SaaS架构
视频号

微信公众号

知识星球

- 172 次浏览
【SaaS协议】SaaS协议101:付款、续订和终止条款(下)
视频号
微信公众号
知识星球
SaaS协议是对提供软件即服务的公司及其客户具有法律约束力的合同。这些服务主要涉及客户端可能订阅的基于云的应用程序。订阅后,客户端可以访问这些基于互联网的服务,以换取经常性费用。SaaS协议的内容因各方而异。它旨在让双方清楚地了解他们的责任和义务。详细了解saas协议中的付款条款、续期条款和终止条款:
支付期限在SaaS协议中定义。它包括付款的期限和方法。认购人可以在协议到期后寻求续约,续约条款通常包含在协议中。客户或提供者可能因各种原因终止合同。SaaS协议中的终止条款通过定义合同终止的先决条件,使流程变得方便。
SaaS协议概述了付款条款和方法、续约条款、终止要求以及终止后的义务。起草良好的SaaS协议对于防止和保护一方免受任何潜在的法律诉讼至关重要。如果你正在寻找为你的企业起草高效SaaS协议的模板,你可以通过Zegal的模板创建SaaS协议。
Saas协议中的付款条款
SaaS协议的支付模式要么采用每月订阅,要么采用定期订阅。对于基于每月订阅的支付条款,客户每月通过电子支付或信用卡系统收费。通常,客户可以随时取消或终止合同,而不会受到任何处罚。在极少数情况下,每月订阅可能会接受年度或季度付款。
定期订阅模式不同于每月付款模式,因为付款期限是为指定的期限设置的。付款期限可以包括也可以不包括有关期限终止的规定。通常,定期订阅被认为更灵活,因为SaaS交易中的各方就支付条款达成了一致。
Saas协议的续期条款
当订阅者或客户选择将与SaaS提供商的交易延长到约定期限之外时,SaaS协议需要续订。SaaS协议通常概述续订方法。然而,由于协议的终止允许客户探索他们在软件服务方面的经验并寻求其他选择,因此续订过程变得不那么简单了。
SaaS协议定义了合同的期限。在大多数情况下,SaaS协议的期限在一年内结束,每年都需要续订。约89%的SaaS供应商在其SaaS协议中包含自动续订条款。这为客户提供了充足的时间来进行成本效益分析,探索他们的替代方案,评估他们的使用情况,并决定是否续签协议。
如果用户打算在指定的到期日前终止合同,他们必须向提供商发出通知。几乎所有供应商都设置了至少30天的时间来发送终止通知。在某些情况下,用户可能需要在终止日期前45至90天提交通知。
SaaS协议的续签对于交易的继续至关重要。制定更新战略的任何延迟都可能给依赖SaaS提供商不受阻碍地运营业务的消费者带来财务后果。这是许多SaaS提供商在协议中包含自动续订的主要原因。因此,订阅者需要随时了解续订日期和合同修订日期。
在包含自动续订条款的SaaS协议中,供应商通常会包含续订期窗口。在这段时间内,客户需要提醒或通知供应商,以避免意外延长合同。
SAAS协议条款的终止
SaaS协议不会以无限期条款自然终止。此类协议的终止通常是由特定事件引起的。当事人也可以修改合同,列入有关终止合同的规定。SaaS协议通常包含有关协议永久续约的条款。除非任何一方主动终止,否则相关条款允许合同自动续签。
许多SaaS协议中都包含为方便而终止协议。
SaaS协议中包含便利终止条款,允许任何一方在方便时终止协议。SaaS协议中包含该条款意味着一方无需证明另一方违约或否认即可终止其交易。关于为方便而终止的条款可以规定一方需要提供终止通知的期限。在某些交易中,可能根本不需要此通知。
SaaS中的原因终止条款允许一方在另一方违约的情况下终止合同。通常,哪些违规行为会导致违反协议可能尚不清楚。一些用户还可能要求生产商继续提供他们的服务,直到通过诉讼证明他们的违规行为。通常,无法履行或不可预见的情况不足以证明违约。大多数客户要求生产商证明其严重违反合同,以证明终止SaaS协议的正当性。
即使在重大违约的情况下,合同也不一定总是根据事实终止。如果SaaS协议要求生产商提供警告通知或关于违约补救的通知,他们必须在阻止提供服务之前提供相应的通知。
SaaS公司从维持其客户中受益。提供者可能会花费他们的资源,期望与客户的合同继续下去。因此,当用户在合同期限前终止合同时,提供商可以收取提前终止费以平衡成本。
双方承担终止后的义务。通常,提供商被要求允许其订户在SaaS协议终止后检索他们的数据。同样,消费者有权根据协议中的过渡条款继续其过渡。服务提供商甚至可能被要求帮助其以前的客户过渡到不同的提供商。
结论
SaaS协议定义了软件服务的订阅方法和支付条款。在协议终止时,客户可能会要求续订协议以继续服务交易。协议通常包括续约条款。公司可以自动续订协议或终止交易。协议包含终止条款,以解决终止便利或原因。
您可能还喜欢:
- 132 次浏览
【SaaS架构】SaaS存储策略
【SaaS架构】SaaS存储策略 - 摘要和简介
视频号
微信公众号
知识星球
摘要
多租户存储是构建和交付软件即服务(SaaS)解决方案的一个更具挑战性的方面。有多种策略可用于划分租户数据,每种策略都有一组独特的细微差别,从而形成您的多租户方法。更为复杂的是,需要将这些策略中的每一种映射到AWS提供的不同存储模型,如Amazon DynamoDB、Amazon关系数据库服务(Amazon RDS)和Amazon Redshift。尽管有一些高级主题可以普遍应用于这些技术,但每个存储模型都有自己的方法来确定多租户环境中的范围、管理和保护数据。本文为SaaS开发人员提供了一系列数据分区选项的见解,使他们能够确定哪种策略和存储技术的组合最符合SaaS环境的需求。
您的架构是否完善?
AWS良好架构框架有助于您了解在云中构建系统时所做决策的利弊。框架的六大支柱使您能够学习设计和运行可靠、安全、高效、经济高效和可持续系统的架构最佳实践。使用AWS管理控制台中免费提供的AWS良好架构工具,您可以通过回答每个支柱的一组问题,对照这些最佳实践检查工作负载。
在SaaS镜头中,我们专注于在AWS上构建软件即服务(SaaS)工作负载的最佳实践。
有关云架构参考架构部署、图表和白皮书的更多专家指南和最佳实践,请参阅AWS架构中心。
介绍
AWS为软件即服务(SaaS)开发人员提供了一系列丰富的存储解决方案,每个解决方案都有自己的范围、资源调配、管理和保护数据的方法。每个服务表示、索引和存储数据的方式为您的多租户策略添加了一组独特的考虑因素。作为SaaS开发人员,这些存储选项的多样性为您提供了将SaaS解决方案的存储需求与最符合您的业务和客户需求的存储技术相结合的机会。
在权衡AWS存储选项时,还必须考虑SaaS解决方案的多租户模型如何与每种存储技术相适应。正如存储有多种风格一样,也有多种风格的多租户分区策略。目标是找到存储和租户分区需求的最佳交集。
本文探讨了这个谜题的所有活动部分。它检查并分类通常用于实现多租户的模型,并帮助您权衡影响分区模型选择的利弊。它还概述了每个模型是如何在Amazon RDS、Amazon DynamoDB和Amazon Redshift上实现的。当您深入了解每种存储技术时,您将了解如何使用AWS构造来确定和管理多租户存储。
尽管本文为您提供了选择多租户分区策略的一般指导,但必须认识到,环境的业务、技术和运营维度通常会引入一些因素,这些因素也会影响您选择的方法。在许多情况下,SaaS组织采用本文中描述的变体的混合。
- 101 次浏览
【SaaS架构】SaaS存储策略 -- SaaS分区模型
视频号
微信公众号
知识星球
首先,您需要一个定义良好的概念模型来帮助您理解各种实现策略。
下图显示了在SaaS环境中划分租户数据时通常使用的三个基本模型思洛存储器、网桥和池。
每个分区模型采用非常不同的方法来管理、访问和分离租户数据。以下各节对模型进行了快速分解,使您能够在任何特定存储技术的上下文之外探索每个模型的价值和原则。
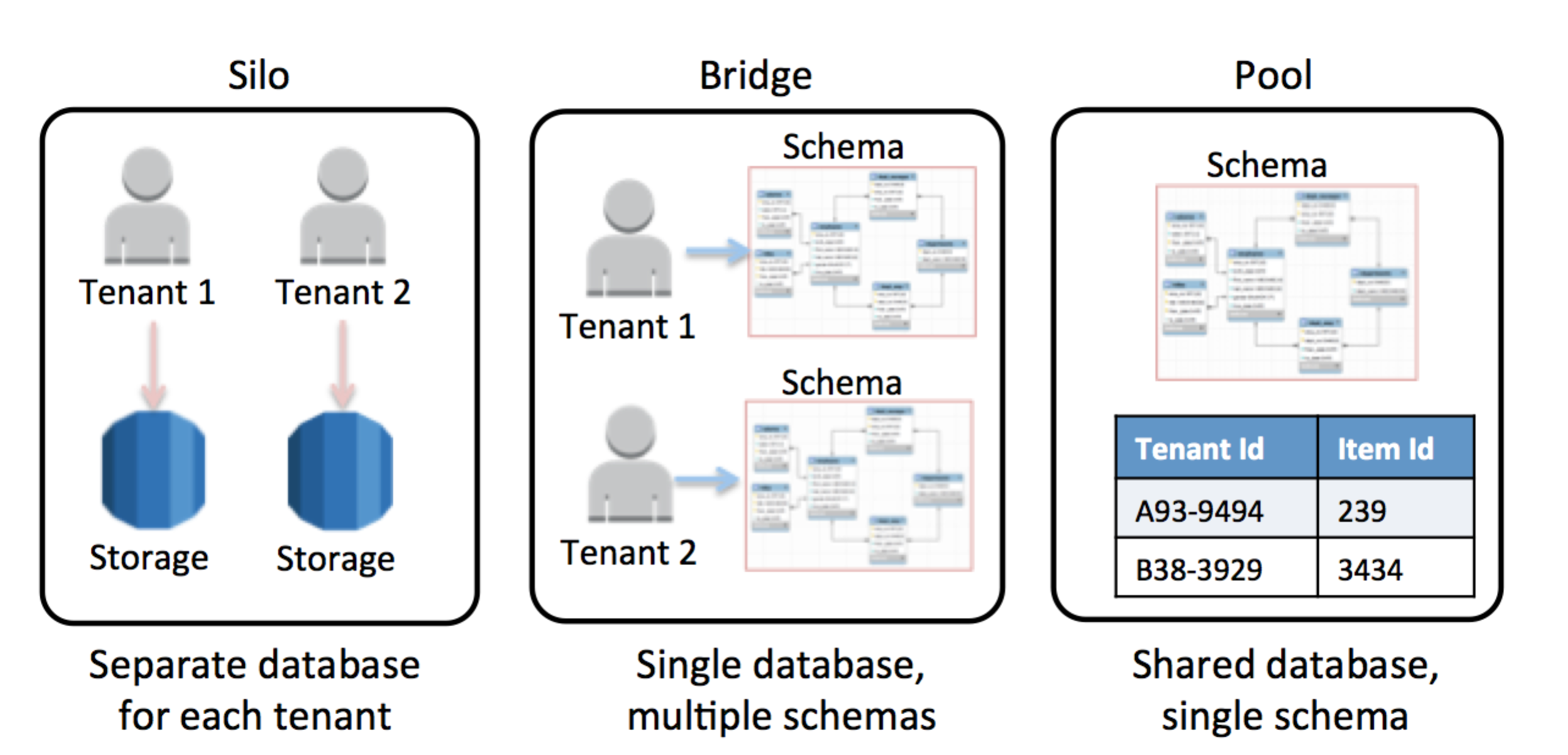
SaaS分区模型
筒仓模型
在思洛存储器模型中,租户数据的存储与任何其他租户数据完全隔离。用于表示租户数据的所有构造都被认为是该客户端在逻辑上“唯一”的,这意味着每个租户通常都有不同的表示、监视、管理和安全足迹。
桥梁模型
桥接模型通常是SaaS开发人员的一种极具吸引力的折衷方案。Bridge将租户的所有数据移动到单个数据库中,同时仍允许每个租户有一定程度的差异和分离。通常,通过为每个租户和allow创建单独的表来实现这一点,每个租户和允许表都有自己的数据表示(模式)。
水池模型
池模型表示多租户模式,其中租户共享系统的所有存储结构。租户数据被放置在一个公共数据库中,所有租户共享一个公共表示(模式)。这需要引入一个分区键,用于确定和控制对租户数据的访问。该模型倾向于简化SaaS解决方案的供应、管理和更新体验。它也很好地符合SaaS提供商所必需的持续交付和敏捷性目标。
设置背景
筒仓、桥梁和水池模型为我们的讨论提供了背景。当您深入了解每种AWS存储技术时,您将发现这些模型的概念元素是如何在特定的AWS存储技术上实现的。有些模型非常直接地映射到这些模型;其他人需要更多的创造力来实现每种类型的租户隔离。
值得注意的是,这些模型都同样有效。尽管我们将讨论每种方法的优点,但给定环境的监管、业务和遗留方面通常在最终选择的方法中起着重要作用。这里的目标是简单地介绍与每种方法相关的机制和权衡。
- 106 次浏览
【SaaS架构】SaaS存储策略 -找到合适的策略
视频号
微信公众号
知识星球
选择多租户分区存储模型策略受到许多不同因素的影响。如果您正在从现有解决方案迁移,您可能会倾向于采用筒仓模型,因为它可以创建最简单、最干净的方式来过渡到多租户,而无需重写SaaS应用程序。如果您的监管或行业动态需要一个更独立的模型,那么池模型的效率和灵活性可能会为您打开通向快速、持续发布环境的道路。这里的关键是要认识到,您选择的战略将由您环境中的业务和技术考虑因素的组合驱动。
在以下各节中,我们重点介绍了每个模型的优点和缺点,并为您提供了一组定义良好的数据点,作为更广泛评估的一部分。您将了解每个模型如何影响您与敏捷性目标保持一致的能力,而敏捷性目标通常是采用SaaS模型的核心。在为SaaS环境选择架构策略时,请考虑该策略如何影响您在零停机环境中快速构建、交付和部署版本的能力。
评估权衡
如果您将三个分区模型(筒仓、桥和池)放在一个谱上,您将看到与采用任何一种策略相关的自然紧张关系。在一个模型中被列为优势的质量通常在另一模型中被表示为劣势。例如,筒仓模型的原则和价值体系往往与池模型的原则与价值体系相反。
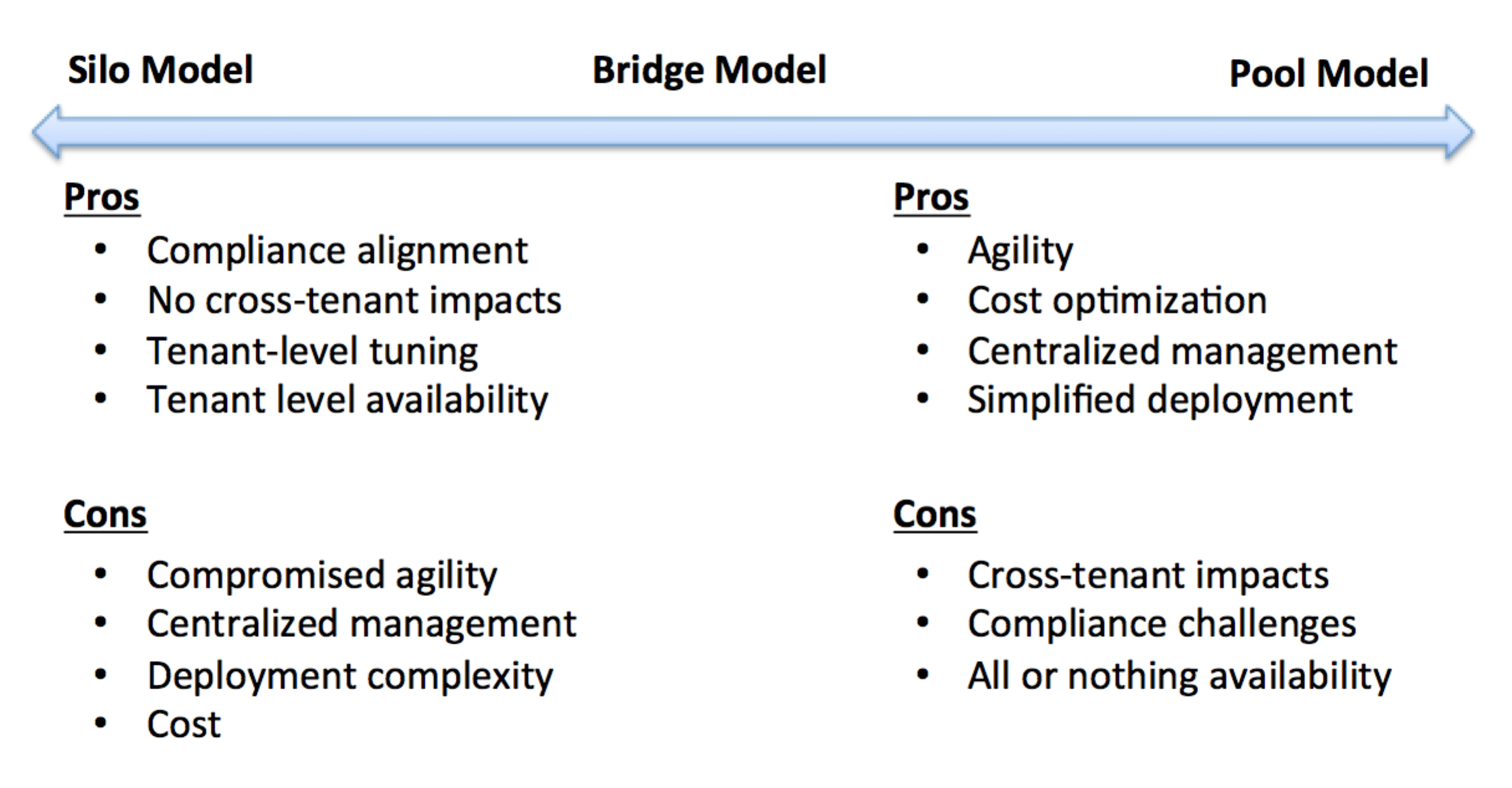
分区模型权衡
上图突出了这些相互竞争的原则。在图的顶部,您将看到所表示的三个分区模型。左边是筒仓模型的优点和缺点。在右边,我们为池模型提供了类似的列表。桥梁模型有点混合了这些考虑因素,因此代表了极端情况下的利弊。
筒仓模型权衡
在完全独立的数据库中表示租户数据可能很有吸引力。除了简化现有单租户解决方案的迁移之外,这种方法还解决了一些租户可能对运行完全共享的基础设施的担忧。
优点
思洛对具有严格监管和安全约束的SaaS解决方案很有吸引力-在这些环境中,您的SaaS客户对其数据必须如何与其他租户隔离有非常明确的期望。思洛存储器模型允许您为租户提供一个选项,在租户数据之间创建一个更具体的边界,并让您的客户感觉到他们的数据存储在一个更专用的模型中。
跨租户的影响是有限的——这里的想法是,通过隔离思洛存储器模型,您可以确保一个租户的活动不会影响另一个租户。该模型允许租户特定的调整,其中系统的数据库性能SLA可以根据给定租户的需要进行调整。用于调整数据库的旋钮和刻度盘通常也具有到筒仓模型的更自然的映射,这使得配置以租户为中心的体验更加简单。
可用性是在租户级别进行管理的,最大限度地减少了租户的停机风险-每个租户都在自己的数据库中,您不必担心数据库停机可能会波及所有租户。如果一个租户存在数据问题,则不太可能对系统的其他租户产生不利影响。
缺点
资源调配和管理更为复杂——无论何时引入每租户的基础设施,都会引入另一个移动部分,必须逐个租户进行配置和管理。例如,您可以想象一个孤立的数据库解决方案会如何影响系统的租户登录体验。您的注册过程需要自动化,以便在注册过程中创建和配置数据库。这当然是可以实现的,但它增加了一层复杂性,也增加了SaaS环境中的潜在故障点。
您查看租户活动并对其做出反应的能力会受到影响-使用SaaS,您可能需要一种管理和监控体验,以提供跨租户的系统运行状况视图。您希望主动预测数据库性能问题,并以更全面的方式对策略作出反应。然而,筒仓模型使您更加努力地寻找和引入工具,以创建覆盖所有租户的聚合的、系统范围的健康视图。
思洛存储器模型的分布式影响了您跨租户有效分析和评估性能趋势的能力—每个租户都将数据存储在自己的思洛存储器中,您只能在以租户为中心的模型中管理和调整服务负载。这基本上导致引入一组一次性设置和策略,您必须独立管理和调整这些设置和策略。这可能既效率低下,又可能造成开销,从而削弱您快速响应客户需求的能力。
筒仓限制了成本优化—筒仓模型的一次性特性可能会限制您调整存储资源消耗的能力,这可能是最显著的缺点。
池模型权衡
池模式代表了SaaS生活方式的终极承诺。使用池模型,您的重点是为租户提供统一的方法,使您能够优化租户存储资源调配、迁移、管理和监控。
优点
灵活性—一旦您的所有租户数据集中在一个存储结构中,您就可以更好地创建工具和生命周期,以支持一种简化的通用方法,快速为所有租户部署存储解决方案。这种灵活性也扩展到您的入职流程。使用池模型,您不需要为注册SaaS服务的每个租户提供单独的存储基础架构。您可以简单地配置新租户,并使用该租户的ID作为索引,从所有租户使用的共享存储模型中访问租户的数据。
存储监控和管理更简单—在池模型中,使用工具和聚合分析来总结租户存储活动更为自然。这里可以利用您用来管理单个存储模型的日常工具来构建系统运行状况的全面、跨租户视图。使用池模型,您可以更好地引入可用于主动响应系统事件的全局策略。通常,将数据统一到单个数据库和共享表示中简化了多租户存储、部署和管理体验的许多方面。
其他选项有助于优化SaaS解决方案的成本足迹-成本机会通常以性能调整的形式出现。例如,您可以将吞吐量优化作为一个策略应用于所有租户(而不是逐个租户管理单独的策略)。
池提高了部署自动化和操作灵活性—池模型的共享特性通常会降低数据库部署自动化的总体复杂性,这与SaaS对持续频繁发布新产品功能的需求非常吻合。
缺点
灵活性意味着管理规模和可用性的门槛更高—想象一下在池化多租户环境中存储中断的影响。现在,不是只有一个客户倒下,而是所有客户都倒下了。这就是为什么采用池模型的组织也倾向于在其环境的自动化和测试方面投入更多的资金。池式解决方案需要主动监控解决方案和健壮的版本控制、数据和模式迁移。发布必须顺利进行,租户问题需要得到有效捕捉和解决。
池对租户数据分布的管理提出了挑战—在某些情况下,租户数据的大小和分布也可能成为池存储的挑战。租户往往会在您的系统上施加不同程度的负载,这些变化可能会破坏您的存储性能。池模型需要更多地考虑您将使用哪些机制来解释租户负载的这些变化。数据的大小和分布也会影响数据迁移的方式。这些问题通常是特定存储技术所特有的,需要逐个解决。
共享环境的共享性质可能会在某些领域遇到阻力——对于某些SaaS产品,客户将需要一个筒仓模型来满足其法规和内部数据保护要求。
混合:商业妥协
对于许多组织来说,战略的选择并不像选择筒仓、桥梁或池模型那么简单。您的租户和您的企业将对您选择存储策略的方式产生重大影响。
在某些情况下,团队可能会确定一小部分需要筒仓或桥梁模型的租户。一旦他们做出了这一决定,他们就认为必须使用该模型实现所有存储。这人为地限制了您接受可能对池模式开放的租户的能力。事实上,这可能会增加一层租户的成本或复杂性,因为他们不需要筒仓或桥梁模型的属性。
一种可能的折衷方案是构建一个完全支持池存储的解决方案作为基础。然后,您可以为那些需要孤立存储解决方案的租户创建一个单独的数据库。下图提供了这种方法的一个实例。

混合筒仓/池存储
这里,我们有两个租户(租户1和租户2)正在利用思洛存储器模型,其余租户在池存储模型中运行。数据访问层将开发人员从租户的底层存储中隐藏起来,从而神奇地将其抽象出来。
尽管这可能会增加数据访问层和管理配置文件的复杂性,但它也可以为您的业务提供一种方式,将您的产品分层,以代表两个世界的最佳。
- 62 次浏览
【SaaS架构】SaaS存储策略--AWS Redshift上的多租户
视频号
微信公众号
知识星球
Amazon Redshift为您的多租户思维带来了额外的变化。Amazon Redshift专注于构建高性能集群,以容纳大型数据仓库。AmazonRedshift还对您可以在每个集群中创建的构造设置了一些限制。考虑以下限制:
- 每个群集60个数据库
- 每个数据库256个schemas
- 每个数据库500个并发连接
- 50个并发查询
通过访问群集,可以访问群集中的所有数据库
您可以想象这些限制如何影响交付给Amazon Redshift的规模和性能。您还可以看到这些限制如何影响您使用Amazon Redshift进行多租户的方法。如果您的目标是适度的租户数量,这些限制可能对您的解决方案影响不大。然而,如果您的目标是大量租户,则需要将这些限制因素纳入您的总体战略。
以下部分重点介绍了在AmazonRedshift上实现每种多租户存储模型时常用的策略。
筒仓模型
在AmazonRedshift上实现租户的真正筒仓模型隔离需要为每个租户提供单独的集群。通过集群,您可以在租户之间创建定义良好的边界,这通常是确保客户的数据与跨租户访问成功隔离所必需的。这种方法最好地利用了AmazonRedShift中的自然安全机制,因此您可以使用IAM策略和数据库权限的组合来控制和限制租户对集群的访问。IAM控制整个群集管理,数据库权限用于控制对群集内数据的访问。
思洛存储器模型为您提供了为每个租户创建优化体验的机会。使用AmazonRedshift,您可以配置集群中节点的数量和类型,以便创建针对每个租户的负载配置文件的环境。您还可以将此作为优化成本的策略。
正如我们在其他思洛存储器模型中所看到的那样,该模型的挑战在于,每个租户的集群都必须作为入职流程的一部分进行配置。自动化此过程并吸收与资源调配过程相关的额外时间和开销会给您的部署足迹增加一层复杂性。它也会对分配新租户的速度产生一些影响。
桥梁模型
桥梁模型在Amazon Redshift上没有自然映射。从技术上讲,您可以为每个租户创建单独的模式。然而,您可能会遇到AmazonRedshift限制256个模式的问题。在有大量租户的环境中,这根本无法扩展。在桥接模式中,安全性也是Amazon Redshift面临的挑战。当您被授权为AmazonRedshift集群的用户时,您可以访问该集群中的所有数据库。这就需要对SaaS应用程序实施更细粒度的访问控制。
考虑到桥接模型的动机和这些技术考虑,大多数SaaS提供商考虑在Amazon Redshift上使用这种方法似乎不切实际。即使您的解决方案可以管理这些限制,客户也可能无法接受隔离配置文件。最终,最好的答案是对任何需要隔离的租户简单地使用筒仓模型。
水池模型
在AmazonRedshift上构建池模型与我们讨论过的其他存储模型非常相似。其基本思想是将所有租户的数据存储在一个具有共享数据库和表的AmazonRedshift集群中。在这种方法中,通过引入表示唯一租户标识符的列来划分租户的数据。
这种方法提供了我们在其他游泳池模型中看到的大部分优点。当然,通过将所有租户数据存储在一个AmazonRedshift集群中,整体管理、监控和灵活性都得到了改善。
并发连接的限制为在AmazonRedshift上实现池模型增加了一定的难度。通过500个并发连接的上限,许多多租户SaaS环境可以很快超过这个限制。这并不能消除池模型的争用。相反,它将更多的责任推给SaaS开发人员,以制定有效的策略来管理如何以及何时使用和释放这些连接。
有一些常见的方法来解决连接管理问题。开发人员通常利用基于客户端的缓存来限制他们对Amazon Redshift的实际连接需求。连接池也可以应用于此模型。开发人员需要选择一种策略,以确保在不超过AmazonRedshift连接限制的情况下有效满足其应用程序的数据访问模式。
采用池模型还意味着要关注在共享基础设施中运行时出现的典型问题。例如,数据的安全需要一些应用程序级别的策略来限制跨租户访问。此外,您可能需要不断调整和优化环境的性能,以防止任何一个租户降低其他租户的体验。
- 119 次浏览
【SaaS架构】SaaS存储策略--DynamoDB上的多租户
视频号
微信公众号
知识星球
DynamoDB如何确定数据范围和管理数据的性质为您如何处理多租户增加了一些新的变化。尽管一些存储服务与传统的数据分区策略很好地保持一致,但DynamoDB对思洛存储器、网桥和池模型的映射略不直接。使用DynamoDB,在选择多租户策略时,您必须考虑一些其他因素。
接下来的章节将探讨AWS机制,这些机制通常用于在DynamoDB上实现每个多租户分区方案。
筒仓模型
在研究如何在DynamicDB上实现思洛存储器模型之前,必须首先考虑服务的作用域和控制数据访问的方式。与RDS不同,DynamicDB没有数据库实例的概念。相反,在DynamoDB中创建的所有表都是区域内某个帐户的全局表。这意味着该区域中的每个表名对于给定帐户都必须是唯一的。
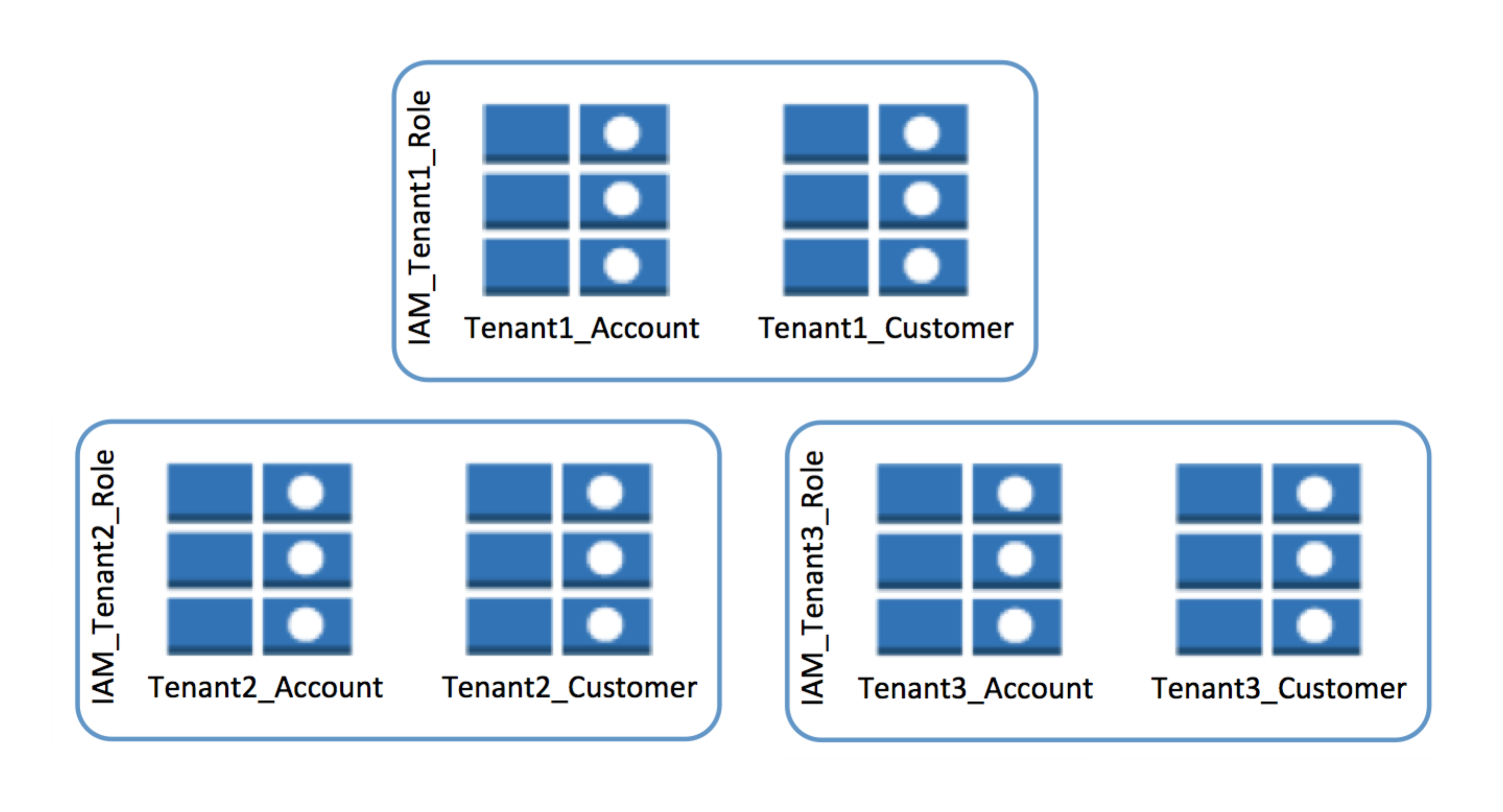
带DynamoDB表的筒仓模型
如果您在DynamoDB上实现了一个思洛存储器模型,则必须找到某种方法来创建一个或多个与特定租户关联的表的分组。该方法还必须创建这些表的安全、受控视图,以满足思洛存储器客户的安全要求,防止任何跨租户数据访问的可能性。
上图显示了如何实现租户范围的表分组的一个示例。请注意,为每个租户创建了两个表(Account和Customer)。这些表还具有一个在表名称前附加的租户标识符。这解决了DynamoDB的表命名要求,并在表及其关联租户之间创建了必要的绑定。
通过引入IAM政策,也可以访问这些表。您的配置过程需要自动为每个租户创建策略,并将该策略应用于给定租户拥有的表。
这种方法实现了筒仓模型的基本隔离目标,在每个租户的数据之间定义了清晰的边界。它还允许逐个租户进行调整和优化。您可以调整两个特定区域:
- Amazon CloudWatch度量可以在表级别捕获,从而简化了存储活动租户度量的聚合。
- 表写入和读取容量(以每秒输入和输出(IOPS)衡量)应用于表级别,允许您为每个租户创建不同的扩展策略。
这种模式的缺点往往更多地体现在运营和管理方面。显然,使用这种方法,租户的操作视图需要了解租户表命名方案,以便在以租户为中心的上下文中过滤和显示信息。该方法还为需要与这些表交互的任何代码添加了一层间接层。与DynamoDB表的每次交互都需要插入租户上下文,以将每个请求映射到相应的租户表。
采用基于微服务架构的SaaS提供商也有另一层考虑。对于微服务,团队通常将存储责任分配给各个服务。每个服务都可以自由决定如何存储和管理数据。这可能会使DynamoDB上的隔离情况变得复杂,需要您扩展表的数量以适应每个服务的需求。它还添加了作用域的另一个维度,其中每个服务的每个表都标识其与服务的绑定。
为了抵消这些挑战并更好地与DynamoDB最佳实践保持一致,请考虑为所有租户数据提供一个表。此方法提供了多种效率,并简化了解决方案的资源调配、管理和迁移配置文件。
在大多数情况下,使用单独的DynamoDB表和IAM策略来隔离租户数据可以满足思洛存储器模型的需要。您唯一的其他选择是考虑前面描述的链接帐户筒仓模型。然而,如前所述,链接帐户隔离模型还存在其他限制和考虑因素。
桥梁模型
对于DynamoDB,桥梁模型和筒仓模型之间的界限非常模糊。本质上,如果您使用网桥模型的目标是为每个客户端提供一个具有一次性模式变化的单一帐户,那么您可以看到如何使用前面描述的思洛存储器模型实现这一点。
对于桥接器,唯一的问题是您是否可以放宽筒仓模型中描述的一些隔离要求。您可以通过取消引入任何表级IAM策略来实现这一点。假设您的租户不需要完全隔离,您可以认为删除IAM策略可以简化您的资源调配方案。然而,即使在桥上,隔离也有好处。因此,尽管放弃IAM隔离可能很有吸引力,但利用可以限制跨租户访问的结构和策略仍然是一个很好的SaaS实践。
水池模型
在DynamoDB上实现池模型需要您后退一步,并考虑服务如何管理数据。由于数据存储在DynamoDB中,服务必须不断评估和划分数据以实现规模。而且,如果您的数据分布均匀,您可以简单地依靠这种底层分区方案来优化SaaS租户的性能和成本分布。
这里的挑战是,多租户SaaS环境中的数据通常没有统一的分布。SaaS租户有各种各样的形状和大小,因此,他们的数据并不统一。SaaS供应商很常见的情况是,最终只有少数租户占用了他们大部分的数据。
了解了这一点,您可以看到它是如何在DynamicDB之上实现池模型的。如果您简单地将租户标识符映射到DynamoDB分区键,您将很快发现您还创建了分区“热点”。想象一下,有一个非常大的租户会破坏DynamoDB如何有效地划分数据。这些热点会影响解决方案的成本和性能。由于密钥分布不理想,您需要提高IOPS以抵消热分区的影响。对更高IOPS的需求直接转化为解决方案的更高成本。
为了解决这个问题,您必须引入一些机制来更好地控制租户数据的分布。您需要一种不依赖单个租户标识符来划分数据的方法。这些因素都导致了一条路径,您必须创建一个辅助分片模型,以将每个租户与多个分区键相关联。
让我们看一个例子,说明你如何为生活带来这样的解决方案。首先,您需要一个单独的表,我们称之为“租户查找表”,以捕获和管理租户到其对应的DynamoDB分区键的映射。下图显示了如何构建租户查找表的示例。
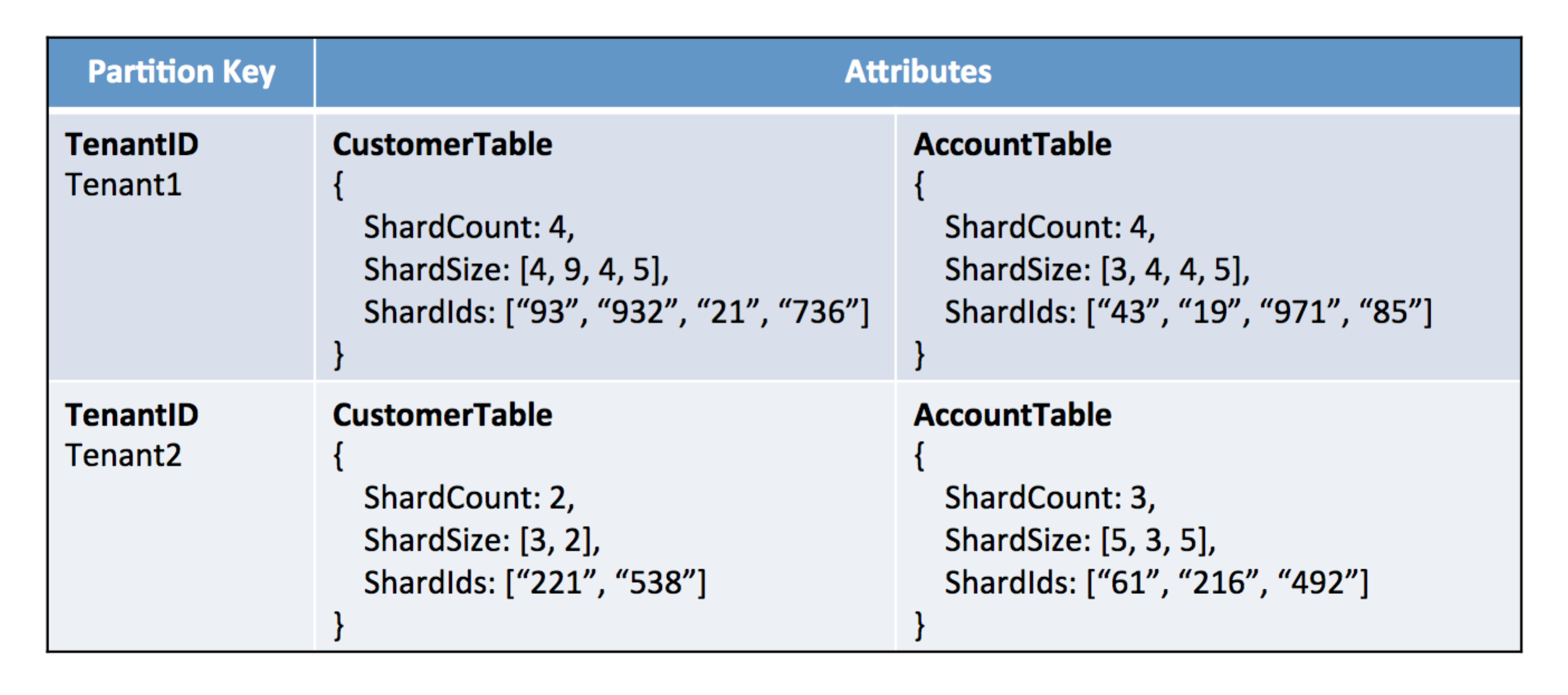
引入租户查找表
此表包括两个租户的映射。与这些租户关联的项目具有包含与租户关联的每个表的分片信息的属性。在这里,我们的租户都有其Customer和Account表的分片信息。还要注意,对于每个租户表组合,有三条信息表示表的当前分片配置文件。这些是:
- ShardCount-表示当前与表关联的碎片数。
- ShardSize-每个碎片的当前大小
- ShardId-映射到租户的分区键列表(用于表)
使用此机制,您可以控制如何为每个表分配数据。查找表的间接性为您提供了一种根据租户存储的数据量动态调整租户分片方案的方法。数据占用量特别大的租户将获得更多碎片。因为该模型在逐个表的基础上配置分片,所以您可以更精确地控制租户的数据需求映射到特定的分片配置。这使您能够更好地将分区与租户数据配置文件中经常出现的自然变化相一致。
尽管引入租户查找表为您提供了一种解决租户数据分布问题的方法,但它并不是免费的。这个模型现在引入了一个间接级别,您必须在解决方案的数据访问层中解决这个问题。与其使用租户标识符直接访问数据,不如先查看该租户的碎片映射,然后使用这些标识符的联合来访问租户数据。下面的示例Customer表显示了如何在此模型中表示数据。
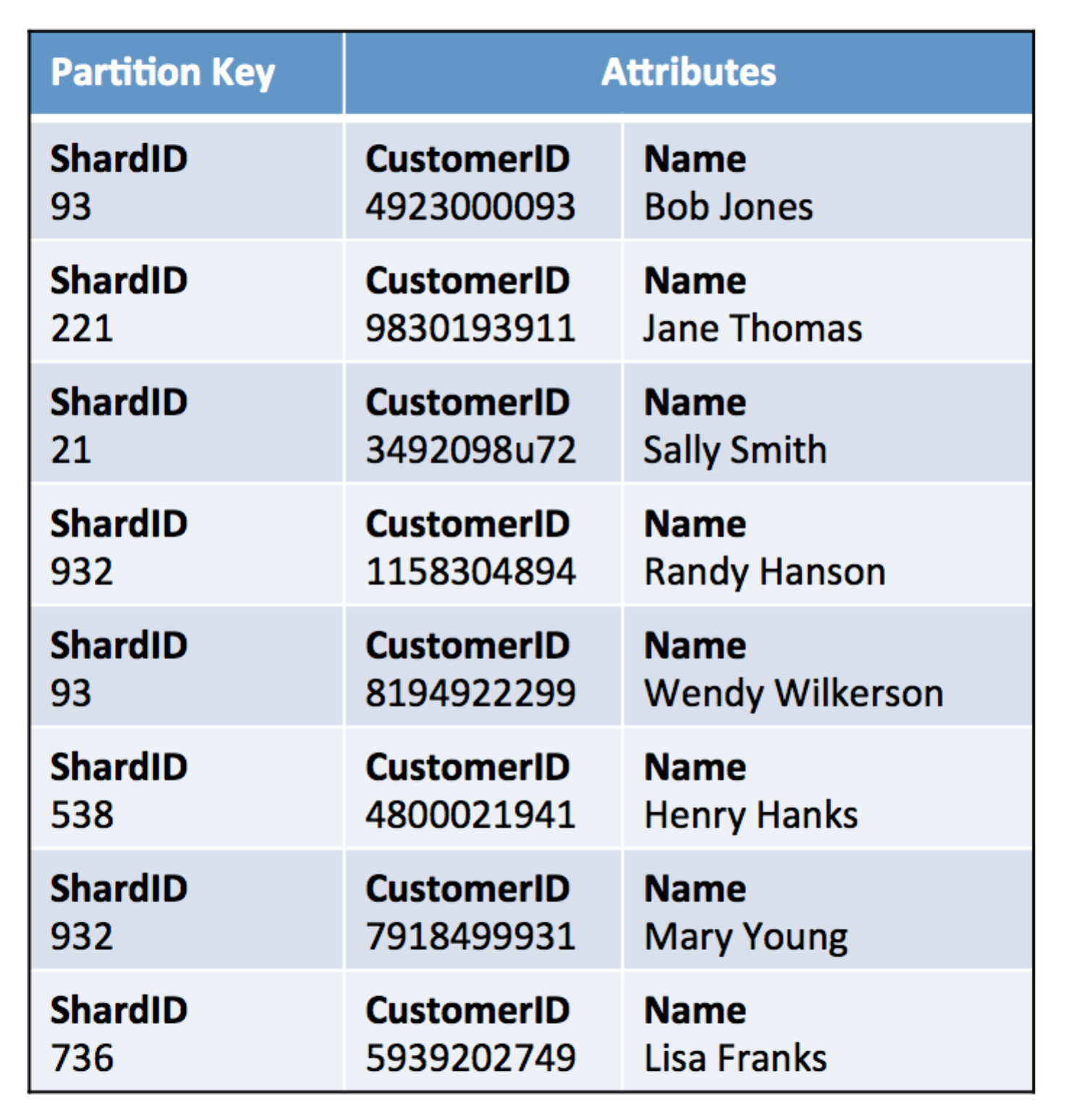
具有碎片ID的客户表
在本例中,ShardID是租户查找表的直接映射。租户查找表包括Customer表的两个单独的碎片标识符列表,一个用于Tenant1,一个为Tenant2。这些碎片标识符与您在示例客户表中看到的值直接相关。请注意,实际租户标识符从未出现在此Customer表中。
管理碎片分发
这个模型的机制并不特别复杂。当你考虑如何实施一个有效地分发数据的策略时,这个问题会变得更加有趣。如何检测租户何时需要额外的碎片?您可以收集哪些度量和标准来自动化此过程?您的数据和域的特性如何影响您的数据配置文件?没有一种单一的方法可以为每一种解决方案普遍解决这些问题。一些SaaS组织根据其客户洞察手动调整这一点。其他人有更自然的标准来指导他们的方法。
这里概述的方法是处理数据分布的一种方法。最终,您可能会发现我们所描述的原则与您的环境需求最为吻合。关键之处在于,如果采用池模型,请注意DynamoDB如何划分数据。盲目移动数据而不考虑数据将如何分布,可能会破坏SaaS解决方案的性能和成本。
动态优化IOPS
SaaS环境的IOPS需求很难管理。租户在系统上的负载可能会有很大变化。将IOPS设置为最坏情况下的最大值会破坏根据实际负载优化成本的愿望。
相反,请考虑实现一个动态模型,其中表的IOPS根据应用程序的负载配置文件实时调整。DynamicDynamicDB是一个可配置的开源解决方案,您可以使用它来解决这个问题。
支持多种环境
当您考虑DynamoDB概述的策略时,请考虑在多个环境(QA、开发、生产等)下如何实现这些模型中的每一个。对多个环境的需求会影响您如何进一步划分您的体验,以将AWS上的每一种存储策略分开。例如,使用网桥和池模型,您可以在表名中添加一个限定符,以提供环境上下文。这增加了一点误导,您必须将其考虑到表名的配置和运行时解析中。
迁移效率
DynamoDB的无模式特性为SaaS提供商提供了真正的优势,允许您将更新应用于应用程序并迁移租户数据,而无需引入新的表或复制。DynamoDB简化了在SaaS版本之间迁移租户的过程,允许您在最新版本的SaaS解决方案上同时托管灵活租户,同时允许其他租户继续使用早期版本。
权衡权衡
当您确定哪种模型最符合您的业务需求时,每种模型都需要考虑权衡。筒仓模式可能看起来很有吸引力,但资源调配和管理增加了复杂性,从而削弱了解决方案的灵活性。支持单独的环境和创建独特的表组无疑会影响自动化部署的复杂性。该桥代表了DynamicDB上筒仓模型的轻微变化。因此,它反映了我们在筒仓模型中发现的大部分内容。
DynamoDB上的池模型提供了一些显著的优势。数据的整合占地面积简化了资源调配、迁移以及管理和监控体验。它还允许您在跨租户的基础上调整读写IOPS,从而采用更加多租户的方法来优化消费和租户体验。这使您能够对性能问题做出更广泛的反应,并带来了将成本降至最低的机会。这些因素往往使池模型对SaaS组织非常有吸引力。
- 87 次浏览
【SaaS架构】SaaS存储策略--RDS上的多租户
视频号
微信公众号
知识星球
在关系数据库上交付了这么多早期SaaS系统之后,开发人员社区已经建立了一些常见的模式来解决这些环境中的多租户问题。事实上,RDS具有到筒仓、网桥和池模型的更自然的映射。
RDS中数据的构造和表示在很大程度上是非管理关系环境的扩展。例如,MySQL中可用的基本机制也可以在RDS中使用。这使得在所有RDS风格上实现多租户相对简单。
以下部分概述了在RDS上实现分区模型时常用的各种策略。
筒仓模型
您可以通过多种方式在AWS上实现筒仓模式。然而,实现隔离的最常见和最简单的方法是为每个租户创建单独的数据库实例。通过实例,您可以实现一个通常满足客户法规遵从性需求的分离级别,而无需调配完全独立的帐户。
RDS实例作为思洛存储器
上图显示了可以在RDS上实现的基本思洛存储器模型。这里,为每个租户提供了两个单独的实例。
该图描述了每个租户实例的主数据库和两个读取副本。这是一个可选概念,旨在强调如何使用此方法为每个租户设置和配置优化的、高度可用的策略。
桥梁模型
在RDS上实现桥接模型符合我们在所有存储模型中看到的相同主题。基本方法是为所有租户利用单个实例,同时为该数据库中的每个租户创建单独的表示。这就需要有配置和运行时表解析来将每个表映射到给定的租户。
网桥模型为您提供了在迁移租户数据时使用不同模式和一些灵活性的租户的机会。例如,您可以让不同的租户在给定的时间点运行不同版本的产品,并逐个租户逐步迁移模式更改。
下图提供了一个在RDS上实现网桥模型的方法示例。在此图中,您有一个RDS数据库实例,其中包含Tenant1和Tenant2的单独客户表。
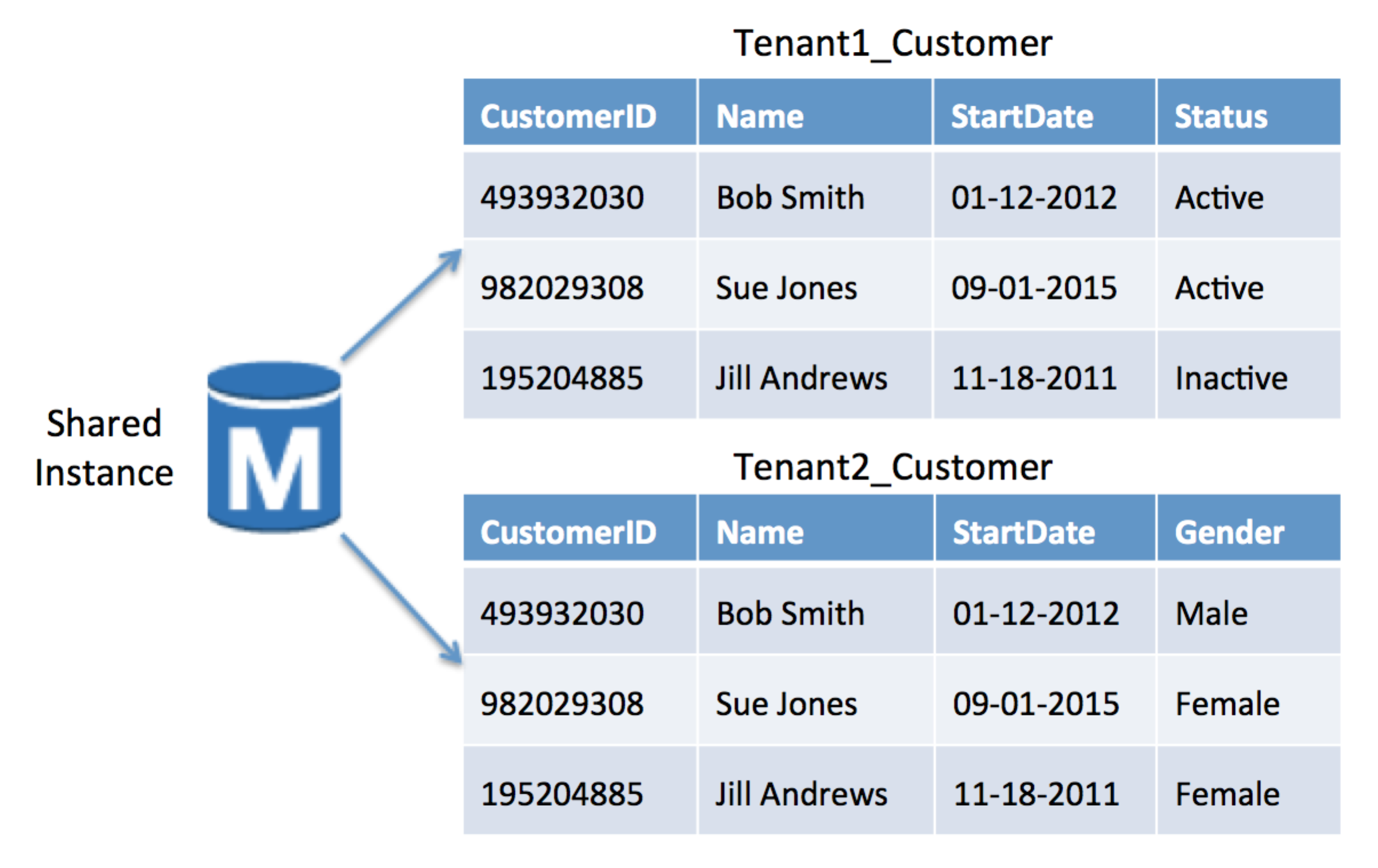
RDS上的网桥模型示例
这个示例强调了在租户级别具有模式变化的能力。Tenant1的模式有一个Status列,而该列被删除,并由Tenant2使用的性别列替换。
这里的另一个选择是为实例中的每个租户引入单独数据库的概念。RDS的术语各不相同。一些RDS存储容器将其称为数据库;其他人将其标记为模式。
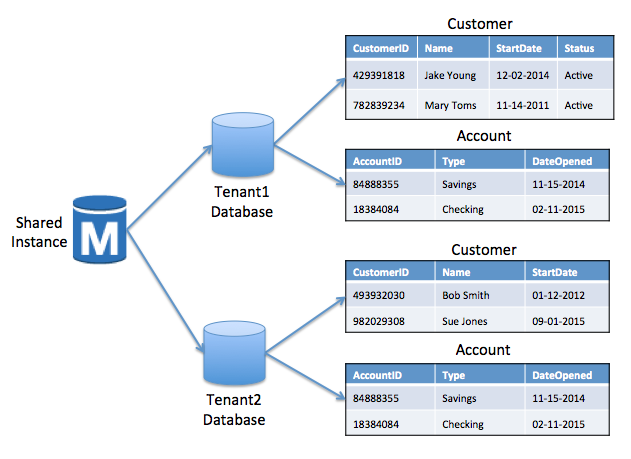
具有独立表/模式的RDS网桥
上图提供了该替代桥梁模型的图示。注意,我们为每个租户创建了数据库,然后租户拥有自己的表集合。对于一些SaaS组织,这更自然地确定了租户数据的管理范围,避免了将命名传播到单个表的需要。
这个模型很有吸引力,但它可能不是最适合所有类型的RDS。某些RDS容器限制了可以为实例创建的数据库/模式的数量。例如,SQL Server容器每个实例只允许30个数据库,这对于大多数SaaS环境来说可能是不可接受的。
尽管网桥模型允许租户之间的变化,但重要的是要知道,通常情况下,您仍然应该采用限制模式更改的策略。每次引入模式更改时,您都可以在不占用任何停机时间的情况下,成功地将SaaS租户迁移到新模型。因此,尽管该模型简化了这些迁移,但它不会促进一次性租户模式或租户数据表示的定期更改。
水池模型
RDS的池模型依赖于传统的关系索引方案来划分租户数据。作为将所有租户数据移动到共享基础结构模型的一部分,您将租户数据存储在单个RDS实例中,租户共享公共表。这些表使用唯一的租户标识符进行索引,该标识符用于访问和管理每个租户的数据。
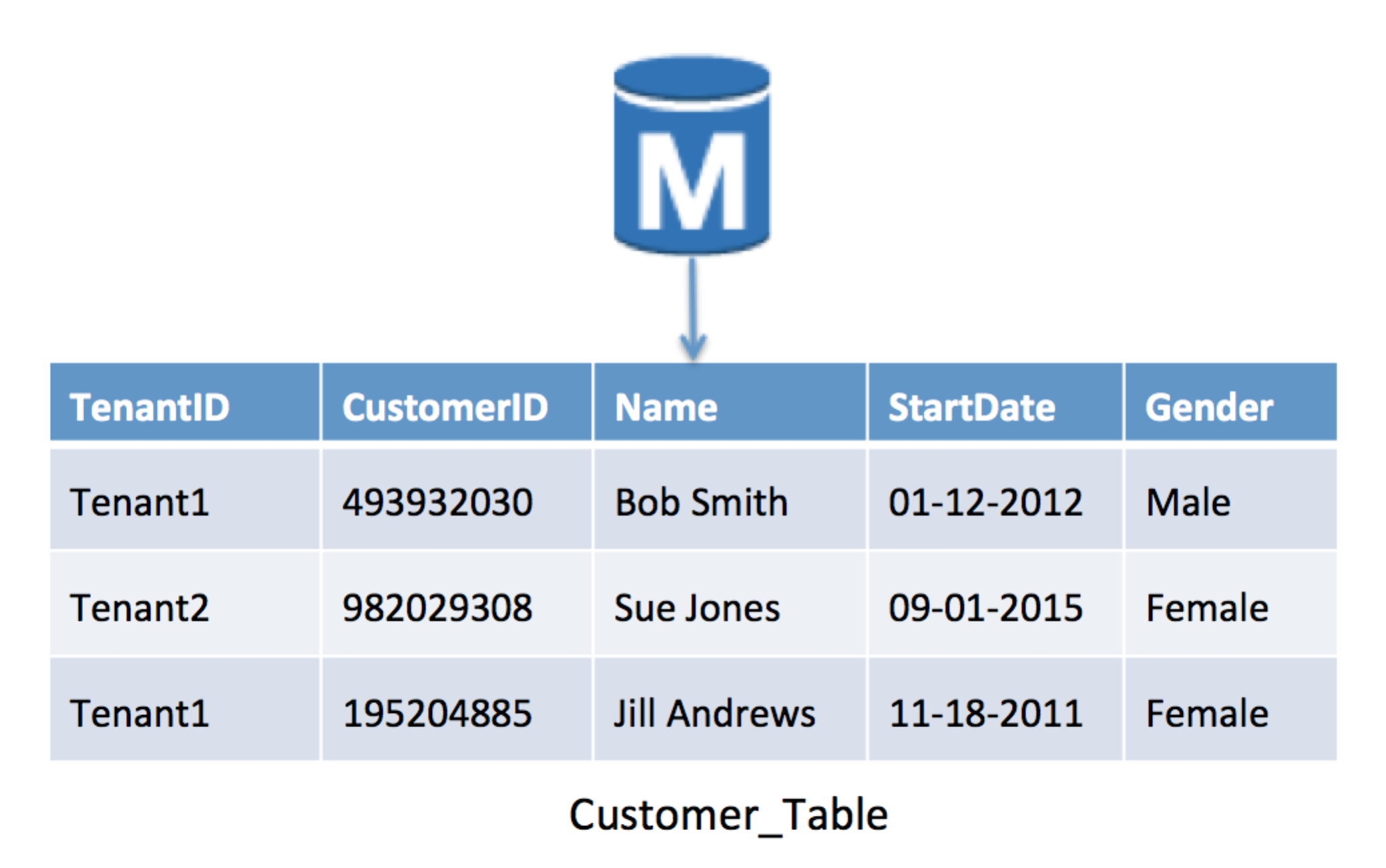
具有共享模式的RDS池模型
上图提供了运行中的池模型的示例。这里,具有一个Customer表的单个RDS实例保存应用程序所有租户的数据。RDS是RDBMS,因此所有租户必须使用相同的模式版本。RDS不像DynamoDB,它有一个灵活的模式,允许每个租户在一个表中有一个唯一的模式。
单个实例限制中的因子
我们描述的许多模型主要集中于将数据存储在单个实例中,并在该实例中划分数据。根据SaaS环境的大小和性能需求,使用单个实例可能不符合租户数据的配置文件。RDS对单个实例中可存储的数据量有限制。以下是限额明细:
- MySQL、MariaDB、Oracle、PostgreSQL–6 TB
- SQL Server–4 TB
- Aurora–64 TB
此外,单个实例还引入了资源争用问题(CPU、内存、I/O)。
在单个实例不切实际的情况下,自然的扩展是引入一种分片方案,其中租户数据分布在多个实例中。使用这种方法,您可以从一小部分碎片实例开始。然后,不断观察租户数据的配置文件并扩展实例的数量,以确保没有单个实例达到限制或成为瓶颈。
权衡权衡
使用RDS的权衡相当简单。主要主题通常更多地是交易管理和灵活的供应复杂性。总体而言,RDS上的思洛存储器模型可能会降低资源调配自动化的痛点。然而,与池模型相关的成本和管理效率往往令人信服。当您考虑这些模型将如何与您的持续交付环境保持一致时,这一点尤为重要。
- 58 次浏览
【SaaS架构】SaaS存储策略--关注敏捷性
视频号
微信公众号
知识星球
多租户存储选项的矩阵可能令人望而生畏。确定能够代表灵活性、隔离性和可管理性的最佳组合的解决方案可能是一项挑战。尽管考虑所有选项很重要,但在多租户存储思维中不断考虑灵活性也是至关重要的。SaaS组织的成功通常很大程度上取决于其解决方案中的灵活性。
您选择的存储技术和隔离模式直接影响您轻松部署新特性和功能的能力。数据的结构和内容的形状经常会发生变化,以支持新功能,这意味着您的基础存储模型必须适应这些变化而不需要停机。在支持这种无缝迁移方面,每个隔离模型都有利弊。当你考虑你的选择时,给这些因素适当的权重。
尽管筒仓、桥梁和水池模型都具有敏捷性,但您可以应用通用原则来帮助您尽可能保持敏捷。一个关键原则是,需要尽量减少租户数据的一次性变化,这一点非常明显,但有时会违反。例如,思洛存储器和桥接器模型可能会导致存储变化,从而使您将新功能作为单个自动化事件的一部分推送给所有SaaS客户的能力变得复杂。团队通常使用自动化和连续部署来限制多租户存储策略带来的摩擦。
当您制定存储战略时,请期待并接受存储需求不断发展的现实。SaaS客户的需求是一个不断变化的目标,您今天选择的存储模式可能不适合明天。AWS还将继续推出新的功能和服务,这些功能和服务将为您提供新的机会,以增强您的存储方法。
- 98 次浏览
【SaaS架构】SaaS存储策略--分层存储模型
视频号
微信公众号
知识星球
AWS为开发人员提供了广泛的存储服务,每种服务都可以组合应用,以满足SaaS租户不同的成本和性能要求。这里的关键是不要人为地将您的存储策略限制在任何一种AWS服务或存储技术上。
在分析应用程序的存储需求时,请采取更精细的方法,将给定存储服务的优势与应用程序各个组件的特定需求相匹配。例如,DynamoDB可能非常适合一种应用程序服务,而RDS可能更适合另一种应用。如果您的解决方案使用微服务架构,其中每个服务都有自己的存储视图,请考虑哪种存储技术最适合每个服务的配置文件。在组成应用程序的一组微服务中发现一系列不同的存储解决方案并不罕见。
这一战略还为将存储作为分层SaaS解决方案的另一种方式创造了机会。每一层基本上都可以利用一个单独的存储战略,提供不同级别的性能和SLA,以区分解决方案各层的价值主张。通过使用此方法,您可以更好地将租户层与他们对基础架构施加的成本和负载相一致。
- 114 次浏览
【SaaS架构】SaaS存储策略--安全注意事项
视频号
微信公众号
知识星球
数据安全必须是SaaS提供商的首要任务。当采用多租户策略时,您的组织需要一个强大的安全策略,以确保租户数据得到有效保护,防止未经授权的访问。保护这些数据并传达您的系统已采用适当的安全措施,对于获得SaaS客户的信任至关重要。
您选择的存储策略可能使用AWS支持的常见安全模式。例如,静态数据加密是一种横向策略,可以在任何模型中普遍应用。这提供了一个基本的安全级别,确保即使存在对数据的未经授权的访问,如果没有解密信息所需的密钥,也将是无用的。
现在,当您查看思洛存储器、网桥和池模型的安全配置文件时,您将注意到每种模型在实现安全性方面的其他变化。例如,您会发现AWS身份和访问管理(Amazon IAM)在如何确定和控制对租户数据的访问方面存在细微差别。通常,思洛存储器和网桥模型与IAM策略更自然,因为它们可以用于限制对整个数据库或表的访问。一旦您转换到池模型,您可能无法利用IAM来确定对数据的访问范围。相反,更多的责任转移到应用程序服务的授权模型上。这些服务必须使用用户的身份来解析它们在共享表示中对数据的范围和控制。
隔离和安全
支持租户隔离对于某些组织和域来说是至关重要的。即使在虚拟化环境中,数据也是分离的,这一概念对于具有特定监管或安全要求的SaaS提供商来说也是必不可少的。
在考虑每个AWS存储解决方案时,请考虑如何在每个AWS存储服务上实现隔离。正如您将看到的,在RDS上实现隔离与在DynamicDB上实现隔离看起来非常不同。在选择存储策略和评估客户的安全考虑事项时,请考虑这些差异。
- 91 次浏览
【SaaS架构】SaaS存储策略--开发者体验
视频号
微信公众号
知识星球
作为一般的体系结构原则,开发人员通常尝试引入层或框架,以集中和抽象其应用程序的水平方面。这里的目标是集中和标准化策略和租户解决策略。例如,您可以引入一个数据访问层,将租户上下文注入到数据访问请求中。这将简化开发并限制开发人员对租户身份如何在系统中流动的了解。
设置此层还为您提供了更多策略和策略选项,这些策略和策略可能因租户而异。它还为集中配置和跟踪存储活动创造了一个自然的机会。
- 18 次浏览
【SaaS架构】SaaS存储策略--总结
视频号
微信公众号
知识星球
SaaS客户的存储需求并不简单。SaaS的现实是,您的业务领域、客户和遗留问题会影响您如何确定多租户存储选项的组合最能满足您的业务需求。
尽管没有一种策略能够普遍适用于每个环境,但很明显,某些模型确实与SaaS交付模型的核心原则更为一致。总的来说,任何AWS存储技术上基于池的存储方法都与管理和操作多租户环境的统一方法的需求相一致。将所有租户放在一个共享的存储库和表示中可以简化和统一您的方法的操作和部署足迹,从而实现跨租户的健康和性能视图。
筒仓和桥梁模型当然有自己的位置,对于一些SaaS提供商来说,这是绝对必要的。这里的关键是,如果你沿着这条路走下去,敏捷性会变得更加复杂。某些AWS存储技术更适合支持独立租户存储方案。例如,在RDS上构建思洛存储器模型比在DynamicDB上构建要简单。通常,每当您依赖链接帐户作为分区模型时,您将解决更多的资源调配、管理和扩展难题。
除了实现多租户的机制之外,请考虑每种AWS存储技术的概要如何满足多租户应用程序功能的不同需求。考虑租户将如何访问数据,以及数据的形状需要如何演变以满足租户的需求。您越能将应用程序分解为自主服务,就越能为每个服务选择和选择单独的存储策略。
在研究了这些服务和分配方案之后,您应该对指导您选择多租户存储策略的模式和拐点有了更好的理解。AWS为SaaS提供商提供了丰富的服务和结构,可以组合这些服务和结构来满足任何数量的多租户存储需求。
- 38 次浏览
【SaaS架构】SaaS存储策略--数据迁移
视频号
微信公众号
知识星球
数据迁移是竞争SaaS存储模型评估中经常忽略的领域之一。然而,对于SaaS,请考虑您的架构选择将如何影响您不断部署新特性和功能的能力。尽管需要强调性能和一般租户体验,但也必须考虑存储解决方案如何适应数据基础表示的不断变化。
迁移和多租户
每种多租户存储模型都需要自己独特的方法来处理数据迁移。在思洛存储器和网桥模型中,您可以逐个租户迁移数据。您的组织可能会发现这一点很有吸引力,因为它允许您谨慎地迁移每个SaaS租户,而不会让所有租户都面临迁移错误的可能性。然而,这种方法可能会给部署生命周期的整体协调带来更多复杂性。
在池模型中迁移数据既有吸引力,也有挑战性。在一方面,池模型中的迁移提供了一个单一点,一旦迁移,所有租户都可以成功地转换到新的数据模型。另一方面,在池迁移过程中引入的任何问题都可能影响您的所有租户。
从一开始,您就应该考虑数据迁移如何适合您的整体多租户SaaS战略。如果您尽早将这种迁移编排融入到您的交付管道中,那么您将在发布过程中获得更大程度的灵活性。
最小化侵入性变化
作为经验法则,在考虑系统中的数据将如何演变时,您应该遵循明确的政策和原则。只要可能,团队应该支持与早期版本向后兼容的数据更改。如果您能够找到最小化对应用程序数据表示的更改的方法,那么将限制将数据转换为新表示的高开销。
您可以利用常用的工具和技术来协调迁移过程。事实上,尽管最小化侵入性更改对SaaS开发人员来说非常重要,但这并不是SaaS领域独有的。因此,这超出了我们将在本文中讨论的范围。
- 46 次浏览
【SaaS架构】SaaS存储策略--链接帐户筒仓存储器模型
视频号
微信公众号
知识星球
在深入了解每个存储服务的细节之前,让我们看看如何使用AWS链接帐户在任何AWS存储解决方案之上实现思洛存储器模型。要使用此方法实现筒仓,您的解决方案需要为每个租户提供单独的链接帐户。这可以真正实现筒仓,因为租户的整个基础设施与其他租户完全隔离。
链接账户方法依赖于合并账单功能,该功能允许客户将子账户与整体付款人账户相关联。这里的想法是,即使每个租户都有单独的链接账户,这些租户的账单仍然是汇总的,并作为单个账单的一部分提交给付款人账户。
下图显示了如何使用链接帐户实现思洛存储器模型的概念视图。在这里,您有两个拥有独立账户的租户,每个租户都与一个付款人账户相关联。通过这种隔离,您可以自由利用任何可用的AWS存储技术来存放租户的数据。
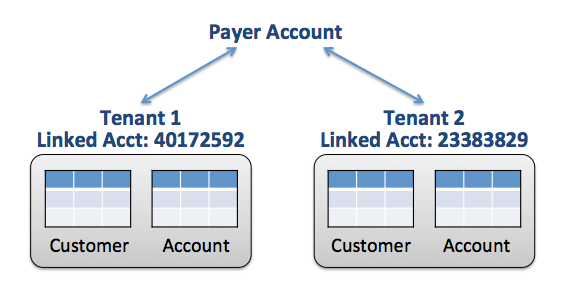
具有链接帐户的筒仓模型
乍一看,对于那些需要筒仓环境的SaaS提供商来说,这似乎是一个非常有吸引力的策略。它当然可以简化个别租户的管理和迁移的某些方面。构建租户成本视图也会更加简单,因为您可以在链接账户级别汇总AWS费用。
即使有这些优点,链接帐户筒仓模型也有重要的局限性。例如,资源调配当然更复杂。除了创建租户的基础设施外,您还需要自动创建每个链接帐户并调整需要的任何限制。然而,更大的挑战是规模。AWS对您可以创建的链接账户数量有限制,这些限制不太可能与将创建大量新SaaS租户的环境相一致。
- 91 次浏览
【SaaS架构】SaaS架构基础
【SaaS架构】SaaS架构基础 - 控制平面与应用程序平面
视频号
微信公众号
知识星球
上图提供了核心SaaS架构概念的概念视图。现在,让我们深入了解,并更好地定义SaaS环境如何分解为不同的层。对SaaS概念之间的界限有了更清晰的了解,将更容易描述SaaS解决方案的移动部分。
下图将SaaS环境划分为两个不同的平面。右侧是控制平面。图的这一侧包括用于机载、认证、管理、操作和分析多租户环境的所有功能和服务。
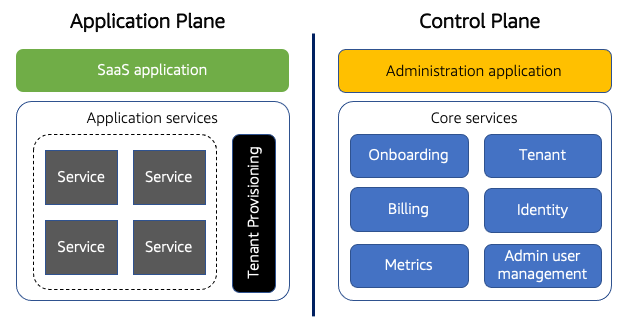
控制平面与应用平面
该控制平面是任何多租户SaaS模型的基础。无论应用程序部署和隔离方案如何,每个SaaS解决方案都必须包含那些服务,这些服务使您能够通过单一、统一的体验管理和运营租户。
在控制平面内,我们进一步将其分解为两个不同的元素。这里的核心服务代表用于协调多租户体验的服务集合。我们已经包括了一些常见的服务示例,这些服务通常是核心的一部分,承认每个SaaS解决方案的核心服务可能会有所不同。
您还将注意到,我们显示了一个单独的管理应用程序。这表示SaaS提供商可能用来管理其多租户环境的应用程序(web应用程序、命令行界面或API)。
一个重要的警告是,控制平面及其服务实际上不是多租户的。该功能没有提供SaaS应用程序的实际功能属性(它确实需要多租户)。例如,如果您查看任何一个核心服务,您都不会发现租户隔离和其他构造是多租户应用程序功能的一部分。这些服务面向所有租户。
图的左侧引用SaaS环境的应用程序平面。这是应用程序的多租户功能所在的位置。图中显示的内容需要保持一定的模糊,因为每个解决方案都可以根据您的领域需求、技术足迹等进行不同的部署和分解。
应用程序域分为两个元素。SaaS应用程序代表您解决方案的租户体验/应用程序。这是租户与SaaS应用程序交互时所接触的表面。然后是表示SaaS解决方案的业务逻辑和功能元素的后端服务。这些可以是微服务,也可以是应用程序服务的其他打包。
您还将注意到,我们已经中断了资源调配。这样做是为了强调这样一个事实,即在入职期间为租户提供的任何资源都将是该应用程序域的一部分。有些人可能认为这属于控制平面。然而,我们将其放置在应用程序域中,因为它必须提供和配置的资源更直接地连接到在应用程序平面中创建和配置的服务。
将其分解为不同的平面,可以更容易地思考SaaS架构的整体布局。更重要的是,它强调需要一组完全超出应用程序功能范围的服务。
- 91 次浏览
【SaaS架构】SaaS架构基础 -- 核心服务
视频号
微信公众号
知识星球
前面提到的控制平面提到了一系列核心服务,它们代表了用于机载、管理和操作SaaS环境的典型服务。进一步强调其中一些服务的作用可能有助于突出它们在SaaS环境中的范围和用途。以下是这些服务的简要概述:
- 入职——每个SaaS解决方案都必须提供一种无摩擦的机制,以将新租户引入您的SaaS环境。这可以是自助注册页面,也可以是内部管理的体验。无论哪种方式,SaaS解决方案都应该尽其所能消除此体验中的内部和外部摩擦,并确保此过程的稳定性、效率和可重复性。它在支持SaaS业务的增长和规模方面发挥着至关重要的作用。通常,该服务协调其他服务以创建用户、租户、隔离策略、资源调配和每租户资源。
- 租户–租户服务提供了一种集中租户的策略、属性和状态的方法。关键是租户不是个人用户。事实上,租户可能与许多用户关联。
- 身份–SaaS系统需要一种明确的方式来将用户连接到租户,从而将租户上下文带入其解决方案的身份验证和授权体验。这会影响入职体验和用户档案的总体管理。
- 计费–作为采用SaaS的一部分,组织通常采用新的计费模式。他们还可以探索与第三方计费提供商的集成。这项核心服务主要集中于支持新租户的入职,并收集用于为租户生成账单的消费和活动数据。
- 指标–SaaS团队非常依赖于他们捕获和分析丰富的指标数据的能力,这些数据可以让租户更清楚地了解他们如何使用系统、他们如何使用资源以及他们如何使用他们的系统。这些数据用于制定运营、产品和业务战略。
- 管理员用户管理–SaaS系统必须同时支持租户用户和管理员用户。管理员用户代表SaaS提供商的管理员。他们将登录到您的运营经验中,以监控和管理您的SaaS环境。
- 66 次浏览
【SaaS架构】SaaS架构基础 : SaaS与托管服务提供商(MSP)
视频号
微信公众号
知识星球
SaaS和托管服务提供商(MSP)模型之间的界限也存在一些混淆。如果您查看MSP模型,它可能具有与SaaS模型类似的目标。
然而,如果您深入了解MSP,您会发现MSP和SaaS实际上是不同的。下图提供了MSP环境的概念视图。
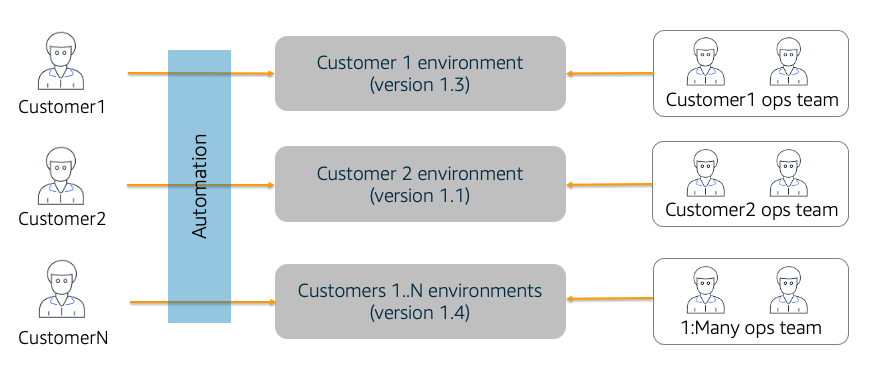
托管服务提供商(MSP)模型
该图表示MSP模型的一种方法。在左侧,您将看到使用MSP模型运行的客户。通常,这里的方法是使用任何可用的自动化来配置每个客户环境,并为该客户安装软件。
右边是MSP为支持这些客户环境而提供的运营足迹的近似值。
需要注意的是,MSP通常安装和管理给定客户想要运行的产品版本。所有客户都可以运行相同的版本,但MSP模型通常不需要这样做。
总的策略是通过拥有这些环境的安装和管理来简化软件提供商的生活。虽然这让提供商的生活更简单,但它并没有直接映射到SaaS产品所必需的价值观和思维方式。
重点是减轻管理责任。这样做并不等同于让所有客户都在同一版本上运行,并拥有统一的管理和运营经验。相反,MSP通常允许单独的版本,并且通常将这些环境中的每一个视为在操作上独立的。
在某些领域,MSP可能开始与SaaS重叠。如果MSP本质上要求所有客户运行相同的版本,并且MSP能够通过一次体验对所有租户进行集中安装、管理、运营和计费,那么可能会开始比MSP更多的SaaS。
更广泛的主题是,自动化环境安装并不等于拥有SaaS环境。只有当您添加了前面讨论的所有其他注意事项时,这才更能代表真正的SaaS模型。
如果我们从本故事的技术和运营方面进行回顾,MSP和SaaS之间的界限将变得更加明显。通常,作为SaaS业务,您的产品能否成功取决于您是否能够深入参与体验的所有活动部分。
这通常意味着掌握入职体验的脉搏,了解运营事件如何影响租户,跟踪关键指标和分析,并与客户保持密切联系。在MSP模型中,如果这项工作交给了其他人,那么您可能最终会从SaaS业务运营的核心关键细节中脱离一个层次。
- 124 次浏览
【SaaS架构】SaaS架构基础--删除单个租户术语
视频号
微信公众号
知识星球
作为使用术语多租户的一部分,人们自然会使用术语单租户来描述SaaS环境。然而,鉴于前面概述的背景,“单一租户”一词造成了混乱。
上图是否为单租户环境?虽然从技术上讲,每个租户都有自己的堆栈,但这些租户仍在多租户模式下运行和管理。这就是为什么通常避免使用“单一租户”一词的原因。相反,所有环境都被描述为多租户,因为它们只是实现了一些租赁的变体,其中一些或全部资源是共享的或专用的。
引入筒仓和水池
考虑到模型的所有这些变化以及多租户这一术语带来的挑战,我们引入了一些术语,使我们能够更准确地捕捉和描述构建SaaS时使用的不同模型。
我们用来描述SaaS环境中资源使用的两个术语是筒仓和池。这些术语允许我们标记SaaS环境的性质,使用多租户作为可应用于任何数量的基础模型的总体描述。
在最基本的层面上,术语思洛用来描述资源专用于给定租户的场景。相反,池模型用于描述租户共享资源的场景。
在我们研究筒仓和池术语的使用方式时,必须明确筒仓和池不是全部或全部概念。筒仓和池可以应用于整个租户的资源堆栈,也可以选择性地应用于整个SaaS环境的一部分。因此,如果我们说某些资源使用了筒仓模型,这并不意味着该环境中的所有资源都是筒仓。这同样适用于我们如何使用术语pooled。
下图提供了一个示例,说明如何在SaaS环境中更细粒度地使用孤立模型和合并模型:
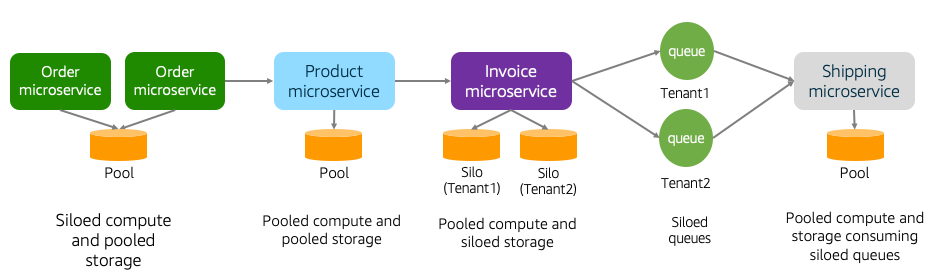
筒仓和水池模型
该图包括一系列示例,旨在说明筒仓和池模型的更具针对性。如果您从左到右执行此操作,您将看到我们从一个订单微服务开始。该微服务具有孤立的计算和池存储。它与具有池计算和池存储的产品服务交互。
然后,产品服务与一个发票微服务交互,该服务汇集了计算和孤立存储。此服务通过队列将消息发送到发货服务。队列以孤立模型部署。
最后,运送微服务从孤立队列获取消息。它使用池计算和存储。
虽然这看起来有点复杂,但目标是突出筒仓和池概念的粒度特性。在您设计和构建SaaS解决方案时,预计您将根据您的领域和客户的需求做出这些筒仓和池决策。
嘈杂的邻居、隔离、分层以及许多其他原因可能会影响您选择应用筒仓或池模型的方式和时间。
- 109 次浏览
【SaaS架构】SaaS架构基础-走向统一体验
视频号
微信公众号
知识星球
为了解决这一经典软件困境的需求,组织转向了一种模式,该模式允许他们创建一种单一的、统一的体验,从而允许对客户进行集体管理和操作。
下图提供了一个环境的概念视图,其中所有客户都通过共享模型进行管理、入职、计费和运营。
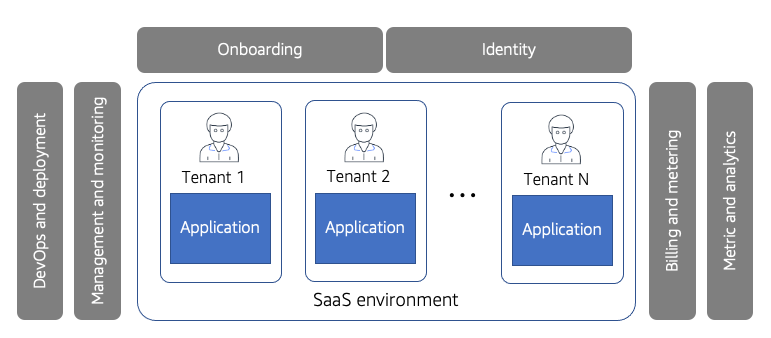
一个环境的概念视图,其中所有客户都通过共享模型进行管理、入职、计费和运营
乍一看,这可能与以前的模型没有什么不同。然而,当我们进一步深入研究时,您会发现这两种方法存在根本性的显著差异。
首先,您将注意到客户环境已重命名为租户。租户的概念是SaaS的基础。基本思想是,您有一个单一的SaaS环境,您的每个客户都被视为该环境的租户,消耗他们所需的资源。租户可以是一家拥有许多用户的公司,也可以直接与单个用户关联。
为了更好地理解租户的想法,可以考虑公寓或商业建筑的想法。这些建筑中的每一个空间都出租给了单独的租户。租户依靠建筑物的一些共享资源(水、电等)来支付他们的消费。
SaaS租户遵循类似的模式。您拥有SaaS环境的基础设施,以及使用该环境基础设施的租户。每个租户消耗的资源量可能不同。这些租户也是集体管理、计费和运营的。
如果你回头看图表,你会看到租赁的概念变得生动起来。在这里,租户不再拥有自己的环境。相反,所有租户都被安置在一个集体SaaS环境中并在其中进行管理。
该图还包括围绕SaaS环境的一系列共享服务。这些服务对SaaS环境的所有租户都是全球性的。这意味着,例如,该环境的所有租户都共享登录和身份。管理、运营、部署、计费和度量也是如此。
这种统一的服务集的思想是SaaS的基础,这些服务普遍应用于所有租户。通过分享这些概念,您可以解决与上述经典模型相关的许多挑战。
这个图的另一个关键的、有点微妙的元素是,这个环境中的所有租户都在运行相同版本的应用程序。为每个客户运行单独的一次性版本的想法已经不复存在。让所有租户运行同一版本是SaaS环境的一个基本区别属性。
通过让所有客户运行相同版本的产品,您不再面临经典安装软件模型的许多挑战。在统一模型中,新功能可以通过一个共享流程部署到所有租户。
这种方法使您能够使用一个单一的操作面板来管理和操作所有租户。这使您能够通过共同的运营体验来管理和监控租户,从而允许在不增加增量运营开销的情况下添加新租户。这是SaaS价值主张的核心部分,它使团队能够减少运营费用,并提高整体组织敏捷性。
想象一下,在这个模型中增加100或1000个新客户意味着什么。不用担心这些新客户会如何侵蚀利润并增加复杂性,您可以将这种增长视为它所代表的机会。
通常,SaaS的重点是如何实现此模型中间的应用程序。企业希望关注数据的存储方式、资源的共享方式等。然而,现实是,尽管这些细节非常重要,但有许多方法可以构建应用程序,并将其作为SaaS解决方案呈现给客户。
重要的是,更广泛的目标是为租户环境提供单一、统一的体验。拥有这种共享的经验,使您能够推动与SaaS业务总体目标相关的增长、敏捷性和运营效率。
- 49 次浏览
【SaaS架构】SaaS架构基础: 最初的动机
视频号
微信公众号
知识星球
为了理解SaaS,让我们从一个相当简单的概念开始,了解我们在创建SaaS业务时要实现的目标。最好的开始是看看传统(非SaaS)软件是如何创建、管理和操作的。
下图提供了几个供应商如何打包和交付其解决方案的概念视图。
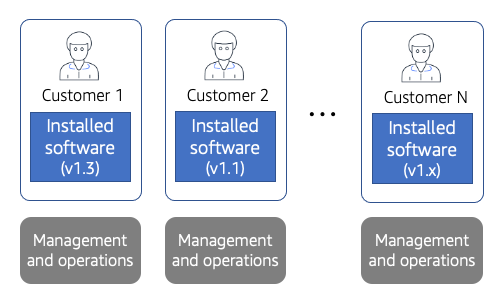
打包和交付软件解决方案的经典模型
在这个图中,我们描述了一组客户环境。这些客户代表购买了供应商软件的不同公司或实体。这些客户中的每一个基本上都在一个独立的环境中运行,在这个环境中他们安装了软件提供商的产品。
在此模式下,每个客户的安装都被视为专用于该客户的独立环境。这意味着客户将自己视为这些环境的所有者,可能需要一次性定制或支持其需求的独特配置。
这种心态的一个常见副作用是,客户将控制他们运行的产品版本。这种情况可能有多种原因。客户可能担心新功能,或者担心采用新版本带来的干扰。
您可以想象这种动态会如何影响软件提供商的运营足迹。您越允许客户拥有一次性环境,管理、更新和支持每个客户的不同配置就越具有挑战性。
这种对一次性环境的需求通常要求组织创建专门的团队,为每个客户提供单独的管理和运营经验。虽然这些资源中的一些可能会在客户之间共享,但该模型通常会为每个新入职的客户引入增量费用。
让每个客户在自己的环境中(在云中或内部)运行他们的解决方案也会影响成本。虽然您可以尝试扩展这些环境,但扩展将仅限于单个客户的活动。本质上,您的成本优化仅限于在单个客户环境的范围内实现的目标。这也意味着您可能需要单独的扩展策略来适应客户之间的活动变化。
最初,一些软件企业会将此模型视为一个强大的架构。他们利用提供一次性定制的能力作为销售工具,允许新客户提出其环境特有的要求。尽管客户数量和业务增长仍然温和,但这种模式似乎完全可持续。
然而,随着公司开始取得更广泛的成功,这种模式的限制开始产生真正的挑战。例如,设想一个场景,您的业务达到了显著的增长高峰,从而快速增加了大量新客户。这种增长将开始增加运营开销、管理复杂性、成本和一系列其他问题。
最终,这种模式的总体开销和影响可能开始从根本上破坏软件业务的成功。第一个痛点可能是运营效率。与吸引客户相关的人员配置和成本增加开始侵蚀业务利润。
然而,运营问题只是挑战的一部分。真正的问题是,这种模式随着规模的扩大,直接开始影响企业发布新功能和跟上市场步伐的能力。当每个客户都有自己的环境时,提供商必须在尝试将新功能引入其系统时平衡一系列更新、迁移和客户需求。
这通常会导致更长和更复杂的发布周期,这往往会减少每年发布的数量。更重要的是,这种复杂性使得团队在每个新特性发布给客户之前就花了更多的时间来分析它们。团队开始更专注于验证新功能,而不是交付速度。发布新功能的开销变得如此巨大,以至于团队更加专注于测试机制,而较少关注推动其产品创新的新功能。
在这种较慢、更谨慎的模式下,团队往往会有较长的周期时间,这会在创意开始与客户手中之间产生越来越大的差距。总的来说,这会阻碍你对市场动态和竞争压力做出反应的能力。
- 46 次浏览
【SaaS架构】SaaS架构基础:SaaS是一种商业模式
视频号
微信公众号
知识星球
定义SaaS意味着什么首先要同意一个关键原则:SaaS是一种商业模式。这意味着最重要的是,SaaS交付模型的采用是由一组业务目标直接驱动的。是的,技术将被用来实现其中的一些目标,但SaaS就是要建立一套针对特定业务目标的思维方式和模式。
让我们更仔细地看看与采用SaaS交付模式相关的一些关键业务目标。
- 敏捷性——这一术语概括了SaaS的更广泛目标。成功的SaaS公司是建立在这样一个理念之上的:他们必须做好准备,不断适应市场、客户和竞争动态。伟大的SaaS公司的结构是不断接受新的定价模式、新的细分市场和新的客户需求。
- 运营效率–SaaS公司依靠运营效率来提高规模和灵活性。这意味着要建立一种文化和工具,专注于创建一个可促进频繁快速发布新功能的运营足迹。它还意味着拥有一种单一、统一的体验,允许您集体管理、操作和部署所有客户环境。支持一次性版本和定制的想法已经不复存在。SaaS业务将运营效率作为其成功增长和扩展业务能力的核心支柱。
- 无摩擦加入——作为更加灵活和包容增长的一部分,您还必须重视减少租户客户入职过程中的任何摩擦。这普遍适用于企业对企业(B2B)和企业对客户(B2C)客户。无论您支持哪一个细分市场或哪种类型的客户,您都需要关注客户的价值实现时间。向以服务为中心的模式的转变要求SaaS业务专注于客户体验的各个方面,特别强调整个入职生命周期的可重复性和效率。
- 创新——转向SaaS不仅仅是为了满足当前客户的需求;这是关于让你进行创新的基本要素。您希望在SaaS模型中对客户需求做出反应和响应。然而,您也希望利用这种灵活性来推动未来的创新,从而为您的客户打开新的市场、机会和效率。
- 市场反应——SaaS不再是传统的季度发布和两年计划的概念。它依靠其敏捷性,使组织能够对市场动态做出反应和响应。对SaaS的组织、技术和文化元素的投资为基于新兴客户和市场动态的业务战略提供了机会。
- 增长–SaaS是一种以增长为中心的业务战略。围绕敏捷性和效率调整组织的所有活动部分,使SaaS组织能够以增长模式为目标。这意味着要建立一种机制,以接受并欢迎您的SaaS产品的快速采用。
您会注意到,这些项目中的每一项都集中在业务结果上。有多种技术策略和模式可用于构建SaaS系统。然而,这些技术策略并没有改变更广泛的商业故事。
当我们与组织坐下来,询问他们在采用SaaS的过程中想要实现什么时,我们总是从以业务为中心的讨论开始。技术选择很重要,但必须在这些业务目标的背景下实现。例如,在没有实现敏捷性、运营效率或无摩擦的情况下成为多租户会破坏SaaS业务的成功。
以此为背景,让我们尝试将其形式化为更简洁的SaaS定义,该定义符合前面概述的原则:
SaaS是一种业务和软件交付模式,它使组织能够以低摩擦、以服务为中心的模式提供解决方案,从而为客户和提供商实现最大价值。它依靠敏捷性和运营效率作为促进增长、覆盖和创新的业务战略的支柱。
您应该看到业务目标之间的一致性,以及它们如何依赖于为所有客户提供共享体验。迁移到SaaS的很大一部分意味着远离可能是传统软件模型一部分的一次性定制。任何为客户提供专业化服务的努力通常都会使我们偏离我们试图通过SaaS实现的核心价值。
- 105 次浏览
【SaaS架构】SaaS架构基础:你是服务,而不是产品
视频号
微信公众号
知识星球
采用“服务”模式不仅仅是营销或术语。在服务思维中,您会发现自己正在远离传统的基于产品的开发方法。虽然特性和功能对每种产品都很重要,但SaaS更强调客户对您的服务的体验。
这是什么意思?在以服务为中心的模式中,您需要更多地考虑客户如何加入您的服务,他们如何快速实现价值,以及您如何快速引入满足客户需求的功能。与您的服务构建、运营和管理方式相关的详细信息不在客户的视野之内。
在这种模式下,我们将SaaS服务视为我们可能使用的任何其他服务。如果我们在餐馆,我们当然关心食物,但我们也关心服务。你们的服务员多久来到你们的餐桌上,多久给你们补充一次水,食物多久送来,这些都是服务体验的衡量标准。这是我们构建SaaS服务的思维方式和价值体系。
这种“服务即服务”模式应该对您构建团队和服务的方式产生重大影响。您的积压工作现在将使这些体验属性与特性和功能处于同等或更高的地位。企业还将这些视为SaaS产品长期增长和成功的基础。
- 30 次浏览
【SaaS架构】SaaS架构基础:抽象和介绍
视频号
微信公众号
知识星球
摘要
在软件即服务(SaaS)模型中运行业务的范围、目标和性质可能很难定义。用于描述SaaS的术语和模式因其来源而异。本文档的目标是更好地定义SaaS的基本元素,并创建在AWS上设计和交付SaaS系统时应用的模式、术语和价值体系的更清晰的图景。更广泛的目标是提供一系列基础见解,让客户更清楚地了解他们在采用SaaS交付模式时应考虑的选项。
本文针对的是SaaS构建者和架构师,他们正处于SaaS之旅的开始阶段,以及更多经验丰富的构建者,他们希望完善对核心SaaS概念的理解。这些信息中的一些信息对SaaS产品所有者和策略师也很有用,他们希望更加熟悉SaaS环境。
您的架构是否完善?
AWS良好架构框架有助于您了解在云中构建系统时所做决策的利弊。框架的六大支柱使您能够学习设计和运行可靠、安全、高效、经济高效和可持续系统的架构最佳实践。使用AWS管理控制台中免费提供的AWS良好架构工具,您可以通过回答每个支柱的一组问题,对照这些最佳实践检查工作负载。
有关云架构参考架构部署、图表和白皮书的更多专家指南和最佳实践,请参阅AWS架构中心。
介绍
术语软件即服务(SaaS)用于描述业务和交付模型。然而,挑战在于,SaaS意味着什么并没有得到普遍理解。
虽然在SaaS的一些核心支柱上达成了一些共识,但对于SaaS意味着什么仍然存在一些困惑。团队看待SaaS的方式自然会有所不同。同时,SaaS概念和术语的不清晰可能会给那些探索SaaS交付模型的人带来一些困惑。
本文档侧重于概述用于描述核心SaaS概念的术语。围绕这些概念有一个共同的思维方式,可以清晰地了解SaaS架构的基本元素,为您提供描述SaaS架构结构的共同词汇。当您深入挖掘基于这些主题的其他内容时,这尤其有用。
本白皮书回顾了多租户的体系结构细节,并探讨了我们如何定义SaaS的基本概念。理想情况下,这也将提供一组更清晰的术语,使组织能够更快地调整其SaaS解决方案的风格和性质。
- 212 次浏览
【SaaS架构】SaaS架构基础—SaaS身份
视频号
微信公众号
知识星球
SaaS为应用程序的身份模型添加了新的考虑因素。当每个用户都经过身份验证时,他们必须连接到特定的租户上下文。此租户上下文提供了整个SaaS环境中使用的租户的基本信息。
租户与用户的这种绑定通常被称为应用程序的SaaS身份。当每个用户进行身份验证时,身份提供者通常会生成一个包含用户身份和租户身份的令牌。
将租户与用户连接是SaaS架构的一个基本方面,具有许多下游影响。此身份过程中的令牌流入应用程序的微服务,用于创建租户感知日志、记录度量、计费、强制租户隔离等。
必须避免依赖于将用户映射到租户的独立机制的场景。这会破坏系统的安全性,并经常在架构中造成瓶颈。
- 108 次浏览
【SaaS架构】SaaS架构基础——B2B和B2C SaaS
视频号
微信公众号
知识星球
SaaS产品面向B2B和B2C市场。虽然市场和客户肯定有不同的动态,但SaaS的总体原则不会以某种方式改变每个市场。
例如,如果您查看入职培训,B2B和B2C客户可能有不同的入职体验。的确,B2C系统可能更关注自助登机流程(尽管B2B系统可能也支持这一点)。
虽然在如何向客户提供入职培训方面可能存在差异,但入职培训的基本基本价值基本相同。即使您的B2B解决方案依赖于内部入职流程,我们仍然希望该流程尽可能无摩擦和自动化。B2B并不意味着我们会改变对客户的期望值。
- 107 次浏览
【SaaS架构】SaaS架构基础——总结
视频号
微信公众号
知识星球
本文档的目标是概述基本的SaaS架构概念,围绕用于描述SaaS模式和策略的模型和术语提供一些澄清。希望这将使组织能够更清晰地了解SaaS的整体情况。
这里所涉及的大部分内容都集中在SaaS意味着什么,重点是创建一个环境,让您通过统一的体验管理和运营所有SaaS租户。这与SaaS首先是一种商业模式的核心思想相联系。您构建的SaaS架构旨在促进这些基本业务目标。
- 65 次浏览
【SaaS架构】SaaS架构基础——重新定义多租户
视频号
微信公众号
知识星球
多租户和SaaS这两个术语通常紧密相连。在某些情况下,组织将SaaS和多租户描述为同一回事。虽然这看起来很自然,但将SaaS和多租户等同起来往往会导致团队对SaaS采取纯粹的技术观点,而实际上,SaaS更多的是一种业务模式,而不是一种架构策略。
为了更好地理解这个概念,让我们从多租户的经典观点开始。在这个纯粹以基础设施为中心的视图中,多租户用于描述租户如何共享资源以提高灵活性和成本效率。
例如,假设您有一个由SaaS系统的多个租户使用的微服务或Amazon弹性计算云(Amazon EC2)实例。该服务将被视为在多租户模式中运行,因为租户共享运行该服务的基础设施。
这个定义的挑战在于它太直接地将多租户的技术概念附加到SaaS上。它假设SaaS的定义特征是它必须拥有共享的多租户基础设施。当我们研究SaaS在不同环境中实现的各种方式时,SaaS的这种观点开始瓦解。
下图提供了SaaS系统的视图,揭示了我们在定义多租户时面临的一些挑战。
在这里,您将看到前面描述的经典SaaS模型,其中包含一系列由共享服务包围的应用程序服务,允许您共同管理和运营租户。
新的是我们包含的微服务。该图包括三个示例微服务:产品、订单和目录。如果仔细观察这些服务的租赁模式,您会发现它们都采用了稍微不同的租赁模式。
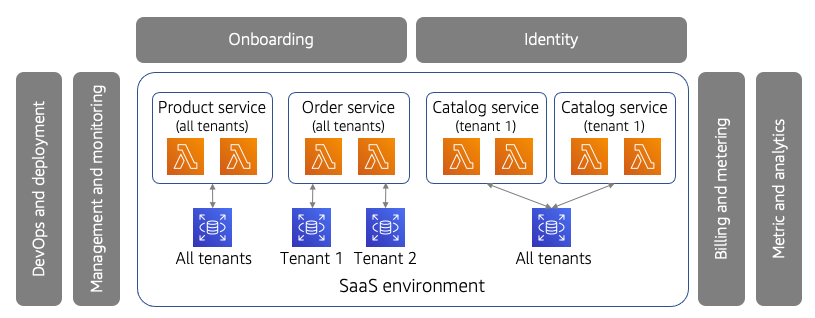
SaaS和多租户
产品服务与所有租户共享其所有资源(计算和存储)。这符合多租户的经典定义。然而,如果您查看订单服务,您会发现它为每个租户提供了共享计算,但存储空间是独立的。
目录服务添加了另一种变体,其中每个租户的计算是独立的(每个租户都有单独的微服务部署),但它为所有租户共享存储。
这种性质的变化在SaaS环境中很常见。嘈杂的邻居、分层模型、隔离需求这些都是您可能会选择性地共享或隔离SaaS解决方案的原因之一。
考虑到这些变化和许多其他可能性,弄清楚如何使用术语“多租户”来描述这种环境变得更具挑战性。总体而言,就客户而言,这是一个多租户环境。然而,如果我们使用最技术的定义,这个环境的某些部分是多租户的,有些则不是。
这就是为什么有必要不再使用术语多租户来描述SaaS环境。相反,我们可以讨论如何在应用程序中实现多租户,但避免使用它来将解决方案描述为SaaS。如果要使用术语“多租户”,那么将整个SaaS环境描述为多租户更有意义,因为知道架构的某些部分可能是共享的,而有些部分可能不是共享的。总体而言,您仍在多租户模式中操作和管理此环境。
极端情况
为了更好地强调这种租赁的概念,让我们来看一个SaaS模型,其中租户共享零资源。下图提供了一些SaaS提供商使用的示例SaaS环境。
每个租户的堆栈
在这个图中,您将看到我们仍然有共同的环境围绕着这些租户。然而,每个租户都部署了一个专用的资源集合。在此模型中,租户不共享任何内容。
这个例子挑战了多租户的含义。这是一个多租户环境吗,即使没有共享任何资源?使用该系统的租户对具有共享资源的SaaS环境有着相同的期望。事实上,他们可能不知道在SaaS环境下如何部署资源。
即使这些租户在一个孤立的基础设施中运行,他们仍然是集体管理和运营的。他们共享统一的入职、身份、指标、计费和运营经验。此外,当发布新版本时,它将部署到所有租户。为了实现这一点,您不能允许为单个租户进行一次性定制。
这个极端的例子为测试多租户SaaS的概念提供了一个很好的模型。虽然它可能无法实现共享基础设施的所有效率,但它是一个完全有效的多租户SaaS环境。对于一些客户,他们的领域可能会规定他们的一些或所有客户在这个模型中运行。这并不意味着它们不是SaaS。如果他们使用这些共享服务,并且所有租户运行相同的版本,这仍然符合SaaS的基本原则。
考虑到这些参数和SaaS的更广泛定义,您可以看到需要发展多租户这一术语的使用。将任何以多租户的方式共同管理和操作的SaaS系统称为多租户更有意义。然后,您可以使用更精细的术语来描述在SaaS解决方案的实现中如何共享或专用资源。
- 198 次浏览
【SaaS架构】SaaS架构基础—计量、度量和计费
视频号
微信公众号
知识星球
SaaS的讨论也倾向于包括计量、度量和计费的概念。这些概念通常合并为一个概念。然而,区分计量、度量和计费在SaaS环境中扮演的不同角色很重要。
这些概念的挑战在于,它们经常对同一个词有重叠的用法。例如,我们可以讨论用于生成账单的计量。同时,我们还可以讨论用于跟踪与计费无关的资源的内部消耗的计量。我们还讨论了许多上下文中的度量和SaaS,这些上下文可以混合到讨论中。
为了帮助解决这个问题,让我们将一些特定的概念与这些术语中的每一个联系起来(知道这里没有绝对的概念)。
- 计量——这个概念有很多定义,但最适合SaaS计费领域。其想法是,您可以测量租户活动或资源消耗,以收集生成账单所需的数据。
- 度量标准–度量标准代表您为分析业务、运营和技术领域的趋势而捕获的所有数据。该数据用于跨SaaS团队中的许多上下文和角色。
这一区别并不重要,但有助于简化我们对SaaS环境中计量和度量的作用的思考。
现在,如果我们将这两个概念与示例联系起来,您可以考虑使用特定的计量事件来检测应用程序,这些事件用于显示生成账单所需的数据。这可能是请求的数量、活动用户的数量,也可能映射到与对客户有意义的某个单元相关的某个消耗总量(请求、CPU、内存)。
在您的SaaS环境中,您将从应用程序中发布这些计费事件,它们将被您的SaaS系统采用的计费结构吸收和应用。这可能是一个定制的第三方计费系统。
相比之下,衡量标准背后的思维方式是捕捉那些对评估不同租户对您的系统造成的健康和运营影响至关重要的行动、活动、消费模式等。您在这里发布和聚合的度量更多地取决于不同角色(运营团队、产品所有者、架构师等)的需求。在这里,这些度量数据被发布并聚合到一些分析工具中,这些分析工具允许这些不同的用户构建系统活动的视图,以分析系统中最符合其角色的方面。产品所有者可能想了解不同租户是如何使用功能的。架构师可能需要帮助他们理解租户如何消耗基础设施资源的视图,等等。
- 138 次浏览
【SaaS架构】SaaS架构基础知识--全栈筒仓和池
视频号
微信公众号
知识星球
筒仓和池也可以用来描述整个SaaS堆栈。在这种方法中,租户的所有资源都以专用或共享的方式部署。下图提供了如何在SaaS环境中实现这一点的示例。
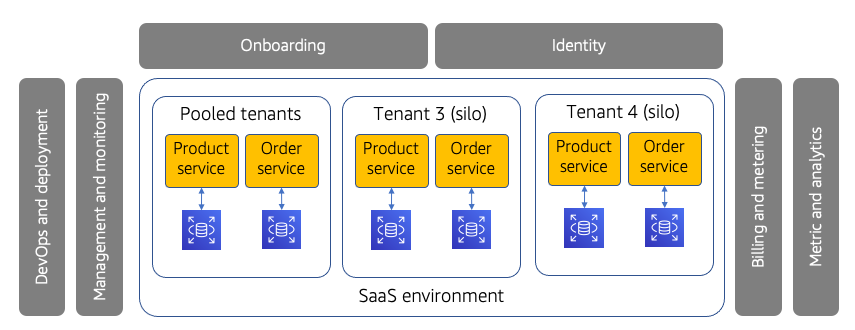
全堆筒仓和水池模型
在该图中,您将看到用于全栈租户部署的三种不同模型。首先,您将看到有一个完整的堆栈池环境。此池中的租户共享所有资源(计算、存储等)。
所示的其他两个堆栈旨在表示全堆栈孤立的租户环境。在这种情况下,租户3和租户4被显示为各自具有自己的专用堆栈,其中没有资源与其他租户共享。
在相同的SaaS环境中,筒仓模型和池模型的混合并不那么典型。例如,假设您有一组基本层租户,他们为使用您的系统支付适中的价格。这些租户被安置在联合环境中。
同时,你也可能有高级租户愿意为在筒仓中运行的特权支付更多费用。这些客户使用单独的堆栈进行部署(如图所示)。
即使在这个模型中,您可能允许租户在自己的全栈筒仓中运行,这些筒仓也必须不允许对这些租户进行任何一次性的更改或定制。在所有方面,这些堆栈中的每一个都应该运行相同的堆栈配置和相同的软件版本。当发布新版本时,它将部署到池租户环境和每个孤立环境。
- 106 次浏览
【SaaS架构】SaaS架构基础知识-数据分区
视频号
微信公众号
知识星球
数据分区用于描述用于在多租户环境中表示数据的不同策略。该术语广泛用于涵盖一系列不同的方法和模型,这些方法和模型可用于将不同的数据结构与单个租户相关联。
请注意,经常有人倾向于将数据分区和租户隔离视为可互换的。这两个概念并不等同。当我们谈论数据分区时,我们谈论的是如何为单个租户存储租户数据。对数据进行分区并不能确保数据被隔离。隔离仍然必须单独应用,以确保一个租户无法访问另一个租户的资源。
每种AWS存储技术都为数据分区策略带来了自己的考虑因素。例如,在AmazonDynamoDB中隔离数据与使用AmazonRelationalDatabaseService(AmazonRDS)隔离数据看起来非常不同。
通常,在考虑数据分区时,首先要考虑数据是孤立的还是汇集的。在孤立模型中,每个租户都有一个不同的存储结构,没有混合数据。对于池式分区,数据根据租户标识符进行混合和分区,租户标识符确定哪些数据与每个租户关联。
例如,对于AmazonDynamoDB,一个孤立的模型为每个租户使用一个单独的表。通过将租户标识符存储在管理所有租户数据的每个AmazonDynamoDB表的分区键中,可以实现AmazonDynamo DB中的数据池化。
您可以想象这在AWS服务的范围内会有怎样的变化,每个服务都引入了自己的结构,这可能需要不同的方法来实现每个服务的筒仓和池存储模型。
虽然数据分区和租户隔离是单独的主题,但您选择的数据分区策略可能会受到数据隔离模型的影响。例如,您可能会存储一些存储,因为这种方法最符合您的领域或客户的要求。或者,您可能会选择思洛存储器,因为池模型可能不允许您以解决方案所需的粒度级别强制隔离。
吵闹的邻居也会影响你的隔离方式。应用程序中的某些工作负载或用例可能需要保持独立,以限制来自其他租户的影响或满足服务级别协议(SLA)。
- 44 次浏览
【SaaS架构】SaaS架构基础知识-租户隔离
视频号
微信公众号
知识星球
您将客户转移到多租户模式中的次数越多,他们就越担心一个租户访问另一个租户的资源的可能性。SaaS系统包括明确的机制,确保每个租户的资源即使在共享基础设施上运行也是隔离的。
这就是我们所说的租户隔离。租户隔离背后的思想是,您的SaaS架构引入了严格控制资源访问的结构,并阻止任何访问另一个租户资源的尝试。
请注意,租户隔离与一般安全机制是分开的。您的系统将支持身份验证和授权;然而,租户用户经过身份验证并不意味着您的系统已实现隔离。隔离与应用程序中的基本身份验证和授权分开应用。
为了更好地理解这一点,假设您使用了身份提供者来验证对SaaS系统的访问。来自该认证体验的令牌还可以包括关于用户角色的信息,该信息可以用于控制该用户对特定应用功能的访问。这些构造提供安全性,但不提供隔离。事实上,用户可以经过身份验证和授权,并且仍然可以访问另一个租户的资源。关于身份验证和授权的任何内容都不一定会阻止此访问。
租户隔离只关注于使用租户上下文来限制对资源的访问。它评估当前租户的上下文,并使用该上下文来确定该租户可以访问哪些资源。它对该租户内的所有用户应用此隔离。
当我们研究如何在所有不同的SaaS架构模式中实现租户隔离时,这变得更具挑战性。在某些情况下,可以通过将整个资源堆栈专用于租户来实现隔离,其中网络(或更粗粒度的)策略阻止跨租户访问。在其他场景中,您可能拥有需要更细粒度策略来控制资源访问的池资源(AmazonDynamoDB表中的项)。
任何访问租户资源的尝试都应仅限于属于该租户的资源。SaaS开发人员和架构师的工作是确定哪些工具和技术组合将支持特定应用程序的隔离需求。
- 116 次浏览
【SaaS架构】SaaS架构基础知识——进一步阅读
【SaaS架构】SaaS镜头
视频号
微信公众号
知识星球
【SaaS透镜】SaaS透镜 -摘要和简介
【SaaS架构】SaaS镜头-术语定义
【SaaS架构】SaaS镜头-一般设计原则
【SaaS架构】SaaS镜头-场景
【SaaS架构】SaaS镜头-场景之无服务器SaaS
【SaaS架构】SaaS镜头-场景之无服务器SaaS : 防止跨租户访问
【SaaS架构】SaaS镜头-场景之无服务器SaaS : 隐藏租户详细信息层
【SaaS架构】SaaS镜头-场景之Amazon EKS SaaS
【SaaS架构】SaaS镜头 : 场景之全栈隔离
【SaaS架构】SaaS镜头-场景之混合SaaS部署
【SaaS架构】SaaS镜头-场景之多租户微服务
【SaaS架构】SaaS镜头-场景之租户洞察
【SaaS架构】SaaS镜头-架构良好的框架
【SaaS架构】SaaS镜头-架构良好的框架的支柱
【SaaS架构】SaaS镜头-架构支柱-运营卓越支柱
【SaaS架构】SaaS镜头-架构支柱-安全支柱之身份和访问管理
【SaaS架构】SaaS镜头-架构支柱-安全支柱之基础设施保护
【SaaS架构】SaaS镜头-架构支柱-安全支柱之参考资料
【SaaS架构】SaaS镜头-架构支柱-可靠性支柱
【SaaS架构】SaaS镜头-架构支柱-性能效率支柱
【SaaS架构】SaaS镜头-架构支柱-成本优化支柱
- 151 次浏览
【SaaS架构】SaaS镜头 : 场景之全栈隔离
视频号
微信公众号
知识星球
SaaS组织的动力来自于跨租户共享基础设施资源带来的规模经济。同时,现实世界中的一些因素可能会导致SaaS架构,其中环境中的一些或所有租户都需要专用的(孤立的)基础设施。法规遵从性、嘈杂的邻居、分层策略、遗留技术,这些都是您为租户提供自己的基础设施的首要考虑因素。这被称为孤立或全栈隔离SaaS。
这种方法经常被误认为是托管服务提供商(MSP),即公司的产品是为单个客户一次性安装和管理的。这种方法虽然有效,但并不符合SaaS原则。SaaS模式的关键是采用价值体系,所有租户都通过单一、统一的体验进行管理和运营。这意味着每个租户都在运行同一版本的软件,他们都在同一时间进行部署,他们都是通过同一流程登录的,他们都通过适用于所有租户的单一操作体验进行管理。
这种方法不能提供共享基础架构模型(池)的成本效率。它的分布式特性也会使操作和部署更加复杂。尽管如此,如果做得好,全栈模型仍然可以实现敏捷性、创新性和运营效率目标,这是SaaS思维的核心。
图7中的图表提供了完整堆栈隔离(筒仓)模型的更清晰视图。该模型中的每个租户环境都很简单。您将看到,我们为每个租户提供了一个单独的VPC。这些VPC包含每个租户将使用的完全隔离堆栈。计算和存储结构可以由AWS服务的任何组合组成。关键是每个租户环境都具有相同的基础结构配置和相同版本的产品。因此,添加新租户就像为每个租户提供具有相同基础设施占地面积的另一个VPC一样简单。
您还将注意到,该模型使用Amazon Route 53将传入流量路由到适当的VPC。路由依赖于将子域分配给每个租户的模型。这是SaaS环境中非常常见的模式。这种路由也可以通过检查租户JWT令牌的内容、确定其租户上下文以及通过注入的租户标头触发路由规则来实现。然而,这种方法可能会推高帐户限制,并且可能需要调整以解决租户身份的运行时解析的延迟问题。尽管如此,对于某些SaaS环境来说,它仍然是一个有效的选项。

图7:全堆(筒仓)隔离
虽然本示例说明了VPC每租户模型,但也有其他架构可用于实现全栈模型。一些组织可能选择使用每个租户的帐户模型,其中每个租户环境都部署在单独的配置帐户中。您选择的选项将根据您需要支持的租户数量和您所针对的总体管理经验而有所不同。在某些情况下,您需要支持的租户数量可能超过AWS帐户中可以创建的VPC数量。
统一的入职、管理和运营
当我们研究这种体验的入职、管理和运营时,全栈隔离(筒仓)模型的真正SaaS元素就出现了。为了实现SaaS的全部价值主张,该模型必须引入一组可用于管理和操作所有租户环境的服务。
图8中的图表提供了这些额外服务层的视图。我们在这里介绍的是一组完全独立的服务,这些服务是围绕SaaS提供商的管理和管理经验需求构建的。
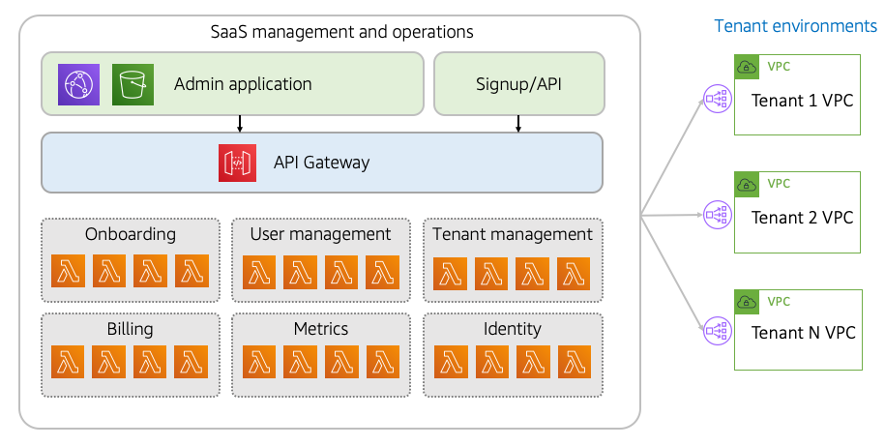
图8:管理全栈隔离环境
虽然租户环境的堆栈是由域、遗留和其他需求形成的,但我们的管理经验的堆栈完全由目标和使用模式驱动,这些目标和使用方式可能与租户的目标和使用情况截然不同。
这种管理非常符合经典的无服务器SaaS应用程序模型。您将看到,我们的管理环境有两个切入点。一个是Admin应用程序,它使用AmazonCloudFront和AmazonS3来提供SaaS管理员用来管理和配置租户环境的应用程序体验。您还将看到这里突出显示的注册和API体验。这表示通过公共API请求触发租户登录的能力。该API也可以是SaaS提供商的开发者API体验的一部分。
最后,我们还强调了一组微服务,它们代表了用于协调入职、管理和运营体验的共享服务。基于Lambda的管理、规模和成本效率模型,我们选择Lambda作为微服务的模型。这些服务可以与其他AWS计算服务一起实现。
在图的右侧,您将看到代表每个租户环境的各个VPC。在这个VPC每租户模型中,您需要为管理平面打开一个有效路径,以便能够配置和访问这些租户环境的资源。AWS为此提供了许多选项,包括AWS PrivateLink、VPC对等和Amazon EventBridge。您选择的选项将取决于您正在建立的管理经验的性质。
- 48 次浏览
【SaaS架构】SaaS镜头-一般设计原则
视频号
微信公众号
知识星球
架构良好的框架确定了一组通用设计原则,以促进SaaS应用程序在云中的良好设计:
没有一刀切的SaaS架构
没有一刀切的SaaS架构:SaaS业务的需求、其领域的性质、法规遵从性要求、市场细分、解决方案的性质——所有这些因素都对SaaS环境的架构有着明显的影响。每一个SaaS架构都应该围绕着一个运营和客户体验,以实现敏捷性和软件即服务原则,这是SaaS产品成功的核心。无论系统是如何构建的,该系统都应使租户能够通过一块玻璃进行入职、管理和操作,从而使SaaS组织实现敏捷性和规模经济,这是构建SaaS业务的基础。
根据每个服务的多租户负载和隔离配置文件分解每个服务
根据每个服务的多租户负载和隔离配置文件分解每个服务:如果您要将系统分解为服务,则分解策略应考虑多租户负载、租户层和隔离需求将如何影响作为系统一部分的服务。在这些场景中,需要单独考虑每个服务。例如,某些服务可能能够汇集数据,而另一些服务可能需要基于合规性或噪声邻居的考虑来隔离它们管理的数据。您可能还会发现,一些服务将部署在思洛存储器模型中,以启用分层策略。例如,高级租户可能会在竖井模型中提供一些服务,作为高级层价值故事的一部分。
隔离所有租户资源
隔离所有租户资源:SaaS系统的成功很大程度上依赖于一种安全模型,该模型确保租户资源始终受到保护,不受任何跨租户访问的影响。一个健壮的SaaS体系结构将在体系结构的所有层引入隔离策略,提供特定的构造,以确保访问租户资源的任何尝试对于当前租户上下文都是有效的。
为增长而设计
为增长而设计:向SaaS模式的转变通常与SaaS组织的增长有关。当您定义SaaS产品的架构和运营足迹时,您必须不断思考您的环境如何能够支持不断增长的新租户。SaaS架构师必须构建一个高度灵活、无摩擦的环境,在不增加大量运营开销的情况下适应租户入职高峰。这里的想法是允许您的客户群增长,而不会扩大SaaS环境的运营或基础架构足迹。
仪器化、捕获和分析租户指标
仪器化、捕获和分析租户指标:当您将多个租户放入一个环境(尤其是共享环境)时,要清楚地了解租户如何使用您的系统可能会很困难。SaaS团队需要投资于度量工具,这些度量工具可以深入了解租户正在使用的功能、他们给您的系统带来的负载、他们面临的瓶颈、他们的活动成本状况等。这些数据是分析租户趋势的核心,这些趋势直接影响业务、架构、,以及SaaS公司的运营状况,并告知其战略。
通过单一的、自动化的、可重复的流程实现租户
通过单一的、自动化的、可重复的流程实现租户:SaaS就是敏捷性。这个敏捷故事的一个关键部分是租户入职流程。一个强大的SaaS系统将包括一个无摩擦、可重复的流程,用于将新租户加入您的系统。这促进了规模,是实现增长的核心。它还可以确保新客户能够更快地实现价值。
计划支持多租户体验:
计划支持多租户体验:SaaS市场和客户并不都适合一个单一的配置文件。SaaS公司通常需要支持一系列租户配置文件,这些文件可以对您的架构和运营提出不同的要求。作为SaaS提供商和架构师,有必要对这些租户角色进行建模,并构建一个单一环境,该环境包括跨越一系列租户体验所需的结构和机制,而不需要一次性版本的产品。确定系统的价值边界非常重要,以使企业能够创建能够覆盖多个细分市场的产品层,并通过这些层促进客户的进步。
通过全球定制支持一次性需求:
通过全球定制支持一次性需求:通过拥有一个由所有客户运行的单一环境来实现SaaS的灵活性和创新。能够共同更新、管理和运营所有客户是SaaS的基础。然而,现实情况是,一些客户可能会要求定制。这些定制应该作为任何客户都可以使用的配置选项引入。将这些功能保持在产品的核心,使SaaS公司能够支持一次性需求,而不会损害业务的灵活性、运营效率和创新目标。
将用户身份绑定到租户身份:
将用户身份绑定到租户身份:架构的每一层都可能需要租户上下文的概念,以便能够记录数据、记录度量、访问数据等。这意味着租户上下文需要成为一个一流的构造,可以在不调用另一个服务的情况下由应用程序的层解析和轻松访问。解决方案的身份验证和授权经验应将租户身份(以及可能的其他租户属性)绑定到已验证用户的身份。这将产生一个通过系统所有层传递的SaaS身份,从而实现对租户上下文的轻松访问。
使基础设施消费与租户活动保持一致:
使基础设施消费与租户活动保持一致:SaaS环境中租户的活动通常是不可预测的。租户正在使用哪些资源,他们如何使用这些资源,以及何时使用这些资源可能会有很大差异。系统中的租户数量也会定期变化。尽管这些因素可能带来扩展挑战,但稳健的SaaS架构将采用限制过度供应的策略,并使应用程序的基础设施消耗与租户活动的实时趋势保持一致。这促进了租户工作负载与整个SaaS基础架构的成本状况之间的更紧密的协调。
限制开发人员对多租户概念的了解:
限制开发人员对多租户概念的了解:虽然租户将在架构的各个层中流动,但您的目标应该是限制开发人员接触租户的程度。根据经验,开发人员编写多租户服务的经验不应与编写没有租户概念的服务有任何不同。如果开发人员需要在其代码中引入租户,这将使管理和强制遵守应用程序的多租户策略和机制变得困难。这意味着向开发人员提供隐藏租赁细节的库和可重用构造。
SaaS是一种业务战略,而不是技术实现:
SaaS是一种业务战略,而不是技术实现:SaaS环境及其底层技术选择直接取决于业务的灵活性、创新和竞争需求。这里的重点和思维集中在为客户创造服务体验上,该服务体验注重零停机、定期更新和与客户的紧密联系。这意味着设计一个架构和运营足迹,以促进持续发展和快速响应市场需求。一个无法实现敏捷性、创新性和运营效率的技术上可靠的架构不太可能跟上市场的竞争格局,尤其是如果您与其他SaaS提供商竞争的话。
创建租户感知的运营视图:
创建租户感知的运营视图:在多租户环境中,运营团队面临一系列新的挑战。尽管在SaaS环境中,对系统的运行状况和活动进行全局查看仍然很重要,但稳健的SaaS运营足迹还将包括对特定租户或租户层如何运行系统的深入了解。SaaS运营团队应构建仪表板和视图,使其能够分析和描述单个租户的活动和负载。能够通过单个租户的视角查看和排除使用情况,对于构建主动、高效的多租户运营体验至关重要。
衡量单个租户的成本影响:
衡量单个租户的成本影响:SaaS公司的业务、架构师和运营团队通常需要清楚了解租户如何影响SaaS环境的成本足迹。例如,基本层租户的成本是否高于高级层租户?租户的消费模式或功能是否会改变您环境的成本状况?这些问题最好通过清晰了解租户成本概况来回答。在租户资源由多个租户共享的环境中,这一点尤其重要。收集和呈现这些数据通常为SaaS业务提供有价值的见解,这些见解可以塑造SaaS公司的架构和业务模型。
- 72 次浏览
【SaaS架构】SaaS镜头-场景之Amazon EKS SaaS
视频号
微信公众号
知识星球
对于许多SaaS提供商来说,Amazon Elastic Kubernetes Service(Amazon EKS)的简介非常符合他们的微服务开发和架构目标。它提供了一种构建和部署多租户微服务的方法,可以帮助他们实现其灵活性、规模、成本和运营目标,而不需要完全改变开发工具和思维方式。丰富的Kubernetes工具和解决方案社区还为SaaS开发人员提供了一系列不同的选择,用于构建、管理、保护和操作其SaaS环境。
对于基于容器的环境,架构的大部分重点是如何成功地确保我们防止跨租户访问。虽然允许租户共享集装箱是一种诱惑,但这意味着租户可以接受软多租户的概念。然而,对于大多数SaaS环境,隔离需求需要更健壮的隔离实现。
这些隔离因素可能会对亚马逊EKS构建的架构模型产生重大影响。使用亚马逊EKS建立SaaS架构的一般指南是防止租户之间共享容器。虽然这增加了架构占地面积的复杂性,但它解决了确保我们创建了一个隔离模型以满足多租户客户的领域、法规遵从性和监管需求的基本需求。
让我们看一个示例架构,以了解SaaS Amazon EKS环境的基本元素。由于这个解决方案有很多移动的部分,让我们先来看看用于支持跨越所有租户的核心水平概念的共享服务(如图4所示)。
首先,您会注意到,我们拥有任何高度可用、高度可扩展的AWS架构的基础元素。该环境包括一个由三个可用区域组成的VPC。来自租户的入站流量路由由Amazon Route 53管理,该路由被配置为将传入的应用程序请求引导到NGINX入口控制器定义的端点。控制器在我们的AmazonEKS集群中启用所选路由,这对于您将在下面看到的多租户路由至关重要。

图4:Amazon EKS SaaS共享服务架构
AmazonEKS集群中运行的服务代表了一些常见服务的示例,这些服务通常是SaaS环境的一部分。注册用于协调新租户的入职。租户管理管理系统中所有租户的状态和属性,并将这些数据存储在AmazonDynamoDB表中。用户管理提供了添加、删除、启用、禁用和更新租户的基本操作。它管理的身份存储在Amazon Cognito中。还包括AWS CodePipeline,以表示用于为系统上的每个新租户提供服务的工具。
此架构仅代表SaaS环境的基本元素。我们现在需要看看将租户引入这一环境意味着什么。考虑到前面描述的隔离考虑,我们的AmazonEKS环境将为每个租户创建单独的命名空间,并保护这些命名空间,以确保我们拥有一个健壮的租户隔离模型。

图5:在Amazon EKS中部署租户环境
图5中的图表提供了SaaS架构中这些名称空间的视图。从表面上看,这个架构与之前的基线图非常相似。关键区别在于,我们将作为应用程序一部分的服务部署到了单独的命名空间中。在本例中,有两个租户具有不同的名称空间。在每项服务中,我们都部署了一些示例服务(订单和产品)。
每个租户名称空间都由上面显示的注册服务提供。这将使用连续交付服务(如AWS CodePipeline)启动创建命名空间、部署服务、创建租户资源(数据库等)和配置路由的管道。这就是入口控制器发挥作用的地方。每个配置的命名空间为该命名空间中的每个微服务创建一个单独的入口资源。这使租户流量能够路由到适当的租户命名空间。
虽然名称空间允许您在AmazonEKS集群中的租户资源之间有清晰的边界,但这些名称空间更多的是一种分组构造。仅使用命名空间无法确保租户负载免受跨租户访问。
为了增强AmazonEKS环境的隔离性,我们需要引入不同的安全构造,以限制在给定命名空间中运行的任何租户的访问。图6中的图表提供了控制每个租户体验的方法的高级说明。

图6:隔离租户资源
这里介绍了两种特定的构造。在命名空间级别,您将看到我们创建了单独的pod安全策略。这些是可以附加到策略的本地Kubernetes网络安全策略。在本例中,这些策略用于限制租户命名空间之间的网络流量。这表示一种粗粒度的方式,以防止一个租户访问另一个租户的计算资源。
除了保护命名空间之外,还必须确保命名空间中运行的服务访问的资源受到限制。在这个例子中,我们有两个隔离的例子。Order微服务使用每个租户的表模型(思洛存储器),并具有限制特定租户访问的IAM策略。Product微服务使用混合租户数据的池模型,并依赖于应用于每个项目的IAM策略来限制租户访问。
- 56 次浏览
【SaaS架构】SaaS镜头-场景之多租户微服务
视频号
微信公众号
知识星球
在多租户环境中运行的微服务必须解决其他问题。这些微服务必须能够在每个服务中引用和应用租户上下文。同时,我们的目标也是限制开发人员在代码中引入租户意识的程度。
为了实现这一目标,SaaS微服务无论其计算模型如何,都应该引入库、模块和共享结构,以将租户特定的处理推送到代码中。这些构造隐藏了解析和应用租户上下文所需的策略和机制。
图10中的图表展示了如何简化微服务的多租户开发。这里的关键思想是,我们采取了任何依赖租户上下文的方法,并使用了库来应用多租户策略。
这个示例说明了SaaS微服务可能需要访问租户上下文的许多场景。流程从调用微服务开始,请求获取产品列表。在我们服务的代码中,您的服务会记录一条消息。微服务开发人员只需将消息记录到日志包装器中。这个包装器从令牌管理器获取租户上下文,并将该上下文注入到我们的消息中,在本例中,该消息发布到AmazonS3。我们的日志策略以及租户数据在日志中的登录方式由我们选择包含在日志助手中的任何策略管理。
这一主题在这里的其他体验中继续。我们对getProducts()的调用首先从令牌管理器获取租户标识符。然后,它使用此上下文从隔离管理器获取租户范围的凭据,然后使用这些凭据从DynamoDB获取产品数据。
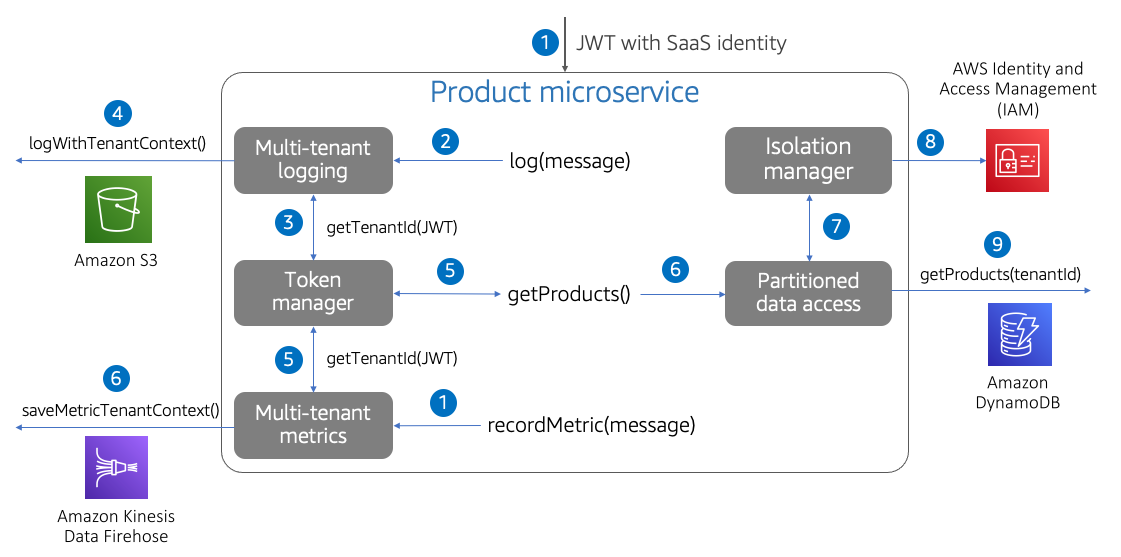
图10:开发多租户微服务
最后,我们的服务使用解析租户标识符和将租户上下文注入度量消息的相同机制来记录度量(可能是执行时间)。
这里概述的实践并不是要将重量级的构造引入到微服务中。这种租赁的抽象遵循将公共概念推入共享代码的一般设计实践。需要注意的是,图中表示的所有概念都在单个微服务的上下文中运行。这些块中的每一个都简单地表示微服务重用的代码。将这些概念分解为单独的服务会增加延迟和复杂性,这通常是不合理的。
- 63 次浏览
【SaaS架构】SaaS镜头-场景之无服务器SaaS
视频号
微信公众号
知识星球
向SaaS交付模式的转变伴随着最大化成本和运营效率的愿望。在租户活动难以预测的多租户环境中,这尤其具有挑战性。找到一种将租户活动与实际资源消耗相结合的扩展策略是很难的。今天有效的策略明天可能行不通。
这些特性使SaaS非常适合无服务器模式。通过从SaaS架构中删除服务器的概念,组织能够依靠托管服务来扩展和交付应用程序所消耗的精确数量的资源。这简化了应用程序的体系结构和操作足迹,无需继续跟踪和管理扩展策略。这也降低了运营开销和复杂性,将更多的运营责任推给了托管服务。
AWS提供了一系列可用于实现无服务器SaaS解决方案的服务。图1中的图表提供了一个无服务器体系结构的示例。
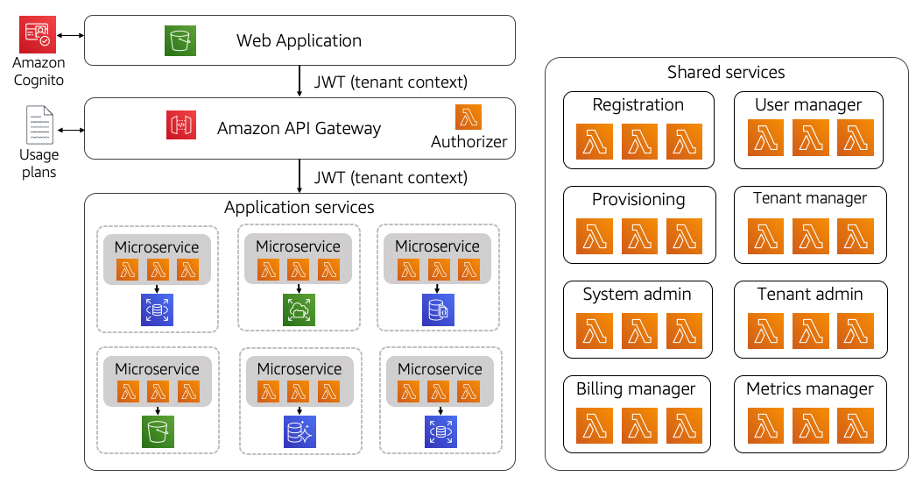
图1:无服务器SaaS架构
在这里,您将看到无服务器SaaS体系结构的移动部分与经典的无服务器web应用程序体系结构没有什么不同。在这个图的左侧,您可以看到我们的web应用程序是由AmazonS3存储桶托管和提供服务的(可能使用了React、Angular等现代客户端框架之一)。
在此架构中,应用程序利用Amazon Cognito作为我们的SaaS身份提供商。这里的身份验证体验产生了一个令牌,其中包括通过JSON Web令牌(JWT)传递的SaaS上下文。然后将此令牌注入到我们与所有下游应用程序服务的交互中。
与我们的无服务器应用程序微服务的交互是由AmazonAPI网关协调的。网关在这里扮演多个角色。它验证传入的租户令牌(通过Lambda授权器),将每个租户的请求映射到微服务,并可用于管理不同租户层的SLA(通过使用计划)。
您还将看到,我们在这里表示了一系列微服务,它们是实现SaaS应用程序的多租户IP的各种服务的占位符。这里的每个微服务都是由一个或多个实现微服务契约的Lambda函数组成的。根据微服务的最佳实践,这些服务还封装了它们管理的数据。这些服务依赖于传入的JWT令牌来获取和应用租户上下文。
我们还展示了每个微服务的存储。为了符合微服务最佳实践,每个微服务都拥有其管理的资源。例如,一个数据库不能由两个微服务共享。SaaS在这里也增加了一个问题,因为数据的多租户表示可以根据服务的不同而变化。一个服务可以为每个租户(思洛存储器)提供单独的数据库,而另一个服务可能将数据合并到同一个表(池)中。您在这里所做的存储选择是由法规遵从性、噪声邻居、隔离和性能考虑因素决定的。
最后,在图的右侧,您将看到一系列共享服务。这些服务提供了图左侧运行的所有租户共享的所有功能。这些服务代表通常作为独立的微服务构建的公共服务,这些服务是机载、管理和运营租户所需的。
有关一般无服务器良好架构的最佳实践的更多信息,请参阅无服务器应用程序镜头白皮书。
- 103 次浏览
【SaaS架构】SaaS镜头-场景之无服务器SaaS : 防止跨租户访问
视频号
微信公众号
知识星球
每个SaaS架构还必须考虑如何防止租户访问另一个租户的资源。有些人怀疑是否需要使用AWS Lambda隔离租户,因为根据设计,在给定的时间内,只有一个租户可以运行Lambda功能。虽然这是正确的,但我们的隔离还必须考虑确保运行函数的租户不访问可能属于另一个租户的其他资源。
对于SaaS提供商,在无服务器SaaS环境中实现隔离有两种基本方法。第一个选项遵循筒仓模式,为每个租户部署一组单独的Lambda函数。使用此模型,您将为每个租户定义一个执行角色,并为每个租户部署单独的功能及其执行角色。此执行角色将定义给定租户可以访问哪些资源。例如,您可以在此模型中部署一组高级租户。然而,这可能很难管理,并且可能会遇到帐户限制(取决于系统支持的租户数量)。
这里的另一个选项更符合池模型。在这里,函数部署了一个执行角色,该角色的范围足够大,可以接受来自所有租户的调用。在此模式下,您必须在运行时在多租户函数的实现中应用隔离范围。图2中的图表提供了如何解决这一问题的示例。

图2:无服务器环境中的隔离
在本例中,您将看到我们有三个租户访问一组Lambda函数。因为这些功能是共享的,所以部署它们的执行角色覆盖所有租户。在这些功能的实现中,我们的代码将使用当前租户的上下文(通过JWT提供)从AWS安全令牌服务(AWS STS)获取一组新的租户范围的凭据。一旦我们有了这些凭据,就可以使用它们访问具有租户上下文的资源。在本例中,我们使用这些作用域凭据来访问存储。
需要注意的是,这个模型确实将隔离模型的一部分推到了Lambda函数的代码中。有一些技术(例如函数包装器)可以将这个概念引入开发人员的视野之外。获取这些证书的细节也可以转移到Lambda层,以使其成为一个更无缝的、集中管理的构造。
- 55 次浏览
【SaaS架构】SaaS镜头-场景之无服务器SaaS : 隐藏租户详细信息层
视频号
微信公众号
知识星球
任何SaaS架构的目标之一都是限制开发人员对租户细节的了解。在无服务器SaaS环境中,您可以使用Lambda层作为创建共享代码的一种方式,该代码可以在开发人员的视野之外实现多租户策略。
图3中的图表提供了如何使用Lambda层来解决这些多租户概念的示例。在这里,您将看到我们有两个单独的微服务(Product和Order),它们需要发布日志和度量数据。这里的关键细节是,这两个服务都需要将租户上下文注入其日志消息和度量事件中。然而,让每个服务自己实现这些策略并不理想。相反,我们引入了一个层,其中包含管理数据发布的代码。

图3:Lambda层隐藏租户细节
您将注意到,我们的层包括接受JWT令牌的日志记录和度量帮助器。这使得每个微服务都可以简单地调用这些函数并提供令牌,而不必担心与哪个租户合作。然后,在该层中,代码使用JWT令牌解析租户上下文,并将其注入日志消息和度量事件中。
这只是如何应用层来隐藏租户上下文的一个片段。真正的价值是,注入租户上下文的策略和机制从开发人员体验中完全删除。它们还分别更新、版本化和部署。这允许在您的环境中更集中地管理这些策略,而无需引入可能增加延迟并造成瓶颈的单独微服务。
- 104 次浏览
【SaaS架构】SaaS镜头-场景之混合SaaS部署
视频号
微信公众号
知识星球
SaaS环境中客户的需求可能因企业而异。虽然构建一个所有客户都在共享基础架构模型(池)中运行的SaaS解决方案具有显著的成本和运营优势,但有时客户可能不愿意与其他租户共享基础架构资源。
对于SaaS提供商来说,一次性客户拥有自己的环境可能是一个挑战。虽然SaaS提供商感到支持这种模式的业务压力,但他们也知道支持这种性质的变化会破坏业务的总体SaaS目标。每个新的一次性客户都会增加运营开销和复杂性。随着每个新客户都加入到这个模型中,您很快就会发现自己离共享基础架构模型带来的创新、灵活性和成本效益越来越远。
然而,有一些架构和运营策略可以在不完全损害您的SaaS愿景的情况下采用这种模式。图9中的图表提供了一个概念视图,说明了如何应对这一挑战。

图9:混合部署模型
在这个图中,您将注意到我们的SaaS环境有两个单独的部署。左侧部署在具有共享基础结构的池模型中。我们的大多数租户都在这样的环境中运营。然而,在右侧,我们部署了托管一个租户(租户4)的多租户环境的单独副本。
该策略的关键在于,两个环境(左侧和右侧)都运行相同版本的SaaS应用程序。任何新的更改或更新都将同时应用于两个环境。更重要的是,您将看到我们拥有跨越这两种环境的单一、统一的管理经验。登录、身份、计量和计费对两种环境都是共享的。
这种共享的经验允许SaaS组织通过一块玻璃来管理和操作这些环境。通过将这些一次性租户纳入此模型,您可以将对SaaS环境的整体灵活性和运营效率的影响降至最低。该模型影响了成本效率并增加了运营复杂性。然而,对于许多SaaS公司来说,这可能是一种合理的妥协。
- 93 次浏览
【SaaS架构】SaaS镜头-场景之租户洞察
视频号
微信公众号
知识星球
随着公司进入多租户模式,捕获和呈现租户如何使用应用程序的洞察变得越来越具有挑战性。租户共享的SaaS环境资源尤其如此。
同时,由于您的所有租户都可能在一个共享环境中运行,因此能够清晰地了解租户的活动和消费情况对于构建强大的SaaS产品至关重要。了解租户正在使用的产品的哪些功能,了解租户如何推动您的环境的架构,以及了解租户的不同层是如何扩展的,这些都是SaaS公司能够有效运营健康SaaS业务所需的见解。
SaaS度量的范围有意宽泛。这是因为SaaS组织中的不同角色在多个上下文中使用度量。这意味着您需要考虑基础设施健康之外的问题。SaaS指标通常包括业务敏捷性、功能消耗、微服务活动、扩展趋势等。其目的是捕获租户和层使用趋势并将其与应用程序和消费活动相关联。
您可以想象为使用这些数据的不同角色设置各种仪表板。例如,产品经理可能希望深入了解面向功能的度量。同时,运营人员可能会使用这些数据来评估各个租户和层的健康和消费趋势。
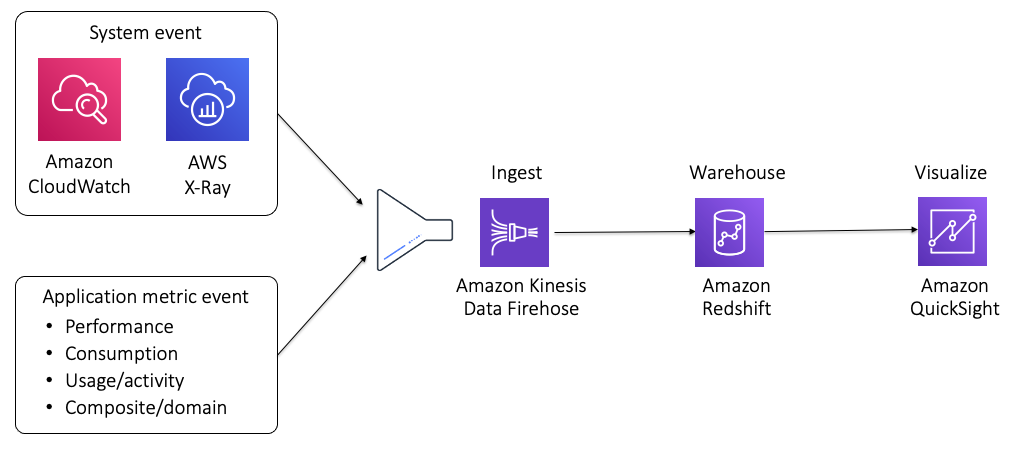
图11:摄取和可视化SaaS指标
捕获和显示这些数据的架构相对简单。它包括传达、发布、摄取、聚合和可视化这些SaaS度量所需的所有机制。图11中的图表提供了可用于在AWS上构建SaaS度量环境的架构视图。
您要捕获的度量数据的来源可能有些不同。如图所示,您的解决方案可能需要从本地AWS源(例如CloudWatch)捕获一些度量。然而,这些数据的很大一部分将来自您在SaaS应用程序中插入的代码。正是在这里,您希望投资于发布最能捕捉洞察的指标,以最大化域数据的业务和运营价值。
这些来源的数据通常用一个通用模式表示,该模式可以表示应用程序中的不同消费类型(计数、持续时间、功能等)。在本例中,这些数据由Amazon Kinesis data Firehose获取,后者将数据发布到Amazon Redshift。最后,AmazonQuickSight用于构建不同的仪表板,这些仪表板用于整个组织,以查看租户和层的趋势。
- 100 次浏览
【SaaS架构】SaaS镜头-术语定义
视频号
微信公众号
知识星球
AWS良好架构框架基于六大支柱:卓越运营、安全性、可靠性、性能效率、成本优化和可持续性。SaaS为这些支柱中的每一个增加了新的考虑因素。SaaS应用程序的多租户性质要求架构师重新考虑如何解决其SaaS环境的安全性、运营效率、稳定性和灵活性。在本节中,我们将概述本文档中使用的SaaS概念。在构建SaaS架构时,您应该考虑10个方面。
话题
- 租户
- 筒仓、水池和桥梁模型
- SaaS身份
- 租户隔离
- 数据分区
- 吵闹的邻居
- 租户入职
- 租户层级
- 租户活动和消费
- 租户感知操作
租户
租户是SaaS环境的最基本结构。作为构建应用程序的SaaS提供商,您正在向客户提供此应用程序。注册使用环境的客户表示为系统的租户。例如,假设您的组织创建了一个会计服务,您希望其他公司可以使用您的服务来管理其业务。这些公司中的每一家都将被视为系统的租户。
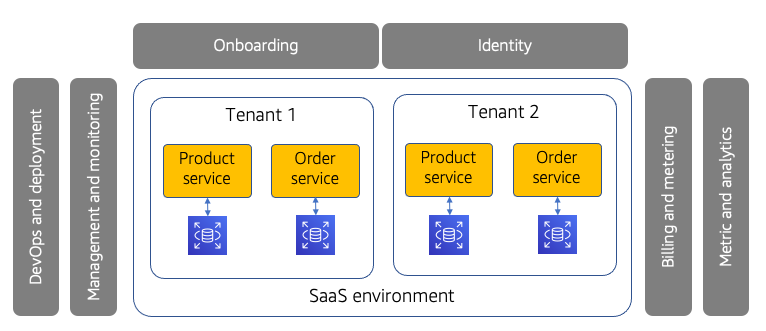
注册后,租户通常会为租户管理员提供用户信息。然后,租户管理员可以登录到系统,并根据其业务需求进行配置。这包括能够将用户添加到给定的租户环境。
该模型中提供的软件被称为多租户SaaS系统,因为服务的每个租户都使用一个单一的共享系统,该系统通过统一的体验支持这些租户的需求。例如,系统的更新通常应用于该系统的所有租户。
筒仓、水池和桥梁模型
SaaS应用程序可以使用各种不同的架构模型构建。监管、竞争、战略、成本效率和市场考虑因素都会对SaaS架构的形状产生一定影响。同时,在定义SaaS应用程序的足迹时,会应用一些策略和模式。这些模式分为三类:筒仓、桥梁和水池。
筒仓模型
筒仓模型是指为租户提供专用资源的体系结构。例如,设想一个SaaS环境,系统的每个租户都有一个完全独立的基础架构堆栈。或者,也许系统的每个租户都有一个单独的数据库。当租户的部分或全部资源以这种专用方式部署时,我们将其称为筒仓模型。需要注意的是,即使筒仓拥有专用资源,筒仓环境仍然依赖于共享身份、入职和运营经验,所有租户都通过共享结构进行管理和部署。这将SaaS与托管服务模式区分开来,在托管服务模式中,客户可能运行不同版本的产品,并具有不同的入职、管理和运营经验。
水池
相比之下,SaaS的池模型是指租户共享资源的场景。这是更经典的多租户概念,租户依靠共享的、可扩展的基础设施来实现规模经济、可管理性、灵活性等。这些共享资源可以应用于SaaS架构的一些或所有元素,包括计算、存储、消息传递等。
桥梁模型
最后的模式是桥梁模型。Bridge旨在承认SaaS业务并不总是完全孤立或集中的现实。相反,许多系统具有混合模式,其中一些系统在筒仓模型中实现,一些系统在池模型中实现。例如,您的体系结构中的一些微服务可能使用思洛存储器实现,而其他微服务可能会使用池。服务数据的监管配置文件及其噪声邻居属性可能会将微服务导向筒仓模型。同时,另一个微服务的灵活性、访问模式和成本概况可能会使其倾向于池模型。
SaaS身份
大多数系统已经依赖身份提供者进行身份验证。在SaaS的世界中,我们需要扩展身份的概念,将租赁纳入我们的身份定义中。这意味着,在验证用户之后,我们需要知道用户是谁以及该用户与哪个租户关联。用户身份与租户身份的合并被称为SaaS身份。这个概念是SaaS架构的一个基本元素,它提供了租户上下文,用于实现SaaS应用程序中的底层多租户策略和策略。
租户隔离
租户隔离是每个SaaS提供商必须解决的基本问题之一。随着独立软件供应商(ISV)转向SaaS并采用共享基础架构模型以实现成本和运营效率,他们还必须承担确定其多租户环境如何确保每个租户无法访问另一个租户的资源的挑战。对于SaaS业务来说,以任何形式跨越这一边界都将是一个重大且可能无法恢复的事件。
尽管租户隔离的需求被视为SaaS提供商的基本需求,但实现这种隔离的策略和方法并不普遍。有很多因素可以影响租户隔离在任何SaaS环境中的实现方式。域、遵从性、部署模型和AWS服务的选择都为租户隔离带来了自己独特的考虑因素。
无论隔离是如何实现的,每个SaaS架构都需要确保其已将确保每个租户的资源已有效隔离所需的构造放置到位。
数据分区
当您查看表示多租户数据的不同体系结构模式时,必须选择如何组织数据。例如,数据是存储在单独的数据库中,还是混合在一个共享结构中?这些多租户存储机制和模式通常称为数据分区。
吵闹的邻居
噪声邻居是一个常用于一般架构模式和策略的术语。噪声邻居背后的想法是,系统的用户可能会对系统的资源施加负载,这可能会对该系统的其他用户产生不利影响。最终结果可能是一个用户会降低另一个用户的体验。
这一概念在多租户环境中扩展了相关性,租户可能正在使用共享资源。更为复杂的是,多租户环境中的工作负载可能是不可预测的。这种组合提高了SaaS架构使用自己的策略的需求,这些策略可以管理和最小化嘈杂租户的潜在影响。
租户入职
SaaS应用程序依赖于一个无摩擦的模型来将新租户引入其环境。这通常需要协调多个组件,以成功地调配和配置创建新租户所需的所有元素。在SaaS架构中,这个过程被称为租户入职。需要注意的是,租户登录可以由租户直接启动,也可以作为提供商管理流程的一部分。
租户层级
SaaS应用程序通常被设计为支持一系列细分市场,为一系列客户提供单独的定价和体验。这些配置文件通常称为层。支持这些不同层的不同需求意味着引入可以塑造每个层体验的体系结构。这些分层模型可以影响SaaS解决方案的成本、运营、管理和可靠性足迹。
租户活动和消费
在多租户SaaS环境中,了解租户如何使用您的应用程序并对系统架构施加负载非常重要。通过在租户级别跟踪这些信息,您可以评估系统有效扩展和支持环境中不断变化的工作负载的能力。从SaaS系统收集的度量和见解通常被称为租户活动和消费。
计量和计费
SaaS产品通常以现收现付模式销售,其中产品的成本是根据客户的消费情况确定的。该模型允许客户拥有一个定价模型,该模型与他们在SaaS系统上的价值和负载更加紧密地耦合。在这种模式下,SaaS提供商将定义并引入计量机制来衡量消费。该计量数据通常被发送到计费系统,该计费系统汇总计费信息并生成账单。基于消费的定价代表了一种定价模型,可以与其他定价策略(例如订阅)相结合。
租户感知操作
SaaS环境的运营经验引入了对附加机制和工具的需求,这些机制和工具可用于创建租户感知洞察,了解各个租户和层的活动和消费模式。这里的想法是,SaaS提供商需要能够通过单个租户和租户层的视角来查看系统活动和健康状况。这对于诊断和评估个体租户的活动和消费趋势和模式至关重要。
- 41 次浏览
【SaaS架构】SaaS镜头-架构支柱-可靠性支柱
视频号
微信公众号
知识星球
可靠性支柱包括系统从基础设施或服务中断中恢复的能力,动态获取计算资源以满足需求的能力,以及减轻诸如错误配置或瞬时网络问题等中断的能力。
设计原则
在云计算中,有许多原则可以帮助您提高可靠性。
释义
云计算中的可靠性有三个最佳实践领域:
- 基础
- 变更管理
- 故障管理
为了实现可靠性,系统必须有一个规划良好的基础和适当的监控,以及处理需求或需求变化的机制。系统应设计为检测故障并自动修复。
最佳实践
话题
基础
SaaS REL 1:如何限制单个租户施加可能影响系统其他租户可用性的负载的能力?
多租户环境中租户的工作量可能会不断变化。租户可能会对系统施加不同类型的负载。具有新工作负载配置文件的新租户也可能会不断添加到系统中。这些因素可能使SaaS公司创建一个具有足够弹性的架构来应对和响应这些不断变化的需求变得非常具有挑战性。
这些负载变化可能会对租户的体验产生不利影响。设想一个场景,其中一个租户最终在系统的某个方面承受了极大的负载。如果它们可以通过API与您的系统交互,这一点尤其明显。在这种情况下,该租户的负载最终可能会消耗不成比例的系统资源,进而影响整个系统的可靠性或其他租户的体验。
对于具有分层服务的系统,一个租户影响另一个租户的能力可能会变得更加复杂。例如,系统可能具有基本、高级和高级层。如果允许这些层中的每一层对系统施加任何级别的负载,我们可能会发现基本层正在影响高级层租户的可靠性。
在多租户环境中,您需要特别主动地识别可能影响系统可靠性的工作负载和消耗模式。多租户环境中的可靠性问题很容易在您的系统中级联,并可能影响所有客户的体验。
为了解决这些工作负载问题,您的系统必须引入能够检测和解决工作负载问题的机制,才能影响应用程序的可靠性。
应用程序的架构和应用程序堆栈将影响您应用的策略,以防止租户影响系统的可靠性和其他租户的体验。一种常见的方法是使用节流来防止租户消耗多余的资源。图21中的图表提供了使用AmazonAPI网关实现这一点的示例。
在本例中,您将看到我们利用API网关的使用计划为系统的每个租户定义了单独的使用体验。这种方法为系统的基本层和高级层使用单独的API密钥,这些密钥与具有不同SLA的使用计划相连接。这种方法实现了两种不同级别的控制。首先,它可以确保通过配置使用计划,防止所有租户在我们的系统中充满请求。另一个好处是,我们可以使用这些使用计划配置来防止较低层租户影响较高层租户的体验。
虽然此模型依赖于API网关来实现节流策略,但此核心概念可以应用于其他基础结构构造。这种方法的基本目标是能够在应用程序的入口点监控和管理访问,检测并限制可能会影响环境整体可靠性的任何租户。

图21:按层级限制租户
SaaS REL 2:如何主动检测和维护租户健康?
SaaS环境中的可靠性通常在很大程度上受到供应商在问题影响租户之前主动识别和补救问题的能力的影响。在多租户环境中构建一个主动的健康视图需要您提供额外的可靠性数据,这些数据可以提供租户工作负载健康趋势的更详细、租户感知的见解。
这些租户感知洞察用于识别租户特定的趋势、活动或洞察,这些趋势、活动和洞察可以有效捕获可能影响租户或整个系统可靠性的情况。拥有这些数据并主动将其呈现出来,允许您构建警报、策略和自动化,以尝试修复系统而不会导致停机。
为了实现这一点,您需要在应用程序中引入代码,以通过租户上下文发布健康洞察。这首先要确定体系结构中表示有用健康数据的工作流和事件。这可能是消费数据、缩放洞察、延迟度量等。这些洞察中的每一个都将通过日志文件或数据仓库发布,以汇总数据。
一旦在存储库中聚合了这些健康数据,就可以引入工具,根据对聚合的健康数据的分析来显示警报或触发策略。
SaaS REL 3:您如何测试SaaS应用程序的多租户功能?
多租户环境的测试模型不仅仅是确保应用程序的功能按预期工作。SaaS提供商还必须创建测试,以验证您的系统是否能够有效解决与多租户解决方案相关的常见可靠性问题。
作为多租户测试策略的一部分,您需要包含许多不同的维度。在许多情况下,这些测试旨在验证您现有的结构,以解决SaaS产品的规模、操作和可靠性问题。
需要注意的是,SaaS测试通常是模拟应用程序可能遇到的极端情况。您应该专注于构建一套测试,这些测试可以有效地建模和评估您的系统将如何响应预期和意外情况。除了确保客户拥有积极的体验外,您的测试还必须考虑实现规模的成本效益。如果您为响应活动而过度分配资源,则可能会影响业务的底线。
您可以在SaaS环境中增强负载和性能测试策略的一些特定领域是:
- 跨租户影响测试–创建模拟场景的测试,其中租户的子集对系统造成不成比例的负载。这将允许您确定当负载未在租户之间均匀分布时系统如何响应,并评估这可能会如何影响租户的整体体验。如果您的系统被分解为单独的可扩展服务,那么您需要创建测试来验证每个服务的扩展策略,以确保它们按照正确的标准进行扩展。
- 租户消耗测试–创建一系列负载配置文件(例如,扁平、尖峰和随机),跟踪资源和租户活动度量,并确定消耗和租户活动之间的增量。您最终可以将此增量作为监控策略的一部分,以确定次优资源消耗。您还可以将此数据与其他测试数据一起使用,以确定是否正确调整了实例的大小,是否正确配置了IOPS,以及是否优化了AWS占用空间。
- 租户工作流测试–使用这些测试来评估SaaS应用程序的不同工作流如何响应多租户环境中的负载。其想法是选择您的解决方案中众所周知的工作流,并将负载集中在具有多个租户的工作流上,以确定这些工作流是否会在多租户环境中造成瓶颈或资源过度分配。
- 租户入职测试–当租户注册您的系统时,您希望确保他们拥有积极的体验,并且您的入职流程具有弹性、可扩展性和高效性。如果您的SaaS解决方案在入职过程中提供了基础设施,则情况尤其如此。您需要确定活动的激增不会影响入职流程。这也是一个您可能依赖第三方集成(例如计费)的领域。您可能希望验证这些集成是否支持其SLA。在某些情况下,您可以实施回退策略来处理这些集成的潜在中断。在这些情况下,您需要引入测试来验证这些容错机制是否按预期执行。
- API节流测试–API节流的概念并非SaaS解决方案独有。通常,您发布的任何API都应该包含节流的概念。对于SaaS,您还需要考虑不同层的租户如何通过您的API施加负载。例如,免费层的租户可能不被允许施加与黄金层租户相同的负载。这使您能够验证与每个层关联的限制策略是否已成功应用和实施。
- 数据分布测试–在大多数情况下,SaaS租户数据不会被统一分布。租户数据配置文件中的这些变化可能会导致总体数据占用量失衡,并可能影响解决方案的性能和成本。为了抵消这种动态,SaaS团队通常会引入分片策略来解释和管理这些变化。共享策略对您的解决方案的性能和成本状况至关重要,因此,它们是测试的首选。数据分发测试允许您验证所采用的分片策略是否能够成功分发系统可能遇到的租户数据的不同模式。在存储了大量客户数据之后,尽早进行这些测试可能有助于避免迁移到新分区模型的高昂成本。
- 租户隔离测试–SaaS客户希望采取一切措施确保其环境安全,其他租户无法访问。为了支持这一需求,SaaS提供商构建了许多策略和机制来保护每个租户的数据和基础设施。引入不断验证这些策略实施的测试对任何SaaS提供商都至关重要。
正如您所看到的,这个测试列表的重点是确保您的SaaS解决方案能够在多租户环境中处理负载。SaaS的负载通常是不可预测的,您会发现这些测试通常是在关键负载和性能问题影响到一个或所有租户之前发现它们的最佳机会。在某些情况下,这些测试还可能出现新的拐点,这些拐点可能值得包含在系统的操作视图中。
变更管理
- SaaS应用程序没有独特的可靠性实践。
故障管理
- SaaS应用程序没有独特的可靠性实践。
资源
请参阅以下资源以了解有关可靠性的最佳实践的更多信息。
文档和博客
-
Monolith to serverless SaaS: Migrating to multi-tenant architecture
-
Partitioning Pooled Multi-Tenant SaaS Data with Amazon DynamoDB
-
Architecting Successful SaaS: Interacting with Your SaaS Customer’s Cloud Accounts
-
Amazon API Gateway: Throttle API requests for better throughput
-
Amazon CloudWatch Observability of your AWS resources and applications on AWS and on-premises
视频
- 110 次浏览
【SaaS架构】SaaS镜头-架构支柱-安全支柱之参考资料
视频号
微信公众号
知识星球
请参阅以下资源以了解有关我们的安全最佳做法的更多信息。
文档和博客
-
Isolating SaaS Tenants with Dynamically Generated IAM Policies
-
Partitioning Pooled Multi-Tenant SaaS Data with Amazon DynamoDB
-
Multi-tenant data isolation with PostgreSQL Row Level Security
-
Managing SaaS Identity Through Custom Attributes and Amazon Cognito
白皮书
视频
- 41 次浏览
【SaaS架构】SaaS镜头-架构支柱-安全支柱之基础设施保护
视频号
微信公众号
知识星球
安全支柱包括帮助保护信息、系统和资产的能力,同时通过风险评估和缓解策略实现业务价值。
设计计原则
在云中,有许多原则可以帮助您加强系统安全性。
定义
云安全有五个最佳实践领域:
- 身份和访问管理
- 侦探控件
- 基础设施保护
- 数据保护
- 事件响应
多租户为您的SaaS架构增加了一层额外的考虑因素。使用SaaS,您的用户现在可以在给定租户的上下文中访问共享环境。必须在应用程序体系结构的所有层中捕获和传递此上下文,并在确保环境的总体占地面积方面发挥基本作用。
从安全角度来看,您需要了解租赁是如何引入您的环境的,以及如何使用它来保护租户资源。总的来说,您需要确保每个租户都有一个谨慎约束的体验,防止他们访问任何其他租户的资源。
最佳实践
话题
- 身份和访问管理
- 检测控制
- 基础设施保护
- 数据保护
- 事件响应
基础设施保护
SaaS SEC 2:您如何确保租户资源免受跨租户访问?
租户隔离是每个SaaS提供商必须解决的基本问题之一。随着独立软件供应商(ISV)转向SaaS并采用共享基础架构模型以实现成本和运营效率,他们还面临着确定其多租户环境如何确保租户无法访问另一租户资源的挑战。对于SaaS业务来说,以任何形式跨越这一边界都将是一个重大且可能无法恢复的事件。
尽管租户隔离的需求被视为SaaS提供商的基本需求,但实现这种隔离的策略和方法并不普遍。有很多因素可以影响租户隔离在任何SaaS环境中的实现方式。域、遵从性、部署模型和AWS服务的选择都为租户隔离带来了自己独特的考虑因素。
隔离心态
在概念层面,许多SaaS提供商都同意保护和隔离租户资源的重要性和价值。然而,当您深入了解实施隔离策略的细节时,您通常会发现,每个SaaS ISV都有自己的隔离定义。
鉴于这些不同的观点,我们在下面概述了一些原则,这些原则将有助于指导租户隔离的整体价值体系。每个SaaS提供商都应该建立一套清晰的高级隔离要求,以指导其团队定义其SaaS环境的隔离足迹。以下是通常形成整个SaaS租户隔离模型的一些关键原则:
隔离不是可选的–隔离是SaaS的一个基本要素,以多租户模式提供解决方案的每个系统都应确保其系统采取措施确保租户资源被隔离。
身份验证和授权不等于隔离–虽然您可以通过身份验证和权限控制对SaaS环境的访问,但超越登录屏幕或API的入口并不意味着您已经实现了隔离。这只是隔离难题的一部分,单靠它本身是不够的。
隔离执行不应留给服务开发人员——尽管开发人员永远不会引入可能违反隔离的代码,但期望他们永远不会无意中跨越租户边界是不现实的。为了缓解这种情况,应该通过一些共享机制来控制对资源的访问范围,该机制负责应用隔离规则(在开发人员的视野之外)。
如果没有现成的隔离解决方案,您可能必须自己构建它——有许多安全机制,如AWS身份和访问管理(IAM),可以帮助您简化租户隔离的路径。将这些工具与更广泛的安全方案相结合,有助于简化隔离过程。。然而,在某些情况下,您的隔离模型可能没有通过相应的工具或技术直接解决。没有一个明确的解决方案不应该是降低隔离要求的机会,即使这意味着要建立自己的解决方案。
隔离不是资源级别的构造——在多租户和隔离的世界中,有些人会将隔离视为在具体基础设施资源之间划出硬边界的一种方式。这通常转化为隔离模型,在该模型中,您可能为每个租户拥有单独的数据库、计算实例、帐户或虚拟私有云(VPC)。虽然这些是常见的隔离形式,但并不是隔离租户的唯一方式。即使在实际上共享资源的场景中,特别是在共享资源的环境中,也有实现隔离的方法。在这个共享资源模型中,隔离可以是由运行时应用的策略强制执行的逻辑构造。这里的关键点是,隔离不应等同于拥有孤立的资源。
域可能会施加特定的隔离要求——虽然实现租户隔离的方法很多,但给定域的现实可能会施加限制,需要特定的隔离风格。例如,一些高合规性行业可能要求每个租户都有自己的数据库。在这些情况下,共享的、基于政策的隔离方法可能不够。
核心隔离概念
隔离的部分挑战是租户隔离有多种定义。对一些人来说,隔离几乎是一种业务结构,他们认为整个客户都需要自己的环境。对于其他人来说,隔离更多的是一种架构构造,它覆盖了多租户环境的服务和构造。以下各节将探讨不同类型的隔离,并将特定术语与不同的隔离结构相关联。
筒仓隔离(Silo Isolation)
尽管SaaS提供商通常专注于共享资源的价值,但在某些情况下,SaaS提供商可能会选择将其部分(或全部)租户部署在一个模型中,每个租户都在运行一个完全孤立的资源堆栈。有人会说,这种全栈模型并不代表SaaS环境。然而,如果您已经用共享身份、入职、计量、度量、部署、分析和运营来围绕这些独立的堆栈,那么这是一种有效的SaaS变体,它以规模经济和运营效率换取法规遵从性、业务或域考虑。使用这种方法,隔离是一种跨整个客户堆栈的端到端构造。图16中的图表提供了这种隔离视图的概念视图。

图16:筒仓隔离模型
此图突出显示了孤立部署模型的基本占地面积。用于运行这些堆栈的技术在这里大多无关紧要。这可以是一个整体,可以是无服务器的,也可以是各种应用程序架构模型的任意组合。关键的概念是获取租户拥有的任何堆栈,并用一些构造将其包围,以封装该堆栈的所有活动部分。这成为隔离的边界。只要您能够防止租户逃离其完全封装的环境,就已经实现了隔离。
通常,这种隔离模型的实施要简单得多。通常有定义良好的构造,使您能够实现健壮的隔离模型。虽然该模型对SaaS环境的成本和敏捷性目标提出了一些实际挑战,但它对那些有非常严格隔离要求的人来说可能很有吸引力。
筒仓模型优点和缺点
每个SaaS环境和业务领域都有自己独特的需求集,这可能会使思洛存储器更适合。然而,如果您正朝着这个方向倾斜,您肯定希望考虑到与筒仓模型相关的一些挑战和开销。如果您正在探索SaaS解决方案的筒仓模型,则需要考虑以下利弊:
优点
- 支持具有挑战性的法规遵从性模型–一些SaaS提供商正在向实施严格隔离要求的受监管环境销售产品。筒仓模型为这些ISV提供了一个选项,使他们能够向部分或所有租户提供在专用模型中部署的选项。
- 无噪音邻居问题–尽管所有SaaS提供商都应尝试限制噪音邻居条件的影响,但一些客户仍会对使用系统的其他租户的活动影响其工作负载的可能性表示保留。筒仓模型通过提供一个专用环境来解决这一问题,该环境不可能出现嘈杂的邻居场景。
- 租户成本跟踪–SaaS提供商通常高度关注了解每个租户如何影响其基础设施成本。在某些SaaS模型中,计算每个租户的成本可能是一项挑战。然而,筒仓模型的粗粒度特性为您提供了一种更简单的方法来捕获和关联每个租户的基础设施成本。
- 减少影响范围–当SaaS解决方案中可能出现停机或事件时,筒仓模型通常会减少您的风险敞口。由于每个SaaS提供商都在其自己的环境中运行,因此在给定租户的环境中发生的任何故障都可能受限于该环境。虽然一个租户可能会遇到停机,但该错误不会在使用系统的其他租户之间级联。
缺点
- 扩展问题–可以调配的帐户数量有限制。此限制可能会阻止您选择基于帐户的模型。还有一个普遍的问题是,快速增长的客户数量可能会破坏您的SaaS环境的管理和运营体验。例如,每个租户拥有20个单独的账户可能是可以管理的。然而,如果您有1000个租户,那么这个数字可能会开始影响运营效率和灵活性。
- 成本–由于每个租户都在自己的环境中运行,传统上与SaaS解决方案相关的大部分成本效率都没有实现。即使这些环境是动态扩展的,您也可能会有一天中闲置资源未被使用的时间。虽然这是一个完全可以接受的模型,但它会破坏您的组织实现规模经济和利润效益的能力,而这些效益对SaaS模型至关重要。
- 敏捷性——向SaaS的转变通常是由以更快的速度进行创新的愿望直接推动的。这意味着采用一种模式,使组织能够快速响应市场动态。其中的一个关键部分是能够统一客户体验并快速部署新功能和功能。尽管筒仓模型可以采取一些措施来限制其对敏捷性的影响,但筒仓模型高度分散的特性增加了复杂性,影响了您轻松管理、运营和支持租户的能力。
- 入职自动化–SaaS环境重视自动化引入新租户。无论这些租户是以自助服务模式还是使用内部管理的资源调配流程进行入职,您仍需要自动化入职。而且,当您为每个租户设置了单独的siloe时,这通常会成为一个更重要的过程。提供新租户将需要提供新的基础设施,并可能需要配置新的帐户限制。这些增加的移动部件引入了额外的开销,从而为整个入职自动化带来了额外的复杂性,使您能够将更少的时间集中在客户身上。
- 去中心化管理和监控——SaaS的目标是拥有一块玻璃,使您能够管理和监控所有租户活动。当您拥有孤立的租户环境时,这一要求尤为重要。这里的挑战是,您现在必须从更分散的租户足迹中聚合数据。虽然有一些机制可以让您创建租户的聚合视图,但在孤立的模型中,构建和管理这种体验所需的努力和精力更为复杂。
池隔离(Pool Isolation)
您可以看到隔离的筒仓模型如何很好地映射到许多SaaS公司。许多正在转向SaaS的公司都在寻求让租户共享部分或全部底层基础设施的效率、灵活性和成本效益。这种共享基础设施方法(称为池模型)为隔离故事增加了一定程度的复杂性。图17中的图表说明了与在池模型中实现隔离相关的挑战。
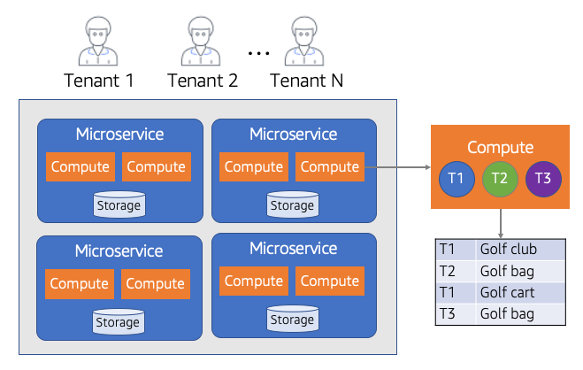
图17:池隔离模型
在这个模型中,您会注意到我们的租户正在使用所有租户共享的基础设施。这使得资源能够与租户施加的实际负载成正比地扩展。图的右侧缩小了其中一个服务的计算方面,突出了租户1-N在任何给定时间都可能在共享计算中并行运行的事实。本例中的存储也是共享的,并表示为由单个租户标识符索引的表。
这种模式可以很好地适用于SaaS提供商,但是,它有可能使整个隔离过程复杂化。在共享资源的情况下,实现隔离并不是那么清晰和典型的网络,IAM结构不能用来在租户之间创建边界。
这里的关键是,即使这是一个更具挑战性的隔离环境,您也不能将其作为放松环境隔离要求的理由。共享模式增加了跨租户访问的机会,因此,它代表了一个需要您特别注意确保资源隔离的领域。
当我们深入研究池隔离模型时,您将看到这个体系结构足迹如何引入独特的挑战组合,每个挑战都需要自己类型的隔离构造来成功隔离租户的资源。
池模型的优点和缺点
尽管共享所有内容可以提高效率和优化,但这也需要SaaS提供商权衡采用该模型所带来的一些权衡。在许多情况下,水池模型的优点和缺点最终表现为筒仓模型的优点与缺点的反面。这些是通常与池隔离模型相关的主要优点和缺点。
优点
- 敏捷性–当您将租户迁移到共享基础架构模型中时,您可以利用自然的效率和简单性,帮助简化SaaS产品的敏捷性。池模式的核心是使SaaS提供商能够以统一的体验管理、扩展和运营所有租户。集中化和标准化体验是使SaaS提供商能够更轻松地管理所有租户并将更改应用于所有租户的基础,而无需逐个租户执行一次性任务。这种运营效率是SaaS环境整体敏捷性的关键。
- 成本效率——许多公司都因其成本效率而被SaaS所吸引。这种成本效率的很大一部分通常与隔离池模型有关。在共享环境中,您的系统将根据所有租户的实际负载和活动进行扩展。如果所有租户都处于离线状态,您的基础设施成本应该是最低的。这里的关键概念是,池化环境可以动态调整租户负载,并使您能够更好地调整租户活动与资源消耗。
- 简化了管理和操作–隔离池模型为您提供了一个系统中所有租户的视图。您可以通过触及系统中所有租户的单一体验来管理、更新和部署所有租户。这使得管理和操作的大部分方面更加简单。
- 创新–集合隔离模型所带来的灵活性也往往是SaaS提供商更快创新的核心。您越是远离分布式管理和筒仓模型的复杂性,就越能自由地关注产品的特性和功能。
缺点
- 吵闹的邻居——共享的资源越多,一个租户影响另一个租户体验的机会就越大。例如,一个租户的任何活动都会给系统带来沉重的负载,这可能会影响其他租户。一个好的多租户体系结构和设计将试图限制这些影响,但在共享隔离模型中,噪声邻居条件总是有可能影响一个或多个租户。
- 租户成本跟踪–在筒仓模型中,将资源消耗归因于特定租户要容易得多。然而,在集合模型中,资源消耗的归属变得更具挑战性。每一个SaaS提供商都应该寻找方法来检测他们的系统,并提供所需的粒度数据,以有效地将消费与单个租户关联起来。
- 减少影响范围–共享所有共享资源也会带来一些运营风险。在思洛存储器模型中,当一个租户发生故障时,该故障的影响可能仅限于该租户。然而,在共享环境中,停机可能会影响系统中的所有租户,这可能会对您的业务产生重大影响。这通常需要更深入地致力于建立一个有弹性的环境,以识别故障、浮出水面并从故障中优雅地恢复。
- 合规性阻碍——尽管您可以采取一些措施来隔离池模式中的租户,但共享基础设施的概念可能会造成您不愿意在这种模式中运行的情况。在域的法规遵从性或管理规则对资源的可访问性和隔离性施加严格限制的环境中尤其如此。尽管如此,即使在这些情况下,这也可能意味着系统的某些部分需要被孤立。
桥梁模型
尽管筒仓和池模型有非常不同的隔离方法,但许多SaaS提供商的隔离环境并不绝对。当您查看实际的应用程序问题并将系统分解为较小的服务时,您通常会发现您的解决方案需要混合使用思洛存储器和池模型。这种混合模型就是我们所说的隔离桥模型。图18中的图表提供了如何在SaaS解决方案中实现桥接模型的示例。
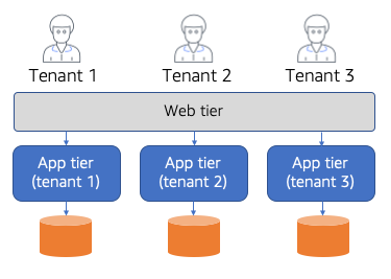
图18:桥梁隔离模型
此图突出显示了网桥模型如何使您能够组合思洛存储器和池模型。这里我们有一个具有经典web和应用程序层的整体架构。对于此解决方案,web层部署在所有租户共享的池模型中。虽然web层是共享的,但我们应用程序的底层业务逻辑和存储实际上部署在一个筒仓模型中,每个租户都有自己的应用程序层和存储。
如果单片被分解为微服务,那么系统中的每个微服务都可以利用筒仓和池模型的组合。关于这种方法的更多细节,将在使用不同AWS构造应用筒仓和池模型的细节描述中介绍。这里的关键信息是,对于分解为具有不同隔离要求的服务集合的环境,您对思洛存储器和池模型的看法将更加精细。
基于层的隔离
虽然我们对隔离的大部分讨论都集中在防止跨租户访问的机制上,但在某些情况下,您的产品的分层可能会影响您的隔离策略。在这种情况下,与其说是如何隔离租户,不如说是如何打包并为具有不同配置文件的不同租户提供不同风格的隔离。然而,这是另一个考虑因素,它可以决定您需要支持哪些隔离模式,以满足您想要接触的所有客户。图19中的图表提供了隔离如何在不同层之间变化的示例。
下面的示例使用了筒仓和池隔离模型的组合,这些模型已作为层提供给租户。Silver层的租户在共享环境中运行。尽管这些租户在共享基础架构模型中运行,但他们仍然完全希望自己的资源不会受到跨租户访问的保护。右边的租户要求提供一个完全专用的(筒仓)环境。为了支持这一点,SaaS提供商创建了一个高级层模型,使租户能够以更高的价格在这种专用模型中运行。
虽然SaaS提供商通常试图限制向其客户提供筒仓模型,但许多SaaS企业都有这种私有定价的概念,即这些租户提供在这种模型中部署的溢价。事实上,SaaS公司不会将其作为一个选项发布,也不会将其确定为一个层来限制选择此选项的客户数量。如果您的租户中有太多人陷入这种模式,您将开始回到完全孤立的模式,并继承前面概述的许多挑战。
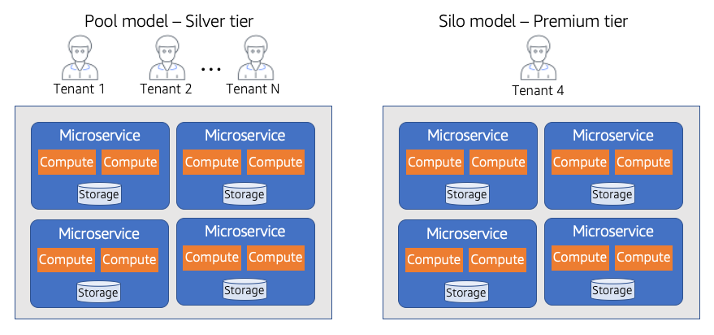
图19:基于层的隔离
为了限制这些一次性环境的影响,SaaS提供商通常会要求这些高级客户运行部署到池环境的相同版本的产品。这使ISV能够通过一块玻璃继续管理和操作这两个环境。从本质上讲,思洛存储器环境变成了恰好支持一个租户的池环境的克隆。
目标的隔离
需要注意的是,系统中的隔离选择可能非常精细。系统中的每个微服务和这些服务接触的每个资源都可以选择配置不同的隔离模型。让我们来看看一些微服务示例,以更好地理解如何在不同的微服务之间改变隔离模型。图20中的图表提供了使用筒仓和池隔离模型的微服务视图。
在这个图中,您将看到一个系统实现了三种不同的微服务:产品、订单和帐户。每种微服务的部署和存储模型都突出了隔离(对于安全或嘈杂的邻居)如何在SaaS环境中实现。
让我们回顾一下这些服务的隔离模型。右上角的Product微服务部署在一个完整的池模型中,所有租户共享计算和存储。这里的表反映了租户在这里的所有土地作为单独的项目,在同一个表中进行索引。假设数据将与可以限制访问此表中租户项的策略隔离。Order微服务仅适用于租户1到租户3,并且也以池模式实现。这里唯一的区别是它支持一部分租户。本质上,任何没有得到Order微服务专用(筒仓)部署的租户都将在这个池部署中运行(将其视为租户1..N,只有少数租户作为筒仓微服务退出)。
出于本讨论的目的,让我们关注由专用订单微服务(右上)和Account微服务(下)表示的孤立服务。您会注意到,我们已经为租户4和5部署了Order微服务的独立实例。这里的想法是,这些租户对订单处理有一些要求(合规性、嘈杂的邻居等),要求在筒仓模型中部署此服务。这里的计算和存储都完全专用于这些租户。
最后,底部是Account微服务,它代表了筒仓模型,但仅在存储级别。微服务的计算由所有租户共享,但每个租户都有一个保存其帐户数据的专用数据库。在这种情况下,隔离问题只关注于分离数据。计算仍然可以共享。
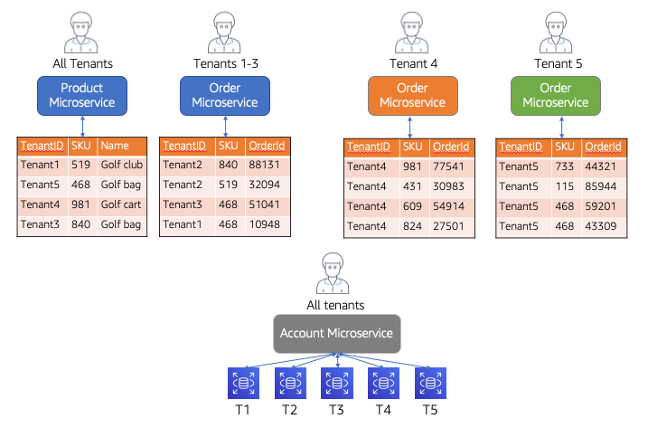
图20:目标隔离
该模型显示了筒仓讨论如何变得更加精细。安全性、嘈杂的邻居以及各种因素将决定如何以及何时为服务采用筒仓隔离模型。这里的关键是,筒仓模型不是一个要么全有要么全无的决定。您可以考虑将思洛存储器模型应用于应用程序的特定组件,并仅在实际需要时(例如当潜在客户要求使用时)吸收该模型的挑战。在本例中,通过与客户进行更详细的讨论,您会发现只有几个特定的存储和处理领域值得关注。这样做将使您能够为系统中那些不需要思洛存储器隔离的部分获得池模型的效率,并为您提供灵活的分层结构,以支持单个服务的思洛存储器和池模型的混合。
- 103 次浏览
【SaaS架构】SaaS镜头-架构支柱-安全支柱之身份和访问管理
视频号
微信公众号
知识星球
安全支柱包括帮助保护信息、系统和资产的能力,同时通过风险评估和缓解策略实现业务价值。
设计计原则
在云中,有许多原则可以帮助您加强系统安全性。
定义
云安全有五个最佳实践领域:
- 身份和访问管理
- 侦探控件
- 基础设施保护
- 数据保护
- 事件响应
多租户为您的SaaS架构增加了一层额外的考虑因素。使用SaaS,您的用户现在可以在给定租户的上下文中访问共享环境。必须在应用程序体系结构的所有层中捕获和传递此上下文,并在确保环境的总体占地面积方面发挥基本作用。
从安全角度来看,您需要了解租赁是如何引入您的环境的,以及如何使用它来保护租户资源。总的来说,您需要确保每个租户都有一个谨慎约束的体验,防止他们访问任何其他租户的资源。
最佳实践
话题
- 身份和访问管理
- 检测控制
- 基础设施保护
- 数据保护
- 事件响应
身份和访问管理
SaaS SEC 1:您如何将租户上下文与用户关联,并在SaaS架构中应用该上下文?
向多租户体系结构的转变通常从身份开始。访问应用程序的每个用户都必须与租户连接。用户身份与租户的这种绑定被非正式地称为SaaS身份。SaaS身份的关键属性是它将租户上下文提升为一个一流的构造,将其直接连接到SaaS应用程序的整体身份验证和授权模型。
这种方法允许租户上下文使用用于传递和访问用户身份的相同体系结构构造流经体系结构的所有层。例如,如果您的应用程序中有100个微服务,您希望这些服务中的每一个都能够获取和应用租户上下文,而不需要往返于另一个服务。通过另一个服务管理此上下文会增加延迟,并经常在架构中造成瓶颈。
将租户上下文注入您的身份可以通过多种模式实现。您为应用程序选择的身份提供商和技术将直接影响您最终应用的方法和策略,以将这种背景引入您的体验。虽然工具可能会发生变化,但最基本的需要是在用户进入应用程序时注入租约的环境的整体身份验证体验中引入租约。
图15中的图表提供了一个使用AWS服务通常如何实现这一点的示例。此示例包括用于将租户上下文注入SaaS环境的常见组件和技术。这在图的左侧进行了说明,租户填写了一个注册表单,并触发对应用程序注册服务的调用。

图15:注入租户内容
该注册服务创建租户,然后在AmazonCognito中创建用户。作为此过程的一部分,您将自定义声明引入用户属性,这些属性包含有关用户与租户关系的信息。这些自定义声明成为用户身份签名的一部分,将它们作为一级构造直接连接到租户。
登录完成后,您可以查看在用户登录时如何应用这些用户和租户属性(图的右侧)。在这里,您将看到用户针对Amazon Cognito进行身份验证,并作为该过程的一部分,返回一个JSON web令牌(JWT),其中包含在入职过程中创建的自定义声明。
现在,您有了一个令牌,它包含了将租户上下文注入到与多租户应用程序服务的交互中所需的所有信息。在本例中,我们将JWT作为承载令牌传递到Product微服务的每个请求的头中。该服务现在可以从该令牌获取并应用上下文,而无需调用其他服务。
最后,这个Product微服务调用Order微服务,在请求的头中传递JWT。这说明了租户上下文如何在所有微服务调用中流动,而无需添加任何额外的查找或延迟。
这个例子恰好依赖于AmazonCognito来连接用户和租户身份。然而,这个相同的模型可以与其他身份提供者或替代身份验证方案一起实现。这里的关键是,您正在构建一种身份验证体验,它可以产生连接租户和用户的表示。然后,该表示应可用于解决方案的所有层。
- 52 次浏览
【SaaS架构】SaaS镜头-架构支柱-性能效率支柱
视频号
微信公众号
知识星球
性能效率支柱侧重于有效利用计算资源来满足需求,并随着需求的变化和技术的发展而保持这种效率。
释义
云计算中的性能效率有四个最佳实践领域:
- 选择(计算、存储、数据库、网络)
- 回顾
- 监测
- 权衡取舍
采用数据驱动方法选择高性能架构。从高层设计到资源类型的选择和配置,收集架构各个方面的数据。通过周期性地审查您的选择,您将确保您正在利用不断发展的AWS云。
监控将确保您意识到与预期性能的任何偏差,并可以对此采取行动。最后,您的体系结构可以进行权衡以提高性能,例如使用压缩或缓存,或放宽一致性要求。
最佳实践
话题
选择
SaaS性能1:如何防止一个租户对另一个租户的体验产生负面影响?
在多租户环境中,租户可能具有对系统施加显著不同负载的配置文件和用例。具有新工作负载配置文件的新租户也可能会不断添加到系统中。这些因素使得SaaS公司构建一个能够满足这些租户快速发展的性能需求的架构非常具有挑战性。
处理和管理租户负载的这些变化是SaaS环境性能概要的关键。SaaS架构必须能够成功检测这些租户消费趋势,并应用能够有效扩展以满足租户需求或限制单个租户活动的策略。
有多种策略可用于管理租户可能对系统造成不成比例负载的情况。这可以通过隔离高需求资源、引入扩展策略或应用节流策略来实现。
在最简单和最极端的情况下,您可以考虑为应用程序的部分创建租户特定的部署。图22中的图表说明了一种分解系统以解决性能挑战的方法。

图22:使用孤立服务解决性能问题
在本例中,您将注意到我们有两个不同的部署足迹(一些在思洛存储器模型中,一些在池模型中)。在图的左侧,您将看到为每个租户部署了Product、Order和Cart微服务的单独实例。同时,在图的右侧,您将看到所有租户共享的微服务集合。
该方法背后的基本思想是开发特定的服务,这些服务被视为对应用程序的性能概要至关重要。通过将它们分开,您的系统可以确保任何一个租户的负载不会影响其他租户的性能(对于这组服务)。此策略可能会增加成本并降低环境的操作灵活性,但仍然是实现性能目标的有效方法。同样的方法也可用于解决合规性和隔离要求。
例如,您可以为每个租户部署一个订单管理微服务,以限制一个租户对另一个租户的订单处理体验产生不利影响的能力。这增加了操作复杂性并降低了成本效率,但可以作为一种暴力手段,有选择地针对应用程序关键领域的跨租户性能问题。
理想情况下,您应该尝试通过构造来解决这些性能需求,这些构造可以解决租户负载问题,而不会吸收单独部署服务的开销和成本。在这里,您将专注于创建一个扩展配置文件,使您的共享基础架构能够有效地响应租户负载和活动的变化。
基于容器的架构(如AmazonEKS或AmazonECS)可以配置为基于租户需求扩展服务,而不需要任何过度资源调配。容器快速扩展的能力增强了系统对急剧租户负载的有效响应能力。将容器的扩展速度与AWS Fargate的成本概况相结合,通常是弹性、运营灵活性和成本效率的完美结合,可以帮助组织解决租户的巨大负载,而不会过度配置环境。
使用AWS Lambda构建的无服务器SaaS架构也可能非常适合解决租户负载过高的问题。AWS Lambda的管理特性允许您的应用程序服务快速扩展,以解决租户负载的峰值问题。这种方法可能需要考虑并发性和冷启动因素。然而,它可以代表限制跨租户性能影响的有效策略。
虽然响应式扩展策略可以帮助解决这个问题,但您可能需要采取其他措施,以简单地防止租户施加可能会造成跨租户影响的负载。在这些场景中,您可以选择通过设置限制(可能按层)来检测和约束租户的活动,这些限制将应用节流来控制系统上的负载级别。这将通过引入节流政策来实现,该政策将检查租户的负载,识别超出限制的活动,并限制他们的体验。
SaaS性能2:您如何确保基础设施资源的消耗与租户的活动和工作负载保持一致?
SaaS公司的商业模式通常严重依赖于一种策略,该策略允许他们将基础设施的成本与租户的实际活动相一致。由于SaaS系统中租户的负载和组成不断变化,因此您需要一种架构策略,该策略可以有效地以一种模式来扩展资源的消耗,这种模式非常反映SaaS体验中的这些实时、不可预测的消耗模式。
图23中的图表提供了一个环境的假设示例,该环境已协调了基础设施消耗和租户活动。这里蓝色实线表示租户在一段时间内的实际活动趋势。红色虚线表示为解决租户负载而配置的实际基础设施。
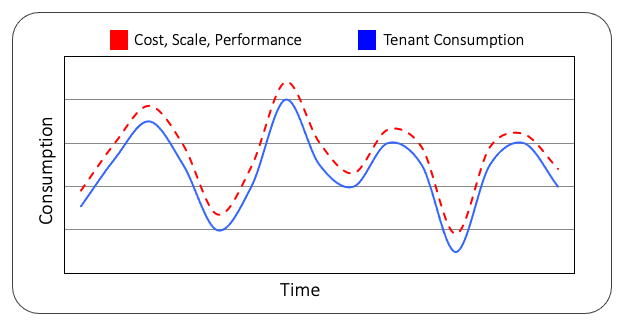
图23:调整租户活动和消费
在理想的环境中,我们的策略是尽量缩小红线和蓝线之间的差距。在这里,您总是有一定的误差余量,因为您有一些缓冲,以确保不会影响系统的可用性或性能。同时,您希望能够提供足够的基础设施,以支持租户当前的性能需求。
这里的关键挑战是,图中显示的负载通常是不可预测的。虽然可能存在一些一般趋势,但您的架构和扩展策略不能假设今天的负载明天甚至未来一小时都会相同。
调整消费与活动的最简单方法是使用提供无服务器体验的AWS服务。这方面的经典例子是AWS Lambda。使用AWS Lambda,您可以构建一个服务器和扩展策略不再由您负责的模型。使用无服务器,您的SaaS应用程序只会产生与租户消费直接相关的费用。如果您的SaaS系统没有负载,那么AWS Lambda将不会产生任何成本。
AWS Fargate还支持基于容器的版本,这是一种无服务器的心态。通过将Fargate与AmazonEKS或AmazonECS一起使用,您只需支付应用程序实际消耗的容器计算成本。
这种使用无服务器模型的能力超出了计算构造。例如,您的解决方案的存储部分也可以依赖于无服务器技术。AmazonAuroraServerless允许您存储关系数据,而无需调整运行数据库的实例的大小。相反,AmazonAuroraServerless将根据实际负载来调整您的环境大小,并且只对您的应用程序消耗的内容收费。
任何让您不再需要创建扩展策略的模型都将简化您的运营和成本体验。您可以将更多的时间和精力集中在应用程序的特性和功能上,而不是继续追求难以捉摸的完美自动缩放配置。这也使该公司能够发展并接受新租户,而不必担心AWS账单的意外增长。
对于无服务器可能不是一个选项的场景,您需要回到传统的扩展策略。在这些场景中,您需要捕获和发布租户消费指标,并根据这些指标定义扩展策略。
回顾
SaaS应用程序没有独特的性能实践。
监测
SaaS性能3:如何为不同的租户层和计划实现不同级别的性能?
SaaS解决方案通常以分层模式提供,租户可以获得不同的体验。性能通常是一个用于区分SaaS环境的层的领域,使用性能作为一种创建价值边界的方式,迫使租户转移到更高级别的层。
在此模型中,您的体系结构将引入用于监视和控制每个层的体验的构造。这不仅仅是为了最大限度地提高性能,还在于限制低层租户的消费。即使您的系统可以容纳这些租户的负载,您也可以纯粹基于成本或业务考虑来限制负载。这通常是确保租户的成本足迹与租户为业务贡献的收入相关的一部分。
解决此问题最简单的方法是引入与单个租户层相关联的限制策略。当租户达到限制时,您将应用限制并限制其消费。
在某些情况下,您可以使用特定的AWS配置来配置租户层的消费配置文件。例如,在AWS Lambda中,可以使用保留并发来限制给定租户层的消耗。图24中的图表提供了如何实现这一点的示例。

图24:使用保留并发控制租户性能
在本例中,我们创建了三个独立的租户层,并为每个层部署了三个不同的SaaS应用程序微服务集合。这些集合还配置有单独的保留并发设置,这些设置用于确定可以为该组函数运行多少个并发函数调用。基本层的保留并发数为100,高级层为300。这里的想法是,我的低端层的消耗将受到限制,将所有剩余的并发留给高级层。
这种方法很好地符合我们的目标,即为我们的首选层提供最佳体验,同时限制较低层消耗多余资源的能力,并影响较高层租户的绩效。
容器还具有解决性能分层问题的独特策略。例如,在AmazonEKS中,您可以配置单独的ResourceQuotas和LimitRanges来控制命名空间中可用的资源量。
虽然这些约束有助于配置租户的性能体验,但一些SaaS应用程序实际上会通过应用程序设计和分解策略来解决性能问题。这可以通过为更高层租户部署孤立的微服务来实现,消除这些特定服务的任何噪音邻居考虑。事实上,您可能会发现,将系统分解为微服务可能会直接受到目标分层和性能配置文件的影响。
在某些情况下,您的SaaS应用程序还可能引入架构结构,以优化更高层租户的体验。例如,想象一下,为高级租户提供关键数据的缓存。通过将缓存仅限于这些用户,可以避免必须支持所有用户的缓存的开销。引入这些优化的努力应该用对客户和业务的足够价值来抵消,以保证投资。
权衡取舍
SaaS应用程序没有独特的性能实践。
资源
请参阅以下资源,以了解有关性能效率的最佳实践的更多信息。
文档和博客
-
Amazon API Gateway: Throttle API requests for better throughput
-
Monitoring CloudWatch metrics for your Auto Scaling groups and instances
白皮书
-
SaaS Storage Strategies Building a Multi-tenant Storage Model on AWS
-
Whitepaper: SaaS Solutions on AWS Tenant Isolation Architectures
视频
- 24 次浏览
【SaaS架构】SaaS镜头-架构支柱-成本优化支柱
视频号
微信公众号
知识星球
成本优化支柱包括系统在其整个生命周期内的不断完善和改进过程。从最初的概念验证设计到生产工作负载的持续运行,采用本文中的实践将使您能够构建和运行具有成本意识的系统,从而实现业务成果并最大限度地降低成本,从而使您的企业实现投资回报最大化。
释义
云计算中的成本优化有四个最佳实践领域:
- 具有成本效益的资源
- 供需匹配
- 支出意识
- 随时间优化
与其他支柱一样,需要考虑权衡。例如,您希望优化上市速度还是成本?在某些情况下,最好优化快速上市、发布新功能,或者只是满足最后期限,而不是投资于前期成本优化。
与经验数据相比,设计决策有时受到匆忙的指导,因为总是存在着过度补偿“以防万一”的诱惑,而不是花时间进行基准测试以获得最具成本效益的部署。
这通常会导致资源调配过度和部署不足。以下各节为部署的初始和持续成本优化提供了技术和战略指导
最佳实践
话题
具有成本效益的资源
- SaaS应用程序没有独特的成本做法。
供需匹配
- SaaS应用程序没有独特的成本做法。
支出意识
SaaS成本1:如何衡量单个租户的资源消耗?
衡量和归因于多租户环境中的成本首先要有一个将消费归因于租户的可靠策略。这将需要团队设计和开发一个消费映射模型,该模型清晰地显示租户如何使用系统资源。最终目标是获得一系列见解,使您能够为系统的每个租户分配一定比例的消费。
在租户可能共享部分或全部系统资源的多租户环境中,组装这种消费视图可能特别具有挑战性。这种更细粒度的消费模型删除了许多选项和工具策略,这些选项和策略通常用于在AWS环境中定义消费(例如标记)。
虽然没有单一的模型来定义如何在SaaS架构中捕获租户消费,但在为应用程序选择策略时,应该考虑一些常见的策略。首先,您需要查看SaaS环境的总体成本概况,并确定应用程序如何影响AWS账单中的成本。对于某些环境,您的成本可能主要集中在应用程序的几个方面。在这些场景中,您可能会在收集对账单贡献最大的领域的消费数据方面获得更好的ROI。例如,如果Amazon S3占您账单的1%,那么计算租户的Amazon S3消费可能没有什么价值。
这里您要考虑的另一个因素是粒度。有一些侵入性较小的方法可以近似租户的消费量,这可能适合您的环境。这实际上可以归结为在您所追求的消费细节水平与检测和捕获数据的复杂性之间取得平衡,而这些数据需要对消费进行属性化。
让我们从最简单的租户消费近似模型开始。图25中的图表提供了一个概念视图,展示了在微创模型中捕获租户活动的一种方法。这里的基本方法是使用AWS Lambda授权器检查对API的每个调用。授权者将从传入的JWT中提取租户上下文,并发布一个事件,为租户记录此活动。另一种方法是使用AWS X射线来捕获这些数据(而不是亚马逊API网关)。
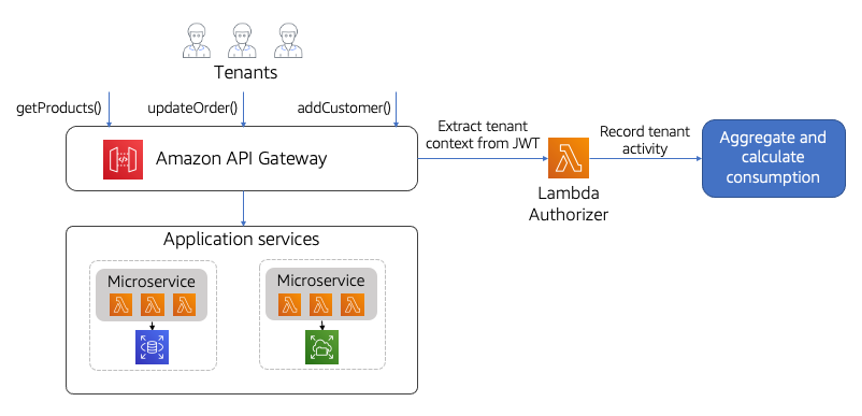
图25:租户消费的微创捕获
图上还有一个占位符,用于聚合和计算租户消费。您选择的填补这一空白的战略和工具将取决于数据的性质、其生命周期,以及它如何适合您更广泛的SaaS度量和分析故事。您可以选择将此数据作为SaaS环境的一般度量足迹的一部分,从而得出对租户分配消费至关重要的见解。
这种特定的方法依赖于跟踪每个租户的呼叫频率,以此推断每个租户的消费水平。虽然对服务的调用次数可能与消耗量不完全相关,但对于某些环境来说,这可能是一种合理的折衷。
通过在应用程序的细节中引入更专门的工具,可以创建更精细的消费视图。图26中的图表展示了如何将度量工具引入SaaS应用程序的微服务。
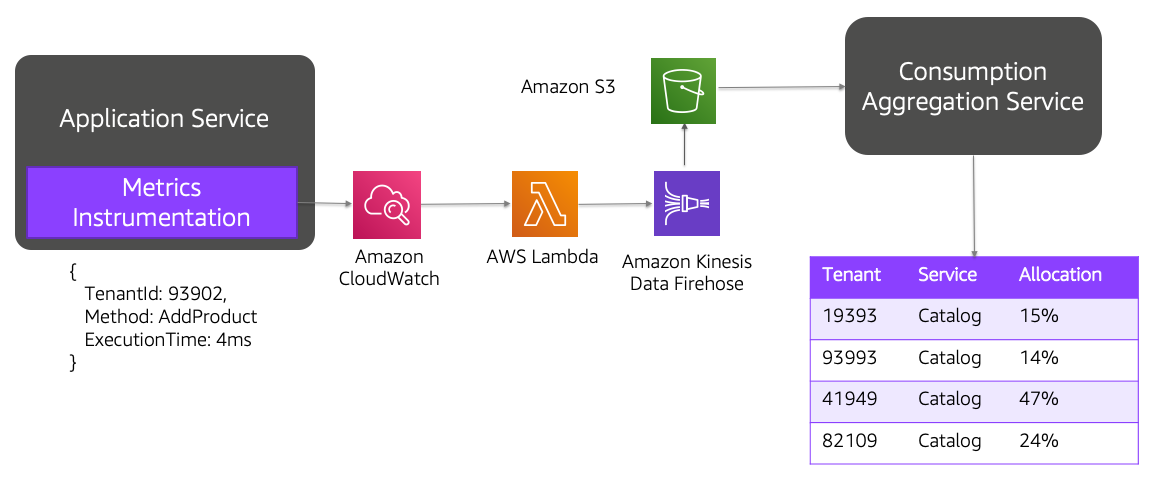
图26:用租户消费事件检测微服务
在本例中,我们将度量工具引入到应用程序的每个微服务中。这些微服务将捕获租户如何使用该服务及其相关资源的更详细数据。此详细数据将作为事件发布并聚合。在这里,我们展示了用于发布和接收数据的Amazon CloudWatch、AWS Lambda、Amazon Kinesis Data Firehose和Amazon S3。然后将分析这些数据,并根据您自己的建模得出租户之间的消费分布。
当您超越应用程序的微服务时,归因于租户消费变得更具挑战性。您可能需要在逐个服务的基础上制定特定的、有针对性的策略。例如,存储服务可能需要一个单独的服务来分析存储消耗。这可能需要查看IOPS、数据占用和其他因素,以分析租户的消费。
SaaS成本2:您如何将租户消费与基础设施成本联系起来?
SaaS环境的动态特性可能会使理解系统基础架构的成本状况可能会如何变化变得很困难。系统中租户的需求和组合的变化可能会导致SaaS环境运营成本的大幅波动。同时,SaaS业务需要清楚地了解租户如何影响成本,以做出关于如何构建、销售和运营其SaaS应用程序的战略决策。
为了了解更好地了解租户如何影响业务成本的商业价值,让我们看一个如何在SaaS环境中应用成本数据的示例。图27中的图表提供了一个场景的示例,其中SaaS环境的成本与这些租户的收入以及这些租户管理的电子商务目录的大小相关。

图27:每层租户的成本
该图说明了SaaS产品各层的成本分布。在这里,您将看到基本层和高级层租户的基础设施成本之间的巨大差异。关键的观察是,产生最小收入的基本层承担了系统基础设施成本的最大部分。同时,产生最多收入的高级层的成本足迹要小得多。这种不平衡可能意味着我们的模型有问题。
这只是一个示例,说明如何获取按租户和层划分的成本对SaaS提供商至关重要。通过访问此租户成本数据,SaaS组织可以评估可能影响环境成本状况的各种架构考虑因素。它还可以帮助指导定价和分层策略。
与汇编每个租户的成本数据相关的两个基本方面。首先,您需要一些方法来确定和计算租户消费,以得出每个租户的消费百分比(有关如何收集该消费数据的详细信息,请参见上文)。获得消费数据后,您需要将该数据与AWS账单中的成本信息相关联,以得出每个租户的成本计算结果。
有许多选项可用于访问收款账单数据。AWS提供了API,可用于获取和聚合这些计费数据,或者您可以探索一系列APN合作伙伴解决方案来获取这些数据并通过这些解决方案获取成本。这里最短的路径通常是与APN合作伙伴合作,处理吸收和汇总AWS成本的细微差别。
该体验的高级视图如图28所示。您将看到我们需要收集两组不同的数据。一个过程将汇总并摄取AWS账单中汇总成本的数据,其方式与与您的每租户成本模型相关的成本粒度一致。接下来,您将看到租户消费聚合,该聚合分析租户活动并为每个租户分配一个消费百分比。最后,将这些消耗百分比应用于基础设施成本,得出每个租户的成本。
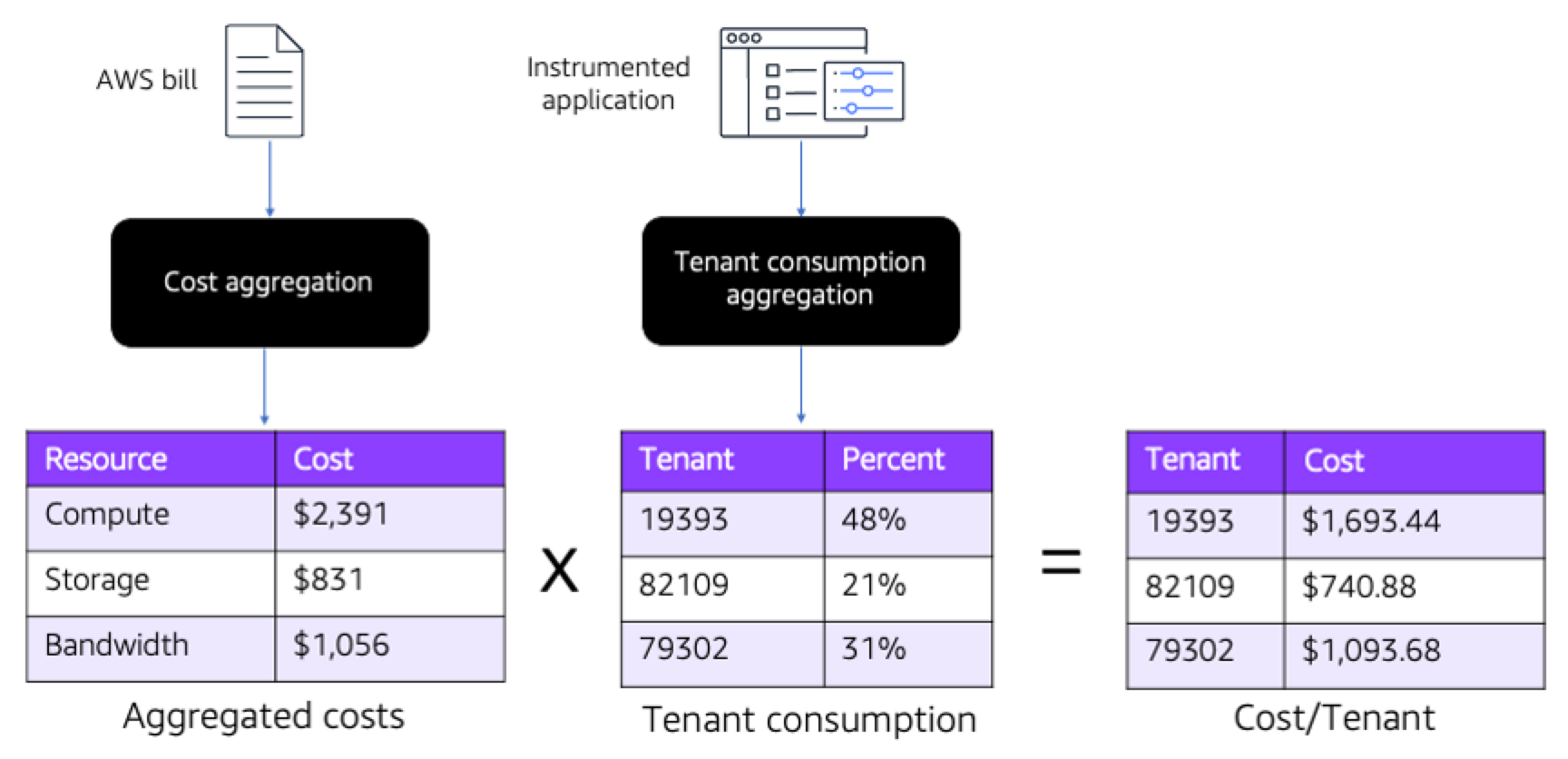
图28:计算每个租户的成本
获得这些数据后,您可以选择如何最好地表示由此产生的成本。通常,在业务核心的一系列服务中,每个租户的成本似乎很有价值。但是,您可以使用权重并计算每个租户的总体成本,以便进行其他分析。
随时间优化
SaaS应用程序没有独特的成本做法。
资源
请参阅以下资源以了解有关AWS成本优化最佳实践的更多信息。
文档和博客
- 计算SaaS环境中的租户成本
- 计算每个租户的SaaS成本:AWS Kubernetes环境中的PoC实现
- SaaS指标深度挖掘:多租户分析
- SaaS分析和度量:捕获和处理对您成功至关重要的数据
- AWS中的监控工具
视频
- SaaS指标:租户消费的终极视角
- 46 次浏览
【SaaS架构】SaaS镜头-架构支柱-运营卓越支柱
视频号
微信公众号
知识星球
卓越运营支柱包括运行和监控系统以实现业务价值并持续改进支持流程和程序的能力。
卓越运营支柱概述了设计原则、最佳实践和问题。您可以在卓越运营支柱白皮书中找到有关实施的规定性指南。
设计原则
在云计算中,有许多原则可以推动卓越的运营。
定义
云计算中有三个最佳实践领域可实现卓越运营:
- 准备
- 运转
- 发展
运营团队需要了解他们的业务和客户需求,以便他们能够有效地支持业务成果。运营部创建并使用程序来响应运营事件,并验证其有效性以支持业务需求。运营部门收集用于衡量预期业务成果实现情况的指标。一切都在不断改变您的业务环境、业务优先级、客户需求等。重要的是,设计运营以支持随着时间的推移而发生的变化,以应对变化,并将从其绩效中吸取的经验教训纳入其中。
最佳实践
话题
准备(Prepare)
SaaS应用程序没有独特的操作实践。
运转(Operate)
SaaS OPS 1:如何有效地监控和管理多租户环境的运行状况?
在多租户环境中,一个组织的所有客户都可能部署在一个共享的基础架构模型中,需要更详细的运行状况视图,这对于SaaS业务的成功和增长至关重要。任何停机或运行状况问题都有可能在系统的所有租户之间级联,并导致所有客户的SaaS服务中断。这意味着SaaS组织必须重视创建运营体验,使运营团队能够有效地分析和响应SaaS环境不断变化的工作负载。
构建强大的多租户运营体验需要SaaS公司创建或定制工具,以引入SaaS环境中所需的更精细的健康和活动视图。这通常意味着使用现有工具和定制解决方案的组合来创建一种支持租赁和租户层作为运营体验中的一流概念的体验。
例如,SaaS运营仪表板应包括通过租户和租户层的视角呈现的健康状况视图。虽然查看全球健康状况仍然是这种体验的一部分,但SaaS运营团队也需要能够查看租户的健康状况和活动。图12中的图表提供了SaaS提供商将租户活动作为一级结构呈现的一种方式的概念视图。
该图中的简化视图突出显示了一些操作视图的示例,这些示例将在多租户环境中增加价值。在页面的左上方,您将看到最活跃租户的健康状况视图。所显示的颜色指示器可以将注意力集中在租户身上,这些租户可能遇到的问题在从全球健康角度来看时尚未浮出水面。这使得运营部门能够对租户可能不太明显的任何问题做出反应和主动响应。
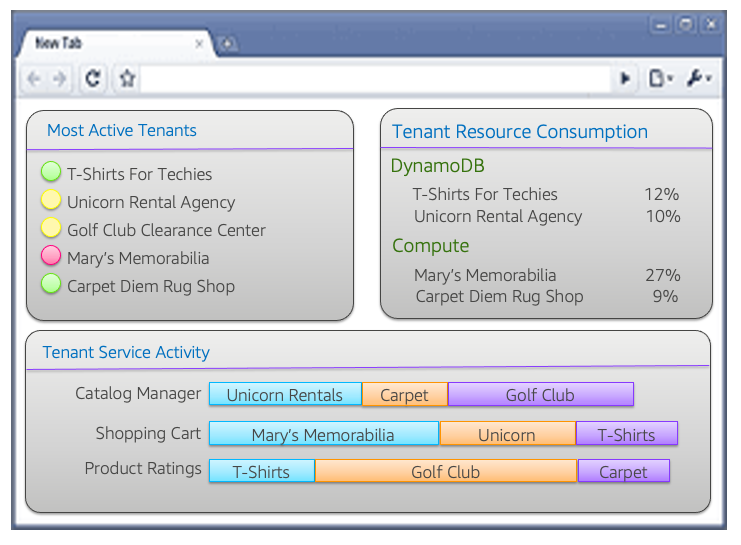
图12:租户感知操作视图
在该视图的右上方,您将看到租户资源消耗的数据。这里的想法是逐个租户查看AWS资源的使用情况,允许您查看特定租户是如何使用特定服务的。在底部,您将看到一个消费视图,说明租户如何消费应用程序的各种微服务。通过这里的数据,操作人员可以了解租户如何使用系统的各种服务,并确定特定租户或层是否正在饱和特定的微服务。
除了提供租户活动的一般视图外,您的运营经验还应包括深入了解各个租户和层的运营数据的能力。设想特定租户或租户层遇到问题的支持场景。在这些情况下,您希望能够访问运营数据,并通过特定租户或层的视角查看数据。这对于能够在多租户环境中解决和诊断问题至关重要。
创建这些操作视图依赖于能够访问操作数据,其中包括租户和分层上下文,而创建操作视图需要这些上下文来分析租户或租户层的见解。这需要SaaS架构师仔细考虑如何以及在何处将租户上下文注入用于记录健康和活动事件的各种机制。例如,日志应包含确保租户上下文(如租户标识符和层)注入系统日志数据的机制。
然而,您选择构建的视图将根据应用程序设计和架构的性质而有所不同。通常,团队应该考虑运营视图,这些视图将使运营团队能够有效地监控租户趋势,并从一开始就将工具构建到他们的环境中。在稍后的开发过程中将这些概念添加到应用程序中更具挑战性,并且可能会破坏开发和操作体验。
笔记
本白皮书中的问题编号已更改,以符合AWS良好架构工具的SaaS镜头中的顺序。SaaS OPS 2在以下最佳实践Evolve中进行了描述。
SaaS OPS 3:新租户如何加入您的系统?
SaaS解决方案高度关注最大化灵活性和创新。租户入职在这个敏捷故事中扮演着关键角色。通过创建一个促进无摩擦、可重复的入职流程的架构,SaaS组织能够简化、优化和扩展其能力,将新租户引入其SaaS环境。这使SaaS公司能够支持快速增长,并为客户提供加速其整体价值实现时间的体验。
需要注意的是,自动入职适用于B2C和B2B SaaS环境。虽然一些SaaS产品可能不包括自助入职体验,但这并不能减少对无摩擦入职体验的需求。即使当入职是一个内部执行的过程时,它仍然应该自动化租户创建的所有元素。减少摩擦的需求是创建符合SaaS最佳实践的解决方案的基础。
通常,SaaS应用程序的入职流程需要协调一系列共享服务,这些服务可以配置和提供引入新租户所需的所有资源。图13中的图表提供了如何通过一系列微服务实现这种入职的高级视图。
本图所示的入职体验流程涵盖了引入租户并让他们开始使用SaaS系统所需的所有步骤。在这个过程的前端,租户调用我们的注册服务,请求创建一个新租户。从这一点开始,注册服务将位于入职流程的中间,协调创建新租户环境所需的所有服务。
此过程的下一步是创建新用户。此新用户将代表此新租户的管理员。为了支持这个过程,我们提供了一个用户管理服务。该服务不保存用户的数据,但它在身份提供者中创建用户(在本例中是AmazonCognito)。它还创建支持此租户的隔离要求所需的任何IAM策略。

图13:无摩擦租户入职
在这个模型中,我们还依赖于为每个租户使用单独的Amazon Cognito用户池的策略。这允许我们为系统的每个租户定制身份体验(密码策略、多因素身份验证等)。通过选择此方法,我们必须将每个用户ID映射到相应的用户池。此映射由用户管理服务管理。
创建用户后,我们的流程现在创建一个租户。租户作为一种独特服务的这种分离对于SaaS环境至关重要。它提供了一种集中的方式来管理租户的状态和属性,与租户关联的用户完全分离。例如,租户的层或状态将由租户管理服务控制。
作为入职培训的一部分,SaaS系统通常必须在计费系统中建立足迹。在本例中,您将看到我们通知计费集成服务,我们正在创建一个新租户。然后,该服务负责向计费提供商创建新帐户。这包括为租户配置计划或层(免费、青铜、白金等)。
图中所示流程的最后一步与租户基础设施的配置有关。一些SaaS架构将包括专用租户资源。在这些情况下,我们的入职流程必须在激活租户之前提供这些新资源。
虽然此处所表示的流程可能会因环境的性质而有所不同,但此处所示的概念对于入职流程来说是通用的。自动化租户资源的创建、配置和供应是创建丰富、可扩展的多租户体验的基础。
SaaS OPS 4:您如何支持租户特定定制的需求?
SaaS架构师面临的一个重大挑战是,需要确保所有租户都运行相同版本的产品。对于已经迁移到SaaS并且已经习惯于通过一次性版本的产品支持独特客户需求的公司来说,这一点尤其如此。
尽管这看起来很诱人,但任何背离统一的客户管理、运营、支持和部署经验的做法都会直接损害SaaS组织的整体灵活性。随着每一个新的定制环境的引入,SaaS组织都会慢慢走向传统的软件模型。最终,这最终会侵蚀成本、运营效率和SaaS业务模式核心的一般创新目标。
因此,挑战是找到一种策略,使您能够满足这些偶尔的一次性需求,而不必创建产品的分叉版本。这里的妥协是通过引入添加到整体产品中的定制选项来实现的。因此,您可以投入额外的时间和精力来研究如何添加这些新功能,从而使所有客户都可以使用这些功能,而不是剥离单独的版本。然后,通过租户配置,您可以确定哪些租户将启用这些新功能。
解决这个问题的常见方法是使用功能标志。功能标志通常被应用程序开发人员用作在一个公共代码库中具有多个执行路径的一种方式,其中包含在运行时启用或禁用每个不同功能的标志。这种技术通常被用作通用开发策略,它提供了一种将定制引入SaaS环境的有效方法。每个功能标志将与租户配置选项相关。此配置将在运行时进行评估,并影响为每个租户启用的功能。
图14中的图表提供了如何应用这些标志的概念视图。将为单个租户打开和关闭一系列标志,以确定为租户启用了哪些功能。当租户注册SaaS产品的新功能时,将更改这些配置选项。在某些情况下,这些标志可以与层(而不是单个租户)相关联。

图14:使用功能标志管理租户需求
功能标志只是实现这一点的一种方式。这里的关键是,即使单个租户需要一个独特的功能,该功能也应该作为核心平台的定制而引入。根据系统的堆栈和设计,应用自定义的方式可能会有所不同。其目的是确保我们可以部署和管理产品的单一版本。
虽然这可能是一个强大的构造,但应谨慎应用。如果通过引入功能标志,您创建了一个复杂的选项迷宫,最终为每个租户提供了独特的体验,那么您的系统将很快变得无法管理。尝试选择如何以及何时引入这些标志。根据经验,企业不应将其视为一种销售工具,使组织能够为新客户提供一次性定制。
发展(Evolve)
SaaS OPS 2:您如何捕获和呈现可用于分析单个租户的使用和消费趋势的度量数据?
要不断发展您的SaaS运营体验,您需要访问丰富的运营数据集合,这些数据可用于分析您的多租户SaaS环境。这通常意味着从您的应用程序中检测和发布更丰富的租户指标集合,这些指标可以准确捕捉正在使用您的环境的租户的活动和消费模式。
SaaS指标超出了基础设施消耗(CPU、内存等)的基础,确定了对理解环境中多租户负载的操作至关重要的特定操作使用模式。对这些数据的分析将使SaaS组织能够评估其系统中正在发生的趋势,并确定对基础架构引入策略或更改的机会,从而不断提高SaaS产品的可靠性、可扩展性、成本效率和整体灵活性。
捕获和显示度量数据有两个不同的元素。首先,应用程序必须发布度量数据,这些数据可以为SaaS环境提供有用的运营见解。您需要确定应用程序中要捕获和发布这些度量的关键点。
这里的另一个难题是这些数据的摄取、聚合和呈现。您可以从AWS或AWS合作伙伴网络(APN)合作伙伴中选择多种工具。最终,这其中的摄取部分更像是一个数据仓库和商业智能问题。本文档前面列出的SaaS架构场景包括Tenant Insights场景。此场景概述了用于接收度量数据的体系结构。该体系结构代表了可以应用于解决这一需求的模式之一。
虽然我们这里的重点是这些租户指标的操作视图,但您可以想象这些指标在SaaS业务的多个上下文中都有使用。运营要求是您的体系结构,以确保组织积极收集和分析租户活动和消费趋势,以确定发展SaaS系统的机会。这符合构建基础工具的更广泛主题,该工具可用于评估租户和租户工作负载不断变化的组合。
Resources
Refer to the following resources to learn more about our best practices related to operational excellence.
Documentation & Blogs
Videos
- 115 次浏览
【SaaS架构】SaaS镜头-架构良好的框架的支柱
视频号
微信公众号
知识星球
本节描述了每一个支柱,并包括定义、最佳实践、问题、注意事项以及为多租户SaaS应用程序设计解决方案时相关的关键AWS服务。
为了简洁起见,我们只包含了SaaS工作负载特有的问题。在设计架构时,仍应考虑本文档中未包含的问题。我们建议您阅读AWS良好架构框架白皮书。
柱子
- 90 次浏览
【SaaS透镜】SaaS透镜 -摘要和简介
视频号
微信公众号
知识星球
摘要
本文介绍了AWS良好架构框架的SaaS镜头,它使客户能够审查和改进其基于云的架构,并更好地理解其设计决策的业务影响。我们讨论了五个概念领域中的一般设计原则以及具体的最佳实践和指导,我们将其定义为良好架构框架的支柱。
介绍
AWS良好架构框架帮助您了解在AWS上构建系统时所做决策的利弊。通过使用该框架,您将学习在云中设计和运行可靠、安全、高效和经济高效的系统的架构最佳实践。它为您提供了一种方法,可以根据最佳实践一致地衡量您的体系结构,并确定需要改进的领域。我们相信,拥有良好的体系结构将大大增加业务成功的可能性。
在本“镜头”中,我们重点关注如何设计、部署和构建AWS云中的多租户软件即服务(SaaS)应用程序工作负载。为了简洁起见,我们只介绍了架构良好的框架中特定于SaaS工作负载的细节。在设计架构时,您仍应考虑本文档中未包含的最佳实践和问题。我们建议您阅读AWS良好架构框架白皮书。
本文档适用于担任技术职务的人员,如首席技术官(CTO)、架构师、开发人员和运营团队成员。阅读本文档后,您将了解在设计SaaS应用程序架构时要使用的AWS最佳实践和策略。
- 115 次浏览
【SaaS架构】使用AWS Lambda令牌自动售货机为Amazon S3实施SaaS租户隔离
视频号
微信公众号
知识星球
多租户SaaS应用程序必须实现系统,以确保租户隔离得到维护。当您在同一Amazon Web Services(AWS)资源上存储租户数据时,例如多个租户在同一亚马逊简单存储服务(Amazon S3)存储桶中存储数据时,您必须确保不会发生跨租户访问。
Created by Tabby Ward (AWS), sravan periyathambi (AWS), and Thomas Davis (AWS)
|
Environment: PoC or pilot |
Technologies: Modernization; SaaS |
AWS services: AWS Identity and Access Management; AWS Lambda; Amazon S3; AWS STS |
总结
多租户SaaS应用程序必须实现系统,以确保租户隔离得到维护。当您在同一Amazon Web Services(AWS)资源上存储租户数据时,例如多个租户在同一亚马逊简单存储服务(Amazon S3)存储桶中存储数据时,您必须确保不会发生跨租户访问。令牌自动售货机(TVM)是保证租户数据隔离的一种方式。这些机器提供了一种获取令牌的机制,同时抽象了如何生成这些令牌的复杂性。开发人员可以使用TVM,而无需详细了解它如何生成令牌。
此模式通过使用AWS Lambda实现TVM。TVM生成一个令牌,该令牌由临时安全令牌服务(STS)凭证组成,这些凭证限制对S3存储桶中单个SaaS租户数据的访问。
TVM和随此模式提供的代码通常与从JSON Web令牌(JWT)派生的声明一起使用,以将AWS资源请求与租户范围的AWS身份和访问管理(IAM)策略相关联。您可以使用此模式中的代码作为实现SaaS应用程序的基础,该应用程序基于JWT令牌中提供的声明生成作用域的临时STS凭证。
先决条件和限制
先决条件
- 活跃的AWS帐户。
- AWS命令行界面(AWS CLI)1.19.0或更高版本,在macOS、Linux或Windows上安装和配置。或者,您可以使用AWS CLI 2.1版或更高版本。
局限性
- 此代码在Java中运行,目前不支持其他编程语言。
- 示例应用程序不包括AWS跨区域或灾难恢复(DR)支持。
- 此模式演示了SaaS应用程序的Lambda TVM如何提供范围内的租户访问。它不打算用于生产环境。
架构
目标技术堆栈
- AWS Lambda公司
- 亚马逊S3
-
IAM
- AWS安全令牌服务(AWS STS)
目标体系结构
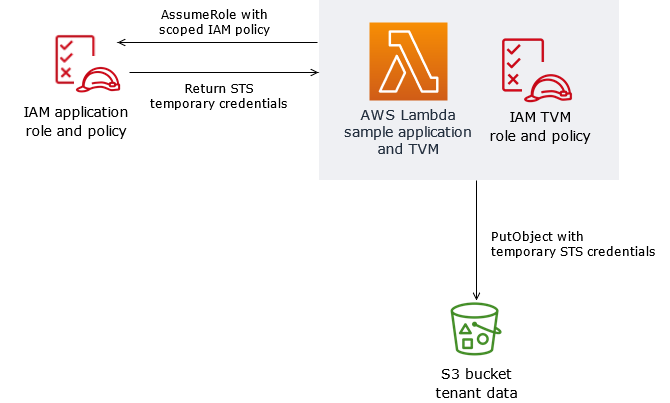
工具
AWS服务
- AWS CLI–AWS命令行界面(AWS CLI)是通过使用命令行shell中的命令与AWS服务交互的统一工具。
- AWS Lambda–AWS Lambda允许您在不配置或管理服务器的情况下运行代码。您只需支付所消耗的计算时间。
- Amazon S3–Amazon Simple Storage Service(Amazon S3)是一种对象存储服务,提供可扩展性、数据可用性、安全性和性能。
- IAM–AWS身份和访问管理(IAM)是一种用于安全控制AWS服务访问的web服务。
- AWS STS-AWS安全令牌服务(AWS STS)使您能够为IAM用户或您认证的用户(联合用户)请求临时、有限的权限凭据。
代码
此模式的源代码作为附件提供,包括以下文件:
- s3UploadSample.jar提供了Lambda函数的源代码,该函数将JSON文档上传到S3存储桶。
- tvm-layer.zip提供了一个可重用的Java库,该库为Lambda函数提供令牌(STS临时凭证),以访问S3存储桶并上载JSON文档。
- token-vending-machine-sample-app.zip提供了用于创建这些工件的源代码和编译说明。
要使用这些文件,请遵循下一节中的说明。
叙事
Determine variable values
| Task | Description | Skills required |
|---|---|---|
| Determine variable values. |
The implementation of this pattern requires includes several variable names that must be used consistently. Determine the values that should be used for each variable, and provide that value when requested in subsequent steps. <AWS Account ID> ─ The 12-digit account ID that is associated with the AWS account you are implementing this pattern in. For information about how to find your AWS cccount ID, see Your AWS account ID and its alias in the IAM documentation. <AWS Region> ─ The AWS Region that you are implementing this pattern in. For more information on AWS Regions, see Regions and Availability Zones on the AWS website. <sample-tenant-name> ─ The name of a tenant to use in the application. We recommend that you use only alphanumeric characters in this value for simplicity, but you can use any valid name for an S3 object key. <sample-tvm-role-name> ─ The name of the IAM role attached to the Lambda function that runs the TVM and sample application. The role name is a string that consists of uppercase and lowercase alphanumeric characters with no spaces. You can also include any of the following characters: underscore (_), plus sign (+), equal sign (=), comma (,), period (.), at sign (@), and hyphen (-). The role name must be unique within the account. <sample-app-role-name> ─ The name of the IAM role that is assumed by the Lambda function when it generates scoped, temporary STS credentials. The role name is a string that consists of uppercase and lowercase alphanumeric characters with no spaces. You can also include any of the following characters: underscore (_), plus sign (+), equal sign (=), comma (,), period (.), at sign (@), and hyphen (-). The role name must be unique within the account. <sample-app-function-name> ─ The name of the Lambda function. This is a string that’s up to 64 characters in length. <sample-app-bucket-name> ─ The name of an S3 bucket that must be accessed with permissions that are scoped to a specific tenant. S3 bucket names:
|
Cloud administrator |
Create an S3 bucket
| Task | Description | Skills required |
|---|---|---|
| Create an S3 bucket for the sample application. |
Use the following AWS CLI command to create an S3 bucket. Provide the <sample-app-bucket-name> value in the code snippet: The Lambda sample application uploads JSON files to this bucket. |
Cloud administrator |
Create the IAM TVM role and policy
| Task | Description | Skills required |
|---|---|---|
| Create a TVM role. |
Use one of the following AWS CLI commands to create an IAM role. Provide the <sample-tvm-role-name> value in the command. For macOS or Linux shells: For the Windows command line: The Lambda sample application assumes this role when the application is invoked. The capability to assume the application role with a scoped policy gives the code broader permissions to access the S3 bucket. |
Cloud administrator |
| Create an inline TVM role policy. |
Use one of the following AWS CLI commands to create an IAM policy. Provide the <sample-tvm-role-name>, <AWS Account ID>, and <sample-app-role-name> values in the command. For macOS or Linux shells: For the Windows command line: This policy is attached to the TVM role. It gives the code the capability to assume the application role, which has broader permissions to access the S3 bucket. |
Cloud administrator |
| Attach the managed Lambda policy. |
Use the following AWS CLI command to attach the This managed policy is attached to the TVM role to permit Lambda to send logs to Amazon CloudWatch. |
Cloud administrator |
Create the IAM application role and policy
| Task | Description | Skills required |
|---|---|---|
| Create the application role. |
Use one of the following AWS CLI commands to create an IAM role. Provide the <sample-app-role-name>, <AWS Account ID>, and <sample-tvm-role-name> values in the command. For macOS or Linux shells: For the Windows command line: The Lambda sample application assumes this role with a scoped policy to get tenant-based access to an S3 bucket. |
Cloud administrator |
| Create an inline application role policy. |
Use one of the following AWS CLI commands to create an IAM policy. Provide the <sample-app-role-name> and <sample-app-bucket-name> values in the command. For macOS or Linux shells: For the Windows command line: This policy is attached to the application role. It provides broad access to objects in the S3 bucket. When the sample application assumes the role, these permissions are scoped to a specific tenant with the TVM's dynamically generated policy. |
Cloud administrator |
Create the Lambda sample application with TVM
| Task | Description | Skills required |
|---|---|---|
| Download the compiled source files. |
Download the |
Cloud administrator |
| Create the Lambda layer. |
Use the following AWS CLI command to create a Lambda layer, which makes the TVM accessible to Lambda. Note: If you aren’t running this command from the location where you downloaded This command creates a Lambda layer that contains the reusable TVM library. |
Cloud administrator, App developer |
| Create the Lambda function. |
Use the following AWS CLI command to create a Lambda function. Provide the <sample-app-function-name>, <AWS Account ID>, <AWS Region>, <sample-tvm-role-name>, <sample-app-bucket-name>, and <sample-app-role-name> values in the command. Note: If you aren’t running this command from the location where you downloaded This command creates a Lambda function with the sample application code and the TVM layer attached. It also sets two environment variables: |
Cloud administrator, App developer |
Test the sample application and TVM
| Task | Description | Skills required |
|---|---|---|
| Invoke the Lambda sample application. |
Use one of the following AWS CLI commands to start the Lambda sample application with its expected payload. Provide the <sample-app-function-name> and <sample-tenant-name> values in the command. For macOS and Linux shells: For the Windows command line: This command calls the Lambda function and returns the result in a Note: Changing the <sample-tenant-name> value in subsequent invocations of this Lambda function alters the location of the JSON document and the permissions the token provides. |
Cloud administrator, App developer |
| View the S3 bucket to see created objects. |
Browse to the S3 bucket ( <sample-app-bucket-name>) that you created earlier. This bucket contains an S3 object prefix with the value of <sample-tenant-name>. Under that prefix, you will find a JSON document named with a UUID. Invoking the sample application multiple times adds more JSON documents. |
Cloud administrator |
| View Cloudwatch logs for the sample application. |
View the Cloudwatch logs associated with the Lambda function named <sample-app-function-name>. For instructions, see Accessing Amazon CloudWatch logs for AWS Lambda in the AWS Lambda documentation. You can view the tenant-scoped policy generated by the TVM in these logs. This tenant-scoped policy gives permissions for the sample application to the Amazon S3 PutObject, GetObject, DeleteObject, and ListBucket APIs, but only for the object prefix associated with <sample-tenant-name>. In subsequent invocations of the sample application, if you change the <sample-tenant-name>, the TVM updates the scoped policy to correspond to the tenant provided in the invocation payload. This dynamically generated policy shows how tenant-scoped access can be maintained with a TVM in SaaS applications. The TVM functionality is provided in a Lambda layer so that it can be attached to other Lambda functions used by an application without having to replicate the code. For an illustration of the dynamically generated policy, see the Additional information section. |
Cloud administrator |
Related resources
-
Isolating Tenants with Dynamically Generated IAM Policies (blog post)
-
Applying Dynamically Generated Isolation Policies in SaaS Environment (blog post)
-
AWS SaaS Boost (an open-source reference environment that helps you move your SaaS offering to AWS)
Additional information
The following Amazon Cloudwatch log shows the dynamically generated policy produced by the TVM code in this pattern. In this screenshot, the <sample-app-bucket-name> is DOC-EXAMPLE-BUCKET and the <sample-tenant-name> is test-tenant-1. The STS credentials returned by this scoped policy are unable to perform any actions on objects in the S3 bucket except for objects that are associated with the object key prefix test-tenant-1.

Attachments
要访问与此文档相关的其他内容,请解压缩以下文件:attachment.zip
- 86 次浏览
【SaaS架构】使用C#和AWS CDK在SaaS架构中为简仓模型注册租户
视频号
微信公众号
知识星球
Created by Tabby Ward (AWS), Susmitha Reddy Gankidi (AWS), Vijai Anand Ramalingam (AWS), and Danil Ko (AWS)
Code repository: |
Environment: PoC or pilot |
Technologies: Modernization; Cloud-native; SaaS; DevOps |
|
Workload: Open-source |
AWS services: AWS CloudFormation; Amazon DynamoDB; Amazon DynamoDB Streams; AWS Lambda; Amazon API Gateway |
总结
软件即服务(SaaS)应用程序可以使用各种不同的架构模型构建。筒仓模型是指为租户提供专用资源的体系结构。
SaaS应用程序依赖于一个无摩擦的模型来将新租户引入其环境。这通常需要协调多个组件,以成功地调配和配置创建新租户所需的所有元素。在SaaS架构中,这个过程被称为租户入职。对于每个SaaS环境,应通过将基础设施用作入职流程中的代码来实现入职完全自动化。
此模式将指导您完成一个创建租户并在Amazon Web Services(AWS)上为租户提供基本基础设施的示例。该模式使用C#和AWS云开发工具包(AWS CDK)。
因为这种模式会产生计费警报,所以我们建议在美国东部(北弗吉尼亚州)或美国东部1号AWS地区部署堆栈。有关更多信息,请参阅AWS文档。
先决条件和限制
先决条件
- 活跃的AWS帐户。
- 具有足够AWS身份和访问管理(IAM)访问权限的用户,可以为此模式创建AWS资源。有关详细信息,请参阅IAM角色。
- 具有编程访问密钥的用户。有关更多信息,请参阅在AWS帐户中创建IAM用户。
- Amazon命令行界面(AWS CLI)。
- 下载并安装了Visual Studio 2022或下载并安装Visual Studio代码。
- AWS Toolkit for Visual Studio安装。
- .NET Core 3.1或更高版本(C#AWS CDK应用程序需要)
- 已安装Amazon.Lambda.Tools。
局限性
- AWS CDK使用AWS CloudFormation,因此AWS CDK应用程序受CloudFormation服务配额限制。有关更多信息,请参阅AWS CloudFormation配额。
- 租户CloudFormation堆栈是使用CloudFormation服务角色创建的,该角色位于CloudFormation角色之下,在操作(sns*和sqs*)上使用通配符,但资源锁定到租户集群前缀。对于生产用例,请评估此设置,并仅提供对此服务角色所需的访问权限。InfrastructureProvisionLambda函数还使用通配符(cloudformation*)来配置cloudformation堆栈,但资源锁定到租户集群前缀。
- 此示例代码的docker构建使用--platform=linux/amd64强制使用基于linux/adm64的映像。这是为了确保最终图像伪影适合Lambda,默认情况下使用x86-64架构。如果您需要更改目标Lambda架构,请确保同时更改Dockerfile和AWS CDK代码。有关更多信息,请参阅将AWS Lambda函数迁移到基于Arm的AWS Graviton2处理器的博客文章。
- 堆栈删除过程不会清理堆栈生成的CloudWatch日志(日志组和日志)。您必须通过AWS管理控制台Amazon CloudWatch控制台或通过API手动清理日志。
此模式是作为示例设置的。对于生产用途,请评估以下设置并根据您的业务需求进行更改:
- 本例中的AWS Simple Storage Service(AmazonS3)存储桶没有启用版本控制以简化操作。根据需要评估和更新设置。
- 为了简单起见,本示例设置了AmazonAPI网关REST API端点,而无需验证、授权或限制。对于生产用途,我们建议将系统与业务安全基础设施集成。评估此设置并根据需要添加所需的安全设置。
- 对于这个租户基础设施示例,Amazon Simple Notification Service(Amazon SNS)和Amazon Simple Queue Service(Amazon SQS)只有最低设置。每个租户的AWS密钥管理服务(AWS KMS)向账户中的Amazon CloudWatch和Amazon SNS服务开放,以便根据AWS KMS密钥策略进行消费。设置只是一个示例占位符。根据您的业务用例,根据需要调整设置。
- 整个设置(包括但不限于API端点和使用AWS CloudFormation进行的后端租户配置和删除)仅涵盖基本的快乐路径情况。根据您的业务需要,使用必要的重试逻辑、其他错误处理逻辑和安全逻辑来评估和更新设置。
- 在编写本文时,使用最新的cdk-nag对示例代码进行了测试,以检查策略。未来可能会实施新政策。这些新策略可能需要您根据建议手动修改堆栈,然后才能部署堆栈。检查现有代码以确保其符合您的业务需求。
- 该代码依赖于AWS CDK生成随机后缀,而不是依赖于大多数创建资源的静态分配物理名称。此设置旨在确保这些资源是唯一的,并且不会与其他堆栈冲突。有关更多信息,请参阅AWS CDK文档。根据您的业务需求进行调整。
- 此示例代码将.NET Lambda工件打包到基于Docker的映像中,并使用Lambda提供的容器映像运行时运行。容器映像运行时在标准传输和存储机制(容器注册表)和更准确的本地测试环境(通过容器映像)方面具有优势。您可以将项目切换为使用Lambda提供的.NET运行时,以减少Docker映像的构建时间,但随后需要设置传输和存储机制,并确保本地设置与Lambda设置相匹配。调整代码以符合用户的业务需求。
产品版本
- AWS CDK 2.45.0版或更高版本
- Visual Studio 2022
架构
技术堆栈
- Amazon API网关
- AWS云形成
- 亚马逊CloudWatch
- 亚马逊动态数据库
- AWS身份和访问管理(IAM)
- AWS公里
- AWS Lambda公司
- 亚马逊S3
- 亚马逊SNS
- 亚马逊简单队列服务
架构
下图显示了租户堆栈创建流程。有关控制平面和租户技术堆栈的更多信息,请参阅附加信息部分。

租户堆栈创建流程
- 用户向AmazonAPI网关托管的REST API发送一个POST API请求,其中包含JSON格式的新租户负载(租户名称、租户描述)。API网关处理请求并将其转发到后端Lambda租户登录功能。在此示例中,没有授权或身份验证。在生产设置中,此API应与SaaS基础设施安全系统集成。
- 租户登机功能验证请求。然后,它尝试将租户记录(包括租户名称、生成的租户通用唯一标识符(UUID)和租户描述)存储到AmazonDynamoDB租户登录表中。
- 在DynamoDB存储记录后,DynamoDB流启动下游的Lambda Tenant Infrastructure功能。
- Tenant Infrastructure Lambda函数基于接收到的DynamoDB流进行操作。如果流用于INSERT事件,则函数使用流的NewImage部分(最新更新记录,租户名称字段)调用CloudFormation,以使用存储在S3存储桶中的模板创建新的租户基础结构。CloudFormation模板需要租户名称参数。
- AWS CloudFormation基于CloudFormation模板和输入参数创建租户基础设施。
- 每个租户基础设施设置都有CloudWatch警报、计费警报和警报事件。
- 报警事件变成一条指向SNS主题的消息,该主题由租户的AWS KMS密钥加密。
- SNS主题将收到的报警消息转发到SQS队列,SQS队列由租户的AWS KMS加密密钥。
其他系统可以与AmazonSQS集成,以根据队列中的消息执行操作。在本例中,为了保持代码的通用性,传入消息保留在队列中,需要手动删除。
租户堆栈删除流程
- 用户将一个带有JSON格式的新租户负载(租户名称、租户描述)的DELETE API请求发送到由Amazon API Gateway托管的REST API,后者将处理该请求并转发到租户登录功能。在此示例中,没有授权或身份验证。在生产设置中,此API将与SaaS基础设施安全系统集成。
- 租户登记功能将验证请求,然后尝试从租户登记表中删除租户记录(租户名称)。
- DynamoDB成功删除记录(记录存在于表中并被删除)后,DynamoDB流启动下游Lambda Tenant Infrastructure功能。
- Tenant Infrastructure Lambda函数基于接收到的DynamoDB流记录进行操作。如果流用于REMOVE事件,则该函数使用记录的OldImage部分(记录信息和租户名称字段,在最新更改之前,即删除)根据该记录信息启动现有堆栈的删除。
- AWS CloudFormation根据输入删除目标租户堆栈。
工具
AWS服务
- Amazon API网关可帮助您创建、发布、维护、监控和保护任何规模的REST、HTTP和WebSocket API。
- AWS云开发工具包(AWS CDK)是一个软件开发框架,可帮助您在代码中定义和配置AWS云基础设施。
- AWS CDK工具包是一个命令行云开发工具包,可帮助您与AWS云开发工具包(AWS CDK)应用程序交互。
- AWS命令行界面(AWS CLI)是一个开源工具,可帮助您通过命令行shell中的命令与AWS服务交互。
- AWS CloudFormation帮助您设置AWS资源,快速、一致地提供资源,并在AWS客户和地区的整个生命周期中对其进行管理。
- AmazonDynamoDB是一个完全管理的NoSQL数据库服务,提供快速、可预测和可扩展的性能。
- AWS身份和访问管理(IAM)通过控制谁经过身份验证和授权使用AWS资源,帮助您安全地管理对AWS资源的访问。
- AWS密钥管理服务(AWS KMS)帮助您创建和控制加密密钥,以帮助保护数据。
- AWS Lambda是一种计算服务,它可以帮助您运行代码,而无需配置或管理服务器。它只在需要时运行您的代码,并自动缩放,因此您只需支付所使用的计算时间。
- 亚马逊简单存储服务(Amazon S3)是一种基于云的对象存储服务,可帮助您存储、保护和检索任意数量的数据。
- 亚马逊简单通知服务(Amazon SNS)帮助您协调和管理发布者和客户之间的消息交换,包括web服务器和电子邮件地址。
- 亚马逊简单队列服务(Amazon SQS)提供了一个安全、持久和可用的托管队列,帮助您集成和分离分布式软件系统和组件。
- AWS Toolkit for Visual Studio是Visual Studio集成开发环境(IDE)的插件。Visual Studio工具包支持开发、调试和部署使用AWS服务的.NET应用程序。
其他工具
- Visual Studio是一个IDE,它包括编译器、代码完成工具、图形设计器和其他支持软件开发的功能。
Epics
- 此模式的代码在SaaS架构中的租户入职筒仓模型APG示例存储库中。
史诗
Set up AWS CDK
| Task | Description | Skills required |
|---|---|---|
|
Verify Node.js installation. |
To verify that Node.js is installed on your local machine, run the following command. |
AWS administrator, AWS DevOps |
|
Install AWS CDK Toolkit. |
To install AWS CDK Toolkit on your local machine, run the following command. If npm is not installed, you can install it from the Node.js site. |
AWS administrator, AWS DevOps |
|
Verify the AWS CDK Toolkit version. |
To verify that the AWS CDK Toolkit version is installed correctly on your machine, run the following command. |
AWS administrator, AWS DevOps |
|
Set up AWS credentials. |
To set up your AWS credentials, run the |
AWS administrator, AWS DevOps |
Review the code for the tenant onboarding control plane
| Task | Description | Skills required |
|---|---|---|
|
Clone the repository. |
Clone the repository, and navigate to the In Visual Studio 2022, open the The following resources are created as part of this stack:
|
AWS administrator, AWS DevOps |
|
Review the CloudFormation template. |
In the The template provisions the tenant-specific infrastructure. In this example, it provisions the AWS KMS key, Amazon SNS , Amazon SQS, and the CloudWatch alarm. |
App developer, AWS DevOps |
|
Review the tenant onboarding function. |
Open Open the Note that the following NuGet packages are added as dependencies to the
|
App developer, AWS DevOps |
|
Review the Tenant InfraProvisioning function. |
Navigate to Open Open the Note that the following NuGet packages are added as dependencies to the
|
App developer, AWS DevOps |
Deploy the AWS resources
| Task | Description | Skills required |
|---|---|---|
|
Build the solution. |
To build the solution, perform the following steps:
Note: Make sure that you update the |
App developer |
|
Bootstrap the AWS CDK environment. |
Open the Windows command prompt and navigate to the AWS CDK app root folder where the If you have created an AWS profile for the credentials, use the command with your profile. |
AWS administrator, AWS DevOps |
|
List the AWS CDK stacks. |
To list all the stacks to be created as part of this project, run the following command. If you have created an AWS profile for the credentials, use the command with your profile. |
AWS administrator, AWS DevOps |
|
Review which AWS resources will be created. |
To review all the AWS resources that will be created as part of this project, run the following command. If you have created an AWS profile for the credentials, use the command with your profile. |
AWS administrator, AWS DevOps |
|
Deploy all the AWS resources by using AWS CDK. |
To deploy all the AWS resources run the following command. If you have created an AWS profile for the credentials, use the command with your profile. After the deployment is complete, copy the API URL from the outputs section in the command prompt, which is shown in the following example. |
AWS administrator, AWS DevOps |
Verify the functionality
| Task | Description | Skills required |
|---|---|---|
|
Create a new tenant. |
To create the new tenant, send the following curl request. Change the place holder The following example shows the output. |
App developer, AWS administrator, AWS DevOps |
|
Verify the newly created tenant details in DynamoDB. |
To verify the newly created tenant details in DynamoDB, perform the following steps.
|
App developer, AWS administrator, AWS DevOps |
|
Verify the stack creation for the new tenant. |
Verify that the new stack was successfully created and provisioned with infrastructure for the newly created tenant according to the CloudFormation template.
|
App developer, AWS administrator, AWS DevOps |
|
Delete the tenant stack. |
To delete the tenant stack, send the following curl request. Change the place holder The following example shows the output. |
App developer, AWS DevOps, AWS administrator |
|
Verify the stack deletion for the existing tenant. |
To verify that the existing tenant stack got deleted, perform the following steps:
|
App developer, AWS administrator, AWS DevOps |
Clean up
| Task | Description | Skills required |
|---|---|---|
|
Destroy the environment. |
Before the stack clean up, ensure the following:
After testing is done, AWS CDK can be used to destroy all the stacks and related resources by running the following command. If you created an AWS profile for the credentials, use the profile. Confirm the stack deletion prompt to delete the stack. |
AWS administrator, AWS DevOps |
|
Clean up Amazon CloudWatch Logs. |
The stack deletion process will not clean up CloudWatch Logs (log groups and logs) that were generated by the stack. Manually clean up the CloudWatch resources by using the CloudWatch console or the API. |
App developer, AWS DevOps, AWS administrator |
相关资源
其他信息
控制平面技术堆栈
- 用.NET编写的CDK代码用于提供控制平面基础结构,该基础结构由以下资源组成:
API网关
- 用作控制平面堆栈的REST API入口点。
承租人登机Lambda功能
此Lambda函数由API网关使用m方法启动。
POST方法API请求导致(租户名称、租户描述)插入到DynamoDB租户登录表中。
在这个代码示例中,租户名称也用作租户堆栈名称和该堆栈中资源名称的一部分。这是为了使这些资源更容易识别。此租户名称在整个安装过程中必须是唯一的,以避免冲突或错误。IAM角色文档和限制部分解释了详细的输入验证设置。
只有在表中的任何其他记录中未使用租户名称时,对DynamoDB表的持久化过程才会成功。
在本例中,租户名称是此表的分区键,因为只有分区键可以用作PutItem条件表达式。
如果以前从未记录过租户名称,则记录将成功保存到表中。
但是,如果表中的现有记录已经使用了租户名称,则操作将失败并启动DynamoDB ConditionalCheckFailedException异常。该异常将用于返回失败消息(HTTP BadRequest),指示租户名称已存在。
DELETE方法API请求将从租户登录表中删除特定租户名称的记录。
即使记录不存在,本例中的DynamoDB记录删除也将成功。
如果目标记录存在并被删除,它将创建一个DynamoDB流记录。否则,不会创建下游记录。
启用Amazon DynamoDB Streams的DynamoDB上的租户
这将记录租户元数据信息,任何记录保存或删除都将向下游的tenant Infrastructure Lambda函数发送一个流。
租户基础设施Lambda功能
此Lambda函数由上一步骤中的DynamoDB流记录启动。如果记录是针对INSERT事件的,它将调用AWS CloudFormation,使用存储在S3存储桶中的CloudFormation模板创建新的租户基础设施。如果记录用于REMOVE,它将根据流记录的Tenant Name字段启动现有堆栈的删除。
S3 桶
这用于存储CloudFormation模板。
每个Lambda功能的IAM角色和CloudFormation的服务角色
每个Lambda函数都有其独特的IAM角色,只有最低权限才能完成其任务。例如,Tenant On-boarding Lambda函数具有对DynamoDB的读/写访问权限,Tenant Infrastructure Lambda函数只能读取DynamoDB流。
为租户堆栈配置创建自定义CloudFormation服务角色。此服务角色包含CloudFormation堆栈配置的其他权限(例如,AWS KMS密钥)。这将在Lambda和CloudFormation之间划分角色,以避免对单个角色(基础架构Lambda角色)的所有权限。
允许强大操作(例如创建和删除CloudFormation堆栈)的权限被锁定,并且仅允许在以tenantcluster-开头的资源上使用。AWS KMS例外,因为它的资源命名约定。从API中获取的租户名称将在前面加上tenantcluster,以及其他验证检查(仅带破折号的字母数字,并且限制为少于30个字符,以适合大多数AWS资源命名)。这确保租户名称不会意外导致核心基础架构堆栈或资源中断。
租户技术堆栈
CloudFormation模板存储在S3存储桶中。该模板提供租户特定的AWS KMS密钥、CloudWatch警报、SNS主题、SQS队列和SQS策略。
AWS KMS密钥用于Amazon SNS和Amazon SQS对其消息进行数据加密。AwsSolutionsSNS2和AwsSolutions-SQS2的安全实践建议您使用加密设置Amazon SNS和Amazon SQS。然而,当使用AWS托管密钥时,CloudWatch警报不适用于Amazon SNS,因此在这种情况下必须使用客户托管密钥。有关更多信息,请参阅AWS知识中心。
SQS策略用于AmazonSQS队列,以允许创建的SNS主题将消息传递到队列。如果没有SQS政策,访问将被拒绝。有关更多信息,请参阅Amazon SNS文档。
- 150 次浏览
【SaaS架构】在单个控制平面上跨多个SaaS产品管理租户
视频号
微信公众号
知识星球
|
Environment: PoC or pilot |
Technologies: SaaS |
AWS services: Amazon API Gateway; Amazon Cognito; AWS Lambda; AWS Step Functions; Amazon DynamoDB |
总结
此模式显示了如何在AWS云中的单个控制平面上跨多个软件即服务(SaaS)产品管理租户生命周期。所提供的参考架构可以帮助组织减少其单个SaaS产品中冗余共享功能的实现,并提供大规模的治理效率。
大型企业可以在不同的业务部门中拥有多个SaaS产品。这些产品通常需要提供给不同订阅级别的外部租户使用。如果没有通用的租户解决方案,IT管理员必须花时间管理跨多个SaaS API的无差别功能,而不是专注于核心产品功能开发。
此模式中提供的公共租户解决方案可以帮助集中管理组织的许多共享SaaS产品功能,包括以下功能:
- 安全
- 租户资源调配
- 租户数据存储
- 租户通信
- 产品管理
- 指标记录和监控
先决条件和限制
先决条件
- 活跃的AWS帐户
- 了解Amazon Cognito或第三方身份提供商(IdP)
- 亚马逊API网关知识
- AWS Lambda知识
- 了解Amazon DynamoDB
- AWS身份和访问管理(IAM)知识
- AWS步骤功能知识
- 了解AWS CloudTrail和Amazon CloudWatch
- Python库和代码知识
- 了解SaaS API,包括不同类型的用户(组织、租户、管理员和应用程序用户)、订阅模型和租户隔离模型
- 了解组织的多产品SaaS需求和多租户订阅
局限性
- 这种模式不包括公共租户解决方案和单个SaaS产品之间的集成。
- 此模式仅在单个AWS区域部署Amazon Cognito服务。
架构
目标技术堆栈
- Amazon API网关
- 亚马逊Cognito
- AWS CloudTrail
- 亚马逊CloudWatch
-
Amazon DynamoDB
-
IAM
- AWS Lambda
- 亚马逊简单存储服务(Amazon S3)
- 亚马逊简单通知服务(Amazon SNS)
-
AWS Step functions
目标架构
下图显示了一个示例工作流,用于在AWS云中的单个控制平面上管理多个SaaS产品的租户生命周期。

该图显示了以下工作流:
- AWS用户通过调用API网关端点来启动租户配置、产品配置或与管理相关的操作。
- 用户通过从Amazon Cognito用户池或其他IdP检索的访问令牌进行身份验证。
- 单个供应或管理任务由与API网关API端点集成的Lambda函数运行。
- 公共租户解决方案(针对租户、产品和用户)的管理API收集所有必需的输入参数、标头和令牌。然后,管理API调用相关的Lambda函数。
- IAM服务验证管理API和Lambda功能的IAM权限。
- Lambda函数从DynamoDB和AmazonS3中的目录(针对租户、产品和用户)存储和检索数据。
- 验证权限后,将调用AWS步骤功能工作流以执行特定任务。图中的示例显示了租户配置工作流。
- 单个AWS步骤功能工作流任务在预定工作流(状态机)中运行。
- 运行与每个工作流任务相关的Lambda函数所需的任何基本数据都可以从DynamoDB或AmazonS3中检索。其他AWS资源可能需要使用AWS CloudFormation模板进行配置。
- 如果需要,工作流会向特定SaaS产品的AWS帐户发送请求,请求为该产品提供额外的AWS资源。
- 当请求成功或失败时,工作流将状态更新作为消息发布到Amazon SNS主题。
- Amazon SNS订阅了Step Functions工作流的Amazon SNS主题。
- 然后,Amazon SNS将工作流状态更新发送回AWS用户。
- 每个AWS服务的操作日志,包括API调用的审计跟踪,都会发送到CloudWatch。可以在CloudWatch中为每个用例配置特定的规则和警报。
- 日志存档在AmazonS3存储桶中,用于审计目的。
自动化和规模
此模式使用CloudFormation模板帮助自动部署公共租户解决方案。该模板还可以帮助您快速向上或向下销售相关资源。
有关更多信息,请参阅《AWS CloudFormation用户指南》中的“使用AWS CloudFormations模板”。
工具
- Amazon API网关可帮助您创建、发布、维护、监控和保护任何规模的REST、HTTP和WebSocket API。
- Amazon Cognito为web和移动应用程序提供身份验证、授权和用户管理。
- AWS CloudTrail帮助您审计AWS账户的治理、合规性和运营风险。
- Amazon CloudWatch可帮助您实时监控AWS资源和在AWS上运行的应用程序的指标。
- AmazonDynamoDB是一个完全管理的NoSQL数据库服务,提供快速、可预测和可扩展的性能。
- AWS身份和访问管理(IAM)通过控制谁经过身份验证和授权使用AWS资源,帮助您安全地管理对AWS资源的访问。
- AWS Lambda是一种计算服务,它可以帮助您运行代码,而无需配置或管理服务器。它只在需要时运行您的代码,并自动缩放,因此您只需支付所使用的计算时间。
- 亚马逊简单存储服务(Amazon S3)是一种基于云的对象存储服务,可帮助您存储、保护和检索任意数量的数据。
- 亚马逊简单通知服务(Amazon SNS)帮助您协调和管理发布者和客户之间的消息交换,包括web服务器和电子邮件地址。
- AWS Step Functions是一种无服务器编排服务,可帮助您将AWS Lambda功能和其他AWS服务结合起来,以构建业务关键型应用程序。
最佳实践
此模式中的解决方案使用单个控制平面来管理多个租户的入职,并提供对多个SaaS产品的访问。控制平面帮助管理用户管理其他四个特定于功能的平面:
-
Security plane
-
Workflow plane
-
Communication plane
-
Logging and monitoring plane
Epics
Configure the security plane
| Task | Description | Skills required |
|---|---|---|
|
Establish the requirements for your multi-tenant SaaS platform. |
Establish detailed requirements for the following:
|
Cloud architect, AWS systems administrator |
|
Set up the Amazon Cognito service. |
Follow the instructions in Getting started with Amazon Cognito in the Amazon Cognito Developer Guide. |
Cloud architect |
|
Configure the required IAM policies. |
Create the required IAM policies for your use case. Then, map the policies to IAM roles in Amazon Cognito. For more information, see Managing access using policies and Role-based access control in the Amazon Cognito Developer Guide. |
Cloud administrator, Cloud architect, AWS IAM security |
|
Configure the required API permissions. |
Set up API Gateway access permissions by using IAM roles and policies, and Lambda authorizers. For instructions, see the following sections of the Amazon API Gateway Developer Guide: |
Cloud administrator, Cloud architect |
Configure the data plane
| Task | Description | Skills required |
|---|---|---|
|
Create the required data catalogs. |
For more information, see Setting up DynamoDB in the Amazon DynamoDB Developer Guide. |
DBA |
Configure the control plane
| Task | Description | Skills required |
|---|---|---|
|
Create Lambda functions and API Gateway APIs to run required control plane tasks. |
Create separate Lambda functions and API Gateway APIs to add, delete, and manage the following:
For more information, see Using AWS Lambda with Amazon API Gateway in the AWS Lambda Developer Guide. |
App developer |
Configure the workflow plane
| Task | Description | Skills required |
|---|---|---|
|
Identify the tasks that AWS Step Functions workflows must run. |
Identify and document the detailed AWS Step Functions workflow requirements for the following:
Important: Make sure that key stakeholders approve the requirements. |
App owner |
|
Create the required AWS Step Functions workflows. |
|
App developer, Build lead |
Configure the communication plane
| Task | Description | Skills required |
|---|---|---|
|
Create Amazon SNS topics. |
Create Amazon SNS topics to receive notifications about the following:
For more information, see Creating an SNS topic in the Amazon SNS Developer Guide. |
App owner, Cloud architect |
|
Subscribe endpoints to each Amazon SNS topic. |
To receive messages published to an Amazon SNS topic, you must subscribe an endpoint to each topic. For more information, see Subscribing to an Amazon SNS topic in the Amazon SNS Developer Guide. |
App developer, Cloud architect |
Configure the logging and monitoring plane
| Task | Description | Skills required |
|---|---|---|
|
Activate logging for each component of the common tenant solution. |
Activate logging at the component level for each resource in the common tenant solution that you created. For instructions, see the following:
Note: You can consolidate logs for each resource into a centralized logging account by using IAM policies. For more information, see Centralized logging and multiple-account security guardrails. |
App developer, AWS systems administrator, Cloud administrator |
Provision and deploy the common tenant solution
| Task | Description | Skills required |
|---|---|---|
|
Create CloudFormation templates. |
Automate the deployment and maintenance of the full common tenant solution and all its components by using CloudFormation templates. For more information, see the AWS CloudFormation User Guide. |
App developer, DevOps engineer, CloudFormation developer |
- 113 次浏览
【SaaS架构】多租户SaaS授权和API访问控制
视频号
微信公众号
知识星球
- 80 次浏览
【SaaS架构】多租户SaaS授权和API访问控制 - 介绍
视频号
微信公众号
知识星球
多租户软件即服务(SaaS)应用程序的授权和API访问控制是一个复杂的主题。当您考虑到必须确保安全的微服务API的激增以及不同租户、用户特征和应用程序状态产生的大量访问条件时,这种复杂性就显而易见了。为了有效地解决这些问题,解决方案必须在微服务、前端后端(BFF)层和多租户SaaS应用程序的其他组件提供的许多API中实施访问控制。这种普遍的方法必须与灵活的实施范式相结合,该范式可以根据许多因素和属性做出复杂的访问决策。
传统上,API访问控制和授权由应用程序代码中的自定义逻辑处理。这种方法容易出错,而且不安全,因为可以访问此代码的开发人员可能会意外或故意更改授权逻辑,从而导致未经授权的访问。此外,API访问控制通常是不必要的,因为没有那么多API需要保护。应用程序设计中偏向微服务和面向服务的架构的范式转变增加了必须使用某种形式的授权和访问控制的API的数量。此外,在多租户SaaS应用程序中维护基于租户的访问的需要可能会变得非常复杂,通常使用孤立的或效率极低的模型来保持这种租赁。
本指南中概述的最佳实践提供了几个好处:
- 授权逻辑可以集中化,并用高级声明性语言编写,而不是特定于任何编程语言。
- 授权逻辑是从应用程序代码中抽象出来的,可以等幂地应用于应用程序中的所有API。
- 该抽象防止了对授权逻辑的意外更改,并使其与SaaS应用程序的集成一致且简单。
- 抽象防止了为每个API端点编写自定义授权逻辑的需要。
- 本指南中概述的方法支持根据组织的要求使用多种访问控制范式。
- 这种授权和访问控制方法提供了一种在SaaS应用程序的API层维护租户数据隔离的简单而直接的方法。
目标业务成果
本规范性指南描述了可用于多租户SaaS应用程序的授权和API访问控制的幂等设计模式。本指南适用于开发具有复杂授权要求或严格API访问控制需求的应用程序的任何团队。该体系结构详细介绍了使用开放策略代理(OPA)创建策略决策点(PDP)或策略引擎,以及在API中集成策略执行点(PEP)。本指南还讨论了基于属性的访问控制(ABAC)模型或基于角色的访问控制模型,或这两种模型的组合来做出访问决策。
我们建议您使用本指南中提供的设计模式和概念来通知和标准化多租户SaaS应用程序中的授权和API访问控制的实现。本指南有助于实现以下业务成果:
- 多租户SaaS应用程序的标准化API授权架构–此架构通过PDP、PEP、策略引擎和OPA实现。这些概念和技术有助于维护多租户SaaS应用程序中的租户隔离,并为应用程序提供API授权的整体方法。
- 授权逻辑与应用程序的解耦–当授权逻辑嵌入应用程序代码中或通过临时强制机制实现时,可能会发生意外或恶意更改,从而导致意外的跨租户数据访问或其他安全漏洞。为了帮助减少这些可能性,您可以使用OPA等策略引擎将授权决策与应用程序代码分开,并在应用程序中实施一致的策略。策略可以在高级声明性语言中集中维护,这使得维护授权逻辑比在应用程序代码的多个部分中嵌入策略要简单得多。这种方法还可确保一致地应用更新。
- 访问控制模型的灵活方法–基于角色的访问控制(RBAC)、基于属性的访问控制或这两种模型的组合都是访问控制的有效方法。这些模型试图通过使用不同的方法来满足业务的授权要求。本指南对这些模型进行比较和对比,以帮助您选择适合您的组织的模型。该指南还详细讨论了这些模型如何应用于策略引擎,尤其是OPA。本指南中讨论的体系结构使其中一个或两个模型都能成功采用。
- 严格的API访问控制–本指南提供了一种以最小的努力在应用程序中一致和普遍地保护API的方法。这对于通常使用大量API来促进应用程序内部通信的面向服务或微服务应用程序架构尤其重要。严格的API访问控制有助于提高应用程序的安全性,使其不易受到攻击或利用。
- 86 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--FAQ
视频号
微信公众号
知识星球
本节提供了关于在多租户SaaS应用程序中实现API访问控制和授权的常见问题的答案。
授权和身份验证之间的区别是什么?
身份验证是验证用户身份的过程。授权授予用户访问特定资源的权限。
为什么我需要考虑授权我的SaaS应用程序?
SaaS应用程序有多个租户。租户可以是客户组织或使用该SaaS应用程序的任何外部实体。根据应用程序的设计方式,这意味着租户可能正在访问共享的API、数据库或其他资源。维护租户隔离非常重要,即按租户分离权限和数据,以防止用户从一个租户访问另一个租户的私人信息。SaaS应用程序中的授权通常旨在确保在整个应用程序中保持租户隔离,并且租户只能访问自己的资源。
为什么我需要访问控制模型?
访问控制模型用于创建确定如何授予对应用程序中资源的访问的一致方法。这可以通过将角色分配给与业务逻辑密切相关的用户来实现,也可以基于其他上下文属性,例如一天中的时间或用户是否满足预定义的条件。访问控制模型构成了应用程序在进行授权决策以确定用户权限时使用的基本逻辑。
我的应用程序是否需要API访问控制?
对API应始终验证调用者是否具有适当的访问权限。普适的API访问控制还确保仅基于租户授予访问权限,以便保持适当的隔离。
为什么建议使用策略引擎或PDP进行授权?
策略决策点(PDP)允许将应用程序代码中的授权逻辑卸载到单独的系统。这可以简化应用程序代码。它还提供了一个易于使用的幂等接口,用于为API、微服务、前端后端(BFF)层或任何其他应用程序组件进行授权决策。
什么是PEP?
策略执行点(PEP)负责接收发送给PDP进行评估的授权请求。PEP可以位于应用程序中必须保护数据和资源或应用授权逻辑的任何位置。与PDP相比,PEP相对简单。PEP仅负责请求和评估授权决策,不要求将任何授权逻辑纳入其中。
OPA有开源替代品吗?
有一些开源系统类似于开放策略代理(OPA),例如通用表达式语言(CEL)。本指南侧重于OPA,因为它被广泛采用、记录在案,并可适应许多不同类型的应用程序和授权要求。
我是否需要编写授权服务来使用OPA,或者我可以直接与OPA交互?
您可以直接与OPA交互。本指南中的授权服务是指将授权决策请求转换为OPA查询的服务,反之亦然。如果您的应用程序可以直接查询和接受OPA响应,则无需引入这种额外的复杂性。
如何监控OPA代理的正常运行时间和审计目的?
OPA确实提供了日志记录和基本的正常运行时间监控,尽管默认配置可能不足以用于企业部署。有关更多信息,请参阅DevOps、监控和日志部分。
我可以使用哪些操作系统和AWS服务来运行OPA?
您可以在macOS、Windows和Linux上运行OPA。OPA代理可以在Amazon Elastic Compute Cloud(Amazon EC2)代理以及容器化服务(如Amazon ElasticContainer Service(Amazon ECS)和Amazon Elastics Kubernetes Service(Amazon EKS))上配置。
我可以在AWS Lambda上运行OPA吗?
您可以将OPA作为Go库在Lambda上运行。AWS博客文章“使用开放策略代理创建自定义Lambda授权者”讨论了如何为API网关Lambda授权器实现这一点。
我应该如何决定分布式PDP和集中式PDP方法?
这取决于您的应用程序。它很可能是基于分布式和集中式PDP模型之间的延迟差异来确定的。我们建议您构建概念验证并测试应用程序的性能,以验证您的解决方案。
除了API之外,我可以将OPA用于用例吗?
对OPA文档提供了Kubernetes、Envoy、Docker、Kafka、SSH和sudo以及Terraform的示例。此外,OPA能够使用Rego部分规则响应查询返回任意JSON。根据查询的不同,OPA可以用来回答JSON响应中的许多问题。
- 209 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--下一步
视频号
微信公众号
知识星球
多租户SaaS应用程序的授权和API访问控制的复杂性可以通过采用标准化、语言无关的方法来进行授权决策来克服。这些方法结合了策略决策点(PDP)和策略实施点(PDU),以灵活和普遍的方式实施访问。可以将多种访问控制方法(如基于角色的访问控制(RBAC)、基于属性的访问控制,ABAC)或两者的组合)结合到一个内聚的访问控制策略中。从应用程序中删除授权逻辑消除了在应用程序代码中包含临时解决方案以解决访问控制的开销。本指南中讨论的实现和最佳实践旨在为多租户SaaS应用程序中的授权和API访问控制的实现提供信息并使其标准化。您可以将本指南作为为应用程序收集信息和设计强大的访问控制和授权系统的第一步。
下一步:
- 检查您的授权和租户隔离需求,并为应用程序选择访问控制模型。
- 实施开放策略代理(OPA)并构建测试概念证明。(或者,编写自己的自定义策略引擎。)
- 确定应用程序中应实施PEP的API和位置。
- 103 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--多租户SaaS架构的设计模型
视频号
微信公众号
知识星球
有许多方法可以实现API访问控制和授权。本指南重点介绍三种对多租户SaaS架构有效的设计模型。这些设计为策略决策点(PDP)和策略执行点(PEP)的实现提供了一个高级参考,从而为应用程序形成了一个连贯且普遍的授权模型。
设计模型:
- 具有API上PEP的集中式PDP
- API上带有PEP的分布式PDP
- 作为库的分布式PDP
具有API上PEP的集中式PDP
在API模型上具有策略执行点(PEP)的集中式策略决策点(PDP)遵循行业最佳实践,为API访问控制和授权创建一个有效且易于维护的系统。该方法支持几个关键原则:
- 授权和API访问控制在应用程序的多个点应用。
- 授权逻辑独立于应用程序。
- 访问控制决策是集中的。
该模型使用集中式PDP来做出授权决策。PEP在所有API中实现,以向PDP发出授权请求。下图显示了如何在假设的多租户SaaS应用程序中实现此模型。

一个示例多租户SaaS应用程序,该应用程序使用带有PEP的集中式PDP
应用程序流程:
 |
具有JWT令牌的认证用户向AmazonCloudFront生成HTTP请求。 |
 |
CloudFront将请求转发到配置为CloudFront源的Amazon API网关。 |
 |
调用API网关Lambda授权器来验证JWT令牌。 |
 |
微服务响应请求。 |
授权和API访问控制流程:
 |
PEP调用授权服务并传递请求数据,包括任何JWT令牌。 |
 |
授权服务(PDP)接收请求数据并查询作为sidecar运行的OPA代理REST API,请求数据作为查询的输入。 |
 |
OPA根据查询指定的相关策略评估输入。必要时导入数据以做出授权决定。 |
 |
OPA向授权服务返回决定。 |
 |
授权决定返回给PEP并进行评估。 |
在此架构中,PEP在CloudFront和API网关以及每个微服务的服务端点请求授权决策。授权决策由具有OPA侧车的授权服务(PDP)做出。您可以将此授权服务作为容器或传统服务器实例来操作。OPA sidecar在本地公开其RESTful API,因此该API只能由授权服务访问。授权服务公开了一个单独的API,可供PEP使用。授权服务充当PEP和OPA之间的中介,允许在PEP与OPA之间插入任何必要的转换逻辑,例如,当PEP的授权请求不符合OPA期望的查询输入时。
您还可以将此架构与自定义策略引擎一起使用。然而,从OPA获得的任何优势都必须用定制策略引擎提供的逻辑来代替。
在API上使用PEP的集中式PDP为为API创建一个健壮的授权系统提供了一个简单的选择。它易于实现,还提供了一个易于使用的幂等接口,用于为API、微服务、前端后端(BFF)层或其他应用程序组件做出授权决策。然而,这种方法可能会在应用程序中造成太多延迟,因为授权决策需要调用单独的API。如果网络延迟是一个问题,您可以考虑使用分布式PDP。
API上带有PEP的分布式PDP
基于API模型的分布式策略决策点(PDP)和策略执行点(PEP)遵循行业最佳实践,以创建有效的API访问控制和授权系统。与API模型上带有PEP的集中式PDP一样,该方法支持以下关键原则:
- 授权和API访问控制在应用程序的多个点应用。
- 授权逻辑独立于应用程序。
- 访问控制决策是集中的。
您可能会想知道,当分发PDP时,为什么访问控制决策是集中的。尽管PDP可能存在于应用程序中的多个位置,但它必须使用相同的授权逻辑来做出访问控制决策。给定相同的输入,所有PDP提供相同的访问控制决策。PEP在所有API中实现,以向PDP发出授权请求。下图显示了如何在假设的多租户SaaS应用程序中实现此分布式模型。

一个示例多租户SaaS应用程序,该应用程序使用带有PEP的分布式PDP
Application flow:
|
具有JWT令牌的认证用户向AmazonCloudFront生成HTTP请求。 |
|
CloudFront将请求转发到配置为CloudFront源的Amazon API网关。 |
|
调用API网关Lambda授权器来验证JWT令牌。 |
|
微服务响应请求。 |
Authorization and API access control flow:
|
PEP调用授权服务并传递请求数据,包括任何JWT令牌。 |
|
授权服务(PDP)接收请求数据并查询作为sidecar运行的OPA代理REST API,请求数据作为查询的输入。 |
|
OPA根据查询指定的相关策略评估输入。必要时导入数据以做出授权决定。 |
|
OPA向授权服务返回决定。 |
|
授权决定返回给PEP并进行评估。 |
在此架构中,PEP在CloudFront和API网关以及每个微服务的服务端点请求授权决策。微服务的授权决策是由授权服务(PDP)做出的,它作为应用程序组件的侧车运行。该模型适用于在容器或Amazon Elastic Compute Cloud(Amazon EC2)实例上运行的微服务(或服务)。API网关和CloudFront等服务的授权决策仍需要联系外部授权服务。无论如何,授权服务公开了PEP可用的API。授权服务充当PEP与OPA之间的中介,允许在PEP和OPA之间插入任何必要的转换逻辑,例如,当PEP的授权请求不符合OPA期望的查询输入时。
您还可以将此架构与自定义策略引擎一起使用。然而,从OPA获得的任何优势都必须用定制策略引擎提供的逻辑来代替。
在API上具有PEP的分布式PDP提供了为API创建健壮授权系统的选项。它易于实现,并提供了一个易于使用的幂等接口,用于为API、微服务、前端后端(BFF)层或其他应用程序组件做出授权决策。这种方法还具有减少集中式PDP模型中可能遇到的延迟的优点。
作为库的分布式PDP
您还可以向PDP请求授权决策,该PDP可以作为库或包在应用程序中使用。OPA可以用作Go第三方库。对于其他编程语言,采用此模型通常意味着您必须创建自定义策略引擎。
- 322 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--实施PDP
视频号
微信公众号
知识星球
策略决策点(PDP)可以被表征为策略或规则引擎。此组件负责应用策略或规则,并返回是否允许特定访问的决定。PDP可以使用基于角色的访问控制(RBAC)和基于属性的访问控制模型(ABAC);然而,PDP是ABAC的要求。PDP允许将应用程序代码中的授权逻辑卸载到单独的系统。这可以简化应用程序代码。它还提供了一个易于使用的幂等接口,用于为API、微服务、前端后端(BFF)层或任何其他应用程序组件进行授权决策。
以下部分讨论了实现PDP的两种方法:开放策略代理(OPA)和自定义解决方案。然而,这并不是一个详尽的列表。
PDP实施方法:
- 使用OPA
- 使用自定义策略引擎
使用OPA
实现PDP的首选方法是使用开放策略代理(OPA)。OPA是一个开源的通用策略引擎。OPA有很多用例,但与PDP实现相关的用例是它将授权逻辑与应用程序分离的能力。这被称为政策脱钩。
由于几个原因,OPA在实现PDP时很有用。它使用名为Rego的高级声明性语言来起草策略和规则。这些策略和规则与应用程序分开存在,可以在没有任何特定于应用程序的逻辑的情况下呈现授权决策。OPA还公开了一个RESTful API,使检索授权决策简单明了。为了做出授权决策,应用程序使用JSON输入查询OPA,OPA根据指定的策略评估输入,以返回JSON形式的访问决策。OPA还能够导入可能与授权决策相关的外部数据。
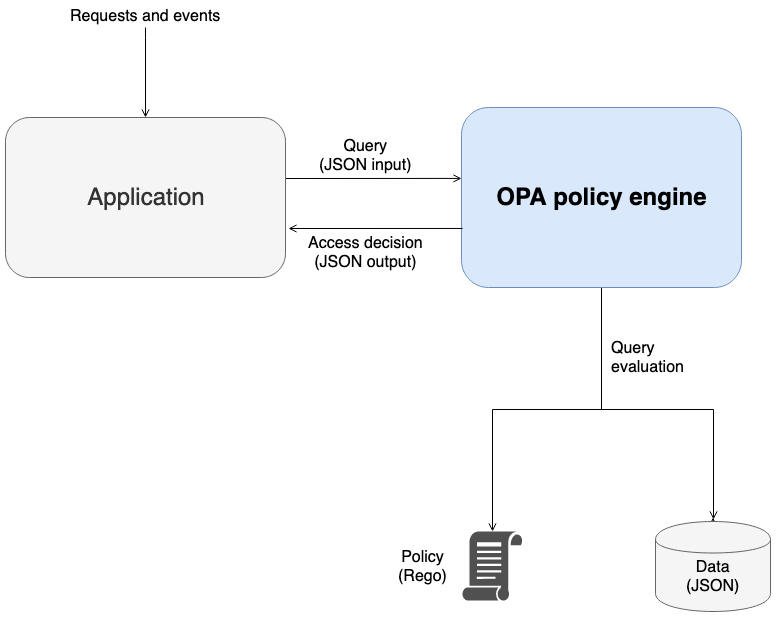
OPA功能
OPA与定制策略引擎相比有以下几个优势:
- OPA及其与Rego的策略评估提供了一个灵活的预先构建的策略引擎,只需要插入策略和做出授权决策所需的任何数据。必须在自定义策略引擎解决方案中重新创建此策略评估逻辑。
- OPA通过使用声明性语言编写策略来简化授权逻辑。您可以独立于任何应用程序代码修改和管理这些策略和规则,而无需应用程序开发技能。
- OPA公开了一个RESTful API,它简化了与策略执行点(PEP)的集成。
- OPA为验证和解码JSON Web令牌(JWT)提供内置支持。
- OPA是公认的授权标准,这意味着如果您需要帮助或研究来解决特定问题,那么文档和示例将非常丰富。
- 采用OPA等授权标准,无论团队应用程序使用何种编程语言,都可以在团队之间共享用Rego编写的策略。
OPA不会自动提供两件事:
- OPA没有用于更新和管理策略的强大控制平面。OPA通过公开一个管理API,为实现策略更新、监控和日志聚合提供了一些基本模式,但必须由OPA用户处理与此API的集成。作为最佳实践,您应该使用连续集成和连续部署(CI/CD)管道来管理、修改和跟踪OPA中的策略版本和管理策略。
- 默认情况下,OPA无法从外部源检索数据。授权决策的外部数据源可以是保存用户属性的数据库。在如何向OPA提供外部数据方面有一定的灵活性,当请求授权决策时,可以预先在本地缓存外部数据或从API动态检索外部数据,但OPA无法代表您获取这些信息。
在本节中:
- Rego概述
- 示例1:带OPA和Rego的基本ABAC
- 示例2:具有OPA和Rego的多租户访问控制和用户定义RBAC
- 示例3:使用OPA和Rego对RBAC和ABAC进行多租户访问控制
- 示例4:使用OPA和Rego进行UI过滤
Rego概述
Rego是一种通用策略语言,这意味着它适用于堆栈的任何层和任何域。Rego的主要目的是接受JSON/YAML输入和数据,这些输入和数据经过评估,以做出有关基础设施资源、身份和操作的策略性决策。Rego使您能够编写关于堆栈或域的任何层的策略,而无需更改或扩展语言。以下是Rego可以做出的一些决策示例:
- 是否允许或拒绝此API请求?
- 此应用程序的备份服务器的主机名是什么?
- 此拟议基础设施变更的风险评分是多少?
- 为了实现高可用性,应将此容器部署到哪些集群?
- 该微服务应使用哪些路由信息?
为了回答这些问题,Rego采用了关于如何做出这些决定的基本哲学。在雷戈起草政策时的两个关键原则是:
- 每个资源、标识或操作都可以表示为JSON或YAML数据。
- 策略是应用于数据的逻辑。
Rego通过定义如何评估JSON/YAML数据输入的逻辑,帮助软件系统做出授权决策。C、Java、Go和Python等编程语言是解决这个问题的常用方法,但Rego的设计重点是表示系统的数据和输入,以及使用这些信息进行策略决策的逻辑。
示例1:带OPA和Rego的基本ABAC
本节描述了一个场景,其中OPA用于决定哪些用户可以访问虚构的Payroll微服务中的信息。提供了Rego代码片段,以演示如何使用Rego来呈现访问控制决策。这些示例既不是详尽的,也不是对Rego和OPA功能的全面探索。为了更全面地了解Rego,我们建议您查阅OPA网站上的Rego文档。
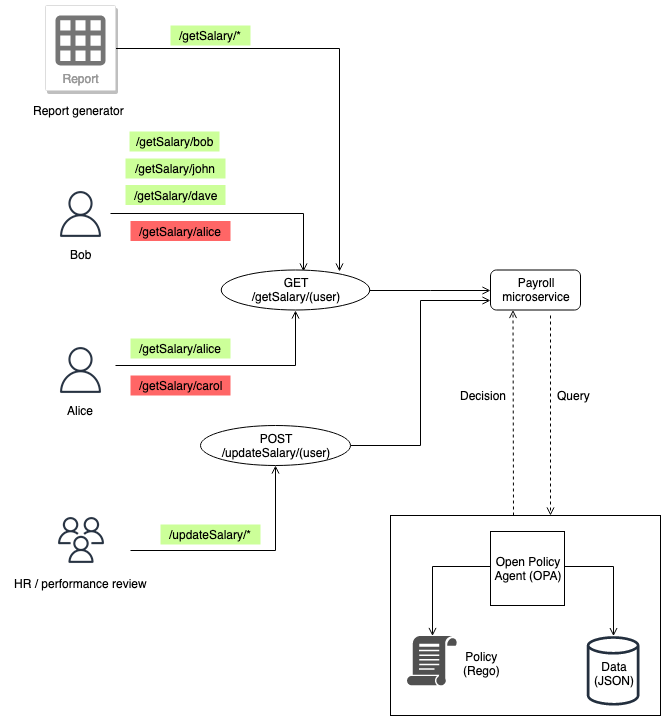
基本OPA规则示例
在上图中,OPA为Payroll微服务实施的访问控制规则之一是:
员工可以读取自己的工资。
如果Bob试图访问Payroll微服务以查看自己的工资,那么Payroll微型服务可以将API调用重定向到OPA RESTful API以做出访问决定。Payroll服务使用以下JSON输入向OPA查询决策:
{
"user": "bob",
"method": "GET",
"path": ["getSalary", "bob"]
}
OPA根据查询选择一个或多个策略。在本例中,以下策略(用Rego编写)评估JSON输入。
default allow = false
allow = true {
input.method == "GET"
input.path = ["getSalary", user]
input.user == user
}
默认情况下,此策略拒绝访问。然后,它通过将查询中的输入绑定到全局变量输入来计算该输入。点运算符与此变量一起使用以访问变量的值。如果规则中的表达式也是true,则Rego规则allow返回true。Rego规则验证输入中的方法是否等于GET。然后,在将列表中的第二个元素分配给变量user之前,它验证列表路径中的第一个元素是getSalary。最后,它通过检查发出请求的用户input.user是否与用户变量匹配来检查访问的路径是否为/getSalary/bob。如果逻辑返回布尔值,则应用规则allow,如输出所示:
{
"allow": true
}使用外部数据的部分规则
要演示其他OPA功能,您可以向正在实施的访问规则添加要求。让我们假设您希望在前面的示例中强制执行此访问控制要求:
员工可以阅读任何向他们汇报的人的工资。
在此示例中,OPA可以访问外部数据,这些数据可以被导入以帮助做出访问决策:
"managers": {
"bob": ["dave", "john"],
"carol": ["alice"]
}
您可以通过在OPA中创建部分规则来生成任意的JSON响应,该规则返回一组值而不是固定的响应。这是部分规则的示例:
direct_report[user_ids] {
user_ids = data.managers[input.user][_]
}
该规则返回一组报告input.user值的所有用户,在本例中,该值为bob。规则中的[_]构造用于迭代集合的值。这是规则的输出:
{
"direct_report": [
"dave",
"john"
]
}检索此信息可以帮助确定用户是否是经理的直接下属。对于某些应用程序,返回动态JSON比返回简单的布尔响应更好。
把这一切放在一起
最后一个访问要求比前两个更复杂,因为它结合了两个要求中指定的条件:
员工可以阅读自己的工资和任何向他们汇报的人的工资。
要满足此要求,您可以使用此Rego策略:
default allow = false
allow = true {
input.method == "GET"
input.path = ["getSalary", user]
input.user == user
}
allow = true {
input.method == "GET"
input.path = ["getSalary", user]
managers := data.managers[input.user][_]
contains(managers, user)
}
策略中的第一条规则允许任何试图查看自己工资信息的用户访问,如前所述。在Rego中有两个同名的规则allow作为逻辑或运算符。第二条规则检索与input.user关联的所有直接报告的列表(从上一个图表中的数据),并将此列表分配给manager变量。最后,该规则通过验证经理变量中是否包含用户的姓名来检查试图查看其工资的用户是否是input.user的直接报告。
本节中的示例是非常基本的,并没有对Rego和OPA的功能进行完整或彻底的探索。有关更多信息,请查看OPA文档,查看OPA GitHub README文件,并在Rego游乐场进行实验。
示例2:具有OPA和Rego的多租户访问控制和用户定义RBAC
本示例使用OPA和Rego演示如何在具有租户用户定义的自定义角色的多租户应用程序的API上实现访问控制。它还演示了如何根据租户限制访问。该模型显示了OPA如何根据高级角色提供的信息做出精细的权限决策。
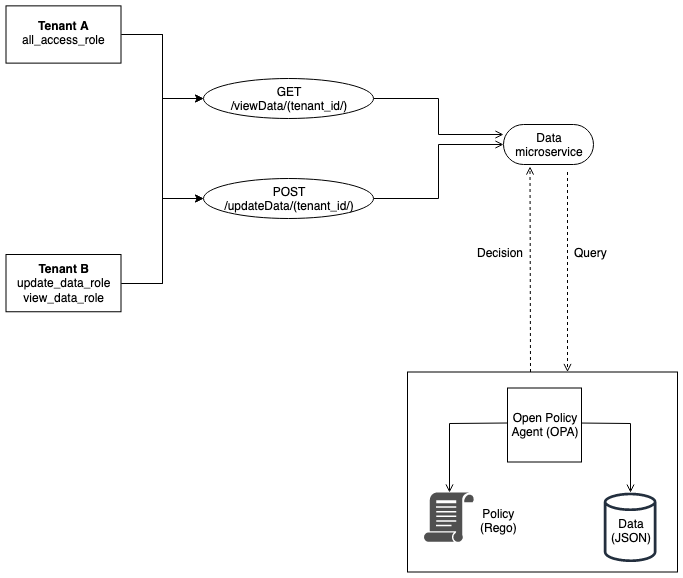
具有自定义角色的多租户访问的OPA用例
租户的角色存储在外部数据(RBAC数据)中,用于为OPA做出访问决策:
{
"roles": {
"tenant_a": {
"all_access_role": ["viewData", "updateData"]
},
"tenant_b": {
"update_data_role": ["updateData"],
"view_data_role": ["viewData"]
}
}
}
当由租户用户定义这些角色时,这些角色应存储在外部数据源或身份提供程序(IdP)中,当将租户定义的角色映射到权限和租户自身时,该身份提供程序可以充当真实的来源。
本示例使用OPA中的两个策略来做出授权决策,并检查这些策略如何强制租户隔离。这些策略使用前面定义的RBAC数据。
default allowViewData = false
allowViewData = true {
input.method == "GET"
input.path = ["viewData", tenant_id]
input.tenant_id == tenant_id
role_permissions := data.roles[input.tenant_id][input.role][_]
contains(role_permissions, "viewData")
}
要显示此规则的功能,请考虑具有以下输入的OPA查询:
{
"tenant_id": "tenant_a",
"role": "all_access_role",
"path": ["viewData", "tenant_a"],
"method": "GET"
}
通过组合RBAC数据、OPA策略和OPA查询输入,该API调用的授权决策如下:
- 租户A的用户对/viewData/Tenant_A进行API调用。
- Data微服务接收调用并查询allowViewData规则,传递OPA查询输入示例中显示的输入。
- OPA使用OPA策略中的查询规则来评估提供的输入。OPA还使用RBAC数据中的数据来评估输入。OPA执行以下操作:
- 验证用于进行API调用的方法是否为GET。
- 验证请求的路径是否为viewData。
- 检查路径中的tenant_id是否等于与用户关联的input.tenant_id。这确保了租户隔离。另一个租户,即使具有相同的角色,也无法被授权进行此API调用。
- 从角色的外部数据中提取角色权限列表,并将其分配给变量role_permissions。通过使用与input.role中的用户关联的租户定义的角色来检索此列表。
- 检查role_permissions以查看它是否包含权限viewData。
- OPA向Data微服务返回以下决定:
{
"allowViewData": true
}该过程显示了RBAC和租户意识如何帮助OPA做出授权决策。为了进一步说明这一点,请考虑使用以下查询输入对/viewData/tenant_b的API调用:
{
"tenant_id": "tenant_b",
"role": "view_data_role",
"path": ["viewData", "tenant_b"],
"method": "GET"
}
该规则将返回与OPA查询输入相同的输出,尽管它是针对具有不同角色的不同租户的。这是因为此调用针对/tenant_b,并且RBAC数据中的view_data_role仍然具有与其关联的viewData权限。要对/updateData实施相同类型的访问控制,可以使用类似的OPA规则:
default allowUpdateData = false
allowUpdateData = true {
input.method == "POST"
input.path = ["updateData", tenant_id]
input.tenant_id == tenant_id
role_permissions := data.roles[input.tenant_id][input.role][_]
contains(role_permissions, "updateData")
}
此规则在功能上与allowViewData规则相同,但它验证不同的路径和输入方法。该规则仍然确保租户隔离,并检查租户定义的角色是否授予API调用方权限。要查看如何执行此操作,请检查/updateData/tenant_b的API调用的以下查询输入:
{
"tenant_id": "tenant_b",
"role": "view_data_role",
"path": ["updateData", "tenant_b"],
"method": "POST"
}
当使用allowUpdateData规则求值时,此查询输入将返回以下授权决策:
{
"allowUpdateData": false
}此呼叫将不被授权。尽管API调用方与正确的tenant_id关联,并使用经批准的方法调用API,但input.role是租户定义的view_data_role。view_data_role没有updateData权限;因此,对/updateData的调用是未授权的。对于具有update_data_role的tenant_b用户,此调用将成功。
示例3:使用OPA和Rego对RBAC和ABAC进行多租户访问控制
为了增强上一节中的RBAC示例,可以向用户添加属性。

具有用户属性的多租户访问的OPA用例
此示例包含与上一示例相同的角色,但添加了用户属性account_lockout_flag。这是一个特定于用户的属性,不与任何特定角色关联。您可以使用先前用于此示例的相同RBAC外部数据:
{
"roles": {
"tenant_a": {
"all_access_role": ["viewData", "updateData"]
},
"tenant_b": {
"update_data_role": ["updateData"],
"view_data_role": ["viewData"]
}
}
}
account_lockout_flag用户属性可以作为用户Bob的/viewData/tenant_a的OPA查询输入的一部分传递给数据服务:
{
"tenant_id": "tenant_a",
"role": "all_access_role",
"path": ["viewData", "tenant_a"],
"method": "GET",
"account_lockout_flag": "true"
}
为访问决策查询的规则与前面的示例类似,但包含一行用于检查account_lockout_flag属性:
default allowViewData = false
allowViewData = true {
input.method == "GET"
input.path = ["viewData", tenant_id]
input.tenant_id == tenant_id
role_permissions := data.roles[input.tenant_id][input.role][_]
contains(role_permissions, "viewData")
input.account_lockout_flag == "false"
}
此查询返回false的授权决定。这是因为account_lockout_flag属性对于Bob为true,并且Rego规则allowViewData拒绝访问,尽管Bob具有正确的角色和租户。
示例4:使用OPA和Rego进行UI过滤
OPA和Rego的灵活性支持过滤UI元素的能力。下面的示例演示了OPA部分规则如何做出授权决策,决定哪些元素应该显示在带有RBAC的UI中。此方法是使用OPA过滤UI元素的多种不同方法之一。

基于RBAC的OPA UI过滤
在本例中,单页web应用程序有四个按钮。假设您希望过滤Bob、Shirley和Alice的UI,以便他们只能看到与其角色对应的按钮。当UI收到来自用户的请求时,它查询OPA部分规则以确定哪些按钮应该显示在UI中。当Bob(使用角色查看器)向UI发出请求时,查询将以下内容作为输入传递给OPA:
{
"role": "viewer"
}
OPA使用为RBAC构建的外部数据来做出访问决策:
{
"roles": {
"viewer": ["viewUsersButton", "viewDataButton"],
"dataViewOnly": ["viewDataButton"],
"admin": ["viewUsersButton", "viewDataButton", "updateUsersButton", "updateDataButton"]
}
}
OPA部分规则使用外部数据和输入生成一组用户可以在UI上查看的按钮:
ui_buttons[buttons] {
buttons := data.roles[input.role][_]
}
在部分规则中,OPA使用作为查询一部分指定的input.role来确定应该显示哪些按钮。Bob具有角色查看器,外部数据指定查看器可以看到两个按钮:viewUsersButton和viewDataButton。因此,Bob(以及具有查看器角色的任何其他用户)的此规则输出如下:
{
"ui_buttons": [
"viewDataButton",
"viewUsersButton"
]
}雪莉具有dataViewOnly角色,她的输出将包含一个按钮:viewDataButton。具有管理员角色的Alice的输出将包含所有按钮。当查询OPA的UI_buttons时,这些响应将返回到UI。UI可以使用此响应来相应地隐藏或显示按钮。
使用自定义策略引擎
实现PDP的另一种方法是创建自定义策略引擎。此策略引擎的目标是将授权逻辑与应用程序分离。自定义策略引擎负责做出授权决策,类似于OPA,以实现策略解耦。此解决方案与OPA的主要区别在于,编写和评估策略的逻辑是定制的。与引擎的任何交互都必须通过API或其他方法公开,以使授权决策能够到达应用程序。您可以用任何编程语言编写自定义策略引擎,也可以使用其他机制进行策略评估,例如公共表达式语言(CEL)。
- 150 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--实施PDP
视频号
微信公众号
知识星球
实施政PEP
策略执行点(PEP)负责接收发送到策略决策点(PDP)进行评估的授权请求。PEP可以位于应用程序中必须保护数据和资源或应用授权逻辑的任何位置。与PDP相比,PEP相对简单。PEP只负责请求和评估授权决策,不需要任何授权逻辑。与PDP不同,PEP不能集中在SaaS应用程序中。这是因为授权和访问控制需要在整个应用程序及其访问点中实现。PEP可以应用于API、微服务、前端后端(BFF)层或应用程序中需要或需要访问控制的任何点。在应用程序中普及PEP可以确保在多个点上经常和独立地验证授权。
要实现PEP,第一步是确定应用程序中应在何处执行访问控制。在决定PEP应集成到您的应用程序中的位置时,请考虑以下原则:
- 如果应用程序公开了API,那么应该对该API进行授权和访问控制。
- 这是因为在面向微服务或面向服务的架构中,API充当不同应用程序功能之间的分隔符。将访问控制作为应用程序功能之间的逻辑检查点是有意义的。我们强烈建议您将PEP作为访问SaaS应用程序中每个API的先决条件。还可以在应用程序的其他点集成授权。在单片应用程序中,可能需要将PEP集成到应用程序本身的逻辑中。对于PEP应包含在何处,没有一刀切的解决方案,但应考虑使用API原则作为起点。
请求授权决策
PEP必须向PDP请求授权决定。请求可以采取多种形式。请求授权决策的最简单和最易访问的方法是向PDP公开的RESTful API发送授权请求或查询(使用OPA术语)。这是将PEP与PDP集成的建议方法,因为这是一种常见的向应用程序中的多个服务公开功能的模式。在此模式中,PEP的唯一功能是转发授权请求或查询所需的信息。这可以像将API接收的请求作为输入转发到PDP一样简单。创建PEP还有其他方法。例如,您可以在本地将OPA PDP与以Go编程语言编写的应用程序集成为库,而不是使用API。
评估授权决策
PEP需要包含评估授权决策结果的逻辑。当PDP作为API公开时,授权决策可能采用JSON格式,并由API调用返回。PEP必须评估此JSON代码,以确定所采取的操作是否得到授权。例如,如果PDP被设计为提供布尔允许或拒绝授权决策,则PEP可以简单地检查该值,然后返回HTTP状态代码200以允许,返回HTTP状态码403以拒绝。这种将PEP作为访问API的先决条件的模式是在SaaS应用程序中实现访问控制的一种容易实现且高效的模式。在更复杂的场景中,PEP可能负责评估PDP返回的任意JSON代码。PEP必须包含解释PDP返回的授权决定所需的任何逻辑。由于PEP可能在应用程序中的许多不同位置实现,我们建议您将PEP代码打包为可重用的库或工件,使用您选择的编程语言。这样,您的PEP可以在应用程序的任何位置轻松集成,只需最少的返工。
- 36 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--实施注意事项
视频号
微信公众号
知识星球
DevOps、监控和日志记录
在这个建议的授权范式中,策略集中在授权服务中。这种集中是故意的,因为本指南中讨论的设计模型的目标之一是实现策略解耦,或从应用程序中的其他组件中删除授权逻辑。开放策略代理(OPA)提供了一种在需要更改授权逻辑时更新策略的机制。此功能由一个简单的REST API提供,您可以将其配置为从已建立的位置拉取新版本的策略(或捆绑包)或按需推送策略。我们建议您创建一个健壮的CI/CD管道,以增强OPA用于进行授权决策的版本控制、验证和更新策略的控制平面。此外,OPA提供了一种基本的发现服务,在该服务中,可以动态配置新的代理,并由分发发现捆绑包的控制平面集中管理。此功能可以减轻管理分布式策略决策点(PDP)的管理负担。
控制平面也为监控和审计提供了额外的好处。您可以通过控制平面监视OPA状态。也许更重要的是,包含OPA授权决策的日志可以导出到远程HTTP服务器以进行日志聚合。这些决策日志对于审计目的非常有用。如果您正在考虑采用访问控制决策与应用程序分离的授权模型,请确保您的授权服务具有有效的监控、日志记录和CI/CD管理功能,以启用新的PDP或更新策略。
检索PDP的外部数据
PDP可能需要额外的数据来做出超出作为输入提供的授权决策。例如,您可能将特定于用户或租户的属性存储在数据库中,PDP必须引用这些属性才能做出授权决策。对于OPA,如果授权决策所需的所有数据都可以作为输入或作为作为查询组件传递的JSON Web令牌(JWT)的一部分提供,则不需要额外配置。(将JWT和SaaS上下文数据作为查询输入的一部分传递给OPA相对简单。)OPA可以通过所谓的重载输入方法接受任意JSON输入。如果PDP需要的数据超出了可以作为输入或JWT令牌的范围,OPA提供了几种检索这些数据的选项。其中包括绑定、推送数据(复制)和动态数据检索。
捆绑
OPA绑定功能支持以下外部数据检索过程:
- 策略执行点(PEP)请求授权决策。
- OPA下载新的政策包,包括外部数据。
- 绑定服务从数据源复制数据。
当您使用捆绑功能时,OPA会定期从集中捆绑服务下载策略和数据捆绑包。(捆绑服务的实现和设置不是OPA提供的。)从捆绑服务中提取的所有策略和外部数据都存储在内存中。如果外部数据大小太大,无法存储在内存中,或者数据更改太频繁,则此选项将不起作用。
有关捆绑功能的更多信息,请参阅OPA文档。
复制(推送数据)
OPA复制方法支持以下外部数据检索过程:
- 策略执行点(PEP)请求授权决策。
- 数据复制器将数据推送到OPA。
- 数据复制器从数据源复制数据。
在捆绑方法的另一种选择中,数据被推送到OPA,而不是被OPA周期性地拉取。(OPA不提供复制器的实现和设置。)推送方法与捆绑方法具有相同的数据大小限制,因为OPA将所有数据存储在内存中。推送选项的主要优点是,您可以使用增量更新OPA中的数据,而不是每次替换所有外部数据。这使得推送选项更适合频繁变化的数据集。
有关复制选项的更多信息,请参阅OPA文档。
动态数据检索
如果要检索的外部数据太大,无法缓存在OPA的内存中,则可以在评估授权决策期间从外部源动态提取数据。使用此方法时,数据始终是最新的。这种方法有两个缺点:网络延迟和可访问性。目前,OPA只能通过HTTP请求在运行时检索数据。如果到外部数据源的调用不能以HTTP响应的形式返回数据,则需要自定义API或其他机制来将这些数据提供给OPA。由于OPA只能通过HTTP请求检索数据,检索数据的速度至关重要,因此我们建议您尽可能使用Amazon ElastiCache或Amazon DynamoDB等AWS服务保存外部数据。
有关拉动方法的更多信息,请参阅OPA文档。
使用授权服务实现
当您使用绑定、复制或动态拉取方法获取外部数据时,我们建议授权服务促进这种交互。这是因为授权服务可以检索外部数据并将其转换为JSON,以便OPA做出授权决策。下图显示了授权服务如何使用这三种外部数据检索方法。
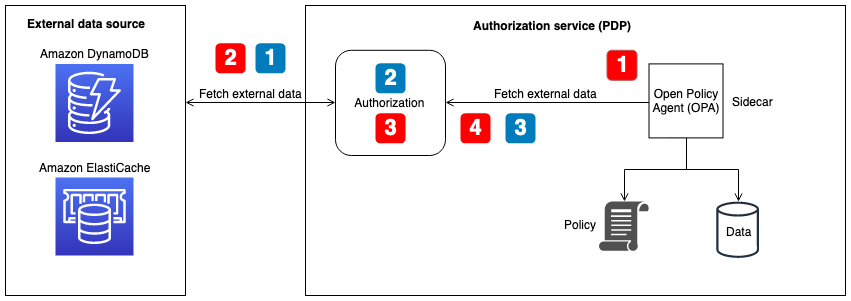
Retrieving external data for OPA flow – bundle or dynamic data retrieval at decision time:
|
OPA调用授权服务本地API端点 此端点被配置为在授权决策期间充当捆绑包端点或动态数据检索的端点。 |
|
授权服务查询或调用外部数据源以检索数据。 (对于捆绑包端点,此数据还应包含OPA策略和规则。捆绑包更新将替换OPA缓存中的所有数据和策略。) |
|
授权服务对返回的数据执行任何必要的转换,以将其转换为预期的JSON输入。 |
|
数据返回OPA。它被缓存在内存中用于捆绑包配置,并立即用于动态授权决策。 |
Retrieving external data for OPA flow – replicator:
|
复制器(授权服务的一部分)调用外部数据源并检索OPA中要更新的任何数据。 这可以包括策略、规则和外部数据。此调用可以以设置的节奏进行,也可以响应外部源中的数据更新而进行。 |
|
授权服务对返回的数据执行任何必要的转换,以将其转换为预期的JSON输入。 |
|
授权服务调用OPA并将数据缓存在内存中。授权服务可以选择性地更新数据、策略和规则。 |
RBAC租户隔离和外部数据隐私建议
上一节提供了将外部数据导入OPA以帮助做出授权决策的几种方法。在可能的情况下,我们建议您使用重载输入方法将SaaS上下文数据传递给OPA,以做出授权决策。然而,在基于角色的访问控制(RBAC)或RBAC和基于属性访问控制(ABAC)混合模型中,这些数据通常不够,因为必须引用角色和权限才能做出授权决策。为了维护租户隔离和角色映射的隐私,这些数据不应驻留在OPA中。RBAC数据应驻留在外部数据源中,例如数据库。此外,OPA不应用于将预定义角色映射到特定权限,因为这使得租户难以定义自己的角色和权限。它还使您的授权逻辑僵化,需要不断更新。
维护RBAC数据隐私和租户隔离的一些安全方法是使用动态数据检索或复制器方法获取OPA的外部数据。这是因为前一图中所示的授权服务可用于仅提供租户特定或用户特定的外部数据,以进行授权决策。例如,当用户登录时,可以使用复制器向OPA缓存提供RBAC数据或权限矩阵,并根据输入数据中提供的用户引用数据。您可以对动态提取的数据使用类似的方法,以便仅检索相关数据以进行授权决策。此外,在动态数据检索方法中,这些数据不必缓存在OPA中。绑定方法在维护租户隔离方面不如动态检索方法有效,因为它更新OPA缓存中的所有内容,无法处理精确的更新。捆绑模型仍然是更新OPA策略和非RBAC数据的好方法。
- 74 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--最佳实践
视频号
微信公众号
知识星球
本节列出了本指南的一些重要内容。有关每一点的详细讨论,请单击相应章节的链接。
选择适用于应用程序的访问控制模型
本指南讨论了几种访问控制模型。根据您的应用程序和业务需求,您应该选择适合您的模型。考虑如何使用这些模型来满足您的访问控制需求,以及访问控制需求可能会如何演变,需要对所选方法进行更改。
实施PDP
策略决策点(PDP)可以被表征为策略或规则引擎。此组件负责应用策略或规则,并返回是否允许特定访问的决定。PDP允许将应用程序代码中的授权逻辑卸载到单独的系统。这可以简化应用程序代码。它还提供了一个易于使用的幂等接口,用于为API、微服务、前端后端(BFF)层或任何其他应用程序组件进行授权决策。PDP可用于在应用程序中一致地强制执行租赁要求。
为组织中的每个API实施PEP
策略实施点(PEP)的实现需要确定应用程序中的访问控制实施位置。作为第一步,找到应用程序中可以合并PEP的点。在决定在何处添加PEP时,请考虑以下原则:
如果应用程序公开了API,那么应该对该API进行授权和访问控制。
考虑使用OPA作为PDP的策略引擎
开放策略代理(OPA)比定制策略引擎具有优势。OPA及其与Rego的策略评估提供了一个灵活的预构建策略引擎,支持使用高级声明性语言编写策略。这使得实现策略引擎所需的工作量大大低于构建自己的解决方案。此外,OPA正在迅速成为一个受支持的授权标准。
为OPA实现DevOps、监控和日志记录的控制平面
因为OPA不提供通过源代码控制更新和跟踪授权逻辑更改的方法,所以我们建议您实现一个控制平面来执行这些功能。这将使更新更容易分发给OPA代理,特别是如果OPA在分布式系统中运行,这将减少使用OPA的管理负担。此外,控制平面可用于收集聚合日志并监视OPA代理的状态。
确定授权决策是否需要外部数据,并选择适合它的模型
如果PDP可以仅基于JSON Web令牌(JWT)中包含的数据做出授权决策,则通常不需要导入外部数据来帮助做出授权决策。如果OPA用作PDP,它也可以接受任意JSON数据作为重载输入,作为请求的一部分传递,即使该数据不作为JWT的一部分。使用JWT或重载输入方法通常比在另一个源中维护外部数据容易得多。如果需要更复杂的外部数据来进行授权决策,OPA提供了几种检索外部数据的模型。
- 143 次浏览
【SaaS架构】多租户SaaS授权和API访问控制--访问控制类型
视频号
微信公众号
知识星球
您可以使用两种广泛定义的模型来实现访问控制:基于角色的访问控制(RBAC)和基于属性的访问控制。每种模型都有优缺点,本节将对此进行简要讨论。您应该使用的模型取决于您的具体用例。本指南中讨论的体系结构支持这两种模型。
RBAC
基于角色的访问控制(RBAC)基于通常与业务逻辑一致的角色来确定对资源的访问。权限将根据需要与角色关联。例如,营销角色将授权用户在受限系统内执行营销活动。这是一个相对简单的访问控制模型,因为它很好地与易于识别的业务逻辑相一致。
RBAC模型在以下情况下不太有效:
- 您有独特的用户,其职责包括多个角色。
- 您有复杂的业务逻辑,难以定义角色。
- 要扩展到较大的规模,需要不断进行管理,并将权限映射到新角色和现有角色。
- 授权基于动态参数。
ABAC
基于属性的访问控制(ABAC)基于属性确定对资源的访问。属性可以与用户、资源、环境甚至应用程序状态相关联。策略或规则引用属性,并可以使用基本布尔逻辑来确定是否允许用户执行操作。以下是权限的基本示例:
在支付系统中,财务部门的所有用户都可以在工作时间内在API端点/付款处处理付款。
财务部门的成员资格是决定访问/付款的用户属性。还有一个与/支付API端点关联的资源属性,它只允许在工作时间内进行访问。在ABAC中,用户是否可以处理付款由策略决定,该策略将财务部门成员资格作为用户属性,将时间作为/付款的资源属性。
ABAC模型在允许动态、上下文和细粒度授权决策方面非常灵活。然而,ABAC模型最初很难实现。定义规则和策略以及枚举所有相关访问向量的属性需要大量的前期投资来实现。
RBAC-ABAC混合方法
结合RBAC和ABAC可以提供这两种模型的一些优点。RBAC与业务逻辑紧密结合,实现起来比ABAC简单。为了在做出授权决策时提供额外的粒度层,可以将ABAC与RBAC结合起来。这种混合方法通过将用户的角色(及其分配的权限)与其他属性相结合以做出访问决策来确定访问。使用这两种模型可以实现简单的权限管理和分配,同时还可以提高授权决策的灵活性和粒度。
访问控制模型比较
下表比较了前面讨论的三种访问控制模型。这一比较旨在提供信息和高水平。在特定情况下使用访问模型可能不一定与本表中的比较相关。
| Factor | RBAC | ABAC | Hybrid |
|---|---|---|---|
| Flexibility | Medium | High | High |
| Simplicity | High | Low | Medium |
| Granularity | Low | High | Medium |
| Dynamic decisions and rules | No | Yes | Yes |
| Context-aware | No | Yes | Somewhat |
| Implementation effort | Low | High | Medium |
- 52 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL
视频号
微信公众号
知识星球
- 85 次浏览
【SaaS架构】在AWS上为多租户SaaS应用程序实施托管PostgreSQL -- 介绍
视频号
微信公众号
知识星球
当您选择一个数据库来存储操作数据时,必须考虑数据的结构、它将回答哪些查询、它将以多快的速度提供答案以及数据平台本身的弹性。除了这些一般考虑因素外,软件即服务(SaaS)对运营数据的影响,如性能隔离、租户安全以及多租户SaaS应用程序数据的典型特性和设计模式。本指南讨论了这些因素如何应用于将AmazonWebServices(AWS)上的PostgreSQL数据库用作多租户SaaS应用程序的主要操作数据存储。具体来说,本指南重点介绍了两个AWS管理的PostgreSQL选项:Amazon Aurora PostgreSQL Compatible Edition和Amazon Relational Database Service(Amazon RDS)for PostgreSQL。
目标业务成果
本指南详细分析了使用Aurora PostgreSQL Compatible和Amazon RDS for PostgreSQL的多租户SaaS应用程序的最佳实践。我们建议您使用本指南中提供的设计模式和概念,为您的多租户SaaS应用程序提供Aurora PostgreSQL Compatible或Amazon RDS for PostgreSQL的实现并使其标准化。
本规范性指南有助于实现以下业务成果:
- 为您的用例选择最佳的AWS管理PostgreSQL选项–本指南将数据库使用的关系和非关系选项与SaaS应用程序进行比较。它还讨论了Aurora PostgreSQL Compatible和Amazon RDS for PostgreSQL的最佳用例。这些信息将有助于为您的SaaS应用程序选择最佳选项。
- 通过采用SaaS分区模型实施SaaS最佳实践–本指南讨论并比较了适用于PostgreSQL数据库管理系统(DBMS)的三种广泛的SaaS分区模型:池、桥接和筒仓模型及其变体。这些方法捕获SaaS最佳实践,并在设计SaaS应用程序时提供灵活性。SaaS分区模型的实施是保持最佳实践的关键部分。
- 在池SaaS分区模型中有效使用RLS–行级安全性(RLS)通过基于用户或上下文变量限制可以查看的行,支持在单个PostgreSQL表中强制执行租户数据隔离。当您使用池分区模型时,需要RLS来防止跨租户访问。
- 45 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL -- 为SaaS应用程序选择数据库
视频号
微信公众号
知识星球
对于许多多租户SaaS应用程序,选择一个操作数据库可以提炼为关系数据库和非关系数据库之间的选择,或者两者的组合。要做出决定,请考虑以下高级应用程序数据要求和特征:
- 应用程序的数据模型
- 数据的访问模式
- 数据库延迟要求
- 数据完整性和事务完整性要求(原子性、一致性、隔离性和持久性或ACID)
- 跨区域可用性和恢复要求
下表列出了应用程序数据需求和特性,并在AWS数据库产品的上下文中讨论了它们:Aurora PostgreSQL Compatible和Amazon RDS for PostgreSQL(关系型),以及Amazon DynamoDB(非关系型)。当您试图在关系型和非关系型操作数据库产品之间做出选择时,可以参考此矩阵。
| 数据库 | SaaS应用程序数据需求和特征 | ||||
|---|---|---|---|---|---|
| 数据模型 | 访问模式 | 延迟要求 | 数据和事务完整性 | 跨区域可用性和恢复 | |
|
Relational (Aurora PostgreSQL-Compatible and Amazon RDS for PostgreSQL) |
关系的或高度规范化的。 | 不必事先彻底计划 | 优选更高的延迟容忍度;默认情况下,Aurora可以通过实现读取副本、缓存和类似功能来实现较低的延迟。 | 默认情况下保持高数据和事务完整性。 | 在Amazon RDS中,您可以为跨区域扩展和故障切换创建一个读副本。Aurora在很大程度上自动化了这一点,但目前还没有针对主动-主动配置的写转发功能。 |
|
非关系型 (Amazon DynamoDB) |
通常是非规范化的。这些数据库利用模式对多对多关系、大型项目和时间序列数据进行建模。 | 在生成数据模型之前,必须彻底了解数据的所有访问模式(查询)。 | 使用Amazon DynamoDB Accelerator(DAX)等选项,延迟非常低,可以进一步提高性能。 | 以性能为代价的可选事务完整性。数据完整性问题转移到应用程序。 | 轻松的跨区域恢复和具有全局表的主动-主动配置。(ACID合规性仅在单个AWS区域内实现。) |
一些多租户SaaS应用程序可能具有独特的数据模型或特殊情况,上表中未包含的数据库可以更好地为其提供服务。例如,时间序列数据集、高度连接的数据集或维护集中交易分类账可能需要使用不同类型的数据库。分析所有可能性超出了本指南的范围。有关AWS数据库产品的全面列表以及它们如何在高级别上满足不同的用例,请参阅《亚马逊Web服务概述》白皮书的数据库部分。
本指南的其余部分重点介绍支持PostgreSQL的AWS关系数据库服务:Amazon RDS和Aurora PostgreSQL Compatible。DynamoDB需要一种不同的方法来优化SaaS应用程序,这超出了本指南的范围。有关DynamoDB的更多信息,请参阅AWS博客文章《使用AmazonDynamoDB分区池多租户SaaS数据》。
在Amazon RDS和Aurora之间选择
在大多数情况下,我们建议使用Aurora PostgreSQL Compatible over Amazon RDS for PostgreSQL。下表显示了在选择这两个选项时应考虑的因素。
| DBMS组件 | Amazon RDS for PostgreSQL | Aurora PostgreSQL-Compatible |
|---|---|---|
| 可扩展性 | 复制延迟分钟,最多5个读取副本 | 复制延迟不到一分钟(对于全局数据库,通常小于1秒),最多15个读取副本 |
| 崩溃恢复 | 检查点间隔5分钟(默认情况下),会降低数据库性能 | 使用并行线程进行异步恢复以实现快速恢复 |
| Failover | 除了崩溃恢复时间外,还有60-120秒 | 通常约30秒(包括崩溃恢复) |
| Storage | 最大IOPS为256,000 | IOPS仅受Aurora实例大小和容量的限制 |
| 高可用性和灾难恢复 | 2个具有备用实例的可用性区域,跨区域故障切换以读取副本或复制的备份 | 默认情况下为3个可用区,使用Aurora全局数据库进行跨区域故障切换 |
| 备份 | 在备份窗口期间,可能会影响性能 | 自动增量备份,无性能影响 |
| 数据库实例类 | See list of Amazon RDS instance classes | See list of Aurora instance classes |
在上表中描述的所有类别中,Aurora PostgreSQL Compatible通常是更好的选择。然而,AmazonRDS for PostgreSQL对于中小型工作负载可能仍然有意义,因为它有更多的实例类选择,可能会以Aurora更强大的功能集为代价提供更具成本效益的选项。有关详细的比较,请参阅AWS博客文章AmazonRDS For PostgreSQL或AmazonAurora PostgreSQL是我更好的选择吗?
- 47 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL --FAQ
视频号
微信公众号
知识星球
本节提供了关于在多租户SaaS应用程序中实现托管PostgreSQL的常见问题的答案。
AWS提供哪些托管PostgreSQL选项?
AWS为PostgreSQL提供Amazon Aurora PostgreSQL兼容和Amazon关系数据库服务(Amazon RDS)。AWS还拥有广泛的托管数据库产品目录。
哪种服务最适合SaaS应用程序?
您可以将Aurora PostgreSQL Compatible和Amazon RDS for PostgreSQL用于SaaS应用程序以及本指南中讨论的所有SaaS分区模型。这两种服务在可扩展性、故障恢复、故障切换、存储选项、高可用性、灾难恢复、备份以及每个选项可用的实例类方面存在差异。最佳选择将取决于您的具体用例。使用本指南中的决策矩阵为您的用例选择最佳选项。
如果我决定在多租户SaaS应用程序中使用PostgreSQL数据库,我应该考虑哪些独特的需求?
与SaaS应用程序使用的任何数据存储一样,最重要的考虑是维护租户数据隔离的方法。正如本指南中所讨论的,有多种方法可以通过AWS管理的PostgreSQL产品实现租户数据隔离。此外,对于任何PostgreSQL实现,您都应该考虑基于每个租户的性能隔离。
我可以使用哪些模型与PostgreSQL保持租户数据隔离?
您可以使用思洛存储器、网桥和池模型作为SaaS分区策略来维护租户数据隔离。有关这些模型及其如何应用于PostgreSQL的讨论,请参阅本指南中的PostgreSQL多租户SaaS分区模型一节。
如何使用多个租户共享的单个PostgreSQL数据库维护租户数据隔离?
PostgreSQL支持行级安全(RLS)功能,您可以使用该功能在单个PostgreSQL数据库或实例中强制租户数据隔离。此外,您可以在单个实例中为每个租户提供单独的PostgreSQL数据库,或在每个租户的基础上创建模式以实现此目标。有关这些方法的优点和缺点,请参阅本指南中的行级安全建议一节。
- 45 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL --PostgreSQL的多租户SaaS分区模型
视频号
微信公众号
知识星球
实现多租户的最佳方法取决于SaaS应用程序的需求。以下部分演示了在PostgreSQL中成功实现多租户的分区模型。
笔记
本节讨论的模型适用于Amazon RDS for PostgreSQL和Aurora PostgreSQL Compatible。本节中对PostgreSQL的引用适用于这两种服务。
PostgreSQL中有三种高级模型可用于SaaS分区:简仓、网桥和池。下图总结了简仓和池模型之间的权衡。桥梁模型是筒仓和水池模型的混合。
| 分区模型 | 优势 | 缺点 |
|---|---|---|
| Silo |
|
|
| Pool |
|
|
| Bridge |
|
|
The following sections discuss each model in more detail.
Partitioning models:
PostgreSQL 简仓模型
筒仓模型是通过为应用程序中的每个租户提供PostgreSQL实例来实现的。筒仓模型擅长租户性能和安全隔离,并完全消除了噪音邻居现象。当一个租户对系统的使用影响到另一个租户的性能时,就会出现噪声邻居现象。思洛存储器模型允许您专门为每个租户定制性能,并可能限制特定租户思洛存储器的中断。然而,通常推动筒仓模型采用的是严格的安全和监管约束。SaaS客户可以激发这些约束。例如,SaaS客户可能会因为内部限制而要求隔离他们的数据,SaaS提供商可能会额外收费提供此类服务。
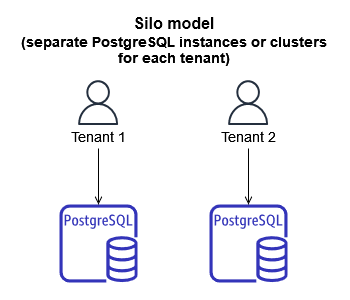
尽管筒仓模型在某些情况下可能是必要的,但它有许多缺点。通常很难以经济高效的方式使用思洛存储器模型,因为跨多个PostgreSQL实例管理资源消耗可能很复杂。此外,该模型中数据库工作负载的分布式特性使得维护租户活动的集中视图变得更加困难。管理如此多独立操作的工作负载会增加操作和管理开销。筒仓模型还使租户注册变得更加复杂和耗时,因为您必须提供特定于租户的资源。此外,整个SaaS系统可能更难扩展,因为不断增加的租户特定PostgreSQL实例将需要更多的操作时间来管理。最后一个考虑是,应用程序或数据访问层必须维护租户到其关联PostgreSQL实例的映射,这增加了实现该模型的复杂性。
PostgreSQL池模型
池模型是通过提供单个PostgreSQL实例(Amazon RDS或Aurora)并使用行级安全性(RLS)来维护租户数据隔离来实现的。RLS策略限制SELECT查询返回表中的哪些行,或INSERT、UPDATE和DELETE命令影响哪些行。池模型将所有租户数据集中在一个PostgreSQL模式中,因此它更具成本效益,维护所需的操作开销也更少。由于其集中化,监控此解决方案也明显更简单。然而,在池模型中监视租户特定的影响通常需要在应用程序中使用一些附加的工具。这是因为PostgreSQL默认情况下不知道哪个租户正在消耗资源。由于不需要新的基础设施,因此简化了租户注册。这种灵活性使实现快速、自动化的租户入职工作流变得更加容易。
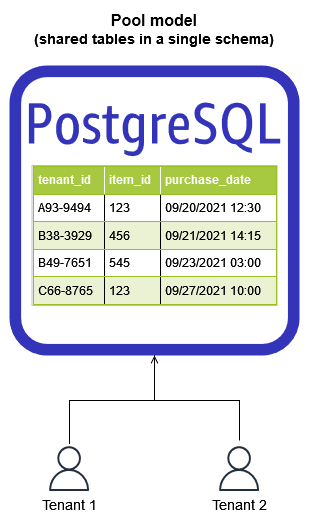
尽管池模型通常更具成本效益且更易于管理,但它确实存在一些缺点。在池模型中,噪声邻居现象不能完全消除。然而,可以通过确保PostgreSQL实例上有适当的资源以及使用减少PostgreSQL中负载的策略(例如将查询卸载到读取副本或AmazonElastiCache)来减轻这种情况。有效的监控在响应租户性能隔离问题方面也发挥着作用,因为应用程序检测可以记录和监控租户特定的活动。最后,一些SaaS客户可能觉得RLS提供的逻辑分离不够,可能会要求额外的隔离措施。
PostgreSQL桥模型
PostgreSQL桥模型是集合方法和孤立方法的组合。与池模型一样,您为每个租户提供一个PostgreSQL实例。为了维护租户数据隔离,您使用PostgreSQL逻辑结构。在下图中,PostgreSQL数据库用于逻辑分离数据。
笔记
PostgreSQL数据库不指单独的Amazon RDS for PostgreSQL或Aurora PostgreSQL Compatible DB实例。相反,它引用PostgreSQL数据库管理系统的逻辑结构来分离数据。
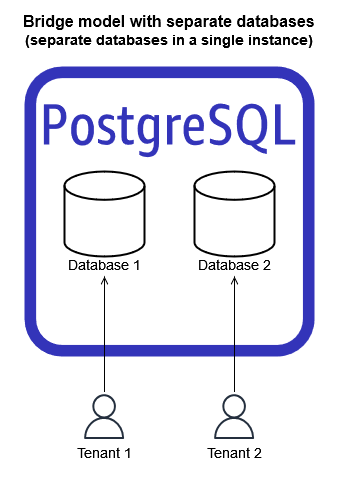
您还可以通过使用单个PostgreSQL数据库实现网桥模型,每个数据库中都有租户特定的模式,如下图所示。
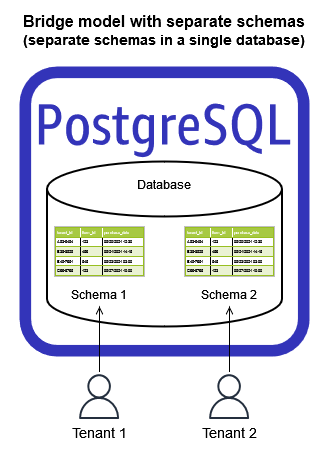
网桥模型与池模型一样受到邻居和租户性能隔离问题的困扰。它还需要在每个租户的基础上配置单独的数据库或模式,从而导致一些额外的操作和配置开销。它需要有效的监控,以快速响应租户的性能问题。它还需要应用程序检测来监视租户特定的使用情况。总体而言,网桥模型可以被视为RLS的替代方案,它通过需要新的PostgreSQL数据库或模式来略微增加租户的入职工作。与思洛存储器模型一样,应用程序或数据访问层必须维护租户到其关联PostgreSQL数据库或模式的映射。
决策矩阵
要决定应使用PostgreSQL的多租户SaaS分区模型,请参阅以下决策矩阵。该矩阵分析了这四个分区选项:
- 简仓–每个租户的单独PostgreSQL实例或集群。
- 桥与独立的数据库–单个PostgreSQL实例或集群中每个租户的独立数据库。
- 桥与独立的模式–单个PostgreSQL数据库、单个PostgreQL实例或集群中每个租户的独立模式。
- Pool–单个实例和模式中租户的共享表。
| 筒仓 | 具有独立数据库的桥 | 具有独立Schema的桥 | 池 | |
|---|---|---|---|---|
| 用例 | 隔离数据并完全控制资源使用是一项关键要求,或者您有非常大且对性能非常敏感的租户。 | 数据隔离是一项关键要求,租户数据的交叉引用是有限的或不需要的。 | 租户数量适中,数据量适中。如果必须交叉引用租户数据,这是首选模型。 | 大量租户,每个租户的数据较少。 |
| 新租户入职灵活性 | 非常慢。(每个租户都需要一个新的实例或集群。) | 适度缓慢。(需要为每个租户创建一个新数据库来存储架构对象。) | 适度缓慢。(需要为每个租户创建一个新的模式来存储对象。) | 最快的选项。(需要最少的设置。) |
| Database connection pool configuration effort and efficiency |
需要大量努力。(每个租户一个连接池。) 效率较低。(租户之间没有数据库连接共享。) |
需要大量努力。(每个租户一个连接池配置,除非您使用Amazon RDS Proxy。) 效率较低。(租户之间没有数据库连接共享和连接总数。基于DB实例类,所有租户之间的使用受到限制。) |
所需的工作量更少。(一个连接池配置适用于所有租户。) 效率适中。(仅在会话池模式下通过SET ROLE或SET SCHEMA命令重新使用连接。使用Amazon RDS Proxy时,SET命令也会导致会话锁定,但可以消除客户端连接池,并为每个请求建立直接连接以提高效率。) |
所需的工作量最少。 效率最高。(为所有租户提供一个连接池,并在所有租户之间高效地重用连接。数据库连接限制基于DB实例类。) |
| 数据库维护(真空管理)和资源使用 | 更简单的管理。 | 中等复杂性。(可能会导致高资源消耗,因为必须在vacuum_aptime之后为每个数据库启动一个真空工作程序,这会导致自动真空启动程序CPU的使用率很高。还可能会有额外的开销与为每个数据库清空PostgreSQL系统目录表相关。) | 大型PostgreSQL系统目录表。(pg_catalog的总大小为几十GB,取决于租户数量和关系。可能需要修改抽真空相关参数以控制表膨胀。) | 表可能很大,这取决于租户的数量和每个租户的数据。(可能需要修改抽真空相关参数以控制表膨胀。) |
| 扩展管理工作 | 巨大的努力(针对不同实例中的每个数据库)。 | 巨大的努力(在每个数据库级别)。 | 最小的工作量(在公共数据库中一次)。 | 最小的工作量(在公共数据库中一次)。 |
| 更改部署工作 | 重大努力。(连接到每个单独的实例并展开更改。) | 重大努力。(连接到每个数据库和schema,并展开更改。) | 适度努力。(连接到公共数据库,并对每个模式进行更改。) | 最小的努力。(连接到公共数据库并展开更改。) |
| 变更部署–影响范围 | 最小的(受影响的单个租户。) | 最小的(受影响的单个租户。) | 最小的(受影响的单个租户。) | Very large. (All tenants affected.) |
| 查询性能管理和工作 | 可管理的查询性能。 | 可管理的查询性能。 | 可管理的查询性能。 | 维护查询性能可能需要大量努力。(随着时间的推移,由于表的大小增加,查询可能运行得更慢。您可以使用表分区和数据库分片来保持性能。) |
| 跨租户资源影响 | 无影响。(租户之间没有资源共享。) | 中等影响。(租户共享公共资源,例如实例CPU和内存。) | 中等影响。(租户共享公共资源,例如实例CPU和内存。) | 严重冲击。(租户在资源、锁冲突等方面相互影响。) |
| 租户级别调整(例如,为每个租户创建额外索引或为特定租户调整DB参数) | 可能的 | 有些可能。(可以对每个租户进行架构级别的更改,但数据库参数在所有租户中都是全局的。) | 有些可能。(可以对每个租户进行架构级别的更改,但数据库参数在所有租户中都是全局的。) | 不可能。(所有租户共享表。) |
| 重新平衡对性能敏感的租户的工作 | 最小的(无需重新平衡。扩展服务器和I/O资源以处理此情况。) | 适度的(使用逻辑复制或pg_dump导出数据库,但停机时间可能会很长,这取决于数据大小。您可以使用Amazon RDS for PostgreSQL中的可移植数据库功能,以更快地在实例之间复制数据库。) | 中等程度,但可能需要较长的停机时间。(使用逻辑复制或pg_dump导出模式,但停机时间可能会很长,具体取决于数据大小。) |
重要,因为所有租户共享同一张桌子。(共享数据库需要将所有内容复制到另一个实例,以及清理租户数据的额外步骤。) 很可能需要更改应用程序逻辑。 |
| 主要版本升级的数据库停机 | 标准停机时间。(取决于PostgreSQL系统目录大小。) | 停机时间可能更长。(根据系统目录的大小,时间会有所不同。PostgreSQL系统目录表也会在数据库中复制) | 停机时间可能更长。(根据PostgreSQL系统目录大小,时间会有所不同。) | 标准停机时间。(取决于PostgreSQL系统目录大小。) |
| 管理开销(例如,用于数据库日志分析或备份作业监视) | 重大努力 | 最小的努力。 | 最小的努力。 | 最小的努力。 |
| 租户级别可用性 | 最高。(每个租户都会出现故障并独立恢复。) | 影响范围更大。(如果出现硬件或资源问题,所有租户都会失败并一起恢复。) | 影响范围更大。(如果出现硬件或资源问题,所有租户都会失败并一起恢复。) | 影响范围更大。(如果出现硬件或资源问题,所有租户都会失败并一起恢复。) |
| 租户级别的备份和恢复工作 | 最少的努力。(每个租户都可以独立备份和恢复。) | 适度努力。(对每个租户使用逻辑导出和导入。需要一些编码和自动化。) | 适度努力。(对每个租户使用逻辑导出和导入。需要一些编码和自动化。) | 重大努力。(所有租户共享同一张表。) |
| 租户级别的时间点恢复工作 | 最小的努力。(使用快照进行时间点恢复,或在Amazon Aurora中使用回溯。) | 适度努力。(使用快照还原,然后导出/导入。但是,这将是一个缓慢的操作。) | 适度努力。(使用快照还原,然后导出/导入。但是,这将是一个缓慢的操作。) | 巨大的努力和复杂性。 |
| 统一的schema 名称 | 每个租户的schema 名称相同。 | 每个租户的schema 名称相同。 | 每个租户的Schema不同。 | 公共Schema。 |
| 每个租户自定义(例如,特定租户的附加表列) | 可能的. | 可能的. | 可能的. | 复杂(因为所有租户共享同一张表). |
| 对象关系映射(ORM)层的目录管理效率(例如Ruby) | 高效(因为客户端连接特定于租户)。 | 高效(因为客户端连接特定于数据库)。 | 效率适中。(根据所使用的ORM、用户/角色安全模型和search_path配置,客户端有时会缓存所有租户的元数据,从而导致数据库连接内存使用率高。) | 高效(因为所有租户共享同一张桌子)。 |
| 整合租户报告工作 | 重大努力。(您必须使用外部数据包装器[FDWs]来合并所有租户中的数据,或者提取、转换和加载[ETL]到另一个报告数据库。) | 重大努力。(您必须使用FDW将所有租户或ETL中的数据合并到另一个报告数据库中。) | 适度努力。(可以使用联合来聚合所有模式中的数据。) | 最小的努力。(所有租户数据都在同一个表中,因此报告很简单。) |
| 用于报告的租户特定只读实例(例如,基于订阅) | 最少的努力。(创建读取副本。) | 适度努力。(您可以使用逻辑复制或AWS数据库迁移服务[AWS DMS]进行配置。) | (您可以使用逻辑复制或AWS DMS进行配置。) | 复杂(因为所有租户共享同一张桌子)。 |
| 数据隔离 | 最好的 | 较好的(您可以使用PostgreSQL角色管理数据库级权限。) | 较好的(您可以使用PostgreSQL角色来管理模式级权限。) | 更糟的(因为所有租户共享相同的表,所以必须实现行级安全[RLS]等功能以隔离租户。) |
| 租户特定的存储加密密钥 | 可能的(每个PostgreSQL集群都可以有自己的AWS密钥管理服务[AWS KMS]密钥用于存储加密) | 不可能。(所有租户共享相同的KMS密钥进行存储加密。) | 不可能。(所有租户共享相同的KMS密钥进行存储加密。) | 不可能。(所有租户共享相同的KMS密钥进行存储加密。) |
| 使用AWS身份和访问管理(IAM)对每个租户进行数据库身份验证 | 可能的 | 可能的 | 可能(通过为每个模式设置单独的PostgreSQL用户)。 | 不可能(因为所有租户共享表)。 |
| 基础设施成本 | 最高(因为没有共享)。 | 适度的 | 适度的 | 最低的。 |
| 数据复制和存储使用 | 所有租户的最高聚合。(PostgreSQL系统目录表和应用程序的静态和公共数据在所有租户之间重复。) | 所有租户的最高聚合。(PostgreSQL系统目录表和应用程序的静态和公共数据在所有租户之间重复。) | 适度的(应用程序的静态和公共数据可以在公共模式中,并由其他租户访问。) | 最小的(没有重复数据。应用程序的静态数据和公共数据可以位于同一架构中。) |
| 以租户为中心的监控(快速找出导致问题的租户) | 最少的努力。(因为每个租户都被单独监控,所以很容易检查特定租户的活动。) | 适度努力。(因为所有租户共享相同的物理资源,您必须应用额外的筛选来检查特定租户的活动。) | 适度努力。(因为所有租户共享相同的物理资源,您必须应用额外的筛选来检查特定租户的活动。) | 重大努力。(因为所有租户共享所有资源,包括表,所以必须使用绑定变量捕获来检查特定SQL查询属于哪个租户。) |
| 集中管理和健康/活动监测 | 重大努力(建立中央监控和中央指挥中心)。 | 适度努力(因为所有租户共享同一实例)。 | 适度努力(因为所有租户共享同一实例)。 | 最小的工作量(因为所有租户共享相同的资源,包括模式)。 |
| 对象标识符(OID)和事务ID(XID)包装的可能性 | 最小的. | 高的(因为OID,XID是一个PostgreSQL集群范围的计数器,所以在物理数据库之间进行有效的抽真空可能会出现问题)。 | 适度的(因为OID,XID是单个PostgreSQL集群范围计数器)。 | 高的(例如,一个表可以达到40亿的TOAST OID限制,这取决于行外列的数量。) |
- 194 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL --最佳实践
视频号
微信公众号
知识星球
本节列出了本指南的一些重要内容。有关每一点的详细讨论,请单击相应章节的链接。
比较托管PostgreSQL的AWS选项
AWS提供了在托管环境中运行PostgreSQL的两种主要方法。(在本文中,托管意味着AWS服务部分或完全支持PostgreSQL基础设施和DBMS。)AWS上的托管PostgreSQL选项具有自动备份、故障切换、优化和PostgreSQL管理的好处。作为托管选项,AWS为PostgreSQL提供Amazon Aurora PostgreSQL兼容版和Amazon关系数据库服务(Amazon RDS)。通过分析PostgreSQL用例,您可以从这两个模型中选择最佳选择。有关更多信息,请参阅本指南中的“在Amazon RDS和Aurora之间进行选择”一节。
选择多租户SaaS分区模型
您可以从三种适用于PostgreSQL的SaaS分区模型中进行选择:思洛存储器、网桥和池。每个模型都有优点和缺点,您应该根据您的用例选择最理想的模型。Amazon RDS for PostgreSQL和Aurora PostgreSQL Compatible支持所有三种模型。选择模型对于在SaaS应用程序中保持租户数据隔离至关重要。有关这些模型的详细讨论,请参阅本指南中PostgreSQL的多租户SaaS分区模型一节。
对池SaaS分区模型使用行级安全性
使用PostgreSQL在池模型中维护租户数据隔离需要行级安全性(RLS)。这是因为在池模型中,基础设施、PostgreSQL数据库或基于每个租户的模式之间没有逻辑分离。RLS将隔离策略的实施集中在数据库级别,并消除了软件开发人员维护隔离的负担。您可以使用RLS将数据库操作限制到特定租户。有关更多信息和示例,请参阅本指南中的行级别安全建议一节。
- 288 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL --池模型的PostgreSQL可用性
视频号
微信公众号
知识星球
池模型本质上只有一个PostgreSQL实例。因此,为高可用性设计应用程序至关重要。池数据库的故障或中断会导致应用程序降级或所有租户都无法访问。
通过启用高可用性功能,AmazonRDS for PostgreSQL DB实例可以在两个可用性区域之间冗余。有关更多信息,请参阅Amazon RDS文档中的Amazon RDS高可用性(Multi-AZ)。对于跨区域故障切换,您可以在不同的AWS区域中创建读取副本。(此读取副本必须作为故障切换过程的一部分进行升级。)此外,您可以复制跨AWS区域复制的备份以进行恢复。有关更多信息,请参阅Amazon RDS文档中的将自动备份复制到另一个AWS区域。
Aurora PostgreSQL Compatible以能够承受多个可用区故障的方式自动备份数据。(请参阅Aurora文档中的Amazon Aurora的高可用性。)为了使Aurora更具弹性并更快地恢复,您可以在其他可用性区域中创建Aurora读取副本。您可以使用Aurora全局数据库将数据复制到另外五个AWS区域,以实现跨区域恢复和自动故障切换。(请参阅Aurora文档中的使用Amazon Aurora全球数据库。)
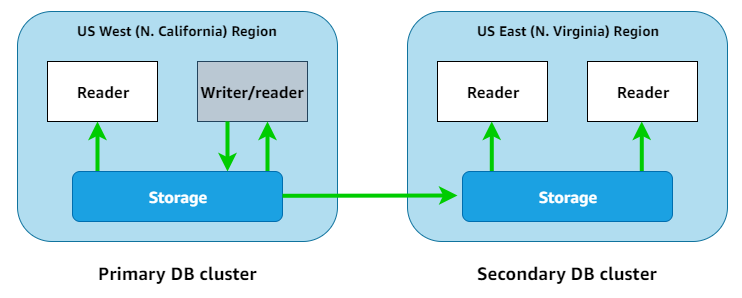
无论您使用的是Amazon RDS for PostgreSQL还是Aurora PostgreSQL Compatible,我们都建议您实施高可用性功能,以减轻所有使用池模型的多租户SaaS应用程序中断的影响。
- 37 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL --行级安全建议
视频号
微信公众号
知识星球
需要行级安全性(RLS)来维护PostgreSQL池模型中的租户数据隔离。RLS将隔离策略的实施集中在数据库级别,并消除了软件开发人员维护隔离的负担。实现RLS的最常见方法是在PostgreSQL DBMS中启用此功能。RLS涉及根据指定列中的值过滤对数据行的访问。您可以使用两种方法来过滤对数据的访问:
将表中指定的数据列与当前PostgreSQL用户的值进行比较。该用户可以访问列中与登录的PostgreSQL用户等效的值。
将表中指定的数据列与应用程序设置的运行时变量的值进行比较。在该会话期间,可以访问列中与运行时变量等效的值。
第二个选项是首选的,因为第一个选项需要为每个租户创建一个新的PostgreSQL用户。相反,使用PostgreSQL的SaaS应用程序应该负责在运行时查询PostgreSQL时设置租户特定的上下文。这将产生强制执行RLS的效果。您还可以逐个表启用RLS。作为最佳实践,您应该在包含租户数据的所有表上启用RLS。
以下示例创建两个表并启用RLS。此示例将一列数据与运行时变量app.current_tempant的值进行比较。
-- Create a table for our tenants with indexes on the primary key and the tenant’s name
CREATE TABLE tenant (
tenant_id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
name VARCHAR(255) UNIQUE,
status VARCHAR(64) CHECK (status IN ('active', 'suspended', 'disabled')),
tier VARCHAR(64) CHECK (tier IN ('gold', 'silver', 'bronze'))
);
-- Create a table for users of a tenant
CREATE TABLE tenant_user (
user_id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
tenant_id UUID NOT NULL REFERENCES tenant (tenant_id) ON DELETE RESTRICT,
email VARCHAR(255) NOT NULL UNIQUE,
given_name VARCHAR(255) NOT NULL CHECK (given_name <> ''),
family_name VARCHAR(255) NOT NULL CHECK (family_name <> '')
);
-- Turn on RLS
ALTER TABLE tenant ENABLE ROW LEVEL SECURITY;
-- Restrict read and write actions so tenants can only see their rows
-- Cast the UUID value in tenant_id to match the type current_setting
-- This policy implies a WITH CHECK that matches the USING clause
CREATE POLICY tenant_isolation_policy ON tenant
USING (tenant_id = current_setting('app.current_tenant')::UUID);
-- And do the same for the tenant users
ALTER TABLE tenant_user ENABLE ROW LEVEL SECURITY;
CREATE POLICY tenant_user_isolation_policy ON tenant_user
USING (tenant_id = current_setting('app.current_tenant')::UUID);
有关更多信息,请参阅PostgreSQL行级安全的多租户数据隔离博客。AWS SaaS工厂团队也在GitHub中提供了一些示例来帮助实现RLS。
- 143 次浏览
【SaaS架构】支持多租户SaaS的PostgreSQL --资源
视频号
微信公众号
知识星球
工具书类
-
SaaS Storage Strategies: Building a Multitenant Storage Model on AWS (AWS whitepaper)
-
Is Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL a better choice for me? (AWS blog post)
-
Cross-Region disaster recovery using Amazon Aurora Global Database for Amazon Aurora PostgreSQL (AWS blog post)
-
Multitenant data isolation with PostgreSQL Row Level Security (AWS blog post)
-
Working with Amazon Aurora PostgreSQL (Aurora documentation)
-
PostgreSQL on Amazon RDS (Amazon RDS documentation)
合作伙伴
- 71 次浏览
【SaaS架构】构建 SaaS 产品所需的技术——第一部分
你有一个新软件产品的想法,你已经完成了你的研究,创建了一个受众并承诺每个人都会解决这个问题。在下文中,我将为您提供一个经过验证的清单和构建 SaaS 的最佳实践。
如今,我们有无数的工具来构建软件。从编程语言、框架和云平台到 nocode 应用程序构建器。此外,市场上充斥着各种提高用户期望的 SaaS 产品。
定义核心
因为竞争如此激烈,你不能不断地重新发明轮子。相反,您的主要目标应该是尽快掌握核心功能。
但核心功能究竟是什么?假设您想创建一个新的送餐应用程序。除非您创建一种新的独特的用户身份验证方式,否则您可能不想推出自己的用户身份验证系统,对吧?用户身份验证似乎不费吹灰之力,但订单管理或交付跟踪等其他子系统可能需要更多考虑。您应该自己构建还是购买解决方案?
在下文中,我将快速介绍一组可能不属于核心的系统和服务,因为它们对许多 SaaS 产品很常见并且可以重用。让我们开始吧。
用户认证
正如已经提到的,我们绝对不应该重新发明轮子进行身份验证,而只是重用现有的服务。您的应用应提供至少一种身份验证提供商,例如 Google 或 Facebook。您甚至可以决定不提供电子邮件注册,这样您就不必自己创建不同的登录、注册和密码重置表单。
电子邮件通知
向您的客户发送诸如订单确认之类的交易电子邮件是必不可少的。有很多服务提供 API 以低价发送交易电子邮件。但你可能会在路上遇到一些惊喜。例如,有一次著名的电子邮件服务提供商刚刚停止为我工作,因为共享 IP 地址被大多数反垃圾邮件服务列入黑名单。支持也无能为力,建议等待,希望共享IP地址尽快下线。在此期间,没有电子邮件可以通过,所以我要么升级并获得一个昂贵的专用 IP 地址(不,谢谢),要么转移到其他服务。最后我决定快速转向另一个电子邮件服务,因为这些服务的 API 都非常相似,只需要对代码进行微小的更改。这里的教训是尽量减少对外部服务的依赖。
但还有更多。如果您正在为欧洲客户服务,那么您需要了解最新的数据隐私法规,看看 Schrems II。查看服务提供商,从他们那里获得签署的 DPA(数据处理协议)并调整您的隐私政策。在某些情况下,您甚至可能需要停止使用该服务。同样在这一点上,尽可能少的依赖是好的。
另一点是多租户。如果您的客户需要从其域发送电子邮件,则电子邮件服务必须支持不同的自定义域。仔细检查自定义域的定价和限制。
多租户
在多租户方面,基本上有两种 SaaS 产品:B2C 和 B2B。
对于 B2B 应用程序,最好为每个客户创建一个逻辑分区或数据库。一方面,这将降低代码的复杂性,因为现在您不必担心层次结构层。团队层次结构和权限管理已经是复杂的主题。此外,您还可以降低您的客户的客户由于某些可能给您带来麻烦甚至破产的错误而混淆的风险。删除客户数据也只是删除数据库的问题,而不是在庞大的数据库中搜索该客户的特定数据,然后将其删除。
对于 B2C 应用程序,使用单个逻辑数据库可能更容易。特别是如果您想创建一个具有社交媒体特征的应用程序或类似约会应用程序的客户相互交互的应用程序,那么您可能会从更紧密的客户数据中受益。但是,如果您的客户数量很少,而对象却很多,那么在单个逻辑数据库中管理角色和权限就变得太繁琐了。
授权
基于角色的授权通常用于定义权限和团队层次结构。通常角色直接附加到身份验证上下文。我不是这种方法的忠实拥护者,因为您需要完全控制身份验证服务才能设置角色。最好将授权规则直接存储在您可以控制的客户数据库中。这也产生了很好的关注点分离。
付款
付款必须完全外包。如果您有许多不同的产品和订阅计划,最好在您身边创建发票并将提供商用作纯粹的支付处理器。这将降低将所有产品与支付处理器系统集成的复杂性,因为发票是与外部系统的唯一接口。这还允许您在将来添加其他支付处理器,例如 POS 终端或切换支付处理器,例如由于费用较低。再一次,过多的外部依赖会减慢你的速度。
托管后端 API
托管后端 API 的选项有很多。从裸机到托管应用服务。我相信作为一家 SaaS 公司,你不会因为构建最精美的 Kubernetes 基础设施而获奖。最佳基础设施应该具有成本效益、易于更换和易于扩展。这可以通过无服务器技术(例如 Google Cloud Run)来实现。只需部署您的 docker 容器即可。一个缺点是第一个请求很可能会有几秒钟的“预热”时间。但是,一旦您的流量增加,这个问题就会完全消失。到目前为止,我发现 Google Cloud Run 是唯一实际收费的服务按请求时间而不是实例时间。查看这个关于如何收取请求时间的插图。这是一个巨大的成本节省。
数据库技术
我曾经是 SQL 数据库的忠实粉丝,直到我意识到 RDBMS 只是过去的应用程序框架。要知道,古希腊人会把他们的代码写在靠近数据的存储过程中。稍后他们会将前端代码转储到表中并从中生成视图。在某一时刻,面向对象的语言变得非常流行,不知何故,我们最终将对象强制放入表中,并将这种痛苦称为:“阻抗不匹配”。
值得庆幸的是,我们不必再处理这个问题了(除非我们真的必须这样做,因为我们的 CTO 强迫我们)。 NoSql 面向文档的数据库,例如 MongoDB 或 RavenDB,正在兴起,它们性能好,易于使用,我们可以直接处理对象,而不必担心 ORM。
将数据作为转储对象处理对我们的整体设计非常有益。我们倾向于更多地关注对我们系统的行为进行建模。数据模型成为行为的结果。文档数据库总是必须有一些非规范化数据的论点已经过时了。今天,我们可以创建高度规范化的关系模型,并轻松地在数据库级别对文档执行连接。面向文档的数据库对生产力非常有益,让我们能够更快地构建应用程序的核心。
托管数据库
与无状态后端 API 不同,您的数据库需要持久存储。许多数据库提供商提供其数据库引擎的云托管。这些服务还包括备份管理和维护。
不过,定价相当高。我们可以使用免费套餐作为起点,但它们的资源往往非常有限。
另一种方法是租用一个小型虚拟机并自行托管一个社区许可的实例,它可以为最初的数百名用户提供足够的电力。我不推荐大型云提供商租用虚拟机,它们在这方面太贵了。自托管当然需要更多的设置工作,但可以让我们获得足够的利润来切换到无服务器数据库解决方案。
后台处理
我们希望在后台异步处理某些类型的工作负载:
- 不需要立即得到结果的数据处理任务,可以放在后台。
- 处理外部事件,例如来自我们的支付服务提供商的支付状态更新或来自其他集成系统的更新
- 处理内部事件
无服务器功能与消息服务总线相结合,为数据处理和内部事件处理提供了一个很好的解决方案。另一方面,外部事件主要是触发我们系统中的 http 端点的 webhook 调用。对于这种情况,最好启动一个 Google Cloud Run 实例,该实例将在后台处理传入的 webhook 调用。 Azure、Aws 和 GCP 为消息总线和无服务器功能提供了良好的解决方案。在撰写本文时,我正在构建一个基于 GCP 的更统一的解决方案,敬请期待!
第一部分结束
在这篇文章变得太长之前,让我们在一个简单的清单中总结到目前为止我们学到的东西:
- 确定您的应用程序的核心业务理念
- 了解您的应用类型是 B2B、B2C 还是两者兼有
- 添加身份验证提供程序
- 为您的交易电子邮件找到合适的电子邮件服务提供商
- 使用发票作为数据接口集成在线支付提供商
- 使用无服务器技术为您的无状态后端 API 提供服务
- 使用面向文档的数据库,例如 RavenDB 或 MongoDB
- 在小型虚拟机上托管您的数据库或在刚开始时选择收费计划,稍后切换到基于云的托管
- 在您选择的云提供商处:创建消息总线并附加无服务器功能以处理内部事件
在第二部分,我将写 UI 框架、代码设计、安全、DevOps 和其他 SaaS 相关主题。同时在这里结帐并加入我们新的聚会小组,并与社区分享您的想法。
- 81 次浏览
【SaaS架构】由 Next JS 和 AWS 组成的单人团队在 2021 年构建 SaaS 的现代技术堆栈
作为热爱尖端技术的人,我选择使用现代技术堆栈构建我的第一个 SaaS。 随着 JAMStack 和无服务器架构的兴起,我创建了带有 Next JS 静态生成的 PostMage,用于前端和部署到 AWS 的 Node.js 后端。
因为我是一个单独的全栈开发人员,所以我的时间和资源非常有限。 在本文中,我将分享我用于构建 SaaS 产品的所有技术:从编程语言到开发工具。 您将了解我如何克服这一挑战,以独立开发者的身份构建 SaaS。
希望我的故事能给你灵感来创建你的 SaaS 产品。
无处不在的TypeScript
为了构建我的 SaaS,我用 TypeScript 编写了每一行代码。 是的,所有代码:前端、后端以及 TypeScript 中的基础设施即代码。

整个项目只使用一种独特的编程语言。 没有时间学习新语言并通过使代码易于维护来节省时间。
我为什么选择 TypeScript? 它通过强类型使开发更加愉快,并且与 IDE 有更好的集成。 所以,如果你还是一个 JavaScript 开发者,你应该试一试。
前端框架
对于前端,我使用 Next.js。 这是一个构建复杂应用程序的 React 框架。 好消息是,Next JS 开箱即用地支持 TypeScript。



我使用 Tailwind CSS 样式化 React 组件。 作为开发人员,您通常会构建一个丑陋的界面。 使用 Tailwind CSS,即使您不是设计师,您现在也可以构建一个不那么难看的界面。
作为 JAMStack 的忠实信徒,我之前花了一些时间尝试 Jekyll、Hexo 和 11ty 用于不同的项目。 我选择使用 Next JS 以静态生成模式构建我的 SaaS。 因此,在构建时,所有页面都会生成并预渲染。 非常适合 SEO、廉价托管、快速、安全和高度可扩展。
静态托管
我使用 Cloudflare Pages 作为前端的托管服务,它是 Netlify 或 Vercel 的全新替代品。 Cloudflare 已于 2020 年 12 月发布测试版,并于 2021 年 4 月向公众发布。

Pages 中有一些小的缺失功能(没什么大不了的)。 在 Cloudflare 团队解决它之前,我找到了临时解决方法。 所以,这没什么大不了的。
Cloudflare Page 的好处是其慷慨的免费套餐:无限带宽(Vercel 和 Netlify 每月限制为 100GB),您可以免费设置受密码保护的网站(Vercel 或 Netlify 中不包括免费)。
无服务器 REST API
在后端,我使用 Express.js 和无服务器框架构建了一个 REST API。 为了在 Serverless Framework 中支持 TypeScript,我使用了 serverless-bundle 插件。 Express.js 需要另一个插件来使用名为 serverless-http 的无服务器框架。


为了获得更好的开发者体验,我还使用了另外两个插件:serverless-dotenv-plugin 和 serverless-offline。第一个插件是支持 dotenv 文件,第二个是在本地计算机上运行无服务器框架。
作为一名独立开发人员,我选择无服务器架构,因为它易于部署、低维护和可扩展的后端,让我的生活更轻松。无需成为 DevOps 工程师:无需 SSH、进行操作系统更新、配置代理/网络服务器/负载均衡器/防火墙等。
认证
REST API 受 IAM 身份验证保护。它是 AWS 的内置功能,可以保护任何 AWS 资源,在我们的例子中是 API 网关和 AWS lambda。当用户未连接到 SaaS 应用程序时,它会拒绝 API 调用。因此,当它受到保护时,外部参与者将无法调用您的资源。
因为 API 部署到 AWS,所以我选择使用 AWS Cognito 进行身份验证。好消息是 Cognito 通过提供为 SaaS 实施身份验证所需的一切,节省了大量时间。您无需任何努力即可访问电子邮件身份验证和社交登录(Facebook、Google、Apple 和 Amazon)。

AWS Cognito 和 React 前端之间的连接是通过 AWS Amplify 完成的。 Amplify 提供 React 组件和代码,让您的前端集成到 AWS 更轻松、更快捷。

NoSQL 数据库
PostgreSQL 和 MySQL 等主要和知名的数据库不太适合无服务器架构。 由于无服务器的性质,它可以创建大量的数据库连接并耗尽数据库连接限制。
在大多数提供商上,即使您的 SaaS 上没有任何流量,您仍然需要为数据库实例付费。 相反,当您的应用程序开始增长时,您的数据库很快就会成为瓶颈。
作为一个单独的全栈开发人员,我想要一些非常容易管理并且 100% 兼容无服务器的东西。 因此,我选择 DynamoDB 作为主数据库。

DynamoDB 是一个完全由 AWS 管理的 NoSQL 数据库,我用它来存储用户状态。 他们几乎处理所有事情,我只需要专注于我的代码。
基础设施即代码
如您所见,我为我的 SaaS 应用程序使用了多种 AWS 服务。 在每个环境(开发、登台或生产)中手动设置云资源非常痛苦,并且很难保持它们之间的一致性。
AWS 允许开发人员访问 AWS CDK,您可以在其中使用 TypeScript 定义您的云资源。 在一个命令中,您可以部署到您的 AWS 账户并预置所有内容。

部署
像许多开发人员一样,我使用 Git 和 GitHub 对我的代码进行版本控制。 许多现代托管服务,如 Vercel 和 Netlify,Cloudflare 页面会在每次提交时自动构建和部署您的代码。 如果您使用 Git 分支,您还可以实时预览结果而无需推送到生产环境。

对于后端和基础架构,我使用名为 Seed.run 的第三方服务在每次提交时自动部署。 与前端一样,它也在 AWS 上构建和部署后端资源。
DNS 和 CDN
您可能会怀疑,我毫无意外地将 Cloudflare 用于 DNS 和 CDN ;) Cloudflare Pages 会自动将您的代码部署在 Cloudflare 网络中,我只需将我的域指向 Cloudflare DNS 服务器,其余的由他们处理。 使用 Cloudflare,您可以获得大量安全功能,例如为您的 SaaS 产品提供防火墙和 DDoS 保护。

错误跟踪
我使用 Sentry 作为错误跟踪解决方案。 当出现问题时,它会自动报告有用的信息,如堆栈跟踪、面包屑(问题之前发生的一系列事件)、浏览器信息、操作系统信息等。它通过丰富的数据使生产中的调试变得更加容易:
Sentry 只为前端设置,而不是为 REST API 设置,我一直使用本机解决方案。 事实上,使用 AWS lambda 的 Sentry 会产生大量开销,而且设置并不简单。 在下一节中,您将找到我在后端用于错误跟踪的解决方案。

记录、监控和警报
AWS Lambda 自动将日志发送到 AWS CloudWatch,因此无需使用 Sentry。 以下是 CloudWatch 中存储的日志示例:
您还可以访问您的 lambda 指标。 非常适合了解您的无服务器函数的行为方式并检测是否有任何错误。

我还使用 Lumigo 为我的日志记录和监控提供更多信息。 与 Cloudwatch 相比,该界面更易于使用:
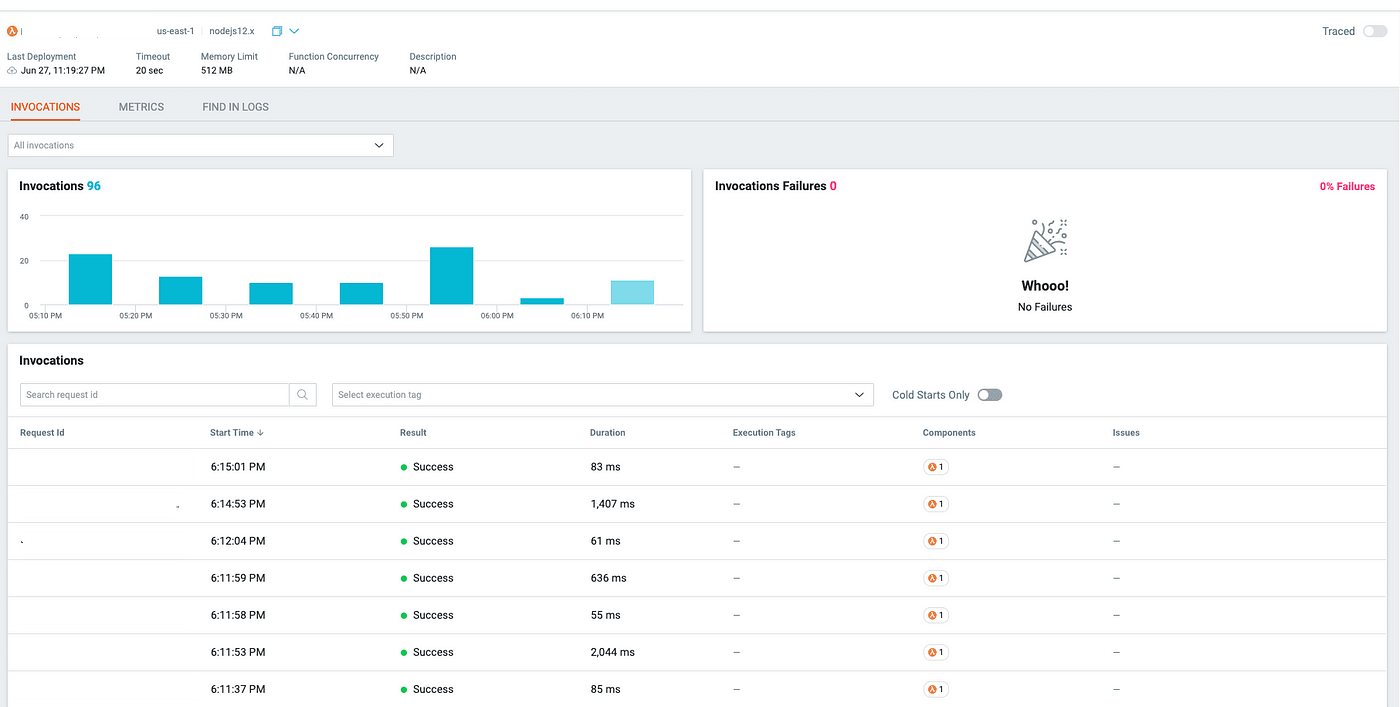
您还可以在 Lumigo 中启用跟踪,您可以在其中可视化您的 AWS 服务和外部 API 调用。 通过让您知道代码中是否存在错误或来自外部服务的错误,它使您的调试会话更容易。
付款和订阅
SaaS 的最后一部分,对企业来说最重要的是接受付款。 接受一次性付款很困难,但重复付款的任务非常复杂。 不幸的是,对于 SaaS 业务,我们需要处理第二种情况。
您的客户在首次订阅时需要选择计划并输入他们的个人信息。
之后,您的用户应该有一个自助服务门户,他们可以在其中管理他们的计划:升级、降级、取消、暂停、恢复他们的订阅计划。
他们有时还需要更新他们的个人信息。 而且,他们还需要在需要时访问他们的发票历史记录。
Stripe 可以管理我在本节中提到的所有内容,它隐藏了所有这些复杂性,并使与支付的集成更容易。

结论
我花了 5 个月的时间来构建这个全栈 React SaaS 模板。 我没有专注于我的业务,而是解决了这些技术细节。 构建您的 SaaS 的第一个版本应该只需要 1 个月而不是 5 个月。
通过这段漫长的旅程,我学到了很多东西,也犯了很多错误。 我希望其他开发人员不会犯同样的错误,所以我为 SaaS 产品构建了 Nextless JS,React Boilerplate。
使用 Nextless.js,您无需编写任何代码即可获得我在本文中提到的所有内容。 节省您的时间,专注于重要的事情并更快地启动您的 SaaS。 在 Nextless JS 中查找更多信息。
原文:https://medium.com/@ixartz/the-modern-tech-stack-to-build-a-saas-in-202…
- 133 次浏览
【SaaS软件】SaaS协议101:订阅者和提供商的权利和责任
视频号
微信公众号
知识星球
SaaS协议是提供软件即服务的公司与其客户之间具有法律约束力的合同。这些服务主要涉及客户端可能订阅的基于云的应用程序。订阅后,客户端可以访问这些基于互联网的服务,以换取经常性费用。SaaS协议的内容因签订合同的各方而异。然而,这些协议旨在让双方清楚地了解他们的期望和责任。
提供商和订阅者的权利和责任在SaaS协议中起草。根据客户与生产商的关系或服务规模,每个SaaS协议都有独特的规定。一份起草良好的SaaS协议阐明了服务的条款和条件以及各方的权利和责任。
与所有具有法律约束力的文件一样,SaaS协议的条款和条件概述了协议可能终止的条件。这可能是在达到协议规定日期后自然发生的,也可能是在一方违约的情况下发生的。
由于软件是SaaS协议中的交换主体,生产商和用户需要接受与交易有关的复杂性。SaaS协议可能会为谈判开辟空间,并要求数据保护。起草良好的SaaS协议对于防止和保护任何潜在的法律诉讼至关重要。
如果你正在寻找起草高效SaaS协议的模板,你可以通过Zegal的模板创建SaaS协议。
Saas协议的条款和条件
SaaS协议包含有关软件控制的条款和条件。在协议中概述所需的条款和条件可以让提供商获得对其提供的应用程序的某些权限。此外,在SaaS协议中包含条款可以在发生冲突时为各方提供法律保护。因此,SaaS协议对于SaaS提供商公司及其订户来说是至关重要的文档。
条款和条件协议定义了客户访问SaaS公司产品所需遵守的规则和条例。它规定了消费者继续获得产品所应遵循的条件。SaaS提供商通常会设置版权限制、争议解决程序以及与其他消费者互动的规则。一旦达成一致,这些条件就具有法律约束力,并构成客户的合同义务。
一份写得很好的SaaS协议清楚地定义了条款和条件,并允许SaaS公司定义他们对交易的期望。由于SaaS提供商可以保留对其服务的控制权,因此降低了滥用的可能性,并为识别客户违反条款的行为奠定了法律基础。
订阅者和生产者的权利
订阅用户和生产者在SaaS协议中设定了他们的权利。生产者通常保留在特定条件下暂停或终止其服务的权利。通常,这些服务的暂停或终止发生在客户违规或无理拒绝的情况下。由于暂停服务违背了订阅SaaS提供商服务的一方的利益,他们可以在SaaS协议范围内进行谈判,将生产者的暂停权利限制在严重违规的情况下。
通过SaaS协议,用户可以获得阻止立即终止的权利。他们可能会概述谈判条款或要求发出通知,以纠正无意的违规行为。在SaaS协议中起草有关这些权利的条款,可以防止由于不可预见的情况而发生违约时协议破裂。
云服务提供商也可能同意发送警告通知。
一些客户的立场是,即使在不付款等严重违规的情况下,供应商也无权终止或暂停服务。他们坚持认为,供应商可以提起诉讼,但有义务继续提供服务,直到证明存在违规行为。
对于以计量模式提供的服务,订户通常有权终止协议,因为这些模式通常不需要承诺。在某些协议中,云提供商可能保留对其提供的服务进行单方面更改的权利。在这样做之前,他们不需要获得客户的许可。在此类协议中,客户有权以物质影响为由为方便终止协议。
SaaS协议中涉及的过渡权利至关重要。当协议自然终止或在期限前终止时,客户可能希望将其业务转移给新的提供商。过渡条款确保客户有权在不受阻碍的情况下这样做。
订阅者和生产者的责任
SaaS生产者有义务按照SaaS协议的详细规定向用户提供服务。作为访问权限的证明,客户持有使用该软件的许可证。他们只能将软件用于协议中列出的目的。客户有义务遵守约定的限制和禁令。
除了提供不间断的服务外,SaaS提供商可能还有义务确保客户获得支持服务。他们有责任根据需要维护或更新软件。
除了与服务相关的义务外,提供商还负有维护客户信息保密的法律责任。这也包括保护客户收集或提供的数据的责任。
由于通过订阅者提供的数据是订阅者的财产,SaaS生产者需要遵守GDPR友好的数据处理条款。客户也可以选择指定他们要求保密的数据。
客户提供的数据是客户的财产,只要这些数据是个人数据,则受GDPR友好数据处理条款的约束。客户数据可能被指定为机密数据。
结论
SaaS协议的条款和条件规定了SaaS用户和生产者的权利和征税义务。SaaS协议可能会使生产者有权在生产者违反规定的情况下暂停其服务。同样,用户可以安排条款,以防止在违约情况下立即暂停服务。他们可以通过包括谈判条款或要求制片人在暂停或终止服务之前提供警告通知以补救违约行为来做到这一点。SaaS协议可以有许多条款,具体取决于相关方的要求。客户可以包括一个过渡条款来处理合同终止的事件。双方都必须遵守协议中规定的条款和条件。一个有效的SaaS协议为软件服务的高效交易奠定了基础。
You may also like:
- 109 次浏览
【多租户】在Amazon OpenSearch Service中构建多租户无服务器架构
视频号
微信公众号
知识星球
|
Environment: PoC or pilot |
Technologies: Modernization; SaaS; Serverless |
Workload: Open-source |
|
AWS services: Amazon OpenSearch Service; AWS Lambda; Amazon S3; Amazon API Gateway |
总结
Amazon OpenSearch服务是一种托管服务,它可以方便地部署、操作和扩展Elasticsearch,这是一种流行的开源搜索和分析引擎。Amazon OpenSearch服务提供免费文本搜索,以及对日志和指标等流数据的近实时接收和仪表板。
软件即服务(SaaS)提供商经常使用Amazon OpenSearch服务来解决广泛的用例,例如以可扩展和安全的方式获取客户洞察,同时减少复杂性和停机时间。
在多租户环境中使用Amazon OpenSearch服务会带来一系列影响SaaS解决方案的分区、隔离、部署和管理的注意事项。SaaS提供商必须考虑如何在不断变化的工作负载下有效地扩展其Elasticsearch集群。他们还需要考虑分层和有噪声的邻居条件如何影响分区模型。
此模式检查用于使用Elasticsearch构造表示和隔离租户数据的模型。此外,该模式以一个简单的无服务器参考架构为例,演示在多租户环境中使用AmazonOpenSearch服务进行索引和搜索。它实现了池数据分区模型,该模型在所有租户之间共享相同的索引,同时保持租户的数据隔离。此模式使用以下Amazon Web Services(AWS)服务:Amazon API Gateway、AWS Lambda、Amazon Simple Storage Service(Amazon S3)和Amazon OpenSearch Service。
有关池模型和其他数据分区模型的更多信息,请参阅附加信息部分。
先决条件和限制
先决条件
- 活跃的AWS帐户
- AWS命令行界面(AWS CLI)2.x版,在macOS、Linux或Windows上安装和配置
- Python版本3.7
- pip3–Python源代码以.zip文件的形式提供,将部署在Lambda函数中。如果您想在本地使用代码或自定义代码,请按照以下步骤开发和重新编译源代码:
- 通过在与Python脚本相同的目录中运行以下命令生成requirements.txt文件:pip3 freeze>requirements.txt
- 安装依赖项:pip3 Install-r requirements.txt
局限性
- 此代码在Python中运行,目前不支持其他编程语言。
- 示例应用程序不包括AWS跨区域或灾难恢复(DR)支持。
- 此模式仅用于演示目的。它不打算在生产环境中使用。
架构
下图说明了此模式的高级架构。该体系结构包括以下内容:
- AWS Lambda对内容进行索引和查询
- Amazon OpenSearch服务执行搜索
- Amazon API网关提供与用户的API交互
- Amazon S3存储原始(非索引)数据
- Amazon CloudWatch监控日志
- AWS身份和访问管理(IAM),用于创建租户角色和策略
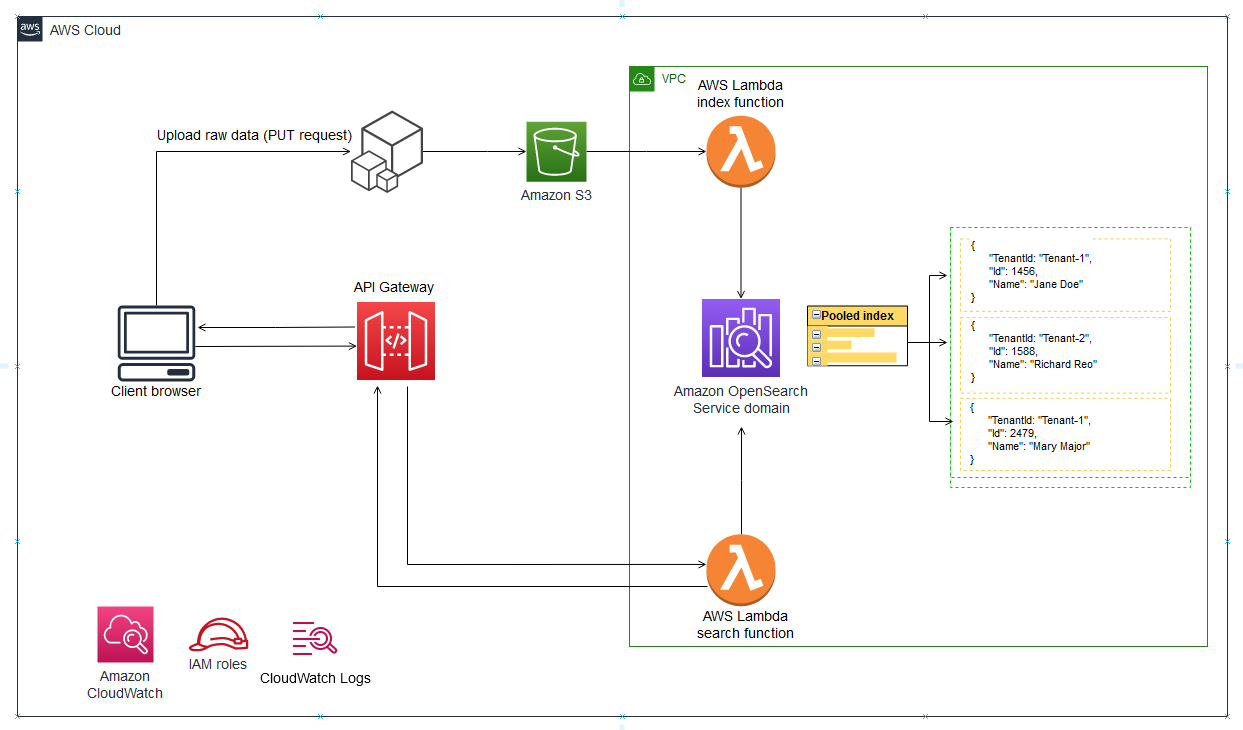
自动化和规模
- 为了简单起见,该模式使用AWS CLI来提供基础结构并部署示例代码。您可以创建AWS CloudFormation模板或AWS Cloud Development Kit(AWS CDK)脚本来自动执行该模式。
工具
AWS服务
- AWS CLI–AWS命令行界面(AWS CLI)是通过在命令行shell中使用命令来管理AWS服务和资源的统一工具。
- AWS Lambda–AWS Lambda是一种计算服务,它允许您在无需配置或管理服务器的情况下运行代码。Lambda只在需要时运行您的代码,并自动扩展,从每天几次请求到每秒数千次。
- Amazon API网关–Amazon API网关是一种AWS服务,用于创建、发布、维护、监控和保护任何规模的REST、HTTP和WebSocket API。
- Amazon S3–Amazon Simple Storage Service(Amazon S3)是一种对象存储服务,它允许您在任何时间、从web上的任何位置存储和检索任意数量的信息。
- Amazon OpenSearch服务–Amazon OpenSearch服务是一项完全管理的服务,可让您轻松部署、安全并以经济高效的方式大规模运行Elasticsearch。
代码
附件提供了此模式的示例文件。其中包括:
- index_lambda_package.zip–使用池模型为Amazon OpenSearch服务中的数据编制索引的lambda函数。
- search_lambda_package.zip–用于在Amazon OpenSearch Service中搜索数据的lambda函数。
- Tenant-1数据–Tenant-1的原始(非索引)数据示例。
- 租户2-data–租户2的原始(非索引)数据示例。
重要提示:此模式中的故事包括为Unix、Linux和macOS格式化的CLI命令示例。对于Windows,将每行末尾的反斜杠(\)Unix连续字符替换为插入符号(^)。
史诗
Create and configure an S3 bucket
| Task | Description | Skills required |
|---|---|---|
|
Create an S3 bucket. |
Create an S3 bucket in your AWS Region. This bucket will hold the non-indexed tenant data for the sample application. Make sure that the S3 bucket's name is globally unique, because the namespace is shared by all AWS accounts. To create an S3 bucket, you can use the AWS CLI create-bucket command as follows: where |
Cloud architect, Cloud administrator |
Create and configure an Elasticsearch cluster
| Task | Description | Skills required |
|---|---|---|
|
Create an Amazon OpenSearch Service domain. |
Run the AWS CLI create-elasticsearch-domain command to create an Amazon OpenSearch Service domain: The instance count is set to 1 because the domain is for testing purposes. You need to enable fine-grained access control by using the This command creates a master user name ( Because the domain is part of a virtual private cloud (VPC), you have to make sure that you can reach the Elasticsearch instance by specifying the access policy to use. For more information, see Launching your Amazon OpenSearch Service domains using a VPC in the AWS documentation. |
Cloud architect, Cloud administrator |
|
Set up a bastion host. |
Set up a Amazon Elastic Compute Cloud (Amazon EC2) Windows instance as a bastion host to access the Kibana console. The Elasticsearch security group must allow traffic from the Amazon EC2 security group. For instructions, see the blog post Controlling Network Access to EC2 Instances Using a Bastion Server. When the bastion host has been set up, and you have the security group that is associated with the instance available, use the AWS CLI authorize-security-group-ingress command to add permission to the Elasticsearch security group to allow port 443 from the Amazon EC2 (bastion host) security group. |
Cloud architect, Cloud administrator |
Create and configure the Lambda index function
| Task | Description | Skills required |
|---|---|---|
|
Create the Lambda execution role. |
Run the AWS CLI create-role command to grant the Lambda index function access to AWS services and resources: where |
Cloud architect, Cloud administrator |
|
Attach managed policies to the Lambda role. |
Run the AWS CLI attach-role-policy command to attach managed policies to the role created in the previous step. These two policies give the role permissions to create an elastic network interface and to write logs to CloudWatch Logs. |
Cloud architect, Cloud administrator |
|
Create a policy to give the Lambda index function permission to read the S3 objects. |
Run the AWS CLI create-policy command to to give the Lambda index function The file |
Cloud architect, Cloud administrator |
|
Attach the Amazon S3 permission policy to the Lambda execution role. |
Run the AWS CLI attach-role-policy command to attach the Amazon S3 permission policy you created in the previous step to the Lambda execution role: where |
Cloud architect, Cloud administrator |
|
Create the Lambda index function. |
Run the AWS CLI create-function command to create the Lambda index function, which will access Amazon OpenSearch Service: |
Cloud architect, Cloud administrator |
|
Allow Amazon S3 to call the Lambda index function. |
Run the AWS CLI add-permission command to give Amazon S3 the permission to call the Lambda index function: |
Cloud architect, Cloud administrator |
|
Add a Lambda trigger for the Amazon S3 event. |
Run the AWS CLI put-bucket-notification-configuration command to send notifications to the Lambda index function when the Amazon S3 The file |
Cloud architect, Cloud administrator |
Create and configure the Lambda search function
| Task | Description | Skills required |
|---|---|---|
|
Create the Lambda execution role. |
Run the AWS CLI create-role command to grant the Lambda search function access to AWS services and resources: where |
Cloud architect, Cloud administrator |
|
Attach managed policies to the Lambda role. |
Run the AWS CLI attach-role-policy command to attach managed policies to the role created in the previous step. These two policies give the role permissions to create an elastic network interface and to write logs to CloudWatch Logs. |
Cloud architect, Cloud administrator |
|
Create the Lambda search function. |
Run the AWS CLI create-function command to create the Lambda search function, which will access Amazon OpenSearch Service: |
Cloud architect, Cloud administrator |
Create and configure tenant roles
| Task | Description | Skills required |
|---|---|---|
|
Create tenant IAM roles. |
Run the AWS CLI create-role command to create two tenant roles that will be used to test the search functionality: The file |
Cloud architect, Cloud administrator |
|
Create a tenant IAM policy. |
Run the AWS CLI create-policy command to create a tenant policy that grants access to Elasticsearch operations: The file |
Cloud architect, Cloud administrator |
|
Attach the tenant IAM policy to the tenant roles. |
Run the AWS CLI attach-role-policy command to attach the tenant IAM policy to the two tenant roles you created in the earlier step: The policy ARN is from the output of the previous step. |
Cloud architect, Cloud administrator |
|
Create an IAM policy to give Lambda permissions to assume role. |
Run the AWS CLI create-policy command to create a policy for Lambda to assume the tenant role: The file For |
Cloud architect, Cloud administrator |
|
Create an IAM policy to give the Lambda index role permission to access Amazon S3. |
Run the AWS CLI create-policy command to give the Lambda index role permission to access the objects in the S3 bucket: The file |
Cloud architect, Cloud administrator |
|
Attach the policy to the Lambda execution role. |
Run the AWS CLI attach-role-policy command to attach the policy created in the previous step to the Lambda index and search execution roles you created earlier: The policy ARN is from the output of the previous step. |
Cloud architect, Cloud administrator |
Create and configure a search API
| Task | Description | Skills required |
|---|---|---|
|
Create a REST API in API Gateway. |
Run the CLI create-rest-api command to create a REST API resource: For the endpoint configuration type, you can specify Note the value of the |
Cloud architect, Cloud administrator |
|
Create a resource for the search API. |
The search API resource starts the Lambda search function with the resource name
|
Cloud architect, Cloud administrator |
|
Create a GET method for the search API. |
Run the AWS CLI put-method command to create a For |
Cloud architect, Cloud administrator |
|
Create a method response for the search API. |
Run the AWS CLI put-method-response command to add a method response for the search API: For |
Cloud architect, Cloud administrator |
|
Set up a proxy Lambda integration for the search API. |
Run the AWS CLI command put-integration command to set up an integration with the Lambda search function: For |
Cloud architect, Cloud administrator |
|
Grant API Gateway permission to call the Lambda search function. |
Run the AWS CLI add-permission command to give API Gateway permission to use the search function: Change the |
Cloud architect, Cloud administrator |
|
Deploy the search API. |
Run the AWS CLI create-deployment command to create a stage resource named If you update the API, you can use the same CLI command to redeploy it to the same stage. |
Cloud architect, Cloud administrator |
Create and configure Kibana roles
| Task | Description | Skills required |
|---|---|---|
|
Log in to the Kibana console. |
|
Cloud architect, Cloud administrator |
|
Create and configure Kibana roles. |
To provide data isolation and to make sure that one tenant cannot retrieve the data of another tenant, you need to use document security, which allows tenants to access only documents that contain their tenant ID.
|
Cloud architect, Cloud administrator |
|
Map users to roles. |
We recommend that you automate the creation of the tenant and Kibana roles at the time of tenant onboarding. |
Cloud architect, Cloud administrator |
|
Create the tenant-data index. |
In the navigation pane, under Management, choose Dev Tools, and then run the following command. This command creates the |
Cloud architect, Cloud administrator |
Create VPC endpoints for Amazon S3 and AWS STS
| Task | Description | Skills required |
|---|---|---|
|
Create a VPC endpoint for Amazon S3. |
Run the AWS CLI create-vpc-endpoint command to create a VPC endpoint for Amazon S3. The endpoint enables the Lambda index function in the VPC to access the Amazon S3 service. For |
Cloud architect, Cloud administrator |
|
Create a VPC endpoint for AWS STS. |
Run the AWS CLI create-vpc-endpoint command to create a VPC endpoint for AWS Security Token Service (AWS STS). The endpoint enables the Lambda index and search functions in the VPC to access the AWS STS service. The functions use AWS STS when they assume the IAM role. For |
Cloud architect, Cloud administrator |
Test multi-tenancy and data isolation
| Task | Description | Skills required |
|---|---|---|
|
Update the Python files for the index and search functions. |
You can get the Elasticsearch endpoint from the Overview tab of the Amazon OpenSearch Service console. It has the format |
Cloud architect, App developer |
|
Update the Lambda code. |
Use the AWS CLI update-function-code command to update the Lambda code with the changes you made to the Python files: |
Cloud architect, App developer |
|
Upload raw data to the S3 bucket. |
Use the AWS CLI cp command to upload data for the Tenant-1 and Tenant-2 objects to the The S3 bucket is set up to run the Lambda index function whenever data is uploaded so that the document is indexed in Elasticsearch. |
Cloud architect, Cloud administrator |
|
Search data from the Kibana console. |
On the Kibana console, run the following query: This query displays all the documents indexed in Elasticsearch. In this case, you should see two, separate documents for Tenant-1 and Tenant-2. |
Cloud architect, Cloud administrator |
|
Test the search API from API Gateway. |
For screen illustrations, see the Additional information section. |
Cloud architect, App developer |
相关资源
其他信息
数据分区模型
在多租户系统中有三种常见的数据分区模型:筒仓、池和混合。您选择的模型取决于环境的合规性、噪声邻居、操作和隔离需求。
筒仓模型
在思洛存储器模型中,每个租户的数据都存储在不同的存储区域中,其中没有租户数据的混合。您可以使用两种方法来实现AmazonOpenSearchService的筒仓模型:每个租户的域和每个租户的索引。
- 每个租户的域–您可以为每个租户使用单独的Amazon OpenSearch服务域(与Elasticsearch集群同义)。将每个租户放置在其自己的域中提供了将数据置于独立构造中的所有好处。然而,这种方法带来了管理和敏捷性方面的挑战。它的分布性使其更难汇总和评估租户的运营状况和活动。这是一个成本高昂的选项,要求每个Amazon OpenSearch服务域至少有三个主节点和两个数据节点用于生产工作负载。
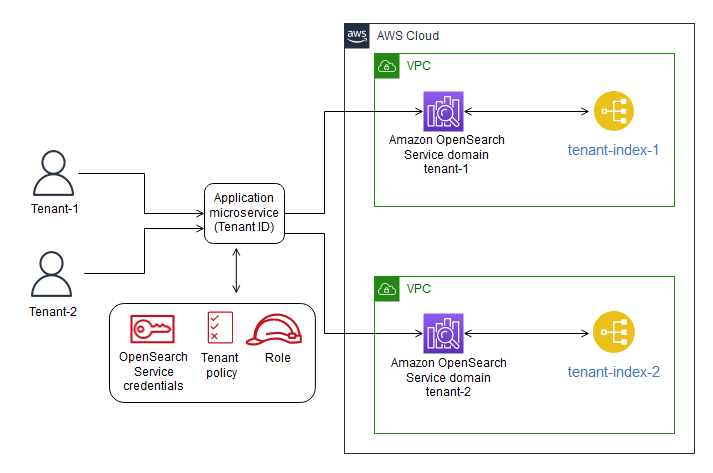
- 每个租户的索引–您可以将租户数据放在Amazon OpenSearch服务集群中的单独索引中。使用这种方法,您可以在创建和命名索引时使用租户标识符,方法是将租户标识符预先挂接到索引名称。每租户索引方法可以帮助您实现筒仓目标,而无需为每个租户引入完全独立的集群。但是,如果索引数量增加,可能会遇到内存压力,因为这种方法需要更多的碎片,而主节点必须处理更多的分配和重新平衡。
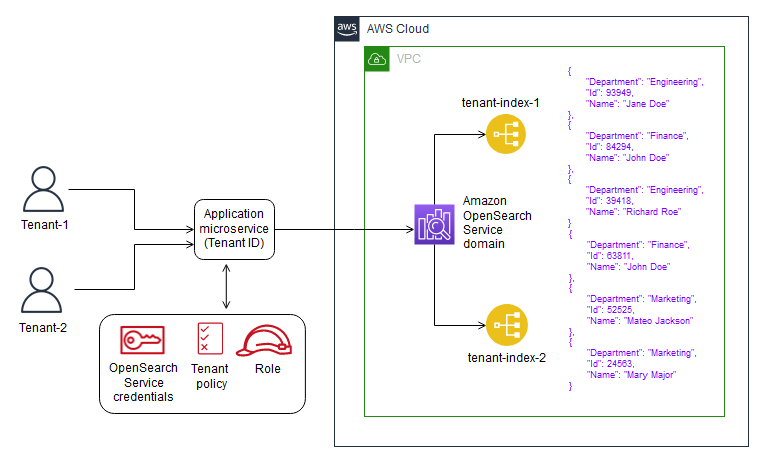
- 筒仓模型中的隔离–在筒仓模型中,您使用IAM策略隔离保存每个租户数据的域或索引。这些策略阻止一个租户访问另一个租户的数据。要实现思洛存储器隔离模型,可以创建基于资源的策略,以控制对租户资源的访问。这通常是一个域访问策略,指定主体可以对域的子资源执行哪些操作,包括Elasticsearch索引和API。使用基于IAM身份的策略,您可以在Amazon OpenSearch Service中指定域、索引或API上允许或拒绝的操作。IAM策略的Action元素描述策略允许或拒绝的特定操作,Principal元素指定受影响的帐户、用户或角色。
以下示例策略仅授予Tenant-1对Tenant-1域上的子资源的完全访问权(由es:*指定)。Resource元素中的尾随/*表示此策略适用于域的子资源,而不是域本身。当此策略生效时,租户不允许创建新域或修改现有域上的设置。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::aws-account-id:user/Tenant-1"
},
"Action": "es:*",
"Resource": "arn:aws:es:Region:account-id:domain/tenant-1/*"
}
]
}
要实现每个索引的租户筒仓模型,您需要修改此示例策略,通过指定索引名称将租户1进一步限制为指定的索引。以下示例策略将Tenant-1限制为Tenant-index-1索引。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/Tenant-1"
},
"Action": "es:*",
"Resource": "arn:aws:es:Region:account-id:domain/test-domain/tenant-index-1/*"
}
]
}
水池模型
在池模型中,所有租户数据都存储在同一域内的索引中。租户标识符包含在数据(文档)中并用作分区键,因此您可以确定哪些数据属于哪个租户。该模型减少了管理开销。与管理多个索引相比,操作和管理合并索引更容易、更高效。但是,由于租户数据混合在同一索引中,因此您将失去思洛存储器模型提供的自然租户隔离。由于噪声邻居效应,这种方法也可能降低性能。
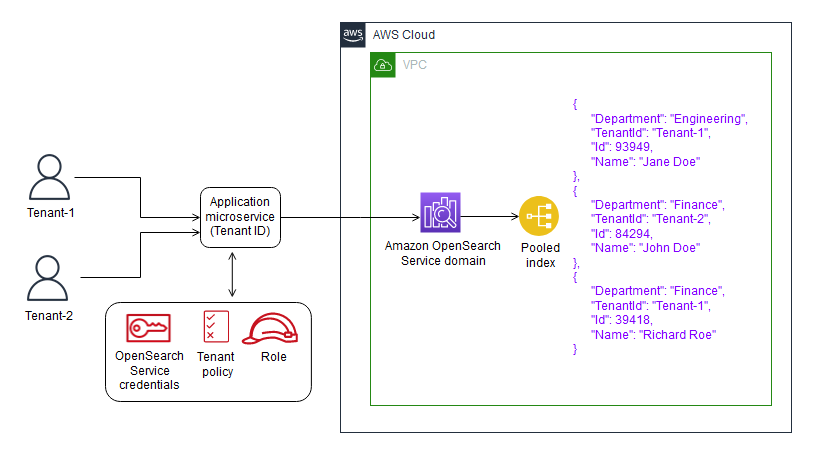
池模型中的租户隔离–通常,在池模型中实现租户隔离很困难。与思洛存储器模型一起使用的IAM机制不允许您根据文档中存储的租户ID描述隔离。
另一种方法是使用Open Distro for Elasticsearch提供的细粒度访问控制(FGAC)支持。FGAC允许您控制索引、文档或字段级别的权限。对于每个请求,FGAC都会评估用户凭据,并对用户进行身份验证或拒绝访问。如果FGAC验证了用户,它将获取映射到该用户的所有角色,并使用完整的权限集来确定如何处理请求。
为了在池模型中实现所需的隔离,可以使用文档级安全性,这允许您将角色限制为索引中的文档子集。以下示例角色将查询限制为Tenant-1。通过将此角色应用于租户1,您可以实现必要的隔离。
{
"bool": {
"must": {
"match": {
"tenantId": "Tenant-1"
}
}
}
}
混合型
混合模型在同一环境中使用筒仓和池模型的组合,为每个租户层(如免费层、标准层和高级层)提供独特的体验。每个层都遵循池模型中使用的相同安全配置文件。
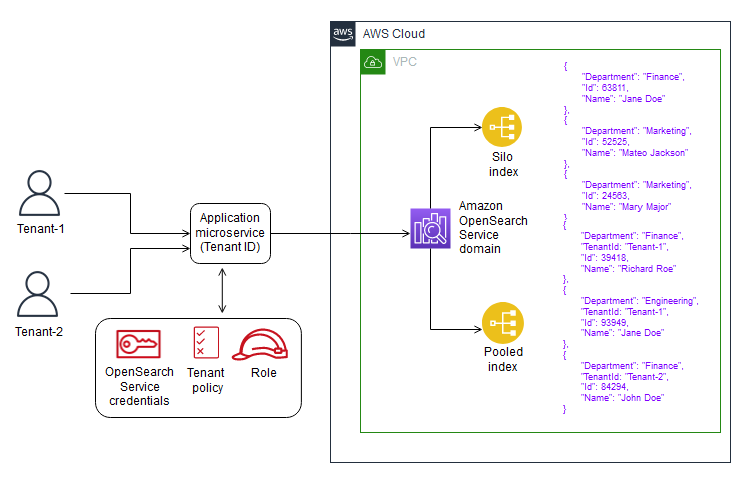
混合模型中的租户隔离–在混合模型中,您遵循与池模型中相同的安全配置文件,其中在文档级别使用FGAC安全模型提供租户隔离。尽管该策略简化了集群管理并提供了灵活性,但它使体系结构的其他方面变得复杂。例如,您的代码需要额外的复杂性来确定哪个模型与每个租户相关联。您还必须确保单个租户查询不会使整个域饱和,并降低其他租户的体验。
在API网关中测试
租户1查询的测试窗口
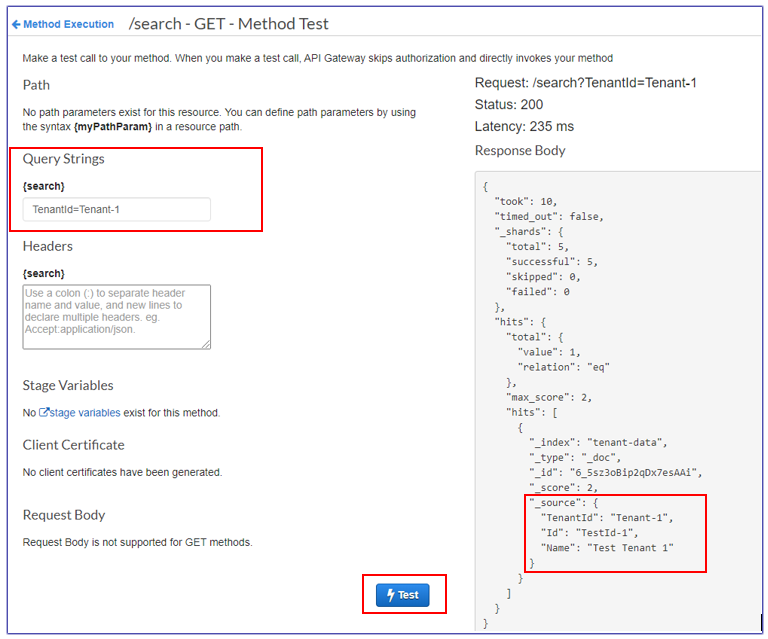
租户2查询的测试窗口

附件
要访问与此文档相关的其他内容,请解压缩以下文件:attachment.zip
- 171 次浏览