不必担心框架更新会出现并弄乱您的代码。虽然在大多数情况下你不会遇到从一个版本到另一个版本的许多问题,但重要的是要注意脉冲,因为一些更新可能更重要,需要调整以保持兼容性。
Angular计划每六个月进行一次重大更新。在任何主要API被弃用之前还有六个月的时间段,这使您有两个发布周期(一年)的时间来进行必要的更改(如果有的话)。
谈到Angular vs React,Facebook表示稳定性对他们来说至关重要,因为像Twitter和Airbnb这样的大公司使用React。通过版本升级通常是React中最简单的,使用react-codemod等脚本可以帮助您进行迁移。
在迁移的FAQ部分中,Vue提到如果从1.x迁移到2,则90%的API都是相同的。有一个迁移帮助工具可以在控制台上运行,以评估应用程序的状态。
第4部分:使用Vue与Angular vs React
这里有一些重要的特征,主要是整体尺寸和加载时间,可用组件和学习曲线。
大小和加载时间⏲️
库的大小如下:
- Angular: 500+ KB
- React: 100 KB
- Vue: 80 KB
尽管框架的大小存在显着差异,但与平均网页大小(2018年的2 + MB)相比,它们仍然很小。此外,如果您使用流行的CDN加载这些库,则很可能用户已将库加载到其本地系统中。
...
组件?️
组件是所有三个框架的组成部分,无论我们是在谈论Vue,React还是Angular。组件通常获取输入,并根据它更改行为。此行为更改通常表现为页面某些部分的UI更改。组件的使用使得重用代码变得容易。组件可以是电子商务站点上的购物车或社交网络上的登录盒。
![]() Angular:
Angular:
在Angular中,组件称为指令。指令只是DOM元素的标记,Angular也可以跟踪和附加特定的行为。因此,Angular将组件的UI部分分离为HTML标记的属性,以及它们以JavaScript代码形式的行为,这就是在查看Angular vs React时将其区分开来的原因。
![]() React:
React:
有趣的是,React结合了UI和组件的行为。例如,下面是在React中创建hello world组件的代码。在React中,代码的相同部分负责创建UI元素并指示其行为。
![]() Vue:
Vue:
在Vue中,UI和行为也是组件的一部分,这使得在查看Vue vs React时更加直观。此外,Vue是高度可定制的,它允许您在脚本中组合UI和组件的行为。此外,您还可以在Vue中使用预处理器而不是CSS,这是一项很棒的功能。在与其他库(如Bootstrap)集成时,Vue非常棒。
为了比较同一个应用程序在不同库中的外观,这里有一篇关于在React和Vue上创建相同的待办事项列表应用程序以及对比两个框架的差异的精彩帖子。
...
学习曲线?
那么学习这些框架有多难?
![]() Angular:
Angular:
Angular有一个陡峭的学习曲线,考虑到它是一个完整的解决方案,掌握Angular需要你学习像TypeScript和MVC这样的相关概念。尽管学习Angular需要时间,但投资在理解前端如何运作方面会产生效益。
![]() React:
React:
React提供了一个入门指南,可以帮助您在大约一小时内设置React。文档是彻底和完整的,可以解决StackOverflow上已经存在的常见问题。 React不是一个完整的框架,高级功能需要使用第三方库。这使得核心框架的学习曲线不那么陡峭,但取决于您使用其他功能所采用的路径。但是,学习使用React并不一定意味着您正在使用最佳实践。
![]() Vue:
Vue:
Vue提供更高的可定制性,因此比Angular或React更容易学习。此外,Vue与Angular和React在功能方面有重叠,就像使用组件一样。因此,从两者中的任何一个过渡到Vue都是一个简单的选择。然而,Vue的简单性和灵活性是一把双刃剑 - 它允许糟糕的代码,使得调试和测试变得困难。
尽管Angular,React和Vue具有重要的学习曲线,但它们在掌握时的用途是无限的。例如,您可以将Angular和React与WordPress和WooCommerce集成,以创建渐进式Web应用程序。
Angular vs React vs Vue:谁赢了?
在这篇文章的最后,让我们回顾一下每个框架的特征,试图回答这个问题:Angular vs React vs Vue:你应该选择哪一个?
![]() angular 是最成熟的框架,在贡献者方面有很好的支持,是一个完整的包。
angular 是最成熟的框架,在贡献者方面有很好的支持,是一个完整的包。
然而,学习曲线陡峭,Angular的开发概念可能会推迟新的开发人员。
对于拥有大型团队和已经使用TypeScript的开发人员的公司而言,Angular是一个不错的选择。
额外?以下是您可能感兴趣的一些Angular管理信息中心模板。
![]() React已经足够成熟并且拥有来自社区的大量贡献。它正在获得广泛认可。 React的就业市场非常好,这个框架的未来看起来很光明。
React已经足够成熟并且拥有来自社区的大量贡献。它正在获得广泛认可。 React的就业市场非常好,这个框架的未来看起来很光明。
对于开始使用前端JavaScript框架,初创公司和喜欢灵活性的开发人员而言,React看起来是个不错的选择。与其他框架无缝集成的能力为那些希望在代码中具有一定灵活性的人提供了极大的优势。
![]() vue 是竞技场的新手,没有大公司的支持。
vue 是竞技场的新手,没有大公司的支持。
然而,在过去的几年里,它作为Angular和React的强大竞争对手取得了很好的成绩。这可能是很多中国巨头如阿里巴巴和百度选择Vue作为他们的主要前端JavaScript框架。
但是,未来它的作用还有待观察,并且有理由谨慎对待它。如果您喜欢简单,也应该像灵活性一样,Vue应该是您的选择。
额外?以下是一些您可能感兴趣的使用Bootstrap构建的Vue管理模板。
Angular vs React vs Vue辩论的答案是,没有绝对正确的选择,你可能已经预料到了。
这些库中的每一个都有其自身的优点和缺点。根据您正在进行的项目以及您的个人要求,其中一项将比其他项目更合适。在决定之前进行自己的研究始终是关键,特别是如果你打算从事商业活动而不是个人项目。
原文:https://www.codeinwp.com/blog/angular-vs-vue-vs-react/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 37 次浏览
【前端架构】Angular、React和Vue: 2018年的比较(更新)

2018年的Angular、React和Vue
不可否认的事实是,web开发和定制软件开发的虚拟世界在过去十年中一直处于蓬勃发展的技术进程中。说到前端,JavaScript一直在主导这一进程。
这种流行带来了大量的JavaScript框架。本指南的目的是深入了解两个如此广泛使用的框架——Angular和Vue——以及一个库——React。
这篇文章写起来很有挑战性,但是我们确信您在过去一定遇到过处理JavaScript框架的问题,而且很有可能,您一定对使用哪个框架感到困惑。
如果你在Angular、React和Vue之间犹豫不决,我们可以帮助你。
本指南分为以下部分-
- 1. 关于框架
- 2. 框架的重要性
- 3.框架的成熟度
- 4. 框架的未来
- 5. 社会质素
- 6. 基本的编程概念
- 7. 易于使用大型应用程序
- 8. 比较性能
好了,让我们切入正题,比较下面的三个。
1. 关于框架
Angular:
Angular是一个基于TypeScript的JavaScript框架,由谷歌开发和维护。其他使用Angular的知名公司有:Wix、Weather.com、Forbes等。
React:
React被称为“构建用户界面的JavaScript库”,是由Facebook开发和维护的。其他使用React的知名公司有:Uber、Twitter、Netflix、沃尔玛等。
Vue:
2014年由前谷歌员工Evan You开发并发布。使用Vue的知名公司有:阿里巴巴、任天堂、GitLab等。
虽然Angular和React已经成为大公司的热门产品,但Vue是一个独力的团队,由于它部署的模型-视图-视图-模型(MVVM)架构模式,它迅速蹿升到时尚的地位。

由于MVVM促进了开发过程中的图形用户界面与业务逻辑或分离结束逻辑的分离,因此Vue正迅速成为构建交互式web应用程序接口的首选语言。
这些框架的重要性
Angular:
- 简单和快速:MVC框架,能够执行复杂的任务和建立依赖之间的控制器和模板
- DOM有标记:在Angular中,标记直接定位在HTML记录中。这个流看起来是这样的:HTML → > DOM — ->> Engine
- 依赖处理:Angular在处理依赖方面非常出色。可以将应用程序隔离到独立的模块中,这些模块之间可能存在条件,也可能不存在条件。
- 简单易读的角模板,主要部署HTML标记👇👇👇。

React:
- 单向的:单向的数据流最终会使代码更加稳定。
- 虚拟DOM:虚拟Dom的存在有助于提高用户体验和开发速度。下一页中的代码片段。
- 开放源码:全世界的开发人员都为这个框架做出贡献。像批处理和修剪这样的特性已经成为了社区的贡献。
- React更好的开发速度👇👇👇

Vue
- 语法:Vue部署的语法应该是简洁流畅的。例如,@keyup.enter.preven = “do Stuff” 可以处理任何需要的事件。
- 学习曲线:在Vue项目中引入新的开发人员非常容易。使用单文件组件,学习曲线很平滑,可以很容易地检查代码库。
- Swift:开发者可以通过引用ring to快速浏览任何项目的存储关于模板、CSS、数据模型、生命周期钩子、映射的Vue提取、监视器等的.Vue文件。
- 声明式模板:简单的HTML模板,无需了解其他编程语言即可阅读。下一页中的代码片段。
- 可读的HTML模板,即使不了解其他语言👇👇👇

框架的成熟度
选择正确的框架是JavaScript项目成功的关键。在做决定时,重要的是要考虑系统是帮助了新元素的添加还是使其复杂化了。当我们谈到这些框架的成熟度时,可以通过GitHub社区的响应来衡量。以下是一些重要的数字,可以帮助你正确看待问题:

*编制时的统计资料
NPM Trends提供了以下图表,显示了在过去两年中,这些框架的NPM包的下载数量。

如果将Github明星绘制在图表上,就会出现一个有趣的趋势。

其他重要的因素
Angular
- 每6个月更新一次
- 每一版本的弃用期为6个月
- 从Angular 4开始的长期支持版本
- 简单的更新过程
- 捆绑提供的完整框架
React
- 稳定的API,如Facebook的设计原则所描述的那样
- 脚本可以从当前的API转移到新的API。例子——react-codemod
- 简单的迁移
- 平滑升级
- 稳定的主版本独立但快速移动的库
Vue
- 在小应用程序中在在版本升级的时候提供类似的API
- 协助升级migration-helper-tool
- 在迁移大型应用程序的版本时遇到的问题
很明显,Vue的人气一路飙升,已经超过了Angular,而且很快就会超过React。此外,这三个框架都在MIT许可下可用。虽然参与React开发的核心开发者的数量还没有正式公布,但是Angular在团队页面上列出了37个贡献者,Vue列出了22个核心开发者和14个社区合作伙伴。
要得出结论,Angular和React是成熟的框架,因为它们被大规模采用了。作为一个新兴的市场参与者,Vue虽然还处于发展阶段,但在知名度上已经处于领先地位。
框架的未来
前景:
为了更好地判断这些技术的发展方向,让我们来看看它们目前的状态。根据Stackoverflow 2017年的调查,JavaScript仍然是最受网络开发者欢迎的语言。

这也适用于其他提到的职业。
在JavaScript框架中,React被证明是66.9%的开发者的首选。相对而言,Angularjs的支持率较低,为51.7%。

感知和满意度:

另外,根据StateofJS前端框架调查,Vue的认知度只有94%,而Angular和React的认知度几乎是100%。但是说到满意度,使用过Angular 1的开发人员中有多达40%不打算再次使用它。这与React和Vue的读数形成鲜明对比。
因此,不可否认的事实是,随着开发人员在其他流行框架中寻找更多的支持,Angular的受欢迎程度正在迅速下降。另一方面,React似乎是目前这三家公司的市场领导者,赢得了社会的信任,前景光明。
但Vue也一样。考虑到它的新生状态,它已经获得了迅速的吸引力,就GitHub社区而言,它的受欢迎程度甚至接近于超过React。
从目前的发展趋势和数据来看,Angularjs的发展是非常受欢迎的,并将持续增长。React是目前的市场领导者,但Vue的牵引力和受欢迎程度将对其构成强烈挑战。
社区的质量
Angular
它拥有一个庞大的用户社区,仅上个月的下载量就在150万到200万之间。此外,GitHub上超级活跃的社区意味着你总会有人帮助你解决遇到的问题。可以探索一系列与不同版本的Angular兼容的解决方案,包括来自资深开发人员的建议。
React
仅过去一个月,它的下载量就达到了1000万次。React得到了Facebook、WhatsApp和Instagram等巨头的支持,也不缺少经验丰富的开发人员的帮助。和Angular一样,React too也吹嘘自己拥有一个令人印象深刻的GitHub社区,在那里人们随时准备伸出援助之手。尽管如此,值得注意的是,React建议使用JSX,它是使用XML语法扩展的JavaScript的修改版本。如果您以前没有使用过JSX,那么由于它的复杂性,这可能会在一开始就造成问题。所以要做好主动依赖社区帮助的准备。
Vue
Vue的社区被认为比React和Angular的社区小得多,因为它是最新的市场参与者。然而,一两年内情况可能会大不相同,因为Vue很可能最终成为最流行的JavaScript框架。
容易找到开发人员
在招聘和寻找合适的人才方面,情况发生了一些变化。
虽然它是开发人员的热门选择,但是如果您使用React,要找到一个有才华的开发人员并不容易,因为找到一个可以修改JSX的开发人员是一项挑战。然而,有一些外包软件开发公司专门从事Javascript和React开发
使用HTML模板被证明相对容易得多。
因此,如果你打算使用Angular或Vue,你可以选择雇佣那些能够快速学习这些框架的优秀HTML开发人员。直接找到一个有才华的Angular或Vue开发人员并不是什么大问题,因为学习曲线是从HTML衍生而来的,而HTML在市场上已经拥有了丰富的人才库。
如果你已经有了一个内部的开发团队,或者对面向对象的开发背景更感兴趣,那么Angular就是最合适的选择。
Angular、React和Vue的基本编程概念
语言:
每个框架使用不同的脚本语言。
- Angular使用了TypeScript。TypeScript是微软开发的一种流行的开源编程语言。它积极地涉及到一些关键的概念,比如静态类型,它提供了一些特定的功能,包括自动重构、跳转到定义等等。
- react将其重点放在了JavaScript ECMAScript 6 (ES 6)上,简单地说,这是JavaScript的一个版本。
- 类似地,Vue使用了JavaScript ES 5。
模板:
要选择正确的框架,您需要弄清楚您是想使用JSX还是HTML。
Angular和Vue都是基于标准的HTML模板和组件,它们简化了结构和代码重用。另一方面,对于新开发人员来说,JSX可能是一个巨大的问题。让我们看看每个-JSX的优点和缺点:
JSX优点缺点
- JSX在代码完成和编译时更好
- 由于打字错误引起的错误很容易被发现,因为React不会编译打字错误并打印打字错误所在的行号。
- React将HTML放到JavaScript中,这更好,因为JS总是更强大
- 因为它是JavaScript + XML + HTML的组合,所以对新开发人员来说是一个障碍
- 与HTML模板相比,具有复杂的特性
- UI模板和内联JavaScript逻辑之间没有界限
HTML优点缺点
- 将视图层与框架的其余部分区分开来
- 能够试验各种技术以获得最佳性能
- 视图的动态和静态部分的清晰分离
- 与JSX相比,调试过程更加困难
- 基于模板的方法,而不是组件
易于使用大型应用程序
各自框架的功能根据需要开发的应用程序的大小而不同。
许多开发人员认为Angular 3不适合处理大型复杂的应用程序。如果复杂性较低,那么它被证明是完美的,但是随着应用程序规模的扩大,问题开始增加。
例如,游戏应用程序通常很大,并且涉及到DOM操作。此外,在涉及太多数据绑定的应用程序中,如果表数超过2500,Angular 1就会变得很慢。
另一方面,如果你打算扩大这个应用程序的规模,React被证明是最好的选择。这一点得到了证实,Facebook、WhatsApp和Instagram都在使用React,而且它们都是全球范围内的大型应用程序。使用React可以轻松开发具有服务器端呈现的可维护架构。
开发人员还认为Vue在处理大型应用程序时很有帮助。框架在学习曲线上遵循了精益的方法,这马上就超过了Angular这样的框架的复杂性,后者常常被证明是新开发人员和大型应用程序开发人员难以接受的。

关于渲染速度和性能测试,为了更清晰,这里有一个图表列出了这三种性能基准测试。
比较性能
| Parameter | Angular | React | Vue |
| Recommended Language | TypeScript | JS, JSX | JS, Vue |
| Architecture Flexibility | No | Yes | Yes |
| Logic Separation | Good | Good | Good |
| Rendering Speed | Slow | Fast | Fast |
| Most Known Architecture | MVC | Flux | Flux |
| Parameter | Angular | React | Vue |
| Server Side Rendering | Yes | Yes | Yes |
| CLI | Yes | Not Official | Yes |
| Debugging Tools | Yes | Yes | Yes |
| Testing | Jasmine and Karma | Developer’s Choice | Karma and Mocha, Jest |
| Data Library | No | No | No |
| Parameter | Angular | React | Vue |
| Mobile Build | Ionic | React-Native | Weex |
| Code Reusability | Yes | No, Only CSS | Yes, HTML and CSS |
| Size | 143k | 43k | 23k |
| Code Stability | Yes | Yes | Yes |
| Bootstrap Integration | Yes | Yes | Yes |
DIY -自我测试:
如果您想自己执行测试,可以使用以下相关命令:
| Angular | React | Vue |
|
|
|
由ITNext编译的这些测试的性能是在谷歌Chrome性能工具计算时间的帮助下进行的,时间从点击按钮开始,到渲染过程结束。这是测试结果*。

性能测试——Vue渲染时间1191ms

性能测试- Angular渲染时间931毫秒
性能测试-反应渲染时间1819毫秒
- Angular 5框架的大小相当臃肿。
- React和Vue具有虚拟dom,可以提高性能。
- Vue拥有最深的内存分配。
原文:https://www.cuelogic.com/blog/angular-vs-react-vs-vue-a-2018-comparison
本文:http://jiagoushi.pro/node/1273
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 41 次浏览
【前端架构】Angular开始慢慢死吗?
不!我将通过直接评论Ceddy Muhoza最热门的回答来回答,但首先我会尽力阐明他真正想说的话,但是大多数开发者都不想承认自己:“我学会了React,现在停止了时间,让没有更好的技术让我的知识过时!“幸运的是,技术史证明了这种意见只是一个小小的挫折。恕我直言React很棒,比AngularJS(v1)好得多,但Angular 2+是前端开发的未来。它体现了软件开发的良好实践,它会像任何其他技术一样,在它变得过时时死亡,并且如果它的开发人员没有“反应”并继续前进,它将会在React之后。通过评论最受欢迎的答案,我将试着阐述为什么我认为这一点,事实,没有情感或偏好。
- “重新发明轮子,Angular v1和Angular v2是两种不同的巨大物种。”
- 发明新的更好的做事方式并不是重新发明轮子。这叫做进步。恕我直言他们只犯了一个错误 - 根本称它为Angular。 v1和v2是不同的世界:v1是前端开发的过去,v2 +未来的开始。
- “将开发人员锁定在盒装解决方案中,2018年请让社区为您的框架添加自己的东西!”
- 你只是在传播错误的信息。在这里你去: angular/angular。把自己弄出来。我相信你会添加大量有用的功能。任何人都可以公开发布Angular模块,任何人都可以将它们添加到项目中。那里有很多这样的模块。很高兴称它为框架。事实上,这是JS的第一个真正的框架,包括React在内的所有其他框架在技术上都只是库。
- “双向数据绑定是2013年的一个非常糟糕的错误,React帮助我们意识到了这一点!”
- 误传。 Angular 2+没有内置的双向数据绑定。只有一个指令实现它,它是一个非常方便的功能,而不是一个bug。它就像魅力一样。这里有更多关于它的信息。
- “类型,装饰,以及反应性,可观察的状态管理,所有这些对于初学者来说非常困难!”
- 我同意,也建立高级Web应用程序不适合初学者。如果您计划更改“初学者”状态,这些内容是您可能需要学习的内容。说实话并不难。如果需要几个小时才能理解的东西对你来说很难,你可能应该选择其他工作。它并不那么难,当你学习它时,你会发现这些东西有多强大,它们如何帮助你编写成熟的应用程序,以及它们如何帮助你的同事理解你实际写的东西。 Typescript使JS成为一种美观而严肃的编程语言。 RxJS(Observables)真棒。 Thinkster建议您查看RxJS的JavaScript代码,就像Henry Ford的汽车制造装配线一样。学习它,你会看到我在说什么。
- “Angular仍然试图让HTML变得更强大,你可以将HTML与JS进行比较吗?”
- 比较他们的是你。苹果和橘子老兄。老实说,我不知道你的意思。
- “简单来说,React,Vue都致力于为JS提供动力,另一方面,Angular 2继续将”JS“放入HTML中。 React将“HTML”放入JS。“
- 又一个错误的信息。您不会在Angular中将HTML放入HTML中。这让他们分开了。保持演示远离逻辑一直是一个很好的做法,不仅在前端,而且在软件开发中。 HTML没有任何问题,React也会让你知道。 Angular的模板系统也遵循在Blade和类似的不同模板引擎中证明的良好实践。它简单而有力。
- “你需要花几天时间来学习我们庞大的框架。”
- 像你拥有的任何其他有用的知识一样,你必须获得它。不要害怕它,真的不是那么难。我个人花了更多时间来理解React。
- “我们记得谷歌吗?”
- 我不知道这与你的观点有什么关系。在“Angular dying?”这个问题的背景下,这是一个巨大的争论,即当网络行业中最强大的公司支持时,它不会轻易死亡。不要忘记Angular应该与TS一起使用,TS是Microsoft的产品。我个人不太喜欢大公司,但质疑他们的工程权威只是一种无知。
- “很多人选择Angular是因为他们听说它是Google创建的工具,因此它必须是主要用于Google的前端应用程序框架?他们在这个假设中会错。事实上,Google信任Closure,用于您熟悉和喜爱的大多数应用程序,包括搜索,新闻,Gmail等。“
- Angular 2于2016年9月14日发布。我认为,切换到谷歌生产应用程序的全新技术是一项庞大且极其昂贵的工作。
- “我们是谷歌,我们根本不放弃,所有开发者都已经信任我们了。”
- 见8
- “战斗结束了:React赢了!”
- 在技术开发中,战斗永远不会结束。但是,对于你作为那些2的用户而言,战斗本身是无关紧要的。知道这两者并做出明智的决定非常有用,而不是你在这里做的事情。有许多类型的项目,其中React更合适,反之亦然。
- “人们常常声称Angular对企业来说更好,这就是这个框架所谓的最佳点。但是,此声明并非由实际生产结果或历史本身支持。今天生产的Angular 2/4企业成果很少。“
- 同样,Angular 2于2016年9月14日发布。当我们谈论社区和专家数量时,它是新技术并且仍然落后于React。由于Angular是自以为是,更严格,并且它实施了应用程序架构和开发的良好实践,因此对于大型项目,在团队工作,文档化,单元测试以及适当的类似测试,它实际上更加实用。在大型应用程序中,它甚至表现出比React更好的性能。
- “没有一些公司将大型代码库从React / Redux迁移到Angular 2/4并且看到生产力,可维护性或性能提升的例子。”
- 只有当React正在死亡时,这种昂贵的操作才有意义,而且绝对不是。它仍然是非常稳定和强大的库。
- “在Google的制作中,Angular的使用率极低。谷歌的网站属性依赖于快速下载和执行,这是Angular没有发挥作用的东西。“
- 同样,它是年轻的框架,我没有任何来自谷歌的内部信息,但我相信它正在被更多地使用,并且它们坚定地支持它。快速下载与JS框架应用程序的使用无关。 Angular的执行时间非常好,而且随着新的更新,它会变得更好。
- “我们是谷歌,所以!”
- 他们是大恶的公司,不是,不是我的专业领域,不想进入政治,但谷歌为这个世界带来了许多革命性和有用的工具,而Facebook,React背后的公司,带来了真正的零实际价值这个世界,除了可能来自React本身。
结论,请学习React和Angular并做出明智的决定,不要让你的朋友/家人根据互联网上懒惰抱怨者的意见而错过伟大的事情,因为所有错误的理由和无知而讨厌东西。
原文:https://www.quora.com/Has-Angular-started-to-slowly-die
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 54 次浏览
【前端架构】Angular的13个主要好处和用例
快速总结:-您曾经为优化应用程序的服务器通信而奋斗过吗?或者发现在应用程序中处理自动同步很困难?你来对地方了。作为顶级前端框架之一,Angular会主动处理这个问题。让我们来讨论一下Angular的一些关键好处和广泛应用的用例。
Angular和用例的13个主要好处
Angular从一开始就走过了漫长的道路。谷歌的Angular团队会随着浏览器的不断发展和支持不同功能的能力而不断升级框架。现在,它是开发功能丰富的web应用程序的首选选择之一。
它的用户界面和功能一次又一次地被一些公司和开发人员社区所认可。多亏了Angular的商业优势,仅在美国就有超过72,924个网站使用这个框架进行网站开发。
开发人员了解开发单页面应用程序(SPA)的主要挑战和缺点。虽然最初Angular开发的好处更多地是为了解决这个挑战,但它逐渐演变为解决一些问题,包括移动优化、渐进的web应用程序开发等等。
我们在Simform从事各种大大小小的项目。虽然有些人使用Angular,但很多人使用React,还有很多人在探索Vue。还有一些人仍然在使用jQuery。这篇文章是针对那些考虑将Angular和TypeScript作为前端工程选择的人。让我们更深入地探讨一下社会的优势和劣势,以帮助你更好地评估你的决定。
Angular对Web开发的好处
如果你想聪明地构建轻量级应用程序,Angular是你最好的选择。这个基于类型的框架使您能够创建干净、可维护和易于测试的交互式spa。
快速链接:
- 自动同步与双向数据绑定
- 优化服务器通信
- POJO模型以消除外部依赖
- Angular测试-一个完整的部分
- Angular材质-一个全面的现代UI
- Angular和单页面应用程序
- 代码一致性和健壮的生态系统
- 模型-视图-视图-模型(MMVC)体系结构来统一独立的结构
- 增强性能的下一代渲染器
- 活跃的社区和容易访问的信息
- 通过代码可重用性提高生产力
- 设计开发流程
- 易于使用的
- 什么时候使用Angular
- 什么时候不用Angular
自动同步与双向数据绑定
由于大多数框架都提供单向数据绑定,这个特性使Angular比其他框架更有优势。那么如何处理双向数据绑定呢?
它在模型和视图之间同步数据。因此,当数据被更改或修改时,这两个组件会自动更新。更重要的是,这是实时发生的,避免了开发人员将额外的精力投入到手工修改中。
其他的web框架通过脆弱的事件监听器和处理程序来实现双向数据绑定,与之不同的是,Angular让这个过程成为其体系结构中不可或缺的功能。因此,几乎不需要顺序回调来处理修改后的数据或开发人员干预。
优化服务器通信
使用Angular,缓存变得毫无问题!
Angular通过创建静态文件来减少cpu的额外负担。此外,框架中对API调用的响应时间非常快。
引用一个Angular应用程序,我们可以看到它在文档对象模型中呈现页面,以供用户操作使用。与其他技术栈不同,该框架仅通过生成静态应用程序页面来减少其工作量。它提供了一个全面快速的用户体验,并且不让用户等待,直到应用程序完全交互。
POJO模型以消除外部依赖
Angular使用了简单的旧Javascript对象(POJO)模型,使代码结构方便且独立。这样,我们就不用在程序中添加复杂的函数或方法了。此外,它消除了对外部框架或插件的依赖。
由于POJO需要的编码更少,用Angular加载构建的应用程序更快,并且提供了优秀的用户访问性,这个模型使我们能够保持代码的整洁,使框架面向目标。
Angular测试-一个完整的部分
测试是Angular框架不可分割的一部分。Angular中的所有JavaScript代码都需要经过一系列测试。在测试中提供的便利允许我们从头开始开发项目并无缝地测试组件。
多亏了Angular中的依赖注入。它管理所有的作用域和控制器。由于这种依赖关系,Angular中的单元测试功能可以通过向控制器中注入模拟/虚拟数据来强制依赖注入来执行测试。这个过程之后是对输出及其行为的评估。更有趣的是,Angular也有模拟HTTP提供者,可以将来自服务器的假响应推送到控制器中。
Angular材质-一个全面的现代UI
Angular材料遵循谷歌的材料设计指南。它提供了内置组件,如导航元素、布局、按钮、指示器和数据表。
此外,Angular Material不仅仅是创建一个赏心悦目的用户界面,它还开发了像谷歌这样的应用程序。例如,谷歌drive、Android OS、Gmail等应用已经成为用户的日常需求。
Angular和单页面应用程序
任何单页面应用程序的平稳运行有两个方面。一种方法是,当页面加载时,所有必需的JavaScript、CSS和HTML代码都在一个实例中检索。第二种是根据用户的行为和动作在需要时进行检索。
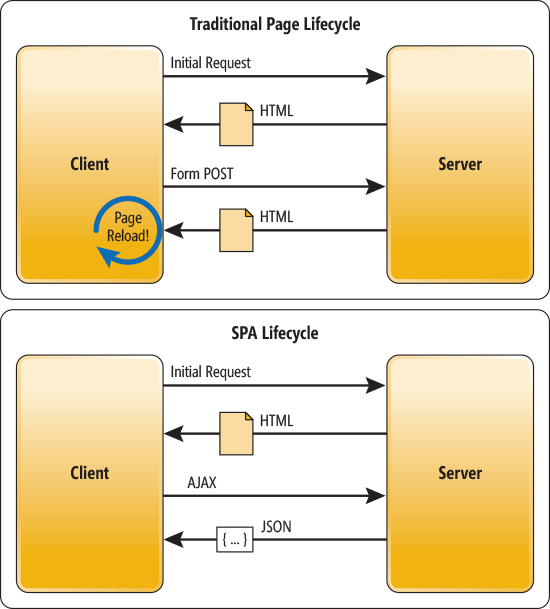
在用户浏览应用程序时,任何时候都不会重新加载页面,这涉及到与服务器之间的动态通信。然而,所有这些复杂性都可以很容易地由Angular处理。如果你的产品理念是围绕着开发一个彻底的单页应用程序,那么选择Angular来开发它将是你最好的选择。
代码一致性和健壮的生态系统
任何强大的开发环境要想成功,代码一致性是关键。多亏了Angular CLI和文档风格指南,它们都在先锋级别上推动了一致性。
Angular CLI工具可以让开发者创建初始项目,运行测试,并在同一个项目中添加不同的特性,同时让整个团队保持在同一个页面上。我发现开发人员经常感谢Angular提供的样式指南。通过这种方式,团队之间的交流变得舒适,并且不太可能被误解。
多亏了框架的健壮生态系统,它为开发人员社区提供了依赖注入和其他资源。
模型-视图-视图模型(MMVC)体系结构来统一独立的结构
Angular通过结合MMVC架构和双向数据绑定来简化开发结构。实际上,这个框架只需花很少的时间就可以更新视图层中对数据所做的更改,反之亦然。因此,这就是为什么大多数开发人员在构建大型应用程序时更青睐Angular。
由于框架将业务逻辑与UI组件隔离开来,开发人员更有信心设计出具有流畅业务逻辑的整洁用户界面。由于控制器在模型和视图组件之间建立了最快的通信。因此数据的显示会尽可能快。
提升性能的下一代渲染器
这个新的Angular引擎是关于它超优化的捆绑包大小、加载速度和组件的动态加载。
Ivy renderer的目标是无与伦比的代码调试和用户友好的应用程序体验。它使框架具有可访问性,并通过使框架成为一个功能丰富的平台来减少文件大小,从而设置了一个示例。由于它是在NG-CONF 2018中引入的,所以它并不是完整的,但目前,Angular 8发挥了它最好的作用。随着Angular 9的发布,现代的Angular引擎将呈现出完整的形式。
活跃的社区和易于获取的信息
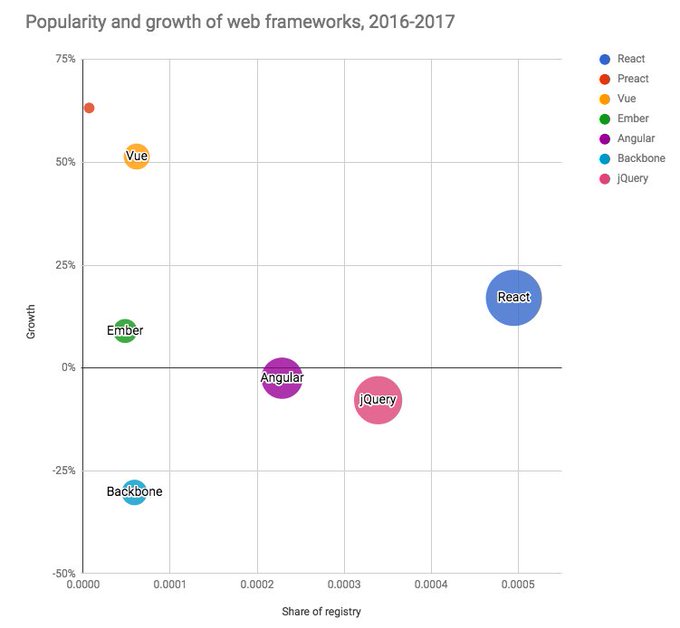
从一开始,Angular就因其众多的优势而成为开发人员和工程师的最爱。有了学习资料、参考文档、常见问题解答等资源池,对于那些想要充分利用它的人来说,Angular很容易集成。
Angular可以加入的杰出社区:
- Dev.to提供了一个非常棒的社区
- Stackoverflow一直是开发者的最爱
- Twitter有很多Angular的支持句柄,但是你会发现这里this 的一切都是Angular提供的
- AngularAir 为最新更新和发言者
- 您可以订阅nng-newsletter 的更新,就在您的收件箱!
通过代码可重用性提高生产力
对于开发人员来说,在构建应用程序时不考虑文件大小过大的问题,还有什么比这更宝贵的呢?
有了Angular,开发人员可以投入更少的时间和精力,因为它可以重用代码,简化开发过程。它带来了更短的代码更多的功能,使它。对于背靠背进行类似项目的团队来说是高效的。
设计开发流程
有了这个优势,程序员在开发应用程序和添加标记时可以避免使用CSS/HTML标记,而不会破坏应用程序。在开发过程中,他们所要做的不是重新安排代码,而是在代码周围移动相应的元素。
易于使用的
Angular在编码方面的灵活性是其他框架无法比拟的,因为它的设计架构很简单。就灵活性而言,它允许初学者开始并无缝地修改他们的应用程序项目。此外,Angular可以很好地处理加载了大量特性和组件的web应用程序。开发人员还能要求什么?
所以,这些就是Angular的优势,到目前为止,我们相信你已经理解了Angular在满足web开发需求方面的潜力。
什么时候使用Angular
作为一个完整的软件堆栈,Angular是庞大的。它使开发人员能够用最简单的工作构建尽可能多的应用程序。让我们看看一些流行的用例:
视频流媒体应用,如Youtube PlayStation 3应用
任何喜欢玩视频游戏的人都不会错过ps3上的YouTube版本。考虑到YouTube的巨大人气,它需要一个框架
自从谷歌拥有了Angular,他们便利用它在PlayStation 3上发布了一个全新版本的Youtube。这个通用框架帮助谷歌重新设计了PS3体验,取代了传统的操作方式,成为一个彻底的现代操作方式。他们把鼠标移动换成了基本的按键。有了Angular的可访问性,就可以广泛地利用像Youtube PS3这样的本地应用的功能。
Angular在创建YouTube PS3上的平滑滚动和视频回放方面做出了更大的贡献。这是Angular提供的最新的超现代和精简的体验,玩家们都亲眼目睹了这一点。
电子商务应用,如T-Mobile
T-Mobile发现它的客户在连接到应用程序时必须等待内容加载。所以为了让它更快更少麻烦,他们使用了Angular来减少服务器端渲染的时间。
此外,他们还使用了Angular,以便能够将HTML解析用于搜索引擎的目的。他们还自动更新站点,无缝地实现了动态页面组成。
这家领先的电信企业在其电子商务应用上获得了巨大成功,其搜索引擎流量也非常可观。使用Angular,他们修改了应用程序的布局,并将其转换为一个运行流畅的应用程序。
实时数据应用,如weather.com
实时天气更新的热门网站之一是weather.com。Angular的成功要归功于它的多用途模块和目录功能,这些功能使它能够加载到桌面和智能手机设备上,利用这个小部件的特性。该框架允许开发人员根据设备的定制需求创建灵活的小部件。通过Angular技术获取实时数据并动态展示到互联网上。
用户生成内容门户网站——Upwork和纽约时报。
用户生成的网站需要高水平的安全和管理。Angular通过引入内部HTML来显示用户生成的内容,并内置一个杀毒软件DomSanitizer - DomSanitizer -作为一个安全特性,让事情变得简单起来。但是,当您使用带有内联样式的元素时可能会遇到麻烦,因为这样做会删除样式。
Angular支持用户生成内容网站需要处理的大技术问题。例如,用户原创内容网站Upwork和需要无限滚动的网站如纽约时报就是两个著名的例子,它们使用Angular作为后台来处理沉重的页面。这些网站看起来很容易获取和渲染在几秒钟内,而不会牺牲其单个页面应用程序的特性。
《卫报》等网站提供最新新闻和内容
《卫报》信息丰富,随时更新。感谢Angular技术栈为使用RxJS扩展设置了一个示例。它允许开发者创建无限滚动的搜索结果。守卫者所持有的巨量是另一个级别的,但它在角后端运行平稳。
什么时候不用Angular
Angular是超级英雄的,但仍然有一些地方使用Angular可能不会给你带来好处。
让我们看看它们是什么?
静态内容网站:
较小的目标和静态内容的小网站。这些类型的网站最好使用有限的技术堆栈,不需要使用Angular,因为这种技术只会增加额外的代码块,而这不是网站或特定项目所需要的。例如:登录页面、信息性网站、事件页面等。
有限的资源和初创企业:
对于小团队和有限的资源来说,Angular并不是一个好主意。Angular需要熟练的可用资源,以便在大型项目中快速解决问题。此外,该技术不应用于小型项目;它们可以使用其他可用的框架构建,不需要太多技术上的便利。
Microservices design选择了灵活的编码方式,允许您选择工具,而不考虑项目的不同模块。但是Angular是一个完整的解决方案,拥有所需的所有工具,因此不提供选择其他外部工具的灵活性。你需要携带所有项目不需要的东西。所以,如果你计划使用微服务设计架构,并且还想使用Angular,你应该迭代你的计划。
游戏应用程序和重型分析应用程序
Angular不适合游戏应用程序。其他框架,如React,可以用于在游戏中创建高度交互的UI。这是因为Angular会在每个文档对象模型改变位置之前检查它。
该框架不能很好地处理繁重和复杂的数学分析,比如游戏应用程序。尽管Linkedin、Upwork、Netflix都是用Angular构建的,但当涉及到数学处理过于复杂的问题时,不要选择Angular。
结论
我们的前端开发人员喜欢这个一直处于领先地位的框架,因为它维护了一致的代码结构、双向数据绑定、使用普通的旧javascript对象模型的代码可重用性。
Angular使开发人员能够编写结构简单的代码,而不需要第三方或外部支持。它通过更好地简化测试配置简化了代码的编写。
我已经试着解释了Simform的Angular团队给我们的所有理由,为什么他们会与这个框架紧密联系在一起。我很乐意参与您对不同前端框架的研究和分析。
原文:https://www.simform.com/key-benefits-angular-use-cases/
本文:http://jiagoushi.pro/node/1287
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 266 次浏览
【前端架构】Grab的前端学习指南

原帖可以在Github上找到。未来的学习指南将在那里更新。如果你喜欢你正在阅读的东西,给它打一颗星吧!?
公司是东南亚(SEA)领先的运输平台,我们的使命是利用公司最新的技术和人才,推动SEA前进。截至2017年5月,我们每天处理230万次乘车,我们正在快速增长和招聘。
为了跟上Grab惊人的增长,我们的网络团队和网络平台也必须增长。幸运的是,或者不幸的是,在Grab上,web团队已经跟上了最新的最佳实践,并在我们的web应用程序中集成了现代JavaScript生态系统。
的结果是,我们的新员工或后端工程师,他们并不一定了解现代JavaScript的生态系统,可能会感到被接二连三的新事物,他们必须学习只是为了完成他们的特性或web应用程序的bug修复。前端开发从未像今天如此复杂和令人兴奋的。每隔一天就会出现新的工具、库、框架和插件,还有很多东西需要学习。必须引导web团队的新成员接受前端的这种演化,学会轻松地在生态系统中导航,并尽可能快地向用户交付代码。我们提出了一个学习指南,介绍我们为什么要做我们所做的,以及我们如何处理前端的规模。
本学习指南的灵感来自于“治愈JavaScript疲劳的学习计划”,在某种意义上,我们建议针对前端开发的每个方面学习特定的库/框架,这些库/框架基于当前认为最适合于Grab的内容。我们解释了为什么选择某个库/框架/工具,并提供了学习资源的链接,让读者能够自己学习。对于其他用例可能更好的备选方案也提供了参考和进一步的自我探索。
如果您的公司也在探索现代的JavaScript堆栈,那么您可能会发现本学习指南对您的公司也很有用!您可以根据自己的需要随意调整它。我们将根据最新的工作和选择,定期更新本学习指南。
-抓取Web团队
必备条件
- 理解核心编程概念。
- 熟悉基本的命令行操作,熟悉源代码版本控制系统,如Git。
- 有网络开发经验。使用Ruby on Rails、Django、Express等框架构建了服务器端呈现的web应用程序。
- 了解网络是如何工作的。熟悉web协议和约定,如HTTP和RESTful api。
表的内容
某些主题可以跳过,如果你有之前的经验。
单页面应用程序(SPA)
如今,Web开发人员将他们开发的产品称为Web应用程序,而不是网站。虽然这两个术语之间没有严格的区别,但web应用程序往往是高度交互和动态的,允许用户执行操作并接收其操作的响应。传统上,浏览器从服务器接收HTML并呈现它。当用户导航到另一个URL时,需要刷新整个页面,服务器为新页面发送新的HTML。这称为服务器端呈现。
但是在现代的SPAs中,使用的是客户端呈现。浏览器从服务器加载初始页面,以及整个应用程序所需的脚本(框架、库、应用程序代码)和样式表。当用户导航到其他页面时,不会触发页面刷新。页面的URL通过HTML5 History API更新。新页面所需的新数据(通常为JSON格式)由浏览器通过对服务器的AJAX请求检索。然后,SPA通过JavaScript动态地更新页面,它在初始页面加载时已经下载了这些数据。这种模式与本地移动应用程序的工作方式类似。
好处:
- 这款应用的响应速度更快,而且由于页面刷新,用户在页面导航之间看不到flash。
- 服务器需要的HTTP请求更少,因为对于每个页面加载,不必再次下载相同的资产。
- 清晰地分离客户端和服务器之间的关注点;您可以轻松地为不同的平台(如移动平台、聊天机器人、智能手表)构建新客户端,而无需修改服务器代码。您还可以独立地修改客户端和服务器上的技术堆栈,只要API契约没有被破坏。
缺点:
- 由于加载多个页面所需的框架、应用程序代码和资产,初始页面加载较重。
- 在您的服务器上还需要完成另一个步骤,即将其配置为将所有请求路由到单个入口点,并允许客户端路由从那里接管。
- SPAs依赖于JavaScript来呈现内容,但并不是所有搜索引擎都在爬行期间执行JavaScript,它们可能会在您的页面上看到空的内容。这无意中损害了你的应用程序2的SEO。
虽然传统的服务器端呈现应用程序仍然是一个可行的选择,但清晰的客户机-服务器分离更适合大型工程团队,因为客户机和服务器代码可以独立开发和发布。当我们有多个客户端应用程序访问同一个API服务器时,这一点在Grab上尤其明显。
随着web开发人员现在构建的是应用程序而不是页面,组织客户端JavaScript变得越来越重要。在服务器端呈现的页面中,通常使用jQuery片段向每个页面添加用户交互性。然而,在构建大型应用程序时,jQuery是不够的。毕竟,jQuery主要是一个用于DOM操作的库,它不是一个框架,它没有为你的应用定义一个清晰的结构和组织。
JavaScript框架的创建是为了在DOM上提供更高层次的抽象,允许您将状态保存在内存中,而不是DOM中。使用框架还可以重用推荐的概念和构建应用程序的最佳实践。团队中有框架经验但没有应用程序经验的新工程师会发现更容易理解代码,因为代码是按照他熟悉的结构组织的。流行的框架有很多教程和指南,利用来自同事和社区的知识和经验可以帮助新工程师快速上手。
研究的链接
- 单页应用:优点和缺点
- (R)Evolution Web开发
新时代的JavaScript
在深入了解构建JavaScript web应用程序的各个方面之前,熟悉web语言—JavaScript或ECMAScript非常重要。JavaScript是一种非常通用的语言,您还可以使用它来构建web服务器、本地移动应用程序和桌面应用程序。
在2015年之前,最后一次主要更新是2011年的ECMAScript 5.1。然而,近年来,JavaScript在短时间内突然出现了巨大的改进。2015年,ECMAScript 2015(以前称为ECMAScript 6)发布了,并引入了大量的语法结构,以减少编写代码时的笨拙。Auth0编写了很好的JavaScript历史。到目前为止,并不是所有的浏览器都完全实现了ES2015规范。Babel等工具使开发人员能够在他们的应用程序中编写ES2015,而Babel将这些工具转换为ES5,以便与浏览器兼容。
熟悉ES5和ES2015是至关重要的。ES2015仍然相对较新,很多开源代码和Node.js应用程序仍然是用ES5编写的。如果在浏览器控制台中进行调试,则可能无法使用ES2015语法。另一方面,我们将在下面介绍的许多现代库的文档和示例代码都是用ES2015编写的。在Grab,我们使用ES2015(与Babel Stage-0预置一起)来支持JavaScript未来提供的语法改进,到目前为止我们一直很喜欢它。
花一两天时间复习ES5和探索ES2015。ES2015中使用较多的特性包括“箭头和词法This”、“类”、“模板字符串”、“析构”、“缺省/Rest/Spread操作符”和“导入和导出模块”。
预计持续时间:3-4天。您可以像学习其他库并尝试构建自己的应用程序一样学习/查找语法。
研究的链接
- Learn ES5 on Codecademy
- Learn ES2015 on Babel
- Free Code Camp
- ES6 Katas
- You Don’t Know JS (Advanced content, optional for beginners)
用户界面-React
![]()
如果最近几年有任何JavaScript项目在前端生态系统中掀起了一场风暴,那就是React。React是一个由Facebook的聪明人创建的开源库。在React中,开发人员为他们的web界面编写组件并将它们组合在一起。
React带来了许多激进的想法,并鼓励开发人员重新思考最佳实践。多年来,web开发人员一直被教导要分别编写HTML、JavaScript和CSS。React的做法正好相反,建议您用JavaScript编写HTML和CSS。这听起来像一个疯狂的想法,但经过尝试后,它实际上并不像听起来那么奇怪。作为前端开发场景的原因正在向基于组件的开发范式转变。React的特点:
- 说明性的——你描述你想在视图中看到什么,而不是如何实现它。在jQuery时代,开发人员必须想出一系列操作DOM的步骤,才能从一个应用程序状态切换到下一个应用程序状态。在React中,只需更改组件中的状态,视图就会根据状态更新自身。通过查看render()方法中的标记也很容易确定组件的外观。
- 功能-视图是一个纯粹的道具和状态的功能。在大多数情况下,React组件由支柱(外部参数)和状态(内部数据)定义。对于相同的道具和状态,会产生相同的视图。纯函数易于测试,功能组件也是如此。在React中进行测试很容易,因为组件的接口定义良好,可以通过向组件提供不同的道具和状态并比较呈现的输出来测试组件。
- 可维护性——以基于组件的方式编写视图可以促进可重用性。我们发现定义组件的proptype可以使React代码自文档化,因为读者可以清楚地知道使用组件需要什么。最后,您的视图和逻辑在组件中是自包含的,不应该受到影响,也不应该影响其他组件。这使得在大规模重构过程中很容易对组件进行移位,只要向组件提供相同的支持即可。
- 高性能——您可能听说过React使用虚拟DOM(不要与影子DOM混淆),当状态发生变化时,它会重新呈现所有内容。为什么需要虚拟DOM?虽然现代JavaScript引擎速度很快,但从DOM读写却很慢。React在内存中保持DOM的轻量级虚拟表示。重新呈现一切是一个误导的术语。在React中,它实际上是指重新呈现DOM在内存中的表示,而不是实际的DOM本身。当组件的底层数据发生更改时,将创建一个新的虚拟表示,并与以前的表示进行比较。然后将差异(所需的最小更改集)打补丁到实际的浏览器DOM。
- 易学-学习反应很简单。与此相比,React API表面相对较小;只有几个api需要学习,而且它们不经常更改。React社区是最大的社区之一,随之而来的是充满活力的工具生态系统、开源的UI组件以及大量的在线资源,可以帮助你开始学习React。
- 开发人员经验—有许多工具可以改进React的开发经验。React Devtools是一个浏览器扩展,允许您检查组件、查看和操作其道具和状态。使用webpack热重载允许您在浏览器中查看代码更改,而不必刷新浏览器。前端开发包括大量的代码调整、保存和刷新浏览器。热重新加载帮助您消除最后一步。当有库更新时,Facebook提供codemod脚本来帮助您将代码迁移到新的api。这使得升级过程相对轻松。向Facebook团队致敬,感谢他们的奉献精神,使React的开发体验变得非常棒。
多年来,出现了比React性能更好的新视图库。React可能不是最快的库,但就生态系统、整体使用体验和好处而言,它仍然是最好的库之一。Facebook也在努力加快反应速度,重写了底层的和解算法。React引入的概念教会了我们如何编写更好的代码、更易于维护的web应用程序,并使我们成为更好的工程师。我们像这样。
我们建议在React主页上阅读关于构建井字游戏的教程,以了解React是什么以及它的功能。更多深入学习,请查看评价较高的免费课程,React Router的创建者提供的React基础知识,他们是React社区的专家。它还涵盖了React文档中没有涵盖的更高级的概念。Facebook的Create React应用程序是一个工具,可以用最少的配置搭建一个React项目,强烈推荐用于启动新的React项目。
React是一个库,而不是框架,它不处理视图下面的层——应用程序状态。稍后再详细介绍。
预计持续时间:3-4天。尝试建立简单的项目,如待办事项列表,黑客新闻克隆与纯反应。你会慢慢地对它产生好感,并可能在这个过程中遇到一些问题,而这些问题不是React能够解决的,这就引出了我们的下一个话题……
研究的链接
- React Official Tutorial
- React Fundamentals
- Simple React Development in 2017
- Presentational and Container Components
选择
状态管理-Flux/Redux
![]()
随着应用程序越来越大,您可能会发现应用程序结构变得有点混乱。整个应用程序的组件可能不得不共享和显示公共数据,但没有优雅的方式来处理React。毕竟,React只是一个视图层,它并没有规定如何在传统MVC模式中构建应用程序的其他层,比如模型和控制器。为了解决这个问题,Facebook发明了Flux,这是一个应用架构,通过利用单向数据流来补充React的可组合视图组件。在这里阅读更多关于Flux的工作原理。综上所述,流量分布具有以下特点:
单向数据流-使应用程序更可预测的更新可以很容易地跟踪。
关注的分离——通量体系结构中的每个部分都有明确的职责,并且是高度解耦的。
在声明式编程中工作得很好——存储可以向视图发送更新,而不需要指定如何在状态之间转换视图。
由于Flux本身不是一个框架,开发人员已经尝试了很多Flux模式的实现。最终,一个明显的赢家出现了,那就是Redux。Redux结合了Flux、Command pattern和Elm体系结构的思想,是目前开发人员与React一起使用的事实上的状态管理库。其核心概念是:
应用程序状态由一个简单的旧JavaScript对象(POJO)描述。
发送一个操作(也是一个POJO)来修改状态。
减速器是一个纯函数,它采用当前状态和动作来产生一个新的状态。
这些概念听起来很简单,但是它们非常强大,因为它们使应用程序能够:
在服务器上呈现它们的状态,在客户端启动它们。
跟踪、记录和回溯整个应用程序中的更改。
轻松实现撤销/重做功能。
Redux的创建者Dan Abramov非常仔细地为Redux编写了详细的文档,并为学习基本和高级Redux创建了全面的视频教程。它们是非常有用的学习资源。
视图和状态的结合
虽然Redux不一定要与React一起使用,但强烈推荐使用Redux,因为它们彼此配合得很好。React和Redux有很多共同的想法和特点:
功能组合范式- React组合视图(纯函数),而Redux组合纯还原剂(纯函数)。给定相同的输入集,输出是可预测的。
很容易推理——你可能听过这个词很多次,但它到底是什么意思呢?根据我们的经验,React和Redux简化了调试。由于数据流是单向的,因此更容易跟踪数据流(服务器响应、用户输入事件),并且很容易确定问题发生在哪个层。
分层结构——app / Flux架构中的每一层都是纯功能,职责明确。为它们编写测试非常容易。
开发经验——在开发过程中,我们花了很多精力来创建工具来帮助调试和检查应用程序,比如Redux DevTools。
您的应用程序可能必须处理异步调用,如发出远程API请求。redx -thunk和redx -saga就是为了解决这些问题而创建的。它们可能需要一些时间来理解,因为它们需要理解函数式编程和生成器。我们的建议是,只有在你需要的时候才去处理它。
React - Redux是Redux的官方React绑定,非常简单易学。
预计时间:4天。egghead课程可能有点耗时,但值得花时间。在学习了Redux之后,您可以尝试将其合并到您已经构建的React项目中。Redux是否解决了您在pure React中遇到的一些状态管理问题?
Study Links
- Flux Homepage
- Redux Homepage
- Egghead Course - Getting Started with Redux
- Egghead Course - Build React Apps with Idiomatic Redux
- React Redux Links
- You Might Not Need Redux
Alternatives
用样式- CSS模块编码
编写好的CSS是困难的。在能够编写可维护和可伸缩的CSS之前,需要多年的经验和挫败感来解决问题。具有全局名称空间的CSS基本上是为web文档设计的,而不是真正为偏爱组件体系结构的web应用程序设计的。因此,有经验的前端开发人员设计了一些方法来指导人们如何为复杂的项目编写有组织的CSS,比如使用SMACSS、BEM、SUIT CSS等。然而,这些方法所带来的样式的封装是由约定和指导方针强制执行的。一旦开发人员不遵循它们,它们就会中断。
幸运的是,前端的生态系统中充斥着各种工具,而不出意料的是,人们发明了一些工具来部分解决大规模编写CSS的一些问题。“大规模”意味着许多开发人员都在同一个项目中工作,并且使用相同的样式表。目前还没有社区同意用JS编写CSS的方法,我们希望有一天能像Redux一样在Flux实现中脱颖而出。现在,我们指望CSS模块。CSS模块是对现有CSS的改进,旨在解决CSS中全局命名空间的问题;它使您能够编写默认情况下是本地的并封装到组件中的样式。此功能通过工具实现。用CSS模块,可以编写大型团队的模块化和可重用的CSS,而不必担心冲突或覆盖应用程序的其他部分。然而,在一天结束的时候,仍在CSS模块编译成正常globally-namespaced CSS的浏览器识别,它仍然是重要的学习生的CSS。
如果你是一个完全的CSS初学者,Codecademy的HTML和CSS课程将是一个很好的介绍你。接下来,阅读Sass预处理器,这是CSS语言的扩展,增加了语法改进,并鼓励了样式的可重用性。学习上面提到的CSS方法,最后学习CSS模块。
预计持续时间:3-4天。尝试使用SMACSS/BEM方法和/或CSS模块设计应用程序的样式。
Study Links
- Learn HTML & CSS course on Codecademy
- Intro to HTML/CSS on Khan Academy
- SMACSS
- BEM
- SUIT CSS
- CSS Modules Specification
- Sass Homepage
- A pattern for writing CSS to scale
Alternatives
可维护性
读代码比写代码更频繁。在Grab尤其如此,在那里团队规模很大,我们有多个工程师在多个项目中工作。我们高度重视代码的可读性、可维护性和稳定性,有几种方法可以实现这一点:“广泛的测试”、“一致的编码风格”和“类型划分”。
测试- - Jest + Enzyme
Jest是Facebook的一个测试库,旨在让测试过程无痛苦。与Facebook项目一样,它提供了一种开箱即用的良好开发体验。测试可以并行运行以获得更快的速度,并且在监视模式下,只运行更改文件的测试。我们喜欢的一个特性是“快照测试”。Jest可以保存React组件和Redux状态生成的输出,并将其保存为序列化文件,这样您就不必自己手动生成预期的输出。Jest还具有内置的模拟、断言和测试覆盖率。一个图书馆来统治他们所有人!
React附带了一些测试工具,但是通过类似于jquery的API,通过Airbnb提供的酶可以更容易地生成、断言、操作和遍历React组件的输出。建议用酶测定反应组分。
Jest和酶使编写前端测试变得有趣和容易。因为定义了明确的职责和接口,所以React组件和Redux操作/缩减器相对容易测试也很有帮助。对于React组件,我们可以测试给定一些道具,呈现所需的DOM,并在某些模拟用户交互时触发回调。对于Redux还原器,我们可以测试给定的一个先验状态和一个动作,会产生一个结果状态。
Jest和ase的文档非常简洁,通过阅读它们应该就足够了。
预计持续时间:2-3天。尝试为你的React + Redux应用程序编写Jest +Enzyme!
Study Links
- Jest Homepage
- Testing React Apps with Jest
- Enzyme Homepage
- Enzyme: JavaScript Testing utilities for React
Alternatives
Linting JavaScript - ESLint
![]()
linter是一个静态分析代码并发现代码问题的工具,它可以潜在地防止bug /运行时错误,同时强制执行一种编码风格。在拉请求审查期间,当审查人员不必对编码风格留下挑剔的评论时,可以节省时间。ESLint是一个用于linting JavaScript代码的工具,具有高度可扩展性和可定制性。团队可以编写自己的lint规则来执行自定义样式。在Grab中,我们使用Airbnb的eslin -config- Airbnb预置,它已经在Airbnb的JavaScript风格指南中配置了通用的良好编码风格。
在大多数情况下,使用ESLint就像调整项目文件夹中的配置文件一样简单。如果您不为ESLint编写新的规则,那么就没有什么可学习的。当错误出现时,请注意它们,并将其谷歌,以找到推荐的样式。
预计持续时间:1/2天。没什么可学的。添加ESLint到您的项目,并修复linting错误!
Study Links
Alternatives
Linting CSS - stylelint
![]()
正如前面提到的,好的CSS是出了名的难写。在CSS上使用静态分析工具有助于保持我们的CSS代码质量和编码风格。对于linting CSS,我们使用stylelint。与ESLint一样,stylelint以一种非常模块化的方式设计,允许开发人员打开/关闭规则并为其编写自定义插件。除了CSS之外,stylelint还能够解析SCSS,并且对Less提供了实验支持,这降低了大多数现有代码库采用它的障碍。

一旦你学会了ESLint,考虑到他们的相似之处,学习stylelint将是毫不费力的。手写笔目前被Facebook、GitHub和Wordpress等大公司使用。
手写笔的一个缺点是,自动修复功能还没有完全成熟,只能修复有限数量的规则。然而,这个问题应该随着时间的推移而改善。
预计持续时间:1/2天。没什么可学的。将stylelint添加到项目中并修复linting错误!
Study Links
Alternatives
Types - Flow
![]()
静态类型在编写应用程序时带来了许多好处。它们可以在早期捕获代码中的常见bug和错误。类型还可以作为代码文档的一种形式,提高代码的可读性。随着代码库的增长,我们看到了类型的重要性,因为它们在我们进行重构时给了我们更大的信心。当清楚每个对象持有什么类型的值和每个函数期望什么时,将团队的新成员加入到项目中也更容易。
向代码中添加类型需要在增加冗长性和语法学习曲线之间进行权衡。但这种学习成本是预先支付的,并随着时间的推移摊销。在复杂的项目中,代码的可维护性很重要,并且处理代码的人员会随着时间的推移而变化,向代码中添加类型带来的好处要多于坏处。
向JavaScript添加静态类型的两大竞争者是Flow (Facebook)和TypeScript(微软)。到目前为止,还没有明确的赢家。现在,我们已经做出了使用流的选择。我们发现与TypeScript相比,Flow的学习曲线更低,并且将现有的代码库迁移到Flow所需的工作相对较少。Flow由Facebook打造,与React生态系统的整合性更好。无论如何,从Flow转移到TypeScript并不十分困难,因为语法和语义非常相似,我们将在以后重新评估这种情况。毕竟,使用一个总比不使用强。
Flow最近更新了他们的文档站点,现在已经很整洁了!
预计持续时间:1天。流非常容易学习,因为类型注释感觉像是JavaScript语言的自然扩展。向您的项目中添加流注释,并利用类型系统的强大功能。
Study Links
Alternatives
Build System - webpack
![]()
这一部分将会很简短,因为设置webpack可能是一个冗长乏味的过程,而且可能会让那些已经被前端开发中需要学习的大量新内容压得喘不过气来的开发人员感到厌烦。简单地说,webpack是一个模块绑定器,它将前端项目及其依赖项编译成一个最终的包,然后提供给用户。通常,项目已经设置了webpack配置,开发人员很少需要更改它。从长远来看,理解webpack仍然是一件好事。这是由于webpack的功能,如热重载和CSS模块是可能的。
我们发现由生存js的webpack演练是学习webpack的最佳资源。这是对官方文档的一个很好的补充,我们建议先进行演练,然后在需要进一步定制时参考文档。
预计持续时间:2天(可选)。
Study Links
Alternatives
Package Management - Yarn
![]()
如果您查看一下node_modules目录,您会对其中包含的目录数量感到震惊。每个babel插件lodash函数都是一个独立的包。当您有多个项目时,这些包在每个项目中都是重复的,它们在很大程度上是相似的。每次在新项目中运行npm安装时,这些包都会被一次又一次地下载,即使它们已经存在于计算机中的其他项目中。
在通过npm安装安装的包中也存在不确定性的问题。我们的一些CI构建会失败,因为在CI服务器安装依赖项时,它会对一些包含中断更改的包进行小的更新。如果库作者尊重semver,而工程师假设API契约一直受到尊重,就不会出现这种情况。
纱线解决了这些问题。通过纱线安装包的不确定性问题。锁定文件,并确保在所有机器上的node_modules中,每个安装都得到完全相同的文件结构。纱线在您的计算机中使用了一个全局缓存目录,以前下载过的包不必重新下载。这也支持离线安装依赖项!
最常见的纱线命令可以在这里找到。大多数其他的纱线命令类似于npm,可以使用npm版本。我们最喜欢的命令之一是纱线升级-交互式,这使得更新依赖项变得非常容易,特别是在现代JavaScript项目需要如此多的依赖项的时候。一定要去看看!
npm@5.0.0于2017年5月发布,它似乎解决了纱线想要解决的许多问题。一定要注意!
预计持续时间:2小时。
Study Links
Alternatives
旅程才刚刚开始
祝贺你走到这一步!今天的前端开发是困难的,但它也比以前更有趣。到目前为止,我们所介绍的内容将帮助任何新工程师快速掌握我们的技术。还有更多的东西需要学习,但是在本质上建立一个坚实的基础将有助于学习其余的技术。这个有用的前端web开发人员路线图显示了各个方面可用的替代技术。
我们的技术决策是基于快速成长的Grab工程团队所看重的——前端代码库的可维护性和稳定性。这些决策可能适用于较小的团队和项目,也可能不适用于较小的团队和项目。评估什么对你和你的公司最有效。
随着前端生态系统的发展,我们正在积极探索、试验和评估新技术如何使我们成为一个更高效的团队,并提高我们的生产力。我们希望这篇文章能让你了解我们在Grab使用的前端技术。如果你对我们正在做的事情感兴趣,我们正在招聘!
感谢Joel Low, Li Kai和Tan Wei Seng审阅了本文的草稿。
原帖可以在GitHub上找到。未来的学习指南将在那里更新。如果你喜欢你正在阅读的东西,给它打一颗星吧!?
More Reading
General
- State of the JavaScript Landscape: A Map for Newcomers
- The Hitchhiker’s guide to the modern front end development workflow
- How it feels to learn JavaScript in 2016
- Roadmap to becoming a web developer in 2017
- Modern JavaScript for Ancient Web Developers
Other Study Guides
Footnotes
-
This can be solved via webpack code splitting. ↩
-
Universal JS to the rescue! ↩
原文:https://engineering.grab.com/grabs-front-end-study-guide
本文:https://pub.intelligentx.net/node/804
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 65 次浏览
【前端架构】Mashup(网络应用混合)
在web开发中,mashup(计算机行业术语)是一个web页面或web应用程序,它使用来自多个源的内容来创建单个新服务,并显示在单个图形界面中。例如,用户可以将其图书馆分支的地址和照片与谷歌映射相结合,以创建地图mashup。这个术语意味着简单、快速的集成,经常使用开放的应用程序编程接口(open API)和数据源来产生丰富的结果,而这些结果不一定是产生原始数据源数据的原始原因。mashup这个术语最初来自于英西印度群岛的俚语,意思是喝醉了,或者描述某人或某事没有达到预期的功能。在最近的英语中,它可以指音乐,人们无缝地将一首歌曲的音频和另一首歌曲的音轨结合在一起,从而创造出新的东西。
mashup的主要特征是组合、可视化和聚合。使现有数据对个人和专业使用更有用是很重要的。为了能够永久地访问其他服务的数据,mashup通常是客户端应用程序或在线托管。
在过去的几年里[什么时候?,越来越多的Web应用程序已经发布了api,这些api使软件开发人员能够以SOA的方式轻松地集成数据和功能,而不是自己构建它们。可以认为mashup在社交软件和Web 2.0的发展中扮演着积极的角色。Mashup组合工具通常非常简单,可供最终用户使用。它们通常不需要编程技能,而是支持GUI小部件、服务和组件的可视化连接。因此,这些工具为Web的新愿景做出了贡献,用户可以在其中做出贡献。(需要澄清)
术语“mashup”并不是由任何标准设置机构正式定义的.
历史
Web历史的更广泛背景为mashup的开发提供了一个背景。在Web 1.0模型下,组织将消费者数据存储在门户网站上,并定期更新它们。他们控制了所有的消费者数据,消费者必须使用他们的产品和服务来获取信息。[引文需要]
Web 2.0的出现引入了一些Web标准,这些标准在传统的竞争对手之间得到了普遍和广泛的采用,从而打开了消费者数据。与此同时,mashup出现了,允许混合和匹配竞争对手的api来开发新服务。
第一个mashup使用映射服务或照片服务将这些服务与任何类型的数据组合起来,从而产生数据的可视化。最初,大多数mashup是基于消费者的,但最近[什么时候?混搭将会被谁看到?这是一个有趣的概念,对企业也很有用。业务mashup可以将现有的内部数据与外部服务组合起来,以生成关于数据的新视图。
混搭的类型
mashup有许多类型,比如业务mashup、消费者mashup和数据mashup。最常见的mashup类型是面向普通大众的消费者mashup。
业务(或企业)mashup定义将其自身的资源、应用程序和数据与其他外部Web服务组合在一起的应用程序。他们将数据集中在一个单一的演示中,并允许企业和开发人员之间的协作行动。这对于敏捷开发项目非常有效,因为敏捷开发项目需要开发人员和客户(或客户代理,通常是产品经理)之间的协作来定义和实现业务需求。企业mashup是安全的、视觉上丰富的Web应用程序,它公开来自不同内部和外部信息源的可操作信息。
使用者mashup在浏览器中组合来自多个公共源的数据,并通过一个简单的浏览器用户界面对其进行组织。[5](例如:Wikipediavision结合了谷歌地图和Wikipedia API)
与消费者mashup相反,数据mashup将类似类型的媒体和来自多个源的信息组合成单一表示。所有这些资源的组合创建了一个新的、独特的Web服务,它最初不是由任何一个源提供的。
通过API类型
mashup也可以根据它们使用的基本API类型进行分类,但其中任何一种都可以相互组合或嵌入到其他应用程序中。
数据类型
- 元搜索引擎使用的索引数据(文档、网络日志、图像、视频、购物文章、工作……)
- 制图和地理数据:地理定位软件,地理可视化
- 提要、播客:新闻聚合器
功能
- 数据转换器:语言翻译,语音处理,网址缩短器…
- 沟通:电子邮件,即时消息,通知…
- 可视化数据绘制:信息可视化,图表
- 安全相关:电子支付系统,身份识别…
- 编辑器
Mashup的推动者
在技术领域,mashup enabler是一种工具,用于将不兼容的IT资源转换为可以轻松组合的形式,从而创建mashup。Mashup使能者允许使用强大的技术和工具(例如Mashup平台)来将数据和服务组合到新的资源类型中。mashup启用程序的一个示例是一个从电子表格(不能轻松用于创建mashup)创建RSS提要的工具。许多mashup编辑器包括mashup推动者,例如Presto mashup连接器、Convertigo Web Integrator或Caspio Bridge。
Mashup推动者也被描述为“使Mashup成为可能的服务和工具提供者”。[引文需要]
历史
早期的mashup是由热情的程序员手工开发的。然而,随着mashup变得越来越流行,公司开始创建用于构建mashup的平台,这些平台允许设计人员通过连接mashup组件来可视化地构建mashup。
Mashup编辑器极大地简化了Mashup的创建,极大地提高了Mashup开发人员的工作效率,甚至向最终用户和非it专家开放了Mashup开发。标准组件和连接器使设计人员能够轻松地以各种复杂的方式组合mashup资源。然而,Mashup平台在扩展Mashup可以访问的资源范围方面做得很少,而且还没有将Mashup从对结构化数据和开放库(RSS提要和公共api)的依赖中解放出来。
Mashup启用程序不断发展,以解决这个问题,提供了将其他类型的数据和服务转换成mashable资源的能力。
Web资源
当然,并不是所有有价值的数据都位于组织内部。事实上,对于业务智能和决策支持最有价值的信息通常来自组织外部。随着富internet应用程序和在线Web门户的出现,越来越多的业务关键流程(例如订购)可以在线使用。不幸的是,这些数据源很少以RSS格式聚合内容,而且很少有这些服务提供可公开访问的api。因此,Mashup编辑器通过提供启用程序或连接器来解决这个问题。
数据集成的挑战
在集成来自不同来源的数据时,有许多挑战需要解决。这些挑战可以分为四组:文本/数据不匹配、对象标识符和模式不匹配、抽象级别不匹配、数据准确性
文本数据不匹配
大部分数据是用文本来描述的。人类的语言常常是含糊不清的——同一家公司可能在几个变体中被提及(例如IBM、国际商业机器公司和蓝色巨人)。这种模糊性使得与结构化数据的交叉链接变得困难。此外,用人类语言表达的数据很难通过软件程序来处理。数据集成系统的功能之一是克服文档与数据之间的不匹配
对象标识和独立的模式
结构化数据有各种各样的格式。因此,将数据提升到公共数据格式是第一步。但是,即使所有数据都以一种通用的格式提供,但在实践中,数据源在如何表述本质上相同的事实方面是不同的。这种差异存在于单独的对象级别和模式级别。作为对象级别不匹配的一个示例,请考虑以下内容:SEC使用所谓的中央索引键(Central Index Key, CIK)来识别人员(ceo、cfo)、公司和金融工具,而其他来源(如DBpedia (Wikipedia的结构化数据版本))使用uri来识别实体。此外,每个源通常使用自己的模式和特性来说明本质上相同的事实。因此,必须使用方法来协调对象和模式的不同表示。
抽象级别
数据源提供不兼容的抽象级别的数据,或者根据与某个扇区相关的分类法对其数据进行分类。由于数据是在不同的抽象层次(如个人、公司、国家或部门)发布的,为个人观点而聚合的数据可能与来自统计部门的数据不匹配。此外,在地理汇总方面也存在差异(例如,来自一个来源的区域数据和来自另一个来源的国家一级数据)。一个相关的问题是使用当地货币(美元对欧元),为了使来自不同来源的数据具有可比性并便于分析,必须对这些货币进行协调。
数据质量
在自动集成来自自治数据源的数据时,数据质量是一个普遍的挑战。在开放环境中,数据聚合器对数据发布服务器几乎没有影响。数据常常是错误的,并且组合数据常常会加重问题。特别是在执行推理(从现有数据自动推断新数据)时,错误的数据可能会对结果数据集的整体质量造成毁灭性的影响。因此,一个挑战是数据发布者如何协调以修复数据或黑名单站点中无法提供可靠数据的问题。需要的方法和技术:检查完整性和准确性;突出、鉴定和确证证据;评估一个给定命题为真的概率;等同市场部门或公司之间的权重差异;设立清算所,以提出和解决相互竞争(可能相互冲突)的数据提供者之间的争端;并与可能来源和质量可疑的混乱的错误Web数据交互。总之,标识、数量、标记和分类中的错误会严重妨碍系统对这些数据进行操作。
Mashup和门户网站
mashup和门户都是内容聚合技术。门户是一种较老的技术,被设计为对传统动态Web应用程序的扩展,其中将数据内容转换为标记的Web页面的过程分为两个阶段:生成标记“片段”和将片段聚合为页面。每个标记片段由一个“portlet”生成,门户将它们组合成单个Web页面。portlet可以本地托管在门户服务器上,也可以远程托管在单独的服务器上。
门户技术定义了一个完整的事件模型,包括读取和更新。在门户上对聚合页面的请求被转换为构成页面的所有portlet上的单个读取操作(本地的“呈现”操作、JSR 168 portlet或远程的“getMarkup”操作、WSRP portlet)。如果在门户页面上的任何portlet上按下了submit按钮,那么它将被单独转换为该portlet上的更新操作(本地portlet上的processAction或远程WSRP portlet上的performBlockingInteraction)。更新之后立即对页面上的所有portlet执行读操作。
门户技术是关于服务器端表示层聚合的。它不能用于驱动更健壮的应用程序集成形式,比如两阶段提交。
mashup与门户在以下方面有所不同:
| Portal | Mashup | |
| 分类 | 较老的技术,使用定义良好的方法对传统Web服务器模型的扩展 | 使用更新的、定义松散的“Web 2.0”技术 |
| 哲学/方法 | 通过将Web服务器的角色划分为标记生成和标记片段聚合两个阶段来实现聚合 | 使用不同内容站点提供的api以另一种方式聚合和重用内容 |
| 内容相关性 | 聚合面向表示的标记片段(HTML、WML、VoiceXML等) | 可以操作纯XML内容,也可以操作面向表示的内容(如HTML) |
| 位置的依赖关系 | 传统上,内容聚合是在服务器上进行的 | 内容聚合可以在服务器上进行,也可以在客户机上进行 |
| 聚合的风格 | “沙拉吧”风格:聚合的内容“并排”显示,没有重叠 | “大熔炉”风格-个别内容可以以任何方式组合,导致任意结构的混合内容 |
| 事件模型 | 读取和更新事件模型是通过特定的portlet API定义的 | CRUD操作基于REST架构原则,但是不存在正式的API |
| 相关标准 | Portlet行为由标准JSR 168、JSR 286和WSRP控制,尽管门户页面布局和门户功能是未定义的,并且是特定于供应商的 | 基本标准是作为REST或Web服务交换的XML。RSS和Atom是常用的。更具体的mashup标准(如EMML)正在出现。 |
门户模式存在的时间更长,并且有更大的投资和产品研究。因此,门户技术更加标准化和成熟。随着时间的推移,mashup技术的日益成熟和标准化可能会使它比门户技术更受欢迎,因为它与Web 2.0和最近的面向服务的体系结构(SOA)联系得更紧密。预计[7]新版本的门户产品最终将添加mashup支持,同时仍然支持遗留portlet应用程序。相比之下,Mashup技术预计不会提供对门户标准的支持。
业务mashup
Mashup在业务环境中的使用正在扩展。业务mashup对于集成业务和数据服务非常有用,因为业务mashup技术提供了快速开发新集成服务的能力,可以将内部服务与外部或个性化信息相结合,并通过用户友好的Web浏览器界面将这些服务呈现给业务用户
业务mashup与消费者mashup在与业务计算环境的集成级别、安全性和访问控制特性、治理以及使用的编程工具(mashup编辑器)的复杂性方面有所不同。业务mashup和消费者mashup之间的另一个区别是,在商业软件即服务(SaaS)中使用业务mashup的趋势越来越明显。
许多业务mashup技术的提供者都添加了SOA特性。
Mashup的体系结构方面
mashup的架构分为三层:
- 演示/用户交互:这是mashup的用户界面。所使用的技术有HTML/XHTML、CSS、JavaScript、异步JavaScript和Xml (Ajax)。
- Web服务:可以使用API服务访问产品的功能。使用的技术有XMLHTTPRequest、XML-RPC、JSON-RPC、SOAP和REST。
- 数据:处理发送、存储、接收等数据。使用的技术有XML、JSON和KML。
在体系结构上,有两种类型的mashup:基于web的和基于服务器的。基于web的mashup通常使用用户的web浏览器来组合和重新格式化数据,而基于服务器的mashup在远程服务器上分析和重新格式化数据,并将数据以最终形式传输到用户的浏览器
mashup似乎是外观模式的变体。这是一种软件工程设计模式,它为更大的代码体提供了一个简化的接口(在本例中,代码使用不同的api聚合不同的提要)。
mashup可以与作为服务(SaaS)提供的软件一起使用。
经过几年的标准开发,主流企业开始采用面向服务的体系结构(SOA),通过将不同的数据作为离散的Web服务提供来集成它们。Web服务提供开放的、标准化的协议,以提供从各种平台(操作系统、编程语言、应用程序)访问信息的统一方法。可以重用这些Web服务来在组织内部和跨组织提供全新的服务和应用程序,从而提供业务灵活性。
讨论:请加入知识星球【首席架构师圈】
- 152 次浏览
【前端架构】React vs Angular vs Vue.js - 在2019年可以选择什么? (更新)

前段时间我们发表了一篇文章,比较了Angular和React。 在那篇文章中,我们展示了这些框架的优缺点,并建议在2018年为特定目的选择什么。 那么,2019年前端花园的情况如何呢?
JavaScript框架正在以极快的速度发展,这意味着今天我们经常更新Angular,React和该市场上的其他玩家版本 - Vue.js.
我们分析了全球需要特定框架知识的开放职位数量。 作为消息来源,我们采用Indeed.com并根据超过60,000个工作机会获得以下分配。

考虑到以下数据,我们决定分享每个前端框架的主要优点和缺点,并帮助技术专业人员或工程师根据他们的开发需求选择最佳的。
Angular的利弊
Angular是一个超级英雄的JavaScript MVVM框架,成立于2009年,非常适合构建高度交互的Web应用程序。
Angular的好处:
创建的Angular与Typescript一起使用。并且对它有特殊的支持。
Angular-language-service - 允许在组件外部HTML模板文件中进行智能和自动完成。
新功能,例如来自CLI的一代基于Angular的npm库,基于Angular的WebComponents的生成和开发。
详细的文档,允许为个人开发人员获取所有必要的信息,而无需询问他的同事。但是,这需要更多的时间进行教育。
单向数据绑定,可为应用程序启用单一行为,从而最大限度地降低可能出错的风险。
MVVM(Model-View-ViewModel),允许开发人员使用同一组数据在同一个应用程序部分上单独工作。
通常使用模块和模块化依赖注入与组件相关的功能。
专为最佳项目可扩展性而创建的结构和体系结构
Angular的缺点:
与React和Vue.js相比,各种不同的结构(注射器,组件,管道,模块等)使得学习起来有点困难,React和Vue.js只考虑了“组件”。
根据不同的基准测试,性能相对较慢。另一方面,它可以通过利用所谓的“ChangeDetectionStrategy”轻松解决,它有助于手动控制组件的渲染过程。
使用Angular的公司:
Microsoft, Autodesk, MacDonald’s, UPS, Cisco Solution Partner Program, AT&T, Apple, Adobe, GoPro, ProtonMail, Clarity Design System, Upwork, Freelancer, Udemy, YouTube, Paypal, Nike, Google, Telegram, Weather, iStockphoto, AWS, Crunchbase.
React的利弊
React是一个JavaScript库,于2013年由Facebook开源,非常适合构建任何规模和规模的现代单页应用程序。
React的好处:
由于其简单的设计,使用JSX(类似HTML的语法)进行模板化和高度详细的文档,因此易于学习。
开发人员花费更多时间编写现代JavaScript,而不必担心特定于框架的代码。
非常快,礼貌的React的虚拟DOM实现和各种渲染优化。
对服务器端呈现的强大支持,使其成为面向内容的应用程序的强大框架。
借助`create-react-app`应用程序生成器,支持一流的渐进式Web应用程序(PWA)。
数据绑定是单向的,意味着更少的不必要的副作用。
Redux是在React中管理应用程序状态的最流行的框架,易于学习和掌握。
React实现了功能编程(FP)概念,创建了易于测试和高度可重用的代码。
使用Microsoft的TypeScript或Facebook的Flow可以使应用程序类型安全,两者都具有对JSX的本机支持。
在版本之间迁移通常非常容易,Facebook提供“codemods”来自动化大部分过程。
在React中学到的技能可以(通常直接)应用于React Native开发。
React的缺点:
React是不受干扰的,让开发人员可以选择最好的开发方式。这可以通过强有力的项目领导和良好的流程来解决。
社区对在React中编写CSS的最佳方式存在分歧,在传统样式表(CSS模块)和CSS-in-JS(即情感和样式组件)之间进行划分。
React正逐渐远离基于类的组件,这可能成为开发人员更容易使用面向对象编程(OOP)的障碍。
最初将模板与逻辑混合(JSX)可能会让一些开发人员感到困惑。
使用React的公司:
Facebook, Instagram, Netflix, New York Times, Yahoo, Khan Academy, Whatsapp, Codecademy, Dropbox, Airbnb, Asana, Atlassian, Intercom, Microsoft, Slack, Storybook, and many more.
Vue.js的优点和缺点
Vue.js是一个JavaScript框架,于2013年推出,非常适合创建高适应性的用户界面和复杂的单页面应用程序。
Vue.js的好处:
赋予HTML权力。这意味着Vue.js与Angular有许多相似的特性,这有助于通过使用不同的组件来优化HTML块处理。
详细文档。 Vue.js具有非常周密的文档,可以为开发人员设置学习曲线,并且仅使用HTML和JavaScript的基本知识就可以节省大量时间来开发应用程序。
适应性强。它提供了从其他框架到Vue.js的快速切换周期,因为它在设计和架构方面与Angular和React相似。
很棒的整合。 Vue.js可用于构建单页面应用程序和更困难的应用程序Web界面。主要的是,较小的交互式部件可以轻松集成到现有基础设施中,而不会对整个系统产生负面影响。
大规模。 Vue.js可以帮助开发相当大的可重用模板,根据其简单的结构,可以在没有为其分配额外时间的情况下制作模板。
小巧的尺寸。 Vue.js的重量可以保持在20KB左右,保持其速度和灵活性,与其他框架相比,可以实现更好的性能。
Vue.js的缺点:
缺乏资源。与React或Angular相比,Vue.js的市场份额仍然很小,这意味着该框架中的知识共享仍处于起步阶段。
过度灵活的风险。有时,Vue.js在整合到大型项目时可能会遇到问题,但仍然没有可能的解决方案经验,但它们肯定会很快到来。
使用Vue.js的公司:
Xiaomi, Alibaba, WizzAir, EuroNews, Grammarly, Gitlab and Laracasts, Adobe, Behance, Codeship, Reuters.
结论
对于真正的工程师来说,选择哪个框架没有太大的区别,因为它只需要一些时间来适应新的框架。在我们公司,我们在React和Angular中积累了大量专业知识,但Vue.js也在其中。每个框架都有自己的优点和缺点,这意味着在产品开发过程中每个案例都应该有正确的选择。
原文:https://medium.com/@TechMagic/reactjs-vs-angular5-vs-vue-js-what-to-choose-in-2018-b91e028fa91d
本文:http://pub.intelligentx.net/react-vs-angular-vs-vuejs-what-choose-2019-updated
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 43 次浏览
【前端架构】React vs Vue -选择正确框架的CTOs指南

快速总结:为项目选择正确的javascript框架或库是CTO和项目经理的基本任务。然而,选择的范围很大程度上取决于几个因素,如项目时间、学习曲线、框架性能和团队规模。这篇文章旨在指导他们选择正确的javascript框架(或库):React vs Vue。
React vs Vue -选择正确框架的CTOs指南
这是一个值得你考虑的案例!
Rever Inc.,一家硅谷公司,在构建他们的最后一个MVP之前,将将近10,000行Angular.js代码移植到了Vuejs上。
好吧,他们需要使用的Angular版本的发布被延迟了,这是不可预见的,他们等不起,因为这会浪费时间和资源。
直接引用Luis Elizondo (Rever的工程总监)的话——
在为我们评估正确的选择框架之前,我必须亲自动手,所以我给了React和Vue.js几天时间来回顾每个不可能被谷歌回答的决策点。由于我对它们一无所知,在两天结束时,我将重新评估我在重写我们将要迁移的实际项目的某些部分时走了多远。
在评估了两个框架之后,Luis和他的团队决定使用Vue,因为他们发现Vue比React更容易使用。
现在想象你自己处于一个类似的情况,你的1000个小时的努力都是徒劳的,这不是你自己的错。
考虑到项目的截止日期很紧,太多的产品经理和CTO落入了一个常见的陷阱——他们选择了一个让他们轻松开始的框架,而没有考虑框架随时间的影响。然而,他们很快就意识到最好事先评估用例并选择合适的框架,以避免任何类型的问题。
在这篇博客文章中,我将比较React和Vue的几个因素,这些因素将帮助我们评估需要的正确技术。
在进行深入的比较之前,你可以先问自己一些问题,这样你就可以对这个问题有一个全面的了解。这些问题只是帮助你评估React和Vue之间正确框架的因素。
React vs Vue: CTO和项目经理的比较因素
- 代码有多干净和直观?
- 框架支持模块化吗?
- 开始使用这个框架有多容易?它是否支持JS导入?
- 框架的测试和调试方面有多好?
- 我的队友和我能够轻松地学习这个工具吗?
- 框架在性能方面是如何脱颖而出的?
- 从项目开始算起,在5-10年以上的时间里,这些代码会给我带来更多的麻烦吗?或者在那些年里,我将被一个几乎无法维护的遗留应用程序所束缚?
- 框架支持服务器端呈现吗?
- 框架适合轻量级还是重量级应用程序?
- 这些框架的顶级实用程序是什么?什么时候使用它们是正确的选择?
现在你有了问题,让我们通过将这些因素与React和Vue并置来深入研究问题的实质,了解它们的区别。
React和Vue的代码质量比较
代码有多干净和直观?
首先:能够让您快速浏览大型项目代码的框架应该是理想的选择。
显然,对于许多CTO和项目经理来说,一切都归结为“代码通过测试的速度有多快,以及这些测试如何处理类型”。
请注意,要提高代码质量,还有很多事情需要考虑。例如,单元测试、linting和类型检查是我的团队和我在Simform积极执行的事情。
我不会在这里拐弯抹角地提到所有这些实践。因为我相信类型检查确实能提高代码质量,所以让我们比较一下Reactjs和Vuejs,看看它们是否支持任何方式的类型检查。
React的静态类型检查
React确实利用了JavaScript ES6基础作为代码语法,但是它是否支持编译时的类型检查之类的功能呢?
嗯,是的!
你可以用Flow来做静态检查,它是Facebook开发人员开发的TypeScript的替代品。它允许您向代码中添加类型,然后在构建(编译)时删除它们,以保留正常的Javascript代码。
[注:如果你喜欢TypeScript,但仍然想使用React,那么你最好去,因为TypeScript对JSX有很好的支持,这可能就是微软在最新版本的office中使用它的原因]
Vue中的静态类型检查
Vue还利用Javascript ES6语法来编写代码。然而,当涉及到静态类型检查时,在Vue中使用Typescript就不是那么简单了。有一些课程是关于如何将Typescript和Vue一起使用的,但是在复杂的项目中是否值得考虑仍然不清楚。
幸运的是,您可以将flow与Vue集成并启用静态类型检查。
React和Vue的模块化
框架支持模块化吗?
根据模块化原则,您的应用程序必须划分为独立的模块,每个模块代表单一的目的或功能。这一原则也被称为单一责任原则。
“做一件事并把它做好”——Unix哲学
让我们用一个简单的现实生活用例来理解模块化:
假设您的代码库包含一组专门为API编写的服务。现在,如果您的客户端需要您从应用程序中删除整个API功能,重要的是您要将这些服务保存在一个单独的模块中,以便在不破坏应用程序的情况下轻松删除这些服务。这就是您需要框架中的模块化的地方。模块化使得在应用程序很大的情况下,可以很容易地插入新特性,而更复杂的特性应该随着版本的每次更改而迭代。
模块化的React
在React中,应用程序的每个部分都要处理组件。
在React中支持模块化的一种理想方式是确保应用程序的每个组件在理想情况下只做一件事。即使组件在增长,更好的方法是将其进一步分解为更小的子组件。
通过将代码库分割成小的、自包含的块,它使React应用程序开发比Angular更直观。您可以单独开发和测试模块,这使得添加特性和识别错误变得更容易。
模块化的Vue
Vue利用了“单文件组件”的概念。这似乎是在分离关注点方面的权衡,因为您的脚本、模板和样式将在一个文件中,但在三个不同的有序部分中。
学习曲线- React和Vue
我和我的同事能够轻松地学习这个工具吗?
React的学习曲线
我观察到许多开发人员声称,如果使用Vue,他们在React中所做的事情会更好、更容易。但是所有这些声明对我来说都没有意义。对我来说,Vue更像是一个简单的JavaScript,还有一些新的想法,单向数据流、组件和事件驱动的模型。
Vue的学习曲线
在学习曲线方面,Vue胜过了其他Javascript框架。您只需要一些像样的JS技能或对ES6的良好理解就可以使用Vue。总的来说,即使使用文档本身,学习起来也容易得多。
开发者友好性和易用性
开始使用这个框架有多容易?
当涉及到开发时,框架应该更容易启动。比较Reactjs与Vuejs或任何其他框架的一种方法是,确定在有项目需求时启动它们的容易程度。
要为您的项目选择正确的框架,您需要确定您和您的团队想要在JSX还是HTML上工作。为了给您一个初步的概述,我想强调一下,基于标准HTML模板和组件的框架通常易于结构和代码重用。然而,新开发人员更有可能发现难以处理JSX。
React:开发者友好性和易用性
React希望您构建组件而不是模板,因为组件是最可重用的,并且对单元测试友好。它依赖于JSX, JSX允许您混合UI模板和JavaScript。但是在一天结束的时候,你会觉得你是在Javascript上工作。使用JSX可以极大地促进开发,因为它允许React显示更有用的错误和警告消息。
由于UI和JS代码不能在React中分离,所以关于样式的使用只有一个问题。
说到风格,你有多种方法来开始:
- 使用webpack提取您的导入' my '.css语句转换成样式表
- 或者使用 “CSS in JS”库
当涉及到React项目时,它更像是一个狂野的西部,您拥有一个庞大的库和工具生态系统来补充您的应用程序。就我个人而言,我真的很喜欢这样,但是对于开发者来说,如果他们有很多选择的话,做出正确的选择并不总是那么容易。此外,React没有明确的规则或规章。每次应用程序的体系结构必然要改变时,您都必须选择不同的内容。这使得事情的范围很容易出错。
Vue:开发者友好性和易用性
Vue被称为“进步web框架”是有原因的,因为有不同的特性会影响正在开发的应用程序的大小。Vue还提供了一个CLI和与webpack等构建工具集成的包。在这种环境中编写组件的最首选方法是单文件组件,即带有模板、脚本和样式标记的文件。
我过去与几家公司合作过,当被问及选择Vue的原因时,他们给出的理由只是他们的开发人员觉得Vue更容易学习。Vue减少了初级开发人员和高级开发人员之间的差距,从而使他们在项目中很好地协作。它甚至对项目也有好处,因为它完成时bug更少,投放市场的时间更短。
测试和调试
框架的测试和调试方面有多好?
在React中测试和调试
测试:Facebook推荐Jest来测试React代码。下面是Jest和Mocha 的比较——还有一篇文章是关于如何在Mocha 中使用Enzyme 的。Enzyme 是Airbnb使用的一个JavaScript测试工具(与Jest、Karma和其他测试运行程序一起使用)。如果您想阅读更多内容,这里有一些关于在React中进行测试的老文章(这里和这里)。
Vue的测试和调试
测试:目前,Vue缺乏任何重要的测试指导,但Evan在他的2017预览中写道,团队计划在这方面工作。他们建议使用Karma。Vue与Jest一起工作,还有Vue test Utils.。
调试:与调试任何其他web应用程序一样,Vue中的调试变得更加容易。您可以利用开发工具、断点、调试器语句等来调试应用程序源代码。还有这个vVue.js devtools ,这样您就可以轻松地调试Vue应用程序。
在React和Vue中支持服务器端呈现
框架支持服务器端呈现吗?
如果web应用程序的目标是优化高搜索引擎,服务器端呈现是一个基本要求。由于任何多页面应用程序都可以由几个较小的spa组成,因此框架拥有这个选项是一个重要的标准。
以下是AirBnB的开发团队对服务器端渲染的看法:
首先,与客户端呈现相比,服务器端呈现具有更好的用户体验。用户获取内容的速度更快,当JS失效或禁用时,网页更容易访问,搜索引擎也更容易索引它。
React中的服务器端呈现
目前,React缺乏关于SSR的官方文件。React API支持一个名为ReactDOMServer的对象,当您希望以HTML代码的形式显示组件时,该对象非常方便。此外,学习如何使用诸如React Router和Redux这样的库,以便在没有任何问题的情况下执行服务器端呈现,也是很重要的。React团队宣布官方支持将很快发布。还有一个框架可以用来创建一个React SSR应用程序,叫做Next.js。因此,React启用了SSR,但没有官方支持,并且使用了额外的第三方包。
Vue中的服务器端呈现
还有一个官方发布的Vue.js指南,用于构建在服务器上呈现的Vue应用程序。该指南放置在一个特殊的领域,与Vue文档分开。它非常详细,并且假设用户已经熟悉Vue,并且对Node.js和Webpack有一定的了解。此外,文档引用了 Nuxt.js,是社区发布的框架,是Vue中对SSR的更高层次的解决方案。它提供了某些附加特性,但是,它限制了开发人员对应用程序结构的直接控制。
Reactjs与Vuejs中的代码可维护性
从项目开始算起,在5-10年以上的时间里,这些代码会给我带来更多的麻烦吗?
几年前,我的一个客户要求转移到一个框架,以便现在和将来的开发团队能够围绕代码工作。很明显,对于他们来说,拥有一个高可维护性的框架是多么重要。在比较框架时,代码的可维护性应该是最重要的方面之一。
也就是说,现在让我们比较一下在代码可维护性方面React和Vue是如何结合在一起的。
React的可维护性
至于React,虽然通往0.14系列的道路也很坎坷,但从React 15开始,Facebook开始以一种更负责任的方式专注于做出突破性的改变。即将到来的破坏性更改现在会在您的应用程序中发出弃用警告,并给您时间迁移到新的api。
当前的稳定版本(第16版)改变了一些核心的生命周期方法,但也正式稳定了一些长期使用的“实验”api,这意味着在达到这一点后,未来的更新会更容易。
由于React在工具上的反应更轻,虽然一些破坏性的更新可以自动化,但不是所有事情都可以。这意味着一些更新可能会比其他的更痛苦,尽管在核心库中的改进通常是值得的。
React的一个明显的烦恼是,旧版本文档的删除,使得现有(和潜在的未来)项目的维护更加困难,除非您保持最新。
Vue的可维护性
考虑到Vue的增长速度,决定Vue是否可以用作长期运行的框架将是未来的事情。我不会详细介绍这个方面,但是有一篇有趣的文章是关于Vue的可维护性因素以及它是如何应对的。
React vs Vue -性能和内存消耗
框架在性能方面是如何脱颖而出的?
说到性能,我想用这个简单的一行代码来说明我的情况:
“每个框架的绩效评估都很重要,它绝对应该是评估一个框架的重要前提指标。””
如果你还想知道这些框架在性能方面的突出之处,那么你可以通过这个综合的研究,在DOM操作的基础上对Reactjs和Vue的性能和内存消耗进行基准测试。这项研究是使用一个基准工具执行的,该工具测量了使用这些框架完成大量DOM操作事件所需的时间。
对React和Vue的性能进行基准测试
基准测试研究中包含的DOM操作基于研究这些框架在操作表行方面的性能。对这一行进行的操作是:
- 向表中添加10行,
- 向表中添加1000行,
- 每隔10行更新一次表,
- 在表中选择一行,并且
- 从表中删除一行
当涉及到React和Vue的内存评估时,该研究利用了Chrome Profiler,它可以让你对网页的JavaScript堆进行快照。
拍摄了两个快照来演示在以下时间的内存使用情况:
- 在执行任何操作之前加载页面
- 在表上执行5个添加10、5个添加1000和5个更新操作之后
研究结果如下:
React性能和内存消耗
性能:如图所示,当DOM更新越来越大,需要更新更多数据时,React的虚拟DOM似乎获得了回报。这就是大多数React出现的性能问题。React在删除和添加1000指标上的性能最好。
内存消耗:React的初始内存占用与Angular非常相似。从初始状态8.3 MB的内存消耗到DOM操作之后15.1 MB的内存消耗,您可以看出响应DOM操作操作的计算开销相当大,但它们仍然可以。
Vue性能和内存消耗
性能:在大多数情况下,Vue的性能与React一样好,比如添加10、更新和选择指标,很可能是这样,因为Vue还利用虚拟DOM来操作操作。
Vue在性能方面反应滞后的唯一区别是增加了1000个指标,这是因为DOM操作操作数量的增加。
内存消耗:Vue在初始状态时的内存占用是7.6,考虑到它是纯JavaScript语言,这比React和Angular都要好。然而,一旦执行了DOM操作,这个值就会增加到16.1,这比React和Angular都要大。
可扩展性——Reactjs vs Vue
框架是否足够成熟,可以构建可伸缩的应用程序?
当谈到可伸缩性时,唯一重要的是您的解决方案如何处理请求的累积数量,以及在负载突然达到峰值时它的显著行为是什么。由于大多数基于JavaScript的web应用程序都是为大量用户设计的,因此评估您选择的解决方案是否具有可扩展性就变得非常有意义。话虽如此,让我们看看React和Vue是否满足可伸缩性预期。
React构建可伸缩的web应用程序
React只是一个用于在页面上创建和呈现可重用组件的库——您仍然需要收集一堆其他库来将它们组合在一起(路由、HTTP请求等)。
web应用程序中的可伸缩性问题主要归结为代码组织得有多好、技术债务的数量以及web应用程序如何作为一个整体进行架构设计。
根据我个人与数千个客户打交道的经验,我发现像Angular这样的框架绝对是可扩展的,因为开发人员从一开始就倾向于遵循这种设计模式。
不要误解我的意思,我喜欢React,但是如果一个React应用程序从一开始就没有经过很好的考虑,它可能会很快失控(比如很多意大利面条式的代码)。我曾经有一个客户为React编写了一个自定义类模块的特性,浏览他们的代码非常愉快。
也就是说,React仍然可以用于构建可伸缩的web应用程序,但只有在从一开始就考虑可伸缩性时才会考虑。
Vue用于构建可伸缩的web应用程序
作为轻量级的JavaScript库,Vue只适合于较小的应用程序。它不适用于构建可伸缩的应用程序。
React vs Vue:应用程序大小
框架适合轻量级还是重量级应用程序?
在为大型应用程序选择框架时,最重要的是一致性和架构决策制定。在大型应用程序中,明智地选择框架是至关重要的。否则,转换将是一个巨大的痛苦。
因此,让我们探讨一下React和Vue的框架大小以及它们的大小对您业务的软件开发项目的影响。
React
框架/库的大小会对软件开发项目产生重大影响。React大小约为100kb,非常适合轻量级应用程序。此外,React还需要其他库对特定任务的支持,其中一个任务就是路由。它的小尺寸非常适合轻量级应用程序。
Vue
Vue是其他框架和库中最小的。它的大小大约为80kb。它甚至比反应还要小。Vue非常适合开发轻量级应用程序。如果您需要一个小于Vue的库,那么您应该选择Preact。
React vs Vue -在哪里使用什么?
这些框架的顶级实用程序是什么?什么时候使用它们是正确的选择?
现在我们已经评估了几乎所有必要的因素,让我们探索您的项目的React和Vue的最重要用例。它将帮助你选择正确的一个,从而避免不必要的成本。
React
我认为React是构建静态网站的最佳选择。您所需要做的就是使用renderToStaticMarkup呈现组件,并将呈现的有效负载发送给客户机。
此外,选择React开发小而简单的应用程序可能并不过分,因为它是为大型web项目创建的。。尽管React需要大量样板代码来设置一个工作项目,但从长远来看,它的架构是值得的。
JSX提供了JavaScript的全部功能(如流控制)和高级IDE特性(如组件视图模板中的自动完成)。
React vs Vue:对照表
Reactjs vs Vue:选择正确框架的专家意见
我快速接触了一些Javascript专家和CTO,询问他们对于在React和Vue中选择一个框架的看法。我感谢@KentCDodds和@TomGoldenberg对这篇博客所做的宝贵贡献。
我们问了他们一些问题,以下是他们对这场辩论的看法:
Thomas Goldenberg,突击队首席技术官

你对著名的“React vs Angular vs Vue”辩论有什么看法?
我用的是React和Angular,不是Vue。但我不会在这方面投入大量资金,因为我觉得它的应用不如另外两种那样广泛。由于有了React和Angular,我肯定觉得React对代码更直观。也就是说,Angular一直在进步,TypeScript也得到了很多支持。
如果有机会构建一个社交网络应用程序,你会选择哪种框架(或语言)?
Social意味着许多连接,这将使React - GraphQL成为一个很好的组合。这将有助于准备所有连接数据。
如果有机会构建基于企业的电子商务web应用程序(有未来迭代的可能性),您会选择哪种框架(或语言)?有什么特殊的原因吗?
对于电子商务网站应用程序,我会使用Next.js,因为服务器端呈现对许多电子商务网站来说很重要,在这些网站中,每个列表都必须是可索引和可搜索的。接下来真是太棒了,时代周刊的团队也让人印象深刻。
如果有机会构建一个基于内容的平台,站点结构不会发生变化,您会选择哪种框架(或语言)?
我也会用Next.js,因为基于内容的平台需要有好的SEO和索引。
Kent C. Dodds, PayPal软件工程师,Javascript/ React专家

当你在React、Angular或Vue(或其他几个)中选择一个合适的框架(或语言)时,你会考虑哪些方面?
所有这些框架在功能和性能方面都非常相似。与其他框架相比,我更喜欢React是有一个原因的,这个原因是我相信它在概念上比其他框架更简单,而其他框架会使应用程序更具可维护性和更容易测试。与其他原因相比,最重要的考虑是我在一个给定的框架下会有多有效,而React对我来说绝对是最好的一个。
如果有机会构建一个社交网络应用程序,你会选择哪种框架(或语言)?
如果我有足够的时间去学习,我可能会尝试使用ReasonML作为语言,而ReasonReact作为框架。如果我需要快速完成它,那么我肯定会使用JavaScript(加上用于静态类型的Flow)并对框架做出反应。
如果有机会构建基于企业的电子商务web应用程序(有未来迭代的可能性),您会选择哪种框架(或语言)?有什么特殊的原因吗?
如果我有足够的时间去学习的话,我仍然更喜欢使用合情合理的语言和合情合理的框架。如果试验和学习的时间更少,我宁愿使用Javascript(加上用于静态类型检查的Flow)并作为框架来响应。
如果你的开发团队并不精通Javascript,你会选择哪种框架(或语言)?
我肯定会选React。原因是,我认为一个开发团队虽然不精通JavaScript,但构建web应用程序时肯定应该学习JavaScript,而能教他们最好的JavaScript框架是React。其他框架在隐藏JavaScript方面做得相当好,你最终会编写比JavaScript更多的框架代码,这在一开始看起来似乎是正确的,但从长远来看,团队最好还是好好学习JavaScript。
结论
React或Vue或任何其他基于Javascript的解决方案就它们自己的用例而言都非常酷。我想说,没有最好的解决办法。最好由您来确定您的用例,并将其映射到这些框架的各个方面。
为了让事情更简单,我总结了用例和React和Vue之间推荐的解决方案(不总是):
- 如果你喜欢摆弄大量的libary、工具或生态系统,那么选择React
- 如果你是一个“JS迷”,并且讨厌把你的UI和代码分开——选择React
- 如果你喜欢编写干净和简单的代码——选择Vue
- 如果你想尽快开始你的项目,选择Vue
- 如果您是一个没有团队的单独开发人员,请选择Vue(或React)
- 如果您希望开发可伸缩的应用程序,而不为测试和调试带来任何麻烦,请选择React
- 如果您想在您的项目中更好地分离关注点,请选择Vue
- 如果你喜欢玩Javascript并且接受应用状态变化的概念-选择React(或Vue)
- 如果你要建立任何复杂的应用程序,有更好的上市时间-选择React
那么你对React vs Vue的比较有什么看法,请在评论中告诉我。
原文:https://www.simform.com/react-vs-vue/
本文:http://jiagoushi.pro/node/1275
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 269 次浏览
【前端架构】React,Angular和Vue:哪一个最好,为什么
这是帮助开发人员构建Web应用程序的三种最流行的工具。 请继续阅读,了解哪一个最适合您的需求。
在当今的发展世界中,技术正在快速增长并且变化迅速,许多开发工具似乎可以解决不同的开发问题。在本次讨论中,我们将比较三种最流行的前端开发技术--Angular,React和Vue。我们正在基于项目架构或从开发人员的角度讨论这种比较,他们将为新项目选择技术。因此,我们首先需要明确决定是否要开发单页面应用程序(SPA)或标准的多页面应用程序。
库或框架?
所以在进行更深入的比较之前,我们首先需要确定需要哪一个 - 库或框架?实际上,库设计用于执行某些特定任务,它们通常并不复杂。因此,如果我们使用库构建应用程序,那么我们需要为每个任务选择一个库,以及设置任务运行器。库的主要优点是我们可以完全控制应用程序。但问题是设置项目需要花费更多的时间。
另一方面,框架是为执行更复杂的事情而设计的。因此,如果我们使用框架,那么它将自动为我们解决许多问题。每个框架都有一个预定义的设计或结构,包括许多库和设置的运行程序。框架的主要优点是开发过程要快得多,因为它包含执行不同任务所需的所有可能的库。但是框架的设计比库更严格。
React是用于构建用户界面的库,而Angular和Vue是用于相同目的的框架。
生命周期与战略比较
- React于2013年3月首次发布,被描述为JavaScript库。 React由Facebook开发和维护。 Facebook在多个页面上使用React用于许多组件,但不用于创建单个页面应用程序。 React也被Uber,Netflix,Twitter,Reddit,Udemy,Paypal,Walmart和其他人使用。
- Angular是一个基于TypeScript的JavaScript框架。它由Google开发和维护。它于2010年10月首次发布,但此后经历了多次更新,目前正在使用Angular 6. Angular被描述为“超级英雄JavaScript MVW框架。”Angular被Google,Wix,weather.com,Forbes和其他人使用。
- Vue是当今世界上发展最快的JavaScript框架之一。 Vue被描述为“用于构建交互式界面的直观,快速且可组合的MVVM。”它于2014年2月首次发布。它是前Google员工Evan You的心血结晶。 2016年,Vue第2版发布。它被阿里巴巴,百度,GitLab和其他公司使用。
Angular,React和Vue都在MIT许可下提供。
核心发展
根据上面的讨论,Angular和React受到Facebook,Google,Whatsapp等大公司的支持和使用。目前,Google在他们的许多项目中使用Angular,例如AdWords UI(使用Angular和Dart实现)。而Vue主要用于小型项目的个人。我们来看看在GitHub上找到的一些统计数据:
- Angular拥有超过25,000颗星和463个贡献者。
- React拥有超过70,000颗星和超过1,000名贡献者。
- Vue拥有近6万颗星,仅有120位贡献者。
灵活性
我们可以通过简单地将JavaScript库添加到源应用程序来开始使用React或Vue进行开发工作。但是对于Angular来说这是不可能的,因为它使用TypeScript。因为在当今的Web开发世界中,我们正在更多地接近微服务和微应用程序,React和Vue通过仅选择那些真正需要的东西来让我们更好地控制应用程序的大小。 Angular最适合作为基于SPA的应用程序的框架。
性能
在库或框架的大小的情况下,Angular相对于其他选项而言相当大。 gzip文件大小为143k,而Vue为23k,React为43k。 React和Vue都使用Virtual DOM,它可以提高浏览器DOM的性能。在整体分析中,Vue具有出色的性能和三者最深的内存分配。但是所有这三个选项在性能方面都非常接近。
如果要检查源,则可以访问下面的GitHub存储库:
结论
React,Angular和Vue对于开发都非常有用,并且它们都没有明显优于其他开发。所以下面我给出了一个表格,它将展示何时选择哪一个:
|
Angular |
React |
Vue |
|
想要使用TypeScript |
想要使用基于JavaScript的方法。 |
最简单的JavaScript学习曲线。 |
|
想要使用OOPS(面向对象编程) |
想要使用大型生态系统。 |
从事小型项目。 |
|
想要使用基于结构的框架 |
想要灵活性。 |
开发团队包含少数开发人员。 |
|
想要构建混合应用程序 |
想要构建本机应用程序。 |
|
|
开发团队拥有大量开发人员。 |
开发团队包含大量开发人员。 |
|
|
如果要将HTML分开以用于设计目的。 |
如果要为JavaScript代码和HTML代码保留单个文件。 |
如果要将HTML分开以用于设计目的。 |
如果你仍然无法决定你需要选择哪一个,我建议你先学习React,然后是Vue,然后是Angular。 因为前两个主要基于JavaScript,第三个完全基于TypeScript。
原文:https://dzone.com/articles/angular-framework-advantages-compare-to-react-amp
本文:https://pub.intelligentx.net/react-angular-and-vue-which-one-best-and-why
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 90 次浏览
【前端架构】Redux vs.MobX的权威指南

大型应用程序的前端管理是最难解决的问题之一。虽然有几种方法可以解决状态管理问题,但Redux和MobX是两个最流行的外部库,用于解决前端应用程序中的状态管理问题。在这篇文章中,我们将研究每个库以及它们是如何匹配的。
本文假设您对web应用程序中的状态管理工作有一个基本的了解。普通JavaScript和Redux框架都适用于普通或不可知的框架。
Redux
Redux是一个流行的状态管理解决方案,它结合了Flux和函数式编程概念。Redux的一些核心原则是:
- Redux只有一个存储——单一来源的真相
- 存储区中的状态是不可变的
- 操作会调用对存储的更改
- Reducers(减速器)更新状态
MobX
MobX是一个状态管理解决方案,可以帮助管理应用程序中的本地状态。
MobX的一些核心原则是:
- MobX可以有多个存储来存储应用程序的状态
- 任何可以从状态派生而不需要任何进一步交互的东西都是派生
- Action是任何可以改变状态的代码
- 当状态发生变化时,所有的派生都会自动和自动地更新
现在让我们比较Redux和MobX的一些关键特性,看看哪些特性更适合您的需求。
人气
在开始学习Redux或MobX之前,让我们看看哪个更受欢迎。
看看下面的谷歌趋势图。截至2019年4月,相比MobX,Redux在谷歌上似乎是一个更受欢迎和搜索的概念。

为了深入了解他们的受欢迎因素,让我们看看2018年JavaScript现状调查。它发布了过去三年里Redux和MobX在开发者中的受欢迎程度的数据。
Redux

Mobx

在过去的几年里,Redux已经获得了大量的人气,并且已经成为状态管理的最佳解决方案。虽然MobX不像Redux那么受欢迎,但它也有自己的优势。
获奖者:Redux
学习曲线
Redux
开发人员对Redux的普遍看法是它不容易学习。2018年JavaScript现状调查分析了Redux最不受欢迎的方面。在这里,开发人员投票认为他们不喜欢Redux的复杂性和它带来的艰苦的学习曲线。
它需要一些时间来理解它的模式和范例。它是通量体系结构和函数式编程概念的结合。如果您是一个函数式程序员,您可能会发现掌握Redux更容易,而如果您来自面向对象编程背景,Redux代码最初看起来很复杂而且很难理解。
学习Redux还意味着您需要了解像Thunk和Saga这样的Redux中间件,这会增加更多的学习内容。
Mobx
众所周知,与Redux相比,MobX更容易掌握。大多数JavaScript开发人员都精通面向对象编程,这使得学习MobX变得简单。另外,MobX中有很多事情是在幕后完成的,为开发人员创造了更好的学习体验。您不必担心状态的规范化或实现类似Thunks的概念。由于已经内置了抽象,因此编写的代码更少。
获奖者:MobX
存储数据-单个存储与多个存储
存储区是我们存储本地数据的地方。它保存整个应用程序的状态。JSON应用程序的状态存储中通常包含一个巨大的对象。
Redux
在Redux,只有一家商店,它是唯一的真理来源。存储中的状态是不可变的,这使得我们更容易知道在哪里可以找到数据/状态。在Redux中,虽然有一个巨大的JSON对象来表示存储,但是您可以始终将代码拆分为多个reducer。这样,就可以用多个reducer在逻辑上分离关注点。对于许多开发人员来说,这是一种更直观的方法,因为他们可以始终引用应用程序状态的单个存储区,并且不存在与当前数据状态相关的重复或混淆的可能性。
Mobx
另一方面,MobX允许多个商店。您可以在逻辑上分离存储区,因此应用程序的所有状态都不在一个存储区中。大多数应用程序设计为至少有两个存储区:一个用于UI状态,一个或多个用于域状态。以这种方式分离存储区的好处是,您也可以在其他应用程序中重用该域。UI存储将特定于当前应用程序。
获奖者:Redux
这个类别的赢家是主观的;这取决于开发者的偏好。我个人喜欢将应用程序的整个状态存储在单个存储中的想法。这有助于我把同一个地方称为真理的唯一来源。有些人可能会说多家商店对他们更有效,更喜欢MobX。
数据结构
Redux
Redux使用普通JavaScript对象作为数据结构来存储状态。使用Redux时,必须手动跟踪更新。在需要维护大量状态的应用程序中,这可能更困难。
Mobx
MobX使用可观测数据。这有助于通过隐式订阅自动跟踪更改。在MobX中,更新是自动跟踪的,因此对开发人员来说更容易。
获奖者:MobX
纯与不纯
Redux
在Redux中,存储中的状态是不可变的,这意味着所有状态都是只读的。Redux中的操作可以调用对状态的更改,reducer可以用新的状态替换以前的状态。这是Redux的核心原则之一。
下面是纯函数的一个简单示例:
function sumOfNumbers(a, b) {
return a + b;
}函数将始终返回相同的输出,给定相同的输入。它没有任何副作用或来自外界的影响。
Redux函数使用以下模式编写。reducer是接受一个状态和动作并返回一个新状态的纯函数。
function(state, action) => newState
这让Redux变得纯洁。如果您有兴趣了解更多关于纯函数以及它们在Redux中如何操作的信息,您可以阅读本文以获得更好的理解。这是Redux最好的特性之一。
Mobx
在MobX中,状态是可变的,这意味着您可以简单地用新值更新状态。这让黑帮变得不纯洁。不纯函数很难测试和维护,因为它们并不总是返回可预测的输出。
获奖者:Redux
由于Redux存储是纯的,因此更容易预测,并且很容易恢复状态更新。在MobX的情况下,如果操作不当,状态更新可能会使调试更加困难。
样板代码
Redux
关于Redux最大的抱怨之一是它附带的大量样板代码。当您将React与Redux集成时,会产生更多的样板代码。这是因为Redux本质上是显式的,很多功能都必须显式地编码。
Mobx
MobX更隐式,不需要很多特殊工具。与Redux相比,它的样板代码要少得多。这使得MobX更容易学习和设置。
获奖者:MobX
开发者社区
对于开发人员社区,Redux轻而易举地赢得了胜利。Redux附带了reduxdev工具,供成千上万的开发人员使用。它为调试Redux代码提供了惊人的支持。
MobX还提供开发人员工具,但它们没有Redux提供的相同质量的调试支持。
GitHub统计数据很好地表明了两个库的社区参与度。Redux拥有约48k星,超过672位投稿人。另一方面,MobX拥有大约1.9万星和155名投稿人。

如果我们看看npm的下载量,Redux是遥遥领先的。Redux平均每周下载300万次,MobX平均每周下载25.4万次。这表明Redux被广泛采用。

获奖者:Redux
可扩展性
由于Redux更加固执己见,并且期望reducer函数是纯的,因此它比MobX更容易扩展。Redux的固执己见和纯粹的特性使得应用程序具有可伸缩性。
纯函数更容易测试,因为它们是可预测的和简单的。这就产生了可伸缩的可维护代码。这是选择Redux而不是MobX的核心优势之一。
获奖者:Redux
结论
好吧,判决结果如何?基于开发人员社区、流行度和可伸缩性,Redux的性能优于MobX。但是,如果你想快速跟上速度,用更少的样板代码构建简单的应用程序,MobX可能是你的朋友。
原文:https://blog.logrocket.com/redux-vs-mobx/
本文:http://jiagoushi.pro/node/1281
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【1110777】
- 199 次浏览
【前端架构】webcomponents 介绍
什么是Web组件?
Web组件是一组Web平台API,允许您创建新的自定义,可重用,封装的HTML标记,以便在网页和Web应用程序中使用。自定义组件和小部件构建在Web组件标准之上,可以在现代浏览器中使用,并且可以与任何使用HTML的JavaScript库或框架一起使用。
Web组件基于现有Web标准。支持Web组件的功能目前正在添加到HTML和DOM规范中,让Web开发人员可以使用封装样式和自定义行为的新元素轻松扩展HTML。
产品规格
Web组件基于四个主要规范:
自定义元素
Custom Elements规范为设计和使用新类型的DOM元素奠定了基础。
影子DOM
shadow DOM规范定义了如何在Web组件中使用封装样式和标记。
ES模块
ES模块规范以基于标准,模块化,高性能的方式定义JS文档的包含和重用。
HTML模板
HTML模板元素规范定义了如何声明在页面加载时未使用的标记片段,但可以在运行时稍后实例化。
我如何使用Web组件?
此站点上的组件提供了可在Web页面和Web应用程序中使用的新HTML元素。
使用自定义元素就像导入它一样简单,并使用HTML文档中的新标记。例如,要使用paper-button元素:
<script type="module" src="node_modules/@polymer/paper-button/paper-button.js"></script> ... <paper-button raised class="indigo">raised</paper-button>
有许多方法可以安装自定义元素。当您找到要使用的元素时,请查看其README以获取安装它的命令。今天的大多数元素都可以与NPM一起安装。 NPM还处理安装组件的依赖项。有关NPM的更多信息,请参阅npmjs.com。
例如,纸张按钮概述描述了使用npm的安装过程:
mkdir my-new-app && cd my-new-app npm install --save @polymer/paper-button
如何定义新的HTML元素?
本节介绍Web组件规范的跨浏览器版本的语法。
使用JavaScript通过customElements全局定义新的HTML元素及其标记。使用您要创建的标记名称调用customElements.define()以及扩展基本HTMLElement的JavaScript类。
例如,要定义移动抽屉面板,<app-drawer>:
class AppDrawer extends HTMLElement {...}
window.customElements.define('app-drawer', AppDrawer);
要使用新标签:
<app-drawer></app-drawer>
使用自定义元素与使用<div>或任何其他元素没有什么不同。可以在页面上声明实例,在JavaScript中动态创建,可以附加事件侦听器等。
<script>
// Create with javascript
var newDrawer = document.createElement('app-drawer');
// Add it to the page
document.body.appendChild(newDrawer);
// Attach event listeners
document.querySelector('app-drawer').addEventListener('open', function() {...});
</script>
创建和使用阴影根 ( shadow root)
本节介绍使用shadow DOM规范的新跨浏览器版本(v1)创建shadow DOM的语法。 Shadow DOM是一种新的DOM功能,可帮助您构建组件。您可以将shadow DOM视为元素中的作用域子树。
影子根是一个附加到“host”元素的文档片段。附加阴影根的行为是元素如何获得其阴影DOM。要为元素创建shadow DOM,请调用element.attachShadow():
const header = document.createElement('header');
const shadowRoot = header.attachShadow({mode: 'open'});
shadowRoot.innerHTML = '<h1>Hello Shadow DOM</h1>'; // Could also use appendChild().
// header.shadowRoot === shadowRoot
// shadowRoot.host === header
用于构建Web组件的库
已经存在许多库,可以更轻松地构建Web组件。该网站的图书馆部分有其他详细信息,但您可以尝试以下内容:
- Hybrids 是一个用于使用简单和功能API创建Web组件的UI库。
- LitElement 使用lit-html渲染到元素的Shadow DOM中,并添加API以帮助管理元素属性和属性。
- Polymer 提供了一组用于创建自定义元素的功能。
- Slim.js是一个opensource轻量级Web组件库,它使用es6本机类继承为组件提供数据绑定和扩展功能。
- Stencil i是一个开源编译器,可生成符合标准的Web组件。
原文:https://www.webcomponents.org/introduction
- 78 次浏览
【前端架构】与平台团队一起铺设前端基础
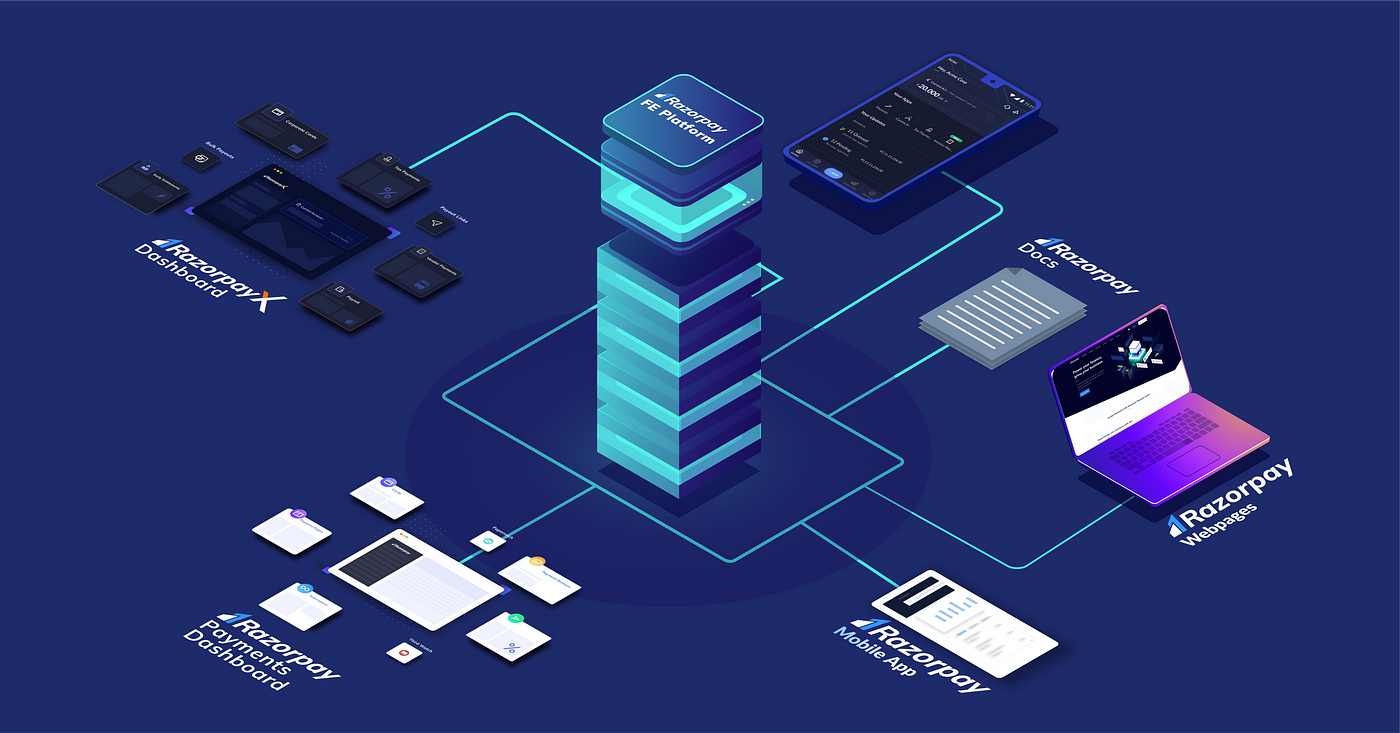
这篇文章是与 Razorpay 的前端核心团队合作的,该团队由 Varun、Kamlesh、Dhruvdutt、Chaitanya、Saurav、Zameer 组成。
去年,我们组建了前端核心团队,为构建与我们一样快的前端应用程序奠定了基础,这样开发人员就可以专注于更快地交付产品,而不会影响质量。
我们将走过这段旅程,了解为什么我们认为 Razorpay 应该存在这样一个团队,我们如何构建它,我们的使命、目标、原则、我们可以做得更好的事情以及我们下一步的发展方向。
为什么要组建前端核心团队?
多年来,随着新工具、框架、模式的出现和成熟,现代前端生态系统呈指数级增长。掌握现代前端堆栈对个人来说是一项巨大的努力。
Razorpay 的工程团队每年都在迅速扩大规模。在过去的两年里,仅我们的前端团队就增加了两倍多📈。
如果我们分解前端工程师的职责,就会做出各种各样的决定。
前端工程师的职责
- Front of Frontend:涉及构建产品、功能、用户界面、UI组件、可访问性、微交互等。
- 前端数据:涉及构建和管理客户端数据存储、状态管理、数据转换、与数据源交互、API 等。
- 前端骨干:涉及设置用于构建和部署应用程序的工具。包括为各种环境配置构建设置:本地、暂存、生产、设置测试框架、代码检查和格式化设置、添加 TypeScript 支持、设置 CI/CD 管道、设置工作流和 PR 检查。
Brad Frost 在他的博客中很好地介绍了这些内容。
我们提升了整个组织的前端工程师正在处理的问题,并创建了团队来建立基础。当时的想法是,只需要 4 名工程师来考虑前端构建工具,而不是 100 人。只有 2 名工程师需要考虑工具提示组件,而不是 50 人。我们建立了一个由专业工程师组成的团队,他们将在这些领域工作并构建一个我们前端堆栈的基础。
缺乏基础设施标准化
设置构建和部署的冗余工作。个别项目所有者必须深入研究这些方面。
缺乏设计一致性
我们在设计/开发过程中遇到了冗余,例如具有相同意图但具有不同变化的组件(按钮、输入字段、颜色等)
复杂的发布管理
复杂的构建和部署过程依赖于构建 ID、提交哈希、shell 脚本和脆弱的 CI 配置。在没有 SLI/SLA 的情况下,缺乏用于可预测错误和性能监控的可观察性工具。
缺乏测试框架
缺乏基础测试,在设置测试方面付出了多余的努力,单元/集成测试的摩擦很大。
复杂的本地环境设置
建立项目的学习曲线很高,本地环境需要很长时间才能构建,这会减慢开发速度,缺少项目指南。
旧版工作流程
让我们看看我们在组建前端核心团队之前遵循的日常工作流程,以及让我们放慢速度的漏洞是什么。
我们有很多移动的部分,它们很脆弱,也有巨大的学习曲线。 随着更多产品和团队的扩展,我们将重做相同的事情,失去在工具基础设施的帮助下自动化此工作流程中的许多部分的巨大潜力。
Lifecycle of frontend app in legacy workflow
涅槃工作流程
这是我们希望为 Razorpay 的所有产品实现的未来工作流程。 我们相信这将显着提高我们产品的开发效率、开发人员体验、可扩展性和性能。
Lifecycle of frontend app in the nirnava workflow
我们的旅程到目前为止 - 奠定基础
在回顾了我们在跨产品的前端工程方面的低效率之后,我们展示了我们的愿景以及我们如何通过以下方式使产品更具弹性和效率:
- 创建有关可以在开发工作流程中填补的空白的详细文档。
- 展示当前的挑战和我们对领导层的愿景
- 为在当前工作流程中投入的时间和金钱以及我们可以优化的地方创建成本估算。
一些单独尝试解决类似挑战的内部工程师聚集在一起建立了前端核心团队。我们实现了我们的愿景,为团队制定了年度目标和 OKR,并开始了这一旅程。
我们主要在两个轨道上工作:
- 工具和核心基础设施
- 设计系统
工具和核心基础设施
由明确标准管理的工具、实用程序和配置的瑞士刀。它们可以组合在一起以构建或扩展到任意数量的产品。
在内部,我们将此项目命名为 Frontend Universe。
我们创建了一个包含多个包的 monorepo,每个包都有自己的边界和范围。
我们的工具链由各种包组成,所有这些包都可以作为单独的包单独使用,也可以通过通用 CLI 使用。
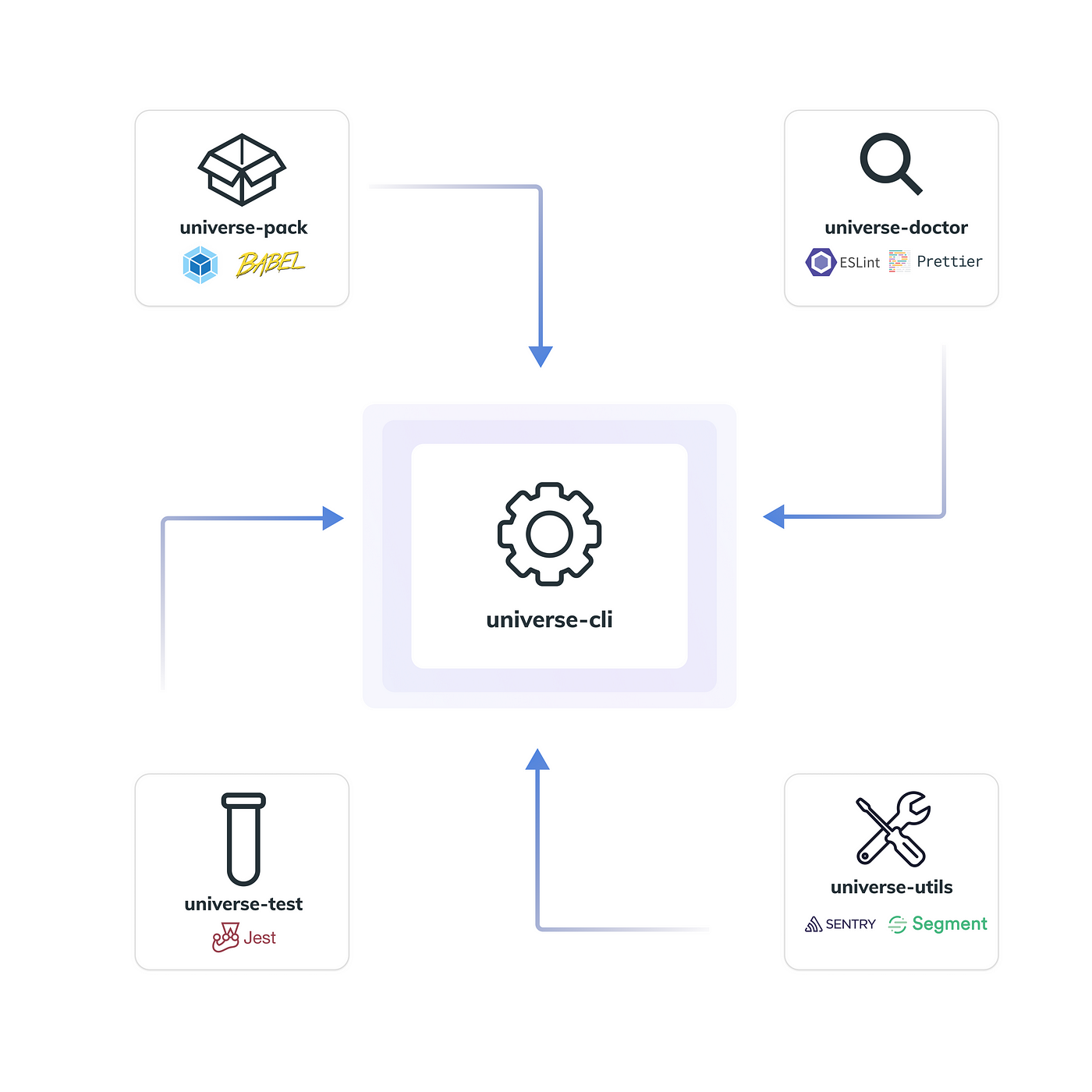
Packages and modules in frontend CLI toolchain
- Universe-cli:所有包的脚手架和作曲家
- Universe-pack:构建由 webpack、babel、metro 组成的工具链。
- Universe-doctor:我们的内部医生诊断所有可能使我们的代码库不卫生的事情(linting、格式化、提交挂钩、PR 检查等)。
- Universe-test:测试环境的工具链(单元、集成和端到端)。
- Universe-utils:通用服务和实用程序,如分析、a/b 服务、错误监控服务等。
这类似于乐高模型(积木),我们提供一组具有合理默认值和接口的模块来扩展或增强它们。 这使产品团队能够专注于构建实际产品,而不必担心使用的底层部件。
Scaffolding a new project using Universe CLI
消费者可以搭建和创建新项目或集成特定模块以向现有项目添加功能。
我们构建了一堆工具、实用程序和配置:
CLI 脚手架
- 使用 React、React Native 为 Web 和移动设备搭建新项目。
CI/CD 设置
- 使用 GitHub Actions 和 Spinnaker 管道预配置的 CI/CD 工作流。
- Docker 构建、Kubernetes 配置、部署管道的自动设置。
- PR 检查以验证构建,使用 DangerJS 自动执行 PR 杂务。
- 使用变更集生成变更日志和发布的自动版本控制。
SSR(服务器端渲染)支持
- 具有代码拆分、路由和 Redis 缓存的 SSR 设置可提供出色的用户体验
监控/可观察性
- 使用 SpeedCurve、Sentry(带有源映射、堆栈跟踪和错误严重性)捕获性能和错误指标。
服务和配置
- 使用 ESLint、Prettier 和 Stylelint 进行 Linting
- 打字稿设置
- A/B 测试 SDK
- 用户事件分析 SDK
- 使用 DangerJS 自动化公关工作
- Monorepo 支持
- 移动应用程序的推送通知
- 像secretlint这样的安全机制
- 常用的实用程序,如 lodash、日期函数等。
所有这些功能都可以在新项目搭建时预配置开箱即用,也可以作为现有项目的可插拔模块使用。这种模型减少了现有项目在加入和迁移到这些新工具时的摩擦,而无需进行大的重构。
设计系统
设计系统是一套工具,由明确的标准管理,使我们的产品(跨平台——网络和移动)保持一致,减少消费者的学习曲线,提高设计师和开发人员的生产力。
我们设计系统的目标不仅限于为开发人员提供可重用的模式,而且还弥合了设计师+开发人员工作流程之间的差距,这促使我们跨越了从设计工具到源代码的界限。

Building apps using cross-platform design system
我们的重点是建立一个成熟的系统,在实施设计的同时简化设计人员的设计工具以及开发人员的生活,这反过来将增强这两个功能的体验,即更好的 DX(设计/开发体验) ) ➡️ 更好的用户体验。
- 我们从 MVP 开始,通过构建实际产品来展示设计系统的价值。
- 基于我们从 MVP 中学到的知识,我们退后一步,开始完善我们的核心原则,如颜色、排版、间距、边框等,然后从那里开始构建组件。
这让我们一瞥我们的前进方向:
Phases of Design System
如前所述,我们正在努力使我们的开发人员和设计体验变得更好。 这是我们构建的一个 Figma 插件的一瞥,它是为了让我们的设计令牌与我们的代码保持同步。 (这个插件也可以很容易地由设计系统设计师运行)。
Plugin to auto-sync tokens between Figma (Design) and GitHub (Code)
我们遵循的原则和实践
随着我们随着时间的推移建立和扩展前端核心团队,有一些原则可以帮助我们与我们的愿景保持一致:
- 一个拥有所有权心态的小型自治团队。
- 构建一个具有合理默认值的固执己见的工具链,但又足够灵活,可以根据产品需求对其进行塑造,从而帮助团队更快地交付和扩展。
- 通过提供集成可插拔模块或选定功能的接口来降低进入门槛。
- 将平台视为产品,将开发人员视为客户。经常收集反馈并进行迭代,增强它。
- 长期胜于短期。除了为今天构建弹性解决方案外,还要以将来可以扩展或增强的方式设计它们。
- 在构建大型功能之前,进行彻底的研究并从团队中的工程师那里获得早期反馈。为此,我们遵循 RFC 流程。请检查我们的设计系统的一些 RFC。
- 尽可能传福音。传播意识并宣布我们发布的主要功能,同时强调它所增加的价值。举办演示功能的会议。
- 教育和授权团队,分享学习以获取意见,通过提供协作帮助鼓励贡献,编写包含示例的文档、迁移指南、常见问题解答、故障排除指南等。
- 通过集中讨论、收集反馈、进行内部会议、进行公开讨论和在办公时间进行咨询,与其他团队互动以了解他们的问题。
- 识别早期采用者(即零客户),从他们那里获取反馈并迭代产品。这也有助于在整个组织的其他工程师之间建立牵引力。
- 除了构建工具外,还要制定指导方针以传播意识并鼓励组织内的正确使用和文化。
我们本可以做得更好吗?
- 足够早地传福音。在我们最初的阶段,我们更多地关注核心能力的建设,而对内部传播的重视不够。这对我们在季度/年度计划期间围绕采用率签署 OKR 产生了影响。
- 假设产品市场从第 0 天起就适合所有人。建立能力,他们就会来找你——这不是真的。每个工具都必须根据消费者和采用需求而发展。
- 测量标准化是困难的。很难找到影响指标并量化开发效率以及代码的标准化和质量。
- 通过做更多的 FGD 来捕捉团队的工程脉搏,捕捉 NPS。这将帮助我们确定我们的优先事项,并始终与消费者的需求保持同步。
- 尽可能地认可和奖励。庆祝采用的胜利,奖励核心以外团队的贡献者,宣传成就。这将大大提高内部牵引力,带来认可并鼓励更多的采用者和外部贡献者。
原文:https://engineering.razorpay.com/laying-the-frontend-foundations-with-a…
- 162 次浏览
【前端架构】从 JQuery 到 React、Vue、Angular——前端框架的演变及其差异
这是前端面试中必然会问到的问题

前端开发多年来一直在不断改进。从简单的静态页面到现在复杂的单页面应用程序,我们的工具变得越来越强大。现在,三大前端框架统治着前端开发,那么你知道这三个框架的区别吗?为什么一直保持着三足鼎立的局面,而不是某种框架来统一其他人?让我们在本文中讨论这些问题。
前端开发的演变
PHP && JSP
早些年,网页的动态内容是在服务器端渲染的,主要使用PHP、JSP等技术。
此时,服务器通过模板引擎填充数据,然后生成HTML,并将HTML返回给浏览器进行渲染。
<!DOCTYPE html> <html> <body><h1>My first PHP page</h1><?php echo "Hello World!"; ?></body> </html>
AJAX
后来有了 AJAX 技术,JavaScript 可以直接在浏览器中发送异步 HTTP 请求,动态地从服务器获取数据,而不是把所有的数据都放在 HTML 中。
<body>
<h2>Hello world</h2>
<div id="demo"></div>
<script>
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function () {
if (this.readyState == 4 && this.status == 200) {
// Typical action to be performed when the document is ready:
document.getElementById("demo").innerHTML = xhttp.responseText;
}
};
xhttp.open("GET", "/api/data", true);
xhttp.send();
</script>
</body>
最早的 AJAX 是基于 XML 的,所以现在我们用 JavaScript 发送 HTTP 请求时,使用的函数叫做 XMLHttpRequest。但是XML中有很多不必要的标签,浪费了服务器带宽,所以JSON格式的数据占据了主流位置。
DOM API && jQuery
过去开发网页时,主要是通过浏览器提供的DOM API来操作DOM。
但是 DOM API 比较繁琐,在不同的浏览器中存在兼容性问题。为了简化dom操作和兼容不同的浏览器,jQuery开始流行起来。在那个时候,jQuery可以说是前端开发者必学的技术。
$( "button.continue" ).html( "Next Step..." )
前端框架
然后在开发网页的时候,我们发现一个网页需要做的就是先从服务器获取数据,然后根据数据更新DOM。
而且这个过程是固定的。为了简化 DOM 操作,人们发明了 MVVM 框架来自动将数据更改映射到 DOM 更新,而无需手动操作 DOM。这就是前端框架 Angular、React、Vue 所做的。
import { useState } from 'react'function Counter() {
const [count, setCount] = useState(0) return (
<div>
<p>you clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>increase</button>
<button onClick={() => setCount(count - 1)}>decrease</button>
</div>)
}
export default Counter
同时前端框架也支持DOM的逻辑划分。我们可以将 DOM 的一部分封装成组件,将组件相互组合,形成整个应用程序。
这种思路让我们可以将一个复杂的页面拆分成不同的组件,方便我们开发项目。
React、Vue、Angular 之间的区别
这些前端框架主要使用以下思想:
UI = f(state)
我们只需要声明一个组件的状态、视图和组件之间的依赖关系,就会自动生成组件的UI。
尽管它们的核心思想相同,但这些框架的实现细节却有所不同。下面我们来分析一下。
React JSX 与 Vue 模板
React 和 Vue 在描述视图层时给出了不同的解决方案。 React 选择扩展 JavaScript 并引入 JSX。而 Vue 创建了一个独立的模板语法。
React JSX:
export default function TodoList() {
let list = ['JavaScript', 'React', 'Vue']
return <div>
{
list.map(item => <li>{ item }</li>)
}
</div>
}
Vue模板:
<ul id="array-rendering">
<li v-for="item in items">
{{ item.message }}
</li>
</ul>
JSX 的优点:
- 在编写 JSX 时,开发人员可以使用他们现有的 JavaScript 知识,而无需太多额外的学习成本。
- JSX 可以利用 JavaScript 本身的特性,因此更加强大。
- JSX 代码和普通的 JavaScript 代码将在同一个执行上下文中执行,因此 JSX 可以很容易地与 TypeScript 结合。 Vue Template 和 JavaScript 执行上下文是分开的,所以在 Vuejs 中引入 TypeScript 比较困难。您需要分别声明 prop、method 和 data 的类型。
当然,Vue Template 也有自己的优势。由于 Vue Template 只能使用有限的语法,因此 Vue 可以更轻松地对其进行静态分析和性能优化,这在 JSX 中是很难做到的。
检查数据更新的不同方法
这三个前端框架都需要观察数据变化来决定是否需要更新 UI,但是他们选择了完全不同的方式来做这件事。
Angular 采用的方式是脏检查。每条可能修改数据的语句执行完毕后,Angular 都会对比前后的数据,判断是否有数据变化。
Vue 直接使用 JavaScript 的原生特性来监控数据变化。 Vue2 使用了 Object.defineProperty ,而 Vue3 使用了 Proxy。
另一方面,React 采取了不同的策略。 React 并不直接监控数据变化,而是在数据和 UI 之间添加了一个虚拟 DOM。每次组件应该更新后都会重新生成一个虚拟 DOM,React 会获取新虚拟 DOM 和旧虚拟 DOM 之间的差异。然后 React 决定是否以及如何更新真实的 DOM。
Vue 和 React 的优化
Vue 的数据监视是在组件级别。当组件内部有很多地方可以看数据变化时,一次更新可能需要大量的计算,这可能会导致丢帧,也就是渲染卡顿。所以Vue的优化方法是将大组件拆分成小组件,这样每个数据不会有太多的watcher。
React 不会观察数据变化,而是渲染整个虚拟 dom,然后进行 diff。所以 React 的优化方法是对于不需要重新渲染的组件,通过 shouldComponentUpdate 跳过渲染。
但是,当应用程序的组件树非常大的时候,仅仅使用 shouldComponentUpdate 来跳过一些组件的渲染,可能仍然是非常耗费计算量的。大量的计算也可能导致渲染冻结。那么我们应该怎么做呢?
树遍历有两种方法:深度优先和广度优先。组件树的渲染是深度优先的,一般通过递归来实现。递归调用不能暂停,可能会导致页面冻结。
但是如果我们用链表来记录访问路径,就可以把树的递归遍历变成数组的循环遍历。循环遍历数组时,可以根据时间片进行分段,这样虚拟dom的生成就不会再阻塞页面渲染了。这与操作系统对多个进程的分时调度非常相似。
将组件树变为链表,将virtual dom的生成由递归变为循环的机制有一个著名的名字:React Fiber。

与之前的组件节点相比,Fiber节点没有parent和children属性,但是有child、sibling和return属性。 React 通过 Fiber 链表树优化渲染性能。
在这里我们可以发现,Vue 的性能优化与 React 有很大的不同:
- Vue 使用组件级的数据监视解决方案。当一个属性有太多的watcher时,可能会出现性能瓶颈,所以优化思路是把大组件拆分成小组件,保证每个属性不会有太多的watcher。
- 但是,React 不会监视或检查数据更改。它每次渲染生成virtual dom,然后对比新旧virtual dom。优化思路是使用 shouldComponentUpdate 跳过部分组件的渲染。
重用代码的不同方法
组件之间会有一些共同的逻辑需要重用。 React 和 Vue 有不同的解决方案。
Vue的组件都是option对象的形式,所以很自然的想到通过对象属性来进行mixins进行逻辑复用。 Vue2组件的内部逻辑复用方案确实是mixin,但是mixin很难区分自己的属性和混合属性,也无法判断方法的来源。所以 mixin 的代码很乱,维护也很差。但是没有更好的解决方案。
React 在开始时也支持 mixins,但后来被弃用了。
React 组件有两种形式:类组件和函数式组件。对于类组件,像高阶函数这样的高阶组件(HOC)是重用代码的一种自然方式。具体来说,我们可以使用父组件包装子组件,在父组件中执行一些逻辑,然后渲染子组件。
除了使用 HOC,我们还可以直接将一些 JSX 作为 props 传递给另一个组件进行复用,也就是 render props。
HOC 和 render props 是 React 的类组件支持的两种逻辑复用方案。
原始功能组件是无状态的,仅作为类组件渲染的辅助而存在。
然而,HOC 的逻辑复用方式最终导致了组件的深度嵌套。而且,类的内部生命周期很多,把不同的逻辑放在一起会使组件更加复杂。
如何解决类组件的深度嵌套?并且解决方案不能进行重大更新。
所以 React 团队看了一下功能组件。他们希望在功能组件中扩展一些 API 以支持状态。
如果一个功能组件要支持状态,那么状态应该存储在哪里?
类组件本身是有状态的,成为纤节点后还是有状态的。功能组件一开始没有状态,成为光纤节点后也没有。
这样想,给功能组件的光纤节点添加状态还不够吗?
所以 React 将 memorizedState 属性添加到功能组件的一个 Fiber 节点中来存储数据,然后开发者可以通过 API 使用功能组件中的数据。这些 API 被称为 React Hooks。因为数据是在光纤节点上使用的,所以 API 被命名为 useXxx。
结论
三个前端框架各有优缺点。简单地比较谁更好是没有意义的。我们需要做的是为一个应用场景选择一个合适的解决方案。
技术在不断变化,但最终目的是提高工作效率,降低开发成本,保证质量。
原文:https://betterprogramming.pub/from-jquery-to-react-vue-angular-the-evol…
- 82 次浏览
【前端架构】使用React进行应用程序状态管理

React是管理应用程序状态所需的全部内容
管理状态可以说是任何应用程序中最难的部分。这就是为什么有这么多的状态管理库可用,而且每天都有更多的库出现(甚至有些库是建立在其他库之上的。。。npm上有数百个“更简单的Redux”的摘要)。尽管状态管理是一个很难解决的问题,但我认为,使之如此困难的一个原因是我们经常过度设计解决问题的方法。
有一个状态管理解决方案,我个人一直在使用React,随着React钩子的发布(以及对React上下文的大量改进),这种状态管理方法已经大大简化。
我们经常把React组件当作乐高积木来构建我们的应用程序,我想当人们听到这些时,他们会认为这不包括状态方面。我个人解决状态管理问题的方法背后的“秘密”是考虑应用程序的状态如何映射到应用程序的树结构。
redux如此成功的原因之一是react redux解决了支柱钻井问题。事实上,通过简单地将组件传递到某种神奇的connect函数中,就可以在树的不同部分共享数据,这一点非常棒。它对reducer/action creators/etc.的使用也很棒,但我相信redux的普遍存在是因为它解决了开发者的道具钻削痛点。
这就是我只在一个项目中使用redux的原因:我经常看到开发人员把他们所有的状态都放到redux中。不仅是全局应用程序状态,还包括本地状态。这会导致很多问题,尤其是当您维护任何状态交互时,它涉及到与reducer、action creator/type和dispatch调用的交互,这最终导致必须打开许多文件并在头脑中跟踪代码,以确定发生了什么以及它对代码库其余部分的影响。
很明显,对于真正全局的状态来说,这是很好的,但是对于简单状态(比如模态是开放的还是表单输入值状态),这是一个大问题。更糟糕的是,它的规模并不是很好。应用程序越大,这个问题就越难解决。当然,您可以连接不同的reducer来管理应用程序的不同部分,但是间接遍历所有这些action creator和reducer并不是最佳的。
将所有应用程序状态都放在一个对象中也会导致其他问题,即使您没有使用Redux。当一个反应<提供程序上下文>获取一个新值,使用该值的所有组件都将更新并必须呈现,即使它是只关心部分数据的函数组件。这可能会导致潜在的性能问题。(React reduxv6也尝试使用这种方法,直到他们意识到它不能正确地与hooks一起工作,这迫使他们在v7中使用不同的方法来解决这些问题。)但我的观点是,如果您的状态在逻辑上更为分离,并且位于React树中更靠近它的位置,那么就不会出现这个问题。
这是真正的关键,如果您使用React构建应用程序,那么您的应用程序中已经安装了状态管理库。你甚至不需要npm安装(或纱添加)它。它不需要为用户额外增加字节,它与npm上的所有React包集成,而且React团队已经对它进行了很好的记录。它自己反应。
React是一个状态管理库
当您构建React应用程序时,您将组装一组组件,以组成一个组件树,从<App/>开始,到<input/>、<div/>和<button/>结束。您不需要在一个中心位置管理应用程序呈现的所有低级复合组件。相反,你让每个单独的组件来管理它,它最终成为构建UI的一种非常有效的方法。你也可以用你的状态来做这件事,而且很可能你今天也会这样做:
function Counter() {
const [count, setCount] = React.useState(0)
const increment = () => setCount(c => c + 1)
return <button onClick={increment}>{count}</button>
}
function App() {
return <Counter />
}请注意,我在这里所说的一切也适用于类组件。钩子只是让事情变得简单一点(特别是我们马上要讨论的上下文)。
class Counter extends React.Component {
state = {count: 0}
increment = () => this.setState(({count}) => ({count: count + 1}))
render() {
return <button onClick={this.increment}>{this.state.count}</button>
}
“好吧,Kent,在一个组件中管理一个状态元素是很容易的,但是当我需要跨组件共享状态时,您会怎么做?例如,如果我想这样做呢:“
function CountDisplay() {
// where does `count` come from?
return <div>The current counter count is {count}</div>
}
function App() {
return (
<div>
<CountDisplay />
<Counter />
</div>
)
“计数是在<Counter/>中管理的,现在我需要一个状态管理库从<CountDisplay/>访问该计数值并在<Counter/>中更新它!”
这个问题的答案和反应本身一样古老(旧?)在我记事的时候,我就在文档里写了很久:提升状态
“提升国家”合法地回答了React中的国家管理问题,这是一个坚如磐石的答案。以下是如何将其应用于这种情况:
function Counter({count, onIncrementClick}) {
return <button onClick={onIncrementClick}>{count}</button>
}
function CountDisplay({count}) {
return <div>The current counter count is {count}</div>
}
function App() {
const [count, setCount] = React.useState(0)
const increment = () => setCount(c => c + 1)
return (
<div>
<CountDisplay count={count} />
<Counter count={count} onIncrementClick={increment} />
</div>
)
}
我们刚刚改变了谁对我们的国家负责,这真的很简单。我们可以一直提升状态,直到我们的应用程序的顶端。
“当然肯特,好吧,但是道具钻的问题呢?”
好问题。您的第一道防线就是改变构建组件的方式。利用组件组成。也许不是:
function App() {
const [someState, setSomeState] = React.useState('some state')
return (
<>
<Header someState={someState} onStateChange={setSomeState} />
<LeftNav someState={someState} onStateChange={setSomeState} />
<MainContent someState={someState} onStateChange={setSomeState} />
</>
)
}
你可以这样做:
function App() {
const [someState, setSomeState] = React.useState('some state')
return (
<>
<Header
logo={<Logo someState={someState} />}
settings={<Settings onStateChange={setSomeState} />}
/>
<LeftNav>
<SomeLink someState={someState} />
<SomeOtherLink someState={someState} />
<Etc someState={someState} />
</LeftNav>
<MainContent>
<SomeSensibleComponent someState={someState} />
<AndSoOn someState={someState} />
</MainContent>
</>
)
}
如果这不是很清楚(因为它是超级做作),迈克尔杰克逊有一个伟大的视频,你可以看,以帮助澄清我的意思。
不过,最终,即使是组合也不能为您做到这一点,所以您的下一步是跳转到React的Context API中。这实际上是一个“解决方案”,但很长一段时间以来,这个解决方案是“非官方的”。正如我所说,很多人求助于react redux,因为它使用我所指的机制解决了这个问题,而不必担心react文档中的警告。但是,既然context是React API的一个官方支持的部分,那么我们可以直接使用它而没有任何问题:
// src/count/count-context.js
import * as React from 'react'
const CountContext = React.createContext()
function useCount() {
const context = React.useContext(CountContext)
if (!context) {
throw new Error(`useCount must be used within a CountProvider`)
}
return context
}
function CountProvider(props) {
const [count, setCount] = React.useState(0)
const value = React.useMemo(() => [count, setCount], [count])
return <CountContext.Provider value={value} {...props} />
}
export {CountProvider, useCount}
// src/count/page.js
import * as React from 'react'
import {CountProvider, useCount} from './count-context'
function Counter() {
const [count, setCount] = useCount()
const increment = () => setCount(c => c + 1)
return <button onClick={increment}>{count}</button>
}
function CountDisplay() {
const [count] = useCount()
return <div>The current counter count is {count}</div>
}
function CountPage() {
return (
<div>
<CountProvider>
<CountDisplay />
<Counter />
</CountProvider>
</div>
)
}
注意:这个特定的代码示例非常做作,我不建议您使用上下文来解决这个特定的场景。请阅读支柱钻井,以获得更好的理解为什么支柱钻井不一定是一个问题,往往是可取的。不要太快接触上下文!
这种方法的酷之处在于,我们可以将更新状态的常用方法的所有逻辑放在useCount钩子中:
function useCount() {
const context = React.useContext(CountContext)
if (!context) {
throw new Error(`useCount must be used within a CountProvider`)
}
const [count, setCount] = context
const increment = () => setCount(c => c + 1)
return {
count,
setCount,
increment,
}
}
你也可以很容易地用这个来说明:
function countReducer(state, action) {
switch (action.type) {
case 'INCREMENT': {
return {count: state.count + 1}
}
default: {
throw new Error(`Unsupported action type: ${action.type}`)
}
}
}
function CountProvider(props) {
const [state, dispatch] = React.useReducer(countReducer, {count: 0})
const value = React.useMemo(() => [state, dispatch], [state])
return <CountContext.Provider value={value} {...props} />
}
function useCount() {
const context = React.useContext(CountContext)
if (!context) {
throw new Error(`useCount must be used within a CountProvider`)
}
const [state, dispatch] = context
const increment = () => dispatch({type: 'INCREMENT'})
return {
state,
dispatch,
increment,
}
}
这为您提供了极大的灵活性,并将复杂性降低了一个数量级。在这样做的时候,要记住以下几点:
- 并非应用程序中的所有内容都需要处于单个状态对象中。保持逻辑上的分离(用户设置不必与通知处于同一上下文中)。使用此方法将有多个提供程序。
- 不是所有的上下文都需要全局访问!让状态政府尽可能靠近需要的地方。
关于第二点的更多信息。你的应用程序树可能如下所示:
function App() {
return (
<ThemeProvider>
<AuthenticationProvider>
<Router>
<Home path="/" />
<About path="/about" />
<UserPage path="/:userId" />
<UserSettings path="/settings" />
<Notifications path="/notifications" />
</Router>
</AuthenticationProvider>
</ThemeProvider>
)
}
function Notifications() {
return (
<NotificationsProvider>
<NotificationsTab />
<NotificationsTypeList />
<NotificationsList />
</NotificationsProvider>
)
}
function UserPage({username}) {
return (
<UserProvider username={username}>
<UserInfo />
<UserNav />
<UserActivity />
</UserProvider>
)
}
function UserSettings() {
// this would be the associated hook for the AuthenticationProvider
const {user} = useAuthenticatedUser()
}
请注意,每个页面都可以有自己的提供程序,其中包含其下组件所需的数据。代码拆分对这种东西也“管用”。如何将数据导入每个提供程序取决于这些提供程序使用的钩子以及如何在应用程序中检索数据,但您知道从何处开始查找(在提供程序中)如何工作。
关于为什么这个托管是有益的,请查看我的“State colosition will make your React app faster”和“colocation”博客文章。有关上下文的更多信息,请阅读如何有效地使用React context
服务器缓存与UI状态
最后我想补充一点。状态有多种类型,但每种类型的状态都可以分为两种类型:
- 服务器缓存—实际存储在服务器上的状态,我们将其存储在客户机中以便快速访问(如用户数据)。
- UI状态—仅在UI中用于控制应用程序交互部分的状态(如模态isOpen状态)。
当我们把两者结合在一起时,我们犯了一个错误。服务器缓存与UI状态有着本质上不同的问题,因此需要进行不同的管理。如果你接受这样一个事实:你所拥有的根本不是状态,而是一个状态缓存,那么你就可以开始正确地思考它,从而正确地管理它。
当然,您可以使用自己的useState或useReducer在这里和那里使用正确的useContext来管理它。但请允许我帮你直截了当地说,缓存是一个非常困难的问题(有人说它是计算机科学中最难的问题之一),在这个问题上站在巨人的肩膀上是明智的。
这就是为什么我对这种状态使用并推荐react query。我知道我知道,我告诉过你不需要状态管理库,但我并不认为react query是状态管理库。我认为这是个藏匿处。这真是个好主意。看看!坦纳·林斯利是个聪明的小甜饼。
性能怎么样?
当你遵循上面的建议时,性能就很少是个问题了。尤其是当你遵循有关托管的建议时。但是,在某些用例中,性能可能会有问题。当您遇到与状态相关的性能问题时,首先要检查的是有多少组件由于状态更改而被重新呈现,并确定这些组件是否真的需要由于状态更改而重新呈现。如果是这样,那么perf问题不在管理状态的机制中,而是在渲染速度上,在这种情况下,需要加快渲染速度。
但是,如果您注意到有许多组件在没有DOM更新或需要的副作用的情况下进行渲染,那么这些组件将不必要地进行渲染。在React中,这种情况一直都会发生,而且它本身通常不是问题(您应该首先集中精力快速进行不必要的重新渲染),但是如果这真的是瓶颈,那么以下是一些在React上下文中使用state解决性能问题的方法:
- 将你的状态划分为不同的逻辑部分,而不是在一个大的存储区中,这样对状态的任何部分进行一次更新都不会触发对应用程序中每个组件的更新。
- 优化上下文提供程序
- 把 jotai带进来
这又是一个库的建议。的确,有些用例React的内置状态管理抽象不太适合。在所有可用的抽象中,jotai对于这些用例是最有前途的。如果您想知道这些用例是什么,那么jotai很好地解决的问题类型实际上在 Recoil: State Management for Today's React - Dave McCabe aka @mcc_abe at @ReactEurope 2020一书中得到了很好的描述。Recoil和jotai非常相似(并且解决了相同类型的问题)。但根据我和他们的(有限)经验,我更喜欢jotai。
无论如何,大多数应用程序都不需要像recoil或jotai这样的原子状态管理工具。
结论
同样,这是你可以用类组件来做的事情(你不必使用钩子)。钩子使这变得容易得多,但是您可以用React 15来实现这一理念。尽可能保持状态的本地性,并且只有在支柱钻井成为问题时才使用上下文。这样做会使您更容易维护状态交互。
原文:https://kentcdodds.com/blog/application-state-management-with-react/
本文:http://jiagoushi.pro/node/1282
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 115 次浏览
【前端架构】利用服务器端包含构造微前端扼杀单一应用程序

Monolith Lake — snarbaz
敏捷的思维方式促进了对流程,产品和业务的迭代。如今,随着时间的推移,渐进式架构正在实现架构的渐进式变革。
迁移大型整体的最常用方法是:
- Big Bang:包括从头开始迁移遗留系统。风险很高,因为没有记录的功能可能会丢失,并且价值交付会下降,因为当时需要在两个系统上实现即将推出的功能,或者根本不需要。
- Strangler:包括稳定地迁移遗留系统将责任转移到新系统或服务,我喜欢将遗留代码称为服务。这种方法需要更多时间来扼杀巨石,但能够持续提供价值。
扼杀Monolith应用程序的旅程
现在可以很容易地选择Nuxt.js和Next.js这样的框架来使用React和Vue.js进行通用渲染页面,也称为同构应用程序,但是对于使用自己的模板引擎的框架来说很困难,而对于非javascript则更难Ruby on Rails,Laravel或Flask等框架。
Airbnb + Hypernova作为案例研究
Airbnb一直在稳步迁移基于Ruby on Rails构建的系统,将前端代码转换为使用Hypernova作为服务器端渲染服务的一致架构。
- 用户在Ruby on Rails服务器上请求页面。
- 服务器收集必要的数据以呈现页面。
- ERB模板使用自定义渲染器向Hypernova服务器请求组件。
- Hypernova服务器使用React呈现所有请求的组件,并将它们发送回Ruby on Rails服务器。
- ERB在生成的页面中注入组件。
- Ruby on Rails将HTML标记和javascript文件发送回浏览器。
- 在浏览器上,JavaScript用于逐步增强应用程序并使其动态化。
使用这种架构,Airbnb可以将其React组件重用于服务器端和客户端呈现,并将基于Ruby on Rails构建的Monolith的展示层解耦。
这是Airbnb工程团队撰写的详细文章。
在Laravel上使用Hypernova
Laravel是一个PHP Web框架,用于构建类似于其他框架(如ASP.net MVC,Ruby on Rails和AdonisJS)的现代Web应用程序。
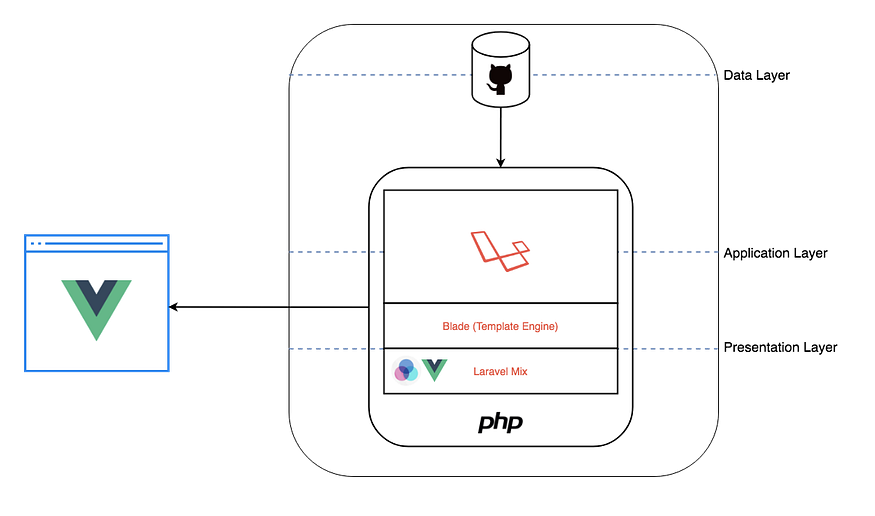
Laravel使用Blade作为服务器端渲染的模板引擎,Laravel Mix使用Javascript,CSS和Vue.js组件等资源进行客户端渲染。
支持Hypernova上的Vue.js.
Airbnb Hypernova不支持开箱即用的Vue.js,但它使我们能够开发自己的Hypernova绑定,所以我创建了hypernova-vue。
我写了这篇关于如何将Vue.js与Hypernova一起使用的文章,你也可以使用这个生成器。
第一种方法 - Hypernova客户端
将Hypernova服务器配置为使用Vue.js后,我在Blade中创建了一个自定义指令,以便将超新星组件放入Blade视图中。
Hypernova指令使用一个Facade,它将请求的组件推送到hypernova-php客户端,并在模板视图中添加一个占位符,以便稍后放置渲染的组件。
hypernova客户端是一个单例,因此我们可以持久保存所请求的组件,以便稍后从hypernova服务器获取它们。
最后,Blade基于模板视图呈现页面,Laravel中间件使用Facade修改原始响应。 场景背后的Facade使用Hypernova客户端向Hypernova服务器请求组件,并仅在一步上用所呈现的组件替换占位符。

我采用了laravel-hypernova包的一些想法,但我没有使用它,因为该库与Laravel 5.8不兼容,我遇到了处理来自hypernova服务器的传入错误的问题。
使用Hypernova指令
Laravel控制器只需要使用视图功能将视图名称和数据传递给Blade。
默认布局包含HTML文档,并使用hypernova指令定义NavBar组件。
欢迎视图使用默认布局,并使用hypernova指令定义Home组件。

呈现HTML后,结果如下:

该页面是服务器端呈现和客户端动态使用相同的Vue.js组件,这对于SEO非常酷。
我使用Hypernova服务器启用了Laravel通用渲染Vue.js组件,但它仍然与一些实现细节相关联。 Laravel需要使用Hypernova客户端直接与Hypernova服务器交互,因此该架构需要为每种语言或Web框架开发Hypernova客户端。
Hypernova代理方法
在深入分析了架构之后,我发现了一个与微前端原则密切相关的通用通信接口。

Blade生成的HTML包含占位符,其中包含生成批量请求到Hypernova服务器所需的所有信息,即使超新星服务器无法呈现视图,客户端脚本也会在浏览器上呈现组件,使前端具有弹性。
基于Laravel中间件方法,我决定在客户端和Laravel应用程序之间放置一个反向代理,以便服务器端包含(SSI)来自Hypernova服务器的视图。
我尝试使用OpenResty对Nginx进行扩展,但是我发现了使用HTML解析器和Lua的HTTP客户端的一些实现约束。
最后,在研究了很多之后,我决定选择Go来开发它。 Go有一个开箱即用的HTTP客户端和反向代理服务器模块,以及一个非常酷的库,可以使用查询选择器解析和改变DOM。
Hypernova代理如何工作
使用Hypernova代理Laravel只需要使用Hypernova指令,以便将Hypernova代理用于服务器端的占位符包含在页面中的Hypernova视图中,就像我们之前使用Laravel中间件一样,但现在我们可以重用Hypernova代理命令使用其他Web框架来通用渲染视图。

Hypernova代理
用户请求Hypernova代理上的页面
Hypernova代理将请求传递给Laravel服务器。
Laravel服务器收集渲染页面所需的数据。
Blade使用模板vue和hypernova指令呈现页面(div标签包含组件的唯一ID和名称,脚本标签包含组件的数据)
Laravel服务器将HTML页面发送回Hypernova代理。
当响应content-type是text / html时,Hypernova代理解析HTML以便为Hypernova服务器创建JSON请求,否则,它会在不修改响应的情况下发回响应。
Hypernova代理请求Hypernova服务器的视图。

Hypernova服务器使用Vue.js组件呈现所有请求的视图,并将它们发送回Hypernova代理。
Hypernova代理使用成功结果的HTML替换占位符,并保留错误结果的占位符,以使客户端脚本在浏览器中呈现它们。
Hypernova代理将修改后的响应发送回用户。
在浏览器上,JavaScript用于逐步增强应用程序并使其动态化。
结论
这种架构可以轻松地将域从monolith分发到新服务,我们还可以开发新服务,例如使用Express.js和Mustache.js partials来生成Hypernova Proxy向Hypernova Server请求视图所需的预期标记。
Resources
- Building Evolutionary Architectures
- Operationalizing Node.js for Server Side Rendering
- Strangler Application
- Using Vue.js with Hypernova Server
- Micro-frontends using Vue.js, React.js, and Hypernova
本文:http://pub.intelligentx.net/node/516
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 74 次浏览
【前端架构】单页应用程序vs多页应用程序—您真的需要SPA吗?

这些天你一定听说过很多关于单页应用程序的愤怒,如果你没有听说过,你可能生活在岩石下。
SPAs提供了许多好处,比如无缝流畅的用户体验、易于开发、简化调试和重用相同的代码来构建移动应用程序。您经常使用的许多应用程序都是单页应用程序。举几个例子:Facebook、Twitter、Gmail、谷歌文档等等。

(Google Docs)
毫无疑问,SPA是这些天的图表杀手,每个人都想要它的业务。但是,在您雇佣web开发公司来构建一个SPA之前,您必须了解SPA是适合您的业务需求,还是传统的多页面web应用程序工作得更好。
要回答这个问题,首先让我们了解web应用程序的类型。
Web应用程序的类型
web的诞生引入了超文本文档,但这些文档被复杂且功能丰富的web应用程序所取代。当前的web应用程序开发场景可以分为两种方法。它们是:
- 多页面应用程序
- 单页面应用程序
什么是多页应用程序?
多页面应用程序是传统的web应用程序,它在用户与web应用程序交互时重新加载整个页面并显示新的页面。
每次来回交换数据时,都会从服务器请求一个新页面,以便在web浏览器中显示。这个过程需要时间在服务器上生成页面,将其发送到客户机并在浏览器中显示,这可能会影响用户体验。
然而,AJAX使呈现应用程序的特定组件成为可能,但这使得开发过程更加困难和复杂。
多页面应用程序的优点
- 在搜索引擎上表现良好。
- 为用户提供web应用程序的可视化地图。
多页面应用程序的缺点
- 相对复杂的开发
- 耦合后端和前端
什么是单页应用程序?
顾名思义,单页面应用程序只包含一个页面。SPAs以一种简单、优雅和有效的方式呈现内容,因为它只在一个页面上加载所有内容,而不是将用户导航到不同的页面。
SPAs比传统web应用程序更快,因为它们在web浏览器本身而不是在服务器上执行逻辑。在初始页面加载之后,只来回发送数据,而不是整个HTML,这会减少带宽。
单页应用程序的优点
- 1. 单页应用程序流畅而快速。
- 2. 它们易于开发和部署。
- 3.spa更容易调试。
- 4. 可以通过重用相同的后端代码转移到移动应用程序。
单页应用程序的缺点
- spa在搜索引擎上表现不佳。但是现在,使用同构呈现/服务器端呈现,甚至SPAs也可以为搜索引擎进行优化。
- 单页面应用程序提供单共享链接。
- 由于其跨站点脚本,与传统的多页面应用程序相比,它们的安全性更低。
那么,你应该选择SPA吗?
虽然单页应用程序方法可以用于构建任何类型的web应用程序,但是在开始之前必须考虑以下几点。
首先,你需要列出你在你的web应用程序中需要的功能和功能。例如,您的站点是内容密集还是图形密集?还是两个?所有的图形和内容都可以适当地放在一个页面上吗?
您的业务是否涉及特定的产品或服务,或者您提供各种产品和服务。如果您的业务只处理一个产品,那么没有什么比一个页面应用程序更完美的了。然而,如果您的企业提供各种服务或产品,那么您肯定需要通过使用多页面应用程序将它们划分为不同的页面,从而对每一个服务或产品给予重视。这甚至可以为您提供每个页面的深度链接。

(Trello -单页申请)
您想为用户提供不刷新页面的实时体验吗?例如,一个实时汽车配置器。查看我们为Rezvani制作的单页实时汽车配置器。
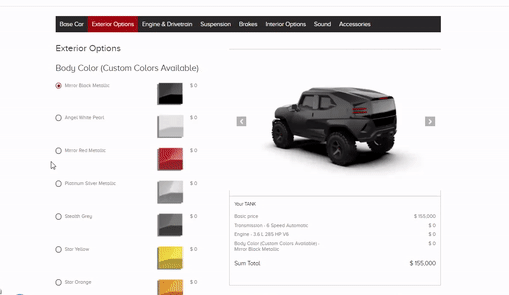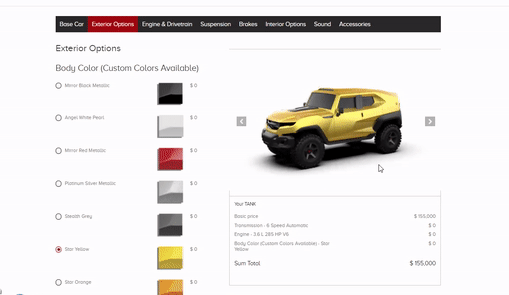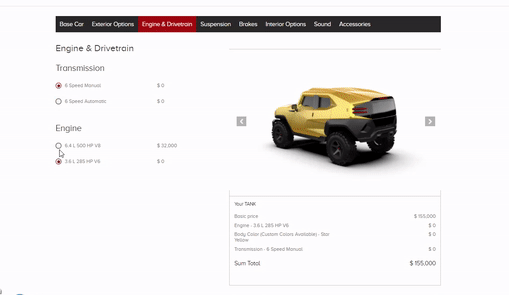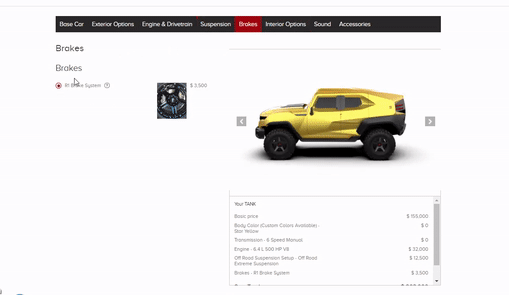
(Techuz的Rezvani实时汽车配置器)
如今的Web应用程序,无论是spa还是MPAs,都非常复杂、功能丰富,并且提供了令人惊叹的用户体验。因此,为了最大限度地利用这两种方法,您必须考虑您的业务和客户的需求。上面,我们试图介绍一些主要因素,这些因素可以帮助您在单页应用程序和传统的多页应用程序之间进行选择,从而为您的业务带来最大的好处。如果您仍然有任何问题,请毫不犹豫地联系经验丰富的web开发公司,如Techuz InfoWeb。
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 239 次浏览
【前端架构】哪个JavaScript框架适合您?Angular vs.Vue vs.React vs.Preact vs.Ember vs.smeltte

Angular、Vue、React、Ember、Preact和Svelte都有各自的优势,但哪一个适合您的下一个Web开发项目?
Angular vs.Vue vs.React vs.Ember vs.Preact vs.Svelte(pheew,在本次更新中添加了最后2项之后,即使是将jQuery委托给了历史,这也算是满嘴口水了!)是一个开发团队和产品所有者在每个新的web开发项目开始时必须问自己的一个问题。每一个流行的JavaScript框架和库都有各自的优缺点。不同的开发者、产品所有者和管理层在不同的选择上都有自己的舒适区和意见。
在我们将要介绍的JS框架和库中,Ember无疑已经达到了顶峰,现在正处于其活跃使用和普及周期的下降曲线上。2019年底发布的Ember Octane有望重回正轨,并吸引一批利基追随者。这似乎是在胡说八道,但现在就完全停止谈论Ember 还为时过早。
jQuery在这篇文章的前一个版本中已经讨论过了,但是我们已经把它放在这里了。这个库仍然用于一些需要支持旧浏览器的遗留应用程序,但是对于处理浏览器间互操作性问题的抽象层的需求现在基本上是多余的,jQuery也是如此。
其他的,Svelte 的和Preact的,是新鲜的感觉而且刚刚开始有了一个势头。他们可能会也可能不会继续严重挑战React、angle和Vue.js版当它们成熟的时候。

但如果只谈论React、Vue和Angular的话,那就太无聊了。Ember有一个重要的遗产,并仍将看到市场的需求一段时间,即使它看起来似乎它也在它的方式,随着技术的车轮转动。另一方面,Preact和Svelte才刚刚开始他们的旅程。它们正在制造一些噪音,但它们是否会成为公认的React、angle和Vue.js在企业层面。实际情况是,如果没有科技巨头的支持,比如谷歌对Angular和Facebook对React的积极支持,组织将新的框架和库视为一种战略风险,即使他们很欣赏自己的技术素质。
组织如何决定使用哪种JavaScript框架或库?
对于一个特定的前端开发项目,做出一个明智的决定,这是任何规划过程开始时的首要任务之一。有许多不同的考虑因素可以并且确实会影响对JS框架/库的选择的最终决定,这些JS框架/库将用于任何给定的前端项目。
当然,在所需功能组合的背景下,技术质量、利弊是在Angular、Vue、Ember和其他产品之间进行选择的一个重要因素。但是,假设每个前端项目选择JS框架归根结底都是对技术质量和特性的分析,这是过于简单的。
可以说,特定框架的优势使其在特定前端开发项目的上下文中具有优势。但是最流行的JavaScript框架和库都非常灵活,而且本身就令人印象深刻。最终的选择通常归结为更广泛的商业案例决策和实践性。
在框架之间的决策过程中,往往可以证明具有决定性的其他因素包括:
- 组织政策,即“我们在前端开发中使用React,除非有特别令人信服的原因说明应用程序无法实现所需的功能”。
- 开发资源的可用性,即“我们目前内部有Angular专家”或“我们的IT外包合作伙伴有Vue.js版团队可在接到通知后立即开始工作。
- 能否经得住时间的考验。将React构建的应用程序更新到框架的最新迭代比使用Angular、Vue.js或Ember要容易得多。从中期到长期来看,框架的积极支持和开源社区参与有多稳定?
- 开发商人气。招募和留住开发人员使用最流行的JS框架更容易。更多具有特定框架经验的开发人员也有助于将成本控制在合理的框架内。
本博客的目的不是试图客观地确定当前使用最多的JavaScript框架/库中哪一个是最好的。原因很简单,当代前端JS生态系统的美丽之处在于它的成熟性——在考虑大多数应用程序的技术需求时,有一些优秀的框架可供选择。
如前所述,在新项目中使用哪个JS框架或迁移遗留应用程序的决定通常与技术利弊一样取决于战略商业案例因素。
但我们要做的是,在React、Angular和,Vue.js还有Ember以及影响这些趋势的因素。这将有助于深入了解可能影响您决策的战略考虑因素。
我们还将全面概述这些框架的技术优势和弱点。这些质量将有助于确定特定框架选择对特定应用程序的适用性,在战略商业案例考虑中所有因素都是平等的。
我们能帮你吗
JavaScript用于什么?
在快速了解主流JavaScript框架生态系统的竞争优势之前,有必要先简单介绍一下JavaScript本身,然后问一下JavaScript作为编码语言的用途是什么?这将为我们深入研究JS库和框架本身提供上下文。
JavaScript最早发布于25年前,自那以后的几年里,JavaScript被认为是web开发的改头换面。尽管有着令人困惑的相似名称,JS完全不同于Java,后者是sunmicrosystems在同一时间发布的通用编程语言。它们唯一真正的共同点是它们都是为跨平台开发而设计的。
简而言之,JavaScript创建者Brendan Eich的目标是使网站更具交互性,改善用户体验。JavaScript在其诞生的头10年里获得了广泛的关注,但可以说微软2005年发布的AJAX才是真正的突破。
AJAX导致微软在其internetexplorer脚本中添加了XMLHttpRequest,这意味着可以通过从服务器下载新数据来实时更新实时web页面的HTML。再也不需要完全重新加载一个web页面来获取新的数据进行更新。其他浏览器很快就采用了suite,网站和服务器之间的异步通信成为了一种常态。
结果是出现了一种新的高度互动的应用程序,如谷歌地图和Gmail,紧随其后的是Facebook等。Google通过创建V8浏览器和解释器,进一步推动了JavaScript作为首选前端语言的采用率。它通过将JS编译成机器代码来弥补JavaScript的弱点,而不是在移动中实时解释它。
随着JS在过去的几年中逐渐成熟,并产生了开源插件,包括节点.js服务器环境和React原生移动应用框架,它已经不仅仅是一种编程语言。今天JavaScript是连接前端和后端、web和移动、基于浏览器和本地应用程序开发的桥梁。
JavaScript库和框架到底是什么?
编程语言、库和框架之间的区别最初可能会令人困惑。非技术管理人员通常认为React、Angular,Vue.js,Ember和jQuery是编程语言。
当然,他们不是。JavaScript是编程语言,以上都是基于JS的框架和库。但是,库和框架已经成为当代web和应用程序开发的标准,因为使用它们可以使软件开发更容易、更快,而且直接的结果是成本更低。
但是到底什么是库和框架?
什么是JavaScript库?
库是预先编写的执行常用JS函数的“代码片段”的集合。这些代码片段像乐高积木一样被用来构建更复杂的函数配置。例如,如果希望应用程序的搜索函数提供自动完成功能,则会插入一段库代码。
最终,库提供的代码片段可以加快构建整个项目的过程。但它们并不是一颗银弹,可以用来从头到尾格式化一个复杂的应用程序。
React、Preact和jQuery都是JavaScript库的示例。
什么是JavaScript框架?
另一方面,JS框架是一个完整的工具箱,可以用来创建网站或应用程序。一个很好的类比是把图书馆想象成房子的固定装置、装置和家具。而框架更像是用来建造预制建筑的模板和构件。
JS框架提供了构建整个web开发项目的框架。框架提供了页面模板,这些模板为以自定义代码的形式插入的详细信息留出了空间。这与使用库不同,在库中开发人员决定在哪里添加代码段。
框架的优势在于它提供了大量的效率和组织。代码结构良好,框架为经常遇到的编码挑战提供了开箱即用的解决方案。框架的缺点是它允许的灵活性较低。用户体验和功能的附加定制编码仅限于框架设计允许插入的地方。
框架和自由度必须根据具体的规则和规则进行调整,但必须根据具体的规则和规则进行调整。可以说,实际上,没有JavaScript框架真正符合“框架”的严格定义。正如StackOverflow上很好地解释的:
“软件框架的一个重要特征是其代码不受修改。在JavaScript中,显然不是这样。任何可以被调用到客户端代码中的库或框架都是可以修改的,尽管修改它们是不符合最佳实践的”。
框架:
- 侦听web请求
- 处理会话
- 调用代码来处理请求
框架调用应用程序的代码。但如果您使用的是库,则应用程序会从库中调用代码片段。
Java Brains的这段解释视频对JavaScript库和JavaScript框架之间的区别进行了更全面的解释:
Angular、Vue和Ember是JS“框架”的例子。Svelte,这个街区的新成员,被描述为一个“组件框架”。当我们更详细地看斯维特的时候,我们将更详细地了解这实际上意味着什么。
- Angular
- Ember JS
- Vue.js
你什么时候会选择JavaScript库,什么时候选择开发项目的框架?
对于什么时候选择JavaScript库,什么时候为特定项目选择一个框架,没有黑白对错的答案。但是根据经验,如果一个应用程序的业务和技术案例意味着您愿意在框架的限制下工作,并失去一些控制权以换取资源效率,那么使用JS框架是有意义的。
如果你想要更大的控制力和灵活性,并且愿意花更多的时间以你想要的方式组装你的应用程序,那么库在这种情况下可能更有意义。
Angular,Vue.js,React,Preact,Ember,Svelte:2020年哪个JavaScript框架最受欢迎?为什么?
在接下来的几个月里,任何一个接近web开发项目的人都会在React、Angular和,Vue.js,Ember,纤细或预燃。我们已经解决了一个非常近似的问题:何时选择JavaScript库,如React或Preact,何时选择Angular、Vue、Ember或Svelte。
现在我们将更仔细地看一下各个选项的相对优势和劣势。但作为一个介绍,让我们看看市场的更广泛的趋势。
开发人员对六大JavaScript框架和库的认识
当然,开源JavaScript框架和库比我们这里关注的6个还要多。例如,主干和米特里尔都有活跃的社区和信徒。但是,将我们的注意力集中在JavaScript状态报告所涵盖的那些方面是有意义的。缺乏在较小的框架和库方面拥有专业知识的开发人员意味着组织使用它们是不寻常的。
下图显示了全球数千名国际JS开发人员对主要框架和库的认识水平,这些开发者为sojs2019报告做出了贡献。它清楚地表明了Ember是如何在过去几年失去人气,与Vue.js版篡夺了它在第一桌的位置。它也展示了Preact和Svelte如何像几年前的Vue一样迅速出现在现场,并对JS景观产生了真正的影响。

下一张图很好地代表了开发者对这六种产品的看法,这可能是一个重要的线索,说明几年后每种产品的使用范围有多广。
我们可以看到React不仅应用非常广泛,几乎80%的JS开发人员都用它编写过代码,而且满意度很高。下一个方面是使用Angular,超过60%的JS开发人员已经使用了这个框架。
但是,尽管它作为付费和管理开发项目的一种选择很受欢迎,开发人员自己在对待Angular的态度上表现出相对较高的焦虑。大约58%的开发人员使用了Angular,接近三分之二的人说他们不想再这样做了。
他们的抱怨显然阻碍了其他人获得Angular方面的经验。那些还没有使用过它的人和那些没有打算或希望在将来使用它的人数是那些没有使用它但想学习Angular的人的三倍多。
这与Vue.js版. 大约有45%的JS开发者使用过Vue,但仍然相对较高,但大多数人对该框架持积极态度,并希望继续使用它。那些没用过的人Vue.js版然而,与那些不愿意的开发者相比,未来愿意加入的开发者要多出近两倍。
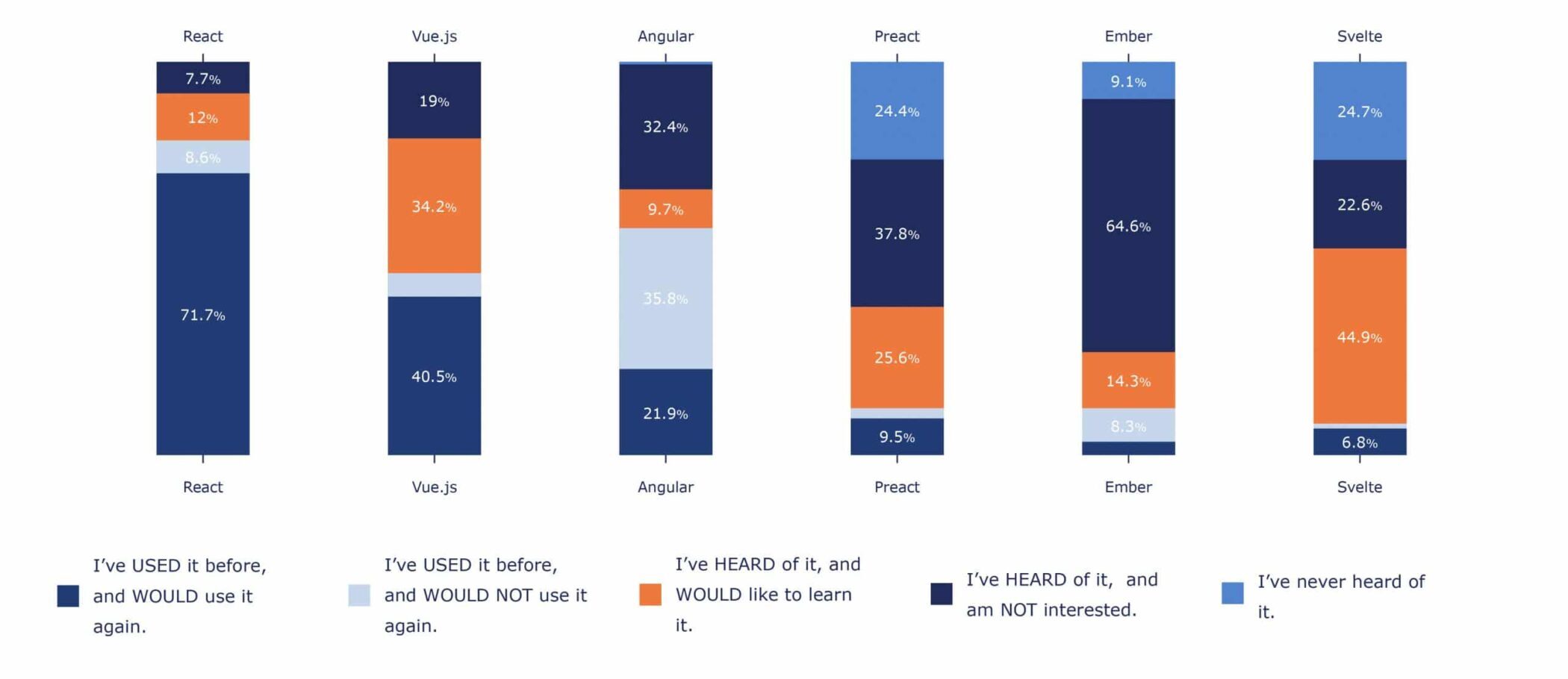
几乎10%的JavaScript开发人员从未听说过Ember,这表明它的流行度和相关性正在下降。在实际使用过Ember的JS开发人员中,有12%的人愿意再次使用Ember。超过80%的使用过Ember的大多数人不想再使用它。大多数熟悉Ember但没有使用过Ember的开发人员对此不感兴趣。
在这两个年轻的假装者中,斯维特周围的情绪最为积极。在使用过Svelte的7%左右的JavaScripts开发人员中,只有一小部分表示他们不想再使用了。其他人对新框架持积极态度。在那些还没有使用过但听说过它的人中,愿意在将来使用它的人比那些不感兴趣的人多出两倍。这可以被认为是基于听到了积极的事情。
Preact的情况大致相同,除了那些还没有使用过这个库的开发人员,与对Svelte的热情相比,对将来使用这个库的兴趣更少。
开发者2020年对Angular,Vue.js,React、Preact、Ember和Svelte的需求
主动的JavaScript开发人员经常在空闲时间探索和熟悉新的框架和库,并在个人项目中使用它们。但是,从利基到主流意味着公司和组织在开发新应用程序时选择使用框架或库。
这才是真正的考验。雇主们是想雇佣苗条的开发人员呢?就业市场上还需要灰烬技能吗?让我们看看。
StackOverFlow上公布2020年8月Angular,Vue.js,React、Preact、Ember和Svelte 公开的职位数量。

LinkedIn上招聘Angular, Vue.js、React、Preact、Ember和Svelte——2020年8月的职位空缺

这里的数字说明得非常清楚。从商业角度来看,JavaScript开发人员正在积极招聘国际上的空缺职位,到2020年,只有3个JS框架和库在使用——React、Angular和Vue.js版.
仍然有一些非常有限的需求,开发人员在烬经验。但是,尽管JavaScript开发社区对此很感兴趣,而且态度积极,但雇主实际上并没有雇佣苗条的或是前卫的开发人员。至少在统计上不相关。
当JavaScript 2020年的状态报告发布时,我们很有兴趣看看这是否反映在2019年至2020年间,这两家新兴企业失去了行业和社区的吸引力。或许斯维特和普莱克的势头并没有动摇。也许他们还有一段路要走,才能让项目发起人充分认识到未来的可行性,从而做出与他们一起构建应用程序的承诺。
比较Angular,Vue.js,React,Ember,Preact和Svelte的优缺点
我们刚刚看到的统计数据的市场证据表明,几乎所有使用JavaScript作为面向用户界面的新web和应用程序开发项目都会在React、Angular和Vue.js版2020年。它们都是很棒的库和框架。其他三种方法也有各自的优点,但在大多数情况下,它们显然不是商业上可行的选择。
这可能是因为人们对Ember、Svelte和Preact的积极支持和持续的OS社区开发的长期性的担忧。事实上,没有足够的开发人员具备这两方面的技能和经验,这意味着可持续招聘将是切实可行的。
但是抛开战略和业务考虑,只关注它们的技术优势,我们六大领先的JavaScript框架和库有哪些优势和弱点,或者说局限性呢?
Angular
AngularJS是一个基于TypeScript的JavaScript框架,也是该框架的第二次主要迭代,自2016年发布以来,AngularJS已逐步淘汰。2010年Google首次发布AngularJS时,作为第一批基于JS的前端框架之一,AngularJS引起了轰动。
Facebook 2013年发布的React库是一个更灵活的框架,它引起了人们对AngularJS局限性的关注,开发人员开始认为AngularJS已经过时,不再使用它。
一个很好的例子说明了为什么一个健康的JavaScript生态系统是由竞争和竞争的工具和标准驱动的,React的到来让Google升级了它的游戏,并创建了一个全新的单页应用程序(SPA)框架,这个框架仅仅是“Angular”发布的。
1.x版本之前的所有AngularJS版本都是AngularJS,2.x以后的所有版本都是AngularJS。与React等JS库不同,Angular是一个端到端的框架,它提供了构建企业级web应用程序所需的所有主要组件。
Angular更严格的结构(也是它的优势)固有的局限性,近年来React的普及率超过了它。有很多开发商会说Vue.js版它是由前谷歌(google)创始人埃文•尤(Evan You)设计的,旨在改善Angular认为的弱点,即卓越的框架。
如果您回顾一下JavaScript图形显示JS开发人员情绪的状态,这是显而易见的。但Angular仍然受到组织的欢迎,因为在谷歌的支持下,Angular被认为是经得起未来考验的。最终,框架仍然是一个强有力的选择,远远不是一个薄弱的工具。
K&C开发人员alexchugaev解释了为什么在企业级应用程序环境中,他更喜欢Angular而不是React和Vue。最终,Angular被证明是可靠的,并且在未来几年内将是一个重要的JavaScript资源。
这段由Fireship制作的视频比较了Angular、React和Vue.js版,辩称安格尔的情况。它还对JavaScript 2019年状态报告中使用的数据集进行了非常有价值的批判性分析。
Angular 优势
- 模块化;
- 如何使用组件和模块;
- 如何使用依赖注入;
- 有许多现成的“优点”,如路由器、表单验证、HttpClient等;
- 高水平的控制;
- 与React不同,Angular支持HTML和CSS的正常使用以及它们的所有特性和优点。
- Angular CLI是JavaScript环境中最好的命令行工具之一。
- TypeScript和将模板与样式和业务逻辑分离,使得Angular开发特别适合企业级应用程序的大型代码库。
- DOM sanitisation等内置功能使Angular成为最安全的前端框架。
- 谷歌对Angular的支持可能与Facebook所支持的资源并不完全相同,但足以确保该框架既能经得起未来考验,又能不断创新和改进。最近增加的功能包括延迟加载、用于改进模块加载时间的差分加载和Angular9的新渲染引擎Ivy,用于改进启动时间、响应时间和减小包大小。
Angular 弱点
- 对于没有经验的开发人员来说,使用Angular可能有点棘手,特别是如果他们没有很强的Typescript背景。然而,对于经验不足的人来说,这仍然比React要容易得多;
- 到目前为止,每一个新版本都与前一个版本有很大的不同,这会导致对框架的不信任,并使应用程序向AngularComplex最新版本的前瞻性迁移变得复杂。尤其是AngularJS和AngularJS之间的情况,不能直接在AngularJS和AngularJS之间切换。
- 依赖注入可能很耗时,并且为组件创建依赖项非常困难。
- 如果开发人员想要创建单页应用程序,那么他/她将受到限制。你不能把它放到你的完整堆栈或多页应用程序中。
- 棱角分明。对于较小的应用程序,它通常不是最佳选择。
React
React是一个用于UI开发的JavaScript库,尽管为了简单起见,它通常被称为framework。Facebook最初创建并维护React,这给了它很大的可信度。Uber、Netflix、PayPal、Airbnb、Twitter、沃尔玛和其他许多“巨头”都使用React,这是大中型项目的一个令人高兴的媒介。
React是一个基于组件的、具有单向数据流的web框架,它对前端web开发产生了重大影响,并在2020年成为JS应用程序的主流框架/库。React引入了函数式、声明式编程、不可变状态等概念,这在以前的前端开发中并不常见。React的另一大名气是引入了虚拟DOM,它有助于改善用户体验和应用程序性能。
React优势
- 优化不需要工作的世界。
- 灵活性。React与React Core是一个面向视图层的基于组件的库,提供几乎完全的灵活性和应用程序的定制。
- React灵活性的进一步表现是,它与不同的库和项目之间的交互几乎没有障碍。
- 图书馆真正践行其“一次学习,随时随地写作”的口号,可用于开发Web、移动(React Native)和桌面(电子)应用程序,也可用于后端开发节点.js.
- React使用javascriptes6,与使用TypeScript进行Angular分析相比,它有一个更温和的学习曲线;
- React设计用于基于JSX呈现内容。它可以在SPA和SSR架构中使用,使其成为此类开发工作的一个非常强大的解决方案。它的服务器端渲染优于竞争对手,并提供非常好的搜索引擎优化支持。
- 声明的。当数据更改时,有效地响应更新并呈现正确的组件。声明性视图还使代码可读,易于调试。
- 得到Facebook的支持,并被Facebook使用,意味着这家科技巨头将大量资源用于持续发展React。这也意味着,在历史上规模最大、流量最高的应用程序之一浏览器和移动原生应用程序上,这些功能都得到了验证。
- React不断创新和改进,最近的例子包括React Fiber用于改进并发性、React hook、减少样板代码和提高渲染效果的悬念。
React弱点
- React非常简单,但是基于React编译一个完整的框架是一项具有挑战性的任务;
- 灵活性可能是一把双刃剑,React提供的自由可能导致浪费时间来决定应对不同挑战的最佳方法。
- React使用JSX语法扩展来混合HTML和JavaScript也有另一面。它的复杂性可以看作是有效使用库的一个障碍,特别是对于初级开发人员。
- React开发涉及到使用广泛的组装工具,以使其功能良好并与其他web开发工具兼容。
- 糟糕的文档常常是React库的一个批评。一个非常活跃的社区和来自Facebook的资源支持可以看到定期发布的更新和工具,但是附带的文档常常缺乏。这会使开发人员很难跟上新特性的速度,而且库集成也很差。
Preact
Preact作为JavaScript库的目标是在更小、更轻的包中提供优势或做出React。作为SPA工具,Preact的重量为3kb,而React为30kb。这个库是由google的jasonmiller在一组贡献者的支持下创建的,被Uber、Lyft、腾讯、Groupon和Domino's使用。
最近发布的Preact X进一步清理了库的代码,并添加了新的特性和兼容性增强,以支持更多的第三方库。
Preact的大小和速度意味着它通常最适合于轻量级的移动web应用程序或web widgets/embedded,这些应用程序的React可能很重。它的极简主义本质意味着Preact通常会被考虑用于那些性能优先的小型项目。
Preact优势
- JavaScript生态系统中最快的虚拟DOM和最小的库之一。
- Preact的简单和可预测的diff实现是其速度的另一个原因。
- 有效的内存存储使Preact非常高效。
- 简单的应用程序可以在浏览器中运行,而不需要使用构建工具
- Preact提供了一个专用的CLI
- 使用React的API
- 可与React项目集成
Preact弱点
- Preact的主要弱点是其主要优点的直接结果,它是一种更轻、更快的React应替代品。它羽毛般的体型意味着它缺乏相同的特征范围。
- React的一个显著区别是“这个道具”和这个州'直接传递给render()方法。以后可以销毁它。
- 基于浏览器的“addEventListener”,Preact不支持合成事件。
- Preact的基本核心不支持PropType验证,这意味着如果您想使用它,则需要从“Preact/compat”模块导入它。
- 单元测试,React使用Airbnb为开发的酶测试工具,是可能的,但是需要一些Webpack配置,并且有一些限制。
Vue.js
Vue.js版2014年首次推出,2016年重新推出。Vue将自己描述为“用于创建交互界面的直观、快速和可集成的MVVM”。在K&C,我们倾向于同意这些形容词。
我喜欢在Packt上的一篇博客文章中对Vue的描述:
“Vue在三大阵营的前端JavaScript框架中占据着一个有趣的位置。它没有像React那样大肆宣传,也没有像Angular那样老牌,在过去的几年里,它一直在默默地关注着自己的业务,并建立了一个积极、热情的开发者社区。”
这个框架项目的主要目标是使webui开发中的思想(组件、声明性UI、热重新加载、时间旅行调试等)更易于理解。与其他框架相比,对于年轻的开发人员来说,学习它要简单得多。
如前所述,Vue.js版这是由前谷歌工程师Evan You创建的,他打算将Angular和React的优势结合起来,并在某种程度上消除各自的弱点。
尽管到达现场后,Angular和React,Vue.js版很快就获得了广泛的关注,并被阿里巴巴、任天堂、Expedia和其他多个企业级项目选中,这一点有时会让人觉得它是一个单页应用程序的框架。事实上Vue.js版不享受“大科技”公司的支持,使其日益增长的成功更加引人注目,并回避了一个问题,即它是否可能没有更受欢迎的程度的财务支持Angular和React受益。
但是Vue.js版的独立性也被视为(双关语意图😊) 被许多在web开发社区被认为是积极的。这也导致了一个特别勤奋的志愿者支持社区在Vue周围涌现。与Angular和React等大型企业支持的框架相比,问题和问题的响应速度通常要快得多。
另一个积极的副作用是没有被“过度设计”的清晰代码/API。这是一个很棒的视频Vue.js版对于任何想要简洁易懂的框架摘要的人来说:
Vue.js优势
- JavaScript代码、模板和CSS代码在React中没有混合;
- 可以使用ES5、ES6和TypeScript(有了警告,设置起来可能更困难);
- 与React一样,Vue可以很好地与其他库甚至项目交互。
- 这也允许渐进式的应用程序开发。大型遗留JavaScript代码库可以通过Vue.js版,这对复杂的迁移项目是一个很大的激励。
- Vue的文档易于理解且结构良好,开源社区在回答问题或问题方面尤其活跃。这使得起步相对轻松。
- Vue.js版同时也是一个固执己见的端到端框架和提供状态管理的视图层。
- 我们提到的目的Vue.js版将React和Angular的优势结合起来,也许最值得注意的例子是反应式双向数据绑定(比如Angular)和虚拟DOM、事件源(比如React)。
- 继续这样做,Vue.js版同时支持JavaScript和TypeScript。
- Vue是一个真正的轻量级框架,下载的.zip只有18KB。下载和安装这个库是超快速和轻巧也有一个积极的影响网站速度,通过扩展用户体验和搜索引擎优化。
- Vue.js版正在经历另一次重大的革新,比如从2014年的原始版本升级到2016年的2.0版本。Vue.js版3.0即将面世。它已经可以在beta版中试用了。正如你总结的创始人所言,VUE3有望成为“更快、更小、更易维护、更容易瞄准本机产品”。
Vue.js弱点
- Vue.js版它还是相对较新的,没有像Angular(谷歌支持)和React(Facebook支持)这样的大型科技公司的支持和资金支持。在大型企业级项目中更经常采用React或React型,Vue.js版仍然缺乏公司倾向于寻找的那种支持,以及为什么它在较小的项目中最常用。
- Vue在中国尤其流行,这意味着该框架的大部分内容、插件描述和说明以及社区讨论都是中文的。
- 反应性复杂性。在Vue中实现的用于管理DOM更新的双向数据绑定是保持组件同步的便利工具。反应性系统只重新呈现由用户激活组件所触发的数据块。在读取数据的过程中经常会出错,需要将数据展平。这是一个已知的问题,有大量的文件解释如何正确设置反应性。
- 与React或Angular相比,插件和工具的生态系统更小。
- 缺乏经验Vue.js开发者。这是一个鸡和蛋的情况,但更少的Vue开发人员可以让公司远离框架,而较低的客户需求阻止更多的开发人员学习它。
- 有趣的是,我们注意到Vue.js几乎所有这些都与框架在社区规模(尽管它也以其质量闻名)和企业级支持方面的成熟程度有关。在技术层面上,对缺陷的抱怨是很难得到的,这表明Vue.js版很可能会继续走红。
Ember
Ember开源框架是开发人员的老朋友,源于苹果音乐。受rubyonrails原则“约定优先于配置”的启发,Ember最出名的是作为应用程序开发字典的大型存储库。它考虑到约定而不是改变配置,并支持双向数据绑定。
自从2012年首次发布以来,Ember几乎没有看到重大变化,这意味着它是一个严格向后兼容的框架。另一方面,该框架每六周更新一次,并声称它坚持对稳定的坚定承诺。Netflix、苹果和微软只是使用Ember的一些公司。
Ember优势
- 在系统上简单配置;
- Ember是一个端到端的固执己见的内聚框架,专注于“约定优于配置”
- Ember得到了包括雅虎和LinkedIn在内的大型科技公司和品牌财团的支持。这意味着它并没有按照一家公司的需要进行调整。
- Embers数据库允许跨多个源同时访问数据,建立异步关系。
- Ember CLI被广泛认为是所有JavaScript框架中最好的CLI。它有助于生成正确的代码,并用正确的结构构建它们,同时考虑到依赖关系。
- Ember Inspector是一个方便的浏览器扩展,允许开发人员实时监控和编辑应用程序。
- Ember的MVVM(Model–View–ViewModel pattern)架构深受用户欢迎,该框架还提供双向数据绑定。
- 最近发布的dember辛烷迭代引入了一种HTML和组件优先的方法,改进了对状态管理和反应性的支持。
- Ember受益于一个活跃的社区,该社区定期向Ember Observer(一个聚合常见任务解决方案的网站)投稿。
- 你可能也会对我们的博客文章感兴趣,直接比较Angular和Ember。
Ember弱点
- 作为一个高度固执己见的框架,定制非常困难。
- 在最重的框架中;
- 难以掌握;
- 有时对小项目来说过于复杂;
- 新版本发布缓慢,几乎没有新选项。
- Ember与jQuery密切相关,对于喜欢使用标准fetch或Axios处理AJAX请求的开发人员来说,jQuery可能被认为是一个缺点。但是,在Ember Octane中,jQuery不再默认包含。
- 下降的人气可能使寻找好的灰烬开发人员棘手。
Svelte
Svelte诞生于2016年软件工程师Rich Harris的“尤里卡时刻”,他想出了构建一个JavaScript框架而不考虑任何特定于框架的运行时的想法。这是通过精巧地将特定于框架的代码编译成干净的JavaScript、HTML和CSS来实现的,并将编译后的代码呈现给浏览器。这种方法在软件开发中并不是新的,而是在前端开发环境中革命性的。
Svelte的第二个独特品质是增加了一流的反应性支持。这使得在不需要虚拟Dom的情况下提高了性能,这使得Svelte的渲染速度在任何JS框架中都是最快的。
基于组件(HTML、CSS和JS)和轻量级、轻量级的Svelte是用TypeScript编写的。但最重要的是,框架不需要掌握TypeScript知识就可以充分使用它。
JavaScript开发人员对此印象深刻,虽然对于sivelte来说还处于非常早期的阶段,但它已经吸引了很多人的兴趣,并迅速在前端开发领域获得了广泛的关注。一些勇敢的人甚至认为,Svelte最终可能取代React成为占主导地位的JS资源。然而,与Vue一样,缺乏强大的技术支持可能会在某个时刻导致牵引力瓶颈,尽管它的技术质量很高。
Svelte的优点
- 对于没有很多JS经验的开发人员来说,使用Svelte很容易。
- 编译时框架不需要任何特定于框架的运行时,并且Svelte的包大小是任何JS框架中最小的。
- 任何框架的最快渲染都要归功于通过反应式编程进行的Dom渲染。
- Svelte基于组件的框架允许通过创建可组合和可重用的组件来构建UI。结果是减少了样板代码和减少了开发时间。
- 和React Core一样,Svelte是一个视图层,没有任何细节。
- 同时支持客户端和服务器端呈现。良好的SEO支持。
- Svelte是跨平台的,可用于开发web、非本地移动和桌面应用程序。
Svelte的弱点
- 缺乏成熟度。仍然年轻,Svelte还没有很多重要的用例或第三方工具。缺少工装和工装支持是目前斯维特的主要批评。
- Svelte提供的特性数量仍然有限,这意味着必须编写大量代码或使用第三方工具来进行更复杂的开发项目。
- 与成熟的、占主导地位的JS框架和库相比,Svelte的社区仍然很小,文档不发达,并且通常缺乏大多数企业级项目所需的支持。
- 子组件不能用作用域样式调整。
- 不支持TypeScript。
- 很少有专门针对苗条开发人员的职位空缺。
有Angular,Vue,React,Preact,Ember还是Svelte?下一个JavaScript项目应该选择哪一个?
最后,你应该为你的应用程序选择Angular、Vue、React、Preact、Ember或Svelte中的哪一个?如上所述,每个框架或库都有其优点和缺点。正确的选择取决于应用程序的特定需求,而且通常至少也受到开发人员资源和业务考虑因素的影响。
但如果我们在对这六个问题进行如此广泛的审查之后,把它放在一边,那我们就是在作弊。因此,以下是一些经验法则可以帮助您决定:
- 如果您喜欢TypeScript,并且喜欢在一个风格和流程中清晰定义的框架中工作,那么您的解决方案是有Angular的。尤其是在大型企业级应用程序中,稳定性、支持和大量经验丰富的开发人员是首要任务。
- 你的解决方案是React. 如果你需要灵活性,喜欢大的生态系统,不想在不同的包之间选择,喜欢JS,喜欢你自己的方法和尖端技术。就像Angular的情况一样,React开发人员的深度池以及成熟的支持和稳定性也对库有利。
- 如果您也在考虑React,但是感觉到前者的轻巧带来的性能优势超过了它更有限的功能,那么您的解决方案就是Preact。
- 你的解决方案是Vue.js版如果您正在寻找一个更温和的学习曲线来帮助初级开发人员,需要一个轻量级的框架或需要干净的HTML文件。考虑到虽然Vue现在已经很成熟,但经验丰富的开发人员库并不像Angular或React那样多。
- 你的解决方案是Ember,如果你个人喜欢与框架合作,不过分担心几年后能够相对容易地雇佣Ember开发人员,并且不把未来验证视为战略必须。
- 如果你准备好优先考虑其技术优势而不是缺乏成熟度,或者不必担心或者愿意在经验丰富的开发人员队伍中冒险,那么你的解决方案就显得Svelte了。
- 如果你还是拿不定主意,那就在不同的环境中尝试一下。你会得出你自己的结论的。
原文:https://kruschecompany.com/ember-jquery-angular-react-vue-what-to-choose/
本文:http://jiagoushi.pro/node/1280
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 266 次浏览
【前端架构】用于企业级应用程序的 React 文件夹结构
以适合项目规模和意图的方式构建项目文件夹是可扩展性和可维护性的关键。 不幸的是,没有多少示例记录了适用于企业级应用程序的结构。 对于完美的文件夹结构是什么样的,也没有单一的正确答案。 以下结构是我多年来一直在发展并已在许多企业级项目中使用的结构。
本文的目的是解释这种结构背后的推理,以便您可以使用这些想法为您的项目构建最佳解决方案。
TL;DR
在解释每个目录的意图之前,让我解释一下这种方法背后的方法论。
可组合性
允许您在组件之间重用代码。这是 React 中一个非常强大的概念,并且对为什么拆分和分组可重用代码很常见的影响很大。
本地优先
在构建组件时,最好将仅与该组件相关的代码保留在本地。在我们上面的示例中,身份验证功能组件包含一个 auth-form 组件和一些实用程序。我们没有将它们分解到各自的组件或 utils 目录中,而是将它们保留在本地,因为它们包含的代码永远不会在另一个组件中使用。这将有助于防止这些目录随着项目规模的扩大而变得不合理。
平一点更好
每次嵌套时,您都会添加到理解组件本地代码所需的心智模型中。嵌套还伴随着其他痛点,因此最好避免过多的嵌套。
随着你的成长筑巢
扁平化可能更好,但也有嵌套的理由。例如,如果您的功能目录变得太大,您可能希望按逻辑对您的功能进行分组。
components/
- 包含最常用于组成功能或页面组件的可重用组件。
- 这些组件几乎总是纯粹的和展示性的,没有副作用。
constants/
- 包含可重用和不可变的字符串,如 URL 或正则表达式模式。
- 对于大多数项目,单个索引文件就足够了。
contexts/
- 包含用于通过组件树提供数据的可重用上下文。
- 如果直接使用 Redux,则可能不需要。
features/
- 包含可重用的功能组件。功能组件是一个受 Redux 启发的概念,其中功能所需的所有逻辑都位于一个目录中。功能组件通常由许多其他组件组成,无论是本地的还是共享的。对于所有资源也是如此:utils、types、hooks 等等。
- 功能组件通常包含副作用。
- 如果使用 Redux 并与 Store 交互,则功能组件将包含一个切片文件,该文件定义了该功能所代表的 Redux Store 的“切片”。
layouts/
- 包含可重用的布局组件。布局组件是组成页面布局的组件。它通常会导入 app-bar、app-footer、app-side-nav 等组件。
- 如果您的项目可能只有一个布局,则此目录可能不是必需的,并且布局组件可以位于 components 目录中。
hooks/
- 包含可重用的 React Hooks。
pages/
- 包含页面组件。每个页面组件都与一个路由相关联。
- 页面组件通过导入组件和功能组件来组成页面的内容。
- 页面组件应该很少包含副作用,而应该将副作用委托给功能组件。
services/
- 包含用于与 API 交互的可重用代码,通常采用钩子的形式,并且最好使用服务器缓存工具,如 React Query 或 RTK Query。
- 不要将其与 Angular-esque 服务混淆,该服务旨在处理将功能注入到组件中。 React 使用上下文和钩子处理这种情况。此目录应仅包含用于与 API 交互的代码。
- 受 RTK Query 建议的启发,将您的 API 定义放在一个中心位置。这是我们故意打破本地优先规则的唯一例子。我喜欢将 API 定义视为它们自己的模块化功能。事实上,用 features/api 目录代替 services 目录的情况并不少见。
“我们的观点是,与在整个应用程序的不同文件中拥有 X 个自定义钩子相比,当请求、缓存失效和一般应用程序配置都在一个中心位置时,跟踪它们的行为要容易得多。” — RTK
styles/
- 可重用或全局样式。
- 可能包括配置、重置或变量。
types/
- 使用 TypeScript 或 Flow 的项目的可重用类型。
- 我经常将我的可重用 Zod Schema 也放在这个目录中,并导出推断类型。
utils/
- 可重用的实用函数。
- 这些函数应该始终是纯函数并且不会产生副作用。
store.ts
- 如果使用 Redux,此文件是您导入所有切片和配置 Redux Store 的位置。
专业提示
- 每次开始新项目时都要阅读官方文档。 您永远不知道自您上次实现某个库以来可能添加了哪些新工具。
- 停止使用 PascalCase 作为文件名。 而是对所有文件使用 kebab-case。
- 使用服务器状态工具,如 React Query 或 Redux Toolkit Query。
- 使用像 MUI 这样的组件库。
- 使用像 usehooks-ts 这样的钩子库来处理常见的钩子。
原文:https://engineering.udacity.com/react-folder-structure-for-enterprise-l…
- 207 次浏览
【前端框架】React、Angular或Vue:为项目选择正确的框架

我们必须承认,我们在这些框架方面有着极不平等的经验。然而,我们将尽量保持公正,并弄清楚React何时可能不是最佳选择,但首先,简短介绍:
- React是Facebook维护的最流行的框架。所有的酷孩子,以及经验丰富的工程师都喜欢它。
- 我们有Angular感谢谷歌。它是企业中最古老、最著名的。
- Evan You从他以前在Google的工作经验中提取出他喜欢AngularJS的部分,从而创建了轻量级Vue。这是亚洲最流行的框架。
框架设计
Vue和Angular共享类似的设计,尽管Angular是一个复杂的平台,而不仅仅是一个小库。另一方面,React具有独特的设计,具有单向数据绑定和虚拟DOM。
React设计原则

React是基于可组合组件的思想构建的。它们是隔离的,在大多数情况下,只公开props 接口。它使团队协作更加容易,因为不同的人可以创建各种协同工作的组件。对组件进行更改也是一件轻而易举的事,而且这很少会导致整个代码库的更改链。
在React中,组件不会直接呈现给Dom。render方法返回需要呈现的内容的描述,React有一种快速而聪明的方法将其应用于DOM。
这个框架是关于组件层次结构的单向数据流。子组件不知道它们的父组件,只接收来自它们的props 。将函数作为属性传递是修改父组件状态的常见做法。它使得所有的东西都是松散耦合的、模块化的、快速的。
Angular 是为了企业

Angular更像是一个使用HTML和TypeScript构建应用程序的平台。它由不同的TypeScript库组成,可以导入到项目中,比如路由或ajax调用。
Angular应用程序总是有一个支持引导的根模块,通常有一堆特性模块。NgModules是将相关代码收集到功能组件中的基本构建块。
组件为屏幕元素定义视图,并使用与视图不直接相关的特定功能的服务。它利用依赖注入使所有东西松散耦合和模块化。
应用程序代码广泛地使用decorator为Angular提供额外的元数据。
对于视图,它有自己的模板语言,带有指令和绑定标记,可以根据数据动态呈现HTML。还有一个事件绑定可以让你的应用程序响应用户输入。与react不同,数据流是双向的。
Vue,两者兼而有之

Vue试图用最简单的API提供可组合视图组件和反应式(reactive )数据绑定的好处。Vue有一篇文章从其他框架的角度将其与其他框架进行了比较,值得一读,尤其是如果您已经熟悉其他两种框架之一的话。
Vue不是Angular那样的平台,而是像React一样的接口框架。与Angular一样,它支持双向数据绑定,但组件之间的单向父子数据流是默认设置。它还有一个独特的模板语言,并且不像React那样使用虚拟DOM。
Vue中的组件与Web组件规范中的自定义元素非常相似。他们故意按照规范对语法进行建模。但是,Vue组件在每个浏览器中都受支持,具有跨组件数据流、自定义事件通信和其他基本功能。
框架的优势

每个框架都有它最好的部分。React使开发变得轻而易举,Angular主要专注于企业,而Vue则是最轻量级的。
React优点
如果你问我们React最喜欢什么,那应该是JSX(TypeScript是TSX)。它是JavaScript的语法扩展,可以为组件编写类似HTML的呈现代码:
function Hello({ name }) { return <div>Hello {name}</div>; }
如果没有JSX,编写React代码会非常痛苦:
function Hello({ name }) { return React.createElement("div", null, `Hello ${name}`); }
上面的JSX在幕后被翻译成了非常相似的JavaScript。想象一下用它编写复杂的组件层次结构。你可以玩一下the online Babel compiler 来获得这个想法。
React团队非常关注API的稳定性。对于像Facebook、Twitter和Airbnb这样在生产中使用React的大公司来说,这一点至关重要。这些api与最初的版本相比没有太大变化。当他们决定删除某些内容时,他们首先将其标记为已弃用,这将触发linter和debug生成警告。
作为一个视图库,react通过互操作性得到了了巨大的好处。您可以快速将其放入现有项目中,并仅将其用于组件的一个子集。
对于性能,它使用“拉动”方法。与其他在新数据可用时执行计算的框架不同,React可以安排生命周期方法来延迟应用更改。
开发经验是React团队的首要任务。它们维护有用的React DevTools,并尝试使框架抛出的警告真正有用。
在React 16.8中引入React钩子使得几乎整个应用程序都可以使用短功能组件。函数式风格使代码更易于编写、阅读和理解。
除了HTML,React还支持Web组件和呈现SVG。它与渲染器无关,可以在浏览器内部工作,也可以在Node.js处理和输出HTML流,甚至在移动设备上使用React Native。
你可以在他们的“设计原则”(“Design Principles”)一文中了解更多关于它们的好处。
Angular 长处
作为一个平台,Angular的所有基础知识都是现成的。因此,应用程序通常具有更好的一致性、更高的代码质量和更高的安全性。您不必为常见任务处理不熟悉的第三方软件包。
默认情况下,Angular附带TypeScript。强类型语言有许多优点,比如出现错误的机会更少、工具更好、重构功能更强大以及总体上可维护性更好。我们也推荐它用于React项目。
与其他鼓励自由的框架不同,Angular通常有一种建议的做事方式。对于新开发人员来说,加入不熟悉的项目更为自然,因为每个应用程序的结构几乎都是一样的。它还使得维护大型代码库更便宜、更高效。
与其他框架中的组件类似,模块允许代码重用和由不同的人甚至团队进行并行开发。Angular社区还提供了带有可重用组件的预制模块。
Vue灵活性
轻量级和简单是Vue设计的核心原则之一。在所有三个框架中,它的包大小最小。Vue代码非常简单易懂。这可能是它受欢迎的主要原因。
与React一样,您可以轻松地将Vue添加到现有项目中,并开始将其用于某些部分。与React不同的是,Vue模板语法类似于HTML,因此转换现有代码更加方便。顺便说一下,它还支持JSX语法。
Vue的核心和最受欢迎的库都有公共CDN。您不必设置复杂的构建过程来使用它,添加头脚本(如jQuery)应该可以让您快速入门。
Vue覆盖了MVVM架构模式的ViewModel层。除了呈现HTML视图外,它还具有双向数据绑定,以使UI中的更改与数据同步,反之亦然。它比React的单向绑定直观得多,使它更容易在静态网站中添加动态功能。
它受到了另外两个框架的启发,并试图从这两个框架中获取最好的部分。组件来自React。指令以及双向数据绑定都是从Angular中借用的。它不仅仅是像React这样的UI库,也不是Angular这样的成熟平台。Vue拥有一个很好的平衡特性,这些特性都是现成的,而且没有固执己见,提供了广泛的选择自由。
每个框架的缺点

本文中涉及的所有框架都是健壮的,经过许多公司的生产测试,没有明显的缺点。但是,在为下一个项目选择框架时,需要记住一些事情。
React 缺点
React不喜欢第三方代码弄乱DOM。在React中提供具有根DOM元素的外部库很容易,并且只处理其生命周期。这就是流行的react-leaflet库如何用react接口包装纯JavaScript单张库。
单向的数据流是一个巨大的好处,在没有经验的人身上会造成很多伤害。清楚的理解是正确使用它的关键。我们认为React与其他框架有很大的不同,因此它需要自己的思考方式。
Angular 缺陷
Angular是一个复杂的平台,具有陡峭的学习曲线。应用程序代码冗长而复杂,这使得它不适合许多开发速度至关重要的敏捷项目。它是为企业级应用程序而创建的,因此可维护性是他们的首要任务。
包的大小通常比另外两个包大得多,尽管它取决于包含的库。再加上缺乏对服务器端渲染的支持,这使得Angular应用程序远不是SEO友好的。有点奇怪,考虑到它的创建者,谷歌是最大的搜索公司。
Angular的受欢迎程度正在慢慢下降,社区开始转向其他框架。许多开发人员认为这个已经有十年历史的框架是一种遗留技术,并且不愿意在基于它的项目上工作。
Vue缺点
Vue依赖于相当复杂的机制来实现其双向反应性(reactivity)。每个开发人员都应该意识到Vue无法检测到的这些情况:
- 对象的属性添加和删除
- 使用相应属性修改数组长度
- 按索引直接分配数组元素
JavaScript本身的局限性导致了这些问题,Vue团队对此无能为力。它们在反应性指南中有完整的记录。
作为最年轻的框架,Vue缺乏经验丰富的开发人员,学习资源有限。不过,生态系统本身相当广泛。
尽管它的受欢迎程度有一个强劲的上升趋势,但在撰写本文时,很少有大型项目是基于Vue构建的。对于应用程序的其余部分,没有多少最佳实践和经过验证的库。它引入了一些风险因素,在选择Vue进行更实质性的项目时需要考虑。
性能
所有的基准都来自Stefan Krause的综合JS框架基准测试。您可以检查每个框架测试的源代码,甚至可以在本地计算机上运行这些基准测试。所有的说明以及每个测试的详细解释都在存储库中。
Dom操作
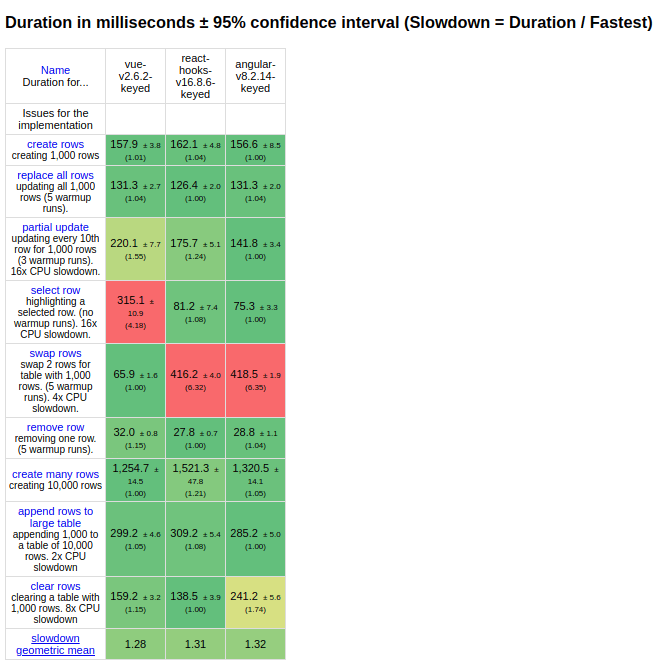
DOM操作测试在应用程序完全加载和预热后测量UI性能。
我们这里没有明确的赢家。Vue可能会使用独特的性能优化来加快交换行的速度。另一方面,Angular和React在highlighting rows测试中的性能都要优于React。
启动时间
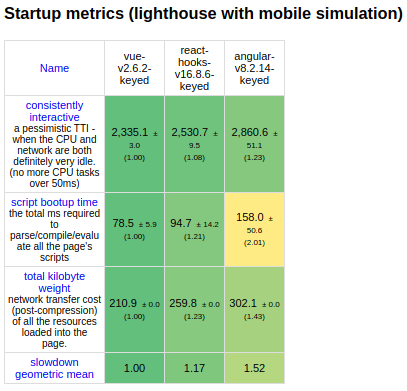
这些测试代表了Google在访问应用程序时推荐的高质量用户体验的“Web关键点”指标。
Vue凭借其轻量级的设计和最小的捆绑包大小击败了这里的所有人。React排在第二,只输了几分。角度,感谢它的束大小和复杂的引导是最后一个明显的区别。
内存分配
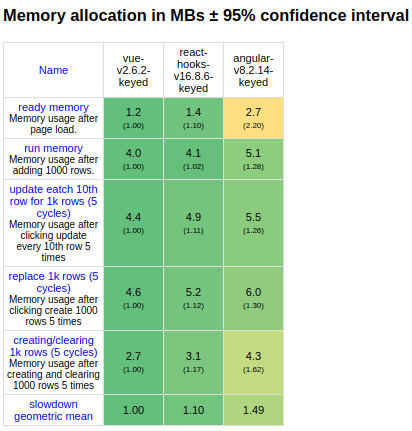
结果与启动时间试验有很强的相关性。Vue排在第一位,反应不远,Angular由于其大小和抽象性而占据了大部分内存。
人气
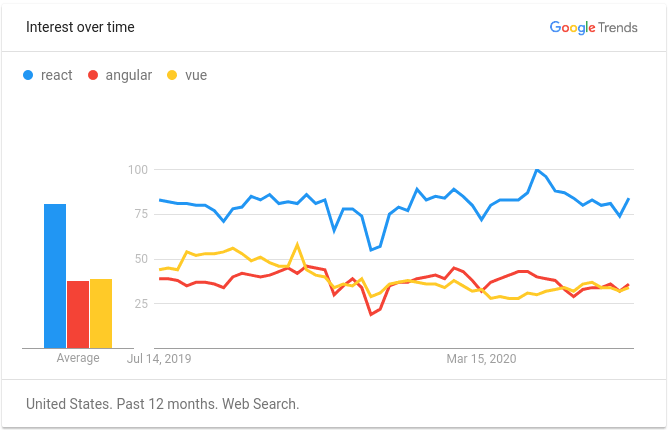
根据googletrends,React仍然是最流行的框架。它有一个活跃的社区和最广泛的第三方npm包集合。

然而,在他们的存储库获得的星数量上,Vue已经克服了这一点。
如果我们看看中国,情况就不同了。中国是Vue的发源地,在附近的亚洲国家也很受欢迎。由于防火墙的存在,中国开发者无法访问谷歌和其他框架上的大部分资源。语言障碍也起着重要作用。
学习曲线
Vue是最容易学的,不用担心。它的模板语法与plain html非常相似。您可以用HTML、Javascript或JSX编写模板。双向响应非常简单。i
整个框架很小,设计中融入了简洁性。
反应其次。JSX也类似于HTML,但有一些区别,比如类名和camelCase命名约定。单向数据流和不变状态是最难理解的部分。但一旦你得到它,其他一切都很容易。
Angular的学习曲线要陡得多,因为它是这三个框架中最复杂的。TypeScript和RxJS对于Angular开发是必需的,因此开发人员也必须了解它们。虽然TypeScript构建在JavaScript之上,而且非常容易学习,但RxJS确实需要一些努力才能掌握。
摘要
| React | Angular | Vue | |
|---|---|---|---|
| Realease | 2013 | 2010 | 2014 |
| Website | reactjs.org | angular.io | vuejs.org |
| Current Version | 16.13.x | 10 | 2.6.x |
| Used by | Facebook, Instagram, Netflix, New York Times | Microsoft, Google, Apple, Paypal | Adobe, Buzzfeed, GitLab, Grammarly |
| Bundle Size | 35 Kb | 500 Kb | 20 Kb |
| Popularity | High | Moderate | High |
| Watchers | 6.7k | 3.2k | 6.2k |
| Stars | 152k | 63.1k | 168k |
| Forks | 29.7k | 17.1k | 25.5k |
| Contributors | 1,468 | 1,165 | 371 |
荣誉提及Preact
PPreact是一个快速的api兼容React的替代品,具有令人惊叹的3Kb包大小。
它与React基本上是生态系统兼容的,这意味着为React设计的第三方npm包中的组件也应该在Preact中工作。在关于从React切换的指南中,它们涵盖了许多常见的迁移问题。
作为最小的UI框架之一,它非常适合于可嵌入的小部件和其他代码,其中bundle的大小至关重要。拥有React经验的开发人员甚至不必牺牲生产力,因为它离它的老大哥太近了。
结论
对于一个新项目来说,这三个框架中的任何一个都不会完全出错。明智的做法是将你的决定主要建立在你的团队现有的专业知识之上。
- 当涉及到小部件和其他可嵌入的UI组件时,Preact是最好的。
- React是一个很好的全能者。由于单向数据流,应用程序的逻辑始终保持清晰。组件提供了高级别的代码重用和较低的更改成本。它对小项目没有问题,而且,当与TypeScript一起使用时,对于大中型项目也非常适用。
- 对于Web设计者来说,Vue是jQuery的最佳替代品。它的功能远不止于此,我们还建议将其用于除企业项目之外的任何项目。由于简单和高效,它对于MVP开发来说一定是很棒的,尽管我们还没有尝试过。
- 随着越来越多的公司迁移到Vue和React,Angular甚至在企业利基市场也失去了主导地位。现在我们不提倡从头开始学习,但是如果你有合理的理由,开始一个新的角度项目并不是一个大错误。然而,它的大量冗长对开发生产力有很大的伤害。
在LeanyLabs,我们重视React设计决策的好处及其广泛的生态系统。我们对Vue没有太多的经验,但是如果它对项目更有意义的话,我们会考虑使用它。今天,我们不能向我们的客户推荐好的老Angular,因为它继续失去人气,我们担心很难很快找到好的Angular开发人员。
原文:https://leanylabs.com/blog/react-angular-vue/
本文:http://jiagoushi.pro/node/1276
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 88 次浏览
【前端框架】哪个框架更好:Angular.js ,React.js或Vue.js

在我回答之前,如果你读这篇文章是为了选择一个“要学习”的框架,不要这样做。还是读读这篇文章吧。
如果你想选择一个框架来使用(在一个实际的项目中),你可以继续:)
“更好”是非常主观的。更好的为了什么?
- 可扩展性。如果我们讨论性能的话,为所有3个框架编写的代码可以根据需要进行扩展。有些框架偶尔会有更智能的优化,但最终所有框架都会遵循经过实战测试的任何优秀智能优化。
- 语法和可读性呢。你(个人或团队)来做裁判!试一试,看看你更喜欢哪种语法。许多框架都有不同的“使用方法”,所以请确保探索所有的选项。
- 开发速度。这取决于你对你所拥有的工具有多精通。有些框架确实为您提供了更多的设计决策,但如果您有足够的经验,您几乎不会注意到任何差异。事实上,您拥有的经验越多,您就越不希望预先为您做出设计决策。
- 可测试性.全靠你了!当您遵循某些编码实践时,一切都是可测试的。
- 互操作性/ Debuggability。框架越小,API越小,效果就越好。
- 可维护性。框架允许您编写的函数/组件越小,就越好。
- 寻找支持或人员加入你的团队。框架越流行越好。React赢得了NPM下载的流行(这可能是最重要的)。Vue在GitHub上的星舰人气相当。Angular的受欢迎程度是有争议的,因为你必须将两种不同的框架结合在一起,但现在它可能和React差不多了。
- 移动集成呢。React是这里发光的那个。您也可以选择其他框架,但它们(在我看来)不如React Native那么好。
如果您不关心最后一点,那么这三个选项或多或少都提供了相同的价值。这绝对是个偏好问题。可以通过构建完全相同的应用程序来尝试所有这些方法,然后选择最让您高兴的一个!对于在线课程来说,这是个不错的主意,哈!我可能有偏见,但我可能会考虑试一试。
原文:https://medium.com/edge-coders/which-framework-is-better-angular-js-react-js-or-vue-js-77c67d00d410
本文:http://jiagoushi.pro/node/1272
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 46 次浏览
【微前端】使用Web组件创建微前端(支持Angular和React)
对于现代UI开发人员,您的“选择框架”是您内心深处的东西,它以某种方式定义了您的身份,并且可能限制了您解决问题的能力。就像我之前说的,如果每个人都和睦相处不是更好吗?
如果您是React或Angular、Ember或Vue,让我们创建一个地方,让它们都可以使用web组件和谐地生活在一起。
使用web组件作为Angular和React组件的包装器,我将展示它们在单个应用程序中协同工作的情况。我还将把数据从父容器传递到两个组件,然后再返回。我们的成品会是这样的:
先决条件
为了让我们能够专注于重要的部分,我把所有的东西都编码并上传到我的github:
https://github.com/chriskitson/micro-frontends-with-web-components?sour…---------------------------
无论如何,这都不是一个深入的研究,但是我将浏览Angular中web组件支持的重要部分并作出反应。
*如果您想完成其他一些框架(Vue, Ember等),请随意在我的repo上创建一个pull request !
我已经使用Angular CLI为我们的Angular项目生成了一个起点。你至少应该熟悉这个工具,这样你就可以浏览代码:
https://cli.angular.io/?source=post_page---------------------------
由于我们的最终目标是web组件,所以我们将把静态JavaScript文件组合成微型服务。为此,我将在我的本地环境中使用serve,这是一个使用node服务静态文件的优秀工具:
https://www.npmjs.com/package/serve?source=post_page---------------------------
Angular 组件作为自定义元素
由于Angular似乎正在采用web组件(带有Angular元素),您可以将Angular组件作为web组件来使用,只需对Angular CLI生成的默认项目做一些小调整。
在/micro-fe-ng目录下,一切都应该正常工作,你需要做的就是安装依赖项并运行启动脚本:
cd micro-fe-ng/
npm i
npm start
现在我们的Angular微前端将自定义元素定义为,应该在http://localhost:5001/main.js上运行。
注意:我们在不同的端口上通过localhost提供文件,但是它们很容易位于共享相同DNS的多个微服务中。
如果你对这是如何实现的感兴趣,这里是一个必要的变化纲要:
我们需要一些新的依赖:
Angular对自定义元素的支持(@angular/elements)和ngx-build-plus,后者是Angular的另一种构建工具(这对Angular元素有很好的支持):
npm i @angular/elements ngx-build-plus -D
我们还需要对包做一些修改。json来构建我们的Angular项目,并作为自定义元素服务于我们的项目:
micro-fe-ng / package.json:
"start": "npm run build && serve -l 5001 dist/micro-fe-ng",
"build": "ng build --prod --output-hashing none --single-bundle true",
我们需要在app.module中定义自定义元素。ts:
micro-fe-ng / src / app / app.module.ts:
import { BrowserModule } from '@angular/platform-browser';
import { NgModule, Injector } from '@angular/core';
import { createCustomElement } from '@angular/elements';import { AppComponent } from './app.component';
import { CustomelementComponent } from './customelement/customelement.component';@NgModule({
declarations: [
AppComponent,
CustomelementComponent
],
imports: [
BrowserModule
],
providers: [],
bootstrap: [],
entryComponents: [
AppComponent,
CustomelementComponent
]
})export class AppModule {
constructor(private injector: Injector) {}
ngDoBootstrap(): void {
const { injector } = this; // create custom elements from angular components
const ngCustomElement = createCustomElement(CustomelementComponent, { injector }); // define in browser registry
customElements.define('ng-el', ngCustomElement);
}}最后,我们需要告诉Angular使用ngx-build-plus构建工具,方法是在Angular内部的三个位置指定它。json如下图所示:
Ngx-build-plus将构建的项目作为一个JS文件返回,这是web组件作为一个服务工作的要求。
micro-fe-ng / angular.json:
..."architect": {
"build": {
"builder": "ngx-build-plus:build",
.... "serve": {
"builder": "ngx-build-plus:dev-server",
... "test": {
"builder": "ngx-build-plus:karma",
将react组件作为自定义元素
由于React对web组件没有开箱即用的支持,我们将不得不编写比以前多一点的代码来包装一个标准的React组件,并将其呈现为一个本地web组件(自定义元素)。
与React组件非常相似,定制元素(web组件)也有生命周期钩子,您可以通过回调方法访问这些钩子。
通过使用定制元素API的connectedCallback()和disconnectedCallback()生命周期方法,我们可以将它们分别映射为render()和unmount()我们的React组件,如下所示:
class MyCustomElement extends HTMLElement {
constructor() {
super();
} connectedCallback() {
ReactDOM.render(<MyReactComponent />, this);
} disconnectedCallback(){
ReactDOM.unmountComponentAtNode(this);
}
}通过映射React道具和事件,我将这一阶段做得更深。如果您想查看它,请查看/micro-fe-react/src/index.js。
在示例存储库中,所有东西都应该很好地工作,这样您就可以执行以下操作来启动和运行React微服务:
cd micro-fe-react/
npm i
npm start
现在我们的React微前端将定制元素定义为< React -el />,应该在http://localhost:5002/main.js上运行
Micro-frontend包装
我们有两个微前端服务;一个用于Angular组件,一个用于React组件。
现在让我们来创造一个他们可以一起生活的世界…
在/micro-fe-wrapper目录下,一切都应该正常工作,你所需要做的就是安装依赖项并运行开始脚本:
cd micro-fe-wrapper/
npm i
npm start
现在,我们的微前端包装器应该运行在http://localhost:5000。
要了解它是如何工作的,请继续阅读……
由于web组件是原生HTML规范的一部分,所以我们不需要做太多花哨的工作来将它们组合在一起。
在现实世界中,您可能想要使用一个框架来实现更好的代码结构和数据绑定等,但是为了简单起见,我们只使用普通的HTML/JS。
micro-fe-wrapper / index . html:
我们需要包括一些来自CDN的外部依赖:
- zone.js 是Angular所需要的。在包装器应用程序中包含一次是很好的实践,因为不能在同一个页面上有多个版本。
- custom-elements-es5-adapter.js 在浏览器中提供自定义元素支持。
此外,我们应该包括来自组件服务的JS文件,我们在前面的步骤中建立和部署:
<script src="https://cdnjs.cloudflare.com/ajax/libs/zone.js/0.9.1/zone.min.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/2.2.10/custom-elements-es5-adapter.js"></script> <script src="http://localhost:5001/main.js"></script> <script src="http://localhost:5002/main.js"></script>
我已经定义了一个方法tellComponents(),它应该将自定义元素标记注入到我们的页面中: <ng-el /> 代表Angular, < React -el />代表React。
我还使用setAttribute()传递一个属性名,以模拟包装器应用程序与组件的对话。
我还使用addEventListener()侦听一个名为helloEvt的事件,该事件将侦听来自组件的事件,使它们能够与父应用程序和其他组件通信。很酷!
React和Angular之间helloEvt()的属性名略有不同。这是由于框架之间的约定不同造成的。我待会再解释……
function tellComponents() {
const name = document.getElementById('yourName').value;
const reactEl = document.createElement('react-el');
reactEl.setAttribute('name', name);
reactEl.setAttribute('onHelloEvt', 'onHelloEvt');
reactEl.addEventListener('onHelloEvt', (e) => helloEvent('react'));
const reactElContainer = document.getElementById('react-container')
if (reactElContainer.children.length > 0) {
reactElContainer.removeChild(reactElContainer.children[0]);
}
reactElContainer.appendChild(reactEl);
const ngEl = document.createElement('ng-el');
ngEl.setAttribute('name', name);
ngEl.addEventListener('helloEvt', (e) => helloEvent('angular'));
const ngElContainer = document.getElementById('ng-container');
if (ngElContainer.children.length > 0) {
ngElContainer.removeChild(ngElContainer.children[0]);
}
ngElContainer.appendChild(ngEl);
}向组件传递值和从组件传递值
还记得我们传递给自定义元素的name属性吗?实际上,在组件中读取这个值非常简单。
在Angular中,我们只是简单地引用一个输入:
export class CustomelementComponent implements OnInit {
@Input() name: string;
...
}
这使得我们的模板中的值可用:
<p>Hello <strong>{{name}}</strong> from your friendly Angular component.</p>
在React中,它将作为一个道具传递给组件:
export class ExampleComponent extends React.Component {
static propTypes = {
name: PropTypes.string
} static defaultProps = {
name: "Chris"
} render() {
const { name } = this.props;
return (
<div className="exampleComponent">
<p>Hello <strong>{name}</strong> from your friendly React component.</p>
</div>
)
}
}从组件发送事件几乎与监听helloEvt一样简单。
在Angular中,我们只需要指定一个输出:
export class CustomelementComponent implements OnInit {
@Input() name: string;
@Output() helloEvt: EventEmitter<string> = new EventEmitter();
...
}
然后我们可以从模板中调用这个事件:
<button type="submit" (click)="helloEvt.next()">Say hello</button>
注意,EventEmitter在Angular中创建了一个可观察对象,因此我们需要调用next()。
在React中,我们的组件包装器(micro-fe-react/src/index.js)将查找前缀为“on”的道具,并将它们视为事件,例如onClick()、onFocus()等原生事件。这就是为什么我们将定制事件onHelloEvt()称为React。
事件在React中被视为道具,所以我们需要做的就是定义道具并将其调用为onClick()处理程序。就是这样!
export class ExampleComponent extends React.Component { static propTypes = {
name: PropTypes.string,
onHelloEvt: PropTypes.func
} static defaultProps = {
name: "Chris"
} render() { const { name, onHelloEvt } = this.props;
return (
<div className="exampleComponent">
<button type="submit" onClick={onHelloEvt}>Say hello</button>
</div>
)
}
}结论
使用这些概念,您应该能够创建一些真正强大的应用程序,通过使用Web组件自定义元素规范混合Angular和React组件。
为什么混合框架是有益的还是有问题的(取决于您的用例),有很多利弊;考虑适应性、可伸缩性、性能、安全性、资源分配、浏览器支持等因素。
如果你还没有查看我的github,这里有一个提醒。享受! !
本文:http://pub.intelligentx.net/creating-micro-frontends-using-web-components-support-angular-and-react
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 175 次浏览
【微前端】在服务器端构建微前端
规模发展
微服务现在已经众所周知好几年了,并被广泛采用。但前端通常仍然是整体式的。这种应用程序结构通常反映在团队结构上:有几个独立的后端团队和一个单一的前端团队。这也阻止了后端开发团队提供完整的可用功能——他们总是缺少前端。要实施前端,所有更改必须由一个前端团队完成。这使得规模化开发变得困难。通过实现微型前端,我们可以组建一个完整的团队,他们可以自己发布完整的功能。这也是ThoughtWorks连续第三次将微型前端放在其著名技术雷达的“采用”部分的原因之一!
微前端组成
对于我们的用例,微型前端由标记(HTML)、样式(CSS)、脚本(JavaScript)和图像组成。我们希望在我们的页面中组成不同的微前端,或通常称之为“片段”。一些片段是交互的。一些片段可能依赖于某些片段。一些片段可能希望与其他片段交互。
有两种方法可以集成来自微前端的片段:客户端和服务器端。两者各有利弊。我们正在比较服务器端组合的不同方式,因为我们专注于搜索引擎优化。谷歌现在支持很多JavaScript,但索引需要更长的时间,这对一个频繁变化的网站是不利的,而其他一些爬虫根本不支持JavaScript。
此外,通过服务器端组合,对慢速移动客户端(如智能手机)的支持更好。移动客户端通常具有较慢的互联网连接,因此它们可以从较小的下载负载中获益。它们的计算能力也较低,因此它们可以从预先呈现的HTML中获益。
服务器端包括(SSI)
SSI是一种简单的服务器端脚本语言,允许使用条件语句并包含来自文件和URL的其他片段。
要在页面中包含另一个片段,请添加和SSI标记,如<--#include virtual=“/url/to/include”->。web服务器获取片段并用片段的内容替换SSI标记。组合输出返回给客户端。
要想更深入地了解SSI的作品,请看我的同事Artun Subasi去年在duesentrieb夏令营所做的介绍。
赞成的意见
- 久经考验
- 在Nginx、Apache和其他web服务器中得到很好的支持
- 支持超时和回退内容
弊端
- 片段以并行方式获取,但仅在获取最后一个片段后交付(Nginx)
- 没有对资产处理的内置支持。ApachePageSpeed(谷歌以前称为modpagespeed)可以进行一些CSS处理并结合片段中的CSS,但自2018年初以来没有收到任何更新,似乎已经死了
边缘侧包括(ESI)
ESI是一种简单的标记语言,允许包含来自其他URL的片段。
ESI的工作原理与SSI非常相似。ESI更侧重于反向代理或CDN层,而SSI则针对web服务器本身。当然,这些边界有些模糊,因为Nginx也经常用作反向代理。ESI本身没有条件逻辑。但Varnish允许在其自己的DSL(称为“VCL”)中使用条件逻辑。
赞成的意见
- 久经考验
- 清漆支持良好(并行抓取需要商业版)。Squid(项目网站已经过时,但有新版本)和Mongrel(自2010年以来没有新版本)也支持它
弊端
- 没有内置的超时支持。专有扩展确实存在。
- 互斥,使用基于CDN的ESI进行缓存
- 没有对资产处理的内置支持
Zalando Tailor
Tailor是一个节点。基于js的片段服务由Zalando开源,作为独立服务运行。它是Mosaic项目的一部分——Zalando的伞式项目——前端模块化。
Zalando Tailor使用自定义标记组成页面。它们定义<fragment src=”http://www.example.com“>-用于指定要加载的片段的标记。可以通过链接头由片段本身填充资源,如样式和脚本。
赞成的意见
- 对资产处理的内置支持
- 作为第一方概念的碎片
- 立即异步获取多个片段和流
弊端
- 专有解决方案,需要带有样式和AMD JS绑定的自定义链接头
Podium
Podium也用JavaScript实现并在节点上运行。js。它是由挪威芬恩公司开发的。没有他们的分类广告网站。Podium是一个将片段(他们称之为“podlet”)集成到页面(他们称页面为“布局”)中的库。
要运行podium,您至少需要两个实例:一个布局服务器和至少一个podlet服务器。podlet服务器公开片段,布局服务器将其集成到页面中。每个片段都需要公开一个“Podlet清单”,其中包含JSON数据资产,并且可能包含回退URL。布局服务器最初获取回退内容,并在Podlet服务器不可用时将其缓存。
赞成的意见
- 内置资产处理支持(片段需要公开元数据端点)
- 作为第一方概念的碎片
- 内置代理支持隐藏片段服务器
- Fragement服务器可以定义回退内容
弊端
- 专有解决方案,与库紧密耦合
最后的想法和建议
ESI和SSI是经过良好测试的稳定技术,易于学习。像Varnish的VCL这样的定制添加增加了复杂性,但引入了许多新的可能性。一般来说,这些解决方案对于资产处理并没有很好的解决方案,并且难以满足现代web应用程序的需求。
像Tailor和Zalando这样的更现代的解决方案解决了老式工具存在的许多问题。但是,他们引入了公平份额的复杂性,并有自己的学习曲线。这两个工具或多或少都是一个人的表演(如果你看贡献日志的话)。所以你应该准备好介入并继续发展,如果是Zalando或Finn。如果您将这些产品中的任何一种作为应用程序的基石,就不要放弃他们的解决方案。
为了更广泛地了解合成技术(包括客户端合成),我可以推荐bluesoft的这篇关于微前端的文章。如果你对微前端感兴趣,你应该看看MichaelGeers的《微前端行动》。
参考:
- 55 次浏览
【微前端】微前端——功能团队中缺失的一块拼图
在任何合法的前端开发团队中,提高可扩展性和敏捷性很少会成为头等大事。在处理大型、复杂的产品时,如何确保快速、频繁地交付同时包含后端和前端的功能?像后端那样将前端单体分解成许多更小的部分似乎是答案。如果执行得当,微前端可以提高团队的有效性和效率。就是这样。
微前端背后的想法是将网站或 Web 应用程序视为由独立团队拥有的功能的组合。每个团队都有自己关心和擅长的不同业务领域或任务。团队是跨职能的,从数据库到用户界面,端到端地开发其功能。
将较大的问题分解为较小的问题以提高敏捷性、可重用性和可扩展性一直是 IT 的圣杯之一,过去二十年来该领域取得的进展令人震惊。但是,使用越来越大的代码库的新限制仍在不断出现。业内最有头脑的人一直在努力应对这一挑战,试图从技术和组织的角度来解决这个问题。迄今为止,微服务架构肯定仍然最接近解决它。
在本文中,您将学习:
- 微服务架构和微前端如何运作;
- 他们最大的优势是什么;
- 实施微前端时必须满足哪些要求;
- 您可以使用哪些技术或方法;
- 以及这些解决方案中的每一个如何相互比较。
微服务架构和微前端——它们解决了什么以及它们如何运作
微服务架构承诺:
- 更容易构建和维护应用程序
- 提高团队生产力
- 使用技术的灵活性
- 可扩展性
解决方案是将大型系统拆分为围绕明确定义的业务能力组织的细粒度、松散耦合的服务。然后,每个服务都足够小,可以由一个开发团队开发,并且可以快速调整以适应新的业务需求并进行部署,而不会破坏系统的其他部分。
这种方法的危险在于系统将被分解成许多不相关的应用程序。尽管这对开发人员来说很好处理,但这并不是用户对系统的期望;大多数人不喜欢使用大量的小型应用程序来完成他们的工作。因此,必须将为此过程分解的内容重新组合到用户界面中。
将碎片重新组合在一起
常见的方法是在用户和微服务之间构建一个单一的前端层。 对于每一个重要的系统,庞大的前端代码库都会威胁到微服务架构的好处。 这就是微前端的用武之地。
微前端的基本思想非常简单——将用户界面由多个围绕明确定义的业务能力组织起来的细粒度部分组成。 然后每个部分都足够小,可以由一个垂直结构的团队开发和拥有。 拥有前端和后端的团队建立了一个真正自给自足的功能团队。

然而不幸的是,微前端带来了同样的挑战,使得微服务难以实现。此外,任何捷径都可能以负面的方式影响用户体验。必须确保一致性、安全性、互操作性、性能、可扩展性和所有权,以确保无缝的用户界面。
尽管不同的微前端方法解决了各种问题,但还没有一个能够涵盖所有这些问题。但在我们深入研究这些不同方法的细节之前,让我们先仔细看看选择微前端的主要动机,以及与单体方法相比的优缺点。
解释微前端的 3 大优势
微前端的优势#1:可扩展的团队设置
3 种不同的前端方法及其对团队组织的影响
选择微前端方法有很多很好的理由,但最重要的(如果不是最重要的)之一来自可扩展的团队设置。
至少可以确定影响开发团队组织的三种可能的前端架构:单片前端和后端、带有后端微服务的单片前端和微前端。下面,我们将描述每个团队组织的后果。
单片前端和后端
构建需要前端和后端的解决方案的常用方法是水平拆分项目并通过 REST API 在这些层之间进行通信。
如果系统足够小,可以供一个团队开发,最好的选择是保持架构简单。您可以通过创建单页应用程序 (SPA) 前端并通过 REST API 将其连接到后端来实现此目的。然后根据每一层所需的工作量调整您的团队设置。
良好的做法是确保从一开始您的代码就结构良好,并且当您的解决方案增长时,您可以引入另一个或两个团队,而无需重新构建它。
但是这种架构的局限性是显而易见的:团队修改代码库的次数越多,就需要更多的协调和集成,这会导致产品开发瘫痪。

带有后端微服务的单片前端
尤其是在大型企业中,对额外开发团队的需求通常从后端开始。 大多数系统需要大量的业务逻辑。 例如,它们需要在浏览器端无法完成的处理,或者与遗留系统的复杂集成。 在这些情况下,一个跨职能团队已经不够了。
大多数公司扩展其架构的第一步是垂直拆分后端代码库以解决复杂性。 前端被分配给一个专门的前端团队,而其余的工作则分配给各个后端团队。 因此,积压的项目被分解成块,并由不同的团队交付。 然后,这些团队要么通过合同谈判解决依赖关系,要么——以更敏捷的方法——通过大量积压计划来解决依赖关系。

这种方法带来的最大挑战是管理这些依赖关系和同步发布。 测试也变得很麻烦,因为您需要等待所有单独的部分到达测试环境才能验证它。
当解决方案必须嵌入来自不同产品 backlog 的功能时,它变得更加复杂(这种情况经常发生)。

在更大的范围内,这种方法需要大量的管理。 日常部署几乎是不可能的。 这就是为什么在具有复杂前端的大型企业中工作的开发人员和架构师寻求最终垂直扩展的解决方案,将前端添加到他们已经改变游戏规则的微服务架构 - 微前端。
微前端
为了快速开发、测试和发布其功能,团队需要能够在不依赖其他团队的情况下工作。 微前端可以在用户界面领域实现后端微服务的相同承诺,并且可以应用支持独立团队合作的相同原则。
在此设置中,前端和后端这两个领域紧密耦合,因为需求来自一个产品待办列表。 再一次,一个团队可以在一个简单的架构中交付整个功能。 如果执行得当,这不会影响用户体验。

为了很好地执行它,微前端带来了许多后端微服务已知的类似问题,必须解决。 否则,用户可能仍将系统感知或体验为不同特征的拼凑。
微前端的优势#2:技术选择自由
除了创建可扩展且独立的团队设置外,微前端方法还有助于处理应用于前端的大量技术。 每个季度都有关于如何开发面向用户的系统部分的新想法。 很多时候,新版本的框架甚至不向后兼容,这意味着每个版本实际上都是一个单独的框架。

微服务架构的优势之一是可以自由选择所使用的技术。当用户界面被拆分成独立的模块时,前端开发人员可以享有同样的自由——至少在一定程度上。
微前端的优势#3:弹性
任何系统的实际成本都不能很好地体现在代码库的初始开发成本上,而是体现在维护上。代码重构和系统重构的无休止螺旋的目的是保持与开始时相同的速度引入功能更改。
微前端架构通过引入以下约束使代码库更具弹性:
- 隔离变更的影响;
- 防止代码耦合;
- 并随着时间的推移保留架构。
这些约束防止不受控制的依赖关系、限制代码重用和强制服务边界。
不再有不受控制的依赖
多年来开发的大型应用程序不可避免地充满了难以跟踪和维护的代码依赖关系。开发人员在上市时间的压力下工作,或者只是试图优化他们的工作方式,会在代码的不同部分之间产生许多不受控制的依赖关系。当引入新的依赖项时,重用一些业务逻辑、缓存数据或资源池似乎总是一个好主意。后来发生的事情是这种共享功能变化的不可预见的后果。
通过将代码库分成几个不相连的部分,很容易避免这种依赖关系。由于两者之间的自然边界,一个微前端不可能重用其他微前端的现有功能。因此,更改的任何意外副作用仅限于一个微前端。
有限的代码重用
普遍遵循的原则不要重复自己(DRY)的目的是限制代码库的大小,从而降低出错的可能性。另一方面,开发成代码的每个抽象都引入了依赖性。随着时间的推移,抽象也经常出现必须根据特定的使用上下文进行调整。当您的微前端代码库仅限于几个功能时,开发人员不太可能试图创建这样的抽象。相反,当他们找到重用代码的机会时,他们只是复制并粘贴相关的片段,这通常比引入依赖项要好得多。
服务边界执行
系统的架构通常受某些分析和设计决策的影响。然而,决定某事和遵守这些决定往往是不一样的。在服务被拆分并就职责达成一致并记录在案之后,漂移就开始了。缺乏明确的边界或跨越边界的能力可能导致并允许开发人员破坏先前商定的设计。有一些工具,例如在 CI/CD 管道中实现的代码审查或依赖检查,但使用单独的微前端,不可能偏离约定的架构。
微前端的 6 个常见要求
为了不失去微前端的任何潜在好处,这种架构的实际实现必须满足一些共同的要求。以下六点很重要,不容忽视:
独立部署
——使用微前端的最大风险是,当它们没有正确实施时,它们将需要部署协调。除了将有意义的功能封装在单个组件中并始终确保向后兼容性的良好设计之外,组件本身必须可以一个一个地部署,而无需任何协调。
热部署
——开发某些应用程序片段的团队必须能够部署新版本而不会造成任何停机。必须考虑使用滚动更新或金丝雀部署等策略。使用带有经过深思熟虑的路径系统的高级 HTTP 路由机制可以提供很大帮助。
统一的样式/组件
——将应用程序构建为不兼容的拼贴块可能会对用户体验产生破坏性影响。如何确保视觉和行为一致性的问题必须从引入微前端的一开始就解决。该解决方案通常涵盖技术(共享 UX 库)和组织方面(共享 UX 团队)。
身份验证和授权
——显然,用户必须只进行一次身份验证。授权上下文和规则必须由前端和后端的所有组件共享。
跨组件通信
——即使组件之间的通信引入了耦合并因此应该避免,但很难想象一个应用程序由完全分离的部分组成。特定的微前端必须能够共享应用程序上下文(即用户或其他资源标识)并相互通知内部状态的变化。选择的通信方法应该更喜欢基于事件或地址栏的间接通信,而不是直接使用其他组件 API。
搜索引擎优化
——这种需求的严重程度取决于具体的用例,但对于某些应用程序来说,它是要解决的第一类公民。
微前端技术——解耦前端的 3 种方法
微前端技术可以分为三类,每一种技术都有一些优点和缺点。我们可以区分:
- 构建时集成——应用程序作为一个捆绑包生成,然后一次性交付给用户
- 服务器端集成——在提供页面的同时集成应用程序,用户浏览器获得完整的应用程序
- 客户端集成 – 应用程序分批交付给用户 Web 浏览器,然后集成到浏览器中
下面我们通过使用像 Strava 或 Endomondo 这样的健身追踪应用程序的示例来仔细研究这三种方法中的每一种。这些应用程序中的每一个都具有相似的特性和功能,例如显示运动员个人资料摘要、他们的最新活动、一些正在进行的挑战等的仪表板。
构建时集成
解耦前端的第一种方法是将代码库组织在独立的存储库中。通过构建时集成,每个微前端都作为独立包构建和发布。完整的应用程序导入这些包并从包含的组件组成用户界面。
这样,在组织团队和适当划分团队之间的功能上稍加努力,就可以实现合理的团队独立性。虽然它不会提供微前端的所有可能好处,例如技术多样性或部署自主性,但它的优点是它不需要任何其他工具,除了开发人员已经使用的工具。
与其他方法相比,构建时集成简化了一致性保证。这也是减少传输到用户浏览器的数据量的最简单和最有效的方法,因为整个应用程序包在构建阶段进行了优化。

在我们的示例中设计健身跟踪应用程序时需要考虑的是使用组件之间的间接通信,这将减少耦合。
服务器端集成
第二种方法的总体思路如下图所示。

浏览器对页面 (1) 的请求来自“布局服务”,该服务首先为页面布局 (2) 请求“页面模板服务”。布局包含 HTML 兼容标签,其中包含要包含的页面片段的 URL (3)。 “布局服务”请求实现特定功能的所有包含部分调用服务的内容。布局服务的更高级实现并行执行查询 (4),支持故障转移和快速响应流。
在检索到所有部分 (5) 之后,准备好请求页面的全部内容并将其返回到浏览器 (6)。
布局服务在从用户角度建立应用程序的一致行为方面发挥着核心作用,但它由独立开发和部署的部分组成。
当应用程序包含由许多独立尾部组成的页面时,服务器端集成非常有用,有些是用户特定的,有些是用户之间共享的,如电子商务网站通常具有的。
有很多技术可以应用这种模式,例如服务器端包含、边缘端包含和 Zalando 的带有“片段”标签的项目 Mosaic。
服务器端包括
服务器端包含 (SSI) 是一种由 Web 服务器解释的脚本语言,用于将一个或多个文件的内容包含到网页中。语言语法基于放置在 HTML 注释中的指令,这些指令由启用 SSI 的 Web 服务器处理。
<!--#directive parameter=value parameter=value -->
最常用的指令是“包含”,允许将一个文档包含到另一个文档中。包含的文档可以通过相对于当前文件目录的路径来引用。例如:
<!--#include file="footer.html" -->
更强大和推荐的选项是使用虚拟参数,它可以指定任何资源,包括 CGI 脚本或远程页面:
<!--# include virtual="/athlete/768769879/details" -->
该语言还提供变量和条件子句,以在页面上创建更多上下文感知内容。
SSI 受到流行的 Web 服务器(如 Apache 或 NGINX)的支持。
边侧包括
Edge Side Includes (ESI) 是一种用于边缘级动态 Web 内容组装的标记语言。 ESI 的目标是解决 Web 基础设施扩展和内容发布的问题。与 SSI 类似,它通过 esi:include 标签提供嵌入:
<esi:include src="http://befit.com/footer.html" />
条件执行命令与大量预定义变量相结合,可以在提供给用户的页面上实现真正的动态内容。
<esi:choose>
<esi:when test="$(HTTP_COOKIE{group})=='Advanced'">
<esi:include src="http://befit.com/advanced.html"/>
</esi:when>
<esi:when test="$(HTTP_COOKIE{group})=='Basic User'">
<esi:include src="http://befit.com/basic.html"/>
</esi:when>
<esi:otherwise>
<esi:include src="http://befit.com/new_user.html"/>
</esi:otherwise>
</esi:choose>缓存代理服务器(如 Varnish 或 Squid)支持 ESI。
Zalando的马赛克项目
Mosaic 内置于 Zalando,是首批成熟的、有目的的、用于实现服务器端集成的微前端框架之一。
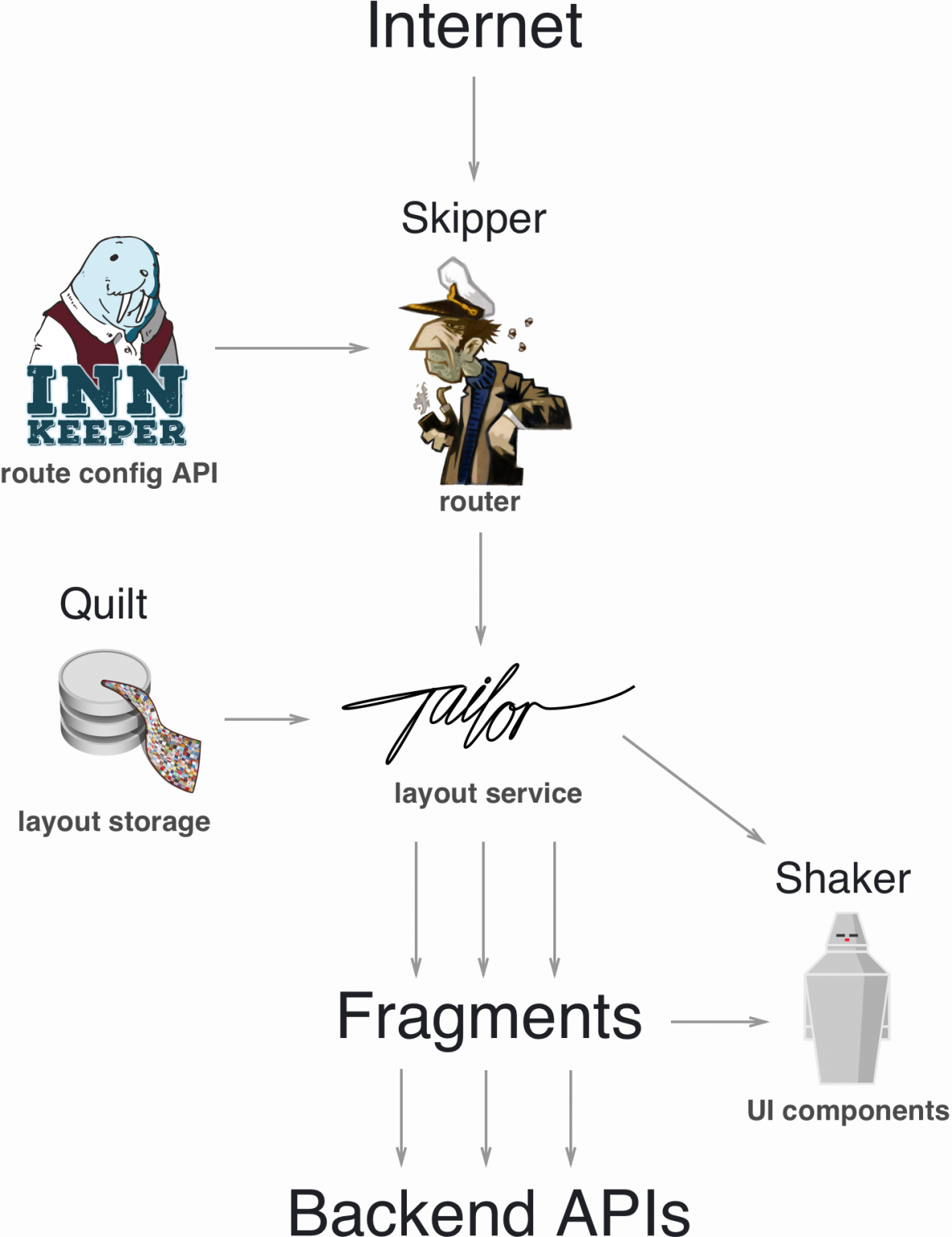
Mosaic 架构的中心点是“Tailor”,即在这种服务器端微前端架构中实现布局服务。为了在页面中包含微前端,使用了“片段”标签:
<html> <head> <script type="fragment" src="http://assets.befit.com"></script> </head> <body> <fragment src="http://athlete.befit.com"></fragment> <fragment src="http://trainng-log.befit.com" primary></fragment> <fragment src="http://challanges.befit.com" async></fragment> </body> </html>
与普通的 SSI 或 ESI 标签相比,片段标签提供了额外的有用属性:
- primary – 表示设置页面响应代码的片段
- timeout – 可选的片段超时时间(以毫秒为单位)(默认为 3000)
- async - 将片段推迟到正文标记的末尾
- public – 防止 Tailor 将过滤后的请求标头从上游转发到片段
- fallback-src – 在当前片段超时/错误的情况下回退片段的 URL
如上所述,Mosaic 旨在为微前端提供服务,并提供以下功能优势:
- 在后端编写预渲染标记。这对 SEO 很重要,并且可以加快初始渲染。
- 确保快速到达第一个字节。 Tailor 并行请求片段并尽快将它们流式传输,而不会阻塞页面的其余部分。
- 执行绩效预算。这在其他设置中非常具有挑战性,因为没有单一的点可以控制性能。
- 容错:呈现有意义的输出,即使页面片段失败或超时。
如果需要更复杂的模板管理,可以简单地从文件系统或专用服务提供页面模板。
马赛克的第二部分是船长。在 Innkeeper 的陪伴下,Skipper 建立了一个先进的 HTTP 路由器,可以在需要隐藏复杂的微服务世界时使用。 Skipper 本身提供了基于规则的 HTTP 请求路由,具有过滤和丰富功能。 Innkeeper 用作运行时 Skipper 规则管理的 API。
服务器端集成允许从微前端轻松编写应用程序,但它不能解决需要真正丰富的前端应用程序时出现的挑战。
客户端集成
最后但并非最不重要的一点是客户端集成方法。在这里,微前端的构建是将应用程序集成到用户 Web 浏览器中。应用程序的每个部分都独立交付给浏览器,然后应用程序在呈现时被粘合。
使用这种方法,在运行时构建应用程序不需要额外的基础设施,而且它似乎是最灵活的。应用程序组件可以共享一些用户上下文,因此就像在构建时集成的那样,而不会影响微前端的其他要求。

Iframes
iframes 是一种旧的客户端集成技术,可用于将一个 HTML 文档嵌入到另一个中。在微前端的上下文中,解决方案在于使用 iframe 标记嵌入每个微前端应用程序页面布局,其中 src 属性指向为应用程序提供服务的 URL。
与这种方法中的 SSI/ESI 类似,每个微前端都可以托管在不同的地址上。与 SSI/ESI 相反,客户端浏览器负责独立下载每个片段并显示完整页面。
<html> <body> <iframe src="http://athlete.befit.com" style="border: none;"/> <iframe src="http://trainng-log.befit.com" style="border: none;"/> <iframe src="http://challanges.befit.com" style="border: none;"/> </body> </html>
要成为一个成熟的微前端,嵌入在 iframe 中的应用程序应该能够与其父级通信。这可以通过使用 window.postMessage() 方法来实现,但在大多数情况下,将这样一个低级 API 与一个从微前端的角度简化集成的库包装是一种很好的做法。
除了涵盖影响渲染内容状态的微前端之间的数据交换的标准用例之外,还需要启用父级和微前端之间的通信。后者确保 iframe 的大小适合微前端内容的大小。当 iframe 内容溢出时,必须将有关嵌入内容的实际大小的信息传播到父应用程序,并且必须由父应用程序调整 iframe 高度。
当微前端平台本身需要基于 iframe 的集成以确保父应用程序和微前端之间的最高级别隔离时,它的效果最好。在这种情况下,可以使用任何技术或框架创建微前端,包括在客户端集成中独一无二的简单遗留应用程序集成。
微前端的部署也不需要任何特殊的方式来构建或打包源代码。
iframe 方法确保部署新版本的微前端不会影响其他已经部署的微前端。这种技术自由保证了整个系统不会卡在某个框架中,因为不需要微前端的兼容性。这样可以根据每个开发团队的实际业务优先级来支付技术债务。
这种高度隔离简化了集成,但同时它会导致一些 UX 限制,在考虑您的集成解决方案时应该考虑这些限制。
当您的主要关注点在于 UX 设计时,iframe 绝对不是最佳选择。可以提供良好的 UX 设计(在响应式网页设计的情况下也是如此),但它比其他方法稍微复杂一些。主要限制是由于微前端内容不能超出 iframe 边界。例如,显示在多个 iframe 上的弹出窗口无法正确显示。
需要考虑的另一个因素是下载到浏览器的资源开销。特定微前端所需的每个资源(css、js等)都必须单独下载。尽管对于现在客户端使用的大多数工作站来说这可能不是问题,但请注意,仅将前端框架核心库的一个实例加载到内存中是不可能的。
Single SPA
Single SPA 是一个 JavaScript 框架,旨在构建由多个单页应用程序组成的用户界面,它承诺许多框架的共存。甚至同一框架的不同版本也可以混合在一个页面中。
使用 Single SPA 时,每个微前端都可以独立部署。另一个不错的功能是延迟加载代码。仅在需要时才加载特定的微前端包,这提高了应用程序的加载速度。
任何 Single SPA 应用程序的架构都包含两个概念:
- 应用程序——微前端本身。每个应用程序都可以响应 URL 路由事件,并且必须知道如何从 DOM 中引导、挂载和卸载自己。传统 SPA 和 Single SPA 应用程序之间的主要区别在于后者必须能够与其他应用程序共存,并且不能各自拥有自己的 HTML 页面。
- Single SPA config – 向单一 SPA 注册应用程序的 HTML 页面和 JavaScript。
将微前端嵌入到 Single SPA 中不需要对前端进行大量调整。新的微前端声明需要实现单个 SPA 生命周期函数并为主应用程序公开具有这些实现的文件。
单个 SPA 生命周期函数与 React 组件生命周期函数非常相似——对象 props 具有属性 domElementGetter,返回应该放置或删除微前端的 DOM 元素。
- bootstrap – 将在第一次安装微前端之前执行一次。
- mount - 将在满足激活功能条件(即正确的 URL)或手动安装微前端时执行。
- unmount – 将在不满足激活功能条件(即不正确的 URL)或手动卸载微前端时执行。
如何在代码中将前端应用程序标记为单个 SPA 微前端
如果要将前端应用程序标记为 Single SPA,第一步是准备一个主微前端文件并实现生命周期方法。这可以手动完成,但框架提供了一个方便的助手来完成它。
import React from 'react'
import ReactDOM from 'react-dom'
import singleSpaReact from 'single-spa-react'
import root from './root.component.js'
const reactLifecycles = singleSpaReact({
React,
ReactDOM,
rootComponent: root
})
export function bootstrap(props) {
return reactLifecycles.bootstrap(props);
}
export function mount(props) {
return reactLifecycles.mount(props);
}
export function unmount(props) {
return reactLifecycles.unmount(props);
}在第二步中,您可以使用 Webpack 将您的应用程序捆绑到一个捆绑文件中,例如运动员.bundle.js,并从客户端可访问的任何服务器公开它。
如何在前端应用程序中使用 Single SPA 微前端
应用概念 = 单一 SPA 作为框架(The application concept = Single SPA as a framework)
第一步是在根应用程序中注册一个微前端。为此,您应该使用以下功能:
registerApplication( appName: string, applicationOrLoadingFn: () => <Function | Promise>, activityFn: (location) => boolean, customProps?: Object );
- appName – 将在单水疗中用作标识符的名称
- applicationOrLoadingFn – 一个可以返回应用程序或应用程序承诺的函数
- activityFn – 一个函数,当必须安装应用程序时返回 true,当必须卸载应用程序时返回 false。
- customProps – 一个可选对象,无论何时调用它们都会传递给生命周期方法。
最后一步是 start() 单一 SPA 引擎,然后一切就绪。
import {registerApplication, start} from 'single-spa';
const domElementGetter = () => document.getElementById('micro-font-end-container');
const pathPrefix = (prefix) => {
return (location) => location.pathname.startsWith(`${prefix}`);
}
registerApplication('athletes', () => import ('athletes.bundle.js'),
pathPrefix('/athletes'), {domElementGetter});
registerApplication('challenges', () => import ('challenges.bundle.js'),
pathPrefix('/challenges'), {domElementGetter});
start();
<html>
<body>
<script src="/dist/root.js"></script>
<a onclick="singleSpaNavigate('/athletes')">Go to athletes</a>
<a onclick="singleSpaNavigate('/challenges)">Go to challenges</a>
<div id="micro-font-end-container">
//i.e. here micro frontends can be injected
</div>
</body>
</html>包裹概念 = 作为库的单一 SPA (The parcel concept = Single SPA as a library)
当使用 Single SPA 作为框架时,容器应用程序是一个简单的应用程序容器,这些应用程序会根据根更改进行切换。 另一种选择是包裹概念。 在这里,您在任何框架中创建一个容器应用程序作为系统的基础,并且必须将包(或实际上是微前端)直接安装在特定位置。 这样一页可以包含多个微前端。 这更接近于将用户界面构建为解耦特征的组合,但同时可见和可访问的概念。
包裹也应该在正确的时间卸载。
在下面的示例中,使用 React 作为主要框架,因此 componentDidMount 和 componentWillUnmount 可用于挂载和卸载包裹。
class AthletesMicrofrontendComponent extends React.Component {
componentDidMount() {
SystemJS.import('athletes.bundle.js')
.then(athletesApp => {
const domElement = document.getElementById('athelete-micro-frontend-id');
mountParcel(athletesApp, {domElement})
});
}
render(){
return <div id="athelete-micro-frontend-id"></div>
}
...
}微前端方案比较
下表总结并强调了每种方法的主要优势和劣势:
| 技术 | 类别 | 例子实现 | 优势 | 弱势 | 建议 |
| 构建时的包 | 构建时集成 | NPN, yarn |
易于设置 - 无需额外工具
代码重复数据删除 轻松实现 UX 一致性 |
锁步释放过程——必须重新编译和部署整个包
|
仅在其他选项似乎非常复杂时才用于小型项目(不超过三个团队) |
| SSI/ESI | 服务器端集成 | SSI – NGINX, Apache Http
ESI – Varnish, Squid |
易于设置——HTTP 服务器和 Cashes 是每个 Web 应用程序架构的一部分
|
缺乏跨组件通信——必须以其他方式解决
缺乏内置的身份验证和授权 |
当应用程序和服务架构波动较小的微服务时,用于电子商务等 Web 应用程序 |
| 专业的微前端中间件 | 服务器端集成 | Zalando’s Mosaic,
Compoxure, micro-fe |
部署完全独立
具有自动发现功能的内置高级动态路由 |
难以设置——需要额外的组件
难以实现一致的用户体验观感 缺乏内置的身份验证和授权 |
当应用程序和服务架构波动较大的微服务时,用于类似 Web 应用程序的电子商务 |
| Iframes | 客户端集成 | 易于设置 - 无需额外工具
部署完全独立 高组件隔离 跨组件通信 真正的框架不可知论者 |
难以实现深度链接
高资源消耗 |
当框架不可知和组件隔离是关键问题并且 UX 不是那么重要时使用 | |
| 微前端框架 | 客户端集成 | Single SPA |
微前端和容器应用程序之间的完全集成
延迟加载 |
没有充分记录的引擎 | 在由许多通信微前端组成的丰富应用程序中使用 |
概括
如果你想充分利用你的微服务架构,微前端模式似乎真的是拼图中缺失的一块。 根据您的需求,确切的解决方案可能会有所不同。 例如,对于电子商务网站,您可以选择任何类型的服务器端集成。 但是,当您的目标是高级覆盖应用程序时,其中一种客户端技术将是您更好的解决方案。
如果您认为微前端仍然会带来太多麻烦,那么至少选择构建时模块化。 从长远来看,它总是会得到回报。
如果您对微前端及其实现有任何经验,请在下面分享。 我们很乐意收到您的想法和疑虑,并进一步讨论该主题。
原文:https://bluesoft.com/micro-frontends-the-missing-piece-of-the-puzzle-in…
- 162 次浏览
【微前端】用React、Vue和Single-spa打造微前端
single-spa 用于前端微服务的javascript框架
在过去的几周里,围绕微前沿(一些负面的,一些正面的)已经有了大量的讨论。
有一个tweet,真正吸引我的目光从乔尔丹宁,single-spa:
Funny how the many of the people recently criticizing #microfrontends (1) haven’t tried them, (2) don’t understand what they are, and (3) have attacked microfrontends and the people using them with almost a bully-like sarcasm.
I’m one of the main popularizers of them - AMA
当我看到一些新的和有争议的东西,像这样,我总是想自己尝试一下,看看所有的炒作是关于什么的,也让我可以形成自己的观点对这个主题。
这引导我创建了一个微前端应用程序,它呈现了两个单独的React应用程序和一个Vue应用程序。
在本教程中,我将分享我所学到的知识,并向您展示如何构建一个由React和Vue应用程序组成的微前端应用程序。
要查看此应用程序的最终代码,请单击这里。
single-spa
我们将使用的工具来创建我们的项目是单SPA -一个javascript框架的前端微服务。
单SPA允许您在单页面应用程序中使用多个框架,允许您根据功能拆分代码,并具有Angular、React和Vue。js等应用都生活在一起。
您可能已经习惯了Create React应用程序CLI和Vue CLI。使用这些工具,您可以快速启动整个项目,完成webpack配置、依赖项和样板文件。
如果您习惯了这种简单的设置,那么第一部分可能有些不和谐。这是因为我们将从头开始创建所有内容,包括安装所需的所有依赖项,以及从头开始创建webpack和babel配置。
如果您仍然好奇Single SPA是做什么的,或者为什么您可能想要使用微前端架构来构建,请查看这个视频。
开始
你需要做的第一件事是创建一个新的文件夹来保存应用程序,并切换到目录:
mkdir single-spa-app cd single-spa-app
接下来,我们将初始化一个新包。json文件:
npm init -y
现在,这是有趣的部分。我们将安装此项目所需的所有依赖项。我将把它们分成不同的步骤。
安装普通的依赖关系
npm install react react-dom single-spa single-spa-react single-spa-vue vue
安装 babel 依赖
npm install @babel/core @babel/plugin-proposal-object-rest-spread @babel/plugin-syntax-dynamic-import @babel/preset-env @babel/preset-react babel-loader --save-dev
安装 webpack 依赖
npm install webpack webpack-cli webpack-dev-server clean-webpack-plugin css-loader html-loader style-loader vue-loader vue-template-compiler --save-dev
现在,所有依赖项都已安装,我们可以创建文件夹结构。
应用程序的主代码将位于src目录中。这个src目录将为每个应用程序保存子文件夹。让我们继续在src文件夹中创建react和vue应用程序文件夹:
mkdir src src/vue src/react
现在,我们可以为webpack和babel创建配置。
创建webpack配置
在主应用程序的根目录下,用以下代码创建一个webpack.config.js文件:
const path = require('path'); const webpack = require('webpack'); const { CleanWebpackPlugin } = require('clean-webpack-plugin'); const VueLoaderPlugin = require('vue-loader/lib/plugin') module.exports = { mode: 'development', entry: { 'single-spa.config': './single-spa.config.js', }, output: { publicPath: '/dist/', filename: '[name].js', path: path.resolve(__dirname, 'dist'), }, module: { rules: [ { test: /\.css$/, use: ['style-loader', 'css-loader'] }, { test: /\.js$/, exclude: [path.resolve(__dirname, 'node_modules')], loader: 'babel-loader', }, { test: /\.vue$/, loader: 'vue-loader' } ], }, node: { fs: 'empty' }, resolve: { alias: { vue: 'vue/dist/vue.js' }, modules: [path.resolve(__dirname, 'node_modules')], }, plugins: [ new CleanWebpackPlugin(), new VueLoaderPlugin() ], devtool: 'source-map', externals: [], devServer: { historyApiFallback: true } };
创建babel 配置
在主应用程序的根目录下,用下面的代码创建一个.babelrc文件:
{ "presets": [ ["@babel/preset-env", { "targets": { "browsers": ["last 2 versions"] } }], ["@babel/preset-react"] ], "plugins": [ "@babel/plugin-syntax-dynamic-import", "@babel/plugin-proposal-object-rest-spread" ] }
初始化Single-spa
注册应用程序是我们告诉single-spa何时以及如何引导、挂载和卸载应用程序的方式。
在webpack.config.js文件中,我们将入口点设置为single-spa.config.js。
让我们继续在项目的根目录中创建该文件并配置它。
single-spa.config.js
import { registerApplication, start } from 'single-spa' registerApplication( 'vue', () => import('./src/vue/vue.app.js'), () => location.pathname === "/react" ? false : true ); registerApplication( 'react', () => import('./src/react/main.app.js'), () => location.pathname === "/vue" ? false : true ); start();
这个文件是您注册所有应用程序的地方,这些应用程序将是主单页应用程序的一部分。每次调用registerApplication都会注册一个新应用程序,并接受三个参数:
- App name
- Loading function (what entrypoint to load)
- Activity function (logic to tell whether to load the app)
接下来,我们需要为每个应用程序创建代码。
React 应用
在src/react中,创建以下两个文件:
touch main.app.js root.component.js
src/react/main.app.js
import React from 'react'; import ReactDOM from 'react-dom'; import singleSpaReact from 'single-spa-react'; import Home from './root.component.js'; function domElementGetter() { return document.getElementById("react") } const reactLifecycles = singleSpaReact({ React, ReactDOM, rootComponent: Home, domElementGetter, }) export const bootstrap = [ reactLifecycles.bootstrap, ]; export const mount = [ reactLifecycles.mount, ]; export const unmount = [ reactLifecycles.unmount, ];
src/react/root.component.js
import React from "react" const App = () => <h1>Hello from React</h1> export default App
Vue应用
在src/vue中,创建以下两个文件:
touch vue.app.js main.vue
src/vue/vue.app.js
import Vue from 'vue'; import singleSpaVue from 'single-spa-vue'; import Hello from './main.vue' const vueLifecycles = singleSpaVue({ Vue, appOptions: { el: '#vue', render: r => r(Hello) } }); export const bootstrap = [ vueLifecycles.bootstrap, ]; export const mount = [ vueLifecycles.mount, ]; export const unmount = [ vueLifecycles.unmount, ];
src/vue/main.vue
<template> <div> <h1>Hello from Vue</h1> </div> </template>
接下来,在应用程序的根目录中创建index.html文件:
touch index.html
index . html
<html> <body> <div id="react"></div> <div id="vue"></div> <script src="/dist/single-spa.config.js"></script> </body> </html>
更新Package.json使用脚本
要运行这个应用程序,让我们在package.json中添加start脚本和build脚本:
"scripts": { "start": "webpack-dev-server --open", "build": "webpack --config webpack.config.js -p" }
运行应用程序
要运行该应用程序,请运行start脚本:
npm start
现在,你可以访问以下网址:
# renders both apps http://localhost:8080/ # renders only react http://localhost:8080/react # renders only vue http://localhost:8080/vue
要查看此应用程序的最终代码,请单击这里。
结论
总的来说,除了所有的初始样板设置外,设置这个项目相当简单。
我认为,在未来,如果能有某种CLI来处理大部分样板文件和初始项目设置,那就太好了。
如果您需要这种类型的架构,那么Single-spa无疑是目前最成熟的方式,并且非常适合您的工作。
原文:https://dev.to/dabit3/building-micro-frontends-with-react-vue-and-single-spa-52op
本文:http://pub.intelligentx.net/building-micro-frontends-react-vue-and-single-spa
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 287 次浏览
【微前端架构】AWS 上的微前端架构
微服务架构的特点是独立服务,这些服务专注于特定的业务功能,并由小型、自包含的团队维护。 微服务架构经常用于在 AWS 上开发的 Web 应用程序,这是有充分理由的。 它们提供了许多众所周知的好处,例如开发敏捷性、技术自由、有针对性的部署等等。 尽管微服务很受欢迎,但许多前端应用程序仍然以单体风格构建。 例如,他们有一个与所有后端微服务交互的大型代码库,并由一大群开发人员维护。
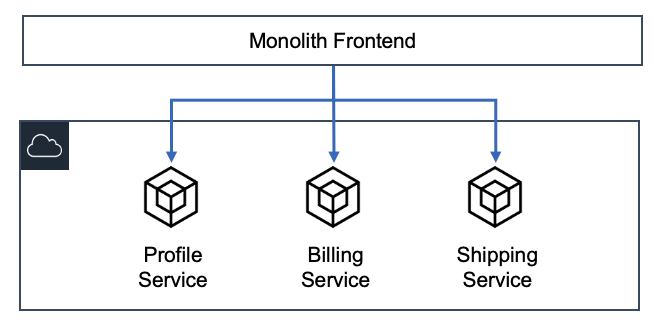
图 1. 带有单体前端的微服务后端
什么是微前端?
微前端架构将微服务开发原则引入前端应用程序。 在微前端架构中,开发团队独立构建和部署“子”前端应用程序。 这些应用程序由“父”前端应用程序组合而成,该前端应用程序充当容器来检索、显示和集成各种子应用程序。 在此父/子模型中,用户与看似单个应用程序的交互。 实际上,他们正在与由不同团队发布的多个独立应用程序进行交互。
图 2. 带有微前端的微服务后端
微前端的好处
与单体前端相比,微前端具有以下优势:
- 独立工件:微服务开发的核心原则是工件可以独立部署,这对于微前端仍然适用。在微前端架构中,团队应该能够独立部署他们的前端应用程序,而对其他服务的影响最小。这些更改将反映在父应用程序中。
- 自治团队:每个团队都是各自领域的专家。例如,计费服务团队成员具有专业知识。这包括与计费服务相关的数据模型、业务需求、API 调用和用户交互。与规模更大、专业性较低的团队相比,这些知识使团队能够更快地开发计费前端。
- 灵活的技术选择:自治允许每个团队做出独立于其他团队的技术选择。例如,计费服务团队可以使用 Vue.js 开发他们的微前端,而配置文件服务团队可以使用 Angular 开发他们的前端。
- 可扩展的开发:微前端开发团队更小,能够在不干扰其他团队的情况下进行操作。这使我们能够通过组建新团队以通过子应用程序提供额外的前端功能来快速扩展开发。
- 更容易维护:保持前端存储库小而专业,可以更容易地理解它们,这简化了长期维护和测试。例如,如果您想更改单体前端的交互,则必须在大型代码库的上下文中隔离功能的位置和依赖关系。在处理与微前端相关的较小代码库时,这种类型的操作会大大简化。
微前端挑战
相反,微前端提出了以下挑战:
- 父/子集成:微前端引入了确保父应用程序以与单体应用程序相同的一致性和性能显示子应用程序的任务。这一点将在下一节中进一步讨论。
- 运营开销:微前端应用程序不是管理单个前端应用程序,而是涉及为所有团队创建和管理单独的基础架构。
- 一致的用户体验:为了保持一致的用户体验,子应用程序必须使用相同的 UI 组件、CSS 库、交互、错误处理等。对于处于开发生命周期不同阶段的子应用程序,保持用户体验的一致性可能很困难。
构建微前端
微前端架构模式最困难的挑战是将子应用程序与父应用程序集成。优先考虑用户体验对于任何前端应用程序都至关重要。在微前端的上下文中,这意味着确保用户可以在父应用程序中从一个子应用程序无缝导航到另一个子应用程序。我们希望避免破坏性行为,例如页面刷新或多次登录。在最基本的定义中,父/子集成涉及父应用程序在加载父应用程序时动态检索和呈现子应用程序。渲染子应用程序取决于子应用程序的构建方式,这可以通过多种方式完成。两种最流行的父/子集成方法是:
将每个子应用程序构建为 Web 组件。
将每个子应用程序作为独立模块导入。这些模块要么声明一个函数来呈现自身,要么由父应用程序动态导入(例如使用模块联合)。
将子应用注册为 Web 组件:
<html>
<head>
<script src="https://shipping.example.com/shipping-service.js"></script>
<script src="https://profile.example.com/profile-service.js"></script>
<script src="https://billing.example.com/billing-service.js"></script>
<title>Parent Application</title>
</head>
<body>
<shipping-service />
<profile-service />
<billing-service />
</body>
</html>将子应用注册为模块:
<html>
<head>
<script src="https://shipping.example.com/shipping-service.js"></script>
<script src="https://profile.example.com/profile-service.js"></script>
<script src="https://billing.example.com/billing-service.js"></script>
<title>Parent Application</title>
</head>
<body>
</body>
<script>
// Load and render the child applications form their JS bundles.
</script>
</html>下图显示了一个基于 AWS 构建的示例微前端架构。
Figure 3. Micro-frontend architecture on AWS
在此示例中,每个服务团队都在运行一个单独的、相同的堆栈来构建他们的应用程序。他们使用 AWS 开发人员工具并使用 Amazon CloudFront 将应用程序部署到 Amazon Simple Storage Service (S3)。 CI/CD 管道使用共享组件,例如 CSS 库、API 包装器或存储在 AWS CodeArtifact 中的自定义模块。这有助于提高父应用程序和子应用程序之间的一致性。
当您检索父应用程序时,它应该会提示您登录身份提供程序并检索 JWT。在此示例中,身份提供商是 Amazon Cognito 用户池。成功登录后,父应用程序从 CloudFront 检索子应用程序并将它们呈现在父应用程序中。或者,当您导航到特定路线时,父应用程序可以选择按需呈现子应用程序。子应用程序不应要求您再次登录到 Amazon Cognito 用户池。应将它们配置为使用父应用程序获取的 JWT,或者从 Amazon Cognito 静默检索新的 JWT。
结论
微前端架构为前端应用程序引入了微服务开发的许多熟悉的好处。微前端架构还允许您管理小型独立组件,从而简化构建复杂前端应用程序的过程。
原文:https://aws.amazon.com/blogs/architecture/micro-frontend-architectures-…
本文:
- 72 次浏览
【微前端架构】微前端-Angular风格-第1部分
在这篇文章中,如果您对第2部分的实现细节感兴趣,我将概述微前端背后的概念。
它是什么,为什么我需要它?
让我们从why部分开始,当单页面应用程序启动的时候,大多数应用程序都非常小,并且由一个FE团队管理,一切都很好……
随着时间的推移,应用程序变得越来越大,管理它们的团队也越来越大。没有必要过多地讨论拥有大型代码库和大型团队的问题……
“微前端”这个术语最近被频繁使用,它提供了一个类似于微服务的概念,我们可以将单个前端应用程序拆分为微应用程序,这些微应用程序可以加载到用户浏览器上运行的单个容器应用程序中。每个应用程序都可以有自己的代码库,由一个面向业务的团队管理,他们可以独立地测试和部署他们的微应用程序。
(taken from https://micro-frontends.org/)
虽然这个概念本身听起来很有希望,但是缺乏实际的实现。特别是那些可以应用于现有大型应用程序的应用程序。
选择
一种可能的解决方案是使用良好的旧Iframe,它在封装和独立性方面提供了许多优势,但它是一种旧技术,并且存在严重的规模问题。
除了iframe之外,Web组件这个术语也出现了一段时间。
Web组件是一种解决方案,您可以在其中创建可以独立运行的自定义DOM元素,并提供分离和css封装,虽然这听起来是正确的方向,但Web组件离实际的解决方案还很远。它们更多的是一个概念,其背后的特性,如shadow DOM仍然缺乏完整的浏览器支持。
我们的解决方案
在Outbrain,我们一直面临着大多数资深SPA (单应用)所面临的问题,我们有一个庞大的FE应用程序,有一个庞大的团队来管理它,它变得越来越粗糙。看到在野外没有出色的MFE解决方案,我们决定尝试寻找一个我们自己的解决方案,一个可以在我们现有的echo系统上快速实现的解决方案。
我们定义了几个关键点,我们认为任何解决方案都必须应用MFE。
独立模式
每个微应用都应该能够完全独立运行,所以每个负责给定应用的团队都应该能够独立于其他应用运行。
这意味着每个应用程序应该托管在一个单独的代码基上,并且能够在开发人员的计算机上本地运行,以及在开发和测试环境中运行。
部署
可以独立每个服务部署到任何环境包括生产为了让业主团队的自由而不干扰其他团队工作,如果一个bug修复需要部署到生产在周末没有其他团队应该参与。
测试
在每个微应用程序上独立运行测试,这样一个应用程序中的bug很容易识别,不会反映到其他应用程序上。也就是说,有必要进行一些集成测试来检查应用程序之间的接口,并确保它们没有被破坏,这些测试应该由所有团队监控。
一个到多个
我们希望能够多次使用每个微应用程序,一个微应用程序不应该关心它在哪里运行,只知道它的输入和输出。
运行时分离和封装
重要的是,每个应用程序在运行时环境中都要沙箱化,这样应用程序之间就不会相互干扰,这包括CSS封装、JS命名空间和HTML分离。
常见的资源共享
因为我们不想要加载大型模块,如角,lodash和多次CSS样式的应用程序是很重要的微型应用程序能够共享公共资源,也就是说,我们也希望能够允许他们只封装资源相关,或封装在应用程序资源有不同的版本,例如应用程序使用lodash 3和应用程序B想迁移到lodash 4。我们不希望等到所有的应用程序都迁移之后才能升级。
通讯
需要有一种解耦的方式,让应用程序在不真正了解彼此的情况下彼此通信,只需要通过预定义的接口和API。
向后兼容性
由于我们不打算重写庞大的代码库,所以我们需要一些可以插入到当前系统的东西,以及可以由其他团队管理的逐渐独立的部分。
Web组件
最后,任何解决方案我们应该尽可能一致的web组件的概念,尽管它目前只是一个概念,似乎这就是未来是标题,如果将来任何解决方案出现,将自己与未来这将帮助我们采取的解决方案。
第2部分
在接下来的部分中,我将详细介绍我们是如何实现这一目标的,以及我们是如何通过写作来实现这一目标的。
下一部分的内容包括Angular、Webpack和一些美味的加载器。
原文:https://medium.com/outbrain-engineering/micro-front-ends-doing-it-angular-style-part-1-219c842fd02e
本文:http://pub.intelligentx.net/micro-front-ends-doing-it-angular-style-part-1
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 57 次浏览
【微前端架构】微前端-Angular风格-第2部分
在前一部分中,我讨论了转向MFE解决方案的动机以及解决方案相关的一些标准。在这一部分中,我将介绍我们如何在Outbrain实现它。
正如我在前一部分中提到的,其中一个标准是能够与我们当前的技术echo系统集成的解决方案,并且不需要对我们当前维护的应用程序进行什么更改。
Angular有一个内建的模块概念,它基本上是一个声明对象,用来指定封装在一个模块中的所有组件、指令、服务和其他模块。
@NgModule({
imports: [CommonModule],
declarations: [ WelcomeComponent],
bootstrap: [],
entryComponents: []
})export class AppB_Module {}通过将模块文件指定为Webpack入口点,我们可以将整个Angular模块(包括css和html)打包为一个单独的js文件。
entry: {
'appB_module': './app/appB.prod.module.ts'
}
使用Angular的延迟加载机制,我们可以动态加载这个js文件并引导到当前的应用程序中。
const routes: Routes = [
{
path: appB,
loadChildren: '/appB/appB_Module#AppB_Module'
}
]
这是朝着将应用程序分离为一个小型应用程序的目标迈出的一大步。
从功能模块转移到迷你应用程序
角功能模块以及Webpack捆绑销售给我们我们需要的代码分离,但这是不够的,因为Webpack只允许我们创建包作为一个构建过程的一部分,我们希望能够产生一个单独的JS包,这是建立在不同的时间,从一个单独的代码在一个单独的构建系统,可以在运行时加载到应用程序和共享公共资源,如角。
为了解决这个问题,我们必须创建自己的Webpack加载器,称为share-loader。
share -loader允许我们指定希望在应用程序之间共享的模块列表,它将一个给定的模块捆绑到一个应用程序js捆绑包中,并提供一个其他捆绑包访问该模块的名称空间。
应用程序A webpack.config:
rules: [
{
test: /\.js?$/,
use: [{
loader: 'share-loader',
options: {
modules: [/@angular/, /@lodash/],
namespace: 'container-app'
}
}]
}
应用程序B webpack.json
const {Externals} = require('share-loader');…externals: [ Externals({ namespace: 'container-app', modules: [/@angular/, /@lodash/] }) ], output: { library: 'appB', libraryTarget: 'umd' },
在这个例子中,我们告诉Webpack将angular和lodash捆绑到应用程序A中,并在“容器-应用程序”命名空间下公开它。
在应用程序B中,我们定义angular和lodash不会绑定在一起,而是由命名空间“container-app”指向它们。
通过这种方式,我们可以跨应用程序共享一些模块,但是维护我们不希望共享的其他模块。
到目前为止,我们已经解决的几个关键的我们以前的文章中指定,我们现在有两个应用程序可以运行独立或在运行时加载远程虽然裹着js名称空间和css和html封装,他们之间也可以分享模块,封装模块不应该共享,现在让我们看看一些其他关键的我们所提到的。
DOM封装
为了解决css封装我们包装每个迷你应用程序与一个通用的角组件,该组件使用角css封装特性,我们有两个选择,我们可以使用模拟模式或本地模式根据我们需要的浏览器支持,不管怎样我们确保css不会泄漏。
@Component({
selector: 'ob-externals-wrapper',
template: require('./externals-wrapper.component.pug')(),
styleUrls: ['./externals-wrapper.component.less'],
encapsulation: ViewEncapsulation.Native
})
这个包装器组件还充当每个迷你应用程序和其他应用程序之间的通信层。所有的通信都是通过一个由每个包装器实例承载的事件总线实例来完成的,通过使用一个事件系统,我们有一种解耦的方式来通信数据的输入和输出,当一个小型应用程序从主应用程序中清除时,我们可以很容易地清除这种方式。
如果我们看看我们迄今为止的情况,我们可以看到,我们有一个解决方案是非常内联与web组件的概念,每个迷你应用程序是由一个独立的包装组件,封装所有js html和css,所有通信通过一个事件系统。
测试
由于每个应用程序也可以独立运行,所以我们可以在每个应用程序上独立运行测试套件,这意味着每个应用程序所有者都知道他的更改何时破坏了应用程序,并且每个团队主要关心他们自己的应用程序。
部署和服务
为了为每个应用程序提供自己的部署,我们为每个应用程序创建了一个节点服务,每当一个团队创建一个新的应用程序部署时,都会创建一个封装应用程序的js包,每个服务都会公开一个端点,该端点返回到包的路径。在运行时,当一个小型应用程序加载到容器应用程序中时,将调用端点并将js文件加载到应用程序并引导到主应用程序。这样,每个应用程序都可以单独构建部署。
例子:
没有什么比示例更好的了,如果您想尝试一下,可以到share-loader repo查看Readme中的示例和example-cli部分。
演示可以在回购本身,享受..
结束笔记:
感谢你的阅读!我希望本文能够帮助正在考虑这一举措的公司认识到,通过彻底改革代码库是有可能做到这一点的。
移动到微前端方法是朝着正确的方向移动,因为应用程序越大,速度越小。
本文展示了一个使用Angular作为框架的解决方案,类似的解决方案也可以使用其他框架来实现。
原文:https://medium.com/outbrain-engineering/micro-front-ends-doing-it-angular-style-part-2-1393ced4ceab?
本文:http://pub.intelligentx.net/micro-front-ends-doing-it-angular-style-part-2
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 96 次浏览
【微前端架构】独立的微前端与SPA 库
我们最近在实用主义者的微前沿黑客马拉松上发表了什么。

什么是微前端?
它是将大型web应用程序设计为由小型子应用程序组成的概念。这个想法与微服务非常相似。区别在于微服务是独立的后端服务,而微前端,顾名思义,是独立的前端组件。如果将这两种体系结构模式组合在一起,就可以设计自包含的应用程序。这意味着我们可以将大型系统垂直地分割成独立的部分,在理想的情况下,每个部分都有自己的前端、后端服务和数据库(如果需要的话)。这听起来像是一个摆脱单一UI的完美方法,支持独立且可伸缩的组件!
简单真实的例子
假设我们要实现一个在线商店。它应该有一个可用产品的列表。客户可以将产品添加到购物车中。从购物车级别来看,应该可以下订单。可选地,推荐系统可以推荐可能引起客户兴趣的产品。
布局
在web页面上有两种定位子应用程序的方法:
- 每个页面一个应用程序——每当URL更改时,都会加载一个新的应用程序

- 每个页面有许多应用程序——一个URL可以访问显示在单个页面上的许多小应用程序。

我们如何实现它?
每个应用程序前端可以从不同的位置提供服务,并具有自己的API。为了实现它,我们需要一个模板,它将应用程序呈现在特定的屏幕位置。我们可以通过两种方式实现:服务器端或客户端。
对于服务器端,我们可以使用:
- 启用ESI模块的清漆。有关详细信息,请参见https://varnish-cache.org/docs/3.0/tutorial/esi.html
- NGINX作为启用SSI和ngx_pagespeed模块的反向代理。有关详细信息,请参见https://www.thoughtworks.com/talks/a-high- performance mansolution to microservice-ui-composition
对于客户端,我们可以使用:
- iFrames — ugly solution with lots of problems. For details, please see http://www.rwblackburn.com/iframe-evil/
- Web Components — sample implementation is here: https://micro-frontends.org/
- hinclude library
- H-include library
- Single SPA library
服务器端和客户端都有各自的优缺点,但我更关注客户端。
微前端的优势
- 应用程序是自包含的——这意味着更高的内聚性,因为每个应用程序只有一个职责。
- 应用程序可以独立开发——开发人员可以专注于他们的工作并交付业务价值;不需要与其他团队进行技术同步。
- 应用程序可以独立部署——部署应用程序时可以自由选择,不会对系统的其他部分造成负面影响。
- 应用程序可以在不同的技术中实现——在前端技术快速发展的世界中,选择一个理想的JS框架是不可能的,这在未来两年内不会被视为遗留问题。如果我们可以使用一个新的框架来编写代码,而不用重写现有的系统,那不是很棒吗?使用微前端,我们可以组合许多框架。额外的好处是,我们可以选择我们喜欢的技术,或者与我们团队的技能相匹配的技术!
潜在的问题
- 一致的外观和感觉。我们如何执行它?我们可以使用共享的CSS样式表,但这意味着所有应用程序都依赖于一个公共资源。有更好的方法吗?答案是肯定的,也不是。没有完美的解决方案,但是我建议为每个应用程序使用单独的样式表。冗余导致用户获取更多数据,从而影响应用程序的加载时间。此外,组件必须至少实现一次,这将影响开发成本和一致性。这种方法的好处是独立性。这样,我们就可以避免团队在开发和部署期间的同步问题。有一个共同的风格指南,例如在Zeplin中设计的,有助于保持整个系统的外观和感觉一致(但不相同)。或者,我们可以使用每个应用程序包含的公共组件库。这种解决方案的缺点是,每当有人更改库时,他们必须确保不会破坏依赖的应用程序。它会引入一个巨大的惯性。此外,库在大多数情况下只能由一个框架使用。实现一个UI组件库没有简单的方法,Angular和React应用程序可以使用这个库。
- 缓慢的加载。如果我们要使用至少两个JS框架(例如,两个应用程序使用Angular,一个使用React),那么我们的web浏览器必须获取大量数据。
- 整体的复杂性。如何将不同技术和由不同团队创建的应用程序编排并组合成一个产品?
让我们开始一个概念项目的客户端证明
我们的目标是:
- 创建带有顶部标题和左侧导航栏的类似门户的应用程序,
- 导航栏有打开子应用程序的链接,
- 每个子应用程序都可以用不同的技术实现(比如Angular 5、React 15和React 16),
- 我们可以在一个页面上呈现一个子应用程序,
- 我们可以在一个页面上呈现许多子应用程序,
- 每个子应用程序都可以独立部署并托管在不同的服务器上,
- CSS样式表是独立的,
- 子应用程序之间的通信是可能的。
核心框架
单个SPA库对于引导项目非常有用。它的功能如下:
- 在同一页面上使用多个框架而不刷新页面,
- 改进初始加载时间的延迟加载代码,
- 顶级路由。
那听起来很棒!让我们继续!
概念项目结构证明
我们将创建3个模块:
- 子app- Angular - Angular 5应用,
- 子应用程序-反应物-反应应用程序,
- main-app - React 15应用;它是一个模板模块,将sub-app-angular和sub-app-react16聚合为一个“门户”应用程序。
我们可以使用create-反应物-app来创建新的React子app-react16和main-app应用程序,以及Angular CLI来创建子app- Angular。由于这些启动程序,我们能够跳过耗时的新项目设置。
部署
我们希望有3个运行的服务器:
- http://localhost:3000,服务于main-app应用程序。用户将使用它在web浏览器中打开门户。
- http://localhost:3001,提供子app-angular包。
- http://localhost:3002,服务于子app-react16 bundle。
这意味着,无论何时我们决定必须更新Angular应用程序(因为bug修复),我们都必须构建新的包,并将它们复制到http://localhost:3001上提供的文件夹中。
子应用等进行实现细节
为了将模块导出为子应用程序,我们需要从入口点JS文件导出3个生命周期函数:
- 引导-将被调用一次,就在注册的应用程序第一次挂载之前,
- 挂载-当已注册的应用程式挂载时,
- 卸载——将在卸载已注册的应用程序时调用。
幸运的是,我们不必手动实现这些函数,因为Single SPA为最常见的JS框架提供了默认实现。我们必须做的是在包中包含单spa-react和单spa-angular2库。json文件并编写一段代码。
React应用程序入口点文件可以是这样的:
React 16应用程序的入口点
我们必须为单spa反应提供以下特性:
- rootComponent —用于呈现React应用程序的根组件,
- domElementGetter ----函数,返回应用程序要呈现的DOM元素。
Angular应用程序入口点文件可以是这样的:
Angular 5应用程序的入口点
我们必须为单spa-angular2提供以下属性:
- mainModule -应用根Angular模块,
- domElementGetter——函数返回应用程序要呈现的DOM元素,
- template- Angular模板。
您可能想知道主应用程序在从服务器获取引导、挂载和卸载函数后如何找到它们。答案是我们必须做一些假设。我们假设,在获取并执行所有Angular应用程序包之后,这些函数都可以在窗口中访问。angularApp对象。类似地,对于React应用程序,我们希望在窗口中有这些函数。reactApp对象。这意味着子应用程序和模板都需要知道单个SPA生命周期函数的全局名称空间中的位置。我们可以将它称为子应用程序与其容器之间的契约。
我们如何执行这些函数的目标位置?我们当然可以使用Webpack !为此,我们必须向module.exports添加2个条目。每个子应用程序的Webpack配置文件中的输出对象。
对于React应用程序,它可能是这样的:
将React应用程序导出为window.reactApp
对于Angular应用程序,它可能是这样的:
将Angular应用程序导出为window.angularApp
太酷了!现在,我们准备配置一个模板项目——主应用程序。我们要做的是渲染:
- sub-app-react16 for /react or / in address bar
- sub-app-angular for /angular or / in address bar
模板工程实现
我们必须为子应用程序准备DOM占位符元素:
子应用等进行容器
接下来,我们必须将single-spa库添加到包中。json文件。
现在,我们准备在单个SPA库中注册子应用程序。React子应用程序由registerReactApp函数调用注册,Angular子应用程序由registerAngularApp函数调用注册。最后,我们必须启动单个SPA库。
main-app入口文件
registerReactApp是这样的:
反应应用程序注册
registerAngularApp是这样的:
角应用程序注册
singleSpa的registerApplication方法需要:
- 要注册的应用程序的逻辑名称,
- 应用程序加载器,它是一个函数返回承诺,解析为引导,挂载和卸载子应用程序提供的函数,
- 接受窗口的函数(谓词)。location作为第一个参数,并在应用程序应该为给定URL激活时返回true。
我们需要一些公用工具:
runScript函数获取外部JS脚本文件,并通过向文档添加一个新的脚本元素来运行它。
您可能会注意到子应用程序和模板项目之间的第二个约定:子应用程序和模板都需要知道子应用程序容器的DOM元素ID。
现在让我们看看我们取得了什么成果:

它完美地!
CSS样式表独立
在理想情况下,所有子应用程序都应该是独立的。这意味着不应该提供CSS选择器,这将影响其他子应用程序,例如:按钮,h1等。
因为我们的测试项目使用PostCSS,所以我们可以利用它提供的插件。其中之一是postcss-wrap。它将CSS规则封装在一个名称空间中,例如.selector{}被转换成.namespace .selector{}。在我们的示例中,每个子应用程序可能有自己的名称空间,仅限于其容器标识符。
这意味着对于使用ID React -app在DOM元素中呈现的React应用程序,所有CSS选择器都可以使用# React -app作为前缀。
为此,我们必须将postcss-wrap库添加到React应用程序依赖项中,然后在Webpack配置文件中配置它。它可以是这样的:
postcss-wrap Webpack配置的示例
最后,您可以看到引导样式表的作用域仅限于React应用程序:

带有名称空间的CSS选择器
这是一个非常简单和功能齐全的解决方案!
应用程序之间的通信
最后缺少的是应用程序间的通信。应用程序在理论上是独立的,但是它们可以对其他应用程序发送的一些事件作出响应。因为我们讨论的是事件,而不是直接同步调用,所以它不会在应用程序之间引入直接耦合。
您可能会注意到,React 16应用程序显示当前时间。我们可以实现的是从Angular应用程序发送的一个事件,它会停止或启动时钟。
我们如何在应用程序之间发送事件?最简单的方法是使用本地web浏览器事件机制,它不需要任何额外的库。
我们可以像这样从Angular应用程序发送一个事件:
发送toggleClock事件
此事件的接收者是React应用程序中的时钟组件。它可以在应用程序挂载时订阅,也可以在卸载时取消订阅:
现在通信已经准备好了。很简单的代码!
总结
我们所验证的是,基于客户端呈现的实现(由单个SPA库支持)可能是一个可行的选择。可能还有一些潜在的问题。
需要调查:
- 如果应用程序使用相同的库(例如Lodash),但是版本不同,它会工作得很好吗?
- 有没有办法卸载不再使用的应用程序的JS代码?
可以改进的地方:
- 包缓存。下载自上次使用以来没有更改过的代码基没有任何意义。
- 减少模板应用程序和子应用程序之间的耦合。目前,主应用程序已经硬编码了每个子应用程序包的列表。这个列表可以作为清单文件移动到子应用程序,并通过公共URL公开。这意味着每个子应用程序将确切地告诉模板应用程序为了运行应用程序必须获取什么。模板应用程序只知道每个应用程序的清单文件的URL。
概念验证代码可以在Github上找到:https://github.com/pragmatists/microfron。它还没有准备好投入生产,但这个想法是为了验证我们的假设,并在一天的黑客马拉松中消除我们的疑虑。
希望你喜欢这篇文章!再见。
原文:https://blog.pragmatists.com/independent-micro-frontends-with-single-spa-library-a829012dc5be
本文:http://pub.intelligentx.net/node/566
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 219 次浏览
【组件开发】可重用革命:组件开发的最佳实践
视频号
微信公众号
知识星球
编写代码并将其作为组件发布是不够的
每个人都知道,根据定义,一个组件应该是可重用的,否则,你为什么一开始就想把代码变成一个组件,对吧?
好吧,虽然每个人都可能知道,但并不是每个人都知道制作可重用组件的最佳方法。有时最终的结果是一个次优的实现,虽然可以重复使用,但肯定会更好。
所以,让我们来看看我作为一名软件开发人员多年来学习的一些最佳实践。
模块化设计
在考虑如何设计新组件时,你应该想到的第一件事是“模块化”。
换句话说,你的组件应该被视为一块乐高积木,一块更大的结构,虽然它在原地工作得很好,但也可以(比喻)移动到其他有意义的地方,它也会同样工作。
用乐高积木构建应用程序正是像Bit这样的开源工具链所能实现的方法。通过将UI的原子单元提取到组件中,并独立地存储、测试和记录它们,您可以推动可组合的UI设计,使其能够更好地扩展和维护。
从上面的陈述来看,“有意义的地方”部分很重要,因为否则你会要求一个可以放在任何地方的神奇组件。
相反,关注现实世界中可以分享的场景,但要考虑以下内容:
- 不应该有任何不必要的外部依赖关系。例如,根据React,如果你正在构建一个React组件是可以的。但是,当你构建一个处理时间的组件时,依赖MomentJS(举个例子)就不是了。相反,尝试允许使用标准接口对库进行依赖注入,并使用所给的任何东西。
- 确保正确定义了所需的输入和预期的输出。如果您希望您的组件是模块化的,那么设计的一部分包括定义它期望的输入,以便其他人可以围绕它们进行编码,以及它返回的值。这样,其他人就可以确保它与他们现有的业务逻辑兼容。
诚然,我们生活在现实世界中,所以试着根据您的环境限制调整上述理想要求。
记住,它不一定是完美的,它需要尽可能好(两者之间有很大的区别)。
保持简单
通常的KISS原则也适用于此。保持简单愚蠢的想法是,你考虑的是谁将为他们使用你的组件和代码,而不是为你。
换句话说,试着让他们的生活更轻松,改善你的模块的开发人员体验,每个人都会想使用它。
同时,作为KISS原则的一部分,尽量保持您的组件较小。
我喜欢这样想的一种方式是将它与Linux的CLI工具进行比较。Linux终端有很多工具,它们都遵循相同的原则:它们只做一件事,而且做对了。您可以结合各自的功能创建极其复杂的脚本,但单独使用它们只能让您做这么多。
您的组件也应该如此。小的、可组合的组件比大的、无所不能的组件具有更大的灵活性和可重用性。
除此之外,您还可以获得额外的好处,即更小、更简单的组件更容易维护和调试。所以双赢!
文档、文档、文档
我知道这听起来很无聊,但如果你不让人们知道如何使用你的东西,你怎么能指望他们使用你的?
就这么简单,请注意,我不是在谈论自动生成的参考页面,您可以使用一些工具在2秒内构建该页面。这些文档可能对您很有用,但对于那些刚刚了解您的组件并想了解如何使用它、添加了什么样的配置选项以及它是否适合他们的特定用例的人来说就不方便了。这些开发人员需要更多。
他们需要例子,需要人工编写的解释(见鬼,你现在甚至可以使用ChatGPT,它可能会起作用),关于每个功能、每个方法和每个选项。
如果你想让你的组件受到重视,那么这种文档就必须存在。
此外,您还可以允许人们提出问题和提出问题。如果你在那里发布了代码,你可以使用GitHub。但这给新用户在使用你的代码时提供了额外的安全级别(毕竟,他们可以看到你关心你的用户),也让他们能够解决任何疑问,而无需联系你(如果其他人已经问过这个问题)。
你使用的工具取决于你,实际上,它可以是任何东西,从GitHub页面,到手动编写的网站,甚至像Bit.dev这样的东西。它们允许你在文档旁边的平台中发布自己的组件。您甚至可以在文档中添加活动部分,在那里人们可以尝试修改您的代码示例,以了解它们是如何工作的。这是一个很好的加分项,看起来很神奇。
看看我的一个旧组件的文档:
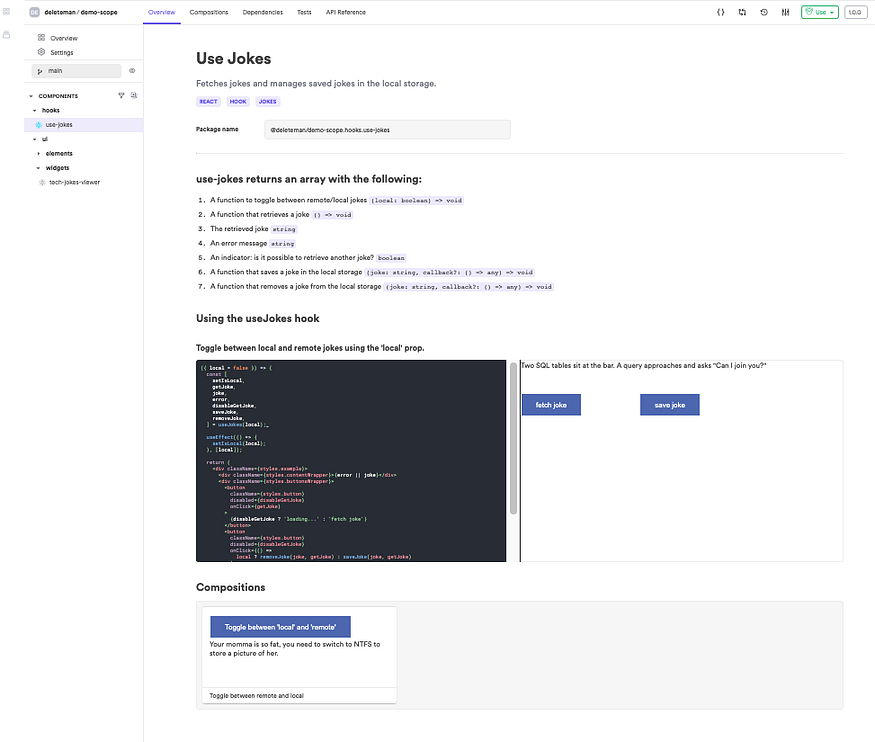
您有一个很好的UI、实时代码示例,甚至可以在页面上直接呈现一个可行的测试。除此之外,您的组件可以通过Bit平台发现。
我知道这听起来可能不好玩,但相信我,从长远来看,您会很高兴为您的组件构建了适当的文档。
彻底测试部件
这一个感觉它甚至不应该成为这个列表的一部分。
不是因为它不重要,而是因为完全相反的原因。我不应该告诉你这一点,你应该已经知道了:无论何时你想共享任何代码,测试都是强制性的。即使您在内部与自己公司内的其他团队共享组件,您唯一能做的负责任的事情就是确保代码按预期工作,这是通过测试来完成的。
单元测试是我的第一个建议,但如果你觉得很慷慨,其他测试,比如端到端甚至集成测试(尤其是如果你正在构建一个需要与专有系统集成的组件)都是不错的主意。
Bit也是一个很好的工具,可以帮助您简化测试实践,特别是如果您不太喜欢编写和运行自己的测试套件。使用Bit,您可以:
- 易于与流行的测试框架集成:Bit支持与一些最流行的前端测试框架(如Jest和Mocha)集成。这意味着您可以在平台内轻松配置和运行组件的测试。最重要的是,如果你正在使用另一个测试库,你可以按照这个详细的指南自己集成它。
- 自动化测试和验证:Bit包括一个自动化的构建和验证过程,确保您的组件没有错误并按预期运行。这个过程可以包括运行测试、linting和其他有助于确保组件质量的检查。不仅如此,无论何时准备发布,组件都会被隔离测试(我可以自动添加)。
- 协作测试:Bit允许开发人员测试和审查彼此的组件,从而实现开发人员之间的协作。这有助于识别问题,并确保组件在各种环境中正确工作。
记住:保持测试的更新,并找到一种自动执行测试的方法(比如使用Bit),这样无论何时发布新版本,都不会忘记运行测试。
使用语义版本控制
尤其是如果你正在建造别人会使用的东西。始终尝试将一些标准版本控制系统添加到组件中。
这样,他们就可以很容易地理解新版本对他们的影响。在semver的情况下,这是我最喜欢的一个BTW,如果你想更新,只需简单看一下新版本就可以理解。
基于semver的版本号由3个数字组成:(主版本)。(次要版本)。(修补程序版本)。
- 如果只是补丁版本发生了变化(即第三个数字),那么您肯定想要更新。这意味着作者发布了一个错误修复程序。
- 如果次要版本发生了更改(可能还有补丁版本),您可以选择忽略它或获取它。这通常意味着作者发布了一些向后兼容的新功能。因此,即使您没有使用它们,将组件更新到该版本也不会破坏系统!。
- 如果主要版本发生了更改,那么您最好在更新组件后测试代码。主要的版本更新意味着该组件上有中断性的更改。所以在进行更新之前,请记住这一点。
这些是您应该遵循的常规指南,它们让您的用户了解您的更新,这样他们就可以很容易地决定如何处理您的新版本,而无需向您提问或在文档中查找更多详细信息。
如果你想知道如何在你的组件库中实现这一点,像Bit这样的工具可以极大地简化这个过程,你甚至不必考虑那么多。
您获得的一些惊人好处包括:
- 自动版本控制:Bit为您的组件提供自动版本控制。每次您对组件进行更改时,Bit都会创建组件的新版本并跟踪它。您可以使用Bit标记命令指定实际版本,也可以让Bit自己决定。这意味着您可以很容易地跟踪组件随时间的变化。如果您想了解更多关于Bit如何处理组件版本控制的信息,请阅读本深度教程。
- 语义版本控制:Bit支持语义版本控制(这是我最喜欢的版本控制策略的原因!)。
- 版本管理:Bit提供了用于管理组件版本的工具。您可以查看零部件更改的历史记录,比较零部件的不同版本,并在必要时回滚到以前的版本。您可以通过Bit的开发人员查看此视频,展示如何使用组件比较功能。
通过使用Bit,您可以确保您的组件得到正确的版本控制,并且可以有效地跟踪更改并将其传达给用户。
也就是说,无论何时发布组件的新版本,都发布变更日志也是一个好主意。这会提供更多关于您发布内容的详细信息,以防您的用户需要该级别的详细信息。只要确保它们是有意义的,说“几个错误修复”是不够的,详细说明你改变了什么,如果有公共对话或公共问题是你修复的,请链接到它们,这样其他人就有必要的上下文来了解他们在系统中添加了什么。
约定高于配置
你可能不同意这种做法,但我喜欢这种做法。
它背后的想法是,默认情况下,您的组件应该在不需要任何配置的情况下工作。事实上,您可以提供一些“约定”,比如CSS类、子组件的命名,或者您的代码将学习并“神奇地”使用的其他约定。
当然,您应该始终让用户能够通过配置覆盖这些约定。这样,他们就可以确切地确定自己在做什么,并完全控制它。
不要,永远不要,只提供没有覆盖的第一部分。将功能隐藏在约定后面是一个糟糕的DX,您应该始终避免。它剥夺了使用它的人应该拥有的对组件的控制感,当这种情况发生时,他们不信任它。
所以,是的,提供一些“神奇的默认值”,但总是让开发人员根据需要覆盖它们。
考虑可访问性
组件在“理想”条件下工作并不意味着您的组件已经准备好了。是的,这是一个很好的第一步,但那些与您的组件交互但看不到您的“理想”用户的用户呢?或者,如果他们根本看不见呢?
“我的组件可以访问吗?”
这应该是你在称之为“完成”之前问自己的一个问题。特别是因为如果在开发阶段完成,检查可访问性问题并添加所需的代码以使其可访问性并不是一项困难的工作。
如果你想知道你能做些什么,请查看这篇详细的帖子,了解你可以通过在组件上做一些额外的工作来影响用户体验的所有方式。
在现有组件中改造可访问性非常困难,所以在规划下一个组件时请记住这一点。
最后,由您来决定您的组件何时“完成”。您可以自由发布和共享任何类型的代码,但在这样做时,您应该从开发人员和用户的角度考虑将要使用它的人。
在这两种情况下,您都有几个考虑因素,可以改善或破坏他们的体验,并确保或否定组件的成功和采用。
我是否错过了您在设计自己的组件时需要牢记的“最佳实践”?在评论中分享,让我们一起讨论!
使用可重复使用的组件构建应用程序,就像乐高一样
Bit的开源工具帮助250000多名开发人员使用组件构建应用程序。
将任何UI、功能或页面变成可重用的组件,并在应用程序中共享。协作更容易,构建速度更快。
将应用程序拆分为组件,使应用程序开发更容易,并享受所需工作流的最佳体验:
best experience for the workflows you want:
- 42 次浏览
【领域驱动设计】Redux 和领域驱动设计
Redux 的创建者 Dan Abramov 说他不知道什么是领域驱动设计。 尽管如此,令人印象深刻的是 Redux 与 DDD 的相似之处。 在本文中,我解释了 DDD 是什么,一些关键概念,以及 Redux 如何实现其思想。 理解两者,我们可以提供更好的实现; 来自不同世界的两种方法相互碰撞并利用相同的设计原则。
领域驱动设计
领域驱动设计是一种软件建模技术,旨在创建强大的微服务架构以及集成多个现有解决方案。
Eric Evans 最初于 2003 年在《领域驱动设计:解决软件核心中的复杂性》一书中提出它。目前,DDD 有更多的书籍、更多的示例,并且已被证明可以有效地扩展和保持大型系统中的高级性能。如果您听说过 Event-Sourcing 或 CQRS,那么您已经与 DDD 擦肩而过。
我们可以将 DDD 分为两个领域:战略和战术。该策略引入了泛在语言和限界上下文。它在开发人员和业务之间创建了一种通用语言,但这种语言超越了会议:所有文档、故事甚至代码都共享该语言。每个声明的变量、函数、类或包名都与通用语言匹配。
策略更多的是关于如何实施系统。主要目标是在许多位置实现跨多个微服务的系统扩展。使用的抽象是查询、命令、域事件和聚合。应用程序将查询和命令指向聚合,聚合执行所有计算,域事件在整个系统中保持最终一致性。
战术的相关概念是:
- 查询:您可以对系统提出的任何问题。它不会更改其状态或任何数据。这是你要求的东西,它会以信息回应。没有副作用。查询示例:列出可用的帖子。
![listPosts(): post[]](https://miro.medium.com/max/300/1*4bClOnjOegInrWmpFyzfJA.png)
- 命令:是对突变的请求。 他们可能会工作,也可能会失败。 系统执行它们并返回结果。 某些变体,例如 CQS,不允许命令返回值。 命令示例:添加新帖子。

- 领域事件:是关键; 它们代表原因的结果; 它们是事实,是已经发生的事情。 事件不会失败,也无法取消。 应用程序中的任何组件都可以监听任何事件; 当它们中的任何一个接收到事件时,它们会更新自身并因此生成新事件。 领域事件使最终的一致性成为可能。 领域事件的示例是:添加了一个新帖子,或者是五点钟。

- Aggregates:是DDD的主要模式。 它代表小块模型(理想情况下只有一个实体和几个对象值)。 模型是合理隔离的。 聚合通过查询、命令和域事件相互通信。 他们消费领域事件以保持其状态一致,同时,他们为每个突变生成新的领域事件。 聚合示例:post。

不幸的是,许多人混淆了命令和领域事件。两者都是动词,都可能暗示状态的变化,但它们是不同的。命令是意图,领域事件是事实。这就是为什么命令可能会失败,但域事件不会。命令是我们想要发生的事情,而领域事件是已经发生的事情。
如果您想了解有关 DDD 的更多信息,我强烈建议您阅读 Vernon Vaughn «Domain-Driven Design Distilled» (2016) 的书。本书快速介绍了所有概念,并全面介绍了如何开始做 DDD。
Redux
Redux 与领域驱动设计有着惊人的关联。虽然它不共享相同的术语,但想法是存在的。 Redux 几乎是功能范式中 DDD 策略的实现。
让我们将之前的概念与 Redux 进行比较:
- 查询:它们是选择器。选择器从状态中获取一条信息。
- 命令:它们是动作。当我们调度一个动作时,我们提交一个新命令。 Redux 不提供结果,因为它实现了纯 CQS。
- 事件:它们也是动作。但是,¿当一个行动变成事实时?一旦减少。在减少一个动作之后,它就变成了一个事实,一个不会改变的东西。
- 聚合:聚合是计算所有更改的人;这是减速机(reducer)。
不幸的是,Redux 词汇表并不容易区分命令和领域事件。 DDD 使用不定式动词来表示命令;和事件的过去分词。尽管如此,通常会看到 redux 操作类型,例如命令“FETCH_POST”或事件“FETCH_POST_SUCCESSFUL”。
Redux 上的 DDD 模式
有两种模式使 DDD 流行起来:事件溯源和 CQRS。两者都源于提高可扩展性和性能的必要性,并且这两种技术通常都应用在 Redux 中。
第一个是事件溯源。
DDD 用于事件溯源的目标是增加数据库中写入的吞吐量。它不会将每个更改保存在数据库中,而是仅存储每个聚合发出的域事件,并在可能的情况下存储聚合的快照。推理很简单:您可以通过重放其事件来重建任何聚合的状态。
例如,您可以通过重播 PostAdded 事件来重建所有帖子。

你熟悉 Redux 中的这个概念吗?几乎可以肯定,是的。在 Redux 中,这称为 Time Traveling,您可能在开发人员工具中调试时经常使用它。
这种模式很棒;它不仅使我们能够更快地修复错误或加快服务器上的写入速度,而且有助于使应用程序更安全。数据丢失?没问题,重播事件,就可以重建状态。由于错误导致数据损坏?解决错误、重播事件并获得原始状态。你在帮助其他用户吗?只需重播他们的事件即可知道他们的状态。
第二个是CQRS。
CQRS 的 DDD 的目标是创建组合来自多个聚合的数据的模型。与其执行大量慢速查询,不如在一个模型上进行一次快速快速查询。如果事件溯源处理慢更新,它解决慢查询。这个想法是,一个独特的模型将消耗多个事件并一致地计算派生状态。然后,使用该新模型。例如,我们可以创建一个模型来统计帖子。它接收 PostAdded 事件并增加每个事件的计数。
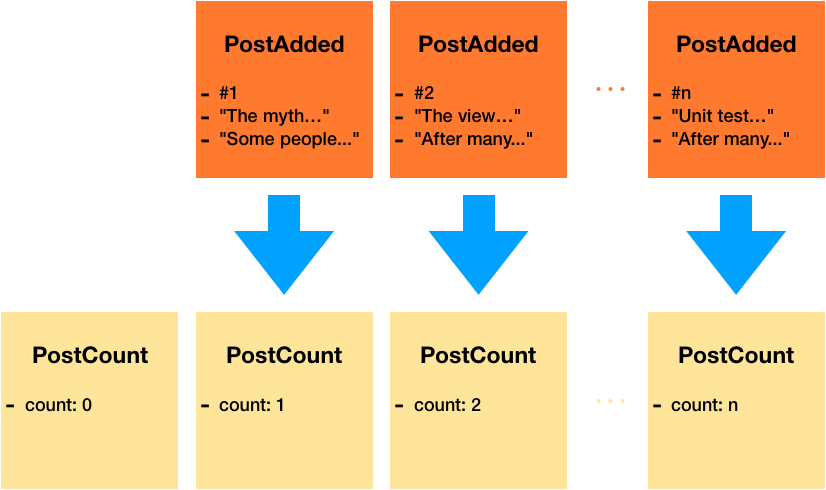
Redux 中的等价物是多个 reducer 在不同的地方使用相同的操作进行更新。 尽管我们有带记忆的选择器,但有时,我们更喜欢保留计算得出的数据以提高性能。 例如,当我们有一个带有由键索引的实体的对象时,但我们有一个带有键的数组。 它加快了列表查询。
function reducePosts(state, action) {
switch (action.type) {
case ADD_POST:
return { ...state, [action.post.id]: action.post };
...
}
}function reducePostList(state, action) {
switch (action.type) {
case ADD_POST:
return [...state, action.post.id];
...
}
}function getPostList(state) {
// instead of Object.keys(state.post)
return state.postList;
}DDD 依赖解耦。
虽然它不是一种模式,但 DDD 很好地解耦了它们之间的聚合。 除了性能的可扩展性之外,它是 DDD 的主要优势之一。 聚合的概念以及它如何与其他人交互它提供了高度的可维护性和更好的实现。 正是这种精确的特性阻止了有害的大泥球的产生。
让我们看一个例子:我们有一家销售产品并使用营销活动来提供报价的公司。 商店中的现有商品最初标有相应的产品售价,但当活动开始时,它会用广告价格重新标记商品。
如果没有 DDD,我们有如下代码:

// Without DDD
class Campaign {
...
startCampaign() {
product.relabelUnits(advertisedPrice);
}
}class Product {
...
relabelUnits(price) {
units.forEach(unit => unit.relabelPrice(price));
}
}class Unit {
...
relabelPrice(price) {
labeledPrice = price;
}
}如果我们应用 DDD,我们可以中继域事件来更新其他聚合:

// With DDD
class Campaign {
...
startCampaign() {
emit(new CampaignStarted(..., productId, advertisedPrice));
}
}class Unit {
...
onCampaignStarted(event) {
labeledPrice = event.advertisedPrice;
}
}你注意到不同了吗? 现在产品已经消失了。 该产品不再依赖于该单元。 我们减少了应用程序的耦合,我们可以在不更改任何代码的情况下从系统中插入和拔出单元。
Redux 做同样的解耦。 每个组合的减速器就像一个聚合体。 当 reducer 收到一个动作时,它会独立地减少它。
function reduceUnit(state, action) {
switch (action.type) {
case START_CAMPAIGN:
return { ...state, labeledPrice: action.advertisedPrice };
...
}
}结论
Redux 和 DDD 有许多相似之处,并且都具有许多优点。 尽管它们是从不同的抽象和不同的背景创建的,但它们都受益于相同的架构原则。
主要区别在于领域事件。 这个概念在 Redux 中并没有明确存在。 它有后果,可能会在进一步的文章中进行研究。
原文:https://levelup.gitconnected.com/redux-and-doman-driven-development-29f…
- 66 次浏览
多体验应用架构
- 65 次浏览
微服务架构
微服务架构 intelligentx- 578 次浏览
「分布式架构」分布式架构中可扩展性的事务一致性
系统架构师角色的一个关键方面是权衡冲突的需求并决定解决方案,通常是通过将一个方面与另一个方面进行权衡。 随着系统变得越来越大,越来越复杂,越来越多关于如何构建应用程序的传统智慧正在受到挑战。 例如,去年3月在伦敦召开的QCon会议上,Dan Pritchard就eBay的架构发表了演讲。 从他的演讲中获得大量后续报道的主要内容之一是eBay不使用事务,事务丢失简单的数据一致性,以显着改善其系统的整体可扩展性和性能。
在他的演讲之后,InfoQ与Dan Pritchard进行了交谈,以获取更多信息:
为什么eBay不使用交易,或者如何决定应用程序级交易?
并不是我们不使用事务。我们只是不使用跨物理资源的事务,因为它跨多个组件创建了依赖关系。组件可以是应用程序服务器和数据库(例如客户端管理的事务),因为客户端故障可能会占用数据库资源的时间超过我们可以容忍的时间。我们也不使用分布式事务,因为使应用程序依赖于多个数据库会降低客户端的有效可用性。相反,我们选择设计缺少事务并构建故障模式,即使在数据库可用性问题的情况下,客户端也能成功。
应用程序级别的事务总是有些问题。无论何时您要求开发人员管理资源生命周期,您都将面临管理出错时出现的错误。事务与内存没什么不同,我们看到语言的一般趋势是由于生命周期问题而从开发人员那里消除内存管理的责任。声明性事务(例如EJB中的事务)是[a]简化事务管理的大锤方法,假设bean背后的每个数据库操作都同等重要。
决定是否使用事务实际上取决于您的可伸缩性和可用性目标。如果您的应用程序需要每秒达到数百个事务,那么您将发现分布式事务不会削减它。如果要在可用性的第3个9之后添加另一个数字,您将无法假设所有数据库提交都必须在网页的上下文中完成,或者在某些情况下完成。不幸的是,没有简单的公式可以何时退出应用程序级别的事务。相反,作为架构师,您必须决定系统上的一个约束何时需要您放松另一个约束。
你是如何为“放置出价”(Place bid)之类的东西建立自己的原子性的?
单独出价是一个有趣的问题,因为它不是关于原子性的,而是更多关于在拍卖的关键后几秒没有阻止任何竞标者。事实证明,如果您决定在展示时间而不是出价时间计算高出价者和出价,这很简单。将出价插入到单独的子表中,这是一种低争用操作。每次显示该项目时,都会检索所有出价并应用用于确定高出价者的业务规则。
你问题背后的真正问题是我们如何实现一致性?要在大规模系统中实现一致性,您必须放弃ACID而是使用BASE:
基本可用
软状态
最终一致
在每个客户端请求结束时,您需要放松数据的一致性,现在您已打开窗口以消除分布式事务并使用其他机制来达到一致状态。例如,在上述投标案例中,我们还更新由投标人组织的查看表,以便在“我的易趣”页面中快速显示。这是使用一对异步事件完成的。一个人依赖于内存队列,因为我们希望在出价和出现在“我的易趣”之间的延迟非常低。但是,在内存中队列不可靠,因此我们还使用具有出价操作的服务器端事务来捕获出价事件。如果内存队列操作失败,则作为恢复机制处理bid事件。因此,投标人视图表是分离的,并不总是与投标表的状态一致。但这是我们能够承受的宽容,并允许我们避免出价和出价视图表之间的ACID合规性。
您对大型系统的其他架构师有什么建议?
他最简单的建议是,大规模扩展不会为设计为小规模扩展的架构增加资源。 您必须摆脱传统模式,例如ACID和分布式事务。 愿意寻找机会放松传统智慧状态无法放松的约束。
对于一些简单的公理,设计所有要拆分的东西,并考虑BASE,而不是ACID。
亚马逊首席技术官Werner Vogels也在QCon上发表讲话,并以Eric Brewer的CAP定理为例,提供了一些权衡的背景。该定理在2000年PODC会议(.pdf文档)的介绍中描述,其中也涵盖了ACID与BASE,它表明,对于共享数据系统的三个属性 - 数据一致性,系统可用性和网络分区容忍度 - 只有两个可以同时发生。换句话说,不能容忍网络分区的系统可以使用诸如事务之类的常用技术来实现一致性和可用性。但是,对于亚马逊和eBay等大型分布式系统,网络分区是给定的。这样做的结果是,处理非常大的分布式系统的架构师必须决定是否放宽对一致性或可用性的要求。这两个选项都给开发人员带来了一些责任,他们需要了解他们正在使用的架构的特征。例如,如果您选择放松一致性,那么开发人员需要决定如何处理对系统的写入不会立即反映在相应读取中的情况。正如Windows Live程序经理Dare Obasanjo所说的那样.
我们在Windows Live平台的某些方面遵循类似的做法,我听说开发人员抱怨这样一个事实,即您通过事务免费获得的错误恢复由应用程序开发人员掌握。 最大的抱怨总是围绕复杂的批量操作。
有趣的是,许多大型网站似乎都独立地得出了相同的结论。 虽然只有少数节点的小型系统不必担心这些类型的权衡,但eBay和亚马逊正在解决的各种问题可能会开始出现在企业系统中,因为它们也会扩展到更大的范围。 更多的观众。
- 95 次浏览
「微服务架构」Google和eBay在构建微服务生态系统方面的深刻教训
当你看到来自谷歌,Twitter,eBay和亚马逊的大规模系统时,他们的架构已演变成类似的东西:一组多语言微服务。
当您处于多语言微服务结束状态时,它看起来像什么? Randy Shoup曾在谷歌和eBay担任过高级职位,他有一个非常有趣的话题就是探索这个想法:规模的服务架构:谷歌和eBay的经验教训。
我真正喜欢Randy的演讲是他如何自觉地试图让你沉浸在你可能没有经验的经历中:创造,使用,延续和保护大规模的架构。
在谈话的服务生态系统部分兰迪问道:拥有大规模多语言微服务生态系统是什么样的?在“规模运营服务”部分,他问:作为服务提供商,运营此类服务的感觉如何?在“建立服务”部分,他问:当您是服务所有者时,它看起来像什么?在服务反模式部分,他问:什么可能出错?
一种非常强大的方法。
对我来说,演讲的亮点是调整激励机制的想法,这是一个贯穿整个努力的一贯主题。虽然从未明确地将其作为一个单独的策略,但这是为什么您希望小团队开发小型清洁服务,为什么内部服务的退款模型如此强大,架构如何在没有架构师的情况下发展,如何清洁设计可以发展的动机自下而上的过程,以及标准如何在没有中央委员会的情况下发展。
我的想法是,有意识地调整激励机制是如何扩展大型动态组织和大型动态代码库。在没有明确控制的情况下,采用正确的激励措施可以促使事情发生,几乎同样的方式是,当您移除锁定,不共享状态,与消息通信以及并行化所有内容时,分布式系统中的更多工作都会完成。
让我们看看现代时代如何建立大规模系统......
多语言微服务是最终的游戏
大规模系统最终演变成看起来非常相似的东西:一组多语言微服务。多语言意味着微服务可以用多种语言编写。
eBay始于1995年。根据您的计算方式,他们是第5代的架构。
- 始于1995年劳动节周末创始人写的单片Perl应用程序。
- 然后它转移到一个单片C ++应用程序,最终在一个DLL中有340万行代码。
- 之前的经验促使人们转向更加分散的Java分区系统。
- 今天的eBay有相当多的Java,但是一套多语言的微服务。
Twitter的演变看起来非常相似。根据您的计算方式,他们是第三代架构。
- 作为单片Ruby on Rails应用程序启动。
- 移动到前端的Javascript和Rails组合,后端有很多Scala。
- 最终,他们已经转向我们今天称之为一组多语言微服务。
亚马逊遵循类似的道路。
- 从单片C ++应用程序开始。
- 然后用Java和Scala编写的服务。
- 结束一组多语言微服务。
服务生态系统
拥有多语种微服务的大规模生态系统是什么样的?
在eBay和Google上,数百到数千个独立服务都在一起工作。
- 现代大规模系统在关系图中组成服务,而不是层次结构或层级组。
- 服务依赖于许多其他服务,同时被许多服务依赖。
- 较旧的大型系统通常以严格的层级组织。
如何建立服务生态系统?
这些性能最佳的系统更多是进化的产物,而不是智能设计。例如,在Google,从未有过系统的自上而下的设计。它以一种非常有机的方式随着时间的推移而发展和成长。
变化和自然选择。当需要解决问题时,会创建新服务,或者更经常从现有服务或产品中提取新服务。只要服务使用,服务就会存在,只要它们提供价值,否则它们会被弃用。
这些大规模系统自下而上发展。清洁设计( Clean design)可以是一种新兴产品,而不是自顶向下设计的产品。
例如,考虑Google App Engine的一些服务分层。
- Cloud Datastore(NoSQL服务)构建在Megastore(一个地理规模的结构化数据库)上,该数据库构建在Bigtable(一种集群级结构化服务)上,该服务基于Colossus(下一代集群文件系统)构建,建立在Borg(集群管理基础架构)之上。
- 分层很干净。每个图层都添加了一些不属于下面图层的内容。它不是自上而下设计的产物。
- 它是自下而上建造的。 Colossus,谷歌文件系统是首先建立的。几年后,Bigtable建成了。几年后,Megastore建成了。几年后,Cloud Database迁移到了Megastore。
- 没有自上而下的架构,您可以将这种关注点分离出来。
这是没有架构师的架构。 Google没有人拥有建筑师的头衔。技术决策没有中央批准。大多数技术决策都是由各个团队在当地为自己的目的做出的,而不是全球性的。
与2004年的eBay相比。有一个架构审查委员会,必须批准所有大型项目。
- 通常他们只是参与项目,因为改变它们已经太晚了。
- 集中审批机构成为瓶颈。它唯一的影响往往是在最后一分钟说不。
eBay处理这种情况的一个更好的方法是在审查委员会中对智能经验丰富的人员的知识进行编码,并将其放入可由各个团队重复使用的内容中。将这种体验编码到库或服务中,甚至是一组人们可以自己使用的指南,而不是在最后一刻进入流程。
标准如何在没有建筑师的情况下发展?
没有中央控制可能最终导致标准化。
- 标准化往往发生在服务和公共基础设施之间的通信中。
- 标准成为标准,因为它们比替代品更健康。
通常标准化的通信部分:
- 网络协议。 Google使用名为Stubby的专有协议。易趣使用REST。
- 数据格式。 Google使用Protocol Buffers。易趣倾向于使用JSON。
- 接口模式标准。 Google使用Protocol Buffers。对于JSON,有JSON模式。
通常标准化的通用基础设施:
- 源代码控制。
- 配置管理。
- 集群管理器。
- 监控系统。
- 警报系统。
- 诊断工具。
- 所有这些组件都可以根据惯例发展。
在进化环境中,标准通过以下方式实施:代码,鼓励,代码审查和代码搜索。
- 鼓励最佳实践的最简单方法是通过实际代码。这不是关于自上而下的审查,也不是前期设计,而是关于生成代码的人,这使得完成工作变得容易。
- 鼓励是通过提供库的团队。
- 鼓励也是通过您希望依赖于支持X协议或Y协议的服务。
- Google以至少一位其他程序员审阅源代码控制的每行代码而闻名。这是沟通常见做法的好方法。
- 除了少数例外,Google的每位工程师都可以搜索整个代码库。当程序员试图弄清楚如何做某事时,这是一个巨大的增值。对于10K工程师来说,如果你正在尝试做一些人已经做过类似事情的话。这允许从一个区域开始的最佳实践通过代码库传播。它还允许错误传播。
为了鼓励共同的实践和标准化的惯例,使得做正确的事情变得非常容易,并且做错事情要困难得多。
个人服务彼此独立。
- 在谷歌,没有标准化的服务内部。服务是外面的黑匣子。
- 有常规和通用库,但没有编程语言要求。通常使用四种语言:C ++,Go,Java,Python。许多不同的服务都是用各种语言编写的。
- 框架或持久性机制没有标准化。
在成熟的服务生态系统中,我们标准化 图的弧,而不是节点本身。定义一个共同的形状,而不是常见的实现。
创建新服务
- 新服务在使用已经过验证后即可创建。
- 通常,为一个特定用例构建了一个功能。然后发现该功能是通用且有用的。
- 一个团队成立,服务分离到自己的独立单位。
- 只有当功能成功并适合许多不同的用例时才会发生这种情况。
- 这些架构通过实用主义而成长。没有人坐在高处并且说应该添加服务。
- Google文件系统支持搜索引擎。毫无疑问,分布式文件系统通常更常用。
- Bigtable最初支持搜索引擎,但更广泛有用。
- Megastore是作为Google应用程序的存储机制构建的,但更广泛有用。
- Google App Engine本身是由一小群工程师发起的,他们认识到需要帮助构建网站。
- Gmail来自一个内部非常有用的副项目,然后被外部化为其他人。
弃用旧服务
如果不再使用某项服务会怎样?
- 可以重新利用的技术可以重复使用。
- 人们可以被解雇或重新部署到其他团队。
- Google Wave并非市场成功,但其中一些技术最终出现在Google Apps中。 例如,多人编辑文档的能力来自Wave。
更常见的情况是核心服务经历多代并且旧代被弃用。 这种情况在Google发生了很多。 通常情况下,谷歌内部的每项服务都被弃用或尚未准备就绪。
建立服务
当您是服务所有者时,在大规模多语言微服务系统中构建服务时,它会是什么样子?
在大型架构中表现良好的服务是:
- 单用途。 它将有一个简单明确的界面。
- 模块化和独立。 我们可以称之为微服务。
- 不共享持久层。 稍后会详细介绍。
服务所有者的目标是什么?
- 满足客户的需求。 以适当的质量水平提供必要的功能,同时满足协商的性能水平,同时保持稳定性和可靠性,同时不断改进服务。
- 以最低的成本和精力满足需求。
- 这一目标以鼓励使用共同基础设施的方式调整激励措施。
- 每个团队都拥有有限的资源,因此利用常见的战斗测试工具,流程,组件和服务符合他们的利益。
- 它还可以激发良好的操作行为。 自动构建和部署您的服务。
- 它还可以优化资源的有效利用。
服务所有者的责任是什么?
- 你构建它运行它。
- 该团队通常是一个小团队,拥有从设计,开发和部署到退役的服务。
- 没有单独的维护或维护工程团队。
- 团队可以自由地制定自己的技术选择,方法和工作环境。
- 团队对他们的选择负责。
- 服务作为有限的边界。
- 团队的认知负荷是有限的。
- 没有必要了解生态系统中的所有其他服务。
- 团队需要深入了解他们的服务以及他们所依赖的服务。
- 这意味着团队可以非常小巧灵活。一个典型的团队是3-5人。 (另外一个美国海军陆战队的火队有四个人。)
- 团队规模小意味着团队内部的沟通具有非常高的带宽和质量。
- 康威定律对你有利。通过组织小团队,你最终会得到一些小的个人组件。
什么是服务之间的关系?
- 考虑服务之间的关系作为供应商 - 客户关系,即使您在同一家公司。
- 非常友好和合作,但在关系中要非常有条理。
- 对所有权非常清楚。
- 要清楚谁应该对什么负责。在很大程度上,这是关于定义一个清晰的界面并维护它。
- 奖励是一致的,因为客户可以选择是否使用服务。这鼓励客户做正确的服务。这是新服务最终建立的方式之一。
- 定义SLA。服务提供商承诺为其客户提供一定程度的服务,以便客户可以依赖该服务。
- 客户团队为服务付费。
- 为服务收费可以协调经济激励措施。它激励双方在资源利用方面极为高效。
- 当事物是自由的时,我们倾向于不重视它们,并且往往不优化它们。
- 例如,内部客户免费使用Google App Engine,他们使用了大量资源。乞求他们更有效地利用资源,结果证明这不是一个好策略。退款开始一周后,通过一两个简单的更改,他们能够将GAE资源的消耗减少90%。
- 并不是使用GAE的团队是邪恶的,他们只是有其他优先事项,因此没有动力让他们优化他们对GAE的使用。事实证明,他们实际上通过更高效的架构获得了更好的响应时间。
- 充电还可以使服务提供商保持高质量,否则内部客户可能会去其他地方。这直接激励了良好的开发和管理实践。代码审查就是一个例子。谷歌的超大规模构建和测试系统是另一个。 Google每天都会运行数百万次自动化测试。每次将代码接受到存储库时,都会运行所有相关代码的验收测试,这有助于所有小型团队保持其服务质量。
- 退回退模式鼓励小额增量变更。小变化更容易理解。此外,代码更改的影响是非线性的。千分线变化的风险不是100线变化的10倍,它更像风险的100倍。
- 保持接口的完全向后/向前兼容性。
- 切勿破坏客户端代码。
- 这意味着维护多个接口版本。在一些令人讨厌的情况下,这意味着维护多个部署,一个用于新版本,另一个用于旧版本。
- 通常由于小的增量变化模型接口没有改变。
- 有明确的弃用政策。然后,服务提供商非常激动地将所有客户从版本N移到版本N + 1。
规模运营服务
作为服务提供商,在大规模多语言微服务系统中运行服务是什么感觉?
可预测的性能是一项要求。
- 大规模服务很容易受到性能差异的影响。
- 性能的可预测性比平均性能重要得多。
- 具有不一致性能的低延迟实际上根本不是低延迟。
- 当客户端提供一致的性能时,它可以更轻松地针对服务进行编程。
- 由于服务使用许多其他服务来执行其工作,因此尾部延迟主导性能。
- 想象一下这样一种服务,在中位数上有1ms的延迟,在99.999%的ile(1 / 10,000)中,延迟是一秒。
- 拨打一个电话意味着你很慢.01%的时间。
- 如果你使用的是5000台机器,就像Google那样的大型服务,那么50%的时间你都会很慢。
- 例如,memcached中百万分之一的问题被追踪到低级数据结构重新分配事件。这个罕见的问题表现为更高级别的延迟峰值。像这样的低级细节在大规模系统中变得非常重要。
深度弹力。
- 服务中断更可能是由于某人的错误而不是硬件或软件故障而发生的。
- 适应机器,集群和数据中心故障。
- 负载平衡并在调用其他服务时提供流量控制。
- 能够快速回滚变化。
增量部署。
- 使用金丝雀系统。不要一次部署到所有计算机。选择一个系统,将该软件的新版本放在该系统上,并查看它在新世界中的表现。
- 如果它工作开始分阶段推出。开始使用10%的机器,移动到20%,依此类推,通过其余的机队。
- 如果在部署中的50%点发生问题,那么您应该能够回滚。
- eBay利用功能标志将代码部署与功能部署分离。通常在关闭功能的情况下部署代码,然后可以打开或关闭代码。这可确保在打开新功能之前正确部署代码。这也意味着如果新功能存在错误,性能问题或业务故障,则可以关闭该功能,而无需部署新代码。
你可以有太多警报,你永远不会有太多的监控。
服务反模式
大型服务
- 服务太多了。 你想要的是一个非常小的清洁服务生态系统。
- 做太多的服务只是另一个巨石。 它很难推理,它很难扩展,很难改变,而且它还创建了比你想要的更多的上游和下游依赖。
共享持久性
- 在分层模型中,服务放在应用程序层中,持久层作为应用程序的公共服务提供。
- 他们在eBay做到了这一点并没有奏效。 它打破了服务的封装。 应用程序可以通过更新数据库来支持您的服务。 它最终重新引入服务耦合。 共享数据库不允许松散耦合的服务。
- 微服务通过小型,隔离和独立来防止这个问题,这是您保持生态系统健康和发展的方式。
- 136 次浏览
「微服务架构」Saga 模式 如何使用微服务实现业务事务-第二部分
在上一篇文章中,我们看到了实现分布式事务的一些挑战,以及如何使用Event / Choreography方法实现Saga的模式。在本文中,我们将讨论如何通过使用另一种类型的Saga实现(称为Command或Orchestration)来解决一些问题,如复杂事务或事件的循环依赖性。
Saga的命令/编曲序列逻辑
在编曲方法中,我们定义了一项新服务,其唯一责任是告诉每个参与者该做什么以及何时做什么。 saga orchestrator以命令/回复方式与每个服务进行通信,告诉他们应该执行哪些操作。
让我们看一下使用我们之前的电子商务示例的样子:
- 订单服务保存挂起的定单并要求Order Saga Orchestrator(OSO)启动创建订单交易。
- OSO向付款服务发送执行付款命令,并回复付款已执行消息
- OSO向库存服务发送准备订单命令,并回复订单准备消息
- OSO向Delivery Service发送Deliver Order命令,并以Order Delivered消息回复
在上面的例子中,Order Saga Orchestrator知道执行“创建订单”事务所需的流程是什么。如果有任何失败,它还负责通过向每个参与者发送命令以撤消先前的操作来协调回滚。
为saga协调器建模的标准方法是状态机,其中每个转换对应于命令或消息。状态机是构建定义明确的行为的极好模式,因为它们易于实现,特别适合测试。
在Saga的命令/编曲中回滚
当你有一个协调器来协调所有事情时,回滚会容易得多:
使用Saga命令/编曲设计的好处和缺点
基于编排的传奇有各种好处:
避免服务之间的循环依赖,因为saga orchestrator调用saga参与者但参与者不调用orchestrator
- 集中分布式事务的编排
- 降低参与者的复杂性,因为他们只需要执行/回复命令。
- 更容易实施和测试
- 添加新步骤时,事务复杂性保持线性
- 回滚更容易管理
- 如果您有第二个愿意更改同一目标对象的事务,您可以轻松地将其保留在协调器上,直到第一个事务结束。
然而,这种方法仍然存在一些缺点,其中之一是在协调器中集中过多逻辑的风险,最终导致智能协调器告诉哑巴服务该做什么的架构。
Saga的Orchestration模式的另一个缺点是它会略微增加您的基础架构复杂性,因为您需要管理额外的服务。
Saga(传奇)模式提示
- 为每个事务创建唯一ID
为每个事务提供唯一标识符是可追溯性的常用技术,但它也有助于参与者以标准方式相互请求数据。例如,通过使用交易ID,交付服务可以询问库存服务在哪里提取产品,如果订单已付款,则可以使用支付服务仔细检查。
- 在命令中添加回复地址
不要将参与者设计为回复固定地址,而是考虑在消息中发送回复地址,这样您就可以让参与者回复多个协调者。
- 幂等运算
如果您使用队列进行服务之间的通信(如SQS,Kafka,RabbitMQ等),我个人建议您使您的操作具有幂等性。大多数队列可能会两次传递相同的消息。
它还可能会增加您的服务的容错能力。通常,客户端中的错误可能会触发/重放不需要的消息并弄乱您的数据库。
- 避免同步通信
随着事务的进行,不要忘记将每个要执行的操作所需的所有数据添加到消息中。整个目标是避免服务之间的同步调用只是为了请求更多的数据。即使其他服务处于脱机状态,它也可以使您的服务执行本地事务。
缺点是您的协调器会稍微复杂一些,因为您需要操纵每个步骤的请求/响应,因此请注意权衡。
- 147 次浏览
「微服务架构」Saga 模式|如何使用微服务实现业务事务 第一部分
最强大的事务类型之一称为两阶段提交,当第一个事务的提交取决于第二个事务的完成时,它是摘要。特别是当您必须同时更新多个实体时,例如确认订单和立即更新库存时,它非常有用。
但是,例如,当您使用微服务时,事情变得更加复杂。每个服务都是一个独立的系统,拥有自己的数据库,您不再可以利用本地两阶段提交的简单性来维护整个系统的一致性。
当你失去这种能力时,RDBMS成为一个非常糟糕的存储选择,因为你可以完成相同的“单实体原子事务”,但只需使用像Couchbase这样的NoSQL数据库就可以快几十倍。这就是为什么大多数使用微服务的公司也在使用NoSQL。
要举例说明此问题,请考虑以下电子商务系统的高级微服务架构:
在上面的示例中,人们不能只在一个ACID交易中下订单,向客户收费,更新库存,并将其发送到交货。要始终如一地执行此整个流程,您将需要创建分布式事务。
我们都知道实现分布式任务是多么困难,不幸的是,交易也不例外。处理瞬态状态,服务,隔离和回滚之间的最终一致性是在设计阶段应该考虑的场景。
幸运的是,我们已经为它提出了一些好的模式,因为我们已经实施分布式事务已有二十多年了。我今天要谈的那个叫做Saga模式。
传奇(Saga)模式
分布式事务最着名的模式之一称为Saga。关于它的第一篇论文发表于1987年,从那时起它就成了一种流行的解决方案。
Saga是一系列本地事务,其中每个事务在单个服务中更新数据。第一个事务由对应于系统操作的外部请求启动,然后每个后续步骤由前一个完成触发。
使用我们之前的电子商务示例,在一个非常高级的设计中,Saga实现如下所示:
有几种不同的方法来实现传奇交易,但最受欢迎的两种方式是:
- 事件/Choreography(编舞):当没有中央协调时,每个服务产生并监听其他服务的事件,并决定是否应该采取行动。
- 命令 / Orchestration(编曲):协调器服务负责集中saga的决策和排序业务逻辑。
让我们更深入地了解每个实现,以了解它们的工作原理。
事件/编舞
在事件/Choreography(编舞)方法中,第一个服务执行事务然后发布事件。该事件由一个或多个服务监听,这些服务执行本地事务并发布(或不发布)新事件。
当最后一个服务执行其本地事务并且不发布任何事件时,分布式事务结束,或者任何传奇(Saga)参与者都不会听到发布的事件。
让我们看看它在我们的电子商务示例中的样子:
- 订单服务保存新订单,将状态设置为挂起并发布名为ORDER_CREATED_EVENT的事件。
- 付款服务侦听ORDER_CREATED_EVENT,向客户收费并发布事件BILLED_ORDER_EVENT。
- Stock Service监听BILLED_ORDER_EVENT,更新库存,准备订单中购买的产品并发布ORDER_PREPARED_EVENT。
- Delivery Service侦听ORDER_PREPARED_EVENT,然后选择并交付产品。最后,它发布了ORDER_DELIVERED_EVENT
- 最后,Order Service侦听ORDER_DELIVERED_EVENT并将订单状态设置为已结束。
在上面的情况中,如果需要跟踪订单的状态,订单服务可以简单地监听所有事件并更新其状态。
分布式事务中的回滚
回滚分布式事务并非免费。通常,您必须实施另一个操作/事务来补偿之前已完成的操作。
假设Stock Service在交易期间失败了。让我们看看回滚会是什么样子:
- 库存服务生产PRODUCT_OUT_OF_STOCK_EVENT;
- 订单服务和付款服务都会收听上一条消息:
- 付款服务退还客户。
- 订单服务将订单状态设置为失败。
请注意,为每个事务定义一个公共共享ID至关重要,因此每当您抛出一个事件时,所有侦听器都可以立即知道它所引用的事务。
Saga 事件/Choreography(编舞)设计的好处和缺点
事件/编排是实现Saga模式的自然方式;它简单,易于理解,不需要太多的努力来构建,并且所有参与者都是松散耦合的,因为他们没有彼此的直接知识。如果您的交易涉及2到4个步骤,那么它可能非常合适。
但是,如果您不断在事务中添加额外的步骤,这种方法很快就会变得混乱,因为很难跟踪哪些服务监听哪些事件。此外,它还可能在服务之间添加循环依赖,因为它们必须订阅彼此的事件。
最后,使用这种设计实现测试会很棘手。为了模拟事务行为,您应该运行所有服务。
在下一篇文章中,我将解释如何使用另一个名为Command / Orchestration的Saga实现解决Saga事件/编舞方法的大部分问题。
- 160 次浏览
「微服务架构」七种微服务反模式
什么是微服务
流行语经常为进化的概念提供背景,并且需要一个良好的“标签”来促进对话。微服务是一个新的“标签”,它定义了我个人一直在发现和使用的领域。文章和会议描述了一些事情,我慢慢意识到,过去几年我一直在发展自己的个人经历。虽然有关微服务的行业和专业讨论已经成为Netflix,亚马逊和谷歌等公司以及成功完成这项工作的从业者的焦点,但我有一些个人经验可以为成功的微服务实施提供见解。
任何架构的三个标准和最常见的业务驱动因素是:
- 提高敏捷性 - 及时响应业务需求以便业务增长的能力
- 改善客户体验 - 改善客户体验,从而减少客户流失
- 降低成本 - 降低添加更多产品,客户或业务解决方案的成本
事实上,我们所有人都在努力在日常工作中这样做。 SOA创建了一个业务一致的软件框架,使企业能够实现这一目标。几家大型软件供应商已经出现并声称他们的产品套件可以使企业提供SOA。
如果您没有合适的人员,文化和投资,SOA将无法实现业务价值。微服务架构与SOA并没有根本的不同,目标和目标是相同的,但是方法略有改进,事实上,我只是说微服务仅仅是SOA可扩展的。微服务使应用程序/系统迫切需要从单一实现转移到服务于许多应用程序的分布式分散服务平台。微服务是独立的,它将敏捷性和应用程序演变视为企业数字化转换。微服务的成功取决于服务独立性和服务灵活性。
我将微服务定义为“通过构建细粒度服务以支持分布和组织为功能域的业务功能来提供SOA的方法”。没有模式是魔术棒或银弹。您应该正确构思和定制模式企业应该专注于解决支持架构所需的项目以构建自适应平台。
一些企业的SOA实施失败了 - 因为他们没有完全分析他们的业务能力模型,并认为开发Web服务意味着SOA或从大型供应商购买SOA套件会使他们启用SOA或无法显示SOA及其业务驱动因素/目标。
举例
经验的一个例子可能会澄清这一点。在过去的一份工作中,该企业的目标是提高敏捷性,客户体验并降低成本。我们决定构建一个标准的多租户SOA平台。该方法旨在开发细粒度的服务,以便我们可以经常进行更改,并为平台部署小的,可管理的更改。如果我们今天采用相同的方法,我们可能会称之为微服务架构。那时我们没有这个词,但它才有意义。
服务是基于业务能力模型建模的,第一个版本进展顺利。它们是基于JMS同步服务的XML,主要侧重于提供向代理,Web和语音通道应用程序公开的声明平台所需的功能。它使我们能够为我们的应用程序无缝部署频繁,小的更改和A / B功能支持。
当需求逐渐增加(并且它们总是如此)时,由于应用程序和消费者之间的集成复杂性,很难快速发布解决方案。集成,功能测试和生产发布需要紧密协调。随着业务开始扩展,更改频率比初始版本高出10倍,并且由于交付生命周期中的大多数任务都是手动的,因此上市时间不符合业务预期。很快,由于糟糕的微服务自动化和生命周期管理导致交付熵,我们的目标都没有实现。
经验教训 - 不要做这些事情,而是......做其他事情
这让我分享了我在旅途中学到的一些课程,以便您在使用微服务上路时能够密切关注这些项目
- 1)凝聚力混乱
我们开发了一项服务,以获取客户信息,旨在提取客户政策信息,个人信息和他们注册的计划。一段时间以来,它开始做的不仅仅是获取客户信息。随着新要求的出现,该服务经历了频繁的更改和部署。它无法扩展并满足所需的可用性。它成了众所周知的“泥球大球”。它是怎么到达那里的?对于初学者来说,没有关于功能性关注分离的治理。如果一个有影响力的消费者要求在这一项服务中加入不相关的逻辑来减少往返行程,那么这个功能就毫无疑问地被打了。也许网关或BPM层本可以避免这种情况,但是没有时间......只是时间来制定另一个业务功能点。
预防性治疗是为了管理与服务无关的业务功能。服务必须与业务能力明确对齐,不应试图在其边界之外做某事。关注的功能分离对于架构管理至关重要,否则会破坏敏捷性,性能和可伸缩性,最终建立紧密耦合的架构,导致传递熵和内聚混乱。
- 2)不认真对待自动化
我们没有自动部署策略和ops服务监控(运行时QoS指标)。它显然增加了部署期间的运营费用和手动错误。多次生产部署导致配置错误导致中断。这些服务始终以HA模式部署,因此容器数量是服务总数的3倍。操作团队无法手动处理每项服务的配置。经过一段时间后,操作人员开始抱怨架构效率低下,因为他们无法处理增加的容器数量。
这是什么疫苗?配方有多种成分。如果您还没有这样做,持续部署是每个企业都应该追求的必须投资和文化变革。至少,如果你没有办法自动测试和部署 - 不要做微服务。微服务的目标是以我们需要改变的速度来提高敏捷性;质量保证涉及每项服务都具有自动化单元,功能,安全性和性能测试。当我们开发与我们无法控制的服务集成的服务时,服务虚拟化是另一个强大的概念。
- 3)分层服务架构
人们用SOA做出的一个常见错误是误解了如何实现服务的可重用性。团队主要关注技术凝聚力,而不是关于可重用性的功能。例如,若干服务用作数据访问层(ORM)以将表公开为服务;他们认为这将是高度可重复使用的。这创建了由横向团队管理的人工物理层,这导致了交付依赖性。创建的任何服务都应该是高度自治的 - 意味着彼此独立。
创建多个技术,物理层的服务只会导致交付复杂性和运行时效率低下。我们最终拥有包装服务,编排服务,业务服务和数据服务。这些服务模型提供了技术问题。各个团队成立以管理这些层,最终导致业务逻辑蔓延,没有单一的业主能力,失去效率,总是有一个责备游戏。
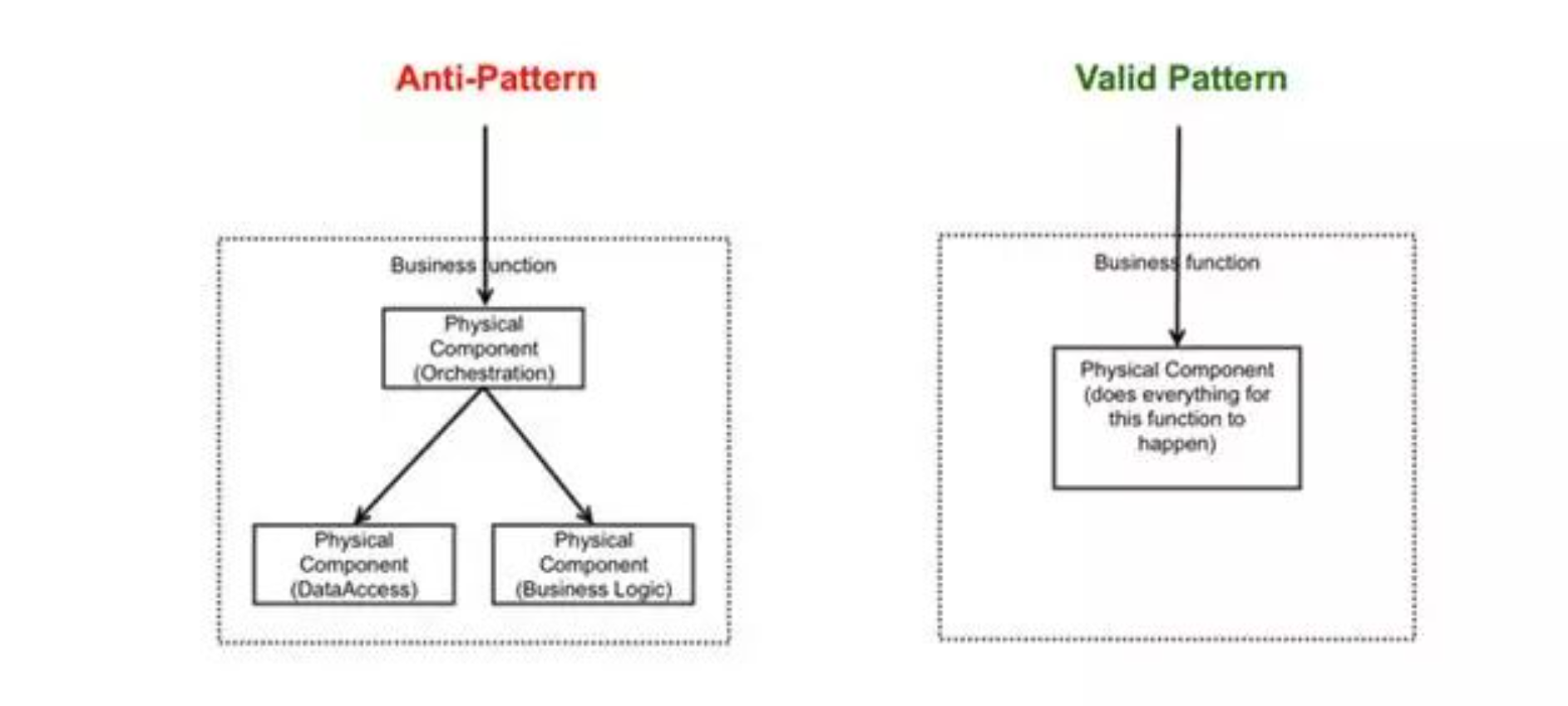
服务中的层的逻辑分离很好,但是,不应该有任何进程外调用。尝试将服务视为一个原子业务实体,它必须实现一切以实现所需的业务功能。自包含服务比分层服务更具自主性和可扩展性。在多个服务中重写一些常用代码是完美的,这很好,并且保持自治级别是一个很好的权衡。最重要的是,没有技术问题分开的服务,而是必须根据业务能力将它们分开。由于这种特性,集装箱化的概念正在蓬勃发展。
- 4)依靠消费者签字
我们有来自三个不同渠道的多个应用程序所消耗的服务,即代理,网络和语音。代理渠道是我们的主要渠道,因此服务必须等待他们在投入生产之前签字。它延迟了语音和Web应用程序的生产版本。是什么将这三个通道紧紧地联系在一起?
当涉及通道特定功能时,该服务不是松散耦合的。为您的服务提供独立性。您提供的每项服务都必须具有测试套件,该套件应涵盖所有当前和未来消费者的所有服务功能,安全性,性能,错误处理和消费驱动测试。这必须作为自动回归测试的构建管道的一部分包含在内。
- 5)手动配置管理:
当我们开始做大量服务(并且由于缺乏服务生命周期治理而导致的不可避免的蔓延表现)时,管理每个服务的配置失控。由于密码错误,URL错误,值不正确等配置失败,我们的大部分生产部署都不顺利。手动管理这些变得越来越难。如果我们只使用应用程序配置管理工具作为PaaS或CD的一部分......但我们没有。
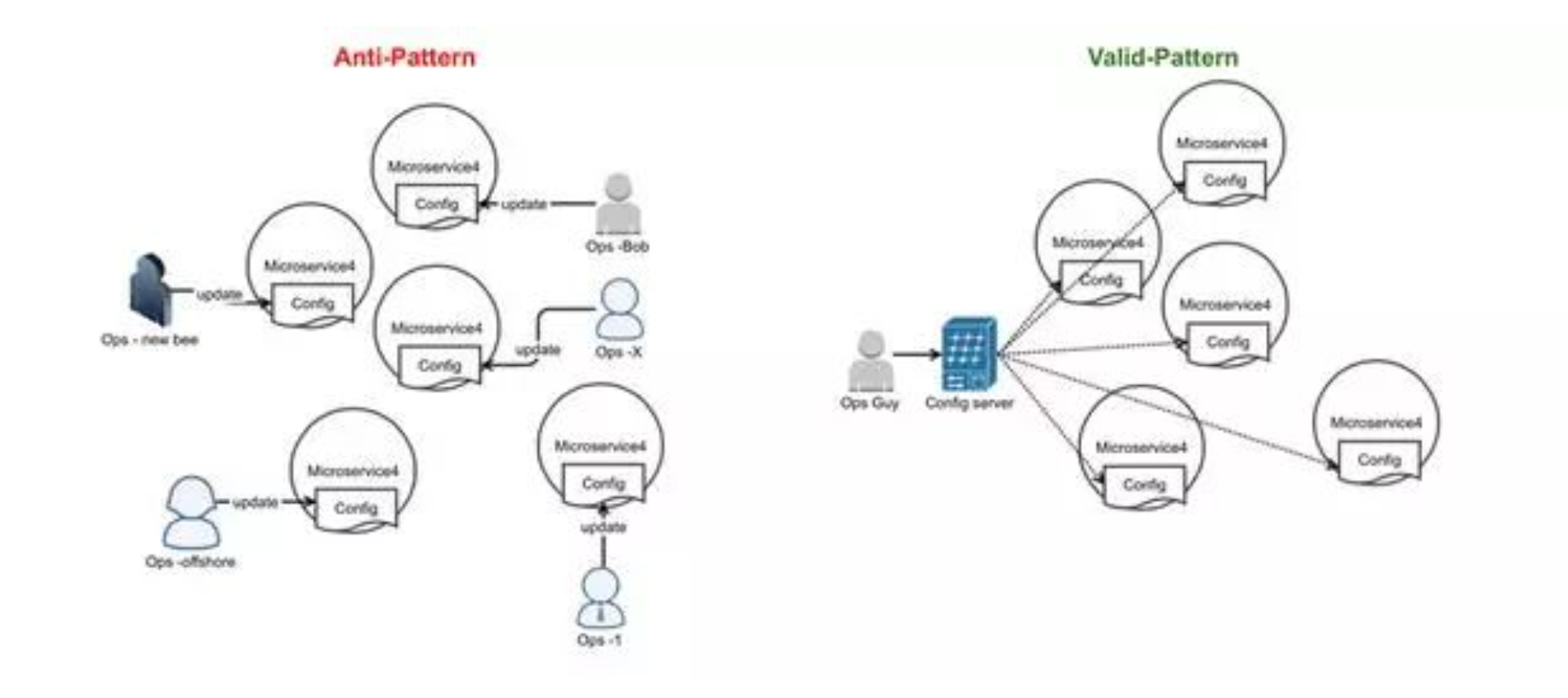
6)版本避免:
天真地,我们认为只需要一个版本的服务。然后我们开始添加主要的次要版本以适应多个消费者和频繁的变化。最终,每个版本都必须是主要版本,因为服务依赖于消费者签名。结果,容器的数量增加得非常快,并且管理它们变得非常痛苦。缺乏运行时治理是导致此问题的另一个方面。有些企业愚蠢地试图避免版本控制。假设变更是不可避免的,需要对服务进行架构。制定策略来管理向前兼容的服务更改,并让您的消费者优雅地升级。否则,它将导致消费者紧密绑定到服务版本并在发生更改时中断。
随着微服务世界所期望的服务数量的增长,复杂性也在增长。有一个版本控制策略,可以让消费者进行优雅的迁移,并确保提供商可以透明地部署更改,而不会影响任何人。限制生产中并排主要版本的数量并管理它们。

- 7)在每个服务中构建网关
我们没有API网关,我们没有运行时治理(我们不知道谁在什么时间消耗什么以及以什么速度消费)。我们开始在每个服务中实现最终用户身份验证,限制,协调,转换和路由等。它增加了每个服务的复杂性,并且我们失去了从服务到服务的实现的一致性,因此我们不知道谁实现了什么和哪里。最重要的是,我们的一些服务是为满足一个消费者的非功能性需求而构建的,而不是另一个。如果我们有一个网关,应用一些数据过滤和丰富模式就可以做到。要是。
投资API管理解决方案,以集中,管理和监控一些非功能性问题,并且还可以消除消费者管理多个微服务配置的负担。可以使用API网关编排可以减少Web应用程序往返的跨功能微服务。
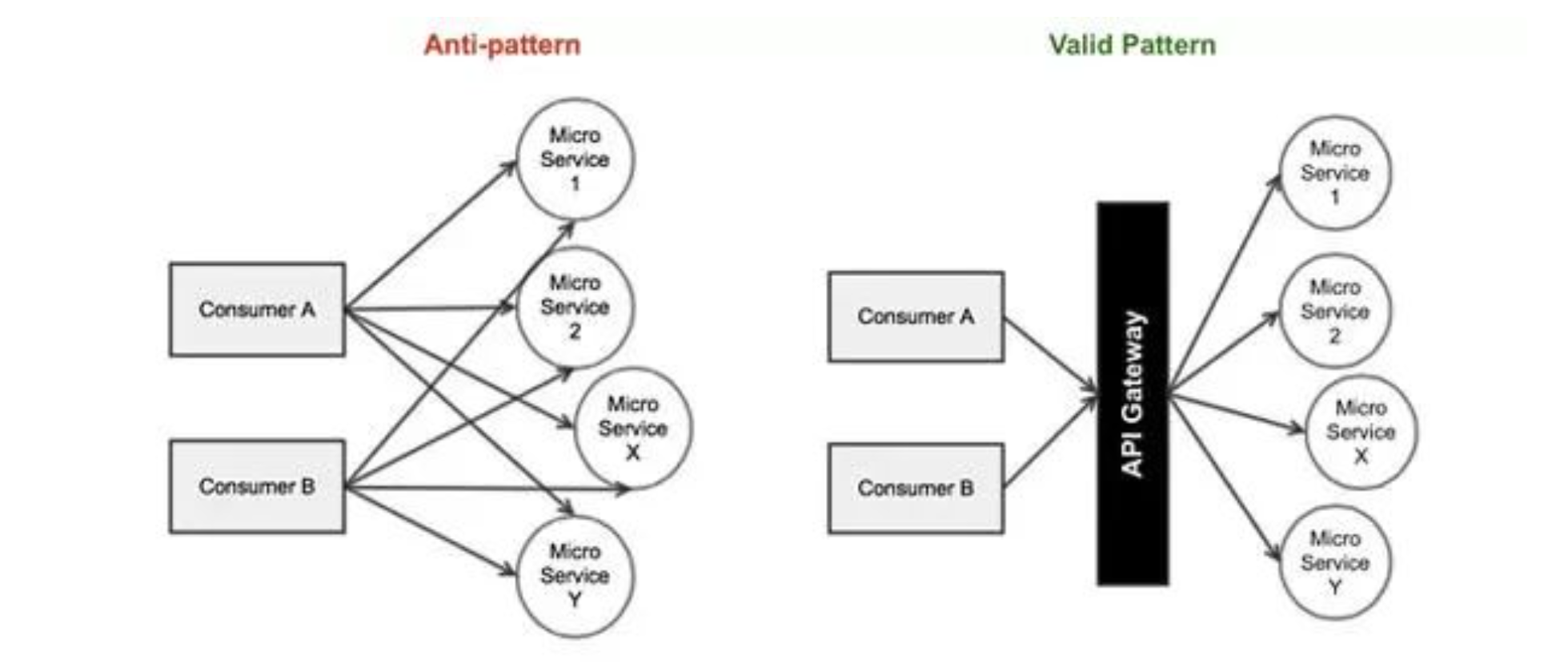
结论
微服务的目标是解决三个最常见的问题,即改善客户体验,高度敏捷地满足新要求,并通过将业务功能作为细粒度服务来降低成本。这不是一个灵丹妙药,需要一个规范的平台,以高质量的敏捷方式提供服务。从其他错误中学习(我的)并避免在架构和交付过程中列出的上述模式。这是我们谈论集装箱化,云采用等之前的第一步。我希望本文能为您的企业提供一些思考,并在将这些反模式编织到您的架构之前解决这些反模式。大多数项目将推动组织内部的文化变革,不能仅靠自己完成,确保与您的高管和高级领导者建立伙伴关系。
- 99 次浏览
「微服务架构」亚马逊引领其自有微服务架构的原因
新堆栈”的真实故事,一次又一次,是关于具有巨大服务器需求的公司如何受到现有架构无法满足这些需求的限制,如何为自己解决问题,然后转而将其解决方案转售给 剩下的世界。 我们多么快地忘记了最早的例子,但也许仍然是最好的,是亚马逊。
“如果你回到2001年,”亚马逊AWS产品管理高级经理Rob Brigham表示,“亚马逊零售网站是一个庞大的单体架构。”
布里格姆星期三在亚马逊举行的2015年拉斯维加斯发布会上发表了一个主要参与人数很多的主要舞台。 他随行的幻灯片显示了一个公认的“2001”单体,这次高耸于辉煌的华盛顿山湖旁边,可能就在附近。 他对亚马逊的历史时机或者他自己的历史时机的聪明才智只是嗤之以鼻。
“现在,不要误会我的意思。 它的架构分为多层,这些层中有很多组件,“Brigham继续说道。 “但他们都非常紧密地联系在一起,他们表现得像一个巨大的巨石。 现在,许多创业公司,甚至是大公司内部的项目,都是以这种方式开始的。 他们采取一体化的方法,因为它很快就能快速行动。 但随着时间的推移,随着该项目的成熟,随着您在其上添加更多开发人员,随着它的增长和代码库变得越来越大,架构变得越来越复杂,这个整体将为您的流程增加开销,而软件开发生命周期也是如此。 开始减速。“
Brigham提出了软件开发生命周期(SDLC)作为开发团队结构的主题 - 特别是,当处理像Amazon.com这样的单一应用程序在2001年面临的实质内容时,开发人员将彼此区分开来,将团队从最终目标中分离出来。他们真正革命性地解决这个问题的方法成为了导致云计算创建的原型之一(美国宇航局的星云项目是其中之一)。
Brigham还透露的是,原始Amazon.com的非常类似tarball的粘性激发了另一个革命性的概念:服务架构的解耦。也许亚马逊没有发明微服务,也许它不是敏捷方法的先驱。但进化并不总是首先在一个地方发生。有大量证据表明亚马逊确实主动提出了这些概念。
Brigham讲述了亚马逊工程团队的故事,该工程团队在2000年有一项艰巨的任务,即协调数百名开发人员的进程内更改,解决他们之间的所有冲突,将它们合并为一个版本,并生成等待的主版本要移入生产的队列。 “即使你有那么庞大的新版本,”他说,“它仍然会在这个交付渠道上增加很多开销。整个新的代码库需要重建。所有测试用例都需要重新运行,以确保没有任何冲动。然后你需要整个应用程序,并将它全部部署到你的完整生产车队。“
亚马逊的方法不是摆脱管道,而是简化它。该公司的持续部署工具 - CodeDeploy,CodePipeline和CodeCommit - 围绕真正的云原生Web应用程序构建,其中该管道的各个部分可以编写脚本并自动化。 Rob Brigham表示,从世纪之交开始,亚马逊制造的建筑和物流变化直接导致了它现在为开发团队提供的工具。
上个月,Pivotal工程师Rohit Kelapure在详细描述整体架构的分解中描述了SpringOne 2GX会议的记忆,亚马逊的Brigham将他和他的同事们如何“将其分开”与Amazon.com单体相关联面向服务的架构。
“我们完成了代码,并提取了功能单元,这些功能单元只用于一个目的,我们用网络服务接口包装了这些功能单元,”他说。例如,有一项服务在零售商的产品详细信息页面上呈现“购买”按钮。另一个人有结账时计算正确税的功能。
在它们创建时,这些单一用途的功能似乎很容易实现。但想象一下数百个开发团队,其中一些由当时的数十个开发人员组成(而不是更舒适的“两个比萨”大小,不超过八个),其简单,单一用途的功能必须合并在一起一周又一周......以及之后的月份,随着SDLC的结构变得更大更庞大。
解耦管道
单一功能问题的解决方案是创建一个规则,开发人员必须遵守该规则,这些功能只能通过自己的Web服务API与世界其他地方进行通信。 “这使我们能够创建一个非常高度分离的体系结构,”Brigham说,“只要这些服务符合标准的Web服务接口,这些服务就可以彼此独立地迭代而不需要任何协调。”
服务的去耦使创建第一个自动部署系统之一,与原型的大部分时间今天亚马逊提供的客户 - 适当命名的“阿波罗”它帮助引进管道模型亚马逊的文化,它可能是Brigham在会议中明智地应用了一些自由编辑,因为这个过程不可能很简单。
但他对这方面很直率:通过能够看到管道作为图形化的东西,具有大小和形状,亚马逊的工程师可以更加确定他们需要多少改变他们的流程。当然,它们可以实现自动化,但为什么要实现冗余自动化?
“我们仍然注意到代码更改要花费很长时间才能从开发人员签到,到生产中运行,客户可以使用它,”他说。 “因此,作为一家以数据为导向的公司,我们对此进行了研究。 我们测量了代码更改在整个部署生命周期中跨越多个团队所花费的时间。 当我们将这些数据相加,并查看结果,并查看平均花费的时间时,我们坦率地感到尴尬。 这大约是几个星期。“
打破这些行动有助于工程师意识到这个管道中段的顺序和排列导致了“死时间” - 没有发生任何事情的间隔。 这尤其发生在部门之间的人工交接之间 - 其个性化应该引入流程完整性的交接,但实际上,这导致了低效率,浪费的空间和长长的队列。
“对于像亚马逊这样以效率而自豪的公司 - 对于一家在我们的履行中心内使用机器人来移动实体商品的公司,一家希望使用无人机将包裹部署到您家门口的公司 - 您可以想象它有多疯狂, “他说,”我们在软件交付过程中使用人来传递这些虚拟位。“
Brigham的演讲引发了CodePipeline的演示,其中包括在部署管道中发生的事件的内联脚本,以及与Amazon和GitHub上的私有存储库的集成。 亚马逊在这一点上表示,它正在避免将开发商店锁定为亚马逊品牌的做事方式,这与其合作伙伴生态系统之外的一些人所说的相反。
在这一点上你可能会想到Rob Brigham正在向合唱团讲道,或者说他正在捕鱼以获得亚马逊应该为这个行业创造的一些应得的赞誉。 事实上,令人尴尬的是,虽然这可能是为了观众中的很多人并观看现场直播而承认,亚马逊2001年的故事是他们2015年的故事。
- 124 次浏览
「微服务架构」从SOA进化看微服务架构治理
许多组织已经从SOA转移,但微服务的引入已经改变了治理游戏。 吐温泰勒解释了事情的变化。
微服务为IT的各个方面带来变化,尤其是IT治理的完成方式。 用英国政府数字服务部技术和运营副主任迈克尔·布伦顿 - 斯帕尔的话来说,"Microservices trade complicated monoliths for complex interacting systems of simple services."(微服务 交易(交换/替代) 用于简单服务的复杂交互系统的复杂整体 )
这组复杂的简单服务需要相互交流,并以与传统巨石/单体不同的方式进行管理。但这在实践中意味着什么?来!我们讨论一下。
分散的微服务治理
整体治理是集中的。决策是自上而下的,并且保持严格的控制以确保整个组织和应用程序堆栈的一致性。随着时间的推移,这种模式退化,创造了一个技术和架构停滞不前的系统,并减缓了创新的步伐。团队被迫仅仅遵循既定的事情顺序,而不是寻找新的,创造性的问题解决方案。
对于微服务治理,分散模型效果最好。正如应用程序本身被分解为众多相互依赖的服务一样,大型孤立的团队也被分解为小型的多功能团队。这是从开发,测试和IT团队转变为较小的DevOps团队的过程。
团队可以使用他们的首选语言和工具来构建他们拥有的服务,而不是使用相同的编程语言或技术框架来解决整个组织中的所有问题。这将导致缺乏统一性,这实际上可能是一个好处而不是一个缺点。首先,当每个决策涉及的繁文缛节较少时,解决方案的实施速度会更快。而且,由于构建服务的团队拥有其实施和维护,因此对服务的运行拥有更多的所有权,并且他们能够将其发展到更高的水平。
因此,对于刚刚创建并且没有单体历史的应用程序,这种分散的治理模型何时开始?它不是最低可行产品(MVP)阶段,因为在那时,应用程序只不过是一个想法。然而,当一个应用程序投入生产时,它很快就需要采用微服务架构,这就是分散治理开始的时候。
创新与治理
创新速度是实施DevOps的关键目标之一。但IT对治理的关注似乎与此结果相矛盾。这就是为什么IT和开发团队在尝试在创新和实际治理之间找到适当平衡时彼此之间往往会相互争吵的原因。
然而,这是一种错误的二分法。真正的创新不会忽视良好的治理,而伟大的治理应该支持最好的创新。因此,开发和运营团队处于同一方并具有相同的优先级和目标的DevOps原则是良好治理的推动因素。
对于微服务,分散治理是必要的。
DevOps团队必须明白,通过选择他们选择的平台和工具的能力,我们有责任遵守IT部门制定的企业标准。这就是为什么亚马逊在大约十年前刚刚开始作为云供应商时采用了“你建立它,你运行它”的座右铭。亚马逊网络服务公司希望其开发人员与IT共享对其提供的应用程序和功能的稳定性和可靠性的责任。这一原则有助于推动它成为当今领先的基础设施即服务平台。
在不牺牲控制的情况下加速治理的一种方法是自动执行任务。这种自动化可以在治理的不同方面发生,例如安全性和可靠性。
安全
自动化安全涉及策略的组合。与单个大型单片应用程序相比,分布式,API可访问的应用程序对攻击者具有更多潜在的入口点,但通常,使用访问控制规则,Web应用程序防火墙(WAF)的组合可以更容易地保护这些入口点。规则,身份验证和速率限制。自动执行这些任务需要一个可以处理负载平衡,内容缓存,安全策略等的现代Web服务器。
这种平台的一个例子是Nginx Plus。其ModSecurity WAF可保护应用程序层免受攻击,例如SQL注入,本地文件包含,跨站点脚本和某些类型的分布式拒绝服务攻击。此工具可用于静态分析代码,针对代码运行渗透测试和模糊输入,并识别常见的安全相关编程错误,例如无效输入。
可靠性
为了使微服务应用程序顺利运行,其服务需要能够彼此通信并且能够很好地协同工作。这需要良好的服务发现。随着为服务提供动力的底层节点或容器的更改,它们需要由系统识别。这样,服务仍然可见,并且可以成功路由请求。
此外,随着请求的激增,它们无法由单个实例处理,需要跨其他实例进行路由以共享工作负载。这种类型的服务发现和负载平衡 - 在协同工作时 - 使您能够构建可承担任何工作负载的可靠应用程序。
对于微服务治理,分散化是必要的。它提供了开发人员所渴望的创新和灵活性,同时保持了IT运营人员所需的安全性和可靠性。当您希望管理您的应用程序以使其更可靠和安全时,促进分散治理的工具是时间的需要。
- 96 次浏览
「微服务架构」企业微服务架构
首先,来自Darren的消息是,微服务架构并不是构建大规模企业应用程序的新方式。 Netflix和亚马逊等公司已经实施了微服务架构,在过去几年中提供了成功的产品。
但是微服务架构适合您的组织吗?答案不是简单的是或否,但我会尝试用Darren的讲话作为指导来引导你找到答案。
微服务架构是一个将在多个方面影响您的组织的旅程 - 在文化,技术和运营方面。让我们考虑一个跨国企业的单体应用程序,该应用程序已经成熟多年并占据了市场主导地位。从软件工程师或架构师的角度来看,简化代码库的复杂区域以使其更易于维护是一种很好的做法。
那么当你遇到一个疯狂的大型Java类时,你会怎么做,这些Java类包含许多代码行和一个不幸的方法,占40%的类?一个自然(和明智)的事情是与团队进行某种形式的讨论,并提出一种策略,将类分解为多个较小的类和/或方法。现在问问自己为什么清理整体Java类很重要?
如果您的答案是更简单的单元测试,更容易进行代码审查,更改影响,那么我建议您将相同的思维过程应用于构成产品的整体服务和模块。
将monolith应用程序拆分为更小,可管理的服务有几个原因。如果您是组织中的业务负责人,以下可能是您的一些担忧:
- 进入新市场
- 支持创新
- 在业务功能和系统之间创建更好的一致性
- 改变治理结构以更好地支持快速决策
- 快速响应新的市场条件
- 抵御市场颠覆者
作为首席技术官或首席架构师,您有责任评估最能解决上述问题的不同解决方案,并设计符合组织愿景的系统。以下是在考虑微服务架构时需要关注的一些关键领域:
- 多种服务之间的依赖关系管理
- 端到端功能测试的大小
- 快速检测故障,正常故障并快速恢复
- 容器作为构建工件
- 跨组织边界重用组件/模块
- 公共使用服务的API合同
- 监控部署生命周期的各个阶段
- 集中式架构团队与分散式架构团队
- 基建自动化
架构师的角色随着微服务的采用而发展,并委托他或她承担挑战性的责任,从而形成架构治理。架构治理是组织尝试开始微服务之旅的关键因素之一,因为如果没有正确的顺序,该过程将很快导致微管理而不是微服务。
将monolith分成多个可管理服务的最大优势之一是使一个小团队能够全面管理其服务的生命周期 - 开发,测试和推向生产。这意味着企业架构师不再需要承担单个服务的内部工作负担,而是高度关注整个系统中服务之间的交互。此外,架构师应密切关注系统的整体运行状况,以确保每项服务以一致的方式生成与监控相关的指标。
为开发团队提供完全的权限,以便在构建服务时选择他们选择的技术堆栈并不意味着架构师不再对其实现有任何发言权。事实上,架构师受到高度鼓励,可以教育和影响开发团队。例如,考虑到服务必须处理的数据的高度非结构化特性,架构师可以建议使用NoSQL数据库而不是关系数据库。例如,Netflix将JVM的使用标准化为一个平台,以便他们可以跨服务使用标准库。
虽然架构师之一忙于与开发团队合作,但另一个人正在与“业务”团队合作,以使技术愿景与业务愿景保持一致。这对于建筑师来说是一个重要特征,因为系统需要能够适应产品愿景或用户反馈的变化。因此,架构师需要始终掌握行业中的最新趋势,工具和框架,并准备好为给定的工作应用正确的工具。
Darren谈到了“部署耦合”的概念,强调了许多单片系统和传统企业架构需要在单个版本中将所有系统的更改同步到生产中这一事实。这反过来导致长时间运行的测试周期从未捕获任何东西,并且感觉没有人可以失败,因为一个系统未达到其截止日期意味着其他所有人都被推出。
通过使用远程调用作为集成服务的机制,可以避免部署耦合。微服务社区建议使用REST over HTTP而不是其他远程通信协议(如RPC或SOAP),因为基于非HTTP的协议往往会将您绑定到特定平台或对互操作性施加限制。通过基于用户级合同使用HTTP集成服务,开发团队可以避免永无止境的端到端测试阶段的陷阱并保持合适的速度。
然而,管理数百个服务会使组织的操作复杂化。作为一个组织,您必须确保拥有可靠的DevOps基础架构,以便处理应用程序监视和警报。正如我上面提到的,架构师必须至少标准化服务发出日志的方式,以便运营团队可以监控整体系统运行状况,并且如果需要进一步调查,则能够深入到服务级别监控。
最后,每个组织都必须努力招募,培训和留住高素质的技术人员,因为“微观团队”之间的沟通和协作需要有效,技术上的刺激以及最重要的乐趣是至关重要的!
我希望这可以解决你对大型企业中微服务架构的一些担忧。我鼓励你观看这个非常有见地的视频录制,其中Darren更详细地讨论了这些非常关注的问题。如果您正在寻找有关微服务架构的其他材料,请查看Martin Fowler的文章或ThoughtWorks网站上的其他微服务洞察博客。
- 104 次浏览
「微服务架构」分散您的微服务组织
适应性 - 快速,轻松地进行变革的能力 - 已成为现代企业的首要目标,并迫使技术团队构建更容易,成本更低的平台。在这样的环境中工作,这些团队越来越多地被软件架构的微服务风格所吸引。吸引他们的是承诺加快软件更改的方法,而不会给业务带来不必要的危险。
微服务的工作方式在很大程度上可以通过支持软件组件和数据的分散来实现 - 更具体地说,通过将“单体”元素分解为更小,更容易更改的部分,并在网络上部署这些部分。要使这种架构运行良好,需要改变工作方式以及如何管理工作。采用微服务的组织是“脱离开发人员的方式”,并提供自由和自主来实现魔术。
在组织设计中,他们的目标是分散决策权。而不是让少数人为组织中的每个人做出架构和软件决策,分散化将使他们能够在执行工作的人员之间分配决策权。
直接向工人推行决策权使他们能够以更大的自由和自主权生产。在适当的情况下,这将导致更好,更快的变化。但是,如果您的组织弄错了,一系列错误的决策可能会降低变更速度 - 或者更糟糕的是,最终会损害您的业务。
诀窍是只分散那些可以帮助你加速的事情,而不会牺牲系统的安全性。
找到正确的权力下放战略是一个进化过程,需要您进行调整,分析和调整。为了帮助您开始正确的方向,以下是您应该考虑的三个最重要的问题:
我们应该针对哪些决策?
我们所有这一切的目标是增强您平台的可变性。因此,您应首先找到阻止变更发生的瓶颈。仔细研究功能和变化如何从概念转变为实施,并找到需要工作的人不能做的过程部分,因为他们正在等待其他人做出决定。
权力下放不是解除瓶颈的灵丹妙药。然而,在一个倾向于集中决策的组织中,权力下放可能会有所帮助。另一方面,如果您找不到因集中决策流程而导致员工陷入困境的许多情况,那么分散化不应成为您最关心的问题。
使微服务系统工作不仅仅需要改变有关组件大小的想法。组织中涉及创建和更改服务的所有区域都可以发挥作用。以下是可能成为微服务领域分散化候选人的决策类型的非详尽列表:
- 服务生命周期 - 服务何时创建或退役?他们叫什么?我们什么时候需要将它们分开?
- 服务实施 - 我们应该在每项服务中使用哪些工具,语言和架构?
- 系统架构 - 服务如何与其他人交谈?开发人员如何了解它们?
- 数据架构 - 如何在服务之间共享数据?
- 变更流程 - 何时可以更改服务?部署和QA有哪些工具和流程?
- 团队管理 - 谁在哪个团队服务?每个团队负责什么?团队成员做什么?
- 人员管理 - 人们如何被雇佣和解雇?员工如何激励和奖励?什么是休假政策?
- 安全管理 - 我们如何降低安全事件的风险?需要做些什么才能提高整个系统的安全性?
- 采购 - 可以购买哪些软件?使用开源软件需要哪些保护措施?
分析这些空间中的决策是如何制定的,这是值得的。它们如何影响系统的更改方式?哪些决策过程阻碍了你?哪些阻止人们进行创新?最后,在哪些情况下,更多的自由和自治会有益吗?
Netflix是一家能够以创新方式下放权力的公司的典范。其政策赋予员工权力,以决定他们需要多少时间来分散传统上受到严密控制的决策。
赋予员工指定自己的假期分配的权限可能听起来很奇怪。但是,如果您希望将组织的可变性提升到更高的档位,那么您应采取的确切方法是消除冗余和不必要的协调工作,同时避免引入新风险。追求构建软件的微服务风格的团队应该考虑在整个组织中进行这些优化。
这并不意味着分发假日决策的政策应该是微服务架构的原则。 Netflix可以做到这一点,因为它的文化和劳动力使这样的政策更容易实施。它的员工可以做出最适合整个系统的决策,而且公司因其对员工的选择而闻名。
并非每个组织都看起来像Netflix,很少有人在Netflix的在线视频内容传输领域运营。每家公司都有自己独特的约束和目标。您需要为自己发现自己的目标和约束。分析,洞察力和实验将帮助您确定权力下放工作的优先顺序,并引导您的系统实现适应性目标。
参与的人是谁?
人们做出的一些决定对他们公司的影响非常大。改变银行账户交易方式的决定对传统银行来说是有风险的。对于具有熟悉旧接口的大型用户群的软件公司而言,更改应用程序的用户体验的决定将是一种风险。
组织试图加强对这些类型决策的控制,以便最大限度地降低风险,从而实现决策权的集中化。例如,在过去的几年中,Apple以拥有一个高度集中的设计小组而闻名,该小组由相对较少的人组成,他们做出了大部分关于其产品设计的决策。
集中化是因为合适的人需要做出最重要的决策。通常,“合适的人”是那些拥有人才,专业知识和经验的人,这使我们能够充分信任他们以做出最佳决策。我们可以称这些人为我们的“明星”决策者。
如果一个组织只有星星,那么它的所有决定都可以分散。如果我们信任更多员工以做出最佳决策,我们会将更多决策分发给更多人。
在实践中,公司拥有数量有限的明星决策者。实际上,大多数团队都有一些明星与更多的决策者相结合,他们有能力但缺乏一些必要的经验或才能来做出完美的决策。
好消息是,你不需要一个全明星团队来采用分权策略。您只需要考虑如何将您的团队组织在一起以及您部署最佳决策者的位置。
微服务风格使这一切变得更加容易,因为决策的影响可以在实现个别变更的速度增加的同时受到限制。如果一个团队在处理微服务时做出了错误的决定,那么错误的爆炸半径应该很小并且包含在内。当系统变更便宜且容易时,团队可以快速改进以前的决策,使他们能够更快地做出最佳决策。
在这种环境中,你不受你的明星力量的限制 - 当目标是达到最佳决策时,你只需要提供一个系统,让有能力的工人获得自由和自主权。
谁拥有哪一部分?
没有立即做出决定。它基于选择,而选择又基于领域知识。决不应立即实施。有时它可能需要某人的祝福,而在其他时候,它可能需要高度专业化的技能或知识来实施。
管理专家Henry Mintzberg为我们提供了一个很好的模型,概述了决策过程的步骤:
- 研究和信息收集
- 产生选择
- 选择(做出选择)
- 授权选择
- 执行和实施
所有这一切的关键在于,在采用决策权力下放时,您不需要绝对。 Mintzberg的每个步骤都可以独立集中或分散,在平衡基于决策的系统变更的速度和安全性时,可以提供更大的灵活性。
考虑一家大公司典型招聘流程的情况:当找到新员工时,它是集中的人力资源部门,广播开放职位并邀请人们申请工作。同一个集中团队筛选候选人并生成该组中最佳的列表。然后将该清单移交给实际的招聘经理,该经理根据进一步的审查选择最佳候选人。从那里,招聘经理将球交还给人力资源中心团队,他们完成了文书工作并完成了整个过程。
这种集中式选择生成模式与分散式选择选择相结合是大公司中常见的选择。事实上,大多数采用微服务风格的组织都以某种形式使用它。
例如,集中式企业团队可以识别所有微服务团队应该使用的三种数据库。由各个团队决定选择,但他们可以从提供的菜单中进行选择。如果他们偏离批准的列表,他们将需要证明他们的决定,从而为集中团队提供反馈机制,他们可以重新评估菜单。
分散流程的选择,授权和执行部分可以使各个团队快速,大规模地进行迁移。集中研究和选择生成步骤,总体上损害了创新,但降低了决策的风险,从而对整个系统产生负面影响。这是一种流行的模式,因为它为大多数组织提供了正确的妥协方式。
当人们谈论微服务组织时,权力下放会出现很多,因为它是提高变革速度的有效方法。但不要忘记它只是等式的一部分。您的员工是谁,您的团队如何协调,以及他们所处理的所有系统,工具和环境同样重要。
您必须了解考虑如何制定决策 - 更重要的是,如何改进流程 - 是向变革友好型组织迈进的一种很好的方式。
- 46 次浏览
「微服务架构」微服务架构中的数据一致性
在微服务中,一个逻辑上原子操作可以经常跨越多个微服务。即使是单片系统也可能使用多个数据库或消息传递解决方案。使用多个独立的数据存储解决方案,如果其中一个分布式流程参与者出现故障,我们就会面临数据不一致的风险 - 例如在未下订单的情况下向客户收费或未通知客户订单成功。在本文中,我想分享一些我为使微服务之间的数据最终保持一致而学到的技术。
为什么实现这一目标如此具有挑战性?只要我们有多个存储数据的地方(不在单个数据库中),就不能自动解决一致性问题,工程师在设计系统时需要注意一致性。目前,在我看来,业界还没有一个广为人知的解决方案,可以在多个不同的数据源中自动更新数据 - 我们可能不应该等待很快就能获得一个。
以自动且无障碍的方式解决该问题的一种尝试是实现两阶段提交(2PC)模式的XA协议。但在现代高规模应用中(特别是在云环境中),2PC似乎表现不佳。为了消除2PC的缺点,我们必须交易ACID for BASE并根据要求以不同方式覆盖一致性问题。
Saga模式
在多个微服务中处理一致性问题的最着名的方法是Saga模式。 您可以将Sagas视为多个事务的应用程序级分布式协调。 根据用例和要求,您可以优化自己的Saga实施。 相反,XA协议试图涵盖所有场景。 Saga模式也不是新的。 它在过去已知并用于ESB和SOA体系结构中。 最后,它成功地转变为微服务世界。 跨越多个服务的每个原子业务操作可能包含技术级别的多个事务。 Saga Pattern的关键思想是能够回滚其中一个单独的交易。 众所周知,开箱即用的已经提交的单个事务无法进行回滚。 但这是通过引入补偿操作来实现的 - 通过引入“取消”操作。
除了取消之外,您还应该考虑使您的服务具有幂等性,以便在出现故障时重试或重新启动某些操作。 应监控故障,并应积极主动地应对故障。
对账
如果在进程的中间负责调用补偿操作的系统崩溃或重新启动,该怎么办? 在这种情况下,用户可能会收到错误消息,并且应该触发补偿逻辑,或者 - 当处理异步用户请求时,应该恢复执行逻辑。
要查找崩溃的事务并恢复操作或应用补偿,我们需要协调来自多个服务的数据。对账
是在金融领域工作的工程师所熟悉的技术。你有没有想过银行如何确保你的资金转移不会丢失,或者两个不同的银行之间如何汇款?快速回答是对账。
在会计中,对账是确保两组记录(通常是两个账户的余额)达成一致的过程。对帐用于确保离开帐户的资金与实际支出的资金相匹配。这是通过确保在特定会计期间结束时余额匹配来完成的。 - Jean Scheid,“了解资产负债表账户调节”,Bright Hub,2011年4月8日
回到微服务,使用相同的原则,我们可以在一些动作触发器上协调来自多个服务的数据。当检测到故障时,可以按计划或由监控系统触发操作。最简单的方法是运行逐记录比较。可以通过比较聚合值来优化该过程。在这种情况下,其中一个系统将成为每条记录的真实来源。
事件簿
想象一下多步骤交易。如何在对帐期间确定哪些事务可能已失败以及哪些步骤失败?一种解决方案是检查每个事务的状态。在某些情况下,此功能不可用(想象一下发送电子邮件或生成其他类型消息的无状态邮件服务)。在其他一些情况下,您可能希望立即了解事务状态,尤其是在具有许多步骤的复杂方案中。例如,预订航班,酒店和转机的多步订单。
复杂的分布式流程
在这些情况下,事件日志可以提供帮助。记录是一种简单但功能强大的技术。许多分布式系统依赖于日志。 “预写日志记录”是数据库在内部实现事务行为或维护副本之间一致性的方式。相同的技术可以应用于微服务设计。在进行实际数据更改之前,服务会写入有关其进行更改的意图的日志条目。实际上,事件日志可以是协调服务所拥有的数据库中的表或集合。
事件日志不仅可用于恢复事务处理,还可用于为系统用户,客户或支持团队提供可见性。但是,在简单方案中,服务日志可能是冗余的,状态端点或状态字段就足够了。
编配(Orchestration)与编排(choreography)
到目前为止,您可能认为sagas只是编配(orchestration )方案的一部分。但是sagas也可以用于编排(choreography ),每个微服务只知道过程的一部分。 Sagas包括处理分布式事务的正流和负流的知识。在编排(choreography )中,每个分布式事务参与者都具有这种知识。
单次写入事件
到目前为止描述的一致性解决方案并不容易。他们确实很复杂。但有一种更简单的方法:一次修改一个数据源。我们可以将这两个步骤分开,而不是改变服务的状态并在一个过程中发出事件。
更改为先
在主要业务操作中,我们修改自己的服务状态,而单独的进程可靠地捕获更改并生成事件。这种技术称为变更数据捕获(CDC)。实现此方法的一些技术是Kafka Connect或Debezium。
使用Debezium和Kafka Connect更改数据捕获
但是,有时候不需要特定的框架。一些数据库提供了一种友好的方式来拖尾其操作日志,例如MongoDB Oplog。如果数据库中没有此类功能,则可以通过时间戳轮询更改,或使用上次处理的不可变记录ID查询更改。避免不一致的关键是使数据更改通知成为一个单独的过程。在这种情况下,数据库记录是单一的事实来源。只有在首先发生变化时才会捕获更改。
无需特定工具即可更改数据捕获
更改数据捕获的最大缺点是业务逻辑的分离。更改捕获过程很可能与更改逻辑本身分开存在于您的代码库中 - 这很不方便。最知名的变更数据捕获应用程序是与域无关的变更复制,例如与数据仓库共享数据。对于域事件,最好采用不同的机制,例如明确发送事件。
事件第一
让我们来看看颠倒的单一事实来源。如果不是先写入数据库,而是先触发一个事件,然后与自己和其他服务共享。在这种情况下,事件成为事实的唯一来源。这将是一种事件源的形式,其中我们自己的服务状态有效地成为读取模型,并且每个事件都是写入模型。
事件优先方法
一方面,它是一个命令查询责任隔离(CQRS)模式,我们将读取和写入模型分开,但CQRS本身并不关注解决方案中最重要的部分 - 使用多个服务来消耗事件。
相比之下,事件驱动的体系结构关注于多个系统所消耗的事件,但并未强调事件是数据更新的唯一原子部分。所以我想引入“事件优先”作为这种方法的名称:通过发出单个事件来更新微服务的内部状态 - 包括我们自己的服务和任何其他感兴趣的微服务。
“事件优先”方法面临的挑战也是CQRS本身的挑战。想象一下,在下订单之前,我们想要检查商品的可用性。如果两个实例同时收到同一项目的订单怎么办?两者都将同时检查读取模型中的库存并发出订单事件。如果没有某种覆盖方案,我们可能会遇到麻烦。
处理这些情况的常用方法是乐观并发:将读取模型版本放入事件中,如果读取模型已在消费者端更新,则在消费者端忽略它。另一种解决方案是使用悲观并发控制,例如在检查项目可用性时为项目创建锁定。
“事件优先”方法的另一个挑战是任何事件驱动架构的挑战 - 事件的顺序。多个并发消费者以错误的顺序处理事件可能会给我们带来另一种一致性问题,例如处理尚未创建的客户的订单。
诸如Kafka或AWS Kinesis之类的数据流解决方案可以保证将按顺序处理与单个实体相关的事件(例如,仅在创建用户之后为客户创建订单)。例如,在Kafka中,您可以按用户ID对主题进行分区,以便与单个用户相关的所有事件将由分配给该分区的单个使用者处理,从而允许按顺序处理它们。相反,在Message Brokers中,消息队列具有一个订单,但是多个并发消费者在给定顺序中进行消息处理(如果不是不可能的话)。在这种情况下,您可能会遇到并发问题。
实际上,在需要线性化的情况下或在具有许多数据约束的情况(例如唯一性检查)中,难以实现“事件优先”方法。但它在其他情况下确实很有用。但是,由于其异步性质,仍然需要解决并发和竞争条件的挑战。
设计一致性
有许多方法可以将系统拆分为多个服务。我们努力将单独的微服务与单独的域匹配。但域名有多细化?有时很难将域与子域或聚合根区分开来。没有简单的规则来定义您的微服务拆分。
我建议务实并考虑设计方案的所有含义,而不是只关注领域驱动的设计。其中一个影响是微服务隔离与事务边界的对齐情况。事务仅驻留在微服务中的系统不需要上述任何解决方案。在设计系统时我们一定要考虑事务边界。在实践中,可能很难以这种方式设计整个系统,但我认为我们应该致力于最大限度地减少数据一致性挑战。
接受不一致
虽然匹配帐户余额至关重要,但有许多用例,其中一致性不那么重要。想象一下,为分析或统计目的收集数据。即使我们从系统中随机丢失了10%的数据,也很可能不会影响分析的业务价值。
与事件共享数据
选择哪种解决方案
数据的原子更新需要两个不同系统之间达成共识,如果单个值为0或1则达成协议。当涉及到微服务时,它归结为两个参与者之间的一致性问题,并且所有实际解决方案都遵循一条经验法则:
在给定时刻,对于每个数据记录,您需要找到系统信任的数据源
事实的来源可能是事件,数据库或其中一项服务。实现微服务系统的一致性是开发人员的责任。我的方法如下:
- 尝试设计一个不需要分布式一致性的系统。不幸的是,对于复杂的系统来说,这几乎是不可能的。
- 尝试通过一次修改一个数据源来减少不一致的数量。
- 考虑事件驱动的架构。除了松散耦合之外,事件驱动架构的强大优势是通过将事件作为单一事实来源或由于更改数据捕获而产生事件来实现数据一致性的自然方式。
- 更复杂的场景可能仍然需要服务,故障处理和补偿之间的同步调用。知道有时候你可能需要在之后进行调和。
- 设计您的服务功能是可逆的,决定如何处理故障情况并在设计阶段早期实现一致性。
- 67 次浏览
「微服务架构」微服务集成中的3个常见缺陷-以及如何避免它们
微服务风靡一时。 他们有一个有趣的价值主张,即在与多个软件开发团队共同开发的同时,将软件快速推向市场。 因此,微服务是在扩展您的开发力量的同时保持高敏捷性和快速的开发速度。
简而言之,您将系统分解为微服务。 分解并不是什么新鲜事,但是通过微服务,您可以为团队提供尽可能多的自主权。
例如,专用团队完全拥有该服务,可以随时部署或重新部署。 他们通常也会使用devops来控制整个服务。 他们可以做出相当自主的技术决策并运行他们自己的基础设施数据库。 被迫操作软件通常会限制有线技术选择的数量,因为当人们知道他们将来必须操作它时,往往会更频繁地选择无聊技术。
Microservices are about decomposition, but giving each component a high degree of autonomy and isolation (微服务是关于分解,但为每个组件提供高度自治和隔离)
微服务架构的一个基本结果是每个微服务都是与其他微服务远程通信的独立应用程序。 这使得微服务环境成为高度分散的系统。 分布式系统有其自身的挑战。 在本文中,我将向您介绍我在最近的项目中看到的三个最常见的陷阱。
1.沟通很复杂
远程通信不可避免地要尊重分布式编程的8个谬误。 隐藏复杂性是不可能的,并且许多努力(例如Corba或RMI)已经失败了。 一个重要原因是您必须在服务中设计失败,以便在失败是新常态的环境中取得成功。 但是有一些共同的模式和框架可以帮助你。 让我们从一个例子开始 - 我经常遇到的真实情况。
我想飞往伦敦。 当我收到办理登机手续的邀请时,我去了航空公司的网站,选择了我的座位,然后按下按钮取回我的登机牌。 它给了我以下回应:
让我们假设航空公司使用微服务(可能不是这种情况,但我知道有其他航空公司这样做)。
我注意到的第一件事:错误返回得相当快,网站的其他部分表现正常。所以他们使用了重要的失败快速模式。条形码生成中的错误不会影响整个网站。我可以做其他一切;我无法获得登机牌。快速失败非常重要,因为它可以防止本地错误导致整个系统崩溃。该领域众所周知的模式是断路器,隔板和维修网。这些模式对分布式系统的生存至关重要。
快速失败是不够的
但快速失败是不够的。它将故障处理卸载到客户端。在这种情况下,我个人不得不重试。在上述情况下,我甚至要等到第二天,直到问题得到解决,我才能拿到登机牌!对我而言,这意味着我必须使用自己的工具来坚持重试(我的日历),以确保我没有忘记。
为什么航空公司不自行重试?他们知道我的联系数据,并且可以在准备好时异步发送登机牌。更好的反应是:
这不仅会更方便,而且还会降低总体复杂性,因为需要查看故障的组件数量会减少:
您可以将相同的原则转移到服务到服务通信。每当服务本身可以解决故障时,它就会封装重要的行为。这使得所有客户的生活更加轻松,API更加清洁。解决故障可能是有状态的(有些人称之为长时间运行)。我认为状态处理是微服务中故障处理的关键问题。
当然,上面描述的行为并不总是你想要的,将故障移交给客户端就可以了。但这应该是根据业务需求做出的有意识的决定。
我观察到大多数情况下,另一个原因导致人们避免有状态重试:它伴随着状态处理的复杂性。该服务必须重试几分钟,几小时或几天。它必须可靠地执行此操作(请记住:即使系统重新启动,我也希望登机牌),这涉及处理持久状态。
如何管理持久状态?
我看到两种处理持久状态的典型方法:
存储在数据库中的实体等持久性事物。
虽然这开始非常简单,但通常会导致很多意外的复杂性。您不仅需要数据库表,还需要一些调度程序组件来进行重试。您可能需要一些监视组件来查看或编辑等待作业。如果整体业务逻辑发生变化,您仍需要进行版本控制,而您仍想进行重试。等等等等。
这种思路导致许多开发人员如上所述跳过正确的故障处理,导致整个架构的复杂性增加 - 以及糟糕的客户体验。
相反,我建议利用轻量级工作流引擎或状态机。
构建这些引擎是为了保持持久状态并处理围绕流语言,监视和操作的后续要求,扩展以处理高容量等等。
市场上有几个轻量级工作流引擎。他们中的许多人使用ISO标准BPMN来定义流,其中许多是开源的。在这里,我将使用Camunda的开源工作流引擎来说明基本原则(快速免责声明:作为该项目背后的公司的共同创始人,我明显偏向于我的工具选择,但这是我最熟悉的工作流引擎)。对于前面描述的简单用例,可以使用Java DSL轻松创建工作流:
另一种选择是在BPMN中以图形方式建模工作流程:
这些工作流引擎在架构方面非常灵活。许多开发人员认为工作流引擎是一个集中组件,但事实并非如此。没有必要引入集中组件!如果不同的服务需要工作流引擎,则每个服务都可以运行自己的引擎来维护服务的自治和隔离。本博文中有关架构选项的更多细节将对此进行详细讨论。
另一个误解是工作流迫使开发人员切换到异步处理。这也不是真的。在上面的示例中,当一切顺利运行时,登记组件可以同步返回登机牌。只有在出现错误时才会回退到异步处理。这可以很容易地反映为HTTP返回码,200表示“一切正常,这是你的结果”,202表示“得到它,我会给你回电话。”有一些具体的示例代码来处理这个,它利用了一个简单的信号。
我将工作流引擎视为工具箱的重要组成部分,用于正确的故障处理,这通常涉及长期运行的行为,如状态重试。
2.异步性需要注意
这导致我们进行异步通信,这通常意味着消息传递。异步性通常被认为是分布式系统中的最佳默认值,因为它提供了解耦,尤其是时间解耦,因为任何消息都可以独立于接收器的可用性发送。一旦服务提供商可用,该消息将立即发送,而无需额外的魔力。
因此,重试的问题已经过时,但会出现类似的问题:您必须担心超时问题。假设航空公司在登记方案中使用异步通信。登记组件向条形码生成服务发送消息,然后等待响应。您无需关心条形码生成器的可用性,因为消息总线将在适当的时候传递消息。
但是,如果请求或响应因任何原因而丢失怎么办?您是否会在办理登机手续时遇到困难,未能在没有注意到的情况下将登机牌发送给客户?我打赌很多公司这样做,这再次导致我,客户监控响应并采取行动,如果没有登机牌在超时内到达。同样,我必须利用我的个人调度基础设施(日历)。
更好的方法是让服务监控超时本身,并在条形码未能及时到达时执行回退。可能的后备是重新发送消息,这实质上是重试。
您也可以利用工作流自动化技术来处理此用例。 BPMN中的工作流可能如下所示:
作为奖励,您可以免费报告重试次数,典型响应时间以及无法及时处理的工作流程数量。操作员可以通过提供大量上下文来轻松检查和修复失败的工作流实例,例如消息中包含的数据以及消息发送的时间。纯粹的基于消息的解决方案通常会忽略这种级别的可见性和操作控制。
我甚至看到公司更进一步,使用工作流引擎而不是消息传递中间件来在微服务之间分配工作。如果工作流引擎不主动调用服务或发送消息(称为推送原则)但依赖于工作者要求工作(称为拉取原则),则这是可能的。现在,工作流引擎中的工作队列就像一个消息队列。当我问他们为什么喜欢工作流引擎时,他们说消息传递解决方案缺乏相同的可见性和工具质量,他们希望避免构建自己的操作工具。
3.分布式交易很难
事务是以全有或全无的方式执行的一系列操作。我们都从数据库中知道这一点。您开始一个事务,做一些事情,然后提交或回滚事务。这些事务称为ACID:原子,一致,隔离和持久。
在分布式系统中,您不能指望ACID事务。是的,有像XA这样的协议实现了所谓的两阶段提交。或WS-AtomicTransaction。或像Google Spanner这样复杂的实施。但目前的共识是,这些协议太昂贵,太复杂,或者根本无法扩展。 Pat Helland的“超越分布式交易的生活:Apostate的意见”是一个很好的背景阅读。
但当然,商业交易的要求并没有消失。在没有ACID的情况下解决业务交易的常见技巧是使用补偿。这意味着您可以对过去不正确执行的所有活动执行撤消活动。 BPMN具有此内置功能,因此您可以定义这些撤消活动,并且工作流引擎负责以正确的顺序可靠地执行它们。这次我将使用预订机票的例子:
这通常也被称为Saga模式,最近变得非常流行。我在“Saga:如何在没有两阶段提交的情况下实现复杂的业务交易”中写到了这一点,其中我还链接了其他来源和一些代码。
请注意,此方法与ACID事务不同,因为您可以具有不一致的中间状态。所以,我可以保留一个座位,但尚未预订有效的机票。或者我可以在没有付款的情况下买票。实际情况是,只要确保最终清理它们并使系统恢复到一致状态,通常可以忍受这些暂时的不一致。这称为最终一致性,这是分布式系统中的一个重要概念。 “在SoA网络中拥抱最终的一致性”指出它非常好:
最终的一致性通常会产生更好的性能,更简单的操作和更好的可伸缩性,同时要求程序员理解更复杂的数据模型。
好消息是工作流程自动化简化了补偿的处理。这是因为工作流引擎可以可靠地调用所有必要的补偿活动。
服务提供商 - 做好功课!
到目前为止,我已经提出了三种简单的补救措施来应对分布式系
- 重试
- 超时
- 赔偿金
所有这些都可以使用轻量级工作流自动化技术实现。但是为了利用这些配方,每个服务提供商都必须做好功课。这意味着
- 提供补偿活动和
- 实现幂等性。
虽然第一个要求应该是显而易见的(如果有取消票证的服务,我只能取消票证),第二个 - 幂等性 - 需要更多解释。
幂等
我谈了很多关于重试的事情。一个常见的问题是,如果我通过重试两次调用服务怎么办?这个问题问得好!
首先要确保您了解每种形式的远程通信都会遇到此问题!无论何时通过网络进行通信,都无法区分三种故障情形:
- 该请求尚未到达提供商
- 请求已到达提供商,但在处理期间它已爆炸
- 提供程序处理了请求,但响应丢失了
一种可能性是询问服务提供商是否已经看到此请求。但更常见的方法是使用重试并以允许重复调用的方式实现服务提供程序。这更容易设置。
我看到两种简单的方法来掌握幂等性:
- 自然的幂等性。有些方法可以随意执行,因为它们只是翻转一些状态。示例:confirmCustomer()
- 商业幂等。有时,您拥有允许您检测重复呼叫的业务标识符。示例:createCustomer(email)
如果这些方法不起作用,您需要添加自己的幂等性处理:
- 唯一身份。您可以生成唯一标识符并将其添加到呼叫中。这样,如果您在服务提供商端存储该ID,则可以轻松发现重复呼叫。如果您利用工作流引擎,您可能会让它完成繁重的工作(例如,当Camunda允许在启动期间对密钥进行重复检查时)。示例:charge(transactionId,amount)
- 请求哈希。如果您使用消息传递,则可以通过存储消息的哈希值来执行相同的操作。您可以再次利用工作流引擎,或者您可以使用具有内置租赁功能的数据库(如Redis)。
长话短说:在您的服务中注意幂等性。这将带来巨大的回报。
给我看一下代码
您可以使用BPMN和开源Camunda引擎找到实现我在此描述的模式的源代码
Java或C#。(需要的后台发消息)
摘要
在本文中,我介绍了三个常见的陷阱,我看到客户在整合微服务时踩到了:低估了远程通信的复杂性,忽略了异步性的挑战,忘记了商业交易。
通过重试,超时和补偿活动的状态模式引入处理这些情况的功能可以降低微服务基础架构的整体复杂性并增强其弹性。它还有助于:
- 将重要的故障处理和事务行为封装在它所属的位置:在服务本身的上下文中。
- 将故障或超时处理的工作量减少到更小的范围,从而降低整体复杂性。
- 简化服务API,只发布对客户真正重要的故障。
- 改善客户体验,客户可能是其他服务,内部员工,甚至是客户。
使用轻量级工作流引擎,您可以通过应用自行开发的解决方案来处理有状态模式,而无需投入大量精力或冒着意外复杂性的风险。随附的源代码提供了具体示例。
- 51 次浏览
「微服务架构」更多关于微服务-边界,治理,重用和复杂性
我最喜欢博客(而且从来没有得到足够的)的一件事就是反馈。我之前发表的文章“雕刻它 - 微服务,巨石和康威定律”,产生了一些评论/讨论,这些评论/讨论合在一起,保证了一个后续帖子。
其中一个讨论是与Ruth Malan和Jeff Sussna就治理进行的Twitter交流。杰夫认为分权治理的概念是“有争议的”,尽管他认为集权治理是“有问题的”和“僵化”。露丝观察到“或者至少是一个权衡轴和(组织)设计......? (甚至“联邦”也有广泛的解释)“。我为一些集中治理的需要辩护,但是克制,注意“管理比必要更深的会导致问题,例如:问题是BDUF(IMO)是B,而不是UF“。
当应用程序跨越多个团队,所有团队都独立部署时,将需要一些集中式治理。关键是制定道路规则,允许团队独立工作而不会相互干扰,不会尝试微观管理。这种编排需求不仅仅局限于技术方面。正如Tom Cagley在我上一篇文章中的评论所指出的那样“在考虑跨团队和组织边界的流程改进时,也可以利用你的论点”。团队之间冲突的流程模型很容易使分布式解决方案复杂化。
另一篇关于“雕刻它 - 微服务,巨石和康威定律”的评论,这一次来自Robert Tanenbaum,讨论了重用,并质疑图书馆在某些情况下是否是更好的选择。 Robert还观察到“敏捷原则告诉我们实现满足需求的最小体系结构,只有在需求超出最小实现时才能使用更复杂的体系结构”。我认为微服务和SOA架构更像是一种分区机制而不是重用工具。因为重复使用会带来更多的成本和负担,而不是大多数人认为,我倾向于不那么热衷于这方面。但是,我绝对同意,分布式架构可能更适合于演进过程的后续步骤,而不是起点。来自Chris Richardson的“微服务:分解应用程序的可部署性和可伸缩性”的引用很好地说明了(重点是我的):
使用微服务架构的另一个挑战是决定在应用程序生命周期的哪个阶段应该使用这种架构。 在开发应用程序的第一个版本时,您通常不会遇到此体系结构解决的问题。 此外,使用精心设计的分布式架构将减缓开发速度。
Michael Brunton-Spall的“什么是微服务及其重要性”为这种架构风格所涉及的权衡性质提供了更多背景:
微服务交易复杂的单块,用于简单服务的复杂交互系统。
一个巨大的整体可能是如此复杂,以至于很难对某些行为进行推理,但在技术上可以推理它。相互交互的简单服务将表现出紧急行为,而这些行为是不可能完全推理的。
对于复杂系统而言,级联故障更是一个问题,一个简单系统中的故障会导致其他系统出现故障。幸运的是,有一些模式,例如背压,死人的开关等等,可以帮助你减轻这种情况,但你需要考虑这一点。
最后,即使问题发生变化,微服务也可以成为解决问题的解决方案。因此,一旦构建,如果您的需求发生变化以使您的有界上下文调整,正确的解决方案可能是抛出两个当前服务并创建三个来替换它们,但通常更容易简单地尝试修改其中一个或两个。这意味着微服务可以很容易地在较小的情况下进行更改,但需要更多的监督才能在大的情况下进行更改。
引号中“复杂(complicated)”和“复杂(complex)”之间的区别尤为重要。所提到的紧急行为意味着复杂系统的行为只能在回顾中完全解释。这意味着分布式应用程序不能被视为具有部件之间空间的整体件,但必须根据其性质进行设计。这是Jeppe Cramon的一个主要主题,他在TigerTeam网站上围绕微服务的持续工作非常值得一读。
Jeppe在我的帖子的LinkedIn讨论中发表了一对评论。在那次讨论中,Jeppe指出,专注于业务能力的小型服务比整体服务更可取,但这与将几个巨型网络与Web服务连接起来并不相同。然而,主要关注的是服务“拥有”的数据的性质。我在上一篇文章中非常简短地提到了这一点,并提到需要权威性的一些概念(中央治理)。 Jeppe表示赞同,并指出整体结构导致多主数据架构,其中多个系统在同一实体上包含冗余的,可能相互冲突的数据。
底线?在我看来,这种架构风格具有增强企业运营的巨大潜力,前提是它没有过度营销(“SOA治愈秃头,肠易激综合症,促进世界和平......免费!!!”)。服务并不是将遗留系统毫不费力地转变为二十二世纪技术的秘诀。有一些警告,权衡和成本。一种务实的方法,考虑到这些以及潜在的好处,应该比昨天的“如果建立它和他就会来”的哲学更有可能取得成功。
- 65 次浏览
【Rust】用Rust构建微服务

Rust是一门很棒的语言,目前是我2019年和2020年(到目前为止)学习最多的语言。Rust几乎可以与任何语言进行互操作。Rust对容器和K8s也很好。今天我要展示如何构建一个简单的微服务。我们将使用Actix、Tokio Postgress和其他库。我们将使用postgres作为事实的来源,并在docker中运行它(为了开发)。我们还将使用Barrel +一些我创建的自定义移植结构。代码将全部是异步和非阻塞IO。希望你玩得开心,我们开始吧。
架构

这里我们有一个多层架构,其中业务规则和rest定义在news-contract中定义。SOA契约在news-contract + news-service中定义,结构(news)在news-contract中定义。rest endpoint definitions+服务是在news-service上定义的。postgress持久性在news dao中定义。
代码结构
我们有5个项目,有一个全局工作区,这是一个项目,顶层的。我们有news-contract:这是SOA契约的一部分,我们在代码中使用了新闻结构。
news-dao:我们有使用tokio postgres的反应式持久性代码和新闻资源的所有CRUD操作。
News-migrations:为了测试,我们使用barrel+自定义逻辑来创建表和添加数据。
News-service:这里有端点、服务实现和配置了actixweb框架的主类。
每个项目都有自己的依赖项,由Cargo.toml文件。
我们还有两个脚本处理Docker容器。一个运行Postgres,另一个运行psql。
迁移
现在让我们看看如何进行迁移(创建表并将记录添加到Postgres SQL中)。

我们连接在docker上运行的Postgres数据库,创建一个包含所有迁移的向量,我们正在运行这个迁移。然后我们将进行一个for all迁移,逐个检查它们是否运行良好。
现在让我们看看下一个rust代码,什么是迁移。
我创建了一个名为NewsMigration的结构,其中有一个新的(用于创建结构的函数)和运行迁移的方法(run)。如您所见,我创建了第二个名为CreateTableNewsMigration的结构,以及一个使用(impl)的trait实现,在我使用的barrel代码中创建了一个表结构,barrel将生成Postgres SQL INSERT语法。最后,我们在Postress中使用pg\u客户机运行生成的脚本。在这里您可能会看到有点奇怪的代码:&news_table[..],在这里我们传递String news_表的引用,并传递一个片段([..]),复制字符串并传递方法。
SOA契约
让我们来看看Soa合同的一部分,Struct新闻。
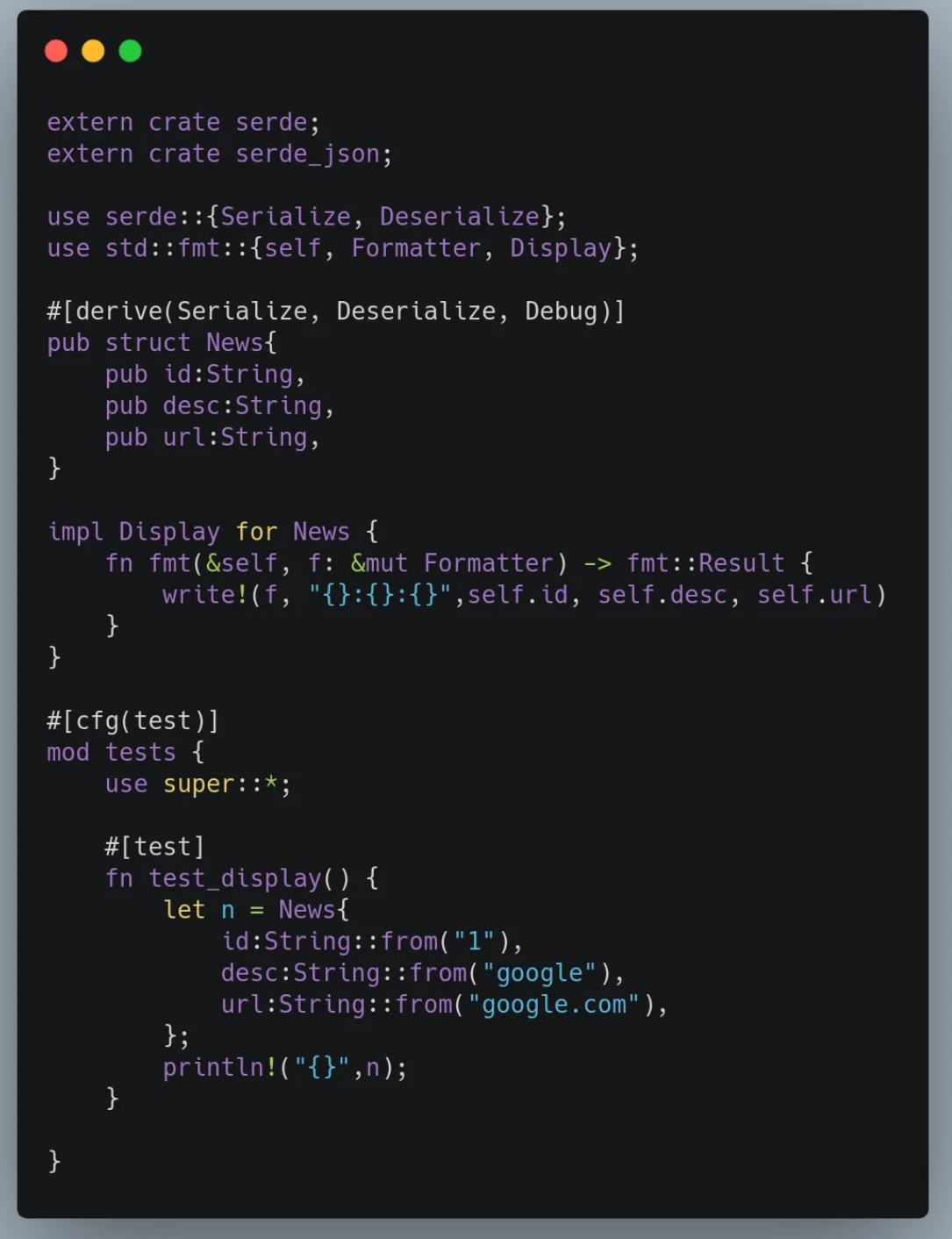
我们正在定义一个名为News的结构,我使用serde和serde_json来序列化和反序列化这个结构。我还实现了一个称为Display的特性,以便能够打印结构。最后,在文件的末尾有一个单元测试,我正在测试是否可以打印这个结构。
端点/服务

这里我定义了HttpServer actix,并定义了几个处理程序,比如:index、list、insert、get、delete等。所有信息都使用日志和env_logger创建来记录。
现在让我们看看端点.rs把剩下的定义归档。
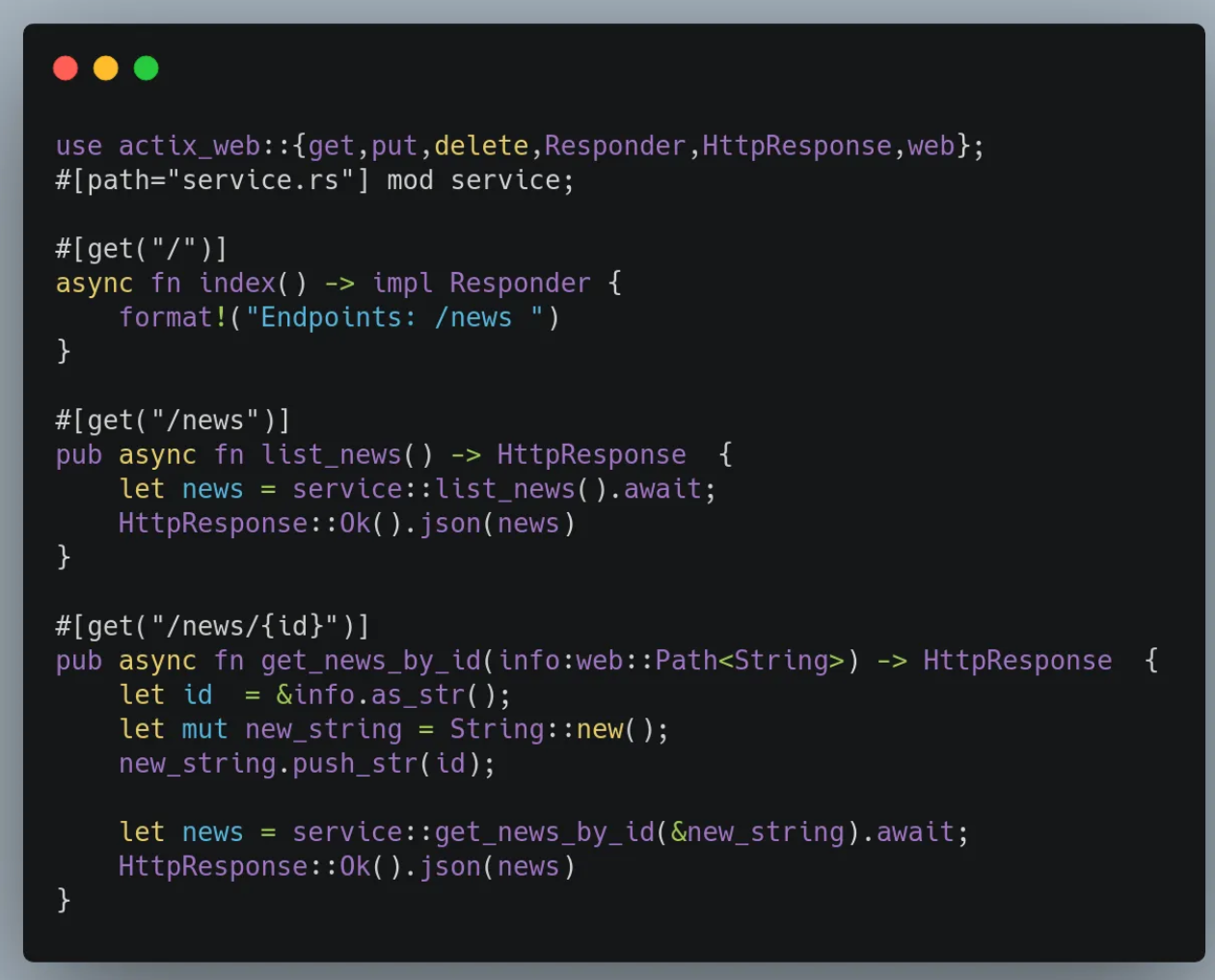
这里有一些宏使用REST操作,比如PUT、DELETE和GET。每个函数处理程序都是公共的,基本上,这里我调用服务并从服务中获取结果并序列化为json结果。
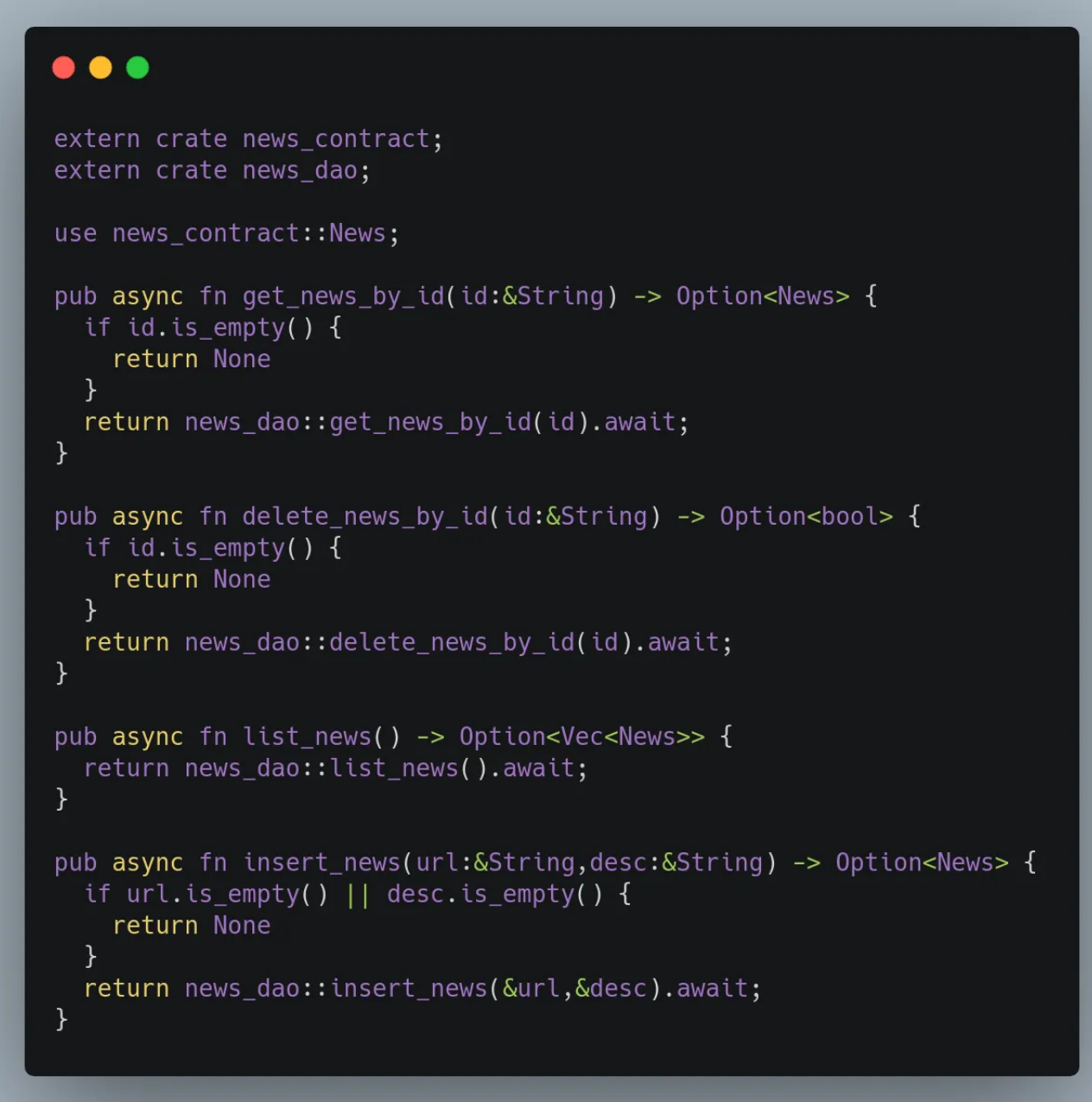
这是服务实现,我们这里没有任何REST或actix依赖关系。这里是实现验证、业务逻辑和委托给dao机箱的正确位置。CRUD上的所有函数都是异步的。
DAO
这是魔术发生的地方,我们有tokio-postgress编码。我们来看看。
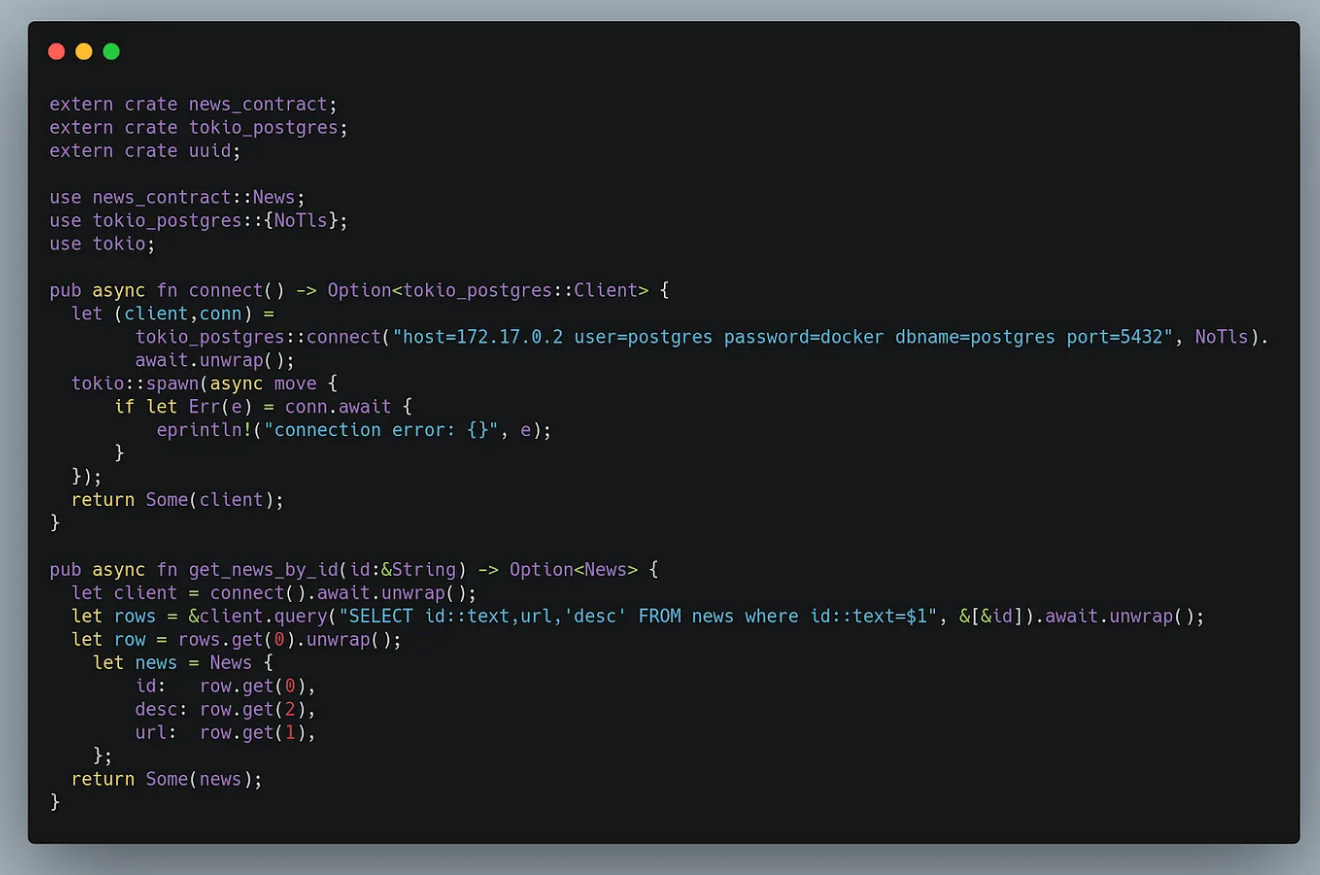
这是DAO实现。有一种方法可以在名为connect()的postgres数据库上进行连接,该方法以异步和非阻塞的方式进行。在这里,我演示了如何通过id进行查找。使用tokio postgress客户端,我执行一个查询,通过SELECT查询执行WHERE by id。在postgress id中,handle作为一个UUDI,所以我需要转换为string,这就是为什么您看到id::text=$1,在同一行中,我用&[&id]传递从参数获得的id。DAO有更多的函数,您可以在mine GitHub中查看完整的代码。
视频:代码演练+死亡演示
让我们看看我用代码演练和死亡演示制作的视频。
讨论:请加入知识星球【全栈和低代码开发】或者小号【chief_dev】或者QQ群【11107767】
- 687 次浏览
【微服务】专家组:在过去十年的微服务中,我们学到了什么?
瓦特(Watt):这是微服务专家组。Chris早些时候谈到了最小化微服务中的设计时耦合。他是microservices.io的创建者,《微服务模式》一书的作者。他也是Java冠军,在微服务领域非常有经验。我期待着与你们一起深入研究其中的一些领域。当然,我们有詹姆斯·刘易斯,他是最早创造和定义术语或架构风格的人之一,我们今天称之为微服务。James是ThoughtWorks的软件架构师和主管。ThoughtWorks技术咨询委员会成员,以及创建技术雷达的小组成员,致力于推动业界采用开源和其他工具和技术。还有凯蒂·加曼吉。凯蒂是CNCF的生态系统技术倡导者。她的重点是更广泛的生态系统和能够帮助微服务生存和繁荣的工具。她帮助发展和领导最终用户社区,同时缩小与其他一些生态系统领域和单位的差距。她过去的角色包括云平台工程师,她构建了很多平台,这些平台都被云本地技术所吸引,其中包括Kubernetes。
微服务还和十年前一样吗?
我想也许我们可以从一个问题开始,实际上,微服务作为一个定义。它真的还意味着我们今天认为它意味着什么吗?James,你不久前创造了这个术语,如果我们考虑敏捷,敏捷在今天的含义可能并不完全相同,因为它今天的含义是一样的。微服务还和十年前一样吗?
理查森(Richardson):那是什么,詹姆斯?
刘易斯(Lewis):我不知道。我应该指出,出于完全开放的考虑,不仅是我,还有弗雷德·乔治。Adrian Cockcroft同时谈到了细粒度SOA和微服务。我认为这只是一种趋同进化,不管它叫什么。时机已经成熟的想法。当时,这在很大程度上是对以技术为中心的大规模软件开发方法的反应。我们专注于技术层和所有的工具和技术,我认为我们真的希望将其从技术层带到更多的业务中,更多地关注业务,发挥更多的DDD,发挥更多的业务能力理念。本质上,我认为它有点像极限编程。有人引用Kent Beck的话说,“它只是一次做了所有的好事,结果变成了11个。”我认为这才是微服务架构真正的意义所在。它将当时存在的许多想法汇集在一起。如果你想想当时的游击队面向服务的架构。吉姆·韦伯是这个想法的始作俑者。显然,领域驱动的设计,着眼于RESTful集成,这是其中的一个重要部分,并通过超媒体实现解耦。
现在它的意思是一样的吗?不,当然不是。十年后。正如你所说,Nikki,语义扩散是一件事。词语改变了它们的意思。事实上,回想起来,我想马丁和我都会同意,我们把名字搞错了。这是零碎的。它卡住了。真的,这和尺寸无关。然后,当马丁给某物命名时,它往往保持命名状态。
理查森(Richardson):你应该使用面向服务的架构,它会消除一些反模式。
Lewis:当然,Dan North更喜欢可替换组件架构,这可能是对其真正意义的更恰当描述。这是关于可替换性而不是可维护性的设计。这是最原始的东西。
微服务中的常见反模式
瓦特:我们尝试微服务已经有相当一段时间了。我认为我们做的很多事情可能都是对的,但我想说的是,有很多是反模式。你的同事们对你一次又一次看到的最流行或最常见的反模式有什么看法,对人们如何实现和使用微服务有什么看法?
理查森:我想说一个明显的原因是人们相信这就像一个神奇的精灵尘埃。我们的工程组织交付软件的速度很慢,我们只做微服务,一切都会很好。然而,在现实中,如果您的软件交付速度慢是因为您的流程,因为缺乏自动化测试,并且您编写的代码无法维护,那么在混合中添加微服务很可能会使事情变得更糟。我觉得在采用微服务之前,或者在采用微服务的同时,您实际上必须清理您的行为并提高组织的成熟度。假设微服务实际上是解决方案的一部分,因为不知何故,你只是改进了所有其他东西。那就足够了。
伽曼吉:我可以附和。我认为这是我所看到的一种模式,当容器的采用得到更多的动力时。这不是关于容器,也不是关于技术,而是关于理解你的问题是什么,并真正触及问题的核心。大多数时候,这也伴随着文化的转变或发展。这不仅仅是关于采用微服务,而是关于你真正理解你试图解决的问题,并尝试应用一些最佳实践。谈到反模式,已经有很多使用微服务的用例,但是仍然有一些代码没有得到很好的维护。部署起来仍然很困难。自动化不是它的一部分。Chris也提到了很多功能。成功的衡量标准也不一定是真正明确定义的。其他一些组织通过他们拥有的微服务数量来衡量他们的成功,这实际上不是你应该追求的目标,不是吗?这不仅仅是关于技术,而是关于文化的转变,真正理解你试图解决的问题的根源。
理查森:我曾经和一个组织合作过。首席信息官读了我写的一本电子书,然后对微服务充满了热情,自上而下,8000人的组织,他刚刚宣布做微服务。这被转化为KPI,进而转化为奖金和其他东西,基本上就像许多微服务决定了你的奖金一样。
分布式事务
刘易斯:我们根本不是这个意思。这是我以前的客户,很有趣。这是关于分布式事务的。当您最终拥有大量服务,并且不得不协调事务并在这些微服务之间进行编排时,这可能是一场噩梦。Sam Newman和我在我们的培训课程中经常说,如果您认为您可能需要分布式事务,最好将这些事务放在一起,因为它们可能需要在同一个位置。我记得在一个组织中,他们有实体服务,然后是业务编排服务,该服务将协调这些事件和服务之间的事务。他们将其实现为ThreadLocal,因此每个调用都将存储在堆栈中的ThreadLocal中。如果他们需要解除分布式事务,他们会解除堆栈并对每个服务发出回滚。我们认为,这是一个很好的开始,因为这是一个很难解决的问题。那么,如果你需要两个呢?如果您需要其中两个,以防需要扩展,会发生什么?他们说,我们有一个计划。我们要把动ZooKeeper 带进来。现在他们遇到了所有的问题,因为现在他们也遇到了ZooKeeper 的问题。我们都知道这可能有点诡计,因为每次他们对其中一个微服务发出请求时,他们也必须与ZooKeeper 交谈。这很有趣。如果您正在构建微服务架构,我也觉得分布式事务是值得注意的。
理查森:我以前讲过,不管怎样,暗物质,暗能量,都是关于希望你分解的相互冲突的力量。那么,在服务和交易之间产生吸引力的力量就是抵制竞争的一个关键吸引力。
瓦特:我认为,在我们工作的一些客户中,我也看到了分布式的整体,在那里有很多服务,比如实体服务反模式,我认为当你从整体分解到微服务时,只是有一些非常传统的概念。然后,您必须将所有内容与事务以及跨越多个调用的所有这些内容放在一起。
Kubernetes如何影响和塑造微服务
就微服务而言,你现在无法摆脱的一件事是Kubernetes似乎与微服务齐头并进,有时甚至在这些句子中互换使用。在我们前进的过程中,库伯内特斯是如何影响和塑造微服务的?
Gamanji:Kubernetes的引入几乎就是容器的采用。对于Kubernetes,我们有一个容器编排器来帮助我们部署这些容器。这不仅仅是关于部署应用程序,而是关于Kubernetes带来的一些额外功能。例如,我们讨论的是可伸缩性。我们有一个水平吊舱自动缩放器,它可以自动识别何时需要缩放应用程序。它具有就绪性和活动性探测,这将确保应用程序重新启动,或者容器重新启动,以确保服务启动并运行。我们还有很多其他功能,如声明性配置,我们与物理基础架构层分离,因为我们需要考虑的是如何在Kubernetes世界中使用资源(如部署、副本集、服务等)定义应用程序。
然而,对于Kubernetes,它还是一种承载应用程序的机制。这并不一定意味着您可以在开发应用程序的阶段应用一些最佳实践。在很多情况下,整个单体都被部署到Kubernetes平台上。它要跑了。这将消耗大量资源。这将不是运行应用程序的最有效方式。它实际上也能让你做到这一点。有了Kubernetes,我认为它能让我们更快地,比如让我们把人们放在一个好的、积极的角度。它使应用程序能够更快地部署,但同时,它具有我刚才提到的一些功能:可达性、自动化、可伸缩性、就绪性探测、活动性探测等等。所有这一切实际上是真正的转变,从如何部署应用程序转变为只部署应用程序,将其容器化。实际上,只需使用Docker或BuildPack之类的工具对其进行打包,无论内部选择什么工具,这就足以让它真正准备好部署到集群中。
刘易斯:我刚才在看ThoughtWorks技术雷达和Kubernetes第一次出现在2015年的《评估》中,当时我认为谷歌只是开源的。微服务最早出现在这之前,Docker也出现在这之前。我认为我们所说的库伯内特斯所支持的模式,它们是更古老的模式。我不知道是否有人记得Dropwizard,它是一种有点时尚的格式。在Dropwizard之前,有一个Java库,来自同一个人Coda Hale,名为Metrics。这是一个典型的示例,放入一个简单的库,然后点击一个端点,每个应用程序都会有这个库。每个应用程序都有一个端点,它将为您提供服务正常运行时间、请求-响应延迟等等。现在,它已经从应用程序发展到基础架构。我认为这真的很吸引人,就像本质复杂性的演变一样,它仍然存在于业务代码中。然后是偶然复杂性,这是Martin Fowler的出发点,偶然复杂性正在迁移到您的网络、服务网格、侧车、容器运行时和编排工具中。我认为这是我们正在进行的一个有趣的轨迹。也许我们最终只需要一个业务分析师就可以将东西拖放到一起,然后部署到Kubernetes中。
Kubernetes是正确的抽象级别吗
瓦特:你认为Kubernetes是正确的抽象级别吗,或者你认为我们仍然需要在其上构建更多的生态系统,以使人们更容易构建微服务,因为有些东西的级别相当低?
理查森:我有几个不同的观点。我认为最重要的是,微服务架构的本质并不是真正的技术或基础设施相关。这一切都是关于正确识别服务边界、服务责任、它们的API和协作。这就是微服务架构的本质。就开发系统时必须做出的众多决策而言,这些是绝对关键的决策。我认为微服务采用的另一个反模式是,它正在反转它,然后思考,让我们找出我们的部署技术、工具和文字技术。这在很大程度上是一种反模式。这实际上都是关于服务定义的。
Kubernetes适合哪里?我将其视为许多可能的部署选项之一。一个明显的替代方案是无服务器,比如将东西打包成AWS Lambdas,然后在AWS或谷歌云功能上运行?如果这不适合,那么,可以考虑使用基于Docker的解决方案。ECS是一种更简单的选择,甚至是Kubernetes。那么Kubernetes实际上相当不错。到处都有。它从树莓皮到公共云,以及介于两者之间的一切。这很吸引人。我将其视为一种部署选项,而不是本质上与微服务定义相关的东西。
加曼吉:我可以在这里加一点,因为我认为,随着Kubernetes的流行,与此同时,我们有了另一种非常突出的文化模式。我在这里明确地定义了DevOps。同样,这不是一个部署过程。这是团队之间协作方法的文化转变。我认为这实际上非常重要,因为当我们讨论定义我们的服务可以做什么时,特别是在架构中,我们有无数的服务,并且有不同的团队控制它们。您如何确保您的API可用?您如何确保同步并了解如何使用API?如果您有一个功能需求,您如何联系该团队?我认为,DevOps文化更强调这一点,它引入了基础架构层,让平台团队与应用程序团队更紧密地协作,以确保服务或应用程序所需的所有需求也将由平台团队来满足。我认为这是关于定义应用程序的,但同时,下一个阶段是如何将其交付给消费者。有时需要更清楚地了解应用程序将部署在何处,以便充分利用现有的基础设施。这也伴随着团队之间的协作处理。
Lewis:这很有趣,不是吗,这个标准化的想法也很有趣,因为我们以前有一个叫做领域应用程序协议的东西,你可以考虑RESTful架构中的微格式。这是我真的看不到团队谈论这么多了。我想这又回到了你刚才说的,克里斯,重要的一点是这些东西是如何交流的?API是什么?我知道我可以通过什么协议和这边的另一个团队交谈?我使用的团队是服务边界的同义词。我认为这似乎正在消失。我不知道是否有其他人看到过。我们实际上要坐下来解决一个难题,即边界是什么?我们的服务之间的接口是什么?让我们商定一种相互交谈的通用方式?因为这本质上就是语义鸿沟。这就是语义问题,你不能通过技术来真正解决它,你只能通过人们相互交谈来解决它。
让人们与技术方面合作改变组织方面的挑战
瓦特:在之前的一些会谈中,围绕着如何解决其中一些挑战的实际工作所需的协作进行了大量讨论。康威定律也经常出现在围绕组织设计服务方面,反之亦然。我认为,我们经常会发现,使用微服务架构是为了帮助组织更快地发展,但这通常不会发生,因为组织实际上不会同时发生变化。我不知道你在这方面有什么经验。在让人们与技术方面合作改变组织方面,您在人力方面遇到了多少挑战?
理查森:人类,他们是麻烦。我使用成功三角的概念。这就像为了快速、频繁、可靠和可持续地交付软件,您需要三个方面的结合。从流程的角度来看,它是精益的,而且是DevOps。从组织的角度来看,这是一个松散耦合的产品团队网络。然后从架构的角度来看,它是一个松散耦合的模块化架构,有时是微服务,有时是一个整体。为了实现快速可靠的软件开发目标,您需要这三个方面。
刘易斯:这就像一句古老的格言,当持续交付是一种新事物,构建管道是一种新事物时,你会发现人们会花几个月的时间定义和构建完美的构建管道,让你的软件投入生产。我们可以按需将软件投入生产,速度非常快。太好了,什么软件?我们没有任何软件。这是一个经典[听不见00:22:47]。如果其他人看到了这一点,你肯定会想,你的构建管道有多好?因为如果你没有任何可用的软件来推动它,那就是解决真正的业务问题或产生真正的成果,那么你就不会交付任何东西。
Gamanji:从工程团队的角度来看,在内部做好战略提升工作是非常重要的。如果我们采用新的概念来部署应用程序或在内部创建应用程序,我认为创建员工可以遵守的内部标准非常重要。我认为这是非常重要的,清晰的沟通、透明和提高技能的机会。我认为人类的问题永远都会存在。但我们似乎有不同的方法来处理它。
刘易斯:组织会找到一切可能不改变的理由。Eli Goldratt几年前,我认为在《目标》(the Goal)的一篇[听不见的00:23:57]中,他谈到了范式转换,组织中的人们最难做的事情就是转换范式。有点像微服务风格的架构,采用云原生,这是一个巨大的转变。这是一个巨大的范式转变,因为它是关于人的。这是关于团队结构的。我想我们忘记了一些事情,比如,对于亚马逊,杰夫·贝佐斯(Jeff Bezos)没有说构建微服务。他说还有很多其他的东西,其他的约束,其他的强制功能,包括直接看到你的客户,建立产品团队,就像Chris说的,拥有小的授权团队,他们自己管理一切。都是这些东西。这就是一种范式转变。Eli Goldratt说,你需要三件事来改变一个范例。您需要做的第一件事是在现有的范例中尝试其他一切。你需要承受巨大的压力。你需要有人帮助你迈出第一步。当然,ThoughtWorks总是可以提供帮助的。
理查森:我也是。
瓦特:你也是,凯蒂?
伽曼吉:是的。我在这里。
如何影响管理层和领导层以适应变化
瓦特:我不知道你们中是否有人读过《团队拓扑》这本书,并且随着旅程的发展,不得不改变团队。有时您可能会有一个完整的产品团队启动,但您可能会有处于不同交互模式的平台团队。我认为这是一个可能在过程中丢失的东西,因为你发现公司倾向于建立,他们说,这是我们的结构,这是我们做事的方式。它不会随着组织和架构的实际变化而变化。对于如何真正影响管理层和领导层,使其能够认识到这一点并加以适应,您有什么建议或看到什么吗?
理查森:我认为最终,一家公司不盈利或盈利能力下降是大多数商人的最终动机。大多数组织往往不会有这样的直接危机,但如果他们有,那么这就是改变和变革的真正令人信服的原因之一。我曾经与一位客户合作过,他们是一家非常成功的公司,但他们有一块老化的单体,它是预先部署的。因为它太大太旧了,他们很难对它进行测试。它是有缺陷的,客户害怕升级,因为这意味着停机。这转化成了一个企业可以理解的问题,因为它涉及资金。然后,这实际上促使他们开始研究微服务架构,这样他们就可以切块,然后对它们进行彻底的测试。
Gamanji:我认为这是相同的问题空间,但它也可以应用于不同的领域。Chris一直在谈论采用或鼓励使用微服务。在采用Kubernetes作为平台时,我看到了一种非常类似的模式。同样,归结到相同的核心原则,每个企业都希望有一个与众不同的优势,这将使他们能够尽快向客户部署其功能。为此,有时候,当涉及到平台时,我们可以真正提供一个非常好的用例,这不仅可以降低维护基础架构的成本,而且可以使您的团队拥有更多的控制权,并且可能更容易地执行一些生命周期管理操作,例如升级和更新集群,确保有机会引入新技术,例如,服务网格。同样,拥有业务差异通常要归结于技术。在公司的不同阶段,可以采用微服务,也可以采用容器和Kubernetes,或者呼叫提供商等等。我认为这是一个正在经历的问题,即公司或组织如何盈利?
刘易斯:关于团队拓扑的话题,还有一本非常棒的书《动态重新团队》。海蒂写了这本精彩的书。这是关于实际改变团队结构的不同技术。不一定是团队拓扑,它是从平台团队到产品团队,再到它是什么。在人员轮换、保持人员新鲜、保持人员想法、保持人员参与方面。我所见过的公司中最好的例子就是制作数据库工具的Redgate,它做到了这一点,而且做得非常好。它们最初用于SQL Server,现在也可以使用其他数据库。他们做得非常成功。他们可以让员工在不同的产品之间来回走动。他们几乎有一个海报会议,每隔几个月,开发人员就会在合理的范围内选择要开发的产品。我认为这使Redgate能够做到这一点。我认为在许多组织中,尤其是大型组织中,你看不到的是,他们拥有真正的变革型领导。他们已经建立了一种学习文化,不仅仅是在他们的团队中围绕技术实践、模式和事物,而是围绕管理实践和变革型领导。我认为这是很多组织所缺少的一点,那就是我们不仅仅停留在自己的方式上。我们不会永远这样做。我们必须适应。我们必须学习。我们必须学习新技术、新风格、新的组织结构,并与管理者一样跟上该领域的最新发展,而不是坚持我们一直在做的事情。
瓦特:我认为,有时试图让这些倡议从基层开始,除非你得到管理层和领导层的认可,否则是行不通的,真的,因为你可以一直尝试,直到脸色发青,但如果高层不理解,这肯定是一个挑战。
微服务的下一次演变
关于微服务的未来,以及我们的发展方向,您是否了解CNCF或您的客户在微服务方面的最新趋势?下一个进化是什么,或者下一个我们应该关注的东西是什么?
Gamanji:我想在这里提到一些方法或工具,特别是在应用程序开发方面。当我们谈论Kubernetes和cloud native时,它围绕着集群,围绕着如何使用Kubernetes资源在配置中定义应用程序,等等。然而,现在有一个转变,重点完全放在应用程序开发人员身上。开放应用程序模型就是这样构建的,两年前在2019年被外包。这几乎允许将重点从基础架构层转移到应用程序层。最重要的是,您将能够在config中的代码中定义应用程序,并且能够跨云提供商部署它。这不仅仅是关于Kubernetes的,如果您想在数据中心或云提供商中部署它,您也可以使用这个特定的工具。
另一件我想从云原生空间提到的事情是Gitpod,它专注于应用程序开发阶段。Gitpod实际上是一个编纂本地开发环境的工具。这是一个巨大的使能器,特别是当有人在本地创建或开发应用程序时,如果遇到bug,他们将能够将其完全编码。它都基于Git存储库,您可以像一个文件一样挥舞,甚至可以像Git存储库一样挥舞,就像一切都在那里一样。其他人将能够完全重新创建它。这将是另一位工程师的镜像。这种可移植的开发环境,也一直是人们关注的焦点。
当然,就应用程序的实际部署而言,我们有不同的方法,同样可以使应用程序更快地推送到生产环境中。这就是GitOps非常突出的地方。这也是一种机制,您可以将应用程序的所需状态存储在Git存储库中。但是,它改变了开发人员将应用程序部署到集群的方式。对于所有这些工具和方法,我想说的是,Kubernetes将留下来。我们有许多调查证实了这一数据。我们有一个来自VMware的关于Kubernetes状态的最新调查,而且每年他们都看到生产中使用Kubernetes的数量在增加。现在不仅仅是基础设施,我们正在努力提高开发人员的体验。这就是我提到的所有这些工具和方法能够真正蓬勃发展的地方,它们最近实际上获得了很多动力。
瓦特:詹姆斯,你觉得怎么样?
刘易斯:对我来说,技术是一回事。这正在演变。发生了巨大的爆炸。我做了一次演讲,回顾了微服务最初出现的地方,以及它之前的内容和之后的内容。在监控、日志记录和容器编排方面,您会遇到这种巨大的爆炸。真是太棒了。我相信,这种情况会继续下去,因为这会让很多人赚很多钱。我认为我们还没有破解更多关于领域的东西,更多关于业务架构的东西。正如克里斯所说,边界是什么。在开始编写代码方面做得很出色,很多是模式,其他人也在做类似的工作。对我来说,这是一条至今仍未落地的信息。是关于生意的。这是关于团队结构的。它关注于如何解决业务问题。我认为可能仍然有太多的注意力集中在技术上。我认为我们仍然需要纠正这一点。没有多少人还在读埃里克·埃文斯的蓝皮书。虽然Data Mesh现在显然又重新流行起来,但它的受欢迎程度似乎在下降。我认为领域驱动的设计、业务能力等仍然是微服务领域的核心。
理查森:技术将继续发展。我觉得这不是微服务的核心。这是一个笑话,但也许XML将取代YAML卷土重来。我只是想说。
刘易斯:而不是在YAML或JSON中隧道XML。
Gamanji:我们将在这里用YAML替换所有东西。实际上有一个项目,它允许您使用Excel电子表格管理应用程序。如果需要,情况可能会变得更糟。
理查森:一切都是YAML。真有趣。实际上,我希望Lisp是一种配置语言,我觉得这是一种更好的方法。我觉得这个问题有两个层次。第一,我完全同意詹姆斯关于编纂设计最佳实践的观点。我认为领域驱动设计和Eric Evans的蓝皮书是关键,以及相关的东西。另一部分是关于整体与微服务的争论。首先,我们应该停止使用Twitter讨论架构。这是一个可怕的格式。所有这些辩论,如果你在推特上说,单体是好的。参与程度超出了预期。我希望我们都能就monolith架构适用于何处以及微服务架构适用于何处达成一致,因为很明显,它们都适用于何处,我们只需要确定何时适用。我希望这场辩论能得出一些结论。
刘易斯:对我来说,技术是一回事。这正在演变。发生了巨大的爆炸。我做了一次演讲,回顾了微服务最初出现的地方,以及它之前的内容和之后的内容。在监控、日志记录和容器编排方面,您会遇到这种巨大的爆炸。真是太棒了。我相信,这种情况会继续下去,因为这会让很多人赚很多钱。我认为我们还没有破解更多关于领域的东西,更多关于业务架构的东西。正如克里斯所说,边界是什么。在开始编写代码方面做得很出色,很多是模式,其他人也在做类似的工作。对我来说,这是一条至今仍未落地的信息。是关于生意的。这是关于团队结构的。它关注于如何解决业务问题。我认为可能仍然有太多的注意力集中在技术上。我认为我们仍然需要纠正这一点。没有多少人还在读埃里克·埃文斯的蓝皮书。虽然Data Mesh现在显然又重新流行起来,但它的受欢迎程度似乎在下降。我认为领域驱动的设计、业务能力等仍然是微服务领域的核心。
理查森:技术将继续发展。我觉得这不是微服务的核心。这是一个笑话,但也许XML将取代YAML卷土重来。我只是想说。
刘易斯:而不是在YAML或JSON中隧道XML。
Gamanji:我们将在这里用YAML替换所有东西。实际上有一个项目,它允许您使用Excel电子表格管理应用程序。如果需要,情况可能会变得更糟。
理查森:一切都是亚马尔。真有趣。实际上,我希望Lisp是一种配置语言,我觉得这是一种更好的方法。我觉得这个问题有两个层次。第一,我完全同意詹姆斯关于编纂设计最佳实践的观点。我认为领域驱动设计和Eric Evans的蓝皮书是关键,以及相关的东西。另一部分是关于整体与微服务的争论。首先,我们应该停止使用Twitter讨论架构。这是一个可怕的格式。所有这些辩论,如果你在推特上说,单体是好的。参与程度超出了预期。我希望我们都能就monolith架构适用于何处以及微服务架构适用于何处达成一致,因为很明显,它们都适用于何处,我们只需要确定何时适用。我希望这场辩论能得出一些结论。
刘易斯:作为对这一点的提醒,每个人。我的一个同事Neal Ford显然在建筑领域非常有名,他写了很多关于它的东西。我想他们有一本书,他和马克,这是另一本即将出版的书。我想这叫做“建筑:硬的部分”,克里斯,他们已经谈论了很多。他们有一个非常好的扰流板,因为这是他们的孩子。他们有一个非常好的模型,围绕如何考虑服务的粒度或应用程序的粒度。注意那件事。
Gamanji:这是关于确定要部署的产品的最佳架构。同时,我想提醒大家,这也是关于迭代的。目前对你有用的东西可能在几年内对你不起作用。尝试为将来的问题构建,这将帮助您拥有可维护的代码库。
原文:https://www.infoq.com/presentations/panel-microservices-architecture/
- 45 次浏览
【微服务】使用Spring Boot&Swagger的微服务 - 第1部分
微服务作为消除软件组件之间隐藏的依赖关系并允许细粒度部署而不拖拽不必要的上下文的方式已经变得流行。通过这种方式,微服务可以促进敏捷开发团队的自主性,并允许应用程序更自然地发展,并在某些情况下更快地开发。
我喜欢Java,所以我将向您展示一个为JVM开发微服务的过程和框架。这是一系列文章的第一部分,介绍了端到端的服务开发。在我们将来的文章中讨论更具体的细节之前,第一篇文章(第1部分)将介绍一些基本方面。第2部分将介绍Swagger规范中的代码生成,之后的文章将深入介绍实现良好服务的一些功能。
微服务特性
微服务的特征由James Lewis和Martin Fowler定义。我们可以总结一下技术特征:
- 单个运行时可执行文件 - 消除运行时库依赖性和对运行时容器打包的依赖性。
- 定义良好的API,支持单个有用的业务功能。
- 用于健康监控和记录的标准接口,便于管理大量独立服务
- 在Spring平台中,以下库支持这些特性:
- Spring Boot提供了单一的可执行特性,它为每个微服务提供了自己的HTTP堆栈(遗憾的是,这些内存占用了一些成本)并允许每个服务独立部署和管理。
- 使用Swagger的“合同优先”开发支持业务功能(有关此内容的更多信息,请参阅下一节)。
- Spring Actuator支持健康监测
- Sleuth支持标准化日志记录
合同优先发展
微服务应该提供单一有用的业务功能。这里有一些细微差别,可以归结为一个微服务,代表其API表示中的抽象业务级别。微服务应该从基础技术细节(例如数据模式或实现细节)中抽象出服务的使用者。抽象允许服务实现发展,同时对消费者的干扰最小。
API设计中常见的反模式是从实现开始,然后生成API规范 - “点击优先”方法。由此产生的接口往往过于技术化,“开发人员充满敌意”,并与实现细节紧密结合。
更好的模式是首先与消费者和其他利益相关者合作设计服务API。然后可以在负责服务实现,消费者实现,测试等的不同开发团队之间共享API规范。
对于此服务,我们将使用Swagger设计REST-ish API,但原理和技术与我们是否为REST-ish无关。例如,可以使用protocol buffers或其他接口规范工具轻松设计RPC样式服务。
我们发现在自己的git存储库中管理API规范是有益的,与服务实现分开。好处包括:
- 由于我们只有API规范,因此在审核后可轻松容纳更改。
- 服务实现者和消费者可以并行地开始他们的开发工作,从而增加团队自治并减少跨团队依赖性。
- 为服务使用者提供测试服务模拟的能力。
让我们将流程分为以下几个步骤:
- 设置服务接口项目。
- 在Swagger文件中定义服务规范并生成代码存根。
- 设置使用生成的代码存根的服务实现项目。
服务接口
我们将构建一个简单的Hello World服务,该服务使用GET方法公开/ greeting资源,该方法在调用时以包含“Hello World”消息字符串的JSON有效负载进行响应。
首先创建一个名为api-helloworld-v1-interface的Hello World Interface项目。项目结构符合标准的maven项目结构。
pom.xml文件包含以下库的依赖项:
- Swagger Codegen Maven插件,用于根据Swagger规范构建服务器存根
- 用于拉出实现JAX-RS规范的CXF模块的Apache CXF依赖项
- JSON编组和解组的Jackson JSON Provider依赖项使用了JAX-RS。提供程序通过JAX-RS自动注册
- Spring Boot依赖和
- PojoBuilder为JSON序列化构建支持POJO。
完整的pom.xml文件在这里可用,但主要的兴趣在于Swagger Codegen插件的配置。
的pom.xml
<plugins> <plugin> <groupId>io.swagger</groupId> <artifactId>swagger-codegen-maven-plugin</artifactId> <version>2.2.2</version> <executions> <execution> <id>generate-client-jar</id> <phase>generate-sources</phase> <goals> <goal>generate</goal> </goals> <configuration> <inputSpec>src/main/resources/swagger.yml</inputSpec> <templateDirectory>src/main/resources/swagger-codegen-templates/jaxrs-cxf</templateDirectory> <language>jaxrs-cxf</language> <configOptions> <sourceFolder>src/gen/java</sourceFolder> <apiPackage>${swagger-gen.api.package}</apiPackage> <modelPackage>${swagger-gen.model.package}</modelPackage> <serializableModel>true</serializableModel> <useJaxbAnnotations>false</useJaxbAnnotations> <dateLibrary>java8</dateLibrary> </configOptions> </configuration> </execution> <execution> <id>generate-html</id> <phase>generate-sources</phase> <goals> <goal>generate</goal> </goals> <configuration> <inputSpec>src/main/resources/swagger.yml</inputSpec> <language>html</language> </configuration> </execution> </executions> </plugin> </plugins>
我们的Swagger Codegen插件配置为两个执行任务:
- 生成代码存根,包括服务器端代码,客户端代码和模型POJO,
- 生成HTML文档。
对于代码生成,我们将输入规范提供为文件src / main / resources / swagger.yml。代码生成模板在文件夹src / main / resources / swagger-codegen-templates / jaxrs-cxf中提供。这些模板使用Mustache语法生成以下代码存根:
API:
代码gen插件使用此模板来定义Java接口。生成的Java接口在swagger规范中定义的每个operationId包含一个方法,该规范使用相应的HTTP方法,请求/响应媒体类型,查询参数,头参数,主体参数和表单参数进行注释。 swagger规范的tags:字段构成了以Api为后缀的Java接口名称的一部分
API实现:
如apiImpl.mustache文件中所指定,此模板生成API的存根实现。
模型POJO:
为Swagger规范中指定的每个对象生成POJO
正文参数:
将输入参数添加到生成的API方法中,这些API方法在API规范中定义为:body
我们使用代码生成语言作为jaxrs-cxf,因为CXF提供了一种使用HTTP绑定通过Annotations构建RESTFul服务的标准方法。
HTML生成非常简单,只需将输入规范指定为swagger.yml文件,将HTML指定为输出语言即可。
package-info.java
这为包级别文档和包级别注释提供了一个主页。
package com.example.api.hello.v1.model;
你好,client.yml
保存要与界面一起提供的可配置属性。
hello.endpoint:http:// localhost:8090 / api / v1 / hello
下一步
这篇文章讨论了我们可以用来开发Java和Spring中的微服务的工具的一些基本原理。我们已经审查了服务接口的项目设置和结构。在本系列的下一部分中,我们将讨论Swagger API定义并查看源代码生成过程。
- 60 次浏览
【微服务】复杂系统:微服务与人类
普罗布斯特:我叫凯瑟琳·普罗布斯特。我是谷歌的工程总监。我在这里向你们介绍复杂系统、微服务和人类。让我们从一个可能会有点意外的问题开始。北极熊与微服务有什么关系?乍一看,你可能会说他们之间可能没什么关系。让我们再深入一点。你可能知道,北极熊吃海豹。很容易理解北极熊的数量与海豹的数量有着密切的关系。如果你再往前走几步,事情就会变得复杂得多,速度也会快得多。让我们这样做吧。随着气候的变化,北极熊和海豹的栖息地也在发生变化。栖息地的变化对海豹以及北极熊种群的影响实际上要复杂得多。那么食物链上的其他动物呢,比如企鹅或磷虾。很快,你就会发现你的生态系统很难让我们真正了解。
微服务架构的行为方式
我认为,在某些方面,微服务体系结构的行为是相似的。我们很少有一个服务实际吃另一个服务,但我们确实有那些复杂的关系。让我们深入探讨一下。如果你已经开始了微服务的旅程,你可能已经从一个架构图开始,这个架构图看起来有点像我们左边的那个。您已经考虑了您的业务逻辑。你想要完成的事情。你的系统必须做什么。您已经绘制了一个架构图,它清楚地说明了所有内容的位置、行为方式以及您将要创建的服务之间的关系。
随着时间的推移,事情变得越来越复杂。也许你会组建新的团队。你有一个商业理由需要有新的功能,或者你意识到你的一项服务仍然包含了太多的行为,你想打破它。然后,当然,您要添加数据库,您要添加缓存,等等。很快,您就到了一个很难看到所有关系甚至写下架构中所有服务之间的所有关系的地步。事实上,这就是理论。实际上,当你与拥有非常复杂系统的公司交谈时,他们的系统看起来更像右边的一个,非常复杂的体系结构,其中许多公司拥有数百甚至数千个服务,并且它们都相互交互。也许并不是所有人都能直接互动,但他们之间有着很强的关系。当你看到如右图所示的东西时,实际上很难只写下体系结构和系统中发生的一切。
我想强调的是,从我的角度来看,这并不意味着巨石是正确的答案,微服务本身让生活变得艰难。这不是我的观点。我的观点是,如果你有和这里一样多的功能,需要数百或数千个服务,如果你把所有这些都放在一个整体中,你会有很多其他的问题。这不一定更容易推理。在我看来,有些情况下,巨石是正确的架构。在许多情况下,微服务也是正确的体系结构。微服务和复杂的微服务系统很难推理,这是我觉得我们应该接受的事实。事实上,该行业正在使用和构建许多工具来帮助我们理解这些系统。
当您构建微服务体系结构时,我们中的许多人都遵循某些最佳实践。例如,您在左侧看到的是一个关于此架构如何与团队协调的提示。有些团队可能拥有多个微服务。我们真正想要避免的反模式是,许多团队共同拥有一个服务。将这些职责清晰地分开确实有助于分解功能,使团队能够对其系统的各个部分进行单独的推理。然后,不仅是关于它的原因,而且也演变了他们在这个系统中的部分。
我们的人类系统就像我们的分布式系统一样
我认为有一个方面值得一提,那就是我们实际上已经有了一个由人组成的组织。我们在通常组织成团队的组织中工作。你可以在左边看到一个理论组织结构图。这看起来就像你在自己的公司里看到的一样。我们有这些组织结构图,还有这些团队组织。那么,组织结构图不一定能很好地映射到微服务架构上,也许它不应该。这些团队之间的相互关系实际上比你在组织结构图中看到的更微妙、更复杂。这是因为如果您有微服务,并且这些微服务之间存在依赖关系以及它们之间的交互,那么拥有它们的团队有时需要相互交互。微服务的构建方式使各个团队尽可能地独立和自主。我们还了解到,微服务仍然可以相互影响,因此,在这些团队之间建立这些强大的联系仍然是有益的。
复杂系统的两个层次
我想说的是,我们实际上有两个层次的复杂系统。我们有我们的微服务,然后我们有我们的人类组织,我们的人类系统覆盖,或者你可以称之为微服务系统的基础。没关系。关键是它们实际上是两个系统,它们都是复杂的。他们都以有趣的方式相互交流,我认为我们需要更深入地讨论和研究。
微服务系统
当我们谈论驯服这些系统的复杂性时,我的思维模式是这分为三个粗略的阶段。这不是唯一的分类方法。这有助于我在谈论如何更好地理解系统、如何创建一个系统、如何保持一个健康、良好运行的系统时,了解需要思考的问题。我的心智模型分为这三类。第一个bucket是配置和设置。这就是你想的,我的架构是什么样子的?我所做的基本设计选择是什么?例如,我是否创建服务网格,甚至是否创建微服务?我希望遵循的最佳实践是什么?
然后,创建系统。然后你就有了一个系统,这个系统需要不断地改变。我们已经讨论过添加新服务,但是在现有服务中也发生了许多变化。您需要改进业务逻辑,添加新功能,等等。在这个领域有很多工作正在进行,讨论如何快速、安全地将新代码交付到生产环境中,比如CI/CD、GitOps。我们的最佳实践是测试和缓慢推出更改。
第三个铲斗是第2天的操作。这意味着生产中正在运行的代码。您的客户正在与该代码交互。您希望确保生产中运行的任何东西都能保持运行,并为您的客户保持良好的运行。有一系列的工作正在进行,我会粗略地描述为掉进了那个桶里,比如负载测试。
了解系统可以承受的负载。监控非常基本的事情,比如日志监控、测试、混沌测试等等。同样,这是我的心理模型,边界有些模糊。显然,我们拥有的一些工具,比如Kubernetes,不仅可以帮助您进行配置和设置,还可以帮助您进行更改。负载测试不仅仅是测试已经在生产环境中运行的系统,它还帮助您进行安全的更改。粗略地说,我觉得它很有用,因为它帮助我理解,我需要注意哪些事情?在这些桶中,我使用了哪些工具来帮助我获得基本的理解?
事件/意外(incidents)
当我们谈论系统和保持系统健康时,我们经常谈论事件。这是一个重要的组成部分,但我想强调的是,拥有一个健康的系统不仅是为了防止事故,也是为了确保我们能够以合理的速度发展我们的系统,以便我们能够快速添加功能。比如说,他们不需要几年的时间来添加。我们的系统实际上是可观察的、经过良好测试的、可维护的。事故是健康系统的重要组成部分。因为我们希望我们的客户体验一个非常可靠的系统,他们可以以适合自己业务需求的方式进行交互。
让我们谈一谈事件。几乎从定义上讲,如果你做得对,事故或停机是令人惊讶的。为什么?因为我们中的许多人都会在事后进行尸检,或者在事情发生后进行反思,或者在事件发生后进行事件回顾。这些事件审查的全部目标是确保同一事件不再发生。如果您这样做是正确的,那么几乎按照定义,停机将让您感到惊讶。我想没关系。我认为接受这一点是可以的,并且说,是的,我们在不断改进。我们有时仍然会遇到麻烦,因为我们需要提供一个没有人可以解释的系统。我认为接受这一点是很好的一步。有助于使我们保持一种心态,不断改善系统的健康状况和对系统的理解。
例如,当事件发生时,它们可能发生在系统中彼此相距很远的部分,实际上很难看到这是如何发生的。你可以举一个例子,比如左边的服务,比如说,这是一个推荐系统。比如说,你推出了一种新的算法,可以帮助你更好地推荐,无论你想推荐什么。然后在右上角有一个系统,假设这是你的计费系统。显然,您的计费系统对您的业务非常重要,因为这是客户向您付款的方式。像左边的推荐系统这样的系统可能会对计费系统产生真正的负面影响。你可能会坐在那里想,为什么会这样?这不应该发生。这是正确的。它永远不应该这样。也许一个答案是你有一个隐藏的依赖。通常,在复杂的微服务系统中,您拥有这些依赖关系,您甚至可能没有意识到您拥有这些依赖关系,或者您没有意识到您拥有这些依赖关系的程度。再次回到我的三个bucket,也许服务网格可以真正帮助您了解这些依赖关系的位置以及它们的强度。
关于事件的另一个重要方面是,它们实际上可能在代码发布后的几天或几个月内发生。问题是,它可以在任何时间点命中。不管什么时候发生,感觉都很不方便。我们在右下角以Alice为例。也许她正在为其中一个系统待命,也许她正在为计费系统待命。一切都进行得很顺利,但是这个新的推荐算法在一段时间后对这个隐藏的依赖性产生了负面影响,现在影响到了她的系统。也许爱丽丝刚刚投入了一整天的工作,她真的很累,正要回家,然后警报响起。
人体系统
这真的让我们讨论了人类系统实际上如何影响我们的微服务系统的健康。当你们谈论人类系统时,我的心智模型实际上和我关于微服务系统的心智模型并没有什么不同。在这一点上,我仍然相信我们有这三个粗糙的桶,帮助我通过我需要思考和需要注意的事情进行推理。在第一个bucket中,我们有配置和设置。这是组织花费大量时间思考工作阶梯和组织文化的地方。如何激励人们。如何设定特定角色的期望。此外,这也是多样性、公平性和包容性发挥巨大作用的地方。真正创建一个高效运作的组织是本书的重点。
第二个因素是承认组织在不断变化。从积极的方面来说,我们有人得到提升,然后他们可能会有更多的发展空间。太好了。看到人们在事业上取得进步真是太好了。这是对我们所拥有的组织体系的改变。这可能意味着这个人现在承担了额外的责任,因此他们不再像以前那样关注系统的某个部分。也许这会留下一个缺口。同样,我们也有新人加入。显然,我们需要训练他们。我们有人离开球队,有时令人遗憾,有时却没有。无论哪种方式,这些都是系统的重大变化。然后,当然,当您移动整个组织时,组织会发生变化,并且需要真正确保新的组织运作良好,团队之间相互作用良好。这是本质上由组织本身推动的变化。
还有一类我称之为第二天操作的东西,只是为了与我们之前的操作相比较。这就是我所认为的外部力量和更广泛的文化变化。外部力量是我们所有组织都经历过的一件大事。一个非常明显的例子是新冠病毒,它不可能以一种全面的方式进行规划。作为一个组织,我们需要处理并充分利用它。我们需要做大量的工作来确保我们的组织仍然健康,尽管由于这些外部因素(如新冠病毒)给我们的组织和员工带来了各种压力。那么积极的文化变革就是我们所做的变革,再一次,也许是为了确保在那里工作的每一个人都感觉到自己的参与,并且能够表现出来,把他们最好的作品带到工作中去。
事件的真实性
如果你想一想这三个桶,你会花一点时间回想一下我们刚刚谈到的事件,爱丽丝在那里待命。她在呼叫计费系统,但它失败了。这三个桶与事件的结局有什么关系?我想说的是,事实上他们与此有很大关系。爱丽丝现在正经历着情绪的过山车。她可能很沮丧。她很害怕。她的晚餐计划被破坏了,她很沮丧。这里起作用的是整个文化,组织的基础文化。例如,她是否从同龄人那里得到了适当的培训?这很清楚。那么,还有,假设她发现她需要联系某人,她觉得这样做舒服吗?她是否拥有了解联系对象所需的正确工具?
通常,事故需要来自世界各地的专家。回到我们这里的事件示例。爱丽丝在这里的右边。她负责计费系统。左边是伊桑,他负责推荐系统。我敢肯定,由于推荐系统的改变,会有更多的人,比如对这种依赖性负责的人,出现问题。现在,让我们考虑一下相互关系。爱丽丝认识伊森吗?她和他接触感到舒服吗?他们一起工作吗?他们是否有共同努力解决这一问题的正确动机?或者,他们是否有动力将问题抛到一边,让其他人来处理,例如,因为他们担心这可能对他们的职业生涯意味着什么。所有这些文化因素在这一事件的发展过程中起着巨大的作用。我想强调的是,这不仅仅是事件。您可以对组织的健康状况提出同样的论点,影响您交付功能的速度、代码的可维护性等等。从我的角度来看,我们必须尽我们所能建立健康的组织,这不仅对组织中的人来说是健康的,这是非常关键的,而且他们实际上也会对底线产生影响。
这里的主要收获是,我相信两个复杂系统之间存在着复杂的相互作用。我们经常说,发生的任何事情都不是一个单一的根本原因,而是许多促成因素。同样,这可能是一个意外事件。它可能是一个延迟的功能启动或类似的事情。也许没有一个根本原因,但有几个因素,如一个人可能有冒名顶替综合征。也许有一个人不会承认他们不知道什么。也许我们没有适当的警报和指标。所有这些东西都相互作用,产生我们可能喜欢也可能不喜欢的结果。
一些现有技术
当我们谈论人类系统时,我会假设,事实上,有很多现有技术。从我的角度来看,我们需要将大量的现有技术带到我们的组织中,并利用它尽我们所能建立健康的组织。我在这里给你们举了一些例子,但这张幻灯片的真正目的是让你们思考哪些方面可以帮助我更好地了解公司?显然,在组织心理学方面有很多研究。还有其他一些领域也涉及到具体方面。例如,人为因素研究人为错误与环境之间的相互作用。你可能会想,我在做什么,让人们更容易慢慢地进行更改?我有什么系统?同样,这可能是我们前面提到的系统之一,比如Kubernetes或服务网格。有一些CI/CD工具在帮助自动化这些步骤方面非常有用,而不是强迫人们在许多步骤中手动操作,而他们可能不会这样做。
然后,这实际上与我在行为经济学中感兴趣的研究有关,比如说,与激励有关。我们是否在我们的环境和组织中建立了正确的激励机制?我们是否确保激励人们寻求帮助,激励他们与其他团队合作?或者,我们真的在为这样做制造障碍,或者不幸的是,将它们推开?这是我在这里举的另一个例子。让他们不要问别人。也许他们看到过这样的例子,他们的绩效评估受到了伤害,因为他们问了某人一个问题,而那个人反应不好。我们需要确保我们的组织是以一种能让我们在这里取得成功的方式建立起来的。
最后一点是关于动机。这真的是深思熟虑,人们真的能够带来他们最好的作品吗?他们是否有这样做的动机?他们学习新事物的动机是掌握吗?他们有权利自主吗?他们是否了解他们的工作如何与更广泛的情况相适应,以及为什么这很重要?同样重要的是要指出,不同的人受到不同事物的驱动,或者这些事物的不同组合。我认为,真正了解我们的组织,而不仅仅是推动一件事情,也是非常有帮助的。这些只是我认为我们可以学习的领域的例子。实际上,我认为这是一个重要的步骤,因为有这么多的工作和这么多的现有技术可以帮助我们真正理解如何使我们的人类系统更好,以及我们的微服务系统更好。
现在怎么办?微服务系统
我们怎么处理这些?我想我想让你们了解的一件主要事情是,从我的角度来看,微服务系统,是的,它们可以是超级复杂的。如果你有成百上千的微服务,它们可能很难解释。然而,正确的选择不是说“它们太复杂了,我不会走那条路。”从我的角度来看,在很多情况下,它们仍然是正确的选择。然后,正确的方法是接受,是的,它们很复杂。现在,我们该怎么办?这就是我要说的,这个行业实际上已经花费了大量的时间和精力来创建各种工具和方法来帮助我们理解和改进我们的系统。我在这里列出了一些。还有很多。我想说的一件事是,弄清楚你在用这些工具做什么实际上非常重要。我建议不要因为其他人都在采用这些工具而采用其中一种,你会说,“我会采用它,然后我会找出它是如何有用的,或者为什么我需要它。”相反,要非常清楚你在努力实现什么。也许我介绍的配置更改和第2天操作的心智模型有助于了解您需要了解的系统类型。为了使您的系统更加自动化、改进和稳定,您需要准备什么样的东西。我认为,明确目标是至关重要的。
现在怎么办?人类系统
当谈到人类系统时,我觉得我们经常谈论游戏日、教育论坛、设计审查和随叫随到的培训。我认为这些都是非常棒和非常重要的。我认为他们做得还不够。我认为我们需要更深入一层。这就是我在谈论文化和包容以及我们建立的合作激励机制时所要表达的意思,等等。因为我认为,如果你的组织运作不好,激励机制也不好,那么世界上所有的比赛日都不会让你处于一个好的位置。世界上所有的随叫随到培训都不会让你处于这样一种境地,即随叫随到的人都会感到舒适,如果这正是你的组织所鼓励的。我的观点是,我们真的需要更深入地思考我们建立的各种工作阶梯,我们建立的组织。我们的人民如何在其中发挥作用。我们如何持续改善组织健康。就我所处的位置而言,组织健康本身就非常关键。让人们觉得他们可以参加工作真的很重要。他们有一条职业道路。他们对此感到高兴。即使你不是出于这种动机,我认为有一个非常清楚的理由可以证明,组织健康对企业健康有着真正的影响。
问答
布莱恩特:在一个团队关系由门票和官僚制度驱动的组织中,你能建议一些快速的胜利来让这些关系更顺利地运行吗?
问题:显然,我认为这取决于组织。我曾见过一些组织,并与那些在组织中工作的人交谈过,在这些组织中,一切都是通过票证来完成的,一切都是通过票证解决的速度来衡量的。这就是激励人们的方式。从某种意义上说,我不知道有什么捷径可以解决整个问题。当我看到一些组织,他们希望做出重大转变,那么可能需要一段时间。将组织推进到一个不同的方向需要很多推动。话虽如此,我认为根据我的经验,当情况恶化到人们只是就门票和事件进行交流,然后把他们放在一个房间里或虚拟房间里,只是相互了解,这对我来说真的很有帮助。也有人发帖说,微笑可能会有所帮助。这也是一个很好的观点。
布莱恩特:接下来,你谈到让团队的开发者拥有微服务?这不会产生额外的筒仓吗?如果是这样,您如何管理或避免这种情况?
问题:我不确定它将如何创建额外的筒仓。根据我的经验,有一件事是有点反模式的,那就是如果你有一组人编写代码,另一组人可能对代码一无所知,但在凌晨3点出错时必须接听电话。这本身在理论上可能不是一个筒仓,但在实践中,这在这两支球队之间造成了差距。基本上,在一个团队中,团队不仅编写代码并推出更改,可能与另一个团队一起,而且在系统出现问题时,至少部分地处于钩子上,我认为这创造了一种感觉,我驱动它。我拥有它。我已经准备好了,这是我的。我认为这确实很有帮助。
布莱恩特:我见过Netflix的人谈论事物的全生命周期所有权,这非常有趣。
问题:当然也可以为单独的团队留出空间,比如SRE团队或类似的团队,这也是整个流程的一部分。我认为,尽可能让这些团队共同拥有它是非常有帮助的。
布莱恩特:我正在设计微服务,但我有大约10个服务,并且已经看到了很多集成问题?您如何管理这些服务中的混乱?
问题:系好安全带。我认为这是完全正确的。事情很快变得复杂起来。我认为这就是为什么在可观察性上有如此多的投资,在这个工具上,所以我们可以让我们的头脑绕过它。我认为,显然,我们需要大量的工具和仪器来尽可能多地了解系统。这也涉及到分布式跟踪和理解系统如何相互影响,等等。我想我的建议是,不要回避,但要投资。投资于尽可能地了解系统的行为。
布莱恩特:现在回到更多的人这边。你能举例说明你过去参与过的组织中的激励措施吗?
问题:我认为当你谈论激励时,人们通常首先开始谈论钱。当然,这是一个激励因素。老实说吧。我觉得有点深。我认为,从我的角度来看,当激励措施以一种创造正确行为的方式建立起来,并且实际上让人们快乐并发展他们的事业时,激励措施最有效。让我们回到这个例子,如果出现问题,开发人员可能还需要在凌晨3点拿起电话。也许在某些组织中,他们不会因此得到任何奖励。这意味着你没有以奖励他人的方式建立激励机制。即使是在绩效考核中,或是在同侪的强化下,或是在领导层的强制执行下,你实际上是在奖励,那么奖励就不同了。它是以不同的方式设置的。这就是我说的动机。例如,如果您需要一个团队协作良好的组织,您如何激励它?你可能不仅通过创建会议,而且还通过奖励那些真正推动合作的人来激励这种合作。
布莱恩特:你能推荐一些关于面对人类挑战的书吗?我知道你放了一些像丹·平克的经典书,就在那里。还有别的书吗?
问题:我有很多我喜欢的。我现在正在重读《轻推》。
布莱恩特:马尔科姆·格拉德威尔?
问题:不,是这个。这并不完全是关于商业的,但它确实讨论了如何创造小的激励和小的推动来慢慢改变行为。我真的很喜欢这样,因为我认为当你有一个大的组织,或者你正试图完成的一个大的改变,通常最好的行动方式就是慢慢地朝一个方向前进。这与商业无关,但一个具体的例子是,如果你尽量不吃太多糖果,而把糖果留在厨房而不是桌子上,你就会少吃糖果。这是关于轻推的建议。您可以将其应用于许多不同的情况。
布莱恩特:我读过这本书。这是一本很棒的书。
再次进入技术领域。如何最好地评估微服务系统。假设你是一名技术领导者。你已经进入了一个组织。您已经对愿景有所了解,并且希望了解技术方面和人员方面的情况。有什么建议吗?
问题:我想如果你对这个系统完全陌生,我首先要考虑的是,你的团队是否了解他们所有的上游和下游依赖关系?这并不总是被理解的。您的团队是否了解其系统的限制?这也不总是很好理解。如果您不能与所有这些下游服务通信,您的系统会发生什么情况?您是否设置了指标、仪表盘和其他设置?那是另一个。然后,我要看的另一件事是速度。您能够以多快的速度进行更改,并在生产中安全地实现这些更改?有时候,你的系统中生长的藤壶越多,事情就越慢。我认为这是另一个非常重要的方面。
布莱恩特:你如何衡量组织的健康状况?
问题:我们谈论微服务系统是复杂的。我认为人类是无限迷人的,人类的组织也许更是如此。当涉及到度量或评估组织的健康状况时,有很多事情。一些更明显的事情是,你的记忆力是什么?人们总是在沮丧中离开吗?这是出问题的明显迹象。我认为,当你也在观察你的组织的生产力时,有很多代理指标,人们会发现它们有很多缺点。我明白为什么。比如代理指标,比如提交了多少代码,或者我们能以多快的速度完成代码审查之类的事情?这些都是代理指标,但它们可以告诉你一些事情,也可以告诉你趋势。这是一件事。另外一件事,老实说,我发现你只需要和人们谈谈,因为每个人都有不同的观点。世界上所有的代理指标都无法让你更深入地了解人们在为什么而挣扎,人们在为什么而高兴。
原文:https://www.infoq.com/presentations/microservices-best-practices/
- 62 次浏览
【微服务】微服务安全 - 如何保护您的微服务基础架构?

在当今行业使用各种软件架构和应用程序的市场中,几乎不可能感觉到您的数据是完全安全的。 因此,在使用微服务架构构建应用程序时,安全问题变得更加重要,因为各个服务相互之间以及客户端之间进行通信。 因此,在这篇关于微服务安全的文章中,我将按以下顺序讨论您可以实施的各种方法来保护您的微服务。
- 什么是微服务?
- 微服务面临的问题
- 保护微服务的最佳实践
什么是微服务?
微服务,又名微服务架构,是一种架构风格,将应用程序构建为围绕业务领域建模的小型自治服务的集合。 因此,您可以将微服务理解为围绕单个业务逻辑相互通信的小型单个服务。

现在,通常当公司从单体架构转向微服务时,他们会看到许多好处,例如可扩展性、灵活性和较短的开发周期。但是,与此同时,这种架构也引入了一些复杂的问题。
那么,接下来在这篇关于微服务安全的文章中,让我们了解一下微服务架构面临的问题。
微服务面临的问题
微服务面临的问题如下:
问题1:
考虑一个场景,用户需要登录才能访问资源。现在,在微服务架构中,用户登录详细信息必须以这样一种方式保存,即用户每次尝试访问资源时都不会被要求进行验证。现在,这产生了一个问题,因为用户详细信息可能不安全,也可能被第 3 方访问。
问题2:
当客户端发送请求时,需要验证客户端详细信息,并且需要检查授予客户端的权限。因此,当您使用微服务时,可能会发生对于每项服务,您都必须对客户端进行身份验证和授权。现在,要做到这一点,开发人员可能会为每项服务使用相同的代码。但是,您不认为依赖特定代码会降低微服务的灵活性吗?好吧,它确实如此。因此,这是该架构中经常面临的主要问题之一。
问题3:
下一个非常突出的问题是每个单独的微服务的安全性。在这种架构中,除了第三方应用程序之外,所有微服务同时相互通信。因此,当客户端从 3 rd 方应用程序登录时,您必须确保客户端无法访问微服务的数据,这样他/她可能会利用它们。
好吧,上述问题并不是微服务架构中发现的唯一问题。我想说的是,根据您拥有的应用程序和架构,您可能会面临许多其他与安全相关的问题。关于这一点,让我们继续阅读这篇关于微服务安全的文章,并了解减少挑战的最佳方法。
微服务安全最佳实践
提高微服务安全性的最佳实践如下:
纵深防御机制
众所周知,微服务会采用任何细粒度的机制,因此您可以应用深度防御机制来使服务更加安全。通俗地说,深度防御机制基本上是一种技术,您可以通过它应用多层安全对策来保护敏感服务。因此,作为开发人员,您只需识别具有最敏感信息的服务,然后应用多个安全层来保护它们。这样,就可以确保任何潜在的攻击者都无法一次性破解安全,而必须向前尝试破解所有层级的防御机制。
此外,由于在微服务架构中,您可以在不同的服务上实施不同的安全层,因此成功利用特定服务的攻击者可能无法破解其他服务的防御机制。
令牌和 API 网关
通常,当您打开应用程序时,您会看到一个对话框,上面写着“接受许可协议和 cookie 许可”。这条消息意味着什么?好吧,一旦您接受它,您的用户凭据将被存储并创建一个会话。现在,下次您进入同一页面时,该页面将从缓存内存而不是服务器本身加载。在这个概念出现之前,会话集中存储在服务器端。但是,这是应用程序水平扩展的最大障碍之一。
令牌
所以,这个问题的解决方案是使用令牌,来记录用户凭据。这些令牌用于轻松识别用户并以 cookie 的形式存储。现在,每次客户端请求网页时,请求都会被转发到服务器,然后服务器会判断用户是否可以访问所请求的资源。
现在,主要问题是存储用户信息的令牌。因此,需要对令牌的数据进行加密,以避免对第三方资源的任何利用。 Jason Web 格式或最常见的 JWT 是一种定义令牌格式的开放标准,提供各种语言的库,并加密这些令牌。
API 网关
API 网关作为一个额外的元素通过令牌身份验证来保护服务。 API 网关充当所有客户端请求的入口点,并有效地向客户端隐藏微服务。因此,客户端无法直接访问微服务,因此,任何客户端都无法利用任何服务。
分布式跟踪和会话管理
分布式跟踪
在使用微服务时,您必须持续监控所有这些服务。但是,当您必须同时监控大量服务时,就会出现问题。为避免此类挑战,您可以使用一种称为分布式跟踪的方法。分布式跟踪是一种查明故障并确定故障原因的方法。不仅如此,您还可以确定发生故障的位置。因此,很容易追踪到哪个微服务面临安全问题。
会话管理
会话管理是保护微服务时必须考虑的重要参数。现在,只要用户进入应用程序,就会创建一个会话。因此,您可以通过以下方式处理会话数据:
- 您可以将单个用户的会话数据存储在特定服务器中。但是,这种系统完全依赖于服务之间的负载均衡,只满足水平扩展。
- 完整的会话数据可以存储在单个实例中。然后可以通过网络同步数据。唯一的问题是,在这种方法中,网络资源会耗尽。
- 您可以确保可以从共享会话存储中获取用户数据,从而确保所有服务都可以读取相同的会话数据。但是,由于数据是从共享存储中检索的,因此您需要确保您有一些安全机制,以便以安全的方式访问数据。
第一次会话和相互 SSL
第一次会议的想法很简单。用户只需登录应用程序一次,即可访问应用程序中的所有服务。但是,每个用户最初都必须与身份验证服务进行通信。好吧,这肯定会导致所有服务之间的大量流量,并且对于开发人员来说,在这种情况下找出故障可能很麻烦。
使用 Mutual SSL 后,应用程序通常会面临来自用户、第 3 方以及相互通信的微服务的流量。但是,由于这些服务是由第 3 方访问的,因此总是存在受到攻击的风险。现在,此类场景的解决方案是微服务之间的相互 SSL 或相互身份验证。这样,服务之间传输的数据将被加密。这种方法唯一的问题是,当微服务数量增加时,由于每个服务都会有自己的 TLS 证书,开发人员更新证书将非常困难。
3rdparty 应用程序访问
我们所有人都访问属于 3 rd 方应用程序的应用程序。 3 rd 方应用程序使用用户在应用程序中生成的 API 令牌来访问所需的资源。因此,第 3 方应用程序可以访问该特定用户的数据,而不是其他用户的凭据。好吧,这是针对单个用户的。但是,如果应用程序需要访问来自多个用户的数据怎么办?您认为如何满足这样的要求?
OAuth 的使用
解决方案是使用 OAuth。当您使用 OAuth 时,应用程序会提示用户授权 3 rd 方应用程序,使用所需的信息,并为其生成令牌。一般使用授权码来请求令牌,以确保用户的回调 URL 不被盗用。
因此,在提及访问令牌时,客户端与授权服务器进行通信,该服务器授权客户端以防止其他人伪造客户端的身份。因此,当您将微服务与 OAuth 结合使用时,服务充当 OAuth 架构中的客户端,以简化安全问题。
好吧,伙计们,我不会说这些是确保服务安全的唯一方法。您可以根据应用程序的架构以多种方式保护微服务。因此,如果您是一个渴望构建基于微服务的应用程序的人,那么请记住,服务的安全性是您需要谨慎的一个重要因素。关于这一点,我们结束了这篇关于微服务安全的文章。我希望你发现这篇文章内容丰富。
如果您想查看更多有关人工智能、DevOps、Ethical Hacking 等市场最流行技术的文章,您可以参考 Edureka 的官方网站。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. What is Microservices?
- 2. Microservices Architecture
- 3. Microservices vs SOA
- 4. Microservices Tutorial
- 5. Building Microservices Application Using Spring Boot
- 6. Microservices Security
原文:https://medium.com/edureka/microservices-security-b01b8f2a9215
- 66 次浏览
【微服务】微服务间通信的最佳实践
一个好的 API 架构对于有效处理微服务之间的通信很重要。不要害怕创建新的微服务,并尽可能地尝试解耦功能。例如,与其创建一个通知服务,不如尝试为电子邮件通知、SMS 通知和移动推送通知创建单独的微服务。
在这里,我假设您有一个 API 网关来管理请求、处理到负载平衡服务器的路由并限制未经授权的访问。
通讯类型
- 同步协议:HTTP 是一种同步协议。客户端发送请求并等待服务的响应。这与客户端代码执行无关,它可以是同步的(线程被阻塞)或异步的(线程未被阻塞,并且响应最终会到达回调)。这里的重点是协议(HTTP/HTTPS)是同步的,客户端代码只有在收到 HTTP 服务器响应后才能继续其任务。
- 异步协议:其他协议如 AMQP(许多操作系统和云环境支持的协议)使用异步消息。客户端代码或消息发送者通常不等待响应。它只是将消息发送到消息代理服务,例如 RabbitMQ 或 Kafka(如果我们使用的是事件驱动架构)。
为什么你应该避免同步协议
- 如果您不断添加相互通信的新微服务,那么在代码中使用端点会造成混乱,尤其是当您必须在端点中传递额外信息时。例如,身份验证令牌。
- 您必须等待耗时的调用才能获得响应。
- 如果响应失败并且您有重试策略,那么它可能会造成瓶颈。
- 如果接收器服务关闭或无法处理请求,那么我们要等到服务启动。例如,在电子商务网站中,用户下订单并请求发送到发货服务以发货,但发货服务关闭,我们丢失了订单。一旦完成,如何将相同的订单发送到运输服务?
- 接收方可能无法一次处理大量请求,因此应该有一个地方让请求必须等待,直到接收方准备好处理下一个请求。
为了应对这些挑战,我们可以使用一个中间服务来处理两个微服务之间的通信,也称为“消息代理”。
RabbitMQ 被广泛用作消息代理服务,如果您将 Azure 云作为托管服务提供商,您也可以使用 Azure 服务总线。
如何使用RabbitMQ来处理微服务之间的通信
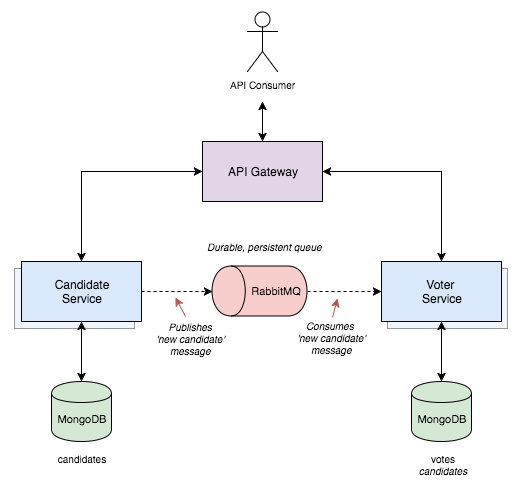
可能存在发件人想要向多个服务发送消息的情况。 让我们看看 RabbitMQ 如何处理的下图。
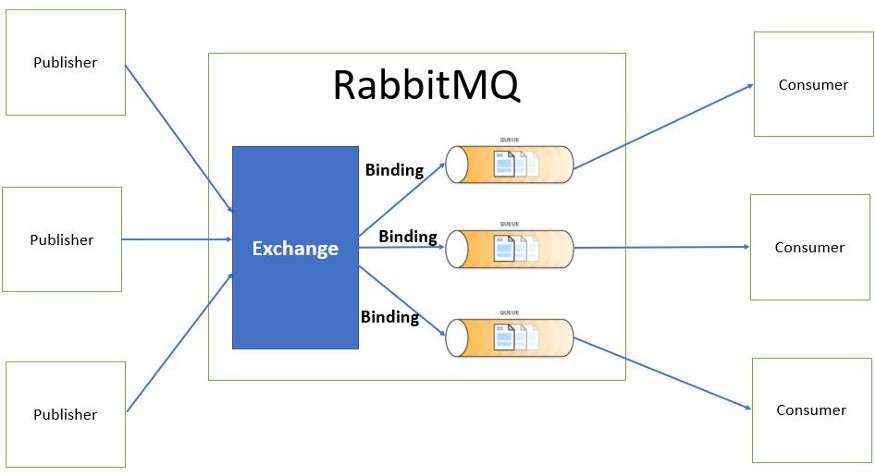
当发布者发送消息时,它被 Exchange 接收,然后 Exchange 将其发送到目标队列。消息保持在队列中,直到接收方接收并处理它。
交换类型
- 直接交换根据消息路由键将消息传递到队列。这是默认的交换类型。
- 扇出交换将消息传递到所有队列。
- Header Exchange 根据消息头标识目标队列。
- 主题交换类似于直接交换,但路由是根据路由模式完成的。它不使用固定的路由键,而是使用通配符。
例如,假设我们有以下路由模式。
- order.logs.customer
- order.logs.international
- order.logs.customer.electronics
- order.logs.international.electronics
“order.*.*.electronics” 的路由模式只匹配第一个词是“order”,第四个词是“electronics”的路由键。
“order.logs.customer.#”的路由模式匹配任何以“order.logs.customer”开头的路由键。
实现RabbitMQ
安装
按照此链接在 Windows 上安装 RabbitMQ。安装后 RabbitMQ 服务将在 http://localhost:15672/ 上启动并运行。在用户名和密码中输入“guest”登录,您将能够看到所有静态信息。

创建发件人服务
RabbitMQ 启动并运行后,创建两个控制台应用程序
Sender:向RabbitMQ发送消息
Receiver:从RabbitMQ接收消息
向两个应用程序添加包“RabbitMQ.Client”。
using System;
using RabbitMQ.Client;
using System.Text;
class Send
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.QueueDeclare(queue: "hello", durable: false, exclusive: false,
autoDelete: false, arguments: null);
string message = "Hello World!";
var body = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchange: "", routingKey: "hello",
basicProperties: null, body: body);
Console.WriteLine(" [x] Sent {0}", message);
}
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
}
}上面的代码将创建一个到 RabbitMQ 的连接,创建一个队列“hello”并向队列发布一条消息。
using RabbitMQ.Client;
using RabbitMQ.Client.Events;
using System;
using System.Text;
class Receive
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.QueueDeclare(queue: "hello", durable: false,
exclusive: false, autoDelete: false, arguments: null);
Console.WriteLine(" [*] Waiting for messages.");
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body.ToArray();
var message = Encoding.UTF8.GetString(body);
Console.WriteLine(" [x] Received {0}", message);
};
channel.BasicConsume(queue: "hello", autoAck: true, consumer: consumer);
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
}
}
}上面的代码将创建一个到 RabbitMQ 的连接,创建一个队列(如果它还没有创建),并注册一个将接收和处理消息的处理程序。
在运行发送方和接收方应用程序时,您将能够看到在 RabbitMQ 门户上创建的队列,以及表示收到新消息的图形上的尖峰。从门户中,您将能够看到哪个服务有待处理的消息,您可以添加该服务的另一个实例以进行负载平衡。
一开始你可以使用rabbitMQ,事情会很顺利。但是当复杂性增加并且您有很多端点调用其他服务时,它就会造成混乱。很快,您会发现自己围绕驱动程序创建了一个包装器,这样您就可以减少需要编写的代码量。例如,每次您调用另一个服务的端点时,您都必须提供身份验证令牌。然后你会发现自己需要处理 ack 与 nack,你将为此创建一个简单的 API。最终,您将需要处理有害消息——格式错误并导致异常的消息。
要处理所有这些工作流,您可以使用 NserviceBus。让我们讨论一个项目结构:
考虑到这种架构,ClientUI 端点将 PlaceOrder 命令发送到 Sales 端点。 因此,Sales 端点将使用发布/订阅模式发布 OrderPlaced 事件,该事件将由 Billing 端点接收。
NserviceBus 配置:
class Program
{
static async Task Main(string[] args)
{
await CreateHostBuilder(args).RunConsoleAsync();
}
public static IHostBuilder CreateHostBuilder(string[] args)
{
return Host.CreateDefaultBuilder(args)
.UseNServiceBus(context =>
{
var endpointConfiguration = new EndpointConfiguration("Sales");
//configure transport - configure where your message will
//be published/saved
//you can configure it for RabbitMq, Azure Queue, Amazon
//SQS or any other cloud provider
endpointConfiguration.UseTransport<LearningTransport>();
endpointConfiguration.SendFailedMessagesTo("error");
//When a message fails processing
//it will be forwarded here.
endpointConfiguration.AuditProcessedMessagesTo("audit");
//All messages received by an endpoint
//will be forwarded to the audit queue.
return endpointConfiguration;
});
}
}然后使用 IMessageSession 对象发送消息:
public class HomeController : Controller
{
static int messagesSent;
private readonly ILogger<HomeController> _log;
private readonly IMessageSession _messageSession;
public HomeController(IMessageSession messageSession, ILogger<HomeController> logger)
{
_messageSession = messageSession;
_log = logger;
}
[HttpPost]
public async Task<ActionResult> PlaceOrder()
{
string orderId = Guid.NewGuid().ToString().Substring(0, 8);
var command = new PlaceOrder { OrderId = orderId };
// Send the command
await _messageSession.Send(command)
.ConfigureAwait(false);
_log.LogInformation($"Sending PlaceOrder, OrderId = {orderId}");
dynamic model = new ExpandoObject();
model.OrderId = orderId;
model.MessagesSent = Interlocked.Increment(ref messagesSent);
return View(model);
}
}最后,添加一个处理程序来接收和处理消息:
public class PlaceOrderHandler :
IHandleMessages<PlaceOrder>
{
static readonly ILog log = LogManager.GetLogger<PlaceOrderHandler>();
static readonly Random random = new Random();
public Task Handle(PlaceOrder message, IMessageHandlerContext context)
{
log.Info($"Received PlaceOrder, OrderId = {message.OrderId}");
return Task.CompletedTask;
}
}这是 NserviceBus 和 RabbitMQ 的基本实现。
概括
在服务之间通信时避免使用同步协议。 使用 RabbitMQ 在服务之间进行通信并在消息从源传送到目标之前临时保存它们。 使用 NserviceBus 解耦应用程序代码和消息代理,并管理长时间运行的请求。
原文:https://irfanyusanif.medium.com/how-to-communicate-between-microservice…
- 74 次浏览
【微服务】构建应用程序的顶级微服务设计模式

在当今市场上,微服务已成为构建应用程序的首选解决方案。 众所周知,它们可以解决各种挑战,但是,熟练的专业人员在使用此架构时经常面临挑战。 因此,相反,开发人员可以探索这些问题中的常见模式,并可以创建可重用的解决方案来提高应用程序的性能。 因此,在这篇关于微服务设计模式的文章中,我将讨论构建成功的微服务所必需的顶级模式。
本文将介绍以下主题:

- 什么是微服务?
- 用于设计微服务架构的原则
- 微服务的设计模式
什么是微服务?
微服务,又名微服务架构,是一种架构风格,将应用程序构建为围绕业务领域建模的小型自治服务的集合。在微服务架构中,每个服务都是自包含的并实现单一的业务能力。如果想详细了解微服务,可以参考我的微服务架构一文。
用于设计微服务架构的原则
用于设计微服务的原则如下:
- 独立自主的服务
- 可扩展性
- 权力下放(去中心化)
- 弹性服务
- 实时负载均衡
- 可用性
- 通过 DevOps 集成实现持续交付
- 无缝 API 集成和持续监控
- 故障隔离
- 自动配置
微服务的设计模式
- 聚合器
- API 网关
- 连锁或责任链
- 异步消息
- 数据库或共享数据
- 事件溯源
- 分支
- 命令查询职责分离器
- 断路器
- 分解
聚合器模式
计算世界中的聚合器是指收集相关数据项并显示它们的网站或程序。因此,即使在微服务模式中,聚合器也是一个基本的网页,它调用各种服务来获取所需的信息或实现所需的功能。
此外,由于输出源在将单体架构分解为微服务时被划分,因此当您需要通过组合来自多个服务的数据来输出时,这种模式被证明是有益的。因此,如果我们有两个服务,每个服务都有自己的数据库,那么具有唯一事务 ID 的聚合器将从每个单独的微服务收集数据,应用业务逻辑并最终将其发布为 REST 端点。稍后,收集到的数据可以由需要收集到的数据的各个服务使用。
聚合设计模式基于 DRY 原则。基于此原则,您可以将逻辑抽象为复合微服务,并将特定业务逻辑聚合到一个服务中。
因此,例如,如果您考虑两个服务:服务 A 和 B,那么您可以通过将数据提供给复合微服务来同时单独扩展这些服务。
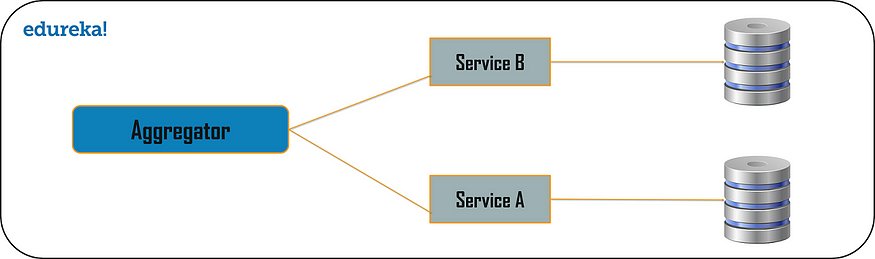
API 网关设计模式
微服务的构建方式使得每个服务都有自己的功能。但是,当应用程序被分解为小型自治服务时,开发人员可能面临的问题可能很少。问题可能如下:
- 如何从多个微服务请求信息?
- 不同的 UI 需要不同的数据来响应同一个后端数据库服务
- 如何根据消费者需求从可重用的微服务中转换数据
- 如何处理多个协议请求?
好吧,这些问题的解决方案可能是 API 网关设计模式。 API 网关设计模式不仅解决了上述问题,还解决了许多其他问题。这种微服务设计模式也可以被认为是代理服务,将请求路由到相关的微服务。作为聚合器服务的一种变体,它可以将请求发送到多个服务,并类似地将结果聚合回组合或消费者服务。 API Gateway 还充当所有微服务的入口点,并为不同类型的客户端创建细粒度的 API。
借助 API Gateway 设计模式,API 网关可以将协议请求从一种类型转换为另一种类型。同样,它也可以卸载微服务的身份验证/授权责任。
因此,一旦客户端发送请求,这些请求就会传递到 API 网关,该网关充当入口点,将客户端的请求转发到适当的微服务。然后,在负载均衡器的帮助下,处理请求的负载并将请求发送到相应的服务。微服务使用服务发现作为指导来找到它们之间的通信路径。然后微服务通过无状态服务器相互通信,即通过 HTTP 请求/消息总线。
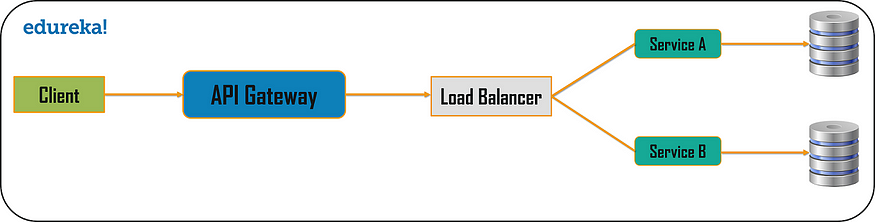
链式或责任链模式
链式或责任链设计模式产生单个输出,该输出是多个链式输出的组合。因此,如果您将三个服务排成一条链,那么,来自客户端的请求首先由服务 A 接收。然后,该服务与下一个服务 B 通信并收集数据。最后,第二个服务与第三个服务通信以生成合并的输出。所有这些服务都使用同步 HTTP 请求或响应进行消息传递。此外,在请求通过所有服务并生成相应的响应之前,客户端不会得到任何输出。所以,总是建议不要做长链,因为客户端会等到链完成
您需要了解的另一个重要方面是,从服务 A 到服务 B 的请求可能看起来与服务 B 到服务 C 不同。同样,从服务 C 到服务 B 的响应可能看起来与服务 B 到服务 A 完全不同。
异步消息设计模式
从上面的模式中,很明显客户端在同步消息中被阻塞或等待很长时间。 但是,如果您不希望消费者等待很长时间,那么您可以选择异步消息传递。 在这种类型的微服务设计模式中,所有服务都可以相互通信,但它们不必按顺序相互通信。 因此,如果考虑 3 个服务:服务 A、服务 B 和服务 C。来自客户端的请求可以直接同时发送到服务 C 和服务 B。 这些请求将排在队列中。 除此之外,请求还可以发送到服务 A,其响应不必发送到请求所经过的同一服务。
数据库或共享数据模式
对于每个应用程序,都存在大量数据。因此,当我们将应用程序从其单体架构分解为微服务时,非常重要的是要注意每个微服务都有足够的数据量来处理请求。因此,系统可以为每个服务拥有一个数据库,也可以为每个服务拥有一个共享数据库。您可以使用每个服务的数据库和每个服务的共享数据库来解决各种问题。问题可能如下:
- 数据重复和不一致
- 不同的服务有不同的存储需求
- 很少有业务可以查询数据,有多种服务
- 数据去规范化
好吧,为了解决前三个问题,我认为您可以使用每个服务的数据库,因为它将由微服务 API 本身访问。因此,每个微服务都有自己的数据库 ID,这会阻止系统中的其他服务使用该特定数据库。除此之外,为了解决反规范化问题,您可以为每个服务选择共享数据库,为每个微服务对齐多个数据库。这将帮助您为分解为微服务的单体应用程序收集数据。但是,您必须记住,您必须将这些数据库限制为 2-3 个微服务;否则,扩展这些服务将是一个问题。
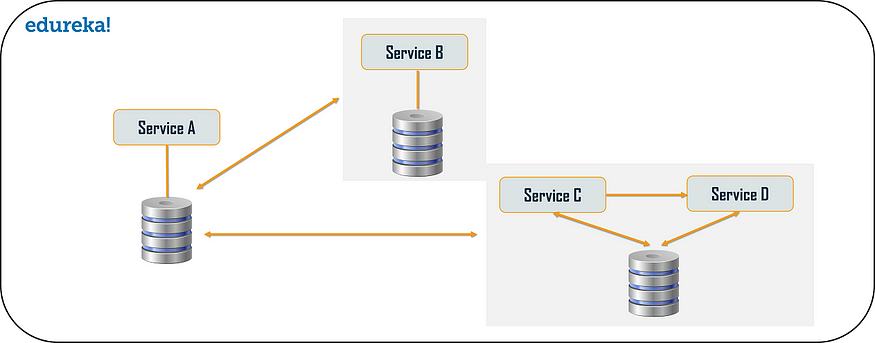
事件溯源设计模式
事件源设计模式创建有关应用程序状态更改的事件。 此外,这些事件被存储为一系列事件,以帮助开发人员跟踪何时进行了哪些更改。 因此,借助此功能,您可以随时调整应用程序状态以应对过去的变化。 您还可以查询这些事件以了解任何数据更改,并同时从事件存储中发布这些事件。 发布事件后,您可以在表示层上看到应用程序状态的变化。
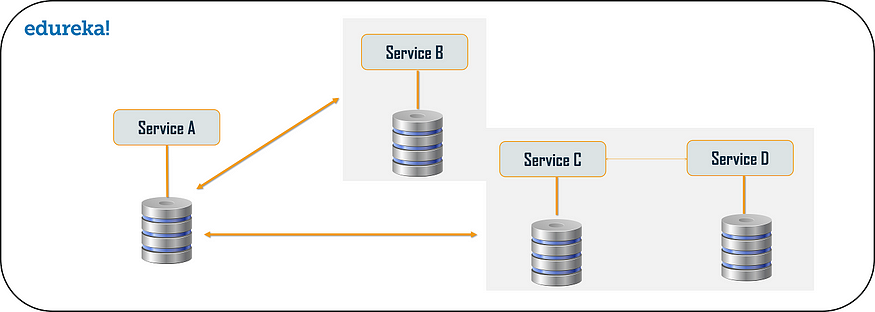
分支模式
分支微服务设计模式是一种设计模式,您可以在其中同时处理来自两个或多个独立微服务的请求和响应。 因此,与链式设计模式不同,请求不是按顺序传递的,而是将请求传递给两个或多个互斥的微服务链。 这种设计模式扩展了聚合器设计模式,并提供了从多链或单链产生响应的灵活性。 例如,如果您考虑一个电子商务应用程序,那么您可能需要从多个来源检索数据,而这些数据可能是来自各种服务的数据的协作输出。 因此,您可以使用分支模式从多个来源检索数据。
命令查询职责分离器 (CQRS) 设计模式
每个微服务设计都有每个服务模型的数据库或每个服务的共享数据库。 但是,在每个服务的数据库模型中,我们无法实现查询,因为数据访问仅限于一个数据库。 因此,在这种情况下,您可以使用 CQRS 模式。 根据这种模式,应用程序将分为两部分:命令和查询。 命令部分将处理与 CREATE、UPDATE、DELETE 相关的所有请求,而查询部分将处理物化视图。 通过使用上述事件源模式创建的一系列事件来更新物化视图。
断路器模式
顾名思义,断路器设计模式用于在服务不工作时停止请求和响应过程。因此,例如,假设客户端正在发送从多个服务检索数据的请求。但是,由于某些问题,其中一项服务已关闭。现在,您将面临主要两个问题:首先,由于客户端不知道某个特定服务已关闭,因此请求将不断发送到该服务。第二个问题是网络资源枯竭,性能低下,用户体验差。
因此,为避免此类问题,您可以使用断路器设计模式。在此模式的帮助下,客户端将通过代理调用远程服务。该代理基本上将充当电路屏障。因此,当故障数量超过阈值数量时,断路器会在特定时间段内跳闸。然后,所有调用远程服务的尝试都将在此超时时间内失败。一旦该时间段结束,断路器将允许通过有限数量的测试,如果这些请求成功,断路器将恢复正常操作。否则,如果出现故障,则超时周期重新开始。
分解设计模式
微服务是根据开发人员的想法开发的,即创建小型服务,每个服务都有自己的功能。但是,将应用程序分解成小的自治单元必须在逻辑上完成。因此,要将小型或大型应用程序分解为小型服务,您可以使用分解模式。
借助此模式,您可以基于业务能力或基于子域来分解应用程序。例如,如果您考虑一个电子商务应用程序,那么如果您按业务能力进行分解,那么您可以为订单、支付、客户、产品提供单独的服务。
但是,在相同的场景中,如果您通过分解子域来设计应用程序,那么您可以为每个类提供服务。在这里,在这个例子中,如果你把客户看作一个类,那么这个类将用于客户管理,客户支持等。所以,分解,你可以使用整个领域模型的领域驱动设计细分为子域。然后,这些子域中的每一个都有自己的特定模型和范围(有界上下文)。现在,当开发人员设计微服务时,他/她将围绕范围或有界上下文设计这些服务。
尽管这些模式对您来说听起来可行,但它们对于大型单片应用程序并不可行。这是因为识别子域和业务能力对于大型应用程序来说并不是一件容易的事。因此,分解大型单体应用程序的唯一方法是遵循藤蔓模式或扼杀者模式。
扼杀者模式或藤蔓模式
扼杀者模式或藤蔓模式是基于与藤蔓的类比,藤蔓基本上扼杀了它所缠绕的树。因此,当将此模式应用于 Web 应用程序时,每个 URI 调用都会来回调用,并且服务会分解为不同的域。这些域将作为单独的服务托管。
根据扼杀者模式,两个独立的应用程序将并排存在于同一个 URI 空间中,并且在一个实例中将考虑一个域。因此,最终,新的重构应用程序会环绕或扼杀或替换原始应用程序,直到您可以关闭单体应用程序
如果您想查看更多有关人工智能、DevOps、Ethical Hacking 等市场最流行技术的文章,您可以参考 Edureka 的官方网站。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. What is Microservices?
- 2. Microservices Architecture
- 3. Microservices vs SOA
- 4. Microservices Tutorial
- 5. Building Microservices Application Using Spring Boot
- 5. Microservices Security
原文:https://medium.com/edureka/microservices-design-patterns-50640c7bf4a9
- 48 次浏览
【微服务原则】利用微服务缩短产品上市时间
无论他们是访问网站还是移动应用,人们对他们经常使用的应用程序抱有很高的期望。 因此,公司必须不断提供新功能和修复。 在过去,这个过程很痛苦,因为应用程序通常是作为单个(通常是单片的)应用程序开发,构建和提供的。
微服务是一种应用程序架构风格,其中应用程序由许多离散的,网络连接的组件组成,称为微服务:
- 大型单片应用程序被分解为小型服务。
- 单个网络可访问服务是微服务应用程序的最小可部署单元。
- 每个服务都在自己的进程中运行。 此规则有时称为“每个容器一个服务”,可能是容器或任何其他轻量级部署机制,例如Cloud Foundry运行时。
客户正在尝试使他们的应用程序现代化,以跟上变化的速度......在过去,操作决定了应用程序的编写方式......人们花了数年时间编写单一应用程序,其中许多应用程序功能都打包在应用程序中。 ..现在他们看到了开发人员在添加新功能以应对不断变化的营销需求方面遇到的困难。----- Roland Barcia,杰出工程师兼首席技术官:微服务
微服务的好处
采用微服务的企业可享受许多好处:
高效的团队
微服务是分成一组可独立部署的小型服务的应用程序。由于微服务旨在独立行动,因此它们自然地与促进端到端团队所有权的敏捷原则保持一致。
简化部署
每个微服务都围绕业务功能构建和对齐,以降低应用程序变更管理过程的复杂性。由于每项服务都是在不影响其他服务的情况下单独更改,测试和部署的,因此加快了上市时间。
适合工作的正确工具
开发微服务的团队可以做出适合工作的技术决策。他们可以尝试新技术,库,语言和框架,从而缩短创新周期。
提高应用质量
由于微服务的“分而治之”方法,微服务的功能和性能测试都比单片应用程序更容易。微服务架构适用于测试驱动的开发,因为组件可以单独测试,并与完整或虚拟化的微服务组合。这种方法可以全面提高应用质量。
可扩展性
微服务比单片应用程序更容易扩展。通过根据各个服务对整体应用程序,吞吐量,内存和CPU负载的关键性来扩展各个服务,团队可以更有效地扩展应用程序。
微服务原则
在为应用程序开发微服务时,请记住以下原则:
单一职责
每个微服务必须针对单个功能进行优化。每项服务都更小,更易于编写,维护和管理。罗伯特马丁称这一原则为“单一责任原则”。
单独的流程
微服务之间的通信必须通过REST API和消息代理进行。从服务到服务的所有通信都必须通过服务API进行,或者必须使用显式通信模式,例如Hohpe的Claim Check Pattern。
执行范围
虽然微服务可以通过API公开自己,但重点不在于接口,而在于运行组件。此图中突出显示了微服务应用程序的粒度:

微服务API通信
CI / CD
每个微服务可以连续集成(CI)并连续交付(CD)。当您构建由许多服务组成的大型应用程序时,您很快就会意识到不同的服务以不同的速率发展。如果每个服务都具有唯一的持续集成或连续交付管道,则该服务可以按照自己的进度进行。在整体方法中,系统的不同方面都以系统中最慢的移动部分的速度释放。
弹性
您可以将高可用性和群集决策应用于每个微服务。当您构建大型系统时,您拥有的另一个实现是,当涉及到群集时,一个大小并不适合所有。在同一级别上扩展整体中所有服务的单一方法可能导致服务的过度使用或使用不足。更糟糕的是,当共享资源被垄断时,服务可能会被忽略。在大型系统中,您可以将不需要扩展的服务部署到最少数量的服务器以节省资源。其他服务需要扩展到大数量。
将应用程序迁移到微服务
微服务是一个小应用程序,通常包含一个功能。该功能通过API和消息传递。每个微服务都可以拥有自己的DevOps管道,可以单独扩展,并拥有自己的数据库,拥有数据模型。
该图显示了单片应用程序架构如何演变为基于微服务的应用程序架构:
微服务示例概述

在单片应用程序中,代码位于单个服务器上。更新单个组件时,必须同时部署其他组件,因此需要一个完全等效的服务器,以通过蓝绿色部署满足高可用性要求。
在重构的微服务应用程序中,简化了更新部署,因为业务服务在独立的基于云的计算基础架构上独立运行。
要了解微服务应用程序的工作方式以及从单片应用程序迁移到微服务,请观看此视频:
下一步是什么?
既然您已了解使用微服务的概念和价值,请通过阅读微服务参考架构了解有关如何设计微服务应用程序的更多信息。在了解了体系结构之后,请参考教程在Kubernetes上部署微服务应用程序。
原文:https://www.ibm.com/cloud/garage/architectures/microservices
本文:http://pub.intelligentx.net/improve-time-market-microservices
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 47 次浏览
【微服务架构 】微服务第3部分:服务注册表
在微服务系列的这篇文章中,我们将讨论服务注册表。在第2部分中,我们讨论了API网关,其中我们提到服务已在数据库中注册。网关根据该数据库中包含的信息调度请求。下面我们将探讨如何填充数据库以及服务,客户端和网关与之交互的方式。
服务注册表
服务注册表是一个数据库,其中包含有关如何将请求分派给微服务实例的信息。注册表和其他组件之间的交互可以分为两组,每组有两个子组:
微服务和注册表之间的交互(注册)
- 自注册
- 第三方注册
客户端与注册表之间的交互(发现)
- 客户端发现
- 服务器端发现
注册
大多数基于微服务的架构都在不断发展。随着开发团队分离,改进,弃用和完成工作,服务会上下波动。每当服务端点发生更改时,注册表都需要了解更改。这就是注册的全部内容:谁发布或更新有关如何联系每项服务的信息。
自注册迫使微服务自己与注册表进行交互。当服务上升时,它会通知注册表。服务中断时会发生同样的事情。无论注册表需要哪些其他数据,都必须由服务本身提供。如果你一直关注这个系列,你就会知道微服务都是关于处理一个问题,所以自我注册可能看起来像一个反模式。但是,对于简单的体系结构,自注册可能是正确的选择。
第三方注册通常在行业中使用。 在这种情况下,有一个管理所有其他服务的进程或服务。 此过程以某种方式轮询或检查哪些微服务实例正在运行,并自动更新服务注册表。 可以以每服务配置文件(或策略)的形式提供附加数据,注册过程使用该文件来更新数据库。 在使用Apache ZooKeeper或Netflix Eureka等工具以及其他服务管理器的架构中,第三方注册很常见。
第三方注册还提供其他好处。例如,当服务出现故障时会发生什么?可以将第三方注册服务配置为为失败的服务提供安全回退。其他案例可能会实施其他政策。例如,服务注册表进程可能会收到高负载情况的通知,并通过请求实例化新的微服务进程或VM来自动添加新端点。可以想象,这些可能性对于大型架构至关重要。
发现
可以想象,从客户的角度来看,发现是注册的对应物。当客户想要访问服务时,它必须找出服务所在的位置(以及执行请求的其他相关信息)。
客户端发现强制客户端在执行实际请求之前查询发现服务。正如自我注册所发生的那样,这要求客户处理除主要目标之外的其他问题。发现服务可能位于API网关后面,也可能不位于API网关后面。如果它不在网关后面,则可能需要为发现服务重新实现平衡,身份验证和其他横切关注点。此外,每个客户端都需要知道要联系发现服务的固定端点(或端点)。这些都是缺点。一个很大的优点是不必在网关系统中编写必要的逻辑。选择发现方法时,请仔细研究。
服务器端发现使API网关处理发现请求的正确端点(或端点)。 这通常用于更大的架构。 由于所有请求都直接发送到网关,所以与之相关的所有好处都适用(参见第2部分)。 网关还可以实现发现缓存,以便许多请求可以具有较低的延迟。 高速缓存失效背后的逻辑特定于实现。
“服务器端发现使API网关能够处理发现请求的正确端点。”
服务器端发现
示例:注册表服务
在第2部分中,我们研究了一个简单的API网关实现。在该示例中,我们通过查询到服务数据库来实现动态调度请求。换句话说,我们实现了服务器端发现。对于此示例,我们将通过处理注册方面来扩展我们的微服务架构。我们将以两种方式这样做:
- 通过提供一个简单的注册库,任何开发团队都可以将其集成到他们的微服务中以执行自我注册。
- 通过提供在启动或关闭期间注册服务的示例systemd单元(使用systemd作为服务管理器的第三方注册)。
为什么要系统?它已成为大多数Linux安装中的事实上的服务管理器。管理服务还有其他选择,但都需要安装和配置。为简单起见,我们选择了大多数发行版中预装的那个,这是systemd。
注册库
我们之前发布的微服务示例是为node.js开发的,所以我们的库也适用于它。这是我们库的主要逻辑:
module.exports.register = function(service, callback) {
if(!validateService(service)) {
callback(new Error("Invalid service"));
}
findExisting(service.name, function(err, found) {
if(found) {
callback(new Error("Existing service"));
return;
}
var dbService = new Service({
name: service.name,
url: service.url,
endpoints: service.endpoints,
authorizedRoles: service.authorizedRoles
});
dbService.save(function(err) {
callback(err);
});
});
}
module.exports.unregister = function(name, callback) {
findExisting(name, function(err, found) {
if(!found) {
callback(new Error("Service not found"));
return;
}
found.remove(function(err) {
callback(err);
});
});
}
执行自注册的微服务需要在启动或关闭期间调用这些功能(包括异常关闭)。 我们已通过以下方式将此库集成到现有的微服务示例中(将SELF_REGISTRY变量设置为任何值以启用此功能)。 启动代码:
// Standalone server setup
var port = process.env.PORT || 3001;
http.createServer(app).listen(port, function (err) {
if (err) {
logger.error(err);
} else {
logger.info('Listening on http://localhost:' + port);
if(process.env.SELF_REGISTRY) {
registry.register({
name: serviceName,
url: '/tickets',
endpoints: [ {
type: 'http',
url: 'http://127.0.0.1:' + port + '/tickets'
} ],
authorizedRoles: ['tickets-query']
}, function(err) {
if(err) {
logger.error(err);
process.exit();
}
});
}
}
});
和关机代码:
function exitHandler() {
if(process.env.SELF_REGISTRY) {
registry.unregister(serviceName, function(err) {
if(err) {
logger.error(err);
}
process.exit();
});
} else {
process.exit();
}
}
process.on('exit', exitHandler);
process.on('SIGINT', exitHandler);
process.on('SIGTERM', exitHandler);
process.on('uncaughtException', exitHandler);
使用systemd进行第三方注册
我们的网关示例从Mongo数据库中读取服务信息。 Mongo提供了一个命令行界面,我们可以在启动或关闭期间使用它来注册服务。 这是一个示例systemd单元(如果您使用此帖子中的示例微服务,请记住禁用SELF_REGISTRY环境变量):
[Unit]
Description=Sample tickets query microservice
#Uncomment the following line when not running systemd in user mode
#After=network.target
[Service]
#Uncomment the following line to run the service as a specific user
#User=seba
Environment="MONGO_URL=mongodb://127.0.0.1:27018/test"
ExecStart=/usr/bin/node /home/seba/Projects/Ingadv/Auth0/blog-code/microservices/server.js
ExecStartPost=/usr/bin/mongo --eval 'db.services.insert({"name": "Tickets Query Service", "url": "/tickets", "endpoints": [{"type": "http", "url": "http://127.0.0.1:3001/tickets"}], "authorizedRoles": ["tickets-query"] });' 127.0.0.1:27017/test
ExecStopPost=/usr/bin/mongo --eval 'db.services.remove({"name": "Tickets Query Service"});' 127.0.0.1:27017/test
[Install]
WantedBy=default.target
注册由ExecStartPost和ExecStopPost指令通过调用命令行Mongo客户端(包含在所有标准MongoDB安装中)来处理。
获取代码https://github.com/auth0/blog-microservices-part3。
另外:使用Auth0作为您的微服务
由于JWT的神奇之处,Auth0和微服务齐头并进。 看看这个:
var express = require('express');
var app = express();
var jwt = require('express-jwt');
var jwtCheck = jwt({
secret: new Buffer('your-auth0-client-secret', 'base64'),
audience: 'your-auth0-client-id'
});
app.use('/api/path-you-want-to-protect', jwtCheck);
// (...)
您可以通过Auth0仪表板获取客户端ID和客户端密钥。 创建一个新帐户并开始黑客攻击!
结论
服务注册表是基于微服务的体系结构的重要组成部分。 有不同的处理注册和发现的方法,适合不同的架构复杂性。 在承诺之前考虑上述每种替代方案的优缺点。 在第4部分中,我们将详细研究服务依赖性以及如何有效地管理它们。
- 52 次浏览
【微服务架构】 微服务API网关,第2部分
在微服务系列的这篇文章中,我们将讨论API网关以及它们如何帮助我们解决基于微服务架构的一些重要问题。我们在本系列的第一篇文章中描述了这些和其他问题。
什么是API网关以及为什么要使用它?
在所有基于服务的体系结构中,有几个关注点在所有(或大多数)服务之间共享。基于微服务的架构也不例外。正如我们在第一篇文章中所说,微服务几乎是孤立开发的。交叉问题由软件堆栈中的上层处理。 API网关是其中一个层。以下是API网关处理的常见问题列表:
- 认证
- 运输安全
- 负载均衡
- 请求调度(包括容错和服务发现)
- 依赖性解决方案
- 运输转型
认证
大多数网关对每个请求(或一系列请求)执行某种身份验证。根据特定于每个服务的规则,网关将请求路由到所请求的微服务或返回错误代码(或更少的信息)。大多数网关在将请求传递给后面的微服务时将身份验证信息添加到请求中。这允许微服务在需要时实现用户特定的逻辑。
安全
许多网关作为公共API的单一入口点。在这种情况下,网关处理传输安全性,然后通过使用不同的安全通道或通过删除内部网络内不必要的安全约束来分派请求。例如,对于RESTful HTTP API,网关可以执行“SSL终止”:在客户端和网关之间建立安全SSL连接,然后通过非SSL连接将代理请求发送到内部服务。
“许多网关作为公共API的单一入口点。”
负载均衡
在高负载情况下,网关可以根据自定义逻辑在微服务实例之间分发请求。每项服务可能都有特定的扩展限制。网关旨在通过考虑这些限制来平衡负载。例如,某些服务可能通过在不同的内部端点下运行多个实例来扩展。网关可以将请求分派给这些端点(甚至请求更多端点的动态实例化)来处理负载。
请求调度
即使在正常负载情况下,网关也可以为调度请求提供自定义逻辑。在大型体系结构中,随着团队工作或生成新的微服务实例(例如,由于拓扑更改),会添加和删除内部端点。网关可以与服务注册/发现过程或描述如何分派每个请求的数据库协同工作。这为开发团队提供了出色的灵活性。此外,故障服务可以路由到备份或通用服务,这些服务允许请求完成而不是完全失败。
依赖性解决方案
由于微服务处理非常具体的问题,一些基于微服务的架构往往变得“健谈”:要执行有用的工作,需要将许多请求发送到许多不同的服务。出于方便和性能的原因,网关可以提供在内部路由到许多不同微服务的外观(“虚拟”端点)。
传输转换
正如我们在本系列的第一篇文章中所了解到的那样,微服务通常是孤立开发的,开发团队在选择开发平台时具有很大的灵活性。这可能导致微服务返回数据并使用对于网关另一侧的客户端不方便的传输。网关必须执行必要的转换,以便客户端仍然可以与其后面的微服务进行通信。
API网关示例
我们的示例是一个简单的node.js网关。它处理HTTP请求并将它们转发到适当的内部端点(在传输过程中执行必要的转换)。它处理以下问题:
认证
使用JWT进行身份验证。单个端点处理初始身份验证:/ login。用户详细信息存储在Mongo数据库中,对端点的访问受角色限制。
/*
* Simple login: returns a JWT if login data is valid.
*/
function doLogin(req, res) {
getData(req).then(function(data) {
try {
var loginData = JSON.parse(data);
User.findOne({ username: loginData.username }, function(err, user) {
if(err) {
logger.error(err);
send401(res);
return;
}
if(user.password === loginData.password) {
var token = jwt.sign({
jti: uuid.v4(),
roles: user.roles
}, secretKey, {
subject: user.username,
issuer: issuerStr
});
res.writeHeader(200, {
'Content-Length': token.length,
'Content-Type': "text/plain"
});
res.write(token);
res.end();
} else {
send401(res);
}
}, 'users');
} catch(err) {
logger.error(err);
send401(res);
}
}, function(err) {
logger.error(err);
send401(res);
});
}
/*
* Authentication validation using JWT. Strategy: find existing user.
*/
function validateAuth(data, callback) {
if(!data) {
callback(null);
return;
}
data = data.split(" ");
if(data[0] !== "Bearer" || !data[1]) {
callback(null);
return;
}
var token = data[1];
try {
var payload = jwt.verify(token, secretKey);
//Your custom validation logic goes here.
if(!payload.jti || revokedTokens[payload.jti]) {
logger.debug('Revoked token, access denied: ' + payload.jti);
callback(null);
} else {
callback({jwt: payload});
}
} catch(err) {
logger.error(err);
callback(null);
}
}
免责声明:此帖中显示的代码未准备好生产。 它仅用于显示概念。 不要盲目复制粘贴:)
传输安全
传输安全性通过TLS处理:所有公共请求首先由具有样本证书的反向nginx代理设置接收。
负载均衡
负载平衡由nginx处理。 请参阅示例配置。
动态调度,数据聚合和故障
根据存储在数据库中的配置动态调度请求。 支持两种类型的请求:HTTP和AMQP。
请求还支持在多个微服务之间拆分请求的聚合策略:单个公共端点可以聚合来自许多不同内部端点(微服务)的数据。 所有返回的数据都是JSON格式。 看看Netflix关于这个策略如何帮助他们实现更好性能的优秀帖子。 另请查看我们关于Falcor的帖子,该帖子允许从多个来源轻松获取数据。
通过记录错误并返回少于请求的信息来处理失败的内部请求。
/*
* Parses the request and dispatches multiple concurrent requests to each
* internal endpoint. Results are aggregated and returned.
*/
function serviceDispatch(req, res) {
var parsedUrl = url.parse(req.url);
Service.findOne({ url: parsedUrl.pathname }, function(err, service) {
if(err) {
logger.error(err);
send500(res);
return;
}
var authorized = roleCheck(req.context.authPayload.jwt, service);
if(!authorized) {
send401(res);
return;
}
// Fanout all requests to all related endpoints.
// Results are aggregated (more complex strategies are possible).
var promises = [];
service.endpoints.forEach(function(endpoint) {
logger.debug(sprintf('Dispatching request from public endpoint ' +
'%s to internal endpoint %s (%s)',
req.url, endpoint.url, endpoint.type));
switch(endpoint.type) {
case 'http-get':
case 'http-post':
promises.push(httpPromise(req, endpoint.url,
endpoint.type === 'http-get'));
break;
case 'amqp':
promises.push(amqpPromise(req, endpoint.url));
break;
default:
logger.error('Unknown endpoint type: ' + endpoint.type);
}
});
//Aggregation strategy for multiple endpoints.
Q.allSettled(promises).then(function(results) {
var responseData = {};
results.forEach(function(result) {
if(result.state === 'fulfilled') {
responseData = _.extend(responseData, result.value);
} else {
logger.error(result.reason.message);
}
});
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify(responseData));
});
}, 'services');
}
角色检查
var User = userDb.model('User', new mongoose.Schema ({
username: String,
password: String,
roles: [ String ]
}));
var Service = servicesDb.model('Service', new mongoose.Schema ({
name: String,
url: String,
endpoints: [ new mongoose.Schema({
type: String,
url: String
}) ],
authorizedRoles: [ String ]
}));
function roleCheck(jwt_, service) {
var intersection = _.intersection(jwt_.roles, service.authorizedRoles);
return intersection.length === service.authorizedRoles.length;
}
传输和数据转换
执行传输转换以在HTTP和AMQP请求之间进行转换。
日志
日志记录是集中的:所有日志都发布到控制台和内部消息总线。在消息总线上侦听的其他服务可以根据这些日志采取措施。
获取完整代码。
旁白:webtask和Auth0如何实现这些模式?
我们在系列的第一篇文章中告诉过你关于webtasks的事情。由于webtasks是微服务,它们也在网关后面运行。 webtasks网关处理身份验证,动态调度和集中式日志记录,因此您也没有。
- 对于身份验证,Auth0是令牌的发布者,webtask将验证这些令牌。它们之间存在信任关系,因此可以验证令牌。
- 对于实时日志记录,webtask实现了无状态弹性ZeroMQ架构,该架构可在整个集群中运行。
- 对于动态调度,有一个定制的Node.js代理,它使用CoreOS etcd作为pub-sub机制来相应地路由webtasks。
结论
API网关是任何基于微服务的架构的重要组成部分。 可以以方便且通用的方式处理诸如认证,负载平衡,依赖性解析,数据转换和动态请求调度之类的横切关注点。 然后,微服务可以专注于他们的特定任务,而无需重复代码。 这使得每个微服务的开发更容易和更快速。
- 64 次浏览
【微服务架构】 您需要知道的所有最佳实践
切换到微服务架构似乎很容易,但技术领导者倾向于低估项目的复杂性并犯下灾难性的错误。
在将单片系统转换为微服务或从头开始之前,您需要仔细考虑将要出现的技术和组织挑战。
如果您想要,这篇文章适合您:
- 从单片系统切换到微服务。
- 从经验丰富的技术领导者那里收集见解。
- 了解微服务的缺点和优点。
- 避免灾难性的错误。
- 对微服务做出更好的技术决策。
我们对来自以色列和美国等5个不同国家的技术领导人进行了13次采访,然后将他们的知识压缩到这个可操作的帖子中。
这篇文章真的很长!您可以使用以下链接跳转到特定部分:
- 了解你的原因
- 明确定义微服务是什么
- 微服务架构的优点和缺点
- 最大的微服务挑战和解决方案
- 避免犯这些错误
- 切换到微服务架构的最佳实践
- 您应该为特定的微服务选择哪些技术?
- 选择适当技术的过程
了解你的原因
您可以犯的最大错误是在没有明确目标的情况下切换到微服务架构。您需要了解并有真正的理由说明为什么要这样做。
“人们盲目地做了很多事情:哦,码头很酷,微服务很棒!它可能不适合您构建的每件作品,您需要了解为什么要这样做。“ - Steven McCord,ICX Media的创始人兼首席技术官
如果你的工作系统运行良好,那你改变它的动力是什么?
仅仅因为微服务被大肆宣传并不意味着你需要加入这个潮流。它可能不是您软件的最佳技术选择。
确定原因至关重要;这就是David Dawson,Steven McCord和Avi Cavale所强调的。
“当我们的客户要求我帮助他们实施微服务时,我问的第一个问题是,为什么?我正在寻找的答案是, “我们希望更快地改变我们的系统”和“我们希望利用云技术。”我让他们意识到,做得对的微服务比 构建单片系统更昂贵,更难。它为您的数据做了有趣的事情,并在您的数据模型中引入了一个网络,可 以随时任意分区,数据丢失。你让自己暴露在分布式计算的全面愤怒之中。“ - David Dawson,系统架构师
推荐方法:
- 西蒙·沃德利的沃德利地图
- Gojko Adziks的影响映射
明确定义微服务是什么
“我不一定会选择微服务。我会选择中型服务,所以不是从单块服务到数百种服务,而是更大的服务,与工 程团队和业务垂直市场保持一致。“ - DanielWeb研发副总裁Daniel Ben-Zvi
如果您在服务,微服务和功能之间找不到适当的平衡,您可以:
- 对您的应用程序进行细分,这样您就不会看到微服务的好处。
- 过度分割您的应用程序,这意味着管理微服务本身的重量将破坏微服务可以提供的价值(Avi Cavale)。
对于微服务特性如何为您的公司寻找一个非常明确的理念至关重要。
你怎么做呢?微观案例研究
“我们通过查看代码片段来确定微服务是什么,如果更改,最终会创建指数测试用例。我们开始解决这些问题 是因为我们的目标是减少我们为每一项改变所做的测试。如果这是你的目标,那么你定义为微服务的方式与有人 说“我希望计费成为微服务”不同。“ - Seippable联合创始人兼首席执行官Avi Cavale
推荐阅读:微服务与单片架构
微服务架构的优点和缺点
微服务的优点
- 可扩展性:您可以分析小块,以查看每个部分的要求。它使您可以单独扩展应用程序的不同部分。
“对我来说,另一大好处是我可以在任何VM之外扩展这些容器。我可以将容器放入我想要的任何配置中,这样我的 应用程序就可以完全移植。“ - Steven McCord,ICX Media创始人兼首席技术官
- 更易于维护:让不同的团队以或多或少的独立方式处理不同的组件。
- 部署和配置没有太多干扰:您可以部署和配置系统的微小部分,而不会影响其他服务。多个团队可以为生产提供多种结果,而不会干扰和踩到彼此的脚趾。
- 问题隔离:更容易隔离和检测问题。
- 更容易招聘:当您正在寻找开发人员或第三方提供商时,您只需要为系统的一小部分进行培训。
- 责任明确定义:一个团队负责给定的微服务。
- 深刻的知识:从事内部工作的团队从内到外都知道。
- 各种各样的编程语言:您可以使用不同的编程语言,具体取决于最适合微服务的目的。
- 更容易监督和理解:您可以将庞大的代码库拆分为较小的项目。这种方法可以让您和您的团队更好地理解项目及其代码。
- 更容易打开组件:当明确定义边界和接口时,更容易向新业务单元或外部实体打开组件或现有功能。
微服务的缺点
- 部署和互操作性:缺点是部署和互操作性成为主要问题。
- 编程语言太多:这可能会限制代码的可重用性和可维护性,并且可能会使招聘变得更加复杂。
- 使组件协同工作:您始终需要确保以他们协同工作的方式组合您的服务。只需考虑更改单个端点,这会破坏旧版本中的其他依赖服务。
- 与整体系统相比,整个系统的集成测试更难,一切都在一个地方。
- 从一开始就必须仔细考虑架构:如果服务之间存在太多的凝聚力,那么即使不是所有优势,也会失去最多。
- 需要更多的沟通工作:在服务之间的沟通方面,您需要进行相关的投资。在服务通信之间可能发生很多失败。
- 难以监控整个系统:你有很多碎片可能是一个噩梦来监控。
- 需要时间学习:使用微服务需要学习,这需要时间。
- 复杂性:拥有越来越多的微服务,使整个系统更加复杂,更难以监督整个操作。
“所有这些作品都在四处闲逛。如果你没有非常好的工程流程,那么你最终将会遇到许多根本无法使用的东西。“ - Seippable联合创始人兼首席执行官Avi Cavale “在基于微服务的平台上调试生产问题是一个完全不同的歌剧。如果没有适当的监控,日志记录和跟踪设施, 系统的复杂性就会显着增加。这就像穿过迷宫一样。工程实践和标准化变得至关重要。“ - DanielWeb研发副总裁Daniel Ben-Zvi
- 登录到一个地方很有挑战性。像Loggly,Splunk或Heroku这样的第三方日志聚合服务是非常好的解决方案,但它们确实以非常高的价格出售。根据我的经验,遥测专门集中测井是一个最大的痛苦。您必须考虑每项服务的详细程度。如果不这样做,您最终可能只需支付50-60%的费用来记录下文。 (微软网站可靠性工程师Sonu Kumar)
最大的微软服务挑战和解决方案
在转向微服务时,这些是技术领导者和开发团队可能面临的最大挑战。
- 挑战1:立即切换系统
- 挑战2:拆分系统
- 挑战3:组织支持
- 挑战4:团队
挑战1:一次性切换你的系统
“从单片架构切换到微服务架构并不是你可以同时做到的。如果您有一个单片服务器,那么您可能拥有存储库, 部署任务,监视以及围绕它紧密设置的许多其他内容。改变这一切并非易事。“ - Bruaka Benavides, Inaka的前首席技术官 “如果一家公司从未有过使用微服务的经验,即使是绿色的现场项目也会比他们想象的更难。” - LogMeIn的DevOps工程师Viktor Tusa
✅可能的解决方案
我们当时所做的是保持整体服务器的位置,但任何新的添加都是作为微服务开发的,所以最终事情从原始服务器中消失,直到它最终成为我们最老和最大的微服务。 (Brujo Benavides)
挑战2:分裂系统
如果组件和服务从项目开始就粘在一起,那么隔离组件和服务可能非常具有挑战性。 (Robert Aistleitner)。 您需要定义各个部分之间的交互和流程。 如果您没有以良好的方式定义,您的系统将产生更多问题。 (StyleSage高级开发人员Jose Alvarez) “没有模式; 将系统拆分成微服务有很多不同的规则,但没有人会告诉你如何在你的应用程序中这样做。 没有两个相同的微服务。“ - Recart首席架构师David Papp
✅可能的解决方案
“将单片系统拆分为微服务的唯一方法是首先检查单片系统,看看它最痛”的地方。 系统的这些部分应该被取出并转换成微服务。“ - Andras Fincza,Emarsys的工程副总裁
如果您没有适当监控,您将无法看到系统的工作方式。监控所有部件的工作情况以及他们正在做的事情。如果您 监控系统,则可以轻松检测并解决问题。 (何塞阿尔瓦雷斯)
逐步增加,逐个模块是拆分单片系统的最佳方式。如果你想一次做所有事情,你肯定会失败。
监控工具提示:
- New Relic
- Datadog
- Influxdb
- Grafana
挑战3:组织买入
“获得组织支持可能是最难的部分。” - Steven McCord,ICX Media的创始人兼首席技术官
这不是技术决定。您需要明确说明微服务架构的好处,以说服您的公司重新分配资源。这是一个漫长而乏味的过程,直到组织接受这样的变更,组织越大,决策就越长。
✅可能的解决方案
说服您的组织切换到微服务的最佳方法是将系统中一个非关键部分转换为微服务。通过这种方式,您可以使用真实的工作微服务来展示其优势。
挑战4:团队
“最大的挑战发生在团队本身,因为它需要不同的思考。” - Shippable联合创始人兼首席执行官Avi Cavale
开发人员必须花费更多时间来了解什么是端到端场景。 他们需要熟悉技术,可能需要转换思维模式,这需要时间。
对于那些在一个可以进行端到端测试的世界工作的人来说,这是不舒服的,现在你突然将它分解成小块。 这更像是一种文化变革。 (Avi Cavale)
✅可能的解决方案
从非常小的东西开始,您可以从中获益并选择一些不是您应用程序关键部分的东西。 获得一个小团队,将应用程序的这一部分转换为微服务。 证明它实际上更好,并逐步扩展到组织(Avi Cavale)。
避免造成这些错误
“避免立即将整个系统切换到微服务。” - Emarsys工程副总裁Andras Fincza
“我想你可能犯的最大错误就是你没有对微服务架构的变化所带来的影响进行概述。在实际开始实施新方法之前,您必须包含 许多移动部件。“ - 用户工程副总裁Robert Aistleitner “使用巨石,可以轻松更改内部界面;您只需重新编译代码并运行测试。使用微服务,您的API必须是黄金。这是依赖, 你不一定了解你的所有客户。在没有API的情况下进行未来验证将在未来产生许多令人头疼的问题。此外,请确保您有 一个分布式跟踪系统。“ - SimilarWeb研发副总裁Daniel Ben-Zvi “避免在没有弄清平台和依赖关系的情况下尝试切换到微服务。此外,相信微服务是好的,因为每个微服务都可以用 不同的语言编写,这是一种不好的做法。“ - Viktor Tusa,LogMeIn的DevOps工程师 “处理数据至关重要。搞砸数据很容易,但很难恢复。数据迁移应该采取更多步骤。“ - Andras Fincza,Emarsys的 工程副总裁 “在微服务之间共享数据是一个很大的禁忌。如果两个服务正在操纵相同的数据,您将开始遇到一致性问题并消除所 有权的歧义。“ - Daniel Ben-Zvi和Varun Villait “将应用程序分解成太多太小的部分,或者强迫将系统转换为不应该是微服务的微服务 - 只是因为炒作”. - Csaba Kassai,Doctusoft的首席开发人员
切换到微服务架构的最佳实践
在微服务之间创建隔离使它们能够根据您的需要进行更改。这通常需要在几个层面进行隔离:
- 运行时进程:这是最明显的,也是通常很快采用的进程。在你有一个过程之前,现在你有很多。这里的主要成本是采用某种形式的分布式计算,这很难做到。这可能会导致您采用容器化,事件体系结构,各种http管理方法,服务网格和断路器。
- 团队/文化。分离团队,给你自主权,意味着你划分人与人之间的沟通。这往往导致知识孤岛和工作重复(选择性与资源效率选择的结合)。推荐阅读:由Peter Naur编写的理论构建
- 数据。采用分布式计算方法(如微服务)的最大影响在于它对数据的影响。您已经以某种形式对数据进行了分区,因此您需要在系统级别重新集成它以给人一种“系统”的印象。这为您提供了一些有关扩展的有趣潜在好处,但它还需要更多想到的不是简单的单片数据架构方法。 (大卫道森)
您应该选择哪种技术来获得特定的微服务?
这是不同意见开始发生碰撞的地方......
一方面,人们认为使用什么技术和编程语言无关紧要。
“几乎所有问题都可以通过任何技术解决。其他人花费太多时间寻找合适的技术,但如果你以反复的方式做到这一点, 你就有时间思考并看到它在行动中。通过这种方式,可以减轻糟糕的决策。“ - Andras Fincza,Emarsys的工程副总裁 “大多数大型现代语言(Python,Java,C#,Node / JavaScript)同样快速且可扩展。从这个角度来看,语言并不重要 。每种语言都有其优点和缺点;大多数时候,语言选择是基于个人偏好而不是技术论据。“ - Viktor Tusa,LogMeIn的DevOps工程师
花费大量时间选择最好的技术是不值得的,因为差异很小。
“选择技术的重要性太高估了。如果运行成本很重要,那么它可以接受,但对我们而言并不重要。“ - Andras Fincza,Emarsys工程副总裁 “如果它是一个绿地项目,那么我使用我的程序员最了解的语言。如果它不是一个绿地项目,那么我在 系统中的业务实体使用客户端覆盖范围最广的语言。“ - Viktor Tusa,LogMeIn的DevOps工程师 “微服务的优点是它封装在一个微服务中,只要你提供一个外部微服务接口来与那个东西交谈。 只要他们有接口,我就不在乎。“ - Steven McCord,ICX Media的创始人兼首席技术官
选择合适的技术不仅仅是一个技术问题,也是一个招聘决策。
如果您选择具有10种不同编程语言的微服务架构,则需要确保您的团队能够处理该问题。
“我不建议混合太多的编程语言,因为招聘人员变得更加困难。此外,程序员的上下文切换会降低开发速度。 “ - Usernap工程副总裁Robert Aistleitner “你必须有意识地选择你想要建立什么类型的开发团队。如果你想使用许多不同的编程语言,你需要建立 一个能够使用和学习不同编程语言的动态团队。“ - Steven McCord,ICX Media的创始人兼首席技术官
一些技术建议:
“我强烈建议在Google Cloud Platform中使用AppEngine等托管服务。从肩膀上承担很多负担。此外, 在选择语言/技术/框架时,为特定的微服务用例选择合适的一个是非常重要的,不要仅仅因为你熟悉它 而强迫某些东西。“ - Csaba Kassai,Doctusoft的首席开发人员
来自Brujo Benavides
另一方面,一些技术领导者很乐意推荐一些技术,这些技术非常适合服务于特定角色的微服务。
在为微服务选择技术时,建议考虑:
- 可维护性
- 容错
- 可扩展性
- 建筑成本
- 易于部署
Brujo团队用于微服务的框架/技术的一些示例:
- Scrapy for web crawling
- Celery + RabbitMQ来传达微服务
- 机器学习部分中的NLTK + Tensorflow(以及其他一些)
- AWS服务
推荐阅读:基于云的应用程序的技术选择案例研究
选择适当技术的过程
为您的微服务选择编程语言/技术时,您需要考虑许多事项。
其中一个最重要的事情是了解您的开发人员具备哪些能力以及语言/技术背后的支持(工具,社区......)。根据我 的经验,公司倾向于根据其开发人员的能力选择一种编程语言。“ - Csaba Kassai,Doctusoft的首席开发人员 “使用拥有大量支持(资源和活跃社区)的技术。我会推荐Ruby和JavaScript,因为你得到了很多支持,如果出现 任何问题,很多人都会帮助你。我想只要你确保有很多人使用它,承担一种语言应该不是问题。因为在这种情况下, 如果您的团队不具备这些知识,您可以依赖外部资源。“ - 工业首席执行官Varun Villait “另一个因素可能是存在一种可用于加速项目的语言库。你理想的语言选择可能没有你可能需要自己发明的某些 东西的库,这可能是另一个时间流失。显然,容错和可扩展性等问题也应该是一个重要因素。如果你不得不在几 个月后从头开始重新编写一些东西,因为最初的选择无法扩展,那么你最好先咬一口。我认为这一切都取决于 具体的团队情况以及他们愿意做出的投资。“ - Greg Neiheisel,天文学家联合创始人兼首席技术官
这是EMARSYS的流程:
在Emarsys,如果他们想要应用新的编程语言,开发人员需要提供真实的逻辑原因并咨询主要开发人员。团队聚集在一起讨论技术的优缺点。
他们总是使用不同的技术创建一个尖峰解决方案。这使他们可以尝试给定技术的边界,看看它是否可以应用于给定的微服务。这非常适合揭示技术的局限性。
“建议使用您的团队已经熟悉的语言。通过这种方式,他们可以更舒适地工作,并且进步更快。“ - Andras Fincza,Emarsys的工程副总裁
这是他们在SIMILARWEB的做法:
作为一家大型数据和分析公司,我们应对非常大规模的挑战,这会增加选择错误技术的风险和影响。单个线程框架(如NodeJS)虽然适用于网络绑定服务,但在处理实时密集型数据处理时无法扩展。
工程师通过平衡战术和战略需求以及查看技术和组织约束来确定使用哪种技术。我们处于快速原型设计阶段吗?该服务是否处理大量数据?我们是否想要在我们的堆栈中添加新技术,因为我们相信它的生态系统还是我们使用已经掌握的现有技术?我们想要实验吗?我们能找到对此充满热情的工程师吗?我们是否愿意长期致力于这项技术?技术生态系统是一个主要因素。我们希望与开源社区合作,而不是重新使用和贡献现有框架,而不是重新发明轮子。
一般来说,我们不希望传播得太薄;否则,你没有获得专业知识。
定义明确的指导方针,甚至是清单,可以帮助促进健康的决策过程,并缩小可能的技术选项,以选择最适合您的团队和产品的选项。
DAVID DAWSON对选择技术的建议:
- 从数据架构的角度来看,您需要能够提供数据的东西,您可以轻松地在服务之间通过网络同步到一致的可用状态。有各种各样的方法,这是我在微服务部署中实际寻找的方法。因此,您可以观察实现这些模式的各种框架和技术(这是Kafka,Spring Data Flow,Akka和朋友等技术人员所在的地方)。
- 一旦我们确定了这些模式和方法,您就可以使用您可用的资源进行网格化。如果您已经决定使用大量反应式编程的数据流方法,并且您已经拥有Java开发人员,那么选择Spring,Spring Cloud Data Flow和Kafka是有意义的,并且可能部署到某种形式的Cloud Foundry(如果你可以得到它!)。
如果您需要大量较重的数据转换,请引入Spark或Kafka Streams来帮助解决这个问题。如果你有JavaScript开发人员,那就没有意义了。相反,你会在JS运行时(clojurescript等)上采用一些函数式语言,再次使用一些类似的反应式集成技术(Kafka肯定会在这个空间中制造波浪)并从中获取它。
关键要点:
- 不要强调选择完美的技术。 采用迭代的实验方法代替。
- 每个微服务架构都是独一无二的; 选定的技术应与系统的需求保持一致。
- 请记住,太多不同的技术使招聘更加复杂。
结论
在切换到微服务架构时,存在许多挑战。
在开始将系统转换为微服务之前,请确保有真正的理由说明为什么要这样做。了解优势和劣势可能会有很大帮助。您不必遵循最新的炒作,而是首先考虑系统的独特功能,而只是改变最容易受到伤害的系统部分。不建议从头开始使用微服务架构,因为很难明确定义微服务的边界。
如果您决定切换到微服务,请采用增量方法并取出系统中一个非常关键的小部分,以了解其工作原理。这也是获得组织支持以创建更多微服务的好方法。
没有一种最佳方法可以为微服务选择完美的技术。每项与技术相关的决策都会受到您团队当前知识以及公司未来招聘计划的影响。在某些情况下,为微服务选择技术更多是招聘决策,而且取决于您希望在未来构建哪种类型的开发人员团队。
为了缩小可能的技术,来自Emarsys的Andras Fincza,来自SimilarWeb的Daniel Ben-Zvi和David Dawson提供了一个可以轻松应用的简短流程。
渴望更多?
4软件团队的有效知识转移方法
招聘开发人员是一个挑战吗?以下是科技公司如何应对它
优先考虑软件开发需求的科学方法
- 322 次浏览
【微服务架构】API版本控制最佳实践介绍

变化是不可避免的,增长是一件好事。当您的API已经超出了最初的意图和容量时,就该考虑下一个版本了。
无论下一次迭代是一个完整的版本升级还是一个功能扩展,重要的是要考虑你如何让你的开发人员知道它的优缺点。与传统的软件版本控制相比,API版本控制可能会对下游使用它的产品产生复杂的影响。
较大的版本调整通常意味着API代码库中一个重要的里程碑。它声明了API使用和实现需求的重大变化。不需要改变现有调用的特性添加是产品有机增长的一部分,不需要同样的考虑。
一旦你开始删除一些东西,或者戏剧性地改变现有的东西,就该考虑另一个版本了。通常,这些新版本会变成全新的产品。尽管它们共享一个共同的祖先,但是遗留api的新版本在实现时需要仔细考虑。
传统的API版本控制:n+1
可以保证新版本的服务更改包括:删除操作、重命名操作、移位数据类型或顺序的操作参数更改,以及数据类型的复杂结构更改。
版本增量还可以指示API使用需求的重大变化。它还可以对API提供的底层资源进行彻底的更改。在任何一种情况下,依赖于API实现核心功能的产品和平台都可能需要进行代码重构来适应。
这可能会耗费大量的时间和资源,因此对于多个涉众来说,使用一种合理且文档记录良好的URI版本控制方法是至关重要的。版本控制在团队中可能是一个有争议的话题,通常第一个问题就是是否使用它。
一个URI来统治所有的URI
一种思想是专注于一个不变的URI,只有一组消费标准。如果改变了API结构、改变了资源或修改了参数集,那么产品将使用相同的URI重新启动。这就把重构代码的责任推给了下游的开发人员。
蒂姆•伯纳斯-李(Tim Berners-Lee)的名字被这种方法的支持者提到。他经常说:“一个酷的URI是不会改变的。”这句话的本意是要说明新兴的互联网依靠网页内的超链接才能生存下去。互联网络在当时是一系列信息节点。
不过,世界已经改变了,我们使用的是一个相互连接的矩阵,它由功能强大、资源丰富的web服务组成。一旦服务变得广泛,早期的方法类似于软件版本号。但是,独立软件对下游的影响与相互依赖的web服务大不相同。
IBM在他们自己的“Web服务最佳实践”中解决了这个问题:
正确处理API版本控制一直是分布式系统开发者面临的最困难的问题之一。人们提出了各种各样的方案,从CORBA(公共对象请求代理体系结构)采用的自由放任的方法,到DCOM中使用的更严格的方案(分布式组件对象模型)。随着Web服务的出现,您可以利用一些新特性来帮助缓解问题,但残酷的事实是,版本控制还没有内置到Web服务体系结构中。”
什么是“最佳实践”已经随着时间的推移而演变,并由供应商对其自己产品的选择决定,而不一定来自任何外部管理机构。因此,当涉及到选择版本控制方法时,有各种各样的实践。
在向后兼容
另一个要考虑的问题是向后兼容性。对于许多web资源API的提供者来说,这是首要考虑的问题。维护一个资源密集型API的多个版本会严重消耗工程团队的时间和精力。它还会给迁移到更现代体系结构的服务带来长期的稳定性问题。
对许多人来说,引入一个实质上改变API的新版本实际上就是启动一个全新的服务。将其作为一个新产品,使用新的文档、服务水平协议、层访问更改等,可能会产生重大的业务影响。许多白板上都写满了数字,争论一个变化是工程选择还是商业转变。
一旦做出了引入新版本的决定,查看一下已建立的提供商,看看是否有经过测试的解决方案,这是很有帮助的。
更广的进行版本控制的例子
我们可以从已建立的web API提供商的版本控制实践中学到什么?谷歌从一开始就直截了当地肯定了编号版本化:“网络API应该使用语义版本化。“没有多少回旋余地。它们也有一个类似的平面系统。版本指示器使用v. major . min . patch形式。
Twilio在URL中使用了时间戳,而不是版本号。Salesforce选择vXX.X在URL的中间。Facebook会将版本预先添加到端点路径中。版本实际上是可选的,未指定的版本请求将被路由到最旧的可用版本。
请注意vX.X提供的粒度,vX.X通常用于开发,而不一定用于生产。首先检查文档,但是在生产代码中选择序号引用是一个好主意。
DevOps人员可能熟悉用于版本定义的UDDI和WDSL方法。HTTP解决方案要流行得多,但是有对这种方法的支持。它需要通过XML交换进行版本请求以获得正确的版本。
像微软、IBM和Oracle这样的巨石公司在他们的一些文档中都引用了这种方法。尽管,HTTP版本标识在许多部门和产品中被接受。
约会网络Badoo选择了持续的版本控制,即添加特性而端点保持不变。旧客户端可以使用旧字段,新客户端可以使用添加的字段。API请求是事务性的,发出一个特性请求调用并返回可用选项列表。特性检查可以作为一种状态请求。
API stylebook在版本控制方面还有其他一些方法可供探索。没有一套成文的规范,公司继续探索不同的选择。
带有Accept标头的版本
路径参数的一种常见替代方法是头交换。它们可以更详细地描述预期的响应,并且通常包含在HTTP请求中。使用特定于资源的头方法允许包含其他参数(如缓存、压缩和内容协商)。
API提供者通常在其响应中传达资源标准和限制,因此开发人员无论如何都需要检查header交换。除了响应代码之外,常见的报头响应还包括速率限制、特定的错误消息、基于时间的数据等等。
聪明的离群值使用MIME类型包含版本指示符。API提供者在其后端注册这些MIME类型,然后用户包括Accept头和Content-type头。IETF在RFC4627中合法化了这种方法。虽然这是可行的,但是选择这种方法的开发人员最终将不可避免地向管理类型解释他们的选择,这些管理类型会说:“但是它不能在HTML表单上工作,那么为什么要这样做呢?”
Accept: application/pre.company.app-v1+json Content-Type: application/pre.company.app-v1+json
关于实施的争论是深刻的,并将继续下去。因此,开发人员和供应商将不得不根据他们的具体需求做出选择。通常,最常见的方法是URI参数和头标准的组合。api接受带有参数的URI请求,然后返回带有适当响应代码的有效负载,以及(希望如此)响应头中的详细元数据。
工程师们会在公司的欢乐时光里,兴高采烈地大声讨论什么是合适的回应码。但是,这里有一些有用的负面反应,它们冗长到足以对下游有所帮助。
400: BAD_REQUEST: ApiVersionUnspecified: An API version is required, but was not specified
400: BAD_REQUEST: InvalidApiVersion: An API version was specified, but it is invalid
400: BAD_REQUEST: AmbiguousApiVersion: An API version was specified multiple times with different values
400, 405: BAD_REQUEST, METHOD_NOT_ALLOWED: UnsupportedApiVersion: The specified API version is not supported
301: MOVED_PERMANENTLY: movedPermanently: This request and future requests for the same operation have to be sent to the URL specified in the Location header of this response instead of to the URL to which this request was sent
410: GONE: deleted: The request failed because the resource associated with the request has been deleted
299: OK: Warning: "Deprecated API"
业务动机将指导版本选择
在某些方面,版本控制的技术方面是最容易解决的。真正的争论归结为产品需求、业务关注点和未来计划。就工程支持、后端资源和简单带宽而言,支持一个API的多个版本的需求可能非常高。
另外,要想做得好,新版本需要丰富的文档来成功地转换。由于对快速发展的公司来说,最新的文档往往没有什么优先级,因此它可能会以新旧文档的混搭而告终。糟糕的文档会导致时间和金钱上的巨大损失。
这里的主要要点是版本控制是一个多方面的对话。这不仅仅是一个技术问题。下游影响和遗留成本可能是巨大的,为了有效增长,应该对整个过程进行仔细考虑。
原文:https://nordicapis.com/introduction-to-api-versioning-best-practices/
本文:http://jiagoushi.pro/node/1208
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群[11107777]
- 183 次浏览
【微服务架构】BPMN和微服务编排,流程语言,引擎和永恒模式(第1部分)
我们正在构建Zeebe作为下一代工作流引擎,用于新兴用例,例如微服务编排用例,这些用例可能需要引擎每秒处理数十万(或数百万)个新工作流实例。
为此,我们使用的图形建模标准已经存在了近15年:BPMN(业务流程模型和表示法)。
尽管BPMN是经过实战考验的ISO标准,但很可能你们中的许多人从未亲自动手或者甚至没有听说过它。
或者更糟糕的是,您已经听说过BPMN,但您已将其作为一种仅在单片或SOA世界中相关的遗留技术编写。
上个月,我们从黑客新闻评论者那里得到了这句话(我们保证他们不是Zeebe团队的隐身成员):
“BPMN是我们IMO领域最被低估的技术。”
我们不能同意,并且本着这种精神,我们将发布一个关于BPMN和微服务编排的两部分博客系列 - 更具体地说,为什么BPMN非常适合工作流程中的新兴用例世界。
在第1部分中,我们将:
- 提供BPMN的快速介绍
- 说明为什么过去蓬勃发展的成熟标准也能在未来蓬勃发展
- 查看BPMN支持的常见业务流程模式
- 讨论Zeebe中BPMN的当前状态和未来计划
在第2部分中,我们将:
- 深入了解BPMN的图形模型(以及定义工作流程的其他方法)
- 看一下使用图形模型而不是基于代码的模型大大简化工作流程定义的示例
关于BPMN的简短入门
BPMN是一种广泛使用的建模标准,用于定义和执行业务流程。 2004年首次发布(随着2011年的现代BPMN 2.0规范 - 这是Zeebe使用的),BPMN自2013年以来一直是ISO标准。
BPMN用于定义图形模型和所谓的执行语义。换句话说,可视模型存储为XML文件,该文件可以直接在引擎上执行,该引擎保持运行工作流实例的持久状态。
举一个例子,下面的模型用这个XML表示。

重要的是要说BPMN不涉及代码生成而且没有转换! XML本身就是源代码。 BPMN只关注流程 - 您可以将正常代码用于解决方案的所有其他方面。
这是微服务编排的关键点,外部工作人员在您的工作流程中执行任务。 当与正确的引擎结合使用时,BPMN可以轻松地将工作流中的任务连接到微服务,并且这样做的方式不会违反松散耦合和服务独立性的原则。
扩展上面的示例订单工作流程,我们可以构建3个不同的微服务来处理付款,库存和运输。 工作流引擎负责在流程的正确位置将工作发送到正确的服务。
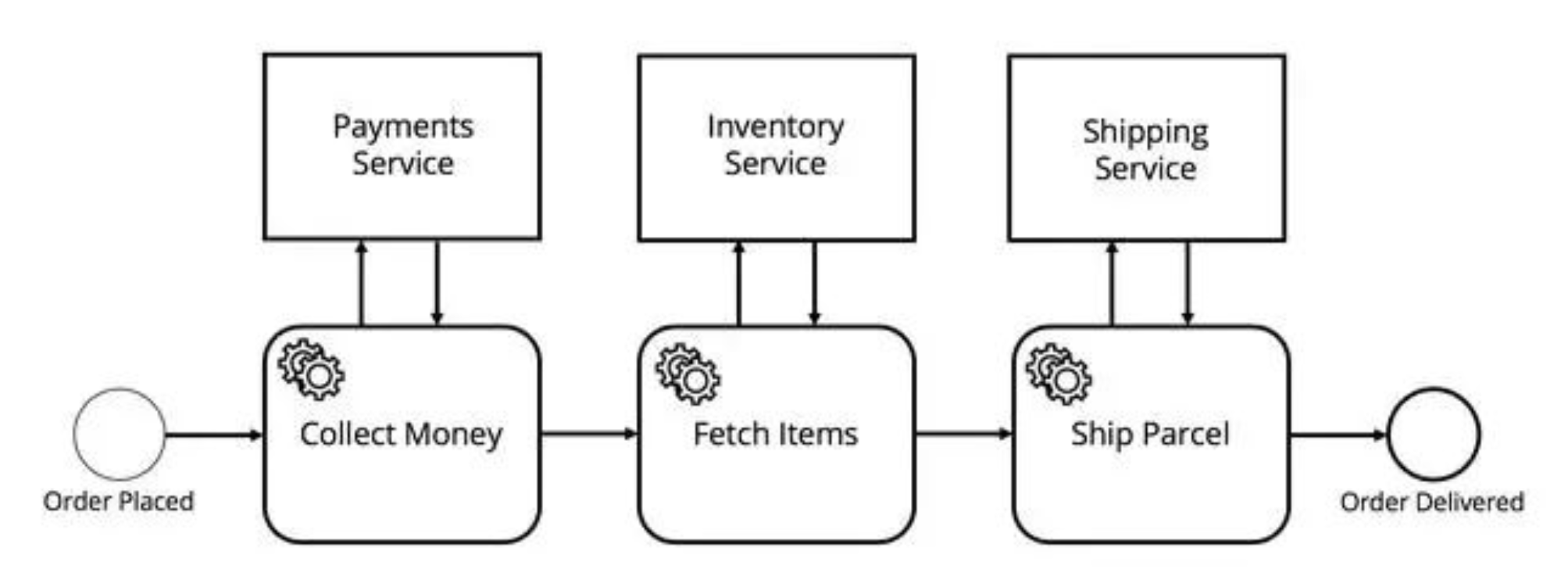
最后,有BPMN的成熟度。 BPMN非常受欢迎且已经成熟,并且已经证明了它在大型和小型公司的许多工作流程自动化项目中的价值。出于这个原因,市场上已经有很多经验丰富的BPMN人才以及教程和书籍,使新手很容易学习这个标准。
一切听起来都不错。但BPMN可以处理我喜欢的新架构吗?
我们暂时进入隐喻模式。
虽然有关汽车历史的具体细节尚未引起争议,但很多人都赞扬卡尔·奔驰在1886年建造了第一辆汽车并将其带到德国曼海姆附近。在过去130年左右的时间里,汽车 - 在这种情况下,字面意思是“引擎” - 已经发展了很多。
然而,“流动”仍然是相当静止的。帮助我们从A点安全地到达B点的道路,标志和法律仍然遵循许多几十年前实施的相同模式。这可能最终会改变(参见:Hyperloop,无人机),但重点是给定的“流动模式”可以支持许多重要的“引擎”进步。
因此,当我们评估像BPMN这样完善的标准时,我们必须区分“流量要求”和“引擎要求”。
BPMN已经围绕流动提出了许多模式,这些模式是永恒的。按顺序或并行执行一系列活动可以应用于更传统的BPMN用例,例如人工任务管理以及在AWS中调用无服务器功能。等待打印和签名文档的传入副本在模式方面与在事件流体系结构中关联多个消息具有可比性。
确实改变的是吞吐量(工作流实例的数量)以及性能和可伸缩性要求。这些问题可以通过执行相同流语言的新引擎来解决 - 这就是我们使用Zeebe所采用的方法,Zeebe可以扩展到每秒数百万个新的工作流实例。
另一种方法是构建一个新引擎,并在您使用时发明一种新的流语言。但是使用新的流语言,你不可避免地会花时间解决BPMN中已经解决的问题。而且您可能无法有效地或以所有利益相关者都能轻易理解的方式解决这些问题。
我们将在本系列的第2部分详细阐述这个想法,我们将比较BPMN中表达的复杂的现实工作流模式与Amazon States Language。
现在,让我们回顾一下常见工作流模式的示例,以帮助说明为什么我们非常有信心BPMN是微服务编排和其他下一代工作流用例的正确流程语言。
在BPMN中定义业务流程模式
我们不打算在这篇文章中提供完整的BPMN教程。我们的目标是让您了解您可以使用的构建块的子集,并提供一些如何使用它们的示例。
如果您愿意,这不应该阻止您深入了解BPMN。我们上面提到的Camunda的BPMN教程是一个开始的好地方,我们的BPMN参考也是如此。
您也可以开始使用我们的Zeebe特定的图形建模工具,我们将在本系列的第2部分中详细介绍图形模型。
现在进入模式。
顺序流程,决策和并行处理
BPMN的核心是序列流,它定义了工作流中的步骤的执行顺序。
正如您可能想象的那样,将工作流限制为一个简单的一个接一个的任务序列会使许多现实世界的业务逻辑无法解决。除了任务(工作单元)之外,BPMN工作流还包括网关(引导流程)和事件(代表工作流可以响应或通知其他系统的事件)。
BPMN提供用于基于关联数据(专用网关)将工作流实例路由到单个序列流的构造,以及用于需要并行执行的一个或多个序列流(并行网关)的构造。
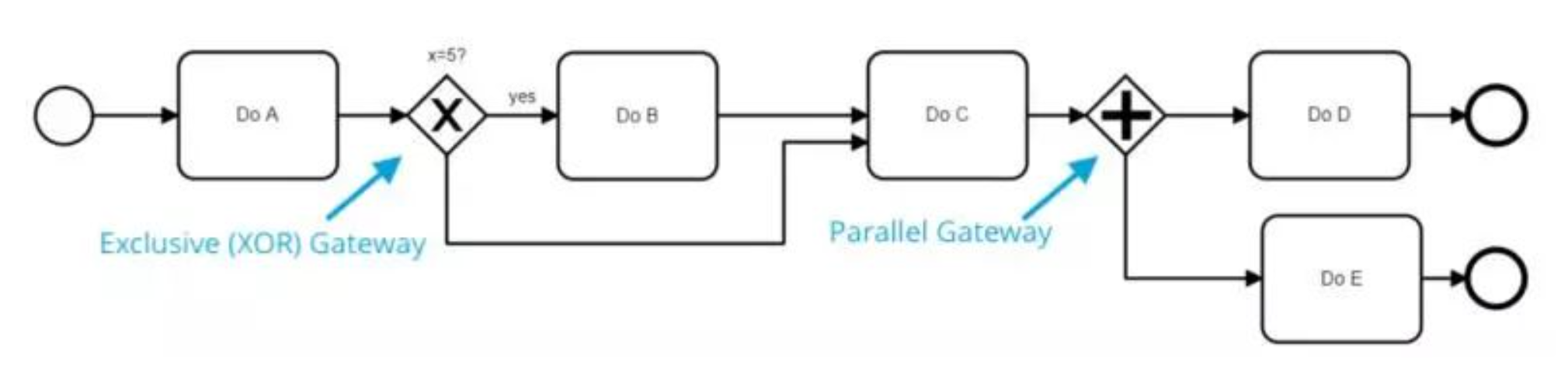
消息与超时的关联
BPMN的接收任务是标准为消息关联提供支持的一种方式,这是一种非常强大的功能,可以将等待的工作流实例向前移动,或者只有在消息可以正确匹配(“关联”)时才能执行其他操作 正在使用公共标识符等待它的特定工作流实例。
这是一项特别难以从头开始构建然后大规模支持的功能 - 并且BPMN与正确的引擎相结合,您可以开箱即用。
BPMN对发送和接收消息的支持意味着模型可以与消息驱动的体系结构无缝集成,这种体系结构在微服务领域尤为常见。
工作流程可以通过某些类型的消息启动; 它们还可以发出要由下游系统使用的消息。 或者工作流实例可以基于接收的消息结束。 例如,可以响应于与特定订单相关联的传入订单取消消息来终止正在进行的工作流实例 - 诸如电子商务公司中的订单履行过程。
正如您将看到的那样(我们将经常重复),可以轻松组合不同元素,这是BPMN如此强大的原因。
例如,接收任务可以与Timer事件组合,以便如果所需消息未在4小时内到达,则任务“超时”并且工作流实例遵循不同的路径。
多条消息的相关性
将一条消息与工作流实例相关联是有帮助的,但如果需要关联两个,三个或十个,该怎么办?
BPMN也涵盖了这种模式。 通过将接收任务与并行网关相结合,您可以等待两个或多个消息同步并合并其有效负载,然后再向前移动工作流实例。
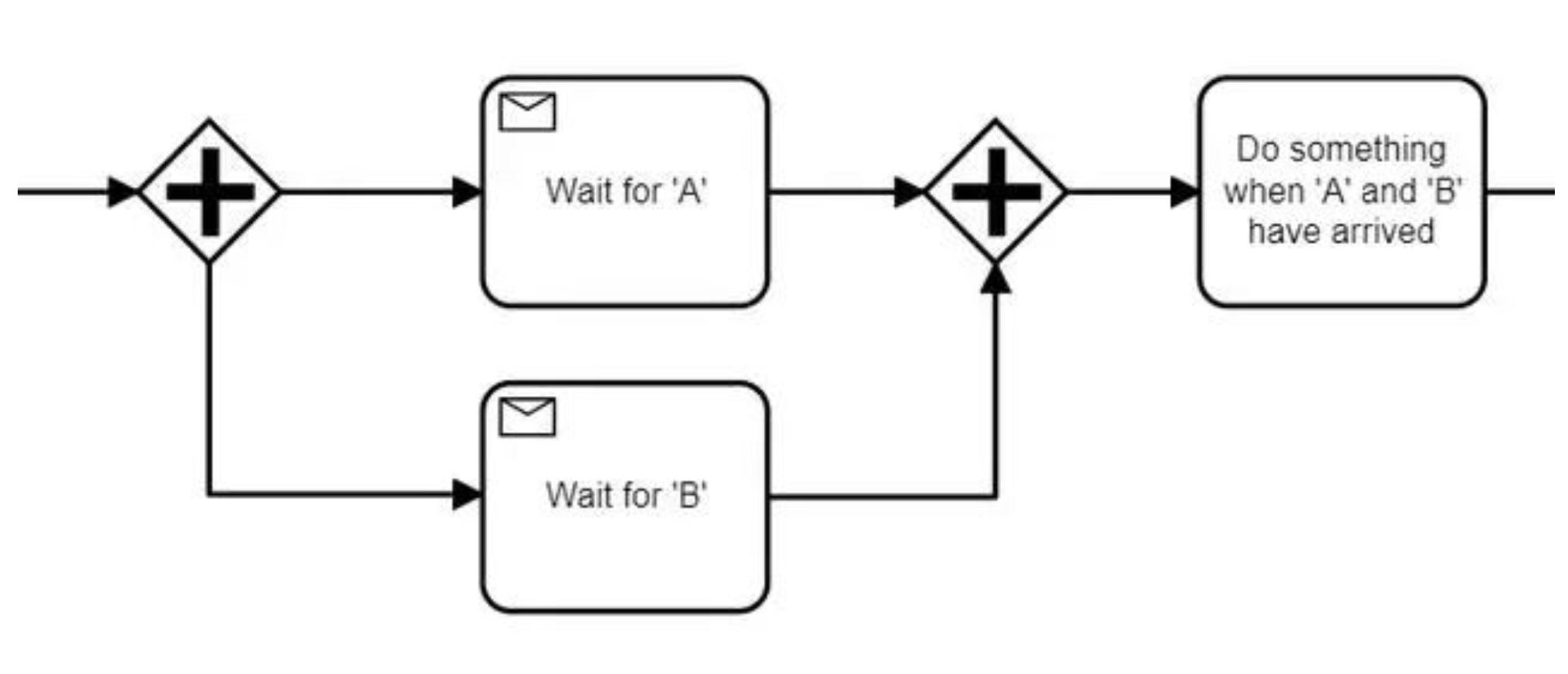
让我们更进一步,将此模式与超时结合起来。
同样,下图中添加的计时器和子流程只是一个例子,说明了如何组合不同的BPMN元素来表达复杂的流程; 当然,某些组合在某种程度上没有逻辑意义,对于如何连接BPMN符号以定义工作流程基本没有限制。
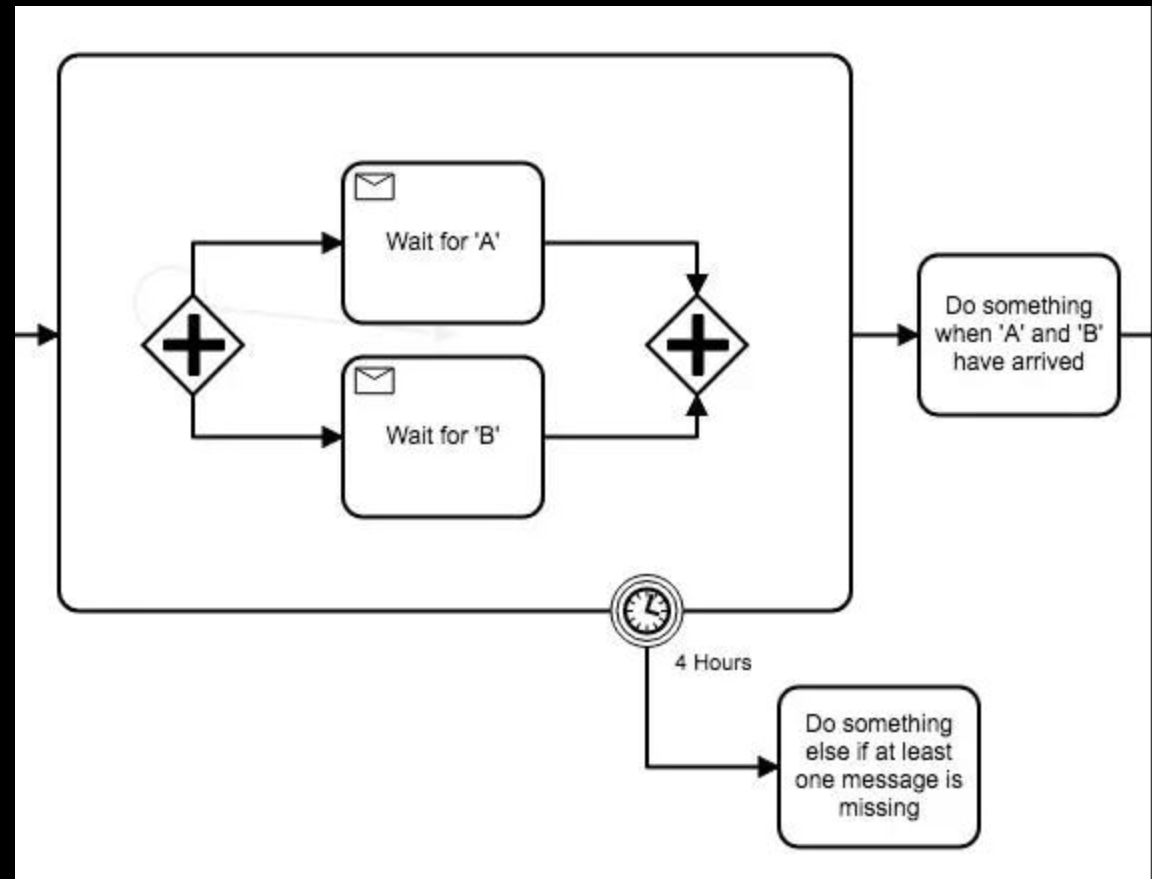
等待任意数量的消息
在某些情况下,我们可能不知道需要等待多少消息将与给定的工作流实例相关联。
考虑一个示例,在我们继续工作流程之前,我们需要为订单中的每个项目接收itemAvailable消息。 每个订单中的项目数量可能差别很大,我们可以使用BPMN的多实例活动在我们的模型中对其进行说明。
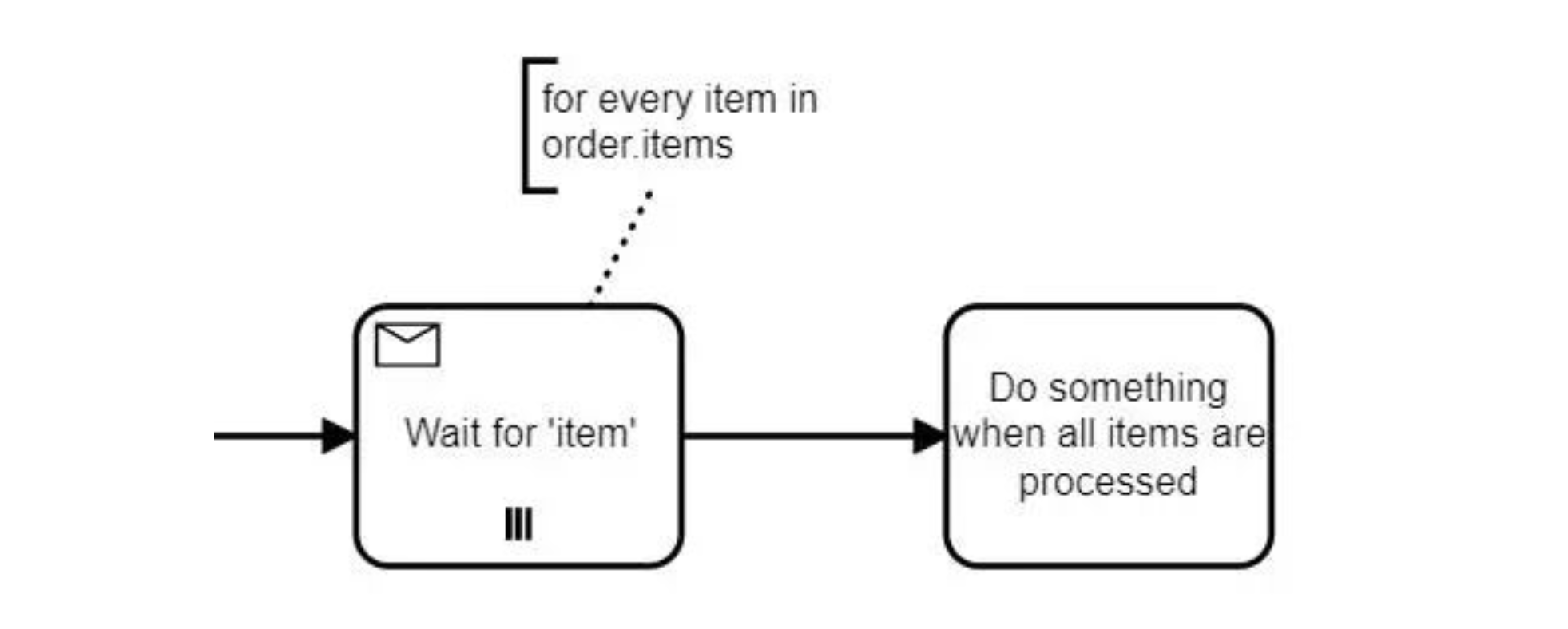
错误处理
您可能需要在工作流程中设计某些“业务逻辑错误”。 在这里,我们不讨论服务因技术原因而失败的错误,而是由于我们可以提前计划的业务问题导致工作流无法进行的情况。 BPMN的错误边界事件是针对这种特殊情况而设计的。
在此示例中,我们尝试向客户的信用卡收费。 如果由于客户帐户中的资金不足而导致费用下降,我们会通知客户该问题。
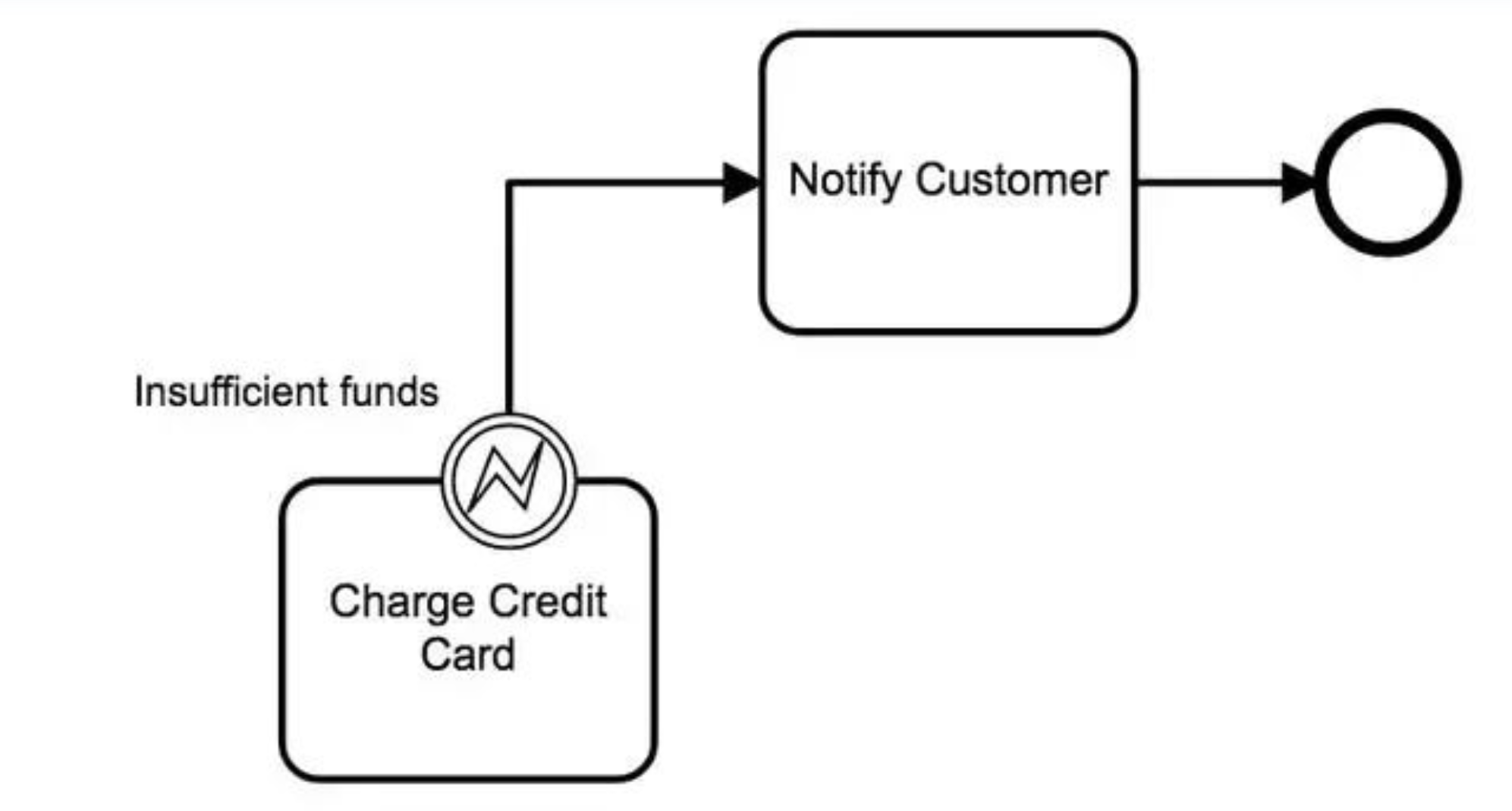
我们可以继续......
谈到BPMN支持的模式,我们只是略微划清界限。 我们希望您能够了解仅使用这些BPMN符号可以表达多少个不同的用例。
我们在这些示例中展示的内容并不是说明性的,也不会告诉您应该如何使用BPMN。 相反,我们的目标是激发您对可以构建的模型类型的想象。
Zeebe的BPMN状态
希望您在这篇文章中了解BPMN在定义和执行复杂工作流程时的可能性。
但真正的问题是:我们在Zeebe中支持多少BPMN?
从长远来看,Zeebe将支持所有对工作流自动化有意义的符号,就像我们使用Camunda BPMN工作流引擎一样。
目前,Zeebe 0.11(最新版本)支持:
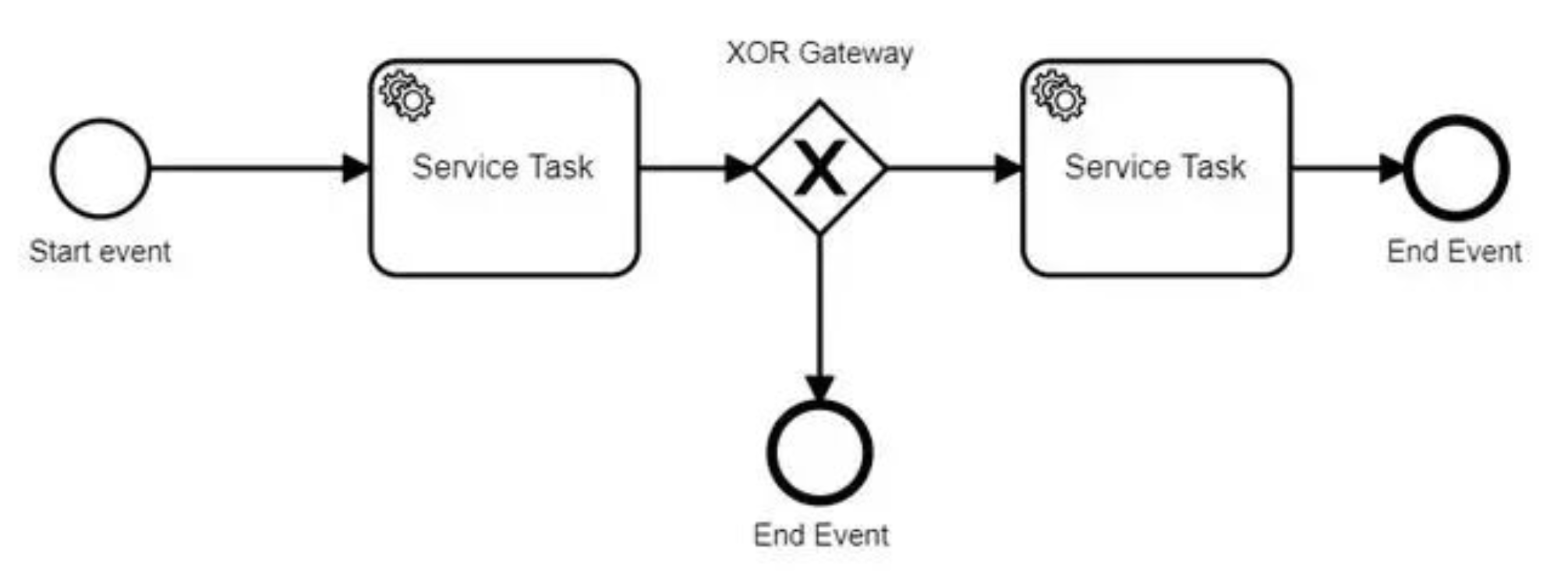
当然,这是一个有限的范围,到目前为止,我们主要关注Zeebe的引擎 - 即确保Zeebe具有处理高吞吐量用例的可扩展性和性能。
但是本季度我们一直在大力投资Zeebe的BPMN支持,我们将在不久的将来支持消息关联:
随着我们在2018年准备生产Zeebe,我们计划增加对更多符号的支持,例如:
- 计时器,
- 范围(子流程)和
- 并行执行
在2019年,我们将根据用户反馈以及我们对Zeebe将要解决的用例的了解来扩展符号支持。
我们处于BPMN系列第1部分的末尾。 我们在这篇文章中只提到了BPMN的一个非常重要的方面:模型可以用图形方式定义,然后由引擎直接执行。
因此,我们将很快回到第2部分,我们将在BPMN中了解图形模型的诸多优势,特别是与为业务流程用例构建的其他流语言相比时。 我们还将解决那些对图形模型有负面经验的开发人员的担忧。
如果您对此帖有任何问题或意见,我们很乐意听取您的意见。
讨论:请加入知识星球【首席架构师圈】
- 659 次浏览
【微服务架构】Consul概述
Consul概述
作为JHipster Registry的替代品,您可以选择使用来自Hashicorp的数据中心管理解决方案Consul。 与Eureka相比,它具有许多优点:
- 在多节点集群中操作比Eureka中更容易。
- 它有利于可用性的一致性,因此可以更快地传播集群状态的变化。
- Consul服务发现可以通过其DNS接口或HTTP API与现有应用程序进行简单的互操作。
架构图
入门
要开始开发依赖Consul注册表的应用程序,您可以在docker容器中启动Consul实例:
- 运行docker-compose -f src/main/docker/consul.yml up 以在开发模式下启动Consul服务器。然后,可以在Docker主机的端口8500上使用Consul,因此如果它在您的机器上运行,则应该在http://127.0.0.1:8500/。
您还可以使用Docker Compose子生成器为多个启用了consul的应用程序生成docker配置。
Consul的应用程序配置
如果您在生成JHipster微服务或网关应用程序时选择了Consul选项,它们将自动配置为从Consul的Key / Value存储中检索其配置。
可以使用http:// localhost:8500 / v1 / kv /或其REST API提供的UI来修改密钥/值(K / V)存储。但是,通过这种方式进行的更改是临时的,并且将在Consul服务器/集群关闭时丢失。因此,为了帮助您轻松地与Key / Value商店进行交互并将配置作为简单的YAML文件进行管理,JHipster团队开发了一个小工具:consul-config-loader。从consul.yml docker-compose文件启动Consul时会自动配置consul-config-loader,但它也可以作为独立工具运行。它可以以两种模式运行:
- 开发模式,来自central-server-config目录的YAML文件自动加载到Consul中。此外,对此目录的任何更改都将立即与Consul同步。
- 一个prod模式,它使用Git2Consul来设置Git存储库中包含的YAML文件,作为Key / Value存储的配置源。
请注意,与JHipster Registry一样,您的配置文件需要命名为appname-profile.yml,其中appname和profile对应于您要配置的服务的应用程序名称和配置文件。例如,在consulapp-prod.yml文件中添加属性将仅为名为consulapp的应用程序设置这些属性,这些应用程序以prod配置文件开头。此外,将为所有应用程序设置application.yml中定义的属性。
原文:https://www.jhipster.tech/consul/
本文:https://pub.intelligentx.net/consul-overview
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 106 次浏览
【微服务架构】IBM 教程 :微服务简介
微服务简介
更小,更快,更强:从头开始构建更好的云应用程序
在整个2014年和2015年,微服务成为热门的新流行词,迅速取代了云计算。本教程将向您介绍微服务的历史以及构建微服务架构的意义。
Netflix流媒体:普及微服务的诞生
无论你是否听说过微服务,我相信你已经听说过Netflix了。感谢Netflix在创建和发布用于管理云基础架构的软件方面的成功,我甚至愿意打赌您已经听说过Netflix开源软件(NOSS) - 这是为Netflix数字娱乐流媒体帝国提供动力的软件。
从2009年左右开始 - 完全由API驱动,并将我们作为微服务所知的最初浪潮 - Netflix完全重新定义其应用程序开发和运营模型。当时,该公司受到行业旁观者的嘲笑:“你们疯了!”或“这可能适用于Netflix,但其他任何人都无法做到这一点。”快进到2013年,当时大部分情绪都变为“我们正在使用微服务。”超过525,000个微服务的谷歌搜索结果表明,这个概念肯定既有效又强大。
但什么是微服务?什么是基于微服务的架构?图1显示了旅行预订服务的微服务的概念视图。图中七个瓦片中的每一个代表一个单独的微服务。它们被安排来显示哪些微服务可以与其他微服务交互,为内部和外部应用程序提供必要的功能。服务的不同垂直高度表示它们如何以不同的量相互使用。在本文中,我将介绍微服务的基础,以便您了解如何表示自己的基于微服务的体系结构。
图1.概念化的微服务
有关微服务开始的深入解释,请阅读Martin Fowler的优秀博客文章。我将在这里尝试捕获的是该帖子的精髓,它在当今环境中的应用,以及如何到达那里。
在一次会议上,前Netflix的Adrian Cockcroft将微服务定义为“细粒度的SOA(面向服务的架构)”。您不需要非常熟悉SOA(十多年前创造的架构风格),只需要在首字母缩略词中使用的术语。理想情况下,从第一天开始就构建整个服务架构。在微服务中,这些服务中的每一项都有一个单独的目的,没有副作用,使您能够以更少的整体专用工程师覆盖更大的规模。
为了定义微服务和相关的架构,我正在调整和修改用于描述现代运动员的“更大,更快,更强”的短语:更小,更快,更强(见图2)。从本质上讲,微服务是许多较小的架构组件,无论是独立还是整体,都可以快速构建和交付。
图2.微服务:更小,更快,更强
较小
微服务意味着不再是巨石。 Monolith很大,很笨重,速度慢,效率低,就像图3中的Grim Monolith一样。我们正在从一个拥有2GB WAR文件的世界(是的,只是WAR文件 - 而不是应用程序服务器或操作系统组件)转向世界 由许多500MB的服务组成,包含整个应用程序,服务器和必要的操作系统组件。
图3.一个严峻的巨石

从大型机到客户端/服务器架构的迁移是一个很大的步骤,也是许多公司和开发人员都在努力解决的问题。 从基于Web的核心应用程序服务器到SOA采用的最新迁移也是类似的问题。 过去几年应用服务器中包含的许多组件都适用于微服务; 但是,它们仍然包含在多GB的安装二进制文件中。 例如,图4显示了使用WebSphere®ApplicationServer和Java™Enterprise Edition组件部署的传统Web应用程序体系结构的体系结构。
图4.标准WebSphere Application Server应用程序体系结构
微服务是与所有交互组件集成的一种练习,它更松散地耦合。 微服务的整个想法变得即插即用。 我将在Stronger部分更多地讨论这个问题,但基本上一个基于微服务的系统大规模采用了霰弹枪方法,以维护和保护更多的小组件而不是更少的大组件。 您可以删除单点故障并在任何地方分发这些故障点。
失败的建筑只能用较小的碎片来完成。 如果你为失败建立一个巨石,你会花太多时间专注于每个边缘情况的低效率。 如果构建单个服务实例以进行故障,则其他服务实例将在消费者发出请求时接管。
图5中的图表是使用微服务的实现的一个示例。
图5.视频流应用程序的概念路由示例
在图5中,每个单独的盒子都是独立维护的,可以自行调整,知道它所在的位置,并知道从何处获取所需的信息。并非每个微服务架构都需要此图中的每个组件,但它们确实有帮助!
比较图4和图5,您可以看到类似应用程序的部署方式的差异。在图4中,所有内容都部署到垂直扩展系统上的单个进程。当需要更多吞吐量时,整个服务器堆栈会一次又一次地被标记出来。每个服务器都在自己的进程内运行。在图4的Web服务引擎或EJB容器中获得更多吞吐量的唯一方法是将整个服务器JVM扩展到集群环境中的新实例。但是,这也会创建另一个Web容器,另一个嵌入式HTTP服务器,另一个消息传递引擎等,无论这些组件是否需要扩展。
与图4的刻度类型相比,图5具有可独立缩放的组件。我将介绍各个组件以及它们如何在Faster部分中扩展,但现在关注每个组件和服务的分布式特性。与图4中的示例应用程序(需要完全高度可用的Web应用程序服务器堆栈以提供可用性)不同,这些组件本质上是分布式的,只提供单一的,集中的功能,通常使用与其他组件不同的技术。此结构使应用程序体系结构能够更快地发展,并包含更新的技术以及更新的版本,而与其他组件无关。
总而言之,较小的开发,操作,维护和交互更好。
快点
与云一起出现的另一个流行语是DevOps。 DevOps运动使开发人员能够在交付管道中控制更多代码,不断集成并实现更高的可见性。 DevOps的主要原理,如图6中顺时针顺序所示,是观察,定位,决定和行动。
图6. DevOps的原理
有什么比更快地交付小件更好,对吧?您无法每两周向单个应用程序服务器实例提供更新,但在同一时间范围内,您绝对可以为许多其他服务所使用的单个服务提供更新。当您构建新的临时环境,通过管道移动项目以及交付到生产环境时,较小的组件会产生较少的开销。
别误会我的意思。仍然可以使用整体进行持续交付和集成。我已经看到它发生了。然而,那时你是杂耍的巨石,而不是大理石。从掉落大理石中恢复比从掉落大石更容易恢复。
与DevOps相关的开发周期非常适合微服务。您的目标是缩短开发周期,不断增加功能,而不是更长的开发周期,从而立即构建完整的整体愿景。这种称为敏捷的开发方法是DevOps成功的基本实践。无论您选择迭代还是增量开发,微服务,DevOps文化和敏捷规划的组合使您能够在过去几年中计划第一个瀑布周期时快速构建整个基础架构。
更快的另一方面涉及执行。微服务建立在这样一种观念之上:如果你需要更快,只需要投入更多的资源。经理的梦想!通过构建可独立扩展的每个服务,您可以允许组件之间的交互,以利用资源池而不是单个组件接口。
回到上一个示例,在图5中,您可以看到Service Registry服务器和客户端。此功能在基于微服务的应用程序中至关重要。在此示例中,边缘服务包含Movie Service和Review Service引用。基于负载,这些服务以不同的速率扩展;因此,你不能再以相同的规模管理它们。
随着Movie Services规模的扩大,Service Registry会自动了解创建的新服务实例。当边缘服务尝试处理请求时,它会调用Service Registry并获取它所依赖的所有服务的客户端引用。 Movie Service客户端引用更可能是最近创建的新引用,而以前使用的旧服务实例可以返回。此Service Registry功能允许您的微服务真正充当“众多之一”,在组件之间具有松散耦合的依赖性,但是在需要时获得更多组件副本的高度可靠性。
图7显示了图5中视频流应用程序的相同概念架构,并为Movie Service添加了扩展的微服务。
图7.视频流应用程序的概念性缩放示例
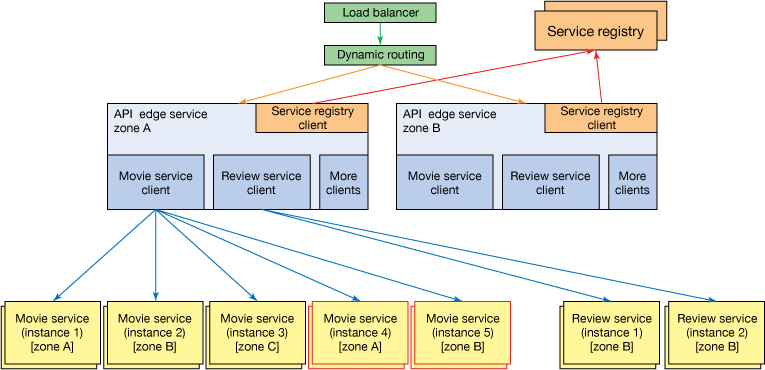
使用能够自我感知新实例的系统,根据需要进行有效扩展。不,这不是天网。这就是使基于微服务架构的应用程序更强大的原因。
更强
并非所有系统都是长寿的。它们在需要时创建,并在不再用于某个目的时被删除。正如我之前提到的,这通过在整个系统中分发这些点来消除单点故障,因为您知道需要机制来考虑不可用或性能不佳的服务和实例。
牛,不是宠物
使用微服务,部署系统的概念变成了牛,而不是宠物:
- Pets are given names; cattle are given numbers.
- Pets are unique; cattle are often identical.
- Pets are nursed back to health; cattle are simply replaced when ill.
- 从Gavin McCance的CERN数据中心Evolution演示文稿中获取。
这个概念导致创建许多服务,以及许多服务中的一个。我们不再一方面计算服务实例或管理长期实例,而是担心维护状态,存储,系统修改等。不要误解我的意思 - 我们仍然对性能调优和配置非常感兴趣,但现在这些事情在开发周期中更早发生,而不是在分段或生产中。这种方法为我们提供了许多服务,以及每项服务的许多实例。
为了验证这一力量支柱,在其旅程中,Netflix开始利用混乱 - 确切地说是混沌之猴(见图8)。混沌猴是一个云应用程序组件,Netflix用它来引入应用程序操作的系统混乱。
图8.混沌之猴

此功能将通过基础结构并有目的地关闭对生产至关重要的服务和服务实例。为什么Netflix会这样做?它怎么能这样做并存活下来?
首先,为什么。这是一种让您轻松识别快速失败所需的方法。新服务太慢了吗?他们需要更有效地扩展吗?当外部服务提供商关闭时,而不仅仅是内部服务会发生什么?所有这些都需要在微服务架构中加以考虑。
第二,如何。由于我之前提到的霰弹枪方法,Netflix可以生存。这个想法很简单:提供足够的服务实例,99.9999%的请求将成功完成。任何失败的请求都将在重试时起作用。拔下服务实例上的插件,另一个本地插件将取代它。拔下整个服务上的插头,您的系统应该将用户补偿或重新路由到具有该特定服务的其他可用区或区域。如果没有别的可用,用户或请求应该快速失败,而不是等待超时。
Netflix扩展了Chaos Monkey的概念并发布了作为Simian Army的功能(见图9),包括Chaos Monkeys,Janitor Monkeys,Conformity Monkeys和Latency Monkeys--云应用程序组件,它们将特定的混乱引入操作,包括延迟和合规性问题。
图9.猿人军队

正如您所看到的,Netflix(以及其他采用微服务的公司)认为杀死您的应用程序的想法使其变得更强大。
结论
我提到的微服务的主要好处是:
- 它们的小尺寸使开发人员的工作效率最高。
- 很容易理解和测试每项服务。
- 您可以正确处理任何相关服务的故障。
- 它们减少了相关故障的影响。
致谢和图片学分
我要感谢Jonathan Bond的演讲,这让我能够捕捉和定位我的想法并借用一些图像(图1,5,6和7)。
- 97 次浏览
【微服务架构】IBM微服务参考架构
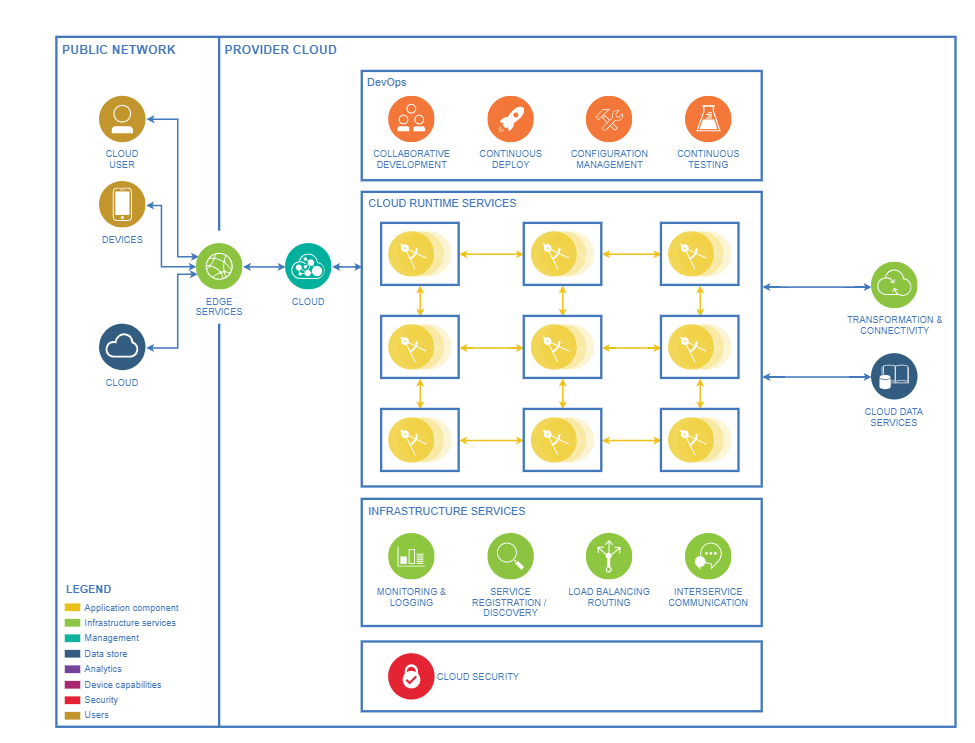
- 78 次浏览
【微服务架构】IBM微服务参考架构
在微服务应用程序架构风格中,应用程序由许多离散的,网络连接的组件组成,称为微服务。微服务架构风格是SOA(面向服务架构)架构风格的演变。使用SOA服务构建的应用程序倾向于专注于技术集成问题,而实现的服务级别通常是细粒度的技术API。相比之下,微服务方法通过更大粒度的业务API实现了明确的业务功能。
这两种方法的最大区别在于它们的部署方式。多年来,应用程序已经以单片方式打包 - 这是一个开发人员团队构建了一个大型应用程序,可以满足业务需求。构建之后,该应用程序随后在应用程序服务器场中多次部署。相比之下,使用微服务架构风格,开发人员可以独立构建和打包几个较小的应用程序,每个应用程序只实现整个应用程序的一部分。
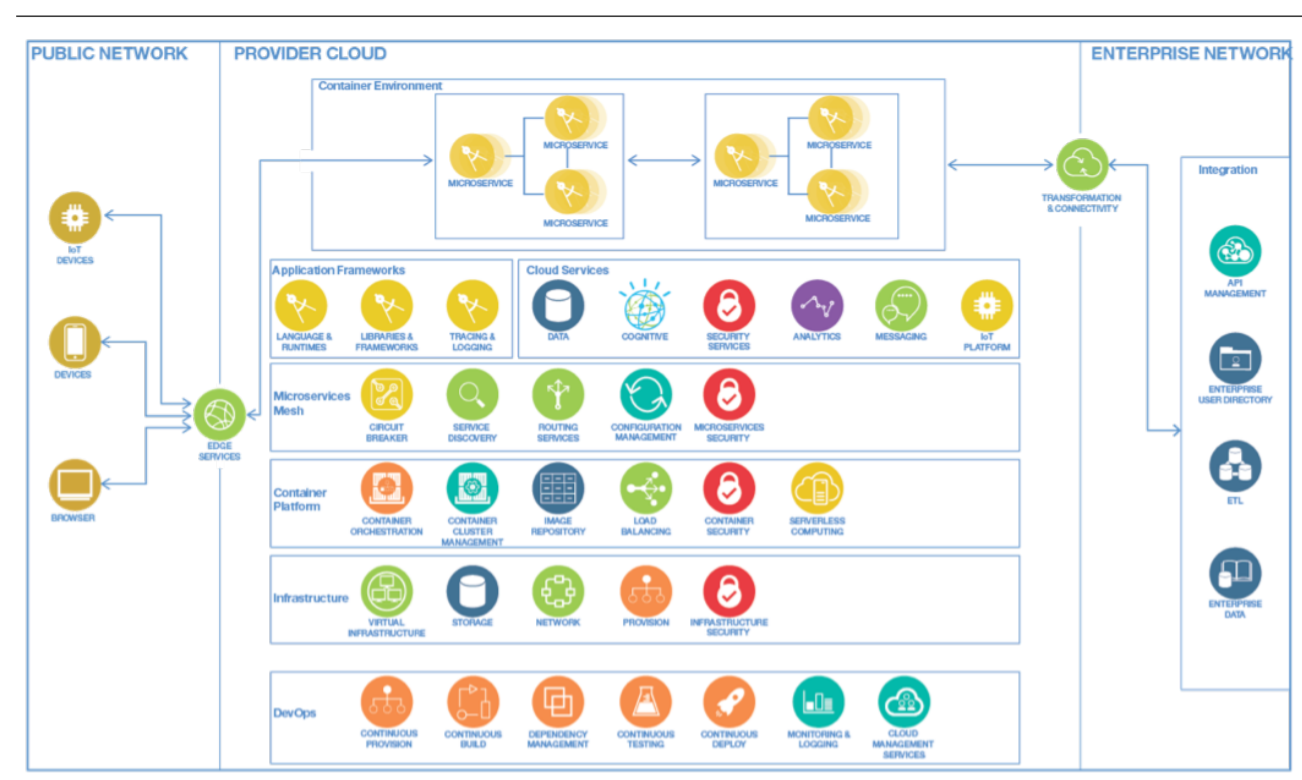
功能要求
-
通过移动和Web应用程序背后的API构建微服务。
-
为微服务提供实现选择,例如Java,Node JS,Swift等。
-
使用API Connect/Gateway将微服务暴露给前端。
-
从iOS或Android中构建的本机移动客户端以及使用AngularJS或ReactJS等技术的Web客户端调用API。
-
使用不同的云工作负载模式部署微服务,例如Docker,Cloud Foundry和基于Apache OpenWhisk的IBM Cloud Functions。
-
使用微服务框架,如Amalgam8或Netflix OSS,实现众所周知的微服务模式,如路由,断路器和自动缩放。
-
通过使用群集,自动扩展,故障转移,断路器,批量头和灾难恢复来创建弹性微服务。
-
为前端应用程序使用关键服务,例如移动分析,推送通知,内容管理等。
-
为基于微服务的应用程序的操作,监视和管理提供指导。
-
通过提供有关如何为微服务和前端构建持续集成/连续交付管道的详细指导,构建端到端DevOps。
-
在微服务环境中使用Garage Method for Cloud,例如测试驱动开发。
- 172 次浏览
【微服务架构】IBM教程:容器和微服务 - 完美的一对
为什么比以往更容易交付更小,更快的应用程序组件
在本系列的第1部分中,我谈到了什么是微服务以及它们与传统构建的系统(monoliths)的区别。第二部分是关于Linux容器的强大功能 - 它们如何彻底改变软件开发并为微服务提供动力以改变整个行业。在基于微服务的应用程序采用基于容器的基础架构时,我将介绍三个对您至关重要的概念:
- 记录和监控
- 零停机持续交付
- 动态服务注册表
我将首先概述容器,容器管理器以及容器与微服务的关系。
容器和微服务:完美的一对
除非您对云技术和云原生应用程序开发完全陌生,否则您可能听说过Linux容器以及过去几年引爆的基于容器的项目。但是如果你还没有,可以将Linux容器视为轻量级虚拟机,可以更灵活地使用,更快地集成,并且更容易分发。领导此项收费的项目之一是Docker。自2012年推出以来,Docker团队(现在的公司)提供了一种通过Linux容器构建,打包和分发云原生应用程序的简单方法。
容器与虚拟机有何不同?每个虚拟机(如下图左侧所示)运行自己的客户机操作系统实例,并包含自己的库和二进制文件。容器(如右图所示)是隔离的,共享底层主机操作系统和库,同时只打包必要的应用程序二进制文件。
“许多行业领导者正在转向基于容器的基础架构,无论是在云端还是在本地,都能获得极大的收益。”
容器作为Linux系统上的最小资源集运行,并且打包的应用程序通常不超过几百兆字节。基于虚拟机的应用程序通常至少要大三到四个数量级(几十千兆字节)。您可以轻松地了解容器如何适应微服务范例,更小更快 - 第1部分中的两个微服务原则。
许多行业领导者正在转向基于容器的基础架构,无论是在云端还是在本地,都可以获得极大的收益。其中一个主要收获是Docker和其他类似的Linux容器技术很容易集成到持续集成和连续交付管道中:根据最近自筹资金的Docker研究,平均而言,Docker用户的软件发送频率是其七倍。像Gilt Groupe这样的公司已经拥抱微服务和集装箱化基础设施,有时每天运送软件100次。能够快速推动代码更改,自动重建最小尺寸的Docker镜像,并从公共代码库管理大量这些部署的图像,从而通过公司的交付管道获得令人印象深刻的速度。
Docker容器的另一个好处是这些打包应用程序的可移植性,称为Docker镜像。 Docker镜像可以跨环境和构建管道无缝移动。例如,BBC新闻(英国广播公司的一个部门)表示,其基于Docker的基础设施的持续集成工作速度提高了60%以上。能够在整个交付流程中移动相同的代码 - 最大限度地减少每个阶段的软件配置需求并在此过程中具有可预测的硬件资源需求 - 通过开发,测试和生产来加快应用程序的速度。公司能够看到效率的提高,因为他们的系统组件在每个Docker镜像中都是模块化的。您无需在每次需要时配置软件。你只需启动一个容器实例,就可以了。
Docker是一个代码的运输容器系统,可以轻松地通过Linux容器进行软件开发和交付。 Docker充当引擎,可以将任何有效负载封装为轻量级,便携式自给自足的容器。这些容器可以使用标准操作进行操作,并且几乎可以在任何硬件平台上运行。
如果您是容器和Docker的新手,请参阅相关链接,了解有关Docker和Linux容器的一般介绍材料。如果您对Docker有经验并希望在云中亲自动手使用Docker,那么IBM Cloud Kubernetes Service是一种企业级容器服务,您可以立即免费使用它。您可以使用自己的私有注册表来存储所有映像,访问支持的中间件的IBM公共注册表,托管交付管道集成以及访问150多种IBM Cloud™服务。您可以比以往更快地在Docker容器中运行应用程序。
更快更小:容器作为软件开发的纳米机器人
您可以开始了解容器对于微服务如此重要的原因 - 作为架构风格的关键支持技术之一 - 您也可以开始看到容器的管理同样重要。正如您在第1部分中所了解的那样,我们不是按比例放大,而是在微服务中扩展。我们只是获得了同一类型的另一个微服务运行时,而不是向微服务运行时添加更多RAM。需要更多内存?得到第三个实例。这种方法适用于每个只有一个容器实例的几个服务,但是对于拥有计算机技能和大家庭知识的人来说,当您远程管理数十台服务器时,它可能会很快失控。
想想您需要多快管理100多个单独的实例。如果你从构成你的应用程序的一些微服务开始 - 比如说五个或六个 - 每个应该至少有三个容器实例支持每个微服务。所以马上,你就是18个集装箱实例。假设您添加了另一个微服务,或者您的应用程序非常成功,您需要为某些服务扩展到5到10个容器实例。在一个美好的一天,你很容易接近超过100个容器实例来管理。
值得庆幸的是,许多开源项目可以满足这一需求。例如,Kubernetes,Apache Mesos和fleet使用基于基础结构的特定于域的语言,可以轻松地从单个控制台或命令行管理数千个容器实例。
这种管理概念紧紧地强化了第1部分中与牛相比较的概念。我们的想法是,我们通过持续集成/持续交付流程部署的所有容器都是不可变的。部署后,您无法更改它们。相反,如果您需要更改或更新,请启动一个新的容器集群,并应用正确的更新并拆除旧的容器。管理1,000头牛比1000只宠物要容易得多。不要误会我的意思:我们都喜欢我们的宠物,但如果您想要快速创新并为您的客户创造价值,并为您的企业带来收益,您就无法花费所有必要的时间来为每只宠物提供所有宠物它需要温柔的爱护。诸如Kubernetes,Apache Mesos以及诸如IBM Cloud Kubernetes服务之类的托管和托管容器服务等项目使您可以集成交付管道和图像注册表,从而快速,轻松地管理基础架构的所有阶段,即高效率的牛群。
另外,应该注意的是,虽然某些容器服务仍然使用虚拟机作为Docker主机,但这些仍应被视为牛。这些虚拟机在资源和集成管理功能方面更加强大,但它们通常被认为是牛,因为它们是由基于容器的工作负载的需求动态管理的。
微服务结构:你最好的打击Whack-A-Mole的借口
到目前为止,我已经讨论了为什么更多的容器更好以及如何大规模处理通用基础设施。现在您对容器开发和与宠物说再见的概念感到满意,您需要开始考虑开发应用程序并将其投入生产。
这让我了解了对基于微服务的应用程序开发至关重要的三个关键要素:
- 记录和监控
- 零停机持续交付
- 动态服务注册表
您想从第一天开始考虑这些功能,但不一定要立即解决。
在讨论这些功能时,您还将了解为什么集成的微服务结构(例如IBM Cloud及其相关服务)使您的微服务架构的管理变得更加容易。
记录和监控
如果您为应用程序和服务提供生产级支持,那么您的第一个问题应该始终是“出现问题时我该怎么办?”请注意,在该问题中甚至没有提示“if”。组件将失败,版本将更改,第三方服务将中断。如何保持一定的理智水平,以及为用户提供所需的正常运行时间?这是一个问题。
正如我之前所说,你希望你的容器是不可变的。出于这个原因,大多数IT组织不提供对容器实例的系统级访问 - 没有SSH,没有控制台,没有任何东西。那么你怎么知道你无法改变的黑匣子里面发生了什么?这是第二个问题。
值得庆幸的是,这个问题已经通过ELK stack-Elasticsearch,LogStash和Kibana的概念得到了解决。
这三个独立的组件提供了聚合日志,通过聚合日志搜索自由格式,以及基于日志和跨平台监控活动创建和共享仪表板的功能。这是一个很棒的功能 - 比登录到个人计算机和运行sed,grep和awk的sysadmin工具箱要好得多。您可以全面访问所有日志的中央存储库。您可以跨系统和微服务关联事件,因为您通常会看到事件和ID在您的系统中传播并遇到类似问题。
您可以通过多种方式与ELK堆栈集成,无论您是在云中运行还是在本地运行:通过托管服务,开源变体以及通常构建在平台即服务产品中的选项(如IBM Cloud Kubernetes)例如,服务。在IBM Cloud上的容器运行时内部,您可以访问功能齐全的多租户ELK堆栈,该堆栈自动从Docker基于容器的运行时接收日志,使您可以查看和搜索这些运行时事件,同时还为您提供预配置的Kibana-基于仪表板的开箱即用。如果您希望开始使用容器,这是一个关键功能,它使IBM Containers成为基于容器的微服务的卓越选择。
零停机持续交付
现在你很自在地知道当天空开始下降时该做什么(当然你希望它永远不会发生),你可以继续快速部署你所有惊人的应用程序更新。考虑到一些大型公司每周部署数十,数百或数千次应用程序,您不得不怀疑停机时间。当然,这些公司每次推出新版本时都没有应用程序中断 - 如果他们这样做了,他们就永远不会失败。
这些公司已经掌握了零停机部署。这可以被称为许多东西,通常有多种颜色,从红黑到蓝绿等等,但它们都回归到同样的原则:即使通过丰富的更新,您的应用程序始终可用,无论如何,因为计划停机造成的网站中断对您或您的用户不利。
现在使用第1部分中描述的整体结构,避免计划停机对于每个参与者而言都是危险,耗时,昂贵且耗费精力。需要大量资源的多个镜像图像是非常难以管理的,导致深夜,在一个假设的“非工作时间”窗口,当大量的出汗完成同时使新版本和旧版本下降 - 更不用说计算如果需要回滚或者在直接负责的团队控制范围之外出现问题,该如何处理旧版本。
借助微服务和基于容器的应用程序,即使没有完全删除,这些担忧也会被最小化,尤其是当今IBM Cloud上提供的一些关键服务。通过将组件分解为更小的组件,您可以在对整个系统产生最小影响的情况下部署它们,同时在特定时间保持更多组件以防止中断。较小的团队可以更有效地管理更多应用程序,因为部署的每个版本都可以自动监控维护其正常运行时间,从而降低人工注意力和计算资源的成本。
动态服务注册表
本部分的最后一个主题是动态服务注册表的概念。本主题包括您可能已经知道的服务发现或服务代理的概念。这两个概念无论如何都不尽相同,但它们足够接近这一方法。
既然您将创建数千个容器实例来支持所有应用程序中的微服务,那么应用程序中的其他组件将如何理解正在发生的事情?他们如何知道他们可以使用哪些其他微服务来进行服务呼叫?他们将如何回应对他们的服务电话?
服务发现和服务代理之间的区别取决于您是想自己进行搜索还是让其他人为您处理。作为类比,假设您需要送货服务。您是否希望从单个提供商(例如美国邮政服务(USPS))或多服务清算中心(如Staples)查询服务。
例如,如果我想运送一个包裹,我可以去USPS网站,为我要找的邮局输入几个参数,找回选项列表,选择一个,然后去那里运送我的包。这是服务发现的概念:我使用一个众所周知的可用服务端点注册表,这些服务端点在服务联机并脱机时更新。通过REST API,调用应用程序可以查询服务发现服务,以确定特定服务调用可用的服务类型和数量,直至该请求服务的特定版本。
如果我不想成为我选择运送包装的地方的人 - 我只想说,“把这个包裹拿到地址标签上的内容” - 我可以把它带到Staples。然后Staples根据我提供的所有信息为我的包装选择最具成本效益的运输选项。我正在把这个包带到一个知名的服务提供商那里,让它为我处理我的包的路由。这是服务代理的概念:您调用一个众所周知的端点,并根据预先建立的规则或元数据将该调用自动转发到提供对服务请求的实际响应的支持服务。
优先考虑服务发现优于服务代理,反之亦然,但实际上归结为偏好或实施经验/要求。一些开源服务发现产品,如etcd和Consul,提供分布式服务注册表,您可以使用它们注册,标记和检测所有可用的服务实例。甚至还有像Registrator这样的很酷的项目,只要创建Docker容器,它就会自动将您的服务注册到其中一个端点。
一些比较流行的服务代理项目支持以下关键参数:从长远来看,服务代理方法需要更少的网络跃点才能获得最终的支持服务。 Netflix Hystrix项目是最大和最受欢迎的服务代理项目之一。 Hystrix是一个基于Java™技术的库,它超越了简单的服务代理,但在服务代理库中提供了许多服务质量改进。
显然,这两种模式对于自动管理服务实例并使其成为可用微服务基础架构的一部分非常重要。 IBM Cloud将很快拥有自己的多租户服务发现服务(如果您在阅读本文时尚未拥有它) - 无需管理服务发现服务,这可能是少数几项。想象一下,自动注册所有容器实例,无论是手动启动它们,推送它们通过IBM Cloud的Delivery Pipeline,还是与Jenkins等内部部署管道集成。
结论
您已经在这里看到容器如何加速推动云原生应用程序开发。与以往相比,更小,更快的应用程序组件可以更快,更轻松地交付,具有比以往更多的内置管理功能。在托管服务(例如IBM Cloud Kubernetes Service)上部署容器以及所有支持的微服务功能(包括日志记录和监视,主动部署和服务发现),可以轻松地将下一步从现有的整体块中移除到云。
我们正朝着更智能的模块化系统发展,这些系统从头到尾更加自动化,集成度更高。这些将按照自己的进度发展,自我意识到基础设施中可用的内容,让它知道什么不是,并在需要改变时告知它。所有这些功能和更多功能将在本系列的一些即将发布的系列文章中介绍。
原文 :https://developer.ibm.com/tutorials/cl-ibm-cloud-microservices-in-action-part-2-trs/
- 44 次浏览
【微服务架构】Kafka vs Moskitto-哪种工具更适合微服务之间的通信?
近年来,微服务架构越来越流行。Docker和Kubernetes等编排工具使创建和维护此类应用程序变得非常简单。可以说,这些工具甚至正在推动微服务架构。

微服务之间的通信
不幸的是,这样的架构,除了许多优点之外,也有一些挑战!其中之一就是在微服务之间找到一种良好的通信方式。
如果您遇到这样的问题,您肯定听说过三种解决方案:REST API、MQTT或Kafka。信不信由你,但REST API在这个用例中是不可能的。所以我们只剩下两个解决方案:MQTT和Kafka。
两者都是消息传递代理,它们有不同的协议和服务于不同的目的,所以让我们来比较一下这两者。
完美的消息传递代理
让我们从对微服务来说最重要的事情开始。
微服务应该有持久的数据存储。他们应该能够接受大量的流量和大量的数据集。此外,它们还应该能够将流量分成独立的逻辑部分,例如,主题。最后,微服务应该具有非常高的可靠性和事件交付能力。
考虑到这些要求,让我们来比较一下Kafka和莫斯基托
Kafka:
Kafka最初是由LinkedIn员工在2011年创建的,当时考虑到了他们的信息系统。它后来在Apache许可证上发布。Kafka持久化事件,这意味着消息在收到时立即写入文件系统。
它能够扩展服务而不必担心事件的重复处理。Kafka通过添加更多的分区来扩展,这样来自每个分区的消息可以并行处理,从而使该工具更容易和高度可伸缩。这是因为,从一开始,它就是为大系统开发的。它的规模比其他类似的“有状态”消息代理更好。
Kafka可以轻松处理高速数据摄取。除此之外,这些库是用最流行的语言编写的。它有一些非常有趣的框架,看看这个基于Ruby的框架-Karafka。
不幸的是,Kafka要想正常工作就得靠Zookeeper 了。
Mosquitto:
让我们看看mosquito,另一个用于微服务间通信的工具。
Mosquitto 是最流行的解决方案之一。它是为物联网项目创建的轻量级协议。它基于发布/订阅模型。消息代理独立于其他应用程序或库。
Mosquitto是在EPL/END下授权的,这意味着它是开源的,也是Eclipse基金会的一部分,这对许多项目来说是一个重要因素。Mosquitto有多种语言的多个库,所以可以肯定地说,它是非常通用的,这意味着开发人员可以很容易地根据项目进行调整。
回答:
Kafka更适合微服务。它具有持久性存储,因此可以从一开始就重放来自特定主题的事件,从而引入事件源模式。
原文:https://naturaily.com/blog/kafka-mosquitto-microservices
本文:http://jiagoushi.pro/node/1101
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 64 次浏览
【微服务架构】Kubernetes微型服务(Spring)
部署显示古董计算设备目录的店面购物应用程序。 客户可以浏览目录并从中进行购买。 该应用程序是一个云原生微服务应用程序,基于Kubernetes的IBM Cloud™容器服务构建。 使用DevOps工具实现自动持续集成和持续部署。

流程
步骤1
Kubernetes集群中的Ingress控制器(IBM Cloud Kubernetes服务或IBM Cloud Private)接收来自用户的请求,并将其转发到Web Backend for Frontend(BFF)pod。 Web BFF pod中的容器处理请求并发送响应,呈现Web应用程序主页。
第2步
用户通过单击主页上的链接来浏览目录。
第3步
浏览目录的请求被发送到Web BFF,后者使用Kubernetes专用网络上的kube-dns向后端目录微服务发出HTTP请求。
第4步
目录微服务从按需填充的内存中Elasticsearch数据库中获取当前目录数据,并通过Web BFF将该数据发送给用户。
第5步
用户通过单击Web浏览器中的“登录”链接并输入登录凭据来登录。
第6步
Ingress控制器将登录请求作为OAuth请求发送到Web BFF和身份验证微服务。
第7步
身份验证微服务调用客户微服务,使用用户凭据验证用户名和密码,这些凭据存储在CouchDB数据库中。成功登录后,将生成OAuth令牌并将其返回到请求的浏览器会话。
第8步
经过身份验证的用户通过单击项目详细信息页面上的“购买”按钮来下订单。 Ingress控制器将交易请求转发给Web BFF,后者调用订单微服务来完成购买交易。
第9步
订单存储在MariaDB数据库和订单微服务中。经过身份验证的用户通过单击“配置文件”选项卡来访问订单。
https://github.com/ibm-cloud-architecture/refarch-cloudnative-kubernete…
https://www.ibm.com/cloud/garage/tutorials/microservices-app-on-kuberne…
https://www.ibm.com/cloud/garage/files/microservices-with-kubernetes.pdf
https://www.ibm.com/cloud/garage/files/microservices-with-kubernetes-ed…
原文:https://www.ibm.com/cloud/garage/architectures/microservices/microservices-kubernetes
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 73 次浏览
【微服务架构】Medium的微服务架构实践
微服务¹架构的目标是帮助工程团队更快,更安全,更高质量地交付产品。解耦服务允许团队快速迭代,对系统的其余部分影响最小。
在Medium,我们的技术堆栈始于2012年的单片Node.js应用程序。我们已经构建了几个卫星服务,但我们还没有制定一个系统地采用微服务架构的策略。随着系统变得越来越复杂并且团队不断发展,我们在2018年初转向了微服务架构。在这篇文章中,我们希望分享我们有效地做到这一点并避免微服务综合症的经验。
什么是微服务架构?
首先,让我们花一点时间来思考微服务架构是什么,不是什么。 “微服务”是那些过载和混乱的软件工程趋势之一。这就是我们在Medium认为它是什么:
在微服务架构中,多个松散耦合的服务协同工作。每项服务都专注于一个目的,并具有相关行为和数据的高度凝聚力。
该定义包括三个微服务设计原则:
- 单一目的 - 每项服务应专注于一个目的并做得好。
- 松耦合 - 服务彼此知之甚少。对一项服务的更改不应要求更改其他服务。服务之间的通信应仅通过公共服务接口进行。
- 高内聚性 - 每项服务将所有相关行为和数据封装在一起。如果我们需要构建新功能,则所有更改应仅本地化为一个服务。
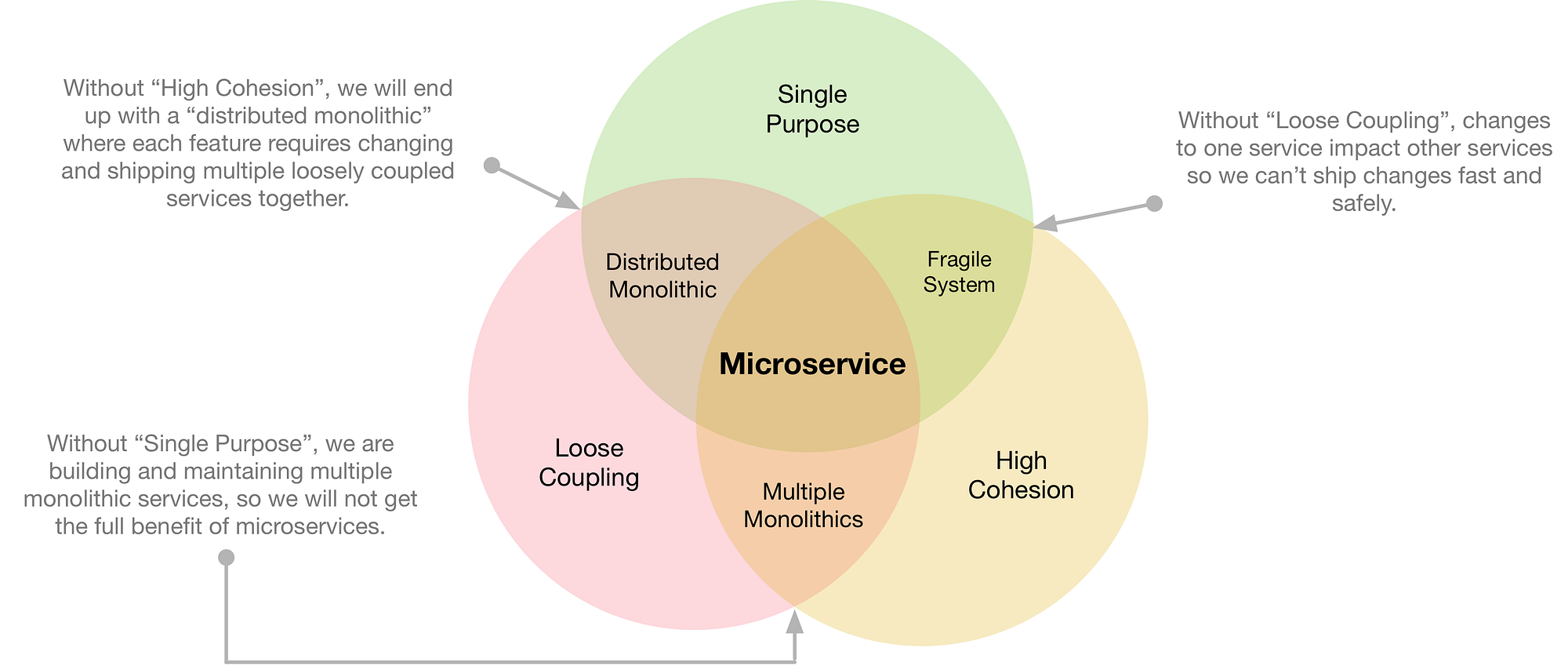
Three Principles of Modeling Microservices
当我们对微服务进行建模时,我们应该遵守所有三个设计原则。这是实现微服务架构全部潜力的唯一途径。错过任何一个都会成为反模式。
没有一个目的,每个微服务最终会做太多事情,成长为多个“单片”服务。我们不会从微服务架构中获得全部好处,我们也会支付运营成本。
如果没有松散耦合,对一个服务的更改会影响其他服务,因此我们无法快速安全地发布更改,这是微服务架构的核心优势。更重要的是,紧密耦合引起的问题可能是灾难性的,例如数据不一致甚至数据丢失。
如果没有高凝聚力,我们将最终得到一个分布式单片系统 - 一组混乱的服务,必须同时进行更改和部署才能构建单一功能。由于多个服务协调的复杂性和成本(有时跨多个团队),分布式单片系统通常比集中式单片系统差得多。
与此同时,了解微服务不是什么很重要:
- 微服务不是具有少量代码行或“微”任务的服务。这种误解来自“微服务”这个名字。微服务架构的目标不是拥有尽可能多的小型服务。只要符合上述三项原则,服务就可能是复杂而实质的。
- 微服务不是一直使用新技术构建的服务。尽管微服务架构允许团队更轻松地测试新技术,但它并不是微服务架构的主要目标。只要团队从分离的服务中受益,就可以使用完全相同的技术堆栈构建新服务。
- 微服务不是必须从头开始构建的服务。如果您已经拥有一个架构良好的单一应用程序,请避免养成从头开始构建每个新服务的习惯。可能有机会直接从单一服务中提取逻辑。同样,上述三个原则应该仍然有效。
为什么现在?
在Medium,我们总是在做出重大产品或工程决策时会问“为什么现在?”这个问题。 “为什么?”是一个显而易见的问题,但它假设我们拥有无限的人,时间和资源,这是一个危险的假设。当你想到“为什么现在?”时,你突然有了更多的限制 - 对当前工作的影响,机会成本,分心的开销等等。这个问题有助于我们更好地优先考虑。
我们现在需要采用微服务的原因是我们的Node.js单片应用程序已经成为多个方面的瓶颈。
首先,最紧迫和最重要的瓶颈是其性能。
某些计算量很大且I / O很重的任务不适合Node.js.我们一直在逐步改进整体应用程序,但事实证明它是无效的。它的低劣性能使我们无法提供更好的产品而不会使已经非常慢的应用程序变慢。
其次,整体应用程序的一个重要且有点紧迫的瓶颈是它会减慢产品开发速度。
由于所有工程师都在单个应用程序中构建功能,因此它们通常紧密耦合。我们无法灵活地改变系统的一部分,因为它也可能影响其他部分。我们也害怕做出重大改变,因为影响太大,有时难以预测。整个应用程序作为一个整体进行部署,因此如果由于一次错误提交导致部署停滞,那么所有其他更改(即使它们完全正常工作)也无法完成。相比之下,微服务架构允许团队更快地发货,学习和迭代。他们可以专注于他们正在构建的功能,这些功能与复杂系统的其余部分分离。更改可以更快地进入生产。他们可以灵活地安全地尝试重大变革。
在我们新的微服务架构中,更改会在一小时内完成生产,工程师不必担心它会如何影响系统的其他部分。该团队还探索了在开发中安全使用生产数据的方法²多年来一直是白日梦。随着我们的工程团队的发展,所有这些都非常重要。
第三,单一应用程序使得难以为特定任务扩展系统或隔离不同类型任务的资源问题。
使用单一的单一应用程序,我们必须扩展和缩小整个系统,以满足更多资源需求的任务,即使这意味着系统过度配置用于其他更简单的任务。为了缓解这些问题,我们对不同类型的请求进行分片,以分离Node.js进程。它们在一定程度上起作用,但不会扩展,因为这些微单一版本的单片服务是紧密耦合的。
最后但同样重要的是,一个重要且即将成为紧迫的瓶颈是它阻止我们尝试新技术。微服务架构的一个主要优点是每个服务都可以使用不同的技术堆栈构建,并与不同的技术集成。这使我们能够选择最适合工作的工具,更重要的是,我们可以快速安全地完成工作。
微服务策略
采用微服务架构并非易事。它可能会出错,实际上会损害工程生产力。在本节中,我们将分享七个在采用早期阶段帮助我们的策略:
- 建立具有明确价值的新服务
- 单片持久存储被认为是有害的
- 解耦“建立服务”和“运行服务”
- 彻底和一致的可观察性
- 并非每项新服务都需要从头开始构建
- 尊重失败因为它们会发生
- 从第一天开始就避免使用“微服务综合症”
- 建立具有明确价值的新服务
有人可能会认为采用新的服务器架构意味着产品开发的长时间停顿以及对所有内容的大量重写。这是错误的做法。我们永远不应该为了建立新的服务而建立新的服务。每次我们建立新服务或采用新技术时,都必须具有明确的产品价值和/或工程价值。
产品价值应以我们可以为用户提供的利益为代表。与在单片Node.js应用程序中构建值相比,需要一项新服务来提供值或使其更快地交付值。工程价值应该使工程团队更好,更快。
如果构建新服务没有产品价值或工程价值,我们将其留在单一的应用程序中。如果十年内Medium仍然有一个支持某些表面的单片Node.js应用程序,那就完全没了问题。从单一应用程序开始实际上有助于我们战略性地对微服务进行建模。
建立具有明确价值的新服务
有人可能会认为采用新的服务器架构意味着产品开发的长时间停顿以及对所有内容的大量重写。这是错误的做法。我们永远不应该为了建立新的服务而建立新的服务。每次我们建立新服务或采用新技术时,都必须具有明确的产品价值和/或工程价值。
产品价值应以我们可以为用户提供的利益为代表。与在单片Node.js应用程序中构建值相比,需要一项新服务来提供值或使其更快地交付值。工程价值应该使工程团队更好,更快。
如果构建新服务没有产品价值或工程价值,我们将其留在单一的应用程序中。如果十年内Medium仍然有一个支持某些表面的单片Node.js应用程序,那就完全没了问题。从单一应用程序开始实际上有助于我们战略性地对微服务进行建模。
单片持久存储被认为是有害的
建模微服务的很大一部分是对其持久数据存储(例如,数据库)进行建模。跨服务共享持久数据存储通常似乎是将微服务集成在一起的最简单方法,然而,它实际上是有害的,我们应该不惜一切代价避免它。这就是原因。
首先,持久数据存储是关于实现细节的。跨服务共享数据存储会将一个服务的实现细节暴露给整个系统。如果该服务更改了数据的格式,或者添加了缓存层,或者切换到不同类型的数据库,则还必须相应地更改许多其他服务。这违反了松散耦合的原则。
其次,持久数据存储不是服务行为,即如何修改,解释和使用数据。如果我们跨服务共享数据存储,则意味着其他服务也必须复制服务行为。这违反了高内聚的原则 - 给定域中的行为泄露给多个服务。如果我们修改一个行为,我们将不得不一起修改所有这些服务。
在微服务架构中,只有一个服务应该负责特定类型的数据。所有其他服务应该通过负责服务的API请求数据,或者保留数据的只读非规范(可能具体化)副本。
这可能听起来很抽象,所以这是一个具体的例子。假设我们正在构建一个新的推荐服务,它需要来自规范帖子表的一些数据,目前在AWS DynamoDB中。我们可以通过两种方式之一为新推荐服务提供发布数据。
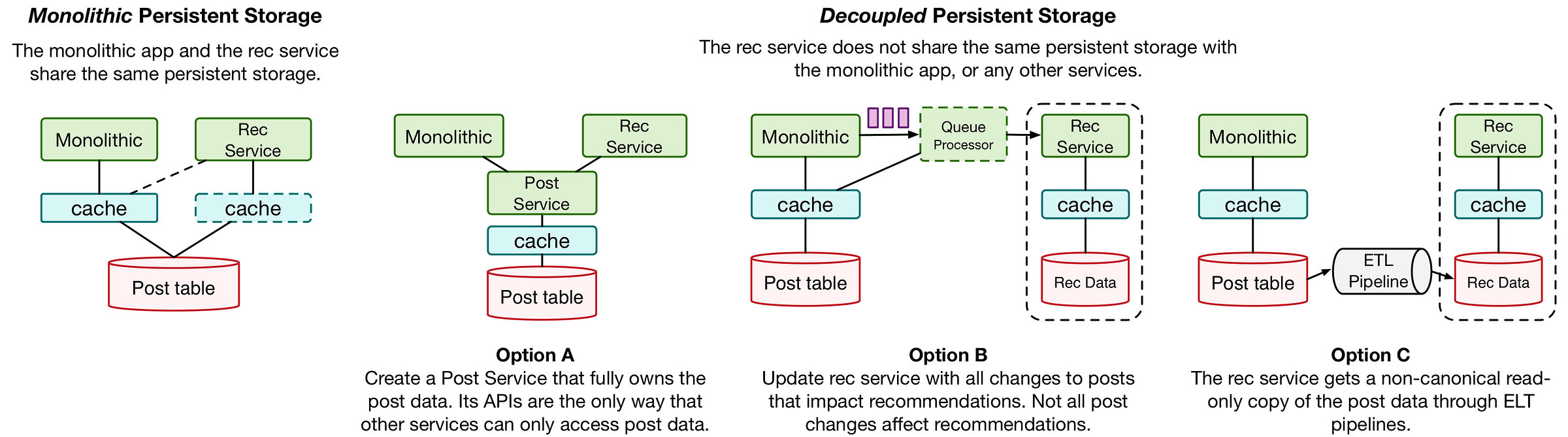
在单片存储模型中,推荐服务可以直接访问单片应用程序所执行的相同持久存储。这是一个坏主意,因为:
缓存可能很棘手。如果推荐服务与单一应用程序共享相同的缓存,我们也必须在推荐服务中复制缓存实现细节;如果推荐服务使用自己的缓存,当单片应用更新帖子数据时,我们将不知道何时使其缓存无效。
如果单片应用程序决定更改为使用RDS而不是DynamoDB来存储帖子数据,我们将不得不重新实现推荐服务中的逻辑以及访问帖子数据的所有其他服务。
单片应用程序具有解释帖子数据的复杂逻辑,例如,如何确定帖子是否应该对给定用户不可见。我们必须在推荐服务中重新实现这些逻辑。一旦整体应用程序更改或添加新逻辑,我们也需要在任何地方进行相同的更改。
即使推荐服务是自己的数据访问模式的错误选项,推荐服务仍然停留在DynamoDB上。
在解耦存储模型中,推荐服务不能直接访问发布数据,也不能直接访问任何其他新服务。发布数据的实现细节仅保留在一个服务中。有不同的方法来实现这一目标。
Option A 理想情况下,应该有一个拥有帖子数据的Post服务,其他服务只能通过Post服务的API访问邮政数据。但是,为所有核心数据模型构建新服务可能是一项昂贵的前期投资。
当人员配置有限时,还有一些更实用的方法。根据数据访问模式,它们实际上可能是更好的方式。
在选项B中,单一应用程序可让推荐服务知道何时更新相关的帖子数据。通常,这不必立即发生,因此我们可以将其卸载到排队系统。
在选项C中,ETL管道生成推荐服务的发布数据的只读副本,以及可能对推荐有用的其他数据。在这两个选项中,推荐服务完全拥有其数据,因此它可以灵活地缓存数据或使用最适合的数据库技术。
解耦“建立服务”和“运行服务”
如果构建微服务很难,那么运行服务往往更难。当运行服务与构建每个服务相结合时,它会减慢工程团队的速度,团队必须不断重新发明这样做。我们希望让每项服务都专注于自己的工作而不用担心如何运行服务的复杂问题,包括网络,通信协议,部署,可观察性等。服务管理应该与每个服务的实现完全分离。
将“构建服务”和“运行服务”分离的策略是使运行服务任务与服务技术无关,并且使自己的意见,以便应用工程师可以完全专注于每个服务自己的业务逻辑。
由于最近在容器化,容器编排,服务网格,应用程序性能监控等方面的技术进步,“运行服务”的解耦变得比以往更容易实现。
网络。网络(例如,服务发现,路由,负载平衡,流量路由等)是运行服务的关键部分。传统方法是为每种平台/语言提供库。它工作但不理想,因为应用程序仍然需要非常繁琐的工作来集成和维护库。通常,应用程序仍然需要单独实现某些逻辑。现代解决方案是在Service Mesh中运行服务。在Medium,我们使用Istio和Envoy作为边车代理。构建服务的应用工程师根本不需要担心网络问题。
通信协议。无论您选择哪种技术堆栈或语言来构建微服务,从一个高效,类型化,跨平台且需要最少开发开销的成熟RPC解决方案开始是非常重要的。支持向后兼容性的RPC解决方案也使部署服务更加安全,即使它们之间存在依赖关系。在Medium,我们选择了gRPC。
一种常见的替代方案是基于HTTP的REST + JSON,它长期以来一直是服务器通信的福音解决方案。但是,尽管该堆栈非常适合浏览器与服务器通信,但它对于服务器到服务器的通信效率很低,尤其是当我们需要发送大量请求时。如果没有自动生成的存根和样板代码,我们将不得不手动实现服务器/客户端代码。可靠的RPC实现不仅仅包装网络客户端。另外,REST是“自以为是”,但总是让每个人都对每个细节都达成一致很困难,例如,这个调用真的是REST,还是只是一个RPC?这是一种资源还是一种操作?等等
部署。拥有一致的方法来构建,测试,打包,部署和管理服务非常重要。所有Medium的微服务都在容器中运行。目前,我们的编排系统是AWS ECS和Kubernetes的混合体,但仅限于Kubernetes。
我们构建了自己的系统来构建,测试,打包和部署服务,称为BBFD。它在一致地跨服务工作和为个人服务提供采用不同技术堆栈的灵活性之间取得平衡。它的工作方式是让每个服务提供基本信息,例如,要监听的端口,构建/测试/启动服务的命令等,BBFD将负责其余的工作。
彻底和一致的可观察性
可观察性包括允许我们了解系统如何工作的过程,约定和工具,以及在不工作时对问题进行分类。可观察性包括日志记录,性能跟踪,指标,仪表板,警报,并且对于微服务架构的成功至关重要。
当我们从单个服务迁移到具有许多服务的分布式系统时,可能会发生两件事:
我们失去了可观察性,因为它变得更难或更容易被忽视。
不同的团队重新发明了轮子,我们最终得到了零碎的可观察性,这实际上是低可观察性,因为很难使用碎片数据连接点或分类任何问题。
从一开始就具有良好且一致的可观察性非常重要,因此我们的DevOps团队提出了一致的可观察性策略,并构建了支持实现这一目标的工具。每项服务都会自动获取详细的DataDog仪表板,警报和日志搜索,这些服务在所有服务中也是一致的。我们还大量使用LightStep来了解系统的性能。
并非每一项新服务都需要从零开始构建
在微服务架构中,每个服务都做一件事并且做得非常好。请注意,它与如何构建服务无关。如果您从单一服务迁移,请记住,如果您可以从单片应用程序中剥离微服务并不总是必须从头开始构建。
在这里,我们采取务实的态度。我们是否应该从头开始构建服务取决于两个因素:(1)Node.js适合该任务的程度如何;(2)在不同的技术堆栈中重新实现的成本是多少。
如果Node.js是一个很好的技术选项并且现有的实现很好,我们将代码从单片应用程序中删除,并用它创建一个微服务。即使采用相同的实现,我们仍将获得微服务架构的所有好处。
我们的单片Node.js单片应用程序的架构使我们可以相对轻松地使用现有实现构建单独的服务。我们将在本文稍后讨论如何正确构建单片。
尊重失败,因为他们会发生
在分布式环境中,更多的东西可能会失败,而且它们会失败。如果处理不当,任务关键型服务的失败可能是灾难性的。我们应该始终考虑如何测试故障并优雅地处理故障。
- 首先,我们应该期待一切都会在某些时候失败。
- 对于RPC调用,需要付出额外的努力来处理故障情况。
- 确保我们在发生故障时具有良好的可观察性(如上所述)。
- 在线提供新服务时始终测试失败。它应该是新服务检查列表的一部分。
- 尽可能构建自动恢复。
从第一天起避免使用微服务综合症
微服务不是灵丹妙药 - 它解决了一些问题,但创造了一些其他问题,我们将其称为“微服务综合症”。如果我们从第一天开始就不去考虑它们,那么事情会变得很快,如果我们以后再照顾它们会花费更多。以下是一些常见症状。
- 建模不良的微服务造成的伤害大于好处,特别是当你有超过几个时。
- 允许太多不同的语言/技术选择,这会增加运营成本并使工程组织分散。
- 将运营服务与构建服务相结合,这大大增加了每项服务的复杂性并减慢了团队的速度。
- 忽略数据建模,最终得到具有单片数据存储的微服务。
- 缺乏可观察性,这使得难以对性能问题或故障进行分类。
- 当遇到问题时,团队倾向于创建新服务而不是修复现有服务,即使后者可能是更好的选择。
- 即使服务松散耦合,缺乏整个系统的整体视图也可能存在问题。
我们应该停止构建单片服务吗?
随着最近的技术创新,采用微服务架构要容易得多。这是否意味着我们都应该停止构建单一服务?
虽然新技术支持得更好,但微服务架构仍然存在高度复杂性和复杂性。对于小型团队来说,单一的应用程序通常仍然是更好的选择。但是,请花些时间来构建单片应用程序,以便以后在系统和团队成长时更容易迁移到微服务架构。
从单一体系结构开始是很好的,但要确保模块化并使用上述三种微服务原则(单一用途,松散耦合和高内聚)来构建它,除了“服务”在同一技术堆栈中实现,一起部署并在同一进程中运行。
在Medium,我们在早期的单片应用程序中做出了一些很好的架构决策。
我们的单片应用程序由组件高度模块化,即使它已经发展成为一个非常复杂的应用程序,包括Web服务器,后端服务和离线事件处理器。脱机事件处理器单独运行,但使用完全相同的代码。这使得将一大块业务逻辑剥离到单独的服务相对容易,只要新服务提供与原始实现相同(高级)的接口即可。
我们的整体应用程序在较低级别封装了数据存储详细信息。每种数据类型(例如,数据库表)具有两层实现:数据层和服务层。
- 数据层处理对一种特定类型数据的CRUD操作。
- 服务层处理一种特定类型数据的高级逻辑,并为系统的其余部分提供公共API。服务不共享它们之间的数据存储。
这有助于我们采用微服务架构,因为一种类型数据的实现细节完全隐藏在代码库的其余部分。创建新服务来处理某些类型的数据相对容易且安全。
单片应用程序还可以帮助我们对微服务进行建模,并使我们能够灵活地专注于系统中最重要的部分,而不是从头开始为所有微服务建模。
结论
单片Node.js应用程序为我们服务了好几年,但它开始减慢我们从运送伟大的项目和快速迭代。我们开始系统地和战略性地采用微服务架构。我们仍处于这一旅程的早期阶段,但我们已经看到了它的优势和潜力 - 它大大提高了开发效率,使我们能够大胆地思考并实现大量的产品改进,并解锁了工程团队以安全地测试新技术。
加入Medium的工程团队是一个激动人心的时刻。如果这听起来很有趣,请查看我们的工作页面 - 在Medium工作。如果您对微服务架构特别感兴趣,您可能需要先了解这两个开头:高级全栈工程师和高级平台工程师。
谢谢阅读。如果您有任何疑问或希望更多地讨论我们如何开始采用微服务架构,请给我们留言。
这篇文章的原始版本发布在Hatch,我们的内部版本的Medium。感谢Kyle Mahan,Eduardo Ramirez,Victor Alor,sachee,Lyra Naeseth,Dan Benson,Bob Corsaro,Julie Russell和Alaina Kafkes对选秀的反馈。
¹在这篇文章中,我们将以两种方式使用“微服务”一词,(1)指微服务架构,(2)指微服务架构中的一项服务。
²在开发中获取生产数据是一把双刃剑。这绝对是值得商榷的,但如果我们能安全地做到这一点,它就会非常强大。需要说明的是,我们不会测试其他用户的数据。工程师只使用自己的帐户。我们非常重视用户的隐私。
原文 :https://medium.engineering/microservice-architecture-at-medium-9c33805eb74f
讨论: 请加入知识星球【首席架构师圈】
- 95 次浏览
【微服务架构】jhipster技术堆栈
在客户端的技术堆栈
单个网页应用程序:
- Angular或 React或Vue
- 使用Twitter Bootstrap进行响应式Web设计
- HTML5 Boilerplate
- 兼容现代浏览器(Chrome,FireFox,Microsoft Edge ......)
- 全面的国际化支持
- 可选的 Sass支持CSS设计
- Spring Websocket支持可选的WebSocket
凭借出色的开发工作流程:
使用NPM轻松安装新的JavaScript库
使用Webpack构建,优化和实时重新加载
使用 Jest 和Protractor进行测试
如果单个网页应用程序不足以满足您的需求,该怎么办?
支持 Thymeleaf模板引擎,在服务器端生成Web页面
服务器端的技术堆栈
A complete Spring application:
- Spring Boot for easy application configuration
- Maven or Gradle configuration for building, testing and running the application
- “development” and “production” profiles (both for Maven and Gradle)
- Spring Security
- Spring MVC REST + Jackson
- Optional WebSocket support with Spring Websocket
- Spring Data JPA + Bean Validation
- Database updates with Liquibase
- Elasticsearch support if you want to have search capabilities on top of your database
- MongoDB and Couchbase support if you’d rather use a document-oriented NoSQL database instead of JPA
- Cassandra support if you’d rather use a column-oriented NoSQL database instead of JPA
- Kafka support if you want to use a publish-subscribe messaging system
微服务的技术堆栈
Microservices are optional, and fully supported:
- HTTP routing using Netflix Zuul or Traefik
- Service discovery using Netflix Eureka or HashiCorp Consul
准备投入生产:
- Monitoring with Metrics and the ELK Stack
- Caching with ehcache (local cache), hazelcast or Infinispan
- Optimized static resources (gzip filter, HTTP cache headers)
- Log management with Logback, configurable at runtime
- Connection pooling with HikariCP for optimum performance
- Builds a standard WAR file or an executable JAR file
- Full Docker and Docker Compose support
- Support for all major cloud providers: AWS, Cloud Foundry, Heroku, Kubernetes, OpenShift, Azure, Docker…
原文:https://www.jhipster.tech/tech-stack/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 36 次浏览
【微服务架构】为故障设计微服务架构
微服务架构可以通过定义明确的服务边界隔离故障。但就像在每个分布式系统中一样,网络、硬件或应用程序级别问题的可能性更高。由于服务依赖关系,任何组件都可能对其消费者暂时不可用。为了最大限度地减少部分中断的影响,我们需要构建可以优雅地响应某些类型的中断的容错服务。
本文基于 RisingStack 的 Node.js 咨询与开发经验,介绍了构建和运行高可用微服务系统的最常用技术和架构模式。
如果您不熟悉本文中的模式,并不一定意味着您做错了什么。建立一个可靠的系统总是需要额外的成本。
更新:本文多次提到 Trace,RisingStack 的 Node.js 监控平台。 2017 年 10 月,Trace 与 Keymetrics 的 APM 解决方案合并。点击这里试一试!
微服务架构的风险
微服务架构将应用程序逻辑转移到服务中,并使用网络层在它们之间进行通信。通过网络而不是内存调用进行通信会给系统带来额外的延迟和复杂性,这需要多个物理和逻辑组件之间的协作。分布式系统的复杂性增加导致特定网络故障的可能性更高。#microservices 允许您实现优雅的服务降级,因为可以将组件设置为单独失败。
与单体架构相比,微服务架构的最大优势之一是团队可以独立设计、开发和部署他们的服务。他们对其服务的生命周期拥有完全的所有权。这也意味着团队无法控制他们的服务依赖关系,因为它更有可能由不同的团队管理。对于微服务架构,我们需要记住,提供者服务可能会因发布、配置和其他更改的中断而暂时不可用,因为它们由其他人控制,并且组件彼此独立移动。
优雅的服务降级
微服务架构的最大优势之一是您可以隔离故障并在组件单独失败时实现优雅的服务降级。例如,在照片共享应用程序中断期间,客户可能无法上传新照片,但他们仍然可以浏览、编辑和共享现有照片。

微服务单独失败(理论上)
在大多数情况下,很难实现这种优雅的服务降级,因为分布式系统中的应用程序相互依赖,您需要应用几种故障转移逻辑(其中一些将在本文后面介绍)来准备 临时故障和中断。
Services depend on each other and fail together without failover logics.
变更管理
谷歌的网站可靠性团队发现,大约 70% 的中断是由实时系统的变化引起的。 当您更改服务中的某些内容时——部署新版本的代码或更改某些配置——总是有可能失败或引入新错误。
在微服务架构中,服务相互依赖。 这就是为什么你应该尽量减少失败并限制它们的负面影响。 要处理变更带来的问题,您可以实施变更管理策略和自动推出。
例如,当您部署新代码或更改某些配置时,您应该逐渐将这些更改应用到您的实例子集,监控它们,甚至在您发现部署对您的关键指标产生负面影响时自动恢复。

Change Management – Rolling Deployment
另一种解决方案可能是您运行两个生产环境。您总是只部署到其中一个,并且只有在验证新版本按预期工作后才将负载均衡器指向新的。这称为蓝绿或红黑部署。
还原代码并不是一件坏事。您不应该将损坏的代码留在生产环境中,然后再考虑问题出在哪里。如有必要,请始终还原您的更改。越早越好。
健康检查和负载均衡
由于故障、部署或自动缩放,实例不断启动、重启和停止。它使它们暂时或永久不可用。为避免出现问题,您的负载均衡器应从路由中跳过不健康的实例,因为它们无法满足客户或子系统的需求。
应用程序实例的健康状况可以通过外部观察来确定。您可以通过重复调用 GET /health 端点或通过自我报告来做到这一点。现代服务发现解决方案不断从实例收集健康信息,并将负载均衡器配置为仅将流量路由到健康组件。
自我修复
自我修复可以帮助恢复应用程序。当应用程序可以执行必要的步骤从损坏状态中恢复时,我们可以谈论自我修复。在大多数情况下,它是由一个外部系统实现的,该系统监视实例的运行状况并在它们长时间处于损坏状态时重新启动它们。在大多数情况下,自我修复非常有用,但是在某些情况下,它可能会通过不断地重新启动应用程序而导致麻烦。当您的应用程序由于过载或数据库连接超时而无法提供积极的健康状态时,可能会发生这种情况。
实施先进的自我修复解决方案,为微妙的情况(如丢失的数据库连接)做好准备可能会很棘手。在这种情况下,您需要向应用程序添加额外的逻辑来处理边缘情况,并让外部系统知道不需要立即重新启动实例。
缓存故障转移
由于网络问题和我们系统的变化,服务通常会失败。然而,由于自我修复和高级负载平衡,这些中断中的大多数都是暂时的,我们应该找到一种解决方案,让我们的服务在这些故障期间正常工作。这就是故障转移缓存可以提供帮助并向我们的应用程序提供必要数据的地方。
故障转移缓存通常使用两个不同的到期日期;较短的表示您在正常情况下可以使用缓存多长时间,较长的表示您可以在故障期间使用缓存的数据多长时间。
故障转移缓存
值得一提的是,您只能在故障转移缓存为过时数据提供服务时使用总比没有好。
要设置缓存和故障转移缓存,您可以使用 HTTP 中的标准响应标头。
例如,使用 max-age 标头,您可以指定资源被视为新鲜的最长时间。使用 stale-if-error 标头,您可以确定在发生故障时应该从缓存中提供资源多长时间。
现代 CDN 和负载均衡器提供各种缓存和故障转移行为,但您也可以为您的公司创建一个包含标准可靠性解决方案的共享库。
重试逻辑
在某些情况下,我们无法缓存数据或想要对其进行更改,但我们的操作最终会失败。在这些情况下,我们可以重试我们的操作,因为我们可以预期资源会在一段时间后恢复,或者我们的负载均衡器将我们的请求发送到一个健康的实例。
向应用程序和客户端添加重试逻辑时应小心谨慎,因为大量重试会使情况变得更糟,甚至会阻止应用程序恢复。
在分布式系统中,一个微服务系统重试可以触发多个其他请求或重试,并启动级联效果。为了最大限度地减少重试的影响,您应该限制重试的数量并使用指数退避算法不断增加重试之间的延迟,直到达到最大限制。
由于重试是由客户端(浏览器、其他微服务等)发起的,并且客户端在处理请求之前或之后不知道操作失败,因此您应该准备应用程序来处理幂等性。例如,当您重试购买操作时,您不应向客户重复收费。为每个事务使用唯一的幂等键有助于处理重试。
速率限制器和减载器
速率限制是一种定义特定客户或应用程序在一段时间内可以接收或处理多少请求的技术。例如,通过速率限制,您可以过滤掉导致流量峰值的客户和微服务,或者您可以确保您的应用程序不会过载,直到自动缩放无法挽救。
您还可以阻止较低优先级的流量,为关键事务提供足够的资源。

A rate limiter can hold back traffic peaks
一种不同类型的速率限制器称为并发请求限制器。当您拥有不应超过指定时间调用的昂贵端点,而您仍想提供流量时,它会很有用。
车队使用负载卸载器可以确保始终有足够的资源可用于服务关键事务。它为高优先级请求保留一些资源,并且不允许低优先级事务使用所有这些资源。卸载程序根据系统的整个状态做出决策,而不是基于单个用户的请求桶大小。卸载程序可帮助您的系统恢复,因为它们可以在您遇到持续事件时保持核心功能正常工作。
要了解有关速率限制器和负载粉碎器的更多信息,我建议查看 Stripe 的文章。
快速失败和独立
在微服务架构中,我们希望让我们的服务能够快速且独立地失败。为了隔离服务级别的问题,我们可以使用隔板模式。您可以稍后在此博客文章中阅读有关隔板的更多信息。
我们还希望我们的组件快速失败,因为我们不想等待损坏的实例直到它们超时。没有什么比挂起的请求和无响应的 UI 更令人失望的了。这不仅浪费资源,还破坏了用户体验。我们的服务是链式调用的,所以我们应该特别注意在这些延迟总结之前防止挂起操作。
您想到的第一个想法是为每个服务调用应用精细等级超时。这种方法的问题在于,您无法真正知道什么是好的超时值,因为在某些情况下发生网络故障和其他问题时只会影响一两次操作。在这种情况下,如果只有少数几个超时,您可能不想拒绝这些请求。
我们可以说,通过使用超时来实现微服务中的快速失败范例是一种反模式,您应该避免它。您可以应用取决于操作的成功/失败统计信息的断路器模式,而不是超时。
隔板
舱壁在工业中用于将船舶分隔成多个部分,以便在船体破裂时可以将部分密封起来。
隔板的概念可以应用于软件开发以隔离资源。
通过应用舱壁模式,我们可以保护有限的资源不被耗尽。例如,如果我们有两种操作与连接数量有限的同一个数据库实例进行通信,我们可以使用两个连接池而不是 shared on。由于这个客户端 - 资源分离,超时或过度使用池的操作不会导致所有其他操作停止。
泰坦尼克号沉没的主要原因之一是它的舱壁设计失败,水可以通过上面的甲板从舱壁顶部倾泻而下,淹没整个船体。

Bulkheads in Titanic (they didn’t work)
断路器
为了限制操作的持续时间,我们可以使用超时。超时可以防止挂起操作并保持系统响应。然而,在微服务通信中使用静态的、微调的超时是一种反模式,因为我们处于一个高度动态的环境中,几乎不可能提出在每种情况下都能正常工作的正确时间限制。
我们可以使用断路器来处理错误,而不是使用小的和特定于事务的静态超时。断路器以真实世界的电子元件命名,因为它们的行为是相同的。您可以通过断路器保护资源并帮助它们恢复。它们在分布式系统中非常有用,其中重复性故障会导致滚雪球效应并导致整个系统瘫痪。
当特定类型的错误在短时间内多次发生时,断路器会打开。一个打开的断路器会阻止进一步的请求——就像真正的断路器阻止电子流动一样。断路器通常在一定时间后关闭,为底层服务恢复提供足够的空间。
请记住,并非所有错误都应该触发断路器。例如,您可能希望跳过客户端问题,例如具有 4xx 响应代码的请求,但包括 5xx 服务器端故障。一些断路器也可以处于半开状态。在这种状态下,服务发送第一个请求以检查系统可用性,同时让其他请求失败。如果第一个请求成功,它将断路器恢复到关闭状态并让流量流动。否则,它会保持打开状态。

Circuit Breaker
测试失败
您应该针对常见问题不断测试您的系统,以确保您的服务能够承受各种故障。您应该经常测试故障,以使您的团队为事件做好准备。
对于测试,您可以使用识别实例组并随机终止该组中的一个实例的外部服务。有了这个,您可以为单个实例故障做好准备,但您甚至可以关闭整个区域以模拟云提供商中断。
最受欢迎的测试解决方案之一是 Netflix 的 ChaosMonkey 弹性工具。
奥特罗
实施和运行可靠的服务并不容易。这需要您付出很多努力,也需要您的公司花钱。
可靠性有很多层面和方面,因此为您的团队找到最佳解决方案非常重要。您应该将可靠性作为业务决策过程中的一个因素,并为此分配足够的预算和时间。
关键要点
- 动态环境和分布式系统(如微服务)会导致更高的故障几率。
- 服务应该单独失败,实现优雅降级以改善用户体验。
- 70% 的中断是由更改引起的,还原代码并不是一件坏事。
- 快速而独立地失败。团队无法控制他们的服务依赖关系。
- 缓存、隔板、断路器和速率限制器等架构模式和技术有助于构建可靠的微服务。
原文:https://www.progress.com/blogs/rest-api-industry-debate-odata-vs-graphq…
本文:
- 47 次浏览
【微服务架构】什么是微服务? — 全面了解微服务架构

What is Microservices — Edureka
您有没有想过,什么是微服务以及扩展行业如何与它们集成,同时构建应用程序以满足客户的期望?
要了解什么是微服务,您必须了解如何将单体应用程序分解为独立打包和部署的小型微型应用程序。本文将让您清楚了解开发人员如何使用微服务根据需要扩展其应用程序。
在本文中,您将了解以下内容:
- 为什么是微服务?
- 什么是微服务?
- 微服务架构的特点
- 微服务架构的优势
- 设计微服务的最佳实践
- 使用微服务的公司
为什么是微服务?
现在,在我告诉你微服务之前,让我们看看在微服务之前流行的架构,即单体架构。
用外行的话来说,你可以说它类似于一个大容器,其中应用程序的所有软件组件都组装在一起并紧密打包。
列出了单体架构的挑战:
Challenges of Monolithic Architecture — What is Microservices
不灵活——无法使用不同的技术构建单体应用程序
不可靠——即使系统的一个功能不起作用,那么整个系统也不起作用
不可扩展——应用程序无法轻松扩展,因为每次需要更新应用程序时,都必须重新构建整个系统
阻碍持续开发——应用程序的许多功能不能同时构建和部署
开发缓慢——单体应用程序的开发需要大量时间来构建,因为每个特性都必须一个接一个地构建
不适合复杂应用程序——复杂应用程序的特性具有紧密耦合的依赖关系
上述挑战是导致微服务发展的主要原因。
什么是微服务?
微服务,又名微服务架构,是一种架构风格,它将应用程序构建为围绕业务领域建模的小型自治服务的集合。
Microservices Representation —What Is Microservices
在微服务架构中,每个服务都是自包含的,并且实现了单一的业务能力。
传统架构与微服务的区别
将电子商务应用程序视为一个用例,以了解它们之间的区别。
我们在上图中观察到的主要区别在于,所有功能最初都在共享单个数据库的单个实例下。 但是,对于微服务,每个特性都被分配了一个不同的微服务,处理它们自己的数据,并执行不同的功能。
现在,让我们通过查看其架构来更多地了解微服务。 参考下图:
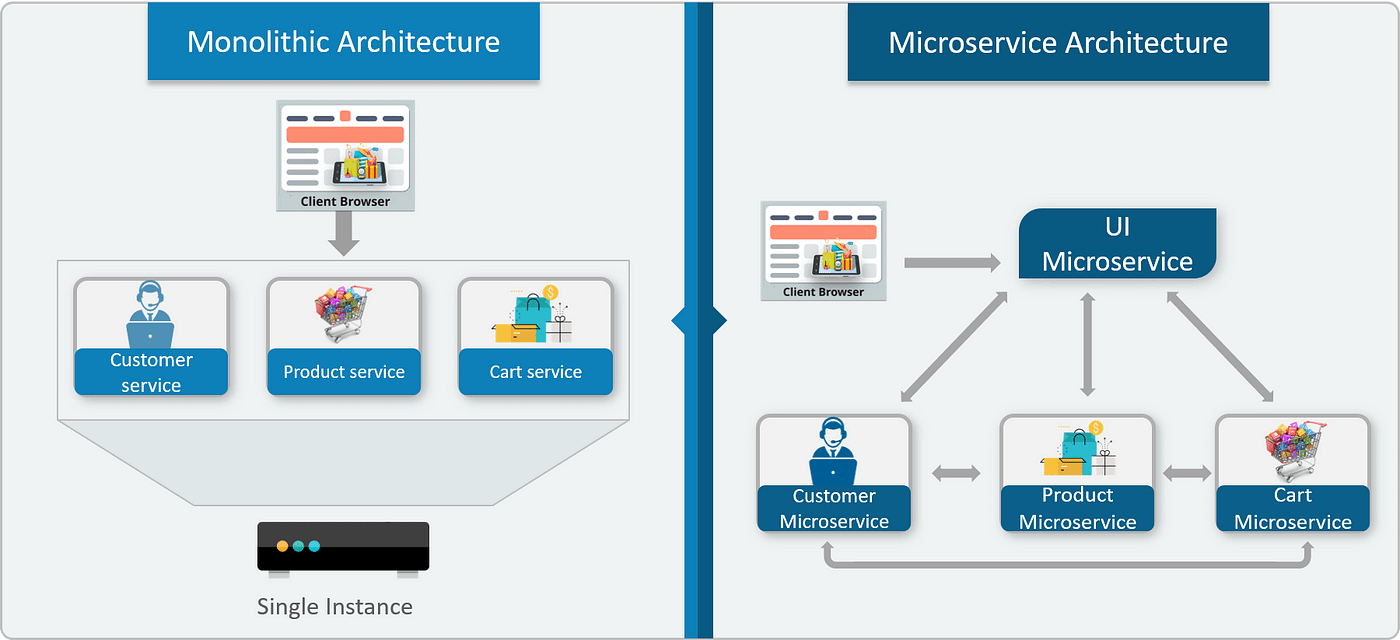
Differences Between Monolithic Architecture and Microservices - What is Microservices
微服务架构
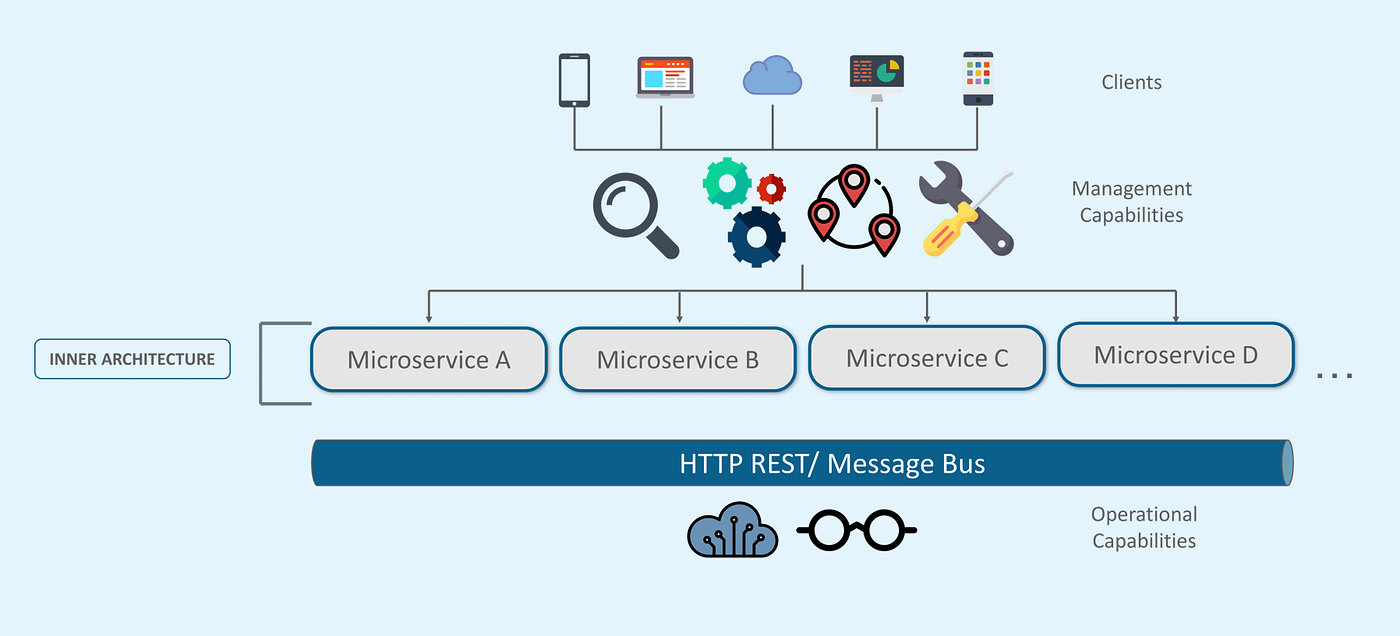
Microservice Architecture - What is Microservices
- 来自不同设备的不同客户端尝试使用不同的服务,例如搜索、构建、配置和其他管理功能。
- 所有服务都根据其域和功能进行分离,并进一步分配给各个微服务。
- 这些微服务有自己的负载均衡器和执行环境来执行它们的功能,同时在自己的数据库中捕获数据。
- 所有微服务都通过无状态服务器(REST 或消息总线)相互通信。
- 微服务借助服务发现了解其通信路径,并执行自动化、监控等操作功能。
- 然后,微服务执行的所有功能都通过 API 网关与客户端通信。
- 所有内部点都从 API 网关连接。因此,任何连接到 API 网关的人都会自动连接到整个系统。
现在,让我们通过查看其特性来了解更多关于微服务的信息。
微服务功能
Features Of Microservices — What is Microservices
- 解耦——系统内的服务在很大程度上是解耦的。因此,整个应用程序可以轻松构建、更改和扩展。
- 组件化——微服务被视为可以轻松更换和升级的独立组件。
- 业务能力——微服务非常简单,专注于单一能力。
- 自治——开发人员和团队可以彼此独立工作,从而提高速度。
- 持续交付——通过软件创建、测试和批准的系统自动化,允许频繁发布软件。
- 责任——微服务不关注应用程序作为项目。相反,他们将应用程序视为他们负责的产品
- 去中心化治理——重点是为正确的工作使用正确的工具。这意味着没有标准化的模式或任何技术模式。开发人员可以自由选择最有用的工具来解决他们的问题
- 敏捷性——微服务支持敏捷开发。任何新功能都可以快速开发并再次丢弃
微服务的优势

Advantages of Microservices - What is Microservices
- 独立开发——所有微服务都可以根据各自的功能轻松开发
- 独立部署——根据他们的服务,他们可以单独部署在任何应用程序中
- 故障隔离——即使应用程序的一项服务不工作,系统仍然继续运行
- 混合技术栈——不同的语言和技术可用于构建同一应用程序的不同服务
- 粒度缩放——单个组件可以根据需要进行缩放,无需将所有组件一起缩放
设计微服务的最佳实践
在当今世界,复杂性已成功渗透到产品中。 微服务架构承诺让团队保持扩展并更好地运作。
以下是设计微服务的最佳实践:
Best Practices To Design Microservices - What is Microservices
现在,让我们看一个用例来更好地理解微服务。
用例:购物车应用程序
让我们看一个购物车应用程序的经典用例。
当您打开购物车应用程序时,您看到的只是一个网站。 但是,在幕后,购物车应用程序具有接受付款的服务、客户服务等。
假设这个应用程序的开发人员已经在一个整体框架中创建了它。 请参考下图:
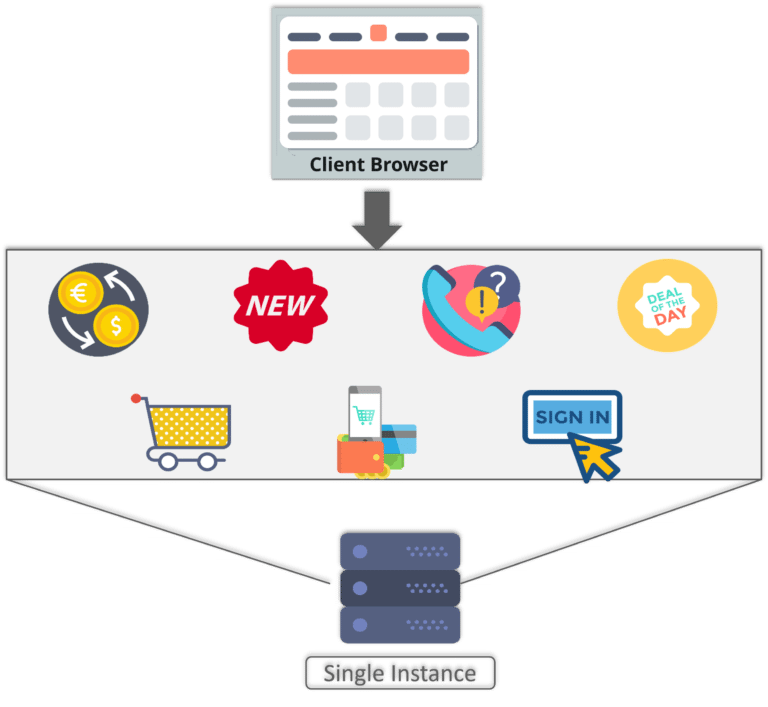
Monolithic Framework Of Shopping Cart Application — What is Microservices
因此,所有功能都放在一个代码库中,并位于一个底层数据库下。
现在,让我们假设市场上出现了一个新品牌,开发人员希望将即将推出的品牌的所有细节都放在这个应用程序中。
然后,他们不仅需要为新标签重新设计服务,还必须重新构建整个系统并相应地进行部署。
为了避免此类挑战,该应用程序的开发人员决定将他们的应用程序从单体架构转变为微服务。 参考下图了解购物车应用的微服务架构。
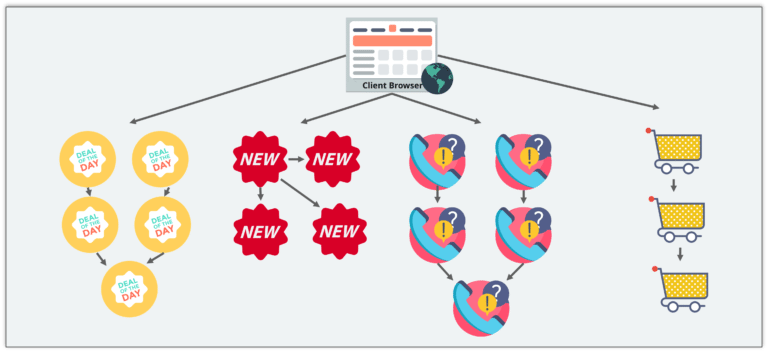
Microservice Architecture of Shopping Cart Application — What is Microservices
这意味着开发人员不会创建 Web 微服务、逻辑微服务或数据库微服务。 相反,他们为搜索、推荐、客户服务等创建单独的微服务。
这种类型的应用程序架构不仅可以帮助开发人员克服以前架构面临的所有挑战,还可以帮助购物车应用程序轻松构建、部署和扩展。
使用微服务的公司
有很多公司使用微服务来构建应用程序,这些只是仅举几例:

Companies using Microservices - What is Microservices
这将我们带到关于什么是微服务的文章的结尾。 我希望您发现这篇文章内容丰富,并为您的知识增加了价值。
。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. Microservice Architecture
- 2. Microservices vs SOA
- 3. Microservices Tutorial
- 4. Building Microservices Application Using Spring Boot
- 5. Microservices Security
原文:https://medium.com/edureka/what-is-microservices-86144b17b836
- 98 次浏览
【微服务架构】介绍KivaKit框架
关键点
- KivaKit是一个模块化Java框架,用于开发需要Java 11+虚拟机但与Java 8源代码兼容的微服务
- KivaKit提供了实现应用程序的基本功能,包括命令行解析和应用程序配置
- KivaKit组件是轻量级组件,使用广播/侦听器消息传递系统传递状态信息
- KivaKit迷你框架,包括转换、验证、资源和日志迷你框架,通过消息传递使用和报告状态信息
- KivaKit配置并运行Jetty、Jersey、Swagger和Apache Wicket,以一致的方式提供微服务接口
- 关键的KivaKit基类也可以作为有状态特征或“mixin”提供
概述
KivaKit是一个Apache许可证开源Java框架,设计用于实现微服务。KivaKit需要一个Java11+虚拟机,但源代码与Java8和Java9项目兼容。KivaKit由一组精心集成的迷你框架组成。每个迷你框架都有一个一致的设计和自己的重点,可以与其他迷你框架配合使用,也可以单独使用。这些框架的简化依赖关系网络提供了KivaKit的良好高级视图:
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1mini-frameworks-1637785248958.png)
每个迷你框架都解决了开发微服务时经常遇到的不同问题。本文简要概述了上图中的微型框架,并简要介绍了如何使用它们。
消息传递
如上图所示,消息传递是KivaKit的核心。消息传递在构建状态可观察的组件时非常有用,这在基于云的世界中是一个有用的功能。KivaKit中的许多对象广播或侦听状态消息,如警报、问题、警告或跟踪。大多数是中继器,侦听来自其他对象的状态消息,并将其重新广播给下游感兴趣的侦听器。这将与终端侦听器形成侦听器链:
C->B->A
通常,链中的最后一个侦听器是某种记录器,但在链的末尾也可以有多个侦听器,任何实现侦听器的对象都可以工作。例如,在Validation mini框架中,ValidationSues类捕获状态消息,然后使用该类确定验证是否成功,以及向用户显示验证失败的特定问题。
给定上面的侦听器链,C和B实现Repeater,最后一个对象A实现listener。在链中的每个类中,侦听器链都扩展为:
listener.listenTo(广播员)
要将消息发送给感兴趣的侦听器,将从广播机继承方便方法,以获得常见类型的消息:
|
Message |
Purpose |
|
problem() |
Something has gone wrong and needs to be addressed, but it’s not fatal to the current operation. |
|
glitch() |
A minor problem has occurred. Unlike a Warning, a Glitch indicates validation failure or data loss has occurred. Unlike a Problem, a Glitch indicates that the operation will definitely recover and continue. |
|
warning() |
A minor issue has occurred which should be corrected, but does not necessarily require attention. |
|
quibble() |
A trivial issue has occurred that does not require correction. |
|
announcement() |
Announces an important phase of an operation. |
|
narration() |
A step in some operation has started or completed. |
|
information() |
Commonly useful information that doesn’t represent any problem |
|
trace() |
Diagnostic information for use when debugging. |
广播器还提供了一种机制,通过对类和包进行模式匹配,从命令行打开和关闭跟踪消息。
混合
在KivaKit中,有两种实现中继器的方法。第一种方法是简单地扩展BaseRepeater。第二种是使用有状态特征或Mixin。实现RepeaterMixin接口与扩展BaseRepeater相同,但是repeater mixin可以在已经有基类的类中使用。注意,下面讨论的组件接口使用相同的模式。如果不能扩展BaseComponent,那么可以实现ComponentMixin。
Mixin接口为缺少的Java语言特性提供了一个解决方案。它的工作原理是将状态查找委托给包私有类MixinState,该类使用实现Mixin的类的this引用在标识哈希映射中查找关联的状态对象。Mixin接口如下所示:
public interface Mixin
{
default T state(Class type, Factory factory)
{
return MixinState.get(this, type, factory);
}
}
如果state()找不到此的state对象,则将使用给定的工厂方法创建新的state对象,然后该对象将与状态映射中的mixin关联。例如,我们的Repeatermxin接口大致如下(为了简洁起见,没有大多数方法):
public interface RepeaterMixin extends Repeater, Mixin
{
@Override
default void addListener(Listener listener, Filter filter)
{
repeater().addListener(listener, filter);
}
@Override
default void removeListener(Listener listener)
{
repeater().removeListener(listener);
}
[...]
default Repeater repeater()
{
return state(RepeaterMixin.class, BaseRepeater::new);
}
}
这里,addListener()和RemovelListener()方法各自通过repeater()检索其BaseRepeater状态对象,并将方法调用委托给该对象。正如我们所见,在KivaKit中实现mixin并不复杂。
应该注意的是,对mixin中方法的每次调用都需要在状态映射中进行查找。标识哈希映射通常应该相当有效,但对于一些组件来说,这可能是一个性能问题。与大多数性能问题一样,我们最好做最简单的事情,直到我们的分析器不这么说。
组件
KivaKit组件通常可能是微服务的关键部分。组件通过扩展BaseComponent(最常见的情况)或通过实现ComponentMixin提供对消息传递的轻松访问。从组件继承不会向对象添加任何状态,但从Repeater继承的侦听器列表除外。这使得组件非常轻量级。大量实例化它们并不是一个问题。由于组件是中继器,因此可以创建侦听器链,如上所述。
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1component-1637785248958.jpg)
除了提供对消息的方便访问外,组件还提供以下功能:
- 注册和查找对象
- 加载和访问设置对象
- 访问包资源
让我们看看这些设施。
对象注册和查找
KivaKit使用服务定位器设计模式,而不是依赖项注入。在组件中使用此模式很简单。一个组件可以使用registerObject()注册对象,另一个组件可以使用require()查找对象:
Database database = [...] registerObject(database); [...] var database = require(Database.class);
如果需要注册单个类的多个实例,可以使用枚举值来区分它们:
enum Database { PRODUCTS, SERVICES } registerObject(database, Database.PRODUCTS); [...] var database = require(Database.class, Database.SERVICES);在KivaKit中,任何可能使用依赖项注入的地方都使用register和require。
设置
KivaKit中的组件也可以使用require()方法轻松访问设置信息:
require(DatabaseSettings.class);
与注册对象一样,如果存在多个相同类型的对象,则可以使用枚举来区分设置对象:
require(DatabaseSettings.class, Database.PRODUCTS);
可以通过多种方式注册设置信息:
registerAllSettingsIn(Folder) registerAllSettingsIn(Package) registerSettingsObject(Object) registerSettingsObject(Object, Enum)
在KivaKit 1.0中,使用RegisterAllSettings sin()方法加载的设置对象由.properties文件定义。将来,将提供一个API,以允许从其他源(如.json文件)加载属性。要实例化的设置类的名称由class属性提供。然后从其余属性中检索实例化对象的各个属性。使用KivaKit转换器(如下所述)将每个属性转换为对象。
例如:
DatabaseSettings.properties
class = com.mycompany.database.DatabaseSettings
port = database.production.mypna.com:3306
DatabaseSettings.java
public class DatabaseSettings
{
@KivaKitPropertyConverter(Port.Converter.class)
private Port port;
public Connection connect()
{
// Return connection to database on desired port
[...]
}
}包资源
KivaKit提供了一个资源迷你框架,它统一了多种资源类型:
- 文件夹
- Sockets
- Zip或JAR文件条目
- 包资源
- HTTP响应
- 输入流
- 输出流
- […]
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1resources-1637785248958.png)
资源是应用程序可以从中读取流数据的组件。WritableResources是应用程序可以向其写入流数据的资源。文件可用的大多数方法在任何给定资源中都可用,但某些资源类型可能会使某些方法不受支持。例如,资源可能是流式的,因此它无法实现sizeInBytes()。
KivaKit文件是一种特殊的资源。它使用服务提供者接口(SPI)来允许添加新的文件系统。kivakit extensions项目提供了以下文件系统的实现:
- HDFS文件
- S3对象
- GitHub存储库(只读)
KivaKit组件便于访问PackageResources。KivaKit中封装资源的风格类似于ApacheWicket中的风格,组件的包将有一个子包,其中包含其运行所需的资源。这允许从单个源代码树轻松打包和使用组件。相对于组件对包资源的访问如下所示:
public class MyComponent extends BaseComponent
{
[...]
var resource = listenTo(packageResource("data/data.txt"));
for (var line : resource.reader().lines())
{
}
}
Where the package structure looks like this:
├── MyComponent
└── data
└── data.txt应用
KivaKit应用程序是一个美化的组件,包含与启动、初始化和执行相关的方法。服务器是应用程序的一个子类:
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1application-1637785248958.jpg)
微服务是KivaKit应用程序最常见的用途,但也可以实现其他类型的应用程序(桌面、web、实用程序等)。microservice应用程序的基本代码如下所示:
public class MyMicroservice extends Server
{
public static void main(final String[] arguments)
{
new MyApplication().run(arguments);
}
private MyApplication()
{
super(MyProject());
}
@Override
protected void onRun()
{
[...]
}
}
这里的main()方法创建应用程序,并使用从命令行传递的参数调用应用程序基类中的run()方法。然后,微服务的构造函数将项目对象传递给超类构造函数。此对象用于初始化包含应用程序的项目以及它所依赖的任何其他项目。继续我们的示例,我们的项目类如下所示:
public class MyProject extends Project
{
private static Lazy project = Lazy.of(MyProject::new);
public static ApplicationExampleProject get()
{
return project.get();
}
protected ApplicationExampleProject()
{
}
@Override
public Set dependencies()
{
return Set.of(ResourceProject.get());
}
}
{
可以使用get()检索MyProject的单例实例。MyProject的依赖项由dependencies()返回。在本例中,MyProject仅依赖于ResourceProject,ResourceProject是kivakit资源迷你框架的项目定义。ResourceProject也有自己的依赖项。KivaKit将确保在调用onRun()之前初始化所有可传递的项目依赖项。
部署
KivaKit应用程序可以从名为deployments的应用程序相关包中自动加载设置对象集合。将微服务部署到特定环境时,此功能非常有用。我们的应用程序的结构如下所示:
├── MyMicroservice
└── deployments
├── development
│ ├── WebSettings.properties
│ └── DatabaseSettings.properties
└── production
├── WebSettings.properties
└── DatabaseSettings.properties
当开关-deployment=在命令行上传递给应用程序时,它将从命名的部署(本例中为开发或生产)加载设置。为微服务使用打包部署设置特别好,因为应用程序的使用非常简单:
java-jar my-microservice.jar-deployment=development[…]
这使得在Docker容器中运行应用程序变得很容易,即使您对它了解不多。
如果不需要打包部署设置,可以通过设置环境变量KIVAKIT_settings_FOLDERS来使用外部文件夹:
-DKIVAKIT_SETTINGS_FOLDERS=/Users/jonathan/my microservice SETTINGS
命令行解析
应用程序还可以通过返回一组SwitchParser和/或ArgumentParser列表来解析命令行:
public class MyMicroservice extends Application
{
private SwitchParser<File> DICTIONARY =
File.fileSwitchParser("input", "Dictionary file")
.required()
.build();
@Override
public String description()
{
return "This microservice checks spelling.";
}
@Override
protected void onRun()
{
var input = get(DICTIONARY);
if (input.exists())
{
[...]
}
else
{
problem("Dictionary does not exist: $", input.path());
}
}
@Override
protected Set<SwitchParser<?>> switchParsers()
{
return Set.of(DICTIONARY);
}
}
这里,KivaKit使用switchParsers()返回的字典开关解析器来解析命令行。在onRun()方法中,通过get(DICTIONARY)检索在命令行上传递的文件参数。如果命令行存在语法问题或未通过验证,KivaKit将自动报告该问题,并提供从description()以及开关和参数解析器派生的用法帮助:
┏-------- COMMAND LINE ERROR(S) -----------
┋ ○ Required File switch -input is missing
┗------------------------------------------
KivaKit 1.0.0 (puffy telephone)
Usage: MyApplication 1.0.0 <switches> <arguments>
This microservice checks spelling.
Arguments:
None
Switches:
Required:
-input=File (required) : Dictionary file
Switch Parsers
In our application example, we used this code to build a SwitchParser:
private SwitchParser<File> INPUT =
File.fileSwitchParser("input", "Input text file")
.required()
.build();
The File.fileSwitchParser() method returns a switch parser builder which can be specialized with several methods before build() is called:
public Builder<T> name(String name)
public Builder<T> type(Class<T> type)
public Builder<T> description(String description)
public Builder<T> converter(Converter<String, T> converter)
public Builder<T> defaultValue(T defaultValue)
public Builder<T> optional()
public Builder<T> required()
public Builder<T> validValues(Set<T> validValues)
The implementation of File.fileSwitchParser() then looks like this:
public static SwitchParser.Builder<File> fileSwitchParser(String name, String description)
{
return SwitchParser.builder(File.class)
.name(name)
.converter(new File.Converter(LOGGER))
.description(description);
}所有开关和参数都是类型化对象,因此builder(Class)方法使用File类型(使用type()方法)创建一个builder。它的名称和描述传递给fileSwitchParser(),File.Converter方法用于在字符串和文件对象之间进行转换。
转换器
KivaKit提供了许多转换器,转换器可以在KivaKit的许多地方使用。转换器是将一种类型转换为另一种类型的可重用对象。它们特别容易创建,并且可以处理异常、空值或空值等常见问题:
public static class Converter extends BaseStringConverter<File>
{
public Converter(Listener listener)
{
super(listener);
}
@Override
protected File onToValue(String value)
{
return File.parse(value);
}
}调用StringConverter.convert(字符串)将字符串转换为文件。调用StringConverter.uncert(文件)将把文件转换回字符串。转换过程中遇到的任何问题都会广播给感兴趣的侦听器,如果转换失败,则返回null。
正如我们所看到的,转换器对侦听器链采取了不同的方法。所有转换器都需要一个侦听器作为构造函数参数,而不是依赖转换器用户来调用listenTo()。这确保所有转换器都能够向至少一个侦听器报告转换问题。
验证
在上面的命令行解析代码中,使用kivakit validation mini框架验证开关和参数。另一个常见的用例是向微服务验证web应用程序用户界面的域对象。
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1validation-1637785949145.jpg)
可验证类实现:
public interface Validatable
{
/**
* @param type The type of validation to perform
* @return A {@link Validator} instance
*/
Validator validator(ValidationType type);
}
要实现此方法,可以匿名地对BaseValidator进行子类化。BaseValidator提供了检查状态一致性以及广播问题和警告的方便方法。KivaKit使用ValidationSues对象捕获这些消息。然后可以使用Validatable接口中的默认方法查询此状态。用法如下所示:
public class User implements Validatable
{
String name;
[...]
@Override
public Validator validator(ValidationType type)
{
return new BaseValidator()
{
@Override
protected void onValidate()
{
problemIf(name == null, "User must have a name");
}
};
}
}
public class MyComponent extends BaseComponent
{
public void myMethod()
{
var user = new User("Jonathan");
if (user.isValid(this))
{
[...]
}
}
}
这里捕获来自验证的消息以确定用户对象是否有效。同样的消息也会广播到MyComponent的监听器,这些消息可能会记录或显示在某些用户界面中。
日志
KivaKit记录器是一个消息侦听器,记录它听到的所有消息。基本应用程序类有一个日志记录器,用于记录从组件到应用程序级别的任何消息。这意味着不需要在应用程序或其任何组件中创建记录器,只要侦听器链从每个组件一直引导到应用程序。
最简单的记录器是ConsoleLogger。将此设计缩小到基本结构,ConsoleLogger和相关类大致如下所示(请参见下面的UML图):
:
public class ConsoleLogger extends BaseLogger
{
private Log log = new ConsoleLog();
@Override
protected Set<Log> logs()
{
return Sets.of(log);
}
}
public class BaseLogger implements Logger
{
void onMessage(final Message message)
{
log(message);
}
public void log(Message message)
{
[...]
for (var log : logs())
{
log.log(entry);
}
}
}
public class ConsoleLog extends BaseTextLog
{
private Console console = new Console();
@Override
public synchronized void onLog(LogEntry entry)
{
console.printLine(entry.message().formatted());
}
}BaseLogger.log(Message)方法通过添加上下文信息将提供给它的消息转换为日志条目。然后,它将日志条目传递给logs()返回的日志列表中的每个日志。对于ConsoleLogger,将返回一个ConsoleLog实例。ConsoleLog将日志条目写入控制台。
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1logging-1637785248958.jpg)
KivaKit有一个SPI,允许从命令行动态添加和配置新的记录器。KivaKit提供的一些伐木工人包括:
- ConsoleLog
- EmailLog
- FileLog
Web和REST
kivakit扩展项目包含对Jetty、Jersey、Swagger和ApacheWicket的基本支持,因为它们在实现微服务时通常很有用。这些微型框架都集成在一起,因此启动Jetty服务器非常容易,为微服务提供REST和Web访问:
@Override
protected void onRun()
{
final var port = (int) get(PORT);
final var application = new MyRestApplication();
// and start up Jetty with Swagger, Jersey and Wicket.
listenTo(new JettyServer())
.port(port)
.add("/*", new JettyWicket(MyWebApplication.class))
.add("/open-api/*", new JettySwaggerOpenApi(application))
.add("/docs/*", new JettySwaggerIndex(port))
.add("/webapp/*", new JettySwaggerStaticResources())
.add("/webjar/*", new JettySwaggerWebJar(application))
.add("/*", new JettyJersey(application))
.start();
}JettyServer允许Jersey、Wicket和Swagger与一致的API相结合,使代码清晰简洁。通常这就是所需要的。
结论
尽管KivaKit在1.0版上是全新的,但它在Telenav上已经使用了十多年。非常欢迎来自开源社区的输入,包括反馈、bug报告、特性想法、文档、测试和代码贡献。
以下资源可帮助您深入了解详细信息:
|
Resource |
Description |
|
License |
|
|
Related Projects |
|
|
Developer Setup |
|
| Blog | State-of-the-Art |
|
GitHub |
|
|
Code |
git clone https://github.com/Telenav/kivakit.git |
|
|
|
|
|
- 58 次浏览
【微服务架构】介绍NGINX的微服务参考架构
作者注:本博文是系列文章的第一篇:
- Introducing the NGINX Microservices Reference Architecture (this post)
- MRA, Part 2: The Proxy Model
- MRA, Part 3: The Router Mesh Model
- MRA, Part 4: The Fabric Model
- MRA, Part 5: Adapting the Twelve‑Factor App for Microservices
- MRA, Part 6: Implementing the Circuit Breaker Pattern with NGINX Plus
所有六个博客,以及一个关于微服务应用程序的Web前端的博客,都被收集到一个免费的电子书中。
另请查看有关微服务的其他NGINX资源:
- A very useful and popular series by Chris Richardson about microservices application design
- The Chris Richardson articles collected into a free ebook, with additional tips on implementing microservices with NGINX and NGINX Plus
- Other microservices blog posts
- Microservices webinars
- Microservices Solutions page
- Topic: Microservices
介绍
NGINX从一开始就参与了微服务运动。 NGINX的轻巧,高性能和灵活性非常适合微服务。
NGINX Docker映像是Docker Hub上排名第一的应用程序映像,您今天在Web上找到的大多数微服务平台都包含一个演示,它以某种形式部署NGINX并连接到欢迎页面。
因为我们认为转向微服务对于客户的成功至关重要,我们NGINX已经启动了一个专门的程序来开发支持Web应用程序开发和交付这种地震转变的功能和实践。我们还认识到,实现微服务有许多不同的方法,其中许多方法都是新颖的,并且特定于各个开发团队的需求。我们认为需要使用模型来使公司更容易开发和交付自己的基于微服务的应用程序。
考虑到这一切,NGINX专业服务部门正在开发NGINX微服务参考架构(MRA) - 一组可用于创建自己的微服务应用程序的模型。
MRA由两部分组成:三个模型中的每一个的详细描述,以及实现我们的示例照片共享程序的可下载代码,Ingenious。三种型号的唯一区别是用于为每种型号配置NGINX Plus的配置代码。这一系列博客文章将提供每个模型的概述说明; Ingenious示例程序的详细描述,配置代码和代码将在今年晚些时候推出。
我们构建此参考架构的目标有三个:
- 为客户和行业提供随时可用的蓝图,用于构建基于微服务的系统,加速和改进开发
- 创建用于测试NGINX和NGINX Plus中新功能的平台,无论是内部开发还是外部开发,分布在产品核心中或作为动态模块
- 为了帮助我们了解合作伙伴系统和组件,我们可以从整体上了解微服务生态系统
微服务参考架构也是NGINX客户专业服务产品的重要组成部分。在MRA中,我们尽可能使用NGINX开源和NGINX Plus共有的功能,并在需要时使用NGINX Plus特有的功能。 NGINX Plus依赖关系在更复杂的模型中更强,如下所述。我们预计,MRA的许多用户将受益于NGINX专业服务的访问以及NGINX Plus订阅的技术支持。
微服务参考架构概述
我们正在构建参考架构以符合Twelve-Factor App的原则。这些服务设计为轻量级,短暂的和无状态的。
MRA使用行业标准组件,如Docker容器,各种语言 - Java,PHP,Python,NodeJS / JavaScript和Ruby - 以及基于NGINX的网络。
迁移到微服务时,应用程序设计和体系结构的最大变化之一是使用网络在应用程序的功能组件之间进行通信。在单片应用程序中,应用程序组件在内存中进行通信。在微服务应用程序中,该通信通过网络进行,因此网络设计和实施变得至关重要。
为了反映这一点,MRA已经使用三种不同的网络模型实现,所有这些模型都使用NGINX或NGINX Plus。它们的范围从相对简单到功能丰富且更复杂:
- 代理模型 (Proxy Model)- 一种简单的网络模型,适用于实现NGINX Plus作为微服务应用程序的控制器或API网关。该模型建立在Docker Cloud之上。
- 路由器网格模型(Router Mesh Model ) - 一种更强大的网络方法,每台主机上都有一个负载均衡器,可以管理系统之间的连接。该模型类似于Deis 1.0的体系结构。
- 织品模型 (Fabric Model) - MRA的皇冠上的明珠,面料模型在每个容器中都有NGINX Plus,处理所有入口和出口交通。它适用于高负载系统,并支持所有级别的SSL / TLS,NGINX Plus提供减少的延迟,持久的SSL / TLS连接,服务发现以及所有微服务中的断路器模式。
我们的目的是您使用这些模型作为您自己的微服务实现的起点,我们欢迎您提供有关如何改进MRA的反馈。 (您可以从添加到下面的评论开始。)
以下是每种模型的简要说明;我们建议您阅读所有描述,以便开始了解如何最好地使用一个或多个模型。未来的博客文章将详细描述每个模型,每个博客文章一个。
代理模型简介
代理模型是一种相对简单的网络模型。它是初始微服务应用程序的出色起点,或者是转换中等复杂的单片遗留应用程序的目标模型。
在代理模型中,NGINX或NGINX Plus充当入口控制器,将请求路由到微服务。当创建新服务时,NGINX Plus可以使用动态DNS进行服务发现。当使用NGINX作为API网关时,代理模型也适合用作模板。

如果需要进行服务间通信 - 并且大多数应用程序都处于任何复杂程度 - 服务注册表提供集群内的机制。 (有关服务间通信机制的详细列表,请参阅此博客文章。)Docker Cloud默认使用此方法;为了连接到另一个服务,服务查询DNS并获取IP地址以发送请求。
通常,代理模型适用于简单到中等复杂的应用程序。它不是负载平衡最有效的方法/模型,特别是在规模上;如果您有严重的负载平衡要求,请使用下面描述的模型之一。 (“Scale”可以指大量的微服务以及高流量。)
编辑器 - 有关此模型的深入探索,请参阅MRA,第2部分 - 代理模型。
路由器网格模型
路由器网格模型中等复杂,非常适合强大的新应用程序设计,也适用于转换不需要Fabric模型功能的更复杂的单片遗留应用程序。
通过在每个主机上运行负载均衡器并主动管理微服务之间的连接,路由器网状网模型采用比代理模型更强大的网络方法。路由器网格模型的主要优点是服务之间的更高效和稳健的负载平衡。如果使用NGINX Plus,则可以实施活动运行状况检查以监视各个服务实例,并在关闭时优雅地限制流量。
Deis Workflow使用类似于路由器网格模型的方法在服务之间路由流量,NGINX实例在每个主机上的容器中运行。当新的应用程序实例被启动时,进程从etcd服务注册表中提取服务信息并将其加载到NGINX中。 NGINX Plus也可以在这种模式下工作,使用各种位置及其相关的上游。
编辑器 - 有关此模型的深入探索,请参阅MRA,第3部分 - 路由器网格模型(https://www.nginx.com/blog/microservices-reference-architecture-nginx-r…)。
最后 - Fabric模型,带有可选的SSL / TLS
我们NGINX对Fabric模型最为兴奋。它带来了一些最令人兴奋的微服务承诺,包括高性能,负载平衡的灵活性,以及无处不在的SSL / TLS,直到单个微服务的水平。 Fabric模型适用于安全应用程序,可扩展到非常大的应用程序。
在Fabric模型中,NGINX Plus部署在每个容器中,并成为进出容器的所有HTTP流量的代理。应用程序与本地(localhost)主机位置通信以获取所有服务连接,并依赖NGINX Plus进行服务发现,负载平衡和运行状况检查。
在我们的配置中,NGINX Plus向ZooKeeper查询应用程序需要连接的所有服务实例。例如,使用DNS频率设置(有效)设置为1秒,NGINX Plus会每隔一秒扫描ZooKeeper,并适当地路由流量。
由于NGINX Plus中强大的HTTP处理功能,我们可以使用keepalive来维护与微服务的状态连接,减少延迟并提高性能。当使用SSL / TLS来保护微服务之间的流量时,这是一个特别有价值的功能。
最后,我们使用NGINX Plus的主动健康检查来管理健康实例的流量,并且基本上免费构建断路器模式。
编辑 - 有关此模型的深入探索,请参阅MRA,第4部分 - 结构模型(https://www.nginx.com/blog/microservices-reference-architecture-nginx-f…)。
MRA的巧妙演示应用程序
MRA包括一个示例应用程序作为演示:Ingenious照片共享应用程序。 Ingenious在三种模型中实现 - 代理,路由器网格和结构。 Ingenious演示应用程序将于今年晚些时候向公众发布。
Ingenious是照片存储和共享应用程序的简化版本,la Flickr或Shutterfly。我们选择照片共享应用程序的原因有以下几点:
- 用户和开发人员都很容易掌握它的功能。
- 需要管理多个数据维度。
- 在应用程序中很容易融入漂亮的设计。
- 它提供了非对称计算要求 - 高强度和低强度处理的混合 - 可以实现跨不同功能的故障转移,扩展和监视功能的真实测试。

结论
NGINX微服务参考架构对我们来说是一个令人兴奋的发展,对于我们迄今为止共享的客户和合作伙伴而言。 在接下来的几个月里,我们将发布一系列博客文章,详细描述它,我们将在今年晚些时候推出。 我们还将在9月7日至9日在德克萨斯州奥斯汀举行的nginx.conf 2016上详细讨论。 请给我们您的反馈意见,我们期待着与您相见。
原文:https://www.nginx.com/blog/introducing-the-nginx-microservices-reference-architecture/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 93 次浏览
【微服务架构】使用Canary版本来简化API版本控制
API提供者可能面临的最大困难之一是如何管理版本和从实例到实例的构建。迭代的持续需求与组织的持续需求相匹配,使得版本控制成为现代API开发中一个有争议且经常被讨论的方面。但是,对于传统的版本控制,有一些替代方法可以带来一些主要的好处。
今天,我们将讨论其中一个解决方案——canary release。Canary已经迅速成为透明API开发的一个巨大组件,对于开放银行来说,它可能是现代金融机构在不破坏基础互操作性的情况下实现透明、有效的版本控制的最佳工具之一。
为什么API版本控制和金丝雀的发布如此重要?
有时,API提供者和API使用者之间可能存在某种紧张关系。API提供者可能希望在他们有新的、更好的想法时改变API。这些想法很有前途,展示了API的新特性、新方法和可能的新方向。
然而,API使用者通常只想要一些稳定的东西。除非使用者对这个新的、很棒的想法感兴趣,否则他们希望API能够以可预见的方式运行。
这就产生了一个明显的问题,这也是版本控制对许多用户来说如此困难的主要原因。不过,对于版本控制最好的争论来自于REST设计之父Roy Fielding。他对实现版本控制的看法是什么?“不要。”
版本是什么?
具体来说,为什么?为什么我们不应该理所当然地进行版本控制呢?让我们看看版本化api的影响。
版本控制是指在向服务添加特性时,从根本上创建现有对象的新版本。这些版本是截然不同的,并且通常具有完全独立的功能,具有不同的目的,因此,被视为完全独立的开发。
在传统的版本化开发中,这些新版本将被标记为用于测试的beta版本,以及用于全面改进的里程碑版本。一旦进行了测试,通常以一种可选择的方式,这些beta版本将慢慢地转向候选版本,然后是实际版本。
这种类型的版本控制有一些主要的好处,主要的好处是在形式和功能上的主要改进得到了明确的划分。这种划分的能力非常重要,特别是在使用不同的硬件版本时,但最终,这本身就是版本化方法的失败之处。许多用户都知道,当他们尝试使用一个设备时,却发现其固件、软件或其他元素不兼容,需要更新。因此,他们不使用该系统,并在以后返回时发现情况更糟。
这最终导致用户群中大量的更新和未更新的划分,并且把太多的重要性放在单个实例上而不是整体系统本身。
什么是金丝雀发布?
金丝雀释放是一种试图减轻许多负面影响的技术。Canary版本通常被定位为版本控制的替代品,就像lite版本控制一样。
在canary版本中,引入新软件的风险是通过先慢慢地将这些变化推广给一小部分用户来减轻的,而不是像经典版本控制中那样通过选择加入和后来的强制发布来推广它们。这些小的用户子集通过动态负载平衡测试新版本,一旦版本控制被验证为符合预期的功能,新版本就成为默认版本。
我们称之为金丝雀释放,因为它的功能类似于井筒中的金丝雀。金丝雀曾经被矿工用来测试矿井里的空气。如果空气有毒,金丝雀就会死掉,这就向矿工发出他们必须立即离开的信号。同样地,如果正在缓慢测试的API实例是坏的,那么检测它的原因将是小子集中的故障,而不是对一般用户的大规模故障。
应用程序正在调用一个绑定到API的服务实例——随着这些请求逐渐暴露给新版本,特定的应用程序、硬件、方法等可以根据新版本动态地进行粒度测试。最终,如果一切顺利,所有内容都将转到新版本,旧版本将被弃用,用户也不会知道。
这里的一个巨大好处是,回滚很容易——最终,您只需停止向新的canary实例发送请求,而只需将其发送到旧的canary实例。
荷兰国际集团(ING)版本
一旦您看到了它的实际应用,这种方法就更容易理解。Patrice Krakow在2017北欧api平台峰会上做了关于canary发布的演讲,他提供了下面的工作流程作为ING银行如何处理canary发布的例子。
构建系统
在ING系统中,大部分API交互是由API网关驱动的。他们认为他们的网络分为两层——外部网络和内部网络,第三层内部网络代表办公室网络。Patrice注意到,API网关功能在外部边界和内部边界上,但他指出,并没有真正的“内部网关”,正如设计所暗示的那样。
就其API而言,包括负载平衡和逻辑寻址在内的一切都主要通过API服务发现来处理。当创建一个服务的实例时,该服务将作为一个实例、一组端点和一个地址通过路由器交付给API服务器发现。现在,我们必须绕一小段路来讨论一下路由器。在ING,它们不把路由器作为外部组件来处理,而是作为客户端的一部分来处理——通过这种方式,客户端代码处理自己的负载平衡。
在ING系统中,服务和端点是两个独立的东西,但是它们被称为manifest的东西链接和控制。这个清单本质上是服务和API端点列表之间定义良好的显式链接,并作为实例本身如何工作的一种指导。
当一个软件包想要调用一个API端点时,它首先声明它的意图。在ING中,这被称为订阅,它的作用是作为软件包(也称为应用程序)和特定API端点之间的关系。当在内部生成对等令牌时,API规范的版本将从创建此订阅时开始存储,并将实例版本作为更大的canary系统的一部分。
利用该系统
有了所有这些组成部分,ING最终通过它的路由器实现金丝雀释放。流程从API和端点开始,这些API和端点在一个Swagger文件中声明,该文件存在于API注册表中。服务被附加到API端点,然后清单被添加到具有特定规范版本的服务中。当启动一个服务的实例时,它会向API服务发现模块提供其物理地址,以及其所有端点的清单。

摘自帕特里斯·克拉科夫的演讲。幻灯片。
当应用程序想要调用一个端点时,它订阅一个可以调用的端点列表以及它想要与之对话的特定版本。路由器,不管是在代码内部还是在代码外部,然后传递注册对等令牌和信息,并使用端点的物理地址调用API服务发现。如果特定的API规范版本匹配,则可以将代码定向到基础实例或与该版本兼容的向后兼容版本。
通过这种方式,系统可以开始卸载到向后兼容旧实例的新实例,并且一旦测试了整个子集,就可以动态地增加用户基数。最后,当100%的用户基被透明地迁移后,旧的实例id就会被弃用,而新实例将成为清单中的默认实例。
结论:许多行业都能从金丝雀发布中受益
最终,API提供者选择合并canary版本还是坚持传统的版本控制完全取决于API开发人员自身的具体用例。虽然canary的发布确实使版本控制变得更加容易,但如果API每隔几年就只有一个或两个主要版本,那么它有时可能会付出更多的努力。但是,如果一个API不断地移动、不断地迭代,canary release可能是管理这种移动的最强大、最有效的方法之一。
这一概念在各种行业中都有许多应用。我们可以只看一个来看看这个潜在的概念是多么强大。例如,开放银行业运动正在鼓励金融机构远离旧的标准方法。因此,释放金丝雀的想法不仅是一种技术手段——它是一种新的风气,为银行在金融交易和架构构造方面的功能提供了范式转变。
虽然这是一个非常具体的应用程序,但canary版本控制的使用适用于各种函数和目的。由于这个原因,它仍然吸引着许多开发人员。你觉得放金丝雀怎么样?你认为它比它的价值更复杂,还是你认为它像一些人声称的那样是一个有前途的解决方案?请在下面的评论中告诉我们。
原文:https://nordicapis.com/using-canary-release-to-ease-api-versioning/
本文:http://jiagoushi.pro/node/1209
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 91 次浏览
【微服务架构】使用Spring Cloud Config和Vault进行外部配置
让您的应用程序提取其配置和凭据
你开始一个新项目。一开始,它主要是原型;你尝试了一些想法并且还没有修复,所以在你的应用程序配置方面你非常务实。一些属性文件存储在源代码旁边 - 至少您没有使用硬编码的URL和凭据!首次将应用程序部署到开发或演示环境时,只需复制和修改属性文件即可。原型变成了生产代码,但配置仍然是以临时方式管理的。这对你来说听起来很熟悉吗?无论如何,这是我在一年多前的一个当前项目中发现自己的情况。
在不同的环境中维护配置文件的单独副本可能永远不是最好的方法,即使我们曾经部署到少数长时间运行的雪花服务器上也是如此。鉴于我们越来越多地学习利用云产品,因此经常为测试创建短暂的应用程序环境,甚至将我们的生产系统部署为凤凰服务器,我们需要做得更好。
这篇文章描述了我们如何使用Spring Cloud Config和Spring Cloud Vault在我们的一个基于Spring Boot的项目中解决这个问题,以及我们如何定制这些库以满足我们的需求。特别是,该帖子着眼于外部化配置的动机,并在描述(a)我们为实现Spring Cloud Config而实施的扩展之前,对Spring Cloud Vault,Hashicorp Vault和Spring Cloud Vault进行了(非常)高级概述。客户端从Vault获取必要的HTTP基本身份验证凭据,以及(b)我们如何使应用程序从Vault读取所有TLS(客户端或服务器)密钥材料。您可以分别在公共演示项目demo-authorized-spring-config-server和demo-spring-boot-tls-material-from-vault中的GitHub上找到相关代码。
- 外化配置
- Spring服务
- Spring Cloud Config
- 配置服务器
- 配置客户端
- Spring Cloud Config
- Hashicorp Vault
- Spring Cloud Vault
- Vault Authentication
- Haufe的Spring Cloud Vault扩展
- 授权的配置服务器
- PKI密钥和信任库集成
- 来自Vault的Trustore配置
- 来自Vault的TLS客户端配置
外化配置
当然,配置挑战并不新鲜,因此我们可以看到经过测试的概念。例如,十二因素应用程序的宗旨是应用程序将通过环境独家配置:几乎每个操作系统和部署模型都支持环境变量,无论您使用哪种语言或框架,它们都可以轻松访问,并且您可以定义它们而不对您的部署工件进行任何修改。
虽然我接受了12因素应用程序方法的情绪,并同意声称部署到新环境(可能在不同的平台上)不应该要求对部署工件进行任何修改,但我不相信结论由十二因素应用程序绘制:不应将这些配置组合在一起。
原因很简单:严格遵循十二因素应用指南可能确实可以保证您始终可以更改应用程序的任何配置方面。但它只是将配置管理的负担放在部署者身上,它无助于解决这一挑战。根据我的经验,它还将使开发人员只公开他们希望从一个环境变为另一个环境的少数参数;所有其他配置将最终融入部署工件中。
最后但并非最不重要的是,通过环境传递敏感的秘密并不适合我:如果你可以保证应用程序运行的VM根本不共享可能没问题 - 在这种情况下,攻击者很可能能够无论如何,读取环境将能够从您的应用程序中提取秘密。但是,如果您将不同的应用程序部署到同一个VM(或针对不同租户的多个应用程序实例),那么我不相信容器化解决方案提供的进程隔离,以使一个容器的环境变量与确定的攻击者保持对另一个容器的访问权限。同一台机器。
如果传递一组配置属性的名称(或者,更具技术性地说,标识符),则可以避免上述问题。唯一的前提条件是您必须随时可以自由地重新组织这些属性集。
确实,这引入了对服务的依赖,以某种方式可以解析这样的配置集标识符;但是,与依赖于您的应用程序必须可以访问的数据库服务相比,这并没有太大的不同。只要此配置服务具有定义良好的API,您就可以在必要时轻松进行模拟。
Spring 服务
回到我刚才提到的项目:它在文档数据库前面使用一组Spring Boot服务。这些服务被打包到部署到小型集群中的Docker映像中。 (到目前为止,Docker Swarm模式对我们来说效果很好。但是如果像Azure管理的Kubernetes服务(AKS)这样的产品让我们的生活变得更简单,我将不排除在未来的某个地方切换到Kubernetes。)
Spring框架引入了带有配置文件和属性源的环境抽象概念。 Spring Boot构建于此环境抽象之上,开箱即用,提供了许多选项,可以将配置属性传递给应用程序:“传统”属性文件,YAML配置文件,JVM系统属性,命令行参数,OS环境变量和等等。最后,所有适用的属性源(根据活动配置文件)都组织在由环境抽象管理的列表中。当应用程序需要特定属性的值时,Spring会遍历此列表并使用定义相关属性的第一个源中的值。由于列表中属性源的顺序,更具体的源可以覆盖“默认”配置。如果属性值引用了某个其他属性,则再次从列表的头部开始查找。当然,可以向环境添加自定义属性源。
Spring Boot配置概念对我们来说效果很好 - 我们可以定义合理的默认配置,配置属性(例如,如果我们激活安全连接,所有TLS设置)可以轻松地分组到特定于配置文件的配置中,我们可以轻松为新的部署目标定义其他配置文件。我们只错过了两个关键功能:配置文件不应嵌入到docker镜像中,并且不得在配置文件中保留数据库用户凭据或私钥等秘密。
Spring Cloud Config
在Dave Syer和Josh Long的SpringDeveloper演示文稿的录制中,我回忆起Spring Cloud Config至少解决了前者的问题。
配置服务器
Spring Cloud Config的服务器部分是一个“普通”Spring Boot Web应用程序,它以简单的JSON结构提供属性源列表。 最好以示例的方式显示:
以下JSON对象是本地配置服务器对URL http:// localhost:9400 / demo / plain-actuator-access,integration-db的GET请求的响应。 第一个URL路径段指定应用程序名称 - 配置服务器实例可以为多个应用程序提供配置。 第二个路径段指定以逗号分隔的应用程序配置文件列表。 Config Server还支持第三个路径段(此处未使用),其标签可用于例如请求特定版本的配置。
{ "name": "demo", "profiles": [ "plain-actuator-access,integration-db" ], "label": null, "version": null, "state": null, "propertySources": [ { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/demo-integration-db.yml", "source": { "demo.db.host": "integrationtest.demo.contenthub.haufe.io" } }, { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/demo-plain-actuator-access.yml", "source": { "management.security.enabled": false } }, { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/demo.yml", "source": { "demo.db.host": "localhost", "demo.db.database": "demo", "demo.db.url": "jdbc:postgresql://${demo.db.host}/${demo.db.database}", "demo.db.user": "${vault.demo.db.user}", "demo.db.password": "${vault.demo.db.passord}", "management.security.enabled": true } }, { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/application.yml", "source": { "endpoints.shutdown.enabled": true } } ] }
响应的重要部分是数组propertySources:如果演示应用程序是使用指定的配置文件和类路径中的相应配置文件启动的,则此数组中的每个对象都表示将按此顺序加载到Spring环境中的属性源。
请注意,可以在多个源中定义相同的属性,其中属性源的顺序决定“赢家”。此外,Spring递归地解析占位符(使用$ {...}语法)。仅给出此属性源列表,属性demo.db.url因此解析为jdbc:postgresql://integrationtest.demo.contenthub.haufe.io/demo。
由于这个特定的配置服务实例是从我的IDE中运行的,并且我希望它提供反映我的本地工作空间内容的配置,因此我使用本机配置文件启动了配置服务器 - 使用此配置文件,服务器将配置的文件系统文件夹视为只读配置源。
除非服务器用于本地开发,否则更常见的是让服务器从Git存储库中提取配置。更准确地说,配置服务器指向本地Git存储库或配置为在启动时克隆远程存储库。当客户端请求配置时,服务器从远程存储库中提取所有相关更新,并检出客户端请求中指定为标签的分支或版本。 (如果URL中省略了label,则配置服务器默认为主分支的HEAD。)然后,配置服务器才会读取配置文件。
旁注:Config Server依赖Eclipse的JGit库来实现所有Git功能。不幸的是,JGit仅支持ssh-rsa密钥,并且不了解known_hosts文件中的散列条目。如果已经存在远程Git主机的哈希条目,则很容易导致错误。由于JGit抛出的异常中的错误消息根本不清楚,因此很难诊断出这个问题 - 当我第一次尝试配置服务器时,它花了我几个小时。
如果有疑问,您可以使用ssh-keygen -F bitbucket.org查看您的known_hosts文件是否包含bitbucket.org的密钥。如果对于任何返回的键,第一个字段不以纯文本显示相关的主机名,则需要从known_hosts文件中删除键并添加非散列的ssh-rsa键:
$ ssh-keygen -R bitbucket.org
$ ssh-keyscan -t rsa bitbucket.org >>〜/ .ssh / known_hosts
配置客户端
Spring Cloud Config客户端库从配置服务器获取相关配置属性,并将它们作为属性源插入到您的应用程序环境中。仍然支持所有其他配置选项,环境将只有其他来源。对于您的应用程序代码,属性来自哪里没有任何区别。
当然,配置客户端也需要配置 - 至少,它需要配置服务器的地址。 Spring Boot的引导阶段进入图片:在Spring Boot应用程序开始构建其应用程序上下文(应用程序的Spring bean的所有注入和自动装配)之前,它会创建一个引导上下文,其中包含以后用于的所有组件构建应用程序上下文。其中,引导上下文确定如何设置应用程序上下文的环境。
引导上下文的环境使用每个Spring引导应用程序可用的相同源;唯一的区别是配置文件名为bootstrap.yml和bootstrap-profilename.yml(如果您更喜欢使用传统属性文件,则为bootstrap.properties和bootstrap-profilename.properties)。
如上所述,配置服务器可以在底层存储库中的分支之间切换。属性spring.cloud.config.label控制客户端应用程序请求的版本或分支。我们将gradle-git-properties插件添加到我们项目的Gradle构建中,从而构建应用程序的分支在运行时被称为属性git.branch。通过在bootstrap.yml中设置spring.cloud.config.label = $ {git.branch},我们使应用程序从与源分支匹配的分支中获取配置。如果要测试添加或更改配置属性的功能分支,这非常方便。
回顾十二因素应用程序的配置方法,我们可以在应用程序的bootstrap.yml中使用一些默认的配置客户端属性(适用于本地开发),并在部署时使用环境覆盖,例如,配置服务器端点变量。配置服务器地址不敏感,只有很少的属性在部署之间变化,因为环境变量方法可以很好地管理。
作为应用程序运行状况检查的一部分,配置客户端还会定期从服务器重新加载配置。大多数情况下,环境只在应用程序上下文初始化期间读取,因此重新加载不会产生太大影响 - 除非您使用@RefreshScope注释bean。这似乎是即时更改的一个很好的功能,但我还没有第一手的经验。
Hashicorp Vault
使用Spring Cloud Config,我们提供存储在Git存储库中的配置 - 在我们的示例中,在实际的代码存储库中。到目前为止,您应该知道不应该在Git存储库中存储明确的秘密 - 至少,必须使用与存储库分开存储的密钥正确加密机密。 (几年前,一些开发人员在亚马逊收取未经授权的用户可能使用的资源时收取的费用很难,因为在公共存储库中找到了AWS凭据。)
很少有开发人员是密码学专家,因此加密正确很难。并且您不希望保留大量其他代码来拦截您的配置属性,并在应用程序使用它们之前对其进行解密。最后,您最好使用像Hashicorp Vault这样的专用秘密商店解决方案。
Hashicorp Vault是一种安全访问秘密的工具,可以在休息时处理秘密的加密,可以在审计日志中记录任何秘密访问,并附带精心设计的访问控制概念。它还支持动态机密,例如即时创建的数据库密码,一旦相应的Vault令牌过期,它将自动被删除。与Vault实例的所有交互都通过其(通常是TLS安全的)REST接口进行。
我们在通用秘密商店之上使用的功能之一是Vault的PKI后端,可以颁发X.509证书;它本质上提供私人CA. (CA的注册机构事实上是由Vault的角色和访问控制实现实现的。)对于客户和合作伙伴(包括Haufe内的其他项目)访问的端点,我们当然配置由“众所周知的”CA之一颁发的TLS证书;感谢Let's Encrypt,现在获取您的客户可能信任的证书已经不再麻烦了。但在我们的应用程序中,我们需要通过TLS和客户端身份验证来保护一些内部通信路径。我们的加密不会发出客户端证书,因此通过Vault的REST接口可访问的私有CA使操作更加简单。
Spring Cloud Vault
与Spring Cloud Config类似,Spring Cloud Vault客户端将其他属性源插入Spring Boot应用程序的环境中。但是,这些属性是存储在Vault中的机密。
您甚至可以拥有特定于配置文件的机密:Vault将机密存储为JSON对象;您可以通过类似于文件系统路径的分层路径名来解决这些JSON对象,从相应的秘密插件的安装名称开始。
haufe-lexware-blog-chludwig ludwigc$ vault read -format=json local-secrets/ch-integrationtests/CHinteg { "request_id": "0ca07792-c7da-625b-0dd7-57b794fb9856", "lease_id": "", "lease_duration": 604800, "renewable": false, "data": { "vault.content.apiKey": "*********", "vault.content.clientId": "*********", "vault.content.clientSecret": "*********", "vault.ingest.apiKey": "*********", "vault.ingest.clientId": "*********", "vault.ingest.clientSecret": "*********" }, "warnings": null }
当我在路径local-secrets / ch-integrationtests / CHinteg查询对象时,您会看到我从本地Vault实例获得的响应(我用星号标记的实际机密值)。 实际的秘密存储在数据对象中。 鉴于Spring Boot应用程序ch-integration在配置文件CHinteg中运行,Spring Cloud Vault客户端将从Vault位置获取秘密local-secrets / ch-integrationtests / CHinteg,local-secrets / ch-integrationtests,local-secrets / defaultContext / CHinteg 和local-secrets / defaultContext。 defaultContext是应用程序的bootstrap.yml中指定的名称; 它意味着保存多个应用程序共享的秘密。
如果在应用程序中同时激活Spring Cloud Config和Vault,下图显示了数据流:
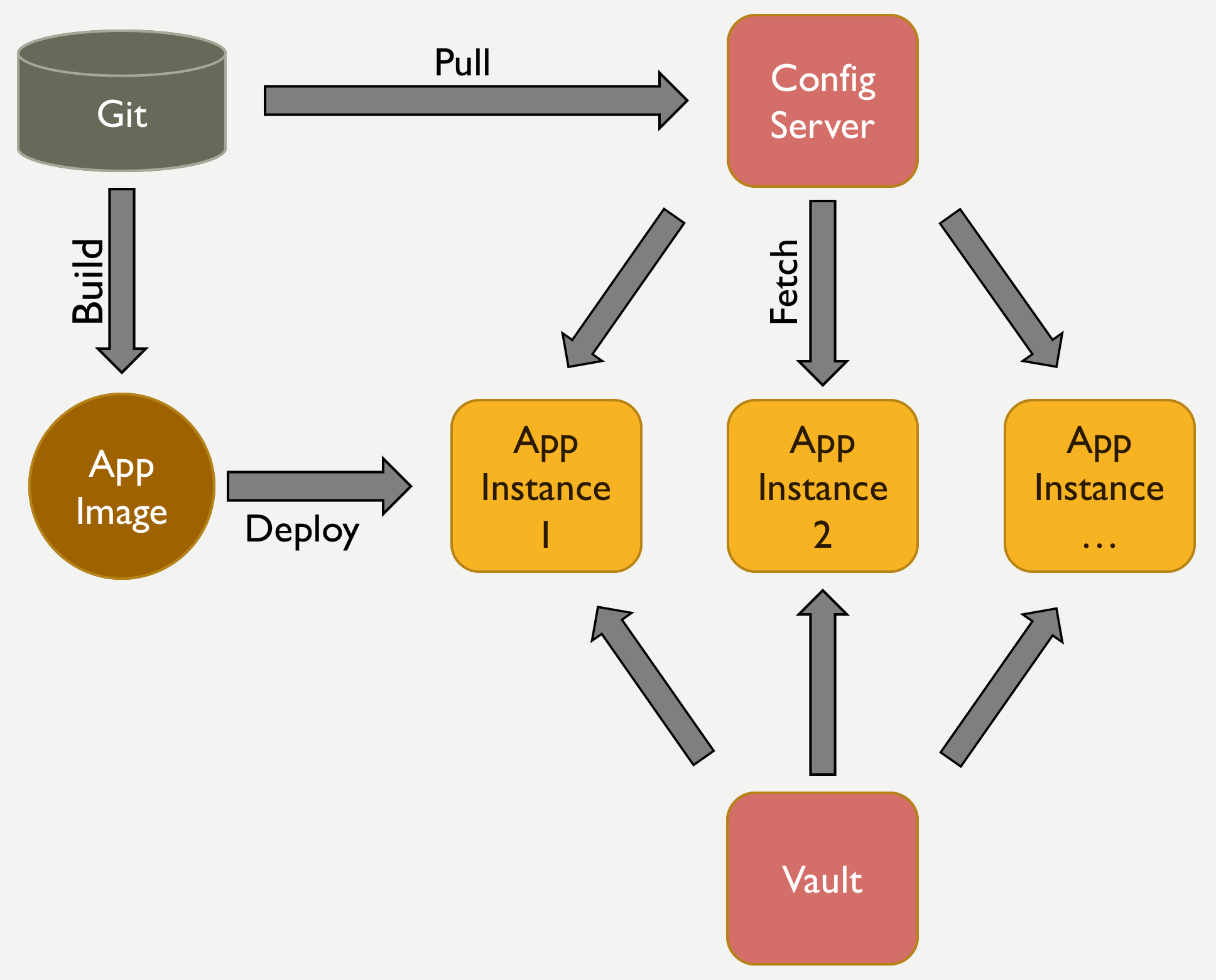
Vault 验证
Spring Cloud Vault支持与服务身份验证相关的Vault身份验证方法;其中,支持AppRole和Token身份验证。 Spring Cloud Vault客户端还负责令牌续订。但是,我们如何将必要的凭据传递给我们的应用程序实例?毕竟,Vault凭据至少与Vault中可访问的最敏感秘密一样有价值。
在项目中,我们有两种类型的应用程序:
1.批量作业,例如,每天运行一次,并且分别仅作为单个实例启动。
在这里,Vault与AppRole身份验证一起使用的一次性秘密ID非常匹配:部署管道从Vault首次使用后请求新的secret-id。这个secret-id通过一个环境变量传递给应用程序。应用程序将立即将此秘密ID替换为Vault令牌 - 之后,secret-id无用。因此,潜在的攻击者只有非常小的时间窗口才能窃取和使用secret-id。
即使攻击者成功,也不会被忽视:如果攻击者使用了secret-id,应用程序的登录尝试将失败。必须将其记录为安全事件,以便立即做出响应。
2. 部署到Docker Swarm集群中的长时间运行的服务。
某些服务被复制,因此在部署后多个应用程序实例需要登录到Vault - 一次性secret-id是不够的。 n-time secret-id(其中n是服务实例的数量)不会削减它,因为集群可以随时自由重启服务实例,以便将实例移动到另一个工作节点。因此,我们必须将一个秘密ID传递给不能进入攻击者手中的服务实例。
幸运的是,Docker Swarm Mode可以与服务实例共享秘密。 (Kubernetes具有类似的功能。)首先,部署管道要求Vault提供新的机密ID,并将其作为集群中的密钥存储。 Docker通过相互认证的TLS连接将密钥发送到集群管理器,并在集群的Raft存储中加密静态的秘密:
$ vault write -f –format=json auth/approle/role/myapprole/secret-id |\ jq -r '.secret_id' |\ docker secret create myapprole_secretid -
其次,部署管道请求swarm启动我们的服务,并使上面创建的秘密可用于服务实例。该秘密将映射到服务实例的容器文件系统,但此挂载仅保留在内存中:
$ docker service create --name="myapp" \ --secret="myapprole_secretid" myapp:alpine
请注意,secret-id的值永远不会出现在命令行或环境变量中。
Haufe的Spring Cloud Vault扩展
在我们使用Spring Cloud Config和Vault时,我们遇到了开箱即用的其他要求。幸运的是,它们提供了足够的定制钩子。
授权的配置服务器
我们拆分了配置属性:敏感属性存储在Vault中,其余属性在我们的Git存储库中管理,并通过Spring Config Server提供给应用程序实例。因此配置服务器不会泄露秘密。
然而,配置服务器提供了对应用程序内部结构的更多洞察,而不是我们想要自由地分发给潜在的攻击者。这不是“默默无闻”的尝试,但不必要的信息暴露(CWE-200)仍然可以帮助攻击者进行攻击。如果可以通过Internet访问配置服务器,或者通过Intranet访问公司的大多数公司,那么我们需要一些客户端身份验证。
基于TLS的HTTP基本身份验证应该足以达到此目的(假设密码足够强)。这也很容易实现 - 我们所要做的就是将Spring Security添加到Spring Config Server。配置服务器中的Spring Cloud Vault客户端从Vault获取凭据,因此Spring Security配置可以设置内存中的用户存储 - 这是一般的Spring Boot服务开发。
在客户端,情况更棘手:使用这种安全配置服务器的服务实例需要访问凭据作为其配置客户端引导程序设置的一部分。凭据是秘密,保存在Vault中。但是,Spring Cloud Vault提取的属性仅在“常规”应用程序上下文环境中可见,它们在引导环境中不可用!
我仔细阅读了文档并使用调试器逐步完成了Spring Boot应用程序初始化代码。我曾希望我能告诉Spring Boot(例如,通过添加@Order注释)来首先从Vault加载秘密,然后才开始初始化Spring Cloud Config客户端 - 无济于事。无论我尝试了什么,Config Client都从未看到Vault客户端读取的属性。
当我再次浏览Spring Cloud Config文档时,我终于有了一个想法:Spring Cloud Config客户端支持服务发现。 Spring Cloud附带了例如Eureka或Consul的实现,并且在其典型用例中,客户端将通过发现来学习配置服务器的地址。但与大多数Spring功能一样,很容易提供发现客户端的自定义实现;并且发现客户端界面支持基本身份验证凭据。以下显示了剥离文档,日志记录和大多数错误处理的发现客户端实现的核心:
public class VaultBasedDiscoveryClient implements DiscoveryClient { public static final String CONFIG_SERVICE_ID = "configserver"; public static final String URI_PROPERTY_NAME = "spring.cloud.config.uri"; public static final String USERNAME_PROPERTY_NAME = "spring.cloud.config.username"; public static final String PASSWORD_PROPERTY_NAME = "spring.cloud.config.password"; public static final String CONFIG_PATH_PROPERTY_NAME = "spring.cloud.config.configPath"; private final ConfigClientProperties configClientProperties; private final PropertySourceLocator vaultPropertySourceLocator; private final Environment environment; private final Supplier<List<ServiceInstance>> memoizedConfigServiceListSupplier; public VaultBasedDiscoveryClient(ConfigClientProperties configClientProperties, PropertySourceLocator vaultPropertySourceLocator, Environment environment) { this.configClientProperties = configClientProperties; this.vaultPropertySourceLocator = vaultPropertySourceLocator; this.environment = environment; } @Override public String description() { return "Vault-based Discovery Client"; } @Override @Deprecated public ServiceInstance getLocalServiceInstance() { return null; } @Override public List<ServiceInstance> getInstances(String serviceId) { VaultBasedConfigServiceInstance serviceInstance = null; if (CONFIG_SERVICE_ID.equals(serviceId)) { serviceInstance = createServiceInstance(); } return serviceInstance != null ? Collections.singletonList(serviceInstance) : Collections.emptyList(); } @Override public List<String> getServices() { return Collections.singletonList(CONFIG_SERVICE_ID); } private VaultBasedConfigServiceInstance createServiceInstance() { PropertySource<?> vaultPropertySource = vaultPropertySourceLocator.locate(environment); URI uri = getUri(vaultPropertySource); if (uri == null) { return null; } String userInfo = uri.getUserInfo(); String username = getUsername(vaultPropertySource, userInfo); String password = getPassword(vaultPropertySource, userInfo); String configPath = getVaultProperty(CONFIG_PATH_PROPERTY_NAME, vaultPropertySource, null); return new VaultBasedConfigServiceInstance(CONFIG_SERVICE_ID, uri, username, password, configPath); } private URI getUri(PropertySource<?> vaultPropertySource) { String uriString = getVaultProperty(URI_PROPERTY_NAME, vaultPropertySource, configClientProperties.getUri()); try { return StringUtils.isNotBlank(uriString) ? new URI(uriString) : null; } catch (URISyntaxException e) { return null; } } private String getUsername(PropertySource<?> vaultPropertySource, String userInfo) { String defaultUsername = configClientProperties.getUsername(); if (userInfo != null) { String[] userInfoParts = userInfo.split(":", 2); defaultUsername = userInfoParts[0]; } return getVaultProperty(USERNAME_PROPERTY_NAME, vaultPropertySource, defaultUsername); } private String getPassword(PropertySource<?> vaultPropertySource, String userInfo) { String defaultPassphrase = configClientProperties.getPassword(); if (userInfo != null) { String[] userInfoParts = userInfo.split(":", 2); if (userInfoParts.length > 1) { defaultPassphrase = userInfoParts[1]; } } return getVaultProperty(PASSWORD_PROPERTY_NAME, vaultPropertySource, defaultPassphrase); } private String getVaultProperty(String propertyName, PropertySource<?> vaultPropertySource, String defaultValue) { Object property = vaultPropertySource.getProperty(propertyName); if (property != null) { return property.toString(); } return defaultValue; } }
如果使用服务标识“configserver”调用VaultBasedDiscoveryClient#getInstances(String serviceId),则它会将请求委派给VaultBasedDiscoveryClient#createServiceInstance(),然后从VaultPropertySourceLocator提供的PropertySource读取所需的属性。 后一类是Spring Cloud Vault的一部分,可以访问从Vault检索的属性。
用户名和密码也在ConfigClientProperties的实例中查找,ConfigClientProperties是Spring Cloud Config客户端的类型安全配置类。 这样,如果Vault中未指定属性,我们仍然可以使用配置客户端的“标准”配置作为后备。
您可能已经注意到VaultBasedDiscoveryClient上没有任何Spring注释 - 它不是@Component或类似的。 将SpringBasedDiscoveryClient实例创建为Spring bean则是配置类VaultBasedDiscoveryClientAutoConfiguration的任务:
@Configuration @ConditionalOnExpression("${haufe.cloud.config.vaultDiscovery.enabled:true} and ${spring.cloud.vault.enabled:true}") @ConditionalOnMissingBean(VaultBasedDiscoveryClient.class) @AutoConfigureAfter(RefreshAutoConfiguration.class) @Import(VaultBootstrapConfiguration.class) public class VaultBasedDiscoveryClientAutoConfiguration { @Resource(name = "vaultPropertySourceLocator") private PropertySourceLocator vaultPropertySourceLocator; @Bean DiscoveryClient discoveryClient(@Autowired ConfigClientProperties configClientProperties, @Autowired Environment environment) { return new VaultBasedDiscoveryClient(configClientProperties, vaultPropertySourceLocator, environment); } }
这个类是Spring Boot部分的一个例子我不是那么热衷于:对我来说,至少,对注释的这种蔑视总是让人很难理解它们的净效应。
无论如何,让我们试一试:
- @Configuration将此类声明为应用程序上下文中Spring bean的贡献者,具体取决于以下注释中的条件。
- 注释@ConditionalOnExpression要求两个属性haufe.cloud.config.vaultDiscovery.enabl…,否则将忽略此配置类。
- 由于@ConditionalOnMissingBean批注,仅当没有通过其他方式实例化VaultBasedDiscoveryClient bean时,才会使用此配置类。
- @AutoConfigureAfter(RefreshAutoConfiguration.class)告诉Spring,只有在Spring的日志记录设置等完成后才应用此配置。
- @Import(VaultBootstrapConfiguration.class)从Spring Cloud Vault的自动配置中加载bean定义 - 特别是名为vaultPropertySourceLocator的bean。
通过类路径上的VaultBasedDiscoveryClientAutoConfiguration(并启用),配置客户端将引用VaultBasedDiscoveryClient以获取其自己的配置,并从Vault加载所需的属性(包括配置服务器凭据)。
PKI密钥和信任库集成
TLS密钥材料的管理通常是令人厌烦的任务。像openssl或Java的keytool这样的工具使用起来不是很直观,很少有开发人员熟悉所有选项。不幸的是,您的应用程序仍然按预期工作的事实并不意味着您的安全性足够强大。因此,更重要的是我们自动处理TLS密钥和信任存储,以避免由于手动操作而导致的未检测错误。
在许多情况下,您可以利用像Let's Encrypt这样的服务 - 以完全自动化的方式 - 发布大多数客户信任的证书。但您仍需要以安全的方式为您的应用程序提供密钥材料。如果您的服务不公开,那么您有时最好使用私有证书颁发机构颁发的证书。特别是,如果您依赖相互身份验证的TLS来保护服务之间的连接,则通常会出现这种情况。
传统上,我们曾经将带有必要密钥材料的密钥(和/或信任)存储文件放入文件系统中,应用程序可以从中加载它们。当然可以将这些密钥库作为通用机密存储在库中,并在应用程序启动之前将它们下载 - 例如,作为Docker入口点脚本的一部分 - 下载到Docker tmpfs mount中的文件夹中。这会将密钥和证书分发给应用程序实例,但您仍需要准备密钥库才能将其上载到Vault中。
Mark Paluch在他的示例代码中演示了如何使Spring Boot应用程序的嵌入式Web服务器直接从Vault加载TLS密钥(即,不触及文件系统)。如果您将Vault的PKI后端用作私有CA,则服务甚至可以即时请求新证书。
实际上,示例代码侧重于后一部分。但它会在通用秘密存储中缓存已颁发的证书,并在可能的情况下从那里加载它们。这可以很容易地适应我们将从外部CA获取的密钥和证书上载到Vault的情况。
我们将服务代码扩展为从库中加载信任库。诚然,信托商店不需要保密;但是,您必须保证信任存储的完整性,否则攻击者可能会使您的应用程序接受由攻击者颁发的证书或为攻击者颁发的证书。此外,我们还添加了配置TLS客户端的功能。
来自Vault的Trustore配置
作为Spring Vault的一部分实现的CertificateBundles包括私钥的Base64字符串表示,证书,颁发者证书以及证书的序列号。 Mark Paluch的示例代码包括EmbeddedServletContainerCustomizer,它使嵌入式Web容器使用Vault中的CertificateBundleread内容进行TLS服务器身份验证。不幸的是,它始终注入一个仅包含服务器证书的颁发者证书的信任库。由于CA颁发服务器证书或客户端证书(但不是两者)非常常见,因此此信任库设置不符合我们的要求。
因此,我们决定从Vault加载受信任的证书。我们扩展的TrustedCertificates类非常简单 - 它包含信任库条目的列表,信任库条目又包含证书的Base64字符串表示以及Java用来引用证书的证书别名。我们添加到CertificateUtils的readTrustedCertificates(VaultOperations,String)方法从Vault读取这样的TrustedCertificates对象。由Spring Vault实现的VaultOperations #read(String,Class <T>)处理所有“繁重的工作”。
TrustedCertificates#createTrustStore()从这些条目构建内存中的Java KeyStore。为方便用户,实现剥离PEM证书开始和结束标记,并从证书表示中删除所有空格。这使得可以以PEM或Base64编码的DER格式将证书存储在Vault中。
通过这些扩展,我们可以在VaultPkiConfiguration中修改EmbeddedServletContainerCustomizer的实现,以便它注入从Vault获取的信任库,或者 - 如果没有配置此信任库,则为JVM的默认信任库的副本。
来自Vault的TLS客户端配置
到目前为止,我们讨论了Spring Boot应用程序的嵌入式servlet容器的配置。通常,您的应用程序还充当后端服务的HTTP客户端,并且客户端还需要自定义TLS配置 - 也许该服务使用来自私有CA的证书,JVM默认不信任该私有CA,或者您的客户端必须使用X.509客户端证书。
Spring @Configuration类ServiceClientTLSConfig创建一个TLSClientKeyMaterial Spring bean,它捆绑私钥材料(即密钥库,密钥库密码和密钥密码)以及信任材料(即信任库和信任库密码)。如果spring.cloud.vault.enabled和haufe.client.ssl.vault.enabled都为真且如果Spring上下文中有可用的VaultOperations bean(即Spring Vault可用且已激活),则TLSClientKeyMaterial将初始化为从Vault通用秘密后端读取的值。用于在Vault中存储密钥材料的数据格式与服务器密钥材料的数据格式相同。
在某些情况下(如针对后端服务的集成实例的本地开发),在文件系统上使用密钥和信任存储可能仍然更方便。 ServiceClientTLSConfig适应这种情况;只需将haufe.client.ssl.vault.enabled设置为false,然后将从文件系统初始化TLSClientKeyMaterial。这是由Spring Boot的bean创建方法的@ConditionalOnXYZ注释控制的:ServiceClientTLSConfig #tlsClientKeyMaterialFromVault(ServiceClientTLSProperties,VaultOperations)仅在满足上述所有条件时才会被调用。在所有其他情况下,ServiceClientTLSConfig#tlsClientKeyMaterialFromFilesystem(ServiceClientTLSProperties)从文件系统加载密钥材料。 (乍一看,使用@ConditionalOnXYZ可能看起来有点过分;但是,如果我们想在关闭Vault支持的情况下运行应用程序,它会避免不满意的Spring bean依赖关系,因为那时不会有VaultOperations bean。)
当然,如何使HTTP客户端使用密钥材料取决于您的HTTP客户端实现。演示存储库包含模块demo-service-frontend中的示例:组件ClientHttpRequestFactoryConfigurer使用Spring注入构造函数的TLCLientKeyMaterial bean来设置SSLContext,而SSLContext又用于构造HttpComponentsClientHttpRequestFactory。我希望其他客户端实现的设置看起来类似。
原文:http://work.haufegroup.io/spring-cloud-config-and-vault/
本文:https://pub.intelligentx.net/externalized-configuration-spring-cloud-config-and-vault
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 207 次浏览
【微服务架构】单片到微服务架构的模式和最佳实践
在本文中,我们将学习如何使用设计模式、原则和最佳实践来设计微服务架构。 我们将使用正确的架构设计模式和技术。
在本文结束时,您将了解如何在微服务分布式架构上设计系统以实现高可用性、高可扩展性、低延迟和对网络故障的弹性,从而处理数百万个请求。

Event-Driven Architecture
本课程将是软件架构设计的旅程,逐步将架构单片演变为事件驱动的微服务。
我们将从设计处理少量请求的电子商务整体架构开始软件架构的基础知识。
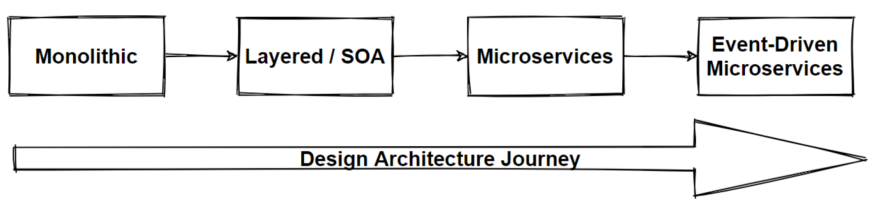
Journey of Design Architectures
之后逐步演变架构
- 分层架构
- SOA
- 微服务
- 最后是事件驱动的微服务架构
一起设计处理数百万个请求。
带课程的逐步设计架构
在本课程中,我们将学习如何使用设计模式、原则和最佳实践来设计微服务架构。我们将从设计单体到事件驱动的微服务开始,并一起使用正确的架构设计模式和技术。
文章流
在文章流中将既有理论信息又有实践信息;
- 我们将学习一个特定的模式,我们应该使用的原因和位置
- 之后,我们将看到应用这些模式的参考架构
- 之后,我们将应用这个新学习的模式来设计我们的架构
- 最后,我们将决定哪些技术可以作为该架构的选择。
所以我们将迭代和演化架构单体到事件驱动的微服务架构。
架构演进
我们将根据问题发展这些架构
- 我们如何扩展应用程序?
- 我们的应用程序需要处理多少个请求?
- 我们的拱门可以接受多少秒的延迟?
因此,我们根据以下问题演变这些问题;

可扩展性和可靠性是衡量您的应用程序对最终用户的服务程度的衡量标准。 如果我们的电子商务应用程序可以在没有明显停机的情况下为数百万用户提供服务,那么我们可以说该系统具有高度可扩展性和可靠性。 可扩展性和可用性可能是设计良好架构的主要因素。
- 可扩展性=电子商务应用程序应该能够为数百万用户提供服务
- 可用性 = 电子商务应用程序应该 24/7 可用
- 可维护性=电子商务应用程序应该发展几年
- 效率 = 电子商务应用程序应响应可接受的延迟,
- 例如 < 2 秒 - 短响应延迟
每秒请求和可接受的延迟
好的,让我们谈谈可接受的延迟,
如果我们的应用程序被越来越多的用户使用,我们如何使我们的应用程序具有可接受的延迟?
请看表格;

正如您在表中看到的,我们将启动一个小型电子商务应用程序,该应用程序仅获得 2K 并发用户,每秒获得 500 个请求。
我们将根据这些预期数量设计我们的电子商务架构。
在那之后,当我们的业务不断发展壮大时,它将需要更多的资源来容纳更大的请求数量,我们将看到如何根据这些数字来发展我们的架构。
单体架构
经过几十年的软件开发,有许多方法和模式演变而来,它们都有自己的好处和挑战。
因此,我们将从了解构建我们的电子商务应用程序的现有方法开始,然后发展和迁移到云。
为了理解云原生微服务,我们需要了解什么是单体应用程序,以及我们是如何从单体转向微服务的。
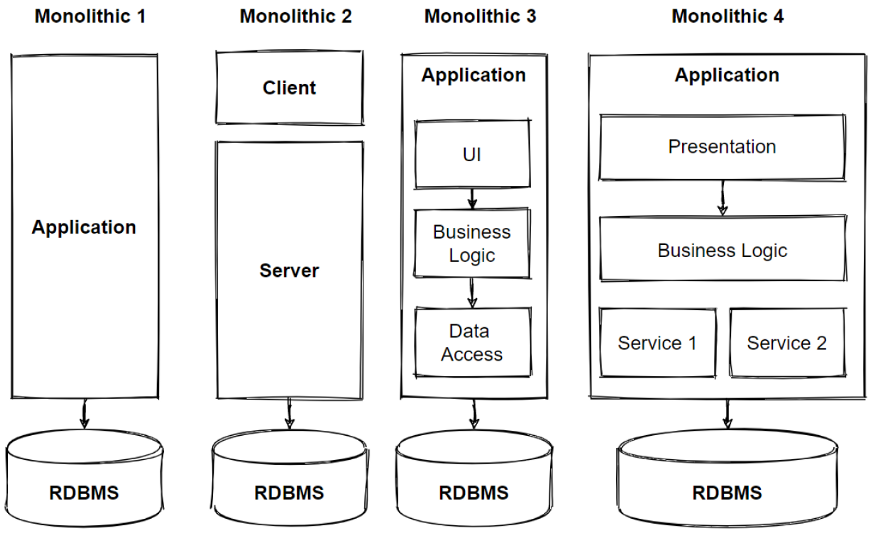
对于遗留应用程序,我们可以说大多数遗留应用程序主要是作为一个单体架构来实现的。
如果一个项目的所有功能都存在于一个代码库中,
那么该应用程序被称为单片应用程序。在单体模式中,用户界面、业务代码和数据库调用等所有内容都包含在同一个代码库中。
所有应用程序关注点都包含在一个大型部署中。
即使是单体应用程序也可以在不同的层(如表示层、业务层和数据层)中进行设计,然后将该代码库部署为单个 jar/war 文件。
整体方法有几个优点,我们将在接下来的视频中讨论它们。但让我在这里说一些主要的优点和缺点。
由于它是单个代码库,因此很容易拉取并开始项目。
由于项目结构在 1 个项目中,并且易于调试跨不同模块的业务交互。
不幸的是,单体架构有很多缺点,我们可以这样说;
- 随着时间的推移,它的代码量变得太大,这就是为什么它真的很难管理。
- 难以在同一代码库中并行工作。
- 难以在遗留的大型单体应用程序上实现新功能
- 任何更改都需要部署整个应用程序的新版本。
等等..
如您所见,我们了解单体架构。
何时使用单体架构
即使是单体架构也有很多缺点,如果您正在构建小型应用程序,那么单体架构仍然是您可以应用于项目的最佳架构之一。因为,在许多方面,单体应用程序都很简单。
它们很简单:
- 建造
- 测试
- 部署
- 疑难解答
- 垂直缩放(放大)
- 非常简单快捷。
相对于需要熟练的开发人员来识别和开发服务的微服务,开发起来很简单。由于只部署了一个 jar/war 文件,因此更易于部署。
设计单体架构
在本节中,我们将逐步设计具有单体架构的电子商务应用程序。
我们将根据需求一一迭代架构设计。
我们应该始终从写下 FR(功能要求)和 NFR(非功能要求)开始。
功能要求
- 列出产品
- 按品牌和类别过滤产品
- 将产品放入购物车
- 申请折扣券并查看购物车中所有商品的总费用
- 结帐购物车并创建订单
- 列出我的旧订单和订单商品历史
非功能性要求
- 可扩展性
- 增加并发用户
此外,最好在我们的图片中添加原则以便始终记住它们。
原则
- KISS
- YAGNI
我们将在设计架构时考虑这些原则。
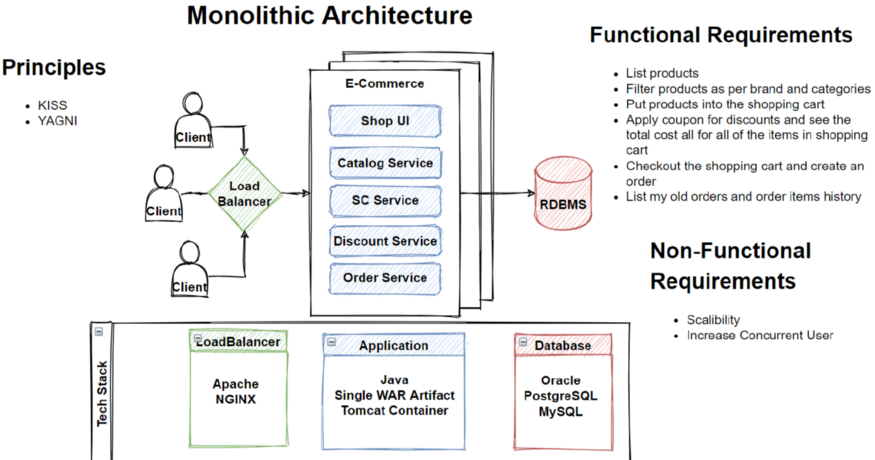
如您所见,我们使用单体架构设计了我们的电子商务应用程序。
我们添加了大电子商务框,我们的电子商务应用程序的组件是什么;商店 UI、目录服务、SC 服务、折扣服务、订单服务。如您所见,这个传统 Web 应用程序的所有模块都是容器中的单个工件。
这个单体应用程序有一个包含所有模块的庞大代码库。如果向该应用程序引入新模块,则必须对现有代码进行更改,然后将具有不同代码的工件部署到 Tomcat 服务器。我们遵循我们的 KISS 原则,即保持简单。
我们将根据需求重构我们的设计,并逐步迭代在一起。
单体架构的可扩展性
如您所见,我们通过添加 2 个应用服务器并在客户端和电子商务应用程序之间的单体应用程序前面放置负载均衡器,通过水平扩展来扩展单体架构。
为了在单体架构上提供可扩展性。我们需要创建电子商务应用服务器。并将负载均衡器放在我们的应用程序前面。
基本上,负载均衡器将使用一致的哈希算法来容纳请求并将请求发送到我们的电子商务应用程序服务器。这将为服务器提供同等负载。
适配技术栈
我们将讨论技术选择——适应技术堆栈。
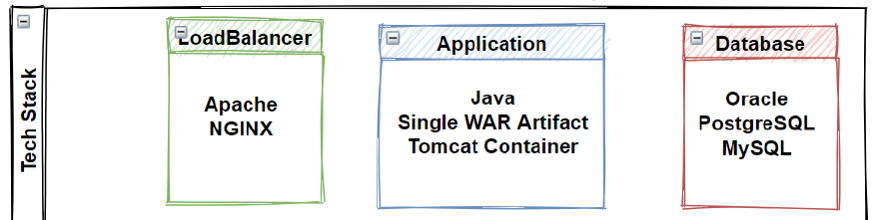
正如您所看到的图像,我们已经为我们的电子商务整体应用程序选择了潜在的选项。 NGINX 是负载平衡和 Java 的非常好的选择——Oracle 是此类应用程序的标准实现。
微服务架构
微服务是可以协同工作并且可以自主/独立部署的小型企业服务。
来自 Martin Fowlers 微服务文章;
微服务架构风格是一种将单个应用程序开发为一组小服务的方法,每个服务都在自己的进程中运行并与轻量级机制(通常是 HTTP 或 gRPC API)进行通信。
所以我们可以说,微服务架构是一种云原生架构方法,其中应用程序由许多松散耦合且可独立部署的较小组件组成。
微服务
- — 拥有自己的技术栈,包括数据库和数据管理模型;
- — 通过 REST API、事件流和消息代理的组合相互通信;
- — 按业务能力组织,分隔服务的线通常称为有界上下文。
在接下来的部分中,我们还将看到如何将微服务与有界上下文解耦。
微服务特征
微服务体积小、独立且松耦合。一个小型开发团队可以编写和维护服务。每个服务都是一个单独的代码库,可以由一个小型开发团队管理。
服务可以独立部署。团队无需重建和重新部署整个应用程序即可更新现有服务。
服务负责保存自己的数据或外部状态。这与传统模型不同,在传统模型中,单独的数据层处理数据持久性。
微服务架构的好处
敏捷。
- 微服务最重要的特征之一是因为服务更小且可独立部署。
- 小而专注的团队。
- 微服务应该足够小,以至于单个功能团队可以构建、测试和部署它。
可扩展性。
- 微服务可以独立扩展,因此您可以扩展需要较少资源的子服务,而无需扩展整个应用程序。
微服务架构的挑战
复杂。
微服务应用程序有很多服务需要协同工作并且应该创造价值。由于有很多服务,这意味着比单体应用程序有更多的移动部件。
网络问题和延迟。
因此,由于微服务很小并且与服务间通信进行通信,我们应该管理网络问题。
数据的完整性。
微服务有自己的数据持久化。因此,数据一致性可能是一个挑战。
设计微服务架构
在本节中,我们将逐步设计微服务架构。 根据需求一一迭代拱设计。

我们在设计微服务架构和放置所有微服务的数据库时遵循了每服务数据库模式。 微服务由具有独立服务的单体应用程序模块分解而成。
所以现在这些数据库可以是多语言持久化的。 也就是说 Product ms 可以使用 NoSQL 文档数据库 SC ms 可以使用 NoSQL 键值对数据库, Order ms 可以根据 ms 数据存储要求使用 Relational 数据库。
发展架构
让我们看看微服务架构图,想想这个架构缺少什么? 这种架构的痛点是什么? 我们如何将这种架构发展为更好的架构,以提高可扩展性、可用性,能够容纳更多并发请求?
看到 UI 和 Microservices 通信是直接的,而且似乎很难管理通信。
我们现在应该专注于微服务通信!
微服务通信
迁移到基于微服务的应用程序时,最大的挑战之一是改变通信机制。因为微服务是分布式的,微服务之间通过网络级别的服务间通信进行通信。每个微服务都有自己的实例和进程。
因此,服务必须使用服务间通信协议(如 HTTP、gRPC 或消息代理 AMQP 协议)进行交互。
由于微服务是独立开发和部署的服务的复杂结构,因此我们在考虑通信类型并将它们管理到设计阶段时应该小心。
微服务通信设计模式——API网关模式
如果您想设计和构建具有多个客户端应用程序的基于微服务的复杂应用程序,建议使用 API 网关模式。
该模式提供了一个反向代理来将请求重定向或路由到您的内部微服务端点。 API 网关为客户端应用程序提供单个端点,并在内部将请求映射到内部微服务。我们应该在客户端和内部微服务之间使用 API 网关。
API 网关可以处理授权等横切问题
因此,无需编写每个微服务,授权可以在集中式 API 网关中处理并发送到内部微服务。 api 网关还管理到内部微服务的路由,并能够在 1 个响应中聚合多个微服务请求。
总之,API 网关位于客户端应用程序和内部微服务之间。它充当反向代理并将请求从客户端路由到后端服务。它还提供横切关注点,如身份验证、SSL 终止和缓存。
设计 API 网关 — 微服务通信设计模式
我们将通过添加 API 网关模式来迭代我们的电子商务架构。
您可以看到在单个入口点收集客户端请求并将请求路由到内部微服务的图像。
这将处理客户端请求并路由内部微服务,
还将多个内部微服务聚合到单个客户端请求中
并执行横切关注点,如身份验证和授权、速率限制和节流等。
发展架构
我们将继续发展我们的架构,但请查看当前的设计并思考如何改进设计?
这里有几个客户端应用程序连接到单个 API 网关。
我们应该小心这种情况,因为如果我们在这里放置一个单独的 api 网关,这意味着这里可能存在单点故障风险。
如果这些客户端应用程序增加,或者为 API 网关中的业务复杂性添加更多逻辑,这将是反模式。
所以我们应该用 BFF-backends-for-frontends 模式来解决这个问题。
Backends for Frontends 模式 BFF — 微服务通信设计模式
前端模式的后端基本上根据特定的前端应用程序分离 api 网关。所以我们有几个后端服务被前端应用程序使用,在它们之间我们放置 API 网关来处理路由和聚合操作。
但这会导致单点故障,所以为了解决这个问题,BFF 提供了创建多个 API 网关并根据它们的边界对客户端应用程序进行分组并将它们拆分为不同的 API 网关。
单个复杂的 api 网关可能存在风险,并成为您架构的瓶颈。 较大的系统通常通过对客户端类型(如移动、Web 和桌面功能)进行分组来公开多个 API 网关。 当您想避免为多个接口定制单个后端时,BFF 模式很有用。
所以我们应该根据用户界面创建几个 api 网关。
这些 api 网关提供最匹配前端环境的需求,而无需担心影响其他前端应用程序。
Backend for Frontends 模式为实现多个网关提供了方向。
为前端模式 BFF 设计后端 — 微服务通信设计模式
我们将根据后端模式 BFF 添加更多 API 网关模式来迭代我们的电子商务架构。
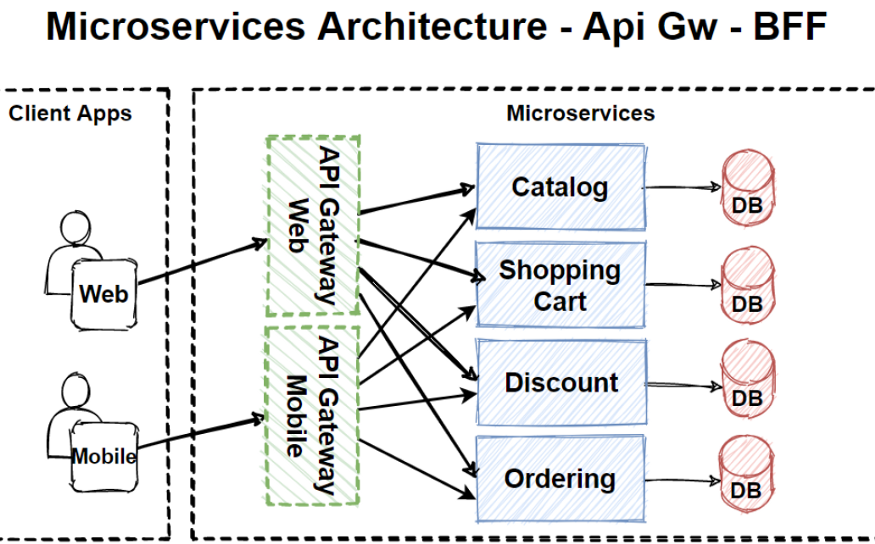
如您所见,我们在应用程序中添加了多个 API 网关。 这些 api 网关提供最匹配前端环境的需求,而无需担心影响其他前端应用程序。 Backend for Frontends 模式为实现多个网关提供了方向。
后端内部微服务之间的服务到服务通信——微服务通信设计模式
好的,我们已经在我们的微服务架构中创建了 API Gws。 并表示所有这些同步请求都来自客户端,并通过 api gws 进入内部微服务。
但是,如果客户端请求需要访问多个内部微服务怎么办? 我们如何管理内部微服务通信?
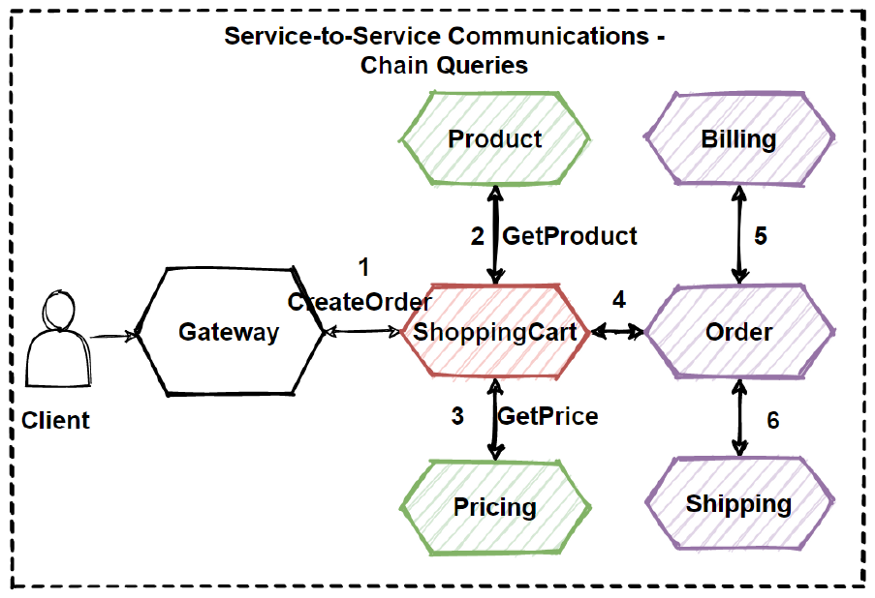
在设计微服务应用程序时,我们应该注意后端内部微服务如何相互通信。最佳实践是尽可能减少服务间通信。
但是,在某些情况下,由于客户要求或请求的操作需要访问多个内部服务,我们无法减少这些内部通信。
例如,查看图像并考虑用例:
- 用户想要结帐购物车并创建订单
那么我们如何实现这个请求呢?
所以这些内部调用使每个微服务耦合,在我们的例子中 sc - Product 和 Pricing 微服务是相互依赖和耦合的。
如果其中一个微服务出现故障,它就无法向客户端返回数据,因此它没有任何容错能力。如果微服务的依赖和耦合增加,那么就会产生很多问题,并且会削弱微服务架构的力量。
如果客户端结帐购物车,这将启动一组操作。
因此,如果我们尝试使用请求/响应同步消息模式来执行这个订单用例,那么它看起来就像这个图像。
如您所见,一个客户端 http 请求有 6 个同步 http 请求。
因此很明显,增加延迟并对我们系统的性能、可扩展性和可用性产生负面影响。
如果我们有这个用例,如果第 5 步或第 6 步失败了怎么办,或者如果某个中间服务宕机了怎么办?
即使没有宕机,也可能是一些服务繁忙,无法及时响应,导致不可接受的高延迟。
那么这种需求的解决方案是什么?
我们可以应用 2 种方法来解决这个问题,
1- 将微服务通信更改为与消息代理系统的异步方式,我们将在下一节中看到这一点。
2- 使用服务聚合器模式在 1 个 api gw 中聚合一些查询操作。
服务聚合器模式——微服务通信设计模式
为了最小化服务到服务的通信,我们可以应用服务聚合器模式。基本上,服务聚合器设计模式是接收来自客户端或 api gw 的请求,然后分派多个内部后端微服务的请求,然后将结果组合并在 1 个响应结构中响应发起请求。

通过服务聚合器模式实现,我们可以减少客户端和微服务之间的聊天和通信开销
设计——服务聚合器模式——服务注册模式——微服务通信设计模式
在本节中,我们将通过添加服务聚合器模式 - 服务注册表模式 - 微服务通信设计模式来迭代我们的电子商务架构。
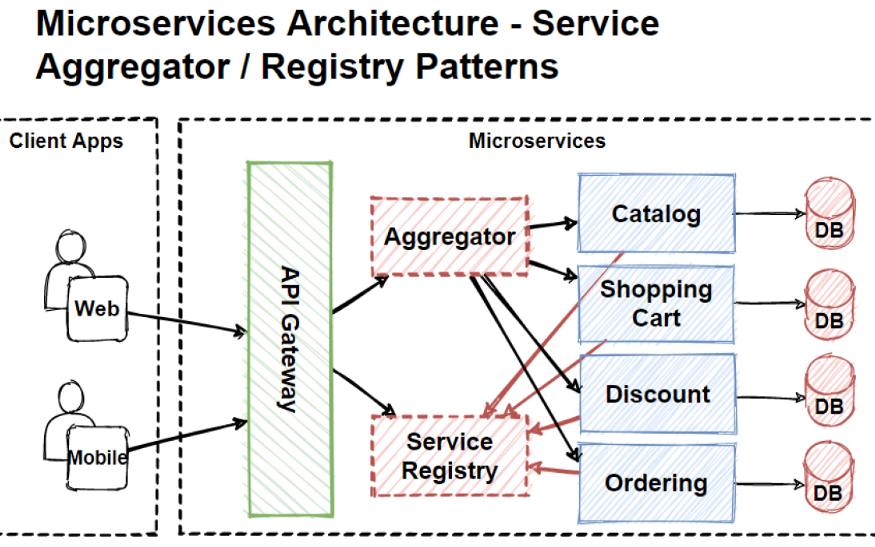
正如你所看到的,我们已经为我们的电子商务架构应用了服务聚合器模式——服务注册模式。
微服务基于消息的异步通信
如果您的通信仅在几个微服务之间进行,则同步通信是好的。 但是当涉及到几个微服务需要相互调用并等待一些长时间的操作直到完成时,我们应该使用异步通信。
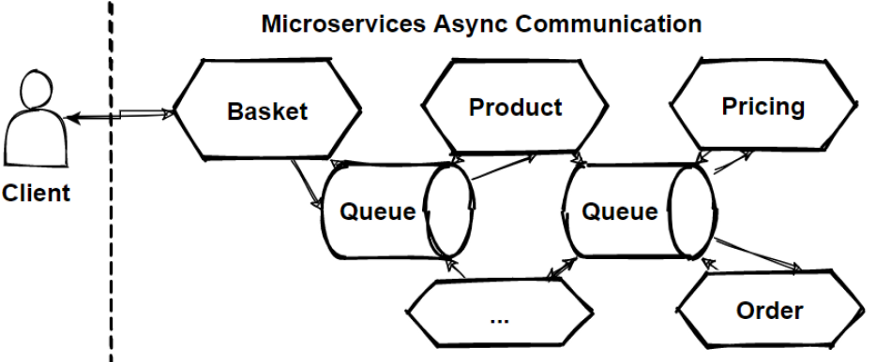
否则,微服务的依赖和耦合将造成瓶颈并造成架构的严重问题。
如果你有多个微服务需要相互交互
如果你想在没有任何依赖或松耦合的情况下与它们交互,那么我们应该在微服务架构中使用基于异步消息的通信。
因为基于异步消息的通信提供了事件处理。 所以事件可以放置微服务之间的通信。
我们称这种通信为事件驱动的通信。
发布-订阅设计模式
发布-订阅是一种消息传递模式,有消息的发送者称为发布者,有特定的接收者称为订阅者。
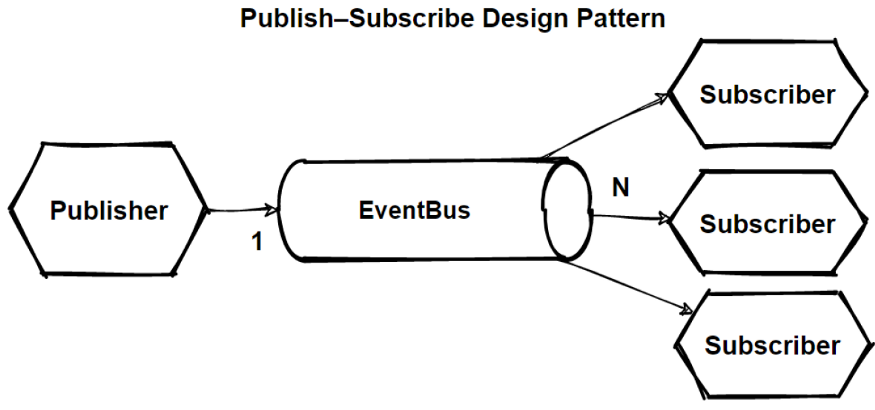
所以发布者不会将消息直接发送给订阅者。
相反,对已发布的消息进行分类并将它们发送到消息代理系统,而不知道那里有哪些订阅者。
类似地,订阅者表示感兴趣并且只接收感兴趣的消息,而不知道哪些发布者发送给他们。
设计——发布/订阅消息代理——微服务异步通信设计模式
在本节中,我们将通过添加 Pub/Sub 消息代理来迭代我们的电子商务架构,以提供微服务异步通信设计。
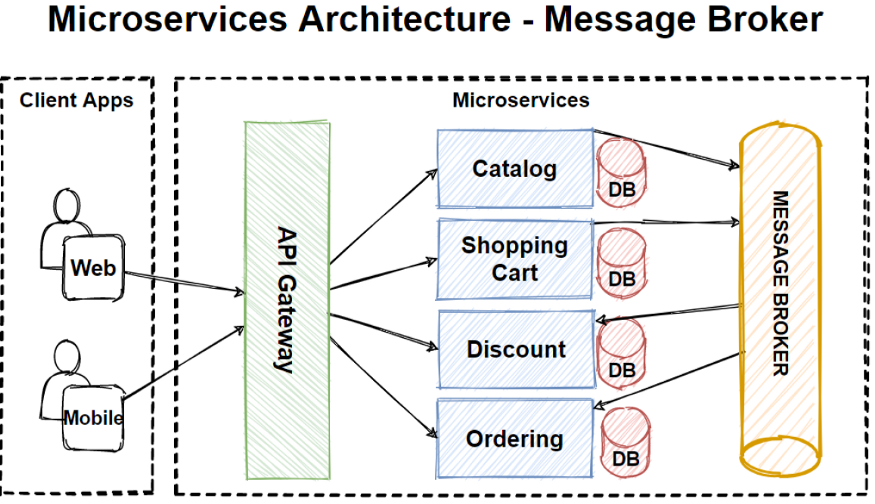
如您所见,我们已经应用了 Pub/Sub Message Broker — 微服务异步通信设计模式。
如果我们调整技术堆栈,我们基本上从 Pub/Sub 消息代理的选项开始。您可以选择 2 个不错的选择;
1- Kafka
2- RabbitMQ
微服务数据管理
在单体架构中,查询不同的实体非常好,因为单个数据库保持数据管理也很简单。跨多个表查询数据很简单。对数据的任何更改都会一起更新或全部回滚。严格一致性的关系型数据库具有ACID事务保证,便于管理和查询数据。
但是在微服务架构中,当我们使用“多语言持久性”时
这意味着每个微服务都有不同的数据库,包括关系数据库和无 sql 数据库,我们应该在执行用户交互时设置策略来管理这些数据。
这意味着我们在处理微服务之间的数据交互时有几种模式和实践,我们将在本节中学习这些模式和原则。
微服务是独立的,只执行特定的功能需求,对于我们在电子商务应用程序中的案例,我们有产品、购物篮、折扣、订购微服务需要相互交互以执行客户用例。这意味着他们需要经常相互整合。大多数这些集成是查询每个服务数据以进行聚合或执行逻辑。
CQRS 设计模式
CQRS 是微服务间查询的重要模式之一。我们可以使用 CQRS 设计模式来避免复杂的查询来摆脱低效的连接。 CQRS 代表命令和查询责任分离。基本上,这种模式将数据库的读取和更新操作分开。
为了隔离命令和查询,其最佳实践是将读写数据库与 2 个数据库物理分离。通过这种方式,如果我们的应用程序是读密集型的,这意味着读多于写,我们可以定义自定义数据模式以优化查询。
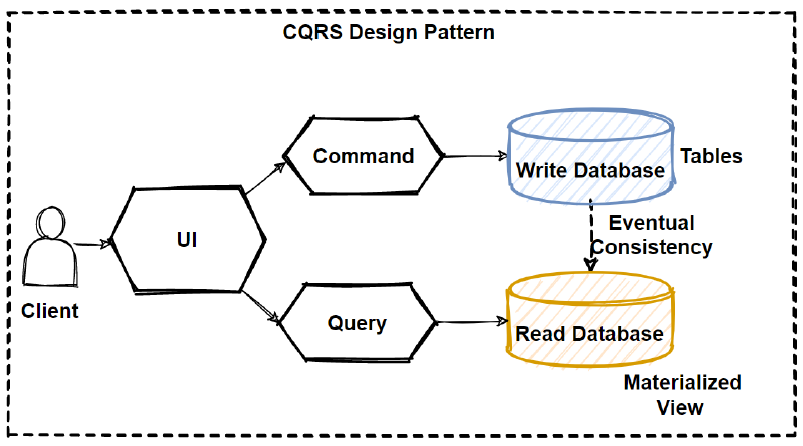
物化视图模式是实现读取数据库的好例子。
因为通过这种方式,我们可以避免使用预定义的细粒度数据进行复杂的连接和映射以进行查询操作。
通过这种隔离,我们甚至可以使用不同的数据库来读取和写入数据库类型,例如使用 no-sql 文档数据库进行读取和使用关系数据库进行 crud 操作。
事件溯源模式
我们已经学习了 CQRS 模式,并且 CQRS 模式主要与 Event Sourcing 模式一起使用。 当使用带有事件溯源模式的 CQRS 时,主要思想是将事件存储到写入数据库中,这将是真实事件数据库的来源。
之后,CQRS 设计模式的读取数据库提供具有非规范化表的数据的物化视图。 当然,这个物化视图读取数据库消耗来自写入数据库的事件并将它们转换为非规范化视图。
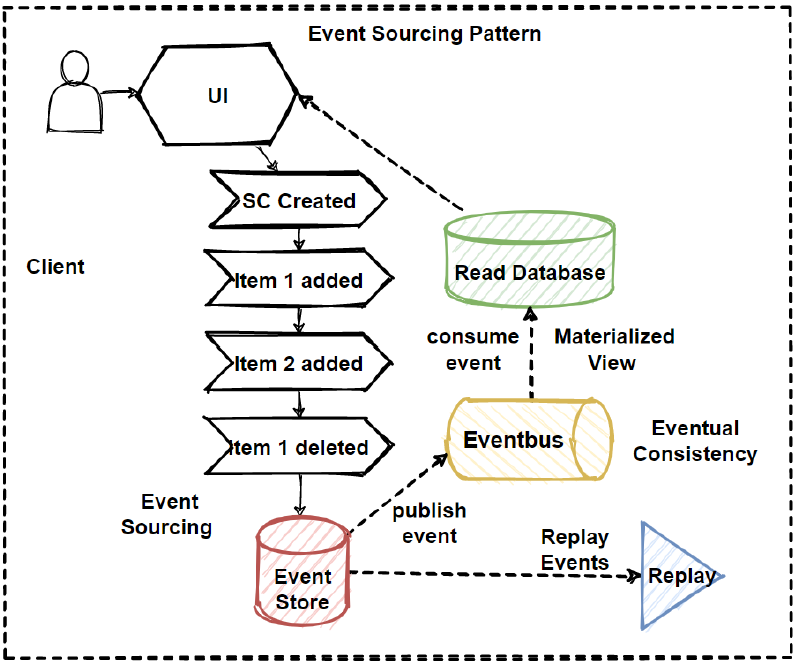
随着事件溯源模式的应用,它正在改变为将数据保存到数据库中的操作。 事件溯源模式不是将数据的最新状态保存到数据库中,而是提供将所有事件按顺序排列的数据事件保存到数据库中。 这个事件数据库称为事件存储。
它不会更新数据记录的状态,而是将每个更改附加到事件的顺序列表中。 因此,事件存储成为数据的真实来源。 之后,这些事件存储转换为遵循物化视图模式的读取数据库。 此转换操作可以通过带有消息代理系统的发布事件的发布/订阅模式来处理。
设计架构——CQRS、事件溯源、最终一致性、物化视图
我们将通过应用 CQRS、事件溯源、最终一致性、物化视图来设计我们的电子商务架构。
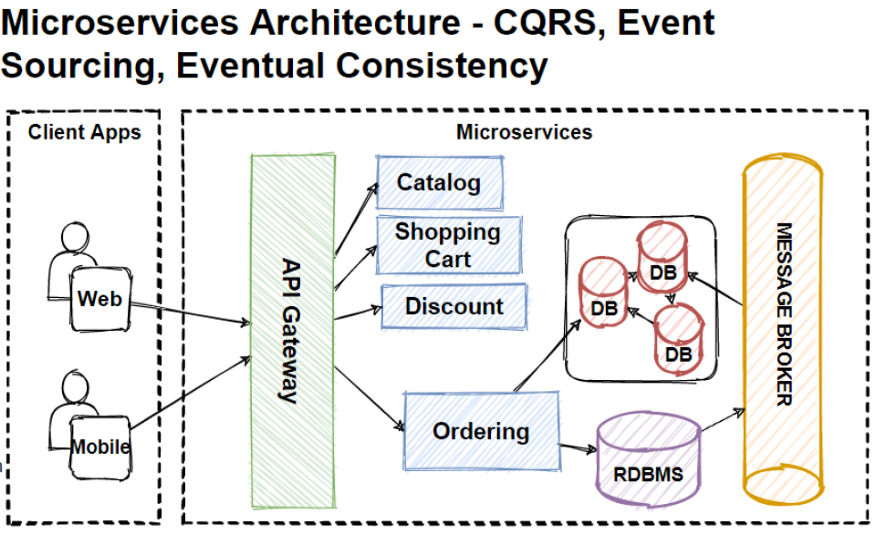
因此,当用户创建或更新订单时,我将使用关系写入数据库,当用户查询订单或订单历史时,我将使用 no-sql 读取数据库,并在使用消息代理系统同步 2 个数据库时使它们保持一致应用发布/订阅模式。
现在我们可以考虑这些数据库的技术栈,我将使用 SQL Server 进行关系写入数据库,使用 Cassandra 进行无 SQL 读取数据库。当然,我们将使用 Kafka 将这 2 个数据库与 pub/sub Kafka 主题交换同步。
如您所见,我们已经完成了微服务数据库模式的设计。让我们深入了解微服务中的这些事件驱动架构。
事件驱动的微服务架构
基本上事件驱动的微服务架构是指通过事件消息与微服务进行通信。我们在微服务异步通信部分的发布/订阅模式和 Kafka 消息代理系统中看到了这一点。
我们说过,使用事件驱动架构,我们可以进行异步行为和松散耦合的结构。例如,服务不是在需要数据时发送请求,而是通过事件使用它们。这将提供性能提升。
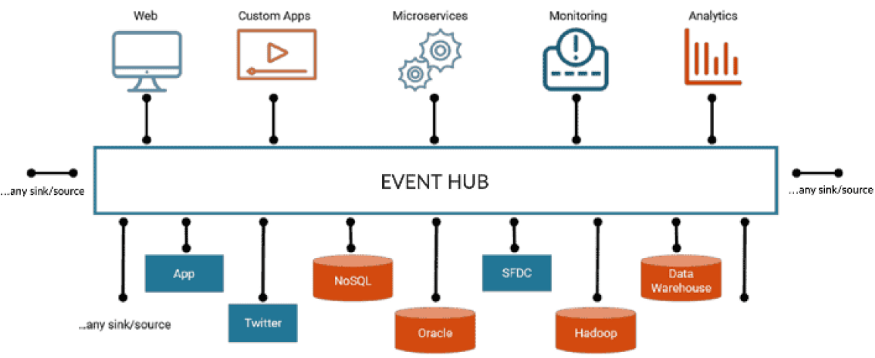
但在事件驱动的微服务架构上也有巨大的创新,例如使用实时消息传递平台、流处理、事件中心、实时处理、批处理、数据智能等。
因此,我们可以使这种事件驱动的方法更通用,并随着这种架构的发展而具有实时事件处理功能。
根据这种新的事件驱动微服务架构,每件事都是通过 Event-Hubs 进行通信。 我们可以认为 Event-Hubs 是一个可以进行实时处理的大型事件存储数据库。
设计架构——事件驱动的微服务架构
我们将使用事件驱动的微服务架构来设计我们的电子商务应用程序。

现在让我们决定在这个架构中使用技术栈。 当然,我们应该选择 Apache Kafka——作为事件中心和 Apache Spark,用于转换或响应数据流的实时和近实时流应用程序。
正如你所看到的,现在我们有了事件驱动微服务架构的反应式设计。
现在我们可以问同样的问题;
多少并发请求可以容纳我们的设计?

借助这种最新的事件驱动微服务架构,它使用容器和编排器进行部署,可以以低延迟满足目标并发请求。
因为该架构是完全松散耦合的,并且设计用于高可扩展性和高可用性。
如您所见,我们设计的电子商务微服务架构具有设计原则和模式的各个方面。 现在,您可以通过这些学习准备设计自己的架构,并知道如何在您的设计中使用这些模式工具箱。
带课程的逐步设计架构
我刚刚发布了一门新课程——使用模式和原则设计微服务架构。
在本课程中,我们将学习如何使用设计模式、原则和最佳实践来设计微服务架构。 我们将从设计单体到事件驱动的微服务开始,并一起使用正确的架构设计模式和技术。
原文:https://medium.com/design-microservices-architecture-with-patterns/mono…
- 160 次浏览
【微服务架构】如何使用SSO保护企业微服务架构
视频号
微信公众号
知识星球
什么是安全?
这是一个重要方面,注意系统完整性的安全性。如果不考虑安全方面,它会传播风险,并可能容易受到其他网站、网络和其他It基础设施上的恶意软件攻击。
什么是SSO及其工作原理?
单点登录(SSO)是一种技术,它将多个不同的应用程序登录屏幕合并为一个。一旦您登录到特定系统,该声明登录令牌就可以在所有应用程序中共享,它们可以在其中定义信任。
身份验证和授权
身份验证:
是检查您是谁的过程。这是我们根据密码验证用户以识别此人的方式。
这方面有两种机制。
身份代理:

您可以通过社交登录实现登录。比如使用google/facebook/apple-like登录。
在这里,您单击任何社交链接,然后它将重定向到您的身份提供商,并提供用户名和密码,然后它会将令牌返回给Keyclock。现在,Keyclock可以使用特定的用户角色生成自己的令牌并将其返回。
身份联合:
在这里,Keyclok可以针对多个数据源验证用户。我们可以教Keyclok如何验证用户,以及在这个过程中应该涉及哪些数据源。它是可定制的。
授权:
它有两个方面。
- 说说你能做什么
- 告诉我你可以做什么
- 当我们实施票证管理解决方案时,支持工程师可以读取用户的配置文件。他可能有配置文件读取权限,但不应该访问任何配置文件。必须有一些限制。只有当特定用户的支持票证分配给他时,他才能读取配置文件。这些是用户策略。
- 因此,使用授权服务器实现和维护这些类型的策略有点困难。
让我们看看如何做到这些。
- 所以通常我们创建用户,创建角色。让我们假设我们创建了一个用户管理服务。因此,我们必须确定用户管理可以做什么。
- 它可以读取/写入/编辑/删除/列出用户。
- read表示您给出特定的用户id并获取该用户信息。
- 列表意味着您可以将所有用户作为列表获取。
- 现在,假设我们创建了以上5个权限。现在,您将这些权限分配给特定角色,然后将该角色分配给特定用户。
- 因此,如果用户属于特定角色,那么我们可以查看属于该角色的权限并应用该权限。
- 所以用户登录到UI。当他们登录到UI时,它将重定向到身份验证服务器。
- 假设我们在这里使用Keyclok(一种开源软件产品,允许使用身份和访问管理进行单点登录(SSO))。在实现Keyclok之后,用户将重定向到Keyclok。在这里,我将对用户进行身份验证。之后,该令牌将返回到UI,然后UI将提交其服务请求。
- 当服务请求到来时,API网关将标识为用户正在尝试创建新用户。然后它将检查此令牌是否携带创建用户权限?如果是:它会让交通流进来
但问题是,该用户可以在哪个部门下创建新用户?
- 因此,我们必须验证这一点。为此,我们可以使用策略管理解决方案。(我们可以使用OPA Open策略代理,这是一个流行的工具)
因此,当流量流动时,在创建新用户之前,我们联系OPA,要求该用户在部门d001上创建新用户。允许吗?这里OPA验证并返回true或false。
让我们看看另一个用例:
- 假设支持工程师现在要读取用户的配置文件。因此,支持工程师属于具有读取用户配置文件权限的角色。当请求到达API网关时,它将允许请求流入服务,因为他具有用户读取权限。
那么现在,如果我们与OPA交谈,询问这位支持工程师是否有从这个特定用户分配的用于尝试读取配置文件的票证?如果是,OPA将返回true。否则为false。
Active directory:当用户已经登录到Active directory时,如果他们来到我们的应用程序,则UI转到Keyclock。然后,keyclock与active directory对话。active directory然后确保该用户已经登录。因此,keycloke将生成令牌。由于此过程,用户无需再次登录即可访问应用程序,我们称之为SSO(单点登录)。
当我们将这里讨论的所有这些东西放在一起并应用到系统中时,我们将能够为我们的应用程序构建更安全的身份验证和授权解决方案。
- 83 次浏览
【微服务架构】实用建议:使用Kubernetes在Java中构建微服务应用程序时的关键决策
作为Java开发人员或解决方案架构师,您的领导团队可能会问您以下问题:
- 我们是否利用云的优势(例如,集中管理,计算效率,可扩展性,安全性,易维护性)?
- 为了鼓励重用和开发效率,我们是否推广微服务方法?
- 我们是否使用基于Docker的容器技术来简化我们的部署和可扩展性策略?
如果我是你,答案将是:“当然!我们正在做这件事。”
最近,我的解决方案工程师团队将这些问题作为开发样本店面应用程序的一部分,作为微服务Garage方法参考架构的一部分。这个应用程序,内部称为BlueCompute,是按照微服务原则设计的(如果感兴趣,您可以阅读其设计的更多细节,并在项目ibm-cloud-architecture / refarch-cloudnative中仔细阅读GitHub上的实现)。
除了遵循微服务原则,我们还决定使用Kubernetes作为我们的容器编排平台。在此过程中,我们制定了关键设计和架构决策,我想以问题/答案的形式分享:
-
Should I use Kubernetes virtual IP or DNS based service lookup?
-
How do I expose the services for external consumption? LoadBalancer or Ingress or NodePort?
-
Which tool should I use for continuous integration and deployment (CI/CD) in Kubernetes cluster?
我们相信,在IBM Bluemix平台上使用Kuberenetes服务构建系统时,在项目早期考虑这些设计决策将会非常有用。
Q1:作为Java开发人员,我应该使用哪个框架作为构建微服务风格应用程序的基础?
Sprint Boot是Java开发人员的热门选择之一。其独立的应用程序方法非常适合微服务模块化原理。作为单个进程运行允许Sprint Boot应用程序轻松打包并作为Docker容器分发。 MicroProfile是另一个新兴的框架,尤其受到企业Java开发人员的青睐。
Q2:我应该在哪里运行Kubernetes平台?
Kubernetes可以在您自己的数据中心或云提供商的开发笔记本电脑,VM或裸机服务器上运行。显然,这个决定必须与您组织的整体云和托管策略保持一致。如果您正在寻找托管的Kubernetes环境(或Kubernetes即服务),那么IBM Bluemix容器服务是一个不错的选择。如果您出于安全性和合规性原因希望在自己的数据中心托管托管Kubernetes服务,则可以选择IBM Spectrum Conductor for Containers或OpenShift。当然,您可以通过在数据中心或基于云的基础架构中作为服务安装和配置Kubernetes环境来自行推出。
根据您的具体情况,您最终可能会采用不同的方法。例如,使用托管Kubernetes服务在公共云上运行开发/测试环境,并将生产工作负载部署到内部部署的Kubernetes平台。这种混合方法利用了Docker容器和Kubernetes的可移植性功能。就个人而言,我尽可能地利用托管的Kubernetes服务,从我的盘子中删除另外一项任务。
问题3:如何处理应用程序服务注册表和发现?
为了从您在分布式弹性云环境中创建的许多微服务中受益,正确的服务注册和发现策略对于允许它们彼此通信或被消费至关重要。作为云原生微服务实现的先驱,Netflix已经构建并发布了一组名为Netflix OSS的自定义库,如Eureka,Zuul,Ribbon等。它们与Spring框架很好地集成在一起。通常,服务注册到Eureka,Ribbon / Zuul处理服务发现和基本负载平衡。然而,我所描述的是近5年前。
今天,Kubernetes本身支持服务注册,发现和负载平衡。您不再需要Netflix OSS来完成这些任务。相反,您将系统设计为Kubernetes方式。您可以利用Kubernetes的服务类型来公开您的微服务,然后通过虚拟IP或DNS方法自动注册到Kubernetes系统(我将在下一个问题/答案中详细说明这个决定)。该发现将通过熟悉的DNS查找样式进行。对于基于服务的集群,Kubernetes提供了一个内置的负载均衡器,用于在Pod(容器)之间分配工作负载。
问题4:我应该使用Kubernetes虚拟IP还是基于DNS的服务查找?
如前面的问题/答案中所述,我们决定服务注册表和查找应该以Kubernetes方式完成。您有两种选择:环境变量或DNS。环境变量由Kubernetes引物开箱即用。在封面下,Kubernetes公开集群中的服务虚拟IP,以便其他Pod / Services可以通过此环境变量条目调用目标服务。这种方法的缺点是服务在依赖Kubernetes服务事务中的创建顺序。一般而言,依赖IP地址并不是一个好主意。
更好的解决方案是基于DNS的方法。假设我有一个“Order”微服务,我将它命名为order-service,作为服务yaml定义中名称的一部分。前端Web服务可以通过REST端点http:// order-service / id简单地调用Order服务。这将从底层基础架构中抽象出应用程序。要使用DNS方法,如果要构建自己的Kubernetes基础结构,则需要安装Kubernetes DNS加载项。但是,如果您使用Kubernetes作为服务,例如使用IBM Bluemix Container服务,则会在群集中自动启用DNS服务。
问题5:Kubernetes处理应用程序弹性,但是如何优雅地处理依赖服务的故障?
Kubernetes通过其内置的自我恢复机制确保应用程序弹性或容错。作为ReplicaSet实现,Kubernetes确保您的应用程序Pod(容器)始终尝试满足所需的状态。例如,在任何给定时间,我的群集中总是有3个订单服务Pod在运行。
这很酷,并由Kubernetes提供服务。但是你仍然需要设计你的微服务以应对依赖性失败。例如,如果下游服务已关闭,或者存在数据库或存储中断。如果发生这种情况,您不希望此服务问题通过阻止资源或降低整个用户体验来影响整个应用程序。您希望优雅地降级或失败保护此服务。对于基于Java的实现,我建议使用Netflix Hystix库来提供命令来实现故障处理模式,如Circuit Breaker或Bulkhead,以及用于查看系统整体运行状况的仪表板。它与基于Spring Boot的容器应用程序集成良好; Hystrix仪表板本身可以轻松打包和部署为容器,并由Kubernetes管理。
问题6:如何公开服务以供外部消费? LoadBalancer或Ingress或NodePort?
您需要确定客户端应用程序(Web 2.0或移动应用程序)如何访问Kubernetes集群上托管的微服务。很可能,您不希望将您的核心业务逻辑或数据微服务直接暴露给Internet,而应该构建一个BFF(前端后端)或一个API网关,后者又决定将哪个后端服务消耗。在此设计下,通常只能通过Kubernetes内部网络访问后端数据微服务。前端层(BFF或API网关)成为面向Internet的组件。
然后问题就变成了如何公开这个前端服务层以供外部消费。您在Kubernetes中有两个选择:LoadBalancer或Ingress(还有第三个选项 - NodePort - 但我不推荐它用于生产用途)。
具有LoadBalancer的服务提供外部可访问的IP地址,可将流量发送到群集节点上的正确端口。 LoadBalancer易于启用,并允许您的客户端应用程序通过服务定义的HTTP路径访问REST API。 LoadBalancer的缺点是为您的应用程序消耗更多的IP(可计费资源),依赖于云供应商实现,以及缺乏处理TLS终止等常见任务的中心入口点。
另一种方法是Ingress。 Ingress不是为您希望向公众公开的每个服务创建LoadBalancer服务,而是提供一种独特的公共路由,允许您根据各自的路径将公共请求转发到群集内的服务。此方法允许您应用程序的中央入口点。因此,您可以轻松地在多个Kubernetes区域中添加DNS路由和全局负载平衡。这是一个很有前景的解决方但在早期阶段 - Ingress控制器仍然不够灵活,无法处理复杂的应用程序/服务路由路径,终止TLS,过滤传入请求等。
在我们的实现中,我们最终部署了另一个具有Ingress服务类型的NGINX服务。在NGINX内部,我应用上述处理。当Ingress成熟时,这可能是一个临时解决方案。
问题7:我应该在Kubernetes集群中使用哪种工具进行持续集成和部署(CI / CD)?
现在您已准备好编码,但请等待!还有一个决定。您不想进行自动持续集成和部署(CI / CD)吗?如果是这样,最好在开始之前制定策略。
CI / CD是一个通用术语;当它引用Kubernetes集群中的微服务应用程序时,它包括自动Spring Boot应用程序构建,构建Docker映像,将映像推送到Docker注册表,以及部署Kubernetes服务或Pod。当开发人员向源控制系统(例如git)提交代码更改或修复问题时,流程通常会启动。
这是最容易做出的决定之一 - 我们只是使用Jenkins作为工具。我们最终确定了一个名为Jenkins-kubernetes-plugin的开源工具(GitHub上的jenkinsci / kubernetes-plugin)。这种方法的主要好处是我们可以轻松地将Jenkins构建主节点和从节点作为Kubernetes组件运行。这使我们免于安装和维护单独的Jenkins环境。同样,对我们来说,少一项任务是好的。
使用此工具,CI / CD流程如下:
- 开发人员在GitHub中提交代码更改
- Git webhook通过插件触发部署在Kubernetes集群中的Jenkins master的构建
- 主服务器在您的Kubernetes集群中部署Jenkins slave Pod
- Jenkins slave Pod开始构建阶段 - 构建Sprint Boot应用程序,构建Docker镜像,推送到Docker注册表。
- 完成构建阶段后,Jenkins master部署了另一个Jenkins slave Pod,它将启动部署阶段。
- 部署阶段(在Jenkins文件中定义)将您的Microservices部署为Kubernetes服务。
所有这些步骤都是自动化的。
结论
要了解我们如何将这些决策付诸实践,请尝试构建在IBM Bluemix Container服务之上的参考实现应用程序。我们的样本店面应用程序是使用Microservices方法构建的,它实现了本文中描述的所有设计原则。 GitHub上的ibm-cloud-architecture / refarch-cloudnative项目的自述文件包括下载代码并在您自己的Bluemix环境中安装代码的体系结构和说明的概述。
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 57 次浏览
【微服务架构】微服务-生存还是毁灭!
上周,我谈到了作为一系列微服务开发的产品技术架构。谈话几分钟后,很明显团队已经支付了微服务高级版,但没有明显的投资回报。这组微服务是由一个由10名工程师组成的团队构建的,所有服务都是用java实现的,并使用消息总线将必要的数据复制到共享postgres实例中的自己的模式中。虽然工程师可能最有意愿建立一个可以扩展的系统,但它立刻让我想起了Donald Knuth的名言,
过早优化是万恶之源
我认为团队会更有效率,如果系统被构建为具有良好模块性和服务之间松散耦合的整体系统,那么系统就不那么复杂了。
让我们看一下微服务架构的优缺点,从我自己的经验来看,我在SAP时为我们构建的产品采用了微服务架构。
释放灵活性
采用微服务使我们能够灵活地根据微服务中代码的成熟度和质量来决定哪些功能可以通过v1发布。另一方面,单片应用程序意味着延迟发布,直到我们把所有事情都弄好。
主题移交
虽然我不是世界各地分布式团队的忠实粉丝,但我们需要接受并继续前进,这是今天的商业现实。通过遍布三大洲(美国,德国和印度)的全球开发团队实施产品非常具有挑战性,但在微服务方面明确分离功能使我们能够灵活地在不同地点之间移动功能。由于团队不需要了解整个代码库以详细了解功能集的一小部分,因此主题切换非常易于管理。
规模
扩展单片应用程序(尤其是水平扩展)绝对是可能的,但并非应用程序的所有部分都可能从扩展中受益,因为吞吐量要求因产品的不同功能而异。微服务架构允许我们根据吞吐量要求扩展应用程序的不同部分,并有效利用可用资源。
自治
我非常相信团队的完全自主权,这与微服务架构相得益彰,因为团队之间的依赖关系减少到最小,并且通过定义良好的接口或API进行通信。团队完全自治的缺点是编程语言,框架,开发工具的动物园,一旦团队扩展到100人,就变得无法管理。虽然微服务架构鼓励多语言运行时,但我建议坚持几个运行时,几个框架以及一个基于一个工具集的构建和发布过程。
监测和支持
由于微服务按照定义分布在许多服务器(物理或虚拟)上以实现水平扩展,因此它们运行的平台应提供强大的监控和支持基础架构。监视和支持在调试和查找日志文件中的错误的根本原因方面由于缺少聚合每个产品的日志和跟踪文件的工具而变得非常麻烦。例如,支持工程师可能需要查看每个微服务的大量日志文件,以找出错误的根本原因。
构建和发布
在微服务部署的情况下,构建和发布过程的复杂性有时会使团队士气高涨,因为他们不断与构建作业和部署作业作斗争。对我们来说,缺乏构建,部署和发布自动化是一项挑战。照顾一个构建工作,一个代码扫描,每个服务就像放牧猫一样。如果有什么东西打破没有人通知。事实上,我们每个微服务都有多个构建作业 - 一个用于拉取请求,一个用于运行代码扫描和集成测试的主构建,另外一个可以发布到工件库中。完全自动化的构建和发布过程是微服务架构有效提高开发人员工作效率的关键。
安全
在微服务架构中获得安全性是一个真正的复杂性助推器。我们花了很多时间来确定基本的安全要求,例如身份验证和授权(特别是在服务到服务通信上下文中),因为每个微服务都运行在它自己的进程中,而不是整体结构。使用单一应用程序,处理安全性就像将spring安全库放入Web应用程序,创建spring-security.xml并向REST端点添加一些安全注释一样简单。使用微服务,使用JWT处理复杂的OAuth流并在服务之间传递令牌并非易事.
数据复制
最后,我认为在微服务方面最重要的权衡是关于是否复制数据的争论(特别是在大数据环境中)。关于如何复制数据的技术 - 消息总线,点对点REST API等是这个决定的简单后续。
通常,为微服务(有界上下文)获取服务边界非常困难。如果服务边界不正确,则会导致数据重复并增加服务之间的耦合。数据重复是一个很大的问题,特别是当微生物主要是分析性的并且需要依赖于或多或少相同的大数据集进行分析时。
在大数据分析环境中,我不是复合服务或复合API的忠实粉丝(我将其定义为需要处理大约数百万个数据点以满足请求 - 如排序,过滤)。复合REST API实现往往性能较慢,无法与DB的响应时间相匹配,DB是处理连接,聚合,过滤等事情的理想场所。
我们最终创建了一个数据服务,它创建了一个像依赖的平台,因为几乎所有其他微服务都依赖于这个服务来查询大数据集。必须在此层中实现任何新查询,这会降低新功能的开发速度。但查询响应时间对于应用程序来说至关重要,因此我们可以进行权衡。
生存还是毁灭 !
与所有软件架构一样,为您的产品采用或不使用微服务是一种权衡讨论和决策。
- 41 次浏览
【微服务架构】微服务不是魔术:处理超时
微服务很重要。它们可以为我们的架构和团队带来一些相当大的胜利,但微服务也有很多成本。随着微服务、无服务器和其他分布式系统架构在行业中变得更加普遍,我们将它们的问题和解决它们的策略内化是至关重要的。在本文中,我们将研究网络边界可能引入的许多棘手问题的一个示例:超时。
在你害怕“分布式系统”这个词之前,请记住,即使是一个带有 Node 后端的小型 React 应用程序,或者一个与 AWS Lambda 对话的简单 iOS 客户端,也代表一个分布式系统。当您阅读这篇博文时,您已经参与了一个分布式系统,其中包括您的 Web 浏览器、内容交付网络和文件存储系统。
在背景方面,我将假设您了解如何使用您选择的语言进行 API 调用并处理它们的成功和失败,但这些 API 调用是同步还是异步、HTTP 或不是。如果您遇到不熟悉的术语或想法,请不要担心!我很高兴在 Twitter 或其他地方进行更多讨论,并且我还尝试在适当的地方添加链接。
我们将要探讨的问题是:如果我们遇到一个非常非常慢的 API 调用最终超时,并且我们假设 (a) 它成功或 (b) 它失败,我们就会遇到错误。超时(或更糟糕的是,无限长的等待)是分布式系统的一个基本事实,我们需要知道如何处理它们。
问题
让我们从一个思想实验开始:你有没有给同事发邮件向他们要东西?
- [星期二,上午 9:58] 你:“嘿,你能把我加到我们公司的潜在导师名单中吗?”
- 同事:“……”
- [星期五,下午 2:30] 你:[?]
你该怎么办?
如果您希望您的请求得到满足,您最终需要确定没有回复。你会等更长的时间吗?你想等多久?
那么,一旦你决定等待多长时间,你会采取什么行动?您是否再次尝试发送电子邮件?你尝试不同的传播媒介吗?你认为他们不会这样做吗?
好的,现在这里到底发生了什么?我们希望看到这种请求-响应行为:

但是出了点问题。 有几种可能性:
- 他们从来没有得到消息。

- 他们收到了邮件,成功处理了邮件,然后给您发回了一个从未收到您的回复(或转到您的垃圾邮件文件夹)。

- 他们得到了信息,但他们仍在思考,或者他们失去了它,或者[喘气!]他们忘记了。

- 最终,我们只是不知道!

正是这个问题出现在分布式系统上的任何通信中。
我们可能会延迟我们的请求、处理或响应,而这些延迟可能是任意长的。因此,与电子邮件示例一样,我们需要确保“我们要等多久?”问题有答案,我们称该持续时间为超时。
如果您只从本文中学到一个教训,那就这样吧:使用超时。否则,您将面临永远等待永远不会完成的操作的风险。
但是一旦我们达到了超时,等待的上限,我们该怎么办?
方法
当人们在远程系统调用中遇到超时时,有几种常见的方法。我并不声称这份清单是详尽无遗的,但它确实涵盖了我见过的许多最常见的场景。
方法#1
当您遇到超时时,假设它成功并继续前进。
请不要这样做。[1]不幸的是,我不得不说这是一个常见的无意识选择,即使在生产应用程序中,也会有一些非常糟糕的用户体验结果。如果我们假设手术成功了,我们可怜的消费者就会合理地假设事情进展顺利——只是后来当他们发现结果时会感到失望和困惑。
任何时候你有一个网络呼叫,寻找成功和失败的案例。例如,如果你在 JavaScript 中通过 Promise.then(...) 使用异步 API,请问问自己对应的 .catch(...) 在哪里。如果它丢失了,你几乎肯定有一个错误。
在一些非常特殊的情况下,您可能理所当然地不在乎请求是成功还是失败。 UDP 是具有此属性的非常成功的协议。另外,很多软件坏了,继续赚钱就好了!但请不要让这成为您的默认设置——先用尽您的其他选项。
方法#2
对于读取请求,请使用缓存或默认值。
如果您的请求是读取请求并且不打算对远程端产生任何影响,那么这可能是一个不错的选择。在这种情况下,您可以使用先前成功请求中的缓存值。或者,如果还没有成功的请求或者缓存在您的情况下没有意义,您可以使用默认值。这种方法相对简单:它不会增加太多的性能开销或实现复杂性。但请记住,如果您使用的是通过网络访问的进程外缓存(例如,memcached、Redis 等),那么您将回到类似的情况,即您的请求对缓存本身可能会超时。
方法#3
当您遇到超时时,假设远程操作失败,然后自动重试。
这提出了更多的问题:
- 如果重试不安全怎么办?网络连接另一端的服务获取重复项只是烦人吗?或者你是双重收取信用卡? (!)
- 您应该同步重试还是异步重试?
- 如果您同步重试,从消费者的角度来看,这些重试会减慢您的速度——您是否有可能无法满足他们的期望?这在服务中尤其重要,而不是最终用户应用程序。
- 如果你异步重试,你告诉你的消费者关于操作成功的什么?您是一次尝试一个,还是在一段时间内分批重试?
- 您应该重试多少次? (一次?两次?10次?直到成功?)
- 您应该如何在重试之间延迟? (指数退避[例如,1s、2s、4s、8s、16s,...] 以最大等待时间为界?使用抖动?)
- 如果远程服务器由于过载而出现性能问题,重试是否会使他们的情况变得更糟?
如果远程 API 可以安全地重试,我们称之为幂等。如果没有幂等属性,您可能会创建重复数据(如信用卡费用的情况)或导致竞争条件(即,如果您尝试更改您的电子邮件地址两次,并且第一个在第二个完成后重试)。
在许多情况下,使自动重试安全可能需要大量的架构工作。但是,如果您可以安全地重试(例如,通过发送请求 UUID,并让远程端跟踪这些),事情就会变得非常非常简单。查看 Stripe API 以了解实际情况的一个很好的示例。
方法#4
检查请求是否成功,如果安全再试一次。
这里的想法是,在某些情况下,我们可以在超时请求之后跟上另一个请求,询问我们原始请求的状态。这种方法显然需要存在一个端点,可以为我们提供我们想要的信息。给定这样一个端点,如果端点说我们的请求成功,我们可以明确地说我们不需要重试。
但是这里有一个严重的问题,我们无法真正知道重试是否安全。因为通常我们的远程服务可以接收到请求,但仍在处理中,因此我们正在检查的查询端点将无法确认成功。当然,检查本身可能会超时!远程服务器可能由于与初始故障相同的原因而完全无法访问,但即使这是真的,我们仍然无法知道问题是在处理初始请求之前还是之后发生的。
方法#5
放弃并让用户弄清楚。
这需要最少的努力,并且可以说可以防止我们做出错误的决定,因此在许多情况下这可能是最佳选择。我们还需要问自己:我们的用户能找出正确的做法吗?他们是否有足够的信息和对其他系统的洞察力来确定如何前进?
在某些情况下,让我们的消费者知道这个问题可能是最好的选择。对于任何涉及重试的方法,如果我们不想允许无限次数的重试,我们最终可能仍会退回到这条路径!
结论
所以在这一点上,事情可能看起来很黯淡。分布式系统很难,看来我们不能只选择其中一种解决方案作为灵丹妙药。如果您感到失败,请振作起来,不要让完美成为美好的敌人。
使用超时。
即使超时时间很长,比如 5 秒、10 秒或 [gulp!] 甚至更多,每个网络请求都应该有一些超时时间。选择超时可能很棘手——当请求最终成功时,您不希望有太多失败(误报),也不希望浪费太多时间并冒着不健康的应用程序的风险。您可以通过查看历史请求的分布和趋势以及您的应用程序自身的性能保证或风险概况来确定好的值。
在任何情况下,我们都不希望我们的应用服务器的队列、连接池、环形缓冲区或任何瓶颈被将永远等待的东西堵塞。您绝对可以根据您的生产需求研究并添加更高级的东西,例如断路器和隔板,但是超时很便宜并且库很好地支持。使用它们!
默认使重试安全。
除了让你的代码更简单、更安全之外,你还会说“幂等性”,这很有趣。
考虑以不同的方式委派工作。
异步消息传递在这里有一些吸引人的特性,因为您的远程服务不再需要保持快速和可用;只有您的消息代理可以。但是,消息传递/异步性并不是灵丹妙药——您仍然需要确保代理收到消息。不幸的是,这可能很难!消息代理也有权衡。您的用户对于何时需要重试会有自己的想法。例如,如果消息处理延迟,他们可能会决定重新提交,因为他们的订单尚未显示在订单历史记录中。分布式日志/流媒体平台也可能出现类似问题。如果您正在考虑消息传递路线(实际上,即使没有!),请仔细查看 Enterprise Integration Patterns — 尽管它年代久远,但其中的模式与当今的架构极为相关。
并且冒着成为派对大便的风险,不要忘记您可能能够完全移动或删除该网络边界!把一个难题变成一个简单的问题并没有什么可耻的。因此,也许您可以使用一个网络请求而不是五个,或者您可以将两个服务内联在一起。或者,也许您采用上述方法之一以可靠和安全的方式处理超时。无论您选择哪种方式,请记住,您的用户并不关心您是否使用微服务——他们只是想让事情正常工作。
原文:https://8thlight.com/blog/colin-jones/2018/09/18/microservices-arent-ma…
- 65 次浏览
【微服务架构】微服务作为进化架构
微服务架构风格正在风靡全球。去年三月,O'Reilly举办了他们的第一次软件架构会议,并且计划委员会在微服务的某些方面获得了大量的摘要。为什么这种建筑风格突然风靡一时?
微服务是DevOps革命后的第一个建筑风格,第一个完全接受持续交付的工程实践。它也是一个演化架构的例子,它支持增量不间断变化,作为应用程序结构层面多维度的第一原则。但是,它只是支持某些进化行为的一组架构之一。本文探讨了这一系列建筑风格的一些特征和原则。
进化架构
软件中的常识曾经认为,建筑元素“以后难以改变”。作为第一原理,进化架构设计用于架构中的增量变化。进化架构很有吸引力,因为改造在历史上很难预测,而且改造成本也很高。如果体系结构中内置了渐进式变更,那么变更就会变得更容易,更便宜,从而允许更改开发实践,发布实践和整体敏捷性。
微服务因其强大的有界环境原理而符合这一定义,使得Evan的域驱动设计中描述的逻辑划分成为物理分离。微服务通过高级DevOps实践(如机器配置,测试和自动部署)实现这种分离。因为每个服务都与所有其他服务(在结构级别)分离,所以将一个微服务替换为另一个微服务类似于将一个乐高积木换成另一个。
进化架构的特征
进化架构具有几个共同的特征。我们已经为即将到来的进化建筑书确定了大量的内容;这里有几个。
模块化和耦合
如果开发人员想要进行不间断的更改,那么将组件沿明确定义的边界分离的能力就会明显受益。没有任何建筑元素,传说中的泥球大球,不支持进化,因为它缺乏区域化。

来自一个未命名的客户项目的泥球大球中的类别(周边点)之间的耦合。]
不恰当的耦合通过以难以预测的方式传播变化来抑制进化。进化架构都支持某种程度的模块化,通常在技术架构上(例如,经典的分层架构)。
围绕业务能力进行组织
现代成功的体系结构越来越多地在域架构级别上具有模块化,受域驱动设计的启发。基于服务的体系结构与传统SOA的区别主要在于分区策略:SOA严格按技术层划分,而基于服务的体系结构倾向于微服务的灵感域分区。
实验
实验是超级大国的进化架构之一,为企业提供服务。对应用程序进行操作上廉价的微不足道的改变可以实现常见的持续交付实践,如A / B测试,Canary Releases等。通常,微服务架构是围绕服务之间的路由来定义应用程序,允许在生态系统中存在特定服务的多个版本。这反过来允许实验和逐步替换现有功能。最终,这种力量使您的企业能够花更少的时间来推测故事积压,而是参与假设驱动的开发。
进化架构原理
思考进化架构的一种方法是通过原则。这些原则描述了架构本身或架构设计方法的各种特征。一些原则将注意力集中在何时在流程中做出特定的架构决策。
合适的功能
我们区分紧急和进化架构,这种区别是重要的。与遗传算法等进化计算技术非常相似,建筑适应度函数指定了我们的目标体系结构。有些系统需要很长的正常运行时间,而有些则更关注吞吐量或安全性。

[雷达图用于突出适用于该软件系统的重要适应度函数。]
关于特定系统的适应度函数的前期思考为决策制定和决策时间提供了指导。建筑决策相对于适应度函数进行评分,以便我们可以看到架构正朝着正确的方向发展。
带来痛苦
由于极限编程社区的启发,持续交付和进化架构中的许多实践都体现了带来痛苦向前的原则。当项目中的某些东西有可能引起疼痛时,强迫自己更频繁,更早地进行,这反过来又会鼓励您自动消除疼痛并尽早发现问题。通过部署管道,自动化机器配置和数据库迁移等常见的持续交付实践,通过消除常见的变更难点,可以简化进化架构。
最后的责任时刻
当决策发生时,传统架构和进化架构之间存在重大区别。这些决策可能围绕应用程序的结构,技术堆栈,特定工具或通信模式。在传统架构中,这些决策在编写代码之前就会早期出现。在进化架构中,我们等待最后一个负责任的时刻来做出决策。延迟决定的好处是可用于做出决定的额外信息。成本是一旦做出决定就必须进行的任何潜在的重新工作,这可以通过适当的抽象来减轻 - 但成本仍然是实际的。但是,过早做出决定的成本也是真实的。考虑选择消息传递工具。各种工具具有不同的支持功能。如果我们选择比我们最终需要的更重的工具,我们已经在我们的项目中引入了技术债务来源。这种债务是以使用错误工具导致的发展拖累的形式出现的。这不是先发制人地“抽象所有事情”的借口 - 我们仍然支持敏捷的YAGNI(你不需要它)原则 - 而是在适当的时候做出决定的明智尝试。
当然,在考虑最后一个负责任的时刻时,当前的问题是决定何时。适应度函数为该决定提供指导。应该更早地做出对其他架构或设计选择产生重大影响的决策,或影响项目关键成功因素的决策。延迟做出决定对项目的影响往往大于等待的好处。
结论
软件架构师有责任通过创建图表来阐明系统如何组合在一起的决策。太多的建筑师没有意识到静态的二维建筑图片的保质期很短。软件世界处于不断变化的状态;它是动态的而不是静态的。架构不是一个等式,而是一个正在进行的过程的快照。
持续交付和DevOps运动说明了忽略实施架构并保持最新状态所需工作的缺陷。建模体系结构和捕获这些工作没有任何问题,但实现只是第一步。架构在实施之前是抽象的。换句话说,除非你不仅实现了它,而且还要升级它,否则你无法真正判断任何架构的长期可行性。甚至可能使它能够承受不寻常的事件。
架构师的操作意识对于进化架构至关重要。 Evolution会影响实现的细节,因此实现细节不容忽视。持续交付对架构的要求使得实施更加明显,并使其演变变得容易。因此,持续交付是任何进化架构的重要推动因素。
其他资源:
在ThoughtWorks Tech Leaders Podcast的这一集中,Rebecca和Neal讨论了进化架构的含义以及组织如何将其用作业务优势。
原文:https://www.thoughtworks.com/insights/blog/microservices-evolutionary-architecture
本文:http://pub.intelligentx.net/microservices-evolutionary-architecture
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 125 次浏览
【微服务架构】微服务可加快产品上市速度并提高应用质量
微服务可加快产品上市速度并提高应用质量
采用云原生方法,使用微服务架构构建移动和Web应用程序。
利用微服务缩短产品上市时间
无论他们是访问网站还是移动应用,人们对他们经常使用的应用程序抱有很高的期望。 因此,公司必须不断提供新功能和修复。 在过去,这个过程很痛苦,因为应用程序通常是作为单个(通常是单片的)应用程序开发,构建和提供的。
微服务是一种应用程序架构风格,其中应用程序由许多离散的,网络连接的组件组成,称为微服务:
大型单片应用程序被分解为小型服务。
单个网络可访问服务是微服务应用程序的最小可部署单元。
每个服务都在自己的进程中运行。 此规则有时称为“每个容器一个服务”,可能是容器或任何其他轻量级部署机制,例如Cloud Foundry运行时。
客户正在尝试使他们的应用程序现代化,以跟上变化的速度......在过去,操作决定了应用程序的编写方式......人们花了数年时间编写单一应用程序,其中许多应用程序功能都打包在应用程序中。 ..现在他们看到了开发人员在添加新功能以应对不断变化的营销需求方面遇到的困难。
-------- Roland Barcia, Distinguished Engineer and CTO: Microservices
微服务的好处
采用微服务的企业可享受许多好处:
高效的团队
微服务是分成一组可独立部署的小型服务的应用程序。由于微服务旨在独立行动,因此它们自然地与促进端到端团队所有权的敏捷原则保持一致。
简化部署
每个微服务都围绕业务功能构建和对齐,以降低应用程序变更管理过程的复杂性。由于每项服务都是在不影响其他服务的情况下单独更改,测试和部署的,因此加快了上市时间。
适合工作的正确工具
开发微服务的团队可以做出适合工作的技术决策。他们可以尝试新技术,库,语言和框架,从而缩短创新周期。
提高应用质量
由于微服务的“分而治之”方法,微服务的功能和性能测试都比单片应用程序更容易。微服务架构适用于测试驱动的开发,因为组件可以单独测试,并与完整或虚拟化的微服务组合。这种方法可以全面提高应用质量。
可扩展性
微服务比单片应用程序更容易扩展。通过根据各个服务对整体应用程序,吞吐量,内存和CPU负载的关键性来扩展各个服务,团队可以更有效地扩展应用程序。
微服务原则
在为应用程序开发微服务时,请记住以下原则:
一份工作/单一职责
每个微服务必须针对单个功能进行优化。每项服务都更小,更易于编写,维护和管理。罗伯特马丁称这一原则为“单一责任原则”。
单独的进程
微服务之间的通信必须通过REST API和消息代理进行。从服务到服务的所有通信都必须通过服务API进行,或者必须使用显式通信模式,例如Hohpe的Claim Check Pattern。
执行范围
虽然微服务可以通过API公开自己,但重点不在于接口,而在于运行组件。此图中突出显示了微服务应用程序的粒度:
CI / CD
每个微服务可以连续集成(CI)并连续交付(CD)。当您构建由许多服务组成的大型应用程序时,您很快就会意识到不同的服务以不同的速率发展。如果每个服务都具有唯一的持续集成或连续交付管道,则该服务可以按照自己的进度进行。在整体方法中,系统的不同方面都以系统中最慢的移动部分的速度释放。
弹性
您可以将高可用性和群集决策应用于每个微服务。当您构建大型系统时,您拥有的另一个实现是,当涉及到群集时,一个大小并不适合所有。在同一级别上扩展整体中所有服务的单一方法可能导致服务的过度使用或使用不足。更糟糕的是,当共享资源被垄断时,服务可能会被忽略。在大型系统中,您可以将不需要扩展的服务部署到最少数量的服务器以节省资源。其他服务需要扩展到大数量。
将应用程序迁移到微服务
微服务是一个小应用程序,通常包含一个功能。该功能通过API和消息传递。每个微服务都可以拥有自己的DevOps管道,可以单独扩展,并拥有自己的数据库,拥有数据模型。
该图显示了单片应用程序架构如何演变为基于微服务的应用程序架构:
在单片应用程序中,代码位于单个服务器上。 更新单个组件时,必须同时部署其他组件,因此需要一个完全等效的服务器,以通过蓝绿色部署满足高可用性要求。
在重构的微服务应用程序中,简化了更新部署,因为业务服务在独立的基于云的计算基础架构上独立运行。
要了解微服务应用程序的工作方式以及从单片应用程序迁移到微服务,请观看此视频:
下一步是什么?
既然您已了解使用微服务的概念和价值,请通过阅读微服务参考架构了解有关如何设计微服务应用程序的更多信息。 在了解了体系结构之后,请参考教程在Kubernetes上部署微服务应用程序。
原文:https://www.ibm.com/cloud/garage/architectures/microservices/overview
交流:知识星球【首席架构师圈】
- 84 次浏览
【微服务架构】微服务安全性如何保护您的微服务基础设施?
在当今的市场中,各个行业都在使用各种软件架构和应用程序,因此几乎不可能认为您的数据是完全安全的。因此,在使用微服务体系结构构建应用程序时,安全问题变得更加重要,因为各个服务之间和客户端之间进行通信。因此,在这篇关于微服务安全性的文章中,我将按照以下顺序讨论保护微服务的各种方法。
- microservices是什么?
- 微服务面临的问题
- 确保微服务的最佳实践
Microservices是什么?
微服务,又称微服务体系结构,是一种体系结构样式,它将应用程序构造为围绕业务域建模的小型自主服务集合。因此,您可以将微服务理解为围绕单个业务逻辑彼此通信的小型独立服务。如果您希望更深入地了解微服务,那么可以参考我的文章。
现在,当公司从单一架构转向微服务时,他们通常会看到许多好处,比如可伸缩性、灵活性和较短的开发周期。但是,与此同时,这种架构也引入了一些复杂的问题。
因此,在本文关于微服务安全性的下一篇文章中,让我们了解微服务体系结构中面临的问题。
微服务面临的问题
微服务面临的问题如下:
问题1:
考虑一个场景,其中用户需要登录才能访问资源。现在,在微服务体系结构中,必须以这样一种方式保存用户登录细节,即在用户每次试图访问资源时都不需要进行验证。现在,这产生了一个问题,因为用户细节可能不安全,也可能被第三方访问。
问题2:
当客户端发送请求时,需要验证客户端详细信息,还需要检查授予客户端的权限。因此,在使用微服务时,可能需要对每个服务进行身份验证和授权。现在,为了做到这一点,开发人员可能对每个服务使用相同的代码。但是,您不认为依赖特定的代码会降低微服务的灵活性吗?当然有。所以,这是这个架构中经常面临的主要问题之一。
问题3:
下一个非常突出的问题是每个微服务的安全性。在这种体系结构中,除了第三方应用程序之外,所有的微服务都可以同时彼此通信。因此,当客户端从第三方应用程序登录时,您必须确保客户端不能访问微服务的数据,以防止他/她利用这些数据。
好了,上述问题并不是微服务体系结构中发现的唯一问题。我想说,基于应用程序和您所拥有的体系结构,您可能会面临许多与安全性相关的其他问题。在这一点上,让我们继续这篇关于微服务安全性的文章,并了解减少挑战的最佳方法。
微服务安全的最佳实践
提高微服务安全性的最佳实践如下:
深度防御机制
众所周知,微服务采用任何细粒度级别的机制,因此可以应用深度防御机制来增强服务的安全性。通俗地说,深度防御机制基本上是一种技术,通过这种技术可以应用多层安全对策来保护敏感服务。因此,作为开发人员,您只需用最敏感的信息标识服务,然后应用多个安全层来保护它们。通过这种方式,您可以确保任何潜在的攻击者都不能在一次攻击中破解安全性,并且必须继续尝试破解所有层的防御机制。
此外,由于在微服务体系结构中,您可以在不同的服务上实现不同的安全层,因此成功利用特定服务的攻击者可能无法破解其他服务的防御机制。
令牌和API网关
通常,当您打开一个应用程序时,您会看到一个对话框,上面写着“接受cookie的许可协议和权限”。这个信息意味着什么?一旦您接受了它,您的用户凭证将被存储并创建一个会话。现在,下一次访问同一页面时,页面将从缓存中加载,而不是从服务器本身加载。在这个概念出现之前,会话集中存储在服务器端。但是,这是横向扩展应用程序的最大障碍之一。
令牌
所以,这个问题的解决方案是使用令牌来记录用户凭证。这些令牌用于轻松地识别用户,并以cookie的形式存储。现在,每当客户机请求web页面时,请求都会被转发到服务器,然后服务器确定用户是否可以访问所请求的资源。
现在,主要的问题是存储用户信息的令牌。因此,需要对令牌数据进行加密,以避免第三方资源的利用。Jason Web Format(通常称为JWT)是一种开放标准,它定义了令牌格式,为各种语言提供库,并且对这些令牌进行加密。
API网关
API网关作为额外的元素添加,以通过令牌身份验证保护服务。API网关充当所有客户端请求的入口点,并有效地向客户端隐藏微服务。因此,客户端不能直接访问微服务,因此,没有客户端可以利用任何服务。
分布式跟踪和会话管理
分布式跟踪
在使用微服务时,您必须不断地监视所有这些服务。但是,当您必须同时监视大量的服务时,就会出现问题。为了避免这些挑战,您可以使用一种称为分布式跟踪的方法。分布式跟踪是一种查明故障并找出故障原因的方法。不仅如此,您还可以确定失败发生的位置。因此,很容易追踪到哪个微服务面临安全问题。
会话管理
在保护微服务时,会话管理是必须考虑的一个重要参数。现在,只要用户进入应用程序,就会创建一个会话。因此,可以通过以下方式处理会话数据:
您可以将单个用户的会话数据存储在特定的服务器中。但是,这种系统完全依赖于服务之间的负载平衡,只满足水平扩展。
完整的会话数据可以存储在单个实例中。然后数据可以通过网络同步。唯一的问题是,在这种方法中,网络资源会被耗尽。
您可以确保可以从共享会话存储中获取用户数据,从而确保所有服务都可以读取相同的会话数据。但是,由于数据是从共享存储中检索的,因此需要确保有某种安全机制,以便以安全的方式访问数据。
第一会话和相互SSL
第一次会议的想法很简单。用户需要登录一次应用程序,然后才能访问应用程序中的所有服务。但是,每个用户最初必须与身份验证服务通信。当然,这肯定会导致所有服务之间的大量通信,而且对于开发人员来说,在这种情况下找出故障可能很麻烦。
对于相互SSL,应用程序经常面临来自用户、第三方以及彼此通信的微服务的流量。但是,由于这些服务是由第三方访问的,因此总是存在被攻击的风险。现在,这种场景的解决方案是微服务之间的相互SSL或相互身份验证。这样,在服务之间传输的数据将被加密。这种方法的惟一问题是,当微服务的数量增加时,由于每个服务都有自己的TLS证书,因此开发人员很难更新证书。
第三方应用程序访问
我们所有人都访问第三方应用程序。第三方应用程序使用用户在应用程序中生成的API令牌来访问所需的资源。因此,第三方应用程序可以访问特定用户的数据,而不能访问其他用户的凭据。这是关于单个用户的。但是,如果应用程序需要访问多个用户的数据呢?你认为如何处理这样的要求?
使用OAuth
解决方案是使用OAuth。当您使用OAuth时,应用程序会提示用户对第三方应用程序进行授权,以使用所需的信息并为其生成一个令牌。通常,授权代码用于请求令牌,以确保用户的回调URL不会被窃取。
因此,在提到访问令牌时,客户机与授权服务器通信,而该服务器授权客户机,以防止其他人伪造客户机的身份。因此,当您与OAuth一起使用微服务时,这些服务充当OAuth体系结构中的客户端,以简化安全问题。
好了,各位,我不会说这是唯一的方式,通过这些您可以确保您的服务。您可以基于应用程序的体系结构以多种方式保护微服务。因此,如果您希望构建基于微服务的应用程序,那么请记住,服务的安全性是您需要谨慎考虑的一个重要因素。关于这一点,我们将结束这篇关于微服务安全性的文章。我希望这篇文章能让你有所收获。
原文:https://www.edureka.co/blog/microservices-security
本文:https://pub.intelligentx.net/microservices-security-how-secure-your-microservice-infrastructure
讨论:请加入知识星球或者小红圈【首席架构师圈】或者飞聊小组【首席架构师智库】
- 46 次浏览
【微服务架构】微服务已死——迷你服务万岁
免责声明警告:这将是那些纯粹主义者的文章之一,这些文章解释了你如何没有做你认为你正在做的事情,仅仅是因为你并不真正了解你认为你正在做的事情的完整定义。
如果您对此表示满意,那么我们可以继续。
您是否曾经定义或实现过基于微服务的架构?你可能错了。对不起,今天我扮演的是“定义警察”的角色。
你最有可能处理的不是微服务,而是:迷你服务。让我们试着解释一下为什么会这样,以及为什么错了是可以的。
微服务,迷你服务,它们都是小服务,不是吗?
我的意思是,是的,你没有错,事实上,这不是混乱发生的地方。
我们倾向于将“微服务”视为小型的、非常注重逻辑的服务,通常处理一项职责。然而,如果我们看一下 Martin Fowler 对微服务的定义——你知道,他是一个非常聪明的人,所以我们通常想知道他的想法——你会注意到我们缺少一个非常小的但关键的微服务特征: 解耦。
让我们仔细看看我们所说的“微服务”。近来这个词被广泛流传,以至于到了与青少年性行为完全一样的地步:每个人都在谈论它,没有人真正知道该怎么做,每个人都认为其他人都在做,所以每个人都声称他们在做.
说实话,在我作为经理接受的 99% 的采访中,当我询问微服务时,我会得到关于 REST API 的回答。不,它们不一定是同一回事。
根据定义,单独的 REST API 不能是微服务,即使您将它们分成多个较小的,每个负责单一的职责。他们不能,因为根据定义,您要能够直接使用 REST API,您需要了解它。
作为相关的旁注:有两种类型的 REST 开发人员(意味着开发人员创建 REST API):
- 那些实现了他们认为需要的尽可能多的关于 REST 的特性。这意味着如果他们愿意,他们可能会关心面向资源的 URL,也许他们会担心他们的 API 是无状态的,因为实现起来并不难。但是这种类型的开发人员将在 99.9% 的时间里放弃 HATEOAS(超媒体作为应用程序状态的引擎)。换句话说,API 结构的自发现性不再是一个特性,客户端和服务器在两者之间有一个硬编码的契约。
- 严格遵守 REST 标准的那些。我想在我的经验中我只见过一个这样的开发者——所以如果你是这样的,请发表评论,让我们联系! — .以这种方式实现 REST API 可能需要更长的时间,但结果要好得多,尤其是因为客户端与服务器的耦合非常少,他们只需要知道它在哪里以及根端点是什么。其余的都是通过自我发现完成的,非常酷。
但是,在这两种情况下,客户端和服务器之间的耦合仍然存在。你不能仅仅通过 REST 获得解耦的通信,这就是为什么如果我们对微服务的定义很严格——而且我们正在努力做到——就不能这样称呼它们。
所以相反,让我们松开定义的腰带,给自己留一些回旋的空间,把这些服务称为:迷你服务。
所以我们可以定义一个小服务为:
足够小的服务(通常是 API)被认为是“迷你”,它们仍然只需要处理一个单一的责任,但是,我们不太担心“与客户端解耦”部分。
诚然,它们的耦合越少,对未来的变化就越有利,拥有一个动态客户端肯定有助于更快地调整,并且对服务器上的变化没有太大影响。这绝对是一个优点,但这不是我们定义的一部分。
提示:使用独立组件构建,以提高速度和规模
与其构建单一的应用程序,不如先构建独立的组件并将它们组合成服务和应用程序。它使开发速度更快,并帮助团队构建更一致和可扩展的应用程序。
像 Bit 这样的 OSS 工具为构建独立组件和编写应用程序提供了出色的开发人员体验。许多团队从通过独立组件构建他们的设计系统或微前端开始。
试试看→
An independently source-controlled and shared “card” component. On the right => its dependency graph, auto-generated by Bit.
那么什么是微服务呢?
如果我们想获得技术,根据定义,我们仍然在处理一个处理单一职责的服务,但同时它能够与任何使用它的客户端分离。
那么我们如何才能实现这种解耦呢?诀窍是在服务之外思考:沟通渠道。
我们倾向于假设微服务 = REST API,同时,REST API 倾向于自动与客户端-服务器通信范式相关联。就这样,我们在一瞬间从微服务变成了客户端-服务器。但让我们倒带一下。
不久前,我写了一篇关于我最喜欢的服务间通信模式的文章,其中我列出了一个特定的选项:异步消息传递。
该选项不会直接连接客户端和我们的服务,而是需要一个中央消息总线来负责在客户端和服务之间来回传递消息,而无需它们彼此了解。你能看到我们刚刚到达那里吗?没错,我们通过一个简单的范式改变将客户端和服务器完全解耦。

看上图,客户端应用程序用一条消息启动一个潜在的多服务请求。它甚至不必知道涉及多少服务,这太棒了。这意味着编排复杂的请求序列不再是客户责任的一部分。这是一个伟大的交易!
最终,客户端应用程序最终会收到它正在寻找的结果。我在这里说“最终”是因为这不是一个同步通信模型,考虑到它的工作原理,它需要是异步的。这不一定是个问题,它只需要改变我们为客户编写代码的方式(以及我们的其他微服务,考虑到这也是他们相互交谈的方式)。
让我们真实一点:基于消息总线的通信模型不仅可以让您正确地将服务称为“微服务”,它还提供了一些不错的优势:
- 您的整个架构,包括您的客户端应用程序的架构,都变得反应式。在我的书中,这是一个了不起的优势,尤其是当您处理本质上需要很长时间才能解决的请求时。也许您正在处理非常复杂的计算、运行一些 ML 模型,或者只是从其他第三方 API 收集数据。无论是什么原因,您的客户都可以在等待响应时继续做其他事情,而不是被活动连接锁定,希望它不会超时。事实上,在我最近的这次演讲中,我介绍了反应式架构的一些好处以及如何使用 Redis 创建一个:
- 水平扩展您的服务非常容易。对于耦合实现,例如让 REST API 直接与客户端对话,您需要有某种负载均衡器或 API 网关,以允许您在同一微型服务的所有副本之间分配负载。但如果我们处理的是解耦架构,我们不必担心,第一个接收消息的微服务会处理它,让副本自由处理下一个传入的消息。
- 添加新服务对客户端没有直接影响。如果你问我,这很残酷。因为通过客户端-服务器通信,添加新服务(因为您正在添加新功能或因为您决定拆分现有服务)意味着客户端现在需要知道在不同情况下与谁联系。要么,要么您将编排移动到所有请求都到达的中央 API,但是,在这种情况下,您还必须更新服务上的编排逻辑。当然,客户端不受影响,但您仍然有副作用。有了基于微服务的架构,情况就不再如此了。编排由消息总线完成,使添加几乎没有影响。
- 更容易重试和更有弹性的架构。这是两个非常相关的点。一方面,您必须担心如果您的服务因任何原因而死(或至少无法访问)会发生什么。对于客户端-服务器通信,这意味着请求将失败。然而,对于消息总线来说,这仅仅意味着在服务恢复之前请求不会完成。消息总线可以将消息存储一段时间,从而允许创建更具弹性的架构。同时,如果你想在失败时有某种重试逻辑,正如我已经提到的,这对于基于微服务的架构是隐含的,而你必须自己为客户端-服务器架构编写代码。
还不相信?真的吗?那可能是因为你的用例不是微服务的完美匹配。也许迷你服务是适合您的解决方案。
本文的主要内容是了解虽然“正式已知的微服务”可能很棒,但它们并不是每个架构都必须使用的。
这都是关于权衡的。微服务可能需要在基础设施层面做更多的工作,甚至可能需要让你的开发团队正确地思考异步通信。然而,从长远来看,最终产品可能会产生更好的结果和更少的麻烦。
没有灵丹妙药的架构可以解决每个人的问题,所以不要把这个狂热者对微服务的定义当我告诉你放弃你的客户端-服务器方式。这与我的意图相去甚远。
本文旨在再次表明,客户端-服务器通信模型虽然可能是最常见且更易于实现的模型,但不一定是最好的模型。
所以你怎么看?您准备好最终尝试一些微服务来进行更改了吗?或者你会暂时坚持使用迷你服务吗?
原文:https://blog.bitsrc.io/microservices-are-dead-long-live-miniservices-40…
- 861 次浏览
【微服务架构】微服务最佳实践

关键需求
-
最大限度地提高团队的自主性:创建一个团队可以完成更多工作而不必与其他团队协调的环境。
-
优化开发速度:硬件便宜,人不是。 使团队能够轻松快捷地构建强大的服务。
-
关注自动化:人们犯错误。 更多的系统操作也意味着更多的事情可能出错。 自动化一切。
-
在不影响一致性的情况下提供灵活性:让团队能够自由地为自己的服务做正确的事情,但是有一套标准化的构建模块可以长期保持健康。
-
为弹性而构建:由于多种原因,系统可能会失败。 分布式系统引入了一整套新的故障场景。 确保采取措施尽量减少影响。
-
简化的维护:而不是一个代码库,你会有很多。 有准则和工具来确保一致性。
挑战:一次切换系统
-
从一个单一的体系结构切换到一个微服务体系结构是不是你可以一次完成的。 如果你有一个单一的服务器,那么你可能会在其周围紧紧地建立一个存储库,部署任务,监视和其他许多事情。 改变这一切并不容易。
-
如果一个公司从来没有使用微服务的经验,那么即使是一个绿地项目也会比他们想象的更难。
-
保留单片服务器,但是任何新的服务都是作为一个微服务来开发的,所以最终的东西都是从原来的服务器中流出来的,直到最终成为我们最老,最大的微服务。
挑战:拆分系统
-
自项目开始以来,如果将组件和服务粘合在一起,将其隔离起来可能相当具有挑战性。
-
您需要定义各个部分之间的交互和流程。 如果你没有很好的定义,你的系统会产生更多的问题。
-
没有模式; 将系统划分为微服务有许多不同的规则,但是没有人会告诉你如何在应用程序中使用它。 没有两个相同的微服务。
-
将整体系统分解成微服务的唯一方法是首先检查整体系统,以查看它最“伤害”的位置。 系统的这些部分应该被取出并转换成微服务。
-
如果你没有适当的监控,你将不会看到你的系统是如何工作的。 监视所有部分是如何工作的,以及他们在做什么。 如果您监控您的系统,您可以轻松检测并解决问题。
-
渐进地,逐渐式是模块分离单片系统的最好方法。 如果你想一次做所有事情,你一定会失败的。
挑战:组织认同
-
获得组织认同可能是最难的部分。
-
这不是一个技术决定。您需要清楚说明微服务架构的好处,以说服您的公司重新分配资源。在这样的变革被组织接受之前,这是一个漫长而乏味的过程,组织规模越大,决策的时间就越长。
-
说服你的组织改用微服务的最佳方式是将系统中的一个非关键部分转换为微服务。 通过这种方式,您可以使用真正的,可用的微服务来展示其优势。
挑战:团队
-
团队本身面临着最大的挑战,因为它需要不同的思考。
-
开发人员必须花更多的时间来了解什么是端到端场景。 他们需要熟悉这些技术,可能需要转换思维方式,这需要时间。
-
对于在一个可以进行端到端测试的世界中工作的人来说,这是不舒服的,现在你突然把它分解成小块。 这更多的是文化上的变化。
-
从非常小的东西开始,在那里你可以真正受益,并选择一些不是你的应用程序的关键部分。 获得一个小团队,并将应用程序的这一部分转换为微服务。 证明它实际上是更好的,并逐步向组织扩展。
-
避免将整个系统一次切换到微服务。
Best Practices:平台:
-
您的平台是一套与支持工具相结合的标准
-
微服务架构转换复杂性。 而不是一个复杂的系统,你有一堆简单的服务与复杂的交互。 我们的目标是保持复杂性可控。
Best Practices:服务要点
-
独立开发和部署服务
-
服务应该有他们自己的私人数据
-
保持服务小到足以保持专注和足够大以增加价值
-
将数据存储在数据库中,而不是短暂的服务实例
-
最终的一致性是你的朋友
-
尽可能将工作卸载到异步工作人员
-
保持在一个共同的地方完成所有服务的帮助文档
-
分配负载平衡器的工作
-
网络边界上的聚合服务可以转化为外部世界
-
分层安全,不要编写自己的加密代码!
Best Practices:服务交互
-
通过HTTP传输数据,使用JSON或protobuf的进行序列化
-
对于HTTP服务,500系列错误或超时意味着服务不健康
-
API应该简单而有效
-
服务发现机制使服务很容易找到对方
-
倾向于集权协调员的分散交互
-
版本所有的API,在相同的服务实例中共存多个版本
-
在服务超载之前,使用资源限制来快速失败
-
连接池可以减少突发请求高峰对下游影响
-
Timouts最大限度地减少下游延误和失败的影响
-
容忍不相关的下游API更改
-
断路器在艰难时期给下游服务中断
-
关联ID可帮助您跟踪跨服务日志的请求
-
确保你能保证最终的一致性
-
对所有API调用进行身份验证可以更清楚地了解使用模式
-
使用随机重试间隔自动重试失败的请求
-
只能通过暴露和记录的API与服务进行交谈
-
经济力量鼓励有效使用可用资源
-
客户端库可以处理所有的基础知识,因此您可以专注于重要的事情
Best Practices:开发
-
为所有服务使用通用的源代码管理平台
-
要么模仿开发或使用孤立的云开发环境
-
推动工作代码经常主线
-
Release更少,Release更快
-
警告:共享库很难更新
-
您的服务模板应该覆盖基本原理
-
简单的服务也很容易替换
Best Practices:部署
-
使用系统映像作为部署包
-
有办法自动将任何版本的任何服务部署到任何环境
-
功能标志将代码部署与功能部署分开
-
配置应该在部署包之外进行管理
Best Practices:运维
-
在一个地方管理所有日志
-
为所有服务使用通用监控平台
-
无状态服务很容易自动扩展
-
无法在您的平台上运行的相关服务也需要自动化
Best Practices:人
-
服务团队开发,部署和运营自己的服务
-
团队在日常运营中应该是自主的
- 81 次浏览
【微服务架构】微服务架构 - 适合您的软件开发吗?
“微服务架构提供了一系列技术优势,有助于提高软件项目的开发速度和产品质量,同时也有助于提高整体业务灵活性” - MARK EMEIS,软件技术高级总监,CA技术
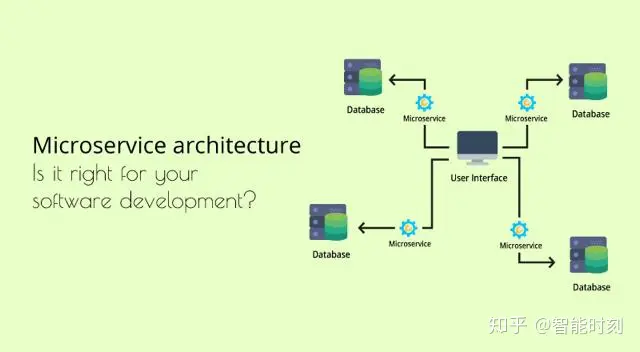
自从该术语成立以来,微服务一直在软件开发中获得成功。微服务(又称微服务架构)是面向服务的体系结构(SOA)的变体,用于开发大型应用程序,其中服务按照业务域分为多个块。它提供了复杂应用程序的持续交付/部署,使应用程序更易于理解,开发,测试,并且对架构侵蚀更具弹性。微服务架构提供了一种以新颖方式编织现有系统的新方法,以便快速提供软件解决方案。由于其提供模块化,可扩展性,可用性的能力,成为软件行业最热门的话题之一;许多企业软件开发公司都热衷于采用它。
但是,微服务究竟是什么?它能改善组织的文化,技能和需求吗?
为了深入理解微服务,让我们首先理解相反方法单片架构的要点。
关于单体软件的一切
维基百科说:“单片应用程序描述了一个单层软件应用程序,其中用户界面和数据访问代码从单一平台组合成一个程序。”
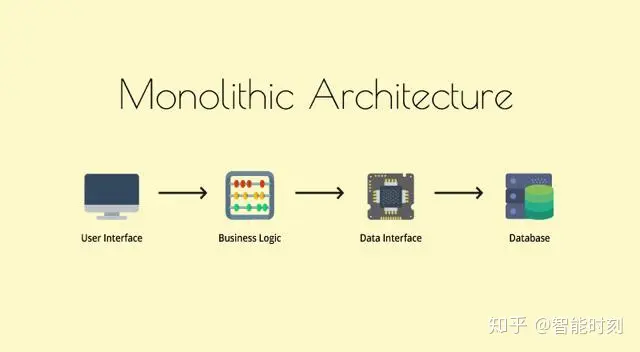
单片软件使用三层架构,即
- 表示层 - 它是应用程序的最顶层,描述了用户界面。主要功能是将任务和结果转换为用户可以理解的内容。用户界面代码使用HTML,JavaScript和CSS等客户端技术编写。
- 业务层 - 该层做出逻辑决策并执行计算。它处理两层之间的数据,并使用像Spring这样的技术。
- 数据访问层 - 这里存储信息并从数据库中检索信息。信息将传递到业务层,最终传递给用户。它使用像Hibernate这样的ORM工具来处理信息。
这里,Web应用程序客户端发送请求;层执行业务逻辑,数据库存储应用程序特定数据,UI将特定数据显示给用户。但是,由于它们共享相同的代码库,因此可能会出现一些问题。
这种类型的架构在一段时间内运行良好,但由于对持续交付的需求不断增加,此模型存在多个问题。
单片架构的缺点
- 运维开销:不同的利益相关者使用不同的单一应用层;因此团队将被限制在特定领域的专业知识。在表示层工作的团队专注于UI技术,但对数据访问层的了解最少。因此,如果要添加新功能,则需要不同的团队来协调和传递特定功能。这导致从构思到上市时间的更长时间跨度,并最终影响业务ROI。
- 软件堆栈自治:它限制了技术选择并迫使整个层使用单一框架。例如,如果表示层是在HTML框架中编写的,则整个层将在同一框架内实现。这避免了实施最新技术,导致应用程序代码在短时间内过时。
- 隐式接口:由于此代码在单个文件中发布,因此应用程序中的微小更改会要求重建整个应用程序。因此,正在进行的应用程序被放下并导致需要重新部署新版本。这种性质导致更新更少,并且无法尽可能快地发展。
- 可扩展性:单片应用程序具有一维可扩展性;因此无法扩展单个组件。因此,即使大多数应用程序可能不需要扩展,也需要扩展整个应用程序。
开发没有良好架构的软件会给组织带来很大的成本。例如:如果软件开发公司通过遵循非模块化方法开发软件,其中UI功能和业务功能混合在相同的源文件中,公司可能需要投入大量资金来支持他们在最新智能手机本机中的应用程序应用。这严重影响了软件的可维护性并延长了产品上市时间,最终影响了公司的销售。
单片体系结构一直是传统方法,但是扩展的限制,维护大型代码库的困难,高风险升级以及大量的前期设置成本迫使企业或软件开发公司探索不同的方法。单片应用程序是一个难以破解的难题,难以理解并随着时间的推移而扩展。
因此,为了避免这些问题,微服务架构可以成为一个救星!它提供360度扭曲以解决上述复杂问题;帮助软件开发公司在竞争对手中脱颖而出。
微服务架构简介
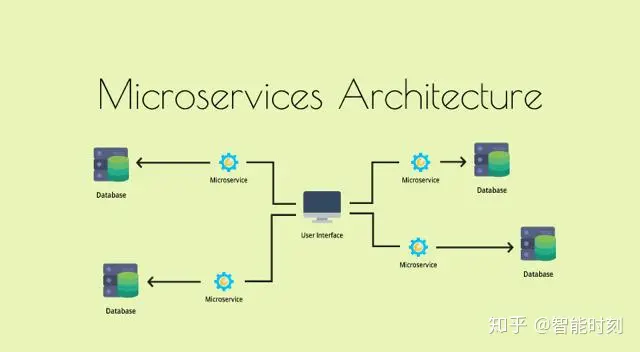
微服务是一种软件开发技术,它将应用程序构建为松散耦合服务的集合。每项服务都是独立的,应该实现单一的业务能力。微服务架构旨在克服较大应用程序的挑战,故障和故障。微服务提供了为系统增加弹性的机会,以便组件可以优雅地处理峰值和错误。有了这个,每个利益相关者都可以专注于整个应用程序的一个特定元素,具有自己的编程风格,而不用担心其他组件。微服务中的通信可以毫不费力地执行,因为它们是无状态的并且在明确定义的接口中(请求和响应是独立的)。
如果使用微服务方法开发应用程序/软件,将有助于采用DevOps方法,并将消除部署效率低下,从而缩短产品上市时间。由于微服务与设备和平台无关,因此可以开发应用程序,在大多数平台上提供增强的用户体验,包括Web,移动,物联网,平板电脑,可穿戴设备等等。
例如:沃尔玛加拿大在2012年之前使用了单片架构!该公司在处理600万页面浏览量/分钟时遇到了麻烦,这耗费了更多时间并导致销售额减少。由于这些问题,他们将自己的软件架构重构为微服务,并在一夜之间找到了即时结果和高转换率。停机时间最小化,公司能够使用更便宜的x86服务器而不是昂贵的硬件商品,从而节省了20%-50%的成本。
微服务和SOA
这是SOA的自然演变,其中各种技术堆栈将技术多样性带入开发团队。 SOA和微服务都允许将复杂的工作负载分解为更小,更易于管理和独立的部分。
但是,它们之间存在一些基本差异。
微服务与SOA

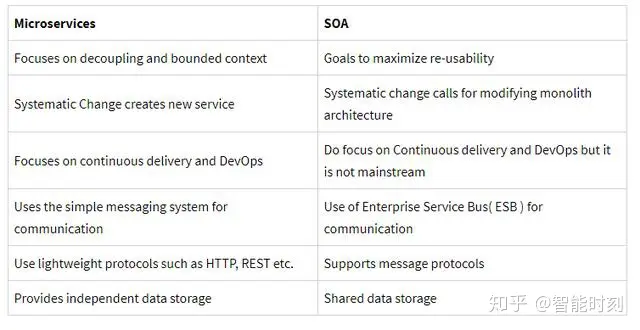
微服务哲学
微服务的哲学类似于Unix哲学,即“做一件事,做得好”。特征描述如下......
- 用于执行单一功能的组件化
- 按业务能力组织
- 专注于不加工的产品
- 分散治理和数据管理
- 服务具有弹性,弹性,可组合性,最小化和完整性
软件开发公司为什么要投资微服务架构?
- 改善了故障隔离
在微服务架构中,开发人员确切地知道在哪里寻找要解决的问题。如果单个模块受到影响,则可以轻松拆卸或解决,而不会影响应用程序的其他部分;提高应用程序的可用性。这在整体应用中完全矛盾;单个组件的故障可以拉低整个应用程序。例如,移动游戏应用程序(基于单片架构),具有不同的组件,如支付,登录,播放器,历史记录等。如果特定组件开始占用更多内存空间,整个应用程序将受到影响,这将导致糟糕的用户体验。
- 易于修改技术堆栈
通过微服务,软件开发公司可以在特定组件上尝试新的堆栈或最新技术,以提高可用性并在应用程序级别获得更大的好处。由于没有依赖性问题,软件开发人员可以避免使用特定的技术堆栈,如果他们不提供一致的用户体验。通过这种持续的现代化,您的系统不会变得容易过时。
- 提供可扩展性
微服务可扩展存在性能问题的部件,并使用最符合服务要求的硬件。由于每个服务都是独立的组件,因此可以使用更多容器部署扩展,从而实现更有效的容量规划,更少的许可成本和适当的硬件。关键服务的组件可以部署在多个服务器上,以提高可用性和性能,而不会影响其他服务的性能。这种可扩展性可带来更好的客户体验并增加成本节约。
- 与该组织保持一致
如果组织使用微服务,则可以定义团队规模以匹配所需任务。此外,团队可以分解为更小的组,并可以专注于应用程序的单个组件。由于最终目标是客户满意度和良好的用户体验,团队不分为UI团队,数据库团队等。例如,如果在阿联酋工作的团队正在处理三项服务,而在加利福尼亚工作的团队正在处理五项服务,那么在加利福尼亚和阿联酋工作的每个团队都可以独立发布和部署不同的功能。这些跨职能团队致力于实现单一功能,打破团队之间的孤岛,促进更好的协作。
- 提高生产力和速度
通过微服务,可以轻松解决生产率和速度问题。不同的团队同时处理不同的组件,而无需等待一个团队完成任务。这样可以加快质量保证,因为每个微服务都可以单独测试。其他利益相关者可以致力于增强已经开发的组件,而其他程序员则在开发其他程序员。这样可以提高速度并加快产品的发布速度。
需要考虑的障碍......
仅仅因为,一切看起来都很华丽,并不意味着它对软件行业来说是完美的;它确实有潜在的痛苦,也需要解决: -
- 由于微服务侧重于分布式系统和独立服务,因此需要在模块之间仔细处理每个请求。可能会发生其中一个服务没有响应,迫使开发人员编写额外的代码以避免中断。
- 基于微服务的应用程序的测试可能是一项痛苦的任务,因为在开始测试之前需要确认每个依赖服务。随着服务数量的增加,复杂性不会留在后台!密切关注所有服务变得不切实际,因为可能会出现数据库错误,网络延迟,缓存问题等。因此,弹性测试和故障注入成为必须。
- 每项服务都依赖于自己的API和平台,追踪所有内容都可能是一项痛苦的堆叠工作。领导者需要监控多个实体并管理整个基础架构,因为如果在任何情况下任何服务都失败,追踪问题就变得很繁琐。因此,强有力的监测变得必要。
随着持续交付和快速发展,员工必须提高灵活性和速度,这需要利用微服务带来的好处。如果他们花费很长时间来配置服务器,公司可能会遇到严重问题。
单体架构和微服务架构的区别
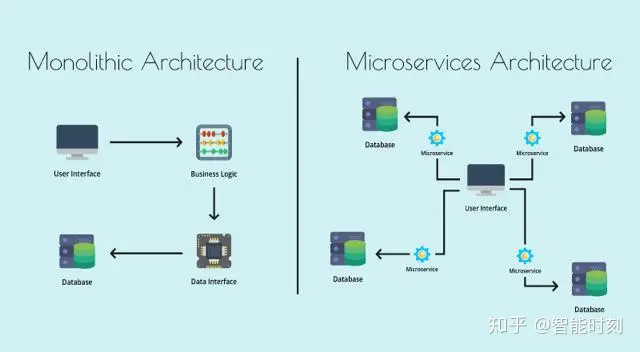
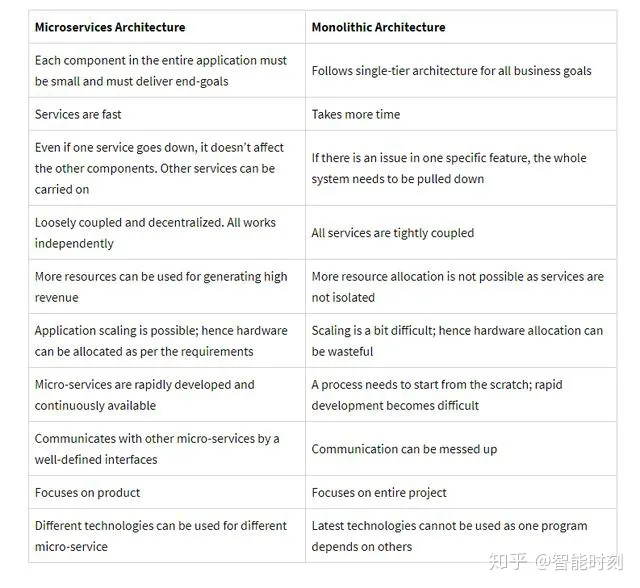
微服务架构的未来
您可能已经清楚了解微服务架构及其改变软件行业所具有的潜力!随着数字技术的使用越来越多,设备支持越来越多;软件开发正在深入到复杂的过程中。但软件行业拥有微服务架构,可以作为解决软件开发公司复杂性的完美解决方案。如果公司考虑采用它,它肯定会在技术和操作上影响文化。
Big Giants已经在使用它......
今天,随着微服务的兴起,大多数组织正在拉低整体架构并采用现代架构来利用激烈的竞争。其中一些包括Netflix,eBay,亚马逊,Twitter,PayPal,沃尔玛等等......
让我们看看NetFlix如何解决......
- NetFlix:NetFlix是最早在SOA架构中使用微服务的采用者之一。公司快速发展的时候,无法建立数据中心来提供可扩展性。开发中的一些小问题需要软件开发人员一次又一次地查找问题。但是,当他们使用微服务重构现有架构时,他们每天能够通过800个不同设备的API处理十亿次呼叫。如今,Netflix正在使用500多个微服务和30多个工程团队。
- 优步:优步以单一建筑为单一城市的单一建筑开始了它的旅程。由于它只在一个城市运营,因此一个代码库选项似乎是一个干净的选择并解决了所有业务问题。但是,当它迅速扩展到其他城市时,组件变得紧密耦合,封装是另一个问题,持续集成变成了一种负担。因此,为了解决所有这些复杂问题,工程团队重构了现有的应用程序并使用了微服务。他们介绍了
- 所有乘客和司机都通过的API网关
- 部署单独的单元以执行单独的功能
- 所有功能都可以单独缩放
因此,优步通过从单片架构转向微服务架构而获益匪浅。
- 亚马逊:亚马逊是大型电子商务商店之一,紧随其后的是整体应用程序,它使开发人员彼此分开,并将团队与最终目标区分开来。该公司必须解决协调过程之间的冲突,将它们合并为一个版本并生成所有版本的主版本。需要重新运行全新的基于代码的测试用例,以确保没有任何冲动。这些故障使公司使用微服务架构!该软件解决方案通过自己的Web服务API与全世界进行通信。因此,它非常成功。
做出选择
无论选择哪种软件解决方案,无论是单片还是微服务,都有它们各有优缺点。最后,选择软件架构取决于您的项目要求,项目规模等等。如果您希望构建小型软件,单片机可以作为一种选择,如果您更喜欢开发复杂的软件,那么微服务架构肯定是一个肯定的镜头。
仍然不清楚您的要求或希望为您的下一个大项目重构现有的软件架构?请联系我们,我们的技术顾问会回复您解决您的疑问!
- 399 次浏览
【微服务架构】微服务架构——探索 UBER 的微服务架构
从我之前的文章中,你一定对微服务架构有了一个基本的了解。 在本博客中,您将深入了解架构概念并使用 UBER 案例研究来实现它们。
在本文中,您将了解以下内容:
- 微服务架构的定义
- 微服务架构的关键概念
- 微服务架构的优缺点
- 优步——案例研究
在我谈论 UBER 的微服务架构之前,如果我给你定义微服务,这将是公平的。
微服务的定义
因此,没有对微服务(也称为微服务架构)的正确定义,但您可以说它是一个框架,由执行不同操作的小型、可单独部署的服务组成。
微服务专注于单个业务领域,可以将其实现为完全独立的可部署服务,并在不同的技术堆栈上实现它们。
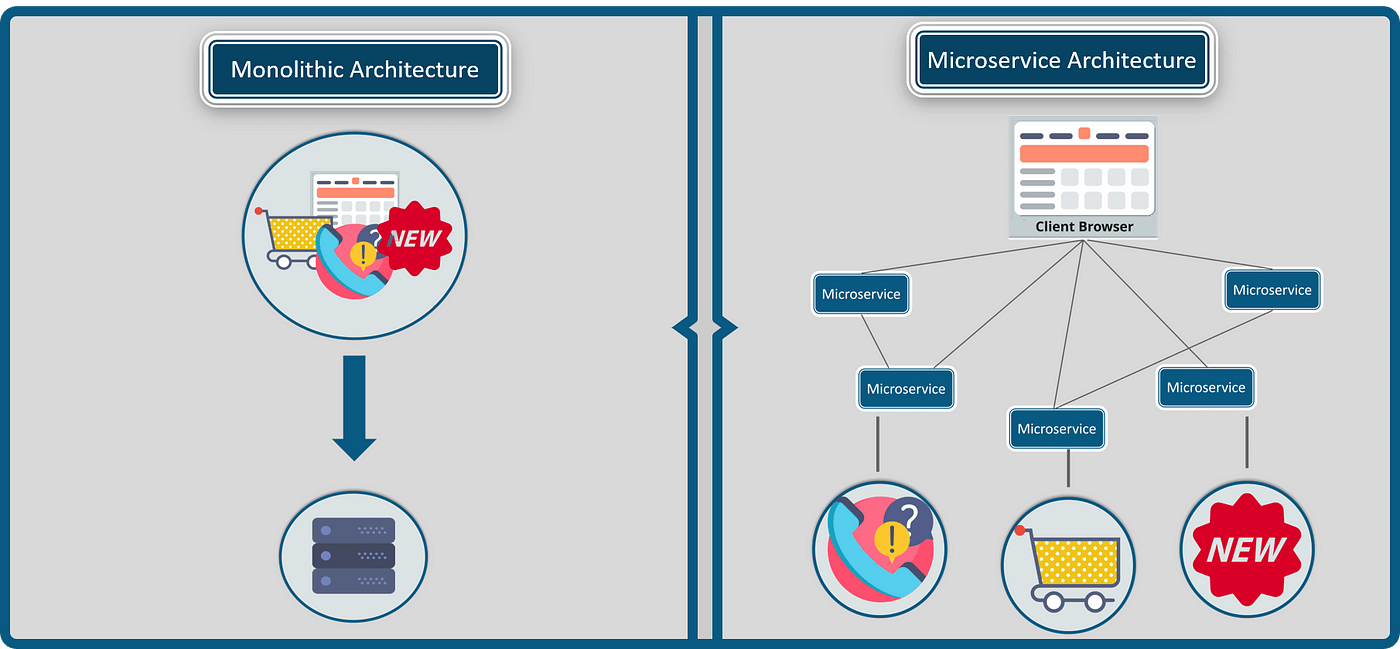
Difference Between Monolithic and Microservice Architecture — Microservice Architecture
参考上图了解单体架构和微服务架构的区别。为了更好地理解这两种架构之间的差异,您可以参考我之前的博客 What Is Microservices。
为了让你更好地理解,让我告诉你一些微服务架构的关键概念。
微服务架构的关键概念
在开始使用微服务构建自己的应用程序之前,您需要清楚应用程序的范围和功能。
以下是讨论微服务时要遵循的一些准则。
设计微服务时的指南
作为开发人员,当您决定构建应用程序时,将域分开并明确功能。
您设计的每个微服务应仅专注于应用程序的一项服务。
确保您以这样一种方式设计了应用程序,即每个服务都可以单独部署。
确保微服务之间的通信是通过无状态服务器完成的。
每个服务都可以进一步重构为更小的服务,拥有自己的微服务。
现在,您已经阅读了设计微服务时的基本指南,让我们了解微服务的架构。
微服务架构如何工作?
典型的微服务架构 (MSA) 应包含以下组件:
- 客户
- 身份提供者
- API 网关
- 消息格式
- 数据库
- 静态内容
- 管理
- 服务发现
请参考下图。
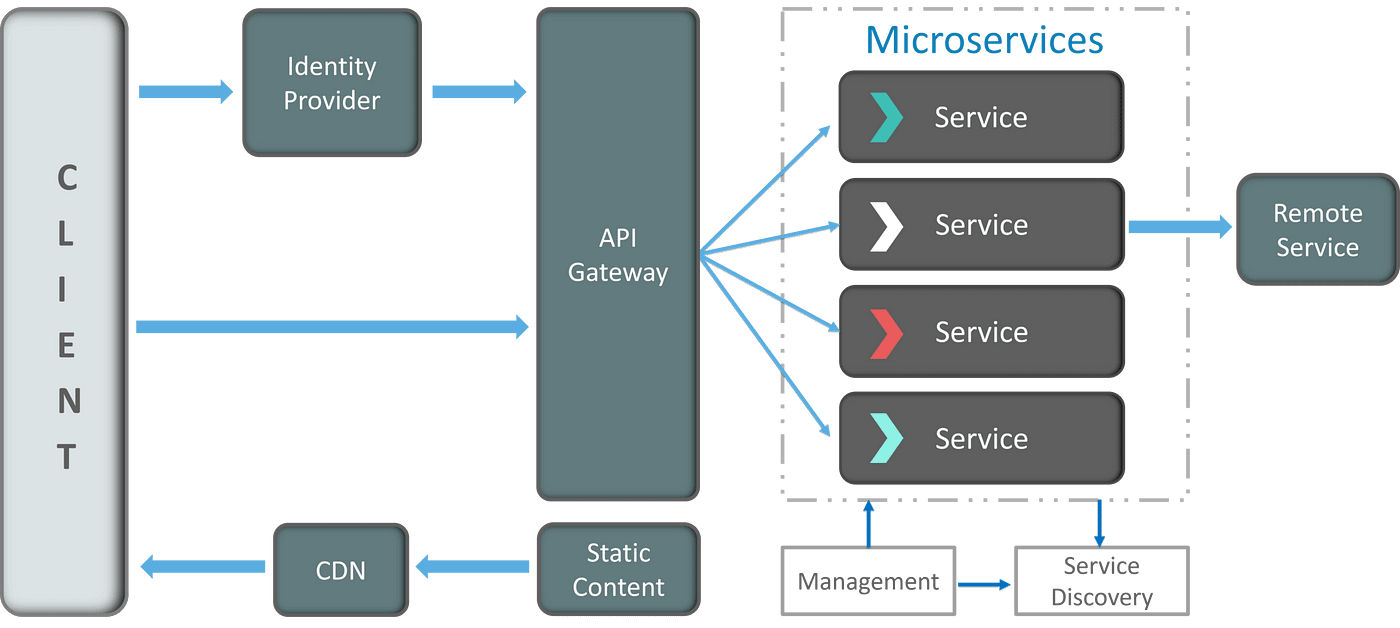
Architecture Of Microservices - Microservice Architecture
我知道架构看起来有点复杂,但让我为您简化一下。
1. 客户
该架构从不同类型的客户端开始,从不同的设备尝试执行各种管理功能,例如搜索、构建、配置等。
2. 身份提供者
然后将来自客户端的这些请求传递给身份提供者,身份提供者对客户端的请求进行身份验证并将请求传递给 API 网关。然后通过定义明确的 API 网关将请求传送到内部服务。
3.API网关
由于客户端不直接调用服务,API Gateway 充当客户端将请求转发到适当微服务的入口点。
使用 API 网关的优势包括:
- 所有服务都可以在客户不知情的情况下更新。
- 服务还可以使用对 Web 不友好的消息传递协议。
- API 网关可以执行横切功能,例如提供安全性、负载均衡等。
在接收到客户端的请求后,内部架构由微服务组成,这些微服务通过消息相互通信来处理客户端请求。
4. 消息格式
他们通过两种类型的消息进行通信:
- 同步消息:在客户端等待服务响应的情况下,微服务通常倾向于使用 REST(Representational State Transfer),因为它依赖于无状态的客户端-服务器和 HTTP 协议。使用该协议是因为它是一个分布式环境,每个功能都用资源表示以执行操作
- 异步消息:在客户端不等待服务响应的情况下,微服务通常倾向于使用 AMQP、STOMP、MQTT 等协议。这些协议用于这种类型的通信,因为定义了消息的性质并且这些消息必须在实现之间是可互操作的。
您可能会想到的下一个问题是使用微服务的应用程序如何处理它们的数据?
5. 数据处理
好吧,每个微服务都拥有一个私有数据库来捕获它们的数据并实现各自的业务功能。此外,微服务的数据库仅通过其服务 API 进行更新。请参考下图:

Representation Of Microservices Handling Data — Microservice Architecture
微服务提供的服务被转发到任何支持不同技术栈的进程间通信的远程服务。
6.静态内容
在微服务内部进行通信后,它们将静态内容部署到基于云的存储服务中,该服务可以通过内容交付网络 (CDN) 将它们直接交付给客户端。
除了上述组件之外,典型的微服务架构中还出现了一些其他组件:
7、管理
该组件负责平衡节点上的服务并识别故障。
8. 服务发现
充当微服务的指南,以查找它们之间的通信路径,因为它维护了节点所在的服务列表。
现在,让我们看看这种架构的优缺点,以便更好地了解何时使用这种架构。
微服务架构的优缺点
请参阅下表。

Pros and Cons of Microservice Architecture — Microservice Architecture
让我们通过比较 UBER 以前的架构和现在的架构来更多地了解微服务。
优步案例研究
UBER 以前的架构
与许多初创公司一样,UBER 的旅程始于为单一城市的单一产品而构建的单体架构。 拥有一个代码库在当时似乎很干净,并且解决了 UBER 的核心业务问题。 然而,随着 UBER 开始在全球扩张,他们在可扩展性和持续集成方面面临着各种问题。
上图描绘了 UBER 之前的架构。
- 存在用于连接乘客和驾驶员的 REST API。
- 三个不同的适配器与其中的 API 一起使用,以执行我们在预订出租车时看到的计费、付款、发送电子邮件/消息等操作。
- 一个 MySQL 数据库来存储他们的所有数据。
因此,如果您注意到这里的所有功能,例如乘客管理、计费、通知功能、支付、行程管理和驾驶员管理,都在一个框架内组成。
问题陈述
虽然 UBER 开始在全球范围内扩张,但这种框架带来了各种挑战。以下是一些突出的挑战
- 所有功能都必须一次又一次地重新构建、部署和测试以更新单个功能。
- 由于开发人员不得不一次又一次地更改代码,因此在单个存储库中修复错误变得极其困难。
- 在全球范围内引入新功能的同时扩展功能很难同时处理。
解决方案
为了避免此类问题,UBER 决定改变其架构,并效仿亚马逊、Netflix、Twitter 等其他高速增长的公司。因此,UBER 决定将其单体架构分解为多个代码库,形成微服务架构。
请参考下图了解 UBER 的微服务架构。
Microservice Architecture Of UBER — Microservice Architecture
- 我们在这里观察到的主要变化是引入了 API 网关,所有司机和乘客都通过它连接起来。从 API 网关连接所有内部点,例如乘客管理、司机管理、行程管理等。
- 这些单元是执行不同功能的单独独立的可部署单元。
例如:如果您想更改计费微服务中的任何内容,那么您只需要部署计费微服务,而不必部署其他微服务。
- 现在所有功能都单独缩放,即删除了每个功能之间的相互依赖关系。
例如,我们都知道搜索出租车的人数比实际预订出租车和付款的人数要多。这让我们推断,在乘客管理微服务上工作的进程数量比在支付上工作的进程数量要多。
通过这种方式,UBER 受益于将其架构从单体架构转变为微服务架构。
我希望你喜欢阅读这篇关于微服务架构的文章。如果您想查看更多有关人工智能、DevOps、Ethical Hacking 等市场最流行技术的文章,您可以参考 Edureka 的官方网站。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. 什么是微服务?
- 2. 微服务设计模式
- 3. 微服务与 SOA
- 4.微服务教程
- 5. 微服务设计模式
- 6. 微服务安全
原文:https://medium.com/edureka/microservice-architecture-5e7f056b90f1
- 151 次浏览
【微服务架构】微服务架构资料
- Microservice Databases: Migrating from Relational Monolith to Distributed Data (By O'Reilly)
- https://www.infoq.com/vendorcontent/show.action?vcr=4348&primaryTopicId=2498&vcrPlace=EMBEDDED
- Why Do We Need Architectural Diagrams?
- https://www.infoq.com/articles/why-architectural-diagrams/
- Enterprise Systems Built with Microservices are Designed to Expect Failures, But Then What? How Do We Handle Failures?
- https://www.infoq.com/presentations/failure-cache-redis-pcc-hazelcast
- Achieving High Throughput with Reliability in Transactional Systems
- https://www.infoq.com/presentations/architecting-transactional-system
- 事件流和工作流引擎——Kafka 与 Zeebe
- https://www.infoq.cn/article/VORC3JP7ky*6tG4OTHI5
- 微服务框架 Lagom 1.5 发布,支持 Kubernetes 和 OpenShift 部署
- https://www.infoq.cn/article/meYfthDexSU7OrL-TMg5
- 分布式事务 Seata TCC 模式深度解析
- https://www.infoq.cn/article/G33hCC-QoSJPlkt4e64E
- 55 次浏览
【微服务架构】微服务架构(示例和图表)
介绍
在设计应用程序时,应用程序体系结构是一个需要考虑的重点,多年来,许多不同的软件开发范例已经过去,不变的主题是,需要以模块化的方式对软件系统进行组件化。由于许多原因,模块化软件是有益的。它使源代码更易于理解和遵循,开发人员可以可视化代码库并大致了解查找缺陷的位置 - 从而提高维护效率。
如果使用您的应用程序的用户数量增加,那么架构良好的软件系统也更容易扩展,更不用说,如果新开发人员加入您的团队,一个架构良好的系统可以使入职流程更快,并减少开发人员配给时间,因为每个人都是编码到一组特定的标准。
构建软件项目有很多方法,例如N-Tiered,面向服务的体系结构(SOA)或微服务体系结构等等。然而,在这篇文章中,针对软件开发人员,开发经理和CTO,我们专门研究微服务架构并涵盖以下主题:
- What is Microservice Architecture? (什么是微服务架构?)
- The need for Microservice Architecture (对微服务架构的需求)
- Benefits of Microservice Architecture (微服务架构的好处)
- Challenges of Microservice Architecture (微服务架构的挑战)
- Should You Adopt Microservice Architecture? (你应该采用微服务架构吗?)
- Sample Microservice Architecture (示例微服务架构)
- Summary (摘要)
当你阅读这篇博文时,你将对微服务架构是什么,它的好处,如果你应该考虑它以及如何构建一个应用程序以采用这种架构范例有一个充分的理解,那么让我们得到开始!
什么是MICROSERVICE架构?
在过去的几十年中,应用程序已经以整体方式开发,从上到下编码为一个单独的单元,有时没有真正的结构或思想用于将来的维护,这可能导致一系列问题。构建不良的软件解决方案也可能会出现问题,无法通过新功能进行调试或扩展,而且通常情况下,处理起来并不是很好。
微服务架构是面向服务的架构(SOA)的一种形式,其中软件应用程序被构建为松散耦合的服务的集合,而不是单个软件应用程序。每个微服务可以独立于另一个创建,或者甚至以完全不同的编程语言创建并独立运行。
在这一切的核心,每个微服务都试图满足您正在处理的特定用户故事或业务需求。它是当今日益增长的互联世界中理想的架构设计模式,有助于支持跨云,移动,物联网(IoT)甚至可穿戴设备的多种平台和设备。
实现微服务的一种流行方式是使用HTTP / REST和JSON等协议作为架构设计模式,我们看到许多主要的SaaS提供商在其解决方案和服务中采用微服务。
从Microsoft到IBM等等,软件供应商和服务提供商正在实施微服务架构。 Twitter,Netflix,eBay和亚马逊等主要厂商也青睐微服务架构,因为它有助于其服务的开发,可扩展性和持续交付。 这带来了微服务架构的一些好处。
作为一种架构实践,微服务架构近年来越来越受欢迎,这降低了它可以带来软件开发团队和企业的好处。随着软件复杂性的增加,能够将应用程序中的功能区域组件化为多组独立(微)服务可以产生许多好处,包括但不限于以下内容:
- 更有效的调试 - 不再跳过应用程序的多个层,实质上是更好的故障隔离
- 加速软件交付 - 可以使用多种编程语言,从而使您可以访问更广泛的开发人才库
- 更容易理解代码库 - 提高生产力,因为每个服务代表一个功能区域或业务用例
- 可扩展性 - 组件化的微服务自然有助于通过REST等行业标准接口与其他应用程序或服务集成。
- 容错 - 由于更具弹性的服务,减少了停机时间
- 可重用性 - 由于微服务是围绕业务案例而非特定项目组织的,由于它们的实现,它们可以重复使用并轻松地插入到其他项目或服务中,从而降低成本。
- 部署 - 因为所有内容都封装在单独的微服务中,您只需要部署已更改的服务而不是整个应用程序。微服务开发的一个关键原则是确保每项服务与现有服务松散耦合。
但是,不要只听我们的话,这里有一些真实的微服务实例,这个架构设计模式如何使沃尔玛和亚马逊受益。
MICROSERVICE架构在真实行动中的行动
在这里,我们探讨如何采用微服务作为软件架构可以增加真正的商业价值,并为亚马逊和沃尔玛带来一系列的好处。
MICROSERVICES拯救了沃尔玛的老化软件架构
零售业巨头沃尔玛的加拿大分支机构在其现有的软件架构方面存在严重问题,特别是在黑色星期五 - 连续两年。在高峰期,沃尔玛网站每分钟无法处理600万次页面浏览量,最终使访问者几乎无法获得任何积极的用户体验。
部分问题在于沃尔玛的软件架构是针对2005年的互联网设计的,该架构以台式机和笔记本电脑为中心。移动,智能和物联网设备的使用尚未完全达到顶峰。该公司决定在2012年使用微服务重新平台其遗留系统,并设定了到2020年能够为40亿个连接提供服务的目标!
通过迁移到微服务架构,沃尔玛确定:
- 移动订单增加了98% -
- 黑色星期五和节礼日的零停机时间(加拿大黑色星期五)
- 转化次数增加20%
AMAZON
亚马逊零售和现在的物流巨头对大规模交付软件并不陌生。高级AWS产品经理Rob Birgham分享了一个关于微服务架构如何与DevOps结合使用的故事。
早在2000年初,Amazons网站就被开发为一个巨大的单块解决方案,公平地说,很多业务都是以这种方式开始的。然而,随着时间的推移,随着功能区域的建立,来自多个开发团队或错误的修复,更不用说随着平台的发展,整合所有这些工作的工作开始影响整体生产力。
几天或有时整整一周致力于将开发人员更改合并到产品的主版本中,必须再次解决合并冲突,这些都会对生产力产生影响。
很快意识到这样的操作是不可持续的,亚马逊决定通过采用微服务架构来解决他们的整体代码库。每个服务都由一个目的负责,因为可以通过Web服务API访问。
一旦完成此练习,这为亚马逊创建高度解耦的架构铺平了道路,每个服务都可以独立运行 - 为每个开发人员提供相应的Web服务接口定义。
微软架构的挑战
与每个新的软件编程架构一样,每个都有优缺点列表,并不总是桃子和奶油和微服务不是这个规则的例外,值得指出其中的一些。
- 太多的编码语言 - 是的,我们将此列为一项好处,但它也可能是一把双刃剑。最终,太多的替代语言可能会使您的解决方案变得笨拙并且可能难以维护。
- 集成 - 您需要有意识地努力确保您的服务尽可能松散地耦合,否则,如果您不这样做,您将对一项服务进行更改,这会对其他服务产生连锁反应,从而使服务集成困难且耗时。
- 集成测试 - 测试一个单片系统可以更简单,因为一切都在“一个解决方案”中,而基于微服务架构的解决方案可能具有生活在其他系统和/或环境上的组件,从而使配置更加困难并且“端到端”测试环境。
- 通信 - 微服务自然需要与其他服务交互,每个服务将依赖于一组特定的输入并返回特定的输出,这些通信通道需要被定义到特定的接口并与您的团队共享。当没有遵守接口定义时,可能会发生微服务之间的故障,从而导致时间浪费。
现在我们已经讨论了微服务架构是什么,它的一些优点是什么,看看现实世界中微服务架构的一些例子以及这种范例的好处,你可能想知道微服务架构是否是对于您或您的软件项目而言,这是一个有效的问题。
您应该采用MICROSERVICE架构吗?

您不希望在项目中实现微服务架构只是为了它,所以我们总结了一些要考虑的点,这将有助于您确定该架构模式是否适合您或您的项目。
如果对这些问题中的任何一个回答“是”,那么您可能需要考虑实施微服务基础架构:
- 您当前的应用程序是否很难维护?
- 您是否预计您的应用程序将需要处理大量流量?
- 模块化和代码可重用性是主要优先事项吗?
- 您的应用程序是否需要在多种设备类型上访问,例如移动设备,物联网和网络?
- 您的应用程序需要能够扩展需求的特定区域吗?
- 您是否希望改进软件产品构建和发布流程?
但是,如果对大多数问题的回答是肯定的,那么您可以使用传统的单片应用程序架构:
- 只需要发货和MVP,来测试市场吗?
- 在您退休之前,是否已有一个稳定的产品/团队继续使用该产品?
- 您的产品“在野外”,产生收入和用户社区是否满意?如果是这样,重新发明轮子没有任何意义
参考微软架构
现在我们已经介绍了微服务架构,讨论了一些好处,各自的挑战,并看了一些微服务如何在现实世界中部署的例子,现在是时候从架构和如何看待基本的微服务了它可以设计。在下图中,您可以使用以下3个微服务:
- 帐户服务
- 库存服务
- 送货服务
在这个虚构的应用程序中,每种微服务都以两种方式之一访问:
- 从API网关(通过移动应用程序)
- 从Web应用程序(通过用户的Web浏览器)
注意:理论上可能更多,因为架构适合于此。
您可以看到每个微服务还公开了一个专用的REST API,这是定义可以针对相应微服务执行的操作的接口,并将详细说明可以传递到微服务的数据结构,数据类型或POCOS。作为其返回类型。例如,Inventory服务REST API定义可能包含一个名为GetAllProducts的端点,它允许微服务的消费者获取电子商务商店中的所有产品,这可以返回Product对象的列表,即JSON,XML甚至C#POCO。
由于每个微服务都有自己的职责,并且只能与其各自的数据库进行交互,因此这样构建的解决方案使不止一个开发人员更容易对系统进行更改。通过实施像我们刚刚详细介绍的微服务,您将获得我们之前概述的一些好处。当您使用这种方法推出架构时,确保每个微服务可以完全独立运行非常重要,否则,它会违背追求这种架构方法的目的。
摘要
那么,你有它,一个概述微服务架构。在这篇博文中,我们研究了微服务架构,我们介绍了关键概念,这种架构设计模式可以为企业带来的好处,以及它如何帮助软件开发专业人员更好地构建他们的产品。
我们还概述了采用微服务架构模式的应用程序的主要组件,并为您提供了一些关于为什么要将微服务引入项目的想法。随意评论或与您的朋友或同事分享这篇文章,或者如果您有评论,请在下面留下一个!
原文:https://www.devteam.space/blog/microservice-architecture-examples-and-diagram/
- 197 次浏览
【微服务架构】微服务的数据管理注意事项
使用微服务有助于提高应用程序质量并简化部署。但在实施微服务解决方案之前,您需要考虑应用程序将处理的数据。必须谨慎管理这些数据,以确保您的应用程序的性能和安全性符合预期和策略。您应该回答几个问题,以了解如何处理微服务用例的数据管理。
- 您的用例是否需要存储它创建或修改的数据以用于将来,趋势或漂移分析;可审计性或合规性;还是可追溯性?
- 您的用例是否适用于持续流动的数据,例如社交媒体源或物联网传感器?
- 您的用例是否适用于来自多个来源的数据,或者需要清理或修改数据以使用它?您的用例是否需要零停机时间?
- 您的用例是否适用于被视为敏感或私密的数据,例如个人身份信息(PII),或受法规控制的数据(如HIPAA或GDPR)?
- 您的用例是否依赖于高度可信的数据,其可以追溯其谱系被认为是成功的,还是专注于提高数据质量和可追溯性?
7数据管理考虑因素
虽然在许多微服务式解决方案中,各个服务大多数都是无状态的,但我们已经确定了七个数据管理接触点,或微服务解决方案中数据管理的注意事项。如果您正在构建微服务解决方案,则可以通过解决这些注意事项来帮助确保有效地管理数据。
- 任何服务都必须根据对该类数据的要求(包括法规,安全性或业务流程)访问或保存数据库或数据高速缓存中的数据。微服务解决方案通常利用可通过定义的API提供这些要求的数据库服务。
- 转换数据的服务需要通过标准消息传递这些更改,以维护沿袭和治理,通常使用定义的API或消息队列。
- 遵守适用于数据的数据访问控制策略。通常,数据访问策略由数据存储库设置,具体取决于它们包含的数据的敏感性。这些服务使用适用于应用程序选区的角色。
- 数据移动和转换服务必须在获取和可用性之间的时间内考虑SLA的性能。这些服务还必须考虑要访问的数据的数量和位置,并相应地设置SLA期望。
- 如果服务需要高度可信的公共数据,请确定它们是否应使用企业指定的主数据源。
- 存储必须考虑要存储的数据量,接收的速度,使用方式以及选择适当数据存储库时的安全性和弹性要求。
- 监视和记录有关数据如何流动以及访问哪些数据的信息,以确保采取适当的安全措施。沟通数据沿袭和治理的转型。
原文:https://www.ibm.com/cloud/garage/architectures/microservices/data-management-for-microservices
讨论:加入知识星球【首席架构师圈】
- 112 次浏览
【微服务架构】微服务简介,第1部分
每个人都在谈论微服务。行业资深人士可能会记住单片或基于SOA的解决方案是做事的方式。时代变了。新工具使开发人员能够专注于特定问题,而不会给部署或通常与隔离服务相关的其他管理任务增加过多的复杂性。选择使用合适的工具来解决正确的问题变得越来越容易。
在本系列文章中,我们将探讨微服务的世界,它如何帮助解决现实问题,以及为什么行业越来越多地将其作为标准的做事方式。在本系列中,我们将尝试解决与此方法相关的常见问题,并提供方便简单的示例。在本系列的最后,我们应该有一个完整的基于微服务的架构的框架实现。今天,我们将关注微服务以及它们与替代方案的比较。我们还将列出我们计划在以下帖子中讨论的问题。
更新:在第2部分中,我们讨论了API网关。
什么是微服务?
微服务是一个孤立的,松散耦合的开发单元,可以解决一个问题。这类似于旧的“Unix”做事方式:做一件事,做得好。诸如如何“组合”服务提供的任何事项的事项留给更高层或政策。这通常意味着微服务往往避免相互依赖:如果一个微服务对其他微服务有一个硬性要求,那么你应该问自己是否有意义将它们全部放在同一个单元中。
"A microservice is an isolated, loosely-coupled unit of development that works on a single concern."
“微服务是一个孤立的,松散耦合的开发单元,可以解决一个问题。”
微服务对开发团队特别有吸引力的是他们的独立性。团队可以自己处理问题或一组问题。这创造了许多开发人员青睐的有吸引力的品质:
- 自由选择合适的工具:您一直想要使用的是新的库或开发平台吗?你可以(如果它是适合这项工作的工具)。
- 快速迭代:第一个版本不是最理想的吗?没问题,版本2可以立即出门。由于微服务往往很小,因此可以相对快速地实现更改。
- 重写是一种可能性:与单片解决方案相比,由于微服务很小,重写是可能的。技术堆栈是错误的选择吗?没问题,切换到正确的选择。
- 代码质量和可读性:隔离开发单元的质量往往更高,新开发人员可以非常轻松地使用现有代码。
生产质量的微服务
现在我们知道微服务是什么,这里列出了在设计基于微服务的架构时需要记住的事项。如果这看起来太抽象,不要担心;我们将在整个系列文章中系统地处理所有这些问题。
必须以这样的方式实施跨领域关注,即微服务不需要处理有关其特定范围之外的问题的细节。例如,身份验证可以作为任何API网关或代理的一部分来实现。
数据共享很难。微服务倾向于支持可以直接更新的每服务或每组数据库。在为您的应用程序进行数据建模时,请注意这种处理方式是否适合您的应用程序。为了在数据库之间共享数据,可能需要实现处理数据库之间的内部更新和事务的内部过程。可以在许多微服务之间共享单个数据库;请记住,如果您需要在将来进行扩展,这可能会限制您的选择。
可用性:由于隔离和独立,需要对微服务进行监控,以尽早检测故障。在一个大型软件堆栈中,一个服务器可能会被忽视一段时间。在选择用于管理服务的软件堆栈时考虑到这一点。
进化:微服务往往快速发展。当专门团队处理特定问题时,可以快速找到新的更好的解决方案。因此,有必要考虑服务的版本控制。只要有客户需要使用旧版本,旧版本通常可用。较新版本以特定于应用程序的方式公开。例如,使用HTTP / REST API,微服务的版本可以是自定义标头的一部分,或嵌入在返回的数据中。说明这一点。
自动部署:现在微服务如此方便的全部原因是,从完全干净的环境部署新服务非常容易。请参阅Heroku,Amazon Web Services,Webtask.io或其他PaaS提供商。如果您要采用自己的内部方法,请记住,部署新服务或预先存在的服务版本的复杂性对于解决方案的成功至关重要。如果不以方便,自动的方式处理部署,您最终可能会达到一定程度的复杂性,这超出了该方法最初带来的好处。
相互依赖性:将它们保持在最低限度。处理服务之间的依赖关系有不同的方法。我们将在稍后的博客文章系列中进一步探讨它们。现在,请记住,依赖性是这种方法的最大问题之一,因此寻求将它们保持在最低限度的方法。
传输和数据格式:微服务适用于任何传输和数据格式;但是,它们通常通过HTTP上的RESTful API公开公开。任何适合您的信息的数据格式。 HTTP + JSON现在非常流行,但是没有什么可以阻止你使用协议缓冲区而不是AMQP。
把事情做正确
所有这些问题都可以系统地处理。我们将探索本系列文章中的技巧和模式来处理它们。以下是我们将来在帖子中讨论的内容:
- API代理
- 记录
- 服务发现和注册
- 服务依赖性
- 数据共享和同步
- 优雅的失败
- 自动部署和实例化
保持真实:样品微服务
现在,这应该很容易。如果微服务从开发团队的脑海中掏出这么多的包袱,写一个应该是小菜一碟,对吧?是的,在某种程度上。虽然我们可以编写一个简单的RESTful HTTP服务并将其称为微服务,但在本文中我们将通过考虑上面列出的一些事情来做到这一点(不要担心:在以下帖子中,我们将扩展此示例包括上面列出的所有问题的解决方案。
对于我们的示例,我们将从Sandrino Di Mattia的关于使用Flux进行调试的优秀帖子中选择后端代码。在Sandrino的帖子中,一个简单的express.js应用程序为React.js应用程序制作了后端。我们将采用后端并对其进行调整。您可以在此处查看原始后端代码。
Sandrino示例中的后端处理许多不同的问题:登录,身份验证,CORS,票证更新操作和查询。对于我们的微服务,我们将专注于一项任务:查询门票。看看这个:
var express = require('express');
var morgan = require('morgan');
var http = require('http');
var mongo = require('mongodb').MongoClient;
var winston = require('winston');
// Logging
winston.emitErrs = true;
var logger = new winston.Logger({
transports: [
new winston.transports.Console({
timestamp: true,
level: 'debug',
handleExceptions: true,
json: false,
colorize: true
})
],
exitOnError: false
});
logger.stream = {
write: function(message, encoding){
logger.debug(message.replace(/
$/, ''));
}
};
// Express and middlewares
var app = express();
app.use(
//Log requests
morgan(':method :url :status :response-time ms - :res[content-length]', {
stream: logger.stream
})
);
var db;
if(process.env.MONGO_URL) {
mongo.connect(process.env.MONGO_URL, null, function(err, db_) {
if(err) {
logger.error(err);
} else {
db = db_;
}
});
}
app.use(function(req, res, next) {
if(!db) {
//Database not connected
mongo.connect(process.env.MONGO_URL, null, function(err, db_) {
if(err) {
logger.error(err);
res.sendStatus(500);
} else {
db = db_;
next();
}
});
} else {
next();
}
});
// Actual query
app.get('/tickets', function(req, res, next) {
var collection = db.collection('tickets');
collection.find().toArray(function(err, result) {
if(err) {
logger.error(err);
res.sendStatus(500);
return;
}
res.json(result);
});
});
// Standalone server setup
var port = process.env.PORT || 3001;
http.createServer(app).listen(port, function (err) {
if (err) {
logger.error(err);
} else {
logger.info('Listening on http://localhost:' + port);
}
});
- 只有一件事:我们的微服务的唯一问题是查询完整的门票清单。而已。身份验证,CORS和其他问题将由我们架构中的上层处理。
- 记录:我们使用'winston'库保持记录。现在我们只需登录到控制台,但在以后的版本中,我们会将预定义格式的日志推送到集中位置进行分析。
- 没有依赖:我们的微服务与其他微服务没有依赖关系。
- 轻松扩展:没有依赖关系,单独的流程,只需一个操作,我们的微服务就可以轻松扩展。
- 小巧可读:我们的微服务小巧可读。新开发人员可以立即修改或重写它。
- 数据共享:现在我们的微服务从自己的数据库中读取数据。我们将在以后的帖子中探讨当其他微服务需要更新或创建票证时会发生什么。
- 注册和失败:我们的微服务独立存在。在以后的文章中,我们将探讨如何管理服务发现以及在微服务失败的情况下您可以做些什么。
获取https://github.com/sebadoom/auth0/blob/master/microservices/microservice-1-webtask/server.js。
旁白:对微服务感兴趣?你会喜欢webtasks!
微服务是Auth0堆栈的重要组成部分,我们提出了一种使它更容易使用的好方法。查看webtask.io。
- 轻量且简单的开发工作流程。
- 简化部署。
- 强大的安全模型,方便HTML5和移动应用程序。
- 适用于HTML和数据API的Web友好编程模型。
我们已将上面的示例转换为webtask,看看它有多简单:
npm install wt-cli -g
# This will send an activation link to your email. One time only.
wt init your.name@email.com
# This will return a new endpoint for your webtask
wt create https://raw.githubusercontent.com/sebadoom/auth0/master/microservices/m…
# Use the endpoint here (we have setup a sample DB for this example)
curl https://webtask.it.auth0.com/api/run/wt-sebastian_peyrott-auth0_com-0/0… -v
看代码。 将它与我们之前的版本进行比较,看看我们有多少变化。
结论
微服务是进行分布式计算的新方法。 部署和监控工具的进步缓解了管理许多独立服务所带来的痛苦。 好处很明显:使用正确的工具来解决正确的问题,并让团队使用他们的专有技术来解决每个问题。 困难的部分是处理共享数据。 在处理共享数据和服务间依赖关系时,必须考虑特殊注意事项。 数据建模是任何设计中必不可少的步骤,在基于微服务的架构中更是如此。 我们将在以下文章中详细探讨其他常见模式和实践。
- 38 次浏览
【微服务架构】微服务设计模式
这是微服务架构系列文章的第 3 篇
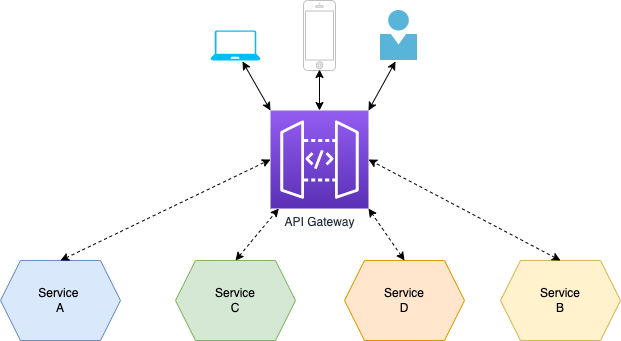
高可用性、可扩展性、故障恢复能力和性能是微服务的特征。 您可以使用微服务架构模式来构建微服务应用程序,从而降低微服务失败的风险。
模式分为三层:
应用模式
应用程序模式解决了开发人员面临的问题,例如数据分解、数据维护、测试、用户界面和一些可观察性模式。

让我们回顾一下这些应用程序模式的基础知识。
分解模式
选择如何将单体系统分解为服务
- 按业务能力分解——服务是围绕业务能力组织的。
- 按子域分解——服务是围绕域驱动设计的子域组织的。
数据模式
- 数据一致性——每个服务使用一个单独的数据库以确保松散耦合。为了跨服务的数据一致性,必须使用 Saga 模式。
- 查询——每个服务使用数据库的另一个问题是某些查询需要连接来自多个服务的数据。不可能对服务的数据库执行分布式查询,因为它的数据只能通过其 API 访问。必须使用其中一种查询模式来检索分散在多个服务中的数据。
- API 组合——对一项或多项服务进行 API 调用并汇总结果。
- 命令查询职责分离 (CQRS) — 数据保存在一个或多个可以轻松查询的副本中。
测试模式
单个微服务更容易测试,因为它们比单体应用程序小得多。在测试不同服务是否协同工作时,重要的是要避免使用同时检查多个服务的复杂、缓慢和不稳定的端到端测试。
- 消费者驱动的合同测试——确保服务满足客户的期望。
- 消费者端合约测试——确保服务的客户端可以与之通信。
- 服务组件测试——隔离服务并对其进行测试。
用户界面模式
显示与不同服务相对应的数据及其显示方式是不同团队的责任。
- 服务器端页面片段组合——每个团队开发一个 Web 应用程序,为他们的服务实现的页面区域生成 HTML 片段。 UI 团队通过在服务器端聚合特定于服务的 HTML 片段来开发页面模板。
- 客户端 UI 组合——每个团队创建一个客户端 UI 组件,为他们的服务实现屏幕区域,例如 AngularJS 指令。通过组合多个特定于服务的 UI 组件,UI 团队实现页面骨架来构建屏幕。
可观察性模式
为了有效地运行应用程序,了解其运行时行为并解决请求失败等问题非常重要。
- 审计日志——审计日志记录每个用户的操作。审计活动日志通常用于协助客户支持、确保合规性和检测可疑活动。
- 应用程序指标——监控和警报是生产环境的关键组成部分。有一系列指标,例如 CPU、内存和磁盘的利用率,到服务请求的延迟和执行的请求数。指标由提供警报和可视化的指标服务收集。
应用基础架构模式
它们适用于也会影响开发的基础设施问题,例如通信、可观察性、可靠性和安全模式。

横切关注点模式
我们必须先了解关注点,才能理解横切关注点。关注点是基于其功能的系统的一部分。有两种担忧:
- 核心关注点——它代表主要需求的单一和特定功能,例如业务逻辑。
- 横切关注点——与次要需求相关的关注点。横切关注点是适用于整个应用程序的关注点,例如安全性和日志记录。
- 外部化配置——在运行时,它向服务提供配置属性值,例如数据库凭据和网络位置。
- 微服务底盘——微服务底盘是处理一系列问题的一个或一组框架,例如外部化配置、健康检查、应用程序指标、服务发现、断路器和分布式跟踪。您可以使用微服务机箱更有效地开发服务的业务逻辑。
- 服务模板——开发人员可以通过复制源代码模板快速开始开发新服务。顾名思义,模板是一个简单的可运行服务,它实现了构建逻辑和横切关注点以及示例应用程序逻辑。
通讯模式
基于微服务的应用程序是分布式系统。微服务架构严重依赖进程间通信(IPC)。
- 远程过程调用 (RPI) — 使用请求/回复协议发出服务请求。
- 特定于域的协议 - 对于服务间通信,例如使用 SMTP/IMAP 的电子邮件,或使用 RTMP/HLS/HDS 的媒体流,请使用特定于域的协议。
- 消息传递——使用异步消息传递进行服务间通信,例如 AMQP
可观察性模式
可观察性模式提供了对应用程序行为方式的洞察。诊断微服务架构的问题要困难得多。在最终将响应返回给客户端之前,请求可以在多个服务之间反弹。
- 日志聚合——将服务活动日志写入可以执行搜索和警报的集中式日志服务器。
- 异常跟踪——应将异常报告给异常跟踪服务,该服务对异常进行重复数据删除、警告开发人员并跟踪其解决方案。
- 健康检查 API — 提供一个返回服务健康状况的端点。
- 分布式跟踪——为每个外部请求提供一个 ID,并在请求在服务之间流动时对其进行跟踪。
可靠性模式
当服务不可用时,如何保证它们之间的可靠通信?
- 断路器——断路器可用于保护跨服务调用。当一定数量的下游资源请求未能达到一定阈值时,断路器会打开。如果断路器打开,系统将很快出现故障。一段时间后,客户端会发送一些请求来检查下游服务是否已经恢复。如果有正常响应,将在健康恢复后再次发送请求。
安全模式
用户通常由微服务架构中的 API 网关进行身份验证。然后必须将用户的身份和角色传递给它调用的服务。一个常见的解决方案是使用访问令牌模式。 API 网关将访问令牌(例如 JWT(JSON Web 令牌))传递给服务,服务可以验证令牌并获取有关用户的信息。
基础架构模式
它们解决了与开发之外的基础设施有关的问题,例如部署、发现和与外部 API 的通信模式。
部署模式
部署微服务有几种模式。传统上,服务以特定语言的方式打包。有两种现代部署方法。
- 虚拟机或容器——虚拟机或容器可用于部署服务。
- 无服务器部署——无服务器平台在您上传服务代码后执行它。自动化的自助服务平台是部署和管理服务的最佳方式。
发现模式
通常,服务需要相互通信。单体应用程序使用语言级方法或过程调用来调用其服务。传统上,分布式系统在固定的、众所周知的位置(主机和端口)运行,因此可以通过 HTTP/REST 或其他一些机制访问服务。然而,大多数基于微服务的现代应用程序都在虚拟化或容器化环境中运行,其中服务实例的数量及其位置会动态变化。
- 自注册——服务向服务注册中心注册自己
- 客户端发现——服务客户端从服务注册表中检索服务实例,然后在它们之间进行负载平衡。
- 3rd Party Registration — 第三方自动向服务注册中心注册服务实例。
- 服务器端发现——服务发现由路由器完成,路由器接收来自客户端的请求。
外部 API 模式
微服务提供的 API 粒度通常与客户端所需的不同。微服务提供的 API 通常是细粒度的,因此客户端必须与多个服务交互。每个客户端需要不同数量的数据,网络性能对每个客户端的影响也不同。
- API Gateway — API Gateway 实现了一项服务,该服务是从外部 API 客户端进入基于微服务的应用程序的入口点。它执行请求路由、API 组合和其他功能,例如身份验证、速率限制、缓存等。
- 前端的后端(BFF)——为每种类型的客户端创建一个单独的 API 网关。每个移动、浏览器和公共 API 团队都将拥有自己的网关,而 API 网关团队拥有公共层。
在以后的文章中,我们将详细介绍每种模式。
- 81 次浏览
【微服务架构】用JHipster做微服务
微服务与单片架构
JHipster会问你的第一个问题是你想要生成的那种应用程序。您可以选择两种架构样式:
- “单片”架构使用单个,一刀切的s应用程序,其中包含前端Angular代码和后端Spring Boot代码。
- “微服务”架构将前端和后端分开,这样您的应用程序就可以更轻松地扩展并承受基础架构问题。
“单片”应用程序更容易处理,因此如果您没有任何特定要求,我们建议使用此选项,以及我们的默认选项。
微服务架构概述
JHipster微服务架构以下列方式工作:
- 网关是JHipster生成的应用程序(在生成应用程序时使用应用程序类型微服务网关)处理Web流量,并为Angular应用程序提供服务。如果您想遵循后端前端模式(Backends for Frontends pattern),可以有几个不同的网关,但这不是强制性的。
- Traefik是一个现代HTTP反向代理和负载均衡器,可以与网关一起使用。
- JHipster Registry是一个运行时应用程序,所有应用程序都可以在其上注册并获取其配置。它还提供运行时监控仪表板。
- Consul是一种服务发现服务,以及一个键/值存储。它可以用作JHipster注册表的替代品。
- JHipster UAA是一个基于JHipster的用户身份验证和授权系统,它使用OAuth2协议。
- 微服务是JHipster生成的应用程序(在生成它们时使用应用程序类型微服务应用程序),它们处理REST请求。它们是无状态的,并且它们的几个实例可以并行启动以处理重载。
- JHipster控制台是一个基于ELK堆栈的监视和警报控制台。
在下图中,绿色组件特定于您的应用程序,蓝色组件提供其底层基础结构。
原文:https://www.jhipster.tech/microservices-architecture/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 57 次浏览
【微服务架构】编曲与编舞——让系统协同工作的不同模式
介绍
Krzysztof(采访者):商业组织是由专家组成的,他们在他们最了解的领域提供产品或服务,以获得共同的商业成果。例如,营销团队努力争取新客户,销售团队向这些客户销售产品,客户关系团队负责积极的客户体验和保留。只有当这些团队一起工作时,才能实现共同的业务目标和利润。如何组合和安排他们的服务以实施业务流程管理的问题是定义整个组织如何运作的关键部分。今天我们将讨论这样做的最佳方法。我们有编排模式和编排模式——我们在辩论中的演讲者。你能介绍一下自己吗?
编曲模式:感谢您组织本次辩论。我是Orchestration Pattern,我相信只有一个集中且组织良好的组件才能为业务流程管理提供稳定性和跟踪。这就像一场管弦乐队音乐会——我们有一位指挥向每组音乐家展示何时发挥他们的作用。没有他,音乐家将演奏混乱而不是交响乐。同样的事情也适用于 IT 系统——如果我们在系统通信中使用 Orchestrator,我们将能够管理我们的流程并轻松验证其状态。
编舞模式:我很高兴被邀请参加这个演讲。 谢谢你有我。 我是编排模式,我对系统通信规则的观点与编排模式相反。 我认为,在我们的 IT 生态系统中间添加一个额外的决策组件是多余的。 更重要的是,我认为组件应该是自主的并且耦合松散,以提供业务价值本身,而不会影响其他组件。 这就像一支爵士乐队,当音乐家正在等待其他人停止演奏,并继续他们与另一支球队介绍的旋律相关的自由泳时。 使用这种方法,我们可以少维护一个组件,并且我们没有一个难以管理的大单点。

第 1 轮:IT 系统设计
Krzysztof(采访者):感谢您的快速介绍。 现在,我们将开始第一轮,我们将首先从技术角度讨论您的想法。 这里的问题是——你不只是同步和异步通信的不同名称吗?
编曲模式:不! 我可以实现这两种通信模式。 这就是我的 Orchestrator 组件如此重要的原因。 让我详细说明一下您在开始时介绍的示例。 当营销团队获得新客户时,客户关系和销售团队应该意识到这一点并更新客户信息——以便当销售人员想要致电客户时,他们可以立即获得有关他们的信息,发生的所有通信以及所有 客户进行的购买。 以下是我将如何实现这两个功能。
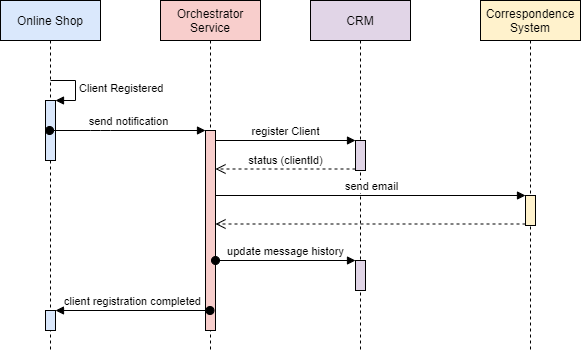
- Async Client Synchronization with Orchestration Pattern
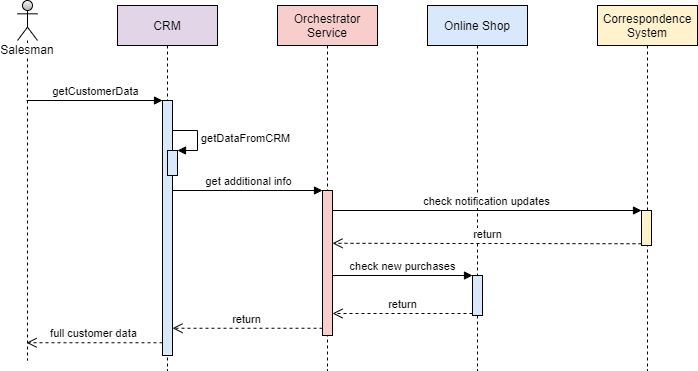
- 使用编曲模式同步客户端详细信息响应
编舞模式:在名称方面我同意编排模式——我也可以实现同步和异步通信。 我只是不同意 Orchestrator 组件至关重要。 让我重新设计一个编排模式的想法,因为我仍然可以提供相同的业务功能,而中间没有一个全能的元素。
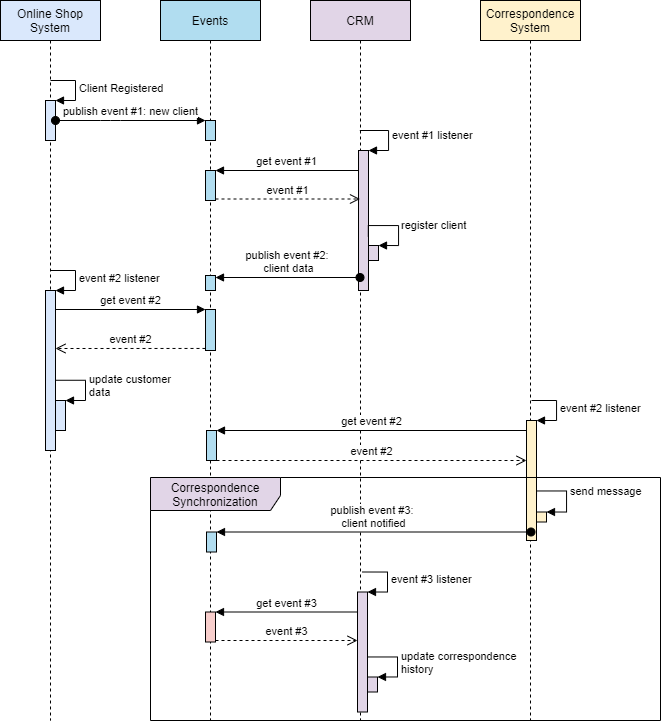
- Async Client Synchronization with Choreography Pattern
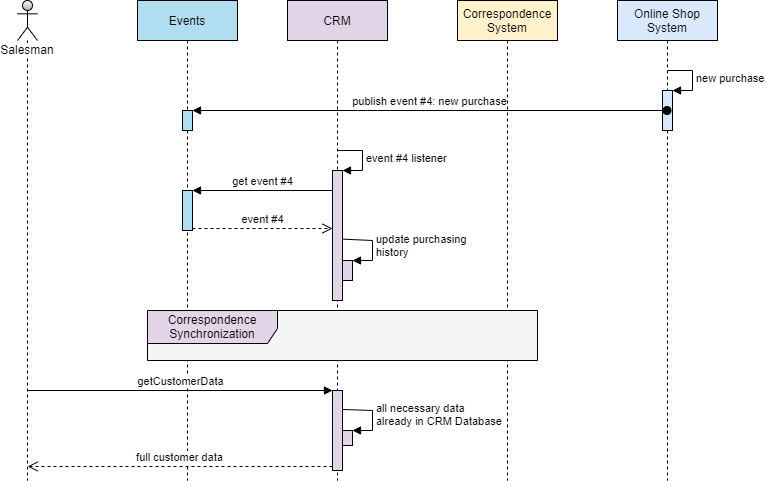
- 将客户端详细信息响应与编排模式同步
正如你所看到的,我可以做同样的业务逻辑,但使用更少的业务逻辑组件,更灵活的设计。
编曲模式:您的设计看起来非常复杂! 而且,我可以在中间看到一个元素——这个事件系统。 所以,我不能同意业务逻辑组件更少。 不只是 Orchestrator 而是另一个名字? 而且,老实说,我在这里看不到这种灵活性……
编舞模式:首先,您错过了这样一个事实,即如果您在 Orchestrator 中进行错误处理,您的设计看起来会非常复杂。 如果 CRM 系统在客户端同步中没有响应,您将如何反应? 您需要围绕通知在线商店有关情况来实现重复和业务逻辑。 让我用这个缺失的部分重新表述你的设计。
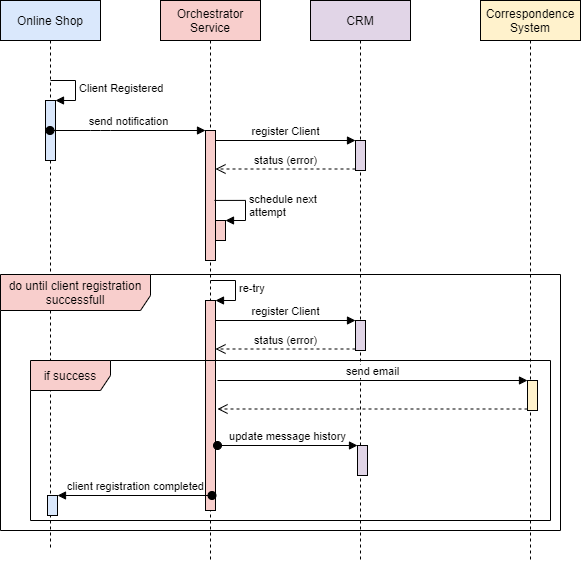
- Orchestrator 需要处理错误和系统不可用。使用 Choreography,组件只需等待适当的事件
同时,我的组件只是等待一个适当的事件——不需要在那里进行任何更改,也不会因为一个系统的不可访问性而由第三方处理错误。这样一来,您的设计看起来并不那么简单,因为您需要处理所有“假设”。
其次——我的事件系统不是业务逻辑组件。这是系统发布有关其处理的事件的空间。不包含任何业务逻辑——它就像一个论坛,每个人都分享他们所做的事情。这给了我刚才所说的灵活性——如果我不希望在客户注册过程中由通信系统发送电子邮件,我只需禁用此通信系统中的侦听器。对于其他组件,这种变化是不可见的。在您的设计中,您需要在 Orchestrator 中进行业务逻辑更改。
编曲模式:只要过程没有因错误或意外行为而中断,这一切听起来都很好。那会发生什么?如果您的元素之一失败,或者根本没有发布适当的事件,整个业务流程就会挂起。而且我们没有地方可以触发这样一个过程的结束。
编舞模式:这就是我们需要监控和跟踪工具的目的。那些轻量级的技术应用程序应该对未使用的事件或没有结束事件的卡住进程发出警报。我们可以通过这些工具自动生成最终事件,或者让人类决定做什么,就像编排模式一样,但不是在一个大而全能的元素中。然而,你说得有道理——与我一起计划和管理比与 Orchestration 更难。
第 2 轮:变更管理
Krzysztof(采访者):感谢您在第一轮中进行的激动人心的讨论。您已经提到了我们现在要讨论的一个主题——变革管理。在这一轮中,我们将着眼于改变和影响您提出的解决方案的变化的灵活性。那么,您可以用您的方法以多快的速度交付新功能和流程?改变现有的会有多困难?最后,如果您在一个组件中引入更改,那么其他组件会发生什么?
编舞模式:编排模式指责我架构的每次更改都需要对多个组件进行大量调整。这并不完全正确。是的,我同意更改流程本身需要更改负责该流程的协调器组件。但这样的变化并不总是会产生巨大的影响。将 ESB 作为集成平台,我们减少了 Orchestrator 中数据映射部分的更改次数。最重要的是,将 BPM 引擎用作协调器,简化了业务流程本身的变更交付。如果我们在一个组件中更改数据的结构,我们将需要在组件中使用类似的结构来使用数据。我怀疑我们可以通过编排模式避免这种情况,所以在变更管理的情况下,我相信我们已经接近了。
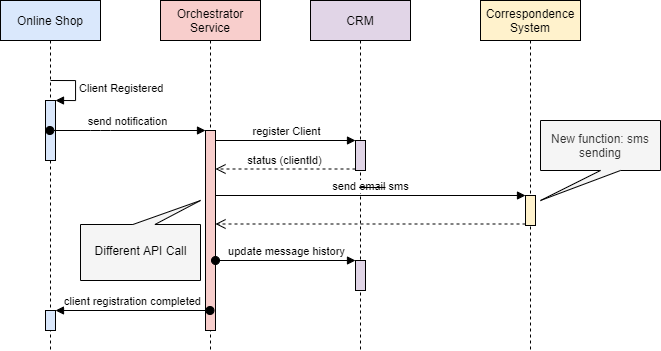
- 使用 Orchestration,很多变化都需要在 Orchestrator Element 中进行一些调整
编舞模式:我强烈不同意我们很接近。为了证明这一点,我想参考我们概念的基础知识。管弦乐就像一场管弦音乐会。如果我们想改变小提琴部分,我们需要每次都为小提琴手写一个新的旋律,有时要求指挥家进行一点不同的指挥。正如我所提到的,我更像是一支爵士乐队——如果我的一位音乐家想要扮演不同的角色,我就允许他这样做。当然,他可以完全改变旋律,其他音乐家也会想对它做出反应——但我只是让他们自己决定。在最坏的情况下,即不同步的变化,他们将完全停止播放,等待老旋律出现。对于管弦乐队来说,最坏的情况是他们演奏的一团糟,会伤到你的耳朵。老实说,我更喜欢沉默……但是好吧,现在让我回到一些例子,参考第一轮的处理。我已经提供了第一个——如果我们想删除发送电子邮件,我们只需禁用通信系统。当然,稍后,我们可能还会删除事件 #3 的 CRM 侦听器,该侦听器负责同步通信历史记录——但不这样做不会导致任何错误。第二个例子是数据映射。在 Orchestration Pattern 中,Orchestrator 负责跟踪数据结构的变化。即使是数据结构的微小变化也需要在 Orchestrator 中进行调整。我的设计也不是没有这样的问题——但我希望我的事件是用仅描述业务对象基本属性的简单数据模型创建的。当然,Orchestrator Pattern 总是可以使用这样的模型,但是在我的设计中,我们还有一个组件需要改变——Orchestrator Element。
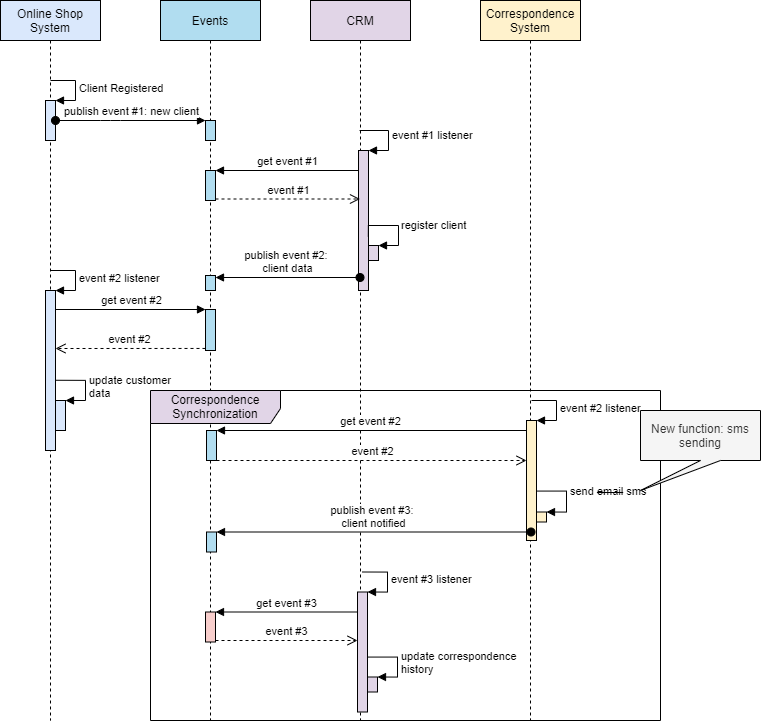
- 使用 Choreography,多于两个组件的更改数量更小
第三轮:业务流程跟踪和数据管理
Krzysztof(采访者):现在,让我们进入第三轮,我们将讨论数据管理和跟踪流程执行。正如 Sam Newman 在构建微服务中所说:“随着我们开始对越来越复杂的逻辑进行建模,我们必须处理管理跨越单个服务边界的业务流程的问题”。这里有几个问题——您如何看待多个组件之间的共享和维护数据?您有什么计划来验证流程实例的状态?
编曲模式:就我的设计而言,这个主题非常简单。让我从数据管理开始。所有信息都被分类并存储在我的组件中,没有任何不必要的重复。如果一个组件需要更多数据,它只需询问 Orchestrator——它会收集并提供所需的数据,并带有适当的数据映射(例如,由 ESB 平台处理)。现在我的最大优势出现了——跟踪流程直接整合到我的 Orchestrator 中。一个端到端的过程发生并由这个元素管理。只需访问一个组件,您就可以准确地知道自己目前处于流程中的哪个位置。我怀疑 Choreography Pattern 的想法和我的一样简单。
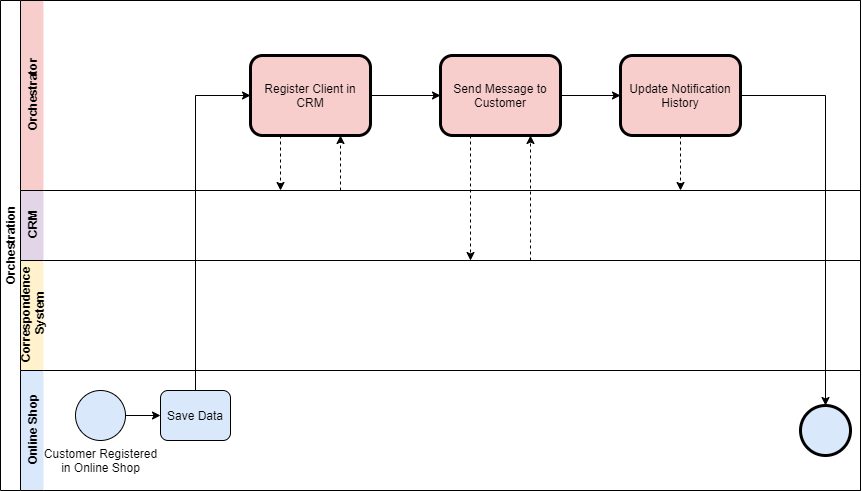
- Orchestration Pattern 中的 Process Tracing 集中在 Orchestrator 组件中
编舞模式:这个话题也可以用我的设计来解决。我也会从数据管理开始。对我来说,数据正在组织中与事件和相关标识符(由业务流程发起者生成)共享。可以在组件中复制数据以供进一步使用,并根据组件业务功能调整模型。再看一下 Synch Client Details Response with Choreography Pattern 序列图。在我的设计中,不需要调用第三方来获取数据,因为它正在组件之间同步,以防业务处理需要。下一个主题是跟踪——在这里我同意它对我来说可能比使用 Orchestrator 更复杂。但是,有了流程发起者生成的相关标识符,我们仍然可以轻松地连接组成更大业务流程的子流程。
- Choreography Pattern 中的流程更加分散,因此跟踪可能是一个挑战
编曲模式:所以,看起来我是对的,而且跟踪过程对我来说更容易。编排需要有额外的专用工具来实现这一目的——我也可以使用我的 Orchestrator 来扮演那个角色。更重要的是,使用存储在我的 Orchestrator 中的数据,我可以轻松地做出报告和关键决策。 Choreography 提出的这种分布式逻辑可能是一个真正的挑战。
编舞模式:我同意——这很有挑战性。但是如果没有集中式决策引擎,我们可以使用更轻量级的工具进行跟踪,而不是使用 Orchestrator 来完成所有工作。报告也是如此——我可以拥有一个专门为此而设计的系统或微服务。这种方法广泛用于微服务生态系统。我只是喜欢我的架构组件是自主的和独立工作的,提供特定的、定义明确的业务功能——而不是一个复杂的 Orchestrator,很容易成为组织的中央 IT 系统。
第 4 轮:组织影响
Krzysztof(采访者):哇,我们在第三轮进行了非常激动人心的讨论。在他们的最后一句话中,Choreography 提到了组织的影响。现在,让我们讨论一个高层次的观点。当组织选择你作为一种广泛使用的模式时,你认为组织会如何改变?您是否认为 IT 系统设计会影响公司的运作方式?或者可能是其他情况——公司结构反映在 IT 生态系统中?
编舞模式:这实际上是一个非常有趣的问题。这位首席执行官兼编舞师会对他的董事们说:“我的愿景是成为欧洲最大的卫生口罩生产商。我现在全神贯注于你的想法”。然后,营销总监会想出一个新市场的活动,营销总监会立即开始计算他当前的销售水平,工厂总监会等待营销总监对销售的预测,这样他们就可以调整他们要购买的产品数量。需要创建。这种方法有两大优势。首先,这些董事对他们的想法和意见负全部责任。他们知道,公司的成长也是他们的功劳。第二个好处是CEO的工作量少了很多,他的责任负担也更小了。
编曲模式:确实,这是一个相关的问题。编排在组织中引入了严格的顺序,这是编排的一个关键弱点,该顺序可能没有明确定义。 CEO-Orchestrator 会对他的董事们说:“我的愿景是成为欧洲最大的卫生口罩生产商。为此,我希望营销总监为新市场创建活动,销售总监专注于当前的销售水平,以免不必要的财务问题困扰我们,工厂总监将产量翻倍”。这位 CEO 考虑周全,整个公司都知道他会带领他们走向成功。也许他的负担更大——但至少他知道组织是如何运作的。当然,在某种抽象层面上——因为他的主管考虑他们的任务,并在他们的单位中编排流程以实现低级流程。如果您问这是否对 IT 系统设计有任何影响,我会说“是的”。 Melving E. Conway 也有同样的观点,这就是他引入康威定律的证据:“任何设计系统(定义广泛)的组织都会产生一个其结构是组织通信结构副本的设计。”就我而言,Orchestrator 将反映组织中强大的管理地位和秩序。
编舞模式:编排不涉及组织中的任何顺序——它只是在多个自主团队之间划分。如果 CEO-Orchestrator 生病了怎么办?如果他错了怎么办?有了编排,我们不仅有更多的讨论空间,还有更多自主、负责任的团队分享他们的投入和改进。我同意编排模式,即 IT 系统设计反映了组织的通信结构。但我会更进一步——我相信在 IT 系统中实施编排模式将使小团队开始以同样的方式工作。然后,编排正在更大的组织单位中传播,最后——它会传到 CEO 身上。明智的人会注意到,他不再孤单地做决定,他可以委派更多的工作,并且他可以依靠团队对他们的业务职能完全负责。归根结底,他的工作会更少,操心的事情也会更少,他的员工也会对组织更有责任感。总结一下——我同意康威定律有效,但对我来说,它也可以反过来起作用。在这种情况下,微服务和编排将导致小型、敏捷、面向业务的团队。
编曲模式:有了我,这位 CEO 会立即知道他错了。通过简单的流程跟踪和监控结果,很容易在流程中发现错误。使用 Choreography Pattern,您可能知道某些事情运行不正常,但您将花费更多时间进行调试并寻找负责的单元。我可以同意的是,康威定律也适用于相反的情况——拥有一个或几个业务规则实施系统,我们很快就会提出一个类似的管理结构来制定关键的业务决策。
结论
Krzysztof(采访者):感谢您的参与、见解和分享的想法。我希望这场辩论会在接下来的几周、几个月和几年内非常有帮助,届时数十个组织将投票选出在他们的项目中使用的最佳模式。就个人而言,我会投票给编舞模式。我不认为编曲模式是一个糟糕的模式——但是使用编舞设计的解决方案更加灵活,与技术无关,并且可以量身定制以满足客户的要求。 Choreography Pattern 还帮助我们构建了 Starboost——微服务画布,它被证明是可靠的、可扩展的和可调整的,适用于真实案例的业务场景。我相信 Choreography 将使 IT 系统再次变得伟大,它在当前和即将到来的项目中拥有我的投票权。亲爱的读者,你呢?
原文:https://bluesoft.com/orchestration-vs-choreography-different-patterns-o…
- 237 次浏览
【微服务架构】让我们谈谈“拥有”他们的数据的微服务
前几天我和一位同事讨论了我的微服务将用来公开特定数据集的接口的设计。 数据由我的微服务保存在 Elastic Search 中,并根据最终用户将选择的过滤器以不同的形式由 UI 使用和呈现。 当我仅仅提出让 UI 后端直接从 Elastic Search 查询数据的亵渎想法时,经典的“微服务不应该暴露其底层数据存储”的论点被点燃了。

- Who owns the data??
暴露数据的服务
我会从头开始。 微服务可以以任何方式或使用他们希望的任何技术公开数据,具体取决于用例。
让我们想象一个简单的数据项并通过一些示例。
有问题的数据项将是这个表示消息的简单 JSON 对象:
{
id: 2321387
sender: “Joe”
message_content: “Hello World Message”
}
公开这些数据的最无争议的方式可能是:
- · REST API
- · GraphQL
这些是“纯”API,因为它们提供了接口和底层数据存储的完全解耦。 今天我可能会在 Couchbase 中保存数据,明天在 Redis 中,下周我会将其移动到 S3。 如果我改变实现,消费者不需要知道任何事情。
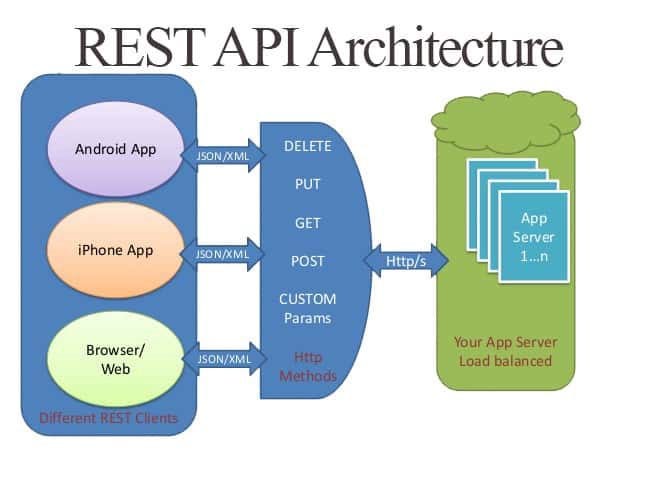
- Exposing Data via REST API — Not Controversial
那么消息队列中的消息呢? 像 Kafka 或 RabbitMQ 之类的东西? 软件工程社区仍将这些技术定义为公开数据的非争议方式。 在许多产品的架构中,微服务通过消息队列相互通信,对吗? 如果我想将我的实现从 Kafka 更改为 RabbitMQ 会发生什么,消费者是否也需要更改他们的实现? 他们当然会,但您可能会争辩说,完全改变产品中的整个消息传递技术确实不太可能。
- Exposing Data via Message Queues — Not Controversial
现在让我们朝这个方向再走一步。 数据仓库和数据湖呢? 将您的数据保存在 S3 中并让消费者使用 Athena/Presto/BigQuery 在其上运行查询怎么样? 在这个用例中封装数据发生了什么? 令人惊讶的是,“接口-数据存储解耦”范式的纯粹主义者根本不认为这是一种不好的做法。
我试图争辩说,数据湖/仓库用例与通过 Elastic Search、Couchbase、Redis 或任何其他技术公开数据之间没有真正的区别。 数据的位置不是问题,因此解耦不是解决方案。 我们以错误的方式看待这个问题。
内部数据 VS 公开数据
真正的区别应该是您定义为服务的“内部”数据或状态,以及您定义为服务的“公开”数据。问题不在于您选择使用哪种技术存储数据。
内部数据是其位置和架构可以更改而不事先通知的数据。它完全在服务和拥有团队内部,任何消费者都不应该依赖它。一天它可以是内存中的 HashMap,另一天它可以是 DynamoDB 中的一个表,第三天开发人员可以决定将它存储在 S3 中,因为它太大而且太贵了。只要将这些数据定义为内部数据,我们就可以在任何时间点引入“破坏性更改”,因为它不会“破坏”任何消费者。
公开数据是您向消费者公开并提交给它及其模式的数据。无论您是通过定义良好的 REST API、定义良好的 Kafka 消息、S3 中定义良好的 ORC 文件还是 Couchbase 中定义良好的记录来公开它都没有关系。只要您和您的消费者同意这是公开的公共数据,您就不能在不通知消费者的情况下引入重大更改。您甚至可以想象一个使用 2 个 Couchbase 存储桶的服务——一个用于内部数据,一个用于公开数据。同样,技术并不重要,重要的是数据用途的定义。
重要的是要澄清,即使这些数据被公开和共享,消费者也只能从中读取。在这种模式下,拥有服务仍然是唯一对公开数据具有写访问权限的实体(显然对内部数据也是如此)。您可以将其视为微服务的一种 CQRS 实现。
为什么你甚至想通过 Couchbase 或 Athena 而不是严格地通过 REST 或 GraphQL 等 WEB API 来公开你的数据,你可能会问。
Amazon Athena 就是一个很好的例子,因为它通过多台服务器并行运行您的查询,因此您的数据消费者可以利用 Athena 的强大功能进行快速的大数据查询。有什么选择?您会在自己的服务中构建类似的功能并通过 Web API 公开它们吗?您将如何通过 Web API 公开丰富的 SQL 语言? GraphQL 能否涵盖 SQL 提供的所有选项? API 是否会是您将在内部传递给 Athena 并将结果分页给消费者的通用字符串?
相同的概念可以应用于 Couchbase、DynamoDB、Aurora 或任何其他数据存储。创建这些工具是为了扩大规模,旨在每秒接受和响应数十万个请求。如果一切都严格通过您的服务进行,则意味着您的开发人员将需要在他们自己的服务中重写这些技术的功能,或者只是在逻辑上降级数据存储的真正底层功能。
总结
您需要在内部和共享之间逻辑划分数据。后者是您与世界共享的数据,而内部数据是您的消费者不需要知道的完全封装的实现。一个数据集可以被认为是内部的并且驻留在 State Store 中,而相同数据的投影可以驻留在同一个 State Store 中并暴露在外部。这完全取决于您的用例,以及向消费者公开数据以优化使用数据的最佳方式是什么。
评论1
SQL server 是隔离的,可独立部署的,通过网络消息与其他服务通信,拥有自己的数据,是唯一可以写入磁盘来持久化它的,那么它怎么不是微服务呢?因为它的边界是由技术要求而不是业务要求决定的?因为太复杂了?因为是第三方?荒谬的。没有人真正根据约束的类型来定义技术概念。
从本质上讲,您的文章侵蚀了微服务的概念,而这正是困扰人们的地方。就是“如果我们允许这样做,它会在哪里停止?”思维。但答案很简单:它不会停止。定义微服务的方式取决于组织内部解决方案的架构师。他们可以准确地确定什么是微服务,什么不是。作为一般概念,对微服务的限制是没有用的。
我会更进一步:微服务纯度(与任何其他类型或对纯度的追求一样,但这已经太笼统了)是有毒的。接受现实中任何值得该死的系统都是技术的混合体,其中微服务只是其中的一部分,这要健康得多。
评论2:
我基本同意,我们应该专注于逻辑划分数据,而纯粹的微服务架构是弊大于利的。 虽然有些观点我认为你没有做对。
当您质疑数据库和仓库是用来回答数千个请求而 API 只能处理一个请求时,问题在于 API 的扩展方式。 瘫痪 API 工作负载可以解决数据库必须提供的资源使用不足的问题。
另一件事是,如果您期望进行临时查询,他们可能应该使用另一种连接数据的方式。 这是BI系统存在的主要原因。
也许我在挑剔,但这些是我对这个主题的想法。 我不愿意让其他人看到我的数据:p
原文:https://blog.devgenius.io/lets-talk-about-microservices-owning-their-da…
本文:
- 39 次浏览
【微服务架构】部署NGINX Plus作为API网关,第1部分 - NGINX
了解着名的Nginx服务器(微服务必不可少的东西)如何用作API网关。
现代应用程序体系结构的核心是HTTP API。 HTTP使应用程序能够快速构建并轻松维护。无论应用程序的规模如何,HTTP API都提供了一个通用接口,从单用途微服务到无所不包的整体。通过使用HTTP,支持超大规模Internet属性的Web应用程序交付的进步也可用于提供可靠和高性能的API交付。
有关API网关对微服务应用程序重要性的精彩介绍,请参阅我们博客上的构建微服务:使用API网关。
作为领先的高性能,轻量级反向代理和负载均衡器,NGINX Plus具有处理API流量所需的高级HTTP处理功能。这使得NGINX Plus成为构建API网关的理想平台。在这篇博文中,我们描述了许多常见的API网关用例,并展示了如何配置NGINX Plus以便以高效,可扩展且易于维护的方式处理它们。我们描述了一个完整的配置,它可以构成生产部署的基础。
注意:除非另有说明,否则本文中的所有信息均适用于NGINX Plus和NGINX开源。
介绍Warehouse API
API网关的主要功能是为多个API提供单一,一致的入口点,无论它们在后端如何实现或部署。并非所有API都是微服务应用程序。我们的API网关需要管理现有的API,单块和正在部分过渡到微服务的应用程序。
在这篇博文中,我们引用了一个假设的库存管理API,即“仓库API”。我们使用示例配置代码来说明不同的用例。 Warehouse API是一个RESTful API,它使用JSON请求并生成JSON响应。但是,当部署为API网关时,使用JSON不是NGINX Plus的限制或要求; NGINX Plus与API本身使用的架构风格和数据格式无关。
Warehouse API实现为离散微服务的集合,并作为单个API发布。库存和定价资源作为单独的服务实施,并部署到不同的后端。所以API的路径结构是:
api └── warehouse├── inventory└── pricing
例如,要查询当前仓库库存,客户端应用程序会向/ api / warehouse / inventory发出HTTP GET请求。
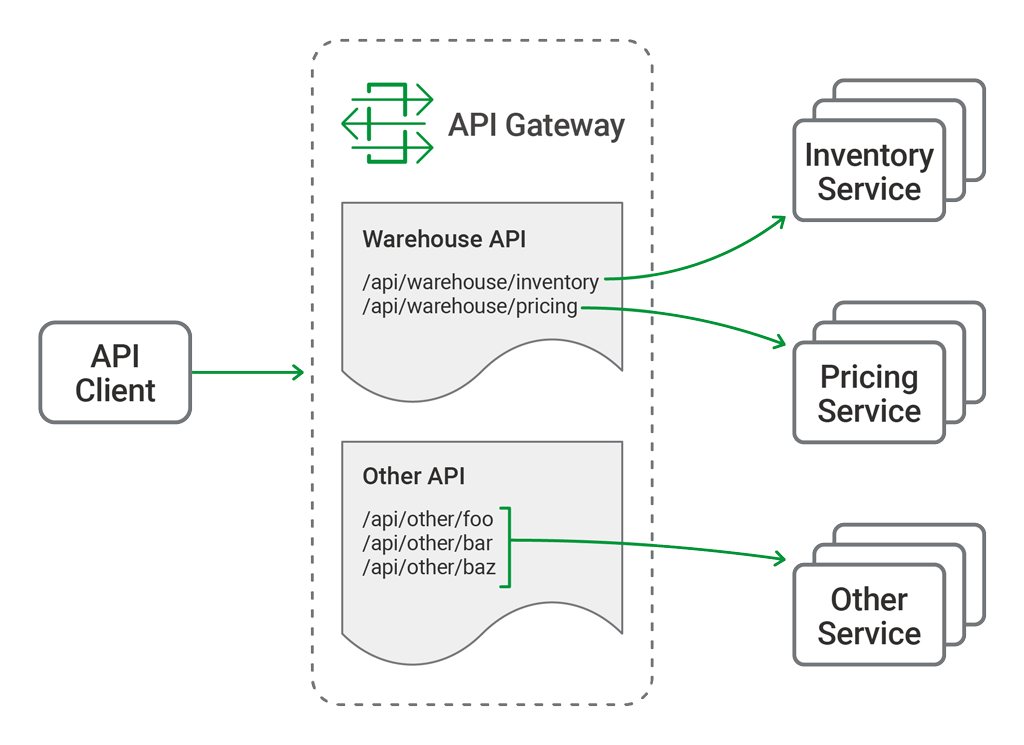
组织NGINX配置
使用NGINX Plus作为API网关的一个优点是,它可以执行该角色,同时充当现有HTTP流量的反向代理,负载平衡器和Web服务器。如果NGINX Plus已经是应用程序交付堆栈的一部分,那么通常不需要部署单独的API网关。但是,API网关所期望的某些默认行为与基于浏览器的流量的预期不同。出于这个原因,我们将API网关配置与基于浏览器的流量的任何现有(或未来)配置分开。
为实现这种分离,我们创建了一个支持多用途NGINX Plus实例的配置布局,并为通过CI / CD管道自动配置部署提供了便利的结构。 / etc / nginx下的结果目录结构如下所示。
etc/ └── nginx/├── api_conf.d/ ....................................... Subdirectory for per-API configuration│ └── warehouse_api.conf ...... Definition and policy of the Warehouse API├── api_backends.conf ..................... The backend services (upstreams)├── api_gateway.conf ........................ Top-level configuration for the API gateway server├── api_json_errors.conf ............ HTTP error responses in JSON format├── conf.d/│ ├── ...│ └── existing_apps.conf└── nginx.conf
所有API网关配置的目录和文件名都以api_为前缀。这些文件和目录中的每一个都启用API网关的不同特性和功能,并在下面详细说明。
定义顶级API网关
所有NGINX配置都以主配置文件nginx.conf开头。要读入API网关配置,我们在nginx.conf的http块中添加一个指令,该指令引用包含网关配置的文件api_gateway.conf(下面的第28行)。请注意,默认的nginx.conf文件使用include伪指令从conf.d子目录中引入基于浏览器的HTTP配置(第29行)。本博文广泛使用include指令来提高可读性并实现配置某些部分的自动化。
include /etc/nginx/api_gateway.conf; # All API gateway configurationinclude /etc/nginx/conf.d/*.conf; # Regular web traffic
api_gateway.conf文件定义了将NGINX Plus公开为客户端的API网关的虚拟服务器。此配置公开API网关在单个入口点https://api.example.com/(第13行)发布的所有API,受第16到21行配置的TLS保护。请注意,此配置纯粹是HTTPS - 没有明文HTTP侦听器。我们希望API客户端知道正确的入口点并默认进行HTTPS连接。
log_format api_main '$remote_addr - $remote_user [$time_local] "$request"''$status $body_bytes_sent "$http_referer" "$http_user_agent"''"$http_x_forwarded_for" "$api_name"';include api_backends.conf;include api_keys.conf;server {set $api_name -; # Start with an undefined API name, each API will update this valueaccess_log /var/log/nginx/api_access.log api_main; # Each API may also log to a separate filelisten 443 ssl;server_name api.example.com;# TLS configssl_certificate /etc/ssl/certs/api.example.com.crt;ssl_certificate_key /etc/ssl/private/api.example.com.key;ssl_session_cache shared:SSL:10m;ssl_session_timeout 5m;ssl_ciphers HIGH:!aNULL:!MD5;ssl_protocols TLSv1.1 TLSv1.2;# API definitions, one per fileinclude api_conf.d/*.conf;# Error responseserror_page 404 = @400; # Invalid paths are treated as bad requestsproxy_intercept_errors on; # Do not send backend errors to the clientinclude api_json_errors.conf; # API client friendly JSON error responsesdefault_type application/json; # If no content-type then assume JSON}
此配置是静态的 - 各个API及其后端服务的详细信息在第24行的include伪指令引用的文件中指定。第27到30行处理日志记录默认值和错误处理,并在响应中讨论错误部分如下。
单服务与微服务API后端
一些API可以在单个后端实现,但是出于弹性或负载平衡的原因,我们通常期望存在多个API。使用微服务API,我们为每个服务定义单独的后端;它们一起作为完整的API。在这里,我们的Warehouse API被部署为两个独立的服务,每个服务都有多个后端。
upstream warehouse_inventory {zone inventory_service 64k;server 10.0.0.1:80;server 10.0.0.2:80;server 10.0.0.3:80;}upstream warehouse_pricing {zone pricing_service 64k;server 10.0.0.7:80;server 10.0.0.8:80;server 10.0.0.9:80;}
API网关发布的所有API的所有后端API服务都在api_backends.conf中定义。这里我们在每个块中使用多个IP地址 - 端口对来指示API代码的部署位置,但也可以使用主机名。 NGINX Plus订户还可以利用动态DNS负载平衡,自动将新后端添加到运行时配置中。
定义Warehouse API
配置的这一部分首先定义Warehouse API的有效URI,然后定义用于处理对Warehouse API的请求的公共策略。
# API definition#location /api/warehouse/inventory {set $upstream warehouse_inventory;rewrite ^ /_warehouse last;}location /api/warehouse/pricing {set $upstream warehouse_pricing;rewrite ^ /_warehouse last;}# Policy section#location = /_warehouse {internal;set $api_name "Warehouse";# Policy configuration here (authentication, rate limiting, logging, more...)proxy_pass http://$upstream$request_uri;}
Warehouse API定义了许多块。 NGINX Plus具有高效灵活的系统,可将请求URI与配置的一部分进行匹配。通常,请求由最具体的路径前缀匹配,并且位置指令的顺序并不重要。这里,在第3行和第8行,我们定义了两个路径前缀。在每种情况下,$ upstream变量都设置为上游块的名称,该上游块分别代表库存和定价服务的后端API服务。
此配置的目标是将API定义与管理API交付方式的策略分开。为此,我们最小化了API定义部分中显示的配置。在为每个位置确定适当的上游组之后,我们停止处理并使用指令来查找API的策略(第10行)。

使用重写指令将处理移至API策略部分
重写指令的结果是NGINX Plus搜索匹配以/ _warehouse开头的URI的位置块。第15行的位置块使用=修饰符执行完全匹配,从而加快处理速度。
在这个阶段,我们的政策部分非常简单。位置块本身标记为第16行,这意味着客户端无法直接向它发出请求。重新定义$ api_name变量以匹配API的名称,以便它在日志文件中正确显示。最后,请求被代理到API定义部分中指定的上游组,使用$ request_uri变量 - 其中包含原始请求URI,未经修改。
选择广泛或者精确的API定义
API定义有两种方法 - 广泛而精确。每种API最合适的方法取决于API的安全要求以及后端服务是否需要处理无效的URI。
在warehouse_api_simple.conf中,我们通过在第3行和第8行定义URI前缀来使用Warehouse API的广泛方法。这意味着以任一前缀开头的任何URI都代理到相应的后端服务。使用基于前缀的位置匹配,对以下URI的API请求都是有效的:
-
/api/warehouse/inventory
-
/api/warehouse/inventory/
-
/api/warehouse/inventory/foo
-
/api/warehouse/inventoryfoo
-
/api/warehouse/inventoryfoo/bar/
如果唯一的考虑是将每个请求代理到正确的后端服务,则广泛的方法提供最快的处理和最紧凑的配置。另一方面,精确的方法使API网关能够通过显式定义每个可用API资源的URI路径来理解API的完整URI空间。采用精确的方法,Warehouse API的以下配置使用精确匹配(=)和正则表达式(〜)的组合来定义每个URI。
location = /api/warehouse/inventory { # Complete inventoryset $upstream inventory_service;rewrite ^ /_warehouse last;}location ~ ^/api/warehouse/inventory/shelf/[^/]*$ { # Shelf inventoryset $upstream inventory_service;rewrite ^ /_warehouse last;}location ~ ^/api/warehouse/inventory/shelf/[^/]*/box/[^/]*$ { # Box on shelfset $upstream inventory_service;rewrite ^ /_warehouse last;}location ~ ^/api/warehouse/pricing/[^/]*$ { # Price for specific itemset $upstream pricing_service;rewrite ^ /_warehouse last;}
此配置更详细,但更准确地描述了后端服务实现的资源。这具有保护后端服务免于格式错误的客户端请求的优点,代价是正常表达式匹配的一些小额外开销。有了这个配置,NGINX Plus接受一些URI并拒绝其他URI无效:

使用精确的API定义,现有的API文档格式可以驱动API网关的配置。可以从OpenAPI规范(以前称为Swagger)自动化NGINX Plus API定义。此博客文章的Gists中提供了用于此目的的示例脚本。
重写客户请求
随着API的发展,有时会发生需要更新客户端的重大更改。一个这样的示例是重命名或移动API资源。与Web浏览器不同,API网关无法向其客户端发送命名新位置的重定向(代码301)。幸运的是,当修改API客户端不切实际时,我们可以动态地重写客户端请求。
在下面的示例中,我们可以在第3行看到定价服务以前是作为库存服务的一部分实现的:rewrite指令将对旧定价资源的请求转换为新的定价服务。
# Rewrite rules#rewrite ^/api/warehouse/inventory/item/price/(.*) /api/warehouse/pricing/$1;# API definition#location /api/warehouse/inventory {set $upstream inventory_service;rewrite ^(.*)$ /_warehouse$1 last;}location /api/warehouse/pricing {set $upstream pricing_service;rewrite ^(.*) /_warehouse$1 last;}# Policy section#location /_warehouse {internal;set $api_name "Warehouse";# Policy configuration here (authentication, rate limiting, logging, more...)rewrite ^/_warehouse/(.*)$ /$1 break; # Remove /_warehouse prefixproxy_pass http://$upstream; # Proxy the rewritten URI}
动态重写URI意味着当我们最终在第26行代理请求时,我们不能再使用$ request_uri变量(正如我们在warehouse_api_simple.conf的第21行所做的那样)。这意味着我们需要在API定义部分的第9行和第14行使用稍微不同的重写指令,以便在处理切换到策略部分时保留URI。
回应错误
HTTP API和基于浏览器的流量之间的主要区别之一是如何将错误传达给客户端。当NGINX Plus作为API网关部署时,我们将其配置为以最适合API客户端的方式返回错误。
# Error responseserror_page 404 = @400; # Invalid paths are treated as bad requestsproxy_intercept_errors on; # Do not send backend errors to the clientinclude api_json_errors.conf; # API client friendly JSON error responsesdefault_type application/json; # If no content-type then assume JSON
顶级API网关配置包括一个定义如何处理错误响应的部分。
第27行的指令指定当请求与任何API定义都不匹配时,NGINX Plus会返回错误而不是默认错误。此(可选)行为要求API客户端仅向API文档中包含的有效URI发出请求,并防止未经授权的客户端发现通过API网关发布的API的URI结构。
第28行指的是后端服务本身产生的错误。未处理的异常可能包含我们不希望发送到客户端的堆栈跟踪或其他敏感数据。此配置通过向客户端发送标准化错误来进一步提供保护。
完整的错误响应列表在第29行的include伪指令引用的单独配置文件中定义,其前几行如下所示。如果首选不同的错误格式,并且通过更改第30行上的default_type值以匹配,则可以修改此文件。您还可以在每个API的策略部分中使用单独的include指令来定义一组覆盖默认值的错误响应。
error_page 400 = @400;location @400 { return 400 '{"status":400,"message":"Bad request"}\n'; }error_page 401 = @401;location @401 { return 401 '{"status":401,"message":"Unauthorized"}\n'; }error_page 403 = @403;location @403 { return 403 '{"status":403,"message":"Forbidden"}\n'; }error_page 404 = @404;location @404 { return 404 '{"status":404,"message":"Resource not found"}\n'; }
有了这种配置,客户端对无效URI的请求就会收到以下响应。
$ curl -i https://api.example.com/fooHTTP/1.1 400 Bad RequestServer: nginx/1.13.10Content-Type: application/jsonContent-Length: 39Connection: keep-alive{"status":400,"message":"Bad request"}
实施身份验证
在没有某种形式的身份验证的情况下发布API以保护它们是不常见的。 NGINX Plus提供了几种保护API和验证API客户端的方法。有关基于IP地址的访问控制列表(ACL),数字证书身份验证和HTTP基本身份验证的信息,请参阅文档。在这里,我们专注于API特定的身份验证方法。
API密钥身份验证
API密钥是客户端和API网关已知的共享密钥。它们本质上是作为长期凭证发布给API客户端的长而复杂的密码。创建API密钥很简单 - 只需编码一个随机数,如本例所示。
openssl rand -base64 18 7B5zIqmRGXmrJTFmKa99vcit
在顶级API网关配置文件api_gateway.conf的第6行,我们包含一个名为api_keys.conf的文件,其中包含每个API客户端的API密钥,由客户端名称或其他描述标识。
map $http_apikey $api_client_name {default "";"7B5zIqmRGXmrJTFmKa99vcit" "client_one";"QzVV6y1EmQFbbxOfRCwyJs35" "client_two";"mGcjH8Fv6U9y3BVF9H3Ypb9T" "client_six";}
API密钥在块中定义。 map指令有两个参数。第一个定义了API密钥的位置,在本例中是在$ http_apikey变量中捕获的客户端请求的apikey HTTP头。第二个参数创建一个新变量($ api_client_name)并将其设置为第一个参数与键匹配的行上的第二个参数的值。
例如,当客户端提供API密钥7B5zIqmRGXmrJTFmKa99vcit时,$ api_client_name变量设置为client_one。此变量可用于检查经过身份验证的客户端,并包含在日志条目中以进行更详细的审核。
地图块的格式很简单,易于集成到自动化工作流程中,从现有的凭证存储生成api_keys.conf文件。 API密钥身份验证由每个API的策略部分强制执行。
# Policy section#location = /_warehouse {internal;set $api_name "Warehouse";if ($http_apikey = "") {return 401; # Unauthorized (please authenticate)}if ($api_client_name = "") {return 403; # Forbidden (invalid API key)}proxy_pass http://$upstream$request_uri;}
客户端应在apikey HTTP头中显示其API密钥。如果此标头丢失或为空(第20行),我们发送401响应以告知客户端需要进行身份验证。第23行处理API键与地图块中的任何键都不匹配的情况 - 在这种情况下,api_keys.conf第2行的默认参数将$ api_client_name设置为空字符串 - 我们发送403响应告诉身份验证失败的客户端。
有了这个配置,Warehouse API现在可以实现API密钥身份验证。
$ curl https://api.example.com/api/warehouse/pricing/item001{"status":401,"message":"Unauthorized"}$ curl -H "apikey: thisIsInvalid" https://api.example.com/api/warehouse/pricing/item001{"status":403,"message":"Forbidden"}$ curl -H "apikey: 7B5zIqmRGXmrJTFmKa99vcit" https://api.example.com/api/warehouse/pricing/item001{"sku":"item001","price":179.99}
JWT身份验证
JSON Web令牌(JWT)越来越多地用于API身份验证。原生JWT支持是NGINX Plus独有的,可以在我们的博客上验证JWT,如使用JWT和NGINX Plus验证API客户端中所述。
摘要
本系列的第一篇博客详细介绍了将NGINX Plus部署为API网关的完整解决方案。可以从我们的GitHub Gist仓库查看和下载此博客中讨论的完整文件集。本系列的下一篇博客将探讨更高级的用例,以保护后端服务免受恶意或行为不端的客户端的攻击。
原文:https://dzone.com/articles/deploying-nginx-plus-as-an-api-gateway-part-1-ngin
本文:http://pub.intelligentx.net/deploying-nginx-plus-api-gateway-part-1-nginx
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 196 次浏览
【微服务架构】面向CTO的微服务简介:微服务对企业的利弊
微服务——在这种程度上,很少有软件趋势能吸引IT决策者的注意。他们应该能够让你的应用程序更高效和可扩展。但这到底意味着什么?什么时候投资于它们而不是其他类型的软件架构是个好主意?软件公司将技术细节转化为可操作的信息,供您在业务中使用。
对于许多软件开发人员来说,基于微服务的架构已经成为他们日常工作的一个重要组成部分,因为越来越多的应用程序是这样制作的。但是,由于宣传太多,很容易把微服务当成一个时髦词。本文试图让每个可能从微服务中受益的人更容易就微服务在组织中的使用做出明智的决定。让我们来谈谈微服务;它们使用的利弊等等。
微服务——它们到底是什么?
根据Gartner的一个流行定义,microservice是应用程序的一个“紧密限定范围、强封装、松散耦合、可独立部署和独立扩展”的组件。让我们把它分解。
- 严格的范围-它有一个明确的定义,通常是非常狭窄的用途。
- 强封装——作为代码的一部分,它包含其功能的整个实现。
- 松散耦合——在大多数情况下,它是独立的,不需要其他微服务来工作。
- 独立部署-它可以单独部署,而不必损害其他微服务。
- 独立的可扩展性——即使一个微服务处理了大部分流量,我们也不需要扩展整个系统,而是只关注于扩展受影响的微服务。
还在困惑吗?基于微服务的应用程序的一个很好的例子可以是一个电子商务商店,其中每个业务领域(例如处理订单、产品目录、内部搜索、帐单、付款、交货单、PCI DSS认证)都是一个单独的微服务。微服务通常按照特定的业务用例进行组织,但是诸如身份验证或通知之类的功能也可以作为单独的微服务工作。
这种将所有这些功能划分为完全独立的块的独特能力使微服务成为分散/分布式团队的理想选择。因此,拥有诸如Netflix或Twitter这样的分布式团队的大公司可以通过将不同的微服务分配给不同的团队来高效地工作。但这并不是许多创新科技公司选择微服务的唯一原因。当你继续读下去的时候,这些优势应该会越来越明显。
微服务是如何工作的?
让我们更深入地研究微服务是如何工作的。如您所知,在一个标准的单片应用程序中,代码库可以大致分为两部分:前端和后端。每一个都有一个独立的代码库。通常,不同的团队会处理这些问题,并且每一层都可以拥有自己的主导技术(例如,针对前端和节点.js用于后端)。如下所示。
在基于微服务的体系结构中,前端层保持不变,但后端被分成多个部分,专门用于特定功能。它们中的每一个都可以有自己的存储库。由于它们是强封装的,每个微服务都可能用不同的语言编写,如下图所示。
对于许多项目——在这些项目中,没有必要(或能力)涉及这么多不同的技术,而且存在如此多的存储库会造成混乱(复杂的项目结构、存储库之间代码组织的差异等等),这些都超过了这种分离的好处——可以使用简化的版本。通过使用monorepos,可以创建包含所有使用相同技术堆栈的微服务的代码的存储库。
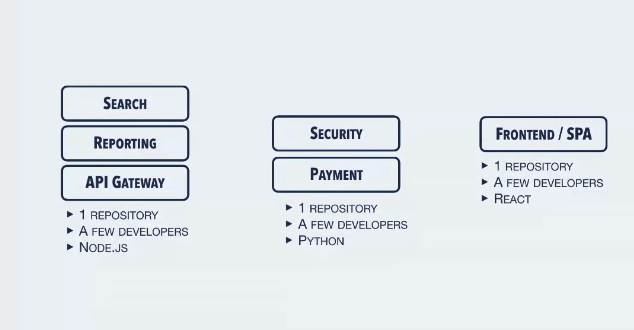
回到单片与微服务的问题。基于微服务的体系结构与整体式架构还有什么不同?
| 微服务 | 单体 | |
| 开发 |
每个服务都是一个独立的应用程序。它可能(但不一定需要)有一个单独的代码存储库,因此冲突不太常见。 为了共享一些代码,您需要有一个单独的库。 您可以更容易地扩展团队,因为每个团队可能被分配到特定的服务。 添加新功能可以扩展现有服务之一,也可以添加新服务。 |
所有的东西都放在一个地方,所以共享代码要容易得多。同时,它可能会导致一个不可维护的状态,所有的东西都是耦合的。 在同一领域工作可能会导致代码冲突,这将导致更长的开发时间。 添加新功能是指向现有应用程序添加新代码。 更难扩大团队规模。 |
| 测试 |
每个服务都是一个单独的应用程序,不仅需要单元测试,还需要组件/契约测试。 更重要的是,我们应该添加一个额外的层,允许我们同时测试多个服务之间的集成。 |
易于测试。一切都在一个地方。 大多数时候,它可以被单元和E2E测试覆盖。 |
| 部署 |
每个服务都需要单独的CI和部署过程。您需要为整个系统协调整个基础设施和配置。 但是,如果出现问题,只有一个服务将无法启动。 |
你设置了一次。不需要太多的编排。但是,如果出现问题,您根本无法部署应用程序。 |
| 维护 | 需要DevOps关于Docker、Kubernetes等的知识 | 易于维护 |
| 可靠性 | 中断一个服务并不会破坏其他服务,因此只有一组功能可能会受到影响。 | 破坏了应用程序中的一个地方,破坏了一切。 |
| 可扩展性 | 每个服务都是独立扩展的。我们只使用我们需要的资源。 | 为了扩展系统的单个部分,您必须扩展整个系统,这可能导致资源没有得到充分利用。 |
| 发布 | 您发布了一个服务,因此只需要与此特定服务相关的测试。 | 一次发布整个系统,所以每次都需要整个回归。 |
使用微服务的好处
为您的软件选择基于微服务的体系结构对您的组织有很多潜在的好处。
- 代码库与业务领域保持一致—您的微服务通常是围绕组织的实际业务功能/目标来组织的,这意味着开发人员和业务人员更容易理解技术和业务是如何联系在一起的。
- 非常适合分布式团队——不同的开发人员/团队可以在不同的微服务上工作,而不会相互妨碍。对于分布式团队来说,这比一个整体式的团队要方便得多。
- 更易于构建和维护——根据功能将代码库拆分为更小的独立片段意味着它们更易于理解和维护。Docker等许多工具简化了新微服务的创建。
- 易于部署–因为您不会中断整个应用程序,所以您可以经常修改和部署新的和现有的微服务。还有一些工具可以让它变得更简单,比如Kubernetes。
- 提高生产力——从事特定微服务的开发人员不需要等待其他开发人员完成他们的工作。接管自己的工作也更容易,因为较小的代码库更容易理解。质量保证也在这个过程中得到了突破。
- 选择技术的自由度——每个微服务都可以用不同的技术开发,这样就可以为每个问题选择最有效的解决方案。这也在很大程度上消除了技术和供应商的锁定——你的应用程序并不完全依赖于任何第三方软件。
- 高性能、高效率和可扩展性–您可以单独扩展每个微服务。这意味着单个服务可以部署在多个服务器中,以服务于增加的流量,而其他服务同时只消耗标准数量的资源。您可以以经济高效的方式保持高性能。
- 可靠性—故障隔离意味着单个服务的故障不太可能影响其他服务的性能。在一个巨石应用程序中,类似的错误可能会导致整个系统崩溃。
微服务:不同场景下的利弊
到目前为止,您可能已经对微服务能够很好地配合的项目有了一个很好的想法。总而言之:
- 由于微服务提供了出色的可伸缩性并鼓励基于敏捷的工作流,因此它们非常适合于在这些领域有高要求的应用程序。
- 由于代码库可以根据功能划分为完全独立开发的单元,因此对于分布式团队来说,这是一个明显的选择,特别是对于代表各种技术堆栈的开发人员。
- 项目越复杂、流量密集、面向长期,就越适合基于微服务的架构。
现在,让我们来看看微服务什么时候不是最好的选择——微服务的缺点。让我们考虑几个场景。
对Netflix有利的事情可能对我们不利
大型公司,如Netflix,在各地都有不同的开发团队,可以从微服务的模块化特性中获益匪浅。实现基于微服务的体系结构的成本往往比构建一个单一的应用程序要高(您需要考虑日志监视系统、请求跟踪和部署整个系统以及任何单个微服务的能力)。对于那些不希望出现大流量、可伸缩性问题和混合各种技术的系统来说,这可能不值得。
太过敏捷会让你变得僵硬
多亏了微服务,您可以通过单独部署每个微服务来更轻松地进行迭代。测试和部署成为日常工作流程的重要组成部分,而不是很少发生。但随之而来的是巨大的责任。随着动态变化的微服务数量的增加,需要大量的DevOps功能和丰富的经验才能掌握它们。
我只是在试水!
你在创建一个新的(绿地)项目吗?你是否有一个想法,并想创造一个最有价值球员?你最好的选择可能是一块巨石。你不仅不知道你需要什么样的微服务,而且从一开始就不需要微服务的复杂性。毕竟,如果有必要的话,将来您总是可以从一个整体式架构转向基于微服务的架构。
如何开始使用微服务?
有几件事你应该记住。首先,让我们考虑一下在任何情况下都成立的观点
从头开始
- 不要急于求成-确保项目证明了微服务的合理性。根据我们上面所做的所有考虑,确保您的项目适合微服务。
- 不要仅仅从理论上讲敏捷。如果没有强大的敏捷文化,您将无法从微服务中获益。
- 投资于您的DevOps文化/能力。DevOps也是如此——你的架构越大,你需要管理的微服务越多,它就越明显。
现在,谈谈更具体的问题(很有可能!)从单一体系结构到微服务的场景。
从单体到微服务
- 不要从头开始!既然你已经有了一个应用程序,你应该从它开始作为你的基础。即使你不打算马上去“微服务一路走来”,你也可以简单地在微服务中开发新功能,同时暂时保持你的基础作为一个整体。
- 避免分散的整体。不要从传统的巨石直接进入微服务。否则,你可能会得到一个分布式的整体——一个表面上模块化的应用程序,其中所有模块实际上都高度依赖于彼此。
- 去做一个模块化的整体。最好的方法是将你的整体分割成更小的、独立的部分,然后逐步地将它们转化为服务。
微服务TSH方式
你想知道软件公司是如何使用微服务的吗?我们将把最佳实践的细节留待下次讨论,但以下是TSH主管的一些最重要的观点节点.js亚当·波拉克。
TSH的一个重要实践就是不要浪费时间创建所谓的样板(创建新服务结构所需的一切)。通过在项目早期阶段创建的一组工具,我们可以快速创建新的服务,并专注于最重要的业务逻辑。”
DevOps对微服务的仔细监控对于效率、稳定性和快速恢复至关重要。
另一个重要的问题是DevOps功能,以及对服务性能的仔细监控——日志记录、跟踪、指标配置。感谢所有这些,我们的服务是稳定的。一旦出现问题,我们就能迅速找到原因。
结论
此时,您应该知道微服务是否适合您。总而言之:
- 微服务潜力巨大
- 但是,只有当项目复杂到足以超过维护和迁移到基于微服务的体系结构的成本时,才应该在项目中使用它们
- 从整体到微服务的转变应该考虑到很多因素
原文:https://tsh.io/blog/basics-of-microservices-pros-and-cons/
本文:http://jiagoushi.pro/node/1095
讨论:请加入知识星球【首席架构师智库】或者加微信小号【jiagoushi_pro】
- 65 次浏览
【微服务架构】面向CTO的微服务设计模式:API网关、前端的后端等
微服务体系结构是软件开发中最热门的趋势之一。作为CTO,你需要知道何时使用它们。但你也需要对这个主题有更深入的了解才能真正掌握你的项目。通过进一步了解微服务中的设计模式,您将确切了解微服务是如何工作的,以及开发人员如何使它们更高效、可伸缩和更安全。满足最流行的微服务设计模式。
在上一篇关于微服务的文章中,我们介绍了这种流行的软件体系结构的基础知识。有了这些知识,您就知道微服务最适合哪种项目了。但是一旦你决定去做它,会有更多的决定要做。这就是为什么你应该学习设计模式。
微服务中的设计模式是什么?
如您所知,微服务是一个很大程度上独立的应用程序组件,其任务是系统中的特定功能。多个微服务,每个微服务负责应用程序的另一个功能,再加上客户端(例如web和移动应用程序的前端)和其他(可选)中间层,构成了基于微服务的体系结构。
这种类型的设置有许多优点,例如能够用不同的技术编写任何服务并独立地部署它们,以及性能提升等等。但它也带来了一些挑战,包括复杂的管理和配置。
设计模式的存在旨在解决微服务中的此类常见挑战,并提供经验证的解决方案,使您的体系结构更高效,整个管理过程更省钱、更麻烦。因此,了解它们是更好地理解微服务的一个很好的方法——比实际的编码更高层次,但又足够具体,可以理解微服务的内部工作原理。
为什么要学习设计模式?
选择正确的设计模式可以决定你的基于微服务的项目的成败。它们是微服务本身并不是万能药的最好证明,要真正从中受益,你需要正确地使用它们。
如果您不关心微服务设计模式:
- 你的应用程序可能表现不佳(由于不必要的调用和资源使用效率低下),
- 整个系统将不稳定(例如连接和集成问题),
- 它可能面临可伸缩性问题(添加更多的服务可能导致难以维护依赖性,甚至可能使其成为事实上的一个整体),
- 它可能会通过向公众公开微服务的端点或通过其他方式危害安全性。
- 您可能有更多的维护和调试工作要做,而不是做更好的准备。
微服务设计模式的类型
微服务中的设计模式几乎存在于架构的每个方面。一些最重要的问题可分为以下几个方面:
通信
它涉及微服务和客户端应用程序(前端层)之间的通信方法。
内部沟通
这些设计模式构成了微服务之间进行通信的各种方式。
安全
各种与安全相关的问题,如安全层的组织、不同类型用户对特定微服务的授权和访问级别等。
可用性
确保所有的微服务都准备好满足系统的需求(不管流量有多大),确保尽可能少的停机时间。这包括确保微服务可以在另一台计算机上重新启动,或者是否有足够的计算机可用,微服务能够自行报告其当前状态,运行状况检查等等。
服务发现
它指的是微服务用来找到彼此并知道它们的位置的方法。
配置
设置参数并监控整个系统的性能,以便在您进行过程中不断优化
在本文的后续部分中,我们将主要关注第一种类型,讨论三种最流行的通信模式——直接模式、API网关和前端后端(BFF)。它们提供了一个很好的机会来了解基于微服务的体系结构是如何工作的,以及开发人员的选择对其性能的影响。
直接模式
这是基于微服务架构的最基本的设置。在这种模式下,客户端应用程序直接向微服务发出请求,如下图所示。每个微服务都有一个公共端点(URL),客户端可以与之通信。
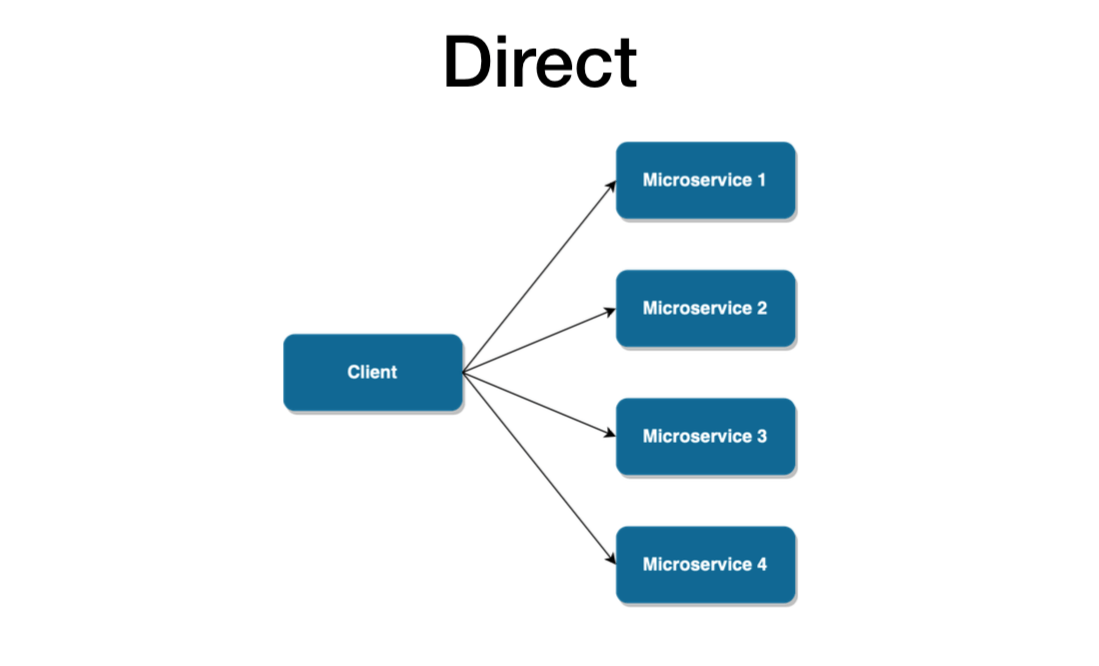
这非常容易设置,对于相对较小的应用程序来说已经足够了,但是随着应用程序的规模和复杂性的增长,这些挑战会变得越来越明显和麻烦:
性能问题
即使是应用程序的一个页面也可能需要对不同的微服务进行多次调用,这可能会导致较大的延迟和性能问题。
可伸缩性问题
因为客户端应用程序直接引用微服务,所以对微服务的任何更改都可能导致应用程序崩溃。这使得维护困难。
安全问题
没有中间层,微服务的端点就会暴露出来。这不一定会使应用程序本身就不安全,但它肯定会使安全问题变得更难处理。
复杂性问题
此外,每个公共微服务都需要包含安全和其他跨服务任务。如果有一个额外的层,它们可以被包含在那里,使所有的微服务更简单。
由于微服务通常被推荐用于复杂的应用程序,因此必须有更具可伸缩性的模式。
API网关
当然有!API网关将这一切提升到一个级别。如下图所述,它提供了一个额外的层,一组微服务和前端层之间的单一入口点。它解决了我们刚刚提到的所有问题,通过向公众隐藏微服务的端点,从客户端抽象对微服务的引用,并通过聚合多个调用来减少延迟。
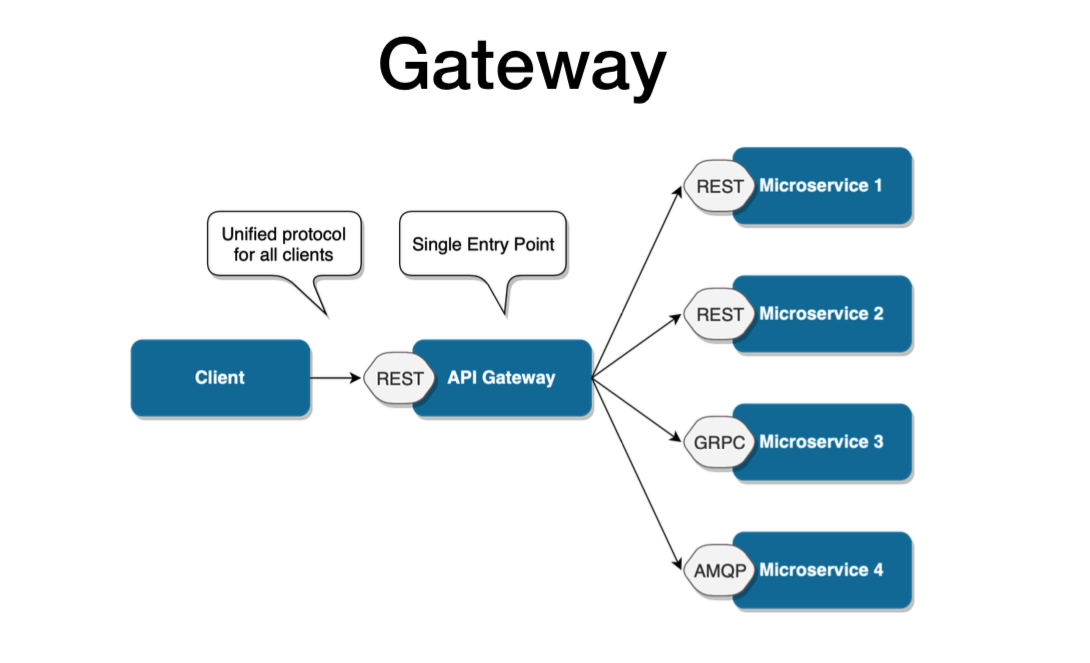
然而,API网关模式仍然不能避免可伸缩性问题。当体系结构围绕一个客户机时,这已经足够了。但是如果有多个客户端应用程序,API网关最终可能会膨胀,因为它吸收了来自不同客户端应用程序的所有不同需求。最终,它可能会成为一个单一的应用程序,并面临许多与直接模式相同的问题。
因此,如果您计划让基于microservices的系统具有多个客户机或不同的业务域,那么您应该从一开始就考虑使用前端后端模式。
前端的后端(BFF)
网关API本质上是BFF模式的变体。它还提供了微服务和客户端之间的附加层。但它不是单一的入口点,而是为每个客户机引入了多个网关。
使用BFF,您可以添加一个为每个客户机的需求量身打造的API,从而消除了由于将它们都放在一个地方而导致的大量膨胀。结果模式如下图所示。
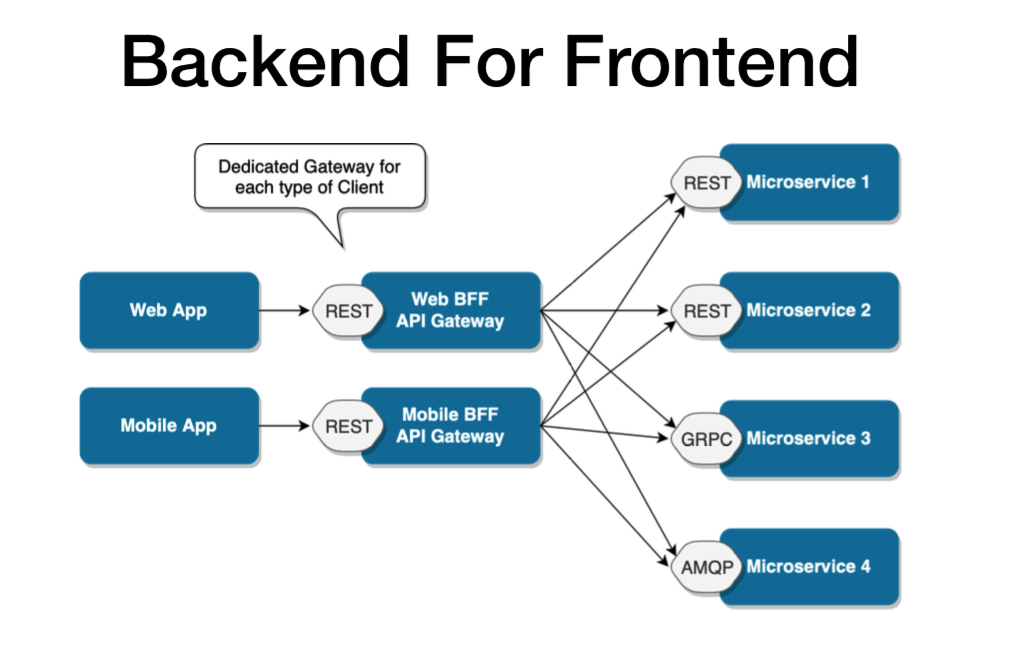
值得一提的是,这种特定的模式可能仍会扩展到特别复杂的应用程序。还可以为特定的业务域创建不同的网关。这个模型足够灵活,可以响应任何类型的基于微服务的情况。
这是否意味着每个基于微服务的架构都应该使用BFF模式?不一定。设计越复杂,需要的设置和配置就越多。并不是每个应用程序都需要这样做。但是如果你想创建一个应用程序的生态系统,或者计划在将来扩展它,为了将来的可扩展性,你可以选择更复杂的通信模式。
如果你想了解更多关于BFF的信息,一定要阅读我们的前端案例研究的后端——这是一个应用程序生态系统的故事,它是使用模式重塑的。
其他值得注意的设计模式
正如我前面提到的,设计模式存在于微服务的各个方面。开发人员常常被迫在这两者之间做出选择,考虑到不同的因素。在其他一些情况下,它们可以组合在一起或一起使用。
对于内部通信,一些最流行的模式包括REST、gRPC、messagebroker或远程过程调用。在安全性方面,访问控制列表(ACL)可以用于每个微服务或每个网关,也可以作为独立的微服务(或者根本不使用)。说到可用性,我们可以使用基于DNS或硬件的负载平衡。服务发现可以在客户端或服务器端执行。至于配置,可以是外部化的(每个微服务都有自己的一个)或集中化(所有配置都在一个地方)。名单还在继续。
另请参阅:gRPC实用介绍
结论
随着微服务越来越流行,新的设计模式出现了,以帮助解决各种开发挑战,并使体系结构更加高效。尽可能多地了解它们是值得的,但归根结底还是要为特定的软件生态系统选择正确的软件。说到这一点-相信你的开发人员,但要确保你知道他们的选择和他们对你的软件的影响。
原文:https://tsh.io/blog/design-patterns-in-microservices-api-gateway-bff-and-more/
本文:http://jiagoushi.pro/node/1088
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 89 次浏览
【架构设计】酒店预订应用程序的系统设计架构(如 Airbnb、OYO)
Airbnb、Booking.com 和 OYO 等酒店预订应用程序如何提供从酒店列表到预订再到付款的流畅流程? 而且都没有一个小故障! 在此博客中,您将获得对此的详细解释。
由于它们非常庞大,以至于它们需要处理大量的用户流量。 所以要管理这些,我们必须遵循微服务架构。 这意味着我们必须为每种类型的任务将系统分成小块。
让我们一一了解流程。 我把它分成了4个部分:
- 酒店管理服务
- 客户服务(搜索+预订)
- 查看预订服务
酒店管理服务
这是将提供给酒店经理/业主的服务。 在此管理人员可以管理他们酒店的相关信息。 在这里,管理者有一个单独的门户来访问和更新数据。
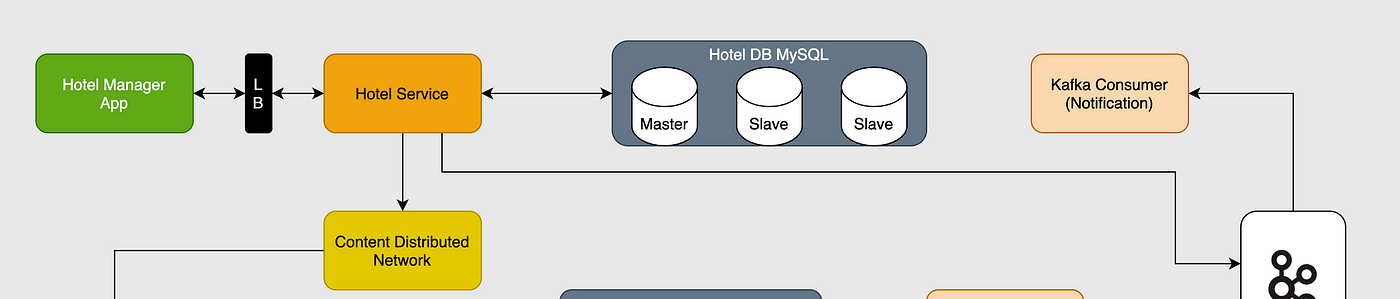
- Hotel Management Service Architecture
每当从酒店管理器应用程序触发 API 时,初始请求都会发送到负载均衡器,然后负载均衡器会将请求分发到所需的服务器进行处理。酒店服务集群有多个服务器,这些服务器具有酒店服务相关 API 的容器。
现在,该酒店服务与遵循主从架构的酒店数据库集群进行交互,以减少数据库中的负载。基本上,在这种方法中,我们创建主数据库的副本,称为从数据库。 Master DB 用于写操作,slave DB 仅用于读操作。每当在主数据库上执行写操作时,它都会将数据同步到从数据库。
每当数据库中的任何数据更新时,API 都会将数据发送到 CDN(内容分布式网络)和消息队列系统(如 Kafka、RabbitMQ)以进行进一步处理。 CDN 是一组地理分布的服务器,它们协同工作以提供 Internet 内容的快速交付。
客户服务(搜索+预订)
这是将提供给客户的服务。在这个客户可以搜索和预订酒店。在这里,客户有一个单独的门户来访问和处理数据。
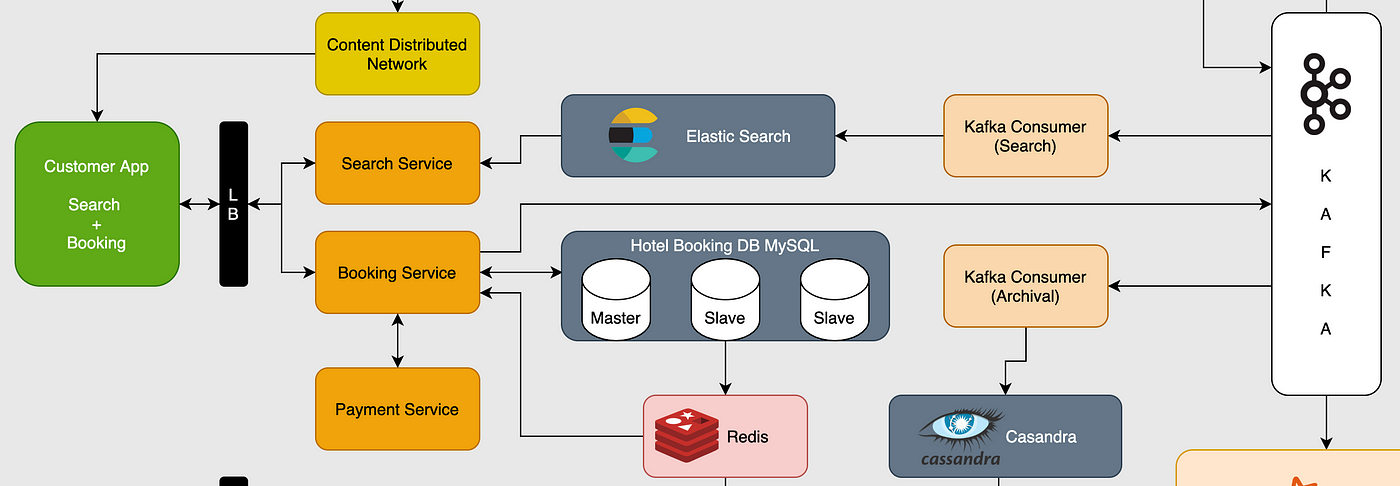
- Customer Service Architecture
CDN 应用程序向客户显示内容,例如附近的酒店、推荐、优惠等。
正如我们在上一节中讨论的,酒店数据在消息队列系统中发送以进行处理。这里我们有一个消息队列消费者,它从队列中获取数据并将数据存储在弹性搜索中。
客户应用点击 API,然后负载均衡器将请求重定向并将请求分发到相应的服务以处理请求。在这里,我们有两种服务,一种是搜索酒店,另一种是预订服务,用于预订酒店,预订服务还与第三方服务的支付服务进行交互。
搜索服务必须从 Elastic Search 中获取数据。 Elasticsearch 是一个 NoSQL 数据库,最适合其搜索引擎功能。
预订服务与 Redis 和预订数据库集群进行通信。 Redis 是缓存系统,它存储临时数据,因此数据不需要从数据库中获取,最终可以减少数据库的负载,也可以减少 API 的响应时间。
对数据库所做的任何更改都将发送到消息传递队列。然后消费者将从队列中取出数据并将其放入 Casandra。对于存档,我们使用 Casandra,因为随着时间的推移,数据库中的数据大小会增加,这会增加查询时间。这就是为什么我们可能需要从数据库中删除旧数据的原因。而 Casandra 是一个 NoSQL 数据库,擅长处理大量数据。
查看预订服务
此处向用户显示所有当前和旧的预订详细信息。经理和客户都使用此服务。

- View Booking Architecture
Customer/Manager 应用程序将请求发送到负载均衡器,并将请求分发到预订管理服务器。 然后通过 Redis 和 Cassandra 对数据的服务请求。 通过 Redis,它请求最近的数据,因为它是一个缓存服务器。 这可以减少应用程序端的加载时间。
最终设计

- Hotel Booking System Design
正如您在上面的设计中看到的,有一个用于通知的 Kafka 消费者,通知消费者发送通知。 这可能是针对客户/经理的,例如,每当客户预订酒店时,就会向经理发送通知,或者如果有新的优惠来了,就会通知客户。
Apache Streaming 服务从消息队列中获取数据并将其存储在 Hadoop 中,可用于大数据分析以用于多种用途。 比如业务分析、寻找潜在客户、受众分类等。
原文:https://medium.com/nerd-for-tech/system-design-architecture-for-hotel-b…
- 699 次浏览
【系统设计】系统设计基础:速率限制器
什么是速率限制器?
速率限制是指防止操作的频率超过定义的限制。 在大型系统中,速率限制通常用于保护底层服务和资源。 速率限制一般在分布式系统中作为一种防御机制,使共享资源能够保持可用性。
速率限制通过限制在给定时间段内可以到达您的 API 的请求数量来保护您的 API 免受意外或恶意过度使用。 在没有速率限制的情况下,任何用户都可以用请求轰炸您的服务器,从而导致其他用户饿死的峰值。
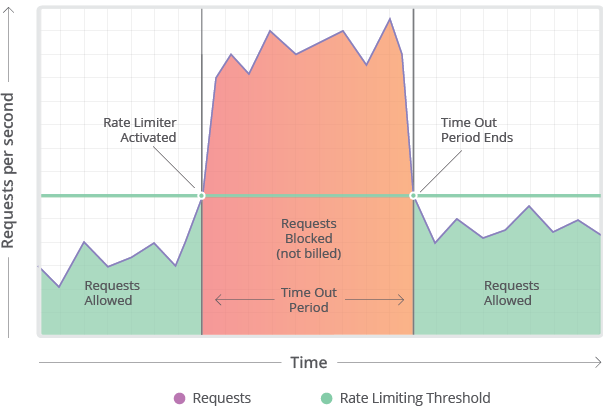
Rate limiting at work
为什么要限速?
- 防止资源匮乏:速率限制的最常见原因是通过避免资源匮乏来提高基于 API 的服务的可用性。如果应用速率限制,则可以防止基于负载的拒绝服务 (doS) 攻击。即使一个用户用大量请求轰炸 API,其他用户也不会挨饿。
- 安全性:速率限制可防止暴力破解登录、促销代码等安全密集型功能。对这些功能的请求数量在用户级别受到限制,因此暴力破解算法在这些场景中不起作用。
- 防止运营成本:在按使用付费模式自动扩展资源的情况下,速率限制通过对资源扩展设置虚拟上限来帮助控制运营成本。如果不采用速率限制,资源可能会不成比例地扩展,从而导致指数级的账单。
速率限制策略
速率限制可应用于以下参数:
- 用户:限制在给定时间段内允许用户的请求数。基于用户的速率限制是最常见和最直观的速率限制形式之一。

- 2. 并发性:这里限制了在给定时间范围内用户可以允许的并行会话数。并行连接数量的限制也有助于缓解 DDOS 攻击。
- 3. 位置/ID:这有助于运行基于位置或以人口统计为中心的活动。可以限制不是来自目标人口统计的请求,以提高目标区域的可用性
- 4. 服务器:基于服务器的速率限制是一种利基策略。这通常在特定服务器需要大部分请求时使用,即服务器与特定功能强耦合
速率限制算法
漏桶:
漏桶是一种简单直观的算法。它创建一个容量有限的队列。在给定时间范围内超出队列容量的所有请求都会溢出。
这种算法的优点是它可以平滑请求的突发并以恒定的速率处理它们。它也很容易在负载均衡器上实现,并且对每个用户来说都是高效的内存。无论请求的数量如何,都保持到服务器的恒定接近均匀的流量。
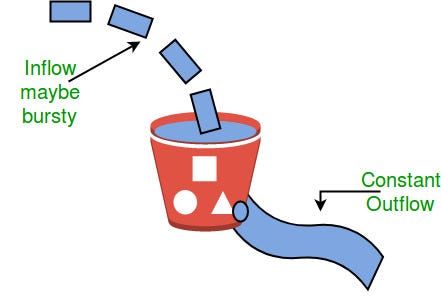
Leaky Bucket
该算法的缺点是请求的爆发可能会填满存储桶,导致新请求的匮乏。它也不能保证请求在给定的时间内完成。
2、令牌桶:
令牌桶类似于漏桶。在这里,我们在用户级别分配令牌。对于给定的持续时间 d,定义了用户可以接收的请求 r 个数据包的数量。每次新请求到达服务器时,都会发生两个操作:
- 获取令牌:获取该用户的当前令牌数。如果它大于定义的限制,则丢弃请求。
- 更新令牌:如果获取的令牌小于持续时间 d 的限制,则接受请求并附加令牌。
该算法具有内存效率,因为我们为我们的应用程序为每个用户节省了更少的数据量。这里的问题是它可能导致分布式环境中的竞争条件。当来自两个不同应用程序服务器的两个请求同时尝试获取令牌时,就会发生这种情况。
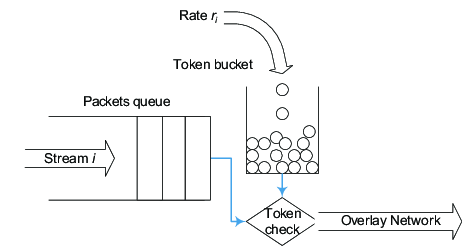
Token Bucket Algorithm
3、固定窗口计数器:
固定窗口是最基本的限速机制之一。 我们在给定的时间内保留一个计数器,并为我们收到的每个请求不断增加它。 一旦达到限制,我们将丢弃所有进一步的请求,直到重置持续时间。
这里的优点是它确保最近的请求得到服务,而不会被旧的请求饿死。 但是,在限制边缘的单个流量突发可能会囤积当前和下一个时隙的所有可用时隙。 消费者可能会轰炸边缘的服务器,以尝试最大化所服务的请求数量。

Fixed Window Counter
4. 滑动日志:
滑动日志算法涉及在用户级别维护带有时间戳的请求日志。系统将这些请求时间排序在一个集合或一个表中。它丢弃所有时间戳超过阈值的请求。我们每一分钟都在寻找旧的请求并将它们过滤掉。然后我们计算日志的总和来确定请求率。如果请求将超过阈值速率,则保留它,否则提供服务。
该算法的优点是不受固定窗口边界条件的影响。速率限制的执行将保持精确。由于系统会跟踪每个消费者的滑动日志,因此不会出现挑战固定窗口的踩踏效应。
但是,为每个请求存储无限数量的日志可能会很昂贵。计算也很昂贵,因为每个请求都需要计算消费者先前请求的总和,可能跨服务器集群。因此,它不能很好地扩展以处理大量流量或拒绝服务攻击。
5、Sliding Window:
这类似于Sliding Log算法,但内存效率高。它结合了固定窗口算法的低处理成本和滑动对数改进的边界条件。
我们保留一个按时间排序的条目列表/表格,每个条目都是混合的,包含时间戳和当时的请求数。我们保留一个持续时间的滑动窗口,并且仅在我们的窗口中以给定的速率提供服务请求。如果计数器的总和大于限制器的给定速率,那么我们只取等于速率限制的第一个条目总和。
滑动窗口方法是最好的方法,因为它提供了扩展速率限制的灵活性和良好的性能。速率窗口是一种向 API 使用者呈现速率限制数据的直观方式。它还避免了漏桶的饥饿问题和固定窗口实现的爆裂问题
分布式系统中的速率限制
上述算法非常适用于单服务器应用程序。但是当分布式系统涉及到多个节点或应用服务器时,问题就变得非常复杂。如果有多个限速服务分布在不同的服务器区域,问题就会变得更加复杂。在这些情况下遇到的两个广泛问题是不一致和竞争条件。
不一致
对于具有分布在不同区域的多个应用服务器并具有自己的速率限制器的复杂系统,我们需要定义一个全局速率限制器。
如果消费者在短时间内收到大量请求,它可能会单独超过全局速率限制器。节点数越多,用户越有可能超过全局限制。
有两种方法可以解决这些问题:
- 粘性会话:在您的负载均衡器中设置一个粘性会话,以便每个消费者都准确地发送到一个节点。缺点包括节点过载时缺乏容错和扩展问题。您可以在此处阅读有关粘性会话的更多信息
- 集中式数据存储:使用 Redis 或 Cassandra 等集中式数据存储来处理每个窗口和消费者的计数。增加的延迟是一个问题,但提供的灵活性使其成为一个优雅的解决方案。
比赛条件
竞争条件以高并发的获取然后设置的方法发生。每个请求都获取 counter 的值,然后尝试增加它。但是当写操作完成时,其他几个请求已经读取了计数器的值(这是不正确的)。因此,发送的请求数量超出了预期。这可以通过在读写操作上使用锁来缓解,从而使其成为原子操作。但这是以性能为代价的,因为它成为导致更多延迟的瓶颈。
节流
限制是在给定时间段内控制客户对 API 的使用的过程。可以在应用程序级别和/或 API 级别定义限制。当超过油门限制时,服务器返回 HTTP 状态“429 — 请求太多”。
节流类型:
- Hard Throttling:API 请求数不能超过限制。
- Soft Throttling:在这种类型中,我们可以将 API 请求限制设置为超过一定百分比。例如,如果我们的速率限制为每分钟 100 条消息并且 10% 超出限制,那么我们的速率限制器将允许每分钟最多 110 条消息。
- 弹性或动态限制:在弹性限制下,如果系统有一些可用资源,请求的数量可能会超过阈值。例如,如果一个用户每分钟只允许发送 100 条消息,我们可以让该用户每分钟发送超过 100 条消息,当系统中有可用资源时。
谢谢阅读!
References
- Sticky sessions:
- Kong API Gateway:
- Token Bucket:
原文:https://medium.com/geekculture/system-design-basics-rate-limiter-351c09…
- 147 次浏览
【韧性架构】让你的微服务容错的 5 种模式

在本文中,我将介绍微服务中的容错以及如何实现它。如果你在维基百科上查找它,你会发现以下定义:
容错是使系统在其某些组件发生故障时能够继续正常运行的属性。
对我们来说,组件意味着任何东西:微服务、数据库(DB)、负载均衡器(LB),应有尽有。我不会介绍 DB/LB 容错机制,因为它们是特定于供应商的,启用它们最终会设置一些属性或更改部署策略。
作为软件工程师,应用程序是我们拥有所有权力和责任的地方,所以让我们照顾好它。这是模式列表,我将介绍:
- 超时
- 重试
- 断路器
- 截止日期(Deadlines)
- 速率限制器
有些模式是众所周知的,你甚至可能怀疑它们是否值得一提,但请继续阅读这篇文章——我将简要介绍基本形式,然后讨论它们的缺陷以及如何克服它们。
超时
超时是允许等待某个事件发生的指定时间段。如果您使用 SO_TIMEOUT(也称为套接字超时或读取超时),则会出现问题——它表示任何两个连续数据包之间的超时,而不是整个响应,因此执行 SLA 更加困难,尤其是当响应负载很大时。您通常想要的是超时,它涵盖了从建立连接到响应的最后一个字节的整个交互。 SLA 通常用这种超时来描述,因为它们对我们来说是人道和自然的。可悲的是,它们不符合 SO_TIMEOUT 理念。要在 JVM 世界中克服它,您可以使用 JDK11 或 OkHttp 客户端。 Go 在 std 库中也有一个机制。
如果您想深入了解,请查看我之前的文章。
重试
如果您的请求失败 - 请稍等,然后重试。基本上就是这样,重试是有意义的,因为网络可能会暂时降级或 GC 命中您的请求所针对的特定实例。现在,想象一下有这样的微服务链:

如果我们将每个服务的总尝试次数设置为 3 并且服务 D 突然开始服务 100% 的错误会发生什么?这将导致重试风暴——链中的每个服务都开始重试它们的请求,因此大大增加了总负载,因此 B 将面临 3 倍负载,C - 9 倍和 D - 27 倍!冗余是实现高可用性的关键原则之一,但我怀疑在这种情况下集群 C 和 D 上是否有足够的可用容量。将总尝试次数设置为 2 也无济于事,而且它会使用户体验在小问题上变得更糟。
解决方案:
- 区分可重试的错误和不可重试的错误。当用户没有权限或负载结构不正确时,重试请求是没有意义的。相反,重试请求超时或 5xx 是好的。
- 采用错误预算——技术,当可重试错误率超过阈值时停止重试,例如如果与服务 D 的 20% 的交互导致错误,请停止重试并尝试优雅降级。在最后几秒内滚动窗口可能会跟踪错误数量。
断路器
断路器可以解释为更严格的错误预算版本——当错误率太高时,函数根本不会被执行,并且会返回回退结果(如果提供的话)。无论如何都应该执行一小部分请求,以了解第 3 方是否恢复。我们想要的是让第 3 方有机会在不进行任何手动工作的情况下恢复。
您可能会争辩说,如果功能处于关键路径上,则启用断路器是没有意义的,但请记住,这种短暂且受控的“中断”可能会阻止一个大的且无法控制的中断。
尽管断路器和错误预算具有相似的想法,但配置它们是有意义的。由于错误预算的破坏性较小,因此其阈值必须更小。
长期以来,Hystrix 是 JVM 中的首选断路器实现。截至目前,它进入了维护模式,建议改用 resilience4j 。
截止日期/分布式超时
我们已经在本文的第一部分讨论了超时,现在让我们看看如何使它们“分布式”。首先,重新访问相互调用的相同服务链:
服务 A 愿意最多等待 400 毫秒并请求需要所有 3 个下游服务完成一些工作。假设服务 B 花了 400 毫秒,现在准备调用服务 C。这是否合理?不!服务超时,不再等待结果。进一步进行只会浪费资源并增加重试风暴的敏感性。
为了实现它,我们必须在请求中添加额外的元数据,这将有助于理解什么时候中断处理是合理的。理想情况下,这应该得到所有参与者的支持并在整个系统中传递。
在实践中,此元数据是以下之一:
- 时间戳:通过您的服务将停止等待响应的时间点。首先,网关/前端服务将截止日期设置为“当前时间戳+超时”。接下来,任何下游服务都应该检查当前时间戳是否≥截止日期。如果答案是肯定的,那么关闭它是安全的,否则 - 开始处理。不幸的是,当机器可以有不同的时钟时间时,时钟偏差就会出现问题。如果发生这种情况,请求将被卡住或/并立即被拒绝,从而导致中断发生。
- 超时:通过服务允许等待的时间量。这实现起来有点棘手。与尽快设定截止日期之前一样。接下来,任何下游服务都应该计算它花费了多少时间,从入站超时中减去它并传递给下一个参与者。重要的是不要忘记排队等候的时间!所以,如果允许服务 A 等待 400ms,服务 B 花费 150ms,则在调用服务 C 时,它必须附加 250ms 的期限超时。虽然它不计算在线上花费的时间,但期限只能稍后触发,而不是更早,因此,可能会消耗更多的资源,但不会破坏结果。截止日期在 GRPC 中以这种方式实现。
最后要讨论的是——当超过最后期限时,不中断调用链是否有意义?答案是肯定的,如果你的服务有足够的可用容量并且完成请求会使它变得更热(缓存/JIT),那么继续处理是可以的。
速率限制器
前面讨论的模式主要解决了级联故障的问题——依赖服务崩溃后依赖崩溃,最终导致完全关闭的情况。现在,让我们介绍一下服务超载时的情况。它可能发生的原因有很多技术和特定领域的原因,假设它发生了。

每个应用程序都有其未知的容量。这个值是动态的,取决于多个变量——例如最近的代码更改、当前运行的 CPU 应用程序的模型、主机的繁忙程度等。
当负载超过容量时会发生什么?通常,会发生这种恶性循环:
- 响应时间增加,GC 占用空间增加
- 客户端获得更多超时,甚至更多负载到达
- 转到 1,但更严重
这是可能发生的事情的一个例子。当然,如果客户有错误预算/断路器,第二项可能不会产生额外的负载,从而有机会离开这个循环。相反,可能会发生其他事情——从 LB 的上游列表中删除实例可能会在负载和关闭邻居实例等方面造成更多不平等。
限制器来救援!他们的想法是优雅地卸载传入的负载。这就是理想情况下应该如何处理过多的负载:
- 限制器降低超出容量的额外负载,从而让应用程序根据 SLA 处理请求
- 过度负载重新分配到其他实例/集群自动缩放/集群由人工缩放
有两种类型的限制器——速率(rate )和并发,前者限制入站 RPS,后者限制任何时刻正在处理的请求数量。
为了简单起见,我假设所有对我们服务的请求在计算成本上几乎相等并且具有相同的重要性。计算不平等源于这样一个事实,即不同的用户可以有不同数量的与之关联的数据,例如喜欢的电视剧或以前的订单。通常,采用分页有助于实现请求的计算平等。
速率限制器使用更广泛,但没有提供像并发限制那样强大的保证,所以如果你想选择一个,坚持并发限制,这就是原因。
在配置速率限制器时,我们认为我们强制执行以下操作:
该服务可以在任何时间点每秒处理 N 个请求。
但我们实际上声明的是这样的:
假设响应时间不会改变,该服务可以在任何时间点每秒处理 N 个请求。
为什么这句话很重要?我会用直觉“证明”它。对于那些愿意基于数学证明的人——检查利特尔定律。假设速率限制为 1000 RPS,响应时间为 1000 毫秒,SLA 为 1200 毫秒,在给定的 SLA 下,我们很容易在一秒钟内准确地处理 1000 个请求。
现在,响应时间增加了 50 毫秒(依赖服务开始做额外的工作)。从现在开始服务的每一秒都会面临越来越多的请求同时被处理,因为到达率大于服务率。拥有无限数量的工作人员意味着您将耗尽资源并崩溃,尤其是在工作人员以 1:1 映射到操作系统线程的环境中。 1000 名工作人员的并发限制如何处理?它将可靠地提供 1000/1.05 = ~950 RPS 而不会违反 SLA,并放弃其余的。此外,无需重新配置即可赶上!
我们可以在每次依赖关系发生变化时更新速率限制,但这是一个巨大的负担,可能需要在每次变化时重新配置整个生态系统。
根据设置限制值的方式,它可以是静态限制器,也可以是动态限制器。
静止的
在这种情况下,限制是手动配置的。价值可以通过定期的性能测试来评估。虽然它不会 100% 准确,但为了安全起见,它可以被悲观。这种类型的限制需要围绕 CI/CD 管道完成工作,并且资源利用率较低。静态限制器可以通过限制工作线程池的大小(仅限并发)、添加计数请求的入站过滤器、NGINX 限制功能或 envoy sidecar 代理来实现。
动态的
在这里,限制取决于度量,它会定期重新计算。 很有可能,您的服务在过载和响应时间增长之间存在相关性。 如果是这样,度量可以是响应时间的统计函数,例如 百分位、中等或平均水平。 还记得计算相等属性吗? 此属性是更准确计算的关键。
然后,定义一个谓词来回答指标是否健康。 例如,p99 ≥ 500ms 被认为是不健康的,因此应该降低限制。 如何增加和减少限制应该由应用反馈控制算法决定,如 AIMD(用于 TCP 协议)。 这是它的伪代码:
if healthy {
limit = limit + increase;
} else {
limit = limit * decreaseRatio; // 0 < decreaseRatio < 1.0
}

AIMD in action
如您所见,限制增长缓慢,探测应用程序是否运行良好,如果发现错误行为,则急剧减少。
Netflix 率先提出了动态限制的想法并开源了他们的解决方案,这里是 repo。 它实现了几种反馈算法、静态限制器实现、GRPC 集成和 Java servlet 集成。
呵呵,就是这样! 我希望你今天学到了一些新的和有用的东西。 我想指出,这个列表并不详尽,您还希望获得良好的可观察性,因为可能会发生意想不到的事情,最好了解您的应用程序目前正在发生什么。 然而,实施这些将解决您当前或潜在的大量问题。
参考
- Google SRE book, especially chapters Addressing Cascading Failures and Handling Overload
- Netflix article about dynamic limits
原文:https://itnext.io/5-patterns-to-make-your-microservice-fault-tolerant-f…
本文:
- 74 次浏览
无服务器架构
- 167 次浏览
【无服务器架构】节俭 Kubernetes operator 第一部分:简介
什么是Operator?
Kubernetes平台是围绕控制器的软件设计模式构建的,该控制器是管理两个实体之间数据流的软件组件。 在Kubernetes中,控制器监视在一个资源中发现的声明状态的更改,然后通过创建或更改其他下游资源来响应状态更改请求。 由于控制器对帐过程连续发生,因此此过程称为“主动对帐”。 如图1所示。

创建部署时,可以观察到此行为的一个示例。创建新的部署资源后,将向部署控制器通知资源更改,并通过创建新的副本集做出反应。反过来,副本集控制器对副本集资源做出反应,并导致创建一个或多个Pod。稍后,如果您要修改部署的图像属性,则部署控制器将使用新的图像属性创建新的副本集,同时逐步淘汰旧的副本集。尽管对下游资源采取的操作根据资源而有所不同,但其他控制器的行为类似。
像其他控制器一样,操作员也要注意Kubernetes资源的修改。但是,与Kubernetes平台概念(如部署,状态集和服务(在许多类型的软件中通用))不同,操作员将特定于软件的知识体现在控制器中。考虑一个复杂的工作负载,例如集群数据库,其中需要按照该软件独有的精确顺序来组织常见的操作活动。
实践中的Operator
让我们考虑一个例子。也许升级数据库需要先启动数据格式的先决条件步骤,然后再启动最新版本的容器软件,并且所有吊舱都需要在数据迁移之前停止。或者,可能需要按特定顺序启动Pod,以确保共识算法可以识别所有群集成员。操作员负责协调这些活动,同时利用最终用户可以编辑的资源模型中的声明性或所需状态。
将声明的状态与特定于实现的活动分开,使用户可以在没有特定于软件的知识的情况下控制软件的实例。知识被编码到操作员提供的控制器中。同时,另一软件的操作特性以其自己的方式是独特的,因此具有自己的运算符。
规模化Operator
如果单独部署operator,他们将消耗很少的资源。实际上,我们通过使用Kube Builder SDK和golang语言生成控制器来进行一些分析。然后,我们分析了生成的控制器的实际CPU和内存使用情况,以及对生成的资源请求和限制进行自省。下表中汇总了此信息:

这些数目是针对单个控制器容器的,集群中容器的总数由以下各项确定:
软件包中特定于软件的运算符的数量(Redis的一个运算符,Postgres的一个运算符)。
单个运算符的唯一实例数。 为了隔离起见,Redis运算符可能安装在一个命名空间中,而Redis运算符实例的另一个实例存在于另一个命名空间中。
上面的指标是针对每个Pod的,但是出于冗余的考虑,每个操作员部署可能会部署3次。
如果我们要计划由10个名称空间隔离的10个运算符,并且冗余为3,这将导致以下资源消耗:
我们可以对这些数据进行一些重要的观察:
- 在上述规模下,一个以上的内核将专门用于保持空闲操作员的运行。
- 除了实际的资源消耗外,operator还计入集群的资源配额。
- 您选择安装哪些操作程序,以及在什么作用范围内(例如名称空间或群集范围)进行大规模安装。
我们可以无服务器吗?
当然,许多操作员实例的资源利用率可能会影响集群资源需求,但是它是否非常适合无服务器?现实情况是,许多控制器的需求并不恒定,尤其是当单个操作员实例的范围已限于特定的名称空间时。
Kubernetes资源修改事件通常源于两个用户修改单个资源以及通过机器驱动或批处理作业。单个用户可能会强烈地操纵资源一段时间,然后一段时间不会。例如,您可以创建一个Redis集群,然后在根据自己的特定需求微调该集群时编辑各个参数,但是在此之后,您将继续编辑应用程序的其他部分。对于机器驱动的作业,其中一些按计划运行,而另一些则由源更改事件驱动,这些事件通常在工作日左右聚集。
单一资源或资源种类上的活动集群趋向于倾向于无服务器模型。在此模型中,容器进程仅在工作到达时才保持活动状态,但是可以在活动停止的时间段内停止这些容器。
请继续关注有关现有operator部署和新设计模式的更多帖子
随着operator继续在Kubernetes生态系统中获得关注,并且自定义控制器变得越来越普遍,这些容器流程的资源需求值得注意。在本系列的第2部分中,我们将考虑一些既适用于现有operator部署又适用于利用Knative提供无服务器功能的新设计模式的特定技术方法。
原文:https://www.ibm.com/cloud/blog/new-builders/being-frugal-with-kubernetes-operators
本文:http://jiagoushi.pro/node/873
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 50 次浏览
【无服务器架构】Apache Openwhisk 概览
Apache OpenWhisk是什么?
Apache OpenWhisk是一个开放源代码的分布式无服务器平台,该平台可以执行功能(fx)以响应各种规模的事件。 OpenWhisk使用Docker容器管理基础架构,服务器和扩展,因此您可以专注于构建出色而高效的应用程序。
OpenWhisk平台支持一种编程模型,在该模型中,开发人员可以使用任何受支持的编程语言编写功能逻辑(称为“动作”),该逻辑可以动态地调度和运行,以响应来自外部源(Feed)或HTTP请求的关联事件(通过触发器) 。 该项目包括基于REST API的命令行界面(CLI)以及其他支持打包,目录服务和许多流行的容器部署选项的工具。
部署到任何地方
由于Apache OpenWhisk使用容器构建其组件,因此可以轻松地支持本地和Cloud基础架构中的许多部署选项。 选项包括当今许多流行的Container框架,例如Kubernetes和OpenShift,Mesos和Compose。 总的来说,社区支持使用Helm图表在Kubernetes上进行部署,因为它为Devloper和Operator都提供了许多简便的实现。

用任何语言编写函数
与您所知道和所爱的人一起工作。 OpenWhisk支持越来越多的您喜欢的语言,例如NodeJS,Go,Java,Scala,PHP,Python,Ruby和Swift,以及Ballerina,.NET和Rust的最新添加。
如果需要当前不支持“即用即用”运行时的语言或库,则可以使用Docker SDK将自己的可执行文件创建并自定义为Zip Actions,并在Docker运行时上运行。 如何使用Docker Actions支持其他语言的一些示例包括Rust的教程和Haskell的完整项目。
编写函数后,请使用wsk CLI定位到Apache OpenWhisk实例,并在几秒钟内运行您的第一个操作。

与许多受欢迎的服务轻松集成
OpenWhisk使开发人员可以轻松地使用Packages将其Actions与许多流行的服务集成在一起,这些Packages作为OpenWhisk系列下的独立开发项目或作为我们默认目录的一部分提供。
软件包提供与常规服务(例如Kafka消息队列,包括Cloudant的数据库,移动应用程序的推送通知,Slack消息传递和RSS feed)的集成。 开发管道可以利用与GitHub,JIRA的集成,或轻松连接Weather公司的自定义数据服务。
您甚至可以使用“警报”程序包来安排时间或重复间隔来运行操作。

将您的功能组合成丰富的组合
使用JavaScript / NodeJS,Swift,Python,Java等不同语言编写的代码,或者通过与Docker打包代码来运行自定义逻辑。 同步,异步或按计划调用代码。 使用诸如序列之类的高级编程构造将多个动作声明式链接在一起。 使用参数绑定可以避免在代码中对服务凭据进行硬编码。 并且,使用各种开发工具实时调试代码。
按需扩展规模和最佳资源利用
在不到一秒的时间内,即可一次执行一万次,或者每周一次。 动作实例可以根据需要进行扩展以满足需求,然后消失。 在不为空闲资源付费的情况下,享受最佳利用率。
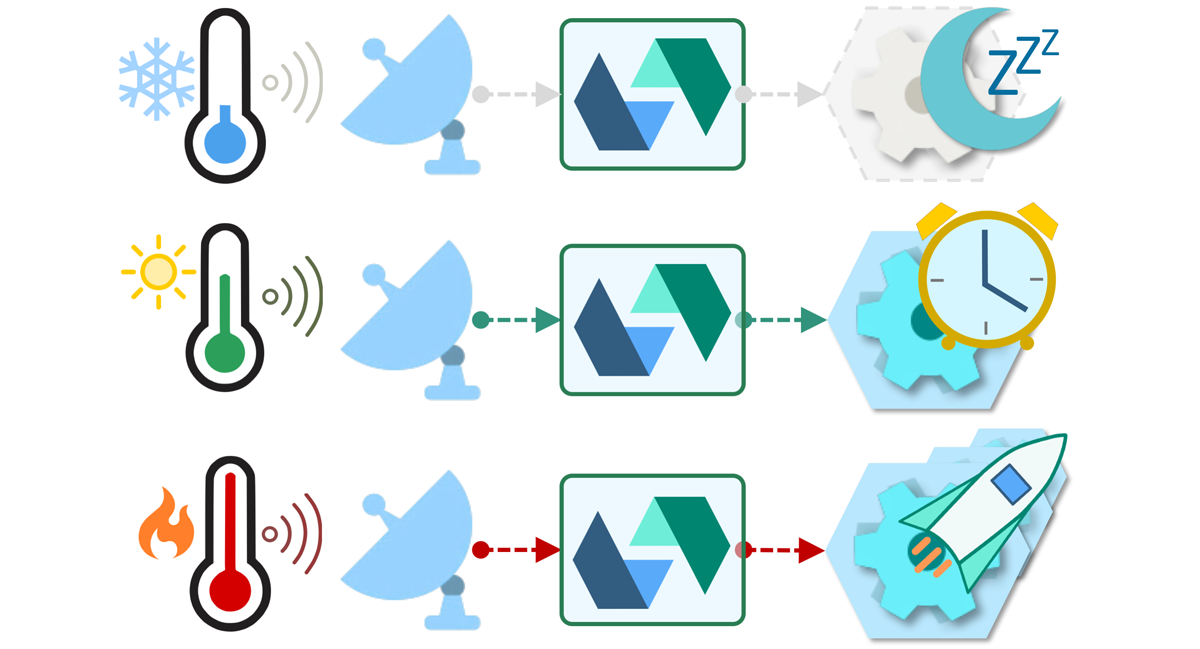
原文:http://openwhisk.apache.org/
本文:http://jiagoushi.pro/node/900
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 74 次浏览
【无服务器架构】Knative Eventing 介绍
Knative Eventing是一个旨在满足云原生开发的常见需求的系统,并提供可组合的原语以启用后期绑定事件源和事件使用者。
设计概述
Knative Eventing是围绕以下目标设计的:
- 原始事件服务是松散耦合的。这些服务可以在各种平台上(例如Kubernetes,VM,SaaS或FaaS)独立开发和部署。
- 事件生产者和事件消费者是独立的。任何生产者(或源)都可以在有活动的事件使用者监听之前生成事件。在有生产者创建事件之前,任何事件消费者都可以对事件或事件类别表示兴趣。
- 可以将其他服务连接到Eventing系统。这些服务可以执行以下功能:
- 创建新的应用程序而无需修改事件生产者或事件使用者。
- 从生产者那里选择事件的特定子集并将其作为目标。
- 确保跨服务的互操作性。 Knative Eventing与由CNCF Serverless WG开发的CloudEvents规范一致。
事件消费者
为了能够交付到多种类型的服务,Knative Eventing定义了两个通用接口,可以由多个Kubernetes资源实现:
- 可寻址对象能够接收和确认通过HTTP发送到其status.address.url字段中定义的地址的事件。作为一种特殊情况,核心的Kubernetes Service对象还实现了Addressable接口。
- 可调用对象能够接收通过HTTP传递的事件并转换该事件,从而在HTTP响应中返回0或1个新事件。可以以与处理来自外部事件源的事件相同的方式来进一步处理这些返回的事件。
事件经纪人和触发器
从v0.5开始,Knative Eventing定义了Broker和Trigger对象,使过滤事件更加容易。
代理提供了一系列事件,可以通过属性选择事件。它接收事件并将其转发给由一个或多个匹配触发器定义的订户。
触发器描述了事件属性的过滤器,应将其传递给可寻址对象。您可以根据需要创建任意数量的触发器。

事件注册表
从v0.6开始,Knative Eventing定义了一个EventType对象,以使消费者更容易发现可以从不同的Broker消费的事件类型。
注册表包含事件类型的集合。注册表中存储的事件类型包含(全部)必需的信息,供消费者创建触发器而不使用某些其他带外机制。
若要了解如何使用注册表,请参阅事件注册表文档。
事件频道和订阅
Knative Eventing还定义了事件转发和持久层,称为Channel。每个通道都是一个单独的Kubernetes自定义资源。使用订阅将事件传递到服务或转发到其他渠道(可能是其他类型)。这使群集中的消息传递可以根据需求而变化,因此某些事件可能由内存中的实现处理,而其他事件则可以使用Apache Kafka或NATS Streaming持久化。
请参阅渠道实施清单。
更高级别的事件构造
在某些情况下,您可能希望一起使用一组协作功能,对于这些用例,Knative Eventing提供了两个附加资源:
- 序列提供了一种定义功能的有序列表的方法。
- 并行提供了一种定义事件分支列表的方法。
未来的设计目标
下一个Eventing版本的重点是使事件源的易于实现。源使用Kubernetes Custom Resources管理来自外部系统的事件的注册和传递。在Eventing工作组中了解有关Eventing开发的更多信息。
安装
目前,Knative Eventing要求安装的Istio版本> = 1.0或Gloo版本> = 0.18.16的Knative Serving。按照说明在您选择的平台上进行安装。
架构
事件基础结构目前支持两种形式的事件传递:
- 从源直接传递到单个服务(可寻址端点,包括Knative服务或核心Kubernetes服务)。在这种情况下,如果目标服务不可用,则源负责重试或排队事件。
- 使用渠道和订阅从源或服务响应向多个端点进行扇出交付。在这种情况下,通道实现可确保将消息传递到请求的目标,并且如果目标服务不可用,则应缓冲事件。
实际的消息转发是由多个数据平面组件实现的,这些组件提供可观察性,持久性以及不同消息传递协议之间的转换。
来源
每个源都是一个单独的Kubernetes自定义资源。这允许每种类型的Source定义实例化Source所需的参数和参数。 Knative Eventing在sources.eventing.knative.dev API组中定义了以下Sources。以下类型以golang格式声明,但在YAML中可以表示为简单列表等。所有源都应属于源类别,因此您可以使用kubectl get源列出所有现有源。当前实现的源描述如下。
除了核心资源(如下所述)外,您还可以安装其他资源。
如果您需要可用的Source实现中未涵盖的Source,则提供有关编写自己的Source的教程。
如果您的代码需要将事件作为其业务逻辑的一部分发送,并且不适合源模型,请考虑将事件直接馈送给Broker。
KubernetesEventSource
每当创建或更新Kubernetes事件时,KubernetesEventSource都会触发一个新事件。
规格字段:
- namespace:string要监视事件的名称空间。
- serviceAccountname:string用于连接到Kubernetes apiserver的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
请参阅Kubernetes事件源示例。
GitHub源
GitHubSource为选定的GitHub事件类型触发一个新事件。
规格字段:
- ownerAndRepository:string从中接收事件的GitHub所有者/组织和存储库。该存储库可以保留下来以接收来自整个组织的事件。
- eventTypes:[]字符串“ Webhook事件名称”格式的事件类型列表(lower_case)。
- accessToken.secretKeyRef:包含用于配置GitHub Webhook的GitHub访问令牌的SecretKeySelector。必须设置此之一或secretToken。
- secretToken.secretKeyRef:SecretKeySelector,其中包含用于配置GitHub Webhook的GitHub秘密令牌。必须设置其中之一或accessToken。
- serviceAccountName:string用来运行容器的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
- githubAPIURL:字符串可选字段,用于指定API请求的基本URL。如果未指定,则默认为公共GitHub API,但可以将其设置为要与GitHub Enterprise一起使用的域端点,例如https://github.mycompany.com/api/v3/。应始终在该基本URL后面加上斜杠。
参见GitHub Source示例。
GcpPubSubSource
每次在Google Cloud Platform PubSub主题上发布消息时,GcpPubSubSource都会触发一个新事件。
规格字段:
- googleCloudProject:字符串拥有该主题的GCP项目ID。
- topic:字符串PubSub主题的名称。
- serviceAccountName:字符串用于访问gcpCredsSecret的ServiceAccount的名称。
- gcpCredsSecret:ObjectReference对Secret的引用,其中包含用于与PubSub对话的GCP刷新令牌。
- sink:ObjectReference对应该接收事件的对象的引用。
请参阅GCP PubSub来源示例。
AwsSqsSource
每次在AWS SQS主题上发布事件时,AwsSqsSource都会触发一个新事件。
规格字段:
- queueURL:从中提取事件的SQS队列的URL。
- awsCredsSecret:用于轮询AWS SQS队列的凭证。
- sink:ObjectReference对应该接收事件的对象的引用。
- serviceAccountName:字符串用于访问awsCredsSecret的ServiceAccount的名称。
ContainerSource
ContainerSource将实例化一个容器映像,该映像可以生成事件,直到ContainerSource被删除。例如,可以使用它来轮询FTP服务器上的新文件,或在设定的时间间隔内生成事件。
规格字段:
- image(必填):字符串要运行的容器的docker镜像。
- args:[] string命令行参数。如果未提供--sink标志,则将添加一个并用接收器对象的DNS地址填充。
- env:map [string] string要在容器中设置的环境变量。
- serviceAccountName:string用来运行容器的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
-
CronJobSource
CronJobSource根据给定的Cron时间表触发事件。
规格字段:
- schedule(必填):字符串Cron格式的字符串,例如0 * * * *或@hourly。
- data:字符串发送到下游接收器的可选数据。
- serviceAccountName:string用来运行容器的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
请参阅Cronjob源示例。
Kafka资
KafkaSource从Apache Kafka集群读取事件,并将事件传递给Knative Serving应用程序,以便可以使用它们。
规格字段:
- ConsumerGroup:字符串Kafka消费者组的名称。
- bootstrapServers:字符串用逗号分隔的Kafka Broker主机名:端口对列表。
- topic:字符串,用于吸收消息的Kafka主题的名称。
- net:可选的网络配置。
- sasl:可选的SASL身份验证配置。
- enable:布尔值如果为true,则使用SASL进行身份验证。
- user.secretKeyRef:包含要使用的SASL用户名的SecretKeySelector。
- password.secretKeyRef:包含要使用的SASL密码的SecretKeySelector。
- tls:可选的TLS配置。
- enable:布尔值如果为true,则在连接时使用TLS。
- cert.secretKeyRef:包含要使用的客户端证书的SecretKeySelector。
- key.secretKeyRef:包含要使用的客户端密钥的SecretKeySelector。
- caCert.secretKeyRef:包含要验证服务器证书时使用的服务器CA证书的SecretKeySelector。
参见Kafka Source示例。
CamelSource
CamelSource是事件源,可以代表提供用户端并允许将事件发布到可寻址端点的任何现有Apache Camel组件。每个Camel端点都具有URI的形式,其中方案是要使用的组件的ID。
CamelSource要求将Camel-K安装到当前名称空间中。
规格字段:
- 来源:有关应创建的骆驼来源类型的信息。
- component:默认类型的源,可通过配置单个Camel组件来创建EventSource。
- uri:字符串包含应用于将事件推送到目标接收器的骆驼URI。
- 属性:键/值映射包含Camel全局选项或特定于组件的配置。每个现有的Apache Camel组件的文档中都提供了选项。
- serviceAccountName:字符串,可用于运行源容器的可选服务帐户。
- image:字符串(可选)用于源pod的可选基本图像,主要用于开发目的。
参见CamelSource示例
原文:https://knative.dev/docs/eventing/
本文:
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 415 次浏览
【无服务器架构】Knative Serving 介绍
Knative Serving建立在Kubernetes和Istio之上,以支持无服务器应用程序和功能的部署和服务。服务易于上手,并且可以扩展以支持高级方案。
Knative Serving项目提供了中间件原语,这些原语可实现:
- 快速部署无服务器容器
- 自动放大和缩小到零
- Istio组件的路由和网络编程
- 部署的代码和配置的时间点快照
服务资源
Knative Serving将一组对象定义为Kubernetes自定义资源定义(CRD)。这些对象用于定义和控制无服务器工作负载在集群上的行为:
服务:
service.serving.knative.dev资源自动管理您的工作负载的整个生命周期。它控制其他对象的创建,以确保您的应用为服务的每次更新都具有路由,配置和新修订版。可以将服务定义为始终将流量路由到最新修订版或固定修订版。
路由:
route.serving.knative.dev资源将网络端点映射到一个或多个修订版。您可以通过几种方式管理流量,包括部分流量和命名路由。
配置:
configuration.serving.knative.dev资源维护部署的所需状态。它在代码和配置之间提供了清晰的分隔,并遵循了十二要素应用程序方法。修改配置会创建一个新修订。
修订版:
revision.serving.knative.dev资源是对工作负载进行的每次修改的代码和配置的时间点快照。修订是不可变的对象,可以保留很长时间。可以根据传入流量自动缩放“服务提供修订”。有关更多信息,请参见配置自动缩放器。

入门
要开始使用Serving,请查看您好世界示例项目之一。这些项目使用服务资源,该资源为您管理所有详细信息。
使用服务资源,已部署的服务将自动创建匹配的路由和配置。每次更新服务时,都会创建一个新修订。
有关资源及其交互的更多信息,请参阅Knative Serving存储库中的“资源类型概述”。
更多样本和演示
本地服务代码示例
设置日志记录和指标
- 安装日志记录,度量和跟踪
- 访问日志
- 访问指标
- 访问跟踪
- 设置日志记录插件
调试基本服务问题
- 调试应用程序问题
- 调试性能问题
配置和网络
- 配置集群本地路由
- 使用自定义域
- 在Google Kubernetes Engine上为Knative分配静态IP地址
已知的问题
- 有关已知问题的完整列表,请参见“服务问题”页面。
原文:https://knative.dev/docs/serving/
本文:http://jiagoushi.pro/knative-eventing-introduction
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 84 次浏览
【无服务器架构】openwhisk 系统概览
OpenWhisk是一个事件驱动的计算平台,也称为无服务器计算或功能即服务(FaaS),用于响应事件或直接调用而运行代码。 下图显示了高级OpenWhisk体系结构。

事件的示例包括数据库记录的更改,超过特定温度的IoT传感器读数,将新代码提交到GitHub存储库或来自Web或移动应用程序的简单HTTP请求。来自外部和内部事件源的事件通过触发器进行传递,并且规则允许操作对这些事件做出反应。
操作可以是小的代码片段(支持JavaScript,Swift和许多其他语言),也可以是嵌入在Docker容器中的自定义二进制代码。每当触发触发器时,OpenWhisk中的操作就会立即部署并执行。触发次数越多,调用的动作越多。如果没有触发触发器,则不会运行任何操作代码,因此没有成本。
除了将动作与触发器相关联之外,还可以通过使用OpenWhisk API,CLI或iOS SDK直接调用动作。一组动作也可以链接在一起,而无需编写任何代码。依次调用链中的每个动作,并将一个动作的输出作为输入传递到序列中的下一个动作。
对于传统的长期运行的虚拟机或容器,通常的做法是部署多个VM或容器以抵御单个实例的故障。但是,OpenWhisk提供了一种替代模型,没有与弹性相关的成本开销。按需执行操作可提供固有的可伸缩性和最佳利用率,因为正在运行的操作数始终与触发率匹配。此外,开发人员现在只关注代码,而不必担心监视,修补和保护基础服务器,存储,网络和操作系统基础结构。
与其他服务和事件提供程序的集成可以随包一起添加。一揽子计划是一堆提要和操作。提要是一段代码,用于配置外部事件源以触发触发事件。例如,使用Cloudant变更Feed创建的触发器将配置服务,以在每次文档被修改或添加到Cloudant数据库时触发该触发器。包中的动作表示服务提供者可以提供的可重用逻辑,以便开发人员不仅可以将服务用作事件源,还可以调用该服务的API。
现有的软件包目录提供了一种快速的方法来增强具有有用功能的应用程序,并访问生态系统中的外部服务。启用了OpenWhisk的外部服务的示例包括Cloudant,The Weather Company,Slack和GitHub。
OpenWhisk的工作方式
作为一个开源项目,OpenWhisk站在Nginx,Kafka,Docker,CouchDB等巨头的肩膀上。所有这些组件共同构成了“无服务器基于事件的编程服务”。为了更详细地解释所有组件,让我们跟踪动作在系统发生时的调用。无服务器引擎的核心工作是OpenWhisk中的调用:执行用户输入到系统中的代码,并返回执行结果。
创建动作
为了提供一些上下文说明,我们首先在系统中创建一个动作。 我们将在稍后浏览系统时使用该操作来解释概念。 以下命令假定已正确设置OpenWhisk CLI。
首先,我们将创建一个包含以下代码的action.js文件,该代码会将“ Hello World”打印到标准输出,并在键“ hello”下返回一个包含“ world”的JSON对象。
function main() { console.log('Hello World'); return { hello: 'world' }; }
我们使用创建该动作。
wsk action create myAction action.js
做完了 现在我们实际上要调用该动作:
wsk action invoke myAction --result
内部处理流程
OpenWhisk幕后实际上发生了什么?

进入系统:nginx
第一:OpenWhisk的面向用户的API完全基于HTTP,并采用RESTful设计。 因此,通过wsk CLI发送的命令实际上是针对OpenWhisk系统的HTTP请求。 上面的特定命令大致翻译为:
POST /api/v1/namespaces/$userNamespace/actions/myAction Host: $openwhiskEndpoint
注意这里的$ userNamespace变量。用户可以访问至少一个名称空间。为了简单起见,假设用户拥有放置myAction的名称空间。
进入系统的第一个入口是通过nginx,“ HTTP和反向代理服务器”。它主要用于SSL终止并将适当的HTTP调用转发到下一个组件。
进入系统:控制器
对我们的HTTP请求没有做很多事情,nginx将其转发到Controller,这是我们通过OpenWhisk进行的下一个组件。它是实际REST API(基于Akka和Spray)的基于Scala的实现,因此可以用作用户可以做的所有事情的接口,包括在OpenWhisk中对实体的CRUD请求和动作的调用(这就是我们的现在正在做)。
控制器首先消除用户要做什么的歧义。它基于您在HTTP请求中使用的HTTP方法来执行此操作。根据上面的翻译,用户向现有动作发出POST请求,控制器将其转换为动作的调用。
鉴于控制器的中心作用(因此得名),以下步骤在一定程度上都会涉及它。
身份验证和授权:CouchDB
现在,控制器将验证您的身份(身份验证),以及您是否有权对实体执行您想做的事情(授权)。将根据CouchDB实例中的所谓主题数据库验证请求中包含的凭据。
在这种情况下,将检查用户是否存在于OpenWhisk的数据库中,并检查该用户是否有权调用动作myAction,我们假设该动作是用户拥有的命名空间中的动作。后者有效地赋予了用户调用该操作的特权,这是他希望执行的操作。
一切正常后,门打开,进入下一阶段的处理。
采取行动:再次CouchDB…
由于Controller现在确定允许用户进入并具有调用其操作的特权,因此它实际上是从CouchDB的拂数据库中加载了此操作(在本例中为myAction)。
动作记录主要包含要执行的代码(如上所示)和要传递给动作的默认参数,并与实际调用请求中包含的参数合并。它还包含执行时对其施加的资源限制,例如允许使用的内存。
在这种特殊情况下,我们的操作没有任何参数(该函数的参数定义是一个空列表),因此我们假设我们没有设置任何默认参数,也没有向该操作发送任何特定的参数,从这个角度来看,最琐碎的情况。
谁来执行该操作:负载均衡器
作为控制器一部分的负载均衡器通过连续检查其运行状况来全局查看系统中可用的执行器。这些执行者被称为祈求者。知道哪些可用的调用程序的负载均衡器会选择其中之一来调用请求的操作。
请排队:Kafka
从现在开始,您发送的调用请求可能主要发生两件事:
- 系统可能崩溃,丢失您的调用。
- 系统可能会承受如此沉重的负担,以至于调用需要先等待其他调用才能完成。
两者的答案都是Kafka,“一个高吞吐量,分布式,发布-订阅消息系统”。 Controller和Invoker仅通过Kafka缓冲和保留的消息进行通信。这样就减轻了控制器和调用者的内存缓冲负担,并冒出OutOfMemoryException的风险,同时还确保在系统崩溃的情况下不会丢失消息。
为了调用该动作,控制器将消息发布到Kafka,其中包含要调用的动作和传递给该动作的参数(在本例中为无)。该消息发送给控制器从上方从可用调用者列表中选择的调用者。
Kafka确认收到消息后,将使用ActivationId响应对用户的HTTP请求。用户稍后将使用它来访问此特定调用的结果。请注意,这是一个异步调用模型,在该模型中,一旦系统接受了调用某个动作的请求,HTTP请求就会终止。可以使用同步模型(称为阻塞调用),但本文不会介绍。
实际上已经在调用代码了:调用者
调用程序是OpenWhisk的心脏。调用者的职责是调用一个动作。它也在Scala中实现。但是还有更多的东西。为了以隔离和安全的方式执行操作,它使用Docker。
Docker用于为我们以快速,隔离和受控的方式调用的每个动作设置一个新的自封装环境(称为容器)。简而言之,对于每个动作调用,都会产生一个Docker容器,该动作代码被注入,并使用传递给它的参数执行该操作代码,获得结果,该容器被销毁。这也是进行大量性能优化以减少开销和缩短响应时间的地方。
在我们的特定情况下,由于手头有一个基于Node.js的操作,Invoker将启动一个Node.js容器,从myAction注入代码,不带任何参数运行它,提取结果,保存日志并销毁再次使用Node.js容器。
存储结果:再次CouchDB
由于调用者获得了结果,因此将其存储为激活数据库,作为上面进一步提到的ActivationId下的激活。激活数据库位于CouchDB中。
在我们的特定情况下,Invoker从操作中获取返回的JSON对象,获取Docker编写的日志,将它们全部放入激活记录中并将其存储到数据库中。大致如下所示:
{ "activationId": "31809ddca6f64cfc9de2937ebd44fbb9", "response": { "statusCode": 0, "result": { "hello": "world" } }, "end": 1474459415621, "logs": [ "2016-09-21T12:03:35.619234386Z stdout: Hello World" ], "start": 1474459415595, }
注意记录如何包含返回的结果和写入的日志。 它还包含操作调用的开始时间和结束时间。 激活记录中有更多字段,为简化起见,这是简化版本。
现在,您可以再次使用REST API(再次从步骤1开始)以获取激活,从而获得操作结果。 为此,您可以使用:
wsk activation get 31809ddca6f64cfc9de2937ebd44fbb9
摘要
我们已经了解了一个简单的wsk动作如何调用myAction贯穿OpenWhisk系统的不同阶段。 系统本身主要仅包含两个自定义组件,即Controller和Invoker。 其他一切都已经存在,由开源社区中如此众多的人开发。
您可以在以下主题中找到有关OpenWhisk的其他信息:
- 实体名称
- 动作语义
- 限度
- REST API
原文:https://github.com/apache/openwhisk/blob/master/docs/about.md
本文:http://jiagoushi.pro/node/899
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 101 次浏览
【无服务器架构】openwhisk 通用使用案例
OpenWhisk提供的执行模型支持各种用例。以下各节包括典型示例。有关无服务器体系结构,示例用例,优缺点讨论和实现最佳实践的更详细讨论,请阅读Martin Fowler博客上的Mike Roberts优秀文章。
微服务
尽管具有微服务的优势,基于微服务的解决方案仍然难以使用主流的云技术来构建,通常需要控制复杂的工具链以及独立的构建和运营管道。小型而敏捷的团队花费大量时间来处理基础架构和操作复杂性(容错,负载平衡,自动缩放和日志记录),尤其希望使用一种方式来开发精简的,增值的代码,这些代码已经使用了已知的编程语言。爱,最适合解决特定问题。
OpenWhisk具有模块化和固有的可伸缩性,因此非常适合在操作中实现细粒度的逻辑。 OpenWhisk动作彼此独立,可以使用OpenWhisk支持的多种不同语言来实现,并可以访问各种后端系统。每个动作都可以独立部署和管理,并且可以独立于其他动作进行扩展。 OpenWhisk以规则,序列和命名约定的形式提供动作之间的互连性。这对于基于微服务的应用程序来说是个好兆头。
Web应用
尽管OpenWhisk最初是为基于事件的编程而设计的,但它为面向用户的应用程序提供了许多好处。例如,将其与较小的Node.js存根结合使用时,可以使用它为相对容易调试的应用程序提供服务。而且,由于与在PaaS平台上运行服务器进程相比,OpenWhisk应用程序的计算强度要低得多,因此它们的价格也要便宜得多。
可以使用OpenWhisk构建和运行完整的Web应用程序。将无服务器API与用于站点资源的静态文件托管相结合,例如HTML,JavaScript和CSS意味着我们可以构建整个无服务器的Web应用程序。与站起来并操作Node.js Express或其他传统服务器运行时相比,操作托管OpenWhisk环境的简单性(或者因为它托管在IBM Cloud上而根本不需要操作任何东西)是一个巨大的好处。
其中一项有用的功能是使用OpenWhisk CLI wsk工具(称为“ --annotation web-export true”)的选项,该工具可从Web浏览器访问代码。
以下是一些有关如何使用OpenWhisk构建Web应用程序的示例:
Web操作:具有OpenWhisk的无服务器Web应用程序。
使用IBM Cloud Functions和Node.js构建面向用户的OpenWhisk应用程序
使用OpenWhisk的无服务器HTTP处理程序
物联网
当然可以使用传统的服务器架构来实现物联网应用,但是在许多情况下,不同服务和数据桥的结合需要高性能和灵活的管道,从物联网设备到云存储和分析平台。通常,预配置的网桥缺乏实现和微调特定解决方案体系结构所需的可编程性。鉴于可能的管道种类繁多,并且一般而言,尤其是在IoT中,围绕数据融合的问题缺乏标准化,因此在许多情况下,管道需要自定义数据转换(用于格式转换,过滤,扩充等)。 OpenWhisk是一种出色的工具,可以以“无服务器”方式实现这种转换,其中自定义逻辑托管在完全托管且具有弹性的云平台上。
物联网场景通常固有地是传感器驱动的。例如,如果需要对超过特定温度的传感器做出反应,则可能会触发OpenWhisk中的操作。物联网交互通常是无状态的,在发生重大事件(自然灾害,重大天气事件,交通拥堵等)的情况下,可能会产生非常高的负载水平。这产生了对弹性系统的需求,该系统的正常工作量可能很小,但需要具有可预测的响应时间,能够迅速扩展,并且能够处理大量事件,而无需事先向系统发出警告。使用传统的服务器体系结构来构建满足这些要求的系统非常困难,因为它们要么功率不足,无法处理流量高峰,要么配置过度且极其昂贵。
这是一个使用OpenWhisk,NodeRed,Cognitive和其他服务的示例IoT应用程序:使用OpenWhisk对IoT实时数据进行无服务器转换。

API后端
无服务器计算平台为开发人员提供了一种无需服务器即可快速构建API的方法。 OpenWhisk支持自动生成用于操作的REST API,并且很容易将您选择的API管理工具(例如IBM API Connect或其他)连接到OpenWhisk提供的这些REST API。与其他用例相似,适用于可伸缩性和所有其他服务质量(QoS)的所有注意事项。
这是使用Serverless作为API后端的示例和讨论。
移动后端
许多移动应用程序需要服务器端逻辑。对于不想管理服务器端逻辑而宁愿专注于设备或浏览器上运行的应用程序的移动开发人员,使用OpenWhisk作为服务器端后端是一个很好的解决方案。此外,对Swift的内置支持使开发人员可以重用其现有的iOS编程技能。移动应用程序通常具有不可预测的负载模式,并且托管的OpenWhisk解决方案(例如IBM Cloud Functions)可以扩展以满足几乎任何工作负载需求,而无需提前配置资源。
数据处理
由于现在可用的数据量很大,因此应用程序开发需要具有处理新数据并可能对其做出反应的能力。此要求包括处理结构化数据库记录以及非结构化文档,图像或视频。可以通过提供的系统或自定义提要来配置OpenWhisk,以对数据更改做出反应并自动对传入的数据提要执行操作。可以对动作进行编程以处理更改,转换数据格式,发送和接收消息,调用其他动作,更新各种数据存储,包括基于SQL的关系数据库,内存中的数据网格,NoSQL数据库,文件,消息传递代理和各种其他系统。 OpenWhisk规则和序列提供了无需编程即可灵活地更改处理管道的灵活性-只需通过配置更改即可。这使得基于OpenWhisk的系统具有高度的灵活性,并易于适应不断变化的需求。
认知应用
认知技术可以与OpenWhisk有效结合,以创建功能强大的应用程序。例如,IBM Alchemy API和Watson Visual Recognition可与OpenWhisk一起使用,以自动从视频中提取有用的信息,而无需实际观看。
这是一个示例应用程序Dark vision,它就是这样做的。在此应用程序中,用户使用Dark Vision Web应用程序上载视频或图像,该应用程序将其存储在Cloudant DB中。视频上传后,OpenWhisk通过听Cloudant更改(触发)来检测新视频。然后,OpenWhisk触发视频提取器操作。在执行过程中,提取器将生成帧(图像)并将其存储在Cloudant中。然后使用Watson Visual Recognition处理帧,并将结果存储在同一Cloudant DB中。可以使用Dark Vision Web应用程序或iOS应用程序查看结果。除Cloudant外,还可以使用对象存储。这样做时,视频和图像元数据存储在Cloudant中,媒体文件存储在对象存储中。
原文:https://github.com/apache/openwhisk/blob/master/docs/use_cases.md
本文:http://jiagoushi.pro/openwhisk-common-use-cases
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 70 次浏览
【无服务器架构】什么时候无服务器架构是应用程序的正确选择?考虑利弊
在适当的情况下,我们喜欢无服务器架构。但这些情况是什么呢?
在前一篇关于web开发中的无服务器架构的文章中,我们讨论了为什么我们相信无服务器将是云原生开发的未来。不可否认的是,重点是无服务器架构的优势。在我们的无服务器系列的这一期中,我们将通过概述无服务器的缺点以及在哪些情况下它可能不是你的下一个应用的最佳方法来增加更多的平衡。
当然,没有任何技术或架构是适用于所有情况的完美解决方案。在无服务器的web开发中,可以感知到的弱点在某种程度上得到弥补,这意味着它们不会拖累技术解决方案或业务案例,以达到优势被削弱的程度?
我们还将把无服务器web开发的优缺点理论应用于示例应用程序。这将说明在何种情况下,serverless的优点和缺点的平衡使得它成为技术堆栈的最佳选择,而在哪些情况下它可能不是最佳选择。
为了平衡我们上一篇文章中略显夸张的pro-serverless的立场,让我们从这次无服务器web开发的缺点开始:
Serverless缺点
那么,采用无服务器开发方法可能存在哪些问题和缺点呢?
厂商锁定
在与我们自己的架构师和客户讨论serverless是否是一个新的开发项目的正确方式时,我们经常会看到对供应商锁定的担忧。有一种看法认为,一旦应用程序的无服务器架构由一家云供应商(通常是GCD、AWS和Azure)建立起来,如果环境发生变化,那么要迁移到另一家云供应商就非常困难(昂贵且耗时)。
在现实中,如果从一个新的应用程序项目开始就提供正确的方法,供应商锁定不一定是无服务器开发的缺点。至少对大多数应用程序来说不是这样。对于真正的大型应用程序来说,供应商之间的迁移不可避免地会非常复杂。
例如,你正在设计一个具有以下功能的web应用程序:
- 安全的用户标识
- 收集及储存一些个人资料
- 应用程序功能的用户界面
让我们比较一下传统web开发和无服务器开发方法所需要的技术栈。
传统的web开发:
- 身份识别:Spring安全框架(Java)
- 数据存储:NoSQL更适合这里,因为不需要事务(MongoDB)
- 通知:带有Websockets的Spring
- 支付方式:第三方服务
- 业务逻辑核心:带有REST端点的Spring框架(Java)
无服务器web开发与AWS:
- 标识:AWS Cognito
- 数据存储:AWS DynamoDB
- 通知:AWS简单通知服务
- 支付方式:第三方服务
- 业务逻辑核心:AWS Lambda
许多不同的应用程序都需要用户标识、数据存储、通知和支付。除此之外,只有应用程序的“核心”才能被认为是“独特的”。
传统的web开发需要对用户标识、数据存储、通知和支付进行自定义配置和编码。因此,任何改进、开发或修复应用程序中的问题的改变都需要一个新的软件开发迭代周期。这意味着任何改变都需要大量的资源(时间和金钱)。
另一方面,无服务器的web开发允许您使用“即插即用”技术来实现应用程序涉及的常见功能——用户识别、支付等。上面列出的AWS工具(Cognito、DynamoDB等)只需要配置,然后就可以在测试和生产环境之间快速、轻松地进行更改。
这意味着在最初的开发阶段以及在需要引入任何后续更改或更新时,无服务器开发可以节省大量的时间和金钱。
但是,上面所说的与围绕无服务器开发的“供应商锁定”问题有什么关系呢?假设您想将您的应用程序从AWS移动到谷歌云。在您的应用程序中使用了几种AWS技术。这在使用AWS云时非常棒。但现在就有问题了,对吧?是的。将它们转换成谷歌云的等价物将是一个痛苦的过程。这就是对无服务器开发的供应商锁定批评的症结所在。
但事实并非如此。如果从一开始就采用无服务器框架,那么无服务器应用程序可以构建为“云供应商不可知论”。无服务器框架解决方案允许您使用一个常见的配置文件来设置无服务器架构,在这个配置文件中,您只需更改云供应商的名称,就可以将AWS技术转换为谷歌云(或任何其他主要供应商的云)的对等产品。不需要任何其他操作,你的应用程序将在新的云home中像以前一样工作。
正确的无服务器开发应该意味着在云供应商之间迁移就像改变移动运营商而保持你的旧号码在最近几年变得一样容易。支持无服务器开发的框架正在迅速成熟,并且解决了供应商锁定等明显的弱点。企业越来越确信,无服务器技术栈的主要缺点正在被消除,使其优势不受损害。
可口可乐公司的方案架构师Patrick Brandt最近表示:
无服务器框架是可口可乐公司降低IT运营成本和更快部署服务计划的核心组成部分。
太积极了?我们是不是把缺点滑向了无服务器?,Serverless?在我看来只有一件事可能意味着厂商锁定是一种担心,可能阻止你为您的下一个项目采用serverless开发——常见的组件需要使用功能需要独特的代码完全控制没有商量的余地。
无服务器的运行成本是骗局吗?
反对新应用程序的无服务器开发方法的另一个常用论据是潜在的计算成本。我多次听说云资源很昂贵,用户无法控制成本。
这是部分正确的。传统的发展意味着可以准确地预测计算资源的开销。一个企业确切地知道一个应用程序需要多少服务器,它们的位置等等。预算是很容易的。
如果您选择一个没有云服务器的环境,您会在月底收到账单,并且很难预测准确的成本。尾巴上的刺是可能的。这种对管理费用缺乏控制的情况经常阻碍公司投资于无服务器的技术。
从商业的角度来看,不能准确地控制或预测成本会导致交易失败。这是否会成为瓶颈,意味着未来的无服务器开发将无法与当前的炒作相匹配?
我不这么想。首先,如果您知道自己在做什么,那么准确预测无服务器应用程序的云资源成本其实并不困难。你只需要定义你的应用将使用什么云资源,以及这些资源如何适应供应商的定价结构。是的,您可能无法准确地预测应用程序的需求和使用水平。如果它像病毒一样传播开来,你会不会被云计算供应商的发票所咬,从而毁掉你的公司?
这是一个需要考虑的问题,但在绝大多数情况下,它不会真正影响Serverless是否是合适的技术。事实上,初创企业之所以经常青睐Serverless,正是因为成本被重新加载了。运行一个应用程序是非常便宜的,直到它有大量的用户,在这一点上额外的成本是合理的。这也使得Serverless成为MVPs和新产品的理想架构。
首先,如果一个应用程序是直接盈利的,那么在需求激增的情况下,收入应该随着云资源成本的增加而增加。如果一个应用程序不能直接变现,那么它可能会增加另一种商业价值,间接代表公司的经济收益。
可能会出现意想不到的高云资源成本会对业务现金流产生负面影响的情况,尽管应用程序的正面需求高于预期。但从一开始就应该清楚,这种情况是否有可能出现。除了简单地拒绝Serverless及其作为技术堆栈的优势之外,可能还有其他解决方案。
在大多数场景中,应用程序在需求高峰期间保持一致的性能将是压倒一切的业务考虑。您是否曾经因为门户运行缓慢或在使用高峰期崩溃而离开门户?上周给亲戚买礼物时,我就是这么做的。
三个电子市场以同样的价格提供同样的产品。其中两个明显比第三个慢(过滤慢2-4秒)。是的,也许缓慢的应用程序只是低劣的架构的结果。但是,如果他们有相同的代码,他们如何有效地扩展以满足需求?
如果您使用硬件连接服务器容量,如何知道峰值需求可能需要哪些资源?您的服务器很少接近最佳容量。它们要么提供了太多的容量,而你已经为此付费,90%的时间都处于闲置状态,要么在高峰时刻容量不足,要么速度变慢,要么崩溃,失去你的业务。
有了Serveless,你就不需要‘hard plan’的能力了。它将无缝地扩展以满足需求。有很多方法可能会让您失去业务,但服务器容量运行在您需要的水平不是其中之一。
如果您真的不知道应用程序可能会有什么需求,Serverless是一个特别好的选择。你只会为你使用的东西付费,这让你能够感受事情的真相。这并不意味着成本计划在Serverless中不重要。组件成本应努力研究和技术优化的数据查询规划,lambda内存和时间消耗规划。
总之,如果您的应用程序是成熟的,并且需求趋势和服务器容量需求可以准确地长期预测,那么Serverless可能不是您可用的最便宜的选择。选择自己的固定服务器资源可能是有意义的。但是,即使在这种情况下,能够适应任何意想不到的需求高峰的混合云解决方案仍然值得考虑。
复杂的集成/迁移,从当前的非无服务器解决方案
我同意将现有体系结构迁移到无服务器体系结构或混合解决方案是具有挑战性的。然而,根据我的经验,问题的关键在于依赖于缺乏相关专业知识的开发人员。向云计算转型需要对新技能进行投资。这可能意味着为内部开发专业人员提供培训,或者引入有经验的外部帮助。
无服务器开发和传统开发之间的一个根本区别是,无服务器开发人员需要考虑并能够准确计算与他们如何构建应用程序相关的成本。所使用的技术组件、数据库请求、计算时间和性能成本有多少?这些成本是否与应用程序的业务案例和计划相匹配?传统的web开发人员不必担心这些问题。这不是他们的工作。
对于我个人来说,作为一个已经从传统开发过渡到无服务器开发的开发人员,这是工作性质中最难掌握的变化之一。组织向无服务器的转变,无论是完全的还是特定的应用程序,都应该考虑到这一点。开发人员需要接受再教育,他们的工作现在涉及在其业务案例的上下文中管理应用程序的运行成本。
什么时候无服务器开发是应用程序的最佳选择?
让我们总结一下业务考虑和应用程序的技术质量,广泛地说,这意味着它通常会受益于无服务器:
- 中小型应用程序
- 市场尚未建立,负荷难以预测
- 应用程序需要进行大量快速(快速失败)试验
- 公共模块(身份识别、通知)无独特主张
- 团队准备利用没有服务器的优势
当Serverless可能不是一个应用程序的最佳技术堆栈:
- 大型应用程序
- 确定和可预测的市场需求和高峰负荷时间
- 应用程序的特点是迭代和缓慢-实验不受欢迎
- 在公共模块中需要细粒度控制,并且它们包含唯一的流
- 团队没有做好准备,没有采用云服务器思维
在下一篇关于无服务器开发的文章中,我们将概述AWS提供的常见“即插即用”组件的优势和好处。
原文:https://kruschecompany.com/serverless-pros-and-cons/
本文:http://jiagoushi.pro/node/1278
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 75 次浏览
【无服务器架构】接触Knative -第1部分
我最近一直在研究Knative。在这个由三部分组成的博客系列中,我想解释一下我的收获,并展示一些我在GitHub上发布的Knative教程中的例子。
Knative到底是什么?
Knative是运行在Kubernetes上的无服务器容器的开源构建块集合。
此时,您可能会想:“Kubernetes,没有服务器,这是怎么回事?”但是,当你仔细想想,这是有道理的。Kubernetes是非常流行的集装箱管理平台。应用程序开发人员希望使用Serverless来运行他们的代码。Knative用一套积木将两个世界连接在一起。
谈到积木,它由3个主要组成部分:
- Knative Serving 用于快速部署和自动调整无服务器容器。
- Knative Eventing用于松散耦合、事件驱动的服务的Knative事件处理。
- Knative Build,用于注册表中的无痛苦的代码到容器的工作流。
让我们从本地服务开始。
什么是 Knative Serving ?
简而言之,Knative服务允许快速部署和自动调整无服务器容器。您只需指定要部署什么容器,而Knative负责如何创建该容器并将流量路由到它的详细信息。一旦您将您的无服务器容器部署为Knative服务,您将获得诸如自动扩展、针对每个配置更改的修订、不同修订之间的流量分割等功能。
Hello World服务(Serving)
要将你的代码部署为Knative服务,你需要:
将代码装入容器并将映像推入公共注册中心。
创建一个服务yaml文件,告诉Knative在哪里可以找到容器映像及其所有配置。
在我的Knative教程的Hello World服务部分中,我详细描述了这些步骤,但是在这里重述一下,这是一个最小的Knative服务定义service-v1的方式service-v1.yaml的样子:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-csharp
namespace: default
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# replace {username} with your DockerHub
image: docker.io/{username}/helloworld-csharp:v1
env:
- name: TARGET
value: "C# Sample v1"
runLatest意味着我们希望立即使用指定的容器和配置部署最新版本的代码。部署服务:
kubectl apply -f service-v1.yaml
此时,您将看到创建了许多东西。首先,创建一个Knative服务及其pod。其次,创建一个配置来捕获Knative服务的当前配置。第三,将修订创建为当前配置的快照。最后,创建一个路由将流量导向新创建的Knative服务:
kubectl get pod,ksvc,configuration,revision,route
NAME READY STATUS RESTARTS
pod/helloworld-csharp-00001-deployment-7fdb5c5dc9-wf2bp 3/3 Running 0
NAME
service.serving.knative.dev/helloworld-csharp
NAME
configuration.serving.knative.dev/helloworld-csharp
NAME
revision.serving.knative.dev/helloworld-csharp-00001
NAME
route.serving.knative.dev/helloworld-csharp
改变配置
在Knative服务中,每当您更改服务的配置时,它都会创建一个新的修订,这是代码的时间点快照。它还创建了一个新的路线,新的修订将开始接收流量。
在我的Knative教程的更改配置一节中,您可以看到更改Knative服务的环境变量或容器映像如何触发新修订的创建。
流量分裂
在Knative中,您可以很容易地在服务的不同版本之间分配流量。例如,如果您想推出一个新的修订版本(0004)并将20%的流量路由到它,您可以执行以下操作:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-csharp
namespace: default
spec:
release:
# Ordered list of 1 or 2 revisions.
# First revision is traffic target "current"
# Second revision is traffic target "candidate"
revisions: ["helloworld-csharp-00001", "helloworld-csharp-00004"]
rolloutPercent: 20 # Percent [0-99] of traffic to route to "candidate" revision
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/helloworld-csharp:v1
env:
- name: TARGET
value: "C# Sample v4"
注意,我们将runLatest模式更改为release模式,以分割服务的流量。
我的Knative教程的流量分割部分有更多的例子,比如如何在现有的版本之间分割流量。
与其他服务集成
Knative服务可以很好地与其他服务集成。例如,您可以使用Knative服务作为外部服务(如Twilio)的webhook。如果您有一个暮光之城号码,您可以回复短信发送到该号码从Knative服务。
整合暮光部分我的Knative教程有详细的步骤,但它本质上归结为创建代码处理暮光的消息:
[Route("[controller]")]
public class SmsController : TwilioController
{
[HttpGet]
public TwiMLResult Index(SmsRequest incomingMessage)
{
var messagingResponse = new MessagingResponse();
messagingResponse.Message("The Knative copy cat says: " + incomingMessage.Body);
return TwiML(messagingResponse);
}
}
定义一个Knative服务:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: twilio-csharp
namespace: default
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/twilio-csharp:v1
然后指定Knative服务为Twilio短信的一个webhook:

原文:https://medium.com/google-cloud/hands-on-knative-part-1-f2d5ce89944e
本文:http://jiagoushi.pro/node/880
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 39 次浏览
【无服务器架构】接触Knative -第二部分
在上一篇文章中,我讨论了Knative用于快速部署和自动调整无服务器容器。如果您希望您的服务由HTTP调用同步触发,那么Knative服务是很好的选择。然而,在没有服务器的微服务世界中,异步触发器更加常见和有用。这时,Knative三项赛就开始发挥作用了。
在Knative系列的第2部分中,我将介绍Knative事件并展示一些来自我的Knative教程的示例,这些示例介绍了如何将它与各种服务集成在一起。
什么是Knative Eventing?
Knative事件处理与Knative服务密切相关,它为松散耦合的事件驱动服务提供了基元。典型的Knatives事件架构是这样的:
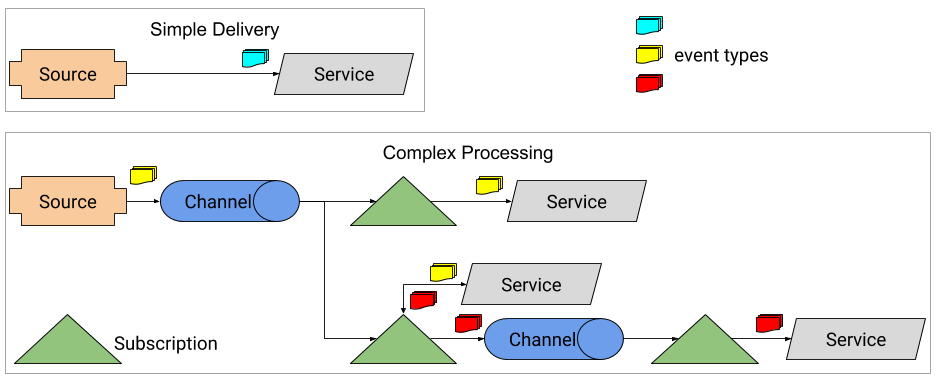
主要有4个组成部分:
- Source(也称为Producer)从实际的源中读取事件,并将事件向下转发到一个通道,或者直接转发到一个服务,这种情况比较少见。
- Channel从源接收事件,保存到其底层存储(稍后详细介绍),并向所有订阅者展开。
- 订阅连接一个通道和一个服务(或另一个通道)。
- 服务(也称为消费者)是使用事件流的Knative服务。
让我们更详细地看看这些。
来源,渠道和订阅
Knative事件的最终目标是将事件从源路由到服务,这是通过我前面提到的原语实现的:源、通道和订阅。
Source从实际源读取事件并将它们转发到下游。到目前为止,Knative支持从Kubernetes、GitHub、谷歌云发布/订阅、AWS SQS主题、容器和CronJobs读取事件。
一旦事件被拉入Knative,它就需要保存到内存中,或者保存到更持久的地方,比如Kafka或谷歌云发布/订阅。这发生在通道上。它有多个实现来支持不同的选项。
从Channel将事件传递给所有感兴趣的Knative服务或其他通道。这可以是一对一的,也可以是扇出的。订阅决定了这种交付的性质,并充当通道和Knative服务之间的桥梁。
现在我们已经了解了Knative三项赛的基础知识,让我们来看一个具体的例子。
Hello World事件
对于Hello World事件,让我们读取来自谷歌云发布/订阅的消息并在Knative服务中注销它们。我的你好世界三项赛教程有所有的细节,但在这里重述,这是我们需要设置:
- 从谷歌云发布/订阅读取消息的GcpPubSubSource。
- 将消息保存在内存中的通道。
- 链接频道到Knative服务的订阅。
- 接收消息并注销的Knative服务。
gcp-pubsub-source。yaml定义了GcpPubSubSource。它指向一个名为测试的发布/订阅主题,它有访问发布/订阅的凭证,并指定应该像这样转发哪个频道事件:
apiVersion: sources.eventing.knative.dev/v1alpha1
kind: GcpPubSubSource
metadata:
name: testing-source
spec:
gcpCredsSecret: # A secret in the knative-sources namespace
name: google-cloud-key
key: key.json
googleCloudProject: knative-atamel # Replace this
topic: testing
sink:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
name: pubsub-test
接下来,我们使用Channel .yaml定义通道。在这种情况下,我们只是在内存中保存消息:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
metadata:
name: pubsub-test
spec:
provisioner:
apiVersion: eventing.knative.dev/v1alpha1
kind: ClusterChannelProvisioner
name: in-memory-channel
继续创建源和通道:
kubectl apply -f gcp-pubsub-source.yaml
kubectl apply -f channel.yaml
你可以看到源和通道被创建,有一个源pod也被创建:
kubectl get gcppubsubsource NAME AGE testing-source 1mkubectl get channel NAME AGE pubsub-test 1mkubectl get pods NAME READY STATUS gcppubsub-testing-source-qjvnk-64fd74df6b-ffzmt 2/2 Running
最后,我们可以创建Knative服务,并使用订阅服务器中的订阅将其链接到subscriber.yaml文件:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: message-dumper-csharp
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/message-dumper-csharp:v1---
apiVersion: eventing.knative.dev/v1alpha1
kind: Subscription
metadata:
name: gcppubsub-source-sample-csharp
spec:
channel:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
name: pubsub-test
subscriber:
ref:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
name: message-dumper-csharp如您所见,message-dump -csharp只是一个普通的Knative服务,但它是通过其订阅的Knative事件异步触发的。
kubectl apply -f subscriber.yamlservice.serving.knative.dev "message-dumper-csharp" created subscription.eventing.knative.dev "gcppubsub-source-sample-csharp" configured
一旦你kubectl apply所有的yaml文件,你可以使用gcloud发送消息到发布/订阅主题:
gcloud pubsub topics publish testing --message="Hello World"
你应该可以看到pods 的服务创建:
kubectl get pods
NAME READY
gcppubsub-testing-source-qjvnk-64fd74df6b-ffzmt 2/2 Running 0 3m
message-dumper-csharp-00001-deployment-568cdd4bbb-grnzq 3/3 Running 0 30s
服务将Base64编码的消息记录在Data下面:
info: message_dumper_csharp.Startup[0]
C# Message Dumper received message: {"ID":"198012587785403","Data":"SGVsbG8gV29ybGQ=","Attributes":null,"PublishTime":"2019-01-21T15:25:58.25Z"}
info: Microsoft.AspNetCore.Hosting.Internal.WebHost[2]
Request finished in 29.9881ms 200
查看我的Hello World事件教程,了解更多关于步骤和实际代码的细节。
与云存储和Vision API集成
当您试图以无缝的方式连接完全不相关的服务时,Knative事件就会真正地发挥作用。在我的集成与视觉API教程中,我展示了如何使用Knative事件连接谷歌云存储和谷歌云视觉API。
云存储是一种全球可用的数据存储服务。可以将bucket配置为在保存映像时发出发布/订阅消息。然后,我们可以使用Knative事件侦听这些发布/订阅消息,并将它们传递给Knative服务。在服务中,我们使用图像进行一个Vision API调用,并使用机器学习从中提取标签。所有的细节都在教程中进行了解释,但是我想在这里指出一些事情。
首先,在Knative中,所有的出站流量在缺省情况下都会被阻塞。这意味着在默认情况下,您甚至不能从Knative服务调用Vision API。这最初让我感到惊讶,所以请确保配置了网络出站访问。
其次,无论何时将图像保存到云存储中,它都会发出CloudEvents。Knative三项赛通常与CloudEvents一起使用。你需要将传入的请求解析为CloudEvents,并提取你需要的信息,如事件类型和图像文件的位置:
var cloudEvent = JsonConvert.DeserializeObject<CloudEvent>(content); var eventType = cloudEvent.Attributes["eventType"]; var storageUrl = ConstructStorageUrl(cloudEvent);
有了这些信息,很容易为图像构造存储URL并使用该URL进行Vision API调用。完整的源代码在这里解释,但这里是相关的部分:
var visionClient = ImageAnnotatorClient.Create();
var labels = await visionClient.DetectLabelsAsync(Image.FromUri(storageUrl), maxResults: 10);
一旦代码准备好了,我们就可以通过定义一个ubscriber.yaml将服务挂接到Knative事件上。它和以前很相似。我们正在重用现有的源和通道,所以我们不必重新创建它们。我们只是创建一个新的订阅指向我们新的Knative服务与愿景API容器:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: vision-csharp
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/vision-csharp:v1
---
apiVersion: eventing.knative.dev/v1alpha1
kind: Subscription
metadata:
name: gcppubsub-source-vision-csharp
spec:
channel:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
name: pubsub-test
subscriber:
ref:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
name: vision-csharp
一旦使用kubectl apply创建了所有内容,无论何时将映像保存到云存储桶中,都应该看到该映像的Knative服务日志标签。
例如,我有一张我最喜欢的地方的照片:
当我把图片保存到桶里时,我可以在日志中看到Vision API中的以下标签:
info: vision_csharp.Startup[0]
This picture is labelled: Sea,Coast,Water,Sunset,Horizon
info: Microsoft.AspNetCore.Hosting.Internal.WebHost[2]
Request finished in 1948.3204ms 200
可以看到,我们使用Knative事件将一个服务(云存储)连接到另一个服务(Vision API)。这只是一个例子,但可能性是无限的。在本教程的翻译API集成部分中,我展示了如何将发布/订阅连接到翻译API。
这就是Knative三项赛。在本系列的下一篇也是最后一篇文章中,我将讨论Knative构建。
原文:https://medium.com/google-cloud/hands-on-knative-part-2-a27729f4d756
本文:http://jiagoushi.pro/hands-knative-part-2
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 33 次浏览
【无服务器架构】无服务器架构的特点
每当新技术出现时,技术专家的首要任务就是理解采用它的含义。无服务器架构就是一个很好的例子。
不幸的是,目前很多关于无服务器体系结构的文献只关注它的优点。许多文章(以及使用的例子)都是由云提供商驱动的,因此,毫不意外地提到了积极的一面。本文试图更好地理解无服务器体系结构的特性。
我特意选择了trait这个词,而不是characteristic,因为这些是无服务器体系结构中无法更改的元素。性格是可塑的,性格是与生俱来的。性格也是中性的,因此它既不是积极的也不是消极的。在某些情况下,我将描述的性格类型可能有积极的含义,但我将保持中立的态度,这样你就会明白你将要面对的是什么。
性格也是与生俱来的,因此你必须接受它们,而不是与之抗争,因为这样的尝试很可能代价高昂。另一方面,性格特征需要花费精力去塑造,但你仍然可能犯错误。
我还应该指出Mike Robert撰写的这篇文章——他还探讨了无服务器服务的特性(https://blog.symphonia.io/defining-serverless-part-1-704d72bc8a32)。尽管我们在这里共享相同的术语,但值得注意的是,本文讨论的是体系结构的特性,而不是您使用的服务。
本文的目的不是帮助您深入理解所有的主题,而是为您提供一个大致的概述。这些是本文定义的无服务器架构的特征:
- 低的壁垒
- Hostless
- 无状态的
- 弹性
- 分布式
- 事件驱动的
低的壁垒
开始在无服务器体系结构中运行代码相对简单。您可以按照任何教程开始并让您的代码在生产级生态系统中运行。在许多方面,与典型的DevOps技能相比,学习无服务器体系结构的过程并没有那么困难——当您采用无服务器体系结构时,许多DevOps的元素并不是必需的。例如,您不必学习服务器管理技能,比如配置管理或补丁。这就是为什么低进入壁垒是无服务器体系结构的特征之一。
这意味着最初,开发人员的学习曲线比许多其他体系结构样式要低。这并不意味着学习曲线会保持在较低的水平,实际上,随着开发人员继续他们的旅程,整个学习曲线会变得更陡。
由于这种架构特性,我已经看到许多新开发人员非常快地加入到项目中,并且他们能够有效地为项目做出贡献。开发人员能够快速地达到最新的速度,这可能是无服务器项目具有更快的上市时间的原因之一。
正如我们所注意到的,事情确实变得更加复杂。例如,将基础设施作为代码、日志管理、监视,有时还包括网络,这些仍然是必需的。您必须了解如何在没有服务器的世界中实现它们。如果您来自不同的开发背景,那么您需要了解许多无服务器体系结构特性(本文将介绍这些特性)。
尽管最初进入门槛很低,但开发人员不应该假设他们可以忽略重要的体系结构原则。
我注意到的一件事是,一些开发人员倾向于认为无服务器架构意味着他们不必考虑代码设计。理由是它们只是处理函数,所以代码设计无关紧要。事实上,像SOLID这样的设计原则仍然适用——您不能将代码可维护性外包给您的无服务器平台。尽管您可以打包并将代码上传到云中以使其运行,但我强烈反对这样做,因为在无服务器体系结构中,持续交付实践仍然是相关的。
Hostless
无服务器体系结构的一个明显特征是您不再直接处理服务器。在这个时代,有各种各样的主机可以安装和运行服务——无论是物理机器、虚拟机、容器等等——用一个词来描述这一点很有用。为了避免使用已经重载的术语serverless,我将在这里使用host1,因此特性的名称为hostless。
无主机的一个优点是,您在服务器维护上的操作开销将显著减少。您无需担心升级服务器,安全补丁将自动为您应用。没有主机还意味着您将监视应用程序中不同类型的指标。这是因为您使用的大多数底层服务不会发布CPU、内存、磁盘大小等传统指标。这意味着您不再需要解释体系结构的底层操作细节。
但是不同的监视指标意味着您必须重新学习如何调优您的体系结构。AWS DynamoDB为您提供了监视和调优的读和写能力,这是一个您必须理解的概念,并且这种学习不能转移到其他没有服务器的平台上。您使用的每个服务都有其局限性。AWS Lambda有并发执行的限制,而不是CPU内核的数量。更奇怪的是,改变Lambda的内存分配大小将会改变CPU内核的数量。如果您共享一个AWS帐户用于性能测试和生产环境,那么如果性能测试意外地消耗了您的整个并发执行限制,您可能会降低生产。AWS很好地记录了这些服务的限制,所以一定要检查它,以便做出正确的体系结构决策。
由于安全补丁被自动应用到底层服务器,所以普遍存在一种误解,认为没有服务器的应用程序更安全。这是一个危险的假设。
由于无服务器体系结构具有不同的攻击载体,传统的安全保护将不适用。您的应用程序安全实践仍然适用,在代码中存储秘密仍然是一个很大的禁忌。AWS在其共享责任模型中概述了这一点,例如,如果数据包含敏感信息,您仍然需要保护数据。我强烈建议您阅读OWASP Serverless Top 10以获得关于这个主题的更多见解。
虽然您的操作开销显著减少,但值得注意的是,在极少数情况下,您仍然需要管理底层服务器更改的影响。您的应用程序可能依赖于本机库,您需要确保在升级底层操作系统时它们仍然在工作。例如,在AWS Lambda中,操作系统最近已升级到AMI 2018.03。
无状态的
函数即服务(或FaaS)是短暂的,因此不能在内存中存储任何东西,因为运行代码的计算容器将被平台自动创建和销毁。因此,无状态是无服务器体系结构中的一个特性。
无状态是横向扩展应用程序的一个好特性。无状态的概念是不鼓励在应用程序中存储状态。通过在应用程序中不存储状态,您将能够在不考虑应用程序状态的情况下水平伸缩更多实例。我在这里发现的有趣之处在于,您实际上是被迫成为无状态的,因此错误的空间大大减少了。是的,有一些注意事项:例如,计算容器可能被重用,您可以存储状态,但是如果采用这种方法,一定要小心处理。
在应用程序开发方面,您将无法使用需要状态的技术,因为状态管理的负担是强加给调用者的。例如,不能使用HTTP会话,因为您没有具有持久文件存储的传统web服务器。如果您想使用需要WebSockets这样的状态的技术,您必须等待,直到它被相应的后端作为服务支持,或者应用您自己的解决方案。
弹性
由于您的体系结构是无主机的,所以您的体系结构也具有弹性的特性。您使用的大多数无服务器服务都设计为高度弹性的,您可以从0扩展到允许的最大值,然后再回到0,大部分服务都是自动管理的。弹性是无服务器体系结构的一个特性。
弹性的好处对于可伸缩性是巨大的。这意味着您不必手动管理资源伸缩。资源配置的许多挑战消失了。在某些情况下,弹性可能只意味着您将只为您所使用的东西付费,因此如果您的使用模式较低,您将降低运行成本。
您可能不得不将您的无服务器体系结构与不支持这种灵活性的遗留系统集成在一起。当这种情况发生时,您可能会破坏下游系统,因为它们可能无法像您的无服务器体系结构那样伸缩。如果您的下游系统是关键系统,那么考虑如何缓解这个问题是很重要的——可能通过限制AWS Lambda并发性或使用队列与下游系统通信。
尽管如此高的弹性会让“拒绝服务”变得更加困难,但相反,你很容易受到“拒绝钱包”攻击。这就是攻击者试图破坏应用程序的地方,他们强迫您通过增加资源分配来超过云帐户限制。为了防止这种攻击,您可能会发现在应用程序中使用DDoS保护(如AWS Shield)很有帮助。在AWS中,设置AWS预算也很有用,这样当您的云账单飙升时,您就会得到通知。如果高弹性不是您在这里所期望的,那么在您的应用程序上设置约束也是很有用的—例如通过限制AWS Lambda的并发性。
分布式
由于无状态计算是一种特性,所以您拥有的所有持久性需求都将作为服务(BaaS)存储在后端,通常是它们的组合。一旦您更多地使用FaaS,您还会发现您的部署单元(即功能)比您所习惯的要小。因此,默认情况下,无服务器体系结构是分布式的——而且有许多组件必须通过网络集成。您的体系结构还包括将服务连接在一起,比如身份验证、数据库、分布式队列等等。
正如我们前面讨论过的,分布式系统有很多好处,包括灵活性。分布式还为您的体系结构带来了一个区域,即默认情况下的高可用性。在没有服务器的上下文中,当您的云供应商所在的区域中的一个可用性区域出现故障时,您的体系结构将能够利用仍在运行的其他可用性区域——从开发人员的角度来看,所有这些可用性区域都是不透明的。
在选择体系结构时总是要进行权衡。在这个特性中,您正在用可用性来交换一致性。通常在云计算中,每个没有服务器的服务也有自己的一致性模型。例如,在AWS S3中,对于S3桶中放入的新对象,您将获得写后读一致性。对于对象更新,S3最终是一致的。对于您来说,必须决定使用哪个BaaS是非常常见的,所以要注意它们一致性模型的行为。
另一个挑战是要熟悉分布式消息传递方法。您需要熟悉并准确理解一次性交付的难题,例如,因为分布式队列的常见消息交付方法是至少一次交付。由于这种交付方法,AWS Lambda可以被调用不止一次,因此您必须确保您的实现是幂等的(理解FaaS重试行为也很重要,其中AWS Lambda可能在失败时被执行不止一次)。您需要了解的其他挑战包括分布式事务的行为。然而,随着微服务的普及,构建分布式系统的学习资源一直在改善。
事件驱动
您的无服务器平台提供的许多BaaS自然会支持事件。对于第三方服务来说,这是一个向用户提供可扩展性的好策略,因为您无法控制它们的服务的代码。由于您将在您的无服务器体系结构中使用大量BaaS,所以您的体系结构是由trait驱动的。
我也认识到,即使您的体系结构是由trait驱动的,但这并不意味着您需要完全接受一个事件驱动的体系结构。然而,我注意到团队倾向于采用事件驱动的体系结构,当它自然地提供给他们时。这是一个类似的想法,将弹性作为特性,您仍然可以关闭它。
事件驱动带来了很多好处。您的体系结构组件之间的耦合程度很低。在无服务器架构中,很容易引入一个新函数来侦听blob存储中的更改:

图1:添加新的无服务器函数
注意,当您添加函数B时,函数A是如何不变的(参见图1)。具有高度内聚功能有很多好处,其中之一是,当一个操作失败时,可以很容易地重试它。当函数B失败时,重新尝试它意味着您不需要运行昂贵的函数A。
特别是在云环境中,云供应商将确保您的FaaS很容易与他们的BaaS集成。FaaS可以通过设计通过事件通知触发。
事件驱动体系结构的缺点是,您可能开始失去系统作为一个整体的整体视图。这使得对系统进行故障排除非常困难。分布式跟踪是您应该研究的一个领域,即使它在无服务器体系结构中仍然是一个成熟的领域。AWS X-Ray是一项可以在AWS中开箱即用的服务。x射线也有它自己的局限性,如果你已经超越了它,你应该关注这个领域,因为有第三方产品正在出现。这就是为什么日志关联id的实践是必不可少的,特别是当您在事务中使用多个BaaS时。所以一定要实现相关id。
结论
我在本文中介绍了六个无服务器体系结构特性:低进入壁垒、无主机、无状态、弹性、分布式和事件驱动。我的意图是尽可能广泛,以便您能够很好地采用无服务器体系结构。无服务器架构带来了一个有趣的范例转换,它使许多软件开发方面变得更好。但它也带来了技术人员必须适应的新挑战。还有一些关于如何处理每个特性带来的挑战的简短建议,希望这些挑战不会阻止您采用无服务器体系结构。
原文:https://www.thoughtworks.com/insights/blog/traits-serverless-architecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 54 次浏览
【无服务器架构】节俭Kubernetes Operator 第2部分:将控制器缩放到零
在本系列博客的第1部分中,我们介绍了这样一种想法,即Kubernetes运营商(在大规模部署时)可以消耗大量资源,无论是实际资源消耗还是可调度容量的消耗。我们还介绍了一种想法,即无服务器技术可以通过在活动控制器部署空闲时减少其规模来减少对Kubernetes集群的影响。在本文中,我们将基于闲置时将Pod实例的数量缩放为零的想法,介绍一种无需进行源修改即可减少现有控制器的资源开销的技术。
将控制器缩放至零
除了核心的Kubernetes平台之外,大多数运营商和其他通用控制器都使用Deployments或StatefulSets进行部署。这两种构造都具有将标度设置为特定值的能力。然后,Kubernetes平台添加或删除吊舱以实现所需的价值。但是,将控制器扩展到一个以上的实例通常仅提供冗余。这是由于内置的一致性检查所致,该检查可确保控制器容器不会相互干扰。以下是许多控制器和操作员所特有的部署:

如果将此类部署的规模设置为0,Kubernetes控制器管理器将终止任何正在运行的Pod,从而使我们没有任何活动的控制器实例来处理资源事件。实际上,在更改比例时,我们将禁用当前控制器的事件处理。
在最简单的情况下,控制器停止时不会发生资源修改,并且在修改监视的资源之前会恢复控制器规模。在这种情况下,只需将部署规模设置为大于零的标量值,即可将控制器恢复到之前的状态。但是,当控制器停止时发生资源修改的情况又如何呢?
Kubernetes中的和解是基于称为“级别触发”的概念构建的。在级别触发的系统中,对帐是针对整个状态进行的,而不是依赖于单个事件或自上次对帐以来发生的那些事件的顺序。当进行扩展时,我们的控制器将仅查看要监视的资源,并将其状态与目标资源协调一致,而不管过渡期间发生了多少个人更改。要了解有关Kubernetes中的电平触发的更多信息,请查看James Bowes的文章“ Kubernetes中的电平触发和对帐”。
自动缩放到零
如果Kubernetes控制器部署可以容忍从零扩展到零并且可以再次备份,那么这可以根据实际活动自动完成吗?绝对是,这是控制器零缩放器的目标。
控制器零缩放器本身就是一个Kubernetes控制器,它监视Kubernetes API的活动,一旦它们变得空闲,就会自动按比例缩小控制器,稍后在发生相关资源修改后恢复缩放。由于它是由各个控制器部署上的注释完全驱动的,因此可以在现有Kubernetes部署中启用零标度控制器而无需进行源代码修改。
图2显示了控制器零缩放器如何针对正在运行的控制器部署进行工作。

启动时,控制器零缩放器开始监视具有一组批注的部署。这些注释将部署标识为控制器零缩放器应对其执行操作的控制器。一旦确定部署正在管理中,控制器零缩放器便开始监视与该控制器相关的API服务器活动。一旦在一段时间内没有发生任何资源修改,就确定该单个控制器为空闲,并且其规模设置为零。
同时,控制器零缩放器会继续监视控制器需要处理的任何Kubernetes API服务器活动。如果确实发生资源更改,将恢复规模,这将对控制器吊舱做出反应。最终结果是,在发生诸如“ kubectl apply”之类的操作之后的几分钟内,下游资源修改将完成。
让我们来看一个使用Banzai Cloud中Istio Operator的示例。我们将执行以下顺序:
- 安装Istio操作员。
- 安装控制器零缩放器。
- 以零比例标注并观察Istio Operator。
- 创建一个Istio资源,并观察Istio Operator扩大规模并处理资源修改。
首先,将通过克隆项目并利用makefile来安装相关的“自定义资源定义”(CRD)和用于部署控制器容器的StatefulSet,来安装Istio Operator:
git clone git@github.com:banzaicloud/istio-operator.git
cd istio-operator
make deploy
通过查看正在运行的实例数(应为1)来验证此部署是否成功。 您可能需要等待片刻才能激活控制器,因为首先需要拉动图像。
kubectl get statefulsets -n istio-system istio-operator-controller-manager
NAME DESIRED CURRENT AGE
istio-operator-controller-manager 1 1 8s
现在,让我们部署控制器零缩放器。 由于Docker映像尚未公开可用,因此我们需要首先构建该映像。
再次,我们将验证控制器部署实际上已经开始:
|
现在,让我们来看看自动缩放的作用。 首先,我们需要在这个特定的控制器上启用零缩放,我们将使用一组注释来做到这一点。
kubectl annotate -n istio-system statefulset -l \
controller-tools.k8s.io='1.0'\
controller-zero-scaler/idleTimeout='30s'\
controller-zero-scaler/watchedKinds='[{"apiVersion": "istio.banzaicloud.io/v1beta1", "Kind": "Istio"}]'
statefulset.apps/istio-operator-controller-manager annotated
这将添加两个与零标度活动相关的注释:
- idleTimeout:定义将控制器确定为空闲状态的速度。 在这种情况下,我们需要至少等待30秒才能观察Istio控制器的当前状态
- watchedKinds:指示哪些API对象对该控制器有意义。 对于Istio运算符,它对名称为“ Istio”的自定义资源定义感兴趣。
等待至少30秒后,您应该看到Istio控制器容器已停止:
|
|
到目前为止,我们已成功将Istio控制器缩放为零。 现在,我们来看看更改Istio资源时会发生什么。 让我们使用istio-operator目录中提供的示例:
|
|
现在,我们可以通过查看Istio控制器的容器数量来验证放大是否成功。 我们还可以检查下游操作员动作是否发生。 对于Istio Operator,将安装一些自定义资源定义(CRD)(以及多个部署)。
|
|
博客系列的第3部分
控制器零标度解决方案非常适合现有的控制器实现,因为可以在单个集群上启用它而无需进行任何源修改。 这意味着您可以直接购买操作员,并带有正确的注释,即可立即受益。
Knative是另一种在运营商和Kubernetes控制器之外具有广泛吸引力的无服务器技术。 在本系列的最后一篇博文中,我们将探讨如何将Knative事件(使用Kubernetes API Server作为事件源)用作构建Kubernetes控制器和运算符的基础。
原文:https://www.ibm.com/cloud/blog/new-builders/being-frugal-with-kubernetes-operators-part-2
本文:http://jiagoushi.pro/node/874/
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 39 次浏览
【无服务器架构】跨平台的无服务器计算Knative 简介
Knative(发音为kay-nay-tiv)扩展了Kubernetes,以提供一组中间件组件,这些组件对于构建可在任何地方运行的现代,以源代码为中心和基于容器的应用程序必不可少:本地,云端或什至是第三方数据中心。
Knative项目下的每个组件都试图识别常见的模式,并整理成功的,真实的,基于Kubernetes的框架和应用程序共享的最佳实践。关键组件专注于解决平凡而又困难的任务,例如:
-
部署容器
-
通过蓝/绿部署路由和管理流量
-
自动缩放并根据需求调整工作负载
-
将运行中的服务绑定到事件生态系统
Knative上的开发人员可以使用熟悉的习惯用法,语言和框架来部署功能,应用程序或容器工作负载。
组件
Knative由服务和事件组件组成:
- 事件-事件的管理和交付
- 服务-可扩展至零的请求驱动计算
听众
Knative专为不同的角色而设计:
该图显示了Knative的不同受众

开发者
Knative组件为开发人员提供了Kubernetes本机API,用于将无服务器风格的功能,应用程序和容器部署到自动扩展运行时。
要加入对话,请转到Knative用户Google组。
运维者
Knative组件旨在集成到更精美的产品中,大型企业的云服务提供商或内部团队可以操作这些产品。
任何企业或云提供商都可以在自己的系统中采用Knative组件,并将收益传递给客户。
贡献者
通过明确的项目范围,轻量级的治理模型以及可插拔组件之间清晰的分隔线,Knative项目建立了有效的贡献者工作流程。
Knative是一个多元化,开放且包容的社区。 要参与其中,请参阅贡献并加入Knative社区。
您自己成为Knative贡献者的道路可以从以下任何组件开始:
- 服务
- 事件
- 文件资料
本文:http://jiagoushi.pro/node/876
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 56 次浏览
移动架构
【移动应用开发】2022 年 8 大移动应用设计趋势
大流行从根本上改变了我们的生活方式。 我们发现自己比以往任何时候都更热衷于数字和移动平台。 美国人平均每天检查他或她的手机 344 次,即每四分钟一次。 大约 88% 的美国成年人花时间在移动应用上。 在工作、在家、吃饭时、在床上,甚至在我们的车里——希望不是在开车时——我们都在使用手机。 您现在可能正在移动设备上阅读此内容。
随着移动应用程序的日益普及,公司正在加大投资以增强其用户体验,以使其更具竞争力并实现业务增长。 移动应用程序的用户体验设计趋势在不断变化。 每年,移动应用程序的世界都会发生巨大而渐进的变化,因此跟上最新的市场趋势至关重要。 在本文中,我将分享 2022 年您应该了解的最重要的移动应用设计趋势。
1. 聊天机器人
聊天机器人是改善客户体验和提供卓越服务的重要工具。
随着按需消息传递的兴起,客户的通信偏好也发生了变化。由于聊天机器人趋势的兴起,越来越多的商业部门将聊天机器人纳入其业务运营中,以提供持续的客户参与。聊天机器人是改善客户体验和提供卓越服务的重要工具。他们正在重新定义组织与现有客户和潜在客户的沟通方式。
聊天机器人是公司与客户建立长期关系的绝佳方式。它们还有助于建立值得信赖的品牌。随着人工智能(AI)的进步,您可以创建更智能的聊天机器人,更好地满足用户的需求。据 Gartner 称,在未来几年内,人工智能将成为主流的客户体验投资。图 1 显示了一个聊天机器人应用程序的示例。
2. 新拟态
Neumorphism 是拟物化和扁平化设计的演变。 Skeuomorphism 是一种设计风格,其中用户界面 (UI) 元素尽可能接近地复制真实世界对象的原始形状、纹理和颜色。 虽然在某些方面类似于拟物化,但新拟物是一种介于平面和 3D 图形之间的外观。\
neumorphism 的整体设计风格使用最小的调色板,并通过使用阴影来实现维度。 在拟态中,整个屏幕为中性色,并带有少量的亮色,如图2所示。拟态现在流行于移动应用程序图标和其他UI元素的设计中,观众似乎被迷住了 这种设计趋势对设计师来说很有趣,因为它允许他们尝试形式和颜色。
3. 语音助手
基于语音的助手需要出色的语音用户界面 (VUI),使用户能够仅使用语音命令与系统进行通信。
基于语音的助手市场正在迅速增长,这是最热门的移动应用程序设计趋势之一。 仅在美国,就有大约 1.1 亿虚拟助理用户。 根据 Statista 的报告,到 2024 年,数字语音助手的数量将达到 84 亿。
基于语音的助手需要出色的语音用户界面 (VUI),使用户能够仅使用语音命令与系统进行通信。 谷歌助手、Siri 和亚马逊的 Alexa 是三个最受欢迎和知名的语音用户界面。 VUI 的主要好处是它们允许用户与系统交互,而无需查看或使用他们的手。 图 3 显示了一个基于语音的助手的示例

在设计 VUI 时,您必须执行以下操作:
- 研究你的目标受众。
- 进行竞争分析。
- 定义明确的要求。
- 通过可用性测试验证设计和实现。
- 了解语音命令的结构。
4.黑暗模式
深色模式是一种低光用户界面,主要使用深色。在过去几年中,暗模式已成为移动应用程序设计中非常受欢迎的功能。一些世界上最知名的品牌在其移动应用程序中加入了明暗模式。
用户可以从黑暗模式中受益,因为它可以通过降低整体屏幕亮度来放松眼睛并减少眼睛疲劳。它还通过减少明亮像素的使用来节省能源并延长电池寿命。深色主题尤其适合有机发光二极管 (OLED) 屏幕,因为它们可以节省能源并延长显示器的使用寿命。
类似于图 4 中所示的黑暗主题在移动应用程序用户界面设计中变得越来越普遍。它们引人注目的外观很吸引人,并引起了对用户体验的更多关注。在设计黑暗主题时,您必须确保它们清晰、稳定和有趣。如果深色主题设计不正确,可能会降低应用的可访问性。
5. 3D动画
近年来,移动应用程序设计中 3D 功能的使用发生了变化。这样的设计元素不仅仅用于装饰;它们还具有明确的功能目的。
虽然并不新鲜,但 3D 设计趋势正变得越来越流行。多年来,移动应用程序和网站一直使用 3D 图形元素。然而,近年来,移动应用程序设计中 3D 功能的使用发生了变化。这样的设计元素不仅仅用于装饰;它们还具有明确的功能目的。由于智能手机的硬件能力有了显着提升,它们现在支持处理日益复杂的 3D 图形效果。
当然,为移动应用程序设计 3D 图形需要专业知识并且是一项具有挑战性的工作,但结果可能是惊人的。在制作 3D 图形时,UX 设计师必须记住优先考虑提高交互效率,其次才是追求令人惊叹的效果。当用户可以 360 度查看产品时,这可以改善整个电子商务用户体验。
使用 3D 效果可以将用户的注意力吸引到应用程序上,并使其看起来更具吸引力。因此,越来越多的公司将 3D 效果整合到他们的应用程序和服务中,以复制真实世界的体验,如图 5 和图 6 所示。


6. 数据可视化
数据可视化提高了用户参与度和转化率。
您希望数据可视化成为您的移动应用程序的基石吗?那么你肯定走在正确的轨道上,因为数据可视化提高了用户参与度和转化率。
当所有用户必须查看的是一堆数字或步骤时,数据并不总是最容易理解或解释的东西。由于比较多个不连贯的数据点需要脑力劳动,因此纯文本形式的数据通常更难于用户理解。但是,如果您通过图形和图表等视觉效果呈现数据,则更容易理解。这就是数据可视化如此有价值的原因。
每当用户必须搜索大量历史数据时,分析数据的任务就会变得更加困难。数据可视化通过允许用户查看数据中的关键趋势和模式来解决这个问题。
例如,在图 7 所示的投资应用程序中,通过查看股票价格图或图表,用户可以立即了解趋势和波动。
当数据采用可视化格式时,我们的大脑可以更快、更有效地掌握它的含义。根据 Sprinklr 的 Ekaterina Walter 的说法,我们的大脑处理视觉的速度比文本快 60,000 倍。因此,数据可视化是任何包含大量复杂信息的应用程序的重要组成部分。
7. 渐变
渐变或颜色过渡通过使他们能够使用多种颜色,为设计师提供了很大的灵活性。颜色的力量可以成就或破坏产品。近年来,随着移动应用设计趋势的快速变化,一些设计元素在一段时间内消失,然后逐渐卷土重来。渐变就是这样一种元素。它们现在正在复苏,多色调效果在现代设计中发挥着关键作用。
您可以通过多种方式使用渐变。它们可以是设计的焦点,也可以仅仅是背景元素。他们可以是侵略性的或微妙的。渐变还可以让您生成感觉不同和现代的新鲜颜色组合。如图 8 所示,混合和混合不同深浅的颜色可以为您的设计带来独特的氛围。
8.圆形
我们在移动应用程序设计中看到了很多圆形。 什么时候应该使用圆角矩形? 这取决于您想要在用户中引起的感受以及您想要传达的品牌形象。
根据形状心理学,圆形、椭圆形和椭圆形代表永恒,没有开始也没有结束。 圆角矩形唤起对用户的温暖和信任。 出于这个原因,人们经常将它们称为友好的矩形。 这就是为什么这么多注册、登录和购买按钮都有圆角的原因,如图 9 所示。这些设计元素帮助客户确信他们应该与品牌保持关系或开展业务。

人脑将圆角与安全联系在一起,因此圆形看起来更有吸引力,如图 10 所示。 考虑所有现代 Android 和 iOS 智能手机设计。 它们没有任何锋利的边缘,是吗? 将此类设计元素融入移动应用程序可增强整体用户体验。 今天,所有移动应用程序和网站都具有与这些高级设备的设计相呼应的圆润外观。 这些是未来的用户体验设计解决方案。
用户体验设计对移动应用程序的意义
移动应用程序设计的主要目标是增加应用程序的流量,进而增加公司的投资回报……
今天,拥有一个好的移动应用程序是必不可少的。通过 UX 设计,我们可以提供成功的移动应用程序并创造持久的客户体验。移动应用程序设计的主要目标是增加应用程序的流量,进而提高公司的投资回报率 (ROI)。
更多地关注 UX 和 UI 设计是使您的移动应用程序成功的最重要的事情。在这个数字时代,有如此多的应用程序可以满足各种目的,因此设计始终是应用程序成功的关键因素。
在移动应用市场中,具有吸引人的外观和精确导航的移动应用更有可能获得成功。例如,考虑一下我们几乎每天都在使用的一些应用程序。 WhatsApp、Instagram 和 Facebook 具有出色的功能并且看起来很棒。
公司如何从出色的用户体验设计中受益
开发设计良好的移动应用程序的公司可以从中获得以下好处:
- 提高客户满意度
- 更高的转化率
- 更高的投资回报
- 更好的客户保留
结论
您现在已经精通当今最热门的移动应用程序设计趋势。与这些设计趋势保持同步可确保您的应用程序处于移动用户体验设计的最前沿。然而,由于移动应用程序设计趋势不断变化,跟上当前的设计趋势需要不断努力并理解用户体验设计对移动应用程序的重要性。
本文:https://jiagoushi.pro/top-8-mobile-app-design-trends-2022
- 97 次浏览
【移动应用开发】2022/2023 年 8 大移动应用程序开发趋势
迄今为止,技术进步见证了超过 500 万个应用程序的开发。在全球范围内,应用程序开发市场很火爆,预计未来几年将继续火爆。
到 2022 年,预计会更大、更快,总体上会带来向应用程序的巨大转变。让我们分解专家们正在寻求深入研究移动应用程序开发的一些趋势和机会。
5G
为提高性能速度、快速数据传输和降低延迟提供服务,5G 的采用已经开始,预计到 2030 年它将成为移动技术的新标准。
人工智能和机器学习
为了提供个性化的用户体验,人工智能和机器学习已经并将成为关键技术。虽然前者对于导航、语音识别和自然语言处理至关重要,但后者将通过分析用户行为来确保更高的安全性。
增强和虚拟现实
AR 和 VR 已经使卖家和服务提供商能够与他们的客户进行个人互动。在未来几年,他们肯定会改善学习体验,使应用程序更具吸引力和吸引力。
区块链
这项技术确实是今年最新的移动应用程序开发趋势之一。区块链是应用程序用户担心的安全问题的解决方案。由于不需要单一的服务提供商或看门人,它提供了一个分散的数据库,这使其成为一种新兴趋势。
移动商务
移动商务经常被误认为是电子商务。他们不一样。移动商务可以被称为电子商务的扩展,其中交易通过移动应用程序在线进行,而不是移动网页。这一趋势表明,参与度和转化率的提高导致了企业的收入增长。
PWA 和即时应用
PWA 越来越受欢迎,因为它们填补了大多数原生应用程序和网页的空白。由于减少了对互联网连接的依赖、更快的加载和开发时间、自动更新等,这些对消费者和服务提供商都有好处。
即时应用程序也将类似地开发,因为允许用户在下载和安装应用程序之前对其进行测试。
烽火科技
尽管早在 2013 年就推出了信标技术,但它越来越受欢迎,尤其是在零售业务中。 它使企业能够了解客户的购物偏好和模式,从而为他们提供更加个性化的体验。
可穿戴设备
可穿戴移动应用程序开发也将在 2022 年出现大幅增长。可穿戴技术不仅限于智能手表。 它包括所有可以佩戴在身上或附在衣服上的设备。
除此之外,未来几年可能会出现无数其他移动应用程序开发趋势。 大流行进一步加速了这些趋势,掌握最新趋势总是好的,因为它提供了比竞争对手明显的优势。 整合相关趋势肯定会让您的业务取得成功。
本文:https://jiagoushi.pro/top-8-mobile-app-development-trends-20222023
- 59 次浏览
【移动应用趋势】2022 年值得关注的 15 大移动应用开发趋势
移动应用程序开发行业正在以惊人的速度发展。为了在这个数字达尔文时代生存和发展,您必须熟悉不断变化的移动应用程序开发趋势。
今天,智能手机是数字媒体成功的关键。它以惊人的速度从根本上改变了商业模式、运营模式和市场。到 2022 年,移动应用市场收入预计将达到 6930 亿美元。
然而,另一个可怕的事实是大多数移动应用程序都失败了。无法跟踪和实施最新的移动应用技术趋势是此次失败的主要原因。这一缺点也导致输给技术适应性更强的竞争对手。
为了让您的移动应用程序取得成功,向前迈出的第一步是紧跟 2022 年的移动应用程序开发趋势。让我们详细讨论其中的一些最新趋势。
2022 年的顶级移动应用程序开发趋势是什么?
虽然今年移动应用程序开发出现了许多新趋势,但以下是我们在基于事实的详尽研究后挑选出的 14 大移动应用程序开发趋势。
一、5G崛起
5G技术已经存在了一段时间。但今年,它成为了一个流行词。科技公司已开始全面整合 5G,我们在市场上看到支持 5G 的设备。到明年,预计将有 6.6 亿部智能手机拥有 5G 连接,约占所有设备的 47.5%。
看看未来几年全球 5G 连接预计将如何增长。
5G 的兴起对 App 开发意味着什么?
5G 将改变我们构建和使用应用程序的方式。速度和效率将显着提高。以下是我们可以期待的几件事:
- 5G 将比 4G 快 100 倍。
- 延迟将从 50 毫秒 (4G) 减少到 1 毫秒。
- 凭借更高的分辨率、更少的延迟和更快的性能——视频流应用程序将得到显着改进。
- 5G 将为 AR 和 VR 带来更多机会,因为将这些技术集成到应用程序中会更容易。
- 在设备和智能手机之间传输数据将更快、更顺畅。
- 5G 将允许开发人员构建新功能,而不会对应用程序性能产生负面影响。
- 由于生物识别数据的处理速度更快,移动支付将更快、更安全。
总体而言,5G 技术将使应用程序更快、更流畅、更高效。它还将为创新打开空间。您可能对您的应用程序拥有的所有令人兴奋的想法将不再是想法。借助 5G,您可以将它们变为现实。我们迫不及待地想看看这项技术带来了什么。
2. 可折叠设备的应用程序
尽管可折叠设备是整个智能手机市场份额的一小部分,但未来几年情况将会发生变化。据 Statista 称,到 2022 年将出货 5000 万台。因此,在规划移动应用程序开发策略时,您也应该牢记可折叠设备。确保您的应用程序在可折叠设备上无缝运行——这是 2022 年具有挑战性的移动应用程序开发趋势。
展开设备以提供更大的屏幕可以对用户产生积极影响:
- 更大的屏幕意味着更多的空间,可提供详细和身临其境的体验。
- 使用多窗口,用户可以同时执行多个任务。
视频流和游戏应用程序可以通过简单地增加屏幕尺寸来从可折叠设备中获得最大的好处——或者相反,使用额外的空间来提供额外的信息和控制。因此,开发牢记屏幕的应用程序将是 2022 年最大的移动应用程序开发趋势之一。

3. 增强现实和虚拟现实
Pokemon Go 的成功可能是暂时的,但它为 AR 在移动应用程序开发中铺平了道路。它向世界展示了我们实际上可以使用 VR 为用户提供身临其境的体验。
今天,环顾四周,我们可以发现很多品牌使用AR&VR来提升用户体验的场景。
- 宜家使用 AR 让用户在购买前了解家具的外观。
- 欧莱雅有一个虚拟化妆应用程序,让用户可以看到他们脸上的妆容。
- Lenskart 让用户在购买之前虚拟试戴眼镜。
甚至苹果、谷歌和 Meta 都在 AR 和 VR 领域带来了创新。谷歌在谷歌地图中引入了一项名为“实时视图”的功能,用户可以在现实世界的图像上实时查看方向。
LiDAR 是我们最近在 AR 领域看到的另一项重大技术进步。被 Apple 称为光速增强现实——我们看到这项技术在 iPad Pro、iPhone 12 Pro 和 iPhone Pro 12 Pro max 中首次亮相。它将AR带入了一个全新的水平。借助 LiDAR,可以在低光照条件下拍摄出高质量的照片。
苹果甚至通过与宜家合作推出使用激光雷达技术的新工作室模式功能,彻底改变了家具购物流程。 使用该功能,用户可以将他们的设备指向他们想要放置家具的地方,激光雷达技术将扫描房间以虚拟放置真实比例的家具模型。
今年,我们将看到 AR 和 VR 以我们无法想象的方式塑造移动应用开发行业。 移动应用程序趋势将变得更加主流。 据 Statista 称,AR 和 VR 技术的全球市场将从 2018 年的 270 亿美元增长到 2022 年的约 2090 亿美元。
今年我们还将看到 AR 和 VR 用户数量激增。 这意味着您有很好的机会利用这些移动应用程序开发趋势为移动用户带来改变游戏规则的体验。
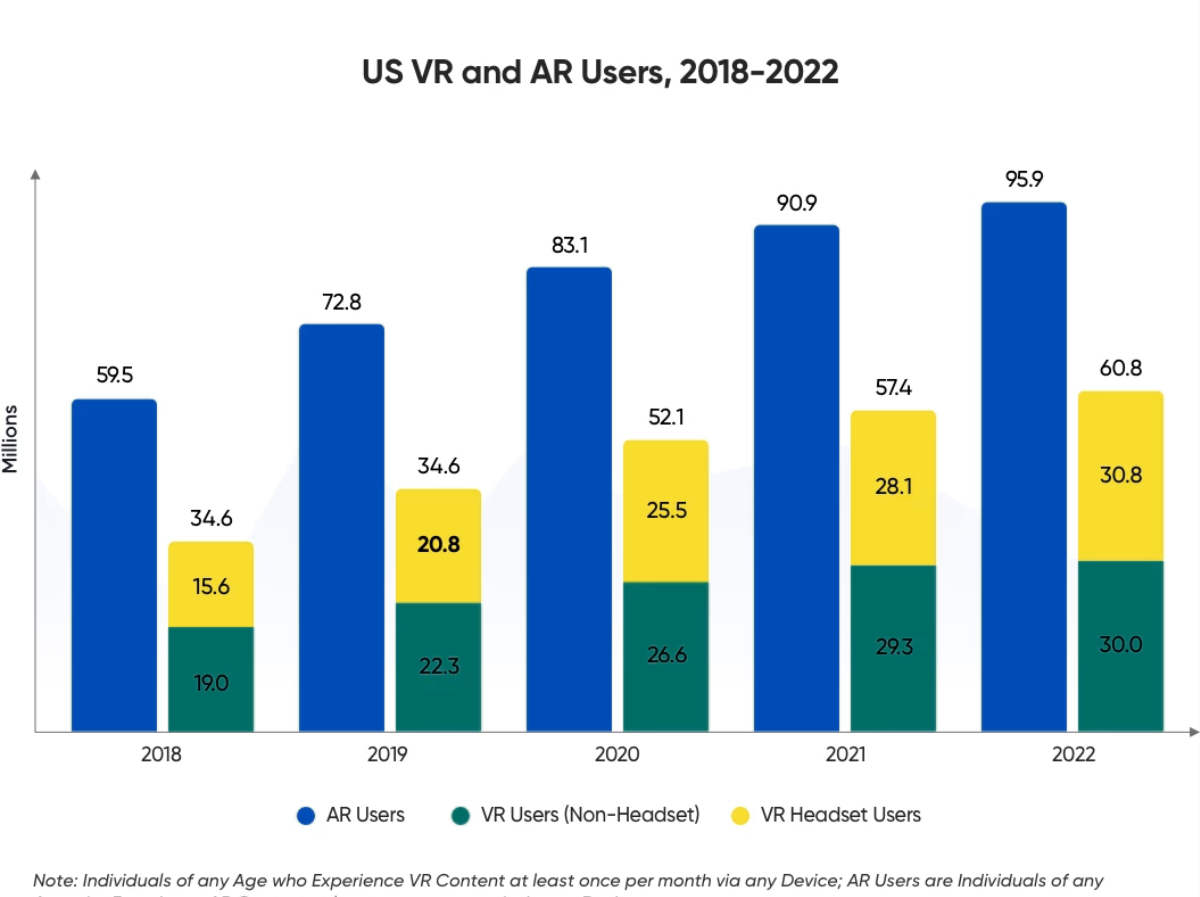
4. 可穿戴应用集成
可穿戴设备已经统治着世界。根据 Statista 的数据,2017 年连接的可穿戴设备达到 4.53 亿台,到 2022 年将达到 9.29 亿台。
今年,我们看到可穿戴设备行业发生了许多重要的事情。 Apple 宣布其 WatchOS 8 更新。它为 Apple Watch 用户带来了新功能、全新的表盘、增加了钱包访问权限以及重新设计的界面。
甚至谷歌也宣布了一个统一的可穿戴设备平台,将其可穿戴操作系统与三星的 Tizen 软件平台相结合——将应用程序启动时间提高了 30%。
它标志着可穿戴技术的兴起——这是 2022 年重要的移动应用程序开发趋势之一。
换句话说,应用程序开发人员和企业应该准备好为智能手表和可穿戴设备上的用户提供出色数字体验的应用程序,从而比那些不这样做的人获得明显优势。
拥抱这种移动应用程序开发趋势,并通过为他们提供无缝的数字体验来接近您的目标客户。
5. 食品和杂货配送应用
人们在封锁后呆在家里,开始严重依赖 Instacart 和餐包等应用程序。因此,这两个是 2020-21 年增长最快的应用程序类别。
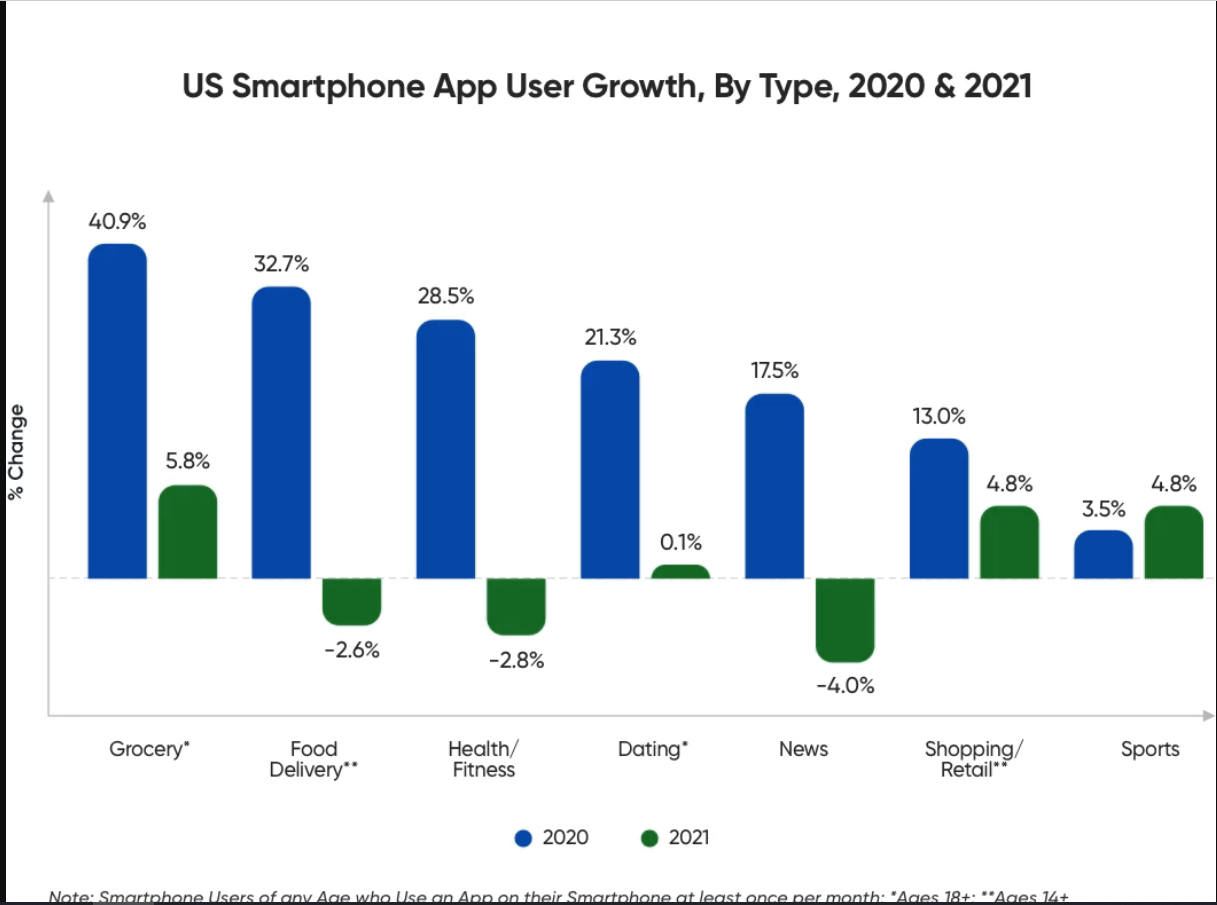
如您所见,2020 年杂货应用程序用户增长了 40.9%。大多数人更喜欢在网上购买杂货,而不是去实体店。
送餐应用程序也是如此。他们看到了 32.9% 的增长,因为人们更喜欢在线订购食物,因为它感觉更安全。
然而,正如你所看到的,这两款应用的受欢迎程度在 2021 年都有所下降。虽然杂货应用增长了 5.8%,但送餐应用的用户却下降了 2.6%。
随着我们恢复正常,我们可能会看到它们的增长略有下降。食品和杂货应用程序仍将是我们生活的重要组成部分。人们将永远不会停止在线订购食品,杂货应用仍将占智能手机用户的 15.5%。
无论如何,只有时间会证明一切。但看看 2022 年道路食品和杂货配送应用程序会采取什么措施将会很有趣。
6. 移动娱乐和游戏
娱乐和游戏应用程序已成为生活方式的一部分。有些人甚至无法想象没有他们可以度过一天。
我们可以猜测移动娱乐应用程序的受欢迎程度,因为 Netflix 在美国和加拿大拥有约 74% 的活跃用户。不仅如此,拥有超过 1.591 亿的手机游戏玩家,移动设备是游戏玩家的最爱——占美国数字游戏玩家的 89% 以上。
正如我们已经在这些统计数据中看到的那样,这个数字在 2022 年甚至会上升:

为什么移动娱乐和游戏应用如此受欢迎?
- 他们提供了方便的娱乐方式。人们不再需要购买昂贵的小工具甚至昂贵的笔记本电脑。相反,他们可以在移动设备上享受它们。
- 用户不再需要将自己限制在一个地方看电影或玩游戏。相反,他们可以在旅途中自娱自乐。
- AR、VR 和人工智能等技术进步使游戏和娱乐应用程序更加身临其境。
- 移动娱乐和游戏应用程序提供了一个很好的逃避。尤其是在大流行期间,人们花时间在游戏和娱乐应用上来分散自己的注意力。
7. 人工智能与机器学习
在 FaceApp 取得突破性的成功之后,大多数人都在想:下一步是什么?就在那时,人工智能带来了一些将我的期望提升到一个全新水平的东西。 MyHeritageApp 带来了强大的照片动画功能,可将图片转换为逼真的动画。这些动画令人印象深刻,让您感觉您所爱的人在对您微笑。它导致了一些史诗般的反应。
这不是去年 AI 领域发生的唯一令人兴奋的事情。我们还看到谷歌为其地图应用程序推出了新功能,使用人工智能来增强用户体验。其中一项功能是实时视图,可在大型室内空间为用户提供 AR 导航。谷歌还使用人工智能通过优化路线以降低油耗来建议碳密集度较低的路线。
在过去的几年里,人工智能和机器学习一直是顶级移动应用程序开发趋势之一。但是这些技术进步为 2022 年的移动应用程序开发设定了非常高的标准,看看它今年会带来什么将会很有趣。
机器学习是另一个令人兴奋的领域,我们正在等待看到革命性的事情发生。当深度学习与 ML 携手合作时,它可以通过提供有价值的数据和实时分析,为移动应用程序开发项目创造奇迹。
全球 ML 行业以 42% 的复合年增长率增长,到 2022 年下半年将价值近 90 亿美元。——2019 年的机器学习
苹果一直是机器学习领域的主要参与者之一。其智能 ML 模型使开发人员能够创建身临其境的新体验。您不仅可以轻松添加预先存在的功能,还可以创建新功能。此外,您可以使用 ML API 添加新功能。
今年,我们建议您更深入地了解这些技术,并正确熟悉它们的功能和许多组件。
8. 将更加关注移动应用安全
根据 Check Point 2021 年移动安全状况报告,大约 46% 的组织至少有一名员工下载了恶意移动应用程序。考虑到员工对移动设备的依赖程度,这是企业关注的问题。
这就是为什么大多数企业都希望在网络安全方面进行更多投资,因为它与数据保护和信息隐私法直接相关。因此,数字安全已成为 2022 年移动应用程序开发的主要趋势之一。业内最优秀的人才正在加大赌注,以消除围绕移动应用程序的不确定性。在 WWDC 2021 中,Apple 通过引入一项名为“iCloud 链中的密码”的新功能,迈出了迈向无密码未来的第一步。有了它,Apple 将用更安全的登录过程替换密码。

2022 年,移动应用程序开发行业预计将见证向安全优先方法的转变,从而为稳健的 DevOps 战略奠定路线图。
9. 超级应用
一个应用,一个目的——多年来一直是移动应用开发公司的做法。 但现在,方法正在发生变化。 公司正在从单一用途的应用程序转变为解决多种用途的一站式解决方案。
这样的应用程序被称为超级应用程序,它们在亚洲非常受欢迎。 然而,这一趋势也在西方迎头赶上。 美国市场上一个有趣的例子是由加利福尼亚公司 Brain Technologies Inc. 开发的 Natural AI。它致力于改变人们与手机交互的方式,使他们能够通过一个应用程序解决多个目的。

此外,您可能已经观察到 Facebook 是如何从一个社交媒体平台扩展而来的。它现在还提供人们可以买卖产品的市场。同样,除了在线购物之外,您现在还可以从亚马逊支付账单和付款。
西方世界对超级应用的热潮并不高,因为人们更喜欢在确定一个解决方案之前尝试不同的解决方案。尽管如此,便利是每个人最终追求的。所以,超级应用是2022年我们值得期待的移动应用发展趋势。
10. 移动商务
电子商务部门的销售额为 3.56 万亿美元,其中 72.9% 的销售额发生在移动设备上。因此,移动商务是一个上升的应用程序发展趋势。
在 COVID 大流行之后,我们看到了生活方式的重大转变。从大型零售商到小型企业和个人消费者,每个人都开始依赖移动应用程序。
它使无法适应的电子商务企业处于不利地位。他们正在失去很多客户,并错过了他们可以转化的客户。
因此,企业需要适应这一趋势并拥有电子商务业务应用程序。这是他们在激烈的竞争中生存下来的唯一途径。
但是,移动商务作为流行语不应该是您拥有适合您业务的应用程序的唯一原因。我们在博客中详细介绍了为什么您需要电子商务业务应用程序的许多其他原因。你必须检查一下。
11. P2P 移动应用
P2P 移动应用程序是移动应用程序开发领域的另一个重要趋势。根据 eMarketer 的预测,到 2023 年,P2P 移动交易额预计将达到 6122.3 亿美元。这意味着目前 P2P 移动应用程序的发展空间很大。

便利性是 P2P 移动应用程序在企业和用户中越来越受欢迎的原因。用户可以快速付款,而卖家可以直接将款项存入他们的账户。因此,没有不必要的麻烦。
以下是我们今年可以在我们周围看到的一些类型的 P2P 移动应用程序:
- 具有内置支付功能的社交媒体平台。
- 带有内置支付系统的移动操作系统。例如 Apple Pay、Samsung Pay、Android Pay。
- 提供自己的支付系统的独立提供商。
- 涉及银行作为支付方的 P2P 应用程序。
- 加密货币钱包。
如果您有一个 P2P 移动应用程序的想法,现在就是将其变为现实的最佳时机。
12. 区块链
我们第一次听说区块链是在加密货币繁荣时期。但现在这项技术已经取得了长足的进步,并适用于不同的领域。它正在以显着的速度增长,预计到 2024 年将累积 200 亿美元的收入。区块链也在移动应用程序开发中发挥着关键作用。
如今,去中心化的应用程序已经成为一种趋势。有超过 7000 万个区块链钱包,其中移动钱包是最受欢迎的区块链钱包形式。这些统计数据还显示了区块链钱包用户的数量是如何显着增加的,
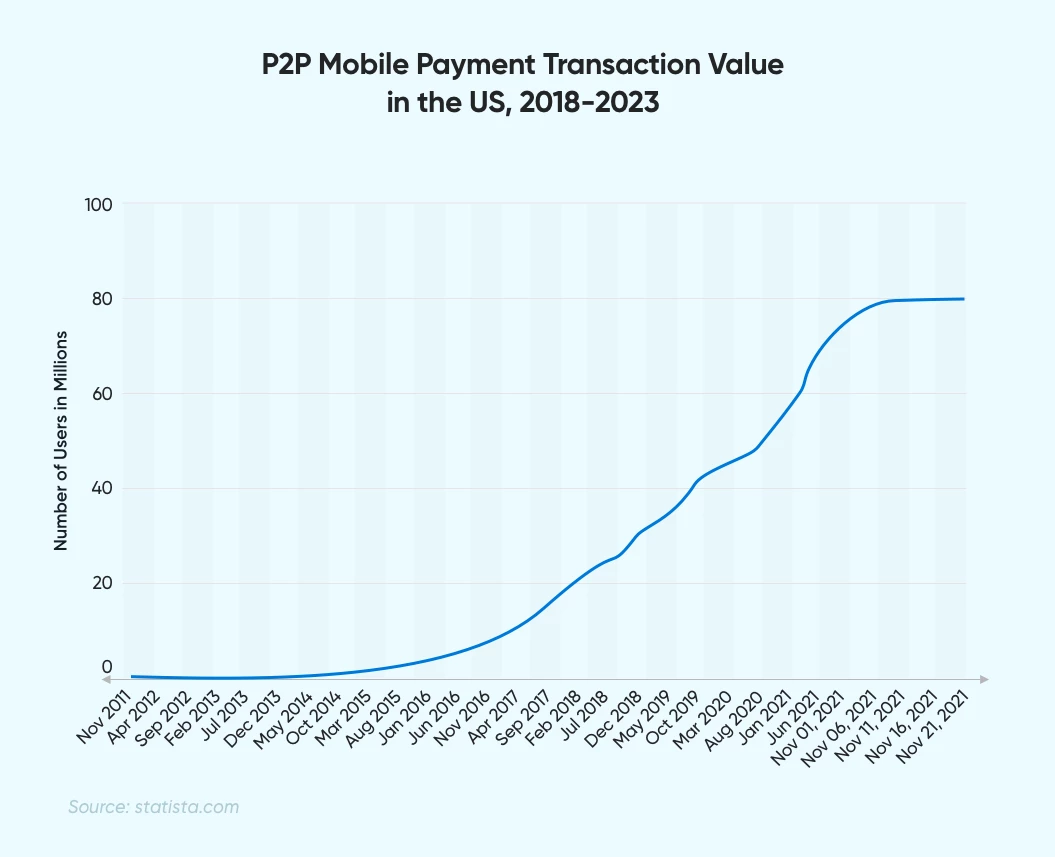
此外,我们还看到使用区块链来跟踪数字资产、保护数字身份和跟踪忠诚度计划的货币转换器。
在 2022 年及以后,我们看到智能合约、反盗版软件、调节选举的工具和区块链即服务 (BaaS) 平台的趋势将变得更加主流。特别是在移动商务和移动支付应用程序中,我们可以使用区块链来防止欺诈的发生。
13. 预测分析
一段时间以来,企业一直在移动应用程序中使用预测分析。 Netflix 使用它根据用户的观看习惯推荐电影和电视节目。此外,亚马逊利用预测分析来个性化产品推荐。
今年,我们将看到预测分析变得更加主流。在以下两个领域,我们可以看到这一趋势在 2022 年的移动应用程序开发中发挥着至关重要的作用:
- 优化开发流程:企业可以处理从开发人员那里收集的数据,以便在问题发生之前发现问题并提出更好的替代方案。
- 改善用户体验:企业可以使用用户数据来预测用户的行为并个性化他们的旅程。
因此,我们可以显着缩短开发时间,同时保持卓越的质量并更加专注于提供创新。
14. 移动学习
据 Statista 称,35% 的员工经常使用移动设备进行学习。此外,预计到 2025 年,移动学习市场将达到 585 亿美元,预计 2020-2025 年的复合年增长率为 21.45%。因此,移动学习是一个很有前途的趋势,它将改变移动应用程序开发的面貌。
移动学习之所以出名,原因有很多。首先,它使学习变得容易。学习者感到有能力,因为他们可以从任何地方和任何人那里学习。此外,持续反馈和 360 度学习等体验使学习变得互动和有趣。
甚至企业现在也偏爱移动学习,因为它可以带来更好的课程完成率、更快的学习、更高的参与度和更好的知识保留。
因此,对移动学习应用程序的需求很高。如果您有一个开创性的想法或计划推出移动学习解决方案来培训您的员工,那么现在正是联系专门从事教育应用程序开发的团队的最佳时机。
15. 支持物联网的移动应用
互联网已经深入我们的生活。从智能手机、笔记本电脑和平板电脑到语音控制的智能家居设备——我们被连接到互联网的设备所包围。物联网 (IoT) 已不仅仅是一种趋势。到 2022 年,估计价值 5940 亿美元,它已成为我们日常生活的一部分。
在过去的几年里,我们看到亚马逊和谷歌等品牌充分利用了这项技术。他们分别推出了“Echo”系列设备和谷歌家庭语音控制器,加强了物联网的竞争。
但现在三星、小米、博世和霍尼韦尔等品牌也在快速转向物联网技术。零售、智能家居和精明的健康保险计划中的连续供应链不再是科幻小说,而是现实生活。
随着对物联网小工具和系统需求的增加,对支持物联网的应用程序的需求也将同步增加;因此,我们将其列入了 2022 年顶级移动应用程序开发趋势列表。
结论
Google 和 Apple App Store 上共有 663 万个应用程序。 您将如何确保您的应用程序脱颖而出?
事实是,除非您紧跟最新的移动应用程序开发趋势,并且知道如何利用它们来交付强大、功能丰富的应用程序,否则您将无法做到这一点。
移动应用行业将继续快速扩张,移动应用发展空间将不断演变。 新兴的移动应用平台开发技术、新兴的后端平台和微服务,结合新的硬件能力,将继续引领移动应用解决方案。 不断的学习和不断的意识是在激烈的竞争中生存下来的唯一途径。
2022 年我们还可以期待哪些其他移动应用程序开发趋势? 请在评论中告诉我们。
本文:https://jiagoushi.pro/top-15-mobile-app-development-trends-watch-2022
- 137 次浏览
【移动开发】2022 年 12 大移动应用程序开发趋势
据统计,Google Play Store 和 Apple App Store 中有超过 500 万个应用程序可用。对于更具创新性的解决方案,企业需要顶级移动应用程序开发趋势来帮助企业持续增长的端到端软件开发。然而,随着技术和数字化世界的发展,需求也在增加。
顺应移动应用程序开发趋势的想法为出于个人目的使用该应用程序的用户提供了机会和更大的灵活性。因此,移动设备的使用正在增加,因此大多数公司都期待通过应用程序展示他们的服务或产品。
2022 年的移动应用程序开发趋势不断更新,从人工智能 (AI)、可穿戴设备、增强现实 (AR) 和按需应用程序的最佳使用到指定团队和开发高效的移动应用程序解决方案。
假设您在印度选择了一家经验丰富的软件开发公司、熟练的开发人员和 QA 团队测试应用程序以获得更好的生产力和功能,这表明了应用程序的兼容性。如果您计划开发一款在市场上持续存在的成功应用程序,那么这篇关于即将到来的移动应用程序趋势的文章将帮助您更好地为客户服务。
为什么要提前思考正确的策略?
至于移动应用程序开发的最新趋势,2022 年为寻求开发成功应用程序的企业带来了新机遇。它更多地是将技术整合到您的业务应用程序中,为您的用户提供卓越的体验。
移动应用程序的 AR 和 VR 开发、物联网的商业用途、可折叠设备的应用程序等技术是即将推出的移动应用程序功能的示例。有多种趋势需要密切关注,它们会带来剧烈的变化,包括:
- 2021 年 2 月,Google Play Market 发布了 85,500 个应用程序,并且竞争更加激烈。
- 随着移动应用程序的需求,供应也在增加。经验丰富的开发人员正在提供出色的移动应用程序。
- 在竞争激烈的世界中,新的和相关的产品应用赢得了比赛。
每个组织都遵循最新趋势,尤其是软件开发公司,这将帮助您根据您的应用需求和不断变化的市场趋势获得合适的开发人员和技能组合。
移动应用程序趋势可以改变您对如何以及哪个应用程序在全面移动应用程序开发中发挥关键作用的想法。此外,当市场可能有类似的想法或可能还没有为任何相关应用程序做好准备时,市场研究和推迟发布可能是有益的。
下面的 2022 年移动应用趋势列表不仅仅是一个怀疑。我们已经展示了一些基于研究的顶级移动应用程序开发趋势,这些趋势将超过 2022 年。
1. 融入 5G 技术
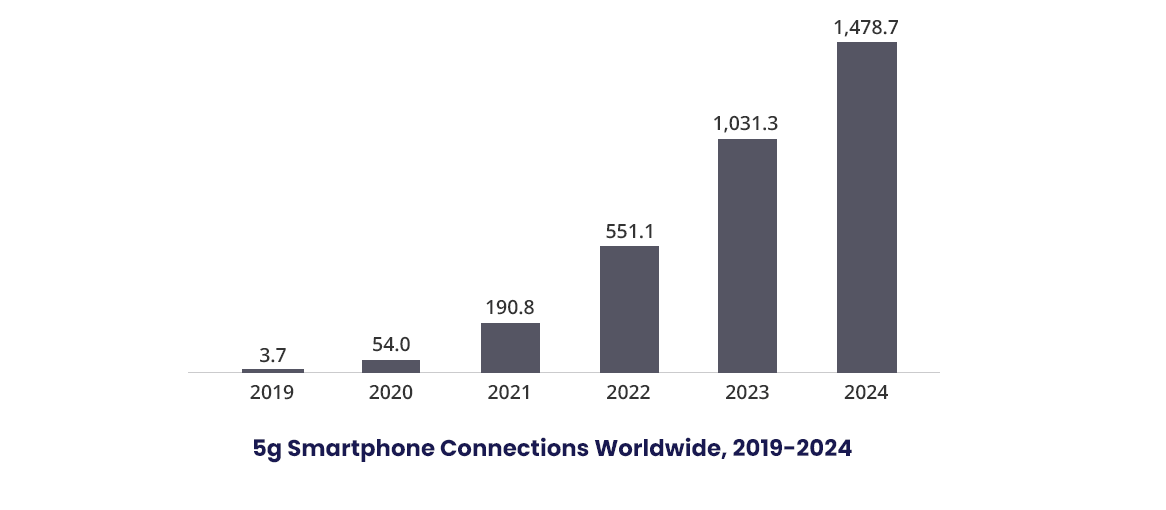
我们已经看到了移动应用程序的发展趋势及其对 5G 技术的贡献,以通过不断变化的技术提供卓越的客户体验。作为 2022 年这一趋势的一部分,移动设备的准确性和效率将显着提高。
随着 IT 行业的发展,软件开发公司正在向现代发展方向发展,并借助 5G 技术提供从提高网络效率到流量容量的成功应用。
在应用程序开发和测试期间使用 5G 技术,该组织可以提供改进的解决方案并更快地取得成果。
财富 5G 应用包括:
- 无人驾驶汽车技术
- 机器驱动的解决方案
- 云计算
- 无线医疗/保健服务
2. 物联网 (IoT) 应用集成
物联网代表了一个不断增长的互连设备网络,为消费者提供自动化控制和便利。被称为智能家居的智能设备和自动家电是物联网技术和移动应用程序开发的精确例子。
物联网不是一个新概念,而是随着技术的进步而大幅增长。借助物联网,移动设备在各个领域和类别中的普及率不断提高,创造了无穷无尽的机会。
用户已经习惯并且对移动应用程序的要求更高,印度的软件开发公司提供基于技术的解决方案来改善他们的日常生活。
移动应用程序不仅可以通过电话、安排、开会和订购食物让您的日常生活变得轻松,而且还可以从远程位置(如锁或解锁前门并连接到家)满足家庭需求安全系统。
根据该报告,预计 2022 年全球物联网市场将达到 2640 亿美元。其中 1900 亿美元预计将来自移动应用解决方案。
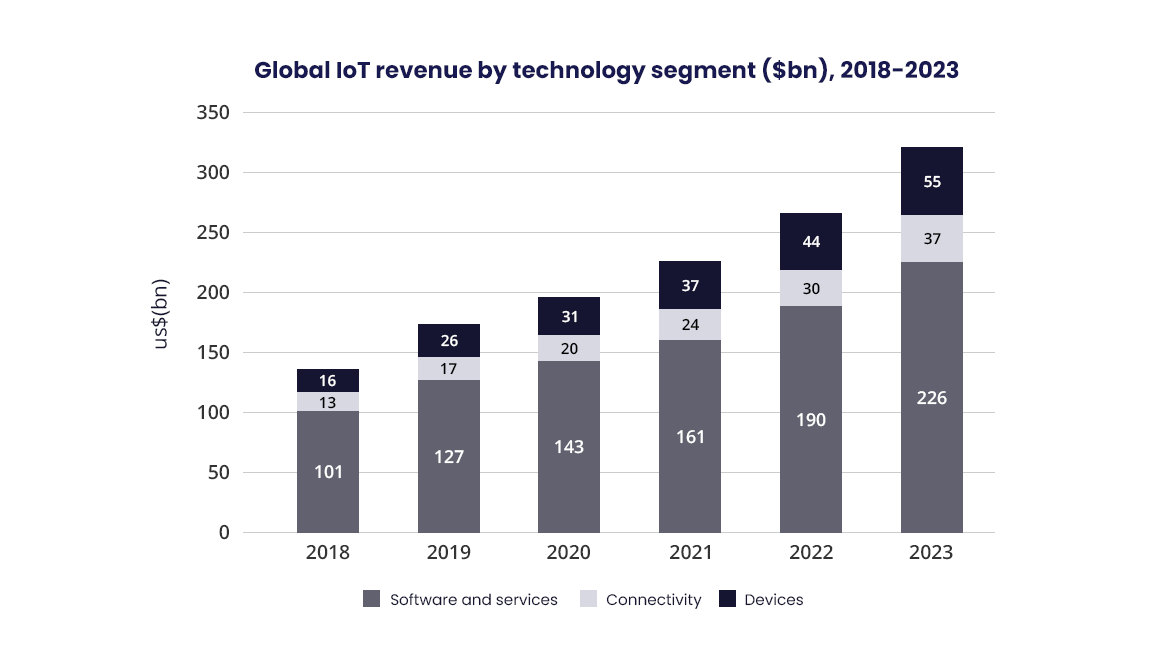
该图显示,物联网在未来几年将暂停以实现稳定增长,而软件开发在技术和移动应用市场中处于领先地位。物联网设备的数量正在增长,Statista 表示,到 2025 年,物联网等技术的收入将达到 1.6 万亿。
3. 可折叠设备的应用程序
十年前,我们大多数人都使用过翻盖手机。但是,是的,可折叠设备是手机从触摸屏转向 GPS 功能的新常见设备,市场上只有一个或没有按钮。
在创新方面,可折叠设备已经在移动市场卷土重来。这里的理论是,应用程序应该提供灵活性并在屏幕折叠或展开时无缝修改其显示。
- 2019 年,三星 Galaxy Fold 与华为 Mate X 以及新的摩托罗拉 Razr 一起退出了有吸引力且灵活的可折叠设备。
- 根据 Statista 的数据,2019 年,大约有 320 万部可折叠手机被运输。这一预测假装在 2022 年提高到 5000 万台。毫无疑问,2022 年的移动应用趋势将为可折叠设备带来巨大的一年。
另请阅读:2021 年定制软件开发终极指南。
4. 应用依赖区块链
区块链的需求已经有一段时间了,因此它在加密货币中发展得更多,并增强了大多数数字资产。
2020 年最流行的新兴移动应用程序趋势之一是区块链,因为它允许设计去中心化数据库。这些分散的数据库在没有单个或公司看门人的情况下工作。
由于其安全性,任何人都无法通过更改数据库来访问敏感用户的数据,因此区块链应用程序非常安全。
2022 年移动应用程序开发趋势的最佳区块链用途
到 2021 年,企业正朝着采用新技术的方向发展,手机制造商正在采用区块链技术。知名品牌 HTC 和三星已经发布了支持区块链技术的设备。
我们使用移动钱包和便捷支付来帮助加密货币,与此同时,移动设备也出现了 DApps(去中心化应用程序)。
到 2022 年,大多数 IT 巨头和技术专家将效仿微软,通过机密联盟 (Coco) 框架,开启区块链技术。
5. 移动商务
移动商务是关键,列出任何移动应用趋势都离不开移动商务。正是这种趋势带来了 2022 年移动应用程序解决方案的变化,因为它自 2020 年以来一直蓬勃发展。
移动电子商务特性是移动应用程序经销商展示客户宣传的首要功能。我们每隔一天就会看到新的移动应用程序,并且在大流行之后,该比率正在无限上升。
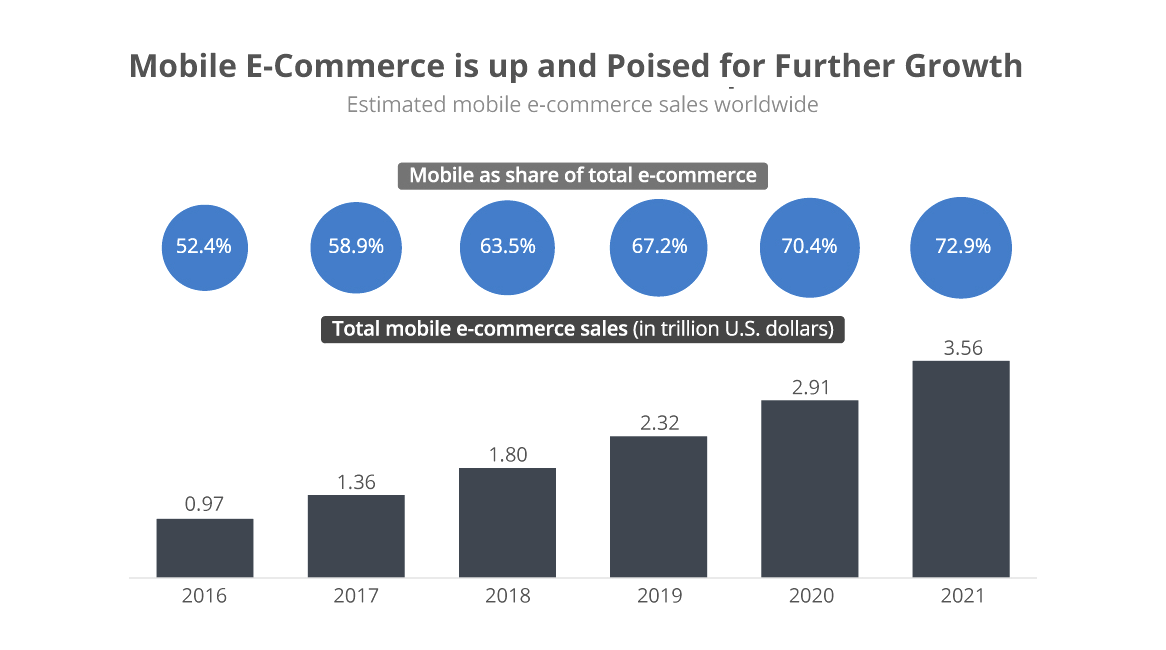
研究表明,到 2021 年,超过 72.9% 的电子商务总销售额来自移动设备。这些移动应用程序中的大多数在用户的日常生活中发挥着至关重要的作用。
在业务中,每个人都将移动应用程序作为目标,通过为客户提供最好的服务来增加收入。 IT行业是巨大的,在这个市场上赚钱的变化是巨大的。从软件开发公司到大型零售商,再到个人内容创建者和个人品牌,您都可以从它们中受益,紧跟移动应用程序开发的热门趋势。
另请阅读:2022 年最佳点播应用创意
6. 增强现实 (AR) 集成
企业专注于移动应用程序开发,以提供以最佳方式呈现产品的增强现实体验。在使用 AR 应用程序时,用户可以获得 3D 体验,移动应用程序开发人员将开发更多创新功能和应用程序功能。
在软件开发公司的帮助下,包括房地产、按需、零售、工程等在内的多个应用市场将继续使用增强的虚拟现实。
由于 AR 远离标准技术,AR 将在 2022 年继续成为新兴趋势。
2022 年最佳使用移动应用程序开发趋势
宜家,一个知名品牌,以最好的方式将增强现实用于应用程序。宜家一直在投入大量资源,将最好的服务作为购物体验不可或缺的一部分。
他们使用增强现实让用户看到家具在您家中不同尺寸的外观。此外,宜家的在线购物者强烈推荐从宜家购买,因为它在 AR 的帮助下为他们提供了从虚拟试衣到家具体验和其他相关在线购物的独特体验和服务。
7. 信标科技
信标技术对许多人来说并不新鲜,但在移动应用程序开发中并未得到广泛使用。几年来,它在移动行业中获得了关注,并且似乎在 2022 年增长。
通过 Beacon 技术,人们可以连接线上和线下世界的连接。如今,企业正处于连接设备和应用程序的边缘,这些设备和应用程序可以通过了解客户与移动应用程序的交互方式为客户完美运行。
客户的数据和店内购买行为是企业使用信标技术和连接数据进行处理的重要提示。因此,如果您打算使用本机或跨平台开发应用程序,这里是本机与跨平台开发之间的区别。
2022 年移动应用程序开发趋势的最佳用途
零售行业率先利用用户的线下数据为其在线商店实施 Beacon 技术。今天,技术对任何行业来说都不是新鲜事物,零售商正在使用该技术来实时跟踪购物者在实体店的交流和行为方式。
这家软件开发公司和顶级移动应用程序开发公司正在帮助零售企业提高产量,并通过开发最佳解决方案来帮助他们成长。
2022 年,零售商和其他行业将采用具有更多移动功能的信标技术,例如轻松购物和移动支付。
8.机器学习和人工智能
人工智能 (AI) 和机器学习极大地改变了 IT 行业;特别是,他们将移动应用程序提升到了一个新的水平。
您是否想过,YouTube 识别您的视频并在您的屏幕上显示您的方式与您的推荐最相似?以及您的电话协助如何自动获取您的通知?
它是通过人工智能和机器学习算法发生的。
通过 Siri 应用和聊天机器人等功能,我们可以管理整个手机的大部分通知和活动。这些功能是 Google 帮助、Amazon Alexa 和 Apple 的 Siri 的理想例证。
毫无疑问,电子商务使用这样的算法,特别是为了便于身份验证、面部或指纹识别等等。
它将帮助从应用程序中吸引更多客户并征服机器学习以改善服务。
Snapchat、Netflix、Tinder 和 Spotify 是 AI 和机器学习应用程序的示例。
9. 移动应用程序的 3D 图形
3D 设计广泛应用于各行各业,是 3D 打印、建筑、动画、游戏和工业设计的基本要素。 3D 图形被整合到移动应用程序中,用于提供实时效果的数字制作。
随着技术的进步,3D 图形元素也就不足为奇了。设计领域也在增长。无论是 iPod touch、iPhone 还是 iPad,3D 应用程序都可以免费为您提供高质量的结果。
这种有用且有吸引力的图形将很快成为智能手机和平板电脑的重要元素,因为它们为活动和复杂图形对象的创建提供了巨大的空间。
一些提供 3D 设计的应用程序包括:
- 3D Creationist 是最简单的应用程序,可以轻松制作 3D 模型。
- Morphi 是一款应用程序,可让您在没有 Wi-Fi 或鼠标的情况下自由进行设计(拉伸、可视化、发明和原型制作)。
- Gravity Sketch 是一款免费、有趣且令人愉悦的 3D 创作 iPad 应用程序。
- utoq3D 是一款类似的 3D 应用程序,通过提供方便直观的工作空间,为用户开发 3D 雕塑。
10. 手机钱包和手机支付
Google Pay、Apple Pay、Samsung Pay 等移动钱包正在流行,大多数移动应用都在使用它们。
根据 2019 年的研究,价值 61 亿美元的交易是通过移动钱包完成的。迄今为止,这一比例已提高到 139.8 亿美元。
因此,在移动钱包市场上拥有巨大商机的企业将在未来几年翻一番。
- 移动钱包将在 2022 年进入移动应用程序开发的画面,其中钱包集成应该成为标准功能。
- 对于每一个处理交易的应用来说,移动支付都是新的常态。
- 目前,应用程序中的移动钱包渗透率将在未来几年增加。
- 企业已经打开了大门,通过结合移动支付为用户提供最好的服务。
11. 按需应用

你了解 Drizly、Uber、Drizly 和 Zomato 之间的共同点吗?它们都是按需应用程序的最佳示例,可提供用户在各自领域的所有需求。
按需移动应用程序开发是 2022 年最受欢迎的移动应用程序趋势之一。
Uber 和 Airbnb 等移动应用在应用市场上已经显示出成功的变化。在以互联网为中心和数字化的世界中,移动环境是推动企业从任何地方吸引他们的观众的东西。按需服务应用程序很受欢迎,因为它们为客户和应用程序所有者轻松组装东西。
该报告称,用户每年在按需服务上花费 576 亿美元来满足他们的需求。随着需求的增加和移动应用程序开发的高速增长,按需应用程序的机会显然是无穷无尽的。
借助 B2C、B2B 和 C2C 商业模式,企业家正在转向按需服务,以协助货物和服务的交易到家门口。按需应用程序就像企业和客户之间的中介,提供最佳体验和生产力。
通过利用按需应用程序功能,企业可以加快流程周期并增加收入。而且,客户可以在他们的应用程序中添加尖端功能以增加利润。
重塑点播行业的点播应用类型示例:
- 医生随叫随到
- 汽车清洗
- 虚拟导师和教练
- 洗衣服务
- 送外卖
- 房子清洁
- 按需健身
- 维修服务
- 宠物护理
- 美容院
12. 即时应用
即时应用程序将使用户无需下载即可对其进行测试。是的,您可以将免安装应用程序用作试用版,而无需先安装它。
它们专门设计用于节省移动空间并方便地使用应用程序将用户链接到应用程序的特定功能。
这些功能允许您在决定最适合您要求的应用程序之前尝试各种应用程序。
即时应用程序的示例包括:
- Skyscanner:帮助获取廉价航班和酒店机票、住宿和汽车租赁等。
- 纽约时报填字游戏:这是纽约时报的填字游戏。
- Buzzfeed:平台可访问的测验、美味和新闻应用程序。
由于即时应用程序如今很流行,因为用户可以节省空间,并且还可以在决定长时间使用之前试用该应用程序。熟练的移动应用程序开发人员将更多注意力集中在创建出色的外观上。 2022 年,即时应用程序将产生大量流量,从而为企业带来收入。
结论
移动应用程序已经彻底改变了业务领域,并且在技术的帮助下变得更加发展。消费者使用移动应用程序可以轻松完成日常任务并节省时间。
从在线账单支付、银行交易、食品订购和订票,用户可以在几分钟内通过移动设备完成所有操作。
移动应用市场广阔,如果牢记顶级移动应用开发趋势,2022 年可能会改变商业游戏。
企业依靠移动应用程序来帮助产生巨额收入并协助与客户建立联系。希望在 2022 年保持竞争力并领先竞争对手一步的公司应该关注上述移动应用程序开发趋势。
为了在这些数字化和先进的时代发展您的业务,您必须牢记移动应用程序趋势并从印度著名的移动应用程序开发公司获得最佳的移动应用程序开发服务。
常见问题
目前移动端的发展趋势是什么?
人工智能和物联网是 2022 年值得关注的已知移动应用程序开发趋势。可折叠设备应用程序、依赖应用程序的区块链、移动商务、增强现实 (AR) 集成、信标技术、机器学习等趋势,以及人工智能、移动应用程序的 3D 图形等,为用户赋能并提供实时体验。
为什么发展趋势在开发移动应用程序时具有重要意义?
随着技术的进步,企业开始提供创新的解决方案,并随着数字化而流行。让知情和不知情的人发挥想象力、了解障碍以及智能解决方案的可能性起着关键作用。顶级移动应用程序开发趋势将为成功的解决方案节省精力和时间。
移动应用程序开发的下一件大事是什么?
为了让我们的日常生活更轻松、更省时,移动应用程序正在全球范围内使用。为了简化移动应用程序流程,2022 年的大多数移动应用程序开发趋势都用于多平台设计和开发,这是打造创新和极具竞争力的应用程序的下一件大事。与我们联系以开发具有竞争力且灵活的移动应用程序解决方案。
移动应用程序开发的未来是什么?
到 2023 年,人工智能和机器学习将成为新常态,移动应用程序将与 Beacon 和物联网以及可折叠应用程序相结合,以方便用户使用。人工智能软件市场收入将很快达到 709.4 亿美元。大多数应用程序将使用先进技术开发,例如移动钱包和移动支付、预测分析和机器学习算法。
本文:https://jiagoushi.pro/top-12-mobile-app-development-trends-2022
- 100 次浏览
【移动开发】InfoQ 2022 年移动和物联网趋势报告
关键要点
- 由于 SwiftUI 和 Jetpack Compose 的日益成熟和采用,构建声明式 UI 显然已成为 iOS 和 Android 世界的一种趋势。
- 移动应用程序的跨平台故事也在缓慢而稳定地显示出对原生跨平台工具包(如 Dart+Flutter、Multiplatform Kotlin 和 Compose Multiplatform 以及适用于 Android 的 Swift)的兴趣和努力不断增长。这总结了在桌面上运行移动应用程序的可能性带来的新机会。
- 我们在移动应用程序和可穿戴领域看到的另一个趋势是依赖 AR/VR 以及机器学习和计算机视觉的高级 UI。此外,我们看到了一种新的基于手势和姿势的 UI 的新生范例,以及与所谓的智能眼镜相关的日益增长的兴趣和价值主张。总体而言,这有望实现全新的用户体验。
- 移动应用程序和物联网设备的日益复杂性激发了人们对旨在确保使用移动 DevSecOps 和可靠性工程实践及时、安全地部署新功能的方法的浓厚兴趣。同样,围绕“平台团队”的理念组织开发团队的想法正在获得认可,尤其是对于大型项目。
- 通过从 ML-in-the-Cloud 模型转变为 Edge-ML 甚至设备上 ML,物联网设备变得越来越“智能”,这可能在减少延迟和数据隐私方面提供巨大的好处。
- 仍然在物联网世界中,WebOfThings 提案试图为能够相互无缝通信的新一代设备铺平道路。 IOTA 提供了利用区块链促进物联网技术大规模采用的视角。
InfoQ 最引人注目的功能之一是我们的主题图,它综合了我们对不同主题如何在技术采用曲线中叠加的理解。 当需要从编辑的角度决定我们想要涵盖的内容时,它们作为优先考虑不同和竞争利益的指南非常有用,但我们也相信分享它们可以帮助我们的读者更好地了解当前和未来的技术前景并帮助 告知他们的决策过程。
主题图建立在 Geoffrey Moore 在他的著作“Crossing the Chasm”中开发的著名框架之上。Moore 的框架描述了五个阶段,通过“创新者”、“早期采用者”、“早期多数”来描述技术采用如何随时间演变 、“晚期多数”和“落后”阶段。
/filters:no_upscale()/articles/mobile-and-iot-trends-2022/en/resources/1InfoQ-Mobile-IoT-2022-1645096791707.jpg)
InfoQ 倾向于识别那些属于创新者、早期采用者和早期大众阶段的想法和技术。我们还努力承认我们认为已经进入后期多数的主题。您通常会在 InfoQ 上找到大量关于后期多数和落后阶段的内容,作为我们之前报道的产物。
对于我们的读者来说,拥有五个不同的阶段意味着他们可以更轻松地调节自己的注意力并自己决定现在应该探索什么,或者等待它如何展开。
本报告总结了 InfoQ 编辑团队和软件行业的几位从业者对我们统称为移动和物联网领域的多个领域的新兴趋势的看法。这是一个相当异构的空间,包括从智能手机到智能手表、从物联网设备到智能眼镜、语音驱动助手等的设备和小工具。
所有这些设备的共同点在于它们都是“伪装的连接计算机”。在某些情况下,它们的计算能力已经发展到与个人电脑相当的水平,例如智能手机和平板电脑。在其他情况下,它们的计算能力以及它们提供的功能可能会显得更加受限。在所有情况下,我们都连接了具有一些特殊外形的设备。作为将它们结合在一起的附加元素,我们还可以考虑人机交互 (HCI) 问题。事实上,虽然该领域中不同类别的设备遵循不同的 HCI 范式,但它们的共同点是远离软件行业其他领域普遍存在的键盘鼠标或文本点击范式。
属于移动和物联网领域的所有设备都有一个重要的硬件组件,使它们成为可能或有用。然而,我们的报告不会过分关注硬件方面,而是考虑软件开发角度的影响,以符合 InfoQ 的使命。例如,虽然可折叠设备肯定会带来很多技术创新,但我们会对如何对其 UI 进行编程更感兴趣,这会导致声明式用户界面的兴起,等等。
后期多数和落后者
在后期多数阶段,很容易确定在移动领域构建应用程序和解决方案的一些行之有效的方法。它们代表了被广泛接受的、几乎标准化的完成事情的方式,我们完全理解利弊是什么,为什么以及它们在哪里是有益的,等等。
例如,原生移动应用程序就属于这一类。这意味着使用 Android 或 iOS 提供的原生 SDK 以及它们选择的相应编程语言(即 Kotlin/Java 或 Swift/Objective-C)来构建移动应用程序。根据 AppBrain 的数据,超过 80% 的前 500 名 Android 应用程序是用 Kotlin 编写的,超过 75% 的所有 Android 应用程序使用原生 Android 框架。
我们认为,使用混合应用程序开发框架作为跨平台的一种方式应该被视为属于落后阶段。混合应用程序是嵌入在 WebView 或类似组件中并使用 Web 技术编写的移动应用程序。这有两个主要动机:使用独特的堆栈来开发您的移动和 Web 应用程序,以及创建使用单一代码库在所有移动平台上运行的移动应用程序。这并不意味着混合应用程序在今天不适用。相反,这意味着有替代方法可以解决这两个问题,由于它们的优势,它们正在获得更多关注,例如 React Native 和 Flutter,稍后将讨论。
继续关于移动应用程序开发的主题,两种已经成熟且属于后期多数阶段的做法是使用持续集成/持续部署工具和利用设备群进行测试。例如,像 fastlane 这样的工具在很大程度上帮助开发人员从繁琐的工作中解脱出来,例如拍摄快照、测试版和通过相关应用商店进行预审部署等。同样,有许多公司提供对设备场的访问来运行您的应用程序自动化测试,鉴于市场上大量不同的智能手机,这似乎是确保您的应用程序可靠性的合理方法。
作为关于晚期大众阶段的最后一点,我们还考虑了晚期大众主题,如 Siri/Alexa/Google 助理设备、面向健身的可穿戴设备和智能家居。这种选择与这些技术今天的使用范围并没有真正的关系,而是与我们对它们的一般理解以及它们在提供的那种特性方面已经达到某种成熟状态的事实有关.
早期多数
在早期的多数阶段,我们看到技术和方法已经在支持开发人员的需求方面取得了长足的进步,但尚未占主导地位或在某种程度上仍在不断变化。
声明式用户界面 (SwiftUI)
一个很好的例子是使用 SwiftUI 为 iOS 原生应用创建 UI。 SwiftUI 已经到了第三次迭代,它是一个现代的声明式框架,它依赖于 Swift 启用的一些高级语法特性,为 iOS 开发人员提供了全新的体验。
SwiftUI 确实是完全声明式和反应式的。使用 SwiftUI,您无需逐个构建 UI,而是使用文本抽象来描述它的外观并定义其每个组件如何与您的模型交互。得益于其设计,SwiftUI 在 Xcode 中实现了交互式开发风格,您可以在其中预览 UI 并实时调整其参数,而无需编译完整的应用程序。
就 Storyboard 或 UIKit 编程而言,SwiftUI 无疑具有令人信服的价值主张,如果您开始一个新的 iOS 项目,很难不将其评估为候选 UI 框架。但这并不意味着 Storyboard 和 UIKit 在新应用程序中没有位置,只是 SwiftUI 在技术上日趋成熟,采用率不断提高,并且似乎正朝着成为 iOS UI 开发事实上的方式的方向发展。
原生跨平台应用
在跨平台移动应用方面,有很多方法,包括 React Native、Flutter 和 Xamarin,应该被认为是早期的主流。当然,很难想象 React Native、Flutter 或任何其他现有的跨平台解决方案会轻易取代原生开发。因此,将它们纳入早期的大多数意味着它们正在跨平台移动应用程序开发领域迅速取得进展,主要是以牺牲混合应用程序方法为代价。
事实上,如果你喜欢这种方法的原因是利用你在 Web 堆栈(即 HTML、CSS、JavaScript 和相关工具)上的投资,那么当你可以拥有 React Native 时,很难证明使用混合方法是合理的,它为您提供原生、性能更高的用户体验的优势。对于 Xamarin,我们可以应用相同的推理,只是在 Microsoft 技术堆栈而非 Web 的保护下。
另一方面,如果您的动机是通过只编写一次应用程序来节省开发工作量,那么您也有可能使用 Flutter,这不会为您提供原生用户体验,但您可能更喜欢其他考虑因素,包括使用编译的、严格类型的语言。
基于云的机器学习
我们在此阶段还包括使用基于云的机器学习服务,例如您可以在 Snapchat、Tinder 和许多其他应用程序中找到的应用程序,例如,对图片进行分类或检测在云上进行计算的对象并仅传输结果返回应用程序。
物联网网络安全
在物联网和工业物联网方面,我们认为网络安全是早期的主流。理想情况下,我们希望在晚期大众阶段拥有此功能,但令人遗憾的是,家电安全的前景,包括大多数人用来连接互联网的无处不在的 ADSL 路由器,并不能让人放心。除此之外,通过自动固件更新、安全启动和通信以及用户身份验证来保护家用电器和物联网设备的重要性已广为人知,并且正在努力将所有这些付诸实践。
受控推出(Controlled rollout)
说到移动应用程序部署,一些已经开始使用的技术是功能标志、增量发布和 A/B 测试,两者都在 Google Play 商店中得到支持,以及应用程序的强制更新。
这些都属于受控推出的类别,旨在降低与新部署相关的风险。事实上,与服务器或 Web 应用程序不同,移动应用程序中的错误一旦发布就很难恢复。
功能标志可以使用可以启用或禁用特定功能的特定标志来控制应用程序提供的一组功能。强制更新允许开发人员淘汰旧版本的应用程序,而增量发布有助于减少潜在风险更改对用户群子集的影响。
小程序
同样流行的是所谓的 MiniApps,也称为 SuperApps 或 Mobile MicroFrontends,它们是作为原生应用程序的插件或扩展开发的与平台无关的应用程序。由微信、支付宝等应用程序普及,它们通常实现为 PWA 或 React 原生模块,并依靠其原生容器通过微平台或微应用桥提供对 OS 级功能的访问。
MicroApps 的主要好处是它们独立于 App Store 和 Play Store 的审查/发布过程,从而降低了开发成本和时间。
移动平台团队
核心组件平台化的需求在任何软件开发中都是必不可少的,移动应用程序也不例外。例如,日志记录、分析、架构框架等都属于组件类别,这些组件自然会导致自己创建一个平台,在该平台上构建不同应用程序所需的其余功能。
在这种情况下,在构建这样一个平台时,考虑具体的职责就具有相关性。因此,预测客户需求、定义标准最佳实践、选择正确的技术堆栈、评估工具等将成为专门平台团队的责任。
这种方法承诺提供清晰的抽象,同时指导整个组织保持一致的开发风格和基本的护栏。它肯定需要一个足够大的移动团队才能使这种方法可行,就像优步、Twitter、亚马逊等几个采用它的大型组织一样。
早期采用者
当谈到早期采用者阶段时,我们指的是软件开发的技术和方法,这些技术和方法正在获得更多关注,并为开发人员开辟了新的可能性。
设备端机器学习、Edge-ML
首先,我们想在这里提到设备上或边缘机器学习,您实际上是直接在移动设备或边缘上运行预训练的 ML 模型,而不是在云上运行它。
得益于 TensorflowLite、PyTorch Mobile 等解决方案,这种方法越来越受欢迎。这些解决方案显着降低了与云请求相关的开销和延迟,并支持以实时预测为关键的全新应用类别。
另一个重要的优势是用户数据永远不会离开设备,这也可能是许多或用例中的关键问题,例如健康应用程序。
增强现实和虚拟现实
增强现实和虚拟现实的应用也在增长。特别是,iOS 和 Android 都为许多 AR 功能提供了强大的支持,例如表面和平面检测、遮挡、面部跟踪等。
AR 的使用并不普遍,但肯定会引起越来越多的兴趣,因为它不需要专门的硬件,而且集成到应用程序中相对简单。另一方面,虚拟现实主要针对专门的耳机,如 Oculus、索尼 PlayStation VR、HP Reverb 等,它们主要专注于游戏。这个领域的新动力也可能来自智能眼镜的发展。
语音驱动的移动应用程序和家用电器
AR 和 VR 都促进了对新 HCI 范式的探索,这些范式更适合归类为创新者阶段。但是,由于基于语音的界面的发展,新的 HCI 方法在早期多数阶段也看到了一些吸引力。
在这种情况下,我们不是在谈论像 Alexa 或作为操作系统接口运行的 Siri/Google Assistant 之类的专用设备。相反,我们指的是将语音功能集成到移动应用程序和物联网设备本身中。
在桌面上运行移动应用程序
借助 Apple Catalyst 等技术,移动开发人员可以利用的另一个机会是在桌面上运行他们的移动应用程序。特别是一些系统 macOS 应用程序是由 Apple 通过 Catalyst 和 Xcode 实现的,并且 App Store 支持它。微软还为 Windows 10 上的 Android 应用程序提供了一种类似的解决方案,即应用程序在手机上运行并镜像到桌面计算机的窗口内。
集中记录
集中式日志记录在此也值得一提,它旨在将系统生成的所有日志收集到一个存储中。集中式日志记录的使用对应于基于云的系统的一个重要趋势,但这种方法也越来越多地用于移动应用程序。
应用于移动应用程序的集中日志记录的主要优势之一是它有助于实时查看客户应用程序发生的情况,从而有助于解决他们的问题并提高客户满意度。
包括 AWS Central Logging、SolarWinds Centralized Log Management 等在内的众多服务支持采用这种做法。
持久连接
作为关于早期采用者阶段的最后一点,我们提到了在客户端和服务器之间使用持久连接。最初由消息应用程序普及,现在更多地用于电子商务应用程序,例如 Halodoc 和 GoJek,以及移动和其他领域。
持久连接倾向于取代推送通知和网络轮询,旨在减少访问延迟和功耗。
在 MQTT 和 gRPC 等轻量级协议方面,物联网设备也出现了类似的趋势。
一个需要密切观察的有趣子趋势是最终创建标准化协议和/或专门的第三方解决方案,以使持久连接像即插即用一样简单。
声明式用户界面(Jetpack Compose)
最近达到 1.0 的 Jetpack Compose 是 Google 的基于 Kotlin 的 Android 声明式 UI 框架。
关于声明式 UI 为开发带来的好处,Jetpack Compose 与 SwiftUI 的情况大致相同,如上所述。然而,SwiftUI 已经进行了第三次重大迭代,iOS 开发者社区已经在很大程度上采用了它,而 Jetpack Compose 仍处于采用的初始阶段。
创新者
跨平台移动应用
虽然仍然是少数,但跨平台应用程序肯定代表了一组开发要求和约束的答案。从历史上看,混合 Web 应用程序以及最近的 Reach Native、NativeScript 和 Flutter 等方法都试图为它们提供解决方案。
最近尝试解决构建跨平台移动应用程序的问题的代表是 Swift for Android 和 Multiplatform Kotlin 等项目。这种方法会引导您选择一个参考平台,即 iOS 或 Android,并使用其技术堆栈为您的参考平台构建您的应用程序,并尽可能为另一个平台构建您的应用程序。
在 UI 方面,Swift for Android 提供了 Crystal,一个用于构建原生 UI 的跨平台、高性能图形引擎。使用 Multiplatform Kotlin,您可以选择使用 Multiplatform-Compose,但它仍处于高度试验阶段。 JetBrains 最近发布了名为 Compose Multiplatform 的测试版,旨在将声明式 UI 编程引入 Multiplatform Kotlin,但尚不支持 iOS。
虽然这两种解决方案都提供了良好的语言互操作性,因此您肯定可以跨两个平台共享您的代码库的一部分,但对于依赖于操作系统的代码,您的里程可能会有所不同。例如,适用于 Android 的 Swift 提供了 Fusion,它是一组自动生成的 Swift API,在某种程度上提供了对 Android API 的惯用访问。
移动可靠性工程(MRE)
在移动应用程序上大规模持续交付功能是一项真正的挑战。多个团队必须相互协调以交付功能,并采用简化的最佳实践、流程和原则。
软件可靠性工程 (SRE) 的诞生旨在实现大规模分布式系统的可靠性,并且最近也获得了作为移动应用程序有用方法的可见性。
MRE 仍处于采用的初期阶段,旨在促进整个组织采用最佳实践。到目前为止,一些成熟的组织和初创公司在各种工具、流程和组织动态的帮助下遵循这种方法,尽管没有明确表示,目的是使功能交付成为一个更敏捷的过程。
基于手势和姿势的 UI
AR 和 VR 都为与应用程序和环境交互提供了新的可能性,这导致了人机交互的新方法,特别是使用手势识别或 2D 姿势检测的可能性。虽然我们将 AR 和 VR 归类为早期采用者阶段,但也有一种趋势是将这些 HCI 方法引入与 VR 或 AR 无关的移动应用程序。
这些方法的基础是用于手和人体姿势检测的 ML 和计算机视觉算法。例如,Apple 通过 Core ML 提供支持,而 Google 有自己的适用于 Android 和 iOS 的 MLKit。
已经存在许多使用这些技术的应用程序,主要专注于健身,例如计算深蹲或运动技能,如跳舞或做瑜伽。很容易预测,在 SDK 级别提供手势和身体姿势检测可能只会促进其他应用程序的开发,将这些 UI 方法扩展到更多领域。
语音驱动的 UI
虽然 Alexa 等设备以及 Siri、Cortana 和 Google Assistant 等智能助手已经普及了使用语音控制设备的想法,但本地语音驱动的 UI 直到最近才开始受到关注。这一趋势是由最近机器学习在多个领域取得的进展推动的,包括语音识别、NLP、问答系统等。
语音驱动界面的好处之一是在许多不同的环境中使用您的声音与机器/程序进行交互很方便,例如驾驶、烹饪、步行等。此外,语音可以为患有某些特定疾病的人提供巨大的帮助。残疾。
许多不同的技术支持将语音驱动的 UI 集成到移动应用程序和物联网设备中,这些技术要么基于基于云的模型,要么使用嵌入式模型。例如,谷歌有它的文本转语音 API 和 Dialogflow,而 AWS 则提供与 AWS IoT 集成的 Alexa 语音服务。
Web物联网
Web of Things 是物联网的 Web 标准,用于实现智能事物和基于 Web 的应用程序之间的通信。它试图通过定义一种让物联网设备与其他设备和 Web 互操作的方式来为物联网设备的高度异构世界提供答案。
虽然物联网标准的定义已经持续了好几年,但大多数物联网设备仍然拥有自己的管理界面和应用程序。这些 UI 和应用程序中的每一个都了解每个制造商采用的低级网络协议和标准。这导致用户无法从单个接入点控制所有设备的情况不太理想。此外,设备不能相互交谈。
Mozilla WebThing 网关、AWS IoT 等解决方案有望加速 Web of Things 协议的采用。
IOTA
IOTA 试图利用区块链技术来解决阻碍物联网大规模采用的一系列挑战,包括异构性、网络复杂性、互操作性差、资源限制、隐私问题、安全性等。
比特币和以太坊等传统区块链系统使用一系列顺序区块链,在一个区块内包含多个交易,而 IOTA 使用名为 Tangle 的多路径有向无环图 (DAG)。其他一些协议,如 Byteball、Avalanche,也使用 Tangle 并进行了某些修改。这些协议的目标之一是在分布式测量中容纳物联网数据,与线性区块链相比,具有改进的性能、可扩展性和可追溯性。
IOTA 被定位为一种免费、矿工和无抵押、高度可扩展的区块链解决方案。它承诺实现与其他基于区块链的分布式账本相同的好处,包括去中心化、分布、不变性和信任,但不会出现资源浪费和交易成本的缺点。
智能眼镜
在可穿戴计算方面,智能眼镜似乎是下一件事情。事实上,关于智能眼镜兴起的预测和预感已经存在多年,至少从谷歌眼镜开始,该项目未能取得任何重大成功,但有助于提高人们对与智能眼镜相关的潜在隐私问题的认识。使用智能眼镜。
从人机交互的角度来看,智能眼镜是推动新方法和技术发展的巨大领域,包括语音和手势识别、眼动追踪和脑机接口。
虽然许多不同的制造商在他们的智能眼镜方面取得了相对成功,包括 Microsoft HoloLens、Oculus Rift、Vuzix 等,但该技术似乎正在等待一个更引人注目的价值主张,这可能使其更加普及。预测想拥有它。尽管如此,对这项技术的兴趣仍在增长,最近有几家大公司进入了这一领域,例如,Facebook 的 Ray-Ban Stories 以及其他传闻正在开发新产品的公司,包括苹果、小米等。
结论
正如科技界经常出现的情况一样,在移动和物联网领域,创新发生的速度也非常快。我们试图传达一个非常广泛的图景,即目前的技术格局以及明年的发展方向。只有时间会告诉我们哪些最新趋势会继续存在,哪些会迅速消失或化为乌有。我们在 InfoQ 的团队将继续履行其使命,即提供从业者优先的视角并覆盖移动和物联网领域。
本文:https://jiagoushi.pro/infoq-mobile-and-iot-trends-report-2022
- 52 次浏览
【移动开发趋势】2022 年移动应用程序开发的主要趋势
移动应用开发的现状如何?五年后移动应用程序开发会是什么样子?
要回答这些问题,您必须了解 2022 年移动应用行业可能出现的趋势。
在一般的移动市场中,关于元宇宙和移动应用程序区块链集成的兴起引起了很多关注。同样,在 iOS 和 Android 平台上,在增强现实、聊天机器人和语音识别方面都有令人兴奋的发展。与此同时,谷歌的开源 UI 软件开发工具包 Flutter 和 Facebook 的开发工具 React Native 也出现了值得注意的创新。
在这篇文章中,我们想讨论一些最紧迫的移动应用程序开发趋势,并尝试了解它们如何影响移动应用程序解决方案和技术的未来。
一般移动市场
元界和区块链是移动应用程序开发的两大趋势。以下是有关它们对移动应用解决方案影响的一些信息。
元宇宙
元宇宙的统治迫在眉睫?这是许多应用程序开发人员在 2022 年设计和开发时应该问自己和考虑的一个问题。
2021 年 10 月 28 日,Facebook 宣布将公司名称更改为 Meta。随着世界上最大的公司之一表明他们打算专注于元宇宙,很明显,移动应用程序开发人员也需要改变他们的优先事项。
Metaverse 是一个虚拟现实空间,用户可以在其中与计算机生成的环境和其他用户进行交互。它是互联网的一种可能迭代,您可以在其中存在于几乎无穷无尽的各种 3-D 虚拟环境中。
元界游戏已经出现了一种新兴趋势,可以合理地假设越来越多的手机游戏将过渡到那个世界。
在 2022 年,应用程序开发人员将需要检查他们的应用程序是否已准备好与不同的元节进行基本集成,以及如果元节获得牵引力,是否还有转动空间。
元节是科技的最新趋势之一,而移动很可能是元节的主要平台。根据最近的研究,元界手机游戏预计将在 2022 年增长到超过 31 亿英镑。元界对于手机游戏开发商来说具有很大的潜力。在这个 2021 年吸引了约 907 亿美元消费者支出的行业中,移动游戏和应用程序也是元界开发人员和公司集中注意力的理想场所。
区块链
除了元宇宙,2022 年可能冲击一般移动市场的趋势之一是区块链。 2024 年的估计是,全球区块链市场将达到 200 亿美元左右。区块链已经开始涉足移动应用程序开发领域。
区块链和一般的加密货币在许多有利于移动应用程序开发的领域都表现出色,包括数据安全性、透明度、可靠性、实施和可访问性。该技术是开源的,这意味着开发人员可以提出对区块链实施和功能进行实际更改的建议。
同样,区块链也有一个潜在的令人兴奋的机会,可用于解决应用内购买问题。
去中心化的区块链模式意味着移动应用程序开发者将获得更大的利润份额,而对中间商的损失更少。
移动应用程序开发人员和用户参与区块链有大量的经济和实际激励措施。
然而,在当前形势下,区块链在应用内购买中的使用很可能会被苹果和谷歌等主要参与者阻止,因为这会削弱他们的权力。商店市场的多元化可能会在不久的将来发生,但我们认为 2022 年不会有任何重大进展。
iOS
在过去的几年里,有许多与苹果 iOS 平台相关的移动应用程序开发亮点。
Swift
Swift 是一种强大的 iOS 编程语言。 Apple 引入了一种新的、现代的、更清晰的 API,用于在 Swift 应用程序中植入并发。
它们可以称为“异步/等待 API”。它们使编写更安全、更容易遵循并发代码的能力成为可能,这比以前难以使用的 API 有了很大的改进。 Apple 提高了开发人员与这些“异步/等待 API”同时工作的能力,其明显的有效性表明它们很可能在未来几年成为标准。
Apple 的 SwiftUI 也出现了令人鼓舞的趋势。如今,遗留项目中的集成越来越多。新项目往往是用 SwiftUI 编写的。 SwiftUI 是 Swift 的 UI 框架,它在去年获得了许多新功能,包括异步图像、扩展列表视图和支持拉取刷新。
2022 年,SwiftUI 可能会添加更多功能,这对于希望在 iOS 平台上改进工作的应用程序开发人员来说将是一个令人振奋的消息。
增强现实 (AR) 和虚拟世界的发展在去年也引发了一些兴奋。一些虚拟世界可能很快就能够使用 VR 装备提供完全身临其境的体验。
增强现实眼镜
同样令人兴奋的是,根据最近的报道,苹果的 AR 眼镜可能很快就会上市。 AR 眼镜的传言已经有一段时间了,有迹象表明,当它们真正发布时,它们可以重新定义可穿戴和个人计算。到目前为止,智能眼镜在很大程度上未能引起人们的广泛关注,并且一度成为一个可笑的怪人。
然而,这个想法有潜力,苹果的 AR 眼镜可能会在未来几年改变游戏规则。有报道表明,该设备的长期目标是取代智能手机成为主要的“计算”和通信设备。一旦技术足够成熟,可以为临时用户提供完整的功能并且在经济上可行,这可能会成为现实。
安卓
超宽带 (UWB) API、Jetpack Compose、Kotlin Multiplatform Mobile (KMM) 和聊天机器人是 Android 应用程序开发的主要亮点。
超宽带 (UWB) API
2021 年初,谷歌在 Android 中添加了超宽带 (UWB) API。超宽带通常被认为是无线技术领域的新兴技术。多年来,智能手机一直使用并依赖蓝牙和 Wi-Fi,但 UWB 承诺提供不同的东西。
超宽带 (UWB) API 支持智能家居设备的高速点对点数据共享和精确的室内定位。超宽带技术可用于控制和组织智能家居生态系统。
目前,唯一拥有 UWB 硬件的 Android 设备是三星 Galaxy Note 20,而三星的 SmartThings 应用程序是唯一使用该硬件的应用程序。尽管 UWB 仍处于起步阶段,但移动应用程序开发人员在未来充分利用这项技术的潜力很大。在 2022 年的某个时候,Google 将添加 API 以支持 UWB,这些 API 也可用于第三方应用程序。
Jetpack Compose
Jetpack Compose 是 Android 用于构建原生 UI 的工具包,将于 2022 年推出其第一个稳定版本。该软件旨在简化应用程序开发过程并提高效率。我们预计越来越多的移动应用程序开发人员将在不久的将来开始使用 Jetpack Compose for Android 设备进行构建,因为它可以创建直观、简单且功能强大的应用程序。
Kotlin 多平台移动 (KMM)
Kotlin Multiplatform Mobile (KMM) 技术允许您编写一次代码,然后在 iOS 或 Android 等多个平台上使用此代码。它是一种统一的技术,可以更轻松地共享代码,并确保您只需要在必要的地方编写特定于平台的代码。 KMM 支持许多移动目标,包括 Android 应用程序和库,以及 ARM32 和 ARM64 平台上的 Android NDK。
安卓聊天机器人
最后,我们还预计 Android 聊天机器人将在 2022 年对移动应用程序开发发挥重要作用。聊天机器人更智能、更先进,因此对用户和应用程序开发人员都更有用。使用聊天机器人的企业中有 58% 属于 B2B 领域。将您的在线零售或食品配送应用程序与聊天机器人集成可以为您节省大量时间。
此外,开发人员比以往任何时候都更容易使用聊天机器人进行构建和发挥创意,我们预计这将成为未来几年的主要应用程序开发趋势之一。
React Native
Facebook 的开源 UI 软件框架 React Native (RN) 正面临来自 Flutter 等公司的激烈竞争,但仍显示出它有能力生成一流的应用程序。它是开发人员非常喜爱的框架,并且仍在快速增长。
React Native手势处理程序(React Native Gesture Handler)
React Native Gesture Handler 版本 2 于 2022 年发布,是一个原生触摸和手势系统,允许应用程序开发人员使用 React Native 构建最佳的基于触摸的体验。手势处理程序使手势跟踪变得流畅和可靠,并且可供不同专业水平的开发人员使用。
复活(Reanimated)
同样,Reanimated 是一个 React Native 库,可以创建流畅的动画和交互,看起来多年来一直帮助应用程序开发人员处理布局动画和过渡。这个综合库为开发人员提供了创建令人兴奋和创新的应用程序和功能所需的所有工具。
多平台功能
2022 年 React Native 可能增长的另一个领域是其多平台功能。对多平台编程的支持有助于减少一遍又一遍地编写相同代码所花费的时间,但它也确保您可以保留本机编程的灵活性。
大多数 React Native API 是跨平台的,跨 iOS 和 Android 等两个平台的代码重用很常见。
对于开发人员和创作者来说,这种跨平台功能可以节省大量资金,因为不必花费大量时间和资源为两个不同的平台构建两个完全不同的应用程序。
React Native 在移动应用市场的增长潜力是无限的。 React Native 框架非常适合复杂的多平台应用程序开发,预计 2023 年移动应用程序收入将达到 9350 亿美元,RN 已为增长做好准备。
Flutter
谷歌创建的开源 UI 软件开发工具包 Flutter 可能在 2022 年也有一些令人兴奋的新趋势。与 React Native 一样,Flutter 是一个非常有用且强大的框架,用于构建跨平台的移动应用程序。
出于多种原因,Flutter 将在 2022 年引领移动应用程序开发的趋势。首先,使用 Google 创建的应用程序有很多优势,即强大的支持、卓越的性能和 Flutter 原生 Google 广告的提升。
其次,Flutter 已成为企业在短时间内创建中小型企业应用程序的绝佳选择。
送餐应用、通信应用和服务都可以从 Flutter 框架的广泛支持和直观功能中受益。
第三,Flutter 提供了多种内置动画,移动应用程序开发人员可以使用这些动画来轻松增强应用程序的功能。出于这个原因和许多其他原因,Flutter 也是一项伟大的技术,可供希望创建最小可行产品 (MVP) 的初创公司采用。使用 Flutter,开发成本会很低,而令人兴奋的功能的潜力会很高。
Flutter Web 支持
网页版 Flutter 近年来也有了长足的发展。 Flutter Web 支持在 2021 年初达到了稳定的里程碑,并且看起来将在不久的将来提供一系列出色的特定于 Web 的功能。目前,Flutter 团队还组织了一场关于为 Web 开发 Flutter 的全球黑客马拉松。
Flutter for web 的主要好处之一是,在所有平台上的 UI、UX 和动画方面,一切都将 100% 看起来像设计师想象的那样。这对于具有定义样式指南的品牌应用程序来说是理想的选择。此外,Flutter for web 的另一个好处是可以在某个时候将移动设备中使用的所有组件移植到 Web 上以供消费者使用。
随着品牌的成长,有一个扩大平台的潜在领域。 Flutter 还支持将应用程序开发到桌面平台,包括 Windows、Mac 和 Linux。在许多方面,Flutter 框架的可访问性和灵活性表明,Flutter 已准备好在 2022 年取得成功。
移动应用程序开发的未来
在过去的几年里,移动应用程序开发领域取得了许多令人兴奋和充满希望的进展。设计师、创作者和开发人员不断为日常问题提出创新的、具有前瞻性的解决方案。同样,他们继续迭代并逐步改进已建立的想法,以改善移动用户的用户体验。
无论是机器学习、云计算集成还是增强现实,今天的趋势似乎都将影响未来十年移动应用程序开发的增长。跨 iOS 和 Android 设备的应用程序开发人员正在充分利用语音识别、区块链技术和信标技术方面最前沿的进步来创建引人入胜的移动应用程序和解决方案。
本文:https://jiagoushi.pro/top-trends-mobile-app-development-2022
- 183 次浏览
【移动架构】Flutter vs React Native:最后一句话。(2021年)
首先,有点离题。做出决定的最简单方法是回顾历史。让我们沿着怀旧之路走一趟。早在2000年初,JAVA就有两个UI框架。一个是AWT,它是一种为多个操作系统构建UI的方法,同时仍然保持操作系统的外观。
每个操作系统都有自己的组件,这些组件映射回使用AWT框架创建的AWT组件。
Java随后决定开发自己的渲染组件库Swing。Swing所做的是处理自己的渲染
依赖底层操作系统组件的风险。Swing得了这场战斗,不久AWT就从地球上消失了。

这有什么关系?我为什么要离题?
如果您一直在关注React Native vs Flutter 的辩论,您应该很熟悉这一点。React Native 组件被传输到IOS或android组件,而Flatter使用自己的渲染引擎(基于称为SKIA的2d渲染引擎)渲染自己的UI。(类似于游戏引擎自己进行渲染的方式)。它仍然依赖于材料设计(Android风格)和Cupertino(苹果风格)
小部件模仿本机平台像素完美的外观和感觉。如果我们回顾一下Swing与AWT之战作为参考,那么Flutter 可能会在这里获胜。
第一轮:Flutter
我又离题了,但传统上基于操作系统的开发是基于小部件的,而基于浏览器的开发依赖于模板和DSL。尽管WPF/Silverlight等异常试图将相同的模板机制(XAML)引入操作系统,但它们已经多次失败。
开发人员需要什么?
React Native有一个使用React Underthe hood的绝妙策略,它允许您转移现有的React开发者技能集。颤振使用Dart,这是一种新时代的语言,具有更陡峭的学习曲线(主观),尽管它是一种更好的UI开发语言。[6]
在“人才大战”和“大辞职”的时代[2],这比以往任何时候都更为重要,因为你不能指望雇佣最好的开发人员并让他们永远被占用。它比以往任何时候都更有意义保持你的技术堆栈精简,而不是分散在不同的技术。
第二轮:React Native
那么移动和网络上的通用代码库呢?
啊哈,圣杯。有两种方式来看待这个问题。React Native开始考虑利用React开发者技能集进行移动开发。在抽象屏幕和组件的同时,有一些简单的方法可以维护用于状态管理和行为的单个代码库。[5]
微软还发布了一个伟大的项目,允许您使用React Native for the web。[4]
另一方面,Flutter 将传输到web的JS。任何透明都是不好的,因为它是一个泄漏的抽象[3]。(记住GWT)。我对漏洞百出的抽象法则的推论是,你永远不应该选择一种可以转换成另一种语言的语言。
Flutter 还可能提供编译到web组装(WASM)的选项,允许在移动和web上使用通用的代码库。WASM将提供支持javascript以外语言的选项
未来在撰写本文时,WASM仍然存在SEO和性能问题,并且还没有为web产品做好准备。苹果承诺在safari中支持WASM。如果苹果足够体贴地为PWA提供全面支持,我们就永远不会做出选择。
尽管关于React Native和它的JS桥已经写了足够多的文章,导致了很多性能问题,但我相信这很快就会得到解决[1]
第三轮:React Native。可能是2022年
受欢迎程度如何?
截至11月11日,
github
Flutter 132K stars
React Native 99.2K stars
Stackowverflow:

此外,谷歌的趋势率也比谷歌高。这可能是因为框架的新颖性
第四轮:没有明显的赢家。
开发人员的生产力如何?
有两种方式来看待这个问题。
JS根深蒂固。Dart是一个相对较新的语言(已经存在10年了),尽管它是一种更好的语言。使用react Native和我们的react技能,起步更快。
一旦您忽略了初始起飞时间,与React Native相比,Flutter上市更快。虽然这是有争议的,但由于每个平台可能需要进行性能优化,我还是让颤振占上风。
总而言之,由于Flutter在框架本身内置了许多开发人员友好性(部署、CI/CD、丰富的组件库、调试、IDE支持),所以它在这里绝对是一个赢家。尽管像Expo、react native paper和fastlane这样的第三方组件确实为react native提供了很多便利。
第五轮:一触即发
最后决定:
如果要利用现有的开发人员技能集,请选择React Native。在当前的人才争夺战中,当你不能总是吸引最好的人才时,这比以往任何时候都更加真实。
如果你想首先成为移动用户,那么就选择Flutter,并且不介意开发两次,一次用于移动,一次用于网络。(目前)而且你没有开发商或现金短缺。它将成为未来单一前端框架的选择。
参考资料:
- [1] https://dev.to/wjimmycook/how-the-react-native-bridge-works-and-how-it-will-change-in-the-near-future-4ekc
- [2] https://www.forbesindia.com/article/news-by-numbers/what-is-fuelling-the-great-resignation-in-america/71443/1
- [3] https://www.joelonsoftware.com/2002/11/11/the-law-of-leaky-abstractions/
- [4] https://microsoft.github.io/react-native-windows/
- [5] https://blog.bitsrc.io/learn-to-share-code-between-react-native-and-react-js-14065ce5b0c3
- [6] I am a huge fan of Dart. Although react native edges out in the current blog, Dart is way better than Javascript. Below is one of the best introductions to Dart.
- https://www.freecodecamp.org/news/https-medium-com-rahman-sameeha-whats-flutter-an-intro-to-dart-6fc42ba7c4a3/
本文:
- 49 次浏览
网格应用和服务架构
【服务网格】eBPF 和 Wasm:探索服务网格数据平面的未来
2021 年 12 月 2 日,Cilium 项目宣布了 Cilium Service Mesh 的 beta 测试计划。 基于 Google Cloud 基于 eBPF 的 Google Kubernetes Service (GKS) Dataplane V2 开创的概念,Cilium Service Mesh 于一年前于 2020 年 8 月宣布,推广了“无边服务网格”的理念。 它扩展了 Cilium eBPF 产品以处理服务网格中的大部分 Sidecar 代理功能,包括 L7 路由和负载平衡、TLS 终止、访问策略、健康检查、日志记录和跟踪以及内置的 Kubernetes 入口。
Cillium 的创建者 Isovalent 在题为“eBPF 如何解决服务网格 - 再见 Sidecars”的文章中解释了使用 eBPF 作为 sidecar 代理的替代方案的基本原理。
它将我们从 sidecar 模型中解放出来,并允许我们将现有的代理技术集成到现有的内核命名空间概念中,从而使它们成为我们每天都在使用的美丽容器抽象的一部分。
简而言之,eBPF 承诺解决服务网格中的一个主要痛点——当有许多细粒度的微服务时缺乏性能。 然而,使用 eBPF 代替 sidecar 代理是一个新颖的想法,并非没有争议。

(source: How eBPF will solve Service Mesh - Goodbye Sidecars)
服务网格中的数据平面是指管理数据流量如何路由和传递到微服务应用程序的基础设施服务。目前,这是通过使用服务代理来实现的。这种设计模式通常也被称为边车模式。 Sidecar 允许其附加的微服务透明地向服务网格中的其他组件发出和接收请求。
Sidecar 通常包含一个 L7 网络代理,例如 Envoy、Linkerd 或 MOSN。代理处理流量路由、负载平衡、健康检查、身份验证、授权、加密、日志记录、跟踪和统计信息收集。 Sidecar 还可以包含基于 SDK 的应用程序框架,例如 Dapr,以提供网络代理之外的应用程序服务。此类应用服务的示例包括服务注册、服务发现、资源绑定、基于名称的服务调用、状态管理、参与者框架和秘密存储。
Sidecar 代理和服务通常在 Kubernetes pod 或容器中运行。微服务应用程序也在容器内运行,它们通过网络接口连接到 sidecar。但是,这些容器化应用程序的一个重要问题是资源消耗。 Sidecar 服务随着微服务的数量呈几何级数增长。当应用程序具有数百个相互关联且负载平衡的微服务时,开销可能会变得不堪重负。服务网格代理供应者在性能上展开竞争。正如 InfoQ 之前报道的那样,Linkerd 将其代理从 Go 重写为 Rust,并取得了显着的性能提升。
不出所料,现有的服务网格提供者并不认为 eBPF 是解决我们所有问题的圣杯。伊迪特莱文等人。来自基于 Envoy Proxy 和 Istio 的领先服务网格提供者 Solo.io 写了一篇文章来回应 Cilium 的公告。这篇文章的标题是“eBPF for Service Mesh?是的,但是 Envoy Proxy 将继续存在”。
在 Solo.io,我们将 eBPF 视为优化服务网格的强大方法,并将 Envoy 代理视为数据平面的基石。
Solo.io 作者提出的关键点是,sidecar 代理现在所做的不仅仅是简单的网络流量管理。当今的服务网格部署有复杂的需求,远远超出了 eBPF 支持的有限编程模型,这是图灵不完整的,并且对内核的安全性有许多限制。 Cilium eBPF 产品可以处理由 sidecar 代理执行的许多但不是全部的各种任务。此外,Solo.io 的作者指出,与传统代理的每个 pod 一个代理设置相比,eBPF 的每个节点一个代理设置提供的灵活性要小得多,因此增加了总体开销。这些 eBPF 缺点对于开发人员必须编写和部署到服务网格代理中的流量路由、负载平衡和授权的应用程序特定逻辑尤其明显。
Terate.io 的开发人员在对 Cilium 公告“社区中关于 Istio 和 Service Mesh 的辩论”的回应中提出了类似的论点。他们指出,今天的 sidecar 代理的性能是合理的,开源社区已经想出了进一步提高性能的方法。同时,开发人员很难在像 eBPF 这样新颖且图灵不完备的技术中构建特定于应用程序的数据平面逻辑。
Istio 架构稳定且可用于生产,生态系统正在萌芽。
eBPF 的许多问题都与它是一种内核技术有关,因此必须有安全限制。 有没有一种方法可以将复杂的特定于应用程序的代理逻辑合并到数据平面中,而不会使用使用空间技术降低性能? 事实证明,WebAssembly (Wasm) 可能就是这样的选择。 Wasm 运行时可以以接近本机的性能安全地隔离和执行用户空间代码。
Envoy Proxy 开创了使用 Wasm 作为扩展机制来对数据平面进行编程的方法。 开发人员可以使用 C、C++、Rust、AssemblyScript、Swift 和 TinyGo 等语言编写特定于应用程序的代理逻辑,并将模块编译成 Wasm。 通过 proxy-Wasm 标准,代理可以在 Wasmtime 和 WasmEdge 等高性能运行时执行那些 Wasm 插件。 目前,Envoy Proxy、Istio Proxy、MOSN 和 OpenResty 都支持 proxy-Wasm。

(Wasm in the container ecosystem. Source: WasmEdge Book)
此外,Wasm 可以充当通用应用程序容器。它在服务网格数据平面上的应用不仅限于 sidecar 代理。附加到 sidecar 的微服务可以在其自己的轻量级 Wasm 运行时中运行。 WasmEdge WebAssembly Runtime 是一个安全、轻量级、快速、可移植和多语言的运行时,可以由 Kubernetes 作为容器直接管理。到 2021 年 12 月,WasmEdge 贡献者社区证明,基于 WasmEdge 的微服务可以与 Dapr 和 Linkerd 边车一起使用,作为具有来宾操作系统和完整软件堆栈的重量级成熟 Linux 容器的替代方案。与 Linux 容器应用程序相比,WebAssembly 微服务消耗 1% 的资源,冷启动时间为 1%。
eBPF 和 Wasm 是服务网格应用程序在数据平面中实现高性能的新手。它们仍然是新兴技术,但有可能成为微服务生态系统中当今 Linux 容器的替代品或补充品。
原文:https://www.infoq.com/news/2022/01/ebpf-wasm-service-mesh/
本文:https://jiagoushi.pro/node/1851
- 79 次浏览
软件架构基础
- 149 次浏览
【性能】性能比较:REST vs gRPC vs 异步通信

微服务之间的通信方式对微服务架构内的各种软件质量因素有重大影响(有关微服务网络内通信的关键作用的更多信息)。沟通方式会影响软件的性能和效率等功能性需求,以及可变性、可扩展性和可维护性等非功能性需求。因此,有必要考虑不同方法的所有优缺点,以便在具体用例中合理选择正确的沟通方式。
本文比较了以下样式:REST、gRPC 和使用消息代理 (RabbitMQ) 的异步通信,在微服务网络中了解它们对软件的性能影响。沟通方式的一些最重要的属性(反过来会影响整体表现)是:
- 数据传输格式
- 连接处理
- 消息序列化
- 缓存
- 负载均衡
数据传输格式
虽然使用 AMQP 协议(高级消息队列协议)的异步通信和 gRPC 通信使用二进制协议进行数据传输,但 REST-API 通常以文本格式传输数据。与基于文本的协议相比,二进制协议的效率要高得多 [1,2]。因此,使用 gRPC 和 AMQP 进行通信会导致较低的网络负载,而使用 REST API 时可以预期更高的网络负载。
连接处理
REST-API 通常建立在 HTTP/1.1 协议之上,而 gRPC 依赖于 HTTP/2 协议的使用。 HTTP/1.1、HTTP/2 以及 AMQP 都在传输层使用 TCP 来确保稳定的连接。要建立这样的连接,需要在客户端和服务器之间进行详细的通信。这些性能影响同样适用于所有沟通方式。但是,对于 AMQP 或 HTTP/2 连接,通信连接的初始建立只需要执行一次,因为这两种协议的请求都可以多路复用。这意味着可以将现有连接重用于使用异步或 gRPC 通信的后续请求。另一方面,使用 HTTP/1.1 的 REST-API 为与远程服务器的每个请求建立新连接。

Necessary communication to establish a TCP-Connection
消息序列化
通常,在通过网络传输消息之前,使用 JSON 执行 REST 和异步通信以进行消息序列化。另一方面,gRPC 默认以协议缓冲区格式传输数据。协议缓冲区通过允许使用更高级的序列化和反序列化方法来编码和使用消息内容 [1] 来提高通信速度。然而,选择正确的消息序列化格式取决于工程师。关于性能,protocol buffers 有很多优势,但是当必须调试微服务之间的通信时,依赖人类可读的 JSON 格式可能是更好的选择。
缓存
有效的缓存策略可以显着减少服务器的负载和必要的计算资源。由于其架构,REST-API 是唯一允许有效缓存的通信方式。 REST-API 响应可以被其他服务器和缓存代理(如 Varnish)缓存和复制。这减少了 REST 服务的负载并允许处理大量的 HTTP 流量 [1]。但是,这只有在基础架构上部署更多服务(缓存代理)或使用第三方集成后才有可能。 gRPC 官方文档和 RabbitMQ 文档都没有介绍任何形式的缓存。
负载均衡
除了临时存储响应之外,还有其他技术可以提高服务速度。负载均衡器(例如 mod_proxy)可以高效透明的方式在服务之间分配 HTTP 流量 [1]。这可以实现使用 REST API 的服务的水平扩展。 Kubernetes 作为容器编排解决方案,无需任何调整即可对 HTTP/1.1 流量进行负载均衡。另一方面,对于 gRPC,需要在网络上提供另一个服务(linkerd)[3]。异步通信无需进一步的帮助即可支持负载平衡。消息代理本身扮演负载均衡器的角色,因为它能够将请求分发到同一服务的多个实例。消息代理为此目的进行了优化,并且它们的设计已经考虑到它们必须具有特别可扩展性的事实[1]。
实验
为了能够评估各个通信方法对软件质量特性的影响,开发了四个微服务来模拟电子商务平台的订单场景。
微服务部署在由三个不同服务器组成的自托管 Kubernetes 集群上。服务器通过千兆 (1000 Mbit/s) 网络连接,位于同一数据中心,服务器之间的平均延迟为 0.15 毫秒。每次实验运行时,各个服务都部署在相同的服务器上。这种行为是通过 pod 亲和性来实现的。
所有微服务都是用 GO 编程语言实现的。个别服务的实际业务逻辑,例如与数据库的通信,为了不被选择的通信方法之外的其他影响,故意不实现。因此,收集的结果不能代表这种类型的微服务架构,但可以使实验中的通信方法具有可比性。相反,业务逻辑的实现是通过将程序流程延迟 100 毫秒来模拟的。因此,在通信中,总延迟为 400 毫秒。
开源软件k6用于实现负载测试。
实现
Golang 标准库中包含的 net/http 模块用于提供 REST 接口。使用标准库中也包含的 encoding/json 模块对请求进行序列化和反序列化。所有请求都使用 HTTP POST 方法。
“谈话很便宜。给我看看密码。”
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"github.com/google/uuid"
"gitlab.com/timbastin/bachelorarbeit/common"
"gitlab.com/timbastin/bachelorarbeit/config"
)
type restServer struct {
httpClient http.Client
}
func (server *restServer) handler(res http.ResponseWriter, req *http.Request) {
// only allow post request.
if req.Method != http.MethodPost {
bytes, _ := json.Marshal(map[string]string{
"error": "invalid request method",
})
http.Error(res, string(bytes), http.StatusBadRequest)
return
}
reqId := uuid.NewString()
// STEP 1 / 4
log.Println("(REST) received new order", reqId)
var submitOrderDTO common.SubmitOrderRequestDTO
b, _ := ioutil.ReadAll(req.Body)
err := json.Unmarshal(b, &submitOrderDTO)
if err != nil {
log.Fatalf(err.Error())
}
checkIfInStock(1)
invoiceRequest, _ := http.NewRequest(http.MethodPost,
fmt.Sprintf("%s/invoices", config.MustGet("customerservice.rest.address").
(string)), bytes.NewReader(b))
// STEP 2
r, err := server.httpClient.Do(invoiceRequest)
// just close the response body
r.Body.Close()
if err != nil {
panic(err)
}
shippingRequest, _ := http.NewRequest(http.MethodPost,
fmt.Sprintf("%s/shipping-jobs", config.MustGet("shippingservice.rest.address").
(string)), bytes.NewReader(b))
// STEP 3
r, err = server.httpClient.Do(shippingRequest)
// just close the response body
r.Body.Close()
if err != nil {
panic(err)
}
handleProductDecrement(1)
// STEP 5
res.WriteHeader(201)
res.Write(common.NewJsonResponse(map[string]string{
"state": "success",
}))
}
func startRestServer() {
server := restServer{
httpClient: http.Client{},
}
http.HandleFunc("/orders", server.handler)
done := make(chan int)
go http.ListenAndServe(config.MustGet("orderservice.rest.port").(string), nil)
log.Println("started rest server")
<-done
}
RabbitMQ 消息代理用于异步通信,部署在同一个 Kubernetes 集群上。 消息代理和各个微服务之间的通信使用 github.com/spreadway/amqp 库进行。 该库是 GO 编程语言官方文档推荐的。
package main
import (
"encoding/json"
"log"
"github.com/streadway/amqp"
"gitlab.com/timbastin/bachelorarbeit/common"
"gitlab.com/timbastin/bachelorarbeit/config"
"gitlab.com/timbastin/bachelorarbeit/utils"
)
func handleMsg(message amqp.Delivery, ch *amqp.Channel) {
log.Println("(AMQP) received new order")
var submitOrderRequest common.SubmitOrderRequestDTO
err := json.Unmarshal(message.Body, &submitOrderRequest)
utils.FailOnError(err, "could not unmarshal message")
checkIfInStock(1)
handleProductDecrement(1)
ch.Publish(config.MustGet("amqp.billingRequestExchangeName").(string), "",
false, false, amqp.Publishing{
ContentType: "application/json",
Body: message.Body,
})
}
func getNewOrderChannel(conn *amqp.Connection) (*amqp.Channel, string) {
ch, err := conn.Channel()
utils.FailOnError(err, "could not create channel")
ch.ExchangeDeclare(config.MustGet("amqp.newOrderExchangeName").
(string), "fanout", false, false, false, false, nil)
queue, err := ch.QueueDeclare(config.MustGet("orderservice.amqp.consumerName").
(string), false, false, false, false, nil)
utils.FailOnError(err, "could not create queue")
ch.QueueBind(queue.Name, "", config.MustGet("amqp.newOrderExchangeName").
(string), false, nil)
return ch, queue.Name
}
func startAmqpServer() {
conn := common.NewAmqpConnection(config.MustGet("amqp.host").(string))
defer conn.Close()
orderChannel, queueName := getNewOrderChannel(conn)
msgs, err := orderChannel.Consume(
queueName,
config.MustGet("orderservice.amqp.consumerName").(string),
true,
false,
false,
false,
nil,
)
utils.FailOnError(err, "could not consume")
forever := make(chan bool)
log.Println("started amqp server:", queueName)
go func() {
for d := range msgs {
go handleMsg(d, orderChannel)
}
}()
<-forever
}gRPC 客户端和服务器使用 gRPC 文档推荐的 google.golang.org/grpc 库。 数据的序列化是使用协议缓冲区完成的。
package main
import (
"log"
"net"
"context"
"gitlab.com/timbastin/bachelorarbeit/common"
"gitlab.com/timbastin/bachelorarbeit/config"
"gitlab.com/timbastin/bachelorarbeit/pb"
"gitlab.com/timbastin/bachelorarbeit/utils"
"google.golang.org/grpc"
)
type OrderServiceServer struct {
CustomerService pb.CustomerServiceClient
ShippingService pb.ShippingServiceClient
pb.UnimplementedOrderServiceServer
}
func (s *OrderServiceServer) SubmitOrder(ctx context.Context,
request *pb.SubmitOrderRequest) (*pb.SuccessReply, error) {
log.Println("(GRPC) received new order")
if s.CustomerService == nil {
s.CustomerService, _ = common.NewCustomerServiceClient()
}
if s.ShippingService == nil {
s.ShippingService, _ = common.NewShippingServiceClient()
}
checkIfInStock(1)
// call the product service on each iteration to decrement the product.
_, err := s.CustomerService.CreateAndProcessBilling(ctx, &pb.BillingRequest{
BillingInformation: request.BillingInformation,
Products: request.Products,
})
utils.FailOnError(err, "could not process billing")
// trigger the shipping job.
_, err = s.ShippingService.CreateShippingJob(ctx, &pb.ShippingJob{
BillingInformation: request.BillingInformation,
Products: request.Products,
})
utils.FailOnError(err, "could not create shipping job")
handleProductDecrement(1)
return &pb.SuccessReply{Success: true}, nil
}
func startGrpcServer() {
listen, err := net.Listen("tcp", config.MustGet("orderservice.grpc.port").(string))
if err != nil {
log.Fatalf("could not listen: %v", err)
}
grpcServer := grpc.NewServer()
orderService := OrderServiceServer{}
// inject the clients into the server
pb.RegisterOrderServiceServer(grpcServer, &orderService)
// start the server
log.Println("started grpc server")
if err := grpcServer.Serve(listen); err != nil {
log.Fatalf("could not start grpc server: %v", err)
}
}收集数据
检查成功和失败的订单处理的数量,以确认它们所经过的时间。如果直到确认的持续时间超过 900 毫秒,则订单流程被解释为失败。选择此持续时间是因为在实验中可能会出现无限长的等待时间,尤其是在使用异步通信时。每次试验都会报告失败和成功订单的数量。
每种架构总共进行了 12 次不同的测量,每种情况下同时请求的数量不同,传输的数据量也不同。首先,在低负载下测试每种通信方式,然后在中等负载下,最后在高负载下测试。低负载模拟 10 个,中等负载模拟 100 个,高负载模拟 300 个同时向系统发出的请求。在这六次测试运行之后,要传输的数据量会增加,以了解各个接口的序列化方法的效率。数据量的增加是通过订购多个产品来实现的。
结果
gRPC API 架构是实验中研究的性能最佳的通信方法。在低负载下,它可以接受的订单数量是使用 REST 接口的系统的 3.41 倍。此外,平均响应时间比 REST-API 低 9.71 毫秒,比 AMQP-API 低 9.37 毫秒。
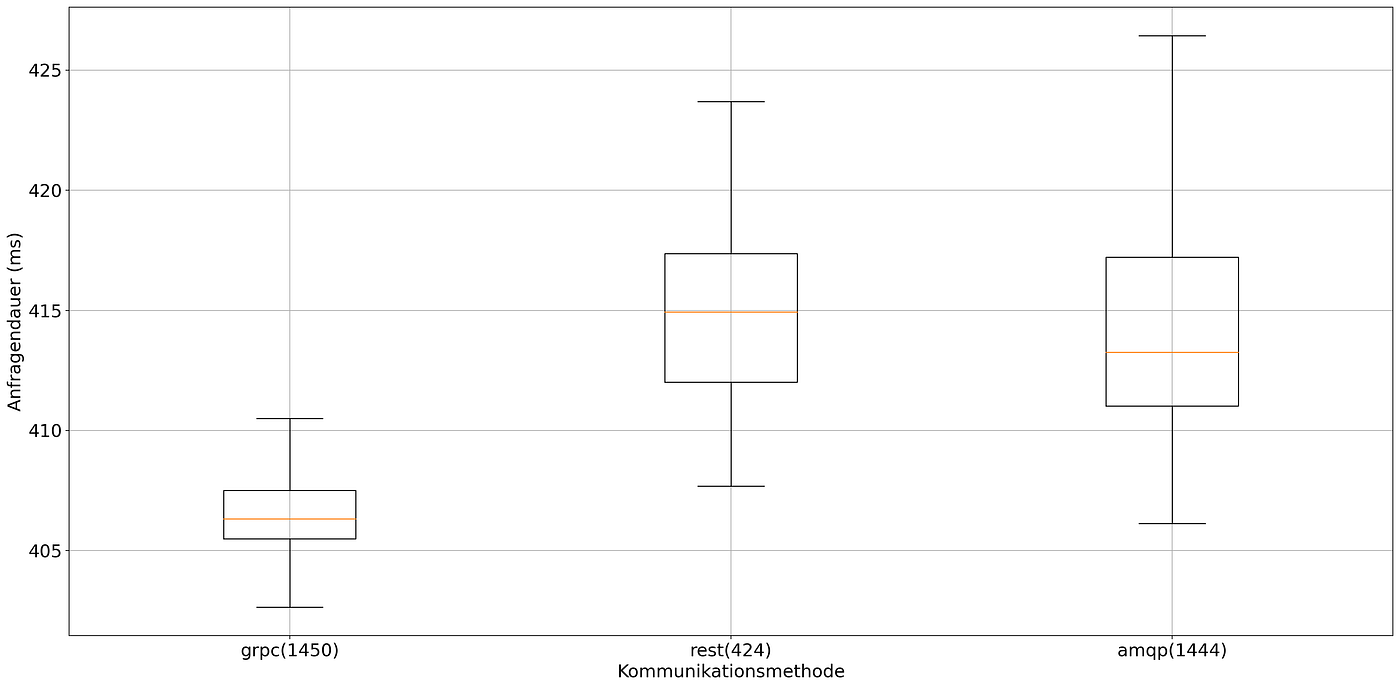
1 simultaneous request, low bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
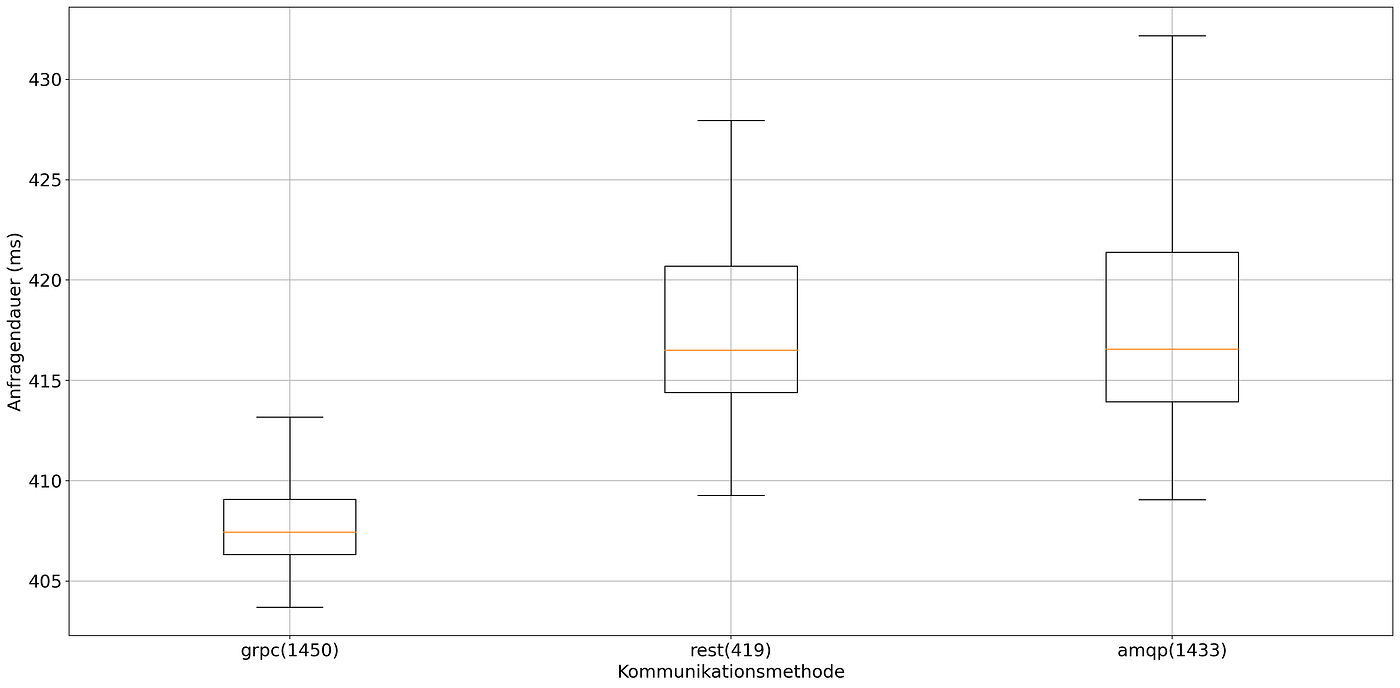
1 simultaneous request, high bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
总体而言,这种趋势在更多并发请求的实验中继续存在。 对于 100 个并发请求,使用 gRPC-API 架构可以处理的订单数量是 REST-API 的 3.7 倍。 与 AMQP 的差异要小得多。 GRPC 的处理能力比 AMQP 多 8.06%(1170 个订单)。 虽然 gRPC 可以在 418.99 毫秒内处理 95% 的请求,但 AMQP 只能在 557.39 毫秒内完成,而 REST 在 1425.13 毫秒内完成。
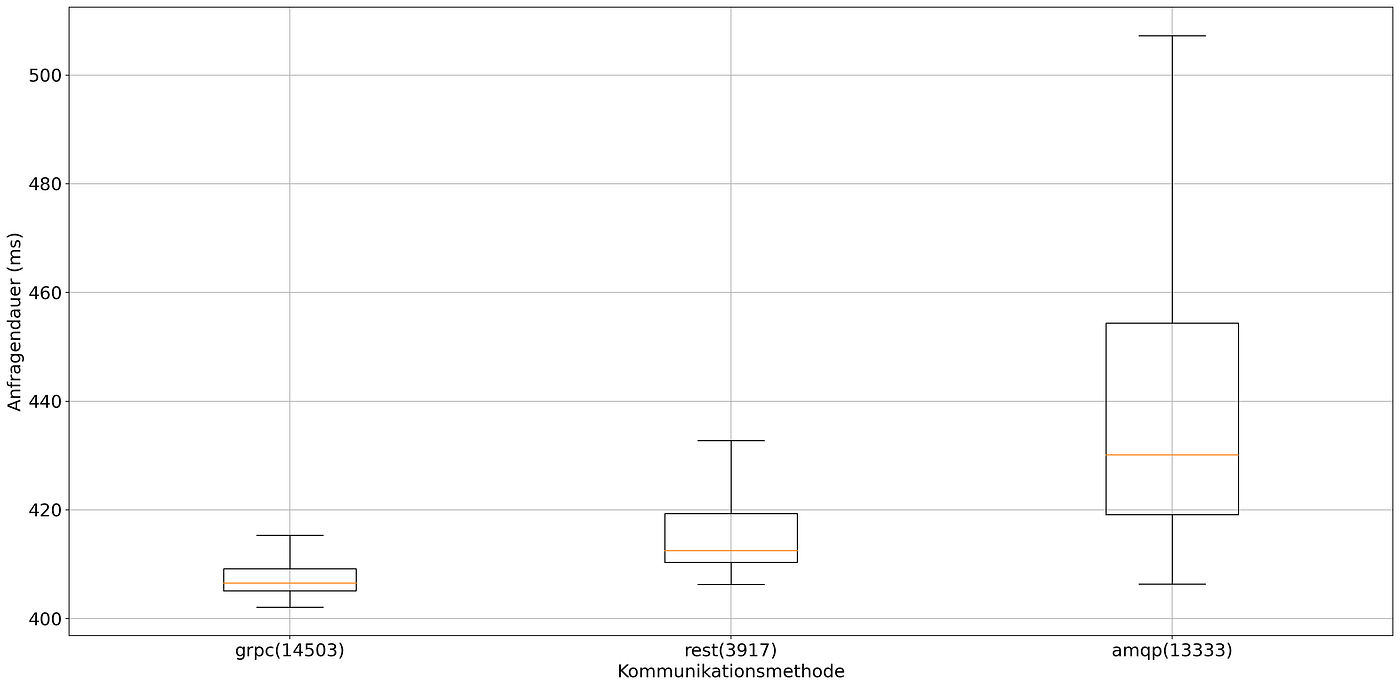
100 simultaneous requests, low bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
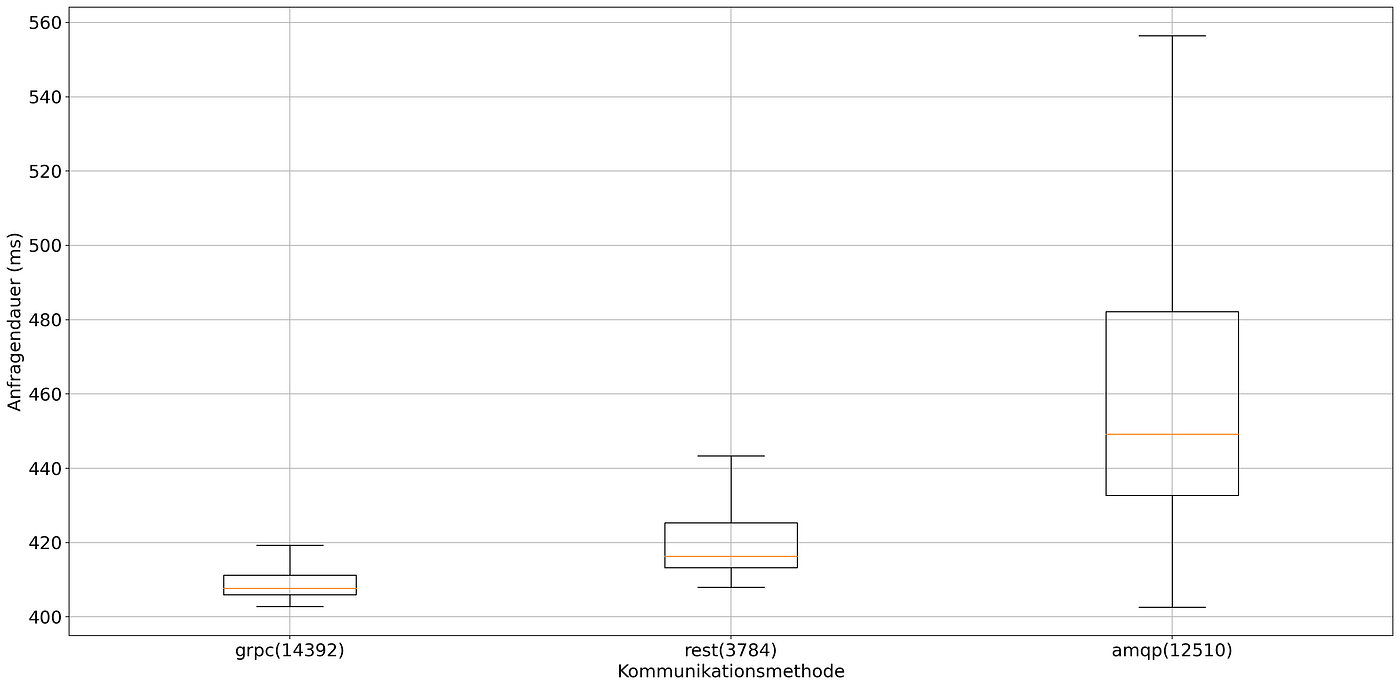
100 simultaneous requests, high bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
在高负载下的第三次运行中,使用 gRPC API 的微服务架构可以成功确认 43122 个订单。 这是使用 REST-API 的相同架构的 4.8 倍,是使用异步通信的架构的 2.02 倍。
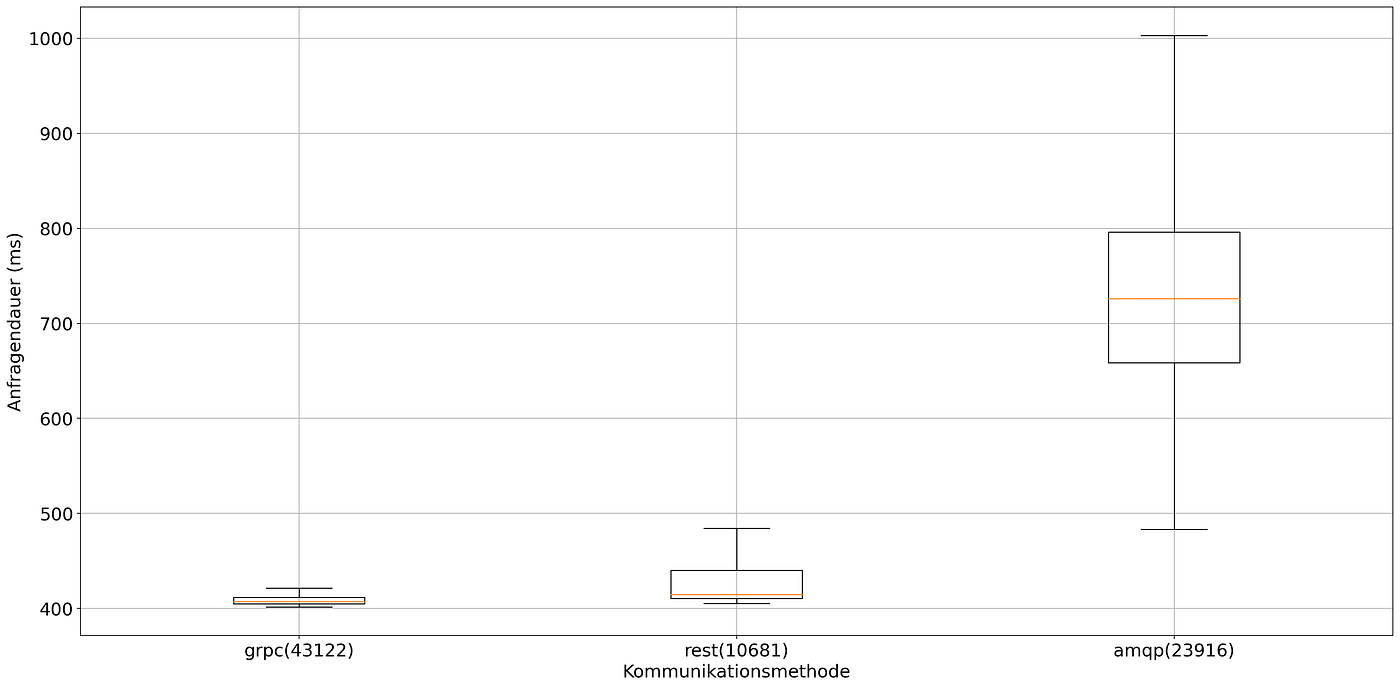
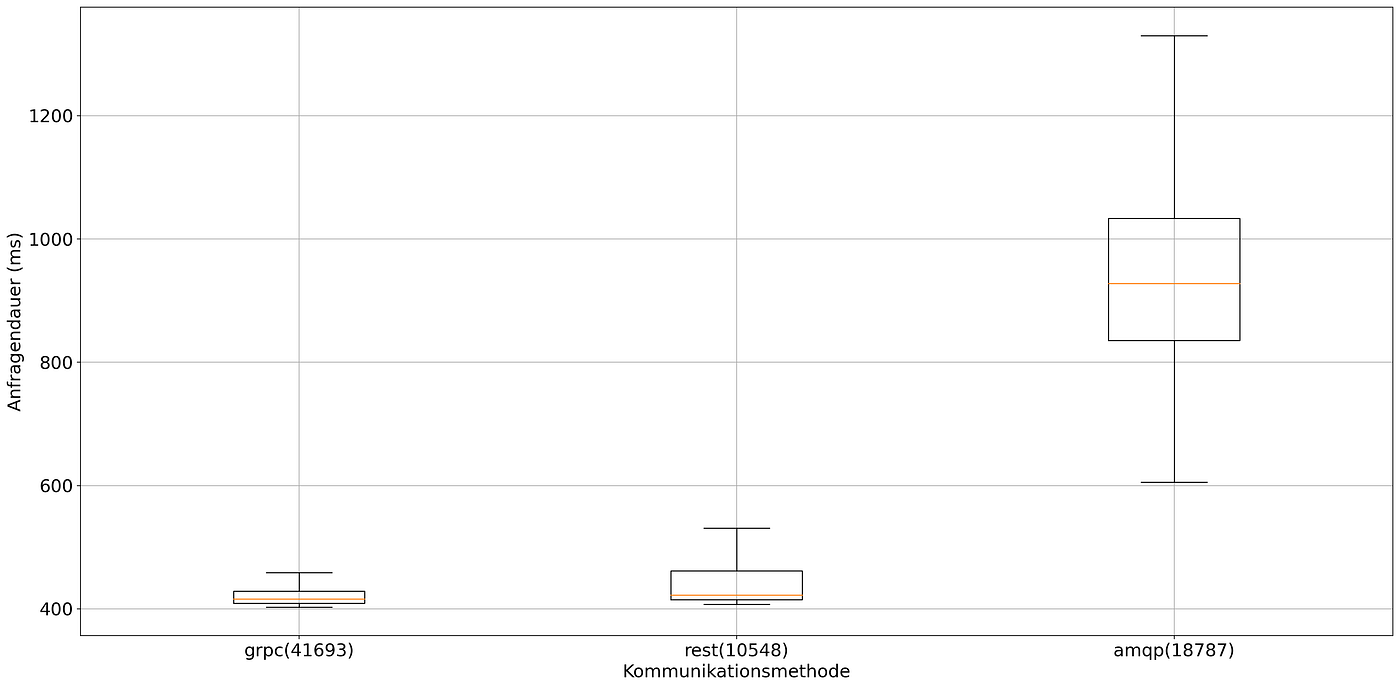
300 simultaneous requests, high bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
从 JSON 格式的客户端请求大小与协议缓冲区格式的大小对比来看,对于单个产品,使用 gRPC 传输的数据量与 REST 相比减少了 34.202%。这种差异可以通过优化的协议缓冲区序列化来证明,它提供了比 JSON 更有效的编码。
结论
gRPC 被证明是最有效的 API 架构,其次是带有消息代理的 AMQP。 gRPC 提供了一种比带有协议缓冲区的 JSON 更有效的序列化方法。总体而言,与 REST 相比,可以多处理 3.4-4.03 个订单。特别是在有许多并发连接的情况下,gRPC 可以提供优于 REST-API 的优势,因为 TCP 连接可以被重用。与异步通信 1.0–2.2 相比,可以处理更多的订单。通过实验显现的 gRPC 的另一个优点是 gRPC 提供了可预测的性能,而响应时间没有大的异常值。在实验过程中,AMQP,尤其是 REST,在平均响应时间和 95% 分位数之间显示出很大的差异。该实验检查了每种通信方式如何在可变数量的并发请求和传输数据下执行,但这项研究只能近似现实的复杂性。负载均衡器和缓存代理等支持技术可能会产生重大影响,尤其是在使用 REST API 时。必须在考虑实验设置的情况下评估该实验的结果。
不能说 gRPC 允许在微服务网络中进行最有效的通信。
参考
- [1]Sam Newman. 构建微服务:设计细粒度系统。卷。 2. O'ReillyMedia, Inc,2015 年。
- [2]吉姆·韦伯、萨瓦斯·帕拉斯塔蒂迪斯和伊恩·罗宾逊。实践中的 REST:超媒体和系统架构。 O'Reilly 媒体公司,2010 年,第448.
- [3]William Morgan.gRPC 在 Kubernetes 上进行负载平衡,无需泪水。 https://kubernetes.io/blog/2018/11/07/grpc-load-balancing-on-kubernetes…。 (于 2021 年 9 月 15 日访问)。 2018 年 11 月。
原文:https://medium.com/l3montree-techblog/performance-comparison-rest-vs-gr…
- 445 次浏览
【架构治理】在代码存储库中记录软件架构
Markdown 是一种标准的简单语法,用于创建具有专业外观的文档。 它比 HTML 更简单,无需专门的编写编辑器即可进行管理。 Git配置管理工具也支持markdown格式。 在 Git 环境中,markdown 一般用于项目的简单介绍和构建说明。 (自述文件)。 本文介绍了如何将 Markdown 格式与模板一起用于架构文档。

带有 Markdown 的架构文档
与代码一起管理软件的架构设计和设计决策将为项目提供极大的便利。 当我们的设计与代码一起保存在配置管理环境中时,我们可以一起进行设计变更和代码变更。 当新工程师开始项目并将代码拉到他的计算机上时,他有机会看到系统的架构。
准备 Markdown 文档 IDE
您可以使用 Visual Studio Code 和类似的 IDE 与您的代码一起准备 markdown 文档。(市场上有 markdown 编辑器,但使用 IDE 来做会更实用)。 您可以在 Visual Studio Code 中使用“Markdown Preview Enhanced”插件。 使用这个插件,你可以在 VS Code (Preview) 中直观地看到 markdown 文档。 您还可以使用相同的工具生成 HTML、World 或 PDF 文档。
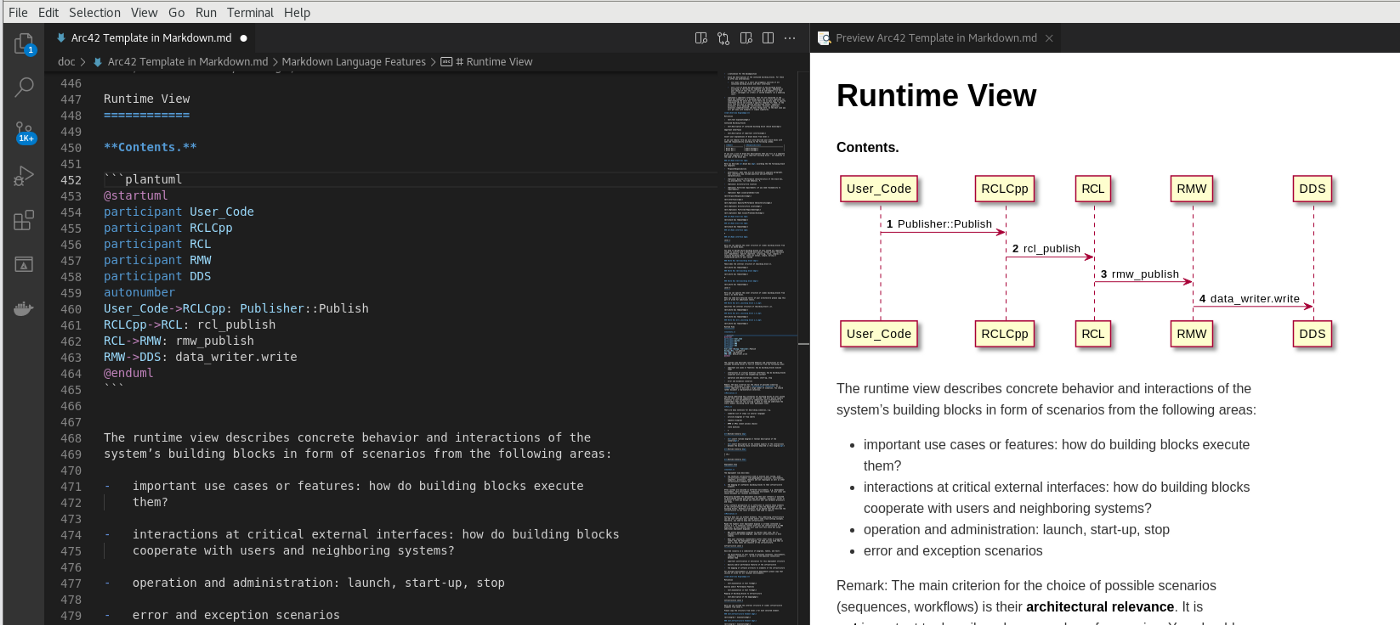
MD Document Preparation with VS Code
UML 和 C4 图
您可以将使用 Plant UML 脚本语言绘制的 UML 和 C4 图放入 Markdown 文档中。 这样,您可以将整个设计(包括绘图)保存在一个地方。 您放入 Markdown 文档中的 UML 和 C4 图可以在预览窗口中看到。 (带有一个名为“PlantUML”的插件)。 此外,当您导出 pdf 或 html 时,您将能够将这些图表视为图形。 GIT 工具具有可视化显示在此 PlantUML 中编写的设计脚本的功能。 通过这种方式,可以看到带有 Bitbucket 的设计(具有适当的版本和配置)。 此功能在开源 Github 站点上尚不可用。
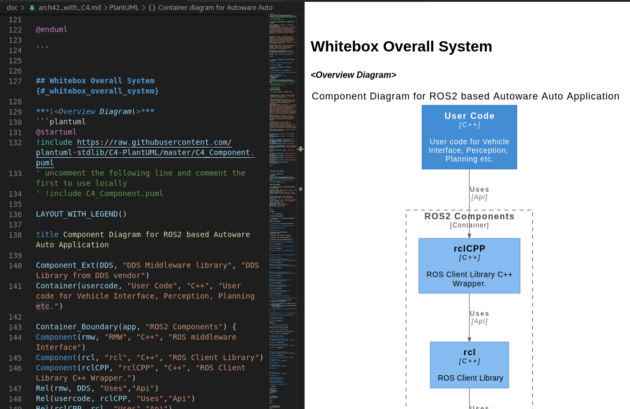
- Adding a C4 Component Diagram to a Markdown document
如果git服务器不支持可视化,可以先从plantuml服务器站点制作一张png或svg的图,然后将相关的图发送到Git服务器。然后你可以在markdown文档中将此图作为绘图链接。您可以在使用其他工具制作的图纸中使用此方法。
Arch 42 模板
Arc 42 是架构文档的模板。通过正确完成此 Arc42 模板,您将在一个地方拥有软件架构和设计的关键设计决策。
- — 简介和目标
- — 约束
- - 背景和范围
- — 解决方案策略
- - 构建块视图
- — 运行时视图
- — 部署视图
- — 交叉切割概念
- — 架构决策
- - 质量属性
- — 风险和技术债务
您可以在 Arch42 网站上访问 markdown 模板。相关网站上有一个草稿作为单个文件或作为每个部分的单独文件。
您可以在此模板中使用 C4 模型和 UML 图。例如,我们可以使用第 3 章中的 C4 范围图,第 5 章中的容器图和组件图。第 6 章中可以使用 C4 动态图或 UML 序列图。部署图可以使用 C4 或 UML 符号在第 7 章。
对于第 10 章,我们可以使用为架构权衡分析方法 (ATAM) 准备的表格。在这种情况下,您可以访问和使用我准备的降价表草稿。

结论
建议使用 Arch 42 模板以 Markdown 格式准备软件架构文档,并在代码中包含 Git 结构中的 C4 模型和 UML 图。 该解决方案提供了高质量、可管理、版本控制和可追溯的架构文档。
- 72 次浏览
【架构设计模式】MITRE 设计模式
定义:
软件中的设计模式(通常)是简短的描述,用于捕捉过去证明是成功的实践。它们不是具体的软件,而是在某些情况下应用的一种模板。它们通常不是规定性的,而是建议性的,并且包括关于何时最适合使用它们的指导,并提供来自现有系统的示例。它们最重要的用途是描述对象或系统与其环境(即其他对象或系统)的交互。设计模式可以出现在系统设计的不同级别,从低级编程到系统系统。在后一层,它们与界面设计和耦合最为相关。
关键词:
耦合,设计模式,接口
MITRE SE 角色和期望:
MITRE 系统工程师 (SE) 应了解信息技术 (IT) 密集型系统的设计模式的一般原则和最佳实践。他们应选择和推荐适合应用程序的模式,了解出现的挑战和选择,就设计模式选择的适用性向政府提供建议,并了解企业环境中界面设计的问题和挑战。
背景
设计模式的概念通常归功于建筑师 Christopher Alexander 的工作,并被 Kent Beck 和 Ward Cunningham 改编为软件。 1995 年,流行的书籍设计模式(其作者通常被称为“四人帮”(GOF))建立了一组持续使用的模式,并提供了描述模式的“模式”[1]。这 23 种模式分为创造型、结构型和行为型。已经定义了许多其他模式,以及其他类别,例如用户界面。
例如,一个 GOF 模式是抽象工厂,这是一种创建模式,它提供了一个用于创建新对象的接口,而调用者并不知道正在创建的对象的具体类型。这可以用于实现不同的外观和感觉,只需对程序进行最小的更改。其他示例是代理结构模式,其中一个对象成为另一个对象的代理(具有相同的接口),通常用于远程过程调用;单例模式,其中一个类只允许创建自己的一个实例,通常用于管理共享资源;和中介者行为模式,它允许类之间的松散耦合,因为它是唯一一个对其方法有详细了解的类。
与审查接口调用的细节相比,设计模式使对软件设计的审查和讨论能够在更高和更抽象的层次上进行——“你应该在这里使用单例模式吗?”或“抽象工厂模式有帮助吗?”
GOF 模式有几个共同点:它们是根据面向对象的软件定义的,它们(通常)描述一个对象与其环境(例如,其他对象)的交互,它们通常用在一个内部设计中。单个应用程序(即本地调用环境)。
然而,模式也可以在更广泛的设计层次上进行查看,而 MITRE SE 更经常地涉及到这方面。与审查组件之间或更高级别的系统之间的接口相比,MITRE SE 不太可能参与系统组件的详细内部工作的开发。这需要一组设计模式,这些模式专注于跨系统边界建立连接的方式。许多 GOF 模式不会直接应用。
企业工程面向服务环境中的设计模式
在为大型企业服务环境进行设计时,会出现两个考虑:(1)用户可能会以设计者没有预料到的方式将服务、接口等放在一起,以及(2)任何接口更改都会影响更大的用户集.深思熟虑地使用设计模式可以帮助解决这两个问题。扩展到企业的第三个问题是服务通常必须处理(当前)未知且潜在的大量用户。设计模式在直接处理这个问题时用处不大。
在企业环境中,当考虑系统到系统的接口时,可以扩展设计模式的概念,以包含有关如何管理接口中的耦合的更一般的指导。作为一般规则,只要可能,松耦合优于紧耦合。松散耦合意味着接口一侧实现的变化不会影响另一侧的实现。例如,在具有必须分发给用户的查找表的字段中使用代码不是松散耦合。此外,松散耦合的接口不应锁定会抑制可扩展性的特定限制。作为一个简单的例子,在联系信息的界面中,只允许一个(或两个)10 位数字的电话号码可能是不够的。一个更可扩展的接口可能允许任意长度的不确定长度的电话号码列表。
松散耦合将接口的用户与实现中的更改隔离开来。例如,一个设计良好的界面应该能够向界面添加更多参数,同时在没有新参数的情况下仍然可以生成和接受消息。这允许增长和创新,而不会使以前版本的界面的用户陷入困境。但是,另一方面,必须谨慎管理此扩展机制,否则仅参数不同的受支持接口的数量可能会变得很大,并且维护这些接口可能会淹没向后兼容性的价值。
示例接口标准化工作
Cursor on Target (CoT) [2] 是企业努力简化接口集合并提供松散耦合的一个示例。美国空军在许多组件之间拥有大量紧密耦合的点对点接口。 John P. Jumper 将军(前空军参谋长)启发 MITRE 提出了一组数据元素,可以满足大多数用户的大部分需求。 MITRE 研究了几个月的消息,发现有少量数据元素被重复使用。 CoT 以易于生成和解析的 XML 格式对这些元素的定义进行了标准化。它提供了兼容的扩展,因此可以添加新元素而不会破坏现有用户。
国家信息交换模型 (NIEM) [3] 是一个基于 XML 的信息交换接口。它源于全球司法 XML 数据模型,是司法部和国土安全部之间的合作项目。它已被许多州和国防部采用。它提供了一个信息元素词汇表,合作伙伴可以从中选择创建消息。
与 MITRE 系统工程能力模型 (SE CM) 保持一致
具有设计模式的系统工程工作与 MITRE SE CM [4] 中的“架构”(第 2.3 节)和“软件和信息工程”(第 4.7 节)能力最接近。在前者中,设计模式可以成为讨论、可视化、比较和记录架构界面决策的有用工具。在后者中,因为设计模式现在是软件工程中一种成熟的范式,所以对技术和术语的理解有助于促进客户/用户和软件专家之间的沟通。
最佳实践和经验教训
以下实践规则可以看作是企业级以及详细实现级的接口设计模式。
- 避免接口的复杂性。复杂的接口通常不能很好地扩展。复杂性被推送给所有用户,处理它的技能可能会有所不同。例如,不是以 10 种可能不同的格式提供纬度和经度,每种格式都必须由用户处理,而是以单一格式提供。如果一个接口过于复杂,则很可能会被误解,或者开发人员会复制用户端的次优实现。复杂性会导致错误,从而导致可能无法纠正的不良性能,甚至可能成为安全风险。
- 尽可能使用松散耦合的接口。松散耦合意味着接口一侧实现的变化不会影响另一侧的实现。这为双方提供了极大的自由来进行改进并保持开发计划不连贯。严格的时序要求或软件版本要求可能是需要重新评估和放宽这种做法的考虑因素,但在这种情况下应该明确说明并记录在案。
- 只有在性能需要时才使用紧密耦合的接口。紧密耦合会导致代码有缺陷和脆弱。紧密耦合的一个例子是 Link-16 接口,因为它是一个战术链接,所以使用一个数字来表示飞机的类型。这将用户与特定版本的转换表联系起来。如果表格在一侧更新,则用户可能会留下一个无意义的数字,直到表格也被更新。当然,更广泛的通信协议可以明确地携带飞机上的所有信息,但带宽限制可能会禁止将其作为替代方案。
- 如果可能,从松散耦合开始设计。即使在使用紧耦合的情况下,初始设计也可以从松耦合接口开始。记录使用紧密耦合的原因。这类似于以独立于数据库管理系统 (DBMS) 的方式定义逻辑模式,但在依赖于 DBMS 的物理模式中实现它。对于系统的系统,这可能是一个有用的模式。
- 关注接口中的数据一致性,而不是内部表示。在 1990 年代,政府组织试图在所有应用程序中强制执行数据一致性,甚至指定如何在应用程序及其数据库中表示数据。这从未实现。最近,重点是为数据交换创建通用定义,让应用程序可以自由选择如何在内部表示数据。事实证明,这是一个更容易实现的目标。
- 认识到数据表示的差异是由数据的不同用途造成的。例如,考虑一把枪。射手想知道它的射程、口径等。托运人想知道它的大小、重量等。财务想知道它的成本、估计寿命等。同样的枪在不同的系统中自然会有不同的表示。强制所有系统上的所有特征将是繁重的。但是,可以通过组合模式来实现数据的意想不到的创新使用,以创建基于现有表示的新数据表示。
- 在设计界面时,请考虑 80/20 规则。实现大多数用户大部分时间需要的 80%(左右)可能会更好,特别是如果这可以通过简单的界面快速完成。这减少了实施的成本和时间。
- 构建扩展接口的能力。一些用户需要至少达到剩余 20% 的一部分,并且无论如何,界面必须随着时间的推移而增长和变化。松散耦合的接口应该构建兼容扩展的机制,以便可以在不影响不需要扩展的用户的情况下进行更改和添加。
- 考虑可扩展接口的治理。接口的扩展会创建必须管理的多个版本/副本。考虑这样做的理由并理解这样做的影响。
- 不要忘记界面中的语义理解水平。有人能够正确解析您的界面很好,但也必须对数据元素的含义达成一致。
- 让开发人员参与系统接口的开发。那些将实现接口的人应该参与设计,因为他们可能对可能抑制可扩展性或导致其他问题的决策有洞察力。
References and Resources
- Gamma, E., R. Helm, R. Johnson, and J. Vlissides, 1995, Design Patterns: Elements of Reusable Object-Oriented Software, Boston, Mass. Addison-Wesley Longman.
- Miller, R. W. and D. G. Winkowski, June 2007, Loose Couplers as an Information Design Strategy, The MITRE Corporation.
- National Information Exchange Model, accessed August 5, 2014. (By the way, they are looking for NIEM design patterns.)
- The MITRE Institute, September 1, 2007, MITRE Systems Engineering Competency Model.
Additional References and Resources
- Bell, M., 2010, SOA Modeling Patterns for Service Oriented Discovery and Analysis, Hoboken, N.J., John Wiley & Sons.
- Erl, T., 2009, SOA Design Patterns, New York, Prentice Hall.
- Fowler, M., 2002, Patterns of Enterprise Application Architecture, Addison-Wesley.
- Hohpe, G., and B. Woolf, 2003, Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions, Boston, Mass., Addison-Wesley Longman.
- Van Welie, M., A Pattern Library for Interaction Design, accessed April 14, 2014.
- Vora, P., 2009, Web Application Design Patterns, San Fransisco, Calif., Morgan Kaufmann Publishers.
原文:https://www.mitre.org/publications/systems-engineering-guide/enterprise…
- 66 次浏览
【软件工程】内聚和耦合的区别
视频号
微信公众号
知识星球
1.简介
内聚和耦合是设计模块化软件系统中常见的概念。它们由Larry Constantine在20世纪60年代末开发,已被证明是从软件设计到软件度量等领域的基础。它们后来成为标准术语。
在本教程中,我们将研究内聚和耦合,以及它们如何相互关联。
2.凝聚力
内聚性是一个模块内的元素属于一起的程度。模块可以是一个类、一个包,甚至是一个微服务。简单地说,它的意思是“一起改变的代码,保持在一起”。
具有高内聚性的模块包含彼此紧密相关并在其目的上统一的元素。例如,User类中的所有方法都应该表示用户行为。
如果一个模块包含不相关的元素,则称其内聚性较低。例如,User类包含一个关于如何验证电子邮件地址的方法。用户类可以负责存储用户的电子邮件地址,但不负责验证或发送电子邮件:
这应该属于其他类,比如电子邮件。
正如你所看到的,内聚的概念与单一责任原则(SRP,SOLID原则之一)密切相关,该原则规定一个类应该只有一个责任。SRP之后的模块可能具有高内聚性。
2.1高内聚性的优点
具有单一、定义明确的目的的模块易于理解,可读性更强。这些模块的名称清楚地表明了它们的目的,而这些模块正是这样做的。它有助于读者在不阅读模块中的每一行的情况下建立对模块正在做什么的直觉。此外,在阅读这些模块的代码时也不会感到意外。
例如,如果User类包含用于验证电子邮件地址的代码,读者会感到困惑。
由于所有相关的代码都在模块中,因此更改代码更容易。例如,如果开发人员必须对用户行为进行更改,他们可以跳到user类并在一个类中进行所有更改。这将限制影响范围。将此与用户行为分布在多个类中并且每个类都必须进行更改以实现所需更改的设计进行比较。
测试代码更容易。由于此类模块的目的不依赖于其他模块,因此它们很容易进行单元测试。此外,当更改仅限于单个模块时,构建和部署更改也很容易。
对此类模块的更改不太容易出现错误。跨模块进行更改时更容易出错。
最后,它们是可重复使用的。由于此类模块履行单一职责,因此往往会在有此类需求的地方使用。
总的来说,高度内聚的模块反映了更好的软件设计质量。因此,在模块中查找与主要目的没有直接关系的元素。将它们移到更符合目的的其他模块或创建一个新模块。
3.耦合
耦合是指软件模块之间的相互依赖程度。模块可以是一个类、一个包,甚至是一个微服务。实际上,耦合是关于改变一件事需要改变另一件事。
如果两个模块紧密连接,则具有高度耦合(或紧密耦合)。例如,两个具体的类存储对彼此的引用并调用彼此的方法。如下图所示,Customer和Order是紧密耦合在一起的。Customer存储客户下的所有订单的列表,而Order存储对Customer对象的引用。
每次客户下新订单时,我们都需要将其添加到客户内部的订单列表中。这似乎是一种不必要的依赖。此外,Order只需要知道客户标识符,并且确实需要对customer对象的引用。通过进行以下更改,我们可以使这两个类松散耦合:
它们之间具有低耦合的模块大多彼此独立地工作。
3.1低耦合的优点
松散耦合的模块更易于开发和维护。由于它们相互独立,我们可以并行开发和测试它们。此外,它们可以在不相互影响的情况下进行修改和更新。我们可以独立构建和部署此类模块,大大缩短了部署时间。
紧密耦合的模块很难更换。开发人员需要了解多个模块以及它们之间的关系。他们需要谨慎地对所有模块进行一致的更改。这使得它更容易出错。此外,我们需要构建、测试和部署每个更改后的模块,从而进一步增加开发工作量。
紧密耦合的模块也很难测试。单元测试单个模块是困难的,因为它严重依赖于其他模块。必须花费大量精力来模拟对其他模块的调用,以便对模块进行独立的单元测试。
集成测试也很难设置。总的来说,测试是脆弱的,因为任何一个模块的变化都可能破坏测试。调试这样的模块也很复杂,因为它需要运行所有依赖的模块。
紧密耦合的模块不太可能被重用。这样的模块本身不执行任何有用的操作。因此,它很少适合其他人重复使用。此外,将其作为依赖项也很困难,因为它会带来其他依赖模块。
整体松耦合反映了软件设计的更高质量。因此,我们应该致力于设计尽可能独立的模块。
4.内聚与耦合
内聚和耦合是相互关联的。每一个都可以影响另一个的级别。
高内聚力与松散耦合相关。一个模块的元件彼此紧密相关,并用于单一目的,该模块将很少交互并依赖于其他模块。因此,将与其他模块松耦合。
类似地,紧密耦合可能是低内聚性的标志。由于元件分布在两个模块之间,模块之间可能存在严重的相互依赖关系。因此,将具有低内聚性。
以下是内聚和耦合之间的快速比较表:
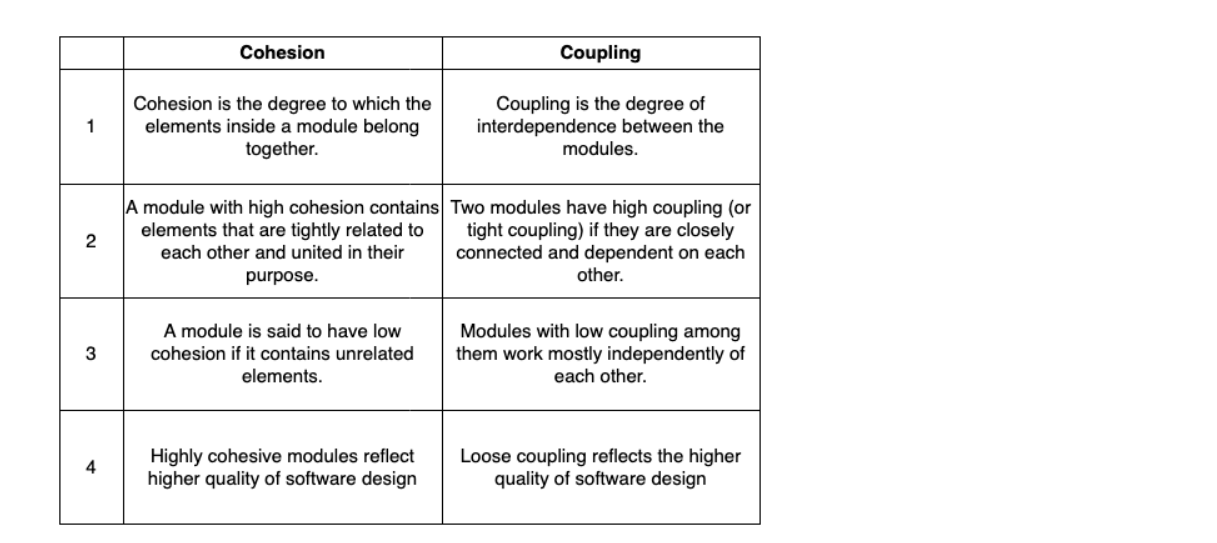
- 208 次浏览
【软件工程】软件工程|耦合与内聚
视频号
微信公众号
知识星球
简介:软件开发生命周期中设计阶段的目的是为SRS(软件需求规范)文档中给出的问题提供解决方案。设计阶段的输出是软件设计文档(SDD)。
耦合和内聚是软件工程中用来衡量软件系统设计质量的两个关键概念。
- 耦合是指软件模块之间的相互依赖程度。高耦合意味着模块紧密连接,一个模块中的变化可能会影响其他模块。低耦合意味着模块是独立的,一个模块中的变化对其他模块的影响很小。
- 内聚性是指模块中的元素协同工作以实现单一、明确定义的目的的程度。高内聚性意味着要素密切相关并专注于单一目的,而低内聚性则意味着要素松散相关并服务于多个目的。
- 耦合和内聚是决定软件系统可维护性、可扩展性和可靠性的重要因素。高耦合和低内聚性会使系统难以更改和测试,而低耦合和高内聚性则使系统更容易维护和改进。
基本上,设计是一个由两部分组成的迭代过程。第一部分是概念设计,告诉客户系统将做什么。第二部分是技术设计,让系统建设者了解解决客户问题所需的实际硬件和软件。
耦合和高内聚
系统概念设计:
- 用简单的语言书写,即客户可以理解的语言。
- 关于系统特性的详细说明。
- 描述系统的功能。
- 它独立于实施。
- 与需求文档链接。
系统技术设计:
- 硬件组件和设计。
- 软件组件的功能和层次结构。
- 软件体系结构
- 网络架构
- 数据结构和数据流。
- 系统的I/O组件。
- 显示界面。
模块化:
模块化是将软件系统划分为多个独立模块的过程,每个模块独立工作。模块化在软件工程中有许多优点。其中一些如下所示:
- 易于理解系统。
- 系统维护很容易。
- 一个模块可以根据其需求多次使用。不需要一遍又一遍地写。
耦合:
耦合是衡量模块之间相互依存程度的指标。一个好的软件将具有低耦合。
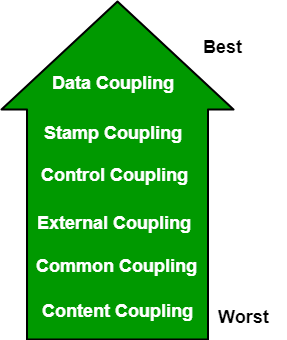
耦合类型:
- 数据耦合:如果模块之间的依赖关系是基于它们只通过传递数据进行通信的事实,那么这些模块就被认为是数据耦合的。在数据耦合中,组件相互独立,并通过数据进行通信。模块通信不包含不定期数据。客户计费系统示例。
- 印记耦合(Stamp Coupling)。在印记耦合中,完整的数据结构从一个模块传递到另一个模块。因此,它涉及不定期数据。由于效率因素,这可能是必要的——这个选择是由富有洞察力的设计师做出的,而不是懒惰的程序员。
- 控制耦合:如果模块通过传递控制信息进行通信,则称其为控制耦合。如果参数指示完全不同的行为,这可能是坏的,而如果参数允许功能的分解和重用,这是好的。示例-将比较函数作为参数的排序函数。
- 外部耦合:在外部耦合中,模块依赖于正在开发的软件或特定类型硬件外部的其他模块。Ex-协议、外部文件、设备格式等。
- 公共耦合:模块具有共享数据,如全局数据结构。全局数据的变化意味着要追溯到访问该数据的所有模块,以评估变化的影响。因此,它存在模块重用困难、数据访问控制能力降低、可维护性降低等缺点。
- 内容耦合:在内容耦合中,一个模块可以修改另一个模块的数据,或者控制流从一个模块传递到另一个。这是最糟糕的耦合形式,应该避免。
- 时间耦合:当两个模块取决于事件的时间或顺序时,就会发生时间耦合,例如一个模块需要在另一个模块之前执行。这种类型的耦合可能会导致设计问题以及测试和维护方面的困难。
- 顺序耦合:当一个模块的输出用作另一个模块输入时,会发生顺序耦合,从而创建依赖关系链或序列。这种类型的联轴器可能难以维护和修改。
- 通信耦合:当两个或多个模块共享一个公共通信机制(如共享消息队列或数据库)时,就会发生通信耦合。这种类型的耦合可能会导致性能问题和调试困难。
- 功能耦合:当两个模块依赖于彼此的功能时,就会发生功能耦合,例如一个模块从另一个模块调用函数。这种类型的耦合可能导致难以修改和维护的紧密耦合代码。
- 数据结构耦合:当两个或多个模块共享一个公共数据结构(如数据库表或数据文件)时,会发生数据结构耦合。这种类型的耦合可能导致难以维护数据结构的完整性,并可能导致性能问题。
内聚性:
内聚性是衡量模块元素在功能上相关程度的指标。它是指向执行单个任务的所有元素都包含在组件中的程度。基本上,内聚性是将模块保持在一起的内部粘合剂。一个好的软件设计将具有很高的内聚性。
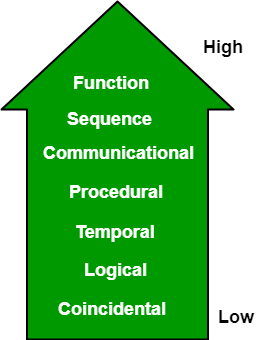
内聚类型:
- 函数内聚:单个计算的每个基本元素都包含在组件中。功能衔接执行任务和功能。这是一个理想的情况。
- 顺序衔接:一个元素输出一些数据,这些数据成为另一个元素的输入,即各部分之间的数据流。它自然地出现在函数式编程语言中。
- 通讯衔接:两个元素对相同的输入数据进行操作或对相同的输出数据做出贡献。示例-更新数据库中的记录并将其发送到打印机。
- 过程衔接:程序衔接的要素保证了执行的秩序。操作仍然是弱连接的,不太可能被重用。例如计算学生平均成绩,打印学生记录,计算累计平均成绩,印刷累计平均成绩。
- 时间衔接:这些元素因其所涉及的时间而相关。一个与时间衔接相连的模块,所有任务都必须在同一时间段内执行。这种衔接包含用于初始化系统所有部分的代码。在单位时间内会发生许多不同的活动。
- 逻辑衔接:这些元素在逻辑上是相关的,而不是功能性的。Ex-一个组件从磁带、磁盘和网络读取输入。这些函数的所有代码都在同一个组件中。操作是相关的,但功能明显不同。
- 巧合衔接:元素不相关(不相关)。除了源代码中的位置之外,这些元素没有其他概念关系。这是偶然的,也是最糟糕的凝聚力。Ex-打印下一行,并反转单个组件中字符串的字符。
- ----------------------------------
- 过程衔接:当元素或任务根据其执行顺序在模块中分组时,就会发生这种衔接,例如按特定顺序执行一组相关过程的模块。过程衔接可以在结构化编程语言中找到。
- 交际衔接:当元素或任务根据彼此之间的互动被分组到一个模块中时,就会发生交际衔接,例如处理与特定外部系统或模块的所有互动的模块。这种类型的内聚可以在面向对象的编程语言中找到。
- 时间衔接:当元素或任务根据执行的时间或频率在一个模块中分组时,就会发生时间衔接,例如处理系统中所有周期性或计划任务的模块。时间内聚通常用于实时和嵌入式系统。
- 信息衔接:当元素或任务根据它们与特定数据结构或对象的关系(例如对特定数据类型或对象进行操作的模块)在模块中分组时,就会发生信息衔接。信息内聚通常用于面向对象编程。
- 功能衔接:当一个模块中的所有元素或任务都为一个定义明确的功能或目的做出贡献,并且元素之间几乎没有耦合时,就会发生这种类型的衔接。函数内聚被认为是最理想的内聚类型,因为它可以产生更可维护和可重用的代码。
- 层内聚:当模块中的元素或任务根据其抽象级别或职责分组在一起时,就会发生层内聚,例如只处理低级硬件交互的模块或只处理高级业务逻辑的模块。层内聚通常用于大型软件系统,将代码组织成可管理的层。
低耦合的优点:
- 提高了可维护性:低耦合减少了一个模块中的更改对其他模块的影响,使修改或更换单个组件变得更容易,而不会影响整个系统。
- 增强的模块性:低耦合允许隔离开发和测试模块,提高了代码的模块性和可重用性。
- 更好的可扩展性:低耦合便于添加新模块和删除现有模块,从而更容易根据需要扩展系统。
高内聚力的优点:
- 提高了可读性和可理解性:高内聚性产生了具有单一、明确目的的清晰、集中的模块,使开发人员更容易理解代码并进行更改。
- 更好的错误隔离:高内聚性降低了模块某个部分的更改影响其他部分的可能性,使
- 隔离并修复错误。提高了可靠性:高内聚性导致模块不太容易出错,并且功能更一致,
- 从而导致系统的可靠性的整体提高。
高耦合的缺点:
- 复杂性增加:高度耦合增加了模块之间的相互依赖性,使系统更加复杂和难以理解。
- 灵活性降低:高度耦合使得在不影响整个系统的情况下修改或更换单个组件变得更加困难。
- 模块性降低:高耦合性使得隔离开发和测试模块变得更加困难,降低了代码的模块性和可重用性。
内聚力低的缺点:
- 代码重复增加:内聚性低可能导致代码重复,因为属于一起的元素被拆分为单独的模块。
- 功能减少:低内聚性可能导致模块缺乏明确的目的,并且包含不属于一起的元素,从而减少其功能并使其更难维护。
- 理解模块的困难:低内聚性会使开发人员更难理解模块的目的和行为,从而导致错误和缺乏清晰度。
- 186 次浏览
【软件架构】5分钟看懂软件架构模式
当有人潜入软件工程世界时,有一天他需要学习软件架构模式的基础知识。当我刚接触编码时,我不知道从哪里获得简要介绍现有架构模式的资源,这样它就不会太详细和混乱,而是非常抽象和易于理解。
在我找到 Mark Richards 的一本书 Software Architecture Patterns 之前,这一直是个问题。在这里,我想与大家分享本书的一些最重要的部分和架构模式。 (有关更多信息,我强烈建议您阅读这本书或他的报告)。
作为软件工程师,为什么至少要学习基本的架构模式?
我相信有很多文章回答了这个问题,但我会给你一些考虑的理由。首先,如果您了解架构模式的基础知识,那么您就更容易遵循架构师的要求。其次,了解这些模式将帮助您在代码中做出决策:例如,如果您的应用程序设计基于事件驱动的微服务,那么作为软件工程师,您必须将您的代码解耦到一个单独的服务中,如果您注意到日益增加的复杂性和现有服务中的逻辑责任。 (如果您没有得到这部分内容,请按照文本进行操作,此处简要说明了此模式)。
Mark Richards 在书中描述了 5 种模式:
- 分层架构
- 事件驱动架构
- 微内核架构(或插件架构)
- 微服务架构
- 基于空间的架构(或云架构模式)
1.分层架构
它是单体应用程序最常见的架构。 该模式背后的基本思想是将应用程序逻辑划分为若干层,每一层都封装了特定的角色。 例如,持久层将负责您的应用程序与数据库引擎的通信。
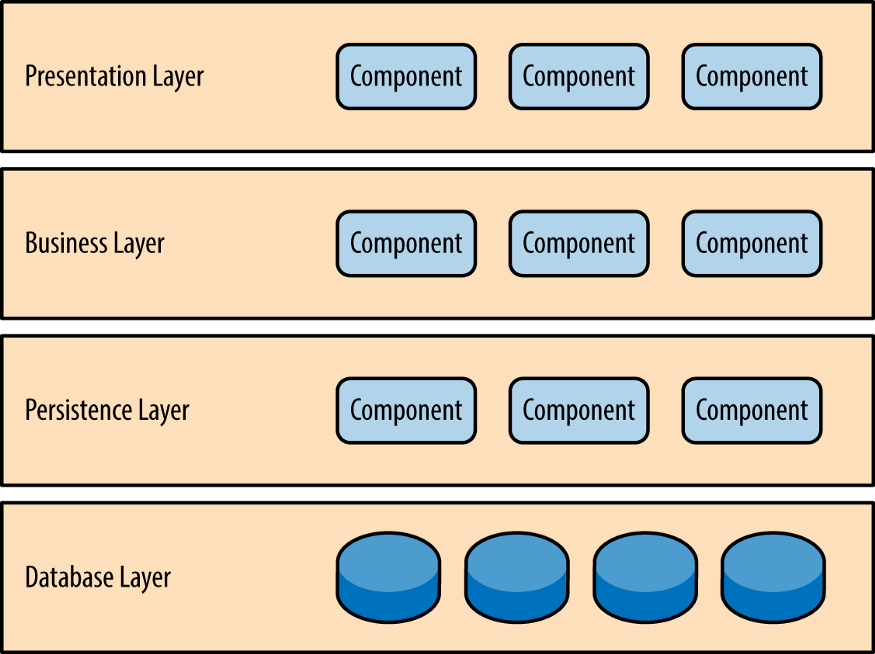
2. 事件驱动架构
这种模式背后的想法是将应用程序逻辑解耦为异步接收和处理事件的单一用途事件处理组件。 这种模式是流行的分布式异步架构模式之一,以高可扩展性和适应性着称。
3. 微内核架构
Mikrokernel 架构,也称为插件架构,是具有两个主要组件的设计模式:核心系统和插件模块(或扩展)。 一个很好的例子是 Web 浏览器(核心系统),您可以在其中安装无穷无尽的扩展(或插件)。
4. 微服务架构
微服务架构由单独部署的服务组成,理想情况下,每个服务都有单一的职责。 这些服务相互独立,如果一项服务失败,其他服务将不会停止运行。

5. 基于空间的架构
基于空间的模式背后的主要思想是分布式共享内存,以缓解在数据库级别经常发生的问题。 假设通过使用内存数据处理大多数操作,我们可以避免在数据库中进行额外操作,因此可能会从那里演变出任何未来的问题(例如,如果您的用户活动数据实体已更改,您不需要 更改一堆持久化的代码并从数据库中检索该数据)。
基本方法是将应用程序分成处理单元(可以根据需要自动扩展和缩减),其中数据将在这些单元之间复制和处理,而不需要对中央数据库进行任何持久性(尽管会有本地存储用于 系统故障的场合)。

您可以在我的 GitHub 帐户中找到其中一些架构模式的最简单示例。 这里的链接:
如果您想快速了解如何扩展应用程序的基础知识,请阅读我的下一篇文章如何扩展您的应用程序:5 分钟阅读,然后是文章缓存作为软件架构的一部分:5 分钟阅读,更接近 通过缓存查看性能调整。
原文:https://orkhanscience.medium.com/software-architecture-patterns-5-mins-…
- 86 次浏览
【软件架构】9大软件架构工具
视频号
微信公众号
知识星球
⚡ Tl;dr
- 软件体系结构工具可以分为三组,建模工具、作为代码的图表和图表工具。
- 建模和图表作为代码工具更适合长期文档,而图表工具更适合快速的一次性草图。
- 作为代码的建模和图表有更多的结构,需要更多的设置,而图表工具更通用,但需要更少的思考
🚀 我们开始吧
图解软件体系结构为我们如何沟通复杂性提供了几个好处。经过深思熟虑的图表使工程团队能够更好地理解设计和未来开发计划,同时识别潜在问题。
下面是一些我们发现适合软件体系结构的特定类别的建模和绘图工具的例子。
📦 可视化建模工具
建模最适合长期的系统设计文档,并且需要一些设置工作。可重用的对象和关系存储在模型中,使所有关系图保持最新。
1️⃣ IcePanel
是一个基于web的图形SaaS工具,用于使用C4模型对软件架构进行协作建模。
免费和付费。
最适合寻找轻量级协作工具来建模和记录其软件体系结构的敏捷开发团队。
它包括以下功能:
- 可放大到不断增加的技术细节级别的交互式图表。
- 在绘制图表的同时创建模型的敏捷建模。
- 通过将其他元数据覆盖到现有图表上来查看不同的透视图。
- 用于将消息序列叠加到现有图表上并进行通信的流程。
- 将对象链接到现实中的资源,如源代码管理或云资源,并在图表偏离现实时收到通知。
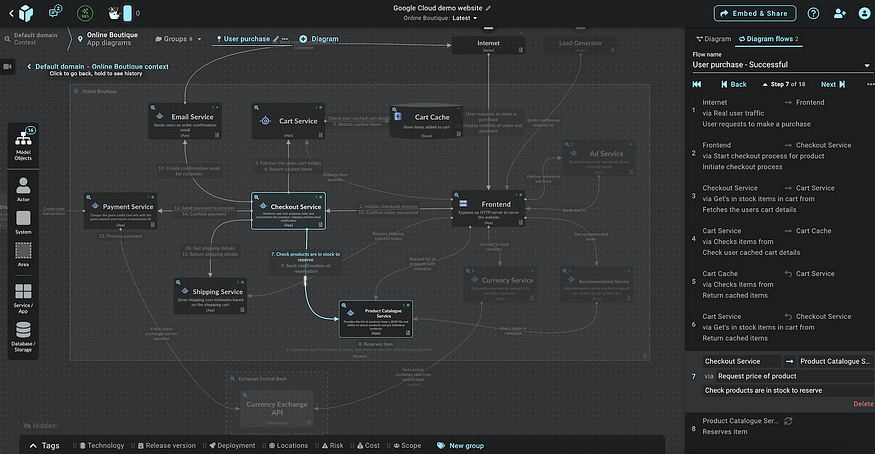
2️⃣ Enterprise Architect
Enterprise architect by Sparx Systems是一款用于业务、IT和软件系统建模的图形桌面应用程序。
支付。
最适合需要为各种行业标准创建模型的大型企业。
它包括以下功能:
- 分析、设计、实施、测试和维护模型。
- UML、SysML和BPMN标准。
- 高性能,可在几秒钟内加载超大型号。
- 动态模型模拟是用Javascript编写的。
- 许多流行语言的源代码往返,包括C、C++、Java、PHP、Python和Visual Basic。
- 从需求、分析和设计模型到实施和部署的完整可追溯性。
3️⃣ Archi
是一个用于建模的图形桌面应用程序,用于创建ArchiMate模型和草图。
免费开源。
最适合那些希望使用ArchiMate语言创建模型而不需要在昂贵的工具上花费预算的个人。
它包括以下功能:
- ArchiMate 3.1语言的最新版本。
- 创建ArchiMate元素、关系、视图和视点。
- 提示视图可帮助您理解ArchiMate语言。
- 用于显示关系、草图视图和画布建模的可视化工具。
🧑💻 Diagrams as code tools
图作为代码包括使用标记语言编写模型对象、关系和图,标记语言可以检查到源代码管理中。这些功能通常包括自动布局功能。
1️⃣ Structurizr
构建在“图即代码”的基础上,允许您使用多种工具和编程语言从单个模型创建多个图。
免费和付费。
最适合那些希望将C4模型与DSL一起使用并将其检查到源代码管理中的技术人员。
它包括以下功能:
- 将图表作为代码,使用StructurezrDSL绘制图表
- 存储在工程团队所在的源代码管理中
- 设计用于支持C4型号
- 文档工具中的体系结构决策记录
2️⃣ PlantUML
是一个允许您编写序列图、对象图、组件图、用例图、类图等图表的工具。
自由的
最适合那些希望灵活地创建许多不同的图表类型并将其检查到源代码管理中的技术人员。
它包括以下功能:
- 图表是使用简单直观的文本语言定义的。
- C4插件
- 序列图
- 用例图
- 类图
- 对象关系图
- 活动图(此处为传统语法)
- 组件示意图
- 部署示意图
3️⃣ Ilograph
允许使用带有自动布局的YAML绘制交互式图表,当您想要查看不同的透视图时可以更改视图。
免费和付费。
最适合那些想要基于web的解决方案来可视化以代码形式编写的图表的半技术人员。
它包括以下功能:
- 并排代码编辑
- 图表对象的自动布局
- 动态布局,根据透视图更改图表
- 在图中显示用例的图序列
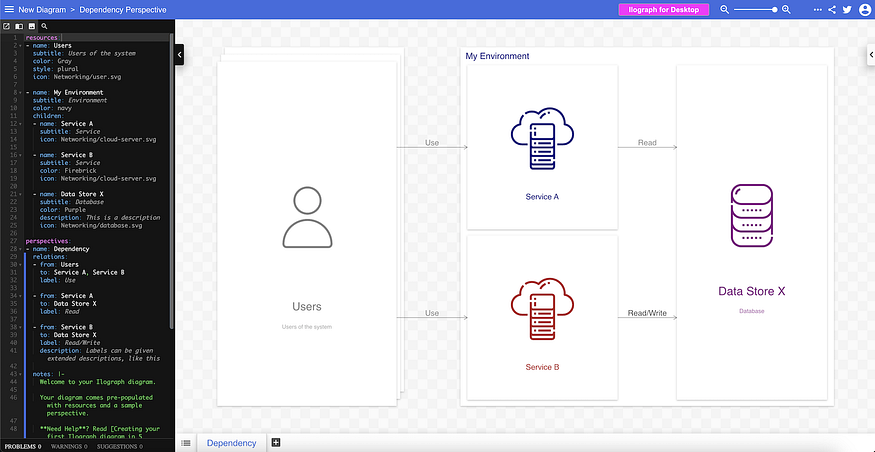
🖼️ Diagramming tools
图表最适合在对话和想法实验中快速绘制草图。它们很容易制作,但经常被扔掉,很难跟上时代。
1️⃣ Diagrams.net
是一个流行的免费绘图工具,具有很高的灵活性,可以绘制从流程图到房屋蓝图的任何内容;具有将数据存储在您选择的位置的选项。
自由的
最适合需要灵活性的快速图表,并且技术人员和非技术人员可以轻松访问。
它包括以下功能:
- 扩展形状库
- 正在建立模板
- 完全灵活的绘图
- 可定制的存储和集成
2️⃣ Lucidchart
是一个具有模板和形状类型的协作绘图工具,用于创建许多图表类型,如流程图、流程图、思维导图等。
免费和付费。
最适合在快速灵活的图表上进行协作的团队。
它包括以下功能:
- 与您的团队进行实时协作
- 连接到数据
- 与堆栈中的其他工具集成
- 帮助指导您的模板
- 一个学习校园,学习你可以在工具中做什么
3️⃣ Miro
是一个协作白板工具,带有模板和基于团队的工具,有助于促进研讨会。
免费和付费。
最适合在图表上进行协作并为研讨会提供便利的团队。
它包括以下功能:
- 在交互式白板上进行实时编辑
- 鼠标悬停在协作上,查看谁在查看您的图表
- 计时器和投票等研讨会便利工具
- 社区制作模板
🏁
结束
有很多软件体系结构工具可供选择,首先要考虑创建体系结构可视化的原因,这一点很重要。如果只是简单地可视化一个潜在解决方案的想法,我们建议使用一些快速的工具,比如绘图工具,但预计从长远来看不会那么有用。
如果你想创建一个别人会在很长一段时间内参考的工件,我们建议你使用建模工具。从长远来看,建模工具更有益的原因是,你可以通过简单地更新模型来推动所有图表的更改,而使用绘图工具,你必须查找该对象的每个实例,以保持设计的同步。
保持冷静🧊
- 751 次浏览
【软件架构】DDD,六边形,洋葱的,干净的,CQRS,我怎么把它们放在一起的
这篇文章是软件架构编年史的一部分,一系列关于软件架构的文章。在这些文章中,我写了我对软件架构的了解,我如何看待它,以及我如何使用这些知识。如果您阅读了本系列以前的文章,那么本文的内容可能更有意义。
大学毕业后,我从事了高中教师的职业,直到几年前,我决定放弃它,成为一名全职软件开发人员。
从那以后,我总是觉得我需要找回失去的时间,尽可能多地、尽可能快地学习。因此,我有点沉迷于试验、阅读和写作,特别关注软件设计和体系结构。这就是我写这些帖子的原因,来帮助我学习。
在我的上一篇文章中,我写了很多我学过的概念和原则,以及我是如何推理的。但我认为这些只是拼图的一部分。
今天的帖子是关于我如何将所有这些部分组合在一起的,我似乎应该给它起个名字,我称它为显式架构(Explicit Architecture)。此外,这些概念都“通过了它们的考验”,并被用于高要求平台上的生产代码中。一个是SaaS的e-com平台,在全球拥有数千个网络商店,另一个是市场,在两个国家都有一个消息总线,每个月处理超过2000万条消息。
- 系统的基本模块
- 工具
- 将工具和交付机制连接到应用程序核心
- 端口
- 主适配器或驱动适配器
- 辅助或被驱动适配器
- 控制反转
- 应用程序的核心组织
- 应用程序层
- 领域层
- 域服务
- 域模型
- 组件
- 解耦的组件
- 触发逻辑在其他组件
- 从其他组件获取数据
- 组件之间共享的数据存储
- 每个组件隔离数据存储
- 控制流
系统的基本模块
我首先回顾一下EBI和端口及适配器架构。它们都明确区分了哪些代码是应用程序内部的,哪些是外部的,以及哪些用于连接内部和外部代码。
此外,端口和适配器体系结构明确标识了系统中的三个基本代码块:
- 是什么使得运行一个用户界面成为可能,不管它是什么类型的用户界面;
- 系统业务逻辑,或应用程序核心,由用户界面使用,以实际使事情发生;
- 基础构架代码,它将我们的应用核心与数据库、搜索引擎或第三方api等工具连接起来。

应用程序核心是我们真正应该关心的。是代码允许我们的代码做它应该做的事情,是我们的应用程序。它可能使用多个用户界面(渐进式web应用程序、移动应用程序、CLI、API等),但是实际执行工作的代码是相同的,并且位于应用程序内核中,不管什么UI触发它,都应该是一样的。
可以想象,典型的应用程序流从用户界面中的代码开始,通过应用程序核心到基础设施代码,然后返回到应用程序核心,最后向用户界面交付响应。

工具
远离系统中最重要的代码(应用程序核心),我们拥有应用程序使用的工具,例如数据库引擎、搜索引擎、Web服务器或CLI控制台(尽管后两个也是交付机制)。
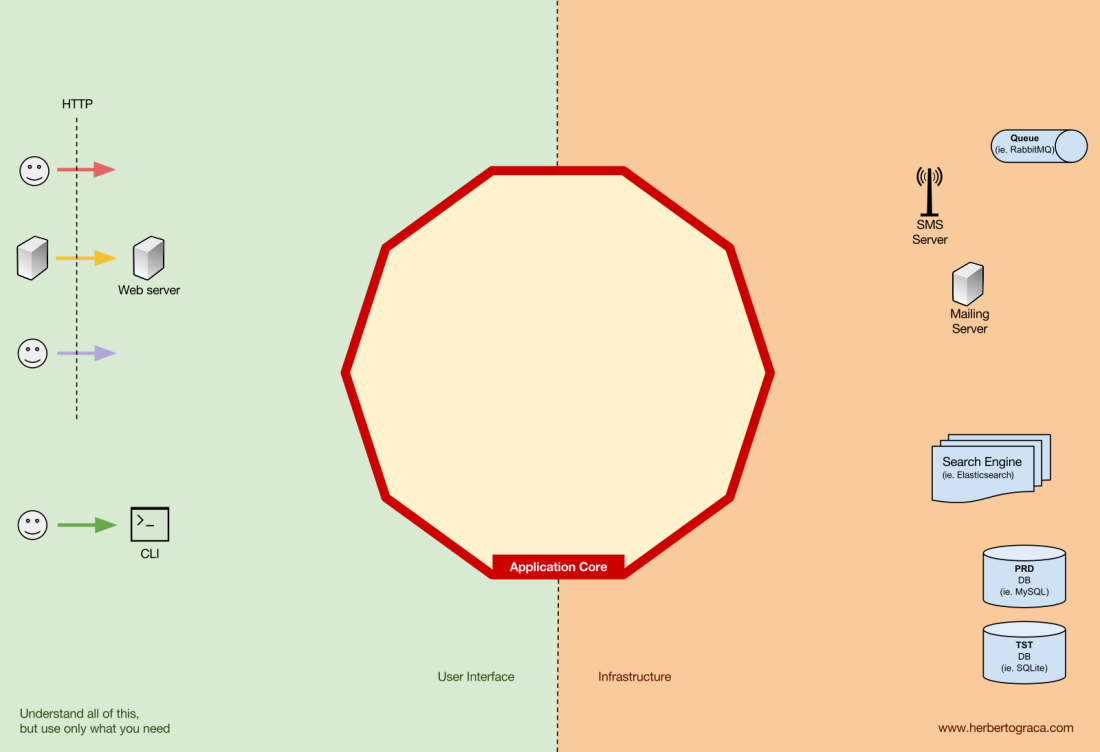
虽然将CLI控制台与数据库引擎放在同一个“bucket”中可能感觉有些奇怪,尽管它们有不同类型的用途,但它们实际上是应用程序使用的工具。关键的区别在于,虽然CLI控制台和web服务器用于告诉应用程序执行某些操作,但是数据库引擎是由应用程序执行某些操作的。这是一个非常相关的区别,因为它对我们如何构建将这些工具与应用程序核心连接起来的代码有很强的影响。
将工具和传送机制连接到应用程序核心
将工具连接到应用程序核心的代码单元称为适配器(端口和适配器体系结构)。适配器是那些有效地实现代码的适配器,这些代码将允许业务逻辑与特定的工具通信,反之亦然。
告诉我们的应用程序做某事的适配器称为主适配器或驱动适配器,而由我们的应用程序告诉我们做某事的适配器称为辅助适配器或驱动适配器。
端口
然而,这些适配器不是随机创建的。创建它们是为了将特定的入口点安装到应用程序核心(一个端口)。端口只不过是工具如何使用应用程序内核或应用程序内核如何使用它的规范。在大多数语言及其最简单的形式中,这个规范,即端口,将是一个接口,但它实际上可能由几个接口和dto组成。
需要注意的是,端口(接口)属于业务逻辑内部,而适配器属于业务逻辑外部。要使此模式正常工作,最重要的是创建适合应用程序核心需求的端口,而不是简单地模仿工具api。
主适配器或驱动适配器
主适配器或驱动适配器围绕一个端口,并使用它来告诉应用程序核心要做什么。它们将来自交付机制的任何东西转换为应用程序核心中的方法调用。

换句话说,我们的驱动适配器是控制器或控制台命令,它们在构造函数中注入一些对象,这些对象的类实现控制器或控制台命令所需的接口(端口)。
在更具体的示例中,端口可以是控制器所需的服务接口或存储库接口。然后将服务、存储库或查询的具体实现注入并在控制器中使用。
或者,端口可以是命令总线或查询总线接口。在这种情况下,将命令或查询总线的具体实现注入控制器,然后控制器构造命令或查询并将其传递给相关总线。
辅助或被驱动适配器
与围绕端口的被驱动适配器不同,驱动适配器实现一个端口和一个接口,然后将其注入到应用程序核心中,无论哪里需要端口(类型暗示)。

例如,假设我们有一个需要持久化数据的简单应用程序。所以我们创建一个持久性接口,满足其需要,用一个方法来保存数组的数据和方法来删除表中的一行的ID。从那时起,无论应用程序需要保存或删除数据,我们需要在其构造函数实现持久化的对象我们定义的接口。
现在我们创建一个特定于MySQL的适配器来实现这个接口。它将具有保存数组和删除表中的一行的方法,并且我们将在需要持久性接口的地方注入它。
如果在某个时候我们决定改变数据库供应商,比如PostgreSQL或MongoDB,我们只需要创建一个新的适配器来实现PostgreSQL特定的持久化接口,并注入新的适配器而不是旧的。
控制反转
关于此模式需要注意的一个特征是,适配器依赖于特定的工具和特定的端口(通过实现接口)。但是我们的业务逻辑只依赖于端口(接口),它被设计成适合业务逻辑需求,所以它不依赖于特定的适配器或工具。
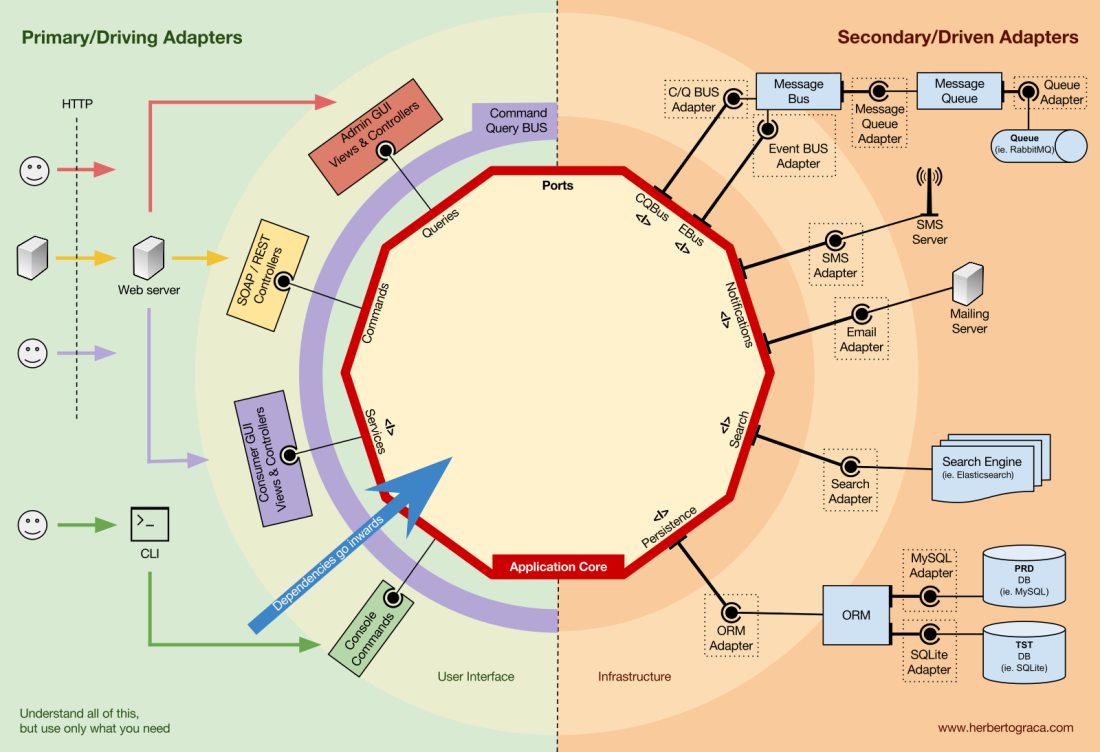
这意味着依赖的方向是朝向中心的,这是建筑层面的控制原则的倒置。
尽管如此,创建端口是为了满足应用程序的核心需求,而不是简单地模仿工具api,这一点非常重要。
应用程序的核心组织
Onion架构采用DDD层,并将它们合并到端口和适配器架构中。这些层旨在为业务逻辑、端口和适配器的内部“六边形”带来一些组织,就像端口和适配器一样,依赖关系的方向是向中心的。
应用程序层
用例是可以由应用程序中的一个或多个用户接口在应用程序核心中触发的流程。例如,在CMS中,我们可以有普通用户使用的实际应用程序UI、CMS管理员使用的另一个独立UI、另一个CLI UI和web API。这些ui(应用程序)可以触发特定于其中一个或由其中几个重用的用例。
用例在应用层中定义,这是DDD提供的第一层,由Onion Architecture使用。

这一层包含作为第一类公民的应用程序服务(及其接口),但它也包含端口和适配器接口(端口),其中包括ORM接口、搜索引擎接口、消息传递接口等等。在我们使用命令总线和/或查询总线的情况下,这一层是命令和查询各自的处理程序所在的地方。
应用程序服务和/或命令处理程序包含展开用例(业务流程)的逻辑。一般来说,他们的职责是:
- 使用存储库查找一个或多个实体;
- 告诉那些实体去做一些域逻辑;
- 并使用存储库再次持久化实体,有效地保存数据更改。
命令处理程序可以用两种不同的方式使用:
- 它们可以包含执行用例的实际逻辑;
- 它们可以在我们的体系结构中用作简单的连接块,接收命令并简单地触发存在于应用程序服务中的逻辑。
使用哪种方法取决于上下文,例如:
我们是否已经准备好了应用程序服务并正在添加命令总线?
命令总线是否允许指定任何类/方法作为处理程序,或者它们是否需要扩展或实现现有的类或接口?
这一层还包含应用程序事件的触发,这些事件表示用例的一些结果。这些事件触发的逻辑是用例的副作用,比如发送电子邮件、通知第三方API、发送推送通知,甚至启动属于应用程序不同组件的另一个用例。
领域层
再往里,我们有域层。这个层中的对象包含数据和操作数据的逻辑,这是特定于域本身的,它独立于触发逻辑的业务流程,它们是独立的,完全不知道应用层。

域服务
如前所述,应用服务的作用是:
- 使用存储库查找一个或多个实体;
- 告诉那些实体去做一些域逻辑;
- 并使用存储库再次持久化实体,有效地保存数据更改。
然而,有时我们会遇到一些涉及不同实体的域逻辑,不管它们是否属于同一类型,我们觉得域逻辑不属于实体本身,我们觉得那个逻辑不是它们的直接责任。
因此,我们的第一反应可能是将逻辑放在实体之外的应用程序服务中。然而,这意味着该域逻辑将不能在其他用例中重用:域逻辑应该远离应用程序层!
解决方案是创建一个域服务,它的角色是接收一组实体并在其上执行一些业务逻辑。域服务属于域层,因此它对应用层中的类一无所知,比如应用程序服务或存储库。另一方面,它可以使用其他域服务,当然还有域模型对象。
域模型
在最中心的是域模型,它不依赖于它之外的任何东西,它包含表示域内某些内容的业务对象。这些对象的示例首先是实体,但也包括值对象、枚举和域模型中使用的任何对象。
域模型也是域事件“活动”的地方。当特定的一组数据发生更改时,将触发这些事件,并将这些更改随身携带。换句话说,当一个实体发生更改时,将触发一个域事件,它将携带更改后的属性新值。例如,这些事件非常适合用于事件源。
组件
到目前为止,我们一直在基于层隔离代码,但这是细粒度的代码隔离。粗粒度的代码隔离至少是同样重要的,它是根据子域和有界上下文来隔离代码的,遵循Robert C. Martin在尖叫声架构中表达的思想。这通常被称为“按功能包”或“按组件包”,而不是“按层包”,Simon Brown在他的博客“按组件包和体系结构对齐测试”中对此做了很好的解释:
我是“按组件打包”方法的倡导者,并且根据Simon Brown关于按组件打包的图表,我将无耻地将其更改为以下内容:
这些代码部分与前面描述的层是交叉的,它们是我们的应用程序的组件。组件的示例可以是身份验证、授权、计费、用户、审查或帐户,但它们始终与域相关。像授权和/或身份验证这样的有界上下文应该被视为外部工具,我们为其创建适配器并隐藏在某种端口之后。
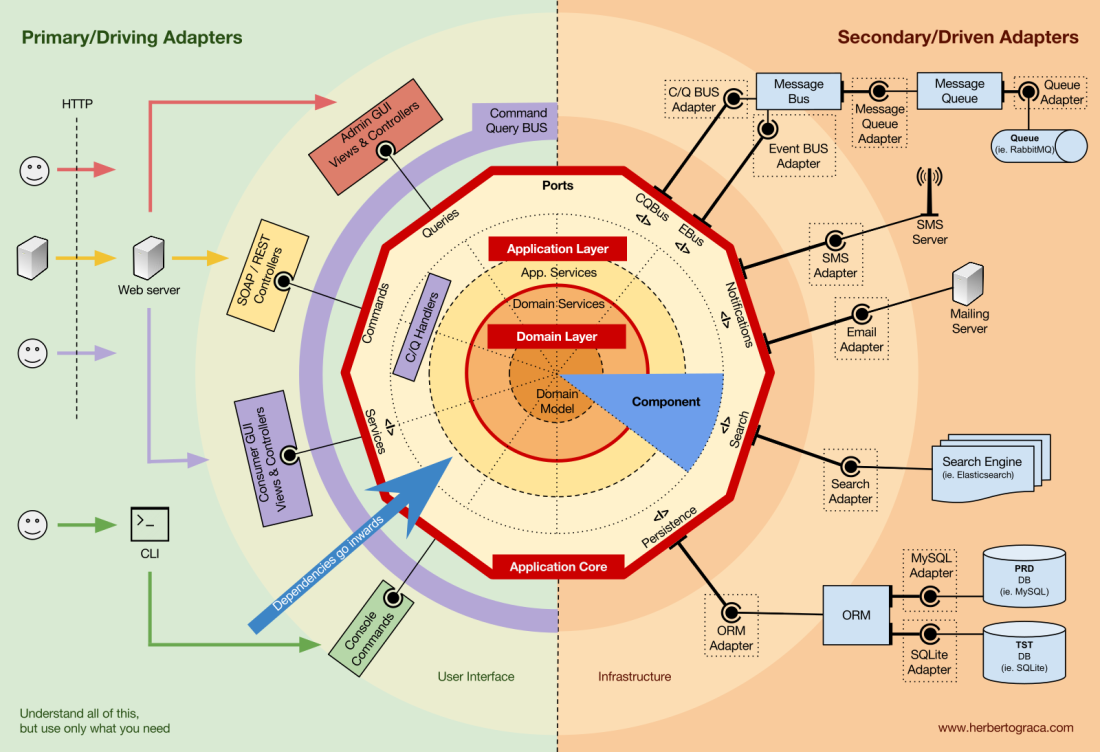
解耦的组件
就像细粒度的代码单元(类、接口、特征、混合等)一样,粗粒度的代码单元(组件)也受益于低耦合和高内聚。
为了解耦类,我们使用依赖注入,将依赖注入到类中而不是在类中实例化,依赖倒置,使类依赖于抽象(接口和/或抽象类)而不是具体类。这意味着子类不知道它将要使用的具体类,它没有引用它所依赖的类的完全限定类名。
同样,完全解耦的组件意味着一个组件不直接知道任何其他组件。换句话说,它没有引用来自另一个组件的任何细粒度代码单元,甚至没有接口!这意味着依赖注入和依赖倒置不足以解耦组件,我们需要某种架构结构。我们可能需要事件、共享内核、最终一致性,甚至发现服务!
在其他组件触发逻辑
当我们的一个组件(组件B)需要在另一个组件(组件A)中发生其他事情时执行某个操作时,我们不能简单地从组件A直接调用组件B中的类/方法,因为这样A就会被耦合到B。
然而,我们可以使用事件分派器来分派一个应用程序事件,该应用程序事件将被交付给监听它的任何组件,包括B,而B中的事件侦听器将触发所需的操作。这意味着组件A将依赖于事件分配器,但它将与B解耦。
然而,如果事件本身“存在”于A中,这意味着B知道A的存在,它与A是耦合的。这意味着组件都依赖于共享内核,但是它们之间是解耦的。共享内核将包含应用程序和域事件之类的功能,但它也可以包含规范对象,以及任何需要共享的内容,请记住,共享内核的任何更改都将影响到应用程序的所有组件,因此共享内核应该尽可能少。此外,如果我们有一个多语言系统,假设是一个微服务生态系统,其中它们是用不同的语言编写的,那么共享内核需要是语言无关的,以便所有组件都可以理解它,无论它们是用什么语言编写的。例如,它将包含事件描述,而不是包含事件类的共享内核。名称、属性、甚至方法(尽管这些在JSON之类的不可知语言中可能更有用),这样所有组件/微服务都可以解释它,甚至自动生成它们自己的具体实现。请在我的后续文章中阅读更多相关内容:不仅仅是同心圆层。

这种方法既适用于单片应用程序,也适用于像微服务生态系统这样的分布式应用程序。然而,当事件只能异步交付时,对于需要立即在其他组件中执行触发逻辑的上下文,这种方法是不够的!组件将需要一个直接的HTTP调用组件b。在这种情况下,解耦的组件,我们需要发现服务,将要求它应该发送请求来启动所需的行动,或者使请求发现服务代理的相关服务,最终将响应返回给请求者。此方法将把组件耦合到发现服务,但将使它们彼此解耦。
从其他组件获取数据
在我看来,一个组件不允许改变它不“拥有”的数据,但是它可以查询和使用任何数据。
组件之间共享的数据存储
当一个组件需要使用属于另一个组件的数据时,假设一个账单组件需要使用属于accounts组件的客户端名称,账单组件将包含一个查询对象,该对象将查询该数据的数据存储。这仅仅意味着账单组件可以知道任何数据集,但是它必须通过查询的方式将不“拥有”的数据作为只读数据使用。
每个组件隔离数据存储
在本例中,应用了相同的模式,但是我们在数据存储级别上更加复杂。组件拥有自己的数据存储意味着每个数据存储包含:
- 它拥有的一组数据,并且是唯一允许更改的数据,使其成为唯一的真理来源;
- 一组数据是其他组件数据的副本,它不能自己更改这些数据,但是组件功能需要它,并且需要在所有者组件中发生更改时对其进行更新。
每个组件将从其他组件创建所需数据的本地副本,以便在需要时使用。当拥有该组件的组件中的数据发生更改时,该所有者组件将触发承载数据更改的域事件。持有该数据副本的组件将侦听该域事件,并相应地更新其本地副本。
控制流
正如我上面所说的,控制流当然是从用户到应用程序核心,再到基础设施工具,最后回到应用程序核心,最后回到用户。但是类到底是如何组合在一起的呢?哪些取决于哪些?我们如何组合它们?
在Bob叔叔关于干净架构的文章中,我将尝试用UMLish图来解释控制流……
没有命令/查询总线
在我们不使用命令总线的情况下,控制器将依赖于应用程序服务或查询对象。
[编辑- 2017-11-18]我完全错过了我用来从查询返回数据的DTO,所以我现在添加了它。感谢MorphineAdministered公司为我指出了这一点。
在上面的图中我们使用应用程序的接口服务,尽管我们可能认为这不是真正需要从应用程序服务是我们应用程序代码的一部分,我们不会想交换另一个实现,尽管我们可能完全重构它。
查询对象将包含一个优化的查询,该查询将简单地返回一些原始数据以显示给用户。该数据将以DTO的形式返回,并注入到ViewModel中。这个视图模型可能有一些视图逻辑,它将被用来填充一个视图。
另一方面,应用程序服务将包含用例逻辑,当我们希望在系统中执行某些操作时,而不是简单地查看某些数据时,将触发该逻辑。应用程序服务依赖于存储库,存储库将返回包含需要触发的逻辑的实体。它还可能依赖于域服务来协调多个实体中的域流程,但情况并非如此。
在展开用例之后,应用程序服务可能希望通知整个系统该用例已经发生,在这种情况下,它还将依赖于事件分派器来触发事件。
值得注意的是,我们在持久性引擎和存储库上都放置了接口。虽然看起来有些多余,但它们有不同的用途:
- 持久性接口是ORM上的一个抽象层,因此我们可以交换正在使用的ORM,而不需要更改应用程序的核心。
- repository接口是对持久性引擎本身的抽象。假设我们想从MySQL切换到MongoDB。持久性接口可以是相同的,如果我们想继续使用相同的ORM,那么即使是持久性适配器也可以保持不变。但是,查询语言是完全不同的,所以我们可以创建使用相同持久性机制的新存储库,实现相同的存储库接口,但是使用MongoDB查询语言而不是SQL构建查询。
使用命令/查询总线
在我们的应用程序使用命令/查询总线的情况下,除了控制器现在依赖于总线和命令或查询外,关系图几乎保持不变。它将实例化命令或查询,并将其传递给总线,总线将找到适当的处理程序来接收和处理命令。
在下面的关系图中,命令处理程序然后使用应用程序服务。然而,这并不总是需要的,事实上在大多数情况下,处理程序将包含用例的所有逻辑。如果需要在另一个处理程序中重用相同的逻辑,则只需要将逻辑从处理程序提取到单独的应用程序服务中。
[编辑- 2017-11-18]我完全错过了我用来从查询返回数据的DTO,所以我现在添加了它。感谢MorphineAdministered公司为我指出了这一点。
您可能已经注意到,总线与命令、查询和处理程序之间没有依赖关系。这是因为,为了提供良好的解耦,它们实际上应该彼此不了解。总线知道什么处理程序应该处理什么命令或查询的方式应该通过简单的配置来设置。
如您所见,在这两种情况下,跨越应用程序核心边界的所有箭头和依赖项都指向内部。如前所述,这是端口和适配器体系结构、Onion体系结构和Clean体系结构的基本规则。
结论
一如既往,我们的目标是拥有一个松散耦合和高内聚的代码库,这样修改起来就容易、快速和安全。
计划是没有价值的,但计划就是一切。
艾森豪威尔
这个信息图是一个概念图。了解和理解所有这些概念将帮助我们规划一个健康的架构,一个健康的应用程序。
然而:
地图不是领土。
阿尔弗雷德Korzybski
这意味着这些只是指导方针!应用程序是我们需要应用知识的领域、现实和具体用例,这就是定义实际体系结构的内容!
我们需要理解所有这些模式,但是为了解耦和内聚,我们还需要思考并准确地理解我们的应用程序需要什么,我们应该走多远。这个决策可以依赖于许多因素,从项目功能需求开始,但是也可以包括诸如构建应用程序的时间框架、应用程序的生命周期、开发团队的经验等因素。
就是这样,这就是我理解这一切的方式。这就是我在脑海里给它找的合理解释。
我在后续的文章中进一步扩展了这些想法:不仅仅是同心圆层。
但是,我们如何在代码库中显式地实现这一切呢?这是我下一篇文章的主题:如何在代码中反映体系结构和域。
讨论:请加入知识星球【首席架构师圈】
- 456 次浏览
【软件架构】为杠杆设计软件
卡瓦尔康蒂:我在这里谈论的是如何利用软件架构。首先,我将在这里定义杠杆的含义。这是谷歌的定义。杠杆率是相对于你所做投资的深度,你可以获得的价值量。我们希望获得比您所做的投资更高的价值。在软件环境中,是您所做的决定、所做的选择,或者您所获得的与您所能创造的价值量相关的技术债务。我想看一看我们在Nubank的整个发展过程中所做的一些架构决策的例子,这些决策的目的是在当时获得尽可能高的杠杆率。你可能在你的公司中处于类似的位置,或者在未来的公司中处于你将做出这些决定的阶段。你可以以我们为例,或者至少有一种心态。
背景
我是卢卡斯·卡瓦尔康蒂。自2013年底以来,我一直是Nubank的首席软件工程师。七年多一点了。我住在巴西圣保罗。
在一个复杂的领域中迅速成长
Nubank是拉丁美洲领先的金融科技公司,是世界上最大的数字银行。在《时代》杂志上,我们获得了全球100家最具影响力的公司之一。我们也登上了《时代》杂志的特写。这是一个巨大的成就,来自一家拥有七年多一点历史的公司。这是我们的增长曲线的一个例子。以下是此图中绘制的实际客户数。我们现在有3500万客户。我们每天处理数十亿条卡夫卡消息和HTTP请求,在一个拥有数百个微服务并由数百名工程师签名的系统中。这是一个相当大的规模,并不总是这么大。
概述
我将介绍公司的一些阶段。第一个是启动时间,我们重视上市时间和反馈。进入成长期,我们将重点转向恢复力和适应性。接下来是整合时间,最重要的方面是可靠性和可观察性。当我们重视灵活性和可扩展性时,最后是扩展时间。这些是在这些阶段对我们很重要的价值观。
启动时间(2013-2015)
创业时间是一个神奇的时刻,任何事情都有可能发生,包括失败和没有公司。在我们的案例中,这发生在2013年末到2015年初。我们经历了不可思议的变化,那是一个神奇的时刻,当你有一个绿地项目,你可以选择任何你喜欢的技术。你必须有充分的理由这样做。在圣保罗一个友好社区的一间小办公室里,实际上是一所小房子。当我们推出第一款产品时,这是一款无需付费的数字信用卡,并提供了当时闻所未闻的实时体验。至少在巴西,我们是第一个这样做的。太多的未知数,我们不知道公司将走向何方,也不知道它是否会成功。有限的资源,只有十几个人在管理整个公司,我们需要让这一切顺利进行。在我们的案例中,我们有一个许可期限。如果我们在2014年5月之前没有运营,我们将不得不申请一个许可证,该许可证将需要两年的时间才能授予,这对公司来说基本上是死亡。
创业时间是一个神奇的时刻,任何事情都有可能发生,包括失败和没有公司。在我们的案例中,这发生在2013年末到2015年初。我们经历了不可思议的变化,那是一个神奇的时刻,当你有一个绿地项目,你可以选择任何你喜欢的技术。你必须有充分的理由这样做。在圣保罗一个友好社区的一间小办公室里,实际上是一所小房子。当我们推出第一款产品时,这是一款无需付费的数字信用卡,并提供了当时闻所未闻的实时体验。至少在巴西,我们是第一个这样做的。太多的未知数,我们不知道公司将走向何方,也不知道它是否会成功。有限的资源,只有十几个人在管理整个公司,我们需要让这一切顺利进行。在我们的案例中,我们有一个许可期限。如果我们在2014年5月之前没有运营,我们将不得不申请一个许可证,该许可证将需要两年的时间才能授予,这对公司来说基本上是死亡。
技术选择
我们需要做的第一个杠杆是技术选择。这里的价值是上市时间。我们需要尽快发射。这里的杠杆类型是最大化不需要做的工作量。不要创造一件你在那个阶段需要做的更复杂的事情。我们选择了Datomic作为一个数据库,一个非常小的数据库,它是一个不可变的事实分类账。你可以免费获得审计服务。每次更新都会保留历史记录,因此不会丢失以前的值。您可以在任何时间点查询数据库,因此这对以后的审核和调试都非常有用。我们选择了Clojure,这是一种在JVM上运行的函数式编程语言。我们可以利用整个Java生态系统。所有用Java编写的东西,我们都可以在Clojure中使用。默认情况下,我们获得了不变性。几乎每一个语言的决定都让我们变得简单。“简单变得容易,”是里奇·希基的一句好话。这是真的,我们在生产中使用它。我们有接近财务的函数式编程,这也是我们选择Clojure的原因。在函数式编程语言中映射财务逻辑更容易。
我们选择使用六边形架构,这样我们就可以有一种有组织的方式来查看代码。我们选择Kafka作为消息传递技术,这在当时非常流行,它有一个带有TTL的消息持久性日志。它不是永远的,但在一段时间内,您可以检查和查看生成的所有消息。我们可以重置偏移量,因此您可以在必要时重新处理旧消息。一开始我们不得不做几次。默认情况下,我们也会得到分区。当时,卡夫卡的推广也稍微容易一些。当时我们欠下的债务是我们选择了一些非常利基的技术,有些是未整合的。它们尚未建立。很难找到对这些语言有一定经验的人。在公司成立之初,我们基本上不需要为了教人们这一点而要求这样做。
Vendors
下一个杠杆是供应商。当你考虑上市时间时,好几次,购买而不是建造是最好的选择。第一个是使用云。在公司的这个阶段,您不想管理自己的机器。我们从一开始就将AWS与CloudFormation一起用于部署自动化。我们使用DynamoDB作为Datomic的后端数据库,这也很容易操作。我们选择购买现成的信用卡解决方案。我们并没有开始构建整个信用卡系统,而是开始使用一家已经处理信用卡交易的公司。我们可以利用,而不是建设,我们只是与该公司集成,我们可以更快地创建第一个产品。这里的债务是,现在,通过使用这些供应商,我们受到其增长、规模和应对我们问题的能力的限制,而这并不总是理想的。
实践
关于启动时间的最后一个问题是练习。这一次的价值是获得快速和早期的反馈。为了得到这一点,我们需要在顶部建立一个良好的基础,这样我们就可以在时间上更快地建立在上面。这里的事情是建筑基础需要时间,当你想启动的时候,你不可能总是在启动的时候使用。幸运的是,我们能做到。我们有一些时间。我们也利用这个机会构建了一个良好的CI/CD环境,因此持续部署在当时对我们来说非常重要。我们建立了一些连续部署的实践。我们有一个非常基本的容错能力,但仍然存在。我们从一开始就拥有不变的基础设施。每次部署时,我们都会在EC2上创建一个新实例并销毁旧实例,这样您就不会有处理基础架构更改的复杂性。我们从一开始就选择使用微服务,因为我们知道金融领域非常复杂。在这个例子中,将这种复杂性包含在小块中,一个较小的服务,在当时对我们来说非常重要。我们已经开始了。
关于启动时间的最后一个问题是练习。这一次的价值是获得快速和早期的反馈。为了得到这一点,我们需要在顶部建立一个良好的基础,这样我们就可以在时间上更快地建立在上面。这里的事情是建筑基础需要时间,当你想启动的时候,你不可能总是在启动的时候使用。幸运的是,我们能做到。我们有一些时间。我们也利用这个机会构建了一个良好的CI/CD环境,因此持续部署在当时对我们来说非常重要。我们建立了一些连续部署的实践。我们有一个非常基本的容错能力,但仍然存在。我们从一开始就拥有不变的基础设施。每次部署时,我们都会在EC2上创建一个新实例并销毁旧实例,这样您就不会有处理基础架构更改的复杂性。我们从一开始就选择使用微服务,因为我们知道金融领域非常复杂。在这个例子中,将这种复杂性包含在小块中,一个较小的服务,在当时对我们来说非常重要。我们已经开始了。
成长时间(2015-2016)
再往前走一点,如果我们幸运并且成功的话,公司将进入一个增长阶段,在我们的案例中,这是在2015年和2016年之间,当时我们经历了比预期更快的增长。我们曾期望在5年内获得100万客户,而我们在大约18个月内实现了这一目标。我们需要对此作出回应。起初,办公室规模不大,我们不得不搬到一个更大的地方。供应商没有进行扩展。信用卡处理器没有扩展,所以我们需要保持系统工作,即使供应商没有扩展。这项技术,我们在一开始做出的决定,也开始不具有规模。我们开始看到第一个瓶颈,在这种超增长场景中很难修复。
实践
关于成长时间的第一个杠杆是实践。有了可伸缩性或容错的价值,我们可以而且应该尽可能避免优化,或者至少延迟优化。因为优化代码比常规代码复杂得多。在一个复杂的领域,这可能会很快偏离轨道。为此,我们使用了基础设施分片,而不是只分片数据库或基础设施的一部分。我们有好几份Nubank系统的副本。每个碎片都是整个基础设施的副本,这些基础设施是可伸缩性单元。我们可以对在该副本上运行的客户数量进行限制,并在到达新客户集时转到下一个副本,并随着基础的增长不断创建副本。如果碎片足够小,就不必优化代码,或者可以尽可能地延迟代码。为此,我们必须改进CI/CD。我们需要频繁的自动部署。
我们从一开始就开始进行端到端测试,但测试规模开始缩小,因此测试开始需要一个多小时的时间。我们必须用消费者驱动的契约测试来代替它们,这将在保证少一点的情况下运行得更快,但最好保持频繁部署,而不是等待太多时间来部署。我们开始迁移到Docker,而不是使用EC2。这里的投资是与sharding一起运行的项目长达一年多,这在当时是公司的一个非常大的项目。我们必须设计新的工具来适应这种情况。这里的债务是,该项目的时间比预期的要长,客户群的增长比预期的要快。我们最终得到了比其他碎片更大的第一个碎片。在很长一段时间里,这个碎片是一个特殊的碎片,基本上是系统中任何性能问题的金丝雀,这是第一个碎片。此外,无论有多少客户,每个碎片都有一个最低成本。我们开始花很多钱来运行碎片的每个副本。
In-Housing
下一个操纵杆在内部IT。特别是,因为我们的供应商没有扩展,所以我们开始在业务最重要的方面掌握自己的命运。我们开始在内部处理信用卡,将信用卡的一个又一个功能带到内部,这样我们就可以控制自己的规模。客户支持也是如此。取悦客户是我们在公司的最大优势,因此我们还将客户支持工具和客户支持人员带到了公司内部。我们还必须为此进行设计。这里最大的投资是,实现信用卡的这些功能花费了18个多月。每一个小功能都是我们必须进行的迁移。这是一项巨大的投资,回报巨大。供应商不会扩展到3500万客户,我们可以。这里的债务是,由于带来了内部的几个功能,我们花了很长时间没有进行任何重大的产品更改。那有点糟糕。
巩固时期(2017-2018)
如果我们足够幸运,我们将进入下一阶段,也就是整合时间。2017年到2018年间,当我们在公司进入巡航模式时,我们可以扩展,但不是以稳定的方式,切分在扩展方面帮助很大。我们达到了这样的规模:每一个影响0.1%客户的小角落案例都发生在数千名客户身上。我们必须有一种比我们预期的更稳定的产品或系统。办公室也没有规模,所以我们需要搬到一个能容纳1000人的更大的办公室,靠近圣保罗最著名的街道之一的Avenuda Paulista。此时,我们推出了第二个产品,即支票账户。在这个阶段,我们已经生成了大量的数据,所以我们开始分析这些数据。这对我们来说也是非常重要的一点。
技术
技术方面的第一个优势是,我们的目标是可扩展性和适应性。这里的杠杆就是这样的规模,我们需要能够更轻松地进行基础设施更改,因此我们迁移到Kubernetes,这在当时也很繁荣。它附带了一个由多种基础设施工具组成的生态系统。随着我们获得的服务数量的增加,它比AWS CloudFormation扩展得更好。我们还开始建立更好的监控工具,以便使用Prometheus plus Grafana收集实时指标。这些指标也被其他工具(如Opsgenie、Slack或CI/CD)用于canary部署。这对我们扩大规模非常重要。这里的投资是另一个长达一年的项目,我们必须建立Kubernetes,并将碎片逐个迁移到Kubernetes,而该系统已经为数百万客户运行。他们是相当复杂的行动,我们能够完成。这里的债务是,虽然我们没有完全迁移,但我们开始在创建资源或资源数量方面达到AWS的限制,并在项目完成之前在重复的基础设施上花费大量资金。这是一件大事。
内部工具
我们还必须在用于恢复力和可观察性的内部工具上投入大量资金。我们需要让工程师们更容易操作这个系统,特别是在有这么多服务和人员的情况下。我们创建了一个名为NuCLI的命令行存储库,其中包含最常见的操作,如重新启动服务,或使用我们的凭据向服务发送HTTP请求,这些操作只需一个命令即可运行。此外,还有一个用于声明性infra的工具。一个存储库,当你可以描述你可以从你的服务中获得的资源时,它被工具自动应用。这里的投资是我们需要一个专门的团队来策划、维护和确保所有这些变化都得到应用。
数据
在这一点上,当我们进行整合时,数据变得非常重要。我们拥有的数据量无法通过常规工具处理。你几乎需要数据来做你公司的每一项决策,因此我们使用Scala plus Spark来处理所有数据,方法是从所有服务的数据库中跨所有碎片提取数据。我们有一个ETL过程,它是一个数据集定义的存储库,公司中几乎每个人或公司中几乎每个地方都参与其中,它将所有内容输出到数据仓库,以便每个人以后都可以访问。它与一些人工智能工具集成,我们可以用来支持我们的机器学习模型。我们也可以将其用作一致性工具。有了这么多的数据,并使用分布式体系结构,失败的分布式事务变得非常重要。我们还使用ETL检查一致性,同时检查系统。同样,创建初始ETL版本并开始对其进行迭代是另一个大项目。我们也有一个专门的团队,以确保这一切顺利进行。
扩张器(2019- )
最后,我们到了扩展时间,我们现在的位置。从2019年到现在,我们开始为每个人提供产品。这就是为什么你会在曲线上看到这个拐点。例如,我们不再对要求信用卡的客户说不,我们开始为每个人提供产品。我们开始在许多国家、许多办事处以及我们正在制造的许多其他产品推出。我们开始收购公司,因此这些公司之间的接口也变得很重要。
水平平台
这里关于扩展时间的第一个杠杆是可扩展性和生产力,我在这里称之为水平平台。基本上有一个专门的技术团队,为其他团队构建抽象的工具。例如,移动和网络,我们在颤振、设计系统和组件库方面有一个团队建设工具,这样普通工程师、非专家工程师仍然可以发展和使用该系统。对于基础设施也是一样,我们创建抽象工具,让每个工程师都能做到,而不是让每个人都知道如何操作Kubernetes。我们还建立了一个实验平台,因为在这种规模下,我们希望进行实验,我们希望改进您的产品。拥有一个平台,允许您在监控KPI和与测试相关的任何内容时轻松完成这项工作,这是非常关键的。我们现在需要专门的团队来创建、维护和操作这些平台,以确保每一位工程师都能在我们使用的任何技术上发挥生产力。
业务平台
最后,这里是面向领域专家团队的业务平台,用于构建供所有其他产品团队使用的抽象API。这里是我们可以进行创新的要点,我们可以构建的每一个可能的平台产品都有无限的可能性。it的例子是银行即服务,因此创建平台来运行银行的基本业务。例如,信贷平台。你不必弄清楚如何发放贷款,或者如何报告贷款,如何核算贷款,我们有一个平台,每个产品都可以发放贷款。一旦完成,产品就可以做它想做的任何事情。开放银行业务中的资产和支付平台也是如此。这些是我们可以用来建造银行的积木。此外,在信用卡方面,我们必须在其他国家推出信用卡,因此我们必须使系统更加通用。为了做到这一点,我们将系统划分为与信用卡最相关的部分。例如,在这种情况下,我们每个月都在处理信用额度或结账单,或者以不同的方式处理信用卡交易。如果客户未向我们全额支付账单,也会产生债务并重新协商客户债务。另外,当你得到太多的产品时,拥有一个灵活的采购流程也是非常重要的,所以我们使用它。这里的投资是,对于领域平台,我们需要对领域有非常深入的了解才能做到这一点。我们经过了长时间的讨论来设计平台端系统的正确突破点,因为在这里创建错误的抽象也会导致失败。您必须确保您正在创建抽象的广度,因为重建抽象的成本非常高。
简要回顾
在创业的时候,我们试图尽可能多地推迟编写代码,同时为成长奠定基础。当我们实现增长时,我们开始在内部提供我们需要的所有核心功能,并开始进行切分,以便能够更快地扩展。整合的时间是使我们的基础架构成熟并创建一个数据环境,这样每个人都可以使用数据来促进公司的发展。最后,扩展时间是关于构建横向和业务平台,因此可能性将成倍增加,每个人的生产力将成倍增加。
问答
波切利:你是从使用微服务开始的。通常,当人们选择微服务架构时,更多的是康威定律的正当性,当你很小的时候,你没有,但是你切换到那个,你考虑去做一个整体吗?这方面的思考过程如何?
卡瓦尔康蒂:我认为主要原因是领域的复杂性。我们知道金融领域非常复杂,因此当时我们对该系统的关注已经非常不同,比如处理信用卡交易、处理客户数据和处理收购流程。我们一开始只有很少的服务。我想大概有四五个,但已经进入了服务领域,因为我们知道,如果我们要成功并扩大规模,我们最终将不得不采用这种架构。
波切利:这是一个挑战,因为分布式系统比单个整体要复杂得多。
这也涉及到一些关于切分的问题。开始缩放时,您提到了切分。你在某种程度上平衡了切分和创建切分的挑战。你必须在这方面处理异常值吗?在这个切分中需要更多的资源?
卡瓦尔康蒂:我认为我们确实有一些人比其他人运行10倍或100倍的事务。它最终只会影响到特定的客户,比如他们的账单可能不会及时打开,因为那里有太多的交易。它不会影响其他操作,因为我们的大多数操作已经是批处理的。这对我们没有多大影响。我们在第一个碎片上确实遇到了这个问题,因为我们花了比预期更长的时间来构建碎片基础设施。第一个碎片与年龄太大的客户相处得太久。客户在Nubank的时间最长,客户数量最多。这给我们带来了一些挑战。有时仍然如此,但现在所有碎片的大小都差不多了。我们正在更好地管理它们。
波切利:那么,连接到切丁。迁移到库伯内特斯的情况如何?关于库伯内特家族的一些问题。你是否采用了像EKS之类的Kubernetes服务,或者你去了Kubernetes?从您的基础架构的这种转变是如何进行的?你已经提到它是不可变的。
卡瓦尔康蒂:我认为这里要考虑的主要问题是,这是七、八年前的事了。Kubernetes刚刚推出,2014年公开发布。我们创立公司时没有这些工具。我们成立公司时甚至没有Docker,所以我们不得不迁移到Docker,然后迁移到Kubernetes。然后最终迁移到EKS,因为EKS在当时也不存在。我想,它是从今年开始在圣保罗地区出现的。我想如果我们今天开始创业,我们可能会在亚马逊上使用EKS,就这样。我们当时没有那些工具。
波切利:我在这里经常看到的另一个问题是Clojure的使用,以及您提到的堆栈。我想说,这并不常见。你利用了生态系统。您还提到了JVM。你能帮我们理解一下这种二分法吗?你开始很容易,但你选择了很少有人会选择的东西。
卡瓦尔康蒂:对我们来说,Clojure最重要的一点是,语言从一开始就将你推向简单,从某种意义上说,你必须学习的语言数量是非常少的。你可以在Clojure学习几周来提高工作效率。我们所有的服务看起来都差不多。一旦你摆脱了那些括号,你就可以从大括号切换到括号,然后就可以了。其他一切都比较简单。我们没有大多数语言必须学习语法和语言结构的认知负荷。Clojure是Lisp的括号和符号。您不必学习很多语言特性,就可以像我们一样使用它或复制粘贴其他代码。
波切利:现在关于更多业务方面的一个问题是,您是如何将成本因素纳入架构决策的?当你从事金融业务时,你会遵守很多规定。您如何处理这一区别、基础设施、业务代码以及法规的所有挑战?
卡瓦尔康蒂:我们确实有特定的团队,比如当我们达到一定规模时,有一个专注于特定方面的团队是值得的。我们有一个团队只负责管理运营风险,或者一个团队只负责为公司的受监管部分提供平台。发放贷款在市场上是非常受监管的,至少在巴西是这样,所以我们围绕它创建了一个平台。每次我们需要贷款时,平台都会处理,我们有许多团队可以轻松发放贷款。这就是我们处理这件事的主要方式,就是有一个专门的团队,知道很多关于规章制度的知识,知道如何评估风险。然后,来自可能受it影响的其他团队的定期评估。
波切利:你提到过几次,有专门的团队和专家。Nubank的团队规模是什么样的?
卡瓦尔康蒂:通常,团队不仅仅是工程师。我们有BAs团队、产品经理团队、业务产品经理团队,有时还有数据科学家团队。对于工程部分,我们通常有一名技术经理,每个团队有两到六名工程师。它在上下文上有很大的不同,但每个团队的规模都差不多。
波切利:两个比萨饼规则。
现在让我们切换到数据。您提到了ETL,您使用什么工具进行ETL?
卡瓦尔康蒂:我们使用Spark构建所有基础设施来转换数据。我们必须在内部构建很多工具来提取数据组数据,并以ETL可以使用的方式进行转换。我不是数据方面的专家,所以我对细节不太了解。我知道我们使用Mesos集群来运行将运行ETL过程的集群。我们使用一些BI工具,比如Databricks,比如Looker。我认为整个生态系统都在使用几种工具。我们有自己的数据集定义存储库,由整个公司提供。它是Scala和Spark,以及我们创建的一些抽象概念,因此人们可以更容易地使用它。
波切利:你从卡夫卡开始,今天,很多事情都是关于流的,但是你选择了批处理ETL路线。有没有理由不全神贯注于流媒体?那时候不是很流行,你需要调整吗?
卡瓦尔康蒂:主要原因是,当我们需要ETL时,卡夫卡流在当时并不稳定或不被释放。当时我们已经从数十家微服务公司获得了Datomic的数据。我们很难在当时选择的架构上迁移到卡夫卡流模式。如果我们从今天开始,我们将进入流媒体。我们确实有一些更适合流的用例。例如,我们在实时收集指标时使用它。我们确实使用卡夫卡流。对于常规数据库部分,我们没有。
原文:https://www.infoq.com/presentations/nubank-architectural-decisions/
本文:
- 72 次浏览
【软件架构】使用ChatGPT和PlantUML的思维导图
视频号
微信公众号
知识星球
在我之前的关于将Mermaid.js与ChatGPT一起使用以构建系统图的系列文章(第1部分和第2部分)中,我们研究了ChatGPT构建序列、活动、状态和C4模型的能力。
我有兴趣进一步探索这一点,下面是我关于使用PlantUML使用ChatGPT构建更复杂的图的下一个系列
PlantUML允许您根据文本描述创建广泛的图表。在目前的状态下,除了所有UML图之外,它还可以支持甘特图、思维导图、概念图等
我对构建思维导图特别感兴趣,所以这是我关于PlantUML系列的第一篇文章。我与ChatGPT的交互,并使用它与PlantUML创建思维导图

思维导图简介
Prompt: What's a mindmap
ChatGPT: A mind map represents ideas or information organized around a central concept or key idea. Mind maps are often used to visually organize information and create a clear structure for thoughts and concepts. The nodes in a mind map can branch out to show relationships between ideas. They can be colour-coded, labelled with icons, or annotated with text to clarify the relationships further. Mind maps are commonly used in note-taking, brainstorming, problem-solving, and decision-making, as they help to capture and organize thoughts visually and intuitively.
基本思维导图
Prompt: Okay, Let's start by creating a simple MindMap on the topic of
Artificial Intelligence
Can you give the mindmap inPlantUMLformat. Keep it structured from the core central topic branching out to other domains and sub-domains. Let's go to 4 levels to begin with. Add the start and end mindmap tags and keep it expanding on one side for now
ChatGPT: Sure, here's a simple mind map of the topic "Artificial Intelligence" in PlantUML format, with four levels
@startmindmap * Artificial Intelligence ** AI Technologies *** Machine Learning **** Supervised Learning **** Unsupervised Learning **** Reinforcement Learning *** Natural Language Processing (NLP) **** Sentiment Analysis **** Part-of-Speech Tagging **** Named Entity Recognition @endmindmap
为了将其可视化,让我们打开draw.io或diagrams.net,然后转到
排列->插入->高级->PlantUML
并粘贴上面的片段
opening plantUML diagrams in draw.io
下面是可视化
凉的我们有思维导图!!
让我们试着调整一些设置。
提高级别
Prompt: Can you increase it by two more levels and add further domains
ChatGPT: Sure, here's the expanded mind map of the topic "Artificial Intelligence" in PlantUML format, with six levels:
@startmindmap * Artificial Intelligence ** AI Technologies *** Machine Learning **** Supervised Learning ***** Regression ***** Classification **** Unsupervised Learning ***** Clustering ***** Association Rules **** Reinforcement Learning *** Natural Language Processing (NLP) **** Sentiment Analysis ***** Polarity Analysis ***** Emotion Analysis **** Part-of-Speech Tagging **** Named Entity Recognition ** AI Applications *** Computer Vision **** Object Recognition **** Image Segmentation *** Robotics **** Navigation **** Manipulation *** Speech Recognition **** Speaker Verification **** Speech Synthesis @endmindmap
添加颜色代码
接下来,让我们为我们的思维导图添加颜色代码。
注意:我必须提供提供颜色代码的语法,因为ChatGPT可能使用了一个旧的语法,该语法在预处理时破坏了plantUML代码
Prompt: Can you add colour codes to the above mind map? Use the format
*[#FFFF00] Artificial Intelligence. The above is just an example; use your colour codes for each node based on the complexity of each node in terms of the time it takes to learn that topic for a beginnerChatGPT: Here's an updated version of the mindmap, with colour codes indicating the complexity of each topic
@startmindmap
*[#red] Artificial Intelligence
**[#red] AI Technologies
***[#orange] Machine Learning
****[#orange] Supervised Learning
*****[#yellow] Regression
*****[#yellow] Classification
****[#orange] Unsupervised Learning
*****[#yellow] Clustering
*****[#yellow] Association Rules
****[#orange] Reinforcement Learning
***[#orange] Natural Language Processing (NLP)
****[#yellow] Sentiment Analysis
*****[#green] Polarity Analysis
*****[#green] Emotion Analysis
****[#yellow] Part-of-Speech Tagging
****[#yellow] Named Entity Recognition
**[#red] AI Applications
***[#orange] Computer Vision
****[#yellow] Object Recognition
****[#yellow] Image Segmentation
***[#orange] Robotics
****[#yellow] Navigation
****[#red] Manipulation
***[#orange] Speech Recognition
****[#yellow] Speaker Verification
****[#yellow] Speech Synthesis
@endmindmap
和表示

但是这些颜色是什么意思?让我试着找到一个传奇
Prompt: can you create a PlantUML legend for the colour codes above? Mark them against the time duration based on which the colours were selected
ChatGPT: Here is a PlantUML legend for the colour codes, indicating the time duration for a beginner to learn each topic:
legend - Green: Topics that can be learned in less than a week (around 10-20 hours of study) - Yellow: Topics that take a few weeks to a month to learn (around 30-50 hours of study) - Orange: Topics that take a few months to learn (around 100-150 hours of study) - Red: Topics that require substantial effort and time to learn (around 200-300 hours or more of study) endlegend
和在draw.io中导入

太好了,我们有一个带有颜色代码的思维导图和一个相应的图例,其中包含每个颜色代码的描述。
添加图标
接下来,让我们尝试将图标添加到我们的思维导图中
注意:我必须提供提供图标的语法,因为ChatGPT可能使用了一种旧的语法,它在预处理时破坏了plantUML代码
Prompt: Can you add icons to the above MindMap using plantUML-supported icons from the open iconic library? The format for usage is as
*[#red] <&star> Manipulation. The above is an example of a red colour node and start icon from the open iconic library. Keep the same colour codes as above but use relevant icons as appropriate
ChatGPT:@startmindmap *[#red] <&home> Artificial Intelligence **[#red] <&aperture> AI Technologies ***[#orange] <&puzzle-piece> Machine Learning ****[#orange] <&tag> Supervised Learning *****[#yellow] <&code> Regression *****[#yellow] <&circle-check> Classification ****[#orange] <&dashboard> Unsupervised Learning *****[#yellow] <&list> Clustering *****[#yellow] <&tag> Association Rules ****[#orange] <&pulse> Reinforcement Learning ***[#orange] <&cog> Natural Language Processing (NLP) ****[#yellow] <&pulse> Sentiment Analysis *****[#green] <&arrow-top> Polarity Analysis *****[#green] <&eye> Emotion Analysis ****[#yellow] <&tag> Part-of-Speech Tagging ****[#yellow] <&bookmark> Named Entity Recognition **[#red] <&aperture> AI Applications ***[#orange] <&image> Computer Vision ****[#yellow] <&target> Object Recognition ****[#yellow] <&crop> Image Segmentation ***[#orange] <&code> Robotics ****[#yellow] <&map-marker> Navigation ****[#red] <&star> Manipulation ***[#orange] <µphone> Speech Recognition ****[#yellow] <&person> Speaker Verification ****[#yellow] <&audio> Speech Synthesis @endmindmap
和代表

这些图标看起来并不都合适,但至少是ChatGPT根据主题映射关闭图标的一次非常好的尝试。
进入下一步
添加说明
Prompt: Can you add a definition to only the leaf nodes? These definitions should be word-wrapped using PlantUML format and not have a surrounding box. Keep the Icons and Colors of the nodes as-is, and add additional description nodes to all leaf nodes. The format for adding leaf nodes is
****_ description
ChatGPT:
@startmindmap *[#red] <&home> Artificial Intelligence **[#red] <&aperture> AI Technologies ***[#orange] <&puzzle-piece> Machine Learning ****[#orange] <&tag> Supervised Learning *****[#yellow] <&code> Regression ******_ A statistical approach to finding the relationship between a dependent and one or more independent variables. *****[#yellow] <&circle-check> Classification ******_ The task of categorizing a set of data into classes based on their features. ****[#orange] <&dashboard> Unsupervised Learning *****[#yellow] <&list> Clustering ******_ A method of organizing a set of data into groups (clusters) based on their similarities. *****[#yellow] <&tag> Association Rules ******_ A statistical approach for finding relationships between variables in large datasets. ****[#orange] <&pulse> Reinforcement Learning *****_ An area of machine learning that focuses on training an agent to make a sequence of decisions by maximizing a reward. ***[#orange] <&cog> Natural Language Processing (NLP) ****[#yellow] <&pulse> Sentiment Analysis *****[#green] <&arrow-top> Polarity Analysis ******_ A method of identifying the sentiment expressed in a text as positive, negative, or neutral. *****[#green] <&eye> Emotion Analysis ******_ The task of detecting and classifying emotions in text or speech. ****[#yellow] <&tag> Part-of-Speech Tagging *****_ The task of marking each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, etc. ****[#yellow] <&bookmark> Named Entity Recognition *****_ A NLP technique that identifies named entities in a text, such as organizations, people, locations, etc. **[#red] <&aperture> AI Applications ***[#orange] <&image> Computer Vision ****[#yellow] <&target> Object Recognition *****_ The task of recognizing objects in images or videos based on their features and attributes. ****[#yellow] <&crop> Image Segmentation *****_ The process of dividing an image into multiple segments or regions, each of which corresponds to a different object or part of the image. ***[#orange] <&code> Robotics ****[#yellow] <&map-marker> Navigation *****_ The task of guiding a robot from one place to another. ****[#red] <&star> Manipulation *****_ The task of manipulating objects in the environment using a robot. ***[#orange] <µphone> Speech Recognition ****[#yellow] <&person> Speaker Verification *****_ The task of verifying the identity of a speaker based on their speech. ****[#yellow] <&audio> Speech Synthesis *****_ The task of generating speech from text. @endmindmap
and the representation
就在这里。用ChatGPT制作的复杂思维导图,用图例、图标和描述性进行颜色编码。
感谢阅读!
- 209 次浏览
【软件架构】使用ChatGPT构建系统图-第一部分
视频号
微信公众号
知识星球
对思维导图感兴趣 — 阅读我们关于使用plantUML和ChatGPT创建令人敬畏的思维导图的博客文章
ChatGPT的受欢迎程度不断增长,目前已被广泛应用。作为一名软件架构师,我有机会探索ChatGPT在金融领域的功能,特别是财富管理。
我想确认ChatGPT是否可以为用例解释生成图表,并同时分析多个因素。
所以,我登录了chat.openai.com,下面是我的对话
步骤1:让我们定义用例
我本可以定义自己的用例,但我想测试ChatGPT的所有方面,所以我要求它为我定义一个。

步骤2:让我们为用例定义一个数据模型
在我看来很好,让我们从定义数据模型开始——所以我请ChatGPT来做,这就是我得到的

这听起来不错,让我们看看它能为图表做些什么。我想更深入地研究数据模型,所以我的下一个提示是
Prompt:describe the data model in more detail or tabular format using markdownChatGPT: I can describe the structure of the data model in a tabular format using markdown.
这是一个良好的开端。接下来,我要求定义关系
第3步:让我们定义关系-实体关系图
Prompt: this is perfect, I would like to depict the relationships in a mermaid diagram, can you give me the markdown code to do this
ChatGPT: I apologize, but as a text-based model, I am not able to generate Mermaid diagrams or any other visual diagrams. However, I can provide you with an example of how the relationships could be represented in Mermaid syntax:
在{merma}标签内的降价编辑器中复制这个,我得到了

太好了,我们正在取得进展。
我有一个类图/实体关系图。让我们看看还有什么可能
步骤4:序列图
接下来,我尝试做出假设性提示来检查响应。我的第一个意图是创建一个序列图
Prompt: how would a Buy transaction for an asset impact the tables mentioned above, I would like to depict this as a sequence diagram. Can you help describe the diagram in markdown format for mermaid
ChatGPT: Sure, aBuytransaction would have an impact on the following tables:
Assettable: thecurrent_valueof the asset would be updated to reflect the current market value of the asset
Portfoliotable: thecurrent_valueof the portfolio would be updated to reflect the new asset and its market value, and theasset_allocationwould be updated to reflect the new asset.
Transactiontable: a new transaction would be added with the transaction details such as the transaction type, transaction date, asset_id, and portfolio_idHere is an example of how the process could be represented in a Mermaid sequence diagram:
在markdown编辑器中复制这个
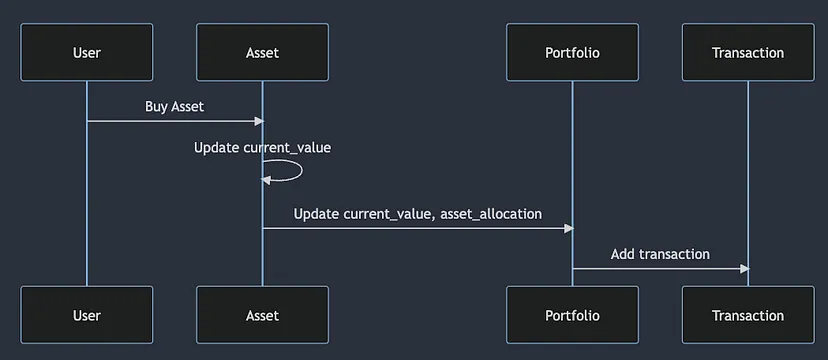
给人印象深刻的但我还没有完成
步骤5:状态转换图
让我问一下状态转换图
Prompt: Will the account have states like new, closed, active inactive etc? I would like to depict the states in a state diagram using mermaid. Can you help describe the diagram in markdown format
ChatGPT: It is common for financial accounts to have different states, such as new, closed, active, and inactive, to reflect the current status of the account.
newaccount would be one that has just been opened and is awaiting funding or verification.
activeaccount would be one that is currently open and being used for transactions.
inactiveaccount would be one that is not currently being used but has not been closed.
closedaccount would be one that has been closed by the customer or the financial institution, and no longer able to be used for transactions.
Pendingstate could be used to indicate that the account is under review or awaiting verification.
Suspendedstate could be used to indicate that the account has been temporarily suspended, for example, due to suspicious activity or non-compliance with terms and conditions.
Frozenstate could be used to indicate that the account has been frozen, for example, due to a legal dispute or regulatory action.
Expiredstate could be used to indicate that the account has reached its expiration date and is no longer in use.here is an example of how the states of an account could be represented in a Mermaid state diagram:
看起来,此格式较旧,可能会由于循环依赖关系而中断。所以我要求ChatGPT对此进行改进
Prompt: can you try giving the state diagram markdown syntax in new format using
[*]
ChatGPT: Sure, here is an example of how a state diagram for a wealth management system's account management component could be represented in Mermaid using the new format with[*]:
标记编辑器表示
此图显示了帐户的不同状态以及它们之间可能的转换。
- 初始状态为[*],表示开始状态。
- 帐户可以通过激活从“新建”状态转换为“活动”状态。
- 帐户可以通过关闭从“新建”状态转换为“关闭”状态。
- 帐户可以通过停用从活动状态转换到非活动状态。
- 帐户可以通过关闭从活动状态转换到关闭状态。
- 帐户可以通过激活从非活动状态转换为活动状态。
- 帐户可以通过关闭从非活动状态转换为关闭状态。
现在我们正在取得进展。让我们进一步扩展到包括其他州
Prompt: please include expired, frozen and other relevant states as well
ChatGPT: Sure, here is an example of how a state diagram for a wealth management system’s account management component could be represented in Mermaid including additional states such asExpired,Frozen, etc:Description:
This diagram shows the different states of an account and the possible transitions between them.The initial state is
[*]which denotes the start state.
The account can transition fromNewstate toActivestate by activating it.
The account can transition fromNewstate toClosedstate by closing it.
The account can transition fromActivestate toInactivestate by deactivating it.
The account can transition fromActivestate toFrozenstate by freezing it.
The account can transition fromActivestate toClosedstate by closing it.
The account can transition fromInactivestate toActivestate by activating it.
The account can transition fromInactivestate toFrozenstate by freezing it.
The account can transition fromInactivestate toClosedstate by closing it.
The account can transition fromFrozenstate toActivestate by unfreezing it.
The account can transition fromFrozenstate toClosedstate by closing it.
The account can transition fromClosedstate toExpiredstate if the account is expired.
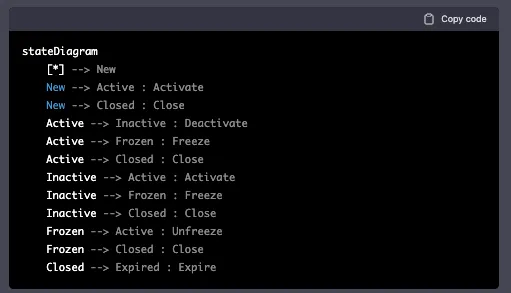
和图解表示
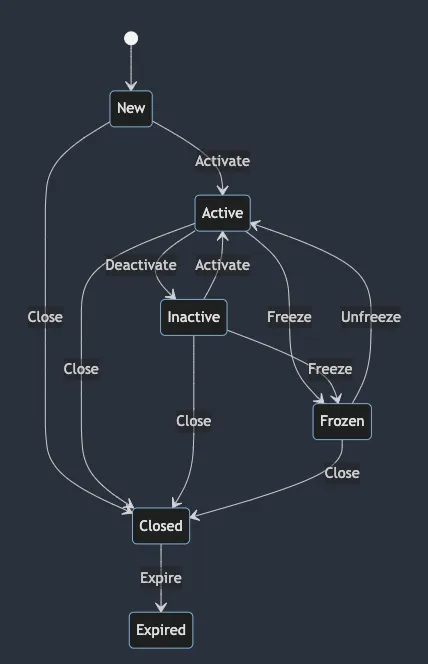
这太棒了。ChatGPT和Mermaid所能取得的成就令人印象深刻
接下来,我将使用C4模型描述和构建更多的图表,并将它们添加到后续文章中
感谢阅读!
- 630 次浏览
【软件架构】利用ChatGPT在软件架构中利用即时工程
视频号
微信公众号
知识星球
转变软件体系结构开发生命周期。
介绍
作为一名解决方案架构师,掌握软件架构的最新进展至关重要。一种越来越受欢迎的前沿方法是即时工程,这是一种利用GPT-4等人工智能模型根据给定提示生成输出的技术。在这篇博客文章中,我们将深入研究如何将提示工程应用于软件架构过程的不同阶段,并讨论在每个阶段最有效的提示类型。
收益汇总:
- 节省时间:快速工程通过快速生成摘要、提取数据和提供有价值的见解,帮助解决方案架构师节省时间。
- 提高质量:利用人工智能生成的输出可以通过提出设计备选方案、确定瓶颈和提供最佳实践来提高架构设计质量。
- 简化的开发:在整个软件架构过程中集成即时工程有助于简化开发,确保阶段之间的过渡更加顺利。
- 优化的性能:通过生成重构建议和确定优化机会,即时工程有助于提高系统性能。
- 适应性:及时的工程让架构师了解新兴技术,帮助他们设计能够适应未来变化的系统。
需求收集和分析
需求收集和分析阶段的主要目标是清楚地了解利益相关者的需求和期望。通过使用即时工程,解决方案架构师可以:
- 生成长文档或对话的摘要。
- 将非结构化信息转换为结构化格式。
- 识别缺失或矛盾的要求。
要使用的提示类型:
- 总结提示:“用200字总结以下文档。”
- 数据提取提示:“从以下对话中提取主要需求。”
- 矛盾检测提示:“识别给定需求集中的任何矛盾。”
架构设计
解决方案架构师在架构设计过程中创建系统结构和组件的高级蓝图。快速工程可用于:
- 根据给定的需求生成设计备选方案。
- 比较和对比不同的架构模式。
- 确定拟议架构中的潜在瓶颈或问题。
要使用的提示类型:
- 设计建议提示:“根据以下要求,提出三种不同的架构设计。”
- 模式比较提示:“对微服务和单片架构模式进行比较和对比。”
- 瓶颈识别提示:“识别拟议架构中潜在的性能瓶颈。”
实施
在实施阶段,将架构设计转化为代码。即时工程可以通过以下方式为开发人员提供支持:
- 基于架构设计生成代码片段或伪代码。
- 为要使用的库或框架提供建议。
- 推荐编码标准和样式的最佳实践。
要使用的提示类型:
- 代码生成提示:“生成用于实现以下架构组件的Python代码片段。”
- 库建议提示:“建议合适的JavaScript库来实现以下功能。”
- 最佳实践提示:“推荐在Java中实现RESTful API的最佳实践。”
测试和验证
在测试和验证阶段,根据其要求对系统进行验证。及时的工程可以通过以下方式提供帮助:
- 基于系统需求生成测试用例或场景。
- 识别可能导致问题的潜在边缘案例。
- 提供有关测试方法和工具的指导。
要使用的提示类型:
- 测试用例生成提示:“生成五个测试用例来验证以下需求。”
- 边缘案例识别提示:“识别以下系统组件的潜在边缘案例。”
- 测试方法提示:“为分布式系统推荐合适的测试方法。”
部署和持续集成
开发的系统在部署和持续集成阶段发布并与其他组件集成。快速工程可用于:
- 生成部署脚本或配置文件。
- 提供有关部署战略和最佳做法的指导。
- 提供有关监控和日志记录技术的见解。
要使用的提示类型:
- 部署脚本生成提示:“生成用于部署以下应用程序的Dockerfile。”
- 部署策略提示:“解释蓝绿色部署与滚动部署的优缺点。”
- 监控和日志提示:“推荐微服务架构中监控和日志记录的最佳实践。”
维护和发展
在维护和发展阶段,根据用户反馈和不断变化的需求,不断改进和更新系统。及时的工程可以通过以下方式提供帮助:
- 正在生成重构或改进现有代码的建议。
- 确定优化或性能改进的潜在领域。
- 提供对新兴技术及其对系统的潜在影响的见解。
要使用的提示类型:
- 重构建议提示:“建议对以下代码片段进行改进,以获得更好的可维护性。”
- 优化识别提示:“识别以下系统组件中性能优化的潜在领域。”
- 新兴技术提示:“讨论边缘计算对当前系统架构的潜在影响。”
Prompt engineering提供了一种通用而强大的方法来增强软件架构过程,将其优势扩展到设计阶段之外。通过在各个阶段整合人工智能生成的输出,解决方案架构师可以简化开发过程,优化系统性能,并确保他们的解决方案能够适应未来的变化。成功的关键在于尝试各种提示类型,并利用人工智能的能力在旅程的每一步提供有价值的见解和支持。
解决方案架构师可以针对未来的变化设计更快、更高效、适应性更强的软件解决方案。通过利用人工智能生成的提示,架构师可以提高生产力,更有效地协作,并提供满足用户需求的高质量设计。及时的工程设计是释放解决方案架构的全部潜力并彻底改变我们构建软件的方式的关键。
- 133 次浏览
【软件架构】最佳软件架构书籍终极榜单(2024)
视频号
微信公众号
知识星球
在这篇文章中,我为您列出了2024年应该阅读的最佳软件架构书籍。

软件架构是软件产品成功开发的基础。
一个精心设计的软件架构可以对系统的质量产生很大的影响。它还可以帮助降低出错的风险,并使将来添加新特性和功能变得更容易。
在这篇博客文章中,我为您列出了2024年应该阅读的最佳软件架构书籍,以及2024年将出版哪些有趣的软件架构书籍。
当然,这些书中的大多数也是2023年最好的软件架构和设计书籍之一。
我希望这份软件架构师书籍清单能帮助你找到你需要学习更多关于软件架构的书籍,并成为一名更好的软件架构师。
这篇文章可能包含附属链接。作为亚马逊、Manning和O'Reilly的关联合伙人,我通过符合条件的购买获得收入。
2024年你应该阅读的最好的软件架构书籍(TL;DR):
- Fundamentals of Software Architecture
- Continuous Architecture in Practice
- Software Architecture: The Hard Parts
- The Software Architect Elevator
- Building Evolutionary Architectures
- Software Architecture in Practice
- Software Architecture For Developers
- Communication Patterns
- Architecture Modernisation
- Software Architecture and Decision-Making
- Software Architecture Metrics
- Enterprise Integration Patterns
- Designing Data-Intensive Applications
- Sustainable Software Architecture
2024年软件架构新书:
- Head First Software Architecture
- Collaborative Software Design
- Facilitating Software Architecture
- Building Multi-Tenant SaaS Architectures
2024年最佳软件架构书籍
软件架构基础
一种工程方法
马克·理查兹和尼尔·福特
这本书是一本全面的软件架构指南,由经验丰富的从业者撰写。它涵盖了软件架构的各个方面,从架构特征和模式到组件确定、绘制和呈现架构图、进化架构和软技能。

这本书是在现代背景下写的,考虑到了该领域的最新创新。它还强调了工程实践和操作方法在软件架构中的重要性。
这本书对于有抱负的和现有的软件架构师来说都是必读之作。它全面概述了该领域以及取得成功所需的技能。
实践中的连续架构
Continuous Architecture in Practice
敏捷时代的软件架构与DevOps
Murat Erder、Pierre Pureur和Eoin Woods
《实践中的连续架构》是一本关于敏捷、DevOps和云平台时代的软件架构的书。作者Murat Erder、Pierre Pureur和Eoin Woods分享了他们丰富的经验,并为在现实世界环境中利用连续架构方法提供了实践建议。

Continuous Architecture in Practice
这本书涵盖了广泛的主题,包括:
- 创建符合功能要求和质量属性的可持续、连贯的系统
- 将基于团队的软件架构和架构理解为“决策流”
- 解决数据管理、集成和更改的关键问题
- 针对安全性、可扩展性、恢复能力、性能和新兴技术构建架构
这本书还包括一个从开始到结束的案例研究,展示了作者对复杂软件环境的深刻体验。
这本书对于那些想要更新架构实践以应对新的软件挑战的技术人员来说是一个宝贵的资源。对于想要了解更多关于连续架构的知识的软件架构师和软件工程师来说,这也是一本很好的书。
软件架构:难点
Software Architecture: The Hard Parts
分布式架构的现代权衡分析
作者:Neal Ford、Mark Richards、Pramod Sadalage和Zhamak Dehghani

Software Architecture: The Hard Parts
软件架构是一个复杂的领域,没有简单的决策。这本书提供了批判性思考分布式架构中所涉及的权衡的策略。
作者利用一个关于Sysops Squad的虚构故事,研究了以下关键主题:
- 服务粒度
- 工作流和编排
- 管理和脱钩合同
- 分布式事务
- 可扩展性、弹性和性能
通过关注常见问题,本书提供了帮助架构师发现和权衡他们面临的权衡的技术。
所涵盖的具体主题包括:
- 分析权衡并有效记录决策
- 就服务粒度做出更好的决策
- 了解拆分单片应用程序的复杂性
- 管理和分离服务之间的合同
- 在高度分布式的架构中处理数据
- 学习在分解应用程序时管理工作流和事务的模式
对于那些希望对分布式架构做出更好决策的软件架构师来说,这本书是一本宝贵的资源。
对于想要了解更多关于设计和构建分布式系统所涉及的挑战和权衡的软件工程师来说,这也是一本很好的书。
软件架构师Elevator
The Software Architect Elevator
重新定义架构师在数字企业中的角色
作者Gregor Hohpe
在数字经济中,软件和IT架构师的角色正在发生转变。架构师需要将组织和技术知识结合起来,以实现公司结构和流程的变革。他们需要将IT机房连接到顶层公寓,在那里定义业务战略。这本书分享了现实世界中的建议和从实际IT转型中汲取的经验教训。
它是软件架构师、高级开发人员、企业架构师、CTO和It经理的理想选择。

The Software Architect Elevator
这本书的主题包括:
- 塑造公司的技术方向
- 协助组织转型
- 浏览技术和组织主题
- 制定影响组织工作方式的IT战略
- 学习在大规模转型中哪些有效,哪些无效
对于任何想在组织中扮演更具战略性角色的IT专业人士来说,这本书都是一本宝贵的资源。
构建进化架构
Building Evolutionary Architectures
自动化软件治理
作者:Neal Ford,Rebecca Parsons,Patrick kua&Promod Sadalage
这本书提供了关于如何创建可以随时间发展的软件架构的实用建议。它是由经验丰富的软件架构师编写的,他们对现代软件开发的挑战有着深刻的理解。
这本书很及时,因为它解决了软件行业的两个关键趋势:对快速交付和质量的需求不断增加,以及软件架构师角色的变化。

这本书充满了务实和深刻的建议,对所有软件工程师和架构师来说都是一个宝贵的资源。
如果你是一名软件工程师或架构师,这本书是必读的。它将帮助您构建更好的软件,以满足不断变化的世界的需求。
实践中的软件架构
作者:Len Bass、Paul Clements、Rick Kazman
《实践中的软件架构》(Software Architecture in Practice),第四版,是一本永恒的经典而全面的软件体系架构指南。它涵盖了软件架构的整个生命周期,从设计到实例化再到分析再到进化再到管理。
这本书由三位著名的软件架构师撰写,共更新了十一章,涵盖了该领域的最新趋势,如移动、云、能源管理、DevOps和量子计算。
这本书提供了实用指南、专家方法和测试模型,可用于任何软件项目,无论多么复杂。它还解释了如何使用架构来优化关键质量属性,如性能、可修改性、安全性、可用性、互操作性、可测试性、可使用性、可部署性等。

Software Architecture in Practice
此外,本书还介绍了如何管理和完善现有架构,对其进行转换以解决新问题,以及构建可重用的架构,使其成为战略业务资产。
总的来说,对于任何想了解该领域最新趋势和最佳实践的软件架构师来说,《实践中的软件架构》第四版都是必不可少的资源。
面向开发人员的软件架构
Software Architecture For Developers
技术领导力与灵活性的平衡
西蒙·布朗
面向开发人员的软件架构是现代软件架构的实用指南,专门针对软件开发人员。

Software Architecture for Developers
本书涵盖以下主题:
- 软件架构的本质。
- 为什么软件架构的角色应该包括编码、指导和协作。
- 在编码之前,您真正需要考虑的事情。
- 如何使用C4模型可视化您的软件架构。
- 一种轻量级的软件文档化方法。
- 为什么敏捷和架构之间没有冲突。
- “刚好够”的前置设计意味着什么。
- 如何通过风险风暴识别风险。
通信模式
开发者和架构师指南
作者Jacqui Read
Jacqui Read的《通信模式》一书为利益相关者和团队提供了一个有效沟通软件架构的实用指南。它强调了清晰、简洁和可访问的沟通在确保每个人都理解和支持架构方面的重要性。

本书首先讨论了通信在软件开发中的重要性。然后,它将继续涵盖与通信软件架构相关的各种主题,包括:
- 为不同的受众和项目阶段设计图表和文档
- 创建可访问的文档和图表
- 掌握技术环境中的书面、口头和非口头交流
- 将通信模式应用于真实世界的项目和软件设计
- 与分散的团队进行沟通和协作
这本书充满了建设性的例子和模式,可以应用于各种软件开发项目。
对于任何想要学习如何有效地沟通软件架构的人来说,这是一个必不可少的资源。
软件架构度量
提高架构质量的案例研究
作者:Christian Ciceri、Dave Farley、Neal Ford、Andrew Harmel Law、Michael Keeling、Carola Lilienthal、Joao Rosa、Alexander von Zitzewitz、Rene Weiss和Eoin Woods
软件架构度量是一本实用的书,介绍了每个软件架构师都应该知道的度量。
这不是一本关于理论的书,而是一本关于实践和实施的书。这本书是由从业者为渴望探索成功案例研究的软件架构师和软件开发人员撰写的。

本书涵盖以下主题:
- 如何衡量您的软件架构在多大程度上满足了您的目标
- 如何选择正确的指标进行跟踪(并跳过不需要的指标)
- 如何提高可观测性、可测试性和可部署性
- 如何确定软件架构项目的优先级
- 如何构建富有洞察力和相关性的仪表板
这本书由10位杰出的从业者撰写,分享了关键的软件架构指标,以帮助您设置正确的KPI并衡量结果。
架构现代化
软件、战略和结构的社会技术一致性
Nick Tune与Jean-Georges Perrin

Book Architecture Modernization
架构现代化:软件、战略和结构的社会技术一致性是一本关于如何将软件架构与业务领域、组织设计、团队拓扑和公司战略相一致的书。它提供了具体的工具、技术和流程,以帮助组织发展其软件、团队和业务战略,从而充分发挥其潜力。
这本书涵盖了广泛的主题,包括:
- 将架构、业务域和团队拓扑设计为面向业务战略的独立价值流
- 规划和领导一项渐进式现代化倡议
- 提升组织中的架构实践以创造持久的变革
- 利用协同产品开发技术,如Event Storming和Wardley Mapping
- 使用原理、启发法和实践技术对域和子域进行建模
这本书是为软件架构师、工程师和其他想要学习如何使其软件和组织现代化的专业人士而写的。对于想要了解软件架构如何支持其业务目标的业务领导者来说,这也是一个宝贵的资源。
软件架构与决策
Software Architecture and Decision-Making
利用领导力、技术和产品管理打造卓越产品
作者:Srinath Perera
《软件架构与决策》是一本教软件架构师如何在面对不确定性时做出更好决策的书。这本书提供了一个基于五个关键问题和七个重要原则的决策框架。它还强调了强大的领导力和产品管理知识对软件架构师的重要性。

Software Architecture and Decision-Making
这本书是为软件行业的所有技术领导者准备的,他们对自己构建的系统做出全面的判断,也为未来学习这门技术的领导者准备的。
企业集成模式
Enterprise Integration Patterns
设计、构建和部署消息传递解决方案
Gregor Hohpe和Bobby Wolf
企业集成模式是设计和实现消息传递解决方案的宝贵资源。它提供了65种模式的目录、真实世界的例子和一个案例研究,以说明实践中的模式。

Enterprise Integration Patterns
这本书还涵盖了企业集成的新兴标准和未来趋势。它提供了一个一致的词汇表和可视化表示框架,用于描述不同技术之间的集成解决方案。它深入研究了异步消息传递架构的优点和局限性,并就设计应用程序到消息传递系统接口提供了实用的建议。它指导您确定消息发送、路由和监视策略。如果您想有效地管理和维护消息传递系统,这本书是一本重要的指南。
设计数据密集型应用程序
Designing Data-Intensive Applications
可靠、可扩展和可维护系统背后的大创意
作者:Martin Kleppmann
Martin Kleppmann的《设计数据密集型应用程序》是软件工程师和架构师的实用指南,他们希望了解设计和部署数据密集型的应用程序所涉及的原则和权衡。这本书涵盖了广泛的主题,包括关系数据库、NoSQL数据存储、流处理和批处理。它还讨论了可扩展性、一致性、可靠性和效率方面的挑战。

Designing Data-Intensive Application
关键要点:
- 本书通过考察每种方法的优缺点,帮助您了解数据处理和存储技术的多样性。
- 它提供了对支撑这些技术的基本原理的深入了解,使您能够对应用程序的架构做出明智的决策。
- 您将学习如何理解不同数据处理模式之间的权衡,以及如何平衡可扩展性、一致性和性能的需求。
- 这本书深入探讨了现代数据密集型应用程序的分布式系统研究。
- 它提供了主要在线服务的真实例子,以说明这些原则在实践中的应用。
如果你正在研究数据密集型应用程序,这本书是了解这个不断发展的领域的挑战和机遇的宝贵资源。
可持续软件架构
Sustainable Software Architecture
分析和减少技术债务
作者:Carola Lilienthal博士
今天的软件开发主要是维护和重构遗留系统。本书就如何重构单片系统、应用架构和设计模式、使用分层架构以及采用领域驱动的设计和微服务提供了实用建议。

Sustainable Software Architecture
作者Carola Lilienthal在重构300多个软件系统方面拥有丰富的经验。这本书借鉴了她的专业知识,并提供了真实世界的例子来说明她的建议。
这本书以200多幅彩色图像为特色,帮助读者将概念形象化,并有效地应用作者的建议。
读者可以通过提供的实用建议和建议,将作者的知识直接应用到日常工作中。
2024年软件架构新书
以下几本有趣的软件架构书籍最终将于2024年出版。
Head First软件架构
Head First Software Architecture
架构思维的学习指南
拉朱·甘地、马克·理查兹和尼尔·福特
Head First软件架构是对软件架构世界的快速而简单的介绍。它教你如何从架构上思考,并探索软件架构的独特挑战。您将通过生动有趣的示例了解架构和设计之间的区别,代码、组件和架构风格之间的关系,以及如何使用一些常见的架构风格。这本书还使用了视觉丰富的格式来吸引你的思维,创造多感官的学习体验。

Head Firrst Software Architecture - A Learner's Guide to Architectural Thinking
为什么这本书不同?
Head First软件架构不同于其他软件架构书籍,因为它基于认知科学和学习理论的最新研究。它使用视觉丰富的形式来吸引你的思维,创造多感官的学习体验。这意味着你将能够比传统的重文本书籍更快、更容易地学习新概念。
谁应该读这本书?
Head First Software Architecture是一本很好的书,适合那些正在寻找快速进入软件架构的软件开发人员。对于任何想了解更多关于软件系统是如何设计和构建的人来说,这也是一本好书。
协同软件设计
如何促进领域建模决策
作者:Evelyn van Kelle、Gien Verschatse和Kenny Baas Schwegler
协作软件设计:如何促进领域建模决策是一本关于如何让所有利益相关者参与软件设计过程的书。它提供了促进富有成效的决策会议的工具和技术,即使在与不同的商业和技术利益相关者群体打交道时也是如此。

Collaborative Software Design
本书涵盖以下主题:
- 使用商业模型画布、事件风暴、示例映射和Wardley映射等工具准备和促进协作建模会话
- 启发式方法在建模软件设计中的选择与应用
- 结构化、可视化和制定可持续的软件设计决策
- 从团队中获得所有所需见解的最佳实践
- 应对阻力
- 在建模课程中提高对偏见和排名的认识
- 建模会话后跟进的最佳实践
- 记录会议并向利益相关者报告
这本书强调了协同建模在软件设计中的重要性。协作建模是一种将利益相关者直接纳入决策过程的高效方法。它使用流程可视化、参与式会议和社会动态管理来确保每个人都在为共同的目标做出贡献。
这本书还就如何克服协作软件设计中的常见挑战,如阻力、偏见和冲突,提供了实用的建议。
促进软件架构
Facilitating Software Architecture
授权团队做出架构决策
Andrew Harmel Law
由于复杂的系统和分布式团队,传统的软件架构师角色变得不那么有效。架构师和开发人员需要一种新的方法来在系统架构上进行有效的协作。本书提供了一种将软件架构和开发结合在一起的方法论。

这本书涵盖了理解现代软件交付动态,培养决策,以及创建一种适合组织文化的方法。它还指导识别和预防故障模式。
构建多租户SaaS架构
Building Multi-Tenant SaaS Architectures
使用AWS的原则、实践和模式
Tod Golding
本书全面概述了SaaS架构和开发,重点介绍了构建多租户SaaS应用程序的挑战。作者Tod Golding是AWS的全球SaaS领导者,他带来了丰富的经验。

Building Multi-Tenant SaaS Architectures
这本书涵盖了广泛的主题,包括:
- SaaS架构模式和策略的前景
- SaaS环境的移动部分
- 通过真实世界SaaS解决方案的视角构建多租户
- 多租户微服务
- 支持一系列工作负载和租户体验的设计和架构策略
- 构建强健的多租户SaaS产品的基本原则
- SaaS架构模式,包括租户隔离、嘈杂的邻居、分层、入职、身份和数据分区
这本书是以实用的风格写成的,面向希望了解更多关于如何设计和构建强大SaaS解决方案的SaaS构建者和架构师。
总之,这本书对于任何认真构建SaaS应用程序的人来说都是必读之作。它以全面和实际的方式涵盖了所有重要的主题。
- 804 次浏览
【软件架构】架构与设计InfoQ趋势报告 - 2019年1月
关键要点
- 我们看到了对“进化架构”设计的更多需求,这种架构建立在先前关于可替换性设计和需要关注架构中“胶水”组件的讨论的基础之上。进化架构支持功能和跨功能需求和约束的未来变化。
- 对“微服务”架构风格的认识可能正在进入后期多数,但“正确设计分布式系统”的相关主题,以及反应性和容错性的设计并未沿着采用曲线进行。
- 我们推测,有些架构主题永远不会沿着采用曲线转移到早期多数或晚期多数,不幸的是,它们包括几种针对特定用例的高效模式,如基于事件溯源/ CQRS或基于Actor模型系统。
- 我们越来越多地将“架构师”的角色视为越来越注重技术领导力,架构模式识别和框架意识,以及处理跨领域问题的设计。
- 虽然我们认为术语“无服务器”可能含糊不清,但我们很欣赏有可能将重点放在设计事件驱动系统以及自动消除某些平台问题的可能性上,如果这是正确实现的
InfoQ和QCon都关注我们认为属于“创新者,早期采用者和早期多数阶段”的主题。我们尝试做的是确定适合Geoffrey Moore所谓的早期市场的想法,其中“客户群由技术爱好者和有远见的人提供,他们希望领先于机遇或迫在眉睫的问题”。我们也在寻找可能“跨越鸿沟”的想法,以便更广泛地采用。在这种情况下,或许值得一提的是,技术在采用曲线上的确切位置可能会有所不同。例如,湾区公司在这一点上广泛采用微服务,但在其他地方可能不太广泛采用,也许不太合适。
本文概述了我们目前如何看待“架构和设计”(A&D)领域,该领域侧重于基础架构模式,技术框架中模式的实现,以及软件架构师必须培养的设计流程和技能。
自我们上次审查这一主题以来的显着变化包括“微服务”进入后期多数,但我们的内部讨论还强调,“正确设计分布式系统”的密切相关的主题,以及反应性和容错性的设计并不是沿着采用曲线。对于Gartner炒作周期,我们可能正在接近微服务“幻灭的低谷”的底部。
我们还推测,架构领域永远不会沿着采用曲线走向早期多数或晚期多数,不幸的是,它们包括几种高效模式 - 例如基于事件溯源/ CQRS或Actor 模型 - 基于系统 - 可以为某些组织和业务问题提供高效的解决方案。
虽然我们认为“无服务器”一词略显模糊,但我们很欣赏将重点放在设计模块化,事件驱动系统以及自动化几个底层操作平台问题的可能性上。在一个相关主题上,我们还看到围绕对支持未来需求和约束变化的演化架构的需求的更多讨论。
我们越来越多地看到“架构师”的角色正在变得更加专注于软技能,例如技术领导,除了现代技术技能,如架构模式识别和框架感知,以及处理跨领域问题的设计。
对于上下文,这是2018年下半年主题图的样子.2019版本位于文章的顶部。

以下是三个InfoQ架构和设计主题编辑之间相应内部聊天记录的轻微编辑副本,它为我们在采用图上的推荐定位提供了更多上下文。
Daniel Bryant,独立技术顾问,Datawire产品架构师和InfoQ新闻经理:
作为十人的首发,我认为HTTP2转向早期采用者(EA),HTTP3进入创新者。 GraphQL(以及可能的gRPC)可能是EA(或创新者?)。我也认为Chaos Engineer属于DevOps队列。微服务可能是晚期多数(LM),BDD,DDD和TDD也是如此。
我很想看到“进化架构”出现在某个地方 - 可能是EA?那么“架构师作为技术领导者”(强调角色的非技术演变)呢?
我有兴趣听听您的想法,并询问我们是否需要移动,添加或删除主题?
Jan Stenberg,IT顾问,在.Net / C#和JVM / Java平台上构建系统超过25年:
我认为架构与设计(AD)在某种程度上与我们在InfoQ上讨论的其他主题不同。
在AD中,我们没有新的或更新版本的架构的常规基础。相反,由于新的工具,框架或智能架构使其成为可行,现有的想法再次流行,并且可能打包和品牌化。
我们也有可能适合两个队列的区域。在更高级别,它们可能适用于AD,而更多技术部分适用于另一个队列。我认为无服务器就是一个例子,在更高层次上它是AD的一个重要领域,技术部分可能属于云队列。微前端和类似技术是另一个例子,它是AD还是HTML5和JavaScript?
还有一些我认为永远不会在EM或LM中出现的领域或架构,不幸的是,它们包括我最喜欢的几种架构,如基于事件源/ CQRS或基于Actor模型的系统。我认为他们在可预见的未来将是少数人使用的小众架构。我不确定我们应该如何应对这些问题,也许它们会在架构师和开发人员不再谈论它们时消失?
所以,我对AD未来的看法(或许我的希望):
- 无服务器。从我去年听过的演讲中,我的印象是,这将越来越自动化,对底层基础架构的工作量减少。
- 像Camunda这样的工作流程平台。我认为它们在具有更复杂业务逻辑的微服务或分布式系统中非常重要。
- 事件溯源/ CQRS。我希望它会变得更加主流。可能是EA或EM。
- 事件驱动的体系结构。 EA或EM。
- Actor 模特/反应。去年我和Vaughn Vernon讨论了这件事,他相信有一天它会成为主流,但我对此持怀疑态度。
- 进化架构很有趣,我认为EA是正确的。
- 混沌工程。是的,通常它是DevOps,从AD角度讨论主题的演示可能是一个例外。
- GraphQL和类似的工具是I或EA我认为,取代REST(希望也正确实现)。
- 架构师为技术领导者。我一直在与家里的各种架构师会面,其中许多人的主要工作是让商业/政府领域专家了解他们自己的领域。但也许它更像是一个敏捷队列故事?
- 微服务是LM。 (我认为微服务很快将成为“今天的SOA”。许多人正在以一种好的方式使用它们。太多人将标签放在分布式整体上)。
- DDD是晚期的多数,但我希望它仍然是InfoQ的一个有趣的主题。
- BDD是迟到的多数或相当“迟到的少数民族”
- TDD仍然有一些或多或少有趣的讨论。太少或太多,单元测试或黑盒测试,Ice-cream cone 或什么,但LM,至少。
当我在日常生活中遇到架构师,开发人员,领域专家和其他人,而不是在会议和类似的活动中,我经常意识到我们在这里讨论的许多概念对于他们来说是未知的或非常分散的,这也使得他们看到了InfoQ的好处。我记得大约两年前我在开发者大会(我认为是在加拿大)听过的一个演讲,其中Vaughn Vernon询问了多少人对DDD有所了解,大约一半的观众举起了手。
当我开始为InfoQ编写时,我写了一些关于框架和库的更新,我认为这些功能可能会影响架构,但随着时间的推移,我的写作越来越集中在有趣的博客文章和演示文稿上,只有几个项目关于像Axon,Akka和其他我认为与特定架构密切相关的框架。
在QCon会议期间进行这种讨论会很棒。
InfoQ主编Charles Humble:
我和Vaughn Vernon一起关于Actor 模特 - 并认为它很可能成为主流 - 直接或通过消息传递等方式。在JVM领域,Akka在推广这种方法方面做得很好,基于消息传递的系统长期以来一直是在金融系统中像Actor 一样做事的流行方式。
Actor 似乎很容易被人们掌握和推理,也是处理大规模并行工作的好方法。我希望看到Ponyas周围的势头成为一个现代的,基于Actor 的系统的例子,但我不得不说我认为这不太可能。
关于进化架构,我有兴趣听到马丁福勒去年在播客上谈到这个问题,并且他参加了极端编程。我很期待阅读这本关于Thoughtworks的书。
Thomas Betts,IHS Markit首席软件工程师和InfoQ Architecture Queue负责人:
在很高的层面上,我同意丹尼尔提出的大部分内容。 Jan是正确的,一些架构模式非常适合主题图的自然进展,而其他架构模式可能永远不会超越早期采用者阶段,因为它们不是广泛适用的。
我有时会对A&D与InfoQ上的其他主题之间的重叠感到困惑,尤其是文化与方法。我想是责怪康威定律。关于架构的很多内容都归结为通信 - 进入和离开系统的外部通信点是什么?我的内部服务将如何相互通信?如何保存和访问我的数据?
在许多方面,公司回答这些问题的方式以及他们可以选择的选项将基于他们在A&D和C&M的采用生命周期曲线上的位置。我想说A&D是等式的技术方面,而C&M是非技术性的,但这似乎过于简单化了。此外,技术实现可能会落入开发和/或语言队列中。 A&D处于两者之间的软弱处,处理交叉问题,希望为如何实施该系统提供指导。
我将停止哲学咆哮,并添加一些具体的讨论要点。
- 无服务器 - 虽然我个人不喜欢这个术语,因为它似乎没有任何特定的含义,无需服务器,可能在EA中。
- 反应性 - 可能是EA。我认为反应式架构会变得更加普遍,因为开发人员熟悉反应式编程,特别是在JavaScript中。那可能是尾巴摇着狗。
- DDD - 虽然DDD本身可能会转向LM,但有许多衍生创意与DDD密切相关,并且在I或EA中。例如,事件溯源值得提及为EA / LM。但是,我不认为很多这些子主题可以包含在AD主题图中。
- 微服务 - 在那里使用“无服务器”作为一个常被滥用或误解的术语。我认为这是在广泛采用方面进入后期多数,但可能只是EA用于稳固的分布式架构。
- 分布式系统 - 我不认为将其作为主题图上的项目是有效的,因为它太宽泛了。但是我想看到我们谈论设计时考虑到分布。像反应性和容错性这样的想法对于强大的分布式系统至关重要,而这种方式在整体结构中并不重要。这将是在A&D主题图上留下混乱的论点。
我完全支持在QCon上进行这次讨论!
InfoQ编辑团队的建立是通过招聘和培训专家从业者来撰写新闻和文章,并分析当前和未来的趋势。通过编辑页面申请成为编辑,并参与对话。
原文:https://www.infoq.com/articles/architecture-trends-2019
讨论:知识星球【数字化和智能转型】
- 215 次浏览
【软件架构】软件工程师和架构师的平面设计
视频号
微信公众号
知识星球
如果你在软件工程或技术领域工作,你可能会看到这样的图表:
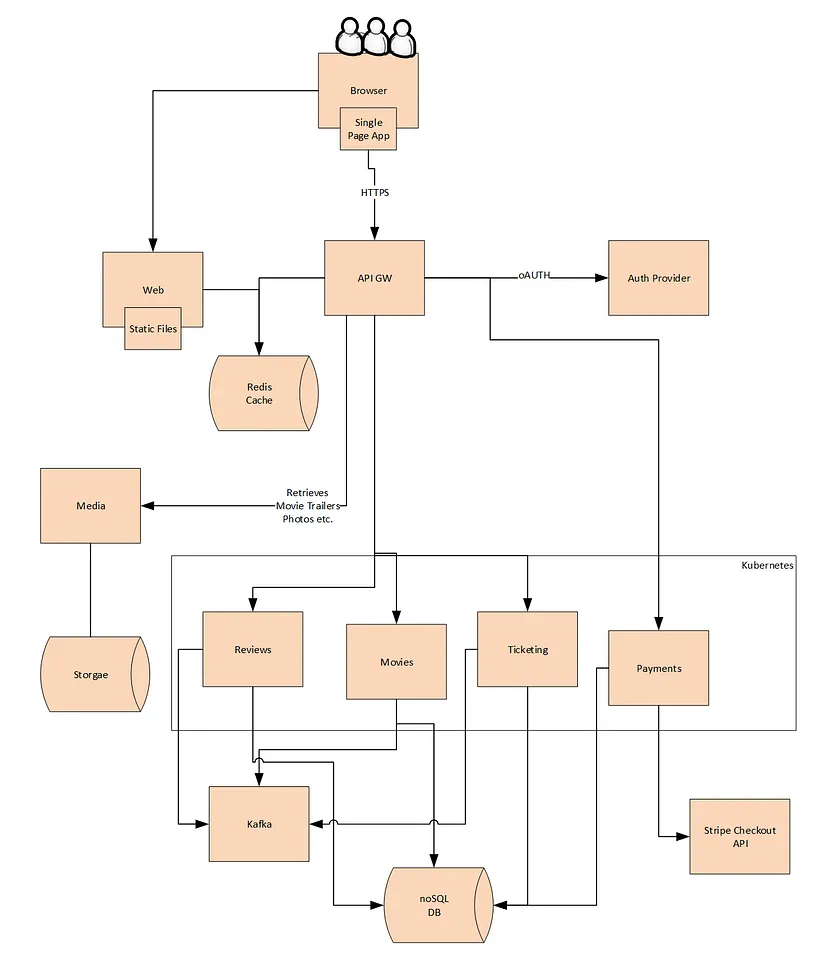
你可能是这样一张图表的作者,却没有发现任何错误。一切都在那里——服务、箭头、一些协议信息等等。你很理解它,因为你画了它,但你的观众,他们看到的是一个由纠缠的箭头组成的鸟巢里的十几个米色盒子。让我们把你的图表和你的代码一样干净,并把它们变成这样:
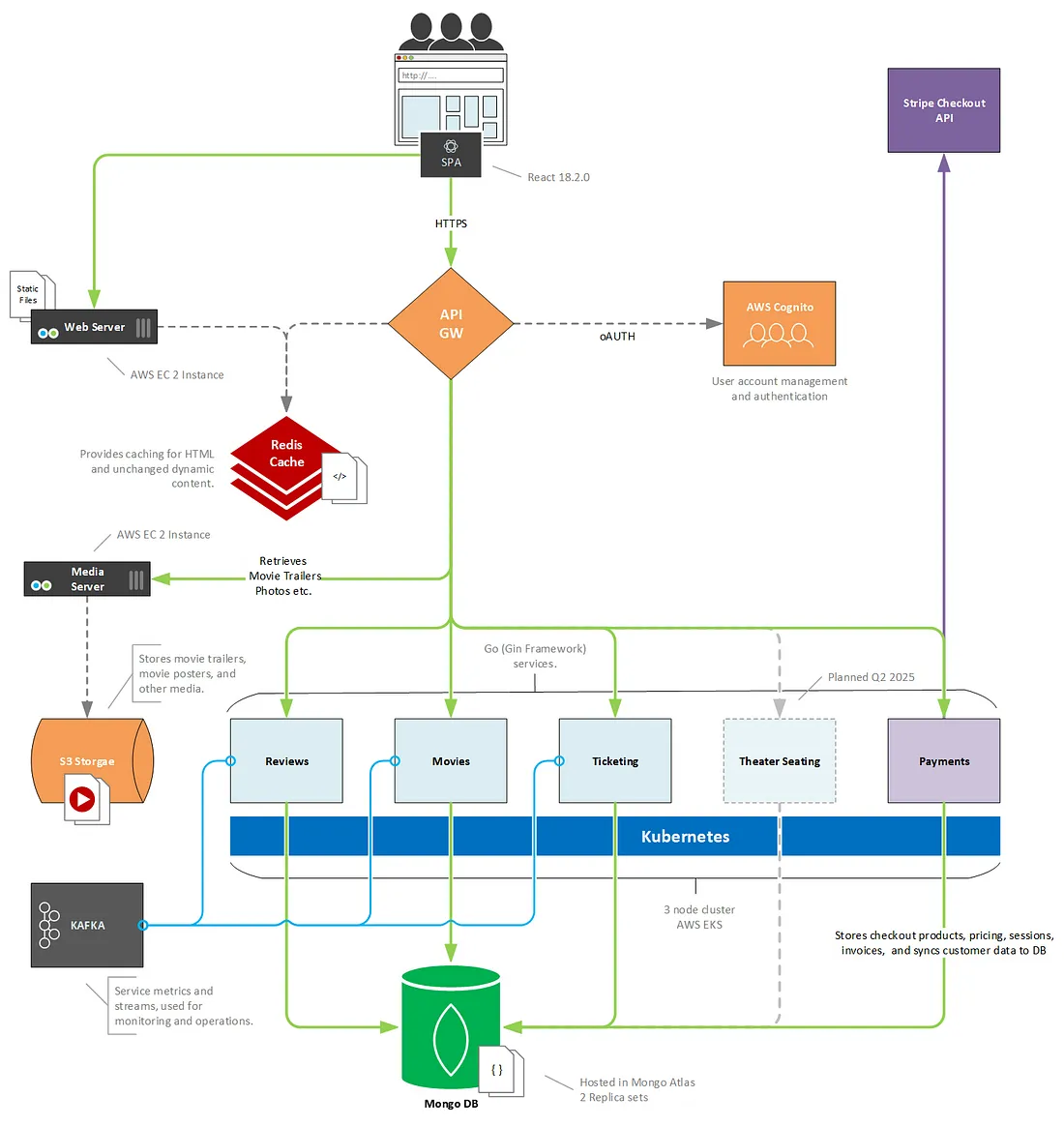
为什么平面设计在软件设计中很重要
“一张照片胜过1000个字”这句古老的谚语在今天仍然适用,尤其是在技术环境中。作为一名软件工程师或架构师,你的职责是有效地将技术解决方案传达给其他工程师、领导层、客户等。你在图表中传达的信息越多,就越不需要用语言来解释。
不是写或说,
浏览器向APIGW发出请求,然后APIGW将请求代理到一个或多个后端服务
为什么不把它想象出来呢?
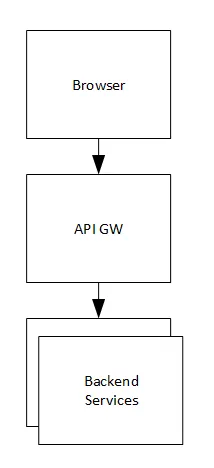
图表还说明了最终解决方案,包括所有涉及的组件,即“大局”
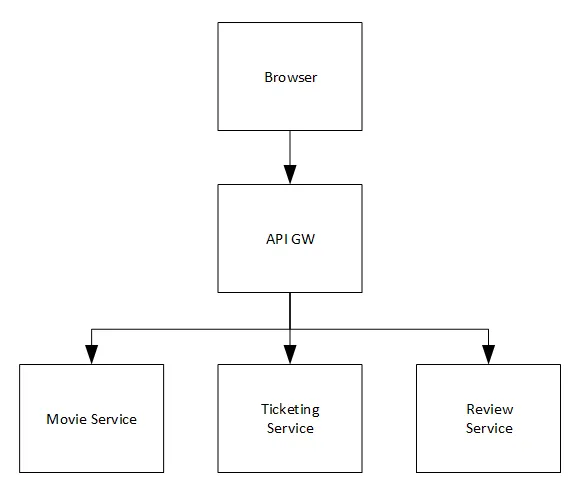
最重要的是,它可以给你的解决方案带来“感知质量”。换句话说,如果它看起来不错,人们会认为它很好,即使这是一个坏主意。
什么是糟糕的设计?
再看第一张图,不讨人喜欢的方面,即设计的“坏”部分是:
- 注意力不集中。所有元素都使用默认的颜色、线条等。
- 混乱的线路。图中的线条需要努力。
- 没有明确的关系。哪些组件是相似的,哪些显然是独特的?
- 没有畅通的水流。通过体系结构的主要流程是什么,次要流程是什么等等。?
创建更好的图表
让我们接受这个糟糕的设计,并将其构建到最终结果中,发现在工作中关心设计和视觉交流的更多好处。
对齐和组合
制作一个糟糕的图表并使其变得更好的第一步是清理对齐和组合。尽最大努力将元素彼此对齐,并通过“解开”图表来消除不必要的线交叉。
以下是将这些更改应用于全局时的情况:
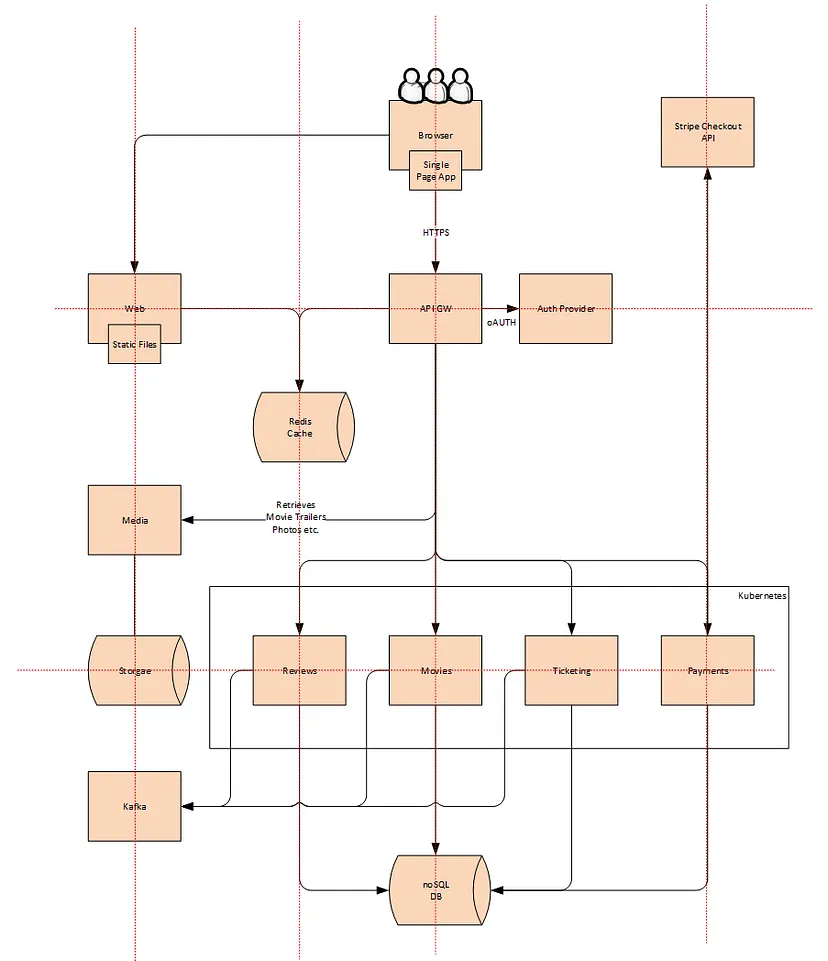
颜色和意义
颜色是图表的一个重要方面。它可以传达组件之间的关系,“统一”,或者表示某些组件是唯一的。
此外,我总是努力使图表的方框或组件与它所代表的技术或公司的颜色相同。
Redis是红色的,容器是蓝色的。我给盒子上色,你也应该。

以下是将颜色应用于大图的效果:
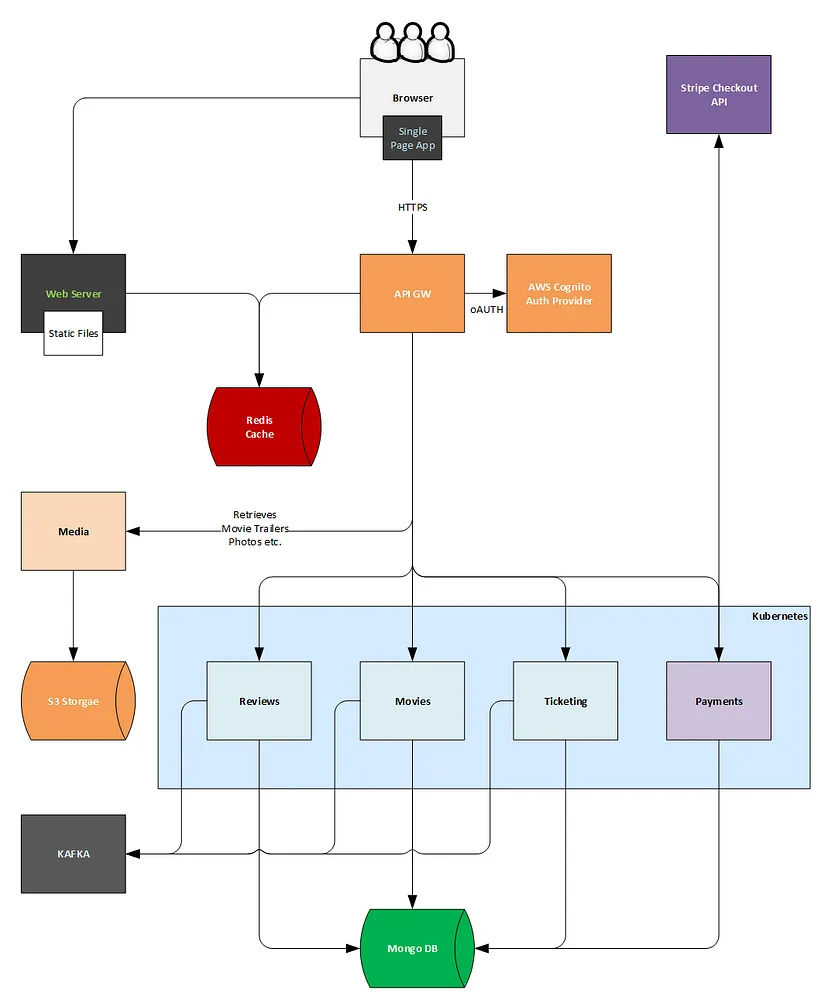
有效地使用形状
形状也起着至关重要的作用,就像颜色一样。它们可以统一或隔离设计中的某些组件。同样重要的是,不要通过引入混合风格来降低您的设计。
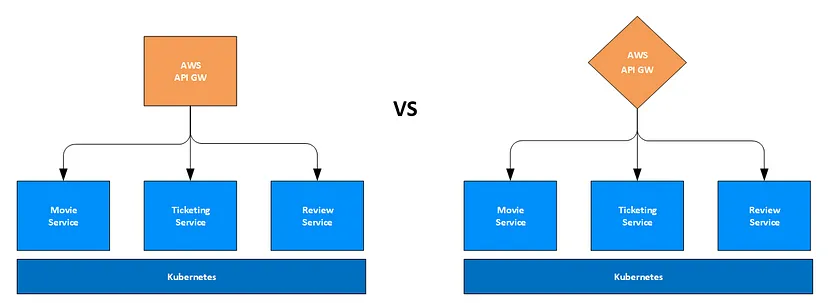
如果你的设计非常“扁平”,在Viso中挖掘出旧的用户图标可能看起来很诱人,但如果你找到一个更适合你的图表,那就更好了。

以下是如何将有效的形状应用于全局:
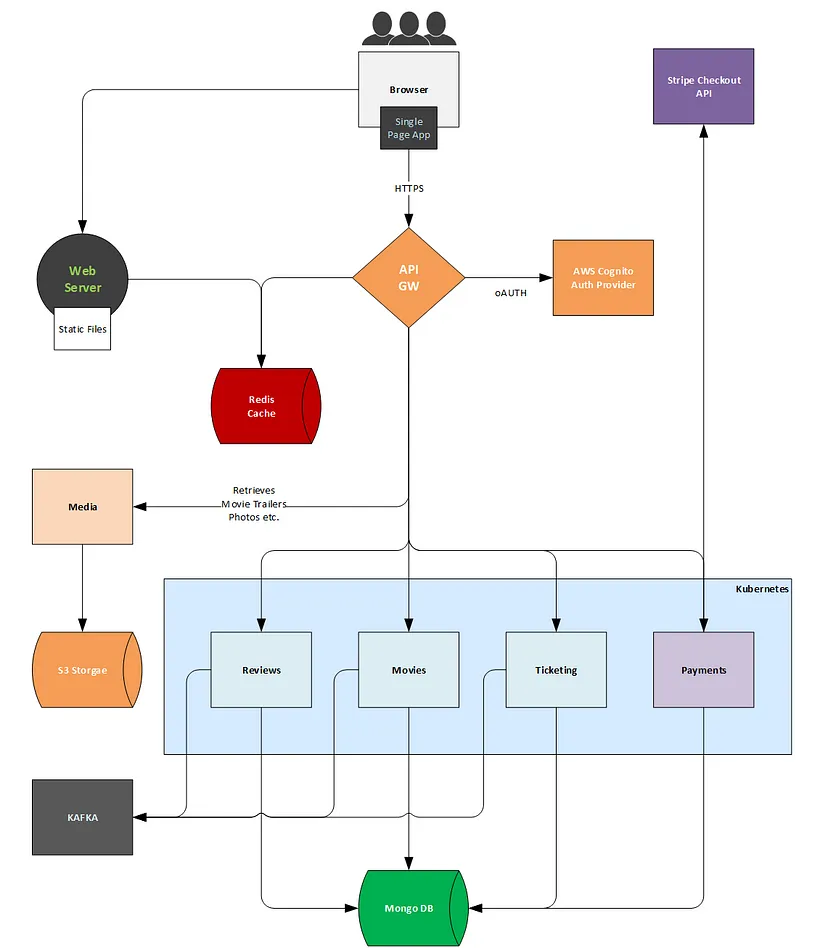
视觉流动,引导眼球
如果您的关系图很复杂并且有很多交互,那么应该始终突出显示主要流或主流。它通常源于客户或最终用户,并终止于他们想要的东西,例如数据。
使用更大胆、更生动的线条将向观众显示您想要突出显示解决方案中的主要流程。以下是在主站点和辅助站点之间进行平衡的负载平衡器示例:
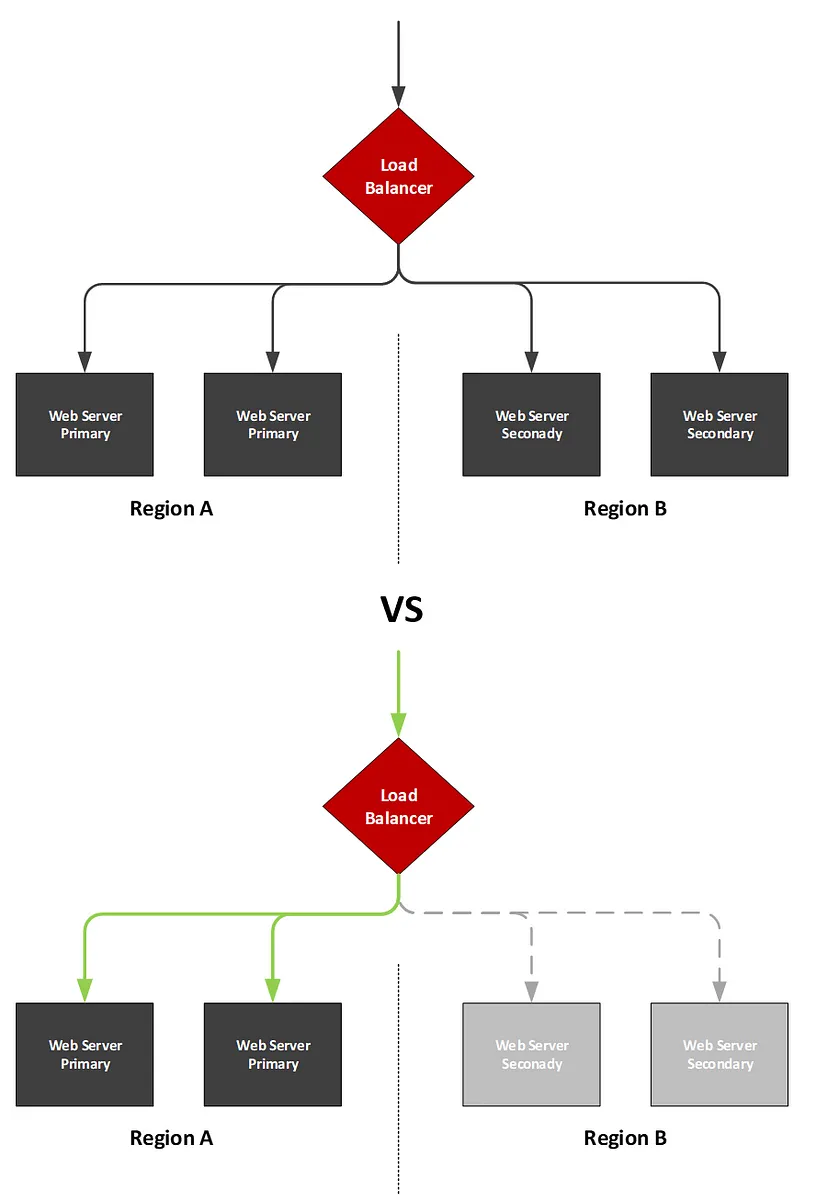
这就是当你把它应用到全局时的样子:
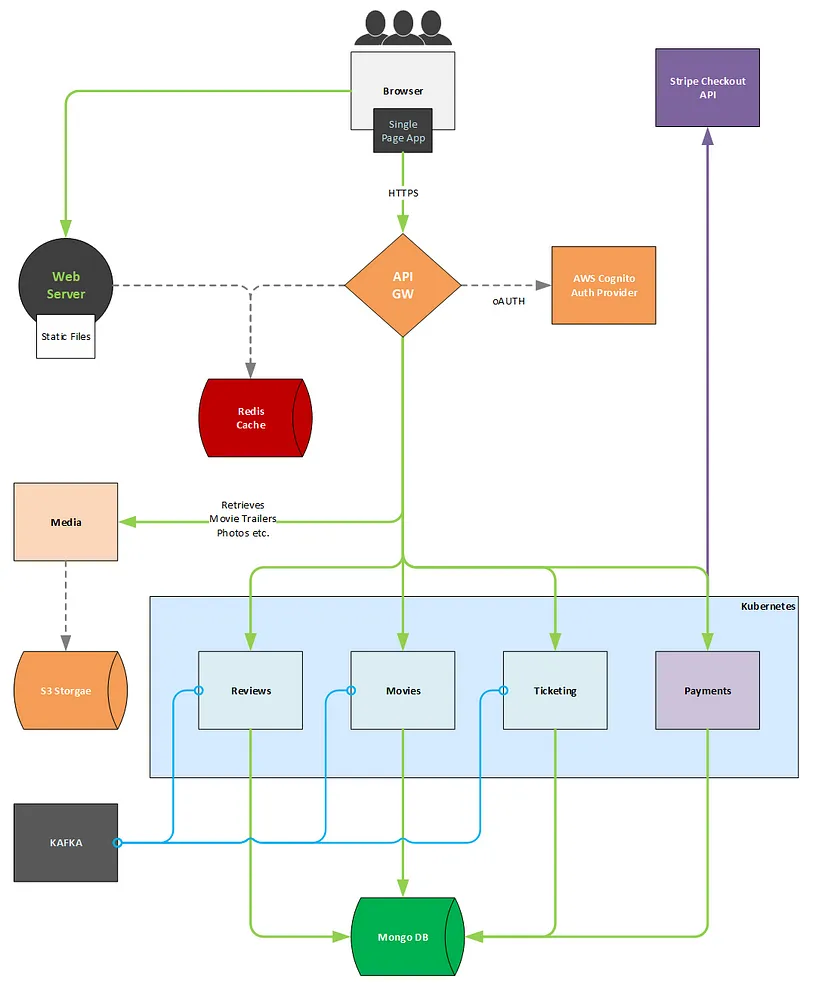
设计中的怀疑论
(使其与所代表的事物相似)
skeumorphism是一种巧妙的设计技术,为用户或观众提供熟悉感。一个典型的例子是当你在iPhone上打开记事本应用程序时;它看起来像一个你熟悉的记事本。
您可以通过将方框转换为更真实的/概念性的表示来传达设计中的熟悉感。
例如,如果它是一台服务器,那么让它看起来像一台服务器。如果是Kubernetes,那么,Kubernete是一个开发人员将容器“部署到”上的平台,所以一个带有正方形的平表可以帮助传达这一点。
以下是skeomorphism应用于更大图片时的外观:

构建自己的形状
通常,你在一个非常基本的应用程序中工作,如PowerPoint、Viso、Gify等。这些程序可能没有你想要的东西,或者如果它们有,它就不符合你的风格。
您可以使用基本形状轻松创建自己的形状和图标。
代表计划和未来状态
随着时间的推移,您的解决方案可能会在演示之间发生变化。您可能希望在图表中添加新的组件或更改,但重要的是要确保这些尚不存在的新项目或组件能够很好地可视化表示。以下是几种方法:
- 使用虚线表示流动,使用造型线表示尚未构建的事物。
- 避免将新服务着色为与现有服务相同的颜色。使用稍微浅一点的阴影。
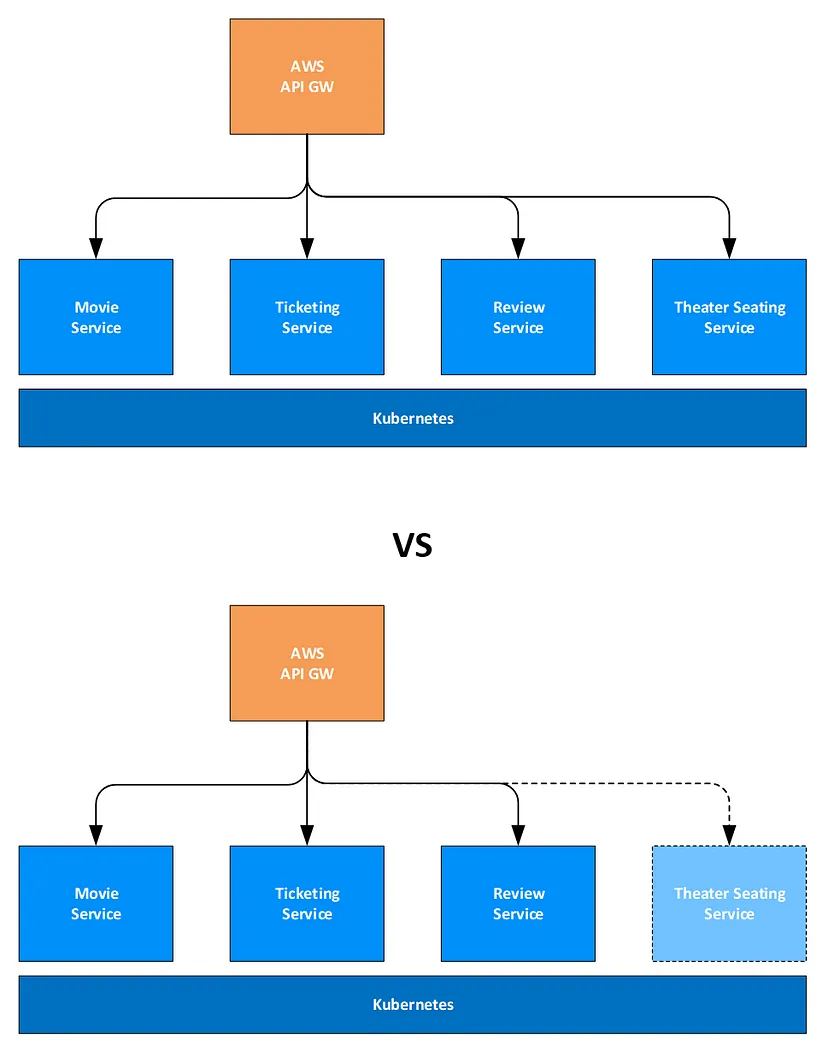
让我们将此新组件添加到现有解决方案中:
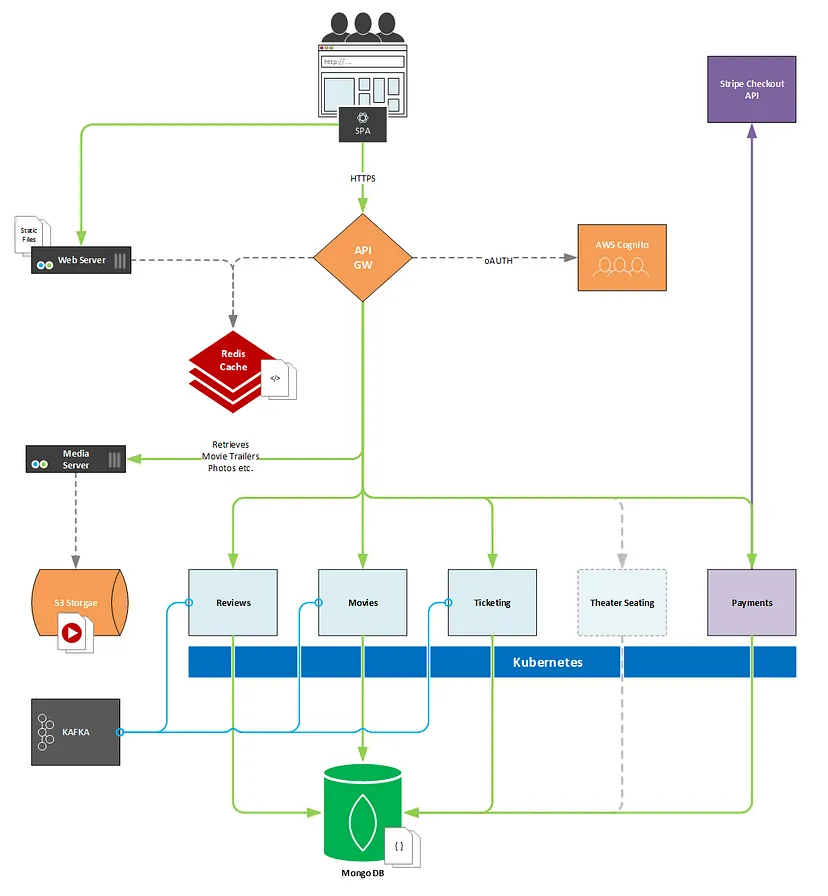
强制聚焦
当你想迫使你的听众专注于你的解决方案的特定部分时,你可以把除了你的焦点之外的一切都模糊掉。
这在做演示时非常棒。你展示了解决方案,点击下一张幻灯片,然后突出显示一些非常具体的东西,这样你的注意力就不会集中在哪里了。一旦谈论完它,你就可以“重新打开颜色”,并显示一个正常的图表。
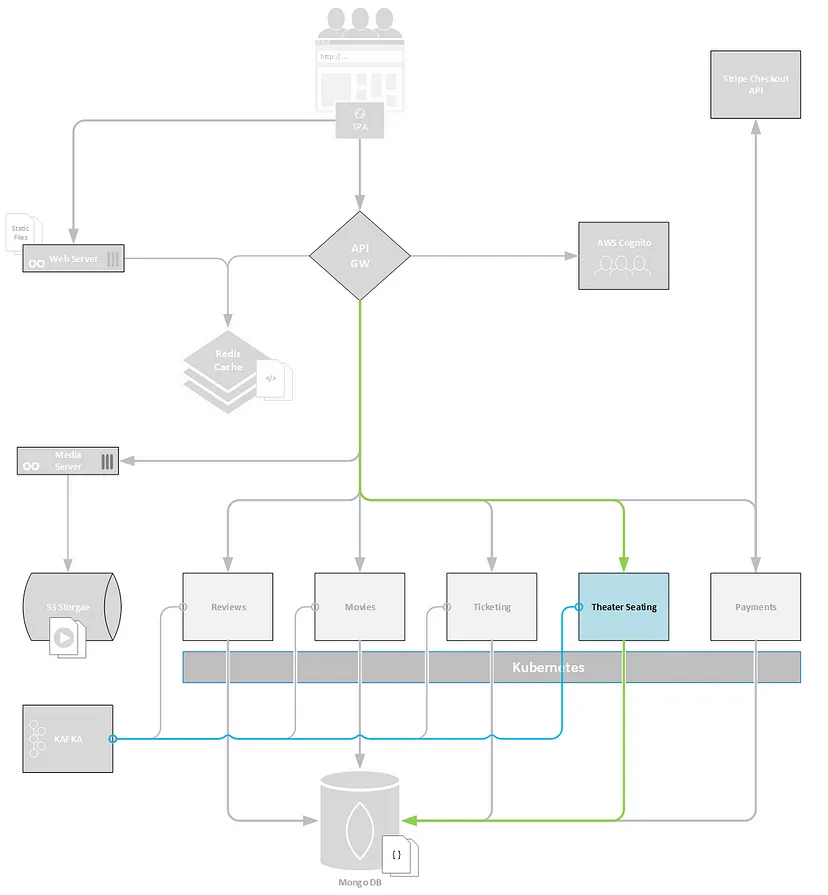
注释和注释
评论和注释可以在视觉效果的同时提供另一层细节。添加额外但微妙的信息可以让你的图表为你做更多的对话。它还可以让你的观众在想深入了解的情况下深入了解,或者在不需要这种信息的情况下完全忽略他们。
评论和注释不应为纯黑色;最好使用中灰色或一些微妙的颜色,以免引起太多注意。
以下是如何应用它们:
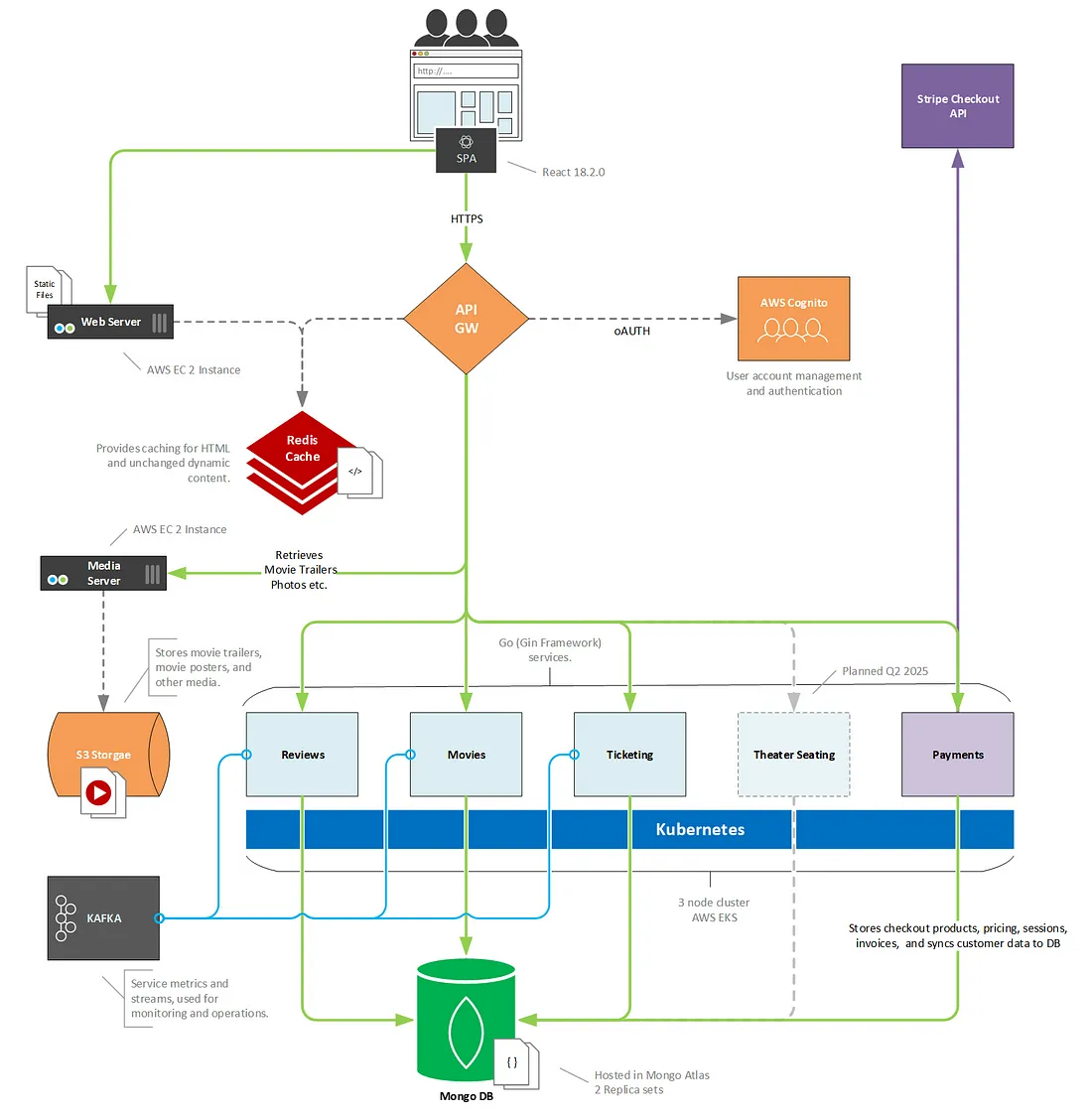
将工作努力与图表联系起来
我们经常采用一个完整的设计,并在一些敏捷过程中从中创建Epic、Features和Stories。作为一名首席工程师,我喜欢走得更远,通过圈出关键部分并用Epic、Feature或Story标记它们,将敏捷带回图表中。
这样做可以清楚地了解哪些工作与解决方案的哪个部分相关,作为领导者,我可以很容易地将图表“分割”为其他开发人员的工作。
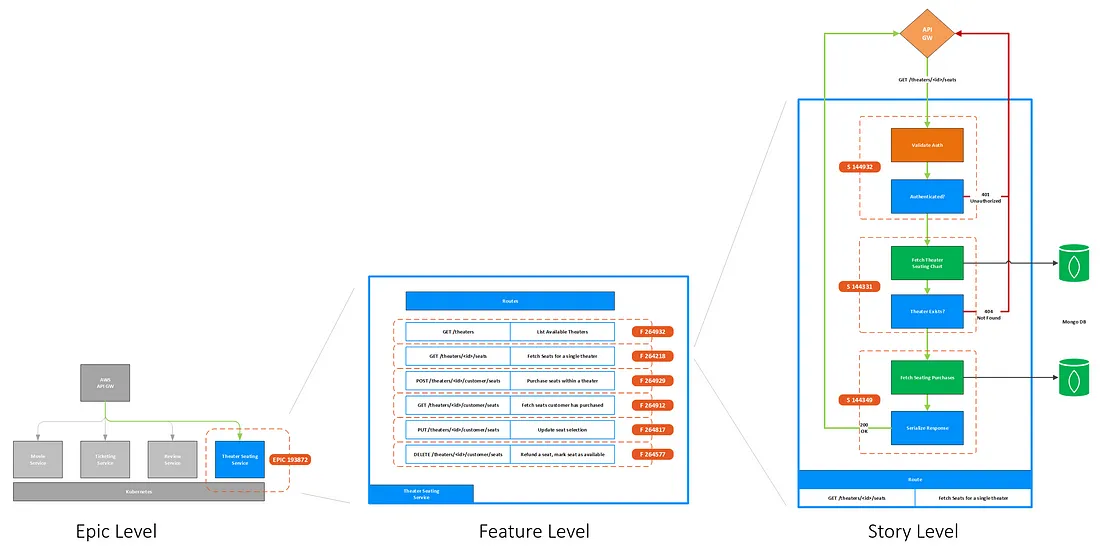
更多设计技巧
以下是其他设计技巧,可供您将其纳入图表中:
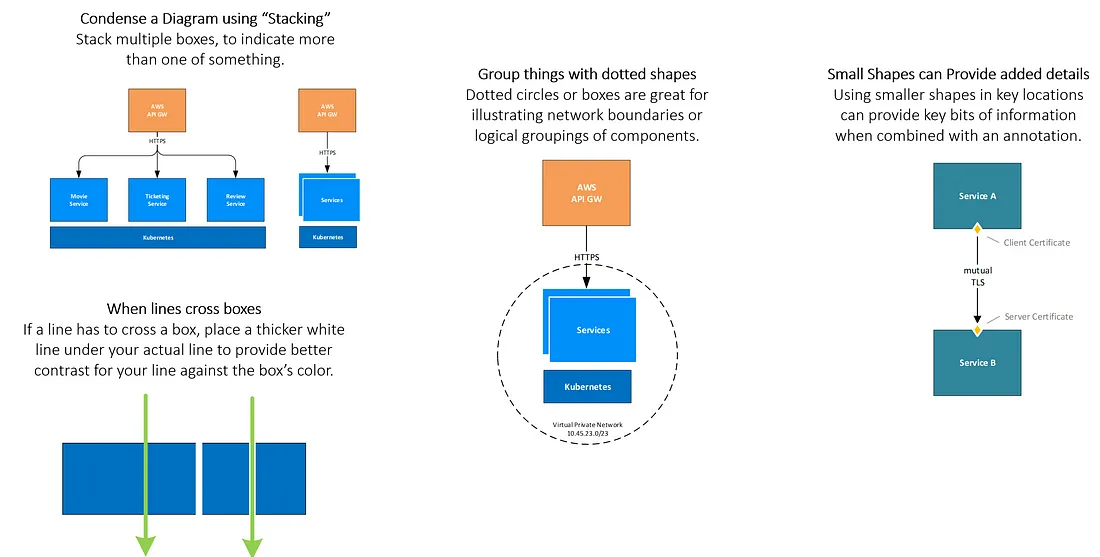
Different diagram types I use
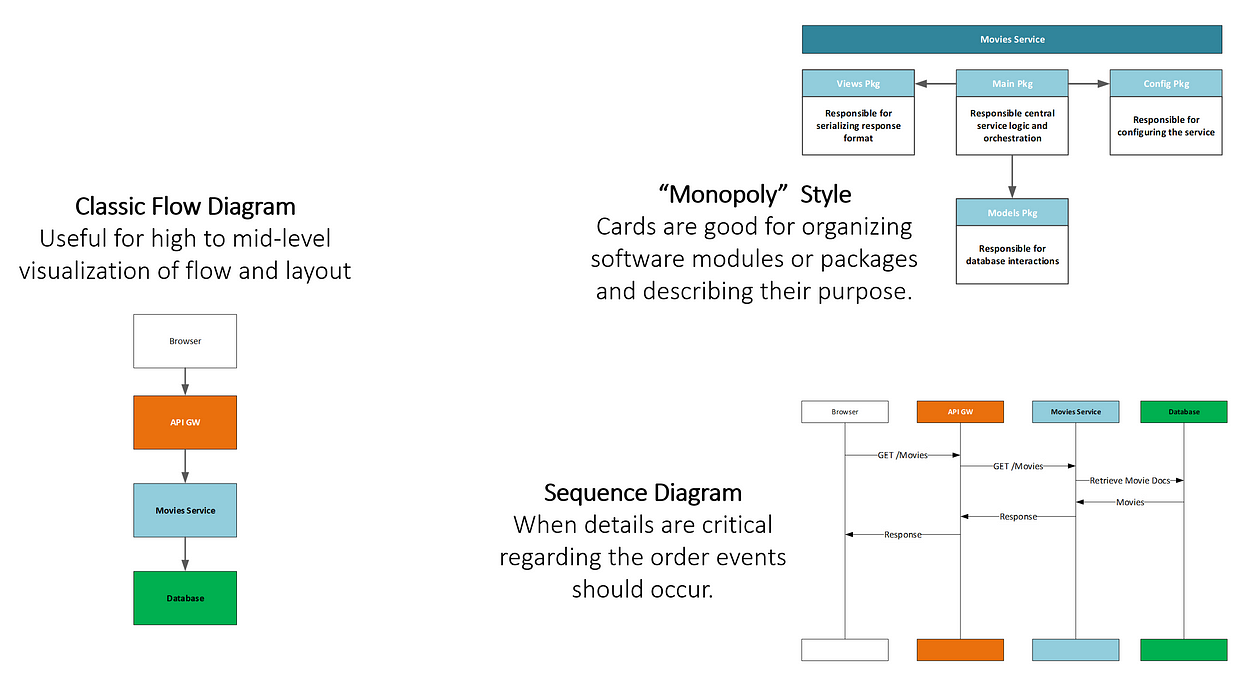
结论
我希望你已经学会了一些方法,让你的下一个设计在向同事、同事或领导层展示时脱颖而出。
设计可以传达质量、对细节的关注以及其他积极的属性,你甚至在拿起代码编辑器之前就希望你的软件与之相关。
最后,使用设计将敏捷过程重新引入到图表中,可以让你消除困惑,在规划会议中找到差距,让你的开发人员有信心理解他们的工作在“大局”中的位置
- 125 次浏览
【软件架构】软件架构和设计 InfoQ 趋势报告—2021 年 4 月
关键要点
- 在云原生世界中,架构师正在重新确定他们认为最重要的事项的优先级。创新的架构师正在设计弹性、可观察性、可移植性和可持续性。
- Dapr 和开放应用程序模型是使构建分布式系统更容易的两种方法,观察它们在未来如何被采用将会很有趣。
- 在单体应用和微服务之间摇摆到极端之后,钟摆似乎要停止了。因此,无论底层技术如何,架构师都依赖于专注于高内聚和低耦合的成熟模式和设计。
- 在完全远程的工作环境中,架构师正在寻找与团队沟通的新方式,并寻找有助于收集知识的饮水机聊天的替代品。
- 下一代 GraphQL 功能,尤其是 GraphQL 联合和 GraphQL 微服务,正在展示公司大力采用 GraphQL 之后的下一步发展方向。
/filters:no_upscale()/articles/architecture-trends-2021/en/resources/1Architecture-2021-1618415938711.jpg)
每年,InfoQ 的编辑都会讨论软件架构和设计的当前状态,并确定需要关注的关键趋势,从而产生这份报告和随附的图表。今年,我们让您在 InfoQ 播客的一集中收听讨论。 IBM 企业战略团队的创新领导者 Holly Cummins 和 QCon 的前任发言人也加入了编辑的行列。
为___设计
我们首先看看哪些“-ilities”对架构师来说最重要。软件架构师负责横切关注点,并确保大型系统的各个组件可以无缝协作以实现总体目标。在 2021 年,我们认为架构师关注的四个领域是弹性设计、可观察性设计、可移植性设计和可持续性设计。
弹性设计对于现代分布式系统至关重要,其中任何单个组件都可能出现故障,而整个系统应保持可用。在许多方面,正在实施的想法并不新鲜——随着分布式系统和模块化架构越来越普遍,它变得越来越重要。 Daniel Bryant 提到了 David Parnas 在 1970 年代所做的工作,以及 Michael Nygard 最近的著作《Release It!》,作为有关断路器、超时、重试和弹性系统的其他基本要求的想法的良好来源。新的是寻找跨系统解决这些问题的方法,例如使用云原生服务网格,甚至在 Dapr 等框架上构建。
在采用曲线的下方,异步编程技术和事件驱动架构的采用一直在稳步增长。这种采用是实现异步模式的较低准入门槛和提高系统弹性的内置优势的结果。
然而,事件驱动架构和异步系统的另一面,一般来说,它们仍然难以推理和理解。这与可观察性设计的兴起有关。很多时候,可观察性被视为一种运行时需求——我们能否判断系统是否按预期运行?但是,对于架构师来说,可观察性作为设计时的需求变得越来越重要——我们能理解复杂系统中发生的所有交互吗?
2021 年,创新者正在寻找几乎自动提供运行时和设计时可观察性优势的方法。通过消除开发人员必须手动实现可观察性非功能性需求的负担,系统大图中缺少关键组件的可能性变得更小。这将导致能够使用可观察性来创建准确的、生动的架构图,以及相应的系统心智模型。
架构师的另一个重点领域是设计可移植性,无论是多云还是混合云。在大多数情况下,架构师没有理由为实现真正的多云可移植性或避免供应商锁定而设计最低公分母。然而,尤其是在企业收购时,CTO 更有可能拥有在不同的托管环境中运行的系统,包括 AWS、Azure、GCP 和本地。在做出有关标准化的决策时,架构师需要选择他们的战斗。
Holly Cummins 谈到了可持续设计的主题,这是新的创新趋势之一。这种情况正在出现,因为人们意识到软件行业的碳使用水平与航空业相当。其中一些几乎可以直接衡量,因为计算使用的账单与能源消耗高度相关。 CTO 和架构师可以通过减少不必要的计算使用或利用更可持续的云托管选项来产生影响。一些云数据中心使用 100% 的绿色能源运行,而弗吉尼亚州的数据中心则使用煤炭供电。如果延迟不是问题,那么在冰岛而不是弗吉尼亚举办可能是有意义的。虽然许多公司纯粹出于经济原因希望降低托管成本,但有些公司选择将可持续性作为优先事项,并相应地构建和部署他们的系统。
正确构建的分布式系统
微服务的主题在趋势图中稳步移动,并且在一段时间内被归类为晚期主流趋势,因为构建分布式系统变得更加容易。然而,我们继续看到一些反对过度使用微服务作为解决所有问题的尝试。在某些情况下,这导致了重大逆转,例如回到单体应用。随着钟摆停止摆动,似乎我们终于为大多数系统设置了一种理智的方法。
围绕构建分布式系统或模块化单体的一些趋势都回到了基本的架构原则,例如高内聚和低耦合。领域驱动设计虽然被认为是一种晚期主流趋势,但仍然受到寻求上下文映射和识别系统边界的良好指导的架构师的重视。同样,C4 模型对于创建分层架构图集以帮助理解您的系统非常有用。
数据架构
InfoQ 继续在软件架构和数据架构之间的重叠中看到创新。去年添加到图表中的数据网格今年仍然是创新趋势。它由数据网关加入,这有点像 API 网关,但专注于数据方面。由于微服务导致了多语言持久层,API 网关提供抽象、安全、扩展、联合和合同驱动的开发功能。
架构师的角色
我们将继续关注软件架构师在其组织中所扮演的角色。除了传统的“盒子和箭头”职责之外,架构师还担任其他团队成员的技术领导和导师。架构师还需要能够与许多观众进行交流,Gregor Hohpe 将其描述为乘坐架构师电梯——与 CTO 和其他高管交谈,然后前往机房与开发人员一起工作。
对于许多团队来说,由于大流行以及许多公司采用了长期的远程工作策略,沟通方式被打乱了。这意味着架构师失去了通过渗透学习的能力,仅仅是因为他们可以和开发人员坐在同一个房间里偷听对话。在这有帮助的地方,它导致了更多的书面交流,无论是在 IM 聊天室,还是在架构决策记录中,并保持最新,因为团队经常引用它们。领先的架构师正在寻找方法来利用完全远程团队的限制来发挥自己的优势,并因此创建更好的软件设计。
其他主题
Dapr 和开放应用程序模型 (OAM) 都是微软在 2019 年底推出的。OAM 是一种用于定义云原生应用程序的规范,专注于应用程序,而不是容器或编排器。同样,Dapr 是一个具有可插拔组件的框架,旨在简化云原生开发。尽管微软参与了他们的创建,但两者都是开源项目,可以在任何云提供商上工作,而且 Dapr 可能会成为 CNCF 项目。 Dapr 和 OAM 都还没有被大规模采用,因此显然是值得关注的创新趋势。
WebAssembly 是另一个创新趋势。对于架构师来说,看看它是否只是作为 Web 框架和移动开发的补充,或者系统是否会在设计时考虑到 WebAssembly,以及这将如何体现,将会很有趣。
关于 GraphQL 的最后一点,它在去年跨越了趋势图上的鸿沟。从那时起,对于下一代 GraphQL 功能,尤其是 GraphQL 联合和 GraphQL 微服务,出现了创新,特别是在 Netflix。正如微服务造成的蔓延导致了管理这种蔓延的新模式一样,对于在 GraphQL 上投入巨资的公司来说,他们需要 GraphQL 联合来帮助管理新的复杂性。这不是每家公司都会遇到的问题,但了解并了解它在未来的发展方向仍然很有用。
- 41 次浏览
【软件架构】软件架构样式和模式列表
架构模式是一种通用的、可重用的解决方案,用于解决给定上下文中软件架构中常见的问题。架构模式通常被记录为软件设计模式。
架构样式目录
- 三层
- 多层体系结构
- 模型视图控制器
- 领域驱动设计
- 微内核
- 黑板模式
- 传感器控制器执行器
- 表现-抽象-控制
架构风格目录
结构
- 基于组件
- 整体应用
- 分层的
- 管道和过滤器
- 微服务
共享内存
- 以数据库为中心
- 黑板
- 基于规则
消息传递
- 事件驱动 aka隐式调用
- 发布订阅
- 异步消息传递
自适应系统
- 插件
- 微内核
- 反射
- 特定于域的语言
分布式系统
- 客户机服务器(2层、3层、n层展示了这种风格)
- 无共享架构
- 基于空间架构
- 对象请求代理
- 点对点
- 代表性状态转移(REST)
- 面向服务架构
- 云计算模式[2]
原文:https://en.wikipedia.org/wiki/List_of_software_architecture_styles_and_patterns
本文:http://jiagoushi.pro/node/960
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 105 次浏览
【软件架构】软件架构概述
视频号
微信公众号
知识星球
软件架构(architecture)是指软件系统的基本结构以及创建这种结构和系统的规程。每个结构都包含软件元素、它们之间的关系以及元素和关系的属性。[1]软件系统的架构是一个隐喻,类似于架构物的架构。[2]它作为系统和开发项目的蓝图,布置设计团队需要执行的任务。[3]
软件架构(architecture)是指做出基本的结构选择,一旦实现,改变这些选择的代价是高昂的。软件架构(architecture)选择包括软件设计中可能出现的特定结构选项。例如,控制航天飞机运载火箭的系统要求非常快和非常可靠。因此,需要选择合适的实时计算语言。此外,为了满足可靠性的需要,可以选择有多个冗余和独立生成的程序副本,并在交叉检查结果的同时在独立硬件上运行这些副本。
记录软件架构有助于利益相关者之间的沟通,捕获有关高级设计的早期决策,并允许在项目之间重用设计组件。
范围
对于软件架构的范围,人们的看法各不相同:[5]
-
宏观系统结构:这是指架构,它是一个软件系统的高级抽象,由一组计算组件和描述这些组件之间交互的连接器组成。[6]
-
不管是什么重要的东西:这指的是软件架构师应该关注那些对系统及其涉众有重大影响的决策。[7]
-
对理解一个系统在其环境中所处的环境至关重要的东西[8]
-
人们认为很难改变的事情:由于设计架构发生在软件系统生命周期的开始,所以架构师应该关注那些“必须”在第一时间正确的决策。按照这种思路,一旦架构设计问题的不可逆性能够被克服,它们就可能变成非架构性的问题
-
一组架构设计决策:软件架构不应仅仅被视为一组模型或结构,而应包括导致这些特定结构的决策及其背后的理论基础。[9]这种见解导致了对软件架构知识管理的大量研究。[10]
软件架构(architecture)与设计(design)和需求工程(requirement engineering)之间没有明显的区别(参见下面的相关字段)。它们都是从高层意图到底层细节的“意向链”的一部分
特点
软件架构展示了以下内容:
-
利益相关者众多:软件系统必须迎合各种利益相关者,如业务经理、所有者、用户和运营商。这些利益相关者对系统都有自己的关注点。平衡这些关注点并证明它们得到了解决是系统设计的一部分。[4]:29–31这意味着架构涉及到处理各种各样的关注点和涉众,并且具有多学科性质。
-
关注点分离:架构师降低复杂性的既定方法是分离驱动设计的关注点。架构(Architecture)文档显示,所有涉众关注点都是通过从与各种涉众关注点相关联的不同角度建模和描述架构来解决的。[12]这些单独的描述称为架构视图(例如,请参见4+1架构视图模型)。
-
质量驱动:经典的软件设计方法(如Jackson结构化编程)是由系统所需的功能和数据流驱动的,但目前的观点[4]:26-28是软件系统的架构与其质量属性(如容错性、向后兼容性)的关系更为密切,可扩展性、可靠性、可维护性、可用性、安全性、可用性和其他此类功能。干系人关注点通常转化为对这些质量属性的需求,这些属性被不同地称为非功能需求、额外功能需求、行为需求或质量属性需求。
-
重复样式:与构建架构一样,软件架构规程已经开发了解决重复问题的标准方法。这些“标准方法”在不同的抽象层次上由不同的名称来调用。重复性解决方案的常用术语是架构样式,[11]:273–277策略,[4]:70–72参考架构[13][14]和架构模式。[4]:203–205
-
概念完整性:Fred Brooks在《神话人月》中引入的一个术语,用来表示软件系统的架构代表了它应该做什么以及应该如何做的总体构想。这一设想应与实施分开。架构师承担着“视觉守护者”的角色,确保系统的添加与架构一致,从而保持概念的完整性。[15]:41–50
-
认知约束:计算机程序员Melvin Conway在1967年的一篇论文中首次观察到,设计系统的组织被限制生成设计,这些设计是这些组织的通信结构的副本。与概念完整性一样,弗雷德·布鲁克斯在其优雅的经典作品《神话人月》(Mythical Man Month)中引用了这篇论文和这一理念,并称之为“康威定律”(Conway's Law),将其介绍给了更广泛的读者
动机
软件架构(architecture)是复杂系统的“智能可理解”抽象。[4]:5–6该抽象提供了许多好处:
-
它为在系统构建之前对软件系统的行为进行分析提供了基础。[2]验证未来软件系统是否满足其利益相关者的需求而无需实际构建它的能力代表了大量的成本节约和风险缓解。[16]已经开发了许多技术来执行此类分析,比如阿塔姆。
-
它为元素和决策的重用提供了基础。[2][4]:35一个完整的软件架构或其部分,如单个架构策略和决策,可以跨多个系统重用,这些系统的涉众需要相似的质量属性或功能,从而节省设计成本并降低设计错误的风险。
-
它支持影响系统开发、部署和维护寿命的早期设计决策。[4]:31正确地做出早期、高影响的决策对于防止进度和预算超支非常重要。
-
它促进了与涉众的沟通,有助于建立一个更好地满足其需求的系统。[4]:29–31从涉众的角度沟通复杂系统,有助于他们理解所述需求的后果以及基于这些需求的设计决策。架构使得在系统实现之前就设计决策进行交流的能力,而这些决策仍然相对容易适应。
-
它有助于风险管理。软件架构有助于减少风险和失败的机会
-
它可以降低成本。软件架构是在复杂的IT项目中管理风险和成本的一种手段
历史
软件设计和(民用)架构的比较最早出现在20世纪60年代末,[18] 但是直到20世纪90年代,“软件架构”这个术语才被广泛使用。[19]计算机科学领域自形成以来就遇到了与复杂性相关的问题。[20]早期的复杂性问题是由开发人员通过选择正确的数据结构、开发算法和应用关注点分离。虽然“软件架构”这个术语对业界来说是相对较新的,但自20世纪80年代中期以来,该领域的基本原理就被软件工程的先驱们零星地应用。早期捕获和解释系统的软件架构的尝试是不精确和无序的,通常以一组方框图和折线图为特征。[21]
软件架构作为一个概念起源于1968年Edsger Dijkstra和70年代早期David Parnas的研究,这些科学家强调软件系统的结构至关重要,正确的结构至关重要。在20世纪90年代,有一个共同的努力来定义和编纂该学科的基本方面,研究工作集中在架构风格(模式)、架构描述语言、架构文档和形式方法上
作为一门学科,研究机构在促进软件架构的发展方面发挥了突出的作用。卡内基梅隆大学的Mary Shaw和David Garlan在1996年写了一本书,名为《软件架构:对一门新兴学科的展望》,该书提倡软件架构概念,如组件、连接器和样式。加州大学欧文软件研究所致力于软件架构研究,主要针对架构风格、架构描述语言和动态架构。
IEEE 1471-2000《软件密集型系统架构描述推荐规程》是软件架构领域的第一个正式标准。它于2007年被ISO采用为ISO/IEC 42010:2007。2011年11月,IEEE 1471-2000被ISO/IEC/IEEE 42010:2011“系统和软件工程-架构描述”(由IEEE和ISO联合发布)取代
在IEEE 1471中,软件架构是关于“软件密集型系统”的架构,定义为“软件对整个系统的设计、构建、部署和演化产生重要影响的任何系统”,2011年版更进一步,包括了ISO/IEC 15288和ISO/IEC 12207对系统的定义,这些定义不仅包括硬件和软件,还包括“人、过程、程序、设施、材料和自然发生的实体”。这反映了软件架构、企业架构和解决方案架构之间的关系。
架构活动
软件架构师执行的活动有很多。软件架构师通常与项目经理合作,与干系人讨论架构上重要的需求,设计软件架构,评估设计,与设计师和干系人沟通,记录架构设计等。[23]软件架构设计中有四个核心活动。[24]这些核心架构活动是在初始软件开发生命周期的不同阶段以及系统的演化过程中迭代执行的。
-
架构(architecture)分析是理解所提议的系统将在其中运行的环境并确定系统需求的过程。分析活动的输入或需求可以来自任何数量的涉众,包括以下项目:
-
系统运行时将做什么(功能需求)
-
系统将如何执行运行时非功能性需求,如可靠性、可操作性、性能效率、安全性、ISO/IEC 25010:2011标准[25]中定义的兼容性
-
开发时非功能性需求,如ISO 25010:2011标准[25]中定义的可维护性和可转移性
-
一个系统的业务需求和环境背景可能会随着时间而改变,例如法律、社会、金融、竞争和技术问题[26]
-
分析活动的输出是那些对软件系统架构有可测量影响的需求,称为架构上重要的需求
-
架构综合或设计是创造一个架构的过程。考虑到通过分析确定的架构上的重要需求、设计的当前状态和任何评估活动的结果,创建并改进了设计。[24][4]:311–326
-
架构(Architecture)评估(evaluation)是确定当前设计或其一部分如何满足分析期间导出的需求的过程。每当架构师考虑设计决策时,评估就可能发生,评估可能发生在设计的某一部分完成之后,评估可能发生在最终设计完成之后,评估也可能发生在系统构建之后。一些可用的软件架构(architecture)评估技术包括架构(architecture)权衡分析方法(ATAM)和TARA。[28]比较这些技术的框架在SARA报告[16]和架构评审:实践和经验[29]等框架中进行了讨论
-
架构演化是维护和调整现有软件架构以满足需求和环境变化的过程。由于软件架构提供了软件系统的基本结构,其演化和维护必然会影响其基本结构。因此,架构演进涉及添加新功能以及维护现有功能和系统行为。
架构需要关键的支持活动。这些支持活动贯穿于核心软件架构(architecture)过程。它们包括知识管理和沟通、设计推理和决策以及文档。
架构支持活动
软件架构(architecture)支持活动在核心软件架构(architecture)活动期间执行。这些支持活动帮助软件架构师进行分析、综合、评估和演化。例如,架构师必须在分析阶段收集知识、做出决策和文档。
-
知识管理和通信是一种探索和管理知识的行为,对设计软件架构至关重要。软件架构师不是孤立地工作的。它们从不同的涉众那里获得输入、功能性和非功能性需求以及设计上下文;并向涉众提供输出。软件架构知识通常是默认的,并保留在涉众的头脑中。软件架构知识管理活动是关于发现、交流和保留知识的活动。由于软件架构设计问题错综复杂且相互依存,设计推理中的知识缺口可能导致不正确的软件架构设计。[23][30]知识管理和沟通活动的示例包括搜索设计模式、原型设计、询问有经验的开发人员和架构师,评估类似系统的设计,与其他设计师和利益相关者共享知识,并在wiki页面中记录经验。
-
设计推理与决策是评价设计决策的活动。这项活动是所有三个核心软件架构活动的基础。[9][31]它需要收集和关联决策上下文,制定设计决策问题,寻找解决方案选项,并在做出决策之前评估权衡。当评估重要的架构需求和软件架构决策,以及软件架构分析、合成和评估时,此过程在不同的决策粒度级别上发生。推理活动的例子包括理解需求或设计对质量属性的影响,质疑设计可能引起的问题,评估可能的解决方案选项,以及评估解决方案之间的权衡。
-
文档是记录软件架构(architecture)过程中生成的设计的行为。系统设计使用几个视图进行描述,这些视图通常包括显示系统代码结构的静态视图、显示系统在执行期间的操作的动态视图和显示系统如何放置在硬件上执行的部署视图。Kruchten的4+1视图建议描述用于记录软件架构的常用视图;[32]记录软件架构:views and Beyond描述了视图描述中可以使用的各种符号。[1]文档活动的示例正在编写规范,记录系统设计模型,记录设计原理,开发观点,记录视图。
软件架构主题
软件架构描述
Main article: Software architecture description
软件架构描述涉及使用架构描述语言、架构视点和架构框架等机制对架构进行建模和表示的原则和实践。
架构描述语言
Main article: Architecture description language
架构描述语言(ADL)是用来描述软件架构(ISO/IEC/IEEE 42010)的任何表达方式。自20世纪90年代以来,开发了许多专用ADL,包括AADL(SAE标准)、Wright(由卡内基梅隆开发)、Acme(由卡内基梅隆开发)、xADL(由UCI开发)、Darwin(由伦敦帝国理工学院开发)、DAOP-ADL(由马拉加大学开发)、SBC-ADL(由国立中山大学开发)和ByADL(意大利拉奎拉大学)。
架构视角
Main article: View model
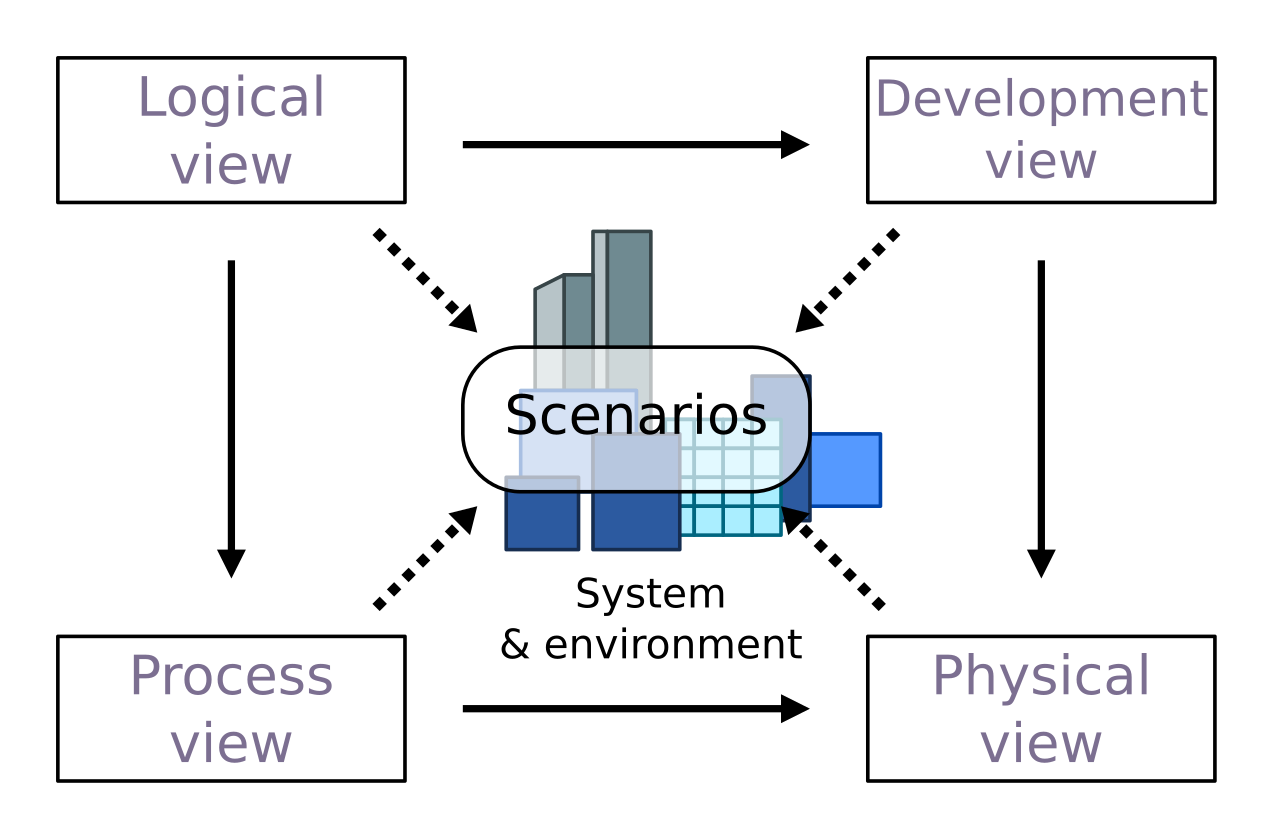
4+1架构视图模型。
软件架构描述通常被组织成视图,类似于在架构架构中生成的不同类型的蓝图。每个视图都按照其视点的约定处理一组系统关注点,其中视点是一个规范,描述了要在视图中使用的符号、建模和分析技术,该视图从给定的一组涉众及其关注点的角度表示所讨论的架构(ISO/IEC/IEEE42010)。该视点不仅指定了所构建的关注点(即要解决的关注点),而且还指定了表示、使用的模型类型、使用的约定以及任何保持视图与其他视图一致的一致性(对应)规则。
架构框架
Main article: Architecture framework
架构(architecture)框架捕获“描述在特定应用领域和/或利益相关者社区中建立的架构的惯例、原则和实践”(ISO/IEC/IEEE42010)。框架通常是根据一个或多个视点或adl来实现的。
架构风格和模式
Main article: Architectural pattern
架构模式是一种通用的、可重用的解决方案,用于解决给定上下文中软件架构中常见的问题。架构模式通常被记录为软件设计模式。
“软件架构风格”是继传统架构风格之后的一种特殊的架构方法,其特点是使其引人注目(架构风格)。
架构样式定义:以结构组织模式表示的一系列系统;组件和连接器的词汇表,以及如何组合它们的约束条件。[33]
“架构样式是可重用的设计决策和约束的‘包’,应用于架构以获得所选的理想质量。[34]”
有许多公认的架构模式和风格,其中包括:
-
黑板
-
客户端服务器(2层、3层、n层,云计算展示了这种风格)
-
基于组件
-
以数据为中心
-
事件驱动(或隐式调用)
-
分层(或多层架构)
-
微服务架构
-
整体应用
-
模型视图控制器(MVC)
-
对等(P2P)
-
管道和过滤器
-
插件
-
反应式架构
-
代表性状态转移(REST)
-
基于规则
-
服务导向
-
无共享架构
-
空间架构
有些人认为架构模式和架构风格是一样的,[35]有些人认为风格是模式的专门化。它们的共同点是模式和风格都是架构师使用的习语,它们“提供了一种共同的语言”[35]或“词汇”[33]来描述系统的类。
软件架构与敏捷开发
Main article: Agile development
也有人担心软件架构会导致太多的大设计,特别是在敏捷软件开发的支持者中。已经开发了许多方法来平衡前期设计和敏捷性之间的权衡,[36]包括敏捷方法DSDM,DSDM要求在“基础”阶段打下“足够”的架构基础。IEEE软件专门出版了一期专门讨论敏捷性和架构之间的交互的专刊[37]。
软件架构侵蚀
软件架构侵蚀(或称“衰退”)是指在软件系统的实现过程中,在软件系统的计划架构和实际架构之间观察到的差距。[38]当实现决策没有完全实现计划架构或违反这种架构。[2]计划架构和实际架构之间的差距有时可以用技术债务的概念来理解。
例如,考虑一个严格分层的系统,其中每个层只能使用它下面的层提供的服务。任何不遵守此约束的源代码组件都表示违反了架构。如果不加以纠正,这种违规行为可能会将架构转换为一个整体块,从而对可理解性、可维护性和可演化性产生不利影响。
已经提出了各种办法来解决侵蚀问题。”这些方法,包括工具、技术和过程,主要分为三大类,试图最小化、防止和修复架构侵蚀。在这些大类中,每一种方法都进一步细分,反映了为解决侵蚀问题而采取的高级别战略。这些是面向过程的架构一致性、架构演化管理、架构设计实施、架构到实现的链接、自适应和架构恢复技术,包括恢复、发现和协调
检测架构冲突有两种主要技术:反射模型和领域特定语言。反射模型(RM)技术将系统架构师提供的高级模型与源代码实现进行比较。还有一些特定于领域的语言,重点是指定和检查架构约束。
软件架构恢复
Main article: Software architecture recovery
软件架构(architecture)恢复(或重构,或逆向工程)包括从可用信息(包括其实现和文档)中揭示软件系统架构的方法、技术和过程。在面对过时或过时的文档和架构侵蚀时,架构恢复通常是做出明智决策所必需的:实现和维护决策与设想的架构不同。[40]存在将软件架构恢复为静态程序分析的实践。这是软件智能实践课程的一部分。
相关领域
设计
Main article: Software design
架构是设计,但并非所有的设计都是架构。[1]实际上,架构师是在软件架构(架构设计)和详细设计(非架构设计)之间划清界线的人。没有适合所有情况的规则或准则,尽管有人试图将这种区别形式化。根据内涵/局部性假设,[41]架构设计和详细设计之间的区别是由局部性标准定义的,[41]根据局部性标准,关于软件设计的陈述是非局部的(架构),前提是满足它的程序可以扩展成不满足它的程序。例如,客户机-服务器样式是架构(战略性的),因为基于此原则构建的程序可以扩展为非客户机-服务器的程序,例如,通过添加对等节点。
需求工程
Main article: Requirements engineering
需求工程和软件架构可以看作是互补的方法:当软件架构以“解决方案空间”或“如何”为目标时,需求工程解决“问题空间”或“什么”。[42]需求工程需要启发、协商、规范、验证,要求的文件和管理。需求工程和软件架构都围绕涉众的关注点、需求和愿望。
需求工程(engineering)和软件架构(architecture)之间存在相当大的重叠,例如,对五种工业软件架构(architecture)方法的研究表明,“输入(目标、约束等)通常定义不清,只有当架构开始出现时才能被发现或更好地理解,并且“虽然大多数架构关注点被表达为系统上的需求,但它们也可以包括强制性的设计决策”[24]简而言之,所需的行为影响解决方案架构,这反过来又可能引入新的需求。[43]双峰模型等方法[44]旨在利用需求和架构之间的协同关系。
其他类型的“架构”
Main articles: Computer architecture, Systems architecture, and Enterprise architecture
计算机架构
计算机架构以计算机系统的内部结构为目标,以协作硬件组件(如CPU或处理器、总线和内存)为基础。
系统架构
术语系统架构最初应用于由硬件和软件组成的系统架构。系统架构解决的主要问题是将软件和硬件集成到一个完整、正常工作的设备中。在另一个共同的(更广泛的)含义中,这个术语适用于任何复杂系统的架构,这些系统可能具有技术性、社会技术性或社会性。
企业架构
企业架构的目标是“将业务远景和战略转化为有效的企业”[45]企业架构框架,如TOGAF和Zachman框架,通常区分不同的企业架构层。尽管术语因框架而异,但许多术语至少包括业务层、应用程序(或信息)层和技术层之间的区别。企业架构解决了这些层之间的对齐问题,通常采用自顶向下的方法。
另见
架构模式(计算机科学)
-
反模式
-
属性驱动设计
-
计算机架构
-
分布式数据管理架构
-
分布式关系数据库架构
-
系统架构
-
系统设计
-
软件架构分析方法
-
时间触发系统
讨论:请加入知识星球【首席架构师圈】
- 291 次浏览
【软件架构】软件架构的7种建模语言
视频号
微信公众号
知识星球
比较用于设计和建模软件系统的7种流行语言

我们开始吧
由于软件的复杂性,一直需要以图形方式可视化软件体系结构,并与其他软件体系结构进行通信。通过对这些系统及其抽象进行建模和绘图,我们可以分析和改进设计,从而在构建它们时实现更高质量的实现。
在本文中,我们将比较七种流行的视觉建模语言。
1.️统一建模语言(UML)
统一建模语言是由一群软件工程师和研究人员在20世纪90年代创建的,现在由对象管理小组(OMG)维护。UML是一种图形语言,它为软件系统建模提供了一组标准的符号和表示法。UML2.5包括14种不同的图表类型,用于对软件开发生命周期的各个部分进行建模。
👍 优点
- UML提供了强大而广泛的标准化表示法,可以改善大型组织中的通信。
- 在需要时只使用符号的特定部分的灵活性。
- 该工具通常支持代码生成,这可以加快开发速度。
👎 缺点
- 对于初学者来说,复杂的记法是一条陡峭的学习曲线,以便有效地学习和使用。
- UML可能过于复杂和耗时,尤其是对于小型和简单的软件系统。
- 工具通常很昂贵,难以使用,并且需要培训。

2.️ C4模型
C4模型是一种为特定受众可视化软件体系结构的轻量级结构化方法。它是由一位名叫Simon Brown的软件架构师和作者于2011年创建的。C4模型本质上只是两件事,一组常见抽象的层次结构和四种标准图类型。C4型号是独立于符号的,这意味着没有规定标准的形状、颜色或风格。
👍 优点
- 层次结构允许为需要它的受众放大更多的技术细节。
- 简单易学,便于工程师、利益相关者和非技术团队成员理解。
- C4模型具有灵活性和适应性,因此可以用于各种工具和符号。
👎 缺点
- 对于需要广泛图表类型(如用例图、活动图和类图)的大型组织来说,一组有限的功能可能是一种限制。
- C4模型仍然越来越受欢迎,并且与UML等标准相比没有被广泛采用。
- 有一些C4模型工具,但与更成熟的建模语言相比,仍然有一套相对有限的工具。
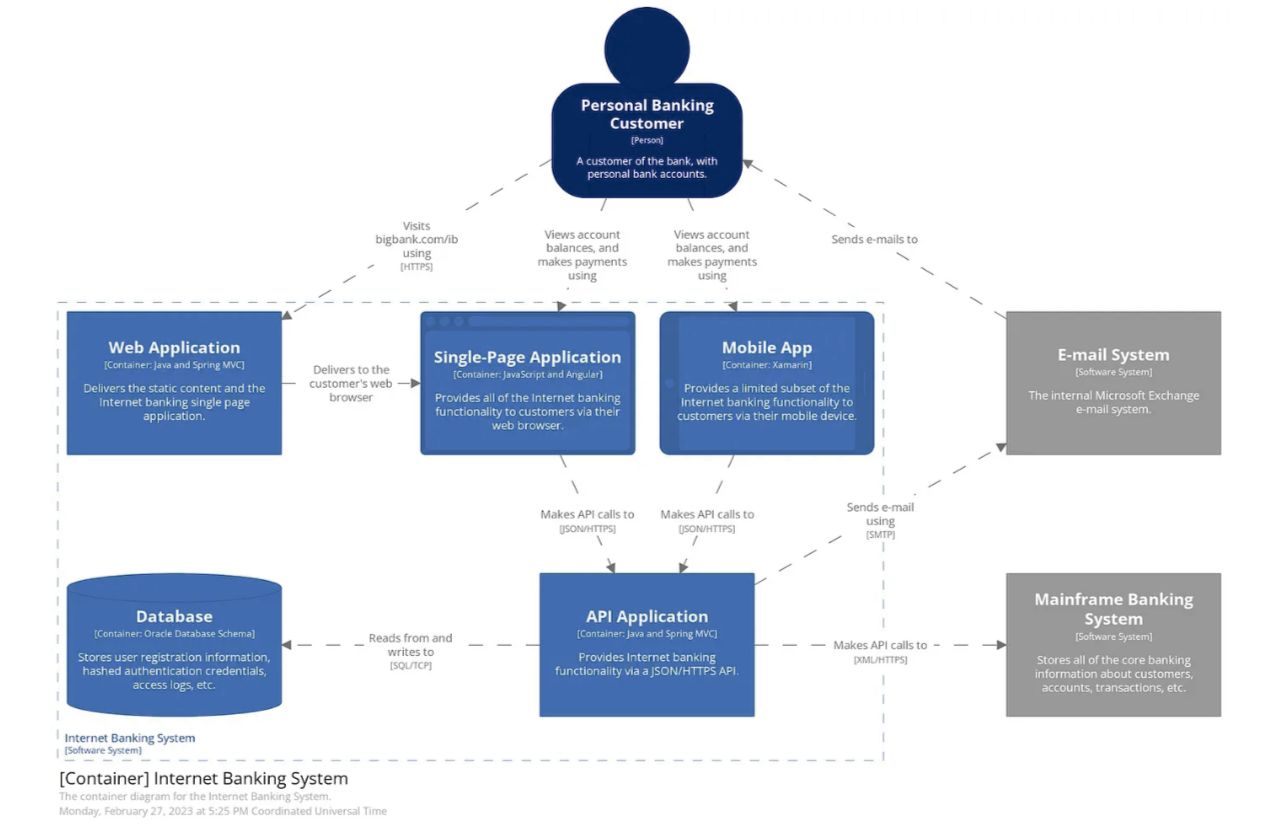
3.️ArchiMate
ArchiMate是一种用于企业体系结构的开放且独立的建模语言。它是由开放集团于2011年开发的,该集团是一个开发和维护多个开放标准的行业联盟。它提供了三层抽象(业务、应用程序和技术)、标准建模元素(包括业务参与者、业务流程和应用程序组件)以及它们之间的关系。
👍 优点
- ArchiMate提供了一个全面的框架,具有广泛的抽象和符号来描述和交流体系结构。
- 包括用于区分建筑组件类型的颜色编码方案。
- 设计为与其他企业体系结构标准(如TOGAF和BPMN)兼容。
👎 缺点
- 尽管在欧洲被广泛使用,但在世界部分地区采用仍然有限。
- ArchiMate是一种复杂的建模语言,可能需要时间来学习如何有效地使用它,这可能会成为一些人进入的障碍。
- 通常与特定的软件工具一起使用,这有时会限制ArchiMate模型的可移植性。
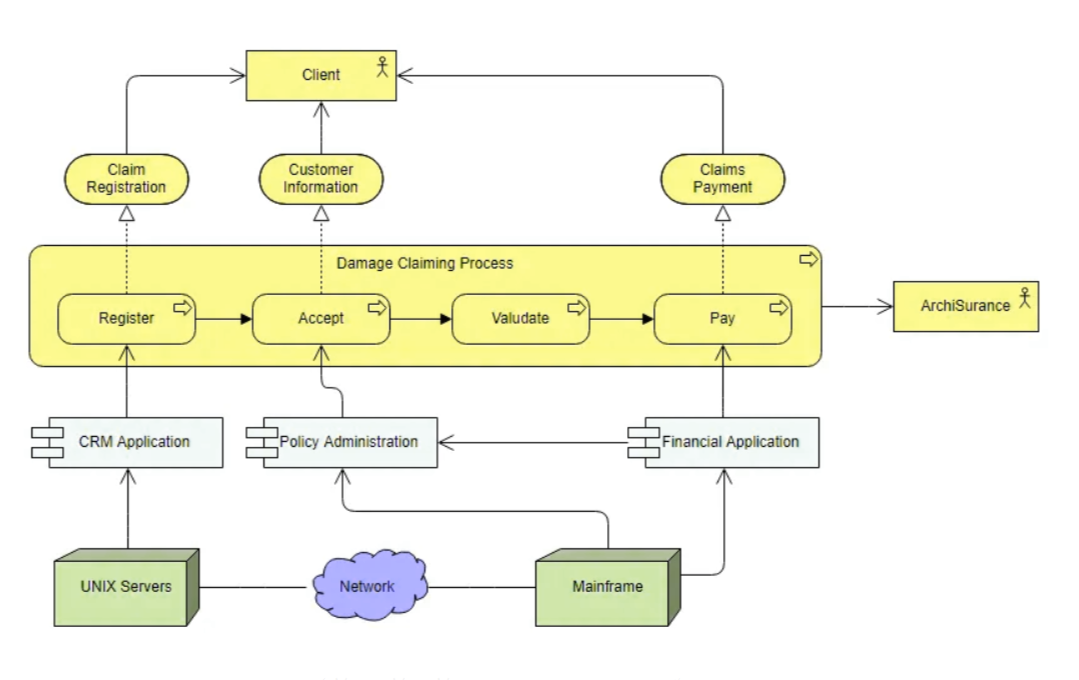
4.️⃣ 开放式组架构框架(TOGAF)
开放式集团架构框架或TOGAF是一个企业架构框架,分为4个关键领域:业务、应用程序、数据和技术。它最初由开放集团创建于1995年,该集团还负责维护ArchiMate。TOGAF提供了一种全面而系统的方法,包括企业架构的开发和实现的逐步过程。
👍 优点
- 提供了一种全面且适应性强的语言,这意味着组织可以随着时间的推移根据其特定需求进行调整。
- 与供应商无关,这意味着它可以与任何技术或供应商解决方案一起使用,为组织提供灵活性。
- TOGAF是一个被世界各地的组织广泛认可和使用的行业标准,可以为利益相关者提供保证和可信度。
👎 缺点
- 对于那些不熟悉该框架的人来说,TOGAF和ADM过程可能特别难以学习,并且可能需要大量时间来实现。
- TOGAF对标准和治理的重视有助于保持一致性,但也有变得过于僵化和不灵活的风险。
- 认证和培训可能很昂贵,这可能会成为一些想要使用该框架的组织的障碍。
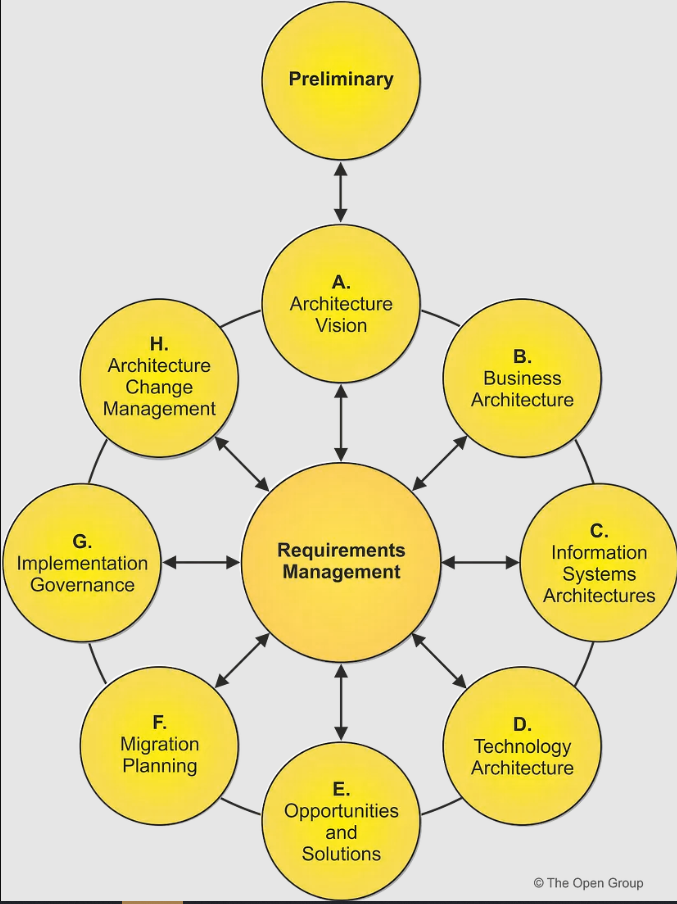
5.️ 业务流程模型和符号(BPMN)
BPMN是一种图形建模语言,为业务流程、活动、事件、网关、流和工件提供标准表示法。它是分析和改进业务流的强大工具。BPMN最初由一群组织创建于2004年,令人反感,此后一直由对象管理小组(OMG)维护。
👍 优点
- BPMN设计为易于技术和非技术利益相关者理解,使其适用于广泛的受众。
- 提供了一种易于理解的标准表示法,并为设计和实现业务流程弥合了沟通差距。
- 子模型以一种查看者可以轻松发现最适用于它们的区域的方式划分图表。
👎 缺点
- 符号是全面的,可能很难从头到尾学习,这意味着那些产生模型的人可能会有一个陡峭的学习曲线。
- 一些供应商实现和执行BPMN图的方式略有不同,尽管有明确的标准。
6.️⃣ 系统建模语言(SysML)
SysML是一种开源建模语言,它扩展了UML,旨在分析复杂系统。它最初创建于2001年,后来被对象管理小组(OMG)采用。系统工程师使用SysML来通信和分析广泛的系统,例如:软件、硬件、信息、流程和人员。
👍 优点
- 删除了UML的软件特定限制,以允许对更广泛的系统(如物理和人员)进行建模。
- SysML删除了UML的一些特性,使其更简单、更容易学习。
- 为UML中有限的模型、视图和视点提供广泛的支持。
👎 缺点
- 由于SysML是基于UML的,它继承了UML的许多困难和缺点。
- 关于图的完整程度的模糊规则可能会导致错误。
- 各种SysML工具之间缺乏互操作性,这使得共享模型变得困难。
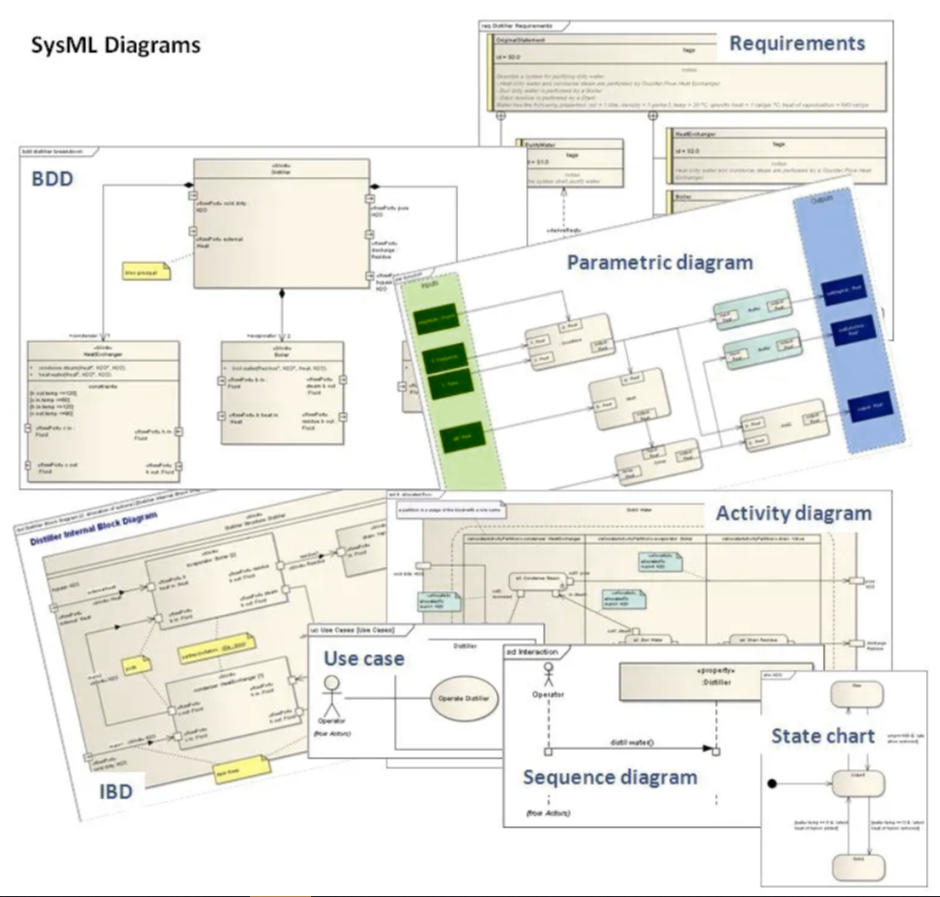
7.️4+1视图模型
4+1是一个视图模型,用于使用多个并发视图来描述大型系统,每个视图都来自不同的利益相关者。它最早是由加拿大软件工程师Philippe Kruchten于1995年提出的。它定义的5个视图分别是逻辑视图、流程视图、开发视图和场景。
👍 优点
- 该方法允许利益相关者轻松地使用模型中对他们最重要的区域。
- 4+1非常适合组织和提供图表和系统信息的结构。
- 如果视图对模型没有贡献,则可以忽略这些视图。
👎 缺点
- 4+1没有强制执行正式的表示法或标准,这可能会导致模型应用方式的不一致。
- 可能无法为设计决策的某些领域提供足够的细节,例如安全性、性能或可扩展性。
- 不适用于非常小的系统或具有非常特定焦点的系统。

🏁 结束
我确信还有其他视觉建模语言我们没有时间在本文中介绍。如果你还有其他最喜欢的,以及你在使用它时喜欢或不喜欢什么,请在评论中告诉我们。
- 120 次浏览
【软件架构】软件架构的7种建模语言
视频号
微信公众号
知识星球
比较用于设计和建模软件系统的7种流行语言

🚀
我们开始吧
由于软件的复杂性,一直需要以图形方式可视化软件体系结构,并与其他软件体系结构进行通信。通过对这些系统及其抽象进行建模和绘图,我们可以分析和改进设计,从而在构建它们时实现更高质量的实现。
在本文中,我们将比较七种流行的视觉建模语言。
1️⃣ Unified Modeling Language (UML)
统一建模语言是由一群软件工程师和研究人员在20世纪90年代创建的,现在由对象管理小组(OMG)维护。UML是一种图形语言,它为软件系统建模提供了一组标准的符号和表示法。UML2.5包括14种不同的图表类型,用于对软件开发生命周期的各个部分进行建模。
👍 优点
- UML提供了强大而广泛的标准化表示法,可以改善大型组织中的通信。
- 在需要时只使用符号的特定部分的灵活性。
- 该工具通常支持代码生成,这可以加快开发速度。
👎 缺点
- 对于初学者来说,复杂的记法是一条陡峭的学习曲线,以便有效地学习和使用。
- UML可能过于复杂和耗时,尤其是对于小型和简单的软件系统。
- 工具通常很昂贵,难以使用,并且需要培训。
2️⃣ C4 Model
C4模型是一种为特定受众可视化软件体系结构的轻量级结构化方法。它是由一位名叫Simon Brown的软件架构师和作者于2011年创建的。C4模型本质上只是两件事,一组常见抽象的层次结构和四种标准图类型。C4型号是独立于符号的,这意味着没有规定标准的形状、颜色或风格。
👍 优点
- 分层结构允许为需要它的受众放大更多的技术细节。
- 简单易学,便于工程师、利益相关者和非技术团队成员理解。
- C4模型具有灵活性和适应性,因此可以用于各种工具和符号。
👎 缺点
- 对于需要广泛图表类型(如用例图、活动图和类图)的大型组织来说,一组有限的功能可能是一种限制。
- C4模型仍然越来越受欢迎,与UML等标准相比并没有被广泛采用。
- 有一些C4模型工具,但与更成熟的建模语言相比,仍然有一组相对有限的工具。
3️⃣ ArchiMate
ArchiMate 是一种用于企业体系结构的开放且独立的建模语言。它是由开放集团于2011年开发的,该集团是一个开发和维护多个开放标准的行业联盟。它提供了三层抽象(业务、应用程序和技术)、标准建模元素(包括业务参与者、业务流程和应用程序组件)以及它们之间的关系。
👍 优点
- ArchiMate提供了一个全面的框架,具有广泛的抽象和符号来描述和交流架构。
- 包括用于区分架构组件类型的颜色编码方案。
- 设计为与其他企业架构标准(如TOGAF和BPMN)兼容。
👎 缺点
- 尽管在欧洲被广泛使用,但世界部分地区的采纳仍然有限。
- ArchiMate是一种复杂的建模语言,可能需要时间来学习如何有效地使用它,这可能会成为一些人进入的障碍。
- 通常与特定的软件工具一起使用,这有时会限制ArchiMate模型的可移植性。
4️⃣ The Open Group Architecture Framework (TOGAF)
The Open Group Architecture Framework TOGAF是一个企业架构框架,分为4个关键领域:业务、应用程序、数据和技术。它最初由开放集团创建于1995年,该集团还负责维护ArchiMate。TOGAF提供了一种全面而系统的方法,包括企业架构的开发和实现的逐步过程。
👍 优点
- 提供了一种全面且适应性强的语言,这意味着组织可以随着时间的推移根据其特定需求进行调整。
- 与供应商无关,这意味着它可以与任何技术或供应商解决方案一起使用,为组织提供灵活性。
- TOGAF是一个被世界各地的组织广泛认可和使用的行业标准,它可以为利益相关者提供保证和可信度。
👎 缺点
- 对于那些不熟悉该框架的人来说,TOGAF和ADM过程可能特别难以学习,并且可能需要大量时间来实现。
- TOGAF对标准和治理的重视有助于保持一致性,但也有变得过于僵化和不灵活的风险。
- 认证和培训可能很昂贵,这可能会成为一些想要使用该框架的组织的障碍。
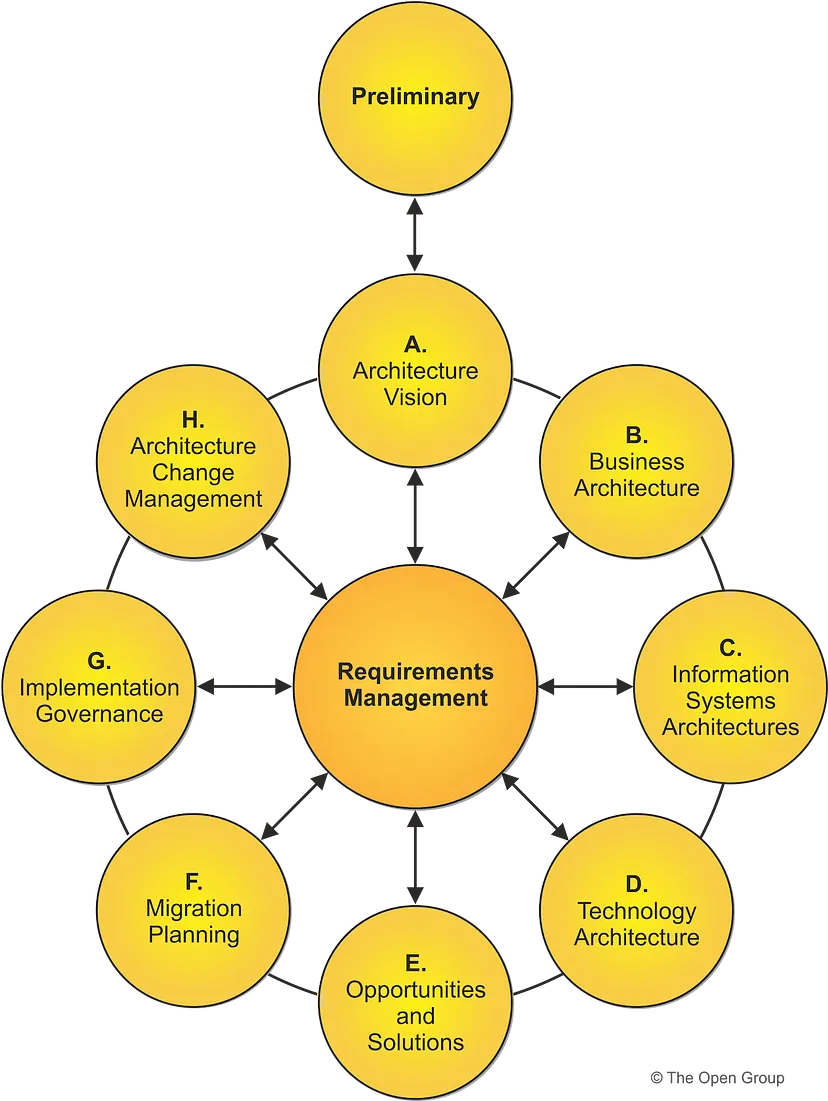
5️⃣ Business Process Model and Notation (BPMN)
是一种图形建模语言,为业务流程、活动、事件、网关、流和工件提供标准表示法。它是分析和改进业务流的强大工具。BPMN最初由一群组织创建于2004年,令人反感,此后一直由对象管理小组(OMG)维护。
👍 优点
- BPMN的设计便于技术和非技术利益相关者理解,因此非常适合广泛的受众。
- 提供易于理解的标准表示法,并为设计和实现业务流程弥合沟通差距。
- 子模型以一种查看者可以轻松发现最适用于它们的区域的方式来划分图表。
👎 缺点
- 符号是全面的,可能很难从头到尾学习,这意味着对于那些生产模型的人来说,可能会有一个陡峭的学习曲线。
- 一些供应商实现和执行BPMN图的方式略有不同,尽管有明确的标准。
6️⃣ Systems Modeling Language (SysML)
SysML 是一种扩展UML的开源建模语言,旨在分析复杂系统。它最初创建于2001年,后来被对象管理小组(OMG)采用。系统工程师使用SysML来通信和分析各种系统,例如:软件、硬件、信息、流程和人员。
👍 优点
- 删除了UML的软件特定限制,允许对更广泛的系统(如物理和人员)进行建模。
- SysML删除了UML的一些特性,使其更简单、更容易学习。
- 为UML中有限的模型、视图和视点提供广泛的支持。
👎 缺点
- 由于SysML是基于UML的,它继承了UML的许多困难和缺点。
- 关于图的完整程度的模糊规则可能会导致错误。
- 各种SysML工具之间缺乏互操作性,使得共享模型变得困难。
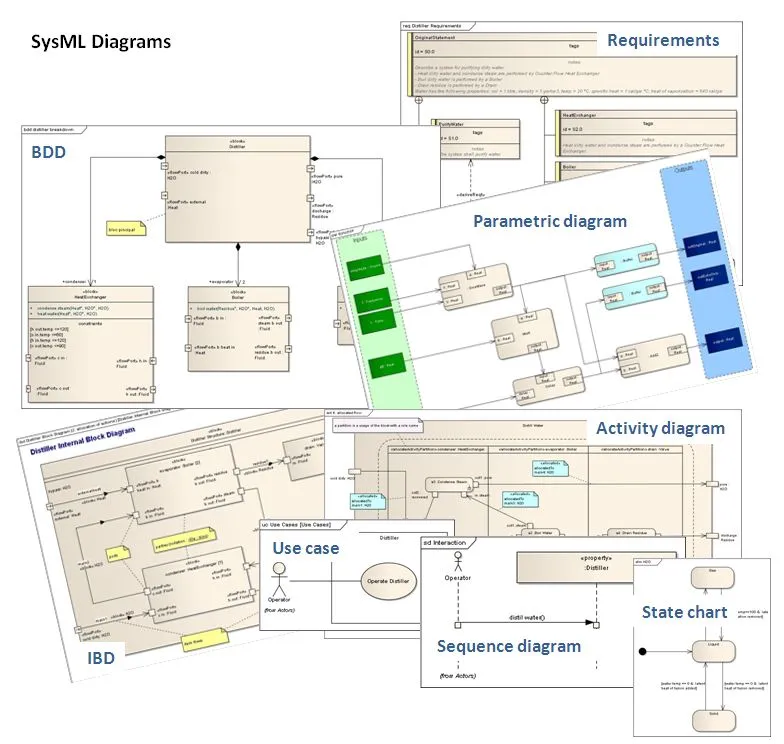
7️⃣ 4+1 View Model
The 4+1 is a view model 用于使用多个并发视图来描述大型系统,每个视图都来自不同的利益相关者。它最早是由加拿大软件工程师Philippe Kruchten于1995年提出的。它定义的5个视图分别是逻辑视图、流程视图、开发视图和场景。
👍 优点
- 该方法允许利益相关者轻松地使用模型中对他们最重要的区域。
- 4+1非常适合组织和提供图表和系统信息的结构。
- 如果视图对模型没有贡献,则可以省略视图。
👎 缺点
- 4+1没有强制使用正式的表示法或标准,这可能会导致模型应用方式的不一致。
- 可能无法为设计决策的某些领域提供足够的细节,例如安全性、性能或可扩展性。
- 不适用于非常小的系统或具有非常特定焦点的系统。
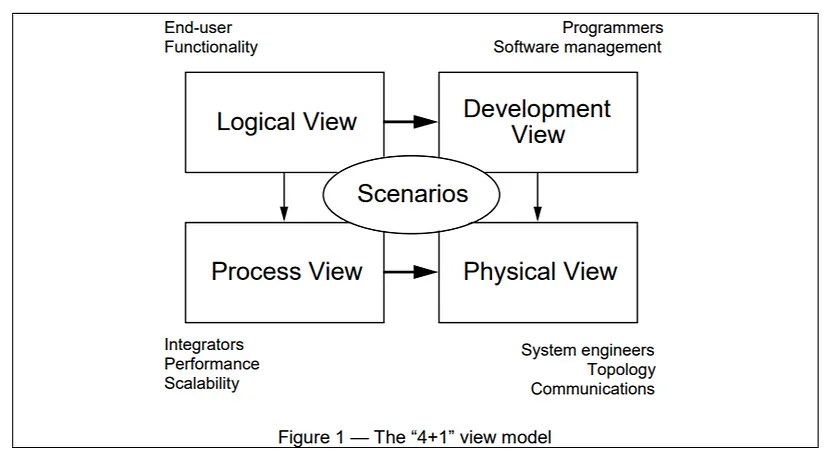
🏁 To wrap up
我相信还有其他视觉建模语言我们没有时间在本文中介绍。如果你还有其他最喜欢的,以及你在使用它时喜欢或不喜欢什么,请在评论中告诉我们。
保持冷静🧊
- 137 次浏览
【软件架构】软件架构资料
与 800 位挚友一起做架构:谈 Comcast 架构协议的演变
https://www.infoq.cn/article/dYCKYXZORi_JE4MCtwz5
Segment 放弃了微服务
https://www.infoq.cn/article/v3VjP*BYtY3qhD3438ay
微服务架构体系的深度治理
https://www.infoq.cn/article/q65dDiRTdSbF*E6Ki2P4
Qarkus Java 框架答疑
https://www.infoq.cn/article/j3XQTfHg*3gdbLZme7ls
- 107 次浏览
软件架构风格
- 72 次浏览
【ChatGPT】ChatGPT和软件架构
视频号
微信公众号
知识星球
最近几周,OpenAI对ChatGPT产生了很多兴趣,出现了各种有趣的用例。
在许多方面,这是与建筑师白板相当的AI,但它有很多用途,而不仅仅是绘制线条和方框。在这篇文章中,我想使用这项创新技术来演示启动软件架构过程的另一个用例。
就像在白板上画画一样,这个过程有点混乱,因为典型的相互作用会导致不断修改以找到最佳答案。本文旨在演示我在ChatGPT中成功使用的一些提问技巧,这些技巧产生了真正有价值的结果。
ChatGPT的一个警告是它仍在学习,所以不要期望一致性。在另一天问同样的问题可能会产生不同的结果。
设置ChatGPT帐户本身很简单,可以按照以下地址的说明进行操作:https://openai.com/blog/chatgpt/
用户故事
因此,让我们先让ChatGPT对用户故事做出回应。

正如你所看到的,这个用户故事是我所在行业特有的。ChatGPT拥有庞大的知识库,因此需要进行实验来了解ChatGPT的知识深度——它知道什么?
第一个问题的关键是非常明确关键细节,以获得最佳结果。通过这种方式,ChatGPT可以得到一组不错的结果,例如:

如果您的结果与上述类似,那么您知道ChatGPT已经找到了线索,并将基于您提出的进一步问题。要记住的关键是,以下所有结果都将基于这个初始上下文,因此,为什么值得花时间好好定义第一次交互。
所以现在我们可以做一些非常了不起的事情。建立一个数据库!
让我们制作一个数据库
…这就是ChatGPT的响应方式:
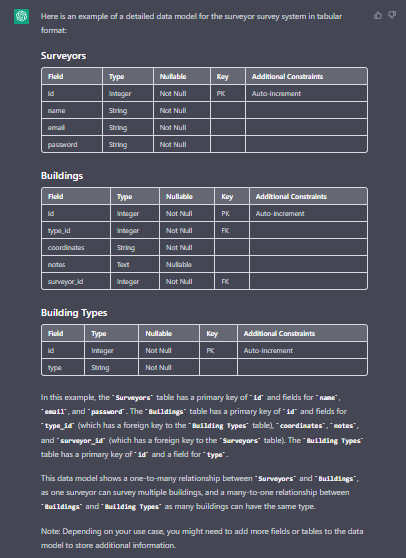
但我们不要就此止步。让我们继续…

CREATE TABLE Surveyors ( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(255) NOT NULL, email VARCHAR(255) NOT NULL, password VARCHAR(255) NOT NULL, PRIMARY KEY (id) ); CREATE TABLE Buildings ( id INT NOT NULL AUTO_INCREMENT, type_id INT NOT NULL, coordinates VARCHAR(255) NOT NULL, notes TEXT, surveyor_id INT NOT NULL, PRIMARY KEY (id), FOREIGN KEY (type_id) REFERENCES BuildingTypes(id), FOREIGN KEY (surveyor_id) REFERENCES Surveyors(id) ); CREATE TABLE BuildingTypes ( id INT NOT NULL AUTO_INCREMENT, type VARCHAR(255) NOT NULL, PRIMARY KEY (id) );
…ChatGPT以完全可接受的SQL响应,SQL数据库创建时不会有问题。然而,让我们不要再止步于此…
创建图表

<script src="https://cdn.jsdelivr.net/npm/mermaid@8.6.0/dist/mermaid.min.js"></script>
<script>mermaid.initialize({startOnLoad:true});</script>
<div class="mermaid">
classDiagram
class Surveyors {
+id: int
+name: string
+email: string
+password: string
}
class Buildings {
+id: int
+type_id: int
+coordinates: string
+notes: string
+surveyor_id: int
}
class BuildingTypes {
+id: int
+type: string
}
Surveyors --> Buildings
Buildings --> BuildingTypes
</div>ChatGPT生成的图表如下…

ChatGPT充满惊喜:


ChatGPT不会显示图表,而是在Mermaid脚本中生成代码,该脚本将创建图表。ChatGPT完全熟悉美人鱼脚本,因此它可以生成这种脚本语言所允许的图表。
编程
正如我们已经建立的那样,ChatGPT已经学会了编码,因此您可以继续要求ChatGPT编写JavaScript、CSS和HTML,通过简单的请求将一个工作的原型放在一起。ChatGPT经过培训,可以用许多流行的编程语言生成代码。
如果有足够的时间,这是一个熟练的人可以做的事情。但这不是生产就绪代码;要使代码达到这样的质量和实用性,需要做更多的工作。但ChatGPT没有理由在做这件事时袖手旁观。
因此,让我们尝试使用ChatGPT提高代码质量:

ChatGPT是这样回应的:
public class Surveyor
{
private readonly string _name;
private readonly string _email;
private readonly List<ISurvey> _surveys;
private readonly IDatabaseAccess _databaseAccess;
public Surveyor(string name, string email, IDatabaseAccess databaseAccess)
{
_name = name;
_email = email;
_databaseAccess = databaseAccess;
_surveys = new List<ISurvey>();
}
public void AddSurvey(ISurvey survey)
{
try
{
_surveys.Add(survey);
_databaseAccess.SaveSurvey(survey);
}
catch (Exception ex)
{
// Log the error
}
}
public void RemoveSurvey(ISurvey survey)
{
try
{
_surveys.Remove(survey);
_databaseAccess.DeleteSurvey(survey);
}
catch (Exception ex)
{
// Log the error
}
}
public List<ISurvey> GetSurveys()
{
try
{
return _databaseAccess.GetSurveys();
}
catch (Exception ex)
{
// Log the error
return new List<ISurvey>();
}
}
}
public interface IDatabaseAccess
{
void SaveSurvey(ISurvey survey);
void DeleteSurvey(ISurvey survey);
List<ISurvey> GetSurveys();
}
public class DatabaseAccess : IDatabaseAccess
{
public void SaveSurvey(ISurvey survey)
{
// Implementation for saving the survey to a database
}
public void DeleteSurvey(ISurvey survey)
{
// Implementation for deleting the survey from the database
}
public List<ISurvey> GetSurveys()
{
// Implementation for retrieving a list of surveys from the database
}
}
public interface ISurvey
{
decimal Latitude { get; set; }
decimal Longitude { get; set; }
string BuildingType { get; set; }
Dictionary<string, string> BuildingCharacteristics { get; set; }
}
public class Survey : ISurvey
{
public decimal Latitude { get; set; }
public decimal Longitude { get; set; }
public string BuildingType { get; set; }
public Dictionary<string, string> BuildingCharacteristics { get; set; }
public Survey(decimal latitude, decimal longitude, string buildingType, Dictionary<string, string> buildingCharacteristics)
{
Latitude = latitude;
Longitude = longitude;
BuildingType = buildingType;
BuildingCharacteristics = buildingCharacteristics;
}
}……作为一套开始上课的课程,这多少有些令人尊敬。
我让ChatGPT做的下一个任务是为基于REST的API创建Swagger。ChatGPT再次做出了值得尊敬的努力,足以开始开发。
结论
ChatGPT可以开始开发,因为它具有广泛的功能,但尚未显示其深度。每次转弯时,我都必须让ChatGPT来完成任务;那里没有主动权,我已经开始并推动下一步行动。
然而,开发一组你知道的标准问题会促使ChatGPT提供一个好的结果,这可能很简单。在sprint计划中,这可能足以以多种方式开始开发。
这项技术现在就在这里,我们不妨完全接受它并继续实验,这样我们就可以进一步了解这种先进的自动化可以继续提供什么价值。
- 206 次浏览
【思维模型】零原理思维
一个人如何想出一个真正原创的想法? 一个改变了几个世纪的社会。
了解数字零的发现,以及它的哲学表现——虚无——改变了我对变革性思维的定位。
读完《零:一个危险想法的传记》后,我的第一个想法是,我想建立一个坚固的心智模型来探索类似的难以理解的概念。 我想找到大写的Z Zeros。
直觉上,这是我出售公司 Braintree Venmo 多年后一直在尝试做的事情,但我只是没有文字或概念来具体化我有意识地经历的事情。 当我出售公司并可以重新探索时,我试图回答的问题是:我能做些什么来帮助人类最大程度地繁荣发展? 时代精神缺少什么但必不可少?

硅谷到处都是“第一原则”公司以及工程师和设计师的想法。但是我评估的每一个“第一原则”衍生的可能性都感觉它没有达到广泛的可能性,也没有达到人类现在为未来存在所需要的东西。跳出框框思考可以带来富有成效的见解,但这还不够;我想质疑盒子本身。
现在,当我运行 Kernel 和 OS Fund 时,我每天都在想 Zeros,这两家公司试图开创人类意义的未来。每一个都同时通过第一性原理思维实现,并由零发现推动,时间锁定在我们所有未来(2025 年、2050 年和 2500 年)有意义的视野。
零发现很难用我们今天可以使用的词语和概念来表达,但我知道找到零的情感概况。在对 AlphaGo 与世界上最好的人类围棋棋手的一场比赛进行专业分析时,一位观察者表示,这些动作就像是在观看 AI 下的“从另一个维度围棋”。那是个人资料。这就是见证零发现的感觉。
自从听到这个,我不断地回到这个“从另一个维度”的想法。对于训练有素的人来说,AlphaGo 似乎在玩新的想法或策略,这些想法或策略要么是全新的,要么是古老到足以被现代专业人士抛弃的。 AI 并没有将我们人类的假设视为既定事实,而是使用潜伏在游戏结构中的新概念原语进行游戏,即使专家也无法看到。这些动作已经存在。如果他们知道的话,人类可以玩它们。他们总是可能的。但人类大脑的某些东西让我们从未见过它们,即使在我们迭代了数千年的围棋文化和策略之后。为什么不?
AlphaGo 在围棋游戏中找到了零点,但围棋是一个有限的、完全信息的游戏。我的主要兴趣:我们如何为智能存在的未来找到最好的动作——那些“来自另一个维度的”?
上一代人从未有过我们现在所做的机会:看看我们预期的一生,并看到进化为/进入全新的意识体验形式的真正可能性。一个如此转变的存在,以至于我们现在的自己,以及今天的现实,将在历史上显得原始而无趣。
这些可能是什么?根据定义,零是无法定义的,也很难想象。我想到了一些:如果我们的动力不是社会地位、别人的认可或财富积累怎么办?如果我们没有感觉到部落的倾向怎么办?如果我们主要关心的是和谐游戏,一种我们今天甚至没有语言或概念的类型,与我们周围的一切事物? ([输入你最不直观、最违反直觉和不太可能的断言] 你在想什么我看不到的?)毕竟,我们的现代世界会出现所有这些东西,对我们的祖先来说同样陌生。
即使是在几十年前,这些沉思也很容易被认为实际上是不可能的,或者对于任何真正想要完成某事的人来说都是浪费时间。 (当我们建立我们的自主自我时,我们的精神能量将被释放以探索这些前沿。)
从我们如何应对气候变化、我们如何适应技术颠覆、我们如何构建人工智能、我们如何管理自己,以及我们如何发展和激发我们继续前进的理由,以保持现存的。
最近,我浓缩了这些想法,开始练习“零原理”思维,旨在发现变革性的新思想元素。它是具有“第一原则”思维的双胞胎。零原理思维是关于构建块或所有事物的结构,而第一原理思维是关于系统规律或事物如何相互作用。第一性原理思维以已知术语设定目标,然后追求它们,必要时发明和学习新事物,但它很少发现世界需要的那种全新的概念原语。
当人们说“从第一原则……”开始他们的论点时,他们的意思是他们希望在给定的框架内假设尽可能少的事情。太空探索的创新是一个很好的例子,说明了仅来自第一原理思考的好处。我们今天在太空的议程很有价值,也很困难,我们没有宇宙中存在的所有答案,但我们确实对问题和构建模块有很好的了解。很长一段时间以来,几乎没有发现用于太空旅行的新构建块——我们仍在研究 1970 年代相同基本概念的含义和规律,可以说,从牛顿一直追溯到。
夏洛克·福尔摩斯是一位经典的第一原则思想家,凭借他自己的谨慎逻辑品牌取得成功:“当你消除了不可能的事情时,剩下的任何事情,无论多么不可能,都必须是真实的。”在这一点上,福尔摩斯——毕竟被困在一本书中——可以假设一个封闭的物体宇宙,如果 X 和 Y 是唯一存在的事物,则非 X 与 Y 相同。
然而,道格拉斯·亚当斯(Douglas Adams)创造的与福尔摩斯(Sherlock Holmes)形成对比的“整体侦探”德克·詹特利(Dirk Gently)的演绎却有不同的方法:“我不喜欢消除不可能的事情”。这就是零原理思维。看穿盲点。
在谋杀案调查中,福尔摩斯不会考虑时间旅行可能发挥作用的可能性,甚至假设。不过,德克·金特利不排除这种可能性。部分原因是他怎么知道什么是可能的,什么是不可能的?这两种虚构的检测风格说明了逻辑上的根本区别。
说“从零原则……”是什么意思?
零阶技术
人类生存的未来不能仅从第一性原理思维推导出来。我们需要零探险家。如果我们不能完全模拟我们要去哪里或我们可以追求什么,那么制定具有明确目标并激发大规模合作的实际计划将具有挑战性。我认为这是一个功能,而不是一个错误。
我们与 AI 共同进化的未来将引入创纪录数量的类似零的构建块,这反过来又会提升我们的抱负。当大脑接口允许一个人的思想与人工智能实时配对时,我们可能会体验到类似寒武纪大爆发的 Zeros 的出现。我们的潜意识之于我们的思维,就像深度学习之于人工智能一样,当人工智能被利用时,它将能够产生看起来像是“来自另一个维度”的思想。
根据定义,你不能“归零”或直接在思考中引入新元素,所以你必须尝试将第一性原理的努力推向极端,直到没有边际收益。作为智能系统架构师的人类如何提高零发现的速度?
首先,来自技术和科学的更多示例:
- Andrej Karpathy 的软件 2.0 愿景是零阶软件工程,它使用“抽象的、对人类不友好的语言”通过深度神经网络 (DNN) 实现目标。这与软件 1.0 形成鲜明对比,在软件 1.0 中,人类编写显式代码来实现目标。也许 Karpathy 的范式可以标记为 Software 0.0?
- Daniel Dennett 的“Joosting”(跳出系统)概念旨在发现 Zeros。
- 当爱因斯坦假设所有观察者的光速可能是恒定的时,他发现了零,这揭示了一个新的概念原语。字面意思是“从另一个维度移动”。
或者,考虑引入零(原始的字面数字/概念)之前和之后的欧洲几何的历史例子。欧洲人认为他们对数学的理解必须从头开始重建,以在引入零概念后包含它。并不是说希腊时代的欧几里得元素突然变得过时或毫无价值。零的力量在于它允许重建现有的数学,以便对包括零概念在内的几何有更强有力的理解。这导致了笛卡尔几何——包括平面上坐标系原点在 (0, 0) 处的想法——并且突然之间,几何和代数可以通过十进制在概念上联系起来。
在欧洲人了解零之前,笛卡尔不可能提出笛卡尔几何。任何人都曾尝试过做越来越好的欧几里得几何。
我们需要更多这样的见解。在一个我们不断扩大我们的理解范围的世界里,每一个第零原理的洞察力都有可能解锁一组更广阔的领域。这不仅仅是由 Ray Kurzweil 推广的那种指数效应,即“向上”/曲棍球棒/曲线膝盖风格的东西。零是游戏规则的改变者。该图不仅是指数的 - 单位会发生变化。该图重新组织其轴。添加维度以适应“来自另一个维度”的想法。这就是 Zeros 带给你的东西。
在您发现新的构建块并了解它们的属性之前,您不知道什么大目标值得追求。
这是一个大问题,零探险者的口头禅:哪些概念隐藏在显而易见的地方,但任何人都看不到?我们如何以有限的人类认知开始“从另一个维度”思考?
与其渴望成为第一,不如成为零。
原文:https://medium.com/future-literacy/zeroth-principles-thinking-9376d0b7e…
- 53 次浏览
【系统架构】使用 ChatGPT 构建系统图——第二部分
视频号
微信公众号
知识星球
对思维导图感兴趣 — 阅读我们关于使用 plantUML 和 ChatGPT 创建很棒的思维导图的博文
继续我之前的帖子,我想专注于 C4 图表模型。 为了不让 ChatGPT 偏离初衷,我从下面的提示开始
提示:展望未来,我希望你充当软件架构师并使用 mermaid.js 构建 C4 图。 保留降价语法的答案,并始终牢记软件功能和非功能方面,包括但不限于可伸缩性、可用性、冗余、容器化、安全性和灾难恢复。
ChatGPT:当然,作为一名软件架构师,我可以帮助您使用 Mermaid.js 创建 C4 图,这些图考虑了功能和非功能方面,例如可扩展性、可用性、冗余、容器化、安全性和灾难恢复。
C4图是表示软件系统架构的一种方式,分为四个主要层次:
- 上下文级别(Context level),表示与系统交互的外部因素
- 容器级别(Container level),表示部署单元及其依赖项
- 组件级别(Component level),代表系统的不同组件
- 代码层级(Code level),代表了系统的实现细节
好的,让我们开始吧
上下文图(The Context Diagram)
Prompt: Let’s start by creating a context diagram of the services in Wealth Management ChatGPT: Sure, here’s an example of a context diagram in Mermaid format for a Wealth Management System:

在markdown 编辑器中

context diagram
此图显示了与财富管理系统交互的主要参与者以及系统提供的主要服务。
- 用户与账户管理服务、投资组合管理服务、资产管理服务和交易管理服务交互。
- 金融机构还与账户管理服务、投资组合管理服务、资产管理服务和交易管理服务交互。
- 市场与市场数据服务交互。
- 此图概述了参与者和服务之间的主要交互,它可能有助于理解系统的高级架构。
容器图(The Container Diagram)
到目前为止看起来不错。 接下来,让我们为其中一个服务构建一个容器级别的图表
Prompt: Let’s take the Portfolio service and break it down by creating a container diagram for its sub-functionalities ChatGPT: Sure, here’s an example of a container diagram in Mermaid format for the Portfolio Management Service of a Wealth Management System:

Container diagram
and markdown diagram

此图显示了组成投资组合管理服务的容器及其依赖项。
- Portfolio Management API 是用户和其他系统与服务交互的入口点。
- 投资组合管理工作者负责执行后台任务,例如根据市场变化更新投资组合。
- 投资组合管理数据库存储与投资组合相关的数据,如每个投资组合中持有的资产、它们的当前价值等。
- 负载均衡器在 Kubernetes 集群中运行的投资组合管理 API 实例之间分配传入流量。
- Kubernetes 集群负责管理容器的扩展、可用性和部署。
组件图(The Component Diagram)
Prompt: Next lets create the component level diagram for portfolio management api with all relevant details ChatGPT: Here’s an example of a component diagram in Mermaid format for the Portfolio Management API

and the corresponding mermaid diagram
 Component diagram for Portfolio Management API
Component diagram for Portfolio Management API
这是描述
此图显示了构成 Portfolio Management API 的不同组件及其依赖关系。
- 投资组合管理 API 的 API 网关组件是传入请求的入口点。
- 身份验证组件负责对用户进行身份验证。
- 授权组件负责检查用户的访问权限。
- Request Validator 组件负责验证传入的请求。
- 业务逻辑组件负责处理请求和执行业务逻辑。
- Response Formatter 组件负责在将响应发送回客户端之前格式化响应。
- 投资组合服务组件负责执行与投资组合管理相关的操作,如创建、读取、更新和删除投资组合,并与投资组合管理数据库通信以保存与投资组合相关的数据。
这看起来棒极了。 大多数细节与我的理解一致。 让我们尝试为 Portfolio Management Worker 构建相同的
Prompt: can we do the same for portfolio management worker container ChatGPT: Sure, here’s an example of a component diagram in Mermaid format for the Portfolio Management Worker container of a Wealth Management System:

and the mermaid diagram

Component Diagram for PM Worker
此图显示了构成 Portfolio Management Worker 容器的组件及其依赖项。
- Task Scheduler 组件负责安排更新公文包的后台任务。
- 投资组合更新器组件负责根据市场变化更新投资组合,它与市场数据服务通信以获取最新的市场数据。
- 市场数据服务组件负责为投资组合更新程序提供市场数据。
- 投资组合服务组件负责执行与投资组合管理相关的操作,如创建、读取、更新和删除投资组合,并与投资组合管理数据库通信以持久保存与投资组合相关的数据。
代码图(The Code Diagram)
让我们做最后一点,并为 Portfolio Management API 创建代码图
Prompt: Can you also do the code diagram for Portfolio Management API ChatGPT: Sure, here’s an example of a code diagram in Mermaid format for the Portfolio Management API of a Wealth Management System:

但是,当我尝试使用 Mermaid.js 在markdown 编辑器中创建它时,它无法指示循环依赖性。 我们在这里需要做的就是删除这些,如下所述

Corrected Code Graph
and the mermaid diagram

Portfolio Management API code packages
此图显示了构成 Portfolio Management API 的不同包及其依赖项。
- api 包是应用程序的入口点,它定义了路由和中间件。
- auth 包负责请求的认证和授权。
- 配置包负责加载配置文件。
- 控制器包负责处理请求和调用服务。
- errors 包定义自定义错误。
- 中间件包负责为处理 CORS、请求验证等请求提供中间件。
- 模型包定义了数据库实体的 ORM 模型。
- 服务包负责执行业务逻辑并与数据库通信。
- utils 包提供实用功能
太棒了,这是一篇描述 ChatGPT 功能的博客文章,尤其是在 C4 图表模型上。
谢谢阅读!
- 381 次浏览
【软件架构】5种软件架构的基本模式
软件是必不可少的。 用于创建我们每天都依赖的软件的主要架构模式是什么?

世界几乎每一项人类活动都越来越依赖软件。从我们用来与他人联系的移动应用程序到医疗保健应用程序和深度学习模型,从金融技术系统到利用技术自动化许多活动的智能建筑,软件系统已经渗透并简化了人类生活的许多方面。为了让这些软件系统提供我们想要的解决方案,它们必须建立在正确的架构上以产生最佳结果。
什么是架构模式?
就像建筑物的架构一样,软件架构描述了将组件设计和收集到构成软件构建块的系统中。软件架构解释了软件程序的结构组成和元素之间的交互。为这些软件系统定义软件组织模式的原则称为架构模式。
架构模式捕获各种系统和软件元素的设计结构,以便它们可以被重用。在编写软件代码的过程中,开发人员在一个项目中、公司内部以及他们的职业生涯中多次遇到类似的问题。解决这个问题的一种方法是创建设计模式,为工程师提供解决这些问题的可重用方法,允许软件工程师在结构上为给定项目实现相同的输出。
从工程师的角度来看,软件架构模式很重要,因为它们提高了效率和生产力。由于开发人员已经了解项目中使用的架构模式,因此开发人员可以在任何时候加入有限的入职培训项目。新功能也可以毫无困难地添加到项目中,并且可以轻松解决常见的应用程序问题。
从客户的角度来看,架构模式优化了开发成本,加快了项目的时间线,并允许工程师交付高质量的产品。成本估算是基于对架构系统的理解,因此产品经理拥有更准确的项目成本,从而可以进行早期规划和预算。此外,明确定义的架构意味着系统已经过验证和范围。这有助于工程师专注于产品的基本要素,并允许管理人员为项目完成做好充分的计划。
有不同类型的软件架构模式,但在本文中,我们将探讨其中的五种以及它们如何成为软件开发的组成部分。
模型-视图-控制器模式
模型-视图-控制器 (MVC) 模式将应用程序分为三个组件:模型、视图和控制器。
模型是模式的核心组件,包含应用程序数据和核心功能。它是软件应用程序的动态数据结构,它控制着应用程序的数据和逻辑。但是,它不包含描述数据如何呈现给用户的逻辑。
视图显示应用程序数据并与用户交互。它可以访问模型中的数据,但无法理解数据,也无法理解如何操作数据。
控制器处理来自用户的输入并在模型和视图之间进行调解。它监听来自视图或用户的外部输入并创建适当的输出。控制器通过调用模型上的方法来与模型交互以生成适当的响应。
这三个组件通过某种形式的通知进行交互,例如事件或回调。这些通知包含状态信息,例如状态更改,它们被传达以更新这些组件。例如,可以将来自用户的外部事件传输到控制器以更新视图。因此,MVC 模式将软件组件解耦并允许轻松重用代码。

JavaScript、Python、Java 和 Swift 等主要编程语言都有 MVC 框架来开发 Web 和移动应用程序。 Web 应用程序框架,例如 Ruby on Rails 和 Django(用于 Python)都是基于这种架构。
MVC 模式的一个优点是多个工程师可以同时处理所有三个组件而不会发生冲突。此外,MVC 允许对相关输出进行逻辑分组,以从模型中生成大量视图。然而,一个缺点是导航框架可能很复杂,因为它引入了几个抽象层。
有用的参考资料:
- 通过编码恐怖理解模型-视图-控制器(2008)
- 来自原始 XEROX PARC 的 MVC 定义 (1978-79)
- Codecademy 对 MVC 的介绍
微服务模式
微服务模式涉及创建多个可以相互依赖地工作的应用程序或微服务。尽管每个微服务都可以独立开发和部署,但其功能与其他微服务交织在一起。
微服务模式中的一个关键概念是单元的单独部署。这创建了一个简化的交付管道,允许轻松部署微服务并提高应用程序的可扩展性。该模式的另一个关键特性是它是一种分布式架构,这意味着该结构的组件可以完全解耦,并可以通过 REST、SOAP 或 GraphQL 等远程访问协议进行访问。该模式的这种分布式特性使其具有高可扩展性。
微服务架构使用了几种设计模式:聚合器模式、API 网关设计模式、责任链模式、分支模式和异步消息传递设计模式。每种方法都提供了一种操作数据以产生服务的方法。

微服务架构的一个主要优势是每个微服务的独立部署。工程师可以独立于其他微服务编写和维护每个微服务,从而潜在地增加其功能和可扩展性。此外,由于每个微服务都很小,因此更容易重写和更新。微服务架构最适合具有小型组件的 Web 应用程序和网站。它对于边界明确的企业数据中心也很有用。微服务面临的一些挑战来自复杂性,尤其是在网络层。此外,将服务解耦以完全独立工作需要大量的架构专业知识。
有用的参考资料:
- Martin Fowler (2014) 的微服务定义
- 微服务架构中的分布式事务模式 (2018)
- 微服务教程,包括 Kubernetes 实践
客户端-服务器模式
在客户端-服务器架构模式中,有两个主要组件:客户端,即服务请求者,以及服务器,即服务提供者。尽管客户端和服务器可能位于同一系统中,但它们通常通过网络在不同硬件上进行通信。
客户端组件启动与服务器的某些交互以生成所需的服务。客户端组件具有描述所需服务的端口,而服务器具有描述它们提供的服务的端口。这两个组件都由请求/回复连接器链接。这种架构模式的一个典型例子是万维网。客户端-服务器模式也用于在线应用程序,例如文件共享和电子邮件。

一个简单的例子是网上银行服务。当银行客户使用网络浏览器访问网上银行服务时,客户端会向银行的网络服务器发起请求。在这种情况下,Web 浏览器是客户端,使用客户的登录详细信息访问银行的 Web 服务器以获取数据。应用程序服务器使用银行的业务逻辑解释这些数据,然后将适当的输出提供给 Web 服务器。
这种架构模式的一个主要优势是数据的中央计算;所有文件都存储在该网络的中心位置。因此,数据以及网络外围设备都是集中控制的。然而,一个缺点是服务器的购买和管理成本很高。
客户端-服务器模型与点对点架构模式相关,通常被描述为该模式的一个子类别。后者使用分散系统,其中对等方直接相互通信。
有用的链接:
- 什么是客户端-服务器架构?
- Red Hat 对 REST 架构的介绍
控制器-响应者模式
这通常被称为主/从架构模式,但由于它不是一个有用的比喻,一些工程师和软件公司采用了替代术语,如主/从、主/副本、父/助手、主/副本或控制器/响应者模式。最值得注意的是,IEEE 已将此作为网络技术的更好术语。
与客户端-服务器架构模式一样,此模式由两个组件组成:控制器和响应器。控制器组件在相同的响应器组件之间分配输入或工作,并从每个响应器生成的结果中生成复合结果。

简单来说,控制器是实际的数据保管者,而响应者复制存储在控制器数据库中的数据。写入数据仅在控制器数据库中完成,由响应者数据库读取。控制器确定响应者的通信优先级并对其进行控制。这与点对点架构模式不同,其中计算机平等通信并分担责任。
控制器-响应者模型的一个示例包括使用盒式磁带或光盘记录器完成的复制。
这种模式的一个关键优势是可以从响应程序组件中读取分析应用程序,而无需更改控制器组件的数据内容。此外,响应者可以离线并同步回来,而不会浪费任何时间。但是,当控制器发生故障时,所有数据都可能丢失,并且可能必须重新启动应用程序。在这些情况下,响应者可能会被提升为控制者,但并非没有一些数据和技术缺陷。
有用的链接:
- 来自 IEEE (2006) 的分布式进化计算的主从架构分析
- Packt 的主从架构
分层图案
分层架构模式在开发人员中最为常见。它对于包含多组子任务的程序很有用,每组子任务都处于不同的抽象级别。这些子任务中的每一个都由软件中的一个层表示——一个产生一组内聚服务的模块单元——并且每一层以单向模式向下一个更高层提供服务。
每一层在应用程序中都有一个特定的角色,该角色与其他层的角色相关联。例如,表示层(也称为 UL 层)将处理所有 UI 和浏览器通信逻辑,而业务逻辑层将执行某些业务请求。
其他类型的层包括应用程序层和数据访问或持久层,然后访问数据库层。这允许分离数据库层,并使您能够从 Oracle 服务器切换到 SQL 服务器,而不会影响其他层——它可以降低转换成本。
这些层以单向模式交互,因此当用户发起输入(例如单击按钮)时,表示层将消息发送到较低层,即应用层,后者又调用业务层,然后是数据访问数据库的访问层。因此,呼叫以分层模式向下流动,从较高层流向较低层。

分层架构模式存在于许多电子商务 Web 应用程序和桌面应用程序中。它对于需要快速构建的应用程序和需要采用传统 IT 流程的企业应用程序也很有用。此外,分层模式非常适合需要严格的可测试性标准的应用程序。
这种模式的一个关键优势是它允许以一种简单的方式来编写一个组织良好的应用程序。由于它是一种流行的架构模式,因此开发人员已经了解它的使用方式。但是,它确实有两个主要缺点:复杂性和添加更多层的成本。这些层最终可能难以拆分。
有用的参考资料:
- Mark Richards 的软件架构模式中的分层架构
- 软件架构模式 — Priyal Walpita 的分层架构
底线
其他几种架构模式,包括管道过滤器模式、黑板模式、代理模式和事件总线模式,在软件开发的不同方面也很有用。这个概念对所有人都是一样的:定义应用程序的基本特征,增强产品的功能,提高应用程序构建过程的效率和生产力。
但是,使用错误的架构模式可能会延迟您的项目,甚至可能导致软件故障。因此,关键是要充分了解架构模式以及它们最适合哪些应用程序,以便您可以选择适合您的软件需求的应用程序。
原文:https://www.redhat.com/architect/5-essential-patterns-software-architec…
- 154 次浏览
非常棒
非常棒