数据库



MySQL架构
- 250 次浏览
【MySQL】MySQL高可用性框架解释 - 第三部分:失败场景
在这个由三部分组成的博客系列中,我们在第一部分中介绍了MySQL托管的高可用性(HA)框架,并在第二部分中讨论了MySQL半同步复制的细节。现在在第三部分中,我们将回顾框架如何处理一些重要的MySQL故障情况并进行恢复以确保高可用性。
MySQL失败场景
场景1 - Master MySQL关闭
- Corosync和Pacemaker框架检测到主MySQL不再可用。如果可能的话,Pacemaker会降级主资源并尝试通过重新启动MySQL服务来恢复。
- 此时,由于复制的半同步性质,至少一个从设备已接收在主设备上提交的所有事务。
- 起搏器等待,直到所有收到的交易都应用于奴隶并让奴隶报告他们的促销分数。分数计算以如下方式进行:如果从属设备与主设备完全同步则得分为“0”,否则为负数。
- Pacemaker选择已报告0分的奴隶,并提升该奴隶,该奴隶现在担任允许写入的主MySQL角色。
- 从属升级后,资源代理会触发DNS重新路由模块。模块使用新主服务器的IP地址更新代理DNS条目,从而促进所有应用程序写入重定向到新主服务器。
- Pacemaker还设置可用的从站以开始从这个新主站复制。
因此,每当主MySQL出现故障时(无论是由于MySQL崩溃,操作系统崩溃,系统重启等),我们的HA框架都会检测到它并促使合适的从服务器接管主服务器的角色。这可确保系统继续可供应用程序使用。
场景2 - Slave MySQL关闭
- Corosync和Pacemaker框架检测到从属MySQL不再可用。
- Pacemaker尝试通过尝试在节点上重新启动MySQL来恢复资源。如果它出现,它将作为从属添加回当前主服务器并继续复制。
- 如果恢复失败,Pacemaker会将资源报告为已关闭 - 基于可生成的警报或通知。如有必要,ScaleGrid支持团队将处理此节点的恢复。
在这种情况下,对MySQL服务的可用性没有影响。
场景3 - 网络分区 - 网络连接在主节点和从节点之间分解
这是任何分布式系统中的经典问题,其中每个节点认为其他节点已关闭,而实际上,仅断开节点之间的网络通信。这种情况通常被称为裂脑情景,如果处理不当,可能会导致多个节点声称自己是主MySQL,从而导致数据不一致和损坏。
让我们用一个例子来回顾一下我们的框架如何处理集群中的裂脑情景。我们假设由于网络问题,集群已分为两组 - 一组中的主机和另一组中的两个机箱,我们将其表示为[(M),(S1,S2)]。
- Corosync检测到主节点无法与从节点通信,并且从节点可以相互通信,但不能与主节点通信。
- 主节点将无法提交任何事务,因为半主机可以提交之前,半同步复制需要来自至少一个从服务器的确认。与此同时,由于缺乏基于Pacemaker设置'no-quorum-policy = stop'的法定人数,Pacemaker在主节点上关闭了MySQL。仲裁在这里意味着大多数节点,或3节点集群设置中的两个节点。由于在此群集的分区中只运行一个主节点,因此会触发no-quorum-policy设置,从而导致MySQL主服务器关闭。
- 现在,分区上的Pacemaker [(S1),(S2)]检测到群集中没有可用的主服务器并启动促销过程。假设S1与主服务器是最新的(由半同步复制保证),则它将被提升为新主服务器。
- 应用程序流量将重定向到此新的主MySQL节点,从属S2将开始从新主节点复制。
因此,我们看到MySQL HA框架有效地处理裂脑情况,确保在主节点和从节点之间网络连接中断时数据的一致性和可用性。
以上是关于使用半同步复制和 Corosync 加 Pacemaker堆栈的MySQL高可用性(HA)框架的3部分博客系列。在ScaleGrid,我们在AWS上为MySQL提供高度可用的托管,在Azure上提供MySQL,这是基于本博客系列中介绍的概念实现的。请访问ScaleGrid控制台,免费试用我们的解决方案。
原文:https://scalegrid.io/blog/mysql-high-availability-framework-explained-part-3/
本文:http://pub.intelligentx.net/mysql-high-availability-framework-explained-part-iii-failure-scenarios
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 67 次浏览
【MySQL】MySQL高可用性框架解释 - 第二部分:半同步复制
在第一部分中,我们介绍了MySQL托管的高可用性(HA)框架,并讨论了各种组件及其功能。现在在第二部分中,我们将讨论MySQL半同步复制的细节以及相关的配置设置,这些设置有助于我们确保HA设置中数据的冗余和一致性。请务必重新检入第III部分,我们将审查可能出现的各种故障情况以及框架响应和恢复这些条件的方式。
什么是MySQL半同步复制?
简单地说,在MySQL MySQL semisynchronous replication配置中,主设备仅在收到来自至少一个从设备的确认后才将事务提交到存储引擎。只有在收到事件并将其复制到中继日志并刷新到磁盘后,从站才会提供确认。这保证了对于提交并返回到客户端的所有事务,数据至少存在于2个节点上。半同步(复制)中的术语“半”是由于主设备在接收到事件并将其刷新到中继日志后提交事务,但不一定提交给从设备上的数据文件。这与完全同步复制形成对比,完全同步复制在会话返回客户端之前,事务将在从服务器和主服务器上提交。
半导体复制(在MySQL中本机可用)可帮助HA框架确保已提交事务的数据一致性和冗余。如果主服务器出现故障,主服务器上提交的所有事务都将被复制到至少一个从服务器(保存到中继日志)。因此,故障转移到该从站将是无损的,因为从站是最新的(在从站的中继日志完全耗尽之后)。
复制和半同步相关设置
让我们讨论一些关键的MySQL设置,这些设置用于确保我们框架中的高可用性和数据一致性的最佳行为。
管理Slave的执行速度
第一个考虑因素是处理半同步复制的“半”行为,它只保证数据已被接收器的I / O线程接收并刷新到中继日志,但不一定由SQL线程提交。默认情况下,MySQL从属服务器中的SQL线程是单线程的,无法与多线程的主服务器保持同步。这样做的明显影响是,在主服务器发生故障时,从服务器将不会是最新的,因为它的SQL线程仍在处理中继日志中的事件。这将延迟故障转移过程,因为我们的框架期望从服务器在可以升级之前完全是最新的。这对于保持数据一致性是必要的。为解决此问题,我们使用slave_parallel_workers选项启用多线程从站,以设置处理中继日志中事件的并行SQL线程数。
此外,我们配置以下设置,以确保从站不会进入主站不在的任何状态:
- slave-parallel-type = LOGICAL_CLOCK
- slave_preserve_commit_order = 1
这为我们提供了更强的数据一致性。通过这些设置,我们将能够在从属设备上获得更好的并行化和速度,但是如果并行线程太多,则线程之间协调所涉及的开销也会增加,并且不幸地会抵消这些优势。
我们可以用来提高从站上并行执行效率的另一个配置是调整主站上的 binlog_group_commit_sync_delay 。通过在master上设置它,主服务器上的二进制日志条目以及从服务器上的中继日志条目将具有可由SQL线程并行处理的批量事务。这在 J-F Gagné’s blog 中有详细解释,他将这种行为称为“减慢主人加速奴隶的速度”。
如果您通过ScaleGrid控制台管理MySQL部署,则可以持续监视和接收有关从属服务器复制延迟的实时警报。它还允许您动态调整上述参数,以确保从站与主站一起工作,从而最大限度地减少故障转移过程中的时间。
重要的半同步复制选项
根据设计,MySQL半同步复制可以基于从确认超时设置或基于任何时间点可用的具有半同步能力的从设备的数量而回退到异步模式。根据定义,异步模式不能保证已提交的事务被复制到从属服务器,因此主服务器丢失会导致丢失尚未复制的数据。 ScaleGrid HA框架的默认设计是避免回退到异步模式。让我们来看看影响这种行为的配置。
rpl_semi_sync_master_wait_for_slave_count
此选项用于配置在半同步主服务器提交事务之前必须发送确认的从站数。在3节点主从配置中,我们将其设置为1,因此我们始终确保数据在至少一个从站中可用,同时避免在等待来自两个从站的确认时所涉及的任何性能影响。
此选项用于配置半同步主控器在切换回异步模式之前等待来自从器件的确认的时间。我们将其设置为相对较高的超时值,因此不会回退到异步模式。
由于我们使用2个从站运行并且rpl_semi_sync_master_wait_for_slave_count设置为1,因此我们注意到至少有一个从站确实在合理的时间内确认,并且主站在临时网络中断期间不会切换到异步模式。
rpl_semi_sync_master_wait_no_slave
这将控制主服务器是否等待rpl_semi_sync_master_timeout配置的超时时间到期,即使从服务器计数降至小于超时期间rpl_semi_sync_master_wait_for_slave_count配置的从服务器数。我们保留默认值ON,以便主服务器不会回退到异步复制。
失去所有半同步从属的影响
如上所述,如果所有从站都关闭或无法从主站访问,我们的框架会阻止主站切换到异步复制。这样做的直接影响是写入在主服务器上停滞不前影响服务的可用性。这基本上如CAP定理所述,关于任何分布式系统的局限性。该定理指出,在存在网络分区的情况下,我们必须选择可用性或一致性,但不能同时选择两者。在这种情况下,网络分区可以被视为与主服务器断开连接的MySQL从服务器,因为它们已关闭或无法访问。
我们的一致性目标是确保对于所有已提交的事务,数据至少在2个节点上可用。因此,在这种情况下,ScaleGrid HA框架有利于可用性的一致性。虽然MySQL主服务器仍将提供读取请求,但不会从客户端接受进一步的写入。这是我们作为默认行为的有意识的设计决策,当然,它可以根据应用程序要求进行配置。
请务必订阅ScaleGrid博客,这样您就不会错过第三部分,我们将讨论更多故障情景和MySQL HA框架的恢复能力。敬请关注!!
原文:https://scalegrid.io/blog/mysql-high-availability-framework-explained-part-2/
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 53 次浏览
【MySQL】为什么甲骨文继续诋毁自己的产品MySQL?
甲骨文首席技术官拉里·埃里森(Larry Ellison)无法在他的财报电话中充分利用MySQL。 有这种疯狂的方法吗?

从大多数人的角度来看,甲骨文一直是MySQL的一个相当好的管家,MySQL是几年前甲骨文收购Sun Microsystems时所采用的开源数据库。甲骨文为MySQL提供了重要的工程资源,以确保“在长期以来被认为无法解决的领域中提高性能”,正如之前的MySQL产品主管Zack Urlocker所说的那样。
最近,Oracle首席技术官兼董事长拉里·埃里森毫不掩饰他对MySQL的蔑视,告诉分析师“你必须愿意放弃大量的可靠性,大量的安全性,大量的性能[使用MySQL而不是甲骨文因为......我们拥有巨大的技术优势。“这对于竞争对手来说是公平的游戏,但这是Ellison谈论主要由Oracle开发的产品。
陷入交火
并非埃里森开始贬低该行业第二大流行数据库 - 他试图破坏对亚马逊网络服务的信心,亚马逊网络服务提供MySQL作为数据库服务,无论是作为RDS还是作为Aurora。埃里森因为伸展事实以适应他的竞争姿态而闻名,他相信“亚马逊Aurora只是MySQL的开源,亚马逊Redshift也只是一个借来的开源系统。”正如Gartner分析师Nick Heudecker指出的那样,这两个断言都是可疑的。
确实,AWS客户可以购买具有MySQL智能功能的Aurora服务,但除此之外还有更多内容。
MySQL还有比“非常古老的系统[]更多”。 (来自甲骨文的一个好奇的批评,甚至推翻了更老的数据库技术。)而且,“Oracle的自主数据库拥有甲骨文所拥有的最大技术领先优势”(在任何有意义的意义上)都是不对的。 (尽管AWS产生的IaaS收入比Oracle高出80倍,PaaS收入比Oracle高出10倍,但这个同样的传闻听起来像甲骨文的前笑语“AWS落后甲骨文20年”。)甲骨文新的许可收入一直在下降很多年了。相比之下,MySQL和它的亲吻表兄PostgreSQL仍然很受欢迎,无论是通过像AWS这样的云公司购买还是在本地运行。
甲骨文酒店加州
事实是,甲骨文让人难以置信地离开。如果没有[那么多]努力,如果亚马逊甚至无法到达亚马逊数据库,那么“没有人(但亚马逊)会如何通过强制游行进行宣传”,埃里森提出了迁移数据库的困难,特别是,Oracle的数据库,还有其他任何东西。 “但就技术而言,没有人可以移动 - 一个普通人会从Oracle数据库转移到亚马逊数据库。这只是非常昂贵和复杂。”
对于渴望资金的金融分析师来说,这种声音可能会很好,但如果你是开发人员或CIO阅读埃里森的评论,它会发出什么样的信号?
看看:甲骨文的埃里森:“正常”的人不会转向AWS(ZDNet)
它说,正如一位Twitter评论员所说的那样,“埃里森是正确的,离开甲骨文是昂贵和复杂的。这就是它的设计方式。这就像邀请臭虫进入你的房子。”甲骨文... ...臭虫确实。
这只是许多开发人员根本没有开始使用Oracle的原因之一。事实上,我猜想几乎没有开发人员选择Oracle。他们怎么样? Oracle技术不仅繁琐复杂,而且价格昂贵。开发人员可以以0.00美元的价格开始使用MySQL,或者使用在AWS上运行的MySQL(或RDS或Aurora),价格为0.01美元。纯粹从便利因素来看,Oracle每次都会失败。
甲骨文唯一要做的就是惯性。正如Gartner分析师Merv Adrian所说:“遗留DBMS中最大的力量就是惯性。”不是技术优势。没有成本优势。除习惯和钙化方案设计,物理数据放置等多年以外,其他任何事情都不是
但这仅仅是旧应用程序的护城河。随着公司构建未来,他们并没有在Oracle上构建它,尽管他们有时可能会在Oracle似乎鄙视的开源数据库上构建它,MySQL。鉴于埃里森对自己的产品感到厌恶,很难看出甲骨文长期以来一直是MySQL的管家。
原文:https://www.techrepublic.com/article/why-does-oracle-keep-trashing-mysql-its-own-product/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 58 次浏览
【MySQL架构】MariaDB versus MySQL: Compatibility
完全替代MySQL
MariaDB版本的功能相当于一个“完全替代”的MySQL版本,但有一些限制。这意味着:
- MariaDB的数据文件通常是二进制的,与MySQL版本的数据文件兼容。
- 所有的文件名和路径通常是相同的。
- 数据和表定义文件(.frm)文件是二进制兼容的。
- 请参阅下面的注释,查看与视图的不兼容性!
- MariaDB的客户端协议与MySQL的客户端协议是二进制兼容的。
- 所有的客户端api和结构都是相同的。
- 所有端口和套接字通常是相同的。
- 所有的MySQL连接器(PHP、Perl、Python、Java、. net、MyODBC、Ruby、MySQL C连接器等)都可以不加修改地使用MariaDB。
- 您应该注意PHP5的一些安装问题(旧的PHP5客户机如何检查库兼容性的一个bug)。
这意味着在很多情况下,你可以卸载MySQL并安装MariaDB,这样就可以了。
通常不需要转换任何数据文件。但是,您仍然必须运行mysql_upgrade来完成升级。
这是确保mysql特权和事件表使用MariaDB使用的新字段更新所必需的。我们每月都会合并MySQL代码库,以确保MariaDB有任何相关的bug修复添加到MySQL中。
也就是说,MariaDB有很多新的选项、扩展、存储引擎和修复MySQL中没有的bug。
你可以在不同的MariaDB发布页面上找到不同版本的特性集。
特定MariaDB版本的完全兼容性
就InnoDB而言,MariaDB 10.2、MariaDB 10.3和MariaDB 10.4是MySQL 5.7的有限替代。然而,在每一个新的MariaDB版本中,实现差异都在不断增加。
就InnoDB而言,MariaDB 10.0和MariaDB 10.1可以作为MySQL 5.6的有限替代。
但是,在某些特性中存在一些实现差异。MariaDB 5.5是MySQL 5.5的替代版本。
MariaDB 5.1、MariaDB 5.2和MariaDB 5.3可以作为MySQL 5.1的完全替代。
复制的兼容性
| Master→ | MariaDB-5.5 | MariaDB-10.1 | MariaDB-10.2 | MariaDB-10.3 | MariaDB-10.4 | MySQL-5.6 | MySQL-5.7 | MySQL-8.0 | |
|---|---|---|---|---|---|---|---|---|---|
| Slave ↓ | |||||||||
| MariaDB-5.5 | ✅ | ⛔ | ⛔ | ⛔ | ⛔ | ⛔ | ⛔ | ⛔ | |
| MariaDB-10.1 | ✅ | ✅ | ✅ | ||||||
| MariaDB-10.2 | ✅ | ✅ | ✅ | ✅ | ✅ | ||||
| MariaDB-10.3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| MariaDB-10.4 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| MySQL-5.6 | ∗ | ∗ | ∗ | ||||||
| MySQL-5.7 | ∗ | ∗ | ∗ | ||||||
| MySQL-8.0 | ∗ | ∗ | ∗ |
- 支持✅:这种组合。
- 不支持⛔:这种组合。
- ∗:Mariadb不能对mysql的组合进行任何断言。要确定受支持的组合,请参阅特定MySQL版本的文档。
注意:当以GTID模式从MySQL复制时,MariaDB将删除MySQL GTID事件,并将它们替换为MariaDB GTID事件。
原文:https://mariadb.com/kb/en/library/mariadb-vs-mysql-compatibility/
本文:https://pub.intelligentx.net/mariadb-versus-mysql-compatibility
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 82 次浏览
【PostgreSQL架构】PostgreSQL和堆元组更新-第1部分
这是一系列文章,重点介绍版本11中的新功能。
在此版本的开发过程中,一个功能引起了我的注意。可以在发行说明中找到:https://www.postgresql.org/docs/11/static/release-11.html
当表达式的值不变时,允许对表达式索引进行仅堆元组(HOT)更新(Konstantin Knizhnik)
我承认这不是很明确,并且此功能需要有关postgres如何工作的一些知识,我将尝试通过几篇文章进行解释:
- How MVCC works and heap-only-tuples updates
- When postgres do not use heap-only-tuple updates and introduction to the new feature in v11
- Impact on performances
在11.1中已禁用此功能,因为它可能导致实例崩溃1。我选择发布这些文章是因为它们有助于了解HOT更新的机制以及此功能可能带来的好处。
我感谢Guillaume Lelarge对本文的评论;)。
MVCC如何运作
由于MVCC,postgres不会直接更新行:它会复制行并提供可见性信息。
为什么会这样工作?
使用RDBMS时,需要考虑一个关键因素:并发性。
您正在编辑的行可能被先前的事务使用。正在进行的备份,例如:)
为此,RDBMS采用了不同的技术:
- 修改该行并将以前的版本存储在另一个位置。例如,这就是oracle对撤消日志所做的事情。
- 复制该行并存储可见性信息,以了解哪条交易可以看到哪条交易。这就需要一种清洁机制,以消除任何人都不可见的管线。这是Postgres中的实现,并且真空负责执行此清洁。
让我们看一个非常简单的表,并使用pageinspect扩展观看其内容的演变:
CREATE TABLE t2(c1 int);
INSERT INTO t2 VALUES (1);
SELECT lp,t_data FROM heap_page_items(get_raw_page('t2',0));
lp | t_data
----+------------
1 | \x01000000
(1 row)
UPDATE t2 SET c1 = 2 WHERE c1 = 1;
SELECT lp,t_data FROM heap_page_items(get_raw_page('t2',0));
lp | t_data
----+------------
1 | \x01000000
2 | \x02000000
(2 rows)
VACUUM t2;
SELECT lp,t_data FROM heap_page_items(get_raw_page('t2',0));
lp | t_data
----+------------
1 |
2 | \x02000000
(2 rows)
我们可以看到引擎复制了管路和真空清洁的位置,以备将来使用。
heap-only-tuple 【HOT】机制
让我们来看另一种情况,稍微复杂一点,该表包含两列,并且在两列之一中有一个索引:
CREATE TABLE t3(c1 int,c2 int);
CREATE INDEX ON t3(c1);
INSERT INTO t3(c1,c2) VALUES (1,1);
INSERT INTO t3(c1,c2) VALUES (2,2);
SELECT ctid,* FROM t3;
ctid | c1 | c2
-------+----+----
(0,1) | 1 | 1
(0,2) | 2 | 2
(2 rows)
以相同的方式可以读取表块,也可以使用pageinspect读取块:
SELECT * FROM bt_page_items(get_raw_page('t3_c1_idx',1));
itemoffset | ctid | itemlen | nulls | vars | data
------------+-------+---------+-------+------+-------------------------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
(2 rows)
到目前为止,这非常简单,我的表包含两个记录,索引也包含两个记录,这些记录指向表中的相应块(ctid列)。
如果我使用新值3更新列c1,则必须更新索引。
现在,如果我更新列c2。 c1的索引会更新吗?
乍看起来,我们可能会说不,因为c1不变。
但是由于上面介绍的MVCC模型,理论上答案是肯定的:我们刚刚看到postgres将复制该行,因此其物理位置将有所不同(下一个ctid为(0.3))。
让我们来看看:
UPDATE t3 SET c2 = 3 WHERE c1=1;
SELECT lp,t_data,t_ctid FROM heap_page_items(get_raw_page('t3',0));
lp | t_data | t_ctid
----+--------------------+--------
1 | \x0100000001000000 | (0,3)
2 | \x0200000002000000 | (0,2)
3 | \x0100000003000000 | (0,3)
(3 rows)
SELECT * FROM bt_page_items(get_raw_page('t3_c1_idx',1));
itemoffset | ctid | itemlen | nulls | vars | data
------------+-------+---------+-------+------+-------------------------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
(2 rows)
读取表块可确认该行已重复。通过仔细查看字段t_data,我们可以区分列c1的1和列c2的3。
如果阅读索引块,可以看到其内容未更改!如果我搜索WHERE c1 = 1行,则索引将我指向对应于旧行的记录(0,1)!
发生了什么?
实际上,我们刚刚揭示了一种相当特殊的机制,称为堆仅元组别名HOT。当更新一列时,没有索引指向该列,并且该记录可以插入同一块中,Postgres将仅在新旧记录之间建立一个指针。
这使postgres避免必须更新索引。所有这些暗示着:
避免读/写操作
减少索引碎片,从而减少其大小(很难重用旧索引位置)
如果查看表块,第一行的列t_ctid指向(0.3)。如果再次更新该行,则表的第一行将指向行(0.3),而行(0.3)将指向(0.4),形成所谓的链。抽真空将清理自由空间,但始终保持指向最后记录的第一行。
一行已更改,索引仍然没有更改:
UPDATE t3 SET c2 = 4 WHERE c1=1;
SELECT * FROM bt_page_items(get_raw_page('t3_c1_idx',1));
itemoffset | ctid | itemlen | nulls | vars | data
------------+-------+---------+-------+------+-------------------------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
(2 rows)SELECT lp,t_data,t_ctid FROM heap_page_items(get_raw_page('t3',0));
lp | t_data | t_ctid
----+--------------------+--------
1 | \x0100000001000000 | (0,3)
2 | \x0200000002000000 | (0,2)
3 | \x0100000003000000 | (0,4)
4 | \x0100000004000000 | (0,4)
(4 rows)
真空清洁可用空间:
VACUUM t3;
SELECT lp,t_data,t_ctid FROM heap_page_items(get_raw_page('t3',0));
lp | t_data | t_ctid
----+--------------------+--------
1 | |
2 | \x0200000002000000 | (0,2)
3 | |
4 | \x0100000004000000 | (0,4)
(4 rows)
更新将重用第二个位置,并且索引保持不变。 查看t_ctid列的值以重建链:
UPDATE t3 SET c2 = 5 WHERE c1=1;
SELECT lp,t_data,t_ctid FROM heap_page_items(get_raw_page('t3',0));
lp | t_data | t_ctid
----+--------------------+--------
1 | |
2 | \x0200000002000000 | (0,2)
3 | \x0100000005000000 | (0,3)
4 | \x0100000004000000 | (0,3)
(4 rows)
SELECT * FROM bt_page_items(get_raw_page('t3_c1_idx',1));
itemoffset | ctid | itemlen | nulls | vars | data
------------+-------+---------+-------+------+-------------------------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00
(2 rows)
嗯,第一行是空的,而postgres重用了第三位置?
实际上,信息不会出现在pageinspect中。 让我们直接使用pg_filedump读取该块:
注意:您必须首先请求CHECKPOINT,否则该块可能尚未写入磁盘。
pg_filedump 11/main/base/16606/8890510
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility - Version 10.1
*
* File: 11/main/base/16606/8890510
* Options used: None
*
* Dump created on: Sun Sep 2 13:09:53 2018
*******************************************************************Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 40 (0x0028)
Block: Size 8192 Version 4 Upper 8096 (0x1fa0)
LSN: logid 52 recoff 0xc39ea148 Special 8192 (0x2000)
Items: 4 Free Space: 8056
Checksum: 0x0000 Prune XID: 0x0000168b Flags: 0x0001 (HAS_FREE_LINES)
Length (including item array): 40<Data> ------
Item 1 -- Length: 0 Offset: 4 (0x0004) Flags: REDIRECT
Item 2 -- Length: 32 Offset: 8160 (0x1fe0) Flags: NORMAL
Item 3 -- Length: 32 Offset: 8096 (0x1fa0) Flags: NORMAL
Item 4 -- Length: 32 Offset: 8128 (0x1fc0) Flags: NORMAL
第一行包含标志:REDIRECT。 这表明该行对应于HOT重定向。 记录在src / include / storage / itemid.h中:
/*
* lp_flags has these possible states. An UNUSED line pointer is available
* for immediate re-use, the other states are not.
*/
#define LP_UNUSED 0 /* unused (should always have lp_len=0) */
#define LP_NORMAL 1 /* used (should always have lp_len>0) */
#define LP_REDIRECT 2 /* HOT redirect (should have lp_len=0) */
#define LP_DEAD 3 /* dead, may or may not have storage */实际上,通过显示列lp_flags可以用pageinspect看到它:
SELECT lp,lp_flags,t_data,t_ctid FROM heap_page_items(get_raw_page('t3',0));
lp | lp_flags | t_data | t_ctid
----+----------+--------------------+--------
1 | 2 | |
2 | 1 | \x0200000002000000 | (0,2)
3 | 1 | \x0100000005000000 | (0,3)
4 | 1 | \x0100000004000000 | (0,3)
如果我们再次进行更新,则进行清理,然后执行CHECKPOINT将块写入磁盘:
SELECT lp,lp_flags,t_data,t_ctid FROM heap_page_items(get_raw_page('t3',0));
lp | lp_flags | t_data | t_ctid
----+----------+--------------------+--------
1 | 2 | |
2 | 1 | \x0200000002000000 | (0,2)
3 | 0 | |
4 | 0 | |
5 | 1 | \x0100000006000000 | (0,5)
(5 rows)CHECKPOINT;
pg_filedump 11/main/base/16606/8890510
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility - Version 10.1
*
* File: 11/main/base/16606/8890510
* Options used: None
*
* Dump created on: Sun Sep 2 13:16:12 2018
*******************************************************************Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 44 (0x002c)
Block: Size 8192 Version 4 Upper 8128 (0x1fc0)
LSN: logid 52 recoff 0xc39ea308 Special 8192 (0x2000)
Items: 5 Free Space: 8084
Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0005 (HAS_FREE_LINES|ALL_VISIBLE)
Length (including item array): 44<Data> ------
Item 1 -- Length: 0 Offset: 5 (0x0005) Flags: REDIRECT
Item 2 -- Length: 32 Offset: 8160 (0x1fe0) Flags: NORMAL
Item 3 -- Length: 0 Offset: 0 (0x0000) Flags: UNUSED
Item 4 -- Length: 0 Offset: 0 (0x0000) Flags: UNUSED
Item 5 -- Length: 32 Offset: 8128 (0x1fc0) Flags: NORMAL
*** End of File Encountered. Last Block Read: 0 ***
Postgres保留了第一行(标志REDIRECT),并在位置5处写了新行。
但是,在某些情况下,postgres无法使用此机制:
当该块中没有更多空间时,他必须写另一个块。 我们可以推断出表的碎片在这里有益于HOT。
当更新的列上存在索引时。 在这种情况下,postgres必须更新索引。 Postgres可以通过在新值和前一个值之间进行二进制比较来检测是否发生了更改2。
在下一篇文章中,我们将看到一个示例,其中postgres无法使用HOT机制。 然后是postgres可以使用此机制的版本11的新功能。
原文:https://blog.anayrat.info/en/2018/11/12/postgresql-and-heap-only-tuples-updates-part-1/
本文:http://jiagoushi.pro/node/882
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 84 次浏览
PostgreSQL架构
视频号
微信公众号
知识星球
- 393 次浏览
【PostgreSQL 】PostgreSQL 12的8大改进

PostgreSQL 12专注于性能和优化。此版本的发布并未考虑到全新的闪亮功能;相反,它是对现有PostgreSQL功能的微调和精心设计的实现。因为PostgreSQL每年都会发布新版本,所以并不是每一个新功能都完全具备。在发布了几个版本之后,当该功能有机会从其最初的实现中发展出来时,其性能将得到改善,边缘情况将得到支持,缺失的功能将得到实现。
这是PostgreSQL 12中发现的八个最重要的改进。
1.分区性能
分区并不是一项新功能,它已经存在了好几年了,但是分区开销却降低了性能。 PostgreSQL 11引入了一些分区性能改进,而PostgreSQL 12提供了完善的实现。对于从具有数千个分区的其他数据库迁移来的用户,PostgreSQL 12现在通过提供可同时有效处理数千个分区的功能而带来性能优势。分区性能增强可以提高查询性能,尤其是INSERT和COPY语句的性能。此外,用户现在可以更改分区表而不会阻止查询,并可以使用外键引用分区表。
2. B树增强
B-Tree功能是近年来对PostgreSQL添加的最复杂的功能之一。使用B树的好处是减少了访问的磁盘块的数量。考虑到B-Tree技术可以追溯到1970年代,很难对已经存在数十年的可靠功能进行改进。但是PostgreSQL 12团队致力于提供可自动启用的重大性能改进,旨在避免某些极端情况和B树代码中曾经存在的“病理行为”。现在,通过更有效地利用空间,多列索引大小最多可减少40%,从而节省了磁盘空间。具有重复项(非唯一B树索引)的索引的性能得以提高,并且从索引中删除元组(行)的真空运行效率更高。此外,索引更新期间的锁定要求有所降低。
3.多列最有价值(MCV)统计信息
此更新已经进行了几年的开发,旨在解决多年来引起投诉的问题:查询中相关列的边缘情况。以俄亥俄州辛辛那提为例-您有一个标记为“城市”的字段,另一字段称为“州”,其中“辛辛那提”位于一列,而俄亥俄州则在另一列。俄亥俄州的辛辛那提市将相当普遍,但亚利桑那州的辛辛那提市却很少见。在此功能之前,PostgreSQL仅记录了多个列的单个相关值。从本质上讲,它将俄亥俄州的辛辛那提和亚利桑那州的辛辛那提视为同一件事。现在,您可以比较多个列并关联组合以优化查询索引。
4.公用表表达式(CTE)
正确实现的另一个过期功能是通用表表达式(带有查询内联)。公用表表达式充当优化障碍,公用表表达式中的查询首先执行,然后PostgreSQL将在查询中执行之后的任何操作。一些用户采用通用表表达式来提高SQL的可读性和调试,而不是优化SQL的执行。这些用户不可避免地会遇到优化行为。 PostgreSQL 12使用关键字“ MATERIALIZE”实现了一项新功能,该功能允许用户打开优化围栏。如果您不使用MATERIALIZE,则不会获得优化范围,并且可能会看到更快的查询。
5.准备好的计划控制
一项重要的新功能使用户可以控制PostgreSQL优化器的行为,并有可能提高性能。早期版本的PostgreSQL将使用自定义计划五次,第六次创建一个通用计划,并在与自定义计划一样好的情况下使用它。现在,可以通过名为“ plan_cache_mode”的新变量手动控制此行为,该变量允许用户立即强制执行通用计划。这为那些知道其参数恒定并且知道通用计划将起作用的用户带来了显着的性能优势。
6.即时编译
PostgreSQL 11最初引入的一项功能是现在在PostgreSQL 12中默认启用即时复杂功能。即时编译允许处理大量数据的数据仓库查询来更有效地运行执行程序。由于许多用户启用了此功能,因此该功能现已成为PostgreSQL 12的默认功能。
7.校验和控制
追溯到2013年,PostgreSQL引入了一种校验和功能,用于识别数据损坏。首次初始化数据库时必须打开此功能,否则用户必须转储,打开该功能并重新加载数据。这使得某些用户几乎无法使用该功能。在PostgreSQL 12中,通过一个称为“ pg checksums”的命令(以前称为pg verify checksum),用户可以在不转储和重新加载数据的情况下将群集从无校验和更改为校验和。当前,在此更改期间,群集必须处于脱机状态,但是正在开发联机校验和支持。
8.并发重新编制索引
索引并发功能已经存在多年,允许用户创建索引而又不阻止写入索引。重新索引不允许您在写入数据库时创建索引。同时使用reindex,通过在同一位置创建新索引来替换现有索引。同时使用Reindex可以写入索引并保留原始索引名称。显然,当替换索引时,最小的锁定将发生,直到实现替换为止。长期以来要求的功能很难开发,但最终在PostgreSQL 12中交付。
升级到PostgreSQL 12
这八个功能只是PostgreSQL 12中许多改进中的几个。从分区改进到公用表表达式的实现,PostgreSQL 12提供了显着的可用性增强,将使许多新用户和长期用户满意。
Postgres已成为数据库领域的巨头。 根据2019年Stack Overflow对近90,000名开发人员的调查,Postgres的部署现在比SQL Server部署得更为普遍。
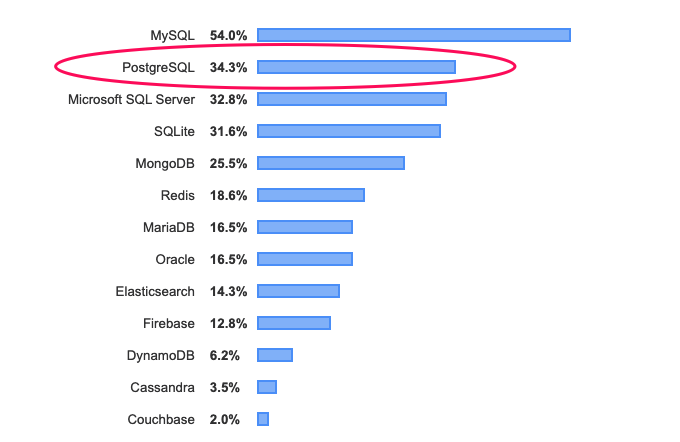
原文:https://www.enterprisedb.com/ko/blog/8-major-improvements-postgresql-12
本文:http://jiagoushi.pro/8-major-improvements-postgresql-12
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 95 次浏览
【PostgreSQL 】PostgreSQL 16扩展分析功能
视频号
微信公众号
知识星球
最近的版本还包括对支持新体系结构的逻辑表示和超级用户权限的改进。
最近发布的PostgreSQL 16之所以意义重大,原因有很多。它实现了更灵活的访问控制机制,这对涉及托管服务提供商(MSP)的部署具有直接影响。
EnterpriseDB(EDB)高级产品经理Adam Wright肯定道,版本16还支持热备用功能,当它作为逻辑复制的源时,它能够“允许新的体系结构”。EDB是PostgreSQL 16(一个开源关系数据库管理系统)最重要的代码贡献者之一。
然而,最重要的是,最新版本的PostgreSQL包含了分析功能,用于促进复杂的聚合和窗口查询。当与数据库分别用于管理地理空间数据和矢量数据的扩展相结合时,这种增强可能是事务数据库与分析相关性日益增强的最新指标。
“我认为你开始看到的是,对专业数据仓库的需求开始降低,”Wright反思道。“在数据仓库市场的极端,拥有专业系统是必要的。但这真的开始成为极端,在很多用例中,你可以只使用Postgres,而不需要专业系统。”
分析
尽管PostgreSQL在事务系统中被广泛使用,但它在版本16中实现了Wright所说的“任意值函数”,具有明确的分析含义。此函数是SQL:2023标准的一部分。“这个函数实际上主要用于分析数据库,”Wright透露。“复杂的聚合/窗口查询是一种可以用来做什么的副标题。”
这个特殊的函数允许管理员和开发人员跨表中的一组行进行计算。Wright解释道:“你可以比较一行与另一行的计算方式,并对这两行进行汇总。”。“因此,可以通过几行SQL轻松地获得一个运行总数。”这一功能对于比较零售中库存订购的产品类型等用例很有价值,尤其是在大表中表示的不同位置。
向量和地理空间数据
根据Wright的说法,在数据库级别管理此任务通常比在应用程序级别更高效。使用后一种方法,管理员或开发人员将不得不编写比其他方法更多的代码,以及编写多个函数。然后,他们必须将数据带回并进行比较,而不是从数据库服务器中过滤所有内容。然而,“如果我在数据库服务器上编写这个聚合查询,我会比较表中的不同行,”Wright提到。“一旦全部完成,我将只流式传输应用程序所需的记录。”
PostgreSQL扩展PostGIS使用户能够存储和查询地理空间数据。Wright引用了另一个用于管理矢量工作负载的扩展,包括存储矢量数据和支持矢量运算符。Wright评论道:“这只是Postgres中的另一个用例,你不需要去找专业数据库供应商,获得另一份合同和另一份支持,也不需要加入任何你可能需要的东西来实际支持这些工作负载。”
逻辑复制
尽管Wright提到的扩展不是PostgreSQL 16中发布的新功能的一部分,但它们证明了数据库日益增长的分析实用性,这与最近发布的聚合和窗口功能不谋而合。Wright表示,新版还包括对其逻辑复制功能的增强,其中最重要的是“您可以从备用服务器中进行逻辑表示”。有了这种范式,用户可以从Wright所说的热备用中进行逻辑表示,他将其描述为将PostgreSQL数据中的每一个更改物理复制到目标系统——通常是为了实现高可用性。
Wright观察到:“有了逻辑表示,你可能只想复制几个表、一个销售表、一份订单表,并将它们提供给这些不同的系统,而不是从数据库中获取所有更改。”。逻辑表示使用户能够指定要复制的表,当与从备用系统进行复制的能力相结合时,可以广泛扩展复制和体系结构方法的可能性。Wright说:“你可以级联多个复制和类似的事情。”。“你可以在一个系统中做任何事情,但也可以更容易地从Postgres中获取数据子集,进入只读系统……由于这些原生功能,将支持更多的体系结构。”
超级用户改进
PostgreSQL 16还增强了与超级用户相关的控制程度和范围,超级用户拥有相当多的数据和系统访问权限。Wright承认,在以前的版本中,超级用户几乎可以做任何事情,包括篡改底层的“作为Postgres运行的服务的操作系统”。“这对托管数据服务来说是个大问题。”因此,托管服务提供商(包括一些超规模提供商)会将数据库、用户和设置从原始集群“分叉”或复制到另一个集群。
根据Wright的说法,这个过程可能会导致“错误和安全问题”。因此,最新版本的PostgreSQL中更精细的超级用户控件使“你能够对权限进行细粒度管理,并委托DBA管理数据库所需的任务,但不会给他们一些东西,让他们脱离数据库,”Wright说。或者,您可以管理一个角色,但不一定要管理该角色的数据
数据库空间
PostgreSQL 16的新增内容在很大程度上表明了正在影响整个数据库空间的发展。传统上用于事务目的的系统正在承担更多的分析责任。PostgreSQL对用于编写聚合和窗口查询的聚合函数的原生支持,以及对与地理空间和矢量数据相关的工作负载的扩展,可能预示着未来事务数据库和分析数据库之间的传统区别不再那么明显。
- 117 次浏览
【PostgreSQL 】PostgreSQL 中的并行性
PostgreSQL 是最好的对象关系数据库之一,它的架构是基于进程而不是基于线程的。虽然几乎所有当前的数据库系统都使用线程进行并行处理,但 PostgreSQL 基于进程的架构是在 POSIX 线程之前实现的。 PostgreSQL 在启动时启动一个进程“postmaster”,之后每当有新客户端连接到 PostgreSQL 时都会跨越新进程。
在版本 10 之前,单个连接中没有并行性。诚然,来自不同客户端的多个查询由于进程架构而具有并行性,但它们无法从彼此之间获得任何性能优势。换句话说,单个查询串行运行并且没有并行性。这是一个巨大的限制,因为单个查询不能利用多核。 PostgreSQL 中的并行性是从 9.6 版开始引入的。从某种意义上说,并行性是单个进程可以有多个线程来查询系统并利用系统中的多核。这为 PostgreSQL 提供了查询内并行性。
PostgreSQL 中的并行性是作为涵盖顺序扫描、聚合和连接的多个功能的一部分实现的。
PostgreSQL 中的并行组件
PostgreSQL 中有三个重要的并行性组件。这些是进程本身、聚集器和工人。如果没有并行性,进程本身会处理所有数据,但是,当规划器决定查询或其一部分可以并行化时,它会在计划的可并行化部分中添加一个 Gather 节点,并生成该子树的一个 Gather 根节点。查询执行从进程(领导者)级别开始,计划的所有串行部分都由领导者运行。但是,如果对查询的任何部分(或全部)启用并允许并行性,则为它分配带有一组工作人员的收集节点。工作者是与需要并行化的部分树(部分计划)并行运行的线程。关系的块在线程之间划分,使得关系保持顺序。线程数由 PostgreSQL 配置文件中的设置控制。工作人员使用共享内存进行协调/通信,工作人员完成工作后,将结果传递给领导者进行积累。

并行顺序扫描
在 PostgreSQL 9.6 中,添加了对并行顺序扫描的支持。 顺序扫描是对表的扫描,其中依次评估一系列块。 就其本质而言,这允许并行性。 因此,这是第一个实现并行性的自然候选者。 在这种情况下,整个表在多个工作线程中被顺序扫描。 这是一个简单的查询,我们查询 pgbench_accounts 表行 (63165),它有 1,500,000,000 个元组。 总执行时间为 4,343,080ms。 由于没有定义索引,因此使用顺序扫描。 整个表在没有线程的单个进程中扫描。 因此,无论有多少内核可用,都使用 CPU 的单核。
db=# EXPLAIN ANALYZE SELECT *
FROM pgbench_accounts
WHERE abalance > 0;
QUERY PLAN
----------------------------------------------------------------------
Seq Scan on pgbench_accounts (cost=0.00..73708261.04 rows=1 width=97)
(actual time=6868.238..4343052.233 rows=63165 loops=1)
Filter: (abalance > 0)
Rows Removed by Filter: 1499936835
Planning Time: 1.155 ms
Execution Time: 4343080.557 ms
(5 rows)如果这 1,500,000,000 行在一个进程中使用“10”个工作人员并行扫描会怎样? 它将大大减少执行时间。
db=# EXPLAIN ANALYZE select * from pgbench_accounts where abalance > 0;
QUERY PLAN
----------------------------------------------------------------------
Gather (cost=1000.00..45010087.20 rows=1 width=97)
(actual time=14356.160..1628287.828 rows=63165 loops=1)
Workers Planned: 10
Workers Launched: 10
-> Parallel Seq Scan on pgbench_accounts
(cost=0.00..45009087.10 rows=1 width=97)
(actual time=43694.076..1628068.096 rows=5742 loops=11)
Filter: (abalance > 0)
Rows Removed by Filter: 136357894
Planning Time: 37.714 ms
Execution Time: 1628295.442 ms
(8 rows)现在总执行时间是1,628,295ms; 使用 10 个工作线程进行扫描时,这提高了 266%。

用于基准的查询:SELECT * FROM pgbench_accounts WHERE abalance > 0;
表大小:426GB
表中的总行数:1,500,000,000
用于基准测试的系统:
CPU:2 Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
内存:256GB DDR3 1600
磁盘:ST3000NM0033
上图清楚地显示了并行性如何提高顺序扫描的性能。添加单个工作人员时,性能会降低,这是可以理解的,因为没有获得并行性,但是创建额外的收集节点和单个工作会增加开销。但是,使用多个工作线程时,性能会显着提高。此外,重要的是要注意性能不会以线性或指数方式增加。它会逐渐改善,直到添加更多工人不会带来任何性能提升;有点像接近水平渐近线。该基准测试是在 64 核机器上执行的,很明显,拥有 10 名以上的工作人员不会带来任何显着的性能提升。
并行聚合
在数据库中,计算聚合是非常昂贵的操作。在单个过程中进行评估时,这些需要相当长的时间。在 PostgreSQL 9.6 中,通过简单地将它们分成块(分而治之的策略)添加了并行计算这些的能力。这允许多个工作人员在基于这些计算的最终值由领导者计算之前计算聚合的部分。从技术上讲,PartialAggregate 节点被添加到计划树中,每个 PartialAggregate 节点从一个工作人员那里获取输出。然后将这些输出发送到 FinalizeAggregate 节点,该节点组合来自多个(所有)PartialAggregate 节点的聚合。如此有效地,并行部分计划包括根处的 FinalizeAggregate 节点和将 PartialAggregate 节点作为子节点的 Gather 节点。

db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts;
QUERY PLAN
----------------------------------------------------------------------
Aggregate (cost=73708261.04..73708261.05 rows=1 width=8)
(actual time=2025408.357..2025408.358 rows=1 loops=1)
-> Seq Scan on pgbench_accounts (cost=0.00..67330666.83 rows=2551037683 width=0)
(actual time=8.162..1963979.618 rows=1500000000 loops=1)
Planning Time: 54.295 ms
Execution Time: 2025419.744 ms
(4 rows)以下是要并行评估聚合时的计划示例。 您可以在这里清楚地看到性能改进。
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts;
QUERY PLAN
----------------------------------------------------------------------
Finalize Aggregate (cost=45010088.14..45010088.15 rows=1 width=8)
(actual time=1737802.625..1737802.625 rows=1 loops=1)
-> Gather (cost=45010087.10..45010088.11 rows=10 width=8)
(actual time=1737791.426..1737808.572 rows=11 loops=1)
Workers Planned: 10
Workers Launched: 10
-> Partial Aggregate
(cost=45009087.10..45009087.11 rows=1 width=8)
(actual time=1737752.333..1737752.334 rows=1 loops=11)
-> Parallel Seq Scan on pgbench_accounts
(cost=0.00..44371327.68 rows=255103768 width=0)
(actual time=7.037..1731083.005 rows=136363636 loops=11)
Planning Time: 46.031 ms
Execution Time: 1737817.346 ms
(8 rows)使用并行聚合,在这种特殊情况下,当涉及 10 个并行工作人员时,由于 2,025,419.744 的执行时间减少到 1,737,817.346,我们的性能提升了 16% 以上。

用于基准的查询:SELECT count(*) FROM pgbench_accounts WHERE abalance > 0;
表大小:426GB
表中的总行数:1500000000
用于基准测试的系统:
CPU:2 Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
内存:256GB DDR3 1600
磁盘:ST3000NM0033
并行索引(B-Tree)扫描
对 B-Tree 索引的并行支持意味着索引页面是并行扫描的。 B-Tree 索引是 PostgreSQL 中最常用的索引之一。 在 B-Tree 的并行版本中,worker 扫描 B-Tree,当它到达其叶节点时,它会扫描块并触发阻塞的等待 worker 扫描下一个块。
使困惑? 让我们看一个例子。 假设我们有一个包含 id 和 name 列的表 foo,有 18 行数据。 我们在表 foo 的 id 列上创建一个索引。 系统列 CTID 附加到表的每一行,用于标识该行的物理位置。 CTID 列中有两个值:块号和偏移量。
postgres=# <strong>SELECT</strong> ctid, id <strong>FROM</strong> foo; ctid | id --------+----- (0,55) | 200 (0,56) | 300 (0,57) | 210 (0,58) | 220 (0,59) | 230 (0,60) | 203 (0,61) | 204 (0,62) | 300 (0,63) | 301 (0,64) | 302 (0,65) | 301 (0,66) | 302 (1,31) | 100 (1,32) | 101 (1,33) | 102 (1,34) | 103 (1,35) | 104 (1,36) | 105 (18 rows)
让我们在该表的 id 列上创建 B-Tree 索引。
CREATE INDEX foo_idx ON foo(id)

假设我们要选择 id <= 200 且有 2 个工作人员的值。 Worker-0 将从根节点开始扫描,直到叶子节点 200。它将节点 105 下的下一个块移交给处于阻塞和等待状态的 Worker-1。如果还有其他工作人员,则将块划分为工作人员。重复类似的模式,直到扫描完成。
并行位图扫描
要并行化位图堆扫描,我们需要能够以非常类似于并行顺序扫描的方式在工作人员之间划分块。为此,对一个或多个索引进行扫描,并创建指示要访问哪些块的位图。这是由领导进程完成的,即这部分扫描是按顺序运行的。但是,当将识别出的块传递给工作人员时,并行性就会启动,这与并行顺序扫描中的方式相同。
平行连接
合并连接支持中的并行性也是此版本中添加的最热门功能之一。在这种情况下,一个表与其他表的内部循环哈希或合并连接。无论如何,内部循环不支持并行性。将整个循环作为一个整体进行扫描,当每个worker作为一个整体执行内部循环时,就会发生并行。每个连接发送到聚集的结果累积并产生最终结果。

概括
从我们已经在本博客中讨论过的内容可以明显看出,并行性可以显着提升某些情况的性能,而对另一些情况则略有提升,并且在某些情况下可能会导致性能下降。 确保正确设置了 parallel_setup_cost 或 parallel_tuple_cost,以使查询计划程序能够选择并行计划。 即使为这些 GUI 设置了较低的值,如果没有生成并行计划,请参阅 PostgreSQL 并行性文档以获取详细信息。
对于并行计划,您可以获得每个计划节点的每个工作人员的统计信息,以了解负载在工作人员之间的分布情况。 您可以通过 EXPLAIN (ANALYZE, VERBOSE) 做到这一点。 与任何其他性能特性一样,没有适用于所有工作负载的规则。 应根据需要仔细配置并行性,并且您必须确保获得性能的概率明显高于性能下降的概率。
原文:https://www.percona.com/blog/2019/07/30/parallelism-in-postgresql/
- 70 次浏览
【PostgreSQL 】PostgreSQL 简介
PostgreSQL,也称为Postgres,是一个免费的开源关系数据库管理系统(RDBMS),强调可扩展性和技术标准合规性。 它旨在处理各种工作负载,从单机到数据仓库或具有许多并发用户的Web服务。 它是macOS Server的默认数据库,[11] [12] [13],也适用于Linux,FreeBSD,OpenBSD和Windows。
PostgreSQL具有原子性,一致性,隔离性,耐久性(ACID)属性,自动可更新视图,物化视图,触发器,外键和存储过程的事务。[14] PostgreSQL由PostgreSQL全球开发小组开发,该小组是众多公司和个人贡献者的多元化小组。[15]
名称
PostgreSQL的开发人员将PostgreSQL称为/poʊstɡrɛsˌkjuːːl/。[16]它简称为Postgres,因为关系数据库中对SQL标准的支持无处不在。最初命名为POSTGRES,名称(Post Ingres)指的是该项目起源于加州大学伯克利分校的RDBMS。[17] [18]经过审查,PostgreSQL核心团队在2007年宣布该产品将继续使用PostgreSQL这个名称。[19]
历史
PostgreSQL是从加州大学伯克利分校的Ingres项目发展而来的。 1982年,Ingres团队的负责人Michael Stonebraker离开伯克利,制作了Ingres的专有版本。[17]他于1985年回到伯克利,并开始了一个后Ingres项目,以解决当代数据库系统的问题,这些系统在20世纪80年代早期变得越来越清晰。他在2014年为这些项目和其他项目赢得了图灵奖,[20]以及其中首创的技术。
新项目POSTGRES旨在增加完全支持数据类型所需的最少功能。[21]这些功能包括定义类型和完全描述关系的能力 - 广泛使用的东西,但完全由用户维护。在POSTGRES中,数据库理解关系,并且可以使用规则以自然的方式检索相关表中的信息。 POSTGRES使用了Ingres的许多想法,但没有使用它的代码。[22]
从1986年开始,已发表的论文描述了该系统的基础,并在1988年的ACM SIGMOD会议上展示了原型版本。该团队于1989年6月向少数用户发布了第1版,随后是1990年6月重新编写规则系统的第2版。1991年发布的第3版再次重写了规则系统,并增加了对多个用户的支持。存储管理器[引证需要]和改进的查询引擎。到1993年,随着支持和功能的要求,用户数量开始超过项目。 1994年6月30日发布版本4.2 [23]后 - 主要是清理 - 项目结束。 Berkeley在MIT许可证变体下发布了POSTGRES,这使得其他开发人员可以将代码用于任何用途。当时,POSTGRES使用了受Ingres影响的POSTQUEL查询语言解释器,该解释器可以与名为monitor的控制台应用程序交互使用。
1994年,伯克利大学的研究生Andrew Yu和Jolly Chen用一种SQL查询语言替换了POSTQUEL查询语言解释器,创建了Postgres95。监视器也被psql取代。 Yu和Chen于1995年5月5日向beta测试者宣布了第一个版本(0.01).Postgres95的1.0版本于1995年9月5日宣布,更加自由的许可证使软件可以自由修改。
1996年7月8日,Hub.org Networking Services的Marc Fournier为开源开发工作提供了第一个非大学开发服务器。[1]在Bruce Momjian和Vadim B. Mikheev的参与下,工作开始稳定从伯克利继承的代码。
1996年,该项目更名为PostgreSQL以反映其对SQL的支持。 PostgreSQL.org网站的在线展示始于1996年10月22日。[24]第一个PostgreSQL版本于1997年1月29日形成6.0版。从那时起,全世界的开发人员和志愿者都将该软件作为PostgreSQL全球开发组维护。[15]
该项目继续根据其免费和开源软件PostgreSQL许可证发布。代码来自专有供应商,支持公司和开源程序员的贡献。
多版本并发控制(MVCC)
PostgreSQL通过多版本并发控制(MVCC)管理并发,它为每个事务提供数据库的“快照”,允许在不影响其他事务的情况下进行更改。这在很大程度上消除了对读锁的需要,并确保数据库保持ACID原则。 PostgreSQL提供三个级别的事务隔离:Read Committed,Repeatable Read和Serializable。因为PostgreSQL不受脏读操作的影响,所以请求Read Uncommitted事务隔离级别提供read committed。 PostgreSQL通过可序列化快照隔离(SSI)方法支持完全可序列化。[25]
存储和复制
复制
PostgreSQL包括内置的二进制复制,它基于将更改(预写日志(WAL))异步传递到副本节点,并能够对这些复制节点运行只读查询。这允许有效地在多个节点之间分割读取流量。早期允许类似读取扩展的复制软件通常依赖于向主服务器添加复制触发器,从而增加负载。
PostgreSQL包含内置的同步复制[26],可确保对于每个写入事务,主服务器等待至少一个副本节点已将数据写入其事务日志。与其他数据库系统不同,可以按数据库,每用户,每会话甚至每个事务指定事务的持久性(无论是异步还是同步)。这对于不需要此类保证的工作负载非常有用,并且可能不需要所有数据,因为由于需要确认事务到达同步备用数据库而导致性能降低。
备用服务器可以是同步或异步的。可以在配置中指定同步备用服务器,以确定哪些服务器可用于同步复制。列表中第一个主动流式传输将用作当前的同步服务器。当此操作失败时,系统将故障转移到下一行。
PostgreSQL核心中不包含同步多主复制。 Postgres-XC基于PostgreSQL,提供可扩展的同步多主复制。[27]它的许可与PostgreSQL相同。一个相关项目叫做Postgres-XL。 Postgres-R是另一个分支。[28]双向复制(BDR)是PostgreSQL的异步多主复制系统。[29]
repmgr等工具可以更轻松地管理复制集群。
有几个基于异步触发器的复制包可用。即使在引入扩展核心功能之后,对于完整数据库集群的二进制复制不合适的情况,这些仍然有用:
Slony聚-I
Londiste,SkyTools的一部分(由Skype开发)
Bucardo多主复制(由Backcountry.com开发)[30]
SymmetricDS多主,多层复制
索引
PostgreSQL包括对常规B树和散列表索引的内置支持,以及四种索引访问方法:广义搜索树(GiST),广义反向索引(GIN),空间分区GiST(SP-GiST)[31]和Block范围索引(BRIN)。此外,可以创建用户定义的索引方法,尽管这是一个非常复杂的过程。 PostgreSQL中的索引还支持以下功能:
可以使用表达式或函数的结果索引创建表达式索引,而不仅仅是列的值。
可以通过在CREATE INDEX语句的末尾添加WHERE子句来创建仅索引表的一部分的部分索引。这允许创建较小的索引。
规划器能够使用多个索引来使用临时内存位图索引操作来满足复杂查询(对于将大型事实表连接到较小维度表(例如以星型模式排列的那些),数据仓库应用程序非常有用)。
k-最近邻(k-NN)索引(也称为KNN-GiST [32])提供了对指定的“最接近的值”的有效搜索,对于查找相似的单词或用地理空间数据关闭对象或位置很有用。这是在没有穷尽的值匹配的情况下实现的。
仅索引扫描通常允许系统从索引获取数据,而无需访问主表。
PostgreSQL 9.5引入了块范围索引(BRIN)。
Schema
在PostgreSQL中,Schema包含除角色和表空间之外的所有对象。模式有效地像名称空间一样,允许同名对象在同一个数据库中共存。默认情况下,新创建的数据库具有名为public的模式,但可以添加任何其他模式,并且公共模式不是必需的。
search_path设置确定PostgreSQL检查非限定对象(没有前缀模式的对象)的模式的顺序。默认情况下,它设置为$ user,public($ user指当前连接的数据库用户)。此缺省值可以在数据库或角色级别设置,但由于它是会话参数,因此可以在客户端会话期间自由更改(甚至多次),仅影响该会话。
在对象查找期间,将以无提示方式跳过search_path中列出的不存在的模式。
在search_path中首先出现新的对象,无论哪个有效的模式(当前存在的模式)都出现.Schema是数据库的概要。
数据类型
支持各种本机数据类型,包括:
- 布尔
- 任意精度数值
- 字符(text,varchar,char)
- 二进制
- 日期/时间(时间戳/时间有/无时区,日期,间隔)
- 钱
- 枚举
- 位串
- 文字搜索类型
- 综合
- HStore,PostgreSQL中支持扩展的键值存储[33]
- 数组(可变长度,可以是任何数据类型,包括文本和复合类型),总存储大小最多为1 GB
- 几何图元
- IPv4和IPv6地址
- 无类别域间路由(CIDR)块和MAC地址
- 支持XPath查询的XML
- 通用唯一标识符(UUID)
- JavaScript Object Notation(JSON)和更快的二进制JSONB(自版本9.4起;与BSON [34]不同)
此外,用户可以创建自己的数据类型,通常可以通过PostgreSQL的索引基础结构 - GiST,GIN,SP-GiST完全索引。这些示例包括来自PostgreSQL的PostGIS项目的地理信息系统(GIS)数据类型。
还有一种称为域的数据类型,它与任何其他数据类型相同,但具有由该域的创建者定义的可选约束。这意味着使用域输入到列中的任何数据都必须符合作为域的一部分定义的任何约束。
可以使用表示一系列数据的数据类型,称为范围类型。这些可以是离散范围(例如,所有整数值1到10)或连续范围(例如,在上午10:00到11:00之间的任何时间)。可用的内置范围类型包括整数范围,大整数,十进制数,时间戳(有和没有时区)和日期。
可以创建自定义范围类型以使新类型的范围可用,例如使用inet类型作为基础的IP地址范围,或使用float数据类型作为基础的浮点范围。范围类型分别使用[/]和(/)字符支持包含和排除范围边界。 (例如,[4,9]表示从4开始包括但不包括9的所有整数。)范围类型也与用于检查重叠,包含,权限等的现有运算符兼容。
用户定义的对象
可以创建数据库中几乎所有对象的新类型,包括:
- 类型转换
- 转换
- 数据类型
- 数据域
- 功能,包括聚合函数和窗口函数
- 索引包括自定义类型的自定义索引
- 运营商(现有运营商可能超载)
- 程序语言
继承
可以将表设置为从父表继承其特征。子表中的数据似乎存在于父表中,除非使用ONLY关键字从父表中选择数据,即SELECT * FROM ONLY parent_table;。在父表中添加列将导致该列显示在子表中。
继承可用于实现表分区,使用触发器或规则将父表的插入指向正确的子表。
截至2010年,尚未完全支持此功能 - 特别是,表约束目前不可继承。父表上的所有检查约束和非空约束都由其子表自动继承。其他类型的约束(唯一,主键和外键约束)不会被继承。
继承提供了一种将实体关系图(ERD)中描述的泛化层次结构的特征直接映射到PostgreSQL数据库的方法。
其他存储功能
- 参照完整性约束,包括外键约束,列约束和行检查
- 二进制和文本大对象存储
- 表空间
- 每列整理
- 在线备份
- 使用预写日志记录实现的时间点恢复
- 使用pg_upgrade进行就地升级以减少停机时间(支持从8.3.x及更高版本升级)
控制和连接
外国数据包装器
PostgreSQL可以链接到其他系统,通过外部数据包装器(FDW)检索数据。[35]这些可以采用任何数据源的形式,例如文件系统,另一个关系数据库管理系统(RDBMS)或Web服务。这意味着常规数据库查询可以使用常规表等这些数据源,甚至可以将多个数据源连接在一起。
接口
PostgreSQL有几个可用的接口,并且在编程语言库中也得到广泛支持。内置接口包括libpq(PostgreSQL的官方C应用程序接口)和ECPG(嵌入式C系统)。外部接口包括:
- libpqxx:C ++接口
- Pgfe:C ++接口
- PostgresDAC:PostgresDAC(适用于Embarcadero RadStudio,Delphi,CBuilder XE-XE3)
- DBD :: Pg:Perl DBI驱动程序
- JDBC:Java数据库连接(JDBC)接口
- Lua:Lua接口
- Npgsql:.NET数据提供程序
- ST-Links SpatialKit:链接工具到ArcGIS
- PostgreSQL.jl:Julia界面
- node-postgres:Node.js接口
- pgoledb:OLE DB接口
- psqlODBC:打开数据库连接(ODBC)接口
- psycopg2:[36] Python接口(也被HTSQL使用)
- pgtclng:Tcl接口
- pyODBC:Python库
- php5-pgsql:基于libpq的PHP驱动程序
- 后现代:一个Common Lisp接口
- pq:Go数据库/ sql包的纯Go PostgreSQL驱动程序。驱动程序通过了兼容性测试套件。[37]
- RPostgreSQL:R接口[38]
- dpq:libpq的D接口
- epgsql:Erlang接口
- Rust-Postgres:Rust界面
程序语言
过程语言允许开发人员使用自定义子例程(函数)扩展数据库,通常称为存储过程。这些函数可用于构建数据库触发器(在修改某些数据时调用的函数)以及自定义数据类型和聚合函数。[39]在SQL级别使用DO命令,也可以在不定义函数的情况下调用过程语言。[40]
语言分为两组:用安全语言编写的程序是沙箱,可以由任何用户安全地创建和使用。以不安全语言编写的过程只能由超级用户创建,因为它们允许绕过数据库的安全限制,但也可以访问数据库外部的源。像Perl这样的语言提供了安全和不安全的版本。
PostgreSQL内置了对三种过程语言的支持:
普通的SQL(安全)。更简单的SQL函数可以内联扩展到调用(SQL)查询,这样可以节省函数调用开销,并允许查询优化器“查看”函数内部。
过程语言/ PostgreSQL(PL / pgSQL)(安全),类似于Oracle的SQL(PL / SQL)过程语言和SQL /持久存储模块(SQL / PSM)的过程语言。
C(不安全),允许将一个或多个自定义共享库加载到数据库中。用C语言编写的函数提供了最佳性能,但代码中的错误可能会崩溃并可能破坏数据库。大多数内置函数都是用C语言编写的。
此外,PostgreSQL允许通过扩展将过程语言加载到数据库中。 PostgreSQL包含三种语言扩展,以支持Perl,Python [41]和Tcl。有外部项目可以添加对许多其他语言的支持,[42]包括Java,JavaScript(PL / V8),R,Ruby等。
触发器
触发器是由SQL数据操作语言(DML)语句的操作触发的事件。例如,INSERT语句可能会激活一个触发器,该触发器检查语句的值是否有效。大多数触发器仅由INSERT或UPDATE语句激活。
触发器完全受支持,可以附加到表。触发器可以是每列和条件的,因为UPDATE触发器可以定位表的特定列,并且可以告诉触发器在触发器的WHERE子句中指定的一组条件下执行。可以使用INSTEAD OF条件将触发器附加到视图。按字母顺序触发多个触发器。除了调用本机PL / pgSQL中编写的函数之外,触发器还可以调用用其他语言编写的函数,如PL / Python或PL / Perl。
异步通知
PostgreSQL提供了一个异步消息传递系统,可通过NOTIFY,LISTEN和UNLISTEN命令进行访问。会话可以发出NOTIFY命令以及用户指定的通道和可选的有效负载,以标记发生的特定事件。其他会话能够通过发出LISTEN命令来检测这些事件,该命令可以侦听特定通道。此功能可用于多种用途,例如让其他会话知道表何时更新,或者让单独的应用程序检测何时执行特定操作。这样的系统可以防止应用程序连续轮询以查看是否有任何更改,并减少不必要的开销。通知是完全事务性的,因为在提交它们的事务之前不会发送消息。这消除了为正在执行的操作发送消息的问题,然后回滚。
PostgreSQL的许多连接器都支持这个通知系统(包括libpq,JDBC,Npgsql,psycopg和node.js),因此外部应用程序可以使用它。
规则
规则允许重写传入查询的“查询树”。 “查询重写规则”附加到表/类,并将传入的DML(选择,插入,更新和/或删除)“重写”到一个或多个查询中,这些查询替换原始DML语句或执行除此之外。查询重写发生在DML语句解析之后,但在查询规划之前。
其他查询功能
- 交易
- 全文检索
- Views
- 物化Views43]
- 可更新的Views44]
- 递归Views[45]
- 内,外(全,左,右)和交叉连接
- 子选择
- 相关的子查询[46]
- 正则表达式[47]
- 公用表表达式和可写公用表表达式
- 通过传输层安全性(TLS)加密连接;当前版本不使用易受攻击的SSL,即使使用该配置选项[48]
- 域
- 保存点
- 两阶段提交
- 超大属性存储技术(TOAST)用于通过自动压缩在单独的区域中透明地存储大型表属性(例如大型MIME附件或XML消息)。
- 嵌入式SQL使用预处理器实现。 SQL代码首先被嵌入到C代码中。然后代码通过ECPG预处理器运行,它将SQL替换为对代码库的调用。然后可以使用C编译器编译代码。嵌入也适用于C ++,但它不能识别所有C ++构造。
并发模型
PostgreSQL服务器是基于进程的(非线程化的),每个数据库会话使用一个操作系统进程。多个会话由操作系统自动分布在所有可用的CPU上。从PostgreSQL 9.6开始,许多类型的查询也可以跨多个后台工作进程并行化,利用多个CPU或核心。[49]客户端应用程序可以使用线程并从每个线程创建多个数据库连接。[50]
安全
PostgreSQL基于每个角色管理其内部安全性。角色通常被视为用户(可以登录的角色)或组(其他角色是其成员的角色)。可以在列级别的任何对象上授予或撤消权限,还可以允许/阻止在数据库,模式或表级别创建新对象。
PostgreSQL的SECURITY LABEL功能(SQL标准的扩展)允许额外的安全性;带有捆绑的可加载模块,支持基于安全增强型Linux(SELinux)安全策略的基于标签的强制访问控制(MAC)。[51] [52]
PostgreSQL本身支持大量的外部认证机制,包括:
- 密码:MD5或纯文本
- 通用安全服务应用程序接口(GSSAPI)
- 安全支持提供程序接口(SSPI)
- Kerberos的
- ident(将标识服务器提供的O / S用户名映射到数据库用户名)
- 对等(将本地用户名映射到数据库用户名)
- 轻量级目录访问协议(LDAP)
- 活动目录(AD)
- 半径
- 证书
- 可插拔认证模块(PAM)
- GSSAPI,SSPI,Kerberos,对等,身份和证书方法也可以使用指定的“映射”文件,该文件列出允许该身份验证系统匹配的用户作为特定数据库用户进行连接。
这些方法在集群的基于主机的身份验证配置文件(pg_hba.conf)中指定,该文件确定允许的连接。这允许控制哪个用户可以连接到哪个数据库,他们可以从哪里连接(IP地址,IP地址范围,域套接字),将强制执行哪个身份验证系统,以及连接是否必须使用传输层安全性(TLS)。
符合标准
PostgreSQL声称与SQL标准的一致性很高,但并不完整。一个例外是处理不带引号的标识符,如表名或列名。在PostgreSQL中,它们被折叠 - 内部 - 小写字符[53],而标准则表示不带引号的标识符应折叠成大写字母。因此,根据标准,Foo应该等同于FOO而不是foo。
基准和表现
PostgreSQL的许多非正式表演研究已经完成。[54]旨在提高可伸缩性的性能改进始于8.1版。 8.0版和8.4版之间的简单基准测试表明,后者在只读工作负载上的速度提高了10倍以上,在读写工作负载上的速度提高了至少7.5倍。[55]
第一个行业标准和同行验证的基准测试于2007年6月完成,使用Sun Java System Application Server(GlassFish的专有版本)9.0 Platform Edition,基于UltraSPARC T1的Sun Fire服务器和PostgreSQL 8.2。[56] 778.14 SPECjAppServer2004 JOPS @ Standard的结果与基于Itanium的HP-UX系统上的874 JOPS @ Standard与Oracle 10相比毫不逊色。[54]
2007年8月,Sun提交了一份改进的基准分数813.73 SPECjAppServer2004 JOPS @ Standard。随着被测系统的降价,价格/性能从84.98美元/ JOPS提高到70.57美元/ JOPS。[57]
PostgreSQL的默认配置仅使用少量专用内存用于性能关键目的,例如缓存数据库块和排序。这种限制主要是因为较旧的操作系统需要更改内核以允许分配大块共享内存。[58] PostgreSQL.org在维基中提供有关基本推荐性能实践的建议。[59]
2012年4月,EnterpriseDB的Robert Haas使用64核的服务器演示了PostgreSQL 9.2的线性CPU可扩展性。[60]
Matloob Khushi在Postgresql 9.0和MySQL 5.6.15之间进行基准测试,以处理基因组数据。在他的表现分析中,他发现PostgreSQL提取的重叠基因组区域比MySQL快8倍,使用两个80,000个数据集,每个数据集形成随机的人类DNA区域。 PostgreSQL中的插入和数据上传也更好,尽管两个数据库的一般搜索能力几乎相同。[61]
平台
PostgreSQL可用于以下操作系统:Linux(所有最新发行版),Windows(Windows 2000 SP4及更高版本;可编译,例如Visual Studio,现在最近的2017版本),FreeBSD,OpenBSD,[62] NetBSD,macOS (OS X),[13] AIX,HP-UX,Solaris和UnixWare;尚未正式测试:DragonFly BSD,BSD / OS,IRIX,OpenIndiana,[63] OpenSolaris,OpenServer和Tru64 UNIX。大多数其他类Unix系统也可以工作;最现代化的支持。
PostgreSQL适用于以下任何指令集体系结构:Windows和其他操作系统上的x86和x86-64;除了Windows之外,还支持这些:IA-64 Itanium(HP-UX的外部支持),PowerPC,PowerPC 64,S / 390,S / 390x,SPARC,SPARC 64,ARMv8-A(64位)[64]和较旧的ARM(32位,包括较旧的,如Raspberry Pi [65]中的ARMv6),MIPS,MIPSel和PA-RISC。它也被称为Alpha(在9.5中删除),M68k,M32R,NS32k和VAX。除此之外,还可以通过禁用自旋锁来为不受支持的CPU构建PostgreSQL。[66]
数据库管理
另请参见:数据库工具的比较
用于管理PostgreSQL的开源前端和工具包括:
- PSQL
-
- PostgreSQL的主要前端是psql命令行程序,可用于直接输入SQL查询或从文件执行它们。此外,psql提供了许多元命令和各种类似shell的功能,以便于编写脚本和自动执行各种任务;例如,对象名称和SQL语法的选项卡完成。
- pgAdmin的
- pgAdmin包是PostgreSQL的免费开源图形用户界面(GUI)管理工具,许多计算机平台都支持该工具。[67]该计划有十几种语言版本。第一个原型名为pgManager,是从1998年开始为PostgreSQL 6.3.2编写的,并在后几个月以GNU通用公共许可证(GPL)的形式重写并发布为pgAdmin。第二个版本(名为pgAdmin II)是完全重写的,首次发布于2002年1月16日。第三个版本pgAdmin III最初是在Artistic License下发布的,然后在与PostgreSQL相同的许可下发布。与以Visual Basic编写的先前版本不同,pgAdmin III是用C ++编写的,使用wxWidgets [68]框架允许它在大多数常见操作系统上运行。查询工具包括一个名为pgScript的脚本语言,用于支持管理和开发任务。 2014年12月,pgAdmin项目创始人兼主要开发人员Dave Page [69]宣布,随着向基于网络的模式的转变,pgAdmin 4的工作已经开始,旨在促进云部署。[70] 2016年,pgAdmin 4发布。 pgAdmin 4后端是用Python编写的,使用Flask和Qt框架。[71]
- phpPgAdmin的
- phpPgAdmin是一个基于Web的PostgreSQL管理工具,用PHP编写,基于最初为MySQL管理编写的流行的phpMyAdmin接口。[72]
- PostgreSQL Studio
- PostgreSQL Studio允许用户从基于Web的控制台执行必要的PostgreSQL数据库开发任务。 PostgreSQL Studio允许用户使用云数据库而无需打开防火墙。[73]
- TeamPostgreSQL
- 用于PostgreSQL的AJAX / JavaScript驱动的Web界面。允许通过Web浏览器浏览,维护和创建数据和数据库对象。该界面提供带选项卡的SQL编辑器,包括自动完成,行编辑小部件,行和表之间的点击式外键导航,常用脚本的收藏夹管理以及其他功能。支持Web界面和数据库连接的SSH。安装程序可用于Windows,Macintosh和Linux,以及一个从脚本运行的简单跨平台存档。[74]
- LibreOffice,OpenOffice.org
- LibreOffice和OpenOffice.org Base可以用作PostgreSQL的前端。[75] [76]
- pgBadger
- pgBadger PostgreSQL日志分析器从PostgreSQL日志文件生成详细报告。[77]
- pgDevOps
- pgDevOps是一套Web工具,用于安装和管理多个PostgreSQL版本,扩展和社区组件,开发SQL查询,监视正在运行的数据库并查找性能问题。[78]
- 许多公司为PostgreSQL提供专有工具。它们通常由适用于各种特定数据库产品的通用核心组成。这些工具主要与开源工具共享管理功能,但在数据建模,导入,导出或报告方面提供了改进。
知名的用户
使用PostgreSQL作为主数据库的着名组织和产品包括:
- 2009年,社交网站Myspace使用Aster Data Systems的nCluster数据库进行数据仓库,这是基于未经修改的PostgreSQL构建的。[79] [80]
- Geni.com使用PostgreSQL作为他们的主要家谱数据库。[81]
- OpenStreetMap,一个创建免费可编辑世界地图的合作项目。[82]
- Afili,.org,.info等域名注册机构。[83] [84]
- 索尼在线多人在线游戏。[85]
- 巴斯夫,他们的农业综合企业门户网站的购物平台。[86]
- Reddit社交新闻网站。[87]
- Skype VoIP应用程序,中央商业数据库。[88]
- Sun xVM,Sun的虚拟化和数据中心自动化套件。[89]
- MusicBrainz,开放在线音乐百科全书。[90]
- 国际空间站 - 收集轨道上的遥测数据并将其复制到地面。[91]
- MyYearbook社交网站。[92]
- Instagram,一种移动照片共享服务。[93]
- Disqus,在线讨论和评论服务。[94]
- TripAdvisor,旅游信息网站,主要是用户生成的内容。[95]
- 俄罗斯互联网公司Yandex将其Yandex.Mail服务从Oracle改为Postgres。[96]
- Amazon Redshift是AWS的一部分,是基于ParAccel Postgres修改的柱状在线分析处理(OLAP)系统。
- 国家海洋和大气管理局(NOAA)国家气象局(NWS),交互式预报准备系统(IFPS),该系统集成了NEXRAD天气雷达,地面和水文系统的数据,以建立详细的本地化预报模型。[84] [ 97]
- 英国的国家气象服务部门Met Office已经开始将Oracle for PostgreSQL转换为部署更多开源技术的战略。[97] [98]
- WhitePages.com一直在使用Oracle [99] [循环引用]和MySQL,但是当它在内部移动其核心目录时,它转向了PostgreSQL。由于WhitePages.com需要结合来自多个来源的大量数据,因此PostgreSQL以高速率加载和索引数据的能力是决定使用PostgreSQL的关键。[84]
- FlightAware,一个航班跟踪网站。[100]
- Grofers,一种在线杂货店送货服务。[101]
- 卫报在2018年从MongoDB迁移到PostgreSQL。[102]
服务实施
一些着名的供应商提供PostgreSQL作为软件即服务:
- 作为服务提供商的平台Heroku从2007年开始就支持PostgreSQL。[103]它们提供增值功能,如完全数据库回滚(从任何指定时间恢复数据库的能力),[104]基于WAL-E,由Heroku开发的开源软件。[105]
- 2012年1月,EnterpriseDB发布了PostgreSQL和他们自己专有的Postgres Plus Advanced Server的云版本,并自动配置了故障转移,复制,负载平衡和扩展。它在Amazon Web Services上运行。[106]
- 自2012年5月起,VMware为VMware vSphere上的私有云提供了vFabric Postgres(也称为vPostgres [107])。[108]
- 2013年11月,亚马逊网络服务公司宣布将PostgreSQL添加到他们的关系数据库服务产品中。[109] [110]
- 2016年11月,亚马逊网络服务公司宣布将PostgreSQL兼容性添加到其原生的Amazon Aurora托管数据库产品中。[111]
- 2017年5月,Microsoft Azure宣布为PostgreSQL提供Azure数据库[112]
原文:https://en.wikipedia.org/wiki/PostgreSQL
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 311 次浏览
【PostgreSQL 】如何在CentOS 7 / CentOS 8上安装PostgreSQL 12
本指南将引导您完成在CentOS 7 / CentOS 8 Linux服务器上安装PostgreSQL 12的步骤。 PostgreSQL是一个基于POSTGRES 4.2的对象关系数据库管理系统。开发人员和数据库管理员可以使用PostgreSQL 12。
PostgreSQL项目为最常见的发行版提供了所有受支持版本的软件包的存储库。支持的发行版包括所有Red Hat系列,其中包括CentOS,Fedora,Scientific Linux,Oracle Linux和Red Hat Enterprise Linux。
使用以下步骤在CentOS 8 / CentOS 7上安装PostgreSQL 12。
步骤1:将PostgreSQL Yum存储库添加到CentOS 7 / CentOS 8
PostgreSQL Yum存储库将与您的常规系统和补丁程序管理集成,并在PostgreSQL的整个支持期限内为所有受支持的PostgreSQL版本提供自动更新。
可以通过运行以下命令将其添加到CentOS系统中:
CentOS 8:
sudo yum -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
CentOS 7:
sudo yum -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
您可以通过运行以下命令获取有关已安装软件包的更多信息:
$ rpm -qi pgdg-redhat-repo Name : pgdg-redhat-repo Version : 42.0 Release : 4 Architecture: noarch Install Date: Thu 19 Sep 2019 06:34:53 PM UTC Group : System Environment/Base Size : 6915 License : PostgreSQL Signature : DSA/SHA1, Wed 17 Apr 2019 04:12:42 AM UTC, Key ID 1f16d2e1442df0f8 Source RPM : pgdg-redhat-repo-42.0-4.src.rpm Build Date : Wed 17 Apr 2019 04:12:41 AM UTC Build Host : koji-centos7-x86-64-pgbuild Relocations : (not relocatable) Vendor : PostgreSQL Global Development Group URL : https://yum.postgresql.org Summary : PostgreSQL PGDG RPMs- Yum Repository Configuration for Red Hat / CentOS / Scientific Linux Description : This package contains yum configuration for Red Hat Enterprise Linux, CentOS and Scientific Linux. and also the GPG key for PGDG RPMs.
步骤2:在CentOS 8 / CentOS 7上安装PostgreSQL 12
添加YUM存储库后,我们可以使用以下命令在CentOS 7/8上安装PostgreSQL 12。
CentOS 8上的PostgreSQL 12
禁用内置的PostgreSQL模块:
sudo dnf -qy module disable postgresql
然后安装客户端和服务器软件包:
sudo dnf -y install postgresql12 postgresql12-server
CentOS 7上的PostgreSQL 12
安装PostgreSQL客户端和服务器软件包:
sudo yum -y install epel-release yum-utils sudo yum-config-manager --enable pgdg12 sudo yum install postgresql12-server postgresql12
样本安装输出:
Dependencies Resolved =================================================================================================================================================== Package Arch Version Repository Size =================================================================================================================================================== Installing: postgresql12 x86_64 12beta4-1PGDG.rhel7 pgdg12-testing 1.8 M postgresql12-server x86_64 12beta4-1PGDG.rhel7 pgdg12-testing 5.4 M Installing for dependencies: libicu x86_64 50.2-3.el7 base 6.9 M postgresql12-libs x86_64 12beta4-1PGDG.rhel7 pgdg12-testing 383 k python3 x86_64 3.6.8-10.el7 base 69 k python3-libs x86_64 3.6.8-10.el7 base 7.0 M python3-pip noarch 9.0.3-5.el7 base 1.8 M python3-setuptools noarch 39.2.0-10.el7 base 629 k Transaction Summary =================================================================================================================================================== Install 2 Packages (+6 Dependent packages) Total download size: 24 M Installed size: 104 M Downloading packages: (1/8): libicu-50.2-3.el7.x86_64.rpm | 6.9 MB 00:00:00 warning: /var/cache/yum/x86_64/7/pgdg12-testing/packages/postgresql12-libs-12beta4-1PGDG.rhel7.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID 442df0f8: NOKEY Public key for postgresql12-libs-12beta4-1PGDG.rhel7.x86_64.rpm is not installed (2/8): postgresql12-libs-12beta4-1PGDG.rhel7.x86_64.rpm | 383 kB 00:00:00 (3/8): python3-3.6.8-10.el7.x86_64.rpm | 69 kB 00:00:00 (4/8): python3-setuptools-39.2.0-10.el7.noarch.rpm | 629 kB 00:00:00 (5/8): postgresql12-12beta4-1PGDG.rhel7.x86_64.rpm | 1.8 MB 00:00:00 (6/8): python3-libs-3.6.8-10.el7.x86_64.rpm | 7.0 MB 00:00:00 (7/8): postgresql12-server-12beta4-1PGDG.rhel7.x86_64.rpm | 5.4 MB 00:00:00 (8/8): python3-pip-9.0.3-5.el7.noarch.rpm | 1.8 MB 00:00:00 --------------------------------------------------------------------------------------------------------------------------------------------------- Total 15 MB/s | 24 MB 00:00:01 Retrieving key from file:///etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Importing GPG key 0x442DF0F8: Userid : "PostgreSQL RPM Building Project <pgsqlrpms-hackers@pgfoundry.org>" Fingerprint: 68c9 e2b9 1a37 d136 fe74 d176 1f16 d2e1 442d f0f8 Package : pgdg-redhat-repo-42.0-4.noarch (installed) From : /etc/pki/rpm-gpg/RPM-GPG-KEY-PGDG Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : libicu-50.2-3.el7.x86_64 1/8 Installing : postgresql12-libs-12beta4-1PGDG.rhel7.x86_64 2/8 Installing : python3-libs-3.6.8-10.el7.x86_64 3/8 Installing : python3-setuptools-39.2.0-10.el7.noarch 4/8 Installing : python3-3.6.8-10.el7.x86_64 5/8 Installing : python3-pip-9.0.3-5.el7.noarch 6/8 Installing : postgresql12-12beta4-1PGDG.rhel7.x86_64 7/8 Installing : postgresql12-server-12beta4-1PGDG.rhel7.x86_64 8/8 Verifying : postgresql12-libs-12beta4-1PGDG.rhel7.x86_64 1/8 Verifying : python3-pip-9.0.3-5.el7.noarch 2/8 Verifying : libicu-50.2-3.el7.x86_64 3/8 Verifying : python3-libs-3.6.8-10.el7.x86_64 4/8 Verifying : postgresql12-12beta4-1PGDG.rhel7.x86_64 5/8 Verifying : postgresql12-server-12beta4-1PGDG.rhel7.x86_64 6/8 Verifying : python3-setuptools-39.2.0-10.el7.noarch 7/8 Verifying : python3-3.6.8-10.el7.x86_64 8/8 Installed: postgresql12.x86_64 0:12beta4-1PGDG.rhel7 postgresql12-server.x86_64 0:12beta4-1PGDG.rhel7 Dependency Installed: libicu.x86_64 0:50.2-3.el7 postgresql12-libs.x86_64 0:12beta4-1PGDG.rhel7 python3.x86_64 0:3.6.8-10.el7 python3-libs.x86_64 0:3.6.8-10.el7 python3-pip.noarch 0:9.0.3-5.el7 python3-setuptools.noarch 0:39.2.0-10.el7
步骤3:初始化并启动数据库服务
安装后,需要先进行数据库初始化,然后才能启动服务。
sudo /usr/pgsql-12/bin/postgresql-12-setup initdb
数据库主要配置ifile写入:/var/lib/pgsql/12/data/postgresql.conf
启动并启用数据库服务器服务。
sudo systemctl enable --now postgresql-12
确认服务已启动,没有任何错误。
$ systemctl status postgresql-12 ● postgresql-12.service - PostgreSQL 12 database server Loaded: loaded (/usr/lib/systemd/system/postgresql-12.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2019-09-19 18:50:10 UTC; 39s ago Docs: https://www.postgresql.org/docs/12/static/ Process: 10647 ExecStartPre=/usr/pgsql-12/bin/postgresql-12-check-db-dir ${PGDATA} (code=exited, status=0/SUCCESS) Main PID: 10652 (postmaster) CGroup: /system.slice/postgresql-12.service ├─10652 /usr/pgsql-12/bin/postmaster -D /var/lib/pgsql/12/data/ ├─10654 postgres: logger ├─10656 postgres: checkpointer ├─10657 postgres: background writer ├─10658 postgres: walwriter ├─10659 postgres: autovacuum launcher ├─10660 postgres: stats collector └─10661 postgres: logical replication launcher Sep 19 18:50:10 cent7.novalocal systemd[1]: Starting PostgreSQL 12 database server... Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.207 UTC [10652] LOG: starting PostgreSQL 12beta4 on x86_64-pc-lin... 64-bit Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.209 UTC [10652] LOG: listening on IPv6 address "::1", port 5432 Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.209 UTC [10652] LOG: listening on IPv4 address "127.0.0.1", port 5432 Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.214 UTC [10652] LOG: listening on Unix socket "/var/run/postgresq...L.5432" Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.229 UTC [10652] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432" Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.254 UTC [10652] LOG: redirecting log output to logging collector process Sep 19 18:50:10 cent7.novalocal postmaster[10652]: 2019-09-19 18:50:10.254 UTC [10652] HINT: Future log output will appear in directory "log". Sep 19 18:50:10 cent7.novalocal systemd[1]: Started PostgreSQL 12 database server. Hint: Some lines were ellipsized, use -l to show in full.
如果您有正在运行的防火墙服务,并且远程客户端应连接到数据库服务器,则允许PostgreSQL服务。
sudo firewall-cmd --add-service=postgresql --permanent sudo firewall-cmd --reload
第4步:设置PostgreSQL管理员用户的密码
设置PostgreSQL管理员用户
$ sudo su - postgres ~]$ psql -c "alter user postgres with password 'StrongPassword'" ALTER ROLE
步骤5:启用远程访问(可选)
编辑文件/var/lib/pgsql/12/data/postgresql.conf并将所有服务器的“监听地址”设置为服务器IP地址或“ *”。
listen_addresses ='192.168.10.10'
还设置PostgreSQL接受远程连接
$ sudo vim /var/lib/pgsql/12/data/pg_hba.conf # Accept from anywhere host all all 0.0.0.0/0 md5 # Accept from trusted subnet host all all 192.168.18.0/24 md5
提交更改后,重新启动数据库服务。
sudo systemctl restart postgresql-12
步骤6:安装pgAdmin 4 Web界面
pgAdmin是领先的开源功能丰富的PostgreSQL管理和开发平台,可在Linux,Unix,Mac OS X和Windows上运行。 这是在CentOS上安装pgAdmin4的链接。
How To Install pgAdmin 4 on CentOS 8 Linux
原文:https://computingforgeeks.com/how-to-install-postgresql-12-on-centos-7/
本文:http://jiagoushi.pro/node/920
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 177 次浏览
【PostgreSQL 技术】扩展Postgresql到TB甚至更大的想法
在最近与一位DBA交谈后,他迈出了将大型数据库从Oracle迁移到Postgres的第一步。
我认为没有足够的文章介绍PostgreSQL的特性和黑客,从硬件中挤出最后一部分,安全地容纳好几个tb大小的数据库以实现可伸缩性。特别是在有相当多的选择的情况下,我很惊讶有这么多的人担心PostgreSQL在伸缩性方面是非常有限的。也许确实曾经是这样(我在2011年开始使用Postgres),但在2018年,事情已经相当稳固了——所以请继续读下去,看看如何轻松地处理tb。
标准Postgres设施
如果你不喜欢出汗太多,然后做一些开拓性的尺度。应该是最安全的方法坚持证明Postgres的开箱即用的特性,首先我建议看看以下关键词和一些简短的解释,也许是你需要的一切。
轻量级/特殊用途索引
对于支持数百个奇怪查询的复杂OLTP系统,索引实际上占用的磁盘空间比保存数据的表文件要多得多,这是很常见的。为了改善这一点(特别是对于不经常使用的索引),可以通过适当使用部分、BRIN、GIN甚至少量实验性BLOOM索引来大幅减小索引的大小。总共支持7种不同的索引类型……但是大多数人只知道和使用默认的b -树——这在多tb设置中是个大错误!
部分索引只允许数据的一个子集——例如,在销售系统中,我们可能对快速访问状态为“FINISHED”的订单不感兴趣(一些夜间报告通常会处理这个问题,它们可能会花很多时间),那么我们为什么要索引这样的行呢?
GIN可能是最知名的非默认索引类型,它已经存在很长时间了(全文搜索),简而言之,它非常适合索引有很多重复值的列——考虑各种状态或老的Mr/Mrs/Miss。GIN只将每个惟一的列值存储一次,对于默认的b树,您将拥有1,000,000个叶节点,其中包含整数“1”。
BRIN(block-range又名min-max指数)另一方面,是新的和非常不同——它是一种有损压缩指数与一个很小的磁盘占用,并不是所有的列值建立索引,但只有最大和最小值的行范围(1 MB的默认表)——这仍然很有效有序的值,例如适合时间序列数据或其他“日志”类型的表。
BLOOM可能有点奇怪,但如果你能找到一个很好的用例(“位图/矩阵搜索”),它的效率会比传统索引高出20倍——这里有一个看起来过于抽象的用例。
但是为什么我要把索引这个有点不太原创的话题放在列表的最前面呢?因为这个解决方案的最大优点是您不需要更改任何应用程序—DBA可以让它轻松地在幕后工作,就像一次性工作一样!完美的。
表分区
Postgres分区已经15年我相信……但“弄脏你的手”的方式——一个不得不做一些附加的低级管理分区,添加检查约束和直接插入行纠正子表,或路由通过父表插入触发器。所有这些都是从Postgres version 10开始的历史,有声明式分区,并且在version 11中变得更好,在版本11中,功能可以被称为功能完整的功能,支持主键和外键。
但何苦呢?分区的优点是:它可以干净地分离“冷数据”和“热数据”,这给了我们一些不错的选项如使用VACUUM FULL最大限度压缩旧数据或把它放在另一个媒体(参见下面的“表空间”)作为一个副作用较小的索引,以少得多的“shared_buffers”空间所以我们有更多的空间数据。对于统一访问的数据场景(通过名称/电子邮件/散列),这种影响最大,大型索引的所有部分仍然需要遍历/读取/缓存,但实际使用的只是其中很小的一部分。同样类似于索引,在良好的应用程序条件下,dba无需在后台更改任何代码就可以实现分区。
表空间
如上所述——借助表空间可以有选择地将表/索引移动到不同的磁盘介质。这里可以实现不同的目标之一——为了节省资金,使用较慢/负担得起的磁盘分区来处理“冷”数据,只在快速/昂贵的媒体上保存最新/重要的数据,对重复次数很多的数据使用一些特殊的压缩文件系统,对大量非持久性数据使用一些网络共享甚至远程节点上的内存文件系统——有一些选项。而且表空间的管理实际上也非常简单,由于完全锁定,只有在实时操作期间传输现有的表/索引才会有问题。
最大限度地使用多进程特性
从Postgres 9.6开始,可以对数据的一些常见操作进行并行化。在Postgres 10/11中,默认情况下也启用了相关参数“max_parallel_workers_per_gather”,其值为2,因此是max。使用了2个后台进程。对于“大数据”用例,增加更多(以及一些相关参数)是有意义的。此外,对并行化操作的支持也会随着每一个新的主要发行版的增加而增加。例如,即将发布的version 11现在可以执行并行散列连接、索引扫描和UNION-s。
使用副本进行查询负载平衡
现在我们已经走出了“单节点”或“扩展”的领域……但是考虑到非常合理的硬件价格和可用的Postgres集群管理软件(Patroni是我们的最爱),它不仅适用于更大的“商店”,而且应该适用于每个人。当然,这种扩展只能在主要是读取数据的情况下使用……按照目前(以及未来几年)的官方规定,一个接受写操作的集群中只能有一个“主/主”节点。此外,根据您选择的技术栈,您可能需要处理一些技术细节(特别是连接路由),但实际上,Postgres 10确实在驱动程序级别增加了对多主机用例的支持——因此电池也包括在内!更多信息请看这里。同样,从Postgres 9.6开始,副本可以在“镜像”模式下运行,这样您选择哪个节点运行就无关紧要了!不过,作为一个友好的警告——这只能在读取查询是纯OLTP的情况下工作,也就是说非常快。
有一些妥协的方法
所以现在我们已经完成了传统的事情…但是如果你准备走一条非常规的路
也许对您的应用程序做一些细微的调整,或者尝试一些命名有趣的扩展,您可能会从单节点硬件中挤出最后一滴性能。我的意思是:
混合/外部表
我称之为混合表,实际上是基于Postgres的优秀的MED SQL标准的实现也被称为外部数据包装(FDW),基本上,他们看起来像正常Postgres表读取查询,但数据可能存在或管道从字面上任何地方——它可能是来自Twitter、LDAP或Amazon S3,看到疯狂的数据源支持的完整列表。实际上,最常用的外部数据包装程序可能是使正常(正确格式化的)文件看起来像表,例如将服务器日志公开为表,以便更容易监视。
你可能会问扩展部分在哪里?FDW方法工作得非常好,因为它能够通过使用一些聪明的文件格式或仅仅压缩来减少数据量,这通常会减少数据大小10-20x,以便数据适合节点!这对于“冷”数据非常有效,为“热”数据的真实表留下更多的磁盘空间/缓存可用。由于Postgres 10,它也很容易实现——这里是示例代码。
另一个非常有前途的用例是使用柱状数据存储格式(ORC)—查看“c_store”扩展项目以获得更多信息。它特别适合帮助扩展大型数据仓库,其中的表可以小到10倍,查询速度可以快到100%。
为什么我没有把这个特性添加到上面的“标准Postgres设施”部分,尽管外部数据包装基础设施已经牢固地构建到Postgres中?好的,缺点是您通常不能通过SQL更改数据和添加索引或约束,因此它的使用有一定的限制。
外表继承,即分片!(Foreign table inheritance a.k.a. sharding!)
与上一点基本相同——但是引入了表分区并将子表驻留在远程节点上!数据可以被植入到附近的Postgres服务器,并根据需要通过网络自动提取。实际上,它们不必是Postgres表!它很可能是MySQL、Oracle或MS SQL任何其他流行的服务器,对某些查询子集工作得很好。这有多酷?虽然只有“postgres_fdw”支持所有的写操作、事务和聪明的过滤器下推,所以通过网络传递的数据量最小化,但是可以从postgres_fdw到postgres的交互中得到最好的结果。
terabyte-hunting快乐!
原文:https://www.cybertec-postgresql.com/en/ideas-for-scaling-postgresql-to-multi-terabyte-and-beyond/
本文:http://jiagoushi.pro/node/1180
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 67 次浏览
【PostgreSQL 架构】PostgreSQL 10和逻辑复制-概述
- 58 次浏览
【PostgreSQL 架构】PostgreSQL 11和即时编译查询
PostgreSQL 11正在酝酿之中,即将发布。同时,使用您自己的应用程序对其进行测试是确保社区在零点发行之前捕获所有剩余错误的好方法。
下一个PostgreSQL版本的重大变化之一是Andres Freund在查询执行器引擎上的工作成果。 Andres已经在系统的这一部分上工作了一段时间,在下一发行版中,我们将看到执行引擎中的一个新组件:一个JIT表达式编译器!
基准和TPC-H
我喜欢在Citus Data进行工程工作以通过Citus扩展扩展PostgreSQL的一件事就是,我可以运行基准测试!基准测试是一个很好的工具,可以显示性能改进可带来哪些好处。当前,JIT表达式编译器在以下情况下效果最佳:
- 该查询包含多个复杂的表达式,例如聚合。
- 该查询读取了大量数据,但没有IO资源短缺。
- 该查询非常复杂,以至于需要花费大量的JIT精力。
通过主键代理ID获取某些信息的查询不太适合查看PostgreSQL中新的JIT基础结构所提供的改进。
TPC-H基准测试第1季度查询可以很好地评估新执行程序堆栈的影响,因此我们在这里使用它。
基准测试的规范可在137页的名为TPC Benchmark™H的PDF文档中找到。该规范中的每个查询都附带一个业务问题,因此请参阅第一季度
定价摘要报告查询(Q1)
此查询报告已开票,发货和退回的业务量。
定价摘要报告查询提供了给定日期发货的所有订单项的摘要定价报告。该日期位于数据库中包含的最晚发货日期的60-120天之内。该查询列出了扩展价格,折扣扩展价格,折扣扩展价格加税,平均数量,平均扩展价格和平均折扣的总计。这些聚合按RETURNFLAG和LINESTATUS分组,并按RETURNFLAG和LINESTATUS的升序排列。包括每个组中的行项目数的计数。
这就是SQL中的样子:
select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from lineitem where l_shipdate <= date '1998-12-01' - interval ':1' day group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus :n -1 ;
此外,该规范还提供有关查询的注释:
注释:1998-12-01是数据库填充中定义的最高可能的发货日期。 (这是ENDDATE-30)。 该查询将包括该日期之前减去DELTA天之前发货的所有订单项。 目的是选择DELTA,以便扫描表中95%至97%的行。
为了使查询有资格显示新的PostgreSQL表达式以执行JIT编译器,我们将选择适合内存的比例因子。
结果
选择10的比例因子时,我们得到的数据库大小为22GB,包括创建的索引。 此处使用的完整架构在tpch-schema.sql上可用,而索引在tpch-pkeys.sql和tpch-index.sql上。
在我的测试中,执行TPCH Q1查询时,PostgreSQL 11比PostgreSQL 10快29.31%。 在循环中运行查询10分钟时,当PostgreSQL 10仅执行同一查询时,它允许PostgreSQL 11执行30次。 21次。

如我们所见,PostgreSQL 10中的Andres工作已经对该查询产生了巨大影响。在此版本中,对执行程序的表达式评估进行了全面修订,以考虑到CPU缓存行和指令管道。在此基准测试中,我们选择在PostgreSQL中禁用并行查询,以便评估主要由新执行程序导致的改进。 PostgreSQL 10 then 11中的并行支持能够大大增强我们在此看到的查询时间!
在PostgreSQL 11中,由于在查询计划时使用LLVM编译器基础结构,SQL表达式已转换为机器代码,这对查询性能产生了另一个非常好的影响!
工具
基准测试规范有两个文件可用:
llvm-q1-infra.ini定义了用于运行此测试的AWS EC2实例。
- 在这里您可以看到我们选择了c5.4xlarge实例来托管我们的PostgreSQL数据库。它们每个都有30GB的RAM,因此我们的22GB数据集和索引非常适合RAM。
- 另外,我们使用http://apt.postgresql.org中的软件包选择了debian操作系统,该软件包提供了我们在此处一直使用的PostgreSQL 11开发快照。
llvm-q1-schedule.ini定义了我们的基准计划,这在这里非常简单:
[schedule]
full = initdb, single-user-stream, multi-user-stream
- 在initdb阶段,在8个并发进程中加载比例因子10的数据,每个进程一次执行一个步骤,考虑到我们将工作负载分为10个子进程。
- 我们在这里使用TPC-H s语。另外,在我研究的PostgreSQL的TPC-H实现中,我增加了对直接加载机制的支持,这意味着dbgen工具连接到数据库服务器并使用COPY协议。
- 然后执行一个单用户流,该流包括在客户端的单个CPU上运行尽可能多的查询,并持续10分钟。
- 然后执行一个多用户流,该流包含从所有8个CPU并行运行尽可能多的查询,并持续10分钟。
此处使用的基准测试工具是“开源”,可从https://github.com/dimitri/tpch-citus免费获得。这是一个简单的应用程序,可以自动在动态的AWS EC2基础架构中运行TPCH。
这个想法是,在创建几个配置文件后,可以在多个系统上并行驱动一个完整的基准测试,并在合并的数据库中检索结果以供以后分析。
此外,该项目还包括适用于PostgreSQL的TPCH C代码版本,并使用COPY协议实现直接加载。然后,该项目使用dbgen工具生成数据,并使用qgen工具为每个客户端根据规范生成新的查询流。
期待未来的Postgres
PostgreSQL 11引入了一个新的PostgreSQL执行引擎,借助LLVM框架,该引擎将您的SQL代码编译为机器代码。对于足够昂贵的查询(遍历许多行并一次又一次地计算表达式的查询),其好处可能是巨大的!
为了帮助PostgreSQL实现版本11的最佳发行,请考虑在测试和CI环境中使用beta版本,并报告您可能会发现的所有错误或性能下降,并通过一种简便的方法来再现它们。有关声明和如何报告相关发现的详细信息,请参见PostgreSQL 10.5和11 Beta 3 Released。
在我们的基准测试中,PostgreSQL 11 JIT是一项很棒的技术,它提供了高达29.31%的速度改进,在使用PostgreSQL 10时以20.5s的比例因子10执行TPC-H Q1而不是29s。
在Citus,我们几个月来一直在忙于针对PostgreSQL测试Citus扩展。因为Citus是Postgres的纯粹扩展,而不是fork,这意味着当时候到来时,您应该能够升级以获得Postgres 11的所有新优势,以帮助您保持扩展。
原文:https://www.citusdata.com/blog/2018/09/11/postgresql-11-just-in-time/
本文:http://jiagoushi.pro/node/924
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 95 次浏览
【PostgreSQL 架构】PostgreSQL的大量处理开发
- 45 次浏览
【PostgreSQL】PostgreSQL CDC:如何设置实时同步
视频号
微信公众号
知识星球

PostgreSQL是使用最广泛的开源关系数据库之一。其全面的查询层和符合技术标准的特性使其成为OLTP工作负载,数据仓库和分析用例等各种用例的最爱。在典型的体系结构中,组织将有一个关系数据库来处理事务负载,然后有一个单独的数据仓库来执行所有分析用例和汇总报告。这里的挑战是确保数据仓库具有事务数据库中存在的最新数据版本。通常有时间紧迫的报告要求,无法在这些数据库之间进行每小时或每天的批处理同步。使用基于变更数据捕获范例的实例之间的连续同步来处理此类需求。这篇文章是关于PostgreSQL CDC及其实现方法的。
在本文中,您将学习:
- 实现PostgreSQL CDC的方法
- 方法1 –使用自定义代码的Postgres CDC
- 方法1 –使用审核触发器
- 方法2:使用Postgres逻辑解码
- 方法3:使用时间戳列
- 方法2 –实施PostgreSQL CDC的简便方法
实施PostgreSQL变化数据捕获(CDC)的方法
有很多实现Postgres CDC的方法。 该博客讨论了以下两种方法:方法1:构建自定义代码以实现PostgreSQL CDC
我们将在此博客中讨论以下方法:
- 使用Postgres审核触发器
- 使用Postgres逻辑解码
- 使用时间戳列
方法2:使用完全自动化的数据管道解决方案,如Hevo Data
尽管构建自定义代码可能看起来是非常有利可图的选择,但仍有许多障碍,挑战和限制使其变得很费力。 实施类似Hevo的解决方案有助于实现PostgreSQL CDC到您选择的任何目标,而无需编写任何代码。
Postgres使用自定义代码更改数据捕获
方法1:使用Postgres审核触发器(Audit Triggers)
基于触发器的方法涉及在数据库上创建审核触发器,以捕获与INSERT,UPDATE和DELETE方法有关的所有事件。这种方法的优点是,一切都发生在SQL级别,并且开发人员只需要读取一个包含所有审核日志的单独表。
要在Postgres表中创建触发器,请执行以下命令。
SELECT audit.audit_table('target_table');
该语句将以具有访问审核模式权限的用户角色执行。写入表的应用程序一定不能使用超级用户角色连接到数据库。
如果要求不需要跟踪不经常更改的字段,则可以在特定字段的情况下关闭这些审核日志。
然后,我们有了一个捕获审计日志的表。开发人员仍然需要编写程序来读取和解析这些日志并将其推送到目标数据库中。此逻辑的复杂性还将取决于将数据推送到的目标数据库或数据仓库。
在PostgreSQL CDC中使用Postgres审计触发器的局限性
这种方法的缺点是触发器会影响数据库的性能。避免这种性能下降的常见做法是拥有一个单独的表来跟踪主表,并在第二个表上具有触发器。可以使用Postgres逻辑复制功能完成主表和辅助表之间的同步。
方法2:使用Postgres逻辑解码( Logical Decoding)
逻辑解码使用预写日志的内容来创建数据库中发生的活动的日志。预写日志是内部日志,描述了存储级别上的数据库更改。这种方法的优点是它不会以任何方式影响数据库的性能。
该方法基于输出插件的安装而工作。为了启用逻辑解码,需要在Postgres配置中设置以下参数。
wal_level = logical max_replication_slots = 10
设置完这些参数后,执行以下命令以创建逻辑解码槽。
SELECT * FROM pg_create_logical_replication_slot('slot_repl', 'decode_test');这将确保对表的每次更新都将创建可在视图选择语句中访问的审计事件。 逻辑解码支持两种选择语句来访问这些事件。 以下命令可用于窥视事件,
SELECT * FROM pg_logical_slot_peek_changes('slot_repl', NULL, NULL);要使用或获取结果,请使用以下命令。
SELECT * FROM pg_logical_slot_get_changes('slot_repl', NULL, NULL);“消费”和“窥视”之间的区别在于,第二条命令在消费事件后便将其删除。 让我们尝试通过一个例子来理解这一点。
假设有一个学生表,我们在该表中插入了一个条目。
Insert into students (id, name, age) values (1, ‘Peter’, '30');
一旦执行了peek命令,结果将如下所示。
SELECT * FROM pg_logical_slot_peek_changes('slot_repl', NULL, NULL);0/16CEE88 | 102 | BEGIN 102 0/16CEE88 | 102 | table public.students: INSERT: id[integer]:1 name[character varying]:' Peter' age[integer]:30 0/16CEFA0 | 102 | COMMIT 102
同样,如果我们执行相同的命令,您仍然会看到相同的审核事件。
SELECT * FROM pg_logical_slot_peek_changes('slot_repl', NULL, NULL);0/16CEE88 | 102 | BEGIN 102 0/16CEE88 | 102 | table public.students: INSERT: id[integer]:1 name[character varying]:' Peter' age[integer]:30 0/16CEFA0 | 102 | COMMIT 102
现在执行get命令。
SELECT * FROM pg_logical_slot_get_changes('slot_repl', NULL, NULL);0/16CEE88 | 102 | BEGIN 102 0/16CEE88 | 102 | table public.students: INSERT: id[integer]:1 name[character varying]:' Peter' age[integer]:30 0/16CEFA0 | 102 | COMMIT 102
结果是一样的。 但是,如果再次执行相同的命令或peek命令,则会发现结果为零。
SELECT * FROM pg_logical_slot_get_changes('slot_repl', NULL, NULL);
(0 rows)这意味着当执行get命令时,将提供结果并删除结果,从而大大增强了我们编写使用这些事件创建表副本的逻辑的能力。
Postgres还支持使用输出插件-基本上是c程序,可以基于INSERT,UPDATE和DELETE事件执行,并将事件转换为更加用户友好的格式。 Wal2json是一个这样的插件,可以以JSON格式输出这些事件。大多数Degrecium之类的Postgres CDC附件都广泛使用了此插件。
这里要注意的一点是,这些事件不会捕获表的创建和修改步骤。
对Postgres CDC使用Postgres逻辑解码的缺点
同样,在这种情况下,开发人员需要编写复杂的逻辑来处理这些事件,然后将其转换为目标数据库的语句。根据您要解决的用例,这可能会增加项目时间表。
方法3:使用时间戳列
Postgres引擎提供了以上两种方法来实现CDC。如果您在表中具有timestamp列的灵活性,那么还有一个稍微复杂的自定义方法。这意味着开发人员将需要定期查询表并监视对timestamp列的更改。当检测到更改时,脚本可以创建适当的数据库语句以将这些更改写入目标数据库。但是,这种方法需要大量的精力,并且需要开发人员花费大量的时间和精力。
简而言之,即使Postgres提供了通过触发器,逻辑解码或通过自定义逻辑的连续同步支持,开发人员仍然需要捕获这些事件并将其转换为目标数据库。根据用例,将需要为不同的目标数据库专门编写此逻辑。一种替代方法是使用像Hevo这样的基于云的服务,该服务可以使用Postgres CDC将数据连续同步到大多数目的地。
设置POSTGRESQL更改数据捕获的简便方法
Hevo是一个完全托管的数据集成平台,可以帮助您将数据从PostgreSQL实时加载到您选择的任何目标,而无需编写任何代码。
Hevo开箱即用地支持Postgres CDC,并提供了一个点击式视觉界面来启用更改数据捕获。 您只需要将Hevo指向Postgres数据库中的auto-crementing列或timestamp列即可。
Hevo将完成所有艰苦的工作,并确保您的Postgres数据始终在目标数据库/数据仓库中是最新的。
本文:http://jiagoushi.pro/node/1041
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】
- 1378 次浏览
【PostgreSQL】PostgreSQL变更数据捕获(CDC):完整指南
视频号
微信公众号
知识星球
本指南帮助您开始将CDC与PostgreSQL数据库系统一起使用。
目录
- 介绍
- PostgreSQL中使用触发器的变更数据捕获
- PostgreSQL中使用查询进行变更数据捕获
- PostgreSQL中带有逻辑复制的变更数据捕获
- 总结
介绍
PostgreSQL是一个著名的开源数据库管理系统,目前正在众多企业生产。在典型的设置中,PostgreSQL管理应用程序的事务数据,例如电子商务商店中的产品,并集成第三方数据系统用于其他目的,例如用于分析的数据仓库、用于报告的BI工具等。

连接PostgreSQL与其他数据存储的传统方法是基于批处理的。数据管道时不时地从PostgreSQL中提取所有数据并发送到下游的数据存储中,这不仅效率低下,而且容易出错。
变更数据捕获(CDC)是一种现代的替代方案,可以从PostgreSQL中实时提取记录级变更事件(插入、更新和删除)。变更数据捕获的主要好处是:
- CDC实时捕获更改事件,保持下游系统(如数据仓库)始终与PostgreSQL同步,并启用完全事件驱动的数据体系结构。
- 使用CDC可以减少PostgreSQL的负载,因为只处理相关信息,例如更改。
- CDC支持高效地实现需要访问PostgreSQL更改事件(如审核或更改日志)的用例,而无需修改应用程序代码。
在本文中,我们将提供一个完整的介绍,介绍如何将变更数据捕获与PostgreSQL结合使用。我们介绍了实现更改数据捕获的三种常用方法:触发器、查询和逻辑复制。虽然每种方法都有各自的优缺点,但在DataCate,我们最喜欢的是使用逻辑复制的基于日志的CDC。
在PostgreSQL中使用触发器更改数据捕获
使用PostgreSQL的触发器特性,我们可以侦听感兴趣的表中发生的所有插入、更新和删除事件,并为每个事件将一行插入第二个表中,从而构建变更日志。
PostgreSQL社区提供了一个通用触发器函数(代码),该函数支持PostgreSQL 9.1版及更高版本,并将所有更改事件存储在表audit.logged\u actions中。如果希望为表public.users启用基于触发器的更改数据捕获,则可以运行以下SQL语句:
SELECT audit.audit_table('public.users');为表public.users启用基于触发器的CDC。
CDC的这种方法只在PostgreSQL中存储捕获的事件。如果要将更改事件同步到其他数据系统(如数据仓库),则必须重复查询包含更改事件的PostgreSQL表(此处为audit.logged\u操作),这会增加实现的复杂性。
让我们比较一下在PostgreSQL中使用触发器实现更改数据捕获的优缺点:
- 可以立即捕获更改,从而实现更改事件的实时处理。
- 触发器可以捕获所有事件类型:插入、更新和删除。
- 默认情况下,此处使用的PostgreSQL触发器函数将有用的元数据添加到事件中,例如导致更改的语句、事务ID或会话用户名。
- 触发器会增加原始语句的执行时间,从而影响PostgreSQL的性能。
- 触发器需要更改PostgreSQL数据库。
- 如果更改事件应同步到同一PostgreSQL数据库以外的数据存储,则需要设置单独的数据管道,该管道轮询触发器函数(此处为audit.logged\u actions)填充的表。
- 创建和管理触发器会导致额外的操作复杂性。
在PostgreSQL中使用查询更改数据捕获
使用PostgreSQL实现更改数据捕获的第二种方法是基于查询的。
如果受监视数据库表的模式具有一个timestamp列,该列指示上一次更改行的时间,那么我们可以使用该列重复查询PostgreSQL,并请求自上次查询PostgreSQL以来已修改的所有记录。假设有一个名为public.users的表和一个名为updated\u at的时间戳列,这样的查询可以按如下方式实现:
SELECT * FROM public.users WHERE updated_at > 'TIMESTAMP_LAST_QUERY';示例:提取自上次访问时间以来已修改的所有用户的SQL查询(请替换TIMESTAMP\u last\u查询)。
请注意,基于查询的CDC无法捕获删除(除非使用软删除),但仅限于插入和更新事件。
- 如果模式具有指示行修改时间的timestamp列,则可以实现基于查询的CDC,而无需对PostgreSQL进行任何更改。
- 基于查询的CDC实现使用查询层提取数据,这给PostgreSQL带来了额外的负载。
- 基于查询的CDC需要对受监视表(此处为public.users)进行周期性轮询,如果数据很少更改,这将浪费资源。
- 基于查询的CDC需要一个列(此处为updated\u at)来跟踪记录上次修改的时间。
- 基于查询的CDC无法捕获删除事件(除非应用程序使用软删除)。
在PostgreSQL中使用逻辑复制更改数据捕获
自9.4版以来,PostgreSQL提供了逻辑复制,以便在可能不同的物理机器上的不同PostgreSQL实例之间高效、安全地复制数据。从技术上讲,它是一个磁盘上的预写日志,它保存更改PostgreSQL数据库数据的所有事件,例如插入、更新和删除。
PostgreSQL使用具有发布服务器和订阅服务器的订阅模型来实现逻辑复制。为了实现变更数据捕获,我们可以使用感兴趣的数据库作为发布者并订阅其日志。
虽然许多数据库系统可能已经使用复制,但默认情况下不启用复制。您可以通过对配置文件postgresql.conf引入以下更改来启用逻辑复制。
wal_level = logical
在postgresql.conf中启用逻辑复制。
在下一步中,您需要修改配置文件pga\u hba.conf以允许复制(请参阅PostgreSQL文档了解各个配置):
host all repuser 0.0.0.0/0 md5
允许在pga\u hba.conf中进行逻辑复制。
假设您要从public.users表中捕获更改。您可以通过创建新发布为该表启用CDC,如下所示:
CREATE PUBLICATION newpub FOR TABLE public.users;为表public.users创建发布。
在下一步中,您可以开始订阅此出版物。订阅从初始快照开始,然后复制所有增量更改。如果要使用另一个PostgreSQL实例中的事件,可以按如下方式创建订阅:
CREATE SUBSCRIPTION newsub CONNECTION 'dbname=foo host=bar user=repuser' PUBLICATION newpub;为使用更改创建订阅。
从技术上讲,逻辑复制是通过逻辑解码插件实现的。如果您使用的PostgreSQL版本早于10,则需要在PostgreSQL数据库中手动安装插件,例如wal2json或decoderbufs。从版本10开始,PostgreSQL默认提供插件pgoutput。
对于基于日志的变更数据捕获的技术实现,我们强烈建议使用现有的开源项目之一,例如Debezium。DataCate的PostgreSQL源连接器基于Debezium。
据我们所知,大多数托管PostgreSQL服务都提供对逻辑复制的支持,例如AWS RDS、Google Cloud SQL或Azure数据库。
下表显示了使用PostgreSQL的逻辑复制实现CDC的优缺点:
- 基于日志的CDC支持实时捕获事件驱动的数据更改。下游应用程序始终可以访问来自PostgreSQL的最新数据。
- 基于日志的CDC可以检测PostgreSQL中的所有更改事件类型:插入、更新和删除。
- 通过逻辑复制使用事件归结为直接访问文件系统,这不会影响PostgreSQL数据库的性能。
- 非常旧版本的PostgreSQL(早于9.4)不支持逻辑复制。
总结
在比较使用PostgreSQL实现变更数据捕获的三种方法时,使用逻辑复制显然是胜利者。它不仅高效、实时捕获所有事件类型而不损害PostgreSQL数据库的性能,而且广泛可用(无论您使用的是自管理还是托管PostgreSQL安装),并且在不更改数据库模式的情况下适用。
CDC连接器通常比传统的SELECT*FROM表更复杂;查询。在DataCate中,我们提供用于更改数据捕获的即插即用连接器,它使您能够在几分钟内使用PostgreSQL设置基于日志的CDC,并降低操作复杂性。试试看!
- 992 次浏览
【PostgreSQL】PostgreSQL在性能和可伸缩性方面是否与SQL SERVER匹配?

数据库系统的性能和可伸缩性可以对任何项目产生重大影响。在许多情况下,开发人员必须从一个数据库系统迁移到另一个数据库系统,以提高数据库密集型应用程序的性能和操作速度。不仅如此,每个应用程序都会进行修改,以获得更好的用户体验,并引入新功能,对数据库存储的需求也会大大增加。如果您的应用程序的数据库系统没有提供健壮的可伸缩性功能,并且如果随着负载的增加性能受到影响,那么应用程序的受欢迎程度将受到影响。今天,让我们来比较两个最流行的数据库系统MS SQL Server和PostgreSQL的性能和可伸缩性因素。
性能-
并发性-
并发性是决定数据库系统性能的一个重要因素。并发性是指多个进程可以同时访问和修改共享数据的特性。在每一个应用程序中,某些数据被运行的各种并发进程共享,数据的这种并发性可以是健壮的,数据库和应用程序的性能将是更快、更完美的。SQL Server的并发性不足,您肯定会在日志中得到各种锁定、阻止和死锁的报告。这会导致数据管理不当,应用程序的进程变得非常缓慢。相比之下,PostgreSQL具有更好的并发管理系统,并且由于其优化MVCC的特性,死锁的可能性更小。
分区-
与并发性一样,分区也是数据库系统的一大特性。分区是将大表分成小部分的过程。随着数据库大小,特别是表大小的增长,分区是很重要的。这有助于在访问分数数据而不是整个大表时提高性能。从可伸缩性的角度来看,分区也很重要。随着应用程序规模的增大,数据库会变得很大,如果不进行拆分,数据库会变得更大,访问数据将需要很多时间。至于SQL Server,有一个合适的分区特性,但是你必须购买这个特性作为附加组件,而在PostgreSQL中,你可以以更低的价格和更高的效率获得它。
索引-
技术更新的速度比以往任何时候都快。在这种情况下,SQL Server在几年后发布新版本的方法已经过时。PostgreSQL定期发布更新版本,并紧跟潮流,提供更快的性能。接下来,PostgreSQL的可索引函数特性将把数据库的性能提升到另一个级别。不仅如此,PostgreSQL还支持模块或扩展,您可以做很多SQL server无法做到的事情。由于缺乏正确的索引实现是SQL server,它们省略了一个最常用的变量系统array。
可扩展性-
数据库系统的可伸缩性直接取决于数据的压缩能力。理想情况下,数据库系统必须具有先进的现成的压缩技术。在某些数据库系统中,开发人员必须手动压缩,不仅耗时而且效率低下。MS SQL Server提供了开箱即用的压缩,但您必须手动实现它。另一方面,PostgreSQL免费提供,整个过程是自动的。
平台-
在当今世界,应用程序必须是通用的。这意味着每个操作系统的人,无论是Windows、Linux、Mac还是其他什么,都应该可以访问应用程序。数据库系统也应该如此,这样开发人员可以根据自己的选择在任何操作系统上工作。由于SQL Server是微软的产品,它只能在Windows上运行,而拥有Mac或Linux的开发人员不能在它上工作。这是开发可伸缩性和灵活性方面的一个主要缺点。值得庆幸的是,PostgreSQL在每一个平台上都能工作,为开发人员开辟了一条新的途径。这也是将数据库从SQL Server迁移到PostgreSQL的主要原因之一,因为各种商业公司的开发人员都在基于Mac的计算机上开发应用程序。JSON和JavaScript统治着web世界,PostgreSQL支持JSON。您可以正确地同步客户机、服务器和数据库,但SQL server仍然停留在XML上。甚至PostgreSQL的数据类型也优于SQL server,克服了所有缺点,使PostgreSQL具有更好的性能和可扩展性。
最终裁决-
PostgreSQL不仅与SQL Server的性能或可伸缩性相匹配,而且在多个参数上都明显优于sqlserver。就企业级而言,它的定价比SQL Server好,而且在PostgreSQL中有一些特性是免费的,而sqlserver对它们收费很高。
本文:http://jiagoushi.pro/does-postgresql-match-sql-server-terms-performance-and-scalability
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 72 次浏览
【PostgreSQL】SQL还是NoSQL?为什么不同时使用(与PostgreSQL一起使用)?
视频号
微信公众号
知识星球
对于任何一个开始新项目的开发人员来说,这都是一个艰难的决定。您应该将数据存储在标准的、经过时间测试的SQL数据库中,还是使用较新的基于NoSQL文档的数据库?这个看似简单的决定实际上可以决定你的项目的成败。正确选择并构建好数据结构,你就可以顺利进入生产阶段,看着你的应用程序起飞。如果选择错误,你可能会在应用程序问世之前做噩梦(甚至可能会进行一些重大重写)。
简洁与强大
SQL和NoSQL解决方案都存在折衷。通常,开始使用NoSQL数据结构更容易,尤其是在数据复杂或层次结构时。您只需从前端代码中获取一个JSON数据对象,并将其放入数据库中即可完成操作。但以后,当您需要访问该数据来回答一些基本的业务问题时,这将更加困难。SQL解决方案使收集数据和得出结论变得更加容易。让我们看一个例子:
每天我都会跟踪我吃的食物,以及每种食物中的卡路里数:
| Day | Food Item | Calories | Meal |
|---|---|---|---|
| 01 Jan | Apple | 72 | Breakfast |
| 01 Jan | Oatmeal | 146 | Breakfast |
| 01 Jan | Sandwich | 445 | Lunch |
| 01 Jan | Chips | 280 | Lunch |
| 01 Jan | Cookie | 108 | Lunch |
| 01 Jan | Mixed Nuts | 175 | Snack |
| 01 Jan | Pasta/Sauce | 380 | Dinner |
| 01 Jan | Garlic Bread | 200 | Dinner |
| 01 Jan | Broccoli | 32 | Dinner |
我还跟踪我喝的水的杯数以及何时喝:
| Day | Time | Cups |
|---|---|---|
| Jan 01 | 08:15 | 1 |
| Jan 01 | 09:31 | 1 |
| Jan 01 | 10:42 | 2 |
| Jan 01 | 12:07 | 2 |
| Jan 01 | 14:58 | 1 |
| Jan 01 | 17:15 | 1 |
| Jan 01 | 18:40 | 1 |
| Jan 01 | 19:05 | 1 |
最后,我跟踪我的锻炼:
| Day | Time | Duration | Exercise |
|---|---|---|---|
| Jan 01 | 11:02 | 0.5 | Walking |
| Jan 02 | 09:44 | 0.75 | Bicycling |
| Jan 02 | 17:00 | 0.25 | Walking |
对于每一天,我还跟踪我当前的体重以及当天的任何笔记:
| Day | Weight | Notes |
|---|---|---|
| Jan 01 | 172.6 | This new diet is awesome! |
| Jan 14 | 170.2 | Not sure all this is worth it. |
| Jan 22 | 169.8 | Jogged past a McDonald's today. It was hard. |
| Feb 01 | 168.0 | I feel better, but sure miss all that greasy food. |
收集所有数据
需要收集、存储、检索和稍后分析大量不同的数据。它的组织简单而容易,但记录的数量每天都有所不同。在任何一天,我可能没有或更多关于食物、水和锻炼的条目,我可能有零或一个关于体重和笔记的条目。
在我的应用程序中,我在一个页面上收集一天的所有数据,让我的用户更轻松。因此,我每天都会得到一个JSON对象,如下所示:
{
"date": "2022-01-01",
"weight": 172.6,
"notes": "This new diet is awesome!",
"food": [
{ "title": "Apple", "calories": 72, "meal": "Breakfast" },
{ "title": "Oatmeal", "calories": 146, "meal": "Breakfast" },
{ "title": "Sandwich", "calories": 445, "meal": "Lunch" },
{ "title": "Chips", "calories": 280, "meal": "Lunch" },
{ "title": "Cookie", "calories": 108, "meal": "Lunch" },
{ "title": "Mixed Nuts", "calories": 175, "meal": "Snack" },
{ "title": "Pasta/Sauce", "calories": 380, "meal": "Dinner" },
{ "title": "Garlic Bread", "calories": 200, "meal": "Dinner" },
{ "title": "Broccoli", "calories": 32, "meal": "Dinner" }
],
"water": [
{ "time": "08:15", "qty": 1 },
{ "time": "09:31", "qty": 1 },
{ "time": "10:42", "qty": 2 },
{ "time": "10:42", "qty": 2 },
{ "time": "12:07", "qty": 1 },
{ "time": "14:58", "qty": 1 },
{ "time": "17:15", "qty": 1 },
{ "time": "18:40", "qty": 1 },
{ "time": "19:05", "qty": 1 }
],
"exercise": [{ "time": "11:02", "duration": 0.5, "type": "Walking" }]
}保存数据
一旦我们收集了一天的所有数据,我们就需要将其存储在数据库中。在NoSQL数据库中,这可能是一个非常简单的过程,因为我们只需为特定日期的特定用户创建一个记录(文档),然后将文档放入集合中,就完成了。使用SQL,我们有一些必须在其中工作的结构,在这种情况下,它看起来像4个独立的表:食物、水、锻炼和笔记。我们想在这里做4个单独的插入,每个表一个。如果我们没有特定表格的数据(比如今天没有记录锻炼),那么我们可以跳过该表格。
如果您使用SQL来存储这些数据,您可能希望在数据输入表单中输入每个表的数据时保存该表的数据(而不是等到输入完所有数据后再保存。)或者您可能希望创建一个数据库函数,该函数获取所有JSON数据,对其进行解析,并在单个事务中将其写入所有相关表。有很多方法可以处理这一问题,但只要这样说就足够了:这比将数据保存在NoSQL数据库中要复杂一些。
检索数据
如果我们想显示一天的所有数据,那基本上是一样的。使用NoSQL,您可以获取用户当天的数据,然后在应用程序中使用它。美好的使用SQL,我们需要查询4个表来获取所有数据(或者我们可以使用一个函数在一次调用中获取所有数据。
分析数据
现在我们已经保存了数据,并且可以检索和显示它,让我们使用它进行一些分析。让我们展示一张我在过去一个月里总共摄入了多少卡路里的图表。使用SQL,这是一项简单的任务:
select date, sum(calories) as total_calories from food_log group by date where user_id = 'xyz' and day between '2022-01-01' and '2022-01-31' order by date;
砰!完成!现在我们可以把这些结果发送到我们的绘图库,并把我的饮食习惯画得很漂亮。
但是,如果我们将这些数据存储在NoSQL中,它会变得更加复杂。我们需要:
- 为用户获取当月的所有数据
- 解析每天的数据以获得食物日志信息
- 每天循环并计算热量
- 将聚合数据发送到我们的绘图模块
如果这是我们要定期做的事情,那么计算每天的总热量并将其存储在当天的文档中是有意义的,这样我们就可以更快地获取数据。但这需要更多的前期工作,我们仍然需要提取每天的数据,并首先解析出卡路里总量。如果我们更新数据,我们仍然需要重新计算并更新总数。最终,我们会想在水和运动总量方面做到这一点。代码最终会变得越来越长、越来越复杂。
SQL和NoSQL在一起-FTW
让我们看看如何在同一个数据库中使用SQL的强大功能和NoSQL的易用性,使这一切变得更容易。我们将为每天的数据(为每个用户)创建一个表,并首先存储权重和注释等基本字段。然后,我们将在JSONB字段中抛出food_log、water_log和exercise_log字段。
CREATE TABLE calendar (
id uuid DEFAULT gen_random_uuid() NOT NULL,
date date,
user_id uuid NOT NULL,
weight numeric,
notes text,
food_log jsonb,
water_log jsonb,
exercise_log jsonb
);
-- (Optional) - create a foreign key relationship for the user_id field
ALTER TABLE ONLY calendar
ADD CONSTRAINT calendar_user_id_fkey FOREIGN KEY (user_id) REFERENCES auth.users(id);
现在让我们在表中插入一些数据。PostgreSQL同时提供JSON和JSONB字段,由于后者更容易被数据库优化,查询处理速度更快,所以我们几乎总是希望使用JSONB。我们将使用food_log、water_log和exercise_log的JSONB字段,并将从应用程序中获得的数据作为字符串直接转储到这些字段中:
insert into calendar
(date, user_id, weight, notes, food_log, water_log, exercise_log)
values
(
'2022-01-01',
'xyz',
172.6,
'This new diet is awesome!',
'[
{ "title": "Apple", "calories": 72, "meal": "Breakfast"},
{ "title": "Oatmeal", "calories": 146, "meal": "Breakfast"},
{ "title": "Sandwich", "calories": 445, "meal": "Lunch"},
{ "title": "Chips", "calories": 280, "meal": "Lunch"},
{ "title": "Cookie", "calories": 108, "meal": "Lunch"},
{ "title": "Mixed Nuts", "calories": 175, "meal": "Snack"},
{ "title": "Pasta/Sauce", "calories": 380, "meal": "Dinner"},
{ "title": "Garlic Bread", "calories": 200, "meal": "Dinner"},
{ "title": "Broccoli", "calories": 32, "meal": "Dinner"}
]',
'[
{"time": "08:15", "qty": 1},
{"time": "09:31", "qty": 1},
{"time": "10:42", "qty": 2},
{"time": "10:42", "qty": 2},
{"time": "12:07", "qty": 1},
{"time": "14:58", "qty": 1},
{"time": "17:15", "qty": 1},
{"time": "18:40", "qty": 1},
{"time": "19:05", "qty": 1}
]',
'[
{"time": "11:02", "duration": 0.5, "type": "Walking"}
]'
);
虽然这是一个很大的insert语句,但它肯定比在4个单独的表上进行insert要好。对于所有这些食物条目和水日志条目,我们必须在主表中创建1个条目,然后是9个食物日志条目、9个水日志条目和一个锻炼日志条目,总共20个数据库记录。我们把它包装成一张唱片。
但是我们如何查询这些数据?
很好,我们现在正在收集数据,而且很容易将数据插入数据库。编辑数据也不算太糟,因为我们只是将数据下载到客户端,根据需要更新JSON字段,然后将它们扔回数据库。不太难。但我如何查询这些数据?以前的任务怎么样?让我们展示一张我在过去一个月里总共摄入了多少卡路里的图表。
在这种情况下,该数据存储在日历表的food_log字段中。如果PostgreSQL能够将JSONB数组转换为单独的数据库记录(记录集)就好了。的确如此!jsonb_array_elements函数将为我们做这件事,允许创建一个简单的表,我们可以使用它来计算我们的热量摄入。
以下是一些SQL,用于将food_log数组转换为单独的输出记录:
select user_id, date, jsonb_array_elements(food_log)->>'title' as title, jsonb_array_elements(food_log)->'calories' as calories, jsonb_array_elements(food_log)->'meal' as meal from calendar where user_id = 'xyz' and date between '2022-01-01' and '2022-01-31';
这将返回一个如下所示的表:
| date | title | calories | meal |
|---|---|---|---|
| 2022-01-01 | Apple | 72 | Breakfast |
| 2022-01-01 | Oatmeal | 146 | Breakfast |
| 2022-01-01 | Sandwich | 445 | Lunch |
| 2022-01-01 | Chips | 280 | Lunch |
| 2022-01-01 | Cookie | 108 | Lunch |
| 2022-01-01 | Mixed Nuts | 175 | Snack |
| 2022-01-01 | Pasta/Sauce | 380 | Dinner |
| 2022-01-01 | Garlic Bread | 200 | Dinner |
| 2022-01-01 | Broccoli | 32 | Dinner |
需要注意的几点:
- jsonb_array_elements(food_log)->>'title' as title 作为title这将返回一个文本字段,因为->>运算符返回text
- jsonb_array_elements(food_log)->'calories' as calories ,这返回一个JSON对象,因为->运算符返回JSON
如果我们想对卡路里求和以获得一些总数,我们就不能有JSON对象,所以我们需要将其转换为更有用的对象,比如INTEGER:
- (jsonb_array_elements(food_log)->'calories')::INTEGER as calories,返回一个整数
现在我们不能只在这个问题上加上求和运算来得到一天的总热量。如果我们尝试这样做:
select date, sum((jsonb_array_elements(food_log)->'calories')::integer) as total_calories from calendar where user_id = 'xyz' and date between '2022-01-01' and '2022-01-31' group by date;
我们从PostgreSQL得到一个错误:运行sql查询失败:聚合函数调用不能包含返回集合的函数调用。
相反,我们需要将其视为一组构建块,其中我们的第一条SQL语句返回一个表:
select date, (jsonb_array_elements(food_log)->'calories')::integer as calories from calendar where user_id = 'xyz' and date between '2022-01-01' and '2022-01-31';
现在,我们可以使用“table”语句,在它周围插入一些(括号),然后查询它:
with data as
(
select
date,
(jsonb_array_elements(food_log)->'calories')::integer as calories
from calendar
where user_id = 'xyz'
and date between '2022-01-01' and '2022-01-31'
)
select date, sum(calories)
from data
group by date;
这正是我们想要的:
| date | sum |
|---|---|
| 2022-01-01 | 1838 |
如果我们在这个月剩下的日子里添加更多的数据,我们将拥有一个漂亮的图表所需的所有数据。
搜索数据
如果我们想回答这个问题:我上个月吃的大蒜面包里有多少卡路里?这些数据存储在日历表的food_log字段中。我们可以使用以前使用的相同类型的查询来“压平”food_log数据,以便进行搜索。
要获得我在一月份吃的每一件东西,我们可以使用:
select date, jsonb_array_elements(food_log)->>'title' as title, (jsonb_array_elements(food_log)->'calories')::integer as calories from calendar where user_id = 'xyz' and date between '2022-01-01' and '2022-01-31'
现在,为了搜索大蒜面包,我们可以在它周围放(括号)来制作一张“桌子”,然后搜索我们想要的物品:
with my_food as
(
select
date,
jsonb_array_elements(food_log)->>'title' as title,
(jsonb_array_elements(food_log)->'calories')::integer as calories
from calendar
where user_id = 'xyz'
and date between '2022-01-01' and '2022-01-31'
)
select
title,
calories
from my_food
where title = 'Garlic Bread';这给了我们:
| title | calories |
|---|---|
| Garlic Bread | 200 |
结论
如果我们花一点时间研究PostgreSQL提供的JSON函数和运算符,我们可以将Postgres变成一个易于使用的NoSQL数据库,它仍然保留了SQL的所有功能。这为我们在数据库中存储来自应用程序代码的复杂JSON数据提供了一种非常简单的方法。然后,我们可以使用强大的SQL功能来分析数据,并在应用程序中显示这些数据。这是两全其美!
- 88 次浏览
【PostgreSQL】使用PostgreSQL和ApacheAGE实现多模型:图形数据库的实验
视频号
微信公众号
知识星球
让我们探索多种可用的数据库,并使用PostgreSQL和ApacheAGE进行图形模型实验
数据库环境
当谈到数据库时,对大多数人来说,第一个想到的是经典的关系数据库,或者他们经常提到的SQL数据库。在这些数据库中,数据存储在表中的行和列中,这些行和列可以通过外键相关联,外键是一个或多个链接回另一个表中行的主键(也称为ID)的列。
近五十年来,关系数据库一直是常态,但近年来,出现了其他类型的数据库来处理关系模型可能显示其局限性(主要是性能和可扩展性)的特定用例。
在过去的十五年里,已经创建了许多不同类型的数据库,如列数据库(例如AWS Dynamo DB或Apache Cassandra)、文档数据库(MongoDB或CouchDB)和图形数据库(Neo4J)。
创建这些新形式的数据库中的每一种都是为了更好地满足特定应用程序领域的需求,并提高传统关系系统的性能和可扩展性。
为什么要使用图形数据库
如果我们谈论存储数据并能够查询数据,那么关系数据库几乎可以很好地对每个应用程序领域进行建模。但在某些情况下,关系模型在性能或复杂性方面并不是最佳选择。在这些上下文中,关系与实体本身具有相同甚至更大的含义。
让我们借用《图形数据库》第二版一书中关于数据中心域上下文的一个例子(您可以从Neo4J网站上获取该书的副本)。
A Datacenter ER example model
这仍然是一个非常简单的域上下文,但它有足够数量的实体和关系,可以开始使传统数据库上的查询变得又大又慢。
以下是先前ER模型上的密钥和关系的可能建模

现在,让我们试着想象一个查询,它查找受基础结构的某个组件(服务器、负载均衡器、数据库等)故障影响的用户。您可能会得到一个带有许多JOIN的怪物查询,或者有很多小查询,每个查询都指向模型中的特定资产。当然,我们将能够得到问题的答案,但性能可能会成为一个问题,尤其是当资产数量开始增长时。
现在,让我们尝试将上一个域建模为具有资产和它们之间关系的Graph。
Example graph model for the Datacenter context
首先你可以注意到,现在关系已经成为模型中的“头等公民”,这意味着现在每个箭头都有一个特定的含义,比如HOSTED_BY、RUNS_ON、USES、USER_OF等等。在关系模型中,您只知道一个表链接到另一个表,但这种关系的含义可能很难理解。
例如,如果现在前一张图片的用户3报告了一个问题,我们可以通过发出以下查询来查询该图,以查找任何可能涉及的资产:
MATCH (user:User)-[*1..5]-(asset:Asset)
WHERE user.name = 'User 3' AND asset.status = 'down'
RETURN DISTINCT asset等待这是什么样的疑问?!?这是一种名为Cypher的查询语言,由Neo4J引入,旨在以一种简单的方式查询图。它被定义为“在图表中导航的某种ASCIIart”。
前面的查询用通俗英语翻译如下:查找任何名为“用户3”的用户,该用户与状态为“向下”的资产有一到五个关系,然后返回找到的不同资产列表。
如果你在SQL中也这么想。。。这可能吗?可能是的,但不是以如此简短和富有表现力的方式。现在,您应该开始了解图形模型的要点了。
NEO4J
我们之前讨论过Neo4J作为一个图形数据库,有充分的理由,它是市场上最广为人知的图形数据库,它已经存在了十多年,所以它非常坚固,经过了战斗测试。
但是,如果我必须在Neo4J中找到我不喜欢的东西,那就是Graph Only,所以传统的关系数据库没有“平稳过渡”,如果你已经编写了一些软件,你必须重写所有内容才能使用新的数据模型。除此之外,Neo4J是用Java编写的,即使我每天都使用Java进行应用程序开发,我也有偏见地认为用Java编写数据库可能有点内存不足。
不要误解我的意思,如果你需要使用纯图数据模型,Neo4J仍然是最好的选择,它有很多功能,如果你想要支持,开发它的公司会提供企业支持。
一种混合方法
我想在我的应用程序中介绍图数据库的强大功能,但正如一切一样,没有一刀切的方法,图数据库也不例外,它们有利于图遍历,但不是所有可能场景的最佳选择。
应用程序的需求有时可能涉及广泛,在谈论数据库时,最好是将数据模型的一部分作为图,另一部分作为一组表,也许另一部分在文档集合中。问题是,我不喜欢在同一个应用程序中使用许多不同的数据库引擎。
有解决办法吗?
PostgreSQL与Apache AGE
PostgreSQL在数据库领域是一个众所周知的名字,原因有很多。举几个例子,它是可用的最强大的开源数据库之一,同时它坚如磐石,性能卓越。有几十兆字节的PostgreSQL数据库的例子。
PostgreSQL的一个好处是,它允许使用扩展来增强数据库本身的功能,并且有许多强大的扩展允许PostgreSQL跨越许多不同的上下文。扩展示例如下:
- TimescaleDB:处理时间序列和窗口的扩展
- PostGIS:用于地理信息系统(GIS)的扩展,允许使用坐标和地理空间计算
- ZomboDB:在与Elasticsearch集成的同时增强PostgreSQL全文搜索功能的扩展
Apache AGE(其中AGE代表“图形扩展”)是其中的另一个扩展,它是关系数据库、文档数据库和图形数据库世界之间的桥梁,利用PostgreSQL数据库的稳定性和稳定性,同时利用图形数据库的强大功能增强其功能。
AGE仍在Apache孵化器中,这意味着它仍处于早期开发阶段(当前版本i 0.7),但它是基于BitNine的AgentsGraph所做的工作,即使采用了不同的方法。AgentsGraph是一个基于PostgreSQL 10分支构建的商业图形数据库,而Apache AGE是作为标准PostgreSQL的扩展构建的(在撰写本文时,它支持版本11,但预计2022年会支持新版本),因此它可以用作标准功能的“升级”,而不会失去其余功能。
这种方法的好处在于,您可以将关系模型的特性与图数据库的特性混合在一起,这意味着您可以将表上的SQL查询与图上的OpenCyhpher查询混合在一起。
如果您认为PostgreSQL还支持JSON和JSONB数据类型,这样您就可以拥有文档数据库的部分功能,那么您就可以理解为什么这种混合解决方案是一个不错的选择。
让我们看看如何使用Docker开始使用ApacheAGE,然后在下一篇文章中,我们将看到OpenCyhper的一些功能以及与标准关系世界的集成。
使用Docker开始使用Apache AGE
开始使用Apache AGE的最快方法是在预构建的Docker容器中运行它,您可以使用以下命令来完成:
docker run -it -e POSTGRES_PASSWORD={MyPassword} -p {HostPort}:5432 sorrell/apache-age这是Docker的“官方”镜像,但在撰写本文时,它已经有三个月的历史了,所以它没有最近添加的所有功能和错误修复。为了测试所有功能,让我们使用GitHub repo的最新来源构建一个新的映像。
使用Docker从源代码构建最新版本
- GitHub - apache/incubator-age: Graph database optimized for fast analysis and real-time data processing. It is provided as an extension to PostgreSQL.
- Graph database optimized for fast analysis and real-time data processing. It is provided as an extension to PostgreSQL. - GitHub - apache/incubator-age: Graph database optimized for fast analysis a...
- GitHubapache
您可以认为从源代码构建Docker映像可能是一个复杂的过程,但实际上这很容易,只需使用以下命令在您的机器上克隆存储库即可:
git clone https://github.com/apache/incubator-age.git
cd incubator-age并告诉Docker构建镜像:
docker build -t apache/age .几分钟后(取决于网络连接的速度和计算机的电源),该过程应该完成。
使用Docker启动AGE实例
要使用PostgreSQL 11和AGE扩展启动新建映像的实例,可以运行以下命令:
docker run -it -e POSTGRES_PASSWORD=mypassword -p 5432:5432 apache/age一旦容器启动,您就可以连接到数据库并开始使用SQL和OpenCypher。
如果您更喜欢查询输出的图形表示,还可以试用AGE Viewer,这是一个node.js应用程序(处于早期开发阶段),允许您直接在浏览器内以图形或表格的方式查询和导航结果。
- GitHub - apache/incubator-age-viewer: Graph database optimized for fast analysis and real-time data processing. It is provided as an extension to PostgreSQL.
- Graph database optimized for fast analysis and real-time data processing. It is provided as an extension to PostgreSQL. - GitHub - apache/incubator-age-viewer: Graph database optimized for fast ana...
- GitHubapache
正在连接到数据库
使用ApacheAGE的另一个好处是,您正在使用标准的PostgreSQL数据库进行数据处理,因此要连接到它,您可以使用标准的psql命令行客户端
psql -h 0.0.0.0 -p 5432 -U postgres
or your preferred SQL client, like DBeaver.
如果在启动时未自动加载AGE扩展,则可以通过发出以下SQL命令来启用AGE扩展:
CREATE EXTENSION IF NOT EXISTS age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;
现在您已经准备好开始使用新的图形数据库了。
创建图形
开始玩grap模型需要做的第一件事是…创建一个图形。您可以使用create_graph('graph_NAME')函数执行此操作:
SELECT create_graph('my_graph_name');创建图形后,您可以使用Cypher('graph_NAME',QUERY)函数执行Cypher命令,如下所示:
SELECT * from cypher('my_graph_name', $$
CypherQuery
$$) as (a agtype);
例如,要创建节点(或图形语言中的“顶点”),可以运行:
SELECT * from cypher('my_graph_name', $$
CREATE (a:User { firstName: 'Fabio', lastName: 'Marini'})
RETURN a
$$) as (a agtype);
这将创建一个带有标签User以及firstName和lastName属性的顶点。图形数据库的另一个好方面是,“顶点”和“边”都可以包含可以动态添加和查询的属性。
我们刚刚触及了图形数据库的表面,您可以查看AGE的文档来了解OpenCypher查询语言的功能和语法
- 381 次浏览
【PostgreSQL架构】PostgreSQL 10和逻辑复制-设置
This article is the result of a series of articles on logical replication in PostgreSQL 10
This one will focus on the implementation of logical replication.
- PostgreSQL 10 : Logical replication - Overview
- PostgreSQL 10 : Logical replication - Setup
- PostgreSQL 10 : Logical replication - Limitations
Table of Contents
Installation
When writing this article Postgres 10 is not released yet. However, the community provides packages of beta versions. Of course, do not use in production.
Repository installation (PostgreSQL Developpement Group)
From http://www.postgresql.org then “download” -> “debian”. On this page, the site tells you how to install the pgdg repository. However it will only offer stable versions. But, the site sends you to a wiki page:
For more information about the apt repository, including answers to frequent questions, please see the apt page on the wiki.
You will find :
For packages of development/alpha/beta versions of PostgreSQL, see the FAQ entry about beta versions.
Who tells you :
To use packages of postgresql-10, you need to add the 10 component to your
/etc/apt/sources.list.d/pgdg.listentry, so the 10 version of libpq5 will be available for installation
So for debian, commands are :
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)-pgdg main 10" > /etc/apt/sources.list.d/pgdg.list'
sudo apt-get update
Packages installation
sudo apt install postgresql-10
Create instances
A first instance is created during installation. We will install a second one. Thus one will be the publisher and the other will be subscriber. So for debian, commands are:
# pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
10 main 5432 online postgres /var/lib/postgresql/10/main /var/log/postgresql/postgresql-10-main.log
# pg_createcluster 10 sub
Creating new PostgreSQL cluster 10/sub ...
/usr/lib/postgresql/10/bin/initdb -D /var/lib/postgresql/10/sub --auth-local peer --auth-host md5
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /var/lib/postgresql/10/sub ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting dynamic shared memory implementation ... posix
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
/usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/sub -l logfile start
Ver Cluster Port Status Owner Data directory Log file
10 sub 5433 down postgres /var/lib/postgresql/10/sub /var/log/postgresql/postgresql-10-sub.log
# pg_ctlcluster 10 sub start
# pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
10 main 5432 online postgres /var/lib/postgresql/10/main /var/log/postgresql/postgresql-10-main.log
10 sub 5433 online postgres /var/lib/postgresql/10/sub /var/log/postgresql/postgresql-10-sub.log
Logical replication setup
Prerequisites
There are very few changes to the default configuration. Most parameters are already set to set up logical replication. However, there is one parameter to modify on the instance that “publishes”: wal_level. Set to “replica”, it must be “logical”.
In /etc/postgresql/10/main/postgresql.conf
wal_level = logical
To apply changes we must restart the cluster:
pg_ctlcluster 10 main restart
Publication
Let’s create a database b1 that contains a table t1.
postgres=# create database b1;
CREATE DATABASE
postgres=# \c b1
You are now connected to database "b1" as user "postgres".
b1=# create table t1 (c1 text);
CREATE TABLE
b1=# insert into t1 values ('un');
INSERT 0 1
b1=# select * from t1;
c1
----
un
(1 row)
Then, we use this order to create publication:
b1=# CREATE PUBLICATION pub1 FOR TABLE t1 ;
And that’s all! Note that it is possible to use the keyword FOR ALL TABLES to add all present and future tables to the publication.
We can verify that the publication was created with the following psql meta-command:
b1=# \dRp+
Publication pub1
All tables | Inserts | Updates | Deletes
------------+---------+---------+---------
f | t | t | t
Tables:
"public.t1"
Subscription
Logical replication does not replicate DDL orders, so we must create the table on the “sub” instance. It is not necessary to have the same database name, so we will create a database b2.
postgres@blog:~$ psql -p 5433
psql (10beta2)
Type "help" for help.
postgres=# CREATE DATABASE b2;
CREATE DATABASE
postgres=# \c b2
You are now connected to database "b2" as user "postgres".
b2=# create table t1 (c1 text);
CREATE TABLE
As for the publication, the subscription is created with an SQL order:
b2=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=/var/run/postgresql port=5432 dbname=b1' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTION
b2=# select * from t1;
c1
----
un
(1 row)
Most importing part is: CONNECTION 'host=/var/run/postgresql port=5432 dbname=b1'
Indeed, we indicate to the subscriber how to connect to the publication. In my example the two instances are on the same server and listen on a local socket. If you have instances on different server you will have to specify IP address. Then the port and do not forget the database where the publication was created.
As you can see, Postgres automatically synchronize data that was already present in table t1.
Now if I add rows in table t1, they will automatically be replicated to the instance “sub”:
postgres@blog:~$ psql b1
psql (10beta2)
Type "help" for help.
b1=# insert into t1 values ('deux');
INSERT 0 1
postgres=# \q
postgres@blog:~$ psql -p 5433 b2
psql (10beta2)
Type "help" for help.
b2=# select * from t1;
c1
------
un
deux
(2 rows)
As for the publication, there is a meta-command to display subscriptions:
\dRs+
List of subscriptions
Name | Owner | Enabled | Publication | Synchronous commit | Conninfo
------+----------+---------+-------------+--------------------+----------------------------------------------
sub1 | postgres | t | {pub1} | off | host=/var/run/postgresql port=5432 dbname=b1
(1 row)
That’s all for this article, in a future article we will see limitations.
- 392 次浏览
【PostgreSQL架构】PostgreSQL 10:性能改进
- 52 次浏览
【PostgreSQL架构】PostgreSQL-JSONB和统计
- 61 次浏览
【PostgreSQL架构】PostgreSQL中的并行性
PostgreSQL是最优秀的对象关系数据库之一,其体系结构是基于进程的,而不是基于线程的。虽然目前几乎所有的数据库系统都使用线程来实现并行性,但是PostgreSQL的基于进程的体系结构是在POSIX线程之前实现的。PostgreSQL在启动时启动一个进程“postmaster”,之后每当一个新的客户端连接到PostgreSQL时,它就会跨越新的进程。
在版本10之前,单个连接中没有并行性。诚然,由于流程架构的原因,来自不同客户机的多个查询可以具有并行性,但它们无法从彼此获得任何性能好处。换句话说,单个查询是串行运行的,没有并行性。这是一个巨大的限制,因为单个查询不能利用多核。PostgreSQL中的并行性是从9.6版引入的。在某种意义上,并行是指一个进程可以有多个线程来查询系统并利用系统中的多核。这就提供了PostgreSQL内部查询并行性。
PostgreSQL中的并行性是作为多个功能的一部分实现的,这些功能包括顺序扫描、聚合和连接。
PostgreSQL中的并行组件
在PostgreSQL中,并行性有三个重要组成部分。这些是过程本身,聚集,和工人。如果没有并行,进程本身将处理所有数据,但是,当planner决定某个查询或其一部分可以并行时,它会在计划的可并行部分中添加一个Gather节点,并生成该子树的Gather根节点。查询执行从流程(leader)级别开始,计划的所有序列部分都由leader运行。但是,如果对查询的任何部分(或全部)启用并允许并行,则为其分配具有一组工作线程的gather节点。工作线程是与需要并行化的部分树(部分计划)并行运行的线程。关系的块在线程之间被划分,这样关系就保持顺序。线程数由PostgreSQL配置文件中设置的设置控制。工人使用共享内存进行协调/交流,一旦工人完成工作,结果将传递给领导进行积累。
并行顺序扫描
在PostgreSQL 9.6中,增加了对并行顺序扫描的支持。顺序扫描是对一个表的扫描,在这个表中,一个块序列一个接一个地被求值。这就其本质而言,允许并行性。所以这是第一个并行实现的自然候选。在这种情况下,整个表在多个工作线程中被顺序扫描。这里是一个简单的查询,我们在这里查询pgbench_accounts表行(63165),它有150000000个元组。总执行时间为4343080ms。由于没有定义索引,因此使用顺序扫描。整个表在一个没有线程的进程中被扫描。因此,无论有多少可用内核,都要使用CPU的单核。
db=# EXPLAIN ANALYZE SELECT *
FROM pgbench_accounts
WHERE abalance > 0;
QUERY PLAN
----------------------------------------------------------------------
Seq Scan on pgbench_accounts (cost=0.00..73708261.04 rows=1 width=97)
(actual time=6868.238..4343052.233 rows=63165 loops=1)
Filter: (abalance > 0)
Rows Removed by Filter: 1499936835
Planning Time: 1.155 ms
Execution Time: 4343080.557 ms
(5 rows)
如果这些150000000行在一个进程中使用“10”个工作线程并行扫描呢?它将大大缩短执行时间。
db=# EXPLAIN ANALYZE select * from pgbench_accounts where abalance > 0;
QUERY PLAN
----------------------------------------------------------------------
Gather (cost=1000.00..45010087.20 rows=1 width=97)
(actual time=14356.160..1628287.828 rows=63165 loops=1)
Workers Planned: 10
Workers Launched: 10
-> Parallel Seq Scan on pgbench_accounts
(cost=0.00..45009087.10 rows=1 width=97)
(actual time=43694.076..1628068.096 rows=5742 loops=11)
Filter: (abalance > 0)
Rows Removed by Filter: 136357894
Planning Time: 37.714 ms
Execution Time: 1628295.442 ms
(8 rows)
现在,总的执行时间是1628295ms;这是一个266%的改进,而使用10个工人线程用于扫描。
用于基准的查询:从abalance>0的pgbench_帐户中选择*;
表大小:426GB
表中总行:150000000
用于基准测试的系统:
CPU:2个Intel(R)Xeon(R)CPU E5-2643 v2@3.50GHz
内存:256GB DDR3 1600
磁盘:ST3000NM0033
上图清楚地显示了并行性如何提高顺序扫描的性能。添加单个工作进程时,由于没有获得并行性,性能下降是可以理解的,但是创建额外的聚集节点和单个工作会增加开销。但是,使用多个工作线程时,性能会显著提高。另外,需要注意的是,性能不会以线性或指数方式增加。它会逐渐改善,直到增加更多的工人不会给性能带来任何提升;有点像接近水平渐近线。这个基准测试是在一个64核的机器上执行的,很明显,拥有10个以上的工人不会显著提高性能。
平行聚合
在数据库中,计算聚合是非常昂贵的操作。当在单个过程中进行评估时,这些过程需要相当长的时间。在PostgreSQL 9.6中,通过简单地将它们分成块(一种分而治之的策略)来增加并行计算这些数据的能力。这允许多个工人在领导计算基于这些计算的最终值之前计算聚合部分。更严格地说,PartialAggregate节点被添加到一个计划树中,每个PartialAggregate节点从一个worker获取输出。这些输出随后发送到FinalizeAggregate节点,该节点组合来自多个(所有)PartialAggregate节点的聚合。因此,有效的并行部分计划包括一个FinalizeAggregate节点和一个Gather节点,后者将PartialAggregate节点作为子节点。
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts;
QUERY PLAN
----------------------------------------------------------------------
Aggregate (cost=73708261.04..73708261.05 rows=1 width=8)
(actual time=2025408.357..2025408.358 rows=1 loops=1)
-> Seq Scan on pgbench_accounts (cost=0.00..67330666.83 rows=2551037683 width=0)
(actual time=8.162..1963979.618 rows=1500000000 loops=1)
Planning Time: 54.295 ms
Execution Time: 2025419.744 ms
(4 rows)
下面是并行计算聚合时计划的示例。在这里你可以清楚地看到性能的提高。
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts;
QUERY PLAN
----------------------------------------------------------------------
Finalize Aggregate (cost=45010088.14..45010088.15 rows=1 width=8)
(actual time=1737802.625..1737802.625 rows=1 loops=1)
-> Gather (cost=45010087.10..45010088.11 rows=10 width=8)
(actual time=1737791.426..1737808.572 rows=11 loops=1)
Workers Planned: 10
Workers Launched: 10
-> Partial Aggregate
(cost=45009087.10..45009087.11 rows=1 width=8)
(actual time=1737752.333..1737752.334 rows=1 loops=11)
-> Parallel Seq Scan on pgbench_accounts
(cost=0.00..44371327.68 rows=255103768 width=0)
(actual time=7.037..1731083.005 rows=136363636 loops=11)
Planning Time: 46.031 ms
Execution Time: 1737817.346 ms
(8 rows)
对于并行聚合,在这种特殊情况下,当涉及10个并行工作线程时,执行时间2025419.744减少到1737817.346,我们的性能提升略高于16%。
用于基准的查询:从abalance>0的pgbench_帐户中选择count(*);
表大小:426GB
表中总行:150000000
用于基准测试的系统:
CPU:2个Intel(R)Xeon(R)CPU E5-2643 v2@3.50GHz
内存:256GB DDR3 1600
磁盘:ST3000NM0033
并行索引(B树)扫描
对B树索引的并行支持意味着索引页被并行扫描。B树索引是PostgreSQL中最常用的索引之一。在并行版本的B-Tree中,一个worker扫描B-Tree,当它到达它的叶节点时,它会扫描块并触发阻塞的等待worker扫描下一个块。
困惑的?我们来看一个例子。假设我们有一个具有id和name列的表foo,其中有18行数据。我们在表foo的id列上创建一个索引。系统列CTID附加在表的每一行,用于标识行的物理位置。CTID列中有两个值:块号和偏移量。
postgres=# <strong>SELECT</strong> ctid, id <strong>FROM</strong> foo;
ctid | id
--------+-----
(0,55) | 200
(0,56) | 300
(0,57) | 210
(0,58) | 220
(0,59) | 230
(0,60) | 203
(0,61) | 204
(0,62) | 300
(0,63) | 301
(0,64) | 302
(0,65) | 301
(0,66) | 302
(1,31) | 100
(1,32) | 101
(1,33) | 102
(1,34) | 103
(1,35) | 104
(1,36) | 105
(18 rows)
让我们在该表的id列上创建B树索引。
CREATE INDEX foo_idx ON foo(id)
假设我们要选择id<=200的值,其中有两个工人。Worker-0将从根节点开始扫描,直到叶节点200。它将把节点105下的下一个块移交给Worker-1,Worker-1处于阻塞等待状态。如果还有其他工人,就把街区分成工人区。重复类似的模式,直到扫描完成。
并行位图扫描
要并行化位图堆扫描,我们需要能够以非常类似于并行顺序扫描的方式在工作线程之间划分块。为此,将对一个或多个索引进行扫描,并创建指示要访问哪些块的位图。这是由一个引导进程完成的,即扫描的这一部分是按顺序运行的。然而,当识别出的块被传递给workers时,并行性就会启动,就像并行顺序扫描一样。
平行连接
合并联接支持中的并行性也是此版本中添加的最热门功能之一。在这种情况下,表与其他表的内部循环哈希或合并相连接。在任何情况下,内部循环中都不支持并行性。整个循环作为一个整体进行扫描,并行性在每个工作进程作为一个整体执行内部循环时发生。发送到gather的每个连接的结果都会累积并产生最终结果。
摘要
从我们在本博客中已经讨论过的内容中可以明显看出,并行性在某些情况下会显著提高性能,而在某些情况下会导致性能下降。确保已正确设置并行设置成本或并行元组成本,以使查询计划器能够选择并行计划。即使为这些gui设置了较低的值,如果没有生成并行计划,请参阅PostgreSQL并行性文档以了解详细信息。
对于并行计划,您可以获取每个计划节点的每个工作进程统计信息,以了解如何在工作进程之间分配负载。你可以通过解释(分析,详细)来做到这一点。与任何其他性能特性一样,没有一条规则适用于所有工作负载。无论需要什么,都应该仔细配置并行性,并且必须确保获得性能的概率明显高于性能下降的概率。
原文:https://www.percona.com/blog/2019/07/30/parallelism-in-postgresql/
本文:http://jiagoushi.pro/node/1049
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 145 次浏览
【PostgreSQL架构】PostgreSQL和仅堆元组更新-第2部分
- 35 次浏览
【PostgreSQL架构】PostgreSQL的最佳PG群集高可用性(HA)解决方案
如果您的系统依赖PostgreSQL数据库并且您正在寻找HA的集群解决方案,我们希望提前告知您这是一项复杂的任务,但并非不可能实现。
我们将讨论一些解决方案,您可以从中选择对您的容错要求。
PostgreSQL本身不支持任何多主群集解决方案,例如MySQL或Oracle。尽管如此,仍有许多商业和社区产品提供此实现,以及其他产品,例如PostgreSQL的复制或负载平衡。
首先,让我们回顾一些基本概念:
什么是高可用性?
它是服务可用的时间量,通常由企业定义。
冗余是高可用性的基础;万一发生事故,我们可以继续毫无问题地运转。
持续恢复
如果发生事件,则必须还原备份,然后应用wal日志;恢复时间将非常长,我们不会谈论高可用性。
但是,如果我们将备份和日志存档在应急服务器中,则可以在日志到达时应用它们。
如果日志每隔1分钟发送和应用一次,则应急基础将处于连续恢复状态,并且到生产的时间最多为1分钟。
备用数据库
备用数据库的想法是保留生产数据库的副本,该副本始终具有相同的数据,并且可以在发生事件时使用。
有几种方法可以对备用数据库进行分类:
根据复制的性质:
- 物理备用数据库:复制磁盘块。
- 逻辑备用数据库:流式传输数据更改。
通过事务的同步性:
- 异步:可能会丢失数据。
- 同步:不会丢失数据;主服务器中的提交等待备用服务器的响应。
通过用法:
- 热备用:它们不支持连接。
- 热备用:支持只读连接。
集群
群集是一组一起工作的主机,被视为一个主机。
这提供了一种实现水平可伸缩性的方法,并提供了通过添加服务器来处理更多工作的能力。
它可以抵抗节点的故障并继续透明地工作。
根据共享的内容,有两种模型:
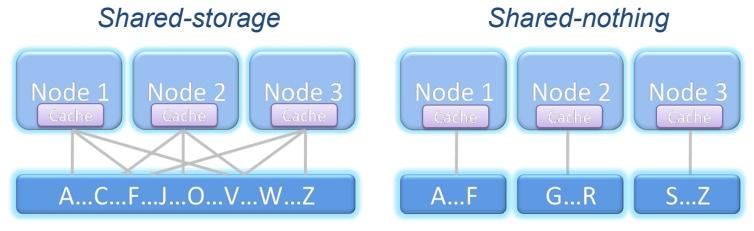
- 共享存储:所有节点都使用相同的信息访问相同的存储。
- 不共享:每个节点都有自己的存储,取决于我们系统的结构,该存储可能与其他节点具有相同的信息。
现在让我们回顾一下PostgreSQL中的一些集群选项。
分布式复制块设备 (Distributed Replicated Block Device)
DRBD是一个Linux内核模块,可使用网络实现同步块复制。 它实际上不实现群集,也不处理故障转移或监视。 为此,您需要补充软件,例如Corosync + Pacemaker + DRBD。
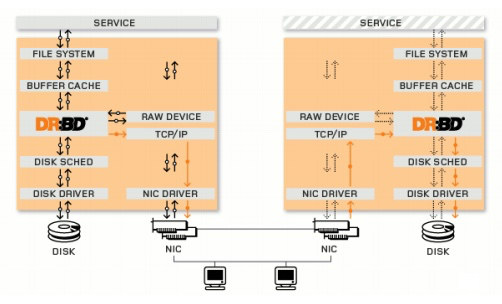
例:
- Corosync:处理主机之间的消息。
- Pacemaker:启动和停止服务,确保它们仅在一台主机上运行。
- DRBD:在块设备级别同步数据。
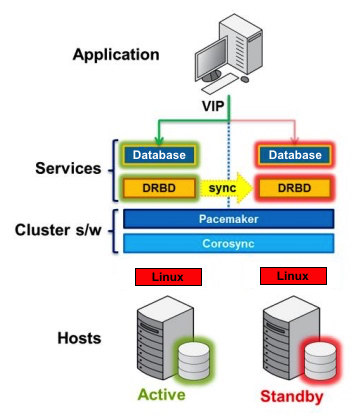
集群控制(ClusterControl)
ClusterControl是用于数据库集群的无代理管理和自动化软件。 它可直接从其用户界面帮助部署,监视,管理和扩展数据库服务器/集群。
ClusterControl能够处理维护数据库服务器或群集所需的大多数管理任务。
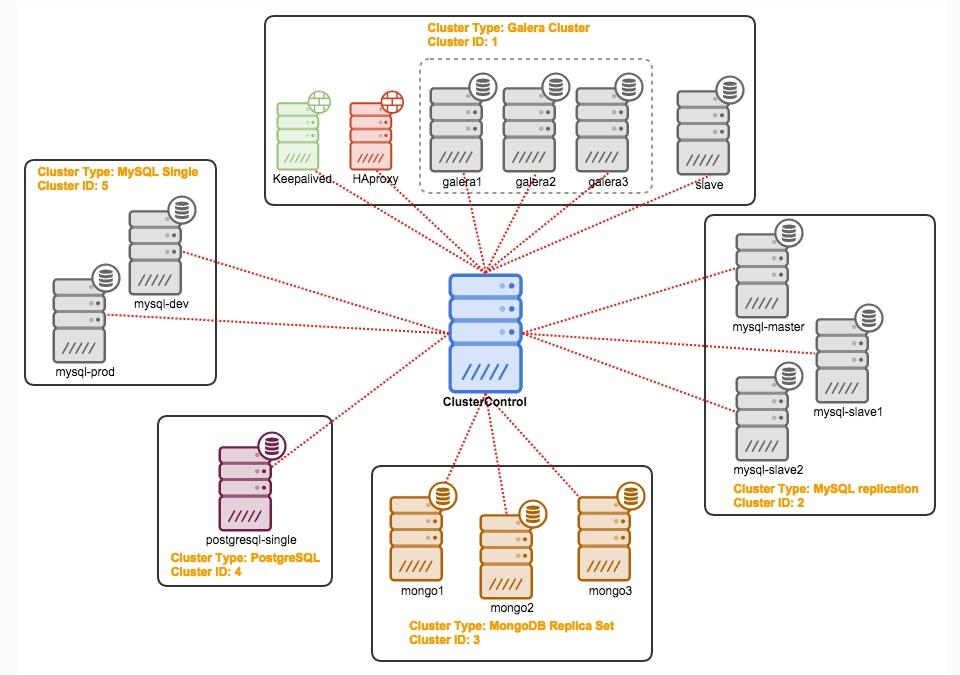
使用ClusterControl,您可以:
- 在您选择的技术堆栈上部署独立的,复制的或群集的数据库。
- 跨多语言数据库和动态基础架构统一自动化故障转移,恢复和日常任务。
- 您可以创建完整或增量备份并计划它们。
- 对整个数据库和服务器基础结构进行统一和全面的实时监控。
- 只需一个操作即可轻松添加或删除节点。
在PostgreSQL上,如果发生事件,可以自动将您的从属提升为主状态。
它是一个非常完整的工具,带有免费的社区版本(还包括免费的企业试用版)。
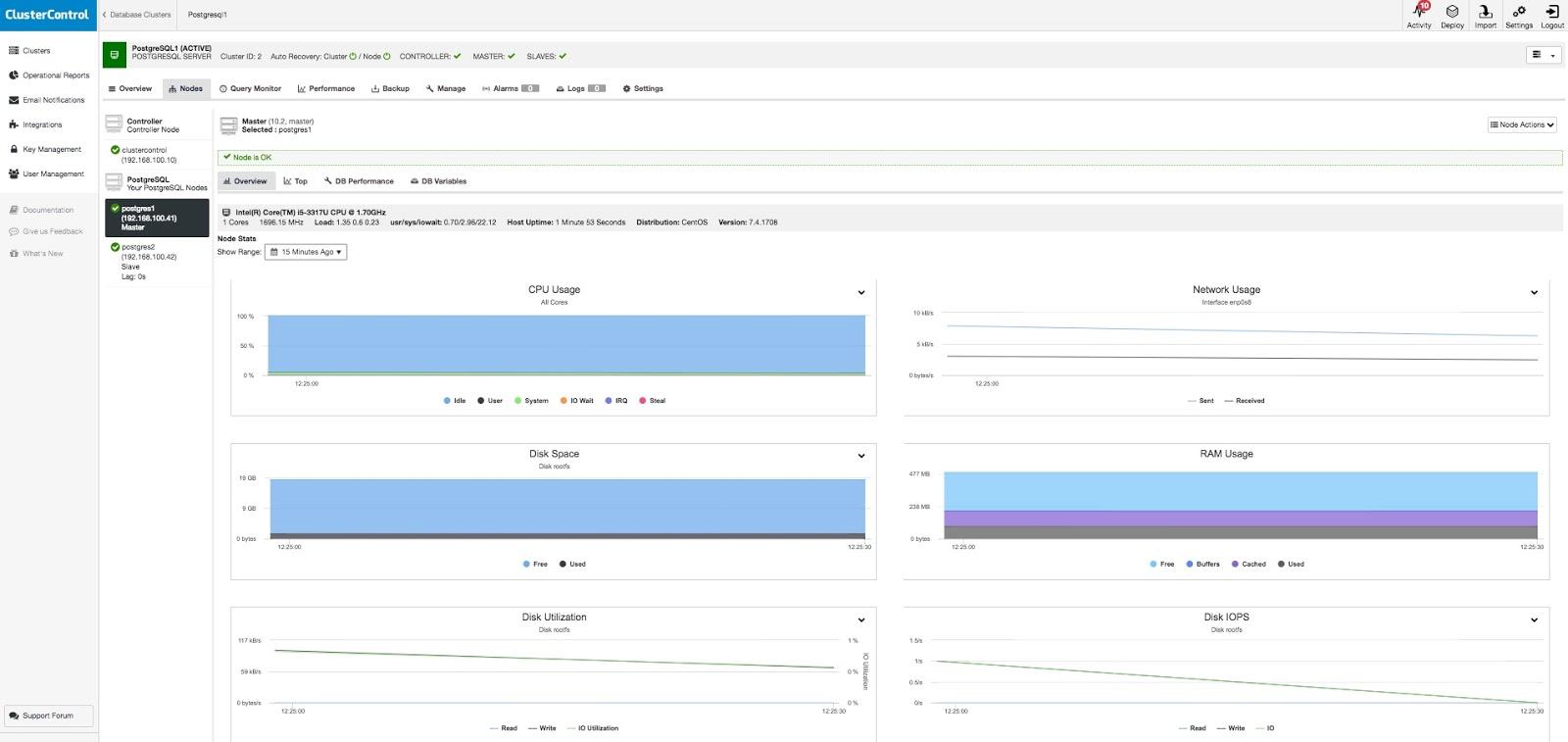
红宝石 (Rubyrep)
异步,多主机,多平台复制(在Ruby或JRuby中实现)和多DBMS(MySQL或PostgreSQL)的解决方案。
基于触发器,它不支持DDL,用户或授权。
使用和管理的简单性是其主要目标。
一些功能:
- 配置简单
- 安装简单
- 平台独立,表格设计独立。
Pgpool II
它是一种在PostgreSQL服务器和PostgreSQL数据库客户端之间工作的中间件。
一些功能:
- 连接池
- 复写
- 负载均衡
- 自动故障转移
- 并行查询
Bucardo
基于行的异步级联主从复制,使用触发器在数据库中排队;基于行的异步主-主复制,基于行,使用触发器和自定义冲突解决方案。
Bucardo需要专用的数据库并作为Perl守护程序运行,该守护程序与此数据库以及复制中涉及的所有其他数据库进行通信。它可以作为多主机或多从机运行。
主从复制涉及到一个或多个目标的一个或多个源。源必须是PostgreSQL,但是目标可以是PostgreSQL,MySQL,Redis,Oracle,MariaDB,SQLite或MongoDB。
一些功能:
- 负载均衡
- 从站不受限制,可以写
- 部分复制
- 按需复制(更改可以自动或在需要时推送)
- 从站可以“预热”以快速设置
缺点:
- 无法处理DDL
- 无法处理大物件
- 没有唯一键无法增量复制表
- 不适用于Postgres 8之前的版本
Postgres-XC
Postgres-XC是一个开源项目,旨在提供可写扩展,同步,对称和透明的PostgreSQL集群解决方案。它是紧密耦合的数据库组件的集合,可以将其安装在多个硬件或虚拟机中。
写可伸缩性意味着Postgres-XC可以配置任意数量的数据库服务器,并且与单个数据库服务器相比,可以处理更多的写操作(更新SQL语句)。
您可以有多个客户端连接到的数据库服务器,该服务器提供数据库的单个一致的群集范围视图。
来自任何数据库服务器的任何数据库更新对于在不同主服务器上运行的任何其他事务都是立即可见的。
透明意味着您不必担心内部如何将数据存储在多个数据库服务器中。
您可以配置Postgres-XC在多个服务器上运行。您为每个表选择的数据以分布式方式存储,即分区或复制。发出查询时,Postgres-XC会确定目标数据的存储位置,并向包含目标数据的服务器发出相应的查询。
Citus
Citus用内置的高可用性功能(例如自动分片和复制)替代了PostgreSQL。 Citus分片将您的数据库分片,并在整个商品节点集群中复制每个分片的多个副本。如果群集中的任何节点不可用,Citus会将所有写入或查询透明地重定向到其他一个包含受影响的分片副本的节点。
一些功能:
- 自动逻辑分片
- 内置复制
- 用于灾难恢复的数据中心感知复制
- 具有高级负载平衡功能的中查询容错
您可以增加由PostgreSQL支持的实时应用程序的正常运行时间,并最大程度地减少硬件故障对性能的影响。您可以使用内置的高可用性工具来实现此目标,从而最大程度地减少成本高昂且易于出错的手动干预。
PostgresXL
它是一种无共享的多主群集解决方案,可以透明地在一组节点上分配表,并并行执行这些节点的查询。它具有一个称为全局事务管理器(GTM)的附加组件,用于提供群集的全局一致视图。该项目基于PostgreSQL 9.5版本。一些公司,例如2ndQuadrant,为该产品提供商业支持。
PostgresXL是可水平扩展的开源SQL数据库集群,具有足够的灵活性来处理各种数据库工作负载:
- OLTP写密集型工作负载
- 需要MPP并行性的商业智能
- 运营数据存储
- 键值存储
- GIS地理空间
- 混合工作负载环境
- 多租户提供商托管环境
组件:
- 全局事务监视器(GTM):全局事务监视器确保群集范围内的事务一致性。
- 协调器:协调器管理用户会话并与GTM和数据节点进行交互。
- 数据节点:数据节点是存储实际数据的位置。
结论
还有许多其他产品可以为PostgreSQL创建我们的高可用性环境,但是您必须注意以下几点:
- 新产品,未经充分测试
- 停产项目
- 局限性
- 许可费用
- 非常复杂的实现
- 不安全的解决方案
您还必须考虑您的基础架构。如果只有一台应用程序服务器,那么无论您配置了多少数据库的高可用性,如果应用程序服务器发生故障,则将无法访问。您必须很好地分析基础架构中的单点故障,并尝试解决它们。
考虑到这些要点,您可以找到一种适合您的需求和要求的解决方案,而不会产生麻烦,并且能够实施您的高可用性群集解决方案。来吧,祝你好运!
原文:https://severalnines.com/database-blog/top-pg-clustering-high-availability-ha-solutions-postgresql
本文:http://jiagoushi.pro/top-pg-clustering-high-availability-ha-solutions-postgresql
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 2161 次浏览
【PostgreSQL架构】设置和部署具有高可用性的企业级PostgreSQL集群
业务应用程序要求其后端数据库集群具有高可用性。 2ndQuadrant为Single Master体系结构提供了企业级解决方案,该解决方案允许部署具有高可用性,滚动升级,自动故障转移等功能的PostgreSQL。 该架构依赖于行业最佳实践,并根据多年满足企业需求的经验为生产使用提供了高水平的可靠性。
要了解有关如何部署PostgreSQL以获得高可用性的最佳实践的更多信息,请下载HA Postgres白皮书。

![]()
备份策略和灾难恢复
该解决方案具有内置的能力,可以制定备份策略并从灾难中恢复。 我们依靠Barman(一种用于备份和恢复管理的领先工具)直接从主节点传输数据流。 该解决方案还提供了时间点恢复的功能。
![]()
高可用性
无论对于计划的切换还是计划外的故障,可用性对于任何业务应用程序都是至关重要的。 该解决方案具有处理任何一种情况的能力。 内置控件将使您轻松计划切换。 如果发生节点故障(主节点或备用节点),该解决方案将进行故障转移以确保数据库可用于您的应用程序。 它甚至在数据中心完全故障的情况下提供冗余配置!
原文:https://www.2ndquadrant.com/en/resources/highly-available-postgresql-clusters/
本文:http://jiagoushi.pro/node/931/
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 316 次浏览
【Postgres 架构】pg_auto_failover简介:高可用性和自动故障转移Postgres扩展
作为Citus团队的一员(Citus横向扩展Postgres,但这不是我们要做的全部),我从事pg_auto_failover已有相当一段时间了,我很高兴我们现在已经将pgautofailover作为开源引入了,为您提供自动故障转移和高可用性!
在设计pg_auto_failover时,我们的目标是:为Postgres提供易于设置的业务连续性解决方案,该解决方案实现系统中任何一个节点的容错能力。关于pg_auto_failover架构的文档章节包括以下内容:
重要的是要了解pgautofailover已针对业务连续性进行了优化。万一丢失单个节点,由于PostgreSQL同步复制,pgautofailover能够继续PostgreSQL服务,并在这样做时防止任何数据丢失。
pg_auto_failover简介
用于Postgres的pg_auto_failover解决方案旨在提供一种易于设置且可靠的自动化故障转移解决方案。该解决方案包括由软件驱动的决策,以决定何时在生产中实施故障转移。
任何自动故障转移系统中最重要的部分是决策策略,我们在线上有完整的文档章节,内容涉及pgautofailover故障容忍机制。
使用pgautofailover时,将部署多个活动代理来跟踪您的生产Postgres安装属性:
- 监视器是一个本身具有pg_auto_failover扩展名的Postgres数据库,它注册并检查活动Postgres节点的运行状况。
- 在pg_auto_failover监视器中注册的每个Postgres节点也必须运行本地代理pg_autoctl运行服务。
- 每个受管理的Postgres服务在同一个组中有两个设置在一起的Postgres节点。一个监视器设置可以根据需要管理多个Postgres组。
通过这样的部署,监控器会定期连接到每个已注册的节点(默认为20秒),并在其pgautofailover.node表中注册成功或失败。
除此之外,每个Postgres节点上的pg_autoctl运行服务还会检查Postgres是否正在运行,并监视其他节点的pgstatreplication统计信息。此Postgres系统视图使我们的本地代理能够发现主节点和备用节点之间的网络连接。本地代理定期每隔5s向监视器报告每个节点的状态,除非需要进行转换,然后立即进行。
pg_auto_failover监视器根据集群中两个节点的已知状态做出决策,并且仅遵循我们精心设计以确保节点收敛的有限状态机。特别是,只有在pg_autoctl代理报告成功实现了确定的过渡到新状态后,FSM才取得进展。关于故障转移逻辑的体系结构文档部分包含FSM的映像,我们使用这些映像来确保pgautofailover中的自动故障转移决策。

pg_auto_failover快速入门
再一次,请参阅pg_auto_failover的“快速入门”文档部分以获取更多详细信息。 首次尝试该项目时,最简单的方法是创建一个监视器,然后注册一个主要的Postgres实例,然后注册一个辅助的Postgres实例。
下面列出了一些Shell命令,这些命令在localhost上都实现了简单的部署,以用于项目发现。
监控器
在第一个终端,终端选项卡,屏幕或tmux窗口中,运行以下命令来创建监视器,包括使用initdb初始化Postgres集群,安装我们的pg_auto_failover扩展以及在HBA文件中打开连接特权。
首先,我们在终端中准备环境:
$ mkdir /tmp/pg_auto_failover/test
$ export PGDATA=/tmp/pg_auto_failover/test/monitor然后,我们可以使用刚刚准备的PGDATA环境设置在本地端口6000上的本地主机上创建Monitor Postgres实例:
$ pg_autoctl create monitor --nodename localhost --pgport 6000
12:12:53 INFO Initialising a PostgreSQL cluster at "/tmp/pg_auto_failover/test/monitor"
12:12:53 INFO Now using absolute pgdata value "/private/tmp/pg_auto_failover/test/monitor" in the configuration
12:12:53 INFO /Applications/Postgres.app/Contents/Versions/10/bin/pg_ctl --pgdata /tmp/pg_auto_failover/test/monitor --options "-p 6000" --options "-h *" --wait start
12:12:53 INFO Granting connection privileges on 192.168.1.0/24
12:12:53 INFO Your pg_auto_failover monitor instance is now ready on port 6000.
12:12:53 INFO pg_auto_failover monitor is ready at postgres://autoctl_node@localhost:6000/pg_auto_failover
12:12:53 INFO Monitor has been succesfully initialized.现在我们可以将连接字符串重新显示到监视器:
$ pg_autoctl show uri
postgres://autoctl_node@localhost:6000/pg_auto_failoverPostgres主节点
在另一个终端(选项卡,窗口,以通常的方式进行操作)中,现在创建一个主要的PostgreSQL实例:
$ export PGDATA=/tmp/pg_auto_failover/test/node_a
$ pg_autoctl create postgres --nodename localhost --pgport 6001 --dbname test --monitor postgres://autoctl_node@localhost:6000/pg_auto_failover
12:15:27 INFO Registered node localhost:6001 with id 1 in formation "default", group 0.
12:15:27 INFO Writing keeper init state file at "/Users/dim/.local/share/pg_autoctl/tmp/pg_auto_failover/test/node_a/pg_autoctl.init"
12:15:27 INFO Successfully registered as "single" to the monitor.
12:15:28 INFO Initialising a PostgreSQL cluster at "/tmp/pg_auto_failover/test/node_a"
12:15:28 INFO Now using absolute pgdata value "/private/tmp/pg_auto_failover/test/node_a" in the configuration
12:15:28 INFO Postgres is not running, starting postgres
12:15:28 INFO /Applications/Postgres.app/Contents/Versions/10/bin/pg_ctl --pgdata /private/tmp/pg_auto_failover/test/node_a --options "-p 6001" --options "-h *" --wait start
12:15:28 INFO CREATE DATABASE test;
12:15:29 INFO FSM transition from "init" to "single": Start as a single node
12:15:29 INFO Initialising postgres as a primary
12:15:29 INFO Transition complete: current state is now "single"
12:15:29 INFO Keeper has been succesfully initialized.此命令将PostgreSQL实例注册到监视器,使用pg_ctl initdb创建实例,为监视器运行状况检查准备一些连接权限,并为您创建一个名为test的数据库。 然后,执行由监视器排序的第一个转换,从状态INIT到达状态SINGLE。
现在,我们仍在测试中,因此在终端中以交互方式启动pg_autoctl运行服务。 对于生产设置,这将进入需要引导时间的系统服务,例如systemd。
$ pg_autoctl run
12:17:07 INFO Managing PostgreSQL installation at "/tmp/pg_auto_failover/test/node_a"
12:17:07 INFO pg_autoctl service is starting
12:17:07 INFO Calling node_active for node default/1/0 with current state: single, PostgreSQL is running, sync_state is "", WAL delta is -1.最后一行将每5s重复一次,这表明主节点运行状况良好,并且可以正常连接到监视器。 而且,它现在处于SINGLE状态,一旦新的Postgres节点加入该组,它就会改变。
Postgres辅助节点
现在是时候在另一个终端上创建辅助Postgres实例了:
$ export PGDATA=/tmp/pg_auto_failover/test/node_b
$ pg_autoctl create postgres --nodename localhost --pgport 6002 --dbname test --monitor postgres://autoctl_node@localhost:6000/pg_auto_failover
12:21:08 INFO Registered node localhost:6002 with id 5 in formation "default", group 0.
12:21:09 INFO Writing keeper init state file at "/Users/dim/.local/share/pg_autoctl/tmp/pg_auto_failover/test/node_b/pg_autoctl.init"
12:21:09 INFO Successfully registered as "wait_standby" to the monitor.
12:21:09 INFO FSM transition from "init" to "wait_standby": Start following a primary
12:21:09 INFO Transition complete: current state is now "wait_standby"
12:21:14 INFO FSM transition from "wait_standby" to "catchingup": The primary is now ready to accept a standby
12:21:14 INFO The primary node returned by the monitor is localhost:6001
12:21:14 INFO Initialising PostgreSQL as a hot standby
12:21:14 INFO Running /Applications/Postgres.app/Contents/Versions/10/bin/pg_basebackup -w -h localhost -p 6001 --pgdata /tmp/pg_auto_failover/test/backup -U pgautofailover_replicator --write-recovery-conf --max-rate 100M --wal-method=stream --slot pgautofailover_standby ...
12:21:14 INFO pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/2000028 on timeline 1
pg_basebackup: starting background WAL receiver
32041/32041 kB (100%), 1/1 tablespace
pg_basebackup: write-ahead log end point: 0/20000F8
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: base backup completed
12:21:14 INFO Postgres is not running, starting postgres
12:21:14 INFO /Applications/Postgres.app/Contents/Versions/10/bin/pg_ctl --pgdata /tmp/pg_auto_failover/test/node_b --options "-p 6002" --options "-h *" --wait start
12:21:15 INFO PostgreSQL started on port 6002
12:21:15 WARN Contents of "/tmp/pg_auto_failover/test/node_b/postgresql-auto-failover.conf" have changed, overwriting
12:21:15 INFO Transition complete: current state is now "catchingup"
12:21:15 INFO Now using absolute pgdata value "/private/tmp/pg_auto_failover/test/node_b" in the configuration
12:21:15 INFO Keeper has been succesfully initialized.这次向监视器的注册返回了状态WAITSTANDBY,该状态驱动pgautoctl创建辅助节点。 这是因为服务器已存在于组中,并且当前为SINGLE。 与此并行,监视器将目标状态WAIT_PRIMARY分配给主节点,localpgautoctlagent将在其中从监视器数据库和openpghba.conf中检索新节点的节点名称和端口以进行复制。 完成后,辅助节点继续pg_basebackup,安装arecovery.conf`文件,启动本地Postgres服务,并通知监视器有关达到目标状态的信息。
不过,我们仍在CATCHING_UP。 这意味着尚无法进行自动故障转移。 为了能够安排故障转移,我们需要在新节点上运行本地服务,监视Postgres的运行状况和复制状态,并每5秒向监视器报告一次:
$ pg_autoctl run
12:26:26 INFO Calling node_active for node default/5/0 with current state: catchingup, PostgreSQL is running, sync_state is "", WAL delta is -1.
12:26:26 INFO FSM transition from "catchingup" to "secondary": Convinced the monitor that I'm up and running, and eligible for promotion again
12:26:26 INFO Transition complete: current state is now "secondary"
12:26:26 INFO Calling node_active for node default/5/0 with current state: secondary, PostgreSQL is running, sync_state is "", WAL delta is 0.现在,新节点处于SECONDARY状态,并继续向监视器报告,准备在监视器做出决定时提升本地Postgres实例。
使用pg_auto_failover进行自动和手动故障转移
每个节点使用pg_auto_failover来配置具有自动故障转移功能的PostgreSQL集群所需要做的就是:每个节点使用两个命令:首先使用pg_autoctl create ...创建节点,然后运行pg_autoctl来运行本地服务,以实现由监视器决定的转换。
要见证故障转移,最简单的方法是停止pg_autoctl运行服务(在运行它的终端中使用^ C或在其他任何地方使用pg_autoctl stop --pgdata ...;然后也使用pg_ctl停止Postgres实例- D ...停下来。
当仅停止Postgres时,pg_autoctl运行服务将检测到该情况为异常,然后首先尝试重新启动Postgres。仅当使用默认pg_auto_failover参数连续3次未能启动Postgres时,才认为故障转移是适当的。
注入故障转移条件的另一种方法是礼貌地要求监视器为您安排一个:
$ psql postgres://autoctl_node@localhost:6000/pg_auto_failover
> select pgautofailover.perform_failover();应用程序和客户端的连接字符串
整个设置以pg_auto_failover条款的形式运行。 默认格式名为default,并且包含两个Postgres实例的单个组。 想法是只有一个入口,可以将应用程序连接到任何给定的形式。 要获取到我们的pg_auto_failover托管的Postgres服务的连接字符串,请发出以下命令,例如 在监视器终端上:
$ pg_autoctl show uri --formation default
postgres://localhost:6002,localhost:6001/test?target_session_attrs=read-write我们在这里使用libpq的多主机功能。 当它基于libpq(大多数都是这样)时,可以与任何现代Postgres驱动程序一起使用,并且已知其他本地驱动程序也可以实现相同的功能,例如JDBC Postgres驱动程序。
当然,如果适用于psql:
$ psql postgres://localhost:6002,localhost:6001/test?target_session_attrs=read-write
psql (12devel, server 10.7)
Type "help" for help.
test# select pg_is_in_recovery();
pg_is_in_recovery
═══════════════════
f
(1 row)当使用这样的连接字符串时,连接驱动程序将连接到第一台主机并检查是否接受写操作,如果不是,则连接到第二台主机并再次检查。那是因为我们说过我们希望targetsessionattrs是可读写的。
使用核心Postgres的此功能,我们实现了客户端的高可用性:在发生故障转移的情况下,我们的node_b将成为主要对象,并且我们需要应用程序现在将node_b定位为写入对象,并且该操作将在连接驱动程序中自动完成水平。
高可用性,容错和业务连续性
因此pgautofailover就是关于业务连续性的,并且为每个主要的Postgres服务器使用一个备用服务器。
在用于Postgres的经典HA设置中,我们依靠每个主服务器都有两个备用服务器的同步复制。当您想要实现零或接近零的RTO和RPO目标时,这就是预期的架构。
同样,每个主节点使用两个备用节点的想法是,您会丢失任何备用服务器,并且仍然知道在两个不同的地方仍可以使用数据,因此仍然乐于接受写入。这在许多生产设置中都是非常好的属性,并且是其他现有Postgres HA工具的目标。
在某些情况下,最佳的生产设置折衷方法与当前Postgres HA工具支持的方法有所不同。有时可以在需要执行灾难恢复过程时面对服务中断,因为对这种情况下必要风险的评估符合生产预算,预期的SLA或其组合。
并非所有项目都需要超过99.95%的可用性,即使没有走到最后一英里,有时也需要达到99.999%的目标。此外,尽管物联网和其他一些用例(例如庞大的用户群)需要HA解决方案,这些解决方案需要将TB级数据扩展到PB级数据,但许多项目却是针对较小的受众和数据集的。当您拥有千兆字节的数据,甚至数十千兆字节的数据时,灾难恢复的时机也将不再可能被吞噬,具体取决于您的SLA条款。
数据可用性
pg_auto_failover使用PostgreSQL同步复制来确保在故障转移操作时没有数据丢失。 sync rep Postgre功能可确保当客户端应用程序收到来自Postgres的COMMIT消息时,数据便将其发送到我们的辅助节点。
面对系统中任何一个ONE节点丢失的情况,pg_auto_failover可以正常工作。如果丢失了主服务器,然后又丢失了辅助服务器,那么除了备份之外,什么都没有。使用pg_auto_failover时,对于一次丢失多台服务器的情况,您仍然必须设置适当的灾难恢复解决方案。是的,这发生了。
还请注意臭名昭著的_file系统是否已满_,由于我们习惯于部署类似规格的服务器,因此它喜欢同时攻击主服务器和辅助服务器……
结论
微软在这里的整个Citus团队都对pg_auto_failover扩展的开源版本感到兴奋。我们根据Postgres开放源代码许可发布了pg_auto_failover,因此您可以以与部署Postgres完全相同的能力享受我们的贡献。该项目是完全开放的,欢迎每个人参与并在我们的GitHub存储库上为https://github.com/citusdata/pg_auto_failover做出贡献。我们正在遵循Microsoft开放源代码行为准则,并确保所有人都受到欢迎和聆听。
我的希望是,由于有了pg_auto_failover,你们中的许多人现在将能够使用自动故障转移解决方案在生产中部署Postgres。
原文:https://www.citusdata.com/blog/2019/05/30/introducing-pg-auto-failover/
本文:http://jiagoushi.pro/node/922
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 318 次浏览
【Postgresql】PostgreSQL和MySQL:每秒数百万的查询
这篇博客比较了PostgreSQL和MySQL每秒处理数百万次查询的方式。
Anastasia:开源数据库可以应对每秒数百万次查询吗?许多开源倡导者会回答“是”。然而,断言并不足以提供充分的证据。这就是为什么在这篇博文中,我们分享了Alexander Korotkov(开发,Postgres Professional首席执行官)和Sveta Smirnova(首席技术服务工程师,Percona)的基准测试结果。 PostgreSQL 9.6和MySQL 5.7性能的比较研究对于具有多个数据库的环境尤其有用。
这项研究背后的想法是提供两个流行的RDBMS的诚实比较。 Sveta和Alexander希望使用相同的工具在相同的挑战性工作负载下使用相同的配置参数(如果可能)测试PostgreSQL和MySQL的最新版本。但是,由于PostgreSQL和MySQL生态系统都是独立发展的,每个数据库都使用标准的测试工具(pgbench和SysBench),这不是一件容易的事。
这项任务落到了具有多年实践经验的数据库专家手中。 Sveta曾在Oracle MySQL支持小组的Bugs Verification Group担任高级首席技术支持工程师超过八年,自2015年起担任Percona的首席技术服务工程师。 Alexander Korotkov是PostgreSQL的主要贡献者,也是PostgreSQL众多功能的开发者 - 包括CREATE ACCESS METHOD命令,通用WAL接口,无锁Pin / UnpinBuffer,基于索引的正则表达式搜索等等。所以我们有一个相当不错的演员阵容!
Sveta:Dimitri Kravtchuk定期发布MySQL的详细基准测试,因此我的主要任务不是确认MySQL每秒可以进行数百万次查询。正如我们的图表所示,我们已经通过了那个标记。作为支持工程师,我经常与在他们的商店中拥有异构数据库环境的客户合作,并希望了解将作业从一个数据库迁移到另一个数据库的影响。相反,我发现有机会与Postgres专业公司合作,并确定两个数据库的优点和缺点是一个绝佳的机会。
我们希望使用相同的工具和测试在相同的硬件上测试PostgreSQL和MySQL。我们期望测试基本功能,然后进行更详细的比较。这样我们就可以比较不同的真实用例场景和流行的选项。
剧透:我们距离最终结果还很远。这是博客系列的开始。
大机器上的OpenSource数据库,系列1:“那是关闭......”
Postgres Professional与 Freematiq一起提供了两台现代化,功能强大的测试机器。
硬件配置:
Processors: physical = 4, cores = 72, virtual = 144, hyperthreading = yes
Memory: 3.0T
Disk speed: about 3K IOPS
OS: CentOS 7.1.1503
File system: XFS
我还使用了较小的Percona机器。
硬件配置:
Processors: physical = 2, cores = 12, virtual = 24, hyperthreading = yes
Memory: 251.9G
Disk speed: about 33K IOPS
OS: Ubuntu 14.04.5 LTS
File system: EXT4
请注意,具有较少CPU核心和较快磁盘的计算机比具有较大核心数的计算机更常见于MySQL安装。
我们需要达成共识的第一件事是使用哪种工具。如果工作负载尽可能接近,那么公平的比较才有意义。
用于性能测试的标准PostgreSQL工具是pgbench,而对于MySQL,它是SysBench。 SysBench支持Lua编程语言中的多个数据库驱动程序和脚本化测试,因此我们决定将这个工具用于这两个数据库。
最初的计划是将pgbench测试转换为SysBench Lua语法,然后在两个数据库上运行标准测试。在初步结果之后,我们修改了测试以更好地检查特定的MySQL和PostgreSQL功能。
我将pgbench测试转换为SysBench语法,并将测试放入开放式数据库工作台GitHub存储库中。
然后我们都遇到了困难。
正如我已经写过的那样,我也在Percona机器上运行测试。对于此转换测试,结果几乎相同:
Percona machine:
OLTP test statistics:
transactions: 1000000 (28727.81 per sec.)
read/write requests: 5000000 (143639.05 per sec.)
other operations: 2000000 (57455.62 per sec.))
Freematiq机器:
OLTP test statistics:
transactions: 1000000 (29784.74 per sec.)
read/write requests: 5000000 (148923.71 per sec.)
other operations: 2000000 (59569.49 per sec.)
我开始调查了。 Percona机器比Freematiq更好的唯一地方是磁盘速度。所以我开始运行pgbench只读测试,这与SysBench的点选择测试相同,内存中有完整的数据集。但这次SysBench使用了50%的可用CPU资源:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4585 smirnova 20 0 0,157t 0,041t 9596 S 7226 1,4 12:27.16 mysqld
8745 smirnova 20 0 1266212 629148 1824 S 7126 0,0 9:22.78 sysbench
反过来,Alexander遇到了SysBench的问题,当使用预处理语句时,它无法在PostgreSQL上创建高负载:
93087 korotkov 20 0 9289440 3,718g 2964 S 242,6 0,1 0:32.82 sysbench
93161 korotkov 20 0 32,904g 81612 80208 S 4,0 0,0 0:00.47 postgres
93116 korotkov 20 0 32,904g 80828 79424 S 3,6 0,0 0:00.46 postgres
93118 korotkov 20 0 32,904g 80424 79020 S 3,6 0,0 0:00.47 postgres
93121 korotkov 20 0 32,904g 80720 79312 S 3,6 0,0 0:00.47 postgres
93128 korotkov 20 0 32,904g 77936 76536 S 3,6 0,0 0:00.46 postgres
93130 korotkov 20 0 32,904g 81604 80204 S 3,6 0,0 0:00.47 postgres
93146 korotkov 20 0 32,904g 81112 79704 S 3,6 0,0 0:00.46 postgres
我们联系了SysBench的作者Alexey Kopytov,他修复了MySQL问题。解决方案是:
- Use SysBench with the options --percentile=0 --max-requests=0 (reasonable CPU usage)
- Use the concurrency_kit branch (better concurrency and Lua processing)
- Rewrite Lua scripts to support prepared statements (pull request: https://github.com/akopytov/sysbench/pull/94)
- Start both SysBench and mysqld with the jemalloc or tmalloc library pre-loaded
PostgreSQL的修复程序正在进行中。目前,Alexander将标准的SysBench测试转换为pgbench格式,我们坚持使用它。对于MySQL来说并不是什么新鲜事,但至少我们有一个比较基线。
我面临的下一个难题是默认的操作系统参数。长话短说,我将它们改为推荐的(如下所述):
vm.swappiness=1
cpupower frequency-set --governor performance
kernel.sched_autogroup_enabled=0
kernel.sched_migration_cost_ns= 5000000
vm.dirty_background_bytes=67108864
vm.dirty_bytes=536870912
IO scheduler [deadline]
对于PostgreSQL性能,相同的参数也更好。亚历山大同样设置他的机器
解决了这些问题后,我们学习并实施了以下内容:
- 我们不能使用单一工具(暂时)
- 亚历山大为pgbench编写了一个测试,模仿标准的SysBench测试
- 我们仍然无法编写自定义测试,因为我们使用不同的工具
但我们可以将这些测试用作基线。在亚历山大完成工作后,我们坚持使用标准的SysBench测试。我将它们转换为使用准备好的语句,亚历山大将它们转换为pgbench格式。
我应该提一下,对于Read Only和Point Select测试,我无法获得与Dimitri相同的结果。它们很近但略慢。我们需要调查这是不同硬件的结果还是我缺乏性能测试能力。读写测试的结果是类似的。
另一个区别是PostgreSQL和MySQL测试。 MySQL用户通常有很多连接。如今,设置变量max_conenctions的值,并将并行连接的总数限制为数千并不罕见。虽然不推荐,但即使没有线程池插件,人们也会使用此选项。在现实生活中,大多数这些联系都在睡觉。但是,在网站活动增加的情况下,他们总是有机会被使用。
对于MySQL,我测试了多达1024个连接。我使用了2的幂和核心数的倍数:1,2,4,8,16,32,36,64,72,128,144,256,512和1024个线程。
对亚历山大来说,以较小的步骤进行测试更为重要。他从一个线程开始,增加了10个线程,直到达到250个并行线程。因此,您将看到PostgreSQL的更详细的图表,但在250个线程之后没有结果。
这是我们的比较结果。
Point SELECTs

- pgsql-9.6 is standard PostgreSQL
- pgsql-9.6 + pgxact-align is PostgreSQL with this patch (more details can be found in this blog post)
- MySQL-5.7 Dimitri is Oracle’s MySQL Server
- MySQL-5.7 Sveta is Percona Server 5.7.15
OLTP RO

OLTP RW

PostgreSQL中的同步提交是一个功能,类似于InnoDB中的innodb_flush_log_at_trx_commit = 1,异步提交类似于innodb_flush_log_at_trx_commit = 2。
您会看到结果非常相似:两个数据库都在快速发展,并且可以很好地使用现代硬件。
MySQL results which show 1024 threads for reference.
Point SELECT and OLTP RO

OLTP RW with innodb_flush_log_at_trx_commit set to 1 and 2

收到这些结果后,我们做了一些功能特定的测试,这些测试将在单独的博客文章中介绍。
更多信息
用于OLTP RO和Point SELECT测试的MySQL选项:
# general
table_open_cache = 8000
table_open_cache_instances=16
back_log=1500
query_cache_type=0
max_connections=4000# files
innodb_file_per_table
innodb_log_file_size=1024M
innodb_log_files_in_group=3
innodb_open_files=4000# Monitoring
innodb_monitor_enable = '%'
performance_schema=OFF #cpu-bound, matters for performance#Percona Server specific
userstat=0
thread-statistics=0# buffers
innodb_buffer_pool_size=128000M
innodb_buffer_pool_instances=128 #to avoid wait on InnoDB Buffer Pool mutex
innodb_log_buffer_size=64M# InnoDB-specific
innodb_checksums=1 #Default is CRC32 in 5.7, very fast
innodb_use_native_aio=1
innodb_doublewrite= 1 #https://www.percona.com/blog/2016/05/09/percona-server-5-7-parallel-dou…
innodb_stats_persistent = 1
innodb_support_xa=0 #(We are read-only, but this option is deprecated)
innodb_spin_wait_delay=6 #(Processor and OS-dependent)
innodb_thread_concurrency=0
join_buffer_size=32K
innodb_flush_log_at_trx_commit=2
sort_buffer_size=32K
innodb_flush_method=O_DIRECT_NO_FSYNC
innodb_max_dirty_pages_pct=90
innodb_max_dirty_pages_pct_lwm=10
innodb_lru_scan_depth=4000
innodb_page_cleaners=4# perf special
innodb_adaptive_flushing = 1
innodb_flush_neighbors = 0
innodb_read_io_threads = 4
innodb_write_io_threads = 4
innodb_io_capacity=2000
innodb_io_capacity_max=4000
innodb_purge_threads=4
innodb_max_purge_lag_delay=30000000
innodb_max_purge_lag=0
innodb_adaptive_hash_index=0 (depends on workload, always check)
MySQL Options for OLTP RW:
#Open files
table_open_cache = 8000
table_open_cache_instances = 16
query_cache_type = 0
join_buffer_size=32k
sort_buffer_size=32k
max_connections=16000
back_log=5000
innodb_open_files=4000#Monitoring
performance-schema=0#Percona Server specific
userstat=0
thread-statistics=0#InnoDB General
innodb_buffer_pool_load_at_startup=1
innodb_buffer_pool_dump_at_shutdown=1
innodb_numa_interleave=1
innodb_file_per_table=1
innodb_file_format=barracuda
innodb_flush_method=O_DIRECT_NO_FSYNC
innodb_doublewrite=1
innodb_support_xa=1
innodb_checksums=1#Concurrency
innodb_thread_concurrency=144
innodb_page_cleaners=8
innodb_purge_threads=4
innodb_spin_wait_delay=12 Good value for RO is 6, for RW and RC is 192
innodb_log_file_size=8G
innodb_log_files_in_group=16
innodb_buffer_pool_size=128G
innodb_buffer_pool_instances=128 #to avoid wait on InnoDB Buffer Pool mutex
innodb_io_capacity=18000
innodb_io_capacity_max=36000
innodb_flush_log_at_timeout=0
innodb_flush_log_at_trx_commit=2
innodb_flush_sync=1
innodb_adaptive_flushing=1
innodb_flush_neighbors = 0
innodb_max_dirty_pages_pct=90
innodb_max_dirty_pages_pct_lwm=10
innodb_lru_scan_depth=4000
innodb_adaptive_hash_index=0
innodb_change_buffering=none #can be inserts, workload-specific
optimizer_switch="index_condition_pushdown=off" #workload-specific
MySQL SysBench parameters:
LD_PRELOAD=/data/sveta/5.7.14/lib/mysql/libjemalloc.so
/data/sveta/sbkk/bin/sysbench
[ --test=/data/sveta/sysbench/sysbench/tests/db/oltp_prepared.lua | --test=/data/sveta/sysbench/sysbench/tests/db/oltp_simple_prepared.lua ]
--db-driver=mysql --oltp-tables-count=8 --oltp-table-size=10000000
--mysql-table-engine=innodb --mysql-user=msandbox --mysql-password=msandbox
--mysql-socket=/tmp/mysql_sandbox5715.sock
--num-threads=$i --max-requests=0 --max-time=300
--percentile=0 [--oltp-read-only=on --oltp-skip-trx=on]
PostgreSQL pgbench parameters:
$ git clone https://github.com/postgrespro/pg_oltp_bench.git
$ cd pg_oltp_bench
$ make USE_PGXS=1
$ sudo make USE_PGXS=1 install
$ psql DB -f oltp_init.sql
$ psql DB -c "CREATE EXTENSION pg_oltp_bench;"
$ pgbench -c 100 -j 100 -M prepared -f oltp_ro.sql -T 300 -P 1 DB
$ pgbench -c 100 -j 100 -M prepared -f oltp_rw.sql -T 300 -P 1 DB
MySQL 5.7中的功能显着改善了性能:
- InnoDB: transaction list optimization
- InnoDB: Reduce lock_sys_t::mutex contention
- InnoDB: fix index->lock contention
- InnoDB: faster and parallel flushing
- MDL (Meta-Data Lock) scalability
- Remove THR_LOCK::mutex for InnoDB: Wl #6671
- Partitioned LOCK_grant
- Number of partitions is constant
- Thread ID used to assign partition
- Lock-free MDL lock acquisition for DML
Anastasia:这项研究的最初发现在Percona Live Amsterdam 2016上公布。更多的调查结果被添加到 Moscow HighLoad++ 2016的同一个演讲的第二版中。希望本次演讲的第三次演示将在Percona Live Open Source Database Conference 2017 in Santa Clara.上发布。年圣克拉拉数据库大会。
本文:http://pub.intelligentx.net/node/553
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 237 次浏览
【Postgresql架构】Citus实时执行程序如何并行化Postgres查询
Citus有多个不同的执行程序,每个执行程序的行为都不同,以支持各种用例。对于许多概念而言,分布式SQL似乎必须是一个复杂的概念,但是其原理并不是火箭科学。在这里,我们将看几个有关Citus如何采用标准SQL并将其转换为以分布式形式运行以便可以并行化的示例。结果是您可以看到单节点数据库的查询性能提高了100倍或更多。
我们如何知道某物是分布式的还是单片?
在了解实时执行器的工作方式之前,值得对Citus执行器进行全面的复习。
当Citus收到查询时,我们首先查看它是否具有where子句的分片键(也称为分发列)。如果您要分拆诸如CRM应用程序之类的多租户应用程序,则可能会有一个org_id,您总是会限制查询。在这种情况下,只要org_id是where子句的一部分,我们就知道它的目标是单个分片,因此可以使用路由器执行程序。如果未使用该查询,我们会将查询拆分并跨节点并行发送给所有分片。
作为快速更新,Citus中的一个表是另一个表。如果您有一个表事件并想要分发它,则可以创建32个分片,这意味着我们可以轻松扩展到32个节点。如果您从2个节点开始,则每个节点包含32个分片。这意味着每个节点将一次接收16个查询,并且如果它有16个可用的内核,那么所有工作将并行完成,从而导致2个节点x 16个内核,或者说,与在单个内核上执行相比,速度提高了32倍。
对于后面的示例,我们将仅创建4个分片以简化它们,但是随着添加的分片和对应的内核的增加,事情几乎线性地扩展。
用SQL编写,用MapReduce思考
Citus对实时分析的支持是自从我们早期以来,人们就一直使用Citus的工作负载,这要归功于我们先进的查询并行化。结果就是您能够用标准SQL表示事物,并让Citus的分布式查询计划器完成重写查询的艰苦工作,从而为您提供出色的性能,而无需创建复杂的工程胶带。
深入研究一些示例,从count(*)开始
我们可以开始处理的最简单的查询是count(*)。对于count(*),我们需要从每个分片中获取一个count(*)。首先,针对事件表运行一个解释计划,以了解其运作方式:
QUERY PLAN ------------------------------------------------------------------------------------------------------- Aggregate (cost=0.00..0.00 rows=0 width=0) -> Custom Scan (Citus Real-Time) (cost=0.00..0.00 rows=0 width=0) Task Count: 4 Tasks Shown: One of 4 -> Task Node: host=ec2-18-233-232-9.compute-1.amazonaws.com port=5432 dbname=citus -> Aggregate (cost=11.62..11.63 rows=1 width=8) -> Seq Scan on events_102329 events (cost=0.00..11.30 rows=130 width=0) (8 rows) Time: 160.596 ms
查询中有一些注意事项。 首先是它使用的是Citus Real-Time执行程序,这意味着查询正在击中所有碎片。 第二个是任务是4个之一。该任务在所有节点上通常是相同的,但是由于它是纯粹的Postgres计划,可以根据数据分布和估算值进行更改。 如果要查看所有查询计划,则可以扩展输出以获取所有4个分片的任务。 最后,您具有针对该特定分片的查询计划本身。
让我们以集群示例为例:

如果我们要对该集群执行count(*),Citus将重新编写查询并将四个count(*)查询发送到每个分片。 然后将所得的计数返回给协调器以执行最终聚合:

性能远远超过count(*)
虽然count(*)很容易看出它是如何工作的,但是您可以执行更多操作。 如果要获得四个平均值并将它们平均在一起,则实际上并不会获得结果平均值。 相反,对于普通的Citus将执行sum(foo)和count(foo),然后在协调器上将sum(foo)/ count(foo)相除,以得出正确的结果。 最好的部分仍然可以编写AVG,Citus负责底层的复杂性。
除了汇总之外,Citus还可以告诉您何时加入并在本地执行这些加入。 让我们向事件表中添加另一个表:会话。 现在,对于每个事件,我们都将会话ID记录为其中的一部分,以便我们加入。 有了这两个表,我们现在想要一个查询,该查询将告诉我们会话的平均事件数,以及上周创建的会话:
SELECT count(events.*),
count(distinct session_id)
FROM events,
sessions
WHERE sessions.created_at >= now() - '1 week'::interval
AND sessions.id = events.session_id在这两个表上都分配有会话ID的情况下,Citus会知道这些表在同一位置。 使用共置的表,Citus将重新编写查询以将连接向下推送到本地,从而不会通过网络发送太多数据。 结果是,我们将从每个分片(而不是所有原始数据)中将2条记录发送回协调器,从而大大缩短了分析查询时间。 内部重写的内容可能类似于:
SELECT count(events_01.*),
count(distinct session_id)
FROM events_01,
sessions_01
WHERE sessions_01.created_at >= now() - '1 week'::interval
AND sessions_01.id = events_01.session_id
SELECT count(events_02.*),
count(distinct session_id)
FROM events_02,
sessions_02
WHERE sessions_02.created_at >= now() - '1 week'::interval
AND sessions_02.id = events_02.session_id
...分布式SQL不一定很困难,但是可以肯定很快
下推连接和并行化的好处是:
您不必通过网络发送太多数据,这比在内存中扫描要慢您可以一次利用系统中的所有内核,而不是在单个内核上运行查询您可以超出可以在一台计算机中装载多少内存/内核的限制
希望这次对Citus实时执行器的浏览简化了幕后工作的方式。 如果您想更深入地学习,请阅读我们的文档。
原文:https://www.citusdata.com/blog/2018/08/17/breaking-down-citus-real-time-executor/
本文:http://jiagoushi.pro/node/927
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 93 次浏览
【Postgresql架构】PGDay:全文搜索如何工作?
- 55 次浏览
【Postgresql架构】PostgreSQL和仅堆元组更新-第3部分
- 40 次浏览
【Postgresql架构】Postgresql BRIN 索引– 概览
- 51 次浏览
【Postgresql架构】Postgresql 数据库的近似算法
在较早的博客文章中,我写了关于如何将问题分解为MapReduce样式的方法可以如何为您提供更好的性能。当我们能够在集群中所有核心之间并行化工作负载时,我们发现Citus比单节点数据库快几个数量级。虽然计数(*)和平均数很容易分解成较小的部分,但我立即想到了一个问题,即计数不重复数,列表中的最高值或中位数是什么?
公认的是,在大型分布式设置中,确切的非重复计数更难解决,因为它需要在节点之间进行大量数据转换。 Citus确实支持不重复计数,但是在处理特别大的数据集时有时会很慢。任何中型到大型数据集的中位数都可能对最终用户完全禁止。幸运的是,几乎所有这些算法都有近似算法,可以提供足够接近的答案,并且具有令人印象深刻的性能特征。
HyperLogLog的近似唯一性
在某些类别的应用程序中,例如网络分析,物联网(物联网)和广告,计算某事物发生的不同次数是一个共同的目标。 HyperLogLog是PostgreSQL数据类型扩展,它允许您获取原始数据并将其压缩为一段时间内存在的唯一身份值。
将数据保存到HLL数据类型的结果是,星期一的值将为25,而星期二的值将为20。与原始数据相比,此数据压缩后的压缩量要大得多。但是真正令人赞叹的是,您可以然后合并这些存储桶,通过合并两个HyperLogLog数据类型,您可以返回星期一和星期二有25个唯一身份,因为星期二您有10个重复访客:
SELECT hll_union_agg(users) as unique_visitors FROM daily_uniques; unique_visitors ----------------- 35 (1 row)
于HyperLogLog可以通过这种方式拆分和组合,因此还可以跨Citus群集中的所有节点很好地并行化
使用TopN查找重要事项
我们通常在Web分析,广告应用程序和安全性/日志事件应用程序中发现的另一种计数形式是希望知道已发生的最主要的操作或事件集。 这可能是您在Google Analytics(分析)中看到的首页视图,也可能是事件日志中发生的主要错误。
TopN利用基础JSONB数据类型存储其所有数据。 但随后会维护一个列表,其中是最重要的项目以及有关这些项目的各种数据。 随着订单的改组,它会清除旧数据,从而使其现在必须维护所有原始数据的完整列表。
为了使用它,您将以与HyperLogLog类似的方式插入它:
# create table aggregated_topns (day date, topn jsonb); CREATE TABLE Time: 9.593 ms # insert into aggregated_topns select date_trunc('day', created_at), topn_add_agg((repo::json)->> 'name') as topn from github_events group by 1; INSERT 0 7 Time: 34904.259 ms (00:34.904)
在查询时,您可以轻松获取数据的前十名列表:
SELECT (topn(topn_union_agg(topn), 10)).* FROM aggregated_topns WHERE day IN ('2018-01-02', '2018-01-03'); ------------------------------------------------+----------- dipper-github-fra-sin-syd-nrt/test-ruby-sample | 12489 wangshub/wechat_jump_game | 6402 ...
不只是计数和列表
前面我们提到过,像中位数这样的运算可能会困难得多。 尽管扩展可能尚不存在,但未来可以支持这些操作。 对于中位数,存在多种不同的算法和方法。 可以应用于Postgres的两个有趣的方法:
- T-digest
-提供大约百分位数 - HDR (high dynamic range)
-提供更好的压缩效果,但只专注于前99%和更高的百分位数
如果答案能在数TB的数据范围内达到亚秒级响应,那么答案是否完全接近但又不能完全满足您的需求? 以我的经验,答案通常是肯定的。
因此,下次您认为分布式设置中不可能实现某些功能时,请研究一下存在哪些近似算法。
原文:https://www.citusdata.com/blog/2019/02/28/approximation-algorithms-for-your-database/
本文:http://jiagoushi.pro/node/925
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 67 次浏览
【Postgresql架构】Postgres中关注者(只读副本)的用例
Citus将Postgres扩展为可水平扩展的数据库。水平扩展是指数据分散在多台计算机上,您不仅可以扩展存储,还可以扩展内存和计算,从而提供更好的性能。无需使用Citus之类的工具即可将PostgreSQL转换为分布式数据库,请确保您可以添加只读副本以进行扩展,但是您仍将维护数据的单个副本。当您遇到Postgres数据库的扩展问题时,添加只读副本并将某些流量分流到只读副本是降低速度的一种常见的创可贴,但这只是时间问题,直到它失效为止再进一步。而使用Citus,向外扩展数据库就像拖动滑块并重新平衡数据一样简单。
只读副本对水平可伸缩数据库是否仍然有用?
但这留下了一个问题,只读副本仍然有用吗?好吧,可以肯定。
在Citus Cloud(我们的完全托管数据库即服务)中,我们支持只读副本,在我们的情况下称为追随者。追随者群集利用了我们与叉式利用相同的许多基础灾难恢复基础架构,但是它们支持非常不同的用例集。
之前,我们讨论过如何在Citus Cloud中使用forks来将生产数据集转移到暂存阶段,以帮助测试迁移,重新平衡或SQL查询优化。叉子通常在短时间内用作一次性物品。相比之下,关注者通常是长期运行的Citus数据库集群,可以成为运行业务的关键机制,可帮助您在需要时获取见解。
追随者群集通常仅比主数据库群集落后几秒钟(如果有)
跟随者群集以异步方式从主Citus群集接收所有更新。追随者通常仅比主数据库集群落后几秒钟(如果有的话),尽管有时可能会滞后几分钟。关注者拥有您数据的完整副本,但位于单独的群集中。这意味着您将拥有数据的单独副本,并拥有自己的计算能力,内存和磁盘。
关于跟随者形成的有趣事实,您也可以跨区域创建它们。是否要在另一个区域中拥有数据库的完整副本,以便在发生灾难时可以进行故障转移?是否希望为不同地理位置的特定读取提供较低的延迟?跨区域的Citus追随者可以提供帮助。
追随者=有助于将分析工作负载与核心生产活动分开
那么追随者在Citus中什么时候有用?关注者对于可能需要较长时间运行的分析工作负载最有帮助。是否要针对您的整个数据集计算一些复杂的报告?从主数据库到其他数据仓库执行ETL,在该仓库中数据在进入之前已经清理和混淆了?
这些用例中的每一个对您的业务而言都可能很重要,但是长时间运行的SQL查询与数据库的主要工作负载争用相同的资源。这种性能竞争有时会导致数据库中主要工作负载的性能问题。通过将分析工作量拆分出来以在Citus追随者群集上运行,您可以为内部数据分析人员提供所需的访问权限,而不必让他们接受相同的生产代码审查流程,同时又可以确保生产数据库的安全。
只读副本和关注者仍然有位置
虽然使用只读副本来扩展您的主应用程序可能会带来各种不必要的复杂性,并且要比解决的问题产生更多的工作,但是只读副本仍然有自己的位置。当使用对Postgres的Citus扩展来解决扩展性能问题时,您可以创建跟随者形式(也称为只读副本)以在内部提供对数据的访问,而不必冒生产可用性的风险。这是一个强大的组合。
原文:https://www.citusdata.com/blog/2018/09/19/use-cases-for-read-replicas/
本文:http://jiagoushi.pro/node/923
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 126 次浏览
【Postgresql架构】使用PostgreSQL中的JSONB数据类型加快操作
从版本9.4开始,PostgreSQL在使用JSON数据的二进制表示jsonb时提供了显着的加速,这可以为您提供增加性能所需的额外优势。
什么是jsonb
由PostgreSQL文档定义的数据类型json和jsonb几乎相同;关键的区别在于json数据存储为JSON输入文本的精确副本,而jsonb以分解的二进制形式存储数据;也就是说,不是ASCII / UTF-8字符串,而是二进制代码。
这有一些直接的好处:
- 效率更高,
- 加工速度明显加快
- 支持索引(这可能是一个重要的优势,我们稍后会看到),
- 更简单的模式设计(用jsonb列替换实体 - 属性 - 值(EAV)表,可以查询,索引和连接,从而使性能提高到1000倍!)
还有一些缺点:
- 输入稍慢(由于增加的转换开销),
- 它可能需要比普通json更多的磁盘空间,因为更大的表占用空间,尽管并非总是如此,
- 由于缺乏统计信息,某些查询(尤其是聚合查询)可能会变慢。
最后一个问题背后的原因是,对于任何给定的列,PostgreSQL保存描述性统计信息,例如不同和最常见值的数量,NULL条目的分数,以及 - 对于有序类型 - 数据分布的直方图。当信息作为JSON字段输入时,所有这些都将不可用,并且您将遭受严重的性能损失,尤其是在大量JSON字段之间聚合数据(COUNT,AVG,SUM等)时。
为避免这种情况,您可以考虑存储稍后可能在常规字段上汇总的数据。
有关此问题的进一步评论,您可以阅读Heap的博客文章何时在PostgreSQL架构中避免使用JSONB。
用例:书籍条目
让我们使用带有书籍条目的玩具模型来说明在PostgreSQL中使用JSON数据时的一些基本操作。
如果您使用json或jsonb,本节中的操作将基本相同,但让我们回顾它们以刷新我们可以用JSON做什么,并在我们看到jsonb好吃之后立即设置我们的用例。
在表中定义列
很简单,我们使用jsonb数据类型指定数据列:
CREATE TABLE books ( book_id serial NOT NULL, data jsonb );
插入JSON数据
要将数据输入books表,我们只需将整个JSON字符串作为字段值传递:
INSERT INTO books VALUES (1, '{"title": "Sleeping Beauties", "genres": ["Fiction", "Thriller", "Horror"], "published": false}'); INSERT INTO books VALUES (2, '{"title": "Influence", "genres": ["Marketing & Sales", "Self-Help ", "Psychology"], "published": true}'); INSERT INTO books VALUES (3, '{"title": "The Dictator''s Handbook", "genres": ["Law", "Politics"], "authors": ["Bruce Bueno de Mesquita", "Alastair Smith"], "published": true}'); INSERT INTO books VALUES (4, '{"title": "Deep Work", "genres": ["Productivity", "Reference"], "published": true}'); INSERT INTO books VALUES (5, '{"title": "Siddhartha", "genres": ["Fiction", "Spirituality"], "published": true}');
查询数据
我们现在可以查询JSON数据中的特定键:
SELECT data->'title' AS title FROM books;
这将从JSONB数据中提取的标题作为列返回:
title
---------------------------
"Sleeping Beauties"
"Influence"
"The Dictator's Handbook"
"Deep Work"
"Siddhartha"
(5 rows)
过滤结果
您也可以使用WHERE子句但通过JSON键以正常方式过滤结果集:
SELECT * FROM books WHERE data->'published' = 'false';
在这种情况下,返回原始JSON数据:
book_id | data
---------+-------------------------------------------------------------------------------------------------
1 | {"title": "Sleeping Beauties", "genres": ["Fiction", "Thriller", "Horror"], "published": false}
(1 row)
展开数据
这是一个重要的问题,因为它将使我们能够在处理关系数据库时使用我们熟悉的聚合函数,但是在JSON数据的反直觉环境中也是如此。
SELECT jsonb_array_elements_text(data->'genres') AS genre FROM books WHERE book_id = 1;
这会将JSON数组扩展为一列:
genre
----------
Fiction
Thriller
Horror
(3 rows)
特殊的jsonb功能
除了效率之外,还有其他方法可以让您以二进制形式存储JSON。
其中一个增强功能是GIN(广义倒置索引)索引以及随附的新品牌运营商。
检查遏制(Checking Containment)
Containment测试一个文档(一个集合或一个数组)是否包含在另一个文档中。这可以使用@>运算符在jsonb数据中完成。
例如,数组[“Fiction”,“Horror”]包含在数组[“Fiction”,“Thriller”,“Horror”]中(其中t代表true):
SELECT '["Fiction", "Thriller", "Horror"]'::jsonb @> '["Fiction", "Horror"]'::jsonb;
t
然而,相反的是["Fiction", "Thriller", "Horror"]包含在["Fiction", "Horror"]中,是错误的:
SELECT '["Fiction", "Horror"]'::jsonb @> '["Fiction", "Thriller", "Horror"]'::jsonb;f
使用这个原则,我们可以轻松检查单一书籍类型:
SELECT data->'title' FROM books WHERE data->'genres' @> '["Fiction"]'::jsonb;"Sleeping Beauties" "Siddhartha"
通过传递一个数组(注意它们的关键顺序根本不重要),或者同时使用多个类型:
SELECT data->'title' FROM books WHERE data->'genres' @> '["Fiction", "Horror"]'::jsonb;"Sleeping Beauties"
此外,从9.5版开始,PostgreSQL引入了检查顶级键和空对象包含的功能:
SELECT '{"book": {"title": "War and Peace"}}'::jsonb @> '{"book": {}}'::jsonb;t
检查存在
作为包含的变体,jsonb还有一个存在运算符(?),可用于查找是否存在对象键或数组元素。
在这里,让我们计算出输入作者字段的书籍:
SELECT COUNT(*) FROM books WHERE data ? 'authors';
在这种情况下只有一个(“独裁者的手册”):
count
-------
1
(1 row)
创建指数/索引
让我们花点时间提醒自己索引是关系数据库的关键组成部分。没有它们,每当我们需要检索一条信息时,数据库就会扫描整个表格,这当然效率很低。
jsonb相对于json数据类型的显着改进是能够索引JSON数据。
我们的玩具示例只有5个条目,但如果它们是数千或数百万个条目,我们可以通过构建索引来减少一半以上的搜索时间。
例如,我们可以索引出版的书籍:
CREATE INDEX idx_published ON books (data->'published');
由于idx_published索引,这个简单的索引将自动加速我们在已发布的书籍上运行的所有聚合函数(WHERE data - >'published'='true')。
事实上,我们可以 - 并且可能应该在DB大小增加时 - 索引在过滤结果时要在WHERE子句上使用的任何内容。
注意事项
切换到jsonb数据类型时,您需要考虑一些技术细节。
jsonb更严格,因此,除非数据库编码为UTF8,否则它不允许非ASCII字符(U + 007F以上的字符)的Unicode转义。它还拒绝NULL字符(\ u0000),它不能用PostgreSQL的文本类型表示。
它不会保留空白区域,它会剥离JSON字符串中的前导/滞后空白区域以及JSON字符串中的空白区域,所有这些都只会使代码不整齐(毕竟这对你来说可能不是件坏事) 。)
它不保留对象键的顺序,处理键的方式与Python字典中的处理方式非常相似 - 未排序。如果您依赖JSON密钥的顺序,则需要找到解决此问题的方法。
最后,jsonb不会保留重复的对象键(这可能不是一件坏事,特别是如果你想避免数据中的歧义),只存储最后一个条目。
结论
PostgreSQL文档建议大多数应用程序应该更喜欢将JSON数据存储为jsonb,因为我们已经看到有显着的性能增强和仅有的小警告。
jsonb带来的功能非常强大,您可以很好地处理关系数据,就像在常规RDBMS中一样,但是所有这些都在JSON中,并且在性能上有非常显着的提升,结合了NoSQL解决方案的实用性。 RDBMS的强大功能。
切换到jsonb时的主要缺点是遗留代码,例如,可能依赖于对象密钥的排序;这是需要更新以按预期工作的代码。并且说明显而易见的是,作为9.4版中引入的一个特性,jsonb不是向后兼容的,你需要使用的jsonb关键字设置JSON表将破坏传统平台上的SQL代码。
最后,请注意我已经涵盖了指数及其运算符的一些典型用法;有关更多详细信息和示例,请查看官方PostgreSQL文档中的jsonb索引以及JSON函数和运算符。
原文:https://www.compose.com/articles/faster-operations-with-the-jsonb-data-type-in-postgresql/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 117 次浏览
【Postgresql架构】用MapReduce的方式思考,但使用SQL
对于那些考虑使用Citus的人来说,如果您的用例看起来很合适,我们通常愿意花一些时间与您一起帮助您了解Citus数据库及其可以提供的性能类型。我们通常与我们的一位工程师进行大约两个小时的配对,以完成此操作。我们将讨论架构,加载一些数据并运行一些查询。如果最后有时间,将相同的数据和查询加载到单节点Postgres中并查看我们如何进行比较总是很有趣。在看了多年之后,我仍然很高兴看到单节点数据库的性能提高了10到20倍,在高达100倍的情况下也是如此。
最好的部分是,它不需要对数据管道进行大量的重新架构。它所要做的只是一些数据建模以及与Citus的并行化。
第一步是分片
我们之前已经讨论过这一点,但是获得这些性能提升的首要关键是Citus将您的数据隐藏在更小的,更易于管理的部分。这些碎片(是标准Postgres表)分布在多个物理节点上。这意味着您可以从系统中获得更多的集体能力。当您定位单个分片时,它非常简单:查询被重新路由到基础数据,一旦获得结果,它就会返回它们。
用MapReduce的方式思考
MapReduce已经存在了很多年,并由Hadoop普及。关于大规模数据的问题是为了从中获得及时的答案,您需要对问题进行分解并并行进行操作。或者,您会找到一个非常快的系统。使用更大,更快的设备的问题在于,数据增长超过了硬件改进的速度。

MapReduce本身是一个框架,用于拆分数据,根据需要将数据改组到节点,然后在重新组合结果之前对数据的子集执行工作。让我们举一个例子,例如累计总浏览量。如果我们想在此基础上利用MapReduce,我们会将浏览量分成4个单独的存储桶。我们可以这样做:
for i = 1 to 4:
for page in pageview:
bucket[i].append(page)
现在,我们将有4个存储桶,每个存储桶都具有一组网页浏览量。从这里我们可以执行许多操作,例如搜索以找到每个存储桶中最近的10个,或计算每个存储桶中的综合浏览量:
for i = 1 to 4:
for page in bucket:
bucket_count[i]++
现在,通过合并结果,我们可以获得页面浏览总数。如果将工作分配到四个不同的节点,则与使用一个节点的所有计算来执行计数相比,可以看到性能大约提高了4倍。
MapReduce作为一个概念
MapReduce在Hadoop生态系统中广为人知,但您不必跳入Java来利用。 Citus本身有多个不同的执行器来处理各种工作负载,我们的实时执行器实质上与成为MapReduce执行器是同义的。
如果您在Citus中有32个分片并运行SELECT count(*),我们将其拆分并运行多个计数,然后将最终结果汇总到协调器上。但是,除了计数(*)以外,您还可以做更多的事情,而平均值呢。对于平均值,我们从所有节点和计数中获得总和。然后,我们将总和与计数加在一起,并在协调器上进行最终数学运算,或者您可以将每个节点的平均值求和。实际上,它是:
SELECT avg(page), day FROM pageviews_shard_1 GROUP BY day; average | date ---------+---------- 2 | 1/1/2019 4 | 1/2/2019 (2 rows) SELECT avg(page), day FROM pageviews_shard_2 GROUP BY day; average | date ---------+---------- 8 | 1/1/2019 2 | 1/2/2019 (2 rows)
当我们将以上结果输入表中,然后取它们的平均值时,我们得到:
average | date ---------+---------- 5 | 1/1/2019 3 | 1/2/2019 (2 rows)
请注意,在Citus中,您实际上不必运行多个查询。 在后台,我们的实时执行器可以处理它,实际上就像运行一样简单:
SELECT avg(page), day FROM pageviews GROUP BY day; average | date ---------+---------- 5 | 1/1/2019 3 | 1/2/2019 (2 rows)
对于大型数据集,MapReduce中的思路为您提供了无需费力即可获得出色性能的途径。 最好的部分可能是您不必编写数百行来完成它,您可以使用与编写相同的SQL来完成。 在幕后,我们负责繁重的工作,但是很高兴知道它在幕后如何工作。
原文:https://www.citusdata.com/blog/2019/02/21/thinking-in-mapreduce-but-with-sql/
本文:http://jiagoushi.pro/node/926
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 80 次浏览
【Postgresql架构】解释CREATE INDEX CONCURRENTLY
- 70 次浏览
【Postgresql架构】逻辑复制内幕
- 82 次浏览
【Postgresql架构】部分索引( Partial Indexes)如何影响Postgres中的UPDATE性能
部分索引是节省磁盘空间和提高记录查找性能的好方法。共同的规则是“用它当你能负担得起”——换句话说,如果你所有的查询涉及到一些过滤器,这是通常被认为是一个好主意,以包括过滤索引定义,以减少其规模和改善其性能(指数越小,越快就会执行相应的索引扫描或IndexOnlyScan)。
但是,部分索引是否总是提供更好的性能?好,让我们看看。
举个简单的例子:
create table asset(
id bigserial primary key,
owner_id int8 not null,
name text not null,
price int8
);
假设在这个表格中我们存储了一些资产的信息,让我们用一些样本数据来填充它:
insert into asset(
owner_id,
name,
price
)
select
i,
round(random()*100000)::text,
round(random() * 10000)
from generate_series(1, 600000) _(i);
再加入更多的样本数据,这次的价格“未知”:
insert into asset( owner_id, name, price ) select i, round(random()*100000)::text, null -- price is unknown (yet) from generate_series(600001, 1000000) _(i); vacuum analyze asset;
现在我们有100万条记录,其中40%的价格未知(无效)。
价格会不时变化,因此任何记录都可能被更新为新的、经过修正的价格值。
接下来,考虑这样一种情况:我们需要快速找到属于某个特定用户的所有资产,但我们从不对价格未知的记录感兴趣:
select *
from asset
where
owner_id = :owner_id
and price is not null;
我们需要使用什么索引?我们很自然地认为,这部分指数将完美地满足我们的需要:
create index i_asset_price_partial
on asset
using btree(owner_id)
where price is not null;
但是拥有最好的表现真的有帮助吗?
这得视情况而定。
首先,这样的索引会小得多,即常规的全表索引:
create index i_asset_price_full
on asset
using btree(owner_id);
让我们来比较一下它们的大小:
test=# \x Expanded display is on.test=# \di+ i_asset_price_partial -[ RECORD 1 ]---------------------- Schema | public Name | i_asset_price_partial Type | index Owner | nikolay Table | asset Size | 13 MB Description |test=# \di+ i_asset_price_full -[ RECORD 1 ]-------------- Schema | public Name | i_asset_price_full Type | index Owner | nikolay Table | asset Size | 21 MB Description |
正如预期的那样,全表索引的大小更高——21 MB vs 13 MB,因此比部分索引大60%左右。这是您可以决定的时候—好吧,我最好使用部分索引(就像我在优化的一个Postgres实例中所做的那样)。但是不要着急,等一会儿。
那么SELECT性能呢?让我们用pgbench快速检查一下,这是Postgres的本地基准测试工具:
echo "\set owner_id random(1, 1 * 1000000)" > selects.bench echo "select from asset where owner_id = :owner_id and price is not null;" >> selects.bench pgbench -n -T 30 -j 4 -c 12 -M prepared -f selects.bench -r test
在没有索引的情况下,我的笔记本只有13.12 TPS(每秒事务数):
$ pgbench -n -T 30 -j 4 -c 12 -M prepared -r test -f selects.bench
transaction type: selects.bench
scaling factor: 1
query mode: prepared
number of clients: 12
number of threads: 4
duration: 30 s
number of transactions actually processed: 397
latency average = 915.767 ms
tps = 13.103765 (including connections establishing)
tps = 13.113909 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.003 \set owner_id random(1, 1 * 1000000)
908.755 select from asset where owner_id = :owner_id and price is not null;
连续扫描不适合在干草堆里找针。这里没有惊喜。
全表索引(单独定义,不包含部分索引):
$ pgbench -n -T 30 -j 4 -c 12 -M prepared -r test -f selects.bench
transaction type: selects.bench
scaling factor: 1
query mode: prepared
number of clients: 12
number of threads: 4
duration: 30 s
number of transactions actually processed: 779801
latency average = 0.462 ms
tps = 25963.230818 (including connections establishing)
tps = 25972.470987 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.001 \set owner_id random(1, 1 * 1000000)
0.460 select from asset where owner_id = :owner_id and price is not null;
和部分索引(再次定义,没有全文):
$ pgbench -n -T 30 -j 4 -c 12 -M prepared -r test -f selects.bench
transaction type: selects.bench
scaling factor: 1
query mode: prepared
number of clients: 12
number of threads: 4
duration: 30 s
number of transactions actually processed: 817490
latency average = 0.440 ms
tps = 27242.705122 (including connections establishing)
tps = 27253.100588 (excluding connections establishing)
script statistics:
- statement latencies in milliseconds:
0.001 \set owner_id random(1, 1 * 1000000)
0.439 select from asset where owner_id = :owner_id and price is not null;
可以看到,使用部分索引的select要比使用全表索引的select快一点(~5%)。这是我们所期望的。
现在让我们看看更新性能的不同。我们将只接触那些已经定义了价格的记录,以保持null(40%)的数量不变,以防我们想要做更多的实验:
echo "\set id random(1, 1 * 600000)" > updates.bench echo "update asset set price = price + 10 where id = :id;" >> updates.benchpsql test -c 'vacuum full analyze asset;' && \ psql test -c 'select pg_stat_reset();' >> /dev/null && \ pgbench -n -T 30 -j 4 -c 12 -M prepared -r test -f updates.bench
当除主键外没有索引时:14553 tps。
全文索引:14371 tps。
部分索引:12198 tps。
这看起来可能令人惊讶——部分索引显著地(约14%)减慢了更新速度!
为什么如此?要回答这个问题,让我们看看Postgres内部统计信息pg_stat_user_tables。注意到我们在运行pgbench进行更新之前调用了pg_stat_reset()函数吗?这是为了重置整个Postgres集群的统计数据并收集新的数据。现在,如果我们用这个查询每次实验后检查这个查询的结果:
select
n_tup_upd,
n_tup_hot_upd,
round(100 * n_tup_hot_upd::numeric / n_tup_upd, 2) as hot_ratio
from pg_stat_user_tables
where relname = 'asset';
我们会看到这样的情况:
-- no indexes except PK
n_tup_upd | n_tup_hot_upd | hot_ratio
-----------+---------------+-----------
436808 | 409220 | 93.68-- full-table index
n_tup_upd | n_tup_hot_upd | hot_ratio
-----------+---------------+-----------
431473 | 430807 | 99.85-- partial index
n_tup_upd | n_tup_hot_upd | hot_ratio
-----------+---------------+-----------
366089 | 0 | 0.00这些数字很清楚——在部分索引的情况下,我们将完全失去热更新。HOT表示仅堆元组,这是PostgreSQL执行元组更新的内部技术。虽然在PostgreSQL的主文档中没有详细的说明,但是你可以在README中找到详细的解释。来自Postgres源文件的热(或阅读本文:“使用热更新提高更新查询的速度”)。
简而言之,如果在更新期间,新老元组(行你更新的版本)都位于同一页面的内存,这更新不修改任何索引列,特殊类型的优化会发生,这将允许Postgres节省时间,首先,因为它不会改变索引条目。
但是这里的索引列究竟是什么呢?自述文件。热解释:
HOT解决了一个受限但有用的特殊情况:一个tuple以不改变其索引列的方式重复更新。(这里的“索引列”是指在索引定义中引用的任何列,包括例如在部分索引谓词中测试但不存储在索引中的列。)
在我们的例子中,索引依赖于price列,它是我们的部分索引谓词,一旦我们更改它,Postgres就不能使用HOT,因此我们的更新(和删除)通常会变慢。
我相信这可以在Postgres内部进行优化:如果tuple中的旧值和新值都有price不为空,这意味着没有理由触及索引。但是Postgres内部没有这样的优化(到2018年3月,最新版本是Postgres 10),所以开发人员在优化数据库模式和查询时必须牢记这一点。
我希望你不会认为部分索引是不利于更新性能——这并不坏,但是你需要注意你使用的组列索引定义和记住这个增益之间的权衡选择性能和更新性能可能的损失。
这只是众多例子中的一个,在非专业人士的眼中,数据库优化过程是多么棘手——我经常听说Postgres DBA的工作是一种“魔法”。如果您需要处理数百或数千个表、索引和其他DB对象,并试图玩打地鼠游戏,那么猜测哪些更改对您最有帮助。在优化一个SQL查询时,通常会损害其他查询的性能
我相信在不久的将来会出现新的自动化数据库管理工具,帮助dba和开发人员进行性能优化。
同时,我建议使用我的新项目postgres_dba——它是一个SQL报告集合,绑定到一个方便的工具集,可以在psql中以交互模式运行。这是一个名为“3 - Load Profile”的特殊报告,它允许您查看每个表中选择、插入、更新和删除了多少元组,以及所有更新中热更新的比例:

来自postgres_dba工具集的报告“3 - Load Profile”显示了数据库中每个表的热更新比率
这是控制表的更新性能的一种非常基本的方法。如果您看到一个表的热更新率很低,那么为了理解为什么需要检查这个表的所有索引定义—它们是否允许热更新,或者更新查询是否涉及参与某些索引定义的列?
原文:https://medium.com/@postgresql/how-partial-indexes-affect-update-performance-in-postgres-d05e0052abc
本文:http://jiagoushi.pro/how-partial-indexes-affect-update-performance-postgres
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 143 次浏览
【Postgres】最有用的Postgres扩展:pg_stat_statements
扩展能够扩展,更改和推进Postgres的行为。 怎么样? 通过挂钩到低级的Postgres API挂钩。 可以水平扩展Postgres的开源Citus数据库本身是作为PostgreSQL扩展实现的,这使Citus可以与Postgres版本保持最新,而不会像其他Postgres fork那样落后。 尽管我想更深入地研究最有用的Postgres扩展:pg_stat_statements,但我之前已经写过各种扩展类型。
你看,我刚从FOSDEM回来。 FOSDEM是在布鲁塞尔举行的年度免费开源软件会议,在活动中,我在PostgreSQL开发室中发表了有关Postgres扩展的演讲。 到今天结束时,Postgres开发室中进行的一半以上的讨论都提到了pg_stat_statements:
如果您使用Postgres,但尚未使用pg_stat_statements,则必须将其添加到工具箱中。而且,即使您很熟悉,也可能值得重温。
pg_stat_statements入门
Pg_stat_statements是所谓的contrib扩展名,可以在PostgreSQL发行版的contrib目录中找到。这意味着它已经随Postgres一起提供了,您无需从源代码构建它或安装软件包。如果尚未启用数据库,则可能必须启用它。这很简单:
CREATE EXTENSION pg_stat_statements;
如果您在主要的云提供商上运行,则很有可能他们已经为您安装并启用了它。
一旦安装了pg_stat_statements,它就会开始悄悄地在后台运行。 Pg_stat_statements记录针对您的数据库运行的查询,从中删除一些变量,然后保存有关该查询的数据,例如花费了多长时间以及基础读/写发生了什么。
注意:它不会保存每个查询,而是对其进行参数化,然后保存汇总结果
让我们来看几个示例。假设我们执行以下查询:
SELECT order_details.qty, order_details.item_id, order_details.item_price FROM order_details, customers WHERE customers.id = order_details.customer_id AND customers.email = 'craig@citusdata.com'
它将查询转换为:
SELECT order_details.qty, order_details.item_id, order_details.item_price FROM order_details, customers WHERE customers.id = order_details.customer_id AND customers.email = '?'
如果这是我在应用程序中经常执行的查询,以获取诸如零售订单历史记录之类的订单详细信息,那么它不会节省我为每个用户运行该订单的频率,而是节省了汇总视图。
看数据
从这里我们可以查询pg_stat_statements的原始数据,我们将看到类似以下内容:
SELECT * FROM pg_stat_statements; userid | 16384 dbid | 16388 query | select * from users where email = ?; calls | 2 total_time | 0.000268 rows | 2 shared_blks_hit | 16 shared_blks_read | 0 shared_blks_dirtied | 0 shared_blks_written | 0 local_blks_hit | 0 local_blks_read | 0 local_blks_dirtied | 0 local_blks_written | 0 ...
使用pg_stat_statements提取见解
现在,这里有大量有价值的信息,作为高级用户,有时它们都可以证明是有价值的。但是,即使没有开始理解数据库的内部结构,您仍然可以通过以某些方式查询pg_stat_statements来获得一些真正强大的见解。通过查看total_time和每个查询被调用一次的次数,我们可以非常快速地查看哪些查询经常运行以及它们平均消耗了多少:
SELECT (total_time / 1000 / 60) as total, (total_time/calls) as avg, query FROM pg_stat_statements ORDER BY 1 DESC LIMIT 100;
您可以通过多种不同的方式对此进行过滤和排序,您可能只想关注运行1000多次的查询。或平均超过100毫秒的查询。上面的查询向我们显示了数据库消耗的总时间(以分钟为单位)以及平均时间(以毫秒为单位)。通过上面的查询,我会得到类似以下内容的信息:
total | avg | query --------+--------+------------------------- 295.76 | 10.13 | SELECT id FROM users... 219.13 | 80.24 | SELECT * FROM ... (2 rows)
根据经验,我知道快速获取记录时,PostgreSQL应该能够在1ms内返回。鉴于此,我可以开始优化工作。在上面的内容中,我看到将第一个查询降低到1ms会有所改善,但是优化第二个查询将对整个系统的性能产生更大的提升。
特别说明:如果要构建多租户应用,则可能不希望pg_stat_statements参数化tenant_id。为了解决这个问题,我们构建了citus_stat_statements来为每个租户提供见解。
原文:https://www.citusdata.com/blog/2019/02/08/the-most-useful-postgres-extension-pg-stat-statements/
本文:http://jiagoushi.pro/node/930
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 109 次浏览
【Postgres架构】Postgres中的物化视图与汇总表
多年来,物化视图一直是Postgres期待已久的功能。他们最终到达了Postgres 9.3,尽管当时很有限。在Postgres 9.3中,当刷新实例化视图时,它将在刷新时在表上保持锁定。如果您的工作量是非常繁忙的工作时间,则可以工作,但是如果您要为最终用户提供动力,那么这将是一个大问题。在Postgres 9.4中,我们看到了Postgres实现了同时刷新实例化视图的功能。现在,我们已经完全烘焙了物化视图的支持,但即使如此,我们仍然看到它们可能并不总是正确的方法。
什么是视图view?
对于那些不是数据库专家的人,我们将做一点备份。要了解什么是实体化视图,我们首先来看一个标准视图。视图是已定义的查询,您可以像表一样对其进行查询。当您具有通常用于某些标准报表/构建块的复杂数据模型时,视图特别有用。稍后我们将介绍一个实例化视图。
视图非常适合简化复杂SQL的复制/粘贴。缺点是每次执行视图时都会重新计算结果。对于大型数据集,这可能会导致扫描大量数据,使缓存无效,并且通常速度较慢。输入实例化视图
物化你的视图
让我们从一个可能包含大量原始数据的示例架构开始。在这种情况下,一个非常基本的网络分析工具会记录综合浏览量,发生时间和用户的会话ID。
CREATE TABLE pageviews ( id bigserial, page text, occurred_at timestamptz, session_id bigint );
基于这些原始数据,有很多不同的视图可能非常普遍。而且,如果我们有一个实时仪表板,我们将为它提供动力,因为它可能花费很长时间来查询原始数据,因此很快变得不可行。相反,我们可以对物化视图进行一些汇总:
CREATE MATERIALIZED VIEW rollups AS SELECT date_trunc('day') as day, page, count(*) as views FROM pageviews GROUP BY date_trunc('day'), page;
对于每天至少浏览一次的页面,这将为我们每天提供1条记录。
对于每天晚上批处理的事情,可以处理前一天的事情。但是对于面对客户的事情,您可能不希望等到一天结束后再提供有关网页浏览量如何进行分析的信息。当然,您可以定期刷新一次:
refresh materialized view rollups;
这种刷新方式的缺点是每次刷新时都会重新计算当天的总数,这实际上是在进行不必要的处理。
为了可扩展性增量汇总
另一种方法是使用upsert,它使我们能够增量汇总数据而不必重新处理所有基础数据。 Upsert本质上是创建或更新。为此,我们将创建一个表而不是物化视图,然后在其上施加唯一约束:
CREATE TABLE ( day as timestamptz, page text, count as bigint, constraint unq_page_per_day unique (day, page) );
现在开始汇总,我们将执行以下操作:
INSERT INTO rollups SELECT date_trunc('day') as day, page, count(*) as views FROM pageviews GROUP BY date_trunc('day'), page;
这基本上与我们的物化视图相同。但是由于我们的独特限制,当遇到已经插入的记录时,插入会出错。为了完成这项工作,我们将调整查询以完成两件事。一项我们将只处理新记录,另一项我们将使用upsert语法。
为了处理新记录,我们将保留上次停止记录的记录,仅处理新记录。我们在本文中概述了一组方便使用的函数/表。使用适当的函数和表格来跟踪我们上次中断的位置,现在我们将查询更新为仅汇总自上次处理后的数据。然后,我们将其与upsert结合在一起。 upsert将尝试插入当天/页面的任何新记录,如果已经看到这些值,则将增加它们:
INSERT INTO rollups SELECT day, page, count(*) as views FROM pageviews WHERE event_id > e GROUP BY day, page ON CONFLICT (day, page) DO UPDATE SET views = views + EXCLUDED.views;
物化视图与汇总表哪个正确?
物化视图是一种非常简单直接的方法。它们的易用性使它们成为快速简便的事情的理想选择。但是,对于具有较大活动负载的较大数据集和数据库,仅处理上一次汇总的净新数据可以更有效地利用资源。哪种方法最合适取决于时间和系统资源。尽管如您所见,汇总方法仅需要一点点努力,并且可以进一步扩展。
原文:https://www.citusdata.com/blog/2018/10/31/materialized-views-vs-rollup-tables/
本文:http://jiagoushi.pro/node/928
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 88 次浏览
【Postgres架构】Postgres和Netdata:适用于autovacuum和pg_stat_bgwriter
- 34 次浏览
【Postgres架构】为什么RDBMS是分布式数据库的未来,请参见Postgres和Citus
大约10年前,我加入了Amazon Web Services,在那里我第一次看到了在分布式系统中进行权衡的重要性。在大学里,我已经了解了一致性和可用性之间的权衡(CAP定理),但实际上,频谱要比这深得多。任何设计决策都可能涉及延迟,并发性,可伸缩性,耐用性,可维护性,功能性,操作简便性以及系统其他方面之间的权衡,而这些权衡会对应用程序的功能和用户体验产生有意义的影响,并且即使是业务本身的有效性。
也许在权衡需求最明显的分布式系统中最具挑战性的问题是构建分布式数据库。当应用程序开始需要可以在许多服务器上扩展的数据库时,数据库开发人员开始做出极端的权衡。为了在许多节点上实现可伸缩性,分布式键值存储(NoSQL)抛弃了传统关系数据库管理系统(RDBMS)提供的丰富功能集,包括SQL,联接,外键和ACID保证。由于每个人都想要可伸缩性,因此RDBMS消失只是时间问题,对吗?实际上,关系数据库继续主导着数据库领域。这就是为什么:
在分布式系统(或任何系统)中进行权衡时,要考虑的最重要方面是开发成本。
数据库软件所做出的权衡将对应用程序的开发成本产生重大影响。在高级应用程序中处理需要可用性,可靠性和性能的数据是一个固有地需要解决的问题。成功解决每个小问题所需的工时数量可能很大。幸运的是,数据库可以解决许多这些子问题,但是数据库开发人员也面临成本问题。实际上,要使数据库足以满足大多数应用程序的功能,保证和性能,就需要数十年的时间。那就是建立关系数据库如PostgreSQL和MySQL的地方。
在Citus Data,我们从不同角度解决了数据库可伸缩性的需求。我和我的团队在过去的几年中花费了很多时间将已建立的RDBMS转换为分布式数据库,而又不会失去其强大功能或从基础项目中分叉。通过这样做,我们发现RDBMS是构建分布式数据库的理想基础。
通过在RDBMS之上构建来降低应用程序开发成本
使RDBMS对开发应用程序(尤其是开源RDBMS,尤其是云RDBMS)如此吸引人的原因在于,您可以有效地利用数十年来对RDBMS进行的工程投资,并利用这些RDBMS功能。您的应用,降低了开发成本。
RDBMS为您提供:
- 围绕数据完整性和持久性的有意义的保证
- 极大的灵活性来操纵和查询数据
- 最先进的算法和数据结构,可在各种工作负载下获得高性能。
这些功能几乎对任何非平凡的应用都很重要,但是要花很长时间才能开发。另一方面,某些应用程序的工作量对于单台计算机来说太过苛刻,因此需要水平可伸缩性。
许多新的分布式数据库正在开发中,并且正在分布式键值存储(“ NewSQL”)之上实现RDBMS功能,例如SQL。尽管这些较新的数据库可以使用多台计算机的资源,但是在SQL支持,查询性能,并发性,索引,外键,事务,存储过程等方面,它们仍远未建立在关系数据库系统上。您遇到许多要在应用程序中解决的复杂问题。
许多大型互联网公司采用的替代方法是RDBMS的手动,应用程序层分片(通常是PostgreSQL或MySQL)。手动分片意味着有许多RDBMS节点,并且应用程序会根据某种条件(例如,用户ID)决定连接到哪个节点。应用程序本身负责如何处理数据放置,架构更改,查询多个节点,复制表等,因此,如果执行手动分片,最终将在应用程序中实现自己的分布式数据库,这可能甚至更多。昂贵。
幸运的是,有一种方法可以解决开发成本难题。
PostgreSQL已有数十年的发展历史,其令人难以置信的重点是代码质量,模块化和可扩展性。这种可扩展性提供了一个独特的机会:无需分叉就可以将PostgreSQL转换为分布式数据库。这就是我们构建Citus的方式。
Citus:成为世界上最先进的分布式数据库
大约5年前,当我加入一家名为Citus Data的初创公司时,我为在竞争激烈的市场中建立高级分布式数据库而无任何现有基础架构,品牌知名度,进入市场,资本或大量工程师的挑战感到沮丧 。 仅开发成本就似乎是无法克服的。 但是,就像应用程序开发人员利用PostgreSQL来构建复杂的应用程序一样,我们利用PostgreSQL来构建……分布式PostgreSQL。
我们创建了Citus,这是开源的PostgreSQL扩展,而不是从头开始创建分布式数据库,它以提供水平扩展的方式透明地分发表和查询,但是应用程序开发人员需要具备所有PostgreSQL功能才能成功。
通过使用在计划查询时Postgres调用的内部挂钩,我们能够将分布式表的概念添加到Postgres。

分布式表的分片存储在具有所有现有功能的常规PostgreSQL节点中,Citus发送常规SQL命令以查询分片,然后合并结果。 我们还添加了参考表的概念,该参考表可在所有节点上复制,因此可以通过任何列与分布式表连接。 通过进一步增加对分布式事务,查询路由,分布式子查询和CTE,序列,更新等的支持,我们达到了最先进的PostgreSQL功能可以使用的规模,但现在已经可以大规模使用。

Citus相对来说还很年轻,但是已经建立在PostgreSQL之上,已经成为世界上最先进的分布式数据库之一。与PostgreSQL的完整功能集相比,这令人毛骨悚然,还有许多工作要做,Citus现在提供的功能及其扩展方式使其在分布式数据库环境中具有很大的独特性。许多当前的Citus用户最初使用Postgres中的许多高级功能在单节点PostgreSQL服务器上建立业务,然后仅用几周的开发工作就迁移到Citus,以将其数据库模式转换为分布式表和引用表。对于任何其他数据库,从单节点数据库到分布式数据库的这种迁移可能要花费数月甚至数年的时间。
使用Citus将Postgres功能转变为超级强大
像PostgreSQL这样的RDBMS具有几乎无限的功能和成熟的SQL引擎,可让您以多种方式查询数据。当然,这些功能只有在速度很快时才对应用程序有用。幸运的是,PostgreSQL很快,并且通过诸如实时查询编译之类的新功能不断提高,但是当您拥有大量数据或流量以至于一台机器速度太慢时,那些强大的功能就不再那么有用了……除非您可以结合许多计算机的计算能力。这就是功能成为超级大国的地方。
通过采用PostgreSQL功能并进行扩展,Citus具有许多超级功能,这些功能使用户可以将数据库扩展到任意大小,同时保持高性能及其所有功能。
- 查询路由意味着获取查询(作为查询的一部分),并让存储相关分片的RDBMS节点处理查询,而不是收集或重新整理中间结果,当查询通过分发列进行过滤和合并时,这是可能的。查询路由使Citus能够为多租户(SaaS)应用程序大规模支持底层PostgreSQL服务器的所有SQL功能,这些应用程序通常按租户ID进行过滤。就分布式查询计划时间和网络流量而言,此方法具有最小的开销,可实现高并发性和低延迟。
- 与顺序执行相比,跨分布式表中所有分片的并行,分布式SELECT允许您在短时间内查询大量数据,这意味着您可以构建具有一致响应时间的应用程序,即使您的数据和客户数量通过扩展数据库来增长。 Citus查询计划程序将从多个分片中读取数据的SELECT查询转换为一个或多个类似于map-reduce的步骤,其中并行查询每个分片(map),然后合并或重新组合结果(reduce)。对于线性比例尺,大多数工作应在映射步骤中完成,对于联接或按分布列分组的查询通常是这种情况。
- 联接是SQL的重要组成部分,其原因有两个:1)它们提供了极大的灵活性,可以以不同的方式查询数据,从而避免了应用程序中复杂的数据处理逻辑; 2)它们使您的数据表示更加紧凑。 。如果没有联接,则需要在每一行中存储大量冗余信息,这将大大增加存储,扫描表或将其保留在内存中所需的硬件数量。通过联接,您可以存储紧凑的不透明ID并进行高级过滤,而不必读取所有数据。
- 参考表看起来像其他任何表一样,但是它们在群集中的所有节点之间透明地复制。在典型的星型模式中,所有维表都将是参考表,而事实表则是分布式表。然后,事实表可以与任何列上的任何维表结合(并行!),而无需通过网络移动任何数据。在多租户应用程序中,参考表可用于保存在租户之间共享的数据。
- 子查询下推是并行,分布式SELECT,查询路由和联接之间的结合。可以通过子查询下推在单个回合中并行化包含高级子查询树的所有分片中的查询(例如子查询之间的联接),只要它们可以联接分布列上的所有分布式表(而引用表可以在任何列上联接)。这将启用非常高级的分析查询,该查询仍具有线性可伸缩性。 Citus可以利用PostgreSQL计划程序已经对所有查询进行的转换来识别可下推的子查询,并为所有剩余的子查询生成单独的计划。这允许有效地分布所有子查询和CTE。
- 索引就像桌子的腿。没有它们,要从桌子上拿东西会很费力,而且实际上不是桌子。 PostgreSQL特别提供了非常强大的索引功能,例如部分索引,表达式索引,GIN,GiST,BRIN和覆盖索引。这使查询(包括联接!)即使在大规模时也能保持快速。值得记住的是,索引查找通常比扫描数据的一千个内核快。 Citus通过索引各个分片来支持所有PostgreSQL索引类型。像Heap和Microsoft这样的高级用户尤其喜欢使用部分索引来处理针对许多不同事件类型的各种查询。
- 分布式事务允许您一次或根本不进行一组更改,这大大提高了应用程序的可靠性。 Citus可以使用类似于查询下推的方法将事务委派给PostgreSQL节点,并继承其ACID属性。对于跨碎片的交易,Citus使用PostgreSQL的内置2PC机制,并添加了一个分布式死锁检测器,该检测器使用PostgreSQL内部函数从所有节点获取锁表。
- 并行,分布式DML允许以相对较少的时间和事务方式转换和维护大量数据。分布式DML的常见应用是INSERT…SELECT命令,该命令将原始数据表中的行聚合到汇总表中。通过在所有可用内核上并行执行INSERT…SELECT,数据库将始终足够快以聚集传入的事件,而应用程序(例如仪表板)将查询紧凑的,高索引的汇总表。另一个例子是Citus用户,他吸收了260亿行不良数据,并使用分布式更新对其进行了修复,平均每秒修改了70万行。
- 批量加载是分析大量数据的应用程序的一项基本功能。即使在单个节点上,PostgreSQL的COPY命令也可以每秒向表追加数十万行,这已经超过了大多数分布式数据库基准测试。 Citus可以散出COPY流,以在许多PostgreSQL服务器上并行添加和索引许多行,这可以扩展到每秒数百万行。
- 存储过程和函数(包括触发器)在数据库内部提供了一个编程环境,用于实现单个SQL查询无法捕获的业务逻辑。当您需要一组操作来进行事务处理而无需在应用程序服务器和数据库之间来回移动时,对数据库进行编程的功能特别有用。使用存储过程可以简化您的应用程序,并使数据库更高效,因为您可以避免在进行网络往返时保持事务打开。尽管它可能会给数据库带来更多的负载,但是在数据库扩展时,这将不再是一个大问题。
尽管大多数这些功能对于开发需要扩展的复杂应用程序来说似乎都是必不可少的,但并不是所有分布式数据库都支持它们。下面我们根据公开提供的文档对一些流行的分布式数据库进行比较。

让我们的力量结合起来……
与在分布式数据库中拥有超级功能相比,更重要的是能够组合数据库超级功能来解决复杂的用例。

星球队长
图片由特纳广播公司提供。 ©特纳广播。由芭芭拉·皮尔(Barbara Pyle)和特德·特纳(Ted Turner)创建的Planet队长。
由于支持查询路由,参考表,索引,分布式事务和存储过程,因此即使最先进的多租户OLTP应用程序(例如Copper)也可以使用Citus扩展到单个PostgreSQL节点之外,而不会在应用程序中做出任何牺牲。
如果将子查询下推与并行的分布式DML结合使用,则可以在数据库内部转换大量数据。一个常见的示例是使用INSERT…SELECT构建汇总表,该表可以并行化以适应任何类型的数据量。结合通过COPY,索引,联接和分区进行的批量加载,您将拥有一个非常适合时间序列数据和实时分析应用程序(如Algolia仪表板)的数据库。
正如Microsoft的Min Wei在谈到Microsoft如何使用Citus和PostgreSQL分析Windows数据时指出的那样:Citus使您能够使用分布式OLTP解决大规模OLAP问题。
GoodOldSQL
Citus与其他分布式数据库有些不同,后者通常是从头开始开发的。 Citus没有引入PostgreSQL中尚未提供的任何功能。 Citus数据库以满足需要扩展的用例的方式扩展了现有功能。重要的是,大多数PostgreSQL功能已经针对各种用例进行了数十年的开发和测试,而当今用例的功能要求最终并没有太大不同;主要是数据的规模和大小不同。因此,在构建现代应用程序时,基于世界上最先进的开源RDBMS(PostgreSQL!)构建的分布式数据库(如Citus)可以成为您的武器库中最强大的工具。
原文:https://www.citusdata.com/blog/2018/11/30/why-rdbms-is-the-future-of-distributed-databases/
本文:http://jiagoushi.pro/node/929
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 87 次浏览
【关系型数据库】数据库深度探索:PostgreSQL
在最新一期的数据库深度挖掘中,我们采访了Brad Nicholson和Dave Cramer,了解了他们在PostgreSQL世界中的经历。
来自Crunchy Data的Dave (@dave_cramer)是PostgreSQL JDBC驱动程序的维护者。来自IBM的Brad是IBM云数据库组合的架构师和工程师。

阅读下面的采访,了解PostgreSQL社区是如何成为其最大的优势——但有时也是弱点——以及新的可插拔存储引擎如何帮助Postgres从数据库变成应用程序开发平台。
跟我们谈谈你自己和你今天在做什么?
戴夫·克莱默(华盛顿特区):我目前住在加拿大安大略省的一个小镇上,我很幸运,在我的职业生涯中一直在家工作。为了乐趣和刺激,我喜欢在赛道上开车探索我目前对物理学的理解。
至于我今天在做什么,复杂的数据让我可以全职工作在Postgres上,这真的,真的很酷。我目前正在JDBC驱动程序上工作,修复bug;实际上,正如我们所说的,在PostgreSQL的后端添加一些东西来帮助JDBC驱动程序和其他驱动程序处理像人们改变它们的搜索路径这样的事情。
我还帮助使用了Joe Conway编写的PL/R过程语言(他也处理复杂的数据)。还有一堆其他有趣的技术我正在帮助或参与。我最喜欢的一个是逻辑解码,它以一种只有Postgres才能做到的独特方式支持更改数据捕获。最近在Java PostgreSQL中,有许多我非常感兴趣的反应/异步驱动程序。
布拉德·尼科尔森(BN):我住在多伦多。今天,我在IBM Cloud数据库工作。我是一名架构师和工程师,在Postgres空间和其他数据库工作。真正处理将数据库即服务从内部自主开发的解决方案引入成熟的kubernet本地平台和产品的挑战。
你是如何加入PostgreSQL的?
完全是意外。我的职业生涯是从web开发人员开始的。我所从事的工作是MySQL(在事务出现之前),当时发生了各种奇怪的事情,比如列被悄悄地截断,人们会在那一天停止浏览器,让一个表写入,而不是另一个表。我在想,肯定有比这更好的方法,而那正是在Postgres成为一个可行的开源产品的时候。
我不记得具体的版本了,但是像Tom Lane这样的人接管了它,并开始在它上面做很多工作。所以,我打开它,它很快就解决了我的问题,因为它像你期望的那样工作。从那以后,我开始了一份博士后DBA的工作。
DC:这几乎是一种意外,有点……也许吧。这里有一个故事——大约在1998年,我辞去了工作,成为了一名顾问。该合同支持一个Java应用程序,在那时,这意味着获得微软网络订阅。
我遇到了一个问题,我打电话给支持部门,他们说需要三周时间。我说,“啊,这怎么可能呢?”我是按小时计酬的,所以三周的时间看起来有点长。我想一定会有更好的方法,于是我开始关注开源。
(一开始)我对它一无所知,所以我问一个朋友如何开始。他说:“打开邮件列表,开始回答你能回答的所有问题。”我对Java很感兴趣,所以我找到了JDBC列表,开始回答每个问题。第一次花了几天时间才弄明白,第二次花得少一些,一两个月后,我就可以不用做研究就能回答问题了。
在某个时候,维护JDBC驱动程序的家伙决定辞职,于是Bruce Momjian问我是否有兴趣支持它。我说,“是的。”现在我已经做了20年了。这就是我如何融入社区的。
在你看来,PostgreSQL的优点和缺点是什么?
DC:哦,哇,这是个有趣的挑战。我认为优势和劣势在于社区,而不是技术。引用路线图——我要总结一下,因为它有点长——它说这是一个“非商业的,全是志愿者的,自由的软件项目,因此,开发不需要正式的功能需求列表。”我们喜欢让开发者探索他们所选择的主题。”还有更多,但这就是要点。
我在某些方面看到了它的优势,因为项目往往不会被锁定在一个特定的解决方案上,因为有公司在营销特定的解决方案。因为它是完全开源的,当我们意识到我们所做的是错误的或者有更好的方法去做的时候,我们对维持现状没有既得利益。所以,我们放弃它,改变我们的路径。
举一个具体的例子,几年前,有一个关于复制的事实标准,这是一个基于触发器的解决方案。它有很多挑战,从那时起,社区开发了一种叫做逻辑复制的东西,它取代了基于触发的复制。我们现在有一个更好的解决方案。
在我看来,优势实际上也是劣势——认为我们有这个大项目和所有这些不同的解决方案。通常,在公司开发的产品中,只有一种方法来做一件特定的事情,这也是唯一的方法。
在PostgreSQL中,做一件事有10到15种方法。现在,Postgres正在被大量的人采用,这意味着有很多新用户试图找到做事情的正确方法。可能没有正确的方法,但可能有一大堆错误的方法。
对于习惯于使用商业软件的人(其中有一种受支持的解决方案)来说,弄清楚如何使用Postgres来架构您的解决方案是相当具有挑战性的。的好事,我和松脆的数据,这为公司提供了一个机会脆数据为已知的工作提供支持解决方案(至少知道工作的解决方案,我们理解,可以支持)。这就是为什么我认为这是一个优点和一个缺点。
BN:当然,社区是优势之一。与之相吻合的是许可证。最近有很多关于Mongo, Redis和Elasticsearch的开源许可的新闻。
在Postgres中,许可证是开放的——人们不能改变它或从它那里拿走东西。没人能买到Postgres;只要它还存在,它就会是一个开源项目。这是一个非常非常大的好处。
在更技术的方面,以及一个明显而乏味的事情,是稳定。总的来说,这是一个非常可靠的数据库,只要你远离一些可能会有一些边缘情况的前沿事物。
(它也)非常安全。我真正喜欢它的一点是——尤其是与大多数数据库相比——它的可预测性。总的来说,它的运作方式和失败方式都是可以预测的。它如何失败的可预测性是非常非常好的,特别是当你要为它进行自动化解决方案时。在我所使用的其他一些数据库中,缺乏可预测性是最大的挑战之一(有太多奇怪的边界情况)。
另一件事是可扩展性。当你研究扩展系统时,你可以在Postgres上构建的东西,而不需要派生主代码基,这实际上是很了不起的。你看一下这个东西,它在30年前以关系数据库的形式出现,现在正逐渐成为应用程序开发平台,甚至是数据库开发平台。这是很酷的。
在缺点方面,我们开始越来越多地看到的一件事是缺乏本地扩展故事,比如本地分片,它允许在Postgres上本机运行更大的工作负载。
我认为连接模型也确实有局限性。整个进程连接以及使用外部连接池;我们有一些第三方工具可以解决这个问题,但它们在多租户中并不能很好地工作,因为需要将连接总数保持在相对较低的水平,并且不能在数据库用户之间共享连接,因此您必须在某些时候放松您的安全模型。
逻辑解码和本地Postgres逻辑复制也非常酷。我认为现在有一个大漏洞——它实际上并不能很好地与流复制一起工作。您不能切换或故障转移一个成员并让它同步您的位置。构建下游系统来使用它们的更改确实很好,但是一旦您必须切换或故障转移,您就会失去位置。你必须考虑重新同步你的系统,这很麻烦。
我要提到的最后一个问题是过度依赖外部工具来正确地完成许多基本工作。Postgres为您提供了这个坚如摧的数据库,它带有用于部署、备份、复制等的钩子,但将解决方案组合在一起取决于您。我想Dave之前提到过,这样做会很复杂。您必须具备丰富的知识,才能组织可靠的Postgres部署,使用DbaaS解决方案,或者花钱请人来为您完成这些工作。
我认为,如果你看更现代的数据库,设置复制和故障转移等等并不是那么困难。这是一种配置,它内置在系统中,可以正常工作。
说到现代数据库,PG 12很快就会面世。你在那里期待什么?
DC:这和我之前说的很酷的新功能以及人们的各种各样的痒感是一致的。发生的一件事基本上是Postgres能力的下一个飞跃的基础——可插拔表存储接口。这是我感兴趣的“开发酷东西”。
从一开始,就像Postgres做事情的方式一样——在一个版本中,我们将开始一个特性的框架,它不会特别有用,但下一个版本会更有用一些,[下一个版本会更有用。Pluggable table storage接口将支持柱状存储、加密列和其他特定于领域的存储系统。此外,我们开始看到分区方面的改进。我们在每个主要版本中都为分区添加了功能。这将使PostgreSQL能够处理更大的工作负载。
BN:对我来说也是可插拔的表存储。这对Postgres来说是非常令人兴奋的事情。我之前提到了可扩展性这与之相吻合,对吧?一旦您开始考虑将扩展和可插拔表存储组合在一起,您就有了这个开发平台,您可以在上面开始构建各种很酷的东西。
另一件更以开发人员为中心的事情是JSON路径。Postgres具有非常棒的JSON功能。但如果你不是一个Postgres用户,你从使用一个文档存储来使用它,它使用起来会很奇怪。JSON路径更接近于能够在Postgres中以一种开发人员会觉得更友好的方式使用JSON。
你会给那些想要在Kubernetes上部署PostgreSQL的人什么建议?
BN:不要。说真的,现在每个人都想这么做,因为这是buzz技术。它确实解决了某些问题,但它引入了另一组问题。这一切都是关于权衡和理解你需要做出的选择。
你必须问问自己为什么要运行它。当你进入Kubernetes的世界时,你需要真正理解你在购买什么。从一个更加标准的部署配置文件来看,你完全改变了你的部署平台——事情如何被部署,事情如何移动。
很可能您还没有在容器中运行数据库。所以,当你来到Kubernetes,你就进入了集装箱化。你将不得不把很多你所知道的(关于内存管理和资源利用的)知识扔到一边,然后重新学习。这是一项伟大的事业。
您还可能需要熟练地破解Kubernetes的源代码,并弄清楚为什么它在做您认为它不应该做的事情(因为它有时会做)。
从那以后,如果你想继续前进,就不要白费力气了。基本上,有几家运营商(比如Dave, Crunchy有一家Postgres运营商),而经营Patroni(我们很喜欢)的Zalando也有一家Postgres运营商。所以,如果你真的想这么做,看看这些运算符,然后从那里开始。不要从零开始。
DC:与“不做”相反,我想说的是,调用复杂的数据。您知道,Kubernetes最初是为无状态的工作负载设计的。当你使用PostgreSQL时,这当然是一个挑战;两者有一些阻抗不匹配。
Crunchy数据对Kubernetes世界和Postgres世界有深刻的见解。正如Brad指出的,尝试自己做这是相当艰巨的。在这里你必须是两个世界的主人!一个人同时做到这两点是一个相当大的挑战。如果你想在Kubernetes上运行它,你必须雇人或者打电话给我们。
BN:还有一件事——博客圈有很多关于在Kubernetes上运行数据库的东西。他们非常专注于第一天:建立一个数据库。现在那些东西很容易。这之后发生的所有事情——数据库的生命周期——都变得非常困难。
DC:同样的,我们有很多问题的解决方案。如果你想让数据库运行,那很好。但如果你想让它继续运行,这是一个更大的问题。例如,Kubernetes可能会决定关闭您的pods。重新安排一个运行后的时间——我们有这类事情的解决方案。我告诉你,有人揪头发来找那些东西。我要重申布拉德说过的话:“不要白费力气。”
自己在Kubernetes上运行可能会犯一个错误,那么人们在使用PostgreSQL时还会犯哪些错误呢?
BN:我想说的是,最上面的一个没有使用连接池,不理解Postgres连接模型及其限制。人们启动了20份应用程序。每一个都试图打开几百个连接,接下来您就会发现连接不足或出现性能问题。您必须了解Postgres中的连接模型是如何工作的,并使用像PgBouncer这样的池程序将事情简化到更易于管理的数量。
DC:差不多是一样的。我认为这取决于项目的规模。有一些大型项目可以从一些初步的建筑咨询中受益。他们不是数据库专家(尤其是Postgres专家)。
实际上,有一天有人给我打电话说关于物联网项目,那个人有一个特别的解决方案,我知道这个方案行不通。他有一个天真、简单的解决方案,但这个方案注定会失败。阅读、研究,或者给有这方面知识的人打电话(并且说,“这是我想做的,有什么工具可以做吗?”)在项目的开始会有很长的路要走。
当然,在较小的规模上,如果你不试图做一些具有建筑挑战性的东西,学习如何调整Postgres。至少,阅读有关设置和安全性的文档对简化您的工作大有帮助。我们有一个很棒的文档网站,只是看起来没有多少人会读它。我猜这有点像试图吃掉一头大象,你从哪里开始呢?但我认为一些阅读是很有帮助的。
您有什么秘密的性能调优技巧吗?
BN:我不认为有任何秘密的性能调优技巧。我想对人们说的是
- 学习如何读取查询计划和优化查询。
- 调整数据模型。
- 修复错误的访问模式。
老实说,根据我的经验,你可以调整旋钮来改变计划,增加内存,诸如此类的事情。但是,总的来说,最大的好处来自于正确地修复错误的查询和错误的访问模式。为此,安装pg_stat_statements扩展并学习如何使用它。分析访问模式,验证访问模式。用一种迭代的方式去做——不要只做一次就忘记它。在你的产品发展的过程中就这样做。
在Postgres和大多数数据库中,更为微妙的一点是索引开销很大。Postgres深受文字放大的困扰。人们会抛出一堆索引来处理任何类型的查询,但他们没有意识到作为其中一部分的所有写操作的总体影响。因此,要仔细索引,查找您没有使用的索引并删除它们。你可以很容易地在网上找到你想要的东西。
DC:和布拉德说的差不多。在一天结束时,在数据库中,读和写磁盘花费的时间最多。这是非常简单的数学——I/O通道有一定的带宽,并且您试图在磁盘上读/写一定数量的字节,并且您有一定数量的时间。这个问题无法解决,但可以确保查询正常运行。
我所见过的每一个擅长于此的人都对监控他们的数据库保持警惕和无情。他们确保他们添加到代码中的每个查询不会爆炸。当他们发布新代码时,他们检查回归,他们测量每条SQL语句或测量应用程序。只是要确保你明白自己在做什么。
另一件重要的事情是他们的开发系统和开发数据比他们的生产数据要小几个数量级。然后他们在制作中得到了这些巨大的惊喜!有这样一个典型的时刻:“为什么不使用索引?”因为索引实际上更慢。这是因为他们没有足够的开发数据或测试数据来实际“测试”他们在生产中所做的事情。说到底,这是常识。测试一切,再次检查它,验证它,测量它,并修复损坏的部分。
PostgreSQL vs. MySQL:应用程序开发人员在选择数据库时应该考虑哪些事情?
DC:我对MySQL不是很熟悉,不能很好地回答这个问题。但是我可以谈谈他们在Postgres中应该注意什么。他们应该理解这个问题,“什么是事务?”他们应该理解问题的答案,“什么是事务隔离?”
我们今天在大型应用中看到的是,应用框架本身非常大。它们是大型的、复杂的框架,需要花费时间和精力来掌握它们。他们倾向于把数据库看作是一种“愚蠢”的存储。他们不会真的去注意它,直到它做了一些他们没有预料到的事情。所以,我认为他们至少应该知道什么是事务,什么是事务隔离。他们应该叫人……复杂的数据会很乐意提供帮助。
BN:我在这里没有太多的贡献,因为我不太了解MySQL从应用程序开发的角度。我已经很长时间没有在这种情况下使用它了,它已经改变了很多。
最后,你认为Postgres在未来5-10年里会走向何方?
DC:这是一个非常好的问题,这意味着我真的没有答案。我确实认为有些事情我们可以看看。
我可以给你们一些猜测;我们已经克服了在大企业中使用开源的污名。我敢打赌,没有一家《财富》500强公司是没有Postgres的。这意味着它的受欢迎程度将呈几何级数增长。使用它的人越多,就会有越多的人告诉他们的朋友。他们告诉朋友的越多,使用它的人就越多。对于这个项目来说,这意味着我们将有更多的人致力于代码库。
我发现在开源社区工作的人非常聪明。这是一种羞辱。有一些聪明的人将会解决我们今天遇到的一些难题。最大的挑战是,社区将不得不弄清楚如何与更多的人打交道。我不知道未来会发生什么,但我知道我们会有更多的人。
BN:我想补充一下Dave的观点,这是一个很好的观点。我认为Postgres做事情的方式将会有摩擦——他们有自己的方式来做事情,这与当今大多数人所习惯的github风格的工作流程不同。这并没有什么错,但是对于那些来自GitHub工作流之类的平台的人来说,这是一个更高的门槛。
在这方面会有一些挑战。我认为作为一个数据库,没有人能预测未来。但是如果你看看它是从哪里来的,它是从一个学术性的关系数据库到一个可靠的、开放源码的关系数据库到一个混合模型系统的关系和非关系的东西。
当您开始研究可插拔表存储和扩展框架时,我认为您会开始看到Postgres更像是一个瑞士军刀数据库。您将开始看到它处理更多的工作负载。
这是它。非常感谢Brad和David加入我们并分享他们对PostgreSQL的看法。请留意我们未来几周的下一次采访。特别感谢Emily Hu对这次采访的帮助。如果你还没有,看看我们的其他部分。
原文:https://www.ibm.com/cloud/blog/database-deep-dives-postgresql
本文:http://jiagoushi.pro/node/1142
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 61 次浏览
【数据库架构】PostgreSQL常用的开源扩展
如果您使用的是PostgreSQL,您可以利用优秀的开源扩展来根据您的业务需求增强或添加功能。这些扩展是由其社区积极开发的,这些社区与PostgreSQL社区本身是分开的。PostgreSQL有数百个OSS扩展,其中许多是在生产环境中实现的。
尽管它们功能强大,但要检查规范并验证其行为以做出符合您需求的最佳选择并不容易。本文介绍富士通客户和普通用户经常使用的OSS扩展。这可以作为选择OSS扩展的指南。
PostgreSQL社区简介
PostgreSQL相关社区有两种类型:
- 开发社区
- 除了PostgreSQL本身的开发社区之外,每个OSS扩展都有一个开发社区。
- 促进PostgreSQL广泛使用的社区
- 世界各地都有PostgreSQL用户组。
富士通热衷于与PostgreSQL社区合作。我们的一些员工是PostgreSQL开发社区的积极贡献者,我们的一名员工作为PostgreSQL企业联盟的董事会成员。富士通还赞助各种活动,如PGDay Down Under、PGDay Asia和PGCon。
常用OSS扩展
下面的列表显示了PostgreSQL经常使用的OSS扩展。该分类基于非功能需求的概念,包括性能、可扩展性、可操作性、监控、可用性、兼容性和安全性。
可操作性
- pg_bulkload-提供高速加载大量数据的能力。
- pg_rman—支持备份操作,如备份/恢复简化和备份生成管理。
- pgBackRest—备份/恢复管理工具,提供多线程格式的数据库备份和高速备份所需的功能。
- Barman—备份/恢复管理工具,简化了PostgreSQL的时间点恢复过程,集中管理多个数据库集群的时间点备份。
- pg_repack-通过重新组织臃肿的表和索引,删除不必要的区域并重新排列行。由于它持有锁的时间很短,因此可以在正常业务操作期间使用。
- pgAdmin-简化数据库对象的创建、维护和使用的图形用户界面。
可扩展性
- pg_bigm-通过名为2-gram(bigram)的方法为全文搜索创建索引,允许对字符串进行高速搜索。
- PostGIS-允许用户使用SQL管理、编辑、搜索和计算地理空间信息。
- oracle_fdw-提供从PostgreSQL访问oracle表和视图的外部数据包装器。在此查看如何使用Oracle_fdw链接到Oracle数据库。
- PostgreSQL JDBC驱动程序-提供用于从Java连接到PostgreSQL的API。
- psqlODBC-PostgreSQL的ODBC驱动程序,提供用于从Microsoft Access、Microsoft Excel等连接到PostgreQL的API。
- Npgsql-一个.NET数据提供程序,提供用于从Microsoft.NET连接到PostgreSQL的API。
性能
- pg_hint_plan-通过在查询中指定提示子句,在不更改SQL语句或GUC参数的情况下控制执行计划。
- pg_dbms_stats-管理PostgreSQL统计信息并间接控制执行计划。
- PgBouncer-在PostgreSQL服务器和客户端之间运行的软件。提供连接池功能。
监测
- check_postgres-监视数据库运行状况并报告异常情况。
- pgBadger-分析PostgreSQL日志文件并生成统计报告,如SQL执行状态。
- pg_statsinfo-定期收集和累积PostgreSQL操作统计信息,以监控数据库操作。生成累积信息的文本报告。
- pg_stats_reporter-根据pg_statsinfo获取和累积的信息生成HTML格式的图形报告。
可用性
- pgpool II-在PostgreSQL服务器和客户端之间运行的软件。提供连接池、负载平衡、复制和自动故障切换等功能。
兼容性
- orafce—提供与Oracle数据库兼容的函数和数据类型等兼容性。
- ora2pg-支持从Oracle迁移到PostgreSQL的工具。从Oracle数据库读取对象定义和数据,并将其转换为PostgreSQL可执行的格式。
安全
- pgaudit-使用PostgreSQL的日志功能获取审计日志。
有关每个OSS扩展规范的详细信息,请参阅其网站。
按类别映射
PostgreSQL特性和OSS扩展的分类和映射如下所示。
从上图中,您可以看到用于可伸缩性、可操作性和监控的OSS扩展的数量非常多。这是因为这些扩展是作为一个组件或工具提供的,可以嵌入到PostgreSQL主体中,以执行重要任务,例如使PostgreSQL与各种应用程序的API兼容,将PostgreSQL链接到各种外部数据,或者根据各种需求和操作模式调整PostgreSQL。
为了根据您的业务需求选择最佳的OSS扩展,了解每个OSS扩展的特性和好处非常重要。
- 105 次浏览
【数据库架构】使用pgpool II的PostgreSQL高可用性
企业数据库系统要求高可用性——系统应能容忍故障并始终稳定运行。同样重要的是可扩展性,以便随着系统的发展可以添加服务器。即使数据量或访问量增加,也需要保持响应速度和处理能力。
在本文中,我们讨论了使用pgpool II(PostgreSQL开源扩展之一)的高可用性系统设置。它是我们的解决方案之一,可以满足这两个要求:高可用性和可扩展性。
什么是pgpool II?
pgpool II是一个中间件,可以在Linux和Solaris上运行,在应用程序和数据库之间运行。其主要特点包括:
| Feature | Classification | 解释 |
| Load balancing | 高效地将只读查询分发到多个数据库服务器,以便可以处理更多查询。 | 性能改进 |
| Connection pooling | 保留/重用与数据库的连接,以减少连接开销,并在重新连接时提高性能。 | |
| Replication | 在任何给定时间点将数据复制到多个数据库服务器,以实现数据库冗余。† | 数据库的高可用性 |
| Automatic failover | 如果主数据库服务器发生故障,将自动切换到备用服务器以继续操作。 | |
| Online recovery | 在不停止操作的情况下还原或添加数据库服务器。 | |
| Watchdog | 链接pgpool II的多个实例,执行心跳监测,并共享服务器信息。当发生故障时,开关自动导通。 | pgpool II的高可用性 |
pgpool II可以使用自己的复制功能或其他软件提供的复制功能,但通常建议使用PostgreSQL的流式复制。流复制是一种通过将PostgreSQL(主)的事务日志(WAL)传送到PostgreSQL的多个实例(备用)来复制数据库的功能。这一功能在文章“什么是流式复制,以及如何设置它?”中进行了解释。

Diagram illustrating streaming replication
负载平衡和连接池
横向扩展是通过添加服务器来提高整个数据库系统处理能力的一种方法。PostgreSQL允许您使用流复制进行扩展。在此场景中,将查询从应用程序高效地分发到数据库服务器至关重要。PostgreSQL本身没有分发功能,但您可以利用pgpoolII的负载平衡,它可以高效地分发只读查询,以平衡工作负载。
另一个很棒的pgpool II功能是连接池。通过使用pgpool II的连接池,可以保留和重用连接,从而减少连接到数据库服务器时发生的开销。
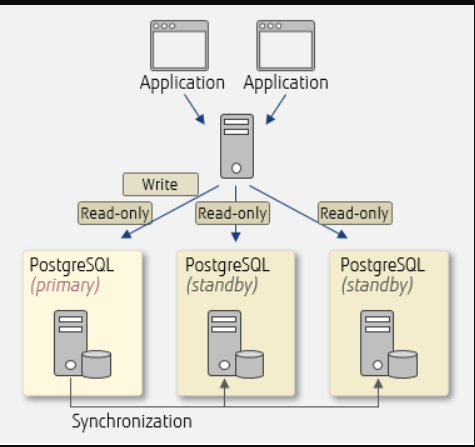
要使用这些功能,需要在pgpool.conf中设置相关参数。
自动故障切换和在线恢复
本节介绍使用pgpool II的自动故障切换和在线恢复。解释假设使用PostgreSQL的流复制。
下图说明了pgpool II在PostgreSQL(主)中检测到错误时如何执行自动故障切换。

- 1.分离出现故障的主服务器并停止pgpool II的查询分发
- 2.将备用服务器升级为新的主服务器
- 3.更改每个PostgreSQL的复制同步位置
注意,您需要事先为2和3创建脚本,并在pgpool II中设置它们。
在线恢复功能执行来自pgpool II的在线恢复命令,并将分离的旧PostgreSQL(主)恢复为PostgreQL(备用)。命令操作如下所述。
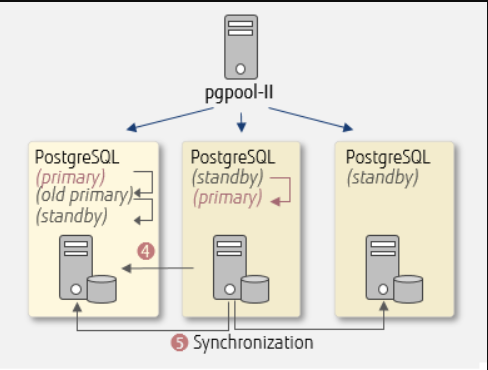
- 4.根据新PostgreSQL(主)的数据重建旧的PostgreSQL,并将其恢复为PostgreSQL
- 5.更改每个PostgreSQL的复制同步位置
您需要预先为这些进程创建脚本,并将它们存储在数据库服务器端。
笔记
pgpool II的在线恢复功能必须作为PostgreSQL的扩展功能安装在数据库服务器端。
监控狗(Watchdog)
为了实现整个系统的高可用性,pgpool II本身也需要冗余。此冗余的此功能称为看门狗。
下面是它的工作原理。看门狗在活动/备用设置中链接pgpool II的多个实例。然后,链接的pgpool II实例执行相互监听并共享服务器信息(主机名、端口号、pgpoolⅡ状态、虚拟IP信息、启动时间)。如果提供服务的pgpool II(活动)发生故障,pgpoolⅡ(备用)会自动检测并执行故障切换。执行此操作时,新的pgpool II(活动)启动一个虚拟IP接口,而旧的pgpool-II(活动的)停止其虚拟IP接口。这允许应用程序端使用具有相同IP地址的pgpool II,即使在服务器切换之后也是如此。通过使用Watchdog,pgpool II的所有实例协同工作,以执行数据库服务器监视和故障切换操作-pgpoolⅡ(活动)充当协调器。

在冗余配置中,我们还需要考虑pgpool II和数据库(PostgreSQL)大脑分裂的可能后果。分裂大脑是存在多个活动服务器的情况。在此状态下更新数据将导致数据不一致,恢复将变得繁重。为了避免大脑分裂,建议将pgpool II配置为3个或更多服务器,并且服务器数量为奇数。以下是大脑分裂可能发生的例子:
- pgpool II的裂脑
- 当设置了2个pgpool II实例并且仅在连接这些pgpoolⅡ实例的网络中发生错误时,将不会发生故障切换,但pgpool II的协调将停止。
- 数据库的分割大脑(PostgreSQL)
- 当设置了2个pgpool II实例并且连接pgpoolⅡ(活动)和PostgreSQL(主要)的网络中发生错误时。在两站式设置中,将不进行投票以判断故障转移(稍后描述)。
现在,让我们看一个例子,当有3个pgpool II实例时,看门狗可以避免数据库中出现分裂的大脑:
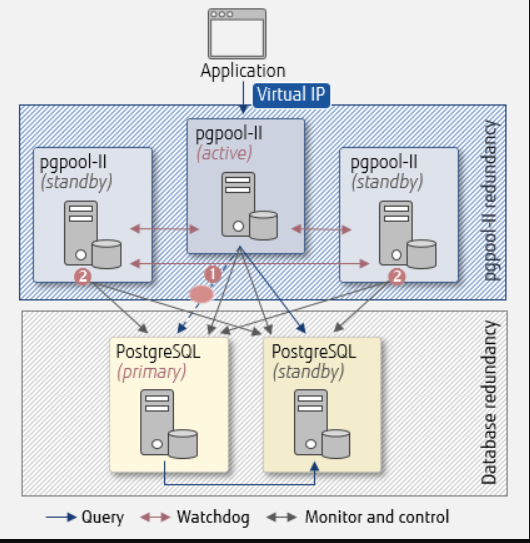
对pgpool II使用看门狗-网络故障
- 1.pgpool II(活动)检测到由于自身和PostgreSQL(主)之间的网络断开而导致的故障,但无法确定PostgreQL(主)是否正在运行。
- 2.pgpool II(备用)的其他实例投票判断故障切换
之后,pgpool II的实例决定采取行动:
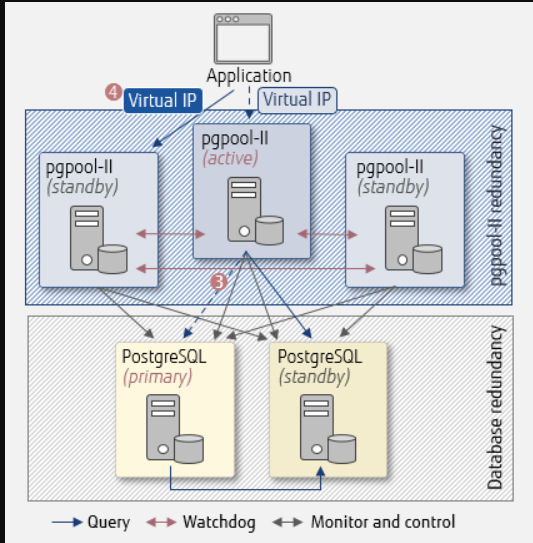
将看门狗与pgpool II一起使用
- 3.没有故障转移,因为它不是多数票。在这里,避免了大脑分裂。pgpool II(活动)阻止PostgreSQL(主要)停止查询分发
- 4.如果在pgpool II(活动)上检测到故障,则将连接切换到pgpoolⅡ(备用)
因此,应用程序端的更新查询可以继续运行。
使用pgpool II进行系统设置
在这里,我们介绍了一个基于真实业务的系统设置,并执行了一个简单的操作检查。
系统设置
我们将设计一个满足以下要求的示例系统设置,假设使用pgpool II的实际业务场景:
- 考虑到大脑分裂的高可用性设置
- 未来扩展
- 负载平衡和连接池以提高性能
通常,为了选择硬件和软件,我们会分析性价比,并以简单高效的设置为目标。这样做的第一个因素是pgpool II的分配。下表总结了可能的位置及其对系统的影响:
| 位置 | Server load | Network | Server cost (quantity) |
| 专用服务器 | 不受其他软件影响。 |
受网络影响:
|
需要额外的服务器来运行pgpool II。 我们建议准备奇数个服务器,从3开始。 |
| 数据库服务器(共存) |
受共存数据库的性能影响。 需要考虑服务器的冗余和可扩展性。 |
网络影响小。 pgpool II和数据库之间的部分连接可以是本地的。 |
我们建议使用3个或更多共存的pgpool II服务器。 根据可用数据库服务器的数量,还需要更多的服务器。 |
| 应用服务器或web服务器(共存) |
受共存软件性能的影响。 需要考虑服务器的冗余和可扩展性。 |
无网络影响。 应用程序(web服务器)和pgpool II可以本地连接。 |
我们建议使用3个或更多共存的pgpool II服务器。 此外,还需要更多的服务器,具体取决于可用应用程序服务器或web服务器的数量。 |
pgpool II在数据库服务器上共存
首先,让我们来看看pgpool II在数据库服务器上共存的配置设置。
我们假设一个实际的系统设置可以在实际的业务案例中使用。如下图所示,来自客户端的请求由负载平衡器分发,应用程序在3个应用程序服务器上并行运行。
pgpool II的多个实例将与看门狗一起工作。将PostgreSQL(备用)添加到数据库服务器3以进行扩展,然后根据需要添加更多服务器。
在此设置中,请注意,工作负载集中在运行pgpool II(活动)的数据库服务器上。在计算负载平衡时要考虑到这一点。

pgpool II配置示例
pgpool II在应用程序服务器上共存
接下来,让我们看一个pgpool II在应用程序服务器上共存的示例设置。pgpool II现在以多主机配置运行,因此分配了固定IP。好处如下。
- pgpool II的负载平衡
- 在pgpool II(活动)和pgpoolⅡ(备用)上接受更新和只读查询
- 减少应用程序和pgpool II之间的网络开销
注意,即使在多主机配置中,pgpool II(活动)仍然是控制数据库的协调器。添加第三个数据库服务器以及更多的扩展。

pgpool II配置示例
操作检查
让我们检查应用程序服务器上同时存在pgpool II的设置中的自动故障切换和在线恢复。假设PostgreSQL和pgpool II已经安装、配置和启动。该示例使用以下内容:
- host0:数据库服务器1的主机
- host1:数据库服务器2的主机
- host5:运行pgpool II(活动)的应用程序服务器1的主机
1连接到应用程序服务器1上的pgpool II(活动),并检查数据库服务器的状态。
$ psql -h host5 -p 9999 -U postgres postgres=# SHOW pool_nodes; node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change ---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+--------------------- 0 | host0 | 5432 | up | 0.500000 | primary | 2 | false | 0 | 2020-08-27 14:43:54 1 | host1 | 5432 | up | 0.500000 | standby | 2 | true | 0 | 2020-08-27 14:43:54 (2 rows)
2强制停止数据库服务器1(主机0)上的PostgreSQL(主)。
$ pg_ctl -m immediate stop
3从应用程序服务器1再次检查数据库服务器状态。
第一个连接将失败,但第二个连接将成功,因为重置后将恢复到数据库的连接。
请注意,host0的状态已更改为“关闭”,角色已交换。我们刚刚确认,到主机1的故障切换是自动完成的,并且已升级到主服务器。
postgres=# SHOW pool_nodes;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | down | 0.500000 | standby | 2 | false | 0 | 2020-08-27 14:47:20
1 | host1 | 5432 | up | 0.500000 | primary | 2 | true | 0 | 2020-08-27 14:47:20
(2 rows)4从应用程序服务器1执行数据库服务器1(主机0)的联机恢复命令。
确认已正常完成。
$ pcp_recovery_node -h host5 -p 9898 -U postgres -n 0 Password: (yourPassword) pcp_recovery_node -- Command Successful
5从应用程序服务器1再次检查数据库服务器状态。
在线恢复后,将在第一次连接到数据库时重置连接,第二次连接将成功。由于host0的状态已更改为“up”,您可以看到它已恢复并处于待机状态。
postgres=# SHOW pool_nodes;
ERROR: connection terminated due to online recovery
DETAIL: child connection forced to terminate due to client_idle_limitis:-1
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# SHOW pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | last_status_change
---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+---------------------
0 | host0 | 5432 | up | 0.500000 | standby | 2 | true | 0 | 2020-08-27 14:50:13
1 | host1 | 5432 | up | 0.500000 | primary | 2 | false | 0 | 2020-08-27 14:47:20
(2 rows)笔记
我们已经看到,pgpool II是PostgreSQL的一个有效的开源扩展,用于企业使用。它适用于具有大量同时连接并需要扩展的中大型系统。
在采用pgpool II时,请务必注意以下事项:
- 构建环境需要许多配置设置,用户必须创建所需的脚本。
- 彻底检查和验证设计和环境设置。
- 负载平衡中只分发只读查询。
- 在处理许多更新查询的系统中看不到性能改进。类似地,只读性能随着数据库服务器数量的增加而提高,但更新性能可能会降低。
- 429 次浏览
【数据库架构】设置 PostgreSQL 多主复制:变得简单
多主复制是一种允许多个节点接受写入请求的方法。在本文中,您将了解如何使用 BDR 设置 PostgreSQL 多主复制。这是本文的大纲。
目录
- 什么是复制?
- 单主复制
- 什么是多主复制?
- PostgreSQL 多主复制
- 使用 BDR 设置 PostgreSQL 多主复制的步骤
- 第 1 部分:初始配置
- 第 2 部分:创建单个 BDR 节点
- 第 3 部分:创建另一个 BDR 节点
- 第 4 部分:配置 HAProxy
- 第 5 部分:将 PgBouncer 与 HAProxy 结合使用
- 第 6 部分:节点切换
- 结论
什么是复制?
复制是将数据从一个数据库服务器复制到另一个数据库服务器。源服务器一般称为主服务器或主服务器。接收数据库服务器也称为副本或从属服务器。
复制通常用于提高性能、创建备份、可扩展性并减少主服务器上的负载。对主服务器所做的更改会传递到从服务器。这些更改可以同时复制,也可以分批复制。如果它在两个服务器中同时发生,则称为同步复制。如果它分批发生,则称为异步。
复制允许您在不影响主节点操作的情况下执行分析。您可以使用复制进行横向扩展,尤其是在写入次数较少而读取次数较多的情况下。
单主复制
在单主多从场景中,只允许一台服务器(主服务器)对数据进行更改。其他服务器不接受来自除主服务器之外的任何地方的写查询。
什么是多主复制?
考虑有几个可以更新数据的连接数据库服务器的情况。在这种情况下,组中的一个成员所做的更改会波及所有其他成员。这可以通过多主复制系统来完成。因此,多主复制为该过程添加了一个双向元素。
多主复制允许多个节点接受写入查询,并且所有涉及的节点都包含相同的数据。多主复制的主要目的当然是高可用性。当主服务器发生故障时,无需等待物理备用服务器被提升。
建议 PostgreSQL 用户不要通过单主复制就足够的多主复制来使设计复杂化。这是因为多主复制使系统变得复杂和混乱。例如,如果您的应用程序具有增量字段并且两个节点没有集成此因素,则可能会导致冲突。
PostgreSQL 多主复制

虽然 PostgreSQL 中内置了单主复制,但多主复制没有。 有一些 PostgreSQL 分叉由小公司和社区管理。
目前有一种流行的产品在 PostgreSQL 中支持多主复制。 它被称为由 2ndQuadrant 创建的双向复制。 BDR 的早期版本是开源的,但不是最新版本。
请注意,在事务速度和防止数据冲突之间进行权衡时,BDR 更喜欢低延迟,允许出现一些冲突(如果不可避免)并在以后解决它们。
使用 BDR 设置 PostgreSQL 多主复制的步骤
第 1 部分:初始配置
在安装 BDR 和 pglogical 插件(充当逻辑复制解决方案)后的此步骤中,您修改 postgresql.conf 和 pg_hba.conf 文件,然后重新启动服务。
Step1:安装 BDR 和 pglogical 插件。
第 2 步:将 postgresql.conf 配置为这些值。
wal_level = logical shared_preload_libraries= ‘pg_logical, bdr’ track_commit_timestamp= ‘on’ # This is necessary for conflict resolution.
第 3 步:创建具有超级用户权限的用户来管理 BDR 连接。
CREATE USER my_user WITH SUPERUSER REPLICATION PASSWORD ‘my_password’;
第 4 步:通过添加这些行来更改 pg_hba.conf 文件。
host all bdr 10.20.30.40/24 md5 host replication bdr 10.20.30.40/24 md5
第 5 步:将用户添加到 .pgpass 文件。
hostname:port:database:my_user: my_password
第 6 步:重新启动 Postgresql。
第 2 部分:创建单个 BDR 节点
将主机 my_host1 上的 my_db 上的 BDR 激活为 my_user。
第 1 步:创建扩展。
CREATE EXTENSION bdr CASCADE; # CASCADE also creates the pglogical extension.
第 2 步:使用 bdr.create_node 函数初始化当前节点。
SELECT bdr.create_node ( node_name:= ‘initail_node’, local_dsn:= ‘dbname=my_db host= my_host1 user=my_user’);
第 3 步:使用 bdr.create_node_group 函数创建 BDR 集群定义。
SELECT bdr.create_node_group(node_group_name:='the_node_group');
第 4 步:使用 bdr.wait_for_join_completion 函数等待全部完成。
SELECT bdr.wait_for_join_completion();
第 3 部分:创建另一个 BDR 节点
第 1 步:创建 BDR 扩展。
CREATE EXTENSION bdr CASCADE;
第 2 步:使用 bdr.create_node 函数初始化当前节点。
SELECT bdr.create_node ( node_name:= ‘next_node’, local_dsn:= ‘dbname=my_db host= my_host2 user=my_user’);
第 3 步:使用 bdr.join_node_group 函数创建 BDR 集群定义。
SELECT bdr.join_node_group (join_target_dsn:= ‘dbname=my_db host= my_host1 user=my_user’, wait_for_completion:=True);
第 4 部分:配置 HAProxy
HAProxy 是一个提供高可用性的开源代理软件。它会自动将流量引导到任何在线节点。为此,您需要先安装 HAProxy。
第 1 步:修改 haproxy.cfg 文件的全局部分。
global state socket /var/run/haproxy/sock level admin # This allows us to get information and send commands to HAProxy.
第 2 步:修改 haproxy.cfg 文件的 bk_db 部分。
stick-table type ip size 1 stick on dst server bdr_initial_node my_host1: 5432 check server bdr_next_node my_host2: 5432 backup check
步骤 3:通过触发 HAProxy 重新加载配置文件。
sudo systemctl reload haproxy
第 5 部分:将 PgBouncer 与 HAProxy 结合使用
PgBouncer 是 PostgreSQL 的连接池。在 PgBouncer 的帮助下,PostgreSQL 可以与更多的客户端进行交互。这对于事务管理来说是必不可少的。当 HAProxy 重定向流量时,PgBouncer 允许交易完成。以下步骤需要安装 PgBouncer。
第 1 步:修改 ft_postgresql 部分的 haproxy.cfg 文件。
frontend ft_postgresql bind *: 5433 default_backend bk_db
第 2 步:更改 pgbouncer.ini 文件中的数据库部分以包含以下行。
* = host= proxy_server port= 5433
修改 pgbouncer 部分。
listen_port = 5432
第 3 步:重新启动 HAProxy,然后重新启动 PgBouncer。
第 6 部分:节点切换
我们正在将连接从初始节点移开。首先,我们使用 HAProxy 禁用 bdr_initial_node,以便不会向它发送新连接。我们将 RECONNECT 命令传递给 pgbouncer 以确保在当前事务之后重新连接。现在 HAProxy 将导致重新连接到第二个服务器。然后在进行更改后,再次启用初始服务器。
第 1 步:在 HAProxy 中禁用 initial_node。
echo “disable server bk_db/bdr_initial_node” | socat /var/run/haproxy/sock –
步骤 2:交易完成后,PgBouncer 应该重新连接并等待连接重新建立。
psql –h proxy_server –U pgbouncer pgbouncer –c “RECONNECT” psql –h proxy_server –U pgbouncer pgbouncer –c “WAIT_CLOSE”
第 3 步:在重新启用之前处理初始节点。
第 4 步:再次重新启用初始节点。
echo “enable server bk_db/bdr_initial_node” | socat /var/run/haproxy/sock –
结论
上述步骤绝不是完整的。在处理序列、安装、在线版本之间的升级以及测试故障转移过程时,您会遇到一些复杂情况。您可以在 PostgreSQL 12 High Availability Cookbook 中找到完整而全面的指南。这本书不仅详细介绍了 PostgreSQL 多主机复制,还详细介绍了设计高可用性服务器的其他几种方法。
无论如何,PostgreSQL多主复制需要大量的技术理解和学习。但 Hevo 可以帮助您应对这些挑战。 Hevo Data 是一种无代码数据管道,可以帮助您实时复制数据,而无需编写任何代码。 Hevo 作为一个完全托管的系统,提供了一个高度安全的自动化解决方案,使用其交互式 UI 只需单击几下即可帮助执行复制。
原文:https://hevodata.com/learn/postgresql-multi-master-replication/
- 1059 次浏览
Postgresql
- 126 次浏览
【PostgreSQL】利用PostgreSQL中的NoSQL功能
视频号
微信公众号
知识星球
NoSQL文档存储非常适合管理大量非结构化数据。但是,有些组织使用非结构化数据,但仍然需要传统SQL数据库所具备的功能。例如,媒体或新闻内容机构可能会运行以大量文本和图像内容为中心的高流量网站。尽管他们需要存储这些非结构化数据,但他们可能并不真正需要NoSQL数据库所附带的灵活模式或水平可扩展性。相反,他们需要PostgreSQL这样的关系数据库所带来的数据库管理的易用性和一致性。
有可能两全其美吗?对
PostgreSQL的数据类型旨在支持非结构化数据,它提供了一个愉快的媒介,使您能够在一个经济高效且易于管理的关系数据库中利用NoSQL功能。在本文中,我们将研究如何使用PostgreSQL中的HStore和JSONB数据类型来处理非结构化数据。
在我们深入讨论之前,让我们简要了解一下SQL和NoSQL数据库之间的主要区别。
理解SQL与NoSQL
SQL和NoSQL数据库各有其独特的优势和劣势。对于哪种最能满足您的数据需求,做出明智的决定取决于对其差异的深刻理解。
SQL(关系型)数据库,如PostgreSQL和MySQL,在表、行和列中以清晰和可预测的结构表示数据。它们遵循ACID属性(原子性、一致性、隔离性和持久性),通过确保数据库事务得到可靠处理,为数据完整性奠定了坚实的基础。
SQL数据库在数据一致性和完整性至关重要的地方大放异彩,例如在处理复杂查询和事务系统(如金融应用程序)时。
相比之下,NoSQL数据库(文档存储)满足了不一定适用于表格表示的大量变化的数据集。NoSQL数据库的例子包括MongoDB、Cassandra和Couchbase。NoSQL数据库使用灵活的模式,允许数据结构随着时间的推移而发展。它们还支持水平可扩展性,将数据分布在多个服务器上,以改进对大数据负载和高流量的处理。
NoSQL数据库通常用于可扩展性至关重要的应用程序,例如在实时应用程序或大型语言模型(LLM)中处理大量数据。NoSQL数据库在处理不断变化的数据结构时也很有用,因为它们允许组织根据数据需求的变化进行调整。
为什么您可以使用PostgreSQL作为文档存储?
PostgreSQL是一个关系型数据库,因此将其视为满足NoSQL需求的选项似乎是不传统的。然而,您的情况可能有充分的理由使用PostgreSQL作为文档存储。
如果您的数据存储需求多种多样——既需要结构化的、符合ACID的数据存储,也需要灵活的、无模式的文档存储——那么您可以利用PostgreSQL来组合关系模型和非关系模型。或者,也许您想要某些NoSQL功能,但也想要ACID属性提供的数据一致性保证。最后,作为一种拥有活跃社区的成熟技术,PostgreSQL提供了全面的SQL支持、高级索引和全文搜索。这些特性,再加上它的NoSQL功能,使PostgreSQL成为一个通用的数据存储解决方案。
将PostgreSQL用于NoSQL样式数据的局限性
尽管PostgreSQL具有多功能性,但与传统的NoSQL数据库相比,它有一定的局限性。虽然PostgreSQL可以垂直扩展,但它本身并不支持水平扩展或具有自动分片的分布式数据,这是NoSQL数据库通常提供的功能。PostgreSQL也不为某些NoSQL数据结构(如宽列存储或图形数据库)提供优化。最后,PostgreSQL没有为优化性能提供可调的一致性,这可能来自一些NoSQL数据库。
当您考虑将PostgreSQL用于大型非结构化数据集时,要知道这些限制可能会影响性能和扩展能力。此外,混合使用SQL和NoSQL数据操作会带来复杂性。仔细规划和理解这两种模式将帮助您避免潜在的陷阱。
然而,有了正确的理解和用例,PostgreSQL可以作为一个强大的工具,提供SQL和NoSQL世界中最好的。
PostgreSQL中的HStore和JSONB
当我们考虑使用PostgreSQL作为NoSQL解决方案的可能性时,我们遇到了三种提供类似NoSQL功能的数据类型,但它们都有独特的特征和用例。
- HStore:这种数据类型允许您将键值对存储在单个PostgreSQL值中。它对于存储没有固定模式的半结构化数据非常有用。
- JSONB:这是类JSON数据的二进制表示。与HStore相比,它可以存储更复杂的结构,并支持完整的JSON功能。JSONB是可索引的,是处理大量数据的好选择。
- JSON:这类似于JSONB,尽管它缺乏JSONB的许多功能和效率。JSON数据类型存储输入文本的精确副本,其中包括空白和重复键。
当您不需要JSONB提供的全部功能时,我们提到JSON数据类型是存储JSON格式数据的有效选择。然而,本文剩余部分的主要关注点将是HStore和JSONB。
HStore
PostgreSQL文档将HStore描述为“具有许多很少检查的属性或半结构化数据的行”时非常有用。在使用HStore数据类型之前,请确保启用HStore扩展:
> CREATE EXTENSION hstore;
HStore表示为零个或多个键=>值,用逗号分隔。对的顺序不重要,也不可靠地保留在输出中。
> SELECT 'foo => bar, prompt => "hello world", pi => 3.14'::hstore;
hstore
-----------------------------------------------------
"pi"=>"3.14", "foo"=>"bar", "prompt"=>"hello world"
(1 row)每个HStore密钥都是唯一的。如果HStore声明使用重复的密钥,则只会存储其中一个重复密钥,并且不能保证是哪一个。
> SELECT 'key => value1, key => value2'::hstore;
hstore
-----------------
"key"=>"value1"
(1 row)凭借其扁平的键值结构,HStore提供了简单快捷的查询,非常适合简单的场景。然而,HStore只支持文本数据,不支持嵌套数据,这使得它仅限于复杂的数据结构。
另一方面,JSONB可以处理更广泛的数据类型。
JSONB
JSONB数据类型接受JSON格式的输入文本,然后将其存储为分解的二进制格式。尽管这种转换会使输入稍微慢一点,但结果是处理速度快,索引效率高。JSONB不保留空白或对象键的顺序。
> SELECT '{"foo": "bar", "pi": 3.14, "nested": { "prompt": "hello", "count": 5 } }'::jsonb;
jsonb
-----------------------------------------------------------------------
{"pi": 3.14, "foo": "bar", "nested": {"count": 5, "prompt": "hello"}}
(1 row)如果给定了重复的对象键,则保留最后一个值。
> SELECT '{"key": "value1", "key": "value2"}'::jsonb;
jsonb
-------------------
{"key": "value2"}
(1 row)由于JSONB支持复杂的结构和完整的JSON功能,因此它是复杂或嵌套数据的理想选择,优于HStore或JSON。但是,与HStore相比,使用JSONB会带来一些性能开销和增加的存储使用量。
实际示例:使用HStore和JSONB
让我们考虑一些实际的例子来演示如何使用这些数据类型。我们将学习创建表、基本查询和操作以及索引。
基本HStore操作
与使用任何其他数据类型一样,您可以将PostgreSQL数据表中的字段定义为HStore数据类型。
> CREATE TABLE articles ( id serial primary key, title varchar(64), meta hstore );
插入具有HStore属性的记录如下所示:
> INSERT INTO articles (title, meta) VALUES ( 'Data Types in PostgreSQL', 'format => blog, length => 1350, language => English, license => "Creative Commons"'); > SELECT * FROM articles; id | title | meta ----+--------------------------+------------------------------------------ 1 | Data Types in PostgreSQL | "format"=>"blog", "length"=>"1350", "license"=>"Creative Commons", "language"=>"English"(1 row)
使用HStore字段,您可以从字段中提取由您提供的键指定的特定键值对:
> SELECT title, meta -> 'license' AS license, meta -> 'format' AS format FROM articles;
title | license | format
---------------------------------+------------------+------------
Data Types in PostgreSQL | Creative Commons | blog
Advanced Querying in PostgreSQL | None | blog
Scaling PostgreSQL | MIT | blog
PostgreSQL Fundamentals | Creative Commons | whitepaper
(4 rows)您还可以使用基于HStore字段中特定值的条件进行查询。
> SELECT id, title FROM articles WHERE meta -> 'license' = 'Creative Commons'; id | title ----+-------------------------- 1 | Data Types in PostgreSQL 4 | PostgreSQL Fundamentals (2 rows)
您有时可能只想查询HStore字段中包含特定键的行。例如,以下查询只返回元HStore中包含注释键的行。要做到这一点,你会使用?操作人员
> SELECT title, meta->'note' AS note FROM articles WHERE meta ? 'note'; title | note ---------------------------------+----------------- PostgreSQL Fundamentals | hold for review Advanced Querying in PostgreSQL | needs edit (2 rows)
这里列出了一些有用的HStore运算符和函数。例如,您可以将HStore的密钥提取到数组中,也可以将HSstore转换为JSON表示。
> SELECT title, akeys(meta) FROM articles where id=1;
title | akeys
--------------------------+----------------------------------
Data Types in PostgreSQL | {format,length,license,language}
(1 row)
> SELECT title, hstore_to_json(meta) FROM articles where id=1;
title | hstore_to_json
--------------------------+------------------------------------------------
Data Types in PostgreSQL | {"format": "blog", "length": "1350", "license": "Creative Commons", "language": "English"}
(1 row)基本JSONB操作
在PostgreSQL中使用JSONB数据类型非常简单。表创建和记录插入如下所示:
> CREATE TABLE authors (id serial primary key, name varchar(64), meta jsonb);
> INSERT INTO authors (name, meta) VALUES ('Adam Anderson', '{ "active":true, "expertise": ["databases", "data science"], "country": "UK" }');请注意,jsonb元字段是以JSON格式的文本字符串提供的。如果您提供的值不是有效的JSON,PostgreSQL会抱怨。
> INSERT INTO authors (name, meta) VALUES ('Barbara Brandini', '{ "this is not valid JSON" }');
ERROR: invalid input syntax for type json错误:json类型的输入语法无效
与HStore类型不同,JSONB支持嵌套数据。
> INSERT INTO authors (name, meta) VALUES ('Barbara Brandini', '{ "active":true, "expertise": ["AI/ML"], "country": "CAN", "contact": { "email": "barbara@example.com", "phone": "111-222-3333" } }');与HStore类似,JSONB字段可以部分检索,只使用某些键。例如:
> SELECT name, meta -> 'country' AS country FROM authors; name | country ------------------+--------- Adam Anderson | "UK" Barbara Brandini | "CAN" Charles Cooper | "UK"(3 rows)
JSONB数据类型有许多在用法上与HStore相似的运算符。例如,以下使用?运算符只检索元字段中包含联系人关键字的那些行。
> SELECT name, meta -> 'active' AS active, meta -> 'contact' AS contact FROM authors WHERE meta ? 'contact'; name | active | contact ------------------+--------+----------------------------------------------- Barbara Brandini | true | {"email": "barbara@example.com", "phone": "111-222-3333"} Charles Cooper | false | {"email": "charles@example.com"} (2 rows)使用索引
根据文档,HStore数据类型“支持@>、?、?&和?|运算符的GiST和GIN索引。”有关这两种类型索引之间差异的详细解释,请参阅此处。JSONB的索引使用GIN索引来促进对键或键值对的有效搜索。
创建索引的语句如下所示:
> CREATE INDEX idx_hstore ON articles USING GIN(meta); > CREATE INDEX idx_jsonb ON authors USING GIN(meta);
具有NoSQL灵活性的SQL结构
让我们回顾一下我们在引言中提到的原始用例。想象一下,一家新闻内容机构以与NoSQL文档存储非常相似的方式存储文章。也许文章可以在JSON中表示为表示部分的有序对象数组,每个部分都有文本内容、符号和格式。此外,每一篇文章都关联着大量的元数据,这些元数据属性在一篇文章与下一篇文章之间是不一致的。
上面的描述概括了组织的大部分NoSQL需求,但它如何管理和组织数据的其他一切都与关系数据模型密切相关。
通过将JSONB等数据类型的NoSQL功能与PostgreSQL的传统SQL优势相结合,组织可以在嵌套数据中享受灵活的模式和快速查询,同时仍然能够执行联合操作和强制执行数据关系。PostgreSQL的HStore和JSONB数据类型为那些需要关系数据库结构但也需要NoSQL风格数据存储的开发人员提供了强大的选择。
PostgreSQL规模
您是否希望在传统关系数据库的框架内支持NoSQL风格的数据存储和查询?也许您的组织处理文档的方式与我们在本文中描述的类似。或者,您正在为大型语言模型(LLM)或其他一些AI/ML项目寻找处理非结构化数据存储的选项。
Linode Marketplace中的PostgreSQL集群为您提供了SQL数据库的关系模型和结构,以及NoSQL数据库的水平可扩展性。将其与使用HStore或JSONB数据类型相结合,您就有了一个理想的混合解决方案,可以在PostgreSQL中使用NoSQL功能。
- 242 次浏览
【向量存储】向量存储方案一览
视频号
微信公众号
知识星球
|
RECOM |
ACPT |
PROH |
|---|---|---|
| Recommended | Accepted | prohibitive |
|
Software |
Comments |
|---|---|
| ES | License Issue |
| Faiss | For Dev or exploration |
| Milvus | For HA and Performance, depends on MinIO now,need k8s for deployment |
| Open Search | Combined with full-text serch |
| PgVector | Need hybrid serch with SQL |
| Qdrant | Easy deploy on Win,Liunx,K8s |
| Redis Stack Server | License Issue |
| Solr | Combined with full-text serch |
| Factor | Sub-Factor | Qdrant | Weaviate | Milvus | Faiss | PgVector | Chroma | Vald | Vespa | Redis | OpenSearch | ES | Solr | Pinecone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Has Hosting offer | Yes | Yes | No | No | No | Will | Yes | Yes | Yes | Yes | No | Yes | ||
| Has Commercial offer | Yes | Yes | No | No | No | No | Yes | Yes | Yes | Yes | Yes | |||
| Has OSS offer | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | |
|
OSS License |
Apache | BSD | Apache | MIT | PG | Apache | Apache | Apache |
RSAL/SSPL (Redis Stack Server) |
Apache |
SSPL/ ELv2 |
Apache | ||
| Commercial Use | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | Yes | Yes | Yes | |
| EA Advise | RECOM | RECOM | RECOM | PROH | RECOM | PROH | RECOM | |||||||
| Github | Github | Github | Github | Github | Github | Github | Github | Github | ||||||
| Owner | Qdrant | Weaviate | LF AI & Data Foundation | PG | chroma | vdaas | Vespa.ai | Redis | Amazon | Elastic | Apache | Pinecone | ||
| Star | 10.6k | 6.2k | 19.1k | 22.1k | 3.5k | 5.7k | 1.2k | 4.4k | ||||||
| HA | Yes | Yes | Yes | Yes | Yes | Yes | ||||||||
| Scalability | Yes | Yes | Yes | Yes | Yes | Yes | ||||||||
| Backup | Yes | Yes | Yes | Yes | Yes | Yes | ||||||||
| Performance | ||||||||||||||
| Operation | Simple | Complex | Complex | Simple | Simple | Complex | Complex | |||||||
| Architecture | Complexity | |||||||||||||
| Embeded/Local instance |
Yes . (Memory, Disk) |
No |
Yes (duckdb+parquet) |
No | ||||||||||
| Number of components | 2 | 16 | 5 | 2 | 2 | 6 | ||||||||
| Number of instances of the component for standalone | 1 Process | 1+N | 3 Pods | 1 | 4 Pods | 1 (docker) | ||||||||
| Number of instances of the component for cluster | 2 Processes | 2+N | 28 Pods | 2 | 6+ | |||||||||
| Development | Server language | Rust | Golang | Golang | C++ | C++ | Python | Golang | Java | |||||
| Client language | Python | Python | Python | Python | Python | Python | Python | |||||||
| Java | Java | Java | Java | |||||||||||
| Node.js | Node.js | Node.js | Node.js | |||||||||||
| Go | Golang | Golang | Go | Go | ||||||||||
| JavaScript | JavaScript | |||||||||||||
| TypeScript | ||||||||||||||
| Rust | Rust | |||||||||||||
| Protocal | REST | |||||||||||||
| gRPC | ||||||||||||||
| JDBC | ||||||||||||||
| Integration | LangChain | Yes | Yes | Yes | Yes | Yes | Yes | Yes | ||||||
| LLamaIndex | Yes | Yes | ||||||||||||
| Installation & Deploymnet | K8s | Yes | Yes | No | No | Yes | Yes | |||||||
| Docker Compose | Yes | Yes | No | Yes (ALPHA STATUS) | Yes | Yes | ||||||||
| Windows | Yes | Yes | Yes | No | No | Yes (need Docker) | ||||||||
| Linux | Yes | Yes | Yes | No | No | Yes | ||||||||
| Backend-Store | RocksDB |
prometheus, AWS S3/ Azure Blog/ GCP/ MinIo grafana/ keycloak |
Etcd, MinIo, pulsar/Kafka, gorocksdb/ rocksdb (standalone) |
PG | ClickHouse | |||||||||
| Full-Text Index | Yes | Yes | Yes | Yes | Yes | Yes | ||||||||
| Hybrid search | Yes | Yes | Yes | Yes | ||||||||||
| Filtering | Pre-filtering | Yes? | Yes | Yes? | Yes | |||||||||
| Post-filtering | Yes? | Yes | Yes? | Yes | ||||||||||
|
Cachable Filters |
Yes | |||||||||||||
| Vector Index Algorithm (ANN) |
FLAT |
Yes | Yes | |||||||||||
| FlatL2 | Yes | |||||||||||||
| FlatIP | Yes | |||||||||||||
| HNSW | Yes | Yes | Yes | Yes | Yes | Yes | Yes | |||||||
| bm25 | Yes | |||||||||||||
| HNSWFlat | Yes | |||||||||||||
|
IVF_FLAT |
Yes | Yes | Yes | |||||||||||
|
IVF_SQ8 |
Yes | Yes | ||||||||||||
|
IVF_PQ |
Yes | Yes | ||||||||||||
| PQ | Yes | Yes | ||||||||||||
| IVF+SQ | Yes | |||||||||||||
| IVFPQR | Yes | |||||||||||||
|
ANNOY |
Yes | |||||||||||||
|
DISKANN |
Yes | |||||||||||||
| LSH(Locality-sensitive hashing) | Yes | Yes | ||||||||||||
|
BIN_FLAT |
Yes | Yes | ||||||||||||
|
BIN_IVF_FLAT |
Yes | Yes | ||||||||||||
| BHNSW | Yes | |||||||||||||
| BHash | Yes | |||||||||||||
| Vector Query Algorithm
|
KNN | Yes | Yes | Yes | Yes | |||||||||
|
Script Scoring |
Yes | |||||||||||||
|
Painless Scripting |
Yes | |||||||||||||
|
K-means |
Yes | |||||||||||||
|
Linear regression |
Yes | |||||||||||||
|
Random Cut Forest (RCF) |
Yes | |||||||||||||
|
RCF Summarize |
Yes | |||||||||||||
|
Localization |
Yes | |||||||||||||
|
Logistic regression |
Yes | |||||||||||||
|
Metrics correlation |
Yes | |||||||||||||
KNN distance metrics
|
Euclidean distance (L2) |
Yes | Yes | Yes | Yes | Y | ||||||||
|
Inner product (IP) |
Yes | Yes | Yes | |||||||||||
|
Jaccard |
Yes | |||||||||||||
|
Tanimoto |
Yes | |||||||||||||
|
Hamming |
Yes | Yes | yes | |||||||||||
| geodegrees | Yes | |||||||||||||
|
Superstructure |
Yes | |||||||||||||
|
Substructure |
Yes | |||||||||||||
| cosine | Yes | Yes | Yes | Yes | Yes | Yes | ||||||||
| dot | Yes | Yes | Yes | Yes | ||||||||||
| l2-squared | Yes | |||||||||||||
| manhattan | Yes | |||||||||||||
|
Projecttion Algorithm |
t-sne | Yes | ||||||||||||
| UMAP | Yes | |||||||||||||
|
Random Projection |
Yes | |||||||||||||
|
Clustering Algorithm |
HDBSCAN | Yes | ||||||||||||
| PCA | Yes | |||||||||||||
|
Deduplication Algorithm |
Yes | |||||||||||||
|
Multimodal Algorithm |
CLIP | Yes | ||||||||||||
|
Fine-tuning manifold Algorithm |
Yes | |||||||||||||
|
Expanded vector search Algorithm |
MMR | Yes | ||||||||||||
| Polytope | Yes | |||||||||||||
| Memo |
Complexity Architecture, depends MinIo |
Need RedisJSON | ||||||||||||
| Introduction | Link | Link | ||||||||||||
| Archi Doc | Archi | |||||||||||||
| Algorithm | Algo | Algo | Algo | Algo | Algo | Algo | ||||||||
| Benchmark | Link | Link |
- 252 次浏览
【数据库架构】Postgres正在吞噬数据库世界
视频号
微信公众号
知识星球
PostgreSQL不仅仅是一个简单的关系数据库;它是一个数据管理框架,有可能吞噬整个数据库领域。“一切皆用Postgres”的趋势不再局限于少数精英团队,而是正在成为主流的最佳实践。
OLAP的新挑战者
在2016年的一次数据库会议上,我认为PostgreSQL生态系统中的一个重大差距是缺乏一个足够好的用于OLAP工作负载的柱状存储引擎。虽然PostgreSQL本身提供了许多分析功能,但它在大型数据集上进行全面分析的性能并不能完全满足专用实时数据仓库的要求。
以ClickBench为例,它是一个分析性能基准,我们在其中记录了PostgreSQL、其生态系统扩展和衍生数据库的性能。未经编辑的PostgreSQL表现不佳(x1050),但经过优化可以达到(x47)。此外,还有三个与分析相关的扩展:柱状存储Hydra(x42)、时间序列TimescaleDB(x103)和分布式Citus(x262)。

Clickbench c6a.4xlarge, 500gb gp2 results in relative time
这种性能并不算差,尤其是与MySQL和MariaDB(x3065,x19700)等纯OLTP数据库相比;然而,它的第三层性能还不够“好”,落后于第一层OLAP组件,如Umbra、ClickHouse、Databend、SelectDB(x3~x4)一个数量级。这是一个棘手的问题——使用起来不够令人满意,但又太好了,无法丢弃。
然而,ParadeDB和DuckDB的到来改变了游戏!
ParadeDB的原生PG扩展PG_analytics实现了第二级性能(x10),将与顶级的差距缩小到仅3–4倍。考虑到额外的好处,这种级别的性能差异通常是可以接受的——ACID、新鲜度和实时数据无需ETL,无需额外的学习曲线,无需维护单独的服务,更不用说其ElasticSearch级全文搜索功能了。
DuckDB专注于纯OLAP,将分析性能推向极致(x3.2)——不包括专注于学术的闭源数据库Umbra,DuckDB可以说是实用OLAP性能最快的。它不是PG扩展,但PostgreSQL可以通过DuckDB FDW和PG_gak等项目,充分利用DuckDB作为嵌入式文件数据库的分析性能提升。
ParadeDB和DuckDB的出现将PostgreSQL的分析能力推向了OLAP的顶级,填补了其分析性能的最后一个关键缺口。
数据库领域的钟摆
OLTP和OLAP之间的区别在数据库诞生之初并不存在。OLAP数据仓库与数据库的分离出现在20世纪90年代,原因是传统的OLTP数据库难以支持分析场景的查询模式和性能需求。
长期以来,数据处理的最佳实践包括将MySQL/PostgreSQL用于OLTP工作负载,并通过ETL过程将数据同步到专门的OLAP系统,如Greenplum、ClickHouse、Doris、Snowflake等。
DDIA ch3: Republic of OLTP & Kingdom of Analytics
与许多“专用数据库”一样,专用OLAP系统的优势往往在于性能——比原生PostgreSQL或MySQL提高了1-3个数量级。然而,成本是冗余数据、过度的数据移动、分布式组件之间对数据值缺乏一致性、专业技能的额外人工费用、额外的许可成本、有限的查询语言能力、可编程性和可扩展性、有限的工具集成、与完整的DMBS相比数据完整性和可用性较差。
然而,俗话说,“来龙去脉”。在摩尔定律之后的三十多年里,随着硬件的改进,性能呈指数级增长,而成本却直线下降。2024年,单个x86服务器可以拥有数百个内核(512 vCPU,EPYC 9754 x2)、几个TB的RAM,单个NVMe SSD可以容纳高达64TB/3M 4K rand IOPS/14GB/s,单个全闪存机架可以达到几个PB;像S3这样的对象存储提供了几乎无限的存储。
I/O Bandwidth doubles every 3 years
硬件的进步解决了数据量和性能问题,而数据库软件开发(PostgreSQL、ParadeDB、DuckDB)解决了访问方法的挑战。这使得分析行业(即所谓的“大数据”行业)的基本假设受到审查。
正如DuckDB的宣言“大数据已死”所暗示的那样,大数据时代已经结束。大多数人没有那么多数据,而且大多数数据很少被查询。随着硬件和软件的发展,大数据的前沿正在消退,99%的场景都不需要“大数据”。
如果99%的用例现在可以在具有独立PostgreSQL/DackDB(及其副本)的单机上处理,那么使用专用分析组件有什么意义?如果每部智能手机都可以自由发送和接收文本,那么寻呼机又有什么意义呢?(需要注意的是,北美医院仍在使用寻呼机,这表明可能只有不到1%的情况真正需要“大数据”。)
基本假设的转变正在引导数据库世界从多样化阶段回到趋同阶段,从大爆炸到大灭绝。在这个过程中,一个统一的、多模型的、超级融合的数据库的新时代将出现,OLTP和OLAP将重新结合起来。但是,谁将领导这项重新整合数据库领域的重大任务呢?
PostgreSQL:数据库世界的食客
数据库领域有很多利基:时间序列、地理空间、文档、搜索、图形、矢量数据库、消息队列和对象数据库。PostgreSQL让所有这些领域都能感受到它的存在。
PostGIS扩展就是一个很好的例子,它为地理空间数据库设定了事实上的标准;TimescaleDB扩展笨拙地定位了“通用”时间序列数据库;矢量扩展PGVector将专用的矢量数据库利基变成了一条笑点。
这已经不是第一次了;我们在最古老、最大的子域OLAP分析中再次见证了这一点。但PostgreSQL的雄心并没有止步于OLAP;它正在关注整个数据库世界!

PostgreSQL Ecosystem
是什么让PostgreSQL如此强大?当然,它是先进的,但甲骨文也是如此;它是开源的,MySQL也是。PostgreSQL的优势来自于其先进性和开源性,使其能够与Oracle/MySQL竞争。但其真正的独特之处在于其极端的可扩展性和蓬勃发展的扩展生态系统。
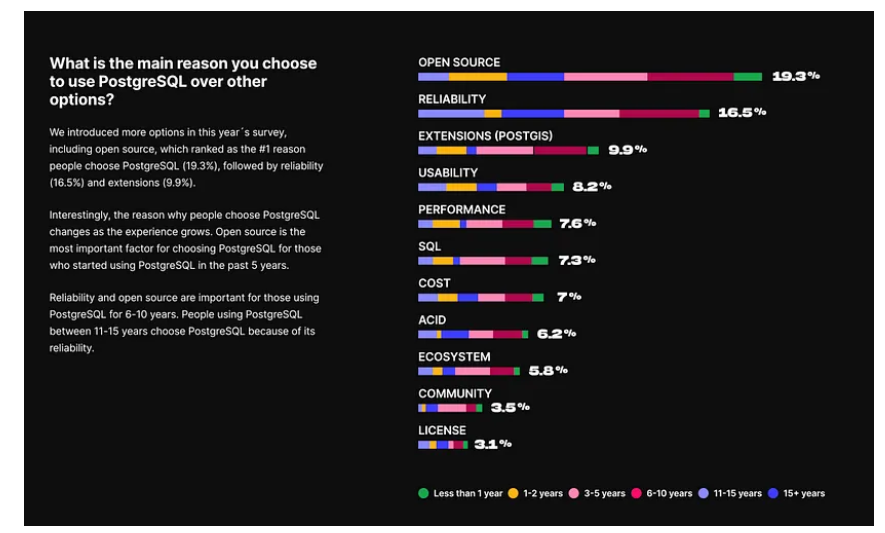
极限可扩展性的魔力
PostgreSQL不仅仅是一个关系数据库;这是一个能够吞噬整个数据库星系的数据管理框架。其核心竞争力除了源代码和先进性外,还源于可扩展性,即基础设施的可重用性和可扩展性的可组合性。
PostgreSQL允许用户开发扩展,利用数据库的公共基础设施以最低成本提供功能。例如,矢量数据库扩展pgvector只有几千行代码,与PostgreSQL的数百万行代码相比,其复杂性可以忽略不计。然而,这种“微不足道”的扩展实现了完整的矢量数据类型和索引功能,优于许多专门的矢量数据库。
为什么?因为pgvector的创建者不需要担心数据库的一般附加复杂性:ACID、恢复、备份和PITR、高可用性、访问控制、监控、部署、第三方生态系统工具、客户端驱动程序等,这些都需要数百万行代码才能很好地解决。他们只关注问题的本质复杂性。
例如,ElasticSearch是在Lucene搜索库的基础上开发的,而Rust生态系统有一个改进的下一代全文搜索库Tantivy,作为Lucene的替代方案。ParadeDB只需要将其封装并连接到PostgreSQL的接口,就可以提供与ElasticSearch相当的搜索服务。更重要的是,它可以站在PostgreSQL的肩膀上,利用整个PG生态系统的联合力量(例如,与pgvector的混合搜索)与另一个专用数据库进行“不公平”的竞争。

Pigsty & PGDG has 234 extensions available. And there are 1000+ more in the ecosystem
可扩展性带来了另一个巨大的优势:扩展的可组合性,允许不同的扩展协同工作,在1+1»2的情况下产生协同效应。例如,TimescaleDB可以与PostGIS相结合,用于时空数据支持;用于全文搜索的BM25扩展可以与PGVector扩展组合,从而提供混合搜索功能。
此外,分布式扩展Citus可以透明地将独立集群转换为水平分区的分布式数据库集群。该功能可以与其他功能正交组合,使PostGIS成为分布式地理空间数据库,PGVector成为分布式矢量数据库,ParadeDB成为分布式全文搜索数据库,等等。
更强大的是,扩展是独立发展的,而不需要繁琐的主分支合并和协调。这允许扩展——PG的可扩展性允许许多团队并行探索数据库的可能性,所有扩展都是可选的,不会影响核心功能的可靠性。那些成熟和健壮的特性有机会稳定地集成到主分支中。
PostgreSQL通过极端可扩展性的魔力实现了基本的可靠性和敏捷功能,使其成为数据库世界中的异类,并改变了数据库格局的游戏规则。
DB竞技场的游戏改变者
PostgreSQL的出现改变了数据库领域的范式:致力于打造“新数据库内核”的团队现在面临着一场艰巨的考验——如何在开源、功能丰富的Postgres中脱颖而出。他们独特的价值主张是什么?
除非出现革命性的硬件突破,否则实用的、新的、通用的数据库内核似乎不太可能出现。没有一个单一的数据库能与PG的整体实力相媲美,因为PG有着开源和免费的王牌,即使是Oracle也无法与之匹敌;-)
如果一个利基数据库产品在特定方面(通常是性能)能比PostgreSQL好一个数量级,那么它可能会为自己开辟空间。然而,PostgreSQL生态系统通常不需要很长时间就可以产生开源扩展替代方案。选择开发一个PG扩展而不是一个全新的数据库,可以让球队在追赶中获得压倒性的速度优势!
遵循这一逻辑,PostgreSQL生态系统将像滚雪球一样越滚越大,积累优势,不可避免地走向垄断,在几年内反映出Linux内核在服务器操作系统中的地位。开发人员调查和数据库趋势报告证实了这一轨迹。

StackOverflow 2023调查:十项全能运动员PostgreSQL

StackOverflow过去7年的数据库趋势
PostgreSQL一直是HackerNews和StackOverflow最喜欢的数据库。许多新的开源项目默认PostgreSQL作为他们的主要(如果不是唯一的)数据库选择。许多新一代公司都在PostgreSQL中运行。
正如“Radical Simplicity:Just Use Postgres”所说,“Just Use Postgres”可以实现简化技术堆栈、减少组件、加速开发、降低风险和添加更多功能。Postgres可以取代许多后端技术,包括MySQL、Kafka、RabbitMQ、ElasticSearch、Mongo和Redis,毫不费力地为数百万用户服务。Just Use Postgres不再局限于少数精英团队,而是成为主流的最佳实践。
还能做什么?
数据库域的结局似乎是可以预测的。但是我们能做什么,我们应该做什么?
对于绝大多数场景,PostgreSQL已经是一个近乎完美的数据库内核,这使得内核“瓶颈”的想法变得荒谬。PostgreSQL和MySQL将内核修改标榜为卖点的分支基本上没有进展。
这与今天Linux操作系统内核的情况类似;尽管Linux发行版过多,但每个人都选择相同的内核。Linux内核的分叉被视为制造了不必要的困难,业界对此表示反对。
因此,主要的冲突不再是数据库内核本身,而是两个方向——数据库扩展和服务!前者涉及内部可扩展性,而后者涉及外部可组合性。与操作系统生态系统非常相似,竞争格局将集中在数据库分发上。在数据库领域,只有那些以扩展和服务为中心的分布才有可能获得最终的成功。
内核仍然不温不火,MySQL母公司的分支MariaDB即将退市,而AWS则从免费内核之上提供服务和扩展中获利,蓬勃发展。投资已流入众多PG生态系统扩展和服务分发:Citus、TimescaleDB、Hydra、PostgresML、ParadeDB、FerretDB、StackGres、Aiven、Neon、Suabase、Tembo、PostgresAI,以及我们自己的PG分发版--Pigsty。
PostgreSQL生态系统中的一个困境是许多扩展和工具的独立进化,缺乏统一的协同机制。例如,Hydra发布了自己的包和Docker映像,PostgresML也是如此,每个映像都使用自己的扩展分发PostgreSQL映像,而且只有自己的扩展。这些图片和包与AWS RDS等全面的数据库服务相去甚远。
即使是像AWS这样的服务提供商和生态系统集成商,在众多扩展面前也存在不足,由于各种原因(AGPLv3许可证、多租户的安全挑战),无法包括许多扩展,从而无法利用PostgreSQL生态系统扩展的协同放大潜力。

云RDS(PG 162024-02-29)上没有许多重要的扩展,请查看完整的扩展列表了解详细信息:Pigsty RDS&PGDG/AWS RDS PG/Aliyun RDS PG
扩展是PostgreSQL的灵魂。一个没有使用扩展自由的Postgres就像无盐烹饪,一个巨大的约束。
解决这一问题是我们的主要目标之一。
我们的决心:Pigsty
尽管我之前接触过MySQL和MSSQL,但当我在2015年第一次使用PostgreSQL时,我确信它未来在数据库领域的主导地位。近十年后,我从用户和管理员转变为贡献者和开发人员,见证了PG朝着这个目标前进。
与不同用户的交互表明,数据库领域的缺点不再是内核——PostgreSQL已经足够了。真正的问题是利用内核的功能,这也是RDS蓬勃发展的原因。
然而,我认为这种功能应该像免费软件一样可访问,就像PostgreSQL内核本身一样——每个用户都可以使用,而不仅仅是从网络封建领主那里租用。
因此,我创建了Pigsty,这是一个包含电池的本地第一个PostgreSQL发行版,作为一个开源的RDS替代品,旨在利用PostgreSQL生态系统扩展的集体力量,并使生产级数据库服务的访问民主化。

Pigsty stands for PostgreSQL in Great STYle
我们定义了六个核心命题来解决PostgreSQL数据库服务中的核心问题:可扩展Postgres、可靠基础设施、可观察图形、可用服务、可维护工具箱和可组合模块。
这些价值主张的首字母缩写提供了Pigsty的另一个缩写:
Postgres,基础设施,图形,服务,工具箱,你的。
Postgres, Infras, Graphics, Service, Toolbox, Yours.
您的图形化Postgres基础设施服务工具箱。
可扩展的PostgreSQL是这个发行版的关键。在最近推出的Pigsty v2.6中,我们集成了DuckdbFDW和ParadeDB扩展,极大地增强了PostgreSQL的分析能力,并确保每个用户都能轻松利用这种能力。
我们的目标是整合PostgreSQL生态系统中的优势,创造一种类似于数据库世界Ubuntu的协同力量。我相信核心争论已经解决,真正的竞争前沿就在这里。

开发人员,您的选择将决定数据库世界的未来。我希望我的工作能帮助你更好地利用世界上最先进的开源数据库内核:PostgreSQL。
- 180 次浏览
【文档数据库】Postgres JSONb与MongoDB相遇。。。
视频号
微信公众号
知识星球
前言
我听说开发人员不想接受MongoDB是他们操作数据库的可行选择的原因之一是PostgreSQL的JSON支持非常好,没有理由另谋高就。我经常对此感到好奇,并决定为了真正建立任何意见,我需要卷起袖子参与进来。
在这一系列的文章中,我将研究Postgres基于JSON的特定功能(我还不太熟悉),并将它们与MongoDB的JSON功能进行比较(鉴于我在那里的工作,我应该非常了解这些功能)。我希望能学到很多关于Postgres的知识,以及如何使用它,最终形成我自己的观点:现在Postgres支持JSON,还需要MongoDB吗?
我不会把Postgres看作一个RDBMS。对于那些真正想使用20世纪70年代制定的模式对数据进行建模的人来说,Postgres是一个不错的选择。如果你只想通过外键来建模你的关系,并且不介意通过一些脆弱的ORM将所有结果重新映射到JSON中,那么作为我的客人,Postgres无疑是最适合你的RDBMS。
然而,与许多现代开发人员一样,如果您认识到高效构建应用程序和服务需要使用一个存储层,该存储层可以按照我们想要的方式存储数据,那么MongoDB与Postgres的JSONb支持问题是非常有先见之明的。
花了很多时间研究这些帖子,阅读关于JSONb的问题和评论页面,我在Postgres留言板和论坛上一次又一次地看到一个问题出现:“为什么我不应该把所有数据都存储在一个JSONb专栏中?”。如果你熟悉MongoDB,这个问题会让你大吃一惊。
让我们开始吧。
第一部分。基本查询。
在我写这篇文章的时候,这是英国一个温暖晴朗的日子,我坐在郊区小花园的一张桌子旁。我们将首先构建一些在PGJSONb中使用JSON数据的快速示例,然后在MongoDB中比较相同的内容。
对于PG:
create table plants (
id serial not null primary key,
plant jsonb not null
);
insert into plants values (1,'{"name": "Sweet Pea", "currentHeightCM": 82, "maxHeightCM":120, "tags": ["scented", "climber"]}');
insert into plants values (2,'{"name": "Sunflower", "currentHeightCM": 24, "maxHeightCM":240, "tags": ["fast growing", "tall", "phototropic"]}');你会期望在MongoDB中同样的事情会更容易,当然,作为一个原生的JSON文档(对象)存储,它确实如此。
db.plants.insert({"name": "Sweet Pea", "currentHeightCM": 82, "maxHeightCM":120, "tags": ["scented", "climber"]})
db.plants.insert({"name": "Sunflower", "currentHeightCM": 24, "maxHeightCM":240, "tags": ["fast growing", "tall", "phototropic"]})您不需要任何创建表定义(一个模式),Postgres定义中的id字段被MongoDB中自动生成的名为_id的objectID所取代。
让我们把这两条记录都拉回来,检查一下它们是否像预期的那样。
jim=# SELECT * FROM plants;
id | plant
----+-------------------------------------------------------------------------------------------------------------------
1 | {"name": "Sweet Pea", "tags": ["scented", "climber"], "maxHeightCM": 120, "currentHeightCM": 82}
2 | {"name": "Sunflower", "tags": ["fast growing", "tall", "phototropic"], "maxHeightCM": 240, "currentHeightCM": 24}
(2 rows)
jim=#
garden> db.plants.find()
[
{
_id: ObjectId("62add6426e4370b84d1ff2ef"),
name: 'Sweet Pea',
currentHeightCM: 82,
maxHeightCM: 120,
tags: [ 'scented', 'climber' ]
},
{
_id: ObjectId("62ade2dccc74a951c921497b"),
name: 'Sunflower',
currentHeightCM: 24,
maxHeightCM: 240,
tags: [ 'fast growing', 'tall', 'phototropic' ]
}
]
garden> 通过属性查找文档也相当容易。对于MongoDB来说,它只是:
garden> db.plants.find({"name":"Sunflower"})
[
{
_id: ObjectId("62ade2dccc74a951c921497b"),
name: 'Sunflower',
currentHeightCM: 24,
maxHeightCM: 240,
tags: [ 'fast growing', 'tall', 'phototropic' ]
}
]
garden> 在Postgres中,它仍然是非常基本的东西,尽管因为SQL不是用JSON构建的,所以我们必须引入几个新的操作符之一来处理JSON数据。(附带说明,JSON最近被添加到SQL:2016标准中作为模型,然后更新为SQL:2019作为数据类型,如本文所述,尽管我认为SQL:2019实际上还不存在)
在这种情况下,我们将使用包含运算符@>,它询问短语是否包含在JSONb字段中。这个操作符很有趣,因为它似乎只存在于Postgres中,所以您创建的任何使用它的SQL都不能在MySQL上运行。在这个博客的上下文中,这并不是什么大不了的事情,但我觉得奇怪的是,SQL标准定义了JSON的存储方式,但每个DB都有自己的查询方式。比这个更了解情况的博客也建议在这里使用GIN索引,因为事情变得非常慢,非常快。
jim=# SELECT * FROM plants WHERE plant @> '{"name": "Sunflower"}';
id | plant
----+-------------------------------------------------------------------------------------------------------------------
2 | {"name": "Sunflower", "tags": ["fast growing", "tall", "phototropic"], "maxHeightCM": 240, "currentHeightCM": 24}
(1 row)好了,我们不需要花了,让我们看看一些树。我的花园很小,但我设法进了不少,我喜欢它们带来的结构和高度。我可以使用JSON轻松地描述树木,而不是复制每棵树的信息,我可以描述一种类型的树,然后在我的花园周围嵌入该树的实例数组。例如,我有三棵苹果树(虽然只有一棵是真正的大树,但今年我靠着栅栏种了另外两棵,它们很小)。我有一个JSON对象,它描述了我需要了解的关于苹果树的信息,它们有多大,它们的花(花)的颜色和结出的果实。
这个对象中嵌入了一组子对象,这些子对象描述了这棵树在我的花园中的每个实例的位置、它的健康程度以及它的大小
{
name: 'Corkscrew Willow',
species: 'Salix matsudana Tortuosa',
flowerColor: 'Yellow Catkins',
maxHeightCM: 1200,
instance: [
{
location: 'left fence',
currentHeightCM: 400,
health: 'vigorous'
},
{
location: 'left fence',
currentHeightCM: 420,
health: 'vigorous'
}
],
tags: [ 'tree', 'twisted' ]
}这种类型的数据建模仍然是非规范化的,但关系建模的爱好者会认为,我可以将实例放入一个单独的表中,并在查询时将它们重新连接在一起。
是的,我可以,但为什么?JOIN很昂贵,ORM很脆弱,需要维护。我更愿意在我的应用程序将使用数据的状态下将数据返回到我的API,而数据库所做的工作量最小。(尽管我承认将API绑定到DB的模式从来都不是一个好主意,但它适用于本例。)
因此,这是我们将加载到数据库中的内容(我们将首先删除以前的数据):
db.plants.drop()
db.plants.insertMany([
{"name":"Apple Tree","species":"Malus domestica","flowerColor":"White","maxHeightCM":500,"fruit":{"color":"green","avSizeCM":10,"taste":"sweet"},"instance":[{"location":"right fence","currentHeightCM":83,"health":"good"},{"location":"right fence","currentHeightCM":65,"health":"poor"},{"location":"back left corner","currentHeightCM":450,"health":"vigorous"}],"tags":["tree","fruiting","slow growing"]},
{"name":"Wild Cherry","species":"Prunus avium","flowerColor":"Pink","maxHeightCM":3000,"fruit":{"color":"red","avSizeCM":2,"taste":"sour"},"instance":[{"location":"next to decking","currentHeightCM":600,"health":"vigorous"}],"tags":["tree","fruiting"]},
{"name":"Silver Birch","species":"Betula pendula","flowerColor":"Yellow Catkins","maxHeightCM":3100,"instance":[{"location":"next to decking","currentHeightCM":140,"health":"good"}],"tags":["tree"]},
{"name":"Rowan","species":"Sorbus aucuparia","flowerColor":"White","maxHeightCM":1500,"fruit":{"color":"red","avSizeCM":0.5,"taste":"inedible"},"instance":[{"location":"back door","currentHeightCM":400,"health":"good"}],"tags":["tree","Ward Off Evil Spirits"]},
{"name":"Olive","species":"Olea europaea","flowerColor":"White","maxHeightCM":1500,"fruit":{"color":"green","avSizeCM":1.5,"taste":"sweet"},"instance":[{"location":"back door","currentHeightCM":450,"health":"good"}],"tags":["tree","Mediterranean"]},
{"name":"Corkscrew Willow","species":"Salix matsudana Tortuosa","flowerColor":"Yellow Catkins","maxHeightCM":1200,"instance":[{"location":"left fence","currentHeightCM":400,"health":"vigorous"},{"location":"left fence","currentHeightCM":420,"health":"vigorous"}],"tags":["tree","twisted"]},
])Postgres不太容易插入多个JSONb对象,StackOverflow认为*如果插入的次数不多,性能就会出现问题。人们认为,最好的方法是创建一个临时表,将JSON的原始文本加载到其中,然后作为第二步将其解析为所需的表/状态。在我们的情况下,我们可以直接这样做,因为我们只有六条记录。(*公平地说,SO关心的可能更多的是将JSON批量解析为非JSON结构)
TRUNCATE plants;
INSERT INTO plants (plant)
SELECT * FROM json_array_elements ('[
{"name":"Apple Tree","species":"Malus domestica","flowerColor":"White","maxHeightCM":500,"fruit":{"color":"green","avSizeCM":10,"taste":"sweet"},"instance":[{"location":"right fence","currentHeightCM":83,"health":"good"},{"location":"right fence","currentHeightCM":65,"health":"poor"},{"location":"back left corner","currentHeightCM":450,"health":"vigorous"}],"tags":["tree","fruiting","slow growing"]},
{"name":"Wild Cherry","species":"Prunus avium","flowerColor":"Pink","maxHeightCM":3000,"fruit":{"color":"red","avSizeCM":2,"taste":"sour"},"instance":[{"location":"next to decking","currentHeightCM":600,"health":"vigorous"}],"tags":["tree","fruiting"]},
{"name":"Silver Birch","species":"Betula pendula","flowerColor":"Yellow Catkins","maxHeightCM":3100,"instance":[{"location":"next to decking","currentHeightCM":140,"health":"good"}],"tags":["tree"]},
{"name":"Rowan","species":"Sorbus aucuparia","flowerColor":"White","maxHeightCM":1500,"fruit":{"color":"red","avSizeCM":0.5,"taste":"inedible"},"instance":[{"location":"back door","currentHeightCM":400,"health":"good"}],"tags":["tree","Ward Off Evil Spirits"]},
{"name":"Olive","species":"Olea europaea","flowerColor":"White","maxHeightCM":1500,"fruit":{"color":"green","avSizeCM":1.5,"taste":"sweet"},"instance":[{"location":"back door","currentHeightCM":450,"health":"good"}],"tags":["tree","Mediterranean"]},
{"name":"Corkscrew Willow","species":"Salix matsudana Tortuosa","flowerColor":"Yellow Catkins","maxHeightCM":1200,"instance":[{"location":"left fence","currentHeightCM":400,"health":"vigorous"},{"location":"left fence","currentHeightCM":420,"health":"vigorous"}],"tags":["tree","twisted"]}
]');让我们做一些非常简单的查询。
- 我有多少棵树?
- 哪些类型的树开白花?
- 哪些树结出甜美的果实
- 我花园里哪棵树最高?
- 我有多少棵超过2米高的树?
我有多少棵树?
如果我想知道我有多少类型的树,也就是行的数量,这可能是一个非常简单的查询。但是,我想知道我总共有多少棵树,所以我需要计算实例数组的所有元素。
事实上这是MongoDB中一个非常简单的操作,因为它是为这类工作从头开始设计的。
db.plants.aggregate([
{$unwind: {path: '$instance'}},
{$count: 'TreeCount'}
])我们首先展开数组,将元素打开到它们自己的文档中,然后计算所有结果。
[ { TreeCount: 9 } ]对于Postgres来说,过程是不同的…
SELECT SUM(jsonb_array_length(plant -> 'instance')) FROM plants;
或者,有人建议我,这也会起作用…
SELECT COUNT(plant) FROM plants AS s, jsonb_array_elements(s.plant ->'instance') AS t;
如果你不知道PostgresJSONb操作符,那么解释这里发生了什么就有点困难了,但这里的关键是用于提取JSON对象的->操作符。
两个选项都给出了正确的结果:
sum ----- 9 (1 row)
哪些类型的树开白花?
这对两个平台来说都是另一个简单的操作,对于Postgres,我们使用@>包含运算符,它看起来与左侧选择中运算符右侧的JSON匹配。
SELECT plant['name'] FROM plants WHERE plant @> '{"flowerColor":"White"}';plant
--------------
"Apple Tree"
"Rowan"
"Olive"
(3 rows)
此查询中使用了MongoDB的find()运算符。
db.plants.find({'flowerColor': 'White'},{_id:0,name:1})[
{ name: 'Apple Tree' },
{ name: 'Rowan' },
{ name: 'Olive' }
]在上面的MongoDB查询中,我还包含了一个投影参数{_id:0,name:1},它禁止在结果集中返回_id字段,包含name:1意味着我将传入一个我确实希望返回的字段列表,在本例中仅返回name。它完全是可选的,省略它以返回完整的文档。
哪些树结出甜美的果实?
这是一个有趣的问题,因为我花园里的一些树根本没有结果,所以JSON对象不包含水果字段。这对MongoDB来说不是问题,查询再简单不过了…
db.plants.find({'fruit.taste': 'sweet'},{_id:0,name:1})[
{ name: 'Apple Tree' },
{ name: 'Olive' }
]在这里,我们正在做一个简单的查找,其余的由MongoDB完成,它不担心某些文档中没有水果对象,而且无论嵌套有多深,都可以很容易地使用嵌套对象。
然而,Postgres的情况就不同了。我承认我不是Postgres的超级明星,但我的SQL并不太生疏。我应该能够做到这一点…
首先,我尝试了类似于MongoDB的查询,我认为它会起作用,因为它看起来很合乎逻辑…
SELECT * FROM plants WHERE plant @> '{"fruit.taste": "sweet"}';这应该有效,它被要求返回包含{"fruit.taste": "sweet"}的所有行,有趣的是,它没有出错,只是返回(0行)
啊,也许Postgres不理解JSONb嵌套上下文中的点表示法,这很公平。
SELECT * FROM plants WHERE plant @> '{"taste": "sweet"}';{"taste":"sweet"} 必须包含在JSONb结构中的某个位置,对吗?nope,(0行)
好吧,也许它不是递归的,它需要指向子对象中属性的位置,但我们不能,因为有些行根本没有水果子对象!
然后我发现了一个著名的Postgres支持团队的博客文章,其中介绍了各种紧密的解决方案。他们提出的一个选项是将JSONb转换为文本,然后再转换回JSON,这似乎是一个非常冗长的选项…
select id, t.* from plants, jsonb_to_recordset((plant->>'fruit'::text)::jsonb) as t(color text,taste varChar(100), avSizeCM text) where taste like 'sweet';
这对我来说仍然不起作用。他们在博客文章中提供的其他选项真的很复杂,而且他们自己也承认,性能不好,使用了生成的列和表达式索引以及其他我不完全理解的东西。
最后,在r/postgreSQL中四处询问后,我找到了一条与许多Postgres爱好者流行的不和通道。我解释了这个问题,值得赞扬的是,他们像对待公牛一样接受了挑战。过了一段时间,解决方案发布了!
with fruit_cte as ( select plant->>'name' as name, plant->'fruit' as fruit from plants ) select name,fruit->>'taste' as taste from fruit_cte where fruit->>'taste' = 'sweet'; name | taste ------------+------- Apple Tree | sweet Olive | sweet (2 rows)
(好吧,我知道橄榄不是很甜,但它们也不酸,我正在制作这个数据集,所以不要根据我的水果定义来挑剔我!)
我们终于到了!我花了两天的时间进行实验,尝试不同的东西,用头撞墙,才放弃。即使是前面提到的备受尊敬的专业支持团队也找不到这个解决方案,这取决于一些非常有才华的以社区为导向的人,他们喜欢解决棘手的挑战,能够不假思索地在MongoDB中完成一些事情。
我花园里哪棵树最高?
我花园里最高的树不是maxHeightCM最高的树,而是instance.currentHightCM最高的树。
在MongoDB中实现这一点的一种方法是使用聚合管道,像这样的查询显示了它是多么容易使用。(如果你想看看它有多神奇,请查看@thedonester的权威文本)
db.plants.aggregate([
{$unwind: {path: "$instance"}},
{$sort: {"instance.currentHeightCM" :-1}},
{$limit: 1},
{$project: {
_id:0,
name:1,
"location":"$instance.location",
"height":"$instance.currentHeightCM"
}}
])聚合由多个阶段组成,第一阶段的输出通过管道连接到第二阶段的输入
第一个阶段是展开,这是处理数组的一个非常方便的工具,因为它允许您将数组分解并为每个元素创建一个单独的文档。
接下来,我们对数组进行排序,在limit阶段之前,它只返回一个文档。
最后,我将在项目阶段运行结果集,以重塑数据。这是可选的,但如果不打算使用所有原始文档,您可能不希望将其返回到应用程序。
您还将注意到,我已经使用投影阶段重命名了几个属性,这只是为了可读性。
它会产生正确的结果:
[{ name: 'Wild Cherry', location: 'next to decking', height: 600 }]还有其他方法可以做到这一点,有些甚至更简单,它们不使用聚合框架,但这个例子很好地介绍了使用管道进行处理的能力。
我们如何在Postgres中做到这一点?第一项工作是列出所有的树。
SELECT plant->>'name' AS name, plant->'instance' AS instance FROM plants
输出如下所示:
name | instance
------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Apple Tree | [{"health": "good", "location": "right fence", "currentHeightCM": 83}, {"health": "poor", "location": "right fence", "currentHeightCM": 65}, {"health": "vigorous", "location": "back left corner", "currentHeightCM": 450}]
Wild Cherry | [{"health": "vigorous", "location": "next to decking", "currentHeightCM": 600}]
Silver Birch | [{"health": "good", "location": "next to decking", "currentHeightCM": 140}]
Rowan | [{"health": "good", "location": "back door", "currentHeightCM": 400}]
Olive | [{"health": "good", "location": "back door", "currentHeightCM": 450}]
Corkscrew Willow | [{"health": "vigorous", "location": "left fence", "currentHeightCM": 400}, {"health": "vigorous", "location": "left fence", "currentHeightCM": 420}]
(6 rows)
在下一阶段,我大量借鉴了上面关于甜水果的例子。如果没有乐于助人的Postgres社区的支持,我不可能做到这一点
现在,我们需要在该结果集上运行SELECT,但使用一个名为jsonb_to_recordset()的新(对我们来说)运算符,该运算符会分解数组并为每个数组元素创建一行。它相当于Postgres的MongoDB的$unver,但是,对于Postgres,您必须使用AS条件显式地强制转换jsonb_to_recordset()的输出。
with instance_cte as ( SELECT plant->>'name' AS name, plant->'instance' AS instance FROM plants ) SELECT * FROM instance_cte, jsonb_to_recordset(instance_cte.instance) AS items(health jsonb, location jsonb, currentHeightCM jsonb);
我们还没到。结果集如下所示:
name | instance | health | location | currentheightcm
------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+------------+--------------------+-----------------
Apple Tree | [{"health": "good", "location": "right fence", "currentHeightCM": 83}, {"health": "poor", "location": "right fence", "currentHeightCM": 65}, {"health": "vigorous", "location": "back left corner", "currentHeightCM": 450}] | "good" | "right fence" |
Apple Tree | [{"health": "good", "location": "right fence", "currentHeightCM": 83}, {"health": "poor", "location": "right fence", "currentHeightCM": 65}, {"health": "vigorous", "location": "back left corner", "currentHeightCM": 450}] | "poor" | "right fence" |
Apple Tree | [{"health": "good", "location": "right fence", "currentHeightCM": 83}, {"health": "poor", "location": "right fence", "currentHeightCM": 65}, {"health": "vigorous", "location": "back left corner", "currentHeightCM": 450}] | "vigorous" | "back left corner" |
Wild Cherry | [{"health": "vigorous", "location": "next to decking", "currentHeightCM": 600}] | "vigorous" | "next to decking" |
Silver Birch | [{"health": "good", "location": "next to decking", "currentHeightCM": 140}] | "good" | "next to decking" |
Rowan | [{"health": "good", "location": "back door", "currentHeightCM": 400}] | "good" | "back door" |
Olive | [{"health": "good", "location": "back door", "currentHeightCM": 450}] | "good" | "back door" |
Corkscrew Willow | [{"health": "vigorous", "location": "left fence", "currentHeightCM": 400}, {"health": "vigorous", "location": "left fence", "currentHeightCM": 420}] | "vigorous" | "left fence" |
Corkscrew Willow | [{"health": "vigorous", "location": "left fence", "currentHeightCM": 400}, {"health": "vigorous", "location": "left fence", "currentHeightCM": 420}] | "vigorous" | "left fence" |
(9 rows)它返回的信息比我们实际需要的要多得多,所以我们将在下一步进行投影,但至少每个实例有一行,而不是每棵树有一行。
但有些可疑的事情正在发生,如果你看看在最右边专栏,对于currentHeightCM来说,它是空的,这是一个遗憾,因为它是我们将需要的。我们也必须解决这个问题。
让我们把我们不想要的东西都投射出来。
with instance_cte as ( SELECT plant->>'name' AS name, plant->'instance' AS instance FROM plants ) SELECT instance_cte.name, items.location, items.currentheightcm FROM instance_cte, jsonb_to_recordset(instance_cte.instance) AS items(location jsonb, currentHeightCM jsonb);
now we are being more explicit about what we want to return, we can see the problem clearly.
name | location | currentheightcm ------------------+--------------------+----------------- Apple Tree | "right fence" | Apple Tree | "right fence" | Apple Tree | "back left corner" | Wild Cherry | "next to decking" | Silver Birch | "next to decking" | Rowan | "back door" | Olive | "back door" | Corkscrew Willow | "left fence" | Corkscrew Willow | "left fence" | (9 rows)
currentHeightCM出了什么问题?它是子对象中唯一一个int而不是text的字段,但这不可能是问题所在(我试着将其转换为int,但仍然不起作用)。
几个小时过去了。
为什么它将结果集中的列名转换为小写?不,等等,这是我写为Lower Camel Case的唯一属性名称。不可能,那太疯狂了。为什么Postgres的属性名称必须全部小写?为了确定起见,我最好测试一下。
我创建了一个名为plants3的新表,并插入了与以前相同的数据,但将所有对currentHeightCM的引用都更改为currentHeightCM,然后重新运行与上面完全相同的查询。
name | location | currentheightcm
------------------+--------------------+-----------------
Apple Tree | "right fence" | 83
Apple Tree | "right fence" | 65
Apple Tree | "back left corner" | 450
Wild Cherry | "next to decking" | 600
Silver Birch | "next to decking" | 140
Rowan | "back door" | 400
Olive | "back door" | 450
Corkscrew Willow | "left fence" | 400
Corkscrew Willow | "left fence" | 420
(9 rows)这正是使用连接到RDBMS上的一个好主意(JSONb)来处理这种工作负载的问题。无论你认为数据建模的灵活性有多大,总会有一些令人讨厌的陷阱潜伏在那里,作为关系模式僵化的后遗症。
我后来发现了一份关于这个主题的错误报告,报告者建议他们不能将camelCase与jsonb_to_recordSet()一起使用,然而,受访者认为这是故意的行为…。
未引用的标识符在postgres中用小写字母表示
在我们因沮丧而死之前,让我们先完成剩下的查询。
我需要ORDERBY和LIMIT来匹配MongoDB的输出。
with instance_cte as ( SELECT plant->>'name' AS name, plant->'instance' AS instance FROM plants3 ) SELECT instance_cte.name, items.location, items.currentheightcm FROM instance_cte, jsonb_to_recordset(instance_cte.instance) AS items(location jsonb, currentheightcm jsonb) ORDER BY items.currentheightcm DESC LIMIT 1;
and at last…
name | location | currentheightcm -------------+-------------------+----------------- Wild Cherry | "next to decking" | 600 (1 row)
我本应该将高度强制转换为int,但我很高兴看到Postgres仍然可以对其进行排序,即使它被强制转换为JSONb。对于下一个查询,我肯定要这样做。此外,我不确定为什么location是唯一一个用双引号括起来的字段。
我有多少棵超过2米高的树?
这里的计划是在上一个查询的基础上添加一个范围匹配。我怀疑这对两个平台来说都很容易。
对于MongoDB,查询比以前更简单:
db.plants.aggregate([
{$unwind: {path: "$instance",}},
{$match: {"instance.currentHeightCM":{$gt: 200}}},
{$count: 'Trees_GT_2m'}
])and the output is:
[{ Trees_GT_2m: 6 }]For Postgres, I’m going to start with my previous query, this time casting the height into an int and drop a WHERE clause and COUNTin there.
with instance_cte as ( SELECT plant->>'name' AS name, plant->'instance' AS instance FROM plants3 ) SELECT COUNT(*) FROM instance_cte, jsonb_to_recordset(instance_cte.instance) AS items( location jsonb, currentheightcm int) WHERE items.currentheightcm > 200;
And the result…
count
-------
6
(1 row)这个没有什么可补充的,现在我们已经完成了Postgres查询的所有繁重工作,一切都很顺利。我仍然建议,如果并排比较这两个查询,MongoDB查询看起来更干净、直观,而且更易于阅读。
结论
在第一部分中,我们研究了在Postgres中查询JSONb,并与MongoDB进行了比较。Postgres中对JSONb(和JSON)运算符的支持看起来很棒,但单独使用文档来告知您的可用性和实用性是危险的。实际情况是,一旦你走出了一个相当狭窄的简单查询范围,构建任何远程复杂的东西(例如Postgress应该能够进行的实时分析的分组或聚合)都会变得不直观且耗时。我很容易遇到一些问题,这些问题只有那些最聪明、渴望益智的Postgres超级用户才能解决(他们手头有时间)。如果我在构建、运行和维护生产服务,我会非常担心这一点。
我认为不可否认的是,如果你是现代开发社区的一员,需要使用JSON格式的数据作为你的应用程序和服务的主要来源,那么使用MongoDB而不是Postgres会更有效率。
在下一部分中,我们将增加数据量并重新运行一些查询,以了解MongoDB Postgres JSONb在更大范围内的表现。
- 62 次浏览
云数据库
【云数据库】2019年最佳云数据库
有了这些出色的云提供商,您的数据库可以在未来得到保障。

数据库已经成为IT服务的重要组成部分,是存储和检索数据的重要场所。但是,可以通过不同的方式记录数据,这取决于您希望使用的不同信息是如何相互引用的。传统上最常见的数据库形式是关系型数据库,如Microsoft Access中使用的,它是功能更强大的老大哥MySQL。在这类数据库中,数据的不同点之间有直接的关系,按列和行排列。然而,如今非关系数据库已经变得越来越普遍,在这种数据库中,数据存储没有显式的结构和机制来链接它。如今,人们对商业智能的需求越来越大,因为商业智能试图将原本可能被隐藏的潜在趋势联系起来。无论您需要哪种类型的数据库,大多数提供者都会根据需要提供不同数据库格式的选择。在这里,我们将看到其中最好的。

1. Amazon关系数据库
如果您有能力,可以利用AWS的处理能力来运行数据库750小时免费只支持多个DB类型的高级用户亚马逊网络服务(AWS)是亚马逊公司的子公司,成立于2006年。它为个人和企业提供随需应变的云计算。AWS是一个基于云的程序,用于使用集成的web服务构建业务解决方案。它们为用户提供了广泛的云服务,如内容交付和数据库存储。Amazon关系数据库是一种数据库即服务(DBaaS)。它适合有经验的数据用户、数据科学家和数据库管理员。对于已经熟悉AWS服务的开发人员来说,这是一个很好的选择。用户需要联系数据库管理员进行设置,因为该过程涉及技术。用户可以根据自己的需要构建特定的数据库。您可以创建模板或编写代码。用户可以控制数据库的类型以及数据存储的位置。支持的特定数据库格式包括Amazon Aurora、PostgreSQL、MySQL、MariaDB、Oracle数据库和SQL Server。这项服务提供750小时的免费服务。网上有一个价格计算器来帮助计算AWS的成本,但这很难计算出来。用户可以从他们的数据库管理员那里获得帮助。AWS有三种不同的定价模式;“量入为出”、“先存后用”、“少花钱多办事”。然而,AWS提供了一个自由层。它为用户提供12个月的特定服务。在此之后,您必须选择注册上述任何计划或取消您的AWS订阅。您必须拥有现有的AWS订阅才能访问Amazon关系数据库服务。您可以在这里注册Amazon关系数据库
2. Microsoft Azure SQL数据库
免费试用Azure一年,看看它是否适合你12个月免费为你的支持问题Microsoft Azure是由Microsoft创建的,用于通过其数据中心构建、测试、部署和管理应用程序和服务。它于2010年发布。Microsoft Azure不仅提供数据库服务,还提供平台服务、软件服务和基础设施服务。使用Azure,客户可以纯粹在云上使用服务,也可以将其与任何现有的应用程序、数据中心或基础设施相结合。Azure的SQL数据库有微软熟悉的外观和感觉。它具有强大的SQL引擎兼容性和机器学习能力。该服务提供创建数据库所需的所有SQL工具和应用程序。它很容易使用。Microsoft Azure SQL数据库有一个在线门户,可以访问您需要的所有内容。安装是快速和无痛,但用户需要有一个微软帐户开始。订阅者可以使用“连接库”来选择他们想要连接的操作驱动程序。在这里,您还可以选择您喜欢的语言设置、数据库名称、标识源和价格层。Azure为用户提供12个月的免费使用。这包括200美元的信贷和超过25项“永远免费”的服务。该平台采用“即付即付”的订阅模式,因此你只需为你使用的内容付费。网上的评论者们报道了一些问题,并表示支持。你可以在这里注册微软Azure SQL数据库。
3.Oracle数据库
选择Oracle进行安全加密的简单数据库设置易维护、安全加密、部分支持问题甲骨文云数据库是甲骨文云的一部分,属于甲骨文公司,成立于1977年。Oracle云平台是开源技术和Oracle技术的结合。这使用户能够更有效地构建、部署、集成和管理所有平台应用程序。该解决方案将机器学习和人工智能结合起来,提供一种提供自我修复能力的服务。它还降低了创业成本,并提供了预测性的见解。Oracle数据库服务支持任何规模的企业。它提供了跨越多层的高级加密。可以在几分钟内设置数据库,并且易于导航。用户可以增加“随需应变需求”,这样随着用户的增长,他们可以扩大规模。广告您的所有数据和应用程序都可以集成。该解决方案允许用户将所有进程迁移到云上。一切都通过一个单一的平台进行管理。所有数据默认加密。甲骨文云平台声称他们的解决方案可以为你做任何事情。这节省了系统维护、部署解决方案和必要的更新等重复性任务的时间。该平台提供30天的免费试用,包括300美元的信用额度和3500个小时。有“随你付”级别或“每月灵活”计划。在“Flex”计划中,用户承诺每月支付1-7年不等的云服务费用。为了注册上述任何一种,用户需要直接与Oracle联系。用户报告了客户支持方面的一些问题。您可以在这里注册Oracle数据库
4. SAP的云平台
Sap是一个高度可定制的云平台,提供简单的数据库迁移免费试用容易迁移相对昂贵SAP云平台是SAP SE开发的平台即服务。它在一个安全的云环境中创建新的应用程序。它成立于2012年。广告该平台包括内存SAP HANA数据库管理系统。它既连接本地系统,也连接运行SAP或其他第三方软件的基于云的系统。SAP云平台面向拥有大量数据集的大型企业。该系统通常是直接向前设置,并将指导您一步一步的过程。使用“数据和存储”选项选择要使用的数据库管理系统。您还可以选择数据迁移的类型。SAP为用户提供免费试用。有两种商业定价方案可供选择。Sap已经创建了一个PDF,其中清楚地解释了所有的价格。网上评论人士抱怨称,SAP的定价不如其他供应商有竞争力。您可以在这里注册SAP云平台
5. Rackspace的云
Rackspace是高度可定制的,支持任何云模型或数据库支持多种数据库类型,优秀的客户支持少的文档Rackspace云是美国Rackspace公司的一套云计算产品。它成立于2006年。该解决方案提供web应用程序托管、平台即服务和云服务等。广告Racksapce允许您选择云提供商,然后可以通过Rackspace的平台与之交互。该服务已经与微软Azure、亚马逊网络服务和WMware等主要云服务提供商合作。这个系统的优点是,您可以获得一些最大的云提供商的可伸缩性,但是可以获得较小公司的客户支持。Rackspace提供广泛的云服务。这些包括公共云、私有云、混合云和多云。当谈到IaaS和DBaaS解决方案时,Rackspace现在完全构建在开源的OpenStack云操作系统上。云数据库为用户提供了简单的、按需供应的和开放的API。用户可以部署MySQL、Persona服务器或MariaDB。Rackspace云数据库允许用户添加或删除副本,在实例之间移动,最大可达64GB RAM,最大可扩展存储空间1TB。用户可以调度备份和恢复。该平台为接近裸机的性能提供了基于容器的隔离。该平台提供24/7的支持,数据库专家可以帮助任何查询。您可以免费注册Rackspace,其中包括一个技术客户经理、安全指南和免费的服务器监控和报告。Rackspace对它们的价格有深入的介绍。这样您就可以选择最适合您需要的包。用户提到了文档方面的问题,但是优秀的服务支持弥补了这一点。你可以在这里注册Rackspace云。
其他需要考虑的云数据库
近年来,许多公司提供了大量的云平台。由于数据库驱动的软件仍然是规范,所以确保您选择的任何云平台都能够支持您的数据库类型和大小,并与其他it基础设施适当地集成(尤其是监视安全性或错误)仍然是关键。在这里,我们将简要介绍一些额外的云数据库选项,也值得一看:DataStax使用Apache Cassandra作为其云平台的主干,支持本地、混合和多云服务。它的企业服务旨在交付一个强大的、可伸缩的、始终在线的数据库。DataStax还为AWS、Azure和谷歌云提供管理服务。该公司还将推出星座云数据平台,为零操作提供智能服务。广告IBM云上Db2只是服务巨头IBM提供的服务之一,是其综合云管理平台的一部分。IBM的云上Db2是一个在云中运行的完全托管的SQL数据库。它快速且容易设置,并且允许灵活的扩展,因此您只需根据实际使用的资源支付费用。安全补丁它自动化,它很容易检索数据集,当你需要看他们。云上的Db2也可以在私有VPN上设置。Zoho Creator有点不同——它不是一个云数据库管理平台,而是一个在云中构建自己的数据库的简单方法。这对于那些想要构建自己的应用程序的小公司来说尤其有用,否则他们会发现一个大的云管理包是大材小用。它运行在一个简单的拖放界面,允许完全定制,作为Zoho应用套件的一部分,意味着它将很容易与其他Zoho产品集成。Couchbase也有一点不同,它允许您构建自己的数据库,运行N1QL,这比MySQL通常允许的数据存储复杂得多。这意味着能够在云中构建分层的数据库,这些数据库更适合JSON。此外,它还具有内置的分析功能、易于复制和企业级安全性。因此,如果您需要一个具有NoSQL灵活性的更具创新性的数据库平台,Couchbase可能值得考虑。MongoDB Atlas是一种自动化的云服务,它使得在云中管理数据库变得更加容易,允许用户专注于应用程序开发。它提供对60多个云区域的全局支持,并提供分布式容错和备份选项,以确保业务连续性。按需扩展、资源优化和完全自动化的结构供应意味着MongoDB对创新企业特别有吸引力。谷歌云数据库服务是谷歌云平台服务的一部分,也是我们在这里提到的最后一家知名云提供商。用户可以从很多选项中进行选择,而不是关系型和非关系型。云SQL选项为PostgreSQL和MySQL提供托管支持,而BigTable选项为大型分析和操作工作负载提供pb级的、完全托管的NoSQL数据库服务。
原文:https://www.techradar.com/news/best-cloud-database
本文:https://pub.intelligentx.net/best-cloud-databases-2019
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 69 次浏览
【无服务器数据库】如何创建一个非常便宜的无服务器数据库
云对象存储可以用作功能强大且非常便宜的数据库
您是否相信您可以使用完全托管、可大规模扩展、高度可用且价格低廉的无服务器数据库,每月只需 5 美元,您就可以存储数亿条记录并读写数十亿条记录?如果您的数据库需求可以通过非常简单的键值存储来满足,则可以。解决方案是使用廉价的云对象存储。
亚马逊于 2006 年发布了他们的 S3(简单存储服务)对象存储产品。从那时起,所有其他主要的云服务提供商以及许多其他云提供商都提供了对象存储解决方案。
对象存储可用于存储照片、视频、备份等,但也可用于存储数据。数据可以以任何您想要的格式存储,例如 JSON、BSON、XML、CSV、协议缓冲区、MessagePack、纯文本或任何其他数据序列化格式。
对象存储在桶中。存储桶通常可以在全球特定区域的数据中心创建。这使您可以使您的数据更接近将要访问数据的用户。对于某些提供商,可以将存储桶配置为网站,从而允许您将对象存储用作廉价的网站主机。
价钱
对象存储相对于无服务器数据库的主要优势在于价格。存储成本通常为每 GB 1 美分至 2 美分,而最便宜选项的出站网络成本通常为每 GB 1 美分。
许多对象存储产品还对读取和写入 API 请求收费。如果你使用对象存储作为数据库解决方案,如果你每个月收到数亿或数十亿的请求,这可能会大大增加你的成本,所以最好避免对读写请求收费的产品。有很多解决方案不对请求收费。在下表中,Read 和 Write 列表示每百万请求中的美分。带有“-”的产品没有请求费用。
为了进行比较,以下是一些无服务器数据库的相同定价。(请参阅“移动或Web应用的无服务器数据库”。)budget object存储产品的价格只是无服务器数据库的一小部分。

下表显示了一些具有不同存储量和读写请求的对象存储服务和数据库的每月成本。 记录大小假定为 500,但最后两列除外,它们的记录大小为 100 小和 4000 大。 这表明,在您开始存储和读取和写入数亿条记录之前,定价实际上变化不大。 然而,除此之外,您选择的产品可能会产生很大的不同。
访问数据
大多数对象存储产品都与亚马逊的 S3 REST API 兼容。两个主要的例外是 Google 和 Azure。 S3 兼容性意味着您可以使用为 S3 构建的工具和 SDK。您还可以轻松切换供应商,避免供应商锁定,或者只需更改访问 URL 即可使用多个供应商。
简单的 S3 REST API 非常适合移动和 Web 应用程序使用,无需单独的 API 服务器即可直接访问数据。
对象以扁平结构存储在存储桶中,没有文件系统中的层次结构。但是,您可以使用路径分隔符来模拟这种情况,通常是“/”。例如,“photos/photo1.jpg”创建一个模拟的“photos”文件夹,其中包含“photo1.jpg”。
S3 API 允许您读取、写入和删除对象。对象通过其唯一键访问,可能类似于文件名。无法进行诸如“SELECT * FROM Employees WHERE City='San Diego'”之类的查询。这可能会极大地限制您将对象存储用作数据库的方式,但是在许多应用程序中,您所需要的只是通过 id 访问数据。
使用对象存储也无法进行记录更新。对记录的任何更改都是通过重写整个记录来完成的。
存储桶和对象具有访问权限来限制谁可以读取和写入。可以向存储桶和/或对象授予公共访问权限,以允许任何人读取或写入。
性能
对象存储性能通常非常好,即使与常规数据库相比也是如此。我验证了一些对象存储产品的响应时间,发现时间为 50 毫秒 - 300 毫秒。我在无服务器数据库中发现了类似的结果。尽管数据库通常可以在不到 10 毫秒的时间内访问数据,但当请求和响应通过 Internet 传输时,访问时间会大大增加。
速率限制
请注意,提供商通常对每秒可以发出的请求数有限制。限制可能足够高,您不会受到影响。并非所有提供商都指定其速率限制。谷歌是唯一声称他们会扩展以满足您的请求率的公司。
AWS 每个前缀(文件夹)每秒可以读取 5,500 个对象并写入 3,500 个对象。如果您需要更多请求,请将数据拆分到文件夹中。
备份
执行数据库备份通常是为了避免在服务器故障的情况下丢失数据或从用户或应用程序错误中恢复数据。
数据库持久性是衡量提供商可以保证您的数据不会丢失的程度,通常表示为包含许多 9 的百分比。例如,10 个九的持久性将是 99.999999%。在主要供应商中,AWS 和 Google 获得 11 个 9,Azure 获得 12 个。通过在位于不同地理区域的数据中心复制数据来增强耐用性。由于高持久性,可能不需要备份对象存储数据。
几乎每个对象存储提供程序都允许您对对象进行版本控制。这意味着每次用更新替换对象时,旧对象都会保留一个版本号,从而可以返回到以前的版本。这在用户或应用程序错误的情况下提供了自动备份。
产品详情
AWS S3
AWS S3 是比较所有其他对象存储产品的黄金标准。 S3 的定价与其他供应商的同类产品类似。
- 优点:庞大的 AWS 系统的一部分;稳定安全;非常高的速率限制;世界各地的许多数据中心
- 缺点:请求费用
AWS Lightsail
Lightsail 是 AWS 的一个部门,拥有服务器和其他一些云产品,这些产品的定价可以与 DigitalOcean 等预算云提供商竞争。与常规 AWS 产品相比,Lightstail 产品通常也更容易设置和使用。
2021 年 7 月,Lightsail 宣布了一款基于 AWS S3 的廉价对象存储产品。这在某种程度上改变了游戏规则。您似乎以更低的价格获得了 S3 的所有好处。捆绑包每月 1、3 或 5 美元,存储空间为 5、100 或 250 GB,网络传输为 25、250 或 500 GB。超出这些限制的存储和网络按正常 S3 费率收费。但是,在捆绑限制之内或之外都没有请求费用。
5 美元的计划使 S3 的价格类似于 DigitalOcean、Linode 和 Vultr 提供的预算计划。但是,与其他预算提供商的计划不同,Lightsail 捆绑包似乎仅限于单个存储桶。如果您需要在世界各地设置多个存储桶,一个好的定价策略可能是设置多个 1 美元存储桶,然后根据需要增加到 3 美元或 5 美元存储桶。 Lightsail 允许您在计费期间切换一次定价计划。
- 优点:与 S3 相同,但价格便宜得多;无申请费;低 1 美元的最低价格
Azure Blob 存储
Azure 对象存储称为 blob 存储。
- 优点:庞大的 Azure 系统的一部分;稳定安全;非常高的速率限制;世界各地的许多数据中心
- 缺点:请求费用;不兼容 S3
谷歌云存储
谷歌云存储是谷歌的对象存储产品。
- 优点:庞大的 Google Cloud 系统的一部分,稳定且安全,无限制的速率限制,遍布全球的许多数据中心,3 个区域的免费选项(5GB 存储,5,000 次写入/月,50,000 次读取/月,1GB 网络/月)
- 缺点:总是免费限制后的请求费用;任何提供商的最高网络费率;不兼容 s3
Firebase
Firebase 是一家 Google 公司,以合理的价格提供大量云产品,这些产品通常易于设置和使用。凭借大量的免费选项,许多公司可以免费使用 Firebase Cloud Storage。
- 优点:与 Google 相同,但有更好的免费选项(每天 20K 写入、每天 50K 读取、每天 1GB 网络)
甲骨文云
Oracle 云对象存储的定价比其他大型提供商更优惠。
- 优点:写请求的价值;前 10TB/月没有网络费用,之后非常便宜
- 缺点:请求费用;高存储价格
阿里巴巴
阿里巴巴的对象存储服务(OSS)是一个非常划算的选择。有一个即用即付计划或具有存储和网络限制的计划,可以节省一点成本。中国有21个数据中心,其中10个。
- 优点:世界各地的许多数据中心;除非您达到每月 5 亿次请求,否则没有请求费用的良好定价
DigitalOcean
DigitalOcean 是一家规模较小的云公司,提供易于快速部署且价格低于大型云提供商的服务器和数据库。他们的对象存储被称为 Spaces,是第一个提供 250GB 存储、1TB 出站传输和无请求费用且每月 5 美元的惊人低价。任何超出限制的存储或网络都以非常损失的价格收费。这种费用结构非常适合将对象存储用作非常便宜的数据库。
Spaces 的一个问题是速率限制。每个空间(存储桶)限制为大约 200 个请求/秒。如果这是一个问题,您可以通过使用多个空格来解决这个问题。您最多可以在同一帐户中创建 100 个空间。 (我发现一些用户在访问 Spaces 的速度远低于 200/秒时遇到了问题。)
- 优点:难以置信的价值
- 缺点:速率限制可能会限制某些用户;只有 5 个数据中心
Linode
Linode 类似于 DigitalOcean,以易于部署的高价格提供云服务。他们的对象存储产品定价与 DigitalOcean 相同。
- 优点:难以置信的价值
- 缺点:只有 4 个数据中心
Vultr
Vultr 类似于 DigitalOcean 和 Linode。他们的对象存储产品的价格与其他两个相同。
- 优点:难以置信的价值
- 缺点:新泽西州只有 1 个数据中心
Exoscale
Exoscale 的对象存储在欧洲的 6 个数据中心中具有竞争力的价格。
- 优点:物有所值
- 缺点:数据中心仅在欧洲
Scaleway
Scaleway 的对象存储在欧洲拥有 3 个数据中心,价格极具竞争力。您每月可获得 75GB 的存储空间和免费网络。
- 优点:非常好的定价和免费套餐
- 缺点:数据中心仅在欧洲
Wasabi
Wasabi 只做一件事,那就是对象存储。他们提供任何其他提供商的最优惠价格。读取、写入或网络不收取任何费用。唯一的成本是 0.006 美元/GB 的存储成本,这非常便宜。
但是,定价常见问题解答揭示了一些可能使 Wasabi 不适合用作数据库的细节。对象的最短持续时间为 90 天。如果一个对象在 90 天之前被删除,它仍被计为整个 90 天的存储。如果在 90 天内多次更新对象会发生什么,似乎没有任何文档说明。
然后是这样的:“如果您每月的出口数据传输量大于您的活动存储量,那么您的存储用例就不适合 Wasabi 的免费出口政策。”并且:“如果您的用例经常超出我们免费 API 请求政策的指导方针,我们保留限制或暂停您的服务的权利。”
- 优点:总体最优价格
- 缺点:限制可能禁止使用芥末作为数据库
Backblaze B2
Backblaze 进行计算机备份和 B2 对象存储。 B2 的存储价格最低,为 0.005GB/月,下载价格非常低,为 0.01GB/月。但是,它确实会为读取请求收取典型的每百万美元 0.40 美元。如果您每月不处理数亿或数十亿个请求,这可能是一个不错的选择。
- 优点:价格优惠
- 缺点:阅读请求费;只有 3 个数据中心;无法选择数据中心
Tebi
Tebi 是一个非常新的组织,只做对象存储。它们的主要功能是实时复制到其他服务器,以使数据更接近用户。不幸的是,他们目前只有 4 个数据中心。
- 优点:价格优惠;免费提供 25GB 存储空间和 250GB 网络
- 缺点:只有 4 个数据中心;很新,所以没有经过时间的考验
注释
如果您使用对象存储作为数据库解决方案,我很想听听您的意见。我目前只在一个使用 Cloud Storage for Firebase 的网络应用程序上完成了这项工作,而且效果非常好。我目前正在评估一种产品的对象存储选项,该产品需要相当多的存储空间,每月可能有数亿个请求。
原文:https://aws.plainenglish.io/very-inexpensive-serverless-database-6ed6df…
- 99 次浏览
内存数据库
- 88 次浏览
【内存数据库】调整插入和数据负载的HANA性能
插入和数据加载将写入新数据,而SELECT、UPDATE或DELETE等其他操作必须对现有数据进行操作。
因此,典型的性能因素是部分不同的。如果你想提高插入和数据加载的性能,你可以考虑以下方面:
|
Area |
Details |
||||
|
Lock waits |
参见1999998,如果需要,优化锁等待情况。插入必须等待锁的典型情况是:
|
||||
|
Columns |
在插入期间,必须分别维护每一列,因此插入时间在很大程度上取决于表列的数量。 |
||||
|
Indexes |
每个现有索引都会减慢插入操作的速度。检查是否可以在大量插入和数据加载期间减少索引的数量。SAP BW提供了在数据加载期间自动删除和重新创建索引的可能性。主索引通常不能被删除。 |
||||
|
Bulk load |
如果加载了大量记录,就不应该对每条记录执行插入。相反,您应该尽可能利用批量加载选项(即使用单个插入操作插入多个记录)。 |
||||
|
Parallelism |
如果加载了大量记录,则应该考虑客户端上的并行性,以便使用到SAP HANA的多个连接来加载数据。 |
||||
|
Commits |
确保在执行大规模插入时定期执行COMMIT (after each bulk of a bulk load)。 |
||||
|
Delta merge |
大的增量存储会降低负载性能,所以要确保定期执行增量合并。 避免重复合并小的增量存储或使用大量未提交的数据,以避免不必要的开销。 |
||||
| Table vs. record lock |
如果只可能进行一次非并行插入,并且不需要对底层表进行并发更改,那么使用全局表锁而不是大量的单独记录锁可能会很有用。表锁可以通过以下方式设置: LOCK TABLE "<table_name>" IN EXCLUSIVE MODE 之后,SAP HANA不再需要维护单独的记录锁。这种方法也适用于INSERT…选择可以在内部并行化的操作。 |
||||
| Savepoints |
需要保存点将修改后的数据写入磁盘。通常的主要意图是尽可能缩短阻塞保存点阶段,同时接受较长的保存点持续时间。在大量导入期间,相反的情况可能更好:保存点更短,阻塞阶段增加的风险更大。较短的保存点可以减少写入磁盘的数据量,还可以减少需要保留的日志量,从而降低文件系统溢出的风险。 在大量更改期间,可以考虑以下参数调整来减少总体保存点持续时间:
|
||||
| Bugs |
以下SAP HANA bug可能会对插入性能产生负面影响:
|
典型的插入量为:
|
星座 |
典型的吞吐量 |
|
问题情况,如长临界保存点阶段或其他锁 |
< 500 records / second |
|
正常的、连续的单行插入 |
1,000 - 10,000 records / second |
|
高度并行的批量加载 |
1,000,000 records / second |
原文:https://www.stechies.com/performance-inserts-data-loads-tuned/
本文:https://pub.intelligentx.net/tuning-hana-performance-inserts-and-data-loads
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 170 次浏览
【首席架构看HANA】SAP HANA行和列存储表
SAP HANA Modeler视图只能在基于列的表的顶部创建。在列表中存储数据并不是什么新鲜事。在此之前,假定将数据存储在基于柱状结构的结构中需要更大的内存大小,并且没有优化性能。
随着SAP HANA的发展,HANA在信息视图中使用了基于列的数据存储,并展示了与基于行的表相比,柱状表的真正优点。
列存储
在列存储表中,数据是垂直存储的。因此,类似的数据类型组合在一起,如上面的示例所示。在内存计算引擎的帮助下,它提供了更快的内存读写操作。
在传统的数据库中,数据是以行为基础的结构,即水平存储的。SAP HANA以基于行和列的结构存储数据。这为HANA数据库提供了性能优化、灵活性和数据压缩。
将数据存储在基于列的表中有以下好处
- 数据压缩
- 与传统的基于行的存储相比,对表的读写访问更快
- 灵活性和并行处理
- 以更快的速度执行聚合和计算
功能差异—行存储与列存储
如果SQL语句必须执行聚合函数和计算,则始终建议使用基于列的存储。当运行诸如Sum、Count、Max、Min之类的聚合函数时,基于列的表的性能总是更好。
当输出必须返回完整行时,首选基于行的存储。下面给出的例子很容易理解。
当在sales列中运行带有Where子句的聚合函数(Sum)时,它将只在运行SQL查询时使用Date和sales列,因此如果它是基于列的存储表,那么它将进行性能优化,速度更快,因为只需要来自两列的数据。
在运行简单的Select查询时,必须在输出中打印完整的行,因此建议根据此场景将表存储为行。
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 395 次浏览
【首席看HANA】SAP HANA的秘密- 不要告诉任何人!
- 将文件保存在RAM或磁盘上,哪个更好?这取决于……
- 按原样写文件和压缩文件哪个更好?这取决于……
- 当一行发生更改时修改文件还是保留历史记录,哪种方法更好?这取决于……
- 以A或B格式存储数据,哪种更好?这取决于……
如何处理“视情况而定”
简单的方法是两者都做,例如以柱状和行状两种格式存储数据。通过这种方式,用户可以访问其中之一,或者其他更有意义的。当然,这个选择是有代价的。在这种情况下,数据需要存储两次——将优点和缺点结合起来。
更好的方法是以某种方式组合特性,这样一方面的缺点就可以由另一种技术弥补(反之亦然)。优点和缺点的结合。这就是SAP HANA的秘密。不只是内存中的能力,不列存储,不压缩;而是这两者的巧妙结合。在内存空间中,没有其他数据库供应商能够达到这种程度,主要是出于历史原因。
为什么?享受这2分钟的视频。当然,用我们今天的知识回顾过去是不公平的,但是这个视频仍然很有趣。
主要的论点是你不能把所有的事情都记在脑子里,这是不可能的。如果我们把这句话视为理所当然,那么压缩可能是一条出路。假设1TB的RAM服务器太贵,如果数据可以压缩10倍,那么RAM需求将下降到更便宜的128GB RAM计算机。压缩有缺点,有什么技术可以绕过它?
SAP HANA使用四种技术来实现全利无弊的组合:
| -Memory |  |
Columnar Storage |  |
| Compression |  |
Insert-Only |  |
每种技术的优缺点
内存
基本思想是内存比磁盘快得多。实际上,这种差别比人们通常看到的要大得多。现代CPU的内存带宽为20g字节/秒或更高,单个磁盘的ssd带宽约为550MByte/秒,硬盘驱动器的带宽约为180MByte/秒,两者相差36和110倍。如果一个程序频繁地使用相同的内存,它会被缓存在CPU的L1或L2缓存中,从而将内存带宽提高10倍。相反,180MB/秒的磁盘速度仅适用于顺序读访问,随机访问对磁盘系统的性能要差得多,而对RAM没有负面影响,对SDDs影响很小。
内存的缺点是内存芯片本身的成本(截至2017年,RAM的成本为7美元/GByte,而磁盘的成本为0.05美元/GByte)和硬件平台需要的成本,以便处理尽可能多的内存。
从绝对数字上看,1TB的内存将是7000美元——可以负担得起。
那么内存计算的优点和缺点是什么呢?
优点:
- 更新数据快
- 插入数据很快
- 阅读是快速
缺点:
- 当电力耗尽时,所有的数据也随之耗尽
- 128GB的服务器便宜,1TB的服务器便宜,64TB的服务器贵,1000TB的服务器根本不存在(比如这里)
压缩
压缩的思想很简单:单个CPU比磁盘快得多,因此压缩数据以减少数据量是有益的,只要它的开销不是太大。因此,每个主要的数据库都支持压缩。但它不是很流行,因为压缩数据库块和解压缩它需要付出代价。最明显的成本开销是在数据库块内更新数据时。必须解压数据库块,将更改的数据合并到其中,然后必须再次压缩该块。
优点:
- 减少所需的大小
缺点:
- 插入需要更多的CPU能力
- 读需要更多的CPU能力
- 更新需要更多的CPU能力
列存储
对于一个简单的select sum(收益),柱状存储是完美的。只有一列是只读的,这只是整个表的一部分。这将比所有表数据都在一个文件中的传统行定向表快得多。
如果选择一整行,则行定向存储听起来更合适。插入新行—相同的参数。
优点:
- 同一列的所有数据都是紧密相连的
缺点:
- 同一行的所有数据都存储在不同的地方
只插入
真正的数据库应该具有这样的一致性:“当触发select语句时,此时提交的所有数据都是可见的,而且只有这些数据”。如果另一个事务确实更改了尚未读取的行,那么它仍然应该在查询执行开始时返回有效的版本。所以旧的值必须保留在某个地方。
从一开始,我所知道的唯一支持这一功能的主流数据库是Oracle (SQL Server可以选择打开/关闭这一功能),但是您必须为这种一致性付出代价。每当Oracle数据库写入器用新数据覆盖一个块时,旧版本就会被复制到数据库的回滚段中。因此,一个简单的更新或插入到现有块需要两个操作,实际的更改加上保留旧的版本。
如果只使用insert,情况就完全不同了。在每个表中,旧数据不会被覆盖,只会被追加。更新现有行意味着使用时间戳作为版本信息附加新行。select语句根据查询执行时间戳选择最新的版本。
优点:
- 写的快
缺点:
- 读起来更慢
- 需要更多的存储空间
结合技术
好吧,所以单独来说,所有的技术都是好主意,其他的供应商也尝试过这些,并且已经建立了适当的利基产品,主要围绕分析用例。一个数据库是纯内存数据库,它需要一个常规数据库来持久存储数据—一个缓存系统,其他数据库可以插入数据,但不能更新或删除。许多支持压缩,但客户通常不支持压缩。
SAP HANA的目标是成为一个真正的RDBMS数据库,它支持分析和事务用例,并且在所有方面都优于其他数据库。所以以上这些缺点都是不可接受的。这是通过结合SAP HANA的四项技术实现的……
首先,我想展示两种技术的结合如何对彼此产生积极的影响。
压缩与列式存储的组合
当出现重复模式时,压缩数据的效果最好。这是一个真实的例子,材料主表(SAP ERP中的MARA)。
| MANDT | MATNR | ERSDA | VPSTA | LVORM | MTART | MBRSH | MATKL |
|---|---|---|---|---|---|---|---|
| 800 | 000000000000000023 | 23.01.2004 | K | false | ROH | 1 | |
| 800 | 000000000000000038 | 04.09.1995 | KDEVG | true | HALB | M | 00107 |
| 800 | 000000000000000043 | 23.01.2004 | KBV | false | HAWA | 1 | |
| 800 | 000000000000000058 | 05.01.1996 | KLBX | false | HIBE | M | |
| 800 | 000000000000000059 | 05.01.1996 | KLBX | false | HIBE | M | |
| 800 | 000000000000000068 | 12.01.1996 | KEDPLQXZ | false | FHMI | A | 013 |
| 800 | 000000000000000078 | 10.06.1996 | KVX | true | DIEN | M |
什么可以更好地压缩整个文件,一行还是一列?
答案是显而易见的,但是,尽管如此,我还是从MARA表中导出了这些列(我的系统的全部20,000行)到一个CSV文件中(1 ' 033KB大),并将包含所有9列的一个文件压缩了。为了进行比较,还创建了9个文件和一个列。

显然,主键不能被压缩太多,它是整个文件大小的一半。其他所有的列都压缩得很好。MANDT文件甚至只有303字节大,ERSDA文件与许多创建日期是12 ' 803字节大。原因很明显,一列中的数据看起来很相似,可以很好地压缩,因此,一行中的数据本质上是不同的,可以压缩得不那么有效。
但这并不是一个公平的比较,因为zip算法倾向于更大的数据集,因为它可以更容易地查找模式,而且它是一个相当积极的算法。在数据库中,目标是降低压缩比,从而减少CPU周期。但是,虽然zip支持单个文件,但是在本例中,9个单独的文件加起来是104KB,但是一个文件中的相同数据是111KB。如果数据量更大,节省的数据量将进一步增长。
优点:
- 压缩柱状存储比压缩行存储更有效
缺点:
- 压缩需要CPU能力
- 需要找到一个比zip更适合的压缩算法
- 读取、插入和更新整个行仍然没有解决
压缩与插入
压缩有一个重要的缺点,如果一行被更新或删除怎么办?压缩跨越多个行,因此当更新单个值时,必须重新解压、修改和压缩整个单元。使用传统数据库并打开压缩,这正是在磁盘块级别上发生的事情。
那么SAP HANA是做什么的呢?它不更新和删除现有的数据!
相反,它将更改作为一个新版本附加一个时间戳作为版本信息,当表被查询时,它将返回每一行的最老版本,即与查询执行开始时间匹配的最老版本。因此不需要重新压缩,数据被追加到表的末尾,而未压缩的区域一旦超过限制,它就会被一次性压缩。
这种方法的另一个优点是,如果单个行被多次更新,那么将更新哪一行?十年前订的?不太可能。它将是一个最近的,一个仍然是在未压缩的地区?
优点:
- 更新和删除不会影响压缩数据
- 压缩是成批完成的,而不是单独的行,这使它更有效率
- 未压缩区域中同一行的更新会增加此空间,但在压缩时,只获取最新的版本
- 因此,只执行插入的方法不会使表增长太多
缺点:
- 压缩需要CPU能力
- 更新压缩区域中的行会导致表仍然增长
- 为每个表提供未压缩和压缩的区域是有权衡的
柱状存储与纯插入(+内存)
由于数据只插入到最后,所以每个操作在表中都有唯一的行号。最初表是空的,然后插入第一行,即第1行。下一行是#2。第一行的更新意味着添加行号为#3的新行。
反对使用列存储的主要理由是,由于现在需要读取多个列,因此读取整个行的成本更高。但这是真的吗?
在这个例子中什么更快?
| Column A | Column B | Column C | |
| Row 1 | Kathryn | Bigelow | female |
| Row 2 | Quentin | Tarantino | male |
| Row 3 | Fritz | Lang | male |
读取细胞(3,A) + (3,B) + (3,C)还是读取细胞(A,3) + (B,3) + (C,3)?这么说吧,答案显然是两者都不是。没关系。
那么“行定位更适合读取整行”的假设是从哪里来的呢?因为数据非常接近。如果数据存储在磁盘上,这是一个有效的点。读取文件中的一行意味着将磁盘头定位在该位置,然后立即读取整行。这比阅读每行一列的三行要有效得多。即使对于ssd也是如此,因为那里的数据是按4k页面组织的。最重要的是,磁盘I/O在内部使用512字节块。它们都倾向于水平存储而不是垂直存储。
对于不适用的内存访问。微处理器向DRAM发送一个地址并获取该地址下的数据。如果下一次读取就在附近,或者一个完全不同的地址(几乎)是不相关的。当且仅当地址本身的计算是直接向前的。
这里纯插入帮助细胞容易计算的地址——列和访问第三个值,然后列B和价值立场三个最后列c内存访问是一样的访问,然后列第一,第二和第三的价值。
这没有区别。没有。行式阅读的整个观点都是基于水平阅读比垂直阅读更快的假设。如果数据以水平方式存储在磁盘上,则是正确的。然后将一行的数据紧密地放在一起,这样就可以从磁盘圆筒中一次性读取数据。但对于凭记忆阅读来说,这一点都不重要。
优点:
- 从几个列中读取所有行非常快
- 读取一行的所有列也很快
- 事实上,每个操作都很快
缺点:
- 仅插入会导致表增长
- 如果值的长度不同,如何计算内存地址?
压缩与内存
这很简单。由于压缩,需要的内存更少。因此,更大的数据库可以适合更小的服务器。
另一个方面是压缩的类型。上面已经展示了压缩的几个方面。压缩必须是有效的,但只需要消耗很少的额外CPU开销。压缩必须支持容易计算的内存地址给定行号。
字典压缩作为一种压缩类型怎么样?一个区域存储列数据中实际出现的所有惟一值,并为这个列表建立索引。对于MARA表的MTART列,它将是(1,ROH), (2, HALB), (3, HAWA), (4, HIBE), (5, FHMI), (6, DIEN),……
| MANDT | MATNR | ERSDA | VPSTA | LVORM | MTART | MBRSH | MATKL |
|---|---|---|---|---|---|---|---|
| 800 | 000000000000000023 | 23.01.2004 | K | false | ROH | 1 | |
| 800 | 000000000000000038 | 04.09.1995 | KDEVG | true | HALB | M | 00107 |
| 800 | 000000000000000043 | 23.01.2004 | KBV | false | HAWA | 1 | |
| 800 | 000000000000000058 | 05.01.1996 | KLBX | false | HIBE | M | |
| 800 | 000000000000000059 | 05.01.1996 | KLBX | false | HIBE | M | |
| 800 | 000000000000000068 | 12.01.1996 | KEDPLQXZ | false | FHMI | A | 013 |
| 800 | 000000000000000078 | 10.06.1996 | KVX | true | DIEN | M |
现在实际的列只能存储索引。这里存储的不是每个字符4个的20,000行,而是一个字节的索引号(希望如此)。对于有更长的字符串、值的均匀分布和少数不同的值的情况,这是完全合理的。
如果这些值是集群的,那么这个压缩可以得到增强,就像MANDT是一个完美的候选,它到处都有值800。所以需要存储的是“第一行的值是800,接下来的2万行也是800”。
另一种方法是为每个不同的值设置一个位图。
ROH: 1000000
HALB: 0100000
HAWA: 0010000
HIBE: 0001100
FHMI: 0000010
DIEN: 0000001
所有这些字符串都可以非常有效地压缩,因为它们包含了很多0。在最简单的情况下,这样的压缩将是ROH=1*1,然后是6*0。使用这种方法计算给定行的地址偏移量是非常有效的CPU操作:以及字节操作。此外,过滤记录甚至更有效,而且不需要显式索引!选择*从玛拉MTART = ' ROH ' ?获取ROH的位图,并按照位图中1的位置读取带有数字的行。所以表中的第一行是唯一的结果。
Hana实现了各种不同的压缩方法,以选择最适合每个列的压缩方法。对于主键,对于自由形式的字符串列,对于具有很少不同值的列,对于只有一点不同的列,……所有这些都适合压缩算法。
是的,实现起来可能更复杂,但是这些算法是针对cpu最擅长的方面进行调整的。
优点:
- 需要更少的内存
- 快速压缩和解压缩
- 快速扫描,快到除了主键之外不需要单独的索引
缺点:
- 压缩仍然需要一些CPU能力
- 提交的数据仍然需要以某种方式持久化到磁盘上,否则在服务器关闭时所有数据都将消失
把这四个放在一起
当将这四种技术结合在一起时,几乎所有的缺点都被消除了。
- 压缩:从一种开销变为读写数据的有效方式
- 列存储:它的实现方式对于所有查询的组合都是最优的,少列——多行,多列——单行,任何东西
- 只插入:在最严格的版本中支持读一致性的直接方法,而不需要像乐观锁定这样的侧假设
- 内存:即使大型数据库也能装入内存
但是,仍然存在三个问题:
- 为了不丢失任何提交的数据,需要将数据保存在磁盘上
- 将压缩的行版本与未压缩的版本合并,以限制表的增长
- 数据库太大时的硬件成本
解决点1)是一种常见的技术:每个更改都存储在磁盘上的事务日志文件中。所有数据库都这样做,这是有意义的。如果出现电源故障,并且在提交时将数据持久化到磁盘,则什么也不会发生。重启之后,所有提交的事务都可以从那里读取,内存结构可以重新构建。性能也不是问题,因为磁盘是以非常快的顺序方式写入的——包括硬盘和ssd。
当然,我们不想将事务日志存储永远和重建时间点上的数据库安装,因此压缩的表存储区域一次磁盘作为起点和事务日志需要从那个时候开始的。如果表的压缩区域甚至没有变化(对于许多表来说,这是一个合理的假设),那么它就不需要再次转储到磁盘上。例如按年份划分的财务表。不太可能有人会改变前几年的争吵。或者所有那些永远不会改变的小型帮助表,浮现在我的脑海中……
仅插入(2)仅根据此处提供的信息部分解决。在我们所说的压缩期间,未压缩区域确实会将所有版本折叠成最新的版本,但这并不会阻止在压缩区域中出现同一行的多个版本。考虑到压缩算法的工作方式,没有什么可以阻止我们偶尔合并这些行。是的,这要多做一些工作,但仍然比每次插入/更新/删除时解压缩和重新压缩整个数据要好。通过选择适当的分区方法,希望不会处理整个表,而只处理最近的分区。
很明显,这种批处理正在付出代价。这确实是不可避免的。结果,管理员将看到很多CPU大部分时间处于空闲状态,并且周期性地使用更多的CPU资源——每当大型表的增量合并开始时。
剩下的问题是当数据库太大时该怎么办……
扩展和动态分层
对于大型数据库,一种解决方法是询问“您的ERP或数据仓库数据库有多大?”“真的有那么多客户的数据库,假设10的压缩系数是真实的,我们假设4TB的内存是负担得起的,50%的内存储备是合理的,大于20TB吗?”我得承认,这是个站不住脚的论点。
然后,有一些方法可以突破这个极限
- 向外扩展:不是使用一个大型服务器,而是使用两个较小的服务器。这可以降低成本,但不会永远扩大规模。它让我们超过了数据库大小的两倍,数据库大小的三倍。
- 动态分层:将热数据保存在内存中,热数据存储在磁盘上。从Hana数据库用户的角度来看,所有这些看起来仍然像一个表。惟一的区别是,查询暖数据是在磁盘数据库性能上运行的,而不是在Hana性能上。可能是降低大型数据库成本的另一种选择。
- 两者的结合。

如果数据量更大,我就会问自己,这是否是数据库用例,而不是大数据场景。数据库保证像事务保证、严格的读一致性、并发性……都是必需的吗?如果有疑问,请阅读本文以获取更多信息。在这种情况下,利用大数据技术的数据湖用来存储原始数据,具有集群处理的优点和缺点,而Hana则是包含有趣事实的数据库。这提供了大量数据的廉价存储和处理,以及SAP HANA的响应时间和连接性能。使用诸如智能数据访问之类的SAP HANA选项可以用来隐藏差异。
其他常见的误解
运行所有数据库块都缓存在RAM中的经典数据库不是内存中的数据库。同意吗?以上的解释说明了这一点。是的,当然从缓存读取数据要比从磁盘快。但是随后,磁盘访问模式(集中于顺序访问,将数据放在一个512字节扇区中)被复制到与内存访问无关的地方。在最好的情况下,这毫无理由地提供了性能优化,而实际上,这些假设确实会消耗额外的性能。
最近的一篇新闻稿也激起了我的兴趣:“……Terracotta DB,新一代分布式内存数据库平台……”数据库具有某些特性,如前面提到的事务保证、锁定和读一致性。把不支持SQL的数据库称为…大胆。是的,SAP HANA是一个RDBMS,具有您所期望的所有特性。
然而,我同意SAP HANA中没有什么新东西的说法。柱状存储并不是为SAP HANA而发明的,事实上我在大约20年前就使用过这种工具。同样的,只有插入,整个大数据世界都是建立在这种技术上的。SAP HANA的独特之处在于将这些技术组合起来形成一个数据库。我希望鼓励每个人检查所有其他数据库供应商的脚注,即使是最知名的,在内存的支持方式方面。你会发现诸如“内存特性的权衡”、“乐观锁定”等语句。
原因很简单,因为您需要将这四种技术以一种巧妙的方式组合在一起,以实现所有的好处。由于这些技术影响数据库工作的核心,因此不能将它们添加到现有数据库中,而是需要从头开始构建数据库。
原文:https://blogs.saphana.com/2017/12/01/secret-hana-pssst-dont-tell-anyone/
本文:https://pub.intelligentx.net/secret-sap-hana-pssst-dont-tell-anyone
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 96 次浏览
列式数据存储
- 193 次浏览
【内存数据库】HANA和Oracle 12C哪个更快?
执行摘要
- SAP建议HANA在性能上比所有其他数据库都有优势,因为它的数据库运行速度是其他数据库的10万倍。
- 如果HANA真的比甲骨文快,我们就来讨论一下。

缺乏财务偏见注意:
互联网上有关SAP的绝大多数内容都是SAP、SAP合作伙伴或SAP付费在媒体网站上进行营销的媒体实体发布的营销小把戏。这些实体中的每一个都试图对读者隐藏自己的财务偏见。下面的文章很不一样。
- 首先,它是由一个研究实体出版的。
- 第二,没有人为这篇文章付费,它不是假装通知你,而被操纵向你出售软件或咨询服务。与谷歌关于这个话题的几乎所有其他文章不同,它没有任何公司的营销或销售部门的意见。
视频介绍:HANA与Oracle的比较
文字介绍(如果您观看了视频,请跳过)
HANA一直是SAP项目讨论的焦点。SAP的声明是巨大的,但有多少是真实的。SAP建议HANA在性能上比所有其他数据库都有优势,因为它的数据库运行速度是其他数据库的10万倍。由于硬件速度和数据库设计的混合,HANA与Oracle性能的混淆。SAPs使用HANA锁定其他数据库供应商的策略(如Teradata所声称的)。我们报道了SAP在不认证Oracle 12c for s/4HANA方面的利益冲突。您将从一个独立的来源了解这场辩论,了解HANA与Oracle之间的真相,以及SAP声称的多个方面。
本文的参考文献
如果您想查看本文和相关Brightwork文章的参考资料,请参阅此链接(https://www.brightworkresearch.com/references-for-brightwork-sap-hana-p…)。
*注:本文最初撰写于2016年4月,引用了SAP在此之前的一些文章。不过,该条已于2020年2月更新,几年后适用。
HANA的历史
SAP已经推广了HANA,其运行速度远远超过了任何其他数据库,这主要意味着HANA与Oracle的竞争。
这就是为什么SAP不将S/4(SAP的新ERP系统)等新应用程序移植到Oracle的逻辑(由于Oracle在支持SAP应用程序方面占有最大的市场份额,尽管SAP也瞄准了IBM和SQL Server)
这一论点甚至很少有独立党派调查这一问题。
HANA与Oracle之争:硬件速度与数据库设计的混合
HANA与Oracle之间的一个令人困惑的方面是,两个不同的主题混合在一起,就像它们是一个主题一样。
- 一个是硬件问题,因为SAP HANA需要将活动数据库移动到内存中。
- 第二个方面是数据库设计,即基于列的数据库。
SAP讨论这两个主题就像它们是同一个主题一样。
可以说,SAP在解释这种区别方面做得很差。我不认为SAP试图明确这一领域,主要是希望客户感到困惑。
- SAP的客户对潜在利益的来源越不清楚,谈判时SAP的优势就越大。
- 它就越有能力将SAP HANA与Oracle作为一种差异化产品进行市场营销。
- 它越能将SAP-HANA定位为值得付出沉重代价的公司。
SAP没有讨论的是SAP HANA如何既是一种技术战略,又是一种战略 有针对性的战略,将Oracle从SAP客户中推出。
带上女王:SAP把其他供应商排除在外的战略
这是SAP数十年来一直显著影响的一项战略的延伸,但有一点扭曲。SAP把ERP系统当作棋盘上的皇后,不让客户接触其他应用程序。
我们称之为“抢占女王”的软件战略。

通过宣布所有其他SAP应用程序都能更好地与queen集成,SAP的客户可以获得更低的实施风险。这最终是错误的——一个主要原因是SAP的应用程序的风险远远高于他们竞争对手的应用程序。
“夺魁”销售策略的结果
即使大多数供应商已经接近SAP与其适配器的集成,这一策略还是取得了巨大的成功。只有ERP系统是“完全集成的”。所有模块都运行在同一个数据库上,所有其他SAP应用程序都通过适配器连接,而且许多SAP收购的应用程序的适配器比非SAP应用程序的适配器差。
ERP系统的账户控制功能在文章中被描述为一个特洛伊木马 (http://www.brightworkresearch.com/erp/2016/04/09/erp-systems-trojan-hor…),ERP成为一个失控的章鱼(http://www.brightworkresearch.com/erp/2018/11/12/how-erp-is-similar-to-…)。
SAP不仅仅向一家公司销售ERP系统。ERP系统只是打入账户的楔子。像章鱼一样,SAP在不同的领域不断敲打,这些领域必须成为“SAP标准”。所使用的开发语言,其他应用程序也必须是SAP。现在SAP已经进入了数据库层。SAP正试图通过HANA将SAP客户挤出的主要供应商甲骨文(Oracle)也以同样的方式运作。
利用应用层控制推送到数据库层
一次性横向竞争,即应用层的竞争。HANA是这种封锁策略的一个转折点,但它将其带到了数据库层。这就是为什么SAP如此坚定地定位HANA与Oracle。它通过不认证Oracle的数据库来阻止Oracle(和其他数据库)与S/4竞争,即使Oracle、IBM和SQL Server没有理由不能完全支持S/4。进一步回顾一下,混合数据库中没有一个是开源的,即使像Postgresql或MariaDB这样的开源数据库可以很容易地支持SAP。这是一场垄断性的高开销和控制性软件供应商之间的战争。

一旦Oracle资源部门想大喊大叫,请记住,Oracle还比SAP更严格地限制为其应用程序认证的数据库。
代码下推和存储过程
为什么S/4HANA被限制为HANA,SAP的主要论点是SAP已经将一些S/4HANA代码推入了HANA,而不是针对Oracle或其他数据库。放入HANA的存储过程的逻辑是一个幌子,因为SAP使用S/4HANA的独占认证来推动HANA的销售,我们在SAP关于代码下推的论证一文中介绍了这一点。
让我们明确这个话题。
SAP不关心客户的性能是否提高。SAP推出了HANA,并表示它对HANA的做法有一个原因,那就是增加销售额,并将Oracle赶出客户。SAP咨询公司的SAP顾问重复HANA的谈话要点,他们不知道这些观点是否属实,通常也不在乎。他们发表声明以增加计费时间。
最后,SAP内部和SAP咨询公司的一般数据库知识相对较差。在Brightwork,我们忽略了SAP资源对HANA的评价,因为它与我们从SAP客户那里收到的数据点从不匹配。我们已经广泛地研究了我们可以访问的私有基准信息,或者HANA性能的证据和历史。
HANA与Oracle的真正机会是什么?
有人提出,HANA的真正机会是公司将ERP和所有其他SAP应用程序放在HANA上。然后分析引擎就可以放在同一个硬件上。现在,不需要集成或转换,现在分析报告就在应用程序表之外。
SAP将所有数据放在HANA上的想法
在经历了五年多令人窒息的关于分析新世界的会议,以及最新的大数据和总体分析师的痴迷(这导致的好处远远少于最初的提议)之后,SAP提出,通过将所有公司数据放在HANA上,这一切都将变得更好。多方便啊。然而,我们现在是不是要把所有的硬件都改造成针对分析的优化?
另外,非SAP应用程序呢?他们不会坐在HANA上,所以他们必须被整合和改造。
SAP现在是否会认为这些应用程序是遗留的,因为它们不属于公司的“战略平台”?
其次,使用HANA是昂贵的。如何理解HANA和S/4HANA的定价,这是我们在本文中讨论的一个主题。HANA比甲骨文贵很多,甲骨文已经很贵了。如果遵循甲骨文的“建议”并激活更高端的功能,它就属于过高的类别。
HANA不贵…Hasso ?
哈索·普拉特纳(Hasso Plattner)一直认为SAP HANA并不昂贵。
通常,hasso platner将使用基于列的数据库中可用的压缩示例来减少占用空间。Hasso经常谈论压缩,因为HANA是按GB定价的,这对于数据库来说很奇怪,因为大多数商业数据库是按CPU定价的。如果Hasso或SAP客户代表能让数据库听起来比实际的要小,那么SAP就能获得更多的销售额。
但是,如果您与SAP客户主管交谈,他们会告诉您SAP HANA很贵。此外,他们会告诉你,由于这个原因,HANA很难定位;一旦价格标签回来,顾客就退缩了。我们经常为客户定价HANA,根本无法回避这样一个事实:HANA是竞争对手中最昂贵的数据库。
我们在如何理解S/4HANA和HANA定价的文章中讨论了HANA定价(https://www.brightworkresearch.com/saphana/2017/03/18/understanding-pri…)。
对于Hasso Plattner来说,在访谈中提出SAP-HANA如何在某种假设意义上不会太贵,这是一件简单的事情。但所有其他来源都指出,HANA相当昂贵。您将不会从Hasso购买HANA,而是从SAP客户经理那里购买。
哈索·普拉特纳的恒定误差
需要考虑的是,哈索的准确度在历史上相对较差,我没有看到分析师或传统IT媒体记录或评论这种不准确。
我对哈索关于哈纳的言论进行了详细的分析,当哈索说什么的时候,他通常是错的。
- 哈索将他的荣誉博士学位。作为一个真正的博士,正如我在文章中提到的,SAP的Hasso Plattner有博士学位吗。?
- 哈索经常谎报HANA的来历,就像我在文章中提到的哈索·普拉特纳和他的博士一样。学生们发明了HANA?,总体而言,它在计算主题和SAP方面都是一个不可靠的信息来源(什么有效,什么无效,什么真实,什么不真实)。
- Hasso撰写了支持其观点的“同行评审”期刊,正如我在文章中所述,Hasso Plattner对SAP HANA出版物的准确度如何?
哈索认为自己是一个教授和高度技术远见。然而,他的准确性使他接近一个销售人员。正如我们在文章托马斯·爱迪生、伊丽莎白·福尔摩斯和哈索·普拉特纳中所谈到的,哈索·普拉特纳应该因为撒谎而被裁掉多少?

正如我们在几段中所述,SAP永远不会允许与Oracle或其他数据库进行公平竞争,因为SAP知道自己会输。SAP既是该场景中的持枪者,又是监督枪战的实体,因为它是认证实体。SAP还有权阻止任何数据库提供商根据合作协议发布任何基准。
西方最快的数据库(HANA vs.Oracle)?
有证据表明,HANA并不是SAP所说的速度冠军。HANA的主要性能弱点之一很少被解决。HANA作为一个基于列的数据库,并不是非分析(Non-OLAP)应用程序的正确数据库设计。SAP曾说过,这是,但这是从计算机科学的角度看,不是真的。
尽管SAP掩盖了HANA不能100%基于列或面向列的事实。
正如我在文章中(https://www.brightworkresearch.com/saphana/2016/04/02/how-sap-hana-is-s…) 指出的 HANA的速度,用于插入、删除或更新——事务处理系统始终执行的操作是,基于列的表是 比基于行的慢。
面向行的数据库有 所谓关系数据库,但它是基于行的数据库。
数据库速度的大辩论
约翰·索特是一位为Oracle工作的作家,和Hasso一样,在这个主题上并不是一个独立的来源。然而,约翰在福布斯的文章中对HANA与Oracle的主题提出了一些好的观点。其中一个突出的问题是SAP在发布HANA事务处理性能基准时的异议。
SAP尚未发布在HANA上运行的任何事务处理应用程序的单一基准结果。为什么不?
我想说很明显为什么不。这是针对像ERP系统这样的事务处理系统。这些基准不会特别快。
在SAP Nation 2.0出版时,Vinnie Mirchandani是SAP HANA/Oracle 12C辩论的独立来源,他在《SAP Nation 2.0》(https://www.amazon.com/SAP-Nation-2-0-empire-disarray-ebook/dp/B013F5BK…)一书中写道, 强化了johnsoat关于基准的观点。
SAP对HANA基准的不透明并没有帮助。20年来,它的SD基准(衡量SAP在其Sales and Distribution(SD)模块中处理的客户订单行)一直是衡量新硬件和软件基础设施的黄金标准。它还没有使用HANA数据库发布这些指标。
约翰·阿普比的误导
有没有可能是SAP执行了基准测试,但很差,所以它只是停止报告结果?
John Appleby是Bluefin Consulting的HANA全球负责人,也是一位著名的HANA倡导者,他提供了大量关于HANA的虚假信息,他对这个主题有这样的看法—SAP Nation 2.0中也有相关的记录。
“SAP Business Suite目前的答案很简单:必须横向扩展(Scale up)。这一建议在未来可能会改变,但即使是8插槽6TB系统也能满足95%的SAP客户的需要,而且世界上最大的Business Suite安装也能满足24 TB的SGI 32插槽的需要—这是在考虑简单的财务或数据老化之前提出来的,这两种方法都能显著减少内存占用。”
我不知道这是否是对交易基准缺乏透明度的直接回应,但如果是的话,这是一个不充分的回应。在我看来,约翰·阿普尔比正在改变他的回答的主题。
我们跟踪了约翰·阿普比的准确性,并展示了《Appleby精度检查器:约翰·阿普比在HANA上的准确性研究》(https://www.brightworkresearch.com/saphana/2019/04/03/the-appleby-paper…)一文。2013年,Appleby积极和虚假地宣传HANA,以使其公司准备出售给Mindtree,正如我们在文章《Appleby的虚假HANA声明和Mindtree收购》中所述(https://www.brightworkresearch.com/saphana/2019/04/06/applebys-false-ha…)。
Appleby(以前称为Hasso)枢轴
这个问题与HANA与Oracle上的事务处理系统的性能有关。约翰·阿普瑞很快讨论了公司应该购买更多硬件而不必担心的数量。约翰·阿普比在这里说什么?
他说“对于SAP业务套件”,然后他声明了这个套件的答案。
SAP业务套件中唯一准备好HANA的部分(在本报价时)是S/4 Finance。目前,关于S/4金融如何实施,有很多争论。
其次,我说,现在称为SAP HANA Enterprise Management的套件的其余部分目前无法购买。约翰·阿普比把他对未来时态的反应表述成现在时态。
事实上,扩大规模以获得尚未存在的东西是否至关重要?
Oracle Monkeying是否具有S/4认证?
JohnSoat还指出,尽管Oracle在一个特定基准上表现非常出色,但SAP不会证明结果,因为SAP声明Oracle操纵了测试。
现在我没有在审判中,所以我无法说出甲骨文做了什么或没有做什么。甲骨文有它的故事,SAP有他们的故事。索特在文章中对双方的立场都有很好的解释。
此外,Oracle性能数据库顾问StephanKohler也对这个主题有以下几点要说。
SAP已经回答了他们为什么不接受基准测试结果(您也可以在上面提到的文章“复制与粘贴”中找到这一点:“Oracle通过使用一个自定义设置来操纵其BW-EML基准测试,该设置涉及称为tr的数据库函数
igger和物化视图可能导致难以发现的数据不一致,并且在实际生产环境中不受支持。”)。原因是使用了触发器和物化视图,而这些应该是不受支持的。但是,如果SAP检查了他们自己的SAPnotes,您可以看到它得到了明确的支持,而且在SAP ECO Space中也得到了使用。SAPnote#105047:“物化视图–允许使用。
有关更多信息,请参阅SAP注释741478。“SAPnote#105047:”触发器–允许作为SAP标准系统的一部分使用(例如,根据SAP注释449891,增量转换ICNV,BW触发器/BI0/05*)。根据SAP Note 712777允许使用登录触发器。允许作为Oracle功能的一部分隐式使用(例如,在线重组、物化视图、GridControl/Enterprise Manager)。只要没有可用的扁平多维数据集作为替代,就允许在sapbw系统中与物化视图结合使用。没有SAP集成,SAP也不提供对此的支持。“自2016年第1季度起,测试版就提供了扁平立方体,因此与2015年起的Oracle基准测试无关。
这就引出了下一个话题,这是个大话题。
SAP不认证Oracle 12c的利益冲突
SAP现在完成了与所有硬件供应商的合作,使SAP在认证数据库时存在利益冲突;这是一种利益冲突,在投资汉纳之前,它没有这种利益冲突。曾经是一个简单的过程现在充斥着政治阴谋,人们现在必须分析SAP和Oracle的声明,看看谁说的是实话。
如果通过认证Oracle,SAP削减了他们在HANA的市场份额,那么SAP如何认证Oracle,也就是说,给他们一个公平的听证会?
Oracle12c模式转换&HANA与Oracle的新窍门
Oracle 12c可以在“模式”之间切换,在内存列的内存行中显示其中一个。这是一个严重的优势。ibmblu具有类似的能力。然而,没有太多证据表明,需要一个既能执行OLTP又能执行OLAP的数据库——并且设计一个能够同样好地处理每种类型数据库的数据库可能是不可行的。数据库的发展趋势与此相反,随着NoSQL等专业数据库设计的蓬勃发展,索引数据库也蓬勃发展。
然而,回到HANA与Oracle 12c的讨论:
- Oracle灵活的设计在性能上应该优于SAP HANA,而不是纯粹的分析应用程序。
- SAP提出的整个数据库应该是列式的逻辑从来没有意义,因为分析中使用的表很少。因此,为每个应用程序表使用分析优化表(列式)是否有意义?
- 关于Oracle内存数据库的成熟程度,目前有一个争论。SAP列出7000个SAP HANA客户。然而,大多数客户都知道他们不使用软件(即,它是货架软件)或测试系统,而不是实时系统。因此,SAP HANA技能仍然很难找到。
此外,Oracle的内存模式开关在许可证和维护方面都增加了Oracle 12c的价格。
SAP的作弊的基准
SAP有足够的机会证明他们在HANA方面的优势,但从未这样做。SAP从未允许在事务处理中使用一个比较基准,SD-HANA基准的隐藏问题(https://www.brightworkresearch.com/saphana/2019/03/29/the-hidden-issue-…)一文对此进行了介绍。由于HANA在事务流程基准测试中的表现如此糟糕,它创建了一个新的引用,试图掩盖这一事实。但他们提供的参考是围绕分析而设计的,这篇文章介绍了SAP的BW-EML基准测试的四个隐藏问题(https://www.brightworkresearch.com/saphana/2019/03/28/the-hidden-issues…)。由于许多公司都抱怨HANA的事务处理性能,这就引出了一个问题,即HANA在多大程度上可以支持ERP系统,这在文章HANA中被称为s/4HANA和ERP的不匹配(https://www.brightworkresearch.com/saphana/2017/12/05/hana-mismatch-s4h…)。
结论
使用oracle12c,oracle12c可以在基于行和基于列的表之间进行切换,并为同一个表进行切换,这是一项新功能。
据我所知,几乎所有关于HANA的SAP营销文档都是在这一开发之前编写的。如果我在SAP负责HANA营销,我就不想谈论Oracle 12c,因为我没有正确的答案。这是因为Oracle 12c破坏了在SAP上花费的大量精力,使SAP客户认为SAP HANA技术是SAP独有的,从而将SAP HANA定位为独特和更好的技术。
Oracle 12c的新功能 破坏多年来提出的一些SAP争议。SAP尚未涉及Oracle 12c,在SAP HANA上创建的大部分资料都是在Oracle 12c发布之前开发的。IBM和mssqlserver具有类似的列存储功能。不是因为开发它们有很大的理由,而是因为SAP通过其巨大的市场营销,将重点放在了这种类型的数据库功能上。
首先,SAP现在没有一个好的理由——或者说,如果它把客户的利益放在首位,只将新的SAP应用程序(如s/4)移植到SAP HANA是个好主意。
向客户口述数据库?
前面的论点认为只有SAP才能提供足够快的数据库 很可能是假的。不管什么原因,这始终是一个软弱的论点。无应用程序供应商 应该向客户说明数据层。然而,SAP一再表示,它希望这样做。
SAP仍然相信在云端和本地运行新系统,但只有SAP S/4HANA才能在未来的一个软件版本中实现这一点。这将降低总体拥有成本(TCO),并加快迈向未来所需的步伐。数据输入、标准报告、分析和预测、数字会议室或多渠道客户交互等每一个应用领域都成为世界级的组件 就其本身而言。仅此一点就可以考虑更早地迁移到SAP S/4HANA哈索·普拉特纳
SAP对将IT行业赶回到过去的兴趣
在山景城的计算机历史博物馆里,有一个展览解释说,这个软件曾经是硬件供应商的专利。那时,软件不是一个“产业”,IBM发布的程序只能在IBM硬件上运行。软件没有单独收费,因此在软件层面没有竞争。
我们今天所知道的软件产业,是在与硬件脱钩之后才发展起来的。而这只是因为美国威胁要对专有软件模型和硬件供应商实施反垄断立法。HANA作为应用程序和数据库层之间的耦合,由一个供应商控制,将我们带回过去。
这将创建相当于专有应用程序/数据库的组合。
- SAP认为只有基于列的数据库才有前途的观点也是不正确的。
- 最后,对于那些了解数据库供应商及其历史的人来说 只有SAP能够开发出符合HANA速度能力的高性能数据库是不真实的。
SAP的论点并不是说它们等同于其他所有数据库供应商。使用HANA,它们比其他任何数据库供应商都优越。当然,这包括HANA与Oracle或其他任何人的竞争。
SAP当然可以而且将继续出售HANA与Oracle的竞争。但SAP一直提出的排他性观点已不再是一个可以相信的立场。
原文:https://www.brightworkresearch.com/which-is-faster-hana-or-oracle-12c/
本文:http://jiagoushi.pro/node/1492
讨论:请加入知识星球【首席架构师智库】或者小号【cea_csa_cto】或者QQ【2808908662】
- 149 次浏览
【列式数据库】Cassandra 101(介绍)
Cassandra 是一个简单的分布式 NoSQL 数据库。 分布式意味着 Cassandra 有多个相互连接的节点,负责存储和检索数据。 需要多个节点来实现 Cassandra 著名的可用性、可扩展性和高性能。
说到分布式系统,我们需要了解 CAP(Consistency, Availability & Partition Tolerance)定理。 根据它,“任何分布式数据存储只能提供这三个(即 CAP)保证中的两个”。 由于分布式系统中必然会发生网络故障,因此我们需要注意“分区容限”,以确保在由复制因子配置的节点之间保持数据的多个副本。 所以有两种选择,要么优先考虑可用性,要么在发生网络故障时优先考虑一致性。
一般来说,Cassandra 被称为 AP(可用性和分区容限)数据库,因为那是 Cassandra 最适合的数据库。 然而,更高的一致性是可调的,牺牲了 Cassandra 中的可用性和性能,用于一些需要但 Cassandra 不适合的用例。
Cassandra 中使用的基本术语
- 节点:运行 Cassandra 软件并存储数据子集的服务器。
- 集群:作为一个 Cassandra 数据库的许多节点的集合。
- Column :Cassandra 中用于存储数据字段的键和值的最小存储单元,也称为 Cell。
- 列族:特定用例的列集合。与表相同。
- 分区:它是表的特定节点上的数据子集。一个节点可以有多个分区。
- 分区键:一组列,用于标识数据在节点的特定分区中的位置。
- 聚类键:用于按排序顺序存储多条记录的列集。
- 行键:唯一标识数据库中记录的主键。主键 = 分区键 + 集群键
- Keyspace :用于组成多个列族的存储单元,类似于关系数据库中的模式
可能没有任何集群键列具有与分区键相同的行/主键。虽然分区键的主要目的不是作为主键,而是将数据分布在不同小分区的不同节点上。但是,分区键绝对不应该具有低基数,您是否应该具有非常高的基数取决于您查询数据的用例和数据大小。
当我们有聚类键(这里是时间戳字段)时,下图会更清楚:
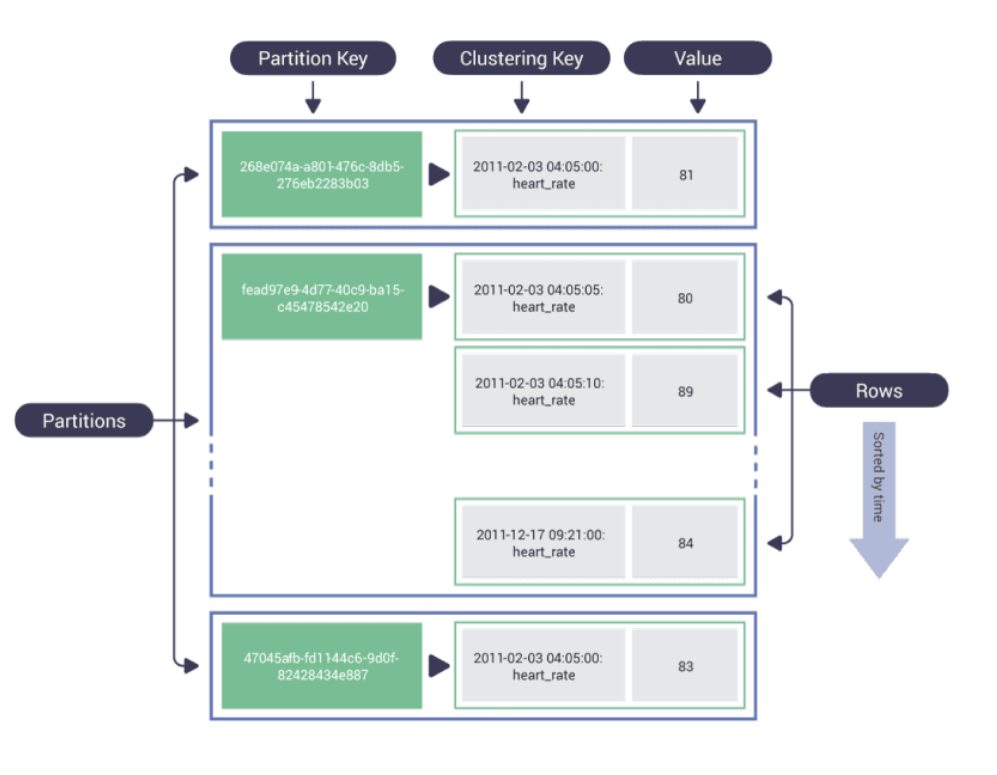
Cassandra 擅长什么
- 高可用性:Cassandra 没有单点故障,即在大多数节点仍然可用和连接的情况下始终可用于读取和写入。这是可以实现的,因为 C* 中没有主从拓扑,所有节点都是相同的(当然,这些节点上的数据可能因集群中少数节点上的复制而不同)。所以即使你没有很强的一致性、可扩展性和性能要求,只是想拥有跨不同区域的高可用数据库,Cassandra 也是一个不错的选择。这就是为什么 Kong(API Gateway) 也将其用作数据库选择之一。
- 写入负载的水平可扩展性和高性能:这是可以实现的,因为我们可以有多个节点来处理不同分区的写入负载,并且在单个节点内,Cassandra 以仅追加方式将新数据写入名为 commitlog 的文件,该文件会写入磁盘更快(与 Kafka 相同)。除此之外,Cassandra 使用 memtables 将新数据存储在内存中,然后定期将数据从内存刷新到称为 SSTable 的数据文件中。因此,提交日志仅用于节点故障场景。
- 数据大小水平可扩展:这是可以实现的,因为我们可以在集群中添加更多节点来处理更多数据。
- 读取负载水平可扩展(有条件):基于单个分区键从 Cassandra 查询数据是快速且可扩展的,但有一些因素可能会影响性能和可扩展性。例如,如果单个分区中有太多数据,或者正在为同一分区键更新数据,导致数据驻留在同一分区的不同数据文件(SSTables)中。尽管有不同的 SSTable 压缩策略来最大限度地减少影响,但需要根据确切的用例以及使用 Cassandra 数据库时最重要的部分数据建模仔细测试事情。
Cassandra不擅长或根本不支持的地方
- ACID(原子性,一致性,隔离性,持久性)合规性:不支持金融系统等应用程序所需的。
- 聚合函数:Cassandra 不适合计数、最大值、平均值等聚合。
- 联接:不支持,尽管数据非规范化是 Cassandra 中的一种常见做法,用于将查询的相关数据保存在一个分区中,但这应该在限制范围内。
- 排序:Cassandra 仅支持对聚类列进行排序,并且一旦插入,您就无法更改聚类列的值。所以在 Cassandra 中排序是一个设计决策。
- 新用例:我们需要根据查询模式将数据存储在 Cassandra 中,因此如果出现任何新需求,除非我们按照 Cassandra 数据建模要求再次存储数据,否则很难处理它。
概括
在这篇文章中,我们了解了 Cassandra 的基础知识,它的用例以及我们需要小心或避免使用 Cassandra 的地方。
我们将在即将发布的帖子中介绍更高级的场景和用例,在此之前,请务必为这篇文章鼓掌,并关注我以在未来查看更多此类帖子。
原文:https://itsmanish.medium.com/cassandra-101-introduction-eb7556a85bc
- 158 次浏览
【列式数据库】利用Apache Cassandra 4.0中的虚拟表
多亏了CASSANDRA-7622,Apache CASSANDRA 4.0有了一个名为“虚拟表”的新功能在本文中,我们将讨论虚拟表、它们在Apache Cassandra 4.0中的实现,以及如何使用它们来提高集群的可观察性。
虚拟表本质上是位于API之上的表接口,而不是存储在磁盘上的数据。它们可以在数据库级别进行交互,但不支持“普通”表所具有的所有功能。Cassandra中的虚拟表不能写入、更改、删除或截断,也不能支持其他索引、函数或物化视图。
此外,虚拟表只能存在于虚拟键空间中。虚拟键空间是由Cassandra管理的特殊键空间。它们不是复制的,只针对本地节点。
Apache Cassandra 4.0安装了两个虚拟密钥空间:
- System_virtual_schema:包含所有虚拟表和键空间(包括其本身)的模式数据
- System_views:Cassandra中唯一真实的虚拟键空间
那么你能用它们做什么呢?
在当前的迭代中,虚拟表大大简化了管理和监视Apache Cassandra所需的工具。访问度量一直是通过Java管理扩展(JMX)实现的,但对于虚拟表,这些度量中的许多现在通过虚拟表公开。
以下是system_views键空间中包含的虚拟表列表:
让我们来看一些简单的例子。
设置
你是否曾经在一个讨论论坛上为一个集群在线解决问题,结果却被问到:“你的压缩吞吐量是多少?”或者,“你使用了多少memtable_flush_编写器?”
之前,你必须检查卡桑德拉。该节点上的yaml文件——假设您有权访问它。现在,您可以简单地查询它:
> SELECT * FROM settings
WHERE name='compaction_throughput_mb_per_sec';name | value
----------------------------------+-------
compaction_throughput_mb_per_sec | 64(1 rows)
> SELECT * FROM settings
WHERE name='memtable_flush_writers';name | value
------------------------+-------
memtable_flush_writers | 2(1 rows)
正如您所见,使用Cassandra查询配置参数从来都不容易!
系统属性
相关的系统属性也通过虚拟表公开。当您的企业安全团队发现安全漏洞并需要了解节点的Java运行时环境(JRE)时,这一点非常有用:
> SELECT * FROM system_properties
WHERE name IN ('java.vm.name','java.version');name | value
--------------+--------------------------
java.version | 11.0.10
java.vm.name | OpenJDK 64-Bit Server VM
请注意,由于虚拟表仅特定于本地节点,因此使用IN-CQL操作符不会产生性能问题。
类似地,如果您正在处理一个新集群,并且想知道日志写入的位置,可以使用:
> SELECT * FROM system_properties
WHERE name='cassandra.logdir';name | value
------------------+-------------
cassandra.logdir | bin/../logs
这样,您可以快速查看Cassandra的相关系统属性。以前,获取此信息的唯一窗口是通过SSH(Secure Shell)连接上运行的命令。
节点性能指标
在Apache Cassandra 4.0之前,您只能通过JMX接口访问性能指标。但通过虚拟表,您可以看到集群中特定节点的性能。
假设你想了解更多关于跟踪“书呆子假期”的表格的阅读模式该数据存储在rows_per_read表中,您可以按键空间和表名查询它:
> SELECT * FROM rows_per_read
WHERE keyspace_name='datastax'
AND table_name='nerd_holidays';keyspace_name | table_name | count | max | p50th | p99th
---------------+---------------+-------+-----+-------+-------
datastax | nerd_holidays | 6 | 24 | 14 | 24
或者,您希望查看此节点的密钥缓存统计信息:
> SELECT * FROM caches
WHERE name='keys';name | capacity_bytes | entry_count | hit_count | hit_ratio | recent_hit_rate_per_second | recent_request_rate_per_second | request_count | size_bytes
------+----------------+-------------+-----------+-----------+----------------------------+--------------------------------+---------------+------------
keys | 104857600 | 65 | 311 | 0.827128 | 0 | 0 | 376 | 6488
这提供了一种使用Cassandra查看性能指标的简单方法。与使用附加工具(如JConsole或JMXTerm)直接与JVM交互相比,这是一个巨大的改进。
图1。通过JMXTerm与Apache Cassandra交互。有人真的错过了这样做吗?
总结
虚拟桌子是Cassandra的一个受欢迎的补充。能够通过cqlsh以编程方式访问配置属性、系统变量和度量是一个巨大的时间节省。通过这种方法,您可以大大简化对有价值的可观测数据的访问。
最后,以下是关键要点:
- 虚拟表是查看单个节点数据的快速方法
- 无需访问cassandra即可验证配置属性。yaml文件
- 与Cassandra相关的系统属性可以在没有SSH连接的情况下进行验证
- 现在可以不用JMX查询许多指标
关注媒体上的DataStax,获取有关所有内容Cassandra、流媒体、Kubernetes等的独家帖子。要加入一个由来自世界各地的开发人员组成的繁忙社区,并留在数据循环中,请关注Twitter和LinkedIn上的DataStaxDev。
Resources
- Virtual Tables | Apache Cassandra Documentation
- CASSANDRA-7622 — Implement virtual tables
- Arithmetic Operators in Apache Cassandra 4.0
- Deploy Apache Cassandra 4.0 on Kubernetes and AWS
- 3 Things You Should Know About Data Consistency, Distribution, and Replication with Apache Cassandra
原文:https://medium.com/building-the-open-data-stack/leveraging-virtual-tabl…
本文
- 76 次浏览
【列式数据库】将YugabyteDB与其他数据库进行比较
查看YugabyteDB与分布式SQL和NoSQL类别中的其他操作数据库的比较。要获得详细的比较,请单击数据库名称。
分布式SQL数据库
| 特性 | CockroachDB | TiDB | Vitess | Amazon Aurora | Google Cloud Spanner | YugabyteDB |
|---|---|---|---|---|---|---|
| 水平写入可伸缩性(带有自动分片和再平衡) | 是 | 是 | 是 | 是 | 是 | 是 |
| 自动故障转移和修复 | 是 | 是 | 否 | 是 | 是 | 是 |
| 分布式ACID事务 | 是 | 是 | 否 | 是 | 是 | 是 |
| SQL外键 | 是 | 否 | 是 | 是 | 是 | 是 |
| SQL Joins | 是 | 是 | 是 | 是 | 是 | 是 |
| 可序列化的隔离级别 | 是 | 否 | 是 | 是 | 是 | 是 |
| 跨多个DC/区域的全球一致性 | 是 | 不确定 | 否 | 否 | 是 | 是 |
| 追随者读取 | 否 | 是 | 是 | 是 | 否 | 是 |
| 内置的企业特性(如CDC) | 否 | 是 | 是 | 是 | 是 | 是 |
| SQL 兼容性 | PostgreSQL | MySQL | MySQL | MySQL, PostgreSQL | Proprietary | PostgreSQL |
| 开源 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
NoSQL databases
| 特性 | Mongo | Foundation | Apache Cassandra | Amazon Dynamo | MS Azure Cosmos | Yugabyte |
|---|---|---|---|---|---|---|
| 水平写入可伸缩性(带有自动分片和再平衡) | 是 | 是 | 是 | 是 | 是 | 是 |
| 自动故障转移和修复 | 是 | 是 | 是 | 是 | 是 | 是 |
| 分布式ACID事务 | 是 | 是 | 否 | 是 | 否 | 是 |
| 共识驱动、强一致性复制 | 否 | 是 | 否 | 否 | 否 | 是 |
| 强一致性二级索引 | 否 | 是 | 否 | 否 | 否 | 是 |
| 多重读取一致性级别 | 是 | 是 | 是 | 是 | 是 | 是 |
| 高数据密度 | 否 | 否 | 否 | 否 | 否 | 是 |
| API | MongoQL |
Proprietary
KV, Mongo QL |
Cassandra QL | Proprietary KV, Document | Cassandra QL, Mongo QL | Yugabyte Cloud QL w/ native document modeling |
| 开源 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
请注意
关于第三方数据库的任何特定功能的或是基于我们对公开信息的最大努力的理解。我们总是建议读者进行自己的独立研究,以了解更详细的细节。
原文:https://docs.yugabyte.com/latest/comparisons/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 273 次浏览
【宽列数据库】Apache Cassandra 简介——NoSQL 世界的“兰博基尼”
欢迎阅读我们关于 Apache Cassandra® 的五部分系列的第一篇文章。作为一个无限可扩展的数据库,Cassandra 被广泛认为是 NoSQL 数据库世界的兰博基尼。在这篇文章中,我们将向您介绍 NoSQL 数据库、CAP 定理,并解释 Cassandra 的工作原理。
Apache Cassandra® 是绝大多数财富 100 强公司使用的分布式 NoSQL 数据库。通过帮助 Apple、Facebook 和 Netflix 等公司以可靠、可扩展的方式处理大量快速移动的数据,Cassandra 已成为我们今天所依赖的关键任务功能的关键。
在这篇基于我们介绍 Apache Cassandra 的视频教程的帖子中,我们将:
- 讨论 NoSQL 数据库以及专用数据库的强大功能
- 介绍 Cassandra,一个点对点数据库
- 解释一致性、可用性和分区容限 (CAP) 定理(即分布式系统定律)
- 演示如何使用表和分区构造数据
- 分享可以在 GitHub 上完成的动手练习
从 SQL 到 NoSQL:为什么要发明 NoSQL
关系数据库管理系统 (RDBMS) 主导了市场数十年。然后,随着 Apple、Facebook 和 Instagram 等大型科技公司的崛起,全球数据领域在过去十年中飙升了 15 倍。而且,RDBMS 根本没有准备好应对新的数据量,也没有准备好应对新的性能要求。
Figure 1. Skyrocketing data needs.
NoSQL 的发明不仅是为了应对海量数据,而且也是为了应对速度(速度要求)和多样性(市场上所有不同类型的数据和数据关系)的挑战。
除了像 Cassandra 这样的表格数据库,我们还看到了其他类型的 NoSQL 数据库的兴起,例如:
- 时间序列数据库(例如 Prometheus)
- 文档数据库(例如 MongoDB)
- 图数据库(例如 DataStax Graph)
- 分类帐数据库(例如 Amazon QLDB)
- 键/值数据库(例如 Amazon DynamoDB)
是什么让Cassandra 如此强大?
Cassandra 以其大规模的性能而闻名,被认为是 NoSQL 数据库世界的兰博基尼:它本质上是无限可扩展的。没有领导节点,Cassandra 是一个点对点系统。
例如,在 Netflix,Cassandra 在其最活跃的单个集群上运行 3000 万次操作/秒,98% 的流数据存储在 Cassandra 上。 Apple 运行 160,000 多个 Cassandra 实例和数千个集群。
Cassandra 强大的功能有 8 个:
- 大数据就绪:分布式架构上的分区使数据库能够处理任何大小的数据:PB 级。需要更多音量?添加更多节点。
- 读写性能:单个节点的性能非常好,但具有多个节点和数据中心的集群将吞吐量提升到一个新的水平。去中心化(无领导架构)意味着每个节点都可以处理任何请求,读取或写入。
- 线性可扩展性:对容量或速度没有限制,也没有新节点的开销。 Cassandra 可根据您的需求进行扩展。
- 最高可用性:理论上,由于复制、分散和拓扑感知放置策略,您可以实现 100% 的正常运行时间。
- 自我修复和自动化:大型集群的操作可能会让人筋疲力尽。 Cassandra 集群减轻了很多麻烦,因为它们很智能——能够自动扩展、更改数据替换和恢复。
- 地理分布:多数据中心部署赋予了卓越的容灾能力,同时让您的数据靠近您的客户,无论他们身在何处。
- 平台无关:Cassandra 不受任何平台或服务提供商的约束,它允许您轻松构建混合云和多云解决方案。
- 独立于供应商:Cassandra 不属于任何商业供应商,而是由非营利性开源 Apache 软件基金会提供,确保开放可用性和持续开发。
Cassandra 是如何工作的?
在 Cassandra 中,所有服务器都是平等的。与传统架构不同,其中有一个用于写入/读取的领导服务器和用于只读的跟随服务器,导致单点故障,Cassandra 的无领导(对等)架构将数据分布在集群内的多个节点(也称为数据中心或环)。
Figure 2. Apache Cassandra structure.
一个节点代表一个 Cassandra 实例,每个节点存储几 TB 的数据。节点“八卦”或交换有关自身和集群中其他节点的状态信息,以实现数据一致性。当一个节点出现故障时,应用程序会联系另一个节点,确保 100% 的正常运行时间。
在 Cassandra 中,数据被复制。复制因子 (RF) 表示用于存储数据的节点数。如果 RF = 1,则每个分区都存储在一个节点上。如果 RF = 2,则每个分区都存储在两个节点上,依此类推。行业标准是三倍的复制因子,尽管在某些情况下需要使用更多或更少的节点。
有关更详细的说明,请观看我们的 Cassandra 简介教程,以了解数据复制在 Cassandra 上的工作原理。
CAP 定理:Cassandra 是 AP 还是 CP?
著名的“CAP”定理指出,分布式数据库系统在发生故障情况下只能保证这三个特性中的两个:一致性、可用性和分区容错性:
- 一致性:这意味着“没有陈旧的数据”。查询返回最新的值。如果其中一台服务器返回过时的信息,则您的系统不一致。
- 可用性:这基本上意味着“正常运行时间”。如果服务器出现故障但仍然给出响应,那么您的系统是可用的。
- 分区容限:这是分布式系统在“网络分区”中生存的能力。网络分区意味着部分服务器无法到达第二部分。
Figure 3. CAP Theorem governing databases.
包括 Cassandra 在内的任何数据库系统都必须保证分区容错性:它必须在数据丢失或系统故障期间继续运行。为了实现分区容错,数据库必须优先考虑一致性而不是可用性“CP”,或者可用性优先于一致性或“AP”。
Cassandra 通常被描述为“AP”系统,这意味着它在确保数据可用性方面犯了错误,即使这意味着牺牲一致性。但这还不是全部。 Cassandra 具有可配置的一致性:您可以设置所需的一致性级别,并根据您的用例将其调整为更多的 AP 或 CP。如果您想更深入地了解,您可以在我们的视频教程中找到更详细的说明。
Cassandra 如何构建和分发数据?
Cassandra 的先天架构可以在数千台服务器上处理和分发大量数据,而不会出现停机。每个 Cassandra 节点甚至每个 Cassandra 驱动程序都知道集群中的数据分配(称为令牌感知),因此您的应用程序几乎可以联系任何服务器并获得快速响应。
Figure 4. Data distribution across multiple nodes.
Cassandra 使用基于键的分区。 Cassandra 数据结构的主要组成部分包括:
- Keyspace:数据容器,类似于模式,包含多个表。
- 表:在分区中存储数据的一组列、主键和行。
- 分区:一组行以及相同的分区令牌(Cassandra 中的基本访问单元)。
- 行:表中的单个结构化数据项。
Figure 5. Overall data structure on Cassandra.
Cassandra 将数据存储在分区中,表示跨集群的表中的一组行。每一行都包含一个分区键——一个或多个列,这些列被散列以确定数据如何在集群中的节点之间分布。
为什么要分区?因为这使得缩放变得更加容易!大数据不适合单个服务器。取而代之的是,它被分成很容易分布在数十、数百甚至数千台服务器上的块,如果需要,可以添加更多。
为表设置分区键后,分区器会将分区键中的值转换为令牌(也称为散列),并为每个节点分配一个称为令牌范围的数据范围。
Cassandra 然后通过令牌值自动在集群中分配每一行数据。如果您需要扩大规模,只需添加一个新节点,您的数据就会根据新的令牌范围分配重新分配。另一方面,您也可以轻松缩小规模。
数据架构师需要知道如何在创建数据模型之前创建准确快速地返回查询的分区。一旦为表设置了主键,就无法更改。
相反,您需要创建一个新表并迁移所有新数据。要更好地了解如何创建良好的分区,请观看我们的视频教程以逐步了解真实示例。
Cassandra 的动手练习
现在,让我们使用 DataStax 的 Astra DB 在云中创建您自己的 Cassandra 数据库。注册一个 Astra DB 帐户并选择 80 GB 的免费套餐。使用数据库名称、键空间名称、提供程序和区域设置您的数据库。我们的 GitHub 和视频教程将介绍:
- Creating your Astra DB instance
- Creating tables
- Executing CRUD (create, read, update, delete) operations
无论您是加入我们的现场研讨会还是按照自己的步调进行,存储库都会向您展示强大的分布式 NoSQL 数据库 Apache Cassandra 最重要的基础知识,供每位想要尝试学习新数据库的开发人员使用:创建表和 CRUD 操作.
结论
我们希望您喜欢这个对 Cassandra 的初步介绍,其中包含帮助您入门的基本练习。请继续关注 Cassandra 在高级数据建模和数据库性能基准测试等主题上的更多实际应用。
同时,如果您想了解有关 Cassandra 的更多信息,请查看我们在 DataStax Academy 上的 Apache Cassandra 课程,并加入我们的社区,与该领域的专家讨论 NoSQL。您还可以阅读我们关于如何使用 Cassandra 部署机器学习模型的帖子。
Resources
- Apache Cassandra: Open-source NoSQL Database
- DataStax Astra DB: Multi-cloud DBaaS built on Apache Cassandra
- Astra DB Sign Up
- DataStax Apache Cassandra Course
- YouTube Tutorial: Introduction to Apache Cassandra
- Introduction to Apache Cassandra GitHub
- DataStax Enterprise Graph
- DataStax Academy
- Real-World Machine Learning with Apache Cassandra and Apache Spark (Part 1)
- Build CRUD Operations with Node JS and Python on DataStax Astra DB
- Data Age 2025: The Datasphere and Data-readiness From Edge to Core
原文:https://medium.com/building-the-open-data-stack/introduction-to-apache-…
本文:
- 263 次浏览
向量数据库
视频号
微信公众号
知识星球
- 104 次浏览
图形数据库
- 118 次浏览
【关系知识图谱】微软元老鲍勃·穆格利亚:关系知识图谱将改变商业
微软资深人士鲍勃·穆格利亚(Bob Muglia)表示,我们正处于知识图表的全新时代的开始,这与2013年现代数据堆栈的到来类似。
Bob Muglia表示,二十年来在数据库创新方面的工作将把E.F.Codd的关系演算引入知识图,他称之为“关系知识图”,从而彻底改变商业分析。
关系AI
鲍勃·穆格利亚有点像一个数据库诗人,能够讲述技术发展中的故事。
这就是周三上午,微软前高管、前Snowflake首席执行官穆格利亚在纽约知识图谱会议上发表主旨演讲时所做的。
他演讲的主题是“从现代数据堆栈到知识图”,以一种新的形式结合了大约50年的数据库技术。
基本情况是这样的:五家公司创建了现代数据分析平台,Snowflake、Amazon、Databricks、Google和Azure,但这些数据分析平台无法进行业务分析,最重要的是,它们代表了作为合规和治理基础的规则。
穆格利亚说:“业界知道这是一个问题。”。他说,这五个平台代表了“现代数据堆栈”,允许“新一代的这些非常、非常重要的数据应用程序得以构建”。“然而,”当我们审视现代数据堆栈,审视我们可以有效地做什么和不能有效地做哪些时,我想说,客户在这五个平台中面临的首要问题是治理。"
此外:以太网创建者梅特卡夫:Web3将具有各种“网络效应”
Muglia在微软经营SQL Server业务,在30年的数据库职业生涯中取得了其他成就,他举例说明了数据平台无法建模的业务规则。
“所以,如果你想执行一个查询,说‘嘿,告诉我Fred Jones在这个组织中可以访问的所有资源’,这是一个很难写的查询,”他说。“事实上,如果组织非常庞大和复杂,这是一个可能无法在任何现代SQL数据库上有效执行的查询。”
Muglia说,问题是基于结构化查询语言(SQL)的算法无法执行如此复杂的“递归”查询。
作为一种数据库技术的吟游诗人,Muglia经常用华丽的修辞来传达技术细节:Binary Join!二进制联接!二进制联接!
2022年知识图谱会议
穆格利亚说:“已经有很多代算法都是围绕着二进制一的思想创建的。”。“它们有两个表,键将这两个表连接在一起,然后得到一个结果集,查询优化器将获取并优化这些连接的顺序-二进制连接、二进制连接、二元连接!”
他说,弗雷德·琼斯(Fred Jones)的权限等递归问题“无法用这些算法有效地解决”
Muglia表示,与数据关系不同的业务关系的正确结构是知识图。
“什么是知识图表?”穆格利亚用修辞的方式问道。他为一个有时神秘的概念给出了自己的定义。知识图是一个数据库,它对业务概念、它们之间的关系以及相关的业务规则和约束进行建模
Muglia现在是初创公司Relational AI的董事会成员,他告诉观众,业务应用程序的未来将是建立在数据分析之上的知识图,但有一个转折点,即它们将使用关系演算,一直追溯到关系数据库先驱E.F.Codd。
“回到开头,”穆格利亚催促道。“关系技术的基本算法能力是什么?可以用它做什么?”
Muglia指出,有五个基于SQL的分析平台,但没有一个平台能够单独进行业务分析,而不是数据分析。
关系AI
“如果我们看看Codd在20世纪70年代创造的东西,这个定理说关系代数和关系查询在表达能力上是完全等价的-太有趣了!我一直知道这很有趣,现在我知道为什么了。”
Muglia表示,使用关系人工智能的技术,特别是创始人兼首席执行官Molham Aref开发的用于查询优化的技术,结合知识图,可以将相同的关系代数应用于业务概念的组织。
“如果我们转向关系知识图,我们现在就转向关系演算的基础,我们发布的关系演算语句是无序的,它们包含业务规则和约束。”

Muglia说,SQL不会消失,但它无法真正处理业务分析的查询。
关系AI
穆格利亚说,“从根本上重新定义我们如何使用关系代数”的工作已经进行了大约20年,但在2010年,随着阿雷夫的工作,以及在众多大学和公司内部的工作,这项工作得到了发展,发表了数百篇关于这个主题的论文。
他说:“这是全世界研究界之间令人难以置信的合作努力。”。“物化在他们执行的物化内部以一种基本的方式使用它。LinkedIn通过他们使用的称为Liquid的图形数据库采用了这一点。”
关系知识图引入了一种称为Rel的新语言,尽管Muglia说,“SQL仍然很重要”,“SQL不会消失”,因为它是关系知识图新世界的一种入口。
“我甚至可以说,SQL最好的日子还在后头。”
Muglia在谈到关系知识图时表示:“从软件开发的角度来看,他预见到了惊人的、惊人的潜力,所有的事情都来自于此。”。“随着技术的成熟——我想重点关注的是,它还没有成熟——但随着技术的发展,我们将看到我们可以用它做一些我们甚至做梦都想不到的事情。”
这包括在商业分析中更多地使用机器学习,正如Relational AI这个名字所暗示的那样。此外,Muglia表示,业务模型将不再是“我们在白板上张贴的东西,工程师需要查看这些东西来编写一些Java代码。”
穆格利亚说:“模型变成了程序,因此业务分析师可以参与其中,并对数据结构进行更改。”
“想想成千上万了解这项业务的人参与进来——想想看!”
他说,目前,关系型人工智能的技术是“漂亮的白手套”。“我们有很多组织在做有限的试验,”该公司希望明年“开放自助服务”,“广泛的开发者测试版,让人们可以注册并开始使用该系统。”。
穆格利亚说:“我们正处于一个全新时代的开端。”。“这就像2013年、2014年的现代数据堆栈——这就是我们在生命周期中所处的位置。
“就像现代数据堆栈彻底改变了分析一样,我完全相信知识图,尤其是关系知识图,将改变企业的运行方式。”
知识图谱会议已进入第四个年头,2019年在哥伦比亚大学的一个舞厅里开始了一场小小的活动。今年,经过两年的纯虚拟会议,会议发展成为一场规模庞大的混合活动,在纽约市罗斯福岛的康奈尔理工学院校园举行了数十场专题讨论会和现场会议。该计划将持续到5月6日。
- 102 次浏览
【图型数据库】在Windows上安装PostgreSQL+Apache AGE的分步指南
视频号
微信公众号
知识星球
在这篇文章中,我们将逐步讨论如何在Windows机器上安装PostgreSQL和ApacheAGE。在本指南结束时,您将拥有一个功能齐全的PostgreSQL数据库和ApacheAGE图形数据库,可以用于数据驱动的应用程序。
什么是PostgreSQL?
PostgreSQL是世界上最著名的关系数据库之一,旨在管理和存储大量结构化数据。
PostgreSQL是开源的,以其可靠性、健壮性和可扩展性而闻名。它提供了各种高级功能,包括对事务、存储过程和触发器的支持。
PostgreSQL支持广泛的数据类型,包括文本、数字和日期/时间数据,以及更复杂的数据结构,如数组、JSON和XML。
什么是Apache AGE?
ApacheAGE是一个建立在PostgreSQL之上的图形数据库系统。它允许用户以高性能和可扩展的方式存储、管理和分析大规模图形数据。
ApacheAGE将强大的关系数据库管理系统(PostgreSQL)的优势与图形数据库的灵活性和可扩展性相结合。这意味着用户可以以关系格式存储数据,还可以对数据执行基于图的查询和分析。
如何安装PostgreSQL和Apache Age?
目前,Apache AGE不支持Windows。因此,在本教程中,我们将使用Windows Subsystem for Linux(WSL)作为替代方案。
1. Install WSL.
To enable WSL on your computer, follow these steps: First, go to the Control Panel, and then select Programs. Next, select Turn Windows features on or off. From the list of features, enable both Virtual Machine Platform and Windows Subsystem for Linux, as shown in the image

After enabling WSL, the next step is to install a Linux distribution for Windows. To do this, open the Microsoft Store and search for 'Linux.' You will see several options available, and you can choose the one you prefer. For the purposes of this tutorial, we will be using 'Ubuntu 22.04.2 LTS'.
2. Installing PostgreSQL from source code.
Please note that currently, Apache AGE only supports PostgreSQL versions 11 and 12, so we must install one of these versions. Before proceeding, we need to install some dependencies. To do this, open a bash terminal by navigating to any directory and typing 'bash' in the address bar, and then run the appropriate command.
sudo apt install git libreadline-dev zlib1g-dev bison flex build-essential
Next, create a directory where you want to install PostgreSQL and clone the Postgres repository into it.
mkdir postgres-AGE-project
cd postgres-AGE-project
git clone https://git.postgresql.org/git/postgresql.git
Navigate to the 'postgresql' directory and switch to a compatible version branch. For the purposes of this tutorial, we'll be using version 12.
cd postgresql
git checkout REL_12_STABLE
Compile the source code and specify the directory where you want the binaries to be installed. Note that this process may take some time to complete.
./configure –prefix=/usr/local/pgsql-12
make
After the compilation process is complete, run the following command to add permissions for the binaries directory and replace user by your username. Once this is done, proceed to install PostgreSQL
sudo mkdir /usr/local/pgsql-12
sudo chown user /usr/local/pgsql-12
make install
To ensure that PostgreSQL can be accessed from anywhere in the terminal, it is necessary to set up the following environment variables
These commands will add the PostgreSQL binaries directory to the system path and set the PGDATA directory to the location of the PostgreSQL data files.
export PATH=/usr/local/pgsql-12/bin/:$PATH
export PGDATA=/usr/local/pgsql-12/bin/data
Now that you have installed PostgreSQL, you can create a new cluster, which is a collection of databases managed by a single instance of the PostgreSQL server. To create a new cluster, run the following command:
initdb
After initializing the cluster, you can start the PostgreSQL server by running the following command:
pg_ctl -D /usr/local/pgsql-12/bin/data -l logfile start
Now you can start PostgreSQL by running the following command:
psql postgres
Congratulations! You have successfully installed and started PostgreSQL.
To exit PostgreSQL run \q
To stop the server run the following command:
pg_ctl -D /usr/local/pgsql-12/bin/data -l logfile stop
If you would like more detailed information about the installation process, you can visit the following link: PostgreSQL documentation
3. Installing Apache AGE from source code.
To install Apache AGE from source code, go to the main directory of the postgres-AGE-project that we created earlier and execute the following command to clone the AGE project.
git clone https://github.com/apache/age.git
To proceed with the installation, navigate to the project directory and switch to the latest stable release, which is version 1.1.0.
cd age
git checkout release/PG12/1.1.0
Set the environment variable PG_CONFIG. we need to set the PG_CONFIG environment variable to specify the location of the PostgreSQL pg_config utility. pg_config is a command-line utility that provides information about the installed version of PostgreSQL, including the location of files and libraries required for compiling and linking programs against PostgreSQL. Apache AGE uses pg_config to determine the location of the PostgreSQL header files and libraries needed to compile the AGE extension.
export PG_CONFIG=/usr/local/pgsql-12/bin/pg_config
Then install AGE extension by running this command:
make install
Now you have AGE installed to add the extension in your postgres server run the following SQL commands:
CREATE EXTENSION age;
Then every time you want to use AGE you must load the extension.
LOAD 'age';
Great job! You have successfully installed Apache AGE on your system.
You can find further information on AGE installation and usage on the official Apache AGE documentation at AGE documentation.
References
PostgreSQL
AGE - Installation giude
Contribute to Apache AGE
Apache AGE website: https://age.apache.org/
Apache AGE Github: https://github.com/apache/age
- 559 次浏览
【图型数据库】在您的计算机上安装Apache AGE
视频号
微信公众号
知识星球
Install AGE & PSQL from Source
You can convert your existing relational database to a graph database by simply adding an extension. Apache AGE is a PostgreSQL extension that provides graph database functionality. It enables users to leverage a graph database on top of the existing relational databases.
We will take a look at
- Installing Postgres from source.
- Installing & configuring Apache AGE with Postgres.
- Installing AGE-Viewer for Graphs analysis.
This article will explain to you how to install age on your Linux machine from the source. For macOS users, there is a detailed video for the overall installation process. Linux users can also watch this video as most of the steps are identical.
Getting Started
We gonna install the age and PostgreSQL from the source and configure it.
mkdir age_installation
cd age_installation
mkdir pg
cd pg
Dependencies
Install the following essential libraries before the installation. Dependencies may differ based on each OS You can refer to this for further details https://age.apache.org/age-manual/master/intro/setup.html#pre-installation.
So in case, you have ubuntu installed
sudo apt-get install build-essential libreadline-dev zlib1g-dev flex bison
It is also recommended to install postgresql-server-dev-xx package. These are development files for PostgreSQL server-side programming. For example if you are using ubuntu.
sudo apt install postgresql-server-dev-11
Further you can refer to https://age.apache.org/age-manual/master/intro/setup.html#postgres-11
Installing From source
PostgreSQL
Downloading
You will need to install an AGE-compatible version of Postgres, for now AGE only supports Postgres 11 and 12. Download the source package for postgresql-11.8 https://www.postgresql.org/ftp/source/v11.18/
Downloading it and extracting it to the /age_installation/pg
wget https://ftp.postgresql.org/pub/source/v11.18/postgresql-11.18.tar.gz && tar -xvf postgresql-11.18.tar.gz && rm -f postgresql-11.18.tar.gz
This will download the tar file for the Linux users and also extract it in the working directory.
Installing
Now we will install the pg. The —prefix have the path where we need to install the psql. In this case, we are installing it in the current directory pwd .
cd postgresql-11.18
# configure by setting flags
./configure --enable-debug --enable-cassert --prefix=$(pwd) CFLAGS="-ggdb -Og -fno-omit-frame-pointer"
# now install
make install
# go back
cd ../../
We should configure it by setting the debugging flags. In case of the macOS users
./configure --enable-debug --enable-cassert --prefix=$(pwd) CFLAGS="-glldb -ggdb -Og -g3 -fno-omit-frame-pointer"
AGE
Downloading
Now download the AGE from the GitHub repo https://github.com/apache/age. Clone it under /age_installation directory.
git clone https://github.com/apache/age.git
Installing
Now we will configure age with PostgreSQL.
cd age/
# install
sudo make PG_CONFIG=/home/imran/age_installation/pg/postgresql-11.18/bin/pg_config install
# install check
make PG_CONFIG=/home/imran/age_installation/pg/postgresql-11.18/bin/pg_config installcheck
PG_CONFIG require the path to the pg_config file. Give the path from the recently installed PostgreSQL.

DB Initialization
Now we will initialize the database cluster using the initdb
cd postgresql-11.18/
# intitialization
bin/initdb demo
So we named our database cluster demo.
Start Server
Now start the server and make a database named demodb
bin/pg_ctl -D demo -l logfile start
bin/createdb demodb
If you wanna change the port number use bin/createdb --port=5430 demodb
Start Querying
AGE added to pg successfully. Now we can enter in to pg_sql console to start testing.
bin/psql demodb
If you have server running on some other port like in my case it is 5430 use bin/createdb --port=5430 demodb
Now when you have initialize a new DB we have to load the AGE extension in order to start using AGE. Also, we need to set search_path and other variables if didn’t set them earlier in the /postgresql.conf file.
Note that you can also set these parameter in the
postgresql.conffile. See more
CREATE EXTENSION age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;
Now try some queries having cypher commands.
SELECT create_graph('demo_graph');
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "james", bornIn : "US"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ MATCH (v) RETURN v $$) as (v agtype);

Installing AGE-Viewer
So age-viewer is a web app that helps us visualize our data.
Dependencies
Install nodejs and npm to run that app. You are recommended to install node version 14.16.0. You can install the specific version using the nvm install 14.16.0. You can install nvm from https://www.freecodecamp.org/news/node-version-manager-nvm-install-guide/.
sudo apt install nodejs npm
or
# recommended
nvm install 14.16.0
Downloading
Go back to directory /age_installation
git clone https://github.com/apache/age-viewer.git
Starting
Now set up the environment.
cd age-viewer
npm run setup
npm run start
Viewer will now be running on the localhost. Now connect the viewer with the database server.Enter the details required to login
# address (default : localhost)
url: server_url;
# port_num (default 5432)
port: port_num;
# username for the database
username: username;
# password for the user
pass: password;
# database name you wanna connect to
dbname: demodb;
Note that If you are following the above steps and installed postgres form source, then postgres a user would be created automatically during the installation. The username will be same as the name of your linux user. In my case a user with name imran was created as my linux user name was imran. Also there would be no password on this default user, you can set the password later.
In my case i used the following settings.
url: localhost;
port: 5432;
username: imran;
# radom pass as password is not set for this user.
pass: 1234;
dbname: demodb;

Visualizing Graphs
Now try creating some nodes and then you can visualize their relationship on the age-viewer.
First we will create PERSON nodes
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "imran", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "ali", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "usama", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "akabr", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "james", bornIn : "US"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "david", bornIn : "US"}) $$) AS (a agtype);
Now creates some nodes of COUNTRY.
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Country{name : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Country{name : "US"}) $$) AS (a agtype);
Now create a relationship between them.
SELECT * FROM cypher('demo_graph', $$ MATCH (a:Person), (b:Country) WHERE a.bornIn = b.name CREATE (a)-[r:BORNIN]->(b) RETURN r $$) as (r agtype);
Now we can visualize our whole graph created.
SELECT * from cypher('demo_graph', $$ MATCH (a:Person)-[r]-(b:Country) WHERE a.bornIn = b.name RETURN a, r, b $$) as (a agtype, r agtype, b agtype);

Help
Config File
In case you want to change the port number (default5432) and other variables you can take a look at thedemo/postgresql.conf file. You have to restart the server after that. Setting the parameters here will save you from the initialization commands like LOAD 'age'; as used earlier.
nano demo/postgresql.conf
# In postgresql.conf file update and uncomment
port = 5432 #new port if wanted
shared_preload_libraris = 'age'
search_path = 'ag_catalog, "$user", public'
You can also set these variables using the commands shown earlier.
Error with WSL
When installing age-viewer. If you are using WSL restart it from PowerShell after installing node, npm using wsl --shutdown. WSL path variable can intermingle with node path variable installed on windows. https://stackoverflow.com/questions/67938486/after-installing-npm-on-wsl-ubuntu-20-04-i-get-the-message-usr-bin-env-bash
Now start WSL again. Don’t forget to start the pg server again after the WSL restart. Run server again using bin/pg_ctl -D demo -l logfile start .
Acknowledgment
These resources helped me a lot during the installation. You can also refer to these if help is needed.
- 239 次浏览
【图型数据库】基于PostgreSQL的图型数据库Apache Age 介绍
视频号
微信公众号
知识星球
Age 是一个领先的多模型图形数据库
关系数据库的图形处理与分析
 什么是Apache AGE?
什么是Apache AGE?
ApacheAGE是PostgreSQL的扩展,它允许用户在现有关系数据库的基础上利用图形数据库。AGE是图形扩展的缩写,其灵感来自Bitnine的AgentsGraph,PostgreSQL的一个多模型数据库分支。该项目的基本原则是创建一个处理关系数据模型和图形数据模型的单一存储,以便用户可以使用标准的ANSI SQL以及当今最流行的图形查询语言之一openCypher。

由于AGE基于功能强大的PostgreSQL RDBMS,因此它是健壮的,功能齐全。AGE针对处理复杂的连通图数据进行了优化。它提供了大量对数据库环境至关重要的健壮数据库功能,包括ACID事务、多版本并发控制(MVCC)、存储过程、触发器、约束、复杂的监控和灵活的数据模型(JSON)。具有关系数据库背景、需要图形数据分析的用户可以毫不费力地使用此扩展,因为他们可以在不进行迁移的情况下使用现有数据。
强烈需要有凝聚力、易于实现的多模型数据库。作为PostgreSQL的扩展,AGE支持PostgreSQL所有的功能和特性,同时还提供了一个可引导的图形模型。
 总览
总览
Apache AGE是:
- 强大:为已经流行的PostgreSQL数据库添加了图形数据库支持:苹果、Spotify和美国国家航空航天局等组织都在使用PostgreSQL。
- 灵活:允许您执行openCypher查询,这使复杂的查询更容易编写。它还允许同时查询多个图。
- 智能:允许您执行图形查询,这些查询是许多下一级web服务的基础,如欺诈检测、主数据管理、产品推荐、身份和关系管理、体验个性化、知识管理等。
 特性
特性

Cypher Query:支持图形查询语言
- 混合查询:启用SQL和/或Cypher
- 查询:启用多个图
- 层次结构:图形标签组织
- 特性索引:在顶点(节点)和边上
- 完整的PostgreSQL:支持PG功能
- 375 次浏览
【图型数据库】数据库深度探索:JanusGraph
在数据库深度挖掘的第三部分中,我们与JanusGraph PMC成员Florian Hockmann和Jason Plurad进行了交流,以获得关于广泛的Graph世界的一些指导。

JanusGraph是一个可扩展的图形数据库,用于存储和查询分布在多机集群中的包含数千亿顶点和边的图形。该项目由Titan出资,并于2017年由Linux基金会(Linux Foundation)开放管理。
阅读下面的文章,从G Data的Florian Hockmann和IBM的Jason Plurad那里了解JanusGraph是如何与Neo4j进行比较的,为什么应该关注TinkerPop 4,并获得关于图形数据建模的专家提示。
跟我们谈谈你自己和你今天在做什么?
弗洛里安·霍克曼(FH):我的名字是弗洛里安·霍克曼,我是德国杀毒软件供应商G DATA的一名研发工程师。我所在的团队负责分析我们每天收到的成千上万的恶意软件样本。我们使用一个图形数据库来存储关于这些恶意软件样本的信息,以便能够在相似的恶意软件样本之间找到连接。
Jason Plurad (JP):我是Jason Plurad,一名开放源码开发人员,也是IBM认知应用程序的倡导者。我一直活跃在像JanusGraph和Apache TinkerPop这样的图形社区中,帮助发展这些开源社区,并使我们的产品团队和客户能够使用图形和其他开源数据技术。我也和我的团队一起探索其他新兴的开源数据和人工智能项目。
你是怎么和JanusGraph合作的?
JP: IBM是JanusGraph的创始成员之一,我是这个团队的一员。我们一直在用它的前身Titan生产几种不同的产品。我们喜欢Titan是因为它的开源许可,以及它在构建整体图形平台方面给予我们的灵活性。
当创建泰坦的Aurelius公司被DataStax收购时,开源社区都在猜测泰坦的未来会是什么样子。最终,DataStax发布了作为DataStax企业一部分的图,但是没有开源选项。我们知道我们并不是唯一想要开源图形数据库的人,所以我们在社区中找到了其他人,一起创建了Titan,并将JanusGraph带到了Linux基金会。
我们最初使用的是泰坦,它是JanusGraph的前身。Titan很适合我们,因为我们正在寻找一个可以水平伸缩的数据库,使我们能够找到恶意软件样本之间的连接,这是一个典型的图形数据库用例。在开发Titan的公司被收购后不久,它就停止了在Titan上的所有工作,我们剩下的数据库系统不再需要维护了。所以,当IBM和其他公司在Titan上创建JanusGraph时,我们当然非常高兴,我们想为这个新项目贡献自己的力量,以确保JanusGraph成功地成为一个可扩展的开源图形数据库。
我已经参与了Apache tinkerpop的开发——主要开发Gremlin. net变体Gremlin。因此,为JanusGraph贡献一个扩展库是很自然的。但我也为项目的其他部分做出了小小的贡献,帮助了邮件列表或StackOverflow上的新用户。这是一个很好的方式,让我了解这个项目的各个部分,让我更多地参与其中。
在选择Neo4j和JanusGraph时,人们应该知道什么?
JP:人们还应该知道JanusGraph和Neo4j支持Apache TinkerPop图形框架。TinkerPop使您能够使用相同的图结构和Gremlin图遍历语言,使用相同的代码来生成多个图数据库。TinkerPop与许多其他供应商兼容,包括Amazon Neptune、Microsoft Azure Cosmos DB和DataStax Enterprise Graph,不过请记住,许多TinkerPop实现都不是免费的开源的。
这可能不是人们所期望的答案,但是团队应该与他们的律师一起评估许可证,以确定哪种许可证适合他们的需要。JanusGraph使用Apache许可证,这是一个自由的开放源码许可证,允许您使用它几乎没有限制。Neo4j Community Edition使用GNU通用公共许可证,该许可证对发布软件有更严格的要求。许多开发人员最终需要Neo4j企业版提供的可伸缩性和可用性特性,而Neo4j企业版需要商业订阅许可证。
FH:我认为这两种图形数据库之间主要存在两个区别因素。首先,Neo4j基本上是一个自包含的项目。我这么说的意思是,它实现了自己的存储引擎、索引、服务器组件、网络协议和查询语言。
另一方面,JanusGraph在这些方面的大部分都依赖于第三方项目。这背后的原因是,对于这些问题,已经有了适合其具体工作的解决方案。通过使用它们,JanusGraph可以真正专注于图形方面,而不必再去解决这些问题。
例如,JanusGraph可以使用Elasticsearch或Apache Solr实现高级索引功能(如全文搜索),并使用可伸缩数据库(如Apache Cassandra或HBase)存储数据。正因为如此,使用Neo4j可能更容易上手,因为涉及的移动部件更少,但是JanusGraph提供了更大的灵活性,用户可以根据自己的特定需求在不同的存储和索引后端之间进行选择。用户可以自己决定他们喜欢哪种方法。
我看到的其他关键区别因素是这两个图形数据库面向用户的界面,查询语言是其中的中心方面。JanusGraph为此实现了TinkerPop(它可以被认为是图形数据库事实上的标准,因为目前大多数图形数据库都实现了它),它为用户提供了跨越不同图形数据库的基本相同的体验,类似于SQL在关系数据库中扮演的角色。
虽然也可以将TinkerPop及其查询语言Gremlin和Neo4j一起使用,但Neo4j主要是促进它们自己的查询语言——cipher。因此,大多数Neo4j用户最终可能会使用这种语言。
当然,用户必须再次自己决定他们更喜欢哪种查询语言,Gremlin还是Cipher,以及能够在将来的某个时候轻松切换到另一个图形数据库对他们来说有多重要。
当然,除了这些技术方面,我还想指出JanusGraph是一个完全由社区驱动的开源项目。因此,希望看到某个特性实现的用户可以自己实现它。
对于想要在生产环境中部署JanusGraph的人,您有什么建议?
FH:我已经提到JanusGraph使用几个不同的组件来创建图形数据库,它提供了丰富的功能,比如索引和存储引擎。虽然这种方法为用户提供了极大的灵活性和丰富的特性集,但它也可能让新用户感到有些难以承受。
但是,我想指出,开始使用JanusGraph并不需要对所有组件都有深入的了解。当我开始使用泰坦的时候——基本上和janusgraph一样——我对Cassandra和Elasticsearch一无所知,但我仍然能够通过这些后端快速地安装和部署泰坦。
多年来,我们从Cassandra切换到Scylla,添加了用于机器学习的Apache Spark,并通过将JanusGraph移动到Docker容器中,使我们的部署更易于扩展。
因此,我的建议是先进行小型而简单的部署,然后根据需要增加部署的规模和复杂性。JanusGraph的文档还包含“部署场景”一章,描述了一个相对简单的开始场景,以及如何将其发展成更高级的场景。
另一个对JanusGraph非常重要的项目是TinkerPop,我已经提到过几次了。因此,我建议新用户熟悉TinkerPop,最重要的是,熟悉它的图形查询语言Gremlin。有很多很好的资源可以帮助你入门,比如TinkerPop的教程或者免费的电子书Practical Gremlin。
JP:首先,也是最重要的,准备好完全接受开源并为之做出贡献。JanusGraph是一个社区项目,它不是由单个供应商拥有或驱动的。您的团队应该与JanusGraph社区合作,识别并解决您遇到的bug,因为您最有动力去修复它们。随着时间的推移,通过持续的贡献,您的团队可以成为JanusGraph的领导者,帮助推动项目向前发展。在团队进入生产阶段时,操作可能是一个大障碍。当您在处理团队可能尚未熟悉的大量技术时,您应该花足够的精力来理解如何保持数据基础设施正常运行。由于JanusGraph依赖于外部存储后端(如Apache Cassandra或Apache HBase),最终,您的团队将需要部署和操作那些水平可扩展数据库及其依赖关系的技能。当然,您也应该参与这些开源社区。
在接下来的几年里,你对JanusGraph和TinkerPop有什么期待?
帕森斯:我从事图形数据领域已经好几年了,但它仍处于新兴阶段。在接下来的几年里,我很乐意看到图形生态系统中工具的改进。这将包括用于图形建模、图形可视化和图形数据库操作的工具。
在总体数据体系结构中,图通常不是唯一的,因此能够在图数据和其他数据模型之间架起桥梁的工具将有助于推动图数据进入主流。
今年,W3C对图形数据(包括属性图、RDF和SQL)的标准化越来越感兴趣。有了图形数据的开放标准规范,图形数据库供应商就可以更好地提高它们在数据库市场上的份额。
FH:特别是对于JanusGraph来说,很难预测未来的发展,因为这个项目完全是由社区驱动的,而且很多贡献都来自于那些对JanusGraph感兴趣的用户,他们希望根据自己的经验和需求来改进JanusGraph。
除了许多小的性能改进之外,JanusGraph很可能很快就会有一个性能得到显著改善的内存后端,也可以用于生产使用,而不是目前的内存后端,后者仅用于测试目的。这个改进后的后端是JanusGraph用户做出贡献的一个很好的例子,在这个例子中是高盛的开发人员。
总的来说,我希望JanusGraph在接下来的几年里在后端有实质性的改进。当然,我们只是从新发布的后端本身的改进中获益,但是全新的后端也可以为JanusGraph提供巨大的改进或全新的功能。
例如,FoundationDB看起来非常有前途,因为它完全专注于实现一个可伸缩的存储引擎,提供具有ACID属性的事务,而其他层可以添加丰富的数据模型或高级索引功能等特性。这种方法似乎很适合JanusGraph的模块化架构,并且有可能解决JanusGraph的一些常见问题,比如存储超级节点或执行升级。
但是,很高兴你还提到了TinkerPop,因为JanusGraph的许多改进实际上来自TinkerPop,尤其是下一个主要版本TinkerPop 4的发布。
TinkerPop 4的开发仍处于非常早期的状态,但是一些主要的改进已经可以确定了。我个人尤其期待的是为Gremlin遍历提供更广泛的执行引擎。现在,人们可以选择使用单个线程执行遍历(这非常适合实时使用情况),或者在使用Spark的计算集群上执行遍历(例如,用于机器学习或图形分析)。
在G数据,我们往往用例在中间的这两个选项,因为他们应该回答的几秒也不太可能引发,因为它有一些空中他们涉及穿越大量的边缘,也不是一个适合单线程执行。一个额外的执行引擎能够使用更多的计算资源,但不需要首先加载整个图,它可能非常适合这些用例。
目前,人们还花费了大量精力为TinkerPop创建一个更抽象的数据模型,该模型并不特定于图形。这有可能使TinkerPop也可以用于非图形数据库和计算引擎。所以,它真的可以增加支持tinkerpop的数据库的生态系统。
你有什么提示或技巧的性能图形建模?
FH:这可能听起来很明显,但我认为许多用户仍然没有这样做——即在将模式投入生产之前评估新的模式或对其进行重大更改。
如果可能的话,应该使用真实的数据来完成,并且评估应该包括建模实际用例的查询。确实没有其他方法可以确保您的模式实际上很好地适合您的用例,并且在生产后期更改模式要比进行初始评估花费更多的时间。
对于所有的图形数据库来说,超级节点是一个非常重要的主题,因为超级节点非常麻烦,并且会导致非常高的查询执行时间。因此,最好尽早检查数据模型中是否会出现超级节点,然后绕过它们,例如,通过相应地更改模式。
对于图模型,另一个需要考虑的问题是,某个东西是否应该是一个顶点上的属性,还是它自己连接到另一个带边的顶点上的另一个顶点。我通常的方法是决定我是否希望能够搜索具有相同属性值的其他顶点,在这种情况下,我将它建模为自己的顶点,用边将它连接到所有具有该值的顶点。否则,它通常只能是一个顶点属性。
JP:图形建模需要时间。从一个幼稚的图形模型开始是很容易的,但是,您很可能不会在第一次尝试时就得到最好的模型。通常需要几次迭代才能得到适合您的用例的模型。
准备好使用您的域的一个小的代表性数据集和您想要运行的查询列表,这样您就可以看到模型对您的用例的执行情况。当您从一个顶点跳到另一个顶点时,请密切关注分支因子。即使给定顶点上有合理数量的边,查询将触及的图元素的数量也会随着几次跳跃呈指数增长。考虑将图结构反规范化,这样就可以更好地利用过滤(在标签或属性上匹配)来减少查询早期的元素数量。
怎样才能和JanusGraph联系起来呢?
FH:这取决于您是想贡献代码、改进文档,还是想以其他方式提供帮助,比如帮助邮件中遇到问题并知道如何解决的其他用户。
对于代码或文档更改,您可以在GitHub上查看我们的开放问题,找到您感兴趣的,或者创建一个新问题来描述建议的改进,然后提交一个pull request。
这与其他开源项目没有什么不同。可能JanusGraph新的贡献者的一个优点是,它由很多不同的模块,还有一个广泛的话题作出贡献,卡桑德拉等一些特定于某个后端或Elasticsearch核心领域像如何执行一个查询工具方面JanusGraph像模式管理或客户端库在一定的编程语言。所以,你可以选择一个你已经了解或感兴趣的领域来做贡献。
如果有人有兴趣为JanusGraph做贡献,但需要一些指导才能开始,那么当然总是可以问我或其他积极贡献者,我们非常乐意帮助。
JP: JanusGraph是一个开放的社区,我们社区的多样性帮助推动了这个项目向许多新的方向发展。我们的社区为扩展JanusGraph做出了坚实的贡献,为不同的编程语言提供了驱动程序,为不同的数据库后端提供了存储适配器。
我们IBM的开发人员将贡献的特性返回到开源服务器,用于服务器上的动态图形管理。我们已经收到了对构建和测试基础设施的改进,以及与Docker和Apache Ambari的集成。
我们希望看到更多的人参与进来,除了编写源代码之外,还有很多方法可以提供帮助。我认为作为一个协作社区,人们分享他们的知识和经验是最重要的——通过在论坛上回答问题,通过更新JanusGraph文档,通过以创新的方式构建使用JanusGraph的示例项目,通过在JanusGraph的本地会议或会议上展示。最好的接触方式是在我们的谷歌组。如果谷歌受到您公司防火墙或地理位置的限制,您可以通过邮件地址订阅他们。https://github.com/JanusGraph/janusgraph/#community
原文:https://www.ibm.com/cloud/blog/database-deep-dives-janusgraph
本文:http://jiagoushi.pro/node/1143
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 173 次浏览
【图型数据库】用Apache AGE实现最短路径(Dijkstra)
视频号
微信公众号
知识星球
Apache AGE is a PostgreSQL extension that provides graph database functionality. The goal of the Apache AGE project is to create single storage that can handle both relational and graph model data so that users can use standard ANSI SQL along with openCypher, the Graph query language. This repository hosts the development of the Python driver for this Apache extension (currently in Incubator status). Thanks for checking it out.
Apache AGE is:
- Powerful -- AGE adds graph database support to the already popular PostgreSQL database: PostgreSQL is used by organizations including Apple, Spotify, and NASA.
- Flexible -- AGE allows you to perform openCypher queries, which make complex queries much easier to write.
- Intelligent -- AGE allows you to perform graph queries that are the basis for many next level web services such as fraud & intrustion detection, master data management, product recommendations, identity and relationship management, experience personalization, knowledge management and more.
Features
- Shortest Path implemented using dijkstra algorithm
- Used Apache AGE graph database
Installation
Requirements
- Python 3.9 or higher
- This module runs on psycopg2 and antlr4-python3
sudo apt-get update
sudo apt-get install python3-dev libpq-dev
pip install --no-binary :all: psycopg2
Install via PIP
pip install apache-age-dijkstra
pip install antlr4-python3-runtime==4.9.3
Build from Source
git clone https://github.com/Munmud/apache-age-dijkstra
cd apache-age-python
python setup.py install
View Samples
Instruction
Import
from age_dijkstra import Age_Dijkstra
Making connection to postgresql (when using this docker reepository)
con = Age_Dijkstra()
con.connect(
host="localhost", # default is "172.17.0.2"
port="5430", # default is "5432"
dbname="postgresDB", # default is "postgres"
user="postgresUser", # default is "postgres"
password="postgresPW", # default is "agens"
printMessage = True # default is False
)
Get all edges
edges = con.get_all_edge()
- structure :
{ v1 : start_vertex, v2 : end_vertex, e : edge_object }
Get all vertices
nodes = []
for x in con.get_all_vertices():
nodes.append(x['property_name'])
Create adjacent matrices using edges
init_graph = {}
for node in nodes:
init_graph[node] = {}
for edge in edges :
v1 = edge['v1']['vertices_property_name']
v2 = edge['v2']['vertices_property_name']
dist = int(edge['e']['edge_property_name'])
init_graph
init_graph[v1][v2] = dist
Initialized Graph
from age_dijkstra import Graph
graph = Graph(nodes, init_graph)
Use dijkstra Algorithm
previous_nodes, shortest_path = Graph.dijkstra_algorithm(graph=graph, start_node="vertices_property_name")
Print shortest Path
Graph.print_shortest_path(previous_nodes, shortest_path, start_node="vertices_property_name", target_node="vertices_property_name")
Create Vertices
con.set_vertices(
graph_name = "graph_name",
label="label_name",
property={"key1" : "val1",}
)
Create Edge
con.set_edge(
graph_name = "graph_name",
label1="label_name1",
prop1={"key1" : "val1",},
label2="label_name2",
prop2={"key1" : "val1",},
edge_label = "Relation_name",
edge_prop = {"relation_property_name":"relation_property_value"}
)
For more information about Apache AGE
- Apache Incubator Age: https://age.apache.org/
- Github: https://github.com/apache/incubator-age
- Documentation: https://age.incubator.apache.org/docs/
- apache-age-dijkstra GitHub: https://github.com/Munmud/apache-age-dijkstra
- apache-age-python GitHub: https://github.com/rhizome-ai/apache-age-python
- 112 次浏览
【图型计算架构】GraphTech生态系统2019-第1部分:图形数据库
这篇文章是关于GraphTech生态系统的3篇文章的一部分,截至2019年。这是第一部分。它涵盖了图形数据库环境。第三部分是图形可视化工具。

The graph database landscape in 2019
动态生态系统
图形存储系统的吸引力比以往任何时候都强劲,自2013年以来,人们对图形存储系统的兴趣稳步增长。
A dynamic ecosystem
The traction for graph storage systems is stronger than ever, with interest steadily growing since 2013.

DBMS popularity trend by database model between 2013 and 2019 — Source: DB-Engine
图形数据库的市场份额不断增加,市场上的产品数量也在增加,供应商数量是5年前的7倍。新的市场研究和越来越大的财务预测每学期出版。有人说,图表数据库市场在2017年为3900万美元,其他为6.6亿美元,预测范围从2024年的4.45亿美元到2023年的24亿美元。
虽然很难就确切的数字达成一致,但所有报告都指出了相同的增长动力:
- 需要速度和改进的性能以减少发现新数据相关性的成本和时间
- 当前实时处理多维数据技术的局限性
- 基于图形的人工智能与机器学习工具与服务的开发
- 在金融犯罪、欺诈和安全等特定领域:更快速地解决现有风险和利用相关数据的迫切需要。
总而言之,我们有越来越多的应用程序依赖于连接的数据来产生洞察力,以及处理不断增长的数据量和复杂性的紧迫技术问题,这些都推动了图形市场的发展。
很难追踪。在这篇文章中,我建议至少尽可能地展示当前的市场。我将图形生态系统划分为三个主要层,尽管现实更复杂,而且这些层通常是可渗透的。
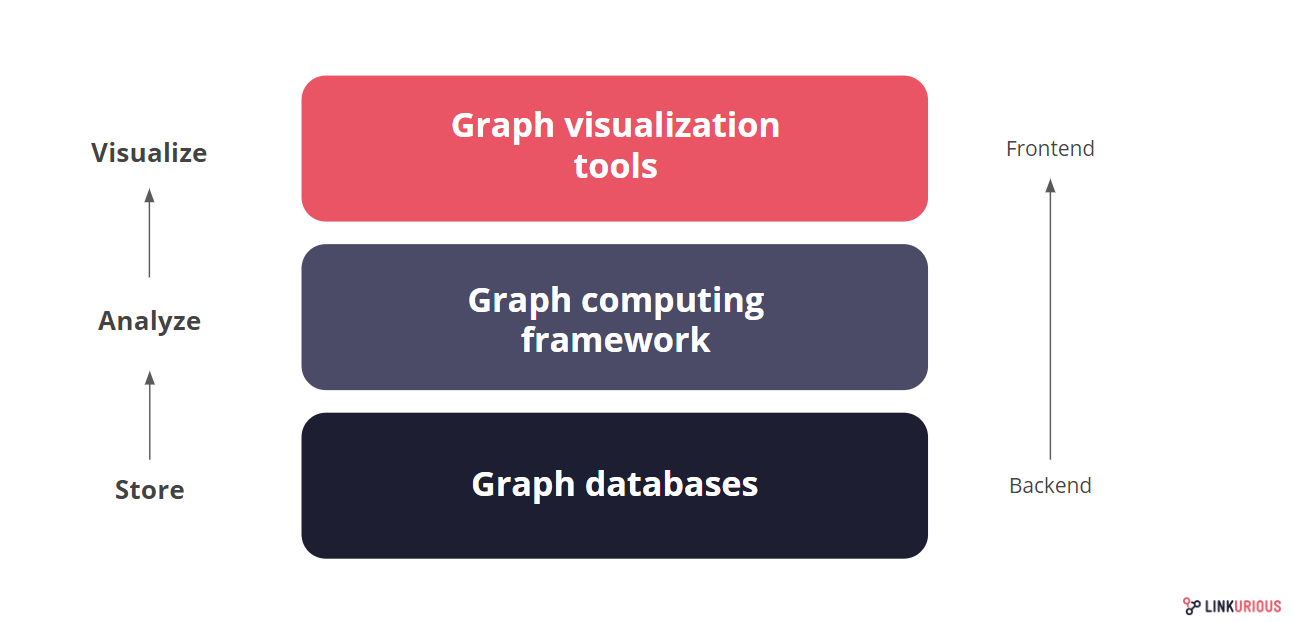
The GraphTech ecosystem layers
图形数据库布局
GraphTech的第一层在生态系统增长中起着关键作用。图形数据库管理系统(GDBMS)正在驱动生态系统。他们是它的主要演员。这些系统帮助组织解决存储复杂的连接数据和从非常大的数据集中提取见解的技术挑战。
塑造市场
自20世纪60年代以来,网络模型已经出现在数据库领域,但图结构的使用仍然局限于学术界。性能和模型还不是最佳的,我们不得不等到21世纪初和引入ACID图形数据库后才能看到更大规模的采用。从那时起,图形数据库开始作为一种合法的业务解决方案出现,以解决关系系统的一些缺点。
专门为存储类似图形的数据而构建的本机系统和具有不同主数据模型(例如关系数据库或其他NoSQL数据库)的非本机系统构成了市场。在这两个方面,我们发现商业和开源系统以及属性图和RDF三元组存储是存储图形数据的两个主要模型。
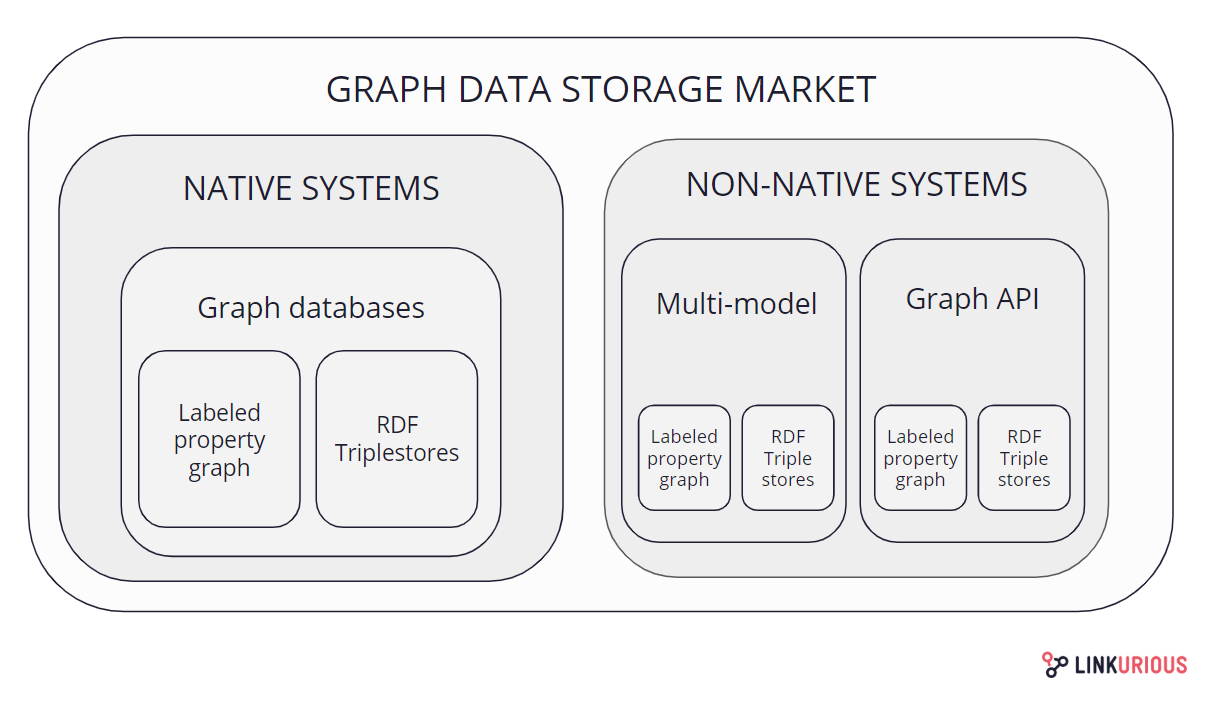
Type of storage for graph-like data
原生系统
在主要的原生系统中,Neo4j是市场领导者,这些系统的模型都经过了完全优化,可以处理类似图形的数据。NativeGraph数据库的第一个版本于2010年发布,提出了一个双重商业和开源版本,供开发人员试验图形。此后,该公司获得了大量客户,募集资金超过1.5亿美元。
在开源社区,JanusGraph接管了Titan项目,其母公司于2015年被DataStax收购。JanusGraph项目现在提出了一个分布式的、开源的图形数据库,这个数据库最近受到了广泛的关注。DGraph是另一个用Go编写的开源项目,在2017年发布了一个可供生产的版本,同时筹集了300万美元的种子资金。
其他的解决方案包括Stardog、RDF的知识图三重存储,或者最近发布的TigerGraph(以前称为GraphSQL)。商业系统InfiniteGraph和Sparksee已经出现了一段时间。其他开源系统,如HypergraphDB,提出了基于有向超图的数据库。
多模型数据库和混合系统
随着NoSQL模型的成功,多模型数据库应运而生,以解决筒仓系统的倍增所带来的复杂性。这些数据库旨在支持各种数据类型,在一个单独的数据存储中处理各种模型,如文档、键值、RDF和图形。如果您需要处理多种数据类型,但又希望避免管理各种筒仓的操作复杂性,则它们特别方便。
在包含graph作为支持模型的原生多模型数据库中,我们可以将ArangoDB命名为ArangoDB。这个开源的多模型数据库于2011年发布,支持三种数据模型:key/value、documents和graph。cosmosdb是微软Azure在多模型领域的最新产品。该分布式云数据库于2017年推出,支持四种数据类型:键值、文档、列族和图形。datatax Enterprise也是一个分布式云数据库,构建在开源nosql apache cassandra系统之上。自2016年新增数据税企业图以来,系统支持列族、单据、键值、图形。最后,MarkLogic是一个历史上的涉众,他在2013年为其现有的受支持文档模型添加了rdf triples支持。
另一个强烈的市场吸引力信号是数据库主要参与者策略的演变。在过去的几年中,我们看到传统的关系存储重量级者通过专用的api将图形功能添加到他们的系统中。2012年,IBM在其数据库中添加了NoSQL图形存储DB2-RDF。一年后,甲骨文将它的数据库图形选项更名为oraclespatial和graph,今天称为Oracle大数据空间和图形。最近在2016年,SAP Hana宣布发布SAP Hana Graph,通过对图形的支持扩展了其关系型DBMS的功能。
在下面的演示中,我列出并展示了大多数用于图形数据的存储系统。

Slide presentation of the graph database landscape
原文:https://medium.com/@Elise_Deux/the-graphtech-ecosystem-2019-part-1-graph-databases-c7c2f8a5e6bd
本文:http://jiagoushi.pro/node/1092
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 87 次浏览
【图形数据库】图形查询语言比较:Gremlin与Cypher与nQL
视频号
微信公众号
知识星球
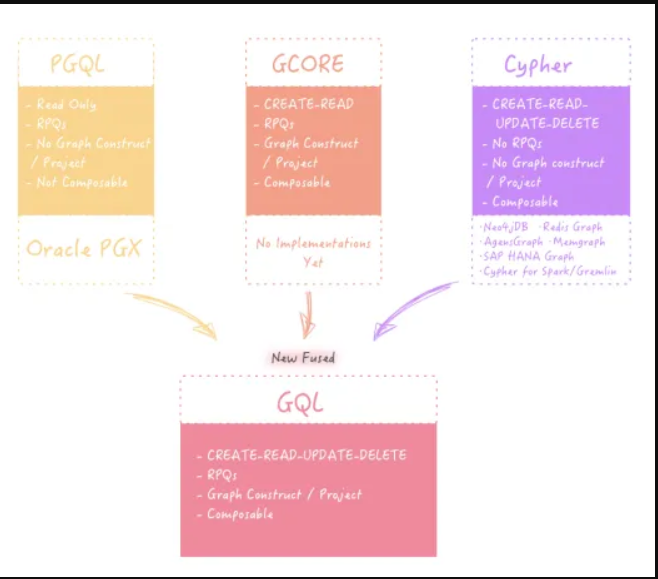
要比较哪些图查询语言
Gremlin
Gremlin是Apache TinkerPop开发的一种图遍历语言,已被许多图数据库解决方案所采用。它可以是声明性的,也可以是命令性的。
Gremlin是基于Groovy的,但有许多语言变体,允许开发人员用许多现代编程语言(如Java、JavaScript、Python、Scala、Clojure和Groovy)本地编写Gremlin查询。
支持的图形数据库:Janus graph、InfiniteGraph、Cosmos DB、DataStax Enterprise(5.0+)和Amazon Neptune。
Cypher
Cypher是一种声明性图查询语言,它允许在属性图中进行富有表现力和高效的数据查询。
该语言是利用SQL的强大功能设计的。Cypher语言的关键字不区分大小写,但属性、标签、关系类型和变量区分大小写。
支持的图形数据库:Neo4j、AgentsGraph和RedisGraph
nQL
NebulaGraph引入了自己的查询语言nQL,这是一种与SQL类似的声明性文本查询语言,但专为图形设计。
nQL语言的关键字是区分大小写的,它支持语句组合,因此不需要嵌入语句。
支持图形数据库:Nebula graph
术语比较
在比较这三种图查询语言之前,让我们先来看看它们的术语和概念。下表解释了这些语言如何定义节点和边:
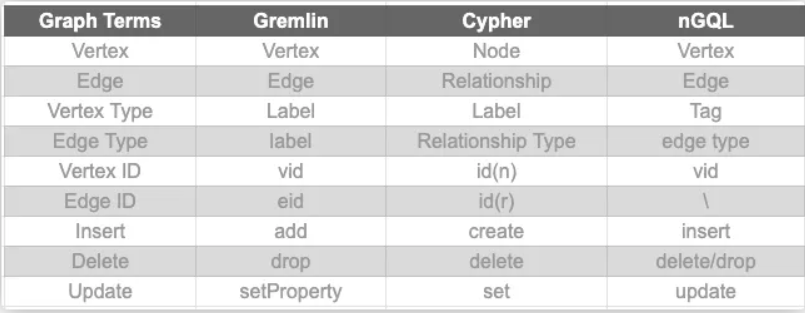
语法比较--CRUD
在理解了Gremlin、Cypher和nQL中的常见术语后,让我们来看看这些图查询语言的一般语法。
本节将分别介绍Gremlin、Cypher和nQL的基本CRUD语法。
图表
请参阅以下关于如何创建图形空间的示例。我们省略了Cypher,因为在向图数据库添加任何数据之前,您不需要创建图空间。
# Create a graph that Gremlin can traverse
g = TinkerGraph.open().traversal()# Create a graph space in nGQL
CREATE SPACE gods
角顶
我们都知道图是由节点和边组成的。Cypher中的节点在Gremlin和nQL中称为顶点。边是两个节点之间的连接。
请参阅以下分别在这些查询语言中插入新顶点的示例。
# Insert vertex in Gremlin
g.addV(vertexLabel).property()# Insert vertex in Cypher
CREATE (:nodeLabel {property})# Insert vertex in nGQL
INSERT VERTEX tagName (propNameList) VALUES vid:(tagKey propValue)
顶点类型
节点/顶点可以有类型。它们在Gremlin和Cypher中称为标签,在nQL中称为标记。
一个顶点类型可以具有多个特性。例如,顶点类型Person有两个属性,即name和age。

Create Vertex Type
请参阅以下关于顶点类型创建的示例。我们省略了Cypher,因为在插入数据之前不需要标签。
# Create vertex type in Gremlin
g.addV(vertexLabel).property()# Create vertex type in nGQL
CREATE tagName(PropNameList)
请注意,Gremlin和nQL都支持IF NOT EXISTS。该关键字会自动检测是否存在相应的顶点类型。如果它不存在,则会创建一个新的。否则,不会创建任何顶点类型。
Show Vertex Types
创建顶点类型后,可以使用以下查询显示它们。它们将列出所有标签/标记,而不是某些标签/标记。
# Show vertex types in Gremlin
g.V().label().dedup();# Show vertex types in Cypher method 1
MATCH (n)
RETURN DISTINCT labels(n)
# Show vertex types in Cypher method 2
CALL db.labels();# Show vertex types in nGQL
SHOW TAGS
顶点上的CRUD
本节介绍使用三种查询语言对顶点进行的基本CRUD操作。
插入顶点
Insert Vertices# Insert vertex of certain type in Gremlin
g.addV(String vertexLabel).property()# Insert vertex of certain type in Cypher
CREATE (node:label) # Insert vertex of certain type in nGQL
INSERT VERTEX <tag_name> (prop_name_list) VALUES <vid>:(prop_value_list)Get Vertices# Fetch vertices in Gremlin
g.V(<vid>)# Fetch vertices in Cypher
MATCH (n)
WHERE condition
RETURN properties(n)# Fetch vertices in nGQL
FETCH PROP ON <tag_name> <vid>Delete Vertices# Delete vertex in Gremlin
g.V(<vid>).drop()# Delete a vertex in Cypher
MATCH (node:label)
DETACH DELETE node# Delete vertex in nGQL
DELETE VERTEX <vid>Update a Vertex's Property
本节介绍如何更新顶点的特性。
# Update vertex in Gremlin
g.V(<vid>).property()# Update vertex in Cypher
SET n.prop = V# Update vertex in nGQL
UPDATE VERTEX <vid> SET <update_columns>
Cypher和nQL都使用关键字SET来设置顶点类型,只是在nQL中添加了UPDATE关键字来标识操作。Gremlin的操作与上述获取顶点的操作类似,只是添加了更改属性的操作。
边
本节介绍边缘上的基本CRUD操作。
边缘类型
与顶点一样,边也可以具有类型。
# Create an edge type in Gremlin
g.edgeLabel()# Create an edge type in nGQL
CREATE EDGE edgeTypeName(propNameList)
边缘CRUD
Insert Edges of Certain Types
插入边类似于插入顶点。Cypher使用-[]->和nQL分别使用->来表示边。Gremlin使用关键字to()来指示边缘方向。
默认情况下,边以三种语言定向。下面左边的图表是有向边,而右边的图表是无向边。
# Insert edge of certain type in Gremlin
g.addE(String edgeLabel).from(v1).to(v2).property()# Insert edge of certain type in Cypher
CREATE (<node1-name>:<label1-name>)-
[(<relationship-name>:<relationship-label-name>)]
->(<node2-name>:<label2-name>)# Insert edge of certain type in nGQL
INSERT EDGE <edge_name> ( <prop_name_list> ) VALUES <src_vid> ->
<dst_vid>: ( <prop_value_list> )Delete Edges# Delete edge in Gremlin
g.E(<eid>).drop()# Delete edge in Cypher
MATCH (<node1-name>:<label1-name>)-[r:relationship-label-name]->()
DELETE r# Delete edge in nGQL
DELETE EDGE <edge_type> <src_vid> -> <dst_vid>Fetch Edges# Fetch edges in Gremlin
g.E(<eid>)# Fetch edges in Cypher
MATCH (n)-[r:label]->()
WHERE condition
RETURN properties(r)# Fetch edges in nGQL
FETCH PROP ON <edge_name> <src_vid> -> <dst_vid>
其他操作
除了顶点和边上常见的CRUD之外,我们还将向您展示三种图查询语言中的一些组合查询。
遍历边
# Traverse edges with specified vertices in Gremlin
g.V(<vid>).outE(<edge>)# Traverse edges with specified vertices in Cypher
Match (n)->[r:label]->[]
WHERE id(n) = vid
RETURN r# Traverse edges with specified vertices in nGQL
GO FROM <vid> OVER <edge>
反向遍历边
在反向遍历中,Gremlin使用中表示反转,Cypher使用<-。nQL使用关键字REVERSELY。
# Traverse edges reversely with specified vertices Gremlin
g.V(<vid>).in(<edge>)# Traverse edges reversely with specified vertices Cypher
MATCH (n)<-[r:label]-()# Traverse edges reversely with specified vertices nGQL
GO FROM <vid> OVER <edge> REVERSELY
双向遍历边
如果边缘方向不相关(任何一个方向都可以接受),则Gremlin使用bothE(),Cypher使用-[]-,nQL使用关键字BIDIRECT。
# Traverse edges reversely with specified vertices Gremlin
g.V(<vid>).bothE(<edge>)# Traverse edges reversely with specified vertices Cypher
MATCH (n)-[r:label]-()# Traverse edges reversely with specified vertices nGQL
GO FROM <vid> OVER <edge> BIDIRECT
沿指定边缘查询N个跃点
Gremlin和nQL分别使用时间和STEP来表示N个跳。Cypher使用关系*N。
# Query N hops along specified edge in Gremlin
g.V(<vid>).repeat(out(<edge>)).times(N)# Query N hops along specified edge in Cypher
MATCH (n)-[r:label*N]->()
WHERE condition
RETURN r# Query N hops along specified edge in nGQL
GO N STEPS FROM <vid> OVER <edge>
查找两个顶点之间的路径
# Find paths between two vertices in Gremlin
g.V(<vid>).repeat(out()).until(<vid>).path()# Find paths between two vertices in Cypher
MATCH p =(a)-[.*]->(b)
WHERE condition
RETURN p# Find paths between two vertices in nGQL
FIND ALL PATH FROM <vid> TO <vid> OVER *
查询示例
本节介绍一些演示查询。
演示模型:众神之图
本节中的示例广泛使用了Janus graph分发的玩具图,称为“众神之图”,如下图所示
这个例子描述了罗马万神殿的存在和地点之间的关系。

Inserting data
# Inserting vertices
## nGQL
nebula> INSERT VERTEX character(name, age, type) VALUES hash("saturn")
:("saturn", 10000, "titan"), hash("jupiter"):("jupiter", 5000, "god");
## Gremlin
gremlin> saturn = g.addV("character").property(T.id, 1).property('name', 'saturn').property('age', 10000).property('type', 'titan').next();
==>v[1]
gremlin> jupiter = g.addV("character").property(T.id, 2).property('name', 'jupiter').property('age', 5000).property('type', 'god').next();
==>v[2]
gremlin> prometheus = g.addV("character").property(T.id, 31).property('name', 'prometheus').property('age', 1000).property('type', 'god').next();
==>v[31]
gremlin> jesus = g.addV("character").property(T.id, 32).property('name', 'jesus').property('age', 5000).property('type', 'god').next();
==>v[32]
## Cypher
cypher> CREATE (src:character {name:"saturn", age: 10000, type:"titan"})
cypher> CREATE (dst:character {name:"jupiter", age: 5000, type:"god"})# Inserting edges
## nGQL
nebula> INSERT EDGE father() VALUES hash("jupiter")->hash("saturn"):();
## Gremlin
gremlin> g.addE("father").from(jupiter).to(saturn).property(T.id, 13);
==>e[13][2-father->1]
## Cypher
cypher> CREATE (src)-[rel:father]->(dst)
Deleting
# nGQL
nebula> DELETE VERTEX hash("prometheus");
# Gremlin
gremlin> g.V(prometheus).drop();
# Cypher
cypher> MATCH (n:character {name:"prometheus"}) DETACH DELETE n
Updating
# nGQL
nebula> UPDATE VERTEX hash("jesus") SET character.type = 'titan';
# Gremlin
gremlin> g.V(jesus).property('age', 6000);
==>v[32]
# Cypher
cypher> MATCH (n:character {name:"jesus"}) SET n.type = 'titan';
Fetching/Reading
# nGQL
nebula> FETCH PROP ON character hash("saturn");
===================================================
| character.name | character.age | character.type |
===================================================
| saturn | 10000 | titan |
---------------------------------------------------
# Gremlin
gremlin> g.V(saturn).valueMap();
==>[name:[saturn],type:[titan],age:[10000]]
# Cypher
cypher> MATCH (n:character {name:"saturn"}) RETURN properties(n)
╒════════════════════════════════════════════╕
│"properties(n)" │
╞════════════════════════════════════════════╡
│{"name":"saturn","type":"titan","age":10000}│
└────────────────────────────────────────────┘
Finding the name of Hercules’s Father
# nGQL
nebula> LOOKUP ON character WHERE character.name == 'hercules' | \
-> GO FROM $-.VertexID OVER father YIELD $$.character.name;
=====================
| $$.character.name |
=====================
| jupiter |
---------------------
# Gremlin
gremlin> g.V().hasLabel('character').has('name','hercules').
out('father').values('name');
==>jupiter
# Cypher
cypher> MATCH (src:character{name:"hercules"})-[:father]->
(dst:character) RETURN dst.name
╒══════════╕
│"dst.name"│
╞══════════╡
│"jupiter" │
└──────────┘
Finding the name of Hercules’s Grandfather
# nGQL
nebula> LOOKUP ON character WHERE character.name == 'hercules' | \
-> GO 2 STEPS FROM $-.VertexID OVER father YIELD $$.character.name;
=====================
| $$.character.name |
=====================
| saturn |
---------------------
# Gremlin
gremlin> g.V().hasLabel('character').has('name','hercules').out('father').
out('father').values('name');
==>saturn
# Cypher
cypher> MATCH (src:character{name:"hercules"})-[:father*2]->
(dst:character) RETURN dst.name
╒══════════╕
│"dst.name"│
╞══════════╡
│"saturn" │
└──────────┘
Find the characters with age > 100
# nGQL
nebula> LOOKUP ON character WHERE character.age > 100 YIELD
character.name, character.age;
=========================================================
| VertexID | character.name | character.age |
=========================================================
| 6761447489613431910 | pluto | 4000 |
---------------------------------------------------------
| -5860788569139907963 | neptune | 4500 |
---------------------------------------------------------
| 4863977009196259577 | jupiter | 5000 |
---------------------------------------------------------
| -4316810810681305233 | saturn | 10000 |
---------------------------------------------------------
# Gremlin
gremlin> g.V().hasLabel('character').has('age',gt(100)).values('name');
==>saturn
==>jupiter
==>neptune
==>pluto
# Cypher
cypher> MATCH (src:character) WHERE src.age > 100 RETURN src.name
╒═══════════╕
│"src.name" │
╞═══════════╡
│ "saturn" │
├───────────┤
│ "jupiter" │
├───────────┤
│ "neptune" │
│───────────│
│ "pluto" │
└───────────┘
Find who are Pluto’s cohabitants, excluding Pluto himself
# nGQL
nebula> GO FROM hash("pluto") OVER lives YIELD lives._dst AS place |
GO FROM $-.place OVER lives REVERSELY WHERE \
$$.character.name != "pluto" YIELD $$.character.name AS cohabitants;
===============
| cohabitants |
===============
| cerberus |
---------------
# Gremlin
gremlin> g.V(pluto).out('lives').in('lives').where(is(neq(pluto))).
values('name');
==>cerberus
# Cypher
cypher> MATCH (src:character{name:"pluto"})-[:lives]->()<-[:lives]-
(dst:character) RETURN dst.name
╒══════════╕
│"dst.name"│
╞══════════╡
│"cerberus"│
└──────────┘
Pluto’s Brothers
# which brother lives in which place?
## nGQL
nebula> GO FROM hash("pluto") OVER brother YIELD brother._dst AS god | \
GO FROM $-.god OVER lives YIELD $^.character.name AS Brother,
$$.location.name AS Habitations;
=========================
| Brother | Habitations |
=========================
| jupiter | sky |
-------------------------
| neptune | sea |
-------------------------
## Gremlin
gremlin> g.V(pluto).out('brother').as('god').out('lives').as('place').
select('god','place').by('name');
==>[god:jupiter, place:sky]
==>[god:neptune, place:sea]
## Cypher
cypher> MATCH (src:Character{name:"pluto"})-[:brother]->
(bro:Character)-[:lives]->(dst)
RETURN bro.name, dst.name
╒═════════════════════════╕
│"bro.name" │"dst.name"│
╞═════════════════════════╡
│ "jupiter" │ "sky" │
├─────────────────────────┤
│ "neptune" │ "sea" │
└─────────────────────────┘
除了三种图查询语言中的基本操作外,我们还将对这些语言中的高级操作进行另一项比较。敬请期待!
- 234 次浏览
【图形计算】用Scylla+JanusGraph赋能图形数据系统

如果你在读这个博客,你可能已经意识到Scylla 提供的力量和速度。也许您已经在生产中使用Scylla 来支持高I/O实时应用程序。但是当你遇到一个需要一些本地Scylla 不易实现的特性的问题时,会发生什么呢?
我最近在一家大型网络安全公司从事主数据管理(MDM)项目。他们的分析团队希望为业务用户提供更好、更快、更具洞察力的客户和供应链活动视图。
但是,任何试图构建这样一个解决方案的人都知道,主要的困难之一是包含现有数据源的绝对数量和复杂性。这些数据源通常作为独立设计和实现的系统的后端。每一个都包含了客户活动的整体情况。为了提供一个真正的解决方案,我们需要能够将这些不同的数据放在一起。
这个过程不仅需要性能和可伸缩性,还需要灵活性和快速迭代的能力。我们试图揭示重要的关系,并使它们成为数据模型本身的一个明确部分。
以JanusGraph为基础,以Scylla 为后盾的图形数据系统非常适合解决这一问题。
什么是图形数据系统?
我们将它分成两部分:
- 图形-我们将数据建模为图形,顶点和边表示我们的每个实体和关系
- 数据系统-我们将使用几个组件来构建一个单一的系统来存储和检索我们的数据
市场上有几种图形数据库的选择,但是当我们需要可伸缩性、灵活性和性能的结合时,我们可以寻找由JanusGraph、Scylla和Elasticsearch构建的系统。
在较高的层次上,它看起来是这样的:
让我们重点介绍这个数据系统真正闪耀的三个核心领域:
- 灵活性
- 模式/纲要支持
- OLTP+OLAP支持
1 . 灵活性
虽然我们当然关心数据加载和查询性能,但图形数据系统的致命特性是灵活性。大多数数据库在启动后都会将您锁定到数据模型中。定义一些支持系统业务逻辑的表,然后存储和检索这些表中的数据。当您需要添加新的数据源、交付新的应用程序功能或提出创新性问题时,您最好希望它可以在现有模式中完成!如果您必须打开现有数据模式的引擎盖,那么您已经开始了一个耗时且容易出错的更改管理过程。
不幸的是,这不是企业成长的方式。毕竟,今天要问的最有价值的问题是那些我们昨天都没有想到的问题。
另一方面,我们的图形数据系统允许我们灵活地随着时间发展我们的数据模型。这意味着,当我们了解更多关于数据的信息时,我们可以在模型上迭代以匹配我们的理解,而不必从头开始。(请查看本文以了解该过程的更完整的演练)。
这对我们的实践有什么帮助?这意味着我们可以将新的数据源合并为新的顶点和边,而不必破坏图上现有的工作负载。我们还可以立即将查询结果写入到图表中—消除每天运行的重复OLAP工作负载,这些工作负载只会产生相同的结果。每一个新的分析都可以建立在之前的基础之上,为我们提供了一种在业务团队之间共享生产质量结果的强大方式。所有这些都意味着我们可以用我们的数据来回答更具洞察力的问题。
2. 纲要/模式强制
虽然schema lite乍一看似乎不错,但使用这样的数据库意味着我们将大量工作卸载到应用程序层中。一阶和二阶效果是跨多个使用者应用程序复制的代码,由不同的团队用不同的语言编写。强制执行应该包含在数据库层中的逻辑是一个巨大的负担。
JanusGraph提供了灵活的模式支持,可以在不惹麻烦的情况下减轻我们的痛苦。它具有现成的可靠数据类型支持,我们可以使用它预先定义给定顶点或边可以包含的属性,而不需要每个顶点都必须包含所有这些已定义的属性。同样,我们可以定义允许哪些边类型连接一对顶点,但这对顶点不会自动强制具有该边。当我们决定为一个现有的顶点定义一个新的属性时,我们不必为已经存储在图中的每个现有顶点编写该属性,而是可以只在适用的顶点插入中包含它。
这种模式实施方法对于管理大型数据集(尤其是将用于MDM工作负载的数据集)非常有帮助。当我们的图表看到新的用例时,它简化了测试需求,并且清晰地将数据完整性维护和业务逻辑分开。
3.OLTP+OLAP支持
与任何数据系统一样,我们可以将工作负载分为两类:事务性和分析性。JanusGraph遵循Apache TinkerPop项目的图形计算方法。总的来说,我们的目标是“遍历”我们的图,通过连接边从一个顶点到另一个顶点。我们使用Gremlin图遍历语言来实现这一点。幸运的是,我们可以使用相同的Gremlin遍历语言来编写OLTP和OLAP工作负载。
事务性工作负载从少量顶点开始(在索引的帮助下找到),然后遍历相当少量的边和顶点以返回结果或添加新的图形元素。我们可以将这些事务性工作负载描述为图形本地遍历。我们对这些遍历的目标是最小化延迟。
分析工作负载需要遍历图中的大部分顶点和边才能找到答案。许多经典的分析图算法都适合这个领域。我们可以将其描述为图全局遍历。我们对这些遍历的目标是最大化吞吐量。
有了我们的JanusGraph-Scylla图形数据系统,我们可以混合这两种功能。在“Scylla ”高IO性能的支持下,我们可以为事务性工作负载实现可伸缩的单位数毫秒响应。我们还可以利用Spark来处理大规模的分析工作。
部署我们的数据系统
这在理论上是很好的,所以让我们开始实际部署这个图形数据系统。我们将在Google云平台上进行部署,但是下面描述的所有内容都应该可以在您选择的任何平台上复制。
下面是我们将要部署的图形数据系统的设计:
我们的架构有三个关键部分:
- Scylla ——我们的存储后端,我们数据存储的最终场所
- Elasticsearch–我们的索引后端,加速了一些搜索,并提供强大的范围和模糊匹配功能
- JanusGraph–提供我们的图形本身,作为服务器或嵌入到独立应用程序中
我们将尽可能多地使用Kubernetes进行部署。这使得扩展和部署变得容易和可重复,而不管部署具体在哪里进行。
我们是否选择使用K8s来部署“Scylla ”,这取决于我们有多冒险!“Scylla ”小组一直在努力为K8s(Kubernetes:Scylla Operator)的生产准备部署。目前作为Alpha版本提供,Scylla 操作员遵循CoreOS Kubernetes“操作员”范式。虽然我认为这最终将是JanusGraph的100%k8s部署的一个极好的选择,但现在我们将研究VMs上更传统的Scylla部署。
为了继续,您可以在 https://github.com/EnharmonicAI/scylla-janusgraph-examples。在进入生产阶段时,您会希望更改一些选项,但这个起点应该演示概念并使您快速前进。
最好在GCP虚拟机上运行此部署,并完全访问Google云api。您可以使用已有的虚拟机,也可以创建新的虚拟机。
gcloud compute instances create deployment-manager \
--zone us-west1-b \
--machine-type n1-standard-1 \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--image 'centos-7-v20190423' --image-project 'centos-cloud' \
--boot-disk-size 10 --boot-disk-type "pd-standard"然后ssh进入VM:
gcloud compute ssh deployment-manager [ryan@deployment-manager ~]$ ..
我们假设所有其他东西都是从这个GCP VM运行的。让我们安装一些prereq:
sudo yum install -y bzip2 kubectl docker git sudo systemctl start docker curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh sh Miniconda3-latest-Linux-x86_64.sh
部署Scylla
我们可以使用Scylla 自己的Google计算引擎部署脚本作为Scylla 集群部署的起点。
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/gce_deploy_and_install_scylla_cluster
创建一个新的conda环境并安装一些必需的包,包括Ansible。
conda create --name graphdev python=3.7 -y conda activate graphdev pip install ruamel-yaml==0.15.94 ansible==2.7.10 gremlinpython==3.4.0 absl-py==0.7.1
我们还将做一些ssh密钥管理和应用项目范围的元数据,这将简化到我们的实例的连接。
touch ~/.ssh/known_hosts SSH_USERNAME=$(whoami) KEY_PATH=$HOME/.ssh/id_rsa ssh-keygen -t rsa -f $KEY_PATH -C $SSH_USERNAME chmod 400 $KEY_PATH gcloud compute project-info add-metadata --metadata ssh-keys="$SSH_USERNAME:$(cat $KEY_PATH.pub)"
我们现在可以设置集群了。在上面克隆的scylla-code-samples/gce_deploy_and_install_scylla_cluster 目录中,我们将运行gce_deploy_and_install_scylla_cluster.sh。我们将创建一个由三个Scylla 3.0节点组成的集群,每个节点都是一个n1-standard-16vm,带有两个NVMe本地ssd。
./gce_deploy_and_install_scylla_cluster.sh \
-p symphony-graph17038 \
-z us-west1-b \
-t n1-standard-4 \
-n -c2 \
-v3.0完成配置需要几分钟的时间,但完成后,我们可以继续部署JanusGraph的其余组件。
克隆 scylla-janusgraph-examples GitHub repo:
git clone https://github.com/EnharmonicAI/scylla-janusgraph-examples cd scylla-janusgraph-examples
接下来的每个命令都将从克隆的repo的顶级目录运行。
建立Kubernetes集群
为了保持部署的灵活性,而不是锁定在任何云提供商的基础设施中,我们将通过Kubernetes部署所有其他内容。Google Cloud通过他们的Google Kubernetes引擎(GKE)服务提供一个托管的Kubernetes集群。
让我们用足够的资源创建一个新的集群。
gcloud container clusters create graph-deployment \
--project [MY-PROJECT] \
--zone us-west1-b \
--machine-type n1-standard-4 \
--num-nodes 3 \
--cluster-version 1.12.7-gke.10 \
--disk-size=40我们还需要创建一个防火墙规则,允许GKE pod访问其他非GKE vm。
CLUSTER_NETWORK=$(gcloud container clusters describe graph-deployment \
--format=get"(network)" --zone us-west1-b)
CLUSTER_IPV4_CIDR=$(gcloud container clusters describe graph-deployment \
--format=get"(clusterIpv4Cidr)" --zone us-west1-b)
gcloud compute firewall-rules create "graph-deployment-to-all-vms-on-network" \
--network="$CLUSTER_NETWORK" \
--source-ranges="$CLUSTER_IPV4_CIDR" \
--allow=tcp,udp,icmp,esp,ah,sctpDeploying Elasticsearch
部署Elasticsearch
在GCP上部署Elasticsearch有很多方法——我们将选择在Kubernetes上部署ES集群作为有状态集。我们将从一个3节点集群开始,每个节点有10 GB的可用磁盘。
kubectl apply -f k8s/elasticsearch/es-storage.yaml kubectl apply -f k8s/elasticsearch/es-service.yaml kubectl apply -f k8s/elasticsearch/es-statefulset.yaml
(感谢Bayu Aldi Yansyah和他的媒体文章为部署Elasticsearch设计了这个框架)
运行Gremlin控制台
我们现在已经启动并运行了存储和索引后端,所以让我们为图形定义一个初始模式。一个简单的方法是启动一个控制台连接到我们运行的Scylla 和Elasticsearch集群。
构建JanusGraph docker映像并将其部署到Google容器注册中心。
scripts/setup/build_and_deploy_janusgraph_image.sh -p [MY-PROJECT]
更新k8s/gremlin-console/janusgraph-gremlin-console.yaml使用项目名指向GCR存储库映像名的文件,并添加Scylla 节点之一的正确主机名。您会注意到在YAML文件中,我们使用环境变量帮助创建JanusGraph属性文件,我们将使用该文件在控制台中用JanusGraphFactory实例化JanusGraph对象。
创建并连接到JanusGraph Gremlin控制台:
kubectl create -f k8s/gremlin-console/janusgraph-gremlin-console.yaml
kubectl exec -it janusgraph-gremlin-console -- bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
...
gremlin> graph = JanusGraphFactory.open('/etc/opt/janusgraph/janusgraph.properties')现在我们可以继续为我们的图创建一个初始模式。我们将在这里从更高的层次讨论这个问题,但我将在本文中详细讨论模式创建和管理过程。
在本例中,我们将查看联邦选举委员会关于2020年总统竞选捐款的数据样本。样本数据已经过分析,并对其进行了一些清理(向我的兄弟Patrick Stauffer致敬,因为他允许我利用他在这个数据集上的一些工作),并且作为资源包含在repo中/贡献.csv.
以下是我们的贡献数据集的架构定义的开始:
mgmt = graph.openManagement()
// Define Vertex labels
Candidate = mgmt.makeVertexLabel("Candidate").make()
ename = mgmt.makePropertyKey("name").
dataType(String.class).cardinality(Cardinality.SINGLE).make()
filerCommitteeIdNumber = mgmt.makePropertyKey("filerCommitteeIdNumber").
dataType(String.class).cardinality(Cardinality.SINGLE).make()
mgmt.addProperties(Candidate, type, name, filerCommitteeIdNumber)
mgmt.commit()您可以在scripts/load/define中找到完整的模式定义代码_schema.groovy模式存储库中的文件。只需将其复制并粘贴到Gremlin控制台中即可执行。
加载模式后,我们可以关闭Gremlin控制台并删除pod。
kubectl delete -f k8s/gremlin-console/janusgraph-gremlin-console.yaml
部署JanusGraph服务器
最后,让我们将JanusGraph部署为服务器,准备接受客户机请求。我们将利用JanusGraph对Apache TinkerPop的Gremlin服务器的内置支持,这意味着我们的图形将可以被多种客户端语言(包括Python)访问。
编辑k8s/janusgraph/janusgraph-server-service.yaml指向正确的GCR存储库映像名的文件。部署JanusGraph服务器现在非常简单:
kubectl apply -f k8s/janusgraph/janusgraph-server-service.yaml kubectl apply -f k8s/janusgraph/janusgraph-server.yaml
加载数据
我们将通过在图中加载一些初始数据来演示对JanusGraph服务器部署的访问。
无论何时我们将数据加载到任何类型的数据库(Scylla 、关系、图表等),我们都需要定义源数据将如何映射到数据库中定义的模式。对于graph,我喜欢使用一个简单的映射文件。回购协议中包含了一个示例,下面是一个小示例:
vertices:
- vertex_label: Candidate
lookup_properties:
FilerCommitteeIdNumber: filerCommitteeIdNumber
other_properties:
CandidateName: name
edges:
- edge_label: CONTRIBUTION_TO
out_vertex:
vertex_label: Contribution
lookup_properties:
TransactionId: transactionId
in_vertex:
vertex_label: Candidate
lookup_properties:
FilerCommitteeIdNumber: filerCommitteeIdNumber此映射是为演示目的而设计的,因此您可能会注意到此映射定义中存在重复数据。这个简单的映射结构允许客户端保持相对“哑”的状态,而不是强制它预处理映射文件。
我们的示例repo包含一个简单的Python脚本load_fron_csv.py年,它接受一个CSV文件和一个映射文件作为输入,然后将每一行加载到图形中。它一般采用您想要的任何映射文件和CSV,但它是单线程的,不是为速度而构建的,它旨在演示从客户端加载数据的概念。
python scripts/load/load_from_csv.py \
--data ~/scylla-janusgraph-examples/resources/Contributions.csv \
--mapping ~/scylla-janusgraph-examples/resources/campaign_mapping.yaml \
--hostname [MY-JANUSGRAPH-SERVER-LOAD-BALANCER-IP] \
--row_limit 1000这样,我们就可以启动并运行数据系统,包括定义数据模式和加载一些初始记录。
结束
我希望你喜欢这个进入JanusGraph-Scylla 图形数据系统的短暂尝试。它应该为您提供一个良好的起点,并演示如何轻松地部署所有组件。记住关闭任何不想保留的云资源,以避免产生费用。
我们真的只是触及了这个强大的系统所能完成的事情的表面,而你的胃口也被激起了。请给我任何想法和问题,我期待着看到你的建设!
原文:https://www.scylladb.com/2019/05/14/powering-a-graph-data-system-with-scylla-janusgraph/
本文:http://jiagoushi.pro/node/1045
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 204 次浏览
【知识图谱】实现知识图谱——Python
视频号
微信公众号
知识星球
在这个由两部分组成的系列的第一部分(链接到第一部分)中,我们看到了如何使用知识图来模拟思维过程。在这部分,让我们把手弄脏!😄
我们将使用一个名为Cayley的开源图形数据库作为KG后端。根据您的操作系统,从这里获取最新的二进制文件。下载后,转到根目录并找到cayley.yml文件。如果它不存在,请创建它。应该有一个cayley_example.yml文件来指导您。该文件是cayley的配置文件。该文件的一个重要用途是设置存储图形的后端数据库。有几个选项可用(请参阅文档)。我们将使用MySQL作为数据库。我假设你已经安装了MySQL。如果没有,安装它非常简单(谷歌:P)。现在,请确保您的cayley.yml文件如下所示:(将<your_root_password>替换为MySQL根的实际密码,并将<your_database_name>替换为数据库名称。
cayley.yml:
store:
# backend to use
backend: "mysql"
# address or path for the database
address: "root:<your_root_password>#@tcp(localhost:3306)/<your_database_name>"
# open database in read-only mode
read_only: false
# backend-specific options
options:
nosync: false
query:
timeout: 30s
load:
ignore_duplicates: false
ignore_missing: false
batch: 10000now let’s start our graph I am using windows so exact commands might differ from Mac and Linux. You can see (this file):
打开命令提示符/terminal,转到cayley根目录,并在terminal中键入以下内容:
cayley init
Cayley将自动检测Cayley.yml文件中的配置并建立数据库。现在要加载一个图形数据库,我们需要了解一种叫做“模式”的东西。
模式是表示信息的一种特定方式。例如,JSON(JavaScript对象表示法)就是模式的一个例子。有关模式的更多信息,请访问Schema.org的网站。在这里,我们将使用一个名为“N-quads”的模式。有关N-quad的更多信息,请点击此处。
在上面的示例N-quad文件中,我们有一个类似的模式:<person><follows><person><status>。这意味着两个<person>是图的节点,<followes>是它们之间的“方向关系”<status>是可选的,并对关系进行了更多描述。
现在,下一步是将其加载到我们的MySQL数据库中。要执行此操作,请运行:
cayley load -i <path_to_nquads_file>
将<path_to_quads_file>替换为N-quads文件的相对路径。制作一个N-quad文件很容易。只需在N-quad模式中写入并使用“.nq”扩展名保存即可。
将图形加载到cayley后,您可以运行一个web实例,使用gizmo查询语言(这并不难理解)与您的KG进行交互和可视化。运行:
cayley http
Go to localhost:64210 on your browser and you can see something like this:
您可以在此处键入任何查询以与您的KG交互。示例查询为:
g.V().All()
这意味着获取图形对象“g”的所有顶点。有关查询语言的更多信息,请点击此处。
您还可以在web应用程序中可视化图形。阅读文档以便能够做到这一点。
现在是有趣的部分(没有人告诉你):
我们使用Cayley图数据库和MySql实现了一个简单的知识图。我们可以在不使用网络应用程序的情况下远程与此图形交互吗?对Cayley向API端点公开图形:http://127.0.0.1:64210/api/v1/query/gizmo
我们可以使用python“requests”库来进行POST请求,并在任何需要的地方查询Graph(Cayley应该在后台运行以提供API端点)。
import requests import jsonquery = "g.V().All()" endpoint = "http://127.0.0.1:64210/api/v1/query/gizmo" response = requests.post(endpoint, data=query)#the response is a JSON object json_response = response.json() print(json_response)
在Jupyter Notebook中运行上面的代码,您应该能够看到API的JSON响应并使用它!
那都是人!希望你喜欢这个。
- 203 次浏览
搜索引擎
- 224 次浏览
【全文搜索】全文搜索 PostgreSQL 或 ElasticSearch
在本文中,我记录了在 PostgreSQL(使用 Django ORM)和 ElasticSearch 中实现全文搜索 (FTS) 时的一些发现。
作为一名 Django 开发人员,我开始寻找可用的选项来在大约一百万行的标准大小上执行全文搜索。有两个值得尝试的选项:PostgreSQL 和 ElasticSearch。
在深入研究我的发现之前,让我们澄清一下全文搜索 (FTS)(或“搜索”)与数据库过滤器或查询之间的区别。 “搜索”涉及从零开始,然后向其中添加结果。数据库过滤从一个集合开始,然后根据条件从中删除条目。过滤不适用于模糊输入,但可以使用模糊输入完成“搜索”。
PostgreSQL 全文搜索
我的大部分项目都使用 Django Web 框架和 PostgreSQL。 PostgreSQL 从 2008 年开始支持全文搜索 (FTS),Django 从 1.10 (2016) 开始通过 django.contrib.postgres 支持 FTS。因此,它是我集成的最快和最简单的选择。以下是我的一些发现:
这是一种更便宜、更快捷的选择,因为它不需要任何额外的设置和维护。
在我的本地(Razer Blade 2.4 GHz 6 Core i7)测试中,使用 GIN Index 的多达 500,000 条记录始终在大约 30 毫秒左右得到结果。在网上查看其他人所做的基准测试时,我发现它会在大约 30-50 毫秒内返回 150 万条记录的结果。
使用 Trigram 最多可以将其减慢 5 倍。
当前的 Django 集成不直接支持 Stemming 或 Fuzziness
ElasticSearch
ElasticSearch 是一个非常成熟的名称,有很多库可用于与 Django 和其他框架集成。 以下是调查结果:
该技术仅针对搜索进行了优化,但设置和维护基础架构可能非常耗时。
自己设置需要专用的服务器或服务,这比 PostgreSQL 选项昂贵。
随着数据的增长进行扩展更易于管理,它支持所有搜索选项,例如 Trigram、EdgeGram、Stemming、Fuzziness
在我的本地(Razer Blade 2.4 GHz 6 Core i7)测试多达 500,000 条记录时,它始终在大约 25 毫秒内返回结果。 在网上查看其他人所做的基准测试时,我发现它会在大约 5-30 毫秒内返回 150 万条记录的结果。
比较图
Postgresql vs ElasticSearch performance graph
结论
随着 PostgreSQL 的每个新版本,搜索响应时间都在改进,并且与 ElasticSearch 相比,它正在朝着苹果与苹果的比较前进。因此,如果项目不打算拥有数百万条记录或大规模数据,Postgresql 全文搜索将是最佳选择。
术语
- 词干提取:这是将单词简化为其根形式的过程,以确保该单词的变体在搜索过程中与结果匹配。例如,Referencing、Reference、References 可以归结为一个词 Refer 并且在搜索词时,refer 将返回具有该词的任何变体的结果。
- NGram:它就像一个在单词上移动的滑动窗口——一个连续的字符序列,直到指定长度。例如,术语 Refer 将变成 [R, RE, REF, E, EF, EFE, F, FE, FER]。 NGram 可用于部分搜索单词,甚至从中间搜索单词。最常用的 NGram 类型是 Trigram 和 EdgeGram。
- 模糊性:模糊匹配允许您获得不完全匹配的结果。例如,搜索单词框也会返回包含 fox 的结果。常见应用包括拼写检查和垃圾邮件过滤。
原文:https://fueled.com/the-cache/posts/backend/fulltext-search-postgresql-v…
- 149 次浏览
【全文搜索】全文搜索之战:PostgreSQL vs Elasticsearch
2020-09-08 更新:使用一个 GIN 索引而不是两个,websearch_to_tsquery,添加 LIMIT,并将 TSVECTOR 存储为单独的列。 更多细节在文章末尾。
我最近开始研究全文搜索选项。 用例是实时搜索键值对,其中键是字符串,值是字符串、数字或日期。 它应该启用对键和值的全文搜索以及对数字和日期的范围查询,并将 150 万个唯一键值对作为预期的最大搜索索引大小。 搜索公司 Algolia 建议端到端延迟预算不超过 50 毫秒,因此我们将使用它作为我们的阈值。
PostgreSQL
我已经熟悉 PostgreSQL,所以让我们看看它是否满足这些要求。 首先,创建一个表,
CREATE TABLE IF NOT EXISTS search_idx
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
key_str TEXT NOT NULL,
val_str TEXT NOT NULL,
val_int INT,
val_date TIMESTAMPTZ
);接下来,用半真实的数据播种它。 以下可以将〜20,000行/秒插入到没有索引的表中,
const pgp = require("pg-promise")();
const faker = require("faker");
const Iterations = 150;
const seedDb = async () => {
const db = pgp({
database: process.env.DATABASE_NAME,
user: process.env.DATABASE_USER,
password: process.env.DATABASE_PASSWORD,
max: 30,
});
const columns = new pgp.helpers.ColumnSet(
["key_str", "val_str", "val_int", "val_date"],
{ table: "search_idx" }
);
const getNextData = (_, pageIdx) =>
Promise.resolve(
pageIdx > Iterations - 1
? null
: Array.from(Array(10000)).map(() => ({
key_str: `${faker.lorem.word()} ${faker.lorem.word()}`,
val_str: faker.lorem.words(),
val_int: Math.floor(faker.random.float()),
val_date: faker.date.past(),
}))
);
console.debug(
await db.tx("seed-db", (t) =>
t.sequence((idx) =>
getNextData(t, idx).then((data) => {
if (data) return t.none(pgp.helpers.insert(data, columns));
})
)
)
);
};
seedDb();现在已经加载了 150 万行,添加全文搜索 GIN 索引(详细信息),
CREATE INDEX search_idx_key_str_idx ON search_idx
USING GIN (to_tsvector('english'::regconfig, key_str));
CREATE INDEX search_idx_val_str_idx ON search_idx
USING GIN (to_tsvector('english'::regconfig, val_str));注意:如果在创建索引后向表中添加更多数据,VACUUM ANALYZE search_idx; 更新表统计信息并改进查询计划。
是时候测试以下查询的性能了,
-- Prefix query across FTS columns
SELECT *
FROM search_idx
WHERE to_tsvector('english'::regconfig, key_str)
@@ to_tsquery('english'::regconfig, 'qui:*')
OR to_tsvector('english'::regconfig, val_str)
@@ to_tsquery('english'::regconfig, 'qui:*');
-- Wildcard query on key (not supported by GIN index)
SELECT *
FROM search_idx
WHERE key_str ILIKE '%quis%';
-- Specific key and value(s) query
SELECT *
FROM search_idx
WHERE to_tsvector('english'::regconfig, key_str)
@@ to_tsquery('english'::regconfig, 'quis')
AND (to_tsvector('english'::regconfig, val_str)
@@ to_tsquery('english'::regconfig, 'nulla')
OR (to_tsvector('english'::regconfig, val_str)
@@ to_tsquery('english'::regconfig, 'velit')));
-- Contrived range query, one field wouldn't have both val_int and val_date populated
SELECT *
FROM search_idx
WHERE to_tsvector('english'::regconfig, key_str)
@@ to_tsquery('english'::regconfig, 'quis')
AND val_int > 1000
AND val_date > '2020-01-01';在任何查询前添加 EXPLAIN 以确保它使用索引而不是进行全表扫描。 在前面添加 EXPLAIN ANALYZE 将提供时间信息,但是,如文档中所述,这会增加开销,并且有时会比正常执行查询花费更长的时间。
在我的 MacBook Pro(2.4 GHz 8 核 i9,32 GB RAM)上,我总是在第一个可能是最常见的查询上得到大约 100 毫秒。 这远远超过了 50 毫秒的阈值。
Elasticsearch
接下来,让我们试试 Elasticsearch。 启动它并确保状态为绿色,如下所示,
docker run -d -p 9200:9200 -p 9300:9300
-e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.9.0
curl -sX GET "localhost:9200/_cat/health?v&pretty" -H "Accept: application/json"接下来,为索引播种。 第一个脚本创建一个文件,每行一个半真实的文档,
const faker = require("faker");
const { writeFileSync } = require("fs");
const Iterations = 1_500_000;
writeFileSync(
"./dataset.ndjson",
Array.from(Array(Iterations))
.map(() =>
JSON.stringify({
key: `${faker.lorem.word()} ${faker.lorem.word()}`,
val: faker.lorem.words(),
valInt: Math.floor(faker.random.float()),
valDate: faker.date.past(),
})
)
.join("\n")
);第二个脚本将 ~150 MB 文件中的每个文档添加到索引中,
const { createReadStream } = require("fs");
const split = require("split2");
const { Client } = require("@elastic/elasticsearch");
const Index = "search-idx";
const seedIndex = async () => {
const client = new Client({ node: "http://localhost:9200" });
console.debug(
await client.helpers.bulk({
datasource: createReadStream("./dataset.ndjson").pipe(split()),
onDocument(doc) {
return { index: { _index: Index } };
},
onDrop(doc) {
b.abort();
},
})
);
};
seedIndex();注意:此脚本可用于测试目的,但在生产中,请遵循有关调整批量请求大小和使用多线程的最佳实践。
现在,运行一些查询,
curl -sX GET "localhost:9200/search-idx/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": {
"simple_query_string" : {
"query": "\"repellat sunt\" -quis",
"fields": ["key", "val"],
"default_operator": "and"
}
}
}
'我在低端聚集的 136 个匹配结果上得到 5-24 毫秒,运行查询的次数越多。 这比 PostgreSQL 快约 5 倍。 因此,为了获得我所追求的性能,维护 Elasticsearch 集群的额外开销似乎是值得的。
2020-09-08 更新
在@samokhvalov 的帮助下,我创建了一个 GIN 索引而不是使用两个,
CREATE INDEX search_idx_key_str_idx ON search_idx
USING GIN ((setweight(to_tsvector('english'::regconfig, key_str), 'A') ||
setweight(to_tsvector('english'::regconfig, val_str), 'B')));但是,我在生产中使用 PostgreSQL 10,因为我使用的是最新版本的 Elasticsearch,所以拉取最新版本的 PostgreSQL 是公平的(在撰写本文时,postgres:12.4-alpine)。 然后我更新了查询以使用新索引 websearch_to_tsquery,并添加了 Elasticsearch 使用的相同默认 LIMIT,
SELECT *
FROM search_idx
WHERE (setweight(to_tsvector('english'::regconfig, key_str), 'A') ||
setweight(to_tsvector('english'::regconfig, val_str), 'B')) @@
websearch_to_tsquery('english'::regconfig, '"repellat sunt" -quis')
LIMIT 10000;这更像是一个苹果与苹果的比较,并在我的 MacBook Pro 上大幅减少了 172 个匹配结果的查询时间,从 ~100 毫秒到 ~13-16 毫秒!
作为最后的测试,我创建了一个独立的列来保存 TSVECTOR,如文档中所述。 它通过触发器保持最新,
CREATE TABLE IF NOT EXISTS search_idx
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
key_str TEXT NOT NULL,
val_str TEXT NOT NULL,
val_int INT,
val_date TIMESTAMPTZ,
fts TSVECTOR
);
CREATE FUNCTION fts_trigger() RETURNS trigger AS
$$
BEGIN
new.fts :=
setweight(to_tsvector('pg_catalog.english', new.key_str), 'A') ||
setweight(to_tsvector('pg_catalog.english', new.val_str), 'B');
return new;
END
$$ LANGUAGE plpgsql;
CREATE TRIGGER tgr_search_idx_fts_update
BEFORE INSERT OR UPDATE
ON search_idx
FOR EACH ROW
EXECUTE FUNCTION fts_trigger();
CREATE INDEX search_idx_fts_idx ON search_idx USING GIN (fts);
SELECT *
FROM search_idx
WHERE fts @@ websearch_to_tsquery('english'::regconfig, '"repellat sunt" -quis')
LIMIT 10000;在 psql 中测量时,这会将查询缩短到 6-10 毫秒,实际上与针对此特定查询的 Elasticsearch 相同。
如果有人知道进一步的优化,我会更新我的粗略数字和代码片段以包含它们。
原文:https://www.rocky.dev/full-text-search
本文:https://jiagoushi.pro/node/2018
- 415 次浏览
【全文搜索】如何为您的应用程序启用强大的全文搜索 - MySQL 与 Elasticsearch
MySQL 和 Elasticsearch 之间全文搜索和比较的分步指南
您是否曾经在超市或百货公司四处走动,但找不到您要找的物品?在网上购物时,您可能会遇到同样的情况。尽管大多数网站按类别排列产品,但如果您不知道目标产品的类别,浏览类别仍然是一件苦差事。搜索栏为我们节省了大量时间,因为我们可以简单地输入关键字或文本短语,然后它会向我们显示所有相关项目。毫无疑问,全文搜索是所有电子商务网站的基本功能。
全文搜索是 MySQL 和 Elasticsearch 等许多数据库支持的流行功能。但是,在全文搜索能力方面,MySQL 和 Elasticsearch 有什么区别呢?如果您正在寻找实现全文搜索的解决方案,则无法在不了解差异的情况下做出正确的决定。在本文中,我将向您展示 MySQL 和 Elasticsearch 上全文搜索的用法,并强调它们的区别。
什么是全文搜索?
如果搜索引擎通过完全匹配来查找数据记录,您几乎不会得到任何搜索结果。例如,下面的 SQL 语句不太可能返回任何记录,因为可能不存在名称或描述与名称或描述中的文本短语“鱼和番茄罐头”完全相同的此类产品。
SELECT * FROM products WHERE name = ‘canned food with fish and tomato’ OR description = ‘canned food with fish and tomato’
如果我们使用通配符“LIKE %”可能会有所帮助,但您只会收到在数据字段中包含确切文本短语的记录。
SELECT * FROM products WHERE name LIKE ‘%canned food with fish and tomato%’ OR description LIKE ‘%canned food with fish and tomato%’
全文搜索的想法是将文本短语分解为标记。上例中的文本短语分为以下标记:“罐头”、“食物”、“与”、“鱼”、“和”和“番茄”。然后,搜索引擎查找与任何一个标记匹配的所有记录。记录匹配的标记越多,它与文本短语的相关性就越高。因此,搜索引擎通过在搜索结果中分配分数来指示相关性。如果您的查询字符串中的标记包含诸如“食物”之类的常用词,并且许多产品可能匹配一个或多个标记,您可能会收到包含大量记录的搜索结果。但是,您始终可以按分数过滤结果,以获得最相关的记录。
全文搜索是 MySQL 和 Elasticsearch 等许多数据库支持的流行功能。启用此功能的设置实际上非常简单明了。例如,您可以在 MySQL 上打开选定数据字段的全文搜索功能,而无需对表架构进行任何更改。说到 Elasticsearch 就更直接了,因为它默认支持全文搜索,不需要额外的配置。
全文搜索概览 — MySQL 与 Elasticsearch
简而言之,MySQL 和 Elasticsearch 在全文搜索方面有着相似的想法。它是通过将文本内容分解为标记来创建索引。然后,查询会将查询文本分解为标记并与索引匹配。根据匹配结果,搜索引擎计算得分并分配给代表相关性的搜索结果。
主要区别在于固定解决方案和可配置解决方案之间的解决方案方法。 MySQL 以 3 种不同的模式提供全文搜索的固定功能——自然语言、布尔和扩展查询。它几乎没有调整和微调的空间。
相反,Elasticsearch 的设计是高度可配置的。标记分解和查询执行的过程是基于分析器、标记器和过滤器的集合来执行的。这些组件可以定制并组合在一起,以实现更高级的功能。
我将逐步介绍 MySQL 和 Elasticsearch 上的全文搜索用法。
样本数据集
全文搜索功能的演示基于一个样本数据集,该样本数据集是一组图书馆图书记录。架构相当简单,包含以下列:id、title 和 publicationPlace。

MySQL
运行下面的 SQL 语句创建图书馆图书表并导入示例数据。
CREATE TABLE `library-book` (
`id` int(11) NOT NULL,
`title` text COLLATE utf8_unicode_ci,
`publicationPlace` text COLLATE utf8_unicode_ci
);
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('1', 'How To Grow Your Own Fruit and Veg: A Week-by-week Guide to
Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural
Balance Gardening', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('2', 'The Life of God in the Soul of the Church: The Root and
Fruit of Spiritual Fellowship', 'Edinburgh');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('3', 'Fruit and vegetable production in Africa - The important
fruits are bananas, pineapples, dates, figs, olives, and citrus;
the principal vegetables include tomatoes and onions', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('4', 'Silver fruit upon silver trees', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('5', 'A life to live', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('6', 'The emergency medical services in Edinburgh', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('7', 'SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH
VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual
Herb Recipes', 'Auckland');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('8', 'Good Food For Bad Days - Tasty vegan meals really
don''t have to take all the time in the world or grand ingredients', 'Edinburgh');
MySQL 需要为全文搜索设置索引,假设读者有兴趣根据这两个数据字段查找书籍,则运行以下语句为“title”和“publicationPlace”创建全文索引。
ALTER TABLE `library`.`books` ADD FULLTEXT `book_free_text_index` (`title`, `publicationPlace`);
Elasticsearch
Elasticsearch 的所有 CRUD 操作都是通过 REST API 调用来完成的。 要将同一组示例书籍记录加载到 Elasticsearch 中,请运行下面的 curl 命令,该命令会提交 POST 请求以进行批量数据插入。 如果您想知道如何在本地机器上运行 Elasticsearch 和 Kibana 进行测试,请按照本文在 docker 上部署 Elasticsearch 节点。
与 MySQL 不同,Elasticsearch 是一个 NoSQL 数据库,无需事先创建表模式即可完成数据插入。 Elasticsearch中的“索引”是指关系数据库中的数据库,如果该索引尚不存在,它会自动创建一个名为“library-book”的索引,如请求中指定的那样。 此外,无需创建全文搜索索引,因为 Elasticsearch 在数据插入或更新过程中将文本内容分解为令牌并存储在索引中。
curl --request POST \
--url 'http://localhost:9200/_bulk?pretty=' \
--header 'Content-Type: application/json' \
--data '{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "1" } }
{ "title" : "How To Grow Your Own Fruit and Veg: A Week-by-week Guide to
Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural
Balance Gardening", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "2" } }
{ "title" : "The Life of God in the Soul of the Church: The Root and
Fruit of Spiritual Fellowship", "publicationPlace": "Edinburgh" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "3" } }
{ "title" : "Fruit and vegetable production in Africa - The important fruits
are bananas, pineapples, dates, figs, olives, and citrus; the principal
vegetables include tomatoes and onions", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "4" } }
{ "title" : "Silver fruit upon silver trees", "publicationPlace": "London" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "5" } }
{ "title" : "A life to live", "publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "6" } }
{ "title" : "The emergency medical services in Edinburgh",
"publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "7" } }
{ "title" : "SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH
VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual
Herb Recipes", "publicationPlace": "Auckland" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "8" } }
{ "title" : "Good Food For Bad Days - Tasty vegan meals really
don'\''t have to take all the time in the world or grand ingredients",
"publicationPlace": "Edinburgh" }简单的关键字搜索
让我们从一个简单的搜索开始,假设我们搜索一个关键字“爱丁堡”。
MySQL
要查找与该关键字匹配的所有记录,请在 MySQL 中使用 match() 以布尔模式进行全文查询。 运行此 SQL 语句以搜索“爱丁堡”。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('edinburgh' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC
搜索结果为每条记录分配一个分数,以显示相关性。 分数越高,记录与关键字的相关性越高。 有 3 条记录的得分 > 0,因为标题和 publicationPlace 与关键字“爱丁堡”匹配,而其他记录与关键字不匹配,因此分配零分。
Elasticsearch
Elasticsearch 支持多种查询方法,例如关键字、文本短语、前缀等。我们在此示例中使用查询类型“multi_match”来搜索多个数据字段——“title”和“publicationPlace”。 提交此 POST 请求以搜索关键字“edinburgh”。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title",
"publicationPlace"
]
}
}
}'

根据指定数据字段微调分数
对于某些用例,某些数据字段更重要,这些字段上的关键字匹配应给予更高的分数。 虽然 MySQL 不提供这种灵活性,但可以在 Elasticsearch 中通过将插入符号“^”附加到数据字段来实现它。 此处的示例将“title”字段的重要性设置为 3 倍。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title^3",
"publicationPlace"
]
}
}
}'由于“title”更重要,“title”字段与关键字匹配的记录得分更高。

使用逻辑条件搜索
您可能想要指定某些搜索条件,例如 AND / OR / NOT。 比如说,我们想搜索同时匹配关键字“生活”和“生活”的书籍。 为此,我们在每个关键字前面添加一个符号“+”,以表明它是一个“AND”条件。
MySQL
MySQL 提供的 BOOLEAN 模式支持带逻辑条件的查询。 让我们搜索关键字“生活”和“生活”的书籍。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('+life +live' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC;现在只有“A life to live”这本书与 score > 0 相关,而所有其余书籍的 score = 0。
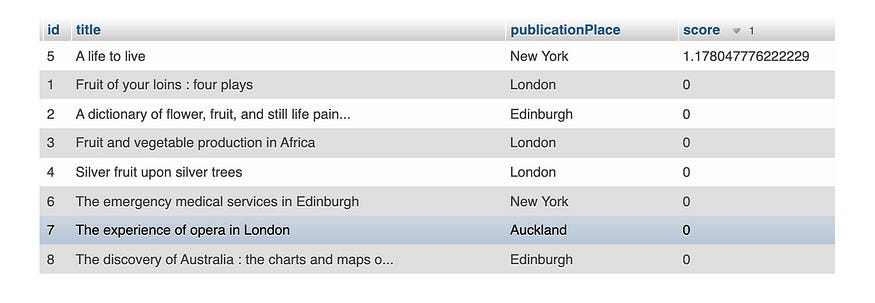
布尔模式不仅支持 AND 运算符(+),还支持其他符号,如 NOT(~)、高相关性(>)、低相关性(<)等,具体请参考 MySQL 官方参考。
弹性搜索
同一组符号可以应用于 Elasticsearch。 我们可以在带有逻辑条件的文本短语的 POST 请求中使用查询类型“simple_query_string”。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"simple_query_string": {
"query": "+life +live",
"fields": [
"title",
"publicationPlace"
]
}
}
}'结果只显示一条记录,与 MySQL 的结果相同。

文本短语搜索
“Recipes Of A Delicious And Tasty Meal”的文本短语的搜索结果是什么? 由于文本短语被分解为小写“recipes”、“of”、“a”、“delicious”、“and”、“tasty”和“meal”的标记。 记录匹配更多标记,这意味着它与文本短语更相关。
人们自然会用人类语言输入文本短语以进行查询。 考虑到人类语言,需要进行特殊处理才能产生准确的结果。 例如,匹配那些在英语中出现频率很高的单词,如“a”、“an”、“of”、“the”等,就不太可能产生有意义的结果。 这些词被称为“停用词”,搜索引擎应该在文本短语查询中忽略它们。
MySQL
MySQL 支持忽略“停用词”并运行不区分大小写的搜索的自然语言模式。 运行此查询语句以搜索文本短语。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST
('Recipes Of A Delicious And Tasty Meal' IN NATURAL LANGUAGE MODE) AS score
FROM `library-book`
ORDER BY score DESC;得分最高的前 3 条记录与搜索文本短语中的大多数标记匹配。

Elasticsearch
Elasticsearch 的默认索引设置不具备 MySQL 提供的自然语言模式等功能。
当您将此 POST 请求发送到 Elasticsearch 以搜索相同的文本短语时,您将看到不同的结果。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
}'默认设置将停用词考虑在内以进行匹配和分数计算。 结果,与“of”和“and”等大多数停用词匹配的得分最高的搜索结果显然是不相关的。

不用担心,Elasticsearch 实际上是一个非常强大的搜索引擎,可以通过在索引设置中为停用词配置标记过滤器来支持自然语言搜索。
Elasticsearch 提供了 15 个 tokenzier 和 50 多个适用于各种用例的 token 过滤器。 要实现类似于 MySQL 的全文搜索,只需在分析器中添加停用词标记过滤器即可。 下图显示分析仪由以下组件组成:
- 标准分析器——将文本短语分解为标记
- 小写标记过滤器 - 将标记转换为小写以进行不区分大小写的搜索
- 停用词标记过滤器 - 删除常用词的标记,例如“of”、“a”、“and”等。
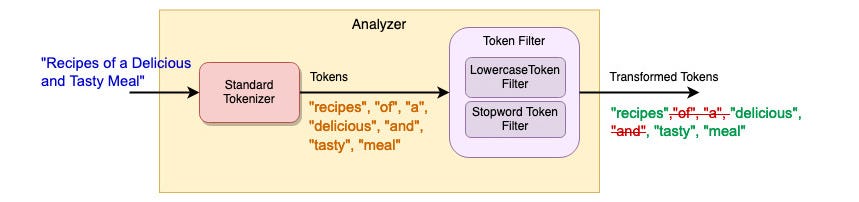
Analyzer 在索引设置中配置,并映射到数据字段“title”和“publicationPlace”。
提交此 PUT 请求以使用新的分析器配置和字段映射创建一个名为“library-book-text-phrase”的新索引(即 Elasticsearch 中的数据库)。
curl --request PUT \
--url http://localhost:9200/library-book-text-phrase \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'然后,提交这个 POST 请求,将数据从原始索引“library-book”复制到新创建的索引“library-book-text-phrase”。
curl --request POST \
--url 'http://localhost:9200/_reindex \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-text-phrase"
}
}'让我们对新索引“library-book-text-phrase”运行相同的查询。 结果现在更有意义了。
curl --request POST \
--url http://localhost:9200/library-book-text-phrase/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
MySQL — 扩展搜索条件
强大的搜索引擎不仅可以通过token匹配进行搜索,还可以理解关键字并扩展搜索其他具有相似含义的关键字。 例如,当您搜索关键字“woods”时,预计搜索引擎应该寻找与“timber”、“lumber”和“trees”等其他类似关键字匹配的记录。
MySQL 能够使用“QUERY EXPANSION”模式猜测您要查找的内容。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('green' WITH QUERY EXPANSION) AS score
FROM `library-book`
ORDER BY score DESC当我们搜索关键字“绿色”时。 将返回 3 条记录。 第 2 条和第 3 条记录的标题字段实际上并不包含关键字“green”,但搜索引擎以某种方式猜测这些记录的内容与关键字“green”相关

但是,当我们在搜索条件中添加更多关键字时,搜索结果会包含更多“噪音”。 几乎所有的图书记录都在查询扩展模式下搜索到了文本短语“美好生活”。
如果您对准确性不满意,则无法微调搜索结果。

Elasticsearch - 使用同义词标记过滤器的广泛搜索
Elasticsearch 提供了多种方式来实现类似于 MySQL 支持的扩展模式的扩展搜索。 令牌过滤器的使用不是提供固定的解决方案,而是可以实现高级全文搜索的能力。
我们来看看对同义词搜索的支持。 我们配置令牌过滤器,以便将搜索扩展到同义词。 我们使用了一个名为 WordNet 的免费词汇数据库。 一般来说,它存储超过 2 万个单词和同义词的映射。
配置是为同义词添加新的标记过滤器,过滤器从 WordNet 文件中读取同义词映射。

要启用新的索引设置,请下载 WordNet 文件并复制到 [elasticsearch 文件夹]/config/analysis,然后提交此 PUT 请求以创建一个名为“library-book-synonym-wordnet”的新索引
curl --request PUT \
--url http://localhost:9200/library-book-synonym-wordnet \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"format": "wordnet",
"lenient": true,
"synonyms_path": "analysis/wn_s.pl"
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'然后,提交这个 POST 请求,将数据从原始索引“library-book”复制到新创建的索引“library-book-synonym-wordnet”。
curl --request POST \
--url 'http://localhost:9200/_reindex' \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-synonym-wordnet"
}
}'现在,在新索引上搜索关键字“green”。 然后,您将获得与“green”同义词匹配的记录列表。
curl --request POST \
--url http://localhost:9200/library-book-synonym-wordnet/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "green",
"fields": [
"title",
"publicationPlace"
]
}
}
}'结果:

具有自定义词映射的 Elasticsearch 令牌同义词过滤器
如果 WordNet 不能满足您的需求,Elasticsearch 支持自定义同义词映射。 我们配置了一个同义词标记过滤器,以便将关键字“fruit”映射到关键字列表——“banana”、“pineapple”、“date”、“fig”、“olive”和“citrus”。 因此,搜索关键字“banana”将匹配任何带有“fruit”的记录。
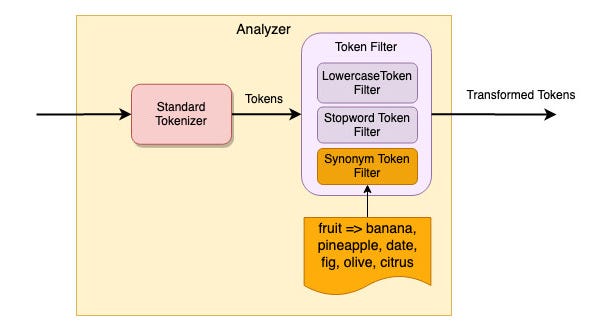
提交此 PUT 请求以使用令牌过滤器“synonym_filter”创建新索引和自定义分析器。
curl --request PUT \
--url http://localhost:9200/library-book-custom-synonym \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"lenient": true,
"synonyms": [
"fruit => banana, pineapple, date, fig, olive, citrus"
]
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'将数据复制到新创建的索引后,提交此 POST 请求以搜索关键字“banana”。 然后,您将看到结果包含与“fruit”关键字匹配的所有记录。
curl --request POST \
--url http://localhost:9200/library-book-custom-synonym/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "banana"
}
}
]
}
}
}'结果:

最后的想法
MySQL 和 Elasticsearch 都提供了强大的全文搜索能力。 如果您的系统使用 MySQL 作为数据存储,则可以通过为目标数据字段创建全文索引来快速启用全文搜索功能。 该解决方案适用于大多数用例,因为它为用户提供了一种在多个数据字段上搜索关键字和文本短语的快捷方式。 但是,在搜索结果微调和自定义方面,MySQL 中可用的选项有限。 因此,Elasticsearch 可能是高级功能和定制搜索行为的更好选择,因为该解决方案具有高度可配置性且更加灵活。
原文:https://blog.devgenius.io/how-to-enable-powerful-full-text-search-for-y…
- 127 次浏览
【内容处理】Aspire内容处理4.0
Aspire是一种专门为非结构化数据(如Office文档、pdf、web页面、图像、声音和视频)设计的内容摄取和处理技术。它提供了超过40个连接到各种企业内容源的连接器,包括文件共享、SharePoint、Documentum、OneDrive和Box。SalesForce.com, ServiceNow, Confluence, Yammer等。
Aspire提供了一种强大的解决方案,用于连接、清理、充实和向企业搜索、非结构化内容分析和自然语言处理应用程序发布内容。
作为我们支持搜索和非结构化内容分析的技术资产集合的一部分,Aspire可以独立使用,也可以作为应用智能平台AIP+的一部分使用。
今年秋天,我们的团队激动地宣布了Aspire最新的增强版本——Aspire 4.0——带有显著的创新进展。
Aspire 4.0的新增强
1. 现在可以使用Elasticsearch来保存Aspire爬行数据库。
Aspire将此数据库用于内部处理和作业队列。
已经使用Elasticsearch作为搜索引擎的客户端可以使用同一个服务器集群来保存Aspire的抓取数据库。这可以极大地减少使用Aspire和Elasticsearch的客户对基础设施、硬件和技术的需求。
在Aspire 4.0中,MongoDB和HBase仍然是可供选择的数据库提供者。
2. 新的端点用于接收已配置内容源的实时文档更新。
除了实时更新之外,这些新的端点还可以用于重新处理可能在下游系统中失败的文档更新,或者根据审计检查发现的文档更新。
3.后台处理和二进制存储层
——我们的智能文档x射线计划的一部分——允许在资源可用时对运行缓慢的后台任务进行排队和处理。
对于长时间运行的进程,如机器学习和光学字符识别(OCR),这是一个理想的框架。
目前,只允许文件存储作为存储层。其他存储层,例如Amazon S3、Azure Blobs、谷歌云平台存储,将在不久的将来提供。
4. 提供了许多bug修复以及稳定性和性能改进。

其他主要特点
Aspire 4.0还包括:
- 重构故障转移实现以获得更高的稳定性、准确性和可用性
- 内置在连接器框架中的节流功能支持内容爬行节流,以保护遗留系统不过载。以前,这是通过减少线程数来实现的。新的框架强制执行更精确的每秒文档控制。
- 增强的安全措施,允许编写业务规则脚本来处理特殊的安全需求,例如,根据用户的电子邮件地址自动添加组
- 有助于简化安装和许可证管理的改进
- 在我们不断增长的40多个连接器中增加了新的和改进的连接器,这些连接器支持从企业存储库获取非结构化内容
- 充分改进了Confluence连接器,具有完整的层次安全支持
- 谷歌云搜索的改进出版商
- 一个新的“测试爬行”特性可以帮助快速、轻松地测试新的内容源
- 用户界面改进和样式调整
本文:http://jiagoushi.pro/aspire-content-processing-40
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】
- 177 次浏览
【技术选型】Elasticsearch vs. Solr-选择您的开源搜索引擎
我们为什么在这里?我存在的目的是什么?我应该运动还是休息并节省能量?早起上班或晚起并整夜工作?我应该将炸薯条和番茄酱或蛋黄酱一起吃吗?
这些都是古老的问题,可能有也可能没有答案。其中一些是非常困难或非常主观的。但是,让我付出一些努力来尝试回答其中之一:我应该使用Elasticsearch还是Solr?
这是场景。您的组织正在寻求实现您的第一个搜索引擎,并切换到另一个搜索引擎-呼吁所有Google Search Appliance(GSA)用户寻找替代品! -或尝试通过开源来省钱。作为一个熟练而有能力的开发人员,您已经被要求解决一个难题。您的问题有许多业务需求,但从根本上讲,这是一个“大数据和搜索”问题。
您需要从多个数据源中提取大量内容,并从这些数据中获取见解,以帮助您的公司发展并实现其今年的目标。
一击致命
这里有很多危险。您不会错过任何一个镜头。您需要合适的搜索引擎来工作,您正在考虑开放源代码,并且有两个受欢迎的选择:Elasticsearch或Solr,根据DB-的说法,这两个都稳居开放源和商业搜索引擎的前两位。引擎。

您会选择哪个开源搜索引擎?
这不是抛硬币也不是容易的选择。两种搜索引擎都很棒,没有一个“正确”的选择。这完全取决于您的要求。
因此,第一步是了解您必须构建什么应用程序。然后,下一步是查看每个搜索引擎必须提供的功能。顺便说一句,如果您仍处于开源与商业解决方案的交汇处,请获取我们的免费电子书,以深入了解选择搜索引擎时要考虑的10个关键标准。
功能概要
几年前,我们写了一个关于Elasticsearch vs. Solr的高级概述博客,其中讨论了总体趋势和非技术见解。现在,随着Elasticsearch的发展壮大并成为开放源代码搜索引擎市场的主导者,让我们重新审视一下每个领域,看看它将带给我们什么。
年龄和成熟度
在这种情况下,可以说Solr的历史悠久,它由CNET Networks的Yonik Seely于2004年创建,后来在2006年将其贡献给Apache。它最终在2007年毕业于顶级项目。我们拥有的是Elasticsearch,该软件于2010年正式创建,尽管它实际上是由其创始人Shay Bannon于2001年以Compass的名字开始的。从那时起,Kibana,Logstash和Beats的创建者加入了Elasticsearch,创建了Elastic Stack产品系列,该产品系列已成为搜索和日志分析领域的强大参与者。话虽如此,Solr的优势在于可以较早地在市场上看到。
社区和开源
两者都有非常活跃的社区。如果您查看Github,您会发现它们是非常受欢迎的开源项目,发布了很多版本。

一个非常重要的细节是,尽管两者都是在Apache许可下发布的,并且都是开源的,但是它们的工作方式却有所不同。 Solr确实是开源的-任何人都可以提供帮助和贡献。使用Elasticsearch,尽管人们仍然可以提供他们的捐款,但是只有Elastic的员工(Elasticsearch和Elastic Stack背后的公司)可以接受这些捐款。
这是好事还是坏事?这取决于你怎么看了。这意味着,如果有您需要的功能,并且您以足够的质量向社区做出了贡献,那么它可以被Solr接受。借助Elasticsearch,由Elastic来决定是否接受捐助。因此,Solr上可能有更多功能选项。另一方面,对Elasticsearch的贡献要经过更高级别的质量检查,可能会提供更高的一致性和质量。
文献资料
Elasticsearch和Solr都有文档齐全的参考指南。 Elasticsearch在Github之上运行,而Solr使用Atlassian Confluence。您可以通过下面的链接找到它们。
Elasticsearch参考指南
Solr参考指南
核心技术
让我们多一点技术。 Elasticsearch和Solr是两个不同的搜索引擎。但在下面,它们都使用Lucene,这意味着两者都建立在“巨人的肩膀”上。
对于那些想知道为什么我将Lucene视为“巨人”的人来说,它是许多搜索引擎支持下的实际信息检索软件库。它非常快速,稳定,并且可能无法比这更好。 Lucene是由Hadoop的创建者之一Doug Cutting于1999年创建的。因此,Lucene是在搜索引擎中使用的理想选择。
Java API和REST
Elasticsearch具有更多的“ Web 2.0” REST API,但是Solr的SolrJ确实有更好的Java API-如果使用Microsoft技术,则为SolrNet。 Elasticsearch拥有Nest和Elasticsearch.Net。 Solr的REST API可能没有那么灵活,但是它可以很好地满足您的需求:建立索引和查询。 Elasticsearch会说JSON,因此,如果您周围都使用JSON,那么这是一个不错的选择。 Solr也支持JSON,但是它是在以后的阶段添加的,因为它最初是针对XML的。
内容处理
内容处理由于它们都公开了API,因此很容易从您的自定义应用程序或已经存在且可配置的应用程序中索引内容。例如,我们的Aspire内容处理框架能够连接到多个数据源并发布到Elasticsearch或Solr。
Solr还具有使用Apache Tika从二进制文件提取文本的功能。因此,您可以通过ExtractRequestHandler上传PDF,Solr将知道如何处理它。
另一方面,Elasticsearch与Logstash配合良好,后者可以处理任何来源的数据并为其编制索引。
可扩展性
缩放是一个关键的考虑因素。在这种情况下,当Solr仍然受限于Master-Slave时,Elasticsearch赢得了比赛。但是,SolrCloud最近才进入游戏。在Zookeeper的帮助下,现在可以以更加轻松快捷的方式扩展Solr集群-与具有Master-Slave的旧版本Solr相比,这是一个增强。仍然需要进行大量改进,但是就可以在Solr中摄取和搜索的数据集的大小而言,前途一片光明。
供应商支持
有几家公司不得不决定哪种产品最适合他们。例如,Cloudera选择了Solr作为他们的搜索引擎,以集成到开源CDH(包括Hadoop的Cloudera Distribution)中。另一方面,还有其他供应商选择Elasticsearch作为其解决方案的搜索引擎。 Search Technologies的我们将为两个搜索引擎提供咨询,部署和支持。
愿景与生态
Solr更加侧重于文本搜索。 Elasticsearch迅速树立了自己的利基市场,通过创建Elastic Stack(以前称为ELK Stack)来进行日志分析,Elastic Stack代表Elasticsearch,Logstash,Kibana和Beats。双方都有清晰的愿景,并且正在朝着自己的方向大步前进。
值得重申的一件事是,如何将两个搜索引擎用作许多领先搜索和大数据平台的基础。例如,Elasticsearch是Microsoft Azure搜索的一部分,而Solr已集成到Cloudera Search中。
性能
在性能方面,根据我从许多开发人员那里获得的经验,我们可以说这两个引擎都表现出色。因此,对于大多数用例而言,无论是内部还是外部搜索应用程序,只要开发人员正确设计和配置它们,性能都不会成为问题。
网络管理
Solr捆绑了Web管理,而Elasticsearch还有其他多个高级插件可用于安全性,警报和监视。此列表展示了Elastic的整个产品系列。
可视化
有许多方法可以在Elasticsearch和Solr中可视化数据-您可以构建自定义可视化仪表板,也可以使用搜索引擎的标准可视化功能(可能需要进行一些调整)。但是有一个区别值得一提。
Solr主要专注于文本搜索。它在这方面做得很好,成为了搜索应用程序的标准。但是,Elasticsearch朝着另一个方向发展,它超越了搜索范围,可以通过Elastic Stack解决日志分析和可视化问题。以下是您可以使用Kibana 5进行的一些可视化处理。

这并不意味着一个人胜于另一个。 它仅表示每个搜索引擎在不同的用例和需求中都有自己的优势,而您的选择将在很大程度上取决于您的组织要完成的工作。
长话短说,Elasticsearch和Solr都是出色的开源选择,将帮助您从数据中获取更多收益。 这完全取决于您的要求,预算,时间安排以及项目的复杂性。
有用的资源
- 这本电子书详细介绍了选择搜索引擎的关键条件。 它可以帮助指导您完成决策过程。
- 如果您正在寻找评估搜索引擎和实施方案的专家帮助,请与我们联系以详细了解我们的评估。
原文:https://www.searchtechnologies.com/blog/solr-vs-elasticsearch-top-open-source-search
本文:http://jiagoushi.pro/node/908
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 74 次浏览
【技术选型】Solr与Elasticsearch:性能差异及更多。如何决定哪一个最适合你
“Solr还是Elasticsearch ?至少这是我们从Sematext的咨询服务客户和潜在客户那里听到的普遍问题。Solr和Elasticsearch哪个更好?哪个更快?哪一种比较好?哪一个更容易管理?我们应该使用哪一个?从Solr迁移到Elasticsearch有什么好处吗?-还有很多。
这些都是伟大的问题,虽然不总是有明确的,普遍适用的答案。那么我们建议你使用哪一种呢?你最终如何选择?那么,让我们分享一下我们如何看待Solr和Elasticsearch的过去、现在和未来,让我们做一些比较,希望通过总结Solr和Elasticsearch之间最重要的差异,帮助您根据特定需求做出正确的选择。

如果您是Elasticsearch和Solr的新手,那么阅读我们的Elasticsearch教程和Solr教程可能会使您受益匪浅。
Elasticsearch和Solr是两个领先的、相互竞争的开源搜索引擎,任何曾经研究过(开源)搜索的人都知道它们。它们都是围绕核心的底层搜索库Lucene构建的,但是它们在可伸缩性、部署便利性、社区存在性等功能方面有所不同。对于静态数据,Solr有更多的优势,因为它有缓存,并且能够使用一个非反向读取器进行面形和排序——例如,电子商务。另一方面,Elasticsearch更适合——而且使用频率更高——用于timeseries数据用例,比如日志分析用例。
在选择Solr和Elasticsearch时,它们都有各自的优缺点,因此没有对错之分。虽然看起来Elasticsearch更受欢迎,但根据您的需要和期望,它们的适用性可能更好或更差。
我们希望这两个领先的开源搜索引擎的对比能够提供足够的信息和指导,帮助您为您的组织做出正确的选择:
比较Solr和Elasticsearch:主要区别是什么?
两个搜索引擎都在迅速发展,因此,无需多说,以下是关于Elasticsearch和Solr之间差异的最新信息:
1. Solr与Elasticsearch Engine的性能和可伸缩性基准测试
在性能方面,Solr和Elasticsearch大致相同。我们说“粗略”是因为没有人做过好的、全面的、公正的基准。对于95%的用例来说,这两个选择在性能方面都很好,剩下的5%需要用它们特定的数据和特定的访问模式来测试这两个解决方案。
也就是说,如果您的数据大多是静态的,并且需要数据分析的完全精度和非常快的性能,那么应该考虑Solr。
你也可以观看视频从我们的两个工程师——拉和拉法ł给并排Elasticsearch & Solr第2部分——性能和可伸缩性(或者你可以查看演示幻灯片)在柏林流行语。这次演讲——包括现场演示、视频演示和幻灯片——深入探讨了Elasticsearch和Solr如何伸缩和执行,这些见解在2015年仍然有效。
Radu和Rafal向与会者展示了如何针对两个常见用例调整Elasticsearch和Solr:日志和产品搜索。然后他们展示了调谐后得到的数字。还分享了一些最佳实践,用于扩展大规模的Elasticsearch和Solr集群;例如,如何将数据划分为考虑增长的碎片和索引/集合,何时使用路由,以及如何确保协调的节点不会失去响应。
通过这个视频中提到的测试,我们看到了在静态数据上Solr是非常棒的。
更重要的是,与Elasticsearch相比,Solr中的facet是精确的,不会失去精度,这在Elasticsearch中并不总是正确的。在某些边缘情况下,您可能会发现Elasticsearch聚合中的结果并不精确,这是因为碎片中的数据是如何放置的。
2. 年龄、成熟度和搜索趋势
索拉还没死。根据db引擎,Elasticsearch和Solr都是开发人员社区中最流行的搜索引擎。以下是支持这一点的最新使用统计数据:
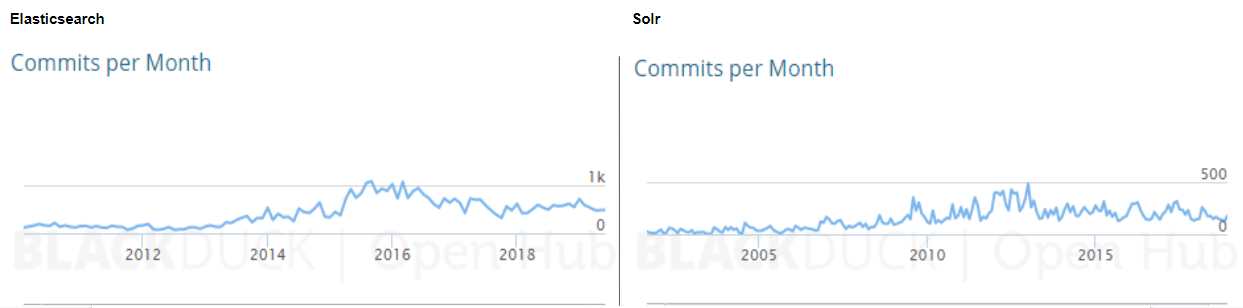
Apache Solr是一个成熟的项目,背后有一个活跃的大型开发和用户社区,以及Apache品牌。
Solr在2006年首次发布为开源版本,长期以来一直主导着搜索引擎领域,是任何需要搜索功能的人的首选引擎。它的成熟转化为丰富的功能,超越了普通的文本索引和搜索;如人脸识别、分组(即字段崩溃)、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
然后,在2010年左右,Elasticsearch作为另一种选择出现在市场上。那时,它还远没有Solr那么稳定,没有Solr那样的功能深度,没有认同度和品牌等等。但是它还有一些其他的优点:Elasticsearch还很年轻,建立在更现代的原则之上,针对更现代的用例,并使处理大索引和高查询率更容易。
此外,因为它是那么年轻,没有一个社区,它在跳跃前进的自由,不需要任何形式的共识或与他人合作(用户或开发人员),向后兼容,或者其他更成熟的软件通常必须处理。因此,它在Solr之前就公开了一些非常受欢迎的功能(例如,近实时搜索)。
从技术上讲,NRT搜索的能力实际上来自Lucene,它是Solr和Elasticsearch使用的底层搜索库。具有讽刺意味的是,由于Elasticsearch首先暴露了NRT搜索,人们将NRT搜索与Elasticsearch关联起来,尽管Solr和Lucene都是同一个Apache项目的一部分,因此,人们希望Solr首先具有如此高要求的功能。
Elasticsearch,更现代,呼吁几个团体的人和组织:
- 那些还没有自己的搜索引擎,也没有投入大量时间、金钱和精力去采用、整合搜索引擎的人。
- 那些需要处理大量数据、需要更容易地分片和复制数据(搜索索引)以及缩小或扩大搜索集群的公司
当然,让我们承认,也总会有一些人喜欢跳到新的闪亮的东西上。
快进到2020年。弹性搜索不再是新的,但它仍然闪亮。它弥补了与Solr的功能差距,在某些情况下甚至超过了它。它当然有更多的传闻。在这一点上,两个项目都非常成熟。两者都有很多特点。两者都是稳定的。我们不得不说,我们确实看到了更多的Elasticsearch集群问题,但我们认为这主要是因为以下几个原因:
- Elasticsearch在传统上更容易上手,这使得任何人都可以开箱即用,而不需要对其工作原理有太多了解。开始时这样做很好,但是当数据/集群增长时就会很危险。
- Elasticsearch使其易于伸缩,吸引了需要更多数据和更多节点的更大集群的用例。
- Elasticsearch更具动态性——当节点来来往往时,数据可以轻松地在集群中移动,这可能会影响集群的稳定性和性能。
- 虽然Solr传统上更适合于文本搜索,但Elasticsearch的目标是处理分析类型的查询,而这样的查询是有代价的。
尽管这听起来很可怕,但让我这样说吧——Elasticsearch暴露了大量的控制旋钮,人们可以玩来控制野兽。当然,关键是你必须知道所有可能的旋钮,知道它们的作用,并利用它们。例如,尽管你刚刚读过关于Elasticsearch的内容,但在我们的组织中,我们在几个不同的产品中都使用了它,尽管我们对Solr和Elasticsearch都很了解。
不是完全重叠的
Solr呢?Solr并没有完全静止不动。Elasticsearch的出现实际上对Solr及其开发人员和用户社区很有帮助。尽管Solr已经有14岁以上的历史,但它的开发速度比以往任何时候都要快。它现在也有一个友好的API。它还能够更容易地扩展和缩小集群,更动态地创建索引,动态地对它们进行分片,路由文档和查询,等等。注意:当人们提到SolrCloud时,他们指的是这种非常分布式的、类似于elasticsearch的Solr部署。
我们参加了在华盛顿特区举行的Lucene/Solr革命会议,并惊喜地看到:一个强大的社区,健康的项目,许多知名公司不仅使用Solr,而且通过采用、通过开发/工程时间对其进行投资,等等。如果你只关注新闻,你会被引导相信Solr已经死了,所有人都蜂拥到Elasticsearch。事实并非如此。Elasticsearch更新了,写起来自然更有趣。Solr是10多年前的新闻。当然,当Elasticsearch出现的时候,也有一些人从Solr转向Elasticsearch——一开始,根本没有Elasticsearch用户。
3.开源
Elasticsearch在开源日志管理用例中占主导地位——许多组织在Elasticsearch中索引他们的日志,使其可搜索。虽然Solr现在也可以用于此目的(请参阅Solr对日志进行索引和搜索,并对Solr进行日志调优),但它在此方面错过了人心。
Elasticsearch和Solr都是在Apache软件许可下发布的,然而,Solr是真正的开源——社区而不是代码。Solr代码并不总是那么漂亮,但是一旦该特性存在,它通常会一直存在,不会从代码库中删除。任何人都可以为Solr做出贡献,如果你对这个项目表现出兴趣和持续的支持,新的Solr开发人员(又名提交者)将根据成绩选出。此外,提交者来自不同的公司,并且没有单一的公司控制代码库。
另一方面,Elasticsearch在技术上是开源的,但在精神上却并非如此。任何人都可以在Github上看到源代码,任何人都可以改变它并提供贡献,但是只有Elastic的员工才能真正对Elasticsearch做出改变,所以你必须成为Elastic公司的一员才能成为提交者。
此外,Elasticsearch背后的公司Elastic混合了Apache 2.0软件许可下发布的代码,而code one只允许在商业许可下使用。毫无疑问,Elasticsearch用户社区对此并不满意。AWS在Apache许可下构建了自己的Elasticsearch发行版,并捆绑了许多特性,比如警报、安全等。您可以看到Sematext对AWS Elasticsearch开放发行版的回顾。
许多组织选择Solr而不是Elasticsearch作为他们的竞争对手(例如Cloudera, Hortonworks, MapR等),尽管他们也与Elasticsearch合作。
社区和开发人员
Solr和Elasticsearch都拥有活跃的用户和开发人员社区,并且正在迅速开发中。
如果您需要向Solr或Elasticsearch添加某些缺失的功能,那么使用Solr可能会更幸运。诚然,古老的Solr JIRA问题仍然存在,但至少它们仍然是开放的,而不是关闭的。在Solr世界中,社区有更多的发言权,尽管最终还是由Solr开发人员来接受和处理贡献。
这里有一些图表来说明我们的意思:
Elasticsearch与Solr贡献者(来源:Opensee)单击放大
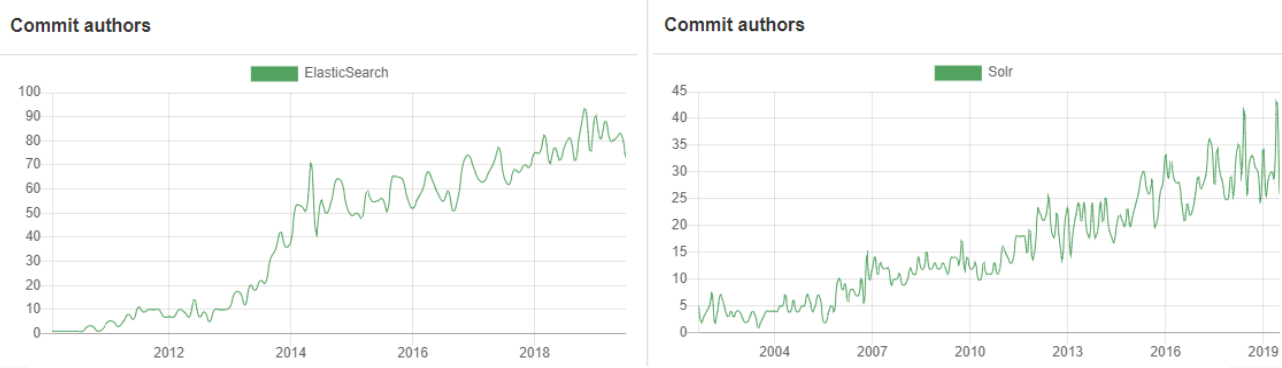
Elasticsearch vs. Solr Commits (source: Open Hub) click to enlarge
如您所见,Elasticsearch数量呈急剧上升趋势,现在Solr提交活动已超过两倍。这不是一种非常精确或绝对正确的比较开源项目的方法,但它给了我们一个想法。例如,Elasticsearch是在Github上开发的,这使得合并其他人的Pull请求变得非常容易,而Solr贡献者倾向于创建补丁,将它们上送到JIRA,在那里Solr提交者在应用之前对它们进行审查——这是一个不那么流畅的过程。此外,Elasticsearch存储库包含文档,而不仅仅是代码,而Solr在Wiki中保存文档。这使得对于Elasticsearch的提交和贡献者都有更高的数字。
4. 学习曲线和支持
Elasticsearch更容易启动—只需一个下载和一个命令就可以启动一切。Solr在传统上需要更多的工作和知识,但是Solr最近在消除这一点上取得了很大的进步,现在只需要改变它的声誉。
从操作上讲,Elasticsearch更简单一点,它只有一个过程。Solr在其elasticsearch式完全分布式部署模式(SolrCloud)中依赖于Apache ZooKeeper。ZooKeeper非常成熟,应用非常广泛,等等,但它还是另一个让人感动的部分。也就是说,如果您正在使用Hadoop、HBase、Spark、Kafka或其他一些较新的分布式软件,那么您可能已经在组织的某个地方运行了ZooKeeper。
虽然Elasticsearch有内置的类似于zookeperzen的组件,但ZooKeeper能更好地防止在Elasticsearch集群中有时会出现的可怕的裂脑问题。公平地说,Elasticsearch开发人员已经意识到这个问题,并在过去几年改进了Elasticsearch的这方面。
两者都有良好的商业支持(咨询、生产支持、培训、集成等)。两者都有很好的操作工具,不过Elasticsearch由于其API更易于使用,吸引了很多DevOps用户,因此围绕它形成了一个更活跃的工具生态系统。
5. 配置
让我们快速了解一下Solr和Elasticsearch是如何配置的。让我们从索引结构开始。
在Solr中,需要托管模式文件(以前的schema.xml)来定义索引结构、定义字段及其类型。当然,您可以将所有字段定义为动态字段并动态地创建它们,但是您仍然至少需要某种程度的索引配置。但是在大多数情况下,您将创建一个schema.xml来匹配您的数据结构。
Elasticsearch有点不同——它可以称为无模式搜索。你可能会问,这到底是什么意思。简而言之,这意味着可以启动Elasticsearch并开始向它发送文档,以便在不创建任何索引模式的情况下为它们建立索引,而Elasticsearch将尝试猜测字段类型。它并不总是100%准确的,至少与手动创建索引映射相比是这样,但它工作得相当好。
当然,您也可以定义索引结构(称为映射),然后使用这些映射创建索引,或者甚至为索引中存在的每种类型创建映射文件,并让Elasticsearch在创建新索引时使用它。听起来很酷,对吧?此外,当在索引的文档中发现一个以前未见的新字段时,Elasticsearch将尝试创建该字段并猜测其类型。可以想象,这种行为是可以关闭的。
让我们讨论一下Solr和Elasticsearch的实际配置。在Solr中,所有组件、搜索处理程序、索引特定内容(如合并因子或缓冲区、缓存等)的配置都在solrconfig.xml文件中定义。每次更改之后,都需要重新启动Solr节点或重新加载它。
在Elasticsearch中的所有配置都被写入到Elasticsearch.yml文件,它只是另一个配置文件。然而,这并不是存储和更改Elasticsearch设置的唯一方法。Elasticsearch公开的许多设置(虽然不是全部)可以在活动集群中更改——例如,您可以更改碎片和副本在集群中的放置方式,而Elasticsearch节点不需要重新启动。在Elasticsearch碎片放置控制中了解更多。
6. 节点的发现
Elasticsearch和Solr之间的另一个主要区别是节点发现和集群管理。发现的主要目的是监视节点的状态,选择主节点,在某些情况下还存储共享的配置文件。
当集群最初形成时,当一个新的节点加入或集群中的某个节点发生故障时,根据给定的条件,必须有一些东西来决定应该做什么。这是所谓的节点发现的职责之一。
Elasticsearch使用它自己的发现实现Zen,为了实现全容错(即不受网络分割的影响),建议至少有三个专用主节点。Solr使用Apache ZooKeeper进行发现和领袖选举。在这种情况下,建议使用外部ZooKeeper集成,对于容错和完全可用的SolrCloud集群,它至少需要三个ZooKeeper实例。
Apache Solr使用一种不同的方法来处理搜索集群。Solr使用Apache ZooKeeper集成——它基本上是一个或多个一起运行的ZooKeeper实例。ZooKeeper用于存储配置文件和监控——用于跟踪所有节点的状态和整个集群的状态。为了让新节点加入现有的集群,Solr需要知道要连接到哪个ZooKeeper集合。
原文:https://sematext.com/blog/solr-vs-elasticsearch-differences/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 255 次浏览
【技术选型】Solr与Elasticsearch:性能差异及更多。如何决定哪一个最适合你(续)
比较Solr和Elasticsearch:主要区别是什么?
两个搜索引擎都在迅速发展,因此,无需多说,以下是关于Elasticsearch和Solr之间差异的最新信息:
7. 切分位置
一般来说,就建立索引和碎片的位置而言,Elasticsearch是非常动态的。当某个动作发生时,它可以在集群周围移动碎片——例如,当一个新节点加入或从集群中删除一个节点时。我们可以通过使用感知标签来控制碎片应该放在哪里和不应该放在哪里,我们还可以告诉Elasticsearch使用API调用按需移动碎片。
Solr往往是更静态的开箱。默认情况下,当Solr节点加入或离开集群时,Solr自己不做任何事情。但是,在Solr 7及以后版本中,我们有了自动排序API:我们现在可以定义整个集群范围的规则和特定于集合的策略来控制分片的位置,我们可以自动添加副本,并告诉Solr根据已定义的规则在集群中使用节点。
8. API
如果您了解Apache Solr或Elasticsearch,您就会知道它们公开了HTTP API。
熟悉Solr的人都知道,为了从它获得搜索结果,需要查询一个已定义的请求处理程序,并传递定义查询条件的参数。根据您选择使用的查询解析器的不同,这些参数将有所不同,但方法仍然是相同的——将一个HTTP GET请求发送给Solr以获取搜索结果。
这样做的好处是您不必局限于单一的响应格式—您可以选择XML格式、JavaBin格式的JSON格式以及其他一些由响应编写器开发的格式来获得结果。因此,您可以选择对您和您的搜索应用程序最方便的格式。当然,Solr API不仅用于查询,因为您还可以获得关于不同搜索组件或控制Solr行为(例如集合创建)的一些统计信息。
那么Elasticsearch呢?Elasticsearch公开了一个可以使用HTTP GET、DELETE、POST和PUT方法访问的REST API。它的API不仅允许查询或删除文档,还允许创建索引、管理它们、控制分析并获得描述Elasticsearch当前状态和配置的所有指标。如果您需要了解有关Elasticsearch的任何信息,您可以通过REST API获得它(我们在Sematext云中也使用它来获取日志和事件)。
如果您习惯了Solr,那么有一件事在一开始可能会让您感到奇怪——Elasticsearch只能以JSON格式响应——例如,它没有XML响应。Elasticsearch和Solr之间的另一个大区别是查询。在Solr中,所有查询参数都是作为URL参数传递的,而在Elasticsearch中查询是JSON表示的。以JSON对象的形式结构化的查询给了一个很大的控制权,可以控制Elasticsearch应该如何理解查询,以及返回什么结果。
9. 缓存
另一个很大的不同是Elasticsearch和Solr的架构。为了不深入讨论这两个产品的缓存是如何工作的,我们只指出它们之间的主要区别。
让我们从什么是分段开始。段是Lucene索引的一部分,由各种文件构建,大部分是不可变的,并且包含数据。当你建立数据索引时,Lucene会生成段,并且可以在段合并的过程中将多个较小的、已经存在的段合并为较大的段。
Solr具有全局cashes,即一个片段的给定类型的单一缓存实例,用于其所有段。当单个段发生更改时,需要使整个缓存失效并刷新。这需要时间和硬件资源。
在Elasticsearch中,缓存是每段的,这意味着如果只有一个段更改,那么只有一小部分缓存的数据需要无效和刷新。我们将很快讨论这种方法的利弊。
10. 分析引擎
Solr非常大,有很多数据分析功能。我们可以从好的、旧的方面开始——第一个实现允许对数据进行切分以理解并了解它。然后是具有类似特性的JSON facet,但速度更快,占用内存更少,最后是基于流的表达式,称为流表达式,它可以组合来自多个来源的数据(如SQL、Solr、facet),并使用各种表达式(排序、提取、计算重要术语等)对其进行修饰。
Elasticsearch提供了一个强大的聚合引擎,它不仅可以像Solr遗留平面(facet)一样进行一级数据分析但是也可以嵌套数据的分析(例如,计算平均价格为每一个产品类别在每个商店部门),但支持分析聚合结果,导致功能像移动平均计算。最后,虽然还处于实验阶段,但Elasticsearch提供了对矩阵聚合的支持,它可以计算一组字段的统计信息。
11. 全文搜索功能
当然,Solr和Elasticsearch都利用了Lucene接近实时的功能。这使得查询可以在文档被索引后立即匹配文档。
在查看Solr代码库时,与全文搜索相关的特性和接近全文搜索的特性非常丰富。
我们的Solr培训班上就满是这种东西!从广泛的请求解析器选择开始,通过各种建议器实现,到使用拼写检查器纠正用户拼写错误的能力,以及高度可配置的广泛突出显示支持。
Elasticsearch有专门建议案API隐藏了实现细节的用户给我们一个更简单的方法实现建议的成本降低灵活性和当然强调不如强调可配置在Solr(虽然都是基于Lucene高亮显示功能)。
Solr仍然更加面向文本搜索。另一方面,Elasticsearch通常用于过滤和分组(分析查询工作负载),而不一定用于文本搜索。
Elasticsearch开发人员在Lucene和Elasticsearch级别上都投入了大量精力来提高查询效率(降低内存占用和CPU使用)。
12. DevOps友好
如果你问一个DevOps人员,他喜欢Elasticsearch的哪些方面,答案可能是它的API、可管理性和易于安装。当涉及到故障排除时,Elasticsearch很容易获得关于其状态的信息——从磁盘使用情况信息,通过内存和垃圾收集工作统计数据,到Elasticsearch内部的缓存、缓冲区和线程池使用情况。
Solr还没有到那一步——您可以通过JMX MBean和新的Solr Metrics API从它那里获得一些信息,但这意味着您必须查看一些地方,并不是所有的东西都在那里,尽管它正在到达那里。
13. 非平面数据处理
你有非平面数据,在一个嵌套对象中有很多嵌套对象在另一个嵌套对象中你不想让数据变得扁平,而只是索引你漂亮的MongoDB JSON对象并准备好全文搜索?Elasticsearch将是实现这一目标的完美工具,它支持对象、嵌套文档和父子关系。Solr可能不是最适合这里的,但请记住,在索引XML文档和JSON时,它还支持父-子文档和嵌套文档。此外,还有一件非常重要的事情—Solr支持不同集合内部和跨不同集合的查询时间连接,因此您不受索引时间父-子处理的限制。
14. 查询DSL
我们大声说,Elasticsearch的查询语言真的很棒。如果你喜欢JSON,那就是。它允许您使用JSON构造查询,因此它将具有良好的结构并使您能够控制整个逻辑。您可以混合不同类型的查询来编写非常复杂的匹配逻辑。当然,全文搜索不是一切,你可以包括聚合,结果崩溃等等-基本上你需要从你的数据的一切都可以用查询语言表达。
在Solr 7之前,Solr仍然在使用URI搜索,至少在其最广泛使用的API中是这样。所有参数都进入了URI,这可能导致长且复杂的查询。从Solr 7开始,JSON API部分得到了扩展,现在可以运行结构化查询来更好地表达您的需求。
15. 索引/收集领导人控制
当谈到集群周围的切分位置时,Elasticsearch本质上是动态的,但对于哪些切分将充当主切分,哪些切分将作为副本,我们并没有太多的控制权。这是我们无法控制的。
与Elasticsearch相比,在Solr中,你有这种控制,这是一件很好的事情,当你考虑到在索引期间,领导者做了更多的工作,因为他们把数据转发给所有的副本。通过对leader碎片位置的精确信息,我们能够重新平衡leader碎片的位置,或者明确地指出它们应该放在哪里,这样我们就能够在整个集群中平衡负载。
16. 机器学习
Solr中的机器学习以一种contrib模块的形式免费提供,并建立在流聚合框架之上。通过使用contrib模块中的其他库,您可以在Solr之上使用机器学习的排序模型和特征提取,而基于流聚合的机器学习主要关注使用逻辑回归的文本分类。
另一方面,我们有Elasticsearch和它的X-Pack商业产品,附带一个Kibana插件,支持机器学习算法,专注于异常检测和时间序列数据中的离群点检测。这是一套捆绑了专业服务的不错的工具,但价格相当昂贵。因此,我们对X-Pack进行了拆解,并列出了可用的X-Pack替代品:来自开源工具、商业替代品或云服务。
17. 生态系统
说到生态系统,Solr附带的工具很好,但它们让人感觉很谦虚。我们有一个叫做Banana的Kibana端口,它走自己的路,还有像Apache Zeppelin integration这样的工具,它允许在Apache Solr上运行SQL。当然,还有其他工具可以从Solr读取数据、将数据发送到Solr或使用Solr作为数据源—例如Flume。大多数工具都是由各种爱好者开发和支持的。
相比之下,如果你看看Elasticsearch周围的生态系统,它是非常现代和有序的。你有一个新版本的Kibana,每个月都有新功能出现。如果你不喜欢Kibana,你有Grafana,它现在是一个提供多种功能的产品,你有一长串的数据传送者和工具可以使用Elasticsearch作为数据源。最后,这些产品不仅得到了爱好者的支持,还得到了大型商业实体的支持。
18. 指标
如果你喜欢监控和测量,那么有了Elasticsearch,你将会感觉非常棒。除夕夜,它比你能挤进时代广场的人还要多!Solr提供了关键指标,但远不及Elasticsearch那么多。无论如何,如果您想处理指标和其他操作数据,那么拥有像Sematext Cloud这样全面的监控和集中的日志记录工具是非常必要的,尤其是当它们像这两者一样无缝地协同工作时。
综上所述,以下是Solr和Elasticsearch之间的主要区别:
Top Solr和Elasticsearch的区别
Feature |
Solr/SolrCloud |
Elasticsearch |
|---|---|---|
|
社区和开发人员 |
Apache软件基金会和社区支持 | 单一商业实体及其雇员 |
| 节点的发现 | Apache Zookeeper,成熟且经过了大量项目的实战测试 | Zen内置在Elasticsearch中,它要求专用的主节点用于验证脑裂 |
| 切分位置 | 本质上是静态的,需要手工迁移碎片,从Solr 7开始——自动缩放API允许一些动态操作 | 根据集群状态,可以根据需要移动动态的碎片 |
| 缓存 | 全局的,随着每一段的改变而失效 | 每段,更好地动态更改数据 |
| 分析引擎 | 平面和强大的流聚合 | 复杂和高度灵活的聚合 |
| 优化查询执行 | 目前没有 | 根据上下文更快的范围查询 |
| 搜索速度 | 最适合静态数据,因为有缓存和非反向读取器 | 非常适合快速更改数据,因为每段缓存 |
| 分析引擎的性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据位置 |
| 全文检索功能 | 基于Lucene的语言分析,多种暗示,拼写检查,丰富的高亮显示支持 | 语言分析基于Lucene,单一建议API实现,突出 rescoring |
| DevOps 友好性 | 还没有完全实现,但即将实现 | 很好的API |
| 非扁平数据处理 | 嵌套文档和父-子支持 | 自然支持嵌套和对象类型,允许无限嵌套和父-子支持 |
| Query DSL | JSON(有限)、XML(有限)或URL参数 | JSON |
| 索引/收集领导人控制 | Leader放置控制和Leader再平衡的可能性来平衡节点上的负载 | 不可能的 |
| 机器学习 | 内置-在流媒体聚合的基础上,专注于逻辑回归和学习排名contrib模块 | 商业特征,专注于异常和异常值和时间序列数据 |
| 生态系统 | Modest – Banana, Zeppelin 与社区支持 | Rich – Kibana, Grafana, 拥有庞大的实体支持和庞大的用户基础 |
Lucene呢?
由于Solr和Elasticsearch都基于Apache Lucene,您可能想知道是否使用纯Lucene会更好。可以这样想:Lucene是Linux内核,而Solr或Elasticsearch是Ubuntu。
您可以直接使用内核并在其上构建自己的应用程序。如果您对内核有很好的理解,并且用例比较狭窄,那么这将是您的选择。同样,Lucene是一个用Java编写的搜索引擎库。你可以在它上面写你自己的搜索引擎(用Java),你可以完全控制Lucene做什么。
就像内核的例子一样,如果你不熟悉Lucene,可能会花费很长时间和大量的试验和错误。但是假设你知道Lucene。如果您有广泛的用例,比如需要使您的搜索引擎分布式,那么您可能最终会得到一个解决方案,它可以完成Solr和Elasticsearch已经完成的工作。
Solr和Elasticsearch都提供了最有用的功能——尽管不是全部!- Lucene功能通过一个REST API。就像Ubuntu对Linux所做的一样,Solr和Elasticsearch在上面添加了它们自己的功能。比如分布式模型、安全性、管理api、复杂分析(方面、流聚合)等等。大多数用例都需要这种功能。
Solr和Elasticsearch。给我总结一下:哪个是最好的?
这显然不是Solr和Elasticsearch不同之处的详尽列表,当然也不是要告诉您选择哪一个。我们可以继续写几篇博客文章,然后把它写成一本书,但希望下面的列表能让你知道从其中一篇和另一篇中可以期待什么,这样你就可以根据你的需要来看待它。
总之,以下是我们认为对那些不得不做出选择的人来说影响最大的几点:
- 如果您已经在Solr上投入了大量时间,请坚持使用它,除非有它不能很好地处理的特定用例。如果您认为是这样的话,请与熟悉Solr和Elasticsearch项目的人交谈,以节省您的时间、猜测、研究和避免错误。
- 如果您是真正开源的忠实信徒,那么Solr比Elasticsearch更接近于此,由一家公司控制Elasticsearch可能会让您感到厌恶。
- 如果您需要一个除了文本搜索之外还能处理分析查询的数据存储,那么Elasticsearch是当前更好的选择,特别是考虑到更大的生态系统的可用性。
原文:https://sematext.com/blog/solr-vs-elasticsearch-differences
本文:http://jiagoushi.pro/node/1179
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 522 次浏览
【搜索引擎】Apache Solr 神经搜索
Sease[1] 与 Alessandro Benedetti(Apache Lucene/Solr PMC 成员和提交者)和 Elia Porciani(Sease 研发软件工程师)共同为开源社区贡献了 Apache Solr 中神经搜索的第一个里程碑。
它依赖于 Apache Lucene 实现 [2] 进行 K-最近邻搜索。
特别感谢 Christine Poerschke、Cassandra Targett、Michael Gibney 和所有其他在贡献的最后阶段提供了很大帮助的审稿人。即使是一条评论也受到了高度赞赏,如果我们取得进展,总是要感谢社区。
让我们从简短的介绍开始,介绍神经方法如何改进搜索。
我们可以将搜索概括为四个主要领域:
- 生成指定信息需求的查询表示
- 生成捕获包含的信息的文档的表示
- 匹配来自信息语料库的查询和文档表示
- 为每个匹配的文档分配一个分数,以便根据结果中的相关性建立一个有意义的文档排名
神经搜索是神经信息检索[3] 学术领域的行业衍生产品,它专注于使用基于神经网络的技术改进这些领域中的任何一个。
人工智能、深度学习和向量表示
我们越来越频繁地听到人工智能(从现在开始是人工智能)如何渗透到我们生活的许多方面。
当我们谈论人工智能时,我们指的是一组使机器能够学习和显示与人类相似的智能的技术。
随着最近计算机能力的强劲和稳定发展,人工智能已经复苏,现在它被用于许多领域,包括软件工程和信息检索(管理搜索引擎和类似系统的科学)。
特别是,深度学习 [4] 的出现引入了使用深度神经网络来解决对经典算法非常具有挑战性的复杂问题。
就这篇博文而言,只要知道深度学习可用于在信息语料库中生成查询和文档的向量表示就足够了。
密集向量表示
可以认为传统的倒排索引将文本建模为“稀疏”向量,其中语料库中的每个词项对应一个向量维度。在这样的模型中(另见词袋方法),维数对应于术语字典基数,并且任何给定文档的向量大部分包含零(因此它被称为稀疏,因为只有少数术语存在于整个字典中将出现在任何给定的文档中)。
密集向量表示与基于术语的稀疏向量表示形成对比,因为它将近似语义意义提取为固定(和有限)数量的维度。
这种方法的维数通常远低于稀疏情况,并且任何给定文档的向量都是密集的,因为它的大部分维数都由非零值填充。
与稀疏方法(标记器用于直接从文本输入生成稀疏向量)相比,生成向量的任务必须在 Apache Solr 外部的应用程序逻辑中处理。
BERT[5] 等各种深度学习模型能够将文本信息编码为密集向量,用于密集检索策略。
有关更多信息,您可以参考我们的这篇博文。
近似最近邻
给定一个对信息需求进行建模的密集向量 v,提供密集向量检索的最简单方法是计算 v 与代表信息语料库中文档的每个向量 d 之间的距离(欧几里得、点积等)。
这种方法非常昂贵,因此目前正在积极研究许多近似策略。
近似最近邻搜索算法返回结果,其与查询向量的距离最多为从查询向量到其最近向量的距离的 c 倍。
这种方法的好处是,在大多数情况下,近似最近邻几乎与精确最近邻一样好。
特别是,如果距离测量准确地捕捉到用户质量的概念,那么距离的微小差异应该无关紧要[6]
分层导航小图
在 Apache Lucene 中实现并由 Apache Solr 使用的策略基于 Navigable Small-world 图。
它为高维向量提供了一种有效的近似最近邻搜索[7][8][9][10]。
Hierarchical Navigable Small World Graph (HNSW) 是一种基于邻近邻域图概念的方法:
与信息语料库相关联的向量空间中的每个向量都唯一地与一个
vertex 

顶点基于它们的接近度通过边缘连接,更近的(根据距离函数)连接。
构建图受超参数的影响,这些超参数调节每层要构建多少个连接以及要构建多少层。
在查询时,邻居结构被导航以找到离目标最近的向量,从种子节点开始,随着我们越来越接近目标而迭代。
我发现这个博客对于深入研究该主题非常有用。
Apache Lucene 实现
首先要注意的是当前的 Lucene 实现不是分层的。
所以图中只有一层,请参阅原始 Jira 问题中的最新评论,跟踪开发进度[11]。
主要原因是为了在 Apache Lucene 生态系统中为这种简化的实现找到更容易的设计、开发和集成过程。
一致认为,引入分层分层结构将在低维向量管理和查询时间(减少候选节点遍历)方面带来好处。
该实施正在进行中[12]。
那么,与 Navigable Small World Graph 和 K-Nearest Neighbors 功能相关的 Apache Lucene 组件有哪些?
让我们探索代码:
注:如果您对 Lucene 内部结构和编解码器不感兴趣,可以跳过这一段
org.apache.lucene.document.KnnVectorField 是入口点:
它在索引时需要向量维度和相似度函数(构建 NSW 图时使用的向量距离函数)。
这些是通过 #setVectorDimensionsAndSimilarityFunction 方法在 org.apache.lucene.document.FieldType 中设置的。
更新文档字段架构 org.apache.lucene.index.IndexingChain#updateDocFieldSchema 时,信息从 FieldType 中提取并保存在 org.apache.lucene.index.IndexingChain.FieldSchema 中。
并且从 FieldSchema KnnVectorField 配置最终到达 org.apache.lucene.index.IndexingChain#initializeFieldInfo 中的 org.apache.lucene.index.FieldInfo。
现在,Lucene 编解码器具有构建 NSW 图形所需的所有特定于字段的配置。
让我们看看如何:
首先,从 org.apache.lucene.codecs.lucene90.Lucene90Codec#Lucene90Codec 你可以看到 KNN 向量的默认格式是 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsFormat。
关联的索引编写器是 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsWriter。
该组件可以访问之前在将字段写入 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsWriter#writeField 中的索引时初始化的 FieldInfo。
在编写 KnnVectorField 时,涉及到 org.apache.lucene.util.hnsw.HnswGraphBuilder,最后是
org.apache.lucene.util.hnsw.HnswGraph 已构建。
Apache Solr 实现
可从 Apache Solr 9.0 获得
预计 2022 年第一季度
这第一个贡献允许索引单值密集向量场并使用近似距离函数搜索 K-最近邻。
当前特点:
- DenseVectorField 类型
- Knn 查询解析器
密集向量场(DenseVectorField)
密集向量字段提供了索引和搜索浮点元素的密集向量的可能性。
例如
[1.0, 2.5, 3.7, 4.1]
以下是 DenseVectorField 应如何在模式中配置:
<fieldType name="knn_vector" class="solr.DenseVectorField"
vectorDimension="4" similarityFunction="cosine"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>-----------------------------------------------------------------------------------------------------
|Parameter Name | Required | Default | Description |Accepted values|
-----------------------------------------------------------------------------------------------------
|vectorDimension | True | |The dimension of the dense
vector to pass in. |Integer < = 1024|
—————————————————————————————————————————
|similarityFunction | False | euclidean |Vector similarity function;
used in search to return top K most similar vectors to a target vector.
| euclidean, dot_product or cosine.
———————————————————————————————————————
- 欧几里得:欧几里得距离
- dot_product:点积。注意:这种相似性旨在作为执行余弦相似性的优化方式。为了使用它,所有向量必须是单位长度的,包括文档向量和查询向量。对非单位长度的向量使用点积可能会导致错误或搜索结果不佳。
- 余弦:余弦相似度。注意:执行余弦相似度的首选方法是将所有向量归一化为单位长度,而不是使用 DOT_PRODUCT。只有在需要保留原始向量且无法提前对其进行归一化时,才应使用此函数。
DenseVectorField 支持属性:索引、存储。
注:目前不支持多值
自定义索引编解码器
要使用以下自定义编解码器格式的高级参数和 HNSW 算法的超参数,请确保在 solrconfig.xml 中设置此配置:
<codecFactory class="solr.SchemaCodecFactory"/> ... 以下是如何使用高级编解码器超参数配置 DenseVectorField: <fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="4"similarityFunction="cosine" codecFormat="Lucene90HnswVectorsFormat" hnswMaxConnections="10" hnswBeamWidth="40"/> <field name="vector" type="knn_vector" indexed="true" stored="true"/>
| Parameter Name | Required | Default | Description | Accepted values |
codecFormat |
False |
|
Specifies the knn codec implementation to use |
|
|
False | 16 |
Lucene90HnswVectorsFormat only:Controls how many of the nearest neighbor candidates are connected to the new node. It has the same meaning as M from the paper[8]. |
Integer |
hnswBeamWidth |
False | 100 |
Lucene90HnswVectorsFormat only: It is the number of nearest neighbor candidates to track while searching the graph for each newly inserted node.It has the same meaning as efConstruction from the paper[8]. |
Integer |
请注意,codecFormat 接受的值可能会在未来版本中更改。
注意 Lucene 索引向后兼容仅支持默认编解码器。如果您选择在架构中自定义 codecFormat,升级到 Solr 的未来版本可能需要您切换回默认编解码器并优化索引以在升级之前将其重写为默认编解码器,或者重新构建整个索引升级后从头开始。
对于 HNSW 实现的超参数,详见[8]。
如何索引向量
下面是 DenseVectorField 应该如何被索引:
JSON
[{ "id": "1",
"vector": [1.0, 2.5, 3.7, 4.1]
},
{ "id": "2",
"vector": [1.5, 5.5, 6.7, 65.1]
}
]XML
<field name="id">1 <field name="vector">1.0 <field name="vector">2.5 <field name="vector">3.7 <field name="vector">4.1 <field name="id">2 <field name="vector">1.5 <field name="vector">5.5 <field name="vector">6.7 <field name="vector">65.1
Java – SolrJ
final SolrClient client = getSolrClient();
final SolrInputDocument d1 = new SolrInputDocument();
d1.setField("id", "1");
d1.setField("vector", Arrays.asList(1.0f, 2.5f, 3.7f, 4.1f));
final SolrInputDocument d2 = new SolrInputDocument();
d2.setField("id", "2");
d2.setField("vector", Arrays.asList(1.5f, 5.5f, 6.7f, 65.1f));
client.add(Arrays.asList(d1, d2));knn 查询解析器
knn K-Nearest Neighbors 查询解析器允许根据给定字段中的索引密集向量查找与目标向量最近的 k 文档。
它采用以下参数:
| Parameter Name | Required | Default | Description |
f |
True | The DenseVectorField to search in. | |
topK |
False | 10 | How many k-nearest results to return. |
以下是运行 KNN 搜索的方法:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
检索到的搜索结果是输入 [1.0, 2.0, 3.0, 4.0] 中与向量最近的 K-nearest,由在索引时配置的similarityFunction 排序。
与过滤查询一起使用
knn 查询解析器可用于过滤查询:
&q=id:(1 2 3)&fq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
knn 查询解析器可以与过滤查询一起使用:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fq=id:(1 2 3)
重要:
在这些场景中使用 knn 时,请确保您清楚地了解过滤器查询在 Apache Solr 中的工作方式:
由主查询 q 产生的文档 ID 排名列表与从每个过滤器查询派生的文档 ID 集合相交 fq.egRanked List from q=[ID1, ID4, ID2, ID10] Set from fq={ID3, ID2 , ID9, ID4} = [ID4,ID2]
用作重新排序查询
knn 查询解析器可用于重新排列第一遍查询结果:
&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=4 reRankWeight=1}
&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
重要:
在重新排序中使用 knn 时,请注意 topK 参数。
仅当来自第一遍的文档 d 在要搜索的目标向量的 K 最近邻(在整个索引中)内时,才计算第二遍分数(从 knn 派生)。
这意味着无论如何都会在整个索引上执行第二遍 knn,这是当前的限制。
最终排序的结果列表将第一次通过分数(主查询 q)加上第二次通过分数(到要搜索的目标向量的近似相似度函数距离)乘以乘法因子(reRankWeight)。
因此,如果文档 d 不存在于 knn 结果中,即使与目标查询向量的距离向量计算不为零,您对原始分数的贡献也为零。
有关使用 ReRank 查询解析器的详细信息,请参阅 Apache Solr Wiki[13] 部分。
未来的作品
这只是 Apache Solr 神经功能的开始,更多功能即将推出!
我希望您喜欢概述并继续关注更新!
参考
- [6] Andoni, A.; Indyk, P. (2006-10-01). “Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions”. 2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS’06). pp. 459–468. CiteSeerX 10.1.1.142.3471. doi:10.1109/FOCS.2006.49. ISBN 978-0-7695-2720-8.
- [7] Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, Vladimir Krylov,Approximate nearest neighbor algorithm based on navigable small world graphs,Information Systems,Volume 45,2014,Pages 61-68,ISSN 0306-4379,https://doi.org/10.1016/j.is.2013.10.006.
- [8] Malkov, Yury; Yashunin, Dmitry (2016). “Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs”. arXiv:1603.09320 [cs.DS].
- 90 次浏览
【搜索引擎】Solr:提高批量索引的性能
几个月前,我致力于提高“完整”索引器的性能。 我觉得这种改进足以分享这个故事。 完整索引器是 Box 从头开始创建搜索索引的过程,从 hbase 表中读取我们所有的文档并将文档插入到 Solr 索引中。
我们根据 id 对索引文档进行分片,同样的文档 id 也被用作 hbase 表中的 key。 我们的 Solr 分片公式是 id % number_of_shards。 mapreduce 作业扫描 hbase 表,通过上述分片公式计算每个文件的目标分片,并将每个文档插入相应的 solr 分片中。 这是在过去几年中为我们提供良好服务的初始模型的示意图:
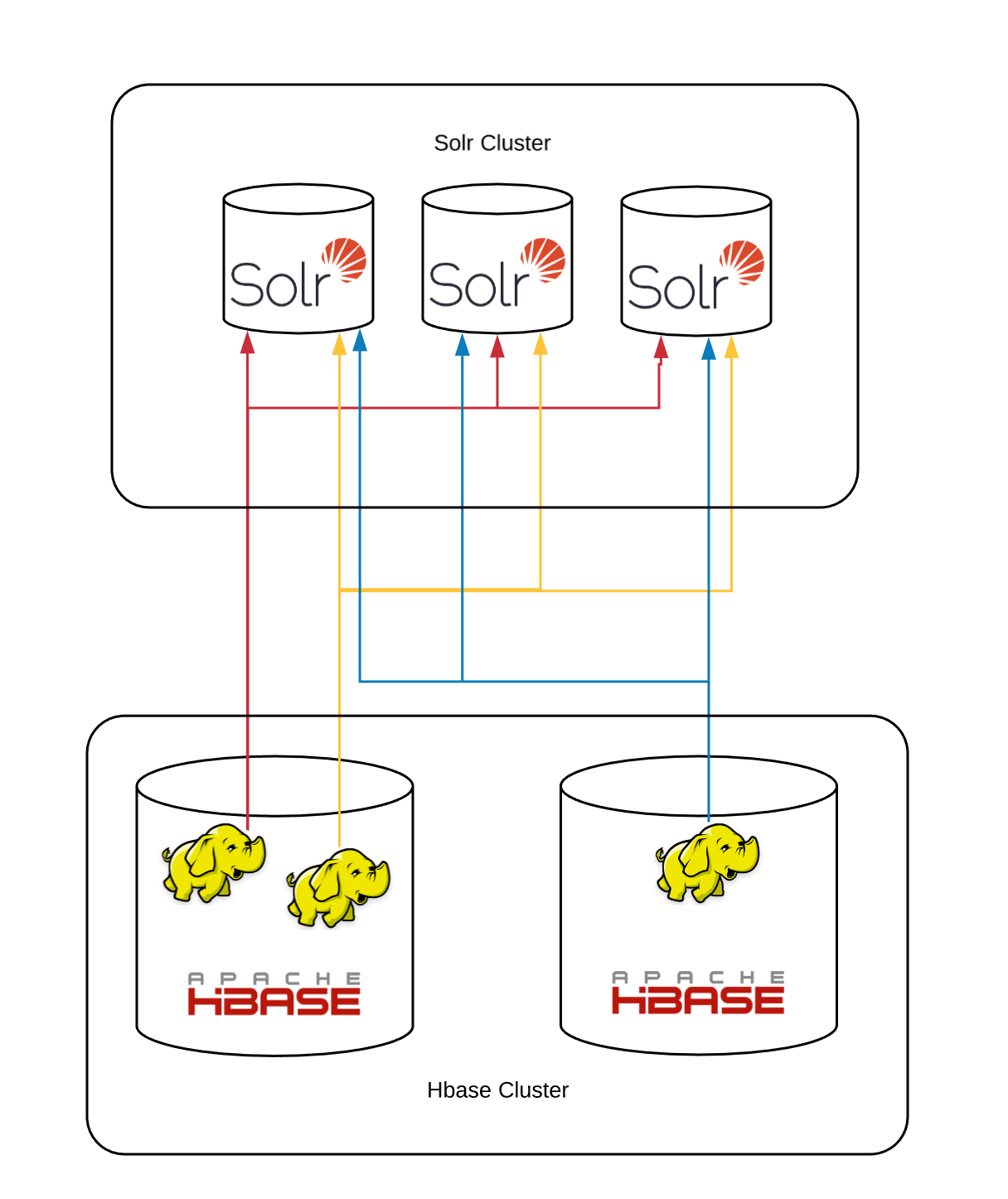
所有 mapreduce 作业都与所有分片对话,因为每个分片的数据分布在所有 hbase 区域中。 该作业是仅地图作业,没有减少作业。 hbase 表扫描以及更新请求都在映射器中完成。
在每个映射器中,都有一个批处理作业的共享队列; 和一个 http 客户端共享池,它们从队列中获取作业并将其发送到相应的分片。 每个单独的文档都不会直接插入到队列中。 相反,需要在同一个分片上索引的文档在插入队列之前会一起批处理(当前默认值为 10)。 队列是有界的,当它已满时,文档生产者必须等待才能扫描更多行。

如果所有 Solr 分片继续以一致且一致的速度*摄取文档,则该系统以稳定的速度运行。 但是,Solr 时不时地会将内存中的结构刷新到文件中,这种 I/O 可能会导致一些索引操作暂时变慢。 在这个阶段,集群不提供查询服务,所以这不是问题。
如果分片的总数为 n,并且给定分片的间歇性慢索引速率的概率为 p,则:
- P(至少 n 个分片中的一个很慢)= P(恰好一个分片很慢)+ P(正好两个分片很慢)+ ... + P(所有 n 个分片都很慢)
要么
- P(至少一个分片很慢)= 1 - P(没有一个分片很慢)
- P(n 个分片中至少有 1 个很慢)= 1 — (1-p)ⁿ
如果我们假设对于给定的时间间隔 p = 0.01,这是 P 的图表(集群中至少有一个分片很慢):
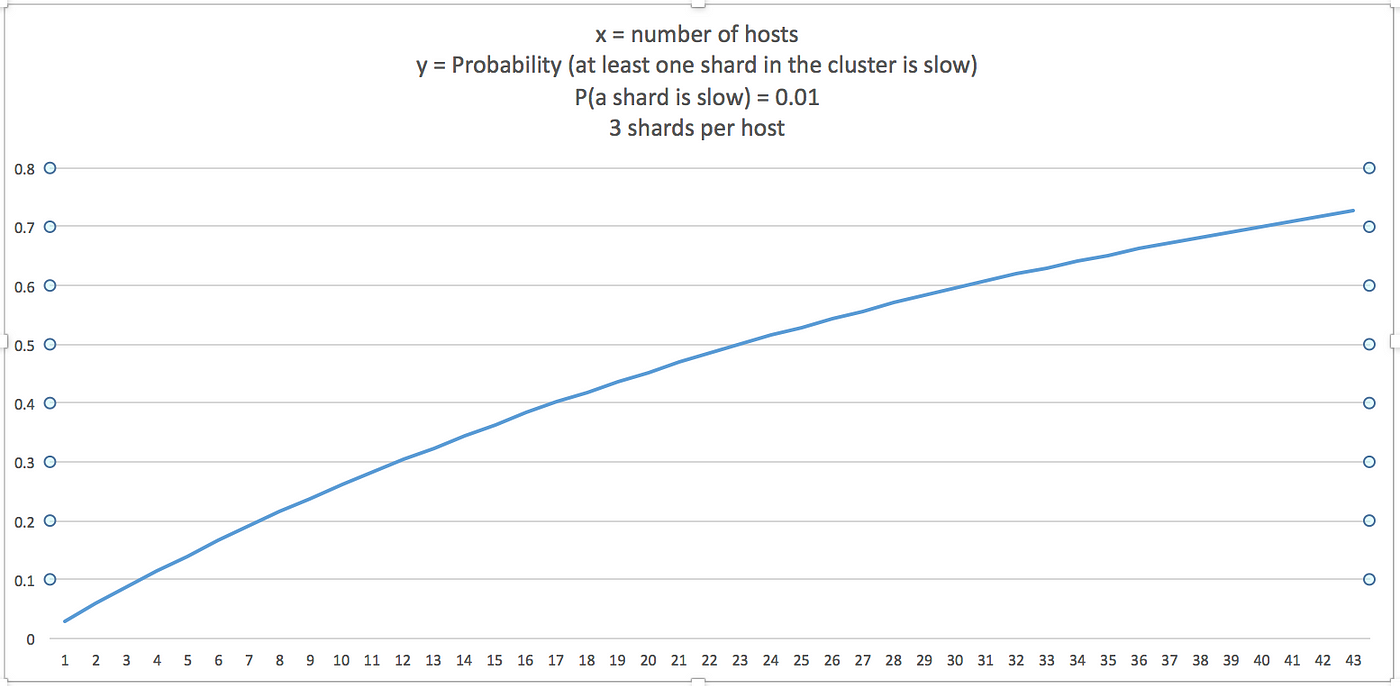
这意味着要在更多分片上获得良好的索引性能,我们需要隔离一个分片的瓶颈,以免影响其他分片的索引。我的第一个尝试是增加工作人员池,这样如果一些工作人员由于速度慢而被卡在一个分片上,那么其余工作人员可以继续处理队列。这有所帮助,但仍然有可能让所有或许多工人在选择工作时陷入困境,这些工作会间歇性地进入缓慢的分片。在这种情况下,文档生产者线程将不会创建新文档,因为队列已满,并且所有工作人员都无法继续进行,因为他们正在等待缓慢的工作完成。在我的第二次尝试中,我为每个分片(在每个映射器上)创建了单独的队列和工作人员,这确保了如果一些分片很慢,那么其余分片不必闲置,因为他们的工作人员将继续阅读队列中的作业并将它们发送以进行索引。最终,正在呼吸的碎片将再次开始更快地索引,而其他一些碎片可能会开始缓慢响应等等。这极大地改善了系统的总流量。
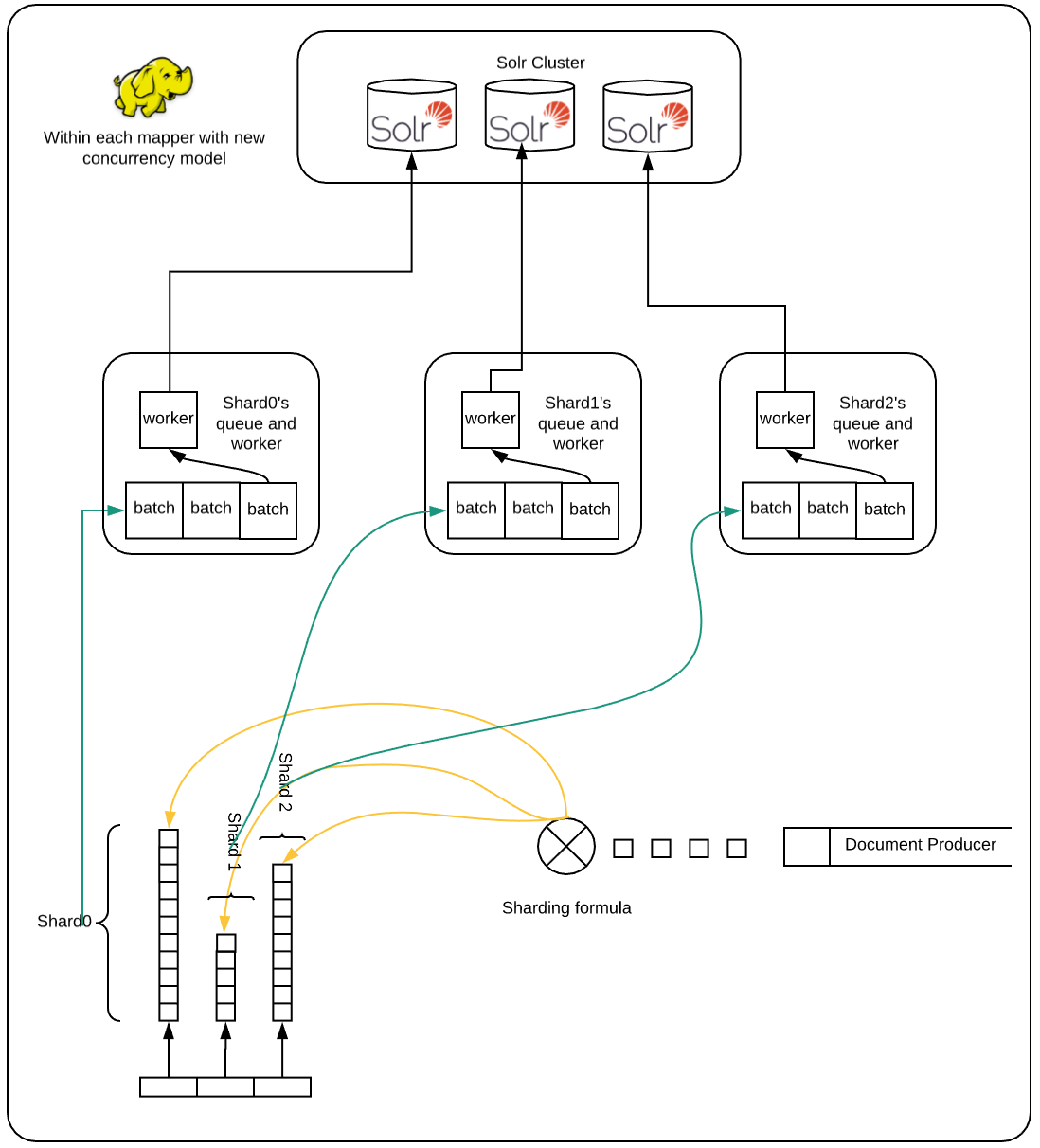
这是具有较旧并发模型的 39 台主机的图表。 该作业在运行三天后崩溃。 即使在崩溃之前,它的表现也不一致。 此外,分片的平均索引速度低于我们过去看到的总分片较少的情况。
这是在具有新并发模型的同一组主机上执行的相同工作,它的性能要好得多且更一致:
y 轴上的单位是每秒读取次数。它增加了一倍多。 Box 拥有近 500 亿份文档**,通过改进,完整索引器能够在不到两天的时间内完成此索引阶段。
但是,这种新模型也有其缺点,例如:
- 此模型在针对同一分片的工作人员之间没有通信。因此,当一个分片响应缓慢时,来自其他并行运行的映射器的工作人员继续向它发送请求(并且失败,然后重试),即使一个或多个工作人员(在其他映射器中)已经确定该分片很慢。
- 由于每个映射器为每个分片分配一个固定长度的队列,因此设计不会扩展到超过一定数量的分片;因为队列的内存需求将超过映射器的堆大小。
更具可扩展性的模型将涉及映射器和 Solr 分片之间的队列。并且应该有特定于分片的客户端,它们可能运行在分片的主机上,它将从队列中读取分片的文档并发送到 Solr 进行索引(通过 REST API 或 SolrJ)。
* Hbase 表扫描和文档生成器不是我们的瓶颈,因此我在这里只提到 Solr 索引性能。
原文:https://medium.com/box-tech-blog/solr-improving-performance-for-batch-i…
- 70 次浏览
【搜索引擎】如何选择企业搜索引擎
在本博客系列的第一部分中,我们详细展示了智能企业搜索的旅程:起点、要访问的地标和预想的目的地。这篇后续的博客文章是关于导航到我们之前定义的一个里程碑:选择企业搜索引擎。
人们很容易认为搜索引擎的选择是一项技术任务:哪个引擎比其他引擎更好?然而,如果单纯考虑搜索引擎的功能,您可能会发现不同搜索引擎之间的差异是微乎其微的。当比较智能搜索引擎增加的人工智能认知功能时,这种差异就更明显了。尽管如此,在我们的旅程中还是有很多变量需要考虑。
我将描述为我们的客户在选择他们的新搜索引擎时工作良好的步骤。
选择企业搜索引擎

5步选择企业搜索引擎
步骤1:确定潜在的搜索引擎
让我们先列出所有可能适合您需要的搜索引擎。
列表的第一个来源是您当前的供应商。您的组织中可能已经有两个或更多的搜索引擎在运行。任何由供应商或活跃的开源社区维护和支持的当前部署的搜索引擎都可以考虑。如果你的搜索引擎还没有升级到最新的稳定版本也没关系。在这种情况下,将搜索引擎的最新版本添加到您的列表中,以便您最终将最新版本与其他选项进行比较。
第二个来源可能是分析师报告,比如Gartner的Insight引擎魔力象限报告或Forrester Wave™认知搜索报告。一定要找最新的。这些资源为你的研究提供了很好的概览信息。
如果您从事电子商务或其他特定领域,那么除了针对您所在行业的专门功能外,您可能还希望寻找具有强大嵌入式搜索的目标应用程序的报告。在这种情况下,您可能寻找的不是企业搜索引擎,而是更侧重于用例的搜索解决方案。本博客仍然适用于选择这样的搜索平台。
行业分析师通常根据某些条件创建他们的列表,可能不会产生一个详尽的列表。因此,完成你的列表的第三个来源将是任何你可能读到或听说过的搜索引擎。它可能是您尚未从现有供应商使用的产品。或者你在营销邮件、会议、网络研讨会上看到的东西。
第二步:缩小你的候选搜索引擎列表
如果你的列表中有超过12个搜索引擎,我建议你将搜索范围缩小到几个——也就是说五个或更少。对于我们通常做的评估类型,我更喜欢最多使用三个引擎。
为了从名单中删除一些候选人,我喜欢从检查每个候选人与主要破坏者之间的关系开始。通常情况下,我只需要做一点点工作就可以取消一些申请者的资格。下面的列表展示了我过去看到的一些潜在的阻碍。每个组织都是不同的,有些组织可能有反对或支持下面一项或多项内容的政策或指示。所以,在经历每一件事的时候,考虑一下你目前的情况和对未来的期望。
- 自托管。这是DIY模型。无论它在您的数据中心还是基于云的虚拟机中,您都负责部署、配置、维护和更新搜索引擎。许多组织正在远离这种传统的模型,以避免需要在内部管理软件。如果您更喜欢托管服务,那么任何自托管引擎都将从列表中消失。
- 来自搜索引擎供应商的软件即服务(SaaS)或平台即服务(PaaS)。这些是托管云服务,如AWS Elasticsearch或Amazon Kendra,谷歌云搜索,Azure认知搜索等。我的一些客户更喜欢PaaS而不是SaaS,因为PaaS方法提供了额外的数据控制。您可能需要与您的安全、隐私或法律团队就遵从性进行检查。这有助于迅速取消一些候选人的资格。
- 封闭引擎。您可能熟悉现已停产的谷歌搜索设备(GSA)。它对于某些应用程序或组织来说很好,但对于其他应用程序或组织来说还不够。这基本上是一个黑箱解决方案。虽然有像GSA这样的产品,但需要定制或更多的控制将取消一个封闭引擎的资格。
- 混合式。混合式有多种变种。它可能是一个整合了推荐服务的自托管搜索引擎;您的私有云与本地云的组合;或您的私有云与第三方云服务;等。这些是更复杂的解决方案,但是组织有合理的理由要求这样的部署。有些搜索引擎在混合解决方案中表现不佳,因此不适合进行评估。
根据您的组织需求,您可能有一组更具体的项目。可能有基于预先批准的供应商列表的限制,因为加入一个新的供应商可能太耗时或复杂。我们的目标是在没有太多分析的情况下,快速地将一些搜索引擎从列表中划掉。请记住,我们试图将我们的名单缩小到最有前途的候选人,希望缩小到三个或一个可管理的名单,以便进行更深入的比较。
第三步:定义评估标准
根据我的经验,当你与多个利益相关者打交道时,你选择一个多年有用的搜索引擎的几率会增加。与你当前的搜索利益相关者合作,但不要忘记未来的利益相关者。同时考虑当前和未来的搜索客户端,可以让你更好地评估现有的选择。
虽然您组织的一些应用程序可能已经具有了搜索功能,但它们可以从企业平台而不是筒仓实现中获益。
以下是你的评估标准的一些一般类别。我将深入到每个类别,并概述我们的客户通常需要或希望拥有的特定元素。
- 连接器或爬虫。这些机制用于将数据从源加载到搜索引擎中。对于需要索引的数据源,搜索引擎有多少个连接器?除了现在必须索引的源之外,还应该包括将来可能索引的源。如果您计划在一到两年内停用一个源,您可能想要排除该源,因为您可能不希望在其数据迁移到新的源之前对其进行索引。
- 索引前的数据处理。为索引准备数据是最有价值的活动之一,但在搜索实现中经常被忽略。为了提高可查找性、搜索相关性计算、过滤、排序或其他需要,数据需要清理、规范化或丰富。一些搜索引擎包括开箱即用的数据处理器,并支持针对特定数据处理需求的定制处理器。
- 查询处理。搜索术语,或者在某些情况下,用于查询的非结构化文本也可以从搜索方面的一些准备中获益。就像它在索引、查询清理、规范化或充实方面所做的那样,这将使搜索引擎能够更好地查找匹配的文档或根据相关性对它们进行评分。一些搜索引擎提供了您可能会使用的具有特定意图的开箱即用的查询解析器。最后,寻找将来可能需要添加自定义查询组件的可扩展性功能。
- 语言学的支持。如果您的内容采用多种语言,那么支持或可扩展性能力可能是选择一种引擎而不是另一种引擎的关键原因。语言通常同时应用于索引端和查询端。语言学可以用作处理管道组件或文本分析特性。
- 第三方系统集成。随着时间的推移,一些搜索引擎与内容管理系统或软件结成了强大的合作伙伴关系,甚至可能为软件中的搜索功能提供支持。在这种情况下,搜索引擎可能已经与其他软件进行了本地集成。这是针对特定搜索需求的加速器。
- 搜索结果安全性调整。企业搜索应用程序必须保证用户只能从为他们准备的数据集获得搜索结果。许多搜索引擎提供对文档级别或元数据字段的访问控制。然而,一些搜索引擎足够灵活,可以实现字段级安全性。有些引擎不提供开箱即用的安全性调整,但可以通过自定义集成或插件来支持它。
- 用户界面(UI)工具包。虽然您可能拥有自己的UI开发团队,但您可能需要开箱即用的UI组件来促进搜索客户机应用程序的集成。一些发动机带有这样的部件;其他一些工具允许您创建独立的搜索应用程序或完整的搜索结果页面(SERP),以嵌入到您自己的系统中。
- 搜索分析和网站分析。搜索引擎通常生成或允许生成搜索信号或事件。不断增长的搜索和网站分析功能使智能搜索引擎能够提供更相关和个性化的搜索结果。这些分析特性可以使用机器学习(ML)或其他高级方法来分析信号或产生见解。
- 高级人工智能(AI)功能。智能搜索引擎获得他们的资格基于他们提供的人工智能功能。相关性评分、基于mlb的查询建议、推荐、查询意图和各种其他ai支持的特性的自动调优并不是搜索引擎的标准,这可能是选择一个而不是另一个的原因。
- 授权模型。与任何软件一样,许可证是至关重要的。供应商使用的模型规定了成本、可扩展性、可伸缩性或其他需要为您的需求仔细分析的条件。
- 测试支持。一些引擎内置了执行A/B测试、ML模型测试或比较、相关性排名评估等功能。我很高兴看到添加了这些特性,使产品负责人、搜索管理员和开发人员更容易改进相关性。
您可以使用其他标准来扩展上述列表,如管理用户界面、软件开发工具包(SDK)、日志、监控、文档或其他您感兴趣的领域。
第四步:根据标准评估你的候选搜索引擎
你现在应该有了三个左右的候选人,以及评估标准。多年来,我和我的同事制作了多个电子表格用于搜索引擎评估。一般流程如下:
- 创建一个表
- 列举您定义的所有标准
- 确定每个标准的权重
- 评估所有候选搜索引擎的每个标准
- 将你对该标准的评估与分配的权重相乘,这会生成每个引擎的标准得分
- 在搜索引擎的所有标准中总结得分
在步骤4之后,您应该对所有潜在搜索引擎的所有标准进行评估。这一步包括研究搜索引擎的文档,咨询搜索引擎专家,在某些情况下,联系供应商。
第五步:检查你的分数卡,选择最合适的
电子表格的目的是为潜在的搜索引擎提供一个客观的评估。这个步骤应该很简单,因为电子表格已经计算了每个类别的分数以及每个搜索引擎的总分数。
但通常情况下,不同选项的总分差别并不大。这时分类就派上用场了。您可以根据对您的需要更重要的某些类别来选择最终的引擎。如果你选择把重点放在比较某些类别的小计分值上,就不要有一个非常主观的因素,因为它可能会在最终的选择中造成偏差。
旅程的下一站:计划您的搜索引擎实现
恭喜你!经过仔细的评估,您已经选择了您的下一个企业搜索引擎。旅程还在继续,但在实施之前还有很多事情要做:
- 计划实施新的搜索引擎,
- 准备一个多学科的团队以确保成功的实施,
- 规划对现有引擎的支持,
- 培训你的员工使用新引擎
- 还有很多其他的东西。
它可能是压倒性的…因此,计划你的下一段旅程是必要的。还记得我在本系列的第一部分中描述的地标吗?在搜索引擎选择过程中,您可能会识别出其他地标,并弄清楚如何到达它们。
我相信你会有一个更好的想法,下一步后评估候选人搜索引擎对你的详细要求和期望。例如,在实现新的搜索引擎时,可能需要调整资源来维护当前的搜索引擎。您可能需要将搜索与一些现有的应用程序解耦,甚至可能需要开发一个API层来最小化以后更改搜索引擎的影响。因此,确保在实现所选搜索引擎之前访问了这些准备里程碑。
本文:http://jiagoushi.pro/node/1153
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 138 次浏览
【搜索引擎】提高 Solr 性能
这是一个关于我们如何设法克服搜索和相关性堆栈的稳定性和性能问题的简短故事。
语境
在过去的 10 个月里,我很高兴与个性化和相关性团队合作。我们负责根据排名和机器学习向用户提供“个性化和相关的内容”。我们通过一组提供三个公共端点的微服务来做到这一点,即 Home Feed、Search 和 Related items API。我记得加入团队几个月后,下一个挑战是能够为更大的关键国家提供优质服务。目标是保持我们在较小国家/地区已经拥有的完美性能和稳定性。
我们使用 Zookeeper 在 Openshift 上的 AWS 中使用 SolrCloud (v 7.7)。在撰写本文时,我们很自豪地提到,该 API 每分钟服务约 15 万个请求,并每小时向我们最大区域的 Solr 发送约 21 万个更新。
基线
在我们最大的市场中部署 Solr 后,我们必须对其进行测试。我们使用内部工具进行压力测试,我们可以大致获得所需的流量。我们相信 Solr 配置良好,因此团队致力于提高客户端的性能并针对 Solr 设置更高的超时时间。最后我们同意我们可以稍微松散地处理交通。
迁移后
服务以可接受的响应时间进行响应,Solr 客户端表现非常好,直到由于超时而开始打开一些断路器。超时是由 Solr 副本响应时间过长的明显随机问题产生的,这些问题在没有信息显示的情况下更频繁地影响前端客户端。以下是我们遇到的一些问题:
- 高比例的副本进入恢复并且需要很长时间才能恢复
- 副本中的错误无法到达领导者,因为它们太忙了
- 领导者承受过多的负载(来自索引、查询和副本同步),这导致它们无法正常运行并导致分片崩溃
- 对“索引/更新服务”的怀疑,因为减少其到 Solr 的流量会阻止副本停止或进入恢复模式
- 完整的垃圾收集器经常运行(老年代和年轻代)。
- 运行在 CPU 之上的 SearchExecutor 线程,以及垃圾收集器
- SearchExecutor 线程在缓存预热时抛出异常 (LRUCache.warm)
- 响应时间从 ~30 ms 增加到 ~1500 ms
- 发现某些 Solr EBS 卷上的 IOPS 达到 100%
处理问题
分析
作为分析的一部分,我们提出了以下主题
Lucene 设置
Apache Solr 是一个广泛使用的搜索和排名引擎,经过深思熟虑并在后台使用 Lucene 进行设计(也与 ElasticSearch 共享)。 Lucene 是所有计算背后的引擎,并为排名和 Faceting 创造了魔力。是否可以对 Lucene 进行数学运算并检查设置?我可以根据大量文档和论坛阅读资料分享一个近似结果,但是它的配置不如 Solr 的数学那么重。
调整 Lucene 是可能的,前提是您愿意牺牲文档的结构。真的值得努力吗?不,当您进一步阅读时,您会发现更多信息。
文档与磁盘大小
假设我们有大约 1000 万个文档。假设平均文档大小为 2 kb。最初,您的磁盘空间将至少占用以下空间:

分片
一个集合拥有多个分片并不一定会产生更具弹性的 Solr。当一个分片出现问题而其他分片无论如何都可以响应时,时间响应或阻塞器将是最慢的分片。
当我们有多个分片时,我们将文档总数除以分片数。这减少了缓存和磁盘大小并改进了索引过程。
索引/更新过程
是否有可能我们有一个过度杀伤的索引/更新过程?鉴于我们的经验,这并不过分。我将把这个问题的分析留给另一篇文章。否则,这将过于广泛。在我们的主要市场,我们已经达到每小时 21 万次更新(高峰流量)。
Zookeeper
Apache Zookeeper 在此环境中的唯一工作是尽可能准确地保持所有节点的集群状态可用。如果副本恢复过于频繁,一个常见问题是集群状态可能与 Zookeeper 不同步。这将在正在运行的副本之间产生不一致的状态,并且尝试恢复的副本最终会进入一个可能持续数小时的长循环。 Zookeeper 非常稳定,它可能仅由于网络资源而失败,或者更好地说是缺少它。
我们有足够的内存吗?
理论
Solr 性能最重要的驱动因素之一是 RAM。 Solr 需要足够的内存用于 Java 堆,并需要可用内存用于 OS 磁盘缓存。
强烈建议 Solr 在 64 位 Java 上运行,因为 32 位 Java 被限制为 2GB 堆,这可能会导致更大的堆不存在的人为限制(在本文后面部分讨论) .
让我们快速了解一下 Solr 是如何使用内存的。首先,Solr 使用两种类型的内存:堆内存和直接内存。直接内存用于缓存从文件系统读取的块(类似于 Linux 中的文件系统缓存)。 Solr 使用直接内存来缓存从磁盘读取的数据,主要是索引,以提高性能。
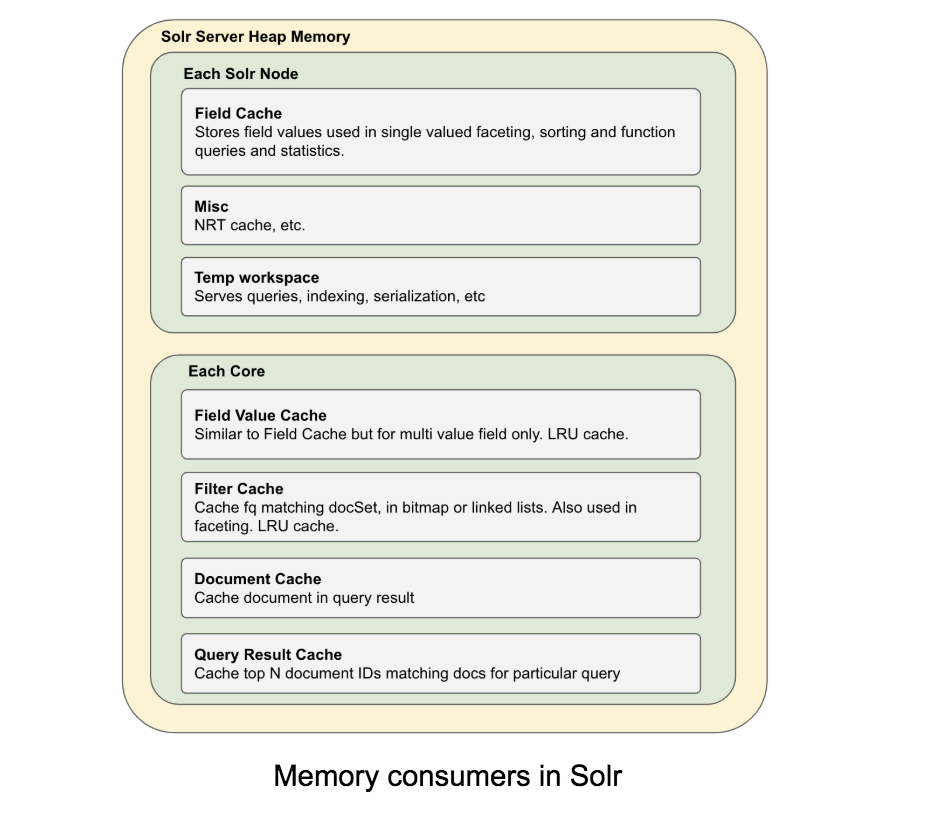
当它被暴露时,大部分堆内存被多个缓存使用。
JVM 堆大小需要与 Solr 堆需求估计相匹配,以及更多用于缓冲目的。 堆和操作系统内存设置的这种差异为环境提供了一些空间来适应零星的内存使用高峰,例如后台合并或昂贵的查询,并允许 JVM 有效地执行 GC。 例如,在 28Gb RAM 计算机中设置 18Gb 堆。
让我们记住我们一直在为 Solr 改进的方程式,与内存调整最相关的领域如下:

虽然下面的解释很长而且很复杂,但是为了建立另一个帖子,我仍然想分享我们一直在研究的数学。 我们在解决问题之初就使用了自己的计算器,只是为了实现后来在线社区共享的类似问题。
此外,我们确保在启动 Solr 时在 JVM Args 中正确启用垃圾收集器。

缓存证据
我们根据 Solr 管理面板中的证据调整缓存,如下所示:
- queryResultCache 的命中率为 0.01
- filterCache 的命中率为 0.43
- documentCache 的命中率为 0.01
垃圾收集器和堆
使用 New Relic,我们可以检查实例上的内存和 GC 活动,并注意到 NR 代理由于内存阈值而频繁打开其断路器(浅红色竖线):20%; 垃圾收集 CPU 阈值:10%。 此行为是实例上可用内存问题的明确证据。
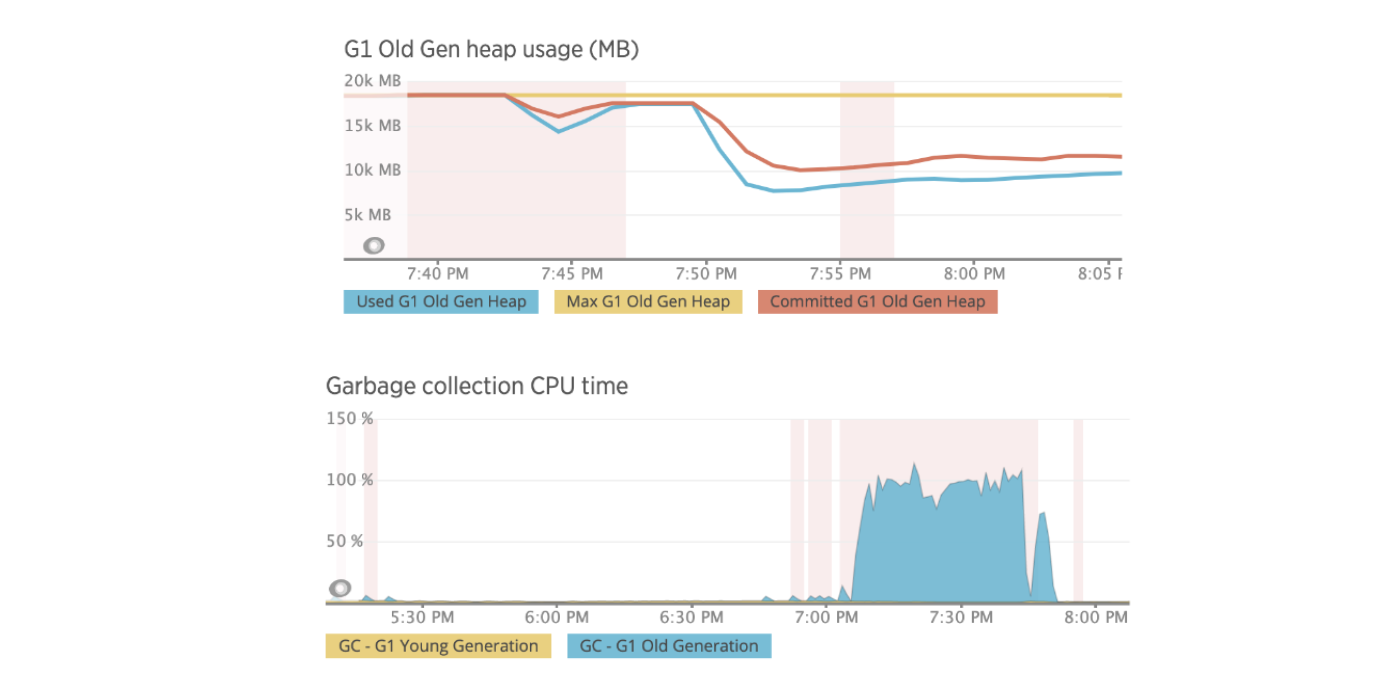
我们还可以监控一些高 CPU 实例进程,发现在 searcherExecutor 线程使用 100% 的 CPU 时占用了大约 99% 的堆。 使用 JMX 和 JConsole,我们遇到了包含以下内容的异常:
…org.apache.solr.search.LRUCache.warm(LRUCache.java:299) …作为堆栈跟踪的一部分。 上述异常与缓存设置大小和预热有关。
磁盘活动 — AWS IOPS
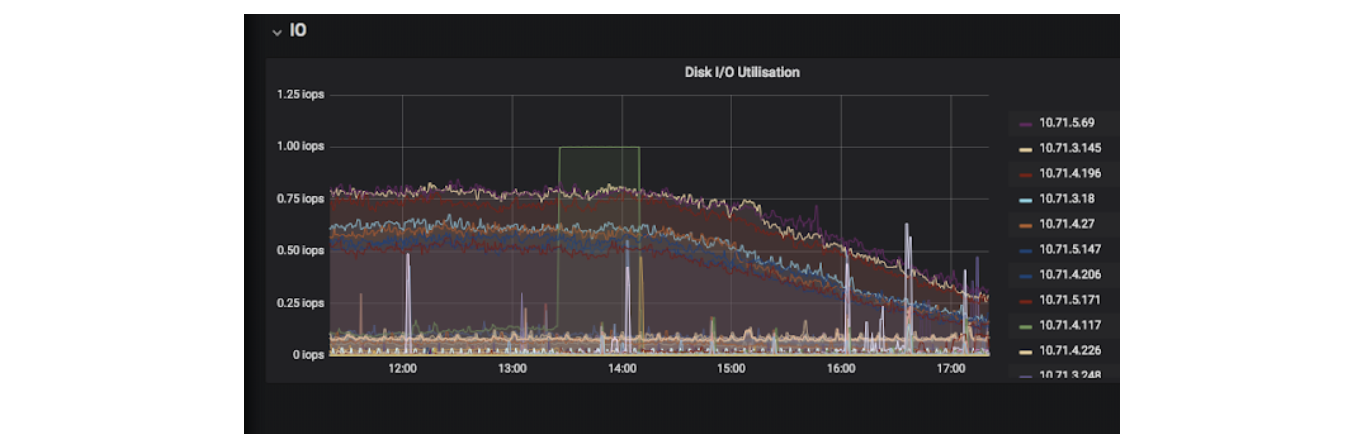
开始解决问题
搜索结果容错
为前端客户端提供搜索结果的第一个想法是始终让 Solr 副本仍然存在以响应查询,以防集群由于副本处于恢复甚至消失状态而变得不稳定。 Solr 7 引入了在领导者及其副本之间同步数据的新方法:
- NRT 副本:在 SolrCloud 中处理复制的旧方法。
- TLOG replicas:它使用事务日志和二进制复制。
- PULL 副本:仅从领导者复制并使用二进制复制。
长话短说,NRT 副本可以执行三个最重要的任务,索引、搜索和引导。另一方面,TLOG 副本将以稍微不同的方式处理索引,搜索和引导。差异因素在于 PULL 副本,它只为带有搜索的查询提供服务。
通过应用这种配置,我们可以保证只要分片有领导者,PULL 副本就会响应,从而大大提高可靠性。此外,这种副本不会像处理索引过程的副本那样频繁地进行恢复。
当索引服务满负荷时,我们仍然面临问题,导致 TLog 副本进入恢复。
调整 Solr 内存
基于这个问题我们是否有足够的 RAM 来存储文档数量?,我们决定进行实验。最初的担忧是为什么我们在文档的“单位”中配置这些值,如下所示:

根据之前共享的公式,考虑到我们有 700 万份文档,估计的 RAM 约为 3800 Gb。 但是,假设我们有 5 个分片,那么每个分片将处理大约 140 万个直接影响副本的文档。 我们可以估计,使用该分片配置,所需的 RAM 约为 3420 Gb。 这不会产生根本性的变化,所以我们继续前进。
缓存结果
从缓存证据中,我们可以看到只有一个缓存被使用得最好,即 filterCache。 测试的解决方案如下:

通过之前的缓存配置,我们获得了以下结果:
- queryResultCache 的命中率为 0.01
- filterCache 的命中率为 0.99
- documentCache 的命中率为 0.02
垃圾收集器结果
在本节中,我们可以看到 New Relic 提供的垃圾收集器指标。 我们没有老年代活动,通常会导致 New Relic 代理打开它的断路器(内存耗尽)。
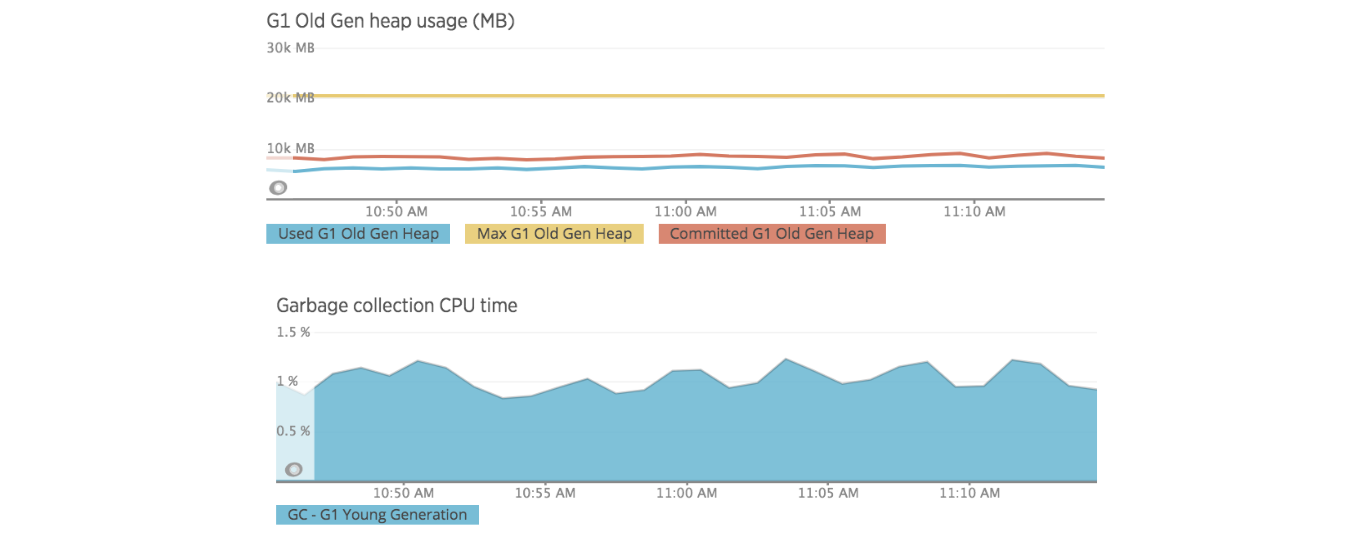
磁盘活动结果
我们在磁盘活动方面也取得了惊人的成果,索引也大幅下降。
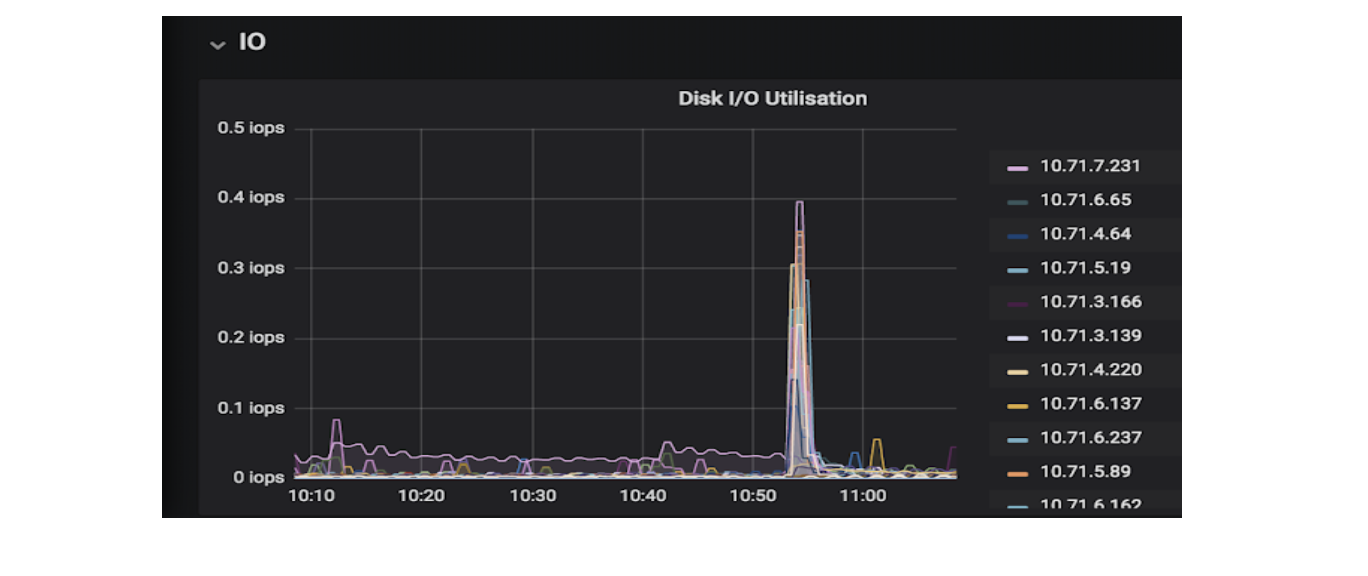
外部服务结果
其中一项访问 Solr 的服务在 New Relic 中的响应时间和错误率显着下降。
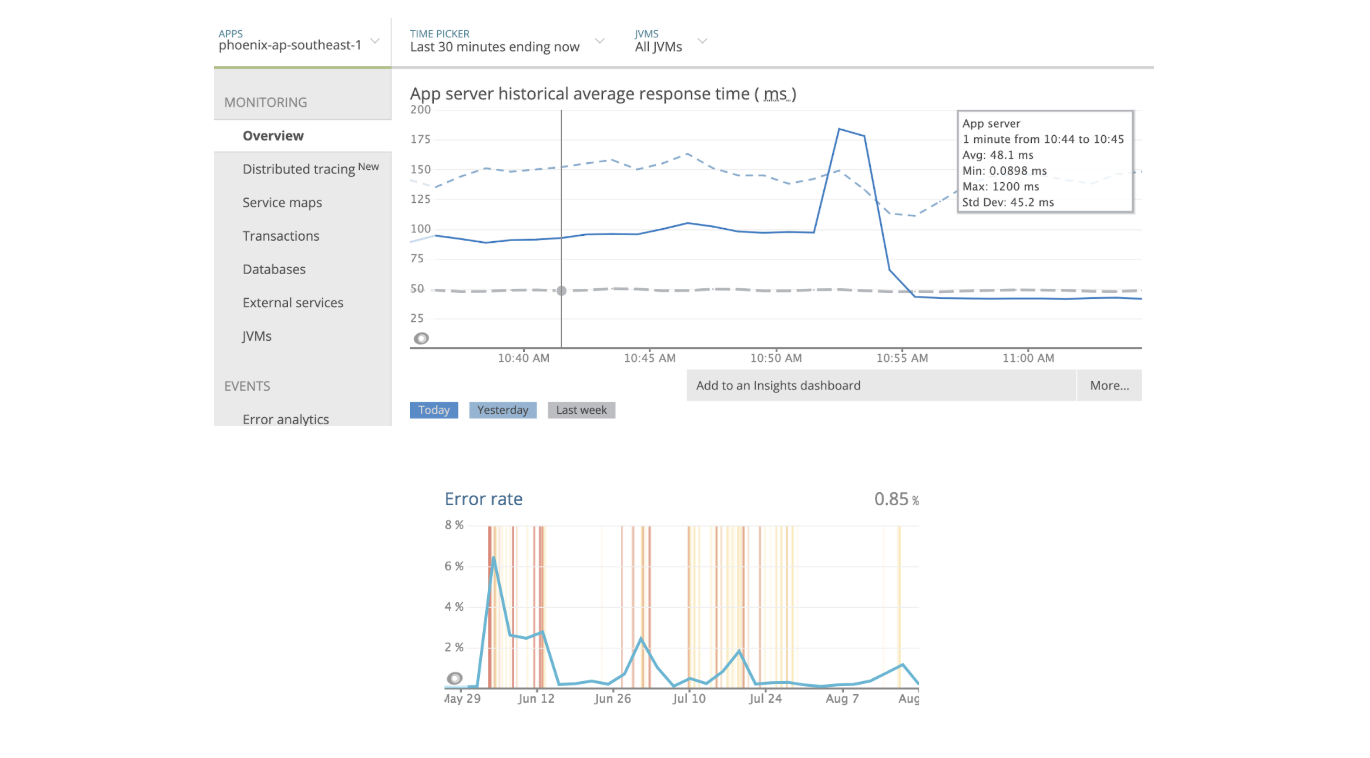
调整 Solr 集群
多分片模式的一个缺点是,如果任何副本被破坏,分片领导者将比其对等节点花费更多的时间来回答。这导致分片中最差的时间响应,因为 Solr 会在提供最终响应之前等待所有分片回答。
为了缓解上述问题并考虑到前面描述的结果,我们决定开始逐渐减少节点和分片的数量,这对降低内部复制因子有影响。
结论
经过数周的调查、测试和调优,我们不仅摆脱了最初暴露的问题,而且通过减少延迟提高了性能,通过设置更少的分片和更少的副本降低了管理复杂性,获得了对索引/更新的信任服务满负荷工作,并通过使用几乎一半的 AWS EC2 实例帮助公司减少开支。
我要特别感谢使这成为可能的团队,以及 SRE 和 AWS TAM 的指导和支持。
原文:https://tech.olx.com/improving-solr-performance-f4202d28b72d
本文:https://tech.olx.com/improving-solr-performance-f4202d28b72d
- 155 次浏览
【搜索引擎】搜索和非结构化数据分析:2020年值得关注的5大趋势
大多数组织都很好地利用了结构化数据(表格、电子表格等),但是很多未开发的业务关键的见解都在非结构化数据中。
80%组织正在意识到他们80%的内容是非结构化的。
企业中近80%的数据是非结构化的——工作描述、简历、电子邮件、文本文档、研究和法律报告、录音、视频、图片和社交媒体帖子。虽然这些数据过去非常难以处理和使用,但神经网络、搜索引擎和机器学习的新技术发展,正在扩展我们使用非结构化内容进行企业知识发现、搜索、业务洞察和行动的能力。
搜索加人工智能正在解决现实世界的问题
想想你智能手机上的应用程序——Siri, Alexa, Shazam, Lyft等等。您可能没有意识到这一点,但它们都是由一大批搜索引擎在幕后工作提供动力的。这些应用程序将搜索与人工智能技术(如自然语言处理、神经网络和机器学习)相结合,可以处理你的语音命令或文本输入,搜索不同的数据源,并返回所需的答案,所有这些都是实时且非常准确的。
在企业内部,这些技术可以将员工与他们所需要的内容和答案联系起来,而不管答案在哪里——在文档、财务系统、人力资源系统或政策和程序数据库中。

搜索已经从寻找文件发展到提供答案
到2020年,我们希望看到更多的人工智能搜索和基于搜索的分析应用支持企业。
下面是搜索和非结构化数据分析领域中值得关注的五大趋势。
1. 神经网络和搜索引擎
埃森哲的《峡湾趋势2020》显示,神经网络是支持创新型企业人工智能系统的关键技术,它可以通过模式识别“学习”执行任务。通过分析大量的数字数据,神经网络可以学会识别照片,识别语音命令,并对自然语言搜索查询作出反应。神经网络超越了简单的关键词搜索,使搜索引擎能够理解用户的意思和意图,从而提供最个性化、最相关的结果。
最新的神经网络(BERT及其衍生产品)能够创建一个“语义空间”——对企业内容的抽象理解——可以用于:
- 深入搜索:识别具有相同含义的句子,而不是仅仅包含相同的搜索关键词(如“公司费用政策”和“商务旅行报销”)
- 更好的分类:为更好的导航或管理对内容进行分类(例如,合规性、筛选、补救等)
- 提问/回答:从文件中提取事实,回答与原始材料相关的具体问题(例如:“美国上季度的收入是多少?”)
这些神经网络已经被用于高度管理的内容,如知识库文章、政策和程序、文档、测试标准等等。在接下来的几年里,我们希望看到更多的组织应用神经网络来更好地理解他们的文档内容和用户查询,提供高度相关的、基于上下文的答案。
2. 语义搜索
语义搜索扩展到神经网络,处理范围广泛的企业用户的查询和请求,并可以直接从业务系统得到即时的回答。这使得语义搜索成为用户社区所需的文档、问题、事实和业务数据的单一访问点。语义搜索的目的是为用户的问题提供精确、准确、即时的答案,包括短尾和长尾。语义搜索包括四个部分:
- 理解查询中的实体(业务对象)
- 理解查询的目的
- 将请求映射到应答代理
- 获取答案并将其报告给最终用户
语义搜索已经使搜索引擎从基于关键词显示结果列表发展到理解这些词的意图并显示用户真正需要的目标内容。如果用户正在搜索“Q1营收”,他/她可能不是在寻找包含“Q1营收”的结果列表,而是一个快速响应,比如“1.23亿美元”。“更多的是什么?也许收入数字甚至可以按市场细分进行细分。
许多因素支持语义搜索的兴起:
- 数据仓库、数据湖和内容摄入技术的增长正在打破数据竖井,使有价值的内容在组织之间随时可用。
- 为实现业务应用程序语义搜索而设计的新工具的出现,帮助组织解决了集成挑战,并极大地降低了实现成本。
- 新的机器学习方法,如先进的神经网络,允许语义搜索引擎更好地理解用户的搜索请求,分析查询中的对象,并将查询映射到意图和确定回答代理。
请阅读我的短文,进一步了解语义搜索和示例业务用例。
3.文档的理解
当计算机阅读文档时,它们不会注意文体细节,比如某个单词在页面上的位置,或者它与其他单词的关系。但是表示元素——定位、颜色、字体、图形元素等等——包含了文本本身无法传达的重要语义信息。作为人类,我们无需思考就能理解这一切。例如,我们知道,字体大小可以表示重要性,标题、段落或图像的位置可以影响这些项目在文档中的意义。然而,由于计算机目前忽略了大多数这些表示元素,组织无法从其文档中提取实质性的价值。
人工智能正在通过检查这些表现元素,使从非结构化内容中提取洞察力成为可能。可以对智能文档处理引擎进行培训,使其能够阅读这种表示性信息并向最终用户交付洞察力。想象一下可以利用文档理解的各种企业用例:
- 自动PDF发票处理:提取表,总计,名称/值对
- 从纸质流程到电子流程的转变:药品生产从批记录到电子批记录;或从pdf文件到实验室信息管理系统记录实验室测试程序
- PowerPoint内容搜索:搜索幻灯片,突出显示幻灯片内的搜索,提取标题,删除页脚
- 搜索地球科学报告:找到测井、地震剖面、地图和其他元素,并将这些项目与全球的地理位置联系起来
- 自动邮件路由和表格填写:减少邮件项目的处理时间,包括蜗牛邮件和电子邮件
- 工程图纸的自动转换:转换为材料清单,并最终转换为连接图和流程图
- 策略和过程文档搜索:搜索和匹配各个段落,或从文本中提取直接答案
- 和更多的
阅读更多关于我们如何为企业构建这些文档理解应用程序的内容。
4. 图像和语音搜索
2019年埃森哲数字消费者调查发现,大约一半的受访者已经在使用数字语音助手(DVA), 14%的人计划在未来12个月内购买。虚拟助手——Siri、Alexa、谷歌助理等等——正变得无处不在。在人工智能技术的推动下,它们使人类和计算机在日常互动中能够对话。它们带来了更深入的自然语言理解,不仅增强了搜索功能,而且提供了一种全新的查找信息的方式。
语音助理已经进入企业,使客户和员工能够更容易地与企业数据进行交互。例如,员工现在可以问“我们在欧洲的数据科学专家是谁?”或“我如何预订巴黎办公室的会议室?”从外部来看,语音和图像搜索功能超越了传统的文本搜索,为客户和合作伙伴提供了在公司网站上查找信息的更简单的方法。
“到2021年,那些重新设计网站以支持视觉和语音搜索的早期采用率品牌将增加30%的数字商务收入。
这些工具和语义搜索(上面讨论过)之间有天然的协同作用。在许多情况下,聊天机器人可以被删除——后端可以完全由一个健壮而全面的语义搜索引擎来处理。
5. 知识图谱
根据我们去年的预测,知识图的发展将继续推动整个企业更智能的搜索交互。
将组织的现有数据聚合到一个存储库(通常是企业数据湖)是一个起点。但是我们如何利用这些数据呢?我们需要给它添加上下文、关系和意义。从不同企业功能的片段数据记录中,自然语言理解(NLU)算法可以创建一个相互连接的信息网络,表明数据记录是如何相互连接的,从而创建企业知识图。当用户提出问题时,搜索引擎和问答系统可以立即抓取相关信息的快照,并提供相关的见解。
请注意,知识图可以跨越广泛的复杂性:
- 适度相互联系:
- 雇员和雇员信息
- 业务单位和主要团队成员
- 办公室的位置
- 产品和支持人员
- 物理平面机械位置
- 丰富的相互关联的:
- 组织层次结构
- 办公室走廊、楼梯和会议室位置
- 机器部件及其邻近性/相互连接性
- 产品类别、血统及配套配件
- 物理设备和机器的相互连接
- 客户、联系人、销售人员和购买的产品
- 策略和过程约束、条件和要求
随着新的数据点和深刻的关系的无限增加,知识图将会不断增长。
除了搜索
展望2020年和未来几年,我们预计这五项发展将进一步发展,并在企业内部得到更广泛的利用。重点将放在如何应用这些智能技术来发现和最大限度地使用非结构化数据。超越传统的搜索应用程序,新的搜索和人工智能驱动的用例每天都被发明出来,以提供更多的价值和更好的结果。随着人工智能技术和方法的改进,它们可以被组织用来以更低的成本和更强大的结果解决技术和组织的挑战。有了实际的策略、领域的专业知识和专家的实施,组织可以为创新释放无限的机会。
本文:http://jiagoushi.pro/node/1156
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 212 次浏览
【搜索引擎】搜索引擎过时了,“寻找引擎”流行起来
研究报告简述
- 多年来,像谷歌这样的搜索引擎一直在改变内容的呈现方式,通过更好地理解用户需求,提供更准确的结果。
- 现在,技术使得组织采用这种新的语义搜索功能比以往任何时候都更容易。
- 这使得企业内部大量的知识得以释放,并将其置于员工的指尖。
- 因此,搜索引擎正在成为“寻找引擎”,寻找用户需要的答案。
如果你理解用户在搜索什么,你可以制作一个更好的搜索引擎:更好的理解=更好的结果。这是贯穿整个搜索引擎发展的指导原则。问题是,语言是复杂的。一个搜索查询中可能有很多单词——更不用说这些单词和它们不同的意思可能的组合——直到现在我们才开发出更好地理解用户意图并使更好的搜索成为现实的工具。
花点时间考虑这些统计数据,您就会明白为什么过去许多提高语义理解的尝试都失败了。迄今为止规模最大的百分比的话(超过90%)将只用于我们日常生活的一个小的次数,因此在任何数据集。太少的出现使得这些话不适合机器学习(ML)方法需要大量的训练数据集。
另一方面,有一小部分词汇使用所有的时间(这样的词“的”或“和”),变得过于模糊,因此也不适合毫升。这使得少量常用的“金发姑娘”字足以产生足够的例子,但不是经常,他们变得无用。所以,第一个挑战就是识别这些词——大海捞针。
第二个挑战是理解人们在对话中使用这些词汇时通过共享的世界知识给语言带来的意义。这就解释了为什么过去的语义搜索方法没有成功,为什么花了这么长时间才达到今天的水平。
但是,如果我们能够训练计算机,使其获得有效理解语言所必需的世界知识,并将其应用于语义搜索,情况会怎样呢?
一个搜索查询中可能有太多的单词,直到现在我们才开发工具来更好地理解用户意图,并使更好的搜索成为现实。
欢迎来到新的语义搜索时代
新的语义搜索已经将搜索引擎从基于用户在搜索栏中输入的字面词来显示内容,转向理解这些词的意图并显示用户真正需要的内容。换句话说,搜索引擎正变得越来越像文字搜索引擎。
例如,请考虑在谷歌这样的搜索引擎中输入“1 USD in GBP”或“country code 56”会产生什么结果。搜索结果会给出你想要的答案,而不仅仅是一系列包含你的搜索语言的结果。
新的语义搜索已经将搜索引擎从基于用户在搜索栏中输入的字面词来显示内容,转向理解这些词的意图并显示用户真正需要的内容。
通过从外部获取文本数据,新的语义搜索方法比过去的方法对细微差别有更广泛和更准确的理解。多亏了神经网络(NNs)和通用句子编码器,计算机正在接受阅读句子的训练,并对内容进行“抽象语义理解”。例如,搜索“1美元兑换成英镑”或“1美元兑换成英镑”可以用来训练系统将查询“理解”为[数字][货币][动作或短语][货币]。这个模式的意思是“将一种货币转换成另一种货币。”
通常,这些网络神经网络都是使用维基百科和MedLine等来源的内容广泛、目的交叉的文本进行培训的。有了足够的文本,我们就会有更多的例子来说明单词(和短语)是如何使用的,这会让我们对内容有更丰富的理解。通过这种方式,我们将外部世界的知识引入到我们的“搜索和发现”经验中,从而产生更好的结果。
为企业带来新的语义搜索
谷歌引入了新的语义搜索功能,通过真正理解用户的需求,它开始重新定义当前的挑战。这听起来很简单,作为消费者,我们已经开始期待每个服务提供商和搜索引擎都能提供这种搜索能力。
但在企业中,这并不总是可能的。由于无法访问成千上万的数据科学家和机器学习专家来实现更复杂的语义搜索功能,组织在很大程度上难以驾驭这种方法。语义搜索功能既昂贵又费时。
根据我们的经验,采用企业范围的搜索方法也遇到了三个主要障碍:
- 1. 传统上,数据是不可访问的,被锁在孤立的业务系统中。
- 2. 到目前为止,将最好的搜索引擎与最好的机器学习和自然语言处理(NLP)功能集成起来是很困难的,而且几乎是不可能的。
- 3.为了解决语言歧义问题,需要手工编码,因此技术未能有效和大规模地解决这个问题。
幸运的是,这些障碍正在逐渐消失。
对此,我们有信心-新语义搜索将成为每一个组织的信息的瑞士军刀。
数据仓库、数据湖和数据摄取工具的增长正在打破竖井,使数据更容易跨组织使用。专门为实现业务应用程序语义搜索而设计的新工具的出现,正在解决集成的挑战。
虽然搜索引擎、ML和NLP仍然是不同的技术,但我们正在更好地集成它们。事实上,许多搜索引擎公司和云服务提供商(如谷歌、微软和AWS)现在都提供了现成的伞形解决方案。此外,技术的发展使得不需要编码就可以实现更准确的模糊解决方案和NLP,这意味着新的语义搜索正在迅速成为企业组织现实和可维护的选择。
以我们的一个航空航天制造客户为例。制造车间的员工只需将条形码阅读器对准飞机部件的条形码,该工具的系统就会对如何使用或维护该部件进行全公司范围的搜索,只显示最相关的信息。我们将条形码解释为用户的查询“告诉我这部分的一切,包括如何维护或更换它。”
通过从组织内的专家那里获取企业知识,并通过这个新的语义搜索功能使这些知识变得可操作,我们帮助缩短了用户和所有业务系统之间的距离,并收集了知识。
与其去金融网站查询发票号码或去IT网站询问技术问题,不如想象一下拥有一个能够理解你的需求并提供正确回复的搜索工具的价值。
如果语义搜索最终是创造获取答案和信息的途径,那么创造一个单一的真理来源将是不可分割的一部分。设想使用一个查找工具来查找整个组织中所有问题的答案。在更广泛的业务环境中,可以使用新的语义搜索来改进对任意数量的信息点的访问,例如产品名称、收费代码、电子邮件地址、发票和合同编号、办公地点等等。
与其去金融网站查询发票号码、电子邮件地址,或者去IT网站询问技术问题,不如想象一下拥有一个能够理解你的需求并提供正确答复的搜索工具的价值——更不用说安慰了。
对此,我们有信心-新语义搜索将成为瑞士军刀的每一个组织的信息。公共搜索引擎提升了游戏的实用性和用户体验。现在企业也可以为客户和员工做同样的事情。
原文:https://www.accenture.com/us-en/insights/digital/find-engines
本文:http://jiagoushi.pro/node/1158
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 84 次浏览
【搜索引擎】智慧企业搜索之旅
您当前的企业搜索引擎提供商宣布了该软件的生命周期。供应商建议迁移到一个更现代的引擎。您要考虑他们提供的服务和您组织的需求。此时,您可能会遇到以下一个或多个场景:
- 您将从具有可预测成本计算的固定许可模式转向可变定价模式。
- 您将从一个包含所有所需组件的搜索引擎,转变为以搜索应用程序所需的任何方式集成来自供应商新平台的服务。
- 如果您决定迁移到新搜索引擎,那么在迁移到新引擎时必须维护当前的搜索引擎。
当然,你的情况可能与上述情况有所不同。也许你的搜索引擎来自一家最近宣布被收购的公司(比如ServiceNow在2019年10月宣布收购Attivio搜索引擎)。母公司会继续提供这款引擎并对其进行改进,还是会让它退役?
也许你收购的公司有价值的数字资产存在于不同的搜索引擎中;又一个要添加到您的搜索软件列表管理。这增加了您组织的压力,要求您选择一个引擎来支持所有自定义企业搜索功能,从而降低成本和复杂性。我所说的定制是指您实现和维护的搜索功能,而不是那些已经嵌入的开箱即用的功能。
你在人工智能和云计算时代的企业搜索策略
评估和选择一个搜索引擎是困难的,而且我敢说,随着云计算、分析和人工智能(AI)技术推动的革命,这变得更加困难。但是由于这些技术,现代企业搜索引擎已经发展成为智能搜索引擎(也被称为问答系统、认知搜索或洞察力引擎),提供答案而不仅仅是结果列表。
我开始写这个博客的时候,再次帮助一个组织选择一个新的搜索引擎。这是他们旅程的第一站:绘制出他们想要的企业搜索的路径。这篇文章旨在为你提供实际的开始步骤。

5个步骤定义一个实用的企业搜索策略
第一步:我们在哪里?对情况进行评估
很可能你已经有了一个现代的搜索引擎。然而,它并不是一个简单的升级到最新版本的项目,因为:
- 它的实现方式阻碍了搜索引擎最大限度地发挥自己的功能;
- 在部署过程中,搜索引擎无法从云计算或人工智能等强大技术中获益;
- 以前的一些架构决策限制了您添加新的需求或提供新的搜索应用程序;或
- 描述一下你的问题…
无论你现在的情况如何,把它看作是一种交通需求。如果不提供当前位置,你就无法得到正确的驾驶指南或拼车服务。所以,首先要正确地确定你的搜索引擎在哪里。这是搜索系统的当前状况,而不是它的服务器、数据中心或云位置。
第二步:我们要去哪里?定义目标
如果你还没有,这将是你戴上未来视力眼镜的最佳时机。5年或5年以后,你的搜索解决方案需要在哪里?您肯定对搜索相关功能有一些短期需求。但是,长远的考虑会使你选择搜索引擎的过程变得更容易,选择一个仍能满足你不断变化的需求的搜索引擎,希望包括那些你现在无法想象的搜索引擎。如果你需要一些灵感,请阅读我们的创新引领最近的博客。我将总结一下那篇文章中讨论的主要企业搜索趋势:
- 神经网络和搜索引擎
- 语义搜索
- 文档的理解
- 图像和语音搜索
- 知识图
在定义你的搜索视觉时,你还可以考虑很多其他的特性:认知搜索、洞察和分析、上下文搜索、自然语言处理(NLP)等等。我建议您超越术语,尝试理解每个概念在您的上下文中的含义。关键是向前看,同时保持现实。例如,当你的组织没有当前或计划的人工智能能力时,你会从允许你加入自己的人工智能的搜索引擎中受益吗?在这种情况下,内置的人工智能搜索解决方案或人工智能服务合作伙伴可能比建立自己的更好。
在此步骤中,下面的成熟度模型可以作为评估您的情况和定义企业搜索远景的指导方针。

第三步:对我们有什么好处?设定清晰的期望
现在,你应该有一个清晰的开始和结束你的旅程。作为可视化未来搜索的一个副作用,你可能会想,并希望写下你的理由和好处。我这里并不是在谈论具体的要求。以下是在此阶段需要考虑的一些领域:
- 为终端用户提供更多的自助服务机会
- 搜索引擎的基础设施更少
- 更自动化的管理和操作
- 提高了生产率
- 超越更好的搜索:发现数据和产生见解
稍后将有时间深入每个领域的细节。记住,我们只是清楚地定义了你努力的期望和目的。如果你在去目的地的路上迷路了,他们会提醒你为什么开始旅行。
第四步:沿途我们会在哪些地方停留?计划的旅程
在我写这一部分的时候,我对“旅程”这个词产生了好奇。我了解到,当然是通过一个主要的互联网搜索引擎,这个词有拉丁语和法语的起源。在这两种情况下,这个词都指在一天内发生的事情。持续一天的旅行。最初,这也是它在英语中的用法。然而,它的现代用途,通常是用于需要超过一天的事情。同时,在前进的道路上也可能会遇到阻碍或改变。这就是为什么我将它与搜索应用程序相关联。仅仅实现就可能花费数周的时间,甚至对于小型、简单的搜索索引,从开始到生产都有多个里程碑。
巧合的是,当我在考虑企业搜索引擎选择过程中的站点时,我听到有人在一个项目的上下文中说的是“里程碑”而不是“里程碑”。“里程碑”这个词意味着度量。您可以估计到达每个项目里程碑所需的工作量、时间和其他资源。我们还没到那一步。相反,地标是你在旅行中想要去的地方,但你不一定知道怎么去或什么时候去。你需要在你出发前往下一个地标前弄清楚这些细节。
我想您的不是一个简单的搜索应用程序。您已经读到这里,因为为您的需求选择下一个企业搜索引擎是复杂的。即使是确定要比较的合适候选技术也具有挑战性。我建议你在旅途中确定你想要到达的地标。现在,不用担心订单的问题。简单地列出它们,这样当你更精确地定义事物时就可以引用它们。
以下是一些改变搜索引擎地标的一般例子:
- 选择一个搜索引擎(开源的,如Elasticsearch和Solr;商业引擎,如SharePoint搜索,Sinequa等;或基于云的搜索引擎,如谷歌云搜索、Amazon Kendra、Azure搜索、Microsoft搜索等)
- 扩充你的搜索团队
- 将现有应用程序迁移到新的搜索引擎
- 添加更多搜索应用程序
- 使用基本人工智能增强搜索,如内容丰富、基于人工智能的相关性排名和调优、聚类,或其他现代搜索引擎中已经包含的功能
- 结合高级人工智能,如高级自然语言理解和处理(NLU/NLP),你自己的机器学习模型,与第三方人工智能库或服务(视觉,音频,或其他)集成,等等。
针对您的具体情况,尝试定义比上述示例更具体的里程碑。这些界标不一定每次都是这个顺序。您可能决定首先迁移关键搜索应用程序,为这些应用程序实现一些AI功能,然后返回迁移现有应用程序的另一个子集。或者您可能会发现,您希望从向搜索团队添加人员开始,或者将当前单独的人员加入到单个、集中的搜索团队中。这样做可以从高级搜索团队成员中腾出一些时间来选择下一个引擎。
第五步:想象你的旅程
是时候把所有的东西放在一起了。现在我们有了在地图上绘制我们旅行的主要元素:
- 起点
- 地标性建筑
- 目的地
你甚至可能知道一路上应该拍些什么:你对旅程的期待。你可能会注意到,我们还没有确定到达每个地标的具体方向。现在还可以。我们有一个参照来指导我们从开始到结束,连同主要的转弯和停止。
您的列表中的一些里程碑可能是您的组织所独有的。这个过程应该会帮助您认识到搜索不仅仅是搜索团队的责任。它应该是一种数字资产,将使您的组织的许多部分受益。因此,决定访问它们的顺序可能需要来自多个业务功能的协调和参与。您还应该有一个沟通工具来支持这个过程,并在更新搜索的同时让涉众参与进来。
下一步:选择你的企业搜索引擎
虽然搜索引擎选择可能不会成为你访问的下一个里程碑,但在某种程度上它会。这是我们非常熟悉的旅程的一部分,我将在下一篇博客文章中描述。
本文:http://jiagoushi.pro/node/1155
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 65 次浏览
【搜索引擎】智能企业搜索:为什么知识图和NLP可以提供所有正确答案
在获取信息和洞察力方面,我们正处于一个彻底转变的边缘,我们需要更聪明、更有效地工作。在这篇博客中,我将展示人工智能技术如何增强互联网搜索,现在如何应用于组织内部,从而彻底改变企业搜索所能实现的目标。
信息指数增长
我们所能得到的信息量是惊人的。而且它一直在呈指数级增长:数据量已经达到了44千兆字节,预计在未来五年内将达到175千兆字节(IDC)。80%的数据是非结构化的(电子邮件、文本文档、音频、视频、社交帖子等等),只有20%是某种结构化的系统。
为了从这些海量资源中找到答案,并准确定位我们要寻找的东西,我们需要一种方法从文件中提取事实,并将这些事实存储在便于获取的地方。今天,搜索引擎巨头谷歌和必应正是这样做的,他们将这些事实存储在一个“知识图”中,这个图与他们已经使用多年的搜索引擎紧密相连。
他们的方法是否有效?它如此成功地提供了答案——并且以惊人的规模提供了答案——以至于我们认为这一切都是理所当然的。
搜索变得越来越智能
在过去的几年里,你会注意到我们在日常生活中使用搜索引擎寻找答案的方式发生了微妙而深刻的变化。
当搜索引擎首次被引入时,人们很快就发现,问题越长越复杂,得到正确答案的可能性就越小。因为像“乐购最畅销的汤里有多少卡路里?”虽然不太可能产生结果,但我们成了关键词搜索方面的专家。通过将我们的查询转换成带有“Tesco soup nutrition”这样的关键词的短语,我们发现搜索引擎提供了更多相关的文件,甚至提供了直接的答案,挖掘出了一些重要的信息,这些信息可以让我们改进工作任务,加深我们的知识,或者解决争论。
然而,如今,我们对搜索的期望更多地与我们使用数字助手的方式一致,如Siri、谷歌Home和Alexa,所有这些都是由幕后的搜索引擎驱动的。当我们向他们提问时,我们得到了事实作为回报。因此,我们看到搜索引擎的查询在本质上变得越来越“发现事实”。
大的变化?现在,搜索引擎可以找到,优先排序,并显示我们需要的事实。它们不再像以前那样简单地返回页面(url)列表。相反,它们在可能的时间和地点为问题提供答案,同时提供详细的知识卡片和其他相关的搜索查询,所有这些都旨在帮助我们缩短访问关键事实所需的时间。同样令人印象深刻的是,搜索引擎和数字助手返回的结果比以往任何时候都更准确、更直观。
这对企业搜索意味着什么?
像谷歌和必应这样的搜索引擎在很大程度上归功于两项重大创新。首先,在2012年,谷歌在其搜索引擎中添加了一个知识图。后来,在2015年,该公司推出了RankBrain。两者都是具有里程碑意义的进展。
同样的方法现在也可以应用于企业搜索。将这一技术层添加到企业搜索引擎中,有可能使它们比以往任何时候都更智能。这里的游戏规则改变者是智能企业搜索(也被称为认知搜索或洞察力引擎)。通过将搜索与大量人工智能技术(如自然语言处理、语义理解、机器学习和知识图)相结合,智能企业搜索可以为用户提供一个显著改进的搜索体验——具有更多的洞察力。
知识图谱——为知识建模的一种非常强大的方法
第一个图的知识。在将其搜索引擎转变为“知识引擎”的过程中,谷歌一直在使用知识图来提供有关人物、地点、公司和主题等实体的结构化和详细信息。回想一下你最近一次搜索名人的年龄或者当地药剂师的营业时间,而不是浏览搜索结果列表而直接得到答案的情形。这些信息可能来自知识图,而不是搜索引擎。
因此,它们在问答系统中被证明是非常强大的。知识图越含水,搜索就变得越有洞察力。从结构化数据填充知识图相对简单(假设您信任数据源),从非结构化数据填充知识图需要使用复杂的自然语言处理(NLP)技术和文档权限模型。
为了说明可以实现什么,考虑下面的一段文字。里面有很多信息:
Gillian Russell出生在Invercargill。她是Gingerbeard有限公司的首席执行官,也是Gingerbeard咨询集团的公司秘书。Gillian和她的丈夫Phil Lewis住在英国的沃金厄姆。”
我们可以使用NLP来提取和分类文本示例中提到的事实作为语义三元组。这是三种信息:主体-谓词-对象,它们几乎可以建模实体之间的任何关系。这种编码信息的方法使知识能够以机器可读的方式呈现。
从这些语义三元组中可以生成表示相关实体的知识图。这个知识图是问答系统的强大基础,然后可以遍历它以提供答案,甚至是复杂的问题。
然而,在我们把知识图表放在所有文档上之前,有许多事情需要考虑:
- 我们是否信任此位置的数据源/文档中的信息?
- 吉尔/吉莉安和上面提到的吉莉安·拉塞尔是同一个人吗?
- 是“姜胡子”公司吗?还是海盗类型的人?
- 我们想要提取和记住这些实体之间的什么关系?
- 当他们询问时,谁被允许“接受”这些事实?
假设我们可以为一个给定的用例解决这些类型的问题,下面说明了建模知识和从这个文本示例创建知识图的一般过程。

图1所示。建模知识
这个知识模型可以开始回答如下问题:
- Gillian Russell是哪家公司的顶级员工?
- 谁是姜须有限公司的老板?
- 吉尔认识菲尔·刘易斯吗?
- 沃金厄姆有谁出生在Invercargill?
正如你所看到的,这是一种强大的资源。
单词向量——机器理解意思的方式
这个领域的第二个创新是“单词向量”,它利用机器学习技术来模拟单词含义的多样性和深度。巧妙的是,通过将单词表示为向量,基于人工智能的系统建立了一种我们如何使用单词以及它们之间关联的感觉。
例如,在一个基于人工智能的系统的简化的“心理空间”中,单词“阿姨”(一个亲戚)与“Beeb阿姨”(英国新闻频道BBC的昵称)占据了不同的“心理空间”。“山姆大叔”(联邦政府)和“叔叔”的意思不一样。而在人工智能的“心理空间”中,“阿姨”和“叔叔”的意思是紧密相连的,而“Beeb阿姨”和“山姆大叔”则不是。

图2:将单词表示为向量
以人工智能为基础的系统甚至可以理解一些单词的意思是如何随时间变化的(见图3)。单词向量让搜索引擎知道,当搜索50年代的“radio broadcasts”时,不应该找到写于19世纪50年代的含有“broadcast”的文件。

图3。单词的意思会随着时间而变化
毫不奇怪,对于某些查询类型,单词向量立即使谷歌的准确性提高了15%。随后的创新,如BERT和其他创新,进一步细化了性能,使人们能够更好地理解所使用的词汇。
为企业带来更智能的搜索
对企业来说,真正令人兴奋的事情是什么?我们现在可以开始在组织内部复制谷歌式的搜索体验——重新定义当人们被智能机器增强时可以实现的目标。
谷歌、亚马逊和微软的云搜索产品最近都宣布了与知识图集成的增强企业搜索解决方案。其他传统的内部搜索解决方案也开始意识到与知识图集成的好处。
我们可以利用表面上迥然不同的技术创新带来的巨大碰撞,来彻底改变人们寻找事实并得到他们想要答案的方式。
我已经在搜索行业工作了30年,为世界各地的组织工作过数百个企业搜索项目。而且从来没有这么多的机会来彻底重新定义搜索的功能。利用最新的技术,我们可以从支离破碎的数据点中创造新的价值。现在可以对多个数据片段如何组合在一起获得独特的见解。
由于人工智能技术如NLP和知识图正在迅速成熟,企业将受益于这些技术不断发展的解决问题的能力。不久,我们将能够比以往更准确、更快地回答令人难以置信的复杂问题。无论是发现新的医疗方法,发现看不见的市场变化,还是发现欺诈,每个行业的组织都将获得巨大的利益。
本文:http://jiagoushi.pro/node/1154
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 63 次浏览
【搜索引擎】配置 Solr 以获得最佳性能
Apache Solr 是广泛使用的搜索引擎。有几个著名的平台使用 Solr; Netflix 和 Instagram 是其中的一些名称。我们在 tajawal 的应用程序中一直使用 Solr 和 ElasticSearch。在这篇文章中,我将为您提供一些关于如何编写优化的 Schema 文件的技巧。我们不会讨论 Solr 的基础知识,我希望您了解它的工作原理。
虽然您可以在 Schema 文件中定义字段和一些默认值,但您不会获得必要的性能提升。您必须注意某些关键配置。在这篇文章中,我将讨论这些配置,您可以使用它们在性能方面充分利用 Solr。
事不宜迟,让我们开始了解这些配置是什么。
1.配置缓存
Solr 缓存与索引搜索器的特定实例相关联,索引的特定视图在该搜索器的生命周期内不会更改。
为了最大化性能,配置缓存是最重要的一步。
配置`filterCache`:
过滤器缓存由 SolrIndexSearcher 用于过滤器。过滤器缓存允许您控制过滤器查询的处理方式,以最大限度地提高性能。 FilterCache 的主要好处是当打开一个新的搜索器时,它的缓存可以使用旧搜索器的缓存中的数据进行预填充或“自动预热”。所以它肯定有助于最大限度地提高性能。例如:
<filterCache class="solr.FastLRUCache" size="512" initialSize="512" autowarmCount="0" />
类:SolrCache 实现 LRUCache(LRUCache 或 FastLRUCache)
size:缓存中的最大条目数
initialSize:缓存的初始容量(条目数)。 (参见 java.util.HashMap)
autowarmCount:要从旧缓存预填充的条目数。
配置`queryResultCache`和`documentCache`:
queryResultCache 缓存保存先前搜索的结果:基于查询、排序和请求的文档范围的文档 ID 的有序列表 (DocList)。
documentCache 缓存保存 Lucene Document 对象(每个文档的存储字段)。由于 Lucene 内部文档 ID 是瞬态的,因此该缓存不会自动预热。
您可以根据您的应用程序配置它们。它在您主要使用只读用例的情况下提供更好的性能。
假设您有一个博客,一个博客可以在帖子上有帖子和评论。在 Post 的情况下,我们可以启用这些缓存,因为在这种情况下,数据库读取远远超过写入。所以在这种情况下,我们可以为 Posts 启用这些缓存。
例如:
<queryResultCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0" /><documentCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0" />
如果您主要使用只写用例,请在每次软提交时禁用 queryResultCache 和 documentCache,这些缓存会被刷新,并且不会产生太大的性能影响。 因此请记住上面提到的博客示例,我们可以在评论的情况下禁用这些缓存。
2.配置SolrCloud

如今,云计算非常流行,它允许您管理可扩展性、高可用性和容错性。 Solr 能够设置结合容错和高可用性的 Solr 服务器集群。
在 setupSolrCloud 环境中,您可以配置“主”和“从”复制。 使用“主”实例来索引信息,并使用多个从属(基于需求)来查询信息。 在主服务器上的 solrconfig.xml 文件中,包括以下配置:
<str name="confFiles"> solrconfig_slave.xml:solrconfig.xml,x.xml,y.xml </str>
查看 Solr Docs 了解更多详细信息。
3.配置`Commits`
为了使数据可用于搜索,我们必须将其提交到索引。在某些情况下,当您拥有数十亿条记录时,提交可能会很慢,Solr 使用不同的选项来控制提交时间,让您可以更好地控制何时提交数据,您必须根据您的应用程序选择选项。
“提交”或“软提交”:
您可以通过发送 commit=true 参数和更新请求来简单地将数据提交到索引,它将对所有 Lucene 索引文件进行硬提交到稳定存储,它将确保所有索引段都应该更新,并且成本可能很高当你有大数据时。
为了使数据立即可用于搜索,可以使用附加标志 softCommit=true,它会快速提交您对 Lucene 数据结构的更改但不保证将 Lucene 索引文件写入稳定存储,此实现称为Near Real Time,一项提高文档可见性的功能,因为您不必等待后台合并和存储(如果使用 SolrCloud,则为 ZooKeeper)完成,然后再进行其他操作。
自动提交:
autoCommit 设置控制挂起更新自动推送到索引的频率。您可以设置时间限制或最大更新文档限制来触发此提交。也可以在发送更新请求时使用 `autoCommit` 参数定义。您还可以在 Request Handler 中定义如下:
<autoCommit> <maxDocs>20000</maxDocs> <maxTime>50000</maxTime> <openSearcher>false</openSearcher> </autoCommit>
maxDocs:自上次提交以来发生的更新数。
maxTime:自最旧的未提交更新以来的毫秒数
openSearcher:执行提交时是否打开一个新的搜索器。如果这是错误的,则提交会将最近的索引更改刷新到稳定存储,但不会导致打开新的搜索器以使这些更改可见。默认值为真。
在某些情况下,您可以完全禁用 autoCommit,例如,如果您将数百万条记录从不同的数据源迁移到 Solr,您不希望在每次插入时都提交数据,甚至不希望在批量的情况下提交数据。每 2、4 或 6 千次插入都不需要它,因为它仍然会减慢迁移速度。在这种情况下,您可以完全禁用 `autoCommit` 并在迁移结束时进行提交,或者您可以将其设置为较大的值,例如 3 小时(即 3*60*60*1000)。您还可以添加 <maxDocs>50000000</maxDocs>,这意味着仅在添加 5000 万个文档后才会自动提交。发布所有文档后,手动或从 SolrJ 调用一次 commit - 提交需要一段时间,但总体上会快得多。
此外,在您完成批量导入后,减少 maxTime 和 maxDocs,以便您对 Solr 所做的任何增量帖子都会更快地提交。
4.配置动态字段
Apache Solr 的一项惊人功能是 dynamicField。当您有数百个字段并且您不想定义所有字段时,它非常方便。
动态字段与常规字段一样,只是它的名称中带有通配符。在索引文档时,不匹配任何明确定义的字段的字段可以与动态字段匹配。
例如,假设您的架构包含一个名为 *_i 的动态字段。如果您尝试使用 cost_i 字段索引文档,但架构中没有明确定义 cost_i 字段,则 cost_i 字段将具有为 *_i 定义的字段类型和分析。
但是你在使用dynamicField时必须小心,不要广泛使用它,因为它也有一些缺点,如果你使用投影(如“abc.*.xyz.*.fieldname”)来获取特定的动态字段列,使用正则表达式解析字段需要时间。在返回查询结果的同时也增加了解析时间,下面是创建动态字段的示例。
<dynamicField name="*.fieldname" type="boolean" multiValued="true" stored="true" />
使用动态字段意味着您可以在字段名称中拥有无限数量的组合,因为您指定了通配符,有时可能会很昂贵,因为 Lucene 为每个唯一字段(列)名称分配内存,这意味着如果您有一行包含列A、B、C、D 和另一行有 E、F、C、D,Lucene 将分配 6 块内存而不是 4 块,因为有 6 个唯一列名,所以即使有 6 个唯一列名,万一百万行,它可能会使堆崩溃,因为它将使用 50% 的额外内存。
5. 配置索引与存储字段
索引字段意味着您正在使字段可搜索,indexed="true" 使字段可搜索、可排序和可分面,例如,如果您有一个名为 test1 且 indexed="true" 的字段,那么您可以像 q= 一样搜索它test1:foo,其中 foo 是您要搜索的值,因此,仅将搜索所需的那些字段设置为 indexed="true",如果需要,其余字段应为 indexed="false"在搜索结果中。例如:
<field name="foo" type="int" stored="true" indexed="false"/>
这意味着我们可以减少重新索引时间,因为在每次重新索引时,Solr 都会应用过滤器、标记器和分析器,这会增加一些处理时间,如果我们的索引数量较少的话。
6.配置复制字段
Solr 提供了非常好的功能,称为 copyField,它是一种将多个字段的副本存储到单个字段的机制。 copyField 的使用取决于场景,但最常见的是创建单个“搜索”字段,当用户或客户端未指定要查询的字段时,该字段将用作默认查询字段。
对所有通用文本字段使用copyField并将它们复制到一个文本字段中,并使用它进行搜索,它会减少索引大小并为您提供更好的性能,例如,如果您有像ab_0_aa_1_abcd这样的动态数据,并且您想要复制所有 具有后缀 _abcd 到一个字段的字段。 您可以在 schema.xml 中创建一个 copyField,如下所示:
<copyField source="*_abcd" dest="wxyz"/>
source:要复制的字段的名称
dest:复制字段的名称
7. 使用过滤查询‘fq’
在搜索中使用 Filter Query fq 参数对于最大化性能非常有用,它定义了一个查询,可用于限制可以返回的文档的超集,而不影响分数,它独立缓存查询。
Filter Queryfq 对于加速复杂查询非常有用,因为使用 fq 指定的查询独立于主查询进行缓存。 当后面的查询使用相同的过滤器时,会发生缓存命中,并且过滤器结果会从缓存中快速返回。
下面是使用过滤器查询的 curl 示例:
POST
{
"form_params": {
"fq": "id=1234",
"fl": "abc cde",
"wt": "json"
},
"query": {
"q": "*:*"
}
}过滤 qeury 参数也可以在单个搜索 qeury 中多次使用。 查看 Solr Filter Qeury 文档以获取更多详细信息。
8. 使用构面查询
Apache Solr 中的 Faceting 用于将搜索结果分类为不同的类别,执行聚合操作(如按特定字段分组、计数、分组等)非常有帮助,因此,对于所有聚合特定查询,您可以使用 Facet 来 开箱即用地进行聚合,它也将成为性能提升器,因为它纯粹是为此类操作而设计的。
下面是向 solr 发送构面请求的 curl 示例。
{
"form_params": {
"fq" : "fieldName:value",
"fl" : "fieldName",
"facet" : "true",
"facet.mincount": 1,
"facet.limit" : -1,
"facet.field" : "fieldName",
"wt" : "json",
},
"query" : {
"q": "*:*",
},
}fq:过滤查询
fl:结果中要返回的字段列表
facet:true/false 启用/禁用构面计数
facet.mincount:排除计数低于 1 的范围
facet.limit:限制结果中返回的组数,-1 表示全部
facet.field:该字段应被视为构面(对结果进行分组)
结论:
将 Solr 投入生产时,性能改进是关键步骤。 Solr 中有许多调整旋钮可以帮助您最大限度地提高系统的性能,其中一些我们在本博客中讨论过,在 solr-config 文件中进行更改以使用最佳配置,使用适当的索引选项或字段更新架构文件 类型,尽可能使用过滤器 queriesfq 并使用适当的缓存选项,但这又取决于您的应用程序。
这就结束了。 我希望这篇文章对您有所帮助,如果您想了解更多信息,请查看下面链接的 Solr 参考
原文:https://medium.com/tech-tajawal/tips-and-tricks-to-maximize-apache-solr…
本文:https://jiagoushi.pro/configuring-solr-optimum-performance
- 146 次浏览
【搜索引擎选型】Solr vs. Elasticsearch:选择开源搜索引擎时应考虑的事项
结合了云,分析和认知搜索的观察结果
Solr vs. Elasticsearch在我们的客户项目和企业搜索社区中经常讨论。但是,随着传统企业搜索已演变为Gartner所谓的“ Insight Engines”,我们重新讨论了该主题,以提供结合了Cloud,Analytics和Cognitive Search功能的最新观察结果,以帮助您评估Solr和Elasticsearch。
通常,当我们帮助客户进行围绕其企业解决方案中使用开源搜索引擎的评估时,会提出以下问题:“ Solr还是Elasticsearch,哪个更好?”虽然可能会有先入为主的观念,这个问题比另一个要好,当被圈定为“哪个对我更好?”时,这个问题更相关。
可以使用多种搜索引擎技术,但是最受欢迎的开放源代码变体是那些依赖于Apache Lucene底层核心功能的技术,从本质上讲,这是使搜索引擎正常工作的部分。 Solr和Elasticsearch是搜索库之上的组件,为完整的搜索产品提供了自己的实现和功能。 Lucene的核心功能为Solr和Elasticsearch的基本搜索功能提供了相同的体验,但是围绕Lucene的实现方法才是差异化的原因。
搜索引擎的作用已经从有效地查找信息转变为在内容分析,预测建模以及与认知/智能搜索功能(例如自然语言处理(NLP),机器学习(ML)和相关性)的集成中发挥关键作用得分。我们已经在客户工作中探索并实现了这些智能功能-在此处了解更多信息。
Solr vs. Elasticsearch:哪个对我的组织更好?
这得看情况。
关于采用一种技术而不是另一种技术有许多用例。但是当被问到这个问题时,我通常会从运营管理的角度来类比地回答:“ Solr就像Linux。您可以根据自己的需求进行大量自定义和定制Solr,但与Elasticsearch所需的工作相比,管理和部署要涉及更多的资源,而且要消耗大量资源。 Elasticsearch具有非常好的设计的用户界面(Kibana),非常易于部署,管理和监视(使用X-Pack),该界面允许进行数据探索和创建分析可视化,但是自定义其功能是有限的,并且使用插件框架。
如果您愿意,Elasticsearch可能适合您:
- 使您的搜索引擎快速启动并运行,而几乎不会产生任何开销;
- 尽快开始探索您的数据;和
- 将分析和可视化视为用例的核心组成部分。
如果您满足以下条件,Solr可能适合您:
- 需要大规模索引和重新处理大量数据;
- 有可用的资源来投资于管理Solr和可用于交互的工具;和
- 具有可与Solr配合使用的现有企业框架(例如其他Apache产品(例如Hadoop)或企业框架(例如Cloudera,Hortonworks或基于Hadoop的HDInsights))。
这并不是说Hadoop平台无法与Elasticsearch配合使用(我们已向客户提出了此方案),但是某些平台(尤其是Cloudera和Hortonworks)提供了额外的工具和方法来对生态系统内的数据建立索引和管理Solr(尤其是即将发布的支持Solr 7的Cloudera CDH 6版本。
观察结果:性能,功能和用例
根据经验,评估可以为帮助客户定义策略和实施路线图提供巨大的价值。在评估过程中,我们使用搜索引擎比较矩阵,根据特定客户的优先级,采用加权评分机制,根据特定客户的需求和用例评估搜索引擎的适用性。基于此分析,在为搜索引擎提出整体建议时,有一些共同的功能和用例可作为关注点。
The chart below captures some of the observations about Solr and Elasticsearch:
| SOLR | ELASTICSEARCH | |
|---|---|---|
| Use Cases |
|
|
| Visualization Tools |
|
|
| Cloud and Big Data |
|
|
| Cognitive Search Capabilities and Integration |
|
|
| Management and Operations |
|
|
| Development Architecture |
|
|
| Cluster State Management |
|
|
| Security |
|
|
| Bulk Indexing Tools |
|
|
| Near Real Time (NRT) Indexing (not a comprehensive list) |
|
|
| Analytics |
|
|
| Nested Data Structures |
|
|
| Query Operations |
|
|
| API Interaction |
|
|
在Solr和Elasticsearch之间选择?考虑这些
决定哪种搜索引擎最适合您的特定用例和需求,不应基于“非此即彼”的假设。 Solr中特定功能的总体重要性可能超过Elasticsearch中的运营优势,例如:
在一个客户端的情况下,与Solr部署相关联的开销以及必须使用SolrNET的过期客户端(当时)的开销被Solr的可插入性所抵消。需要使用自定义加密更新和请求处理程序,才能使用旋转数据加密密钥对索引内容进行加密,从而需要在Elasticsearch上使用Solr。索引加密过程所需的功能无法在Elasticsearch中有效实现。
相反,在不考虑大数据或分析因素的情况下,针对一般搜索用例评估搜索引擎选项时,由于减少了维护和部署的开销以及用于完全托管和托管环境的选项,Elasticsearch成为更受欢迎的选项。
在某些情况下,根据对客户最重要的因素,尽管应用了计分规则,但尚不清楚哪个搜索引擎(包括商业引擎)最能满足客户的需求。在这种情况下,可以使用样本数据集进行“烘焙”,以评估每个引擎在一组特定用例中的表现,从而对客户进行评估。
归根结底,Solr和Elasticsearch都是强大,灵活,可扩展且功能强大的开源搜索引擎。总体用例和业务需求,以及所需的功能,操作注意事项以及与新的认知搜索和分析功能的集成,最终将决定您选择Solr还是Elasticsearch。
本文:http://jiagoushi.pro/node/906
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 183 次浏览
【数据库】Elasticsearch PostgreSQL 比较:6 个关键差异
数据现在被认为是任何组织最有价值的资产之一。它使企业内的交易更容易,并促进运营的顺畅流动。随着组织比以往任何时候都更依赖基于证据的决策,数据也充当了关键的决策工具。因此,每个组织都在寻找一种以最有效的方式存储数据的方法。
在选择现代数据库时,公司通常会在选择像 PostgreSQL 这样的 SQL 数据库还是像 Elasticsearch 这样的 NoSQL 数据库方面遇到难题。尽管这两者对于企业来说都是可行的选择,但它们之间存在一些必须考虑的关键差异。考虑到这些差异后,组织应该能够判断哪个数据库适合他们的要求。
本文将帮助您了解 PostgreSQL Elasticsearch 的各种差异,从而帮助您针对您独特的业务和数据需求做出明智的决定。
目录
- 什么是弹性搜索?
- 了解 Elasticsearch 的主要功能
- 什么是 PostgreSQL?
- 了解 PostgreSQL 的主要特性
- ElasticSearch PostgreSQL 主要区别
- Elasticsearch PostgreSQL 主要区别:数据库模型
- Elasticsearch PostgreSQL 主要区别:事务支持
- Elasticsearch PostgreSQL 主要区别:架构灵活性
- Elasticsearch PostgreSQL 主要区别:CAP 定理实现
- Elasticsearch PostgreSQL 主要区别:安全性
- Elasticsearch PostgreSQL 主要区别:基于云的产品
- 结论
什么是Elasticsearch ?
Elasticsearch 可以定义为一个免费的、分布式的、开源的搜索和分析引擎,可用于处理多种类型的数据,例如数字、文本、结构化、非结构化等。Elasticsearch 的第一个版本于 2010 年发布,建立在一个名为 Apache Lucene 的搜索引擎软件库之上。 Elasticsearch 现在以其简单的 REST API、速度、分布式特性和可扩展性而闻名。 Elasticsearch 现在也是 Elastic Stack 的核心组件,这是一组免费的开源工具,允许用户无缝地执行数据摄取和丰富、数据分析和可视化。
Elasticsearch 将数据存储为相互关联的文档集合,因此可以被视为面向文档的搜索引擎,可用于存储、管理和检索结构化、半结构化或非结构化数据。 Elasticsearch 将数据存储为 JSON 文档,这意味着每个文档都由一组键及其对应的值组成。
Elasticsearch 利用一种称为倒排索引的数据结构,使其能够执行异常快速的全文搜索。 Elasticsearch 存储所有文档并在索引过程中构建一个倒排索引,使其能够实时搜索文档数据。
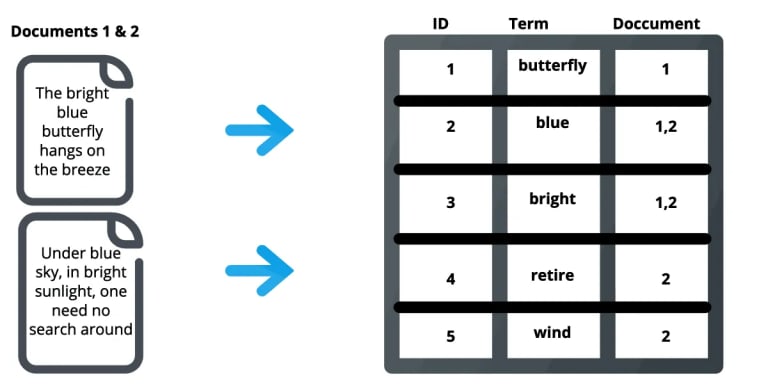
了解 Elasticsearch 的主要功能
Elasticsearch 的主要特点如下:
- 快速数据访问:Elasticsearch 中的所有文档都存储在靠近索引中相应元数据的位置。这减少了数据所需的读取操作次数,从而缩短了整体搜索结果响应时间。
- 自动节点恢复:如果节点因节点故障、故意移除等任何原因离开 Elasticsearch 集群,主节点会采取必要的措施,将节点替换为其副本并重新平衡所有分片以自动管理负载。
- 升级助手 API:升级助手 API 使用户能够检查其 Elasticsearch 集群的升级状态并重新索引在以前版本的 Elasticsearch 中创建的索引。该助手可帮助用户为 Elasticsearch 的下一个主要版本做好准备。
- 索引生命周期管理:Elasticsearch 索引生命周期管理 (ILM) 允许用户定义和自动化许多策略,这些策略有助于控制 Elasticsearch 索引在每个阶段的生存时间。它还允许用户设置在每个阶段对索引执行的操作。
- 搜索引擎的可扩展性:Elasticsearch 实现了一个分布式架构,使其能够扩展到数千台服务器并处理 PB 级的数据,而不会遇到任何性能问题。这种分布式设计由 Elasticsearch 自动处理,因此客户可以专注于执行所需的操作。
什么是 PostgreSQL?
PostgreSQL 是一个免费的开源数据库。它现在被认为是市场上最强大的关系数据库管理系统 (RDBMS) 之一。它结合了 SQL 并添加了一组新功能,允许将 PostgreSQL 用于事务性数据库并用作用于分析目的的数据仓库。
使用 PostgreSQL 最显着的优势之一以及为什么它成为大多数使用关系数据库的企业的首选是它支持对象关系模型的能力,它允许用户根据应用程序中的用例定义自定义数据类型。
了解 PostgreSQL 的主要特性
PostgreSQL 的主要特性如下:
- 数据完整性:PostgreSQL 通过让用户能够创建主键和外键、唯一和非空约束、显式和咨询锁、排除约束等来确保数据完整性。
- 多种数据类型:PostgreSQL 支持多种数据类型,包括 Integer、String、Boolean 等原始数据类型,数组、日期、时间等结构化数据类型,以及 Document 数据类型等如 XML、JSON 等。
- 高度可扩展性:PostgreSQL 被认为具有高度可扩展性,因为它支持各种过程语言,例如 PL/pgSQL、Perl、Python 等、JSON/SQL 路径表达式、可用于通过标准连接到不同数据库的外部数据包装器SQL 接口。
- 强大的安全性:PostgreSQL 拥有强大的访问控制系统以及多个安全身份验证,包括轻量级目录访问协议 (LDAP)、SCRAM-SHA-256 等,使其成为可用的最安全的关系数据库管理系统 (RDBMS) 之一。
- 高度可靠:PostgreSQL 支持多种灾难恢复技术,例如 Active Standbys、时间点恢复 (PITR)、表空间,以及多种类型的复制,例如逻辑、同步和异步
Elasticsearch PostgreSQL 主要差异
虽然 Elasticsearch 和 PostgreSQL 都是著名的数据库管理系统,但它们之间有很多不同之处,如下所示:
- Elasticsearch PostgreSQL 主要区别:数据库模型
- Elasticsearch PostgreSQL 主要区别:事务支持
- Elasticsearch PostgreSQL 主要区别:架构灵活性
- Elasticsearch PostgreSQL 主要区别:CAP 定理实现
- Elasticsearch PostgreSQL 主要区别:安全性
- Elasticsearch PostgreSQL 主要区别:基于云的产品
1) Elasticsearch PostgreSQL 主要区别:数据库模型
PostgreSQL 是一个关系数据库管理系统 (RDBMS),因此,它以行和列的形式在众多表中存储数据。 它还使用户能够在表之间形成关系。 PostgreSQL 是一种 SQL 数据库,允许使用结构化查询语言 (SQL) 来查询数据。 一个示例 PostgreSQL 数据库如下:
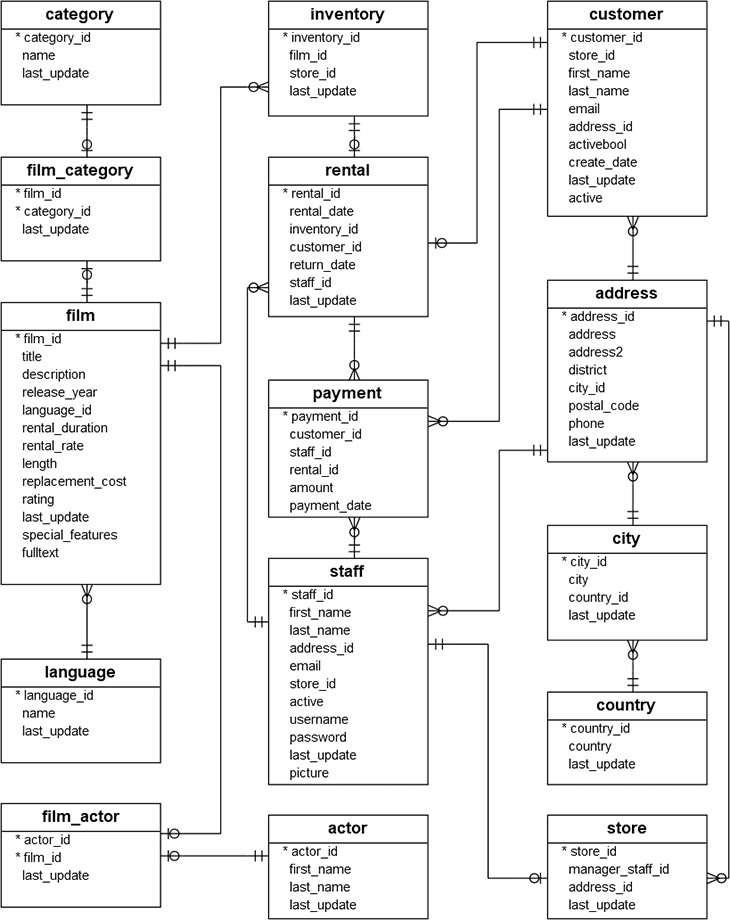
Elasticsearch 是一个 NoSQL 分布式文档存储。 这意味着 Elasticsearch 不是将数据存储在表中,而是存储复杂的数据结构,序列化为 JSON 文档。 这些文档分布在集群中的多个节点上,如果需要,可以从任何节点立即访问。 Elasticsearch 中的示例索引如下:
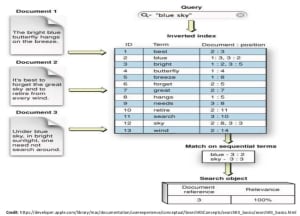
2) Elasticsearch PostgreSQL 主要区别:事务支持
Elasticsearch 旨在为其用户提供高速数据库操作。由于将数据库功能作为事务执行需要复杂的操作,这会减慢进程,因此 Elasticsearch 不包含典型意义上的事务支持。因此,无法回滚已提交的文档或提交一组文档,并在 Elasticsearch 中索引全部或不索引。相反,Elasticsearch 包含一个预写日志,它只能帮助确保所有数据库操作的持久性,而无需执行任何提交。用户还可以选择指定索引操作的一致性级别,即有多少副本必须在返回之前确认数据库操作。
另一方面,PostgreSQL 支持健壮的事务机制。 PostgreSQL 中的事务将多个步骤捆绑为一个,或者所有这些步骤都被执行,或者一个都不被执行。用户可以利用 BEGIN 和 COMMIT 命令将操作捆绑在一起,并利用 ROLLBACK 和 SAVEPOINT 命令将操作回滚到给定点。
3) Elasticsearch PostgreSQL 主要区别:架构灵活性
用户不必预先指定 Elasticsearch 索引的架构。 Elasticsearch 可以通过分析用户尝试存储的数据来自动推断数据类型。它在识别数字、布尔值和时间戳方面做得相当不错。它利用标准分析器来识别字符串。
然而,PostgreSQL 实现了一个严格的模式。这意味着模式必须包含带有类型列的预定义表。严格的模式允许 PostgreSQL 提供一组丰富的功能,否则这些功能是不可能的。
4) Elasticsearch PostgreSQL 主要区别:CAP 定理实现
任何数据库管理系统都可以提供的三个特性如下:
一致性:连接到数据库的所有客户端看到相同的数据,这意味着一旦在数据库中写入或更新任何数据,也应该在其所有副本上执行相同的操作。
可用性:来自客户端的任何请求至少会从数据库中获得一些响应。
分区容限:即使很少有节点宕机,集群也会继续执行所需的操作。
CAP 定理指出,任何数据库都只能提供三个 CAP 属性中的两个。
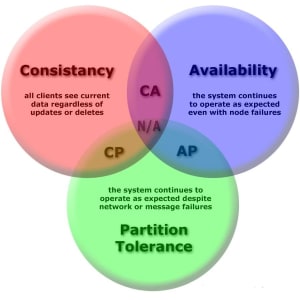
PostgreSQL 只能为其用户提供一致性和可用性,但不能提供分区容差,而 Elasticsearch 可以为其用户提供可用性和分区容差。然而,ElasticSearch 仅确保每个文档的一致性,这意味着所有写入将自动在“文档所有者”分片上执行,并最终在副本分片上复制。
5) Elasticsearch PostgreSQL 主要区别:安全性
Elasticsearch 不包含任何内置功能来确保用户身份验证或授权。这意味着任何能够连接到 Elasticsearch 集群的用户都将拥有管理员权限。因此,用户必须在其应用层中配置授权和身份验证机制,因为 Elasticsearch 会将每个用户都视为超级用户。
PostgreSQL 拥有强大的访问控制系统以及多种安全身份验证,包括轻量级目录访问协议 (LDAP)、SCRAM-SHA-256 等,使其成为最安全的关系数据库管理系统 (RDBMS) 之一。
6) Elasticsearch PostgreSQL 主要区别:基于云的产品
Elasticsearch 为其用户提供了许多不同层次的基于云的官方产品。每层提供的定价和功能如下:

PostgreSQL 不提供任何基于云的官方产品或解决方案。因此,用户将不得不依赖 PostgreSQL 开发人员推荐的第三方供应商。这些第三方供应商包括 2ndQuadrant、Aiven、Amazon Web Services 等等。
结论
本文让您深入了解 Elasticsearch 和 PostgreSQL 以及 Elasticsearch PostgreSQL 的各种差异。除非知道需求,否则不能说一个数据库比另一个更好。因此,您可以在了解各种 Elasticsearch PostgreSQL 差异后,根据您的业务用例和数据需求做出最终选择。
当今大多数现代企业都使用多个数据库进行运营。这导致了一种复杂的情况,因为如果必须执行整合来自所有这些数据库的数据的通用分析,这可能是一项复杂的任务。必须首先构建一个数据集成解决方案,该解决方案可以集成来自这些数据库的所有数据并将其存储在一个集中位置。企业可以选择制作自己的数据集成解决方案,也可以使用现有的自动化无代码平台,如 Hevo Data。
- 445 次浏览
数据库基础
视频号
微信公众号
知识星球
- 100 次浏览
【数据库】如何选择合适的数据库
视频号
微信公众号
知识星球
在当今数据驱动的世界中,技术变化非常迅速,数据库也不例外。 当前的数据库市场提供了数百种数据库,它们在数据模型、用途、性能、并发性、可扩展性、安全性和提供的供应商支持数量方面各不相同。
选择数据库是另一类挑战。 为您的企业选择合适的数据库并非易事。 能够对数据库技术做出严格、明智的选择需要详细了解以下内容:
- 了解业务需求
- 技术评估
- 技能集映射
了解您的业务需求
无论您考虑使用哪种类型的数据库,第一个关键步骤是定义您的业务需求。 对于小额采购,此步骤可能涉及与其他员工的快速对话,但对于大型、关键任务软件,可能需要数月的工作时间。
数据库选择过程的关键驱动因素包括对以下问题的回答:
- 业务应用是什么?
- 您希望存储的数据的性质是什么?
- 您期望什么样的数据增长?
- 如果数据库出现故障,会有什么影响?
- 数据访问的频率是多少?
- 您的业务需要哪些 ACID 属性?
让我们考虑一个例子:如果您的应用程序需要灵活地保存动态数据内容,那么您可能不会选择关系数据库,而可能更喜欢文档存储或键值数据库。
对非结构化数据的业务需求有不同种类的数据库,如 S3 对象存储、基于文件的系统等。
技术评估
任何数据库都支持写入数据并再次读回。 一些数据库允许查询任意字段。 有些为快速查找提供索引。 一些支持临时查询,而查询必须为其他人计划。 有这么多不同的数据库系统的原因很简单,任何系统不可能同时获得所有需要的特性。
对于任何数据库选择过程都很重要的常见通用数据库组件包括:
- 存储引擎
- 查询处理器
- 查询语言
- 元数据目录
- 优化引擎
- 分片或分区
- 数据可用性
- 缩放
选择数据库时,技术评估是一个关键部分,任何数据库的性能都取决于它内部构建的内容。
存储引擎:存储引擎是数据库管理系统(DBMS)的核心组件,它在操作系统级别与文件系统交互以存储数据。 所有与底层数据交互的 SQL 查询都通过存储引擎。
查询处理器:这是用户查询和数据库之间的中介。 查询处理器解释用户的查询,并使它们成为可操作的命令,数据库可以理解这些命令以执行适当的功能。
查询语言:与数据库交互需要数据库访问语言,从创建数据库到简单地插入或检索数据。 在许多查询语言中,查询语言的功能可以根据具体任务进一步分类:
- 数据定义语言 (DDL):它由可用于定义数据库模式或修改数据库对象结构的命令组成。
- 数据操作语言 (DML):直接处理数据库中数据的命令。 所有 CRUD 操作都在 DML 之下。
- 数据控制语言(DCL):它处理数据库的权限和其他访问控制。
- 事务控制语言 (TCL):处理内部数据库事务的命令。
元数据目录:这是数据库中所有对象的集中目录。 创建对象时,数据库使用元数据目录保存该对象的记录以及有关它的一些元数据。
分片:分片是一种跨多个数据库分布单个数据集的方法,然后可以将其存储在多台机器上。 这允许将较大的数据集拆分成较小的块并存储在多个数据节点中,从而增加系统的总存储容量。 分片可以是:
- 基于键的分片/哈希分片
- 基于范围的分片
- 基于字典的分片
分区:分区使用分区键/键将数据划分为某种逻辑形式。 数据库分区通常是出于可管理性、性能或可用性原因而完成的。
数据可用性:数据库高可用性是应用程序高可用性的一个重要组成部分,但这并不是全部。 某些情况(例如,区域性灾难或系统性损坏)需要适当的备份和恢复机制。 同样,并非所有数据库都提供相同级别的功能。
缩放:可扩展性描述了系统的弹性。 它指的是系统的增长能力。 您可以相应地缩小、放大和缩小。 良好的可扩展性可以保护您免受未来停机的影响,并确保您的服务质量。 水平扩展是指通过向资源池添加更多机器进行扩展(也称为“向外扩展”),而垂直扩展是指通过向现有机器添加更多功能(例如 CPU、RAM)进行扩展(也称为“扩展” 向上”)。
在垂直扩展中,数据存在于单个节点上,扩展是通过多核完成的,例如,在机器的 CPU 和 RAM 资源之间分配负载。
技能集映射
在没有适当指导的情况下处理未知技术通常会增加更多的不确定性。 如果您在没有适当的技术支持的情况下处理复杂的数据库,那将是一场噩梦。 一般来说,人们更喜欢稳定、流行的数据库,主要原因是在市场上有适当的支持和资源。
数据库评估最重要的部分是评估可用的技能集,并在选择正确的数据库之前找出组织中缺失的技能。 以下是非技术评估的一些重要标准:
- 技术普及
- 它支持的功能
- 产品成本
- 知识库或技术支持
- 可用资源和帮助
- 工程师的可用性及其成本
数据库即服务
DBaaS(数据库即服务)是一种云计算托管服务提供模型,使用户能够通过某种形式的数据库访问来设置、操作、管理和扩展,而无需在物理硬件上进行设置、安装软件、 或配置它以提高性能。
云服务提供商提供三类数据库服务:
- 关系数据库管理系统
- 无SQL
- DW
流行的 DBMS 产品包括:

数据库即服务的好处
- 敏捷性:云 DBaaS 应用程序本质上是敏捷的,因此它们可以根据业务或技术进步无缝适应任何升级。 DBaaS 允许快速配置数据库资源,以在尽可能短的时间内提供新的计算资源和存储设施。
- 保护您的数据:安全性是 DBaaS 领域中最关键的挑战之一。 随着越来越多的企业将数据托管在云端,DBaaS 提供商必须防止对数据资源的未授权访问,禁止滥用存储在第三方平台上的数据,并确保数据的机密性、完整性和可用性。
- 根据业务需求扩展:DBaaS 模型提供自动化和动态扩展。 DBaaS 提供商适应工作负载变化,并可以通过在高峰时段增加资源而不中断任何服务来管理负载变化,或者通过在非高峰使用期间分配更少的资源来帮助降低成本。 用户可以快速增加存储和计算能力以满足高处理需求,同时还可以为系统在需求波动期间的行为方式定义使用阈值策略。
- 高可用性:在当今快节奏的数字世界中,保持 24/7 的正常运行时间是任何现代企业的必备条件。 中断与收入损失成正比。 随着数字化转型变得越来越重要,您的应用程序服务应保持 24/7 不停机而变得越来越重要。
- 提高运营效率:由于 DBaaS 是一项服务,您可以一次从一个节点开始,然后在不中断业务的情况下扩大规模。 组织可以随着发展而扩展,这更具成本效益; 通过一次添加一个或多个节点,然后关闭不再需要的资源,IT 团队可以防止代价高昂的超支。
概括
在为业务需求选择合适的数据库时,有多个评估过程——从业务需求到运营管理,从技能集映射到技术审查。 拥有正确的工具和技术可以提高运营效率并减少干扰。 从数以千计的可用选项中选择最佳选项之一并不容易,需要技术娴熟的人员和学科专家。
- 229 次浏览
【数据库选型】ClickHouse vs PostgreSQL vs TimescaleDB
目录
- 什么是ClickHouse?
- ClickHouse与PostgreSQL
- ClickHouse与TimescaleDB
- 结论
在过去的一年里,我们不断听到的一个数据库是ClickHouse,这是一个由Yandex最初构建并开源的面向列的OLAP数据库。
在这篇经过三个月研究和分析的详细文章中,我们回答了我们听到的最常见的问题,包括:
- 什么是ClickHouse(包括对其架构的深入了解)
- ClickHouse与PostgreSQL相比如何
- ClickHouse与TimescaleDB相比如何
- 与TimescaleDB相比,ClickHouse在时间序列数据方面的表现如何
向Timescale的工程师Alexander Kuzmenkov(最近是ClickHouse的核心开发人员)和Aleksander Alekseev(同时也是PostgreSQL的贡献者)大喊,他们帮助检查了我们的工作并让我们对这篇文章保持诚实。
标杆管理,而不是“标杆营销”(Benchmarking, not “Benchmarketing”)
在Timescale,我们非常认真地对待我们的基准。我们发现,在我们的行业中,有太多供应商偏向的“基准市场营销”,而没有足够诚实的“基准”。我们认为开发人员应该得到更好的服务。因此,我们竭尽全力真正了解我们正在比较的技术,并指出其他技术的闪光点(以及TimescaleDB可能的不足之处)。
您可以在我们的其他详细基准测试与AWS Timestream(29分钟读取)、MongoDB(19分钟读取)和InfluxDB(26分钟读取)中看到这一点。
我们也是真正喜欢学习和挖掘其他系统的数据库呆子。(这就是为什么这些帖子——包括这个帖子——这么长的几个原因!)
因此,为了更好地了解ClickHouse的优缺点,我们在过去的三个月和数百个小时里进行了基准测试、测试、阅读文档以及与贡献者合作。
ClickHouse在我们的测试中表现如何
ClickHouse是一项令人印象深刻的技术。在一些测试中,ClickHouse被证明是一个极快的数据库,能够比我们迄今为止测试过的任何其他数据库(包括TimescaleDB)更快地接收数据。在一些复杂的查询中,特别是那些进行复杂分组聚合的查询,ClickHouse是很难击败的。
但数据库中没有任何内容是免费的。ClickHouse之所以能够实现这些结果,是因为它的开发人员已经做出了具体的架构决策。这些架构决策也带来了局限性,尤其是与PostgreSQL和TimescaleDB相比。
ClickHouse的局限性/弱点包括:
- 在Time-Series Benchmark Suite中的几乎所有查询中,查询性能都低于TimescaleDB,但复杂聚合除外。
- 在小批量大小(例如100-300行/批)下,插入不良和磁盘使用率高出很多(例如,磁盘使用率比TimescaleDB高2.7倍)。
- 类似SQL的非标准查询语言,有几个限制(例如,不鼓励连接,语法有时不标准)
- 健壮的SQL数据库(如PostgreSQL或TimescaleDB)缺少其他功能:没有事务、没有相关子查询、没有存储过程、没有用户定义的函数、除了主索引和辅助索引之外没有索引管理、没有触发器。
- 无法以高速率和低延迟修改或删除数据,而必须批量删除和更新
- 批量删除和更新异步进行
- 因为数据修改是异步的,所以很难确保一致的备份:确保一致备份的唯一方法是停止对数据库的所有写入操作
- 缺少事务和数据一致性也会影响其他特性,如物化视图,因为服务器不能一次自动更新多个表。如果在向包含物化视图的表的多部分插入过程中出现中断,最终结果是数据的状态不一致。
我们列出这些缺点并不是因为我们认为ClickHouse是一个糟糕的数据库。实际上,我们认为它是一个很棒的数据库,更准确地说,是一个适合某些工作负载的很棒的数据库。作为开发人员,您需要为工作负载选择合适的工具。
为什么ClickHouse在某些情况下表现良好,但在其他情况下表现较差?
答案是底层架构。
数据库通常有两种基本架构,每种架构都有优缺点:在线事务处理(OLTP)和在线分析处理(OLAP)。
| OLTP | OLAP |
|---|---|
| Large and small datasets | Large datasets focused on reporting/analysis |
| Transactional data (the raw, individual records matter) | Pre-aggregated or transformed data to foster better reporting |
| Many users performing varied queries and updates on data across the system | Fewer users performing deep data analysis with few updates |
| SQL is the primary language for interaction | Often, but not always, utilizes a particular query language other than SQL |
ClickHouse、PostgreSQL和TimescaleDB体系结构
从较高的层次上讲,ClickHouse是一个为分析系统设计的优秀OLAP数据库。
相比之下,PostgreSQL是一个通用数据库,旨在成为一个多功能、可靠的OLTP数据库,用于具有高用户参与度的记录系统。
TimescaleDB是用于时间序列的关系数据库:专门构建在PostgreSQL上用于时间序列工作负载。它结合了PostgreSQL的优点和新功能,可以提高性能、降低成本,并为时间序列提供更好的总体开发体验。
因此,如果您发现自己需要对几乎不可变的大型数据集(即OLAP)执行快速分析查询,那么ClickHouse可能是更好的选择。
相反,如果您发现自己需要更通用的软件,那么它可以很好地为具有许多用户的应用程序提供支持,并且可能会频繁更新/删除,即OLTP、PostgreSQL可能是更好的选择。
如果您的应用程序具有时间序列数据,特别是如果您还希望PostgreSQL的多功能性,那么TimescaleDB可能是最佳选择。
时间序列基准套件结果汇总(TimescaleDB与ClickHouse)
我们可以看到这些架构决策对TimescaleDB和ClickHouse处理时间序列工作负载的影响。
在这个基准测试研究期间,我们花了数百个小时与ClickHouse和TimescaleDB合作。我们测试了从1亿行(10亿指标)到10亿行(100亿指标)的插入负载,从1亿到1000万的基数,以及其间的许多组合。我们真的想了解每个数据库是如何跨各种数据集工作的。
总的来说,对于插件,我们发现ClickHouse的表现优于批量较大的插件,但低于批量较小的插件。对于查询,我们发现ClickHouse在基准测试套件中的大多数查询中表现不佳,但复杂聚合除外。
插入性能
当每次插入的行数在5000到15000行之间时,两个数据库的速度都很快,ClickHouse的性能明显更好:
ClickHouse、PostgreSQL和TimescaleDB体系结构
从较高的层次上讲,ClickHouse是一个为分析系统设计的优秀OLAP数据库。
相比之下,PostgreSQL是一个通用数据库,旨在成为一个多功能、可靠的OLTP数据库,用于具有高用户参与度的记录系统。
TimescaleDB是用于时间序列的关系数据库:专门构建在PostgreSQL上用于时间序列工作负载。它结合了PostgreSQL的优点和新功能,可以提高性能、降低成本,并为时间序列提供更好的总体开发体验。
因此,如果您发现自己需要对几乎不可变的大型数据集(即OLAP)执行快速分析查询,那么ClickHouse可能是更好的选择。
相反,如果您发现自己需要更通用的软件,那么它可以很好地为具有许多用户的应用程序提供支持,并且可能会频繁更新/删除,即OLTP、PostgreSQL可能是更好的选择。
如果您的应用程序具有时间序列数据,特别是如果您还希望PostgreSQL的多功能性,那么TimescaleDB可能是最佳选择。
时间序列基准套件结果汇总(TimescaleDB与ClickHouse)
我们可以看到这些架构决策对TimescaleDB和ClickHouse处理时间序列工作负载的影响。
在这个基准测试研究期间,我们花了数百个小时与ClickHouse和TimescaleDB合作。我们测试了从1亿行(10亿指标)到10亿行(100亿指标)的插入负载,从1亿到1000万的基数,以及其间的许多组合。我们真的想了解每个数据库是如何跨各种数据集工作的。
总的来说,对于插件,我们发现ClickHouse的表现优于批量较大的插件,但低于批量较小的插件。对于查询,我们发现ClickHouse在基准测试套件中的大多数查询中表现不佳,但复杂聚合除外。
插入性能
当每次插入的行数在5000到15000行之间时,两个数据库的速度都很快,ClickHouse的性能明显更好:
Performance comparison: ClickHouse outperforms TimescaleDB at all cardinalities when batch sizes are 5,000 rows or greater
然而,当批处理大小较小时,结果会以两种方式反转:插入速度和磁盘消耗。ClickHouse的批量较大,每批5000行,在测试期间消耗了约16GB的磁盘,而TimescaleDB消耗了约19GB的磁盘(均在压缩之前)。
使用较小的批处理大小,TimescaleDB不仅在100-300行/批之间保持了比ClickHouse更快的稳定插入速度,而且ClickHouse的磁盘使用量也高2.7倍。由于每个数据库的体系结构设计选择,应该可以预料到这种差异,但它仍然很有趣。
Performance comparison: Timescale outperforms ClickHouse with smaller batch sizes and uses 2.7x less disk space
查询性能
为了测试查询性能,我们使用了一个“标准”数据集,该数据集在三天内查询4000台主机的数据,总共有1亿行。在我们过去运行基准测试的经验中,我们发现这种基数和行计数可以作为基准测试的代表性数据集,因为它允许我们在几个小时内跨每个数据库运行许多摄取和查询周期。
基于ClickHouse作为快速OLAP数据库的声誉,我们预计ClickHouse在基准测试中的几乎所有查询中都会优于TimescaleDB。
当我们在没有压缩的情况下运行TimescaleDB时,ClickHouse确实表现得更好。
然而,当我们启用TimescaleDB压缩(这是推荐的方法)时,我们发现了相反的情况,TimescaleDB几乎在所有方面都表现出色:
Results of query benchmarking between TimescaleDB and ClickHouse. TimescaleDB outperforms in almost every query category
(对于那些想复制我们的研究结果或更好地理解ClickHouse和TimescaleDB在不同情况下的表现方式的人,请阅读整篇文章以了解详细信息。)
汽车与推土机
今天,我们生活在数据库的黄金时代:有太多的数据库,所有这些行(OLTP/OLAP/时间序列等)都变得模糊了。然而,每个数据库的架构都不同,因此有不同的优缺点。作为开发人员,您应该为工作选择合适的工具。
在花了大量时间与ClickHouse打交道,阅读他们的文档,并通过几周的基准测试,我们发现自己在重复这个简单的类比:
ClickHouse就像一台推土机,对于特定用例来说非常高效和高效。PostgreSQL(和TimescaleDB)就像一辆汽车:通用、可靠,在你生活中面临的大多数情况下都很有用。
大多数时候,“汽车”会满足你的需求。但如果你发现自己在做大量的“建筑”工作,无论如何,找一台“推土机”
我们不是唯一有这种感觉的人。以下是stingraycharles在HackerNews上分享的类似观点(我们不知道他是谁,但如果你正在阅读本文,那么stingraycharles——我们喜欢你的用户名):
“TimescaleDB有一个很好的时间序列故事,一个普通的数据仓库故事;Clickhouse有一个很棒的数据仓库案例,一个一般的时间序列案例,还有一个小小的集群故事(YMMV)。”
在本文的其余部分中,我们深入探讨了ClickHouse体系结构,然后重点介绍了ClickHouse、PostgreSQL和TimescaleDB的一些优缺点,这些都是由其每个开发人员(包括我们)所做的体系结构决策所导致的。最后,我们进行了更详细的时间序列基准分析。我们还详细描述了我们的测试环境,以便自己复制这些测试并验证我们的结果。
是的,我们是TimescaleDB的制造商,所以您可能不信任我们的分析。如果是这样,我们请您在接下来的几分钟内保持怀疑态度,并阅读本文的其余部分。正如你(希望如此)将看到的,我们花了很多时间来理解ClickHouse的对比:首先,确保我们以正确的方式进行基准测试,以便我们对ClickHouse公平;而且,因为我们本质上是数据库书呆子,并且非常想了解ClickHouse是如何构建的。
后续步骤
你对TimescaleDB感兴趣吗?最简单的入门方法是创建一个免费的TimescaleCloud帐户,这样您就可以访问一个完全托管的Timescale DB实例(30天内100%免费)。
如果您想自己托管TimescaleDB,您可以完全免费—访问我们的GitHub了解更多选项、获取安装说明等(⭐️ 非常感谢!🙏)
最后一件事:你可以加入我们的社区休闲活动,提问、获取建议,并与其他开发人员联系(我们正在7000人以上!)。我们,这篇文章的作者,在所有的渠道上都非常活跃——我们所有的工程师、团队时间尺度成员和许多热情的用户也是如此。
什么是ClickHouse?
ClickHouse是“Clickstream Data Warehouse”的缩写,是一个专栏式OLAP数据库,最初是为Yandex Metrica的web分析而构建的。通常,ClickHouse以其高插入率、快速分析查询和类似SQL的方言而闻名。
Timeline of ClickHouse development (Full history here.)
我们是ClickHouse的粉丝。它是一个围绕某些体系结构决策构建的非常好的数据库,这使得它成为OLAP风格分析查询的一个很好的选择。特别是,在我们使用时间序列基准测试套件(TSBS)进行基准测试时,ClickHouse在数据接收方面的表现比我们迄今为止测试过的任何时间序列数据库(包括TimescaleDB)都要好,在一个实例上,当行被适当批处理时,平均每秒超过600k行。
但是数据库中没有任何内容是免费的,正如我们将在下面展示的那样,这种体系结构也对ClickHouse造成了很大的限制,使得许多类型的时间序列查询和一些插入工作负载的速度变慢。如果您的应用程序不符合ClickHouse(或TimescaleDB)的体系结构边界,那么您可能最终会遇到一个令人沮丧的开发体验,需要重新进行大量工作。
ClickHouse架构
ClickHouse是为具有特定特征的OLAP工作负载而设计的。从ClickHouse文档中可以看出,这类工作负载的一些要求:
- 绝大多数请求都是读访问。
- 数据以相当大的批量(>1000行)插入,而不是以单行插入;或者根本没有更新。
- 数据已添加到数据库,但未修改。
- 对于读取,数据库中处理了相当多的行,但只处理了列的一小部分。
- 表是“宽”的,这意味着它们包含大量列。
- 查询相对较少(通常每台服务器上有数百个查询,或者每秒更少)。
- 对于简单查询,允许大约50毫秒的延迟。
- 列值相当小:数字和短字符串(例如,每个URL 60字节)。
- 处理单个查询时需要高吞吐量(每台服务器每秒最多数十亿行)。
- 交易是不必要的。
- 数据一致性要求低。
- 每个查询有一个大表。所有的桌子都很小,只有一张除外。
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合,因此结果适合于单个服务器的RAM。
ClickHouse是如何为这些工作负载设计的?以下是其体系结构的一些关键方面:
- 压缩的、面向列的存储
- 表引擎
- 索引
- 矢量计算引擎
压缩的、面向列的存储
首先,ClickHouse(与几乎所有OLAP数据库一样)是面向列的(或列的),这意味着同一表列的数据存储在一起。(相比之下,在几乎所有OLTP数据库都使用的面向行的存储中,相同表行的数据存储在一起。)
面向列的存储有几个优点:
- 如果查询只需要读取几列,那么读取数据的速度会快得多(不需要读取整行,只需要读取列)
- 将相同数据类型的列存储在一起会导致更大的可压缩性(尽管如我们所示,可以将列压缩构建为面向行的存储)。
Table engines
为了改进ClickHouse中数据的存储和处理,使用表“引擎”集合实现了列数据存储。表引擎确定表的类型和可用于处理存储在其中的数据的功能。
ClickHouse主要使用MergeTree表引擎作为数据写入和组合的基础。几乎所有其他的表引擎都是从MergeTree派生而来的,并允许在(稍后)处理数据以进行长期存储时自动执行其他功能。
(快速澄清:从这一点开始,每当我们提到MergeTree时,我们都指的是整个MergeTre体系结构设计和从中派生的所有表类型,除非我们指定了特定的MergeTree-type)
在较高的级别上,MergeTree允许将数据快速写入和存储到多个不可变文件(ClickHouse称为“部分”)。这些文件稍后会在将来的某个时候在后台进行处理,并合并为一个较大的部分,目的是减少磁盘上的部分总数(文件越少,以后读取数据的效率越高)。这是ClickHouse在大批量上惊人的高插入性能的关键原因之一。
表中的所有列存储在单独的部分(文件)中,每个列中的所有值都按主键的顺序存储。这种列分离和排序实现使未来的数据检索更加高效,特别是在计算大范围连续数据的聚合时。
索引
一旦数据被存储并合并到每个列的最有效部分集中,查询就需要知道如何高效地查找数据。为此,Clickhouse依赖于两种类型的索引:主索引和辅助索引(数据跳过)。
与知道如何定位表中任何行的传统OLTP BTree索引不同,ClickHouse主索引本质上是稀疏的,这意味着它没有指向主索引每个值位置的指针。相反,因为所有数据都是按主键顺序存储的,所以主索引每N行存储主键的值(默认情况下称为index_granuclear,8192)。这是为了实现特定的设计目标,即将主索引拟合到内存中,以实现极快的处理速度。
当您的查询模式适合这种索引样式时,稀疏特性可以帮助显著提高查询速度。一个限制是,您不能在特定列上创建其他索引来帮助改进不同的查询模式。我们稍后将对此进行更多讨论。
矢量计算引擎
ClickHouse的设计初衷是希望以其他OLAP数据库无法实现的方式进行“在线”查询处理。即使使用压缩和列式数据存储,大多数其他OLAP数据库仍然依赖增量处理来预计算聚合数据。通常是预先聚合的数据提供了速度和报告功能。
为了克服这些限制,ClickHouse实现了一系列矢量算法,用于逐列处理大型数据数组。通过矢量化计算,ClickHouse可以专门处理成千上万块或行(每列)中的数据进行多次计算。矢量化计算还提供了一个机会,可以编写更高效的代码,利用现代SIMD处理器,并使代码和数据更紧密地结合在一起,以获得更好的内存访问模式。
总的来说,这对于处理大型数据集和在有限的列集上编写复杂查询来说是一个很好的功能,随着我们探索更多利用列数据的机会,TimescaleDB可以从中受益。
也就是说,正如您将从基准测试结果中看到的,在TimescaleDB中启用压缩(将数据转换为压缩的列存储),可以以比ClickHouse更好的方式提高许多聚合查询的查询性能。
ClickHouse的缺点在于其架构(又名:没有免费的东西)
数据库架构中没有免费的内容。显然,ClickHouse的设计考虑了非常具体的工作量。同样,它也不是为其他类型的工作负载而设计的。
我们可以从ClickHouse文档中看到一组最初的缺点:
- 没有正式的交易。
- 无法以高速率和低延迟修改或删除已插入的数据。可以使用批删除和更新来清理或修改数据,例如,为了符合GDPR,但不适用于常规工作负载。
- 稀疏索引使得ClickHouse对于通过键检索单行的点查询来说没有那么有效。
有几个缺点值得详细说明:
- 不能在表中直接修改数据
- 有些“同步”操作实际上并不同步
- 类似SQL,但不完全是SQL
- 备份中没有数据一致性
MergeTree限制:不能在表中直接修改数据
ClickHouse中的所有表都是不可变的。无法直接更新或删除已存储的值。相反,UPDATE或DELETE数据的任何操作只能通过“ALTER TABLE”语句来完成,该语句应用过滤器,并在后台重新写入整个表(逐部分)以更新或删除相关数据。本质上,它只是应用了一些过滤器的另一个合并操作。
因此,存在多个MergeTree表引擎来解决此缺陷,以解决通常需要频繁修改数据的情况。然而,这可能导致意外行为和非标准查询。
例如,如果只需要存储最近读取的值,则创建CollapsingMergeTree表类型是最佳选择。使用此表类型,将向表中添加一个附加列(称为“Sign”),该列指示当所有其他字段值都匹配时,哪一行是项目的当前状态。然后,ClickHouse将异步删除带有“Sign”的行,这些行相互抵消(值为1对-1),并在数据库中保留最新状态。
例如,考虑一种常见的数据库设计模式,其中传感器的最新值与长期时间序列表一起存储,以便快速查找。我们将此表称为SensorLastReading。在ClickHouse中,每当数据库中存储新信息时,该表都需要以下模式来存储最新的值。
传感器上次读取
| SensorID | Temp | Cpu | Sign |
|---|---|---|---|
| 1 | 55 | 78 | 1 |
当接收到新数据时,您需要向表中再添加两行,一行用于对旧值求反,另一行用于替换旧值。
| SensorID | Temp | Cpu | Sign |
|---|---|---|---|
| 1 | 55 | 78 | 1 |
| 1 | 55 | 78 | -1 |
| 1 | 40 | 35 | 1 |
在插入之后的某个时候,ClickHouse将合并更改,删除在Sign上相互取消的两行,只留下这一行:
| SensorID | Temp | Cpu | Sign |
|---|---|---|---|
| 1 | 40 | 35 | 1 |
但请记住,MergeTree操作是异步的,因此在执行类似折叠操作之前,可以对数据进行查询。因此,从CollapsingMergeTree表中获取数据的查询需要额外的工作,如将行乘以其“Sign”,以确保在表处于仍然包含重复数据的状态时获得正确的值。
这里是ClickHouse文档提供的一个解决方案,针对我们的示例数据进行了修改。注意,对于数字,可以通过将所有值乘以Sign列并添加HAVING子句来获得“正确”答案。
SELECT SensorID, sum(Temp * Sign) AS Temp, sum(Cpu * Sign) AS Cpu FROM SensorLastReading GROUP BY SensorId HAVING sum(Sign) > 0
同样,这里的价值在于,MergeTree表以事务和简单概念(如UPDATE和DELETE)为代价提供了真正快速的数据摄取,就像传统应用程序尝试使用这样的表一样。有了ClickHouse,管理这种数据工作流只需要更多的工作。
因为ClickHouse不是一个ACID数据库,所以这些后台修改(或者任何数据操作)都无法保证能够完成。因为没有事务隔离,任何在更新或删除修改(或我们前面提到的折叠修改)过程中接触数据的SELECT查询都将获得每个部分中当前的任何数据。例如,如果删除过程只修改了列的50%的部分,查询将从尚未处理的其余部分返回过期数据。
更重要的是,这适用于存储在ClickHouse中的所有数据,不仅是存储类似时间序列数据的大型分析型表,还包括相关元数据。例如,虽然可以理解时间序列数据通常只插入(很少更新),但随着时间的推移,以业务为中心的元数据表几乎总是有修改和更新。无论如何,您可以存储在ClickHouse中以进行复杂连接和深入分析的相关业务数据仍在MergeTree表(或MergeTree's的变体)中,因此,无论何时进行修改,更新或删除都需要进行完全重写(通过使用“ALTER table`)。
分布式MergeTree表
分布式表是异步修改可能导致您更改查询数据方式的另一个示例。如果应用程序将数据直接写入分布式表(而不是高级用户可能写入的不同群集节点),则首先将数据写入“启动器”节点,后者又会尽快将数据复制到后台的碎片。因为没有事务来验证数据是否作为两阶段提交(在PostgreSQL中可用)的一部分被移动,所以您的数据可能并不是您认为的那样。
如何处理分布式数据至少还有一个问题。由于ClickHouse不支持事务,并且数据处于不断移动的状态,因此无法保证集群节点状态的一致性。将100000行数据保存到分布式表并不能保证所有节点的备份都是一致的(我们稍后将讨论可靠性)。其中一些数据可能已被移动,而一些数据可能仍在传输中。
同样,这是精心设计的,所以ClickHouse中发生的事情没有什么特别的错误!当将ClickHouse与PostgreSQL和TimescaleDB之类的东西进行比较时,需要注意这一点。
有些“同步”操作实际上并不同步
ClickHouse中的大多数操作都不是同步的。但我们发现,即使一些标记为“synchronous”的也不是真正同步的。
在基准测试期间,一个特别的例子让我们感到惊讶,那就是“TRUNCATE”的工作原理。我们针对ClickHouse和TimescaleDB运行了许多测试周期,以确定行批量大小、工作线程甚至基数的变化如何影响每个数据库的性能。在每个周期结束时,我们将“TRUNCATE”每个服务器中的数据库,希望磁盘空间能够快速释放,以便开始下一个测试。在PostgreSQL(和其他OLTP数据库)中,这是一个原子操作。一旦截断完成,磁盘上的空间就会释放出来。

TRUNCATE是TimescaleDB/PostgreSQL中的一个原子操作,几乎可以立即释放磁盘
我们对ClickHouse也有同样的期望,因为文档中提到这是一个同步操作(而且ClickHouse中的大多数操作都不是同步的)。然而,事实证明,这些文件只会被标记为删除,而磁盘空间会在稍后的、未指定的时间在后台释放出来。这种情况何时发生没有具体的保证。

TRUNCATE is an asynchronous action in ClickHouse, freeing disk at some future time
对于我们的测试来说,这是一个小小的不便。我们必须在测试周期中加入10分钟的睡眠时间,以确保ClickHouse完全释放了磁盘空间。在实际情况中,像使用临时表的ETL处理一样,“TRUNCATE”实际上不会立即释放临时表数据,这可能会导致您修改当前进程。
我们指出其中的一些场景,只是为了强调一点,即ClickHouse并不是现代应用程序中记录系统(OLTP数据库)常用的许多功能的直接替代品。异步数据修改可能需要花费更多的精力才能有效地处理数据。
类似SQL,但不完全是SQL
在许多方面,ClickHouse选择SQL作为首选语言,走在了时代的前列。
ClickHouse在开发初期选择了使用SQL作为管理和查询数据的主要语言。考虑到对数据分析的关注,这是一个明智而明显的选择,因为SQL已经被广泛采用并被理解用于查询数据。
在ClickHouse中,SQL并不是为了满足部分用户社区的需要而添加的。也就是说,ClickHouse提供的是一种类似SQL的语言,不符合任何实际标准。
类SQL查询语言的挑战很多。例如,重新培训将访问数据库的用户(或编写访问数据库的应用程序)。另一个挑战是缺乏生态系统:使用SQL的连接器和工具不仅可以开箱即用,也就是说,它们需要一些修改(以及用户的知识)才能工作。
总的来说,ClickHouse能够很好地处理基本的SQL查询。
然而,由于数据的存储和处理方式与大多数SQL数据库不同,因此您可能希望从SQL数据库(例如,PostgreSQL、TimescaleDB)中使用许多命令和函数,但ClickHouse不支持这些命令和函数或对它们的支持有限:
- 未针对JOIN进行优化
- 除了主索引和辅助索引之外,没有索引管理
- 无递归CTE
- 无相关子查询或LATERAL联接
- 没有存储过程
- 没有用户定义的函数
- 没有触发器
ClickHouse最突出的一个例子是,join本质上是不受欢迎的,因为查询引擎缺乏优化两个或多个表的连接的能力。相反,我们鼓励用户使用单独的子选择语句查询表数据,然后使用类似“ANY INNER JOIN”的语句,严格查找连接两侧的唯一对(避免标准JOIN类型可能出现的笛卡尔积)。JOIN产品也没有缓存支持,因此如果一个表被多次联接,那么对该表的查询将被多次执行,从而进一步减慢查询速度。
例如,TSBS中的所有“double groupby”查询都按多个列分组,然后连接到标记表以获取最终输出的“hostname”。下面是如何为每个数据库编写查询。
Timescale数据库:
WITH cpu_avg AS ( SELECT time_bucket('1 hour', time) as hour, hostname, AVG(cpu_user) AS mean_cpu_user FROM cpu WHERE time >= '2021-01-01T12:30:00Z' AND time < '2021-01-02T12:30:00Z' GROUP BY 1, 2 ) SELECT hour, hostname, mean_cpu_user FROM cpu_avg JOIN tags ON cpu_avg.tags_id = tags.id ORDER BY hour, hostname;
ClickHouse:
SELECT hour, id, mean_cpu_user FROM ( SELECT toStartOfHour(created_at) AS hour, tags_id AS id, AVG(cpu_user) as mean_cpu_user FROM cpu WHERE (created_at >= '2021-01-01T12:30:00Z') AND (created_at < '2021-01-02T12:30:00Z') GROUP BY hour, id ) AS cpu_avg ANY INNER JOIN tags USING (id) ORDER BY hour ASC, id;
可靠性:备份中没有数据一致性
作为ClickHouse体系结构的一部分,需要考虑的最后一个方面是备份中没有数据一致性,而且它缺乏对事务的支持。如前所述,所有数据修改(甚至跨集群的切分)都是异步的,因此,确保一致备份的唯一方法是停止对数据库的所有写入,然后进行备份。数据恢复也面临同样的限制。
事务和数据一致性的缺乏也会影响其他特性,如物化视图,因为服务器不能一次原子地更新多个表。如果在向包含物化视图的表的多部分插入过程中出现中断,最终结果是数据的状态不一致。
ClickHouse意识到了这些缺点,并且肯定正在为将来的版本进行更新或计划更新。某种形式的事务支持已经讨论了一段时间,备份正在进行中,并被合并到代码的主要分支中,尽管还不建议在生产中使用。但即便如此,它也只为交易提供有限的支持。
ClickHouse与PostgreSQL
(正确的ClickHouse与PostgreSQL比较可能需要另外8000个单词。为了避免让这篇文章更长,我们选择了对两个数据库进行简短的比较,但如果有人想提供更详细的比较,我们很乐意阅读。)
如上所述,ClickHouse是一个架构良好的OLAP工作负载数据库。相反,PostgreSQL是一个架构良好的OLTP工作负载数据库。
此外,PostgreSQL不仅仅是一个OLTP数据库:它是增长最快、最受欢迎的OLTP数据库(DB Engines,StackOverflow,2021开发者调查)。
因此,我们不会比较ClickHouse和PostgreSQL的性能,因为继续之前的类比,这就像比较推土机和汽车的性能。这是为两个不同的目的而设计的两种不同的东西。
我们已经确定了为什么ClickHouse非常适合分析工作负载。现在让我们了解为什么PostgreSQL在事务性工作负载方面如此受欢迎:多功能性、可扩展性和可靠性。
PostgreSQL的通用性和扩展性
多功能性是PostgreSQL的突出优势之一。这是PostgreSQL最近在更广泛的技术社区复苏的主要原因之一。
PostgreSQL支持多种数据类型,包括数组、JSON等。它支持多种索引类型,不仅支持通用B树,还支持GIST、GIN等。全文搜索?检查基于角色的访问控制?检查当然,还有完整的SQL。
此外,通过使用扩展,PostgreSQL可以保留它擅长的东西,同时添加特定功能以提高开发工作的ROI。
您的应用程序需要地理空间数据吗?添加PostGIS扩展名。有利于时间序列数据工作负载的功能是什么?添加TimescaleDB。您的应用程序能从使用三角图搜索的功能中受益吗?添加pg_trgm。
凭借所有这些功能,PostgreSQL非常灵活,这意味着它基本上是经得起未来考验的。随着应用程序的变化或工作负载的变化,您将知道您仍然可以根据需要调整PostgreSQL。
(关于PostgreSQL强大可扩展性的一个具体示例,请阅读我们的工程团队如何使用客户操作员将函数编程构建到PostgreQL中。)
PostgreSQL可靠性
作为开发人员,我们决心面对这样一个事实:程序崩溃、服务器遇到硬件或电源故障、磁盘故障或出现损坏。您可以减轻这种风险(例如,稳健的软件工程实践、不间断电源、磁盘RAID等),但不能完全消除它;这是系统生命中的一个事实。
作为回应,数据库是通过一系列机制构建的,以进一步降低此类风险,包括流式复制到副本、完整快照备份和恢复、流式备份、强健的数据导出工具等。
PostgreSQL在20多年的开发和使用中受益匪浅,这不仅造就了一个可靠的数据库,还造就了一系列经过严格测试的工具:流式复制用于高可用性和只读副本,pg_dump和pg_recovery用于完整数据库快照,pg_basebackup和日志传送/流式传输用于增量备份和任意时间点恢复,pgBackrest或WAL-E用于连续归档到云存储,以及强大的COPY FROM和COPY to工具,用于快速导入/导出各种格式的数据。这使得PostgreSQL能够提供更大的“心灵平和”,因为衣柜中的所有骨架都已经找到(并解决)。
ClickHouse与TimescaleDB
TimescaleDB是建立在PostgreSQL之上的领先的时间序列关系数据库。它提供PostgreSQL所能提供的一切,外加一个完整的时间序列数据库。
因此,PostgreSQL的所有优点也适用于TimescaleDB,包括通用性和可靠性。
但TimescaleDB添加了一些关键功能,使其在时间序列数据方面表现更佳:
- Hypertables是TimescaleDB许多功能(如下所示)的基础,Hypertables提供跨时间和空间的自动分区数据,以实现更高性能的插入和查询
- 连续聚合-智能更新时间序列数据的物化视图。TimescleDB不是每次都重新创建物化视图,而是仅根据原始数据的底层更改更新数据。
- 列压缩—对大多数时间序列数据进行90%以上的高效数据压缩,大大提高了历史查询、长查询和窄查询的查询性能。
- Hyperfunctions-添加到PostgreSQL的以分析为中心的函数,通过近似百分位数、高效下采样和两步聚合等功能增强时间序列查询。
- 功能管道(本周发布!)-通过应用函数编程原理和Python的Pandas和PromQL等流行工具,从根本上改进开发人员在PostgreSQL和SQL中分析数据的人体工程学。
- 水平扩展(多节点)—跨多个节点的存储和分布式查询的时间序列数据的水平扩展。
时间序列数据的ClickHouse与TimescaleDB性能
时间序列数据之所以流行起来,是因为跟踪和分析事物随时间变化的价值在各个行业都变得显而易见:DevOps和IT监控、工业制造、金融交易和风险管理、传感器数据、广告技术、应用事件、智能家居系统、自动驾驶汽车、职业体育等等。
它与更传统的业务类型(OLTP)数据至少在两个主要方面有所不同:它主要是插入量大,数据的规模不断增长。这会影响数据收集和存储,以及我们如何分析价值本身。传统OLTP数据库通常无法每秒处理数百万事务,也无法提供有效的数据存储和维护方法。
时间序列数据也比一般分析(OLAP)数据更独特,因为查询通常具有时间成分,并且查询很少触及数据库中的每一行。
然而,在过去几年中,OLTP和OLAP数据库的功能之间的界限开始模糊。在过去十年中,许多NoSQL架构缓解了存储挑战,但仍然无法有效处理时间序列数据所需的查询和分析。
因此,许多应用程序试图在OLTP数据库的事务功能和OLAP数据库提供的大规模分析之间找到适当的平衡。因此,许多应用程序尝试使用ClickHouse是有道理的,它为时间序列数据提供了快速摄取和分析查询功能。
因此,让我们看看ClickHouse和TimescaleDB如何使用我们的标准TSBS基准比较时间序列工作负载。
性能基准
让我首先说,这不是一个我们在几个小时内完成的测试,然后再继续。事实上,就在昨天,在完成这篇博客帖子时,我们安装了最新版本的ClickHouse(3天前发布),并再次运行了所有测试,以确保获得尽可能好的数据!(基准,而非基准营销)
为了准备最后一组测试,我们分别在TimescaleDB和ClickHouse上运行了几十次基准测试——至少是几十次。我们尝试了不同的基数、生成数据的不同时间长度,以及对TimescaleDB的“chunk_time_interval”等易于控制的内容的不同设置。我们想真正了解每个数据库在典型的云硬件和我们在野外经常看到的规格下的性能。
我们还承认,大多数实际应用程序的工作方式与基准测试不同:首先接收数据,然后查询数据。但是,分离每个操作使我们能够了解在不同阶段哪些设置影响了每个数据库,这也使我们能够调整每个数据库的基准设置,以获得最佳性能。
最后,我们始终将这些基准测试视为一种学术和自我反思的体验。也就是说,花几百个小时处理这两个数据库通常会使我们考虑改进TimescaleDB(特别是)的方法,并仔细考虑何时我们可以而且应该说另一个数据库解决方案是特定工作负载的好选择。
机器配置
对于这个基准测试,我们有意识地决定使用基于云的硬件配置,这些配置对于初创企业和成长型企业的中等工作量来说是合理的。在以前的基准测试中,我们使用了具有专用RAID存储的较大机器,这是生产数据库环境的典型设置。
但是,随着时间的推移,我们看到越来越多的开发人员使用Kubernetes和模块化基础架构设置,而没有进行大量专门的存储和内存优化,因此在与我们在野外看到的更接近的实例上对每个数据库进行基准测试更为真实。当然,我们总是可以投入更多的硬件和资源来帮助实现峰值,但这通常无助于传达大多数现实应用程序的期望。
为此,为了比较插入和读取延迟性能,我们在AWS中使用了以下设置:
- 版本:TimescaleDB版本2.4.0,社区版,带PostgreSQL 13;ClickHouse 21.6.5版(测试时这两个数据库的最新非测试版)。
- 1台运行TSBS的远程客户端计算机,1台数据库服务器,两者位于同一云数据中心
- 实例大小:客户端和数据库服务器都运行在Amazon EC2虚拟机(m5.4xlarge)上,每个虚拟机有16个vCPU和64GB内存。
- 操作系统:服务器和客户机都运行Ubuntu 20.04.3
- 磁盘大小:1TB EBS GP2存储
- 部署方法:使用官方源通过apt-get安装
数据库配置
ClickHouse:没有对ClickHouse进行配置修改。我们只是根据他们的文档进行了安装。目前,ClickHouse还没有像timescaledb这样的工具。
TimescaleDB:对于TimescaleDB,我们遵循了时间刻度文档中的建议。具体来说,我们运行了timescaledb-tune并接受了基于EC2实例规范的配置建议。我们还在postgresql.conf中设置synchronous_commit=off。这是一种常见的性能配置,用于写入繁重的工作负载,同时仍保持事务性和日志完整性。
插入性能
为了提高插入性能,我们使用了以下数据集和配置。这些数据集是使用仅含cpu用例的时间序列基准套件创建的。
- 数据集:100-100000000台模拟设备每10秒生成10个CPU指标,读取间隔约为1亿次。
- 每个配置使用的间隔如下:100台设备31天;4000台设备3天;100000台设备需要3小时;30分钟,1000000
- 批量大小:插入是使用5000的批量大小制作的,ClickHouse和TimescaleDB都使用了该批量大小。我们尝试了多种批量大小,发现在大多数情况下,每个数据库每批5000到15000行之间的总体插入效率几乎没有差异。
- TimescaleDB块大小:我们根据数据量设置块时间,目标是每个配置总共7-16个块(这里有更多关于块的信息)。
最后,这些是使用5000行的批处理大小将TSBS客户机预生成的时间序列数据接收到每个数据库的性能数字。
Insert performance comparison between ClickHouse and TimescaleDB with 5,000 row/batches
说实话,这并不让我们感到惊讶。我们最近看到了许多关于ClickHouse摄取性能的博客文章,由于ClickHouse使用了不同的存储体系结构和机制,不包括事务支持或ACID遵从性,所以我们通常预计它会更快。
然而,当你考虑到ClickHouse被设计成将接收到的行的每个“事务”都保存为单独的文件(稍后使用MergeTree架构进行合并)时,情况确实有所改变。事实证明,当您要接收的数据批次更少时,ClickHouse会比TimescaleDB慢得多,并且会消耗更多的磁盘空间。
(吸收1亿行,4000台主机,3天的数据-22GB的原始数据)
Insert performance comparison between ClickHouse and TimescaleDB using smaller batch sizes, which significantly impacts ClickHouse's performance and disk usage
你注意到上面的数字了吗?
无论批处理大小如何,TimescaleDB在压缩之前始终使用每个数据摄取基准消耗约19GB的磁盘空间。这是chunk_time_interval的结果,它决定了为给定的时间序列数据范围创建多少块。虽然较小的批处理可能会降低接收速度,但会为相同的数据创建相同的块,从而产生一致的磁盘使用模式。在压缩之前,很容易看到TimescaleDB无论批大小如何,都会持续消耗相同数量的磁盘空间。
相比之下,ClickHouse存储需求与需要写入的文件数量相关(这部分取决于要保存的行批的大小),实际上,在将数据合并到更大的文件之前,将数据保存到ClickHouse需要更多的存储空间。即使在500行的批处理中,对于22GB大小的源数据文件,ClickHouse消耗的磁盘空间也比TimescaleDB多1.75倍。
读取延迟
对于基准读取延迟,我们对每个数据库使用以下设置(机器配置与插入比较中使用的配置相同):
- 数据集:4000/10000模拟设备每10秒生成10个CPU指标,持续3天(100M+读取间隔,1B+指标)
- 我们还启用了TimescaleDB上的本机压缩。除了最近的数据块外,我们压缩了所有数据,使其保持未压缩状态。通常建议使用这种配置,其中未压缩的原始数据保存在最近的时间段,而较旧的数据被压缩,从而提高查询效率(有关更多信息,请参阅我们的压缩文档)。我们用于启用压缩的参数如下:我们按tags_id列进行分段,并按时间降序和usage_user列进行排序。
在读取(即查询)延迟时,结果更复杂。与插入不同,插入主要取决于基数大小(可能还有批大小),可能的查询范围基本上是无限的,特别是对于像SQL这样强大的语言。通常,对读取延迟进行基准测试的最佳方法是使用计划执行的实际查询进行基准测试。对于这种情况,我们使用一组广泛的查询来模拟最常见的查询模式。
下面显示的结果是每个查询类型的1000个查询的中间值。此图表中的延迟均以毫秒为单位显示,另一列显示TimescaleDB与ClickHouse相比的相对性能(当TimescaleDB更快时以绿色突出显示,当ClickHouse更快时以蓝色突出显示)。
Results of benchmarking query performance of 4,000 hosts with 100 million rows of data
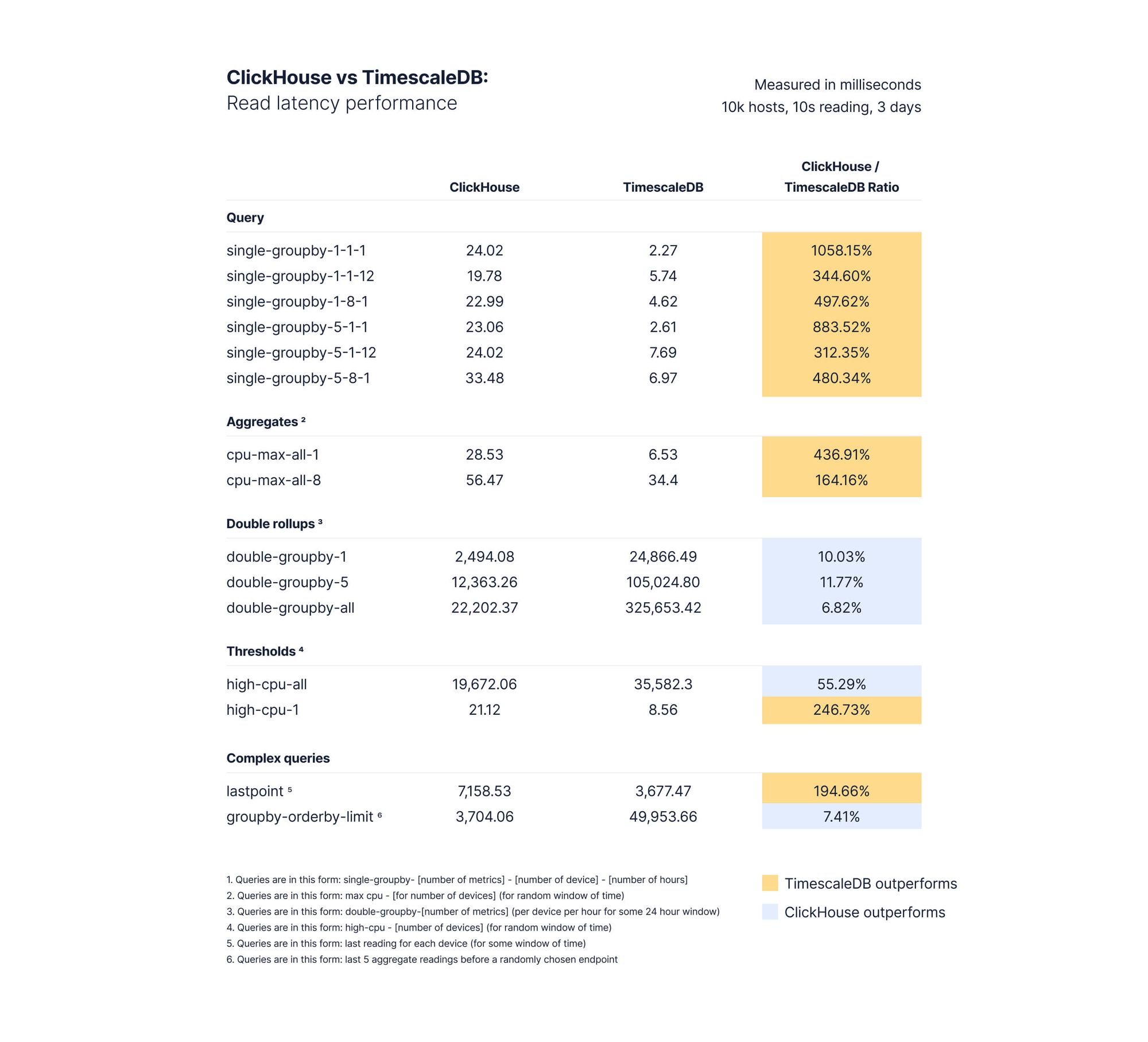
Results of benchmarking query performance of 10,000 hosts with 100 million rows of data
简单滚动
对于简单的汇总(即单个groupby),当在单个主机上聚合一个指标1或12小时,或在一个或多个主机上聚合多个指标(1小时或12小时)时,TimescaleDB通常在低基数和高基数方面都优于ClickHouse。特别是,TimescaleDB在4000和10000台设备的配置上表现出高达1058%的ClickHouse性能,每个读取间隔生成10个独特的指标。
AGGREGATES
在计算1个设备的简单聚合时,TimescaleDB在任何数量的设备上都始终优于ClickHouse。在我们的基准测试中,TimescaleDB在4000台设备上聚合8个指标时,其性能达到了ClickHouse的156%,在10000台设备上集合8个指标后,其性能提高了164%。TimescaleDB在高端场景中再次超越ClickHouse。
DOUBLE ROLLUPS
ClickHouse在查询延迟方面始终优于TimescaleDB的一组查询是按时间和另一个维度(例如,GROUPBY time、deviceId)聚合度量的双汇总查询。下面我们将详细讨论为什么会这样,但这也并非完全出乎意料。
THRESHOLDS
当根据阈值选择行时,TimescaleDB在计算单个设备的阈值时显示出249-357%的ClickHouse性能,但在计算随机时间窗口中所有设备的阈值后,仅显示出130-58%的ClickHouse性能。
COMPLEX QUERIES
对于超出汇总或阈值的复杂查询,比较有点微妙,特别是在查看TimescaleDB时。区别在于TimescaleDB让您可以控制压缩哪些块。在大多数时间序列应用程序中,尤其是像物联网这样的应用程序,经常需要通过某种聚合来查找某个项的最新值或前X个项的列表。这是lastpoint和groupby orderby limit查询的基准。
正如我们之前在其他数据库(InfluxDB和MongoDB)中所展示的,以及ClickHouse本身所记录的那样,获取项目的单个有序值并不是类似MergeTree的/OLAP数据库的用例,通常因为没有可以为时间、键和值定义的有序索引。这意味着询问项目的最新值仍然会导致对OLAP数据库中的数据进行更密集的扫描。
我们在结果中看到了这一点。在搜索数据库中每个项目的最新值(lastpoint)时,TimescaleDB比ClickHouse快3486%左右。这是因为在接收数据时,最新的未压缩块通常会保存这些值的大部分,这是一个很好的例子,说明为什么压缩的灵活性会对应用程序的性能产生重大影响。
然而,我们完全承认,压缩并不总是对每个查询表单都返回良好的结果。在最后一个复杂的查询中,ClickHouse以相当大的速度超过TimescaleDB,几乎快了15倍。我们的结果没有显示,从未压缩块(最近的块)读取的查询比ClickHouse快17倍,平均每个查询64毫秒。TimescaleDB中的查询如下所示:
SELECT time_bucket('60 seconds', time) AS minute, max(usage_user) FROM cpu WHERE time < '2021-01-03 15:17:45.311177 +0000' GROUP BY minute ORDER BY minute DESC LIMIT 5
正如您可能猜测的那样,当块被解压缩时,可以使用PostgreSQL索引按时间快速排序数据。压缩区块时,必须首先解压缩与谓词匹配的数据(上例中为“WHERE time<”2021-01-03 15:17:45.31177+0000”),然后再对其进行排序和搜索。
当“lastpoint”查询的数据落在未压缩的块中时(对于具有诸如“WHERE time<now()-INTERVAL‘6 hours’”谓词的短期查询,通常是这种情况),结果令人吃惊。
(未压缩区块查询,4k主机)
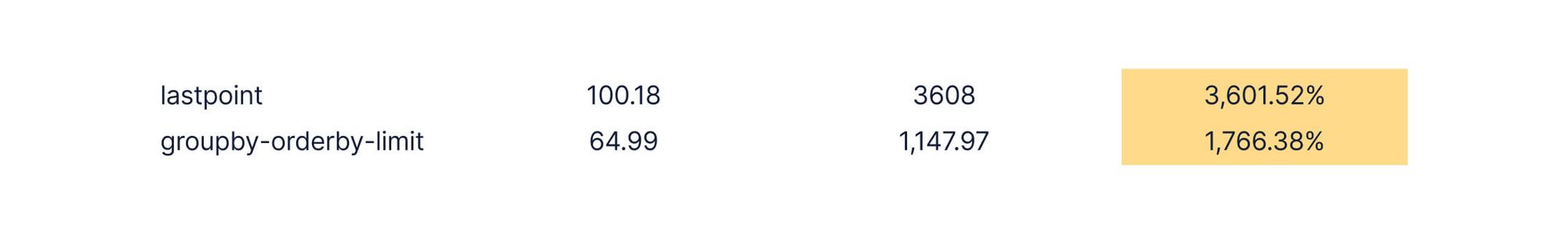
Query latency performance when lastpoint and groupby-orderby-limit queries use an uncompressed chunk in TimescaleDB
最后一组查询的关键结论之一是,数据库提供的功能可能会对应用程序的性能产生重大影响。有时它只是工作,而其他时候能够微调数据存储方式可能会改变游戏规则。
读取延迟性能摘要
- 对于简单查询,无论是否使用本机压缩,TimescaleDB都优于ClickHouse。
- 对于典型的聚合,即使在许多值和项中,TimescaleDB也优于ClickHouse。
- ClickHouse执行更复杂的双汇总,每次都优于TimescaleDB。在某种程度上,我们对这种差距感到惊讶,并将继续了解如何更好地适应对原始时间序列数据的此类查询。在实际应用程序中,解决这种差异的一个方法是使用连续聚合来预聚合数据。
- 当根据阈值选择行时,TimescaleDB的性能优于ClickHouse,速度快了250%。
- 对于一些复杂的查询,特别是像“lastpoint”这样的标准查询,TimescaleDB的性能大大优于ClickHouse
- 最后,根据查询的时间范围,TimescaleDB在分组和有序查询方面比ClickHouse快得多(高达1760%)。当这些类型的查询进一步回到压缩块时,ClickHouse的性能优于TimescaleDB,因为必须解压缩更多的数据才能找到合适的max()值来排序。
结论
你成功了!感谢您抽出时间阅读我们的详细报告。
了解ClickHouse,然后将其与PostgreSQL和TimescaleDB进行比较,使我们意识到在当今的数据库市场上有很多选择,但通常仍然只有一个合适的工具来完成这项工作。
在决定使用哪一个应用程序之前,我们建议后退一步,分析您的堆栈、团队的技能以及您现在和将来的需求。现在选择最适合您的情况的技术,可以在未来带来所有不同。相反,您希望选择一种随您发展和成长的体系结构,而不是一种在数据开始从生产应用程序流动时迫使您从头开始的体系结构。
我们总是对反馈感兴趣,我们将继续与更大的社区分享我们的见解。
- 1306 次浏览
【数据管理】开源数据库:它们是什么?它们为什么重要?
对于开发人员来说,这是一个没有争议的特性。数据库的未来是开源的。2022年对约70000名代码争论者进行的堆栈溢出调查显示,几乎所有的专业人士都使用两种领先的开源RDBMSE之一,PostgreSQL(46.5%)或MySQL(45.7%),尽管他们也使用其他系统。
以RDBMS为起点建立全球软件帝国的甲骨文(Oracle)仅被约12%的开发人员使用,而银行和全球零售商使用的IBM数据主力Db2仅为2%。
毫无疑问,领先优势是开源——构建新系统的人正是他们自己的选择。问题是为什么他们在开发人员中占据主导地位。
数据库咨询公司Percona的首席执行官彼得·扎伊采夫(Peter Zaitsev)是MySQL AB的早期员工,由原始开源数据库作者迈克尔·蒙蒂·维德尼乌斯(Michael“Monty”Widenius)领导。对扎伊采夫来说,这是20世纪初创业场景中的一个经济学问题。
“如果你看看Oracle和Db2,它们可能是非常非常昂贵的系统。在21世纪初,就在互联网时代之后,缺乏资金的新一代创业公司需要但无法负担Oracle、Db2或SQL Server,”他说。
但在使用开源数据库的过程中,新一代创业公司——Facebook、Uber和谷歌等——开始发现他们可以根据自己的需求调整系统,为开源代码做出贡献,同时从社区其他地方的开发中获益。
Zaitsev说:“这是一种无许可的创新,你与社区一起定制和改进软件的能力非常重要。”。
快进十年,这一批初创企业——吸引了数十亿用户,吸引了金融市场和迷人的数字转型大师——开始主导网络原生开发者的思维。
Zaitsev说:“创业开发者文化开始渗透到整个生态系统,因为人们正在关注谷歌、Airbnb或优步可能采取的方式。”。
“这得到了数据库领域的关注。它转向了开源数据库。你可能很难找到一些真正酷的基于Oracle的系统作为后端数据库。在企业和政府机构的肚子里,这可能非常重要,但非常无聊。这一切都很好,但不是开发人员所期望的。”
PostgreSQL和MySQL已经有超过50年的发展历史,但新一代开源数据库已经出现在市场上,并引发了围绕其开源模式的激烈辩论。
MySQL的分支MariaDB和分布式RDBMS CockroachDB采用了他们所称的业务源许可证(BSL)。根据MariaDB的定义,这是“封闭源代码或开放核心许可模型的新替代方案”。源代码始终是公开可用的,代码的非生产性使用始终是免费的,许可方还可以提供额外的使用许可,允许有限的生产性使用。源代码保证在某个时间点成为开放源代码。
同时,流行的基于文档的NoSQL数据库MongoDB提供了服务器端公共许可证(SSPL)v1.0,该版本要求向社区发布MongoDB的增强功能。这些限制意味着公司不能将MongoDB作为托管服务提供给其他用户。
SSPL或BSL都不满足开放源代码倡议(OSI)设定的所有开放源代码软件标准。
扎伊采夫说,这些公司的做法在一定程度上是由于投资者倾向于开源的想法。
认为需要抵御企业狼
“金钱可以创造现实。这对开源来说可能是一种危险。开源运动的一些地区有点浪漫,希望改变世界。现在,商业开源是为了赚钱。是的,人们认为开源是好的:这是我们20多年来学到的东西。所以现在,许多新的兴趣正试图重新定义什么是开源软件,而ch允许他们保护自己,但仍然是开源的。但这与开源截然相反,开源应该像科学一样——放弃它,让每个人都能够构建和使用它。”
Zaitsev认为,通过这种方式,开源软件的用户可以自由终止与供应商的关系,并与其他公司签订合同,开发或支持他们的系统,同时保留原始代码的所有权,避免所谓的供应商锁定。
但是,倡导这些许可证的公司这样做是为了保护自己不受占主导地位的云超级规模商的影响,这些超级规模商在开发人员中拥有惊人的市场影响力和影响力。数据库公司担心,如果他们采用自由和开源软件(FOSS)方法,AWS、Google Cloud和Microsoft Azure等公司会简单地复制他们的代码,并将其商业化为托管服务,例如AWS的完全管理关系数据库服务,在这种模式下提供MySQL和PostgreSQL系统。他们认为,这将使开源软件背后的主要公司缺乏收入。
数据管理分析师Gartner veep Merv Adrian在最近一篇关于开源数据库商业可行性的博客中指出,云服务提供商从其开源数据库即服务(DBaaS)产品中获得的收入可能远远超过独立供应商的收入总和。
MongoDB、Cockroach Labs和MariaDB认为,他们采用的模型允许开源的重要特性在这种商业环境中生存。在本文中,我们为这些公司提供了扩展这些观点的机会,同时也为那些采用更宽松的开源方法的公司提供了一个平台,包括Yugabyte、DataStax和PostgreSQL公司EDB,以捍卫他们的立场。Oracle拒绝了谈论MySQL的机会。
作为一个对比,我们邀请了分析领域的一个相对新手Exasol,就其选择专有模型的原因发表评论。
我们还想讨论为什么开源在现代开发中很重要,为什么它可能不重要。首先,我们求助于EDB,这是一家支持和贡献PostgreSQL的商业公司,同时提供一些专有工具和DBAA。
EDB:社区控制和自由
可以说,Postgres是最古老的主要开源数据库,由加州大学伯克利分校的Michael Stonebraker和Lawrence Rowe于1986年首次提出,作为Ingres的继承者。其创建目标之一是数据类型、运算符和访问方法的可扩展性。根据OSI批准的PostgreSQL许可证,对象关系数据库已被证明是可扩展的,支持图形和JSON等新数据类型。
在2022年堆栈溢出调查中,它是开发者中最受欢迎的数据库,在数据库引擎排名中排名第四,十年来一直稳步攀升。
PosgreSQL咨询公司和贡献者EDB的首席技术官马克·林斯特(Marc Linster)表示,该系统的优势不仅在于许可,还在于吸引开发人员的贡献的多样性。
他区分了“俘虏式开源”项目和“真正的社区开源”项目,前者的绝大多数贡献来自单个公司,后者的贡献来自软件供应商、用户和其他相关方。
“如果你看Linux,或者看PostgreSQL,你会发现它背后有一个充满活力的社区。PostgreSQL是由EDB合作开发的——是的——还有VMware、富士通、NTT、微软、亚马逊等等。有很多公司在这方面投资,”他说。
“从技术上讲,你有其他开源软件拥有开源许可证,但它们实际上被一家公司所控制——比如说MongoDB。如果你是一个社区驱动的过程,会有更多的创新,因为在过程中的这些动态中,有很多推动和拉动来快速实现创新。同时,也有很多质量控制,这两个都来自于desi。”从gn的角度和执行的角度来看,因为审查、集成到代码中,所有这些都是公开的,并且完全公开。
“社区驱动的过程也保护了开源,使其不会突然获得BSL等人工许可或其他许可,因为其背后的社区不会接受。”
虽然核心PostgreSQL项目独立于EDB,但该公司销售自己的专有软件,以帮助保护和管理数据库。
Linster解释说,这些元素没有进入开源项目,因为虽然有些用户可能需要它们,但整个社区没有。
“我们做了一些社区不会做的事情。它不会说它需要数据库中的密码配置文件,比如Oracle。Postgres社区不太可能这样做,但客户通常有非常具体的需求,”他说。
Linster说,客户可以“拥有Postgres中所有的东西”,但也可以获得PostgreSQL社区无法接受的功能,如Oracle兼容性,EDB认为这是“独立的竞争优势”。
DataStax:没有人喜欢陷入陷阱
Apache Cassandra最初是由Facebook工程师Avinash Lakshman和Prashant Malik开发的分布式结构化存储系统,用于支持社交媒体公司的收件箱搜索功能。2008年7月,Facebook将Cassandra作为Google代码的开源项目发布,到2010年,它已成为顶级Apache项目。
DataStax的开发者关系副总裁帕特里克·麦克法丁(Patrick McFadin)表示,该项目由商业公司DataStax支持,该公司提供有偿DBaaS,但开源项目的想法对该公司仍然至关重要,因为开发者希望在云中获得自由和灵活性。
“因为云,它变得非常有趣。我们进入了这个世界,有很多项目和公司开始做这种假开源,你可以说它在你的笔记本电脑上工作,但在其他任何地方你都必须付费。
“没有人喜欢陷入陷阱。[开源]对于开发人员来说仍然是非常重要的,因为他们希望有选择的自由和扩展的自由。如果你看看所有主要的开源数据库,包括Cassandra、MySQL和PostgreSQL,它们都做得很好。有一个企业版,你可以付费,还有一个托管服务,你可以付钱。但是,还有一个免费版本。”
麦克法丁补充道:“如果你看看DataStax的客户,他们雇佣了这三家公司。我们有非常大的客户会购买我们的企业版,他们会使用我们的托管服务,然后他们会在同一个环境中拥有很多开源的Cassandra。他们有一种心理安全感,知道他们可以根据当前的业务四处移动。没有开源数据库,你无法做到这一点。”
例如,亚马逊有自己的键值数据库DynamoDB,它将其作为服务提供。
“你不能在亚马逊之外运行DynamoDB,因为它有一个非常明确的API。因此,开源不仅仅是软件,还有标准、API或查询语言等,”McFadin说。
他表示,DataStax将向开源社区发布其云服务的任何扩展,因为其付费卡桑德拉迭代和Apache卡桑德拉的API之间存在分歧。他认为,这意味着客户可以自由地离开任何付费系统,而无需对其应用程序进行重大重写。
麦克法丁说:“客户有时也会离开。我想的第一件事是,‘哦,那太糟糕了’。但这不是正确的说法。更像是‘我很高兴你还在使用卡桑德拉,我会在社区里看到你’,这是正确的答案。”。
Yugabyte:都是关于DBaaS的
YugabyteDB是过去几年中备受关注的分布式RDBMS供应商之一。其他获得NewSQL这个可疑名字的人包括CochroachDB,在某种程度上还有MariaDB。
Yugabyte是一个双层数据库。它的灵感来自下面的Google Panner,并与上面的PostgreSQL兼容,目的是创建一个高度可用、可扩展的分布式数据库。
去年10月,该公司在C轮融资中筹集了1.88亿美元,其业务价值约为13亿美元。
YugabyteDB在Apache 2.0许可下可用,并跨私有、公共和混合云环境在Kubernetes、VM和裸机上运行。
该公司由前Facebook工程师Kannan Muthukkaruppan、Karthik Ranganathan和Mikhail Bautin创建,于2017年脱离了秘密状态,但直到2019年才采用Apache 2.0。这一原因暴露了一些关于开源数据库的公开争论。
现在担任首席技术官的Ranganathan在接受注册时表示,所有创始人从一开始就希望完全开源,但投资者说服了他们。
“投资者群体非常清楚,开源是一种正在消亡的商业模式。因此,我们决定从根本上说,我们将成为一家开源公司,但因为他们的投资者说完全开源是一场失败的游戏,我们选择了开放核心,这意味着我们的数据库将有80%的价值是开放的,20%是关闭的,”他说。
然而,在该软件获得早期客户的支持后,它决定改变主意。
Ranganathan说:“我们意识到,除了在数据库中找出我们需要什么之外,如果没有DBaaS方面的支持,这就像刚到就死了一样。”。
这个启示意味着在DBAA上的竞争力与在数据库上的竞争力一样重要,客户希望数据库是开源的。Ranganathan指出:“我们告诉客户,我们喜欢PostgreSQL,但它是分布式的,他们说‘但PostgreSQL是非常开放的’。”。
Ranganathan说,尽管供应商担心——如果他们完全开放源代码——AWS或其他云提供商会通过提供自己的DBAA来吃午餐,但这没有抓住要点。
“如果——作为拥有该项目的主要供应商——您的DBaaS产品足够好,那么就应该很容易为人们提供使用该托管服务的理由。AWS只能为AWS提供这种服务;我们可以在任何云上(包括云外)提供这种服务,因为我们没有特别的偏好;我们实际上希望它在任何地方都可用。AWS只有在拥有整个基础设施时才能成功。”cture数据,即使客户想要拥有它,我们也是成功的。”
MariaDB:开源,但用于商业主干
MariaDB是从MySQL中分割出来的,MySQL是一个开源关系数据库,始于1995年。自2008年以来,MySQL一直是Sun Microsystems的一部分,但2010年甲骨文收购Sun时,MySQL联合创始人Widenius将代码分给了一个新的开源数据库MariaDB。
MariaDB采用了业务源代码许可证(BSL),批评者认为它不是真正的开源,因为它不允许用户或开发人员使用代码做他们想做的事情。在BSL下,源代码始终是公开的,非生产使用的代码始终是免费的,并且源代码最终保证开放。
该公司表示,许可模式只要求生产使用该软件的人获得商业许可,这通常表明环境为企业带来了巨大价值。
虽然BSL不符合OSI定义,但MariaDB确实坚持开源精神,同时确保其成为可持续发展的公司。
MariaDB首席执行官迈克尔·霍华德,告诉Reg:“开源最初是一种意识形态和一种生活方式。它是关于自由软件和非商业商业商业模式。在当今世界,世界上最大、最强大的公司在商业化努力中为自己的目的重用开源,人们意识到开源不能独立。独立、独立和依赖独立取决于强大的商业支柱。”
虽然BSL是“对开源的认可”,但它也为给定产品提供了强大的商业化平台。霍华德说:“这与Apache BSD或GPL(Linux使用的)非常不同,后者有悬而未决的需求和障碍,要求人们贡献一部分,并自动将其返回存储库,让任何人使用。”。
通过这种方式,它阻止了世界上最大的云公司围绕MariaDB数据库提供商业软件作为服务。“hyperscalers业务中的商业模式无疑推动了新的许可证模式,包括BSL。然而,当它最初设计时,更多的是关于企业家建立一个良好的企业,”他说。
Howard说,虽然MariaDB的许可证比其他开源项目更严格,但它可能比任何开源数据库都吸引更多的贡献,包括MySQL和PostgreSQL,这两个数据库都更老。
但与专有软件不同的是,无论是来自用户还是支持公司的开发人员,都可以自由查看源代码,一旦他们的数据库被转移到更为宽松的许可证,就可以为用户提供支持选项。
“大型机构将开源视为给他们提供了一种选择,他们可以与供应商合作,就像MariaDB一样,或者如果必须,他们可以修复自己的错误。他们可以雇佣人来修复错误,而不必依赖商业项目。这是一个深刻的区别,”他说。
CockroachDB:开源历史,商业前景
蟑螂实验室在这一领域相对来说是个新手。它由前谷歌程序员斯宾塞·金博尔(Spencer Kimball)、彼得·马蒂斯(Peter Mattis)和本·达内尔(Ben Darnell)于2015年创建。
该公司的数据库CockroachDB是一个分布式RDBMS,与PostgreSQL兼容,并由一个键值存储支持,该键值存储是RocksDB或一个专门构建的名为Pebble的衍生工具。
2021 12月,该公司通过2.78亿美元的F轮融资达到了50亿美元的名义估值。它的客户包括康卡斯特、eBay和Nubank。
像MariaDB一样,CockroachDB严重依赖于BSL。源代码是可用的,但未经Cockroach Labs同意,用户不得将CockroachDB用作服务。其他核心功能受CCL(Cockroach Community许可证)约束,根据该许可证,某些功能是付费或免费的,但代码是可用的。发布几年后,代码转移到Apache 2.0许可证。
Cockroach说,BSL没有被认证为开源许可证,但大多数OSI标准都得到了满足。
尽管开源和商业模式混合在一起,首席产品经理Jim Walker表示,公司一直沉浸在开源运动中。早期的版本是在Apache许可下发布的,而共同创始人Kimball和Mattis是流行的开源GIMP照片处理工具的幕后推手,该工具是由一个大学项目产生的。
但对沃克来说,开源不仅仅是许可证。“我并不是说它不重要,绝对不重要。如果你打算纯粹基于这一因素来做一个二进制的‘什么是开源?’?好吧,很好,我理解开源与否。然而,对我来说,开源远远不止于此。有一个社区的人参与其中。他们喜欢贡献和讨论(计算问题)。第一,这是关于人的。
“第二,它是关于代码的。它是关于开放源代码库的。如果你正在攻读分布式系统博士学位,你可以查看蟑螂实验室的代码库。现在,它完全开放。任何人都可以查看。”
批评者指出,对于采用混合模式的公司来说,他们的项目最终往往依赖于一个供应商,该供应商可以控制项目的方向,而不管更广泛社区的观点如何。贡献的多样性是一个健康的迹象。
但就贡献而言,沃克承认,大部分都是蟑螂实验室。那么,为什么不全力以赴,通过使软件成为专有软件来保护其知识产权呢?
沃克说:“对我来说,这是一条死胡同。考虑到过去三到五年来,由于开源,世界的发展速度。我说的不仅仅是我们的软件:世界发生了变化,因为我们可以从我们的系统中获得效率和规模。我们绝对是一个公民,也是其中的一部分。”。
他还认为,CockroachDB为用户提供了未来选择软件的自由:他们可以将数据和模式迁移到数据库的免费版本,并让其他人托管,或者自己运行。
但沃克表示,开发商面临的压力可能会阻止他们放弃付费托管服务。
“人们只是不这样做。没有人愿意这样做。CockroachDB的一部分价值基本上是,我不需要雇佣很多人,我也不需要那么多的资源来运行数据库。市场上出现了一种新的愿望,即低运营成本,并消除了我必须做的大量工作。”
MongoDB:超尺度(hyperscalers )将我们排除在外的风险
随着13年前第一次发布,MongoDB在某种程度上是NoSQL运动的鼻祖。至少根据DB引擎,它也是避免关系模型的数据库中排名最高的。
该公司于2017年首次公开募股,目前估值约220亿美元。
MongoDB为2018年10月16日之后发布的所有版本提供服务器端公共许可,而自由软件基金会的GNU AGPL v3.0适用于该日期之前发布的MongoDB软件。
SSPL由MongoDB引入,要求向社区发布MongoDB的增强功能。如果出于法律原因无法接受,则可以使用MongoDB Enterprise Advanced获得商业许可。
产品管理高级副总裁安德鲁·戴维森(Andrew Davidson)表示:“开源是MongoDB成功的关键部分。在当今时代,如果没有开源第一的理念,就不可能成为广泛采用的开发解决方案。”
但多年来,该公司开始意识到,超尺度者将MongoDB投资的产品作为服务交付的风险,将MongoDB排除在外,他说。
“SSPL是非常明确的,旨在澄清一个模糊性,即您不能将MongoDB作为托管云服务交付,目标是超规模者。通过SSPL许可的社区版让我们的用户可以自由地在任何他们想要的地方运行它,并将其用于他们想要的任何应用程序。唯一的限制是,他们不能将其作为管理服务销售。”d云服务,”戴维森说。
但他们可以在MongoDB之上构建自己的软件,并将其作为服务提供,他说。
在MongoDB早期开发之后的几年中,该公司开始意识到未来是托管服务,因此投入了创建Atlas的工作,即其DBAA,例如,该公司通过解决分析问题的附加功能对其进行了修饰。
批评者提出的关于混合模式开源的一个问题是未来自由的问题:一旦客户构建了应用程序,他们是否有能力离开供应商?他们可以复制数据库并在其他地方托管应用程序吗?
对于MongoDB Atlas,答案是“可能”和“取决于”
“我们已将Atlas扩展到OLTP数据库之外,以提供触发器、数据湖产品、数据联盟、API服务器和应用服务等……基本上,您可以完全移动这些服务。如果您正在使用这些辅助服务中的任何一项,那么如果您离开Atlas,您必须构建自己的体验这些类型用例的方式。”
虽然开源倡导者认为项目受益于多种贡献者,如PostgreSQL,但戴维森认为,亚马逊、微软和EDB等贡献者的企业对项目的成功感兴趣。
MongoDB可能更像是一个单一的供应商项目,但这允许它“沉迷于开发人员体验,并以一种与脱节的联合体模式稍有不同的方式创造优雅的集成体验,”戴维森说。
无论对开源的解释如何,它都有一个共同的核心价值,那就是对代码的信任。“你需要能够知道,你可以进去,用显微镜[和]检查这个东西是如何建造的。
“当然,你可能不会真的这么做,但知道无数其他人——博士、学生、学者和行业专业人士——正在这么做是非常关键的。我们谈论的是人们应用程序的核心,这是他们业务的关键。这一切都是关于知道你正在构建的是社区验证的东西。”
魔鬼的拥护者也可能会指出,世界各地的银行都在运行专有的Oracle和Db2,而且它们似乎很好。但这些系统都是由大型公司多年来设计的。开放源代码模型允许在没有这种支持的情况下可靠地引入新数据库。
Exasol:社区无法实现的专有技术
最后,观察者认为所有现代数据库都以某种方式基于开源软件,这是可以原谅的,但事实并非如此。德国的Exasol开发了一种内存分析系统,戴尔和体育巨头阿迪达斯使用该系统。长期以来,它一直声称在TPC价格/性能基准方面处于领先地位。
首席技术官Mathias Golombek告诉《注册》杂志,并行硬件有一些细节,这意味着开源路线对他们的核心产品不起作用。
“开源系统非常流行,尤其是事务数据库,”他说。“在更动态的数据分析领域,Exasol以各种方式拥抱开源软件;然而,我们的核心数据库引擎仍然是专有的,因为到目前为止,还没有能够访问MPP硬件设置并专门从事内存计算的合适的开发人员社区。
“为了充分利用这两个世界,并支持开源作为软件行业的一个基本概念,Exasol通过利用敏捷社区帮助创建各种集成项目,增加了数十个开源项目,如通过我们的语言容器的数据科学,或通过虚拟模式的数据虚拟化。
“随着时间的推移,我们了解到,与封闭源代码相比,开放源代码的重要性越来越小,而是软件体系结构是否与数据问题相关。开放源代码商业模式已经让尚未实现这一目标的企业软件供应商失败了。”
本文:https://jiagoushi.pro/open-source-databases-what-are-they-and-why-do-th…
- 135 次浏览
【数据管理】顶级数据库管理系统供应商
确定哪种类型的数据库或数据库服务最适合您的企业的最佳方法是什么?这完全取决于您需要什么类型的用例。在本文中了解更多信息。
基本上,我们每天使用的所有数字信息都在世界某处的数据库管理系统或存储阵列中。这些存储设备可以小到智能手机,也可以大到基本上不受限制的云存储系统。
如何最好地找出哪些DBMS适合您的企业?你应该订阅AWS、Azure、Google或其他云服务提供商提供的服务,还是购买数据中心存储和服务器并自己运行?这完全取决于您需要哪种类型的用例;例如,如果您是金融服务、医疗保健或国防部门的受监管行业,则可能需要同时安装这两种类型的用例。如果你是一个小企业,也许你需要的只是云服务。这里的大多数公司都提供这两种选择。
自20世纪80年代《个人电脑周》(PC Week)出版以来,eWEEK一直在研究和报告数据库及其管理系统,当时IBM的DB2、微软的SQL Server和Sybase是该行业的大腕。在这篇文章中,我们找到并评估了2019年前十大现代数据库管理系统,包括专有和开源系统,并将它们编译到本文中。
Oracle RDMS
加州红木海岸。
潜在买家的价值主张:大型、功能强大且相对昂贵的条款通常附属于Oracle的企业数据库,但你可以得到你所付出的代价。
甲骨文在这一领域统治了30多年,该公司在这一领域已有42年的历史。甲骨文设计了其数据库硬件和软件,以便在云端和数据中心协同工作。该公司声称,这消除了复杂性,简化了一般性。这通常是正确的,但是如果用例和环境发生变化,用户通常会被锁定在一个单一的供应商系统中,以后很难更改。
甲骨文对它的所有层都采用开放标准的方法,但它需要本地企业it人员的专业知识才能在预先配置的甲骨文系统之外更换各种组件,而且许多中小型企业都没有这种专业知识。定价sla也会发生变化。复杂度较低,维护较少的点解决方案和一般一流的性能的权衡往往过于压倒许多企业忽视。
作为一家早年对云系统嗤之以鼻的公司,它现在是一家积极销售基于云的DBMS系统的公司,以配合其Exadata数据中心服务器。时代确实变了,甲骨文也跟着时代变了。
对于需要模块化解决方案的客户,Oracle的开放式体系结构和多个操作系统选项提供了来自堆栈每一层中同类最佳产品的无与伦比的好处。这允许客户为其企业构建尽可能优化的基础架构。
关键价值/差异:
- Oracle SQL的基于UNIX的数据库管理系统提供了在任何操作系统中选择运行企业数据库的灵活性。专用语言仅与同一制造商的操作系统兼容。例如,只能在基于Windows的计算机上运行Microsoft SQL Server。相比之下,您可以在Unix服务器上安装Oracle SQL,在保持SQL标准化的同时,还可以从Unix的可靠性中获益。
- Unix不易受到许多常见的计算机病毒的攻击,从而保证信息的安全。
- Oracle SQL也是向后兼容的,因此用户可以选择在将来升级而不丢失任何数据。
- 对于需要模块化解决方案的客户,Oracle的开放式体系结构和多种操作系统选项提供了来自堆栈每一层中同类最佳产品的好处。这允许客户为其企业构建尽可能优化的基础架构。
路线图:
- Oracle数据库管理系统每年更新一次或两次,并定期迭代发送。
谁使用它:中大型企业
工作原理:云部署、物理on-prem服务
埃韦克分数:4.9/5.0
Oracle提供的MySQL
加州红木海岸。
潜在买家的价值主张:Oracle拥有的MySQL是一个流行且广泛使用的开源关系数据库管理系统。
这是一个节省成本和有效的数据库管理系统,但它需要专门知识的数据库系统安装和维护。它的名字是“My”和“SQL”的组合,前者是联合创始人MichaelWidenius的女儿,后者是结构化查询语言的缩写。MySQL是GNU通用公共许可条款下的免费开源软件,也可以在各种专有许可下使用。MySQL是由瑞典MySQL公司创建和赞助的,该公司被Sun Microsystems收购。2010年,当甲骨文收购Sun时,Widenius将开源MySQL项目分给了MariaDB。
关键价值/差异:
- 它有一个令人印象深刻的用户列表。MySQL被许多数据库驱动的web应用程序使用,包括Drupal、Joomla、phpBB和WordPress。MySQL也被许多流行网站使用,包括Facebook、Twitter、Flickr和YouTube。
- MySQL长期以来一直受到好评,评论人士称它在一般情况下表现非常好,开发人员界面也在那里,文档(更不用说通过网站等在现实世界中的反馈)非常非常好。
- 它还被测试为一个快速、稳定、真正的多用户、多线程的SQL数据库服务器。
- 它的开源核心和属性支持用例所需的任意数量的配置。
- 甲骨文拥有一支庞大而专业的支持人员队伍,可以与MySQL客户合作。
- MySQL在大多数企业服务器上工作,它们不必是Oracle服务器。
路线图:
- MySQL每年都会从Oracle的团队那里获得几次更新,并且会定期迭代发送。
谁使用它:中小企业到大企业
工作原理:订阅云服务、物理on-prem服务
埃韦克分数:4.9/5.0
Microsoft SQL服务器
雷蒙德,华盛顿。
潜在买家的价值主张:这是一个行业标准的数据库管理系统。
Microsoft SQL Server的历史始于第一个microsoftsqlserver产品(SQL Server 1.0,1989年用于IBM OS/2操作系统的16位服务器),一直延续到今天。微软重新开发了Microsoft SQL Server,使其能够与自己的Windows操作系统最佳地协同工作。与其他数据库管理系统类似,它的主要功能是根据其他软件应用程序的请求存储和检索数据,这些应用程序可以运行在同一个数据中心上,也可以运行在网络(包括internet)上的另一台计算机上。事实上,近一半的微软SQL Server实例部署在微软的Azure云中。
关键价值/差异:
以下是自2019年4月起SQL Server的新功能列表。
- 微软已经开发了至少十几个版本的Microsoft SQL Server,针对不同的受众和工作负载,从小型的单机应用程序到大型的面向Internet的应用程序,这些应用程序有许多并发用户。因此,它是迄今为止最通用的MySQL部署。
- SQL Server企业版:这包括核心数据库引擎和附加服务,以及一系列用于创建和管理sqlserver集群的工具。它可以管理高达524petabytes的数据库,处理12tb的内存,并支持640个逻辑处理器(CPU核)。
- 标准版:SQL Server标准版包括核心数据库引擎和独立服务。它不同于企业版,因为它支持较少的活动实例(集群中的节点数),并且不包括一些高可用性功能,如热添加内存(允许在服务器仍在运行时添加内存)和并行索引。Web SQL Server Web版是一个低TCO的Web宿主选项。
- 商业智能:在SQL Server 2012中引入,专注于自助服务和企业商业智能。它包括标准版功能和商业智能工具:PowerPivot、Power View、BI语义模型、主数据服务、数据质量服务和xVelocity内存分析。
路线图:
- SQL Server每年会获得一到两次主要更新,今年晚些时候将发布一个新版本,其中包括智能查询处理、大数据集群和更多功能。
谁使用它:中小企业、中端服务器、边缘服务器、大型企业
工作原理:订阅云服务和物理on-prem服务
埃韦克分数:4.7/5.0
PostGres SQL
费城,宾夕法尼亚州。
对潜在购买者的价值定位:PostgreSQL是一个对象关系数据库管理系统,强调可扩展性和标准遵从性。它可以处理许多并发用户的工作负载,从单机应用程序到Web服务或数据仓库。PostgreSQL是由PostgreSQL全球开发小组开发的,该小组由许多公司和个人贡献者组成。它是自由和开放源代码的软件,在一个宽松的软件许可下发布。
键值/差异:
- PostgreSQL是跨平台的,可以在许多操作系统上运行,包括Linux、FreeBSD、Solaris和Microsoft Windows。它可以处理从小型单机应用程序到具有许多并发用户的大型面向internet的应用程序等各种工作负载。最近的版本还提供了数据库本身的复制,以保证安全性和可伸缩性。
- PostgreSQL支持ANSI SQL和SQL/MED等标准,但具有高度可扩展性,支持12种以上的过程语言、GIN和GIST索引、空间数据支持,以及基于文档或键值的应用程序的多个类似于SQL的特性。
- PostgreSQL是acid兼容和事务性的。它提供了对RDBMS特性的支持,如可更新和物化视图、触发器、外键;函数和存储过程。
路线图:
- PostgreSQL每年都会有几次主要的更新。
谁在使用它:中小型企业、中型企业、边缘服务器、大型企业
它是如何工作的:订阅云服务,物理预发布服务
eWEEK评分:4.8/5.0
MongoDB
纽约,纽约
对潜在购买者的价值定位:MongoDB是一个开源的、跨平台的面向文档的数据库管理系统。
作为一个NoSQL数据库管理系统,MongoDB使用类似json的文档和模式。MongoDB由MongoDB公司开发,并在服务器端公共许可证(SSPL)下授权。作为一种开源产品,定价对于小公司来说要合理得多,这与大型、成熟的数据库供应商提供的全服务是不同的。
键值/差异:
- MongoDB可以运行在多个服务器上,平衡负载或复制数据以保持系统正常运行,以防硬件故障。
- MongoDB提供高可用性的副本集,其中包含两个或多个副本的数据。每个副本集成员可以在任何时候充当主副本或次副本的角色。默认情况下,所有的写和读都是在主副本上完成的。
- 辅助副本使用内置的复制来维护主副本的数据副本。当主副本失败时,副本集将自动执行一个选择过程,以确定哪个辅助副本应该成为主副本。二级服务器可以选择性地提供读操作,但是默认情况下这些数据最终是一致的。
- MongoDB使用分片进行水平扩展(分片是一个拥有一个或多个副本的主机)。
路线图:
- MongoDB每年都会有几次重大更新。
谁在使用它:中型到大型企业
它是如何工作的:订阅云服务,物理预发布服务
eWEEK评分:4.8/5.0
IBM DB2
纽约州阿蒙克市
潜在购买者的价值主张:IBM DB2是一种行业标准数据库管理系统。
DB2代表了一组完整的数据管理系统,包括可在云环境中使用的服务器,这些服务器最初是由IBM在20世纪80年代早期开发的。它们支持关系数据库模型,但近年来,一些产品已经扩展为支持对象关系特性和非关系结构,如JSON和XML。从1983年创建到2017年,该品牌被命名为DB2。
IBM在2019年为Db2制定的目标是成为帮助增强认知应用程序的人工智能数据库。IBM混合数据管理(HDM)是在Db2公共SQL引擎上构建的,它提供了一个平台来跨所有源和目标管理所有数据类型。
由于该软件的高可靠性、弹性和安全性等特点,成千上万的组织使用IBM混合数据管理和db2(在线事务处理(OLTP)、在线分析处理(OLAP)和大数据段中的市场支柱)来运行关键任务应用程序。IBM打算使用Db2(混合数据管理平台的核心组件)让用户能够加速他们的AI应用程序开发,同时自动化一些数据管理。
IBM Db2现在为流行的数据科学语言和框架提供了驱动程序,包括Go、Ruby、Python、PHP、Java和Node。使开发人员和数据科学家能够第一次使用Db2数据构建AI应用程序。这些驱动程序现在可以在GitHub上使用。
键值/差异:
- IBM的商标,在几十年的产品开发和服务中建立起来的声誉,在所有数据中心系统软件和设备中意义重大。
- DB2系统的一个重要特性是错误处理。SQL communications area (SQLCA)结构曾经专门用于DB2程序中,在执行每条SQL语句之后将错误信息返回给应用程序。主要的(但不是特别有用的)错误诊断位于SQLCA块中的SQLCODE字段中。
路线图:
- DB2每年进行一次或两次重大更新,并根据需要进行增量修复。
谁在使用它:中小型企业到大型企业
它是如何工作的:云服务,物理预启动服务
eWEEK评分:4.8/5.0
Microsoft Access
华盛顿州雷德蒙德
潜在买家的价值主张:Microsoft Access是第二代数据库管理系统(DBMS),它将关系型Microsoft Jet数据库引擎与图形用户界面和它自己的一套软件开发工具结合在一起。
它是Microsoft Office应用程序套件的成员,包含在专业版和高级版中,或单独出售。Microsoft Access基于Access Jet数据库引擎以自己的格式存储数据。它还可以导入或直接链接到存储在其他应用程序和数据库中的数据。与其他Microsoft Office应用程序一样,Visual Basic for applications (VBA)支持访问,这是一种基于对象的编程语言,可以引用各种对象,包括DAO(数据访问对象)、ActiveX数据对象和许多其他ActiveX组件。窗体和报表中使用的可视化对象在VBA编程环境中公开它们的方法和属性,VBA代码模块可以声明和调用Windows操作系统操作。
键值/差异:
- 除了用作自己的数据库存储文件之外,Microsoft Access还可以用作程序的前端,而其他产品用作后端表,如Microsoft SQL Server和非Microsoft产品,如Oracle和Sybase。Microsoft Access Jet数据库(ACCDB和MDB格式)可以使用多个后端源。
- 类似地,一些应用程序如Visual Basic, ASP。NET或Visual Studio .NET将对其表和查询使用Microsoft Access数据库格式。Microsoft Access也可能是更复杂的解决方案的一部分,它可能与其他技术集成,如Microsoft Excel、Microsoft Outlook、Microsoft Word、Microsoft PowerPoint和ActiveX控件。
- 访问表支持各种标准字段类型、索引和引用完整性,包括级联更新和删除。访问还包括查询接口、用于显示和输入数据的表单以及用于打印的报告。包含这些对象的底层Jet数据库是多用户的,它处理记录锁定。
- 重复的任务可以通过带有指向和单击选项的宏实现自动化。在网络上放置数据库,让多个用户共享和更新数据,而不覆盖彼此的工作,这也很容易。数据被锁定在记录级别,这与Excel锁定整个电子表格有很大的不同。
路线图:
- Microsoft give Access每年获得一到两次重大更新,并根据需要进行增量修复。预计今年不会有重大更新。
谁在使用它:中型到大型企业
它是如何工作的:云服务,物理预启动服务
eWEEK评分:4.6/5.0
Redis 实验室
加州山景城。
潜在买家的价值主张:Redis内存数据库管理系统是为速度和效率而设计的第二代核心开源系统。Redis Labs是商业Redis提供商市场的老大,它的企业级Redis DBMS速度快于平均水平,为前沿应用程序提供了强大的支持。它的Redis Labs企业集群和Redis云解决方案因高性能、高可伸缩性、真正的高可用性、一流的专业知识和支持用例而受到数千名开发人员和企业客户的信任。这些包括实时分析、快速的大容量事务、社交应用程序功能、应用程序作业管理和缓存。
键值/差异:
- Redis Labs是Redis的主要贡献者,该数据库已成为2019年可用的最快数据库。
- Redis在开发者中排名第一,在所有开发者工具和服务中排名第12。
- Redis被认为是以下用例的一流数据库:分析、大数据、云数据服务、企业软件、信息技术、开源、软件即服务。
路线图:
- Redis定期获得主要更新,有时每周更新一次。
谁在使用它:中型到大型企业
工作原理:只提供云服务
eWEEK评分:4.9/5.0
Apache Cassandra
门洛帕克,加利福尼亚州。
对潜在买家的价值定位:Apache Cassandra最初是在Facebook开发的,用于支持其收件箱搜索功能,现在是世界上领先的内存开源数据库管理系统之一。它是一个免费的、开源的、分布式的、宽列存储的NoSQL数据库管理系统,设计用于跨许多普通服务器处理大量数据,提供高可用性,没有单点故障。Cassandra为跨多个数据中心的集群提供了健壮的支持,异步无主复制允许所有客户端进行低延迟操作。
键值/差异:
- 集群中的每个节点都具有相同的角色。没有单一的失败点。数据分布在集群中(因此每个节点包含不同的数据),但是没有主节点,因为每个节点都可以为任何请求提供服务。
- 支持复制和多数据中心复制:复制策略是可配置的。Cassandra被设计为一个分布式系统,用于跨多个数据中心部署大量节点。Cassandra的分布式架构的关键特性是专门为多数据中心部署、冗余、故障转移和灾难恢复而定制的。
- 可伸缩性:设计为读写吞吐量均随着新机器的添加而线性增加,目标是不停机或不中断应用程序。
- 容错:自动将数据复制到多个节点以实现容错。支持跨多个数据中心的复制。失败的节点可以替换为没有停机时间。
- 可调一致性:Cassandra通常归类为一个美联社系统,这意味着可用性和分区容忍通常被认为是更重要的比一致性在卡桑德拉,写入和读取的提供一个可调水平的一致性,从“写永远不会失败”“阻止所有副本可读,”中间的群体水平。
路线图:
- Cassandra每年都会有几次重大更新。
谁在使用它:中型到大型企业
工作原理:只提供云服务
eWEEK评分:4.8/5.0
荣誉奖:Sybase by SAP (SAP Adaptive Server), SAP HANA, Quest, CA, BMC
原文:https://www.eweek.com/database/top-database-management-systems-vendors
本文:http://jiagoushi.pro/top-database-management-systems-vendors
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 153 次浏览
【流式数据库】如何选择正确的流式数据库
视频号
微信公众号
知识星球
在当今实时数据处理和分析的世界中,流媒体数据库已成为希望保持领先地位的企业的重要工具。这些数据库专门设计用于处理连续大量生成的数据,非常适合物联网(IoT)、金融交易和社交媒体分析等用例。然而,市场上有这么多选择,选择合适的流媒体数据库可能是一项艰巨的任务。
👉 这篇文章帮助您了解什么是SQL流、流数据库、何时使用以及为什么使用它,并讨论了在为您的业务选择合适的流数据库时应该考虑的一些关键因素。
学习目标📖
您将在本文中学习以下内容:
- 什么是流数据(事件流处理)?
- 什么是流式SQL方法?
- 流式处理数据库、功能和用例。
- 排名前五的流媒体数据库(包括开源和SaaS)。
- 选择流式数据库的条件。
让我们在接下来的几节中快速回顾一些概念,比如什么是流式数据、流式SQL和数据库。
什么是流式数据?⤵️
流是随着时间的推移而可用的事件/数据元素的序列。数据流是一种实时处理和分析数据的方法,数据由各种来源生成,如传感器、电子商务购买、网络和移动应用程序、社交网络等。它涉及以事件或消息的形式持续不断地收集、处理和传递数据。
您可以使用更改数据捕获(CDC)从不同的数据源获取数据,如消息代理Kafka、Redpanda、Kinesis、Pulsar或数据库MySQL或PostgreSQL,这是识别和捕获数据更改的过程。
什么是流式SQL?⤵️
收集数据后,您可以将这些数据存储在流式数据库中(在下一节中,将对此进行解释),在那里可以使用SQL查询和SQL流式处理和分析这些数据。这是一种使用SQL查询处理实时数据流的技术。它允许企业使用与批处理相同的SQL语言来实时查询和处理数据流。
数据可以从流中实时转换、过滤和聚合为更有用的输出,如物化视图(CREATE materialized view),以提供见解并实现自动化决策。
☝️ 物化视图通常用于需要频繁执行复杂查询或查询结果需要长时间计算的情况。通过预计算结果并将其存储在物化视图(虚拟表)中,可以更快地执行查询,并减少开销。PostgreSQL、Microsoft SQL Server、RisingWave或Materialize支持自动更新的物化视图。
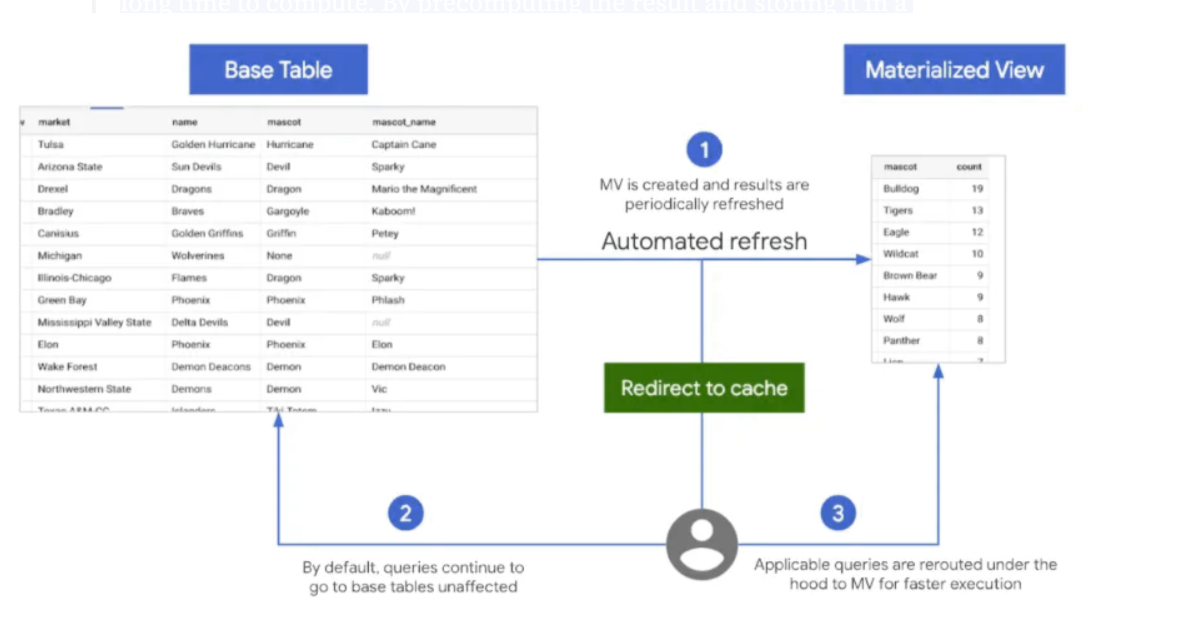
SQL流的一个主要好处是,它允许企业利用现有的SQL技能和基础设施来处理实时数据。这可能比学习Java、Scala等新的编程语言或处理数据流的工具更有效👍.
什么是流式数据库?⤵️
流式数据库,也称为实时数据库,是一种设计用于实时处理连续数据流的数据库管理系统。它经过优化,可处理和存储以连续快速流形式到达的大量数据。
流式数据库使用与传统数据库相同的声明性SQL和相同的抽象(表、列、行、视图、索引)。与传统数据库不同,数据存储在与写入(插入、更新)结构匹配的表中,所有计算工作都发生在读取查询(选择)上,流式数据库在连续的基础上运行,在数据到达时处理数据,并以物化视图的形式将其保存到持久存储中。这允许对实时事件进行即时分析和响应,使企业能够根据最新信息做出决策和采取行动。
流式数据库通常使用专门的数据结构和算法,这些结构和算法经过优化以实现快速高效的数据处理。它们还支持复杂事件处理(CEP)和其他实时分析工具,以帮助企业实时获得见解并从数据中提取价值。
流式数据库独有的功能之一是能够更新增量物化视图💪.
您可以对Stream数据库做些什么?⤵️
以下是您可以使用流式数据库执行的一些操作:
- 从不同的流/数据源(如Apache Kafka)收集和转换数据。
- 为需要增量聚合的数据创建物化视图。
- 使用简单的SQL语法查询复杂的流数据。
- 在聚合和分析实时数据流之后,您可以使用实时分析来触发下游应用程序。
5个顶级流媒体数据库⤵️
由于有各种类型的流式数据库可用,并且每个流式数据库都提供了许多功能。
下面,我分享了5个顶级流媒体数据库(包括开源和SaaS),并注意到它们并没有按流行或使用的特定顺序排列。
如何选择流媒体数据库⤵️
选择合适的流媒体数据平台可能是一项具有挑战性的任务,因为需要考虑几个因素。在选择流媒体数据平台时,需要记住以下一些关键注意事项:
- 数据源:考虑平台可以接收和处理的数据源类型。确保平台能够处理您需要的数据源。Kafka、Redpanda、Apache Pulsar、AWS Kinesis、Google Pub/Sub主要用作流源服务/消息代理。或者PostgreSQL或MySQL等数据库。
- 可扩展性:考虑平台随着数据需求的增长而扩展的能力。一些平台的扩展能力可能有限,而另一些平台可以处理大量数据和多个并发用户。确保缩放过程几乎可以在不中断数据处理的情况下立即完成。例如,开源项目RisingWave使用一致的哈希算法将数据动态划分到每个计算节点。这些计算节点通过计算数据的唯一部分进行协作,然后相互交换输出。就云提供商中的流媒体数据平台而言,它们支持开箱即用的自动扩展功能,因此这不是问题。
- 集成:考虑平台与其他系统和工具(如BI和数据分析平台)集成的能力,您目前正在使用或计划在未来使用这些平台。确保平台支持与其他系统连接所需的协议和API。RisingWave集成了许多BI服务,包括Grafana、Metabase、Apache Superset等。
- 性能:考虑平台的速度和效率。一些平台在查询速度、数据处理和分析方面可能比其他平台表现更好。因此,您需要选择一个流式数据库,该数据库可以在几秒钟内提取、转换和加载数百万条记录。流数据平台的关键性能指标(KPI)是事件速率、吞吐量(事件速率乘以事件大小)、延迟、可靠性和主题数量(对于发布子架构)。有时与基于JVM的系统相比,使用诸如Rust之类的低级编程语言设计的平台可能速度极快。
- 安全性:考虑平台的安全功能,如访问控制、数据加密和合规认证,以确保您的数据得到保护。
- 易用性:考虑平台的易用性,包括其用户界面、文档和支持资源。确保该平台易于使用,并为您的团队提供足够的支持。
- 成本:考虑平台的成本,包括许可费、维护成本以及任何额外的硬件或软件要求。确保该平台符合您的预算,并提供良好的投资回报。
总结⤵️
总之,流式数据库提供了几个独特的功能,包括实时数据处理、事件驱动架构、连续处理、低延迟、可扩展性、对各种数据格式的支持以及灵活性。这些功能能够在实时应用程序中实现更快的洞察力、更好的决策和更高效的数据使用。
适合您的用例的最佳流式数据库将取决于您的特定需求,例如支持的数据源、容量和速度、数据结构、可扩展性、性能、集成和成本。重要的是要根据这些因素仔细评估每个选项,以确定最适合您的组织。
相关资源
- What Are Materialized Views in Databases?
- What is Streaming SQL?
- How to choose a streaming data platform?
推荐内容
- 427 次浏览
文档数据库
【MongoDB】开源MongoDB替代FerretDB现已全面可用
视频号
微信公众号
知识星球
FerretDB,一个开源的MongoDB替代数据库,最近宣布全面可用。该项目以Apache 2.0许可证发布,允许开发人员使用现有的PostgreSQL基础架构来运行MongoDB工作负载。
FerretDB充当代理,将MongoDB有线协议查询转换为SQL,PostgreSQL作为数据库后端。FerretDB最初是MongoDB的开源替代品,它提供了相同的MongoDB API,而开发人员无需学习新的语言或命令。FerretDB联合创始人兼首席执行官Peter Farkas解释道:
我们正在为文档数据库创建一个与MongoDB兼容的新标准。FerretDB是MongoDB的替代品,但它也旨在制定一个新的标准,不仅将易于使用的文档数据库带回其开源根源,还使不同的数据库引擎能够使用标准化接口运行文档数据库工作负载。
虽然FerretDB是在PostgreSQL上构建的,但该数据库采用可插拔架构设计,以支持其他后端,目前正在进行针对Tigris、SAP HANA和SQLite的项目。该项目最初是在Go中编写的,因为MongoDB在2018年采用的服务器端公共许可证(SSPL)不符合开源计划设定的所有开源软件标准。FerretDB背后的团队写道:
MongoDB最初是作为开源软件构建的,它改变了许多开发人员的游戏规则,使他们能够构建快速而强大的应用程序。它的易用性和丰富的文档使它成为许多寻找开源数据库的开发人员的首选。然而,当他们转向SSPL许可证,远离开源根源时,所有这些都发生了变化。
Farkas表示,流行的数据库管理工具,如mongosh、MongoDB Compass、NoSQL Booster和Mingo,已经与FerretDB的当前功能集兼容。自由软件基金会在其月度新闻摘要中评论道:
对于那些理所当然地关心MongoDB在2018年更改许可条件的人来说,这确实是一个好消息。
在1.0版本中,FerretDB添加了对createIndexes命令的支持,而1.1.0版本包括添加renameCollection、对投影字段分配的支持、$project管道聚合阶段,以及在SAP HANA处理程序中创建和删除命令。
在Reddit上,MongoDB的替代品的普遍可用性得到了褒贬不一的反馈,一些用户支持抽象层,而另一些用户则不认为FerretDB是一个“真正的”数据库。YugabyteDB和AWS Data Hero的开发倡导者Franck Pachot最近写了一篇文章,介绍如何在YugabyteDB上启用与MongoDB兼容的API:
想要在分布式SQL数据库上使用与MongoDB兼容的API吗?很容易将FerretDB连接到YugabyteDB,所有这些都是开源的。
FerretDB并不是MongoDB的唯一替代品:其他支持MongoDB API的基于无架构文档的数据库包括Amazon DocumentDB、Azure CosmosDB和MariaDB MaxScale。在最近的一次网络研讨会上,Udemy的首席数据库可靠性工程师David Murphy将CosmosDB、DocumentDB、MongoDB和FerretDB作为文档数据库进行了比较。
FerretDB项目和路线图可在GitHub上获得,包括Docker镜像、RPM和DEB包。
- 408 次浏览
【性能优化】如何优化MongoDB和Mongoose 的性能

表现是避免不必要工作的艺术。这些是我关于优化MongoDB查询的发现,你可以滚动下面的性能测试和结果。
1. 对GET操作使用精益查询
这可能是提高查询性能的最好方法。Mongoose允许您在查询的末尾添加.lean(),通过返回纯JSON对象而不是Mongoose文档,可以极大地提高查询的性能。
默认情况下,Mongoose 查询返回一个Mongoose 文档类的实例。文档比普通的JavaScript对象要重得多,因为它们有很多内部状态需要跟踪更改。启用lean option将告诉Mongoose跳过实例化完整的Mongoose文档,而只给您POJO。
精益选项告诉Mongoose 跳过补水的结果文件。这使得查询速度更快,内存消耗更少,但是结果文档是普通的旧式JavaScript对象(pojo),而不是Mongoose 文档。
然而,这是有代价的,这意味着精益文档没有:
- 更改跟踪
- 铸造和验证
- getter和setter
- 虚拟(包括“id”)
- save()函数
因此,对于不使用.save()或virtuals的GET端点和.find()操作通常是最优的。
2. 为您的查询创建自定义索引
MongoDB允许您在模式中的其他属性上创建索引,而不是默认的“_id”索引。这样,您的文档就可以根据您在数据库中定义的属性建立索引,以便更快地访问。
您还可以创建多个属性的复合索引。如果您要查询多个字段,这将非常有用。假设你有一些数据库,你想找到所有灭绝的动物,你可能会写一个查询模型这样。Model.find({type: “Animal”, status: “extinct"})
MongoDB将不得不查看所有的文档来找到符合这个条件的,为了优化这个查询,你可以通过添加ModelSchema为“type”和“status”创建一个复合索引。ModelSchema.index({type: 1, status: 1}).MongoDB现在会去哪里查找相关文档。
“1”或“-1”表示属性的排序顺序。字段添加到索引中的顺序很重要。有关索引的更详细说明,请参见
https://mongoosejs.com/docs/guide.html#indexes and https://docs.mongodb.com/manual/indexes/
3.最小化DB请求(如果可能,避免.populate())
请求越多,应用程序的响应时间就越慢。尽可能地将数据库查询最小化,并将它们组合在一起,或者通过消除重复或不必要的db操作来完全避免它们。你也可以在redis中缓存你的数据库结果。
尝试以不需要过多依赖.populate()和模型之间的双向关系的方式定义模式。因为这是NoSQL数据库不是很理想的地方。在模型中添加的每个属性都将从查询中返回,因此,如果在这些字段中有数组或嵌套对象,那么文档将很容易极大地降低查询的性能。
如果你的文档包含一个数组的引用其他模型,你使用.populate()之间加入数据集合,使用.populate()将需要运行额外的查询来获取数组的实际文档里面,所以它类似于运行额外的每个id为每个文档查询。如果确实需要,最好使用.aggregate()而不是.populate()。
4. 使用.select()选择要返回的特定属性
当查询数据库中的文档时,查询将返回整个文档,但有时您有带有大量字段的大型文档,而字段是如上所述的数组/对象,因此您实际上不需要使用所有返回的属性。
为了防止数据库做额外的工作来返回这些字段增加返回文档的大小,你可以使用mongoose .select()来包括/排除你想要你的查询返回的字段,具体如下:
Model.find({type: "Animal"}).select({name: 1})
Protip:如果您使用的是GraphQL,那么它的工作效果非常好,这样您就可以确切地知道客户机请求的字段,并且可以从数据库中选择这些字段。我在这里写了另一篇文章
https://itnext.io/graphql-performance-tip-database-projection-82795e434b44
5. 并行运行数据库操作
当人们使用异步/等待时,我在NodeJS代码中看到的一个常见错误是人们在不需要的时候一个接一个地运行操作。例如:
const user = new User({name: "bob"})
const post = new Post({title: "hello"})
await user.save()
await post.save()没有理由等待用户被保存后再保存post。相反,可以使用Promise并行运行数据库操作。所有的如下:
const [user, post] = await Promise.all([user.save(), post.save()])
虽然这可以提高API级别上的性能,但我们仍然要对数据库执行两个请求,所以如果您想批量执行多个操作,使用insertMany()或bulkwrite()会更好。
6. 缓存/重用mongoose 连接
确保不要在每次想要从数据库插入/查询内容时或每次端点被触发时连接和断开与数据库的连接。相反,您应该在应用程序开始时连接一次,然后重用该连接。
这是因为建立一个新的TCP连接在时间、网络请求和内存方面都很昂贵,而且新的连接还意味着MongoDB要使用数据库上的内存创建一个新线程。
让我们编写一些性能测试来查看结果
这些技巧能在多大程度上提高您的查询性能?让我们通过编写一些脚本来测试这些差异。
我运行了MongoDB的本地安装,并编写了一个NodeJS脚本,该脚本使用随机生成的用户列表填充数据库。目标是找到年龄超过22岁的用户。
我结合上面提到的方法以不同的方式编写查询,并在使用相同数据集填充的两个不同的数据库集合上尝试它们。一个集合对“age”属性有索引,而另一个没有。使用console.time() API测量结果,使用NodeJS (v12.7.0)和mongoose (v5.6.7)的最新当前版本运行测试。
首先让我们从out模式开始,这里我对用户集合/模式进行了定义,其中一个在age属性上有索引,而其他没有。
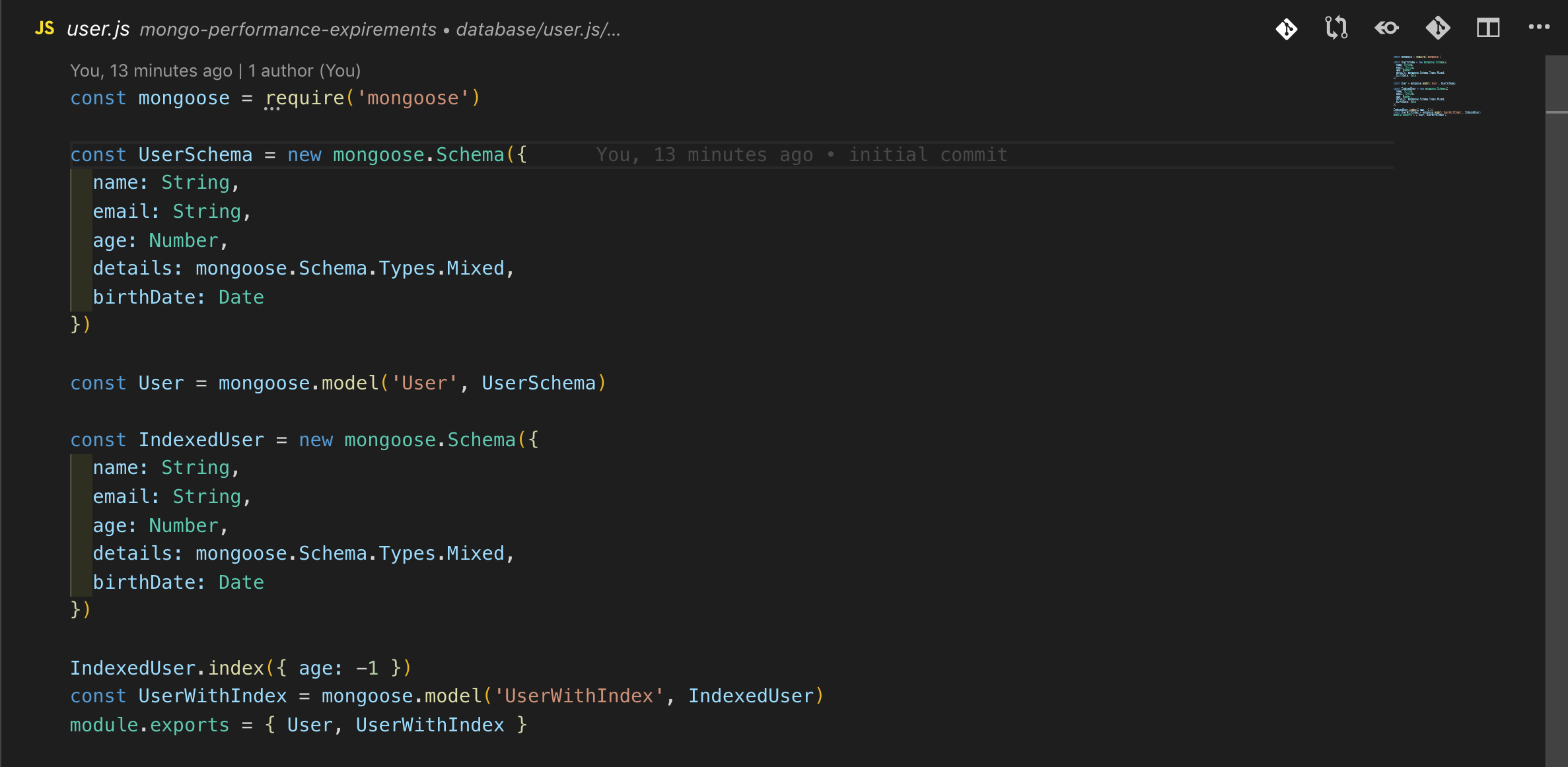
现在让我们编写一些代码来用随机数据填充数据库。我使用了临时库,它非常方便地生成语义模拟数据
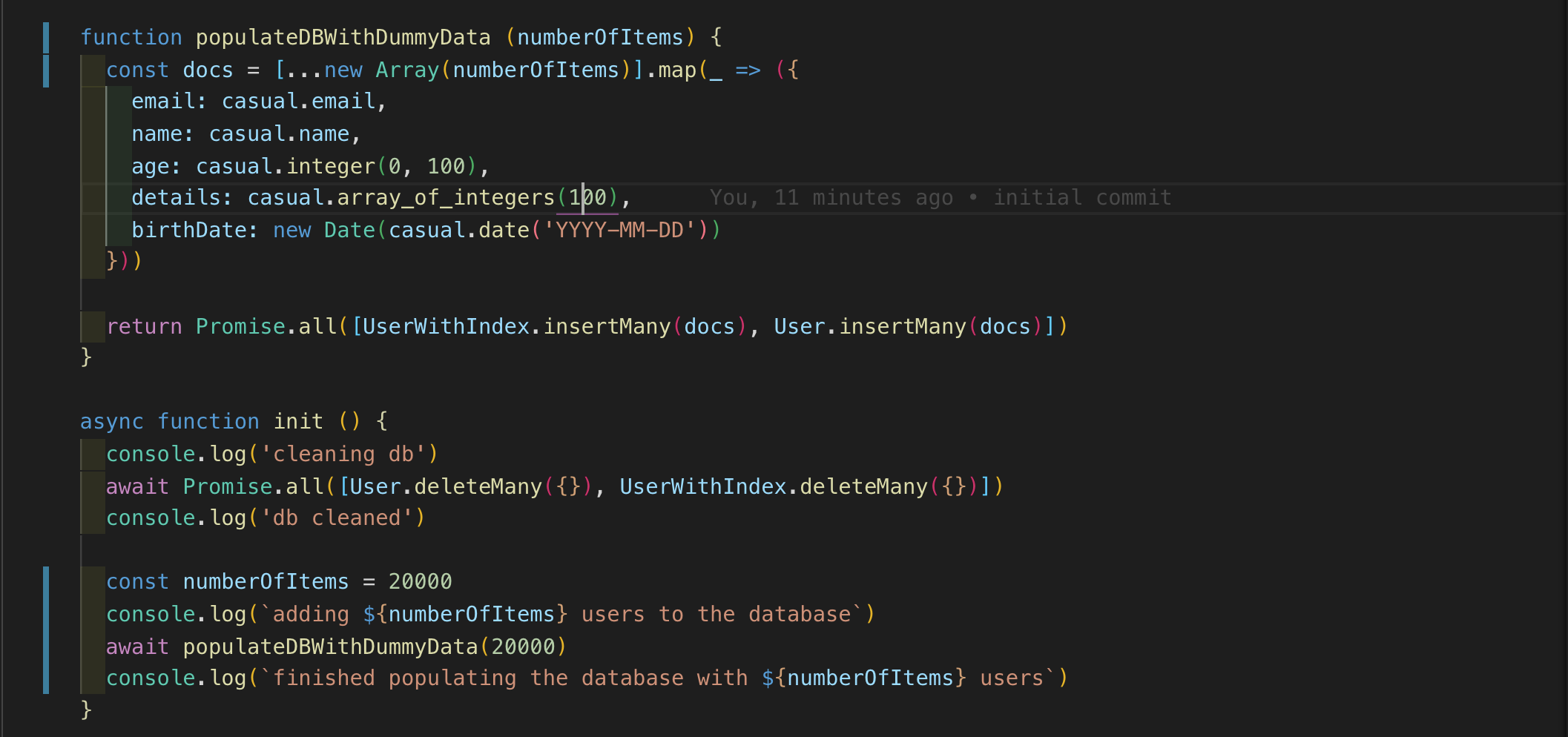
既然数据库已经准备好了,让我们来编写查询
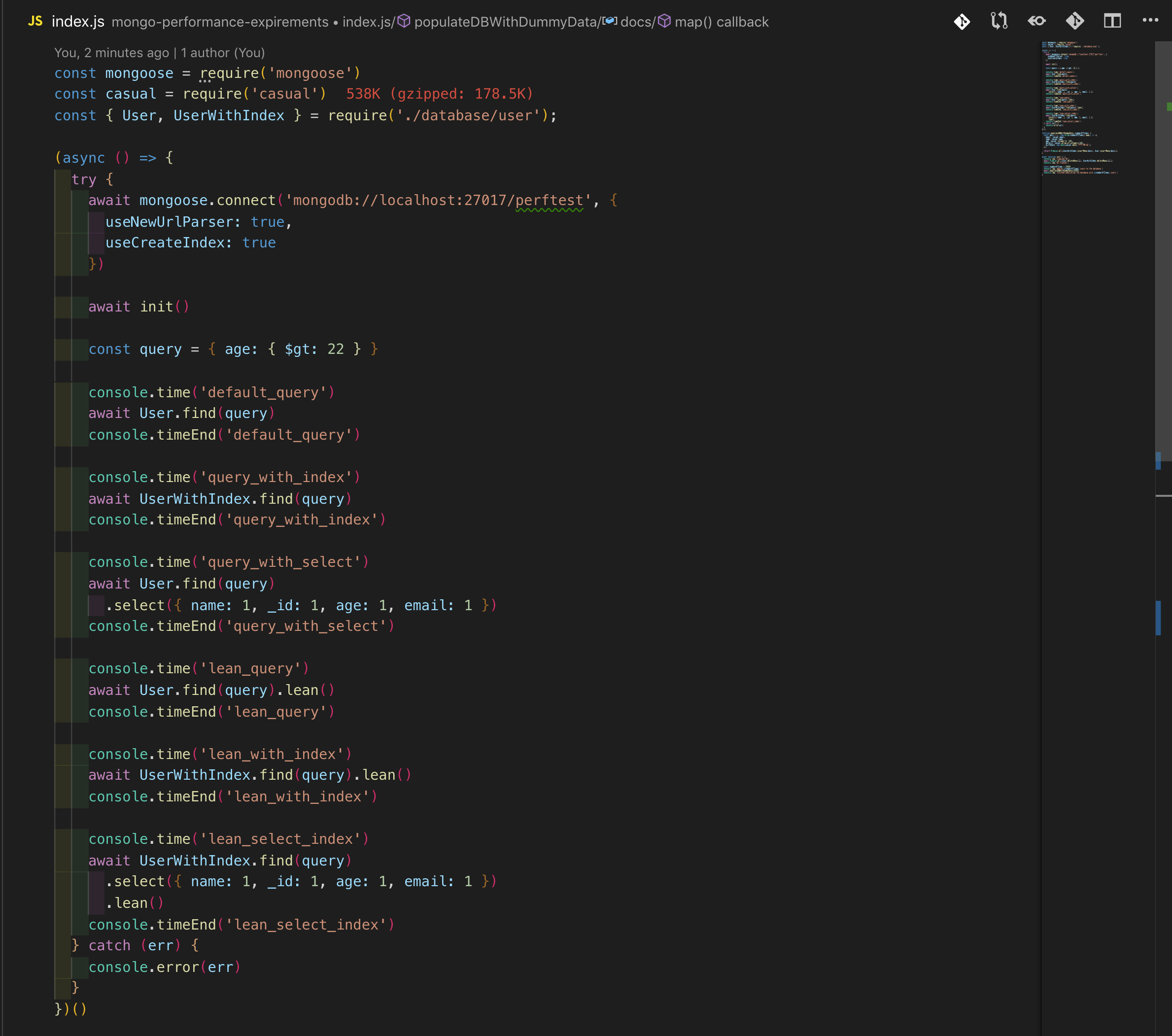
Performance Results & Observations
With 1k users
default_query: 135.646ms
query_with_index: 168.763ms
query_with_select: 27.781ms
query_with_select_index: 55.686ms
lean_query: 7.191ms
lean_with_index: 7.341ms
lean_with_select: 4.226ms
lean_select_index: 7.881ms
With 10k users in the database
default_query: 323.278ms
query_with_index: 355.693ms
query_with_select: 212.403ms
query_with_select_index: 183.736ms
lean_query: 92.935ms
lean_with_index: 92.755ms
lean_with_select: 36.175ms
lean_select_index: 38.456ms
With 100K Users in the database
default_query: 2425.857ms
query_with_index: 2371.716ms
query_with_select: 1580.393ms
query_with_select_index: 1583.015ms
lean_query: 858.839ms
lean_with_index: 944.712ms
lean_with_select: 383.548ms
lean_select_index: 458.000ms
如您所见,使用.lean() .select()和Schema.index({})的优化版本的查询比默认查询快了10倍,这是一个巨大的胜利!
.lean()似乎对性能的影响最大,其次是.select(),这是因为我的自定义索引在这种情况下不起作用,因为索引的选择性不够,因为它只减少了50%的扫描文档。
您可以找到用于这些测试的脚本,您甚至可以自己在https://github.com/khaledosman/mongo- performanceexpirequirements中试用它
原文:https://itnext.io/performance-tips-for-mongodb-mongoose-190732a5d382
本文:http://jiagoushi.pro/node/1175
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 694 次浏览
【文档数据库】Apache Couchdb 最终一致性
1.3 最终一致性
在上一个文档“为什么选择CouchDB?”中,我们看到CouchDB的灵活性使我们能够随着应用程序的增长和变化而发展数据。在本主题中,我们将探讨CouchDB的“细化”工作如何提高应用程序的简单性,并帮助我们自然地构建可扩展的分布式系统。
1.3.1 与Grain合作
分布式系统是可以在广泛的网络上稳定运行的系统。网络计算的一个特殊功能是网络链接可能会消失,并且有许多策略可以管理这种类型的网络分段。 CouchDB与其他数据库的不同之处在于,它接受最终的一致性,而不是像RDBMS或Paxos这样在原始可用性之前放置绝对一致性。这些系统的共同点是认识到,当许多人同时访问数据时,数据的行为会有所不同。在优先考虑一致性,可用性或分区容忍的哪些方面时,他们的方法有所不同。
工程分布式系统是棘手的。随着时间的推移,您将要面对的许多警告和“陷阱”并不是立即显而易见的。我们还没有所有解决方案,而且CouchDB并非万能药,但是当您使用CouchDB的精髓而不是反对时,阻力最小的途径将使您自然地扩展应用程序。
当然,构建分布式系统仅仅是开始。一个仅拥有一半时间可访问数据库的网站几乎一文不值。不幸的是,传统的关系数据库一致性方法使应用程序程序员很容易依赖全局状态,全局时钟和其他高可用性,甚至没有意识到自己正在这样做。在研究CouchDB如何提高可伸缩性之前,我们将研究分布式系统面临的约束。当我们看到了当您的应用程序的各个部分无法相互依赖时会出现的问题之后,我们将看到CouchDB提供了一种直观且有用的方式来围绕高可用性对应用程序进行建模。
1.3.2 CAP定理
CAP定理描述了用于在网络之间分布应用程序逻辑的几种不同策略。 CouchDB的解决方案使用复制在参与的节点之间传播应用程序更改。这是与共识算法和关系数据库根本不同的方法,共识算法和关系数据库在一致性,可用性和分区容忍度的不同交集处运行。
CAP定理,如图1所示。CAP定理确定了三个不同的问题:
- 一致性:即使并发更新,所有数据库客户端也可以看到相同的数据。
- 可用性:所有数据库客户端都可以访问某些版本的数据。
- 分区容限:数据库可以拆分到多个服务器上。
选择两个。
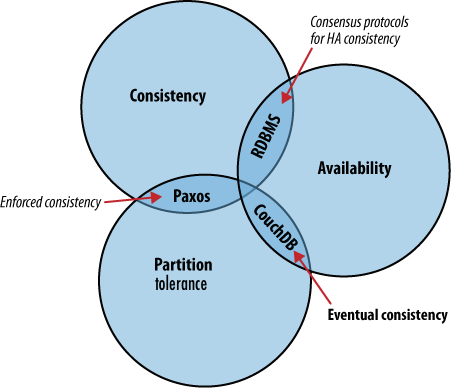
当系统增长到足以使单个数据库节点无法处理施加在其上的负载时,明智的解决方案是添加更多服务器。添加节点时,我们必须开始考虑如何在它们之间分区数据。我们有几个共享完全相同数据的数据库吗?我们是否将不同的数据集放在不同的数据库服务器上?我们是否只允许某些数据库服务器写入数据,而让其他服务器处理读取?
无论采用哪种方法,我们都会遇到的一个问题是使所有这些数据库服务器保持同步。如果您将某些信息写入一个节点,那么如何确保对另一台数据库服务器的读取请求反映了此最新信息?这些事件可能相隔毫秒。即使只有少量的数据库服务器,此问题也会变得非常复杂。
当绝对至关重要的是,所有客户端都必须看到一致的数据库视图时,一个节点的用户将必须等待其他任何节点达成协议,才能读取或写入数据库。在这种情况下,我们看到可用性在一致性方面倒退了。但是,在某些情况下,可用性比一致性要好:
系统中的每个节点都应该能够纯粹基于本地状态做出决策。如果您需要在高负载下做某事且发生故障并且需要达成协议,那么您会迷失方向。如果您担心可扩展性,那么任何迫使您达成协议的算法最终都会成为瓶颈。以此为前提。
—亚马逊首席技术官兼副总裁沃纳·沃格斯(Werner Vogels)
如果优先考虑可用性,我们可以让客户端将数据写入数据库的一个节点,而无需等待其他节点达成协议。如果数据库知道如何照顾节点之间的这些操作,那么我们将获得某种“最终一致性”,以换取高可用性。对于许多应用来说,这是一个令人惊讶的适用折衷。
与传统的关系数据库不同,传统的关系数据库必须对每个执行的操作进行数据库范围的一致性检查,而CouchDB使得构建应用程序变得非常简单,而这些应用程序却牺牲了即时一致性,以简化简单分发带来的巨大性能提升。
1.3.3 本地一致性
在尝试了解CouchDB如何在群集中运行之前,重要的是我们了解单个CouchDB节点的内部工作原理。 CouchDB API旨在提供围绕数据库核心的便捷但精简的包装。通过仔细研究数据库核心的结构,我们将更好地了解围绕它的API。
1.3.3.1 数据的Key
CouchDB的核心是功能强大的B树存储引擎。 B树是一种排序的数据结构,允许以对数时间进行搜索,插入和删除。如图2所示。对视图请求的剖析表明,CouchDB使用此B树存储引擎存储所有内部数据,文档和视图。如果我们理解一个,我们将全部理解。
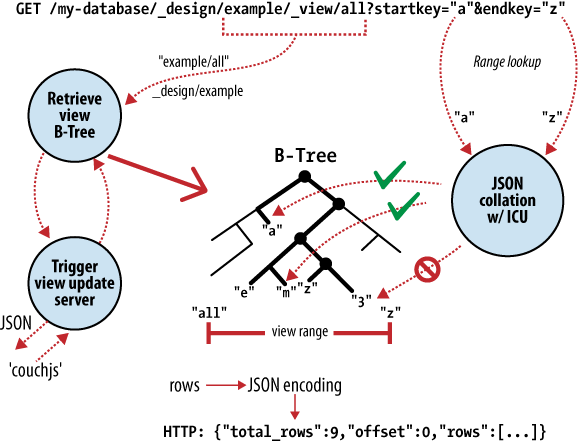
CouchDB使用MapReduce来计算视图的结果。 MapReduce利用了两个函数,即“ map”和“ reduce”,它们分别应用于每个文档。能够隔离这些操作意味着视图计算可以进行并行和增量计算。更重要的是,由于这些函数产生键/值对,因此CouchDB能够将它们按键排序插入B树存储引擎。通过键或键范围进行的查找是使用B树的极其有效的操作,用大O表示法分别表示为O(log N)和O(log N + K)。
在CouchDB中,我们按键或键范围访问文档并查看结果。这是对CouchDB的B树存储引擎上执行的基础操作的直接映射。与文档插入和更新一起,这种直接映射是我们将CouchDB的API描述为围绕数据库核心的薄包装的原因。
只能通过键访问结果是一个非常重要的限制,因为它使我们获得了巨大的性能提升。除了大幅提高速度外,我们还可以在多个节点上划分数据,而不会影响我们独立查询每个节点的能力。正是由于这些原因,BigTable,Hadoop,SimpleDB和memcached通过键限制了对象查找。
1.3.3.2 无锁
关系数据库中的表是单个数据结构。如果要修改表(例如,更新行),数据库系统必须确保没有其他人试图更新该行,并且在更新该行时没有人可以从该行中读取数据。解决此问题的常用方法是使用锁。如果多个客户端要访问一个表,则第一个客户端将获得锁,从而使其他所有人都在等待。当第一个客户的请求得到处理时,下一个客户将获得访问权限,而其他人都将等待,依此类推。即使是并行到达请求,这种串行执行请求也会浪费大量服务器的处理能力。在高负载下,关系数据库比进行任何实际工作要花费更多的时间来确定允许谁执行什么工作以及按照什么顺序执行。
注意
现代的关系数据库通过在幕后实施MVCC来避免锁定,但对最终用户隐藏了MVCC,要求它们协调单个行或字段的并发更改。
CouchDB使用多版本并发控制(MVCC)代替锁,来管理对数据库的并发访问。图3. MVCC表示没有锁定说明了MVCC和传统锁定机制之间的差异。 MVCC意味着CouchDB即使在高负载下也可以一直全速运行。请求是并行运行的,从而充分利用了服务器必须提供的每最后一滴处理能力。

图3. MVCC意味者没有锁定
CouchDB中的文档已经过版本控制,就像在常规版本控制系统(例如Subversion)中一样。如果要更改文档中的值,请创建该文档的全新版本并将其保存在旧版本上。完成此操作后,您将获得同一文档的两个版本,一个旧版本,一个新版本。
这如何提供对锁的改进?考虑一组想要访问文档的请求。第一个请求读取文档。在处理过程中,第二个请求更改了文档。由于第二个请求包含文档的全新版本,因此CouchDB可以简单地将其附加到数据库,而不必等待读取请求完成。
当第三个请求要读取相同的文档时,CouchDB将其指向刚刚编写的新版本。在整个过程中,第一个请求可能仍在读取原始版本。
读取请求在请求开始时始终会看到您数据库的最新快照。
1.3.4 验证方式
作为应用程序开发人员,我们必须考虑应该接受什么样的输入以及应该拒绝什么输入。在传统的关系数据库中对复杂数据进行这种类型的验证的表达能力尚有许多不足之处。幸运的是,CouchDB提供了一种从数据库内部执行按文档验证的强大方法。
CouchDB可以使用类似于MapReduce的JavaScript函数来验证文档。每次您尝试修改文档时,CouchDB都会通过验证功能以传递现有文档的副本,新文档的副本以及其他信息的集合,例如用户身份验证详细信息。验证功能现在可以批准或拒绝更新。
通过使用Grain并让CouchDB为我们做到这一点,我们为自己节省了大量的CPU周期,否则这些CPU周期将被用于从SQL序列化对象图,将它们转换为域对象并使用这些对象进行应用程序级验证。
1.3.5 分布式一致性
对于大多数数据库而言,在单个数据库节点内维护一致性相对容易。当您尝试维护多个数据库服务器之间的一致性时,真正的问题开始浮出水面。如果客户端在服务器A上执行写操作,我们如何确保它与服务器B或C或D一致?对于关系数据库而言,这是一个非常复杂的问题,整本书都专门针对其解决方案。您可以使用多主机,单主机,分区,分片,直写式高速缓存以及各种其他复杂技术。
1.3.6 增量复制
CouchDB的操作在单个文档的上下文中进行。由于CouchDB通过使用增量复制实现了多个数据库之间最终的一致性,因此您不必担心数据库服务器能够保持持续的通信。增量复制是在服务器之间定期复制文档更改的过程。我们能够构建所谓的无共享数据库集群,其中每个节点都是独立且自给自足的,在整个系统中不存在任何争用点。
需要扩展您的CouchDB数据库集群吗?只需投入另一台服务器即可。
如图4所示。在CouchDB节点之间进行增量复制,并使用CouchDB进行增量复制,您可以在任意两个数据库之间随时随地同步数据。复制后,每个数据库都可以独立工作。
您可以使用此功能通过cron之类的作业调度程序在群集内或数据中心之间同步数据库服务器,也可以使用它在便携式计算机上同步数据与笔记本电脑以进行离线工作。可以按常规方式使用每个数据库,并且以后可以在两个方向上同步数据库之间的更改。
当您在两个不同的数据库中更改同一文档并希望彼此同步时会发生什么? CouchDB的复制系统带有自动冲突检测和解决方案。当CouchDB在两个数据库中都检测到文档已被更改时,它将标记该文档为冲突文档,就像它们在常规版本控制系统中一样。
这并不像第一次听起来那样麻烦。如果在复制过程中两个版本的文档发生冲突,则胜出版本将另存为文档历史记录中的最新版本。 CouchDB不会像您期望的那样丢掉丢失的版本,而是将其保存为文档历史记录中的先前版本,以便您可以在需要时访问它。这是自动且一致地发生的,因此两个数据库都将做出完全相同的选择。
由您决定以对您的应用程序有意义的方式来处理冲突。您可以将选定的文档版本保留在原位,还原为较旧的版本,或尝试合并两个版本并保存结果。
1.3.7 案例分析
朋友和同事Greg Borenstein建立了一个小型库,用于将Songbird播放列表转换为JSON对象,并决定将它们存储在CouchDB中作为备份应用程序的一部分。完整的软件使用CouchDB的MVCC和文档修订版,以确保在节点之间可靠地备份Songbird播放列表。
注意
Songbird是基于Mozilla XULRunner平台的具有集成Web浏览器的免费软件媒体播放器。 Songbird适用于Microsoft Windows,Apple Mac OS X,Solaris和Linux。
让我们检查Songbird备份应用程序的工作流程,首先是作为用户从单台计算机备份,然后使用Songbird在多台计算机之间同步播放列表。我们将看到文档修订如何将本来很棘手的问题变成可以解决的问题。
第一次使用此备份应用程序时,我们会将播放列表馈入该应用程序并启动备份。每个播放列表都将转换为JSON对象,并传递到CouchDB数据库。如图5所示。备份到单个数据库时,CouchDB会将每个播放列表的文档ID和修订版本保存到数据库中。
几天后,我们发现我们的播放列表已更新,我们希望备份所做的更改。将播放列表馈入备份应用程序后,它会从CouchDB获取最新版本以及相应的文档修订版。当应用程序移交新的播放列表文档时,CouchDB要求文档修订包含在请求中。
然后,CouchDB确保请求中传递给它的文档修订与数据库中保存的当前修订匹配。因为CouchDB每次修改都会更新修订,所以如果这两个修改不同步,则表明在我们从数据库请求文档到发送更新之间,有人对文档进行了更改。在其他人没有先检查那些更改的情况下对其进行更改通常是一个坏主意。
强迫客户交出正确的文档修订版是CouchDB乐观并发的核心。
我们有一台笔记本电脑,希望与台式机保持同步。在台式机上播放所有播放列表后,第一步是“从备份还原”到笔记本电脑上。这是我们第一次这样做,因此之后我们的笔记本电脑应保留桌面播放列表集合的精确副本。
在笔记本电脑上编辑我们的阿根廷探戈播放列表以添加一些我们购买的新歌曲后,我们要保存更改。备份应用程序替换了我们笔记本电脑CouchDB数据库中的播放列表文档,并生成了新的文档修订版。几天后,我们记住了我们的新歌曲,并希望将播放列表复制到我们的台式计算机上。如图6所示,备份应用程序在两个数据库之间进行同步,将新文档和新修订版本复制到桌面CouchDB数据库中。现在,两个CouchDB数据库都具有相同的文档修订版。
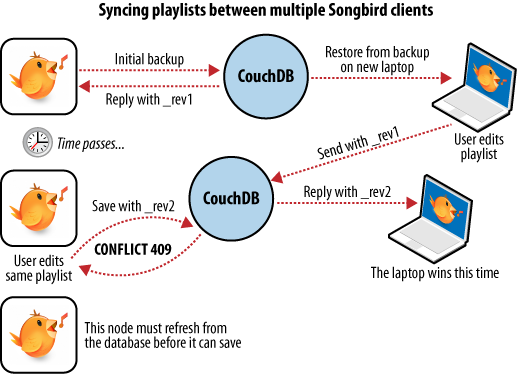
因为CouchDB跟踪文档修订,所以它确保仅当这些更新基于当前信息时这些更新才有效。 如果我们在同步之间对播放列表备份进行了修改,那么事情就不会那么顺利。
我们在笔记本电脑上备份了一些更改,却忘记了同步。 几天后,我们正在台式计算机上编辑播放列表,进行备份,并希望将其同步到笔记本电脑。 如图7所示。两个数据库之间的同步冲突,当我们的备份应用程序尝试在两个数据库之间复制时,CouchDB看到从台式机发送的更改是对过时文档的修改,并有帮助地通知我们 一直是一个冲突。
从应用程序的角度来看,从此错误中恢复很容易完成。 只需下载CouchDB的播放列表版本,即可提供合并更改或将本地修改保存到新播放列表中的机会。
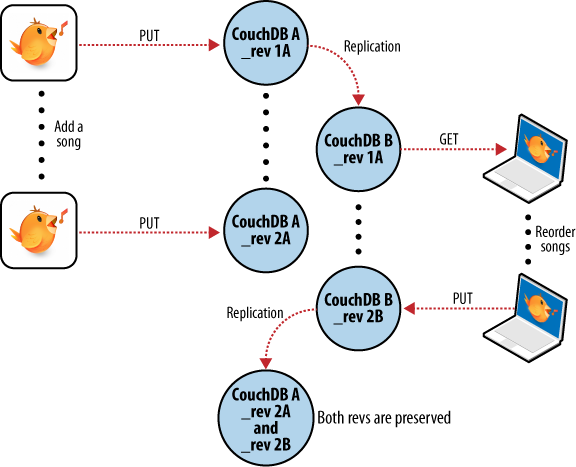
1.3.8 总结
CouchDB的设计大量借鉴了Web架构,并汲取了在该架构上部署大规模分布式系统的经验教训。 通过了解这种体系结构为何能以这种方式工作,并通过学习发现可以轻松分发应用程序的哪些部分而不能轻松分发哪些部分,可以增强使用CouchDB或不使用CouchDB来设计分布式和可伸缩应用程序的能力。
我们已经介绍了有关CouchDB一致性模型的主要问题,并暗示了在使用CouchDB而不是反对使用CouchDB时将获得的一些好处。 但是有足够的理论–让我们开始并运行,看看大惊小怪的是什么!
原文:https://docs.couchdb.org/en/stable/intro/consistency.html
本文:http://jiagoushi.pro/node/919
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 157 次浏览
【文档数据库】IBM Cloudant 取消计划为 CouchDB 的新基础层提供资金
Apache 项目正在考虑下一次大升级的选项,因为 Big Blue 专注于 3.x 迭代
IBM Cloudant 软件团队决定停止推动创建一个新的数据库引擎,该引擎支持 Apache CouchDB,这是 BBC、Apple 和原子研究机构 CERN 使用的 NoSQL 文档存储。
在 Apache 名单上的一篇文章中,前 IBM Cloudant 员工和 Apache CouchDB 项目管理委员会成员 Robert Newson 解释说,IBM Cloudant 支持“使用 FoundationDB 数据库引擎作为其新基础构建下一代 CouchDB 版本的计划”。 。”
“他们不会继续资助这个版本的开发,而是将精力重新集中在 CouchDB 3.x 上,”他说。
CouchDB 的最新版本是 3.2.1,于去年 11 月发布。
使用由 Apple 推出的 Apache 开源项目 FoundationDB 作为基础支持层将有利于可扩展性,但也可以在 1.0 版本后项目留下的集群内重建一致性。
然而,这些改进是有代价的,最终对 IBM Cloudant 来说太高了,Newson 说。
CouchDB 提交者兼顾问 Jan Lehnardt 解释说,并非所有的好处都会以预期的方式实现。首先,3.x 中的某些 API 保证无法使用本机 FoundationDB 功能重新创建。
“我们还了解到,运营 FoundationDB 集群是一项重大工作,这在某种程度上违背了 CouchDB 的大部分“正常工作”性质,”Lehnardt 在线程上说。
他解释说,IBM 取消对在 4.0 版本中过渡到新基础层的支持使该项目有一些选项需要考虑。
鉴于对于 CouchDB 的大用户来说过渡到 FoundationDB 可能是值得的,因此维护两个并行代码库可能是值得的,但是 3.x/4.x 命名将不起作用。
然后选项是为 FoundationDB-CouchDB 提供自己独立的项目名称和版本控制,并在它们之间进行清晰的划分。
Google 追赶 JSON 对分布式 RDBMS Spanner 的支持
DataStax 埋葬了 Apache 的斧头并推出了使 NoSQL Cassandra 更快、更安全和更可图形化的功能
10 岁的 Apache Cassandra:让社区相信 NoSQL
墨西哥退税网站开放了 400GB 敏感客户信息
World-Check 恐怖嫌疑人 DB 在网上仅售 6750 美元
“我们必须维护两个完整的项目,包括发布管理、漏洞管理等。目前,CouchDB 有足够多的人以合理的速度为 [前进] 做出贡献。
“加倍努力可能会很棘手。虽然我们最近有大量贡献者涌入,但这可能需要更专门的计划和外展,”他观察到。
这也意味着新的 API 功能必须实施两次才能保持重叠,给贡献者带来另一个额外的负担。他说可能还有更多选择,并邀请进一步讨论。
咨询和支持公司 Percona 的开源战略负责人 Matt Yonkovit 表示,从长远来看,FoundationDB 可能会支持更新版本的 CouchDB,这取决于社区的承诺。
“整个社区需要或要求的功能往往是独立于赞助商开发的,赞助商只是加快了路线图的速度。
“租用的功能只会持续到资金或公司利益用完为止。您经常会看到通过这种方法引入的一些功能后来在资金用完时被撕掉或转移到生命终止状态,”他说。
原文:https://www.theregister.com/2022/03/15/ibm_cloudant_couchdb/
- 36 次浏览
【文档数据库】数据库深度探索:CouchDB
欢迎来到数据库深度挖掘,这是一系列的采访,在这里我们将与数据库世界的建设者、工程师和领导者进行交谈。

最近,我们有幸与Apache CouchDB项目管理委员会的Adam Kocoloski (@kocolosk)和Jan Lehnardt (@janl)进行了交流。查看下面的采访,了解更多关于Apache CouchDB的优点和缺点、项目的发展方向,以及他们对希望在Kubernetes上运行CouchDB的人的专家建议。
跟我们谈谈你自己和你今天在做什么?
Adam Kocoloski (AK):当然,我的名字是Adam Kocoloski,这些天我在做的是IBM云中的数据库和数据服务的技术策略。我们有一整套数据库和相关的东西来搬运数据,分析数据,并从中提取见解。我的工作是尝试并引导他们形成一个连贯的投资组合,以满足我们客户的需求,并使我们与市场上的其他公司处于一个强有力的竞争地位。
简·莱纳特(左壹):我是简·莱纳特。我做开源工作已经有20年了,CouchDB做了12年。大约五年前,我和我的公司睦邻hoodie一起,开始使我的Apache CouchDB工作服务和支持变得专业化。当我不运行它的时候,我正在开发CouchDB 3.0和4.0,我们决定同时进行,这非常令人兴奋。另外,我们正在开发opservator(我们最近宣布了它),这是一个用于CouchDB安装的连续观察工具。
您是如何加入CouchDB的?
AK:我之所以加入CouchDB,是因为我和我在麻省理工学院的同事们有开公司的想法。我们的一个想法是在数据库空间。我们看到,在2007年和2008年,有各种各样的人在探索不同类型的数据库,而不是传统的用于支持LAMP堆栈应用程序的通用数据库。作为实践中的物理学家,我们有很多处理非传统数据集和非传统管理方法的实用经验。我们认为这可能是一个有趣的方式来应用我们的技能。
我们遇到CouchDB因为它似乎有着很多相同的原则我们的数据分布方法,关注数据的安全性和耐久性,的拥抱网络与数据交互的媒介如您构建您的应用程序。我们认为,与其坐下来构建一个看起来和感觉上像CouchDB的东西,不如更有效地参与到社区中,看看我们是否能在那里做出贡献。这就是我们想要建立的公司的基础。
JL:我当时主要是做LAMP的顾问。我最终擅长于让团队思考“可伸缩”,利用PHP无共享架构的所有优点和基本的最佳实践。我在某个地方的博客上发现了CouchDB,并对它做了一些研究。不到一个星期,我就开始恐慌了,因为如果CouchDB流行起来,我很快就会失业。我想我最好弄清楚如何熟练地使用它,看看它会发展成什么样子。CouchDB取代了所有东西,但结果并没有像我想象的那样。但是我没有错,一些看起来和感觉上像CouchDB的东西现在是数据库领域的主要参与者。我就是这样开始的,从来没有离开过。
您认为CouchDB的优势和劣势是什么?
JL:有一件事使CouchDB独一无二,[这]就是如果您按照动作构建数据库系统,您会被问到“为什么要这样做?”CouchDB存在的原因是其独特的复制功能,它可以从低级点对点(像物联网或移动设备收集数据并相互通信)到完全的多区域集群到集群复制同步数据。正是这种技术允许使用CouchDB的这些用例,而其他数据库实际上没有这种形式或形式。具体来说,CouchDB的复制更像Git而不是MySQL复制。
与其他数据库相比,它的主要优势在于数据的持久性;就像前面提到的Adam一样,它从来不会丢失任何数据!很难搞砸。在设计CouchDB时,我们默认选择安全和可靠,这使得操作非常简单。使用CouchDB很容易启动和运行,如果您不想了解太多的话,它可以完成您需要它完成的工作。
我们还花了几年时间思考REST API。从平易近人、长期有用的角度来看,这仍然是有回报的,而且它对我们来说很有效。我个人认为,使用文档数据库编程比使用其他SQL数据库编程更自然。这可能只是我的观点。
AK:我想我必须回应Jan的大部分评论。2009年,有人胆敢用这种技术创办了一家“数据库即服务”公司,我很感激我们对数据安全性和持久性的重视。在100次中,CouchDB只有99次能够自己解决如何让事情恢复正常运行的问题,我们真的很欣赏这一点。显然,当您遇到CouchDB考虑世界的方式以及在对等点之间复制和同步数据的方式所形成的问题时,复制支持一组用例,这些用例显然是用于该工作的正确工具。
这些绝对是系统的优点。说到缺点——要使CouchDB成为开箱即用的低延迟系统并不容易。您必须了解与web服务的性能访问相关的所有事情。我们看到一些客户端对每个请求都建立一个新的TLS连接。这里有很多来回的握手,这确实没有必要,但是因为它是一个web服务,如果您希望它这样做,CouchDB将很乐意与您协商这些连接。它将继续运行并保持可用性,但很难做到那么快。
我还想说,作为一个社区,我们在客户端库上的投入可能比其他一些项目要少一些。部分原因是我们说:“嗨,我们有这个很好的REST API。它是一种web服务,如果你知道如何与web服务对话,你就知道如何与数据库对话。”
虽然这是真的,但我们不时地看到,它让学习曲线变得比原本更陡峭。一些数据库投入了大量的时间、金钱(和人员)来构建一组不同的客户端库,这些库掩盖了来自最终用户的API的一些细节,并在每个流行框架和生态系统中提供了一个更惯用的编程模型。我认为这是我们近年来学到的东西,并投入了更多的精力。不过,我要说的是,在这一点上,我们还没有那么强大。
你见过的有关Couch的最酷或者最有趣的用例有哪些?
AK:在谈到这些新奇的东西之前,我应该说一件事,那就是我们很高兴CouchDB成为IBM Cloud中大量用例的基础。它为IBM云提供了基础级的支持,如果CouchDB有朝一日垮掉了,云也会垮掉。我认为这很酷,即使大多数用例可能是普通的、无聊的、数据库前的应用程序。它可以工作,可以扩展,可以满足我们的需求。
我们看到人们开发了很多手机游戏和手机钱包。我们看到一些人拿着一堆关系数据库和一大堆存储过程说:“天哪,我们不能再对这个堆栈做任何更改了,我们的存储过程涉及的是一家20年前就倒闭了的公司!”我们如何把这些都拿出来,并给我们的团队一个开发环境,让我们能够以业务所需的速度移动?像CouchDB这样的文档数据库非常适合。它简化了数据模型,并能够适应多年来在不同系统中可能出现的怪癖。
JL:我不得不附和亚当。我对Couch的评价是:“这是一个很好的通用数据库,80%的应用程序可以使用任何数据库,那么为什么不使用Couch呢?”“不过我们也看到了一些很酷的东西。
有一个公司在全球范围内运送货物。任何超出人手可携带范围的内容都通过多区域CouchDB集群进行管理。另一家公司是一家提供飞行娱乐系统的公司,在任何给定时间都有3000架飞机在飞行中使用CouchDB。我们还参与了人道主义危机,比如2016年的埃博拉救援工作,大约有四五个西非国家因为疫情爆发而基本停止了行动。
我们碰巧建立了一个离线的,第一个响应工具来帮助他们比在纸和笔上更快地处理危机,这是在没有电力、边缘网络或3G等基础设施的情况下做事情的通常方法。如果没有CouchDB,这一切都不可能实现。
我们还帮助开发了一款针对该环境的疫苗接种试验软件,从而研制出了第一款埃博拉疫苗。从个人角度来说,这是非常令人羞愧的。如果我们看看过去100年人类取得的重大成就,第一种埃博拉疫苗肯定在其中。就个人而言,或者即使我只是在CouchDB上工作,这都是非常棒的
你对CouchDB 3.0和4.0有什么期待?
JL:我们决定同时做CouchDB 3.0和4.0是有原因的。它们将按顺序发布,但我们正在同时考虑和工作。4.0的主要变化是以CouchDB为基础的重大技术转变。但在此之前,3.0中现有的基础将是我们所做过的最好的CouchDB。不是用“最新最伟大”的营销术语,而是从人们碰到、抱怨或马上询问的10件事的角度来看。CouchDB 3.0将简单地解决所有这些问题。
我们非常感谢IBM将他们在IBM与Cloudant公司合作开发的产品开源,我们也可以将其作为开源产品添加进来,同时我们也在开发其他一些产品,以确保我们能够提供最好的沙发平台。它包含了我们在过去10-15年使用CouchDB的所有经验教训,为需要长期使用该平台的人们提供了一个非常坚实的基础。对于CouchDB 4.0, Adam你可能想谈谈这个。
正义与发展党:是的,当然。因此,4.0版本包含了一个被称为FoundationDB的分布式事务键-值存储系统。这是我个人非常兴奋的事情,对于任何一个足够接近这个项目的人来说,也会对这里的潜力感到兴奋。
FoundationDB是一个商业软件,被苹果收购后关闭了。几年后,它被开源。这为我们提供了运行CouchDB环境的能力,这些环境能够向外扩展到单个区域,同时仍然为更新提供完全强大的一致性。如果你看看我们在Couch 2.0中所做的事情和我们将在3.0中保留的事情,就会发现我们在处理更新的方式和让各个副本相互协调的方式上是不同的。
而且,尽管这是一种持久且可适当扩展的设计,但它也给我们留下了一些难以编程的缺点。有可能让你的数据库在一个区域中出现编辑冲突,尽管你在编辑器中只是循环和写入数据库。我们希望通过使用Couch 4.0和使用FoundationDB来消除这种行为。
另一个是我们在CouchDB中使用分散-聚集机制执行视图索引的方式。它让人们通过高写入数据库提供了大量的索引吞吐量——将这些东西分片,然后每个索引将并行地构建其分片的视图。但查询这些东西是一个相当昂贵的主张。随着数据库变得更大,查询的成本将继续上升。
相反,当我们让视图在FoundationDB上运行时,我们将让它们在一个机器集群中重新组织和重新分发,这样大规模查询视图就像检索单个文档一样便宜。我认为这为采用CouchDB的人们打开了一大堆额外的高吞吐量/高规模用例。这是一个巨大的转变。这实际上意味着现在CouchDB逻辑是部署在FoundationDB之上的无状态应用程序层,它负责数据的所有有状态性、持久性和物化。
这不是我们掉以轻心的事情。我们总是非常重视数据的安全性、持久性以及正确处理人们的数据。我们在分析FoundationDB时也采用了同样的视角,我们很高兴地说,他们的项目与CouchDB有着相同的重点和关注点。
JL:我花了很多时间在台上谈论CouchDB,并向人们解释什么是CouchDB。问题经常出现在最终的一致性和复制,在2.0或3.0中的Dynamo模型集群。这样做的缺点是值得的,因为如果你想要创建一个分布式的、一致的数据库,你就需要找10个世界上最顶尖的分布式系统工程师,给他们5-10年的时间来做正确的事情。没有人有那样的时间。
它是被苹果收购之前的公司,而苹果的需求与之一致。我们面临的[开放]问题是:“我们是应该将我们的CouchDB转换成类似于FoundationDB的东西,还是仅仅在FoundationDB之上构建CouchDB,实现跨行业发展?”
基本上,他们做了一件不可思议的事情,而且做得很好。野外有足够的证据证明他们的做法是正确的。非常非常高兴看到它,而且我们很幸运它是开源的。
最后需要注意的是,这是一个过程问题,但是CouchDB项目并没有正式宣布4.0就是我们刚刚讨论的内容。它很可能很快就会这样做。如果任何CouchDB开发人员正在阅读,那么要使其正式运行需要一些过程。
听到核心代码库的改进是令人兴奋的,但是围绕CouchDB的生态系统并没有停滞不前。随着Kubernetes和它的朋友的出现,您会给想要在容器上部署CouchDB的人们什么建议?
AK:所以,我想我要说的是选择在容器上部署CouchDB,特别是将CouchDB与Kubernetes环境协调在一起,这是一个决定,它将使您能够获得进一步的改进。
我们在这里投入了时间和精力,以确保它是一种开箱即用的体验,能够满足各种应用程序的需求。这是一个不断变化的目标,不仅因为CouchDB支持Kubernetes和基于容器的部署,而且因为整个行业都是这样。
我们看到,今天每个人都在构建掌舵图表来支撑数据库,明天每个人都在构建操作符来管理这些数据库的生命周期。因为空间移动得非常快,所以要记录的东西很多。如果你想在生产中做这些事情,你就必须关注并与社区保持联系。但是,我们对推动支持感兴趣。我认为它提供了一种潜在的体验,在这种体验中,大多数配置在第一次就正确地完成了。
设置分布式系统的一些复杂性是我们可以在Kubernetes这样的受限环境中更好地进行自动检测和自动化,而不是在VMware环境中的虚拟机。
JL:是的,我绝对同意潜在的部分。但是,我要提一下,我们为Couch提供专业的服务,我们现在赚钱的一个领域就是让人们不再用Docker运行CouchDB。我认为这就是缺点所在。
对于某些工作负载,这项技术还不够成熟。并不是说Docker是唯一的容器解决方案,也不是说Kubernetes是我们能进入的唯一的分布情况,但是couchdb——作为一个分布式数据库——充分利用了低延迟、高带宽的网络以及极快的IO吞吐量和磁盘访问。
在某些越来越小的情况下,Kubernetes和Docker都阻碍了这一点。此时,CouchDB会变慢,或者会出现无法解释的超时错误。总的来说,如果你创建了一个知道如何重试的应用,这不是一个大问题,但它是一个不断变化的目标。
我建议,除非您有一个专门的团队负责保持Kubernetes集群上的服务正常运行(尤其是数据库),否则它已经超出了目前大多数用例的范围。在IBM cloud、Microsoft或谷歌上的云虚拟机周围安装一些自动化就可以达到这个目的。
通常,从工作负载的角度来看,移动数据是比较昂贵的部分。因此,增加更多的工作人员在一个小时内处理数据库事务——在数据到达新节点之前,您需要等待半天才能处理这个峰值。所以在[向外扩展]场景中,它的用途有限,这就是为什么许多人从应用程序的角度对它感兴趣的原因(它在今天工作得非常好)。
当涉及到Adam刚才所说的内容时,请确保部署和集群管理或分发管理工作良好,并以声明的方式而不是功能的方式完成。这就是你要使用它的地方。如果您对资源的需求较低,但是想要获得在容器或kubernet中运行的好处——当然,尽管去做吧,只要知道[某些指标的限制],并且如果没有一个专门的团队,您可能会更好地离开。今天的情况有好有坏,但我等不及这一切什么时候结束,什么时候方向很明确。并不是说这永远不会发生,只是等待底层技术赶上现实。
对于那些想要加入社区但以前没有使用过Erlang的人,您有什么建议?
AK:学习Erlang当然不是加入CouchDB社区的先决条件。我们希望在JavaScript层、文档系统和Elixir(我们现在正在移植测试套件以在Elixir中运行)上做出贡献。Elixir是一种极好的方式,可以让您深入了解基于erlang的、基于Beam的vm的系统,这些系统具有吸引开发人员的社区、采用、吸引力,并且与CouchDB的世界很好地结合。
但我认为,总的来说,这是关于参与开源项目的评论。人们会认为,有时候你需要弄清楚这个系统中最深、最黑暗的部分是如何运作的,并进行疯狂的公关才能参与其中。这不是真的。即使没有别的,我们也可以从各个领域的贡献中受益。作为项目管理委员会的成员,我们工作的一部分就是鼓励多样性的贡献,以确保我们有一个全面、包容的社区,让人们参与进来。这里的建议是举起你的手。我们绝对会找到包括你在内的方法,并充分利用你所能带来的:
JL:这都是非常好的建议,我只是想补充一点,虽然一开始可能会让人望而生畏,但Erlang并不像乍一看那样糟糕或困难。它可能看起来很奇怪,但是如果您愿意接受它,您可以在浏览一堆教程之后立即提交富有成效的补丁。有一件事很有帮助——我们基于web的HTTP JSON API可以在一个小时内学会。
然后,您所要做的就是在后台查看HTTP请求是如何处理的,这个JSON是如何解析的,然后就可以开始深入到堆栈中去了。我们帮助没有任何Erlang经验的用户在一个下午就完成了一个小的CouchDB功能。当然,我们引导他们,但如果你有更多的耐心,可能需要一个周末。
AK:说得好,jan。我不知道你是怎么想的,但是我是通过阅读CouchDB源代码和使用Couch来学习Erlang的。
莱托:相同。
感谢我们的受访者抽出时间来分享他们的知识。如果你想更广泛地了解CouchDB,请查看Adam的视频“CouchDB解释”
原文:https://www.ibm.com/cloud/blog/database-deep-dives-couchdb
本文:http://jiagoushi.pro/node/1141
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 132 次浏览
【文档数据库】数据库深度探索:MongoDB
欢迎回到数据库深度探索,在这里我们将与数据库领域的工程师、构建者和领导者进行一对一的交流。最近,我们采访了来自MongoDB的Richard Kreuter。

阅读下面的采访,了解Atlas跨越多个云的未来发展方向,他们如何从一个数据库转变为一个拥有Atlas数据湖的数据平台,以及他们如何在NoSQL数据存储中构建和交付事务。
跟我们谈谈你自己和你今天在做什么?
理查德·克罗伊特(RK):我是理查德·克罗伊特,MongoDB的现场工程高级副总裁。我负责许多面向客户和合作伙伴的团队——我们的解决方案架构师、业务价值顾问、项目经理、咨询工程师、客户成功经理,以及支持我们合作伙伴的技术架构师。
你是如何接触到MongoDB的?
(RK):我第一次了解MongoDB是在2009年11月。我是一名软件工程师,在过去的十年里,我从事的项目确实需要一个比市场上现有的数据库更灵活的数据库。当我第一次看到MongoDB时,我想,“哇,我希望我以前的项目也有这样的功能。”
我申请了一个职位,并在2010年1月加入了公司,负责我们的软件产品。当我加入这家公司的时候,我们还不到10人,而现在,我们已经是一家拥有1500多人的公司,服务着14000多名客户。
我们于2017年10月上市——这是25年来第一家达到这一里程碑的数据库公司。在过去的几年中,我们已经收购了一些公司,这大大加快了我们的增长。在过去的几年中,我们已经将我们的产品从核心数据库扩展到了不同的产品平台,这些产品涵盖了数据管理和数据生命周期的几个不同方面。
随着Atlas的成功和更广泛的支持应用开发服务的生态系统(如Stitch和Charts),你认为MongoDB在未来5-10年将走向何方?
(RK):我们正在完善智能数据平台,这是一套集成的产品和功能,通过MongoDB的文档模型为用户提供处理数据的最佳方式。文档——灵活的、受json启发的文档——比许多人熟悉的处理数据的严格结构的传统方式更加简单、自然、通用和高性能。
如今,我们在核心数据库和其他产品中都有能力,我们正在不断开发这些产品,以使客户能够在全球范围内战略性地放置他们的数据。这可能意味着将数据保存在更接近大用户群的地方,以便为这些用户提供较低的延迟体验,或者为了遵守监管要求,将数据保存在国家和其他地理边界内。
我们还将继续致力于为客户提供在他们需要的任何地方运行MongoDB的自由。我们有可以在移动设备、标准服务器级硬件、云实例、IBM大型机和其他硬件上运行的MongoDB版本。它能够移动工作负载,在许多不同的环境中运行MongoDB软件,这是人们采用MongoDB的一个关键原因。
当然,从长远来看,人们都在为向云计算的宏观过渡而奋斗。但是,在可预见的未来,不同种类的工作负载和环境、国家、行业等仍然在本地运行。MongoDB的平台无论你是在自己的数据中心自己运行,还是通过MongoDB Atlas在公共云上为你运行,在两者之间的所有点上运行,基本上都是一样的。
作为这个更大故事的一部分,我们正在扩展我们平台提供的整体功能集。例如,我们最近发布了一个新产品——Atlas Data lake,它可以利用存储在对象存储中的数据,比如S3,在云中可用。
Atlas数据湖提供了MongoDB查询语言的全部功能,MongoDB查询语言是一种非常强大且丰富的查询语言,人们在操作数据库上下文中已经享受了多年,并将这种能力带到了对象存储中的数据中。由于人们在S3中存储大量数据,其中大部分数据倾向于以常见格式存储,如JSON、逗号分隔值或其他格式。我们可以利用MongoDB查询语言,它非常适合于像JSON这样的半结构化和层次化数据,从而能够充分利用存储在S3 bucket中的信息。
我们最近还收购了一家移动数据库公司,Realm,它有一种非常类似mongodb的灵活方式来处理移动设备中的数据。随着MongoDB的发展,我们从用户和客户那里得知,MongoDB在数据库级别上所解决的挑战在其他领域仍然存在。MongoDB希望将其为开发人员提供处理数据的最佳方式的使命带到更多的数据生态系统中。
让我们来谈谈多文档事务——为什么需要它,公司是如何交付这个特性的?
(RK): MongoDB总是在单个文档级别上具有ACID事务能力。Richard,如果你正在建模关于我的所有数据,作为你公司的一个客户,你可能会存储关于我的大部分信息在一个文档中。当文档从一种状态更改到另一种状态时,我们总是在单文档级别上有ACID事务。
但是,当我们的客户不确定未来的需求是什么时,为了让他们的应用程序经得起时间的限制,多文档事务提供了一个保证,即使他们的应用程序的需求会随着时间的推移而变化,客户也不会以某种方式达到MongoDB能为他们做的极限。MongoDB能够在单个事务中封装跨多个集合和文档的多个操作。
的业务分析为什么我们想要在这个方向提供了完整的、传统的、会话事务应用程序可以做任意的事情的范围内事务和不需要,例如,预定义的操作可以在事务作用域或限制哪些操作可以在执行一个事务。
对多文档事务的技术需求始于MongoDB的第一次收购,一个名为WiredTiger的数据库存储引擎,它是由创建BerkeleyDB嵌入式数据库(世界上最流行的数据库引擎之一)的人创建的。
WiredTiger存储引擎,自从几年前MongoDB 3.2以来就一直是默认的存储引擎,实际上已经支持了多记录事务的底层能力。然后,我们的工程师通过MongoDB的查询语言、复制协议、分片架构将该功能向上线程化,这样MongoDB应用程序就可以利用底层存储引擎提供的这种功能。
今天,我们的客户开始以非常先进的方式利用这些交易。在这方面,它使从传统的表格数据库到MongoDB更容易一些。
你认为在Mongo堆栈中哪里有改进的空间?
(RK):我们正在用MongoDB Atlas扩展我们的多云能力,这可能是我们目前正在做的工作,它最能引起我们最大客户的共鸣。
今天,如果你想启动MongoDB Atlas部署,你必须选择一个特定的云,如IBM云、AWS、Azure或GCP。每个单独的MongoDB部署可以跨越这些云中的多个区域,但不能跨越多个云。
我们的目标是让单个MongoDB部署跨越不同的云提供商,让客户能够利用每个不同云提供的最佳技术。因此,如果他们想利用Amazon特有的一些功能,他们可以这样做,并让这些功能在MongoDB中读写他们的数据。当我们提供跨云集群时,相同管理域下、相同用户权限和访问控制角色下的相同集群也将能够通过复制存在于其他云中,这样用户就可以利用Azure或GCP中可用的技术。
你对自己运行MongoDB的人有什么建议?
(RK):首先,如果你自己运行MongoDB,你就会疏忽,不去看MongoDB Atlas可以提供的功能。Atlas是获得MongoDB好处的最简单方式,因为坦率地说,我们将为您运行它。所以,你会得到你投入到任务和升级操作,安全操作,等等的资源。这是一种让您的团队更高效、更快的方法,同时让构建MongoDB的专家们安心地运行操作。
如果你现在在一些on-prem或其他自管理的情况下运行MongoDB,你应该看看MongoDB的管理工具。我们有几个不同的管理套件,其中一个叫做MongoDB云管理器,它可以在云环境中协调、运行、监控和备份MongoDB。
我们也有一个打包的,on-prem版本的相同功能称为MongoDB Ops Manager,它是运行MongoDB最完整的管理工具套件,包含了你需要的所有功能,包括编排、升级、维护任务、监控和警报。
MongoDB专家组成了一个庞大的生态系统,这也是一个有价值的资源。我们的核心数据库已经有超过7500万的下载量,在线教育平台MongoDB University的注册人数也超过了100万。有非常支持的论坛,如谷歌组为用户支持,以及堆栈溢出为其他关于MongoDB技术的问答。当然,在MongoDB,我们有大量的MongoDB专家,如果你自己运行MongoDB,你需要额外的帮助,他们可以以各种方式帮助你。
原文:https://www.ibm.com/cloud/blog/database-deep-dives-mongodb
本文:http://jiagoushi.pro/node/1144
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 76 次浏览
【文档数据库】时间序列数据与MongoDB:第一部分-简介
时间序列数据正日益成为现代应用的核心——比如物联网、股票交易、点击流、社交媒体等等。随着批量系统向实时系统的转变,对时间序列数据的有效捕获和分析可以使组织能够更好地检测和响应事件,领先于竞争对手,或提高操作效率,以降低成本和风险。使用时间序列数据通常不同于常规应用程序数据,您应该观察一些最佳实践。这个博客系列试图提供这些最佳实践,当你在MongoDB上构建你的时间序列应用程序:
- 介绍时间序列数据的概念,并描述与这类数据相关的一些挑战
- 如何查询、分析和呈现时序数据
- 提供发现问题,帮助您收集成功交付时间序列应用程序所需的技术需求。
什么是时间序列数据?
虽然并非所有的数据在本质上都是时间序列,但越来越多的数据可以被归类为时间序列——这是由允许我们实时而不是批量利用数据流的技术所推动的。每个行业、每个公司都需要对时间序列数据进行查询、分析和报告。假设一个股票日内交易员不断地查看股票价格的feed,并运行算法来分析趋势和确定机会。他们在一段时间内查看数据,例如每小时或每天。联网的汽车公司可以获得发动机性能和能源消耗等遥测数据,以改进零部件设计,并监测磨损率,以便在问题发生前安排车辆维修。他们也会在一段时间内查看数据。
为什么时间序列数据具有挑战性?
时间序列数据可以包括以固定时间间隔捕获的数据(如每秒的设备测量),也可以包括以不规则时间间隔捕获的数据(如从警报和审计事件用例生成的时间间隔)。时间序列数据通常还带有诸如设备类型和事件位置之类的属性,并且每个设备可能提供数量可变的附加元数据。数据模型能够灵活地满足各种快速变化的数据摄入和存储需求,这使得具有严格模式的传统关系(表格)数据库系统难以有效地处理时间序列数据。此外,还有可伸缩性的问题。由于多个传感器或事件产生的高频率读数,时间序列应用程序可以产生大量的数据流,需要消化和分析。因此,允许数据向外扩展并跨许多节点分布的平台比扩展的单块表格数据库更适合这种用例。
时间序列数据可以来自不同的来源,每个来源生成需要存储和分析的不同属性。数据生命周期的每个阶段都对数据库提出了不同的要求——从摄入到使用和归档。
- 在数据摄取期间,数据库主要执行写密集操作,主要包括偶尔更新的插入操作。当数据流在摄入期间检测到异常(例如超过某个阈值)时,数据使用者可能希望得到实时警报。
- 随着越来越多的数据被摄入,消费者可能想要查询这些数据以获得具体的见解,并发现趋势。在数据生命周期的这个阶段,工作负载是读的,而不是写的,但是数据库仍然需要保持较高的写率,因为数据是并发地摄取然后查询的。
- 消费者可能希望查询历史数据,并利用机器学习算法进行预测分析,以预测未来行为或识别趋势。这将对数据库施加额外的读取负载。
- 最后,根据应用程序的需求,捕获的数据可能有一个保质期,需要在一段时间后进行归档或删除。
正如您所看到的,处理时间序列数据不仅仅是简单地存储数据,还需要广泛的数据平台功能,包括处理同时的读和写需求、高级查询功能和归档等等。
谁在使用MongoDB处理时间序列数据?
- MongoDB提供了满足高性能时间序列应用程序需求所需的所有功能。定量投资管理公司Man AHL利用了MongoDB的时间序列能力。
- Man AHL的Arctic应用利用MongoDB存储高频金融服务市场数据(大约每秒250M嘀嗒)。这家对冲基金经理的定量研究人员(“quants”)利用Arctic和MongoDB研究、构建和部署新的交易模型,以了解市场的行为。与现有的私有数据库相比,使用MongoDB, Man AHL节省了40倍的成本。除了节省成本之外,它们还能将处理性能比以前的解决方案提高25倍。Man AHL在GitHub上开源了他们的北极项目。
- 博世集团是一家跨国工程集团,拥有近30万名员工,是全球最大的汽车零部件制造商。物联网是博世的一项战略举措,因此公司选择MongoDB作为物联网套件的数据平台层。该套件不仅为博世集团内部的物联网应用提供了动力,也为其在工业互联网应用领域的许多客户提供了动力,如汽车、制造业、智慧城市、精准农业等。如果您想了解更多关于管理由物联网平台生成的多样化、快速变化和高容量时间序列数据集所面临的主要挑战,请下载Bosch和MongoDB白皮书。
- 西门子是一家专注于电气化、自动化和数字化领域的全球性公司。西门子开发了MongoDB支持的“Monet”平台,提供先进的能源管理服务。Monet使用MongoDB进行实时原始数据存储、查询和分析。
关注应用程序需求
在处理时间序列数据时,您必须投入足够的时间来理解如何创建、查询和过期数据。有了这些信息,您可以优化模式设计和部署架构,以最佳地满足应用程序的需求。
在没有捕获应用程序的需求的情况下,您不应该同意性能指标或sla。
当你开始你的时间序列项目与MongoDB,你应该得到以下问题的答案:
写工作负载
- 摄入的速率是多少?每秒有多少次插入和更新?
随着插入速度的增加,您的设计可能会受益于通过MongoDB自动分片的水平扩展,允许您跨多个节点分区和扩展数据
- 同时有多少客户端连接?
虽然单个MongoDB节点可以处理来自数以万计的物联网设备的同时连接,但您需要考虑通过分片将其扩展,以满足预期的客户机负载。
- 需要存储所有原始数据点吗?还是可以预先聚合数据?如果是预聚合的,可以存储什么粒度或间隔的摘要级别?每分钟?每15分钟吗?
如果你的应用需要证明这一点,MongoDB可以存储你所有的原始数据。但是,请记住,通过预聚合减少数据大小将产生更低的数据集和索引存储,并提高查询性能。
- 每个事件中存储的数据大小是多少?
MongoDB的单个文档大小限制为16 MB,如果你的应用程序需要在一个文档中存储更大的数据,比如二进制文件,你可能想要利用MongoDB GridFS。理想情况下,在存储大量时间序列数据时,最好保持文档大小较小,大约一个磁盘块大小。
阅读工作负载:
- 每秒有多少读取查询?
更高的读取查询负载可能得益于额外的索引或通过MongoDB自动分片进行的水平伸缩。
与写卷一样,读卷可以通过自动分片进行缩放。还可以跨副本集中的辅助副本分布读取负载。
- 客户是地理分散还是位于同一地区?
通过部署地理上更接近数据使用者的只读辅助副本,可以减少网络读取延迟。
- 您需要支持哪些常见的数据访问模式?例如,您是按单个值(如时间)检索数据,还是需要更复杂的查询,即按属性组合(如事件类、按区域、按时间)查找数据?
当创建了适当的索引时,查询性能是最佳的。了解如何查询数据并定义适当的索引对数据库性能至关重要。同时,能够在不干扰系统的情况下实时修改索引策略,是时间序列平台的一个重要属性。
- 您的用户将使用哪些分析库或工具?
如果您的数据消费者正在使用像Hadoop或Spark这样的工具,MongoDB有一个MongoDB Spark连接器,它集成了这些技术。MongoDB也有Python、R、Matlab和其他用于分析和数据科学的平台的驱动程序。
- 您的组织是否使用BI可视化工具来创建报告或分析数据?
MongoDB通过MongoDB BI连接器集成了大多数主要BI报告工具,包括Tableau、QlikView、Microstrategy、TIBCO等。MongoDB还有一个叫做MongoDB Charts的本地BI报告工具,它提供了在MongoDB中可视化数据的最快方法,而不需要任何第三方产品。
数据保存和归档:
- 什么是数据保留策略?数据可以被删除或存档吗?如果有,在什么年龄?
- 如果存档,存档需要多长时间以及可访问性如何?存档数据需要是活动的,还是可以从备份中恢复?
在MongoDB中有不同的删除和归档数据的策略。其中一些策略包括使用TTL索引、可查询备份、分区分片(允许您创建分层存储模式),或者简单地创建一个体系结构,在该体系结构中,您只需在不再需要时删除数据集合。
安全:
- 需要定义哪些用户和角色,每个实体所需的最低特权权限是什么?
- 加密要求是什么?您是否需要同时支持时间序列数据的空中(网络)加密和静止(存储)加密?
- 是否所有针对数据的活动都需要记录在审计日志中?
- 应用程序是否需要符合GDPR、HIPAA、PCI或任何其他监管框架?
监管框架可能需要启用加密、审计和其他安全措施。MongoDB支持这些遵从性所需的安全配置,包括静态和动态加密、审计和基于角色的粒度访问控制。
虽然不是所有可能考虑的事情的详尽列表,但它将帮助您思考应用程序需求及其对MongoDB模式设计和数据库配置的影响。在下一篇博客文章“第2部分:MongoDB中时间序列数据的模式设计”中,我们将探索为不同需求集构建模式的各种方法,以及它们对应用程序性能和规模的相应影响。在第3部分“时间序列数据和MongoDB:第3部分—查询、分析和呈现时间序列数据”中,我们将展示如何查询、分析和呈现时间序列数据。
原文:https://www.mongodb.com/blog/post/time-series-data-and-mongodb-part-1-introduction
本文:http://jiagoushi.pro/node/1334
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 160 次浏览
【文档数据库选型】从MongoDB迁移到Apache CouchDB

本文将指导您完成使用简单的python脚本将数据从MongoDB迁移到Apache CouchDB的步骤。
由于多种原因,包括源数据库和目标数据库之间的基本架构和设计差异,将数据从一个数据库迁移到另一个数据库可能会遇到挑战。
MongoDB和CouchDB都是文档数据库,它们存储一组类似JSON的独立文档。 本文假定您对这两个数据库有基本的了解,并且熟悉如何在这两个数据库中存储数据。 下表提供了两个数据库之间的高级比较。 要获得更深入的了解,您可以访问官方文档,网址为docs.mongodb.com和couchdb.apache.org。
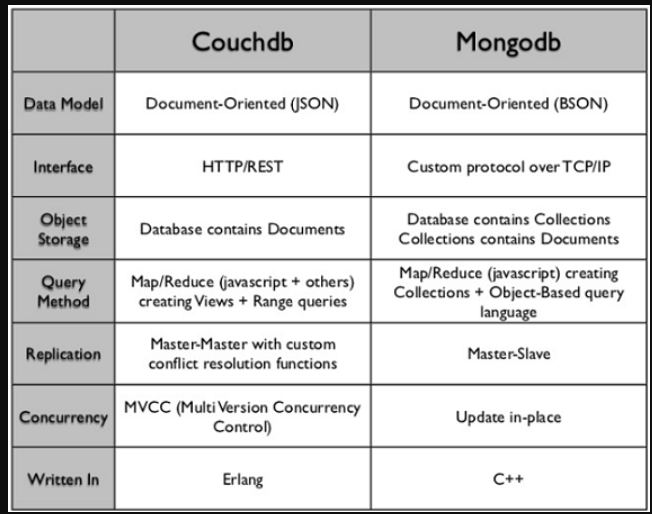
迁移环境
本文支持所有环境,无论您的数据库托管在容器,VM还是裸机系统中。
下图显示了此迁移示例中涉及的组件。
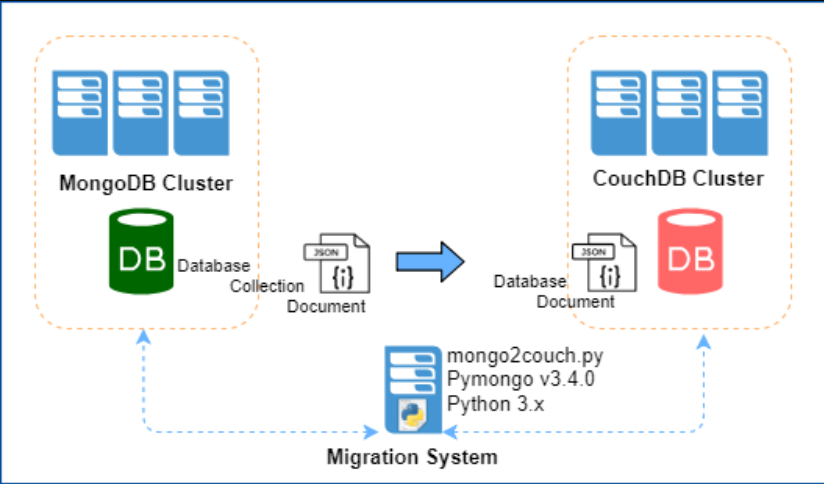
- 源数据库:一个三节点的MongoDB版本3.4.1集群。它具有多个数据库,集合和文档,需要迁移。数据库和相关文件存储在网络文件系统(NFS)共享上。
- 目标数据库:三个节点的CouchDB 2.2版集群。它仅具有在新的CouchDB安装期间创建的默认数据库。新数据库将在迁移过程中即时创建。本文假定您已经在环境中完成了CouchDB的安装。
- 迁移系统:这是一个运行最新的Ubuntu OS,pymongo版本3.4.0,python 3.x,python请求(HTTP库)二进制文件的系统。这用作执行python迁移脚本的迁移系统。该系统能够与MongoDB和CouchDB端点通信。
迁移方式:
以下步骤定义了此示例中遵循的迁移方法。
- 使用pymongo MongoClient启动与MongoDB服务端点的客户端会话。
- 查询和查看MongoDB中的数据库列表。
- 查询MongoDB中的每个数据库,并创建数据库中存在的所有集合的列表。
- 遍历每个集合并一次复制一个文档以进行迁移。
- 使用服务URL和标头信息建立CouchDB REST API连接。
- 使用与MongoDB中相同的数据库名称连接到CouchDB数据库。如果您是第一次连接数据库,则在CouchDB中将不可用。因此,该脚本将创建一个新的数据库,然后插入在步骤4中复制的第一个文档。该脚本将继续所有集合和数据库的文档迁移。
本文介绍的迁移方法适用于较小的数据库
迁移之前
在开始迁移之前,您需要了解这两个数据库之间的关键区别。 MongoDB将文档存储在集合中,而CouchDB将文档直接存储在数据库中(请参阅本文开头显示的比较表中的“对象存储”)。
记住上述差异,此示例在迁移过程中在CouchDB中创建新数据库时将集合名称附加到数据库名称中。参见下面的示例,
MongoDB: Database = SalesDB, Collection = Atlanta Database = SalesDB, Collection = Ohio CouchDB: Database = SalesDB-Atlanta Database = SalesDB-Ohio
在CouchDB数据库中追加集合名称仅出于理智的目的,而不是迁移所必需的。您可以选择使用与MongoDB中相同的数据库名称来创建CouchDB数据库,只要这些名称是唯一的即可。
不支持:此迁移示例不支持包含带有附件的文档的数据库。
让我们迁移
您应该在要运行迁移脚本的迁移系统上安装以下依赖项。
pymongo version 3.4.0
python 3.x
接下来,将下面列出的python脚本(mongo2couch.py)复制到迁移系统,并使用以下命令运行迁移脚本。确保根据您的环境用适当的值替换MongoDB和CouchDB端点。
$ python mongo2couch.py -c 'http://admin:password@testcouchdb:5984' -m 'mongodb://localhost:27017'
档案:mongo2couch.py
https://gist.github.com/Kailashcj/d91ed66e2885db968fecf5de2c9b056d
运行脚本后,它将测试与CouchDB和MongoDB端点的连接。建立成功的连接后,它将读取MongoDB中存在的所有数据库。接下来,它将遍历除“ admin”和“ local”数据库之外的每个数据库中的集合,因为它们是MongoDB的特殊内部数据库。该脚本将读取每个集合中存在的文档,并将其复制到CouchDB数据库。首次插入文档时,它将在CouchDB中创建适当的数据库。
该脚本将报告执行期间的所有错误。默认情况下,所有报告“不可JSON可序列化”错误的文档都会被跳过。如果您的环境中有这些错误,可以参考README.md来解决。
最后,脚本将生成一个迁移摘要,如下所示。

您可以登录到CouchDB Web管理仪表板,以验证新数据库的创建以及这些数据库中已迁移的文档。
摘要
我希望这篇文章易于理解,并能帮助您成功地将文档迁移到CouchDB数据库。
祝好运。
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 169 次浏览