数据科学
视频号

微信公众号

知识星球

- 249 次浏览
【数据科学】12 项数据科学认证将带来回报
视频号
微信公众号
知识星球
希望成为一名数据科学家? 获得这些数据科学证书之一将帮助您在 IT 最热门的职业之一中脱颖而出。
数据科学家是 IT 领域最热门的工作之一。 公司越来越渴望聘请能够理解企业收集的广泛数据的数据专业人员。 如果您想进入这个利润丰厚的领域,或者想在竞争中脱颖而出,认证可能是关键。
数据科学认证不仅让您有机会发展在您想要的行业中难以找到的技能,而且还可以验证您的数据科学知识,以便招聘人员和招聘经理知道如果他们雇用您,他们会得到什么。
无论您是想获得认可大学的认证、获得应届毕业生的经验、磨练特定于供应商的技能,还是展示您的数据分析知识,以下认证(按字母顺序排列)都将适合您。 (没有找到您要找的东西?请查看我们的顶级大数据和数据分析认证列表。)
前 12 名数据科学认证
- 认证分析专家 (CAP)
- Cloudera 数据平台通才认证
- 美国数据科学委员会 (DASCA) 高级数据科学家 (SDS)
- 美国数据科学委员会 (DASCA) 首席数据科学家 (PDS)
- IBM 数据科学专业证书
- Microsoft 认证:Azure AI 基础知识
- Microsoft 认证:Azure 数据科学家助理
- 开放认证数据科学家 (Open CDS)
- SAS 认证的人工智能和机器学习专家
- 使用 SAS 9 的 SAS 认证高级分析专家
- SAS 认证数据科学家
- Tensorflow 开发人员证书
认证分析专家 (CAP)
Certified Analytics Professional (CAP) 是一种供应商中立的认证,可验证您“将复杂数据转化为有价值的见解和行动”的能力,这正是企业在数据科学家中寻找的:理解数据的人,可以得出逻辑 结论并向关键利益相关者表达为什么这些数据点很重要。 在参加 CAP 或准水平 aCAP 考试之前,您需要申请并满足特定条件。 要获得 CAP 认证考试的资格,如果您拥有相关领域的硕士学位,则需要三年相关经验;如果您拥有相关领域的学士学位,则需要五年相关经验;如果您拥有相关领域的学士学位,则需要七年相关经验。 拥有与分析无关的任何学位。 要获得参加 aCAP 考试的资格,您需要拥有硕士学位以及少于三年的数据或分析相关经验。
- 费用:CAP考试:INFORMS会员495美元,非会员695美元; aCAP 考试:INFORMS 会员 200 美元,非会员 300 美元
- 地点:亲自到指定考试中心
- 持续时间:自定进度
- 有效期:三年有效
Cloudera 数据平台通才认证
Cloudera 已停止其 Cloudera 认证专家 (CCP) 和 Cloudera 认证助理 (CCA) 认证,取而代之的是新的 Cloudera 数据平台 (CDP) 通才认证,该认证可验证该平台的熟练程度。 新考试测试平台的一般知识,适用于多种角色,包括管理员、开发人员、数据分析师、数据工程师、数据科学家和系统架构师。 考试包括 60 个问题,考生有 90 分钟的时间完成。
- 费用:300 美元
- 地点:线上
- 时长:90 分钟
- 有效期:两年有效
美国数据科学委员会 (DASCA) 高级数据科学家 (SDS)
美国数据科学委员会 (DASCA) 高级数据科学家 (SDS) 认证计划专为具有五年或五年以上研究和分析经验的专业人士设计。 建议学生了解数据库、电子表格、统计分析、SPSS/SAS、R、定量方法以及面向对象编程和 RDBMS 的基础知识。 该计划包括五个轨道,将吸引一系列候选人——每个轨道在学位水平、工作经验和申请先决条件方面都有不同的要求。 您至少需要学士学位和五年以上的数据科学经验才有资格参加每个课程,而其他课程则需要硕士学位或过去的认证。
- 费用:775 美元
- 地点:线上
- 持续时间:自定进度
- 有效期:5年
美国数据科学委员会 (DASCA) 首席数据科学家 (PDS)
美国数据科学委员会 (DASCA) 提供首席数据科学家 (PDS) 认证,其中包括面向在大数据领域拥有 10 年或以上经验的数据科学专业人士的三个方向。 考试涵盖从基础到高级数据科学概念的所有内容,例如大数据最佳实践、数据业务战略、建立跨组织支持、机器学习、自然语言处理、学术建模等。 该考试专为“经验丰富且成绩斐然的数据科学思想和实践领导者”而设计。
- 费用:850 美元,轨道 1; 1,050 美元,轨道 2; 750 美元,第 3 轨; 1,250 美元,第 4 首曲目
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
IBM 数据科学专业证书
IBM 数据科学专业证书包括九门课程,内容涉及数据科学、开源工具、数据科学方法论、Python、数据库和 SQL、数据分析、数据可视化、机器学习,以及最终的应用数据科学顶点。 认证课程通过 Coursera 在线进行,时间表灵活,平均需要三个月才能完成,但您可以自由选择更多或更少的时间。 该课程包括实践项目,可帮助您构建作品集,向潜在雇主展示您的数据科学才能。
- 费用:免费
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
Microsoft 认证:Azure AI 基础知识
Microsoft 的 Azure AI Fundamentals 认证验证您对机器学习和人工智能概念的了解以及它们与 Microsoft Azure 服务的关系。 这是一项基础考试,因此您不需要丰富的经验即可通过考试。 如果你不熟悉 AI 或 Azure 上的 AI 并想向雇主展示你的技能和知识,这是一个很好的起点。
- 费用:99 美元
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
Microsoft 认证:Azure 数据科学家助理
Microsoft 的 Azure Data Scientist Associate 认证侧重于您利用机器学习在 Azure 上实施和运行机器学习工作负载的能力。 该考试的考生将接受 ML、AI 解决方案、NLP、计算机视觉和预测分析方面的测试。 您需要精通部署和管理资源、管理身份和治理、实施和管理存储以及配置和管理虚拟网络。
- 费用:165 美元
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
开放认证数据科学家 (Open CDS)
Open Group Professional Certification Program for the Data Scientist Professional (Open CDS) 是一种基于经验的认证,没有任何传统的培训课程或考试。 您将从一级认证数据科学家开始,然后可以进入二级认证数据科学家,最后您可以通过三级认证成为杰出认证数据科学家。 认证需要三个步骤,包括申请认证、填写经验申请表和参加董事会审查。
- 成本:联系定价
- 地点:现场
- 持续时间:因级别而异
- 过期:凭证不会过期
SAS 认证的人工智能和机器学习专家
SAS 的 AI 和机器学习专业认证证明您有能力使用开源工具,通过 AI 和分析技能从数据中获得洞察力。 该认证包括多项考试,涵盖机器学习、自然语言处理、计算机视觉以及模型预测和优化等主题。 您需要通过机器学习、预测和优化以及自然语言处理和计算机视觉方面的 SAS 认证专家考试,才能获得 AI 和机器学习专业称号。
- 费用:每次考试 180 美元
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
使用 SAS 9 的 SAS 认证高级分析专家
SAS Certified Advanced Analytics Professional Using SAS 9 证书验证您使用各种统计分析和预测建模技术分析大数据的能力。 您需要具备机器学习和预测建模技术方面的经验,包括它们在大型、分布式和内存中数据集上的使用。 您还应该具有模式检测、业务优化技术实验和时间序列预测方面的经验。 该认证需要通过三门考试:使用 SAS Enterprise Miner 7、13 或 14 进行预测建模; SAS 高级预测建模; SAS 文本分析、时间序列、实验和优化。
- 费用:使用 SAS Enterprise Miner 进行预测建模考试 250 美元; 其他两门必修考试每门 180 美元
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
SAS 认证数据科学家
SAS 认证数据科学家认证是 SAS 提供的其他两种数据认证的组合。 它涵盖了编程技巧; 管理和改进数据; 转换、访问和操作数据; 以及如何使用流行的数据可视化工具。 一旦您同时获得大数据专家和高级分析专家认证,您就有资格获得 SAS 认证数据科学家称号。 您需要完成所有 18 门课程,并通过两个单独认证之间的五门考试。
- 费用:每次考试 180 美元
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
TensorFlow 开发人员证书
TensorFlow 开发人员证书计划是“面向希望通过使用 TensorFlow 构建和训练模型来展示实用机器学习技能的学生、开发人员和数据科学家的基础证书。” 该考试测试您将机器学习集成到各种工具和应用程序中的知识和能力。 要通过考试,您需要熟悉 ML 和深度学习的基本原理、构建 ML 模型、图像识别算法、深度神经网络和自然语言处理。
- 费用:每次考试 100 美元
- 地点:线上
- 持续时间:自定进度
- 过期:凭证不会过期
- 403 次浏览
【数据科学】16个数据学科和数据科学的对比
最初由格兰维尔博士发布。 查看原始文章以阅读大量评论,而不是在此处重新发布。
数据科学,数据挖掘,机器学习,统计学,运筹学等之间有什么区别?
在这里,我比较了几个重叠的分析学科,以解释差异和共同点。 除了历史原因,有时除了存在差异。 有时差异是真实而微妙的。 我还提供典型的职称,分析类型以及传统上与每个学科相关的行业。 带下划线的域是主要的子域。 如果有人可以在我的文章中添加历史视角,那就太好了。
Data Science
首先,让我们从描述数学科学这一新学科开始。
职位包括数据科学家,首席科学家,高级分析师,分析主管等等。它涵盖所有行业和领域,尤其是数字分析,搜索技术,营销,欺诈检测,天文学,能源,健康,社交网络,金融,法医,安全(NSA),移动,电信,天气预报和欺诈检测。
项目包括分类创建(文本挖掘,大数据),应用于大数据集的聚类,推荐引擎,模拟,统计评分引擎的规则系统,根本原因分析,自动投标,取证,外行星检测以及恐怖分子的早期发现活动或流行病,数据科学的一个重要组成部分是自动化,机器对机器通信,以及在生产模式(有时是实时)不间断运行的算法,例如检测欺诈,预测天气或预测房价为每个家庭(Zillow)。
数据科学项目的一个例子是为计算营销创建增长最快的数据科学Twitter概要。它利用大数据,是病毒式营销/增长黑客战略的一部分,其中还包括自动化高质量,相关的联合内容生成(简而言之,数字出版3.0版)。
与大多数其他分析专业不同,数据科学家被认为具有良好的商业头脑和领域专业知识 - 这是他们倾向于成为企业家的原因之一。由于数据科学是一门广泛的学科,因此有许多类型的数据科学家。许多资深数据科学家掌握他们的艺术/工艺,并拥有全部技能和知识;他们真的是招聘人员找不到的独角兽。招聘经理和不知情的高管倾向于狭隘的技术技能,而不是结合深度,广泛和专业的业务领域专业化 - 这是当前教育系统的副产品,有利于学科孤岛,而真正的数据科学是一个孤岛破坏者。独角兽数据科学家(用词不当,因为他们并不罕见 - 有些是着名的VC)通常担任顾问或高管。初级数据科学家往往更专注于数据科学的一个方面,拥有更多热门的技术技能(Hadoop,Pig,Cassandra),如果他们接受过适当的培训和/或有Facebook等公司的工作经验,就可以找到工作。 ,谷歌,eBay,苹果,英特尔,Twitter,亚马逊,Zillow等。潜在候选人的数据科学项目可以在这里找到。
数据科学与之重叠
- 计算机科学:计算复杂性,互联网拓扑和图论,分布式架构,如Hadoop,数据管道(数据流和内存分析的优化),数据压缩,计算机编程(Python,Perl,R)以及处理传感器和流数据(设计自动驾驶的汽车)
- 统计学:实验设计包括多变量检验,交叉验证,随机过程,抽样,无模型置信区间,但不是p值,也不是对大数据诅咒的假设的模糊测试
- 机器学习和数据挖掘:数据科学确实完全包含这两个领域。
- 运筹学:数据科学包括大多数运筹学研究以及旨在根据分析数据优化决策的任何技术。
- 商业智能:数据科学是设计/创建/识别优秀指标和KPI的每个BI方面,创建数据库模式(无论是否为NoSQL),仪表板设计和视觉效果以及数据驱动策略以优化决策和ROI。
与其他分析学科比较
- 机器学习:非常流行的计算机科学学科,数据密集型,数据科学的一部分,与数据挖掘密切相关。机器学习是关于设计算法(如数据挖掘),但重点是生产模式的原型算法,并设计自动更新自己的自动化系统(出价算法,广告定位算法),不断训练/再培训/更新训练集/交叉每天验证,改进或发现新规则(欺诈检测)。 Python现在是ML开发的流行语言。核心算法包括聚类和监督分类,规则系统和评分技术。一个接近人工智能的子域(见下面的条目)是深度学习。
- 数据挖掘:该学科旨在设计算法以从相当大的潜在非结构化数据(文本挖掘)中提取洞察力,有时称为块金发现,例如在查看5000万行数据后发掘大量僵尸网络。技术包括模式识别,特征选择,聚类,监督分类并包含一些统计技术(尽管没有使用大多数统计方法的p值或置信区间)。相反,重点是强大的,数据驱动的,可扩展的技术,对发现原因或可解释性没有太大兴趣。因此,数据挖掘与统计学有一些交集,它是数据科学的一个子集。数据挖掘应用于计算机工程,而不是数学科学。数据挖掘者使用开源和Rapid Miner等软件。
- 预测建模:本身不是一门学科。预测建模项目在所有学科的所有行业中都有发生。预测建模应用程序旨在基于过去的数据预测未来,通常但不总是基于统计建模。预测通常带有置信区间。预测建模的根源在于统计科学。
- 统计。目前,统计数据主要是调查(通常使用SPSS软件进行),理论学术研究,银行和保险分析(营销组合优化,交叉销售,欺诈检测,通常使用SAS和R),统计编程,社会科学,全球变暖研究(和空间天气模拟),经济研究,临床试验(制药业),医学统计,流行病学,生物统计学和政府统计。雇用统计人员的机构包括人口普查局,IRS,CDC,EPA,BLS,SEC和EPA(环境/空间统计)。需要安全许可的工作报酬很高且相对安全,但制药行业中的高薪工作(统计学家的金鹅)受到许多因素的威胁 - 外包,公司合并以及医疗保健费用的压力。由于保守的,风险不利的制药行业的巨大影响,统计已成为一个狭窄的领域,不适应新数据,而不是创新,失去数据科学,工业统计,运筹学,数据挖掘,机器学习 - 使用相同的聚类,交叉验证和统计训练技术,尽管采用更自动化的方式和更大的数据。许多10年前被称为统计人员的专业人士在过去几年中将他们的职位变成了数据科学家或分析师。现代子域包括统计计算,统计学习(更接近机器学习),计算统计(更接近数据科学),数据驱动(无模型)推理,运动统计和贝叶斯统计(MCMC,贝叶斯网络和分层贝叶斯)模特很流行,现代技术)。其他新技术包括SVM,结构方程建模,预测选举结果和集合模型。
- 工业统计。统计数据经常由非统计人员(具有良好统计培训的工程师)执行,从事工程项目,如产量优化或负载平衡(系统分析员)。他们使用非常应用的统计数据,他们的框架更接近六西格玛,质量控制和运营研究,而不是传统统计。也见于石油和制造业。使用的技术包括时间序列,ANOVA,实验设计,生存分析,信号处理(过滤,噪声消除,反卷积),空间模型,模拟,马尔可夫链,风险和可靠性模型。
- 数学优化。使用单纯形算法,傅立叶变换(信号处理),微分方程和Matlab等软件解决业务优化问题。这些应用数学家可以在IBM,研究实验室,NSA(密码学)和金融行业(有时招聘物理或工程专业毕业生)等大公司中找到。这些专业人员有时使用完全相同的技术解决与统计学家完全相同的问题,尽管他们使用不同的名称。数学家使用最小二乘优化进行插值或外推;统计学家使用线性回归进行预测和模型拟合,但这两个概念是相同的,并且依赖于完全相同的数学机制:它只是描述相同事物的两个名称。然而,数学优化比运营研究更接近统计数据,雇用数学家而不是其他从业者(数据科学家)的选择通常由历史原因决定,特别是对于NSA或IBM等组织。
- 精算科学。只是使用生存模型关注保险(汽车,健康等)的一部分统计数据:预测您何时会死亡,您的健康支出将根据您的健康状况(吸烟者,性别,以前的疾病)确定您的保险费。还预测极端洪水和天气事件以确定溢价。后面这些模型出了名的错误(最近)并且导致了比预期更大的支出。出于某些原因,这是一个非常充满活力,秘密的统计学家社区,不再称自己为统计学家(职称是精算师)。随着时间的推移,他们的平均工资增长很快:专业的获取受到限制和监管,就像律师一样,除了保护主义以外,没有其他原因可以提高工资和减少合格申请人的数量。精算科学确实是数据科学(一个子领域)。
- HPC。高性能计算本身不是一门学科,但应该引起数据科学家,大数据从业者,计算机科学家和数学家的关注,因为它可以重新定义这些领域的计算范式。如果量子计算变得成功,它将完全改变算法的设计和实现方式。 HPC不应与Hadoop和Map-Reduce混淆:HPC与硬件相关,Hadoop与软件相关(尽管严重依赖Internet带宽和服务器配置和接近度)。
- 行动调查。缩写为OR。他们一段时间(如20年前)与统计数据分开,但他们就像孪生兄弟,他们各自的组织(INFORMS和ASA)合在一起。 OR是关于决策科学和优化传统业务项目:库存管理,供应链,定价。他们大量使用马尔可夫链模型,Monter-Carlosimulations,排队和图论以及AIMS,Matlab或Informatica等软件。大型传统旧公司使用OR,新的和小型的(初创公司)使用数据科学来处理定价,库存管理或供应链问题。许多运营研究分析师正在成为数据科学家,因为与OR相比,数据科学的创新和增长前景要远得多。此外,OR问题可以通过数据科学解决。 OR与六西格玛(见下文)有重大的重叠,也解决了计量经济学问题,并在军队和国防部门有许多从业者/应用。汽车交通优化是OR问题的一个现代例子,通过模拟,通勤调查,传感器数据和统计建模解决。
- 六个西格玛。它更像是一种思维方式(一种商业哲学,如果不是一种邪教)而不是一种学科,并且几十年前被摩托罗拉和通用电气大力推广。用于质量控制和优化工程流程(参见本文中的工业统计数据),由大型传统公司提供。他们拥有一个拥有270,000名成员的LinkedIn小组,是包括我们数据科学小组在内的任何其他分析LinkedIn小组的两倍。他们的座右铭很简单:将你的努力集中在20%的时间,产生80%的价值。应用简单的统计数据(简单的工作必须是时间,我同意),其目的是消除业务流程中的差异来源,使其更具可预测性并提高质量。许多人认为六西格玛是旧的东西,会消失。也许,但是基本的概念是可靠的并且将保持不变:这些也是所有数据科学家的基本概念。你可以说六西格玛是一个更简单的(如果不是简单的)运算研究版本(参见上面的条目),其中统计建模保持在最低限度。风险:非合格人员使用非强大的黑盒统计工具来解决问题,它可能导致灾难。在某些方面,六西格玛是一个更适合商业分析师的学科(见下面的商业智能条目),而不是严肃的统计学家。
- 定量。定量人士只是在华尔街为高频交易或股票市场套利等问题工作的数据科学家。他们使用C ++,Matlab,来自着名的大学,赚取大笔资金,但当投资回报太快太南时,他们立即失去工作。他们也可以用于能源交易。在经济大衰退期间被解雇的许多人现在都在解决点击仲裁,广告优化和关键字出价等问题。数量有统计学背景(很少),数学优化和工业统计。
- 人工智能。它回来了。与数据科学的交叉是模式识别(图像分析)和自动(有些人会说智能)系统的设计,以在机器对机器通信模式中执行各种任务,例如识别正确的关键字(和正确的出价) Google AdWords(每次点击付费广告系列,每天涉及数百万个关键字)。我还认为智能搜索(创建一个搜索引擎返回您期望的结果并且比Google更广泛)是数据科学中最大的问题之一,可以说也是人工智能和机器学习问题。旧的AI技术是神经网络,但它现在正在流行。相反,神经科学越来越受欢迎。
- 计算机科学。数据科学与计算机科学有一些重叠:Hadoop和Map-Reduce实现,算法和计算复杂性,以设计快速,可扩展的算法,数据管道,以及诸如Internet拓扑映射,随机数生成,加密,数据压缩和隐写术等问题(虽然这些问题与统计科学和数学优化也是重叠的)。
- 计量经济学。为什么它与统计数据分离尚不清楚。因此,许多分支机构与统计数据脱节,因为它们变得不那么通用,并开始开发自己的临时工具。但简而言之,计量经济学在本质上具有很强的统计性,使用时间序列模型,如自回归过程。也与运筹学(本身重叠统计!)和数学优化(单纯形算法)重叠。计量经济学家喜欢ROC和效率曲线(六位sigma从业者也是如此,请参阅本文中的相应条目)。许多人没有强大的统计背景,Excel是他们的主要或唯一的工具。
- 数据工程。由大型组织中的软件工程师(开发人员)或架构师(设计师)(有时是小公司的数据科学家)执行,这是计算机科学的应用部分(参见本文中的条目),适用于允许各种数据的电力系统易于处理内存或近存储器,并可以很好地传输到(和之间)最终用户,包括数据科学家等重要数据消费者。目前受攻击的子域是数据仓库,因为这个术语与静态,孤立的conventational数据库,数据架构和数据流相关联,受到NoSQL,NewSQL和图形数据库的兴起的威胁。将这些旧架构转换为新架构(仅在需要时)或使它们与新架构兼容,是一项利润丰厚的业务。
- 商业智能。简称为BI。重点关注仪表板创建,度量选择,生成和安排通过电子邮件发送或交付/呈现给管理人员的数据报告(统计摘要),竞争情报(分析第三方数据),以及参与数据库架构设计(与数据架构师合作)有效地收集有用的,可操作的业务数据。典型的职称是业务分析师,但有些人更多地参与营销,产品或财务(预测销售和收入)。他们通常拥有MBA学位。有些人已经学习了时间序列等高级统计数据,但大多数人只使用(并且需要)基本统计数据和轻度分析,依靠IT维护数据库和收集数据。他们使用Excel(包括多维数据集和数据透视表,但不包括高级分析),Brio(Oracle浏览器客户端),Birt,Micro-Sreategy或Business Objects(作为运行查询的最终用户)等工具,尽管其中一些工具是越来越多地配备了更好的分析功能。除非他们学习如何编码,否则他们将与一些在决策科学,洞察力提取和呈现(可视化),KPI设计,业务咨询以及ROI /收益/业务/流程优化方面表现优异的多价数据科学家竞争。商业智能和市场研究(但不是竞争情报)目前正在经历下降,而人工智能正在经历一次回归。这可能是周期性的。部分下降是由于不适应需要工程或数据科学技术来处理和提取价值的新类型数据(例如非结构化文本)。
- 数据分析。这是自1995年以来商业统计的新术语,它涵盖了广泛的应用,包括欺诈检测,广告组合建模,归因建模,销售预测,交叉销售优化(零售),用户细分,流失分析,计算客户的长期价值和收购成本等。除大公司外,数据分析师是初级职位;这些从业者比数据科学家具有更为狭隘的知识和经验,他们缺乏(并且不需要)商业愿景。它们是详细的,并向数据科学家或分析主管等管理人员报告。在大公司中,拥有职称的人如数据分析师III可能非常高级,但他们通常都是专业的,缺乏数据所获得的广泛知识。科学家在各种大小公司工作。
- 商业分析。与数据分析相同,但仅限于业务问题。倾向于更多的财务,营销或投资回报率的味道。热门职位包括数据分析师和数据科学家,但不包括业务分析师(请参阅商业智能的商业智能条目,不同的域名)。
- 82 次浏览
【数据科学】2024年数据科学工作导航:角色、团队和技能
视频号
微信公众号
知识星球
无论你是申请第一次实习,还是管理一个由分析师和工程师组成的多学科团队,数据科学职业都会面临一系列特定的挑战。其中一些可能比其他更令人兴奋,而另一些则可能非常乏味——当然,在任何工作中都是如此——但我们相信,将所有这些潜在的缺点都视为深化知识、扩展技能和考虑新观点的机会。
本周,我们的阵容汇集了围绕数据职业中常见障碍的广泛观点和经验,并提出了克服这些障碍的有效方法。无论您在自己的数据科学之旅中身处何处,我们都希望您探索我们推荐的阅读内容,并找到将其融入自己工作的见解。
- 数据ROI金字塔:一种衡量和最大化数据团队的方法。虽然Barr Moses的可操作路线图面向数据领导和高管,但它是公司层级上下数据专业人员的重要资源。毕竟,每个人都可以从了解他们的工作如何为业务做出贡献,以及如何向更广泛的非技术受众展示他们的影响中受益。
- 重建为我找到数据科学家工作的投资组合。一年前,马特·查普曼(Matt Chapman)撰写了关于构建数据科学投资组合的权威实践指南(并在这个过程中迅速走红)。在他的最新帖子中,Matt重新审视了他的方法,并提出了几个关键更新,以实现更精简的工作流程和更可定制的最终产品。
- Spotify资深数据科学家用来提高生产力的5个习惯。在为找到一份好的数据工作付出了所有努力之后,真正的工作开始了:你能做些什么来在新职位上表现出色,而不会有倦怠和/或冒名顶替综合症的风险?Khouloud El Alami提出了五个具体的想法,你可以根据自己的需求进行调整,也不会吝啬细节。
- 英特尔ML实习的7堂课。在银行业长期担任数据科学家后,康纳·奥沙利文最近的职业转折使他在科技巨头英特尔进行了机器学习实习;不要错过他在那里的经历,以及他在探索一个新的行业和组织文化时所学到的教训。
和往常一样,最近几周,我们的作者涵盖了令人眼花缭乱的广泛主题,从人工智能的新兴技能到预测建模和深度学习。以下是我们不希望您错过的突出帖子示例。
- 多模式模型在视觉单词谜题上的表现如何?Yennie Jun测试了GPT-4 Vision和Gemini Pro Vision的能力,试图衡量他们这一代模特的创作过程水平。
- 以物理为基础的神经网络听起来可能是一个崇高的、理论含量很高的概念,但正如郭在一篇全面综述中所展示的那样,它们在现实世界中的应用有很多——而且正在以健康的速度增长。
- 在一个易于理解、图文并茂的解释中,Shrya Rao继续探索基本的深度学习主题,这一次打开了允许神经网络学习的过程。
- 在她的TDS首秀中,Nithya(Nithhya)Ramamorthy提供了一个简单有效的框架,帮助您在数据演示中建立信心。
- 如果你正在寻找一个清晰、详细的R平方指南,也就是决定系数,不要错过Roberta Rocca的一站式资源,它将消除人们对这个无处不在的指标的困惑。
- 有心情进行一次引人入胜、亲力亲为的深潜吗?Tim Forster带领我们完成了使用线性求解器在一维以上优化非线性神经网络的过程。
感谢您对我们作者工作的支持!如果你觉得加入他们的行列很有灵感,为什么不写你的第一篇帖子呢?我们很想读一读。
- 144 次浏览
【数据科学】为什么你应该为了数据科学学习PostgreSQL
SQL是成为数据科学家的必要条件吗?答案是肯定的。数据科学已经发展了,虽然许多数据科学家仍然使用CSV文件(值以逗号分隔的文本文件),但它们不是最好的选择。Python Panda库允许从CSV文件加载数据,但是这些文件有许多约束。例如,它们通常不连接到数据库,这就要求您在每次更新数据时生成一个新的CSV文件提取。在大数据时代,这是完全不切实际的。
关系数据库为使用大数据存储库提供所需的支持和敏捷性。PostgreSQL是领先的关系数据库管理系统之一。专为处理大型数据集而设计的Postgres是数据科学的完美匹配。在本文中,我们将介绍在数据科学中使用Postgres的优点和缺点。

什么是数据科学家?
数据科学是近年来最受欢迎的职业选择之一。随着组织管理着巨大的数据集,对能够从中提取有价值信息的专家的需求也在增加。
数据科学家处理大数据,帮助组织从数据中获得可操作的见解。例如,他们可以发现一个市场利基,或者根据最新的市场趋势改进公司的产品。
数据科学的领域和它所操作的数据一样多样化,但有一些核心技能是每个数据科学家都应该具备的。
- 编程技能:数据科学家使用编码来分析和处理信息,所以有很强的编程技能是很重要的。数据库和统计编程语言,如SQL或R,是必须的。数据科学家了解的编程语言越多,可以应用的工具越多,效果就越好。
- 统计和数学技能:数据科学需要处理统计数据。您需要正确的算法从数据集提取您想知道的内容。要做到这一点,数据科学家需要对统计学和数学概念有很强的掌握。
技术技能是必须的。然而,数据科学家也需要软技能,比如决心、对细节的关注和分析能力。在数据科学领域工作的两个基本技能是好奇心和灵活性。例如,数据科学家经常需要为数据问题提出开箱即用的算法。
PostgreSQL是什么?
关系数据库管理系统(RDBMS)。这个开源平台是由PostgreSQL全球开发小组开发的,该小组由公司和个人贡献者组成。它得到了广泛的软件即服务(SaaS)解决方案市场的支持,这些解决方案用于在云中和本地运行Postgres。
PostgresSQL的主要功能包括:
- 免费许可:该平台可以免费下载、使用、扩展和分发。
- 复杂查询支持:Postgres的基本特性之一是处理复杂查询的能力。复杂查询是从数据库发出的请求,超出了SELECT和WHERE等基本SQL请求的范围。
- 多版本并发控制:该特性允许不同的用户同时对数据库进行读写操作。
- 用户定义类型:用户可以自定义函数来定义单个数据类型。数据科学家使用已知或未知的数据。将两种或三种数据类型组合成一种新的数据类型,可以帮助数据科学家解决来自不同来源的大量数据的复杂问题。
- 高度符合SQL ISO/ iec9075标准:PostgreSQL满足164个强制特性中的150个,完全符合标准要求。从一开始,遵从SQL标准就一直是Postgres的优先事项。
- 强大的社区支持:Postgres拥有一个庞大的贡献者社区,他们致力于扩展和开发这个平台。有广泛的支持文档和论坛。
- 编程语言支持:PostgresSQL支持所有主要的编程语言,如Python、C和Java。它还通过JSON支持NoSQL查询。
- 多环境支持:PostgreSQL的特点之一是支持
云计算和本地环境。这称为多环境或跨环境支持。RightScale最近的一份报告显示,大多数使用Postgres的组织选择了一种混合的云环境,即内部配置和云系统的混合。
Postgres对数据科学的利弊
PostgresSQL支持大数据,为文档添加了JSON-B,为地理定位系统添加了PostGIS。它允许用户根据自己的工作负载调整平台。
该平台在混合事务/分析处理(HTAP)中结合了数据分析和事务功能。该特性使数据库能够同时执行在线分析处理(OLAP)和在线事务处理(OLTP)。例如,组织可以使用Postgres中的HTAP技术来管理来自物联网设备和其他操作应用程序的信息。
由于Postgres的灵活性和可扩展性,它在数据科学家中非常流行。但是,它不将数据存储在列中,这使得大型数据仓库很难处理这些数据。
在数据科学中使用PostgresSQL有利有弊。以下是一些优点和缺点:
优点
- SQL Rich:由于强调SQL标准遵从性,所以Postgres支持很多SQL语法。这包括公共表表达式、表继承和Windows函数。
- 非结构化数据支持:Postgres支持NoSQL数据,如XML、JSON和HStore。
- 并行查询:该特性允许同时运行处理器中的所有核心。这在数据科学中尤其重要,因为在数据科学中经常运行一个通用查询。
- 声明式分区:该功能可以指定如何将表划分为称为分区的部分。例如,当处理地理上分布的大型研究数据集时,这使您能够为每个区号分离不同的分区。
缺点
- 没有压缩:没有足够的空间会限制某些分析的性能。压缩数据有助于避免在向云中上传数据时形成瓶颈。PostgreSQL不提供数据压缩,这使得上传数据的速度慢得多。
- 无列:分析数据库通常以列而不是行存储数据。Postgres缺少列状表,这使得数据难以摄取。例如,如果您有一个包含300列的表,那么您需要将它分成两个或更多的表来读取它。
- 没有内置机器学习:这可能是最大的缺点,因为机器学习对于处理大数据至关重要。机器学习需要自己处理大量的数据来进行学习,而这种内置的特性可以帮助数据科学以一种高效的方式处理巨大的数据集,即使有人工干预,也是最少的。您可以添加Apache MADLib,这是一个用于机器学习的开源数据库算法库,但遗憾的是,它不能在Windows上运行。幸运的是,您可以通过使用一个sci-kit-learn库安装PLP/Python来克服这个挑战,从而直接在Postgres中编写您自己的机器学习算法。
你可以在哪里学习基础?
要学习PostgreSQL,您应该从SQL基础知识开始。这将为您构建PostgreSQL知识提供一个坚实的基础。你可以从免费的教程中学习,比如Codecademy。一旦您掌握了SQL的基础知识,您就可以开始学习如何将它与Postgres一起使用。
虽然从文档中学习可能是最彻底的方法,但也可能很乏味。网上有许多免费和付费的PostgreSQL课程。其中包括:
- PostgreSQL Tutorial: :这个免费的教程涵盖了Postgres的基础知识,包括基本的功能。
- Postgres Video Course::这个免费视频课程使用Postgres来教初学者SQL的基础。
- Postgres Administration Essentials:这个全面的培训面向数据库管理员和架构师。虽然课程本身是免费的,但该项目需要订阅。
- Postgres for Data Engineers: 这个付费课程是为数据工程师准备的,用数据科学的例子和案例涵盖了Postgres的基础知识。
总结
PostgreSQL为数据科学提供了一种低成本、功能强大的处理解决方案。最大的问题是它不提供数据压缩。您可以通过批量上传或仅在云环境中运行数据库来解决这个问题。
尽管如此,一个刚起步的数据科学家还是应该认真考虑学习PostgreSQL。Postgres可以帮助您准备使用大多数数据科学工具,成为掌握数据库知识的瑞士军刀。
原文:https://www.dataversity.net/why-you-should-learn-postgresql-for-data-science/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 87 次浏览
【数据科学】什么是数据科学? 将数据转化为价值
视频号
微信公众号
知识星球
数据科学是一种将业务数据转化为资产的方法,可帮助组织提高收入、降低成本、抓住商机、改善客户体验等。
什么是数据科学?
数据科学是一种使用从统计分析到机器学习的方法从结构化和非结构化数据中收集见解的方法。 对于大多数组织而言,它被用来以提高收入、降低成本、业务敏捷性、改善客户体验、开发新产品等形式将数据转化为价值。 数据科学为组织收集的数据赋予了目的。
数据科学与数据分析
虽然密切相关,但数据分析是数据科学的一个组成部分,用于了解组织的数据是什么样子的。 数据科学利用分析的输出来解决问题。 数据科学家说,用数据调查某事只是分析。 数据科学通过分析进一步解释和解决问题。 数据分析和数据科学之间的区别也是时间尺度之一。 数据分析描述现实的当前状态,而数据科学使用该数据来预测和/或了解未来。
数据科学的好处
数据科学的商业价值取决于组织需求。 数据科学可以帮助组织构建工具来预测硬件故障,使组织能够执行维护并防止意外停机。 它可以帮助预测超市货架上放什么,或者根据产品的属性预测产品的受欢迎程度。
数据科学职位
虽然数据科学学位课程的数量正在快速增加,但它们不一定是组织在寻找数据科学家时所寻找的。 具有统计背景的候选人很受欢迎,特别是如果他们能够证明他们知道他们是否正在查看真实结果; 具有将结果置于上下文中的领域知识; 和沟通技巧,使他们能够将结果传达给业务用户。
许多组织都在寻找拥有博士学位的候选人,尤其是在物理学、数学、计算机科学、经济学甚至社会科学领域。 博士学位证明候选人有能力对某个主题进行深入研究并向他人传播信息。
一些最优秀的数据科学家或数据科学团队的领导者具有非传统背景,即使是很少受过正规计算机培训的人。 在许多情况下,关键能力是能够从非传统的角度看待事物并理解它。
有关数据科学家技能的更多信息,请参阅“什么是数据科学家? 关键的数据分析角色和有利可图的职业”,以及“精英数据科学家的基本技能和特质”。
数据科学薪水
根据 PayScale 的数据,以下是一些与数据科学相关的最受欢迎的职位以及每个职位的平均工资:
- Analytics manager: $71K-$131K
- Associate data scientist: $61K-$101K
- Business intelligence analyst: $52K-$97K
- Data analyst: $45K-$87K
- Data architect: $79K-$159K
- Data engineer: $66K-$132K
- Data scientist: $60K-$159K
- Data scientist, IT: $$60K-$159K
- Lead data scientist: $98K-$178K
- Research analyst: $43K-$82K
- Research scientist: $52K-$123K
- Senior data scientist: $96K-$162K
- Statistician: $55K-$117K
数据科学学位
据《财富》杂志报道,这些是数据科学领域的顶级研究生学位课程:
- University of Illinois at Urbana-Champaign
- University of California—Berkeley
- Texas Tech University
- Bay Path University
- Worcester Polytechnic Institute
- Loyola University Maryland
- University of Missouri—Columbia
- New Jersey Institute of Technology
- CUNY School of Professional Studies
- Syracuse University
数据科学培训和训练营
鉴于目前数据科学人才短缺,许多组织正在制定计划来培养内部数据科学人才。
训练营是另一种快速发展的培训工作者承担数据科学角色的途径。 有关数据科学训练营的更多详细信息,请参阅“促进职业发展的 15 个最佳数据科学训练营”。
数据科学认证
组织需要具有数据分析技术专业知识的数据科学家和分析师。 他们还需要大数据架构师将需求转化为系统,需要数据工程师来构建和维护数据管道,需要熟悉 Hadoop 集群和其他技术的开发人员,还需要系统管理员和经理将所有内容联系在一起。 认证是求职者证明自己具备合适技能的一种方式。
一些顶级大数据和数据分析认证包括:
- Certified Analytics Professional (CAP)
- Cloudera Data Platform Generalist Certification
- Data Science Council of America (DASCA) Senior Data Scientist (SDS)
- Data Science Council of America (DASCA) Principal Data Scientist (PDS)
- IBM Data Science Professional Certificate
- Microsoft Certified: Azure Data Scientist Associate
- Open Certified Data Scientist (Open CDS)
- SAS Certified Data Scientist
有关大数据和数据分析认证的更多信息,请参阅“11 大大数据和数据分析认证”和“12 项有回报的数据科学认证”。
数据科学团队
数据科学通常是一门团队学科。 数据科学家是大多数数据科学团队的核心,但从数据到分析再到生产价值需要一系列技能和角色。 例如,数据分析师应该参与调查,然后再将数据呈现给团队并维护数据模型。 数据工程师需要构建数据管道以丰富数据集并使数据可供公司其他部门使用。
如需进一步了解构建数据科学团队,请参阅“如何组建高效的分析团队”和“高度成功的数据分析团队的秘诀”。
数据科学目标和可交付成果
数据科学的目标是构建从数据中提取以业务为中心的洞察力的方法。 这需要了解价值和信息在企业中的流动方式,以及利用这种理解来识别商机的能力。 虽然这可能涉及一次性项目,但更典型的数据科学团队会寻求识别关键数据资产,这些资产可以转化为数据管道,为可维护的工具和解决方案提供数据。 示例包括银行使用的信用卡欺诈监控解决方案,或用于优化风力涡轮机在风电场中的位置的工具。
递增地,传达团队正在做什么的演示文稿也是重要的可交付成果。
数据科学过程和方法
生产工程团队在冲刺周期内工作,并有预计的时间表。 对于数据科学团队来说,这通常很难做到,因为前期可能会花费大量时间来确定项目是否可行。 必须收集和清理数据。 然后团队必须确定它是否可以有效地回答问题。
理想情况下,数据科学应该遵循科学方法,尽管情况并非总是如此,甚至不可行。 真正的科学需要时间。 您会花一点时间来确认您的假设,然后花很多时间来反驳自己。 在业务中,回答时间很重要。 因此,数据科学通常意味着选择“足够好”的答案,而不是最佳答案。 然而,危险在于结果可能会成为确认偏差或过度拟合的牺牲品。
数据科学工具
数据科学团队使用范围广泛的工具,包括 SQL、Python、R、Java 以及 Hive、oozie 和 TensorFlow 等开源项目的聚宝盆。 这些工具用于各种与数据相关的任务,从提取和清理数据到通过统计方法或机器学习对数据进行算法分析。 一些常用工具包括:
- SAS”这一专有统计工具用于数据挖掘、统计分析、商业智能、临床试验分析和时间序列分析。
- Tableau:Tableau 现在归 Salesforce 所有,是一种数据可视化工具。
- TensorFlow:由 Google 开发并获得 Apache License 2.0 许可,TensorFlow 是一个用于机器学习的软件库,用于深度神经网络的训练和推理。
- DataRobot:这个自动化机器学习平台用于构建、部署和维护 AI。
- BigML:BigML 是机器学习平台,专注于简化数据集和模型的构建和共享。
- Knime:Knime 是一个开源数据分析、报告和集成平台。
- Apache Spark:这个统一的分析引擎专为处理大规模数据而设计,支持数据清理、转换、模型构建和评估。
- RapidMiner:这个数据科学平台旨在支持团队,支持数据准备、机器学习和预测模型部署。
- Matplotlib:这个用于 Python 的开源绘图库提供了用于创建静态、动画和交互式可视化的工具。
- Excel:Microsoft 的电子表格软件可能是周围使用最广泛的 BI 工具。 对于处理较小数据集的数据科学家来说,它也很方便。
- js:此 JavaScript 库用于在 Web 浏览器中进行交互式可视化。
- ggplot2:这个高级数据可视化包让数据科学家可以根据分析数据创建可视化效果。
- Jupyter:这个基于 Python 的开源工具用于编写实时代码、可视化和演示。
- 53 次浏览
【数据科学】从头开始学习 R的数据科学的完整的教程
A Complete Tutorial to learn Data Science in R from Scratch
Introduction
R is a powerful language used widely for data analysis and statistical computing. It was developed in early 90s. Since then, endless efforts have been made to improve R’s user interface. The journey of R language from a rudimentary text editor to interactive R Studio and more recently Jupyter Notebookshas engaged many data science communities across the world.
This was possible only because of generous contributions by R users globally. Inclusion of powerful packages in R has made it more and more powerful with time. Packages such as dplyr, tidyr, readr, data.table, SparkR, ggplot2 have made data manipulation, visualization and computation much faster.
But, what about Machine Learning ?
My first impression of R was that it’s just a software for statistical computing. Good thing, I was wrong! R has enough provisions to implement machine learning algorithms in a fast and simple manner.
This is a complete tutorial to learn data science and machine learning using R. By the end of this tutorial, you will have a good exposure to building predictive models using machine learning on your own.
Note: No prior knowledge of data science / analytics is required. However, prior knowledge of algebra and statistics will be helpful.
Table of Contents
-
Basics of R Programming for Data Science
-
Why learn R ?
-
How to install R / R Studio ?
-
How to install R packages ?
-
Basic computations in R
-
Essentials of R Programming
-
Data Types and Objects in R
-
Control Structures (Functions) in R
-
Useful R Packages
-
Exploratory Data Analysis in R
-
Basic Graphs
-
Treating Missing values
-
Working with Continuous and Categorical Variables
-
Data Manipulation in R
-
Feature Engineering
-
Label Encoding / One Hot Encoding
-
Predictive Modeling using Machine Learning in R
-
Linear Regression
-
Decision Tree
-
Random Forest
Let’s get started !
Note: The data set used in this article is from Big Mart Sales Prediction.
1. Basics of R Programming
Why learn R ?
I don’t know if I have a solid reason to convince you, but let me share what got me started. I have no prior coding experience. Actually, I never had computer science in my subjects. I came to know that to learn data science, one must learn either R or Python as a starter. I chose the former. Here are some benefits I found after using R:
-
The style of coding is quite easy.
-
It’s open source. No need to pay any subscription charges.
-
Availability of instant access to over 7800 packages customized for various computation tasks.
-
The community support is overwhelming. There are numerous forums to help you out.
-
Get high performance computing experience ( require packages)
-
One of highly sought skill by analytics and data science companies.
There are many more benefits. But, these are the ones which have kept me going. If you think they are exciting, stick around and move to next section. And, if you aren’t convinced, you may like Complete Python Tutorial from Scratch.
How to install R / R Studio ?
You could download and install the old version of R. But, I’d insist you to start with RStudio. It provides much better coding experience. For Windows users, R Studio is available for Windows Vista and above versions. Follow the steps below for installing R Studio:
-
In ‘Installers for Supported Platforms’ section, choose and click the R Studio installer based on your operating system. The download should begin as soon as you click.
-
Click Next..Next..Finish.
-
Download Complete.
-
To Start R Studio, click on its desktop icon or use ‘search windows’ to access the program. It looks like this:
Let’s quickly understand the interface of R Studio:
-
R Console: This area shows the output of code you run. Also, you can directly write codes in console. Code entered directly in R console cannot be traced later. This is where R script comes to use.
-
R Script: As the name suggest, here you get space to write codes. To run those codes, simply select the line(s) of code and press Ctrl + Enter. Alternatively, you can click on little ‘Run’ button location at top right corner of R Script.
-
R environment: This space displays the set of external elements added. This includes data set, variables, vectors, functions etc. To check if data has been loaded properly in R, always look at this area.
-
Graphical Output: This space display the graphs created during exploratory data analysis. Not just graphs, you could select packages, seek help with embedded R’s official documentation.
How to install R Packages ?
The sheer power of R lies in its incredible packages. In R, most data handling tasks can be performed in 2 ways: Using R packages and R base functions. In this tutorial, I’ll also introduce you with the most handy and powerful R packages. To install a package, simply type:
install.packages("package name")
As a first time user, a pop might appear to select your CRAN mirror (country server), choose accordingly and press OK.
Note: You can type this either in console directly and press ‘Enter’ or in R script and click ‘Run’.
Basic Computations in R
Let’s begin with basics. To get familiar with R coding environment, start with some basic calculations. R console can be used as an interactive calculator too. Type the following in your console:
> 2 + 3
> 5
> 6 / 3
> 2
> (3*8)/(2*3)
> 4
> log(12)
> 1.07
> sqrt (121)
> 11
Similarly, you can experiment various combinations of calculations and get the results. In case, you want to obtain the previous calculation, this can be done in two ways. First, click in R console, and press ‘Up / Down Arrow’ key on your keyboard. This will activate the previously executed commands. Press Enter.
But, what if you have done too many calculations ? It would be too painful to scroll through every command and find it out. In such situations, creating variable is a helpful way.
In R, you can create a variable using <- or = sign. Let’s say I want to create a variable x to compute the sum of 7 and 8. I’ll write it as:
> x <- 8 + 7
> x
> 15
Once we create a variable, you no longer get the output directly (like calculator), unless you call the variable in the next line.
Remember, variables can be alphabets, alphanumeric but not numeric. You can’t create numeric variables.
2. Essentials of R Programming
Understand and practice this section thoroughly. This is the building block of your R programming knowledge. If you get this right, you would face less trouble in debugging.
R has five basic or ‘atomic’ classes of objects. Wait, what is an object ?
Everything you see or create in R is an object. A vector, matrix, data frame, even a variable is an object. R treats it that way. So, R has 5 basic classes of objects. This includes:
-
Character
-
Numeric (Real Numbers)
-
Integer (Whole Numbers)
-
Complex
-
Logical (True / False)
Since these classes are self-explanatory by names, I wouldn’t elaborate on that. These classes have attributes. Think of attributes as their ‘identifier’, a name or number which aptly identifies them. An object can have following attributes:
-
names, dimension names
-
dimensions
-
class
-
length
Attributes of an object can be accessed using attributes() function. More on this coming in following section.
Let’s understand the concept of object and attributes practically. The most basic object in R is known as vector. You can create an empty vector using vector(). Remember, a vector contains object of same class.
For example: Let’s create vectors of different classes. We can create vector using c() or concatenate command also.
> a <- c(1.8, 4.5) #numeric
> b <- c(1 + 2i, 3 - 6i) #complex
> d <- c(23, 44) #integer
> e <- vector("logical", length = 5)
Similarly, you can create vector of various classes.
Data Types in R
R has various type of ‘data types’ which includes vector (numeric, integer etc), matrices, data frames and list. Let’s understand them one by one.
Vector: As mentioned above, a vector contains object of same class. But, you can mix objects of different classes too. When objects of different classes are mixed in a list, coercion occurs. This effect causes the objects of different types to ‘convert’ into one class. For example:
> qt <- c("Time", 24, "October", TRUE, 3.33) #character
> ab <- c(TRUE, 24) #numeric
> cd <- c(2.5, "May") #character
To check the class of any object, use class(“vector name”) function.
> class(qt)
"character"
To convert the class of a vector, you can use as. command.
> bar <- 0:5
> class(bar)
> "integer"
> as.numeric(bar)
> class(bar)
> "numeric"
> as.character(bar)
> class(bar)
> "character"
Similarly, you can change the class of any vector. But, you should pay attention here. If you try to convert a “character” vector to “numeric” , NAs will be introduced. Hence, you should be careful to use this command.
List: A list is a special type of vector which contain elements of different data types. For example:
> my_list <- list(22, "ab", TRUE, 1 + 2i)
> my_list
[[1]]
[1] 22
[[2]]
[1] "ab"
[[3]]
[1] TRUE
[[4]]
[1] 1+2i
As you can see, the output of a list is different from a vector. This is because, all the objects are of different types. The double bracket [[1]] shows the index of first element and so on. Hence, you can easily extract the element of lists depending on their index. Like this:
> my_list[[3]]
> [1] TRUE
You can use [] single bracket too. But, that would return the list element with its index number, instead of the result above. Like this:
> my_list[3]
> [[1]]
[1] TRUE
Matrices: When a vector is introduced with row and column i.e. a dimension attribute, it becomes a matrix. A matrix is represented by set of rows and columns. It is a 2 dimensional data structure. It consist of elements of same class. Let’s create a matrix of 3 rows and 2 columns:
> my_matrix <- matrix(1:6, nrow=3, ncol=2)
> my_matrix
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> dim(my_matrix)
[1] 3 2
> attributes(my_matrix)
$dim
[1] 3 2
As you can see, the dimensions of a matrix can be obtained using either dim() or attributes() command. To extract a particular element from a matrix, simply use the index shown above. For example(try this at your end):
> my_matrix[,2] #extracts second column
> my_matrix[,1] #extracts first column
> my_matrix[2,] #extracts second row
> my_matrix[1,] #extracts first row
As an interesting fact, you can also create a matrix from a vector. All you need to do is, assign dimension dim() later. Like this:
> age <- c(23, 44, 15, 12, 31, 16)
> age
[1] 23 44 15 12 31 16
> dim(age) <- c(2,3)
> age
[,1] [,2] [,3]
[1,] 23 15 31
[2,] 44 12 16
> class(age)
[1] "matrix"
You can also join two vectors using cbind() and rbind() functions. But, make sure that both vectors have same number of elements. If not, it will return NA values.
> x <- c(1, 2, 3, 4, 5, 6)
> y <- c(20, 30, 40, 50, 60)
> cbind(x, y)
> cbind(x, y)
x y
[1,] 1 20
[2,] 2 30
[3,] 3 40
[4,] 4 50
[5,] 5 60
[6,] 6 70
> class(cbind(x, y))
[1] “matrix”
Data Frame: This is the most commonly used member of data types family. It is used to store tabular data. It is different from matrix. In a matrix, every element must have same class. But, in a data frame, you can put list of vectors containing different classes. This means, every column of a data frame acts like a list. Every time you will read data in R, it will be stored in the form of a data frame. Hence, it is important to understand the majorly used commands on data frame:
> df <- data.frame(name = c("ash","jane","paul","mark"), score = c(67,56,87,91))
> df
name score
1 ash 67
2 jane 56
3 paul 87
4 mark 91
> dim(df)
[1] 4 2
> str(df)
'data.frame': 4 obs. of 2 variables:
$ name : Factor w/ 4 levels "ash","jane","mark",..: 1 2 4 3
$ score: num 67 56 87 91
> nrow(df)
[1] 4
> ncol(df)
[1] 2
Let’s understand the code above. df is the name of data frame. dim() returns the dimension of data frame as 4 rows and 2 columns. str() returns the structure of a data frame i.e. the list of variables stored in the data frame. nrow() and ncol() return the number of rows and number of columns in a data set respectively.
Here you see “name” is a factor variable and “score” is numeric. In data science, a variable can be categorized into two types: Continuous and Categorical.
Continuous variables are those which can take any form such as 1, 2, 3.5, 4.66 etc. Categorical variables are those which takes only discrete values such as 2, 5, 11, 15 etc. In R, categorical values are represented by factors. In df, name is a factor variable having 4 unique levels. Factor or categorical variable are specially treated in a data set. For more explanation, click here. Similarly, you can find techniques to deal with continuous variables here.
Let’s now understand the concept of missing values in R. This is one of the most painful yet crucial part of predictive modeling. You must be aware of all techniques to deal with them. The complete explanation on such techniques is provided here.
Missing values in R are represented by NA and NaN. Now we’ll check if a data set has missing values (using the same data frame df).
> df[1:2,2] <- NA #injecting NA at 1st, 2nd row and 2nd column of df
> df
name score
1 ash NA
2 jane NA
3 paul 87
4 mark 91
> is.na(df) #checks the entire data set for NAs and return logical output
name score
[1,] FALSE TRUE
[2,] FALSE TRUE
[3,] FALSE FALSE
[4,] FALSE FALSE
> table(is.na(df)) #returns a table of logical output
FALSE TRUE
6 2
> df[!complete.cases(df),] #returns the list of rows having missing values
name score
1 ash NA
2 jane NA
Missing values hinder normal calculations in a data set. For example, let’s say, we want to compute the mean of score. Since there are two missing values, it can’t be done directly. Let’s see:
mean(df$score)
[1] NA
> mean(df$score, na.rm = TRUE)
[1] 89
The use of na.rm = TRUE parameter tells R to ignore the NAs and compute the mean of remaining values in the selected column (score). To remove rows with NA values in a data frame, you can use na.omit:
> new_df <- na.omit(df)
> new_df
name score
3 paul 87
4 mark 91
Control Structures in R
As the name suggest, a control structure ‘controls’ the flow of code / commands written inside a function. A function is a set of multiple commands written to automate a repetitive coding task.
For example: You have 10 data sets. You want to find the mean of ‘Age’ column present in every data set. This can be done in 2 ways: either you write the code to compute mean 10 times or you simply create a function and pass the data set to it.
Let’s understand the control structures in R with simple examples:
if, else – This structure is used to test a condition. Below is the syntax:
if (<condition>){
##do something
} else {
##do something
}
Example
#initialize a variable
N <- 10
#check if this variable * 5 is > 40
if (N * 5 > 40){
print("This is easy!")
} else {
print ("It's not easy!")
}
[1] "This is easy!"
for – This structure is used when a loop is to be executed fixed number of times. It is commonly used for iterating over the elements of an object (list, vector). Below is the syntax:
for (<search condition>){
#do something
}
Example
#initialize a vector
y <- c(99,45,34,65,76,23)
#print the first 4 numbers of this vector
for(i in 1:4){
print (y[i])
}
[1] 99
[1] 45
[1] 34
[1] 65
while – It begins by testing a condition, and executes only if the condition is found to be true. Once the loop is executed, the condition is tested again. Hence, it’s necessary to alter the condition such that the loop doesn’t go infinity. Below is the syntax:
#initialize a condition
Age <- 12
#check if age is less than 17
while(Age < 17){
print(Age)
Age <- Age + 1 #Once the loop is executed, this code breaks the loop
}
[1] 12
[1] 13
[1] 14
[1] 15
[1] 16
There are other control structures as well but are less frequently used than explained above. Those structures are:
-
repeat – It executes an infinite loop
-
break – It breaks the execution of a loop
-
next – It allows to skip an iteration in a loop
-
return – It help to exit a function
Note: If you find the section ‘control structures’ difficult to understand, not to worry. R is supported by various packages to compliment the work done by control structures.
Useful R Packages
Out of ~7800 packages listed on CRAN, I’ve listed some of the most powerful and commonly used packages in predictive modeling in this article. Since, I’ve already explained the method of installing packages, you can go ahead and install them now. Sooner or later you’ll need them.
Importing Data: R offers wide range of packages for importing data available in any format such as .txt, .csv, .json, .sql etc. To import large files of data quickly, it is advisable to install and use data.table, readr, RMySQL, sqldf, jsonlite.
Data Visualization: R has in built plotting commands as well. They are good to create simple graphs. But, becomes complex when it comes to creating advanced graphics. Hence, you should install ggplot2.
Data Manipulation: R has a fantastic collection of packages for data manipulation. These packages allows you to do basic & advanced computations quickly. These packages are dplyr, plyr, tidyr, lubridate, stringr. Check out this complete tutorial on data manipulation packages in R.
Modeling / Machine Learning: For modeling, caret package in R is powerful enough to cater to every need for creating machine learning model. However, you can install packages algorithms wise such as randomForest, rpart, gbm etc
Note: I’ve only mentioned the commonly used packages. You might like to check this interesting infographic on complete list of useful R packages.
Till here, you became familiar with the basic work style in R and its associated components. From next section, we’ll begin with predictive modeling. But before you proceed. I want you to practice, what you’ve learnt till here.
Practice Assignment:
As a part of this assignment, install ‘swirl’ package in package. Then type, library(swirl) to initiate the package. And, complete this interactive R tutorial. If you have followed this article thoroughly, this assignment should be an easy task for you!
3. Exploratory Data Analysis in R
From this section onwards, we’ll dive deep into various stages of predictive modeling. Hence, make sure you understand every aspect of this section. In case you find anything difficult to understand, ask me in the comments section below.
Data Exploration is a crucial stage of predictive model. You can’t build great and practical models unless you learn to explore the data from begin to end. This stage forms a concrete foundation for data manipulation (the very next stage). Let’s understand it in R.
In this tutorial, I’ve taken the data set from Big Mart Sales Prediction. Before we start, you must get familiar with these terms:
Response Variable (a.k.a Dependent Variable): In a data set, the response variable (y) is one on which we make predictions. In this case, we’ll predict ‘Item_Outlet_Sales’. (Refer to image shown below)
Predictor Variable (a.k.a Independent Variable): In a data set, predictor variables (Xi) are those using which the prediction is made on response variable. (Image below).
Train Data: The predictive model is always built on train data set. An intuitive way to identify the train data is, that it always has the ‘response variable’ included.
Test Data: Once the model is built, it’s accuracy is ‘tested’ on test data. This data always contains less number of observations than train data set. Also, it does not include ‘response variable’.
Right now, you should download the data set. Take a good look at train and test data. Cross check the information shared above and then proceed.
Let’s now begin with importing and exploring data.
#working directory
path <- ".../Data/BigMartSales"
#set working directory
setwd(path)
As a beginner, I’ll advise you to keep the train and test files in your working directly to avoid unnecessary directory troubles. Once the directory is set, we can easily import the .csv files using commands below.
#Load Datasets
train <- read.csv("Train_UWu5bXk.csv")
test <- read.csv("Test_u94Q5KV.csv")
In fact, even prior to loading data in R, it’s a good practice to look at the data in Excel. This helps in strategizing the complete prediction modeling process. To check if the data set has been loaded successfully, look at R environment. The data can be seen there. Let’s explore the data quickly.
#check dimesions ( number of row & columns) in data set
> dim(train)
[1] 8523 12
> dim(test)
[1] 5681 11
We have 8523 rows and 12 columns in train data set and 5681 rows and 11 columns in data set. This makes sense. Test data should always have one column less (mentioned above right?). Let’s get deeper in train data set now.
#check the variables and their types in train
> str(train)
'data.frame': 8523 obs. of 12 variables:
$ Item_Identifier : Factor w/ 1559 levels "DRA12","DRA24",..: 157 9 663 1122 1298 759 697 739 441 991 ...
$ Item_Weight : num 9.3 5.92 17.5 19.2 8.93 ...
$ Item_Fat_Content : Factor w/ 5 levels "LF","low fat",..: 3 5 3 5 3 5 5 3 5 5 ...
$ Item_Visibility : num 0.016 0.0193 0.0168 0 0 ...
$ Item_Type : Factor w/ 16 levels "Baking Goods",..: 5 15 11 7 10 1 14 14 6 6 ...
$ Item_MRP : num 249.8 48.3 141.6 182.1 53.9 ...
$ Outlet_Identifier : Factor w/ 10 levels "OUT010","OUT013",..: 10 4 10 1 2 4 2 6 8 3 ...
$ Outlet_Establishment_Year: int 1999 2009 1999 1998 1987 2009 1987 1985 2002 2007 ...
$ Outlet_Size : Factor w/ 4 levels "","High","Medium",..: 3 3 3 1 2 3 2 3 1 1 ...
$ Outlet_Location_Type : Factor w/ 3 levels "Tier 1","Tier 2",..: 1 3 1 3 3 3 3 3 2 2 ...
$ Outlet_Type : Factor w/ 4 levels "Grocery Store",..: 2 3 2 1 2 3 2 4 2 2 ...
$ Item_Outlet_Sales : num 3735 443 2097 732 995 ..
.
Let’s do some quick data exploration.
To begin with, I’ll first check if this data has missing values. This can be done by using:
> table(is.na(train))
FALSE TRUE
100813 1463
In train data set, we have 1463 missing values. Let’s check the variables in which these values are missing. It’s important to find and locate these missing values. Many data scientists have repeatedly advised beginners to pay close attention to missing value in data exploration stages.
> colSums(is.na(train))
Item_Identifier Item_Weight
0 1463
Item_Fat_Content Item_Visibility
0 0
Item_Type Item_MRP
0 0
Outlet_Identifier Outlet_Establishment_Year
0 0
Outlet_Size Outlet_Location_Type
0 0
Outlet_Type Item_Outlet_Sales
0 0
Hence, we see that column Item_Weight has 1463 missing values. Let’s get more inferences from this data.
> summary(train)
Here are some quick inferences drawn from variables in train data set:
-
Item_Fat_Content has mis-matched factor levels.
-
Minimum value of item_visibility is 0. Practically, this is not possible. If an item occupies shelf space in a grocery store, it ought to have some visibility. We’ll treat all 0’s as missing values.
-
Item_Weight has 1463 missing values (already explained above).
-
Outlet_Size has a unmatched factor levels.
These inference will help us in treating these variable more accurately.
Graphical Representation of Variables
I’m sure you would understand these variables better when explained visually. Using graphs, we can analyze the data in 2 ways: Univariate Analysis and Bivariate Analysis.
Univariate analysis is done with one variable. Bivariate analysis is done with two variables. Univariate analysis is a lot easy to do. Hence, I’ll skip that part here. I’d recommend you to try it at your end. Let’s now experiment doing bivariate analysis and carve out hidden insights.
For visualization, I’ll use ggplot2 package. These graphs would help us understand the distribution and frequency of variables in the data set.
> ggplot(train, aes(x= Item_Visibility, y = Item_Outlet_Sales)) + geom_point(size = 2.5, color="navy") + xlab("Item Visibility") + ylab("Item Outlet Sales") + ggtitle("Item Visibility vs Item Outlet Sales")
We can see that majority of sales has been obtained from products having visibility less than 0.2. This suggests that item_visibility < 2 must be an important factor in determining sales. Let’s plot few more interesting graphs and explore such hidden stories.
> ggplot(train, aes(Outlet_Identifier, Item_Outlet_Sales)) + geom_bar(stat = "identity", color = "purple") +theme(axis.text.x = element_text(angle = 70, vjust = 0.5, color = "black")) + ggtitle("Outlets vs Total Sales") + theme_bw()
Here, we infer that OUT027 has contributed to majority of sales followed by OUT35. OUT10 and OUT19 have probably the least footfall, thereby contributing to the least outlet sales.
> ggplot(train, aes(Item_Type, Item_Outlet_Sales)) + geom_bar( stat = "identity") +theme(axis.text.x = element_text(angle = 70, vjust = 0.5, color = "navy")) + xlab("Item Type") + ylab("Item Outlet Sales")+ggtitle("Item Type vs Sales")
From this graph, we can infer that Fruits and Vegetables contribute to the highest amount of outlet sales followed by snack foods and household products. This information can also be represented using a box plot chart. The benefit of using a box plot is, you get to see the outlier and mean deviation of corresponding levels of a variable (shown below).
> ggplot(train, aes(Item_Type, Item_MRP)) +geom_boxplot() +ggtitle("Box Plot") + theme(axis.text.x = element_text(angle = 70, vjust = 0.5, color = "red")) + xlab("Item Type") + ylab("Item MRP") + ggtitle("Item Type vs Item MRP")
The black point you see, is an outlier. The mid line you see in the box, is the mean value of each item type. To know more about boxplots, check this tutorial.
Now, we have an idea of the variables and their importance on response variable. Let’s now move back to where we started. Missing values. Now we’ll impute the missing values.
We saw variable Item_Weight has missing values. Item_Weight is an continuous variable. Hence, in this case we can impute missing values with mean / median of item_weight. These are the most commonly used methods of imputing missing value. To explore other methods of this techniques, check out this tutorial.
Let’s first combine the data sets. This will save our time as we don’t need to write separate codes for train and test data sets. To combine the two data frames, we must make sure that they have equal columns, which is not the case.
> dim(train)
[1] 8523 12
> dim(test)
[1] 5681 11
Test data set has one less column (response variable). Let’s first add the column. We can give this column any value. An intuitive approach would be to extract the mean value of sales from train data set and use it as placeholder for test variable Item _Outlet_ Sales. Anyways, let’s make it simple for now. I’ve taken a value 1. Now, we’ll combine the data sets.
> test$Item_Outlet_Sales <- 1
> combi <- rbind(train, test)
Impute missing value by median. I’m using median because it is known to be highly robust to outliers. Moreover, for this problem, our evaluation metric is RMSE which is also highly affected by outliers. Hence, median is better in this case.
> combi$Item_Weight[is.na(combi$Item_Weight)] <- median(combi$Item_Weight, na.rm = TRUE)
> table(is.na(combi$Item_Weight))
FALSE
14204
Trouble with Continuous Variables & Categorical Variables
It’s important to learn to deal with continuous and categorical variables separately in a data set. In other words, they need special attention. In this data set, we have only 3 continuous variables and rest are categorical in nature. If you are still confused, I’ll suggest you to once again look at the data set using str() and proceed.
Let’s take up Item_Visibility. In the graph above, we saw item visibility has zero value also, which is practically not feasible. Hence, we’ll consider it as a missing value and once again make the imputation using median.
> combi$Item_Visibility <- ifelse(combi$Item_Visibility == 0,
median(combi$Item_Visibility), combi$Item_Visibility)
Let’s proceed to categorical variables now. During exploration, we saw there are mis-matched levels in variables which needs to be corrected.
> levels(combi$Outlet_Size)[1] <- "Other"
> library(plyr)
> combi$Item_Fat_Content <- revalue(combi$Item_Fat_Content,
c("LF" = "Low Fat", "reg" = "Regular"))
> combi$Item_Fat_Content <- revalue(combi$Item_Fat_Content, c("low fat" = "Low Fat"))
> table(combi$Item_Fat_Content)
Low Fat Regular
9185 5019
Using the commands above, I’ve assigned the name ‘Other’ to unnamed level in Outlet_Size variable.
Rest, I’ve simply renamed the various levels of Item_Fat_Content.
4. Data Manipulation in R
Let’s call it as, the advanced level of data exploration. In this section we’ll practically learn about feature engineering and other useful aspects.
Feature Engineering: This component separates an intelligent data scientist from a technically enabled data scientist. You might have access to large machines to run heavy computations and algorithms, but the power delivered by new features, just can’t be matched. We create new variables to extract and provide as much ‘new’ information to the model, to help it make accurate predictions.
If you have been thinking all this time, great. But now is the time to think deeper. Look at the data set and ask yourself, what else (factor) could influence Item_Outlet_Sales ? Anyhow, the answer is below. But, I want you to try it out first, before scrolling down.
1. Count of Outlet Identifiers – There are 10 unique outlets in this data. This variable will give us information on count of outlets in the data set. More the number of counts of an outlet, chances are more will be the sales contributed by it.
> library(dplyr)
> a <- combi%>%
group_by(Outlet_Identifier)%>%
tally()
> head(a)
Source: local data frame [6 x 2]
Outlet_Identifier n
(fctr) (int)
1 OUT010 925
2 OUT013 1553
3 OUT017 1543
4 OUT018 1546
5 OUT019 880
6 OUT027 1559
> names(a)[2] <- "Outlet_Count"
> combi <- full_join(a, combi, by = "Outlet_Identifier")
As you can see, dplyr package makes data manipulation quite effortless. You no longer need to write long function. In the code above, I’ve simply stored the new data frame in a variable a. Later, the new column Outlet_Count is added in our original ‘combi’ data set. To know more about dplyr, follow this tutorial.
2. Count of Item Identifiers – Similarly, we can compute count of item identifiers too. It’s a good practice to fetch more information from unique ID variables using their count. This will help us to understand, which outlet has maximum frequency.
> b <- combi%>%
group_by(Item_Identifier)%>%
tally()
> names(b)[2] <- "Item_Count"
> head (b)
Item_Identifier Item_Count
(fctr) (int)
1 DRA12 9
2 DRA24 10
3 DRA59 10
4 DRB01 8
5 DRB13 9
6 DRB24 8
> combi <- merge(b, combi, by = “Item_Identifier”)
3. Outlet Years – This variable represent the information of existence of a particular outlet since year 2013. Why just 2013? You’ll find the answer in problem statement here. My hypothesis is, older the outlet, more footfall, large base of loyal customers and larger the outlet sales.
> c <- combi%>%
select(Outlet_Establishment_Year)%>%
mutate(Outlet_Year = 2013 - combi$Outlet_Establishment_Year)
> head(c)
Outlet_Establishment_Year Outlet_Year
1 1999 14
2 2009 4
3 1999 14
4 1998 15
5 1987 26
6 2009 4
> combi <- full_join(c, combi)
This suggests that outlets established in 1999 were 14 years old in 2013 and so on.
4. Item Type New – Now, pay attention to Item_Identifiers. We are about to discover a new trend. Look carefully, there is a pattern in the identifiers starting with “FD”,”DR”,”NC”. Now, check the corresponding Item_Types to these identifiers in the data set. You’ll discover, items corresponding to “DR”, are mostly eatables. Items corresponding to “FD”, are drinks. And, item corresponding to “NC”, are products which can’t be consumed, let’s call them non-consumable. Let’s extract these variables into a new variable representing their counts.
Here I’ll use substr(), gsub() function to extract and rename the variables respectively.
> q <- substr(combi$Item_Identifier,1,2)
> q <- gsub("FD","Food",q)
> q <- gsub("DR","Drinks",q)
> q <- gsub("NC","Non-Consumable",q)
> table(q)
Drinks Food Non-Consumable
1317 10201 2686
Let’s now add this information in our data set with a variable name ‘Item_Type_New.
> combi$Item_Type_New <- q
I’ll leave the rest of feature engineering intuition to you. You can think of more variables which could add more information to the model. But make sure, the variable aren’t correlated. Since, they are emanating from a same set of variable, there is a high chance for them to be correlated. You can check the same in R using cor() function.
Label Encoding and One Hot Encoding
Just, one last aspect of feature engineering left. Label Encoding and One Hot Encoding.
Label Encoding, in simple words, is the practice of numerically encoding (replacing) different levels of a categorical variables. For example: In our data set, the variable Item_Fat_Content has 2 levels: Low Fat and Regular. So, we’ll encode Low Fat as 0 and Regular as 1. This will help us convert a factor variable in numeric variable. This can be simply done using if else statement in R.
> combi$Item_Fat_Content <- ifelse(combi$Item_Fat_Content == "Regular",1,0)
One Hot Encoding, in simple words, is the splitting a categorical variable into its unique levels, and eventually removing the original variable from data set. Confused ? Here’s an example: Let’s take any categorical variable, say, Outlet_ Location_Type. It has 3 levels. One hot encoding of this variable, will create 3 different variables consisting of 1s and 0s. 1s will represent the existence of variable and 0s will represent non-existence of variable. Let look at a sample:
> sample <- select(combi, Outlet_Location_Type)
> demo_sample <- data.frame(model.matrix(~.-1,sample))
> head(demo_sample)
Outlet_Location_TypeTier.1 Outlet_Location_TypeTier.2 Outlet_Location_TypeTier.3
1 1 0 0
2 0 0 1
3 1 0 0
4 0 0 1
5 0 0 1
6 0 0 1
model.matrix creates a matrix of encoded variables. ~. -1 tells R, to encode all variables in the data frame, but suppress the intercept. So, what will happen if you don’t write -1 ? model.matrix will skip the first level of the factor, thereby resulting in just 2 out of 3 factor levels (loss of information).
This was the demonstration of one hot encoding. Hope you have understood the concept now. Let’s now apply this technique to all categorical variables in our data set (excluding ID variable).
>library(dummies)
>combi <- dummy.data.frame(combi, names = c('Outlet_Size','Outlet_Location_Type','Outlet_Type', 'Item_Type_New'), sep='_')
With this, I have shared 2 different methods of performing one hot encoding in R. Let’s check if encoding has been done.
> str (combi)
$ Outlet_Size_Other : int 0 1 1 0 1 0 0 0 0 0 ...
$ Outlet_Size_High : int 0 0 0 1 0 0 0 0 0 0 ...
$ Outlet_Size_Medium : int 1 0 0 0 0 0 1 1 0 1 ...
$ Outlet_Size_Small : int 0 0 0 0 0 1 0 0 1 0 ...
$ Outlet_Location_Type_Tier 1 : int 1 0 0 0 0 0 0 0 1 0 ...
$ Outlet_Location_Type_Tier 2 : int 0 1 0 0 1 1 0 0 0 0 ...
$ Outlet_Location_Type_Tier 3 : int 0 0 1 1 0 0 1 1 0 1 ...
$ Outlet_Type_Grocery Store : int 0 0 1 0 0 0 0 0 0 0 ...
$ Outlet_Type_Supermarket Type1: int 1 1 0 1 1 1 0 0 1 0 ...
$ Outlet_Type_Supermarket Type2: int 0 0 0 0 0 0 0 1 0 0 ...
$ Outlet_Type_Supermarket Type3: int 0 0 0 0 0 0 1 0 0 1 ...
$ Item_Outlet_Sales : num 1 3829 284 2553 2553 ...
$ Year : num 14 11 15 26 6 9 28 4 16 28 ...
$ Item_Type_New_Drinks : int 1 1 1 1 1 1 1 1 1 1 ...
$ Item_Type_New_Food : int 0 0 0 0 0 0 0 0 0 0 ...
$ Item_Type_New_Non-Consumable : int 0 0 0 0 0 0 0 0 0 0 ...
As you can see, after one hot encoding, the original variables are removed automatically from the data set.
5. Predictive Modeling using Machine Learning
Finally, we’ll drop the columns which have either been converted using other variables or are identifier variables. This can be accomplished using select from dplyr package.
> combi <- select(combi, -c(Item_Identifier, Outlet_Identifier, Item_Fat_Content, Outlet_Establishment_Year,Item_Type))
> str(combi)
In this section, I’ll cover Regression, Decision Trees and Random Forest. A detailed explanation of these algorithms is outside the scope of this article. These algorithms have been satisfactorily explained in our previous articles. I’ve provided the links for useful resources.
As you can see, we have encoded all our categorical variables. Now, this data set is good to take forward to modeling. Since, we started from Train and Test, let’s now divide the data sets.
> new_train <- combi[1:nrow(train),]
> new_test <- combi[-(1:nrow(train)),]
Linear (Multiple) Regression
Multiple Regression is used when response variable is continuous in nature and predictors are many. Had it been categorical, we would have used Logistic Regression. Before you proceed, sharpen your basics of Regression here.
Linear Regression takes following assumptions:
-
There exists a linear relationship between response and predictor variables
-
The predictor (independent) variables are not correlated with each other. Presence of collinearity leads to a phenomenon known as multicollinearity.
-
The error terms are uncorrelated. Otherwise, it will lead to autocorrelation.
-
Error terms must have constant variance. Non-constant variance leads to heteroskedasticity.
Let’s now build out first regression model on this data set. R uses lm() function for regression.
> linear_model <- lm(Item_Outlet_Sales ~ ., data = new_train)
> summary(linear_model)
Adjusted R² measures the goodness of fit of a regression model. Higher the R², better is the model. Our R² = 0.2085. It means we really did something drastically wrong. Let’s figure it out.
In our case, I could find our new variables aren’t helping much i.e. Item count, Outlet Count and Item_Type_New. Neither of these variables are significant. Significant variables are denoted by ‘*’ sign.
As we know, correlated predictor variables brings down the model accuracy. Let’s find out the amount of correlation present in our predictor variables. This can be simply calculated using:
> cor(new_train)
Alternatively, you can also use corrplot package for some fancy correlation plots. Scrolling through the long list of correlation coefficients, I could find a deadly correlation coefficient:
cor(new_train$Outlet_Count, new_train$`Outlet_Type_Grocery Store`)
[1] -0.9991203
Outlet_Count is highly correlated (negatively) with Outlet Type Grocery Store. Here are some problems I could find in this model:
-
We have correlated predictor variables.
-
We did one hot encoding and label encoding. That’s not necessary since linear regression handle categorical variables by creating dummy variables intrinsically.
-
The new variables (item count, outlet count, item type new) created in feature engineering are not significant.
Let’s try to create a more robust regression model. This time, I’ll be using a building a simple model without encoding and new features. Below is the entire code:
#load directory
> path <- "C:/Users/manish/desktop/Data/February 2016"
> setwd(path)
#load data
> train <- read.csv("train_Big.csv")
> test <- read.csv("test_Big.csv")
#create a new variable in test file
> test$Item_Outlet_Sales <- 1
#combine train and test data
> combi <- rbind(train, test)
#impute missing value in Item_Weight
> combi$Item_Weight[is.na(combi$Item_Weight)] <- median(combi$Item_Weight, na.rm = TRUE)
#impute 0 in item_visibility
> combi$Item_Visibility <- ifelse(combi$Item_Visibility == 0, median(combi$Item_Visibility), combi$Item_Visibility)
#rename level in Outlet_Size
> levels(combi$Outlet_Size)[1] <- "Other"
#rename levels of Item_Fat_Content
> library(plyr)
> combi$Item_Fat_Content <- revalue(combi$Item_Fat_Content,c("LF" = "Low Fat", "reg" = "Regular"))
> combi$Item_Fat_Content <- revalue(combi$Item_Fat_Content, c("low fat" = "Low Fat"))
#create a new column 2013 - Year
> combi$Year <- 2013 - combi$Outlet_Establishment_Year
#drop variables not required in modeling
> library(dplyr)
> combi <- select(combi, -c(Item_Identifier, Outlet_Identifier, Outlet_Establishment_Year))
#divide data set
> new_train <- combi[1:nrow(train),]
> new_test <- combi[-(1:nrow(train)),]
#linear regression
> linear_model <- lm(Item_Outlet_Sales ~ ., data = new_train)
> summary(linear_model)
Now we have got R² = 0.5623. This teaches us that, sometimes all you need is simple thought process to get high accuracy. Quite a good improvement from previous model. Next, time when you work on any model, always remember to start with a simple model.
Let’s check out regression plot to find out more ways to improve this model.
> par(mfrow=c(2,2))
> plot(linear_model)
You can zoom these graphs in R Studio at your end. All these plots have a different story to tell. But the most important story is being portrayed by Residuals vs Fitted graph.
Residual values are the difference between actual and predicted outcome values. Fitted values are the predicted values. If you see carefully, you’ll discover it as a funnel shape graph (from right to left ). The shape of this graph suggests that our model is suffering from heteroskedasticity (unequal variance in error terms). Had there been constant variance, there would be no pattern visible in this graph.
A common practice to tackle heteroskedasticity is by taking the log of response variable. Let’s do it and check if we can get further improvement.
> linear_model <- lm(log(Item_Outlet_Sales) ~ ., data = new_train)
> summary(linear_model)
And, here’s a snapshot of my model output. Congrats! We have got an improved model with R² = 0.72. Now, we are on the right path. Once again you can check the residual plots (you might zoom it). You’ll find there is no longer a trend in residual vs fitted value plot.
This model can be further improved by detecting outliers and high leverage points. For now, I leave that part to you! I shall write a separate post on mysteries of regression soon. For now, let’s check our RMSE so that we can compare it with other algorithms demonstrated below.
To calculate RMSE, we can load a package named Metrics.
> install.packages("Metrics")
> library(Metrics)
> rmse(new_train$Item_Outlet_Sales, exp(linear_model$fitted.values))
[1] 1140.004
Let’s proceed to decision tree algorithm and try to improve our RMSE score.
Decision Trees
Before you start, I’d recommend you to glance through the basics of decision tree algorithms. To understand what makes it superior than linear regression, check this tutorial Part 1 and Part 2.
In R, decision tree algorithm can be implemented using rpart package. In addition, we’ll use caret package for doing cross validation. Cross validation is a technique to build robust models which are not prone to overfitting. Read more about Cross Validation.
In R, decision tree uses a complexity parameter (cp). It measures the tradeoff between model complexity and accuracy on training set. A smaller cp will lead to a bigger tree, which might overfit the model. Conversely, a large cp value might underfit the model. Underfitting occurs when the model does not capture underlying trends properly. Let’s find out the optimum cp value for our model with 5 fold cross validation.
#loading required libraries
> library(rpart)
> library(e1071)
> library(rpart.plot)
> library(caret)
#setting the tree control parameters
> fitControl <- trainControl(method = "cv", number = 5)
> cartGrid <- expand.grid(.cp=(1:50)*0.01)
#decision tree
> tree_model <- train(Item_Outlet_Sales ~ ., data = new_train, method = "rpart", trControl = fitControl, tuneGrid = cartGrid)
> print(tree_model)
The final value for cp = 0.01. You can also check the table populated in console for more information. The model with cp = 0.01 has the least RMSE. Let’s now build a decision tree with 0.01 as complexity parameter.
> main_tree <- rpart(Item_Outlet_Sales ~ ., data = new_train, control = rpart.control(cp=0.01))
> prp(main_tree)
Here is the tree structure of our model. If you have gone through the basics, you would now understand that this algorithm has marked Item_MRP as the most important variable (being the root node). Let’s check the RMSE of this model and see if this is any better than regression.
> pre_score <- predict(main_tree, type = "vector")
> rmse(new_train$Item_Outlet_Sales, pre_score)
[1] 1102.774
As you can see, our RMSE has further improved from 1140 to 1102.77 with decision tree. To improve this score further, you can further tune the parameters for greater accuracy.
Random Forest
Random Forest is a powerful algorithm which holistically takes care of missing values, outliers and other non-linearities in the data set. It’s simply a collection of classification trees, hence the name ‘forest’. I’d suggest you to quickly refresh your basics of random forest with this tutorial.
In R, random forest algorithm can be implement using randomForest package. Again, we’ll use train package for cross validation and finding optimum value of model parameters.
For this problem, I’ll focus on two parameters of random forest. mtry and ntree. ntree is the number of trees to be grown in the forest. mtry is the number of variables taken at each node to build a tree. And, we’ll do a 5 fold cross validation.
Let’s do it!
#load randomForest library
> library(randomForest)
#set tuning parameters
> control <- trainControl(method = "cv", number = 5)
#random forest model
> rf_model <- train(Item_Outlet_Sales ~ ., data = new_train, method = "parRF", trControl = control,
prox = TRUE, allowParallel = TRUE)
#check optimal parameters
> print(rf_model)
If you notice, you’ll see I’ve used method = “parRF”. This is parallel random forest. This is parallel implementation of random forest. This package causes your local machine to take less time in random forest computation. Alternatively, you can also use method = “rf” as a standard random forest function.
Now we’ve got the optimal value of mtry = 15. Let’s use 1000 trees for computation.
#random forest model
> forest_model <- randomForest(Item_Outlet_Sales ~ ., data = new_train, mtry = 15, ntree = 1000)
> print(forest_model)
> varImpPlot(forest_model)
This model throws RMSE = 1132.04 which is not an improvement over decision tree model. Random forest has a feature of presenting the important variables. We see that the most important variable is Item_MRP (also shown by decision tree algorithm).
This model can be further improved by tuning parameters. Also, Let’s make out first submission with our best RMSE score by decision tree.
> main_predict <- predict(main_tree, newdata = new_test, type = "vector")
> sub_file <- data.frame(Item_Identifier = test$Item_Identifier, Outlet_Identifier = test$Outlet_Identifier, Item_Outlet_Sales = main_predict)
> write.csv(sub_file, 'Decision_tree_sales.csv')
When predicted on out of sample data, our RMSE has come out to be 1174.33. Here are some things you can do to improve this model further:
-
Since we did not use encoding, I encourage you to use one hot encoding and label encoding for random forest model.
-
Parameters Tuning will help.
-
Use Gradient Boosting.
-
Build an ensemble of these models. Read more about Ensemble Modeling.
Do implement the ideas suggested above and share your improvement in the comments section below. Currently, Rank 1 on Leaderboard has obtained RMSE score of 1137.71. Beat it!
End Notes
This brings us to the end of this tutorial. Regret for not so happy ending. But, I’ve given you enough hints to work on. The decision to not use encoded variables in the model, turned out to be beneficial until decision trees.
The motive of this tutorial was to get your started with predictive modeling in R. We learnt few uncanny things such as ‘build simple models’. Don’t jump towards building a complex model. Simple models give you benchmark score and a threshold to work with.
In this tutorial, I have demonstrated the steps used in predictive modeling in R. I’ve covered data exploration, data visualization, data manipulation and building models using Regression, Decision Trees and Random Forest algorithms.
Did you find this tutorial useful ? Are you facing any trouble at any stage of this tutorial ? Feel free to mention your doubts in the comments section below. Do share if you get a better score.
Edit: On visitor’s request, the PDF version of the tutorial is available for download. You need to create a log in account to download the PDF. Also, you can bookmark this page for future reference. Download Here.
- 104 次浏览
【数据科学】内部发展数据科学技能:真实世界的经验教训
视频号
微信公众号
知识星球
各组织正在向内看,以满足数据科学的需求,发展必要的文化、课程和计划,以深化数据分析专业知识。
几乎每个行业的公司都非常需要数据科学家,因为他们希望启动大数据和分析项目,并从数据资源中获得更多价值和见解。
然而,对这些专业人员的需求继续以相当大的幅度超过供应,而且没有迹象表明这种情况会很快改变。
在线就业网站CareerCast.com将数据科学家列为2018年最佳工作之一,预计今年的需求将增长19%。CareerCast评估了美国劳工统计局关于增长前景、行业招聘趋势、贸易统计、大学毕业生就业数据以及该网站自己的列表数据库的数据,以确定哪些因素推动了招聘需求。
就需求而言,数据科学专业经常跻身于顶级职业之列,组织需要专业地分析数据并将其转化为可操作的信息,这推动了数据科学行业的增长。
对于许多组织来说,填补这些职位的斗争是激烈的。从外部聘请专家当然可以成为建立数据科学团队战略的一部分,但考虑到极端的竞争,一些组织正在转向自己的队伍来培养他们需要的数据科学人才。
以下是一些组织如何鼓励数据驱动的文化,并在内部发展更深入的数据分析专业知识。
在嘉年华培养数据驱动的文化
数据科学是嘉年华风险咨询和保证服务部的战略重点,该部门运营嘉年华邮轮。该部门经理Daniel Bukowski表示,该部门提供内部审计服务,其领导层有力地支持了该领域的专业发展和培训。
例如,该部门支持Bukowski参加Udacity预测分析纳米学位课程,他有审计和会计背景,但没有受过IT或技术知识的正规教育。Udacity在人工智能、数据科学、编程与开发以及自主系统等领域提供了一系列在线高等教育项目。
Bukowski说:“该部门的许多其他审计员看到了数据分析的重要性,并正在寻求领导力支持的培训”,包括如何使用Alteryx、Tableau等供应商的分析工具。他说,该部门2018年7月的年度务虚会包括一次关于数据可视化的外部培训课程和一个关于审计相关数据分析举措的内部培训计划。
审计部门的两名数据科学家被聘为数据科学家。然而,该部门赞助的培训帮助Bukowski和其他几位审计员提高了数据素养,并能够将数据分析概念应用于审计和调查。
Bukowski说:“并不是所有的审计师都需要成为数据科学家,但他们必须具备数据素养。”。他又迈出了一步,报名参加了科学硕士数据分析项目,“因为我看到了数据在我的职业生涯中有多么重要,”他说。
随着数据科学/分析方面的额外教育,Bukowski的角色在过去12个月里从主要执行个人审计和调查演变为为为执行自己审计和调查的同事提供数据分析支持。
使用各种分析工具,Bukowski可以混合和分析大型数据集,而他的同事只能使用Excel电子表格。他说:“这导致了对Excel中较小数据集的分析不太可能发现的多次审计结果。”。
Bukowski表示,审计部门正在根据审计结果启动咨询项目,为嘉年华及其运营公司提供额外的分析驱动价值。
在SessionM让工程师参与数据科学工作
提供客户数据和参与平台的SessionM正在创建一个由专门的数据科学工程师(DSE)组成的团队,负责设计和编写用于生产的人工智能(AI)软件。SessionM负责数据科学、人工智能和机器学习的副总裁Amelio Vázquez Reina表示,这些人对机器学习(ML)、统计学和决策理论都很了解。
Vázquez-Reina表示,他们的主要职责是自动生成见解、预测和建议,并构建软件产品,为整个公司的决策提供自动执行。
Vázquez Reina表示,除了开发正式的DSE外,SessionM还有几项举措来帮助公司提高数据科学素养。他说:“我们定期与其他部门举行会议,要求DSE向我们的销售、业务分析师、产品和解决方案体系结构团队解释他们的数据模型和解决方案。”。
这些会议有两个目标。一个是向员工介绍SessionM的数据科学战略、方法和最佳实践。另一个是帮助公司的每个人理解并宣传其所谓的人工智能“价值生成链”。这是一个过程,包括从每个客户那里收集数据,明确规定客户目标,并强调软件开发的实验,以最大限度地为客户带来结果和见解。
此外,该公司还为软件工程师提供机会,通过其敏捷开发流程和为客户提供的数据科学服务,为其数据科学软件做出贡献。SessionM还举办以人工智能为中心的会议和社交活动。
“这些会议以描述公司感兴趣的问题的SessionM DSE的技术演示开始,然后对该问题进行数学表征,该问题适合公司的所有[软件工程师],最后围绕所选择的解决方案、实施以及在此过程中探索的任何权衡和替代方案进行开放式讨论。”
Ogury培养数据科学人才
Ogury是一家提供移动数据技术的公司,据该公司首席技术官Louis-Marie Brierre介绍,该公司每天接收的数据超过1TB。要获得处理如此大量信息的资源、技能和能力,需要一支敬业且才华横溢的数据科学团队。维持这样一个团队的关键之一是创造一个有吸引力的工作场所。
Brierre说:“我们激励团队的最佳方式是给他们学习和控制个人成长的空间。”。“我们授权我们的数据团队拥有和管理他们的项目,并承担全部责任。”
该公司的数据科学家与数据工程师以及开发和产品团队密切合作。Brierre说:“这让他们了解了业务,并使他们能够了解自己在公司中的角色和影响。”。“我们从不限制他们正在操纵的数据的计算能力以及他们想要测试的想法。”
Brierre说,由于项目和团队的多样性,“我们喜欢挑战人们,并通过每12或18个月加入一个新的部门为他们提供新的增长途径。”。“这让他们有机会离开舒适区,发现新的团队合作伙伴和项目。”
Ogury还致力于保持其数据科学家训练有素。
Ogury首席算法官Christophe Thibault表示:“我目睹了许多公司急切地等待新数据科学家的到来。”。“这些公司相信,他或她会来拯救他们的业务,提高所有(绩效指标)。是的,数据科学家和分析师是组织中的关键人物,但他们仍然需要像其他有价值的团队成员一样得到培养和培训。”
Thibault说,为了建立一支数据科学家团队,公司必须培养优秀的人才。“但他们也有责任为他们的到来做好组织准备,并为他们的成功做好准备,”他说。
自2014年以来,Ogury采取了几种做法来吸引和留住数据科学家。一个是消除技术限制。Thibault说:“我们所有的数据科学家都可以访问云上的沙盒环境,这样他们就可以测量自己的计算能力,并将其与他们正在操纵的数据和他们想要测试的想法进行全面比较。”。
另一个是鼓励合作。Thibault说,数据科学家和数据工程师拥有不同的技能和词汇。但对于一个组织的数据分析工作来说,他们一起工作和合作是至关重要的。“一个组织内知识的自由流动是企业蓬勃发展的方式,”他说。
第三种做法是将算法与数据相匹配,而不是相反。Thibault表示:“数据科学家与商业分析师密切合作,以了解数据。”。“尤其是在Ogury,我们有独特的、细粒度的第一方数据,数据科学家需要时间来理解信息。最重要的是,我们的团队必须确保他们使用的算法能够完美地拟合数据,而不是仅仅因为这是一条简单的出路就扭曲数据以将其拟合到众所周知或预先确定的算法中。”
美光协助获得高级学位
持续的学习和教育是计算机存储器技术提供商美光的首要任务。美光首席信息官Trevor Schulze表示:“由于许多数据科学都需要深入掌握统计学和机器学习,(公司)支持许多人在这一领域攻读高级学位。”。
此外,舒尔茨说,美光的员工发现大规模的在线开放课程(MOOC)有助于巩固某些技能。该公司还通过支持出席外部和内部会议和在会议上发言,向同行学习。
美光在世界各地的数据科学团队中雇佣了数百名员工。舒尔茨说,这些团队中约有一半的数据科学家来自公司的不同岗位,通常是工程部门。
舒尔茨说:“当人们有强大的数据基础、好奇和探索的心态,最关键的是掌握统计学和机器学习方法的能力时,就会成功地向数据科学过渡。”。“这些人在正规、高级教育中可能缺乏的东西,他们往往会在工业和数据知识方面弥补。”
数据科学的兴起对公司产生了巨大的影响。舒尔茨说:“三十多年来,机器人和计算机自动化一直是开发和生产下一代存储芯片的关键推动者。”。“然而,仅靠自动化已经无法推动行业向前发展。随着数据科学成为许多制造流程和商业决策的核心,美光正在发生真正的变革。”
在McAfee的指导并将培训作为首要任务
安全技术公司McAfee创建了一个卓越分析中心(ACE),其框架包括价值主张、宣传(包括培训和指导)、模型/算法和数据管理。该公司首席数据科学家Celeste Fralick表示,这得到了首席技术官和主要副总裁的支持。
为了实现该框架,ACE参与者定期安排关于算法的“技术讲座”;McAfee创建了八个实践社区,即教育、人力资源、工业/学术合作等领域的工作组。它还成立了技术工作组,如分析审查委员会、对抗性机器学习和分析门户网站。
ACE是全球性的,拥有150多名来自公司各个技能水平的人员。Fralick说:“我们现在正在制定一个辅导计划和一个关于数据货币化的短期课程,并探讨管理人员等非数据科学家可以提出的关于算法和模型开发的问题。”。
此外,McAfee还赞助了深入的培训,包括分析、清洁和预处理数据的介绍,以及模型和机器学习的介绍。
Fralick说:“虽然我们不教授‘工具’本身,但我们教授的是一般的‘窍门’和特定主题的概念。”。“工具会改变,但数学和可能破坏算法的陷阱通常不会改变。”
Fralick说,这些努力是故意缓慢而自愿地开始的,目的是在非对抗性的氛围中获得最初的积极影响。她说,对课程的需求猛增。
Fralick说:“我们还推荐特定的外部课程、书籍以及学位或证书课程。”。“我们发现,计算机科学家通常没有被教授数据科学的关键要素。当他们得到信息时,他们会热情地回应,明白数据不仅仅是收集和快速应用模型。开发成功的分析还有更多的工作要做。”
Fralick说,对于训练有素的数据科学家来说,项目“正在知识和智能的金字塔上向上发展,从统计学到机器学习,从深度学习到人工智能”。“由于机器驱动的算法增强了人类的决策,因此人机团队在这一过程中至关重要。”
具体的分析开发需求正在集成到软件产品生命周期中。Fralick说:“我们打算让公司里的每个人都上一门分析入门课程。”。“数据科学工作对组织和我们的业务/数据战略的总体影响已经随着更高的数据量、客户期望和数据融合而凝结,以使我们的业务能够以数据和模型为驱动。”
在Ibotta,课程和合作
在过去的两年里,移动购物应用程序开发商Ibotta通过正式和非正式的培训,在组织内部建立了一个分析团队。
该团队开发了为期六周的SQL、Python和Spark课程,以及关于有效沟通分析结果的技巧和窍门、频率学家与贝叶斯统计的利弊以及利用TensorFlow构建神经网络等主题的简短入门培训课程。
数据分析和科学副总裁Laura Spencer表示:“此外,我们每两周举行一次头脑风暴会议,团队成员在会上讨论和构思各种分析和数据科学主题,以及如何在整个公司利用这些主题。”。
该公司还高度重视具有不同技能的分析师之间的合作项目,以鼓励分享技能、能力和限制。
Spencer说:“例如,我们最近与营销分析、机器学习和用户研究方面的专家进行了一次保留深度挖掘,为业务建立[推荐]。”。“我们还采取了一些举措,鼓励员工继续从外部学习,并将新的工具和方法带回团队。”
Ibotta在其总部附近主持并出席各种大数据和数据科学会议。Spencer说:“我们还赞助每一位数据科学家每年参加他们选择的会议,作为回报,他们会向组织的其他成员提供会议学习的培训。”。
在过去的几年里,Ibotta的分析团队已经发展到大约45人,包括数据工程、统计学和机器学习等技能。
- 41 次浏览
【数据科学】反思十年数据科学和可视化工具的未来

数据科学在过去十年中呈爆炸式增长,改变了我们开展业务的方式,并让下一代年轻人为未来的工作做好准备。但是这种快速增长伴随着对数据科学工作的不断发展的理解,这导致我们在如何使用数据科学从我们的大量数据中获得可操作的见解方面存在很多模糊性。在数据科学的发展塑造了我自己的职业生涯之后,我想深入研究什么是数据科学、数据科学的工作是什么以及谁是数据科学家等问题。我翻阅了研究文献,以提取关于数据科学和数据科学家的各种研究和分析的线索,将这些问题的答案编织在一起。我在一篇题为“传递数据指挥棒:对数据科学工作和工作者的回顾性分析”的研究出版物中介绍了这些结果。
这项研究的部分动机是作为研究和开发的基础,以便我可以确定可视化分析工具可能解决未满足需求的领域。然而,另一个动机是对一个十多年前我第一次开始计算机科学高级研究时还不存在的领域的个人反思。在这篇博文中,我总结了这篇研究论文的几个关键要点,并分享了我对它的发现如何帮助我们为数据科学构建下一代数据可视化工具的想法。
什么是数据科学?

事实证明,数据科学对不同的人来说是不同的东西。对某些人来说,数据科学并不是什么新鲜事物,它只是已经存在很长时间的统计技术的实际应用。对其他人来说,这种观点过于狭隘,因为数据科学不仅需要统计方法的知识,还需要计算技术才能使这些方法的应用变得实用。例如,数据科学家仅了解线性回归是不够的,他们还需要知道如何将其大规模应用于大量数据——这不是传统统计学教育的一部分。尽管如此,即使是那些认为数据科学不仅仅是应用统计学的人也可能会犹豫说它是新事物。收集和分析数据(甚至是大量数据)的做法长期以来一直是科学研究的一部分,例如生物学或物理学;许多人认为数据科学只是经验科学中已经发生的事情的延伸。
但这里还有第三种观点,即数据科学确实是新事物,既不同于统计学,也不同于科学家在研究原子和基因时使用的方法。将统计学和计算机科学与必要的主题专业知识结合在一起,带来了新的挑战,这些挑战由数据科学独特地解决,并由数据科学家解决。此外,数据科学家开展的工作不同于其他类型的数据分析,因为它需要更广泛的多学科技能。我们的研究和其他人的研究认为,数据科学确实是新的和不同的东西,因此我们创建了一个工作定义,作为我们工作的基础:
“数据科学是一个多学科领域,旨在通过主要统计和计算技术的结构化应用, 从现实世界的数据中学习新的见解”
这个定义很重要,因为它有助于我们理解数据科学工作者面临的挑战和未满足的需求,这主要源于使用真实数据而不是模拟数据的挑战,以及伴随应用统计和计算方法的挑战这些数据大规模。
什么是数据科学工作?
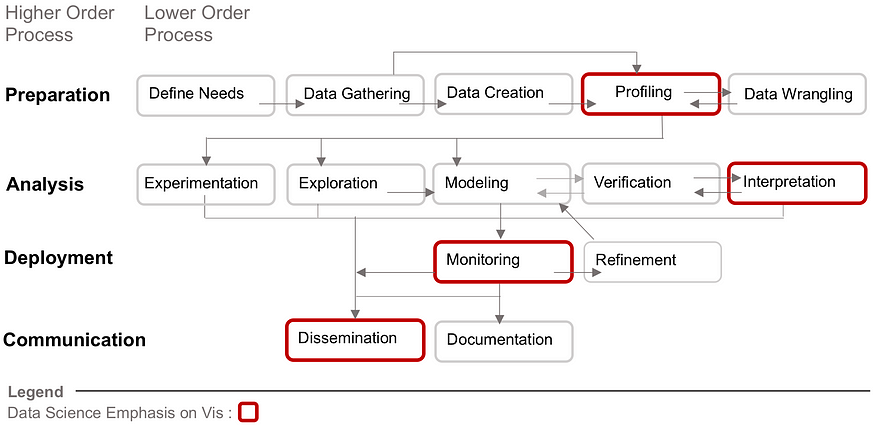
- 将数据科学工作提炼成四个高阶(准备、分析、部署和通信)和 14 个低阶过程。 红色标出的过程是主要使用数据可视化的过程,但这并不排除它在数据科学工作的其他方面的使用。
重要的是,数据科学的工作定义缩小了研究范围。我们没有考虑人们可能希望进行的所有可能类型的数据分析,而是仔细研究数据科学家进行的分析类型。这种区别很重要,因为实验物理学家分析数据所采取的具体步骤与数据科学家可能采取的分析步骤不同,即使它们有共同点。这导致了一个重要的后续问题:数据科学的工作到底是什么?
有几个行业标准用于分解数据科学工作。第一个是 KDD(或数据发现中的知识)方法,随着时间的推移,它被其他人修改和扩展。根据这些推导以及采访数据科学家的研究,我们创建了一个框架,该框架具有四个高阶流程(准备、分析、部署和通信)和 14 个低阶流程。使用红色笔划轮廓,我们还强调了数据可视化已经在数据科学工作中发挥重要作用的特定领域。在我们的研究文章中,我们提供了这些过程的详细定义和示例。
谁是数据科学工作者?

Nine Data Science roles that we found across twelve in depth studies with Data Scientists
这些年来,我听到了很多关于数据科学家是什么的不同看法。我喜欢的一个观点是,数据科学家是“比统计学家更擅长软件工程,比软件工程师更擅长统计”的人。我最近听到的一种厚颜无耻的说法是,数据科学家是“西海岸的统计学家”。
然而,当我们深入研究对数据科学家的现有研究时,我们没有预料到会发现一些东西,但它变得一致且重要,那就是“数据科学家”的多样性以及他们的角色如何在特定的数据科学过程中发生变化。例如,您可能已经注意到数据工程师的崛起,作为一个独特但仍然相邻的数据科学角色。随着数据科学工作的复杂性增加,数据科学家变得不那么笼统而更加专业,他们经常从事数据科学工作的特定方面。哈里斯等人进行的采访。早在 2012 年就已经确定了这一趋势,而且随着时间的推移,这种趋势只会加速。他们敏锐地观察到,数据科学角色之间的这种多样性导致“数据科学家与寻求帮助的人之间的沟通不畅”。
我们在 Harris 工作的结果的基础上,检查了 12 项研究,总计数千名被认定为数据科学家的人。从我们对这些研究的元分析中,我们能够确定 9 个不同的数据角色。这些人具有不同的技能和背景,我们沿着统计、计算机科学和领域专业知识的轴进行了说明。我们还将以人为本的设计纳入我们对数据科学技能的描述中,因为考虑到数据产品(如面部识别应用程序)的影响越来越重要。我们要强调的是,这些角色不是绝对的类别,它们的界限以及担任这些角色的这些人的技术技能强度是流动的。相反,这些类别的角色旨在作为指导,帮助研究人员和其他人了解他们正在与谁交谈以及他们的背景可能是什么。
这将如何改变我们构建可视化和数据分析工具的方式?
当然,最重要的考虑是我们对数据科学的定义以及我们的数据科学工作和工作者框架如何帮助我们构建更好的数据可视化工具。首先,它有助于明确数据科学工作和工作人员的多样性并以证据为基础。我们已经使用这个框架来创建更清晰的标准来分解数据科学中的 Tableau 客户体验。我们可以更精确地确定他们正在尝试做什么,并且可以就这些过程提出更多探索性的问题。知道“数据科学家”这个角色本身包含大量的多样性,我们可以通过将我们正在与之交谈的个人分类为我们的九个数据科学角色来更好地确定谁在执行这项工作。这样的分类使我们更容易理解我们的可视化系统需要支持的任务以及在什么级别上。例如,技术分析师和 ML/AI 工程师,这是我们描述的两个数据科学角色,都可以从事模型构建的共同任务,但需求却截然不同;如果我们忽略这些差异,我们就有可能为这两个角色构建错误的工具。
但也许对我来说最重要的是,这个框架还帮助我思考当前的可视化分析工具生态系统中缺少什么。我得出的一个令人担忧的结论是,现有工具只专注于可视化机器学习模型,并且缺乏支持数据科学工作其他关键方面的工具,例如数据准备、部署或通信。这种工具的缺乏不仅增加了数据科学工作的开销,而且还使数据科学家无论担任什么角色,都更难以让他们的工作影响组织决策和实践。这项关于数据科学工作和工作者的研究帮助我发现了这些挑战,并为构建更好的工具来帮助人们查看和理解他们的数据定义了机会。
原文:https://engineering.tableau.com/reflecting-on-a-decade-of-data-science-…
- 78 次浏览
【数据科学】数据科学中的不同角色
数据科学领域不断发展,随后,在数据科学领域内有大量的职业角色可供选择。该博客列出了人们可以选择的一些数据科学领域最新兴的职业选择。
数据科学是一个需要学科专业知识(例如,如果您打算从事生物信息学,则需要生物学)、编程技能以及数学和统计学培训的领域。数据科学即服务允许公司利用先进的分析技术(包括深度学习)获得业务洞察力,而无需投资于内部数据科学能力。数据科学家帮助公司处理来自各种来源的大量信息。专家数据科学团队可以帮助您快速采用数据科学来满足特定的高级分析目标。
Glassdoor 将数据科学列为 2021 年美国排名第二的工作。数据科学中有许多名称相似的职业:例如,ML 开发人员和 ML 工程师。在本文中,我们将讨论数据科学中的不同角色、该领域的职业有何不同以及对不同职位的候选人的期望。

数据科学家
数据科学家的主要任务是提高机器学习模型的质量。一般来说,他或她的工作可以分为两个块。第一个是在项目中使用完成的模型。有必要不断评估其质量并找到可以改进的地方。在线和离线指标以及测试人员的反馈对此有所帮助。第二个是研究部分本身:寻找新的架构和信号进行预测。
以下是数据科学家需要知道的:
- Python 开发模型。
- C++ 将代码投入生产。
- 深度学习框架(TensorFlow、PyTorch、Caffe 或其他)。
- 数据结构和算法。
很多时候数据科学家都在收集、清理和分析数据以获得有用的见解。准备好数据后,他们将剩下的时间花在训练新模型上,例如在集群上准备数据并编写基础设施以进行有效的训练。复制模型也是工作的一部分:您必须编写模型并检查它在真实数据上的行为是否符合预期,然后优化其性能。一个有趣的事实是,数据科学家的工作还涉及 ML 工程师、数据工程师和数据科学家角色的技能。
机器学习工程师
ML 工程师的职责与数据科学家非常相似。但相比之下,没有必要准备在科学期刊上发表文章并定期开发新技术。比数据科学家更重要的是编写有效且可读的代码的能力,然后同事们可以理解。
以下是 ML 工程师需要了解的内容:
- Python 和 C++ 用于开发模型和训练算法。
- 概率论、统计学和离散数学。
- 深度学习框架(TensorFlow、PyTorch、Caffe 或其他)。
对于 ML 工程师来说,拥有协作开发工具也很有用。他们不仅应该能够训练高质量的模型,还应该能够基于它们创建能够承受高负载的服务。这可能需要掌握低级编程语言和优化机器学习模型的技术。
数据工程师负责为后续分析准备数据。他们的工作是首先从社交网络、网站、博客和其他外部和内部来源收集数据,然后将其转化为可以发送给数据分析师的结构化形式。
数据工程师
想象一下,你需要做一个苹果派。首先,您需要从食谱中找到面粉、苹果、鸡蛋、牛奶和其他成分。这就是数据工程师所做的,只是寻找并引入正确的数据。数据分析师将自己制作馅饼,或者更确切地说,在找到的数据中寻找模式。
以下是数据工程师需要了解的内容:
- 如何设计存储、设置数据收集和数据管道。
- 如何构建 ETL 流程。
- C++、Python 或 Java。
- 用于处理数据库的 SQL。
此外,工程师创建和维护存储基础设施。他们还负责 ETL 系统 - 将数据提取、转换和加载到一个存储库中。可以肯定地说,他们负责购买和储存馅饼的原料。因此,数据分析师可以随时拿起它们来做一道菜,并确保一切都准备就绪并且没有任何问题。
数据分析师
数据分析师帮助公司改进指标并解决中间目标,而不是盲目地朝着大目标(一年内收入翻番)迈进。通常情况下,他们与销售人员密切合作。
数据分析师的任务是处理大量数据并在其中找到模式。例如,他们可能会发现大多数牙刷是由 30 至 40 岁的已婚男性购买的。数据分析师帮助公司更好地了解他们的客户,从而带来更多的销售额。
以下是数据分析师需要了解的内容:
- Python 处理数据。
- 数理统计选择正确的方法来处理数据。
- SQL 方言,如 ClickHouse。
- DataLens、Tableau、PowerBI 和其他仪表板工具。
- Hadoop、Hive 或 Spark 等大数据工具。
在他们的工作中,数据分析师使用数理统计知识,这使他们能够找到模式并帮助预测用户的行为。数据分析师还进行测试,检查用户对新界面的反应,并帮助优化业务流程。
概括
对于那些喜欢精确科学的人来说,数据科学有很多方向和任务。作为数据科学家,您可以执行科学密集型任务,作为 ML 工程师实施新技术,作为数据分析师为业务寻找有用的模式,或者如果您选择作为数据工程师工作,则可以收集和构建数据。此外,您的选择不仅取决于您的专业知识,还取决于您想要解决的问题:也许您梦想推动科学发展并创造其他人将使用的技术。
- 105 次浏览
【数据科学】数据科学难题,怎么解释到底什么是数据科学
通过数据科学领域中几个关键概念之间的关系来检验数据科学的难题。正如我们将要看到的那样,不同意见的是具体的概念,不同意见是不可避免的;这只是另一个需要考虑的意见。
网络上没有任何文章比较和对比数据科学术语。所有类型的人都写了各种各样的文章,将他们的意见传达给任何愿意倾听的人。这几乎是压倒性的。
所以,让我直截了当地记录,对于那些想知道这是否是这类帖子之一的人。是。是的。
为什么另一个?我认为,虽然可能有很多意见部分定义和比较这些相关术语,但事实是这个术语的大部分都是流动的,并未完全同意,坦率地说,暴露于其他人群的观点是测试和改进自己的最佳方法之一。
因此,虽然我可能不完全(甚至是最低限度地)同意我对这个术语的大部分内容,但可能仍然有一些东西可以摆脱这一点。将研究数据科学的几个核心概念。或者,至少,我认为是核心。我会尽力提出它们之间的关系以及它们如何作为一个更大拼图的单个部分组合在一起。
作为一些有些不同意见的例子,在单独考虑任何概念之前,KDnuggets的Gregory Piatetsky-Shapiro汇总了以下维恩图,其中概述了我们将在此考虑的相同数据科学术语之间的关系。我们鼓励读者将这个维恩图与Drew Conway现在着名的数据科学维恩图进行比较,以及下面我自己的讨论以及帖子底部附近的修改过程/关系图。我认为,虽然存在差异,但这些概念在某种程度上具有相似性(参见前几段)。
我们现在将对上述维恩图中描述的相同的6个核心概念进行处理,并提供一些有关如何将它们组合到数据科学难题中的见解。 首先,我们很快就省去了过去十年中最热门的话题之一。
大数据
有各种各样的文章可用来定义大数据,我不会在这里花太多时间在这个概念上。 我将简单地说,大数据通常可以定义为“超出常用软件工具捕获,管理和处理能力”的数据集。 大数据是一个不断变化的目标; 这个定义既模糊又准确,足以捕捉其核心特征。
至于我们将要研究的其余概念,最好先了解一下他们的搜索术语流行度和N-gram频率,以帮助将事实与炒作区分开来。 鉴于这些概念中的一对相对较新,我们从1980年到2008年的“老”概念的N-gram频率如上所示。
最近的谷歌趋势显示了2个新术语的上升,2个其他人的持续上升趋势,以及最后一个逐渐但明显的下降。 请注意,由于已经对数据进行了定量分析,因此大数据未包含在上述图形中。 请继续阅读以进一步了解观察结果。
机器学习
根据Tom Mitchell在他关于这个主题的开创性着作中的说法,机器学习“关注的是如何构建自动改进的计算机程序的问题。”机器学习本质上是跨学科的,并且采用来自计算机科学,统计学和人工智能等领域的技术。机器学习研究的主要工件是可以从经验中自动改进的算法,可以应用于各种不同领域的算法。
我认为没有人怀疑机器学习是数据科学的核心方面。我在下面给出了数据科学详细处理这个术语,但是如果你认为它的目标是从数据中提取洞察力,那么机器学习就是让这个过程自动化的引擎。机器学习与经典统计有很多共同之处,因为它使用样本来推断和推广。在统计学更多地关注描述性的情况下(虽然它可以通过推断,可以预测),机器学习很少涉及描述性,并且仅将其用作中间步骤以便能够进行预测。机器学习通常被认为是模式识别的同义词;虽然这对我来说真的不会有太大的分歧,但我相信模式识别这个术语意味着一套比机器学习实际上更复杂,更简单的过程,这就是为什么我倾向于回避它。
机器学习与数据挖掘有着复杂的关系。
数据挖掘
Fayyad,Piatetsky-Shapiro和Smyth将数据挖掘定义为“从数据中提取模式的特定算法的应用”。这表明,在数据挖掘中,重点在于算法的应用,而不是算法本身。我们可以定义机器学习和数据挖掘之间的关系如下:数据挖掘是一个过程,在此过程中,机器学习算法被用作工具来提取数据集中保存的潜在有价值的模式。
数据挖掘作为机器学习的姐妹术语,对数据科学也至关重要。事实上,在数据科学这个术语爆炸之前,数据挖掘作为Google搜索术语获得了更大的成功。看看谷歌趋势比上图所示延长了5年,数据挖掘曾经更受欢迎。然而,今天,数据挖掘似乎被分割为机器学习和数据科学本身之间的概念。如果要支持上述解释,那么数据挖掘就是一个过程,那么将数据科学视为数据挖掘的超集以及后续术语是有意义的。
深度学习
深度学习是一个相对较新的术语,尽管它在最近的在线搜索急剧上升之前就存在了。由于在许多不同领域取得了令人难以置信的成功,研究和工业正在蓬勃发展,深度学习是应用深度神经网络技术(即具有多个隐藏层的神经网络架构)来解决问题的过程。深度学习是一个过程,如数据挖掘,它采用深度神经网络架构,这是特定类型的机器学习算法。
深度学习最近取得了令人印象深刻的成就。鉴于此,至少在我看来,记住一些事情很重要:
深度学习不是灵丹妙药 - 对于每个问题而言,它并不是一个简单的“一刀切”的解决方案
它不是传说中的主算法 - 深度学习不会取代所有其他机器学习算法和数据科学技术,或者至少它尚未证明如此
淬火期望是必要的 - 尽管最近在所有类型的分类问题上取得了很大进展,特别是计算机视觉和自然语言处理,以及强化学习和其他领域,当代深度学习不能扩展到处理非常复杂的问题,如“解决世界和平”
深度学习和人工智能不是同义词
深度学习可以通过附加过程和工具的形式为数据科学提供大量帮助,以帮助解决问题,并且当从这个角度观察时,深度学习是数据科学领域的一个非常有价值的补充。
人工智能
大多数人发现人工智能的精确定义,通常甚至是广泛定义,难以理解。我不是一名人工智能研究员,所以我的回答可能与那些在其他领域甚至可能会让人不满的人大不相同。多年来,我对人工智能的概念进行了多次哲学思考,我得出的结论是,人工智能,至少是我们在考虑它时通常会想到的概念,实际上并不存在。
在我看来,AI是一个标尺,一个移动的目标,一个无法实现的目标。每当我们走上人工智能成就的道路时,这些成就似乎会变成被称为别的东西。
我曾经读过如下内容:如果你在20世纪60年代问过AI研究员他们对AI的看法是什么,他们可能会同意一个适合我们口袋的小装置,这可以帮助预测我们的下一步行动和愿望,并且随时可以获得的全部人类知识,可能会达成共识,即所述设备是真正的AI。但我们今天都携带智能手机,我们中很少有人会将它们称为人工智能。
AI在哪里适合数据科学?好吧,正如我所说,我不相信人工智能真的是有形的,我想很难说它适合任何地方。但是有许多与数据科学和机器学习相关的领域,其中AI提供了动力,有时与有形的同样有价值;当然的深度学习研究,当然深刻的学习研究,如果不是无限期的,它们在某些方面都受益于人工智能精神,那么计算机视觉肯定会浮现在脑海中。
人工智能很可能是具有最深口袋的研发设备,从来没有在同行业中产生任何东西。虽然我会说从AI到数据科学的直线可能不是查看2之间关系的最佳方式,但两个实体之间的许多中间步骤已经由AI以某种形式开发和完善。
数据科学
那么,在讨论了这些相关概念及其在数据科学中的位置之后,究竟什么是数据科学?对我而言,这是试图精确定义的最艰难的概念。数据科学是一门多方面的学科,它包括机器学习和其他分析过程,统计学和相关的数学分支,越来越多地借鉴高性能科学计算,所有这些都是为了最终从数据中提取洞察力并使用这些新发现的信息来讲故事。这些故事通常伴随着图片(我们称之为可视化),并且针对行业,研究,甚至仅仅针对我们自己,目的是从数据中收集一些新想法。
数据科学使用来自各种相关领域的各种不同工具(参见上文所述的所有内容)。数据科学既是数据挖掘的同义词,也是包含数据挖掘的概念的超集。
数据科学产生各种不同的结果,但它们都有共同的洞察力。数据科学就是这一切以及更多,对你而言,它可能完全是另一回事......我们甚至还没有涵盖获取,清理,争论和预处理数据!顺便说一下,数据甚至是什么?它总是很大吗?
我认为我对数据科学难题的想法,至少是可以用上图表示的数据的版本,与本文顶部的Piatetsky-Shapiro的维恩图很好地吻合。我还建议它也主要与Drew Conway的数据科学维恩图一致,尽管我会补充一点:我相信他非常合理且有用的图形实际上指的是数据科学家,而不是数据科学。这可能是分裂的头发,但我不认为{field |纪律|数据科学本身的概念包括黑客技能;我相信这是科学家们拥有的一项技能,以便能够进行数据科学研究。不可否认,这可能是对语义的争论,但在我看来这是有意义的。
当然,这不是一幅不断发展的景观的全貌。例如,我记得在不久之前阅读数据挖掘是商业智能的一个子领域!即使意见分歧,我也无法想象今天这是一个有效的想法(几年前很难接受,说实话)。
而且你有它:你最喜欢的一些术语以新的方式变形,你不会原谅我。如果你现在感到愤怒,迫不及待地想告诉我我有多错,请记住这篇文章的重点:你刚读过一个人的意见。在这种精神中,您可以随意在评论中发声(可能是激烈的,尖锐的)对比的观点。否则,我希望这或者让新读者接触到数据科学的难题,或者强迫他们在他们的头脑中看看他们自己的这个难题版本。
- 74 次浏览
【数据科学】顶级数据科学备忘单(ML、DL、Python、R、SQL、数学和统计)
“也许对一个人的智力最好的测试是他总结的能力”——Lytton Strachey
数据科学是一个不断发展的领域,有许多工具和技术需要记住。 任何人都不可能记住每个概念的所有功能、操作和公式。 这就是为什么我们有备忘单。 它们帮助我们访问最常用的提醒,使我们的数据科学之旅变得快速而轻松。
但是有大量的备忘单可供使用。 另一方面,质量、简洁和技术备忘单……不是那么多。 一套涵盖理论机器学习概念的良好资源将是无价的。 所以,我决定写这篇文章。
为了读者的方便,我为以下每个主题分别分离了最好的备忘单(全面而简洁)。 . .
- Python (Basic python as well as ML libraries : Numpy /Pandas/Matplotlib/Seaborn)
- R
- SQL
- Data Visualization Tools ( Tableau, Power BI)
- Maths and Statistics
- Machine Learning Algorithms
- Deep Learning
- IDE/OS etc
PYTHON


Basic Python
- gto76 — extensive Python cheat sheet offered by GitHub
- memento
- Pythoncheatsheet.org
- Cheatography
- Python crash course
- DataQuest ( basic and intermediate )
- MementoPython3
Numpy
- DataCamp
- Intellipat
- A Little Bit of Everything
- Data Quest
- NumPy for R (and S-plus) Users
- Ipgp_github
Pandas
- The Most Comprehensive Cheat Sheet
- The Beginner’s Cheat Sheet
- DATACAMP
- Data Science Central (compact)
- INTELLIPAT
Matplotlib
{kind=link}
Seaborn

R

SQL
Data Visualization Tools
Tableau
Maths and Statistics

Machine Learning Algorithms




Deep Learning
- AndrewNG_DeepLearning
- Stanford(deep learning)
- Stanford(neural_nets)
- Datacamp (Keras)
- Aimov_institute
Tensorflow
{kind=link}

IDE and OS
Linux
Jupyter Notebook
ScikitLearn

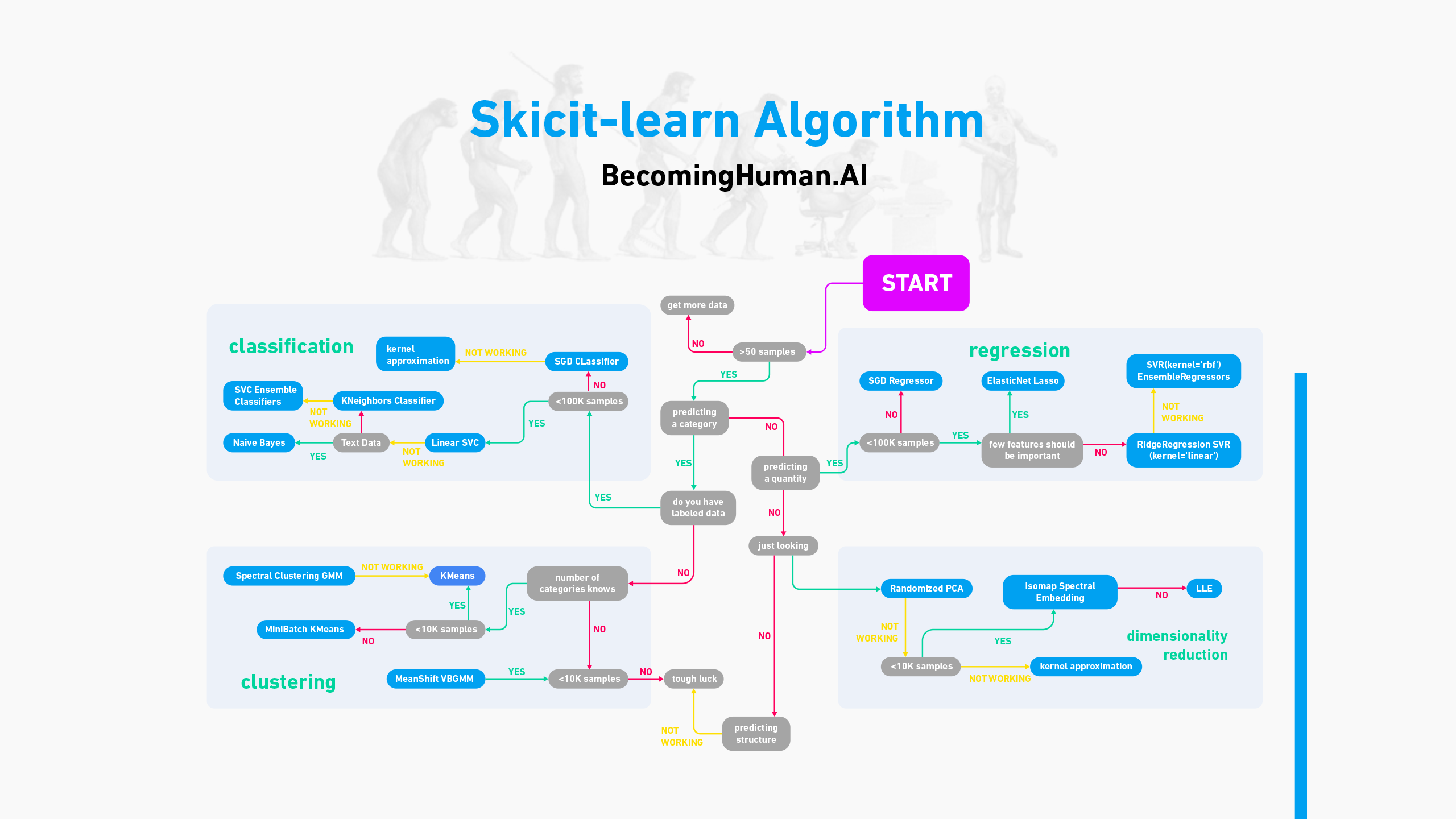
Pytorch
- Pytorch.org
- Pytorch.org (for beginners)
- KDNuggets
- Cheatography
- Github
- ProgrammerSought
- TechRepublic
最后的想法
这就是我在分离和收集有关数据科学各个方面的最佳备忘单方面所做的努力。 我希望它有帮助。 如果我错过了任何或你们有任何建议或疑问,请在下面添加您的评论。
我很乐意将它们添加到上面的列表中!
原文:https://medium.com/@anushkhabajpai/top-data-science-cheat-sheets-ml-dl-…
本文:
- 117 次浏览
【数据科学家】什么是数据科学家? 一个关键的数据分析角色和一个有利可图的职业
视频号
微信公众号
知识星球
数据科学家的角色因行业而异,但有一些共同的技能、经验、教育和培训可以让您在数据科学职业生涯中脱颖而出。
什么是数据科学家?
数据科学家是分析数据专家,他们使用数据科学从大量结构化和非结构化数据中发现见解,以帮助塑造或满足特定的业务需求和目标。 数据科学家在业务中变得越来越重要,因为组织越来越依赖数据分析来推动决策制定,并依赖自动化和机器学习作为其 IT 战略的核心组成部分。
数据科学家职位描述
数据科学家的主要目标是组织和分析数据,通常使用专门为该任务设计的软件。 数据科学家分析的最终结果必须足够容易让所有投资的利益相关者理解——尤其是那些在 IT 之外工作的利益相关者。
数据科学家的数据分析方法取决于他们所在的行业以及他们工作的业务或部门的具体需求。 在数据科学家能够在结构化或非结构化数据中找到意义之前,业务领导和部门经理必须传达他们正在寻找的内容。 因此,数据科学家必须具备足够的业务领域专业知识,才能将公司或部门的目标转化为基于数据的可交付成果,例如预测引擎、模式检测分析、优化算法等。
数据科学家与数据分析师
数据科学家经常与数据分析师一起工作,但他们的角色有很大不同。 数据科学家经常从事长期研究和预测,而数据分析师则寻求支持业务领导者通过报告和临时查询来制定战术决策,这些查询旨在根据当前和历史数据描述其组织的当前现实状态。
因此,数据分析师和数据科学家的工作之间的差异通常归结为时间尺度。 数据分析师可能会帮助组织更好地了解其客户当前如何使用其产品,而数据科学家可能会使用从该数据分析中产生的见解来帮助设计新产品,以预测未来客户的需求。
数据科学家薪水
数据科学是一个快速发展的领域,美国劳工统计局预测从 2020 年到 2030 年的工作岗位增长率为 22%。数据科学家也被证明是一条令人满意的长期职业道路,Glassdoor 的“美国 50 大最佳工作”中,数据科学家位列第三—— 美国最好的工作。
根据 Robert Half 的 2021 年技术和 IT 薪资指南中的数据,数据科学家的平均薪资根据经验细分如下:
- 第 25 个百分点:109,000 美元
- 第 50 个百分位数:129,000 美元
- 第 75 个百分位数:156,500 美元
- 第 95 个百分位数:185,750 美元
数据科学家职责
数据科学家的主要职责是数据分析,从数据收集开始,到基于分析结果的业务决策结束。
数据科学家分析的数据来自许多来源,包括结构化、非结构化或半结构化数据。 数据科学家可用的高质量数据越多,他们可以在给定模型中包含的参数就越多,他们手头上用于训练模型的数据就越多。
- 结构化数据通常按类别进行组织,使计算机可以轻松地自动排序、读取和组织。 这包括通过服务、产品和电子设备收集的数据,但很少包括通过人工输入收集的数据。 您的智能手机收集的网站流量数据、销售数据、银行账户或 GPS 坐标——这些都是结构化的数据形式。
- 非结构化数据是增长最快的数据形式,更有可能来自人工输入——客户评论、电子邮件、视频、社交媒体帖子等。这些数据更难分类,使用技术管理效率更低,因此需要一个 更大的投资来维护和分析。 企业通常依靠关键字来理解非结构化数据,以使用可搜索的术语提取相关数据。
- 半结构化数据介于两者之间。 它不符合数据模型,但确实具有可用于对其进行分组的关联元数据。 示例包括电子邮件、二进制可执行文件、压缩文件、网站等。
通常,企业雇用数据科学家来处理非结构化数据和半结构化数据,而其他 IT 人员则管理和维护结构化数据。 是的,数据科学家确实处理大量结构化数据,但企业越来越多地寻求利用非结构化数据来实现收入目标,从而使处理非结构化数据的方法成为数据科学家角色的关键。
如需进一步了解数据科学家的工作生活,请参阅“数据科学家做什么? 其中 7 位炙手可热的专业人士提供了他们的见解。”
数据科学家要求
每个行业都有自己的数据配置文件供数据科学家分析。 根据美国劳工统计局的说法,以下是一些常见的数据分析形式,科学家可能会在各行各业进行这些分析。
- 业务:业务数据的数据分析可以为效率、库存、生产错误、客户忠诚度等方面的决策提供信息。
- 电子商务:现在网站收集的不仅仅是购买数据,数据科学家帮助电子商务企业改善客户服务、发现趋势以及开发服务或产品。
- 财务:关于账户、信用和借记交易的数据以及类似的财务数据对于正常运作的业务至关重要。 但对于金融行业的数据科学家来说,安全和合规性,包括欺诈检测,也是主要关注的问题。
- 政府:大数据帮助政府制定决策、支持选民并监控整体满意度。 与金融部门一样,安全性和合规性是数据科学家最关心的问题。
- 科学:得益于最近的 IT 进步,当今的科学家可以更好地收集、共享和分析实验数据。 数据科学家可以帮助完成这个过程。
- 社交网络:社交网络数据可以为有针对性的广告提供信息,提高客户满意度,建立位置数据趋势,并增强功能和服务。
- 医疗保健:电子病历需要致力于大数据、安全性和合规性。 在这里,数据科学家可以帮助改善医疗服务并发现可能被忽视的趋势。
数据科学家技能
根据 Quora 数据科学经理 William Chen 的说法,数据科学家的前五项技能包括硬技能和软技能的组合:
- 编程:Chen 说,编程是“数据科学家最基本的技能”,它可以提高您的统计技能,帮助您“分析大型数据集”,并让您能够创建自己的工具。
- 定量分析:定量分析可提高您运行实验分析、扩展数据策略并帮助您实施机器学习的能力。
- 产品直觉:了解产品将帮助您进行定量分析并更好地预测系统行为、建立指标并提高调试技能。
- 沟通:可能是每个行业最重要的软技能,强大的沟通技巧将帮助你“利用所有列出的先前技能,”陈说。
- 团队合作:就像沟通一样,团队合作对于成功的数据科学事业至关重要。 Chen 说,这需要无私、接受反馈并与您的团队分享知识。
Intelligent World 首席执行官 Ronald Van Loon 将商业头脑添加到列表中。 Van Loon 说,强大的商业头脑是引导数据科学家技术技能的最佳方式。 有必要辨别组织发展需要解决的问题和潜在挑战。
要更深入地了解如何成为一名出色的数据科学家,请参阅“精英数据科学家的基本技能和特质”。
数据科学家教育和培训
有很多方法可以成为数据科学家,但最传统的途径是获得学士学位。 根据美国劳工统计局的数据,大多数数据科学家都拥有硕士学位或更高学位,但并不是每个数据科学家都拥有,而且还有其他方法可以培养数据科学技能。 在进入高等教育项目之前,您需要了解自己将从事的行业,以确定最重要的技能、工具和软件。
因为数据科学需要一些业务领域的专业知识,所以角色因行业而异,如果你在高科技行业工作,你可能需要进一步的培训。 例如,如果你在医疗保健、政府或科学领域工作,你需要的技能与在市场营销、商业或教育领域工作不同。
如果您想培养某些技能以满足特定行业的需求,可以使用在线课程、训练营和专业发展课程来帮助磨练您的技能。 对于那些考虑读研究生的人,有许多高质量的数据科学硕士课程,包括:
- 统计学理学硕士:斯坦福大学数据科学
- 信息与数据科学硕士:伯克利信息学院
- 计算数据科学硕士:卡内基梅隆大学
- 数据科学理学硕士:哈佛大学约翰·A·保尔森工程与应用科学学院
- 数据科学理学硕士:华盛顿大学
- 数据科学理学硕士:约翰霍普金斯大学怀廷工程学院
- 分析学硕士:芝加哥大学格雷厄姆学院
数据科学认证
除了新手训练营和专业发展课程,还有很多有价值的大数据认证和数据科学认证可以提升你的简历和薪水。
- Certified Analytics Professional (CAP)
- Cloudera Data Platform Generalist Certification
- Data Science Council of America (DASCA) Senior Data Scientist (SDS)
- Data Science Council of America (DASCA) Principal Data Scientist (PDS)
- IBM Data Science Professional Certificate
- Microsoft Certified: Azure AI Fundamentals
- Microsoft Certified: Azure Data Scientist Associate
- Open Certified Data Scientist (Open CDS)
- SAS Certified AI and Machine Learning Professional
- SAS Certified Advanced Analytics Professional using SAS 9
- SAS Certified Data Scientist
- Tensorflow Developer Certificate
其他数据科学工作
数据科学家只是不断扩展的数据科学领域中的一个职位,并不是每家利用数据科学的公司本身都在招聘数据科学家。 根据 PayScale 的数据,以下是一些与
- Analytics manager – $100,099
- Business intelligence analyst – $70,868
- Data analyst – $62,723
- Data architect – $122,882
- Data engineer – $93,145
- Research analyst – $57,615
- Research scientist – $82,957
- Statistician – $77,545
- 64 次浏览
【数据科学家】公民数据科学家的时代已经到来
视频号
微信公众号
知识星球
软件工具使业务分析师能够在没有软件工程师和数据处理专家帮助的情况下生成分析模型和见解。
数据科学家的价值很高,这对 Google、Facebook、Amazon.com 和 Apple 以外的任何企业都构成了挑战。 有幸从大型科技公司挖走他们或从学术界挖来他们的首席信息官们在谈论他们将与他们的数据专家一起产生的所有商业洞察力时,都会自豪地微笑。
IBM 预计到 2020 年对数据科学家的需求将飙升 28%——这个数字可能是保守的。 为了解决人才短缺问题,公司正在构建软件来为公司完成繁重的工作,有效地从未嵌入 IT 的公司员工中培养“公民”数据科学家。
据研究公司 Gartner 称,公民数据科学包括允许用户在统计和分析领域以外的职位上从数据中提取预测性和规范性见解的能力和实践。 Gartner 分析师 Carlie Idoine 在一篇博文中表示,公民数据科学家是“高级用户”,例如没有计算机科学背景但可以执行简单到中等复杂的分析任务的业务分析师,而这些任务以前需要更多的专业知识。 她补充说,业务分析师等高级用户可以帮助缩小当前的技能差距。
Forrester Research 分析师布兰登·珀塞尔 (Brandon Purcell) 表示:“工具、技术、数据和模型的可用性不断提高,这使得洞察力能够传播给那些通常没有能力了解自己的人。”
数据科学为(几乎)所有人民主化
技术总能找到使信息访问民主化的方法。 那么改变了什么? 在大多数企业仍在采用的传统模型中,业务分析师与 IT 人员和数据科学家合作数月,以规划旨在生成预测洞察力的模型,而数据科学家通常从头开始构建模型。
现在,借助 IBM 的 SPSS 和 Alteryx 等工具,公民数据科学家(其中许多人没有或只有很少的编码经验)可以将数据模型拖放到某种软件画布上以获取见解。 Purcell 说,此类工具“使业务线分析师处理数据比在 Excel 中更容易”。
例如,通用汽车公司建立了 Maxis,这是一个分析平台,允许商业用户进行类似谷歌的查询,以获得销售预测和供应链绩效等运营指标的窗口。 专家们一致认为,通用汽车现在可能是一个异类,但很快就会有很多公司加入。
数据科学是石油巨头壳牌的一个关键重点,员工通过公司的 PB 数据来生成运营和业务洞察力。 壳牌数据科学卓越中心总经理 Daniel Jeavons 说,多亏了自助服务软件,以前可能无法利用分析的员工现在可以在没有技术帮助的情况下做到这一点。 例如,壳牌使用 Alteryx 的自助服务软件来帮助运行预测模型,预测数以千计的石油钻井机械零件何时可能发生故障。
“数据科学工具正在使低端数据科学大众化,因此或多或少任何人都可以做到,”Jeavons 说。 但另一方面,Shell 使用“强大的引擎”,例如 Google TensorFlow 和深度学习库 MXNet,以及 Python 和 R 编程语言。 “总会有一个跨越公民数据科学家和专业数据科学家的范围,我们必须支持两者。”
相反,公民数据科学家确实弥合了业务用户进行的自助式分析与归因于数据科学家的高级分析之间的差距。 Forrester 的 Purcell 表示,专业数据科学家在整个企业中构建和扩展数据模型和算法。
道明银行集团企业信息高级副总裁乔·多桑托斯 (Joe DosSantos) 说,由于现在广为接受的格言是数据是新石油,许多企业已经“被复杂分析的魅力所吸引”。 事实上,数据科学不再是关于巫师和神话中的独角兽。
DosSantos 说,TD Bank 使用范围广泛的基本到复杂的分析工具来更好地调整历史和当前客户数据,以及进行欺诈分析。 例如,该银行使用 AtScale 的软件来帮助业务用户从银行的 Hadoop 数据湖中查询实时数据并快速获得结果。 TD Bank 分析师在 Tableau 的自助可视化软件中查看数据。
数据科学家:仍然需要
其他软件供应商正在加速数据民主化趋势,通常采用机器学习 (ML) 和人工智能 (AI) 功能来构建自动化模型。
例如,Salesforce.com 提供 Einstein Prediction Builder,它允许业务分析师创建自定义 AI 模型,在任何自定义 Salesforce 字段或对象上添加变量以预测结果,例如客户流失的可能性或帐户的生命周期价值。 Adobe 的 Sensei 是另一种 ML 软件工具,可帮助营销人员在几分钟内启动营销活动,从而将任务缩短数小时。
Gartner 表示,到 2020 年,超过 40% 的数据科学任务可能会实现自动化。 “这种 [自动化 ML 方法] 是下一代数据科学,”Purcell 说。
当然,并非所有大数据挑战都能由公民数据科学家轻松解决。 公司仍然需要统计学家、数据科学家、精算师和其他精通高等数学技术的专家,德勤咨询公司认知和分析实践董事总经理比尔·罗伯茨 (Bill Roberts) 表示。 这些专家可以填补数据中的空白和缺失领域,而公民数据科学家不适合完成这些任务。
此外,罗伯茨指出,如果自助服务工具能够正常工作,可以很好地为企业服务,但如果不能正常工作怎么办? 如果出现问题并且数学不正确怎么办? 可能是算法本身有问题。 罗伯茨说:“当遇到困难或问题时,你需要受过一些培训或拥有更高学位的人来解决这个问题。”
- 69 次浏览
【数据科学家】应对数据科学家严重短缺的 6 种方法
视频号
微信公众号
知识星球
组织不应等待招聘广告空缺,而应重新思考、重新培训、重组并伸出援手,以填补数据科学人才缺口。
随着组织寻找能够从他们收集的所有信息中收集见解的专业人员,对数据科学家的看似永无止境的需求持续增长。
在 2019 年 1 月发布的一份报告中,商业和就业社交媒体网站 LinkedIn 根据薪资、职位空缺数量和同比增长等数据,将数据科学家列为 2019 年最有前途的工作。
根据该报告,今年预计将有 4,000 多个数据科学家职位空缺,比 2018 年增长 56%。数据科学类别中的顶级技能包括数据挖掘、数据分析和机器学习。
问题是,由于人才短缺,公司往往不能足够快地填补这些职位。 然而,这并不意味着他们无法获得数据科学家通常拥有的技能类型。 这可能需要一些创造性思维和毅力,但组织可以通过各种方式应对数据科学家的严重短缺。 这里有一些建议。
1. 寻找正在考虑转行的人
随着数据科学如今受到的所有关注,技术专业人士——甚至是非技术人员——可能会考虑进入该领域。
技术咨询公司 SPR 的企业架构执行副总裁 Pat Ryan 说:“我们从训练营中寻找能够改变职业的人。” “这些人有职业道德和自信,可以从他们熟悉的职业转向全新的领域。”
SPR 尽早让人们从工程等职业中走出来,并指导和培训他们掌握所需的数据科学技能。 瑞安说,与直接雇佣数据科学家相比,“这是一项长期得多的投资”。 “但我们的经验是,具有这种独特背景的人除了技术技能外,还具有人际交往能力和情境技能,而我们也很难找到这些。”
SPR 还希望聘用具有正式数据分析学术背景并具有工作经验的人员。 “这些人具有理解数学所需的学术背景,并有能力进行一些必要的开发,”瑞安说。
2.重新培训现有员工
在紧张的劳动力市场中招聘新技术工人可能很困难。 因此,组织正在转向他们自己的技术员工群来寻找潜在的数据科学家。 通过培训计划和卓越中心的使用,公司可以增加具有数据科学技能的内部员工的数量。
“我们希望在内部培训我们的数据工程师,他们了解如何设计数据解决方案,包括如何应用机器学习算法,以及额外的必要数学和统计知识,”Ryan 说。 “通过这种方式,他们可以理解 R 平方或混淆矩阵在告诉他们什么。”
安永咨询公司安永美洲咨询和金融服务办公室创新负责人罗杰帕克表示,许多组织面临的挑战是缩小专业知识和经验之间的差距。 该公司对所有员工进行数据科学方面的培训,而不仅仅是该领域的员工。
“我们激励我们的员工积极参与并完成新的培训,”Park 说。 “例如,我们有一个名为 EY Badges 的项目,该项目允许人们通过获得数字证书来投资自己的职业生涯,这些证书可以使他们在市场上脱颖而出,例如数据可视化、人工智能、数据转换和信息战略。”
Park 说,通过激励人们获得新徽章并提供强大的课程,该公司正在让培训变得更轻松、更有趣。
安永用来帮助激励人们学习新技能的另一种策略是游戏化。 “当新技术出现时,我们还不知道在哪里使用它,我们会开发基于奖励的挑战——想想黑客马拉松——让我们的员工想出有趣的用途和应用程序,”Park 说。 “我们利用人们尝试新产品或工具的愿望,建立新的方法将这些新技术和技能带入我们的日常工作中”
3. 利用导师制并建立卓越中心
许多组织内部已经拥有大量数据科学家,他们可以帮助与有抱负的数据科学家以及已经在该领域工作的人分享知识。 通过指导,经验丰富的专业人士可以向新员工传授有关企业内部运作的知识。
“一种策略是让新人才与了解业务的导师合作,”Park 说。 “每个优秀的数据科学部门都需要三样东西:知道如何编写算法的人、知道如何对这些算法进行编程的人以及具有商业头脑的人。”
Park 说,学术界无法教人们如何将业务部门与数据科学结合起来。 这就是在组织内创建卓越分析中心可以提供帮助的地方,因为它们将志同道合的个人聚集在一起,他们继续相互挑战并尽其所能地使用技能。
通过这些中心,“数据科学家可以嵌入到整个组织中,并可以就其领域之外的项目进行咨询,”Park 说。
4. 依靠技术
谁说只有数据科学家才能利用信息来增加商业价值? 一些公司发现组织中几乎任何人都可以承担数据科学家所扮演的某些角色——至少在某种程度上是这样。
电子商务零售商 Zulily 解决数据科学人才短缺的一种方法是将公司的数据“民主化”到其整个员工群,使数据科学家能够专注于更具战略性的业务挑战和机遇。
“在我们的世界中,我们每天个性化和发布数百万个版本的网站,我们业务的方方面面都归结为我们如何处理、分析和从数据中学习,”技术副总裁 Bindu Thota 说。
Thota 说,无论数据是来自新获得的客户对营销计划的反应,还是为每个购物者提供个性化的最相关的策划销售活动,都是如此。
该公司创建了专有工具,允许其在销售、营销、运营和其他领域的员工访问仪表板和每日报告,从而能够根据业务的任何活动进行自主决策。
商业和技术咨询公司 West Monroe Partners 的高级架构师 Jeremy Wortz 说:“组织中有些人的能力和技能不为人知,领导层帮助员工实践和发展这些才能至关重要。”
“几乎每个组织都有数据科学爱好者,”Wortz 说。 “关键是要有一个展示这些本土技能并评估潜在人才的场所。 “培养自己的人才”一词意味着对您的员工产生兴趣,以发现看不见的人才——直到这些“未知数”成为高技能的科学家和工程师。”
Wortz 说,机器学习自动化技术通过降低构建算法等任务的复杂性,使这变得更加可行。
Monroe Partners 在内部发现了新的数据科学家,并帮助客户这样做。 Wortz 说:“我们帮助一家银行举办了全公司范围的机器学习挑战赛——黑客马拉松——在该挑战赛中,有一些在银行分行工作的初级人员能够确定解决方案。”
5.与高等教育合作
Wortz 说,学院和大学的数据科学项目有所增加,这些项目直到大约八年前才出现。 在可行的情况下,组织应与这些机构建立工作关系。
“虽然这些项目仍在开发中,但它们已经显示出早期的、有希望的迹象,”Wortz 说。 “我们知道这一点,因为我们看到技能在涌入的初级人才中显现出来。”
Monroe Partners 与大学的系主任和兼职教授建立了关系,他们发现并向公司推荐有前途的初级人才。
公司应该与这些机构结成联盟,并制定强有力的校园招聘战略,毕马威咨询公司数据、分析和人工智能领域的美国负责人 Brad Fisher 补充道,该公司拥有一个数据科学家部门。
Fisher 说:“我们的招聘引擎会持续运行一年,招聘人员和招聘经理之间每周都会有接触点。” 该公司与许多机构的分析项目建立了合作伙伴关系。
6. 利用社区和多样性
候选人库越大,找到人才的机会就越大。 一些公司正在探索如何接触更广泛的社区,让人们对数据科学和相关主题感兴趣。
“重要的是培养下一代数据科学家,并创造机会在社区内各个不同层次的教育领域探索该领域,”Thota 说。 “我们引进了来自不同经济背景的女高中生,帮助她们了解数据科学、机器学习和大数据,以便实时构建应用程序。”
Zulily 邀请分析师和数据科学家团队到其位于西雅图的总部,并参与营销分析和数据科学会议等社区,以分享其经验并与其他组织合作。
“与我们处理客户体验的方法类似,我们试图创造独特的方式来引起人们对我们利用数据科学构建的技术的兴趣,”Thota 说。 2019 年 6 月,该公司将与其合作伙伴美国职业足球大联盟球队 Sounders FC 举办一场黑客马拉松,以利用体育数据解决技术挑战。
尽管科技行业拥有大量数据科学家,但 Zulily 在寻找人才时并不局限于该领域。 “在我看来,技术领导层可能犯的最大错误之一就是严格只从技术部门招聘,”该公司首席信息官 Luke Friang 说。 强大的计算机科学工程知识是关键,以及
扎实的数学基础。
“但伟大的人才可以来自许多行业,无论是学术界、医疗保健还是非营利部门,”Friang 说。 “这些行业通常鼓励我们在 Zulily 寻找的特征:发明家、创造性的问题解决者、想要拥有某样东西并让它变得更好的人。”
- 55 次浏览
【数据科学家】数据科学家做什么的? 这些有需求的专业人士中有 7 位提供了他们的见解
视频号
微信公众号
知识星球
我们采访了一些担任此职位的罕见独角兽,以了解这份工作以及让他们到达那里的技能和教育。
认识数据科学家
当我们中的许多人还在上大学时,数据科学家的角色并不存在。 它是分析数据的科学和统计方法的混合体,结合了解如何使用从海量数据库中提取模式和答案的工具。 听起来沉闷? 没那么多。 事实上,早在 2012 年,《哈佛商业评论》就将其称为“21 世纪最性感的工作”。
所以,自然地,每个人都想要一个。 但更重要的是,现在我们已深入信息时代,每个企业——无论最终产品或客户——都需要一个。
据 IBM 称,世界上大部分数据是在过去两年内创建的。 而且我们创造它的速度比以往任何时候都快:作为一个整体,我们每天生成 2.5 quintillion 字节的数据。 但是如果没有一种引导和探测它的方法,一个人更有可能被它淹没,而不是用它来做出明智的商业决策。 一个数据科学家——或他们的团队——知道如何理解那堵噪音墙,帮助公司响应客户需求和投诉,控制开支和制造,了解趋势如何影响利润,以及你可以从中挖掘的所有其他东西 前所未有的数据洪流。
问题是? 数据科学家——如果你在街上听到这个词——和独角兽一样稀有。
好吧,我们找到了一些。 而且,一旦我们将他们逼入绝境,我们就会向这些专业的回答者提出问题。 我们学到了东西。 也就是说,物理学——甚至天体物理学——在这里被使用,工作很混乱,即使是制鞋商也有大量数据,即使你对大量数据提出大问题,仍然需要有人来决定做什么。
继续阅读以认识其中一些性感的独角兽。
Meggie von Haartman
梅吉·冯·哈特曼 (Meggie von Haartman) 在这个头衔出现之前就一直是一名执业数据科学家。 她拥有工业工程博士学位,专攻优化和运筹学,在担任目前的职位之前,她在硅谷的一家初创公司工作了太多时间,在那里她愉快地构建数据模型以帮助 Efinancial 实现其营销目标。 “在某个时候重塑品牌是有意义的,”她谈到自己的头衔时说。
我们这些不是数据科学家的人往往不知道一件事? “数据科学很混乱,”她说。 她的大部分时间都花在打扫卫生上。 “我 20% 的时间花在了实际的数据建模和科学上。 另外 80% 是数据清理和获取。”
不处理数据时,她喜欢自己做一些研究。 “我目前正在研究培养快乐孩子的最佳方法。”
她最近读的书?
每个人都在说谎:大数据、新数据以及互联网可以告诉我们的真实身份塞思·斯蒂芬斯-戴维多维茨 (Seth Stephens-Davidowitz)
在她的杯子里?
比利时特拉普啤酒。 “我最喜欢的是奇美,”她说。 “为了喝啤酒,我去过奇梅小镇两次,后者是从巴黎绕行三个小时的路线。”
安东尼罗斯
从 Anthony Rose 的角度来看,为粒子物理学处理数据与在机场叫优步所面临的数据挑战并没有太大区别。
在优步,他管理着一个数据科学家团队,专注于改善机场、大型活动和郊区等具有挑战性的地方的乘车体验。 他们与工程和产品团队密切合作,处理从统计分析、数据可视化、实验、机器学习和建模在内的一切事情。“我们拥有大量数据,”他说。 “如果有足够的时间,我们可以提出大量有趣的问题。”
这与他为获得粒子物理学博士学位所做的工作没有什么不同。 他在欧洲核子研究中心 (CERN) 的大型强子对撞机进行博士后研究,致力于希格斯粒子的发现、寻找新物理学以及其他涉及大量数据和复杂答案的巨大问题。 “这种工作很好地映射到我在工业界所做的事情,”他说。 “具有隐藏信号、实验设计以及大量统计数据和编码的大数据集。”
Danielle Dean
对于丹妮尔·迪恩 (Danielle Dean) 而言,数据科学始于心理学。 “我攻读了博士学位。 在定量心理学中,因为我对如何使用数学和统计学来大规模研究个人行为很感兴趣。”
这听起来很像我们现在所说的数据科学。 “我学会了如何思考数据测量、分析和可视化,并使用技术——编程语言和工具——来实现它,”她说。 这非常适合她在微软人工智能和研究小组的工作,在那里她领导着一个跨学科团队——有来自物理学、海洋学、计算机科学、统计学和神经科学的代表——数据科学家和工程师构建预测分析 和机器学习解决方案。
“这是一个有趣的角色,因为我既可以与客户一起构建自定义分析解决方案,也可以与产品团队合作以确保产品随着时间的推移得到改进,以便我们可以继续解决更大的问题。”
布拉德莫加特
Morgart 在 Booz Allen 的团队分析不动产和基础设施投资组合,以帮助客户确定资金需求并告知他们的决策。 “基础设施和房地产资产的维护成本非常高,”他说。 “我们的团队使用数据分析来支持我们的客户进行高效的资产管理。”
Morgart 长期以来一直在做这种数据分析。 但在过去一年左右的时间里,他的客户越来越希望利用许多大型数据集来做出决策——通常需要快速的周转时间。 这促使他和他的团队超越了 Microsoft Excel 和 Access to SQL、Python 和 R 等传统工具。
“受到这种需求的刺激,”他说。 “我抓住了这个机会,接受了 Booz Allen 提供的额外培训,成为了一名数据科学家。” 该公司长期以来一直致力于培养一流的数据科学团队,最近推出了帮助分析师向数据科学家转型的基础课程。
他最大的工作挑战是解释客户请求,因此他的团队可以提供有意义的分析。 “您可以使用高级分析工具快速处理和分析大量数据,但您仍然需要了解客户的使命和目标。 分析是我们工作的很大一部分。 但它最终是一种为我们的决策提供信息的工具。”
丽莎伯顿
丽莎·伯顿 (Lisa Burton) 为处于早期阶段、女性领导的媒体和科技初创公司管理温室。 “我们的团队寻找并投资于公司。”
她的博士学位是机械工程,专注于数据驱动的数学建模,这是迈向数据科学的自然步骤。 “当我毕业时,”她说,“数据科学才刚刚开始蓬勃发展。 但当我了解到公司希望从数据科学家那里得到什么时,我很快意识到这就是我喜欢我的研究的一切。”
因此,刚从研究生院毕业,她就成为了奥斯汀一家广告技术初创公司的第一位数据科学家。 她喜欢它。 她使用数据来优化付费搜索广告的出价,以自动化和改进流程。 从那里,她去了一家移动支付初创公司,然后作为一名独立的初创公司数据科学顾问独立出来。 在那里,她遇到了一位客户,这位客户最终成为了她在一家使用社交媒体数据帮助品牌了解客户的公司的联合创始人。
她将所有这些经验带到了她目前的角色中。 “我们遇到了最不可思议的创始人和公司,”她说。 但她在第一份工作中学到的一件事影响了此后的一切:我了解到能够向广大受众传播数据科学并让他们兴奋并接受是非常重要的。 这适用于我从那以后所做的一切。”
尼廷马延德
Mayande 一直对网络及其运作方式着迷。 但在他获得电子和电信学位后,他想学习天体物理学。 在申请研究生院时,他曾在印度的一家工程公司工作。 “我注意到我一直想实施最好的技术解决方案,但管理层总是选择技术上较差但花费更少时间的解决方案。” 这让他对决策科学产生了兴趣,并改变了路线。 他没有攻读天体物理学,而是攻读了工程管理博士学位。 “我挖掘得越深,就越意识到——无论网络的类型是什么——工程、天体物理学或管理——解决方案都是关于它的结构。 这最终让我成为了一名数据科学家。”
如今,Nitin 创建了支持 Nike 重大产品规划决策的预测。
他还想纠正对数据科学家的误解。 “人们认为我们把所有的时间都花在了构建复杂的算法上。 但我们的大部分时间都花在了清理数据以使其成为可用格式上。” 一旦一切正常,分析就会立即发生。 “但要达到这一点需要大量的细节工作和解决问题。”
叶钊
作为一名在 Spotify 的新自助广告平台 Ad Studio 工作的数据科学家,Ye 寻找见解来帮助音乐公司做出产品决策。 这本质上是流媒体音乐公司的营销工作。 但叶一开始是一名物理学家。
她一直对物理感兴趣,在学术界做物理研究,甚至有一颗以她名字命名的小行星来证明。 她是怎么进入 Spotify 的? “我觉得数据科学采用了物理学的严谨和技术部分,并将其应用于一个引人入胜的话题:人类行为,”她说。
她将寻找小行星的物理学家所具备的所有令人讨厌、喜爱泰迪熊的创客精神带到了她在音乐公司的工作中。 “我们在一个由 2000 个 LED 组成的定制 LED 阵列上进行了物理数据可视化,以可视化美国 Spotify 上的流媒体数据。 这是硬件、后端和数据工作的良好结合。 我们在黑客周期间做到了。”
- 44 次浏览
【数据科学家】数据科学家职位描述:吸引顶尖人才的技巧
视频号
微信公众号
知识星球
寻找优秀的数据科学人才始于杀手级的职位描述。 这是正确的方法。
寻找优秀的数据科学人才始于有效的职位描述。 但要恰到好处地发布职位,组织必须了解他们所针对的人才市场和角色。
人工智能和深度学习公司 Skymind 的联合创始人兼首席执行官、开源框架 Deeplearning4j 的联合创始人 Chris Nicholson 表示,在当今的数据科学就业市场,需求远远超过供应。 他说,这意味着组织必须抵制诱惑,不去寻找具备所有最后必需的数据科学技能的候选人,而倾向于招聘有潜力的人,然后在工作中进行培训。
“很多数据科学都与统计、数学和实验有关——所以你不一定要找有计算机科学或软件工程背景的人,尽管他们应该有一些编程经验,”Nicholson 说。 “你需要来自物理科学、数学、物理学、自然科学背景的人; 受过训练来思考统计思想和使用计算工具的人。 他们需要有能力查看数据并使用工具来操纵它,探索相关性并生成进行预测的数据模型。”
Nicholson 说,因为数据科学家的工作不是设计整个系统,所以最少的编程经验就可以了。 毕竟,大多数组织可以依靠软件工程、DevOps 或 IT 团队来构建、管理和维护基础设施以支持数据科学工作。 相反,强大的数据科学候选人通常具有科学背景,并且应该精通一种或多种不同堆栈中的数据科学工具。
以下是如何制作合适的数据科学职位发布——并吸引人才。
一般最佳实践
Triplebyte 的首席数据官兼联合创始人 Ammon Bartram 说,在起草任何职位描述时,你主要是在推销你的组织和职位。 目标是传达为什么该角色是一个令人兴奋的机会,而不是只关注技能和责任。 Bartram 说,许多寻求数据科学家的组织都犯了这个错误,这让他们立即处于劣势。
“招聘人员经常写这样的话,‘必须拥有技术学位,三年的经验,并且对 Apache Hadoop 有深入的了解。’这是一个错误,即使你真的想要具有这些属性的人,”Bartram 说。 “对于像数据科学这样的高技能职位,目标是让可能持观望态度的求职者相信你的公司和你的职位很有趣,值得他们花时间。”
这一点尤其重要,不仅因为市场如此火爆,还因为,Nicholson 说,“许多必要的技能是行业和公司特有的。 组织使用不同的语言,更喜欢某些供应商的技术栈和特定的专有工具,所以这取决于招聘团队来了解哪些。”
Bartram 说,相反,应关注公司的使命、该职位将完成的工作,以及应聘者将要解决的令人兴奋的问题的任何技术细节。 “特别是对于数据科学,写下候选人将可以访问的有趣数据集会很有用——数据科学候选人喜欢在很酷的数据集上钻研,”他说。
通过以这种方式开始你的工作描述,你将更容易吸引候选人,然后你可以继续学习该角色所需的更难的技术技能。
需要特定技能
具体的语言和工具因公司而异,但最重要的是熟练掌握统计数据,其次是一些编程经验,以及对数据系统的熟悉程度,Bartram 说。 在这里,重要的是在必要时具体说明。
“除了基本技能外,公司可能还需要机器学习知识——了解特定的机器学习模型,以及与之合作的常用工具。 Tensorflow 和 scikit-learn 是两个最常用的 ML 库,”Bartram 说。 “公司可能需要在他们使用的任何特定编程语言方面的经验,如 Python、Java、R 等。公司可能希望熟悉他们使用的特定数据系统,如 PostgreSQL、MongoDB、Airflow、Hadoop、Redshift。”
Nicholson 将 Matlab 添加到基础知识列表中,Matlab 是一种数值计算环境和 Mathworks 的专有编程语言。
Nicholson 说:“这些是大多数自然科学专业人士和统计学家都熟悉的工具,因此你可以很好地了解候选人是否能够‘正确’地思考这些问题。” “如果他们从事机器学习——Python 以及 Canvas、Keras 和 Tensorflow 等 Python 工具已成为该领域的首选语言。 不过,如果他们有其中之一但没有另一个,那也不是交易破坏者。 更重要的是他们熟练掌握一种工具,因为这表明他们可以快速掌握新工具。”
销售参与平台公司 Outreach 的数据科学副总裁帕维尔·德米特里耶夫 (Pavel Dmitriev) 在招聘时使用了更广泛的清单,并补充说,要想在 Outreach 取得成功,求职者应该具备所有这些方面的工作知识,但至少要精通其中的几项。
“其中一些是特定领域的; 对我们来说,自然语言对我们的业务非常重要,但在其他公司中可能有所不同,”Dimitriev 说。 “但是,总的来说,我们寻找编码和算法方面的技能; 数据操作; 大数据管理; 机器学习; 自然语言处理; 商业理解; 如何将问题形式化并将其转化为数学问题; 和沟通技巧。”
软技能
Bartram 说,由于数据科学家必须与广泛的同事合作,软技能是必不可少的,在任何职位描述中都不应该被忽视。 沟通、团队合作、协作以及热情和使命对任何数据科学候选人都至关重要。
“软技能很重要,”巴特拉姆说。 “作为一名数据科学家需要与同事沟通并在团队中工作。 这里影响求职者是否收到录取通知书的主要两项技能是他们的沟通能力,以及他们对公司所做工作的热情。”
请务必不仅包括您喜欢的角色软技能,还要简要说明数据科学如何适合您的组织——这样候选人将更好地了解这些软技能将如何在角色中发挥作用。
现在您已经掌握了所有的部分,您可以将一份出色的数据科学职位描述放在一起,这肯定会吸引到优秀的候选人。
- 71 次浏览
【数据科学家】精英数据科学家的基本技能和特质
视频号
微信公众号
知识星球
如今,数据科学家为王。 但从数据中提取真正的商业价值需要技术技能、数学知识、讲故事和直觉的独特结合。
数据科学家的需求量仍然很大,几乎每个行业的公司都希望从其新兴的信息资源中获得最大价值。
“随着组织开始充分利用其内部数据资产并检查数百个第三方数据源的集成,数据科学家的作用将继续扩大相关性,”咨询公司主管 Greg Boyd 说 甫瀚。
“在过去,负责数据的团队被下放到 IT 组织的后台,执行关键的数据库任务,以保持各种公司系统被提供数据‘燃料’,[这] 允许公司高管报告运营情况 活动并交付财务成果,”博伊德说。
这个角色很重要,但业务的后起之秀是那些精明的数据科学家,他们不仅能够使用复杂的统计和可视化技术处理大量数据,而且拥有敏锐的洞察力,他们可以从中获得前瞻性的见解 ,博伊德说。 这些见解有助于预测潜在结果并减轻对业务的潜在威胁。
那么,怎样才能成为数据科学高手呢? 根据 IT 领导者、行业分析师、数据科学家和其他人的说法,这里有一些重要的属性和技能。
批判性思维
数据科学家需要成为批判性思考者,能够在形成观点或做出判断之前对给定主题或问题的事实进行客观分析。
“他们需要了解业务问题或正在制定的决策,并能够‘建模’或‘抽象’对解决问题至关重要的内容,而不是无关紧要且可以忽略的内容,”全球人工智能和创新部门的 Anand Rao 说 咨询公司 PwC 的数据和分析主管。 “这项技能比其他任何东西都更能决定数据科学家的成功,”Rao 说。
Zeta Global 的首席信息官 Jeffry Nimeroff 补充说,数据科学家需要有经验,但也需要有能力保持信念。Zeta Global 提供基于云的营销平台。
“这种特质抓住了这样一种想法,即知道在任何领域工作时会发生什么,但也知道经验和直觉是不完美的,”Nimeroff 说。 “经验会带来好处,但如果我们过于自满,也并非没有风险。 这就是信念的悬念很重要的地方。”
Nimeroff 说,这不是用新手的大眼睛来看待事物,而是退后一步,能够从多个角度评估问题或情况。
编码
一流的数据科学家知道如何编写代码,并且能够轻松处理各种编程任务。
“数据科学的首选语言正在转向 Python,R 也有大量追随者,”Rao 说。 此外,还有许多其他语言在使用,例如 Scala、Clojure、Java 和 Octave。
“作为一名真正成功的数据科学家,编程技能需要包括计算方面——处理大量数据、处理实时数据、云计算、非结构化数据,以及统计方面——[和]工作 使用回归、优化、聚类、决策树、随机森林等统计模型,”Rao 说。
安全软件公司 McAfee 的首席数据科学家 Celeste Fralick 说,从 1990 年代后期开始的大数据的影响要求越来越多的数据科学家了解并能够使用 Python、C++ 或 Java 等语言进行编码。
如果数据科学家不懂如何编码,那么周围都是懂的人会很有帮助。 “将开发人员与数据科学家合作可以证明是非常富有成果的,”Fralick 说。
数学
对于不喜欢或不精通数学的人来说,数据科学可能不是一个好的职业选择。
“在我们与全球组织的合作中,我们与寻求开发复杂财务或运营模型的客户接洽,”博伊德说。 “为了使这些模型具有统计相关性,需要大量数据。 数据科学家的作用是利用他们在数学方面的深厚专业知识来开发可用于制定或转变关键业务战略的统计模型。”
数据科学家天才是擅长数学和统计学的人,同时能够与业务线高管密切合作,以提供再保证的方式传达复杂方程式“黑匣子”中实际发生的事情 博伊德说,企业可以信任结果和建议。
机器学习、深度学习、人工智能
Fralick 说,由于计算能力、连接性和收集的大量数据的增加,这些领域的行业发展非常迅速。 “数据科学家需要在研究中走在前沿,并了解何时应用何种技术,”她说。 “很多时候,数据科学家会应用一些‘性感’的新事物,而他们要解决的实际问题并不那么复杂。”
Fralick 说,数据科学家需要对要解决的问题有深刻的理解,而数据本身会说明需要什么。 “了解生态系统的计算成本、可解释性、延迟、带宽和其他系统边界条件——以及客户的成熟度——本身有助于数据科学家了解应用什么技术,”她说。 只要他们了解技术,情况就是如此。
同样有价值的是统计技能。 大多数雇主不考虑这些技能,Fralick 说,因为今天的自动化工具和开源软件很容易获得。 “然而,理解统计数据是理解这些工具和软件所做假设的关键能力,”她说。
数据存储提供商 Micron Technology 的首席信息官 Trevor Schulze 表示,仅了解机器学习算法的功能接口是不够的。 “要为工作选择合适的算法,成功的数据科学家需要了解方法中的统计数据和适当的数据准备技术,以最大限度地提高任何模型的整体性能,”他说。
舒尔茨说,计算机科学技能也很重要。 因为数据科学主要是在键盘上完成的,所以软件工程的扎实基础会很有帮助。
沟通
沟通技巧的重要性值得重复。 当今的技术几乎没有任何事情是在真空中进行的。 系统、应用程序、数据和人之间总是存在一些集成。 数据科学也不例外,能够使用数据与多个利益相关者进行交流是一个关键属性。
“通过数据‘讲故事’的能力将数学结果转化为可操作的洞察力或干预措施,”Rao 说。 “处于业务、技术和数据的交叉点,数据科学家需要善于向每个利益相关者讲述一个故事。”
这包括向业务主管传达数据的商业利益; 关于技术和计算资源; 关于数据质量、隐私和机密性方面的挑战; 以及组织感兴趣的其他领域。
Nimeroff 说,成为一名优秀的沟通者包括将具有挑战性的技术信息提炼成完整、准确且易于呈现的形式的能力。 “数据科学家必须记住,他们的执行产生的结果可以而且将会用于支持企业的定向行动,”他说。 “因此,能够确保观众理解并欣赏呈现给他们的一切——包括问题、数据、成功标准和结果——是最重要的。”
Schulze 说,一名优秀的数据科学家必须具备商业头脑和好奇心,才能充分采访业务利益相关者以了解问题并确定哪些数据可能相关。
此外,数据科学家需要能够向商业领袖解释算法。 Schulze 说:“交流算法如何得出预测结果是获得领导者对预测模型作为其业务流程一部分的信任的关键技能。”
数据架构
数据科学家必须了解从开始到建模再到业务决策的数据发生了什么。
“不了解架构会对样本量推断和假设产生严重影响,通常会导致不正确的结果和决策,”Fralick 说。
更糟糕的是,架构内的事情可能会发生变化。 Fralick 说,如果一开始不了解它对模型的影响,数据科学家可能最终会“在模型重做的风暴中或突然不准确的模型中不理解原因”。
Fralick 说,虽然 Hadoop 通过将代码交付给数据而不是相反来支持大数据,但理解数据流或数据管道的复杂性对于确保基于事实的良好决策至关重要。
风险分析、流程改进、系统工程
敏锐的数据科学家需要了解分析业务风险、改进流程以及系统工程工作原理的概念。
Fralick 说:“我从未认识过没有这些”技能的优秀数据科学家。 “他们齐头并进,都在内部专注于数据科学家,但在外部则专注于客户。”
Fralick 说,在内心深处,数据科学家应该记住头衔的后半部分——科学家——并遵循好的科学理论。
在模型开发开始时进行风险分析可以降低风险。 “从表面上看,这些都是数据科学家向客户询问他们试图解决的问题所需要的所有技能,”她说。
Fralick 说,将支出与流程改进联系起来,了解公司固有的风险和其他可能影响数据或模型结果的系统,可以提高客户对数据科学家工作的满意度。
解决问题和良好的商业直觉
Nimeroff 说,一般来说,伟大的数据科学家所表现出的特征与任何优秀的问题解决者所表现出的特征相同。 “他们从多个角度看世界,他们在拿出所有工具之前先了解自己应该做什么,他们以严谨和完整的方式工作,他们可以流畅地解释他们的结果 执行,”尼梅罗夫说。
在评估技术专业人员担任数据科学家等角色时,Nimeroff 会寻找这些特征。 “这种方法产生的成功远多于失败,而且还确保了潜在的优势最大化,因为批判性思维被带到了最前沿。”
寻找一个伟大的数据科学家需要找到一个技能有些矛盾的人:处理数据处理和创建有用模型的智能; 商业软件提供商 Paytronix Systems 的 Paytronix Data Insights 负责人 Lee Barnes 表示,以及对他们试图解决的业务问题、数据的结构和细微差别以及模型如何工作的直观理解。
“第一个最容易找到; 巴恩斯说,大多数拥有良好数学技能并拥有数学、统计学、工程学位或其他科学学科学位的人都可能拥有足够的智力来完成这项工作。 “第二个更难找到。 令人惊讶的是,我们采访的人中有多少人建立了复杂的模型,但当追问他们为什么认为该模型有效或为什么选择他们所采用的方法时,他们却没有一个好的答案。”
这些人很可能能够解释模型的准确性,“但如果不了解它为什么以及如何工作,就很难对他们的模型有足够的信心,”巴恩斯说。 “对自己所做的事情有更深刻理解和直觉的人是真正的数据科学奇才,很可能会在这个领域取得成功。”
- 55 次浏览
【数据科学家】雇用(和留住)数据科学家的专家提示
视频号
微信公众号
知识星球
数据科学人才市场紧张。 为了脱颖而出,IT 领导者建议建立创新的、目标驱动的角色,以确保数据科学家能够在您的组织中茁壮成长。
随着 IT 领导者越来越需要数据科学家从不断增长的海量数据中获得改变游戏规则的洞察力,聘用和留住这些关键数据人员变得越来越重要。
由于没有足够的训练有素的高级数据科学家来填补所有职位空缺,首席信息官正在与人力资源和招聘专家合作,寻找吸引求职者的方法。 一旦他们雇用了他们,诀窍就是让这些备受追捧的员工不会离开去寻找另一份工作——尤其是在竞争对手那里。
“公司正在努力招聘真正的数据科学家,”位于马萨诸塞州剑桥的行业分析公司 Forrester 的副总裁兼首席分析师 Brandon Purcell 说。 “这非常非常具有挑战性,尤其是如果 [这些公司不是] 最大的品牌和知名度的话。 数据科学家拥有将数据转化为洞察力的炼金术。 ......关于如何雇用和留住他们有很多想法。
这在每个行业都是如此,从医疗保健到农业,再到零售、制造、金融等等。
这种技能独特、相对较新的数据专家使用统计数据、机器学习、算法和自然语言处理来收集和分析结构化和非结构化数据,以解决实际业务问题。 作为大数据的争论者,他们可以改善客户体验、推动新产品的发展并找到影响关键业务决策的隐藏模式。
但是对于所有希望利用它们的公司来说,训练有素的——更不用说经验丰富的——数据科学家了。 使这个问题更加复杂的是,吸引和雇用这些 IT 专业人员的斗争绝大多数是由科技和互联网巨头领导的,例如亚马逊、谷歌和 Facebook,它们可以提供令人印象深刻的品牌名称,以及各种各样的项目选择,数量巨大 薪资待遇和股票期权。
根据 Gartner 2021 年的一份研究报告,聘请高级数据科学家“非常困难”,甚至寻找初级数据科学人才也具有挑战性。 2021 年 Forrester 的一份报告也得出了类似的结论,该报告指出,55% 的受访公司希望聘请数据科学家。 该报告还指出,62% 的人需要数据工程师,37% 的人需要机器学习工程师——这两者都是关键的数据科学支持角色。
这些工作能带来丰厚的薪水。 Gartner 报告称,华盛顿特区的一名数据科学家,如果拥有八年或以上的经验,预计年薪为 174,000 美元,而经验不超过两年的则为 110,000 美元。 在旧金山,相应的数字是 192,000 美元和 118,000 美元。
是的,在这个市场上吸引熟练的数据科学家时,提供有竞争力或更好的资金是一个关键因素。 但要吸引数据科学人才,通常需要的不仅仅是这些——正如这些 IT 领导者和行业分析师所证明的那样,它远远超出了办公室乒乓球、周五披萨午餐和免费袋装海藻薯片的范围。
专注于目的
Synchrony 的高级副总裁兼首席信息官 Bess Healy 拥有 7240 万个活跃客户账户和 7 万亿个数据点,她一直在寻求扩大她的数据科学团队。
“与许多其他机构一样,我们的数据量正在大幅增长。 它是提供我们洞察力的燃料,”希利谈到这家总部位于康涅狄格州斯坦福德的消费者金融服务公司时说。 “随着时间的推移,我们的需求将继续增长。 我们必须吸引并留住这些技能组合。 我们知道我们每天都在为他们竞争。 保持领先于我们的竞争对手是我们的一大重点。 我们不觉得落后,但我们非常注重不落后。”
为了找到并留住强大的数据科学家,Synchrony 提供灵活的工作时间、继续教育机会和远程工作选项,例如在家工作或混合家庭/办公室时间表。
对于 Oshkosh 的高级副总裁兼首席信息官 Anupam Khare 来说,他们吸引所需数据科学家和其他数据专家的价值主张是为他们提供鼓舞人心的项目。 这家总部位于威斯康星州的工业公司设计并制造了广泛的产品,包括特种卡车、军用车辆和机场消防设备。
“我们可以赋予他们工作意义。 我们基本上设计和制造有助于我们社区的产品,这很吸引人,”Khare 说。 “我们制造的产品服务于日常英雄——消防员、士兵、环保和垃圾处理工人。 这是一个非常强大和鼓舞人心的使命。 ......你可以看到你已经完成了一个有助于生产的分析模型,这意味着我们的消防员会按时完成任务并 [获得] 更好的产品。 这是真实的东西,你能感觉到。”
首席信息官还指出,豪士科专注于利用数据优化其业务的突破性技术,连续四年荣获著名的 CIO 100 奖,该奖项旨在表彰以创新方式使用 IT 的公司。 他们还获得了 2021 年麻省理工学院斯隆 CIO 领袖奖。 这种创造性和引人入胜的工作的声誉有助于吸引想要从事创造性工作的专业人士。
OshKosh 的数据科学团队还面临着广泛的问题需要解决,致力于解决影响从制造到销售和供应链的方方面面的问题。 这不仅使他们的日常工作多样化; Khare 解释说,它还扩展了团队的技能组合。
“在数字技术团队中,我们拥有非常创新和进步的文化,专注于尝试新事物和学习。 他们开始使用新技术并接触到很酷的技术,”Khare 说。 “在这里,您可以将想法变为现实。”
让创新者创新
位于马萨诸塞州尼达姆的行业分析公司 IDC 智能未来研究总监 Chandana Gopal 表示,为数据科学家提供尖端技术和有趣的项目是吸引和留住他们的关键。
招聘经理和 IT 领导者需要记住,数据科学家是受过高等教育和训练有素的专业人士,通常拥有数学或数据科学博士学位。 他们渴望解决对业务至关重要的难题,并可能对科学、他们的社区或社会产生更广泛的好处。 如果这个问题以前从未解决过,那就更好了。
“如果他们对自己所做的事情感到厌倦,他们就不会留下来,”戈帕尔说。 “你必须确保他们是你生态系统中有价值的一部分,他们不做数据准备,他们正在研究重要的、有趣的问题。 确保将他们与业务方面的人员合作,以便他们能够满足大业务需求。 并为他们提供一个由了解数据的人组成的支持团队。”
公司也不应该做出他们无法兑现或无意兑现的承诺,因为留住数据科学家与最初雇用他们一样困难。
“让他们看到项目完成。 如果你有可以执行低级或重复性任务的软件,请确保你培训人们使用它来减轻你的顶级数据人员的这些工作,”Gopal 说。 “确保他们受到挑战。 确保它们受到重视。 向他们展示高管们致力于使用数据。”
招聘技巧和策略
Synchrony 的 Healy 和 Oshkosh 的 Khare 等 IT 领导者同意签约顶级数据科学人才。 但他们与 IDC 的 Gopal 以及其他 IT 领导者和行业分析师一起,为雇用和留住这些备受追捧的 IT 专业人员提供了以下建议:
- 报价目的。 数据科学家有很多工作选择。 如果他们厌倦了他们正在做的事情,他们就不会留下来。 通过为他们提供尖端项目或通过为他们提供进一步事业的工作来激起他们的好奇心和动力。 特别是,应该让数据科学家觉得自己很重要,因为他们可以给他们提供对公司至关重要的项目。
- 释放他们的影响力。 虽然数据科学家通常可以执行所有数据科学任务,从清理数据到从生产模型中收集见解,但数据科学家在得到团队支持时是最有效的,也是最快乐的。 通过引入数据工程师和机器学习工程师来处理工程工作和数据准备,让数据科学家能够专注于创造性工作。 还值得确定您最有数据素养的员工,并将他们作为您的数据科学团队的主题专家,这样他们就可以支持真正的数据科学家推动根据业务需求量身定制的价值。
- 将他们与业务联系起来。 确保您的数据科学家或数据科学团队不是独自在孤岛上工作。 将他们与业务团队联系起来,以便他们在最重要的问题上进行协作,并持续对业务产生可衡量的影响。
- 构建工具和人才管道。 除了确保您的数据科学家得到数据工程师的支持外,实施智能软件来处理低级和重复性任务,并考虑与大学和学院合作创建训练有素的实习生和应届毕业生的管道,以加强您的数据科学支持 团队。
- 为持续的成功而训练。 与任何 IT 领域一样,数据科学技术和工具的进步也在不断涌现。 通过提供继续教育帮助您的数据科学家保持敏锐,并为现有员工提供他们承担数据分析角色所需的培训,这将帮助您真正的数据科学家。
- 好好补偿。 当然,即便如此,如果您不支付市场价格,您将面临一场艰苦的战斗。 确保你的薪酬与其他公司和你的竞争对手持平或超过。 并确保您的报价包包括有竞争力的津贴,例如远程工作和灵活工作时间的选择。
- 59 次浏览
【知识】DIKW(数据,信息,知识,智慧)金字塔
视频号
微信公众号
知识星球
DIKW金字塔,也被称为DIKW层次结构、智慧层次结构、知识层次结构、信息层次结构和数据金字塔,[1]松散地指一类用于表示数据、信息、知识和智慧之间的结构和/或功能关系的模型[2]。“通常信息是用数据来定义的,知识是用信息来定义的,智慧是用知识来定义的”。[1]
并不是DIKW模型的所有版本都引用所有四个组件(早期版本不包含数据,后期版本省略或淡化了智慧),有些还包含其他组件。DIKW模型除了具有层次结构和金字塔结构外,还被表征为链结构,[3][4]为框架结构,[5]为一系列图形,[6]为连续体

历史
图书馆和信息科学教授丹尼p华莱士(Danny P. Wallace)解释说,DIKW金字塔的起源并不确定:
数据、信息、知识,有时甚至是智慧之间关系的分层表示,多年来一直是信息科学语言的一部分。尽管不确定这些关系是何时、由谁首次提出的,但是层次结构概念的普遍性是通过使用DIKW作为数据到信息、知识到智慧转换的简写形式而体现出来的
数据、信息、知识
1955年,英美经济学家、教育家肯尼斯·博尔丁(Kenneth Boulding)提出了一个由“信号、信息、信息和知识”组成的层次结构的变体。然而,“区分数据、信息和知识并使用‘知识管理’一词的第一作者可能是美国教育家尼古拉斯·l·亨利。
数据,信息,知识,智慧
其他涉及数据层的早期版本(1982年以前)包括美籍华裔地理学家yifu Tuan[11][需要验证][12]和社会学家兼历史学家Daniel Bell的版本。(需要验证)[11]。[12]在1980年,爱尔兰出生的工程师Mike Cooley在他的《建筑师还是蜜蜂?:人/技术的关系。[13][验证需要][12]
此后,在1987年,捷克斯洛伐克出生的教育家米兰·泽莱尼(Milan Zeleny)将等级制度的要素映射到知识形式:一无所知、知道什么、专门知识和为什么知道。[14][需要验证]泽莱尼“经常被认为是提出[将DIKW表示为金字塔]……尽管他实际上没有提到任何这样的图形模型
1988年,美国组织理论家罗素•阿科夫(Russell Ackoff)在国际一般系统研究学会(International Society for General Systems Research)发表的一篇演讲中再次出现了这种等级制度。后来的作者和教科书引用Ackoff的理论作为层次结构的“原始表达”[1],或者把Ackoff的建议归功于它。[16] Ackoff版本的模型包括一个理解层(就像Adler之前的[8][17][18]),它介于知识和智慧之间。虽然Ackoff没有以图形的方式呈现层次结构,但他也被认为是以金字塔的形式呈现的
在Ackoff发表演讲的同一年,信息科学家Anthony Debons和他的同事引入了一个扩展的层次结构,在数据之前有“事件”、“符号”和“规则和公式”层
1994年Nathan Shedroff在一个信息设计上下文中提出了DIKW层次结构,后来作为一本书的章节出现。[20]
詹妮弗·罗利(Jennifer Rowley)在2007年指出,在最近出版的大学教科书《[1]》(最近出版的大学教科书)中,关于DIKW的讨论“很少涉及智慧”,而且在她的研究之后,她自己的定义中也没有包含智慧。与此同时,Zins在最近的研究中对数据、信息和知识概念化的广泛分析并没有对智慧做出明确的评论,虽然Zins所引用的一些文献中确实提到了这个术语.
描述
DIKW模型“在信息管理、信息系统和知识管理文献中,在数据、信息和知识的定义中经常被引用,或被隐含地使用,但对层次结构的直接讨论有限”。[1]对教科书[1]的回顾和对相关领域学者的调查显示,对于模型中使用的定义没有达成共识,更不用说“在描述将层次较低的元素转化为层次较高的元素的过程”了
这使得以色列研究人员查寻表明DIKW data-information-knowledge组件的引用一个类不少于五个模型,作为一个函数的数据,信息和知识都视为一种主观,客观(寻什么术语中,“通用”或“集体”)或两者兼而有之。在津斯的使用中,主观和客观“与任意性和真实性无关,而任意性和真实性往往依附于主观知识和客观知识的概念”。Zins认为,信息科学研究的是数据和信息,而不是知识,因为知识是一种内部(主观)现象,而不是外部(普遍-集体)现象
数据
在DIKW的背景下,数据被看作是表征刺激或信号的符号或符号,[2]直到……可用的(即相关的)形式”。[16] Zeleny将数据不可用的特性描述为“一无所知”[14][需要验证]
在某些情况下,数据不仅指符号,还指所述符号所指的信号或刺激——津斯称之为主观数据。其中,对于Zins来说,通用数据是“观察的产物”[16](原始斜体字),主观数据是观察结果。在用“事实”来定义数据时,这一差别往往是模糊不清的。
数据是事实
罗利在研究了课本中给出的DIKW定义之后,[1]将数据描述为“离散的、客观的事实或观察,这些数据没有组织和处理,因此没有意义或价值,因为缺乏上下文和解释。”在亨利早期的层次结构中,数据被简单地定义为“仅仅是原始事实”。最近的两篇文章分别将数据定义为“关于世界现状的大量事实”和“物质事实”。[8] Cleveland不包含显式数据层,而是将信息定义为“…事实和想法”。[8][11]
只要事实具有一个基本属性,即它们是真实的,具有客观的现实性,或者能够得到验证,这样的定义就可以排除来自DIKW模型的虚假的、无意义的和无意义的数据,从而使垃圾输入、垃圾输出的原则不在DIKW下得到解释。
数据信号
在主观领域,数据被理解为“我们通过感官感知的感官刺激”、[2]或“信号读数”,包括“光、声、嗅、味和触觉的传感器和/或感官读数”。另一些人则认为,津斯所称的主观数据实际上是一个“信号”层(就像抱石的[8][9]),它先于DIKW链中的数据
美国信息科学家格林·哈蒙(Glynn Harmon)将数据定义为“一种或多种能量波或粒子(光、热、声音、力、电磁),由有意识的生物体或智能体根据生物体或智能体中预先存在的框架或推理机制而选择的。
感官刺激的意义也可以被认为是主观数据:
信息是这些感官刺激的意义。,经验知觉)。例如,我听到的噪音是数据。这些噪音(例如,汽车发动机在运转)的意思是信息。然而,对于如何定义这两个概念,还有另一种选择——似乎更好。数据是感官刺激,或它们的意义。,经验知觉)。因此,在上面的例子中,响亮的噪音,以及汽车引擎运行的感知,都是数据。[2](斜体补充道。大胆原创。)
如果以这种方式理解主观数据,那么它将与熟人的知识相媲美,因为它是基于对刺激的直接体验。然而,与伯特兰·罗素等人所描述的熟人知识不同,主观领域“与……真实性无关”
津斯的另一个定义是否成立,将取决于“汽车发动机的运行”是被理解为一个客观事实,还是作为一种语境解释。
数据作为象征
无论DIKW对数据的定义是否包括Zins的主观数据(有无意义),数据始终被定义为包括“符号”、[15][28]或“代表经验刺激或感知的一组符号”、[2]“对象的属性、事件或其环境的属性”。[16]的数据,从这个意义上说,是“记录(捕获或存储)符号”,包括“词(文本和/或口头),数字,图表,和图像(仍然和/或视频),这是沟通的基石”,其目的”是记录活动或情况下,试图捕捉真实情况或真实事件,”,“所有的数据都是历史,除非用于说明目的,如预测。”[24]
Boulding版本的DIKW显式地将信息层消息下面的级别命名为级别,将其与底层信号层区分开来。[8][9] Debons和他的同事颠倒了这种关系,将一个显式的符号层标识为底层数据的几个层之一
Zins认为,对于大多数被调查者来说,数据“被描述为普遍领域的现象”。“显然,”Zins澄清道,“将数据、信息和知识作为一组符号而不是作为意义及其构建块联系起来更有用。
信息
在DIKW环境下,信息符合描述对知识的定义(“信息包含在描述中”[16]),与数据的区别在于信息是“有用的”。“信息由数据推断”,[16]在回答疑问句的过程中(如“谁”、“什么”、“在哪里”、“有多少”、“什么时候”),[15][16]从而使数据对[28]的“决策和/或行动”有用。最近的一篇文章“经典地”指出,“信息被定义为具有意义和目的的数据。
结构与功能
罗利回顾了DIKW在教科书中是如何呈现的,之后,[1]将信息描述为“有组织的或结构化的数据,这些数据的处理方式使这些信息现在与特定的目的或上下文相关,因此是有意义的、有价值的、有用的和相关的。”注意,这个定义与Rowley对Ackoff定义的描述形成了对比,其中“数据和信息之间的区别是结构性的,而不是功能性的。
在他对层次结构的定义中,亨利将信息定义为“改变我们的数据”,[8][10]这是数据和信息之间的功能性区别,而不是结构性区别。与此同时,克利夫兰在他的DIKW版本中并没有提到数据级别,他将信息描述为“某一特定时刻某人可以知道的所有事实和想法的总和”
美国教育家鲍勃·博伊科则更为晦涩,他只把信息定义为“实事求是”
象征性的和主观的
在DIKW模型中,信息可以被理解为:(i)普遍的,作为符号和符号存在的;主观的,符号所附加的意义;或(3)。作为符号和意义的信息的例子包括:
美国信息科学家Anthony Debons将信息描述为“一种意识状态(意识)及其形成的物理表现”,如“信息作为一种现象,既代表一个过程,也代表一个产品;认知/情感状态,以及认知/情感状态的物理对应物
丹麦信息科学家Hanne Albrechtsen将信息描述为“与意义或人类意图相关”,或者是“数据库、web等的内容”。(斜体字补充)或“陈述的意义,因为他们是打算由发言者/作家和理解/误解的听众/读者。
泽莱尼以前将信息描述为“知道什么”,[14][引文需要],但后来改进了这一定义,以区分“拥有或拥有什么”(信息)和“做什么、做什么或执行什么”(智慧)。在信息概念化的基础上,他还补充了“为什么是”,与“为什么做”(智慧的另一个方面)不同。泽莱尼进一步指出,没有明确的知识这种东西,而是知识,一旦明确的符号形式,成为信息.
知识
一般认为,DIKW的知识构成是一个难以界定的概念。知识的DIKW定义与认识论的DIKW定义不同。DIKW的观点是,知识是参照信息来定义的。“[16]定义可以指以某种方式处理、组织或结构化的信息,也可以指应用或付诸行动的信息。
Zins认为,知识是主观的而不是普遍的,不是信息科学研究的对象,它经常被定义为命题术语,[2]。,即“一切知识都是默示的”
“最常被引用的定义之一”知识的[8]捕获了其他定义知识的一些不同方式:
知识是由框架式的经验、价值观、上下文信息、专家见解和基于基础的直觉组成的流动组合,为评估和合并新经验和信息提供了环境和框架。它起源于并应用于知识分子的头脑中。在组织中,它常常不仅嵌入到文档和存储库中,而且还嵌入到组织的例程、流程、实践和规范中
知识处理
将信息描述为“有组织的或结构化的数据”,知识有时被描述为:
- “随着时间的推移,多个信息源的综合”
- “组织和处理以传达理解、经验和积累的学习”
- “上下文信息、价值观、经验和规则的混合”[16]
博尔丁对知识的定义之一是“一种心理结构”[8][9],克利夫兰将知识描述为“某个人将提炼者之火应用于[信息],选择并组织对某人有用的东西的结果”。最近的一篇文章将知识描述为“关系中相互联系的信息”
知识过程
泽莱尼将知识定义为“专有技术”。,以及“知道谁”和“知道什么时候”,都是通过“实践经验”获得的。[3]“知识……从经验的背景中产生一套连贯一致的协调行动。”更进一步,隐含地将信息作为描述性的,Zeleny宣称“知识是行动,而不是行动的描述。
Ackoff同样将知识描述为“数据和信息的应用”,它“回答‘如何’的问题”,[15][验证需要][28],即“专有技术”
与此同时,人们发现讨论DIKW的教科书从经验、技能、专业知识或能力等方面对知识进行了不同的描述:
- “学习和体验”
- “综合上下文信息、专家意见、技能和经验”
- “信息与理解和能力相结合”
- “认知、技能、训练、常识和经验”,[16]
商人James Chisholm和Greg Warman将知识简单地描述为“把事情做对”
知识命题
知识有时被描述为“信念结构”和“参照认知框架的内在化”。Boulding对知识的一个定义是“对世界和个人在其中的位置的主观感知”,[8][9],而Zeleny说知识“应该是观察者对‘对象’(整体、统一性)的区分”
同样,Zins发现,知识是用命题的术语来描述的,作为正当的信念(主观领域,类似于隐性知识),有时也作为表示这种信念的符号(普遍/集体领域,类似于显性知识)。泽莱尼拒绝了显性知识的概念(就像津斯的普遍知识一样),他认为一旦将知识符号化,知识就变成了信息。博伊科似乎呼应了这一观点,他声称“知识和智慧可以是信息”
主观领域:
- 知识是个体头脑中的一种思想,其特征是个体有正当理由相信它是真实的。它可以是经验的,也可以是非经验的,例如逻辑和数学知识(例如,“每个三角形都有三条边”)、宗教知识(例如,“上帝存在”)、哲学知识(例如,“Cogito ergo sum”)等等。注意知识的内容被认为在个人看来,由个人的特点合理的相信它是真实的,而“知道”是一种心态特征的三个条件:(1)个人认为[s],它是正确的,(2)他/她可以证明它,和(3)是真的,或者它[出现]是真的。[2](斜体补充道。大胆原创。)
主观知识与主观信息的区别在于,主观知识的特征是有正当信念,而主观信息是关于数据意义的一种知识。
博伊科在将知识定义为“有争议的问题”时,暗示了知识对理性话语和论证都是开放的.
智慧
虽然通常包括作为一个水平在DIKW,“有有限的参考智慧”[1]在讨论模型。博伊科似乎摒弃了智慧,将其描述为“非物质的”
Ackoff认为理解是“对‘为什么’的欣赏”,而智慧是“被评估的理解”,理解被假定为知识和智慧之间的一个离散层。[8][15][28] Adler之前也包括了一个理解层,[8][17][18],而其他作者将理解描述为一个与DIKW相关的维度
克利夫兰将智慧简单地描述为“集成的知识—信息变得超级有用”。其他作者将智慧描述为“知道做正确的事情”和“显然不需要思考就能做出正确判断和决定的能力”。智慧包括为更大的善使用知识。正因为如此,智慧才更深刻、更独特。它需要一种好与坏、对与错、道德与不道德的感觉。
泽莱尼将智慧描述为“知道为什么”,[14]后来改进了他的定义,以便区分“为什么做”(智慧)和“为什么是”(信息),并将他的定义扩展到包括一种形式的知道(做什么,行动或执行)。根据Nikhil Sharma的说法,Zeleny主张在智慧之外给模型增加一层,称为“启蒙”.
表示
图形化表示

DIKW层次结构的流程图。
DIKW是一个层次模型,通常被描述为一个金字塔,[1][8]以数据为基础,智慧为顶点。在这方面,它类似于马斯洛的需求层次结构,因为层次结构的每一层都被认为是上述层次的一个基本前身。与马斯洛的层次结构不同,DIKW描述的是所谓的结构或功能关系(较低的层次包含较高层次的材料)。泽莱尼和阿考夫都被认为是金字塔代表的鼻祖,尽管他们都没有用金字塔来表达他们的思想
DIKW也被表示为二维图表[5][32]或一个或多个流程图。在这种情况下,元素之间的关系可能表现为更少的层次结构,具有反馈循环和控制关系。
Debons和他的同事[19]可能是第一个“用图形表示层次结构”的人
多年来,许多改编的迪克瓦金字塔已经产生。例如,美国陆军的知识管理人员试图展示将数据转换为信息,然后是知识,最后是智慧的过程,以及最终在整个组织中创建共享理解和管理决策风险所涉及的活动

美国陆军知识管理人员改编的DIKW金字塔
计算表示
智能决策支持系统是在基于agent建模的背景下,通过引入建模和仿真领域的新技术和新方法,特别是智能软件agent领域的新技术和新方法来提高决策能力

使用高级分布式仿真来支持信息、知识和智慧表示
下面的示例描述了一个军事决策支持系统,但是体系结构和底层概念思想可以转移到其他应用领域:[34]
- 价值链从描述底层命令和控制系统中的信息的数据质量开始。
- 信息质量跟踪可用数据项和信息语句的完整性、正确性、通用性、一致性和精确性。
- 知识质量处理嵌入在指挥和控制系统中的程序知识和信息,如敌方部队的模板、关于范围和武器等实体的假设,以及通常编码为规则的理论假设。
- 意识质量度量的是使用命令和控制系统中嵌入的信息和知识的程度。意识被明确地置于认知领域。
通过引入一个通用的操作图,将数据放到上下文中,从而得到信息而不是数据。下一个步骤是使用模型和模拟来支持决策,该步骤由面向服务的基于web的基础设施(但尚未在操作上使用)支持。仿真系统是过程知识的原型,是知识质量的基础。最后,使用智能软件代理不断观察战斗领域,应用模型和模拟分析内容,监控计划的执行,并做所有必要的任务,使决策者意识到发生了什么,指挥和控制系统甚至可以支持态势感知,价值链中的水平通常局限于纯粹的认知方法。[34]
批评
德国哲学家拉斐尔•卡普罗(Rafael Capurro)认为,数据是一种抽象,信息是“传达意义的行为”,知识是“一个(心理/社会)系统在其‘世界’的基础上,基于沟通的意义选择事件”。因此,任何对这些概念之间的逻辑层次结构的印象都是“童话”
Zins提出的一个反对意见是,尽管知识可能是一种独有的认知现象,但很难将给定的事实指向具有特殊性的信息或知识,而不是两者都是,这使得DIKW模型无法运行。
爱因斯坦著名的方程式“E = mc2”(它印在我的电脑屏幕上,而且肯定与任何人类的思想是分离的)信息或知识?“2 + 2 = 4”是信息还是知识
或者,信息和知识可以看作同义词。[36]在对这些批评的回答中,Zins认为,撇开主观主义和经验主义哲学不谈,“数据、信息和知识这三个基本概念以及它们之间的关系,就像情报学学术界的主要学者所理解的那样”,有不同的定义。[2]罗利赞同这一点,他认为,在知识的定义可能不一致的地方,“不同的观点都把数据、信息和知识之间的关系作为出发点。
美国哲学家杜威和本特利在他们1949年出版的《认识与已知》一书中认为,“知识”是“一个模糊的词”,并提出了一个复杂的DIKW替代方案,其中包括大约19个“术语指南”
信息处理理论认为,物质世界是由信息本身构成的。在这个定义下,数据要么由物理信息组成,要么与物理信息同义。然而,不清楚DIKW模型中设想的信息是来自物理信息/数据还是等同于物理信息。在前一种情况下,DIKW模型容易出现模棱两可的谬误。在后者中,DIKW模型的数据层被中性一元论的断言所抢占。
教育家马丁Fricke已经发表了一篇文章批判DIKW层次结构,他认为模型是基于“过时的和不令人满意的操作主义的哲学立场和归纳法优越论”,信息和知识都是薄弱的知识,智慧是“占有和使用广泛的实用知识。[38]
另请参阅
- 布鲁姆分类法-教育中的分类系统
- 高等思维——教育改革的理念
- 情报周期
- 梯子的推理
- 层次复杂性模型-一个框架,用来评估一个行为有多复杂
- Bloom's taxonomy – Classification system in education
- Higher-order thinking – A concept of education reform
- Intelligence cycle
- Ladder of inference
- Model of hierarchical complexity – A framework for scoring how complex a behavior is
讨论:请加入知识星球【首席架构师圈】
- 3639 次浏览