集成架构



[Kafka ]全面介绍Apache Kafka™
深入研究作为许多公司架构核心的系统

介绍
卡夫卡是一个现在听到很多的话......许多领先的数字公司似乎也在使用它。但究竟是什么呢?
Kafka最初于2011年在LinkedIn开发,自那时起经历了很多改进。如今它是一个完整的平台,允许您冗余地存储荒谬的数据量,拥有一个具有巨大吞吐量(数百万/秒)的消息总线,并对同时通过它的数据使用实时流处理。
Kafka是一个分布式,可水平扩展,容错的提交日志。
那是一些奇特的话,让我们一个接一个地看看他们的意思。之后,我们将深入探讨它的工作原理。
分布式
分布式系统是分成多个运行的计算机的系统,所有这些计算机在一个集群中一起工作,作为最终用户的一个单一节点出现。 Kafka的分布在于它在不同节点(称为代理)上存储,接收和发送消息。
我也对此有一个全面的介绍
这种方法的好处是高可扩展性和容错性。
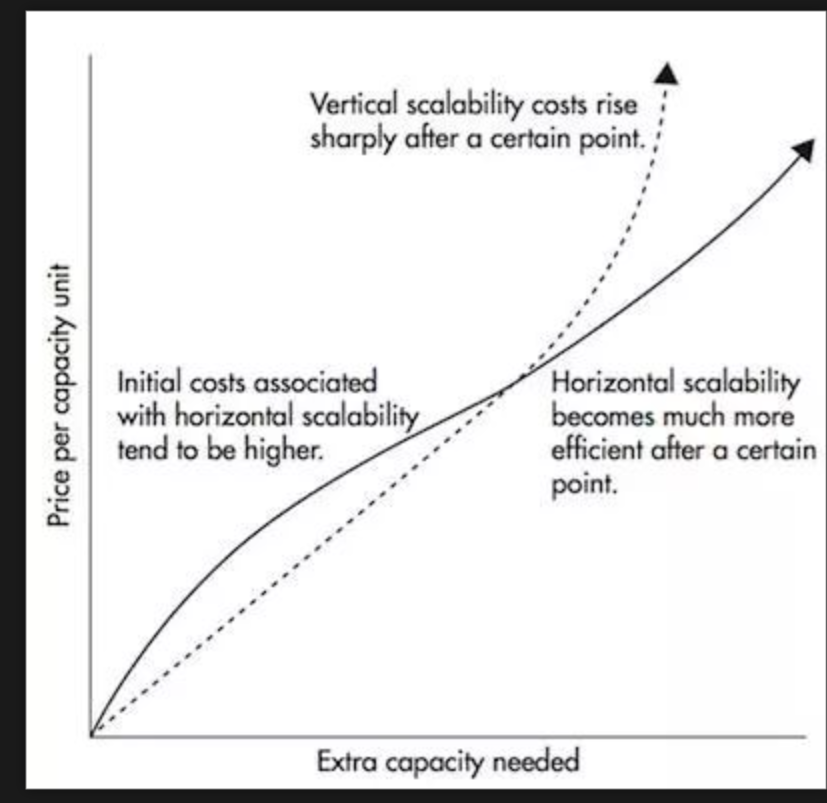
水平可扩展性
我们首先定义术语垂直可伸缩性。比如说,你有一个传统的数据库服务器开始变得过载。解决这个问题的方法是简单地增加服务器上的资源(CPU,RAM,SSD)。这称为垂直缩放 - 您可以向机器添加更多资源。向上扩展有两大缺点:
- 硬件定义了限制。你不能无限期地向上扩展。
- 它通常需要停机时间,这是大公司无法承受的。
水平可扩展性通过向其投入更多机器来解决同样的问题。添加新计算机不需要停机,也不会限制群集中的计算机数量。问题在于并非所有系统都支持水平可伸缩性,因为它们不是设计用于集群中,而是那些通常更复杂的系统。
Horizontal scaling becomes much cheaper after a ce
容错
非分布式系统中出现的一点是它们具有单点故障(SPoF)。 如果您的单个数据库服务器由于某种原因而失败(正如机器那样),那就搞砸了。
分布式系统的设计方式是以可配置的方式适应故障。 在5节点Kafka群集中,即使其中2个节点关闭,您也可以继续工作。 值得注意的是,容错与性能直接相关,因为在您的系统容错程度越高时,性能就越差。
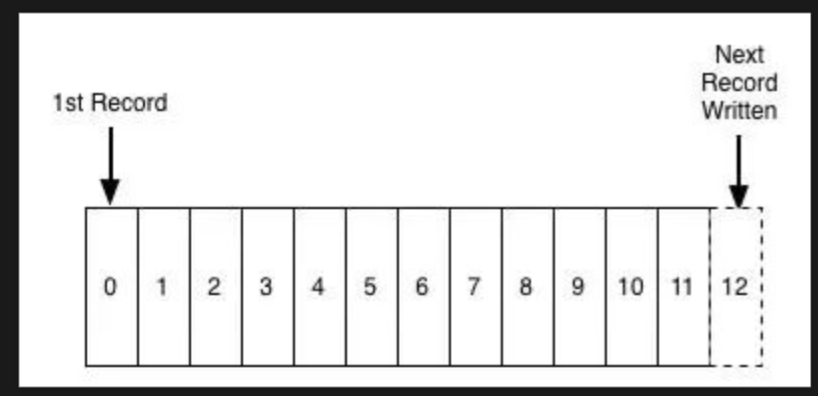
提交日志
提交日志(也称为预写日志,事务日志)是仅支持附加的持久有序数据结构。 您无法修改或删除记录。 它从左到右阅读并保证项目订购。
Sample illustration of a commit log
- 你是在告诉我Kafka是如此简单的数据结构吗?
在很多方面,是的。这种结构是卡夫卡的核心,非常宝贵,因为它提供了排序,而排序则提供了确定性的处理。这两者都是分布式系统中的重要问题。
Kafka实际上将所有消息存储到磁盘(稍后会详细介绍),并在结构中对它们进行排序,以便利用顺序磁盘读取。
读取和写入是一个恒定时间O(1)(知道记录ID),与磁盘上其他结构的O(log N)操作相比是一个巨大的优势,因为每次磁盘搜索都很昂贵。
读取和写入不会影响另一个。写作不会锁定读数,反之亦然(与平衡树相对)
这两点具有巨大的性能优势,因为数据大小与性能完全分离。无论您的服务器上有100KB还是100TB的数据,Kafka都具有相同的性能。
它是如何工作的?
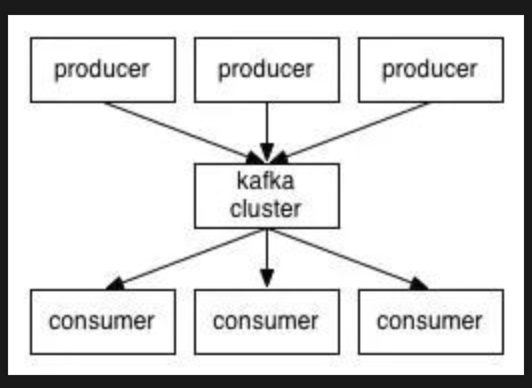
应用程序(生产者)将消息(记录)发送到Kafka节点(代理),并且所述消息由称为消费者的其他应用程序处理。所述消息存储在主题中,并且消费者订阅该主题以接收新消息。
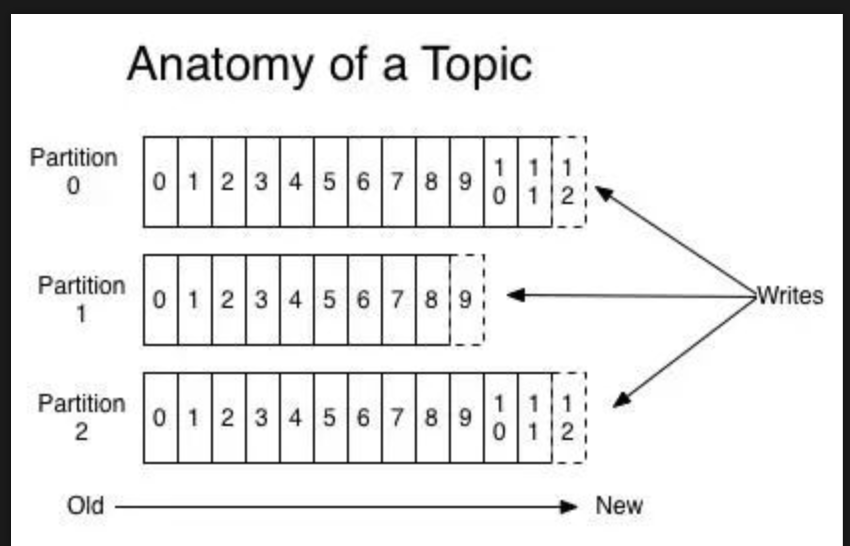
随着主题变得非常大,它们会分成更小的分区,以获得更好的性能和可伸缩性。 (例如:假设您存储了用户登录请求,您可以按用户用户名的第一个字符拆分它们)
Kafka保证分区内的所有消息都按照它们进入的顺序排序。区分特定消息的方式是通过其偏移量,您可以将其视为普通数组索引,序列号对于每个新消息递增 在一个分区。
卡夫卡遵循愚蠢的经纪人和聪明的消费者的原则。 这意味着Kafka不会跟踪消费者读取的记录并删除它们,而是将它们存储一定的时间(例如一天)或直到满足某个大小阈值。 消费者自己向卡夫卡民意调查新消息,并说出他们想要阅读的记录。 这允许它们按照自己的意愿递增/递减它们所处的偏移量,从而能够重放和重新处理事件。
值得注意的是,消费者实际上是消费者群体,其中包含一个或多个消费者流程。 为了避免两个进程两次读取相同的消息,每个分区仅与每个组的一个消费者进程相关联。

持久化到磁盘
正如我之前提到的,Kafka实际上将所有记录存储到磁盘中,并且不会在RAM中保留任何内容。你可能想知道这是如何以最明智的方式做出明智的选择。这背后有许多优化使其可行:
- Kafka有一个将消息组合在一起的协议。这允许网络请求将消息组合在一起并减少网络开销,服务器反过来一次性保留大量消息,消费者一次获取大型线性块
- 磁盘上的线性读/写速度很快。现代磁盘速度慢的概念是由于大量磁盘搜索,这在大型线性操作中不是问题。
- 所述线性操作由OS大量优化,通过预读(预取大块倍数)和后写(组小逻辑写入大物理写入)技术。
- 现代操作系统将磁盘缓存在空闲RAM中。这称为pagecache。
- 由于Kafka在整个流程(生产者 - >代理 - >消费者)中以未经修改的标准化二进制格式存储消息,因此它可以使用零拷贝优化。那时操作系统将数据从pagecache直接复制到套接字,有效地完全绕过了Kafka代理应用程序。
所有这些优化都使Kafka能够以接近网络的速度传递消息。
数据分发和复制
我们来谈谈Kafka如何实现容错以及它如何在节点之间分配数据。
数据复制
分区数据在多个代理中复制,以便在一个代理程序死亡时保留数据。
在任何时候,一个代理“拥有”一个分区,并且是应用程序从该分区写入/读取的节点。这称为分区领导者。它将收到的数据复制到N个其他经纪人,称为追随者。它们也存储数据,并准备好在领导节点死亡时被选为领导者。
这有助于您配置保证任何成功发布的消息都不会丢失。通过选择更改复制因子,您可以根据数据的重要性来交换性能以获得更强的持久性保证。
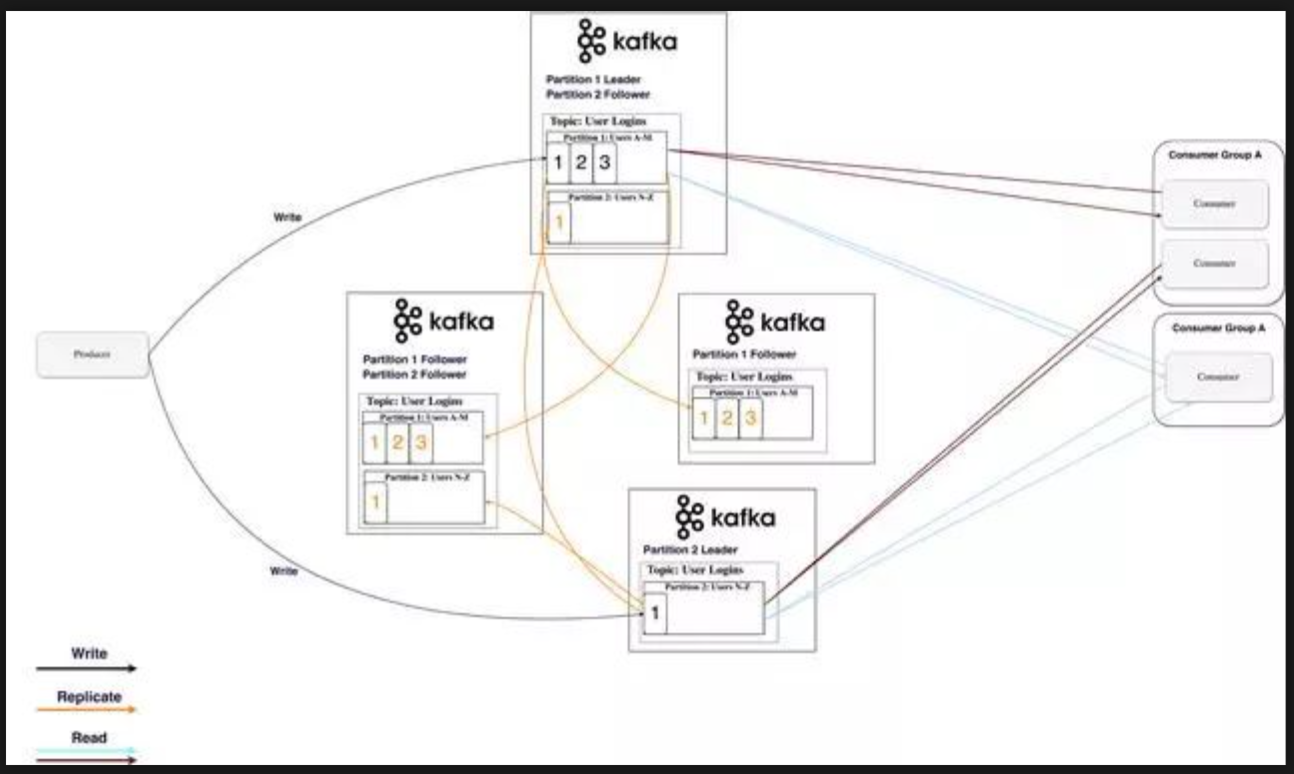
通过这种方式,如果一个领导者失败,追随者可以取代他的位置。
不过你可能会问:
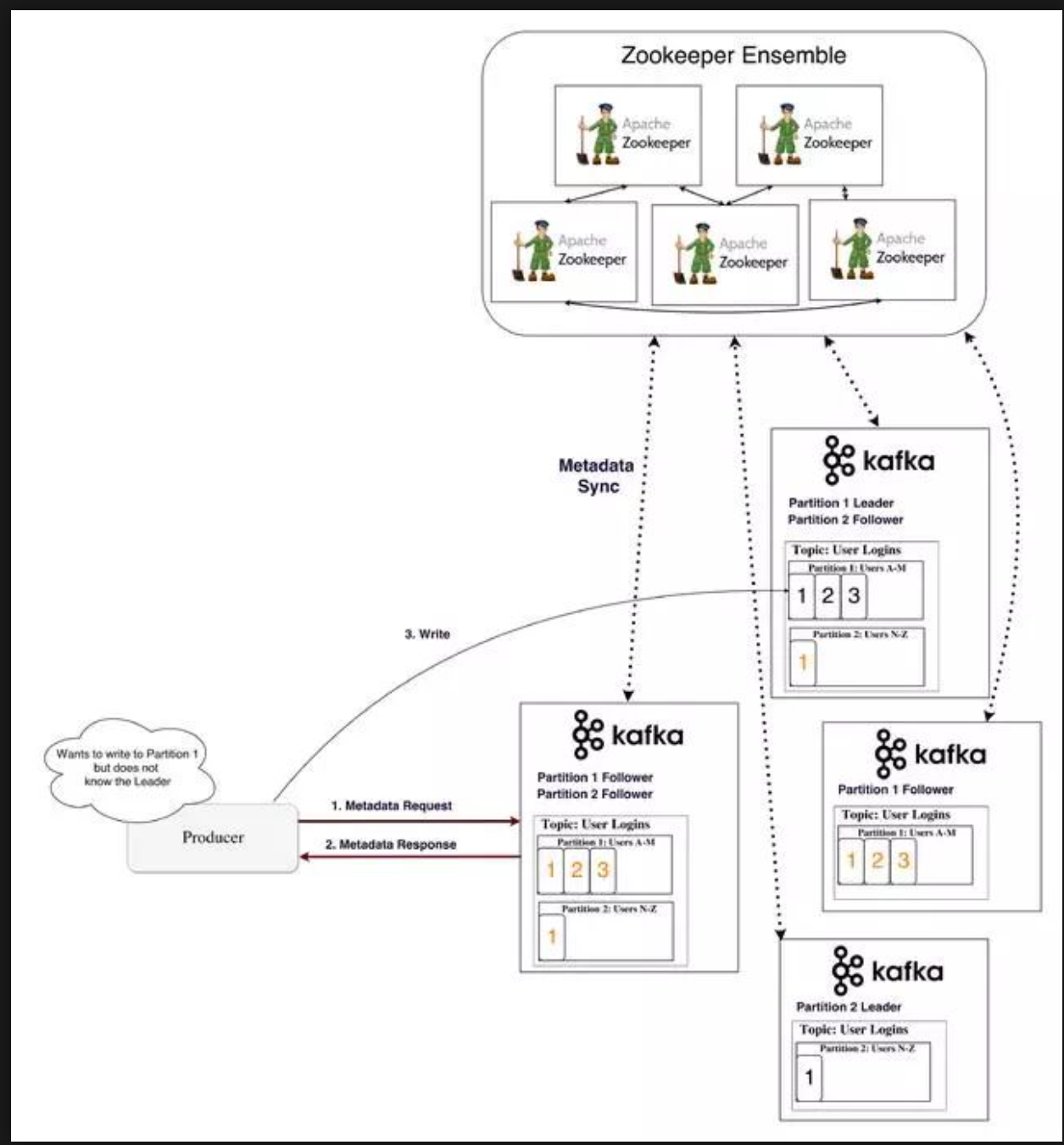
- 生产者/消费者如何知道分区的领导者是谁?
对于生产者/消费者来说,从分区写入/读取,他们需要知道它的领导者,对吗?这些信息需要从某个地方获得。
Kafka将这些元数据存储在名为Zookeeper的服务中。
什么是Zookeeper?
Zookeeper是一个分布式键值存储。它针对读取进行了高度优化,但写入速度较慢。它最常用于存储元数据和处理群集的机制(心跳,分发更新/配置等)。
它允许服务的客户(Kafka经纪人)订阅并在发生变更后发送给他们。这就是经纪人如何知道何时切换分区领导者。动物园管理员也非常容错,应该是,因为卡夫卡在很大程度上依赖它。
它用于存储所有类型的元数据,提到一些:
- 消费者群体的每个分区的偏移量(尽管现代客户端在单独的Kafka主题中存储偏移量)
- ACL(访问控制列表) - 用于限制访问/授权
- 生产者和消费者配额 - 最大消息/秒边界
- 分区领导者及其健康
生产者/消费者如何知道分区的领导者是谁?
生产者和消费者过去常常直接连接并与Zookeeper交谈以获取此(和其他)信息。 Kafka已经远离这种耦合,从版本0.8和0.9开始,客户端直接从Kafka经纪人那里获取元数据信息,他们自己与Zookeeper交谈。
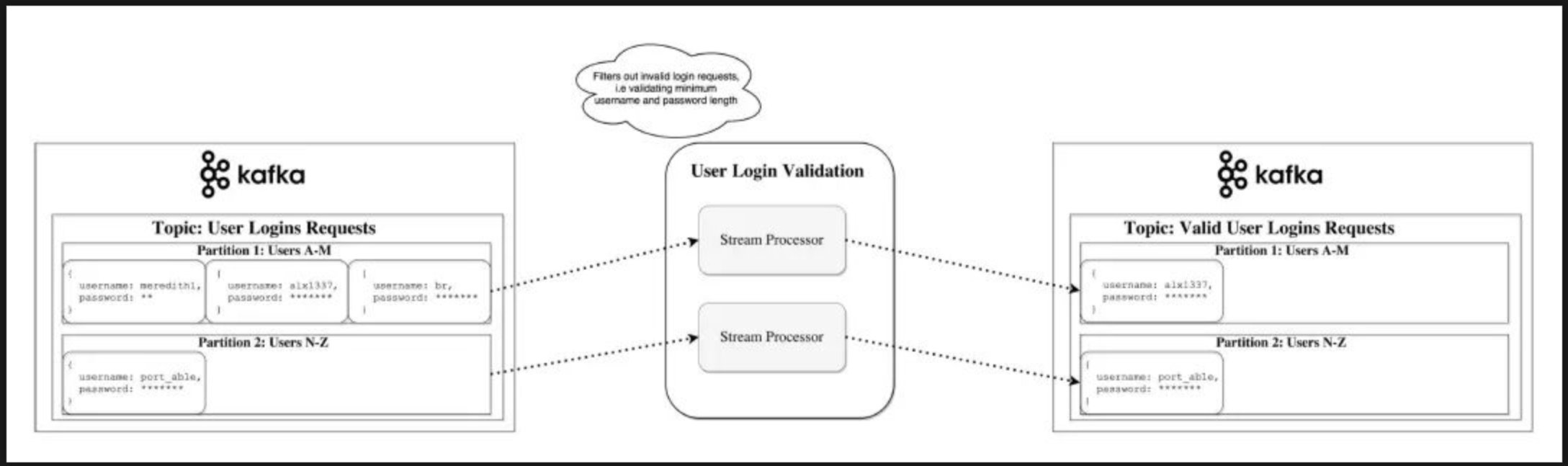
流
在Kafka中,流处理器是从输入主题获取连续数据流,对此输入执行一些处理并生成数据流以输出主题(或外部服务,数据库,垃圾箱,无论何处......)的任何内容。
可以直接使用生产者/消费者API进行简单处理,但是对于更复杂的转换(如将流连接在一起),Kafka提供了一个集成的Streams API库。
此API旨在用于您自己的代码库中,而不是在代理上运行。它与消费者API类似,可帮助您在多个应用程序(类似于消费者组)上扩展流处理工作。
无状态处理
流的无状态处理是确定性处理,其不依赖于任何外部。您知道,对于任何给定的数据,您将始终生成与其他任何内容无关的相同输出。一个例子就是简单的数据转换 - 将某些内容附加到字符串“Hello” - >“Hello,World!”。
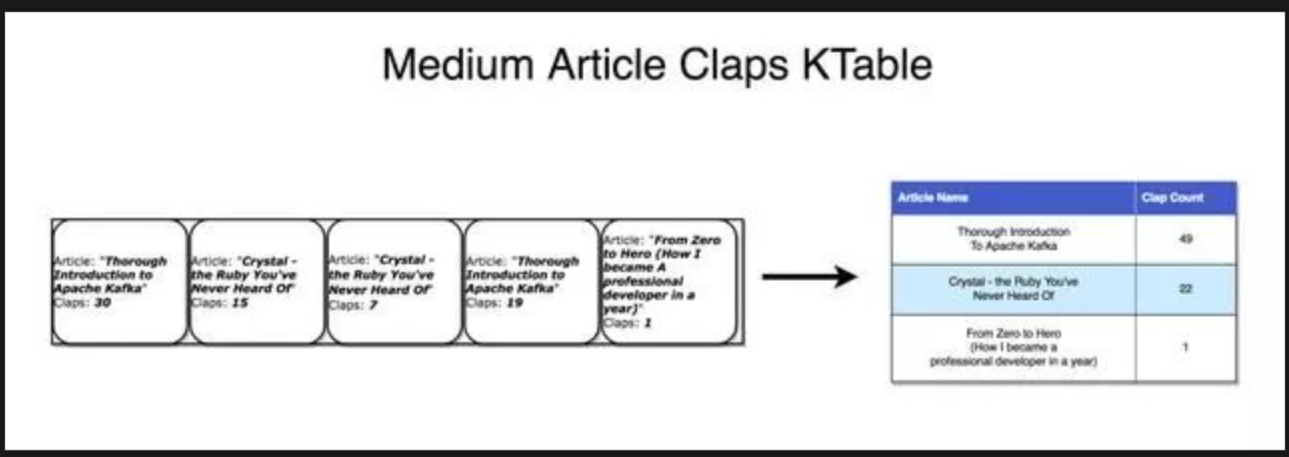
流表双重性
重要的是要认识到流和表基本相同。 流可以解释为表,表可以解释为流。
流作为表
流可以解释为数据的一系列更新,其中聚合是表的最终结果。 这种技术称为事件采购。
如果您了解如何实现同步数据库复制,您将看到它是通过所谓的流复制,其中表中的每个更改都发送到副本服务器。 事件采购的另一个例子是区块链分类账 - 分类账也是一系列变化。
Kafka流可以用相同的方式解释 - 当累积形成最终状态时的事件。 此类流聚合保存在本地RocksDB中(默认情况下),称为KTable。
表作为流
可以将表视为流中每个键的最新值的快照。 以相同的方式,流记录可以生成表,表更新可以生成更改日志流。
有状态处理
一些简单的操作(如map()或filter())是无状态的,不需要您保留有关处理的任何数据。但是,在现实生活中,您所做的大多数操作都是有状态的(例如count()),因此需要您存储当前累积的状态。
在流处理器上维护状态的问题是流处理器可能会失败!你需要在哪里保持这种状态才能容错?
一种简单的方法是简单地将所有状态存储在远程数据库中,并通过网络连接到该存储。这样做的问题是没有数据的位置和大量的网络往返,这两者都会显着减慢您的应用程序。一个更微妙但重要的问题是您的流处理作业的正常运行时间将紧密耦合到远程数据库,并且作业将不会自包含(数据库中的数据库与另一个团队的更改可能会破坏您的处理)。
那么什么是更好的方法呢?
回想一下表和流的二元性。这允许我们将流转换为与我们的处理位于同一位置的表。它还为我们提供了一种处理容错的机制 - 通过将流存储在Kafka代理中。
流处理器可以将其状态保持在本地表(例如RocksDB)中,该表将从输入流(可能在某些任意转换之后)更新。当进程失败时,它可以通过重放流来恢复其数据。
您甚至可以将远程数据库作为流的生产者,有效地广播用于在本地重建表的更改日志。
KSQL
通常,您将被迫使用JVM语言编写流处理,因为这是唯一的官方Kafka Streams API客户端。

发布于2018年4月,KSQL是一项功能,允许您使用熟悉的类似SQL的语言编写简单的流媒体作业。
您设置了KSQL服务器并通过CLI以交互方式查询它以管理处理。它使用相同的抽象(KStream和KTable),保证了Streams API的相同优点(可伸缩性,容错性),并大大简化了流的工作。
这听起来可能不是很多,但在实践中对于测试内容更有用,甚至允许开发之外的人(例如产品所有者)使用流处理。我鼓励您查看快速启动视频,看看它有多简单。
流替代品
Kafka溪流是力量与简约的完美结合。它可以说是市场上流媒体工作的最佳功能,它与其他流处理选择(Storm,Samza,Spark,Wallaroo)相比,更容易与Kafka集成。
大多数其他流处理框架的问题在于它们使用和部署起来很复杂。像Spark这样的批处理框架需要:
- 在一组计算机上控制大量作业,并在整个集群中有效地分配它们。
- 为此,它必须动态地打包您的代码并将其物理部署到将执行它的节点。 (以及配置,库等)
不幸的是,解决这些问题使框架非常具有侵略性。他们希望控制代码的部署,配置,监控和打包方式的许多方面。
Kafka Streams允许您在需要时推出自己的部署策略,无论是Kubernetes,Mesos,Nomad,Docker Swarm还是其他人。
Kafka Streams的基本动机是使所有应用程序能够进行流处理,而无需运行和维护另一个集群的操作复杂性。唯一潜在的缺点是它与卡夫卡紧密结合,但在现代世界中,大多数(如果不是全部)实时处理由卡夫卡提供动力可能不是一个很大的劣势。
你什么时候用Kafka?
正如我们已经介绍的那样,Kafka允许您通过集中式介质获取大量消息并存储它们,而不必担心性能或数据丢失等问题。
这意味着它非常适合用作系统架构的核心,充当连接不同应用程序的集中式媒体。 Kafka可以成为事件驱动架构的中心部分,使您可以真正地将应用程序彼此分离。
Kafka允许您轻松地分离不同(微)服务之间的通信。使用Streams API,现在可以比以往更轻松地编写业务逻辑,从而丰富Kafka主题数据以供服务使用。可能性很大,我恳请您探讨公司如何使用Kafka。
它为什么看到这么多用途?
仅凭高性能,可用性和可扩展性并不足以使公司采用新技术。还有其他系统具有类似的特性,但没有一个被广泛使用。这是为什么?
Kafka越来越受欢迎(并且继续这样做)的原因是一个关键因素 - 现在的企业从事件驱动的架构中受益匪浅。这是因为世界已经发生了变化 - 许多不同的服务(物联网,机器学习,移动,微服务)正在生产和消费大量(并且不断增长)的数据量。
具有持久存储的单个实时事件广播平台是实现这种架构的最简洁方式。想象一下,如果每个服务之间的流数据使用了一种特别适合它的不同技术,那将会是一种混乱。
这与Kafka为这样的通用系统(持久存储,事件广播,表和流原语,通过KSQL进行抽象,开源,积极开发)提供适当特性的事实相结合,使其成为公司的明显选择。
摘要
Apache Kafka是一个分布式流媒体平台,每天可处理数万亿个事件。 Kafka提供低延迟,高吞吐量,容错的发布和订阅管道,并能够处理事件流。
我们回顾了它的基本语义(生产者,代理,消费者,主题),了解了它的一些优化(pagecache),通过复制数据了解了它的容错能力,并介绍了它不断增长的强大流媒体功能。
Kafka已经在全球数千家公司中大量采用,其中包括财富500强企业中的三分之一。随着Kafka的积极开发和最近发布的第一个主要版本1.0(2017年11月1日),有预测这个流媒体平台将会与关系数据库一样,是数据平台的重要核心。
我希望这篇介绍能帮助您熟悉Apache Kafka及其潜力。
进一步阅读资源和我没有提到的事情
以下是我没有机会提到的一些功能,但重要的是要知道:
- Controller Broker,同步副本 - Kafka保持集群健康并确保足够的一致性和持久性的方式。
- Connector API - API帮助您将各种服务连接到Kafka作为源或接收器(PostgreSQL,Redis,ElasticSearch)
- 日志压缩 - 减少日志大小的优化。在更改日志流中非常有用
- 完全一次的消息语义 - 保证消息只被接收一次。这是一个大问题,因为很难实现。
资源
- 121 次浏览
【数据集成】2023年18个最佳ETL工具
视频号
微信公众号
知识星球
信息时代的标志之一是数据无处不在。无论是包裹的预计交付日期,还是对您在手机上花费的屏幕时间的分析,您每天都会访问数据,以告知您的决策和设定目标。
组织以相同的方式利用数据,但规模更大。他们拥有客户、员工、产品和服务的数据,所有这些数据都必须标准化,并在各个团队和系统中共享。这些信息甚至可以提供给外部合作伙伴和供应商。
为了实现这种高度规模化的信息共享并避免数据孤岛,组织转向提取、转换和加载(ETL)实践,以在系统之间格式化、传递和存储数据。由于组织在其所有业务流程之间处理大量数据,ETL工具可以标准化和扩展其数据管道。
什么是ETL工具?
ETL工具是为支持ETL过程而设计的软件:从不同的源中提取数据,清理数据以确保一致性和质量,并将这些信息整合到数据仓库中。如果实施正确,ETL工具将通过提供标准化的获取、共享和存储方法来简化数据管理策略并提高数据质量。
本视频很好地概述了ETL工具和方法:
ETL工具支持数据驱动的组织和平台。例如,客户关系管理(CRM)平台的主要优势是所有业务活动都通过同一界面进行。这允许CRM数据在团队之间轻松共享,以提供更全面的业务绩效和目标进展视图。
接下来,让我们检查四种可用的ETL工具。
ETL工具的类型
ETL工具可以根据其基础结构和支持组织或供应商分为四类。这些类别-企业级、开源、基于云的和定制ETL工具-定义如下。
-2.png?width=650&name=ETL%20Tools%20(V4)-2.png)
1.企业软件ETL工具
企业软件ETL工具由商业组织开发和支持。这些解决方案往往是市场上最健壮和最成熟的,因为这些公司是第一个支持ETL工具的公司。这包括为构建ETL管道提供图形用户界面(GUI),支持大多数关系和非关系数据库,以及广泛的文档和用户组。
尽管企业软件ETL工具提供了更多的功能,但由于其复杂性,通常会有更高的价格,并且需要更多的员工培训和集成服务。
2.开源ETL工具
随着开源运动的兴起,开源ETL工具进入市场不足为奇。如今,许多ETL工具都是免费的,并提供用于设计数据共享过程和监控信息流的GUI。开源解决方案的一个明显优势是,组织可以访问源代码来研究工具的基础设施并扩展功能。
然而,开源ETL工具在维护、文档、易用性和功能方面可能有所不同,因为商业组织通常不支持它们。
3.基于云的ETL工具
随着云和集成平台即服务技术的广泛采用,云服务提供商(CSP)现在提供基于其基础架构的ETL工具。
基于云的ETL工具的一个特殊优势是效率。云技术提供了高延迟、可用性和弹性,因此计算资源可以扩展以满足当时的数据处理需求。如果组织也使用相同的CSP存储其数据,那么管道将进一步优化,因为所有过程都发生在共享基础架构中。
基于云的ETL工具的一个缺点是它们只能在CSP的环境中工作。它们不支持存储在其他云或内部数据中心中的数据,除非先转移到提供商的云存储中。
4.自定义ETL工具
拥有开发资源的公司可以使用通用编程语言生产专有的ETL工具。这种方法的主要优点是可以灵活地根据组织的优先级和工作流定制解决方案。用于构建ETL工具的流行语言包括SQL、Python和Java。
这种方法的最大缺点是构建定制ETL工具所需的内部资源,包括测试、维护和更新。另一个考虑因素是对新用户和开发人员的培训和文档记录,他们都将是平台的新手。
现在,您已经了解了ETL工具是什么以及可用的工具类别,让我们来看看如何评估这些解决方案,以使其最适合您的组织的数据实践和用例。
如何评估ETL工具
每个组织都有独特的商业模式和文化,公司收集的数据和价值观将反映这一点。然而,您可以根据与每个组织相关的通用标准来衡量ETL工具,如下所述。
- 用例:用例是ETL工具的关键考虑因素。如果您的组织规模较小或数据分析需求较小,那么您可能不需要像拥有复杂数据集的大型组织那样强大的解决方案。
- 预算:评估ETL软件时,货币成本是另一个重要因素。开源工具通常是免费使用的,但提供的功能或支持可能不如企业级工具多。另一个考虑因素是,如果软件是代码密集型的,那么雇佣和留住开发人员所需的资源。
- 功能:可以定制最好的ETL工具,以满足不同团队和业务流程的数据需求。重复数据消除等自动化功能是ETL工具提高数据质量并减少分析数据集所需劳动力的一种方式。此外,数据集成简化了平台之间的共享。
- 数据源:ETL工具应该能够满足“数据所在地”的需求,无论是在本地还是在云中。ETL连接器是ETL工具的组件,用于建立到数据源的连接。组织还可能具有复杂的数据结构或非结构化数据,所有这些数据都采用不同的格式。理想的解决方案将能够从所有来源提取信息并以标准格式存储。
- 技术素养:开发人员和最终用户的数据和代码流畅性是一个关键考虑因素。例如,如果该工具需要手动编码,那么开发团队最好可以使用它所构建的语言。然而,如果用户不了解如何构造复杂的查询,那么自动化这个过程的工具将是理想的。
接下来,让我们检查为ETL管道提供动力的各个工具,并按照上面讨论的类型对它们进行分组。
ETL Tools
- Integrate.io
- IBM DataStage
- Oracle Data Integrator
- Fivetran
- Coupler.io
- SAS Data Management
- Talend Open Studio
- Pentaho Data Integration
- Singer
- Hadoop
- Dataddo
- AWS Glue
- Azure Data Factory
- Google Cloud Dataflow
- Stitch
- Informatica PowerCenter
- Skyvia
- Portable
1.Integrate.io
价格:免费14天试用和灵活的付费计划
类型:云
Integrate.io是一个领先的低代码数据集成平台,具有强大的产品(ETL、ELT、API生成、可观察性、数据仓库洞察)和数百个连接器,可在几分钟内构建和管理自动化、安全的管道。获取不断更新的数据,以帮助提供可操作的、数据支持的见解,以实现降低CAC、提高ROAS和推动市场成功等目标。
该平台对任何数据量或用例都具有高度可扩展性,同时使您能够轻松地将数据聚合到仓库、数据库、数据存储和操作系统。
2.IBM DataStage
价格:免费试用,提供付费计划
类型:企业
-Jan-06-2022-09-53-51-32-PM.jpeg?width=650&name=ETL%20Tools%20(V4)-Jan-06-2022-09-53-51-32-PM.jpeg)
IBM DataStage是围绕客户机-服务器设计构建的数据集成工具。从Windows客户端,任务在服务器上的中央数据存储库中创建和执行。该工具旨在支持ETL和提取、加载和转换(ELT)模型,并支持跨多个源和应用程序的数据集成,同时保持高性能。
IBM DataStage是为内部部署而构建的,也有云支持版本:DataStage for IBM cloud Pak for Data。
3.Oracle Data Integrator
价格:可根据要求提供定价
类型:企业
-4.jpeg?width=650&name=ETL%20Tools%20(V4)-4.jpeg)
Oracle Data Integrator(ODI)是一个旨在跨组织构建、管理和维护数据集成工作流的平台。ODI支持从高容量批量加载到面向服务的体系结构数据服务的全系列数据集成请求。它还支持并行任务执行以加快数据处理,并提供与Oracle GoldenGate和Oracle Warehouse Builder的内置集成。
ODI和其他Oracle解决方案可以通过Oracle Enterprise Manager进行监控,以提高整个工具组的可见性。
4. Fivetran
价格:标准选择计划60美元/月;入门计划每月120美元;标准计划为180美元/月$企业计划240/月
类型:企业
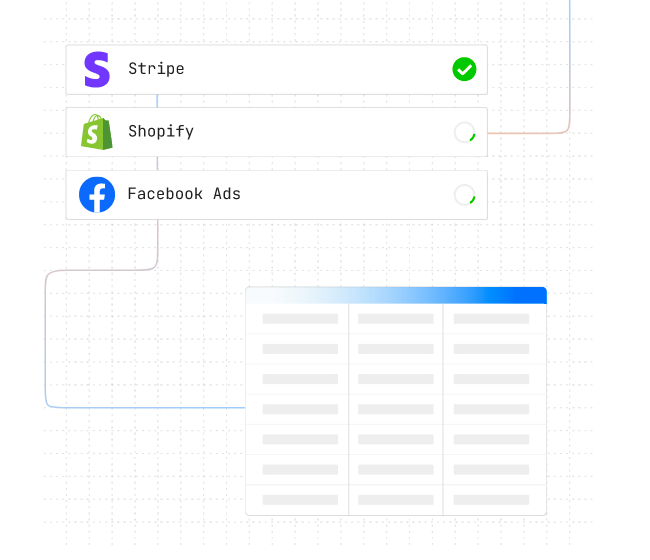
Fivetran旨在通过其便捷工具平台为您的数据管理过程增添便利。易于使用的软件可随时更新API,并在几分钟内从数据库中获取最新数据。
除了ETL工具,Fivetran还提供数据安全服务、数据库复制和24/7支持。Fivetran以其近乎完美的正常运行时间而自豪,让您可以在接到通知后立即访问其工程师团队。
5.Coupler.io
价格:免费14天试用,提供付费计划
类型:云
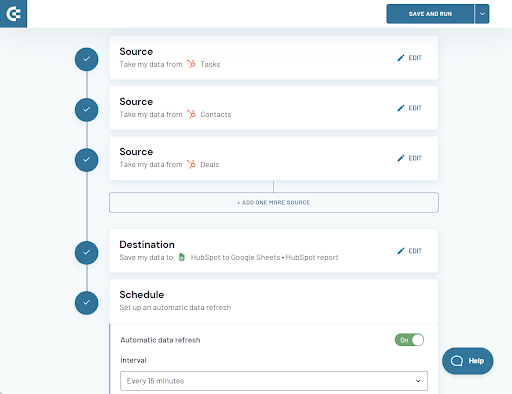
Coupler.io是一个一体化的数据分析和自动化平台,使企业能够充分利用其数据。简而言之,它有助于收集、转换和分析数据流。平台的基础是无需技术技能即可使用的无代码ETL解决方案。您可以将各种业务应用程序中的数据导出并混合到数据仓库或电子表格中。它还可以通过按计划刷新数据来帮助自动化报告。组织可以使用此工具通过创建实时仪表板来收集、跟踪和优化业务指标。
此外,Coupler.io还提供数据分析服务,可以根据要求构建自定义连接器。Coupler.io甚至还与HubSpot集成,允许您自动将HubSpot和其他应用程序中的数据导出到Google Sheets、Excel、Google BigQuery和其他目的地。
6.SAS Data Management
价格:可根据要求提供定价
类型:企业
-Jan-06-2022-09-53-51-52-PM.jpeg?width=650&name=ETL%20Tools%20(V4)-Jan-06-2022-09-53-51-52-PM.jpeg)
SAS数据管理是一个数据集成平台,旨在连接任何存在的数据,包括云、遗留系统和数据湖。这些集成提供了组织业务流程的整体视图。该工具通过重用数据管理规则并授权非IT利益相关者在平台内提取和分析信息来优化工作流。
SAS数据管理也很灵活,可在各种计算环境和数据库中工作,并与第三方数据建模工具集成,以产生引人注目的可视化效果。
7.Talend Open Studio
Price: Free
价格:免费
类型:开源
.png?width=650&name=ETL%20Tools%20(V4).png)
图像源
Talend Open Studio是一个开源工具,旨在快速构建数据管道。数据组件可以通过Open Studio的拖放GUI从Excel、Dropbox、Oracle、Salesforce、Microsoft Dynamics和其他数据源连接到运行作业。Talend Open Studio具有内置连接器,可从各种环境中提取信息,包括关系数据库管理系统、软件即服务平台和打包应用程序。
7. Pentaho Data Integration
价格:可根据要求提供定价
类型:开源
-3.jpeg?width=650&name=ETL%20Tools%20(V4)-3.jpeg)
Pentaho数据集成(PDI)管理数据集成过程,包括以标准化和一致的格式捕获、清理和存储数据。该工具还与终端用户共享这些信息进行分析,并支持物联网技术的数据访问,以促进机器学习。
PDI还提供Spoon桌面客户端,用于构建转换、调度作业以及在需要时手动启动处理任务。
9. Singer
价格:免费
类型:开源
-1.png?width=650&name=ETL%20Tools%20(V4)-1.png)
Singer是一种开源脚本技术,旨在增强组织应用程序和存储之间的数据传输。Singer定义了数据提取和数据加载脚本之间的关系,允许从任何源提取信息并将其加载到任何目的地。这些脚本使用JSON,因此它们可以在任何编程语言中访问,并且还支持丰富的数据类型,并通过JSON Schema强制执行数据结构。
10.Hadoop
价格:免费
类型:开源
-3.png?width=650&name=ETL%20Tools%20(V4)-3.png)
Apache Hadoop软件库是一个框架,旨在通过在计算机集群之间分配计算负载来支持处理大型数据集。该库旨在检测和处理应用程序层和硬件层的故障,在结合多台计算机的计算能力的同时提供高可用性。通过Hadoop YARN模块,该框架还支持作业调度和集群资源管理。
11. Dataddo
价格:免费提供付费计划
类型:云
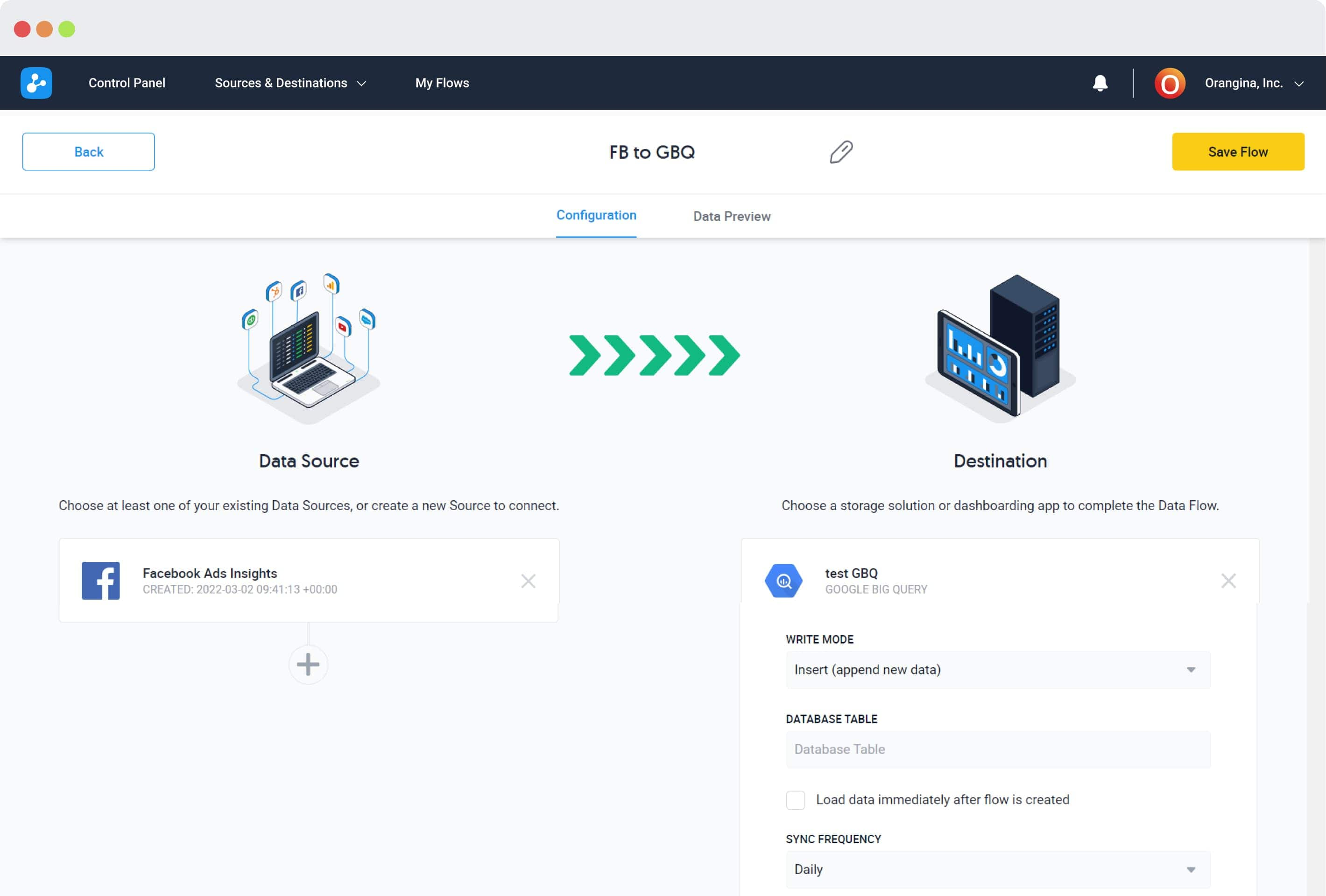
Dataddo平台Dataddo是一个无代码、基于云的ETL平台,使技术和非技术用户能够灵活地集成数据。它提供了广泛的连接器、完全可定制的指标、用于同时管理所有数据管道的中央系统,并且可以无缝地集成到现有技术架构中。
用户可以在创建帐户的几分钟内部署管道,所有API更改都由Dataddo团队管理,因此管道不需要维护。可根据要求在10个工作日内添加新连接器。该平台符合GDPR、SOC2和ISO 27001。
12. AWS Glue
价格:免费提供付费计划
类型:云
-Jan-06-2022-09-53-52-06-PM.jpeg?width=650&name=ETL%20Tools%20(V4)-Jan-06-2022-09-53-52-06-PM.jpeg)
AWS Glue是一种基于云的数据集成服务,支持可视化和基于代码的客户端,以支持技术和非技术业务用户。无服务器平台提供多种功能以提供其他功能,例如用于在组织中查找数据的AWS Glue Data Catalog和用于可视化设计、执行和维护ETL管道的AWS GlueStudio。
AWS Glue还支持自定义SQL查询,以实现更实际的数据交互。
13. Azure Data Factory
价格:免费试用,提供付费计划
类型:云
-Jan-06-2022-09-53-51-03-PM.jpeg?width=650&name=ETL%20Tools%20(V4)-Jan-06-2022-09-53-51-03-PM.jpeg)
Azure Data Factory是一种基于按需付费模式构建的无服务器数据集成服务,可扩展以满足计算需求。该服务提供无代码和基于代码的接口,可以从90多个内置连接器中提取数据。此外,Azure数据工厂与Azure Synapse Analytics集成,以提供高级数据分析和可视化。
该平台还支持Git,用于DevOps团队的版本控制和持续集成/持续部署工作流。
14. Google Cloud Dataflow
价格:免费试用,提供付费计划
类型:云
-2.jpeg?width=650&name=ETL%20Tools%20(V4)-2.jpeg)
谷歌云数据流是一种完全管理的数据处理服务,旨在优化计算能力和自动化资源管理。该服务的重点是通过灵活的调度和自动资源扩展来降低处理成本,以确保使用符合需求。此外,谷歌云数据流还提供了AI功能,在数据转换时支持预测分析和实时异常检测。
15. Stitch
价格:免费试用,提供付费计划
类型:云
-1.jpeg?width=650&name=ETL%20Tools%20(V4)-1.jpeg)
Stitch是一个数据集成服务,旨在从130多个平台、服务和应用程序中获取数据。该工具将这些信息集中在数据仓库中,而不需要任何手动编码。Stitch是开源的,允许开发团队扩展该工具以支持其他源代码和功能。此外,Stitch专注于法规遵从性,提供分析和管理数据以满足内部和外部需求的能力。
16. Informatica PowerCenter
价格:免费试用,提供付费计划
类型:企业
.jpeg?width=650&name=ETL%20Tools%20(V4).jpeg)
Informatica PowerCenter是一个元数据驱动的平台,专注于改善业务和IT团队之间的协作,并简化数据管道。PowerCenter解析高级数据格式,包括JSON、XML、PDF和物联网机器数据,并自动验证转换后的数据以执行定义的标准。
该平台还具有易于使用的预构建转换,并提供了高可用性和优化的性能,可扩展以满足计算需求。
17. Skyvia
价格:免费开始$基本计划为15/月$标准计划为79/月$专业计划399/月
类型:开源

Skyvia创建了完全可定制的数据同步。您可以确切地决定要提取的内容,包括自定义字段和对象。由于Skyvia对自动生成的主键进行操作,因此也无需自定义数据结构。
Skyvia还允许用户将数据导入云应用程序和数据库,复制云数据,并将数据导出到CSV以供共享。
18. Portable
价格:开始无限制的数据量的免费手动同步,计划传输每月200美元
类型:企业
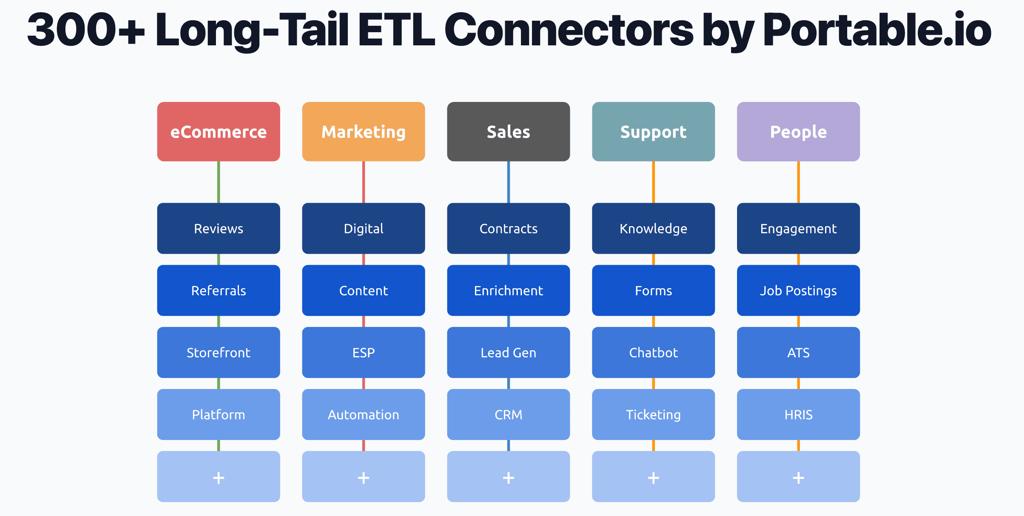
便携式是建立在服务Fivetran不支持的那种长尾连接器上的。Portable提供300多个ETL连接器,并根据需要创建定制集成,专门针对其他数据集成工具不支持的长尾业务应用程序。
对于没有资源创建和维护难以找到的连接器的团队,Portable为集成所有业务数据提供了一种简单的方式。
使用ETL工具支持数据管道。
ETL是一种中心实践,通过该实践,组织可以构建数据管道,将其领导者和利益相关者与更高效地工作和决策所需的信息联系起来。通过使用ETL工具为这一过程提供支持,无论团队的数据多么复杂或不同,团队都可以实现新的速度和标准化水平。
- 1915 次浏览
【数据集成】2023年QA团队的10个最佳开源ETL工具
视频号
微信公众号
知识星球
软件短名单
- CloverDX-数据管理软件,适用于自动化ETL过程
- Singer-基于JSON的数据交换格式的ETL工具
- Scriptella-基于Java的ETL和脚本执行软件
- Apache NiFi-ETL解决方案,利用加密保护数据流
- Apache Kafka-能够处理高吞吐量数据源的分布式事件流平台
- Apache Camel-基于企业集成模式的轻量级集成框架
- Talend Open Studio-ETL和数据集成工具,具有900+个连接器
- Pentaho Kettle-利用Maven框架的ETL解决方案
- Pygrametl-ETL过程的Python框架
- Hevo Data-使用反向ETL工具的无代码数据管道解决方案
开源ETL工具是企业数据集成的重要组成部分。它们有助于集中来自多个来源的数据,使组织内的任何部门都能获得做出数据驱动的业务决策所需的见解。
由于市场上有许多开源ETL软件系统,为业务确定正确的解决方案可能是一项挑战。以下是数据专家用来支持其大数据管理操作的最佳开源ETL工具列表。
比较标准
以下是为您的业务选择最佳ETL工具时应注意的事项。
- 用户界面(UI):一个简单的拖放用户界面允许ETL开发人员可视化数据流并监控管道性能。
- 可用性:易于使用的平台使技术和业务利益相关者能够参与ETL过程。
- 集成:具有广泛集成和连接器的开源ETL工具可以适应当前的数据源,并适应ETL管道中的未来变化。
开源ETL工具:关键特性
- 可扩展性:一个可扩展的开源ETL工具可以有效地处理大量数据,并与您的业务一起增长。
- 安全性:加密是ETL开发人员的一项关键功能,他们在金融和医疗保健等监管行业工作,处理敏感信息。
- 实时处理:通过实时ETL处理,开发人员可以立即通过管道发送数据。此功能非常适用于访问实时见解至关重要的用例,如欺诈检测或IT安全。
QA Lead是读者支持的。当您点击我们网站上的链接时,我们可能会获得佣金-了解更多有关我们如何保持透明度的信息。
10个最佳开源ETL工具概述
以下是对每个开源ETL工具的简要描述,以展示每个解决方案的最佳用例、一些值得注意的特性,以及提供用户界面快照的屏幕截图。
1.CloverDX
数据管理软件非常适合自动化ETL过程
事件侦听器是一种自动化工具,它根据与文件、消息和任务失败相关的各种事件触发数据处理。
CloverDX是ETL软件,它使开发人员能够连接到任何数据源并管理各种数据格式和转换。该平台提供了一个广泛的可定制组件库,允许您读取、写入、聚合、连接和验证数据。CloverDX还提供了一个集成的开发环境,您可以在其中轻松地为ETL过程编写代码和调试解决方案。
CloverDX的自动化工具帮助开发人员减少手动数据优化任务。用户可以构建自动化流程来分析和验证整个管道中的数据。这些自动化流程使开发人员能够扩展ETL测试和错误管理,以确保业务运营与高质量数据保持一致。
CloverDX订阅的价格可根据要求提供。虽然CloverDX是一个商业ETL工具,但平台的某些部分是用开源组件构建的。
2.Singer
基于JSON的数据交换格式的ETL工具

Singer.io的开源特性使得编写和执行ETL脚本变得简单。
Singer提供了一种编写和协作ETL脚本的简化方法。该软件由两个主要组件组成,即抽头和目标。抽头从源提取数据,而目标将数据发送到目的地。用户可以混合和匹配抽头和目标,并在数据库、web API、文件和许多其他系统之间发送数据。
Tap和目标与JSON通信,使用户可以用任何编程语言实现它们。通过对JSON模式的支持,Singer在需要时提供了丰富的数据类型和严格的结构。
用户可以开发自定义抽头和目标,或从Singer网站上提供的50多个应用程序中进行选择,包括Eloqua、GitHub、Oracle和PostgreSQL。Singer应用程序是由管道组成的,这意味着后台进程和复杂的插件不需要实现。
Singer.io是开源的,可以免费使用。
3.Scriptella
基于Java的ETL和脚本执行软件
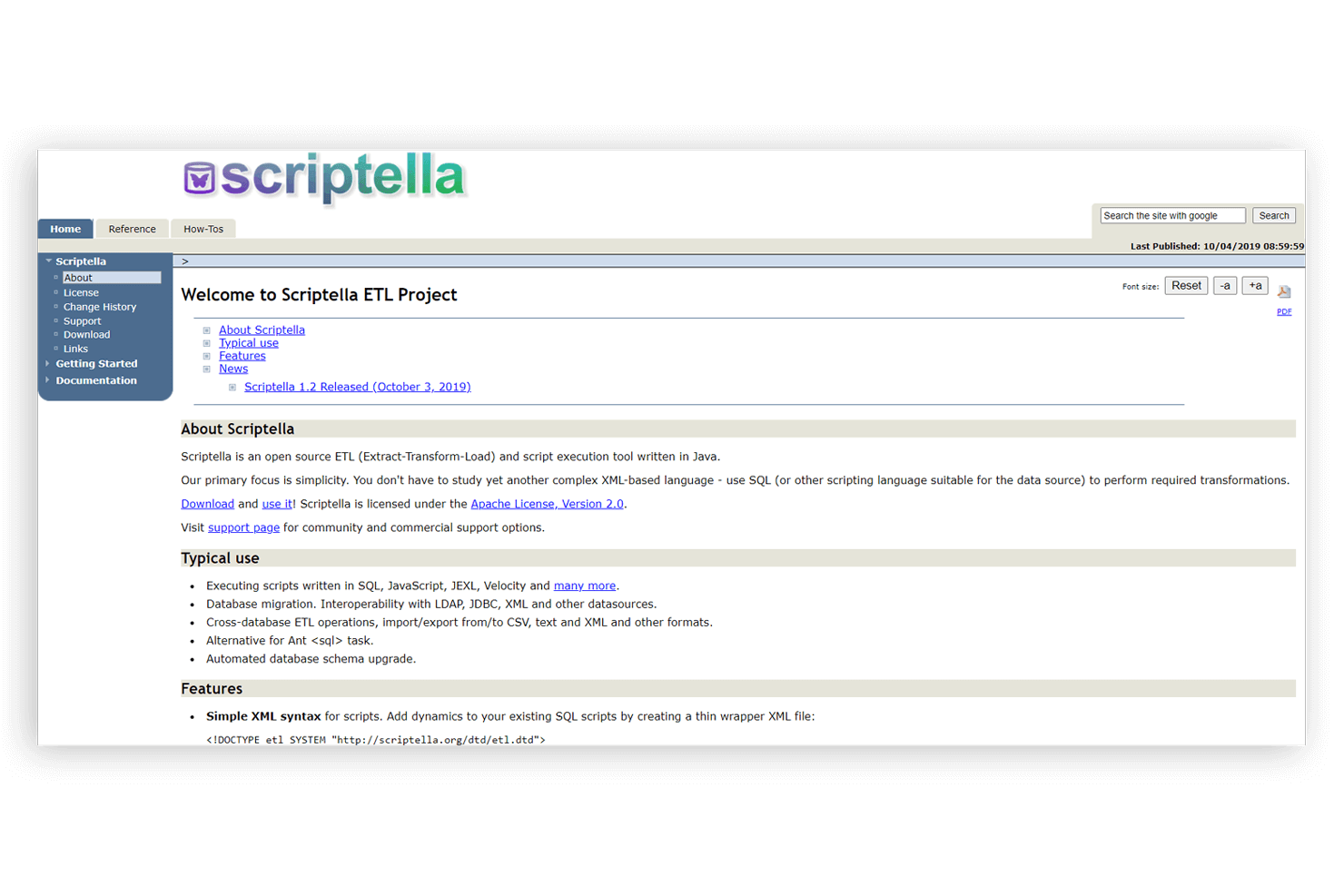
Scriptella允许您执行用SQL、JavaScript、JEXL、Velocity等编写的脚本。
Scriptella是一个用Java编写的开源、简单易用的ETL和脚本执行工具。它大力支持XML,但使其易于使用,同时也促进了ETL过程的自动化。除了执行用JavaScript、SQL、Velocity和JEXL编写的脚本外,Scriptella还可用于以下操作:跨数据库ETL操作、数据库迁移、自动数据库模式升级、导入/导出功能,以及与LDAP、JDBC等数据源的互操作性,Scriptella允许与Groovy等JVM语言集成,并在使用任何JDBC驱动程序时轻松与Ant集成。Scriptella允许事务执行。Scriptella是开源和免费的。
4.Apache NiFi
利用加密保护数据流的ETL解决方案
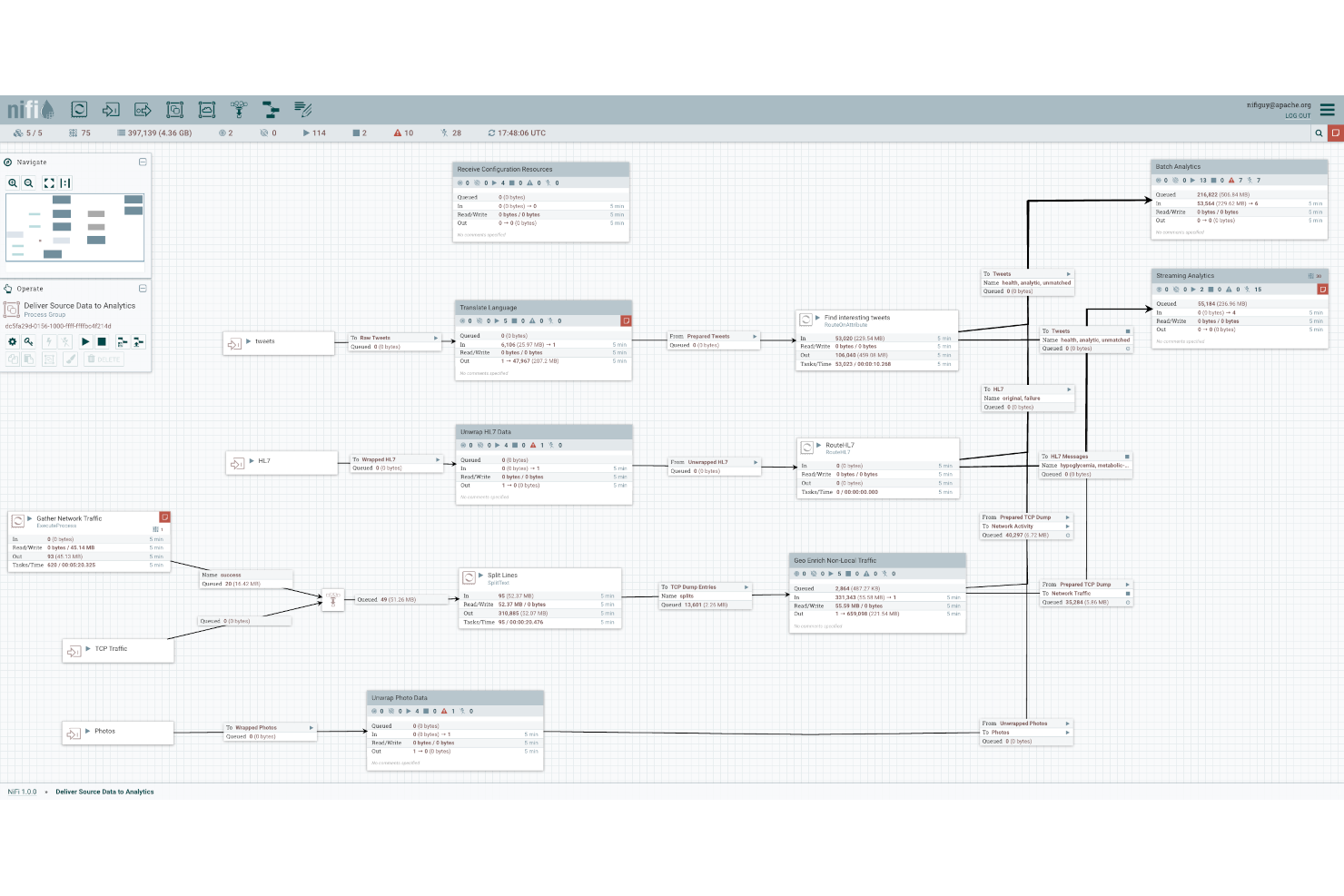
ApacheNiFi使数据流更加可见和可管理。
ApacheNiFi是一种ETL工具,它可以自动化软件系统之间的数据流。NiFi是可扩展的,因为数据转换和路由可以在单个服务器上运行,也可以跨多个服务器集群运行。它的拖放UI使ETL开发人员能够轻松地实时管理数据流。NiFi也是高度可配置的,允许开发人员创建自定义处理器和报告任务。
NiFi通过支持安全协议(包括HTTPS和SSH)来确保数据流的安全。该系统还通过启用双向SSL身份验证和用户角色管理,在用户级别嵌入了安全性。此外,当用户将敏感信息(如密码)输入数据流时,NiFi会自动在服务器端对其进行加密。
开发人员可以通过添加控制器服务、优先级设置器和客户用户界面来扩展NiFi。
5.Apache Kafka
能够处理高吞吐量数据源的分布式事件流平台
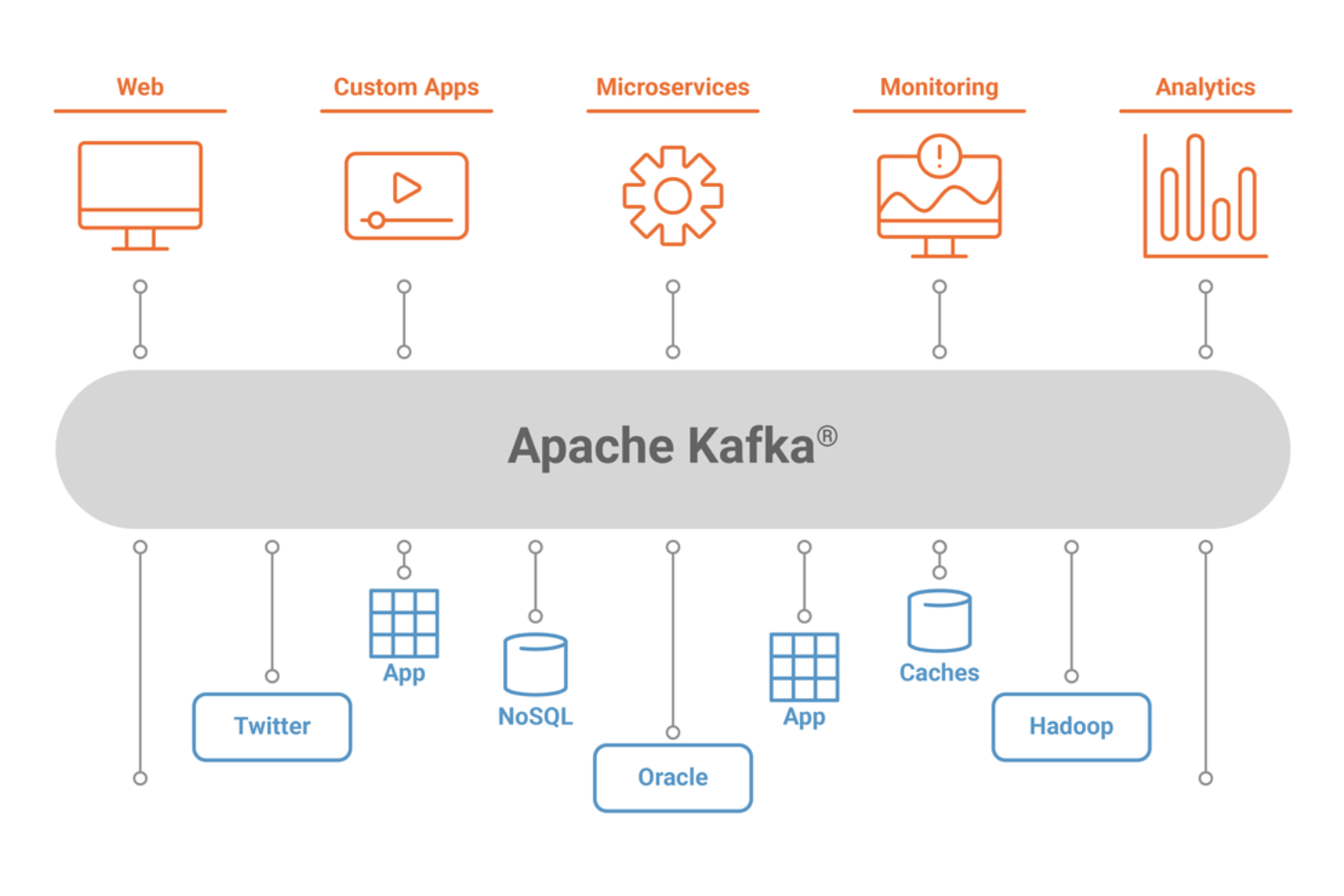
Apache Kafka是一个灵活、可扩展的解决方案,具有无数本地集成。
ApacheKafka是一个分布式事件流平台,它结合了消息传递、存储和流处理。用户可以发布和订阅记录流,按生成顺序存储记录流,并实时处理流。
组织通常使用Kafka来记录和存储付款交易、发货订单和网站活动等事件。该工具具有高度的可扩展性,能够以低延迟处理复杂、高吞吐量的数据馈送。
容错是Apache Kafka的另一个关键特性。该系统跨多个服务器复制和分发分区,从而最大限度地减少了服务器停机时数据丢失的风险。用户可以配置复制因子以指定需要多少分区副本。
Kafka提供与100多个事件源和事件接收器的本地集成,包括Postgres、JMS和AWS S3。
6.Apache Camel
基于企业集成模式的轻量级集成框架
ApacheCamel的开源集成框架有助于简化系统集成。
ApacheCamel是一个生产就绪框架,它使ETL开发人员能够集成使用或生产数据的系统。该平台基于企业集成模式,允许开发人员简化涉及微服务和云的复杂集成。开发人员可以使用EIP、调试器、配置系统和其他一些省时工具的接口来实现企业集成解决方案。
Camel可以处理复杂的集成解决方案,这是因为其轻量级的基于组件的架构和面向消息的路由框架。它采用了一种控制反转的数据路由方法,使各种集成组件之间的消息能够不间断地流动。用户可以用XML、Scala和Java编程路由。
开发人员可以在Spring Boot、Quarkus、应用程序服务器和各种云系统中嵌入Camel作为库。Camel还提供了许多提供额外功能的子项目,包括Camel K(一个在Kubernetes上本地运行的集成框架)和Camel Karavan(一个图形用户界面)。
Apache Camel可以免费下载。
7.Talend Open Studio
ETL和数据集成工具,具有900+个连接器
Talend Open Studio的开源套件使任何ETL开发人员都可以使用它来设置数据管道。
Talend Open Studio是一套开源工具,它使ETL开发人员能够在更短的时间内构建基本数据管道。它具有基于Eclipse的开发环境和900多个预先构建的连接器,包括Oracle、Teradata、Marketo和Microsoft SQL Server。该平台包括五个组件:Talend Open Studio for Data Integration、大数据、数据质量、企业服务总线(ESB)和主数据管理(MDM)。
Talend Open Studio是许多商业智能(BI)工具的理想伴侣。它提供了几种将多个数据集转换为与流行BI平台(包括Jasper、OLAP和SPSS)兼容的格式的方法。用户还可以直接从Talend Open Studio收集见解,该Studio可以生成基本的可视化效果,包括条形图。
Talend Open Studio支持与多个数据库的集成,包括Microsoft SQL Server、Postgres、MySQL、Teradata和Greenplum。
Talend Open Studio对所有用户免费下载。
8.Pentaho Kettle
利用Maven框架的ETL解决方案
为Pentaho Kettle中的表输入创建动态查询的示例。
Pentaho Kettle是一个提取转换加载(ETL)工具,它基于Maven框架提供数据提取和数据集成功能。它是一个多功能的商业智能工具,允许用户高效地摄取、净化、准备和混合来自不同来源的数据。Hitachi Vantara的Pentaho Kettle为团队提供了跨不同数据库节点的一致性。它允许您从不同的源提取数据,同时解决复杂的数据集成问题。它同时提供数据复制和同步、虚拟化和批量数据移动。其他功能包括带有预测分析的仪表板、机器学习算法和灵活的报告解决方案。Pentaho Kettle允许您从各种源和数据库中提取数据,如Oracle、MySQL、SQL Server、PostgreSQL、API、文本文件、,以及NoSQL数据库中的非结构化数据。它是数据不可知的,可以很容易地标记、定制或嵌入(例如)视觉分析第三方工具。Pentaho Kettle是免费的开源软件。
9. Pygrametl
用于ETL过程的Python框架
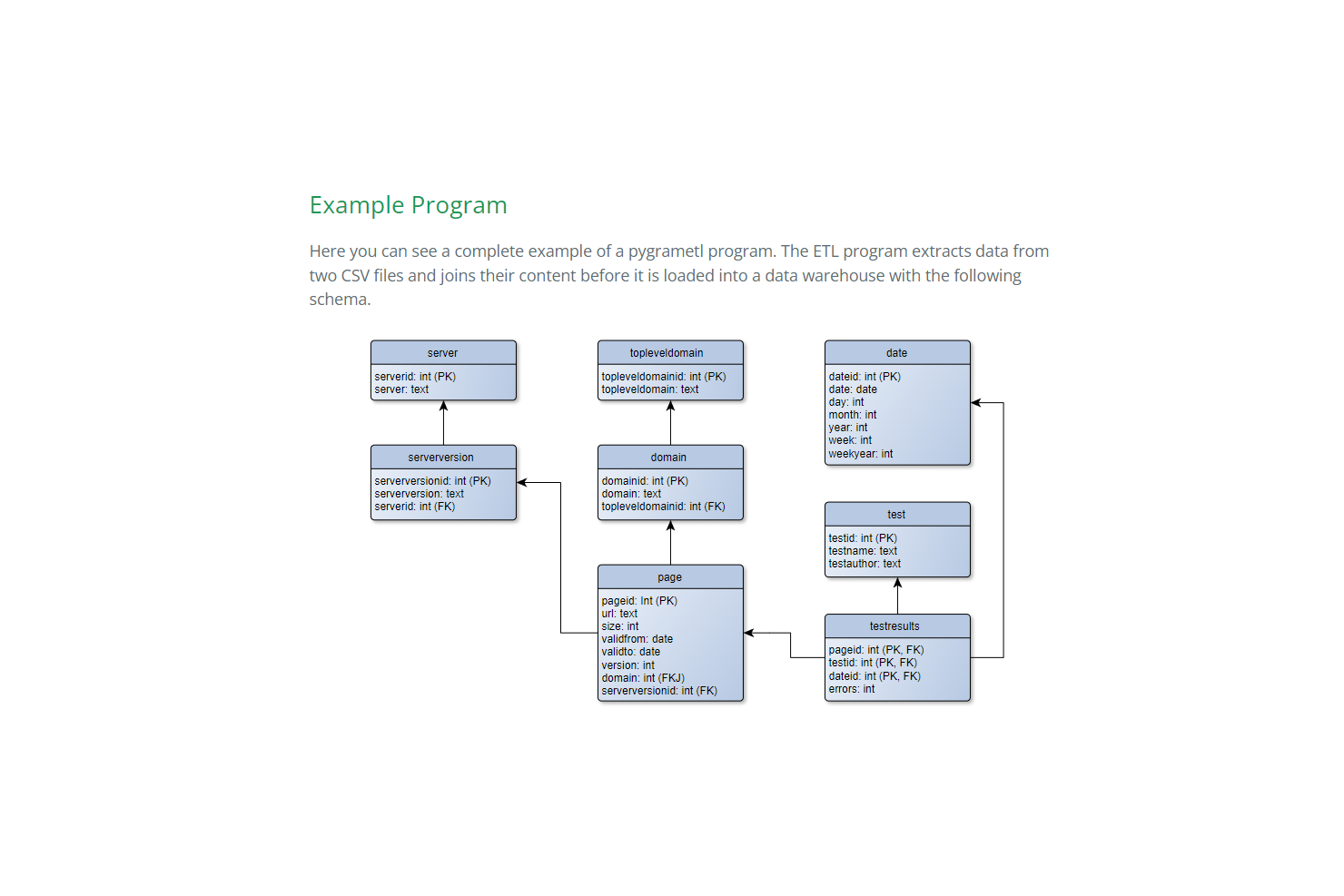
pygrametl易于使用的ETL程序帮助用户将数据转换为任何数据仓库
pygrametl是一个用于开发ETL过程的开源Python框架。它被设计为图形BI程序的替代方案,同时具有相同的易用性。它支持CPython和Jython,使ETL开发人员能够利用现有的Java代码和JDBC驱动程序。
开发人员可以从pygrametl中提供的许多源中提取数据,如SQL、CSV和Pandas。用户还可以定义自己的数据源。该平台提供了用于转换数据的过滤器和聚合器。默认聚合器包括AVG、Count、CountDistinct、Max、Min和Sum。
pygrametl可以将转换后的数据加载到任何支持维度建模的数据仓库中。该系统提供了定义事实表和维度的结构,包括缓慢变化和雪花状维度。
开发者可以免费下载pygrametl。
10. Hevo Data
使用反向ETL工具的无代码数据管道解决方案
Hevo Data易于使用的解决方案使数据管道的设置和可视化成为一个简单的过程。
Hevo将数据从任何来源实时加载到您的仓库,无需编码。该平台高度直观,具有三步设置过程。随着您的业务增长,Hevo也在增长。它被设计为每分钟处理数百万条记录并自动缩放。
企业可以使用Hevo的反向ETL解决方案Hevo Activate将数据从数据仓库传输到任何营销、销售和业务应用程序。该平台在现有数据仓库之上工作,因此您的数据保留在一个位置。激活还可以修复仓库和目标应用程序之间的数据不兼容问题。该工具自动转换仓库中的数据类型以匹配目标应用程序。
Hevo集成了100多个数据库、SaaS应用程序和CRM,包括BigQuery、MySQL和Salesforce。
Hevo根据使用情况提供免费和付费订阅。
- 1192 次浏览
【数据集成】用于数据集成的10个最佳开源ETL工具
视频号
微信公众号
知识星球
今天的每一项业务都是数据驱动的。近94%的企业同意其业务增长取决于数据。然而,只有不到40%的组织能够汇总和分析数据供其使用。虽然ETL过程有帮助,但没有适当的工具是毫无意义的。而且,找到适合您的ETL和数据集成系统非常耗时,而且成本高昂。
但是,免费的开源ETL工具可以消除这种担忧。一些选项是企业支持的,希望为您提供最佳解决方案,而另一些选项则由开发人员社区管理,他们希望使ETL过程变得容易和可访问。
我们策划了当前市场场景中最好的10个开源ETL工具的列表,以帮助您为您的工作选择一个或多个。在讨论了所有这些免费ETL工具之后,我们还将提供一个比较表,供您查看。
目录
- 什么是ETL?
- 提取
- 转型
- 加载
- 10个最佳开源ETL工具
- ETL工具比较标准
- 开源ETL工具:关键特性
- 可扩展性
- 经济的
- 保护
- 数据集成
- 实时处理
- 开源ETL工具的局限性
- ETL数据集成过程的步骤是什么?
- 哪种ETL工具最好?
- 结论
- 常见问题解答(FAQ)
- 使用最多的ETL工具是什么?
- 2023年需要哪种ETL工具?
- 什么是最快的ETL工具?
什么是ETL?
ETL代表提取、转换和加载。这是一个流程,企业可以使用它从各种来源收集的数据中获得关键和可操作的见解,包括社交媒体平台、电子邮件和客户支持工具。ETL是一个三阶段过程:
提取
提取是指统一结构化和非结构化数据,从中提取重要的业务关键信息。只需使用ETL工具单击几下,就可以从收集的数据中提取必要的详细信息。
转型
ETL过程的第二个阶段是转换。这意味着将提取的信息转换为用户、数据仓库或商业智能(BI)可以理解的格式。一些转换技术包括数据排序、清理、删除和验证过程。
加载
ETL过程的第三个阶段是加载,这意味着将转换后的信息保存到数据仓库中。由于BI工具处理信息,为用户和业务利益相关者生成必要的报告和见解,因此正确加载数据至关重要。
10个最佳开源ETL工具
到目前为止,我们已经了解了ETL过程。这里我们列出了10个最好的开源ETL工具,其中一些可以用来满足您的数据处理需求。
Keboola

使用Keboola,“在20分钟内连接任何数据源。”它是您所有数据需求的一体式数据工程平台。
它是一个端到端的ETL工具,将一个完整的数据平台作为服务运行。如果您的数据看起来令人困惑并造成运营混乱,Keboola是在分析和自动化方面进行合作的正确选择。它提供提取、转换、数据管理和管道编排解决方案以及反向ETL。
设计和部署数据管道,了解业务数据背后的科学知识,并使用Keboola与多个云、数据库、协作、CRM和更多平台集成。

CloverDX是一个非常理想的平台,它为您的所有数据发布和处理需求提供了一个集中的位置。它是高效的,提供了对数据的控制,并提供了处理的透明度。您可以将其与云中和本地数据源集成,以处理多种数据格式。
作为一个一体化的数据管理工具,CloverDX连接到多个数据源,消除了数据孤岛,并避免了供应商锁定。它可以完成从设计数据和自动化重复任务到与必要的第三方工具结合以及在数据库、文件、消息等中发布信息的所有工作。
Logstash

Logstash是一个免费的开源ETL工具,它从多个来源收集数据,执行转换过程,并将输出发送回您选择的数据仓库。它由预先构建的过滤器和100多个插件组成,用于执行数据处理操作。无论数据的格式或复杂性如何,Logstash都会动态地摄取、转换信息,并将其发送到您选择的“存储库”。
Logstash最好的特性之一是可扩展的插件生态系统。它有近200个插件和丰富的过滤器库,可以创建最适合您数据处理需求的管道。
Apache Kafka

Apache Kafka是Apache软件基金会开发的开源系统。该平台用Java和Scala编写,旨在为处理数据源提供统一的高吞吐量管道。该工具是一个分布式事件流平台,用于执行高性能数据管道、流分析、数据集成和任务关键型应用程序。
Apache Kafka通过弹性扩展和收缩数据存储和处理能力支持可扩展性。永久存储、内置流处理、无缝集成和一组丰富的客户端库是该工具的一些有用功能,使其成为一个值得信赖的ETL管道工具。
Pygrametl

Pygrametl是一个开源数据集成ETL工具,它是一个Python框架,为执行ETL过程提供了常用的功能。它支持编码以运行任何基于ETL的阶段来管理和处理数据。由于该工具与CPython和Jython都兼容,因此可以在ETL程序中使用现有的Java代码和JDBC驱动程序。尽管ETL阶段的编码可能听起来很麻烦,但与无脚本GUI工具相比,Pygrametl被证明是有用的,因为它节省了手动创建数据管道的时间和精力。
该框架于2009年发布,经过不断发展,为用户提供了高效的ETL流程,并具有充分的编程能力。正如本文中所讨论的,Pygrametl的最新添加是Drawn Table Testing(DTT),它简化了ETL流的测试,因为它可以方便地定义数据处理运行到测试中的前置条件和后置条件。您可以在所附链接中了解有关此框架及其最新版本的更多信息。
Singer

Singer是一个开源工具,可根据您的组织需求提取和整合数据。您可以在数据库、web API、文件、队列等之间发送数据。它与年轻企业用来满足ETL需求的软件集成。
需要记住的一点是,Singer是一个基于脚本的ETL工具;您必须编写特定的代码来执行ETL职责。数据提取脚本被称为“标记”,数据加载脚本被称“目标”这些脚本可以以任何顺序或组合运行,以执行您选择的ETL过程。Singer还允许您创建自己的标签和目标,如果现有标签和目标与您的需求不匹配。
Singer的另一个与众不同之处是其支持模块化数据传输管道的能力。这些模块化数据传输和加载选项易于维护和执行。
Scriptella

另一个流行且非常有用的开源ETL工具是Scriptella。它用Java编写,是一个脚本执行工具,其主要关注点是简单性。该工具拥有相当活跃的社区,并在Apache 2.0版下获得许可。
由于Scriptella是一个基于脚本的工具,您需要使用代码执行ETL功能。但别担心!你不必为此学习任何新的编码语言。您可以使用SQL进行访问和数据传输。除了SQL,它还支持JavaScript、JEXL和Velocity。其他工具功能包括与LDAP、JDBC、XML和其他数据源的互操作性以及跨数据库ETL操作。但如果您正在寻找执行ETL过程的GUI工具,Scriptella可能不是最佳选择,因为它不支持GUI。
以下是该工具的所有不同功能,供您探索。
Pentaho Kettle

Kettle是一个免费的开源ETL数据集成工具,现在是Pentaho数据集成。它是一款综合性软件,能够访问、混合和分析来自多个来源的数据,深受用户欢迎。
术语“Kettle”代表“Kettle-Extraction Transformation Transport Load Environment”。它被称为理想的数据混合、集成和业务分析平台。Pentaho Kettle提供从MySQL、PostgreSQL、Oracle、SQL Server、各种NoSQL API、文本文件等数据源提取数据。与上述两种工具不同,Kettle是无代码的,在从业务数据中提取可操作的见解方面非常有用。
它是一个ETL工具,提供内部数据和文件存储库。因此,如果您正在寻找协作ETL环境,可以使用Pentaho存储库。
Talend Open Studio

Talend Open Studio是一个数据集成和ETL平台,允许用户在几分钟内构建基本数据管道。您只需要最新的操作系统版本、8 GB的内部内存和20 GB以上的内部磁盘空间即可开始安装。
如果您的项目准备好启动,您需要Talend Open Studio及其易于使用的界面和集成功能。此后,您可以监视和安排正在进行的项目需求。您可以进一步利用该工具轻松添加数据质量、大数据集成和处理资源。并在需要时利用AWS或Azure的最新数据源、分析技术和弹性容量。
Apache Camel

如果数据集成和收集是您的首要任务和业务需求,那么ApacheCamel应该是您的首选工具。它是一个开源框架,使您能够轻松地与产生和消费对您有用的数据的源进行集成。它支持来自不同行业的50多种数据格式,包括金融、健康、电信等。
ApacheCamel以其数据集成功能而受欢迎,它支持大多数企业集成模式和微服务架构中的较新集成模式。其目的是帮助您使用最佳行业实践解决业务集成问题。值得注意的是,该工具可以独立运行,并且可以作为库嵌入到Spring Boot、Quarkus、Application Server和流行的云平台中。
ETL工具比较标准
| ETL工具 | 支持的格式 | 集成 | 自动化 | 无代码/基于代码 | 安装和部署 | 订阅 |
| Keboola | All data formats | Salesforce, project management, AWS, and more | Yes | Codeless | Deploy as a service | Free and enterprise plan |
| CloverDX | All data formats | All 3rd party Java libraries | Yes | Codeless | On-premises and cloud-based | Available on the website |
| Logstash | XML, JSON, CSV, logs, and more | Cloud platforms, Kubernetes, Confluence, and CRMs | Yes | Codeless | On-premises and cloud-based | Free |
| Apache Kafka | Event-record format | integrates with hundreds of event sources and event sinks including Postgres, JMS, Elasticsearch, AWS S3, and more. | Yes | Codeless | Can be deployed on virtual machines, containers, and on-premises, and on the cloud | Free |
| Pygrametl | SQL, CSV, TypedCSV, Pandas, and more | Python code | Yes | Code-based | On-premises | Free |
| Singer | Multiple sources | Python-based libraries | Yes | Code-based | Virtual environment or on-premises | Free |
| Scriptella | LDAP, JDBC, XML and other datasources | Java EE, Spring Framework, JMX, JNDI and JavaMail | Yes | Code-based | On-premises | Free |
| Pentaho Data Integration | Multiple data formats | Java-based libraries | Yes | Codeless | On-premises | Enterprise Edition/community Project |
| Talend Open Studio | All big data formats | RDMS,SaaS connectors, CRMs | Yes | Codeless | On-premises and cloud-based | Free |
| Apache Camel | JSON, XML, SOAP, ZIP, and more (50+ types) | Spring, Quarkus, and CDI | Yes | Code-based | On-premises and as an embeddable library | Free |
开源ETL工具:关键特性
开源之所以受到欢迎,是因为他们有一个活跃的开发人员和用户社区,随时可以指导您使用这些工具。尽管经验丰富的人员帮助您满足需求非常有用,但您必须了解开源ETL工具的其他几个关键功能:
可扩展性
一个可扩展的开源ETL工具可以有效地为我们的业务收集和处理数据。在处理大量数据时,它们也不那么复杂且易于使用。
经济的
寻找ETL工具的公司可以选择开源选项,这些工具可以完成工作,但对他们的业务来说仍然经济。这些组织在预算范围内获得最佳的数据集成能力和更高的质量。
保护
开源ETL工具提供了对金融和医疗保健行业公司至关重要的加密设施。有了支持此类工具的开放社区,您还可以选择向负责此类群体的开发人员寻求帮助。
数据集成
开源ETL工具是寻找可嵌入数据集成选项的企业的最佳选择。这些工具提供数据集成、迁移和转换服务,价格与商业同类产品相比合理。
实时处理
您可以使用ETL工具中的实时处理通过管道立即发送数据,这在欺诈检测中非常有用。通过访问实时数据传输洞察,您可以检测并防止IT违规。
开源ETL工具的局限性
当然,ETL工具为执行提取、转换和加载管道提供了坚实的基础。但他们仍在发展,并成为自己的一个完全成熟的版本。目前,开源ETL工具有一定的局限性,特别是在客户支持方面。以下是开源ETL工具的一些限制:
- 它们仍然缺乏与企业使用的内部软件的适当集成和连接。
- 这些开源工具缺乏错误处理能力。
- 这些ETL工具中的大多数都是接口驱动的,这使得它们难以导航和调试,从而引入了再现性问题。
- 有些工具可以分析大型数据集,但它们只能处理小批量的数据,这会导致流水线中的效率问题。
- 所讨论的一些工具与数据管理软件或RDBMS系统不兼容,从而阻碍了从各种平台获取数据后的数据管道性能。
- 具有复杂数据分析和处理需求的企业即使预算很低,也无法通过使用开源ETL工具来满足所有需求。
ETL数据集成过程的步骤是什么?
ETL主要是一个三步过程。但是,简单地提取、转换和加载数据对您的业务不会有用。您还需要构建和分析可用信息。因此,ETL数据集成过程需要遵循5个必要的关键步骤:
摘录:
从非结构化数据集或池中收集原始数据,并将其存储在存储库中以供进一步使用。
清洁:
在进入转换阶段之前,对收集的数据进行抛光和清理,以确保质量。
转换:
将非结构化数据转换为结构化数据;转换过程将可用数据转换为可理解的格式。
负载:
此阶段将结构化数据加载到数据仓库中进行分析并获得有价值的见解
分析:
该分析是对仓库中存储的数据进行的,允许企业提取见解供其使用。
如上所述,每一步都在序列中的另一步之后。通常,数据工程师和开发人员执行这些过程,因为他们掌握了处理数据仓库及其功能所需的知识。
哪种ETL工具最好?
每一个ETL工具的功能都不同,并具有其独有的功能和满足的需求。由于收集、存储和处理数据的业务需求多种多样,从众多工具中选择一种不是正确的做法。例如,如果您正在寻找一种提供无代码数据处理的数据管道工具,那么Talend Open Studio(最常用和最流行的ETL工具之一)可能会给您带来挑战。
最好的ETL工具是符合您的需求并提供您正在寻找的解决方案的工具。也许,你可以选择Keboola、Pentaho Kettle、CloverDX、Logstash和Apache Kafka。然而,如果您的团队想要节省手动创建和连接数据管道的时间,则必须使用Scriptella或Talend Open Studio。这些工具非常适合技术娴熟的企业,他们宁愿选择编码和执行数据处理。
结论
在最终确定ETL工具时,时间、成本和易用性是许多公司的首要因素。该过程相当耗时,需要企业了解其数据集成和处理需求,以搜索执行此任务的工具。
虽然一些数据管道工具提供的功能超出了您的业务需求,但其他工具在技术上已开发,但需要正确的使用技能。你再次陷入困惑。哪种ETL工具最适合您的组织和数据处理需求?
本列表旨在帮助您选择市场上最新的工具,该工具配备了所有必要的功能,以支持您的大数据处理和分析,从而获得正确的可操作见解。您可以查看我们的比较表,以更好地了解所有这些平台及其功能。
常见问题解答(FAQ)
使用最多的ETL工具是什么?
最常用和最流行的ETL工具是Talend Open Studio,它具有易于使用的界面和广泛的功能。它支持多种数据源的多种集成,包括数据库、web服务和文本文件。它是一个基于代码的平台。
甚至Pentaho Kettle也是一个非常流行的数据集成ETL工具,许多企业都依赖它来访问、混合和分析来自多个来源的数据。这是一个无代码平台。
2023年需要哪种ETL工具?
除了上述常见问题解答中讨论的两种流行的ETL工具外,ApacheKafka和Singer在2023年的需求量将很高。然而,每个企业都有不同的ETL工具需求,特定工具的流行程度因行业而异。
什么是最快的ETL工具?
在本文讨论的ETL工具中,Apache是市场上速度最快的工具之一。它允许无缝的数据集成和操作。它是一个开源工具,可供用户使用,并随着时间的推移进行了更新,以支持即将到来的数据集成需求。
- 6041 次浏览
【数据集成】用于数据集成的最佳免费开源ETL工具
视频号
微信公众号
知识星球
开源ETL工具有效地从一个或多个数据源提取数据,对该数据应用一系列转换,然后将生成的数据加载到目标数据仓库中。它用于执行复杂的数据转换,如数据清理、重复数据消除、数据迁移、数据丰富和数据聚合。
在选择ETL应用程序的类型时,开源ETL工具通常是免费的,并得到开发人员社区的良好支持,而且通常比商业ETL系统更具可扩展性和可定制性。
但是市场上有这么多免费的ETL工具,很难知道哪一个适合您。因此,我们已经完成了这项工作,并为大数据管理带来了12个最佳的免费开源ETL工具。
目录
- 顶级ETL工具列表开源:比较图
- 12个最佳开源ETL工具,详细分析
- ETL工具的类型
- 如何找到最佳的开源ETL工具
- 开源ETL工具的局限性
- 常见问题解答
顶级ETL工具列表开源:比较图
下面是一张表,比较了最佳数据集成工具的独特功能和价格。
| ETL Tools List | USP | Price |
| Talend Open Studio | Supports all types of deployment, open source ETL tool for Big Data | 14 Days Free Trial Custom Pricing |
| Singer | Supports 100+ Sources and 10+ Destinations | Free |
| Pentaho Data Integration | Integrated Data extractions and transformation with business analytics | 30 days Free trials Custom Pricing |
| Apache Nifi | Powerful Graphs for Data transformation, routing, and system mediation logic. | Free |
| Apache Camel | Integrates Data producers and consumer with ease | Free |
| Airbyte | Customizable, pre-built and maintenance free Data Connector and API | Free on-premises version Cloud deployed version costs ₹200/credit |
| KETL | Powerful Job scheduling and Execution XML, SQL and OS defined jobs | Free |
| CloverDX | Develop, test and debug entire dataflow pipeline | 45 Days Free Trial Custom Pricing |
| Apatar | Mapping and transforming semi structured and unstructured data | Custom pricing |
12个最佳开源ETL工具,详细分析
以下是一些最好的ETL和数据集成工具及其功能和定价。
Talend Open Studio
使用Talend Open Studio,您可以在图形环境的帮助下轻松快速地转换复杂数据。它还提供拖放功能,以加快数据转换。
Talend功能
- 连接到Hadoop和NoSQL数据库
- 强大的数据集成
- 数据治理和完整性
- 支持云、多云和混合云
- 具有文档和分类的集成数据
- 质量数据访问和生命周期管理
定价:Talend Open Studio提供14天免费试用。但是,您也可以升级到大数据平台和数据结构计划。它有一个定制的定价计划,根据组织的需要而变化。有关详细定价,请联系Techjock团队。
Singer
Singer Tap是一款非专有ETL软件,允许您将数据从MySQL、Salesforce和Postgres等各种平台移动到Redshift、BigQuery和Snowflake等数据仓库。Singer Tap非常轻便,易于使用。您还可以安排数据转换,Singer将自动处理这些任务。
SingerTap功能
- 支持多个数据源和目标
- 批量和实时数据转换·
- 数据调度
- Unix灵感来源于简单的目标和抽头
- 支持JSON,便于实现和定制
- 自动报警和监控系统
Singer Tap Price:这是一款免费的开源ETL软件。
Pentaho Data Integration
Pentaho数据集成和分析(PDI)是日立Vantara DataOps套件的一部分。通过PDI,您可以通过设计和部署企业级端到端数据管道,轻松地提取、转换和操作数据。它允许您分发数据,而不管数据是在湖泊、仓库还是设备中,并以无缝流集成所有数据。
Pentaho功能
- 端到端数据编排
- 拖放界面
- 预先存在的数据流模板
- 灵活的架构
- 机器学习算法
- 强大的数据集成、转换和操作·
Pentaho开源ETL价格:提供30天免费试用。Pentaho企业版的价格因用户的要求而异。有关更多详细信息,请联系技术骑师团队。
ApacheNiFi
ApacheNiFi是一个有用、功能强大、可扩展的开源ETL应用程序,用于路由和转换数据流。它是一个可靠的ETL工具,因为它支持系统中介逻辑和可扩展的数据路由图以及高级数据转换功能。
还有几个其他选项可以自定义数据流,例如确定高吞吐量或低延迟、保证交付或容忍丢失。
Apache Nifi功能
- 基于交互式浏览器的用户界面
- 整个信息生命周期管理
- 带损耗容限的保证交付
- 高吞吐量和低延迟
- 基于动态因素的优先级排序
- 处理器和服务组件体系结构
- 迭代开发和测试
- 多租户策略和授权管理
Apache Nifi定价:它是一个完全免费的开源软件。
Apache Camel
Apache Camel是另一个流行的、功能齐全的企业数据集成框架,它集成了各种数据消费和生成系统。Apache Camel提供了基于Java对象的企业集成模式(Enterprise Integration Patterns,EIP)实现,通过路由引擎使用Javabean转换和路由数据。您可以将Camel作为独立应用程序使用,也可以将其嵌入到其他J2EE应用程序中。
Apache Camel特性
- 用于数据转换和路由的多种EIP模式
- 用于连接不同系统的强大可扩展框架
- 用于配置的域特定语言
- 50+数据平台
- 微服务架构集成模式
Apache骆驼定价:它是一个完全免费的开源数据集成器。
Airbyte
Airbyte是一个开源的ELT工具,它将数据从API、数据库和应用程序同步到仓库。数据工程团队可以使用Airbyte的模块化架构和开源特性,从一个平台管理一切。
Airbyte功能
- 高质量数据连接器,便于API和架构调整
- 可定制的预建连接器
- 连接器开发套件
- 基于DBT的转换
- 基于大型社区
- 高度可配置的数据管道
Airbyte定价:本地开源版本完全免费。然而,Airbyte的云部署版本定价从₹200/学分。
KETL
KETL是另一个具有(通用公共许可证)GPL的ETL平台,它有助于数据整合和转换过程的提取、开发和部署。用户可以使用KETL的调度管理器根据时间或数据事件来调度ETL作业。除了专有的数据库API之外,KETL还支持关系和独立的文件数据源。
KETL功能
- 兼容多个CPU和X-64服务器
- 平台独立发动机
- 基于数据流的作业调度和执行
- 条件异常管理和警报
- 执行XML、SQL和OS定义的作业
- 中央存储库和性能监控
KETL定价:它是一个免费开源的GPL许可证。
CloverDX

CloverDX ETL软件使开发人员能够连接到任何数据源并管理各种数据格式和转换。使用CloverDX,开发人员可以使用广泛的可定制组件编写、读取、合并、连接和验证数据。另外一个好处是,您可以轻松创建数据管道,并使用集成开发环境对其进行调试。
CloverDX功能
- 可视化界面和预构建组件有助于快速开发。
- 实时数据监控
- 内置编码、调试和测试
- 版本控制跟踪
- 协调外部和内部数据流
- 遗留代码集成
CloverDX定价:它提供45天的免费试用。有三种计划:标准型、增强型和增强型,定价模式可变。有关详细报价,请联系Techjock团队。
Apatar
Apatar是一个完整的数据集成解决方案,可帮助用户连接到任何数据源,并转换和自动化数据迁移过程。Apatar还提供了一个转换组件,将数据转换为所需的格式,以及一个调度程序,以自动化数据同步过程。
Apatar功能
- 数据映射和转换
- 用于流行数据库和应用程序的数据连接器
- 掩蔽和匿名化
- 血统和影响分析
- 质量管理
Apatar定价:它有一个自定义的定价计划,取决于用户的需求。
Apache Kafka
Apache Kafka是一个开放的实时ETL平台,世界各地的公司都使用它来实现高效的数据管道、数据集成和流式分析。此事件流平台帮助使用一次性处理工具处理聚合、连接、转换等各种事件流。
Apache Kafka特性
- 连接到数百个事件源和事件接收器
- 用一系列编程语言处理事件流
- 即使在有限的网络中也能传递消息
- 丰富的在线资源,包括指导教程、在线培训
- 存储数据更改事件
Apache Kafka定价:Apache Kafka有一个自定义定价计划,具体取决于用户的需求,您可以从他们的官方网站上请求。
Hevo Data
Hevo Data是一个无代码数据管道,允许您将数据实时复制到您选择的目的地–Firebolt、Redshift等。该平台非常直观,无需设置技术资源。它进一步集成了100多个数据库、CRM、SaaS应用程序和Salesforce软件。
通过Hevo Data的反向ETL解决方案,企业可以轻松地将数据从数据仓库传输到任何销售、营销和业务应用程序。该工具还将数据类型从不同的源转换为您选择的源,以匹配您的目标应用程序。
Hevo功能
- 150多个即插即用集成
- 15个以上目的地–应用程序、数据库等
- 优化和自动化组织范围的数据流
- 以最小的努力操作
Hevo定价:Hevo根据用户需求制定了3种定价计划。它还提供了一个免费计划,包括50多个免费连接器、无限型号、用户等。
Logstash
Logstash是一个免费的开源数据处理管道,它实时提取和混合来自多个源的数据,并使其在首选目的地使用变得简单。它是Elastic公司的产品,是Elasticsearch的一部分。
此ETL工具旨在从日志中收集数据。它可以提取所有类型的数据日志(web和app),并从云和本地数据源中捕获日志格式和网络。
Logstash最初是为从日志收集数据而设计的,但它的功能超出了数据。它可以使用过滤器、本地编解码器和输出插件有效地转换数据。然而,如果你不是程序员或者没有技术专长,你可能会发现使用Logstash很困难。需要在基于开发的环境中安装、验证、运行和维护此工具。
Logstash功能
- 从日志收集、存储和管理数据
- 使用Elastisearch插件过滤器转换数据
- 数据过滤和数据分析
Logstash定价:Logstash有4种定价包,即标准、黄金、白金和企业版。标准套餐从7839卢比起,提供安全、企业搜索和支持功能等。您也可以从官方网站申请免费试用。
ETL工具的类型
随着过去几年技术的发展,不同类型的ETL解决方案已进入市场。以下是三种最流行的类型:
- 商业ETL工具–对于具有复杂工作流程和大量数据的大型企业来说,这类ETL解决方案是一个很好的选择。商业ETL工具解决方案可以是本地的,也可以作为基于云的服务提供。
示例:Oracle Data Integrator、IBM DataStage
- 开源ETL工具——开源工具是多家公司的首选,因为它们提供了强大的功能,而且成本低廉(甚至是免费的)。此外,使用开源工具,用户可以自由修改源代码,省略部分代码等。此外,它们具有简单而准确的UI,甚至允许用户添加新功能。
示例:KETL、Hevo数据
- DIY ETL脚本–DIY ETL脚本涉及具有完全灵活性的手工编码,而不是基于工具的方法,该方法可能受到某些功能的限制。ETL脚本可以用多种编程语言编写,包括SQL、Python等。这个手工编码的系统也可以定制,以直接管理您的业务的任何数据集。
示例:Airflow,Pygrametl
如何找到最佳的开源ETL工具
在选择开源ETL工具时,需要考虑许多因素。一些最重要的因素包括:数据的大小、复杂性、转换要求、更新频率、源和目标数据库。选择最适合您的需求和需求的ETL工具,
如果您有少量不太复杂的数据,您可以使用普通的ETL工具。然而,如果您有大量数据或数据非常复杂,您可能需要使用插件、集成和编码定制开源ETL应用程序。
开源ETL工具的局限性
尽管ETL工具可以是提取、转换和加载管道的坚实组件,但它们确实有一些缺点,特别是在提供支持方面。开源ETL工具的一些限制包括:
- 一些公司无法连接他们的一些应用程序
- 由于缺乏稳健的管理,ETL工具无法轻松处理错误
- 当从各种RDBMS(关系数据库管理系统)收集数据时,ETL工具的非RDBMS连接可能会导致数据管道性能不佳
- 一些ETL工具需要分析大量数据,但数据处理只能在小批量中进行。这会降低数据管道的效率
- 由于开源ETL工具通常缺乏专家的支持,具有复杂转换需求的公司无法使用该工具。
常见问题解答
什么是ETL工具?
ETL代表提取、转换和加载。ETL工具用于从多个数据源提取数据,将其转换为所需的格式并将其加载到数据库中。
开源ETL工具的关键特性是什么?
开源ETL工具的关键特性是,它们可与GPL一起使用,支持多种数据格式,并提供广泛的定制选项。一些流行的开源ETL应用程序是ApacheCamel、Airbyte和CloverDX。
开源ETL工具的好处是什么?
提供几个好处,如易用性、定制性、可扩展性和开发人员社区的支持。
开源ETL工具的局限性是什么?
免费开源ETL工具的最大限制是缺乏供应商的技术支持。如果出现任何问题,用户必须依靠开发人员社区来解决。
哪种是最好的开源ETL工具?
最好的开源ETL工具取决于用户的特定需求。一些流行的工具是Talend Open Studio、Apache Camel和Singer。
选择ETL工具时应考虑哪些因素?
选择ETL工具时应考虑的一些因素是提供的功能、易用性、成本、可扩展性和支持。
ETL和ELT工具之间的区别是什么?
ETL工具通常用于编译关系型、结构化和较小的数据集,而ELT工具主要用于编译半结构化和非结构化数据。此外,ETL工具在将数据加载到数据仓库之前对数据进行转换,而ELT工具在转换之前将数据加载在数据仓库中。
- 1280 次浏览
【集成架构】2020年最好的15个ETL工具(第一部)
最好的开源ETL工具列表与详细比较:
ETL代表提取、转换和加载。它是从任何数据源中提取数据并将其转换为适当格式以供存储和将来参考的过程。
最后,该数据被加载到数据库中。在当前的技术时代,“数据”这个词非常重要,因为大多数业务都围绕着数据、数据流、数据格式等运行。现代应用程序和工作方法需要实时数据来进行处理,为了满足这一目的,市场上有各种各样的ETL工具。
使用这样的数据库和ETL工具使数据管理任务更加容易,同时改进了数据仓库。
市场上可用的ETL平台在很大程度上节省了资金和时间。其中一些是商业的、授权的工具,少数是开源的免费工具。
在本文中,我们将深入研究市场上最流行的ETL工具。
市场上最流行的ETL工具
下面列出了最好的开源和商用ETL软件系统,并进行了详细比较。
推荐的ETL工具
Hevo是一个无代码的数据管道平台,可以帮助您实时地将数据从任何源(数据库、云应用程序、sdk和流)移动到任何目的地。
主要特点:
- 易于实现:Hevo可以在几分钟内设置和运行。
- 自动模式检测和映射:Hevo强大的算法可以检测传入数据的模式,并在数据仓库中复制相同的模式,无需任何人工干预。
- 实时架构:Hevo建立在实时流架构上,确保数据实时加载到仓库。
- ETL和ELT: Hevo具有强大的特性,允许您在将数据移动到数据仓库之前和之后清理、转换和丰富数据。这确保您总是拥有准备好分析的数据。
- 企业级安全性:Hevo符合GDPR、SOC II和HIPAA。
- 警报和监视:Hevo提供详细的警报和粒度监视设置,以便您始终掌握您的数据。
# 1) Xplenty
Xplenty是一个基于云的ETL解决方案,为跨各种源和目的地的自动数据流提供了简单的可视化数据管道。
该公司强大的平台转换工具允许其客户清理、规范化和转换其数据,同时坚持遵从最佳实践。

主要特点:
- 为BI集中和准备数据。
- 在内部数据库或数据仓库之间传输和转换数据。
- 发送额外的第三方数据到Heroku Postgres(然后通过Heroku Connect发送到Salesforce)或直接发送到Salesforce。
- Xplenty是唯一的Salesforce到Salesforce ETL工具。
- 最后,Xplenty支持一个Rest API连接器,可以从任何Rest API拉入数据。
# 2) Skyvia

Skyvia是一个云数据平台,用于无编码数据集成、备份、管理和访问,由Devart开发。Devart公司是一家知名且值得信赖的数据访问解决方案、数据库工具、开发工具和其他软件产品供应商,在两个研发部门拥有超过40000名客户。
Skyvia包括一个ETL解决方案,用于各种数据集成场景,支持CSV文件、数据库(SQL Server, Oracle, PostgreSQL, MySQL)、云数据仓库(Amazon Redshift,谷歌BigQuery)和云应用程序(Salesforce, HubSpot, Dynamics CRM,和许多其他)。
它还包括云数据备份工具、在线SQL客户端和OData服务器即服务解决方案。
主要特点:
- Skyvia是一个商业的、基于订阅的免费云解决方案计划。
- 基于向导的、无需编码的集成配置不需要太多的技术知识。
- 具有常量、查找和强大的数据转换表达式的高级映射设置。
- 按进度进行集成自动化。
- 能够在目标中保存源数据关系。
- 没有重复导入。
- 双向同步。
- 通用集成案例的预定义模板。
#3) DBConvert Studio By SLOTIX s.r.o
![]()
DBConvert Studio是一个用于本地数据库和云数据库的数据ETL解决方案。它在Oracle、MS SQL、MySQL、PostgreSQL、MS FoxPro、SQLite、Firebird、MS Access、DB2、Amazon RDS、Amazon Aurora、MS Azure SQL、谷歌云等多种数据库格式之间提取、转换和加载数据。

使用GUI模式来优化迁移设置和启动转换或同步。在命令行模式下计划运行保存的作业。
首先,DBConvert studio创建到数据库的并发连接。然后创建一个单独的作业来跟踪迁移/复制过程。数据迁移或同步可以是单向的,也可以是双向的。
无论是否有数据,都可以复制数据库结构和对象。可以对每个对象进行审查和定制,以防止潜在的最终错误。
主要特点:
- DBConvert Studio是一个商业授权的工具。
- 可以免费试用。
- 自动模式迁移和数据类型映射。
- 需要基于向导的无编码操作。
- 自动化会话/作业通过调度器或命令行运行。
- 单向同步
- 双向同步
- 查看和查询迁移。
- 它创建迁移和同步日志来监视进程。
- 它包含迁移大型数据库的批量特性。
- 可以启用/禁用表、字段、索引、查询/视图等每个元素的转换。
- 在迁移或同步过程开始之前,可以进行数据验证。
#4) Sprinkle
![]()
Sprinkle是一个端到端数据管理和分析平台,使用户能够自动完成从多个数据源收集数据、将数据转移到首选数据仓库、以及在路上构建报告的完整数据旅程。Sprinkle提供了SaaS和内部部署选项。
Sprinkle的实时数据管道解决方案使企业能够更快地做出业务决策,从而促进业务的整体增长。Sprinkle增强的数据安全性确保没有数据离开客户的前提,从而确保100%的数据安全。

Sprinkle的无代码平台使整个组织的所有员工都可以访问数据,而不管他们的技术能力如何。这确保了更快的业务决策,因为业务团队不必再依赖数据科学团队来提供见解。
Sprinkle还有一个可选的集成的高级报表和BI模块,可以用于构建交互式仪表板,使用拖放式报表和钻取式报表。
撒的特点:
- 零代码摄取:自动模式发现和数据类型到仓库类型的映射。也支持JSON数据。
- 没有专有的转换代码:Sprinkle做ELT(比遗留的ETL提供更多的灵活性和可伸缩性)。用SQL或python编写转换。
- 构建ML管道的jupiter笔记本接口。
- 增量转换的开箱即用:顾名思义,它意味着只对已更改/新数据应用转换。
- 没有数据离开客户的网络:Sprinkle提供可以在客户云内的虚拟机上运行的企业版本。
#5) IRI Voracity
![]()
Voracity是一个支持云计算的本地ETL和数据管理平台,最著名的是其底层CoSort引擎的“负担得起的体积速度”,以及内置的丰富数据发现、集成、迁移、治理和分析功能,以及Eclipse上的功能。
Voracity支持数百个数据源,并作为“生产分析平台”直接提供BI和可视化目标。
Voracity用户可以设计实时或批处理操作,将已经优化的E、T和L操作结合起来,或者出于性能或价格方面的原因,使用该平台“加速或离开”现有的ETL工具,如Informatica。贪婪的速度接近从头开始,但它的成本接近Pentaho。

主要特点:
- 用于结构化、半结构化和非结构化数据、静态数据和流数据、传统数据和现代数据、本地数据或云数据的各种连接器。
- 任务和io合并的数据操作,包括多个转换、数据质量和一起指定的屏蔽函数。
- 由多线程、资源优化的IRI CoSort引擎提供的转换,或可在MR2、Spark、Spark Stream、Storm或Tez中互换。
- 同步的目标定义,包括预先分类的批量加载、测试表、自定义格式的文件、管道和url、NoSQL集合等。
- 数据映射和迁移可以重新格式化端序、字段、记录、文件和表结构,添加代理键等。
- 用于ETL、子集设置、复制、更改数据捕获、缓慢更改维度、测试数据生成等的内置向导。
- 用于查找、筛选、统一、替换、验证、规范、标准化和合成值的数据清理功能和规则。
- 同关报告,争论(用于Cognos, Qlik, R, Tableau, Spotfire等),或集成Splunk和KNIME进行分析。
- 强大的作业设计、调度和部署选项,以及启用Git和iam的元数据管理。
- 与Erwin Mapping Manager的元数据兼容性(用于转换遗留ETL作业),以及元数据集成模型桥。
- Voracity不是开源的,但当需要多个引擎时,它的价格会低于Talend。它的订阅价格包括支持、文档、无限的客户端和数据源,而且还有永久和运行时许可选项可用。
#6) Informatica – PowerCenter

Informatica是企业云数据管理领域的领导者,在全球拥有500多家合作伙伴,每月交易超过1万亿笔。它是一家软件开发公司,成立于1993年,总部设在美国加利福尼亚州。该公司年收入10.5亿美元,员工总数约4,000人。
PowerCenter是Informatica公司开发的一款数据集成产品。它支持数据集成生命周期,并向业务交付关键数据和值。PowerCenter支持海量数据、任何数据类型和任何数据源进行数据集成。
主要特点:
- PowerCenter是一个商业授权的工具。
- 这是一个现成的工具,并具有简单的培训模块。
- 它支持数据分析、应用程序迁移和数据仓库。
- PowerCenter连接各种云应用程序,由Amazon Web Services和Microsoft Azure托管。
- PowerCenter支持敏捷流程。
- 它可以与其他工具集成。
- 跨开发、测试和生产环境的自动结果或数据验证。
- 非技术人员可以运行和监控作业,这反过来降低了成本。
- 从这里访问官方网站。
#7) IBM – Infosphere Information Server

IBM是一家跨国软件公司,成立于1911年,总部设在美国纽约,在170多个国家设有办事处。截至2016年,该公司的营收为799.1亿美元,目前在职员工总数为38万。
Infosphere Information Server是IBM在2008年开发的一个产品。它是数据集成平台的领导者,有助于理解并向业务交付关键价值。主要为大数据公司和大型企业设计。
主要特点:
- 它是一种商业许可的工具。
- Infosphere Information Server是一个端到端数据集成平台。
- 它可以与Oracle、IBM DB2和Hadoop System集成。
- 它通过各种插件支持SAP。
- 它有助于改进数据治理策略。
- 它还有助于自动化业务流程,以节省更多的成本。
- 跨多个系统的所有数据类型的实时数据集成。
- 现有的IBM授权的工具可以很容易地与它集成。
- 从这里访问官方网站。
#8) Oracle Data Integrator

甲骨文公司成立于1977年,是一家总部设在加州的美国跨国公司。截至2017年,该公司的营收为377.2亿美元,员工总数为13.8万人。
Oracle Data Integrator (ODI)是一个用于构建和管理数据集成的图形化环境。本产品适用于有频繁迁移需求的大型组织。它是一个全面的数据集成平台,支持大容量数据,SOA支持数据服务。
主要特点:
- Oracle Data Integrator是一个商业授权的RTL工具。
- 通过对基于流程的界面的重新设计改进用户体验。
- 它支持数据转换和集成流程的声明式设计方法。
- 更快、更简单的开发和维护。
- 它自动识别错误数据,并在移动到目标应用程序之前将其回收。
- Oracle Data Integrator支持IBM DB2、Teradata、Sybase、Netezza、Exadata等数据库。
- 独特的E-LT架构消除了对ETL服务器的需求,从而节省了成本。
- 它与其他Oracle产品集成,使用现有的RDBMS功能处理和转换数据。
从这里访问官方网站。
#9) Microsoft – SQL Server Integrated Services (SSIS)

微软公司是一家成立于1975年的美国跨国公司,总部设在华盛顿。公司员工总数为12.4万人,年收入为899.5亿美元。
SSIS是微软为数据迁移开发的产品。当集成过程和数据转换在内存中处理时,数据集成要快得多。由于SSIS是微软的产品,所以它只支持Microsoft SQL Server。
主要特点:
- SSIS是一种商业许可的工具。
- SSIS导入/导出向导帮助将数据从源移动到目标。
- 实现了对SQL Server数据库的自动化维护。
- 用于编辑SSIS包的拖放用户界面。
- 数据转换包括文本文件和其他SQL server实例。
- SSIS有一个可用于编写编程代码的内建脚本环境。
- 它可以通过插件与salesforce.com和CRM集成。
- 调试功能和容易的错误处理流程。
- SSIS也可以与变更控制软件如TFS, GitHub等集成。
从这里访问官方网站。
#10) Ab Initio

Ab Initio是一家美国私营企业软件公司,成立于1995年,总部设在美国马萨诸塞州。在英国、日本、法国、波兰、德国、新加坡和澳大利亚都设有办事处。从头算是专门用于应用集成和大容量数据处理。
它包含了Co>操作系统、组件库、图形化开发环境、企业元>环境、数据分析器等6个数据处理产品,并进行>It。“从头开始Co>操作系统”是一个基于GUI的ETL工具,具有拖放功能。
主要特点:
- 从头算是一种商业许可的工具,也是市场上最昂贵的工具。
- 从头算的基本特征很容易学。
- 从头开始Co>操作系统为数据处理和其他工具之间的通信提供了一个通用引擎。
- 从头开始的产品提供在一个用户友好的平台并行数据处理应用程序。
- 并行处理提供了处理大量数据的能力。
- 它支持Windows、Unix、Linux和大型机平台。
- 它执行批处理、数据分析、数据操作等功能。
- 使用从头开始产品的用户必须通过签署NDA来维护机密性。
从这里访问官方网站。
#11--40
请看后文
结论
到目前为止,我们深入研究了市场上可用的各种ETL工具。在目前的市场上,ETL工具具有重要的价值,对于识别提取、转换和加载方法的简化方式非常重要。
市场上有各种工具可以帮助你完成工作,但这取决于需求。
一些公司正在使用数据仓库的概念,技术和分析的结合将导致数据仓库的持续增长,这反过来将增加ETL工具的使用。
讨论:请加入知识星球【首席架构师智库】或者小号【cio_cdo】或者QQ群【11107777】
- 961 次浏览
【集成架构】2020年最好的15个ETL工具(第三部)
最好的开源ETL工具列表与详细比较:
ETL代表提取、转换和加载。它是从任何数据源中提取数据并将其转换为适当格式以供存储和将来参考的过程。
最后,该数据被加载到数据库中。在当前的技术时代,“数据”这个词非常重要,因为大多数业务都围绕着数据、数据流、数据格式等运行。现代应用程序和工作方法需要实时数据来进行处理,为了满足这一目的,市场上有各种各样的ETL工具。
使用这样的数据库和ETL工具使数据管理任务更加容易,同时改进了数据仓库。
市场上可用的ETL平台在很大程度上节省了资金和时间。其中一些是商业的、授权的工具,少数是开源的免费工具。
在本文中,我们将深入研究市场上最流行的ETL工具。
市场上最流行的ETL工具
下面列出了最好的开源和商用ETL软件系统,并进行了详细比较。
推荐的ETL工具
Hevo是一个无代码的数据管道平台,可以帮助您实时地将数据从任何源(数据库、云应用程序、sdk和流)移动到任何目的地。
主要特点:
- 易于实现:Hevo可以在几分钟内设置和运行。
- 自动模式检测和映射:Hevo强大的算法可以检测传入数据的模式,并在数据仓库中复制相同的模式,无需任何人工干预。
- 实时架构:Hevo建立在实时流架构上,确保数据实时加载到仓库。
- ETL和ELT: Hevo具有强大的特性,允许您在将数据移动到数据仓库之前和之后清理、转换和丰富数据。这确保您总是拥有准备好分析的数据。
- 企业级安全性:Hevo符合GDPR、SOC II和HIPAA。
- 警报和监视:Hevo提供详细的警报和粒度监视设置,以便您始终掌握您的数据。
1-10请看前文
http://jiagoushi.pro/15-best-etl-tools-2020-part-1
11-20请看前文
http://jiagoushi.pro/15-best-etl-tools-2020-part-2
# 21) Improvado
Improvado是一款数据分析软件,供营销人员使用,帮助他们将所有数据保存在一个地方。这个营销ETL平台将允许您将营销API连接到任何可视化工具,为此不需要具备技术技能。
它能够连接100多种类型的数据源。它提供了一组连接数据源的连接器。您将能够通过云端或本地的一个平台连接和管理这些数据源。

主要特点:
- 它可以根据您的要求提供原始数据或映射数据。
- 它具有比较跨渠道指标的功能,可以帮助您做出业务决策。
- 它具有改变归因模式的功能。
- 它具有将谷歌分析数据与广告数据映射的功能。
- 数据可以在Improvado仪表板中可视化,或者使用您选择的BI工具。
# 22) Matillion
Matillion是一个用于云数据仓库的数据转换解决方案。Matillion利用云数据仓库的强大功能来整合大型数据集,并快速执行必要的数据转换,从而为数据分析做好准备。
我们的解决方案是专门为亚马逊Redshift、Snowflake和谷歌BigQuery构建的,可以从大量来源提取数据,将其加载到公司选择的云数据仓库,并将数据从其孤立状态转换为有用的、连接在一起的、可用于分析的大规模数据。

该产品通过释放数据隐藏的潜力,帮助企业实现简单性、速度、规模和节约。Matillion的软件被40多个国家的650多家客户使用,包括Bose、GE、西门子、Fox和埃森哲等全球企业,以及Vistaprint、Splunk和Zapier等高增长、以数据为中心的公司。
该公司最近还被TrustRadius提名为2019年数据集成方面的最高评级奖项得主,该奖项仅基于客户用户满意度分数的无偏反馈。该公司还拥有AWS市场上评级最高的ETL产品,90%的客户表示他们会推荐Matillion。
主要特点:
- 在您首选的云平台上启动产品,并在几分钟内开始开发ETL作业。
- 在几分钟内使用70多个连接器从各种来源加载数据。
- 低代码/无代码的基于浏览器的环境,用于可视化编排具有事务、决策和循环的复杂工作流。
- 设计可重用的、参数驱动的作业。
- 构建自文档化的数据转换过程。
- 安排和回顾你的ETL工作。
- 为数据建模以实现高性能的BI/可视化。
- 现收现付账单。
名单上的其他几位:
#23) Information Builders – iWay Software
iWay DataMigrator是一个强大的数据集成工具和B2B集成工具,它简化了ETL过程。
它从XML、关系数据库和JSON中检索数据。iWay数据迁移器几乎可以在所有平台上运行,如UNIX、Linux和Windows。它还使用JDBC、ODBC连接来连接各种数据库访问。
从这里访问官方网站。
#24) Cognos Data Manager
IBM Cognos Data Manager用于执行ETL流程和高性能业务智能。
它具有多语言支持的特点,可以创建一个全球性的数据集成平台。IBM Cognos Data Manager自动化业务流程,并且支持Windows、UNIX和Linux平台。
从这里访问官方网站。
#25) Qlik Data Integration Platform
要在数字时代引领潮流,您业务中的每个人都需要轻松获取最新、最准确的数据。Qlik支持一种DataOps方法,通过自动化数据流(CDC)、细化、编录和发布,极大地加速了您选择的云中的实时、可分析数据的发现和可用性。

从这里访问官方网站。
#26) Pervasive Data Integrator
普适数据集成工具是一种ETL工具。它有助于在任何数据源和应用程序之间建立快速连接。
它是一个健壮的数据集成平台,支持实时数据交换和数据迁移。工具中使用的组件是可重用的,因此可以多次部署这些组件。
从这里访问官方网站。
#27) Apache Airflow
目前,Apache气流还处于起步阶段,得到了Apache软件基金会(ASF)的大力支持。
Apache气流以编程方式创建、调度和监视工作流。它还可以修改调度程序,以便在需要时运行作业。
从这里访问官方网站。
#28) DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
特点
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
#29) Debezium
Debezium是一个用于变更数据捕获的开源分布式平台。启动它,将它指向你的数据库,你的应用程序就可以开始响应其他应用程序提交给你的数据库的所有插入、更新和删除。Debezium是持久和快速的,所以你的应用程序可以快速响应,不会错过一个事件,即使事情出错。
结论
到目前为止,我们深入研究了市场上可用的各种ETL工具。在目前的市场上,ETL工具具有重要的价值,对于识别提取、转换和加载方法的简化方式非常重要。
市场上有各种工具可以帮助你完成工作,但这取决于需求。
一些公司正在使用数据仓库的概念,技术和分析的结合将导致数据仓库的持续增长,这反过来将增加ETL工具的使用。
讨论:请加入知识星球【首席架构师智库】或者小号【cio_cdo】或者QQ群【11107777】
- 242 次浏览
【集成架构】2020年最好的15个ETL工具(第二部)
最好的开源ETL工具列表与详细比较:
ETL代表提取、转换和加载。它是从任何数据源中提取数据并将其转换为适当格式以供存储和将来参考的过程。
最后,该数据被加载到数据库中。在当前的技术时代,“数据”这个词非常重要,因为大多数业务都围绕着数据、数据流、数据格式等运行。现代应用程序和工作方法需要实时数据来进行处理,为了满足这一目的,市场上有各种各样的ETL工具。
使用这样的数据库和ETL工具使数据管理任务更加容易,同时改进了数据仓库。
市场上可用的ETL平台在很大程度上节省了资金和时间。其中一些是商业的、授权的工具,少数是开源的免费工具。
在本文中,我们将深入研究市场上最流行的ETL工具。
市场上最流行的ETL工具
下面列出了最好的开源和商用ETL软件系统,并进行了详细比较。
推荐的ETL工具
Hevo是一个无代码的数据管道平台,可以帮助您实时地将数据从任何源(数据库、云应用程序、sdk和流)移动到任何目的地。
主要特点:
- 易于实现:Hevo可以在几分钟内设置和运行。
- 自动模式检测和映射:Hevo强大的算法可以检测传入数据的模式,并在数据仓库中复制相同的模式,无需任何人工干预。
- 实时架构:Hevo建立在实时流架构上,确保数据实时加载到仓库。
- ETL和ELT: Hevo具有强大的特性,允许您在将数据移动到数据仓库之前和之后清理、转换和丰富数据。这确保您总是拥有准备好分析的数据。
- 企业级安全性:Hevo符合GDPR、SOC II和HIPAA。
- 警报和监视:Hevo提供详细的警报和粒度监视设置,以便您始终掌握您的数据。
1-10请看前文
http://jiagoushi.pro/15-best-etl-tools-2020-part-1
#11) Talend – Talend Open Studio for Data Integration

Talend是一家总部位于美国加州的软件公司,成立于2005年。目前,该公司员工总数约为600人。
Talend数据集成开放工作室是该公司于2006年推出的第一个产品。它支持数据仓库、迁移和分析。它是一个支持数据集成和监控的数据集成平台。公司提供数据集成、数据管理、数据准备、企业应用集成等服务。
主要特点:
- Talend是一个免费的开源ETL工具。
- 它是第一个用于数据集成的商业开源软件供应商。
- 超过900个内置组件用于连接各种数据源。
- 拖放界面。
- 使用GUI和内置组件提高了部署所需的生产率和时间。
- 在云环境中易于部署。
- 数据可以合并,并将传统数据和大数据转换为Talend Open Studio。
- 在线用户社区可以提供任何技术支持。
从这里访问官方网站。
#12) CloverDX Data Integration Software

CloverDX帮助中型到企业级的公司应对世界上最严峻的数据管理挑战。
CloverDX数据集成平台为组织提供了一个健壮而又无限灵活的环境,专门为数据密集型操作而设计,包含高级开发工具和可伸缩的自动化和编制后端。
成立于2002年的CloverDX,目前拥有超过100人的团队,整合了所有垂直领域的开发人员和咨询专业人士,在全球范围内运营,帮助企业控制他们的数据。
主要特点:
- CloverDX是一个商业的ETL软件。
- CloverDX有一个基于java的框架。
- 易于安装和简单的用户界面。
- 以单一格式组合来自不同来源的业务数据。
- 支持Windows、Linux、Solaris、AIX和OSX平台。
- 它用于数据转换、数据迁移、数据仓库和数据清理。
- Clover开发者提供了支持。
- 它有助于使用来自源的数据创建各种报告。
- 使用数据和原型进行快速开发。
从这里访问官方网站。
#13) Pentaho Data Integration/Kettle

Pentaho是一家软件公司,提供一种称为Pentaho数据集成(PDI)的产品,也被称为Kettle。总部位于美国佛罗里达州,提供数据集成、数据挖掘和STL功能等服务。2015年,penttaho被日立数据系统(Hitachi Data System)收购。
Pentaho数据集成使用户能够清理和准备来自不同来源的数据,并允许在应用程序之间迁移数据。PDI是一个开源工具,是Pentaho商业智能套件的一部分。
主要特点:
- PDI可用于企业版和社区版。
- 企业平台有额外的组件,增加了Pentaho平台的能力。
- 易于使用,易于学习和理解。
- PDI的实现遵循元数据方法。
- 用户友好的图形界面拖放功能。
- ETL开发人员可以创建自己的工作。
- 共享库简化了ETL的执行和开发过程。
从这里访问官方网站。
#14) Apache Nifi

Apache Nifi是Apache软件基金会开发的一个软件项目。Apache软件基金会(ASF)成立于1999年,总部设在美国马里兰州。ASF开发的软件是在Apache许可下发布的,是一个免费的开源软件。
Apache Nifi使用自动化简化了不同系统之间的数据流。数据流由处理器组成,用户可以创建自己的处理器。这些流可以保存为模板,以后可以与更复杂的流集成。这些复杂的流可以用最少的努力部署到多个服务器上。
主要特点:
- Apache Nifi是一个开源软件项目。
- 易于使用,是一个强大的数据流系统。
- 数据流包括用户发送、接收、传输、过滤和移动数据。
- 基于流的编程和简单的用户界面支持基于web的应用程序。
- GUI是根据特定的需求定制的。
- 端到端数据流跟踪。
- 它支持HTTPS、SSL、SSH、多租户授权等。
- 最小化构建、更新和删除各种数据流的手动干预。
从这里访问官方网站。
#15) SAS – Data Integration Studio

SAS Data Integration Studio是一个用于构建和管理数据集成过程的图形用户界面。
数据源可以是集成过程的任何应用程序或平台。它具有强大的转换逻辑,开发人员可以使用它构建、调度、执行和监视作业。
主要特点:
- 它简化了数据集成过程的执行和维护。
- 易于使用和基于向导的界面。
- SAS Data Integration Studio是一种灵活可靠的工具,用于响应和克服任何数据集成挑战。
- 它以速度和效率解决了问题,从而降低了数据集成的成本。
从这里访问官方网站。
#16) SAP – BusinessObjects Data Integrator

BusinessObjects Data Integrator是数据集成和ETL工具。它主要由数据集成器、作业服务器和数据集成器设计器组成。BusinessObjects数据集成流程分为数据统一、数据分析、数据审计和数据清理。
使用SAP BusinessObjects Data Integrator,数据可以从任何来源提取并加载到任何数据仓库。
主要特点:
- 它有助于在分析环境中集成和加载数据。
- 数据集成商用于构建数据仓库、数据集市等。
- Data Integrator web administrator是一个web界面,允许管理各种存储库、元数据、web服务和作业服务器
- 它有助于调度、执行和监视批处理作业。
- 支持Windows、Sun Solaris、AIX和Linux平台。
从这里访问官方网站。
#17) Oracle Warehouse Builder

Oracle引入了一个被称为Oracle Warehouse Builder (OWB)的ETL工具。它是一个用于构建和管理数据集成过程的图形化环境。
OWB在数据仓库中使用各种数据源进行集成。OWB的核心功能是数据分析、数据清理、完全集成的数据建模和数据审计。OWB使用Oracle数据库来转换来自各种来源的数据,并用于连接其他各种第三方数据库。
主要特点:
- OWB是一种全面而灵活的数据集成策略工具。
- 它允许用户设计和构建ETL流程。
- 它支持来自不同供应商的40个元数据文件。
- OWB支持平面文件、Sybase、SQL Server、Informix和Oracle数据库作为目标数据库。
- OWB支持数据类型,如数字、文本、日期等。
从这里访问官方网站。
# 18) Sybase ETL

Sybase是数据集成市场的强大参与者。Sybase ETL工具用于加载来自不同数据源的数据,然后将它们转换为数据集,最后将该数据加载到数据仓库。
Sybase ETL使用子组件,如Sybase ETL Server和Sybase ETL Development。
主要特点:
- Sybase ETL为数据集成提供了自动化。
- 创建数据集成作业的简单GUI。
- 易于理解,不需要单独的培训。
- Sybase ETL仪表板提供了对进程所处位置的快速视图。
- 实时报告和更好的决策过程。
- 它只支持Windows平台。
- 它最小化了数据集成和提取过程的成本、时间和人力。
从这里访问官方网站。
# 19) DBSoftlab

DB软件实验室推出了一个ETL工具,为世界一流的公司提供端到端数据集成解决方案。DBSoftlab设计的产品将有助于业务流程的自动化。
使用这个自动流程,用户可以在任何时候查看ETL流程,以获得其确切位置的视图。
主要特点:
- 它是一种商业许可的ETL工具。
- 易于使用和更快的ETL工具。
- 它可以与Text, OLE DB, Oracle, SQL Server, XML, Excel, SQLite, MySQL等。
- 它从任何数据源(如电子邮件)提取数据。
- 端到端业务自动化流程。
从这里访问官方网站。
#20) Jasper

Jaspersoft是数据集成领域的领导者,成立于1991年,总部位于美国加利福尼亚州。它从各种其他来源提取、转换并将数据加载到数据仓库中。
Jaspersoft是Jaspersoft商业智能套件的一部分。Jaspersoft ETL是一个具有高性能ETL功能的数据集成平台。
主要特点:
- Jaspersoft ETL是一个开源的ETL工具。
- 它有一个活动监视指示板,可以帮助监视作业的执行及其性能。
- 它可以连接到SugarCRM、SAP、Salesforce.com等应用程序。
- 它还与大数据环境Hadoop、MongoDB等进行连接。
- 它提供了一个图形化编辑器来查看和编辑ETL进程。
- 使用GUI,允许用户设计、调度和执行数据移动、转换等。
- 实时,端到端进程和ETL统计跟踪。
- 适用于中小型企业。
从这里访问官方网站。
#31-40 请看后文
结论
到目前为止,我们深入研究了市场上可用的各种ETL工具。在目前的市场上,ETL工具具有重要的价值,对于识别提取、转换和加载方法的简化方式非常重要。
市场上有各种工具可以帮助你完成工作,但这取决于需求。
一些公司正在使用数据仓库的概念,技术和分析的结合将导致数据仓库的持续增长,这反过来将增加ETL工具的使用。
讨论:请加入知识星球【首席架构师智库】或者小号【cio_cdo】或者QQ群【11107777】
- 309 次浏览
【集成架构】Redhat :理解企业集成
应用程序和数据集成是交付新客户体验和服务的基础。通常,一个团队管理整个企业的单片集成技术,但是应用程序正变得越来越复杂——它们是分布式的,并且必须快速扩展和更改,以在竞争的市场中保持同步。这些新的挑战需要基于云本地集成技术和敏捷团队的迭代方法。
什么是企业集成?
每个现代企业都必须共享数据。如果你是一个试图利用大数据的大企业,你知道大数据是一个集成的挑战。要做到这一点,处于业务策略核心的应用程序和设备必须彼此可访问,并且很可能可以跨多个云环境访问。企业集成包括连接IT组织中各处的数据、应用程序和设备的技术、流程和团队结构。
多年来,企业集成模型已经从具有相对较少的点到点连接的模型,发展到通过企业服务总线(ESB)连接的集中式模型,再到具有许多可重用端点的分布式体系结构。
企业集成的“什么”和“如何”
比如“你要集成什么?”

首先,企业集成是一个数据挑战。现在组织中存在如此多的数据,以至于术语“大数据”经常被用来表示数据源的大小和多样性。以各种非标准格式存在的大量数据可能具有重要的业务价值,但首先必须从多个源或应用程序集成这些数据。物联网(IoT)也代表了一个通过日常设备连接客户和分析有用数据的新机会,但你必须过滤掉进入数据中心的关键数据。Web应用程序进一步增加了企业集成的复杂性,特别是当遗留应用程序必须与基于服务的体系结构(如微服务)集成时。
例如,“您如何集成您的应用程序、设备和数据?”
![]()
在过去,由集中式团队管理的集中式企业服务总线(ESB)可以连接环境中的每个端点。然而,对团队和技术的集中方法可能会限制现代系统,而现代系统需要快速、简单的途径来集成分布式组件。根据您的数据和服务需求,消息传递、应用程序连接器、数据流、企业集成模式和应用程序编程接口(api)的组合更适合现代应用程序开发。
消息传递
消息传递是分布式应用程序体系结构中不同组件进行通信的一种方式。组件可以跨不同的语言、编译器和操作系统发送和接收消息,只要通信的每一方都理解通用的消息传递格式和协议。
服务网格用于在微服务体系结构中路由消息。
应用连接器
应用程序连接器是为组件如何交互的规则建模的体系结构元素。它们是为某些api定制的标准类连接,因此可以用于快速集成新端点。
数据流
数据流提供了一个恒定的信息流,应用程序可以在其中添加或使用这些信息流,而与数据的传输无关。例如,Apache Kafka是一个分布式数据流平台,可以实时发布、订阅、存储和处理记录流
企业集成模式
EIP是针对常见集成问题的独立于技术的解决方案的集合。模式还为开发人员和应用程序架构师提供了描述集成的通用语言。
应用程序编程接口
API是一组用于构建应用程序软件的工具、定义和协议。它允许您的产品或服务与其他产品和服务进行通信,而不必知道它们是如何实现的。
原文:https://www.redhat.com/en/topics/integration
本文:https://pub.intelligentx.net/redhat-understanding-enterprise-integration
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 98 次浏览
【集成架构】Redhat 观点:什么是集成
IT集成或系统集成是跨IT组织的数据、应用程序、api和设备的连接,以提高效率、生产力和敏捷性。当讨论业务转换时,集成是关键——当市场变化时,您如何进行业务以适应的基本变化——因为它使it中的一切都协同工作。集成不仅连接,而且还通过连接不同系统的功能提供的新功能来增加价值。例如,Apache Kafka是一个开放源码平台,它允许您将数据流与应用程序集成,这样它们就可以实时处理数据。
IT集成不同于持续集成(CI),持续集成是一种开发人员的实践,在持续集成中,每天将代码的工作副本多次合并到共享的中央存储库中。CI的目标是自动化构建和验证,以便更早地发现问题,从而加快开发速度。
集成的简史
随着时间的推移,随着IT系统的成长和发展,它们开始彼此分离。一个供应商的解决方案无法与另一个供应商的解决方案进行沟通。接下来你知道的是,你有一个完整的IT堆栈,而连接它的只是你拥有它的事实。因此,需要一种方法来组织这种技术“意大利面条”,以停止重复的工作——特别是在实现和操作业务逻辑方面。
*注意:以下是关于语义的争论:物理拓扑vs逻辑拓扑,方法vs架构vs技术。下面的解释将是总体概述。
企业应用程序集成
企业应用集成(EAI)解决了所有这些分散的问题,它是一种技术、工具和框架,实现了应用程序之间实时的、基于消息的集成。这些消息是由各个应用程序内的更改或参数触发的。EAI有两种实现方式,点对点和中心辐射。
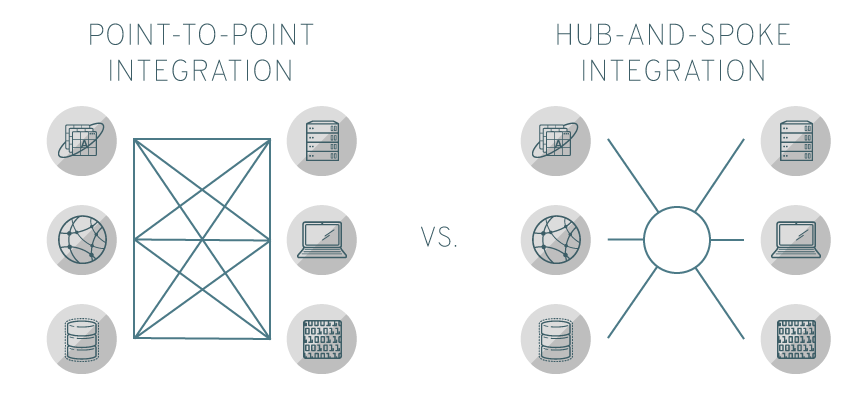
点对点模型意味着必须对每个应用程序进行定制,以便与其他应用程序和IT部分进行对话。这都是为每个IT资产及其连接的每个资产定制的。这也是一项非常繁琐的工作,而且容易出错。更复杂的是,随着你更新你的基础设施和应用程序,这个模型可能很难维护一段时间。
为了解决这个问题,有一个中心辐射型模型,在这个模型中,应用程序和服务之间的连接由一个中央经纪人——中心来处理。连接中心与应用程序和服务的轮辐可以单独维护。这使得应用程序本身更加集中,通过中心和辐条处理所有的集成艺术。这种方法的主要缺点是集线器的集中化。它成为系统和基础设施通信的单一故障点。根据设计,EAI中心辐射模型中的所有集成都依赖于中心的功能。
企业服务总线
遵循EAI中心辐射式方法的是企业服务总线(ESB),这是一个在应用程序之间提供基于消息的抽象模块化服务的工具。
ESB还充当一个中心集线器,所有这些模块化的服务都在其中进行共享、路由和组织,以将应用程序和数据彼此连接起来。这是对EAI中心和分支的更好的解决方案,但随着组织的增长、资产的增加以及所有属性和软件资源需要更快的速度,这可能不是最终的解决方案。

到目前为止,您已经推测ESB看起来很像轮辐模型。这是事实,但是ESB具有一些非常独特的功能,使其在功能方面与众不同。
esb使用开放标准将自己呈现为服务。这样就不需要为每个应用程序编写惟一的接口。
集成服务可以通过对应用程序的最小更改进行部署。
esb依赖于行业标准的开放协议和接口来简化新部署。
然而,典型的ESB部署通常会导致集中式体系结构,这是中心辐射式模型中提到的明显原因——一个承载和控制所有集成服务的地方。但是,集中式ESB部署和体系结构带有严格的中央治理,这无助于交付更快、更适合的解决方案,而这些解决方案是数字转换活动的基础。此外,esb本身常常成为单片应用程序。
敏捷集成
到目前为止,我们已经讨论了集成本身—使所有东西一起工作的技术。那么,什么是敏捷集成?简单地说,这就是Red Hat如何看待连接系统的未来,以及它们如何支持您的it团队必须完成的实际工作,以使其蓬勃发展——特别是在变更发生得更频繁的情况下。
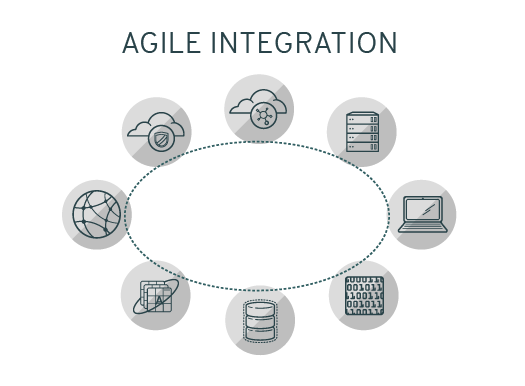
Red Hat认为,传统的集成方法(由集中的团队控制单片技术)可能会妨碍分布式应用程序的开发和长期使用。ESB等传统集成技术具有优先考虑安全性和数据完整性等优点,但它们也依赖于单个团队来定义整个企业的集成。
今天,通过敏捷和DevOps方法开发的松散耦合的云本地应用程序架构需要一种同样敏捷和可伸缩的集成方法。Red Hat对敏捷集成的看法是,它是一种连接资源的方法,结合了集成技术、敏捷交付技术和云原生平台,以提高软件交付的速度和安全性。具体来说,敏捷集成涉及到将诸如api之类的集成技术部署到Linux容器中,并将集成角色扩展到跨功能团队。敏捷集成体系结构可以分解为3个关键功能:分布式集成、容器和应用程序编程接口。
分布式集成
- 小的足迹
- 基于模式的
- 面向事件的
- 社区代码
这给你:
- 灵活性
容器
- 原生云
- 精益,单独部署
- 可伸缩的、高可用性
这给你:
- 可伸缩性
应用程序编程接口 (API)
- 定义良好、可重用、管理良好的端点
- 生态系统影响与利用
这给你:
- 可重用性
原文:https://www.redhat.com/en/topics/integration/what-is-integration
本文:https://pub.intelligentx.net/redhat-view-what-integration
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 230 次浏览
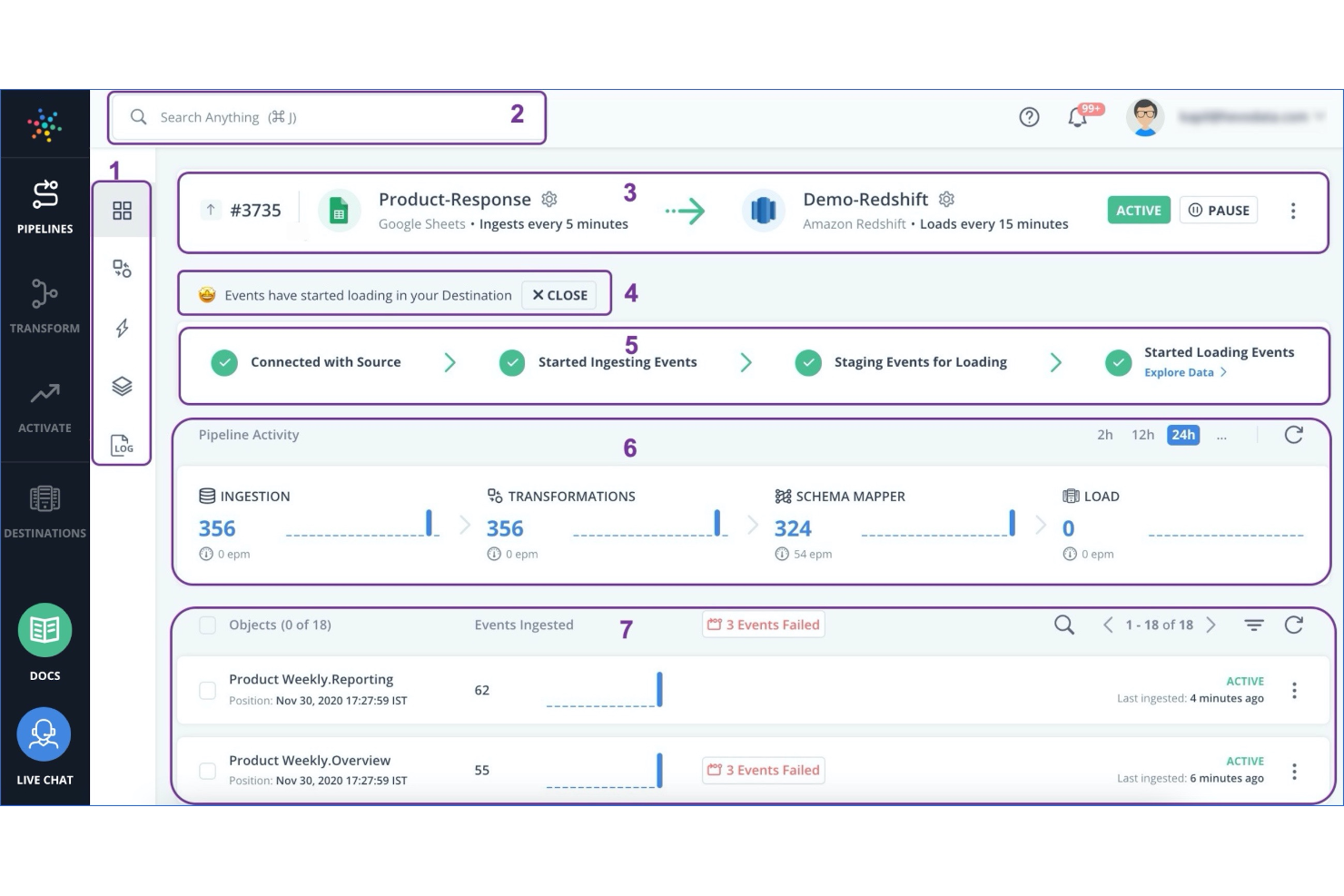
【集成架构】SAP BW/4HANA中的ETL集成选项说明
SAP的旗舰数据仓库应用程序BW/4HANA打破了应用程序级与外部“提取转换和加载”(ETL)工具集成的传统。与SAP Data Services和HANA Smart Data Integration等工具的集成现在在BW/4HANA应用程序之外的HANA层进行。Jan van Ansem解释了如果您计划在BW/4HANA接口上使用ETL工具会产生什么后果。
SAP数据服务通常被客户用于将非SAP系统中的数据转换和加载到SAP Business Warehouse(HANA上的BW或BW,BWoH)应用程序中。数据服务允许您使用图形用户界面设计ETL流程,轻松地连接到各种数据源并以简单的方式设计复杂的转换。我在数据服务部门工作多年,对这个ETL工具非常赞赏。当SAP引入智能数据集成(SDI)时,我更加高兴,SDI提供了与数据服务相同的功能,但却是HANA平台的一个集成部分。当我意识到在BW/4HANA中,与数据服务和SDI等工具的集成已经超出了BW应用层时,我感到有点震惊。ETL集成现在发生在HANA原生层中,这是一种架构改进,但是对于BW的现有数据服务用户来说,这既赋予了许可的含义又带来了转换的挑战。
好消息:架构改进
SAP兑现了简化BW的承诺。与ETL工具的集成更容易,更符合企业数据仓库标准,并且比通过PSA表进行集成时更灵活。这主要是通过从BW/4HANA应用程序中删除PSA层并使用本地HANA表来实现的。
HANA表格比PSA有明显的好处:
- 任何应用程序都可以使用HANA表,其中PSA表只能由BW应用程序使用
- 到HANA表的连接是通过HANA平台管理的,它提供了许多不同的加载和更新表的机制,而PSA表只能通过BW应用程序中的可用选项加载,其中的选项要少得多。
- PSA表是BW应用程序特有的特性,通常忽略对它们的管理。迁移到HANA表意味着该体系结构更符合一般数据仓库体系结构,并且HANA表的管理比管理PSA表简单得多。
从企业数据仓库(EDW)向大数据仓库(BDW)转变的趋势意味着集成来自各种来源的数据变得更加重要。传统的EDW后端系统(S/4HANA和其他SAP源系统)的集成仍然直接通过操作数据供应(ODP)框架在BW/4HANA中进行。现在可以通过HANA本机层轻松地将大多数其他源集成到BW/4HANA中。对于数据仓库架构师和工程师来说,这是一个好消息,但对于那些买单的人来说,这可能不是一个好消息,我将在下一段中展示。
SAP的旗舰数据仓库应用程序BW/4HANA打破了应用程序级与外部“提取转换和加载”(ETL)工具集成的传统。与SAP Data Services和HANA Smart Data Integration等工具的集成现在在BW/4HANA应用程序之外的HANA层进行。Jan van Ansem解释了如果您计划在BW/4HANA接口上使用ETL工具会产生什么后果。
SAP数据服务通常被客户用于将非SAP系统中的数据转换和加载到SAP Business Warehouse(HANA上的BW或BW,BWoH)应用程序中。数据服务允许您使用图形用户界面设计ETL流程,轻松地连接到各种数据源并以简单的方式设计复杂的转换。我在数据服务部门工作多年,对这个ETL工具非常赞赏。当SAP引入智能数据集成(SDI)时,我更加高兴,SDI提供了与数据服务相同的功能,但却是HANA平台的一个集成部分。当我意识到在BW/4HANA中,与数据服务和SDI等工具的集成已经超出了BW应用层时,我感到有点震惊。ETL集成现在发生在HANA原生层中,这是一种架构改进,但是对于BW的现有数据服务用户来说,这既赋予了许可的含义又带来了转换的挑战。
挑战:许可
使用BW/4HANA,不再可能使用外部ETL工具直接加载到BW/4HANA应用程序层。与ETL工具的集成在HANA本机层中进行,但是根据BW/4HANA的HANA运行时许可证,不允许直接在HANA层中创建目标表。HANA企业许可证允许您在HANA本机中创建目标表,这将使您的数据仓库大大增加成本。那么,有什么选择呢?让我们看看几个不同的场景。
场景1:具有智能数据集成的大数据仓库
如果您计划将EDW(报告标准后台应用程序)发展为BDW(将后台数据与社交媒体、传感器数据和其他大数据源结合起来),那么您希望将BW/4HANA的功能与HANA平台功能结合起来。在这种情况下,您需要一个HANA企业许可证。这允许您将SDI用于ETL,您可以为BW/4HANA入站层创建任意数量的HANA本机表,当然您还可以使用HANA平台的许多其他优秀功能。
我预计,在不久的将来,当组织意识到传统EDW与大数据仓库平台紧密集成的好处时,这将成为一种更常见的情况。
场景2:BW/4HANA,使用SAP Data Services作为ETL工具
许多客户目前使用BW或BW on HANA(BWoH),并将SAP数据服务用作ETL工具。当迁移到BW/4HANA时,需要转换数据服务流程。数据服务现在将加载到HANA表中,而不是直接加载到BW应用程序中。除了更改所有数据服务进程需要付出相当大的努力之外,还涉及到许可证问题。运行时许可证不允许您直接创建HANA本机表,因此客户将面临HANA企业许可证的成本。
SAP已确认,他们正在制定解决方案来解决此许可问题。预计今年晚些时候会有更多关于这方面的消息。我只能希望SAP不仅能解决许可问题,还能提出一个转换程序,用HANA目标替换数据流中的BW目标。
对于那些现在正在使用BW或BWoH并且正在考虑迁移到BW/4HANA的客户,我的建议是与他们的SAP客户经理讨论他们的选择。
场景3:BW/4HANA和其他ETL工具
如果您正在使用非SAP ETL工具将非SAP数据加载到BW或BWoH,并且正在考虑迁移到BW/4HANA,那么您与数据服务用户处于同一条船上:您不能再直接加载到BW/4HANA,但必须加载到HANA本机暂存层。不同的是,SAP不大可能推出打折的许可模式来减轻这一打击。再次,与您的SAP客户经理交谈,讨论您的选择。
解释了ETL集成选项
如何在BW/4HANA中使用数据服务和SDI的问题经常出现在SCN和其他讨论论坛上。答案并不总是有帮助的。不同的消息来源有时有矛盾的信息。我希望这个博客已经清楚地表明,ETL工具不再与BW/4HANA应用程序直接集成。集成在HANA本机层中进行。从体系结构的角度来看,这是一个改进,但在某些情况下,会涉及到许可证问题。
原文:https://blogs.sap.com/2018/05/22/etl-integration-options-in-sap-bw4hana-explained/
本文:http://jiagoushi.pro/etl-integration-options-sap-bw4hana-explained
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 361 次浏览
【集成架构】Talend vs Pentaho - 8个有用的比较
Talend和Pentaho的区别
数据总是巨大的,任何行业都必须存储这些“数据”,因为它带有巨大的信息,从而导致他们的战略规划。正如人们需要房子感到安全一样,数据也必须得到保障。这个数据主页在技术上称为数据仓库。
此外,并非所有数据都是真实数据。企业的增长与数据的增长成正比。而这种增长可能会对数据效率产生影响。为了消除这种情况,数据必须没有重复和错误,因为这样的数据不会产生预期的结果。这是数据集成很重要的地方。当数据转向可访问数据时,它使员工的工作变得更加容易,让他专注于有效的计划和预测。
获得此数据后,重要的是从系统中提取数据,并通过各种工具在环境中进一步分析以满足业务需求。这些工具通常称为ETL(提取,转换和加载)工具,Talend和Pentaho是两种这样的ETL工具,广泛用于各个行业。
在深入研究之前,让我们在这里了解基础知识。
以下是ETL工具实际含义的简单说明:
- 提取:通常从化合物数据库收集数据。 'E'的功能是从源读取数据。
- 变换:与'E'相比,'T'功能相当具有挑战性,但并不复杂。它遵循一个简单的过程,其中提取的数据从其原始形式适应它需要的形式(目标),以便它可以与另一个数据库相关联。尽管该过程看起来很简单,但该过程涉及通过从多个数据库合并和同步来实现规则或查找表
- 加载:“L”功能仅遵循一条路线。将数据写入目标数据库。
管理员在没有任何工具的帮助下关联不同数据库是一项艰巨的任务。因此,这些工具不仅可以简化工作,还可以节省时间和金钱。
Talend与Pentaho之间的比较(信息图表)
以下是Talend与Pentaho的比较

Talend与Pentaho之间的主要区别
Talend和Pentaho Kettle在他们自己的市场中是无可挑剔的工具,下面是显着的差异:
Talend:
- Talend是一个开源数据集成工具,而Pentaho Kettle是一个商业开源数据集成工具
- Talend提供与并发数据库和其他形式数据的有限连接,但具有连接到数据源的Java驱动程序的依赖因子,而Pentaho提供与大量数据库和其他形式数据的广泛连接
- Talend的支持主要存在于美国,而Pentaho的支持不仅存在于美国,而且还针对英国,亚太市场
虽然Talend和Pentaho工具都具有相似的特性,但是需要理解Pentaho Kettle具有轻微优势的GUI。
下面我们看到Pentaho Kettle到Talend的显着特征和突出产品:
- Pentaho水壶比Talend快两倍
- 与Talend的GUI相比,Pentaho kettle的GUI更易于运行
- 适应系统
- 可以轻松处理不同的数据集群
- 在转换处理时可以在许多机器上用作从属服务器
- 拥有成本
当存在已经运行/正在实现Java程序的现有系统时,Talend更有用。
下面列出了Talend代码生成方法的优点
- 轻松部署(适用于独立Java应用程序)
- 节省时间
- 经济有效
任何人都同意这样一个事实,即实现ETL工具的整个目的是帮助实体利用数据集成来使用各种部署模型和基础架构来规划其策略。这些工具需要对现有系统和目标系统都具有灵活性,并提供广泛的交付能力。虽然Talend是一个开源数据集成工具,但如果他们利用其提供更多附加功能的订阅,则可以从该工具中获益更多。
Talend与Pentaho之间的比较表
比较Talend和Pentaho Kettle是一项具有挑战性的任务。 不是因为一个人向另一个人挑战的挑战,而仅仅是因为这些工具在彼此之间提供了相似之处。
Talend和Pentaho Kettle可以与两个不同的人进行比较,他们通过自己的优势,能力和能力为社会提供理想的结果。
因此,人们应该非常重视理解这两种工具所提供的并不是最重要的,而是; 取决于辛迪加/企业在战略要求和规划方法方面的回应方式。
比较表详细设计了这两种工具如何在一般情况下发挥作用。
| Comparison | Talend | Pentaho Kettle |
| Approach | Code generating approach | Meta-driven approach |
| Deployment | The java file, Perl file can run on any external machine | A stand-alone java engine that runs on a machine which runs Java |
| Speed | Sluggish when compared to Pentaho | Runs briskly when compared to Talend |
| Risk | Risk level is equal when compared to Pentaho | Risk level is equal when compared to Talend |
| Data Quality (DQ) | Equips DQ features in Graphical User Interface (GUI) | Equips DQ features in GUI and also contains additional features |
| Monitoring | Comprises of adequate monitoring tools and logging | Comprises of adequate monitoring tools and logging |
| Community Support | Strong | Strong |
| Interface | Moderate | Moderate |
* Pentaho是一个BI套件,使用名为Kettle的产品进行ETL
Talend遵循代码生成器方法,处理数据管理网络
Pentaho Kettle遵循元驱动方法,也是网络中的解释器
结论 - Talend与Pentaho
Talend和Pentaho Kettle都是强大的,用户友好的,可靠的开源工具。
Talend更像是我们在数据集成,数据质量和数据管理平台方面遇到的所有复杂挑战的答案
Pentaho Kettle更像是一款易于使用的智能商务智能套件
如上所述,虽然说明了两种工具的正面比较,但结果取决于最终客户的需求方式。
推荐文章
这是Talend和Pentaho之间差异的指南,它们的含义,头对头比较,关键差异,比较表和结论。 您还可以查看以下文章以了解更多信息 -
- 8 Amazing Difference Between Talend vs SSIS
- 12 Best Difference Between Talend Vs Informatica PowerCenter
- Business Intelligence vs Machine Learning-Which One Is Better
- Predictive Analytics vs Data Mining – Which One Is More Useful
原文:https://www.educba.com/talend-vs-pentaho/
本文:https://pub.intelligentx.net/talend-vs-pentaho-8-useful-comparisons-learn
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 158 次浏览
【集成架构】我们得谈谈 Apache Camel

你甚至可以在Kubernetes上运行它…
Apache Software Foundation(ASF)在2019年监督了339个项目,有超过3000名提交者组成的强大社区修改了59309787行代码。
通过提交,最活跃的项目是Apache Camel——一个旨在让企业开发人员集成大量应用程序的工具。
Apache camel缺乏其他ASF项目Hadoop、Kafka或Spark的品牌认知度;这些项目都被知名企业广泛使用,其中许多企业已经在此类开源软件上构建了其架构的关键组件。
但随着企业寻求集成更多的应用程序(例如,综合使用它们生成的数据),Apache Camel变得越来越重要。
(对于那些喜欢开发人员主导的DIY方法,而不是使用第三方承包商并为其软件支付许可费的人来说,情况尤其如此。)
Apache camel:欧盟委员会的开发者喜欢它…
在使用apache camel的人中,有欧洲委员会(EC)的开发人员。
欧洲政策制定者直截了当地希望看到更多的开源工具在各成员国使用,或许这并不奇怪。
正如欧盟委员会一位负责“开发可重用组件,倡导开源软件”的开发人员所说:“我个人喜欢与其他集成框架相比的优雅和性能。”
他还鼓吹一个活跃的社区(在2019年有41164个承诺)。
告诉我更多…
Confluent的Kai Wähner也对这个项目充满热情。
在DZone的一个博客中,他指出“[apachecamel允许您]使用所需的模式轻松地集成不同的应用程序。
“您可以使用Java、springxml、Scala或Groovy。几乎所有您能想到的技术都是可用的,例如HTTP、FTP、JMS、EJB、JPA、RMI、JMS、JMX、LDAP、Netty等等(当然,大多数esb也提供对它们的支持)。此外,可以很容易地创建自己的自定义组件。”
他补充道:“您可以将Apache camel作为独立的应用程序部署在web容器(例如Tomcat或Jetty)、JEE应用服务器(例如jbossas或websphereas)、OSGi环境或与Spring容器结合使用。
“每个集成都使用相同的概念!
“不管你用哪种协议。不管你使用哪种技术。无论您使用哪种领域特定语言(DSL),它可以是Java、Scala、Groovy或springxml。你也是这么做的。永远!有生产者,有消费者,有端点,有EIP,有自定义处理器/bean(例如用于自定义转换)和参数(例如用于凭据)。”
即使是以开源Mule-ESB形式提供类似产品的mulesft也承认Camel的精益框架“使程序员更容易学习。Camel还支持不同的领域特定语言(DSL),允许程序员使用他们认为最合适的语言工作。”
“Camel还通过坚持企业集成模式(EIP)缩小了建模和实现之间的差距,允许程序员将集成问题分解成更容易理解的小部分。
2020年新产品
2019年,Apache Camel团队增加了两个新项目:Camel K和Camel Quarkus。Camel K基本上采用了Camel的工具箱,并在Kubernetes上以原生方式运行,这个版本是专门为无服务器和微服务架构设计的。
(Camel K的用户可以使用Kubernetes或OpenShift在他们首选的云上立即运行用Camel DSL编写的集成代码)。
今年早些时候,它计划添加新的工具,包括Kafka连接器和Camel-springboot(从主存储库中移出),这是一个基于Java的开源框架,用于创建由Pivotal开发的微服务。
欧盟委员会(europeancommission)似乎不太可能成为开拓者,但预计到2020年,人们将听到更多关于apachecamel的消息。
原文:https://www.cbronline.com/feature/apache-camel
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 515 次浏览
【集成架构】明智地选择您的ETL - 商业与开源
作为企业架构师,您有时最终会进行工具评估,并负责为您的企业选择合适的工具。有时候,随机你会得到一个问题 - 你可以检查开源工具的选项。随着开源技术越来越受欢迎,我越来越频繁地面临开源与商业模式的明显问题。而且由于我在ETL领域的专业知识,我在这方面所做的所有工作 - 我想到了两个世界当前的市场领导者,并分析了如何为您的企业做出正确的决策。
首先,我考虑了2个顶级商业ETL工具和2个开源工具。我考虑的商业广告是Informatica和DataStage。我考虑的开源工具是由Pentaho生态系统中的Talend和Pentaho Data Integration PDI(Kettle)开发的Talend Open Studio。
现在让我们了解一下商业ETL工具对于高价格标签的期望,与任何开源选项相比。
- 任何商业选择都会为您提供更好的支持(对我来说这是一个非常重要的参数,我们大多数人在考虑任何工具时都会忽略)和持续的产品升级。
- 此外,在大多数情况下,您最终会获得更好的审计和监视功能以及更好的负载平衡和并行执行选项和功能。
- 更好地覆盖第三方连接器,以便从集成层连接到各种应用程序和软件。与构建自定义Java适配器相比,这越来越成为节省时间和成本的决定性参数。
一般而言,在为您的组织选择合适的ETL平台时应该注意的参数如下 -
- 数据质量和治理能力
- 综合审计平衡和控制框架
- 第三方适配器和连接器
- GUI和易用性
- 集中的可共享元数据,用于在整个组织中扩展和重用元数据
- 监控和管理功能
- 调试功能
- 高可用性,负载平衡和故障转移
- 售后支持(技术支持)
- 市场上的人才(确保您没有利基和罕见的工具,这将增加您的开发和维护成本)
- 最后,随着越来越多的组织转向云 - 支持和兼容领先的云提供商和相关的安全选项
现在说了所有这些,下面是我对上面提到的4个ETL工具的看法,以便为你的任务提供快速入门 -
- Informatica是市场上最稳定的工具之一。 Informatica可以很好地处理大量数据。借助CDC,增量加载,映射参数和变量,动态查找,前后SQL等功能,Informatica可以轻松地灵活处理大量数据。但我希望看到Informatica的主要改进是在GUI界面中。而不必为Designer,WF管理器和WF监视器打开单独的窗口,如果这三个窗口可以合并到三个单独的选项卡中或构建到构建子任务的层次结构中,例如,工作流会打开会话和会话打开一个映射,不像当前只打开映射属性,这将是很好的。
- 对于DataStage,主要优点是易用性,易于调试功能和中央存储库概念,可以将元数据扩展到IBM IIS套件中的所有其他工具。但是一个很大的缺点(如果你是一个老的DS用户)是服务器和企业版的巨大架构差异,这导致从服务器到企业版的迁移可能需要大量的时间和资源。此外,即使经过这么多年,一些标准连接器也不那么强大并且存在性能问题。我对使用DataStage的SF适配器的个人经验对于批处理操作非常糟糕。
- 现在转向开源工具 - 最大的优势当然是成本。它们提供了一种非常经济有效的方式来开始数据质量或主数据管理计划,而无需任何重大投资。这种思维方式也适合当前对迭代和增量项目的偏好,通过在短时间内提供小而有价值的业务功能来降低业务风险。
- Talend在开发过程中投入了大量资源,并且正在补充其他工具来创建真正的数据集成套件。它在Jaspersoft项目中使用,这意味着它只会从这里发展而来。另一方面,Pentaho Data Integration是一个非常直观且易于使用的工具。虽然它错过了对真正集成的项目存储库的管理。这两种工具都是可靠,高性能,用户友好和跨平台(基于Java)。与Talend相比,Pentaho Kettle IDE稍微容易开始,但也不那么全面。 Talend Open Studio的学习曲线有点陡峭,但其灵活性和强大功能极大地弥补了第一次影响。总的来说,Pentaho Kettle非常易于使用,是Pentaho环境中的一个很好的解决方案。 Talend是一个更通用的数据管理平台,可与其Talend ESB,Talend Data Quality和Talend MDM配套使用。
现在,通过上面的内容,我想这将有助于您和您的组织决定正确的ETL工具集,这将有助于其数据集成领域。
原文:https://www.linkedin.com/pulse/choose-your-etl-wisely-commercial-vs-open-source-nath/
本文:https://pub.intelligentx.net/choose-your-etl-wisely-commercial-vs-open-source
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 61 次浏览
【集成架构】速度分层(pace-layered)的集成架构
在自适应企业中实现整合
在现代企业中,很难看到统一整个环境的单一整体应用程序。 虽然仍然可能存在大型主机或其他系统来保存组织的主要数据和事实来源(SoT),但如今大多数环境都具有满足各种业务功能的中型到大型应用程序。 根据企业的规模和复杂程度,这些应用程序可以从少数应用程序到数百种应用程序。
虽然很明显集成成本随着应用程序的数量而增加,但人们也可以争辩说,随着您逐渐远离“一个应用程序完成所有”模型,变更成本会降低。 这一论点背后的原因是,每一次变化,无论多小,通常都会导致整体应用程序的完全重新部署,并且必然会导致整个系统的回归测试成本。
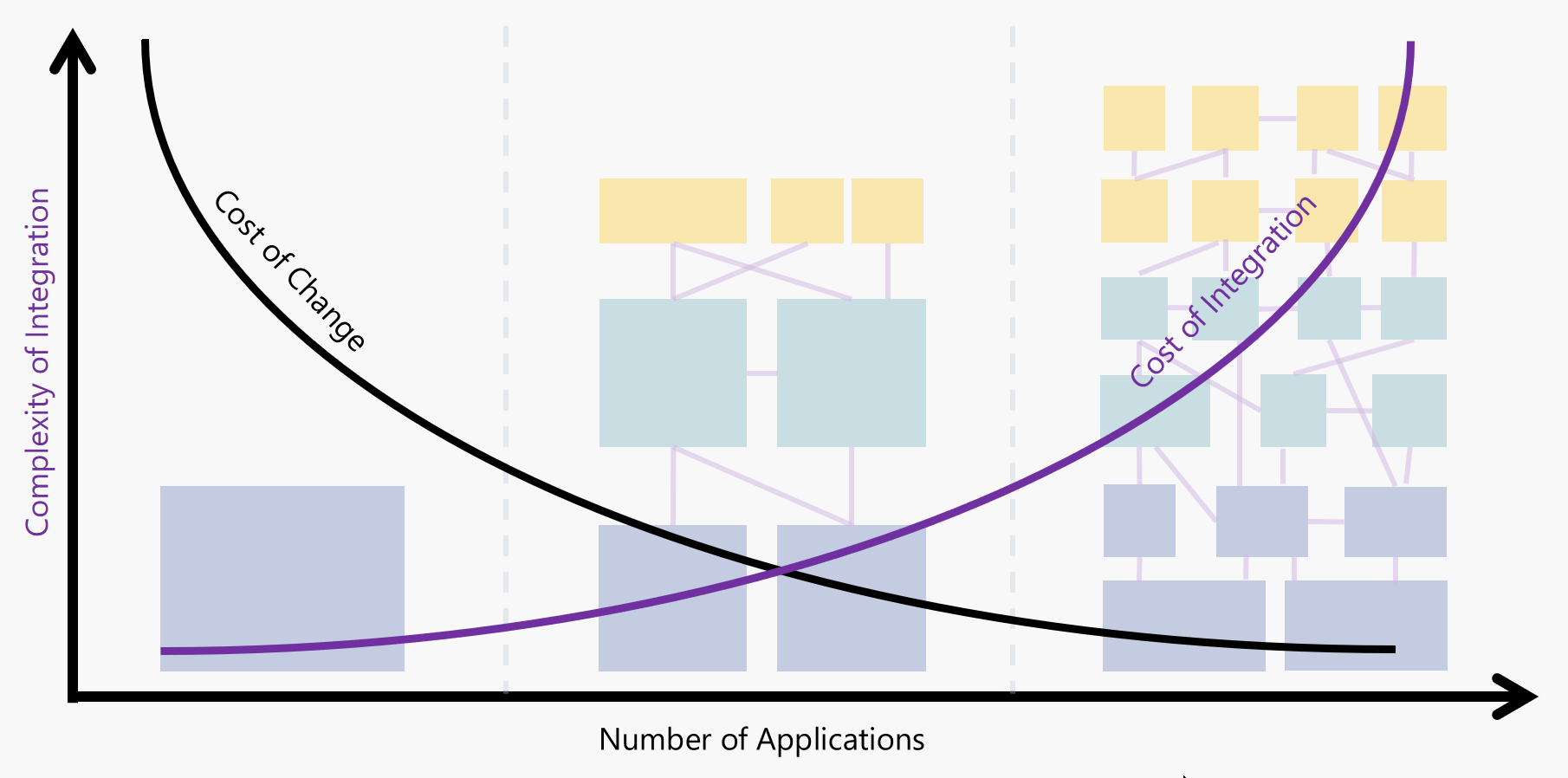
但除了成本和应用数量之外,还有一个额外的维度需要考虑 - 时间。 并非所有应用都是平等的。 任何架构图的问题在于它代表了历史中的单个点 - 它本质上是一个快照。 现实是应用程序随时间而变化; 一些已升级,另一些已修改或扩展,其他可能被删除或替换。 这些应用程序的变化率各不相同,因为有些系统的变化速度比其他系统慢。 这可以在分层视图中表示:
应用程序架构中的层概念并不新鲜;大约十年前,Gartner创建了Pace分层应用战略,以解决业务领导者(他们希望系统灵活并适应业务环境变化)与IT所有者(通常希望系统保持一致)之间的共同脱节。他们运行顺利)。识别这些不同的变化率并相应地对应用程序进行分组有助于应用适当级别的治理,变更控制,测试和DevOps - 使业务能够在需要的地方进行创新,同时保护其关键数据和核心流程。
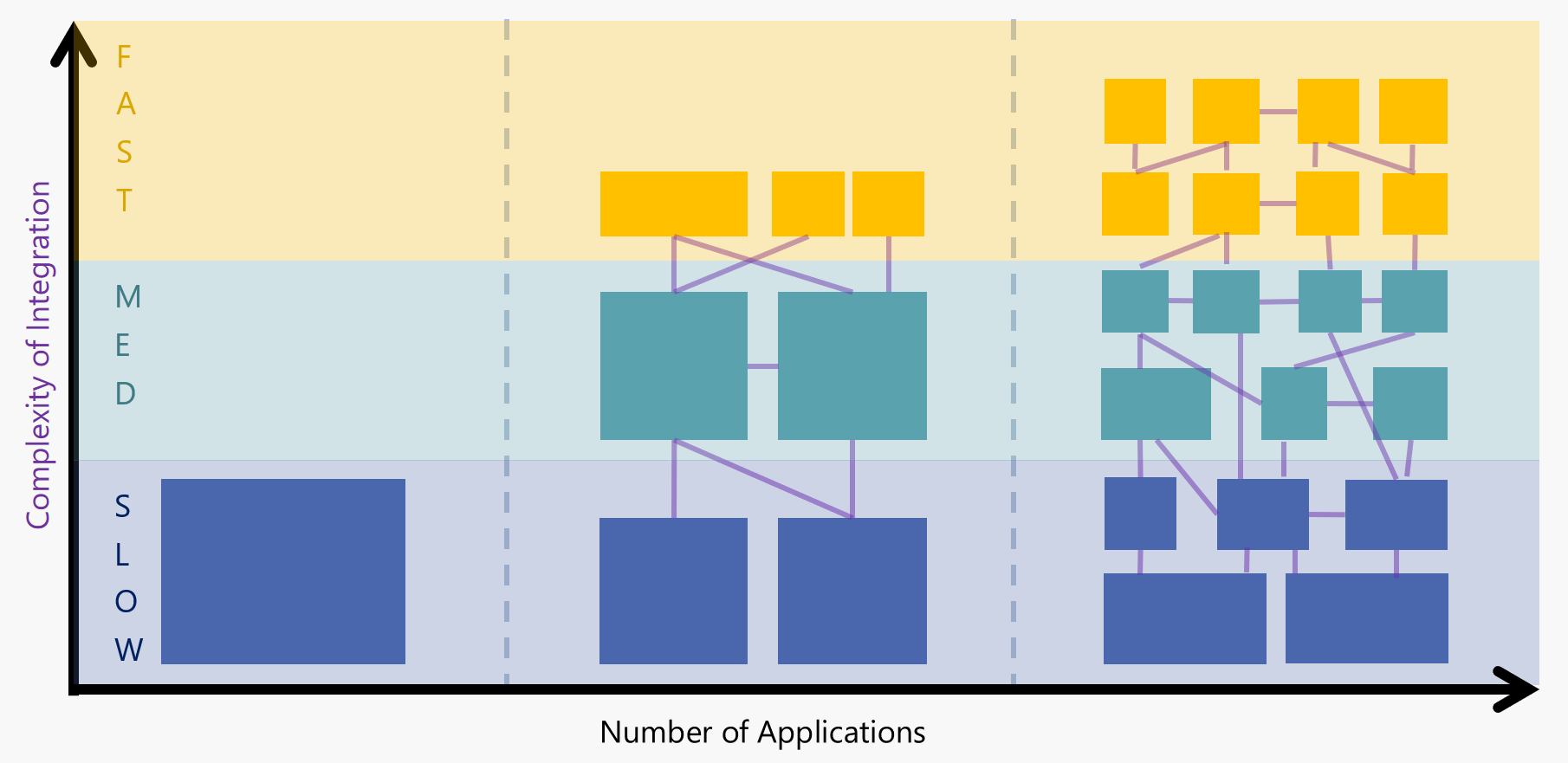
了解Pace-Layered Architecture
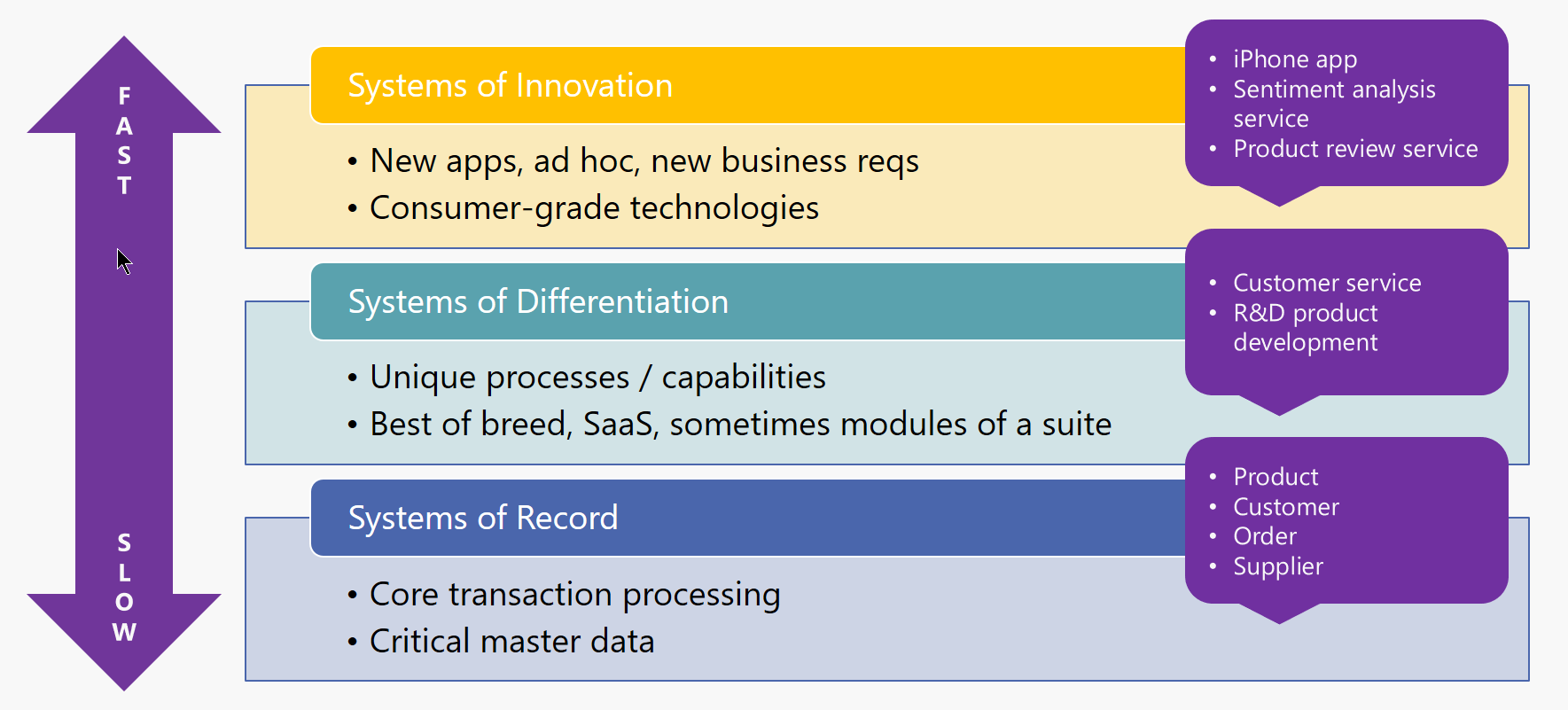
Gartner的Pace-Layered模型由三层组成:
记录系统(SOR) -
这些系统支持组织的核心功能,没有这些功能,企业就无法运行。由于这些通常是整个行业的标准,因此这些功能并非给定品牌或业务所独有(例如,每家银行都需要管理帐户,交易,客户等)。因此,这些系统通常是供应商提供的商业现货(COTS)产品。由于组织的核心能力不会经常发生变化,因此这些系统也不会发生变化 - 变化是递增的,而且速度很慢。
差异化系统 -
虽然核心功能在同一行业中从一个组织到另一个组织的变化不大,但业务流程确实如此。例如,您的银行和我的银行都可以提供贷款,但这两家银行处理贷款的方式可能会有所不同。此层中的应用程序代表使组织独一无二的流程,并且通常不会由供应商提供的记录平台系统开箱即用。业务流程可能不会每天都在变化,但它们确实比核心功能更快地发生变化,例如简化流程和/或整合新技术。
创新系统 -
这一层移动速度最快。这是测试新想法和技术的“沙坑”。这里的实验可能包括特定的概念验证(PoC)应用程序,这些应用程序可以快速开发,然后手动部署和测试。
图片基于Michael Guay(Gartner)的演讲
让我们看一个示例企业,例如银行机构,看看他们的一些应用程序如何映射到速度分层模型。
| LAYER | SYSTEMS / APPLICATIONS | CHARACTERISTICS |
| Systems of Record | ABC银行有几个关键系统,包括核心银行系统,贷款管理系统和文件库。 |
|
| Systems of Differentiation | 自动贷款处理功能由定制的集成解决方案管理,该解决方案集成了多个外部SaaS服务,用于房地产估价,标题搜索,信用评分和在线Web表单提供程序。 |
|
| Systems of Innovation | ABC银行希望提供一个基于聊天的界面,用于提供由智能机器人提供支持的贷款申请。 |
|
在Pace-Layered架构中集成
现在我们了解了分步模型,我们如何在其中实现集成? 让我们看一下API / Services的逻辑模型如何看待它们如何在各层之间组合成应用程序:
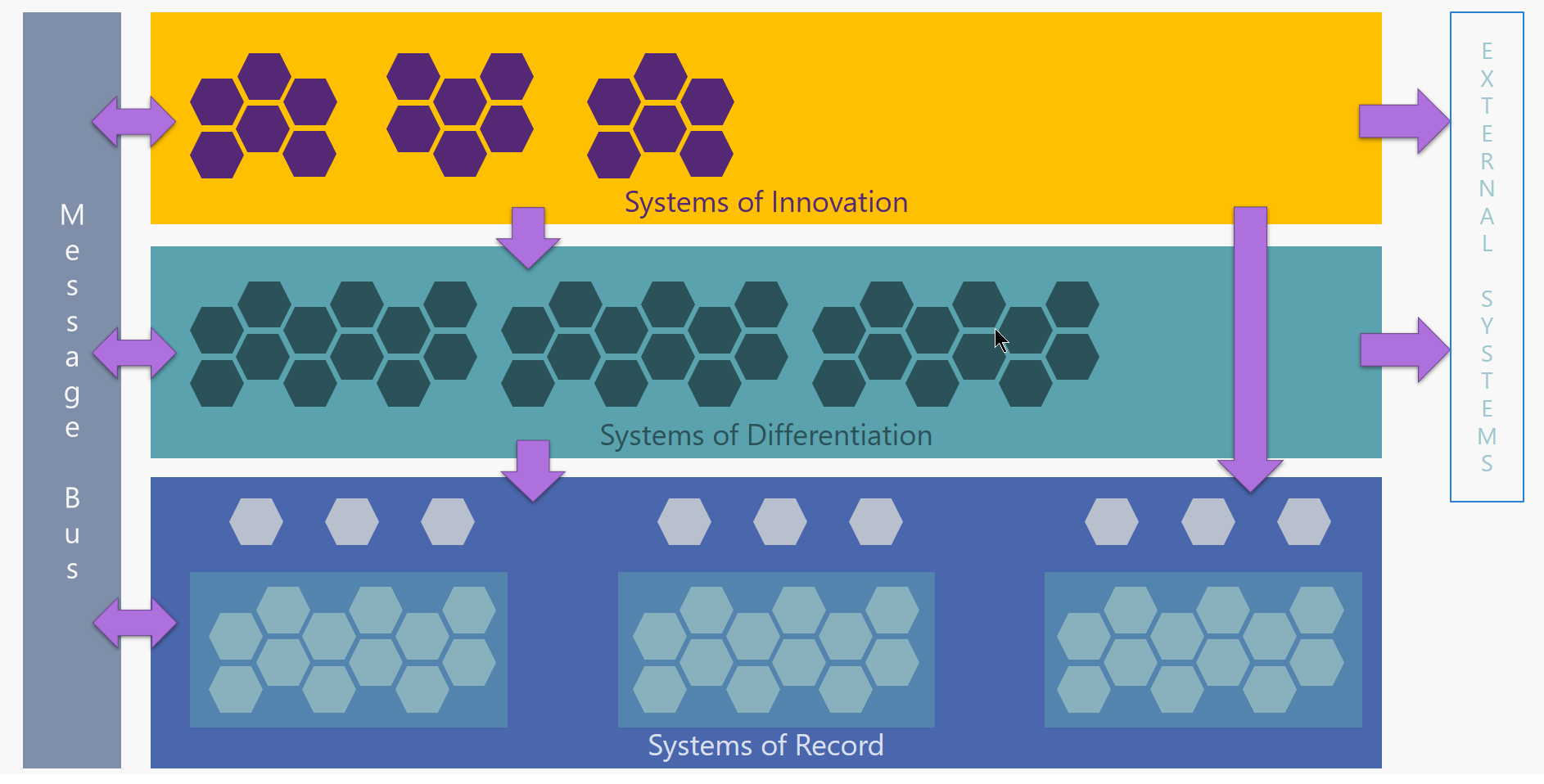
从底层开始,我们看到每个记录系统通常是一个包含多个服务/ API的包。但是,由于与逻辑数据模型,过时协议或其他原因不一致,这些API可能无法由业务直接使用。在这些情况下,最好引入API的“子层”,将SoR与组织内的其他API联系起来。这些抽象API(称为产品适配器)与底层SOR紧密耦合,但以更加可口的格式公开功能。它们还可能引入比SOR本身更严格的访问控制,验证和安全性。 API通常代表核心数据实体(客户,产品,订单等),因此它们是粒度的并且是为可重用性而设计的。因为它们与核心系统紧密相连,所以它们以相同的速度移动,因此被认为是记录系统层的一部分。由于数据的重要性以及使用这些API的服务和流程的高度依赖性,治理和变更控制在此级别通常会非常严格。
在差异化系统层中,我们看到的应用程序由源自记录系统层的粒度服务/ API以及可能的外部API组成。这是组织的业务逻辑所在的位置,例如贷款处理或用户供应。应用程序可以在此层中执行的功能包括数据聚合,路由,过滤以及通常编排/编排。由于它们特定于进程,因此它们可能比它们可能使用的底层SOR API更不可重用。在该层中,组织内的大部分集成发生。而且由于业务流程可以(并且将会)随着时间的推移而发生变化,因此这些应用程序也需要进行调整,而且肯定会比SOR应用程序更快地进行调整。治理也应该在这个层面上应用,尽管可能不像SOR层那样严格;组织希望他们的业务流程足够灵活,以适应效率的提高和功能的扩展。
创新系统层还具有同时使用SOR API和外部API的应用程序,以及可能在差异系统层中使用业务流程的应用程序。作为最快的移动层,它将具有更轻的治理,以促进新应用程序和技术的实验。此层中启用的功能通常是业务核心功能的外围设备,因此在发生故障时可以降低组织的风险。此外,为了证明概念而快速创建的应用程序很少会采用自动化测试或成熟的CI / CD管道,因为它们将被手动部署和测试。
最后,我们使用消息总线以便促进层间和层内通信。异步消息传递模式(如发布 - 订阅)可以使系统松散耦合,并提高可扩展性和灵活性。发布者无需了解订阅者的任何信息,您可以随时添加或减少订阅者,而不会破坏现有的集成。消息总线是润滑不同速度变化的应用之间摩擦的关键因素。
此图提供了几个属性的横截面视图以及它们在各个层之间的变化:
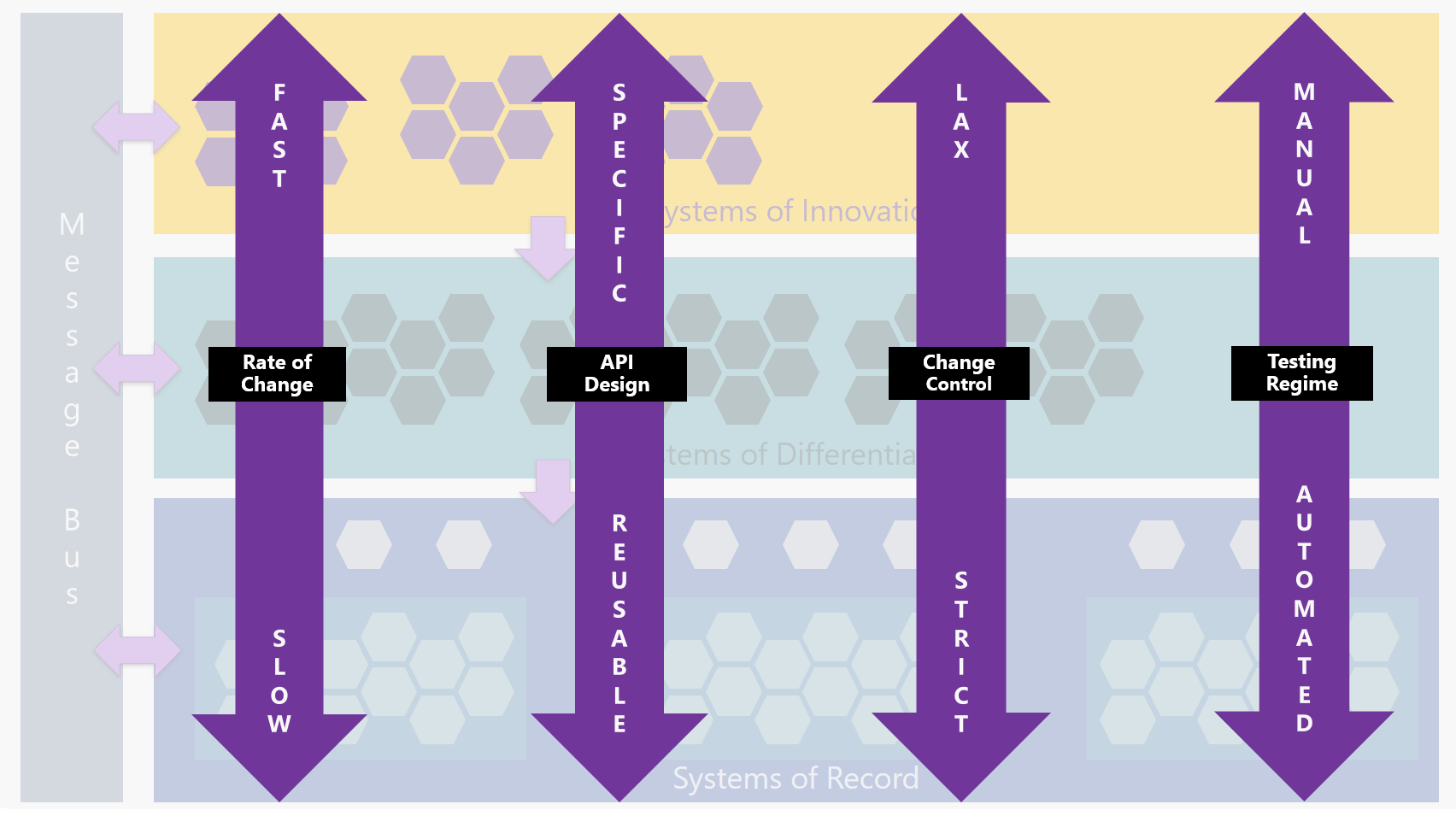
Microsoft如何帮助实现Pace-Layered Integration?
Microsoft提供一系列服务和产品,包括本地和云端,以帮助构建功能强大的集成解决方案,以应对企业应用程序层的不同步伐。 在这里,我们将仅讨论其中一些产品以及它们如何适应速度分层架构(请注意,有许多可能的解决方案;这些建议只是一种可能的方式来看待这一点):
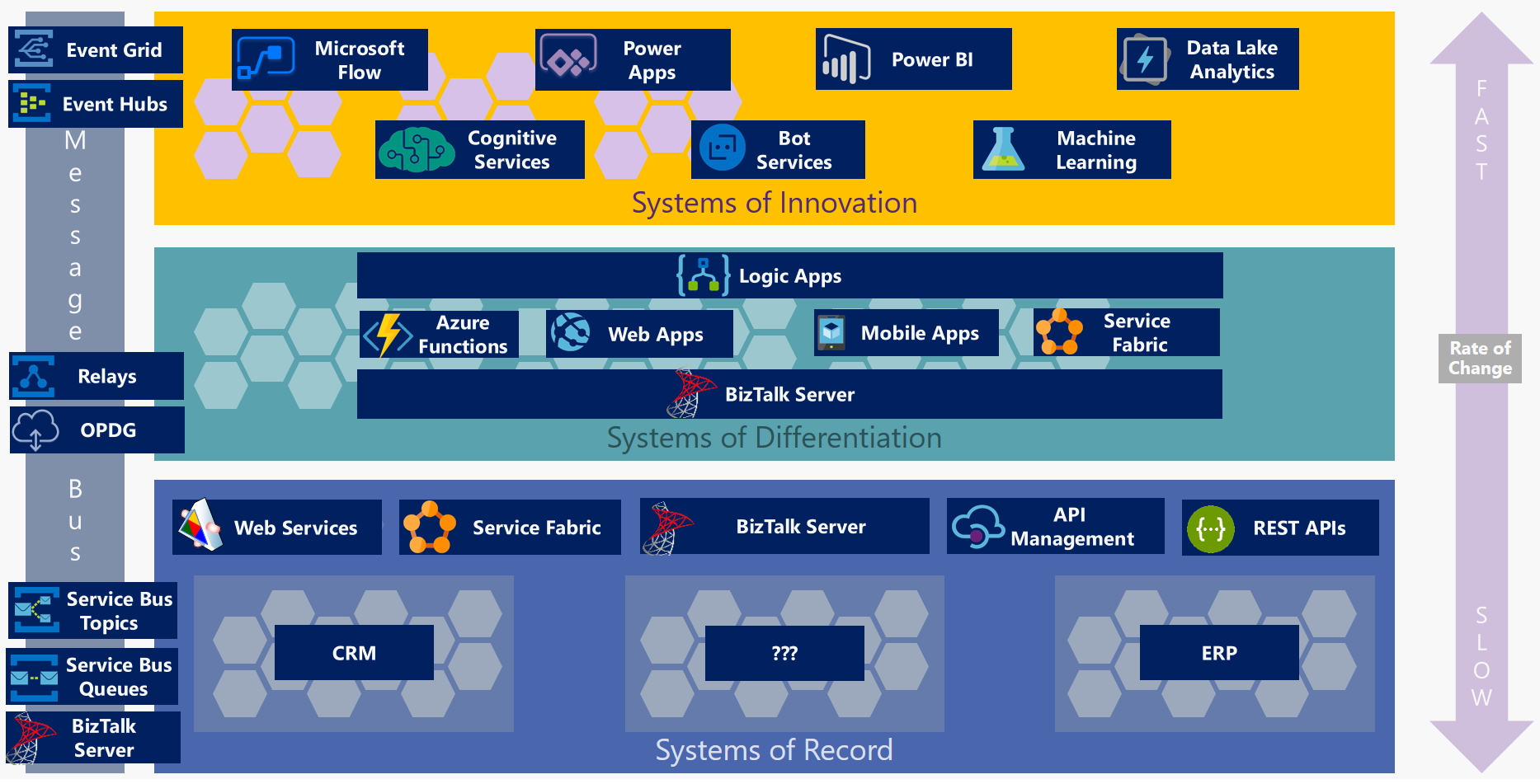
记录系统层
以下产品非常适合在SOR应用程序之上构建API层:
| TECHNOLOGY(技术) | USE WHEN (场景) | CONSIDERATIONS(考虑) |
| Product APIs |
|
+与记录系统紧密集成 - 更改或定制困难或昂贵 - 可能不适合业务数据模型 |
| Web服务/ REST API (IIS托管在本地或 Azure中托管的应用服务计划) |
|
+主机价格低廉 +易于消费 +可以在本地或Azure(IaaS)托管 - 需要开发工作 |
| API Management |
|
+可定制的外观 +开发者门户促进了新的应用创建 - 需要VNet集成 - 没有本地选项 - 如果不使用其他功能,则选择昂贵的选项 |
| Service Fabric |
|
+可以在任何地方托管 +支持容器 - 需要大量开发工作(不提供OOTB软件组件) |
| BizTalk Server |
|
+ BAM跟踪可用 +单一平台集成 - 昂贵的选择 - 需要专业的开发技能 - 未来的支持模型 |
差异化系统层(System of Differentiation Layer)
这些产品能够实现业务逻辑,提供与内部和外部应用程序和服务的连接,并支持跨云和本地应用程序的混合连接:
| TECHNOLOGY(技术) | USE WHEN(场景) | CONSIDERATIONS(考虑) |
| Logic Apps |
|
+快速发展 +超过200个内置连接器! - 没有VNet支持(直到ISE可用) - 没有本地选项(尚未) |
| Azure Functions |
|
+良好的CI / CD支持 + VNet支持 +可以在本地运行 - 没有Logic Apps那么多的连接器 |
| Web/Mobile Apps |
|
+良好的CI / CD支持 +众多部署选项 +支持Azure Relay / VNet集成 - 对于长时间运行的过程本身并不理想 - 考虑混合应用程序的安全层 |
| Service Fabric |
|
+可以在任何地方托管 +支持容器 - 需要大量的开发工作 - 基础设施投资(仅限本地) |
| BizTalk Server |
|
+单一平台进行整合 +可以在本地或Azure(IaaS)托管 - 昂贵的选择 - 需要专业的开发技能 - 未来的支持模型 |
创新系统层
在这里,我们需要能够将技术范围扩展到人工智能,预测分析和业务洞察领域,同时实现快速(甚至临时)开发。 这里有很多可能性,因为与使用它的方式相比,它更少涉及您使用的技术。 但这些产品都非常适合创新的解决方案:
| TECHNOLOGY(技术) | USE WHEN(场景) | CONSIDERATIONS(考虑) |
| Microsoft Flow |
|
+快速发展 +可以轻松迁移到Logic Apps *需要Office365 |
| Power Apps |
|
+与Flow / SharePoint /轻松集成 +多平台 *需要Office365 |
| Power BI |
|
*依赖于对数据源的访问 |
| Cognitive Services |
|
+提供多种服务/ API(Vision,Knowledge, *需要编程技能 |
| Machine Learning |
|
*需要数据科学技能 |
| Bots |
|
*需要编程技能 *机器人需要经过良好的训练才能按预期运行 |
消息总线
如果您主要集成本地系统,BizTalk Server的核心是一个功能强大的消息传递引擎,它不仅可以支持全部的消息传递模式,还可以提供几个开箱即用的连接器以实现连接。 强大的业务流程自动化功能 这就是它在很多层中的特征。 然而,当在云中集成时,Azure Service Bus为企业消息传递,大数据流,事件处理和混合连接提供了许多产品:
| TECHNOLOGY(技术) | USE WHEN (场景) | CONSIDERATIONS(考虑) |
| Event Grid |
|
+弹性(重试最多24小时) +推 - 推模型 +易于集成 *小消息大小 |
| Event Hubs |
|
*至少需要一个下游处理器 - 没有本地选项 |
| Relays |
|
+可以使用混合连接或WCF中继 |
| On-Prem Data Gateway |
|
+如果使用Logic Apps,则可以替代VNet - 仅少数Logic App连接器支持 |
| Service Bus Queues |
|
+极具弹性和功能齐全 - 没有本地选项 |
| Service Bus Topics |
|
+极具弹性和功能齐全 - 没有本地选项 |
| BizTalk Server |
|
+单一平台进行整合 - 昂贵的选择 - 需要专业的开发技能 - 未来的支持模型 |
提示和最佳实践
以下是有关如何在步调分层的企业架构中维护自适应集成的一些技巧。
考虑如何使用您正在集成的应用程序。
- 整合任务是否至关重要?那么Logic Apps将是比Microsoft Flow更好的选择。
- 需要考虑哪些安全风险? API管理层可以提供基于策略的治理,威胁防护和访问控制。
- 解决方案有多快变化?这将影响自动化测试,CI / CD管道等方面的投资。
确保您的系统记录图层是可靠的。
您的API是否足够精细且定义明确?请记住,这些将构成其他层中应用程序的可组合单元。
是否强制执行安全性和数据验证?不要依赖消费者;保护您的关键数据靠近源!
限制每个记录系统中的自定义。
如果您自定义SOR,下一次供应商升级会发生什么?
尽可能地使用差分系统层进行自定义,或者至少在每个SOR的API层中进行自定义。
考虑使用规范数据模型来避免与供应商系统紧密耦合。
这通常需要声音信息架构来定义业务数据实体。
信息架构师可以构建独立于软件实现的逻辑模型;投资于此。
松散地耦合层间通信。
垂直依赖性很难维护 - 除非您是整个堆栈的所有者。
尽可能选择发布 - 订阅消息传递模型,以最大化松散耦合和可扩展性。
留出创新空间!
在每一层采用适当的治理级别。避免严格的变更控制政策,实验既必要又安全。
使业务负责人能够创建自己的解决方案(例如,使用Microsoft Flow自动化普通流程)。
鼓励实验!使用Microsoft iPaaS功能实现“以业务速度进行集成”(Jim Harrer,Microsoft)。
原文: https://platform.deloitte.com.au/articles/a-pace-layered-integration-architecture
- 1893 次浏览
数据集成架构
数据集成架构 intelligentx- 111 次浏览
【事件处理】全面了解Kafka和RabbitMQ选型(1) -两种不同的消息传递方式
视频号
微信公众号
知识星球
超级架构师
架构师的宝库,每天一篇,开拓你的视野和深度。分享企业架构,业务架构,应用架构,数据架构,技术架构,安全架构等。讨论架构框架,规划,治理,标准,落地。交流新兴的架构风格和模型。如微服务,事件驱动,微前端,大数据,数仓,物联网,人工智能架构。
公众号
在这一部分中,我们将探讨RabbitMQ和Apache Kafka以及它们的消息传递方法。每种技术在设计的每个方面都做出了截然不同的决定,每种方面都有优点和缺点。我们不会在这一部分得出任何有力的结论,而是将其视为技术的入门,以便我们可以深入探讨该系列的后续部分。
RabbitMQ
RabbitMQ是一个分布式消息队列系统。分布式,因为它通常作为节点集群运行,其中队列分布在节点上,并可选择复制以实现容错和高可用性。它原生地实现了AMQP 0.9.1,并通过插件提供其他协议,如STOMP,MQTT和HTTP。
RabbitMQ同时采用经典和新颖方式。从某种意义上来说,它是面向消息队列的经典,并且具有高度灵活的路由功能。正是这种路由功能才是其杀手级功能。构建快速,可扩展,可靠的分布式消息传递系统本身就是一项成就,但消息路由功能使其在众多消息传递技术中脱颖而出。
交换机(exchanges)和队列
超简化概述:
-
发布者向交换机(exchanges)发送消息
-
将消息路由到队列和其他交换机(exchanges)
-
RabbitMQ在收到消息时向发布者发送确认
-
消费者与RabbitMQ保持持久的TCP连接,并声明他们使用哪个队列
-
RabbitMQ将消息推送给消费者
-
消费者发送成功/失败的确认
-
成功使用后,消息将从队列中删除
隐藏在该列表中的是开发人员和管理员应该采取的大量决策,以获得他们想要的交付保证,性能特征等,我们将在本系列的后续部分中介绍所有这些决策。
我们来看看单个发布者,交换机(exchanges),队列和消费者:
Fig 1 - Single publisher and single consumer
如果您有多个同一消息的发布者怎么办?如果我们有多个消费者每个人都希望消费每条消息呢?
Fig 2 - Multiple publishers, multiple independent
如您所见,发布者将其消息发送到同一个交换机(exchanges),该交换机(exchanges)将每条消息路由到三个队列,每个队列都有一个消费者。使用RabbitMQ,队列使不同的消费者能够使用每条消息。与下图对比:
Fig 3 - Multiple publishers, one queue with multip
在图3中,我们有三个消费者都在单个队列中消费。这些是竞争的消费者,即他们竞争消费单个队列的消息。人们可以预期,平均而言,每个消费者将消耗该队列消息的三分之一。我们使用竞争消费者来扩展我们的消息处理,使用RabbitMQ它非常简单,只需按需添加或删除消费者。无论您拥有多少竞争消费者,RabbitMQ都将确保消息仅传递给单个消费者。
我们可以将图2和图3组合在一起,使多组竞争消费者,每组消费每条消息。
Fig 4 - Multiple publishers, multiple queues with
交换和队列之间的箭头称为绑定,我们将仔细研究本系列第2部分中的箭头。
担保
RabbitMQ提供“最多一次交付”和“至少一次交付”但不提供“完全一次交付”保证。我们将在本系列的第4部分中深入研究消息传递保证。
消息按照到达队列的顺序传递(毕竟是队列的定义)。当您拥有竞争消费者时,这并不能保证完成与完全相同顺序的消息处理匹配。这不是RabbitMQ的错,而是并行处理有序消息集的基本现实。通过使用Consistent Hashing Exchange可以解决此问题,您将在下一部分中看到模式和拓扑。
推和消费者预选
RabbitMQ将消息推送到流中的消费者。有一个Pull API,但它的性能很糟糕,因为每条消息需要一个请求/响应往返(注意,由于Shiva Kumar的评论,我更新了这一段)。
如果消息到达队列的速度快于消费者可以处理的速度,那么基于推送的系统可能会使消费者感到压力。因此,为了避免这种情况,每个消费者都可以配置预取限制(也称为QoS限制)。这基本上是消费者在任何时候都可以拥有的未确认消息的数量。当消费者开始落后时,这可以作为安全切断开关。
为什么推而不拉?首先,它对于低延迟非常有用。其次,理想情况下,当我们拥有单个队列的竞争消费者时,我们希望在它们之间均匀分配负载。如果每个消费者都会收到消息,那么根据他们拉动工作分布的数量,可能会变得非常不平衡。消息分布越不均匀,延迟越多,处理时消息顺序的丢失越多。因此,RabbitMQ的Pull API只允许一次提取一条消息,但这会严重影响性能。这些因素使RabbitMQ倾向于推动机制。这是RabbitMQ的缩放限制之一。通过将确认组合在一起可以改善它。
路由
交换基本上是到队列和/或其他交换的消息的路由器。为了使消息从交换机传送到队列或其他交换机,需要绑定。不同的交换需要不同的绑定。有四种类型的交换和相关绑定:
-
扇出(Fanout)。路由到具有绑定到交换的所有队列和交换。标准的pub子模型。
-
直接。根据发布者设置的消息随附的路由密钥路由消息。路由键是一个短字符串。直接交换将消息路由到具有与路由密钥完全匹配的绑定密钥的队列/交换机。
-
话题。根据路由密钥路由消息,但允许通配符匹配。
-
头。RabbitMQ允许将自定义标头添加到消息中。标头根据这些标头值交换路由消息。每个绑定包括完全匹配标头值。可以将多个值添加到具有匹配所需的ANY或ALL值的绑定。
-
一致的哈希。这是一个哈希路由密钥或邮件头并仅路由到一个队列的交换。当您需要使用扩展的消费者处理订单保证时,这非常有用。
Fig 5. Topic exchange example
我们将在第2部分中更仔细地研究路由,但上面是主题交换的示例。发布者使用路由密钥格式LEVEL.AppName发布错误日志。
-
队列1将使用多字#通配符接收所有消息。
-
队列2将接收ECommerce.WebUI应用程序的任何日志级别。它使用覆盖日志级别的单字*通配符。
-
队列3将查看来自任何应用程序的所有ERROR级别消息。它使用多字#通配符来覆盖所有应用程序。
通过四种路由消息的方式,以及允许交换路由到其他交换,RabbitMQ提供了一组功能强大且灵活的消息传递模式。接下来我们将讨论死信交换,短暂交换和队列,您将开始看到RabbitMQ的强大功能。
死信交换机(Dead Letter Exchanges)
我们可以配置队列在以下条件下向交换机发送消息:
-
队列超过配置的消息数。
-
队列超出配置的字节数。
-
消息生存时间(TTL)已过期。发布者可以设置消息的生命周期,队列也可以有消息TTL。哪个更短适用。
我们创建一个绑定到死信交换的队列,这些消息将存储在那里直到采取行动。在另一篇文章中,我描述了我已经实现的拓扑,其中所有死信的消息都发送到中央清算所,支持团队可以在此决定采取何种措施。
与许多RabbitMQ功能一样,死信交换提供了最初未考虑的额外模式。我们可以使用消息TTL和死信交换来实现延迟队列和重试队列,包括指数退避。请参阅我之前的帖子。
短暂的交流和队列(Ephemeral Exchanges and Queues)
可以动态创建交换和队列,并赋予自动删除特征。经过一段时间后,他们可以自我毁灭。这允许诸如用于基于消息的RPC的ephermal回复队列之类的模式。
插件
您要安装的第一个插件是Management Plug-In,它提供HTTP服务器,Web UI和REST API。它非常易于安装,并为您提供易于使用的UI,以帮助您启动和运行。通过REST API进行脚本部署也非常简单。
其他一些插件包括:
-
一致的哈希交换,Sharding Exchange等
-
像STOMP和MQTT这样的协议
-
网络钩子
-
额外的交换类型
-
SMTP集成
RabbitMQ还有很多东西,但这是一本很好的入门书,让您了解RabbitMQ可以做些什么。现在我们来看看Kafka,它采用了完全不同的消息传递方法,并且具有惊人的功能。
Apache Kafka
Kafka是一个分布式复制的提交日志。Kafka没有队列的概念,因为它主要用作消息系统,所以最初可能看起来很奇怪。长期以来,队列一直是消息传递系统的代名词。让我们分解一下“分布式,复制的提交日志”:
-
分布式,因为Kafka被部署为节点集群,用于容错和扩展
-
复制,因为消息通常跨多个节点(服务器)复制。
-
提交日志因为消息存储在分区中,所以只追加称为主题的日志。这种日志概念是Kafka的主要杀手特征。
了解日志(主题)及其分区是理解Kafka的关键。那么分区日志与一组队列有什么不同呢?让我们想象一下吧。
Fig 6 One producer, one partition, one consumer
Kafka不是将消息放入FIFO队列并跟踪像RabbitMQ那样在队列中跟踪该消息的状态,而是将其附加到日志中,就是这样。无论消耗一次还是一千次,该消息都会保留。它根据数据保留策略(通常是窗口时间段)删除。那么主题如何被消费?每个消费者跟踪它在日志中的位置,它有一个指向消耗的最后消息的指针,该指针称为偏移量。消费者通过客户端库维护此偏移量,并且根据Kafka的版本,偏移量存储在ZooKeeper或Kafka本身中。ZooKeeper是一种分布式共识技术,被许多分布式系统用于领导者选举等领域。Kafka依靠ZooKeeper来管理集群的状态。
这个日志模型的惊人之处在于它立即消除了消息传递状态的大量复杂性,更重要的是消费者,它允许它们倒回并返回并消耗先前偏移量的消息。例如,假设您部署了一个计算发票的服务,该发票消耗了客户预订。该服务有一个错误,并在24小时内错误地计算所有发票。最好使用RabbitMQ,您需要以某种方式重新发布这些预订,并仅发送给发票服务。但是对于Kafka,您只需将该消费者的偏移量移回24小时。
因此,让我们看一下具有单个分区和两个消费者的主题的情况,每个消费者都需要消费每条消息。从现在开始,我已经开始为消费者贴上标签,因为它不是那么清晰(如RabbitMQ图),它们是独立的,也是竞争对手的消费者。
Fig 7 One producer, one partition, two independent
从图中可以看出,两个独立的消费者都使用相同的分区,但他们正在从不同的偏移中读取。也许发票服务处理消息所需的时间比推送通知服务要长,或者发票服务可能会停机一段时间并且赶上,或者可能存在错误并且其偏移量必须移回几个小时。
现在让我们说发票服务需要扩展到三个实例,因为它无法跟上消息速度。使用RabbitMQ,我们只需部署两个发票服务应用程序,这些应用程序将使用预订发票服务队列。但是Kafka不支持单个分区上的竞争消费者,Kafka的并行单元就是分区本身。因此,如果我们需要三个发票消费者,我们至少需要三个分区。所以现在我们有:
Fig 8 Three partitions and two sets of three consu
因此,这意味着您至少需要与最大规模的消费者一样多的分区。我们来谈谈分区。
分区和消费者组
每个分区都是一个单独的数据文件,可保证消息排序。这一点很重要:消息排序只能保证在一个分区内。这可能会在消息排序需求和性能需求之间引入一些紧张,因为并行单元也是分区。一个分区不能支持竞争消费者,因此我们的发票应用程序只能有一个实例消耗每个分区。
消息可以循环方式或通过散列函数路由到分区:散列(消息密钥)%分区数。使用散列函数有一些好处,因为我们可以设计消息密钥,使得同一实体的消息(例如预订)始终转到同一分区。这可以实现许多模式和消息排序保证。
消费者群体就像RabbitMQ的竞争消费者。组中的每个使用者都是同一应用程序的实例,并将处理主题中所有消息的子集。尽管RabbitMQ的竞争消费者都使用相同的队列,但消费者群体中的每个消费者都使用同一主题的不同分区。因此,在上面的示例中,发票服务的三个实例都属于同一个使用者组。
在这一点上,RabbitMQ看起来更加灵活,它保证了队列中的消息顺序,以及它应对不断变化的竞争消费者数量的无缝能力。使用Kafka,如何对日志进行分区非常重要。
Kafka从一开始就有一个微妙而重要的优势,即RabbitMQ后来添加的关于消息顺序和并行性的优点。RabbitMQ维护整个队列的全局顺序,但在并行处理该队列期间无法维护该顺序。Kafka无法提供该主题的全局排序,但它确实提供了分区级别的排序。因此,如果您只需要订购相关消息,那么Kafka提供有序消息传递和有序消息处理。想象一下,您有消息显示客户预订的最新状态,因此您希望始终按顺序(按时间顺序)处理该预订的消息。如果您按预订ID进行分区,那么给定预订的所有消息都将到达单个分区,我们会在其中进行消息排序。因此,您可以创建大量分区,使您的处理高度并行化,并获得消息排序所需的保证。
RabbitMQ中也存在此功能,它通过Consistent Hashing交换机以相同的方式在队列上分发消息。虽然Kafka强制执行此有序处理,因为每个使用者组只有一个使用者可以使用单个分区,并且当协调器节点为您完成所有工作以确保遵守此规则时,可以轻松实现。而在RabbitMQ中,您仍然可以让竞争消费者从一个“分区”队列中消费,并且您必须完成工作以确保不会发生这种情况。
这里还有一个问题,当你改变分区数量时,订单Id 1000的那些消息现在转到另一个分区,因此订单Id 1000的消息存在于两个分区中。根据您处理邮件的方式,这会引起头疼。现在存在消息不按顺序处理的情况。
我们将在本系列的第4部分“消息传递语义和保证”部分中更详细地介绍此主题。
PUSH VS PULL
RabbitMQ使用推送模型,并通过消费者配置的预取限制来防止压倒性的消费者。这对于低延迟消息传递非常有用,并且适用于RabbitMQ基于队列的架构。另一方面,Kafka使用拉模型,消费者从给定的偏移量请求批量消息。当没有超出当前偏移量的消息时,为了避免紧密循环,Kafka允许进行长轮询。
由于其分区,拉模型对Kafka有意义。由于Kafka在没有竞争消费者的分区中保证消息顺序,我们可以利用消息批处理来实现更高效的消息传递,从而为我们提供更高的吞吐量。这对RabbitMQ没有多大意义,因为理想情况下我们希望尽可能快地分配一个消息,以确保工作均匀并行处理,并且消息处理接近它们到达队列的顺序。但是对于Kafka来说,分区是并行和消息排序的单位,所以这两个因素都不是我们关注的问题。
发布订阅
Kafka支持基本的pub sub,其中包含一些与日志相关的额外模式,它是一个日志并具有分区。生成器将消息附加到日志分区的末尾,并且消费者可以在分区中的任何位置放置它们的偏移量。
Fig 9. Consumers with different offsets
当存在多个分区和使用者组时,这种风格的图表不容易快速解释,因此对于Kafka的其余图表,我将使用以下样式:
Fig 10. One producer, three partitions and one con
我们的消费者群体中没有与分区相同数量的消费者:
Fig 11. Sone consumers read from more than one par
一个消费者组中的消费者将协调分区的消耗,确保一个分区不被同一个消费者组的多个消费者使用。
同样,如果我们拥有的消费者多于分区,那么额外的消费者将保持闲置状态。
Fig 12. One idle consumer
添加和删除消费者后,消费者群体可能会变得不平衡。重新平衡会在分区中尽可能均匀地重新分配使用者。
Fig 13. Addition of new consumers requires rebalan
在以下情况之后自动触发重新平衡:
-
消费者加入消费者群体
-
消费者离开消费者群体(它关闭或被视为死亡)
-
添加了新分区
重新平衡将导致短时间的额外延迟,同时消费者停止阅读批量消息并分配到不同的分区。消费者维护的任何内存状态现在都可能无效。Kafka的消费模式之一是能够将给定实体的所有消息(如给定的预订)指向同一个分区,从而导致同一个消费者。这称为数据局部性。在重新平衡任何内存中有关该数据的数据将是无用的,除非将消费者分配回同一分区。因此,维持国家的消费者需要在外部坚持下去。
日志压缩
标准数据保留策略是基于时间和空间的策略。存储到最后一周的消息或最多50GB,例如。但是存在另一种类型的数据保留策略 - 日志压缩。压缩日志时,结果是仅保留每个消息密钥的最新消息,其余消息将被删除。
让我们假设我们收到一条消息,其中包含用户预订的当前状态。每次更改预订时,都会根据预订的当前状态生成新事件。该主题可能包含一些预订的消息,这些消息表示自创建以来预订的状态。在主题被压缩之后,将仅保留与该预订相关的最新消息。
根据预订量和每次预订的大小,理论上可以将所有预订永久存储在主题中。通过定期压缩主题,我们确保每个预订只存储一条消息。
日志压缩可以实现一些不同的模式,我们将在第3部分中探讨。
有关消息排序的更多信息
我们已经讨论过,RabbitMQ和Kafka都可以扩展和维护消息排序,但是Kafka使它变得容易多了。使用RabbitMQ,我们必须使用Consistent Hashing Exchange并使用像ZooKeeper或Consul这样的分布式共识服务自己手动实现使用者组逻辑。
但RabbitMQ有一个有趣的功能,卡夫卡没有。RabbitMQ本身并不特别,但任何基于发布 - 订阅队列的消息传递系统。能力是这样的:基于队列的消息系统允许订户订购任意事件组。
让我们再深入了解一下。不同的应用程序无法共享队列,因为它们会竞争使用消息。他们需要自己的队列。这使应用程序可以自由地配置他们认为合适的队列。他们可以将多个主题中的多个事件类型路由到其队列中。这允许应用程序维护相关事件的顺序。它想要组合的事件可以针对每个应用程序进行不同的配置。
使用像Kafka这样的基于日志的消息传递系统是不可能的,因为日志是共享资源。多个应用程序从同一日志中读取。因此,将相关事件分组到单个主题中是在更广泛的系统架构级别做出的决策。
所以这里没有胜利者。RabbitMQ允许您维护任意事件集的相对排序,Kafka提供了一种维持大规模排序的简单方法。
更新:我已经构建了一个名为Rebalanser的库,它为RabbitMQ for .NET应用程序提供了使用者组逻辑。查看它上面的帖子和GitHub repo。如果人们表现出任何兴趣,那么我就会用其他语言制作版本。让我知道。
结论
RabbitMQ由于其提供的各种功能,提供了瑞士军刀的消息模式。凭借其强大的路由功能,它可以消除消费者在只需要一个子集时检索,反序列化和检查每条消息的需要。它易于使用,通过简单地添加和删除消费者来完成扩展和缩小。它的插件架构允许它支持其他协议并添加新功能,例如Consistent散列交换,这是一个重要的补充。
卡夫卡的分布式日志与消费者抵消使得时间旅行成为可能。它能够将相同密钥的消息按顺序路由到同一个消费者,从而实现高度并行化的有序处理。Kafka的日志压缩和数据保留允许RabbitMQ无法提供的新模式。最后是的,Kafka可以比RabbitMQ进一步扩展,但是我们大多数人都处理一个可以轻松处理的消息量。
在下一部分中,我们将使用RabbitMQ仔细研究消息传递模式和拓扑。
超级架构师
架构师的宝库,每天一篇,开拓你的视野和深度。分享企业架构,业务架构,应用架构,数据架构,技术架构,安全架构等。讨论架构框架,规划,治理,标准,落地。交流新兴的架构风格和模型。如微服务,事件驱动,微前端,大数据,数仓,物联网,人工智能架构。
公众号
超级工程师
前端后端一锅端,数据物联区块链,AI AR 和VR,分析 安全 元宇宙。全栈开发Java,Python,Go,Groovy,Kotlin,C#,Node,TypeScript,JavaScript,Rust, Swift,R,Ruby。
公众号
CIO和CTO
作为企业高管CIO,CDO,CTO的助手,介绍科技趋势,资讯,商业案例,技术实现。 如数字化转型,5G,量子,物联网,云计算,生物科技,隐私计算,虚拟现实,区块链,移动,人工智能,智能设备,机器人,大数据,数据分析,数据智能等.
公众号
首席数字化转型官
交流企业的数字化转型,创新和整合。帮助CIO,CDO,CDTO成长。关注企业数字化方法,流程,框架,案例以及趋势。探讨企业的业务架构规划设计,企业的IT建设和数字化推进。
公众号
| 本文 :https://architect.pub | ||
| 讨论:知识星球【首席架构师圈】或者加微信小号【ca_cto】或者加QQ群【792862318】 | ||
| 公众号 |
【jiagoushipro】 【架构师酒馆】 精彩图文详解架构方法论,架构实践,技术原理,技术趋势。 我们在等你,赶快扫描关注吧。 |
|
| 微信小号 |
【ca_cea】 50000人社区,讨论:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化. |
|
| QQ群 |
【285069459】深度交流企业架构,业务架构,应用架构,数据架构,技术架构,集成架构,安全架构。以及大数据,云计算,物联网,人工智能等各种新兴技术。 加QQ群,有珍贵的报告和干货资料分享。 |
|
| 视频号 | 【架构师酒馆】 1分钟快速了解架构相关的基本概念,模型,方法,经验。 每天1分钟,架构心中熟。 |
|
| 知识星球 | 【首席架构师圈】向大咖提问,近距离接触,或者获得私密资料分享。 |
|
| 喜马拉雅 | 【超级架构师】路上或者车上了解最新黑科技资讯,架构心得。 | 【智能时刻,架构君和你聊黑科技】 |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 | 知识星球【职场和技术】 |
| 微博 | 【架构师酒馆】 | 智能时刻 |
| 哔哩哔哩 | 【架构师酒馆】 |
|
| 抖音 | 【cea_cio】架构师酒馆 |
|
| 快手 | 【cea_cio_cto】架构师酒馆 |
|
| 小红书 | 【cea_csa_cto】架构师酒馆 |
|
| 网站 | CIO(首席信息官) | https://cio.ceo |
| 网站 | CIO,CTO和CDO | https://cioctocdo.com |
| 网站 | 架构师实战分享 | https://architect.pub |
| 网站 | 程序员云开发分享 | https://pgmr.cloud |
| 官网 | 行天智能科技咨询公司 | https://xingtian.ai |
| 网站 | 开发者闲谈 | https://blog.developer.chat |
| 网站 | 首席隐私官内参 | https://cpo.work |
| 网站 | 首席安全官内参 | https://cso.pub |
| 网站 | CIO内参 | https://cio.cool |
| 网站 | CDO内参 | https://cdo.fyi |
| 网站 | CXO内参 | https://cxo.pub |
| 网站 | 首席架构师社区 | https://jiagoushi.pro |
- 52 次浏览
【数据集成】如何在Web应用程序中集成多个数据库
视频号
微信公众号
知识星球
在许多情况下,您可能需要集成多个数据库。这可能是特定应用程序项目所必需的。提供更加集中和高效的信息访问本身也是一个目标。
然而,实现这一点可能是一个挑战,尤其是对缺乏经验的开发人员来说。
今天,我们将研究两种方法—集成数据库的关键方法,以及Budibase如何让生活更轻松。
不过,首先,我们将从基础知识开始。
什么是数据库集成?
数据库集成意味着从多个不同的源获取数据,并创建一个可在整个组织中共享和管理的权威版本。这可以包括现有数据库,以及其他来源,如web服务或其他输入。
通常,这意味着将多个现有数据库合并为一个单一的统一资源。其他时候,这可能意味着保留单独的数据库,并创建一个查看、访问和管理信息的平台。
稍后我们将更详细地研究这些问题。
在这两种情况下,目标都是提高整个组织的信息共享、效率和决策能力。集成还有助于保护数据的有效性、完整性和安全性,以及基于此的任何工具的性能。
为什么要集成多个数据库?
现代企业收集和存储大量数据。集成在帮助您使用这些信息方面发挥着至关重要的作用,而不是被它淹没。
当你创造了一个真实的来源时,你就可以让你的团队做出更快、更好的决定。这也消除了在多个位置存储类似信息的需要,从而避免了重复和不一致问题。
此外,集成可用于提供更方便的数据管理过程。例如,通过使您的团队能够从一个工具在多个数据库上执行管理任务。
整合数据库还可以提高性能。例如,通过允许您通过查询单个集中数据库来访问相同的信息。
除此之外,在某些情况下,集成多个数据库是不可避免的。也就是说,这可能是应用程序满足其功能要求的要求。
考虑到这一点,让我们看看在实践中集成数据库的一些不同方法。
整合数据 vs 连接到多个数据库
如前所述,我们将研究两种不同的集成数据库的方法。每个都有自己的优点和缺点。一些应用程序项目将更适合其中之一。
第一个选项是将数据库整合到单个源中。即,获取现有数据,并将其迁移到单个新数据库。您可能需要这样做的原因有很多,例如,当将数据集移动到云时。
事实上,这种迁移通常是指数据库集成,尽管它不是唯一的方法。
当然,这里也有缺点。
首先,迁移总是会带来风险,包括服务中断、数据丢失或损坏。至少可以说,缓解这些问题是一项艰巨的任务。在某些情况下,这根本不值得,特别是对于小型内部工具。
在其他情况下,迁移根本不可行。
您经常受到软件堆栈中其他平台需求的限制。
例如,您可能需要从使用自己内部数据库的CRM工具中集成数据。如果一个工具会破坏您需要的其他平台,那么迁移数据来构建一个工具是没有意义的。
那么,如何在不进行大规模迁移的情况下集成多个数据源?
解决方案是创建专用工具来管理来自不同来源的数据。换句话说,创建接口、定义业务流程或创建虚拟表以实现无缝数据集成。
这里的目标是能够无缝地查询不同的数据库,就像它们是一个数据库一样。其中一个要素是保持存储在多个数据库中的类似属性之间的一致性。
例如,CRM和发票平台都存储客户的联系信息。
您可以将其视为一种事实上的集成,因为实际的数据库彼此保持独立和不同。
考虑到这一点,让我们深入探讨每种集成方法的实用性。
整合多个数据库
如前所述,集成通常是指将多个数据库合并到一个源中的做法。
然而,这在实践中可能意味着许多不同的事情。首先,这在很大程度上与所讨论的数据库的不同有关。
让我们来看看几个不同的场景,以及它们的区别。
将数据库与单个模式集成
如果您在不同的位置有多个数据库,但它们共享一个模式,那么整合相对简单。例如,如果不同的用户都具有相同数据集的本地版本。
查看我们关于数据库模式的文章以了解更多信息。
本质上,在这种情况下,我们需要做的就是创建一个与现有模式匹配的主数据库,并从本地版本导入所有值。
根据您用于新数据库的DBMS,这可以通过直接文件上载、自动查询甚至手动数据输入来完成。您选择哪种方法在很大程度上取决于您使用的数据集的规模和复杂性。
例如,如果您有由一个或两个表组成的多个数据库,那么手动上载数据可能是最简单的选择。使用Budibase,您可以使用CSV文件将数据批量导入我们的内部数据库或任何其他连接的源。
举一个简单的例子,假设您的每个销售团队都将他们的销售线索存储在各自的Postgres数据库中。每个人只有一张桌子。您决定将它们以MySQL表的形式集成到一个新的主列表中。
您的目标是构建一个应用程序,帮助销售同事共享信息,避免反复联系同一位同事。
我们可以在Budibase中将每个Postgres数据库添加为单独的数据源,自动获取表,并将所有值导出到CSV文件,而无需编写单个查询。然后,我们可以连接到新的MySQL表,并在Budibase生成器中导入值。
这会将所有现有值移动到主列表中。然后,我们可以创建一个简单的自动化,这样,每当单个销售同事添加新潜在客户时,它也会添加到主列表中。
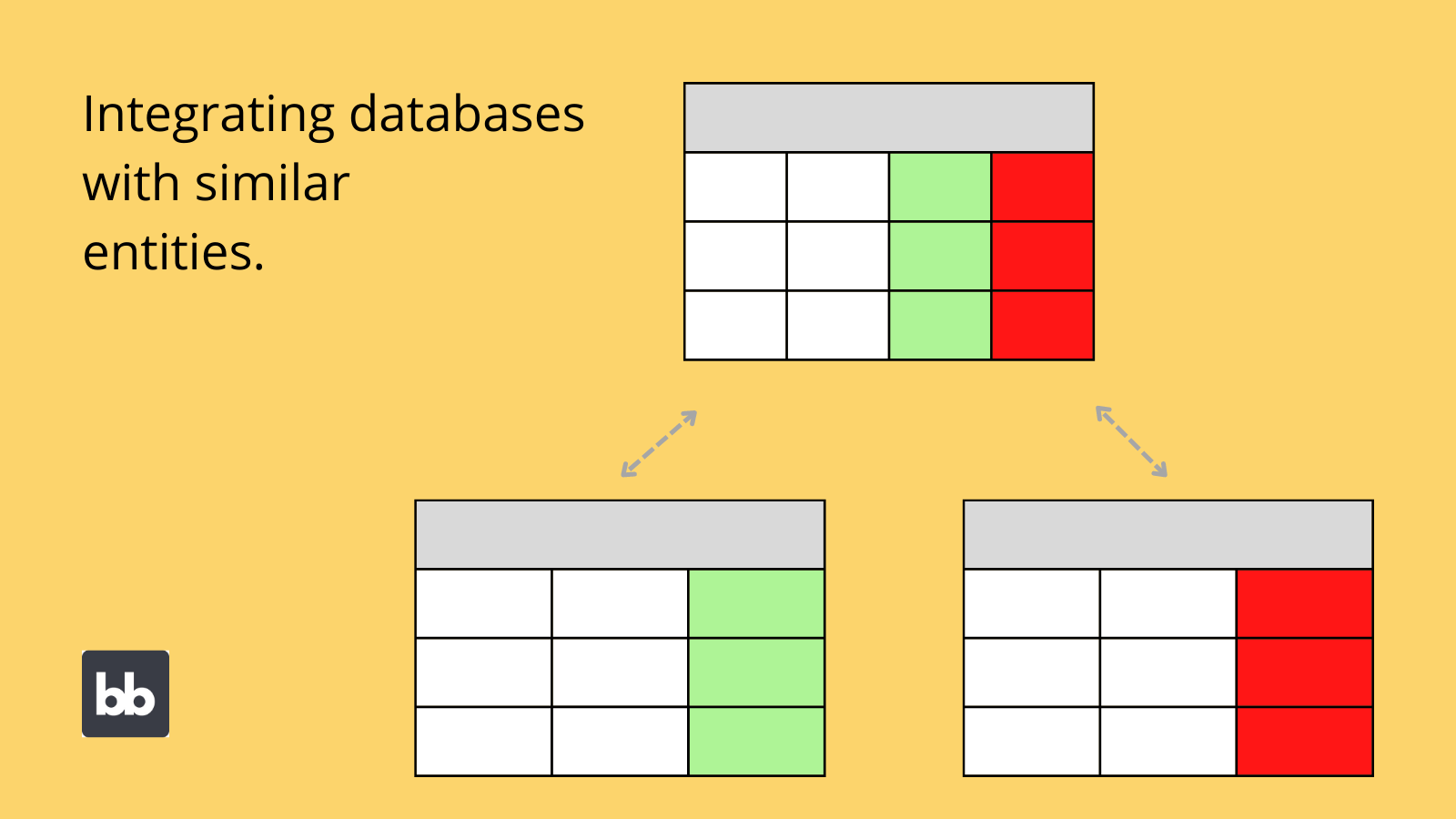
从不同的数据库模式集成数据
自然,当您使用多个不共享公共模式的数据库时,事情会变得更加复杂。例如,如果要将多个完全不同的数据集移动到单个主源中。
在很大程度上,这有时也称为数据仓库。
事实上,这本身就是一门高度专业化的学科,因此建议我们可以在本指南中全面概述如何开展这项工作是有误导性的。
相反,让我们探讨在进行这种集成时必须记住的一些关键考虑因素。
评估您对新数据库的需求
您将在这里做出的许多决定将取决于存储实体之间的相似性或差异程度。这在创建新数据库模式时尤为重要。
因此,您可能有多个数据库存储关于同一实体的不同类型的信息。或者,您可能有几个处理完全不同的实体集的数据库。
例如,集成与客户相关的两组数据可能比集成两个完全不同的数据集要小得多。
在第一个场景中,我们只需要从DBMS中查询每个现有数据库,并为所需的每个实体创建新的主版本。
正如我们稍后将看到的,这在实践中可能会稍微复杂一些。
无论哪种情况,关键都是为主数据库定义一个满足信息需求的模式,同时保留原始源的内容。
保持一致性和完整性
在集成数据库时保持一致性和完整性可能是一项重大挑战。其中一部分与现有数据的类型和格式有关。当不同的数据库已经以不同的方式存储相似的属性时,这是一个特别值得关注的问题。
这可能源于原始数据库所有者做出的决定,或者源于底层DBMS的约定。
例如,不同的数据库可能会以不同的方式处理字符串或数字数据。这将在尝试操作值时造成困难。
这里的关键是有效地转换现有数据以满足新的数据库模式。这里的细节将因项目而异。查看我们的应用程序数据源终极指南,了解有关转换的更多信息。
处理重复和差异
数据库之间的重复值和差异是集成过程中的另一个主要问题。这里,重复意味着相同的值存储两次。当给定对象的相同属性存储两次,但值不同时,就会出现差异。
假设您正在集成两个数据库,每个数据库存储客户电话号码的值。如果在多个数据库中的不同表上保留此属性,则会发生重复。
如果您为同一客户存储了不同的电话号码,则会出现差异。这可以是值本身的级别,也可以是它的格式。
当然,在某些情况下,您可能希望在数据模型中构建冗余,但在单个数据库中实现这一点并不常见。
在集成项目中,这意味着您需要决定对任何重复属性优先考虑哪个源。
管理关系
当您为新的主数据库开发模式时,您可能必须彻底重新考虑不同实体之间的关系。这同样适用,无论您的原始数据库是否处理类似的实体。
在其他情况下,事情可能会简单一点。一些集成项目可能意味着将一个单独的附加表附加到一个更大的数据库中,并将其存储在一个新的模型和模式中。
这将相对简单,因为您可能不需要实质性地改变大多数实体的关系。
在其他情况下,定义实体之间的关系将更加复杂。我们已经创建了一个关于如何创建数据模型的专门指南,您可以查看该指南以了解更多信息。
存储、托管和访问
还有一个问题是如何物理存储和托管新数据库。例如,在云主机或本地存储之间进行选择。
您还需要考虑用于管理迁移数据的实际DMBS。
例如,我们前面提到了一个场景,我们可以将两个Postgres数据库集成到一个MySQL实例中。
显然,您将在这里做出的具体选择高度依赖于特定项目的需求。例如,您可能会选择Postgres、MySQL、MSSQL、SQL Server、Airtable、CouchDB、MongoDB、Oracle、S3或大量其他数据库工具。
移植风险
对于大型数据库整合项目,减轻不同的迁移风险也至关重要。
事实上,任何类型的数据迁移都有无数巨大的风险。
其中最明显的是数据丢失、损坏和服务中断时间延长。因此,彻底审查您在迁移过程中使用的任何集成工具和合作伙伴非常重要。
除此之外,大型集成项目还会对更广泛的软件堆栈产生影响。更具体地说,不同的工具在数据移动后查询数据时可能会遇到问题。它们也可能不支持新的数据存储或DBMS。
例如,当属性名称更改时,可能会出现语义问题,但自动查询没有更新以反映这一点。
如何在web应用程序中集成来自不同来源的数据
如前所述,存在批发整合的替代方案。这包括从一个工具查询多个数据源,实现集成的许多好处,而无需迁移数据。
这是跨不同数据集创建单一、可访问的真实来源的有效方法。我们还可以使用简单的web应用程序,通过定义的工作流提高效率并减轻管理多个数据库的管理负担。
这也消除了与其他类型集成相关的一些风险。
然而,在一个应用程序中使用多个数据库也会带来严重的挑战。例如,查询错误、源之间的不一致性,以及使用单个数据源的所有常见挑战。
因此,这种策略通常更适合于相对简单的工具和数据集。
本质上,这样的网络应用程序必须实现两件事:
- 为用户提供与查询单个主数据库相同的体验。
- 当通过其他现有工具进行更改时,保持连接数据库之间的一致性。
例如,您可能有单独的平台,内部数据库存储不同类型的客户信息。您可以构建一个工具,为您的服务团队提供单一的真实来源,并使其更易于管理和维护客户详细信息。
让我们看看你如何在Budibase建造这座建筑。
1.连接数据
第一步是将数据库连接到Budibase生成器。当然,您可能有几个数据源,但为了简单起见,我们将在示例中使用两个。假设我们有一个来自CRM的MySQL数据库和一个来自开票工具的Postgres数据库。
每个都有多个表,其中一个用于客户详细信息。这些通用表存储了一系列不同的属性,但每个数据库都包含每个客户的联系信息字段。
我们希望构建一个工具,内部用户和客户自己可以通过一个界面在两个数据库中更新他们的联系信息。
Budibase为外部数据提供了一系列直观的连接器。在生成器中,转到“数据”选项卡,然后选择加号图标以添加新源:
首先,我们将通过选择Postgres并输入凭据,连接到发票平台的数据库:
然后,我们可以对CRM的MySQL数据库执行同样的操作:
当我们保存其中的每一个并获取表时,我们将拥有在两个数据库上执行CRUD查询的完整连接。
每个数据库有两个表。我们的CRM为客户和用户存储实体:
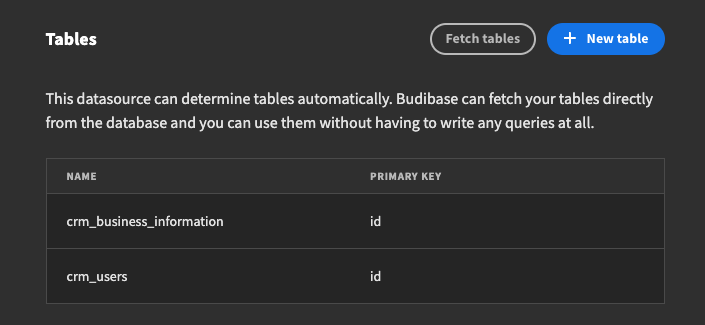
开票工具为客户和发票提供了单独的表格:
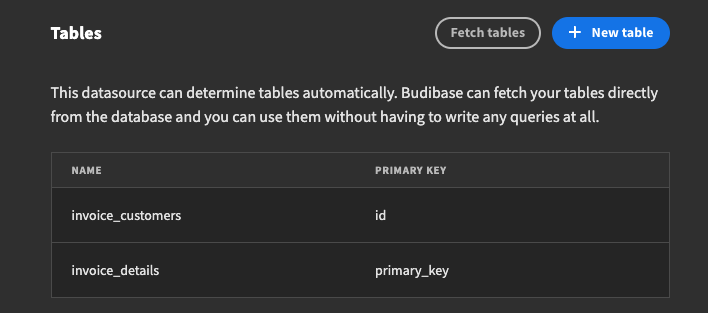
在我们的示例中,我们只关注每个数据库中的customers表。我们可以单独处理这些表和其他内部表之间的关系。
2.创建组合数据表
请记住,我们的数据库共享每个客户的某些属性,但它们也存储一些独特的信息。具体来说,每个存储联系人详细信息以及其他独特属性。
我们的下一个任务是为用户提供一个单独的资源,在那里他们可以看到每个客户存储的所有详细信息。
换句话说,我们需要创建一个表,其中包含两个数据库的客户记录中的所有属性。我们可以用几种不同的方式来实现这一点,例如创建一个虚拟表。
出于我们的目的,我们将创建一个新的物理表。我们可以在现有数据库中使用BudibaseDB或在一个全新的数据库中执行此操作。为了简单起见,我们将在CRM的现有MySQL主机中创建一个新表。
我们将首先编写一个查询来复制CRM的客户表:
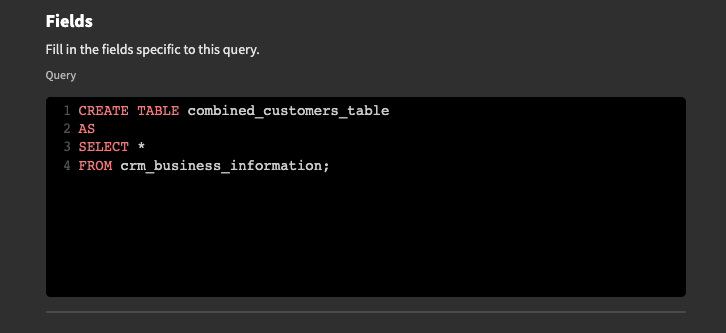
您可以在DMBS中执行此操作,也可以在Budibase中作为自定义查询执行,如上所示。
然后,我们可以使用Budibase将发票工具中所需的任何其他属性添加到新的组合表中。在我们的案例中,我们只有一个-客户的计费周期。
然后,我们将构建一个简单的自动化,将相关的计费周期值添加到新表中。有许多不同的方式可以触发此操作,包括用户操作或设置时间段。
然而,由于我们在发票客户数据集中只有相对较少的条目,我们将使用更新的行触发器,因此我们可以逐个传递每个值。
稍后我们将介绍更多的自动化。目前,我们所需要做的就是将初始值设置到位。首先,我们将在更新crm_business_information表中的行时设置触发器。
接下来,我们需要查询invoice_customers_table,并使用过滤器查找与触发器具有相同业务名称的行。
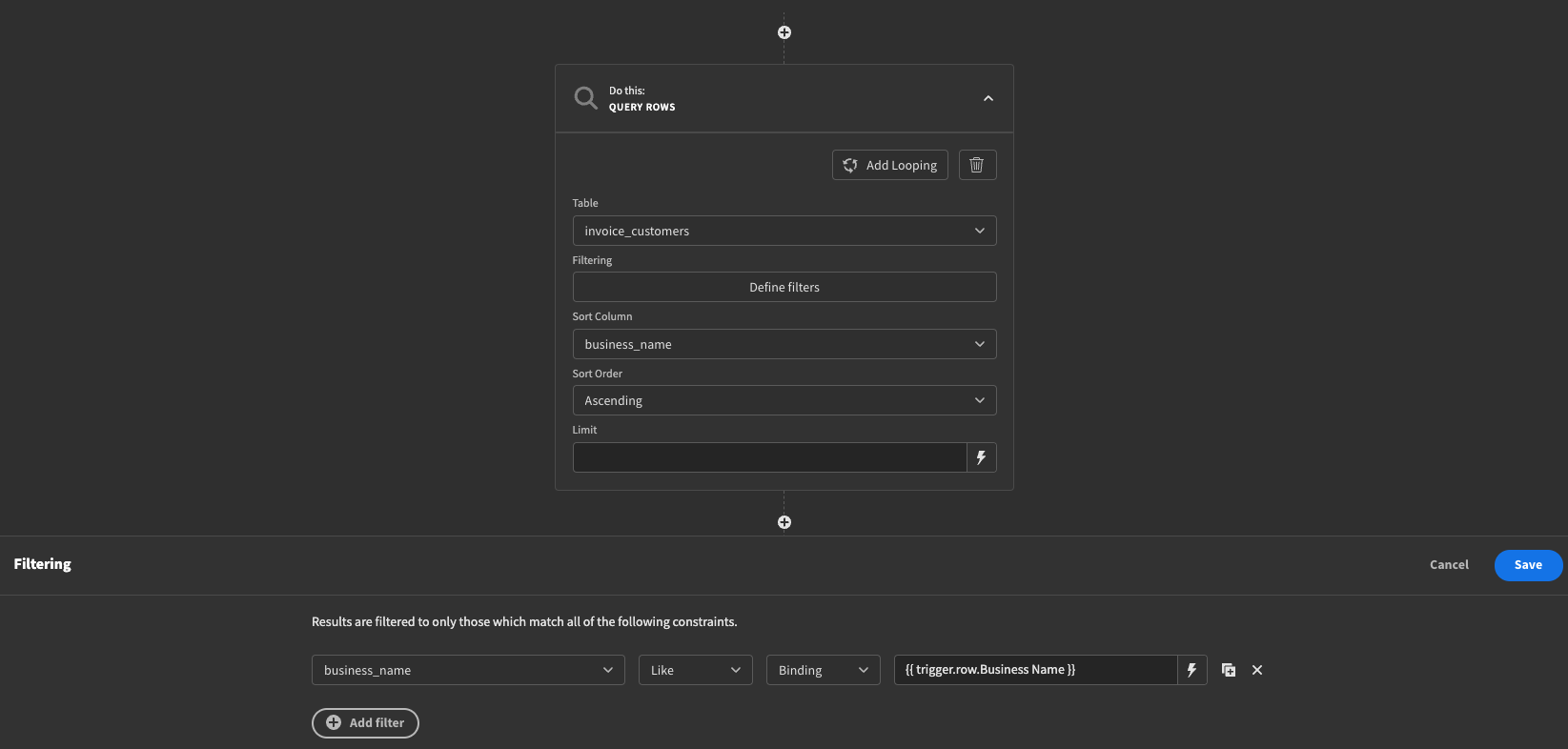
最后,我们将使用触发器行和invoice_customers表中的值的组合来更新combined_customers_table中的相关行。
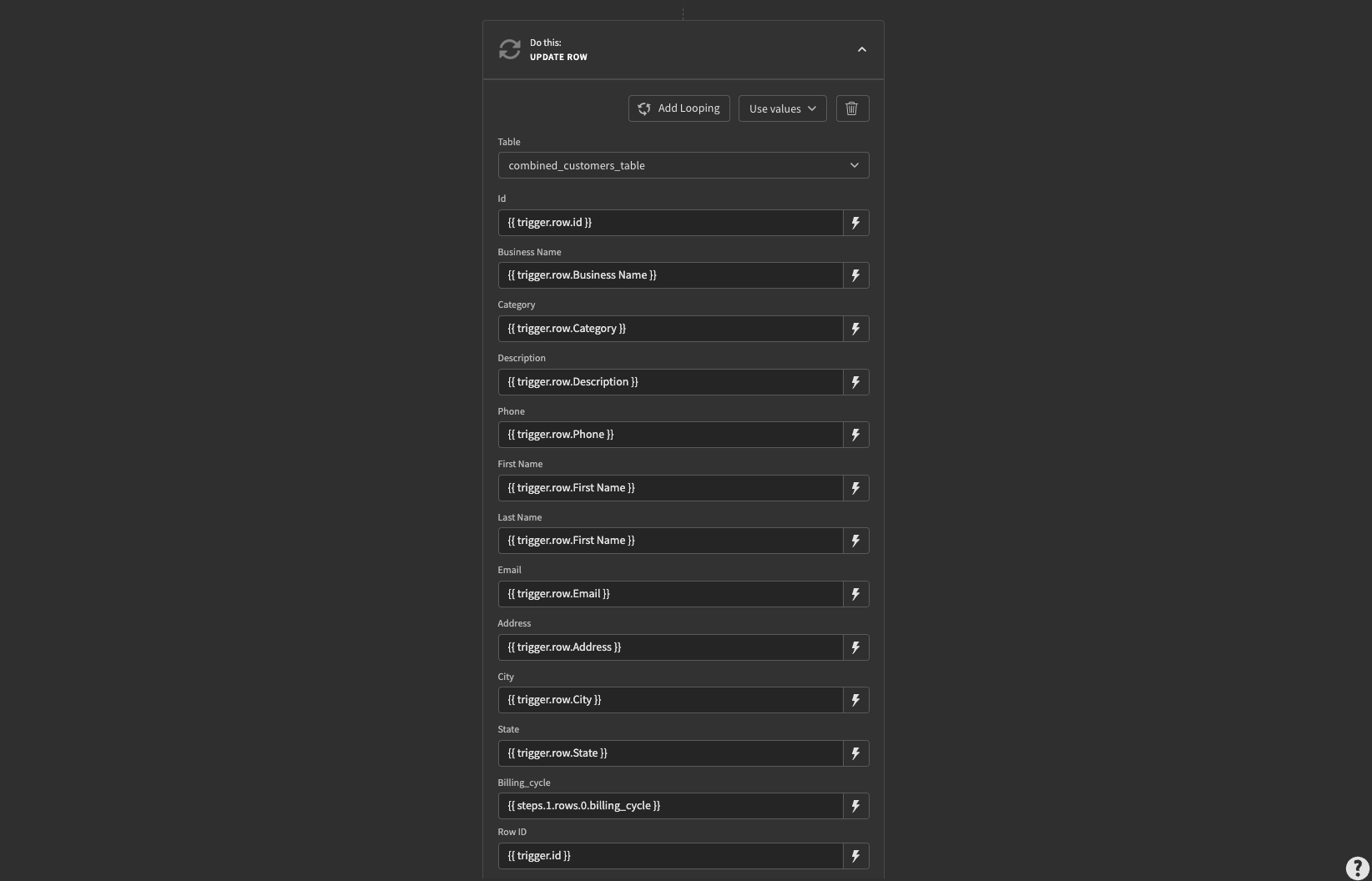
有了这一点,我们就可以手动更新crm_business_infromation表中的任何行,以从发票数据库中携带账单周期值。
如果我们想批量执行此操作,我们可以使用不同的触发器(如用户操作),并更改自动化以遍历两个表中的每一行,并将新值添加到正确的行。
3.构建CRUD屏幕
现在我们有了一个组合表,我们可以开始构建CRUD屏幕来查询我们的两个数据库。记住,我们的目标是拥有一个用于管理两个数据库共享属性的单一接口。
因此,基本上,我们需要创建一个表单,在那里我们可以编辑客户的联系信息,并将这些新信息传递给我们的CRM和发票平台。
显然,最好的用户体验是允许用户通过一个表单完成这一操作。
我们希望这可以更新客户的联系信息,同时将任何唯一属性单独保留在任一数据库中。
首先,我们将自动为组合的customers__table生成CRUD屏幕。
为了简单起见,我们将通过将编辑表单UI设置为以模态打开,使其成为一个单屏幕应用程序。当您在Budibase中自动生成CRUD屏幕时,您还可以创建行表单,但我们不需要这些表单。
现在,我们将开始处理编辑表单。
我们需要做的第一件事是删除不希望用户通过表单编辑的属性的任何字段。因此,在本例中,非接触式详细信息是ID、类别、描述和billing_cycle。
我们现在有了一个工作表单。但是,如果用户完成了这一操作,它只会更改组合表中的条目详细信息,而不会更改两个源表。
接下来,我们需要创建自动操作,以在合并表中的行发生更改时更新源数据库。
4.自动查询
记得前面我们创建了一个自动化,这样当crm_business_information表中的一行被更新时,invoice_customers中的相关客户将被查询,而他们的详细信息将在combined_customers_table中更新。
我们的应用程序要求如下:
- 用户可以使用单个表单界面更新两个源数据库中的客户联系信息。
- 当手动更新其中一个源数据库时,另一个数据库中的联系人详细信息应保持最新。
因此,我们实际上需要三种类似的自动化:
- 表单完成后,两个源数据库都会更新新的联系人详细信息。
- 在外部更新crm_business_information表时,应更新组合列表和invoice_customers表以反映这一点。
- 如果invoice_customers表已更新,则组合列表和crm_business_information也应如此。
首先,我们将在用户完成表单时更新源数据库。因此,我们将再次使用更新的行触发器。然后,我们希望遵循与前面相同的步骤。因此,对于每个源数据库,我们将执行以下操作:
添加一个查询行块,并设置一个过滤器以隔离与触发器具有相同业务名称的行。
添加一个更新行块,使用我们的表单数据更新联系人详细信息。
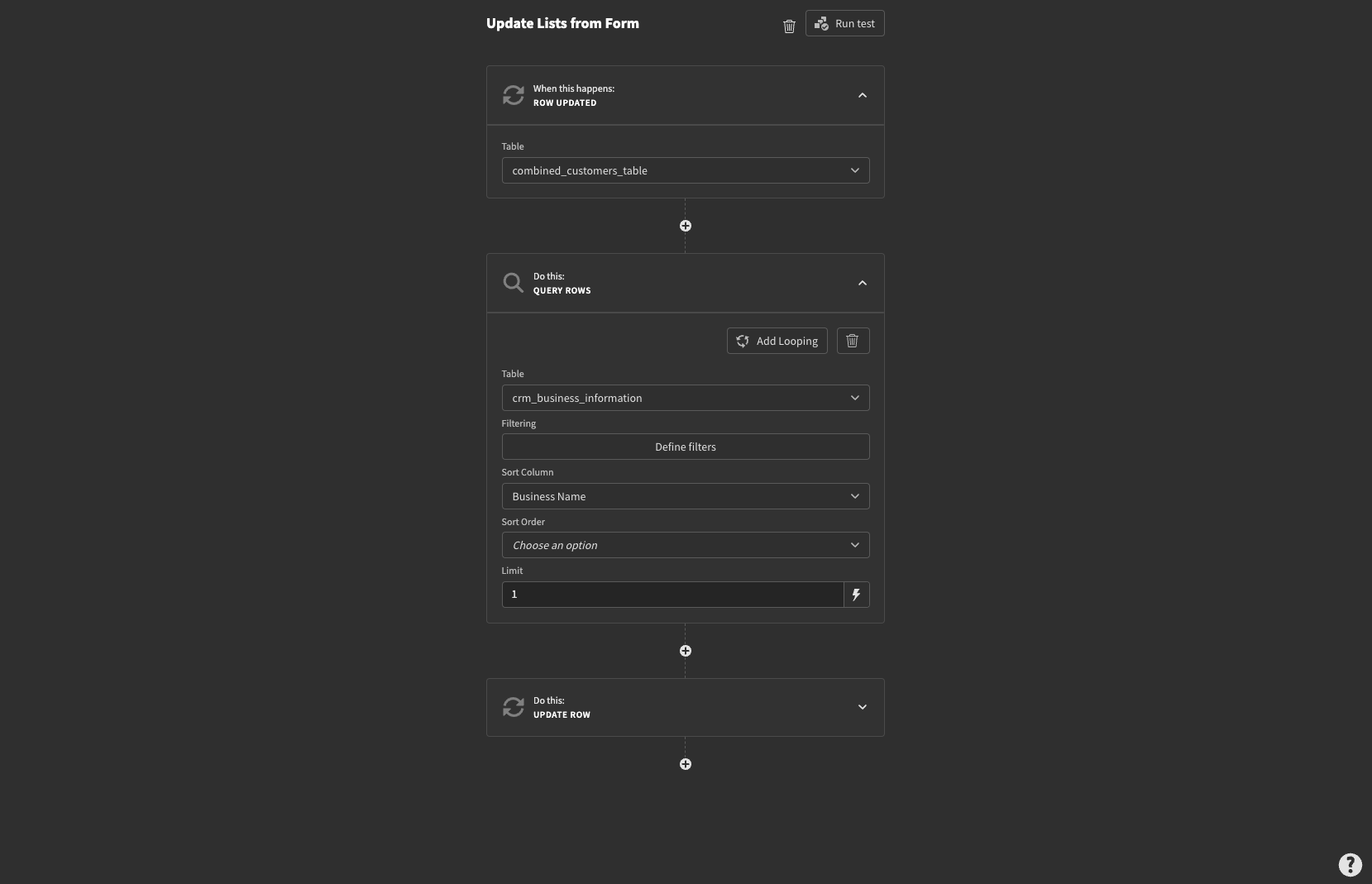
我们使用查询行块输出的ID和原始表单触发器提供的信息来更新相关行:
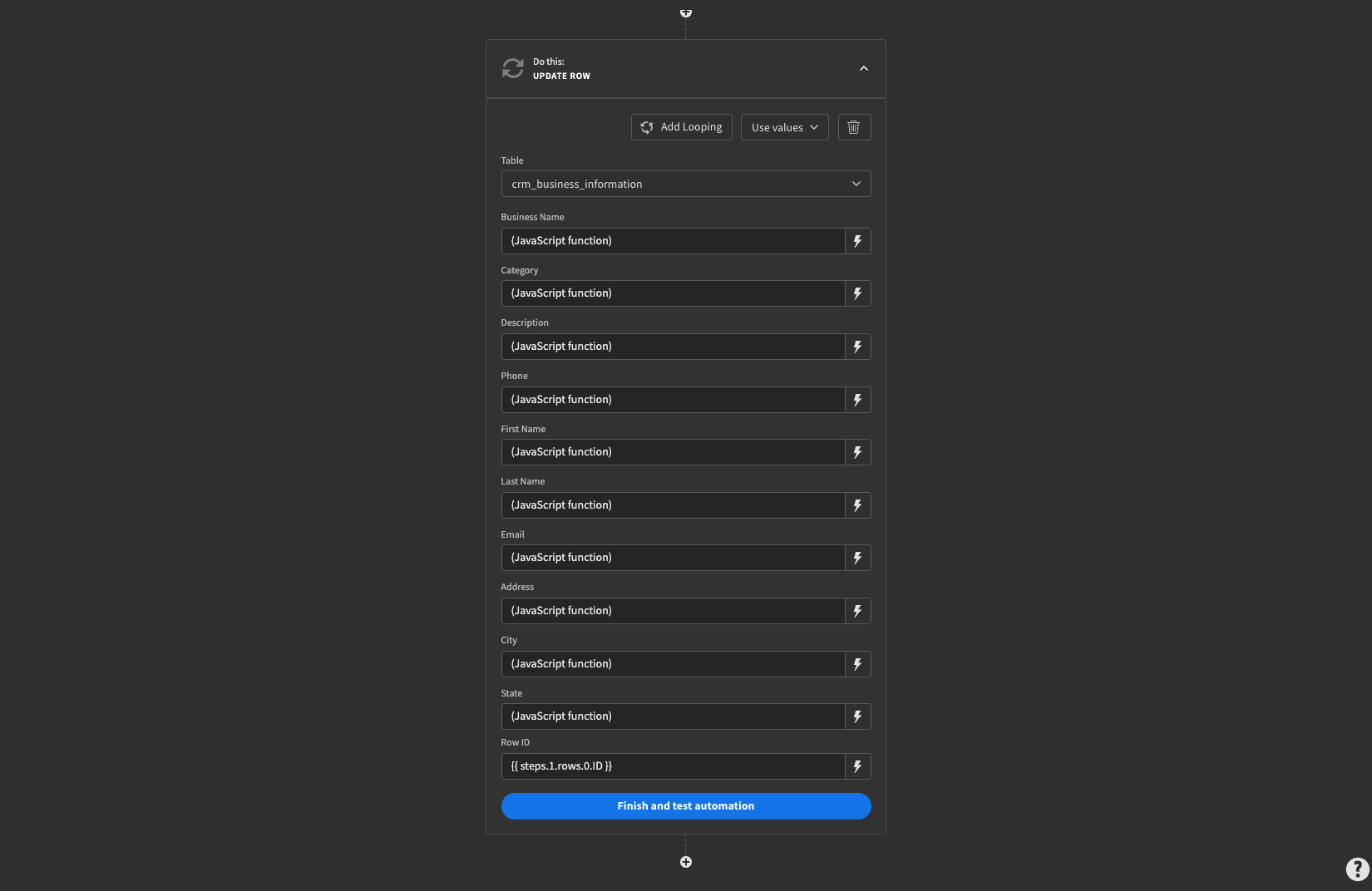
我们使用JavaScript绑定将每个单独的属性传递给我们的自动化:
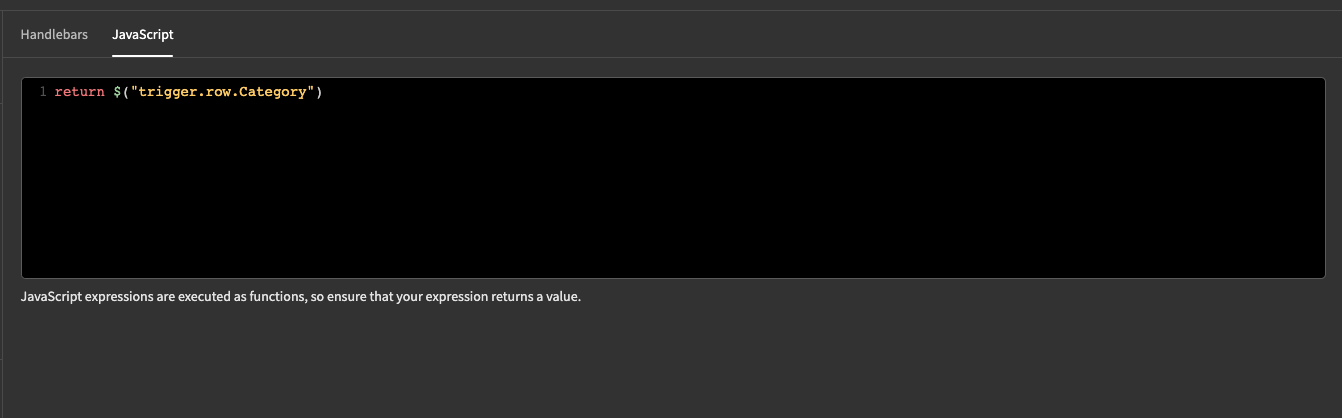
现在,我们可以通过为invoice_customers表添加相同的块来重复这个过程。
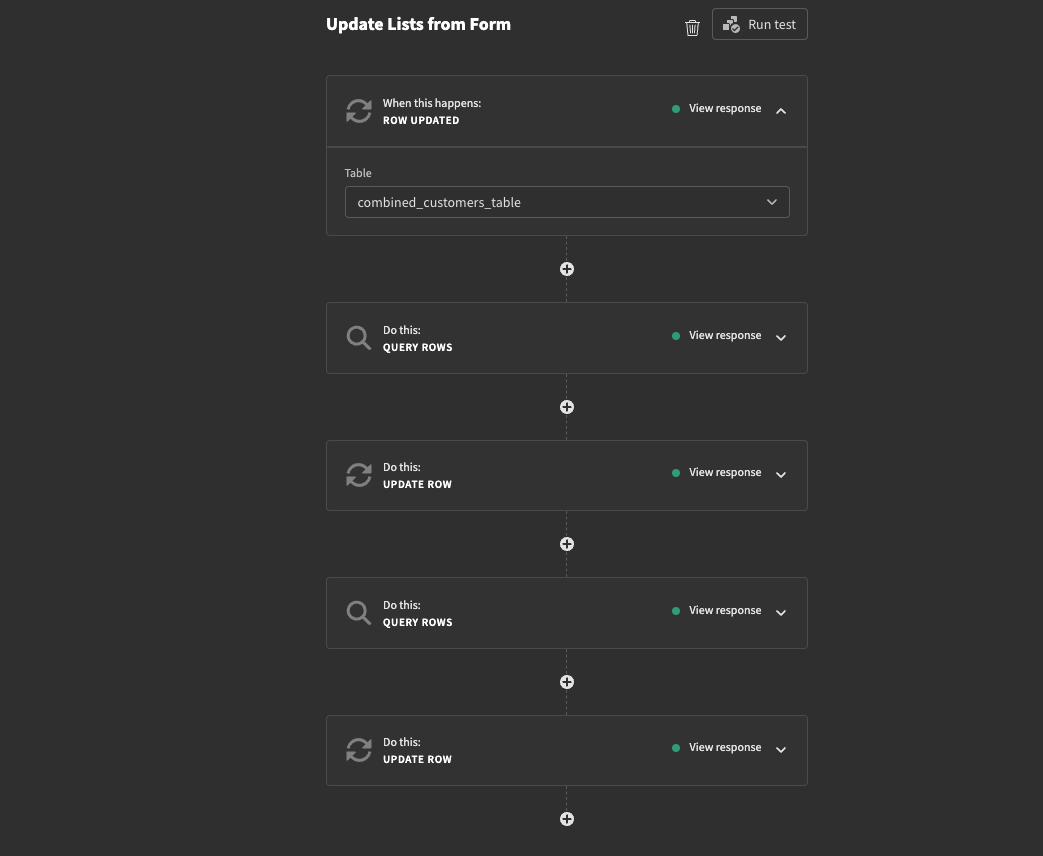
我们可以测试我们的自动化,以确保它在现实生活中工作。我们将使用我们的表单将一个客户的电话号码更新为000-000-000:
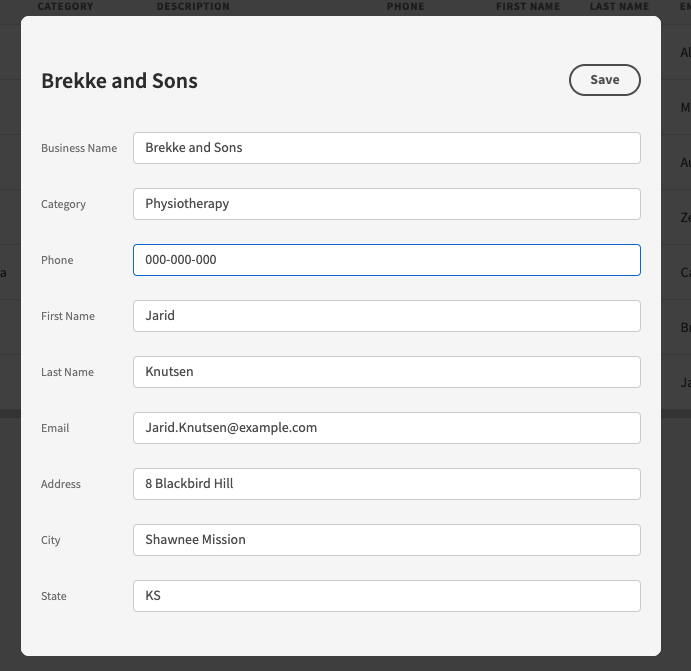
然后,我们将在源DMBS中运行查询,以确保其正常工作。MySQL数据库中的第一个
然后在我们的Postgres表中:
现在,我们可以使用一个表单UI在多个数据库中更新客户的联系信息。
最后一步是创建自动化流程,以便每当在各自的外部平台中更新其中一个数据库时,这一变化都会反映在另一个数据库中。
对于大部分自动化,我们可以使用与上述完全相同的步骤。我们只需要为每个表组合修改它。
我们可以通过几种不同的方式来触发这一点。
一种选择是,当出现差异时,决定我们的哪个表优先。然后,我们可以使用按时间顺序的触发器周期性地遍历两个表中的每一行,并相应地更新它们。
或者,当任何数据库发生更改时,我们可以使用更新行触发器来自动更新所有相关条目,这与我们使用combind_customers_table中的触发器的方式大致相同。
如何确保来自多个源的数据兼容?
最后,请注意在集成多个数据库时保持一致。到目前为止,在我们的所有示例中,我们都使用了具有相对基本模式的小型数据集。当然,情况并不总是这样。
实际上,在许多情况下,不同数据库中类似属性的值不兼容。
在这些情况下,您需要使用转换来确保数据兼容。
例如,如果我们的一个现有数据源将某个特定属性存储为字符串,而另一个数据源将数值存储为同一变量,则需要执行此操作。这可能发生在不同平台上的客户电话号码上。
我们不一定要改变现有数据库的模式。毕竟,我们可能有其他工具依赖这些数据,我们不想打破这些。相反,我们可以在数据库之间传递值时使用JavaScipt表达式来转换值。
在Budibase中,您可以创建自定义查询来执行转换,也可以在创建自动化时绑定任何值时使用自定义JavaScript。
查看我们的web应用程序数据源终极指南,了解有关转换的更多信息,以及如何在使用多个数据库时使用这些数据源。
- 117 次浏览