数据和隐私保护
数据和隐私保护 intelligentx- 350 次浏览
【GDPR】支持GDPR合规决策的人工智能框架:第二部分
视频号

微信公众号

知识星球

2相关工作
我们的工作反映了最近人们对人工智能技术在各种法律领域中对文本数据的作用的兴趣(Dadgostari et al.,2020;De Martino et al.,2022;Tagarelli和Simeri,2021),包括GDPR领域(Kingston,2017)。在这方面,我们首先概述了最近的研究工作,这些工作主要有助于GDPR应用中人工智能的调查。然后,由于我们的重点是意大利PA制作的文本文件的GDPR合规性,我们描述了一些采用NLP来识别和提取敏感数据的工作,特别是在PA文件中。
2.1 AI和GDPR
根据欧盟和国家立法的规定使用人工智能预计将显著提高公司和公共办公室的效率水平(Stamova和Draganov,2020)。这一预期促使最近的几项研究探索人工智能与GDPR之间的关系。这些研究主要可分为两个领域:人工智能的GDPR合规性和人工智能对GDPR的合规性。
2.1.1 AI的GDPR合规性
2020年初,欧盟委员会发布了一份关于人工智能监管的白皮书,正式确定了人工智能遵守GDPR的问题。脚注4该文件强调了审查欧盟立法框架的必要性,以使其适应当前的技术发展。特别是,它澄清了当人工智能技术处理个人数据、进行分析以及基于个人数据和/或影响数据主体的自动决策时,GDPR始终适用于人工智能。针对这些问题,2021年4月发布的欧盟人工智能监管提案Footnote5是欧盟委员会数字战略的最新补充,该战略迈出了《通用数据保护条例》对人工智能监管的第一步。在这方面,Sartor和Lagioia(2020)最近探讨了人工智能在多大程度上符合《通用数据管理条例》的概念框架。这项研究描述了人工智能应用于个人数据的法律基础,以及与人工智能系统有关的信息的义务,特别是涉及分析和自动决策的信息。
从这个角度来看,GDPR制定的“解释权”也带来了一个不小的技术挑战,即在使用人类可解释的逻辑操作的同时,充分利用机器学习或人工智能系统的力量(Selbst&Powles,2017)。事实上,当个人仅根据对其产生重大影响的自动处理做出决定时,GDPR创造了“有关所涉及逻辑的有意义信息”的权利。例如,使用人工智能系统提出治疗计划的医生需要知道为什么确定了某一行动方案,以便向患者解释该决定。需要一种方法来证明、解释和审计不可理解的系统。围绕“解释权”的辩论引起了法律和人工智能界的高度兴趣,而这在技术上是否可行的问题仍然是一个悬而未决的问题。国防高级研究计划局(DARPA)于2016年发起了一项“可解释人工智能”倡议,旨在创建一个由机器学习和人机界面软件模块组成的工具包库,用于开发未来的可解释人工系统。遵循这一研究方向,Sovrano等人的研究。(2020)最近为符合GDPR的值得信赖的人工智能引入了一个以用户为中心的解释模型。特别是,该研究基于ISO 9241中的概念,引入了以用户为中心的解释作为解释性叙述的定义,并通过识别良好解释的基本属性和探索解释空间的启发式方法,提出了交互式解释过程的正式模型。
相反,Meszaros和Ho(2021)的研究确定了学术和商业研究如何在人工智能产品和服务的开发中应用GDPR之间的差异。主要结果是,公司进行的商业研究可能没有像学术研究人员那样的道德和制度保障。此外,该研究强调需要在隐私和创新之间找到适当的平衡。总的来说,欧盟的愿景是,透明度和问责制可以在人工智能的GDPR合规性范围内共同建立信任。然而,这是一个公开的挑战,目前仍需要在欧盟法律方面进行进一步的监管,并在负责任的发展方面进行新的科技努力。
2.1.2符合GDPR的AI
随着GDPR成为法律,最后一刻的匆忙开始变得合规。许多公司开始就如何遵守GDPR提供建议、检查表和咨询。在这样的环境中,人工智能通过提供最佳建议、询问所有相关问题和进行评估而成为一项关键技术(Kingston,2017)。这一想法受到了一些研究的启发,这些研究甚至在GDPR于2018年5月生效之前,就开始探索如何将基于法律的系统(如基于规则的系统)用作智能检查表,以在风险分析中验证GDPR的合规性(Al-Abdulkarim et Al.,2016;金斯敦,2017;van Engers,2005)。
受这些研究的启发,人工智能技术被探索用于隐私政策法律评估自动化中的GDPR合规性,这是公司向用户告知其数据收集和共享实践的主要渠道。自从该领域的开创性人工智能研究(Contissa et al.,2018;Sánchez et al.,2021)依赖于专家手动注释的数据集进行分类以来,自动注释开始受到一些关注。在这方面,Harkous等人探索了一种深度学习方法。(2018),以便用预先指定的分类法中的高级和细粒度标签自动注释以前看不见的隐私策略。
另一方面,在文本数据(如警察报告、医疗档案)本质上是敏感的或受隐私法(如GDPR)保护的情况下,NLP的最新发展导致人们对探索NLP方法在各种数据保护问题中的文本处理越来越感兴趣,如文本匿名化。Mozes和Kleinberg(2021)最近修订了最近的研究,该研究通过分析评估标准来评估保护个人不被基于人工智能的方法重新识别的有效能力,从而在文本匿名化中利用NLP。
人工智能在GDPR合规方面也引起了流程挖掘方面的关注。这是一个通常利用人工智能技术主要依靠流程执行数据来提供业务流程见解的领域(van der Aalst,2016)。在流程挖掘中,如何使业务流程符合GDPR的问题最初由Zaman等人提出。(2019)。根据本初步研究中定义的指导方针,流程挖掘技术最近进行了调整,以确定业务流程执行是否符合数据主体权利,并实现符合GDPR的业务流程发现(Zaman和Hassani,2020)。
最后,Davari和Bertino(2019)研究了表示GDPR同意的语义模型。该模型是明确的、可理解的和可重用的。此外,它还与基于区块链的模型相结合,以确保组织在用户同意方面遵守GDPR。
2.2识别敏感数据的NLP
当开发一个自动系统来将文档分类为是否符合GDPR时,我们必须面对的问题之一是提取相关实体和有意义的特征。识别命名实体并发现它们之间的关系是所提出的框架的核心任务。事实上,在意大利公共管理领域,许多违反GDPR的行为都表现为发布包含个人数据的文件(例如患有某种疾病的员工的姓名)。因此,我们专注于为上述框架定义适当的命名实体识别(NER)策略。特别是,我们评估了NER作为检测文本文档中个人身份信息的一种方法的使用。NER是NLP任务之一,旨在找到文本中存在的命名实体并将其分类为特定和预定义的类别(Yadav&Bethard,2019)。
先前的研究已经采用NER来识别有助于公共行政文件中文本挖掘和分类的实体。例如,(Romano等人,2020)提出了一个从最高上诉法院发布的判决(意大利司法系统的最后一级判决)中提取数据的框架。特别是,该框架以NER为基础,用于检测公司名称及其法律形式;然后,被认可的实体与商业登记中的额外信息联系起来,为分析犯罪事件创造条件。
另一项与拟议框架有关的工作是Silva等人(2020),其中作者评估了NER的使用,将其作为识别、监控和验证合同中个人身份信息(PII)的一种方式。特别是,他们评估了两种工具(Stanford CoreNLP和SpaCy)的性能,并展示了NER在不同场景下如何有效地自动监测PII。
Di Cerbo和Trabelsi(2018)中描述的工作强调了确定性方法(如正则表达式)在将个人信息检测到半结构化或非结构化档案中的局限性。因此,采用了基于朴素贝叶斯和卷积神经网络的NER技术来识别来自社交媒体的数据中个人信息的存在和性质。
Dias等人最近针对GDPR所涵盖的敏感数据开展了另一项关注净入学率的工作。(2020)。作者提出了一种解决葡萄牙语NER问题的混合方法,该方法结合了基于规则、基于词汇的模型、机器学习算法和神经网络等多种技术。不同方法的使用涵盖了代表敏感数据的所有类别的实体。这项工作再次强调,命名实体在行政行为中发挥着重要作用,特别是在识别敏感数据方面,需要努力在这一特定背景下调整最先进的算法。例如,由于“官僚”语言和标准意大利语之间的差异,例如使用不常见的正式术语或特定缩写,用命名实体注释的现有意大利语料库对于训练PA领域的NER来说不是最佳的。
Passaro等人试图解决这个问题。(2017),其中作者描述了为意大利PA文件设计NER系统的过程。他们从头开始创建了一个新的语料库,从市政当局发布的行政文件开始,然后调整通用NE识别器,将标准NE类扩展到与市政当局特别相关的其他实体类型。我们采用了类似的方法来识别可能与GDPR合规性相关的实体类型。此外,我们研究了如何将已识别的命名实体注入文本数据工程步骤,以训练能够分析意大利PA文件的GDPR合规性的分类模型。
最后,基于NER的方法在文本匿名化问题中得到了广泛的探索。例如,Adams等人(2019)描述了一个集成了NER模块和共同参考模块的系统。该系统允许我们识别人机对话文本的块,这些文本包含特定类别的敏感标记(例如个人姓名、地址、设施、组织)。Francopoulo和Schaub(2020)采用了一个NER模块,该模块级联模式匹配规则来识别几个类别中的实体(例如,个人姓名、地点、公司、电子邮件地址),并在客户关系管理的背景下执行匿名操作。Biesner等人(2022)最近探索了基于递归神经网络和转换器架构的NLP方法的性能,以检测和匿名化德国财务和法律文件中的敏感信息。
最后,Csányi等人(2021)探讨了基于NER的工具在匈牙利法院法律文件匿名化中的表现,得出的结论是,数学统计分析对于过滤可能作为主要标识符的独特事件(例如,外科医生截肢)至关重要。然而,这项研究也强调了使用基于机器学习的方法和匿名化模型来降低重新识别风险的必要性。我们的工作遵循这一研究方向,将用于NER的NLP方法和用于分类的机器学习方法相结合。
2.3新贡献
我们的研究可以归类在人工智能的GDPR合规保护伞下。与这一保护伞下的大多数研究类似,我们采用问题的文本分类公式,并采用NLP技术,特别是NER技术,从非结构化文本中提取有用的信息,并将文本分类到预定义的类别中。目前,已经研究了NER工具在各种情况下(如聊天文本、法律文件)的数据保护和文本匿名化。因此,我们研究的一个新颖之处是使用人工智能解决具体的GDPR合规问题。事实上,据我们所知,这是第一项研究如何有效地使用人工智能框架来自动化意大利PA文本语料库数据保护中涉及的GDPR智能的工作。
值得注意的是,本研究开始时解决的一个主要困难是缺乏基准数据。这需要准备一个语料库,并使用适当的管道来平衡用人工标识符替换任何已识别或可识别信息的需要,以及GDPR检查不适用于匿名信息的事实。
与之前的研究相比,另一个不同之处在于将意大利语处理的特定语言资源调整为PA文件的GDPR情报。Passaro等人也进行了调整工作。(2017),但没有探索文档分类步骤的机器学习算法的性能。一般来说,以前的研究主要集中在通过NER调查进行数据保护。相反,在我们的研究中,我们还探索了在基于Bag of Word(boW)和NER的工程数据上训练的各种分类算法(即支持向量机、随机森林和XGBoost)的性能。为此,我们定义了几种基于NER的文本工程方案,并结合BoW信息和各种分类算法来评估它们的性能。
值得注意的是,Contissa等人(2018)和Sánchez等人(2021)也对分类模型进行了训练,用于根据公司的隐私政策是否符合GDPR的数据保护目标对其进行分类。然而,这两项研究都从专家手动注释的数据集中训练支持向量机。不同的是,我们解决了一个更复杂的学习问题,其中必须使用针对所研究的特定问题调整的NER工具自动执行注释。
- 108 次浏览
【GDPR】支持GDPR合规决策的人工智能框架:第五部分
视频号
微信公众号
知识星球
5实验评价
为了评估所提出的框架的有效性,我们在第3节中描述的文本语料库上进行了一系列实验。
5.1评价目标
这项实验研究的主要目的是探索如何有效地将INTREPID作为一种基于人工智能的工具来验证用意大利语编写的PA文件的GDPR合规性。为此,我们评估了如何使用SpaCy和Tint的NER模型来准确定位和分类所考虑的文本语料库中的命名实体。我们研究了基于BoW的特征和基于NER的特征对SVM准确性的影响,SVM被训练来验证文本语料库的GDPR合规性。具体而言,我们打算回答以下问题:
- 问题1:通过改变NER模型,即SpaCy模型和Tint模型,NER阶段的准确性如何变化?(第5.3.1节)
- 问题2:文本预处理操作的使用(即变位、停止语删除、小写转换)如何改变基于BoW的特征产生的GDPR合规性预测的准确性?(第5.3.2节)
- 问题3:每个基于净入学率的特征组如何对GDPR合规性预测的准确性做出贡献?(第5.3.3节)
- 问题4:INTREPID是否比其分别考虑基于BoW的功能或基于NER的功能的基线框架更强大?(第5.3.4节)
作为基线框架,我们考虑了BoW和NER,它们分别从基于BoW的特征和基于NER的特征中训练分类器。我们评估了用SVM、RF和XGBoost训练的分类器的性能。
5.2评价方法和评价标准
我们通过计算用SpaCy和Tint识别和分类的命名实体的Precision、Recall和F分数,测量了NER模型在匿名文本语料库上的性能。对于这两种NER工具,我们考虑了第4.2节中所述的经过预训练的NER模型。这三个指标用于评估NER工具对特定实体类别i的预测能力。实体类别i上的F分越高,NER工具在i上实现的精度和召回率之间的平衡就越好。相反,当一个指标以牺牲另一个指标为代价进行改进时,F分就不那么高。此外,我们通过计算MacroF来测量NER工具的总体性能,即,
MacroF=1k∑i=1kFi.
这是一个标准的多类度量,通常用于评估多类分类模型的整体预测能力。它测量每个命名实体类别i的平均F分数。注意,在MacroF的计算中,我们给每个实体类别赋予相等的权重。通过这种方式,我们避免了我们的评估抵消了实体设置不平衡可能带来的影响。
类似地,我们通过计算文档预测的F分来测量为验证公共文档的GDPR合规性而训练的分类器的性能。我们评估了通过分类算法(SVM、RF和XGBoost)训练的分类器的性能,方法是根据留一交叉验证对训练和测试文档中的匿名文本语料库进行划分(Hastie et al.,2001)。对于每个试验,我们在训练集上训练了比较方法的分类器(89次折叠),并评估了它们在测试集的文档上预测GDPR合规性的能力(保持折叠)。我们计算了所有90项测试试验得出的GDPR合规性预测的F分。
5.3结果
在本节中,我们将说明评估研究中收集的实验结果如何使我们能够解决所提出的研究问题。
5.3.1净入学率分析(Q1)
我们开始分析Tint和SpaCy在标记命名实体时的准确性性能。我们将两个NLP管道提供的输出与语料库中专家提供的注释进行比较。特别是,我们使用两种方法比较了两种NER工具的性能:
精确:如果开始偏移和结束偏移都等于注释中相应的偏移,则输出是正确的;
OVERLAP:如果其跨度与注释的跨度重叠,则输出是正确的。
表4和表5报告了精确度、召回率和F分数,分别用EXACT和OVERLAP为每个实体类别计算。使用精确匹配(表4)计算的结果非常低,特别是对于SpaCy。这些结果是意料之中的,因为NLP工具最初是在一个完全不同的领域上训练的。此外,所考虑的领域非常具体。另一方面,如果我们考虑OVERLAP方法,我们会获得更好的结果(表5)。在任何情况下,无论采用何种方法,Tint都能获得比SpaCy更好的结果。最后,查看每个实体类别的结果,我们可以注意到AMM、LOC和ORG是最难识别的类别,而这两个工具在PER、MED和OM上都实现了更好的性能。
Table 4 NER accuracy results using EXACT match
From: An AI framework to support decisions on GDPR compliance
|
Category |
Tint |
SpaCy |
||||
|---|---|---|---|---|---|---|
|
Precision |
Recall |
F |
Precision |
Recall |
F |
|
|
AMM |
0.6196 |
0.1237 |
0.2062 |
0.5892 |
0.0993 |
0.1700 |
|
LOC |
0.2368 |
0.6750 |
0.3506 |
0.0456 |
0.6000 |
0.0847 |
|
ORG |
0.2652 |
0.2085 |
0.2335 |
0.0926 |
0.0651 |
0.0765 |
|
PER |
0.6862 |
0.6450 |
0.6649 |
0.3069 |
0.3875 |
0.3425 |
|
MED |
0.7351 |
0.6793 |
0.7061 |
0.8222 |
0.6319 |
0.7146 |
|
OM |
0.9902 |
0.9712 |
0.9806 |
0.9894 |
0.8942 |
0.9394 |
|
macroF |
0.5237 |
0.3880 |
||||
- The best MacroF is underlined
Table 5 NER accuracy results using OVERLAP
From: An AI framework to support decisions on GDPR compliance
|
Category |
Tint |
SpaCy |
||||
|---|---|---|---|---|---|---|
|
Precision |
Recall |
F |
Precision |
Recall |
F |
|
|
AMM |
0.8325 |
0.1662 |
0.2771 |
0.8244 |
0.1390 |
0.2378 |
|
LOC |
0.3026 |
0.8625 |
0.4481 |
0.0598 |
0.7875 |
0.1112 |
|
ORG |
0.5226 |
0.4110 |
0.4601 |
0.2938 |
0.2065 |
0.2425 |
|
PER |
0.8191 |
0.7700 |
0.7938 |
0.4693 |
0.5925 |
0.5238 |
|
MED |
0.8480 |
0.7837 |
0.8146 |
0.9111 |
0.7002 |
0.7918 |
|
OM |
1.0000 |
0.9808 |
0.9903 |
1.0000 |
0.9038 |
0.9495 |
|
MacroF |
0.6307 |
0.4761 |
||||
- The best MacroF is underlined
根据本次评估的结果,所有后续分析都将考虑将Tint作为NER工具。
5.3.2基于工程量清单的分类分析(Q2)
我们继续探索通过考虑基于BoW的特征来训练的分类器的准确性性能。分类器采用SVM、RF和XGBoost三种分类算法进行训练。测试配置分别表示为:BoW+SVM、BoW+RF和BoW+XGBoost。在本实验中,我们通过改变分类算法,分析了引理化、停止词去除和小写变换对使用基于BoW的特征训练的分类器的准确性性能的影响。
表6中报告的结果表明,通过应用一些文本预处理操作,在每个分类算法中都实现了最高的准确性性能。然而,所采用的文本预处理操作可能会对分类算法的性能产生不同的影响。值得注意的是,在所有分类算法中,通过执行文本的小写转换来实现最佳的准确性性能。然而,在BoW+SVM中,通过降低文本语料库的大小写和去除停止词来实现最高的准确性性能。另一方面,在BoW+RF中,通过降低文本语料库的大小写、执行旅语化和去除停止词来实现最高的准确性性能。在BoW+XGBoost中,通过降低文本语料库的规模和进行引理来实现最高的准确性。最后,我们注意到,通过将SVM分类器作为亚军来训练XGBoost分类器,实现了基于BoW的特征的最高精度性能。
Table 6 F score of BoW+SVM, BoW+RF and BoW+XGBoost with respect to pre-processing operations (lemmatization, lowercase transformation and stopword removal)
From: An AI framework to support decisions on GDPR compliance
|
Conf. |
Lemm. |
Lowercase |
Stopword |
F-NC |
F-C |
MacroF |
|---|---|---|---|---|---|---|
|
BoW+SVM |
0.7692 |
0.7692 |
0.7692 |
|||
|
× |
0.8132 |
0.8132 |
0.8132 |
|||
|
× |
0.7473 |
0.7473 |
0.7473 |
|||
|
× |
× |
0.8352 |
0.8315 |
0.8333 |
||
|
× |
0.7473 |
0.7473 |
0.7473 |
|||
|
× |
× |
0.7473 |
0.7527 |
0.7500 |
||
|
× |
× |
0.7473 |
0.7473 |
0.7473 |
||
|
× |
× |
× |
0.7473 |
0.7416 |
0.7444 |
|
|
BoW+RF |
0.7363 |
0.7391 |
0.7377 |
|||
|
× |
0.7363 |
0.7447 |
0.7405 |
|||
|
× |
0.7253 |
0.7312 |
0.7282 |
|||
|
× |
× |
0.7253 |
0.7368 |
0.7311 |
||
|
× |
0.7582 |
0.7609 |
0.7596 |
|||
|
× |
× |
0.7582 |
0.7755 |
0.7669 |
||
|
× |
× |
0.7692 |
0.7742 |
0.7717 |
||
|
× |
× |
× |
0.7912 |
0.8000 |
0.7956 |
|
|
BoW+XGBoost |
0.7692 |
0.7742 |
0.7717 |
|||
|
× |
0.8022 |
0.8085 |
0.8054 |
|||
|
× |
0.7802 |
0.7826 |
0.7814 |
|||
|
× |
× |
0.7473 |
0.7473 |
0.7473 |
||
|
× |
0.7692 |
0.7692 |
0.7692 |
|||
|
× |
× |
0.6923 |
0.6889 |
0.6906 |
||
|
× |
× |
0.8462 |
0.8511 |
0.8486 |
||
|
× |
× |
× |
0.6264 |
0.6304 |
0.6284 |
- NC denotes the label “non-compliant”, C denotes the label “compliant”. The best results are underlined
5.3.3基于净入学率的分类分析(Q3)
随后,我们探讨了通过考虑基于NER的特征来训练的分类器的性能。
表7中报告的NER+SVM、NER+RF和NER+XGBoost的结果表明,使用基于NER的特征实现的精度性能随分类算法的不同而变化。在NER+SVM中,通过考虑BoNE特征组的命名实体袋来训练SVM分类器的配置实现了最高的精度性能。进一步的准确性既不能通过利用命名实体的二进制图(BoNNEG特征组)也不能通过将单词信息与命名实体相结合(BoWNe特征组)来获得。另一方面,在NER+RF中,使用与命名实体组合的单词信息(BoWNe特征组)来训练RF分类器的配置实现了最高的精度性能。最后,在NER+XGBoost中,通过分别考虑命名实体的袋(BoNE特征组)或命名实体的二进制图(BoNNEG特征组),或单词信息与命名实体的组合(BoWNe特征组)来实现最高精度。值得注意的是,通过训练具有RF分类器作为亚军的SVM分类器,实现了具有基于NER的特征的最高精度性能。
Table 7 F score of NER+SVM, NER+RF and NER+XGBoost with respect to NER-based feature groups (BoNE, BoNNEG and BoWNE)
From: An AI framework to support decisions on GDPR compliance
|
Conf. |
BoNE |
BoNNEG |
BoWNE |
F-NC |
F-C |
MacroF |
|---|---|---|---|---|---|---|
|
NER+SVM |
× |
× |
× |
0.8352 |
0.8421 |
0.8386 |
|
× |
× |
0.8352 |
0.8421 |
0.8386 |
||
|
× |
× |
0.8352 |
0.8421 |
0.8386 |
||
|
× |
0.8352 |
0.8421 |
0.8386 |
|||
|
× |
× |
0.7473 |
0.7473 |
0.7473 |
||
|
× |
0.7473 |
0.7473 |
0.7473 |
|||
|
× |
0.6593 |
0.6173 |
0.6376 |
|||
|
NER+RF |
× |
× |
× |
0.6703 |
0.6809 |
0.6755 |
|
× |
× |
0.6703 |
0.6809 |
0.6755 |
||
|
× |
× |
0.7582 |
0.7660 |
0.7621 |
||
|
× |
0.7582 |
0.7660 |
0.7621 |
|||
|
× |
× |
0.7582 |
0.7660 |
0.7621 |
||
|
× |
0.7582 |
0.7660 |
0.7621 |
|||
|
× |
0.7912 |
0.7957 |
0.7934 |
|||
|
NER+XGBoost |
× |
× |
× |
0.6374 |
0.6374 |
0.6374 |
|
× |
× |
0.6374 |
0.6374 |
0.6374 |
||
|
× |
× |
0.7582 |
0.7609 |
0.7596 |
||
|
× |
0.7692 |
0.7789 |
0.7741 |
|||
|
× |
× |
0.7692 |
0.7789 |
0.7741 |
||
|
× |
0.7692 |
0.7789 |
0.7741 |
|||
|
× |
0.7692 |
0.7789 |
0.7741 |
- NC denotes the label “non-compliant”, C denotes the label “compliant”. The best results are underlines
5.3.4 INTREPID与基线分析(第4季度)
最后,我们探讨了所提出的框架INTREPID的准确性性能,该框架通过考虑通过同时连接基于BoW的特征和基于NER的特征而获得的特征向量来训练分类器。我们再次通过改变SVM、RF和XGBoost之间的分类算法来分析INTREPID的性能。对于每种分类算法,我们运行了56种不同的INTREPID配置,这些配置是通过改变基于BoW的特征提取中文本预处理管道的设置(引理、小写和停止字去除)以及基于NER的特征提取的基于NER特征工程方案的选择来定义的。实验配置如表8所示。
Table 8 Configurations of INTREPID
From: An AI framework to support decisions on GDPR compliance
|
Feature Group |
Parameter |
Value Range |
|---|---|---|
|
BoW |
Lemmatization |
{enabled, disabled} |
|
Lowercase |
{enabled, disabled} |
|
|
Stopword |
{enabled, disabled} |
|
|
NER |
BoNE |
{enabled, disabled} |
|
BoNNEG |
{enabled, disabled} |
|
|
BoWNE |
{enabled, disabled} |
- In each configuration, both BoW-based features and NER-based features are computed, so that at least one option among BoNE, BoNNEG and BoWNE is enabled
图4显示了为“不符合”(F-NC)和“符合”(F-3)两类计算的F分数的方框图,以及分别为SVM、RF和XGBoost分类算法在INTREPID运行配置上计算的MacroF度量。这些结果表明,XGBoost的性能最高,支持向量机排名第二。
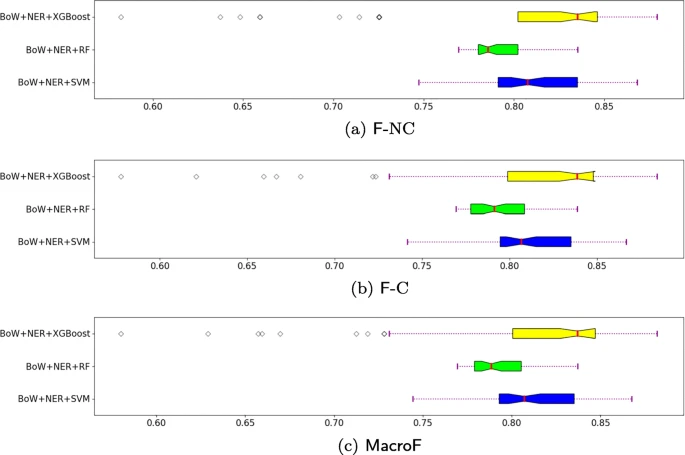
F-NC (Fig. 4a), F-C (Fig. 4b) and MacroF (Fig. 4c) of INTREPID (Bow+NER) with SVM, RF and XGBoost as classification algorithms
我们通过分别考虑基于BoW的特征或基于NER的特征,将INTREPID的准确性性能与训练分类器的基线的准确性性能进行了比较。表9显示了使用这三种方法获得的最高精度性能。这些结果证实,用于构建基于BoW的特征和基于NER的特征的最佳集合随着分类算法的变化而变化。此外,他们还表明,基于NER的特征通常与SVM和RF的基于BoW的特征表现得很接近,而它们的表现比SVM的基于BoW的特征差。无论如何,在同一分类阶段(INTREPID)中利用基于BoW的特征和基于NER的特征,我们可以学习一种分类器,该分类器能够在验证用意大利语编写的PA文件的GDPR合规性时获得准确性。这一结论可以独立于分类算法得出,尽管当分类器使用XGBoost训练时,INTREPID实现了最高的准确性性能。
Table 9 MacroF metric of INTREPID vs. BoW-based and NER-based classifiers trained with SVM, RF and XGBoost
From: An AI framework to support decisions on GDPR compliance
|
Classif. |
Method |
MacroF |
Configuration set-up |
|||||
|---|---|---|---|---|---|---|---|---|
|
BoW-based features |
NER-based features |
|||||||
|
Le. |
Lo. |
St. |
BoNE |
BoNNEG |
BoWNE |
|||
|
SVM |
INTREPID |
0.8673 |
× |
× |
||||
|
BoW |
0.8333 |
× |
× |
|||||
|
NER |
0.8386 |
× |
||||||
|
RF |
INTREPID |
0.8369 |
× |
× |
||||
|
BoW |
0.7956 |
× |
× |
× |
||||
|
NER |
0.7934 |
× |
||||||
|
XGBoost |
INTREPID |
0.8816 |
× |
× |
× |
|||
|
BoW |
0.8486 |
× |
× |
|||||
|
NER |
0.7741 |
× |
||||||
- “Le” denotes “Lemmatization”, “Lo” denotes “Lowercase” and “St” denotes “Stopword”. The best results are underlined
- 131 次浏览
【GDPR】支持GDPR合规决策的人工智能框架:第六部分
视频号
微信公众号
知识星球
6讨论
为了支持意大利PA确保公共文件的GDPR合规性和个人数据的安全,我们制定了INTREPID,这是一个基于人工智能的框架,用于自动检测PA文件中的安全漏洞。作为我们框架的支柱,我们使用了为意大利语处理开发的语言资源,并调整了GDPR的情报。此外,我们定义了一个基于Bag of Word和NER信息的文本数据工程模块,并使用机器学习算法进行分类。最后,我们准备了一个意大利PA文件语料库,用于培训和评估,方法是使用适当的管道来平衡用人工标识符替换任何已识别或可识别信息的需要,以及GDPR检查不适用于匿名信息的事实。对准备好的语料库进行的深入评估强调了INTREPID的有效性以及它所建立的所有组件的设置。
除了INTREPID显示的结果的准确性之外,还需要解决一些限制,以朝着开发有效工具的方向迈出进一步的一步,降低PA文件中安全漏洞的风险。
- 缺乏解释机制。如今,为了让最终用户接受自动决策过程,解释人工智能系统决策的能力至关重要。这与GDPR对所有决定(包括基于人工智能的决定)的“解释权”的评估一致,这些决定可能会对个人产生重大影响。为此,本研究未来的研究方向可以致力于探索可解释的人工智能机制,通过解释文本中如何发现数据泄露来丰富数据泄露警报。
- 定位文档中的数据泄露位置。所提出的框架在文件一级执行分类任务。它允许我们识别可能不符合GDPR标准的PA文件,但这是在没有定位文件中的头寸数据泄露的情况下完成的。
- 数据泄露的多样性。拟议框架的分类模型已经通过与非法披露健康信息有关的数据泄露进行了培训。未来的研究方向可以致力于将分类模型推广到各种数据海滩类别。
- 多语言支持。拟议的框架是为意大利巴勒斯坦权力机构文件设计的。然而,最近出现了新的多语言模型,并已证明在各种文本分类任务中非常准确(Conneau et al.,2020)。这可以在用于数据泄露检测的多语言系统中进行探索。
7结论
在本文中,我们提出了一个新的基于人工智能的框架,以帮助意大利PA的数据保护工作流程自动化。所提出的框架是根据公共文件的数据保护可以被公式化为二进制文本分类问题的想法设计的。基于这一想法,我们准备了一个由意大利PA各城市在线发布的公共文件标记文本语料库。该语料库包含人类专家标记为符合GDPR或不符合GDPR的文本文件。我们描述了一个人工智能框架,从这个标记的文本语料库中学习文本分类模型,以便学习的模型可以用于预测新的公共文件是否符合GDPR标准。为此,我们选择了SpaCy和Tint这两种能够处理意大利语的NLP工具,并将其调整为GDPR情报。具体来说,我们使用NER工具来处理准备好的文本语料库,并定位几个类别的命名实体。我们介绍了在已识别的命名实体出现时提取的三组NER特征。我们利用这些NER功能丰富了文本文档的传统BoW表示,并训练分类器将文档标记为符合或不符合GDPR标准。我们使用了线性支持向量机、随机森林和XGboost作为分类算法。
我们根据NER的注释预测与领域专家的注释的一致性,以及文本分类模型的准确性对提取的特征组的敏感性,评估了所提出的框架的有效性。特别是,对准备好的文本语料库的评估表明,Tint在该领域的注释预测与领域专家的注释一致性方面优于SpaCy。它还表明,所提出的特征提取阶段工作得相当好,因为它使我们能够训练一个文本分类模型,该模型在检测数据泄露的文档时具有很高的准确性,误报率很低。这一结论可以独立于分类算法得出,尽管通过同时考虑基于BoW和基于NER的特征,使用XGBoost训练分类器获得了最高的精度性能。
到目前为止,据我们所知,这项研究首次尝试结合跨学科能力,以开发一个框架,帮助意大利PA自动化(或半自动化)分析公共文件的GDPR合规性。本研究的下一阶段将通过在文本语料库中包括可能涉及不同类别数据泄露的新文件来扩展对所提出框架的有效性的评估,并使用我们的注释语料库提高NER模型的性能。此外,还需要将该框架扩展到其他类别的个人数据,以及集成XAI技术来解释数据泄露警报,并开发人工智能技术来定位被标记为不符合GDPR标准的文件中的数据泄露位置。最后,我们计划探讨多语言资源在GDPR合规性分析问题中的表现。
代码可用性
根据合理要求,可从通讯作者处获得支持本研究结果的代码和为训练分类算法而提取的数据。
注意事项
-
Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation), https://eur-lex.europa.eu/eli/reg/2016/679/oj
-
Norms contained in the Italian Personal Data Protection Code (Legislative Decree 196/2003) were aligned with provisions introduced by GDPR with the legislative decree n. 101/2018 published in the Official Gazette n. 205 on September 4, 2018.
-
https://www.dataguidance.com/news/italy-garante-fines-trento-health-authority-150000
-
https://ec.europa.eu/info/sites/default/files/commission-white-paper-artificial-intelligence-feb2020_en.pd (last access: 2021/10/13)
-
https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206 (last access: 2021/10/13)
-
We used doccano as the platform for the annotation: https://github.com/doccano/doccano.
-
Legal references were extracted by the Linkoln tool https://gitlab.com/IGSG/LINKOLN/linkoln.
-
https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)
References
-
Adams, A., Aili, E., Aioanei, D., Jonson, R., Mickelsson, L., Mikmekova, D., Roberts, F., Mikmekova, D., Fernandez Valencia, J., & Wechsler, R. (2019). Anonymate: a toolkit for anonymizing unstructured chat data. In Proceedings of the workshop on NLP and pseudonymisation, pp. 1–7. Finland: Linköping Electronic Press, Turku.
-
Al-Abdulkarim, L., Atkinson, K., & Bench-Capon, T. (2016). A methodology for designing systems to reason with legal cases using abstract dialectical frameworks. Artificial Intelligence and Law, 24, 1–49. https://doi.org/10.1007/s10506-016-9178-1.
-
Attardi, G., Basile, V., Bosco, C., Caselli, T., Dell’Orletta, F., Montemagni, S., Patti, V., Simi, M., & Sprugnoli, R. (2015). State of the art language technologies for italian: the EVALITA 2014 perspective. Intelligenza Artificiale, 9(1), 43–61. https://doi.org/10.3233/IA-150076.
-
Bansal, A., & Kaur, S. (2018). Extreme gradient boosting based tuning for classification in intrusion detection systems. In M. Singh, P. K. Gupta, V. Tyagi, J. Flusser, & T. Ören (Eds.) Advances in computing and data sciences, communications in computer and information science, (vol. 905 pp. 372–380). https://doi.org/10.1007/978-981-13-1810-8_37. Singapore: Springer.
-
Biesner, D., Ramamurthy, R., Stenzel, R., Lu̇bbering, M., Hillebrand, L. P., Ladi, A., Pielka, M., Loitz, R., Bauckhage, C., & Sifa, R. (2022). Anonymization of german financial documents using neural network-based language models with contextual word representations. International Journal of Data Science and Analytics, 13(2), 151–161. https://doi.org/10.1007/s41060-021-00285-x.
-
Blume, P. (2016). Impact of the EU general data protection regulation on the public sector. Journal of Data Protection & Privacy, 1(1), 53–63.
-
Brandsen, A., Verberne, S., Wansleeben, M., & Lambers, K. (2020). Creating a dataset for named entity recognition in the archaeology domain. In Proceedings of the 12th Language Resources and Evaluation Conference, LREC 2020, pp. 4573–4577. European Language Resources Association (ELRA).
-
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324 .
-
Chen, T., & Guestrin, C. (2016). Xgboost: a scalable tree boosting system. In B. Krishnapuram, M. Shah, A. J. Smola, C.C. Aggarwal, D. Shen, & R. Rastogi (Eds.) Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 785–794. Association for Computing Machinery (ACM). https://doi.org/10.1145/2939672.2939785.
-
Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and psychological measurement, 20(1), 37–46.
-
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmȧn, F., Grave, E., Ott, M., Zettlemoyer, L., & Stoyanov, V. (2020). Unsupervised cross-lingual representation learning at scale. In D. Jurafsky, J. Chai, N. Schluter, & J.R. Tetreault (Eds.) Proceedings of the 58th annual meeting of the association for computational linguistics, ACL 2020, pp. 8440–8451. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.747.
-
Contissa, G., Docter, K., Lagioia, F., Lippi, M., Micklitz, H. W., Palka, P., Sartor, G., & Torroni, P. (2018). CLAUDETTE meets gdpr: automating the evaluation of privacy policies using artificial intelligence. SSRN Electronic Journal, 1–59.
-
Csányi, G. M., Nagy, D., Vági, R., Vadász, J. P., & Orosz, T. (2021). Challenges and open problems of legal document anonymization. Symmetry, 13(8).
-
Dadgostari, F., Guim, M., Beling, P. A., Livermore, M. A., & Rockmore, D. N. (2020). Modeling law search as prediction. Artificial Intelligence and Law, 29, 3–34. https://doi.org/10.1007/s10506-020-09261-5.
-
Datta, P. (2020). Digital transformation of the italian public administration: a case study. Communications of the Association for Information Systems pp. 252–272. https://doi.org/10.17705/1CAIS.04611.
-
Davari, M., & Bertino, E. (2019). Access control model extensions to support data privacy protection based on GDPR. In C. Baru, J. Huan, L. Khan, X. Hu, R. Ak, Y. Tian, R. S. Barga, C. Zaniolo, K. Lee, & Y.F. Ye (Eds.) Proceedings of the 2019 IEEE international conference on big data, big data 2019, pp. 4017–4024. IEEE. https://doi.org/10.1109/BigData47090.2019.9006455.
-
De Felice, I., Dell’Orletta, F., Venturi, G., Lenci, A., & Montemagni, S. (2018). Italian in the trenches: linguistic annotation and analysis of texts of the great war. In E. Cabrio, A. Mazzei, & F. Tamburini (Eds.) Proceedings of the 5th italian conference on computational linguistics, CLiC-it 2018, CEUR Workshop Proceedings, (vol. 2253 pp. 1–5).
-
De Martino, G., Pio, G., & Ceci, M. (2022). PRILJ: an efficient two-step method based on embedding and clustering for the identification of regularities in legal case judgments. Artificial Intelligence and Law, 30, 359–390. https://doi.org/10.1007/s10506-021-09297-1.
-
Di Cerbo, F., & Trabelsi, S. (2018). Towards personal data identification and anonymization using machine learning techniques. In A. Benczúr, B. Thalheim, T. Horváth, S. Chiusano, T. Cerquitelli, C. Sidló, & P. Z. Revesz (Eds.) New trends in databases and information systems, ADBIS 2018, communications in computer and information science, pp. 118–126. https://doi.org/10.1007/978-3-030-00063-9_13. Cham: Springer.
-
Di Nicola, P., Grossi, P., & Preti, A. (2016). Rethinking the organization of public administration through the enhancement of human resources. The Istat case. RIEDS-Rivista Italiana di Economia, Demografia e Statistica- The Italian Journal of Economic. Demographic and Statistical Studies, 70(1), 17–28.
-
Dias, M., Bone, J., Ferreira, J., Ribeiro, R., & Maia, R. (2020). Named entity recognition for sensitive data discovery in portuguese. Applied Sciences, 10, 2303. https://doi.org/10.3390/app10072303.
-
Francopoulo, G., & Schaub, L. P. (2020). Anonymization for the GDPR in the context of citizen and customer relationship management and NLP. In Proceedings of the of the workshop on legal and ethical issues (Legal2020), pp. 9–14. European Language Resources Association (ELRA).
-
Ghosh, M., Raihan, M. M., Raihan, M., Akter, L., Bairagi, A., Alshamrani, S., & Masud, M. (2021). A comparative analysis of machine learning algorithms to predict liver disease. Intelligent Automation and Soft Computing, 29, 917–928. https://doi.org/10.32604/iasc.2021.017989.
-
Grouin, C., Rosset, S., Zweigenbaum, P., Fort, K., Galibert, O., & Quintard, L. (2011). Proposal for an extension of traditional named entitites: from guidelines to evaluation, an overview. In Proceedings of the 5th linguistics annotation workshop (The LAW V), pp. 92–100. USA: Association for Computational Linguistics, Portland, Oregon.
-
Harkous, H., Fawaz, K., Lebret, R., Schaub, F., Shin, K. G., & Aberer, K. (2018). Polisis: automated analysis and presentation of privacy policies using deep learning. In Proceedings of the 27th USENIX conference on security symposium, SEC’18 (pp. 531–548). USA: USENIX Association.
-
Hastie, T., Tibshirani, R., & Friedman, J. (2001). The elements of statistical learning. Springer Series in Statistics. New York: Springer. https://doi.org/10.1007/978-0-387-84858-7.
-
Hoofnagle, C. J., van der Sloot, B., & Borgesius, F. Z. (2019). The European Union general data protection regulation: what it is and what it means. Information & Communications Technology Law, 28(1), 65–98. https://doi.org/10.1080/13600834.2019.1573501.
-
Hripcsak, G., & Rothschild, A. S. (2005). Agreement, the F-measure, and reliability in information retrieval. Journal of the American Medical Informatics Association, 12(3), 296–298. https://doi.org/10.1197/jamia.M1733.
-
Joachims, T. (1998). Text categorization with support vector machines: Learning with many relevant features. In C. Nédellec C. Rouveirol (Eds.) Proceedings of 10th european conference on machine learning: ECML-98, lecture notes in computer science, (vol. 1398 pp. 137–142). Berlin, Heidelberg: Springer. https://doi.org/10.1007/BFb0026683.
-
Kingston, J. (2017). Using artificial intelligence to support compliance with the general data protection regulation. Artificial Intelligence and Law, 25, 429–443. https://doi.org/10.1007/s10506-017-9206-9.
-
Magnini, B., Pianta, E., Girardi, C., Negri, M., Romano, L., Speranza, M., Bartalesi Lenzi, V., & Sprugnoli, R. (2006). I-CAB: the italian content annotation bank. In Proceedings of the 5th international conference on language resources and evaluation (LREC ’06), pp. 963–968. Italy: European Language Resources Association (ELRA), Genoa.
-
Mc Cullagh, K., Tambou, O., & Bourton, S. (eds.) (2019). National adaptations of the GDPR, 1st edn. Blogdroiteuropéen: Collection Open Access Book.
-
Meszaros, J., & Ho, C. (2021). AI research and data protection: can the same rules apply for commercial and academic research under the GDPR? Computer Law & Security Review, 105532, 41. https://doi.org/10.1016/j.clsr.2021.105532.
-
Mozes, M., & Kleinberg, B. (2021). No intruder, no validity : evaluation criteria for privacy-preserving text anonymization . Preprint at arXiv:2103.09263.
-
Nothman, J., Ringland, N., Radford, W., Murphy, T., & Curran, J. R. (2013). Learning multilingual named entity recognition from wikipedia. Artificial Intelligence, 194, 151–175. https://doi.org/10.1016/j.artint.2012.03.006.
-
Palmero Aprosio, A., & Moretti, G. (2018). Tint 2.0: an all-inclusive suite for NLP in italian. In Proceedings of the 5th italian conference on computational linguistics, CLiC-it 2018, CEUR workshop proceedings, (vol. 2253, pp. 1–7).
-
Passaro, L. C., Lenci, A., & Gabbolini, A. (2017). Informed PA: a NER for the italian public administration domain. In R. Basili, M. Nissim, & G. Satta (Eds.) Proceedings of the 4th italian conference on computational linguistics, CLiC-it 2017, CEUR Workshop Proceedings, Vol. 2006.
-
Ricci, A. (2018). E-government, transparency and personal data protection.: a new analysis’ approach to an old juridical issue. Central and Eastern European eDem and eGov Days, 325, 125–135. https://doi.org/10.24989/ocg.v325.11.
-
Romano, M. F., Baldassarini, A., & Pavone, P. (2020). Text mining of public administration documents: preliminary results on judgments. In D. F. Iezzi, D. Mayaffre, & M. Misuraca (Eds.) Text analytics: advances and challenges. proceedings of the 14th international conference on the statistical analysis of textual data (JADT 2018), studies in classification, data analysis, and knowledge organization, pp. 117–126. Cham: Springer. https://doi.org/10.1007/978-3-030-52680-1_10.
-
Sartor, G., & Lagioia, F. (2020). The impact of the General Data Protection Regulation (GDPR) on artificial intelligence. European Parliamentary Research Service. https://doi.org/10.2861/293.
-
Savic, D., & Veinovic, M. (2018). Challenges of general data protection regulation (GDPR). In Proceeding of the 5th international scientific conference on information technology and data related research, sinteza 2018, pp. 23–30. Serbia: Singidunum University, Belgrade. https://doi.org/10.15308/Sinteza-2018-23-30.
-
Selbst, A. D., & Powles, J. (2017). Meaningful information and the right to explanation. International Data Privacy Law, 7(4), 233–242. https://doi.org/10.1093/idpl/ipx022.
-
Silva, P., Gonçalves, C., Godinho, C., Antunes, N., & Curado, M. (2020). Using natural language processing to detect privacy violations in online contracts. In Proceedings of the 35th annual ACM symposium on applied computing, SAC 2020, pp. 1305–1307. New York: Association for Computing Machinery (ACM), DOI 10.1145/3341105.3375774, (to appear in print).
-
Sovrano, F., Vitali, F., & Palmirani, M. (2020). Modelling GDPR-compliant explanations for trustworthy ai. In A. Kȯ, E. Francesconi, G. Kotsis, A. M. Tjoa, & I. Khalil (Eds.) Electronic Government and the Information Systems Perspective. Proceedings of the 9th international conference on electronic government and the information systems perspective, EGOVIS 2020, lecture notes in computer science, (vol. 12394 pp. 219–233). Cham: Springer. https://doi.org/10.1007/978-3-030-58957-8_16.
-
Stamova, I., & Draganov, M. (2020). Artificial intelligence in the digital age. In Proceedings of the international scientific conference “digital transformation on manufacturing, infrastructure and service”, IOP conference series: materials science and engineering, vol. 940. https://doi.org/10.1088/1757-899X/940/1/012067.
-
Sánchez, D., Viejo, A., & Batet, M. (2021). Automatic assessment of privacy policies under the GDPR. Applied Sciences 11(4). https://doi.org/10.3390/app11041762.
-
Tagarelli, A., & Simeri, A. (2021). Unsupervised law article mining based on deep pre-trained language representation models with application to the italian civil code. Artificial Intelligence and Law, 30, 417–473. https://doi.org/10.1007/s10506-021-09301-8.
-
van der Aalst, W. M. P. (2016). Process Mining- Data Science in Action, 2nd edn. Berlin Heidelberg: Springer. https://doi.org/10.1007/978-3-662-49851-4.
-
van Engers, T. M. (2005). Legal engineering: a structural approach to improving legal quality. In A. Macintosh, R. Ellis, & T. Allen (Eds.) Proceedings of the 25th SGAI international conference on innovative techniques and applications of artificial intelligence, AI-2005. https://doi.org/10.1007/1-84628-224-1_1 (pp. 3–10). London: Springer.
-
Yadav, V., & Bethard, S. (2019). A survey on recent advances in named entity recognition from deep learning models. Preprint at arxiv:1910.11470.
-
Zaman, R., Cuzzocrea, A., & Hassani, M. (2019). An innovative online process mining framework for supporting incremental GDPR compliance of business processes. In C. Baru, J. Huan, L. Khan, X. Hu, R. Ak, Y. Tian, R.S. Barga, C. Zaniolo, K. Lee, & Y.F. Ye (Eds.) Proceedings of the 2019 IEEE international conference on big data, big data 2019, pp. 2982–2991. https://doi.org/10.1109/BigData47090.2019.9005705.
-
Zaman, R., & Hassani, M. (2020). On enabling GDPR compliance in business processes through data-driven solutions. SN Computer Science, 1(4), 210. https://doi.org/10.1007/s42979-020-00215-x.
Acknowledgements
We acknowledge the support of the PNRR project FAIR - Future AI Research (PE00000013), Spoke 6 - Symbiotic AI (CUP H97G22000210007) under the NRRP MUR program funded by the NextGenerationEU, as well as the PON “Governance e capacità istituzionale” 2014–2020 project “Modelli, Sistemi e Competenze per l’implementazione dell’Ufficio per il Processo/Start UPP” (CUP: H29J22000390006), funded by the Italian Ministry for Universities and Research (MIUR).
- 48 次浏览
【GDPR】支持GDPR合规决策的人工智能框架:第四部分
视频号
微信公众号
知识星球
4 INTREPID框架
所提出的框架背后的思想是将公共文件的数据保护问题建模为二进制文本分类任务。我们语料库中的每个文档都被标记为符合或不符合GDPR标准。图2显示了INTREPID体系结构的示意图。
Fig. 2
From: An AI framework to support decisions on GDPR compliance
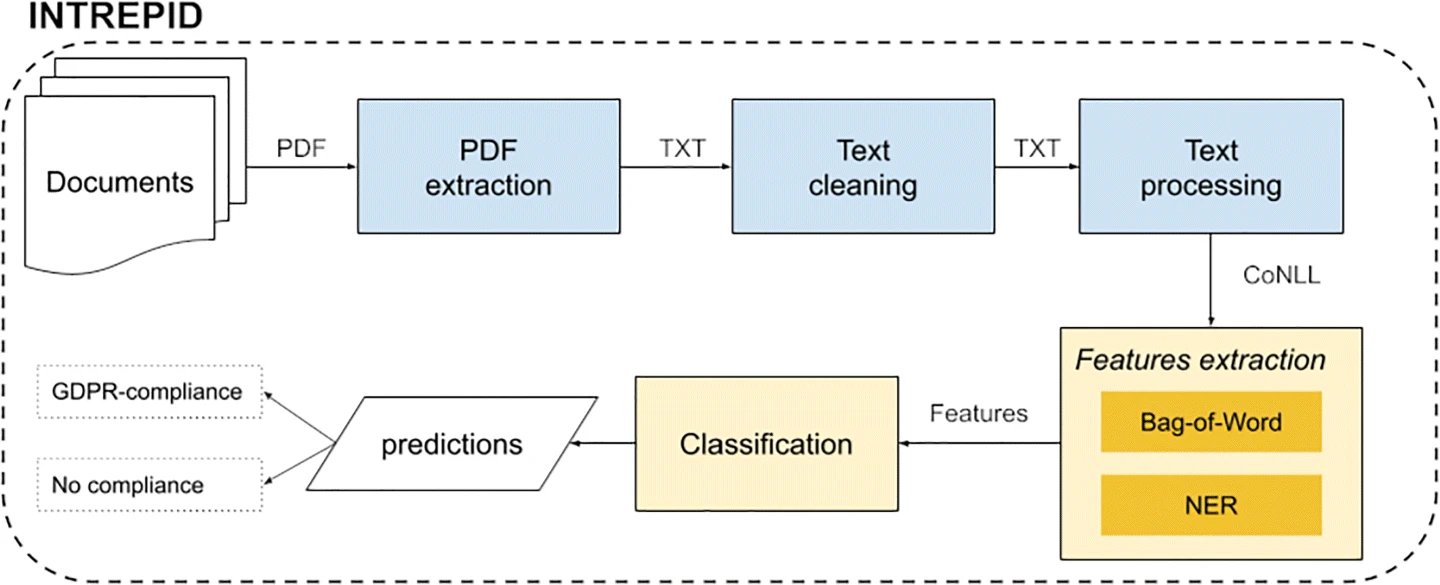
由于语料库是以PDF格式提供的,因此第一步涉及从PDF中提取文本内容。然后,对提取的内容应用清理步骤,以便不删除有效字符并更正OCR错误。为了从PDF中提取文本,我们依赖Apache Tika库;脚注8当PDF中没有直接可用的文本时,我们使用Tesseract.Footnote9软件执行OCR。此外,通过正则表达式发现无效字符。特别是,我们检测非字母数字字符的长序列。NLP管道处理清除的文本。请注意,所提出的框架不依赖于预定义的管道,但可以集成任何可以生成CoNLL格式Footnote10的管道。CoNLL格式是一个文本文件,其中每一行代表一个单词,带有一系列制表符分隔的字段。特别地,句子中的每个记号由与句子中的记号位置相对应的索引(第一列)表示(从1开始)。其他列是管道提取的特征,例如实体识别器的令牌、引理、PoS标签和IOB2标签Footnote11。特别是,在我们的框架中,生成的CoNLL格式必须包括以下文本操作:标记化、旅名化、停止单词删除、PoS标记和实体识别。
在当前版本的框架中,我们为两个NLP管道提供支持:SpaCyFootnote12和Tint(Palmero Aprosio和Moretti,2018)。这种选择的动机是,它们为意大利语提供了最好的支持,不需要进一步的配置或开发步骤。此外,这两个管道都可以轻松地执行实体识别,这是基于命名实体构建特征的核心组件。为了识别依赖领域的实体(健康、管理和省略),我们利用领域专家建立的特定地名录。更详细地说,卫生和行政公报由分别识别医学和行政术语的关键词组成,而省略公报是识别文本中遗漏的语言表达的列表。下一步涉及提取用于分类的特征。在该步骤中,使用CoNLL格式的NLP管道的输出来提取对训练分类器有用的特征。我们利用了两种特征:经典的单词袋(BoW)和基于NER输出的其他特征。我们相信,实体的出现可以帮助分类器检测不符合要求的文档。特征提取步骤的详细说明见第4.1节。提取的特征用于训练分类器,然后用于预测新文档的类别。INTREPID框架可以很容易地进行调整,以支持不同的NLP管道和涉及PA中文本分类的几个任务。
考虑到语料库的小规模和所涉及的特征的数量,在所提出的框架的当前实现中,我们提供了对三个基本分类器的支持:线性支持向量机(Joachims,1998)、随机森林(Breiman,2001)和XGBoost(Chen&Guestrin,2016)。选择这些分类算法是因为各种研究证明它们通常优于几种竞争对手的分类器(Bansal&Kaur,2018;Ghosh等人,2021)。
为了构建最佳分类器并衡量每个特征组的贡献,我们进行了一次评估,其中利用了特征组选择步骤。特别是,我们构建了所有可能的特征组合,并通过使用手动注释的语料库来测试每一个。对于每个组合,我们还选择最佳参数。有关评估的详细信息,请参见第5节。
4.1特征提取
对于特征提取阶段,我们同时考虑基于BoW的特征和基于NER的特征。
4.1.1基于工程量清单的特征
BoW特征模型(Joachims,1998)是NLP中常用的特征生成基本策略。为了表示BoW模型中的每个文本文档,我们首先将文档转换为“单词袋”。然后,我们通过计算词汇表中某个术语出现在文档中的次数来计算BoW词汇表的频率特征。
在所提出的框架中,BoW词汇表中填充了在语料库中至少出现一次的独特单词。我们使用引理化将词汇转换为其基本形式,同时考虑词性上下文(例如,在图1a所示的意大利语文本中,“dichiarato”的基本形式是“dichierare”,而在图1b所示的英语翻译中,“declared”的基本形式是“declare”)。此外,我们使用小写单词来克服大写问题(例如,专有名称“Paolo”小写为“Paolo”)。停止语(即冠词、介词、代词和连词)被删除。
例如,图1a中意大利文本的BoW模型包括以下单词:
|
paolo |
|
rossi |
|
copenaghen |
|
roma |
|
xxxxxx |
|
sclerosi |
|
multipla |
|
roma |
|
... |
BoW特征paolo出现一次,而BoW特征roma在图1a中的意大利语文本中出现两次
4.1.2基于NER的特征
我们考虑了三组基于净入学率的特征。
第1组:命名实体袋(BoNE)
BoNE特征模型扩展了BoW模型,以便生成基于NER的特征。为了表示每个文本文档,我们首先使用NER工具识别文本语料库中的命名实体,将其转换为“命名实体袋”。然后,我们通过计算命名实体类别在文档中出现的次数,从命名实体类别(管理、健康、位置、遗漏、组织和个人)中计算频率特征。
例如,让我们考虑图1a中意大利文本的BoNE模型。它由以下命名实体组成:
|
PERSON |
paolo rossi |
|
LOCATION |
copenaghen |
|
LOCATION |
roma |
|
OMISSIS |
xxxxxxx |
|
HEALTH |
sclerosi multipla |
|
OMISSIS |
xxxxxxx |
|
HEALTH |
fisioterapia |
|
ORGANIZATION |
ragioneria |
|
LOCATION |
roma |
|
PERSON |
maria verde |
BoNE特征是通过计算先前BoNE模型中每个命名实体类别的频率来生成的。在该示例中,我们确定ADMINISTRATION(管理)未出现,HEALTH(健康)出现两次,LOCATION(位置)出现三次,OMISIS(省略)出现两遍,ORGANIZATON(组织)出现一次,PERSON(个人)显示两次。请注意,在所提出的框架的当前版本中,BoNE模型允许我们从每个文档中提取六个特征,每个命名实体类别一个特征。
第2组:命名实体袋双克(BoNNEG)
BoNNEG模型基于将每个文档表示为一袋相邻命名实体(即出现在同一上下文中的相邻实体)的概念。为了表示BoNNEG模型中的每个文本文档,我们首先将文档转换为“一袋命名为实体的邻居”。然后,我们从命名的实体直方图中计算频率特征。让我们考虑命名实体双图X−Y,其中X和Y是NER识别的命名实体类别。当且仅当NER在文本中识别出一个以X命名的实体X和一个以Y命名的实体Y,使得X和Y之间的距离最多为maxd时,双格X−Y才会出现在文档中。该距离通过忽略停止词来计算。在本案例研究中,根据PA文档中相关实体之间预期距离的一些领域知识,将maxd设置为5。
例如,让我们考虑图1a中报告的文件,该文本的BoNNEG模型包括以下邻居命名实体图:
|
PERSON-LOCATION |
paolo rossi-copenhaghen |
d = 1 |
|
PERSON-LOCATION |
paolo rossi-roma |
d = 4 |
|
LOCATION-LOCATION |
copenhaghen-roma |
d = 2 |
|
LOCATION-OMISSIS |
copenhaghen-xxxxxxx |
d = 4 |
|
LOCATION-OMISSIS |
roma-xxxxxxx |
d = 1 |
|
OMISSIS-HEALTH |
xxxxxxx-fisioterapia |
d = 3 |
|
OMISSIS-ORGANIZATION |
xxxxxxx-ragioneria |
d = 5 |
|
HEALTH-ORGANIZATION |
fisioterapia-ragioneria |
d = 1 |
|
HEALTH-LOCATION |
fisioterapia-roma |
d = 3 |
|
HEALTH-PERSON |
fisioterapia-maria verde |
d = 4 |
|
ORGANIZATION-LOCATION |
ragioneria-roma |
d = 1 |
|
ORGANIZATION-PERSON |
ragioneria-maria verde |
d = 2 |
|
LOCATION-PERSON |
roma-maria verde |
d = 0 |
BoNNEG特征是通过计算先前BoNNEG模型中每个命名实体双图的频率来生成的。例如,我们确定,由于名为LOCATION的实体“Copenhaghen”与名为PERSON的实体“Paolo Rossi”相距1个标记,以及名为LOCATION的实体“Roma”与“Paolo-Rosi”相距4个非停止词标记,因此双格PERSON-LOCATION在文本中出现两次(如图3所示)。请注意,BoNNEG模型允许我们从每个文档中提取三十六个特征,每两克命名实体类别一个特征。
Fig. 3
From: An AI framework to support decisions on GDPR compliance
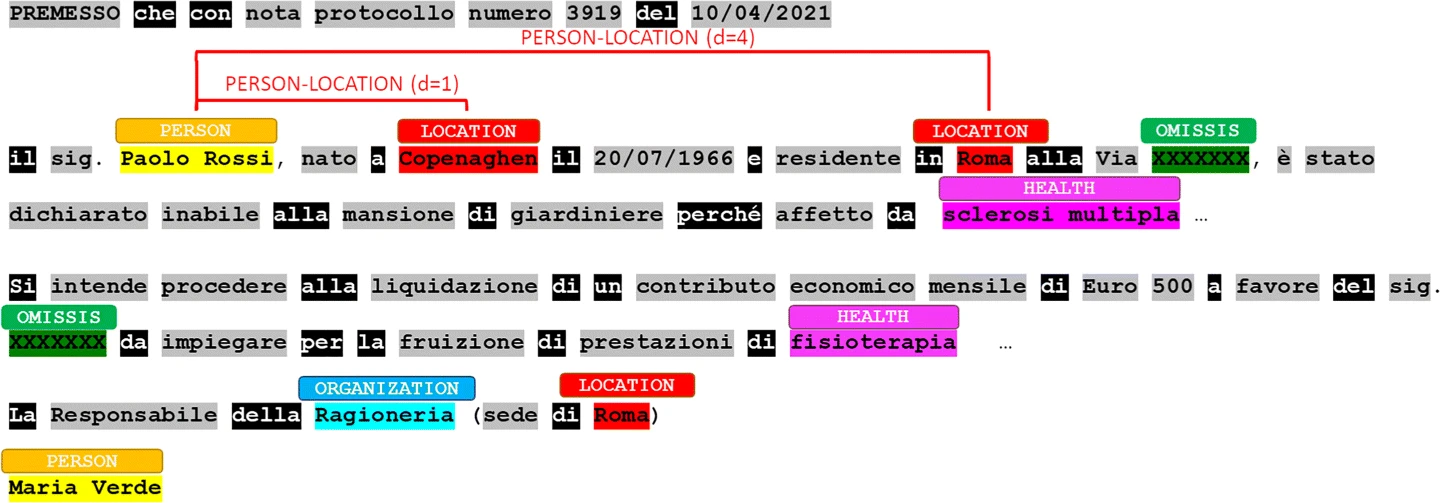
BoNNEG feature PERSON-LOCATION. Stop-words are highlighted in black
第3组:每个命名实体的单词袋(BoWNE)
BoWNE模型从每个文档中提取六个特征,即每个命名实体类别一个特征。为了表示BoWNE模型中的每个文档,我们结合了单词信息和命名实体分类。最后,对于每个命名的实体类别,我们计算在所考虑的类别中命名的不同单词标记的数量,这些标记在文本中至少出现两次。
例如,图1a中报告的文件的BoWNE模型包括以下用命名实体标记的单词袋:
|
paolo rossi/PERSON |
|
copenaghen/LOCATION |
|
roma/LOCATION |
|
xxxxxxx/OMISSIS |
|
sclerosi multipla/HEALTH |
|
xxxxxxx/OMISSIS |
|
fisioterapia/HEALTH |
|
ragioneria/ORGANIZATION |
|
roma/LOCATION |
|
maria verde/PERSON |
BoWNE特征是通过计算每个命名实体类别的重复单词而生成的。因此,在所考虑的示例中,我们确定LOCATION只命名一个在文本中至少出现两次的单词(roma),而ADMINISTRATION、HEALTH、OMISIS、ORGANIZATON和PERSON不命名任何在文本中出现至少两次的词。因此,与LOCATION和OMISIS相关联的BoWNE特征等于1,而分别与ADMINISTRATION、HEALTH、ORGANIZATON和PERSON相关联的BoWNE特征设置为零。
4.2实施细节
该框架是用Python和Java实现的。PDF提取和文本清理是用Java开发的,使用Apache TikaFootnote13库从PDF中提取文本。文本处理模块允许为NLP集成不同的管道。特别是,我们集成了SpaCyFootnote14(Python)和Tint(Palmero Aprosio和Moretti,2018)(Java)。SpaCy提出的模型是在WikiNER语料库上训练的(Nothman et al.,2013),而Tint则利用了意大利内容注释库(I-CAB)(Magnini et al.,2006)。标记化、停止字去除和引理化分别由每个NLP管道执行。
文本处理提供由负责构建BoW和NER特征的特征提取模块处理的CoNLL格式的输出,如第4.1节所述。功能是分类模块的输入,该模块与评估组件一起使用scikit学习工具在Python中开发。对于分类,我们采用了:线性支持向量机(SVM)、随机森林(RF)和XGBoost分类器。这些分类器的参数是通过用k倍(k=5)执行网格搜索来选择的。表3中报告了网格搜索过程中使用的参数和一组值。
Table 3 Parameters and the set of values used during the grid-search
From: An AI framework to support decisions on GDPR compliance
|
Classifier |
Parameters |
|---|---|
|
SVM |
C = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} |
|
RF |
number of estimators = {100, 200, 400, 600, 800} |
|
XGBoost |
learning rate = {0.1, 0.2, 0.3} |
|
max depth = {3, 6, 9} |
|
|
number of estimators = {100, 200, 400} |
- 41 次浏览
【GDPR】支持GDPR合规决策的人工智能框架:第一部分
视频号
微信公众号
知识星球
摘要
意大利公共管理局(PA)依靠昂贵的手动分析来确保公共文件和个人数据的GDPR合规性。尽管人工智能的最新进展使许多法律领域受益,但公共文件数据保护工作流程的自动化仍然只受到轻微影响。这项工作的主要目的是设计一个可以有效采用的框架,以检查用意大利语编写的PA文件是否符合GDPR要求。我们跨学科研究的主要成果是INTREPID(公共广告文件的gdpR合规性的人工智能),这是一个基于人工智能的框架,可以帮助意大利PA确保公共文件的gdpR合规性。INTREPID是通过将一些用于意大利语处理的语言资源(即SpaCy和Tint)调整为GDPR智能来实现的。此外,我们为文本分类方法奠定了基础,以识别意大利PA发布的公开文件,这些文件进行了数据泄露。我们在意大利PA在线发布的公共文件文本语料库上展示了该框架的有效性。我们还进行了注释者间研究,并分析了所提出方法的注释预测与领域专家的注释的一致性。最后,我们评估了所提出的文本分类模型在检测安全漏洞方面的准确性。
1简介
2018年,欧盟推出了《通用数据保护条例2016/679》(GDPR)脚注1,以更新和统一欧盟各国的数据保护条例,使每个成员国不再需要制定自己的数据保护法律,并且整个欧盟的法律保持一致(Hoofnagle et al.,2019)。从那一刻起,《通用数据保护条例》代表了规范公司如何保护欧盟公民的个人数据,即与已识别或可识别的欧盟在世人员有关的任何数据,无论其所在地如何,向欧盟公民销售商品或服务。如今,《通用数据保护条例》共有11章99条,规定了一套基本的隐私和数据保护标准,以更好地保护欧盟公民个人数据的处理和移动。GDPR定义的一些标准包括:要求数据处理主体同意,匿名收集数据以保护隐私,提供数据泄露通知,安全处理跨境数据传输,以及要求某些公司任命一名数据保护官员来监督GDPR的合规性(Savic&Veinovic,2018)。此外,GDPR鼓励合规,允许每个欧盟成员国的数据保护局(DPA)——监督GDPR应用程序的独立公共机构——对违规者处以严厉处罚。例如,不遵守某些GDPR标准的组织可能会被处以高达全球年营业额2%或4%的罚款,或1000万欧元或2000万欧元,以较大者为准(Savic&Veinovic,2018)。
此外,公共行政部门(PA)在处理与欧盟公民有关的个人数据时,必须尊重GDPR的关键原则,保证公平合法的处理、目的限制、数据最小化和数据保留(Blume,2016;Ricci,2018)。特别是,PA需要任命一名数据保护官(DPO),确保实施适当的技术和组织措施来保护个人数据。当个人数据被意外或非法披露给未经授权的接收者,或暂时无法获得或更改时,必须立即通知DPA,最迟在意识到违规行为后72小时内通知。巴勒斯坦权力机构可能还需要将违规行为告知个人。
如果PA中存在违反GDPR的情况,则DPA可以采取一系列行动。如果可能存在侵权行为,则可能会发出警告。在侵权的情况下,可能包括谴责或暂时或最终禁止处理。在一些国家,如意大利,Footnote2公共机构也可能受到行政罚款(Mc Cullagh et al.,2019)。例如,2021年7月20日,意大利国防部以非法披露患者健康数据为由,对特伦托卫生局处以15万欧元的罚款。脚注3另一方面,如果公共文件违反了《通用数据保护条例》,个人也可以要求赔偿,因为他们遭受了物质损害(如经济损失)或非物质损害(例如声誉损失或心理困扰)。
尽管文件管理和工作流程自动化技术正以前所未有的速度发展,但PA仍然将GDPR合规性主要委托给操作人员,他们可能会放慢流程,并且缺乏足够的监管教育(Di Nicola et al.,2016)。另一方面,识别和报告安全违规行为的效率是与欧盟愿景相一致的一项要求,即使巴勒斯坦权力机构开放、高效、包容、无边界和用户友好。在这种情况下,人工智能(AI)技术可以通过为公共服务提供新的数字环境(也称为数据保护)发挥关键作用。根据这一直觉,Kingston(Kingston,2017)最近推动了对人工智能技术的调查,用于不同的GDPR相关任务,例如:遵循合规检查表和行为准则,支持风险评估,遵守有关执行自动分析的技术的法规,以及遵守关于识别和报告违反安全规定的新规定。GDPR引入的数据保护问题也对文档处理系统产生了影响。特别是,我们关注GDPR对发布可能披露个人信息的非结构化(文本)文件的影响。在这种情况下,自然语言处理(NLP)等人工智能技术可以帮助自动检测文本文档中可能构成数据泄露的部分。NLP是人工智能的一个子区域,处理自然人类语言,无论是文本还是语音。谷歌的搜索建议或拼写检查器就是这些技术的常见例子。如今,NLP主要用于律师可以使用的几种智能工具。例如,NLP在法律中最受欢迎和最有用的应用之一是在法律研究中:NLP支持的法律搜索引擎可以搜索概念,而不仅仅是特定的关键词,帮助律师更快地找到他们需要的东西。识别文档中的文本模式有助于检测可能包含必须保护的个人信息的相关文本片段。在这种情况下,机器学习技术,如文本分类,也被用来建立模型,通过从以前的数据泄露例子中学习来预测个人数据是否在文档中被披露。
本文接受了这一挑战,并研究了人工智能技术如何真正帮助PA的数据保护工作流程自动化(或半自动化),以降低公共文件安全漏洞的风险。一项涉及意大利公共行政机构的案例研究对此进行了调查,该机构拥有6000万人口、8000个市镇和22000个地方行政机构,积极支持公共行政效率的数字化转型(Datta,2020)。这项工作的主要贡献是:
- 根据GDPR标准,我们关注的是检测与公共文件中非法披露健康信息有关的安全漏洞问题,这是行政罚款的主要原因之一。具体而言,我们将该问题视为二元分类任务,并将调查领域简化为意大利公共行政部门的文件。我们调查的主要结果是一个人工智能框架——INTREPID(公共广告文件的gdpR合规性的第三方智能)——旨在处理意大利PA制作的公共文件,并将其归类为符合或不符合gdpR标准。
- 鉴于缺乏公共文件GDPR合规性分析的基准,以及建立适当培训集的必要性,我们收集了意大利PA各城市在线发布的公共文件语料库。该语料库既包含45个符合GDPR的文件,可以正确保护个人数据,也包含45个非法披露健康信息的非GDPR文件。语料库中的文档由两位专家进行注释,以识别第3节所述的命名实体。从这些注释开始,我们开发了一个用于匿名化文档的自动管道,这些文档最终用于评估所提出的框架的性能。此外,我们还重点研究了从意大利语文本中提取信息的任务(Attardi et al.,2015;De Felice et al.,2018)。因此,我们求助于为意大利语处理开发的特定语言资源,但将其调整为GDPR情报。尽管这一步骤依赖于语言,但它可以毫不费力地推广到其他语言。收集的用意大利语编写的匿名PA文件语料库对于对INTREPID框架进行实验分析至关重要,该分析证明了该框架的有效性。
- 我们讨论了人工智能模型中通常出现的关键方面,即特征提取和分类。尽管已经为这两项任务提出了各种方法,但迄今为止,还没有发表过与它们在用意大利语编写的PA文件中的数据保护的具体应用有关的相关文献。在这方面,我们研究了如何执行信息提取步骤,该步骤旨在定位意大利文本中的命名实体,并将其分类为预定义的类别,如人名、组织、地点、健康状况、管理部门和“遗漏”的表达。此外,我们还提供了如何在单词袋特征和基于命名实体的特征上建立文本分类的见解。
本文的其余部分组织如下。第2节概述了促使对人工智能进行调查以确保意大利PA中的数据保护的工作,以及人工智能技术在文本分类问题中的背景。第3节描述了我们为本研究收集的用意大利语编写的PA文件的语料库,而第4节介绍了我们提出的验证意大利PA文件符合GDPR的框架。实验评估方法和结果见第5节。第6节说明了该提案的好处以及如何在未来的研究中加以加强。最后,第7节对论文进行了总结。
- 122 次浏览
【GDPR】支持GDPR合规决策的人工智能框架:第三部分
视频号
微信公众号
知识星球
3语料库准备
我们准备了一个由90份文本公共文件组成的意大利语料库,这些文件发布在一些意大利市政当局(74份文件)或公立医院(16份文件)的网站上。收集的文件是关于与工作有关的疾病(30份文件)、福利金(30份)和卫生财政支持(30份报告)的审议或决定。这些文件由巴勒斯坦权力机构根据意大利法律第33/2013号法令发布。对语料库进行的GDPR风险评估显示,在90份文件中,有45份发现了GDPR数据泄露。
这些文件的收集是根据第33/2013号法令进行的,该法令第3条规定,所有可供公民查阅的文件、信息和数据,包括根据现行立法必须公布的文件、资料和数据,都是公开的,任何人都有权了解、免费使用以及使用和重复使用。
该语料库由两名独立的注释者、经验丰富的GDPR律师进行注释,他们仔细阅读文本,定位目标实体,在注释平台Footnote6上突出显示它们,并从预先确定的列表中选择类别:管理、健康、地点、遗漏、组织和人员。除了标准类别(个人、地点、组织)外,我们还引入了一些特定领域的类别,以识别公共管理中的角色和疾病名称,这可能与识别GDPR不合规文件有关。特定领域的类别是由注释者提出的。在阅读了语料库中的所有文档后,他们假设了潜在相关实体的类别。一个带注释的虚构文本的例子如图1所示。

为了评估注释过程的质量,我们决定分析注释器之间匹配的注释数量。考虑到部分匹配的不同大小来计算匹配。部分匹配的大小是具有相同类别的两个重叠注释之间不同的字符数。取两个注释的开头和结尾,计算它们之间重叠的大小;在完全匹配(0)的情况下,两个注释的开头和结尾相等。
此外,我们还检查了注释者之间的相互一致性水平。尽管Cohen的Cappa(Cohen,1960)是许多分类任务的标准注释可靠性度量,但它并没有被证明是令牌级注释任务的相关度量,如NER(Grouin et al.,2011;Hripcsak和Rothschild,2005)。因此,正如Brandsen等人所建议的那样。(2020),我们为此使用了F分数——一种最初为二元分类制定的测试准确性的衡量标准。在下文中,我们提供了适用措施的定义,即:
F=2精度×召回精度+召回。
特别是,精度是真阳性结果的数量除以所有阳性结果的数字,包括未正确识别的结果。召回是指真正阳性结果的数量除以本应确定为阳性的所有样本的数量。公式中:精度=TPTP+FP
,召回=TPTP+FN
,其中TP表示真阳性结果的数量,FP表示假阳性结果的数目,FN表示假阴性结果的数目。在每次比较中,一个注释器的注释被视为黄金标准,而另一个注释者的注释则被视为评估标准。
表1报告了注释器之间匹配的注释的数量(第2列)和通过改变部分匹配的大小(第1列)测量的F分数(第3列)。正如预期的那样,部分匹配的大小越大,注释器之间匹配的注释数量就越高。但是,注释器之间匹配的注释的数量达到了部分匹配集的大小等于5的肘值。此外,我们注意到,在完全匹配的情况下,我们获得了大于0.79的高F分数。这显示了注释的良好质量。
Table 1 The number of annotations that match between the annotators and the computed F score
From: An AI framework to support decisions on GDPR compliance
|
partial match size |
#matches |
F score |
|---|---|---|
|
0 |
3,296 |
0.7981 |
|
3 |
3,707 |
0.8976 |
|
5 |
3,886 |
0.8978 |
|
∞∞ |
3,985 |
0.9649 |
对于语料库的准备,第三个注释者,也是领域专家,解决了两个注释者不同意的情况(两个注释器为同一实体选择了不同的标签,这也包括两个注释中的一个遗漏注释的情况)。关于最终数据集的统计数据如表2所示。该表报告了每个类别的文件数量、GDPR数据泄露数量、NER注释数量和注释实体数量。最常见的类别是:行政、组织、健康和个人。
Table 2 Corpus statistics
From: An AI framework to support decisions on GDPR compliance
|
#documents |
90 |
|---|---|
|
#GDPR data breach |
45 |
|
#NER annotations |
4,188 |
|
#AMM |
2,094 |
|
#ORG |
983 |
|
#MED |
527 |
|
#PER |
400 |
|
#OM |
104 |
|
#LOC |
80 |
考虑到《通用数据保护条例》第4条将个人数据定义为足以识别个人身份的任何数据,以及《通用数据管理条例》第2条声明,当数据匿名时,数据不再是个人数据,个人不再可识别,我们执行了一个匿名化过程,用人工标识符替换任何已识别或可识别的信息。请注意,《通用数据保护条例》第26条将匿名信息定义为与已识别或可识别的自然人无关的信息,或与以数据主体不可识别或不再可识别的方式匿名提供的个人数据无关的信息。GDPR不适用于匿名信息。为了实现匿名化目标,我们采用了一个包括以下步骤的管道:
- 每个人的名字ni都被另一个名字nr取代,该名字nr是从最常见的意大利姓氏和名字列表中随机抽取的。在同一份文件中,名称ni的出现总是被相同的nr取代。
- 每个个人身份证号码或意大利财政代码分别被随机数字序列或随机财政代码所取代。
- 在城市和地区列表中搜索每个位置实体,然后将其随机替换为另一个城市或地区。替代名单只包含居民超过10000人的城市,不包括不常见的城市名称。
- 每个法律引用Footnote7都被一个占位符LEX_u取代。此外,在这种情况下,对于每个ai,整个语料库中的替换总是相同的。
最后,所有文件都进行了手动检查。这个匿名语料库旨在评估所提出的INTREPID框架的性能,而原始语料库被丢弃。
- 117 次浏览
【IAM】隐私和IAM:您需要了解的内容
视频号
微信公众号
知识星球
从信用机构违规、信用卡被盗,到GDPR和社交媒体数据,隐私最近一直是新闻热点,这无疑是每个CEO心中的问题。Gartner的一项调查¹发现,对“快速加速的隐私法规”的担忧已成为高管面临的首要风险。
尽管大多数客户来到Integral Partners寻求围绕身份管理、特权访问和治理的解决方案,但网络安全是一个广泛且相互关联的领域。我们的许多客户也在处理隐私问题,他们想知道IAM和隐私是如何重叠的。
我们喜欢帮助我们的客户看到周围的角落,所以我们想分享我们对隐私话题的看法。我们希望这些考虑将帮助您预测和规划未来的趋势、事件、法规和战略。
客户与员工隐私
当涉及到身份和访问管理(IAM)时,我们基本上看到了两种隐私:客户隐私和员工隐私。它们有何不同?从组织的角度来看,客户是为您的服务付费的人,而员工是您为其服务付费的人员。
许多组织目前对待客户和员工数据都是一样的:他们也将针对员工身份制定的规则和规定应用于客户。然而,这些数据集非常不同,它们需要不同的工具来管理它们的控制。例如,大多数IAM系统通常不管理客户数据生命周期;他们管理管理这些客户的员工,以及可以访问这些客户数据的员工。例如,在一家零售公司,IAM系统将管理能够访问客户奖励计划中数据的员工。在一家将患者视为客户的医疗保健公司,IAM解决方案将管理可能访问患者数据的员工。
客户隐私是最重要的
在许多公司中,客户数据被视为属于与客户交互并管理客户的销售或营销业务组。(这与员工数据形成对比,员工数据通常被视为IT的权限。)客户数据经常被输入到商业智能、营销数据和其他应用程序中,这使其对公司非常有用,但保护其使用的过程变得复杂。因此,许多组织的IT团队尚未承担起保护客户数据的责任和风险。但由于围绕如何处理客户数据引入了新的规则和期望,这一点正在发生变化。
客户隐私是当今许多高管的头等大事,因为侵犯客户隐私的行为充斥着头条新闻。这些漏洞从黑客攻击和安全漏洞到第三方疏忽和内部泄露。这样的违规行为已经司空见惯,给公司带来了数十亿美元的损失,有时还会让首席信息官或首席执行官失去工作。许多高管甚至不知道他们的客户身份保存在哪里,也不知道谁可以访问客户数据,但最终他们要对其安全负责。
GDPR对客户隐私的影响
2018年在欧盟生效的《通用数据保护条例》规定了组织如何收集、管理和保护公民个人数据的规则。例如,数据收集必须公开,存储的数据必须匿名,数据使用必须经过个人的知情同意。法律要求处理用户数据的组织指定一名负责GDPR合规的“数据保护官员”,违反GDPR可能会受到严重的经济处罚。GDPR还为公民提供“被遗忘权”,个人可以要求从公司记录中删除某些类型的信息。
尽管GDPR是欧盟法律,但它适用于任何在欧盟内部“处理”个人数据的跨国组织。许多美国组织已经在遵守GDPR;事实上,任何一家网站对欧洲游客开放的公司都已经修改了服务条款。此外,许多公司现在认为,类似的法规很快就会在美国出台。每当有公司背叛客户信任或滥用用户数据的情况发生时,要求美国实施类似GDPR的要求的呼声就会增加。
许多公司都在努力遵守GDPR,因为“忘记”用户数据集所需的控制措施尚不存在,创建这些数据集所必需的方法将复杂且成本高昂。与此同时,各公司正在努力找出如何在保护客户数据的同时保持良好的声誉,同时在接受审计时不会受到政府机构的惩罚。美国公司担心GDPR会朝着这个方向发展,一些公司正在抓紧准备。
员工隐私
尽管员工隐私通常被视为比客户隐私更不重要的问题,但它仍然是高管关注的焦点。关于如何处理客户数据的观点正在改变,这也影响了关于如何管理员工数据的共识。
工人数据的隐私通常是安全和管理协议的领域。当员工接受公司的职位时,他们与雇主签订合同,并承认需要收集和存储一定数量的私人数据。技术解决方案已经发展起来,可以帮助公司保护这些员工数据,确保其不受外部侵犯,并且只能由公司内部的合适人员在适当的时间访问。这是IAM的域。
工人们传统上认为,与消费者数据相比,他们无权规定如何使用员工数据。当涉及到员工隐私时,没有“被遗忘权”,事实上,为了税务和法律目的,许多组织都必须保留员工数据,即使员工已经离开公司。然而,许多员工对雇主人力资源数据库中的身份越来越有归属感。这可能是日益增长的消费者隐私权运动的影响,但工作场所的人口统计也可能对此负责。虽然老一辈人接受公司会保留他们的信息,但千禧一代人并不一定会做出这样的假设,尽管他们在个人生活中提供了大量信息。
随着雇主以新的方式利用员工的数据,例如,将个人健身追踪器连接到公司激励计划,使用个人指纹作为访问机制,或在公司发行的笔记本电脑上安装监控软件,有关适当数据管理的问题只会升级。
拐角处的变化
有多少客户真正阅读了他们光顾的公司的服务条款?有多少公司对客户的数据及其使用和存储方式透明?到目前为止,对遭受隐私侵犯的公司几乎没有什么影响,因为许多消费者似乎觉得,剥夺隐私是他们为获取技术所付出的代价,其好处大于代价。
然而,随着客户和公司对隐私问题的认识和教育越来越深,头条新闻可能会产生法律后果。Gartner预测,“到2020年,个人数据的备份和归档将成为70%组织面临的最大隐私风险领域,而2018年为10%”。
解决隐私问题不可能很快或很容易。一些公司会倡导客户和员工隐私,有些公司则不会。人们将越来越多地要求隐私,而公司则努力满足这一要求。公司将认识到,他们需要明确数据的所有权,确保数据得到集中管理,并以一致、安全的方式实施控制、法规和工作流程。他们会明白,员工隐私和客户隐私之间的差异可能需要不同的解决方案和专业知识。
隐私考虑建议
以下是从何处开始思考组织内部隐私问题的一些想法。
- 与执行领导层接触,以获得有关隐私的支持和赞助,并与执行利益相关者定期举行会议,以在工作进展过程中提供指导和决策。
- 考虑您的客户数据位于何处,以及谁拥有这些数据。市场营销部或销售部是您客户数据的保管人,还是与其他部门合作?哪些员工或第三方可以访问它?
- 确定现在和将来适用于客户数据的法规或控制措施。例如,如果你是一家医疗保健公司,你需要考虑的不仅仅是HIPAA,GDPR可能很快就会出现在你的后视镜中。
- 确定制定了哪些隐私政策。客户数据的隐私政策应与内部用户数据隐私政策不同,因为每个政策的法规和期望都是独一无二的。审查现有政策,填补任何缺失政策的空白。确保适当级别的权限在涉及风险和安全的政策设计中有发言权。
- 重新评估。通过审查这些法规和控制措施,您发现了哪些您不知道的,需要知道的?您的客户数据的存储和访问方式需要做哪些改变?
- 确保您对所有员工数据拥有集中的IAM控制系统,这不仅意味着员工,还意味着承包商、合作伙伴和供应商。自动化、审计合规性和定期政策审查至关重要;更好的是为您的组织计划如何应对即将到来的监管变化制定路线图和战略。
找一个能为制定战略提供指导的人。例如,合规人员往往非常关注当前,而公司需要考虑近期和长期的未来。客户现在要求什么,一年后他们想要什么?如果公司能够预见这些需求和担忧并做好准备,他们就能以更低的成本更快地做出反应。
- 84 次浏览
【同态加密】通过同态加密实现可搜索的加密:综合分析
视频号
微信公众号
知识星球
PORTIC—Porto Research, Technology and Innovation Center, Polytechnic Institute of Porto (IPP), 4200-374 Porto, Portugal
Author to whom correspondence should be addressed.
Mathematics 2023, 11(13), 2948; https://doi.org/10.3390/math11132948
Received: 10 June 2023 / Revised: 25 June 2023 / Accepted: 27 June 2023 / Published: 1 July 2023
(This article belongs to the Section Mathematics and Computer Science)
摘要
云基础设施的广泛采用彻底改变了数据存储和访问。然而,它也引发了对敏感数据隐私的担忧。为了解决这些问题,加密技术已被广泛使用。然而,传统的加密方案限制了加密数据的有效搜索和检索。为了应对这一挑战,出现了创新的方法,例如在可搜索加密(SE)方案中使用同态加密(HE)。本文全面分析了基于HE的隐私保护技术的进展,重点介绍了它们在SE中的应用。这项工作的主要贡献包括识别和分类现有的利用HE的SE方案,全面分析了SE中使用的HE类型,研究HE如何塑造搜索过程结构并实现额外功能,并为基于HE的SE的未来研究确定有希望的方向。研究结果表明,HE在SE方案中的使用越来越多,尤其是部分同态加密。这类HE方案的流行,尤其是Paillier的密码系统,可以归因于其简单性、已证明的安全性以及在开源库中的广泛可用性。该分析还强调了使用HE的基于索引的SE方案的普遍性,对排名搜索和多关键字查询的支持,以及在可验证性以及授权和撤销用户的能力等功能方面进一步探索的必要性。未来的研究方向包括探索与HE一起使用其他加密方案,解决模糊关键字搜索等功能中的遗漏,以及利用全同态加密方案的最新进展。
Keywords:
searchable encryption; homomorphic encryption; secure search; data privacy; keyword search
MSC:94A60; 68P25
1.简介
云基础设施的快速增长和广泛采用彻底改变了我们存储和访问信息的方式。从Dropbox和Google Drive等个人数据备份和文件共享服务,到企业级数据管理和可扩展的基础设施解决方案,云存储对我们的日常生活产生了深远影响,尤其是在医疗[1,2]和教育[3,4]等领域。根据Netwrix发表的一份报告[5],80%的组织将敏感数据存储在云中。它提供的优势包括高数据可用性、从任何地方方便访问、降低基础设施成本、无限存储空间和成本效益[6]。然而,随着云的采用,托管给云服务器的敏感信息面临潜在的漏洞,如未经授权的访问、数据泄露和内部威胁,安全问题也随之加剧。Netwrix的报告[5]还发现,55%的医疗保健组织在去年经历了涉及第三方实体的数据泄露,这是所有行业中第二高的百分比,仅次于金融部门,金融部门58%的公司经历了类似的泄露。这两个部门严重依赖能够访问其敏感数据的第三方实体,这对网络犯罪分子极具吸引力。此外,他们的研究结果表明,攻击变得更加复杂,更难发现。
为了解决这些问题,确保用户敏感数据的隐私变得至关重要。实现隐私的最常见方式是通过加密,即数据在存储到云中之前进行加密,从而提供端到端的数据隐私。然而,在高效搜索和检索以加密形式存储的数据时,传统的加密方案带来了挑战,限制了加密存储解决方案的可用性。天真的方法,例如下载所有密文、解密它们和搜索明文,是不切实际的。因此,为了应对这些挑战,出现了安全搜索、私人信息检索(PIR)和可搜索加密(SE)等创新概念。安全搜索解决了执行搜索操作的需要,同时保持数据的隐私和机密性[7]。PIR与安全搜索密切相关,使用户能够从数据库中检索特定数据,而无需透露他们正在访问的项目[8]。另一方面,SE是一种加密技术,允许对加密数据进行安全高效的搜索操作[9]。需要注意的是,“安全搜索”和“可搜索加密”这两个术语有时可以互换使用,模糊了这两个概念之间的区别。在实践中,这些术语之间的界限可能是不稳定的,不同的研究人员和从业者使用它们来指代相关的技术和机制。此外,PIR通常被认为是安全搜索或SE方法中的一个组件,因为它可以从数据库中检索私人数据。在这项工作中,我们主要使用“可搜索加密”一词,而“安全搜索”则在我们觉得需要区分的时候使用。
SE可以使用几种不同的加密技术以及这些技术的组合来实现。两种最流行的SE方案是可搜索对称加密(SSE)和带关键字搜索的公钥加密(PEKS),正如名称所示,它们分别依赖于安全对称加密方案或安全非对称加密方案。通常使用的其他技术是基于属性的加密(ABE),以便对SE方案执行细粒度访问控制,以及保序加密(OPE),以便有效地允许对搜索结果进行排序。然而,在SE领域中有一种值得注意的方法,那就是利用同态加密(HE),这是一种允许直接对加密数据执行计算的加密技术[10]。这一特性使其非常适合于隐私保护技术,在保持机密性的同时,可以直接对加密数据进行搜索操作。研究人员越来越关注这种方法,因为它为安全搜索提供了一个有吸引力的框架,而不需要昂贵的设置程序[11]。
已经提出了许多利用同态特性提供隐私保护技术的方法,特别是在SE的背景下。然而,缺乏专门的研究来分析这一领域的进展。另一方面,至关重要的是,科学界要全面了解最先进的技术,并为该学科的进一步探索确定有希望的方向。
在这项工作中,我们旨在对高等教育在SE中的应用进行深入分析。
1.1.相关工作
自2020年Song等人[12]发表第一篇关于SE的工作以来,已经就这一主题提出了几篇调查和评论论文,这突出了在大多数数据存储在第三方云服务中的世界中,安全数据管理的重要性日益增加。
Bösch等人[13]提出了第一项关于SE的调查。在他们的工作中,对每种方案支持的作者和读者数量进行了全面的讨论。作者考虑了四种不同的情况:单作者/单读者、多作者/单阅读器、单作者/多读者和多作者/多阅读器。根据它们的查询表达能力对这些方案进行了组织,并进行了分析,比较了效率和安全性。王等人[14]和韩等人[15]发表了两项关于SE的新的系统调查。前者考虑到现有SE方案在对称和非对称密钥环境中的应用,对其进行了更广泛的展望,而后者根据三个方面对系统进行了分类:安全要求、搜索功能和部署模型。此外,正如作者所说,后者还引入了一种新的部署模型,该模型在Bösch等人的工作中没有涉及,称为服务器-用户模型,其中云服务器是数据的所有者,同时充当数据所有者和存储服务器。
在后来的几年里,发表了其他关于SE方法的综述[16,17,18,19]。
最近,在2022年,Andola等人[20]发表了一篇全面的综述论文,重点分析了这些技术的特点和局限性,基于它们对各种类型攻击的性能和鲁棒性。这项工作的关键方面之一是深入分析每种技术以及决定其效率的密码基础。同年,Noorallahzade等人[21]发表了基于一组全面指标的SE方案的完整分类,包括搜索类型、索引类型、结果类型、安全模型、实现类型、用户的多样性、加密原语和所使用的技术。对每个类别的可用方案进行了比较和评估。Sharma[9]为非安全专家提供了一份关于SE的全面指南。这项工作的主要目标是帮助全科医生根据他们的具体需求选择最合适的SE方案,方法是进行一项调查,根据五个关键特征详细介绍现有方案:关键结构、搜索结构、搜索功能、对读者/作者的支持和读者能力。讨论了对称和非对称SE方案。它还提供了一个比较分析,可以帮助非安全专家就其加密需求做出明智的决定。
多年来,已经出版了其他作品,调查了SE在不同背景下的应用。例如,张等人[22]讨论了SE在医疗保健系统中的应用,而Bader和Michala[23]则重点讨论了其在工业物联网(IoT)中的应用。其他工作也分析了区块链等新技术如何被用于增强SE机制的潜力[24,25]。然而,没有研究将HE用于安全搜索机制。尽管如此,HE在SE方案中具有很高的价值,因为它具有独特的功能,例如允许直接对加密数据执行计算,以及实现隐私保护搜索操作。使用HE,用户可以对他们的查询进行加密,并根据加密的数据对其进行评估,从而确保查询和数据的机密性。因此,利用HE的最新进展可以增强SE方案,使其更适合现实世界的应用。在这种情况下,我们的主要目标是调查将HE纳入其设计的SE技术,同时对HE的使用方式及其带来的好处进行全面分析,并确定该领域应探索的潜在研究方向。
1.2主要贡献
我们工作的主要贡献是:
- 利用HE识别和分类现有SE。我们的分析涵盖了这些系统的几个方面,包括使用的加密技术、搜索过程的结构(基于顺序扫描或索引)以及提供的搜索功能(如处理多个关键字、正则表达式、通配符、短语、范围、出现次数和模糊关键字的能力)。此外,我们还研究了其他功能,如授权和访问撤销、SE的静态和动态方法以及正确性验证。
- 为了对SE方案中使用的最常见的HE类型进行广泛的分析,我们的分析重点是识别所使用的方案是否属于部分同态加密、部分同态加密或全同态加密的类别。此外,我们尽可能明确地识别HE方案。
- 在前面提到的分类的基础上,研究如何使用HE来实现SE中的不同属性和特性。具体来说,我们研究了HE如何塑造搜索过程结构,增强搜索能力,并在SE中启用其他功能。
- 为基于高等教育的SE计划的未来研发确定有希望的方向,旨在为SE提供更灵活、更先进的解决方案。
1.3研究方法
为了对高等教育在SE中的应用进行全面分析,采用了一种系统的方法。这种方法包括搜索几个学术数据库,包括ACM数字图书馆、IEEE Xplore、Elsevier ScienceDirect、Scopus和Web of Science。
为了在前面提到的数据库中进行搜索,在彻底审查了该领域的主要文献后,确定了一个关键词列表。在列出的数据库中搜索在标题、摘要或一组关键词中至少包含一个与SE相关的关键词和一个与HE相关的关键词的作品。与SE相关的关键词包括“可搜索”、“安全搜索”和“关键词搜索”。与HE相关的关键词包括“同态”。
因此,使用的主要研究查询是:
(可搜索或“安全搜索”或“关键字搜索”)AND同态。
搜索于2023年2月进行,表1显示了在每个搜索数据库中获得的研究出版物的数量。可以看出,总共返回了645个结果。
表1.在每个学术数据库中获得的搜索结果数量。

在进行搜索后,我们能够识别出重复的结果,然后将其消除。这一过程总共产生了290篇不同的研究论文。为了选择与我们研究相关的出版物,有必要进行另一个筛选过程。因此,制定并适用了一套纳入和排除标准。表2中列出了这些标准。
Table 2. Inclusion and exclusion criteria.
最后,在应用纳入和排除标准后,在290篇论文中,共有23篇论文被确定符合纳入和排除准则。因此,这23篇论文被选为我们分析的论文。
1.4.组织机构
本文件组织如下:第2节介绍了SE方案中涉及的主要参与者和过程,以及如何在搜索结构、搜索功能、用户多样性和其他功能方面对其进行表征。理解本节中提出的关键概念对于理解后续关于使用HE的SE方案的讨论至关重要。第3节重点介绍高等教育,介绍其定义、现有的主要类型和方法。HE在这项工作中发挥着至关重要的作用,理解基本的相关概念和属性对于理解其对增强安全搜索机制的影响至关重要。在第4节中,对所选作品进行了全面分析,对每一部研究作品进行了描述和分类。第5节涵盖了对研究趋势的讨论,这对于了解该领域的最新进展和新兴方向很重要。它为正在进行的研究工作、潜在的挑战和未来的机遇提供了宝贵的见解。最后,在第6节中,我们总结了关键发现,强调了主要贡献,并对研究的意义提供了见解。这一部分对于得出结论、总结研究意义和启发进一步研究具有重要意义。
2.可搜索加密
术语SE指的是一种加密技术,它可以在不首先解密的情况下搜索加密数据。在使用云服务存储大量敏感数据的情况下,SE特别有用和重要。在这种情况下,隐私保护技术对于搜索和检索存储的敏感数据是必要的。因此,我们在这项工作中的重点是基于云的SE系统。
SE技术可以根据底层加密过程大致分为两种主要类型:对称和非对称。与传统的对称加密方案类似,对称SE技术使用相同的密钥进行加密和解密。另一方面,非对称SE方案使用两个密钥——一个用于加密,另一个用于解密。
图1描述了一个通用的基于云的SE系统的高级架构,该系统通常由以下三个主要实体组成:
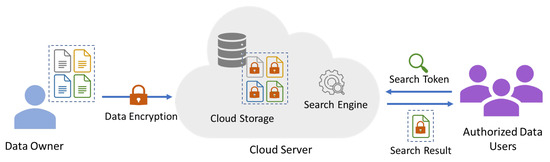
Figure 1. A conceptual overview of a cloud-based SE system.
- 数据所有者(DO)负责数据加密及其外包给云服务器的实体是数据所有者,在相关文献中也称为“客户端”[9]。通常,数据由对其拥有合法控制权和所有权的DO生成。然而,在某些情况下,另一个实体,即数据提供商,可能负责生成数据。使用索引来帮助搜索过程的SE方法,也称为基于索引的SE方案,通常要求数据提供商(无论是否是数据所有者)加密索引并与云共享。
- 数据用户(DU)想要搜索DO保存的加密数据的实体被称为数据用户。理想情况下,它只能在DO已经给予许可的情况下进行搜索。因此,DU负责向云服务器发送搜索请求,云服务器处理该请求,然后检索结果。值得注意的是,在某些系统中,DO也可以充当DU。
- 云服务器(CS)云服务器是负责安全存储加密数据并向授权DU提供SE服务的实体。它在接收DO的加密文档后执行三项主要任务:存储数据、搜索数据和保持搜索数据结构的最新状态。CS执行搜索的方式取决于所使用的SE方案。对于基于索引的SE,CS通过将搜索请求与加密索引进行比较来进行搜索,然后将结果发送给授权的DU。然而,对于不基于索引的SE方案,搜索加密数据的过程通常需要扫描整个文档,这将在本节稍后讨论。
SE系统的体系结构通常包括四个涉及先前描述的实体的过程。根据SE方案的具体设计和要求,每个步骤中使用的具体算法可能有所不同。
考虑到各种因素,例如是否存在基于索引的搜索机制,以及它是对称的还是非对称的SE方案,对每个过程的以下描述已经尽可能广泛。
- Setup()算法根据输入的安全参数生成各种系统参数(P)和所需密钥(K)(𝜆)。非对称SE必须生成公钥和私钥,而对称SE只需要一个密钥。通常,系统所有者运行此算法。
- Encryption()加密算法使用上一个进程K中生成的密钥对数据进行加密,并输出一条消息𝑀′通过使用加密算法E对原始数据M进行加密而获得。如果SE方案是基于索引的,则关键字W的输入集合也将使用(一个或多个)输入密钥K来加密,那么它可以用于生成加密关键字的索引I。DO然后应用该算法将加密的索引I与加密的消息相关联𝑀′以便创建可搜索的密文(𝑆𝐶)。然后可以将SC上传到CS。如果SE方法是基于扫描的(意味着服务器将直接扫描加密的数据),则可以跳过前面的步骤,并且消息𝑀′可以直接存储在CS上而不生成SC。
- TokenGen()搜索查询的创建由授权用户使用此算法完成,也称为Trapdoor。它需要一个输入加密密钥K和一个输入查询𝑄=𝑘1.𝑘2,…,𝑘𝑚并生成搜索令牌𝑇𝑄算法的具体实现取决于SE方案是基于索引还是基于扫描。对于基于索引的方案,该算法使用加密密钥K加密查询Q中的每个关键字,并生成索引𝐼=𝑤′1.𝑤′2,…,𝑤′𝑚的加密关键字。搜索令牌𝑇𝑄然后由I构造。对于基于扫描的方案,该算法生成扫描令牌𝑇𝑆.使用所选择的搜索查询Q和扫描令牌𝑇𝑆,搜索令牌𝑇𝑄然后创建。一旦构建,搜索令牌𝑇𝑄被发送到服务器,服务器使用它来搜索加密数据库中的相关数据。DU可能是唯一可以执行查询的人,具体取决于场景。
- Search()CS使用搜索算法在加密数据中搜索与搜索查询匹配的数据。在基于索引的方案中,搜索算法应用搜索令牌𝑇𝑄到可搜索的密文𝑆𝐶以标识与查询匹配的加密关键字集和相应索引。然后,它将相应的加密数据检索到DU。在基于扫描的方案中,搜索算法应用搜索令牌𝑇𝑄和扫描令牌𝑇𝑠以识别具有与搜索查询的关键字匹配的关键字的可搜索数据段的集合。一旦发现任何匹配,服务器就向DU发送搜索结果。
2.1.SE方案的特征
SE方案可以通过各种方式进行分类,文献中对SE方案有几种分类。例如,Han等人[15]根据三个方面对SE系统进行了分类:安全需求、搜索功能和部署模型。Noorallahzade等人[21]通过考虑其他方面,如搜索类型、索引类型、结果类型、安全模型、实现类型、用户多样性和加密原语,提出了更全面的分类。Sharma[9]基于五个关键特征详细介绍了现有的SE方案:关键结构、搜索结构、搜索功能、对读者/作者的支持以及读者能力。
在我们的工作中,我们将考虑SE方案的分类,包括四类:搜索结构、用户多样性、搜索功能和其他功能。通过使用这种分类,我们分析每个方案并确定它属于哪个类别,使我们能够对使用HE的SE方案中最常见的特征进行适当的分析。
我们将使用的分类如图2所示,每个类别在以下章节中都有详细描述,以供澄清。
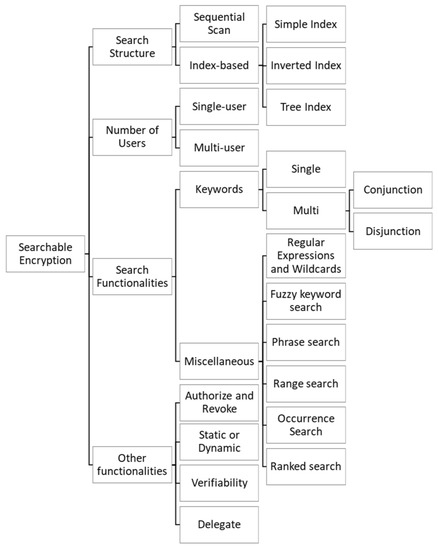
Figure 2. Key characteristics of a cloud-based SE scheme.
2.1.1.搜索结构
SE方案的一个重要方面是用于对加密数据执行搜索的搜索结构,因为它可能会显著影响方案的效率。历史上,由于Song等人[12],第一种方案使用了所谓的顺序扫描搜索结构。此搜索操作包括按顺序扫描数据库中的所有加密文档,以找到与搜索查询匹配的文档。尽管顺序扫描类别中的其他工作已经发表,例如Boneh等人的工作。[26]关于关键字搜索的公共加密,但使用这种方法的著名研究工作并不多[18]。这是由于这些技术效率非常低,不太适合大型数据库或频繁的搜索查询,因为搜索操作可能变得非常耗时且计算成本高昂。此外,这种搜索方法容易将敏感信息暴露给服务器,这损害了数据的隐私和安全性[20]。基于顺序扫描的SE方案的一个潜在优势是,它们可以提供一种简单直接的方式来搜索加密数据,而不需要复杂的索引或搜索结构。
SE中通常用于提高搜索性能的另一种类型的搜索结构是基于索引的搜索结构。在这种方法中,一种称为索引的特殊数据结构与加密文档相关联。这种新的数据结构可以将搜索查询与索引中的条目进行比较,而不是搜索数据库中每个文档的内容。此外,使用索引可以处理各种格式的文件,包括多媒体文件以及压缩和加密文件[19]。然而,使用这种方法,加密的数据和加密的索引必须由DO发送到CS。这两组信息可以使用相同的加密方案进行加密,也可以使用SE方案对索引进行加密,使用另一种可靠的加密方案对敏感数据进行加密。关键字索引主要有三种类型:简单索引、反向索引和树索引。
简单索引。在采用这种策略的系统中,每个文档在被加密并上传到CS之前都会被赋予一个索引。索引由被认为与该文档相关的单词组成。这种索引适用于需要将少量文档上传到CS[9]的应用程序。
反向指数。反向指数这个术语来源于反向构建指数的过程。这是因为,索引不是将每个文档与一组关键字相关联,而是通过将每个关键字与它出现的文档集相耦合来创建的。这种方法显著减少了搜索所需的时间,使其成为最适合将大量文档上传到CS[9]的应用程序的搜索结构。
树索引。树索引也是优化搜索过程的一种非常有效的方法。尽管有各种方法可以构建树索引,但基本思想是通过将一组关键字划分为更小的集合来创建一个包含可搜索关键字的树状结构。当DU搜索特定关键字时,CS将搜索索引树,从根开始,遍历每个相关节点,直到找到匹配。
与顺序扫描方法相比,基于索引的方案效率很高,每个文件的比较次数从𝑂(𝑛)�(�)至𝑂(1)�(1) 。然而,一个缺点是,可以在查询中使用的关键字仅限于在索引生成过程中提取的关键字[19]。
2.1.2.用户的多样性
SE方案允许DO安全地外包数据存储,允许DU根据特定的搜索标准检索数据。基于所涉及的用户的多样性,如果DO扮演DU的角色,我们将这些方案进一步分类为单用户,如果DU与DO不同,则将这些方案分类为多用户。
2.1.3.搜索功能
顾名思义,SE方案的搜索功能决定了可以执行的查询类型、过滤和排序选项以及帮助数据用户完善搜索的其他工具。在这项工作中,根据类似于Sharma[9]的分类,我们区分了与关键字数量直接相关的搜索功能和其他功能。与关键字数量没有直接联系的一组功能被称为“杂项”(图2)。
关于关键字的数量,SE方案可以被分类为单个关键字或多个关键字。在前者中,DU被允许在每个查询中仅包括一个搜索项。因此,如果他/她想使用这种类型的方案搜索多个术语,那么他/她需要执行多个查询,每个搜索术语一个[19]。另一方面,在多关键字SE方案中,允许用户在每个查询中使用多于一个搜索项来执行搜索。然而,值得一提的是,仅仅因为支持多个关键词,并不一定意味着用户可以使用无限数量的关键词进行搜索。一些方案可能被限制为特定数量的关键字。
此外,在多关键字SE方案中,查询可以表示为搜索项的简单列表、连接查询(使用AND关系)或析取查询(使用or关系)。多关键字SE可以属于连接关键字或析取关键字类别,这取决于查询的表达方式。
现有的SE方案除了包含多少关键字之外,还可以根据各种功能将其分组。在这项工作中,我们考虑了以下内容:通配符和正则表达式、模糊关键字搜索、短语搜索、范围搜索、出现搜索和排序搜索。
正则表达式和通配符
当DU知道他们想要在文档中搜索的关键字的特定模式时,允许基于正则表达式或通配符的搜索查询的SE方案非常有用。在这两种情况下,查询都可以使用特殊字符来描述关键字模式。
如果SE方案允许通配符查询,则DU可以用称为通配符的符号替换搜索查询中的单个字符。通常使用两种类型的通配符:“?”和“*”,后者被称为多字符通配符,表示任意数量的字符,而前者仅表示一个字符[27]。如果使用基于正则表达式的SE方案,则可以使用特殊字符和运算符的组合来描述搜索查询中比通配符所允许的更复杂的模式。尽管正则表达式提供了更大的灵活性,但在搜索变化较小的关键字时,基于通配符的SE方案是一种更简单的选择。
模糊关键字搜索
典型的SE方案,即使允许基于通配符或正则表达式的搜索查询,也只能搜索密文中关键字的精确匹配。它排除了搜索词格式中的任何拼写错误或不一致。但是,通过在SE方案中包括模糊关键字搜索功能,可以克服这一限制。有了这一功能,即使DU在搜索过程中拼错了单词,该方案也能够搜索与正确拼写单词相关的结果[19]。
短语搜索
通常,DU更喜欢查找特定的短语,而不仅仅是查找单个关键字。尽管这可以使用允许联合搜索查询的SE方案来实现,但这需要DU执行几个额外的步骤。首先,他们需要将短语转换为连接查询并执行搜索。然后,在从CS获得相应的文档后,他们必须对其进行解密和筛选,以找到包含他们要查找的短语的文档[28]。因此,在处理大型数据库时,这种方法可能效率非常低。另一方面,具有短语搜索功能的SE方案使数据用户能够直接搜索短语[9]。
范围搜索
允许范围查询的SE方案使DU能够在特定的值范围内搜索加密数据,这意味着它们可以根据间隔而不仅仅是精确匹配来执行搜索。例如,数据用户可能希望搜索2020年至2022年间创建的数据库中的所有文档,或者搜索所有者年龄超过30岁的文档。事实上,最后提到的例子属于范围查询的一个特定子类别,称为比较查询[29]。这种搜索查询对于避免多个单一关键字搜索非常有用。
事件搜索
具有此属性的SE方案允许数据用户向云服务器发出包括搜索项和值的查询。此值指定所选关键字必须出现在文档中才能在搜索结果中检索到的最小次数。这一功能非常有助于衡量我们的关键词在数据库中每个文档中的重要性[19]。
排名搜索
此功能的主要目的是通过仅检索与查询匹配的相关文档来增强数据用户的搜索体验。为了实现这一点,信息检索研究界采用了各种评分函数[19]。最常用的评分函数被称为TF-IDF,其中TF代表术语频率,表示该关键字在文档中的重要性,IDF代表倒置的文档频率,表示关键字在数据库中所有文档中的意义[18]。
2.1.4.其他功能
SE方案可能具有其他功能,并且对某些场景很重要。例如,关于访问控制功能,授权和撤销DU的能力至关重要。
授权和吊销用户
顾名思义,SE方案中的这一功能意味着DO可以授予新用户搜索功能,也可以撤销该功能。具有此功能的SE方案并不多,而且现有的方案效率低下且不切实际。这是因为启用此功能需要牺牲安全性[20]。
静态或动态
用于实际应用程序的SE方案中的另一个重要功能是允许动态更新的能力。当在创建加密数据库后没有添加、删除或更新文档时,SE方案被认为是静态的。因此,在数据加密之前,整个数据集必须可用。相比之下,如果用户可以添加、删除或修改文档,而不会危及加密数据的安全性或系统搜索和检索文档的能力,那么SE系统就是动态的。动态SE方案更灵活,更适合实际应用。然而,与动态SE方案相比,静态SE方案通常更有效,实现起来更简单,这使其成为数据相对稳定、不需要频繁更新的简单场景的更好选择。需要注意的是,在动态和基于索引的SE方案中,当对文档集合进行更改时,必须有效地更新索引,并且必须在不添加任何泄漏的情况下进行更新[19]。
可验证性
在大多数应用中,SE系统中的CS被认为是半可信的,这意味着它可能会向DU检索不完整或不正确的结果[19]。因此,对于SE方案来说,允许DU验证CS已经检索到的搜索结果是重要的。这样的SE方案被指定为可验证的SE方案。正如预期的那样,与不允许可验证性的SE方案相比,这种方案在所有站点(DO、DU和CS)上都会遭受更高的计算开销[9]。结果验证可能包括正确性(如果检索到的结果与查询相对应)、完整性(如果返回了所有相关文档)和新鲜度(如果将文档的最新版本检索到DU)[19]。
代表
此功能允许授权用户将搜索功能委托给另一用户。该功能主要出现在非对称SE方案中,也称为带有关键字搜索的公钥加密。这些SE方案包括代理重新加密,也就是说,它们有一个半可信的第三方服务器(代理服务器),将用DO的公钥创建的密文转换为受委托用户可以解密的密文[9]。尽管这不是一种非常常见的SE类型,但已经有几项工作解决了这一特点[21]。
3.同态加密
HE方案背后的主要思想是允许在加密数据上执行计算,而无需首先对其进行解密。这个概念是由Rivest等人[30]引入的,最初被称为“隐私同态”。因此,HE方案是加密函数是同态的任何加密方案。形式上讲,设M表示明文的集合,C表示密文的集合。Let⊙𝑀和⊙𝐶分别是M和C中的运算。如果对于任何加密密钥k加密函数E满足以下性质,
∀𝑚1,𝑚2∈𝑀,𝐸(𝑚1⊙𝑀𝑚2)←𝐸(𝑚1)⊙𝐶𝐸(𝑚2),
其中← 意思是“可以直接从”[31]获得。即在(1)中,𝐸(𝑚1⊙𝑀𝑚2)
可以直接从𝐸(𝑚1) ⊙𝐶𝐸(𝑚2)
而不必执行任何解密。
根据系统允许的操作类型和数量,HE方案可以分为三类:部分同态加密(PHE)、部分同态加密和全同态加密(FHE)。
3.1.部分同态加密
Rivest等人的工作发表后,密码学研究人员开始寻找允许直接对加密数据执行多个操作的HE方案。尽管如此,在接下来的二十年里,大多数尝试都产生了只允许一种操作类型的方案,即PHE方案。在这些方案中,同态性质仅通过一个运算(如加法或乘法)来满足,而不对该运算的执行次数施加任何限制。
众所周知的RSA公钥密码系统[32]是一种PHE方案,它只支持通常的乘积运算,并且是确定性的,这意味着当一个人使用相同的密钥加密相同的明文时,总是会得到相同的密文。
几年后的1982年,Goldwasser和Micali[33]发表了第一个概率PHE方案,这激发了随后几十年发表的大多数PHE方案的灵感,如Benaloh[34],这是Goldwasser等人方案的推广,Naccache和Stern[35],这是Benaloh方案的改进。
Elgamal[36]介绍了一种PHE,它也只允许通常的乘积,Paillier[37]发表了一种只允许通常和的PHE。后一种方案是使用HE的SE方案中最常用的方案,如第5节所示。
3.2.某种同态加密
2005年,Boneh等人[38]发表了第一个能够执行两种运算的HE方案:加法和乘法。然而,尽管加法可以无限次执行,但它只允许一次乘法。这是一种被称为SWHE的HE方案,因为同态性质被满足的次数有限,而不是一次运算。
在引入最初的高等教育计划后不久,就出现了一些关于SWHE计划的建议。尽管由于其局限性,它们不如PHE计划具有吸引力,但对PHE的广泛研究导致了更完整的计划的开发,这些计划是实现FHE计划的垫脚石。事实上,许多研究人员认为Boneh等人[38]提出的方案是FHE方案发展的重要组成部分。
3.3.全同态加密
在这种类型的HE方案中,同态性质适用于不同的运算,并且它们可以执行任意次数。
这一类别被许多人认为是密码学的“圣杯”,因为它允许在加密数据上自由执行计算。2009年,Gentry发布了第一个FHE方案[39]。在他的工作中,Gentry还提出了一种从不完全同态但具有一定同态评估能力的FHE方案构造一般FHE方案的方法[40]。从那时起,HE引发了相当大的兴趣,导致了基于Gentry思想的新型FHE方案的提出。其中最显著的是FV[41]、BGV[42]、CKKS[43]和TFHE[44]。
HE方案中常见的安全问题是0加密的累积。如果恶意参与者能够收集大量0的加密,则可能会危及该方案的安全性。为了解决这个漏洞,许多方案都采用了一种被称为“添加噪声”的技术来伪装零加密。
然而,随着计算次数的增加,这些方案中的噪声往往会增加,可能导致不正确的解密。为了解决这个问题,Gentry引入了自举的概念。然而,这种方法需要大量的计算成本,而Gentry方案复杂的数学基础使其在现实应用中不实用。
根据Acar等人[10],自Gentry于2009年开展工作以来,FHE方案主要有四类:
理想格——在这一类中,本质上存在着对Gentry方案的优化。这一类别的例子包括Scholl和Smart的作品[45]以及Gentry和Haveli的作品[46]。
整数——第一个基于整数的FHE出现在2010年[47]。这些方案背后的主要动机在于其概念的简单性。然而,由于缺乏实用性,它们成为研究人员最不喜欢的类别。
(Rings)Learning With Error,(R)LWE-Brakerski和Vaikuntanathan[48]是第一个提出这类方案的人。这些方案基于LWE问题,这是实时解决的最具挑战性的问题之一,即使对于后量子算法也是如此。LWE有一个称为RLWE的代数变体,在实际应用中更有用;
𝑁𝑡ℎ��ℎ次截断多项式环单元-这些方案允许在使用各种密钥加密的数据之间进行计算。López-Alt等人[49]是第一个提出这种HE方案的人。
由于其在密码应用方面的巨大潜力,已经提出了HE方案来解决几个领域的广泛问题,包括大数据和云计算、安全图像处理、医疗应用、电子投票系统、私人信息检索和生物特征验证,如Challa[50]和Alloghani[51]所述。
4.利用HE的SE方案的分析
在本节中,我们回顾和分析了第1节中所述的筛选过程中产生的23项研究工作。我们只考虑了清楚如何使用HE的拟议方案。该分析的目的是研究它们的功能,考虑图2中所示的特征,并确定这些特征中的哪些利用了HE和所使用的HE类型。表3列出了选定的作品,并概述了它们的功能。它还确定了使用HE实现的特性。该表是一个完整的资源,用于识别和访问本研究中分析的作品,确保透明度并促进未来的参考。
Table 3. Categorization of selected SE schemes that utilize HE.
我们的分析分为以下几类:搜索结构、搜索功能和其他功能。我们没有专门讨论“用户的多样性”这一类别,因为每当我们分析所选作品时,都会提到这一功能。需要注意的是,提供密码结构的详细解释超出了本工作的范围,可以在参考作品中找到。
4.1.搜索结构
SE方案的搜索结构可以包括对整个数据库的顺序扫描,也可以包括基于索引的方法,其中创建索引以促进搜索过程,如第2节所述。在本分析中,我们将重点关注基于顺序扫描的SE方案,因为所有其他方案都是基于索引的,它们将在下一节中讨论。此外,重要的是要记住,安全搜索的概念与SE的概念相似,因此,这两种方法都将包含在本分析中。请注意,安全搜索方法通常包括验证数据库中的所有文档,以找到与查询匹配的文档,这类似于顺序扫描过程。
Akavia等人的工作[7]是第一篇介绍对FHE加密数据进行安全搜索的方法的论文。作者声称,这是通过使用一个多项式来实现的,该多项式的次数相对于数据数组中的条目数量是对数的(而不是线性的)。
他们的安全搜索协议的核心是计算第一个查询匹配的草图,这是使用他们称之为SPiRiT的方法完成的。此方法返回与加密数据数组中的查找值匹配的第一条信息。任何标准的语义安全FHE都可以用于他们提出的方案,前提是明文模参数是素数p,在这种情况下同态运算是加法和乘法模p。他们声称只有一轮通信,并且通信开销只会随着输入和输出大小的增加而增加。
2020年,Wen等人[66]提出了一种用于安全搜索方案的搜索方法,该方法适用于单个用户设置,名为LEAF。这种方法使用了三种新方法:定位、提取和重建。定位技术用于将原始数据库数组划分为长度相等的较小间隔,并识别包含匹配项的第一个数组。返回包含匹配项的加密间隔索引。然后使用提取来找到包含第一个匹配项目的区间,以便在该区间上进行后续搜索操作,并使用重建来组合来自这两种技术的信息,以便在不需要解密任何内容的情况下正确定位我们想要的数据。值得一提的是,这些作者声称安全搜索大致由两个步骤组成,即匹配和搜索。在匹配步骤中,服务器将客户端的加密搜索查询与所有加密数据库项进行比较,返回第二个0和1的加密数组,1表示数据库中与查询匹配的项。搜索步骤将所有1的索引和相应的项目返回给客户端。因此,他们的工作集中在搜索步骤上。FHE在该方案中用于加密敏感数据和搜索查询。事实上,该方案的主要目标之一是通过减少必要的计算次数,即乘法次数,优化FHE在安全搜索中的使用。此外,作者还提出了该方案的一个变体,名为LEAF+,它使用了懒惰自举。从好的方面来说,自举步骤可以控制算法的计算深度,并且数据库越大,优化效果就越大。另一方面,当数据库的大小很小时,这种变体将是无效的,因为它带来了许多额外的乘法运算和计算深度。
Choi等人在2021年[11]提出了一种安全搜索方法,该方法使用标准CPA安全(分级)FHE,用于一次性使用,还对加密数据库进行顺序扫描以执行搜索。事实上,在他们的方法中,安全搜索的计算任务分为两个步骤,称为匹配和获取,这两个步骤对应于Wen等人方法的数学和搜索阶段。在匹配步骤中,云服务器使用底层FHE方案的同态属性将加密的搜索查询与数据库中的所有加密记录进行比较,以找到与该查询相对应的记录。然后,在获取步骤中,同样使用同态属性,从数据库中检索那些对应的记录,并使DU可用,然后DU可以对它们进行解密。关于提取过程,作者提出了两种新的检索算法,即COIE方案(基于幂和或bloom滤波器)和CODE方案(基于bloom滤波器集),并将这些算法的性能与LEAF+[66]和PIR等其他众所周知的检索算法进行了比较。
2022年,Iqbal等人[53]提出了一种机制,用于安全地搜索在医疗环境中外包给CS的加密音频数据,该机制还执行顺序扫描。他们的方法包括使用BGV FHE方案对数据文件进行加密,然后将数据文件发送到云服务器进行存储。当请求搜索时,CS使用同态运算对存储的加密文件执行顺序扫描,以找到包含搜索关键字的文档。然后,使用BGV方案对检索到的文档进行解密。在Iqbal等人进行的实验中,使用了开源编程库HElib 2.1.0版本。该库允许将BGV与自举一起使用,并应用增强功能,如Smart–Vercauteren的密文打包技术和Gentry–Halevi–Smart的优化技术[73]。
在Malik等人[52]于2023年发表的最新工作中,提出了一种使用PHE的单关键字SE方案,该方案使用Paillier密码系统[37]来保护外包给云服务器的机场数据。该方案使用HE来执行搜索操作,并通过使用陷门隐藏搜索模式来提供高级别的安全性。提出了两种方法,一种利用了Paillier密码系统的确定性性质,称为“有效SKSE”,另一种利用其概率性性质,命名为“安全SKSE”。前者适用于将轻量级方法置于安全之上的场景。相比之下,后者更适合于安全性优先于性能的场景。这两种方法都使用顺序扫描搜索结构,并且是为单个用户场景设计的,其中机场充当加密数据的DO和DU。
在该方案中,原始数据文件被加密两次。第一次加密是使用高级加密标准(AES)[74]进行的,之后将加密的文件上传到CS。第二次加密使用Paillier密码系统对原始文件进行加密,得到的加密数据也被上传到CS。这些是将用于执行顺序扫描的加密文件。作为该扫描的输出,系统检索加密结果,该加密结果在DU使用Paillier方案解密后,允许恢复包含搜索关键字的文件的标识符。然后使用AES来解密这些文件并恢复原始数据。
4.2.搜索功能
在本节中,我们将分析所选的涉及搜索功能的作品。我们根据以下特征对本节进行了划分:正则表达式和通配符、连词搜索、范围搜索、短语搜索和排序搜索。我们没有提供单独的章节专门讨论允许多关键字搜索或析取搜索的能力,因为所有拥有这些功能的作品也拥有其他搜索功能,并在其相应的章节中进行分析。此外,在表3中可以很容易地识别出具有特定特征的纸张。
4.2.1正则表达式和通配符
允许通配符查询的SE方案是多余的,在我们的研究中只发现了两个。杨等人于2020年提出了第一个方案[65]。在这项工作中,他们提出了一种新的基于索引的SE方案,该方案专为多用户环境设计。所提出的方案允许通配符查询以及用户授权和撤销。此外,用户可以对搜索关键字进行“与”或“或”查询,还可以获得相关性得分最高的前k个文档。
该方案使用了一种简单的索引方法。更具体地说,文档索引包含三条信息:文档ID、其对应的关键字以及用于保护文档的对称加密方案中使用的密钥。该索引在外包给云服务器之前,使用PHE方案(即Paillier的密码系统)进行加密。另一方面,文档本身使用任何安全对称加密方案进行加密。
The authors cover a wide range of different algorithms to look for a match within the search protocols, regarding different types of wildcard queries. These algorithms can be split into three categories: zero wildcards (1 algorithm), one wildcard (3 algorithms), and two wildcards (4 algorithms). More specifically, for one wildcard we have the following possibilities for a query: *+𝑌1*+�1, 𝑌1+*�1+* and 𝑌1+*+𝑌2�1+*+�2, (𝑌1,𝑌2�1,�2 are strings of any size). When two wildcards are present in the query, we have the following possibilities: *+𝑌1+**+�1+*, 𝑌1+*+𝑌2+*�1+*+�2+*, *+𝑌1+*+𝑌2*+�1+*+�2 and 𝑌1+*+𝑌2+*+𝑌3�1+*+�2+*+�3 (𝑌1,𝑌2,𝑌3�1,�2,�3 are strings of any size). These algorithms take advantage of the homomorphic properties of the Paillier’s cryptosystem to encrypt the keywords in a way that comparisons are possible to identify matches. Finally, with respect to the authorization and revocation functionality, PHE is not utilized. Despite this, the system allows a DO to grant research privileges to other users for a specified period of time and to automatically revoke these privileges once the authorization period expires.
In 2021, Yin et al. [58], suggested a new SE scheme which uses FHE and allow some types of wildcard queries. The scheme was designed to achieve compound substring query on multiple attributes. A substring query, as the name suggests, is a query that allows to search for a contiguous sequence of characters within a string. For example, the substring query “cat” would return all the results which contain the substring cat, e.g., caterpillar, cats, concatenate, ducat. The proposed scheme can, in fact, support two types of substring patterns: *+𝑠+**+�+* and 𝑠1+*+𝑠2�1+*+�2, where s, 𝑠1�1, and 𝑠2�2 represent queried substrings and * represents any string of any length. This is achieved by constructing a tree index structure using a modified version of the well-known position heap technique.
在该方案中,使用对称密钥加密方案对敏感数据进行加密,该方案在所选明文攻击(如AES)下不可区分,并且使用FHE方案(如BGV)和伪随机函数对树索引进行加密。FHE方案用于加密树中每个节点的ID,伪随机函数用于加密沿着从根到该节点的路径的所有边缘标签的级联。
基于FHE方案的性质,作者还设计了一种算法来计算不同搜索关键字的搜索结果的交集,从而实现对多个属性的复合子串查询。在这种情况下,复合公式由查询的子字符串的合取表达式和析取表达式组成,因此,该方案允许第2节中定义的合取和析取查询。
我们没有发现任何文献提出能够使用正则表达式并利用HE的SE方案。
4.2.2.联合搜索
执行联合搜索的能力非常有吸引力,在选定的作品中,有六部作品允许此功能。然而,这些论文中只有4篇使用HE来促进连词搜索。这些论文中的大多数都具有其他搜索功能,并在相应的章节中进行了分析。有趣的是,只有一个作品提供了联合搜索,而没有其他搜索功能。这项工作归功于Wang等人,他们在2022年[56]提出了一种基于索引的SE方案,用于多用户设置,该方案支持联合关键字搜索,并使用特殊的PHE方案来隐藏搜索模式。他们的工作特别利用了辅助服务器和加性同态加密方案PBC[75],以有效地实现联合关键字搜索特性,同时确保DU只能学习所需的搜索结果。事实上,引入辅助服务器是为了允许系统通过采用作者所称的双陷门解密机制来实现所需的属性,该机制在该方案中可用。
为了实现联合关键字搜索特性,作者使用多集的多项式表示,并使用BCP密码系统对多项式进行加密以保持其机密性。然后由云服务器和辅助服务器使用加法和乘法同态性质来联合执行搜索。
这项工作没有详细说明在将文档上传到数据库之前,使用什么样的加密方案来加密文档。
4.2.3.短语搜索
在SE方案中,使用HE来实现短语搜索并不常见。事实上,在23个分析的SE方案中,只有2个能够执行短语搜索,并使用HE来实现该功能。第一个由Shen等人于2019年提出,命名为P3[70]。该方案适用于多用户设置,支持多关键字搜索,特别是短语搜索和联合关键字搜索。该方案的主要思想是建立一个反向索引,该索引不仅包含每个关键字出现的文档标识符,还包含每个关键字在这些文档中的位置。
为了保护位置信息,该方案使用Boneh等人[38]的PHE方案对其进行加密,其同态特性允许服务器分析两个加密的关键字是否相邻。此外,这使得DU能够从与云服务器的单个交互中获得精确的搜索结果。请注意,短语搜索是一种特定类型的连接查询,其中查询的关键字的位置很重要。
文档标识符和关键字分别使用其他技术来保护,特别是伪随机排列原语和安全kNN技术。
随后,在2022年,Hou等人[61]提出了一种SE方案,该方案也使用了Boneh等人的PHE方案。以保护关键字的位置并启用短语搜索。然而,他们提出了一种不同的索引结构,称之为虚拟二叉树。这个索引树只是一个用于存储关键字和相关信息的逻辑结构。它的元素存储在哈希表中(如果它们是叶节点),或者映射到bloom过滤器。同胚性质的使用类似于Shen等人的工作。[70],允许该方案检查关键字是否相邻。此外,他们的方法允许动态更新,这与以前的方案相比是一个优势。
4.2.4范围搜索
执行范围搜索的能力是在使用HE的SE方案中不常见的另一个功能。在我们的研究中,由于郭等人[69],只发现了一项工作。这项工作发表于2019年,它提出了一种用于物联网环境下多用户设置的概率阈值范围搜索方案。该方案解决了在多维不确定数据上执行范围搜索的问题,同时通过返回在感兴趣范围内的概率高于给定阈值的所有加密数据来允许误报。
该方案的概念是,DO从物联网设备中获得不确定的数据,这些设备被建模为多维对象。因此,每个物联网对象都由一个不确定区域及其概率密度函数表示。从这样一个对象收集的一段数据称为实例,包括三个组成部分:对象的标识、实例的坐标及其概率。
他们的方法利用了KD树,这是一种用于索引分布在d维空间中的d维点数据的数据结构。KD树中的每个节点都由一个实例及其相应的范围组成,这些范围是根据实例的坐标计算的。节点使用保序加密(OPE)方案加密,而实例概率使用Paillier密码系统加密
值得注意的是,该方案依赖于两个云服务器。具体来说,第一云服务器负责:存储加密的数据和加密的KD树,执行KD树搜索,并将结果发送给第二服务器。然后,第二服务器有权基于搜索查询中提供的阈值来过滤结果,并将获得的加密文档发送到DU。
当第一个云服务器接收到查询时,它通过比较实例坐标的值,并使用Paillier密码系统的同态加法来计算每个IoT对象相对于搜索的上下出现概率,从而在KD树上进行搜索,因此结果落在查询的范围内。然后,将结果发送到第二服务器进行过滤,最后,将过滤后的结果发送到DU。
4.2.5.排名搜索
执行排序搜索的能力是使用HE的SE中最常观察到的特征,在23个分析的作品中有10个具有这种特性。此外,所有这些工作都利用HE来实现这一功能。
2018年,Elizabeth等人[71]提出了一种允许动态更新的多用户排名前k的SE(TSED)方案。该方案基于反向索引,该索引使用每个关键字的二进制向量来指示每个文件是否包含该关键字(类似于Wu等人提出的Z索引[72])。
在该方案中,使用诸如AES之类的安全对称加密方案对敏感数据进行加密。然后使用两个PHE方案来加密反转索引的两个分量。具体而言,Paillier的密码系统用于加密每个关键字,而Goldwasser–Micali(GM)[33]用于加密每个二进制索引向量。
TSED方案允许使用TF-IDF规则进行排名前k的搜索。该过程由安全协处理器完成,该安全协处理器负责使用加密的分数索引来计算查询关键字的分数,用于基于结果与查询的相关性来对结果进行排名,并且用于将前k个文档标识符返回给CS,CS随后在DU中检索相应的文档。
Elizabeth等人也在2020年提出了该方案的一个变体[63],该方案被指定为具有动态更新(VSED)的加密云数据上的可验证前k位SE。该方案除了具有类似于VSED方案的动态和排序搜索能力外,还具有可验证性。
在VSED方案中,构造了类似的加密反向索引,但现在作者使用了秘密正交向量和Paillier密码系统[37]。使用PHE方案以及预先计算的排名分数对执行搜索时使用的索引和陷门进行加密,并且与TSDE中所做的类似,使用安全协处理器来基于TF-IDF规则查找排名前k的搜索。
Paillier密码系统也用于更新过程,更新过程使用两种不同的算法:一种是添加新关键字,另一种是删除现有关键字。为了验证CS接收到的查询结果,该方案使用了名为HMAC[76]的众所周知的消息认证机制。关于敏感数据,该系统允许使用安全对称加密方案(如AES)对其进行加密,如TSED。
2019年,Boucenna等人[68]提出了一种SE方案,称为基于安全反向索引的SE(SIIS),用于多用户设置,支持使用HE进行排名搜索。事实上,该方案还允许通过使用CP-ABE来加密数据收集来进行用户访问权限管理。正如该方案的名称所示,它涉及反向指数的构建。更具体地说,使用了两个独立的反向索引。一种是用于存储使用双分数加权公式[77]计算的相似性分数。通过使用伪文档技术[78]来允许关键字隐私,创建了第二个反向索引来管理用户的访问权限并降低误报数量。第二个索引中的条目是用户的ID,用于标识他们可以访问的文档集合。然后使用FHE方案BGV对两个索引进行加密,该方案的同态性质用于执行搜索。
2020年,张等人[62]提出了一种针对混合云计算中加密数据的安全排名搜索方案,适用于单个用户环境。“混合云计算”一词指的是公共和私有云的使用,后者主要用于执行昂贵的计算,否则必须在客户端执行。在该方案中,私有云具有加密和解密数据的能力,并且大多数通信轮次在私有云和公共云之间进行。
在该提案中,作者使用Ocapi BM25排名模型[79],并使用未指定的FHE方案在私有云上分别加密TF和IDF。然后,这些信息被用来构建一个反向索引,这是在公共云中完成的。
关于敏感数据的加密,可以使用任何安全的对称加密方案来执行,例如AES。最后,所提出的方案还依赖于私有云用来下载加密文档的检索技术,尽管作者没有具体说明。
同年,李等人[64]提出了一种双服务器排序的动态SE方案(TS-RDSE),用于单用户设置,支持多关键字搜索。该方案使用两个云服务器进行搜索和排序,其中一个服务器负责存储加密数据,另一个服务器用于存储密钥。该方案在反向索引的加密中使用正交向量和两个PHE方案,即Paillier和GM,反向索引包含用于执行排序搜索的TF-IDF分数。更具体地说,该索引分为搜索索引和权重索引,搜索索引使用Paillier和GM进行加密,权重索引仅使用Pailliier。
由于索引的加密基于两种PHE方案,因此用于添加或删除文档的TS-RDSE协议也利用同态性质来有效地更新索引。
关于敏感数据的加密,可以使用任何安全的对称加密方案对其进行加密。
2020年,杨等人[67]提出了一种基于索引的SE方案,用于支持多个数据所有者的多用户设置。该方案还支持多关键字查询、排名前k的结果和用户授权/撤销。
作者使用PHE方案,更具体地说是具有阈值解密的Paillier密码系统(PCTD)来加密索引,该索引由关键字及其权重、文档ID和文档密钥组成(例如,关键字的权重可以使用TF-IDF规则计算)。在给定某个查询的情况下,作者提出了一种新的算法来计算与该查询相关的分数,称为跨域安全多关键字搜索协议(MKS)。
文件本身的加密通过任何安全对称加密方案来执行。
2021年,Tosun等人[60]提出了一种多用户SE方案,称为完全安全文档相似性(FSDS),该方案将安全K近邻(SK-NN)与SWHE相结合,SK-NN是一种对欧几里得空间中的数据集进行操作并使用欧几里得距离测量相似性的安全算法。在该方案中,敏感数据和搜索查询表示为TF-IDF向量,这些向量用SK-NN的变体加密,作者将其命名为mSk-NN。使用TF-IDF表示从文档中生成的可搜索索引首先用mSK NN加密,然后用名为FV[41]的SWHE方案加密。该方案的总体概念是使用余弦相似性比较度量来计算给定查询的k个最近邻居。作者声称,与只使用SWHE对查询进行加密的方法相比,使用mSK NN和SWHE的组合会产生更高效、更安全的系统。这是因为所需的计算量被最小化了。
刘等人在2022年[54]提出了一种基于索引的多关键字SE方案,该方案使用FHE来支持排名搜索,即检索与搜索查询最相关的前k个文档。文档本身使用对称加密方案(未指定)进行加密,而FHE方案用于加密索引和搜索查询。所使用的FHE是由同一作者开发的,并被命名为全同态保序加密(FHOPE)[80]。在加密数据上,这种加密方法提供了同态加法、同态乘法和阶数比较。因此,它被用于计算加密数据的相关性得分,并支持搜索操作。DO负责提取关键字,FHOPE对可搜索索引进行加密,并将其上传到该系统中的CS。CS在代表DU完成搜索操作和排名得分操作之后,将前k个最相关的文档返回给DU。
同年,Andola等人[57]提出了一个多用户SE系统,该系统支持多关键字搜索,并使用HE属性构建和搜索索引。该方案还允许使用TF-IDF实现的排序搜索。作者使用基于椭圆曲线的ElGamal[81]对索引进行加密,敏感数据的加密可以使用任何安全的对称加密算法进行。
4.3. Other Functionalities
In this section, we analyze the selected works that offer other functionalities, although they are not common. Specifically, we did not find any papers that use HE to provide the ability to “Authorize or Revoke” access, nor did we find any works addressing the “Delegate” functionality. As for the remaining functionalities, we have identified six approaches that are “Dynamic” and just one which uses HE to provide the “Verifiability” characteristic.
4.3.1. Dynamic
Even though dynamic SE schemes are more likely to be employed in real-world applications, not many works have been proposed to address this problem. In our research, we identified only five published studies that exploit the HE properties to develop dynamic SE schemes. There are, however, other schemes, which are dynamic, but they do not utilize the HE properties to achieve this functionality, as can be seen in Table 3.
Before 2021, three dynamic SE schemes that use HE to provide index updates were proposed, namely the TSED scheme proposed by Elizabeth et al. [71], a variant of this scheme, named VSED [63], and the TS-RDSE scheme proposed by Li et al. [64]. These schemes are designed for a single-user setting.
Prakash et al. proposed, in 2021 [59], a dynamic and index-based SE scheme, named PINDEX, which is intended for a multi-user setting. Their approach suggests a dynamic index construction method that is multi-linked, and which uses the PHE scheme proposed by Paillier, to encrypt the index, along with secret orthogonal vectors as building blocks. In this scheme, a DO can add and delete keywords or documents without having to reconstruct the encrypted index stored in the CS and the homomorphic properties are used on both the search and update processes.
Furthermore, the proposed scheme achieves forward privacy because of the probabilistic nature of the Paillier cryptosystem and the usage of secret orthogonal vectors. Notice that, in a dynamic SE scheme, forward privacy is a critical requirement since it ensures that newly added data does not reveal any information about previously searched queries. This is especially important in a multi-client setting where different users search different queries, and new data should not reveal anything about previous searches.
Gan et al. [55], in 2022, proposed a new dynamic searchable symmetric encryption scheme for multi-user settings, which uses XOR homomorphic function to ensure forward privacy.
The authors introduced two novel data structures to achieve efficient multi-user search and forward privacy: private links and a public search tree. Each client has three options, namely to search their own private link, the public search tree, or both. The proposed scheme also employs a state-based approach to manage database updates. This involves maintaining a state variable that tracks the current state of the database and allows for efficient updates without requiring its complete re-encryption. The XOR-homomorphic function is used in both the update and search processes. The documents themselves are encrypted using a symmetric cryptosystem.
4.3.2. Verifiability
There is only one paper which uses HE to provide the verifiability characteristic. In fact, only one more paper was found in our research which has this property, but does not use HE to achieve it, namely the work of Elizabeth and Prakash [63]. The former paper is due to Wu et al. and it was published in 2018 [72]. Their work presented a verifiable public key encryption scheme with keyword search meant for multi-user settings.
In this scheme, a standard proxy re-encryption public key algorithm is used to encrypt sensitive data. The authors also suggest a novel index construction, named Z-index, which uses a binary vector for each keyword to indicate whether each file contains that keyword. The index is constructed using an inverted data structure and is encrypted using an FHE scheme, namely DGHV [47], and a homomorphic hash function. The main objective of this scheme is to avoid using query trapdoors and therefore improve search efficiency. The verifiability feature is achieved using the homomorphic hash function.
5. Research Trends and Discussion
The research on SE schemes enhanced by HE properties has significantly increased in recent years. This trend aligns with the broader adoption of HE in various domains. In this section, we aim to provide an overview of the current trends in this research area as well as highlight their significant implications on the design of the studied approaches. Specifically, we will discuss the types of HE schemes used in SE, the application of HE in search structures, in search functionalities, and in other types of functionalities. Finally, we will also discuss the ability to allow multi-users, even though achieving this functionality does not directly rely on HE.
5.1. Types of HE Schemes Used in SE
The use of HE in SE schemes has increased in recent years. In fact, 74% of the 23 selected works were published within the last three years. This is consistent with the overall trend observed in the increased application of HE in diverse areas.
Our analysis revealed that PHE is the most frequently type of HE used in SE, as shown in Figure 3. This is not surprising since PHE is the simplest type of HE among the three. On the other hand, FHE schemes have the most potential, but they are still inefficient. However, despite this, a considerable percentage of SE schemes utilize FHE due to its potential benefits (38% use FHE for 57% of systems using PHE).
Figure 3. Types of HE schemes used in SE.
Finally, we also observed that more than a half of the schemes that rely on a PHE scheme use either the Paillier cryptosystem [52,59,64,65,69], a combination of the Paillier cryptosystem with GM [63,71], or the Paillier cryptosystem with threshold decryption [67]. The reason that so many approaches choose to use the Paillier cryptosystem (or any other variations) is the simplicity and security of the scheme, as well as the number of existing implementations freely available.
The remaining articles using PHE, use several different schemes, such as XOR- homomorphic [55], BCP [56], EC El Gamal [57], Boneh [61] and Shen et al. [70].
SWHE schemes were barely present in the studied schemes. In fact, only one article uses a SWHE scheme, more specifically an implementation of the FV scheme [60]. On the other hand, FHE schemes are used in nine articles, where the BGV [7,53,58,68] and BFV [66] are utilized the most, leveraging the open-source software library HElib, which implements some HE schemes. Table 4 lists the selected works and identifies the HE schemes they use.
Table 4. HE schemes used in selected SE approaches.
5.2. HE Usage in Search Structures
The utilization of HE in SE schemes has been well explored to provide more efficient search structures. This applies to both sequential scan-based approaches and index-based ones. In all the papers that have been studied, HE is used to design the search structure of the respective scheme. It is worth mentioning that index-based SE schemes are predominant (see Figure 4), which is expected since most current applications require efficient search processes on large encrypted databases.

Figure 4. Use of HE on the Search structure.
5.3. HE Usage in Search Functionalities
The usage of HE to improve or allow for search functionalities is very prevalent in the selected works. There is, however, a functionality which is not present in none of the works, namely the ability to perform a fuzzy keyword search. Figure 5 illustrates the number of works that support each search functionality, considering the functionalities that appeared at least once.
Figure 5. Uses of HE on search functionalities.
From our analysis, we observed that ranked search is the most prevailing search functionality, being present in 10 out of the 23 analyzed works. Moreover, in all of those works, this functionality is achieved using the homomorphic properties of the underlying HE scheme. The most commonly used protocol involves ranking documents according to TF-IDF, where the information needed to compute relevance scores is encrypted using HE. Therefore, relevance scores can be computed in the public cloud. One of these schemes, FASE [54], which allows for multi-keyword queries, firstly ranks documents by keyword matching degree, i.e., how many queried keywords are present in the documents, then the secondary criteria are the respective relevance scores. Among all studied schemes, there is only one that uses a technique other than TF-IDF to rank their search results, namely the double score weighting formula (firstly proposed by Boucenna et al. [77] and used in the work of Boucenna et al. [68]).
Another important observation, now regarding schemes that allow for top-k results, is that the majority of these schemes do not allow it in a direct and single round of communication, i.e., most schemes either rely on PIR [60,67], or they include another entity in the framework, such as a coprocessor [63,71], a collaborate server [64] or a private cloud [62], which have access to the private key and are responsible for ranking search results.
Regarding the multiplicity of keywords, we observed that the majority of the works supports multi-keyword queries. There are, however, some articles that support only single-keyword queries [7,52,53,55,62]. Moreover, the ones that support multi-keyword queries can be further split into two categories: multi-keyword for ranked search and multi-keyword meant for conjunctive or disjunctive queries.
Some of the articles allow only for conjunctive queries [56,61,70,72], where the latter two also allow for phrase search, which basically is a conjunctive query where the order of keywords matters. Disjunctive queries are allowed in two of the studied works, namely the one published by Yin et al. [58] and the one by Yang et al. [65]. These approaches also allow conjunctive queries. Additionally, they allow for wildcards in each of the queried keywords, where the latter has a protocol to return the top-k results when the query performed is disjunctive. Besides the above-mentioned work [65], some other schemes allow for multi-keyword queries specifically for ranked search [54,57,60,63,64,67,68]. From all these papers, only the VSED scheme [63] has a slightly different approach on the ranking protocol. More specifically, before ranking the documents, it performs a disjunctive keyword search, to guarantee that every returned document has at least one queried keyword.
5.4. HE Usage in Other Functionalities
HE has also been explored to provide functionalities such as dynamic updates and verifiability. However, during our study, we did not find any work that mentioned the ability to delegate the search. Moreover, only two works allow the revocation of users, and they do not use HE for this purpose.
Among the properties within this category, “Dynamic” is the most frequent, and is always achieved using the properties of HE. Implementing dynamic updates is challenging, especially on index-based schemes, since they required some sort of index updates. Nonetheless, schemes that utilize HE to encrypt the index offer the advantage of performing computations directly on ciphertexts, thereby facilitating efficient index updates.
From the studied articles that allow for dynamic updates, half of them rely on an inverted index [63,64,71]. Hou et al. [61] uses a VBTree, which works as a tree index where the search is performed over keywords, similar to an inverted index. The work of Prakash et al. [59] relies on a novel index type called the multi-linked index.
Regarding the ability to update, most of the approaches allow only for updates of keywords over files. However, Prakash et al. [59] and Li et al. [64] also allow for dynamic updates of files, besides allowing for regular updates over keywords.
The capability to authorize or revoke users is crucial for ensuring data privacy, yet it is not commonly addressed in the selected articles. Only two of them incorporate this property [65,67], and neither of them exploits HE schemes to achieve this functionality. Both articles follow a similar protocol, involving the generation of a search token with an expiration date. Additionally, they allow users to query multiple DOs simultaneously by requesting an authorization token from all DOs at the same time.
5.5. Multiplicity of Users
The multiplicity of users is another property that we have analyzed in the selected works. Even though this property is not directly achieved using HE, we observed that schemes meant for the multi-user setting are the most common, with a total of 63% allowing this functionality (Figure 6). Nonetheless, there are a couple of papers that show different scenarios where single-user SE schemes are suitable. Malik et al. [52], presented an application where the single entity is an airport, and Iqbal et al. [53] presented a use case where both the DO and DU are the same hospital.
Figure 6. Multiplicity of users.
Regarding the schemes that are meant for a multi-user setting, the majority rely on user authorization [54,57,60,65,67,68,70,72]. Note also that Yang et al. [67] proposed a multi-user SE scheme that allows DUs to perform search queries over multiple DOs’ data at the same time. From the remaining schemes, it is worth highlighting the work of Gan et al. [55], which achieves the multi-user functionality by allowing users to search through a private link, a public search tree, or both.
6. Conclusions and Future Work
In this work, we have provided a comprehensive analysis of the research trends on searchable encryption (SE) schemes that utilize homomorphic encryption (HE). This analysis serves as a valuable tool for researchers, enabling them to gain insights into this specific area of research and make well-informed decisions regarding future research directions.
We focused our study on the types of HE schemes used, their application to enhance search structures, to allow several functionalities such as ranked, conjunctive, disjunctive, range, and phrase search, as well as verifiability, dynamic updates, and the ability to add and revoke users. This analysis was conducted on a carefully selected set of 23 works, following a well-defined research methodology.
Our findings revealed that HE usage in SE schemes has increased in recent years, with 75% of the selected works published within the last three years. The most commonly used type of HE schemes in SE is PHE, which accounted for the majority of the analyzed schemes. The popularity of PHE schemes, particularly the widespread adoption of Paillier’s cryptosystem, can be attributed to its simplicity, proven security properties, and availability in several open-source libraries, making it easily accessible for researchers.
When considering the usage of HE in search structures, we found that building the index using HE is the most prevalent approach. This is not surprising, since SE schemes that rely on sequential scans are not suitable for large databases. Additionally, we analyzed the types of indexes used in these schemes and observed that normal indexes are the most common choice, followed by inverted indexes and tree indexes.
Regarding the usage of HE in search functionalities, we found that ranked search is the most prevalent functionality. Relevance scores are computed using homomorphic properties and are often based on TF-IDF ranking. Multi-keyword queries are widely supported, either for ranked search or for conjunctive/disjunctive queries. However, fuzzy keyword search functionality was not found in any of the analyzed works.
In future research, there is a need to explore and improve upon various functionalities when searching over encrypted data using HE schemes. Although dynamic updates consistently take advantage of homomorphic properties, other functionalities such as authorizing and revoking users, verifiability, and delegation of search capability require further development. Among the analyzed works, only one study [72] utilized a HE scheme to achieve verifiability, while none of the articles addressed the ability to authorize and revoke users. However, we found two works that, although not employing HE schemes directly, utilized a cryptographic primitive called homomorphic message authentication to facilitate verifiability, namely the work of Zhang et al. [62], and the work of Wan et al. [82]. Furthermore, Zhang et al.’s work utilized this primitive to enable the authorization and revocation of users’ access. Therefore, considering the potential benefits and the limited exploration in this area, it is worth further exploring and investigating the utilization of homomorphic message authentication and similar cryptographic primitives for achieving verifiability, and the ability to add and revoke users.
Although FHE schemes were present in nearly half of the studied articles, we believe that the percentage could be significantly higher given the recent advancements in FHE schemes. For example, the TFHE scheme, introduced in 2020 [44], is an FHE scheme worth exploring. Leveraging other encryption schemes alongside HE, such as attribute-based encryption used for user access control (e.g., it is used in the work of Boucenna et al. [68]), or OPE for facilitating ciphertext comparison (e.g., it is used in FASE [54]), could lead to the development of more sophisticated schemes.
In our study, we also concluded that the studied articles cover several important search functionalities. However, there were some notable omissions, particularly in the areas of fuzzy keyword search and occurrence queries. Fuzzy keyword search is one of the most desirable functionalities in real-life applications, making it crucial to explore HE schemes that can support this functionality. One approach, as suggested by Dong et al. [83], involves using Hamming distances. Additionally, occurrence queries were not addressed in any of the studied schemes, but we observed that most articles allowing ranked searches could easily accommodate occurrence queries since they already require information such as TF to rank documents.
Finally, it is important for future research to focus on reducing the reliance on retrieval protocols like PIR. The emphasis should be on developing SE schemes that operate effectively with a minimum number of communication rounds, aiming to minimize the overall overhead.
Overall, our work provides a comprehensive summary of the latest research trends in SE enhanced by HE. We emphasize critical components related to the HE schemes most frequently employed, possible search structures, and search functionalities. This contribution significantly advances the scientific understanding in this domain, enabling researchers to explore state-of-the-art methodologies, leverage existing knowledge, and explore new research directions.
Author Contributions
Conceptualization, I.A. and I.C.; Data curation, I.A. and I.C.; Formal analysis, I.C.; Investigation, I.A. and I.C.; Methodology, I.A.; Visualization, I.C.; Project administration, I.A.; Supervision, I.A.; Validation, I.A.; Writing—original draft, I.A and I.C.; Writing—review and editing, I.A. and I.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Norte Portugal Regional Operational Programme (NORTE 2020), under the PORTUGAL 2020 Partnership Agreement, through the European Regional Development Fund (ERDF), within project “Cybers SeC IP” (NORTE-01-0145-FEDER-000044).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All the data are already provided in the manuscript, with quoted reference.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AES | Advanced encryption standard |
| CP-ABE | Ciphertext-policy attribute-based encryption |
| CPA | Chosen plaintext attack |
| CS | Cloud server |
| DO | Data owner |
| DU | Data user |
| FHE | Fully homomorphic encryption |
| FHOPE | Fully homomorphic order-preserving encryption |
| FSDS | Fully secure document similarity |
| GM | Goldwasser–Micali |
| HE | Homomorphic encryption |
| IoT | Internet of Things |
| OPE | Order-preserving encryption |
| PCTD | Paillier cryptosystem with threshold decryption |
| PHE | Partially homomorphic encryption |
| PIR | Private information retrieval |
| RE | Regular expression |
| 𝑆𝐶�� | Searchable ciphertext |
| SE | Searchable encryption |
| SIIS | Secure inverted index-based searchable encryption |
| SK-NN | Secure K nearest neighbor |
| SWHE | Somewhat homomorphic encryption |
| TF-IDF | Term frequency inverse document frequency |
References
- Suguna, M.; Ramalakshmi, M.; Cynthia, J.; Prakash, D. A Survey on Cloud and Internet of Things Based Healthcare Diagnosis. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; pp. 1–4. [Google Scholar]
- Moumtzoglou, A.; Kastania, A.N.; Ghosh, R.; Papapanagiotou, I.; Boloor, K. A Survey on Research Initiatives for Healthcare Clouds. In Cloud Computing Applications for Quality Health Care Delivery; IGI Global: Hershey, PA, USA, 2014; pp. 1–18. [Google Scholar]
- Agrawal, S. A Survey on Recent Applications of Cloud Computing in Education: COVID-19 Perspective. J. Phys. Conf. Ser. 2021, 1828, 012076. [Google Scholar] [CrossRef]
- González-Martínez, J.A.; BoteLorenzo, M.L.; Gómez Sánchez, E.; Cano Parra, R. Cloud computing and education: A state-of-the-art survey. Comput. Educ. 2015, 80, 132–151. [Google Scholar] [CrossRef]
- Netwrix. Cloud Data Security Report; Technical Report; Netwrix: Frisco, TX, USA, 2022. [Google Scholar]
- Yang, P.; Xiong, N.N.; Ren, J. Data Security and Privacy Protection for Cloud Storage: A Survey. IEEE Access 2020, 8, 131723–131740. [Google Scholar] [CrossRef]
- Akavia, A.; Feldman, D.; Shaul, H. Secure Search on Encrypted Data via Multi-Ring Sketch. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS 2018, Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2018; pp. 985–1001. [Google Scholar]
- Xu, W.; Wang, B.; Lu, R.; Qu, Q.; Chen, Y.; Hu, Y.; Maglaras, L. Efficient Private Information Retrieval Protocol with Homomorphically Computing Univariate Polynomials. Sec. Commun. Netw. 2021, 2021, 5553256. [Google Scholar] [CrossRef]
- Sharma, D. Searchable encryption: A survey. Inf. Secur. J. 2023, 32, 76–119. [Google Scholar] [CrossRef]
- Acar, A.; Aksu, H.; Uluagac, A.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. Acm Comput. Surv. 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Choi, S.G.; Dachman-Soled, D.; Gordon, S.D.; Liu, L.; Yerukhimovich, A. Compressed Oblivious Encoding for Homomorphically Encrypted Search. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, CCS’21, Virtual, Republic of Korea, 15–19 November 2021; ACM: New York, NY, USA, 2021; pp. 2277–2291. [Google Scholar]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the Proceeding 2000 IEEE Symposium on Security and Privacy, S&P 2000, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Bösch, C.; Hartel, P.; Jonker, W.; Peter, A. A Survey of Provably Secure Searchable Encryption. Acm. Comput. Surv. 2014, 47, 18:1–18:51. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Chen, X. Secure searchable encryption: A survey. J. Commun. Inf. Netw. 2016, 1, 52–65. [Google Scholar] [CrossRef][Green Version]
- Han, F.; Qin, J.; Hu, J. Secure searches in the cloud: A survey. Future Gener. Comput. Syst. 2016, 62, 66–75. [Google Scholar] [CrossRef]
- Dowsley, R.; Michalas, A.; Nagel, M.; Paladi, N. A survey on design and implementation of protected searchable data in the cloud. Comput. Sci. Rev. 2017, 26, 17–30. [Google Scholar] [CrossRef][Green Version]
- Poh, G.S.; Chin, J.J.; Yau, W.C.; Choo, K.K.R.; Mohamad, M.S. Searchable Symmetric Encryption: Designs and Challenges. Acm Comput. Surv. 2017, 50, 40:1–40:37. [Google Scholar] [CrossRef]
- Pham, H.; Woodworth, J.; Amini Salehi, M. Survey on secure search over encrypted data on the cloud. Concurr. Comput. Pract. Exp. 2019, 31, e5284. [Google Scholar] [CrossRef][Green Version]
- Handa, R.; Krishna, C.R.; Aggarwal, N. Searchable encryption: A survey on privacy-preserving search schemes on encrypted outsourced data. Concurr. Comput. Pract. Exp. 2019, 31, e5201. [Google Scholar] [CrossRef]
- Andola, N.; Gahlot, R.; Yadav, V.; Venkatesan, S.; Verma, S. Searchable encryption on the cloud: A survey. J. Supercomput. 2022, 78, 9952–9984. [Google Scholar] [CrossRef]
- Noorallahzade, M.; Alimoradi, R.; Gholami, A. A Survey on Public Key Encryption with Keyword Search: Taxonomy and Methods. Int. J. Math. Math. Sci. 2022, 2022, 3223509. [Google Scholar] [CrossRef]
- Zhang, R.; Xue, R.; Liu, L. Searchable Encryption for Healthcare Clouds: A Survey. IEEE Trans. Serv. Comput. 2018, 11, 978–996. [Google Scholar] [CrossRef]
- Bader, J.; Michala, A. Searchable Encryption with Access Control in Industrial Internet of Things (IIoT). Wirel. Commun. Mob. Comput. 2021, 2021, 5555362. [Google Scholar] [CrossRef]
- How, H.B.; Heng, S.H. Blockchain-Enabled Searchable Encryption in Clouds: A Review. J. Inf. Secur. Appl. 2022, 67, 103183. [Google Scholar] [CrossRef]
- Pillai, B.; Lal, N. Blockchain-based Asymmetric Searchable Encryption: A Comprehensive Survey. Int. J. Eng. Trends Technol. 2022, 70, 355–365. [Google Scholar] [CrossRef]
- Boneh, D.; Kushilevitz, E.; Ostrovsky, R.; Skeith, W.E. Public Key Encryption That Allows PIR Queries. In Advances in Cryptology—CRYPTO 2007, Proceedings of the 27th Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2007; Menezes, A., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Gremany, 2007; pp. 50–67. [Google Scholar]
- Liu, J.; Zhao, B.; Qin, J.; Zhang, X.; Ma, J. Multi-Keyword Ranked Searchable Encryption with the Wildcard Keyword for Data Sharing in Cloud Computing. Comput. J. 2023, 66, 184–196. [Google Scholar] [CrossRef]
- Zheng, J.; Zhang, J.; Zhang, X.; Li, H. Symmetric searchable encryption scheme that supports phrase search. Microsyst. Technol. 2021, 27, 1721–1727. [Google Scholar] [CrossRef]
- Boneh, D.; Waters, B. Conjunctive, Subset, and Range Queries on Encrypted Data. In Theory of Cryptography, Proceedings of the Fourth Theory of Cryptography Conference, Amsterdam, The Netherlands, 21–24 February 2007; Vadhan, S.P., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Gremany, 2007; pp. 535–554. [Google Scholar]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On Data Banks and Privacy Homomorphisms. Found. Secur. Comput. Acad. Press 1978, 4, 169–179. [Google Scholar]
- Silva, I. Fully Homomorphic Encryption and Its Application to Private Search. Master’s Thesis, University of Porto, Porto, Portugal, 2022. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef][Green Version]
- Goldwasser, S.; Micali, S. Probabilistic encryption & how to play mental poker keeping secret all partial information. In Proceedings of the Fourteenth Annual ACM Symposium on Theory of Computing, STOC’82, New York, NY, USA, 5–7 May 1982; pp. 365–377. [Google Scholar]
- Benaloh, J. Dense probabilistic encryption. In Proceedings of the Workshop on Selected Areas of Cryptography; Clarkson University: Potsdam, NY, USA, 1994; pp. 120–128. [Google Scholar]
- Naccache, D.; Stern, J. A new public key cryptosystem based on higher residues. In Proceedings of the 5th ACM Conference on Computer and Communications Security, San Francisco, CA, USA, 2–5 November 1998; pp. 59–66. [Google Scholar]
- Elgamal, T. A public key cryptosystem and a signature scheme based on discrete logarithms. IEEE Trans. Inf. Theory 1985, 31, 469–472. [Google Scholar] [CrossRef]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Proceedings of the Advances in Cryptology—EUROCRYPT ’99, Santa Barbara, CA, USA, 15–19 August 1999; Stern, J., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Boneh, D.; Goh, E.J.; Nissim, K. Evaluating 2-DNF Formulas on Ciphertexts. In Proceedings of the Theory of Cryptography; Kilian, J., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; pp. 325–341. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Marcolla, C.; Sucasas, V.; Manzano, M.; Bassoli, R.; Fitzek, F.; Aaraj, N.; Marcolla, C. Survey on Fully Homomorphic Encryption, Theory, and Applications. Proc. IEEE 2022, 110, 1572–1609. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. Paper 2012/144. Cryptol. Eprint Arch. 2012, 2012, 144. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, ITCS’12, New York, NY, USA, 8–10 January 2012; pp. 309–325. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic Encryption for Arithmetic of Approximate Numbers. In Proceedings of the Advances in Cryptology—ASIACRYPT 2017; Takagi, T., Peyrin, T., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2017; pp. 409–437. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast Fully Homomorphic Encryption Over the Torus. J. Cryptol. 2020, 33, 34–91. [Google Scholar] [CrossRef]
- Scholl, P.; Smart, N.P. Improved Key Generation for Gentry’s Fully Homomorphic Encryption Scheme. In Proceedings of the Cryptography and Coding; Chen, L., Ed.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; pp. 10–22. [Google Scholar]
- Gentry, C.; Halevi, S. Implementing Gentry’s Fully-Homomorphic Encryption Scheme. In Proceedings of the Advances in Cryptology—EUROCRYPT 2011; Paterson, K.G., Ed.; Lecture Notes in Computer Science. Springer: Berlin/ Heidelberg, Germany, 2011; pp. 129–148. [Google Scholar]
- van Dijk, M.; Gentry, C.; Halevi, S.; Vaikuntanathan, V. Fully Homomorphic Encryption over the Integers. In Proceedings of the Advances in Cryptology—EUROCRYPT 2010; Gilbert, H., Ed.; Lecture Notes in Computer Science. Springer: Berlin/ Heidelberg, Germany, 2010; pp. 24–43. [Google Scholar]
- Brakerski, Z.; Vaikuntanathan, V. Fully Homomorphic Encryption from Ring-LWE and Security for Key Dependent Messages. In Proceedings of the Advances in Cryptology—CRYPTO 2011; Rogaway, P., Ed.; Lecture Notes in Computer Science. Springer: Berlin/ Heidelberg, Germany, 2011; pp. 505–524. [Google Scholar]
- López-Alt, A.; Tromer, E.; Vaikuntanathan, V. On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, New York, NY, USA, 19–22 May 2012; pp. 1219–1234. [Google Scholar]
- Challa, R. Homomorphic Encryption: Review and Applications. Lect. Notes Data Eng. Commun. Technol. 2020, 37, 273–281. [Google Scholar]
- Alloghani, M.; Alani, M.M.; Al-Jumeily, D.; Baker, T.; Mustafina, J.; Hussain, A.; Aljaaf, A.J. A systematic review on the status and progress of homomorphic encryption technologies. J. Inf. Secur. Appl. 2019, 48, 102362. [Google Scholar] [CrossRef]
- Malik, H.; Tahir, S.; Tahir, H.; Ihtasham, M.; Khan, F. A homomorphic approach for security and privacy preservation of Smart Airports. Future Gener. Comput. Syst. 2023, 141, 500–513. [Google Scholar] [CrossRef]
- Iqbal, Y.; Tahir, S.; Tahir, H.; Khan, F.; Saeed, S.; Almuhaideb, A.M.; Syed, A.M. A Novel Homomorphic Approach for Preserving Privacy of Patient Data in Telemedicine. Sensors 2022, 22, 4432. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Yang, G.; Bai, S.; Wang, H.; Xiang, Y. FASE: A Fast and Accurate Privacy-Preserving Multi-Keyword Top-k Retrieval Scheme Over Encrypted Cloud Data. IEEE Trans. Serv. Comput. 2022, 15, 1855–1867. [Google Scholar] [CrossRef]
- Gan, Q.; Wang, X.; Huang, D.; Li, J.; Zhou, D.; Wang, C. Towards Multi-Client Forward Private Searchable Symmetric Encryption in Cloud Computing. IEEE Trans. Serv. Comput. 2022, 15, 3566–3576. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, S.F.; Wang, J.; Liu, J.K.; Chen, X. Achieving Searchable Encryption Scheme With Search Pattern Hidden. IEEE Trans. Serv. Comput. 2022, 15, 1012–1025. [Google Scholar] [CrossRef]
- Andola, N.; Prakash, S.; Yadav, V.K.; Venkatesan, S.; Verma, S. A secure searchable encryption scheme for cloud using hash-based indexing. J. Comput. Syst. Sci. 2022, 126, 119–137. [Google Scholar] [CrossRef]
- Yin, F.; Lu, R.; Zheng, Y.; Tang, X.; Jiang, Q. Achieve Efficient and Privacy-Preserving Compound Substring Query over Cloud. Sec. Commun. Netw. 2021, 2021, 7941233. [Google Scholar] [CrossRef]
- Prakash, A.J.; Elizabeth, B.L. Pindex: Private multi-linked index for encrypted document retrieval. PLoS ONE 2021, 16, e0256223. [Google Scholar] [CrossRef]
- Tosun, T.; Savaş, E. FSDS: A practical and fully secure document similarity search over encrypted data with lightweight client. J. Inf. Secur. Appl. 2021, 59, 102830. [Google Scholar] [CrossRef]
- Hou, J.; Liu, Y.; Hao, R. Privacy-Preserving Phrase Search over Encrypted Data. In Proceedings of the 4th International Conference on Big Data Technologies, ICBDT’21, Beijing, China, 26–28 May 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 154–159. [Google Scholar]
- Zhang, J.; Shen, S.; Huang, D. A Secure Ranked Search Model Over Encrypted Data in Hybrid Cloud Computing. In Cyber Security, Proceedings of the 17th China Annual Conference, CNCERT 2020, Beijing, China, 12 August 2020; Lu, W., Wen, Q., Zhang, Y., Lang, B., Wen, W., Yan, H., Li, C., Ding, L., Li, R., Zhou, Y., Eds.; Springer: Singapore, 2020; pp. 29–36. [Google Scholar]
- Elizabeth, B.; Prakash, A. Verifiable top-k searchable encryption for cloud data. Sadhana-Acad. Proc. Eng. Sci. 2020, 45, 9. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, F.; Xu, Z.; Ge, Y. An Efficient Two-Server Ranked Dynamic Searchable Encryption Scheme. IEEE Access 2020, 8, 86328–86344. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, X.; Deng, R.H.; Weng, J. Flexible Wildcard Searchable Encryption System. IEEE Trans. Serv. Comput. 2020, 13, 464–477. [Google Scholar] [CrossRef]
- Wen, R.; Yu, Y.; Xie, X.; Zhang, Y. LEAF: A Faster Secure Search Algorithm via Localization, Extraction, and Reconstruction. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, CCS’20, New York, NY, USA, 9–13 November 2020; pp. 1219–1232. [Google Scholar]
- Yang, Y.; Liu, X.; Deng, R.H. Multi-User Multi-Keyword Rank Search Over Encrypted Data in Arbitrary Language. IEEE Trans. Dependable Secur. Comput. 2020, 17, 320–334. [Google Scholar] [CrossRef]
- Boucenna, F.; Nouali, O.; Kechid, S.; Tahar Kechadi, M. Secure Inverted Index Based Search over Encrypted Cloud Data with User Access Rights Management. J. Comput. Sci. Technol. 2019, 34, 133–154. [Google Scholar] [CrossRef]
- Guo, C.; Zhuang, R.; Jie, Y.; Choo, K.K.; Tang, X. Secure range search over encrypted uncertain IoT outsourced data. IEEE Internet Things J. 2019, 6, 1520–1529. [Google Scholar] [CrossRef]
- Shen, M.; Ma, B.; Zhu, L.; Du, X.; Xu, K. Secure phrase search for intelligent processing of encrypted data in cloud-based iot. IEEE Internet Things J. 2019, 6, 1998–2008. [Google Scholar] [CrossRef][Green Version]
- Elizabeth, B.; Prakash, A.; Uthariaraj, V. TSED: Top-k ranked searchable encryption for secure cloud data storage. Adv. Intell. Syst. Comput. 2018, 645, 113–121. [Google Scholar]
- Wu, D.; Gan, Q.; Wang, X. Verifiable Public Key Encryption with Keyword Search Based on Homomorphic Encryption in Multi-User Setting. IEEE Access 2018, 6, 42445–42453. [Google Scholar] [CrossRef]
- Halevi, S.; Shoup, V. Algorithms in HElib. In Advances in Cryptology—CRYPTO 2014, Proceedings of the 34th Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Garay, J.A., Gennaro, R., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 554–571. [Google Scholar]
- Dworkin, M.; Barker, E.; Nechvatal, J.; Foti, J.; Bassham, L.; Roback, E.; Dray, J. Advanced Encryption Standard (AES); Federal Inf. Process. Stds. (NIST FIPS), National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001.
- Bresson, E.; Catalano, D.; Pointcheval, D. A Simple Public-Key Cryptosystem with a Double Trapdoor Decryption Mechanism and Its Applications. In Advances in Cryptology—ASIACRYPT 2003, Proceedings of the 9th International Conference on the Theory and Application of Cryptology and Information Security, Taipei, Taiwan, 30 November–4 December 2003; Laih, C.S., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 37–54. [Google Scholar]
- Krawczyk, D.H.; Bellare, M.; Canetti, R. HMAC: Keyed-Hashing for Message Authentication; RFC 2104; RFC Editor: 1997.
- Boucenna, F.; Nouali, O.; Kechid, S. Concept-based Semantic Search over Encrypted Cloud Data. In Proceedings of the 12th International Conference on Web Information Systems and Technologies, Rome, Italy, 23–25 April 2016; pp. 235–242. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 222–233. [Google Scholar] [CrossRef][Green Version]
- Whissell, J.S.; Clarke, C.L.A. Improving document clustering using Okapi BM25 feature weighting. Inf. Retr. 2011, 14, 466–487. [Google Scholar] [CrossRef]
- Liu, G.; Yang, G.; Wang, H.; Xiang, Y.; Dai, H. A Novel Secure Scheme for Supporting Complex SQL Queries over Encrypted Databases in Cloud Computing. Secur. Commun. Netw. 2018, 2018, e7383514. [Google Scholar] [CrossRef]
- Menezes, A.J.; Vanstone, S.A.; Oorschot, P.C.V. Handbook of Applied Cryptography, 1st ed.; CRC Press, Inc.: Boca Raton, FL, USA, 1996. [Google Scholar]
- Wan, Z.; Deng, R. VPSearch: Achieving Verifiability for Privacy-Preserving Multi-Keyword Search over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2018, 15, 1083–1095. [Google Scholar] [CrossRef]
- Dong, Q.; Guan, Z.; Wu, L.; Chen, Z. Fuzzy keyword search over encrypted data in the public key setting. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2013; Volume 7923 LNCS, pp. 729–740. [Google Scholar]
参考:
- 478 次浏览
【尽职调查】尽职调查:你需要知道的
视频号
微信公众号
知识星球
您需要尽职调查(DD)摘要吗?我们回答最重要的问题。
- 尽职调查的含义是什么?
- 尽职调查法
- 谁需要尽职调查?
- 为什么公司和组织需要尽职调查?
- 检查了什么?
- 谁帮公司检查?
- 尽职调查检查表格
- 尽职调查过程
- 尽职调查报告
- 你应该注意什么
我们还推荐我们的第三方尽职调查清单
什么是尽职调查?
尽职调查尽职调查的含义或定义:德国法律中规定的尽职调查概念是指在业务过程中采取合理的谨慎措施。尽职调查包括对企业或个人的经济、法律、财政和财务状况进行仔细调查。这包括销售数字、股东结构以及与腐败和逃税等经济犯罪形式的可能联系等方面。一旦一家公司与商业伙伴建立关系,或计划收购另一家公司或一处房产或投资房地产,就有必要进行此类检查。
根据《剑桥词典》,尽职调查的含义是:“在与公司达成商业安排之前,对公司及其财务记录、商业交易进行的详细检查。”
德国合规协会(DICO)将商业合作伙伴定义为“与公司有商业联系的任何一方,而不是公司的员工或经理”。无论业务关系的范围或类型如何,这包括客户、供应商、分包商、销售代表、合资企业的顾问和合作伙伴以及小型服务提供商、中介机构和投资者。
尽职调查审计使公司能够进行风险和合规检查,通过检查相互关系或要约的假设和条件并识别相关风险来保护自己。适当的尽职调查形式取决于具体情况、业务交易和风险水平。
尽职调查是在做出任何关键商业决策或收购公司之前需要考虑的一项重要商业技术。在你将公司财务状况付诸行动之前,你需要了解公司的尽职调查以及如何正确行事。
尽职调查的含义:尽职调查是一个涉及风险和合规性检查、进行调查、审查或审计以核实特定主题的事实和信息的过程。简单地说,尽职调查意味着在与另一家公司签订任何协议或合同之前,做好功课并获得所需的知识。
尽职调查主要由股票研究公司、基金经理、个人投资者、风险和合规分析师以及公司和经纪交易商进行。同时,个人投资者可以自由进行自己的尽职调查。另一方面,法律要求经纪商在出售证券之前对证券进行尽职调查。
什么是第三方尽职调查?
第三方尽职调查是评估和评估与第三方实体(如供应商、供应商、承包商、代理人或商业伙伴)合作或合作的相关风险的过程。对第三方尽职调查过程进行全面调查和分析,以确保这些第三方实体:
- 遵守法律法规要求,
- 遵守道德标准,
- 对公司没有重大风险
进行第三方尽职调查是为了降低潜在风险,保护组织的声誉、资产和利益。针对第三方的尽职调查指南涉及收集有关第三方背景、财务稳定性、法律和合规历史、商业惯例以及整体声誉的信息。尽职调查的级别可能因关系的性质、行业和所涉及的潜在风险而异。
完整的第三方尽职调查清单对于制定有效的风险评估和监控策略非常重要。进行和维护正式评估,即第三方尽职调查问卷,是供应商尽职调查过程中帮助公司评估第三方关系风险的步骤之一。这些调查问卷可在新供应商或供应商的入职尽职调查过程中使用,而一些公司则选择向现有供应商或供应商发送调查问卷作为常规跟进。联系LexisNexis合规解决方案,以避免因第三方关系而造成的财务和声誉损害。
商业伙伴筛选的形式
-
入职尽职调查
- 在建立新的业务关系或签署新合同时筛选业务合作伙伴
-
正在进行的尽职调查
- 定期对现有业务合作伙伴、供应商、收购方、目标公司进行筛选,以避免出现问题。
-
简化尽职调查
- 在进行低风险评估时,对业务合作伙伴的财务报表进行表面筛选
-
强化尽职调查
- 在签订合同之前,对供应商、业务合作伙伴、卖家、收单机构等高风险联系人进行全面筛查。
强化尽职调查
强化尽职调查包括收集个人和公司的详细信息,以提供保险。为了确保这项背景研究是彻底的,公司需要访问许多不同的数据库:
公司数据库
确定公司与其他相关人员之间可能存在的联系
观察名单
识别受国家监控的个人和公司,如恐怖主义嫌疑人
制裁名单
识别受到经济或法律制裁(禁运)的个人和公司
政治公众人物列表
识别与政府成员或政府机构成员关系密切、特别容易受到腐败或贿赂的政治人物
新闻报道
与新闻报道进行交叉检查,以确保商业合作伙伴与腐败、洗钱、欺诈或贿赂等形式的经济犯罪无关。
根据使用这些数据库和其他数据库对新的和现有的业务合作伙伴进行检查的结果,公司可能需要调整风险方法或终止业务关系的启动。
尽职调查法
在世界各地,通过法律防止贿赂、腐败和洗钱的国家数量都在增加。其中许多国家法律也对国际贸易关系产生影响。

因此,公司必须做的不仅仅是遵守本国法律,如德国2008年的《反洗钱法》,该法规定了进行尽职调查的法律背景,并将该法第3条中的义务从银行转移到其客户或业务合作伙伴。
对于在国际上活跃的公司来说,预防经济犯罪有两项法案尤为重要:
- 英国《反贿赂法》
- 美国《反海外腐败法》
尽管这两项法案都是各自国家的国家法规,但如果德国公司直接或通过子公司、分包商或其员工与这些国家有联系,则会受到影响。执法机构可以对德国公司展开调查,因为无论贿赂发生在哪里,这些行为都适用。
这些法案最近得到了旨在解决现代奴隶制问题的法律的补充。例如,《英国现代奴隶制法案》要求主要的非英国公司每年报告为防止现代奴隶制而采取的措施。
2016年巴拿马文件丑闻引发了国际社会对提高受益所有人透明度的呼吁。
谁需要尽职调查?

- 如果所有公司和组织参与公司合并或收购其他公司的股份、财产、房地产、投资、投资者或保险交易,或者如果他们与商业伙伴合作,特别是在国际环境中,则需要对其进行尽职调查。
- 需要对您的所有业务合作伙伴、供应商、买家和卖家进行持续的尽职调查,以确保合规。
- 在签订销售合同之前评估你的目标公司和潜在客户也是一个好主意,以避免未来出现问题。
如何进行尽职调查?
例如,假设您正在一个合适的地点购买一家企业。在购买业务之前,您将进行尽职调查。现在,在一家小公司执行尽职调查程序可能很困难。它需要查看公司的文件,核实参考资料,仔细检查所有内容,并寻找公司可能隐藏的信息。这就是为什么建议雇佣在这方面有经验的专家。
我们知道如何看到你自己可能会忽视的红色标志。您和其他企业主需要在尽职调查过程开始时签署保密协议。该协议禁止您在未经其他公司所有者许可的情况下接触任何个人或公司,以获取有关业务或产品的进一步信息。
为什么公司和组织需要尽职调查?
尽职调查风险和合规检查工具有助于公司保护其利益,例如在并购活动中,以保护价值链或遵守有关防止洗钱、贿赂和腐败的制裁和立法。尽职调查和持续的市场监控从四个方面帮助公司:
- 英国《反贿赂法》和美国《反海外腐败法》等关于防止腐败和洗钱的立法对直接或间接在这些国家设有代表的德国公司具有约束力。因此,他们必须保护自己,防止通过供应链中的商业伙伴或分包商与贿赂或其他形式的腐败和洗钱联系在一起。
- 不在国际上活跃的公司和组织也受到GWG等立法的约束。
- 与缺乏必要诚信的商业伙伴合作可能会导致巨额经济损失或处罚,甚至被判入狱。
- 与经济犯罪有关联的公司有严重损害其声誉的风险。即使公司本身符合道德和法律标准,商业合作伙伴的不当行为仍可能损害其声誉。近年来,一些知名公司的供应商被发现在中国从事可疑或非法的工作条件等行为。
公司使用风险和合规检查工具进行第三方尽职调查,以验证收购候选人或收购前景的质量。尽职调查检查是在系统分析的基础上进行的,包括对优势和劣势的评估,有助于保护购买并评估风险。

- 采取法律规定的步骤,防止腐败和洗钱,评估风险,筛选参与国际合作的商业伙伴和分包商:
- 防止财务后果:
- 防止声誉风险:
- 出于经济原因,在购买或与公司和组织合并时:
检查了什么?
风险和合规检查涵盖现有和潜在的业务合作伙伴及其分包商以及有责任采取行动的个人。调查内容包括:
- 全球有23.2亿活跃Facebook用户
- 公司所在地
- DACH的1500万XING用户
- 负面国际报告
- 危险信号
- 制裁名单
- 政治公众人物倾听
- 业绩和资产负债表
正在检查什么?
对现有和潜在的业务合作伙伴及其分包商以及负责人进行评估和审查。除其他事项外:
- 总部
- 危险信号
- 国际媒体的负面报道
- 有关个人或公司的制裁名单
- 涉及人员的政治公众人物名单
- 业绩和资产负债表
- 资产和负债、预算
- 工作流程
- 员工资格
- 公司形象
- 质量控制
- 董事会成员、股东、受益人
- μv.m。
谁帮公司检查?
由于要求的复杂性,建议召集受过培训的员工(内部员工、风险和合规分析师)或外部顾问(税务顾问、审计师、律师、技术专家、管理顾问)进行尽职调查。也有尽职调查清单,提供了良好的(初步)主题概述。然而,它们并不总是涵盖具体情况。尽职调查费用可以免税。就公司税而言,如果尽职调查成本为:
- 计入损益账户,
- 用于良好的贸易或商业用途。
一般来说,潜在风险越大,应该投资于支票的资源就越多。

如果一家公司的员工资源不足或无法访问相关的最新信息,手动尽职调查程序可能很快就会出现问题。因此,公司应利用适当的技术实现检查自动化,支持尽职调查,并确保持续的风险监控。
我们如何提供帮助?
我们的第三方尽职调查软件执行尽职调查的唯一目标是为我们的客户提供有价值的尽职调查报告和业务分析,这些报告和分析成为他们决策和谈判过程中不可或缺的一部分。我们提供保密、健全和公正的观点,是对客户内部资源的极好补充。
专注于提供增值服务,通过将对技术、财务、物流和公司战略的全面理解与用简洁易懂的术语总结复杂问题的能力相结合,改进客户的商业决策。
尽职调查检查表格

尽职调查软件执行涵盖各个领域的各种形式的尽职调查检查。最常见的是:
- 经济、技术和组织尽职调查
- 对经理和员工的检查
- 法律和税务检查
- 操作尽职调查(ODD),以评估目标对象的风险和升值潜力
- 市场尽职调查,以探索和分析目标公司当前和未来的市场地位
尽职调查程序

1.标识:
尽职调查过程通常从身份识别开始。最重要的信息是直接从未来的合作伙伴处或通过合规性收集的。简单的调查问卷可以用于此目的。
- 就注册公司而言,收集的信息包括公司、股东、受益人、集团结构、董事会成员及其政治联系的详细信息。现阶段还可能要求提供正式文件和合同。
- 关于个人,所需信息可能包括身份证明和资金来源、政治联系和其他细节,具体取决于计划交易的性质。
2.制裁清单检查:
第二步是与全球制裁名单进行交叉核对。还查阅了与起诉、取消资格和政府机构点名的个人有关的名单。公司也经常列出他们不想与之做生意的其他公司的名单。识别政治公众人物,对照政治公众人物名单进行检查,必要时进行风险评估。
3.风险评估:
根据调查结果,现在进行了风险评估,并制定了基于风险的方法。更多信息见白皮书“尽职调查——从商业负担到商业利益”。
- 67 次浏览
【数据保护】数据去标识
视频号
微信公众号
知识星球
数据去识别是用于防止数据库中的个人身份或私人信息被泄露的过程。过程包括屏蔽个人标识符或用临时数据替换真实信息。通常,取消识别的数据会经过重新识别的过程以供进一步使用。
去标识是防丢失和数据控制总体实践的一部分,几乎每个行业都使用它来保护消费者数据,并提供对受保护健康信息的遵守,如HIPAA(健康保险便携性和责任法案)和许多其他隐私法案或用例。
去识别过程与云
企业数据持续呈指数级增长,向云数据湖的迁移已成为一大趋势,使大数据环境能够灵活无限制地扩展。随着越来越多的组织将云数据湖用于商业分析、机器学习和人工智能,特定的数据隐私保护挑战正在出现。
数据的爆炸导致了另一种趋势——在一些基于云的环境中,数据元素会被无意中暴露或配置错误。显然需要去识别云数据湖中的底层数据或原始数据,同时仍允许企业利用分析和人工智能建模等大数据技术。
在云提供商的“共享责任模式”中,提供商负责提供底层基础设施和数据中心的安全,而客户则负责将数据放入云中。因此,去标识意味着去标识实际的数据值或保护正在放入的底层数据值。
不幸的是,许多去标识技术需要额外的开发或更改数据管道,因此要么减缓基于云的分析的使用,要么让去标识的数据集暴露在外。此外,去标识只是挑战的一部分,因为访问和仓库数据的新方法可能会限制可能需要授权重新标识或分析数据的情况。
数据去标识的常用方法
- 以数据为中心的加密(Data-centric encryption),包括字段级别的加密/记录级别的加密-实际上通过某些形式的加密来保护特定的数据值。
- 数据标记化(Data tokenization),使用标记化库,或标记化,或所谓的无螺栓标记化,或者某种类型的代码簿方法,例如,用另一个值替换账号的方法。
- 格式保留加密(Format-preserving encryption)-数据类型和长度保留加密模式的另一种变体。社会保险号码、医疗记录号码、信用卡号码或电子邮件地址等数据将从格式化的角度进行保存,但根据实际的基础数据值进行随机化。
- 数据屏蔽(Data masking)-用于控制表示层,因此您可能只看到最后四位数字,而不是看到某人的完整信用卡号,或者值可能会完全混淆。
- 基于角色的数据屏蔽(Role-based data masking )–允许组织内的某些角色、处于更特权状态的某些方或可能是外部的第三方,但基本上,可以根据您的组成员身份动态呈现不同的数据视图。
- 高级加密方案(Advanced Encryption schemes)——包括基于飞地的加密,数据的安全性与移动设备上的指纹或人脸ID非常相似,扩展到服务器级计算模式、同态加密和多方计算。
Baffle的数据保护服务允许在飞行中轻松地取消数据识别,并通过无代码模型基于授权角色选择性地重新识别数据。
对象加密与以数据为中心的加密的优势
- 对对象和文件内部的数据进行去标识、标记化或加密。
- 安全港,防止关键隐私和合规法规的意外数据泄露。
- 通过解决关键的安全和隐私问题,加快基于云的数据分析程序。
Baffle允许您不断地将数据推送到云端,动态地对其进行去识别,然后允许组织成员运行他们需要在相应数据集上运行的分析类型,以最大限度地降低重新识别风险:
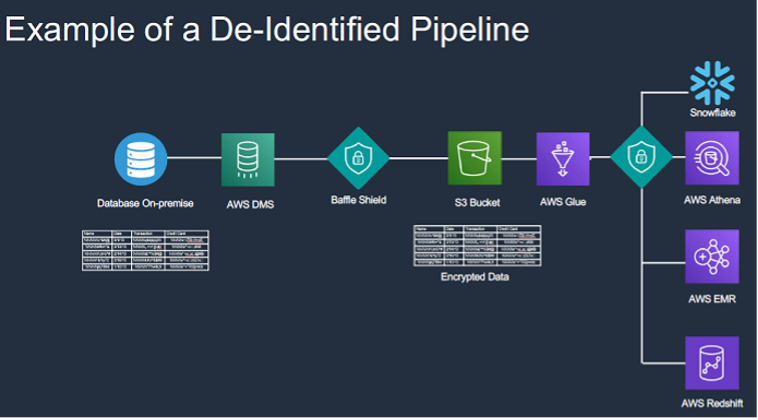
云数据湖为组织提供了更大的灵活性,以适应未来的大规模数据增长。数据泄露的风险仍然存在,但公司可以利用以数据为中心的保护方法和Baffle的解决方案来降低您的风险,释放数据的价值,并帮助将其货币化。
Shared Responsibility Model
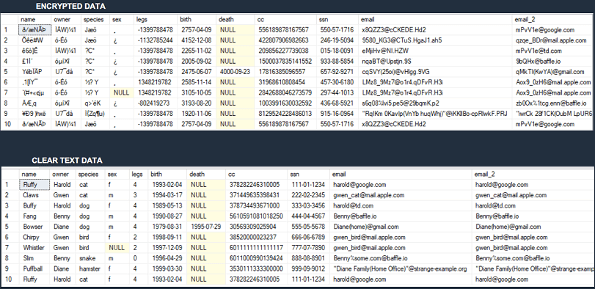
Sample De-Identification of Data vs Clear Text
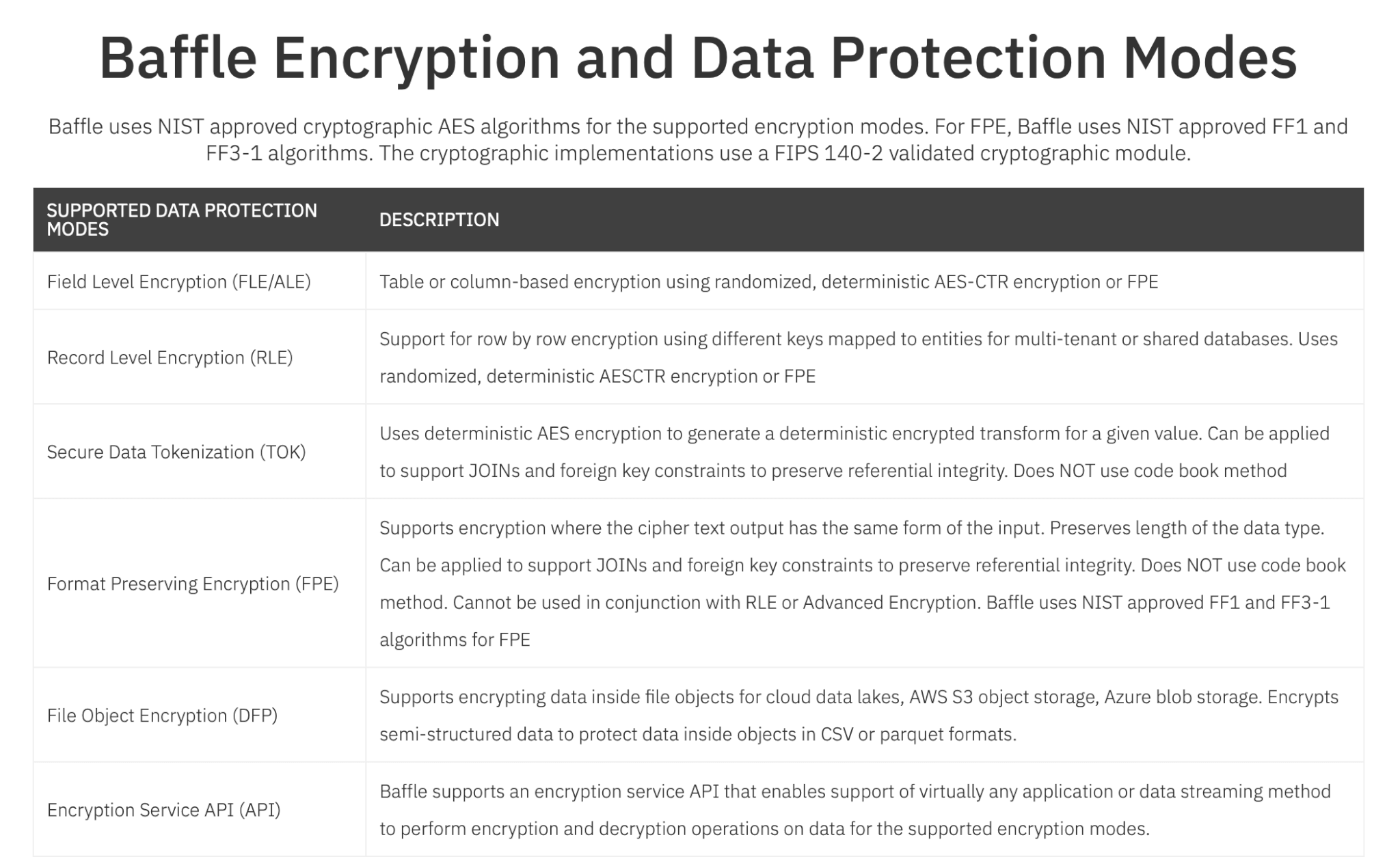
Baffle支持多种数据库和文件加密模式,包括NIST认证和FIPS验证的AES模式。
- 54 次浏览
【数据保护合规】遵守数据保护法规
视频号
微信公众号
知识星球
遵守数据保护法规
许多技术和服务越来越依赖数据,包括敏感数据和个人数据,这提高了保护这些数据免受盗窃、腐败和丢失的重要性。国家和全球权威机构已经介入制定了《通用数据保护条例》(GDPR)等法规。
不符合数据保护的行业标准不仅会导致数据丢失或泄露,还会受到法律和经济处罚,并损害组织的声誉。继续阅读,了解有关数据保护法规以及如何遵守这些法规。
在本文中:
- •什么是数据保护?
- •什么是GDPR?
- •数据保护技术
- •如何实现数据隐私合规
- •使用Cloudian存储设备进行数据保护
什么是数据保护?
数据保护——有时被称为信息隐私或数据安全——是保护重要信息的隐私、完整性和数据可用性的过程。任何处理敏感数据的组织都必须实施数据保护策略,以防止其数据被盗、损坏或丢失,并在发生安全漏洞或灾难时减轻损失。
从数据泄露或数据丢失中恢复是时间敏感的,任何延迟都可能影响业务连续性。许多行业也有法律要求,适用于处理或存储姓名、地址、密码、信用卡详细信息和医疗记录等个人信息的组织。
什么是GDPR?
《通用数据保护条例》(GDPR)于2016年4月通过,并于2018年5月生效,旨在为整个欧盟(EU)和欧洲经济区(EAA)的数据保护提供统一的标准。它规定,任何处理个人数据的公共或私人组织都必须致力于维护高水平的数据安全。
GDPR强调欧盟居民与个人数据相关的权利,包括访问、修改、转移或删除其数据的权利。GDPR中定义的个人数据是指与个人有关的任何信息。这包括个人识别信息(PII),例如姓名;地址;身体特征,包括体重、身高、民族或种族特征;生物特征数据,例如DNA和指纹;以及健康数据。
GDPR规定,组织必须在使用个人数据方面提供透明度,要求他们披露任何数据处理活动,证明使用这些数据的合法依据,并在72小时内报告任何数据泄露。
数据保护是GDPR的重要组成部分,几乎所有在线企业都必须遵守这些或类似的标准。GDPR合规性要求实施数据隐私政策,确保只收集必要的数据;个人对可以收集哪些数据以及如何使用这些数据有发言权;所有敏感数据在达到目的后立即删除。对违规行为的处罚是高达20000000欧元的罚款,即一个组织全球收入的4%。
为了帮助组织满足合规要求,GDPR概述了数据保护官员(DPO)和数据控制者(data controller)等角色的职责。数据管理员的职责包括采取措施,确保个人数据不会被滥用,并保持机密。GDPR赋予数据控制者实施额外数据保护措施的灵活性,但要求数据控制者评估与这些措施相关的风险和成本。
阅读数据存储GDPR合规性完整指南
数据保护技术和实践
有许多数据管理和存储解决方案可以帮助您保护数据。有几种类型的数据安全措施旨在限制对数据的访问,监控网络中的活动,并部署对可疑或已确认的漏洞的响应。一些常见技术和预防性安全措施包括:
- 数据备份--存储定期更新的数据副本。这通常涉及到对数据进行整体“镜像”,以便您可以从多个位置访问数据。您可以利用基于内部部署磁盘的存储系统进行安全、快速访问的本地备份、磁带作为本地或远程备份或云备份。
- 数据丢失预防(DLP)--一种利用多种工具来帮助减轻数据丢失的解决方案。
- 防火墙--帮助您监控网络流量,以便检测和阻止恶意软件。
- 身份验证和授权--确认用户的身份并验证用户的访问权限。凭据(即密码)、访问令牌和身份验证密钥的组合有助于提供额外的安全层。这可以是更大的身份和访问管理(IAM)解决方案的一部分,以及基于角色的访问控制(RBAC)等措施。
- 加密--将数据转换为不可读的格式,这样只有加密密钥才能将其转换回简单文本。数据安全解决方案通常将加密作为其数据保护策略的重要组成部分。
- 端点保护--监控端点活动的软件,当有人在您的网络中传输数据时向您发出警报。
- 数据擦除——一旦敏感数据被处理,就删除它,以降低暴露的风险。这是GDPR等法规的重要要求。
- 灾难恢复计划(DRP)--使您能够在发生损坏数据中心的事件后恢复数据。组织应始终制定计划,以便能够快速轻松地恢复丢失的数据。
阅读 On-Prem vs. Public Cloud for Data Protection 报告。
如何实现数据隐私合规
为了帮助您的组织满足GDPR等数据保护法规的要求,您应该制定一个全面的数据保护战略,并在整个组织中实施。您的合规策略应包括:
- 企业范围内对义务的理解——组织中的每个人都应该知道他们的职责包括什么。您可能还需要遵守运营所在国或影响您所在行业的其他当地法规。确保每位员工都知道如何应对数据安全事件,并且至少熟悉GDPR的七项关键原则。
- 识别风险领域——你应该评估任何使用个人数据的活动所涉及的风险。这可以帮助您识别现有安全策略中的漏洞,以便更新您的合规措施。
- 保持可见性和透明度--使用数据映射等措施来跟踪组织处理的所有个人数据。这应该包括记录您收集的数据类型、存储位置以及为什么需要处理这些数据。
- 任命一名数据保护官(DPO)——这对于处理高风险活动的个人数据的组织来说是强制性的,例如对敏感数据的大规模分析。DPO负责监督GDPR的遵守情况并提供建议。您也可以从DPO中受益,即使法律上没有要求您雇佣DPO。
- 隐私计划——GDPR提倡“默认和设计隐私”的方法,包括在数据处理活动的整个生命周期中实施数据保护措施。组织必须能够证明他们有足够的计划,否则就有可能面临执法行动。因此,您应该将隐私影响评估(PIA)纳入您的隐私保护策略中。
- 58 次浏览
【数据保护和隐私】什么是数据保护和隐私?
视频号
微信公众号
知识星球
数据保护和数据隐私这两个术语经常互换使用,但两者之间有一个重要的区别。数据隐私定义了谁可以访问数据,而数据保护提供了实际限制访问数据的工具和策略。合规性法规有助于确保用户的隐私请求由公司执行,公司有责任采取措施保护私人用户数据。
数据保护和隐私通常应用于个人健康信息(PHI)和个人身份信息(PII)。它在企业运营、发展和财务方面发挥着至关重要的作用。通过保护数据,公司可以防止数据泄露、声誉受损,并可以更好地满足监管要求。
数据保护解决方案依赖于数据丢失预防(DLP)、内置数据保护的存储、防火墙、加密和端点保护等技术。
在本文中:
- 什么是数据保护隐私?为什么它很重要?
- 什么是数据保护原则?
- 什么是数据隐私,为什么它很重要?
- 什么是数据保护法规?
- 数据保护与数据隐私
- 保护您的数据的12种数据保护技术和做法
- 确保数据隐私的最佳实践
- 清点您的数据
- 最小化数据收集
- 对用户开放
- 数据保护趋势
- 数据可移植性
- 移动数据保护
- 勒索软件
- 复制数据管理(CDM)
- 灾难恢复即服务
- Cloudian HyperStore的数据保护和隐私
什么是数据保护?为什么它很重要?
数据保护是一组策略和流程,您可以使用这些策略和流程来保护数据的隐私、可用性和完整性。它有时也被称为数据安全。
数据保护策略对于任何收集、处理或存储敏感数据的组织都至关重要。成功的策略有助于防止数据丢失、盗窃或损坏,并有助于最大限度地减少在发生漏洞或灾难时造成的损害。
什么是数据保护原则?
数据保护原则有助于保护数据,并使其在任何情况下都可用。它涵盖了操作数据备份和业务连续性/灾难恢复(BCDR),并涉及数据管理和数据可用性的实施方面。
以下是与数据保护相关的关键数据管理方面:
- 数据可用性--确保用户能够访问和使用执行业务所需的数据,即使这些数据丢失或损坏。
- 数据生命周期管理--包括将关键数据自动传输到离线和在线存储。
- 信息生命周期管理--涉及对各种来源的信息资产进行评估、编目和保护,包括设施停电和中断、应用程序和用户错误、机器故障以及恶意软件和病毒攻击。
相关内容:阅读我们的数据保护原则指南
什么是数据隐私,为什么它很重要?
数据隐私是根据数据的敏感性和重要性制定的数据收集或处理指南。数据隐私通常应用于个人健康信息(PHI)和个人可识别信息(PII)。这包括财务信息、医疗记录、社会保障或身份证号码、姓名、出生日期和联系信息。
数据隐私问题适用于组织处理的所有敏感信息,包括客户、股东和员工的信息。通常,这些信息在业务运营、发展和财务方面发挥着至关重要的作用。
数据隐私有助于确保敏感数据只能由经批准的各方访问。它防止犯罪分子恶意使用数据,并有助于确保组织满足监管要求。
什么是数据保护法规?
数据保护法规管理某些数据类型的收集、传输和使用方式。个人数据包括各种类型的信息,包括姓名、照片、电子邮件地址、银行账户详细信息、个人计算机的IP地址和生物特征数据。
数据保护和隐私法规因国家、州和行业而异。例如,中国制定了一项数据隐私法,该法于2017年6月1日生效,欧盟的《通用数据保护条例》于2018年生效。不遵守可能导致名誉损失和罚款,具体取决于各法律和管理实体指示的违规行为。
遵守一套法规并不能保证遵守所有法律。此外,每项法律都包含许多条款,这些条款可能适用于一种情况,但不适用于另一种情况。所有法规都可能发生变化。这种复杂程度使得一致、适当地实施法规遵从性变得困难。
在我们的详细指南中了解更多信息:
- 数据保护法规
- GDPR数据保护
数据保护与数据隐私
尽管数据保护和隐私都很重要,而且两者经常结合在一起,但这些术语并不代表同一件事。
一个涉及政策,另一个涉及机制
数据隐私侧重于定义谁可以访问数据,而数据保护侧重于应用这些限制。数据隐私定义了数据保护工具和流程所采用的策略。
制定数据隐私准则并不能确保未经授权的用户无法访问。同样,您可以使用数据保护来限制访问,同时仍然使敏感数据易受攻击。两者都是确保数据安全所必需的。
用户控制隐私,公司确保保护
隐私和保护之间的另一个重要区别是谁通常是控制者。为了隐私,用户通常可以控制他们的数据共享量以及与谁共享。为了保护数据,由处理数据的公司来确保数据保持隐私。合规性法规反映了这一差异,旨在帮助确保用户的隐私请求由公司制定。
在我们的详细指南中了解更多信息:
- 数据保护策略
- 数据保护策略
保护数据的数据保护技术和实践
在保护数据方面,您可以选择许多存储和管理选项。解决方案可以帮助您限制访问、监控活动和应对威胁。以下是一些最常用的实践和技术:
数据发现
在保护您的数据之前,您需要知道您拥有什么以及数据的位置。这一过程被称为数据发现,对于识别敏感信息和确定保护信息的最佳方法至关重要。
盘点和分类
要开始数据发现过程,您必须首先清点组织中的所有数据。这涉及到识别您存储的不同类型的数据,如客户信息、员工记录、知识产权等。一旦你有了一个全面的列表,你就可以根据其敏感性和重要性对每种数据类型进行分类。
数据映射
数据映射是数据发现的下一步,它涉及识别数据的位置以及数据在组织中的流动方式。这有助于您了解各种数据集和系统之间的关系,使您能够就数据保护做出明智的决定。
自动发现工具
为了进一步简化数据发现过程,许多组织现在都使用自动化工具,可以快速扫描和识别敏感数据。这些工具可以帮助您跟踪数据清单,并确保您始终了解任何更改或添加。
数据丢失预防(DLP)
数据丢失预防(DLP)是数据保护的关键组成部分,旨在防止敏感信息的未经授权访问、泄露或盗窃。DLP技术由各种工具和流程组成,可帮助组织保持对其数据的控制。
DLP策略
创建和实施DLP策略是保护数据的关键第一步。这些策略概述了处理敏感信息的规则和程序,应根据组织的具体需要进行定制。
监控和警报
DLP技术通常包括可以检测潜在数据泄露或其他安全事件的监控和警报系统。这些系统可以跟踪用户活动,标记任何可疑行为或访问敏感数据的尝试。
补救
在发生潜在的数据泄露或安全事件时,DLP技术还提供补救选项。这些措施可能包括阻止敏感数据的传输,隔离受影响的文件,或自动撤销对受损帐户的访问。
具有内置数据保护的存储
选择正确的存储解决方案对于确保数据的安全至关重要。现代存储技术现在配备了内置的数据保护功能,提供了额外的安全层。
冗余
存储技术保护数据的主要方式之一是通过冗余。通过创建数据的多个副本并将其存储在不同的驱动器或位置,您可以将由于硬件故障或其他问题而导致的数据丢失风险降至最低。
错误更正
内置纠错是许多现代存储系统的另一个功能。这项技术可以自动检测和修复数据损坏,确保信息的完整性。
访问控制
最后,具有内置数据保护的存储系统通常包括细粒度的访问控制,允许您限制谁可以访问您的数据以及在什么情况下访问。这有助于防止未经授权的访问,并保持信息的机密性。
备份
备份数据是数据保护的一个基本方面。定期备份确保您可以快速记录
备份计划
为了确保备份始终是最新的,制定定期备份计划非常重要。这可能涉及每天、每周甚至每月的备份,具体取决于您组织的需要和数据的敏感性。
快照
快照通过创建系统和文件的时间点拷贝,为您的数据提供了额外的保护层。这些快照可用于在发生安全事件时快速恢复数据。
即时恢复
快照的主要好处之一是能够促进即时恢复。如果您的系统受到威胁,您可以快速恢复到以前的快照,从而最大限度地减少停机时间和数据丢失。
版本控制
快照还提供了一种版本控制形式,允许您维护数据和系统的多个版本。这对于跟踪更改和确定安全事件的原因尤其有用。
存储效率
由于快照的增量特性,快照可以比传统备份更高效地存储。这可以帮助您节省空间,同时保持全面的数据保护策略。
复制
复制包括创建数据的精确副本并将其存储在单独的位置。这可以为数据丢失提供额外的保护,并确保信息的可用性。
故障切换和故障回复
在发生系统故障或其他中断的情况下,复制使您能够快速切换到复制的数据(故障切换),确保将停机时间降至最低。一旦问题得到解决,您就可以切换回原始数据(故障回复)。
负载平衡
复制还可以帮助实现负载平衡,使您能够在多个系统或位置之间分配工作负载。这可以提高性能并防止系统过载。
地域冗余
通过在地理位置不同的位置复制您的数据,您可以保护您的信息免受区域灾难的影响,并在发生局部停机时保持对数据的访问。
防火墙
防火墙作为内部系统和外部世界之间的屏障,在数据保护中发挥着至关重要的作用。它们可以帮助防止未经授权的访问,并保护您的数据免受各种威胁。
入侵检测和预防
许多现代防火墙包括入侵检测和预防功能,可以在潜在威胁到达您的系统之前识别并阻止这些威胁。
应用程序控制
防火墙还可以提供应用程序控制,允许您限制或允许特定应用程序访问您的数据。这有助于防止未经授权的访问并维护信息的完整性。
流量监控
最后,防火墙提供流量监控功能,使您能够跟踪和分析进出组织的数据流。这可以帮助您检测潜在的安全事件并做出相应的响应。
身份验证和授权
身份验证和授权是数据保护的重要组成部分,确保只有经过授权的个人才能访问您的数据。这些过程包括验证用户的身份并授予他们适当的访问级别。
多因素身份验证
多因素身份验证(MFA)要求用户提供两种或多种形式的身份验证来访问您的数据,从而增加了额外的安全层。这可能包括他们知道的东西(例如密码)、他们拥有的东西(如安全令牌)或他们是什么(例如指纹)。
基于角色的访问控制
基于角色的访问控制(RBAC)是一种授权方法,它在组织中为用户分配特定的角色,每个角色都有自己的权限集。这种细粒度的方法有助于确保用户只能访问执行其工作功能所需的数据,从而降低未经授权访问或数据泄露的风险。
身份和访问管理
身份和访问管理(IAM)系统旨在管理整个组织的用户身份和访问权限。通过集中身份验证和授权过程,IAM可以帮助简化数据保护工作并提高安全性。
加密
加密是将数据转换为只能由授权方读取的代码的过程。这项技术是数据保护的关键组成部分,因为它可以帮助防止数据被盗或未经授权的访问。
对称加密
对称加密涉及使用单个密钥来加密和解密数据。这种方法通常比其他加密方法更快,但要求双方都可以访问同一密钥,这就不那么安全了。
不对称加密
非对称加密,也称为公钥加密,使用两个密钥:一个用于加密数据,另一个用于解密数据。这种方法比对称加密慢,但由于私钥仍然保密,因此提供了更大的安全性。
端到端加密
端到端加密是一种加密方法,可确保数据从发送到预期收件人接收之间始终受到保护。这项技术通常用于消息应用程序和其他通信平台。
终端保护
端点,如笔记本电脑、智能手机和其他移动设备,往往是网络攻击的脆弱目标。端点保护技术旨在保护这些设备及其包含的数据。
防病毒和反恶意软件
防病毒和反恶意软件是端点保护的重要组成部分,旨在检测和删除设备中的恶意软件。
设备管理
端点保护还可以涉及设备管理,允许您从中心位置跟踪和控制端点。这可能包括监控设备活动,限制对某些应用程序的访问,以及在设备被盗或丢失时远程擦拭设备。
修补程序管理
修补程序管理是使您的设备保持最新安全修补程序和软件更新的过程。这可以帮助解决漏洞,防止网络攻击利用已知的弱点。
数据擦除
数据擦除包括从系统中安全、永久地删除数据。这一过程对于确保敏感信息不会落入坏人之手至关重要。
安全擦除方法
安全的数据擦除方法包括用新数据覆盖现有数据,从而无法恢复原始信息。这些方法可能包括多次覆盖数据、消磁或物理销毁存储介质。
数据销毁策略
制定数据销毁政策对于确保敏感信息在不再需要时被正确擦除至关重要。这些策略应概述擦除数据的程序以及需要安全擦除的数据类型。
认证(Certification)和审计
最后,认证和审核可以帮助确保您的数据擦除过程有效且符合相关法规。通过获得认证并接受定期审计,您可以证明您对数据保护的承诺,并确保您的程序保持最新。
灾难恢复
灾难恢复包括为可能威胁数据可用性或完整性的意外事件做好准备并作出响应。这一过程对于确保业务连续性至关重要,有助于最大限度地减少灾害的影响。
业务影响分析
在制定灾难恢复计划之前,必须首先进行业务影响分析。这个过程包括识别组织内的关键功能和系统,并确定中断的潜在影响。
灾难恢复规划
一旦进行了业务影响分析,就可以制定灾难恢复计划。该计划应概述应对灾害以及恢复系统和数据的程序。
测试和维护
为了确保灾难恢复计划的有效性,定期测试和维护程序非常重要。这可能包括进行桌面演习或全面模拟,以及随着新技术或威胁的出现更新您的计划。
相关内容:阅读我们的数据保护影响评估指南
确保数据隐私的关键最佳实践
制定数据隐私政策可能具有挑战性,但并非不可能。以下最佳实践可以帮助您确保创建的策略尽可能有效。
清点您的数据
确保数据隐私的一部分是了解您拥有的数据、如何处理以及存储在哪里。您的策略应该定义如何收集和执行这些信息。例如,您需要定义对数据进行扫描的频率,以及定位后如何对其进行分类。
您的隐私政策应明确列出您的各种数据隐私级别需要哪些保护。策略还应包括审核保护的过程,以确保正确应用解决方案。
相关内容:阅读我们的数据保护影响评估指南
最小化数据收集
确保您的策略规定只收集必要的数据。如果你收集的超过了你需要的,你会增加你的责任,并可能给你的安全团队带来不应有的负担。最大限度地减少数据收集也可以帮助您节省带宽和存储空间。
实现这一点的一种方法是使用“验证而非存储”框架。这些系统使用第三方数据来验证用户,并消除了将用户数据存储或传输到系统的需要。
对用户开放
许多用户都意识到隐私问题,并且可能会欣赏您如何使用和存储数据的透明度。反映这一点,GDPR将用户同意作为数据使用和收集的一个关键方面。
通过在界面中设计隐私问题,您可以确保在流程中包含用户及其同意。例如,有明确的用户通知,概述何时收集数据以及为什么收集数据。您还应该为用户提供修改或选择退出数据收集的选项。
数据保护趋势
以下是推动数据保护发展的一些重要趋势。
数据可移植性和数据主权
数据可移植性是许多现代IT组织的一项重要要求。它意味着能够在不同的环境和软件应用程序之间移动数据。通常,数据可移植性意味着能够在本地数据中心和公共云之间以及不同的云提供商之间移动数据。
数据可移植性也有法律意义——当数据存储在不同的国家时,它受到不同的法律法规的约束。这就是所谓的数据主权。
- 相关内容:阅读我们的数据主权指南
传统上,数据是不可移植的,将大型数据集迁移到另一个环境需要付出巨大的努力。在云计算的早期,云数据迁移也极其困难。正在开发新的技术方法,以使迁移更容易,从而使数据更具可移植性。
一个相关的问题是数据在云中的可移植性。云服务提供商往往拥有专有的数据格式、模板和存储引擎。这使得将数据从一个云移动到另一个云变得困难,并造成了供应商锁定。越来越多的组织正在寻找标准化的数据存储和管理方式,以使其在云之间可移植。
在我们的详细指南中了解更多信息:
- 云中的数据保护
- Office 365数据保护
移动数据保护
移动设备保护是指旨在保护存储在笔记本电脑、智能手机、平板电脑、可穿戴设备和其他便携式设备上的敏感信息的措施。移动设备安全的一个基本方面是防止未经授权的用户访问您的公司网络。在现代IT环境中,这是网络安全的一个关键方面。
有许多移动数据安全工具,旨在通过识别威胁、创建备份和防止端点上的威胁到达公司网络来保护移动设备和数据。IT人员使用移动数据安全软件实现对网络和系统的安全移动访问。
移动数据安全解决方案的常见功能包括:
- 通过安全渠道加强通信
- 执行强大的身份验证以确保设备不会受到损害
- 限制使用第三方软件和浏览不安全的网站
- 对设备上的数据进行加密,以防止设备泄露和被盗
- 定期审核端点以发现威胁和安全问题
- 监控设备上的威胁
- 设置允许远程设备安全连接到网络的安全网关
勒索软件
勒索软件是一种日益严重的网络安全威胁,几乎是所有组织的首要安全任务。勒索软件是一种对用户数据进行加密并要求赎金以释放数据的恶意软件。新型勒索软件在加密数据之前将数据发送给攻击者,使攻击者能够勒索组织,威胁公开其敏感信息。
备份是抵御勒索软件的有效防御手段——如果一个组织有其数据的最新副本,它可以恢复数据并重新获得对数据的访问权限。然而,勒索软件可以在网络上传播很长一段时间,而不需要加密文件。在这个阶段,勒索软件可以感染任何连接的系统,包括备份。当勒索软件传播到备份时,数据保护策略就“游戏结束”了,因为无法恢复加密数据。
有多种策略可以防止勒索软件,特别是防止其传播到备份:
- 最简单的策略是使用旧的3-2-1备份规则,将数据的三个副本保留在两个存储介质上,其中一个是非本地存储介质。
- 安全供应商拥有先进的技术,可以在勒索软件的早期阶段检测到,或者在最坏的情况下,在加密过程开始时阻止加密过程。
- 存储供应商正在提供不可变的存储,这可以确保数据在存储后不会被修改。了解Cloudian安全存储如何帮助保护您的备份免受勒索软件的攻击。
相关内容:阅读我们的勒索软件数据恢复指南
复制数据管理(CDM)
大型组织将多个数据集存储在不同的位置,其中许多数据集之间可能存在重复数据。
重复的数据会造成多个问题--它会增加存储成本,造成不一致性和操作问题,还可能导致安全性和法规遵从性方面的挑战。通常情况下,并非所有数据副本都以相同的方式进行保护。当数据在另一个未知位置重复时,保护数据集并确保其符合要求是没有用的。
CDM是一种检测重复数据并帮助管理的解决方案,它可以比较类似的数据,并允许管理员删除未使用的副本。
灾难恢复即服务
灾难恢复即服务(DRaaS)是一种托管服务,为组织提供基于云的远程灾难恢复站点。
传统上,建立二级数据中心极其复杂,成本高昂,而且只与大型企业相关。有了DRaaS,任何规模的组织都可以将其本地系统复制到云中,并在发生灾难时轻松恢复运营。
DRaaS服务利用公共云基础设施,可以跨多个地理位置存储基础设施和数据的多个副本,以提高弹性。
Cloudian HyperStore的数据保护和隐私
数据保护需要强大的存储技术。Cloudian的存储设备易于部署和使用,让您可以存储Petabyte规模的数据并立即访问。Cloudian支持并行数据传输的高速备份和恢复(16个节点每小时写入18TB)。
Cloudian为您的数据提供耐用性和可用性。HyperStore可以备份和归档您的数据,为您提供高可用版本,以便在需要时进行恢复。
在HyperStore中,存储发生在防火墙后面,您可以配置数据访问的地理边界,并定义用户设备之间的数据同步策略。HyperStore为您提供了在内部部署设备中进行基于云的文件共享的功能,以及在任何云环境中保护数据的控制权。
使用Cloudian了解有关数据保护的更多信息。
了解有关数据保护和隐私的更多信息
- 遵守数据保护法规
- 数据可用性:确保业务运营的持续运作
- 如何维护安全的数据存储
- 数据加密:简介
- 连续数据保护
- GDPR数据保护
- S3对象锁——保护数据免受勒索软件威胁和法规遵从性
- Office 365数据保护。它是必不可少的
请参阅我们关于关键数据保护主题的其他指南:
在这些深入的指南中了解有关数据泄露世界的更多信息。
《数据备份指南》
- 数据档案以及为什么需要它们
- 备份云存储:确保业务连续性
- 备份存储:云与内部部署
端点安全性
作者:Cynet
- 云端点保护:保护您最薄弱的环节
- EPP安全:指尖的预防、检测和响应
- 端点安全VPN:保护远程访问
数据分类
作者:Satori
- 数据分类:法规遵从性、概念和4种最佳做法
- 数据分类策略:优点、示例和技术
- 数据分类类型:标准、级别、方法等
- 73 次浏览
【数据加密】Synapse Spark-加密、解密和数据屏蔽
视频号
微信公众号
知识星球
介绍
作为一名数据工程师,在使用Apache Spark准备和转换数据时,我们经常会要求对数据湖中文件中的某些列数据进行加密、解密、屏蔽或匿名处理。Spark的可扩展性特性使我们能够利用非Spark原生的库。其中一个库是Microsoft Presidio,它为私人实体提供快速识别和匿名模块,包括信用卡号、姓名、位置、社会安全号码、比特币钱包、美国电话号码、财务数据等文本。它有助于在多个平台上实现全自动化和半自动化的PII(个人身份信息)去识别和匿名化流程。
在这篇博客文章中,我将逐步演示如何下载和使用这个库来满足Azure Synapse Analytics的Spark池的上述要求。
做好准备
Microsoft Presidio是微软的一个开源库,可以与Spark一起使用,以确保对私人和敏感数据进行正确的管理和治理。它主要提供两个模块,用于快速识别的分析器模块和用于匿名化文本中的私人实体的匿名化模块,如信用卡号、姓名、位置、社会安全号码、比特币钱包、美国电话号码、金融数据等。
Presidio分析仪
Presidio分析器是一种基于Python的服务,用于检测文本中的PII实体。在分析过程中,它运行一组不同的PII识别器,每个识别器负责使用不同的机制检测一个或多个PII实体。它附带了一组预定义的识别器,但可以很容易地使用其他类型的自定义识别器进行扩展。预定义和自定义识别器利用正则表达式、命名实体识别(NER)和其他类型的逻辑来检测非结构化文本中的PII。

You can download this library from here by clicking on “Download files” under Navigation on the left of the page: https://pypi.org/project/presidio-analyzer/
Presidio匿名器(anonymizer)
Presidio匿名器是一个基于Python的模块,用于匿名检测到的具有所需值的PII文本实体。Presidio匿名器通过应用不同的运算符来支持匿名化和去匿名化。运算符是内置的文本操作类,可以像自定义分析器一样轻松扩展。它同时包含匿名者和匿名者:
- 匿名器用于通过应用某个运算符(例如,replace、mask、redact、encrypt)将PII实体文本替换为其他值
- 匿名化器用于恢复匿名化操作。(例如解密加密的文本)。

This library includes several built-in operators.
Step 1 - You can download this library from here by clicking on “Download files” under Navigation on the left of the page: https://pypi.org/project/presidio-anonymizer/
|
Additionally, it also contains, Presidio Image Redactor module as well, which is again a Python based module and used for detecting and redacting PII text entities in images. You can learn more about it here: https://microsoft.github.io/presidio/image-redactor/ |
Presidio uses an NLP engine which is an open-source model (the en_core_web_lg model from spaCy), however it can be customized to leverage other NLP engines as well, either public or proprietary. You can download this default NLP engine library from here:
https://spacy.io/models/en#en_core_web_lg
https://github.com/explosion/spacy-models/releases/tag/en_core_web_lg-3.4.0
Step 2 - Once you have downloaded all three libraries you can upload them to Synapse workspace, as documented here (https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-manage-workspace-package...) and shown in the image below:
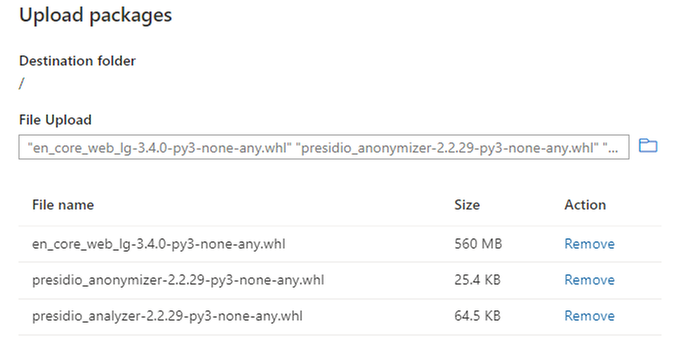
Figure 1 - Upload Libraries to Synapse Workspace
Given that NLP engine library is slightly bigger in size, you might have to wait a couple of minutes for the upload to complete. Once successfully uploaded, you will see a “Succeeded” status message for each of these libraries, as shown below:

Figure 2 - Required libraries uploaded to Synapse Workspace
Step 3 - Next, you have to apply these libraries from the Synapse workspace to the Spark pool where you are going to use it. Here are the instructions on how to do that and the screenshot below shows how it looks:
https://docs.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-manage-pool-packages
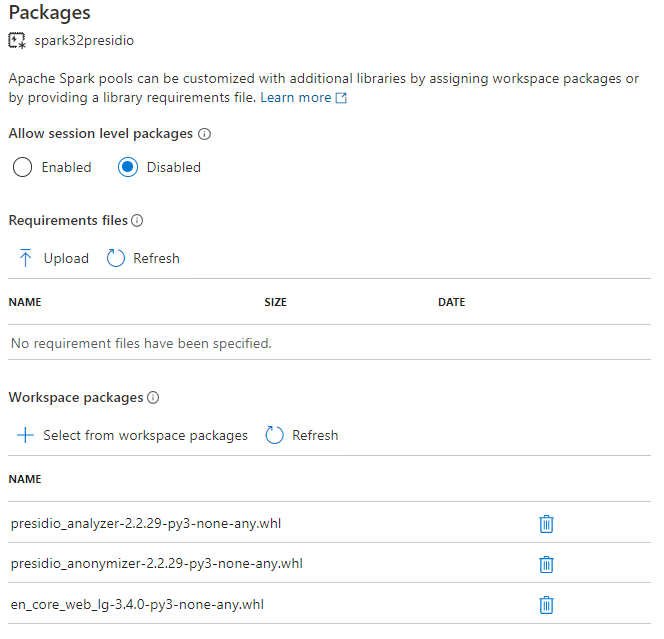
Figure 3 - Applying libraries to Synapse Spark pool
一旦点击“应用”,Synapse将触发一个系统作业,在选定的Spark池上安装和缓存指定的库。此过程有助于减少整个会话启动时间。一旦此系统作业成功完成,所有新会话都将获取更新的池库。
把所有这些放在一起
步骤1-首先,我们需要导入我们刚刚应用到Spark池的相关类/模块(以及其他现有库中的其他相关类/模)。
from presidio_analyzer import AnalyzerEngine, PatternRecognizer, EntityRecognizer, Pattern, RecognizerResult
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
from pyspark.sql.types import StringType
from pyspark.sql.functions import input_file_name, regexp_replace
from pyspark.sql.functions import col, pandas_udf
import pandas as pd
Presidio分析仪
步骤2-接下来,您可以使用分析器模块来检测文本中的PII实体。下面是一个在给定文本中检测电话号码的示例。
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My phone number is 212-555-5555",
entities=["PHONE_NUMBER"],
language='en')
print(results)
As you can see, it detected the phone number which starts at position 19 and ends at position 31 with a score of 75%:

In addition to the phone number entity, which we used earlier, you can use any of the other built-in entities, as below, or use custom developed entities:

For example, the next code uses two entities Person and Phone Number to detect the name of the person and phone number in the given text:
# Set up the engine, loads the NLP module (spaCy model by default) and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text="My name is David and my number is 212-555-1234",
entities=["PERSON", "PHONE_NUMBER"],
language='en')
print(results)

Presidio匿名器
步骤3-使用分析器识别具有私人或敏感数据的文本后,可以使用匿名器类使用不同的运算符对其进行匿名。
匿名示例
以下是通过使用replace运算符对已识别的敏感数据进行匿名化的示例。在这个例子中,为了简单起见,我使用识别器结果作为硬编码值,但是您可以在运行时直接从分析器获得这些信息。
# Anonymization Example
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import RecognizerResult, OperatorConfig
# Initialize the engine with logger.
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer) and
# Operators to get the anonymization output:
result = engine.anonymize(
text="My name is Bond, James Bond",
analyzer_results=[
RecognizerResult(entity_type="PERSON", start=11, end=15, score=0.8),
RecognizerResult(entity_type="PERSON", start=17, end=27, score=0.8),
],
operators={"PERSON": OperatorConfig("replace", {"new_value": "<ANONYMIZED>"})},
)
print(result)

Figure 4 - Person name anonymized by using replace operator
加密示例
步骤4-下一个示例演示如何使用encrypt运算符对文本中已识别的敏感数据进行加密。同样,在这个例子中,为了简单起见,我使用识别器结果作为硬编码值,但是您可以在运行时直接从分析器获得这些信息。
此外,我对加密密钥进行了硬编码,但在您的情况下,您将从Azure KeyVault获得以下信息:
# Encryption Example
encryption_key = "WmZq4t7w!z%C&F)J" # in real world, this will come from Azure KeyVault
engine = AnonymizerEngine()
# Invoke the anonymize function with the text,
# analyzer results (potentially coming from presidio-analyzer)
# and an 'encrypt' operator to get an encrypted anonymization output:
anonymize_result = engine.anonymize(
text="My name is Bond, James Bond",
analyzer_results=[
RecognizerResult(entity_type="PERSON", start=11, end=15, score=0.8),
RecognizerResult(entity_type="PERSON", start=17, end=27, score=0.8),
],
operators={"PERSON": OperatorConfig("encrypt", {"key": encryption_key})},
)
anonymize_result

Figure 5 - Person name anonymized by using encrypt operator
解密示例
步骤5-与加密运算符加密已识别的私人和敏感数据一样,您可以使用解密运算符使用加密过程中使用的相同密钥解密已加密的私人数据。
# Decryption Example
# Initialize the engine:
engine = DeanonymizeEngine()
# Fetch the anonymized text from the result.
anonymized_text = anonymize_result.text
# Fetch the anonynized entities from the result.
anonymized_entities = anonymize_result.items
# Invoke the deanonymize function with the text, anonymizer results
# and a 'decrypt' operator to get the original text as output.
deanonymized_result = engine.deanonymize(
text=anonymized_text,
entities=anonymized_entities,
operators={"DEFAULT": OperatorConfig("decrypt", {"key": encryption_key})},
)
deanonymized_result

Figure 6 - Person name decrypted by using decrypt operator
Spark示例-将其与Dataframe和UDF一起使用
ApacheSpark是一个分布式数据处理平台,要在Spark中使用这些库,可以使用用户定义的函数来封装逻辑。接下来,您可以使用该函数对Spark数据帧执行操作(匿名化、加密或解密等),如下所示,以进行替换。
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()
broadcasted_analyzer = sc.broadcast(analyzer)
broadcasted_anonymizer = sc.broadcast(anonymizer)
# define a pandas UDF function and a series function over it.
# Note that analyzer and anonymizer are broadcasted.
def anonymize_text(text: str) -> str:
analyzer = broadcasted_analyzer.value
anonymizer = broadcasted_anonymizer.value
analyzer_results = analyzer.analyze(text=text, language="en")
anonymized_results = anonymizer.anonymize(
text=text,
analyzer_results=analyzer_results,
operators={"DEFAULT": OperatorConfig("replace", {"new_value": "<ANONYMIZED>"})},
)
return anonymized_results.text
def anonymize_series(s: pd.Series) -> pd.Series:
return s.apply(anonymize_text)
# define a the function as pandas UDF
anonymize = pandas_udf(anonymize_series, returnType=StringType())

Figure 7 - Sample data with no encryption yet (for Email and IP Address)
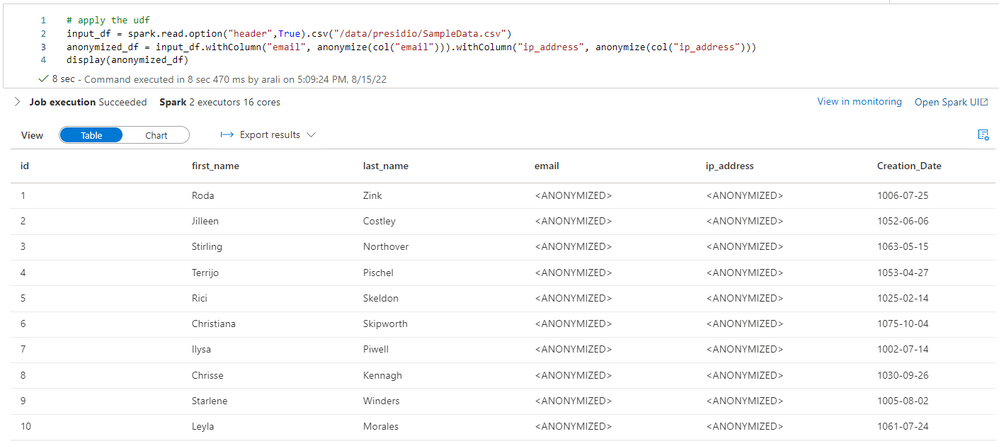
Figure 8 - Sample data anonymized for Email and IP Address
What we discussed so far barely scratched the surface. The possibilities are endless, and Presidio includes several samples for various kinds of scenarios. You can find more details here: https://microsoft.github.io/presidio/samples/
Here is the FAQ: https://microsoft.github.io/presidio/faq/
总结
当我们希望更好地控制和治理法规遵从性时,我们经常被要求加密、解密、屏蔽或匿名某些包含私人或敏感信息的列。在这篇博客文章中,我演示了如何使用Microsoft Presidio库和Azure Synapse Analytics的Spark池来对大规模数据执行操作。
Our team will be publishing blogs regularly and you can find all these blogs here: https://aka.ms/synapsecseblog
For deeper level understanding of Synapse implementation best practices, please refer to our Success By Design (SBD) site: https://aka.ms/Synapse-Success-By-Design
- 93 次浏览
【数据加密】什么是加密?
视频号
微信公众号
知识星球
概述
数据加密是一种计算过程,它将明文/明文(未加密的人类可读数据)编码为密文(加密数据),只有拥有正确密钥的授权用户才能访问。简单地说,加密将可读数据转换为其他形式,只有拥有正确密码的人才能解码和查看,这是数字转型的重要组成部分。
无论您的企业是生产、聚合还是消费数据,加密都是一种关键的数据隐私保护策略,可防止敏感信息落入未经授权的用户手中。这个页面提供了一个关于加密是什么以及它是如何工作的高级视图。
什么是加密
加密是如何工作的?
加密使用密码(一种加密算法)和加密密钥将数据编码为密文。一旦将该密文发送给接收方,就会使用密钥(对于对称加密,为相同密钥;对于非对称加密,则为不同的相关值)将密文解码回原始值。加密密钥的工作原理与物理密钥非常相似,这意味着只有拥有正确密钥的用户才能“解锁”或解密加密数据。
加密与令牌化
加密和标记化是相关的数据保护技术;它们之间的区别已经演变。
在常见用法中,标记化通常指的是保留格式的数据保护:用一个看起来相似但不同的标记来代替单个敏感值的数据保护。加密通常意味着数据保护,将数据(一个或多个值或整个数据集)转换为看起来与原始数据截然不同的胡言乱语。
代币化可以基于各种技术。有些版本使用格式保留加密,例如NIST FF1模式AES;一些生成随机值,将原始数据和匹配的令牌存储在安全令牌库中;其他人从预先生成的一组随机数据中生成令牌。根据上面对加密的定义,任何类型的标记化显然都是加密的一种形式;区别在于标记化的格式保留属性。
加密的目的是什么?
加密在保护通过互联网传输或存储在计算机系统中的敏感数据方面发挥着至关重要的作用。它不仅对数据保密,还可以验证数据的来源,确保数据在发送后不会发生更改,并防止发件人拒绝发送加密消息(也称为拒绝)。
除了提供强大的数据隐私保护外,加密通常也是维护多个组织或标准机构制定的法规遵从性所必需的。例如,联邦信息处理标准(FIPS)是美国政府机构或承包商根据2014年《联邦信息安全现代化法案》(FISMA 2014)必须遵守的一套数据安全标准。在这些标准中,FIPS 140-2要求加密模块的安全设计和实现。
另一个例子是支付卡行业数据安全标准(PCI DSS)。该标准要求商家在客户卡数据静止存储时以及在公共网络上传输时对其进行加密。许多企业必须遵守的其他重要法规包括《通用数据保护条例》(GDPR)和《2018年加州消费者隐私法》(CCPA)。
什么是加密类型?
加密主要有两种类型:对称加密和非对称加密。
对称加密
对称加密算法使用相同的密钥进行加密和解密。这意味着加密数据的发送者或计算机系统必须与所有授权方共享密钥,以便他们可以解密。对称加密通常用于批量加密数据,因为它通常比非对称加密更快、更容易实现。
最广泛使用的对称加密密码之一是高级加密标准(AES),美国国家标准与技术研究所(NIST)于2001年将其定义为美国政府标准。AES支持三种不同的密钥长度,它们决定了可能的密钥数量:128、192或256位。破解任何AES密钥长度都需要一定程度的计算能力,而这些计算能力目前是不现实的,也不太可能成为现实。AES在世界范围内广泛使用,包括国家安全局(NSA)等政府组织。
不对称加密
非对称加密,也称为公钥加密,使用两个不同但数学上相连的密钥——公钥和私钥。通常,公钥是公开共享的,任何人都可以使用,而私钥是安全的,只有密钥所有者才能访问。有时数据会被加密两次:一次是用发送者的私钥加密,另一次是使用接收者的公钥加密,从而确保只有预期的接收者才能解密数据,并且发送者就是他们声称的那个人。因此,非对称加密在某些用例中更灵活,因为公钥可以很容易地共享;然而,与对称加密相比,它需要更多的计算资源,并且这些资源随着受保护数据的长度而增加。
因此,混合方法很常见:生成对称加密密钥并用于保护大量数据。然后使用接收方的公钥对该对称密钥进行加密,并将其与对称加密的有效载荷打包在一起。接收方使用非对称加密对相对较短的密钥进行解密,然后使用对称加密对实际数据进行解密。
RSA是使用最广泛的非对称加密密码之一,1977年以其发明人Ron Rivest、Adi Shamir和Leonard Adleman的名字命名。RSA仍然是使用最广泛的非对称加密算法之一。与目前所有的非对称加密一样,RSA密码依赖于素数分解,即将两个大素数相乘以创建更大的数字。当使用正确的密钥长度时,破解RSA是极其困难的,因为必须从相乘的结果中确定两个原始素数,这在数学上是困难的。
现代加密的弱点
与许多其他网络安全策略一样,现代加密也可能存在漏洞。现代加密密钥足够长,暴力攻击——尝试所有可能的密钥,直到找到合适的密钥——是不切实际的。128位密钥有2128个可能的值:1000亿台计算机每秒测试100亿次操作,需要10亿年才能尝试所有这些密钥。
现代密码漏洞通常表现为加密强度的轻微减弱。例如,在某些条件下,128位密钥仅具有118位密钥的强度。虽然发现这些弱点的研究在确保加密强度方面很重要,但它们在现实世界中的使用并不重要,通常需要不切实际的假设,例如对服务器的物理访问不受限制。因此,对现代强加密的成功攻击集中在未经授权的密钥访问上。
加密如何帮助您的公司?
数据加密是稳健网络安全战略的关键要素,尤其是随着越来越多的企业转向云,并且不熟悉云安全最佳实践。
网络安全是OpenText的一条业务线,其Voltage Data Privacy and Protection产品组合使组织能够加速上云,实现IT现代化,并通过全面的数据加密软件(如OpenText的Voltage SecureData)满足数据隐私合规要求™ 和电压智能密码。CyberRes Voltage产品组合解决方案使组织能够发现、分析和分类所有类型的数据,从而实现数据保护和风险降低的自动化。Voltage SecureData提供了以数据为中心、持久的结构化数据安全性,而Voltage SmartCipher简化了非结构化数据安全,并在多个平台上提供了对文件使用和处置的完全可见性和控制。
电子邮件加密
电子邮件继续在组织的通信和日常业务中发挥着重要作用,并代表着其防御中的一个关键漏洞。通过电子邮件传输的敏感数据往往容易受到攻击和无意披露。电子邮件加密是解决这些漏洞的重要防御手段。

在医疗保健和金融服务等高度监管的环境中,合规是强制性的,但公司很难强制执行。电子邮件尤其如此,因为最终用户强烈抵制对其标准电子邮件工作流程的任何更改。SecureMail在所有平台上提供简单的用户体验,包括计算机、平板电脑和本机移动平台支持,具有发送安全、发起、读取和共享消息的全部功能。例如,在Outlook、iOS、Android和BlackBerry中,发件人可以访问其现有联系人,只需单击“发送安全”按钮即可发送加密电子邮件。收件人在现有收件箱中接收安全邮件,就像他们使用明文电子邮件一样
加密大数据、数据仓库和云分析
释放大数据安全的力量,使用持续的数据保护实现隐私合规,并在云中和本地实现大规模安全分析。公司越来越多地将其工作负载和敏感数据转移到云中,将其IT环境转变为混合或多云。根据MarketsandMarkets发布的一份市场研究报告,云分析市场规模将从2020年的232亿美元增长到2025年的654亿美元。
Voltage for Cloud Analytics通过保护云迁移中的敏感数据,帮助客户降低采用云的风险,并安全地实现分析的用户访问和数据共享。加密和标记化技术通过在云仓库和应用程序中发现和保护静态、动态和使用中的受监管数据,帮助客户遵守隐私要求。这些解决方案还通过以数据为中心的保护集中控制,最大限度地降低了多云的复杂性,无论敏感数据在多云环境中流动,都可以保护敏感数据。

与Snowflake、Amazon Redshift、Google BigQuery和Azure Synapse等云数据仓库(CDW)的集成,使客户能够使用格式保留、标记化的数据在云中进行大规模的安全分析和数据科学,从而在遵守隐私法规的同时降低泄露商业敏感信息的风险。
PCI安全合规性和支付安全
企业、商家和支付处理器面临着严峻而持续的挑战,即确保其网络和高价值敏感数据(如支付持卡人数据)的安全,以遵守支付卡行业数据安全标准(PCI DSS)和数据隐私法。通过我们的格式保护加密和标记化,简化零售销售点、网络和移动电子商务网站的PCI安全合规性和支付安全。
Voltage Secure Stateless Tokenization(SST)是一种先进的、获得专利的数据安全解决方案,为企业、商家和支付处理器提供了一种新的方法,以帮助确保对支付卡数据的保护。SST是SecureData Enterprise数据安全平台的一部分,该平台将市场领先的格式保护加密(FPE)、SST、数据屏蔽和无状态密钥管理结合在一起,以在一个全面的解决方案中保护敏感的公司信息。

保护POS支付数据
在刷卡、插入、点击或手动输入时加密或标记零售销售点信用卡数据。
SST支付技术
我们的电压安全无状态令牌化(SST)使支付数据能够在其受保护状态下使用和分析。
保护web浏览器数据
电压安全数据Web通过OpenText™ 在浏览器中输入支付数据时对其进行加密或标记,从而减少PCI审计范围。
用于移动设备的PCI安全
电压SecureData Mobile by OpenText™ 为在整个支付流程中在移动端点上捕获的数据提供PCI安全性。
- 54 次浏览
【数据加密】什么是数据加密
视频号
微信公众号
知识星球
什么是数据加密
数据加密是一种将数据从可读格式(明文)转换为不可读编码格式(密文)的方法。加密数据只有在使用解密密钥或密码进行解密后才能读取或处理。只有数据的发送方和接收方才能访问解密密钥。
在部署加密解决方案时,您应该意识到加密很容易受到来自以下几个方向的攻击:
- 使用计算机程序破解某些加密算法并访问加密内容是可能的,尽管更强的加密需要大量的计算资源才能破解。
- 传输中的加密数据可能存在漏洞。授权设备可能会被恶意软件感染,当数据在网络中传播时,恶意软件会“嗅探”数据或“窃听”数据。
- 闲置的加密数据可能会被存储设备上的恶意软件或未经授权的用户泄露,这些用户可以访问用户密码或密钥。
尽管如此,数据加密可以阻止黑客访问敏感信息,并且对大多数安全策略至关重要。但是,您的安全策略不应该仅仅依赖于加密。
DES和其他流行的加密算法
数据加密标准(DES)是一种现已过时的对称加密算法——您可以使用相同的密钥来加密和解密消息。DES使用56位加密密钥(从完整的64位密钥中剥离出8个奇偶校验位),并以64位的块对数据进行加密。这些尺寸通常不足以满足今天的使用。因此,其他加密算法已经成功地实现了DES:
- Triple DES——曾经是标准的对称算法。三重DES采用三个单独的密钥,每个密钥有56位。总密钥长度加起来有168位,但根据大多数专家的说法,其有效密钥强度只有112位。
- RSA——一种流行的公钥(非对称)加密算法。它使用一对密钥:用于加密消息的公钥和用于解密消息的私钥。
- Blowfish——一种对称密码,将消息分成64位的块,并一次加密一个。Blowfish是一种遗留算法,它仍然有效,但Twofish已经成功了。
- Twofish——一种对称密码,利用长度高达256位的密钥。Twofish用于许多软件和硬件环境。它是快速的,免费提供和非专利的。
- 高级加密标准(AES)——该算法是目前美国政府和其他组织接受的标准。它在128位形式下工作良好,然而,AES可以使用192和256位的密钥。AES被认为可以抵抗除暴力之外的所有攻击。
- 椭圆曲线密码(ECC)——该算法是SSL/TLS协议的一部分,用于加密网站与其访问者之间的通信。它通过更短的密钥长度提供更好的安全性;256位ECC密钥提供与3072位RSA密钥相同级别的安全性。
静止数据与数据库加密
静止数据是指不在网络或设备之间传输的数据。它包括笔记本电脑、硬盘、闪存驱动器或数据库上的数据。静止数据对攻击者很有吸引力,因为它通常具有有意义的文件名和逻辑结构,可以指向个人信息、信用卡、知识产权、医疗保健信息等。
如果您的公司没有正确处理其数据资产,可能会给自己和客户带来安全风险。始终假设攻击者可以在休息时访问数据。最大限度地减少休息时的数据量,保留所有剩余数据的清单并对其进行保护,是防止数据泄露的关键。
数据库加密
在大多数现代应用程序中,数据由用户输入,由应用程序处理,然后存储到数据库中。在较低级别上,数据库由操作系统管理的文件组成,这些文件存储在物理存储器(如闪存驱动器)上。
加密可以在四个级别执行:
- 应用程序级加密——数据在写入数据库之前,由修改或生成数据的应用程序进行加密。这使得可以根据用户角色和权限为每个用户自定义加密过程。
- 数据库加密——可以对整个数据库或其中的一部分进行加密,以确保数据的安全。加密密钥由数据库系统存储和管理。
- 文件系统级加密--允许计算机用户加密目录和单个文件。文件级加密使用软件代理,软件代理中断对磁盘的读写调用,并使用策略查看数据是否需要解密或加密。与全磁盘加密一样,它可以对数据库以及存储在文件夹中的任何其他数据进行加密。
- 全磁盘加密--自动将硬盘上的数据转换为没有密钥就无法解密的形式。存储在硬盘驱动器上的数据库与任何其他数据一起被加密。
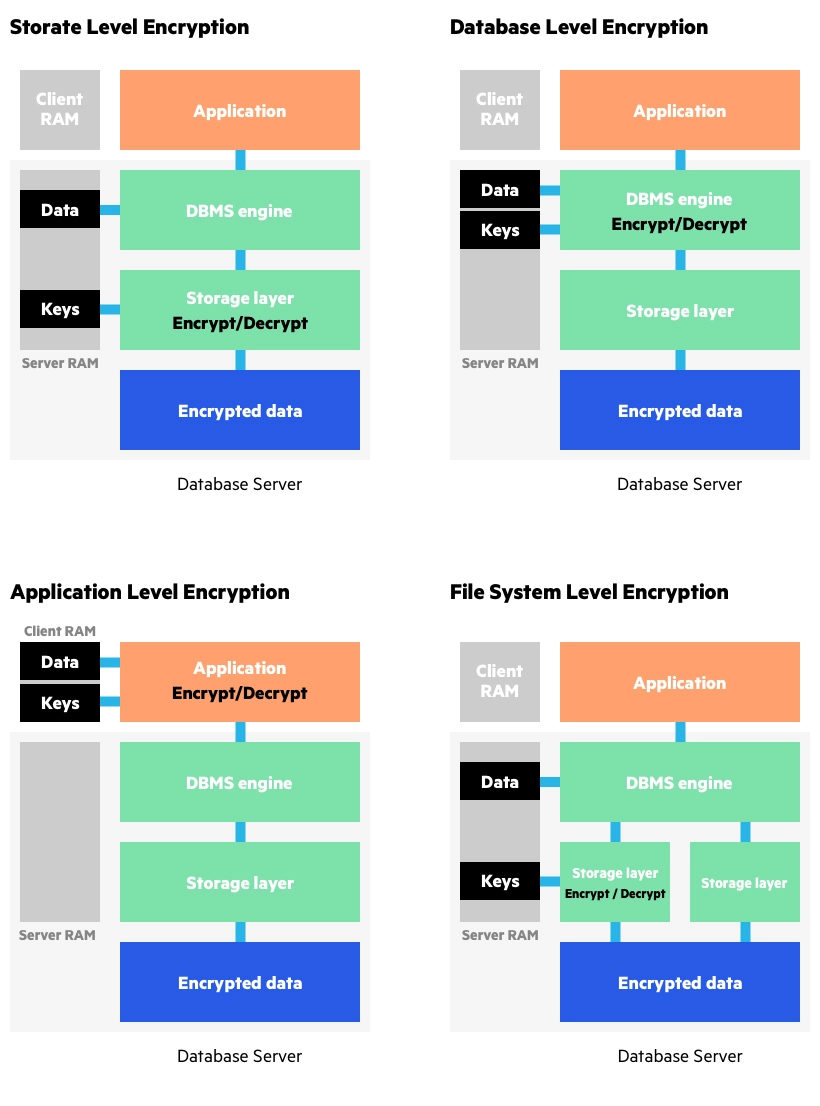
四级数据加密
加密技术
- 列级加密--对数据库中的各个数据列进行加密。每个列都有一个单独且唯一的加密密钥,可提高灵活性和安全性。
- 透明数据加密--加密整个数据库,有效地保护静止的数据。加密对使用数据库的应用程序是透明的。数据库的备份也经过加密,以防止备份介质被盗或被破坏时数据丢失。
- 字段级加密--加密特定数据字段中的数据。创建者可以标记敏感字段,以便对用户在这些字段中输入的数据进行加密。这些可以包括社会保险号码、信用卡号码和银行账号。
- 哈希——将字符串更改为与原始字符串相似的更短的固定长度键或值。哈希通常用于密码系统。当用户最初定义密码时,它会存储为哈希。当用户重新登录到网站时,他们使用的密码会与唯一的哈希进行比较,以确定其是否正确。
- 对称密钥加密——将私钥应用于数据,对其进行更改,使其在未解密的情况下无法读取。如果用户或应用程序提供密钥,数据在保存时会被加密,在检索时会被解密。对称加密被认为不如非对称加密,因为需要将密钥从发送方传输到接收方。
- 非对称加密--包含两个加密密钥:私钥和公钥。公钥可以由任何人检索,并且对一个用户是唯一的。私钥是一种只有一个用户知道的隐藏密钥。在大多数情况下,公钥是加密密钥,私钥是解密密钥。
数据库加密的缺点
数据库加密可能会导致性能下降,尤其是在使用列级加密时。因此,组织可能不愿意使用数据加密或将其应用于所有闲置数据。
许多RDBMS系统提供内置的加密和密钥管理设施。因此,如果数据中心只使用一个供应商的数据库,则数据库加密更容易执行。如果管理来自多个供应商的数据库,密钥管理可能会成为一个问题,密钥管理的失误可能会导致安全漏洞。
另外一个风险是意外数据丢失。如果使用强密码对数据进行加密,并且密钥丢失,则无法检索数据。钥匙的意外丢失或管理不善可能会带来灾难性的后果。
Imperva如何帮助保护您的数据
- Imperva的数据安全解决方案为您的数据添加了多层保护,补充了数据加密策略。
- Imperva保护数据存储以确保合规性,并保留您从云投资中获得的灵活性和成本效益:
- 云数据安全–简化云数据库的安全保护,以赶上并跟上DevOps。Imperva的解决方案使云管理服务用户能够快速获得云数据的可见性和控制权。
- 数据库安全性–Imperva在您的数据资产、内部部署和云中提供分析、保护和响应,为您提供风险可见性,以防止数据泄露并避免合规事件。与任何数据库集成以获得即时可见性、实施通用策略并加快实现价值的速度。
- 数据风险分析--自动检测企业范围内所有数据库中的不合规、有风险或恶意数据访问行为,以加快补救。
- 69 次浏览
【数据加密】什么是数据加密:类型、算法、技术和方法
视频号
微信公众号
知识星球

目录
- 什么是数据加密?
- 数据加密是如何工作的?
- 为什么我们需要数据加密?
- 数据加密技术的两种类型是什么?
- 什么是哈希?
数据加密是一种常见而有效的安全方法,是保护组织信息的合理选择。然而,有几种不同的加密方法可用,那么你该如何选择呢?
在网络犯罪不断上升的世界里,令人欣慰的是,保护网络安全的方法和渗透网络的方法一样多。真正的挑战是决定网络安全专家应该使用哪些技术最适合其组织的具体情况。
看看下面的视频,它解释了什么是加密,加密和解密是如何通过简单的逐步解释、加密类型等进行的。
什么是数据加密?
数据加密是一种保护数据的方法,通过对数据进行编码,使其只能由持有正确加密密钥的个人解密或访问。当个人或实体未经许可访问加密数据时,数据会出现混乱或无法读取的情况。
数据加密是将数据从可读格式转换为加扰信息的过程。这样做是为了防止窥探者在传输过程中读取机密数据。加密可以应用于文档、文件、消息或任何其他形式的网络通信。
为了保持数据的完整性,加密是一种重要的工具,其价值怎么强调都不为过。我们在互联网上看到的几乎所有东西都经过了某种加密层,无论是网站还是应用程序。
卡巴斯基著名的防病毒和端点安全专家将加密定义为“……将数据从可读格式转换为编码格式,只有在解密后才能读取或处理。”
他们接着说,加密被认为是数据安全的基本组成部分,被大型组织、小企业和个人消费者广泛使用。这是保护从端点传递到服务器的信息的最直接、最关键的方法。
考虑到当今网络犯罪风险的上升,每个使用互联网的人和团体至少都应该熟悉并使用基本的加密技术。
希望在数据管理方面表现出色?Simplilearn的数据管理课程提供了专家见解和实用知识,以获得成功。
在网络安全教育领域,一个全面的网络安全训练营提供了一个深入研究数据加密复杂性的机会。参与者深入了解各种加密方法,如对称和非对称加密,以及它们在保护敏感信息方面的重要性。
数据加密是如何工作的?
需要加密的数据被称为明文或明文。明文需要通过一些加密算法传递,这些算法基本上是对原始信息进行的数学计算。有多种加密算法,每种算法都因应用程序和安全索引而异。
除了算法之外,还需要一个加密密钥。使用所述密钥和合适的加密算法,将明文转换为加密数据,也称为密文。密文是通过不安全的通信渠道发送的,而不是将明文发送给接收器。
一旦密文到达预定接收器,他/她就可以使用解密密钥将密文转换回其原始可读格式,即明文。该解密密钥必须始终保密,并且可能与用于加密消息的密钥相似,也可能与用于对消息进行加密的密钥不同。让我们通过一个例子来理解这一点。
让我们通过一个例子来了解工作过程。
实例
一位女士想给她的男朋友发一条私人短信,所以她使用专门的软件对其进行加密,该软件将数据加密成似乎无法读取的胡言乱语。然后她把信息发送出去,她的男朋友反过来用正确的解密方法来翻译。
因此,最初看起来是这样的:
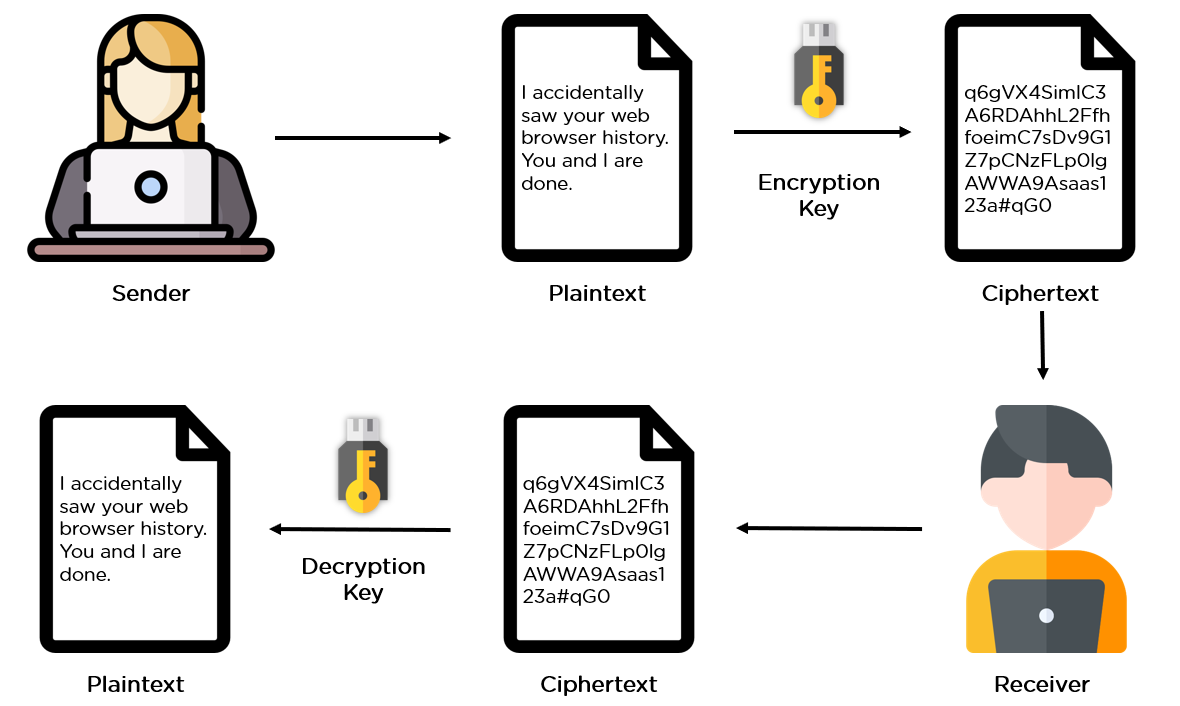
幸运的是,密钥完成了所有实际的加密/解密工作,让两人都有更多的时间在完全隐私的情况下思考他们关系的废墟。
接下来,在我们学习有效的加密方法时,让我们找出为什么需要加密。
为什么我们需要数据加密?
如果有人想知道为什么组织需要练习加密,请记住以下四个原因:
- 身份验证:公钥加密证明网站的原始服务器拥有私钥,因此被合法分配了SSL证书。在一个存在如此多欺诈网站的世界里,这是一个重要的特点。
- 隐私:加密保证除合法收件人或数据所有者外,任何人都不能读取消息或访问数据。这项措施防止网络罪犯、黑客、互联网服务提供商、垃圾邮件发送者,甚至政府机构访问和读取个人数据。
- 法规遵从性:许多行业和政府部门都制定了规则,要求处理用户个人信息的组织对数据进行加密。实施加密的监管和合规标准包括HIPAA、PCI-DSS和GDPR。
- 安全性:加密有助于保护信息不受数据泄露的影响,无论数据是处于静止状态还是在传输中。例如,即使公司拥有的设备放错地方或被盗,如果硬盘驱动器经过适当加密,存储在上面的数据也很可能是安全的。加密还有助于保护数据免受中间人攻击等恶意活动的攻击,并使各方在不担心数据泄露的情况下进行通信。
另请阅读:弥合HIPAA和云计算之间的差距
现在让我们找出重要类型的数据加密方法。
数据加密技术的两种类型是什么?
有几种数据加密方法可供选择。大多数互联网安全(IS)专业人员将加密分解为三种不同的方法:对称、非对称和哈希。这些又被分解成不同的类型。我们将分别探索每一个。
什么是对称加密方法?
这种方法也称为私钥密码学(private-key cryptography)或密钥算法( secret key algorithm),要求发送方和接收方能够访问同一密钥。因此,在解密消息之前,收件人需要拥有密钥。这种方法最适用于第三方入侵风险较小的封闭系统。
从积极的方面来看,对称加密比非对称加密更快。然而,从消极的方面来看,双方都需要确保密钥存储安全,并且只有需要使用密钥的软件才能使用密钥。
什么是非对称加密方法?
这种方法也被称为公钥密码学,在加密过程中使用两个密钥,一个公钥和一个私钥,它们在数学上是相连的。用户使用一个密钥进行加密,另一个密钥用于解密,尽管您首先选择哪一个并不重要。
顾名思义,公钥对任何人都是免费的,而私钥只留给需要它来解密消息的预期收件人。两个键都是不完全相同的大数字,但彼此成对,这就是“不对称”部分的由来。
什么是哈希?
哈希为数据集或消息生成固定长度的唯一签名。每个特定消息都有其唯一的散列,使信息的微小更改易于跟踪。使用哈希加密的数据无法解密或还原为原始形式。这就是为什么哈希仅用作验证数据的方法。
许多互联网安全专家甚至不考虑哈希是一种真正的加密方法,但这条线很模糊,足以让分类成立。最重要的是,这是一种有效的方式来表明没有人篡改信息。
现在我们已经了解了数据加密技术的类型,接下来让我们学习具体的加密算法。
什么是加密算法?
加密算法用于将数据转换为密文。通过使用加密密钥,算法可以以可预测的方式更改数据,导致加密数据看起来是随机的,但可以通过使用解密密钥将其转换回明文。
最佳加密算法
现在有很多不同的加密算法。以下是五种比较常见的。
- AES。高级加密标准(AES)是美国政府和其他组织使用的可信标准算法。尽管AES在128位形式中非常高效,但它也使用192位和256位密钥进行非常苛刻的加密。AES被广泛认为不受任何攻击,除了暴力攻击。无论如何,许多互联网安全专家认为,AES最终将被视为私营部门加密数据的首选标准。
- Triple DES。Triple DES是原始数据加密标准(DES)算法的继任者,该算法是为应对黑客破解DES而创建的。对称加密曾经是业界使用最广泛的对称算法,尽管它正在逐步淘汰。TripleDES将DES算法应用于每个数据块三次,通常用于加密UNIX密码和ATM PIN。
- RSA。RSA是一种公钥加密非对称算法,也是加密通过互联网传输的信息的标准。RSA加密是强大而可靠的,因为它会产生大量的胡言乱语,让潜在的黑客感到沮丧,导致他们花费大量时间和精力来破解系统。
- Blowfish。Blowfish是另一种旨在取代DES的算法。此对称工具将消息分解为64位块,并对其进行单独加密。河豚以速度、灵活性和牢不可破而闻名。它是公共领域的,所以它是免费的,更增加了它的吸引力。Blowfish常见于电子商务平台、安全支付和密码管理工具中。
- Twofish。Twofish是Blowfish的继任者。它是无许可证的对称加密,可以解密128位的数据块。此外,无论密钥大小如何,Twofish总是在16轮中加密数据。Twofish非常适合软件和硬件环境,被认为是同类产品中速度最快的之一。今天的许多文件和文件夹加密软件解决方案都使用这种方法。
- Rivest Shamir Adleman(RSA)。Rivest-Shamir-Adleman是一种非对称加密算法,它可以对两个大素数的乘积进行因子分解。只有知道这两个数字的用户才能成功解码消息。数字签名通常使用RSA,但当加密大量数据时,该算法会减慢速度。
3DES
虽然三重数据加密算法(3DEA)是正式名称,但它通常被称为3DES。这是因为3DES方法使用数据加密标准(DES)密码对其数据进行三次加密。DES是一种基于Feistel网络的对称密钥技术。作为对称密钥密码,它使用相同的密钥进行加密和解密。Feistel网络使这些过程中的每一个几乎相同,从而产生了一种更有效的实现技术。
尽管DES具有64位块和密钥大小,但在实践中密钥仅提供56位保护。由于DES的密钥长度较短,3DES被创建为一种更安全的替代方案。DES算法在3DES中使用三个密钥执行三次;然而,只有使用三个不同的密钥,它才被认为是安全的。
当标准DES的缺点变得明显时,3DES被广泛应用于各种应用中。在AES出现之前,它是使用最广泛的加密算法之一。
其应用实例包括:
- EMV支付系统
- Microsoft Office
- Firefox
因为有更好的替代方案,其中一些网站不再使用3DES。
根据美国国家标准与技术研究所(NIST)提供的提案草案,3DES的所有变体将在2023年之前被弃用,并从2024年开始被禁止。尽管这只是一个草案,但该计划代表着一个时代的结束。
数据加密的未来
因此,该行业正在多个方面推动加密。为了防止暴力解码,正在进行一些增加密钥大小的尝试。其他倡议正在研究新的密码算法。例如,美国国家标准与技术研究所正在测试一种量子安全的下一代公钥算法。
问题是,大多数量子安全算法在传统计算机系统上效率低下。为了克服这个问题,该行业正专注于发明加速器来加速x86系统上的算法。
- 同态加密是一个有趣的概念,它允许用户在不首先解密的情况下对加密数据进行计算。因此,需要它的分析师可以查询包含秘密信息的数据库,而无需获得更高级别分析师的许可或要求解密数据。
- 除了在所有状态下保护数据外,同态加密还可以在运动、使用和静止时(在硬盘上)保护数据。另一个优点是它是量子安全的,因为它使用了一些与量子计算机相同的算法。
应该使用对称加密还是非对称加密?
不对称加密和对称加密都更适合特定场景。对称加密采用单一密钥,对于静止的数据更可取。数据库中包含的数据必须加密,以防止被黑客入侵或窃取。因为这些数据只需要在将来需要检索之前是安全的,所以它不需要两个密钥,只需要对称加密提供的密钥。另一方面,通过电子邮件传输给他人的数据应使用非对称加密。如果只对电子邮件中的数据使用对称加密,攻击者可能会通过获取用于加密和解密的密钥来窃取或泄露材料。由于他们的公钥用于加密数据,发送方和接收方确保只有接收方可以使用非对称加密来解密数据。这两种加密方法都与数字签名或压缩等其他程序结合使用,以提供进一步的数据保护。
企业将加密用于多种用途
企业中的数据加密消除了信息泄露,并降低了其影响的成本。它是保护敏感信息的最有效的安全方法之一,但您必须了解要加密哪些文档以及如何有效地使用它们。
根据2019年的一项调查,大约45%的公司在整个企业中都有一致的加密政策。如果你的公司在云基础设施上运营,你必须首先规划你的云部署的安全要求以及将要转移到云的任何数据。列出所有敏感数据源,这样您就可以知道哪些数据需要使用何种程度的位密钥安全性进行加密。
例如,如果你的组织正在开发一个基于云的网站,你需要允许工程师和制造商之间交换源代码和设计文档。您需要使用本文中讨论的多种方法之一安装端到端加密保护,以保护他们通信所需的敏感数据。即使云存储提供商或您的帐户受到威胁,即使某些云提供商提供某种级别的加密,您也可以确保云中数据的安全。
实施有效加密策略的步骤
协作
开发加密策略需要团队合作。最好将其作为一个大型项目来处理,包括管理层、It和运营部门的成员。首先从利益相关者那里收集重要数据,并确定将影响采购和实施决策的立法、法律、指导方针和外部力量。然后,您可以继续识别高风险场所,如笔记本电脑、移动设备、无线网络和数据备份。
定义您的安全要求
对您的安全需求有一个大致的概念是很有帮助的。威胁评估是一个明智的起点,因为它可以帮助您确定哪些数据需要加密。不同加密系统的强度和处理要求可能会有所不同,因此评估系统的安全性也至关重要。
选择适当的加密工具
一旦确定了安全需求,就可以开始寻找最能满足这些需求的解决方案。请记住,为了有效保护您的网络,您很可能需要安装各种数据加密算法。例如,您可以使用安全套接字层(SSL)协议来加密发送到网站和从网站发送的数据,并使用高级加密标准(AES)来保护休息和备份时的数据。在每个级别的数据存储和传输中使用正确的加密技术将有助于确保您公司的数据尽可能安全。加密应用程序,如加密电子邮件服务,也可能有助于确保整体安全。
准备顺利部署加密计划
你的加密策略的执行,就像你公司的任何重大变革一样,必须有周密的计划。如果你有面向客户的应用程序,你的新加密可能需要集成到应用程序的后端。同样,将新的加密方法与旧系统集成可能需要额外的过程。如果你提前做出出色的计划,你可以在最小的干扰下实施这些更改。与第三方IT服务提供商合作也可能有助于过渡。您不会让自己的IT人员在实现加密方法时承担太多的杂务。
安装后,保持安全文化
尽管数据加密很有价值,但它并不是解决安全问题的灵丹妙药。为了获得良好的结果,请确保您的团队接受了使用正确加密和密钥管理方法的教育。如果员工将加密密钥放在不安全的服务器上,恶意攻击者可能会访问您公司的加密数据。这种人为错误被认为是84%的网络安全漏洞的罪魁祸首。加密应与其他安全技术结合使用,以最大限度地提高安全性。通过部署安全的硬件和强大的防火墙以及数据加密,您的公司可以通过多种安全级别来确保数据的安全。
什么是密码学中的密钥?
密钥是一个特定序列中的随机字符串。加密技术利用密钥来混淆数据,这样任何没有密钥的人都无法解密信息。算法是复杂的数学计算,用于现代加密。现代密钥通常比随机整数的基本字符串随机化得更远。
这是真的,原因有很多:
- 与人类密码学家相比,计算机可以在更短的时间内完成更复杂的计算,这使得更复杂的加密不仅是可以想象的,而且是必需的。
- 计算机可以改变二进制级别的信息,即构成数据的1和0,而不仅仅是字母和数字级别的信息。
- 如果加密数据没有充分随机化,计算机软件可以对其进行解码。真正的随机性对于真正安全的加密至关重要。
当密钥与加密方法结合在一起时,会混淆文本,使其无法被人类识别。
你想了解更多关于网络安全的信息吗?
关于网络安全,有很多东西需要学习,Simplilearn提供了一系列有价值的课程,可以帮助你进入这个充满挑战的领域,或者通过提高技能来提高你现有的知识。例如,如果你想成为一名有道德的黑客,并拥有测试网络系统的职业生涯,请查看我们的CEH认证课程。
或者查看一些企业级安全培训课程,如CISM、CSSP、CISA、CompTIA和COBIT 2019。
如果你不能在以上课程之间做出决定,为什么不在一个方便的程序中学习几门呢?网络安全专家硕士课程教授CompTIA、CEH、CISM、CISSP和CSSP的原理。
你想成为一名网络安全专家吗?
如果你已经准备好在成为网络安全专业人士的道路上迈出第一步,那么你应该从Simplilearn的CISSP认证培训课程开始。本课程培养您在定义IT体系结构以及使用全球认可的信息安全标准设计、构建和维护安全业务环境方面的专业知识。本课程涵盖行业最佳实践,为您参加(ISC)²举办的CISSP认证考试做好准备。
你可以获得60多个小时的深度学习,参加认证考试所需的30份CPE,五份旨在帮助你准备考试的模拟试卷,以及一张考试代金券。无论您选择自学、混合学习选项还是企业培训解决方案,您都将从Simplilearn的专家培训中获益,并准备好开始富有挑战性和回报的网络安全职业生涯!
常见问题
1.什么是数据加密?
数据加密是一种保护和保护数据的过程,通过对数据进行编码,使其只能由拥有加密密钥的人访问或解密。在数据加密中,数据在发送给可以使用密钥对其进行解密的人之前会被加密。
2.数据加密的两种类型是什么?
两种类型的数据加密方法是对称加密和非对称加密。对称加密也称为私钥密码学或密钥算法,要求发送方和接收方都可以访问同一密钥来解密数据。非对称加密,也称为公钥加密,使用两个单独的密钥进行加密过程。一个密钥是公钥,另一个是私钥,它们被链接并用于加密和解密。
3.加密的用途是什么?
加密用于保护正在传输的数据。这确保了数据不会落入网络罪犯、黑客、互联网服务提供商、垃圾邮件发送者甚至政府机构的坏人之手。每当你访问ATM或通过Snapchat等设备发送消息时,这些消息都会被加密,以确保除了发送消息的人之外,没有人可以访问它。
4.对数据加密的见解?
云服务器上存储着大量数据,每天都在传输。如果不存储或传输这些丰富的数据,几乎不可能进行日常操作。数据加密软件可确保数据安全,并可安全地从一个通道传输到另一个通道。
5.数据加密的工作原理
原始数据是纯文本的,这意味着它可以清楚地阅读。然后,这些数据通过加密算法传输,加密算法对“嗨!你好吗?”到“A#$*Y*&%($Y#*%Y%*)”。然后将这些数据传输到接收器,然后接收器经过解密过程,然后以纯文本形式直观地呈现给接收器。
6.加密数据可以被黑客入侵吗?
是的,加密数据可以被黑客入侵。然而,根据应用于数据的加密级别,难度级别会增加。
7.如何实现数据加密?
在开始实施数据加密之前,您需要了解并定义您的安全需求。加密级别将取决于您和您的组织所需的安全级别。选择适合您需要的正确加密工具。创建并实施加密策略。通过我们的网络安全专家课程了解更多有关数据加密的详细信息。
8.什么是数据加密示例?
WEP和WPA是在无线路由器中广泛使用的加密技术。非对称加密的例子包括RSA和DSA。RC4和DES是对称加密的两个实例。除了加密技术之外,还有所谓的通用标准(CC)。
9.什么是数据加密,为什么它很重要?
简单地说,加密就是对数据进行编码,使其对未经授权的用户隐藏或不可用。它有助于保护私人信息和敏感数据,以及客户端应用程序和服务器之间的通信安全。
10.什么是DBMS中的数据加密?
加密数据包括将其从可读(明文)格式更改为不可读的编码格式(密文)。已加密的数据只有在使用解密密钥或密码进行解密后才能查看或处理。
11.加密系统的4种基本类型是什么?
- 高级加密标准(AES)
- 三重DES
- 河豚
- Rivest Shamir Adleman(RSA)
12.三种类型的加密是什么?
DES、AES和RSA是三种主要的加密类型。最近的3DES是一种至今仍在使用的分组密码。三重数据加密标准(3DES)顾名思义。对于三重保护,它使用三个独立的56位密钥,而不是单个56位密钥。高级加密标准(AES)用于政府、安全团体和普通企业的机密通信。“Rivest-Shamir-Adleman”或RSA是另一种常见的加密系统。它经常被用来加密通过互联网传输的数据,并依赖于公钥。接收数据的人将获得自己的私钥来解码通信。
- 986 次浏览
【数据加密】什么是数据加密?
视频号
微信公众号
知识星球
数据加密是一种通过将数据转换为密文来保持数据机密性的方法,密文只能使用加密时或加密前产生的唯一解密密钥进行解码。
数据加密将数据转换为不同的形式(代码),只有拥有密钥(正式称为解密密钥)或密码的人才能访问。未加密的数据被称为明文,而已加密的数据则被称为密文。加密是当今企业界使用最广泛、最成功的数据保护技术之一。
加密是维护数据完整性的关键工具,其重要性怎么强调都不为过。互联网上几乎所有的东西都在某个时刻被加密了。
数据加密的重要性:
加密的重要性怎么强调都不为过。即使你的数据存储在标准的基础设施中,它仍然有可能被黑客入侵。数据总是有可能被泄露,但通过数据加密,您的信息将更加安全。
这样想一下。如果您的数据存储在一个安全的系统中,在发送之前对其进行加密将确保其安全。受制裁的系统不提供相同级别的保护。
那么,你认为这在现实生活中会如何发展?以公司数据的用户在工作时可以访问敏感信息为例。用户可以将信息放在便携式光盘上,并在没有任何加密的情况下将其移动到他们选择的任何地方。如果提前设置了加密,用户仍然可以复制信息,但当他们试图在其他地方查看时,数据将无法理解。这些都是数据加密的好处,证明了它的真正价值。
数据加密类型:
- 对称加密
- 不对称加密
加密通常以两种方式之一使用,即使用对称密钥或使用非对称密钥。
对称密钥加密:

对称加密
密码学算法中使用了一些策略。对于加密和解密过程,一些算法使用唯一密钥。在这种操作中,必须确保唯一密钥的安全,因为知道密钥的系统或人员具有完全的身份验证,可以对消息进行解码以进行读取。这种方法在网络加密领域被称为“对称加密”。
非对称密钥加密:

不对称加密
一些密码学方法使用一个密钥进行数据加密,另一个密钥用于数据解密。因此,任何有权访问此类公共通信的人都将无法解码或读取它。这种类型的密码学被称为“公钥”加密,用于大多数互联网安全协议。术语“非对称加密”用于描述这种类型的加密。
数据加密状态:
数据,无论是在用户之间传输还是存储在服务器上,都是有价值的,必须始终受到保护。
- 传输中的数据加密:从一个点到另一个点的信息,如通过互联网或专用网络,被称为传输中的信息。由于传输技术的弱点,数据在传输过程中被认为不太安全。端到端加密在整个传输过程中对数据进行加密,确保数据即使被拦截也保持私有。
- 静止数据的加密:静止数据是指没有从一个设备主动移动到另一个设备或从一个网络主动移动到其他网络的信息,例如存储在硬盘、笔记本电脑、闪存驱动器上的信息,或以其他方式存档/存储的信息。由于设备安全功能限制了访问,静止的数据通常不如传输中的数据易受攻击,但它仍然易受攻击。它还包含更多有价值的信息,使其成为犯罪分子更具吸引力的目标。
静止的数据加密通过增加访问信息所需的时间,并提供发现数据丢失、勒索软件攻击、远程擦除数据或更改凭据所需的所需时间,降低了设备丢失或被盗、无意中共享密码或意外授予许可所导致的数据被盗风险。
数据加密是如何进行的?
假设一个人拥有一个装有一些文件的盒子。这个人照看箱子并用锁把它锁好。几天后,个人将这箱文件发送给他或她的朋友。钥匙也由一个好友保管。这意味着发送方和接收方都有相同的密钥。好友现在被允许打开盒子并查看文档。加密方法与我们在示例中提到的相同。不过,加密是在数字通信上执行的。该技术程序旨在防止第三方破译信号的秘密内容。
消费者通过互联网进行商品交易。有数以百万计的网络服务可以帮助各种受过培训的员工履行职责。此外,为了利用这些需要个人信息的服务,大多数网站都需要大量的身份证明。被称为“加密”的最常见方法之一是保持此类信息的安全。

加密过程
网络的安全性与加密密切相关。加密对于隐藏正常人无法理解的数据、信息和事物非常有用。由于加密和解密都是密码学的有效方法,密码学是执行安全通信的科学程序,因此加密信息可以在解密过程后转换回其原始状态。数据加密和解密有多种算法。然而,“密钥”也可以用于获得高级数据安全性。
数据加密的用途:
- 使用数字签名,加密用于证明信息的完整性和真实性。数字版权管理和副本保护都需要加密。
- 加密可用于擦除数据。但是,由于数据恢复工具有时可以恢复已删除的数据,如果你先加密数据,然后扔掉密钥,那么任何人都只能恢复密文,而不是原始数据。
- 数据迁移是在网络上传输数据时使用的,以确保网络上没有其他人可以读取数据。
- VPN(虚拟专用网络)使用加密,您应该加密存储在云中的所有内容。这可以对整个硬盘驱动器以及语音通话进行加密。
鉴于数据安全的重要性,许多组织、政府和企业都要求对数据进行加密,以保护公司或用户数据。员工不会因此而对用户数据进行未经授权的访问。
数据加密的优点:
- 加密是一种低成本的解决方案。
- 数据加密使信息与存储信息的设备的安全性不同。加密通过允许管理员通过不安全的通道存储和发送数据来提供安全性。
- 加密可以避免监管罚款
- 远程工作者可以从加密中受益
- 如果密码或密钥丢失,用户将无法打开加密的文件。另一方面,在数据加密中使用更简单的密钥会使数据不安全,任何人都可以随时访问它。
- 加密提高了我们信息的安全性。
- 加密可以增强消费者信任
数据加密的缺点:
- 如果密码或密钥丢失,用户将无法打开加密的文件。另一方面,在数据加密中使用更简单的密钥会使数据不安全,任何人都可以随时访问它。
- 数据加密是一种有价值的数据安全方法,需要大量资源,如数据处理、时间消耗以及使用大量加密和解密算法。因此,这是一种成本较高的方法。
- 当用户为当代系统和应用程序分层时,数据保护解决方案可能很难使用。这可能会对设备的正常操作产生负面影响。
- 如果一家公司未能实现加密技术施加的任何限制,那么就有可能设置可能破坏数据加密保护的任意期望和要求。
数据加密算法示例:
根据使用情况,有多种数据加密算法可供选择,但以下是最常用的:
- DES(数据加密标准)是一种旧的对称加密算法,不再被认为适合现代应用。因此,DES已被其他加密算法所取代。
- 三重DES(3DES或TDES):通过运行DES算法三次来加密、解密和再次加密,以创建更长的密钥长度。它可以使用单个密钥、两个密钥或三个单独的密钥来运行,以提高安全性。3DES很容易受到诸如块冲突之类的攻击,因为它使用块密码。
- RSA是一种单向非对称加密算法,是最早的公钥算法之一。RSA由于其密钥长度长,在互联网上流行并广泛使用。它被浏览器用来在不安全的网络上创建安全连接,是许多安全协议的一部分,如SSH、OpenPGP、S/MIME和SSL/TLS。
- Twofish是速度最快的算法之一,其大小分别为128、196和256位,并且具有复杂的密钥结构以提高安全性。它是免费的,包含在一些最好的免费软件中,包括VeraCrypt、PeaZip和KeePass,以及OpenPGP标准。
- 椭圆曲线密码(ECC)是作为RSA的升级而创建的,它以显著缩短的密钥长度提供了更好的安全性。在SSL/TLS协议中,ECC是一种非对称方法。
- 高级加密标准(AES)是美国政府使用的加密标准。AES算法是一种采用分组密码方法的对称密钥算法。它有128、192和256位的大小,加密轮数随着大小的增加而增加。它被设计为在硬件和软件中都易于实现。
- 55 次浏览
【数据加密】使用托管身份和ODBC访问Power BI报表或Azure数据工厂中的Azure SQL始终加密数据
视频号
微信公众号
知识星球
始终加密是Azure SQL数据库中的一项功能,它允许加密客户端应用程序中的敏感数据,这样加密密钥就永远不会泄露给数据库。此功能的主要好处是,拥有数据的企业主可以保持对数据的完全控制,而不会将实际解密的数据透露给管理数据的团队,如云运营、DBA等。此功能非常有趣,尤其是对于受监管的行业。有关此功能的详细信息,请参阅Microsoft官方文档页 — https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/always-encrypted-database-engine?redirectedfrom=MSDN&view=sql-server-ver15
解决方案解决的主要用例
在报告场景中(使用Power BI等工具),有时需要对此类“始终加密”表进行解密以供业务使用,才能以纯文本形式查看数据,Power BI本机驱动程序此时(2020年3月)无法解密“始终加密的数据”,此处描述的解决方案满足了在Power BI中以纯文本方式查看“始终加密数据”的要求。
解决方案启用的其他相关用例
此处共享的解决方案不仅限于Power BI用例,还适用于许多不同的场景,如:
- Azure数据工厂本机驱动程序无法读取始终加密的数据,因此可能需要从Azure SQL数据库读取加密数据,并将其解密格式保存在数据湖敏感区域中。
- Tableau需要用于对始终加密的Azure SQL数据库进行报告。
- 需要通过ODBC使用Azure虚拟机的Azure Active Directory托管标识访问Azure SQL数据库--这是一个独特的客户用例,其中有用户在Azure中分配了VM,但他们不是Azure Active Directory的一部分,目标是不使用SQL身份验证(需要维护用户名/密码),但同时也有一些原因不将这些用户添加到Azure Active Directory,尽管数据库不是总是加密的(事实上,数据库是Azure Synapse,以前是Azure SQL数据仓库),但这种技术很有用。
解决方案架构
该解决方案需要使用ODBC来连接和解密来自Azure SQL数据库的数据,下图显示了该解决方案的总体架构。
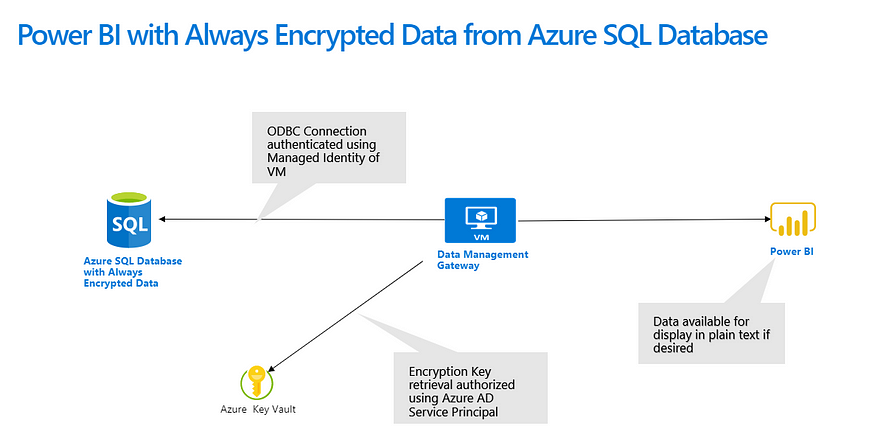
解决方案详细信息
假定具备Azure平台的基本知识和对Azure订阅的访问权限。另一个先决条件是Azure SQL数据库,它有一个表,其中至少有几列使用“始终加密”功能加密,加密密钥保存在Azure密钥库中。此处记录了使用密钥保管库设置此类Azure SQL数据库的详细说明
请注意,“始终加密”功能可以使用Azure密钥库或Windows证书存储中的密钥,但在这篇文章中,我将使用Azure密钥存储(它尚未经过验证,但预计类似的原则也适用于Windows证书存储)。
分步说明
- 创建Azure Windows虚拟机(任何Windows Server 2016或更高版本都应该工作)--此虚拟机用于Power BI内部部署数据网关,创建虚拟机的说明 https://docs.microsoft.com/en-us/azure/virtual-machines/windows/quick-create-portal
- 一旦虚拟机的创建完成,请在虚拟机上启用托管身份,如下面的屏幕截图所示。托管身份是一项非常有用的功能,可作为Azure平台的一部分使用,其中像Azure虚拟机这样的单个服务具有与其关联的Azure AD身份,并且在该虚拟机中运行的代码可以在没有任何密码的情况下使用该身份。您可以在此处阅读有关托管身份的更多信息 — https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
3. 授予Azure SQL数据库上托管标识的权限,因为将使用此标识检索数据库中的数据:
- 如果Azure虚拟机名称为MyDataGatewayVM,则在启用托管身份时会自动创建具有相同名称的Azure AD应用程序。
- 以下是在SQL数据库上授予托管标识权限的示例命令
CREATE USER <Azure_AD_principal_name> FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER Mary;//Command for Azure SQL Data Warehouse to add user to a role is slightly differentEXEC sp_addrolemember ‘db_owner’, ‘Mary’;
Please see the documentation for more detail around granting accessing to Azure SQL and Synapse — https://docs.microsoft.com/en-us/azure/sql-database/sql-database-manage-logins
4.创建Azure AD应用程序--ODBC驱动程序将使用此应用程序从Azure密钥库中检索解密密钥。使用以下链接上的说明创建另一个Azure AD应用程序和密钥,注意ClientID和密钥以备以后使用。
- Only execute the “Create an Azure Active Directory application” section — https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal#create-an-azure-active-directory-application
- Only execute “Create a new application secret” sub-section- https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal#certificates-and-secrets
5. Grant Azure AD application permissions to read keys on Azure Key Vault using the instructions documented here — https://docs.microsoft.com/en-us/azure/key-vault/managed-identity
Make sure to grant “Key Permissions” Get, List, Decrypt, Unwrap and Verify
6. Setup On-Premises Power BI Data Gateway VM in Azure, this is software that will need to be installed on Azure VM which serves as an intermediary between SQL Database and Power BI Service — https://docs.microsoft.com/en-us/power-bi/service-gateway-onprem
Usually this is used to access data from on-premises data stores but in this solution this is required for Azure SQL Database to perform decryption of the Always Encrypted Data
If your use case is for Azure Data Factory, the solution here is exactly the same except Self-Hosted Integration Runtime software needs to be used instead of On-Premises Data Gateway — https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime Self-Hosted Integration Runtime agent works in the same manner as On-Premises Power BI Data Gateway.
7. Download and Install ODBC Driver 17 or newer for SQL Server on the VM — https://www.microsoft.com/en-us/download/details.aspx?id=56567
8.设置ODBC系统DSN--安装ODBC驱动程序后,您需要设置ODBC系统的DSN,如下面的屏幕截图所示
- 通过在搜索栏中键入ODBC启动ODBC应用程序,选择ODBC数据源(64位)
- 选择“系统DSN”选项卡,单击“添加”,选择“ODBC Driver 17 for SQL Server”,然后单击“完成”
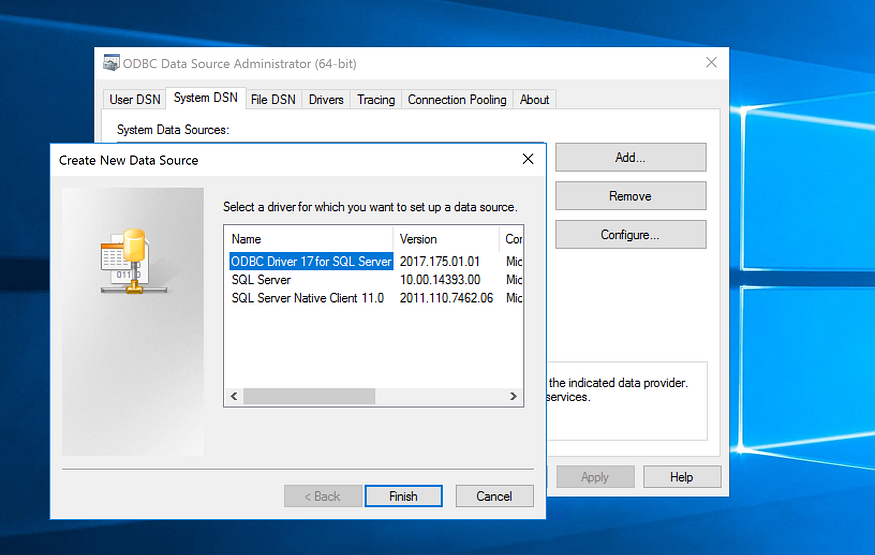
Go through the wizard with default options for most part except couple screens.
Make sure to put Azure SQL Server DNS Name for Server
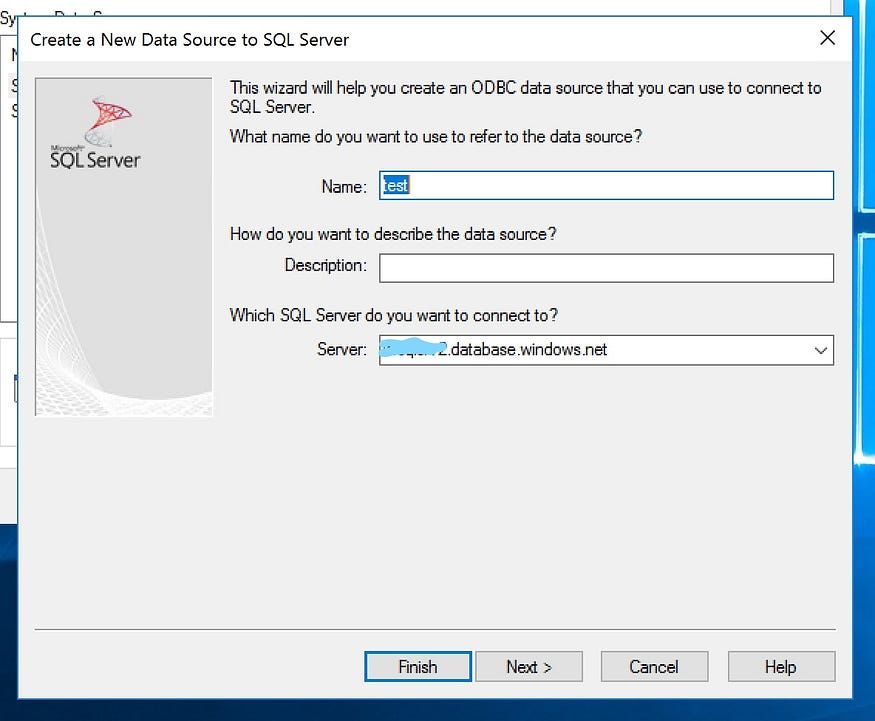
Make use to change the default database to the Azure SQL Database Name and also check Column Encryption Checkbox
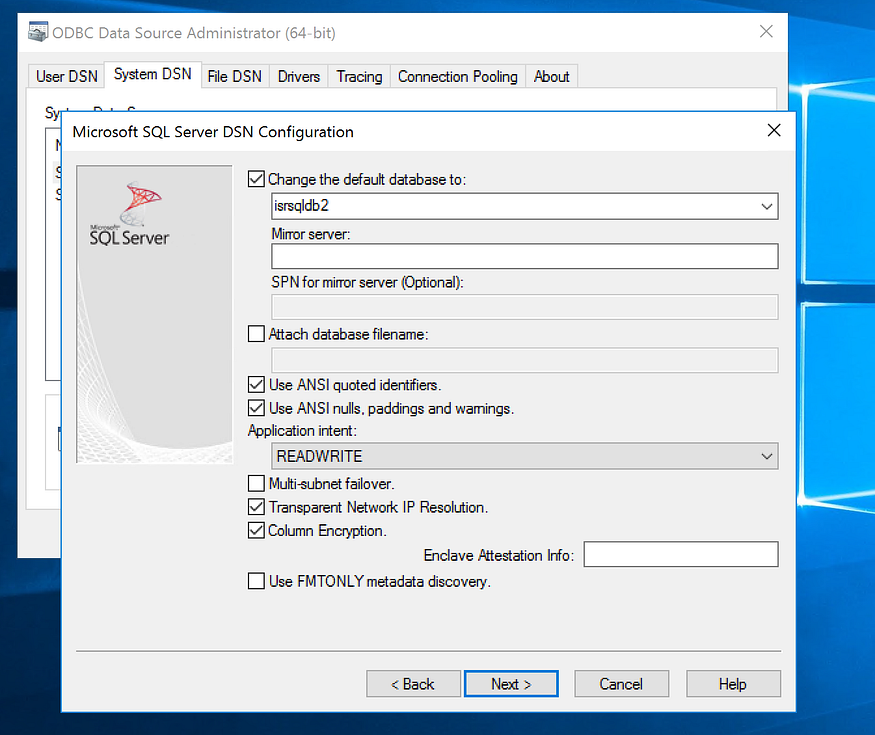
8.ODBC系统DSN的注册表设置更新--使此ODBC连接与Power BI一起工作的关键因素是该连接需要在非交互式模式下工作,为此,我们需要修改Power BI数据网关VM上ODBC连接的一些注册表项。使用RegEdit命令打开注册表编辑器并设置以下注册表项(也显示在下面的屏幕截图中)
- 身份验证--将值设置为ActiveDirectoryMsi
- KeystoreAuthentication--将值设置为KeyVaultClientSecret
- KeystorePrincipalID——这是在上面的步骤2中创建的Azure AD应用程序的ClientID,用于从密钥库中检索解密密钥
- KeystoreSecret--这是在上面的步骤2中创建的Azure AD应用程序的密钥,它与KeyStorePrincipalID一起用于从KeyVault检索解密密钥
注意:出于保密原因,屏幕截图中划掉了KeystorePrincipalID、KeyStoreSecret和Server的值
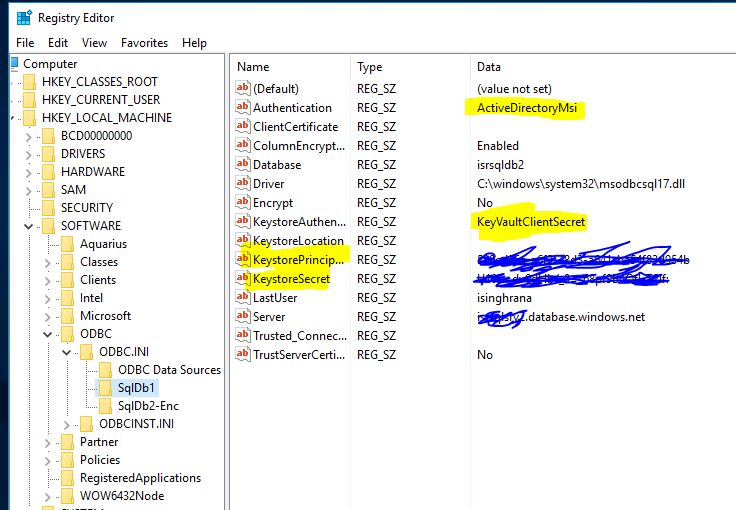
在要求仅使用具有托管身份KeyStoreAuthentication的ODBC访问Azure SQL数据库的用例中,KeyStorePrincipalID和KeystoreSecret值可以保留为空。
9.[可选]使用Powershell测试ODBC连接--现在,您可以在Powershell提示符下使用以下Powershell片段来验证ODBC连接是否正常工作(请不要忘记替换最后一行中的表名和DSN名)。如果一切都设置正确,您应该看到数据库表中的数据以纯文本显示。
function Get-ODBC-Data{
param([string]$query=$(throw 'query is required.'),[string]$dsn)write-output("Dsn: " + $dsn)
$conn = New-Object System.Data.Odbc.OdbcConnection
$conn.ConnectionString = "DSN=$dsn;"
$conn.open()$cmd = New-object System.Data.Odbc.OdbcCommand($query,$conn)$ds = New-Object system.Data.DataSet
(New-Object system.Data.odbc.odbcDataAdapter($cmd)).fill($ds) | out-null
$conn.close()$ds.Tables[0]
}#replace the System DSN Name and the Table Name
Get-ODBC-Data -query "select * from XXXX" -dsn "XXXX"10.实现报告并将其发布到Power BI服务--此时,您可以在VM上使用Power BI Desktop,并使用ODBC连接到Azure SQL数据库,在“数据加载预览”窗口中,您将看到未加密的数据。将Power BI服务配置为使用数据管理网关后,您可以将报告发布到Power BI服务,报告用户将能够看到满足其业务需求的所需数据。访问控制可在Power BI服务中保留。
注意:这里需要注意的一点是,Power BI Reports只支持导入模式,而不能使用直接查询模式。
- 44 次浏览
【数据加密】保护亚马逊API应用程序:数据加密
视频号
微信公众号
知识星球
保护亚马逊API应用程序中的敏感数据
摘要
客户相信他们的数据是安全的,加密是保持这种机密性的机制。这些数据的示例包括但不限于个人身份信息(PII)、密码和专有信息。通过使用密钥,数据从可读的“明文”格式转换为不可读的密文形式。另一种方法是使用密钥加密/锁定数据,只有持有相应密钥的另一方(可能是设备或个人)才能解密/解锁数据。本白皮书中的其他指导将帮助您保护客户共享和委托给您的敏感数据。
数据保护策略(DPP)要求(Data Protection Policy )
- 传输中的加密:开发人员必须对传输中的所有亚马逊信息进行加密(例如,当数据通过网络或在主机之间发送时)。这可以使用HTTP over TLS 1.2(HTTPS)来实现。开发人员必须对客户使用的所有适用的外部端点以及内部通信通道(例如,存储层节点之间的数据传播通道、与外部依赖项的连接)和操作工具实施此安全控制。开发人员必须禁用在传输过程中不提供加密的通信通道,即使这些通道未使用(例如,删除相关的死代码,仅使用加密通道配置依赖关系,以及将访问凭据限制为使用加密通道)。
开发人员必须使用数据消息级加密(例如,使用AWS加密SDK),其中通道加密(例如使用TLS)终止于不可信的多租户硬件(例如,不可信的代理)。
- 静态加密:开发人员必须使用行业最佳实践标准(例如,使用AES-128位或更大的密钥,首选AES-256位,或2048位(或更高)密钥大小的RSA)对所有静态PII进行加密(例如,当数据持久化时)。用于静态PII加密的加密材料(如加密/解密密钥)和加密功能(如实现虚拟可信平台模块和提供加密/解密API的守护进程)必须只能由开发人员的流程和服务访问。开发者不得将PII存储在可移动媒体(如USB)或不安全的公共云应用程序(如通过Google Drive提供的公共链接)中。
开发人员必须安全地处理任何包含PII的打印文档。
数据加密的基础
随着组织寻求更快、更大规模的运营,保护关键信息变得更加重要。通过加密来保护数据的安全会以一种使内容无法读取的方式转换内容,而无需将内容解密回可读格式。加密是将明文编码为另一种称为密文的格式。要加密消息(数据),需要一个密钥。对于数据加密,我们使用密钥(也称为秘密)来加密(锁定)和解密(解锁)消息。只有拥有正确密钥的个人/设备才能解密消息并读取其内容。加密有助于保护亚马逊信息的安全。即使恶意用户获得了密文,如果没有解密密钥,他们也无法读取消息的内容。此外,这些加密密钥在其整个生命周期中都必须受到保护,以防止未经授权的使用、访问、披露和修改。请记住,散列函数和加密是有区别的。散列函数是一种用于将大的随机大小数据转换为小的固定大小数据的加密算法。哈希允许对数据进行验证。另一方面,加密是对消息进行加密和解密的两步过程。加密通过使未经授权的访问无法理解数据来保护数据。数据可以在静止或传输过程中进行加密。使用NIST 800-53作为其框架的开发人员可以参考系统和通信保护(SC),以获得有关保护其环境的具体指导。NIST的主要控制之一是SC-13密码保护。SC-13确定了具体的控制,提供了额外的细节,以帮助开发人员了解亚马逊MWS和SP-API加密要求。
开发人员必须使用加密来保护亚马逊信息和客户PII。在下一节中,我们介绍了数据加密的关键组件,并提供了建议,以帮助开发人员遵守亚马逊MWS和SP-API数据保护政策(DPP)加密要求。
数据分类
数据分类提供了一种根据敏感度级别对组织数据进行分类的方法。它包括了解可用的数据类型、数据存储位置、访问级别和数据的安全性。亚马逊信息可以分为两类数据:PII和非PII。PII数据是可用于识别亚马逊客户的任何数据。非PII数据是任何其他亚马逊数据,例如产品列表信息。开发人员可以通过仔细管理符合DPP要求的适当数据分类系统、访问级别和数据加密来保护亚马逊信息。可用于识别亚马逊客户的亚马逊信息必须加密,必须以受保护的方式存储,并且必须需要授权访问。亚马逊建议采用深度防御的方法,减少人工访问亚马逊客户PII的次数。开发人员在其应用程序中必须具有强大的身份验证机制。此外,开发人员必须确保到其应用程序的所有连接都源自受信任的网络,并具有所需的访问权限。
数据完整性
开发人员必须确保其系统中的亚马逊信息在其系统中移动时保持其完整性。加密散列函数是建立数据完整性的可靠方法。哈希函数是一种不可逆函数,其中任意大小的原始数据被映射到固定大小的哈希值。如果开发人员通过下载提供亚马逊信息,其完整性面临两个主要威胁:网络/存储问题导致的意外数据更改和攻击者的篡改。开发人员可以通过使用哈希函数来验证文件的完整性来减轻这些威胁。例如,开发人员可以在文件可供下载之前对其内容进行散列。当文件被上传回应用程序时,开发人员可以对上传的文件运行哈希函数,并将哈希输出与原始文件的输出进行比较,以验证文件的完整性。无论数据更改是由网络或存储问题意外引起的,还是由攻击者故意引起的,这都能提供最佳的保护,防止数据更改。开发人员可以通过使用多个哈希函数验证哈希来增强他们对数据完整性的信心。
传输中的加密
当数据从一个系统传输到另一个系统时,它很容易受到未经授权的用户或第三方的干扰。数据传输可能仅限于开发人员的专用或公共网络,并且仍然容易受到恶意攻击。
开发人员必须通过在传输中实施加密来保护传输中的亚马逊信息,包括其他服务和最终用户之间的通信。这有助于保护数据的机密性和完整性。
传输中的加密通过使用支持的加密协议(如TLS 1.2或HTTPS(HTTP over TLS))来保护信息。必须在所有外部和内部端点上强制执行此级别的加密。通过通道传播的数据、与外部依赖项的连接和操作工具必须在传输过程中使用加密进行保护。在传输亚马逊信息时,必须对所使用的通信信道进行加密,以免出现未经授权的干扰。最佳做法是加密和验证所有流量。在NIST 800-53中,传输中的加密在控制SC-8传输机密性和完整性中进行了概述。利用这种控制的开发人员应该考虑采用SC-8控制增强,因为每种增强都可以为传输中的数据提供额外的保护。
开发人员在加密传输中的数据时应考虑以下几点:
- 禁用传输中无法支持加密的通信信道。
- 避免通过多租户基础设施节点路由流量。
- 如果不允许端到端TLS,请使用数据消息级别加密。

Figure 1: HTTPS protocol in use
Table 1 lists some Amazon-compliant security protocols for encrypting data in transit.
| Transfer Type | Insecure Protocols (Non-Compliant) | Secure Protocols (Compliant) |
|---|---|---|
| Web Access | HTTP | HTTPS with TLS 1.2+ |
| E-Mail Servers | POP3, SMTP, IMAP | POP3S, IMAPS, SMTPS |
| File Transfer | FTP, RCP | FTPS, SFTP, SCP, WebDAV over HTTPS |
| Remote Shell | Telnet | SSH-2 |
| Remote Desktop | VNC | r-admin, RDP |
Table 1: Secure vs Insecure protocols to encrypt data in transit
静止时的加密
每当开发人员将亚马逊信息保存在数据存储中时,都必须对其进行保护。数据存储是指可以在指定时间段内保存和保留数据的任何存储介质。数据库解决方案、块存储、对象存储和归档数据块都是必须保护的数据存储示例。开发人员可以使用加密来保护数据存储中的数据——这被称为静态加密。实施加密和适当的访问控制可以降低未经授权访问的风险。在NIST中,静态加密在SC-28静态信息保护中进行了解释。SC-28(1)旨在通过密码学保护静态信息,SC-28(2)旨在通过离线存储保护信息。正如亚马逊MWS和SP-API DPP中所解释的,这两种控制都是处理亚马逊客户PII的开发人员所必需的。最佳做法是在将亚马逊信息上传到存储目的地之前对其进行加密,并使用经批准的加密算法保护存储本身。这在两个级别上保护数据:在从源到存储目标的传输过程中,以及在数据在存储目标中的整个使用寿命中。
使用AmazonS3进行存储的开发人员可以使用S3的本地加密功能来保护静止的数据。您不“加密S3”或“加密S3存储桶”,而是S3会在对象级别加密您的数据,因为它会写入AWS数据中心的磁盘。开发人员可以选择通过两种方式进行加密,一种是刚才描述的服务器端加密(SSE)示例,另一种是客户端加密(CSE)。
当开发者想要更多的控制权时,他们可以选择CSE,并负责编写如何加密和解密数据的代码,决定加密算法,从哪里获得密钥,以及发送加密数据。当对象在上传到S3之前被加密时,就会发生CSE(因此密钥不由AWS管理)。开发人员可以实现AmazonS3存储桶策略,防止上传未加密的对象。如果开发人员不需要管理主密钥,那么他们可以使用S3管理的加密密钥(SSE-S3)进行服务器端加密,或者使用AWS KMS管理的密钥(SSE-KMS)进行服务器侧加密。AmazonS3使用信封加密保护静止的数据。每个对象都使用一个唯一的密钥进行加密,该密钥采用强多因子加密。作为额外的保护措施,AWS使用AWS KMS密钥对密钥进行加密。AmazonS3服务器端加密使用AES-256对数据进行加密。在图2中,加密解决方案保护加密密钥和数据。在其他渠道或云提供商中存储数据的开发人员将能够使用他们本机的类似工具(例如Azure密钥库和GCP默认加密)。
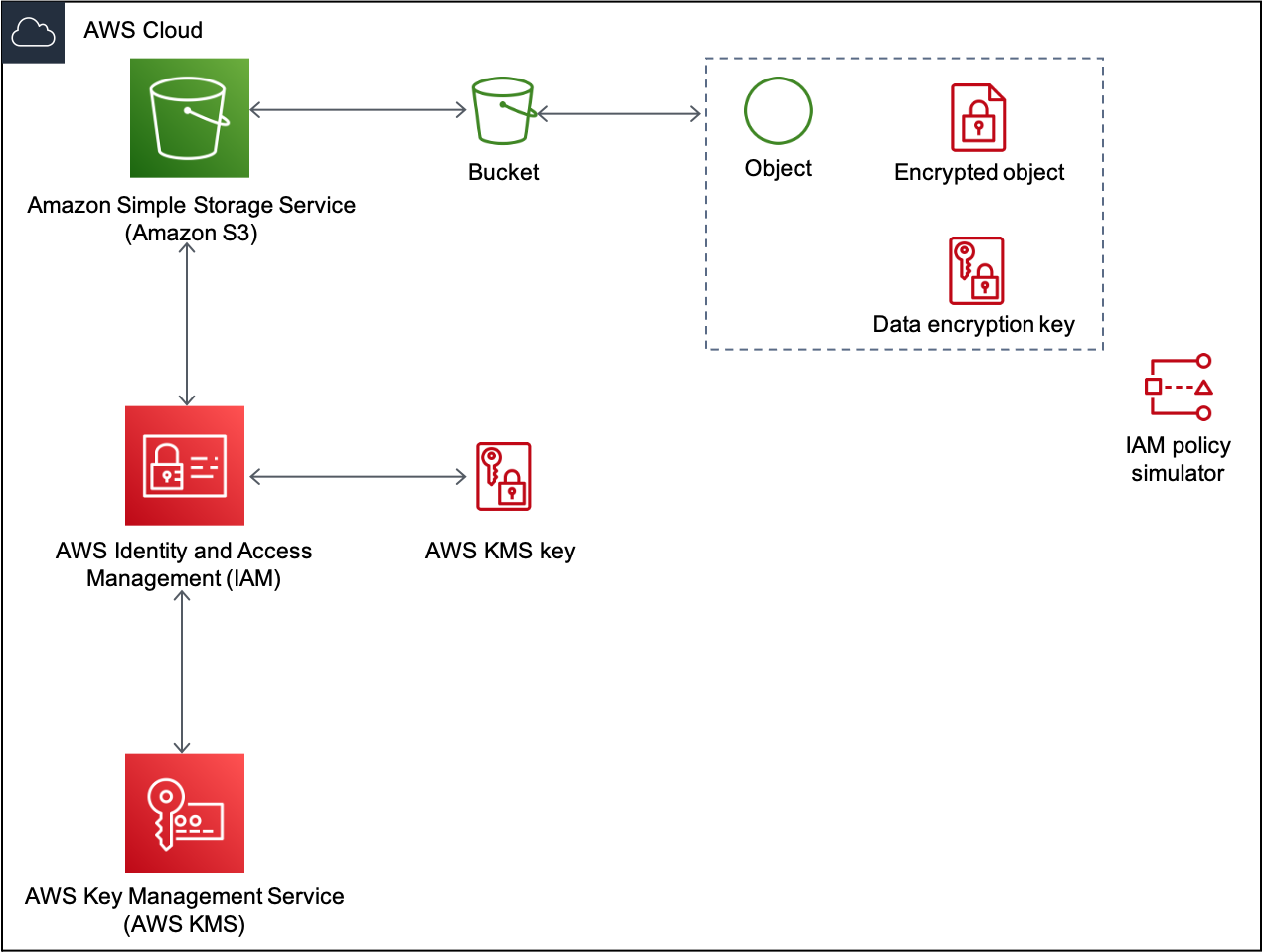
图2:AmazonS3中静止的加密
有关更多信息,请参阅:如何防止未加密对象上传到AmazonS3。
加密类型
以下是常见的加密类型:
- 对称加密。这使用相同的密钥进行加密和解密。因此,发送方和接收方必须具有相同的密钥。
- 不对称加密。这要求发送方和接收方使用不同的密钥——公钥和私钥。公钥被广泛共享,但私钥只由其所有者保护和使用。私钥用于加密数据,公钥用于解密数据。
- 信封加密。这是用加密密钥加密数据,然后用另一个密钥加密加密密钥的做法。
一般来说,对称密钥算法比非对称算法更快,产生的密文更小。但非对称算法提供了固有的角色分离和更容易的密钥管理。信封加密使开发人员能够结合对称和非对称算法的优势。当开发者加密亚马逊信息时,加密密钥也必须受到保护。信封加密有助于开发人员保护加密密钥本身。
使用SSE-KMS的开发人员可以使用一个加密密钥对数据进行加密,并使用另一个密钥对加密密钥进行加密。一个密钥保持为纯文本,因此客户端能够解密加密密钥并使用解密的加密密钥来解密数据。
顶级明文密钥被称为AWS KMS密钥。

图3:AWS KMS存储和管理AWS KMS密钥
有关更多信息,请参阅AWS密钥管理服务。
密钥大小在定义加密密钥的强度时很重要。根据Amazon DPP的要求,密钥的长度必须至少为128位。亚马逊建议开发人员为亚马逊客户PII使用大于128位的密钥(首选256位)。额外的比特成倍地增加了针对加密密钥的暴力攻击的复杂性。对称256位密钥所需的计算能力是128位密钥的2128倍。开发人员应该轮换他们的加密密钥以进一步保护他们的系统。尽管较大的密钥大小更难破解,但暴露的密钥可能会使密钥大小变得无关紧要,因为未经授权的实体可以使用暴露的密钥访问亚马逊信息。关于密钥轮换的具体指导可以在NIST 800-53控制SC-12加密密钥建立和管理中找到。SC-12控件及其增强功能可以帮助开发人员以其组织可以接受的方式建立、保护和轮换密钥,同时确保密钥在需要时仍然可用。
亚马逊API应用程序可接受的加密标准
以下是开发人员应使用的常用和推荐的加密标准的概述:
高级加密标准(AES)
高级加密标准(AES)是一种使用分组密码的对称加密算法。分组密码将固定文本块加密为等长密码文本块。AES对长度为128位的固定长度块进行操作,可配置的对称密钥长度为128、192或256位。即使使用128位密钥,通过检查2128个可能的密钥值中的每一个来破解AES的任务(蛮力攻击)也是计算密集型的,因此最快的超级计算机平均需要超过100万亿年才能完成。如果开发者选择使用AES密钥,密钥大小必须是AES 128位或更大(根据亚马逊DPP的要求)。亚马逊建议使用AES-256。亚马逊还批准使用AES-GCM/CBC/XTS。
Rivest-Shamir-Adlemen加密标准(RSA)
Rivest-Shamir-Adlemen加密标准(RSA)是一种非对称算法,使用公钥加密在不安全的网络上共享数据。RSA对两个大素数的乘积即大整数进行因子运算,以确定密钥大小。它通常使用1024位或2048位密钥。较大的密钥大小提供了更大的安全性,但使用更多的计算能力来加密和解密信息。如果开发人员选择RSA作为他们的加密标准,他们必须确保他们的密钥至少是2048位,这是亚马逊DPP的要求。
其他加密算法
虽然开发人员可以使用其他加密标准,但Amazon DPP要求开发人员使用AES或RSA。表2列出了亚马逊批准的加密算法。
| Encryption algorithm | Amazon-approved type |
|---|---|
| AES | 256-bit (preferred) 128-bit or larger keys |
| AES with GCM mode | 96-bit cryptographically random initialization vector 128-bit tag length |
| AES with CBC mode | 128-bit cryptographically random initialization vector PKCS7 padding |
| AES with XTS mode | Linux: dm-crypt, LUKS Amazon EBS encryption |
| RSA | 2048-bit or larger keys RSA with OAEP |
Table 2: Amazon API Applications approved encryption algorithms
AWS软件开发工具包(SDK)提供了一个客户端加密库,简化了加密的实现。默认情况下,它实现了一个框架,通过如何使用唯一加密密钥和保护这些密钥的行业密码学最佳实践来确保数据的安全。SDK是在GitHub开源库上开发的,因此您可以分析代码、提交问题并查找特定于您的实现的信息。
不使用的标准
这些标准已被业界研究并证明是不安全的:
- DES
- RC4
- RSA-PKCSv1.5 with 1024-bit keys
- RSA-OAEP with 1024-bit keys
- Blowfish
- Twofish
加密的最佳做法
以下是加密亚马逊信息的一些最佳实践:
- 不受保护的数据,无论是在传输中还是在休息时,都会使企业容易受到攻击。开发人员应确保所有数据都通过加密进行保护。开发人员应遵循以下最佳实践,对传输中和静止数据进行强有力的保护:
- 实施强大的网络安全控制,以帮助保护传输中的数据。例如,开发人员可以使用防火墙和网络访问控制列表来保护他们的网络免受恶意软件攻击或入侵。
- 实施主动的安全措施,识别有风险的数据,并对传输和休息中的数据实施有效的数据保护。不要等到发生安全事件才实施安全措施。
- 选择具有启用用户提示和阻止的策略,或自动加密传输中的PII数据的策略的解决方案。例如,当带有PII数据的文件附加到电子邮件、大型或敏感数据文件集传输到外部文件共享网站时,应用程序必须显示警告或阻止该操作\
- 创建对所有亚马逊信息进行系统分类的策略。
- 无论数据存储在何处,都应确保在数据处于静止状态时采取适当的数据保护措施。
- 当未经授权的各方访问、使用或传输任何数据时生成触发器。
- 根据用于存储亚马逊信息的公共、私有或混合云提供商提供的数据安全措施,仔细评估这些提供商。
传输中的数据和静止中的数据的风险状况略有不同,但固有的风险主要取决于亚马逊信息的敏感性和价值。不良行为者会试图在传输或休息时访问有价值的数据。重要的是对数据和安全协议进行分类和分类,以在每个阶段有效保护亚马逊信息。您可以遵循的步骤:
- 将亚马逊信息分类为敏感级别,并对关键数据进行加密。亚马逊客户PII必须始终使用亚马逊批准的加密机制进行加密。
- 建立自动化策略,提示或自动加密传输中的关键数据。
- 使用公开可用的同行评审算法(如AES和密钥)进行加密和解密。
- 使用云基础设施的开发人员必须根据云供应商提供的安全措施和他们持有的安全合规证书来评估他们。
结论
所有数据,尤其是PII,在静止和传输过程中都应该使用加密进行保护。通过对客户委托我们的数据进行加密,我们可以确保没有未经授权的第三方可以出于恶意目的访问和滥用数据。您可以通过这里共享的加密标准、应用策略、访问控制和其他记录在案的最佳实践等机制来实现这一点,以供进一步阅读。
进一步阅读
有关更多信息,请参阅:
- 83 次浏览
【数据加密】公钥基础设施
视频号
微信公众号
知识星球
公钥基础设施(PKI)是颁发数字证书的管理机构。它有助于保护机密数据,并为用户和系统提供唯一身份。因此,它确保了通信的安全。
公钥基础设施使用一对密钥:公钥和私钥来实现安全性。公钥容易受到攻击,因此需要一个完整的基础设施来维护它们。
加密系统中的密钥管理:
密码系统的安全性取决于它的密钥。因此,我们必须有一个坚实的密钥管理系统。关键管理的3个主要领域如下:
- 加密密钥是一段必须由安全管理进行管理的数据。
- 它涉及管理关键生命周期,如下所示:
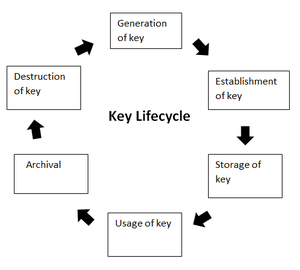
公钥管理进一步要求:
- 保密私钥:只有私钥的所有者才有权使用私钥。因此,任何其他人都不应接触到它。
- 确保公钥:公钥在开放域中,可以公开访问。当公共访问达到这种程度时,很难知道密钥是否正确,以及它将用于什么目的。公钥的用途必须明确定义。
PKI或公钥基础设施旨在实现公钥的保证。
公钥基础设施:
公钥基础设施确认公钥的使用。PKI识别公钥及其用途。它通常由以下组件组成:
- 数字证书也称为公钥证书
- 私钥令牌
- 登记机关
- 认证机构
- CMS或认证管理系统
使用PKI:
让我们分步骤了解PKI的工作原理。
- PKI和加密:PKI的根源在于密码学和加密技术的使用。对称加密和非对称加密都使用公钥。这里的挑战是——“你如何知道公钥属于合适的人或你认为它属于的人?”。MITM(中间人)总是有风险的。此问题通过使用数字证书的PKI解决。它为密钥提供身份,以使所有者的验证变得简单准确。
- 公钥证书或数字证书:数字证书颁发给人们和电子系统,以在数字世界中唯一识别他们。以下是关于数字证书的一些值得注意的事情。数字证书也称为X.509证书。这是因为它们基于ITU标准X.509。
- 证书颁发机构(CA)将用户的公钥以及有关客户端的其他信息存储在数字证书中。对信息进行签名,证书中还包括数字签名。
- 因此,通过使用证书颁发机构的公钥验证签名,可以检索对公钥的肯定。
- 证书颁发机构:CA颁发并验证证书。该授权机构确保证书中的信息是真实和正确的,并对证书进行数字签名。CA或认证机构履行以下基本职责:
- 生成密钥对–CA生成的密钥对可以是独立的,也可以与客户端协作。
- 颁发数字证书–当客户端成功提供有关其身份的正确详细信息时,CA会向客户端颁发证书。然后CA进一步对此证书进行数字签名,这样就不会对信息进行任何更改。
- 发布证书–CA发布证书,以便用户可以找到它们。他们可以将它们发布在电子电话簿中,也可以将它们发送给其他人。
- 证书验证–CA提供一个公钥,有助于验证访问尝试是否被授权。
- 撤销–如果客户有可疑行为或对其失去信任,CA有权撤销数字证书。
数字证书的类别:
数字证书可以分为四大类。这些是:
- 第1类:只需提供电子邮件地址即可获得。
- 第二类:这些需要更多的个人信息。
- 第3类:首先检查提出请求的人的身份。
- 第4类:它们被组织和政府使用。
证书创建过程:
证书的创建过程如下:
- 创建私钥和公钥。
- CA请求识别私钥所有者的属性。
- 公钥和属性被编码到CSR或证书签名请求中。
- 密钥所有者签署CSR以证明拥有私钥。
- CA在验证后签署证书。
在CA层次结构之间创建信任层:
每个CA都有自己的证书。因此,信任是分层建立的,其中一个CA向其他CA颁发证书。此外,还有一个自签名的根证书。对于根CA,颁发者和主体不是两个独立的当事人,而是一个单独的当事人。
根CA的安全性:
正如您在上面看到的,最终的权威是根CA。因此,根CA的安全性非常重要。如果根CA的私钥没有得到处理,那么它可能会变成一场灾难。这是因为任何伪装成根CA的人都可以颁发证书。为了达到安全标准,根CA应该有99.9%的时间处于脱机状态。然而,它确实需要联机才能创建公钥和私钥并颁发新证书。理想情况下,这些活动应该每年进行2-4次。
PKI在当今数字时代的应用:
如今,有大量的应用程序需要身份验证。数以百万计的地方都需要认证。这离不开公钥基础设施。PKI的重要性随着时间的推移而变化,这取决于用例和需求。这是那条赛道的一部分。
- 在1995年至2002年期间,公钥基础设施的使用首次仅限于最重要和价值最高的证书。这包括电子商务网站的证书,使它们能够在搜索栏中显示锁定图标。目标是让消费者对各种网站的安全性和真实性充满信心。
- PKI的第二个阶段出现在2003年至2010年左右,当时企业出现了。正是在这个时候,员工们收到了笔记本电脑,手机的使用量也在增加。因此,即使在办公室之外,员工也需要访问组织的资产。那时,PKI的使用看起来是进行身份验证的最佳方式。
- 第三阶段始于2011年,目前仍在继续。随着物联网(IoT)等新技术的出现,以及对PKI规模的需求,PKI的使用和使用面临的挑战都急剧增加。如今,数以百万计的证书被颁发来认证移动劳动力。然而,管理如此庞大的证书数量是相当具有挑战性的。
- S/MIME、文档签名、代码或应用程序签名也使用PKI。
PKI解决的挑战:
PKI的普及得益于它所解决的各种问题。PKI的一些用例包括:
- 通过SSL/TLS认证保护web浏览器和通信网络。
- 维护对内联网和VPN的访问权限。
- 数据加密
- 数字签名软件
- 无密码Wi-fi接入
除此之外,PKI最重要的用例之一是基于物联网。以下是两个将PKI用于物联网设备的行业:
- 汽车制造商:如今的汽车具有GPS、呼叫服务、助手等功能。这些功能需要大量数据传输的通信路径。确保这些连接的安全对于避免恶意方侵入汽车非常重要。这就是PKI的用武之地。
- 医疗设备制造商:像手术机器人这样的设备需要高度的安全性。此外,美国食品药品监督管理局规定,任何下一代医疗设备都必须是可更新的,这样才能消除漏洞并解决安全问题。PKI用于向此类设备颁发证书。
PKI的缺点:
- 速度:由于PKI使用超级复杂的算法来创建安全的密钥对。因此,它最终减缓了进程和数据传输。
- 私钥泄露:尽管PKI不容易被黑客入侵,但私钥可以被专业黑客入侵,因为PKI使用公钥和私钥来加密和解密数据,所以有了用户的私钥和容易获得的公钥,信息就可以很容易地解密。
- 55 次浏览
【数据加密】加密白皮书
视频号
微信公众号
知识星球
为什么公司要转向云计算?这通常是因为云环境具有可扩展性、可靠性和高可用性。然而,这些并不是唯一的考虑因素——安全性可以胜过云的其他优势。这就是为什么云提供商需要有一个全面的安全策略。Zoho的安全策略涵盖多个方面,加密是其中至关重要的一部分。本页面将告诉您关于Zoho加密策略的所有信息,以及我们如何使用它来确保您的数据安全。
概述
以下是我们将在本白皮书中讨论的内容
- 什么是加密?
- 传输中的加密
- 静止时的加密
- 应用程序级加密
- 密钥管理
- 我们在服务中加密哪些数据?
- 全磁盘加密
什么是加密?
加密主要用于保护邮件的内容,以便只有预期收件人才能阅读。这是通过将内容替换为不可识别的数据来实现的,而这些数据只能由预期收件人理解。这就是加密如何成为一种保护数据免受那些可能想窃取数据的人攻击的方法。
加密是指通过特殊的编码过程更改数据,使数据变得不可识别(加密)。然后你可以应用一个特殊的解码过程,你会得到原始数据(解密)。通过对密钥保密,其他人无法从加密数据中恢复原始数据。
编码过程遵循诸如AES 256的加密算法,该算法是公开的。然而,该过程本身取决于密钥,该密钥用于加密数据和解密数据。
这把钥匙是保密的。如果没有密钥,任何可能成功访问数据的人都只能看到一个“密码文本”,这将没有真正的意义。因此,数据受到保护。
为什么我们加密您的数据
最后一层保护-尽管全面的安全策略有助于公司保护数据免受黑客攻击,但加密是防止窃取数据的最后手段。它完成了数据保护,确保您的数据在不幸的安全漏洞事件中既不会损坏也不会被盗。
隐私-加密是对互联网隐私问题的保证。加密有助于保护隐私,确保除了预期的各方之外,没有人能够理解正在进行的通信。当您与我们互动并将数据存储在我们的服务器中时,加密有助于我们确保您的隐私。
我们所说的“数据”是什么意思
我们处理两种类型的数据-
- 客户数据-您通过Zoho服务与我们一起存储的数据。通常,这些数据由Zoho服务通过客户的帐户处理,该帐户可以在我们的IAM(身份和访问管理)数据库中识别。敏感数据是指暴露后可能对相关个人或组织造成伤害的数据。根据数据的敏感性和用户在各自Zoho服务中的要求,有些客户数据是加密的,而有些则不是。
- 派生数据-不是您直接提供的数据,而是从您的数据派生的数据。例如,身份验证令牌、唯一ID、URL和报告等都与我们一起存储。根据数据的敏感性,一些派生数据是加密的,而另一些则不是。
在后面的章节中,“数据”指的是经过加密的数据。
传输中的加密
当您使用Zoho服务时,您的数据会通过互联网从浏览器传输到我们的数据中心或其他第三方(使用第三方集成时)。加密传输中的数据可以保护您的数据免受中间人攻击。
对传输中的数据进行加密时有两种情况:
- 当数据从您的浏览器传输到我们的服务器时。
- 当数据从我们的服务器传输到非Zoho服务器(第三方)时
在你和Zoho之间
Zoho制定了严格的策略,以使传输层安全性(TLS)适应其所有连接。TLS允许连接双方进行身份验证,并对要传输的数据进行加密,从而确保您和Zoho服务器之间的安全连接。TLS协议确保没有第三方可以窃听或篡改您和Zoho之间的通信。。
我们遵循最新的TLS协议版本1.2/1.3,并使用使用SHA 256和密码生成的证书(AES_CBC/AES_GCM 256位/128位密钥用于加密,SHA2用于消息验证,ECDHE_RSA作为密钥交换机制)。我们还实现了完美的前向保密,并在所有网站上实施HTTPS严格传输安全(HSTS)。
Zoho与第三方之间
我们在与第三方通信时遵循https协议。对于涉及敏感数据和用例的交易,我们使用非对称加密,它利用公钥和私钥系统来加密和解密数据。
对于这种方法,我们在KMS(密钥管理服务)中生成一对公钥和私钥,该服务在所有服务中创建、存储和管理密钥。我们使用主密钥对这些对进行加密,并且加密的密钥对存储在KMS本身中。主密钥存储在一个单独的服务器中。
当我们将私钥存储在KMS中时,我们通过证书将公钥提供给第三方,经过身份验证后,加密的数据在KMS中将被解密。
静止时的加密
有两个主要的加密级别-
- 应用层加密
- 基于硬件的全磁盘加密
在应用程序级别加密数据的策略取决于数据存储的位置和方式-
- 数据库(DB)-存储为表
- 分布式文件系统(DFS)-存储为文件
- URL加密
- 备份
- 日志
- 缓存
下图描绘了我们加密策略的全貌:
应用程序级加密
您使用的任何Zoho服务(或应用程序)都涉及数据:您提供的数据和我们代表您存储的数据,作为服务的一部分。数据可以作为文件或作为数据字段来接收。这些类别中的每一个在加密方式方面都有不同的处理方式。
本节讨论应用程序级别的静态加密。
字段级加密
输入到应用程序中的敏感数据或敏感服务数据存储在各自的Zoho服务数据库中。其中的数据根据AES256标准使用AES/CCB/PKCS5Padding模式进行加密。静止时加密的数据因您选择的服务而异。了解有关我们在服务中加密的数据的更多信息。
加密发生在应用程序层,只有授权的应用程序用户才能查看数据。由于静态数据加密是在应用层完成的,任何正常的数据库或支持用户都无法在没有KMS加密密钥访问的情况下查看数据。在SQL等普通数据库工具中直接查看时,只有加密数据才可见。
加密类型因数据字段的敏感性以及用户的选择和要求而异。
有两种类型的字段级加密-
- 取决于数据的敏感性
- 取决于搜索功能
注:从此以后,我们将使用Zoho服务并拥有有限数量用户的客户或组织称为“组织”。
取决于数据的敏感性
- 类型1-这是我们对所有组织的数据进行的默认加密类型。在这种类型中,我们的KMS为每个组织分配一个密钥。与该组织对应的数据将使用该密钥加密。使用主密钥对密钥进行加密,并且加密的密钥存储在单独的服务器中。
- 类型2-我们对敏感和个人身份信息(PII)进行这种类型的加密。此类别包括银行账号、身份号码和生物特征数据等字段。
- 在这种类型中,KMS为表中的每一列生成一个唯一的键。特定列中的所有数据都将使用为该列生成的密钥进行加密。这些密钥再次使用主密钥进行加密,并存储在单独的服务器中。
取决于搜索功能
加密数据的搜索功能取决于加密期间使用的初始化矢量(IV)。IV是启动加密过程的随机值。该随机值确保每个数据块/单元以不同方式加密。这也意味着对同一数据加密两次会产生不同的密文。
为什么IV很重要?
如果您没有IV,并且只使用密钥使用密码块链接(CBC)模式,那么以相同数据开始的两个数据集将产生相同的第一个块。IVs使得两个不同数据的加密不太可能创建相同的输入/输出对(在分组密码级别,使用相同的密钥),即使其中一个与另一个有某种关系(包括但不限于:从相同的第一个块开始)。
当每个加密请求都允许使用随机IV时,第一个块将是不同的。攻击者无法推断出任何可能帮助他们解码加密数据的信息。
- 保持相等加密:在这种类型中,只有一个IV对应于一个密钥。这意味着,整个密文块可以用于搜索查询。由于组织/列的所有数据的IV都是相同的,因此搜索会为您获取数据。
- 标准加密:在这种类型中,每个数据条目都有一个唯一的IV。即使你用一个密钥加密整个数据,每个加密的数据条目也会产生一个独特的密文。此外,由于IV是随机的,并且对于每个数据都是唯一的,因此搜索查询不会为您获取数据。这是一个比“保持平等”变体更安全的选择。
在什么情况下会使用这些变体?
选择特定变体的决定通常取决于需求。如果数据必须接受最高标准的保护,我们会选择具有标准加密的Type-2。
然而,它并不总是只涉及保护。有时,用户可能希望搜索并获取一个字段,如“电子邮件ID”,以满足他们的要求。在这种情况下,标准选项是没有意义的,我们选择Type-1,使用“保持平等”加密。
文件加密
您创建或附加的文件将保存到我们的分布式文件系统(DFS)中。静止时加密的文件因您选择的服务而异。了解有关我们在服务中加密的数据的更多信息。加密发生在应用程序层,只有授权的应用程序用户才能查看数据。
加密基于标准AES 256算法,加密模式为CTR或GCM。在AES 256中,需要加密的明文被划分为数据包或块。由于我们在这里对文件的内容进行加密,因此算法应确保每个块的加密独立于另一个块,这样即使块密码被泄露,攻击者也不会获得有关文件的任何信息。
伽罗瓦/计数器模式 Galois/Counter Mode(GCM)是使用分组密码算法的典型分组密码操作模式。CTR只提供加密,GCM提供加密和身份验证。
如果加密的文件已损坏,在CTR模式下解密文件时将返回一个垃圾值。另一方面,在GCM模式中,我们有一个身份验证标签,它验证加密文件的真实性,然后解密数据。GCM模式为文件提供了一个附加的完整性层。
与字段级加密一样,文件加密也有两种类型:
- 类型1-在这种类型中,每个组织都有一个密钥。来自该组织的每个文件都使用该密钥加密,但带有一个唯一的随机IV,该IV与文件本身一起存储。该密钥再次使用主密钥加密,并且该密钥存储在KMS中。
- 类型2-在这种类型中,每个文件都有一个唯一的密钥,并使用该密钥进行加密。用于加密文件的每个密钥都使用KEK再次加密,并且加密的密钥存储在Zoho服务数据库中,而文件存储在DFS中。该KEK对于每个组织都是唯一的,并且由KMS存储和管理。
URL加密
Zoho服务内的邀请链接或任何其他通信可能涉及在URL中传递的敏感数据。为了确保此通信的安全,对URL的部分内容进行了加密。如果URL中有任何可识别的内容,比如文档的ID,则该部分是加密的。
这种加密有两种类型-每个组织一个密钥或每个功能一个密钥。同样,这是由URL中数据的敏感性决定的。
备份加密
我们经常备份数据,我们的备份服务器配备了与主服务器相同的保护标准。我们作为备份的所有数据将在休息时进行加密。
日志的加密
Zoho Logs使用Hadoop分布式文件系统(HDFS)来存储和管理日志。我们使用Hadoop的加密技术对数据进行加密,而密钥管理由我们的KMS处理。
缓存加密
我们使用Redis开源软件来存储和管理缓存数据。缓存包含在服务操作中重复使用的数据,并且需要存储一定的时间。有时,您的数据可能会被缓存以改进服务或进行故障排除。如果任何数据包含敏感的个人信息,我们会选择对其进行加密。
密钥管理
我们的内部密钥管理服务(KMS)在所有服务中创建、存储和管理密钥。我们使用KMS拥有并维护密钥。目前,我们没有使用客户拥有的密钥加密数据的规定。
注意:我们正在开发一项支持自带密钥(BYOK)的新功能,通过该功能,您可以从自己选择的外部密钥管理器提供自己的加密密钥。
在加密的不同阶段使用不同类型的密钥:
- 数据加密密钥(DEK):用于将数据从明文转换为密文的密钥,或用于加密数据的密钥。
- 密钥加密密钥(KEK):用于加密DEK的密钥,并且是Zoho服务特定的。KEK是在一个单独的服务器中生成的。它提供了额外的安全层。
主密钥:用于加密KEK的密钥。为了安全起见,此密钥存储在一个独立的服务器中。
KMS是如何工作的?
所有类型的加密都是根据AES 256算法进行的。根据这种算法,数据被视为要加密的“块”。无论它是数据库中的字段还是DFS中的文件,当使用DEK对数据块进行加密时,都会开始加密。
此DEK使用KEK进行进一步加密。KEK再次使用存储在单独服务器中的主密钥进行加密。因此,以下是需要管理的元素-
- Encrypted data
- DEKs
- Encrypted DEKs
- KEKs
- Encrypted KEKs
- Master key
KMS以以下方式管理这些元素:
密钥是如何生成的?
KMS生成符合AES 256协议的256位密钥以及初始化矢量(IV)。IV、 如我们已经讨论过的,确保加密数据的第一块是随机的。这就是为什么在IVs的帮助下,相同的明文被加密成不同的密文。
KMS使用Java安全库和SecureRondom数字生成器生成这些密钥和IV。
钥匙存放在哪里?
KMS中生成的DEK使用KEK进行加密。这提供了一个额外的安全层。加密的DEK存储在KMS数据库中。
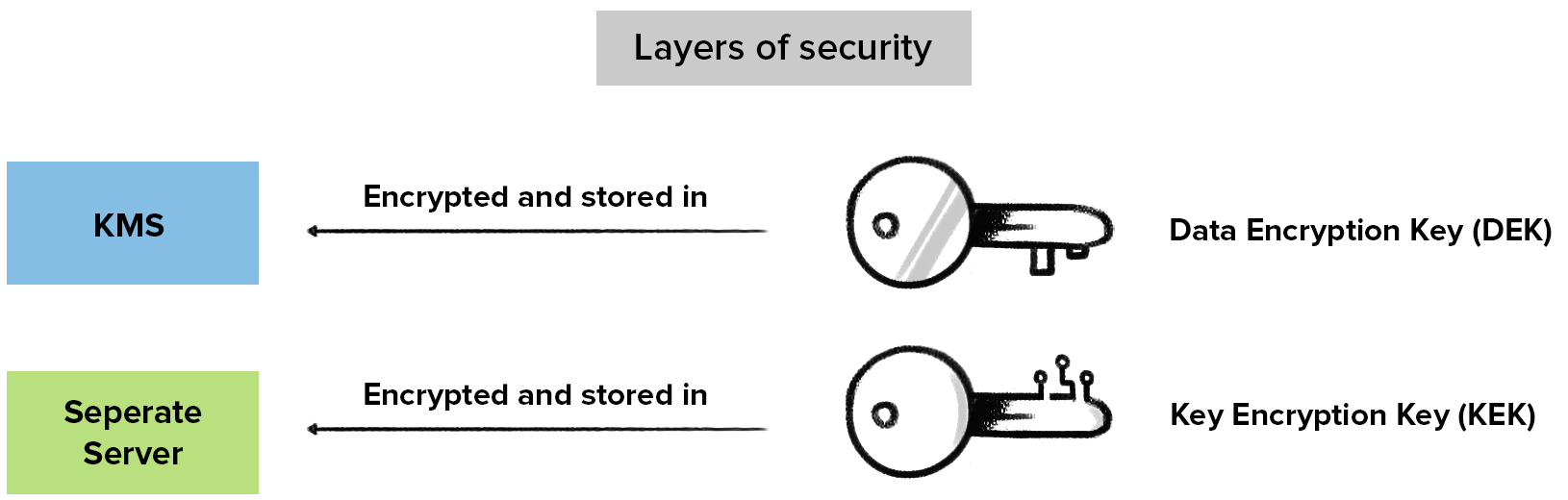
我们将密钥物理分离(将它们存储在不同的位置),这样,掌握一个密钥的攻击者就无法掌握其他相关密钥。我们使用主密钥对KEK进行加密,并将其存储在单独的服务器中。
对于Zoho Workdrive,我们为静态存储的文档提供了一个额外的安全层。
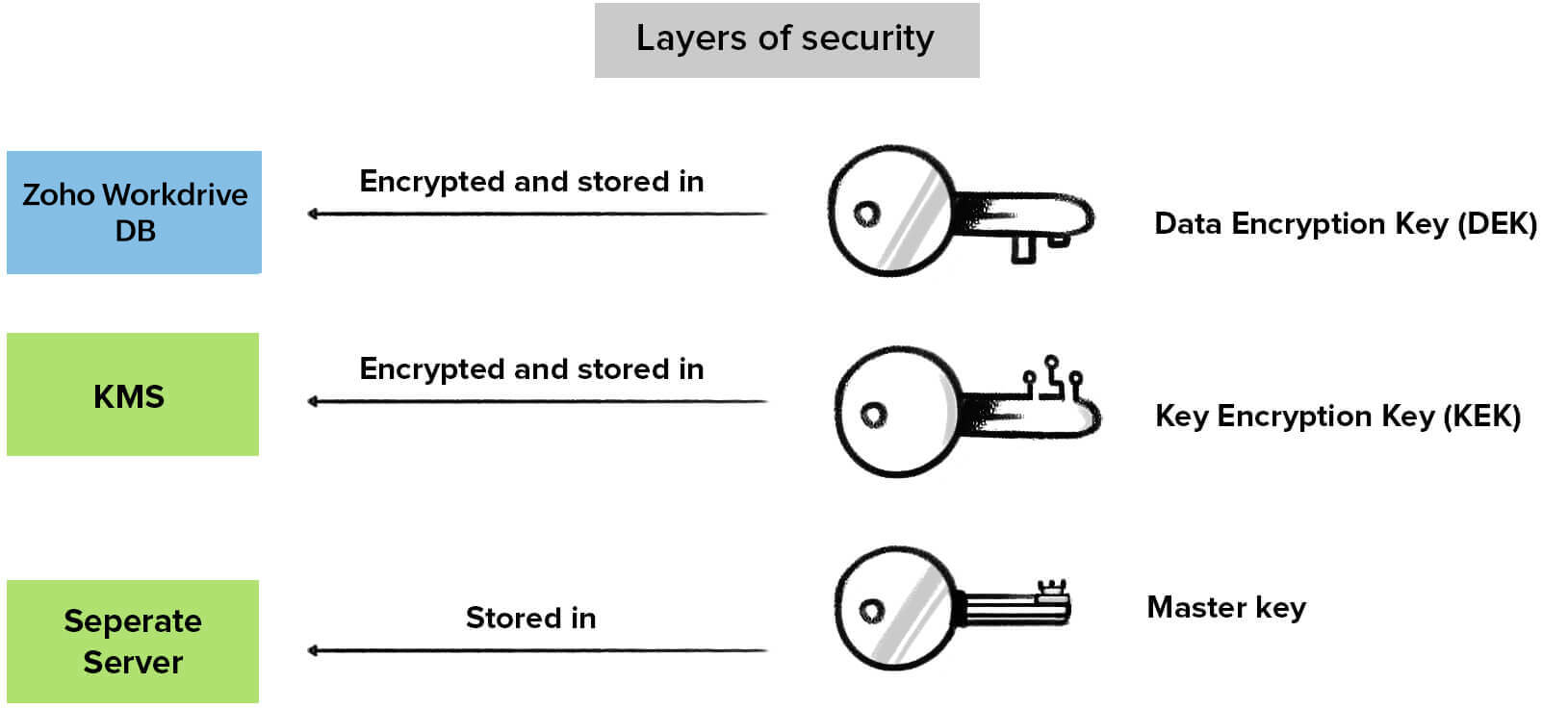
攻击者不能仅以KMS为目标来破坏数据。
钥匙有多安全?
物理分离-如前所述,主密钥保留在物理分离且安全的服务器中。这使得攻击者很难同时破坏DEK和KEK。
访问控制-访问控制有助于我们防止滥用和前所未有的钥匙访问。访问控制列表(ACL)只允许选择服务访问选择密钥。每次访问密钥时,都会对其进行身份验证,并记录该过程。这些日志通过定期审计进行监控。
默认情况下,访问KMS受到限制,并且仅允许Zohocorp的特定人员访问。任何其他访问都是作为票证提出的,只有在管理层批准后才允许。
钥匙旋转-我们有一个钥匙旋转系统,可以更改主钥匙,从而确保额外的安全性。当生成新的主密钥和IV时,意味着数据库中的密钥也必须进行修改。因此,首先使用旧的主密钥获取和解密数据库中的所有密钥,然后使用新的主密钥重新加密并在数据库中更新。
目前,只有在KMS中的密钥发生任何泄露的情况下,才会触发密钥轮换。
密钥的可用性—如果一个数据中心(DC)中的磁盘主存储发生故障,则会有一个从机和一个辅助从机用于备份,它们与主DC保存相同的数据。从设备和次从设备都有加密的密钥,与主设备相同。
我们在服务中加密哪些数据?
静止时加密的数据因您选择的Zoho服务而异。特定数据项的加密类型由您或我们决定,或由双方协商决定。
以下表格列描述了由各种Zoho服务加密的数据:
| Service | Encrypted Fields |
|---|---|
| CRM | Custom fields, all files and all mail content sent and received via CRM. For more details, refer link. |
| Workdrive | All files. For more details, refer link. |
| Creator | Fields. For more details, refer link. |
| Campaigns | Fields that contain personal information, user uploaded files. For more details, refer link. |
| Cliq | ChatTranscript and personal information. For more details, refer link. |
| People | Custom Fields, all files. For more details, refer link. |
| Connect | Title, URL and contents of - feed, forum posts, articles, townhalls, groups, announcements, tasks and their comments, video files and attachments. For more details, refer link. |
| Desk | Ticket thread content, attachments, custom fields and tokens. For more details, refer link. |
| Finance | Bank account details, custom fields that contain personal information, employee details which contain sensitive personal information, travel documents, bank statements and attachments. |
| Projects | Attachments, fields that contain personal information, tokens. For more details, refer link. |
| Sprints | Files, attachments, tokens and fields that contain personal information. For more details, refer link. |
| Notebook | Notecard and Attachments. For more details, refer link. |
| Sign | Documents, signature images and tokens. For more details, refer link. |
| Reports | Custom fields, files uploaded by users, custom queries |
| All mail content, attachments and fields that contain personal information | |
| Recruit | Custom fields and user-imported documents. For more details, refer link. |
| Social | Tokens, fields that contain personal information. For more details, refer link. |
| Service Desk Plus Cloud | Tokens, email server passwords and custom fields. For more details, refer link. |
| SalesIQ | File attachments, tokens, media recordings and chat transcripts. For more details, refer link. |
| Assist | Screenshots and session recordings. For more details, refer link. |
| Survey | Custom fields, files uploaded by respondents and email addresses provided in share feature. For more details, refer link. |
| Show | Presentations, uploaded files and personal information. For more details, refer link. |
| Directory | Custom fields. For more details, refer link. |
| Contracts | Contract Documents, Contract Letters, Negotiation Links' Passwords, Organization & Counterparty Contacts' Phone Number. For more details, refer link. |
| Learn | Contents of articles, lessons, attachments, templates and personal information. For more details, refer link. |
| Sites24x7 | Mobile number, Email address, Hostname, IP address, URL, Access token, Domain name, Credentials provided by the user, Service Account configurations and files uploaded by the user. For more details, refer link. |
| Dataprep | PII (Personally Identifiable Information), ePHI (Electronically Protected Health Data), and credentials. For more details, refer link. |
全磁盘加密
我们采用自加密驱动器(SED)来支持基于硬件的全磁盘加密。SED是一种内置加密电路的硬盘驱动器(HDD)或固态驱动器(SSD)。
自加密只是指写入存储介质的所有数据在写入之前都由磁盘驱动器加密,并在读取时由磁盘驱动器解密。
写入驱动器的数据使用存储在磁盘上的数据加密密钥(DEK)进行加密/解密。制造商提供的默认DEK由我们在设置时重新生成,以维护我们的安全标准。
为了进一步增强SED的安全性,我们使用身份验证密钥。身份验证密钥(AK)用于加密DEK并锁定/解锁驱动器。使用本地密钥管理系统(LKMS)来管理AK。
当服务器中启用加密时,AK会安全地传输到服务器。在磁盘被盗或未经授权的物理访问的情况下,如果没有AK,则无法解密DEK,因此无法访问或读取驱动器上的数据。通过这种方式,AK增加了一层额外的保护。
目前,基于硬件的全磁盘加密默认适用于印度(in)、澳大利亚(AU)和日本(JP)数据中心的所有Zoho服务。在其他DC中,全磁盘加密仅适用于某些Zoho服务。有关更多详细信息,请参阅相应的特定于服务的加密帮助文档。
结论
我们在存储敏感客户数据时、在互联网上传输时以及在我们的DC之间传输时对其进行加密。然而,加密只是我们安全策略的一部分。我们不断创新,努力通过实施最新的协议和技术来加强数据保护。
- 55 次浏览
【数据加密】在Power BI中查看加密的SQL数据
视频号
微信公众号
知识星球
介绍
在基于RDBMS的解决方案中,经常需要通过加密方式混淆敏感数据(如SSN或信用卡号)。这有助于将敏感信息的访问权限限制为仅限一组特权用户。
总的来说,有两种可能的方法可以做到这一点。
- 一种方法是在从数据库插入/检索数据之前,在应用程序级别加密/解密数据。
- 第二种方法是在数据库级别本身处理加密和解密。有多种方法可以在SQL Server中实现加密;请参阅此处的官方文档。
方法的选择取决于特定的业务需求、必要先决条件的可用性和整体解决方案设计。
本文的主要关注点是能够在通过Power BI创建的报告中查看加密数据的要求。在我的案例中,我发现通过SQL加密函数(ENCRYPTBYKEY和DECRYPTBYEY)处理列加密和解密的选项更实用。
在这篇博客文章的剩余部分中,我们将看到如何实现
使用对称密钥和的SQL Server列级加密
查看Power BI报告中的解密数据
目标
将Power BI中SQL Server的加密数据显示给特权用户。
使用的开发工具
- Azure SQL Server
- SQL Server Management Studio/Azure Data Studio
- Power BI桌面应用程序
数据库实现
1.数据库和表的创建
- 从Azure门户创建一个Azure SQL Server实例(如果还不可用)。
- 创建一个名为EmployeeRecords的数据库。
- 通过SSMS或Azure Data Studio连接到EmployeeRecords数据库。
- 创建一个名为EmployeeDetails的表,其中包含如下所示的列。
- 在该表中,SSN列将保存每个员工的加密社会保障号码详细信息。请注意用于此列的数据类型(varbinary)。
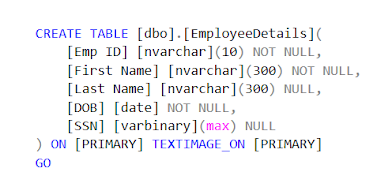
2.SQL Server列加密
如引言部分所述,我们将使用具有对称密钥的SQL加密函数来处理列中数据的加密和解密。
SQL Server如何处理加密、加密层次结构和密钥管理基础结构将在此处进行解释。
使用对称密钥的第一步是创建数据库主密钥和自签名证书。
a.创建数据库主密钥和证书
用于创建DMK和证书的T-SQL语句如下所示。

b.创建对称密钥
在上一步中创建的数据库主密钥和证书将用于创建对称密钥。
此对称密钥将用于在表中插入/更新记录时对列数据进行加密。随后,为了查看敏感信息,将使用相同的密钥对数据进行解密。因此,它被称为“对称”方法。
下面的T-SQL语句使用上一步中创建的证书DBCert创建一个名为EmpSSN_SymmKey的对称密钥。

执行以下语句以验证数据库主密钥和对称密钥的创建。

查询应该返回所创建的键的详细信息。
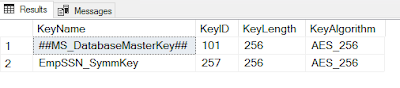
3.将数据插入表格
- 创建一个存储过程,将员工详细信息插入EmployeeDetails表。
- 在其定义中,包括在INSERT语句之前打开对称密钥的语句。
- 在INSERT语句中,使用ENCRYPTBYKEY函数传递对称密钥的GUID和要加密的值,即SSN。
- 在INSERT语句之后关闭键。
- 在下面的屏幕截图中,显示了存储过程sp_insert_empdetails的定义。
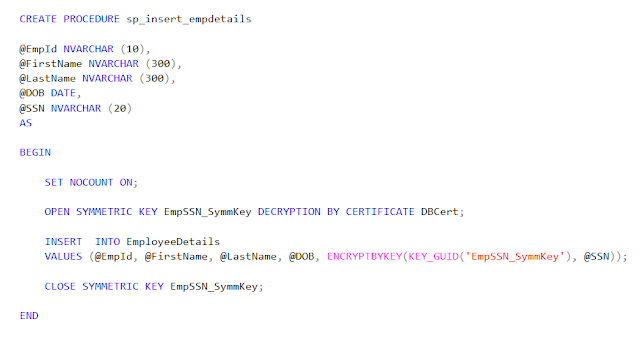
执行存储过程,传递适当的值作为参数。
验证表中的SSN值是否已加密。

4.查看解密值
创建一个存储过程sp_get_empdetails,它将EmpId作为输入参数。
若要查看原始SSN值,SELECT语句必须包含在“Open Symmetric Key”和“Close Symmetric Key'”语句之间,如sp_get_empdetails存储过程的定义中所示。
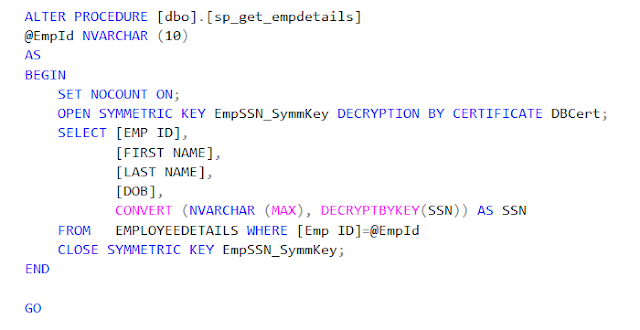
执行存储过程并验证是否返回了解密的值。
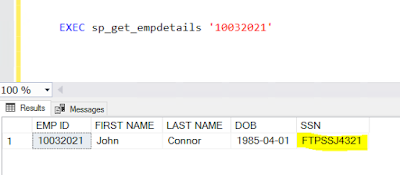
5.向特定用户授予权限
- 创建一个唯一的SQL登录名(下面屏幕截图中的empsecurereader),它将代表特权用户集。

在EmployeeDetails数据库中,创建一个映射到SQL登录名的用户。

- 授予数据库用户对数据库的EXECUTE权限。
- 授予empsecurereader用户对自签名证书DBCert的CONTROL权限。
- 类似地,对对称密钥EmpSSN_SymmKey授予REFERENCES和VIEW DEFINITION权限。
- 如果没有这些权限,用户将无法使用对称密钥进行加密和解密。

可以进行额外的检查,通过拒绝其他用户对存储过程所需的权限来限制他们执行存储过程或查看其定义。
此外,对证书和对称密钥的访问也可能受到限制,从而防止其他用户使用密钥或查看其定义。
Power BI实施
Power BI是微软的一种分析和数据可视化工具,可以连接到各种数据源,SQL Azure就是其中之一。Power BI可以通过两种可能的方式连接到SQL Azure——导入和DirectQuery。
使用Import方法,将数据对象导入Power BI,而使用Direct Query,可以向数据库发出SQL查询,并且仅将结果集导入Power BI。
对于我们的需求,其中我们需要查询EmployeeDetails表并显示解密的数据,我们将使用传递sp_get_empdetails存储过程的Direct query方法来执行。
1.创建数据源连接
- 在Power BI桌面应用程序中,创建一个到Azure SQL的连接,传递SQL语句以执行存储过程sp_get_empdetails,如下所示。
- 请注意,我们在该语句中将一个固定值传递给存储过程。在后面的步骤中,我们将通过使用参数来改变这种动态。
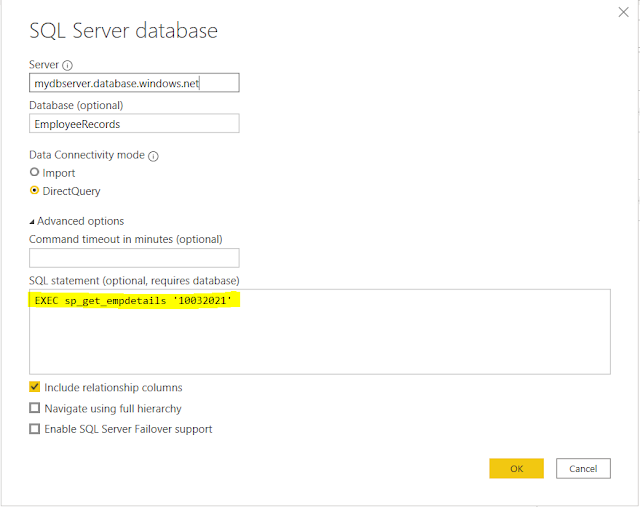
连接到数据库时,请使用上一节步骤5中创建的登录empsecurereader的凭据。我们已经授予该登录对证书和对称密钥的必要权限,使其能够使用该密钥进行加密和解密。
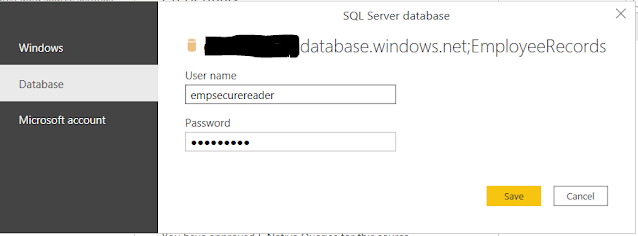
2.通过添加参数使查询具有动态性
- 创建数据连接后,打开Power Query编辑器以查看查询结果集。
- 创建一个名为“Emp-ID”的参数,如下所示。
打开“高级编辑器”并修改查询,如下屏幕截图所示。
保存查询并关闭高级编辑器。回到Power Query编辑器中,输入一个有效的Employee Id,并验证返回的相关详细信息是否已解密SSN值。

摘要:
正如我们所看到的,通过使用对称密钥,我们能够在SQL server中加密和解密列值。通过创建实现这些对称密钥的适当存储过程,我们能够根据需要解密和查看敏感数据。对这些存储过程设置适当的权限可以限制仅对特权用户集的访问。然后可以从Power BI Desktop应用程序调用这些存储过程,并在报告中使用结果集。
- 141 次浏览
【数据加密】在云上用数据加密确保安全
视频号
微信公众号
知识星球
网络攻击经常削弱各种企业和业务。一些行业比其他行业面临更多的恶意企图,但对任何行业的损害程度都可能是巨大的。安全性是组织关注的问题,因为运营完整性是维持业务运营的基础。云原生已经帮助组织通过混合云和多云架构实现了零信任安全措施。在静止和传输时保护数据的需要需要增加一个保护层。

数据加密对于保护敏感和私有数据至关重要。您可以使用多种算法来加密数据以进行保护,例如DES、AES和RSA。云系统可以根据数据传输需求和数据敏感性实现自动数据加密和解密。
在转移到云之后,组织使用云存储来存储大型文件和数据库。存储解决方案,如阿里云对象存储服务(OSS),使用阿里云RAM提供无限存储和基于身份的身份验证。阿里云提供的深度集成提供了无缝的用户访问。
信息和数据安全是各组织最关心的问题。Gartner预测,“全球信息安全市场预计将以8.5%的五年复合年增长率增长,2022年将达到1704亿美元。随着组织应对更复杂威胁的需求不断发展,技术产品经理将看到法规和意识的提高推动了新的支出。”
在本文中,我们将解释阿里云数据加密服务及其使用场景。
数据加密服务
阿里云数据加密服务通过云托管硬件提供硬件安全模块。硬件安全模块是使用加密密钥处理加密数据(加密操作)的硬件设备。阿里云数据加密服务的一些主要优势如下:
- 支持安全的随机数据生成
- 支持使用身份和访问管理系统进行控制的基于角色的访问系统
- 支持监控以维护健康的系统
- 支持在云部署基础架构中基于需求的HSM实例扩展。您可以使用管理控制台调整加密和解密密钥的配置和规格,以满足要求。
- 扩展了对多种密钥类型和安全密钥存储的支持
- 提供了一个完整的加密密钥管理解决方案,包括创建、销毁、导入和导出。密钥管理的完全控制权分配给用户,以便在HSM中创建密钥。数据加密服务管理HSM硬件,以在云基础架构中维护HSM的性能和可用性。
- 支持对称和非对称密钥类型,以方便数据加密和解密
- 支持非对称密钥验证和签名
- 支持HMAC–基于哈希的消息身份验证码
- 阿里云DES保护您的私钥不受证书颁发机构(CA)的保护,以提供数字证书来验证您的身份。阿里云数据加密服务和HSM可以使用加密签名操作。
阿里云数据加密服务使用加密密钥,通过基于硬件的设备保护您的数据,允许您访问阿里云虚拟专用云(VPC)中的HSM实例。这些实例是防篡改的,并使单个租户访问系统能够保护您的加密密钥。数据加密服务还允许使用行业标准API(包括JCE)进行自定义应用程序映射。
使用场景
敏感数据保护
数据加密服务是一种托管服务,可与任何其他阿里云解决方案配合使用。下面列出了一些数据加密服务的使用场景:
- 阿里云数据加密服务支持透明数据加密(TDE),将使用表空间或数据库存储的敏感数据作为加密文件进行保护。TDE使用外部安全模块存储加密密钥。它对数据文件中的敏感数据进行加密,实现未经授权的访问或未经授权解密。
- 阿里云创建了敏感数据发现和保护产品套件,其理念与保护敏感数据相同。我们将在下一篇文章中更详细地讨论它。阿里云数据加密服务通过对金融服务、电子商务、公共领域服务等多个领域的高收益服务相关敏感数据进行加密,为您提供异常保护。让我们来看看下图中描述敏感数据加密场景的架构模型:

在这种情况下,您可以使用应用程序体系结构中的HSM集成来加密敏感数据和商业机密。
金融服务
金融服务容易受到网络攻击。财务动机是网络攻击的主要原因。
Risk Based表示,“2020年上半年,数据泄露暴露了360亿条记录。”
让我们看看下表中金融系统的数据加密服务体系结构流程:

在这种情况下,所有在线支付、基于卡的支付、基于应用程序的支付和POS支付都使用前端系统,该系统由负责财务账簿的结算系统、处理传入付款的支付系统以及将传入和传出付款转发到结算系统的金融系统组成。所有这些系统都使用代理来增加安全措施。HSM在后端发布加密密钥,以帮助在传输过程中提高数据安全性。
财务结构中最严格的安全和合规要求将确保数据在传输和静止期间的支付完整性和机密性。
SSL卸载
使用安全HTTP/HTTPS协议的网站使用公私密钥对。每个会话都使用公钥证书为每个客户端建立一个安全的HTTPS会话。阿里云数据加密服务允许您通过生成私钥直接通过HSM卸载SSL。通过web服务进行处理,可以在不消耗任何web服务器资源的情况下卸载SSL,从而保持web服务器的可用性和效率。

包装
所有阿里云用户都可以使用数据加密服务。您可以使用HSM执行多项操作,例如SSL卸载、TLS web服务器处理、透明数据加密以及敏感和财务数据加密。云数据在传输和静止时必须得到保护,以确保数据的完整性。阿里云数据加密服务让您能够保护组织中最重要的方面——数据。
即将发表的文章
- Developing an Enterprise Cloud Strategy - Part 1
- Developing an Enterprise Cloud Strategy - Part 2
- 51 次浏览
【数据加密】如何使用针对JavaScript和Node.js的AWS加密SDK在浏览器中启用加密
视频号
微信公众号
知识星球
在这篇文章中,我们将向您展示如何使用AWS Encryption SDK(“ESDK”)for JavaScript来处理假设应用程序的浏览器内加密工作负载。首先,我们将回顾加密的一些安全和隐私属性,包括AWS为典型应用程序的不同组件使用的名称。然后,我们将讨论您可能想要加密每个组件的一些原因,重点是浏览器内加密,我们将描述如何使用ESDK执行加密。最后,我们将讨论在设计应用程序时需要注意的一些安全属性,以及在哪里可以找到其他资源。
加密的安全性和隐私性概述
加密是一种技术,可以通过使敏感数据在没有密钥的情况下无法读取来限制对敏感数据的访问。加密过程采用可读或可处理的数据(“明文”),并使用数学原理来模糊内容,这样在不使用密钥的情况下就无法读取。为了保护用户隐私并防止未经授权泄露敏感业务数据,开发人员需要在整个数据生命周期中保护敏感数据的方法。当数据在应用程序的收集、存储、处理和共享组件之间流动时,需要保护数据免受与无意披露相关的风险。在这种情况下,加密通常分为两种不同的技术:用于存储数据的静态加密;以及用于在实体或系统之间移动数据的传输中的加密。
许多应用程序在传输过程中使用加密来保护用户与他们提供的服务之间的连接,然后在数据存储之前对其进行加密。然而,随着应用程序变得越来越复杂,数据必须在更多节点之间移动,并存储在更多样化的地方,数据意外泄露或无意泄露的机会也越来越多。当用户在浏览器中输入数据时,传输层安全性(TLS)可以保护在用户浏览器和服务端点之间传输的数据。但在分布式系统中,端点和处理敏感数据的服务之间的中间服务可能会在传输数据之前记录或缓存数据。在浏览器中收集敏感数据时对其进行加密是一种静态加密形式,可以最大限度地降低未经授权访问的风险,并在数据丢失、被盗或意外暴露时保护数据。在浏览器中加密数据意味着,即使它在其他地方完全暴露,对任何无法访问密钥的人来说,它都是不可读的,毫无价值。
典型的web应用程序
典型的web应用程序会接受一些数据作为输入,对其进行处理,然后存储。当用户需要访问存储的数据时,数据通常遵循输入时使用的相同路径。在我们的示例中,路径有三个主要组件:
- 收集数据(通常通过网络表单或文件上传)
- 数据处理(通过亚马逊弹性计算云(Amazon EC2)、亚马逊弹性容器服务、AWS Lambda或类似服务)
- 数据存储(通过亚马逊简单存储服务(Amazon S3)、亚马逊弹性块存储或在亚马逊Aurora等数据库中)

图1:一个假设的web应用程序,其中应用程序由与浏览器前端交互的最终用户、处理从浏览器接收的数据的第三方组成,处理在Amazon EC2中执行,存储在Amazon S3中
- 最终用户使用浏览器中的界面与应用程序进行交互。
- 当数据被发送到亚马逊EC2时,它会通过第三方的基础设施,第三方可能是互联网服务提供商、用户环境中的设备或运行在云中的应用程序。
- 亚马逊EC2上的应用程序在收到数据后会对其进行处理。
- 一旦应用程序处理完数据,它就会存储在AmazonS3中,直到再次需要它为止。
当数据在组件之间移动时,TLS用于防止无意中泄露。但是,如果其中一个或多个组件是不需要访问敏感数据的第三方服务,该怎么办?这就是加密的用武之地。
静态加密可作为服务器端、客户端和客户端的浏览器保护。
- 服务器端加密(SSE)是AWS客户最常用的加密形式,这是有充分理由的:它很容易使用,因为它受到许多服务的本地支持,如亚马逊S3。当使用SSE时,存储数据的服务将在收到每条数据时使用密钥(“数据密钥”)对其进行加密,然后在授权用户请求时对其进行透明解密。这对应用程序开发人员来说是无缝的,因为他们只需要在AmazonS3中选中一个框就可以启用加密,而且它还通过拥有下载对象和执行解密操作的单独权限来添加额外级别的访问控制。然而,需要考虑安全性/便利性的权衡,因为服务将允许任何具有适当权限的角色执行解密。为了进行额外的控制,包括S3在内的许多AWS服务都支持使用客户管理的AWS密钥管理服务(AWS KMS)AWS KMS密钥(KMS密钥),允许您指定密钥策略或使用授权或AWS身份和访问管理(IAM)策略来控制哪些角色或用户可以访问解密,以及何时访问。使用客户管理的KMS密钥配置解密权限通常足以满足要求“应用程序级加密”的法规遵从性制度
- 一些威胁模型或合规机制可能需要客户端加密(CSE),这可能会以牺牲额外复杂性为代价,增加强大的额外访问控制级别。如上所述,服务在数据离开应用程序边界后对数据执行服务器端加密。TLS用于保护传输到服务的数据,但有些客户可能只想在EC2或浏览器上的应用程序中管理加密/解密操作。应用程序可以使用AWS加密SDK在将数据发送到存储服务之前对应用程序信任边界内的数据进行加密。
但是,如果客户甚至不希望明文数据离开浏览器,该怎么办?或者,如果最终用户输入的数据由属于第三方的中间系统传递或记录,该怎么办?可以创建一个单独的应用程序,只管理加密,以确保您的环境被隔离,但使用AWS encryption SDK for JavaScript可以在数据发送到应用程序之前在最终用户浏览器中对数据进行加密,因此只有您的最终用户才能查看其明文数据。如下图2所示,浏览器内加密可以允许不受信任的中间系统安全地处理数据,同时确保其机密性和完整性。
图2:一个假设的加密web应用程序,其中应用程序由与浏览器前端交互的最终用户、处理从浏览器接收的数据的第三方组成,处理在Amazon EC2中执行,存储在Amazon S3中
- 浏览器中的应用程序请求数据密钥,以便在用户输入的敏感数据传递给第三方之前对其进行加密。
- 由于敏感数据已被加密,第三方无法读取。第三方可能是互联网服务提供商、用户环境中的设备、运行在云中的应用程序或各种其他参与者。
- AmazonEC2上的应用程序可以向KMS请求解密数据密钥,以便对数据进行解密、处理和重新加密。
- 加密的对象被存储在S3中,在S3中进行第二加密请求,从而当对象被存储到服务器侧时可以对其进行加密。
如何在浏览器中加密
浏览器内加密的第一步是包括用于JavaScript的AWS加密SDK的副本,以及用户访问您的应用程序时已发送给用户的脚本。一旦它出现在最终用户环境中,应用程序就可以进行调用。为了执行加密,ESDK将向加密材料提供商请求用于加密的数据密钥,以及将与加密对象一起存储的数据密钥的加密副本。在浏览器中对一段数据进行加密后,密文可以上传到应用程序后端进行处理或存储。当用户需要检索明文时,ESDK可以读取附在密文上的元数据,以确定解密数据密钥的适当方法,并且如果他们可以访问KMS密钥,则解密数据密钥,然后使用它来解密数据。
重要注意事项
基于浏览器的应用程序的一个常见问题是不同浏览器供应商和版本的功能支持不一致。例如,如果浏览器缺乏对推荐的最强加密算法套件的本地支持,应用程序将如何响应?或者,如果用户使用禁用JavaScript的浏览器访问应用程序,会有消息或替代模式吗?ESDK for JavaScript本机支持回退模式,但它可能不适用于所有用例。请务必了解您需要支持哪种浏览器环境,以确定浏览器内加密是否合适,如果您希望获得有限的浏览器支持,请包括对优雅降级的支持。开发人员还应考虑未经授权的用户可能通过浏览器扩展监控用户操作、在用户不知情的情况下发出未经授权浏览器请求或请求“降级”(数学密集度较低)加密操作的方式。
让安全专业人员审查您的应用程序设计总是一个好主意。如果您有AWS客户经理或技术客户经理,您可以要求他们将您与解决方案架构师联系,以审查您的设计。如果您是AWS客户,但没有客户经理,请考虑访问AWS阁楼,参与我们的“询问专家”计划。
- 52 次浏览
【数据加密】如何在本机和浏览器应用程序中使用加密进行深度防御
视频号
微信公众号
知识星球
关键要点
- 应用层加密是将更多基础设施和IT职责转移到开发人员或DevOps角色的趋势的一部分。
- 端到端加密是一种越来越流行的应用层加密类型。
- 这种类型的加密使组织能够使用密钥管理和策略来实施访问控制。
- 根据平台的不同,安全地向最终用户交付代码是非常不同的;基于浏览器的JavaScript是最具挑战性的。
- 使用这些方法可以极大地改善隐私和安全性,因此尽管存在挑战,但这是非常值得的。
任何处理敏感用户数据的人都生活在对数据泄露的恐惧中。我们知道加密可以减少负面影响,但大多数加密都被降级到TLS和VPN等基础设施级别的元素,而不是应用程序层。应用层和端到端加密可能是我们工具包中的一个强大工具,但作为开发人员,我们如何在不引入错误或降低数据实用性的情况下安全地将加密添加到应用程序中?
在本文中,我们讨论了应用层加密的优缺点。我们将介绍浏览器中应用层加密的攻击面,它与本地客户端的区别,以及WebCrypto的帮助。
威胁形势
违规行为的声誉、财务和人员影响可能极高。有助于保护最终用户隐私的新法律是向前迈出的重要一步,但它们可能会带来毁灭性的罚款。
研究表明,加密是减少数据泄露影响和成本的最有效的技术安全措施之一。当攻击者获得加密的数据集时,他们要么必须攻击另一个系统才能获得密钥,要么必须使用元数据和侧通道信息而不是“好东西”
加密通常侧重于“基础结构层”元素,如TLS、VPN、数据库加密标志和全磁盘加密。这些都是我们工具箱中的重要工具,但它们依赖于对基础设施的假设,而不是应用程序代码本身。
事实上,如果你考虑一下最近的数据泄露,至少在老牌公司中是这样,他们肯定在使用TLS和静态数据库加密,但泄露还是发生了。例如,Capital One最近遭到黑客攻击,敏感金融信息被盗。谷歌照片意外地让错误的用户访问了其他用户的照片和视频。这些错误本可以通过应用层或端到端加密来防止,或者至少可以减轻。
作为开发人员,基础设施不是我们的强项,有时也不是我们的工作,因此加密退居功能之后。但对于我们这些真正关心深入防御的人来说,在应用程序本身添加加密是很有意义的。应用层加密可以使我们的系统免受基础设施级别故障、TLS的已知弱点和一些服务器端漏洞的影响。
加密左移:什么是应用层加密?
将更多的安全性、操作和测试转移到开发过程中的做法(称为左移)正在提高软件的灵活性、可靠性和效率。这也意味着,安全性最佳实践需要作为应用程序开发的一部分来实现,而不是在出现问题时事后考虑。然而,绝大多数开发人员都不是安全或密码学专家,同时,安全团队对IT和开发的安全态势的控制比以往任何时候都要少。
应用层加密,或称加密左移,就是这一趋势的一部分。这意味着让开发人员对加密内容和解密密钥有更多的控制权。在某些情况下,用户自己可能是唯一拥有密钥的一方。在其他情况下,应用层加密可以在数据管理上添加访问控制层,提供深度防御。
正如名称所暗示的那样,应用层加密直接添加到应用程序的代码库中,并且对密钥材料的访问由应用程序逻辑控制。因此,您可以认为数据本身在其整个生命周期中都是加密的,而不是依赖于它在加密的网络或磁盘上。
最广泛理解的应用层加密是Signal和WhatsApp提供的端到端加密聊天,所以让我们思考一下这些应用程序是如何工作的。它有点过于简化了,但基本上是这样工作的:
|
nd-user action |
Access Control Logic (Server) |
App-layer Cryptographic Operation (Client) |
|
Add a friend |
Create an access control rule where users are allowed to send each-other messages |
Trust the friend’s cryptographic key |
|
Write the friend a message |
Create an access control rule where the friend can read the message |
Encrypt the message with the friend’s key (and sign it) |
|
Read a message from a friend |
Check for permission to download the message |
Decrypt a message with end user’s key (and check the signature) |
在这个简单的例子中,我们已经可以看到应用层加密的一些威力:
- 用户考虑的是他们想与谁交谈,而不是访问控制或加密,但事实上,用户正在做出策略决策。
- 访问控制逻辑是用密码学(并由谁拥有密钥来定义)强制执行的,而不仅仅是攻击者可能使用的服务器上的规则。
- 服务器无法访问纯文本数据,因此针对服务器的攻击,如SQL注入、内部威胁和根级别泄露,无法泄露数据。
请注意,这是一个端到端加密的示例,但并非所有应用层加密都是端到端的。此外,像这样的应用程序仍然需要TLS和其他基础设施层加密来强制执行身份验证、防止重放攻击以及解决许多其他问题。
为什么TLS还不够
当我们考虑TLS时,我们想象数据在其源处被加密并在服务器上被解密。但这种过度简化掩盖了TLS的实际局限性。
传输中加密的现实忽略了静止数据的加密,这影响了传输两端的安全性。它还完全忽略HTTPS终止后数据会发生什么,这些数据可能比你所知道的更位于网络边缘;例如,在您的负载平衡器上。
那么,在应用程序的其他点进行加密呢?如果你的加密工作高于平均水平,那么你已经在应用程序中编写了健壮、测试良好的代码来加密静止的数据,你已经在网络上使用了HTTPS和IPSec,并且启用了透明的数据库加密。
使用这种方法,我们几乎可以“处处加密”,但随着数据在系统中的移动,它在每一步都会被解密和重新加密。每一个接触纯文本数据的点都是一个潜在的漏洞,导致一个巨大的攻击面,你必须问问自己,“为什么这些中间服务无论如何都需要纯文本数据?”他们可能不需要。
基础设施层加密也会造成安全漏洞,因为基础设施的意外部分可能会获得数据。例如,即使你的数据库是加密的,你的数据库和磁盘备份也可能不会被加密。或者你的健康监测系统可能会以明文形式记录敏感数据,甚至(可怕的是)可能会将其发送给第三方。之所以会出现这些安全漏洞,是因为不同的个人或部门在以下各个方面负责安全:
- 在移动端,您的开发团队或供应商必须编写一些代码(或者至少实现HTTPS权限)。或者你的移动设备管理(MDM)系统封装了数据,或者你可能依赖用户检查“加密电话”框和操作系统供应商在那里做一些明智的事情。
- 在网络中,IT或DevOps负责提供证书并确保HTTPS配置良好,这并不总是那么容易。
- 在你的服务器上,你指望IT和DevOps来确保对你系统的内部访问,你指望云提供商和数据库供应商来实现“透明”的数据库加密。
这些解决方案中的每一个都使用不同的密码、库和密钥大小。你指望很多人把很多事情做好。这是个问题。
提供值得信赖的代码
加密是关于通信的;数据由一方写入和加密,然后由另一方接收和解密。发送方和接收方都必须有一个知道如何进行加密和解密的应用程序,并且可以信任它来正确地进行加密和加密。但这说起来容易做起来难。
如果加密代码是恶意的怎么办?攻击者能做什么?最简单的攻击是让应用程序完全按照预期工作,但也会将未加密的消息发送给坏人。当然,更微妙的攻击是可能的;添加隐藏的漏洞来削弱加密,篡改公钥等等。但它们都是一样的:一点代码可以帮助坏人获得秘密信息。
那么,让我们来谈谈代码交付。对于两个在手机上使用应用程序进行通信的人来说,信任链是这样的:一个好的程序员编写好的加密代码,将其编译成应用程序,用数字签名对应用程序进行签名,然后通过TLS将其上传到应用商店。用户通过TLS下载应用程序,操作系统检查数字签名是否“可信”,用户运行应用程序进行加密通信。请注意,该协议本身就是一个应用层加密数据交换。像DebianLinux这样的系统有类似的协议来安装和升级服务器和桌面应用程序。
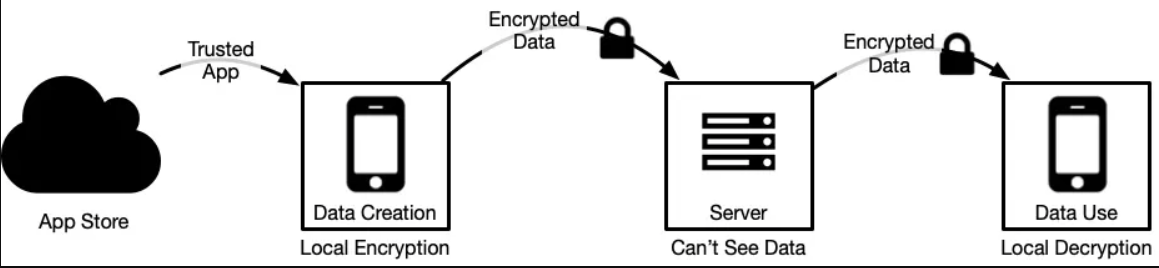
受信任的应用程序下载可能会出现许多问题:用户可能下载了该应用程序的恶意版本。操作系统供应商可能会破坏对应用程序数字签名的检查。攻击者可以诱骗用户安装旧的易受攻击的应用程序版本(或不升级)。任何这些类型的攻击都会使端到端加密通信受到怀疑。但在大多数情况下,这很有效。
应用程序级加密通常在移动设备、笔记本电脑或服务器上运行的本地代码中实现,并且可以使用这样的协议来提供可信的代码。但现代应用程序通常都有一个主要的基于浏览器的组件,即使是对极为敏感的信息也是如此。
那么网络呢?
网络上的代码交付模型看起来与应用程序完全不同。当用户决定要进行安全对话时,他们会访问网页。浏览器通过TLS按需下载一些JavaScript。除了警告用户TLS连接不正确之外,这就是代码传递标准协议的结束。它完全依赖TLS。交付的JavaScript需要执行应用程序层加密,并且不能有任何恶意代码将未加密的文本发送给坏人。
为什么这是个问题?举个例子,我们的安全声明是,数据在一个浏览器中被加密,在另一个浏览器上被解密,而在没有警告标志和烟花熄灭的情况下,介于两者之间的Web服务器无法看到数据。要破坏这一声明,服务器只需在应用程序启动时发送恶意JavaScript。因此,能够控制提供代码或DNS和TLS各个方面的服务器的攻击者可以在不破坏任何加密的情况下发起此攻击。坏代码只能发送到特定的目标,这使得安全研究人员很难检测到。
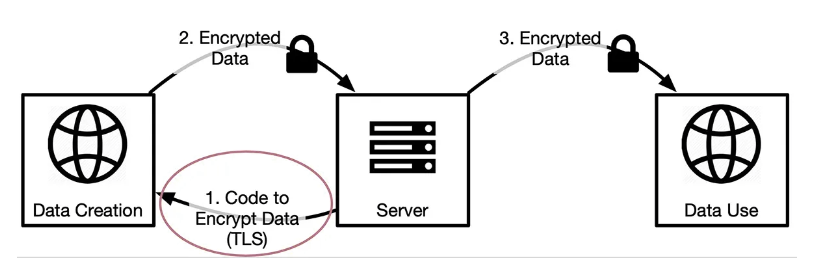
事实上,随着应用程序更新和不断集成的速度,针对移动应用程序和台式机的类似攻击也是可能的。许多现代应用程序使用动态代码技术实时向应用程序传递至少一些代码;许多桌面应用程序可以随意更新自己的代码。这使攻击者能够在不同的时间点劫持代码更新,但也使安全团队能够快速修补。也就是说,基于浏览器的攻击被更好地理解了。
安全和密码学界的一些人指出这个问题,说你不应该进行基于浏览器的加密,或者如果你这样做了,你就不能声称它是端到端安全的。或者至少,它制造了一种虚假的安全感。我们不同意。确实存在弱点,但作为开发人员,我们无论如何都应该这样做,因为简单地说,人们使用网络是出于安全关键目的。
为什么浏览器中的应用层加密仍然具有良好的安全性
尽管存在代码传递问题,但在浏览器中进行应用层加密可以显著提高任何系统的整体安全性。原因是安全性不是全部或全部。在现代服务器基础设施中,很少有一个浏览器只与执行每项任务的单个web服务器对话;现代系统比这更复杂。
例如,假设您的web应用程序使用HTTPS并进行基于浏览器的端到端加密,但它存在SQL注入漏洞。此漏洞的本质是攻击者欺骗应用程序欺骗数据库转储敏感数据(具有讽刺意味的是,通过HTTPS)。但在我们的示例中,数据是端到端加密的,因此数据库只包含加密消息。如果没有应用层加密,坏人会得到更敏感的东西:纯文本消息。请注意,仅凭此漏洞,攻击者就无法更改代码以注入恶意JavaScript;基于浏览器的加密代码仍然健全。

另一方面,如果攻击者在API服务器上利用远程代码执行漏洞,可以随时修改JavaScript或向其中注入恶意代码,则他们可以通过添加向自己发送纯文本数据的代码来破坏端到端加密。
这只是两个例子,一个是应用层加密可以被破坏,另一个是不能被破坏,但端到端加密还可以防止无数其他攻击:也许你有一个太爱管闲事的员工,他在寻找名人的私人信息,但却无法访问代码。也许您将Postgres数据库备份到S3存储桶中,并意外地将其打开在web上。也许攻击者可以破坏TLS,但他们只是被动行动;他们可以窃听,但不能进行代码注入。
正如我们所看到的,浏览器中的应用层加密提供了深度防御,尽管代码交付存在挑战。在下一节中,我们将讨论缓解这些挑战的方法。
改进浏览器的可信代码交付
有许多方法可以提高浏览器中应用层加密的安全性。第一道防线是使用好的、可信的代码。现代应用程序开发要快得多,因为我们重复使用了在网上找到的大量代码,但如果用户浏览器中运行的任何代码是恶意的或易受攻击的,就会严重破坏加密。
保护提供代码的服务器也是至关重要的。在该服务器上分配访问控制权限时,请使用最小权限原则。对管理和代码部署使用多方控制。这将大大降低内部攻击的风险。
还有一些使用不足的代码传递设置指示浏览器采取额外的预防措施。它们不是默认的,因为它们在一定程度上降低了开发和集成过程的灵活性,但无论您的应用程序是否加密,它们提供的安全性都是值得的:
- HTTP严格传输安全性(HSTS):指示浏览器始终通过HTTPS加载此页面。这可以防止降级攻击,例如,如果攻击者可以将您的DNS重定向到恶意服务,则无法将连接降级到未加密的HTTP。
- 严格的内容安全策略(CSP):用于加载代码的白名单安全源。在现代JavaScript的复杂世界中,这会阻止应用程序从您不知道的远程资源动态加载代码。
- 子资源完整性(SRI):只加载您知道可以信任的脚本。这使用加密哈希来标记受信任的脚本。如果攻击者修改加密应用程序的JavaScript,这将更改哈希,并且不会加载代码。
此外,还有一种相对较新的浏览器API,它有助于高效和安全地传递加密原语。WebCrypto API提供低级密码、哈希和其他加密组件。这很有帮助,因为您不必在JavaScript中包含这些密码。浏览器直接实现它们,并可以利用本地本地执行甚至硬件加速。它不能阻止某些攻击,比如向坏人发送未加密的数据副本,但WebCrypto确实使基于浏览器的加密更加标准和可访问。
其他陷阱
安全的代码交付并不是实现应用层加密的唯一挑战。最大的问题是,大多数加密库相对难以安全使用,并且难以在不同的编程语言和平台中一致实现。当你在浏览器中加密并在应用程序上解密时,你可能需要三种不同语言(Android、iOS和JavaScript)的不同实现,它们都使用完全相同的密码和模式。
这些模式的安全操作不是很容易理解。例如,备受喜爱的AES密码是安全的,但将其与ECB(Java中的默认模式)等不安全模式配对是不安全的。将AES与GCM配对被认为是最佳实践,但即使是GCM也有其缺陷;如果使用相同的密钥加密过多的数据,或者初始化向量/noce出错,那么实际上可能会泄露密钥材料,这是其他模式所没有的缺陷。
一个错误可能会使你的加密数据无法恢复,甚至更糟的是,被坏人恢复。
另一个挑战是,如果你把加密数据放在数据库中,它就不再是可搜索的了。你必须提前计划好你希望数据库做什么样的查询和向下选择,或者你希望你的应用程序做什么。例如,如果你加密用户的家庭地址,你不能简单地用字符串“Oregon”为所有行选择*。如果按州向下选择是你应用程序工作流程的一部分,你可以加密用户的整个地址,但是添加一个未加密的元数据字段及其状态,这样您仍然可以执行此查询。从那里,您可以潜在地使用应用层逻辑来解密记录并执行其余的搜索,但数据库并没有多大帮助。
与我交谈的人经常关心应用层加密的性能,但这并不是一个重要的问题。加密速度很快,而且现在硬件的速度往往加快了。毕竟,我们使用HTTPS来流式传输整个社交网络的照片和视频,并没有真正注意到性能的影响。这在应用程序层是类似的,您不太可能发现加密是一个瓶颈。
可以肯定的是,仍然存在针对应用层加密的攻击。各国政府已将运营加密服务或安装加密应用程序定为非法或法律上不切实际的行为。用户选择弱密码或重复使用的密码可能会完全破坏加密。用户忘记密码也是一个难题;在这种情况下该怎么办?用户是否应该能够通过重置密码的电子邮件恢复他们的数据?这本身就削弱了端到端加密的论点。
当然,一旦数据被解密,攻击者就可以攻击终端设备本身。2019年WhatsApp发生了这种情况,让一些人怀疑端到端加密是否值得或重要。但事实上,攻击者必须针对特定个人对WhatsApp进行零日攻击,这足以证明端到端加密有帮助。
如何成功
在应用程序中实施加密时,您需要考虑您的特定安全目标、您可能必须遵守的任何合规规则,以及您需要谁拥有密钥材料。加密技术非常适合您的应用程序。受过训练的密码学家可以帮助你了解你的方法的优点和缺点,没有任何杂志文章可以告诉你什么是对的或错的。然而,你可以做出一些选择,让你更接近“好的密码学”,而且你通常可以安全地使用它们。
首先简要介绍一下三种主要的密码系统——对称、非对称和哈希。对称(共享密钥)快速高效,这些算法通常是加密数据的基线。AES通常是您想要的。
- 对称加密在密钥管理方面面临挑战。您需要一种方法来获得双方的共享密钥,这就是为什么您需要非对称加密。对称多块模式的保密性和完整性各不相同,有些模式在不同类型的数据或不同的系统约束(例如缺乏随机数生成器)下工作得更好:ECB、GCM、CBC、SIV等。
- 非对称(公钥/私钥)加密比对称加密更慢、更复杂,这些算法通常用于交换对称密钥。RSA是这里的“经典”选择;ECC更现代、更高效,而且几乎同样得到广泛支持。大致来说,公钥用于加密数据和验证签名。私钥用于解密数据和生成签名。
- 哈希、加密签名和消息身份验证码(MAC)提供了完整性。哈希生成一个短字符串,证明数据没有改变,或者在消息身份验证码的情况下,证明持有密钥的人对数据进行了“签名”。许多人认为加密意味着完整性,但事实并非如此。例如,AES默认情况下不提供完整性。像SHA2、Poly1305和GCM这样的算法会有所帮助。
管理密钥本身就是一个很大的话题,但需要考虑以下几点重要事项:
- 生成:密钥的随机性、大小、对称与非对称等。
- 存储:是从用户生成的密码派生密钥,还是将其存储以供以后查找。如果存储,您是否有一个安全的地方来放置它们,如钥匙链或硬件安全模块(HSM)?许多操作系统和平台现在都支持安全密钥管理。
- 通信:如何在客户端和服务器或两个用户之间就密钥达成一致。这对对称密钥来说非常困难,但对公钥来说也是一个挑战。公钥不需要是秘密的,但你必须相信它们确实来自你认为它们来自的人。为此,你需要已经有了可以信任的东西,这可能是一个鸡和蛋的问题。
除了关键材料之外,还有其他与加密消息相关的随机性或唯一性元素。初始化向量、salt和nonce属于这一类。这些也需要与解密方通信,因此需要存储或传输。通常,将这些未加密的内容与密文一起传输是安全的,但您应该小心,不要让攻击者修改它们。
您还需要对消息进行填充、编码、序列化和签名。信不信由你,即使是糟糕的填充也会破坏加密消息的机密性。对于JSON对象或HTTP标头等结构化数据的签名,双方都需要相同的方式来序列化和反序列化数据,否则签名将不匹配。
如果你做对了所有这些,你现在就有了一条加密和签名的消息。此时,您可能希望将此消息发送给另一方,后者将检查签名并解密消息。这意味着你需要交流你的所有选择:密钥id、大小、密码、模式、IV、哈希算法等。这种交流本身在许多密码学系统中是一个令人担忧的弱点。例如,攻击者能够诱骗一些对称系统表现得像非对称系统,并将其共享密钥直接发送给攻击者。哎呀。
我们有一些建议,特别是如果您需要或希望坚持使用NIST/FIPS-140密码,这些密码有时是政府工作或银行业合规所必需的:
- 对称加密:AES-GCM是一种很好的操作模式,因为它提供了多块机密性(与ECC不同)和身份验证/完整性(与CBC不同)。它广泛可用,所以当你需要它时,你通常可以指望它在那里。不过,你必须非常小心GCM nonce,因为nonce重用(或者如果攻击者可以选择它)可能会泄露密钥材料。这不好。
- 身份验证:这验证拥有私钥的人是否对数据进行了加密。非常重要。我们的建议与上述相同,使用GCM添加的标签。
- 密钥交换:曲线P-384上的椭圆曲线Diffie-Hellman(ECDH)是一个不错的选择。
- 哈希:如今,SHA256是相当标准的。
- 不要使用旧的/坏掉的东西:虽然这不是一个详尽的列表,但最常用的“旧的或坏掉的”东西包括:DES、MD4、MD5、SHA1、RC4、AES-ECB,(RSA是旧的,但不是坏掉的。如果有,可以使用,但如果可以的话,更喜欢ECC。)
- libSodium:如果你不需要NIST/FIPS合规性,你肯定应该研究libSodium。它非常受欢迎,而且这些库通常比实现类似FIPS密码的库更容易使用。
结论
加密是一种非常有效的数据保护方式,但目前部署的大多数加密都是IT基础架构的一部分,而不是应用程序的一部分。作为开发人员,我们有一个独特的机会,通过将应用层加密作为我们工具箱的一部分,来提高用户的隐私和安全性。确实存在一些挑战;加密数据可能更难管理,大多数加密库对于未经培训的开发人员来说都很难使用,但对我们的用户来说,这是值得的!
术语表
以下不是这些术语的正式定义,而是彩色注释,以帮助您了解这些术语和技术如何适用于应用层加密。
- 高级加密标准(AES):最常见的对称加密标准之一。
- 非对称加密:也称为公钥加密。速度较慢,但在密钥管理方面比对称加密更灵活。算法包括ECC和RSA。通常用于协商对称加密密钥。
- 块密码模式:由于像AES这样的对称密码只处理固定数量的比特(例如128),因此必须使用处理多个块的安全方法。不正确使用此类模式是一个常见的漏洞。常用的块模式有GCM、ECB(尽管它不安全)、CBC、SIV等。
- 域名系统(DNS):用于(通常)根据服务器名称识别服务器的协议。DNS是安全基础设施的关键部分,因为对DNS的控制可以让攻击者向最终用户模拟服务器。
- FIPS 140/NIST密码:由美国联邦政府审查用于各种用途的密码集合。一些行业要求使用经过审查的密码和实现。美国国家标准与技术研究院(NIST)将这些标准化。
- 硬件安全模型(HSM):用于安全管理加密密钥和操作的工具包。硬件层提供了额外的保护,例如防止特权利用。
- 初始化向量、salt和nonces:在加密算法中用作组件的随机数。根据算法和模式的不同,每种方法都可以具有不同的安全属性和用途。
- 完整性:一段数据不能更改的安全属性,或者如果它已经更改,则可以检测到更改,或者证明消息是由授权方生成的。MAC以及SHA2、GCM和Poly1305等算法可以帮助提供这种特性。
- 对称加密:类似AES的算法,双方使用相同的密钥进行加密和解密。比对称加密更快,但更难管理密钥,因为密钥需要在安全通道上交换。
- 传输层安全性(TLS):“传输中”通信加密的广泛标准。有时被称为HTTPS,但也适用于VPN等其他协议。
- 虚拟专用网络(VPN):对基于网络的通信进行加密。它保护用户行为的更多方面,而不仅仅是HTTPS,并且经常使用类似的技术。
- 61 次浏览
【数据加密】密码学教程
视频号
微信公众号
知识星球
密码学是一种通过将明文转换为难以理解的密文来确保通信安全的技术。它涉及各种算法和协议,以确保数据的机密性、完整性、身份验证和不可否认性。密码学的两种主要类型是对称密钥密码学和非对称密钥密码学。它在确保当今数字世界中信息的安全和隐私方面发挥着至关重要的作用,能够实现安全的在线交易,保护存储在数据库中的敏感数据,并确保通信的机密性。随着技术的不断进步,密码学仍然是保护我们的信息免受黑客攻击的关键工具。
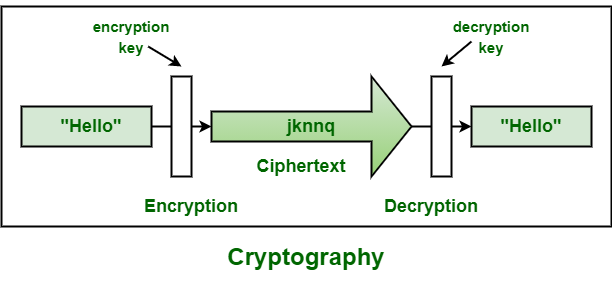
在本密码学教程中,我们介绍了密码学的基础和高级概念,包括对称密钥密码学、非对称密钥密码学以及密码分析、公钥密码学等。它为密码学的核心概念提供了坚实的基础,并深入了解了其实际应用。
在本教程结束时,您将基本了解密码学是如何工作的,以及如何使用它来保护您的信息。
What is Cryptography?
Cryptography is a technique of securing information and communications through the use of some algorithms so that only those persons for whom the information is intended can understand it and process it.
Cryptography Tutorial Index
Here are the latest topics of cryptography(basics to advanced):
Cryptography – Table of Content
- Introduction
- Types of Cryptography
- Data Encryption Standard (DES)
- Advanced Encryption Standard (AES)
- Public Key Cryptography Algorithms and RSA
- Cryptology, Cryptography and Cryptanalysis
- Common Used Cryptography Techniques
- Data Integrity in Cryptography
- Important Difference b/w topics of Cryptography
Introduction
- Introduction to Cryptography
- History of Cryptography
- Cryptography Principles
- Cryptography and its types
- Advantages and Disadvantages of Cryptography
- Applications of Cryptography
- What is Cryptosystem?
- Components of Cryptosystem
- Attacks on CryptoSystem
Types of Cryptography
- Symmetric Key Cryptography
- Stream Cipher
- Block Cipher
- Substitution techniques
- Ceaser Cipher
- MonoAlphabetic Cipher
- Playfair Cipher
- Hill Cipher
- Polyalphabetic Cipher
- One-Time Pad
- Transposition Techniques
- Steganography
- Asymmetric Key Cryptography
- Hash Functions
Data Encryption Standard (DES)
- What is data encryption?
- Encryption Algorithms
- Strength of Data encryption standard (DES)
- Double DES and Triple DES
- Difference between MD5 and SHA1
- Difference between RSA algorithm and DSA
- Difference between RSA and Diffie-Hellman
Advanced Encryption Standard (AES)
- Introduction to AES
- AES Structure
- AES Transformation Function
- Substitute Bytes Transformation
- ShiftRows Transformation
- MixColumns Transformation
- AddRoundKey Transformation
- AES Key Expansion Algorithm
- AES Examples
- Implementation of AES
- Difference between AES and DES ciphers
Public Key Cryptography Algorithms and RSA
- What is Public Key Cryptography?
- Four asymmetric public-key algorithms
- Rivest-Shamir-Adleman (RSA)
- Elliptic Curve Digital Signature Algorithm (ECDSA)
- Digital Signature Algorithm (DSA)
- Diffie-Hellman key agreement protocol
Cryptology, Cryptography and Cryptanalysis(密码学、密码学和密码分析)
- Introduction to Cryptology
- Types of Cryptology
- Cryptography
- Cryptanalysis
- Introduction to Cryptanalysis
- Types of Cryptanalytic Attacks
- Cryptology v/s Cryptography
- Cryptography v/s Cryptanalysis
- Cryptology v/s Cryptanalysis
Common Used Cryptography Techniques
- Custom Building Cryptography Algorithms (Hybrid Cryptography)
- An Overview of Cloud Cryptography
- Quantum Cryptography
- Image Steganography in Cryptography
- DNA Cryptography
- One Time Password (OTP) algorithm in Cryptography
- Modern Cryptography
Data Integrity in Cryptography
- Cryptography Hash functions
- Message Authentication
- Cryptography Digital signatures
- Public Key Infrastructure
Important Difference b/w topics of Cryptography
- Classical Cryptography and Quantum Cryptography
- Difference between Steganography and Cryptography
- Difference between Encryption and Cryptography
- Difference between Cryptography and Cyber Security
- Difference between Hash functions, Symmetric, and Asymmetric algorithms
- Difference between Stream Cipher and Block Cipher
密码学的特点
以下是密码学的一些功能:-
- 保密性:加密技术通过将敏感信息转换为不可读的形式,使其对黑客隐藏。
- 完整性:加密技术确保您的数据在传输或存储过程中保持完整和不变。
- 身份验证:密码学有助于验证发送者的身份并确认消息的来源。
- 不可否认性:密码学防止发送者拒绝参与消息或事务。
- 密钥管理:加密技术安全地管理用于加密和解密的密钥。
- 可伸缩性:密码学可以处理不同级别的数据量和复杂性,从单个消息到大型数据库。
- 互操作性:密码学允许不同系统和平台之间的安全通信。
- 适应性:密码学不断发展,以领先于安全威胁和技术进步。
密码学是如何工作的?
- ■明文:这是作为输入输入到算法中的原始可理解消息或数据。
- ■加密算法:加密算法对明文进行各种替换和转换。

密码学是如何工作的?
- ■密钥:密钥也被输入到加密算法中。密钥是一个独立于明文和算法的值。该算法将根据当时使用的特定密钥产生不同的输出。算法执行的精确替换和转换取决于密钥。
- ■密文:密文是作为输出产生的加扰消息。这取决于明文和密钥。对于一个给定的消息,两个不同的密钥将产生两种不同的密文。密文显然是一个随机的数据流,就目前情况来看,它是难以理解的。
- ■解密算法:这本质上是反向运行的加密算法。它获取密文和密钥并生成原始明文。
例如:-假设你想给你的朋友发一条秘密信息。你可以把信息写在一张纸上,然后封在信封里。然而,如果有人截获了信封,他们可以打开信封阅读信息。相反,您可以使用加密算法对消息进行加密。这将把信息转换成未经授权的个人无法读取的密文。
然后,你可以将密文发送给你的朋友,他可以使用相同的加密算法和密钥对其进行解密。密码系统的安全性取决于密码算法的强度和密钥的保密性。如果加密算法较弱,那么可能会破坏加密并读取明文。如果密钥不保密,那么它们可能会被泄露,这将允许未经授权的个人解密密文。
密码学的应用
- 用途:密码学广泛应用于各个领域,以确保数据安全和保护敏感信息。
- 安全通信:加密技术使加密消息应用程序和虚拟专用网络(VPN)等安全通信渠道能够保护通过互联网传输的对话和数据。
- 电子商务和在线交易:密码学在确保电子商务交易、在线银行和数字支付系统的安全方面至关重要。它保护敏感的金融信息,如信用卡详细信息和个人身份号码(PIN)。
- 密码存储:安全地存储密码对于防止未经授权访问用户帐户至关重要。哈希和盐析等加密技术有助于在数据泄露的情况下保护密码不易被泄露。
- 数字版权管理(DRM):数字版权管理系统使用密码学来加强版权保护,并防止未经授权复制或分发数字内容,如电子书、音乐和电影。
密码学常见问题解答
1.密码学的目的是什么?
密码学的目的是通过以只有授权方才能理解的方式对敏感信息进行编码来保护敏感信息。
2.非对称密钥密码学是如何工作的?
非对称密钥密码学通过使用一对数学上相关的密钥来工作:一个用于加密的公钥和一个用于解密的私钥。
3.哪些是常用的对称密钥算法?
常用的对称密钥算法包括AES(高级加密标准)、DES(数据加密标准)和3DES(三重数据加密标准(Triple Data Encryption Standard))。
4.量子计算机能破坏现有的密码系统吗?
量子计算机有可能打破现有的密码系统,因为它们能够比传统计算机更快地解决某些数学问题。
5.密码学是如何在电子商务交易中使用的?用一行字回答这些问题
加密技术用于电子商务交易,在传输过程中对信用卡信息等敏感数据进行加密,以确保其机密性和完整性。
- 76 次浏览
【数据加密】端到端加密:如何在web应用程序中加密数据
视频号
微信公众号
知识星球
在本文档中,我们讨论了在web环境中进行端到端加密的指导原则,以通过使服务器对加密数据视而不见来确保用户隐私。我们还提供了一个性能基准来评估加密的影响,具体取决于用户设备和数据大小。
介绍
端到端加密,引用自维基百科,是:
只有通信用户才能阅读信息的通信系统
例如,Signal和ProtonMail都使用端到端加密,其中端指的是用户:这保证了除了通信用户之外,没有人可以读取交换的数据。
这有时也被称为客户端加密,而不是服务器端加密,特别是因为当端实际上是服务器时,“端到端”术语有时会被误导性地使用。在这种情况下,数据在客户端和服务器之间被加密,但可以由后者解密。
在本文档中,end指的是用户的设备:目标是以服务器无法解密的方式加密应用程序中的数据。但为了避免任何混淆,我们将在下面使用“客户端加密”术语。
这些通用指南是在个人云环境中制定的,用户(我们称她为Alice)信任服务器正确管理她的数据并提供预期的服务。但她并没有给予它无条件的信任,尤其是对私人数据,如私人图片、机密文件、密码等。事实上,Alice知道,即使服务提供商遵循安全良好做法,并且在用户隐私方面似乎是可靠的,但任何服务器都可能被破坏,用户数据也可能泄露。
因此,我们假设服务器是半可信的威胁模型,即它将诚实地运行服务,不会试图偏离预期的计算,但可能会访问来自合法交易所的信息。请注意,这种威胁模型在垃圾堆中被认为是诚实但好奇的(见本文中的定义1)。
⚠️ 这并不意味着服务器有意对用户数据感到好奇。例如,舒适云对隐私非常谨慎,不会泄露任何用户数据。然而,如前所述,任何服务器都可能被破坏:因此,我们试图将服务器端的数据公开减少到最低限度。此外,值得注意的是,任何托管提供商实际上都可以运行Cozy服务器,因为代码是开源的。授予托管提供商的信任可能会有所不同,人们可能希望将敏感数据排除在服务器之外:端到端加密可以帮助实现这一点。
在本文中,我们提出了一个完整的端到端加密方案,从用户身份验证到加密数据的检索。我们特别关注可用性和可行性,因为我们认为这对加密的整体采用至关重要;安全性,尤其是加密,通常完全在技术方面掌握,很少或根本不考虑用户体验。
因此,我们没有追求最好的理论加密协议,而是更倾向于做出务实的选择,在现实世界的攻击场景中使用最先进的安全性来应对我们的威胁模型。
我们没有对要加密的数据类型做出任何假设,这些数据可以是图片、文本文件、密码等。然而,根据数据大小,可能会出现一些性能问题:因此,我们在一个名为Cozy Drive的开源文件管理应用程序中制定了一个基准,根据文件大小对实际加密影响提供了一些见解。
最后,值得一提的是,我们并没有重新发明轮子并构建自己的加密系统(这在密码学中总是一个坏主意),而是从使用客户端加密的现有行之有效的解决方案中获得了灵感,尤其是密码管理器,如1Password、LastPass或Bitwarden,存储系统,如Tresorit,或电子邮件服务,如ProtonMail。
⚠️ 本文件撰写于2020年上学期,反映了这一时期的知识。某些部分可能已经过时,这取决于实现的演变、最先进的进展等。
基线
- P:用户密码
- Km:从用户密码派生的主密钥。
- Hauth:身份验证哈希,根据用户密码计算。
- Kvault:一个随机生成的AES加密密钥。它由Km加密,并用于加密所有其他加密密钥。
- Kaes-i:AES加密密钥,随机生成。它由Kvault加密,用于加密用户数据。
- ivi:初始化向量,用于使加密不具有确定性。这意味着相同的明文不会产生相同的密码。
ℹ️ 用户密码是安全的根本。虽然它有一些已知的缺点(可能被遗忘、被盗、暴力强制等),但这是当今任何用户都知道的主要身份验证方法。已经有很多关于密码生成和最佳实践指南的资源,比如NIST的资源。作为补充,强烈建议启用双因素身份验证。
ℹ️ 密钥和IV生成必须正确进行,以保证加密的稳健性。参见NIST关于密钥生成的建议和IETF关于初始化矢量的备忘录。
❓ 为什么Kvault和Km
这是因为撤销:如果只使用Km,密码更改将迫使所有AES密钥重新加密,如果对许多文档进行加密,这可能是一个繁重的过程。这种间接方式只允许在密码更改后撤销Km并重新加密Kvault。
身份验证
由于密码用于计算加密主密钥Km,因此永远不应将其明文发送到服务器。
身份验证流由以下架构表示:

加密流程
一旦用户输入了她的密码,就会使用用户电子邮件作为盐,通过密钥推导算法对其进行哈希运算。生成的输出为Km。
然后,Km本身被作为salt与密码进行散列,以生成最终的密码散列。这个散列被发送到服务器,服务器根据它计算一个新的散列,以产生Hauth,即身份验证散列。如果它与数据库中存储的匹配,则服务器授予用户访问权限。
使用此协议,服务器不会了解任何有关用户密码的信息。
ℹ️ 该身份验证协议在很大程度上受到Bitwarden的启发,并在Cozy中进行了实现。
ℹ️ 客户端的密钥推导算法是PBKDF2。我们选择它而不是更现代的算法,如scrypt、bcrypt或argon2,因为它是一种众所周知的算法,通过SubtleCrypto实现,在现代浏览器中得到了广泛的使用和测试,并且本机支持。
在服务器端,我们选择了scrypt,因为它需要大量内存,因此设计成更能抵抗硬件特定的攻击,例如ASIC或GPU。
ℹ️ 迭代次数是一个可调的选择,也是对暴力攻击的鲁棒性和速度之间的权衡。100000是1Password和LastPass使用的值。
ℹ️ 该电子邮件被用作盐,这也是密码管理员Bitwarden做出的选择。任何持久的用户数据都可以使用,只要它足够长以确保唯一性,例如不是名称或邮政编码。在我们的实现中,此电子邮件是从用户域自动构建的。
加密
密钥库创建
加密过程从生成Kvault开始,该密钥将用于加密未来的AES密钥。
密钥库创建
加密
Kvault本身就是一个AES密钥,使用主密钥Km加密。它存储在数据库中,并在用户连接后进行检索和解密。然后,它可以用于加密数据:

数据加密
每个用户数据都使用专用AES密钥Kaes-i加密,Kaes-i本身也使用Kvault加密。请注意,iv必须始终不同,以使加密不具有确定性。
解密
- 当用户想要解密数据时,会执行以下步骤:
- 用户输入密码
- 计算Km
- Kvault由Km检索和解密
- 数据i与其关联密钥Kaes-i一起被检索
- Kaes-i使用Kvault解密
- 数据i用Kaes-i解密
ℹ️ 步骤1到3在会话期间只发生一次。Kvault保存在内存中,因此用户不必每次需要加密/解密时都输入密码。
ℹ️ 对于每个解密步骤,都会检索用于加密的iv。它可以与加密数据一起存储,不需要特定的保护。
密钥重用
Kvault可以用于加密/解密任何数据,只要每次使用不同的iv即可。然而,这可能会在某些加密方案中引入漏洞。
为了说明这一点,让我们假设A和B用相同的密钥K加密(这是一种简化;实际的AES机制实际上比这个例子更复杂):
- A ⊕ K = A'
- A ⊕ K = B'
- A'⊕ B' = (A ⊕ K ⊕ B ⊕ K) = (A ⊕ B) + (K ⊕ K) = A ⊕ B
因此,如果攻击者能够从A中知道一些比特,那么它将能够获得关于B的信息。
也就是说,如果我们假设K=Kaes-iõivi,那么对于两个不同的加密回合,K将永远不会相同,因为ivi总是不同的,这使得我们上面的例子在实践中不可能,因为实际上会有K和K',使得不可能在a和B之间获得任何信息。然而,对不同的数据使用不同的密钥被认为是一种很好的做法,因为如果ivi生成被破坏,它仍然可以保护加密,例如随机生成可能会发生这种情况。
以同样的方式,如果数据被更新,例如图片,则Kaes-i应该被撤销,并且生成另一个密钥Kaes-i以用新的ivi对图片进行重新加密。
数据共享
对每种数据类型使用不同的Kaes-i也可以简化数据共享:如果使用一个Kvault来加密所有内容,则共享将意味着共享Kvault,或者重新加密每个数据以与收件人的公钥共享。
前者在安全性方面是不可接受的,而后者效率不高:与对称加密相比,非对称加密的效率相当低,并且在共享许多和/或巨大文件时会导致严重的性能问题。此外,对共享数据的任何更新都需要使用公钥重新加密。
使用Kaes-i密钥可以简单地将数据密钥共享给接收者,并用他们的公钥加密。因此,接收者能够用他们的私钥解密Kaes-i,用他们自己的Kvault重新加密,并将其与共享数据一起存储。
密钥存储
加密密钥不应不安全地存储在用户设备上,即在没有任何保护的情况下解密。否则,这意味着一个受损的设备将能够解密任何数据。
在移动设备上,可以使用苹果的密钥链或安卓的密钥库。
在桌面环境中,硬盘驱动器可以在操作系统级别加密,也可以在硬件级别加密,例如使用Intel SGX飞地,在那里,密钥将通过直接存储在CPU中的密钥进行安全加密。
不幸的是,在浏览器中,目前没有简单的方法来安全地存储加密密钥;因此,我们强烈反对在浏览器中存储明文密钥。
技术指南
在本节中,我们将提供客户端加密的实现指南,并详细介绍我们所做的一些技术选择。
我们考虑了一个完整的JavaScript环境,因为它可以在浏览器中本地执行,也可以通过Cordova等框架在移动环境中执行,或者使用Electron在桌面中执行。
我们依赖WebCrypto API规范,因为它是W3C推荐的标准,已经过社区审核,并通过SubtleCrypto接口得到大多数现代浏览器的本地支持。
- W3C建议:https://www.w3.org/TR/WebCryptoAPI/
- 文件:https://developer.mozilla.org/en-US/docs/Web/API/Web_Crypto_API
- SubtleCrypto:https://developer.mozilla.org/en-US/docs/Web/API/SubtleCrypto
- 审核:https://hal.inria.fr/hal-01426852/document
尽管此API是最新的,但它主要用于:
ℹ️ WebCrypto API可用于浏览器和移动设备(例如Cordova),我们对其进行了测试。然而,桌面环境需要Node.js Javascript,它没有实现SubtleCrypto接口。本机支持一种替代方案,可以使用polyfill版本,尽管它是实验性的,目前还不推荐使用。
在下文中,术语generate、derival、wrap、unwrap、encrypt、decrypt指代它们的等价实现。
使用的对称加密算法是AES-GCM,它允许:
- 稳健的加密
- 数据完整性,得益于Gallois消息验证码(GMAC)
- 附加任意明文元数据
用于存储加密密钥的加密是AES-KW:它是专门为这项任务设计的,称为包装(反向展开),并允许像AES-GCM一样确保加密的完整性。
AES-KW的一个好处是,iv不需要产生非确定性加密,因为它在算法规范中进行内部处理。
ℹ️ 如果没有特别提及,性能测量是在Thinkpad T480上进行的,该T480配有i7-8550U CPU、16Go RAM和SSD。浏览器是Mozilla Firefox 70.0。
每个给定的度量都是1000次相同计算的平均值。
导出密钥
要从密码和salt(例如Km)派生强密钥,我们使用具有以下参数的SubtleCrypto.deriveKey():
algorithm;;指定派生算法的对象,这里是具有以下属性的Pbkdf2Params:name = PBKDF2salt = emailiterations = 100 000hash = SHA-256
- baseKey=P:派生输入,这里是用户密码
- derivedKeyAlgorithm={name:“AES-KW”}:派生密钥的加密算法
- extractable=false;表示以后不会导出密钥
- keyUsages=[“wrapKey”,“unwrapKey“];此密钥的授权操作。
性能
关键推导性能与迭代次数呈线性关系,如图所示:
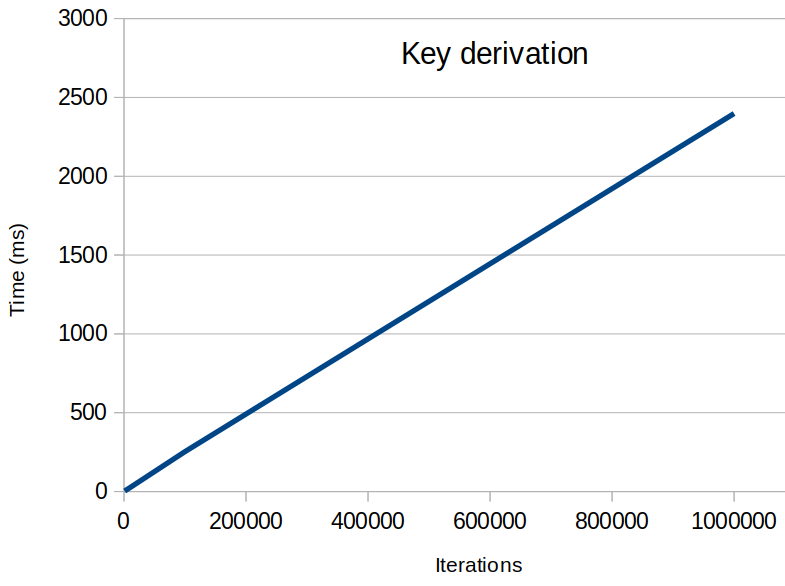
关键衍生性能
有关更精确的值,请参见下表:
| ITERATIONS | 1 000 | 10 000 | 100 000 | 1 000 000 |
|---|---|---|---|---|
| Time (ms) | 3 | 25 | 253 | 2398 |
迭代次数对安全性至关重要:越高越好,因为它会迫使攻击者执行更多操作,从而减缓攻击。
100000次迭代似乎是安全性和性能之间的一个很好的折衷方案。同样不应该忘记的是,我们在现代计算机上进行了测试,而一些用户可能拥有较旧的硬件,导致性能下降,这可能会阻碍用户体验。
有关迭代选择的更多见解,请参阅本文。
密钥生成
为了生成对称密钥,例如Kvault、Kaes-i,我们使用具有以下参数的SubtleCrypto.generateKey():
algorithm = {name: "AES-GCM", length: 256}; the encryption algorithm and the key lengthextractable = true; indicates that the key will be later exportedkeyUsages = ["encrypt", "decrypt", "wrapKey", "unwrapKey"]; the authorized operations for this key. Typically, a Kaes-i will have["encrypt", "decrypt"]while Kvault will be used to wrap/unwrap Kaes-i, thus["wrapKey", "unwrapKey"]
性能
密钥生成操作以及包装和展开在性能级别上并不重要,如下所示:
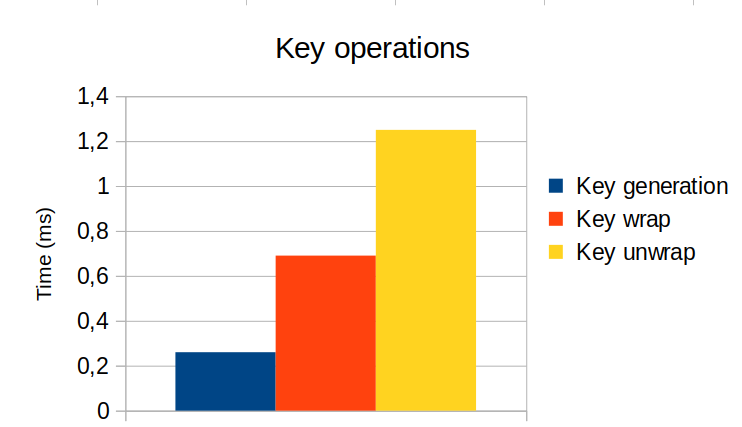
操作不超过1.2毫秒,这低于人类的感知。
密钥包装
要包装加密密钥,即以指定的格式加密并序列化它,我们使用具有以下参数的SubtleCrypto.wrappKey():
format = "raw"; the exported formatkey; the key to export, e.g. Kaes-iwrappingKey; the export key, e.g. KvaultwrapAlgo = "AES-KW"; the encryption wrapping algorithm
密钥展开
要打开包装的密钥,即按指定格式解密和反序列化它,我们使用SubtleCrypto.unwrapKey()和以下参数:
format = "raw"; the expected key formatwrappedKey; the encrypted key, e.g. Kaes-iunwrappingKey; the key used to wrap, e.g. KvaultwrapAlgo = "AES-KW"; the encryption wrapping algorithmunwrappedKeyAlgo = {name: "AES-GCM", length: 256}; the expected imported key format. If thewrappedKeyis Kvault, it will be{name:"AES-KW"}extractable = true; the key can be re-exported laterkeyUsages = ["encrypt", "decrypt", "wrapKey", "unwrapKey"]; the authorized operations on the imported key. Typically, a Kaes-i will have["encrypt", "decrypt"]while Kvault will be used to wrap/unwrap Kaes-i, thus["wrapKey", "unwrapKey"]
数据解密
要解密数据,我们使用具有以下参数的SubtleCrypto.decrypt():
- 算法;指定要解密的算法的对象。我们使用具有以下属性的AesGcmParams:
- name=“AES-GCM”;加密算法
- iv;在加密时随机选择的初始化矢量。它应该与加密数据一起检索。对于AES-GCM,建议使用96位iv。参见NIST建议。
- tagLength=128;预期GMAC长度。有关GMAC长度的见解,请参阅NIST的建议。
- 钥匙加密密钥
- 数据要解密的数据
ℹ️ 数据必须表示为BufferSource对象。
性能
解密的性能与加密大致相同,将在下一节中讨论。
数据加密
要加密数据,我们使用具有以下参数的SubtleCrypto.encrypt():
- 算法;指定要加密的算法的对象。我们使用具有以下属性的AesGcmParams:
- name=“AES-GCM”;加密类型
- iv;在加密时随机生成的初始化矢量。它应该与加密数据一起存储。对于AES-GCM,建议使用96位iv。参见NIST建议。
- tagLength=128;GMAC长度。有关GMAC长度的见解,请参阅NIST的建议。
- 钥匙加密密钥
- 数据要加密的数据
ℹ️ 数据必须表示为BufferSource对象。
加密性能
此外,我们还执行了数据加密的基准测试。为此,我们在Cozy Drive中实现了加密方法,这是一款纯客户端文件管理应用程序,用JavaScript和React编写,可以在浏览器和移动环境中运行,通过Cordova包装器,使用WebView。我们的实现使用WebCrypto API和上面描述的方法和参数。
我们关注的是文件加密,因为从用户的角度来看,它可能是最常见的数据类型。然而,任何类型的数据都可以与此实现一起使用,因为加密模块作为web模块与应用程序逻辑分离。所有代码都是开源的,可以在Github上获得。
除了加密成本本身,我们还评估了读取成本,因为这是加密文件的必要步骤。
我们在以下环境中进行了测试:
Desktop web browser (Firefox 70.0)
- Thinkpad T480 (i7-8550U CPU, 16Go RAM)
Mobile app
- iPhone 11 -iOS 13.3 (simulator)
- MacBook Pro (2.3 GHz i5 CPU, 16Go RAM)
- Webview: UIWebView
- iPhone X - iOS 13.3
Webview: UIWebView
- Xiaomi Mi 9 - Android 9
- Webview: Chrome 80.0
ℹ️ 所有Y轴均为对数刻度。
Firefox 70.0
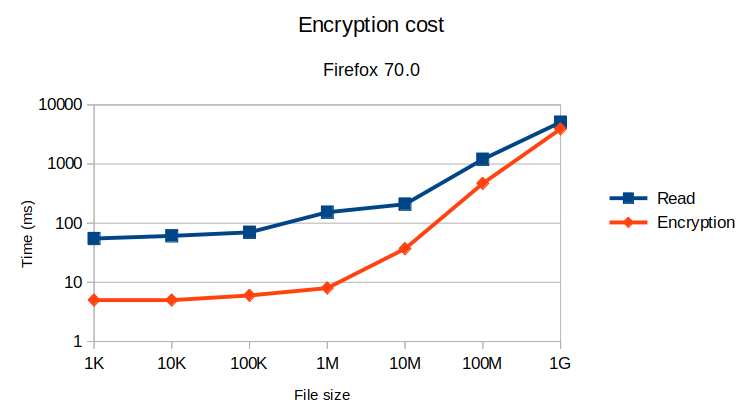
这表示在笔记本电脑上的Firefox浏览器中采取的措施。
正如我们所看到的,加密成本总是低于读取时间,并且只要文件大小较小,加密成本就相当低。
然而,我们可以注意到成本从1MB开始加速。在这个限制之前,加密成本几乎是免费的,不到20毫秒,10 MB的加密成本会跳到100毫秒以上。
有趣的是,这种加速似乎与FileReader API的文件块大小一致:然后我们可以假设这种开销可能是由将文件拆分为较小的块引起的。
然而,尽管有这种加速,成本与文件大小呈次线性关系。这是个好消息,但对于大文件来说仍然会带来巨大的成本:1 GB的文件上传需要大约10秒的读取时间和大约9秒的加密时间,因此总共需要将近20秒。
现在,让我们看看手机上的表演。
iOS 13.3 - Simulator iPhone 11
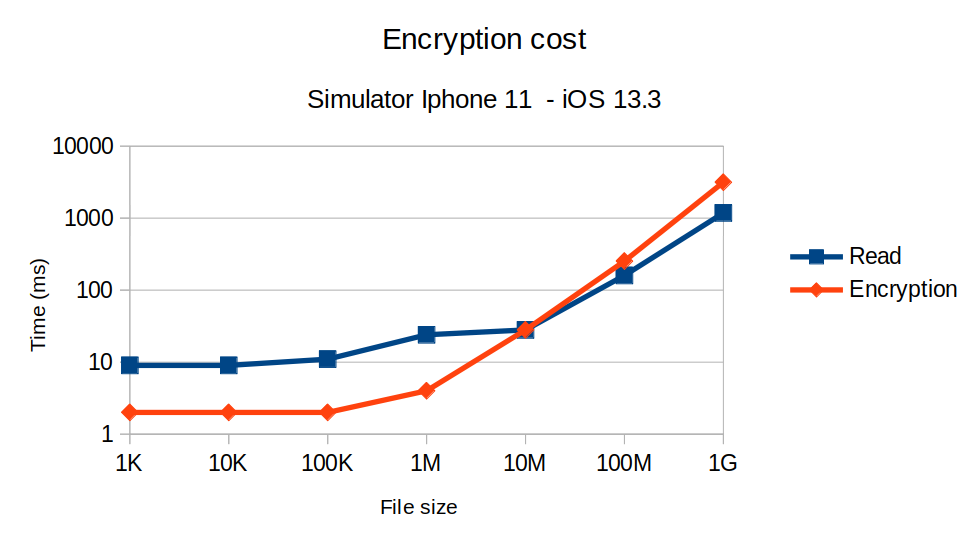
我们在苹果公司提供的iPhone 11模拟器中进行了这项测试。我们可以看到整体性能比在浏览器中要好。同样,当文件大于1MB时,成本往往会增加,尤其是对于加密。读取操作相对稳定,最高可达10MB。
然而,使用模拟器可能会对这种评估产生偏差,因为模拟器可能无法准确模拟移动硬件,尤其是CPU。因此,我们也在实际设备中进行了测量。
iOS 13.3-iPhone X
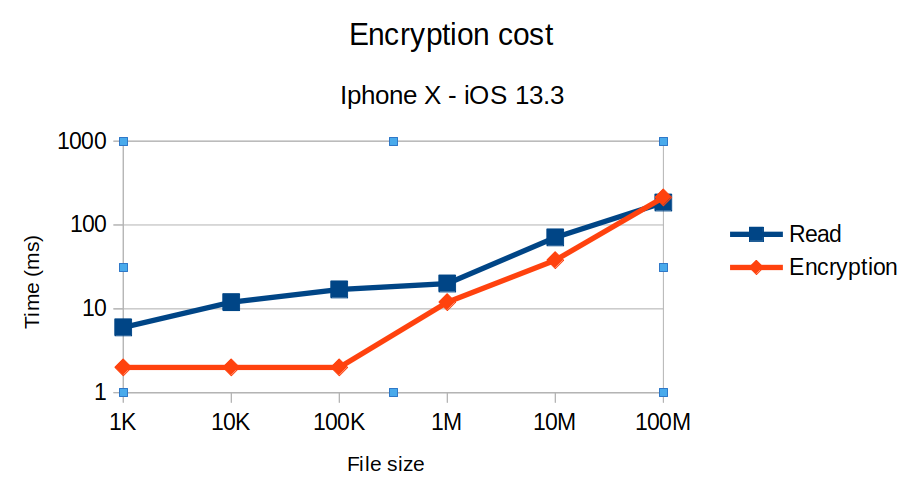
表演的形状实际上看起来与模拟器非常相似。请注意,对于1GB的文件没有度量标准,因为设备需要太多的内存来处理。设计处理大文件的策略可能很有趣,比如将文件分成块并分别加密每个部分,或者执行加密流。有关更多见解,请参阅下一节。
安卓9-小米小米9
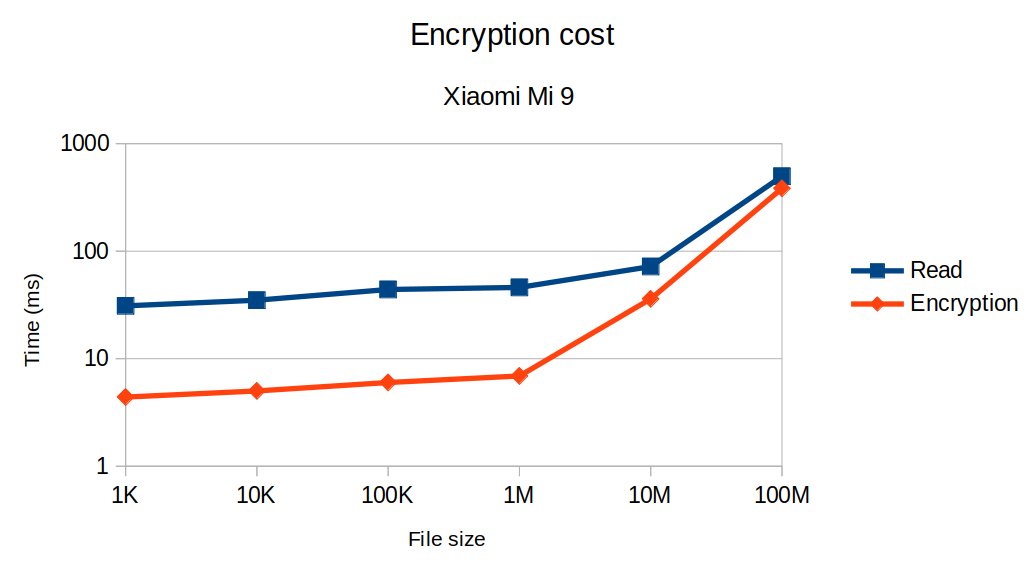
在安卓设备上,整体性能有点落后于iPhone,尤其是在读取方面,这可能是硬件差异造成的。
然而,值得注意的是,从1K到1MB的加密成本几乎相同。加速度为10 MB。
性能by 设备
在这里,我们将所有设备的性能分组,以强调环境差异。
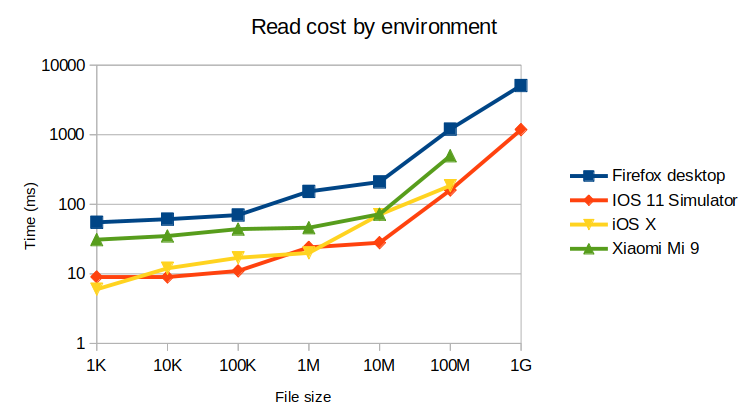
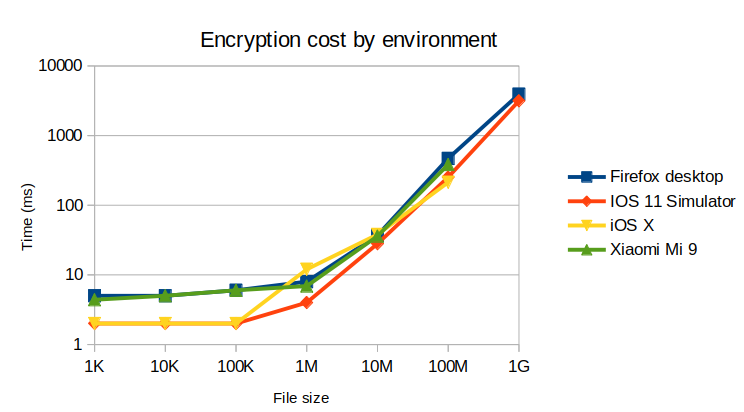
令人惊讶的是,与移动环境相比,Firefox桌面在读取操作方面表现不佳。我们还注意到,iOS在小文件上表现得很好,但所有环境在大文件上都能达到类似的性能,尤其是在加密方面。
性能调查结果
性能基准测试强调了这样一个事实:对于高达1MB的数据,加密成本几乎是微不足道的。因此,只要数据大小保持合理,客户端加密现在是现实的,即使在浏览器中也是如此。
随着文件大小的增长,加密的执行成本往往与读取操作相同,而读取操作对于大文件来说可能是相当大的。然后,有必要研究新的策略,以在不降低用户体验的情况下有效地应对这种成本。
Web workers
在我们的实现中,我们探索了使用网络工作者的可能性。这项最新技术在现代浏览器中可用,提供了在后台线程中运行任务的可能性。这对于会阻塞主线程并为用户提供冻结界面的计算量大的任务特别有用。
我们在一个网络工作者中实现了加密,对任务本身没有影响。然而,实际执行工人需要增加额外的成本。
同样值得注意的是,web工作者不共享内存,如文档中所述:
主页面和辅助进程之间传递的数据是复制的,而不是共享的。对象在交给工作者时进行序列化,然后在另一端进行反序列化。页面和辅助进程不共享同一个实例,因此最终结果是在每一端创建一个重复实例。大多数浏览器将此功能实现为结构化克隆。
因此,应该在web worker中执行整个数据上传,而不是读取主线程中的数据,将数据复制到worker并执行加密,这对于大文件来说可能非常消耗内存。
一个很好的实现例子是Firefox Send。
文件流
WebCrypto API仅允许通过块进行加密/解密;这意味着在执行操作之前必须完全加载数据。
在出现巨大文件的情况下,流式传输数据会更有效,以避免必须将数据完全加载到内存中一次,这可能会导致内存故障,就像我们在移动设备上的测试中所经历的那样。
遗憾的是,目前WebCrypto API还不支持此功能。关于这一问题已经公开,在本文件的编辑过程中仍在讨论。
请注意,仍然可以手动实现此流媒体,就像Mozilla为其发送服务所做的那样,但这需要额外的工作。
结论和观点
通过消息应用程序、电子邮件服务、密码管理器、文件存储等,客户端加密逐渐成为主流。
然而,尽管它对用户隐私有明显的好处,但在很大程度上仍然没有得到充分利用。
一个常见的批评是性能的影响,正如我们在本文档中所示,只要数据大小保持合理,性能就会保持相对较低。网络工作者和文件分割似乎都是降低成本的好选择,而且并不相互排斥。
此外,WebCrypto API的兴起大大减轻了开发人员的任务,提供了一个简单的API来加密/解密数据。然而,这个API的实际使用并不能直接做出正确的选择。我们希望本文档能为任何有兴趣实现客户端加密和身份验证的人提供全面的见解,同时还要记住加密决不能掉以轻心。引用自WebCrypto主页:
如果你不确定自己在做什么,你可能不应该使用这个API。
在客户端加密领域仍有许多挑战需要解决:我们在下面列出了其中一些挑战,并展望了未来。
改进的身份验证安全性
我们的身份验证方法的主要缺点是必须将从密码派生的哈希传输到服务器端。尽管据说它在密码上什么都没有透露,但由于强大的硬件和字典攻击,它仍然可以被窃取,稍后被破解。
SRP协议是一种零知识协议,它不需要从密码中获取秘密,也不会向被破坏的服务器或能够破坏TLS连接并执行中间人攻击的攻击者透露任何信息。该协议声称由1Password和ProtonMail使用,但比上述身份验证方案更复杂,也可以说更慢。
ℹ️ Mozilla有一个开源的Javascript实现,声称在其身份协议的生产中使用。请参见节点srp。
不可靠服务器
在web上下文中,服务器动态地传递由浏览器运行的脚本。然后,服务器被认为是可靠的,可以传递正确的代码。
然而,正如ProtonMail的安全分析中所提到的,欺骗性服务器可能会提供损坏的脚本来拦截用户密码并能够解密其数据。
我们在威胁模型中没有考虑这种攻击,因为它超出了“诚实但好奇”的假设,但我们提到它是为了彻底。
解决这个问题的一种方法是使用SRI安全功能,该功能在浏览器中可用,现在由ProtonMail使用:提供HTML的服务器必须提供脚本的哈希,该哈希将由浏览器计算以确保其完整性。如果值不匹配,则可能表明服务器没有提供预期的资源:因此脚本被阻止。
然而,如果传递脚本的服务器与传递HTML的服务器相同,这是不够的:然后散列可能是损坏的Javascript中的一个。
但是,如果服务提供商以开源的方式发布带有预期哈希的脚本,任何人都可以检查服务器是否提供了预期的代码。虽然这并不令人满意,因为它需要用户手动操作,但它对服务器提供的内容添加了一些控制。
服务器端计算
进行客户端加密时的一个严重缺点是服务器端计算能力的丧失。由于数据被加密,服务器无法对其进行处理,如索引、人工智能计算、搜索等。
没有通用的解决方案来克服这个依赖于许多变量的问题,并且需要在加密表面、性能、协议复杂性等方面找到折衷方案。
例如,可以保持索引数据的清晰,例如文件层次结构、创建日期等,但代价可能会削弱用户隐私。
使用PouchDB这样的浏览器数据库,也可以在客户端加密索引和执行查询,但这是以性能和可扩展性为代价的。
另一种方法包括以确定性的方式加密客户端上的数据,以便可以对加密的术语(例如目录ID)进行索引和检索。这里的缺点是基于频率的攻击的风险,攻击者会观察查询的时间和结果来推断信息。
更复杂的解决方案涉及同态加密,它允许直接对加密数据进行处理,而不需要随时解密。这仍然是一个活跃的研究主题,但目前看来,计算量太大,上下文太特殊,无法成为一个实用的解决方案:在最佳情况下,AES128块需要大约4分钟才能进行评估,任何同态处理都需要特定而复杂的设计,必须仔细分析。
用户密码丢失
在所提出的加密方案中,安全性的根源是用户密码。因此,如果用户丢失了密码,就无法恢复加密的数据,因为服务器永远不会知道加密密钥。这是面向安全的产品(如密码管理器)所承担的风险,但在其他情况下这可能是不可接受的。
在密码丢失后恢复加密数据的一个优雅的解决方案是使用Shamir的秘密共享。其原理如下:
- 用户选择一定数量的可信收件人,例如5个,以及法定人数,例如3个。
- 用户密钥,这里是主密钥,被拆分为与受信任的收件人一样多的共享。
- 用户通过安全通道将共享分发给受信任的收件人。
如果用户丢失了密码,她会联系她信任的收件人以获得他们各自的共享。她只需要取回与法定人数相等的股份就可以收回秘密。
虽然很简单,但该协议提出了许多问题,特别是用户体验、接收者的发现、授予接收者的信任、共享的可持续性等。
- 415 次浏览
【数据加密】选择正确的加密级别来保护您的数据
视频号
微信公众号
知识星球
如今,为了确保组织遵守不同行业和地区的法规,在静止状态下加密数据至关重要。例如,医疗保健组织必须遵守HIPAA。银行和支付组织必须遵守各种法规和标准,包括PCI DSS、SOX和GLBA。存储客户数据的零售商还必须遵守隐私法规,以便在发生安全漏洞时最大限度地减少对客户的影响。除了特定行业的法规外,特定地区的法规(如欧洲的GDPR、加利福尼亚州的CCPA、巴西的LGPD和香港的PCPD)的影响远远超出了其规定的范围。例如,GDPR表面上可能是针对欧洲的,但在欧洲从事任何业务的组织(如为欧洲客户飞行的航空公司)都必须遵守GDPR。
本博客将分析三种不同级别的加密,为什么需要它们来保护您的私人数据免受攻击,以及它们的具体用例。
让我们从一个简单的问题开始:为什么不加密网络上的所有数据,这样我们就可以得到所需的保护?答案是一个挑战:因为我们将无法对加密数据进行分析,也无法从数据中提取见解来推动业务价值(例如,优化供应链,减少客户流失,免费为客户提供更多服务,减少欺诈等)。
数据加密和安全方面的挑战
在讨论数据安全时,我们面临的最大挑战是一方面保护数据,另一方面允许访问受保护的数据进行分析。那么,解决方案是什么呢?
至关重要的是,让数据科学家和分析师能够阅读数据,以获得见解,以营销优化的形式推动业务价值(例如,有针对性的活动),关注销售增长,并优化业务效率以降低运营成本。虽然数据可以帮助实现这些目标,但保护数据对于保持法规遵从性、防止巨额罚款、建立客户信任和提高品牌价值同样重要。
理想情况下,应优先考虑安全和分析;然而,当面临确保安全或执行分析以提取见解的挑战时,由于控制不力,公司会以限制对数据的访问为代价来优先考虑安全性,从而使使用数据可以实现的业务价值达到数百万美元。
加密是保护数据安全的一个方面。我们可以加密所有数据,这将是安全的,但加密的数据对推动见解没有用处。让我们看看三个加密级别以及它们如何保护您:
- 全卷或透明数据加密
- 文件或数据区域级加密
- 属性或字段级加密

Transparent Data Encryption
第一级加密是透明数据加密(TDE)或全卷加密。它通过加密磁盘上的所有数据来工作。例如,在Azure中,可以使用Azure存储服务加密(SSE)启用TDE。当客户端应用程序读取数据时,Azure SSE只需在返回数据之前对其进行解密。这种加密级别的性能开销是最小的,因为它发生在文件系统级别以下,并且整个磁盘都是加密的。因此,解密和加密密钥管理由Azure完成。在AWS上,类似的服务,服务器端加密(SSE-S3),可以用于加密磁盘上的所有数据。
那么,这种级别的加密是如何保护您的呢?TDE可在物理磁盘丢失的情况下防止未经授权的数据访问。例如,如果你的笔记本电脑在机场被盗,TDE会阻止恶意行为者解密和读取你的数据。TDE在数据中心级别似乎没有什么价值,因为有人偷走你的磁盘并实际拿走你的磁盘的可能性很低;然而,在数据中心的情况下,更可能的情况是对旧硬件的不当处理,这可能会导致未经授权的用户访问您的数据——这就是为什么需要在休息时进行全卷加密,以确保符合PCI DSS、GDPR、CCPA、HIPAA和其他一些法规。
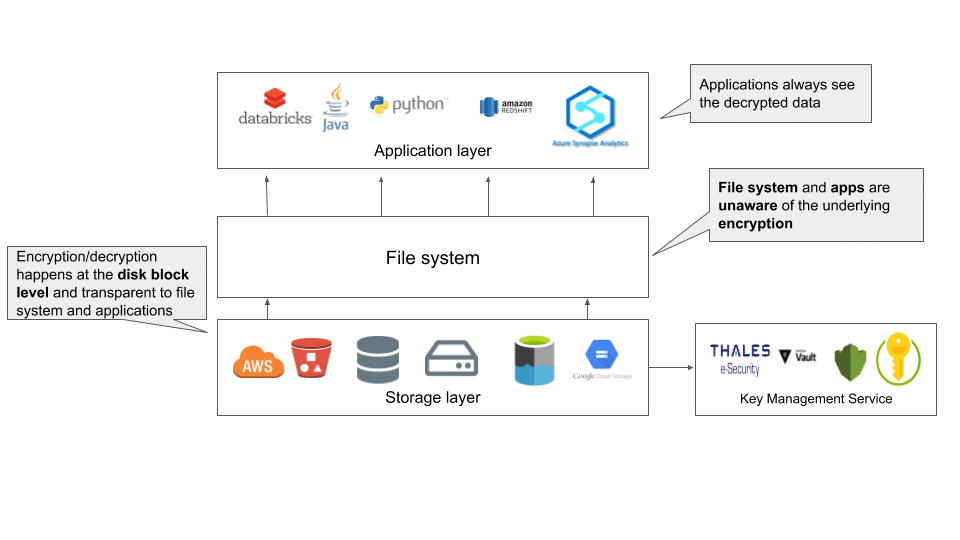
File or Data Zone Level Encryption
全卷加密可在存储介质物理丢失的情况下提供保护,但不能在消耗级别保护敏感数据。因为加密/解密发生在文件系统级别以下,所以所有应用程序和用户都会获得解密的数据,这导致敏感数据暴露给所有读取数据的应用程序和使用者。为了保护敏感数据,组织可以使用文件级加密来加密整个数据文件。这种类型的加密的扩展是区域级加密,即创建加密的区域,并对该区域内的所有文件夹、子文件夹和文件进行加密。文件或数据区域级加密允许企业为所有用户加密数据,并为授权用户设置策略,然后授权用户可以对解密的数据运行分析。
由于这种级别的加密会影响整个文件,因此只有授权用户才能看到解密的数据,因为文件无法部分解密。例如,如果数据文件包含SKU、订购数量、价格、客户名称和地址,任何看到该文件的人都将看到所有五个属性。不可能只选择性地加密一个人的姓名和地址,这意味着任何未被授权访问敏感信息的人都不能使用这些数据来生成见解。
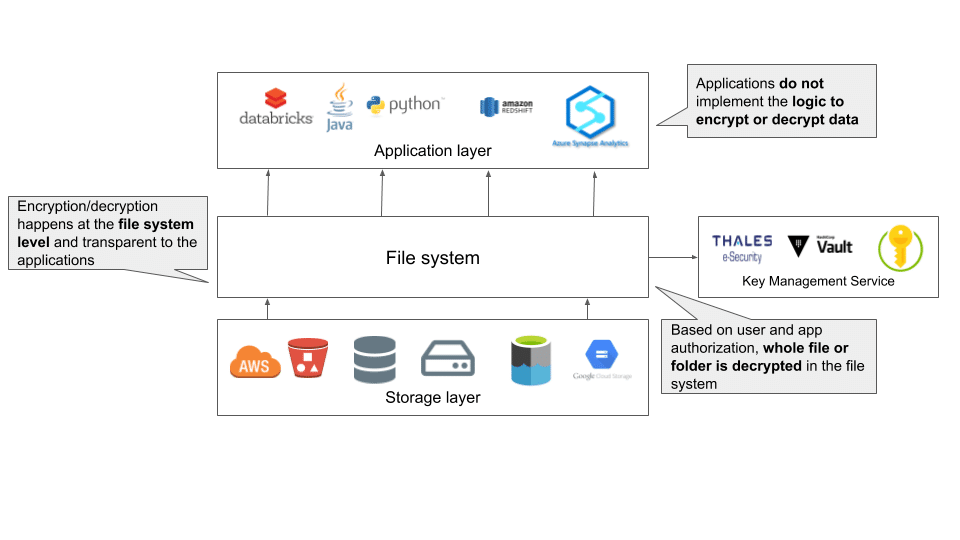
在组织内外共享数据时,文件或数据区域级加密非常有用,因为加密的文件或文件夹可以单独发送,密钥可以安全共享以解密文件。这样可以确保没有恶意行为者能够解密文件并访问内容。建议对不同的文件、文件夹和区域使用单独的密钥,并在安全的密钥管理系统中进行管理。
属性或字段级加密
属性级或字段级加密是最细粒度的加密形式。该过程允许您选择性地仅加密文件或数据库中的敏感数据。实施属性级加密使组织能够只加密敏感信息,并在不影响数据合规性要求的情况下向更大的组织开放数据进行高级分析。敏感数据仅针对基于角色的选定用户进行解密。此外,属性级加密提供了算法,如格式保持加密(FPE),以支持对加密数据的分析,向整个组织开放分析,而不会暴露解密数据的风险。
属性级加密更难实现,因为必须支持应用程序级加密和解密。来自受支持应用程序的授权用户可以看到解密的数据,而所有其他应用程序和用户的数据仍然是加密的。
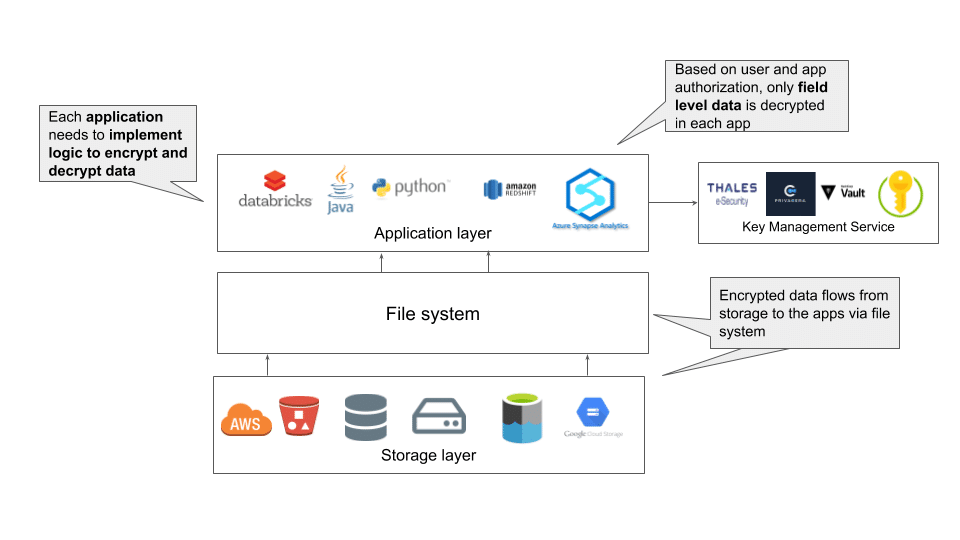
在各个行业和地区,组织必须驾驭与保护其敏感数据相关的新攻击媒介和风险。三种基本的加密方法(全卷加密、文件或数据区域级别以及属性或字段级别)对于保护数据免受这些攻击矢量的攻击至关重要,并为不同的用例提供不同的用途。为了确保敏感数据的全面可见性和控制,组织应采用所有三种加密方法,以确保在整个企业中安全访问其数据,同时严格遵守各种隐私法规和标准。
帮助客户在现场和属性级别加密数据,使数据科学和分析团队能够利用更多数据建立模型和提取见解,以推动新的商业机会,从而提高客户满意度和优化业务效率。
- 60 次浏览
【数据安全】2023年9大秘密管理工具
视频号
微信公众号
知识星球
当涉及到开发软件时,秘密是以安全的方式连接一切所必需的。机密的验证是服务器如何知道他们得到的请求的源标识。通常情况下,通常的做法是将所有内容都写在清晰的文本中,并抱着最好的希望。
但这不是最好的做法。它通过意外的代码版本控制提交,使您的软件和应用程序暴露在潜在的漏洞中。此外,它将您的代码秘密、密钥、身份验证凭据、API和令牌放在一个空间中,如果意外添加到代码库中,则可以很容易地查看这些空间。
创建秘密管理工具是出于这个特定的原因——以确保凭据和代码秘密的安全、有序,并可供合适的人员和机器访问。
在介绍前九大秘密管理解决方案之前,你应该知道2022年,让我们快速回顾一下什么是秘密管理及其好处。
什么是秘密管理?
秘密管理是一类工具,允许开发人员以可访问性控制的方式安全存储密码、密钥、私人信息和令牌等敏感数据。
对于小型应用程序来说,管理机密似乎并不那么复杂。然而,随着团队和软件代码库的增长,应用程序生态系统中的秘密数量也在增加。工具、容器、微服务和API连接需要保密,以确保其内容的安全。

丢失密钥或将其硬编码到脚本中,或者访问需要安全管理的超级用户权限并不困难。秘密管理的功能消除了对硬编码和嵌入秘密的需要,增强了密码安全性,并对自动化脚本、帐户和具有日志的个人用户应用基于权限的会话以保持审计跟踪。
为什么你应该在2023年使用秘密管理工具
虽然许多框架和DevOps进程都是预先准备好的安全凭据,但它们的默认值是公开的,很容易被恶意用户破解。
秘密管理不善经常出现在Jenkins、Ansible、Puppet和Chef等工具中。由于它们是为优化速度和交付而设计的,因此在生产中,安全问题通常会通过自动化配置出现,这需要机密才能访问数据库和SSH服务器等受保护的资源。
据估计,对机密的不当管理每年会给公司带来120万美元的损失。根据1Password的研究,“60%的IT和DevOps组织已经泄露了秘密”,77%的前员工仍然可以访问他们以前的工作场所系统。
这就是为软件开发过程和堆栈提供秘密管理工具的地方。除了确保一切安全和集中之外,这些工具还涉及安全标准,并将合规性外部化给专门从事最佳实践的第三方和供应商。
有大量的秘密管理工具可用。以下是您需要为您的团队、CD/CI流程和软件开发集成检查的前9项。
2022年9大秘密管理工具
1.HashiCorp Vault
基础设施不再是静态的和内部部署的。一切都转移到了云端,这意味着多个供应商和服务提供商。除此之外,自动化还确保了数字资产的动态扩展,应用程序和服务器根据需求不断增长和萎缩。如何实现安全需要匹配未知的网络周长,并安全可靠地执行身份验证。

HashiCorp Vault允许开发团队存储、管理和控制对令牌、密码、加密密钥和证书的访问。这是通过各种访问方法实现的,如用户友好的界面、控制台或通过API,使其易于用于不同类型的用户。
2. Spectral Secret Scanner
秘密管理工具非常适合将所有东西放在一个地方。它们为开发团队提供了当前使用的秘密的集中视图。然而,不能仅仅依靠秘密管理工具。秘密扫描是安全SDLC的关键组成部分,可以避免秘密管理工具无法检测到的泄漏。
Spectral Secrets Scanner是一款秘密扫描工具,可提醒您软件和基础设施中的任何秘密或漏洞。它允许您监控、分类和保护您的代码、资产和基础设施,使其免受暴露的API密钥、令牌、凭据和高风险安全错误配置的影响。
3. AWS Secrets Manager
AWS了解保密和控制秘密的艰巨性。AWS Secrets Manager可让您轻松地旋转、管理和检索数据库凭据、API密钥和密码。如果您的软件开发流程和应用程序已经在AWS服务生态系统中,那么使用AWS Secrets Manager更容易集成到您的工作流程中。
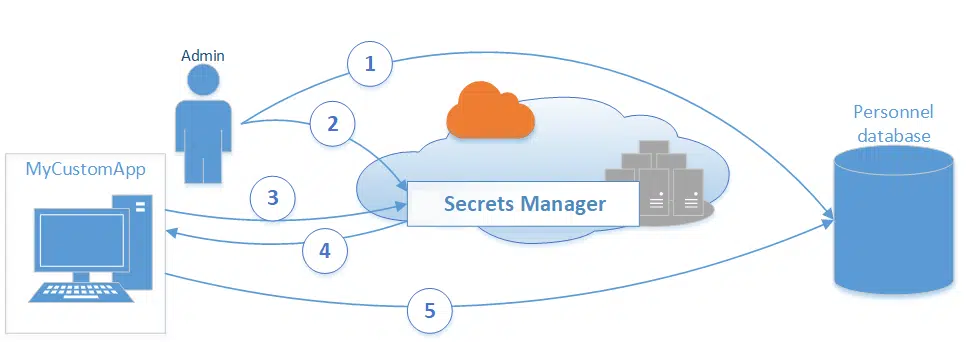
AWS Secrets Manager的功能包括机密加密、机密管理器API和客户端缓存库。如果亚马逊专有网络配置了端点,它也会将流量保持在AWS网络内。
4. Cloud KMS
云密钥管理系统(Cloud KMS)是谷歌云的秘密管理版本。

Cloud KMS旨在以可扩展和超快的方式集中密钥管理,并具有高度的合规性、隐私性和安全性。Cloud KMS的功能包括创建、旋转和销毁对称和非对称密钥。还可以选择创建自动安全策略,允许您批准或拒绝对密钥的访问。
5. Microsoft Azure Key Vault
如果您的软件和应用程序在Azure上运行,Microsoft有Azure密钥库,以确保您的所有机密都在一个存储库中进行管理。这包括密钥、证书、连接字符串和密码。与Cloud KMS类似,您也可以创建加密密钥并将其导入Vault进行管理。
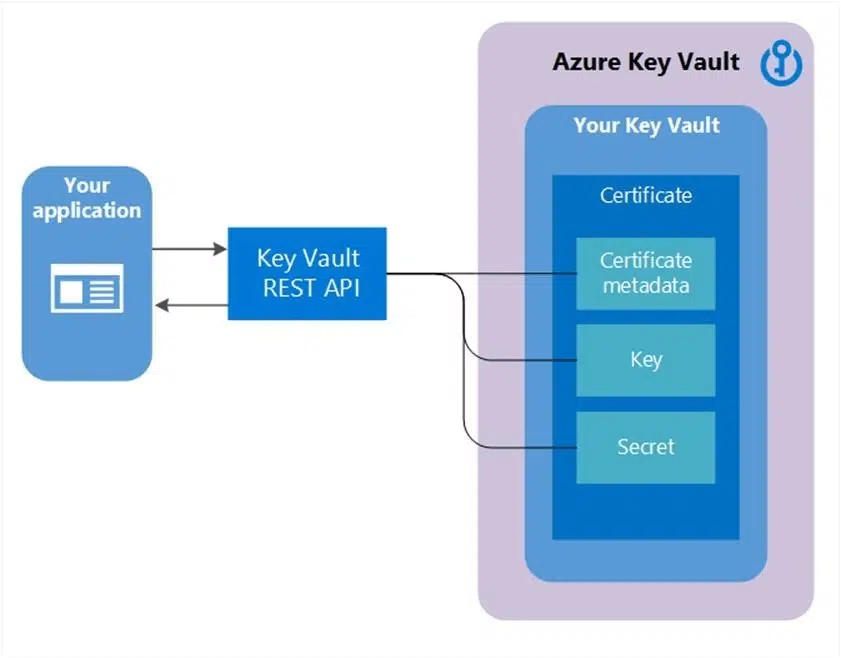
此外,您还可以自动化SSL/TLS证书续订和轮换,以便您的连接始终保持安全。
6.Confidant
Confident由Lyft的开发人员创建,是一个开源的秘密管理系统,提供了一个用户友好的界面来处理安全存储和访问秘密。
创建Confident是为了解决和自动化IAM角色的AWS KMS授予,允许IAM角色生成令牌,以便在服务到服务身份验证之间使用。这意味着加密消息可以通过映射和更改历史记录在具有版本控制可用性的服务之间传递。
7.Keywhiz
Keywhich是Square的一个秘密管理和分发系统。作为一家年收入超过94.9亿美元的金融服务机构,他们了解安全、管理和分发机密的必要性。Keywhich的创建是为了消除在配置文件中放入机密并将文件复制到范围外的服务器的易受攻击的做法。
泄露的钥匙很难追踪。Keywhich使TLS证书、GPG密钥、API令牌和数据库凭据等机密易于存储、管理和由合适的应用程序和用户访问。Keywiz的工作原理是通过mTLS上的自动化API在加密和集中存储的数据库中创建集群服务器。
8.Knox
Pinterest创建了Knox,作为存储和轮换机密、密钥和密码的服务。Knox背后的想法是通过轻松地旋转密钥并将其排除在git存储库之外,来确保密钥不会被泄露。
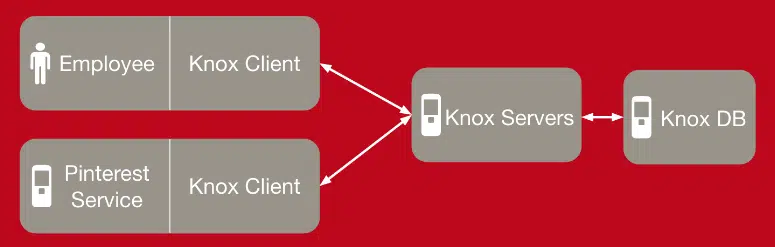
这使开发人员能够访问和使用机密机密、密钥和凭据,而不会受到损害。除了保留审计日志外,密钥轮换还允许通过失效过程和密钥发布实现安全机制。
9. Strongbox
Strongbox开源,兼容KeePass和Password Safe,是iOS和macOS的安全密码管理系统。虽然它表面上看起来像是一个基于设备的密码保管器,但它也允许您访问令牌、私人证书和加密密钥。
您可以选择在本地或基于云的服务中存储凭据,如iCloud、Dropbox、OneDrive、Google Drive和WebDAV。
总结
秘密管理是安全软件开发和基础设施自动化不可或缺的一部分。对于许多组织来说,代码秘密经常被忽视,并保存在不安全的空间中,如配置文件或推送到git存储库。秘密管理工具通过一个集中的系统来帮助组织保守秘密,该系统尽最大努力减少视图的可访问性。
但失误是可能发生的,而且确实会发生。秘密扫描与秘密管理一样重要,因为它通过预防增加了另一层保护。秘密扫描可以帮助防止安全SDLC的关键组件存在漏洞,并通过检测避免泄漏。
- 157 次浏览
【数据安全】秘密管理指南——方法、开源工具、商业产品、挑战和问题
视频号
微信公众号
知识星球
保密管理是个难题。有许多不同的方法和工具,以及该领域的新创新。因为我们非常关注CryptoMove的这一新兴领域,所以我们将这篇帖子作为一种资源,提供给任何正在思考或试图了解更多秘密管理的人。如果这是您感兴趣的领域,我们现在正在为CryptoMove的Tholos Key Vault运行私人测试版,我们正在招聘!
- 概述
- 一、无工具的默认秘密管理方法
- 二、为什么秘密管理很重要
- III、 机密管理的选项、工具和商业解决方案
- IV、 秘密管理的主要目标(双关语)
- 五、保密管理面临的挑战
一、默认秘密管理办法
通常,机密管理默认为最简单、最快的。当开发人员在AWS、GCP、Azure或其他云原生环境中共同开发映像时,这种情况并不少见。PEM文件、SSH密钥和其他配置机密以明文形式通过各种通信通道传递。一些最流行的“反模式”:
- Slack
- GitHub
- Hard-coding
- Clear text config files
- Unencrypted laptop filesystems
有很多例子表明,默认的“快速而简单”的秘密管理和共享方法导致了devops和云转换的问题。
二、为什么秘密管理很重要
由于基础设施和软件开发过程的变化,秘密正在广泛扩散。以下是企业转型影响大规模机密管理的几种方式:
- 云原生开发和多云基础设施。导致秘密激增。随着团队开发云原生应用程序,存储、计算、分析、日志记录和数十种其他服务的秘密变得非常重要,需要共享和管理。AWS仅拥有近100个服务(如果不超过100个的话),所有这些服务都需要通过秘密进行中介,包括API密钥、SSH密钥、令牌、证书和配置。
- 机器身份和机器对机器的通信与用户身份一样重要,甚至更重要。在传统的企业架构中,人类用户是关键。人的身份对于访问文档、电子表格、电子邮件和其他工具非常重要。然而,现代企业通常有数以万计的基于机器的身份,需要通过令牌、API密钥、证书和其他机密进行管理和中介。自动化和AI/ML将继续从人类用户身份向基于机器的身份转变。
- 基于DevOps流程和微服务的架构也导致了秘密的扩散。正在进行DevOps转换的团队行动迅速,并管理许多不同的基础设施环境和服务,以进行开发、测试、集成和部署。DevOps环境的秘密管理作为安全软件开发生命周期的一部分至关重要。
- 人工智能和数据分析也为这些管道带来了许多需要管理的秘密。
- 物联网、机器人和嵌入式设备的激增导致了秘密的激增,因为每个物联网端点都需要加密和证书。
- 企业中的区块链项目也会产生比应用程序中通常使用的更多的私钥。现在需要一个“企业钱包”来管理所有这些私钥。
许多主流的《全球2000强》和《财富》500强企业在这方面落后了,他们坚持使用专注于加密密钥的传统HSM,并在基于多云和服务的架构中努力管理机密。
但是,为什么HSM和传统的加密密钥管理产品不能用于现代秘密管理呢?
在某些情况下,还有用于加密、数据库甚至云服务的遗留密钥管理产品。许多团队遇到的困难是,当这些遗留工具用于devops和云基础设施相关密钥时,如API密钥、pem文件、微服务机密、令牌和其他密钥。我们看到了能力上的差距,由于各种原因,他们无法满足这些需求。以下是我们在与开发现代基于云的devops工作流的团队交谈时收集到的遗留密钥管理解决方案的一些挑战:
- 重点关注加密和PKI相关密钥和证书,而不是真正的API密钥
- 没有云原生架构
- 不是为DevOps流程构建的
- 缺乏使用多云服务生成和轮换动态机密的能力
- 缺乏容器和微服务的能力
CyberArk是一家老牌公司试图填补其产品漏洞的例子。他们实际上购买了一个名为Concur的开源秘密管理工具来增加这一功能。以下是CyberArk宣布收购Concur的方式:
CyberArk旨在利用收购Congur的成果,提供一个“企业级、自动化的特权账户安全和机密管理”平台,以确保DevOps生命周期和云原生环境的安全,从而彻底改变DevOps的安全性。这很好。由于DevOps实践,特权帐户凭据(SSH密钥、API密钥等)在整个IT基础设施中激增。CyberArk收购了Concur,试图训练和驾驭这匹软件开发的野马。
其他传统的密码和密钥管理以及加密供应商没有解决这一能力差距,因此他们在某种程度上落后于8球。
云基础设施和devops的秘密管理能力存在这种差距,这就是为什么许多公司在内部构建了自己的秘密管理工具,并有助于解释为什么有这么多开源方法——如下所示。这种针对秘密管理问题的多种开源解决方案的现象表明,对于现代开发组织来说,这是一个相当大的痛点。
III、 机密管理选项
目前还没有真正的行业标准,因为在这个领域一切都还很早。在CryptoMove,我们正在开发一种企业可扩展的秘密管理解决方案,该解决方案利用了移动目标防御技术。稍后会详细介绍。
由于缺乏太多现成的解决方案,许多公司都试图构建自己的秘密管理工具。以下是一些:
Square — Keywhiz
Keywhich是Square制造的一种工具,在生产中运行了一段时间。它具有许多用于存储和管理应用程序和基础结构机密的功能。Square对Keywhich的描述如下:
“Keywhich使管理机密变得更容易、更安全。群集中的Keywhich服务器将加密的机密集中存储在数据库中。客户端使用相互身份验证的TLS(mTLS)来检索他们可以访问的机密。经过身份验证的用户通过CLI管理Keywhich。为了启用工作流,Keywhich通过mTLS提供了自动化API。”
Pinterest — Knox
Pinterest还建立了自己的秘密管理工具并开源,称其为Knox(如在Fort Knox)。以下是Pinterest面临的问题,这些问题导致了Knox的创建:
“Pinterest有大量的密钥或秘密,比如签名cookie、加密数据、通过TLS保护我们的网络、访问我们的AWS机器、与第三方通信等等。如果这些密钥被泄露,请旋转(或更改我们的密钥)过去是一个困难的过程,通常涉及部署和可能的代码更改。Pinterest中的密钥/机密存储在git存储库中。这意味着它们被复制到我们公司的所有基础设施上,并出现在我们许多员工的笔记本电脑上。无法审核谁访问或谁有权访问密钥。诺克斯就是为了解决这些问题而建造的。”
根据Pinterest,Knox的目标是:
“便于开发人员访问/使用机密机密、密钥和凭据
机密、密钥和凭据的保密性
在出现折衷的情况下,提供钥匙旋转机制
创建审核日志以跟踪哪些系统和用户访问机密数据”
Lyft--Confident
Lyft的秘密管理方法产生了一种名为Confident的工具。Lyft在描述中简洁而甜蜜:“你的秘密守护者。将秘密存储在DynamoDB中,在休息时加密。”
在描述Lyft试图与Confident解决的问题时,Lyft解释说,有了所有新的内部和外部服务,追踪密钥和秘密变得非常困难:
“随着Lyft的发展,我们在基础设施中添加了许多服务。这些服务具有内部服务和外部服务的凭据、SSL密钥和其他类型的机密。这些服务中的每一个都有多个环境,为了使这些环境相互隔离,它们为每个环境都提供了这些机密的一个版本。在许多情况下,其中一些机密可能可以在几个服务之间共享。给定大量的服务,这将导致大量的凭据。
这些秘密的轮换可能是一个费力的过程,尤其是外部服务的凭据,因为大量外部服务没有轮换方法,而这些方法可以在没有一定停机时间和协调的情况下完成。机密轮换的协调在很早的时候就成为了一个困难而耗时的过程,我们知道随着我们增加更多的内部服务和更多的外部依赖,问题只会变得更糟。”
以下是《黑客新闻》对Confident的讨论,有很多有趣的反馈和赞美。
许多其他科技公司已经尝试或正在尝试创建自己的秘密管理工具。说出一家大型科技公司的名字,他们可能正在做这项工作。更主流的《财富》500强或《全球2000强》公司通常还没有意识到这个问题,但随着他们越来越多地转变基础设施和软件交付模式,他们很可能会遇到导致Keywhich、Confident、Knox等公司成立的同样问题。
其他开源解决方案
除了Lyft、Pinterest、Square内部构建的秘密管理工具之外,还有其他开源的秘密管理解决方案(以及我们在其他大型科技公司了解到的许多其他不向公众开放的解决方案)。其中包括Docker、Hashicorp的机密管理产品,Torus、Credstash、Sneaker等工具,以及AWS、Azure和谷歌的可用于机密管理的通用工具,其复杂程度各不相同。
Docker机密
Docker秘密管理是一种较新的秘密管理工具。巧合的是,它是由一些在Square Keywhich工作的重叠人员设计的。以下是Docker如何描述这个问题,以及为什么传统的静态秘密管理工具或加密密钥管理产品无法处理这些问题:
“构建更安全的应用程序的一个关键因素是与其他应用程序和系统进行安全的通信,这通常需要凭据、令牌、密码和其他类型的机密信息,通常被称为应用程序机密。我们很高兴推出Docker secrets,这是一个容器本机解决方案,可以增强容器的Trusted Delivery组件通过将秘密分发直接集成到容器平台中来实现安全性。
有了容器,应用程序现在可以在多个环境中动态和可移植。这使得现有的秘密分发解决方案不足,因为它们主要是为静态环境设计的。不幸的是,这导致了对应用程序机密管理不善的增加,使得人们很容易找到不安全的、自主开发的解决方案,例如将机密嵌入到GitHub等版本控制系统中,或者其他同样糟糕的事后解决方案。”
以下是Docker secret如何工作的架构图:
以下是Docker机密如何用于管理环境变量以及AWS凭据的示例。更多关于Docker机密的文档可在此处获取。
Vault by Hashicorp
Hashicorp是一家拥有许多产品的开源软件公司,最出名的可能是其Vagrant和Terraform等产品,还有一款名为Hashicorp Vault的秘密管理产品。New Stack在这里发布了一个关于Hashicorp Vault优缺点的良好概述,其中讨论了在外部工具中管理秘密与环境变量相比的一些好处,在Hashicorp生态系统中运行良好,以及API集成的好处。
Hashicorp Vault和《新堆栈》中的Keywhich之间还有一个有趣的比较:
虽然以上所有内容都很好——就像软件的典型情况一样——但Vault的设计中进行了某些权衡,并且存在一些局限性。虽然将Vault作为一项服务运行有很多好处,但这确实会增加基础架构成本,并带来管理该基础架构的相关痛苦。此外,并非Vault的所有优点都适用于所有使用情况。例如,动态生成的机密只能与数量有限的其他服务集成。此外,Keywhich by Square是该领域另一个值得关注的大玩家。Vault和Keywhich之间最大的根本区别在于,虽然Vault通过API公开秘密,但Keywhich使用FUSE文件系统。Vault在比较中写了一篇不错且相当客观的文章。最后,如果您使用的是Chef或相关工具,最初使用他们的集成解决方案可能比将其连接到Vault更容易。
由于维护和维护Hashicorp Vault基础设施的复杂性,有相当多的指南和教程。许多公司最终聘请顾问或签订专业服务合同,作为其Hashicorp Vault推出的一部分。这里有一个方便的最佳实践指南和教程:
你有没有安装过Hashicorp Vault,并想知道:“我真的在保护我的组织吗?”你并不孤单。虽然安装Vault很容易,但确保其配置正确以提高生产效率和安全性可能是一项具有挑战性的任务。我建立了相当多的指南和网络研讨会,最近也经常与Vault合作。这使我创建了自己的Vault最佳实践列表。
其他工具包括T-Mobile创建的一个名为“T-Vault”的工具,该工具使用了与Hashicorp Vault的一些集成,并添加了各种企业功能。一位CISO最近在一篇帖子中评论了Hashicorp Vault与CryptoMove的Tholos Vault的比较:
如果你正在使用或正在考虑使用Hashicorp Vault,你应该看看Cryptomove。作为一家早期的初创公司,该产品似乎非常成熟。不断移动密钥和数据的概念非常有趣,我无法在LinkedIn上发表一篇简短的帖子。
Torus
Torus 是另一个秘密管理工具。它采取托管的方式,同时开放客户资源。这里有一个有趣的HN关于Torus的讨论。
Credstash
Credstash是一个非常有趣的分布式凭证管理系统,它建立在AWS KMS之上。以下是它如何描述它试图解决的问题,以及它对秘密管理工具箱的轻量级方法:
软件系统通常需要访问某些共享凭据。例如,您的web应用程序需要访问数据库密码或某些第三方服务的API密钥。
一些组织构建了完整的凭据管理系统,但对我们大多数人来说,管理这些凭据通常是事后才想到的。在最好的情况下,人们使用像ansible vault这样的系统,这做得很好,但会导致其他管理问题(如主密钥存储在哪里/如何存储)。许多凭证管理方案相当于SCP将机密文件发送给车队,或者在最坏的情况下,将机密刻录到SCM中(对密码进行github搜索)。
CredStash是一个非常简单、易于使用的凭据管理和分发系统,它使用AWS密钥管理服务(KMS)进行密钥封装和主密钥存储,使用DynamoDB进行凭据存储和共享。
Sneaker
Sneaker是一款使用AWS KMS和S3创建轻量级机密管理功能的工具:
sneaker是一种使用S3和密钥管理服务(KMS)在AWS上存储敏感信息的实用程序,以提供耐用性、机密性和完整性。秘密存储在S3上,使用AES-256-GCM和一次性KMS生成的数据密钥进行加密。
这里对各种开源秘密管理解决方案和工具进行了非常全面和有用的比较。除了工具的比较之外,这位提供微服务和云架构咨询的作者还提出了一个思考秘密最佳实践的好方法:
- 任何秘密都不应该以明文形式写入磁盘——永远
- 任何秘密都不应该以明文形式通过网络传输——永远
- 所有机密生命周期和访问事件都应记录在不可篡改的审核日志中
- 秘密分发应由权威委托人(如容器/服务调度程序)协调,或与调度程序建立密切信任关系
- 如果没有颠覆性的努力,操作员对秘密明文的访问应该受到限制——如果不是不可能的话
- 秘密版本控制或滚动应该比揭示明文更容易实现
- 与秘密管理和分发相关的所有基础设施组件都应相互验证
- 安全的系统配置应该比高级的、可能不安全的配置更容易
- 机密到服务或容器的附件应该受到丰富(可插入)访问控制机制的保护——基于角色的访问控制是一个优势
- 应该做任何可以使秘密价值最小化的事情
每当一个空间中出现这么多开源项目时,这都是一个很好的迹象,表明许多开发人员、安全专业人员和软件组织都遇到了一个常见的问题。开源解决方案和工具往往是最先出现的。
云供应商方法
云基础设施供应商注意到,他们的用户和客户正在努力进行机密管理,并已开始开发自己的通用解决方案,如AWS secrets Manager、Azure Key Vault和下文所述的其他解决方案。在某些方面,这些产品让人想起亚马逊的Whole Foods 365“Lacroix杀手”或西夫韦著名的苏打水和其他自有品牌产品的“精选”品牌。在我们生活的云世界中,期望此类产品和其他产品的云通用版本出现似乎是合理的。
AWS
AWS Secrets Manager是一种工具,使AWS用户能够管理机密和凭据,而不是将其保存在磁盘上或使用KMS支持的凭据管理开源解决方案之一,如Sneaker。以下是AWS产品经理关于Secrets manager应该如何工作的视频:
reddit上有一个关于AWS Secrets Manager和开源解决方案之一Hashicorp Vault之间比较的方便讨论。AWS Secrets Manager的一些限制(根据Reddit上Hashicorp的一位人士的说法)包括:管理员缺乏零知识、动态秘密生成、一键式/API调用证书生成、SSH CA授权、加密即服务、跨区域/云/数据中心复制、用于多人审批的控制组、可插拔架构等等。
AWS参数存储。AWS参数存储可以是另一种管理机密的方式,而无需使用secrets Manager。以下是如何设置AWS参数库进行机密管理的指南。
AWS-KMS。AWS KMS并不是一个真正的秘密管理工具,尽管使用KMS可以用加密来包装秘密,这就是上面引用的一些开源解决方案对KMS所做的。
Azure
Azure密钥库是一项服务,使客户能够在一个地方管理其云应用程序的所有机密(密钥、证书、连接字符串、密码等)。它与Azure中秘密的来源和目的地开箱即用地集成,但也可以由Azure之外的应用程序使用。
它是AWS KMS和AWS Secrets Manager的结合,两者都支持Azure中的加密服务,并管理非加密机密和凭据。以下是Microsoft如何描述Azure密钥库旨在解决的问题:
Azure密钥保管库有助于解决以下问题
- 机密管理-Azure密钥库可用于安全存储和严格控制对令牌、密码、证书、API密钥和其他机密的访问
- 密钥管理--Azure密钥库也可以用作密钥管理解决方案。Azure密钥库可以轻松创建和控制用于加密数据的加密密钥。
- 证书管理--Azure密钥库也是一项服务,可以让您轻松地设置、管理和部署公共和私有安全套接字层/传输层安全(SSL/TLS)证书,以便与Azure和您的内部连接资源一起使用。
- 由硬件安全模块支持的存储机密--机密和密钥可以由软件或FIPS 140保护–2级验证HSM
以下是微软产品经理在Azure Key Vault上的视频,描述了它的工作原理:
谷歌
谷歌有加密密钥管理服务,但缺少秘密管理器产品。在谷歌云中,最接近的方法是使用KMS将机密进行加密,然后使用其他GCP服务将机密存储在其他地方。以下是谷歌关于如何做到这一点的文档。此外,这里还有一个有趣的教程,介绍如何使用谷歌云平台服务的组合在无服务器应用程序架构中存储机密。谷歌也有一个关于如何存储秘密的通用指南,从存储到代码本身(这是个好主意吗?)。
专注于这一领域的新兴创业公司
除了开源工具和云供应商产品外,还有一些初创公司专注于在密钥和机密管理领域构建产品。
- Envkey是YCombinator最近推出的一家初创公司。它具有良好的UI和UX,比大多数更专注于CLI和API的机密管理产品要好。
- UnboundTech (原名Dyadic)总部位于以色列。他们使用多方计算进行密钥管理,并得到包括花旗银行和高盛在内的战略投资者的支持。
- Fortanix 称其技术为“SDKMS”或软件定义的密钥管理系统。它与Equinix数据中心公司高度集成,基于英特尔SGX技术(也得到英特尔作为战略投资者的支持)。
CryptoMove如何适应这一切?
在CryptoMove,我们从移动任何类型数据的目标数据保护技术开始。随着底层技术的产品化,我们已经看到了各种用例的原型,从保护密钥、机密、文件、数据库,甚至是无人机群中的直播视频或数据,到相机或传感器等嵌入式设备,再到机器人。
然而,在与《财富》100强中的许多早期设计和研发合作伙伴以及国土安全部、NIST等联邦机构合作后,我们意识到,到目前为止,CryptoMove最常见的第一个用例是试图将我们的技术应用于密钥和机密管理。有了这些学习,我们花了一年多的时间与数百个安全团队、devops团队、开发人员、CISO和其他人进行了交谈,以了解现有关键和机密管理工具和流程的痛点,尤其是应用于多云、微服务和物联网基础设施的痛点。
根据我们所了解的情况,我们一直在开发一款云原生SaaS机密管理产品,我们称之为CryptoMove Tholos(Tholos在希腊语中是Vault的意思),其背后隐藏着移动目标数据保护技术。更多信息可以在我们的网站上找到,我们将继续写博客。
IV、 密钥和机密管理人员及金库的重要目标
无论是商业解决方案、开源项目还是自主开发的工具,密钥和机密管理器以及密钥库都有一些共同的目标。
- 秘密管理。当然,秘密生成、轮换、撤销、分配和共享的基本任务很重要。在拥有许多内部和外部服务的现代软件组织中,这些过程通常是费力的。重要的是,秘密管理工具可以使与处理秘密相关的过程变得简单和有组织。
- 身份验证和机器标识。重要的是,机密管理工具具有全面且可访问的API。在现代devops和云原生工作流中,机密管理最常见的用例是对应用程序组件和服务进行身份验证。特别是在服务和业务流程日益自动化的情况下,通过机密管理进行机器对机器身份验证和身份验证至关重要。
- 秘密的存储。这是一个实际上没有太多创新的领域。如今,大多数机密工具都专注于库存以及生成和轮换策略。就密钥和秘密存储而言,最常见的做法是将密钥放入数据库、存储或其他后端,并进行加密。在这里,移动目标防御、碎片化和密钥秘密的分散或分布式存储可能是一种有趣的方法。
- 机密管理基础设施的可靠性。秘密不仅应该有良好的组织、库存、可访问和存储,而且还应该在一个高度可用和有弹性的系统中进行管理。
V.devops/云转换中的机密管理面临的挑战
正如Square、Lyft、Pinterest、T-Mobile和其他公司的例子所示,秘密管理是许多组织遇到的一个问题。除了管理基于云和服务的系统的机密的一般问题之外,组织在机密方面面临的具体挑战是什么?
- 优先级。在一些组织中,仅仅优先考虑机密管理是一项挑战。问题是否会发生并不总是很清楚,尤其是如果安全团队更多地参与公司安全和端点安全,而不是安全软件开发生命周期。许多组织仍然在HSM是唯一选择的框架中运作,加密密钥通常是唯一真正考虑的秘密。通常,这是由于基于云或服务的转换仍处于早期阶段。
- 多基础设施方法。跨基础设施的保密管理可能是一项挑战。组织是否会使用AWS Secrets Manager来管理与Azure存储相关的机密?还是AWS相关机密的Azure密钥库?一些开源密钥和机密管理解决方案可能是一种多云方法,以及企业SaaS保险库。
- 可扩展性和协调性。自动调整机密管理基础设施的规模非常重要,尤其是在服务大规模运行的情况下。机密管理工具还应该与devops堆栈的其他部分以及安全堆栈中的其他工具协调良好。
- IAM集成。秘密管理工具应该与各种身份验证选项集成,如Okta、OneLogin、Active Directory、AWS IAM角色等。在CryptoMove,我们已经与之前列出的一些以及我们喜欢的Auth0进行了集成。
- UX/UI。好的API对机密管理很重要,但正如我们交谈过的许多团队所看到的,好的UI和UX也非常重要。并不是所有的密钥和机密都可以通过编程生成,尤其是在某些遗留系统中。为管理员和策略创建提供一个坚实的接口非常重要。由于一些开源工具并没有过多地关注UI,某些开发人员已经尝试在顶部制作自己的UI。它们并不总是得到完全支持,但可以通过一点创造性的GitHub搜索找到。
- 信任的根源。如何启动秘密管理系统本身一直是一个经典的“海龟”问题。在去年的2017年谜机大会上,网飞公司就如何处理海龟问题进行了精彩的讨论。最终,会有一些信任的根源,无论是HSM、用于解封的Shamir秘密共享、多方计算,还是可能的其他方法。
- 谁拥有它?DevOps还是Security?组织中秘密管理的责任和所有权往往不是一个容易回答的问题。通常,devops团队和实际工程师正在处理与测试、集成和部署相关的工具和流程。安全团队通常参与体系结构、监控、跟踪和安全意识。开发人员会管理自己的秘密吗,还是安全团队应该管理这些秘密?两者兼而有之?我们已经看到一些组织在秘密管理中大量涉及安全,而有些组织则不然。
- 发现。仅仅知道所有的秘密在哪里是一个非常困难的问题。许多组织都在围绕机密进行资产盘点,这使得了解机密攻击表面并对其进行风险建模变得困难。
- 审计和使用情况跟踪。了解何时使用和访问机密在事件响应场景中很有帮助,也有助于发现内部威胁。之前在Square建立Docker机密管理器的工程师们讨论了“加密锚定”的想法,以使这里的过滤更加困难。以下是加密锚定的视频解释:
Developers who worked on secrets management at Square & Docker explain their approach
基础设施设置和管理。任何在开发过程中使用少量云服务或内部服务的组织都有秘密需要管理。但并非所有组织在维护和维护机密管理基础设施方面都拥有相同水平的资源。应该如何设置?作为SaaS服务?单独在不同的环境和基础设施中?需要团队还是服务?这些都是重要的问题,可能取决于项目和组织类型。
思考机密管理时要问的问题
与任何技术转型浪潮一样,在秘密管理之旅的各个阶段都有一个成熟的组织模型。无论组织处于成熟度模型和云原生/devops转换的哪个阶段,在设计、实施、升级或优化机密管理工作流程和基础设施时,都需要考虑一些有用的问题。
- 秘密现在在哪里?他们今天是如何管理的?
- 我们想要管理哪些秘密?云服务?云原生应用程序?容器和微服务?数据分析和数据湖?传统数据库?物联网?加密或区块链应用程序的私钥?
- 用户将是谁?安保团队?Devs?管理员?
- 如何管理机密管理基础设施?有一个敬业的团队吗?作为服务托管?
- 是否需要UI或API?两者的结合?
- 什么是多云或多基础设施机密管理策略?云服务提供商的工具应该管理自己的秘密吗?一个组织是否应该通过多种工具传播秘密?基础设施?
- 现在还有哪些其他工具在管理秘密?有吗?目前团队中是否有秘密管理策略或意识?
- 秘密的备份和恢复策略是什么?
- 组织应该利用开源工具还是以商业企业为中心的工具,或者两者结合?
- 秘密是如何保密的?除了管理,秘密实际上是如何得到保护的?在存储中?在数据库中?其他方式?
- 谁应该有权接触这些秘密?这可能是一个复杂的问题,对于不同的工作流程或机密,答案各不相同。
- 什么政策应该适用于秘密管理?如何跟踪版本?撤销?基于时间的政策?
随着向云原生、服务和物联网基础设施的转型,机密管理是一个复杂而新兴的问题。从Square、Pinterest、Lyft等许多最先进的科技公司可以看出,每一个现代软件组织在机密管理方面都会遇到困难。
机密管理令人兴奋的是,它位于数据安全和应用程序安全的交叉点,为思考风险管理和威胁建模攻击表面开辟了新的途径。如果操作得当,大规模的秘密管理可以加速围绕云和服务转换的业务流程变化。
有一点是明确的——在秘密管理方面,我们正处于曲线的早期,未来还有很大的创新空间。
- 165 次浏览
【数据屏蔽】2023年11款最佳数据屏蔽工具和软件
视频号
微信公众号
知识星球
数据屏蔽工具可以帮助您将数据用于开发、测试、分析和其他此类应用程序,同时使其对外部威胁毫无用处。因此,您可以将数据泄露的影响降至最低。
根据Gartner的说法,使用数据屏蔽工具可以“最大限度地减少敏感数据的占用和传播(或查看),而无需大量的自定义开发。”
本文介绍了适用于小型、中型和大型组织的最广泛使用的数据屏蔽工具。这些工具已经出现在Gartner和G2等流行的评论门户网站上。
以下是2023年最受欢迎的11种数据屏蔽工具:
- Broadcom Data Masking
- Delphix Data Platform
- IBM® InfoSphere® Optim Data Privacy
- iMask™ Dynamic Data Masking
- Immuta
- Informatica Cloud Data Masking
- IRI FieldShield
- K2View Data Masking
- Microsoft Azure (SQL Database, SQL Managed Instance, and Synapse Analytics)
- Oracle Data Masking and Subsetting
- Salesforce Data Mask
Broadcom Data Masking
Broadcom为使用测试数据管理器的组织提供数据屏蔽功能。得益于数据屏蔽,开发人员可以使用此产品生成真实的测试数据或使用现有数据,而不会泄露任何敏感信息。
通过数据屏蔽,开发人员可以在产品或软件开发、测试和QA阶段混淆机密或机密信息。因此,组织可以确保其产品开发过程有效并符合法规要求。
博通数据屏蔽解决方案的主要功能是什么?
- 测试数据管理器支持静态和动态(实时、动态)数据屏蔽。
- 屏蔽敏感数据有助于确保测试期间更好的数据质量,从而缩短上市时间并确保按时交付项目。
博通数据屏蔽资源:
Data Masking Guide | Test Data Management | Mainframe InFlight Masking Best Practices Guide
Delphix
Delphix数据平台为非生产环境中的数据屏蔽提供了一种自动化方法。它用真实的数据掩盖敏感信息(社会安全号码或信用卡信息),以便用于开发、测试、QA和分析。
即使屏蔽算法是预先配置的,您也可以对其进行调整,以满足组织特定的安全要求。
此外,该平台具有直观的用户界面,并具有无代码/低代码设置,从而简化了安装过程。
Delphix的数据屏蔽解决方案的主要功能是什么?
- Delphix通过识别敏感数据并自动屏蔽来执行端到端数据屏蔽。
- Delphix符合数据隐私标准,如GDPR、CCPA、PCI DSS和HIPAA。
- 您可以选择对敏感数据进行标记化,而不是屏蔽以逆转混淆。自动掩蔽是不可逆的。
- 该平台支持数据生态系统和多云环境中的所有类型的应用程序。
Delphix数据屏蔽资源:
Delphix Data Masking | Datasheet | Demo Video
IBM®InfoSphere®Optim数据隐私
IBM®InfoSphere®Optim Data Privacy有助于为开发、测试或QA等非生产环境屏蔽和管理敏感信息(PII和其他机密数据)。
该解决方案可以实时屏蔽数据,以防止或减轻网络攻击的损害。它还可以屏蔽屏幕上的数据,以保证只有合适的人才能访问敏感信息。您还可以使用Optim Data Privacy来混淆ETL工作流和其他数据管道中使用的数据。
IBM Infosphere Optim Data Privacy的主要功能是什么?
- Optim Data Privacy使用流行的预编程数据转换技术来屏蔽敏感数据,而不会丢失其上下文。它提供了30种预定义的数据分类和数据隐私规则。
- 它通过自动发现敏感字段并支持OCR读取,方便了按需屏蔽数据,并简化了敏感数据的发现。
- Optim根据HIPAA、Gramm-Leach-Bliley法案(GLBA)、个人信息保护和电子文件法案(PIPEDA)等法规提供了预定义的合规报告。
IBM Infosphere Optim数据隐私资源
IBM Infosphere Optim Data Privacy | Solution brief | Closing the privacy gap (Whitepaper)
iMask™ Dynamic Data Masking
iMask电脑™ 是Mentis公司的动态数据屏蔽解决方案,该公司提供数据隐私、安全和治理解决方案。它使用NIST批准的fips140加密和标记算法来保护生产环境中使用的敏感应用程序和数据库数据。
该解决方案可容纳来自各种数据源(包括结构化和非结构化数据资产)的数据。
iMask的主要功能是什么™ 动态数据屏蔽?
- iMask电脑™ 实现基于角色、用户、程序和位置的细粒度访问控制和实时监控。
- 您可以从40多种数据匿名化方法中进行选择。
- 静态和动态数据屏蔽技术共存,并且可以进行配置以匹配您的用例。
iMask电脑™ 数据屏蔽资源:
iMask Dynamic Data Masking | Datasheet | User and role-based masking for an airline in Canada (Case Study)
Immuta
Immuta的通用数据访问控制解决方案提供动态数据屏蔽和匿名化。根据HIPAA,该产品使用先进的隐私增强技术(PET)来保护敏感数据的机密性。
Immuta的通用数据访问控制解决方案的主要功能是什么?
- Immuta的解决方案实现了动态数据屏蔽,并使用了多种屏蔽技术。也被称为动态PET的两种突出技术包括:
- K-匿名化:也被称为“隐藏在人群中”,这种技术将个人的数据隐藏在更大的群体中。因此,敏感信息可能属于小组中的任何个人。Immuta自动化了整个过程,以避免手动或基于代码的匿名化方法。
- 差异隐私:这种技术在每次运行查询时都会添加噪声。噪声的添加取决于查询的灵敏度。因此,数据团队可以共享数据,而不用担心敏感数据的机密性。
Immuta数据屏蔽资源:
Dynamic Data Masking | K-anonymity: Everything you need to know (2022 Guide) | What is differential data privacy?
Informatica
Informatica提供永久性数据屏蔽软件,可复制敏感数据,并使用匿名和加密技术来保护其隐私。这些副本可以帮助您使用真实的数据执行测试、开发、分析和其他类似功能。
该软件应用了几种屏蔽算法(替换、随机化或无效)和特定于PII数据(信用卡或财务信息)的技术。它使用NIST标准的FPE转换来实现可逆掩蔽。
Informatica的数据屏蔽工具的主要功能是什么?
- 具有全面日志和报告的单一审计跟踪可帮助您跟踪是否遵守了数据隐私法规。
- 您可以在部署掩蔽规则之前对其进行模拟。
- 无论数据的来源或格式如何,都可以将遮罩技术应用于数据。
- 该软件符合GDPR、CCPA、HIPAA、PCI DSS和GLBA的隐私规定。
Informatica数据屏蔽资源:
Cloud Data Masking | Datasheet | Informatica Advanced Data Masking Solution
IRI Fieldshield
IRI Fieldshield是IRI Data Protector Suite的一部分。此产品处理结构化数据的静态和动态数据屏蔽。他们还提供IRI Darkshield来处理非结构化数据的数据屏蔽和安全问题。
IRI Fieldshield使用几种符合NSA Suite B和FIPS的加密方法进行数据屏蔽。
IRI Fieldshield数据屏蔽解决方案的主要功能是什么?
- Fieldshield支持结构化数据发现和定义(针对上下文)。
- 该产品支持哈希、随机化、加扰、加密、假名化、标记化和编校,以保护生产和测试环境中的敏感数据。
- Fieldshield符合数据隐私标准,如GDPR、CIPSEA、DPA、FERPA、GLBA、HIPAA和PCI DSS。
IRI数据屏蔽资源:
Fieldshield | Data Protector Suite 2022 | Product Overview (Fieldshield)
K2View
K2View数据屏蔽可为生产和测试环境中的结构化和非结构化数据提供静态和动态数据屏蔽。
K2View的数据屏蔽工具的主要功能是什么?
- K2View自动化了静态和动态数据屏蔽,并发现了各种数据源和格式中的敏感信息(PHI和PII)。
- 该工具使用SHA-266和SHA-512加密算法来保护敏感数据。
- 该工具配有用户友好的仪表板,支持内部部署和多云部署。
K2查看数据屏蔽资源:
K2View Unified Data Masking | Data masking tools for data-centric enterprises (Whitepaper)
Microsoft Azure(SQL数据库、SQL托管实例和Synapse Analytics)
Microsoft Azure在其所有服务器、数据库和环境中提供静态和动态数据屏蔽,用于分析和测试。它支持各种云部署,并具有各种可定制的功能,以应对不同的用例。
若要设置动态数据屏蔽策略,您可以使用Azure门户。
Microsoft Azure的数据屏蔽解决方案的主要功能是什么?
- Microsoft提供基于角色的访问控制(RBAC)和屏蔽功能,可以根据您的需求进行自定义。
- 该解决方案附带了一个DDM建议引擎,用于标记数据库中潜在的敏感字段。
- 与第三方数据库的多次集成确保了跨各种数据源和格式的无缝数据屏蔽。
Microsoft Azure数据屏蔽资源:
Dynamic data masking documentation | Dynamic data masking for SQL Server | Configure dynamic data masking in the Azure portal
Oracle Data Masking and Subsetting
Oracle数据屏蔽和子集从非生产环境(测试、开发和分析)中删除敏感信息。该解决方案自动发现并屏蔽敏感数据,只共享相关数据。它还为每一类数据(即信用卡号码、社会保障信息或电话号码)提供了预定义的屏蔽格式。
虽然该解决方案针对Oracle数据库进行了优化,但它也支持非Oracle数据库。
Oracle数据屏蔽和子集的主要功能是什么?
- Oracle数据屏蔽和子集允许发现敏感数据。
- 它支持跨各种环境的部署。
- 您可以从各种掩码(条件掩码、随机化或基于密钥的可逆掩码)和子设置技术(基于目标或基于条件)中进行选择,并根据您的要求进行自定义。
- 它符合GDPR和PCI DSS等数据隐私标准。
Oracle数据屏蔽资源:
Oracle Data Masking and Subsetting | Introduction to Oracle Data Masking and Subsetting | Data Masking | Data Subsetting
Salesforce数据掩码
Salesforce Data Mask允许您在不损害敏感信息(PI和PII)的情况下构建和测试应用程序,方法是将其替换为伪数据。它确保所有数据都保留在Salesforce内部。
该解决方案符合GDPR和CCPA等数据隐私标准。
Salesforce Data Mask的主要功能是什么?
- Salesforce Data Mask允许您从匿名化、假名化和删除等数据屏蔽技术中进行选择。
- 该产品允许您选择要混淆的字段和数据类型。
Salesforce 资源
Salesforce Data Mask | Install and configure Salesforce Data Mask | Secure your sandbox data
在选择数据屏蔽工具之前,需要考虑以下几点。理解并绘制:
- 您拥有的数据量(以及数据存储的位置和方式)
- 您的法规遵从性要求(跨地区)
- 您的私人数据发现过程(整个组织)
- 最适合您的场景的数据屏蔽技术
- 您需要的数据屏蔽功能(例如使用的技术或支持的环境和格式)
- 您的预算
- 您入围的供应商的评论和推荐
数据屏蔽工具常见问题解答
1.为什么我需要一个数据屏蔽工具?DDM是一个需要查找的重要功能吗?
数据屏蔽工具使您能够在不泄露敏感信息的情况下构建和测试应用程序。这对于运行分析算法也是至关重要的。
如果您的应用程序依赖于实时或流式数据,则应该寻找动态数据屏蔽(DDM)。根据Gartner的说法,DDM通过屏蔽敏感数据来修改数据流,使原始生产数据保持不变。
2.哪些数据屏蔽工具在Gartner上获得了最好的评价?
如果你看看Gartner Peer Insights上数据屏蔽技术下列出的产品,这里列出了一些评级最高的产品:
- Microsoft SQL Server and Azure SQL Database
- Oracle Data Masking and Subsetting
- iMask by Mentis
- Informatica Dynamic Data Masking
- IBM® InfoSphere® Optim Data Privacy
- CA Test Data Manager (CA Technologies is a Broadcom company)
3.G2上列出了哪些数据屏蔽供应商?
G2列出了以下一些最流行的数据屏蔽软件:
- VGS Platform
- LiveRamp
- Immuta
- Oracle Data Masking and Subsetting
- CA Test Data Manager (CA Technologies is a Broadcom company)
- Informatica Dynamic Data Masking
4.我应该选择哪种数据屏蔽工具?
在选择工具之前,必须了解数据类型、来源和用例(测试或分析)。下一步是熟悉适合您情况的隐私法律法规。
请仔细阅读我们提到的评估数据屏蔽工具的标准,然后选择最符合您需求的工具。
另请阅读:Data Masking 101: Types, Techniques, Getting Started
数据屏蔽工具:相关读取
- What is data masking: Techniques, types, examples, and best practices
- What is data obfuscation: Importance, techniques and best practices
- What is data governance: Definition, importance, and components
- 8 data governance best practices from data leaders
- 176 次浏览
【隐私保护】大数据时代的隐私:NLP在保护个人信息中的作用
视频号
微信公众号
知识星球
数字技术的激增和大数据的快速增长从根本上改变了个人信息的收集、使用和共享方式。随着个人越来越依赖数字技术来沟通、开展业务和管理个人生活,对隐私和数据保护的担忧变得更加尖锐。
自然语言处理(NLP)已成为数字时代保护个人信息的重要工具。NLP使机器能够理解、解释和生成人类语言,并可用于以多种方式保护个人信息,从数据匿名化到自动数据保护。在本文中,我们将探讨NLP在数据保护中的作用,重点关注数据匿名化的挑战、保护文本数据中的个人信息以及NLP在网络安全中的潜力。我们还将研究NLP在数据保护方面的未来,以及这项技术在数字时代帮助保护个人隐私的潜力。
主题列表:
- 数字时代的隐私
- NLP与数据保护
- 数据匿名化的挑战
- 保护文本数据中的个人信息
- 自动化数据保护
- NLP与网络安全
- NLP在数据保护中的未来
数字时代的隐私
在大数据时代,隐私已经成为一种宝贵的商品。随着在线平台和数字设备的激增,保护个人信息变得越来越困难。每次我们浏览互联网或使用社交媒体时,都会留下可以追溯到我们身上的数字足迹。这种隐私损失的后果可能是深远的,从身份盗窃到声誉损害。自然语言处理(NLP)领域正在提供保护个人信息和保护隐私的新方法。
NLP如何帮助数字时代的隐私示例
假设一个医疗保健提供者有一个庞大的医疗记录数据集,其中包括患者的姓名、地址和病史等个人信息。提供者需要与研究人员共享这些数据,以提高医学知识,但希望保护患者的隐私。在这种情况下,NLP可以用于通过删除任何识别信息(如姓名和地址)来匿名化数据,同时保留重要的医疗信息。
NLP还可以用于检测和防止数据泄露。例如,可以训练NLP模型来识别敏感信息,例如信用卡号、社会安全号码或个人健康信息(PHI)。如果模型在文本数据中检测到这些信息,它可以自动对其进行标记,并防止其被共享或泄露。
此外,NLP可用于帮助个人保护自己的在线隐私。例如,NLP支持的聊天机器人可以通过分析语言并以通俗易懂的语言提供摘要或解释,帮助用户浏览复杂的隐私政策和服务协议条款。NLP还可以用于检测和过滤可能包含有害或误导信息的垃圾邮件或网络钓鱼电子邮件。
NLP与数据保护
NLP是人工智能的一个子领域,处理计算机和人类语言之间的交互。它是分析包括文本数据在内的大量数据的强大工具。近年来,NLP越来越多地用于数据保护,特别是在数据匿名化和数据去识别领域。NLP技术可用于从数据集中删除个人信息,使其匿名,从而保护相关个人的隐私。
使数据集匿名:示例
假设我们有一个数据集,其中包含医院患者的信息,包括他们的姓名、年龄、医疗诊断和治疗计划。我们希望与研究人员共享这些数据集,但需要保护患者的隐私。我们可以使用NLP通过删除任何识别信息(如姓名和地址)来匿名化数据,同时保留重要的医疗信息。
| Name | Age | Medical Diagnosis | Treatment Plan |
|---|---|---|---|
| John | 45 | Diabetes | Insulin shots |
| Sarah | 28 | Asthma | Inhaler |
| David | 36 | Hypertension | ACE inhibitors |
| Alice | 50 | Breast cancer | Chemotherapy |
| Tom | 67 | Osteoarthritis | Physical therapy |
在应用基于NLP的匿名化之后,该表如下所示:
| Patient ID | Age Group | Medical Diagnosis | Treatment Plan |
|---|---|---|---|
| 1 | 40-49 | Diabetes | Insulin shots |
| 2 | 20-29 | Asthma | Inhaler |
| 3 | 30-39 | Hypertension | ACE inhibitors |
| 4 | 50-59 | Breast cancer | Chemotherapy |
| 5 | 60-69 | Osteoarthritis | Physical therapy |
在这个匿名表中,原始患者姓名已被匿名患者ID取代,而他们的年龄已被分组到年龄范围内,以进一步保护他们的身份。医疗诊断和治疗计划得到了保留,使研究人员能够在保护患者隐私的同时使用这些数据进行分析。
数据匿名化的挑战
数据匿名化是一个复杂的过程,涉及删除任何可用于识别个人的信息。这可能很有挑战性,因为即使是看似无害的信息也可以用来重新识别某人。例如,一个人的年龄、性别和地点的组合就足以识别他们。NLP可以通过识别和删除数据集中的敏感信息来帮助克服这些挑战。
在匿名数据集中,有许多不同的信息可以用来重新识别某人,即使他们的身份信息(如姓名或地址)已被删除。以下是几个例子:
- 年龄:如果使用了年龄范围而不是确切的年龄,那么某人的年龄仍然可以缩小到更小的范围,从而更容易识别他们。
- 职业:某些职业或职称可能是特定个人或地区独有的,即使某人的名字被删除,也更容易根据其职业来识别此人。
- 邮政编码:即使一个人的完整地址被删除,邮政编码仍然可以提供某人居住的大致信息,从而更容易重新识别他们。
- 医疗状况:某些医疗状况或治疗可能很罕见,因此更容易识别患有这种状况或正在接受这种治疗的人。
- 其他上下文信息:如果某个事件是唯一的或罕见的,则可以使用其他上下文信息,如事件的日期和地点,来重新识别某人。
需要注意的是,虽然匿名化有助于保护数据集中个人的隐私,但它并非万无一失。重新识别总是一种风险,数据集中包含的信息越多,就越容易重新识别个人。因此,重要的是要采取措施将重新识别的风险降至最低,例如使用统计方法确保数据充分匿名,限制包括的数据点数量,并监控数据使用情况以防止未经授权的重新识别。
保护文本数据中的个人信息
数据保护的挑战之一是保护文本数据中的个人信息。文本数据可以包含丰富的个人信息,从姓名和地址到社会安全号码和信用卡详细信息。NLP可用于识别文本数据中的这些信息并将其删除,从而保护相关个人的隐私。这可以使用基于规则和机器学习技术的组合来实现。
自动化数据保护
NLP在数据保护方面的一个关键好处是它能够实现流程自动化。这可以节省时间和资源,并提高匿名化和去身份识别过程的准确性。NLP可用于开发数据保护的自动化工具,组织可使用这些工具来保护个人信息并遵守数据保护法规。
NLP与网络安全
NLP还可以在网络安全方面发挥关键作用,特别是在威胁情报领域。NLP可用于分析大量文本数据,包括社交媒体和暗网数据,以识别组织安全的潜在威胁。这可以帮助组织采取积极措施保护其数据和系统,降低数据泄露和网络攻击的风险。
NLP在数据保护中的未来
随着我们生成的数据量不断增长,NLP在数据保护中的作用将变得越来越重要。NLP技术不断发展,保护个人信息和保护隐私的新方法正在开发中。NLP在数据保护中的使用将继续扩大,帮助组织遵守数据保护法规,保护其客户和员工的隐私。
- 271 次浏览
【隐私保护】教程:在数据仓库中扫描个人身份信息(PII)的两种方法
视频号
微信公众号
知识星球
实现数据隐私和保护的重要一步是在数据仓库中查找和编目敏感的PII或PHI数据。像Datahub和Amundsen这样的开源数据目录可以对仓库中的信息进行编目,但缺乏扫描、检测和标记包含此类敏感信息的表或列的框架。
这篇文章描述了扫描和检测PII的两种策略,介绍了开源项目PIICatcher,这是一种隔离存储在数据仓库中的信息的工具。
什么是个人身份信息(PII)?
PII或个人身份信息是指能够识别特定个人的任何信息。传统的PII示例包括电子邮件地址、社会安全号码、个人文档ID和金融账户信息。随着技术的发展,PII现在扩展到登录ID、IP地址、地理位置和生物识别。
PII分为两种类型:
- 敏感:与您的身份直接相关的任何数据(信用卡信息、护照号码、SSN、法定姓名)
- 非敏感:可以识别个人身份并可能从互联网上获得的任何数据(地址、种族、IP地址)
世界各地的合规法律对PII的构成有类似的定义:
通用数据保护条例(GDPR)(欧盟):PII是任何有助于识别个人的数据。一些传统上被视为个人身份信息的例子包括英国的国家保险号码、您的邮寄地址、电子邮件地址和电话号码加州消费者保护法(CCPA)(美国):CCPA对“个人信息”或PI有广泛的定义,将其称为“直接或间接识别、涉及、描述、能够与特定消费者或家庭相关或可能合理联系的信息。”其他合规法,包括PDPA(新加坡和泰国)、PIPL(中国)和CPPA(加拿大),也以类似方式提及PII。
除了这些一般定义之外,企业可能会为其独特的需求收集特定的PII数据。例如,医疗保健行业的公司收集个人健康信息(PHI),而银行账户或加密货币钱包ID与金融行业相关。无论行业如何,任何组织都需要管理一个基本的PII:
- 电话
- 电子邮件
- 信用卡
- 住址
- 人员/姓名
- 地方
- 日期
- 性别
- 国籍
- IP地址
- SSN(序列号)
- 用户名
- 密码
PII扫描面临的挑战
下面显示的是新冠肺炎合成患者记录中患者表中的示例记录:
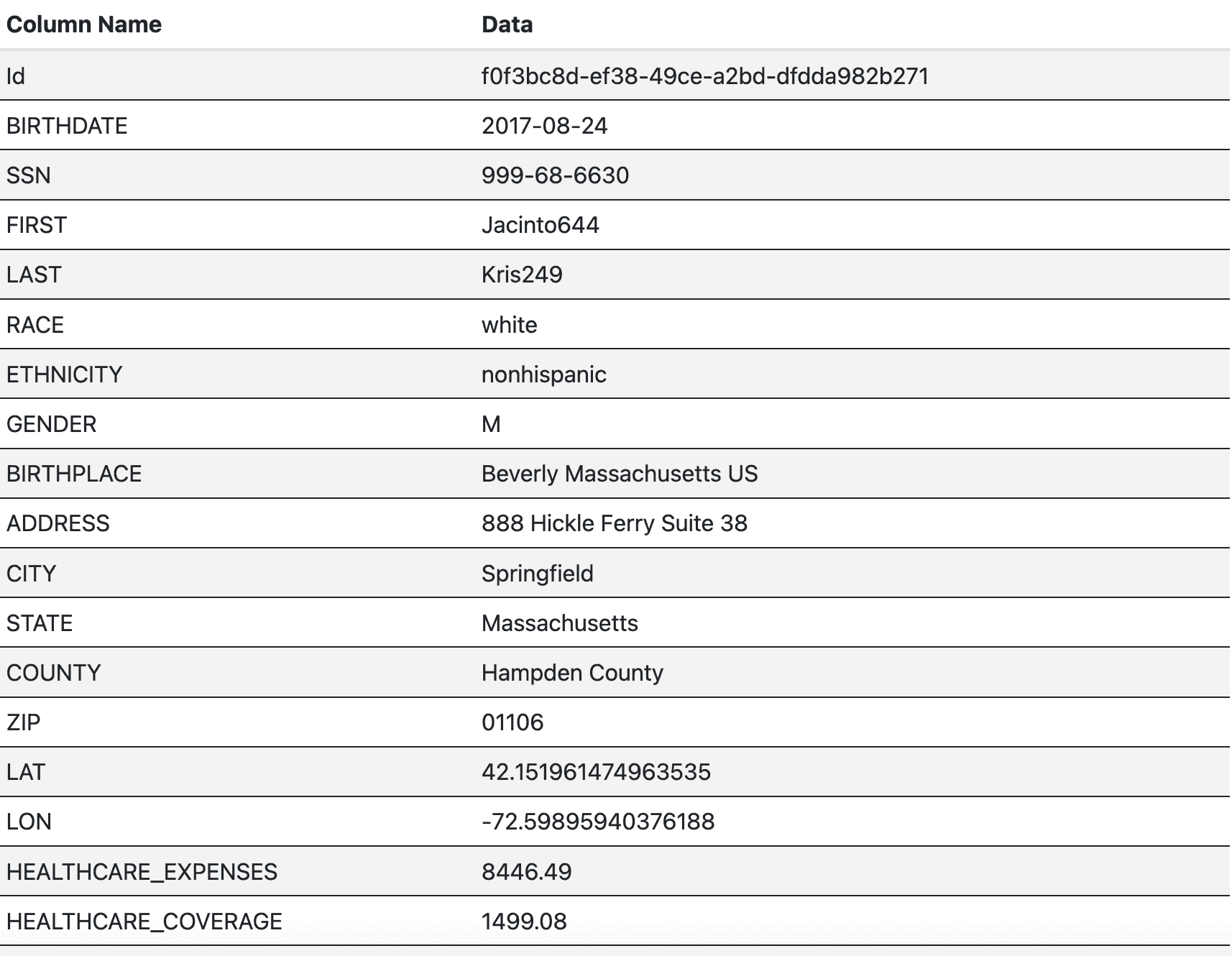
该表中的大多数字段存储PII,但甚至检测列是否存储PII以及如果存储PII的话,检测该PII的类型都可能会令人困惑。例如,如果扫描仪只扫描SSN字段中的数据,则SSN可能被检测为电话号码。同样,文本信息本身,如性别领域的“M”或“F”,或种族领域的“白人”,并不能提供足够的上下文来确定PII的类型。在这两种情况下,扫描字段头会更有效。然而,在某些情况下,实际数据需要扫描。因此,用于扫描数据仓库的技术取决于所讨论字段的上下文。
PII扫描技术
根据上一节中强调的挑战,有两种技术可以扫描数据仓库中的PII:
- 扫描列和表名
- 扫描列内的数据
扫描数据仓库元数据(包括列和表名)
通常,数据工程师会用简单的术语命名数据仓库中的表和列,以便于用户理解。因此,这些名称通常为存储的数据类型提供线索。例如:
- first_name、last_name、full_name或name可能存储一个人的名字。
- ssn或social_security用于存储美国ssn号码。
- phone或phone_number用于存储电话号码。
此外,数据仓库提供了一个信息模式来提取模式、表和列信息。例如,以下查询可用于从Snowflake获取元数据:
SELECT
lower(c.column_name) AS col_name,
lower(c.column_name) AS col_name,
c.comment AS col_description,
lower(c.data_type) AS col_type,
lower(c.ordinal_position) AS col_sort_order,
lower(c.table_catalog) AS database,
lower({cluster_source}) AS cluster,
lower(c.table_schema) AS schema,
lower(c.table_name) AS name,
t.comment AS description,
decode(lower(t.table_type), 'view', 'true', 'false') AS is_view
FROM
{database}.{schema}.COLUMNS AS c
LEFT JOIN
{database}.{schema}.TABLES t
ON c.TABLE_NAME = t.TABLE_NAME
AND c.TABLE_SCHEMA = t.TABLE_SCHEMA
正则表达式可以匹配表名或列名。例如,下面的正则表达式检测存储社会安全号码的列:
^.*(ssn|social).*$
扫描存储在列中的数据
另一种检测PII的方法包括使用两种策略的组合扫描存储在列内的数据:
- 使用正则表达式检测预期模式
- 调用NLP库,如Stanford NER Detector和Spacy
这种方法的一个缺点是NLP库的计算量很大。即使在中等大小的表上运行NLP扫描程序的成本也会迅速上升,更不用说数百万或数十亿行了。取而代之的是,一个随机的行样本进行扫描。数据库提供了选择随机样本的内置函数,例如下面的Snowflake查询:
select {column_list} from {schema_name}.{table_name} TABLESAMPLE BERNOULLI (10 ROWS)
生成随机行后,可以使用regex或NLP库对其进行处理,以检测PII的存在。
断开连接
根据上下文,检测PII数据需要上述两种技术。然而,这些很容易出现假阳性和假阴性。此外,不同的方法往往会提出相互冲突的PII类型。确定正确的类型是未来博客文章的主题。
PIICatcher:扫描数据仓库中的PII数据
PIICatcher执行上述策略来扫描和检测数据仓库中的PII数据。
特征
PIICatcher可以使用任何一种方法扫描数据仓库。它battery-included,,有越来越多的正则表达式用于扫描列名和这些列中的数据。目前,它甚至包括Spacy。
PIICatcher支持增量扫描,并且只扫描等待扫描的新列或现有列。这些功能允许轻松安排扫描。它还提供了强大的选项来包括或排除模式和表,以管理计算资源。此外,Datahub和Amundsen的功能还包括摄取功能,这些功能将用“PII”和“PII类型”标记列和表。
查看AWS Glue&Lake Formation Privilege Analyzer,了解PIIcatcher在生产中的使用示例。
结论
扫描表中的列名和数据有助于检测数据库中的PII。这两种策略都需要可靠地检测PII数据。PIICatcher是一个开源应用程序,可以实现这两种策略。它可以用PII和PII类型标记数据集,使数据管理员能够在数据隐私和安全方面做出更明智的决定。
- 280 次浏览
【隐私保护】有了DataHub,PII分类变得更容易了
视频号
微信公众号
知识星球
无缝、可扩展且安全:自动化PII检测可改进数据治理
管理敏感数据是现代数据治理的核心。无论你是在处理GDPR和CCPA的复杂问题,还是在负责任地向他人授予数据访问权限的问题上,制定一个标记敏感数据的策略至关重要。
DataHub流行的Business Glossary是一种强大的方法,可以对PII和合规类型进行建模,并在数据堆栈中对数据实体进行分类。除了手动分配这些分类外,DataHub现在还可以在接收时自动对敏感数据或PII进行分类和标记,使数据发现和访问无缝、可扩展且安全。
DataHub中的PII分类是什么样子的
DataHub的自动PII分类在摄取过程中识别敏感列和包含这些列的表,因此这些列会自动与预定义的PII相关词汇表术语相关联。
目前,DataHub的自动PII检测可以检测信息类型,包括全名、性别、全名、电子邮件电话、街道地址、信用卡号码、SSN(社会安全号码)、驾照号码、IBAN(国际银行账号)、银行SWIFT代码和IP地址。
TLDR:DataHub的自动PII分类如何工作
TLDR版本
简单地说,这个选择加入功能在列级别分析元数据,为每一列标记一个与PII相关的词汇表术语(信息类型)。
在摄入时,DataHub PII检测模块通过以下方式分析每一列是否存在信息类型
- 检查是否存在某些因素(称为预测因素)
- 为每个预测因子分配可配置的权重,
- 计算信息类型的存在的总体置信水平/得分,和
- 建议将相关的信息类型作为该列的词汇表术语——如果分数超过了您设置的置信度阈值。
作为DataHub管理员,您可以完全控制
- 启用PII分类功能
- 决定要处理的信息类型,以及
- 为信息类型的自动分类设置置信度阈值
查看本视频中DataHub的PII分类:
详细了解DataHub的PII分类工作流程
DataHub的分类器实现使用独立库来预测PII信息类型。它使用以下因素(称为预测因素)来提出适用于每列的信息类型
- 名称
- 描述
- 资料型态
- 价值
每个预测因子的存在是使用简单的基于规则的匹配和像Spacy这样的库(或其他常见的ML库)来检测的,并且为每个预测因素的存在分配置信度分数。
然后,该模块使用这些不同置信度得分的可定制加权组合来计算总体水平,该总体水平确定所提出的信息类型是否适用于该列。您可以配置每个预测因子的权重,以控制其对最终值的影响。
将得到的分数与可配置的阈值(默认配置使用0.7的阈值)进行比较,以确定信息项是否应应用于列。
配置分类信息类型
作为一名DataHub管理员,您可以自定义您的YAML配方,以配置在摄入过程中如何自动分类每种信息类型
您所需要做的就是在应用于您的用例时配置以下参数:
- 预测因子权重-在信息类型分类得分的最终计算中使用的每个预测因子的权重
- Name-要与列名匹配的正则表达式列表
- 描述-要与列描述匹配的正则表达式列表
- Datatype-要与列数据类型匹配的数据类型
- 预测类型-正则表达式或库
- regex-要与列值匹配的regex列表
- library-用于计算列值的库名称
以下是一个示例:

使用DataHub的PII分类模块
要使用分类,您所需要做的就是将分类部分添加到配方中并启用它。
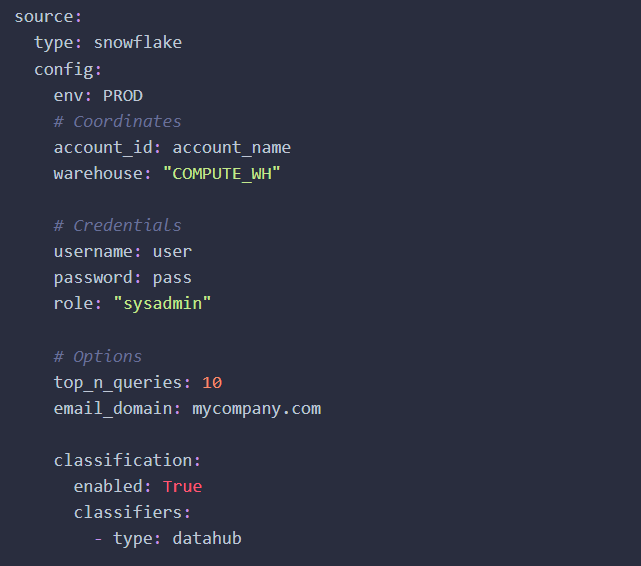
以下是一个示例,说明如何根据您设置的标准和置信度阈值自定义和配置“电子邮件”信息类型的自动分类配方。
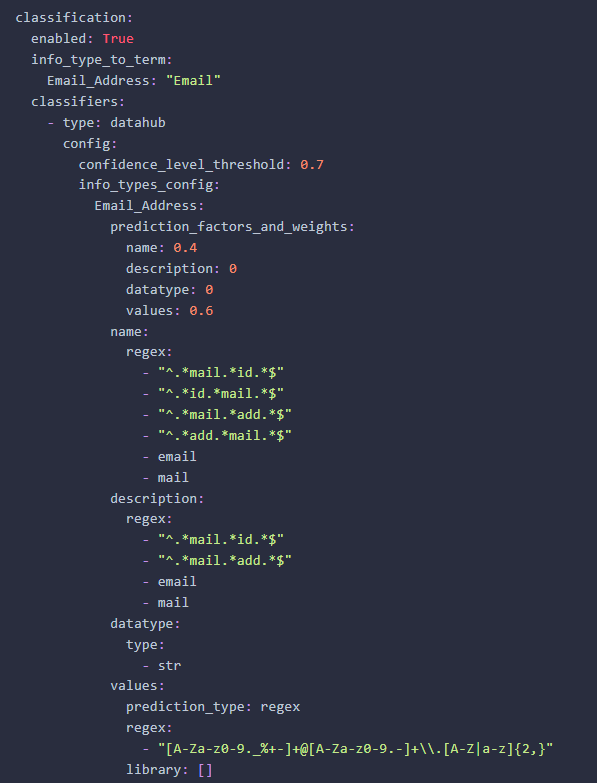
要了解如何对信息类型使用更高级的配置,请查看我们的分类功能指南。
接下来是什么?
DataHub的PII分类功能目前可用于Snowflake;我们很高兴能够将其扩展到其他基于SQL的源代码中,并渴望得到社区关于如何改进集成体验的反馈。
我们正在寻找贡献者-加入DataHub社区,实现这一目标!
- 141 次浏览
【隐私增强技术】隐私增强技术类型和使用案例
视频号
微信公众号
知识星球
数据是公司成功的关键,但维护其隐私和确保法规遵从性很困难。了解保护数据的隐私增强技术。
隐私权是指个人有权控制或影响其信息的收集、使用和存储方式,以及信息的披露对象和披露方式。人们提供的数据不应该直接追溯到他们,也不应该从统计输出中追溯到他们。最后一项要求使企业很难收集和分析用户数据以获得行为见解,改善决策过程,并衡量产品、临床试验或广告活动的性能,尤其是因为这些数据通常与第三方共享。
为了继续使用这些数据,遵守数据隐私和保护法规,如CCPA和GDPR,并避免违规罚款,各组织正在转向隐私增强技术(PET)。PETs确保个人或敏感信息在其整个生命周期内保持隐私。这项技术涵盖了广泛的技术,旨在支持隐私和数据保护原则,同时保持从用户提供的数据中提取价值的能力。大多数PET通过使用密码学和统计技术来混淆敏感数据或减少处理的真实数据量。
让我们来看看一些最常见的加密和统计PET及其用例。
加密隐私增强技术
差异隐私
差异隐私将计算的噪声添加到数据集中,因此数据集中的组模式仍然可以被识别,同时保持个人的匿名性。这使得大型数据集能够发布用于公共研究。科技公司还利用差异隐私来分析大量用户数据并从中获得见解。
同态加密
同态加密能够对加密数据进行计算操作。任何分析的结果都是加密的,只有数据所有者才能解密和查看这些结果。这种加密方法使公司能够分析云存储中的加密数据或与第三方共享敏感数据。谷歌发布了开源库和工具,可以对加密数据集执行全同态加密操作。
安全多方计算(SMPC)
SMPC是同态加密的一个子领域,它在系统和多个加密数据源之间分布计算。这种技术确保任何一方都无法查看整个数据集,并限制任何一方可以获取的信息。OpenMined在其PyGrid对等平台中使用SMPC进行私有数据科学和联合学习。
零知识证明(ZKP)
ZKP是一组加密算法,可以在不泄露证明信息的数据的情况下对信息进行验证。它在身份验证中发挥着至关重要的作用。例如,个人的年龄可以通过ZKP进行认证,而无需透露其实际出生日期。
统计隐私增强技术
联合学习
联合学习是一种机器学习技术,使单个设备或系统能够协作学习共享预测模型,同时将数据存储在本地。例如,手机下载当前模型,通过从手机上的数据中学习来改进它,并仅将其汇总的更改上传到集中式模型。在此基础上,将更改与其他设备更新进行平均,以改进共享模型。
多个实体可以构建更智能的机器学习模型,而无需使用联合学习共享数据。它还减少了必须存储在集中式服务器或云存储中的数据量。谷歌在安卓系统的Gboard中使用联合学习来建议对Gboard的下一次查询建议模型进行改进。
生成对抗性网络
Gan生成模拟真实数据集的新的合成数据实例。这种方法为分析人员、研究人员和机器学习系统提供了大量高质量的合成数据。GANs识别数据中复杂模式的能力正被用于快速发现医学测试和网络流量中的异常。
假名化/模糊处理/数据屏蔽
通过将敏感数据与虚构、分散注意力或误导性的数据互换,可以使用各种方法,包括假名化、模糊处理和数据屏蔽,来替换或模糊敏感信息。这是企业保护用户敏感数据和遵守隐私法的常见做法。某些匿名技术,如删除包含个人身份信息(PII)或屏蔽数据的列,可能容易被重新识别。
设备上学习
用户的操作在他们的设备上进行分析,以识别模式,而无需将单个数据发送到远程服务器。设备上的学习可以用来让算法变得更智能,比如自动校正。苹果的Face ID使用设备上的学习来收集用户面部不同外观的数据,因此其识别方法更加准确和安全。
合成数据生成(SDG)
SDG是从具有相同统计特性的原始数据集中人工创建的数据。由于SDG数据集可能远大于原始数据集,因此该技术用于测试环境以及人工智能和机器学习用例,以减少数据共享和所需的真实数据量。
获得PII的访问权限,但使用PET保持其安全
确保个人数据通过加密和强大的访问控制进行安全存储,对于维护用户数据的隐私和机密性至关重要。
PET是多方共享和分析数据的一种方式。这对用户、组织和社会都有巨大的潜在好处,因为高质量数据的可访问性和可用性是创新的第一步。英国数据伦理与创新中心发布了《善待动物组织采用指南》,旨在帮助组织考虑善待动物组织如何释放数据驱动创新的机会。
PET已经被用于不同的领域,如应用和系统测试,特别是在物联网、金融交易和医疗服务领域。负责监督GDPR执行的欧洲数据保护委员会和欧盟网络安全局发布了技术指南,支持SMPC作为一种有效的隐私保护措施,包括医疗保健和网络安全用例。世界经济论坛估计,医院每年产生50 PB的数据,但97%的数据从未被使用过,这可能会彻底改变医学研究的世界。
- 183 次浏览
【隐私工程】路线图:数据隐私工程
贝塞默揭示了数据收集和新兴市场的七大罪过,这将帮助公司保护和保护消费者数据。
我们访问的网站和应用程序,我们使用的手机,甚至感觉像我们友好宠物的机器人吸尘器,都收集数据。作为消费者,我们越来越习惯于做出小小的妥协,将个人数据的花絮交出来换取“免费”服务。这是一种趋势,感觉就像最新应用程序的条款和条件框一样常见。简言之,科技公司在收集和分析我们的数据方面已经变得令人难以置信的熟练,这完全是设计的。数据是新的石油。无论这句话多么老套,公开上市的科技公司现在占美国股市的四分之一以上,所以客观地说,这是真的!
虽然数据已经渗透到我们的生活和经济中,但只有少数领导人和企业家在谈论这一新现实的后果。由于数据是新的石油,我们相信它也有可能导致下一次“数据石油泄漏”。
虽然许多科技公司的架构是为了收集数据,但它们的架构不一定是为了安全存储数据。如今,数据隐私技术、流程和监管应该在哪里,以及它们在哪里之间不仅存在裂痕,还存在鸿沟,因此产生了大量“隐私债务”
我们访问的网站和应用程序,我们使用的手机,甚至感觉像我们友好宠物的机器人吸尘器,都收集数据。作为消费者,我们越来越习惯于做出小小的妥协,将个人数据的花絮交出来换取“免费”服务。这是一种趋势,感觉就像最新应用程序的条款和条件框一样常见。简言之,科技公司在收集和分析我们的数据方面已经变得令人难以置信的熟练,这完全是设计的。数据是新的石油。无论这句话多么老套,公开上市的科技公司现在占美国股市的四分之一以上,所以客观地说,这是真的!
虽然数据已经渗透到我们的生活和经济中,但只有少数领导人和企业家在谈论这一新现实的后果。由于数据是新的石油,我们相信它也有可能导致下一次“数据石油泄漏”。
虽然许多科技公司的架构是为了收集数据,但它们的架构不一定是为了安全存储数据。如今,数据隐私技术、流程和监管应该在哪里,以及它们在哪里之间不仅存在裂痕,还存在鸿沟,因此产生了大量“隐私债务”
与技术债务一样,隐私债务需要重新设计内部系统,以适应和构建最新标准,这不仅会让消费者更快乐,也会让公司更好。谢天谢地,这正在一个叫做数据隐私工程的新兴领域发生。数据隐私工程不是大多数消费者甚至技术专家都非常熟悉的术语,但我们相信,随着这个问题的出现,这个术语一定会进入公共词典。数据隐私工程代表了网络安全、大数据分析、法律和合规的交叉点,以满足收集、安全存储和道德使用消费者数据所需的要求。
我们相信,数据隐私工程将成为一个独立的类别,这将很快成为创始人和高层管理人员的首要考虑。在本路线图中,我们概述了数据隐私的七大罪过,以此了解我们是如何走到这一步的,并讨论最能激励我们的投资领域。
数据隐私困境
如果Facebook拥有深厚的技术人才,无法防止大规模的用户数据泄露,那么一个更传统的公司应该如何应对?消费者数据收集的激增没有显示出放松的迹象,数据泄露正在加速,2019年是“有记录以来数据泄露活动最糟糕的一年”,尽管企业仅今年就在信息安全方面花费了约1240亿美元。
简而言之,公司未能充分保护消费者数据。为了保护消费者隐私和防止未来的“数据石油泄漏”,每个公司,而不仅仅是科技公司,都必须对数据隐私工程和隐私操作采取不同的方法,以保护我们的安全,避免这些几乎可以预防的灾难。大科技公司和大企业最常见的错误归结为数据隐私工程的七大罪过。
数据隐私工程的七宗罪
- 收集太多不必要的数据并永久存储
- 客户数据安全性不足
- 不知道拥有什么数据或存储在哪里
- 当第三方的政策和实践未知时,与第三方共享
- 缺乏及时的数据泄露报告
- 不响应消费者数据访问请求
- 未经适当同意或以引入偏差的方式对客户数据使用AI/ML
最引人注目和最普遍的问题是第一个罪过——公司不必要地收集了太多数据。在过去几十年中,数据收集一直是工程师和数据库架构师(DBA)的默认习惯。这一做法之所以加速,是因为大规模可扩展数据存储、云应用和摩尔定律推动了与存储数据相关的成本呈指数级下降。此外,工程师倾向于收集更多的数据,因为他们不知道人工智能模型未来是否可能从中受益。
然而,对于为什么要存储这些数据、存储多长时间或是否需要最终用户同意的问题,没有进行太多思考。
隐私工程中有一种称为“最小化”的实践,它涉及到思考公司必须收集的最小客户数据集。这被认为是最佳实践;然而,大多数公司都是由产品和工程驱动的,工程师倾向于尽可能多地保存数据。
这反过来又会导致公司通常不知道自己拥有什么数据,因此无法妥善保护数据,或者在不知道其政策和程序的情况下与第三方共享数据。当发生数据泄露时,没有适当的策略来处理通信,使糟糕的情况更加糟糕。
我们已经看到了数据石油泄漏的后果
所有这些消费者数据处理不当的最终结果是像剑桥分析公司(Cambridge Analytica)这样的丑闻,8700万Facebook用户的数据被第三方共享,最终被用于恶意攻击目的。这一不幸事件不仅为扎克赢得了一个相当不愉快的国会小组的前排席位,而且在舆论法庭上也被判了负面判决。后来,Facebook被联邦贸易委员会罚款50亿美元,扎克伯格同意对未来的事件承担个人责任。在更大的全球范围内,如果公司未能维护GDPR,公司董事可能会承担个人责任。
尽管Facebook罚款,但消费者的行为仍保持一致,大街上也没有明显的变化。例如,在Facebook Cambridge Analytica数据丑闻之后,大约有40万条删除Facebook推文。然而,在同一时期,Facebook的活跃用户增长了4%左右。现代服务似乎与消费者的日常生活交织在一起,无法进行实质性的改变。
我们怀疑消费者的行为是否会很快改变。特别是,通过道德方法收集消费者数据无疑会带来好处,将数据转化为促进创新和改善客户体验的见解。由于数据的激增,新的以数据为中心的商业模式和服务应运而生,从及时提供远程医疗服务以拯救生命的能力,到及时订购墨西哥煎饼以观察办公室。问题不在于数据,而在于未经检查的数据扩散。
各国政府正在介入这场争论,试图堵住这口泄露数据的油井。2016年通过并于2018年生效的《欧盟通用数据保护条例》(GDPR)是第一个倒下的多米诺骨牌,它刺激了企业遵守新制定的隐私规则的势头。这也是一条有着锋利牙齿的法律;公司可能会被处以高达其全球收入4%的罚款。
虽然欧盟是数据隐私运动的早期倡导者,但我们正在目睹其他国家政府和美国个别州效仿。《加州消费者隐私法》(CCPA)是美国首次有意义地涉足现代消费者数据保护领域。虽然许多其他州的数据隐私法案尚未通过,但美国联邦政府也可以(而且我们希望会)接手并通过一项全面的国家法规。否则,公司可能要在50个不同的州政府支持的法案的细微差别中游刃有余。我们认为,这种情况将严重阻碍企业跨州工作的能力。
对消费者来说,幸运的是,许多公司正在兴起,允许公司以更道德和负责任的方式利用个人数据。我们将数据隐私市场划分为几个不同的类别,理想情况下,这些类别代表一套端到端的解决方案,旨在以动态和道德的方式识别、保护和使用数据。虽然这是我们现在的观点,但我们承认,这场比赛肯定是一场漫长的比赛。
可投资机会和数据隐私堆栈
这是我们目前设想的数据隐私环境:
- 数据扫描和分类:在一家公司能够保护其敏感数据之前,它必须首先扫描和分类所有数据,以了解其拥有的数据和所在地。根据规定,该过程不仅包括个人身份信息(PII),还包括结构化较少的个人信息(PI)。PI和PII之间的差异是细微的,但却是一个重要的区别。PII(如电子邮件)通常以定义良好的方式(如SSN)表示,并被认为在结构化数据集中定位相当简单。另一方面,PI可以包括地理位置或产品偏好等细节;数据不属于可识别的人,但属于特定的人,并受到同等保护。所有这些数据都必须跨企业中的所有数据存储(结构化和非结构化)进行定位和清点。这种需求是迫在眉睫的,像BigID这样的公司正在为企业解决这一极其痛苦的问题。
- 数据编目:该类别由工具组成,如数据。这有助于公司在其系统中盘点和组织数据。好处包括改进数据发现、治理和访问。数据编目是一个过程,使公司能够找到并访问数据,同时了解数据的上下文,以确定数据是否适合用于业务和技术用户的给定项目。
- 数据访问治理:这类工具为企业中的特定人员授予对数据的访问控制权,并提高了谁在访问什么信息、何时访问以及访问目的的可见性。随着企业收集和使用更多数据,像Okera这样的公司在跨组织管理和维护数据治理方面越来越重要。
- 数据沿袭:虽然数据治理有助于公司了解数据存储在何处以及如何访问数据,但公司通常不知道互连数据集的转换和依赖关系。数据沿袭子部门的发展填补了这一空白,通过监控数据在组织内的旅程以及使用或与数据交互的应用程序,补充了数据治理。
- 隐私保护技术:一旦企业对其数据进行了清点,并掌握了出处、存储、DSAR和许可,就必须在使用时保护其最敏感的信息——无论是静态还是动态。像Privitar这样的公司利用差异隐私、部分同态加密和其他技术来确保私有数据保持不变,而市场上的其他公司则依赖多方计算和其他技术实现相同的结果。为了使企业在隐私保护技术方面取得成功,公司必须利用一系列不同的技术,不仅达到所需的隐私监管水平(例如,去标识化、化名或完全匿名化),还必须在消费者信任的情况下保护数据的价值。
- 同意管理:一旦公司找到了其数据,充分确定了其来源和治理,并处理了任何相关的法定请求,公司必须确保其拥有并保持充分同意实际使用所述数据。如前所述,数据是大多数企业的竞争优势;同意管理确保企业可以使用该数据,但以消费者友好的方式使用。虽然我们知道这一领域对企业至关重要,但我们还没有在这一新兴且微妙的领域找到明确的领导者。
- 工作流生产力:公司必须能够响应数据主体访问请求(DSAR)和其他监管查询。根据IAPP最近的一项民意调查,只有2%的受访者声称目前已经自动化了这些请求。虽然现在这可能不是一个成本高昂的问题,但这些请求的速度正在急剧加快,企业需要新的软件定义解决方案来有效管理这些流程和其他工作流。例如,Bessemer投资组合公司Virtru提供跨不同应用程序的持久数据保护和控制,因此只有授权用户才能访问数据。TrustArc和OneTrust等公司的高估值表明了这一类别的前景和重要性。
- 数据保险库:除了对公司现有数据进行清点或扫描外,该类别是一种机制,用于保护和检索组织最敏感的数据,作为附加的安全层。在许多情况下,此过程适用于通过API流动的数据。数据保险库公司还跟踪来自数据库的数据,使其成为隐私数据库即服务。
- 消费者隐私工具:我们不认为消费者行为在短期内会发生很大变化,也不认为消费者个人有义务保护自己的隐私-这是一项基本权利。但我们相信,消费者最终会希望看到谁拥有他们的数据以及如何使用数据的更精细的视图。Dashlane等消费者密码管理器已经改进了其产品,为消费者提供基本的隐私功能、警报和信用检查。然而,有机会使用其他工具,帮助消费者通过越来越多的网络服务、社交媒体网站和应用程序控制自己的隐私。Jumbo Privacy等公司正试图通过帮助消费者应对越来越多的不同隐私设置和政策来解决这一难题。
虽然这些是我们发现目前风险投资前景看好的数据隐私领域的主要领域,但我们也发现了adtech、合成数据、隐私存储和道德人工智能市场的邻近领域。我们怀疑,随着时间的推移,这些新兴类别的重要性和需求将不断增长。
数据隐私工程的未来
我们相信,未来赢得市场的数据隐私平台将需要所有这些类别的元素,以便形成一个集成套件,允许企业以可管理、合法和道德的方式识别、保护并最终使用其数据。然而,目前还不清楚是否有任何一家公司将真正拥有完整的解决方案,或者我们是否会在类别中看到专业化和最佳解决方案,类似于我们在网络安全领域所看到的。虽然这是我们今天看待市场的方式,但我们承认,我们的观点以及前景-从监管、技术和公众舆论的角度-正在不断演变。
我们相信,这些集体努力和解决方案的最终结果将有助于企业避免数据隐私工程的七大罪过,尽管我们今天还远未达到这一目标,但公司必须努力以更安全、更消费者友好的方式利用数据。此外,随着数据监管继续像数据本身一样迅速扩散,我们坚信,数据隐私工程将不再是一件好事,而是将演变为新的业务需求。
- 185 次浏览
【隐私架构】数据驱动创新的隐私架构
Bhajaria:让我们尝试定义隐私的含义。与安全不同,许多在科技公司工作甚至不在科技公司工作的人都对安全意味着什么有直观的认识:信用卡泄露、身份盗窃。有一个非常直观的定义。隐私更难定义。为了定义它,让我们回到几十年前的波特斯图尔特大法官。他曾被要求定义铁杆色情的含义。他说他没有定义,但当我看到它时我会知道,这是他的回应。这如何帮助我们定义隐私?
A Lesson in Privacy
为此,让我们以后再回来谈谈我和我的配偶以及我们结婚后第一次与家人见面的旅行。我们结婚后,我认为让她真正见到我的家人是个好主意。我们飞往孟买,我的妻子不顾我的建议,从未去过伦敦东部的任何地方,决定在孟买的街头吃些街头小吃。她很享受,正如我预测的那样,她很快就病倒了。我们去看了医生,一切都很好,只是肚子不舒服。医生说:“这些药吃几天就好了。”到目前为止没有伤害,没有犯规。
然后在预约结束时,就在我们完成之前,他决定向坐在房间对面的助手大声喊出有关处方的详细信息。门开着。他喊出药物的名称,然后是我妻子的名字,然后是她的体重,她的统计数据,以及一堆其他细节。写处方的人得到了所有信息,但坐在外面的所有病人也得到了所有信息。三秒钟内,一个无意伤害我们的人,破坏了我妻子的隐私。斯图尔特大法官说,说到色情,我一看到就知道了。有了隐私,当你失去它时你就会知道它。请记住,当您对其他人和他们的数据做出决定时。当我提倡隐私计划时,我试图将这种敏感性带到我的工作、我的团队和我的执行领导团队中。
Outline
这是具有这种背景的谈话的议程。首先,我将自我介绍一下,在科技行业和整个经济的背景下谈论隐私。然后介绍谈话的两个部分。首先,当您从用户和客户那里收集数据时,您如何构建隐私架构?然后我将讨论为数据共享构建隐私架构。当数据离开您的公司时,就会发生这种情况。您需要一个用于收集、接收数据的架构,以及一个用于从您的公司退出数据的架构。然后我们会看课程和总结。如果我们最后有时间,我会回答你的问题。
Introduction
关于我的一点点。我已经隐私了大约 10 年了。当没有其他人想在其中工作时,我进入了它。我确实接受了这份工作,因为没有其他人想要它,而且与公司中的一些聪明人一起工作是一种简单的方式。我喜欢和一些聪明的律师一起工作。那是在当时的 WebMD 上。几年前,我在耐克和 Netflix 开始了隐私工程项目。我负责管理 Google Cloud 的信任组织 GCP。目前,在过去的几个月里,我一直在 Uber 领导隐私架构组织。
Privacy, Then and Now
正如我之前所说,当我第一次接触隐私时,这是一个非常深奥、抽象的概念。现在它是模因和卡通的主题。当报纸漫画取笑你的纪律时,你就知道你已经到了。我对此感到有些高兴。隐私有严肃的一面。我不想处于孩子的位置。我不想担任总统的职位。我不想处于令我感到惊讶或令其他人感到惊讶的境地。数据和隐私权非常强大,而长期以来,我们作为一个行业做得并不好。我们今天在这里所做的很多事情都是为了纠正其中的一些错误,同时也让我们为成功做好准备,这样我们就可以更负责任地成长。
Privacy: The Rules Are Changing
长期以来,我们与客户之间一直存在这种不成文的合同。我们将打造令人惊叹的产品,我们的用户会使用这些产品,他们会为我们提供大量数据。然后,我们将使用这些数据来构建更好的产品。然后他们将使用它们。我们将获得更多数据。良性循环将继续旋转。在某些时候,合同并没有很好地发挥作用。
Modern Companies
关于隐私,我们现在在这里考虑四个关键事实。答,我们作为企业,我假设在这个房间里的我们大多数人或我们所有人都为收集数据的公司工作,所以我们收集了大量的数据。没有概念上的、确定的方法来衡量风险?您如何确定这些数据的敏感程度?没有一种正确的方法可以做到这一点,但大多数公司甚至不知道从哪里开始。因此,我们并不总是知道如何抢先保护数据。当有违反或同意法令时,我们总是会做出反应。这是一门非常被动的科学。隐私因此受到影响,安全性也因此受到影响。因为当数据进入我们公司时我们没有做好,当数据离开我们公司时我们也没有做好。这种风险只会不断增加。这是一个你不治疗的头痛,它一直在恶化。
Customer Trust Sentiment
客户正在追赶。如果我们认为我们的客户不关心隐私,那么当我准备在 LinkedIn 上教授的课程以启动隐私计划时,我查看了一项普华永道调查,其中有四个关键数字引起了我的注意。首先,69% 的受访者认为公司容易受到黑客攻击。坦率地说,考虑到我们这些天看到的头条新闻,我想知道剩下的 31% 的人在想什么。这个数字应该要高得多。 90% 的受访者认为他们无法完全控制自己的信息,这可以追溯到信任和透明度。只有 25% 的受访者认为大多数公司都能很好地处理敏感数据。这尤其不祥,只有 15% 的人认为我们将以有利于他们的方式使用他们的数据。有这个不成文的合同,为了工作,合同必须公平地使双方受益。在某些时候,这种平衡已经严重失衡。这些数字说明了这一点。
This Trust Deficit Is an Opportunity
这有一线希望。让我谈谈那项研究中的另外两个数字。首先,72% 的受访者还认为企业而不是政府更有能力保护他们的数据,您可能想知道为什么要考虑我们刚刚看到的所有数字。对此有两个见解。首先,当谈到建立隐私基础设施的速度时,企业总是会走得更快。由于政府的固有性质,政府需要更长的时间才能让事情发生。那是第一名。
第二件事是,在与政府打交道时,我们别无选择。您可以停止使用某些应用程序,但不能停止与政府打交道。当我成为美国公民时,入籍过程花了大约 11 个月,我不得不提交这么多文件。政府想要关于我的岳母的文件,我从未见过她,她在我出生前 21 年就去世了。他们想知道她的出生证明。在她出生的时候,他们甚至没有在她出生的地方签发出生证明。对于为什么这些信息与我成为公民或如何保护这些信息密切相关,我没有发言权。那里也存在不平衡。人们想要信任我们是有原因的,我们只需要给他们一个理由。这就是这次谈话的很多内容。
第二个数字是我最喜欢的数字,88%。 88% 的受访者表示,如果他们信任我们,并且如果他们知道他们的数据将如何被使用以及为什么被使用,他们会愿意向我们提供他们的数据。它可以追溯到信任和透明度。即使在缺乏信任的情况下,这里也有机会。
关于隐私,我们现在在这里考虑四个关键事实。答,我们作为企业,我假设在这个房间里的我们大多数人或我们所有人都为收集数据的公司工作,所以我们收集了大量的数据。没有概念上的、确定的方法来衡量风险?您如何确定这些数据的敏感程度?没有一种正确的方法可以做到这一点,但大多数公司甚至不知道从哪里开始。因此,我们并不总是知道如何抢先保护数据。当有违反或同意法令时,我们总是会做出反应。这是一门非常被动的科学。隐私因此受到影响,安全性也因此受到影响。因为当数据进入我们公司时我们没有做好,当数据离开我们公司时我们也没有做好。这种风险只会不断增加。这是一个你不治疗的头痛,它一直在恶化。
客户正在追赶。如果我们认为我们的客户不关心隐私,那么当我准备在 LinkedIn 上教授的课程以启动隐私计划时,我查看了一项普华永道调查,其中有四个关键数字引起了我的注意。首先,69% 的受访者认为公司容易受到黑客攻击。坦率地说,考虑到我们这些天看到的头条新闻,我想知道剩下的 31% 的人在想什么。这个数字应该要高得多。 90% 的受访者认为他们无法完全控制自己的信息,这可以追溯到信任和透明度。只有 25% 的受访者认为大多数公司都能很好地处理敏感数据。这尤其不祥,只有 15% 的人认为我们将以有利于他们的方式使用他们的数据。有这个不成文的合同,为了工作,合同必须公平地使双方受益。在某些时候,这种平衡已经严重失衡。这些数字说明了这一点。
这有一线希望。让我谈谈那项研究中的另外两个数字。首先,72% 的受访者还认为企业而不是政府更有能力保护他们的数据,您可能想知道为什么要考虑我们刚刚看到的所有数字。对此有两个见解。首先,当谈到建立隐私基础设施的速度时,企业总是会走得更快。由于政府的固有性质,政府需要更长的时间才能让事情发生。那是第一名。
第二件事是,在与政府打交道时,我们别无选择。您可以停止使用某些应用程序,但不能停止与政府打交道。当我成为美国公民时,入籍过程花了大约 11 个月,我不得不提交这么多文件。政府想要关于我的岳母的文件,我从未见过她,她在我出生前 21 年就去世了。他们想知道她的出生证明。在她出生的时候,他们甚至没有在她出生的地方签发出生证明。对于为什么这些信息与我成为公民或如何保护这些信息密切相关,我没有发言权。那里也存在不平衡。人们想要信任我们是有原因的,我们只需要给他们一个理由。这就是这次谈话的很多内容。
第二个数字是我最喜欢的数字,88%。 88% 的受访者表示,如果他们信任我们,并且如果他们知道他们的数据将如何被使用以及为什么被使用,他们会愿意向我们提供他们的数据。它可以追溯到信任和透明度。即使在缺乏信任的情况下,这里也有机会。
Lessons learned
我们从所有这些中学到了什么?三件事,首先,隐私是一个全员参与。不要只是让公司的法律团队认为这是他们的辩护。你是来帮忙的。工程师、数据科学家、IT 团队、安全团队,他们都需要在谈判桌上占有一席之地。第二件事是,安全和隐私不是一回事。它们是相关的,但是当您拥有良好的安全性时,隐私就可以开始了。一个依赖于另一个,但它们不是一回事。然后,超越违规思考。当出现违规行为时,不要只是等待您的隐私计划出现。在从您的用户那里收集信息时,请考虑隐私,因为这是用户与您的公司联系的第一个点,它会再次回到信任状态。此外,当数据离开您的公司时,您如何看待隐私?
Privacy by Data and Design
您如何为数据收集构建隐私架构?人们经常谈论设计隐私,但实际上,设计隐私为不同的人推断出许多不同的东西。我喜欢通过数据和设计来考虑隐私。也就是说,您必须将数据和数据背后的人视为一等公民。这不是一组数字。这是一个人,他相信你,或者她,或者他们的数据。在我看来,当涉及到数据分类或为收集正确地进行数据架构时,有四个关键步骤。首先是作为规划阶段一部分的数据分类。第二个是建立治理标准来保护这些数据,这也是规划阶段的一部分。第三个,我将详细讨论的,是数据清单。四是实际执行数据隐私。
Classify Your Data - Planning
首先,您如何对数据进行分类?数据是驱动我们创新引擎的燃料。如果数据处理不当,则根据处理不当的情况,存在不同级别的风险。数据分类是表达您对所收集数据的风险的理解的方式。这是您与法律团队合作的一种方式。我正在考虑法律、隐私、安全、数据科学、营销、法律、业务发展。每个对您作为公司如何与您的用户互动有发言权的人都需要参与进来。让我举个例子,看看会是什么样子。数据分类回答了两个基本问题。首先是,这个数据是什么?第二,它有多敏感?也就是说,如果这些数据处理不当会发生什么?这是一个例子。这是我将如何进行数据分类的一个非常简单的示例。由于我来自优步,这是我们在很早的阶段就开始做的事情。我将只关注第 1 层。如果你是优步司机,什么会非常敏感?你是谁,你在哪里?
我是 Netflix 的校友,如果有人发现的话,你四天前看的内容可能会很尴尬。你是谁以及你在哪里会影响你的人身安全。这是我们非常重视的数据。在我们的分类中,这被适当地标记为第 1 层。其他的例子,当然,你的社会保障卡,你的驾照,但是任何直接和明确地把你固定下来的东西都是第一层的。当然,随着您在层级上上下移动,这种风险会降低,保护它的压力也会下降一点。更全面地说,您希望保护您的数据,就好像它都是第 1 层一样,因为如果您保护数据不好,仅仅因为它是第 4 层,您就会产生弱点和坏习惯。在某些时候,所有这些也会蔓延到第 1 层。这是一项衡量风险的练习,但不要用它来破坏您的保护和安全机制。
Set Governance Standards - Planning
然后,当然,第二步是现在您已经对数据进行了分类,您想就如何保护这些数据提出内部理论理解。根据层级,您现在已经了解这是第 1 层,因此我们需要全力以赴。二层,或许我们可以轻松一点。至少在内部了解您将如何做到这一点,涉及收集,涉及访问、保留、删除。
Data Handling Requirements
回到该幻灯片的左侧,数据分类回答了两个基本问题。这是什么数据?如果它被妥协会发生什么?处理要求回答了第三个同样重要的问题,即,既然您知道数据的风险有多大,您将如何保护数据?这两个步骤按顺序排列是有原因的。
Data Inventory - Execution
第三步是数据盘点。这一点尤其重要,因为在此步骤中,您根据在第一阶段获得的分类标记数据,以便您可以根据在第二阶段设置的标准来保护它。除非您执行此步骤,否则您所做的一切都只是计划。任何没有执行的计划都只是纸上谈兵。
Classify and Inventory Your Data
这是一个非常基本的图表。我将在下一张幻灯片中介绍更精明的图表。将此视为展示数据如何进入公司的漏斗。最左边是客户第一次接触您的服务的地方。随着数据进入您的公司,它会增长。你从中推断出一些东西。它被复制了。它被共享。您有来自其他来源的数据。数据的大小在增长。有时数据的增长速度会超过用户群的规模。如果你想对数据进行分类和清点,在我看来,你应该尽早在漏斗的最左边进行,因为如果你稍后再做,它会变得越来越昂贵。
这更说明了问题。当我们提出预算时,这是我展示了我们的领导力的东西,它真的不需要太多的对话,我们得到了我们想要的一切。因为除非您在使用数据之前进行数据盘点,否则您计划的一切都会一蹶不振。收集后您会注意到,我们在使用前立即有库存。稍后我将在演示文稿中展示有关其工作原理的图表。
Why Data Inventory Is Hard
为什么数据盘点很难?即使您做对了所有事情,库存也很困难,因为通常您会在出现违规行为、同意法令或发生重大变化时执行此操作,或者您意识到“这并不真正有效”,因为您有太多客户在询问获取其数据的副本。作为一家公司,您通常在成长过程的后期才这样做。事实上,上周我正在和几位创业者交谈。他们都没有在第一批或第二批中雇用隐私。通常,像我这样的人会在已经发生足够的增长时加入。不管你什么时候做都会很难,所以最好早点而不是晚点。
Data Inventory at Uber
当谈到优步的数据库存时,我们认为它是五个合乎逻辑的基础设施步骤。首先是我们需要能够抓取我们所有数据存储的东西,然后发现我们的数据集,使这些数据集和相应的元数据可用。然后启用添加新元数据,因为工程师总是在最后一刻出现说:“你没有捕获我的数据。我需要确保它也被标记。”然后是第五步,实际上是从隐私角度应用所有标签。我认为,从第一步到第四步,为了更好的数据卫生和数据科学,无论如何你都需要这样做,只是为了确保人们可以真正将他们的数据用于营销目的。我认为不应将步骤 1 到 4 视为隐私费用。事实上,对于那些运行隐私和安全计划的人来说,与您的数据科学团队交谈并找出一种分摊成本的方法,这样您就不必从头开始争论隐私计划。
How UMS Fits into the Larger Data Inventory Strategy
我们进行数据盘点的系统称为 UMS。它是统一的元数据管理服务。我将其称为 UMS。这张图真正解释了我刚才谈到的一切。 UMS 基本上是万能的,它会爬取数据集,发现所有数据,并根据需要提取数据。这里的四个关键数字是我真正想要谈论的。在左侧,左上角是法律数据分类步骤。那是您与法律合作提出概念分类的地方。第二个是将分类转换为机器可读标签的地方,以便将其应用于数据。第三是您应用策略的地方。你谈到了处理政策。然后第四是数据涌入您的公司的地方。 UMS 是所有标签和相关策略所在的位置。第四个是所有数据被推送的地方。UMS 是所有魔法发生的地方,所有数据都符合保护它的所有逻辑。就如何保护它以及如何确保数据在分类之前不会流向用户而言,这是需要考虑的事情。
The UMS Back-End - A Granular View
我确实想多调用后端。这是这里图表的一个更精细的版本。在左上角,您可以刷新数据目录。数据不会自动拉入 UMS。我们必须构建大量基础设施,以确保有多个管道让数据进入 UMS。我们有爬虫。我们有一个工程师可以使用的 UI 门户,但有多种方法可以确保数据可用于标记目的。
然后在分类器列下方的中间有两个框。我们有能力手动对数据进行分类。许多工程师确切地知道他们拥有的是第 1 层、第 2 层或第 3 层,我们让您有机会标记自己的数据。我们中间还有三个非常受人工智能驱动的算法,它们将基于对列名或 JSON 表达式的爬取和嗅探进行分类。我们有几种方法可以确保数据清单可以在分类器部分下进行。那么我们不只是相信你的话。如果工程师决定 SSN 是第 4 层。它是公开的,我们不要保护它。那显然不会飞。我们在最顶部的最右侧有一个判定器算法,它将再检查一次以确保数据被正确标记和分类。
这是从另一个角度看的图表。我调用了 UMS 两次,UMS 位于最左上角,第二个框位于左侧数据存储下方。它基本上为分类器提供信息,并使所有分类器都能获取列名、列类型、任何已经发生的手动分类等信息。分类器将使用此信息对数据进行适当的标记。 UMS 既是数据的初始接收者,也提供正确的元数据信息以确保分类能够正确进行。
然后在右侧,中间的列,UMS 是分类后的数据存储。一旦决策者完成,所有的数据都会被吐到决策者中。这样想,你已经建立了所有的基础设施,你拥有分散的所有东西,但是 UMS 是我们希望数据分类、标记和数据存储发生的唯一地方。如果您正在查看 UMS 中的数据,它要么是数据预分类,要么是数据后分类。这是唯一发生这种情况的地方。让我们的目标是让工程师的生活更轻松,这样他们就不必去寻找适当保护隐私的数据。
The UMS is "Privacy Central"
我在 Facebook 和我的一个朋友谈过为什么隐私工程很难。这里的创新是工程师将做任何容易的事情。你必须让他们变得很容易,因为如果你让他们做错事变得容易,他们就会做错事。如果你让他们容易做正确的事,他们就会做正确的事。 UMS 是隐私中心。我们的首席执行官 Dara 喜欢说我们以非常分散的方式发展,因此公司发展非常迅速。为了让我们确保隐私得到正确处理,必须有一定程度的集中化。我知道流程、官僚主义和集中化这些词经常会以错误的方式惹恼人们,Netflix 就是这样,Uber 也是如此。您必须构建所有这些自动化以确保隐私是集中的,而 UMS 是我们做到这一点的方式。
Data Inventory Back-End Infrastructure
数据清单基本上需要两个关键属性。这是进入基础设施。我们需要一种在我们的基础架构中尽可能多地捕获元数据的方法,并且我们需要一致的元数据定义。 Uber 的元数据管理不仅涵盖数据集,还涵盖所有实体。 UMS 捕获有关在线-离线、实时数据集以及 ML 功能、仪表板、业务指标的元数据。它收集血统。基本上,任何与底层数据有关的任何事情,将指示数据应该如何分类,UMS 都有能力进入管道。
A Consistent Metadata Definition for Data Inventory
因为我们的元数据服务需要管理不同来源的数据,所以我们谈论的是每个数据、货运、乘车,以及有一天 ATG,也就是自动驾驶汽车。我们构建了这个基础架构,以确保元数据以相同的方式分类,无论数据源是什么或数据来自何处,因此在分类时,它与平台和业务线无关。第 1 层是第 1 层,因此,如果您拥有货运司机的驾驶执照而不是 Uber Eats 司机,那么无论如何它都将被归类为第 1 层。
我们使用类似分类的结构。在此示例中,对于查看此演示的任何人来说,它都非常直观。 MySQL 表和关系数据库被定义为实体类型,因为它们是物理实体的抽象。可以看到 MySQL 表被定义为关系型数据库,其名称的值为 UUID。它非常直观。这很容易。最初,要正确定义此定义,需要为根本不了解隐私的人定义数据库模式的人员的大量参与。确实有人知道隐私但不知道我们的基础设施,也有人知道基础设施但不知道隐私。对我们来说关键是,维恩图在什么时候交叉到足以让我们理解他们的世界而他们也能理解我们的世界?那时我们可以建立隐私权,他们可以做出基础设施决策,使隐私更容易在公司中实施。这是我们经历了几个月的过程。
一旦元数据被很好地定义,那就是我们的重点。这是我们进入完整循环的地方。那时我们才知道整个公司有多少数据,数据在哪里,以及哪些基础设施需要存在哪些管道。我们构建了爬虫,以确保我们基本上可以定制推送并且我们不会压倒接收器,因此有一些可用的节流。我们使用 UI 监听器。我们有 API。我们有用户可以手动输入数据的 UI。不同的团队投入了大量资金,他们意识到他们无法手动完成这项工作。
Classification Techniques
这让我想到了我们的 AI 分类。这是中间的AI模型。请记住,我向您展示了中间的两个方块,其中一个是手动的,另一个是 AI 驱动的。当涉及到实际的分类算法时,我们必须做出一些权衡。当涉及到覆盖范围、准确性和性能三重奏时,我们无法同时获得这三者。我们实际上必须在不同的管道上应用不同的算法,这取决于我们的用例是什么。您将需要四处看看它是如何优化的。因为在一天结束时,您不希望将数据放慢速度,让那些实时决定谁在寻找 Uber Eats 时获得什么推荐的人。
Data Inventory, High-Level Milestone
当我们向高管团队介绍我们拥有多少数据以及其中有多少数据存在风险时,这有点像我们如何根据风险进行推销。您有一条非常明确的隐私信息非常重要,因为我有工程师在我们的团队中工作,他们深入了解爬虫如何工作以及该算法如何工作的最详细的细节,并且它超越了我们行政套房的负责人。看起来我们几乎是在吹嘘我们的技术技能,而不是为隐私辩护。你真的想把你的信息浓缩成这样的东西。当您必须为投资进行宣传时,当您必须为优先级进行宣传时,您是根据基于您所建立的所有学习和所有基础设施汇总的数字来制定的。我做错了。我已经这样做了。这种方式每次都效果更好。
Concerns and Learnings
私人挑战第一,安全是建立隐私的基础。您在什么时候收集了如此多的数据,以至于您的安全基础设施无法跟上?有四个关键的学习,当你发展你的程序时,你必须寻找所有这些学习。您在什么时候拥有如此多的数据,以至于保护它变得异常昂贵?这是你需要考虑的事情,在什么时候你不能删除你的出路?
第二件事是,您在什么时候达到了拐点,您不再发现某些工程师将其隐藏在某个 S3 存储桶中的数据,因为我以后可能需要它。当您不再定期获得这些惊喜时,您就会知道自己已经转了个弯。
第三是,当您大规模删除数据的能力与您的数据收集相形见绌时,您会怎么做?你优化什么?您是否不断增加删除基础设施?你会花更多的钱吗?你让更多的人加入团队吗?你停止复制数据吗?这些是你需要注意的事情。
你想看的第四件事是,隐私对数据质量有什么帮助?如果您有太多无法删除的数据,您必须不断向其中添加基础设施,那么您的数据在什么时候变得无用?当我们在 Uber 帮助一个这样的团队时,我们发现他们的大量数据基本上是当人们在等待 Uber 司机时最小化 Uber 应用程序时捕获的信息。这一定是忙碌的一天,所以人们一次又一次地最小化他们的应用程序,这被捕获了。百分之七十的数据是空白数据。这完全是垃圾数据。我们正在针对它运行查询,针对这些查询进行记录。我们正在存储垃圾数据的副本。不仅是垃圾数据,它不是隐私风险,而且只是无用的数据。当您很好地运行隐私计划并提出这些问题时,您实际上最终可以帮助您的数据科学团队。您可以帮助节省存储成本。不要让隐私程序获得成本中心或减速机器的名声。您可以将其作为帮助您的业务的一种方式。记住这一点。
Privacy Architecture for Data Sharing - Strava Heatmap
我们已经谈了很多关于数据收集以及如何保护数据的问题,让我们谈谈数据共享。在我们进入细节之前,另一个故事。大约 5 年前,我曾经比现在重 100 磅。那时我真的很大。我通过早上跑步和使用名为 Strava 的应用程序减轻了体重。我仍然每天早上跑步。我 4:00 起床。我每天跑大约 10 到 12 英里,这取决于我什么时候喜欢。这是一个很棒的应用程序,因为当你使用 Strava 跑步时,它可以让你记录你的跑步。它可以让你记录你的起点,你的终点。它放置了一个小热图,让您了解您周围的其他人正在运行以及他们在您周围运行的位置的社区感。这个功能非常有用,因为它让我恢复了健康。事实证明,这也让 Strava、公司和美国军方有些头疼。事实证明,五年前,我并不是唯一一个在跑步的人。我们的军队和我们在世界各地的军事基地也在运行。很多人可能都知道这个例子,因为它一发生就引起了一些新闻。
Strava 是一家伟大的公司,他们取得了很大的进步。我们都犯过错误。这绝不是幸灾乐祸。关于我们所有雇主的坏故事已经够多了,所以我们不要对他们笑太多。这是一次学习经历。在这种情况下发生的情况是,您在足够多的这些基地中有足够的服务成员,运行并记录他们的运行。即使在 Twitter 生命的早期阶段,也有足够多的人能够查看这些模型,将它们与外部数据联系起来,并识别出这些军事基地。这本身不是问题,因为这些基地大部分都是公共的,但这些运行不仅确定了基地,还确定了通往基地的供应路线、食堂设施、培训设施,以及人们在这些基地之间来回的其他方式.事实上,借助其他汇总信息,您可以确定哪个服务成员在哪个基地。事实上,研究人员也在事后发现,如果你把跑步的起点和终点模糊不清,你仍然可以识别出所有的士兵、所有的基地、所有的补给线,一切。基本上,因为有些人决定使用 Strava 跑步,所以你有一大堆美国安全、军事基础设施,就这样被曝光了。
Privacy Is about Data and Context
你可能想知道 Strava 在想什么,他们真的没有预见到这会发生。当这条消息传来时,他们的回应是您可以更改设置以确保不会在热图上广播。就目前而言,这是正确的,但对于我们这些从事隐私和安全工作的人来说,如果您必须在隐私或安全问题之后解释您的工具如何工作,那么您就输了。这就是生活的运作方式。我自己去过那里。就是这样。一旦数据进入您的公司,您就拥有数据的安全性和隐私权。当它离开你的公司时,你特别拥有它,因为如果第三方或供应商处理不当,他们没有这样做,你这样做是因为你给了他们数据。故事就是这样展开的。在以增长的名义、以增加大量用户或赚取大量金钱的名义做出决定之前,请记住不要用今天的头痛换取明天的偏头痛。
Privacy Architecture in Action
为了防止这样的事情发生,我们在 Uber 有一个两层计划,我们有法律团队来运行隐私影响评估,这是 GDPR、CCPA、任何数量的标准和法规要求。最重要的是,我启动了一个名为技术隐私咨询的项目,它做了两件事。它可以在影响评估期间帮助律师,因此他们有一个工程师可以帮助查看 ERD 和 PRD 以及设计文档,以了解如果其他隐私意识较低的人做出错误的决定会发生什么。那是第一名。
我们也更非正式地与工程师合作。如果您是一名工程师,在某处发现数据但不知道如何处理,我们将为您提供帮助。如果您不知道实际情况如何,如果您需要了解可用的隐私技术,我们会在您编写 ERD 或 PRD 之前就为您提供非正式的解决方案。工程师与工程师之间的非正式联系,无需任何流程,无需任何判断,非常有帮助。证明反事实是不可能的。我不能站在这里告诉你,“这就是我们阻止的所有坏事。”在事情变得更糟之前抓住东西会带来很多满足感。我会推荐这个模型,因为当我们做这个模型时,它可以帮助我们改进我们的内部隐私工具,因为我们知道人们愿意用数据做什么。
Third Party Data Sharing Checklist
最初,我们所做的是提出非常高层次的问题,只是为了让团队更轻松。您如何保护静态和传输中的数据?您收集或共享它的粒度级别是多少?用户的可识别性如何?是否应用了任何聚合或匿名化?如果涉及第三方,他们是否将数据货币化?就他们将如何处理数据而言,这种透明度是什么样的?
Use Cases for Data Sharing with Cities
我们已经谈了很多关于共享的话题,但回到优步,你可能想要共享数据是有正当理由的,即使是超出正常增长故事的事情。优步需要与市政府合作,以获得在街上运营汽车和车辆、自行车的许可证。城市需要了解对交通、停车和排放的影响。他们还需要按车辆收取费用。他们需要为骑自行车的人、自行车、踏板车执行停车规则。虽然人们在城市里开车的方式我不确定它的效果如何。他们还需要对服务和可能的健康中断做出响应。您需要有关这些汽车、自行车和踏板车的数据。同样,有一个有效的用例。您还需要下车地理位置,例如,在高峰时段实时了解交通状况。您可能需要行程遥测信息来找出并确保您没有进入医院等禁区,例如,您不允许进入的区域。您还需要驾驶执照号码或车牌号码,以确保您没有驾驶过期的车牌或没有琥珀色警报。这种数据共享对社会具有实时价值。
Los Angeles and the MDS tool
当谈到数据共享时,我不能不谈论一些非常当代的事情就离开舞台。有一个争论正在进行,我显然不会进入它的法律方面。我将就优步和洛杉矶市之间正在发生的争端进行高层次的讨论。我相信洛杉矶市对出行数据提出了一些要求,Uber 的团队认为这是极具侵略性的,而不是以隐私为中心的。让我们谈谈那些是什么。
LA Specific Areas of Concern
洛杉矶市希望在他们的 API 上进行实时旅行跟踪。我有几个问题。一是,如果您希望每隔几秒进行一次 GPS ping,就没有真正的理由拥有实时数据。除非存在真正的健康问题,否则您不需要对每辆车进行此操作。您可能会更有选择性,但洛杉矶市的看法不同。
他们需要精确的行程起点和终点坐标。还记得几分钟前我刚刚提到的 Strava 示例,你在世界上一些最安全的基地部署了部队,即使起点和终点都模糊不清,他们也会被淘汰。洛杉矶市需要实时位置。如果一个拥有更似是而非的人权记录的城市需要这些信息,我们会泄露这些信息吗?同样,另一个需要考虑的用例。
他们还需要停放车辆的 GPS 位置。洛杉矶市,与美国的许多其他城市不同,他们没有公布隐私指南,没有我们可以评估的任何匿名技术,他们也没有承诺非货币化,也就是说,他们可以使用用于金钱目的的数据。当然,他们可能会将其扩展到私人车辆。如果您决定为 Uber 或 Lyft 开车,明天,无论您是否愿意,您的数据都可能最终进入洛杉矶市。这就是争论的焦点。至少从我的角度来看,我试图区分我认为是有效用例的用例和我不认为它是有效用例的用例。
我们正在定义几项指导方针,我们将加快其中一些指导方针,以了解我们如何在数据离开公司之前对其进行匿名化。
Data Retention Guidelines
我们要求供应商和合作伙伴记录保留和删除政策,以便我们对其进行评估。甚至除此之外,如果您从上到下查看,当我们与您共享唯一标识符和精确时间时,无论在任何级别,您都只能将它们保留很短的时间。同样,90 天就是一个例子。这不是确切的数字。它因情况而异。那么如果我们粗化正确的数据,也就是让它更近似,你可以保持更长时间。如果你再往下走,我们会寻找更高程度的数据近似值。这张幻灯片的主要内容是,如果您拥有非常精确和非常具体的数据,您可以将其保存的时间更短。如果您想将数据保留更长时间,请将其粗化。你必须在寿命和准确性之间做出选择。你不能同时拥有两者,因为当你拥有两者时,隐私总是会丢失。
Privacy Preservation Techniques (Uber)
我们还要求您删除所有唯一标识符。例如,如果我们为您提供的 ID 可将您唯一标识为 Uber 司机,那么当您获取城市数据时,请取出他们的 ID 并放入您自己的 ID。如果明天旧金山市遭到入侵,那么违反他们的人应该无法将我识别为 Uber 司机或将 Huang 识别为 Lyft 司机。我们应该基本没有区别。然后,我们还希望您处理掉任何个人身份信息或替换为使用 HMAC SHA-256 等伪随机函数生成的值。这是您需要安全人员参与的地方,因为这些技术也可能因具体情况而异。
然后我们还希望您粗化任何存储数据的精度。例如,将时间四舍五入到最接近的 30 分钟增量。如果你在 12:22 离开,而我在 12:30 离开,它会作为两个在 12:30 离开的人存储在数据库中。它更近似一些。它只增加了 50% 的隐私,但在庞大的样本集中,您可以通过这种方式获得更多的匿名性。然后将 GPS 坐标转换为最近的起点或终点或街道中间,或将其四舍五入到一定数量的小数点,例如,在本例中为三个小数点。假设您将文件发送给其他人,并且您认为您已经完成了所有这些。我浏览了四张幻灯片。这是很多粗化。你真的打败了这些数据的废话。你必须假设这里必须有一些隐私。
我们最近在 Uber 对此进行了一项研究,我们看到了这条推文,如果你查看 3 个小数点,并以 15 分钟为增量进行堆叠,这就是它的样子。如果你有一个非常大的校园,比如医院,或者像斯坦福这样的大学校园,在帕洛阿尔托的街道上,我可以很容易地确定你去了斯坦福,你去了三栋建筑中的一栋。如果这不是校园繁忙的时间,如果是春假,或者是春假结束前的周日,或者其他什么,很容易识别你,因为游乐设施的数量将非常有限。即使我们做了到目前为止所做的一切,也很难保证隐私,或者至少,你不能只是将文件发送出去,就认为隐私已经得到了保护。在 Uber,我们非常倾向于 k 匿名化,因为它实际上是在数据离开我们作为一家公司之前的唯一方式,我们可以非常接近保证您拥有一定程度的隐私。
什么是 k 匿名化?我们所做的是,我们确保无论 k 匿名程度如何,都必须至少有 X 个其他人共享您的所有重要属性。如果您谈论 k2-匿名性,那么至少还有一个人可以追溯到 12:30 骑行的示例,您在 12:21 离开而我在 12:23 离开。如果你把它四舍五入到 12:30,我们有一个 k2-匿名。这是一个过于简单的例子,但你得到了一般论点。
Uber Movement Portal
我们使用我们的 Uber 移动门户来练习 k-匿名。这是一个非常漂亮的工具。由于通勤,我每天早上都使用它。它基本上为您提供了从位置 A 到位置 B 的大致时间,这基本上将您从圣莫尼卡带到英格尔伍德。在此示例中,此工具无用,因为没有足够的游乐设施。如果我们给你平均时间,我们基本上给你的时间尽可能接近当时乘坐这些游乐设施的三四个人。必须有一定数量的人搭便车,才能使这些数据以隐私为中心。此外,如果只有两个人搭便车,那么该数据无论如何也不是很有用,因为数字非常少的平均值是毫无用处的。另一个例子,我们正在为隐私做正确的事情,无论如何都会提高数据质量。下次你在推销隐私时提出这个论点。
K- Anonymity - A Case Study: 40,000 Boston Trips
为了真正进行这个演示,我让团队中的某个人对 40,000 次波士顿旅行进行了案例研究,并且发现了一些关于 k-匿名的有趣知识。我会警告说,这些可能不代表您尝试的任何事情,因为这是在特定时间范围内美国一个城市的 40,000 次骑行的特定队列。选择 40,000 种不同的游乐设施,就会出现不同的学习。
这是我们发现的。看看这里的第一行。当你从 0 到 5 时,这就是我们为 GPS 提供的小数位数,如果你从 2 到 1000,这就是 k-匿名性。如果我给你 0 小数点,那是相当粗略的数据,这是非常近似的 GPS 位置。到那时,我至少可以为那 40,000 次旅行,找到至少一个其他人,一路向右至少找到 999 个以上的人。从 k-匿名 2 到 k-匿名 1000,我有 100% 的覆盖率。它以隐私为中心。问题是,业务中的某个人或数据共享方面的某个人可能会说这些数据不是很有帮助。您必须找到一种方法来确保您的数据并非完全无用。您在什么时候觉得有足够的隐私并使数据更有用一点?
让我们看看光谱的另一端。您有 4 个小数点和 5 个小数点。我们先来看5。如果您查看小数点后 5 位,您基本上给出了一个非常精确的 GPS 位置。如果你想要一个 2 的 k-匿名性,你有 68.4%,也就是说,对于 68.4% 的用户,你可以找到另一个人乘坐相同的车。您的匿名率从上一张幻灯片中的 100% 下降到 68%。由于小数点后 5 位,您实际上损失了三分之一。然后假设您减少了 1 个小数点,当您从 5 到 4 时,您的匿名性从 68.4% 到 97.4% 为 2。基本上,在这一点上,97.4% 的人也有其他人满足他们的匿名性。小数点后五位会破坏很多隐私,但会为您提供非常精确的数据。
那么真正的问题就在最右边。如果你想匿名 1000,而且你是一家非常规避风险的公司,如果你有 5 个小数点,那么你的员工中甚至 1% 都不能匿名。然后,如果你减少 1 个小数点,你会得到大约 1% 到 17.3%。这大约是您人口的六分之一。如果您有一个非常规避风险的法律部门,并且您想给出 5 个小数点,那么这不会是一次有趣的对话,正如这张图告诉您的那样。同样,对于不同的队列,您的发现可能会有所不同。我一直在警告这一点。
与我交谈过的每个人(比我更聪明的人)的行业最佳标准是 5。如果您查看 5 的 k-匿名性,也就是说,您要确保至少有 4 个以上的人具有该级别像你一样匿名。如果你有 5 个小数点,你就有 35.5%,这不是很好,但也不是很糟糕。那么当你去掉第五个小数点时,你就有了 93.2%。那么如果你再剃掉一个小数点,也就是你有3个小数点,你就有99.8%。您可以减少 0.2% 的可识别数据。您可以给出 3 个小数点,并且您的匿名性 k 等于 5。这是您可以让法律团队感到安全的地方,您不会损害隐私,您可以对您的数据进行一定程度的精确度。这基本上意味着您可能需要根据具体情况执行此操作。到目前为止,我们讨论的所有其他内容都是顶级大锤。它将适用于您的所有数据。在共享特定文件时,您可能需要进行一些详细调查以避免以后发生任何隐私事故。这是一个有趣的练习,因为我们尝试了几个不同的队列,这个数字非常明显。我把它带到这里只是为了让示例深入人心。
在我们要求市政当局做什么方面,我们还有其他例子。我们希望他们给我们他们的容错能力。有一些关于他们将使用数据的详细信息,因此我们可以在我们这边使用它来操作数据,以便他们可以使用它,但我们不必担心隐私,但我们不会结束破坏他们的实验。
Data Sharing - Case Study: Minneapolis
让我们也看看其他地方是如何做到这些数据共享匿名的。这背后的要点是,美国有一些城市,特别是,他们做一些与我们相同的事情。我们不仅仅是超级隐私狂人,还有一些城市复制了我们的一些最佳实践。
明尼阿波利斯市,他们基本上得到了旅行 ID,但即使他们被散列了,他们也会丢弃它们。他们创建新的 ID 来代替 Uber 或 Lyft ID。他们还降低了起点和终点,并且还缩短了起点和终点的接送时间。我所谈到的一切,如果你在公司内部受到反对,你可以指出其他城市和其他负责任的第三方也遵循一些相同的做法。
他们还在 API 和表访问方面显着限制了他们的数据。它们不会实时存储任何用于处理的数据,这些数据仅存储在内存中。处理后的数据被存储到磁盘上,但在那时,它是高度聚合和匿名的。他们还完善了接送起点。如果您在最顶部注意到,那是一个起点。然后他们将这三个分成三个象限,然后将最接近该点相对于中间三个的位置的拾取或下降进行四舍五入。这些城市有地图,他们很好地使用它们来匿名,至少明尼阿波利斯市是这样。
Sacrificing Time and Location for Privacy
我们最近还吃了一顿午餐,学习了隐私和精确度。研究论文链接在这里。这项研究背后的要点是,“你的数字指纹能比你的真实指纹更能识别你吗?”研究论文谈到了 12 个点如何唯一地识别你的指纹。您需要一定数量的积分。您需要的分数越多,该指标就越以隐私为中心,因此指纹需要 12 分。他们还在 15 个月内调查了 150 万人。他们看了看,你如何根据他们的移动痕迹来识别这些人?也就是说,如果你看看他们是谁,他们在哪里,对于 95% 的人,就 15 个月内 150 万的样本量而言,4 个时空点可以识别他们,95%。这使得在提供隐私方面变得非常困难,尤其是在我们知道您是谁以及您在哪里的情况下。
他们还发现,随着数据变得更粗糙,每损失 10% 的精度,他们只能获得 1% 的隐私。在某些时候,它会成为您失去多少隐私、获得多少隐私与仍有多少数据有用之间的权衡。那是你必须要看的另一件事。
Sacrificing Time and Location for Privacy
这张图确实很好地说明了这一点。在左下角,您会看到 80%。当您仍在图表上时,在垂直轴上的空间分辨率和水平轴上的时间分辨率非常接近的水平上,80% 的人是可识别的。然后你在两边都失去了 40% 的分辨率,你仍然有 70% 的人可以识别。你基本上损失了 30% 的精确度,而你只获得了 10% 的隐私。然后你在 60% 时进一步拉出。在这一点上,你几乎是在图表之外。然后,当您从 50% 中获得收益时,您就几乎不在图表之列。只有当你达到 40% 时,你才会注意到顶线在 A 的右侧,而底线已经在 15 的正上方。问题是,本质上,A 的质量之间存在张力数据和您可以获得的隐私量。这就是我之前提到的原因,k-匿名非常有用,因为你可以构建一个基础设施,让你每次都摆脱它,而你不看它的想法根本不真实。你将不得不进行这项投资。这就是为什么您需要一个集中的隐私团队来至少将这些数据提供给您的公司。
这当然是外部信息的挑战。也就是说,公司外部有可以帮助识别某人的信息。写这篇论文的人发现,如果他们查看医疗信息和选民名单,他们可以识别出现任马萨诸塞州州长。他们能够识别这个人,打电话给医院,并获得他们的医疗记录。这就是他们能够获得的信息量。
Data Minimization
我们如何解决这个问题?我们正在研究一种称为数据最小化的全新技术。我知道这听起来几乎是陈词滥调,但我们正在与整个公司的团队合作,以找出一种方法来开始收集更少的数据。我们正在寻找那些编写服务的人,这些服务基本上是为了让人们叫 Uber 乘车或订购 Uber Eats,我们如何确保我们不会收集诸如位置之类的东西,例如,在标题中?我们从我们已经拥有该位置的平台上使用它。因为如果它在标头中,它会进入系统,存储在其他系统中,被复制到任何地方,因为它是传入数据,它会被新鲜复制。您如何确保尽可能少地收集数据并确保人们一开始就无法访问数据,除非他们绝对真的需要它?在这种情况下,他们确切地知道要去哪里。
数据最小化是 Uber 的一个重要投资点,因为当你拥有的数据越少,要分类的数据就越少,要标记的数据就越少,要根据这些 ML 分类进行分类和排名的数据就越少,要匿名化的数据就越少,而且数据担心与外部第三方数据连接。这是我们在 Uber 非常依赖的东西,这将是我的重点,也是我明年的 OKR。
Takeaways
这些是这里谈话的四个关键要点。隐私不仅适用于律师。我已经说过很多次了。这是一门跨职能的学科。了解您拥有哪些数据,为什么需要它,标记它,并尽可能在流程的早期对其进行盘点。在使用和共享数据时,尽可能粗略。应用一大堆技术。没有一种技术可以让你出狱。最后,正如我之前提到的,最小化您的数据。
Questions and Answers
参与者 1:在 UMS 系统上,如果您通过该系统汇集所有数据,您将如何处理 PCI 合规性和 HIPAA?
你是如何选择明尼阿波利斯的?真的只有明尼阿波利斯在美国各地这样做,还是要求这样做?
Bhajaria:明尼阿波利斯就是一个例子,他们不仅做了所有这些事情,而且还发表了很多这样的事情。明尼阿波利斯之所以具有启发性,是因为在我们与其他市政当局的许多对话中,我们都指向明尼阿波利斯,因为从成本的角度来看,市政当局通常更容易从彼此而不是公司那里获取这些信息。此外,明尼阿波利斯使用的 API 也被全国不同城市普遍使用。奥克兰市的工作也很出色。他们有一个很好的出版。他们的很多东西都更深。事实上,我认为还有更好的选择,尽管 Uber 的其他人不同意。他们俩都非常好。
当谈到单独运行的 HIPAA 时,HIPAA 和 PCI,尤其是一些标记化的信息,因为它在财务或健康方面有多敏感。那只是完全分开运行,因为很多信息首先出现。事实上,从我在耐克时代开始,我就发现 CCPA 将身高和体重视为个人健康数据。这个教训很早就学到了。这主要是因为有大量其他数据也被认为是越来越受保护的数据。我们需要一些可以手动允许人们对其进行大规模分类的东西。使用 ML,您不需要 PCI 和 HIPAA 的所有这些,您知道它很敏感。几乎,让我们不要让它变得容易,很难编程。让我们付出代价。我们几乎有这种两层结构。
参与者 2:我想知道你是否可以谈谈政治挑战,因为所有这些,让人们对数据进行分类,让开发人员使用工具,等等。这需要他们做的工作。我想知道你是否可以谈谈处理这个问题的一些政治方法。
Bhajaria:有一种说法是,要么为隐私买单,要么为没有隐私买单,第二次的成本要高得多。我一直很幸运。我总是在发生不好的事情后进入公司。在获得 Netflix 挑战的同意令后,我进入了 Netflix。我进了耐克,就在 CCPA 的事情发生的时候。在公司过去两年面临的挑战之后,我进入了优步。有时,过去会让你更容易活在当下。这是其中的一部分。此外,由于 GDPR,该公司刚刚经历了巨大的挑战。这是一项极其昂贵的工作。花了很多钱。它还推迟了路线图上的很多事情。当您可以展示之前和之后的情况时,它会是什么样子,如果您现在就这样做,它会有所帮助。我以前做过产品经理。我以前一直是数据收集者。我可以告诉人们清理它是什么感觉,因为我第一次没有做对。你真的希望团队中的人拥有基础设施和产品体验。不要只用政策人员来填补你的隐私团队,否则工程师会讨论他们,然后你真的不会有那种协同作用。你需要有同理心的人,他们了解构建这些工具的感觉,以及这些工具在什么时候真正有用。这并不容易,但我们就是这样做的。
参与者 3:有大量数据以每分钟或每秒 GB 的数据量以多种速率进入组织。这是通过摄取进入组织的大量数据。您如何以有效的方式将其最小化,以免影响下一个流程?
Bhajaria:我现在没有太多要分享的东西,因为我们仍处于构思阶段。让我举个例子,当我们与位置团队交谈时。例如,如果他们在标头中发送位置,则该标头会在整个公司范围内传播。不需要数据、不知道自己拥有数据的人开始收集数据。他们开始存储它。他们的工作与此背道而驰。他们记录下来。真正的隐私挑战始于人们对他们不知道自己拥有的数据的错误处理,因为如果他们不知道,他们就不会对其进行分类,他们不会对它做任何正确的事情。你如何挑战人们理解,你真正需要什么?你要确保你有具有架构和产品背景的人,因为他们可以提出问题,“让我帮你设计这个产品。”我提倡隐私,但我的工作是帮助您更好地构建您的产品。当您使用公司中的三个或四个关键字幕服务执行此操作时,该信息开始向下渗透。然后你可能会破坏一些东西。当这些数据停止输入时,您就会发现谁真正需要它。会有一点点偶然性,但你需要从架构的角度来看它,只需要在边缘层。
参与者 3:有多个数据提供者,第三方数据提供者,正在向我公司发送数据。如果他们正在发送用户数据,那么我是否有责任将数据散列以将其最小化?
Bhajaria:我的论点始终是,第一个接触数据的人会对其进行哈希处理。我认为您的问题也涉及法律政策方面。我不想当律师。我总是主张让我们散列它,或者让我们尽可能在游戏早期匿名化它。为了确定,我会咨询法律团队。
本文:https://jiagoushi.pro/privacy-architecture-data-driven-innovation
- 160 次浏览