软件架构基础
- 193 次浏览
【性能】性能比较:REST vs gRPC vs 异步通信

微服务之间的通信方式对微服务架构内的各种软件质量因素有重大影响(有关微服务网络内通信的关键作用的更多信息)。沟通方式会影响软件的性能和效率等功能性需求,以及可变性、可扩展性和可维护性等非功能性需求。因此,有必要考虑不同方法的所有优缺点,以便在具体用例中合理选择正确的沟通方式。
本文比较了以下样式:REST、gRPC 和使用消息代理 (RabbitMQ) 的异步通信,在微服务网络中了解它们对软件的性能影响。沟通方式的一些最重要的属性(反过来会影响整体表现)是:
- 数据传输格式
- 连接处理
- 消息序列化
- 缓存
- 负载均衡
数据传输格式
虽然使用 AMQP 协议(高级消息队列协议)的异步通信和 gRPC 通信使用二进制协议进行数据传输,但 REST-API 通常以文本格式传输数据。与基于文本的协议相比,二进制协议的效率要高得多 [1,2]。因此,使用 gRPC 和 AMQP 进行通信会导致较低的网络负载,而使用 REST API 时可以预期更高的网络负载。
连接处理
REST-API 通常建立在 HTTP/1.1 协议之上,而 gRPC 依赖于 HTTP/2 协议的使用。 HTTP/1.1、HTTP/2 以及 AMQP 都在传输层使用 TCP 来确保稳定的连接。要建立这样的连接,需要在客户端和服务器之间进行详细的通信。这些性能影响同样适用于所有沟通方式。但是,对于 AMQP 或 HTTP/2 连接,通信连接的初始建立只需要执行一次,因为这两种协议的请求都可以多路复用。这意味着可以将现有连接重用于使用异步或 gRPC 通信的后续请求。另一方面,使用 HTTP/1.1 的 REST-API 为与远程服务器的每个请求建立新连接。

Necessary communication to establish a TCP-Connection
消息序列化
通常,在通过网络传输消息之前,使用 JSON 执行 REST 和异步通信以进行消息序列化。另一方面,gRPC 默认以协议缓冲区格式传输数据。协议缓冲区通过允许使用更高级的序列化和反序列化方法来编码和使用消息内容 [1] 来提高通信速度。然而,选择正确的消息序列化格式取决于工程师。关于性能,protocol buffers 有很多优势,但是当必须调试微服务之间的通信时,依赖人类可读的 JSON 格式可能是更好的选择。
缓存
有效的缓存策略可以显着减少服务器的负载和必要的计算资源。由于其架构,REST-API 是唯一允许有效缓存的通信方式。 REST-API 响应可以被其他服务器和缓存代理(如 Varnish)缓存和复制。这减少了 REST 服务的负载并允许处理大量的 HTTP 流量 [1]。但是,这只有在基础架构上部署更多服务(缓存代理)或使用第三方集成后才有可能。 gRPC 官方文档和 RabbitMQ 文档都没有介绍任何形式的缓存。
负载均衡
除了临时存储响应之外,还有其他技术可以提高服务速度。负载均衡器(例如 mod_proxy)可以高效透明的方式在服务之间分配 HTTP 流量 [1]。这可以实现使用 REST API 的服务的水平扩展。 Kubernetes 作为容器编排解决方案,无需任何调整即可对 HTTP/1.1 流量进行负载均衡。另一方面,对于 gRPC,需要在网络上提供另一个服务(linkerd)[3]。异步通信无需进一步的帮助即可支持负载平衡。消息代理本身扮演负载均衡器的角色,因为它能够将请求分发到同一服务的多个实例。消息代理为此目的进行了优化,并且它们的设计已经考虑到它们必须具有特别可扩展性的事实[1]。
实验
为了能够评估各个通信方法对软件质量特性的影响,开发了四个微服务来模拟电子商务平台的订单场景。
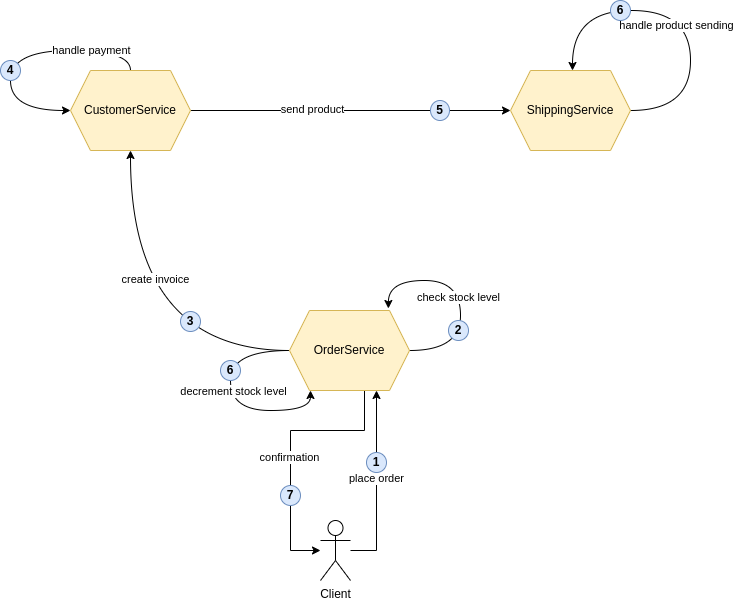
微服务部署在由三个不同服务器组成的自托管 Kubernetes 集群上。服务器通过千兆 (1000 Mbit/s) 网络连接,位于同一数据中心,服务器之间的平均延迟为 0.15 毫秒。每次实验运行时,各个服务都部署在相同的服务器上。这种行为是通过 pod 亲和性来实现的。
所有微服务都是用 GO 编程语言实现的。个别服务的实际业务逻辑,例如与数据库的通信,为了不被选择的通信方法之外的其他影响,故意不实现。因此,收集的结果不能代表这种类型的微服务架构,但可以使实验中的通信方法具有可比性。相反,业务逻辑的实现是通过将程序流程延迟 100 毫秒来模拟的。因此,在通信中,总延迟为 400 毫秒。
开源软件k6用于实现负载测试。
实现
Golang 标准库中包含的 net/http 模块用于提供 REST 接口。使用标准库中也包含的 encoding/json 模块对请求进行序列化和反序列化。所有请求都使用 HTTP POST 方法。
“谈话很便宜。给我看看密码。”
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"github.com/google/uuid"
"gitlab.com/timbastin/bachelorarbeit/common"
"gitlab.com/timbastin/bachelorarbeit/config"
)
type restServer struct {
httpClient http.Client
}
func (server *restServer) handler(res http.ResponseWriter, req *http.Request) {
// only allow post request.
if req.Method != http.MethodPost {
bytes, _ := json.Marshal(map[string]string{
"error": "invalid request method",
})
http.Error(res, string(bytes), http.StatusBadRequest)
return
}
reqId := uuid.NewString()
// STEP 1 / 4
log.Println("(REST) received new order", reqId)
var submitOrderDTO common.SubmitOrderRequestDTO
b, _ := ioutil.ReadAll(req.Body)
err := json.Unmarshal(b, &submitOrderDTO)
if err != nil {
log.Fatalf(err.Error())
}
checkIfInStock(1)
invoiceRequest, _ := http.NewRequest(http.MethodPost,
fmt.Sprintf("%s/invoices", config.MustGet("customerservice.rest.address").
(string)), bytes.NewReader(b))
// STEP 2
r, err := server.httpClient.Do(invoiceRequest)
// just close the response body
r.Body.Close()
if err != nil {
panic(err)
}
shippingRequest, _ := http.NewRequest(http.MethodPost,
fmt.Sprintf("%s/shipping-jobs", config.MustGet("shippingservice.rest.address").
(string)), bytes.NewReader(b))
// STEP 3
r, err = server.httpClient.Do(shippingRequest)
// just close the response body
r.Body.Close()
if err != nil {
panic(err)
}
handleProductDecrement(1)
// STEP 5
res.WriteHeader(201)
res.Write(common.NewJsonResponse(map[string]string{
"state": "success",
}))
}
func startRestServer() {
server := restServer{
httpClient: http.Client{},
}
http.HandleFunc("/orders", server.handler)
done := make(chan int)
go http.ListenAndServe(config.MustGet("orderservice.rest.port").(string), nil)
log.Println("started rest server")
<-done
}
RabbitMQ 消息代理用于异步通信,部署在同一个 Kubernetes 集群上。 消息代理和各个微服务之间的通信使用 github.com/spreadway/amqp 库进行。 该库是 GO 编程语言官方文档推荐的。
package main
import (
"encoding/json"
"log"
"github.com/streadway/amqp"
"gitlab.com/timbastin/bachelorarbeit/common"
"gitlab.com/timbastin/bachelorarbeit/config"
"gitlab.com/timbastin/bachelorarbeit/utils"
)
func handleMsg(message amqp.Delivery, ch *amqp.Channel) {
log.Println("(AMQP) received new order")
var submitOrderRequest common.SubmitOrderRequestDTO
err := json.Unmarshal(message.Body, &submitOrderRequest)
utils.FailOnError(err, "could not unmarshal message")
checkIfInStock(1)
handleProductDecrement(1)
ch.Publish(config.MustGet("amqp.billingRequestExchangeName").(string), "",
false, false, amqp.Publishing{
ContentType: "application/json",
Body: message.Body,
})
}
func getNewOrderChannel(conn *amqp.Connection) (*amqp.Channel, string) {
ch, err := conn.Channel()
utils.FailOnError(err, "could not create channel")
ch.ExchangeDeclare(config.MustGet("amqp.newOrderExchangeName").
(string), "fanout", false, false, false, false, nil)
queue, err := ch.QueueDeclare(config.MustGet("orderservice.amqp.consumerName").
(string), false, false, false, false, nil)
utils.FailOnError(err, "could not create queue")
ch.QueueBind(queue.Name, "", config.MustGet("amqp.newOrderExchangeName").
(string), false, nil)
return ch, queue.Name
}
func startAmqpServer() {
conn := common.NewAmqpConnection(config.MustGet("amqp.host").(string))
defer conn.Close()
orderChannel, queueName := getNewOrderChannel(conn)
msgs, err := orderChannel.Consume(
queueName,
config.MustGet("orderservice.amqp.consumerName").(string),
true,
false,
false,
false,
nil,
)
utils.FailOnError(err, "could not consume")
forever := make(chan bool)
log.Println("started amqp server:", queueName)
go func() {
for d := range msgs {
go handleMsg(d, orderChannel)
}
}()
<-forever
}gRPC 客户端和服务器使用 gRPC 文档推荐的 google.golang.org/grpc 库。 数据的序列化是使用协议缓冲区完成的。
package main
import (
"log"
"net"
"context"
"gitlab.com/timbastin/bachelorarbeit/common"
"gitlab.com/timbastin/bachelorarbeit/config"
"gitlab.com/timbastin/bachelorarbeit/pb"
"gitlab.com/timbastin/bachelorarbeit/utils"
"google.golang.org/grpc"
)
type OrderServiceServer struct {
CustomerService pb.CustomerServiceClient
ShippingService pb.ShippingServiceClient
pb.UnimplementedOrderServiceServer
}
func (s *OrderServiceServer) SubmitOrder(ctx context.Context,
request *pb.SubmitOrderRequest) (*pb.SuccessReply, error) {
log.Println("(GRPC) received new order")
if s.CustomerService == nil {
s.CustomerService, _ = common.NewCustomerServiceClient()
}
if s.ShippingService == nil {
s.ShippingService, _ = common.NewShippingServiceClient()
}
checkIfInStock(1)
// call the product service on each iteration to decrement the product.
_, err := s.CustomerService.CreateAndProcessBilling(ctx, &pb.BillingRequest{
BillingInformation: request.BillingInformation,
Products: request.Products,
})
utils.FailOnError(err, "could not process billing")
// trigger the shipping job.
_, err = s.ShippingService.CreateShippingJob(ctx, &pb.ShippingJob{
BillingInformation: request.BillingInformation,
Products: request.Products,
})
utils.FailOnError(err, "could not create shipping job")
handleProductDecrement(1)
return &pb.SuccessReply{Success: true}, nil
}
func startGrpcServer() {
listen, err := net.Listen("tcp", config.MustGet("orderservice.grpc.port").(string))
if err != nil {
log.Fatalf("could not listen: %v", err)
}
grpcServer := grpc.NewServer()
orderService := OrderServiceServer{}
// inject the clients into the server
pb.RegisterOrderServiceServer(grpcServer, &orderService)
// start the server
log.Println("started grpc server")
if err := grpcServer.Serve(listen); err != nil {
log.Fatalf("could not start grpc server: %v", err)
}
}收集数据
检查成功和失败的订单处理的数量,以确认它们所经过的时间。如果直到确认的持续时间超过 900 毫秒,则订单流程被解释为失败。选择此持续时间是因为在实验中可能会出现无限长的等待时间,尤其是在使用异步通信时。每次试验都会报告失败和成功订单的数量。
每种架构总共进行了 12 次不同的测量,每种情况下同时请求的数量不同,传输的数据量也不同。首先,在低负载下测试每种通信方式,然后在中等负载下,最后在高负载下测试。低负载模拟 10 个,中等负载模拟 100 个,高负载模拟 300 个同时向系统发出的请求。在这六次测试运行之后,要传输的数据量会增加,以了解各个接口的序列化方法的效率。数据量的增加是通过订购多个产品来实现的。
结果
gRPC API 架构是实验中研究的性能最佳的通信方法。在低负载下,它可以接受的订单数量是使用 REST 接口的系统的 3.41 倍。此外,平均响应时间比 REST-API 低 9.71 毫秒,比 AMQP-API 低 9.37 毫秒。
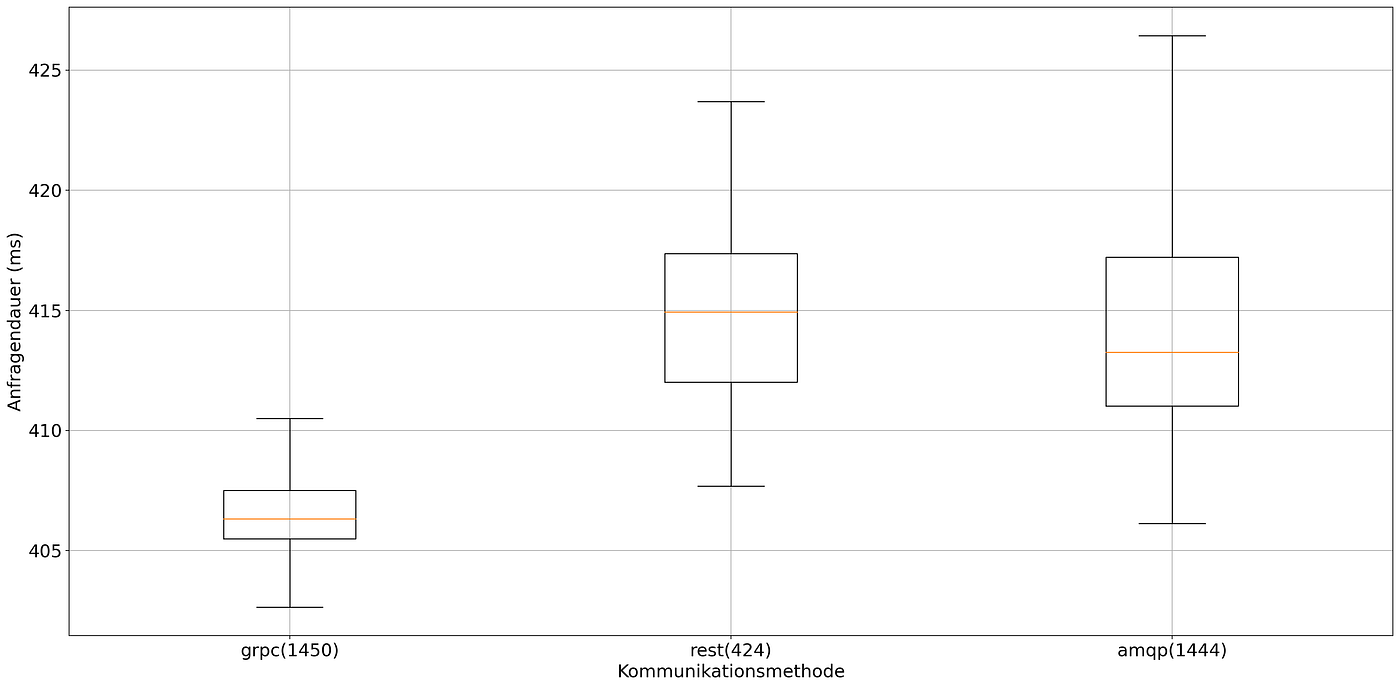
1 simultaneous request, low bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
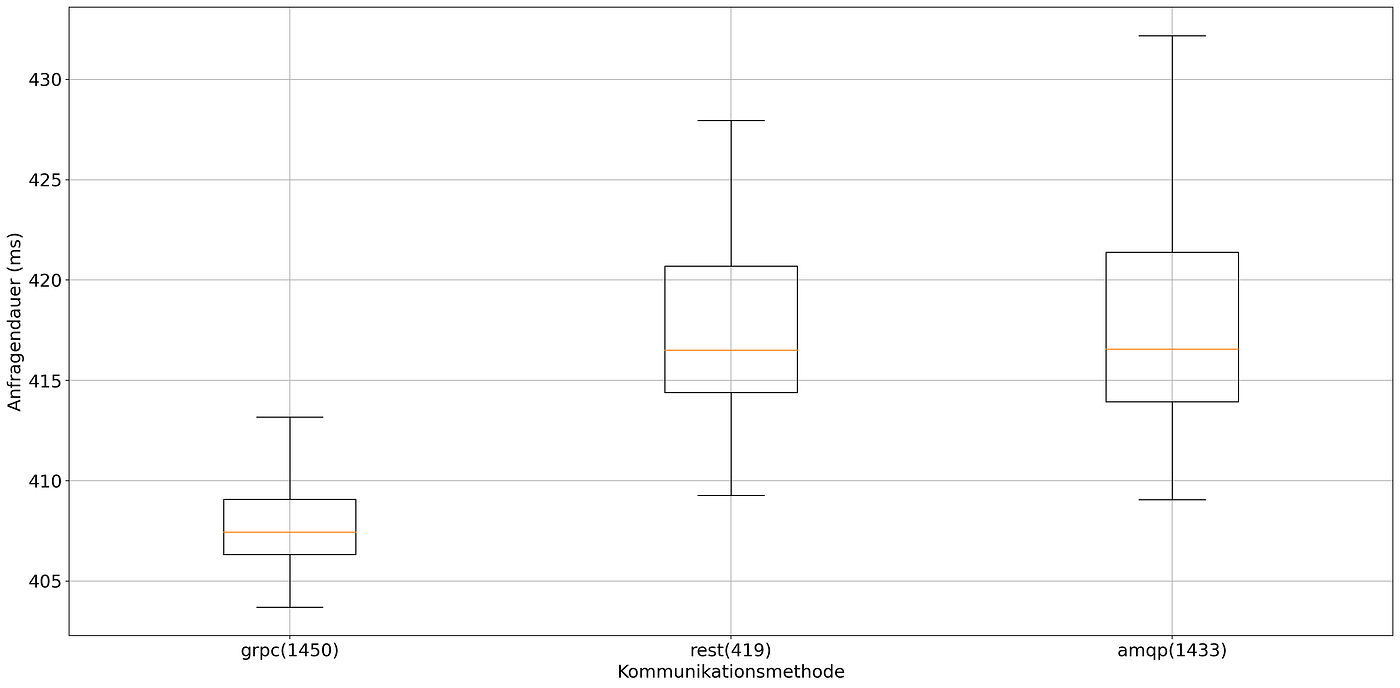
1 simultaneous request, high bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
总体而言,这种趋势在更多并发请求的实验中继续存在。 对于 100 个并发请求,使用 gRPC-API 架构可以处理的订单数量是 REST-API 的 3.7 倍。 与 AMQP 的差异要小得多。 GRPC 的处理能力比 AMQP 多 8.06%(1170 个订单)。 虽然 gRPC 可以在 418.99 毫秒内处理 95% 的请求,但 AMQP 只能在 557.39 毫秒内完成,而 REST 在 1425.13 毫秒内完成。
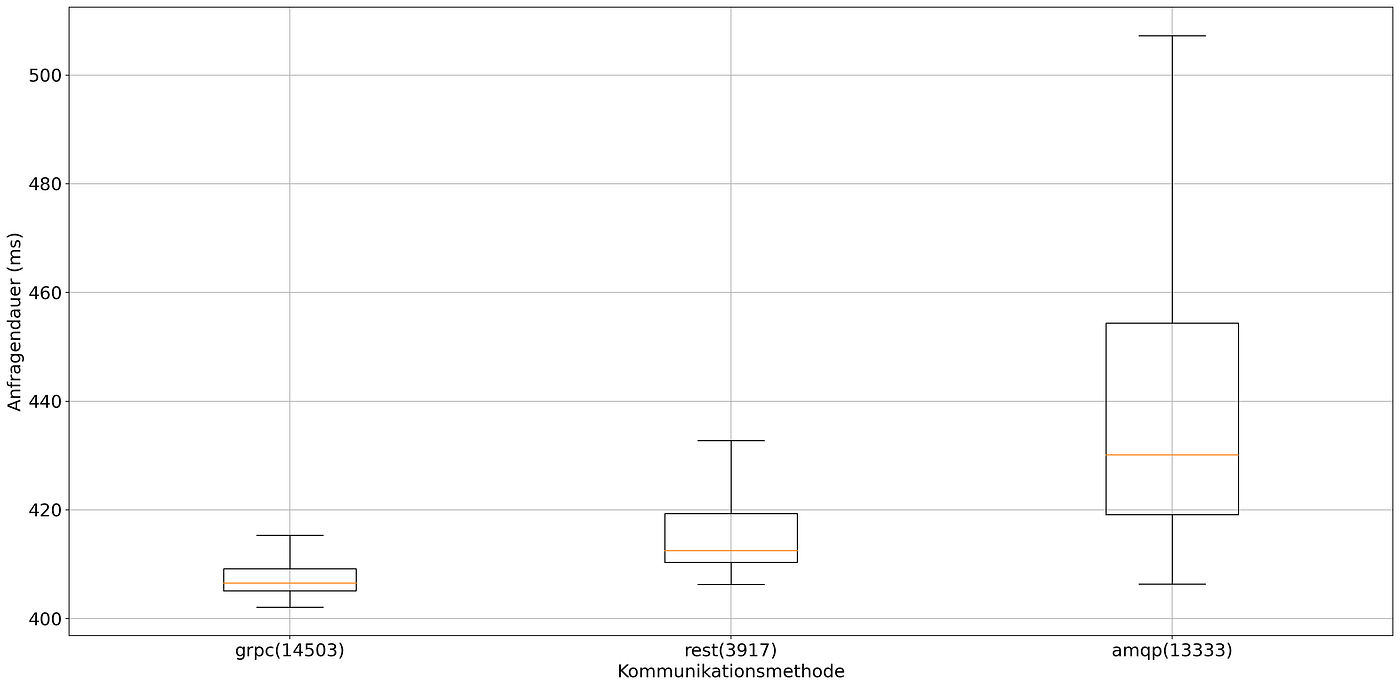
100 simultaneous requests, low bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
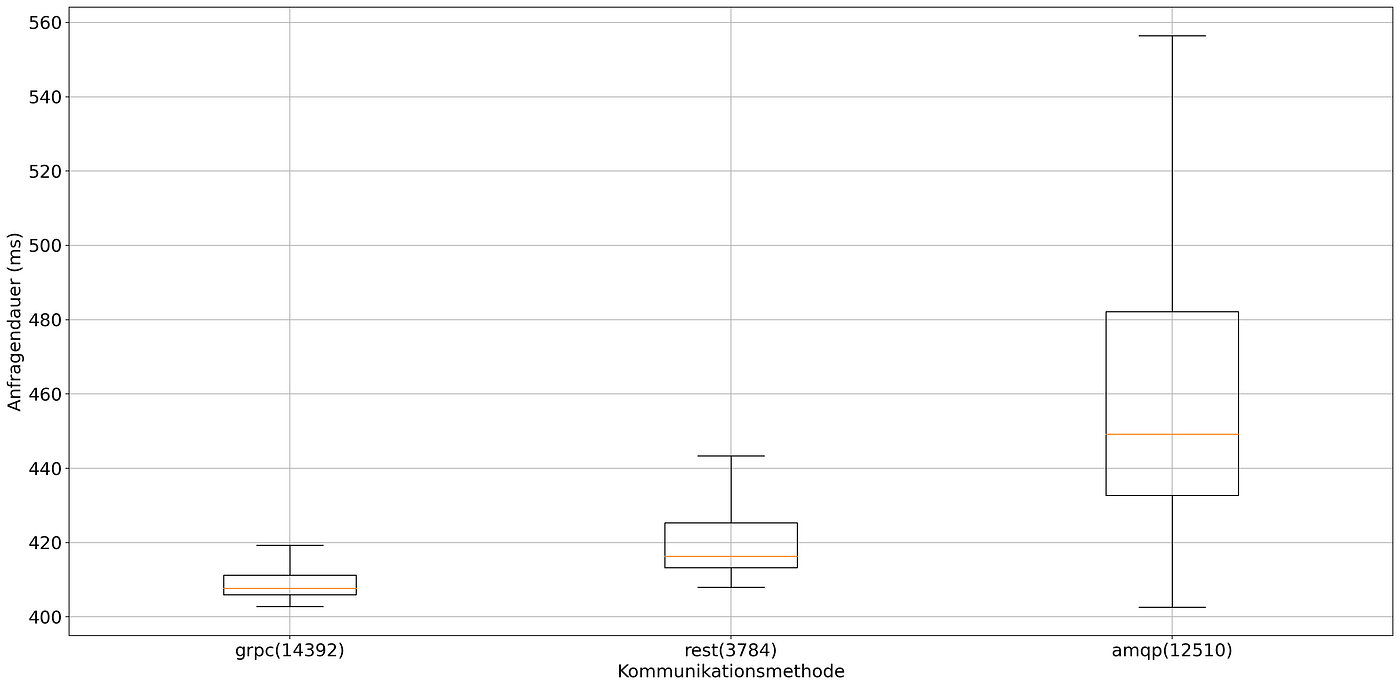
100 simultaneous requests, high bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
在高负载下的第三次运行中,使用 gRPC API 的微服务架构可以成功确认 43122 个订单。 这是使用 REST-API 的相同架构的 4.8 倍,是使用异步通信的架构的 2.02 倍。
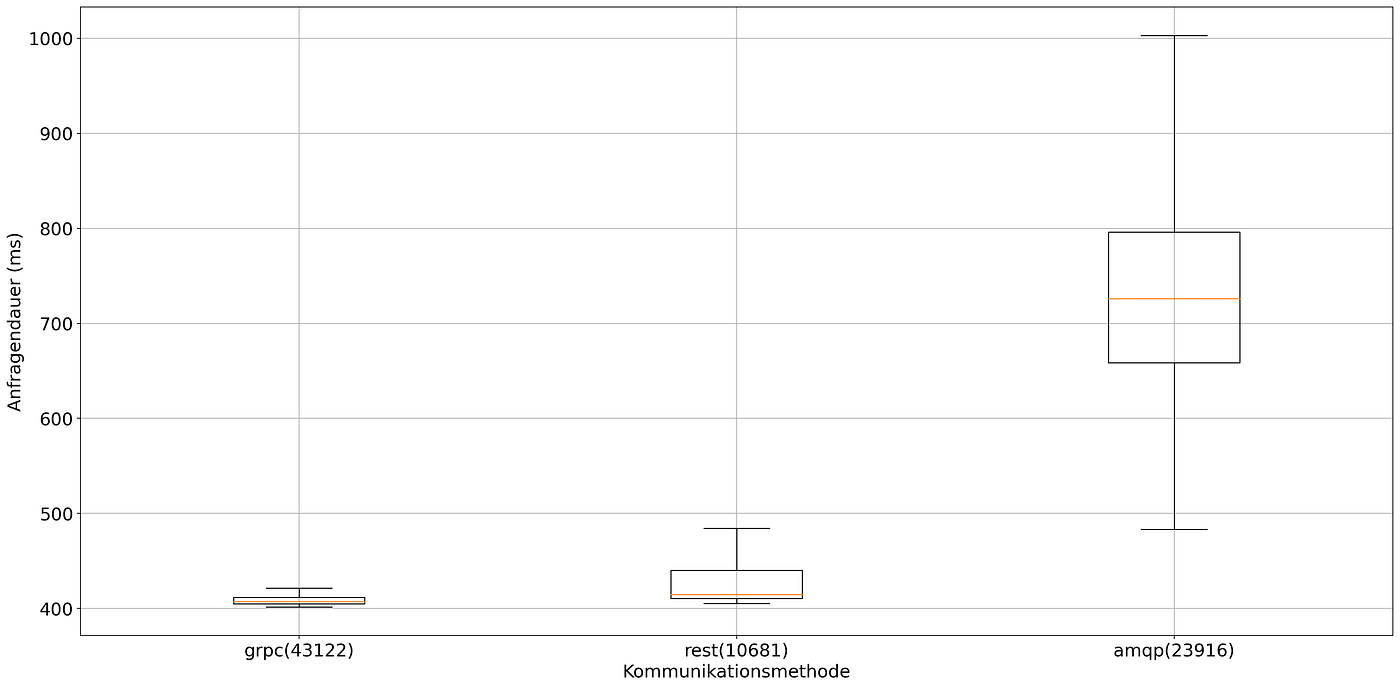
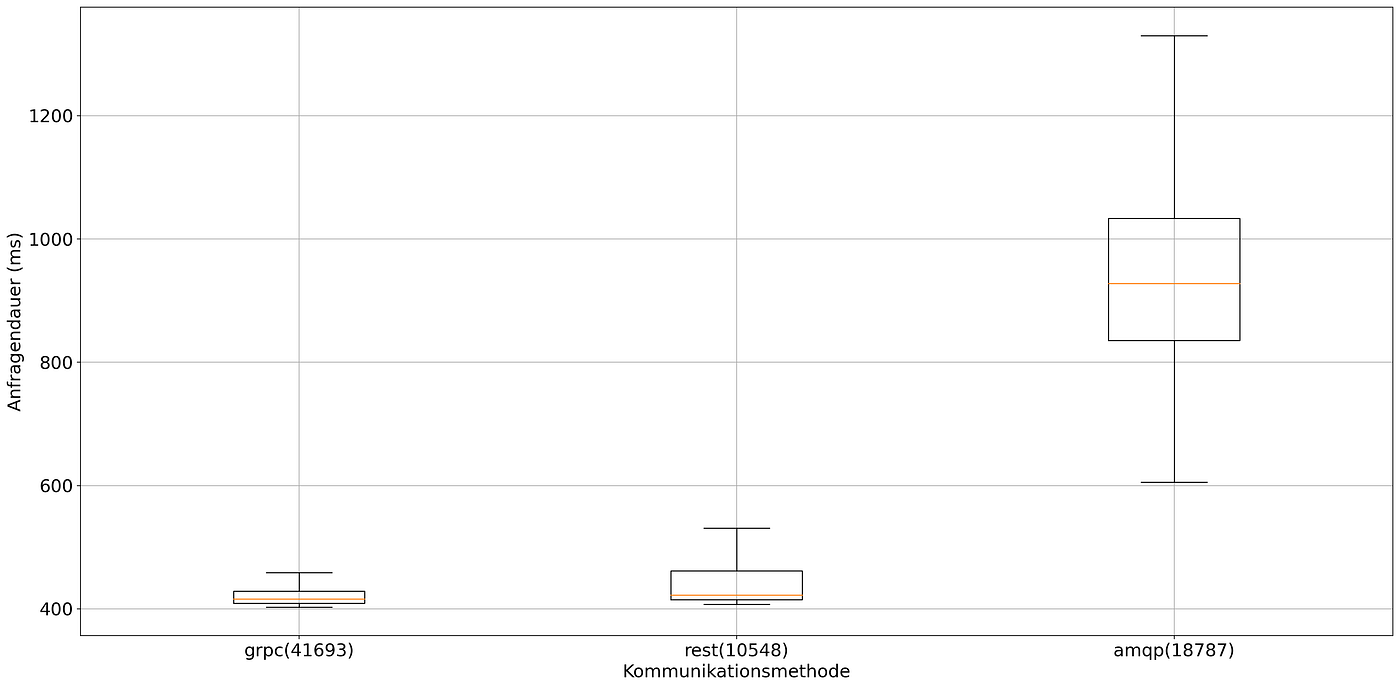
300 simultaneous requests, high bandwidth usage. x: Communication Method (Number of Requests), y: Duration in milliseconds
从 JSON 格式的客户端请求大小与协议缓冲区格式的大小对比来看,对于单个产品,使用 gRPC 传输的数据量与 REST 相比减少了 34.202%。这种差异可以通过优化的协议缓冲区序列化来证明,它提供了比 JSON 更有效的编码。
结论
gRPC 被证明是最有效的 API 架构,其次是带有消息代理的 AMQP。 gRPC 提供了一种比带有协议缓冲区的 JSON 更有效的序列化方法。总体而言,与 REST 相比,可以多处理 3.4-4.03 个订单。特别是在有许多并发连接的情况下,gRPC 可以提供优于 REST-API 的优势,因为 TCP 连接可以被重用。与异步通信 1.0–2.2 相比,可以处理更多的订单。通过实验显现的 gRPC 的另一个优点是 gRPC 提供了可预测的性能,而响应时间没有大的异常值。在实验过程中,AMQP,尤其是 REST,在平均响应时间和 95% 分位数之间显示出很大的差异。该实验检查了每种通信方式如何在可变数量的并发请求和传输数据下执行,但这项研究只能近似现实的复杂性。负载均衡器和缓存代理等支持技术可能会产生重大影响,尤其是在使用 REST API 时。必须在考虑实验设置的情况下评估该实验的结果。
不能说 gRPC 允许在微服务网络中进行最有效的通信。
参考
- [1]Sam Newman. 构建微服务:设计细粒度系统。卷。 2. O'ReillyMedia, Inc,2015 年。
- [2]吉姆·韦伯、萨瓦斯·帕拉斯塔蒂迪斯和伊恩·罗宾逊。实践中的 REST:超媒体和系统架构。 O'Reilly 媒体公司,2010 年,第448.
- [3]William Morgan.gRPC 在 Kubernetes 上进行负载平衡,无需泪水。 https://kubernetes.io/blog/2018/11/07/grpc-load-balancing-on-kubernetes…。 (于 2021 年 9 月 15 日访问)。 2018 年 11 月。
原文:https://medium.com/l3montree-techblog/performance-comparison-rest-vs-gr…
- 463 次浏览
【架构治理】在代码存储库中记录软件架构
Markdown 是一种标准的简单语法,用于创建具有专业外观的文档。 它比 HTML 更简单,无需专门的编写编辑器即可进行管理。 Git配置管理工具也支持markdown格式。 在 Git 环境中,markdown 一般用于项目的简单介绍和构建说明。 (自述文件)。 本文介绍了如何将 Markdown 格式与模板一起用于架构文档。

带有 Markdown 的架构文档
与代码一起管理软件的架构设计和设计决策将为项目提供极大的便利。 当我们的设计与代码一起保存在配置管理环境中时,我们可以一起进行设计变更和代码变更。 当新工程师开始项目并将代码拉到他的计算机上时,他有机会看到系统的架构。
准备 Markdown 文档 IDE
您可以使用 Visual Studio Code 和类似的 IDE 与您的代码一起准备 markdown 文档。(市场上有 markdown 编辑器,但使用 IDE 来做会更实用)。 您可以在 Visual Studio Code 中使用“Markdown Preview Enhanced”插件。 使用这个插件,你可以在 VS Code (Preview) 中直观地看到 markdown 文档。 您还可以使用相同的工具生成 HTML、World 或 PDF 文档。
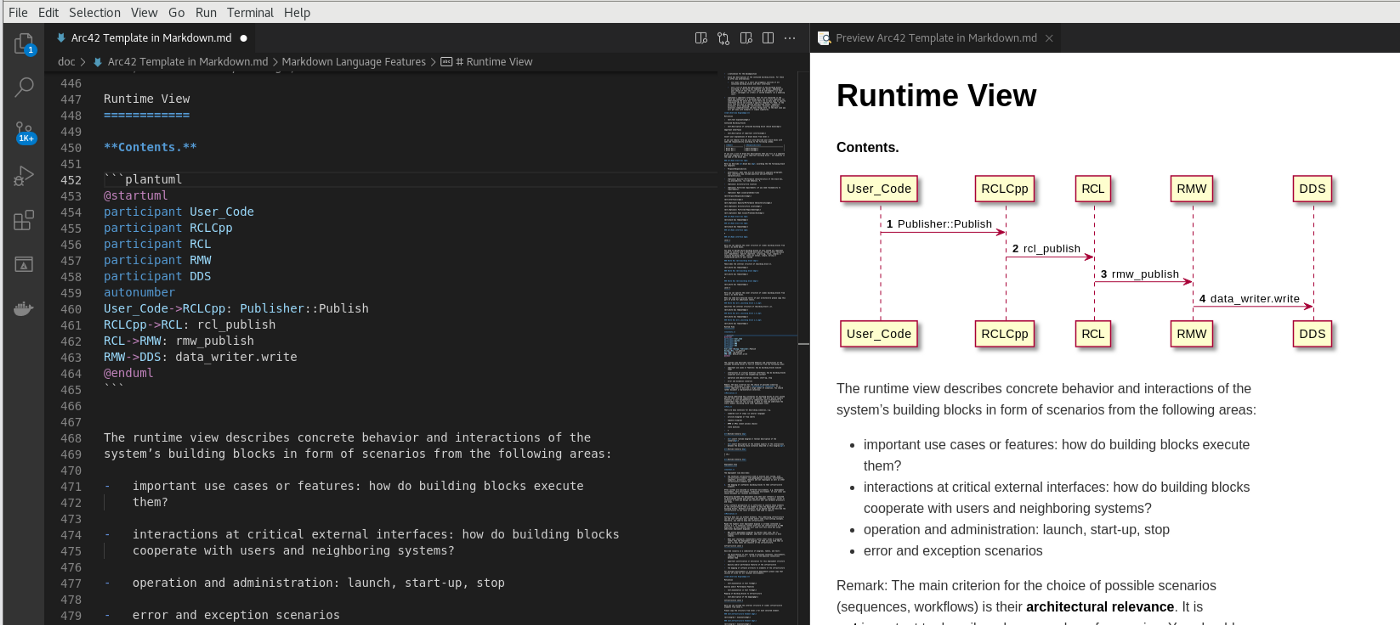
MD Document Preparation with VS Code
UML 和 C4 图
您可以将使用 Plant UML 脚本语言绘制的 UML 和 C4 图放入 Markdown 文档中。 这样,您可以将整个设计(包括绘图)保存在一个地方。 您放入 Markdown 文档中的 UML 和 C4 图可以在预览窗口中看到。 (带有一个名为“PlantUML”的插件)。 此外,当您导出 pdf 或 html 时,您将能够将这些图表视为图形。 GIT 工具具有可视化显示在此 PlantUML 中编写的设计脚本的功能。 通过这种方式,可以看到带有 Bitbucket 的设计(具有适当的版本和配置)。 此功能在开源 Github 站点上尚不可用。
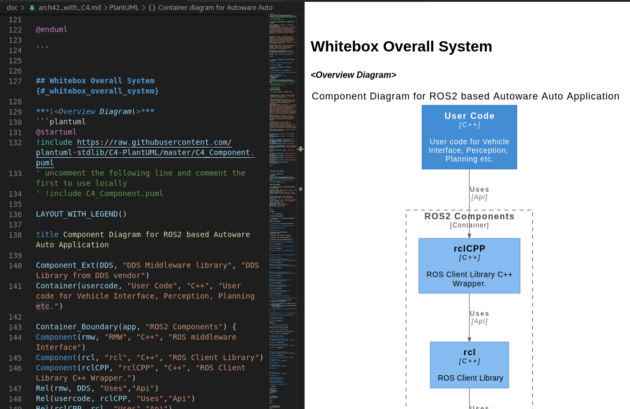
- Adding a C4 Component Diagram to a Markdown document
如果git服务器不支持可视化,可以先从plantuml服务器站点制作一张png或svg的图,然后将相关的图发送到Git服务器。然后你可以在markdown文档中将此图作为绘图链接。您可以在使用其他工具制作的图纸中使用此方法。
Arch 42 模板
Arc 42 是架构文档的模板。通过正确完成此 Arc42 模板,您将在一个地方拥有软件架构和设计的关键设计决策。
- — 简介和目标
- — 约束
- - 背景和范围
- — 解决方案策略
- - 构建块视图
- — 运行时视图
- — 部署视图
- — 交叉切割概念
- — 架构决策
- - 质量属性
- — 风险和技术债务
您可以在 Arch42 网站上访问 markdown 模板。相关网站上有一个草稿作为单个文件或作为每个部分的单独文件。
您可以在此模板中使用 C4 模型和 UML 图。例如,我们可以使用第 3 章中的 C4 范围图,第 5 章中的容器图和组件图。第 6 章中可以使用 C4 动态图或 UML 序列图。部署图可以使用 C4 或 UML 符号在第 7 章。
对于第 10 章,我们可以使用为架构权衡分析方法 (ATAM) 准备的表格。在这种情况下,您可以访问和使用我准备的降价表草稿。

结论
建议使用 Arch 42 模板以 Markdown 格式准备软件架构文档,并在代码中包含 Git 结构中的 C4 模型和 UML 图。 该解决方案提供了高质量、可管理、版本控制和可追溯的架构文档。
- 102 次浏览
【架构设计模式】MITRE 设计模式
定义:
软件中的设计模式(通常)是简短的描述,用于捕捉过去证明是成功的实践。它们不是具体的软件,而是在某些情况下应用的一种模板。它们通常不是规定性的,而是建议性的,并且包括关于何时最适合使用它们的指导,并提供来自现有系统的示例。它们最重要的用途是描述对象或系统与其环境(即其他对象或系统)的交互。设计模式可以出现在系统设计的不同级别,从低级编程到系统系统。在后一层,它们与界面设计和耦合最为相关。
关键词:
耦合,设计模式,接口
MITRE SE 角色和期望:
MITRE 系统工程师 (SE) 应了解信息技术 (IT) 密集型系统的设计模式的一般原则和最佳实践。他们应选择和推荐适合应用程序的模式,了解出现的挑战和选择,就设计模式选择的适用性向政府提供建议,并了解企业环境中界面设计的问题和挑战。
背景
设计模式的概念通常归功于建筑师 Christopher Alexander 的工作,并被 Kent Beck 和 Ward Cunningham 改编为软件。 1995 年,流行的书籍设计模式(其作者通常被称为“四人帮”(GOF))建立了一组持续使用的模式,并提供了描述模式的“模式”[1]。这 23 种模式分为创造型、结构型和行为型。已经定义了许多其他模式,以及其他类别,例如用户界面。
例如,一个 GOF 模式是抽象工厂,这是一种创建模式,它提供了一个用于创建新对象的接口,而调用者并不知道正在创建的对象的具体类型。这可以用于实现不同的外观和感觉,只需对程序进行最小的更改。其他示例是代理结构模式,其中一个对象成为另一个对象的代理(具有相同的接口),通常用于远程过程调用;单例模式,其中一个类只允许创建自己的一个实例,通常用于管理共享资源;和中介者行为模式,它允许类之间的松散耦合,因为它是唯一一个对其方法有详细了解的类。
与审查接口调用的细节相比,设计模式使对软件设计的审查和讨论能够在更高和更抽象的层次上进行——“你应该在这里使用单例模式吗?”或“抽象工厂模式有帮助吗?”
GOF 模式有几个共同点:它们是根据面向对象的软件定义的,它们(通常)描述一个对象与其环境(例如,其他对象)的交互,它们通常用在一个内部设计中。单个应用程序(即本地调用环境)。
然而,模式也可以在更广泛的设计层次上进行查看,而 MITRE SE 更经常地涉及到这方面。与审查组件之间或更高级别的系统之间的接口相比,MITRE SE 不太可能参与系统组件的详细内部工作的开发。这需要一组设计模式,这些模式专注于跨系统边界建立连接的方式。许多 GOF 模式不会直接应用。
企业工程面向服务环境中的设计模式
在为大型企业服务环境进行设计时,会出现两个考虑:(1)用户可能会以设计者没有预料到的方式将服务、接口等放在一起,以及(2)任何接口更改都会影响更大的用户集.深思熟虑地使用设计模式可以帮助解决这两个问题。扩展到企业的第三个问题是服务通常必须处理(当前)未知且潜在的大量用户。设计模式在直接处理这个问题时用处不大。
在企业环境中,当考虑系统到系统的接口时,可以扩展设计模式的概念,以包含有关如何管理接口中的耦合的更一般的指导。作为一般规则,只要可能,松耦合优于紧耦合。松散耦合意味着接口一侧实现的变化不会影响另一侧的实现。例如,在具有必须分发给用户的查找表的字段中使用代码不是松散耦合。此外,松散耦合的接口不应锁定会抑制可扩展性的特定限制。作为一个简单的例子,在联系信息的界面中,只允许一个(或两个)10 位数字的电话号码可能是不够的。一个更可扩展的接口可能允许任意长度的不确定长度的电话号码列表。
松散耦合将接口的用户与实现中的更改隔离开来。例如,一个设计良好的界面应该能够向界面添加更多参数,同时在没有新参数的情况下仍然可以生成和接受消息。这允许增长和创新,而不会使以前版本的界面的用户陷入困境。但是,另一方面,必须谨慎管理此扩展机制,否则仅参数不同的受支持接口的数量可能会变得很大,并且维护这些接口可能会淹没向后兼容性的价值。
示例接口标准化工作
Cursor on Target (CoT) [2] 是企业努力简化接口集合并提供松散耦合的一个示例。美国空军在许多组件之间拥有大量紧密耦合的点对点接口。 John P. Jumper 将军(前空军参谋长)启发 MITRE 提出了一组数据元素,可以满足大多数用户的大部分需求。 MITRE 研究了几个月的消息,发现有少量数据元素被重复使用。 CoT 以易于生成和解析的 XML 格式对这些元素的定义进行了标准化。它提供了兼容的扩展,因此可以添加新元素而不会破坏现有用户。
国家信息交换模型 (NIEM) [3] 是一个基于 XML 的信息交换接口。它源于全球司法 XML 数据模型,是司法部和国土安全部之间的合作项目。它已被许多州和国防部采用。它提供了一个信息元素词汇表,合作伙伴可以从中选择创建消息。
与 MITRE 系统工程能力模型 (SE CM) 保持一致
具有设计模式的系统工程工作与 MITRE SE CM [4] 中的“架构”(第 2.3 节)和“软件和信息工程”(第 4.7 节)能力最接近。在前者中,设计模式可以成为讨论、可视化、比较和记录架构界面决策的有用工具。在后者中,因为设计模式现在是软件工程中一种成熟的范式,所以对技术和术语的理解有助于促进客户/用户和软件专家之间的沟通。
最佳实践和经验教训
以下实践规则可以看作是企业级以及详细实现级的接口设计模式。
- 避免接口的复杂性。复杂的接口通常不能很好地扩展。复杂性被推送给所有用户,处理它的技能可能会有所不同。例如,不是以 10 种可能不同的格式提供纬度和经度,每种格式都必须由用户处理,而是以单一格式提供。如果一个接口过于复杂,则很可能会被误解,或者开发人员会复制用户端的次优实现。复杂性会导致错误,从而导致可能无法纠正的不良性能,甚至可能成为安全风险。
- 尽可能使用松散耦合的接口。松散耦合意味着接口一侧实现的变化不会影响另一侧的实现。这为双方提供了极大的自由来进行改进并保持开发计划不连贯。严格的时序要求或软件版本要求可能是需要重新评估和放宽这种做法的考虑因素,但在这种情况下应该明确说明并记录在案。
- 只有在性能需要时才使用紧密耦合的接口。紧密耦合会导致代码有缺陷和脆弱。紧密耦合的一个例子是 Link-16 接口,因为它是一个战术链接,所以使用一个数字来表示飞机的类型。这将用户与特定版本的转换表联系起来。如果表格在一侧更新,则用户可能会留下一个无意义的数字,直到表格也被更新。当然,更广泛的通信协议可以明确地携带飞机上的所有信息,但带宽限制可能会禁止将其作为替代方案。
- 如果可能,从松散耦合开始设计。即使在使用紧耦合的情况下,初始设计也可以从松耦合接口开始。记录使用紧密耦合的原因。这类似于以独立于数据库管理系统 (DBMS) 的方式定义逻辑模式,但在依赖于 DBMS 的物理模式中实现它。对于系统的系统,这可能是一个有用的模式。
- 关注接口中的数据一致性,而不是内部表示。在 1990 年代,政府组织试图在所有应用程序中强制执行数据一致性,甚至指定如何在应用程序及其数据库中表示数据。这从未实现。最近,重点是为数据交换创建通用定义,让应用程序可以自由选择如何在内部表示数据。事实证明,这是一个更容易实现的目标。
- 认识到数据表示的差异是由数据的不同用途造成的。例如,考虑一把枪。射手想知道它的射程、口径等。托运人想知道它的大小、重量等。财务想知道它的成本、估计寿命等。同样的枪在不同的系统中自然会有不同的表示。强制所有系统上的所有特征将是繁重的。但是,可以通过组合模式来实现数据的意想不到的创新使用,以创建基于现有表示的新数据表示。
- 在设计界面时,请考虑 80/20 规则。实现大多数用户大部分时间需要的 80%(左右)可能会更好,特别是如果这可以通过简单的界面快速完成。这减少了实施的成本和时间。
- 构建扩展接口的能力。一些用户需要至少达到剩余 20% 的一部分,并且无论如何,界面必须随着时间的推移而增长和变化。松散耦合的接口应该构建兼容扩展的机制,以便可以在不影响不需要扩展的用户的情况下进行更改和添加。
- 考虑可扩展接口的治理。接口的扩展会创建必须管理的多个版本/副本。考虑这样做的理由并理解这样做的影响。
- 不要忘记界面中的语义理解水平。有人能够正确解析您的界面很好,但也必须对数据元素的含义达成一致。
- 让开发人员参与系统接口的开发。那些将实现接口的人应该参与设计,因为他们可能对可能抑制可扩展性或导致其他问题的决策有洞察力。
References and Resources
- Gamma, E., R. Helm, R. Johnson, and J. Vlissides, 1995, Design Patterns: Elements of Reusable Object-Oriented Software, Boston, Mass. Addison-Wesley Longman.
- Miller, R. W. and D. G. Winkowski, June 2007, Loose Couplers as an Information Design Strategy, The MITRE Corporation.
- National Information Exchange Model, accessed August 5, 2014. (By the way, they are looking for NIEM design patterns.)
- The MITRE Institute, September 1, 2007, MITRE Systems Engineering Competency Model.
Additional References and Resources
- Bell, M., 2010, SOA Modeling Patterns for Service Oriented Discovery and Analysis, Hoboken, N.J., John Wiley & Sons.
- Erl, T., 2009, SOA Design Patterns, New York, Prentice Hall.
- Fowler, M., 2002, Patterns of Enterprise Application Architecture, Addison-Wesley.
- Hohpe, G., and B. Woolf, 2003, Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions, Boston, Mass., Addison-Wesley Longman.
- Van Welie, M., A Pattern Library for Interaction Design, accessed April 14, 2014.
- Vora, P., 2009, Web Application Design Patterns, San Fransisco, Calif., Morgan Kaufmann Publishers.
原文:https://www.mitre.org/publications/systems-engineering-guide/enterprise…
- 104 次浏览
【软件工程】内聚和耦合的区别
视频号

微信公众号

知识星球

1.简介
内聚和耦合是设计模块化软件系统中常见的概念。它们由Larry Constantine在20世纪60年代末开发,已被证明是从软件设计到软件度量等领域的基础。它们后来成为标准术语。
在本教程中,我们将研究内聚和耦合,以及它们如何相互关联。
2.凝聚力
内聚性是一个模块内的元素属于一起的程度。模块可以是一个类、一个包,甚至是一个微服务。简单地说,它的意思是“一起改变的代码,保持在一起”。
具有高内聚性的模块包含彼此紧密相关并在其目的上统一的元素。例如,User类中的所有方法都应该表示用户行为。
如果一个模块包含不相关的元素,则称其内聚性较低。例如,User类包含一个关于如何验证电子邮件地址的方法。用户类可以负责存储用户的电子邮件地址,但不负责验证或发送电子邮件:
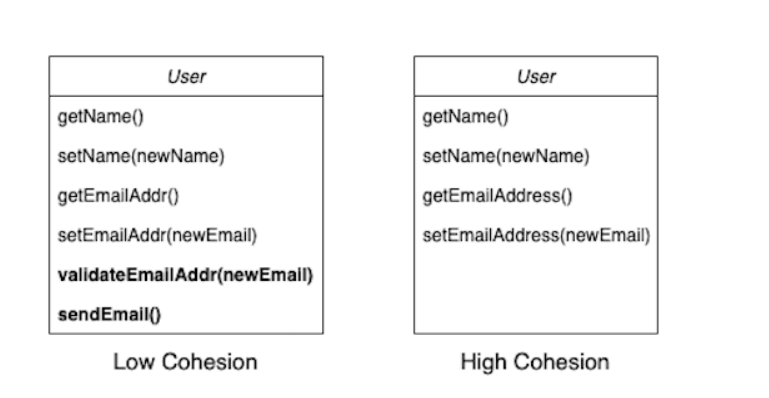
这应该属于其他类,比如电子邮件。
正如你所看到的,内聚的概念与单一责任原则(SRP,SOLID原则之一)密切相关,该原则规定一个类应该只有一个责任。SRP之后的模块可能具有高内聚性。
2.1高内聚性的优点
具有单一、定义明确的目的的模块易于理解,可读性更强。这些模块的名称清楚地表明了它们的目的,而这些模块正是这样做的。它有助于读者在不阅读模块中的每一行的情况下建立对模块正在做什么的直觉。此外,在阅读这些模块的代码时也不会感到意外。
例如,如果User类包含用于验证电子邮件地址的代码,读者会感到困惑。
由于所有相关的代码都在模块中,因此更改代码更容易。例如,如果开发人员必须对用户行为进行更改,他们可以跳到user类并在一个类中进行所有更改。这将限制影响范围。将此与用户行为分布在多个类中并且每个类都必须进行更改以实现所需更改的设计进行比较。
测试代码更容易。由于此类模块的目的不依赖于其他模块,因此它们很容易进行单元测试。此外,当更改仅限于单个模块时,构建和部署更改也很容易。
对此类模块的更改不太容易出现错误。跨模块进行更改时更容易出错。
最后,它们是可重复使用的。由于此类模块履行单一职责,因此往往会在有此类需求的地方使用。
总的来说,高度内聚的模块反映了更好的软件设计质量。因此,在模块中查找与主要目的没有直接关系的元素。将它们移到更符合目的的其他模块或创建一个新模块。
3.耦合
耦合是指软件模块之间的相互依赖程度。模块可以是一个类、一个包,甚至是一个微服务。实际上,耦合是关于改变一件事需要改变另一件事。
如果两个模块紧密连接,则具有高度耦合(或紧密耦合)。例如,两个具体的类存储对彼此的引用并调用彼此的方法。如下图所示,Customer和Order是紧密耦合在一起的。Customer存储客户下的所有订单的列表,而Order存储对Customer对象的引用。
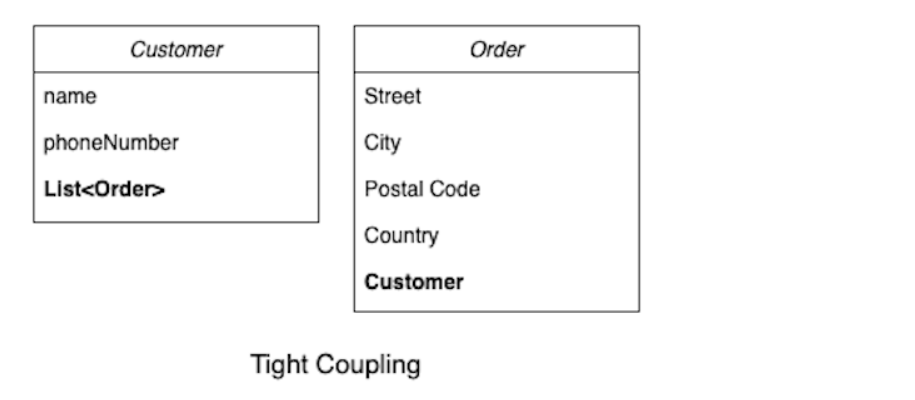
每次客户下新订单时,我们都需要将其添加到客户内部的订单列表中。这似乎是一种不必要的依赖。此外,Order只需要知道客户标识符,并且确实需要对customer对象的引用。通过进行以下更改,我们可以使这两个类松散耦合:
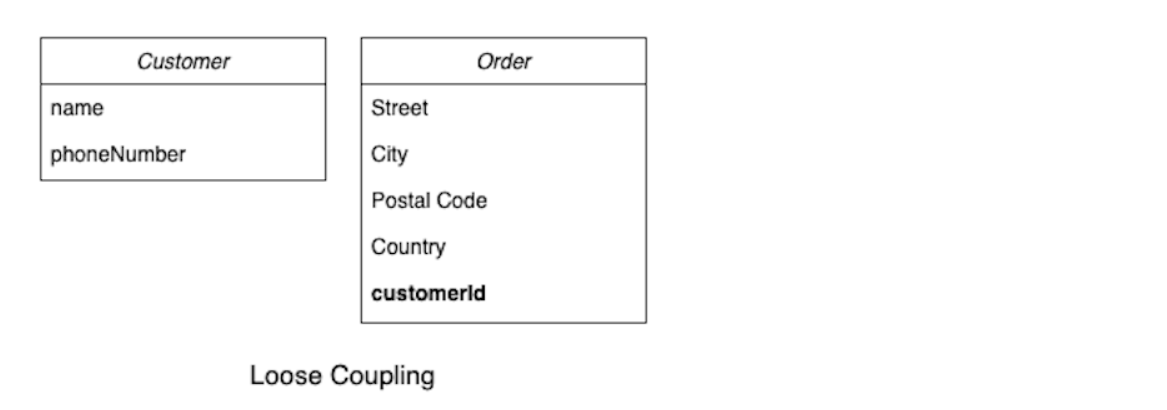
它们之间具有低耦合的模块大多彼此独立地工作。
3.1低耦合的优点
松散耦合的模块更易于开发和维护。由于它们相互独立,我们可以并行开发和测试它们。此外,它们可以在不相互影响的情况下进行修改和更新。我们可以独立构建和部署此类模块,大大缩短了部署时间。
紧密耦合的模块很难更换。开发人员需要了解多个模块以及它们之间的关系。他们需要谨慎地对所有模块进行一致的更改。这使得它更容易出错。此外,我们需要构建、测试和部署每个更改后的模块,从而进一步增加开发工作量。
紧密耦合的模块也很难测试。单元测试单个模块是困难的,因为它严重依赖于其他模块。必须花费大量精力来模拟对其他模块的调用,以便对模块进行独立的单元测试。
集成测试也很难设置。总的来说,测试是脆弱的,因为任何一个模块的变化都可能破坏测试。调试这样的模块也很复杂,因为它需要运行所有依赖的模块。
紧密耦合的模块不太可能被重用。这样的模块本身不执行任何有用的操作。因此,它很少适合其他人重复使用。此外,将其作为依赖项也很困难,因为它会带来其他依赖模块。
整体松耦合反映了软件设计的更高质量。因此,我们应该致力于设计尽可能独立的模块。
4.内聚与耦合
内聚和耦合是相互关联的。每一个都可以影响另一个的级别。
高内聚力与松散耦合相关。一个模块的元件彼此紧密相关,并用于单一目的,该模块将很少交互并依赖于其他模块。因此,将与其他模块松耦合。
类似地,紧密耦合可能是低内聚性的标志。由于元件分布在两个模块之间,模块之间可能存在严重的相互依赖关系。因此,将具有低内聚性。
以下是内聚和耦合之间的快速比较表:
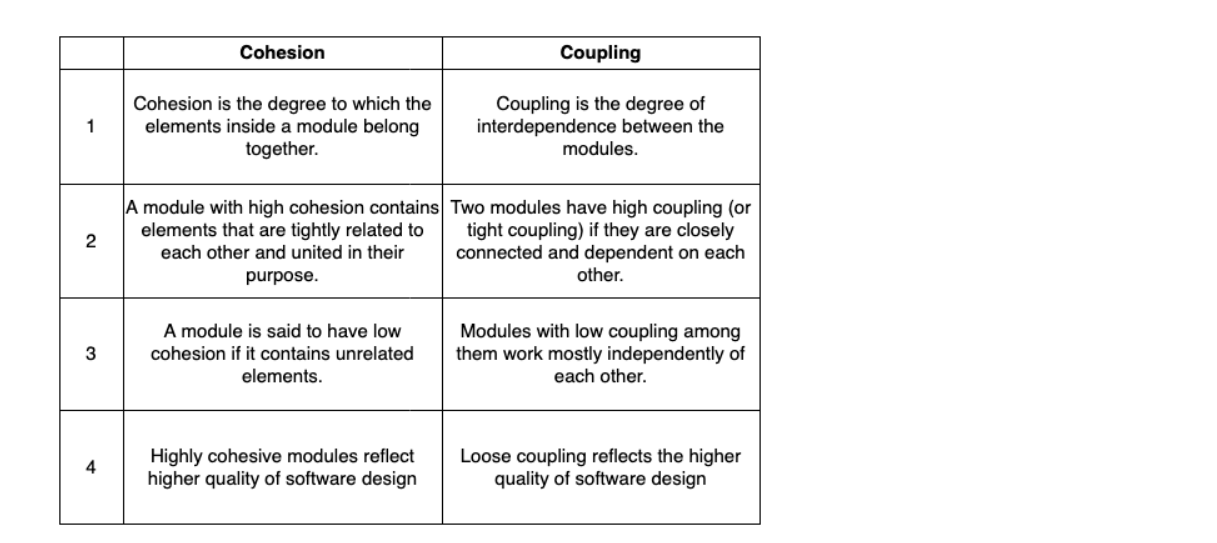
- 237 次浏览
【软件工程】软件工程|耦合与内聚
视频号
微信公众号
知识星球
简介:软件开发生命周期中设计阶段的目的是为SRS(软件需求规范)文档中给出的问题提供解决方案。设计阶段的输出是软件设计文档(SDD)。
耦合和内聚是软件工程中用来衡量软件系统设计质量的两个关键概念。
- 耦合是指软件模块之间的相互依赖程度。高耦合意味着模块紧密连接,一个模块中的变化可能会影响其他模块。低耦合意味着模块是独立的,一个模块中的变化对其他模块的影响很小。
- 内聚性是指模块中的元素协同工作以实现单一、明确定义的目的的程度。高内聚性意味着要素密切相关并专注于单一目的,而低内聚性则意味着要素松散相关并服务于多个目的。
- 耦合和内聚是决定软件系统可维护性、可扩展性和可靠性的重要因素。高耦合和低内聚性会使系统难以更改和测试,而低耦合和高内聚性则使系统更容易维护和改进。
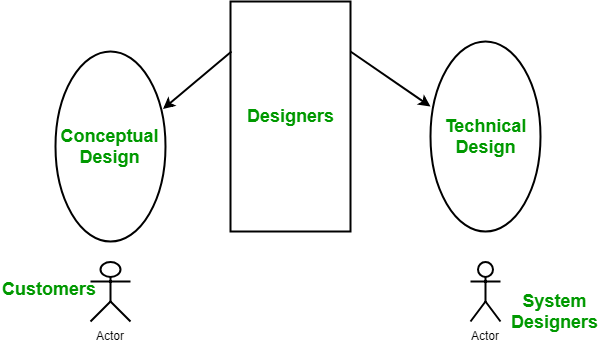
基本上,设计是一个由两部分组成的迭代过程。第一部分是概念设计,告诉客户系统将做什么。第二部分是技术设计,让系统建设者了解解决客户问题所需的实际硬件和软件。
耦合和高内聚
系统概念设计:
- 用简单的语言书写,即客户可以理解的语言。
- 关于系统特性的详细说明。
- 描述系统的功能。
- 它独立于实施。
- 与需求文档链接。
系统技术设计:
- 硬件组件和设计。
- 软件组件的功能和层次结构。
- 软件体系结构
- 网络架构
- 数据结构和数据流。
- 系统的I/O组件。
- 显示界面。
模块化:
模块化是将软件系统划分为多个独立模块的过程,每个模块独立工作。模块化在软件工程中有许多优点。其中一些如下所示:
- 易于理解系统。
- 系统维护很容易。
- 一个模块可以根据其需求多次使用。不需要一遍又一遍地写。
耦合:
耦合是衡量模块之间相互依存程度的指标。一个好的软件将具有低耦合。
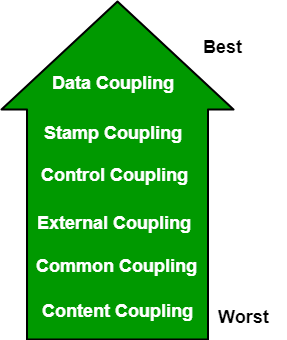
耦合类型:
- 数据耦合:如果模块之间的依赖关系是基于它们只通过传递数据进行通信的事实,那么这些模块就被认为是数据耦合的。在数据耦合中,组件相互独立,并通过数据进行通信。模块通信不包含不定期数据。客户计费系统示例。
- 印记耦合(Stamp Coupling)。在印记耦合中,完整的数据结构从一个模块传递到另一个模块。因此,它涉及不定期数据。由于效率因素,这可能是必要的——这个选择是由富有洞察力的设计师做出的,而不是懒惰的程序员。
- 控制耦合:如果模块通过传递控制信息进行通信,则称其为控制耦合。如果参数指示完全不同的行为,这可能是坏的,而如果参数允许功能的分解和重用,这是好的。示例-将比较函数作为参数的排序函数。
- 外部耦合:在外部耦合中,模块依赖于正在开发的软件或特定类型硬件外部的其他模块。Ex-协议、外部文件、设备格式等。
- 公共耦合:模块具有共享数据,如全局数据结构。全局数据的变化意味着要追溯到访问该数据的所有模块,以评估变化的影响。因此,它存在模块重用困难、数据访问控制能力降低、可维护性降低等缺点。
- 内容耦合:在内容耦合中,一个模块可以修改另一个模块的数据,或者控制流从一个模块传递到另一个。这是最糟糕的耦合形式,应该避免。
- 时间耦合:当两个模块取决于事件的时间或顺序时,就会发生时间耦合,例如一个模块需要在另一个模块之前执行。这种类型的耦合可能会导致设计问题以及测试和维护方面的困难。
- 顺序耦合:当一个模块的输出用作另一个模块输入时,会发生顺序耦合,从而创建依赖关系链或序列。这种类型的联轴器可能难以维护和修改。
- 通信耦合:当两个或多个模块共享一个公共通信机制(如共享消息队列或数据库)时,就会发生通信耦合。这种类型的耦合可能会导致性能问题和调试困难。
- 功能耦合:当两个模块依赖于彼此的功能时,就会发生功能耦合,例如一个模块从另一个模块调用函数。这种类型的耦合可能导致难以修改和维护的紧密耦合代码。
- 数据结构耦合:当两个或多个模块共享一个公共数据结构(如数据库表或数据文件)时,会发生数据结构耦合。这种类型的耦合可能导致难以维护数据结构的完整性,并可能导致性能问题。
内聚性:
内聚性是衡量模块元素在功能上相关程度的指标。它是指向执行单个任务的所有元素都包含在组件中的程度。基本上,内聚性是将模块保持在一起的内部粘合剂。一个好的软件设计将具有很高的内聚性。
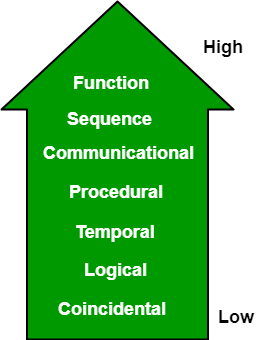
内聚类型:
- 函数内聚:单个计算的每个基本元素都包含在组件中。功能衔接执行任务和功能。这是一个理想的情况。
- 顺序衔接:一个元素输出一些数据,这些数据成为另一个元素的输入,即各部分之间的数据流。它自然地出现在函数式编程语言中。
- 通讯衔接:两个元素对相同的输入数据进行操作或对相同的输出数据做出贡献。示例-更新数据库中的记录并将其发送到打印机。
- 过程衔接:程序衔接的要素保证了执行的秩序。操作仍然是弱连接的,不太可能被重用。例如计算学生平均成绩,打印学生记录,计算累计平均成绩,印刷累计平均成绩。
- 时间衔接:这些元素因其所涉及的时间而相关。一个与时间衔接相连的模块,所有任务都必须在同一时间段内执行。这种衔接包含用于初始化系统所有部分的代码。在单位时间内会发生许多不同的活动。
- 逻辑衔接:这些元素在逻辑上是相关的,而不是功能性的。Ex-一个组件从磁带、磁盘和网络读取输入。这些函数的所有代码都在同一个组件中。操作是相关的,但功能明显不同。
- 巧合衔接:元素不相关(不相关)。除了源代码中的位置之外,这些元素没有其他概念关系。这是偶然的,也是最糟糕的凝聚力。Ex-打印下一行,并反转单个组件中字符串的字符。
- ----------------------------------
- 过程衔接:当元素或任务根据其执行顺序在模块中分组时,就会发生这种衔接,例如按特定顺序执行一组相关过程的模块。过程衔接可以在结构化编程语言中找到。
- 交际衔接:当元素或任务根据彼此之间的互动被分组到一个模块中时,就会发生交际衔接,例如处理与特定外部系统或模块的所有互动的模块。这种类型的内聚可以在面向对象的编程语言中找到。
- 时间衔接:当元素或任务根据执行的时间或频率在一个模块中分组时,就会发生时间衔接,例如处理系统中所有周期性或计划任务的模块。时间内聚通常用于实时和嵌入式系统。
- 信息衔接:当元素或任务根据它们与特定数据结构或对象的关系(例如对特定数据类型或对象进行操作的模块)在模块中分组时,就会发生信息衔接。信息内聚通常用于面向对象编程。
- 功能衔接:当一个模块中的所有元素或任务都为一个定义明确的功能或目的做出贡献,并且元素之间几乎没有耦合时,就会发生这种类型的衔接。函数内聚被认为是最理想的内聚类型,因为它可以产生更可维护和可重用的代码。
- 层内聚:当模块中的元素或任务根据其抽象级别或职责分组在一起时,就会发生层内聚,例如只处理低级硬件交互的模块或只处理高级业务逻辑的模块。层内聚通常用于大型软件系统,将代码组织成可管理的层。
低耦合的优点:
- 提高了可维护性:低耦合减少了一个模块中的更改对其他模块的影响,使修改或更换单个组件变得更容易,而不会影响整个系统。
- 增强的模块性:低耦合允许隔离开发和测试模块,提高了代码的模块性和可重用性。
- 更好的可扩展性:低耦合便于添加新模块和删除现有模块,从而更容易根据需要扩展系统。
高内聚力的优点:
- 提高了可读性和可理解性:高内聚性产生了具有单一、明确目的的清晰、集中的模块,使开发人员更容易理解代码并进行更改。
- 更好的错误隔离:高内聚性降低了模块某个部分的更改影响其他部分的可能性,使
- 隔离并修复错误。提高了可靠性:高内聚性导致模块不太容易出错,并且功能更一致,
- 从而导致系统的可靠性的整体提高。
高耦合的缺点:
- 复杂性增加:高度耦合增加了模块之间的相互依赖性,使系统更加复杂和难以理解。
- 灵活性降低:高度耦合使得在不影响整个系统的情况下修改或更换单个组件变得更加困难。
- 模块性降低:高耦合性使得隔离开发和测试模块变得更加困难,降低了代码的模块性和可重用性。
内聚力低的缺点:
- 代码重复增加:内聚性低可能导致代码重复,因为属于一起的元素被拆分为单独的模块。
- 功能减少:低内聚性可能导致模块缺乏明确的目的,并且包含不属于一起的元素,从而减少其功能并使其更难维护。
- 理解模块的困难:低内聚性会使开发人员更难理解模块的目的和行为,从而导致错误和缺乏清晰度。
- 319 次浏览
【软件架构】5分钟看懂软件架构模式
当有人潜入软件工程世界时,有一天他需要学习软件架构模式的基础知识。当我刚接触编码时,我不知道从哪里获得简要介绍现有架构模式的资源,这样它就不会太详细和混乱,而是非常抽象和易于理解。
在我找到 Mark Richards 的一本书 Software Architecture Patterns 之前,这一直是个问题。在这里,我想与大家分享本书的一些最重要的部分和架构模式。 (有关更多信息,我强烈建议您阅读这本书或他的报告)。
作为软件工程师,为什么至少要学习基本的架构模式?
我相信有很多文章回答了这个问题,但我会给你一些考虑的理由。首先,如果您了解架构模式的基础知识,那么您就更容易遵循架构师的要求。其次,了解这些模式将帮助您在代码中做出决策:例如,如果您的应用程序设计基于事件驱动的微服务,那么作为软件工程师,您必须将您的代码解耦到一个单独的服务中,如果您注意到日益增加的复杂性和现有服务中的逻辑责任。 (如果您没有得到这部分内容,请按照文本进行操作,此处简要说明了此模式)。
Mark Richards 在书中描述了 5 种模式:
- 分层架构
- 事件驱动架构
- 微内核架构(或插件架构)
- 微服务架构
- 基于空间的架构(或云架构模式)
1.分层架构
它是单体应用程序最常见的架构。 该模式背后的基本思想是将应用程序逻辑划分为若干层,每一层都封装了特定的角色。 例如,持久层将负责您的应用程序与数据库引擎的通信。
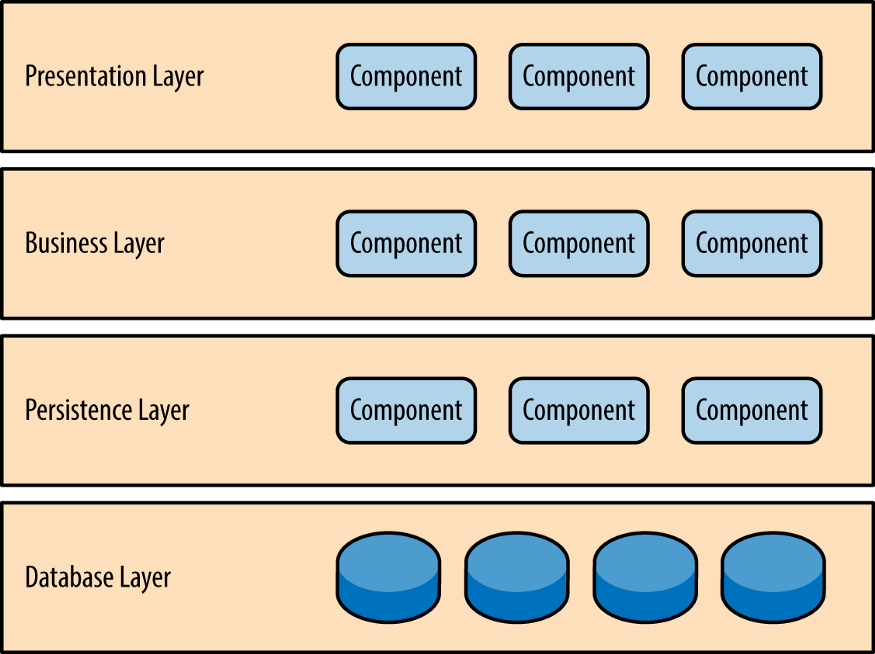
2. 事件驱动架构
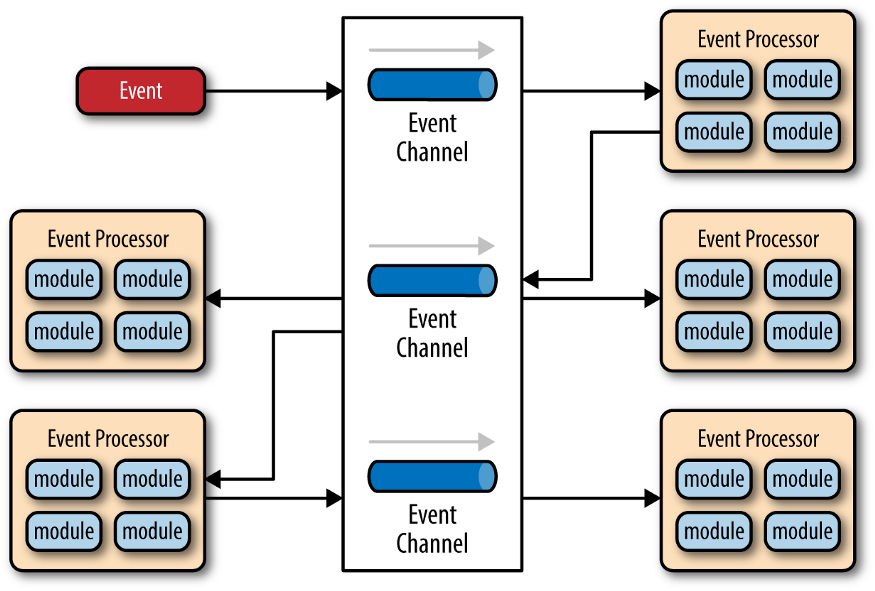
这种模式背后的想法是将应用程序逻辑解耦为异步接收和处理事件的单一用途事件处理组件。 这种模式是流行的分布式异步架构模式之一,以高可扩展性和适应性着称。
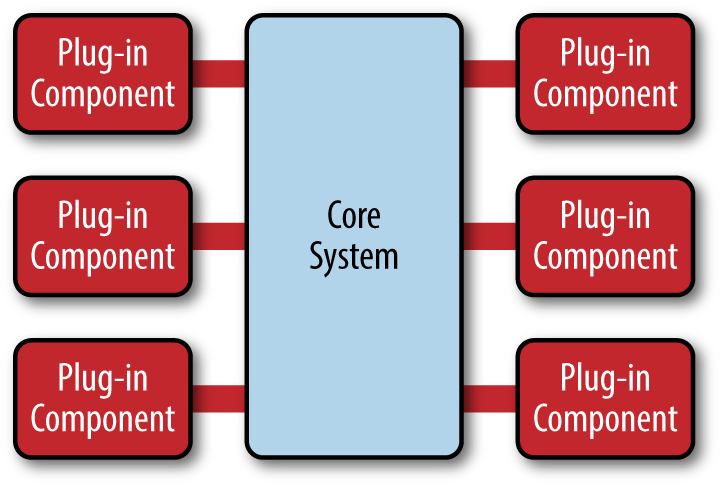
3. 微内核架构
Mikrokernel 架构,也称为插件架构,是具有两个主要组件的设计模式:核心系统和插件模块(或扩展)。 一个很好的例子是 Web 浏览器(核心系统),您可以在其中安装无穷无尽的扩展(或插件)。
4. 微服务架构
微服务架构由单独部署的服务组成,理想情况下,每个服务都有单一的职责。 这些服务相互独立,如果一项服务失败,其他服务将不会停止运行。

5. 基于空间的架构
基于空间的模式背后的主要思想是分布式共享内存,以缓解在数据库级别经常发生的问题。 假设通过使用内存数据处理大多数操作,我们可以避免在数据库中进行额外操作,因此可能会从那里演变出任何未来的问题(例如,如果您的用户活动数据实体已更改,您不需要 更改一堆持久化的代码并从数据库中检索该数据)。
基本方法是将应用程序分成处理单元(可以根据需要自动扩展和缩减),其中数据将在这些单元之间复制和处理,而不需要对中央数据库进行任何持久性(尽管会有本地存储用于 系统故障的场合)。

您可以在我的 GitHub 帐户中找到其中一些架构模式的最简单示例。 这里的链接:
如果您想快速了解如何扩展应用程序的基础知识,请阅读我的下一篇文章如何扩展您的应用程序:5 分钟阅读,然后是文章缓存作为软件架构的一部分:5 分钟阅读,更接近 通过缓存查看性能调整。
原文:https://orkhanscience.medium.com/software-architecture-patterns-5-mins-…
- 120 次浏览
【软件架构】9大软件架构工具
视频号
微信公众号
知识星球
⚡ Tl;dr
- 软件体系结构工具可以分为三组,建模工具、作为代码的图表和图表工具。
- 建模和图表作为代码工具更适合长期文档,而图表工具更适合快速的一次性草图。
- 作为代码的建模和图表有更多的结构,需要更多的设置,而图表工具更通用,但需要更少的思考
🚀 我们开始吧
图解软件体系结构为我们如何沟通复杂性提供了几个好处。经过深思熟虑的图表使工程团队能够更好地理解设计和未来开发计划,同时识别潜在问题。
下面是一些我们发现适合软件体系结构的特定类别的建模和绘图工具的例子。
📦 可视化建模工具
建模最适合长期的系统设计文档,并且需要一些设置工作。可重用的对象和关系存储在模型中,使所有关系图保持最新。
1️⃣ IcePanel
是一个基于web的图形SaaS工具,用于使用C4模型对软件架构进行协作建模。
免费和付费。
最适合寻找轻量级协作工具来建模和记录其软件体系结构的敏捷开发团队。
它包括以下功能:
- 可放大到不断增加的技术细节级别的交互式图表。
- 在绘制图表的同时创建模型的敏捷建模。
- 通过将其他元数据覆盖到现有图表上来查看不同的透视图。
- 用于将消息序列叠加到现有图表上并进行通信的流程。
- 将对象链接到现实中的资源,如源代码管理或云资源,并在图表偏离现实时收到通知。
2️⃣ Enterprise Architect
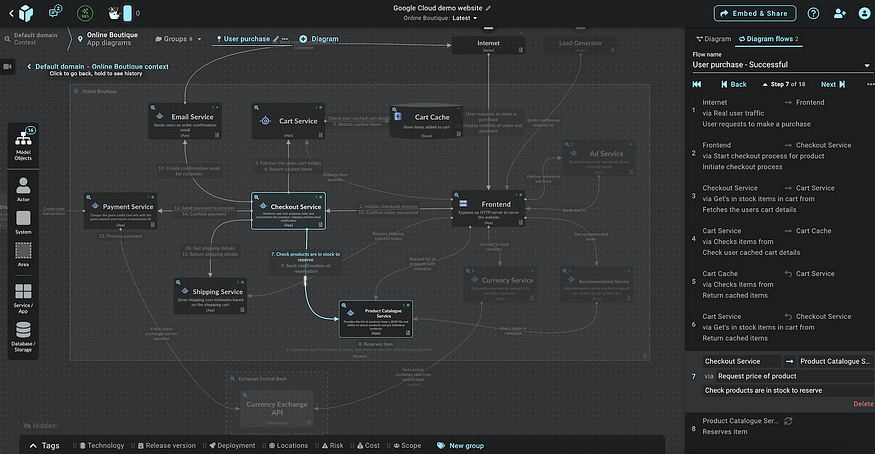
Enterprise architect by Sparx Systems是一款用于业务、IT和软件系统建模的图形桌面应用程序。
支付。
最适合需要为各种行业标准创建模型的大型企业。
它包括以下功能:
- 分析、设计、实施、测试和维护模型。
- UML、SysML和BPMN标准。
- 高性能,可在几秒钟内加载超大型号。
- 动态模型模拟是用Javascript编写的。
- 许多流行语言的源代码往返,包括C、C++、Java、PHP、Python和Visual Basic。
- 从需求、分析和设计模型到实施和部署的完整可追溯性。
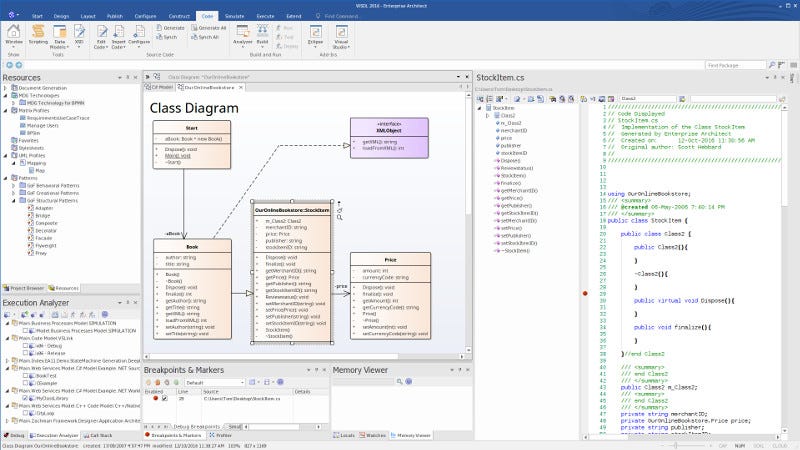
3️⃣ Archi
是一个用于建模的图形桌面应用程序,用于创建ArchiMate模型和草图。
免费开源。
最适合那些希望使用ArchiMate语言创建模型而不需要在昂贵的工具上花费预算的个人。
它包括以下功能:
- ArchiMate 3.1语言的最新版本。
- 创建ArchiMate元素、关系、视图和视点。
- 提示视图可帮助您理解ArchiMate语言。
- 用于显示关系、草图视图和画布建模的可视化工具。
🧑💻 Diagrams as code tools
图作为代码包括使用标记语言编写模型对象、关系和图,标记语言可以检查到源代码管理中。这些功能通常包括自动布局功能。
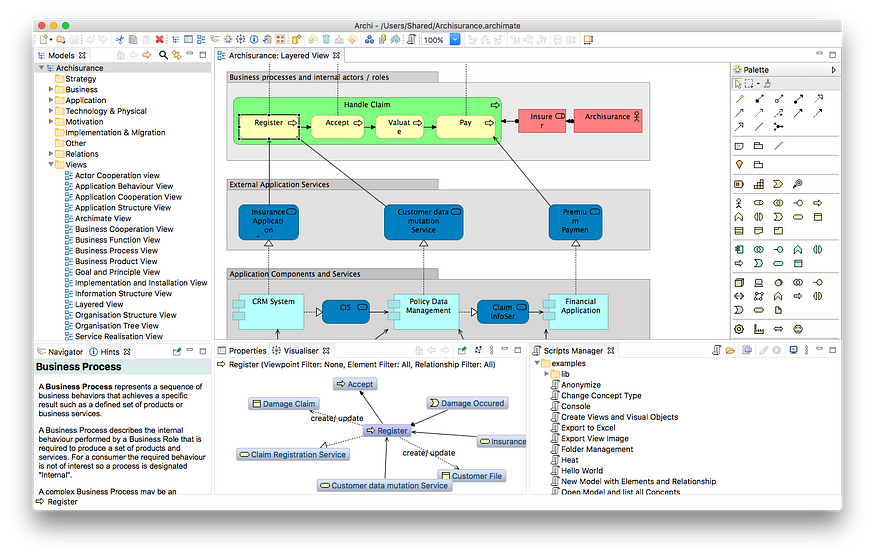
1️⃣ Structurizr
构建在“图即代码”的基础上,允许您使用多种工具和编程语言从单个模型创建多个图。
免费和付费。
最适合那些希望将C4模型与DSL一起使用并将其检查到源代码管理中的技术人员。
它包括以下功能:
- 将图表作为代码,使用StructurezrDSL绘制图表
- 存储在工程团队所在的源代码管理中
- 设计用于支持C4型号
- 文档工具中的体系结构决策记录
2️⃣ PlantUML
是一个允许您编写序列图、对象图、组件图、用例图、类图等图表的工具。
自由的
最适合那些希望灵活地创建许多不同的图表类型并将其检查到源代码管理中的技术人员。
它包括以下功能:
- 图表是使用简单直观的文本语言定义的。
- C4插件
- 序列图
- 用例图
- 类图
- 对象关系图
- 活动图(此处为传统语法)
- 组件示意图
- 部署示意图
3️⃣ Ilograph
允许使用带有自动布局的YAML绘制交互式图表,当您想要查看不同的透视图时可以更改视图。
免费和付费。
最适合那些想要基于web的解决方案来可视化以代码形式编写的图表的半技术人员。
它包括以下功能:
- 并排代码编辑
- 图表对象的自动布局
- 动态布局,根据透视图更改图表
- 在图中显示用例的图序列
🖼️ Diagramming tools
图表最适合在对话和想法实验中快速绘制草图。它们很容易制作,但经常被扔掉,很难跟上时代。
1️⃣ Diagrams.net
是一个流行的免费绘图工具,具有很高的灵活性,可以绘制从流程图到房屋蓝图的任何内容;具有将数据存储在您选择的位置的选项。
自由的
最适合需要灵活性的快速图表,并且技术人员和非技术人员可以轻松访问。
它包括以下功能:
- 扩展形状库
- 正在建立模板
- 完全灵活的绘图
- 可定制的存储和集成
2️⃣ Lucidchart
是一个具有模板和形状类型的协作绘图工具,用于创建许多图表类型,如流程图、流程图、思维导图等。
免费和付费。
最适合在快速灵活的图表上进行协作的团队。
它包括以下功能:
- 与您的团队进行实时协作
- 连接到数据
- 与堆栈中的其他工具集成
- 帮助指导您的模板
- 一个学习校园,学习你可以在工具中做什么
3️⃣ Miro
是一个协作白板工具,带有模板和基于团队的工具,有助于促进研讨会。
免费和付费。
最适合在图表上进行协作并为研讨会提供便利的团队。
它包括以下功能:
- 在交互式白板上进行实时编辑
- 鼠标悬停在协作上,查看谁在查看您的图表
- 计时器和投票等研讨会便利工具
- 社区制作模板
🏁
结束
有很多软件体系结构工具可供选择,首先要考虑创建体系结构可视化的原因,这一点很重要。如果只是简单地可视化一个潜在解决方案的想法,我们建议使用一些快速的工具,比如绘图工具,但预计从长远来看不会那么有用。
如果你想创建一个别人会在很长一段时间内参考的工件,我们建议你使用建模工具。从长远来看,建模工具更有益的原因是,你可以通过简单地更新模型来推动所有图表的更改,而使用绘图工具,你必须查找该对象的每个实例,以保持设计的同步。
保持冷静🧊
- 859 次浏览
【软件架构】DDD,六边形,洋葱的,干净的,CQRS,我怎么把它们放在一起的
这篇文章是软件架构编年史的一部分,一系列关于软件架构的文章。在这些文章中,我写了我对软件架构的了解,我如何看待它,以及我如何使用这些知识。如果您阅读了本系列以前的文章,那么本文的内容可能更有意义。
大学毕业后,我从事了高中教师的职业,直到几年前,我决定放弃它,成为一名全职软件开发人员。
从那以后,我总是觉得我需要找回失去的时间,尽可能多地、尽可能快地学习。因此,我有点沉迷于试验、阅读和写作,特别关注软件设计和体系结构。这就是我写这些帖子的原因,来帮助我学习。
在我的上一篇文章中,我写了很多我学过的概念和原则,以及我是如何推理的。但我认为这些只是拼图的一部分。
今天的帖子是关于我如何将所有这些部分组合在一起的,我似乎应该给它起个名字,我称它为显式架构(Explicit Architecture)。此外,这些概念都“通过了它们的考验”,并被用于高要求平台上的生产代码中。一个是SaaS的e-com平台,在全球拥有数千个网络商店,另一个是市场,在两个国家都有一个消息总线,每个月处理超过2000万条消息。
- 系统的基本模块
- 工具
- 将工具和交付机制连接到应用程序核心
- 端口
- 主适配器或驱动适配器
- 辅助或被驱动适配器
- 控制反转
- 应用程序的核心组织
- 应用程序层
- 领域层
- 域服务
- 域模型
- 组件
- 解耦的组件
- 触发逻辑在其他组件
- 从其他组件获取数据
- 组件之间共享的数据存储
- 每个组件隔离数据存储
- 控制流
系统的基本模块
我首先回顾一下EBI和端口及适配器架构。它们都明确区分了哪些代码是应用程序内部的,哪些是外部的,以及哪些用于连接内部和外部代码。
此外,端口和适配器体系结构明确标识了系统中的三个基本代码块:
- 是什么使得运行一个用户界面成为可能,不管它是什么类型的用户界面;
- 系统业务逻辑,或应用程序核心,由用户界面使用,以实际使事情发生;
- 基础构架代码,它将我们的应用核心与数据库、搜索引擎或第三方api等工具连接起来。

应用程序核心是我们真正应该关心的。是代码允许我们的代码做它应该做的事情,是我们的应用程序。它可能使用多个用户界面(渐进式web应用程序、移动应用程序、CLI、API等),但是实际执行工作的代码是相同的,并且位于应用程序内核中,不管什么UI触发它,都应该是一样的。
可以想象,典型的应用程序流从用户界面中的代码开始,通过应用程序核心到基础设施代码,然后返回到应用程序核心,最后向用户界面交付响应。

工具
远离系统中最重要的代码(应用程序核心),我们拥有应用程序使用的工具,例如数据库引擎、搜索引擎、Web服务器或CLI控制台(尽管后两个也是交付机制)。
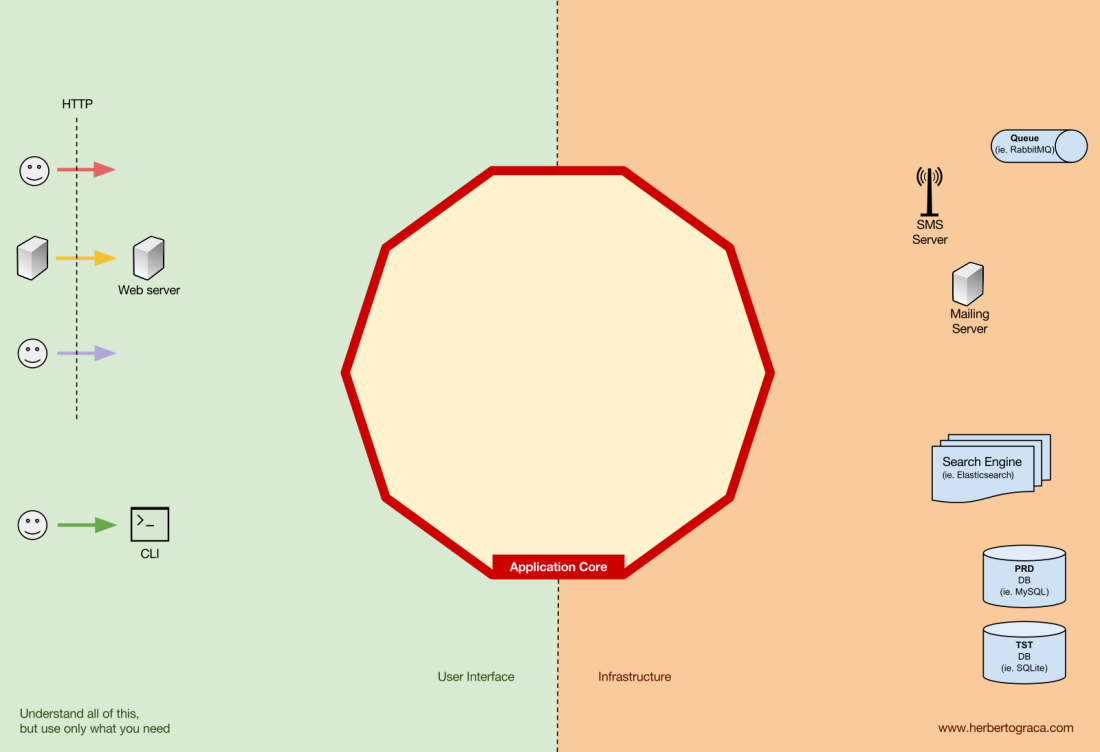
虽然将CLI控制台与数据库引擎放在同一个“bucket”中可能感觉有些奇怪,尽管它们有不同类型的用途,但它们实际上是应用程序使用的工具。关键的区别在于,虽然CLI控制台和web服务器用于告诉应用程序执行某些操作,但是数据库引擎是由应用程序执行某些操作的。这是一个非常相关的区别,因为它对我们如何构建将这些工具与应用程序核心连接起来的代码有很强的影响。
将工具和传送机制连接到应用程序核心
将工具连接到应用程序核心的代码单元称为适配器(端口和适配器体系结构)。适配器是那些有效地实现代码的适配器,这些代码将允许业务逻辑与特定的工具通信,反之亦然。
告诉我们的应用程序做某事的适配器称为主适配器或驱动适配器,而由我们的应用程序告诉我们做某事的适配器称为辅助适配器或驱动适配器。
端口
然而,这些适配器不是随机创建的。创建它们是为了将特定的入口点安装到应用程序核心(一个端口)。端口只不过是工具如何使用应用程序内核或应用程序内核如何使用它的规范。在大多数语言及其最简单的形式中,这个规范,即端口,将是一个接口,但它实际上可能由几个接口和dto组成。
需要注意的是,端口(接口)属于业务逻辑内部,而适配器属于业务逻辑外部。要使此模式正常工作,最重要的是创建适合应用程序核心需求的端口,而不是简单地模仿工具api。
主适配器或驱动适配器
主适配器或驱动适配器围绕一个端口,并使用它来告诉应用程序核心要做什么。它们将来自交付机制的任何东西转换为应用程序核心中的方法调用。

换句话说,我们的驱动适配器是控制器或控制台命令,它们在构造函数中注入一些对象,这些对象的类实现控制器或控制台命令所需的接口(端口)。
在更具体的示例中,端口可以是控制器所需的服务接口或存储库接口。然后将服务、存储库或查询的具体实现注入并在控制器中使用。
或者,端口可以是命令总线或查询总线接口。在这种情况下,将命令或查询总线的具体实现注入控制器,然后控制器构造命令或查询并将其传递给相关总线。
辅助或被驱动适配器
与围绕端口的被驱动适配器不同,驱动适配器实现一个端口和一个接口,然后将其注入到应用程序核心中,无论哪里需要端口(类型暗示)。

例如,假设我们有一个需要持久化数据的简单应用程序。所以我们创建一个持久性接口,满足其需要,用一个方法来保存数组的数据和方法来删除表中的一行的ID。从那时起,无论应用程序需要保存或删除数据,我们需要在其构造函数实现持久化的对象我们定义的接口。
现在我们创建一个特定于MySQL的适配器来实现这个接口。它将具有保存数组和删除表中的一行的方法,并且我们将在需要持久性接口的地方注入它。
如果在某个时候我们决定改变数据库供应商,比如PostgreSQL或MongoDB,我们只需要创建一个新的适配器来实现PostgreSQL特定的持久化接口,并注入新的适配器而不是旧的。
控制反转
关于此模式需要注意的一个特征是,适配器依赖于特定的工具和特定的端口(通过实现接口)。但是我们的业务逻辑只依赖于端口(接口),它被设计成适合业务逻辑需求,所以它不依赖于特定的适配器或工具。
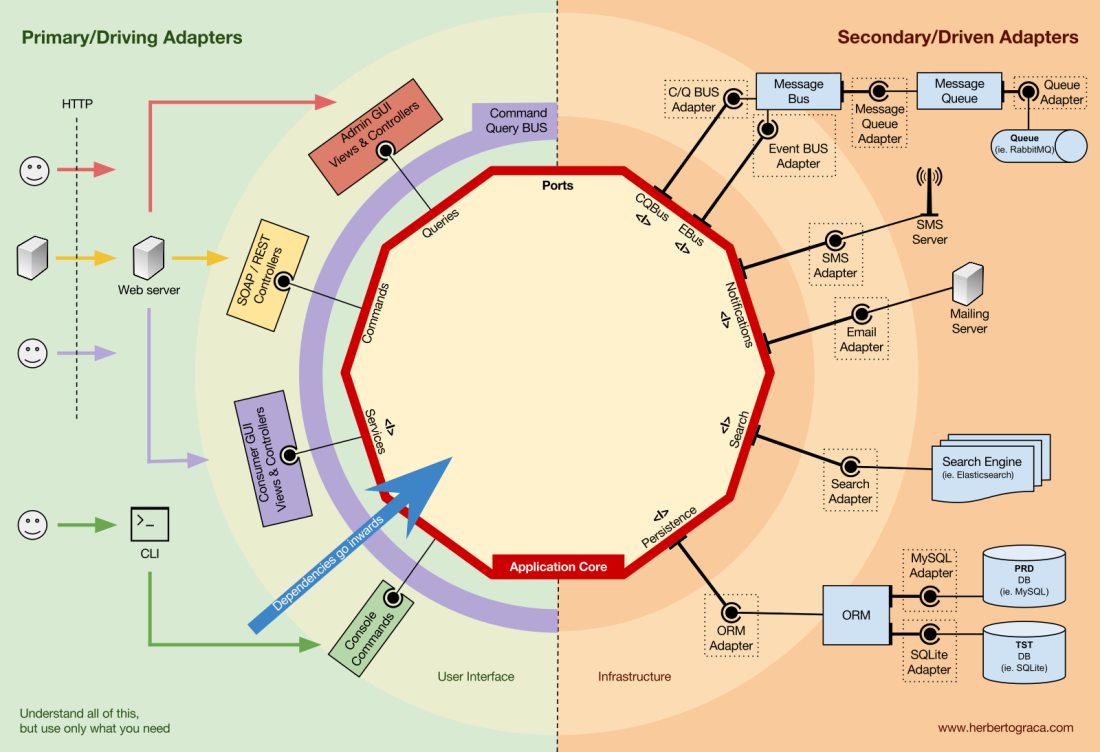
这意味着依赖的方向是朝向中心的,这是建筑层面的控制原则的倒置。
尽管如此,创建端口是为了满足应用程序的核心需求,而不是简单地模仿工具api,这一点非常重要。
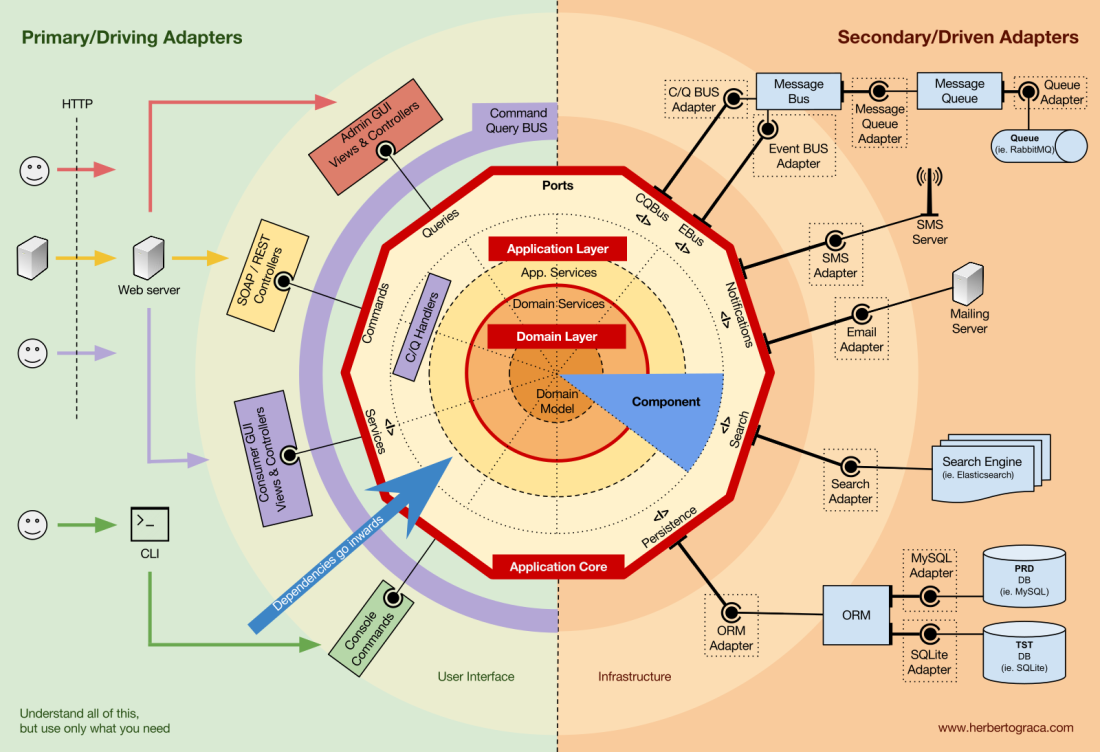
应用程序的核心组织
Onion架构采用DDD层,并将它们合并到端口和适配器架构中。这些层旨在为业务逻辑、端口和适配器的内部“六边形”带来一些组织,就像端口和适配器一样,依赖关系的方向是向中心的。
应用程序层
用例是可以由应用程序中的一个或多个用户接口在应用程序核心中触发的流程。例如,在CMS中,我们可以有普通用户使用的实际应用程序UI、CMS管理员使用的另一个独立UI、另一个CLI UI和web API。这些ui(应用程序)可以触发特定于其中一个或由其中几个重用的用例。
用例在应用层中定义,这是DDD提供的第一层,由Onion Architecture使用。

这一层包含作为第一类公民的应用程序服务(及其接口),但它也包含端口和适配器接口(端口),其中包括ORM接口、搜索引擎接口、消息传递接口等等。在我们使用命令总线和/或查询总线的情况下,这一层是命令和查询各自的处理程序所在的地方。
应用程序服务和/或命令处理程序包含展开用例(业务流程)的逻辑。一般来说,他们的职责是:
- 使用存储库查找一个或多个实体;
- 告诉那些实体去做一些域逻辑;
- 并使用存储库再次持久化实体,有效地保存数据更改。
命令处理程序可以用两种不同的方式使用:
- 它们可以包含执行用例的实际逻辑;
- 它们可以在我们的体系结构中用作简单的连接块,接收命令并简单地触发存在于应用程序服务中的逻辑。
使用哪种方法取决于上下文,例如:
我们是否已经准备好了应用程序服务并正在添加命令总线?
命令总线是否允许指定任何类/方法作为处理程序,或者它们是否需要扩展或实现现有的类或接口?
这一层还包含应用程序事件的触发,这些事件表示用例的一些结果。这些事件触发的逻辑是用例的副作用,比如发送电子邮件、通知第三方API、发送推送通知,甚至启动属于应用程序不同组件的另一个用例。
领域层
再往里,我们有域层。这个层中的对象包含数据和操作数据的逻辑,这是特定于域本身的,它独立于触发逻辑的业务流程,它们是独立的,完全不知道应用层。

域服务
如前所述,应用服务的作用是:
- 使用存储库查找一个或多个实体;
- 告诉那些实体去做一些域逻辑;
- 并使用存储库再次持久化实体,有效地保存数据更改。
然而,有时我们会遇到一些涉及不同实体的域逻辑,不管它们是否属于同一类型,我们觉得域逻辑不属于实体本身,我们觉得那个逻辑不是它们的直接责任。
因此,我们的第一反应可能是将逻辑放在实体之外的应用程序服务中。然而,这意味着该域逻辑将不能在其他用例中重用:域逻辑应该远离应用程序层!
解决方案是创建一个域服务,它的角色是接收一组实体并在其上执行一些业务逻辑。域服务属于域层,因此它对应用层中的类一无所知,比如应用程序服务或存储库。另一方面,它可以使用其他域服务,当然还有域模型对象。
域模型
在最中心的是域模型,它不依赖于它之外的任何东西,它包含表示域内某些内容的业务对象。这些对象的示例首先是实体,但也包括值对象、枚举和域模型中使用的任何对象。
域模型也是域事件“活动”的地方。当特定的一组数据发生更改时,将触发这些事件,并将这些更改随身携带。换句话说,当一个实体发生更改时,将触发一个域事件,它将携带更改后的属性新值。例如,这些事件非常适合用于事件源。
组件
到目前为止,我们一直在基于层隔离代码,但这是细粒度的代码隔离。粗粒度的代码隔离至少是同样重要的,它是根据子域和有界上下文来隔离代码的,遵循Robert C. Martin在尖叫声架构中表达的思想。这通常被称为“按功能包”或“按组件包”,而不是“按层包”,Simon Brown在他的博客“按组件包和体系结构对齐测试”中对此做了很好的解释:
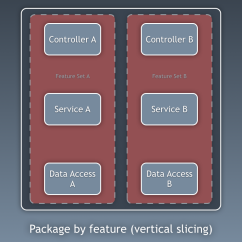
我是“按组件打包”方法的倡导者,并且根据Simon Brown关于按组件打包的图表,我将无耻地将其更改为以下内容:
这些代码部分与前面描述的层是交叉的,它们是我们的应用程序的组件。组件的示例可以是身份验证、授权、计费、用户、审查或帐户,但它们始终与域相关。像授权和/或身份验证这样的有界上下文应该被视为外部工具,我们为其创建适配器并隐藏在某种端口之后。
解耦的组件
就像细粒度的代码单元(类、接口、特征、混合等)一样,粗粒度的代码单元(组件)也受益于低耦合和高内聚。
为了解耦类,我们使用依赖注入,将依赖注入到类中而不是在类中实例化,依赖倒置,使类依赖于抽象(接口和/或抽象类)而不是具体类。这意味着子类不知道它将要使用的具体类,它没有引用它所依赖的类的完全限定类名。
同样,完全解耦的组件意味着一个组件不直接知道任何其他组件。换句话说,它没有引用来自另一个组件的任何细粒度代码单元,甚至没有接口!这意味着依赖注入和依赖倒置不足以解耦组件,我们需要某种架构结构。我们可能需要事件、共享内核、最终一致性,甚至发现服务!
在其他组件触发逻辑
当我们的一个组件(组件B)需要在另一个组件(组件A)中发生其他事情时执行某个操作时,我们不能简单地从组件A直接调用组件B中的类/方法,因为这样A就会被耦合到B。
然而,我们可以使用事件分派器来分派一个应用程序事件,该应用程序事件将被交付给监听它的任何组件,包括B,而B中的事件侦听器将触发所需的操作。这意味着组件A将依赖于事件分配器,但它将与B解耦。
然而,如果事件本身“存在”于A中,这意味着B知道A的存在,它与A是耦合的。这意味着组件都依赖于共享内核,但是它们之间是解耦的。共享内核将包含应用程序和域事件之类的功能,但它也可以包含规范对象,以及任何需要共享的内容,请记住,共享内核的任何更改都将影响到应用程序的所有组件,因此共享内核应该尽可能少。此外,如果我们有一个多语言系统,假设是一个微服务生态系统,其中它们是用不同的语言编写的,那么共享内核需要是语言无关的,以便所有组件都可以理解它,无论它们是用什么语言编写的。例如,它将包含事件描述,而不是包含事件类的共享内核。名称、属性、甚至方法(尽管这些在JSON之类的不可知语言中可能更有用),这样所有组件/微服务都可以解释它,甚至自动生成它们自己的具体实现。请在我的后续文章中阅读更多相关内容:不仅仅是同心圆层。

这种方法既适用于单片应用程序,也适用于像微服务生态系统这样的分布式应用程序。然而,当事件只能异步交付时,对于需要立即在其他组件中执行触发逻辑的上下文,这种方法是不够的!组件将需要一个直接的HTTP调用组件b。在这种情况下,解耦的组件,我们需要发现服务,将要求它应该发送请求来启动所需的行动,或者使请求发现服务代理的相关服务,最终将响应返回给请求者。此方法将把组件耦合到发现服务,但将使它们彼此解耦。
从其他组件获取数据
在我看来,一个组件不允许改变它不“拥有”的数据,但是它可以查询和使用任何数据。
组件之间共享的数据存储
当一个组件需要使用属于另一个组件的数据时,假设一个账单组件需要使用属于accounts组件的客户端名称,账单组件将包含一个查询对象,该对象将查询该数据的数据存储。这仅仅意味着账单组件可以知道任何数据集,但是它必须通过查询的方式将不“拥有”的数据作为只读数据使用。
每个组件隔离数据存储
在本例中,应用了相同的模式,但是我们在数据存储级别上更加复杂。组件拥有自己的数据存储意味着每个数据存储包含:
- 它拥有的一组数据,并且是唯一允许更改的数据,使其成为唯一的真理来源;
- 一组数据是其他组件数据的副本,它不能自己更改这些数据,但是组件功能需要它,并且需要在所有者组件中发生更改时对其进行更新。
每个组件将从其他组件创建所需数据的本地副本,以便在需要时使用。当拥有该组件的组件中的数据发生更改时,该所有者组件将触发承载数据更改的域事件。持有该数据副本的组件将侦听该域事件,并相应地更新其本地副本。
控制流
正如我上面所说的,控制流当然是从用户到应用程序核心,再到基础设施工具,最后回到应用程序核心,最后回到用户。但是类到底是如何组合在一起的呢?哪些取决于哪些?我们如何组合它们?
在Bob叔叔关于干净架构的文章中,我将尝试用UMLish图来解释控制流……
没有命令/查询总线
在我们不使用命令总线的情况下,控制器将依赖于应用程序服务或查询对象。
[编辑- 2017-11-18]我完全错过了我用来从查询返回数据的DTO,所以我现在添加了它。感谢MorphineAdministered公司为我指出了这一点。
在上面的图中我们使用应用程序的接口服务,尽管我们可能认为这不是真正需要从应用程序服务是我们应用程序代码的一部分,我们不会想交换另一个实现,尽管我们可能完全重构它。
查询对象将包含一个优化的查询,该查询将简单地返回一些原始数据以显示给用户。该数据将以DTO的形式返回,并注入到ViewModel中。这个视图模型可能有一些视图逻辑,它将被用来填充一个视图。
另一方面,应用程序服务将包含用例逻辑,当我们希望在系统中执行某些操作时,而不是简单地查看某些数据时,将触发该逻辑。应用程序服务依赖于存储库,存储库将返回包含需要触发的逻辑的实体。它还可能依赖于域服务来协调多个实体中的域流程,但情况并非如此。
在展开用例之后,应用程序服务可能希望通知整个系统该用例已经发生,在这种情况下,它还将依赖于事件分派器来触发事件。
值得注意的是,我们在持久性引擎和存储库上都放置了接口。虽然看起来有些多余,但它们有不同的用途:
- 持久性接口是ORM上的一个抽象层,因此我们可以交换正在使用的ORM,而不需要更改应用程序的核心。
- repository接口是对持久性引擎本身的抽象。假设我们想从MySQL切换到MongoDB。持久性接口可以是相同的,如果我们想继续使用相同的ORM,那么即使是持久性适配器也可以保持不变。但是,查询语言是完全不同的,所以我们可以创建使用相同持久性机制的新存储库,实现相同的存储库接口,但是使用MongoDB查询语言而不是SQL构建查询。
使用命令/查询总线
在我们的应用程序使用命令/查询总线的情况下,除了控制器现在依赖于总线和命令或查询外,关系图几乎保持不变。它将实例化命令或查询,并将其传递给总线,总线将找到适当的处理程序来接收和处理命令。
在下面的关系图中,命令处理程序然后使用应用程序服务。然而,这并不总是需要的,事实上在大多数情况下,处理程序将包含用例的所有逻辑。如果需要在另一个处理程序中重用相同的逻辑,则只需要将逻辑从处理程序提取到单独的应用程序服务中。
[编辑- 2017-11-18]我完全错过了我用来从查询返回数据的DTO,所以我现在添加了它。感谢MorphineAdministered公司为我指出了这一点。
您可能已经注意到,总线与命令、查询和处理程序之间没有依赖关系。这是因为,为了提供良好的解耦,它们实际上应该彼此不了解。总线知道什么处理程序应该处理什么命令或查询的方式应该通过简单的配置来设置。
如您所见,在这两种情况下,跨越应用程序核心边界的所有箭头和依赖项都指向内部。如前所述,这是端口和适配器体系结构、Onion体系结构和Clean体系结构的基本规则。
结论
一如既往,我们的目标是拥有一个松散耦合和高内聚的代码库,这样修改起来就容易、快速和安全。
计划是没有价值的,但计划就是一切。
艾森豪威尔
这个信息图是一个概念图。了解和理解所有这些概念将帮助我们规划一个健康的架构,一个健康的应用程序。
然而:
地图不是领土。
阿尔弗雷德Korzybski
这意味着这些只是指导方针!应用程序是我们需要应用知识的领域、现实和具体用例,这就是定义实际体系结构的内容!
我们需要理解所有这些模式,但是为了解耦和内聚,我们还需要思考并准确地理解我们的应用程序需要什么,我们应该走多远。这个决策可以依赖于许多因素,从项目功能需求开始,但是也可以包括诸如构建应用程序的时间框架、应用程序的生命周期、开发团队的经验等因素。
就是这样,这就是我理解这一切的方式。这就是我在脑海里给它找的合理解释。
我在后续的文章中进一步扩展了这些想法:不仅仅是同心圆层。
但是,我们如何在代码库中显式地实现这一切呢?这是我下一篇文章的主题:如何在代码中反映体系结构和域。
讨论:请加入知识星球【首席架构师圈】
- 487 次浏览
【软件架构】为杠杆设计软件
卡瓦尔康蒂:我在这里谈论的是如何利用软件架构。首先,我将在这里定义杠杆的含义。这是谷歌的定义。杠杆率是相对于你所做投资的深度,你可以获得的价值量。我们希望获得比您所做的投资更高的价值。在软件环境中,是您所做的决定、所做的选择,或者您所获得的与您所能创造的价值量相关的技术债务。我想看一看我们在Nubank的整个发展过程中所做的一些架构决策的例子,这些决策的目的是在当时获得尽可能高的杠杆率。你可能在你的公司中处于类似的位置,或者在未来的公司中处于你将做出这些决定的阶段。你可以以我们为例,或者至少有一种心态。
背景
我是卢卡斯·卡瓦尔康蒂。自2013年底以来,我一直是Nubank的首席软件工程师。七年多一点了。我住在巴西圣保罗。
在一个复杂的领域中迅速成长
Nubank是拉丁美洲领先的金融科技公司,是世界上最大的数字银行。在《时代》杂志上,我们获得了全球100家最具影响力的公司之一。我们也登上了《时代》杂志的特写。这是一个巨大的成就,来自一家拥有七年多一点历史的公司。这是我们的增长曲线的一个例子。以下是此图中绘制的实际客户数。我们现在有3500万客户。我们每天处理数十亿条卡夫卡消息和HTTP请求,在一个拥有数百个微服务并由数百名工程师签名的系统中。这是一个相当大的规模,并不总是这么大。
概述
我将介绍公司的一些阶段。第一个是启动时间,我们重视上市时间和反馈。进入成长期,我们将重点转向恢复力和适应性。接下来是整合时间,最重要的方面是可靠性和可观察性。当我们重视灵活性和可扩展性时,最后是扩展时间。这些是在这些阶段对我们很重要的价值观。
启动时间(2013-2015)
创业时间是一个神奇的时刻,任何事情都有可能发生,包括失败和没有公司。在我们的案例中,这发生在2013年末到2015年初。我们经历了不可思议的变化,那是一个神奇的时刻,当你有一个绿地项目,你可以选择任何你喜欢的技术。你必须有充分的理由这样做。在圣保罗一个友好社区的一间小办公室里,实际上是一所小房子。当我们推出第一款产品时,这是一款无需付费的数字信用卡,并提供了当时闻所未闻的实时体验。至少在巴西,我们是第一个这样做的。太多的未知数,我们不知道公司将走向何方,也不知道它是否会成功。有限的资源,只有十几个人在管理整个公司,我们需要让这一切顺利进行。在我们的案例中,我们有一个许可期限。如果我们在2014年5月之前没有运营,我们将不得不申请一个许可证,该许可证将需要两年的时间才能授予,这对公司来说基本上是死亡。
创业时间是一个神奇的时刻,任何事情都有可能发生,包括失败和没有公司。在我们的案例中,这发生在2013年末到2015年初。我们经历了不可思议的变化,那是一个神奇的时刻,当你有一个绿地项目,你可以选择任何你喜欢的技术。你必须有充分的理由这样做。在圣保罗一个友好社区的一间小办公室里,实际上是一所小房子。当我们推出第一款产品时,这是一款无需付费的数字信用卡,并提供了当时闻所未闻的实时体验。至少在巴西,我们是第一个这样做的。太多的未知数,我们不知道公司将走向何方,也不知道它是否会成功。有限的资源,只有十几个人在管理整个公司,我们需要让这一切顺利进行。在我们的案例中,我们有一个许可期限。如果我们在2014年5月之前没有运营,我们将不得不申请一个许可证,该许可证将需要两年的时间才能授予,这对公司来说基本上是死亡。
技术选择
我们需要做的第一个杠杆是技术选择。这里的价值是上市时间。我们需要尽快发射。这里的杠杆类型是最大化不需要做的工作量。不要创造一件你在那个阶段需要做的更复杂的事情。我们选择了Datomic作为一个数据库,一个非常小的数据库,它是一个不可变的事实分类账。你可以免费获得审计服务。每次更新都会保留历史记录,因此不会丢失以前的值。您可以在任何时间点查询数据库,因此这对以后的审核和调试都非常有用。我们选择了Clojure,这是一种在JVM上运行的函数式编程语言。我们可以利用整个Java生态系统。所有用Java编写的东西,我们都可以在Clojure中使用。默认情况下,我们获得了不变性。几乎每一个语言的决定都让我们变得简单。“简单变得容易,”是里奇·希基的一句好话。这是真的,我们在生产中使用它。我们有接近财务的函数式编程,这也是我们选择Clojure的原因。在函数式编程语言中映射财务逻辑更容易。
我们选择使用六边形架构,这样我们就可以有一种有组织的方式来查看代码。我们选择Kafka作为消息传递技术,这在当时非常流行,它有一个带有TTL的消息持久性日志。它不是永远的,但在一段时间内,您可以检查和查看生成的所有消息。我们可以重置偏移量,因此您可以在必要时重新处理旧消息。一开始我们不得不做几次。默认情况下,我们也会得到分区。当时,卡夫卡的推广也稍微容易一些。当时我们欠下的债务是我们选择了一些非常利基的技术,有些是未整合的。它们尚未建立。很难找到对这些语言有一定经验的人。在公司成立之初,我们基本上不需要为了教人们这一点而要求这样做。
Vendors
下一个杠杆是供应商。当你考虑上市时间时,好几次,购买而不是建造是最好的选择。第一个是使用云。在公司的这个阶段,您不想管理自己的机器。我们从一开始就将AWS与CloudFormation一起用于部署自动化。我们使用DynamoDB作为Datomic的后端数据库,这也很容易操作。我们选择购买现成的信用卡解决方案。我们并没有开始构建整个信用卡系统,而是开始使用一家已经处理信用卡交易的公司。我们可以利用,而不是建设,我们只是与该公司集成,我们可以更快地创建第一个产品。这里的债务是,现在,通过使用这些供应商,我们受到其增长、规模和应对我们问题的能力的限制,而这并不总是理想的。
实践
关于启动时间的最后一个问题是练习。这一次的价值是获得快速和早期的反馈。为了得到这一点,我们需要在顶部建立一个良好的基础,这样我们就可以在时间上更快地建立在上面。这里的事情是建筑基础需要时间,当你想启动的时候,你不可能总是在启动的时候使用。幸运的是,我们能做到。我们有一些时间。我们也利用这个机会构建了一个良好的CI/CD环境,因此持续部署在当时对我们来说非常重要。我们建立了一些连续部署的实践。我们有一个非常基本的容错能力,但仍然存在。我们从一开始就拥有不变的基础设施。每次部署时,我们都会在EC2上创建一个新实例并销毁旧实例,这样您就不会有处理基础架构更改的复杂性。我们从一开始就选择使用微服务,因为我们知道金融领域非常复杂。在这个例子中,将这种复杂性包含在小块中,一个较小的服务,在当时对我们来说非常重要。我们已经开始了。
关于启动时间的最后一个问题是练习。这一次的价值是获得快速和早期的反馈。为了得到这一点,我们需要在顶部建立一个良好的基础,这样我们就可以在时间上更快地建立在上面。这里的事情是建筑基础需要时间,当你想启动的时候,你不可能总是在启动的时候使用。幸运的是,我们能做到。我们有一些时间。我们也利用这个机会构建了一个良好的CI/CD环境,因此持续部署在当时对我们来说非常重要。我们建立了一些连续部署的实践。我们有一个非常基本的容错能力,但仍然存在。我们从一开始就拥有不变的基础设施。每次部署时,我们都会在EC2上创建一个新实例并销毁旧实例,这样您就不会有处理基础架构更改的复杂性。我们从一开始就选择使用微服务,因为我们知道金融领域非常复杂。在这个例子中,将这种复杂性包含在小块中,一个较小的服务,在当时对我们来说非常重要。我们已经开始了。
成长时间(2015-2016)
再往前走一点,如果我们幸运并且成功的话,公司将进入一个增长阶段,在我们的案例中,这是在2015年和2016年之间,当时我们经历了比预期更快的增长。我们曾期望在5年内获得100万客户,而我们在大约18个月内实现了这一目标。我们需要对此作出回应。起初,办公室规模不大,我们不得不搬到一个更大的地方。供应商没有进行扩展。信用卡处理器没有扩展,所以我们需要保持系统工作,即使供应商没有扩展。这项技术,我们在一开始做出的决定,也开始不具有规模。我们开始看到第一个瓶颈,在这种超增长场景中很难修复。
实践
关于成长时间的第一个杠杆是实践。有了可伸缩性或容错的价值,我们可以而且应该尽可能避免优化,或者至少延迟优化。因为优化代码比常规代码复杂得多。在一个复杂的领域,这可能会很快偏离轨道。为此,我们使用了基础设施分片,而不是只分片数据库或基础设施的一部分。我们有好几份Nubank系统的副本。每个碎片都是整个基础设施的副本,这些基础设施是可伸缩性单元。我们可以对在该副本上运行的客户数量进行限制,并在到达新客户集时转到下一个副本,并随着基础的增长不断创建副本。如果碎片足够小,就不必优化代码,或者可以尽可能地延迟代码。为此,我们必须改进CI/CD。我们需要频繁的自动部署。
我们从一开始就开始进行端到端测试,但测试规模开始缩小,因此测试开始需要一个多小时的时间。我们必须用消费者驱动的契约测试来代替它们,这将在保证少一点的情况下运行得更快,但最好保持频繁部署,而不是等待太多时间来部署。我们开始迁移到Docker,而不是使用EC2。这里的投资是与sharding一起运行的项目长达一年多,这在当时是公司的一个非常大的项目。我们必须设计新的工具来适应这种情况。这里的债务是,该项目的时间比预期的要长,客户群的增长比预期的要快。我们最终得到了比其他碎片更大的第一个碎片。在很长一段时间里,这个碎片是一个特殊的碎片,基本上是系统中任何性能问题的金丝雀,这是第一个碎片。此外,无论有多少客户,每个碎片都有一个最低成本。我们开始花很多钱来运行碎片的每个副本。
In-Housing
下一个操纵杆在内部IT。特别是,因为我们的供应商没有扩展,所以我们开始在业务最重要的方面掌握自己的命运。我们开始在内部处理信用卡,将信用卡的一个又一个功能带到内部,这样我们就可以控制自己的规模。客户支持也是如此。取悦客户是我们在公司的最大优势,因此我们还将客户支持工具和客户支持人员带到了公司内部。我们还必须为此进行设计。这里最大的投资是,实现信用卡的这些功能花费了18个多月。每一个小功能都是我们必须进行的迁移。这是一项巨大的投资,回报巨大。供应商不会扩展到3500万客户,我们可以。这里的债务是,由于带来了内部的几个功能,我们花了很长时间没有进行任何重大的产品更改。那有点糟糕。
巩固时期(2017-2018)
如果我们足够幸运,我们将进入下一阶段,也就是整合时间。2017年到2018年间,当我们在公司进入巡航模式时,我们可以扩展,但不是以稳定的方式,切分在扩展方面帮助很大。我们达到了这样的规模:每一个影响0.1%客户的小角落案例都发生在数千名客户身上。我们必须有一种比我们预期的更稳定的产品或系统。办公室也没有规模,所以我们需要搬到一个能容纳1000人的更大的办公室,靠近圣保罗最著名的街道之一的Avenuda Paulista。此时,我们推出了第二个产品,即支票账户。在这个阶段,我们已经生成了大量的数据,所以我们开始分析这些数据。这对我们来说也是非常重要的一点。
技术
技术方面的第一个优势是,我们的目标是可扩展性和适应性。这里的杠杆就是这样的规模,我们需要能够更轻松地进行基础设施更改,因此我们迁移到Kubernetes,这在当时也很繁荣。它附带了一个由多种基础设施工具组成的生态系统。随着我们获得的服务数量的增加,它比AWS CloudFormation扩展得更好。我们还开始建立更好的监控工具,以便使用Prometheus plus Grafana收集实时指标。这些指标也被其他工具(如Opsgenie、Slack或CI/CD)用于canary部署。这对我们扩大规模非常重要。这里的投资是另一个长达一年的项目,我们必须建立Kubernetes,并将碎片逐个迁移到Kubernetes,而该系统已经为数百万客户运行。他们是相当复杂的行动,我们能够完成。这里的债务是,虽然我们没有完全迁移,但我们开始在创建资源或资源数量方面达到AWS的限制,并在项目完成之前在重复的基础设施上花费大量资金。这是一件大事。
内部工具
我们还必须在用于恢复力和可观察性的内部工具上投入大量资金。我们需要让工程师们更容易操作这个系统,特别是在有这么多服务和人员的情况下。我们创建了一个名为NuCLI的命令行存储库,其中包含最常见的操作,如重新启动服务,或使用我们的凭据向服务发送HTTP请求,这些操作只需一个命令即可运行。此外,还有一个用于声明性infra的工具。一个存储库,当你可以描述你可以从你的服务中获得的资源时,它被工具自动应用。这里的投资是我们需要一个专门的团队来策划、维护和确保所有这些变化都得到应用。
数据
在这一点上,当我们进行整合时,数据变得非常重要。我们拥有的数据量无法通过常规工具处理。你几乎需要数据来做你公司的每一项决策,因此我们使用Scala plus Spark来处理所有数据,方法是从所有服务的数据库中跨所有碎片提取数据。我们有一个ETL过程,它是一个数据集定义的存储库,公司中几乎每个人或公司中几乎每个地方都参与其中,它将所有内容输出到数据仓库,以便每个人以后都可以访问。它与一些人工智能工具集成,我们可以用来支持我们的机器学习模型。我们也可以将其用作一致性工具。有了这么多的数据,并使用分布式体系结构,失败的分布式事务变得非常重要。我们还使用ETL检查一致性,同时检查系统。同样,创建初始ETL版本并开始对其进行迭代是另一个大项目。我们也有一个专门的团队,以确保这一切顺利进行。
扩张器(2019- )
最后,我们到了扩展时间,我们现在的位置。从2019年到现在,我们开始为每个人提供产品。这就是为什么你会在曲线上看到这个拐点。例如,我们不再对要求信用卡的客户说不,我们开始为每个人提供产品。我们开始在许多国家、许多办事处以及我们正在制造的许多其他产品推出。我们开始收购公司,因此这些公司之间的接口也变得很重要。
水平平台
这里关于扩展时间的第一个杠杆是可扩展性和生产力,我在这里称之为水平平台。基本上有一个专门的技术团队,为其他团队构建抽象的工具。例如,移动和网络,我们在颤振、设计系统和组件库方面有一个团队建设工具,这样普通工程师、非专家工程师仍然可以发展和使用该系统。对于基础设施也是一样,我们创建抽象工具,让每个工程师都能做到,而不是让每个人都知道如何操作Kubernetes。我们还建立了一个实验平台,因为在这种规模下,我们希望进行实验,我们希望改进您的产品。拥有一个平台,允许您在监控KPI和与测试相关的任何内容时轻松完成这项工作,这是非常关键的。我们现在需要专门的团队来创建、维护和操作这些平台,以确保每一位工程师都能在我们使用的任何技术上发挥生产力。
业务平台
最后,这里是面向领域专家团队的业务平台,用于构建供所有其他产品团队使用的抽象API。这里是我们可以进行创新的要点,我们可以构建的每一个可能的平台产品都有无限的可能性。it的例子是银行即服务,因此创建平台来运行银行的基本业务。例如,信贷平台。你不必弄清楚如何发放贷款,或者如何报告贷款,如何核算贷款,我们有一个平台,每个产品都可以发放贷款。一旦完成,产品就可以做它想做的任何事情。开放银行业务中的资产和支付平台也是如此。这些是我们可以用来建造银行的积木。此外,在信用卡方面,我们必须在其他国家推出信用卡,因此我们必须使系统更加通用。为了做到这一点,我们将系统划分为与信用卡最相关的部分。例如,在这种情况下,我们每个月都在处理信用额度或结账单,或者以不同的方式处理信用卡交易。如果客户未向我们全额支付账单,也会产生债务并重新协商客户债务。另外,当你得到太多的产品时,拥有一个灵活的采购流程也是非常重要的,所以我们使用它。这里的投资是,对于领域平台,我们需要对领域有非常深入的了解才能做到这一点。我们经过了长时间的讨论来设计平台端系统的正确突破点,因为在这里创建错误的抽象也会导致失败。您必须确保您正在创建抽象的广度,因为重建抽象的成本非常高。
简要回顾
在创业的时候,我们试图尽可能多地推迟编写代码,同时为成长奠定基础。当我们实现增长时,我们开始在内部提供我们需要的所有核心功能,并开始进行切分,以便能够更快地扩展。整合的时间是使我们的基础架构成熟并创建一个数据环境,这样每个人都可以使用数据来促进公司的发展。最后,扩展时间是关于构建横向和业务平台,因此可能性将成倍增加,每个人的生产力将成倍增加。
问答
波切利:你是从使用微服务开始的。通常,当人们选择微服务架构时,更多的是康威定律的正当性,当你很小的时候,你没有,但是你切换到那个,你考虑去做一个整体吗?这方面的思考过程如何?
卡瓦尔康蒂:我认为主要原因是领域的复杂性。我们知道金融领域非常复杂,因此当时我们对该系统的关注已经非常不同,比如处理信用卡交易、处理客户数据和处理收购流程。我们一开始只有很少的服务。我想大概有四五个,但已经进入了服务领域,因为我们知道,如果我们要成功并扩大规模,我们最终将不得不采用这种架构。
波切利:这是一个挑战,因为分布式系统比单个整体要复杂得多。
这也涉及到一些关于切分的问题。开始缩放时,您提到了切分。你在某种程度上平衡了切分和创建切分的挑战。你必须在这方面处理异常值吗?在这个切分中需要更多的资源?
卡瓦尔康蒂:我认为我们确实有一些人比其他人运行10倍或100倍的事务。它最终只会影响到特定的客户,比如他们的账单可能不会及时打开,因为那里有太多的交易。它不会影响其他操作,因为我们的大多数操作已经是批处理的。这对我们没有多大影响。我们在第一个碎片上确实遇到了这个问题,因为我们花了比预期更长的时间来构建碎片基础设施。第一个碎片与年龄太大的客户相处得太久。客户在Nubank的时间最长,客户数量最多。这给我们带来了一些挑战。有时仍然如此,但现在所有碎片的大小都差不多了。我们正在更好地管理它们。
波切利:那么,连接到切丁。迁移到库伯内特斯的情况如何?关于库伯内特家族的一些问题。你是否采用了像EKS之类的Kubernetes服务,或者你去了Kubernetes?从您的基础架构的这种转变是如何进行的?你已经提到它是不可变的。
卡瓦尔康蒂:我认为这里要考虑的主要问题是,这是七、八年前的事了。Kubernetes刚刚推出,2014年公开发布。我们创立公司时没有这些工具。我们成立公司时甚至没有Docker,所以我们不得不迁移到Docker,然后迁移到Kubernetes。然后最终迁移到EKS,因为EKS在当时也不存在。我想,它是从今年开始在圣保罗地区出现的。我想如果我们今天开始创业,我们可能会在亚马逊上使用EKS,就这样。我们当时没有那些工具。
波切利:我在这里经常看到的另一个问题是Clojure的使用,以及您提到的堆栈。我想说,这并不常见。你利用了生态系统。您还提到了JVM。你能帮我们理解一下这种二分法吗?你开始很容易,但你选择了很少有人会选择的东西。
卡瓦尔康蒂:对我们来说,Clojure最重要的一点是,语言从一开始就将你推向简单,从某种意义上说,你必须学习的语言数量是非常少的。你可以在Clojure学习几周来提高工作效率。我们所有的服务看起来都差不多。一旦你摆脱了那些括号,你就可以从大括号切换到括号,然后就可以了。其他一切都比较简单。我们没有大多数语言必须学习语法和语言结构的认知负荷。Clojure是Lisp的括号和符号。您不必学习很多语言特性,就可以像我们一样使用它或复制粘贴其他代码。
波切利:现在关于更多业务方面的一个问题是,您是如何将成本因素纳入架构决策的?当你从事金融业务时,你会遵守很多规定。您如何处理这一区别、基础设施、业务代码以及法规的所有挑战?
卡瓦尔康蒂:我们确实有特定的团队,比如当我们达到一定规模时,有一个专注于特定方面的团队是值得的。我们有一个团队只负责管理运营风险,或者一个团队只负责为公司的受监管部分提供平台。发放贷款在市场上是非常受监管的,至少在巴西是这样,所以我们围绕它创建了一个平台。每次我们需要贷款时,平台都会处理,我们有许多团队可以轻松发放贷款。这就是我们处理这件事的主要方式,就是有一个专门的团队,知道很多关于规章制度的知识,知道如何评估风险。然后,来自可能受it影响的其他团队的定期评估。
波切利:你提到过几次,有专门的团队和专家。Nubank的团队规模是什么样的?
卡瓦尔康蒂:通常,团队不仅仅是工程师。我们有BAs团队、产品经理团队、业务产品经理团队,有时还有数据科学家团队。对于工程部分,我们通常有一名技术经理,每个团队有两到六名工程师。它在上下文上有很大的不同,但每个团队的规模都差不多。
波切利:两个比萨饼规则。
现在让我们切换到数据。您提到了ETL,您使用什么工具进行ETL?
卡瓦尔康蒂:我们使用Spark构建所有基础设施来转换数据。我们必须在内部构建很多工具来提取数据组数据,并以ETL可以使用的方式进行转换。我不是数据方面的专家,所以我对细节不太了解。我知道我们使用Mesos集群来运行将运行ETL过程的集群。我们使用一些BI工具,比如Databricks,比如Looker。我认为整个生态系统都在使用几种工具。我们有自己的数据集定义存储库,由整个公司提供。它是Scala和Spark,以及我们创建的一些抽象概念,因此人们可以更容易地使用它。
波切利:你从卡夫卡开始,今天,很多事情都是关于流的,但是你选择了批处理ETL路线。有没有理由不全神贯注于流媒体?那时候不是很流行,你需要调整吗?
卡瓦尔康蒂:主要原因是,当我们需要ETL时,卡夫卡流在当时并不稳定或不被释放。当时我们已经从数十家微服务公司获得了Datomic的数据。我们很难在当时选择的架构上迁移到卡夫卡流模式。如果我们从今天开始,我们将进入流媒体。我们确实有一些更适合流的用例。例如,我们在实时收集指标时使用它。我们确实使用卡夫卡流。对于常规数据库部分,我们没有。
原文:https://www.infoq.com/presentations/nubank-architectural-decisions/
本文:
- 88 次浏览
【软件架构】使用ChatGPT和PlantUML的思维导图
视频号
微信公众号
知识星球
在我之前的关于将Mermaid.js与ChatGPT一起使用以构建系统图的系列文章(第1部分和第2部分)中,我们研究了ChatGPT构建序列、活动、状态和C4模型的能力。
我有兴趣进一步探索这一点,下面是我关于使用PlantUML使用ChatGPT构建更复杂的图的下一个系列
PlantUML允许您根据文本描述创建广泛的图表。在目前的状态下,除了所有UML图之外,它还可以支持甘特图、思维导图、概念图等
我对构建思维导图特别感兴趣,所以这是我关于PlantUML系列的第一篇文章。我与ChatGPT的交互,并使用它与PlantUML创建思维导图

思维导图简介
Prompt: What's a mindmap
ChatGPT: A mind map represents ideas or information organized around a central concept or key idea. Mind maps are often used to visually organize information and create a clear structure for thoughts and concepts. The nodes in a mind map can branch out to show relationships between ideas. They can be colour-coded, labelled with icons, or annotated with text to clarify the relationships further. Mind maps are commonly used in note-taking, brainstorming, problem-solving, and decision-making, as they help to capture and organize thoughts visually and intuitively.
基本思维导图
Prompt: Okay, Let's start by creating a simple MindMap on the topic of
Artificial Intelligence
Can you give the mindmap inPlantUMLformat. Keep it structured from the core central topic branching out to other domains and sub-domains. Let's go to 4 levels to begin with. Add the start and end mindmap tags and keep it expanding on one side for now
ChatGPT: Sure, here's a simple mind map of the topic "Artificial Intelligence" in PlantUML format, with four levels
@startmindmap * Artificial Intelligence ** AI Technologies *** Machine Learning **** Supervised Learning **** Unsupervised Learning **** Reinforcement Learning *** Natural Language Processing (NLP) **** Sentiment Analysis **** Part-of-Speech Tagging **** Named Entity Recognition @endmindmap
为了将其可视化,让我们打开draw.io或diagrams.net,然后转到
排列->插入->高级->PlantUML
并粘贴上面的片段
opening plantUML diagrams in draw.io
下面是可视化
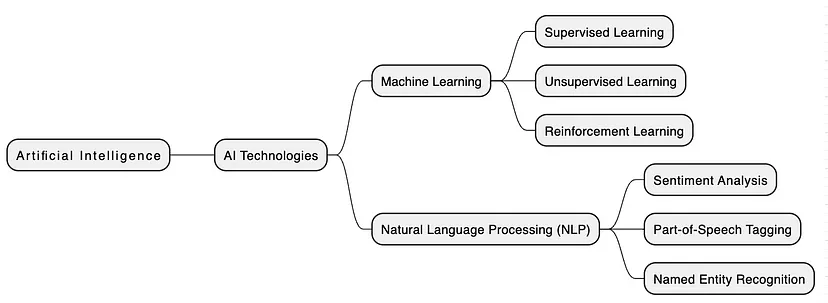
凉的我们有思维导图!!
让我们试着调整一些设置。
提高级别
Prompt: Can you increase it by two more levels and add further domains
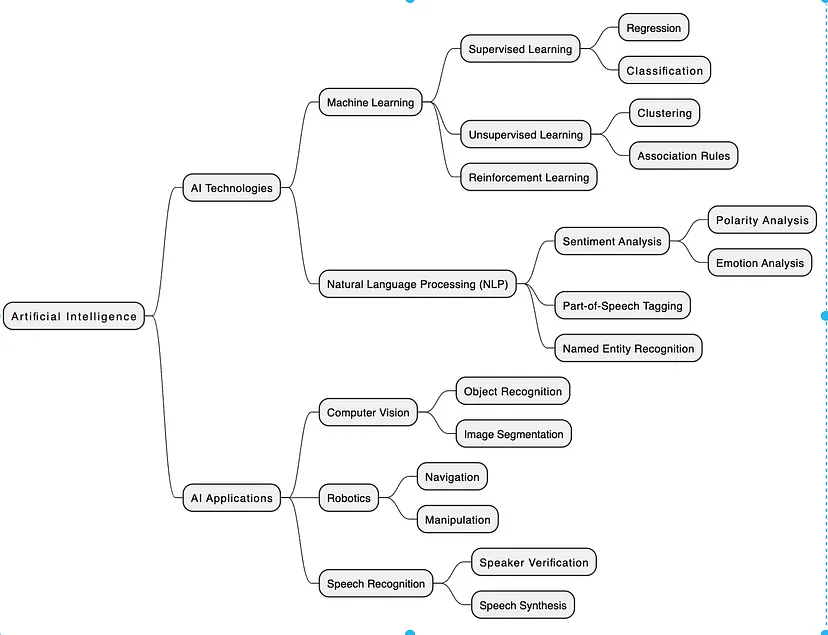
ChatGPT: Sure, here's the expanded mind map of the topic "Artificial Intelligence" in PlantUML format, with six levels:
@startmindmap * Artificial Intelligence ** AI Technologies *** Machine Learning **** Supervised Learning ***** Regression ***** Classification **** Unsupervised Learning ***** Clustering ***** Association Rules **** Reinforcement Learning *** Natural Language Processing (NLP) **** Sentiment Analysis ***** Polarity Analysis ***** Emotion Analysis **** Part-of-Speech Tagging **** Named Entity Recognition ** AI Applications *** Computer Vision **** Object Recognition **** Image Segmentation *** Robotics **** Navigation **** Manipulation *** Speech Recognition **** Speaker Verification **** Speech Synthesis @endmindmap
添加颜色代码
接下来,让我们为我们的思维导图添加颜色代码。
注意:我必须提供提供颜色代码的语法,因为ChatGPT可能使用了一个旧的语法,该语法在预处理时破坏了plantUML代码
Prompt: Can you add colour codes to the above mind map? Use the format
*[#FFFF00] Artificial Intelligence. The above is just an example; use your colour codes for each node based on the complexity of each node in terms of the time it takes to learn that topic for a beginnerChatGPT: Here's an updated version of the mindmap, with colour codes indicating the complexity of each topic
@startmindmap
*[#red] Artificial Intelligence
**[#red] AI Technologies
***[#orange] Machine Learning
****[#orange] Supervised Learning
*****[#yellow] Regression
*****[#yellow] Classification
****[#orange] Unsupervised Learning
*****[#yellow] Clustering
*****[#yellow] Association Rules
****[#orange] Reinforcement Learning
***[#orange] Natural Language Processing (NLP)
****[#yellow] Sentiment Analysis
*****[#green] Polarity Analysis
*****[#green] Emotion Analysis
****[#yellow] Part-of-Speech Tagging
****[#yellow] Named Entity Recognition
**[#red] AI Applications
***[#orange] Computer Vision
****[#yellow] Object Recognition
****[#yellow] Image Segmentation
***[#orange] Robotics
****[#yellow] Navigation
****[#red] Manipulation
***[#orange] Speech Recognition
****[#yellow] Speaker Verification
****[#yellow] Speech Synthesis
@endmindmap
和表示

但是这些颜色是什么意思?让我试着找到一个传奇
Prompt: can you create a PlantUML legend for the colour codes above? Mark them against the time duration based on which the colours were selected
ChatGPT: Here is a PlantUML legend for the colour codes, indicating the time duration for a beginner to learn each topic:
legend - Green: Topics that can be learned in less than a week (around 10-20 hours of study) - Yellow: Topics that take a few weeks to a month to learn (around 30-50 hours of study) - Orange: Topics that take a few months to learn (around 100-150 hours of study) - Red: Topics that require substantial effort and time to learn (around 200-300 hours or more of study) endlegend
和在draw.io中导入

太好了,我们有一个带有颜色代码的思维导图和一个相应的图例,其中包含每个颜色代码的描述。
添加图标
接下来,让我们尝试将图标添加到我们的思维导图中
注意:我必须提供提供图标的语法,因为ChatGPT可能使用了一种旧的语法,它在预处理时破坏了plantUML代码
Prompt: Can you add icons to the above MindMap using plantUML-supported icons from the open iconic library? The format for usage is as
*[#red] <&star> Manipulation. The above is an example of a red colour node and start icon from the open iconic library. Keep the same colour codes as above but use relevant icons as appropriate
ChatGPT:@startmindmap *[#red] <&home> Artificial Intelligence **[#red] <&aperture> AI Technologies ***[#orange] <&puzzle-piece> Machine Learning ****[#orange] <&tag> Supervised Learning *****[#yellow] <&code> Regression *****[#yellow] <&circle-check> Classification ****[#orange] <&dashboard> Unsupervised Learning *****[#yellow] <&list> Clustering *****[#yellow] <&tag> Association Rules ****[#orange] <&pulse> Reinforcement Learning ***[#orange] <&cog> Natural Language Processing (NLP) ****[#yellow] <&pulse> Sentiment Analysis *****[#green] <&arrow-top> Polarity Analysis *****[#green] <&eye> Emotion Analysis ****[#yellow] <&tag> Part-of-Speech Tagging ****[#yellow] <&bookmark> Named Entity Recognition **[#red] <&aperture> AI Applications ***[#orange] <&image> Computer Vision ****[#yellow] <&target> Object Recognition ****[#yellow] <&crop> Image Segmentation ***[#orange] <&code> Robotics ****[#yellow] <&map-marker> Navigation ****[#red] <&star> Manipulation ***[#orange] <µphone> Speech Recognition ****[#yellow] <&person> Speaker Verification ****[#yellow] <&audio> Speech Synthesis @endmindmap
和代表

这些图标看起来并不都合适,但至少是ChatGPT根据主题映射关闭图标的一次非常好的尝试。
进入下一步
添加说明
Prompt: Can you add a definition to only the leaf nodes? These definitions should be word-wrapped using PlantUML format and not have a surrounding box. Keep the Icons and Colors of the nodes as-is, and add additional description nodes to all leaf nodes. The format for adding leaf nodes is
****_ description
ChatGPT:
@startmindmap *[#red] <&home> Artificial Intelligence **[#red] <&aperture> AI Technologies ***[#orange] <&puzzle-piece> Machine Learning ****[#orange] <&tag> Supervised Learning *****[#yellow] <&code> Regression ******_ A statistical approach to finding the relationship between a dependent and one or more independent variables. *****[#yellow] <&circle-check> Classification ******_ The task of categorizing a set of data into classes based on their features. ****[#orange] <&dashboard> Unsupervised Learning *****[#yellow] <&list> Clustering ******_ A method of organizing a set of data into groups (clusters) based on their similarities. *****[#yellow] <&tag> Association Rules ******_ A statistical approach for finding relationships between variables in large datasets. ****[#orange] <&pulse> Reinforcement Learning *****_ An area of machine learning that focuses on training an agent to make a sequence of decisions by maximizing a reward. ***[#orange] <&cog> Natural Language Processing (NLP) ****[#yellow] <&pulse> Sentiment Analysis *****[#green] <&arrow-top> Polarity Analysis ******_ A method of identifying the sentiment expressed in a text as positive, negative, or neutral. *****[#green] <&eye> Emotion Analysis ******_ The task of detecting and classifying emotions in text or speech. ****[#yellow] <&tag> Part-of-Speech Tagging *****_ The task of marking each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, etc. ****[#yellow] <&bookmark> Named Entity Recognition *****_ A NLP technique that identifies named entities in a text, such as organizations, people, locations, etc. **[#red] <&aperture> AI Applications ***[#orange] <&image> Computer Vision ****[#yellow] <&target> Object Recognition *****_ The task of recognizing objects in images or videos based on their features and attributes. ****[#yellow] <&crop> Image Segmentation *****_ The process of dividing an image into multiple segments or regions, each of which corresponds to a different object or part of the image. ***[#orange] <&code> Robotics ****[#yellow] <&map-marker> Navigation *****_ The task of guiding a robot from one place to another. ****[#red] <&star> Manipulation *****_ The task of manipulating objects in the environment using a robot. ***[#orange] <µphone> Speech Recognition ****[#yellow] <&person> Speaker Verification *****_ The task of verifying the identity of a speaker based on their speech. ****[#yellow] <&audio> Speech Synthesis *****_ The task of generating speech from text. @endmindmap
and the representation
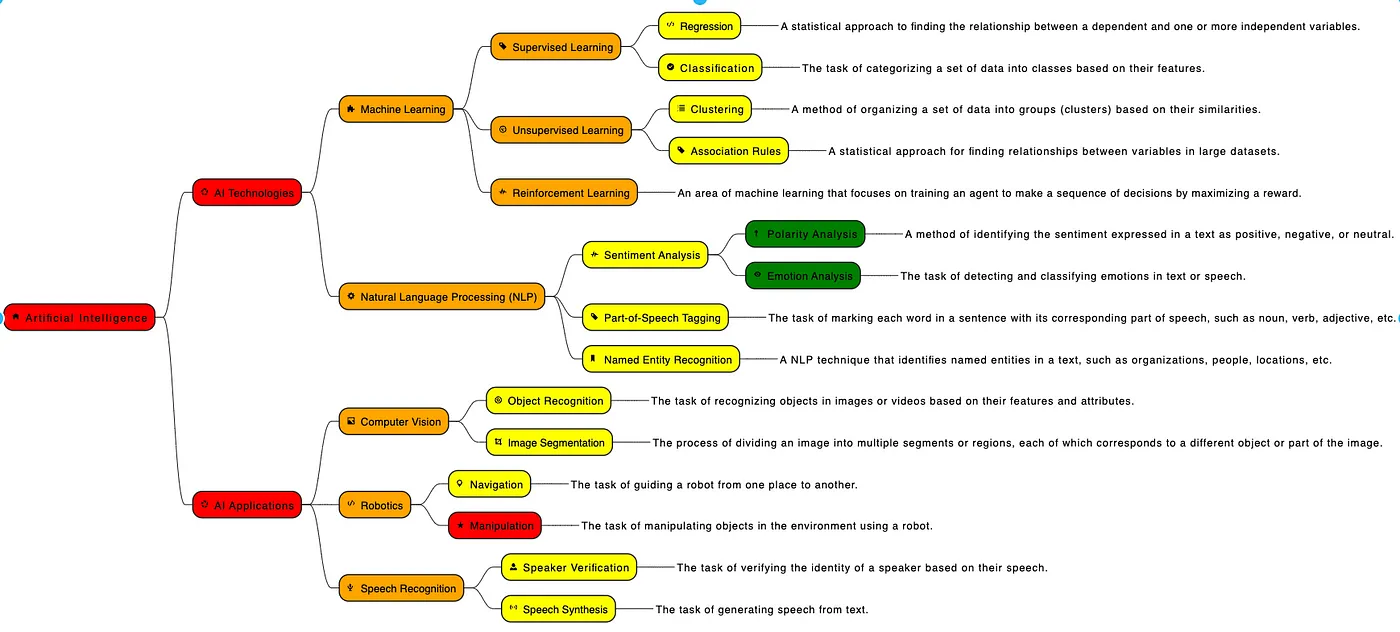
就在这里。用ChatGPT制作的复杂思维导图,用图例、图标和描述性进行颜色编码。
感谢阅读!
- 237 次浏览
【软件架构】使用ChatGPT构建系统图-第一部分
视频号
微信公众号
知识星球
对思维导图感兴趣 — 阅读我们关于使用plantUML和ChatGPT创建令人敬畏的思维导图的博客文章
ChatGPT的受欢迎程度不断增长,目前已被广泛应用。作为一名软件架构师,我有机会探索ChatGPT在金融领域的功能,特别是财富管理。
我想确认ChatGPT是否可以为用例解释生成图表,并同时分析多个因素。
所以,我登录了chat.openai.com,下面是我的对话
步骤1:让我们定义用例
我本可以定义自己的用例,但我想测试ChatGPT的所有方面,所以我要求它为我定义一个。

步骤2:让我们为用例定义一个数据模型
在我看来很好,让我们从定义数据模型开始——所以我请ChatGPT来做,这就是我得到的

这听起来不错,让我们看看它能为图表做些什么。我想更深入地研究数据模型,所以我的下一个提示是
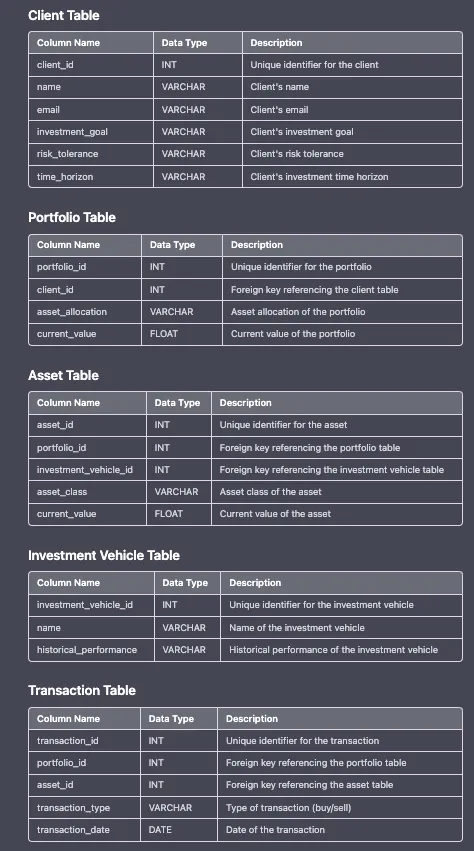
Prompt:describe the data model in more detail or tabular format using markdownChatGPT: I can describe the structure of the data model in a tabular format using markdown.
这是一个良好的开端。接下来,我要求定义关系
第3步:让我们定义关系-实体关系图
Prompt: this is perfect, I would like to depict the relationships in a mermaid diagram, can you give me the markdown code to do this
ChatGPT: I apologize, but as a text-based model, I am not able to generate Mermaid diagrams or any other visual diagrams. However, I can provide you with an example of how the relationships could be represented in Mermaid syntax:
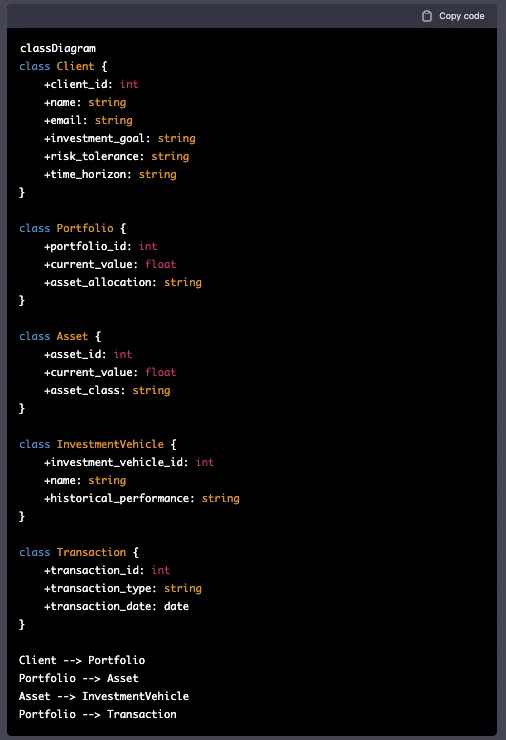
在{merma}标签内的降价编辑器中复制这个,我得到了

太好了,我们正在取得进展。
我有一个类图/实体关系图。让我们看看还有什么可能
步骤4:序列图
接下来,我尝试做出假设性提示来检查响应。我的第一个意图是创建一个序列图
Prompt: how would a Buy transaction for an asset impact the tables mentioned above, I would like to depict this as a sequence diagram. Can you help describe the diagram in markdown format for mermaid
ChatGPT: Sure, aBuytransaction would have an impact on the following tables:
Assettable: thecurrent_valueof the asset would be updated to reflect the current market value of the asset
Portfoliotable: thecurrent_valueof the portfolio would be updated to reflect the new asset and its market value, and theasset_allocationwould be updated to reflect the new asset.
Transactiontable: a new transaction would be added with the transaction details such as the transaction type, transaction date, asset_id, and portfolio_idHere is an example of how the process could be represented in a Mermaid sequence diagram:
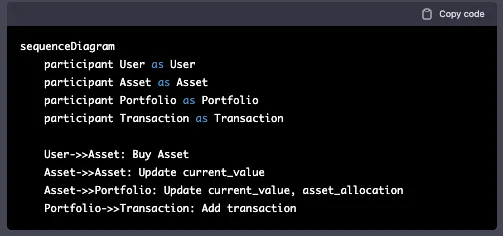
在markdown编辑器中复制这个
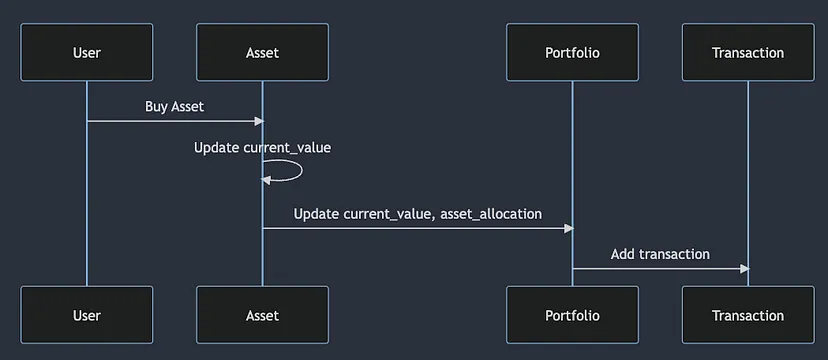
给人印象深刻的但我还没有完成
步骤5:状态转换图
让我问一下状态转换图
Prompt: Will the account have states like new, closed, active inactive etc? I would like to depict the states in a state diagram using mermaid. Can you help describe the diagram in markdown format
ChatGPT: It is common for financial accounts to have different states, such as new, closed, active, and inactive, to reflect the current status of the account.
newaccount would be one that has just been opened and is awaiting funding or verification.
activeaccount would be one that is currently open and being used for transactions.
inactiveaccount would be one that is not currently being used but has not been closed.
closedaccount would be one that has been closed by the customer or the financial institution, and no longer able to be used for transactions.
Pendingstate could be used to indicate that the account is under review or awaiting verification.
Suspendedstate could be used to indicate that the account has been temporarily suspended, for example, due to suspicious activity or non-compliance with terms and conditions.
Frozenstate could be used to indicate that the account has been frozen, for example, due to a legal dispute or regulatory action.
Expiredstate could be used to indicate that the account has reached its expiration date and is no longer in use.here is an example of how the states of an account could be represented in a Mermaid state diagram:
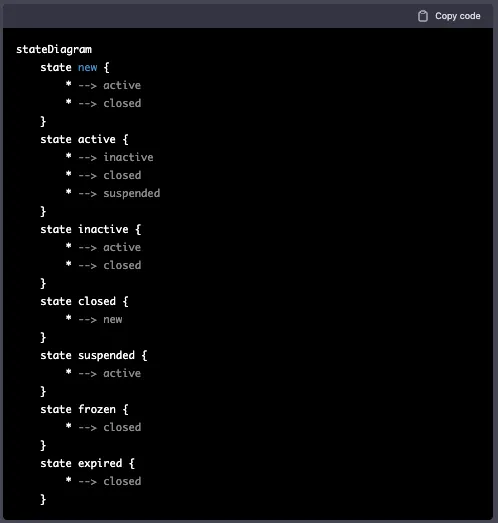
看起来,此格式较旧,可能会由于循环依赖关系而中断。所以我要求ChatGPT对此进行改进
Prompt: can you try giving the state diagram markdown syntax in new format using
[*]
ChatGPT: Sure, here is an example of how a state diagram for a wealth management system's account management component could be represented in Mermaid using the new format with[*]:
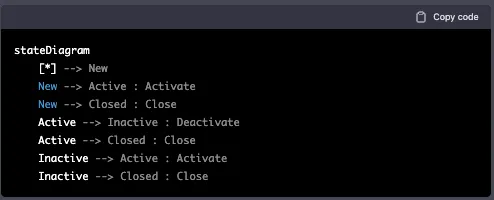
标记编辑器表示
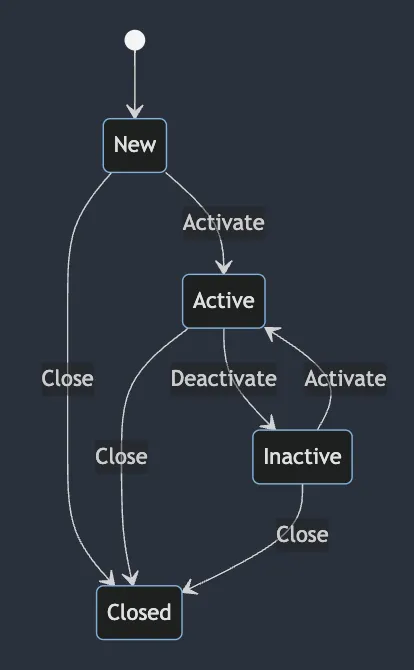
此图显示了帐户的不同状态以及它们之间可能的转换。
- 初始状态为[*],表示开始状态。
- 帐户可以通过激活从“新建”状态转换为“活动”状态。
- 帐户可以通过关闭从“新建”状态转换为“关闭”状态。
- 帐户可以通过停用从活动状态转换到非活动状态。
- 帐户可以通过关闭从活动状态转换到关闭状态。
- 帐户可以通过激活从非活动状态转换为活动状态。
- 帐户可以通过关闭从非活动状态转换为关闭状态。
现在我们正在取得进展。让我们进一步扩展到包括其他州
Prompt: please include expired, frozen and other relevant states as well
ChatGPT: Sure, here is an example of how a state diagram for a wealth management system’s account management component could be represented in Mermaid including additional states such asExpired,Frozen, etc:Description:
This diagram shows the different states of an account and the possible transitions between them.The initial state is
[*]which denotes the start state.
The account can transition fromNewstate toActivestate by activating it.
The account can transition fromNewstate toClosedstate by closing it.
The account can transition fromActivestate toInactivestate by deactivating it.
The account can transition fromActivestate toFrozenstate by freezing it.
The account can transition fromActivestate toClosedstate by closing it.
The account can transition fromInactivestate toActivestate by activating it.
The account can transition fromInactivestate toFrozenstate by freezing it.
The account can transition fromInactivestate toClosedstate by closing it.
The account can transition fromFrozenstate toActivestate by unfreezing it.
The account can transition fromFrozenstate toClosedstate by closing it.
The account can transition fromClosedstate toExpiredstate if the account is expired.
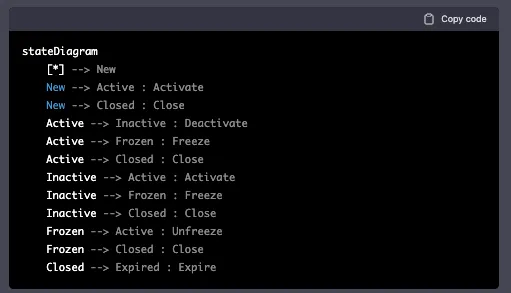
和图解表示
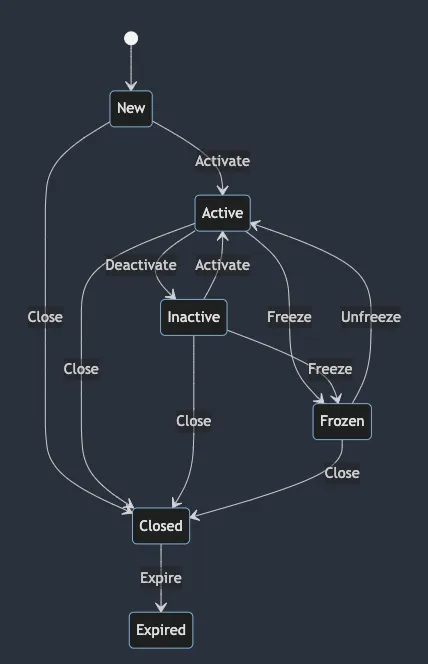
这太棒了。ChatGPT和Mermaid所能取得的成就令人印象深刻
接下来,我将使用C4模型描述和构建更多的图表,并将它们添加到后续文章中
感谢阅读!
- 665 次浏览
【软件架构】利用ChatGPT在软件架构中利用即时工程
视频号
微信公众号
知识星球
转变软件体系结构开发生命周期。
介绍
作为一名解决方案架构师,掌握软件架构的最新进展至关重要。一种越来越受欢迎的前沿方法是即时工程,这是一种利用GPT-4等人工智能模型根据给定提示生成输出的技术。在这篇博客文章中,我们将深入研究如何将提示工程应用于软件架构过程的不同阶段,并讨论在每个阶段最有效的提示类型。
收益汇总:
- 节省时间:快速工程通过快速生成摘要、提取数据和提供有价值的见解,帮助解决方案架构师节省时间。
- 提高质量:利用人工智能生成的输出可以通过提出设计备选方案、确定瓶颈和提供最佳实践来提高架构设计质量。
- 简化的开发:在整个软件架构过程中集成即时工程有助于简化开发,确保阶段之间的过渡更加顺利。
- 优化的性能:通过生成重构建议和确定优化机会,即时工程有助于提高系统性能。
- 适应性:及时的工程让架构师了解新兴技术,帮助他们设计能够适应未来变化的系统。
需求收集和分析
需求收集和分析阶段的主要目标是清楚地了解利益相关者的需求和期望。通过使用即时工程,解决方案架构师可以:
- 生成长文档或对话的摘要。
- 将非结构化信息转换为结构化格式。
- 识别缺失或矛盾的要求。
要使用的提示类型:
- 总结提示:“用200字总结以下文档。”
- 数据提取提示:“从以下对话中提取主要需求。”
- 矛盾检测提示:“识别给定需求集中的任何矛盾。”
架构设计
解决方案架构师在架构设计过程中创建系统结构和组件的高级蓝图。快速工程可用于:
- 根据给定的需求生成设计备选方案。
- 比较和对比不同的架构模式。
- 确定拟议架构中的潜在瓶颈或问题。
要使用的提示类型:
- 设计建议提示:“根据以下要求,提出三种不同的架构设计。”
- 模式比较提示:“对微服务和单片架构模式进行比较和对比。”
- 瓶颈识别提示:“识别拟议架构中潜在的性能瓶颈。”
实施
在实施阶段,将架构设计转化为代码。即时工程可以通过以下方式为开发人员提供支持:
- 基于架构设计生成代码片段或伪代码。
- 为要使用的库或框架提供建议。
- 推荐编码标准和样式的最佳实践。
要使用的提示类型:
- 代码生成提示:“生成用于实现以下架构组件的Python代码片段。”
- 库建议提示:“建议合适的JavaScript库来实现以下功能。”
- 最佳实践提示:“推荐在Java中实现RESTful API的最佳实践。”
测试和验证
在测试和验证阶段,根据其要求对系统进行验证。及时的工程可以通过以下方式提供帮助:
- 基于系统需求生成测试用例或场景。
- 识别可能导致问题的潜在边缘案例。
- 提供有关测试方法和工具的指导。
要使用的提示类型:
- 测试用例生成提示:“生成五个测试用例来验证以下需求。”
- 边缘案例识别提示:“识别以下系统组件的潜在边缘案例。”
- 测试方法提示:“为分布式系统推荐合适的测试方法。”
部署和持续集成
开发的系统在部署和持续集成阶段发布并与其他组件集成。快速工程可用于:
- 生成部署脚本或配置文件。
- 提供有关部署战略和最佳做法的指导。
- 提供有关监控和日志记录技术的见解。
要使用的提示类型:
- 部署脚本生成提示:“生成用于部署以下应用程序的Dockerfile。”
- 部署策略提示:“解释蓝绿色部署与滚动部署的优缺点。”
- 监控和日志提示:“推荐微服务架构中监控和日志记录的最佳实践。”
维护和发展
在维护和发展阶段,根据用户反馈和不断变化的需求,不断改进和更新系统。及时的工程可以通过以下方式提供帮助:
- 正在生成重构或改进现有代码的建议。
- 确定优化或性能改进的潜在领域。
- 提供对新兴技术及其对系统的潜在影响的见解。
要使用的提示类型:
- 重构建议提示:“建议对以下代码片段进行改进,以获得更好的可维护性。”
- 优化识别提示:“识别以下系统组件中性能优化的潜在领域。”
- 新兴技术提示:“讨论边缘计算对当前系统架构的潜在影响。”
Prompt engineering提供了一种通用而强大的方法来增强软件架构过程,将其优势扩展到设计阶段之外。通过在各个阶段整合人工智能生成的输出,解决方案架构师可以简化开发过程,优化系统性能,并确保他们的解决方案能够适应未来的变化。成功的关键在于尝试各种提示类型,并利用人工智能的能力在旅程的每一步提供有价值的见解和支持。
解决方案架构师可以针对未来的变化设计更快、更高效、适应性更强的软件解决方案。通过利用人工智能生成的提示,架构师可以提高生产力,更有效地协作,并提供满足用户需求的高质量设计。及时的工程设计是释放解决方案架构的全部潜力并彻底改变我们构建软件的方式的关键。
- 160 次浏览
【软件架构】最佳软件架构书籍终极榜单(2024)
视频号
微信公众号
知识星球
在这篇文章中,我为您列出了2024年应该阅读的最佳软件架构书籍。

软件架构是软件产品成功开发的基础。
一个精心设计的软件架构可以对系统的质量产生很大的影响。它还可以帮助降低出错的风险,并使将来添加新特性和功能变得更容易。
在这篇博客文章中,我为您列出了2024年应该阅读的最佳软件架构书籍,以及2024年将出版哪些有趣的软件架构书籍。
当然,这些书中的大多数也是2023年最好的软件架构和设计书籍之一。
我希望这份软件架构师书籍清单能帮助你找到你需要学习更多关于软件架构的书籍,并成为一名更好的软件架构师。
这篇文章可能包含附属链接。作为亚马逊、Manning和O'Reilly的关联合伙人,我通过符合条件的购买获得收入。
2024年你应该阅读的最好的软件架构书籍(TL;DR):
- Fundamentals of Software Architecture
- Continuous Architecture in Practice
- Software Architecture: The Hard Parts
- The Software Architect Elevator
- Building Evolutionary Architectures
- Software Architecture in Practice
- Software Architecture For Developers
- Communication Patterns
- Architecture Modernisation
- Software Architecture and Decision-Making
- Software Architecture Metrics
- Enterprise Integration Patterns
- Designing Data-Intensive Applications
- Sustainable Software Architecture
2024年软件架构新书:
- Head First Software Architecture
- Collaborative Software Design
- Facilitating Software Architecture
- Building Multi-Tenant SaaS Architectures
2024年最佳软件架构书籍
软件架构基础
一种工程方法
马克·理查兹和尼尔·福特
这本书是一本全面的软件架构指南,由经验丰富的从业者撰写。它涵盖了软件架构的各个方面,从架构特征和模式到组件确定、绘制和呈现架构图、进化架构和软技能。

这本书是在现代背景下写的,考虑到了该领域的最新创新。它还强调了工程实践和操作方法在软件架构中的重要性。
这本书对于有抱负的和现有的软件架构师来说都是必读之作。它全面概述了该领域以及取得成功所需的技能。
实践中的连续架构
Continuous Architecture in Practice
敏捷时代的软件架构与DevOps
Murat Erder、Pierre Pureur和Eoin Woods
《实践中的连续架构》是一本关于敏捷、DevOps和云平台时代的软件架构的书。作者Murat Erder、Pierre Pureur和Eoin Woods分享了他们丰富的经验,并为在现实世界环境中利用连续架构方法提供了实践建议。

Continuous Architecture in Practice
这本书涵盖了广泛的主题,包括:
- 创建符合功能要求和质量属性的可持续、连贯的系统
- 将基于团队的软件架构和架构理解为“决策流”
- 解决数据管理、集成和更改的关键问题
- 针对安全性、可扩展性、恢复能力、性能和新兴技术构建架构
这本书还包括一个从开始到结束的案例研究,展示了作者对复杂软件环境的深刻体验。
这本书对于那些想要更新架构实践以应对新的软件挑战的技术人员来说是一个宝贵的资源。对于想要了解更多关于连续架构的知识的软件架构师和软件工程师来说,这也是一本很好的书。
软件架构:难点
Software Architecture: The Hard Parts
分布式架构的现代权衡分析
作者:Neal Ford、Mark Richards、Pramod Sadalage和Zhamak Dehghani

Software Architecture: The Hard Parts
软件架构是一个复杂的领域,没有简单的决策。这本书提供了批判性思考分布式架构中所涉及的权衡的策略。
作者利用一个关于Sysops Squad的虚构故事,研究了以下关键主题:
- 服务粒度
- 工作流和编排
- 管理和脱钩合同
- 分布式事务
- 可扩展性、弹性和性能
通过关注常见问题,本书提供了帮助架构师发现和权衡他们面临的权衡的技术。
所涵盖的具体主题包括:
- 分析权衡并有效记录决策
- 就服务粒度做出更好的决策
- 了解拆分单片应用程序的复杂性
- 管理和分离服务之间的合同
- 在高度分布式的架构中处理数据
- 学习在分解应用程序时管理工作流和事务的模式
对于那些希望对分布式架构做出更好决策的软件架构师来说,这本书是一本宝贵的资源。
对于想要了解更多关于设计和构建分布式系统所涉及的挑战和权衡的软件工程师来说,这也是一本很好的书。
软件架构师Elevator
The Software Architect Elevator
重新定义架构师在数字企业中的角色
作者Gregor Hohpe
在数字经济中,软件和IT架构师的角色正在发生转变。架构师需要将组织和技术知识结合起来,以实现公司结构和流程的变革。他们需要将IT机房连接到顶层公寓,在那里定义业务战略。这本书分享了现实世界中的建议和从实际IT转型中汲取的经验教训。
它是软件架构师、高级开发人员、企业架构师、CTO和It经理的理想选择。

The Software Architect Elevator
这本书的主题包括:
- 塑造公司的技术方向
- 协助组织转型
- 浏览技术和组织主题
- 制定影响组织工作方式的IT战略
- 学习在大规模转型中哪些有效,哪些无效
对于任何想在组织中扮演更具战略性角色的IT专业人士来说,这本书都是一本宝贵的资源。
构建进化架构
Building Evolutionary Architectures
自动化软件治理
作者:Neal Ford,Rebecca Parsons,Patrick kua&Promod Sadalage
这本书提供了关于如何创建可以随时间发展的软件架构的实用建议。它是由经验丰富的软件架构师编写的,他们对现代软件开发的挑战有着深刻的理解。
这本书很及时,因为它解决了软件行业的两个关键趋势:对快速交付和质量的需求不断增加,以及软件架构师角色的变化。

这本书充满了务实和深刻的建议,对所有软件工程师和架构师来说都是一个宝贵的资源。
如果你是一名软件工程师或架构师,这本书是必读的。它将帮助您构建更好的软件,以满足不断变化的世界的需求。
实践中的软件架构
作者:Len Bass、Paul Clements、Rick Kazman
《实践中的软件架构》(Software Architecture in Practice),第四版,是一本永恒的经典而全面的软件体系架构指南。它涵盖了软件架构的整个生命周期,从设计到实例化再到分析再到进化再到管理。
这本书由三位著名的软件架构师撰写,共更新了十一章,涵盖了该领域的最新趋势,如移动、云、能源管理、DevOps和量子计算。
这本书提供了实用指南、专家方法和测试模型,可用于任何软件项目,无论多么复杂。它还解释了如何使用架构来优化关键质量属性,如性能、可修改性、安全性、可用性、互操作性、可测试性、可使用性、可部署性等。

Software Architecture in Practice
此外,本书还介绍了如何管理和完善现有架构,对其进行转换以解决新问题,以及构建可重用的架构,使其成为战略业务资产。
总的来说,对于任何想了解该领域最新趋势和最佳实践的软件架构师来说,《实践中的软件架构》第四版都是必不可少的资源。
面向开发人员的软件架构
Software Architecture For Developers
技术领导力与灵活性的平衡
西蒙·布朗
面向开发人员的软件架构是现代软件架构的实用指南,专门针对软件开发人员。

Software Architecture for Developers
本书涵盖以下主题:
- 软件架构的本质。
- 为什么软件架构的角色应该包括编码、指导和协作。
- 在编码之前,您真正需要考虑的事情。
- 如何使用C4模型可视化您的软件架构。
- 一种轻量级的软件文档化方法。
- 为什么敏捷和架构之间没有冲突。
- “刚好够”的前置设计意味着什么。
- 如何通过风险风暴识别风险。
通信模式
开发者和架构师指南
作者Jacqui Read
Jacqui Read的《通信模式》一书为利益相关者和团队提供了一个有效沟通软件架构的实用指南。它强调了清晰、简洁和可访问的沟通在确保每个人都理解和支持架构方面的重要性。

本书首先讨论了通信在软件开发中的重要性。然后,它将继续涵盖与通信软件架构相关的各种主题,包括:
- 为不同的受众和项目阶段设计图表和文档
- 创建可访问的文档和图表
- 掌握技术环境中的书面、口头和非口头交流
- 将通信模式应用于真实世界的项目和软件设计
- 与分散的团队进行沟通和协作
这本书充满了建设性的例子和模式,可以应用于各种软件开发项目。
对于任何想要学习如何有效地沟通软件架构的人来说,这是一个必不可少的资源。
软件架构度量
提高架构质量的案例研究
作者:Christian Ciceri、Dave Farley、Neal Ford、Andrew Harmel Law、Michael Keeling、Carola Lilienthal、Joao Rosa、Alexander von Zitzewitz、Rene Weiss和Eoin Woods
软件架构度量是一本实用的书,介绍了每个软件架构师都应该知道的度量。
这不是一本关于理论的书,而是一本关于实践和实施的书。这本书是由从业者为渴望探索成功案例研究的软件架构师和软件开发人员撰写的。

本书涵盖以下主题:
- 如何衡量您的软件架构在多大程度上满足了您的目标
- 如何选择正确的指标进行跟踪(并跳过不需要的指标)
- 如何提高可观测性、可测试性和可部署性
- 如何确定软件架构项目的优先级
- 如何构建富有洞察力和相关性的仪表板
这本书由10位杰出的从业者撰写,分享了关键的软件架构指标,以帮助您设置正确的KPI并衡量结果。
架构现代化
软件、战略和结构的社会技术一致性
Nick Tune与Jean-Georges Perrin

Book Architecture Modernization
架构现代化:软件、战略和结构的社会技术一致性是一本关于如何将软件架构与业务领域、组织设计、团队拓扑和公司战略相一致的书。它提供了具体的工具、技术和流程,以帮助组织发展其软件、团队和业务战略,从而充分发挥其潜力。
这本书涵盖了广泛的主题,包括:
- 将架构、业务域和团队拓扑设计为面向业务战略的独立价值流
- 规划和领导一项渐进式现代化倡议
- 提升组织中的架构实践以创造持久的变革
- 利用协同产品开发技术,如Event Storming和Wardley Mapping
- 使用原理、启发法和实践技术对域和子域进行建模
这本书是为软件架构师、工程师和其他想要学习如何使其软件和组织现代化的专业人士而写的。对于想要了解软件架构如何支持其业务目标的业务领导者来说,这也是一个宝贵的资源。
软件架构与决策
Software Architecture and Decision-Making
利用领导力、技术和产品管理打造卓越产品
作者:Srinath Perera
《软件架构与决策》是一本教软件架构师如何在面对不确定性时做出更好决策的书。这本书提供了一个基于五个关键问题和七个重要原则的决策框架。它还强调了强大的领导力和产品管理知识对软件架构师的重要性。

Software Architecture and Decision-Making
这本书是为软件行业的所有技术领导者准备的,他们对自己构建的系统做出全面的判断,也为未来学习这门技术的领导者准备的。
企业集成模式
Enterprise Integration Patterns
设计、构建和部署消息传递解决方案
Gregor Hohpe和Bobby Wolf
企业集成模式是设计和实现消息传递解决方案的宝贵资源。它提供了65种模式的目录、真实世界的例子和一个案例研究,以说明实践中的模式。

Enterprise Integration Patterns
这本书还涵盖了企业集成的新兴标准和未来趋势。它提供了一个一致的词汇表和可视化表示框架,用于描述不同技术之间的集成解决方案。它深入研究了异步消息传递架构的优点和局限性,并就设计应用程序到消息传递系统接口提供了实用的建议。它指导您确定消息发送、路由和监视策略。如果您想有效地管理和维护消息传递系统,这本书是一本重要的指南。
设计数据密集型应用程序
Designing Data-Intensive Applications
可靠、可扩展和可维护系统背后的大创意
作者:Martin Kleppmann
Martin Kleppmann的《设计数据密集型应用程序》是软件工程师和架构师的实用指南,他们希望了解设计和部署数据密集型的应用程序所涉及的原则和权衡。这本书涵盖了广泛的主题,包括关系数据库、NoSQL数据存储、流处理和批处理。它还讨论了可扩展性、一致性、可靠性和效率方面的挑战。

Designing Data-Intensive Application
关键要点:
- 本书通过考察每种方法的优缺点,帮助您了解数据处理和存储技术的多样性。
- 它提供了对支撑这些技术的基本原理的深入了解,使您能够对应用程序的架构做出明智的决策。
- 您将学习如何理解不同数据处理模式之间的权衡,以及如何平衡可扩展性、一致性和性能的需求。
- 这本书深入探讨了现代数据密集型应用程序的分布式系统研究。
- 它提供了主要在线服务的真实例子,以说明这些原则在实践中的应用。
如果你正在研究数据密集型应用程序,这本书是了解这个不断发展的领域的挑战和机遇的宝贵资源。
可持续软件架构
Sustainable Software Architecture
分析和减少技术债务
作者:Carola Lilienthal博士
今天的软件开发主要是维护和重构遗留系统。本书就如何重构单片系统、应用架构和设计模式、使用分层架构以及采用领域驱动的设计和微服务提供了实用建议。

Sustainable Software Architecture
作者Carola Lilienthal在重构300多个软件系统方面拥有丰富的经验。这本书借鉴了她的专业知识,并提供了真实世界的例子来说明她的建议。
这本书以200多幅彩色图像为特色,帮助读者将概念形象化,并有效地应用作者的建议。
读者可以通过提供的实用建议和建议,将作者的知识直接应用到日常工作中。
2024年软件架构新书
以下几本有趣的软件架构书籍最终将于2024年出版。
Head First软件架构
Head First Software Architecture
架构思维的学习指南
拉朱·甘地、马克·理查兹和尼尔·福特
Head First软件架构是对软件架构世界的快速而简单的介绍。它教你如何从架构上思考,并探索软件架构的独特挑战。您将通过生动有趣的示例了解架构和设计之间的区别,代码、组件和架构风格之间的关系,以及如何使用一些常见的架构风格。这本书还使用了视觉丰富的格式来吸引你的思维,创造多感官的学习体验。

Head Firrst Software Architecture - A Learner's Guide to Architectural Thinking
为什么这本书不同?
Head First软件架构不同于其他软件架构书籍,因为它基于认知科学和学习理论的最新研究。它使用视觉丰富的形式来吸引你的思维,创造多感官的学习体验。这意味着你将能够比传统的重文本书籍更快、更容易地学习新概念。
谁应该读这本书?
Head First Software Architecture是一本很好的书,适合那些正在寻找快速进入软件架构的软件开发人员。对于任何想了解更多关于软件系统是如何设计和构建的人来说,这也是一本好书。
协同软件设计
如何促进领域建模决策
作者:Evelyn van Kelle、Gien Verschatse和Kenny Baas Schwegler
协作软件设计:如何促进领域建模决策是一本关于如何让所有利益相关者参与软件设计过程的书。它提供了促进富有成效的决策会议的工具和技术,即使在与不同的商业和技术利益相关者群体打交道时也是如此。

Collaborative Software Design
本书涵盖以下主题:
- 使用商业模型画布、事件风暴、示例映射和Wardley映射等工具准备和促进协作建模会话
- 启发式方法在建模软件设计中的选择与应用
- 结构化、可视化和制定可持续的软件设计决策
- 从团队中获得所有所需见解的最佳实践
- 应对阻力
- 在建模课程中提高对偏见和排名的认识
- 建模会话后跟进的最佳实践
- 记录会议并向利益相关者报告
这本书强调了协同建模在软件设计中的重要性。协作建模是一种将利益相关者直接纳入决策过程的高效方法。它使用流程可视化、参与式会议和社会动态管理来确保每个人都在为共同的目标做出贡献。
这本书还就如何克服协作软件设计中的常见挑战,如阻力、偏见和冲突,提供了实用的建议。
促进软件架构
Facilitating Software Architecture
授权团队做出架构决策
Andrew Harmel Law
由于复杂的系统和分布式团队,传统的软件架构师角色变得不那么有效。架构师和开发人员需要一种新的方法来在系统架构上进行有效的协作。本书提供了一种将软件架构和开发结合在一起的方法论。

这本书涵盖了理解现代软件交付动态,培养决策,以及创建一种适合组织文化的方法。它还指导识别和预防故障模式。
构建多租户SaaS架构
Building Multi-Tenant SaaS Architectures
使用AWS的原则、实践和模式
Tod Golding
本书全面概述了SaaS架构和开发,重点介绍了构建多租户SaaS应用程序的挑战。作者Tod Golding是AWS的全球SaaS领导者,他带来了丰富的经验。

Building Multi-Tenant SaaS Architectures
这本书涵盖了广泛的主题,包括:
- SaaS架构模式和策略的前景
- SaaS环境的移动部分
- 通过真实世界SaaS解决方案的视角构建多租户
- 多租户微服务
- 支持一系列工作负载和租户体验的设计和架构策略
- 构建强健的多租户SaaS产品的基本原则
- SaaS架构模式,包括租户隔离、嘈杂的邻居、分层、入职、身份和数据分区
这本书是以实用的风格写成的,面向希望了解更多关于如何设计和构建强大SaaS解决方案的SaaS构建者和架构师。
总之,这本书对于任何认真构建SaaS应用程序的人来说都是必读之作。它以全面和实际的方式涵盖了所有重要的主题。
- 879 次浏览
【软件架构】架构与设计InfoQ趋势报告 - 2019年1月
关键要点
- 我们看到了对“进化架构”设计的更多需求,这种架构建立在先前关于可替换性设计和需要关注架构中“胶水”组件的讨论的基础之上。进化架构支持功能和跨功能需求和约束的未来变化。
- 对“微服务”架构风格的认识可能正在进入后期多数,但“正确设计分布式系统”的相关主题,以及反应性和容错性的设计并未沿着采用曲线进行。
- 我们推测,有些架构主题永远不会沿着采用曲线转移到早期多数或晚期多数,不幸的是,它们包括几种针对特定用例的高效模式,如基于事件溯源/ CQRS或基于Actor模型系统。
- 我们越来越多地将“架构师”的角色视为越来越注重技术领导力,架构模式识别和框架意识,以及处理跨领域问题的设计。
- 虽然我们认为术语“无服务器”可能含糊不清,但我们很欣赏有可能将重点放在设计事件驱动系统以及自动消除某些平台问题的可能性上,如果这是正确实现的
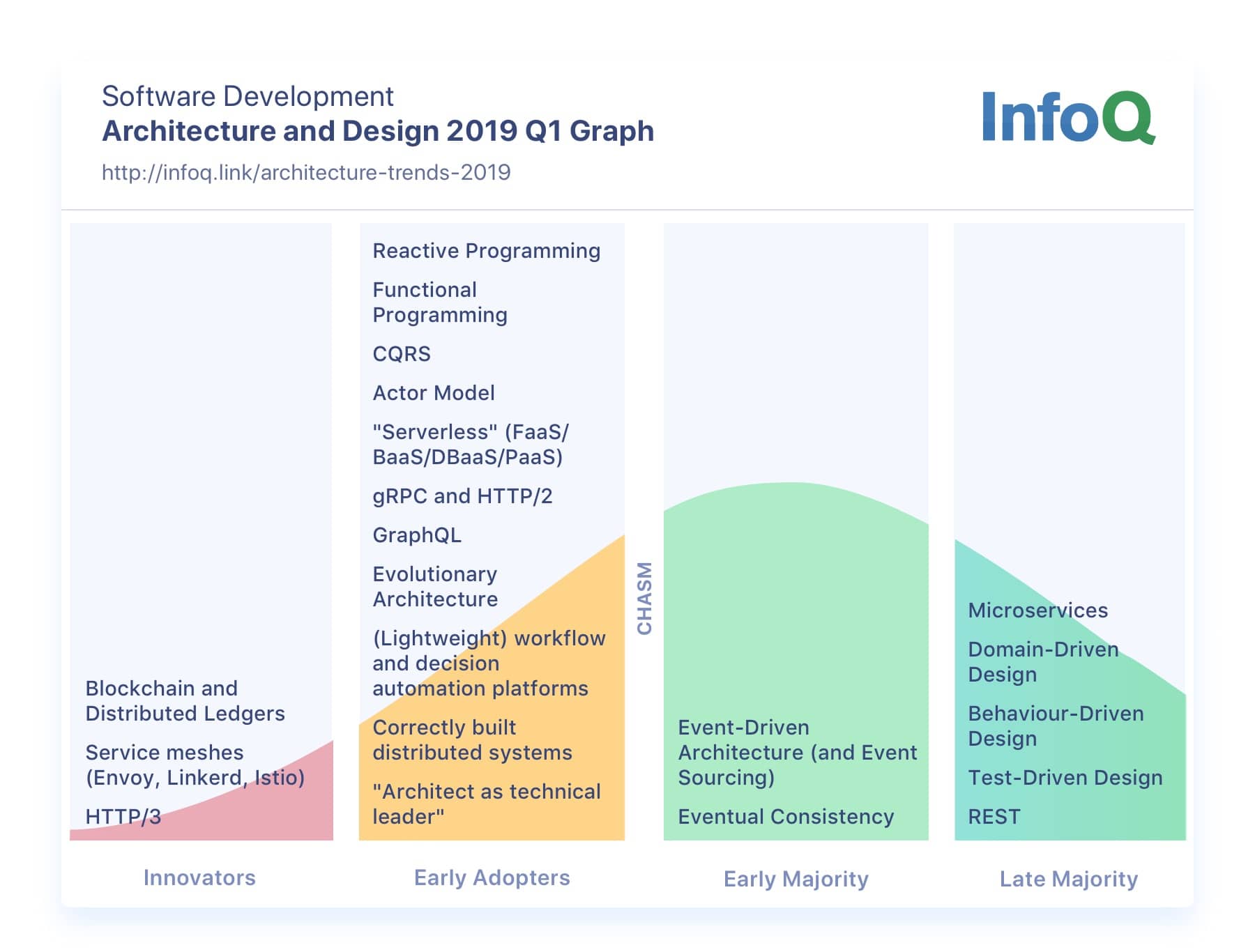
InfoQ和QCon都关注我们认为属于“创新者,早期采用者和早期多数阶段”的主题。我们尝试做的是确定适合Geoffrey Moore所谓的早期市场的想法,其中“客户群由技术爱好者和有远见的人提供,他们希望领先于机遇或迫在眉睫的问题”。我们也在寻找可能“跨越鸿沟”的想法,以便更广泛地采用。在这种情况下,或许值得一提的是,技术在采用曲线上的确切位置可能会有所不同。例如,湾区公司在这一点上广泛采用微服务,但在其他地方可能不太广泛采用,也许不太合适。
本文概述了我们目前如何看待“架构和设计”(A&D)领域,该领域侧重于基础架构模式,技术框架中模式的实现,以及软件架构师必须培养的设计流程和技能。
自我们上次审查这一主题以来的显着变化包括“微服务”进入后期多数,但我们的内部讨论还强调,“正确设计分布式系统”的密切相关的主题,以及反应性和容错性的设计并不是沿着采用曲线。对于Gartner炒作周期,我们可能正在接近微服务“幻灭的低谷”的底部。
我们还推测,架构领域永远不会沿着采用曲线走向早期多数或晚期多数,不幸的是,它们包括几种高效模式 - 例如基于事件溯源/ CQRS或Actor 模型 - 基于系统 - 可以为某些组织和业务问题提供高效的解决方案。
虽然我们认为“无服务器”一词略显模糊,但我们很欣赏将重点放在设计模块化,事件驱动系统以及自动化几个底层操作平台问题的可能性上。在一个相关主题上,我们还看到围绕对支持未来需求和约束变化的演化架构的需求的更多讨论。
我们越来越多地看到“架构师”的角色正在变得更加专注于软技能,例如技术领导,除了现代技术技能,如架构模式识别和框架感知,以及处理跨领域问题的设计。
对于上下文,这是2018年下半年主题图的样子.2019版本位于文章的顶部。

以下是三个InfoQ架构和设计主题编辑之间相应内部聊天记录的轻微编辑副本,它为我们在采用图上的推荐定位提供了更多上下文。
Daniel Bryant,独立技术顾问,Datawire产品架构师和InfoQ新闻经理:
作为十人的首发,我认为HTTP2转向早期采用者(EA),HTTP3进入创新者。 GraphQL(以及可能的gRPC)可能是EA(或创新者?)。我也认为Chaos Engineer属于DevOps队列。微服务可能是晚期多数(LM),BDD,DDD和TDD也是如此。
我很想看到“进化架构”出现在某个地方 - 可能是EA?那么“架构师作为技术领导者”(强调角色的非技术演变)呢?
我有兴趣听听您的想法,并询问我们是否需要移动,添加或删除主题?
Jan Stenberg,IT顾问,在.Net / C#和JVM / Java平台上构建系统超过25年:
我认为架构与设计(AD)在某种程度上与我们在InfoQ上讨论的其他主题不同。
在AD中,我们没有新的或更新版本的架构的常规基础。相反,由于新的工具,框架或智能架构使其成为可行,现有的想法再次流行,并且可能打包和品牌化。
我们也有可能适合两个队列的区域。在更高级别,它们可能适用于AD,而更多技术部分适用于另一个队列。我认为无服务器就是一个例子,在更高层次上它是AD的一个重要领域,技术部分可能属于云队列。微前端和类似技术是另一个例子,它是AD还是HTML5和JavaScript?
还有一些我认为永远不会在EM或LM中出现的领域或架构,不幸的是,它们包括我最喜欢的几种架构,如基于事件源/ CQRS或基于Actor模型的系统。我认为他们在可预见的未来将是少数人使用的小众架构。我不确定我们应该如何应对这些问题,也许它们会在架构师和开发人员不再谈论它们时消失?
所以,我对AD未来的看法(或许我的希望):
- 无服务器。从我去年听过的演讲中,我的印象是,这将越来越自动化,对底层基础架构的工作量减少。
- 像Camunda这样的工作流程平台。我认为它们在具有更复杂业务逻辑的微服务或分布式系统中非常重要。
- 事件溯源/ CQRS。我希望它会变得更加主流。可能是EA或EM。
- 事件驱动的体系结构。 EA或EM。
- Actor 模特/反应。去年我和Vaughn Vernon讨论了这件事,他相信有一天它会成为主流,但我对此持怀疑态度。
- 进化架构很有趣,我认为EA是正确的。
- 混沌工程。是的,通常它是DevOps,从AD角度讨论主题的演示可能是一个例外。
- GraphQL和类似的工具是I或EA我认为,取代REST(希望也正确实现)。
- 架构师为技术领导者。我一直在与家里的各种架构师会面,其中许多人的主要工作是让商业/政府领域专家了解他们自己的领域。但也许它更像是一个敏捷队列故事?
- 微服务是LM。 (我认为微服务很快将成为“今天的SOA”。许多人正在以一种好的方式使用它们。太多人将标签放在分布式整体上)。
- DDD是晚期的多数,但我希望它仍然是InfoQ的一个有趣的主题。
- BDD是迟到的多数或相当“迟到的少数民族”
- TDD仍然有一些或多或少有趣的讨论。太少或太多,单元测试或黑盒测试,Ice-cream cone 或什么,但LM,至少。
当我在日常生活中遇到架构师,开发人员,领域专家和其他人,而不是在会议和类似的活动中,我经常意识到我们在这里讨论的许多概念对于他们来说是未知的或非常分散的,这也使得他们看到了InfoQ的好处。我记得大约两年前我在开发者大会(我认为是在加拿大)听过的一个演讲,其中Vaughn Vernon询问了多少人对DDD有所了解,大约一半的观众举起了手。
当我开始为InfoQ编写时,我写了一些关于框架和库的更新,我认为这些功能可能会影响架构,但随着时间的推移,我的写作越来越集中在有趣的博客文章和演示文稿上,只有几个项目关于像Axon,Akka和其他我认为与特定架构密切相关的框架。
在QCon会议期间进行这种讨论会很棒。
InfoQ主编Charles Humble:
我和Vaughn Vernon一起关于Actor 模特 - 并认为它很可能成为主流 - 直接或通过消息传递等方式。在JVM领域,Akka在推广这种方法方面做得很好,基于消息传递的系统长期以来一直是在金融系统中像Actor 一样做事的流行方式。
Actor 似乎很容易被人们掌握和推理,也是处理大规模并行工作的好方法。我希望看到Ponyas周围的势头成为一个现代的,基于Actor 的系统的例子,但我不得不说我认为这不太可能。
关于进化架构,我有兴趣听到马丁福勒去年在播客上谈到这个问题,并且他参加了极端编程。我很期待阅读这本关于Thoughtworks的书。
Thomas Betts,IHS Markit首席软件工程师和InfoQ Architecture Queue负责人:
在很高的层面上,我同意丹尼尔提出的大部分内容。 Jan是正确的,一些架构模式非常适合主题图的自然进展,而其他架构模式可能永远不会超越早期采用者阶段,因为它们不是广泛适用的。
我有时会对A&D与InfoQ上的其他主题之间的重叠感到困惑,尤其是文化与方法。我想是责怪康威定律。关于架构的很多内容都归结为通信 - 进入和离开系统的外部通信点是什么?我的内部服务将如何相互通信?如何保存和访问我的数据?
在许多方面,公司回答这些问题的方式以及他们可以选择的选项将基于他们在A&D和C&M的采用生命周期曲线上的位置。我想说A&D是等式的技术方面,而C&M是非技术性的,但这似乎过于简单化了。此外,技术实现可能会落入开发和/或语言队列中。 A&D处于两者之间的软弱处,处理交叉问题,希望为如何实施该系统提供指导。
我将停止哲学咆哮,并添加一些具体的讨论要点。
- 无服务器 - 虽然我个人不喜欢这个术语,因为它似乎没有任何特定的含义,无需服务器,可能在EA中。
- 反应性 - 可能是EA。我认为反应式架构会变得更加普遍,因为开发人员熟悉反应式编程,特别是在JavaScript中。那可能是尾巴摇着狗。
- DDD - 虽然DDD本身可能会转向LM,但有许多衍生创意与DDD密切相关,并且在I或EA中。例如,事件溯源值得提及为EA / LM。但是,我不认为很多这些子主题可以包含在AD主题图中。
- 微服务 - 在那里使用“无服务器”作为一个常被滥用或误解的术语。我认为这是在广泛采用方面进入后期多数,但可能只是EA用于稳固的分布式架构。
- 分布式系统 - 我不认为将其作为主题图上的项目是有效的,因为它太宽泛了。但是我想看到我们谈论设计时考虑到分布。像反应性和容错性这样的想法对于强大的分布式系统至关重要,而这种方式在整体结构中并不重要。这将是在A&D主题图上留下混乱的论点。
我完全支持在QCon上进行这次讨论!
InfoQ编辑团队的建立是通过招聘和培训专家从业者来撰写新闻和文章,并分析当前和未来的趋势。通过编辑页面申请成为编辑,并参与对话。
原文:https://www.infoq.com/articles/architecture-trends-2019
讨论:知识星球【数字化和智能转型】
- 225 次浏览
【软件架构】软件工程师和架构师的平面设计
视频号
微信公众号
知识星球
如果你在软件工程或技术领域工作,你可能会看到这样的图表:
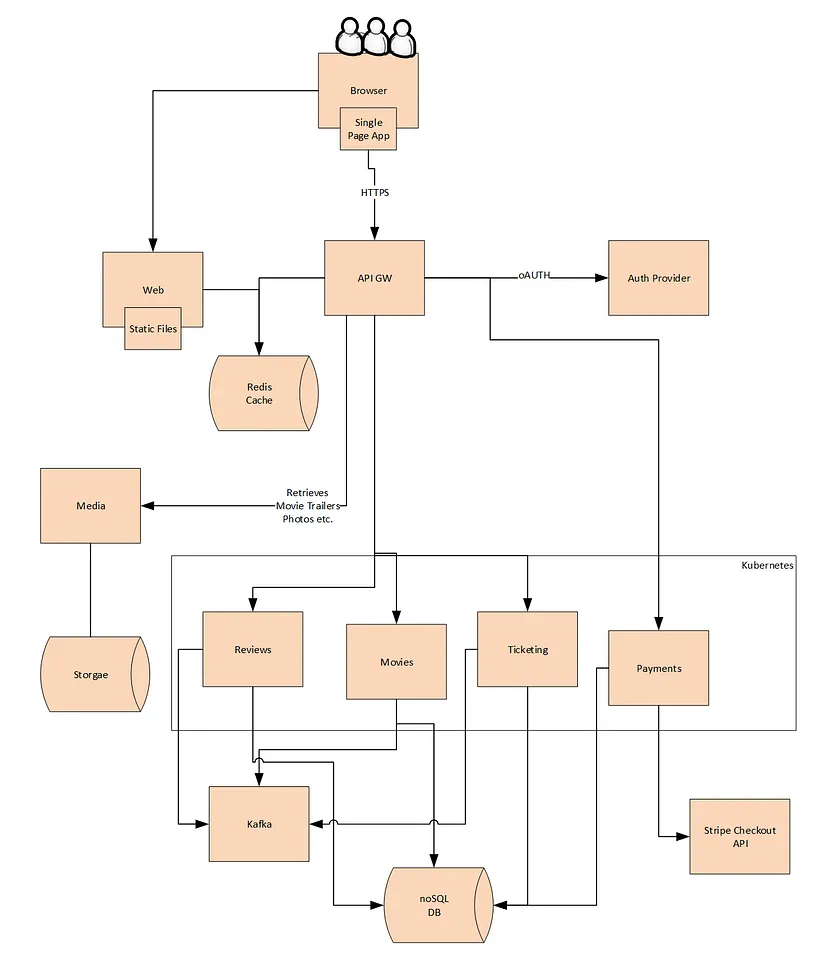
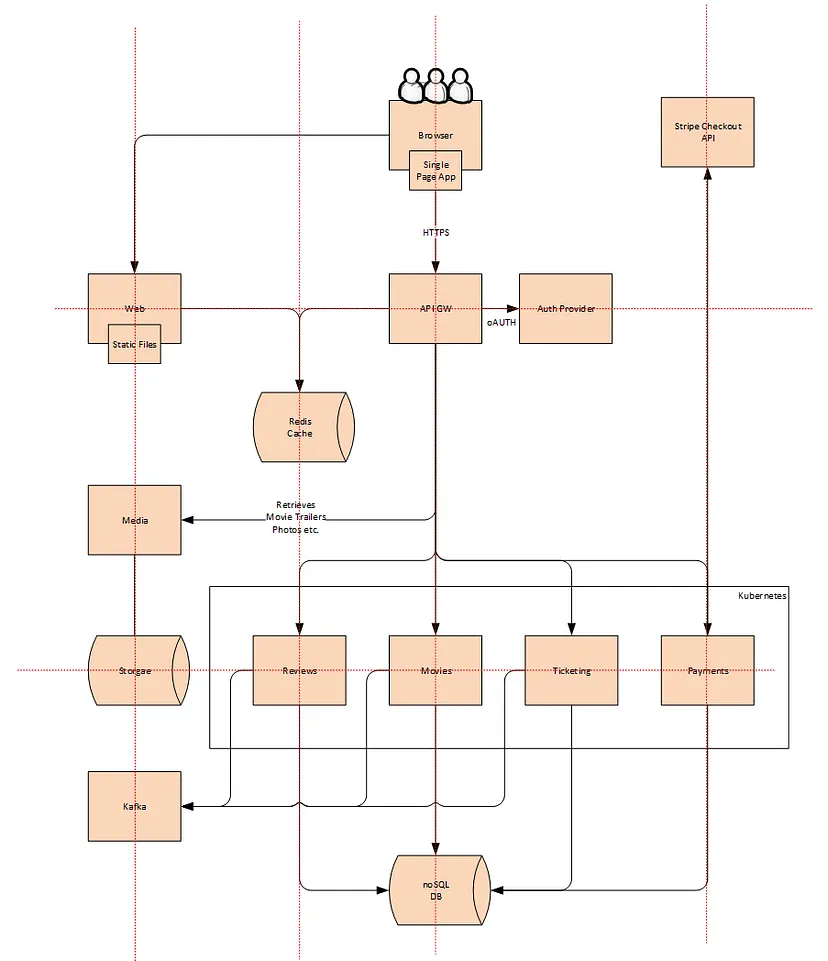
你可能是这样一张图表的作者,却没有发现任何错误。一切都在那里——服务、箭头、一些协议信息等等。你很理解它,因为你画了它,但你的观众,他们看到的是一个由纠缠的箭头组成的鸟巢里的十几个米色盒子。让我们把你的图表和你的代码一样干净,并把它们变成这样:
为什么平面设计在软件设计中很重要
“一张照片胜过1000个字”这句古老的谚语在今天仍然适用,尤其是在技术环境中。作为一名软件工程师或架构师,你的职责是有效地将技术解决方案传达给其他工程师、领导层、客户等。你在图表中传达的信息越多,就越不需要用语言来解释。
不是写或说,
浏览器向APIGW发出请求,然后APIGW将请求代理到一个或多个后端服务
为什么不把它想象出来呢?
图表还说明了最终解决方案,包括所有涉及的组件,即“大局”
最重要的是,它可以给你的解决方案带来“感知质量”。换句话说,如果它看起来不错,人们会认为它很好,即使这是一个坏主意。
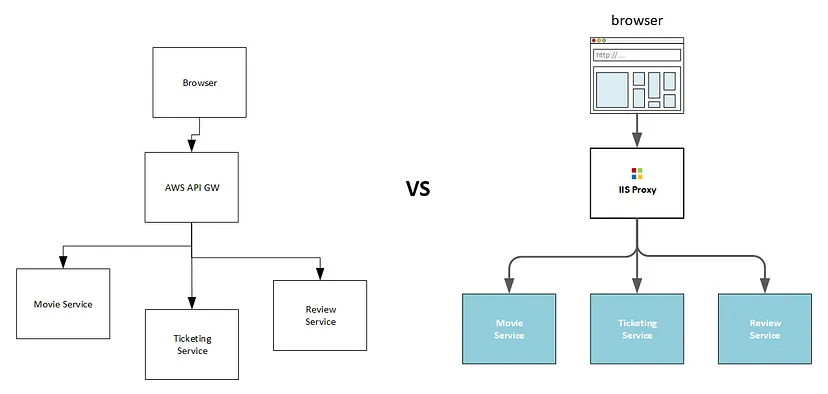
什么是糟糕的设计?
再看第一张图,不讨人喜欢的方面,即设计的“坏”部分是:
- 注意力不集中。所有元素都使用默认的颜色、线条等。
- 混乱的线路。图中的线条需要努力。
- 没有明确的关系。哪些组件是相似的,哪些显然是独特的?
- 没有畅通的水流。通过体系结构的主要流程是什么,次要流程是什么等等。?
创建更好的图表
让我们接受这个糟糕的设计,并将其构建到最终结果中,发现在工作中关心设计和视觉交流的更多好处。
对齐和组合
制作一个糟糕的图表并使其变得更好的第一步是清理对齐和组合。尽最大努力将元素彼此对齐,并通过“解开”图表来消除不必要的线交叉。
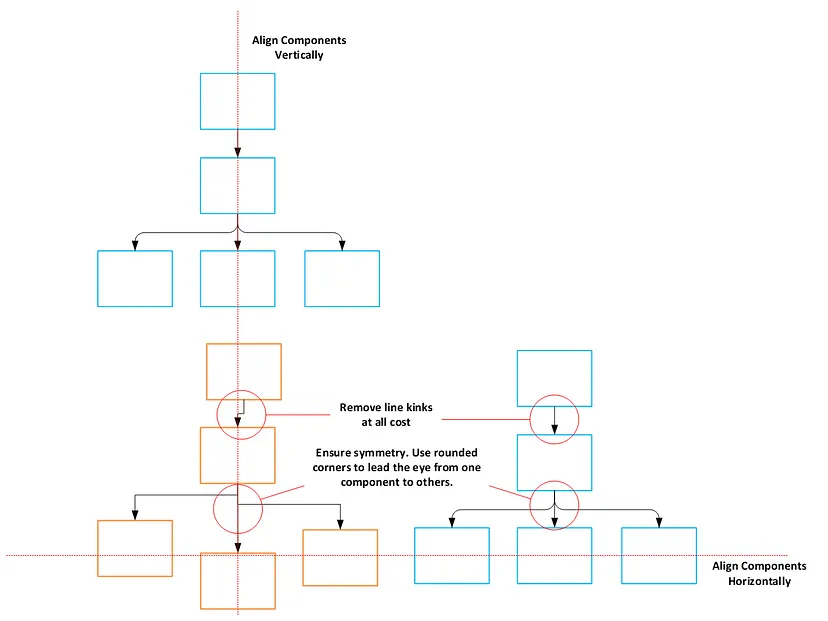
以下是将这些更改应用于全局时的情况:
颜色和意义
颜色是图表的一个重要方面。它可以传达组件之间的关系,“统一”,或者表示某些组件是唯一的。
此外,我总是努力使图表的方框或组件与它所代表的技术或公司的颜色相同。
Redis是红色的,容器是蓝色的。我给盒子上色,你也应该。

以下是将颜色应用于大图的效果:
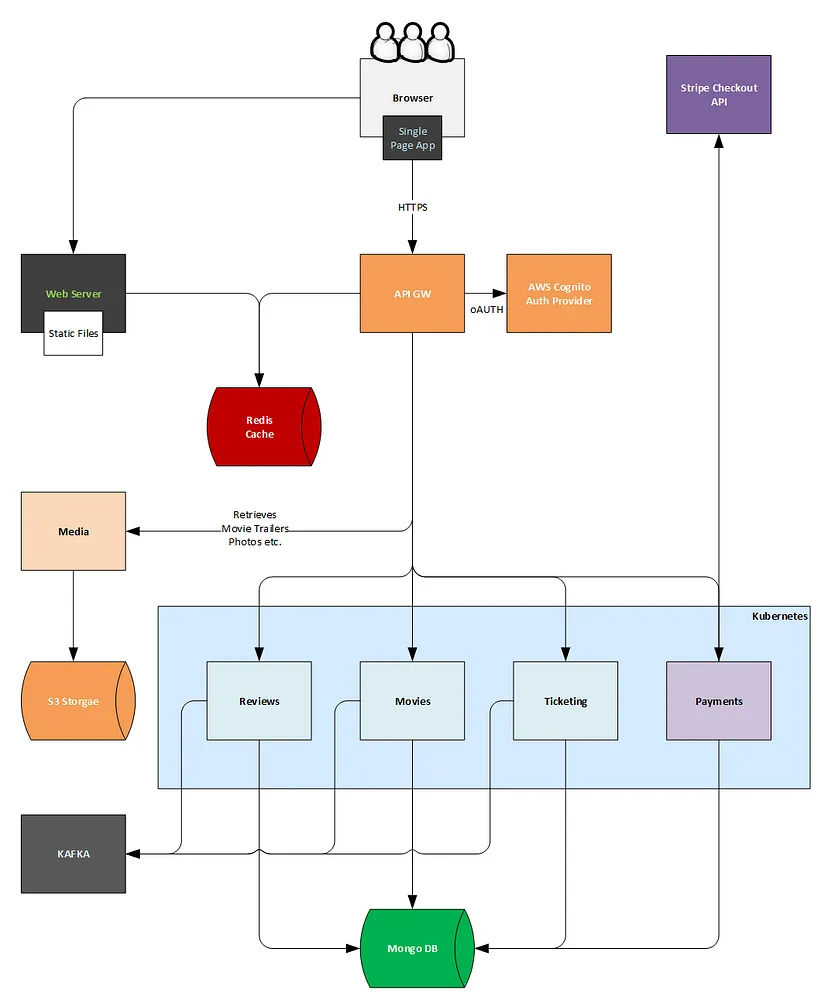
有效地使用形状
形状也起着至关重要的作用,就像颜色一样。它们可以统一或隔离设计中的某些组件。同样重要的是,不要通过引入混合风格来降低您的设计。
如果你的设计非常“扁平”,在Viso中挖掘出旧的用户图标可能看起来很诱人,但如果你找到一个更适合你的图表,那就更好了。

以下是如何将有效的形状应用于全局:
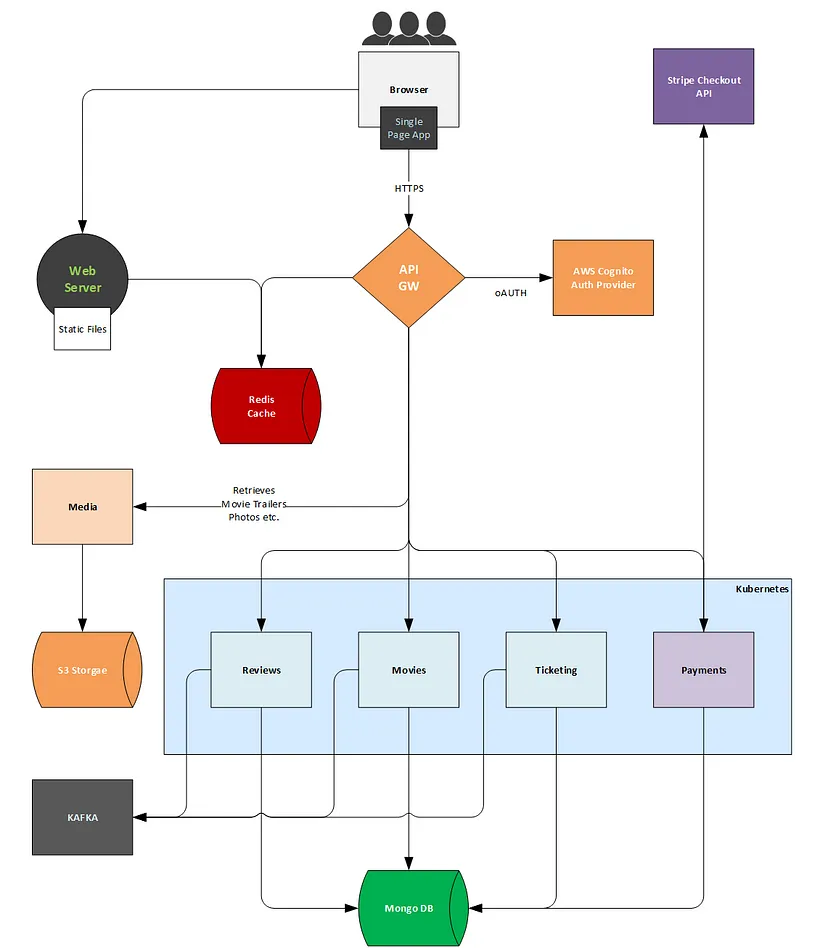
视觉流动,引导眼球
如果您的关系图很复杂并且有很多交互,那么应该始终突出显示主要流或主流。它通常源于客户或最终用户,并终止于他们想要的东西,例如数据。
使用更大胆、更生动的线条将向观众显示您想要突出显示解决方案中的主要流程。以下是在主站点和辅助站点之间进行平衡的负载平衡器示例:
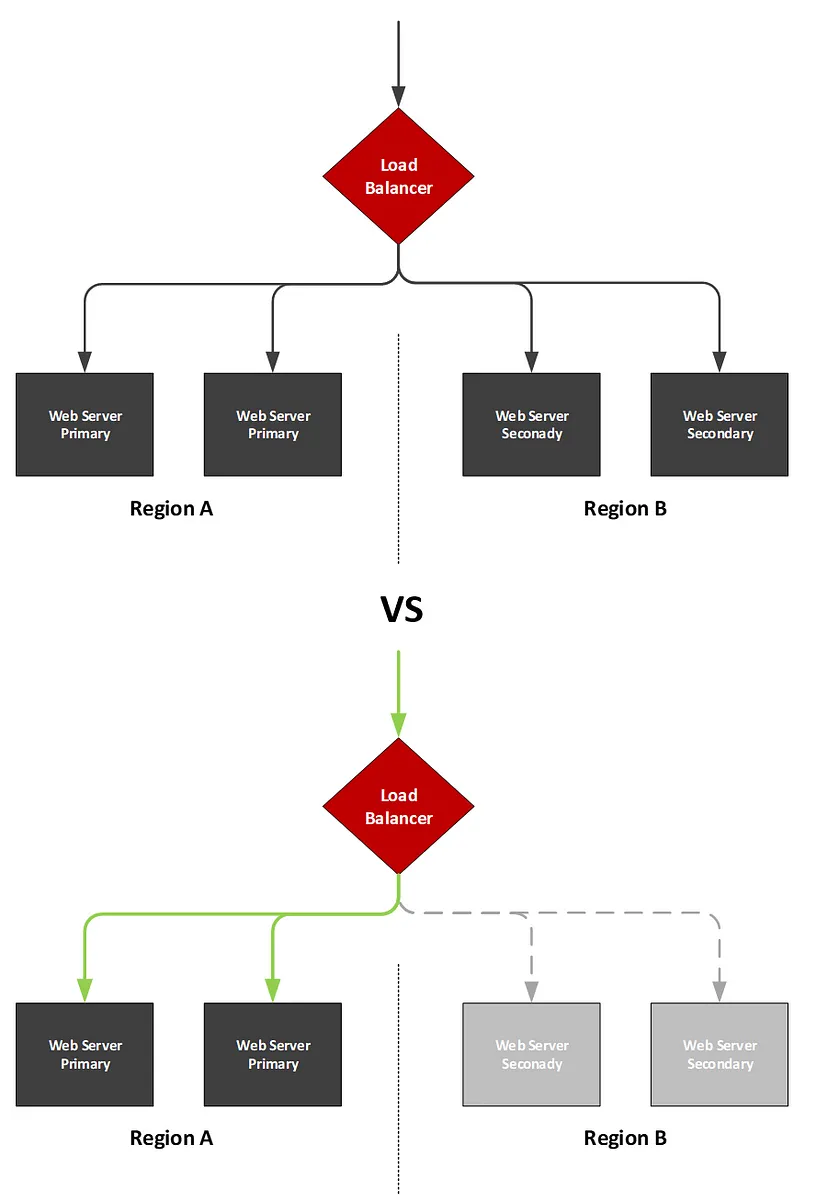
这就是当你把它应用到全局时的样子:
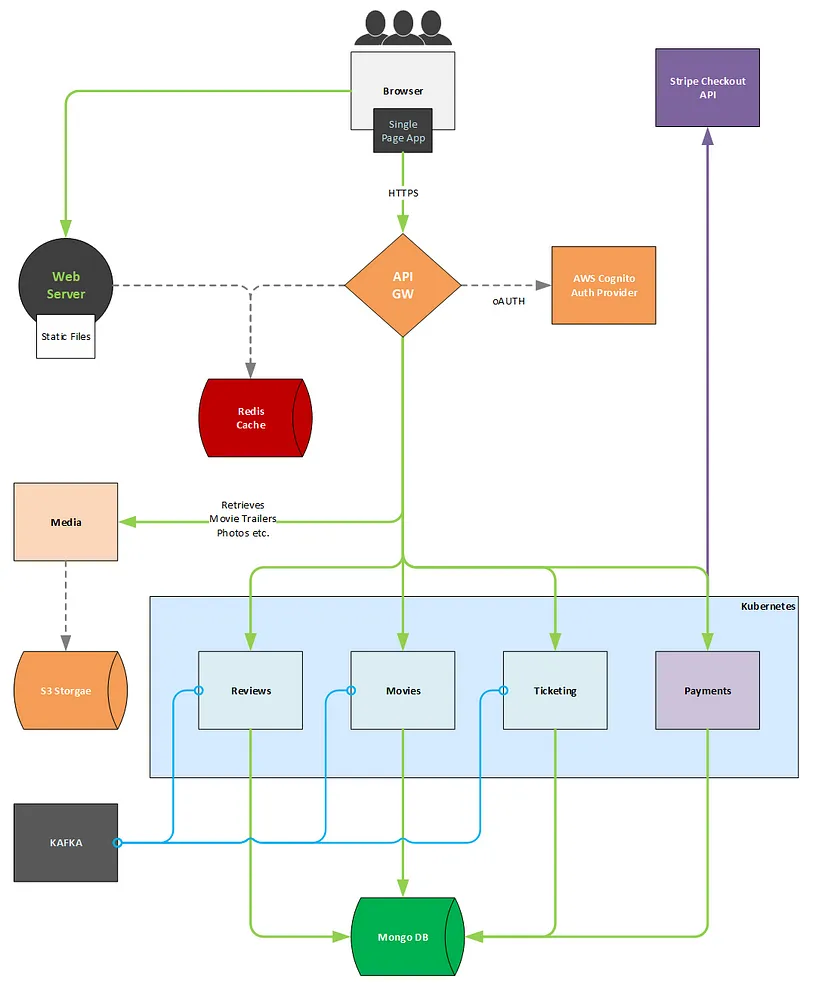
设计中的怀疑论
(使其与所代表的事物相似)
skeumorphism是一种巧妙的设计技术,为用户或观众提供熟悉感。一个典型的例子是当你在iPhone上打开记事本应用程序时;它看起来像一个你熟悉的记事本。
您可以通过将方框转换为更真实的/概念性的表示来传达设计中的熟悉感。
例如,如果它是一台服务器,那么让它看起来像一台服务器。如果是Kubernetes,那么,Kubernete是一个开发人员将容器“部署到”上的平台,所以一个带有正方形的平表可以帮助传达这一点。
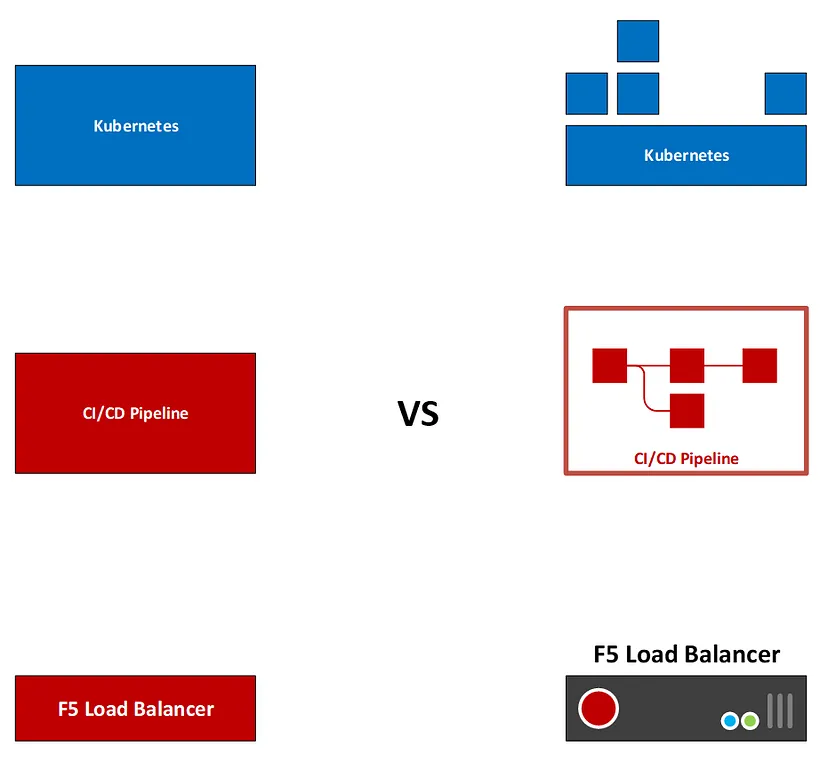
以下是skeomorphism应用于更大图片时的外观:

构建自己的形状
通常,你在一个非常基本的应用程序中工作,如PowerPoint、Viso、Gify等。这些程序可能没有你想要的东西,或者如果它们有,它就不符合你的风格。
您可以使用基本形状轻松创建自己的形状和图标。
代表计划和未来状态
随着时间的推移,您的解决方案可能会在演示之间发生变化。您可能希望在图表中添加新的组件或更改,但重要的是要确保这些尚不存在的新项目或组件能够很好地可视化表示。以下是几种方法:
- 使用虚线表示流动,使用造型线表示尚未构建的事物。
- 避免将新服务着色为与现有服务相同的颜色。使用稍微浅一点的阴影。
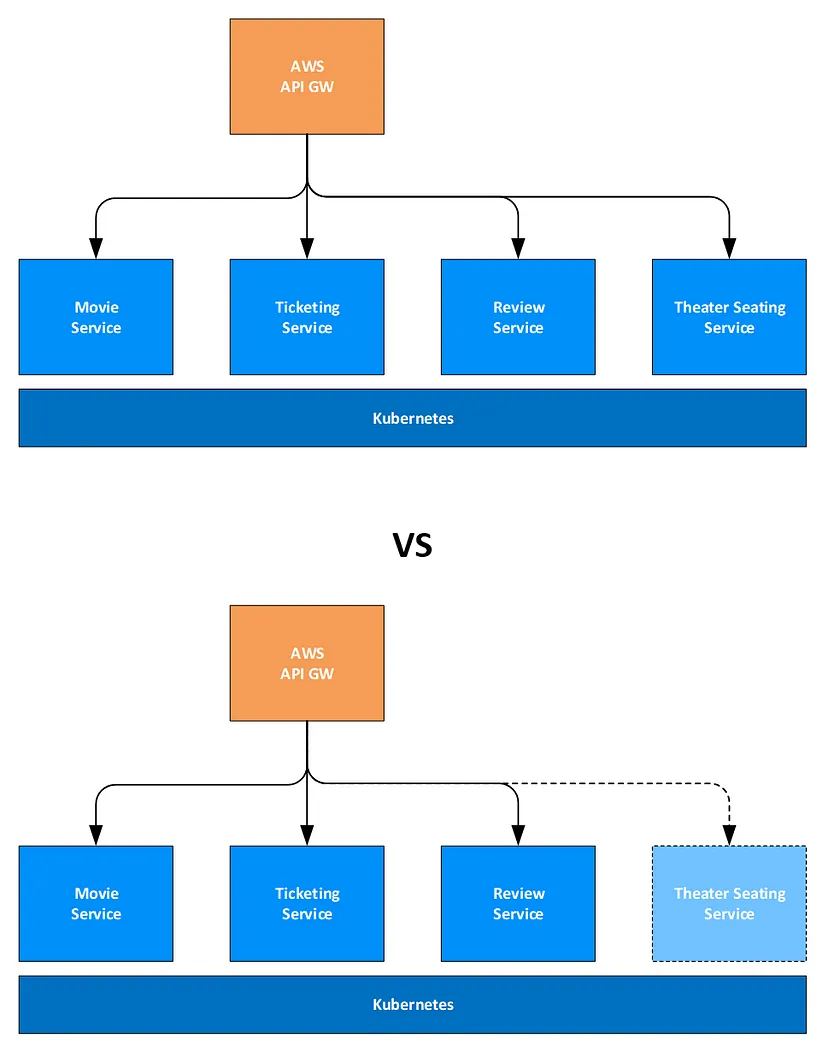
让我们将此新组件添加到现有解决方案中:
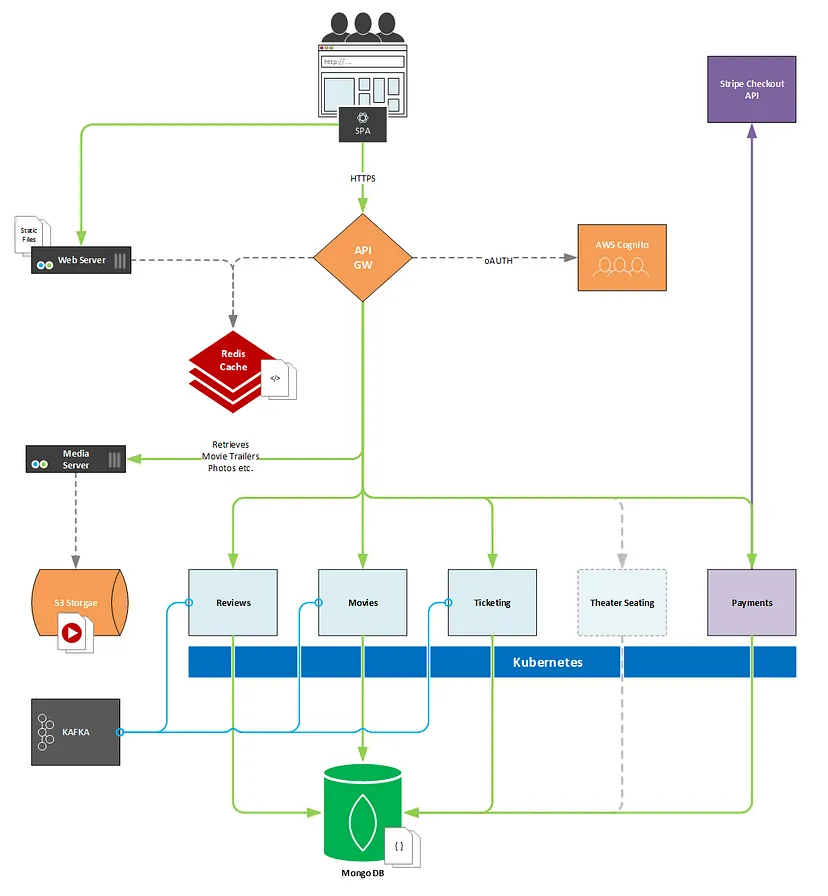
强制聚焦
当你想迫使你的听众专注于你的解决方案的特定部分时,你可以把除了你的焦点之外的一切都模糊掉。
这在做演示时非常棒。你展示了解决方案,点击下一张幻灯片,然后突出显示一些非常具体的东西,这样你的注意力就不会集中在哪里了。一旦谈论完它,你就可以“重新打开颜色”,并显示一个正常的图表。
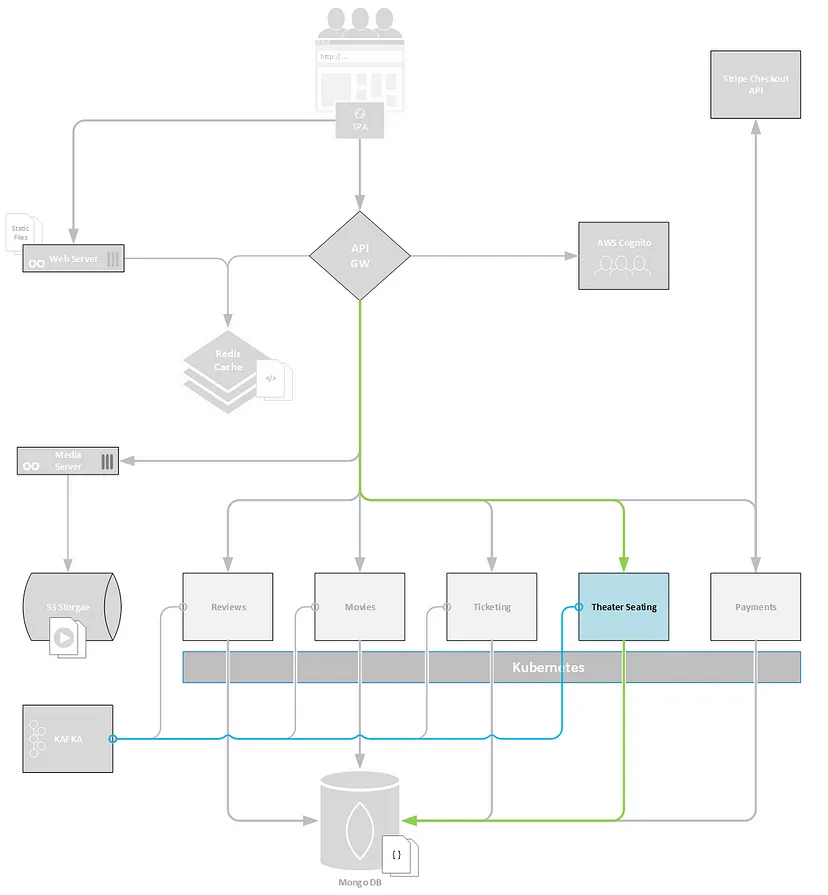
注释和注释
评论和注释可以在视觉效果的同时提供另一层细节。添加额外但微妙的信息可以让你的图表为你做更多的对话。它还可以让你的观众在想深入了解的情况下深入了解,或者在不需要这种信息的情况下完全忽略他们。
评论和注释不应为纯黑色;最好使用中灰色或一些微妙的颜色,以免引起太多注意。
以下是如何应用它们:
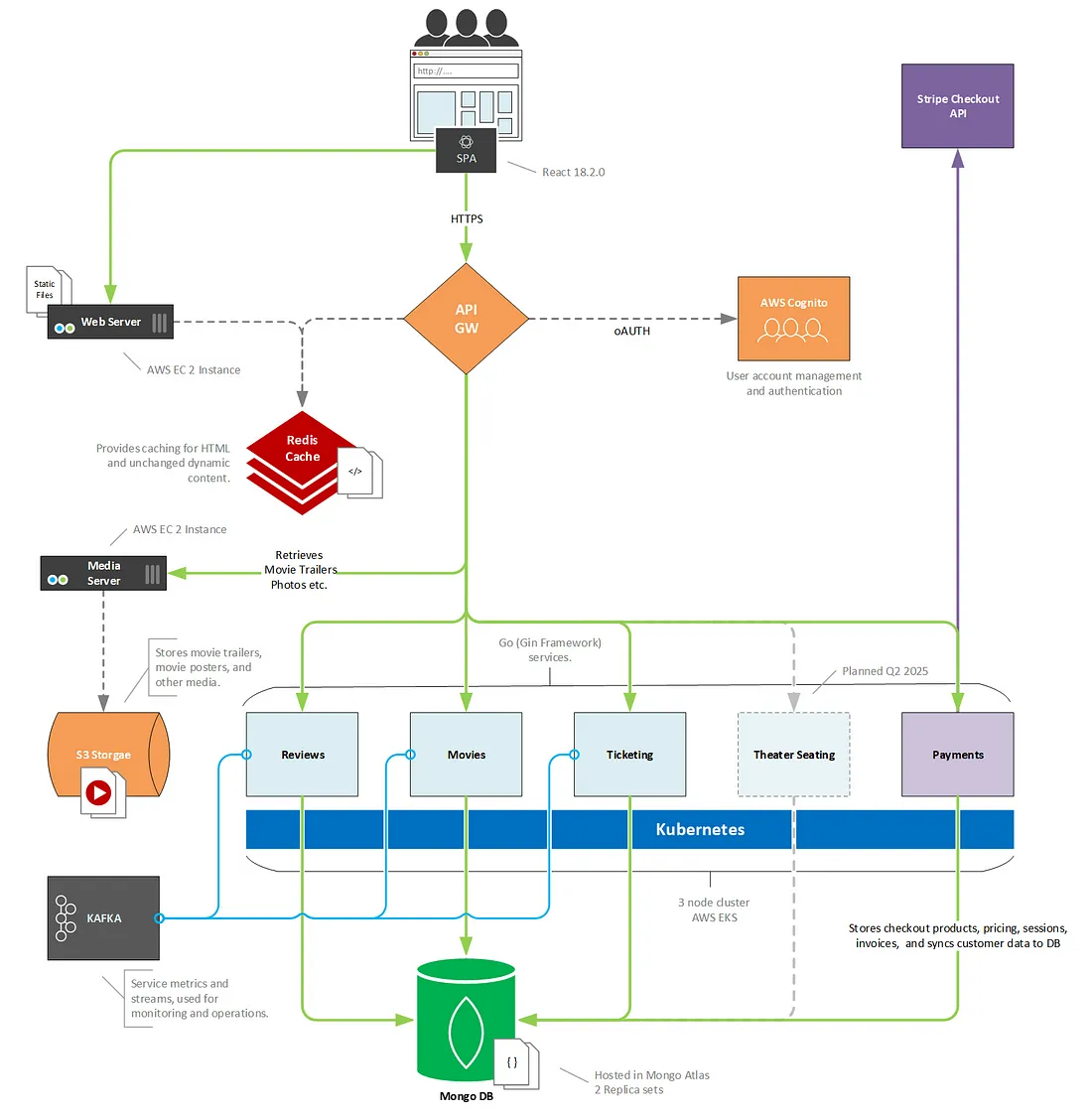
将工作努力与图表联系起来
我们经常采用一个完整的设计,并在一些敏捷过程中从中创建Epic、Features和Stories。作为一名首席工程师,我喜欢走得更远,通过圈出关键部分并用Epic、Feature或Story标记它们,将敏捷带回图表中。
这样做可以清楚地了解哪些工作与解决方案的哪个部分相关,作为领导者,我可以很容易地将图表“分割”为其他开发人员的工作。
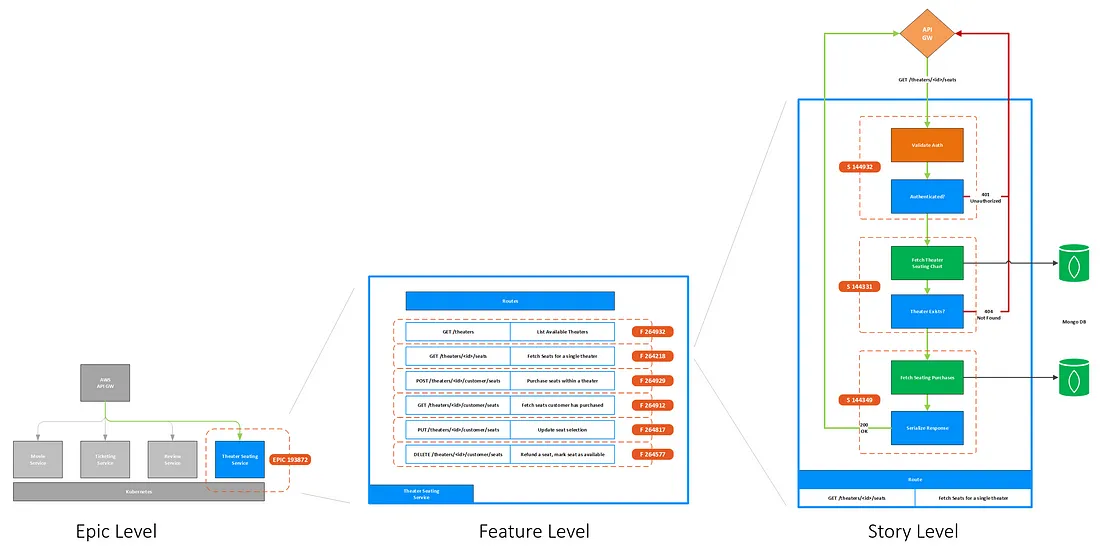
更多设计技巧
以下是其他设计技巧,可供您将其纳入图表中:
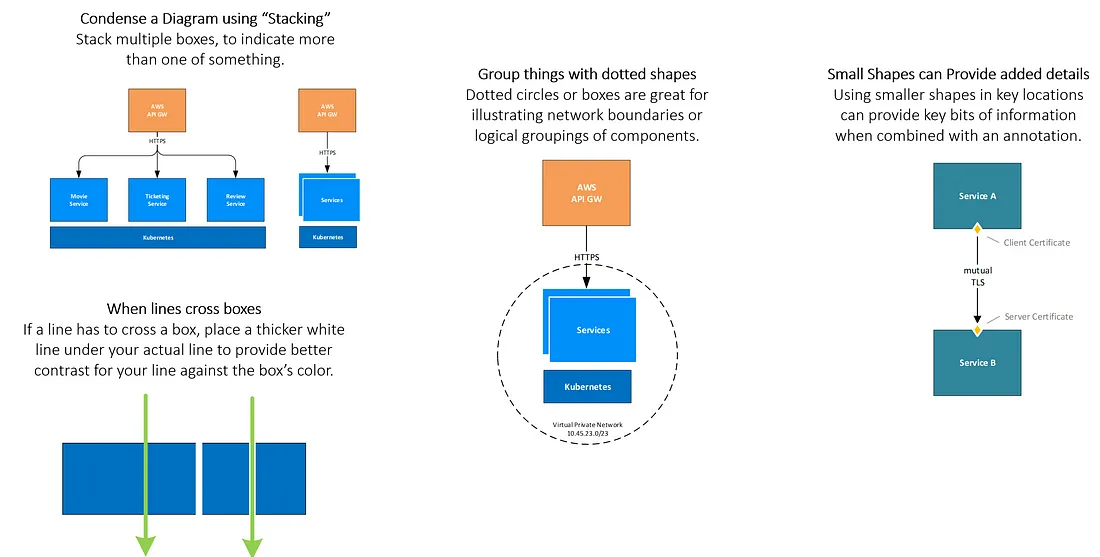
Different diagram types I use
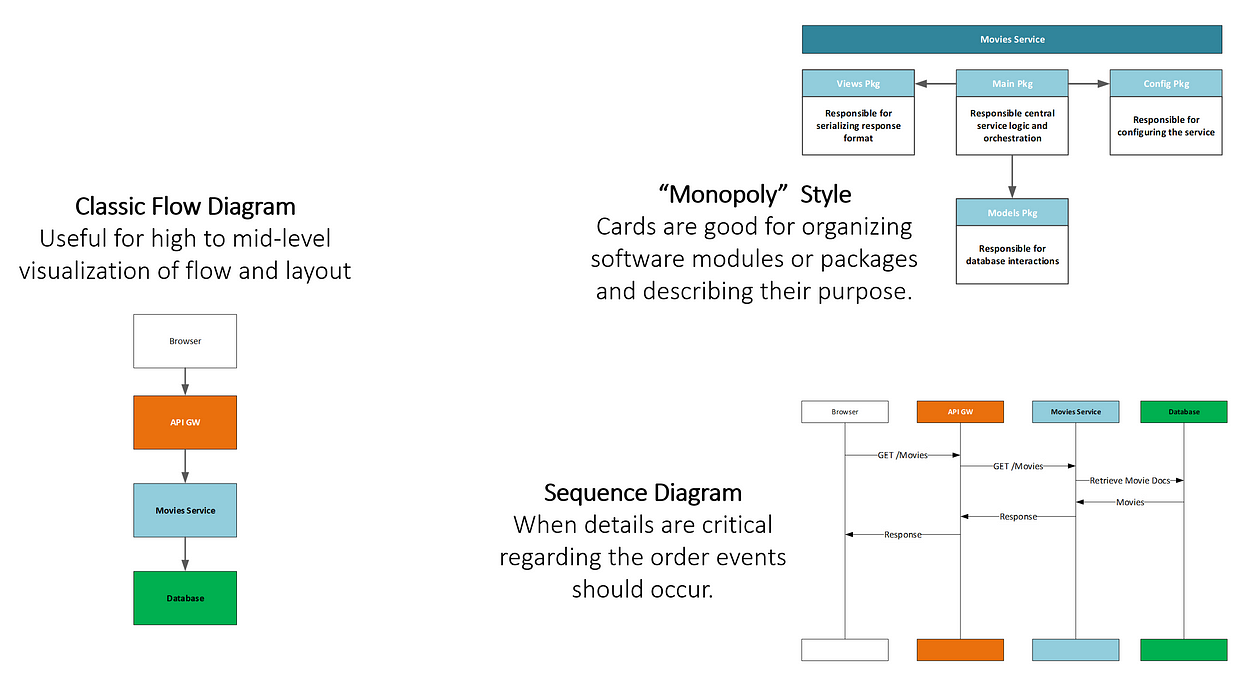
结论
我希望你已经学会了一些方法,让你的下一个设计在向同事、同事或领导层展示时脱颖而出。
设计可以传达质量、对细节的关注以及其他积极的属性,你甚至在拿起代码编辑器之前就希望你的软件与之相关。
最后,使用设计将敏捷过程重新引入到图表中,可以让你消除困惑,在规划会议中找到差距,让你的开发人员有信心理解他们的工作在“大局”中的位置
- 147 次浏览
【软件架构】软件架构和设计 InfoQ 趋势报告—2021 年 4 月
关键要点
- 在云原生世界中,架构师正在重新确定他们认为最重要的事项的优先级。创新的架构师正在设计弹性、可观察性、可移植性和可持续性。
- Dapr 和开放应用程序模型是使构建分布式系统更容易的两种方法,观察它们在未来如何被采用将会很有趣。
- 在单体应用和微服务之间摇摆到极端之后,钟摆似乎要停止了。因此,无论底层技术如何,架构师都依赖于专注于高内聚和低耦合的成熟模式和设计。
- 在完全远程的工作环境中,架构师正在寻找与团队沟通的新方式,并寻找有助于收集知识的饮水机聊天的替代品。
- 下一代 GraphQL 功能,尤其是 GraphQL 联合和 GraphQL 微服务,正在展示公司大力采用 GraphQL 之后的下一步发展方向。
/filters:no_upscale()/articles/architecture-trends-2021/en/resources/1Architecture-2021-1618415938711.jpg)
每年,InfoQ 的编辑都会讨论软件架构和设计的当前状态,并确定需要关注的关键趋势,从而产生这份报告和随附的图表。今年,我们让您在 InfoQ 播客的一集中收听讨论。 IBM 企业战略团队的创新领导者 Holly Cummins 和 QCon 的前任发言人也加入了编辑的行列。
为___设计
我们首先看看哪些“-ilities”对架构师来说最重要。软件架构师负责横切关注点,并确保大型系统的各个组件可以无缝协作以实现总体目标。在 2021 年,我们认为架构师关注的四个领域是弹性设计、可观察性设计、可移植性设计和可持续性设计。
弹性设计对于现代分布式系统至关重要,其中任何单个组件都可能出现故障,而整个系统应保持可用。在许多方面,正在实施的想法并不新鲜——随着分布式系统和模块化架构越来越普遍,它变得越来越重要。 Daniel Bryant 提到了 David Parnas 在 1970 年代所做的工作,以及 Michael Nygard 最近的著作《Release It!》,作为有关断路器、超时、重试和弹性系统的其他基本要求的想法的良好来源。新的是寻找跨系统解决这些问题的方法,例如使用云原生服务网格,甚至在 Dapr 等框架上构建。
在采用曲线的下方,异步编程技术和事件驱动架构的采用一直在稳步增长。这种采用是实现异步模式的较低准入门槛和提高系统弹性的内置优势的结果。
然而,事件驱动架构和异步系统的另一面,一般来说,它们仍然难以推理和理解。这与可观察性设计的兴起有关。很多时候,可观察性被视为一种运行时需求——我们能否判断系统是否按预期运行?但是,对于架构师来说,可观察性作为设计时的需求变得越来越重要——我们能理解复杂系统中发生的所有交互吗?
2021 年,创新者正在寻找几乎自动提供运行时和设计时可观察性优势的方法。通过消除开发人员必须手动实现可观察性非功能性需求的负担,系统大图中缺少关键组件的可能性变得更小。这将导致能够使用可观察性来创建准确的、生动的架构图,以及相应的系统心智模型。
架构师的另一个重点领域是设计可移植性,无论是多云还是混合云。在大多数情况下,架构师没有理由为实现真正的多云可移植性或避免供应商锁定而设计最低公分母。然而,尤其是在企业收购时,CTO 更有可能拥有在不同的托管环境中运行的系统,包括 AWS、Azure、GCP 和本地。在做出有关标准化的决策时,架构师需要选择他们的战斗。
Holly Cummins 谈到了可持续设计的主题,这是新的创新趋势之一。这种情况正在出现,因为人们意识到软件行业的碳使用水平与航空业相当。其中一些几乎可以直接衡量,因为计算使用的账单与能源消耗高度相关。 CTO 和架构师可以通过减少不必要的计算使用或利用更可持续的云托管选项来产生影响。一些云数据中心使用 100% 的绿色能源运行,而弗吉尼亚州的数据中心则使用煤炭供电。如果延迟不是问题,那么在冰岛而不是弗吉尼亚举办可能是有意义的。虽然许多公司纯粹出于经济原因希望降低托管成本,但有些公司选择将可持续性作为优先事项,并相应地构建和部署他们的系统。
正确构建的分布式系统
微服务的主题在趋势图中稳步移动,并且在一段时间内被归类为晚期主流趋势,因为构建分布式系统变得更加容易。然而,我们继续看到一些反对过度使用微服务作为解决所有问题的尝试。在某些情况下,这导致了重大逆转,例如回到单体应用。随着钟摆停止摆动,似乎我们终于为大多数系统设置了一种理智的方法。
围绕构建分布式系统或模块化单体的一些趋势都回到了基本的架构原则,例如高内聚和低耦合。领域驱动设计虽然被认为是一种晚期主流趋势,但仍然受到寻求上下文映射和识别系统边界的良好指导的架构师的重视。同样,C4 模型对于创建分层架构图集以帮助理解您的系统非常有用。
数据架构
InfoQ 继续在软件架构和数据架构之间的重叠中看到创新。去年添加到图表中的数据网格今年仍然是创新趋势。它由数据网关加入,这有点像 API 网关,但专注于数据方面。由于微服务导致了多语言持久层,API 网关提供抽象、安全、扩展、联合和合同驱动的开发功能。
架构师的角色
我们将继续关注软件架构师在其组织中所扮演的角色。除了传统的“盒子和箭头”职责之外,架构师还担任其他团队成员的技术领导和导师。架构师还需要能够与许多观众进行交流,Gregor Hohpe 将其描述为乘坐架构师电梯——与 CTO 和其他高管交谈,然后前往机房与开发人员一起工作。
对于许多团队来说,由于大流行以及许多公司采用了长期的远程工作策略,沟通方式被打乱了。这意味着架构师失去了通过渗透学习的能力,仅仅是因为他们可以和开发人员坐在同一个房间里偷听对话。在这有帮助的地方,它导致了更多的书面交流,无论是在 IM 聊天室,还是在架构决策记录中,并保持最新,因为团队经常引用它们。领先的架构师正在寻找方法来利用完全远程团队的限制来发挥自己的优势,并因此创建更好的软件设计。
其他主题
Dapr 和开放应用程序模型 (OAM) 都是微软在 2019 年底推出的。OAM 是一种用于定义云原生应用程序的规范,专注于应用程序,而不是容器或编排器。同样,Dapr 是一个具有可插拔组件的框架,旨在简化云原生开发。尽管微软参与了他们的创建,但两者都是开源项目,可以在任何云提供商上工作,而且 Dapr 可能会成为 CNCF 项目。 Dapr 和 OAM 都还没有被大规模采用,因此显然是值得关注的创新趋势。
WebAssembly 是另一个创新趋势。对于架构师来说,看看它是否只是作为 Web 框架和移动开发的补充,或者系统是否会在设计时考虑到 WebAssembly,以及这将如何体现,将会很有趣。
关于 GraphQL 的最后一点,它在去年跨越了趋势图上的鸿沟。从那时起,对于下一代 GraphQL 功能,尤其是 GraphQL 联合和 GraphQL 微服务,出现了创新,特别是在 Netflix。正如微服务造成的蔓延导致了管理这种蔓延的新模式一样,对于在 GraphQL 上投入巨资的公司来说,他们需要 GraphQL 联合来帮助管理新的复杂性。这不是每家公司都会遇到的问题,但了解并了解它在未来的发展方向仍然很有用。
- 56 次浏览
【软件架构】软件架构样式和模式列表
架构模式是一种通用的、可重用的解决方案,用于解决给定上下文中软件架构中常见的问题。架构模式通常被记录为软件设计模式。
架构样式目录
- 三层
- 多层体系结构
- 模型视图控制器
- 领域驱动设计
- 微内核
- 黑板模式
- 传感器控制器执行器
- 表现-抽象-控制
架构风格目录
结构
- 基于组件
- 整体应用
- 分层的
- 管道和过滤器
- 微服务
共享内存
- 以数据库为中心
- 黑板
- 基于规则
消息传递
- 事件驱动 aka隐式调用
- 发布订阅
- 异步消息传递
自适应系统
- 插件
- 微内核
- 反射
- 特定于域的语言
分布式系统
- 客户机服务器(2层、3层、n层展示了这种风格)
- 无共享架构
- 基于空间架构
- 对象请求代理
- 点对点
- 代表性状态转移(REST)
- 面向服务架构
- 云计算模式[2]
原文:https://en.wikipedia.org/wiki/List_of_software_architecture_styles_and_patterns
本文:http://jiagoushi.pro/node/960
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 122 次浏览
【软件架构】软件架构概述
视频号
微信公众号
知识星球
软件架构(architecture)是指软件系统的基本结构以及创建这种结构和系统的规程。每个结构都包含软件元素、它们之间的关系以及元素和关系的属性。[1]软件系统的架构是一个隐喻,类似于架构物的架构。[2]它作为系统和开发项目的蓝图,布置设计团队需要执行的任务。[3]
软件架构(architecture)是指做出基本的结构选择,一旦实现,改变这些选择的代价是高昂的。软件架构(architecture)选择包括软件设计中可能出现的特定结构选项。例如,控制航天飞机运载火箭的系统要求非常快和非常可靠。因此,需要选择合适的实时计算语言。此外,为了满足可靠性的需要,可以选择有多个冗余和独立生成的程序副本,并在交叉检查结果的同时在独立硬件上运行这些副本。
记录软件架构有助于利益相关者之间的沟通,捕获有关高级设计的早期决策,并允许在项目之间重用设计组件。
范围
对于软件架构的范围,人们的看法各不相同:[5]
-
宏观系统结构:这是指架构,它是一个软件系统的高级抽象,由一组计算组件和描述这些组件之间交互的连接器组成。[6]
-
不管是什么重要的东西:这指的是软件架构师应该关注那些对系统及其涉众有重大影响的决策。[7]
-
对理解一个系统在其环境中所处的环境至关重要的东西[8]
-
人们认为很难改变的事情:由于设计架构发生在软件系统生命周期的开始,所以架构师应该关注那些“必须”在第一时间正确的决策。按照这种思路,一旦架构设计问题的不可逆性能够被克服,它们就可能变成非架构性的问题
-
一组架构设计决策:软件架构不应仅仅被视为一组模型或结构,而应包括导致这些特定结构的决策及其背后的理论基础。[9]这种见解导致了对软件架构知识管理的大量研究。[10]
软件架构(architecture)与设计(design)和需求工程(requirement engineering)之间没有明显的区别(参见下面的相关字段)。它们都是从高层意图到底层细节的“意向链”的一部分
特点
软件架构展示了以下内容:
-
利益相关者众多:软件系统必须迎合各种利益相关者,如业务经理、所有者、用户和运营商。这些利益相关者对系统都有自己的关注点。平衡这些关注点并证明它们得到了解决是系统设计的一部分。[4]:29–31这意味着架构涉及到处理各种各样的关注点和涉众,并且具有多学科性质。
-
关注点分离:架构师降低复杂性的既定方法是分离驱动设计的关注点。架构(Architecture)文档显示,所有涉众关注点都是通过从与各种涉众关注点相关联的不同角度建模和描述架构来解决的。[12]这些单独的描述称为架构视图(例如,请参见4+1架构视图模型)。
-
质量驱动:经典的软件设计方法(如Jackson结构化编程)是由系统所需的功能和数据流驱动的,但目前的观点[4]:26-28是软件系统的架构与其质量属性(如容错性、向后兼容性)的关系更为密切,可扩展性、可靠性、可维护性、可用性、安全性、可用性和其他此类功能。干系人关注点通常转化为对这些质量属性的需求,这些属性被不同地称为非功能需求、额外功能需求、行为需求或质量属性需求。
-
重复样式:与构建架构一样,软件架构规程已经开发了解决重复问题的标准方法。这些“标准方法”在不同的抽象层次上由不同的名称来调用。重复性解决方案的常用术语是架构样式,[11]:273–277策略,[4]:70–72参考架构[13][14]和架构模式。[4]:203–205
-
概念完整性:Fred Brooks在《神话人月》中引入的一个术语,用来表示软件系统的架构代表了它应该做什么以及应该如何做的总体构想。这一设想应与实施分开。架构师承担着“视觉守护者”的角色,确保系统的添加与架构一致,从而保持概念的完整性。[15]:41–50
-
认知约束:计算机程序员Melvin Conway在1967年的一篇论文中首次观察到,设计系统的组织被限制生成设计,这些设计是这些组织的通信结构的副本。与概念完整性一样,弗雷德·布鲁克斯在其优雅的经典作品《神话人月》(Mythical Man Month)中引用了这篇论文和这一理念,并称之为“康威定律”(Conway's Law),将其介绍给了更广泛的读者
动机
软件架构(architecture)是复杂系统的“智能可理解”抽象。[4]:5–6该抽象提供了许多好处:
-
它为在系统构建之前对软件系统的行为进行分析提供了基础。[2]验证未来软件系统是否满足其利益相关者的需求而无需实际构建它的能力代表了大量的成本节约和风险缓解。[16]已经开发了许多技术来执行此类分析,比如阿塔姆。
-
它为元素和决策的重用提供了基础。[2][4]:35一个完整的软件架构或其部分,如单个架构策略和决策,可以跨多个系统重用,这些系统的涉众需要相似的质量属性或功能,从而节省设计成本并降低设计错误的风险。
-
它支持影响系统开发、部署和维护寿命的早期设计决策。[4]:31正确地做出早期、高影响的决策对于防止进度和预算超支非常重要。
-
它促进了与涉众的沟通,有助于建立一个更好地满足其需求的系统。[4]:29–31从涉众的角度沟通复杂系统,有助于他们理解所述需求的后果以及基于这些需求的设计决策。架构使得在系统实现之前就设计决策进行交流的能力,而这些决策仍然相对容易适应。
-
它有助于风险管理。软件架构有助于减少风险和失败的机会
-
它可以降低成本。软件架构是在复杂的IT项目中管理风险和成本的一种手段
历史
软件设计和(民用)架构的比较最早出现在20世纪60年代末,[18] 但是直到20世纪90年代,“软件架构”这个术语才被广泛使用。[19]计算机科学领域自形成以来就遇到了与复杂性相关的问题。[20]早期的复杂性问题是由开发人员通过选择正确的数据结构、开发算法和应用关注点分离。虽然“软件架构”这个术语对业界来说是相对较新的,但自20世纪80年代中期以来,该领域的基本原理就被软件工程的先驱们零星地应用。早期捕获和解释系统的软件架构的尝试是不精确和无序的,通常以一组方框图和折线图为特征。[21]
软件架构作为一个概念起源于1968年Edsger Dijkstra和70年代早期David Parnas的研究,这些科学家强调软件系统的结构至关重要,正确的结构至关重要。在20世纪90年代,有一个共同的努力来定义和编纂该学科的基本方面,研究工作集中在架构风格(模式)、架构描述语言、架构文档和形式方法上
作为一门学科,研究机构在促进软件架构的发展方面发挥了突出的作用。卡内基梅隆大学的Mary Shaw和David Garlan在1996年写了一本书,名为《软件架构:对一门新兴学科的展望》,该书提倡软件架构概念,如组件、连接器和样式。加州大学欧文软件研究所致力于软件架构研究,主要针对架构风格、架构描述语言和动态架构。
IEEE 1471-2000《软件密集型系统架构描述推荐规程》是软件架构领域的第一个正式标准。它于2007年被ISO采用为ISO/IEC 42010:2007。2011年11月,IEEE 1471-2000被ISO/IEC/IEEE 42010:2011“系统和软件工程-架构描述”(由IEEE和ISO联合发布)取代
在IEEE 1471中,软件架构是关于“软件密集型系统”的架构,定义为“软件对整个系统的设计、构建、部署和演化产生重要影响的任何系统”,2011年版更进一步,包括了ISO/IEC 15288和ISO/IEC 12207对系统的定义,这些定义不仅包括硬件和软件,还包括“人、过程、程序、设施、材料和自然发生的实体”。这反映了软件架构、企业架构和解决方案架构之间的关系。
架构活动
软件架构师执行的活动有很多。软件架构师通常与项目经理合作,与干系人讨论架构上重要的需求,设计软件架构,评估设计,与设计师和干系人沟通,记录架构设计等。[23]软件架构设计中有四个核心活动。[24]这些核心架构活动是在初始软件开发生命周期的不同阶段以及系统的演化过程中迭代执行的。
-
架构(architecture)分析是理解所提议的系统将在其中运行的环境并确定系统需求的过程。分析活动的输入或需求可以来自任何数量的涉众,包括以下项目:
-
系统运行时将做什么(功能需求)
-
系统将如何执行运行时非功能性需求,如可靠性、可操作性、性能效率、安全性、ISO/IEC 25010:2011标准[25]中定义的兼容性
-
开发时非功能性需求,如ISO 25010:2011标准[25]中定义的可维护性和可转移性
-
一个系统的业务需求和环境背景可能会随着时间而改变,例如法律、社会、金融、竞争和技术问题[26]
-
分析活动的输出是那些对软件系统架构有可测量影响的需求,称为架构上重要的需求
-
架构综合或设计是创造一个架构的过程。考虑到通过分析确定的架构上的重要需求、设计的当前状态和任何评估活动的结果,创建并改进了设计。[24][4]:311–326
-
架构(Architecture)评估(evaluation)是确定当前设计或其一部分如何满足分析期间导出的需求的过程。每当架构师考虑设计决策时,评估就可能发生,评估可能发生在设计的某一部分完成之后,评估可能发生在最终设计完成之后,评估也可能发生在系统构建之后。一些可用的软件架构(architecture)评估技术包括架构(architecture)权衡分析方法(ATAM)和TARA。[28]比较这些技术的框架在SARA报告[16]和架构评审:实践和经验[29]等框架中进行了讨论
-
架构演化是维护和调整现有软件架构以满足需求和环境变化的过程。由于软件架构提供了软件系统的基本结构,其演化和维护必然会影响其基本结构。因此,架构演进涉及添加新功能以及维护现有功能和系统行为。
架构需要关键的支持活动。这些支持活动贯穿于核心软件架构(architecture)过程。它们包括知识管理和沟通、设计推理和决策以及文档。
架构支持活动
软件架构(architecture)支持活动在核心软件架构(architecture)活动期间执行。这些支持活动帮助软件架构师进行分析、综合、评估和演化。例如,架构师必须在分析阶段收集知识、做出决策和文档。
-
知识管理和通信是一种探索和管理知识的行为,对设计软件架构至关重要。软件架构师不是孤立地工作的。它们从不同的涉众那里获得输入、功能性和非功能性需求以及设计上下文;并向涉众提供输出。软件架构知识通常是默认的,并保留在涉众的头脑中。软件架构知识管理活动是关于发现、交流和保留知识的活动。由于软件架构设计问题错综复杂且相互依存,设计推理中的知识缺口可能导致不正确的软件架构设计。[23][30]知识管理和沟通活动的示例包括搜索设计模式、原型设计、询问有经验的开发人员和架构师,评估类似系统的设计,与其他设计师和利益相关者共享知识,并在wiki页面中记录经验。
-
设计推理与决策是评价设计决策的活动。这项活动是所有三个核心软件架构活动的基础。[9][31]它需要收集和关联决策上下文,制定设计决策问题,寻找解决方案选项,并在做出决策之前评估权衡。当评估重要的架构需求和软件架构决策,以及软件架构分析、合成和评估时,此过程在不同的决策粒度级别上发生。推理活动的例子包括理解需求或设计对质量属性的影响,质疑设计可能引起的问题,评估可能的解决方案选项,以及评估解决方案之间的权衡。
-
文档是记录软件架构(architecture)过程中生成的设计的行为。系统设计使用几个视图进行描述,这些视图通常包括显示系统代码结构的静态视图、显示系统在执行期间的操作的动态视图和显示系统如何放置在硬件上执行的部署视图。Kruchten的4+1视图建议描述用于记录软件架构的常用视图;[32]记录软件架构:views and Beyond描述了视图描述中可以使用的各种符号。[1]文档活动的示例正在编写规范,记录系统设计模型,记录设计原理,开发观点,记录视图。
软件架构主题
软件架构描述
Main article: Software architecture description
软件架构描述涉及使用架构描述语言、架构视点和架构框架等机制对架构进行建模和表示的原则和实践。
架构描述语言
Main article: Architecture description language
架构描述语言(ADL)是用来描述软件架构(ISO/IEC/IEEE 42010)的任何表达方式。自20世纪90年代以来,开发了许多专用ADL,包括AADL(SAE标准)、Wright(由卡内基梅隆开发)、Acme(由卡内基梅隆开发)、xADL(由UCI开发)、Darwin(由伦敦帝国理工学院开发)、DAOP-ADL(由马拉加大学开发)、SBC-ADL(由国立中山大学开发)和ByADL(意大利拉奎拉大学)。
架构视角
Main article: View model
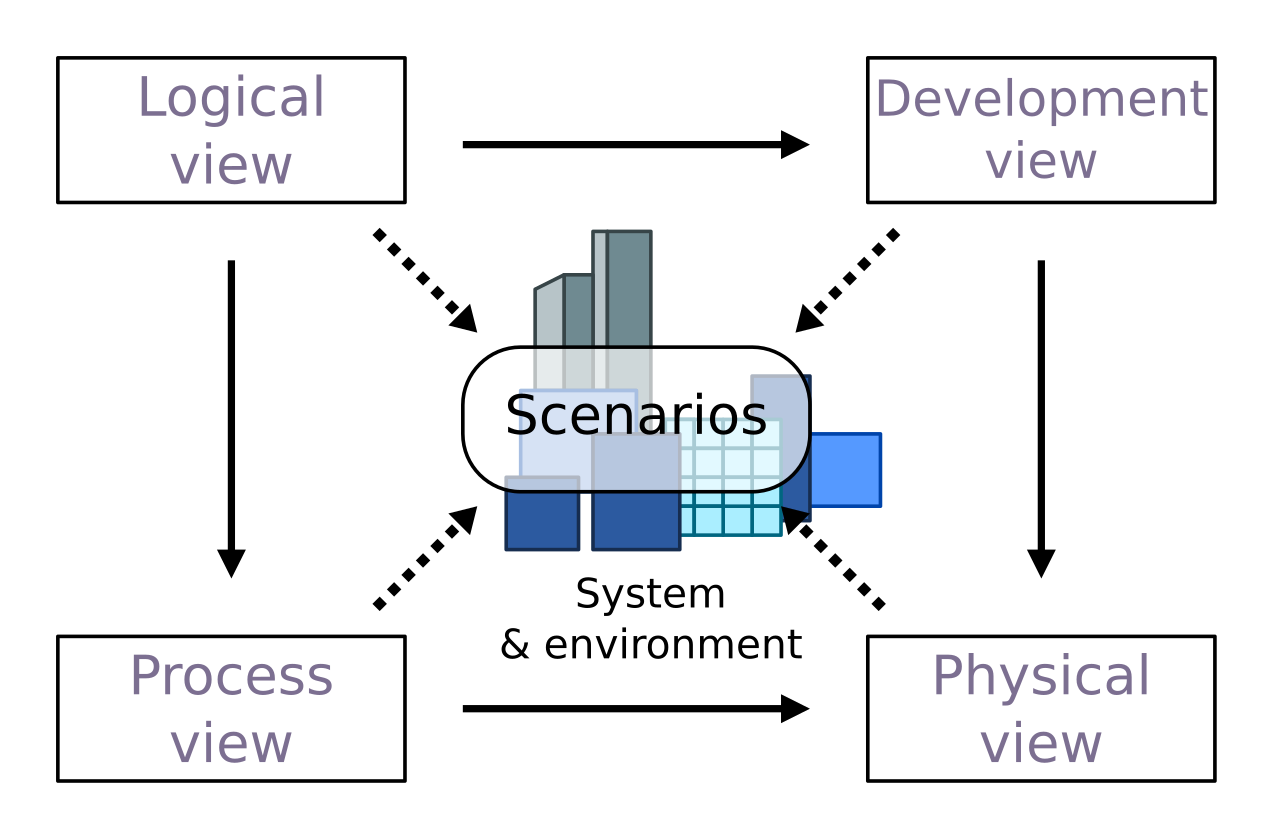
4+1架构视图模型。
软件架构描述通常被组织成视图,类似于在架构架构中生成的不同类型的蓝图。每个视图都按照其视点的约定处理一组系统关注点,其中视点是一个规范,描述了要在视图中使用的符号、建模和分析技术,该视图从给定的一组涉众及其关注点的角度表示所讨论的架构(ISO/IEC/IEEE42010)。该视点不仅指定了所构建的关注点(即要解决的关注点),而且还指定了表示、使用的模型类型、使用的约定以及任何保持视图与其他视图一致的一致性(对应)规则。
架构框架
Main article: Architecture framework
架构(architecture)框架捕获“描述在特定应用领域和/或利益相关者社区中建立的架构的惯例、原则和实践”(ISO/IEC/IEEE42010)。框架通常是根据一个或多个视点或adl来实现的。
架构风格和模式
Main article: Architectural pattern
架构模式是一种通用的、可重用的解决方案,用于解决给定上下文中软件架构中常见的问题。架构模式通常被记录为软件设计模式。
“软件架构风格”是继传统架构风格之后的一种特殊的架构方法,其特点是使其引人注目(架构风格)。
架构样式定义:以结构组织模式表示的一系列系统;组件和连接器的词汇表,以及如何组合它们的约束条件。[33]
“架构样式是可重用的设计决策和约束的‘包’,应用于架构以获得所选的理想质量。[34]”
有许多公认的架构模式和风格,其中包括:
-
黑板
-
客户端服务器(2层、3层、n层,云计算展示了这种风格)
-
基于组件
-
以数据为中心
-
事件驱动(或隐式调用)
-
分层(或多层架构)
-
微服务架构
-
整体应用
-
模型视图控制器(MVC)
-
对等(P2P)
-
管道和过滤器
-
插件
-
反应式架构
-
代表性状态转移(REST)
-
基于规则
-
服务导向
-
无共享架构
-
空间架构
有些人认为架构模式和架构风格是一样的,[35]有些人认为风格是模式的专门化。它们的共同点是模式和风格都是架构师使用的习语,它们“提供了一种共同的语言”[35]或“词汇”[33]来描述系统的类。
软件架构与敏捷开发
Main article: Agile development
也有人担心软件架构会导致太多的大设计,特别是在敏捷软件开发的支持者中。已经开发了许多方法来平衡前期设计和敏捷性之间的权衡,[36]包括敏捷方法DSDM,DSDM要求在“基础”阶段打下“足够”的架构基础。IEEE软件专门出版了一期专门讨论敏捷性和架构之间的交互的专刊[37]。
软件架构侵蚀
软件架构侵蚀(或称“衰退”)是指在软件系统的实现过程中,在软件系统的计划架构和实际架构之间观察到的差距。[38]当实现决策没有完全实现计划架构或违反这种架构。[2]计划架构和实际架构之间的差距有时可以用技术债务的概念来理解。
例如,考虑一个严格分层的系统,其中每个层只能使用它下面的层提供的服务。任何不遵守此约束的源代码组件都表示违反了架构。如果不加以纠正,这种违规行为可能会将架构转换为一个整体块,从而对可理解性、可维护性和可演化性产生不利影响。
已经提出了各种办法来解决侵蚀问题。”这些方法,包括工具、技术和过程,主要分为三大类,试图最小化、防止和修复架构侵蚀。在这些大类中,每一种方法都进一步细分,反映了为解决侵蚀问题而采取的高级别战略。这些是面向过程的架构一致性、架构演化管理、架构设计实施、架构到实现的链接、自适应和架构恢复技术,包括恢复、发现和协调
检测架构冲突有两种主要技术:反射模型和领域特定语言。反射模型(RM)技术将系统架构师提供的高级模型与源代码实现进行比较。还有一些特定于领域的语言,重点是指定和检查架构约束。
软件架构恢复
Main article: Software architecture recovery
软件架构(architecture)恢复(或重构,或逆向工程)包括从可用信息(包括其实现和文档)中揭示软件系统架构的方法、技术和过程。在面对过时或过时的文档和架构侵蚀时,架构恢复通常是做出明智决策所必需的:实现和维护决策与设想的架构不同。[40]存在将软件架构恢复为静态程序分析的实践。这是软件智能实践课程的一部分。
相关领域
设计
Main article: Software design
架构是设计,但并非所有的设计都是架构。[1]实际上,架构师是在软件架构(架构设计)和详细设计(非架构设计)之间划清界线的人。没有适合所有情况的规则或准则,尽管有人试图将这种区别形式化。根据内涵/局部性假设,[41]架构设计和详细设计之间的区别是由局部性标准定义的,[41]根据局部性标准,关于软件设计的陈述是非局部的(架构),前提是满足它的程序可以扩展成不满足它的程序。例如,客户机-服务器样式是架构(战略性的),因为基于此原则构建的程序可以扩展为非客户机-服务器的程序,例如,通过添加对等节点。
需求工程
Main article: Requirements engineering
需求工程和软件架构可以看作是互补的方法:当软件架构以“解决方案空间”或“如何”为目标时,需求工程解决“问题空间”或“什么”。[42]需求工程需要启发、协商、规范、验证,要求的文件和管理。需求工程和软件架构都围绕涉众的关注点、需求和愿望。
需求工程(engineering)和软件架构(architecture)之间存在相当大的重叠,例如,对五种工业软件架构(architecture)方法的研究表明,“输入(目标、约束等)通常定义不清,只有当架构开始出现时才能被发现或更好地理解,并且“虽然大多数架构关注点被表达为系统上的需求,但它们也可以包括强制性的设计决策”[24]简而言之,所需的行为影响解决方案架构,这反过来又可能引入新的需求。[43]双峰模型等方法[44]旨在利用需求和架构之间的协同关系。
其他类型的“架构”
Main articles: Computer architecture, Systems architecture, and Enterprise architecture
计算机架构
计算机架构以计算机系统的内部结构为目标,以协作硬件组件(如CPU或处理器、总线和内存)为基础。
系统架构
术语系统架构最初应用于由硬件和软件组成的系统架构。系统架构解决的主要问题是将软件和硬件集成到一个完整、正常工作的设备中。在另一个共同的(更广泛的)含义中,这个术语适用于任何复杂系统的架构,这些系统可能具有技术性、社会技术性或社会性。
企业架构
企业架构的目标是“将业务远景和战略转化为有效的企业”[45]企业架构框架,如TOGAF和Zachman框架,通常区分不同的企业架构层。尽管术语因框架而异,但许多术语至少包括业务层、应用程序(或信息)层和技术层之间的区别。企业架构解决了这些层之间的对齐问题,通常采用自顶向下的方法。
另见
架构模式(计算机科学)
-
反模式
-
属性驱动设计
-
计算机架构
-
分布式数据管理架构
-
分布式关系数据库架构
-
系统架构
-
系统设计
-
软件架构分析方法
-
时间触发系统
讨论:请加入知识星球【首席架构师圈】
- 319 次浏览
【软件架构】软件架构的7种建模语言
视频号
微信公众号
知识星球
比较用于设计和建模软件系统的7种流行语言

我们开始吧
由于软件的复杂性,一直需要以图形方式可视化软件体系结构,并与其他软件体系结构进行通信。通过对这些系统及其抽象进行建模和绘图,我们可以分析和改进设计,从而在构建它们时实现更高质量的实现。
在本文中,我们将比较七种流行的视觉建模语言。
1.️统一建模语言(UML)
统一建模语言是由一群软件工程师和研究人员在20世纪90年代创建的,现在由对象管理小组(OMG)维护。UML是一种图形语言,它为软件系统建模提供了一组标准的符号和表示法。UML2.5包括14种不同的图表类型,用于对软件开发生命周期的各个部分进行建模。
👍 优点
- UML提供了强大而广泛的标准化表示法,可以改善大型组织中的通信。
- 在需要时只使用符号的特定部分的灵活性。
- 该工具通常支持代码生成,这可以加快开发速度。
👎 缺点
- 对于初学者来说,复杂的记法是一条陡峭的学习曲线,以便有效地学习和使用。
- UML可能过于复杂和耗时,尤其是对于小型和简单的软件系统。
- 工具通常很昂贵,难以使用,并且需要培训。

2.️ C4模型
C4模型是一种为特定受众可视化软件体系结构的轻量级结构化方法。它是由一位名叫Simon Brown的软件架构师和作者于2011年创建的。C4模型本质上只是两件事,一组常见抽象的层次结构和四种标准图类型。C4型号是独立于符号的,这意味着没有规定标准的形状、颜色或风格。
👍 优点
- 层次结构允许为需要它的受众放大更多的技术细节。
- 简单易学,便于工程师、利益相关者和非技术团队成员理解。
- C4模型具有灵活性和适应性,因此可以用于各种工具和符号。
👎 缺点
- 对于需要广泛图表类型(如用例图、活动图和类图)的大型组织来说,一组有限的功能可能是一种限制。
- C4模型仍然越来越受欢迎,并且与UML等标准相比没有被广泛采用。
- 有一些C4模型工具,但与更成熟的建模语言相比,仍然有一套相对有限的工具。
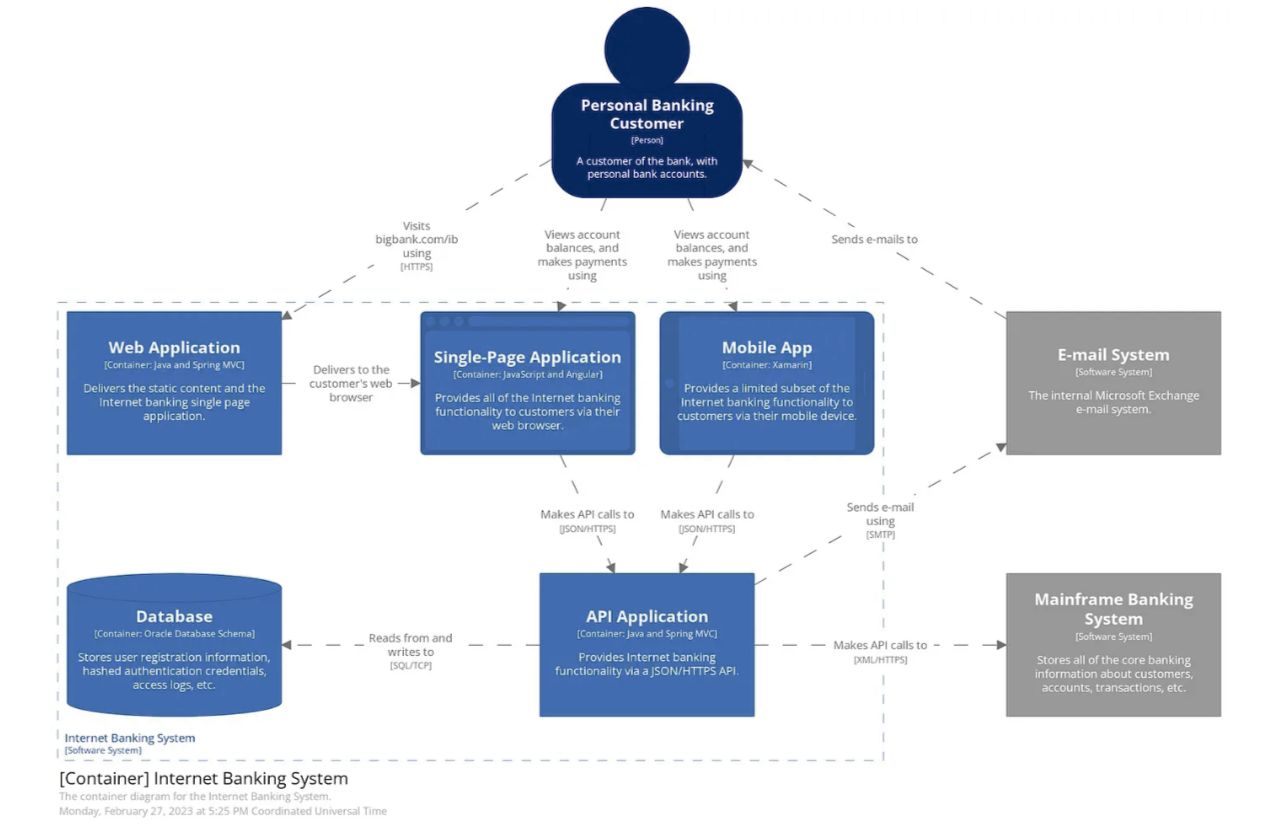
3.️ArchiMate
ArchiMate是一种用于企业体系结构的开放且独立的建模语言。它是由开放集团于2011年开发的,该集团是一个开发和维护多个开放标准的行业联盟。它提供了三层抽象(业务、应用程序和技术)、标准建模元素(包括业务参与者、业务流程和应用程序组件)以及它们之间的关系。
👍 优点
- ArchiMate提供了一个全面的框架,具有广泛的抽象和符号来描述和交流体系结构。
- 包括用于区分建筑组件类型的颜色编码方案。
- 设计为与其他企业体系结构标准(如TOGAF和BPMN)兼容。
👎 缺点
- 尽管在欧洲被广泛使用,但在世界部分地区采用仍然有限。
- ArchiMate是一种复杂的建模语言,可能需要时间来学习如何有效地使用它,这可能会成为一些人进入的障碍。
- 通常与特定的软件工具一起使用,这有时会限制ArchiMate模型的可移植性。
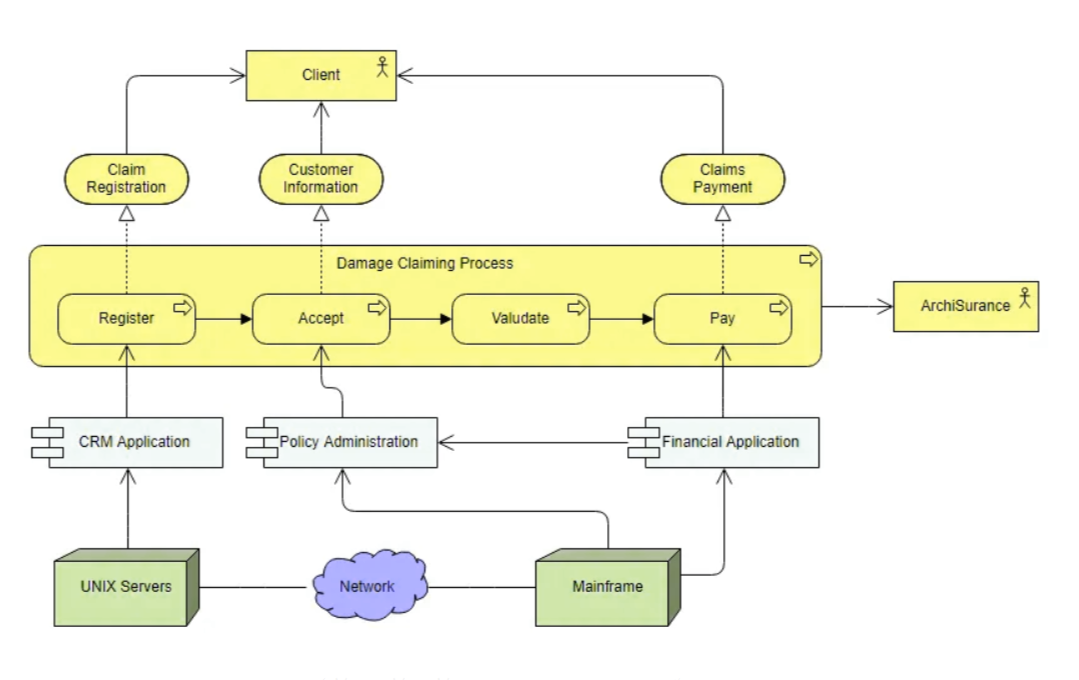
4.️⃣ 开放式组架构框架(TOGAF)
开放式集团架构框架或TOGAF是一个企业架构框架,分为4个关键领域:业务、应用程序、数据和技术。它最初由开放集团创建于1995年,该集团还负责维护ArchiMate。TOGAF提供了一种全面而系统的方法,包括企业架构的开发和实现的逐步过程。
👍 优点
- 提供了一种全面且适应性强的语言,这意味着组织可以随着时间的推移根据其特定需求进行调整。
- 与供应商无关,这意味着它可以与任何技术或供应商解决方案一起使用,为组织提供灵活性。
- TOGAF是一个被世界各地的组织广泛认可和使用的行业标准,可以为利益相关者提供保证和可信度。
👎 缺点
- 对于那些不熟悉该框架的人来说,TOGAF和ADM过程可能特别难以学习,并且可能需要大量时间来实现。
- TOGAF对标准和治理的重视有助于保持一致性,但也有变得过于僵化和不灵活的风险。
- 认证和培训可能很昂贵,这可能会成为一些想要使用该框架的组织的障碍。
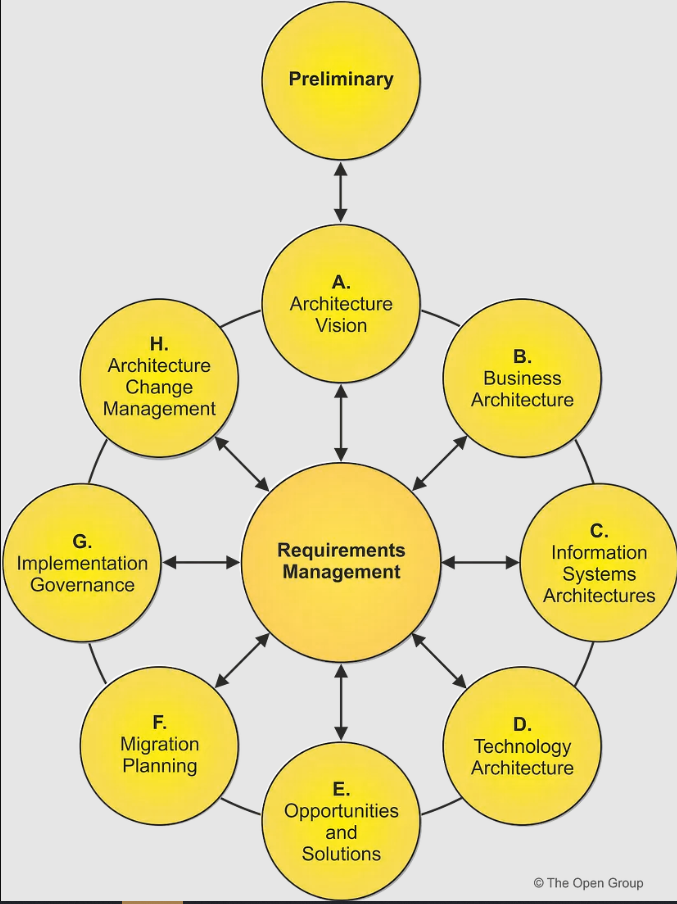
5.️ 业务流程模型和符号(BPMN)
BPMN是一种图形建模语言,为业务流程、活动、事件、网关、流和工件提供标准表示法。它是分析和改进业务流的强大工具。BPMN最初由一群组织创建于2004年,令人反感,此后一直由对象管理小组(OMG)维护。
👍 优点
- BPMN设计为易于技术和非技术利益相关者理解,使其适用于广泛的受众。
- 提供了一种易于理解的标准表示法,并为设计和实现业务流程弥合了沟通差距。
- 子模型以一种查看者可以轻松发现最适用于它们的区域的方式划分图表。
👎 缺点
- 符号是全面的,可能很难从头到尾学习,这意味着那些产生模型的人可能会有一个陡峭的学习曲线。
- 一些供应商实现和执行BPMN图的方式略有不同,尽管有明确的标准。
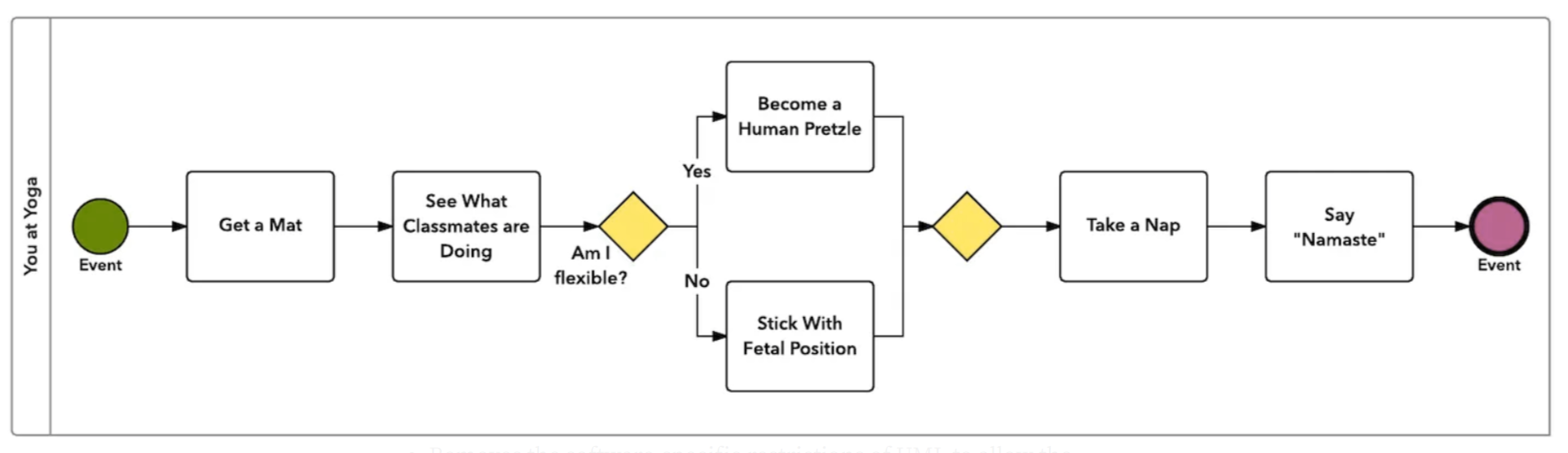
6.️⃣ 系统建模语言(SysML)
SysML是一种开源建模语言,它扩展了UML,旨在分析复杂系统。它最初创建于2001年,后来被对象管理小组(OMG)采用。系统工程师使用SysML来通信和分析广泛的系统,例如:软件、硬件、信息、流程和人员。
👍 优点
- 删除了UML的软件特定限制,以允许对更广泛的系统(如物理和人员)进行建模。
- SysML删除了UML的一些特性,使其更简单、更容易学习。
- 为UML中有限的模型、视图和视点提供广泛的支持。
👎 缺点
- 由于SysML是基于UML的,它继承了UML的许多困难和缺点。
- 关于图的完整程度的模糊规则可能会导致错误。
- 各种SysML工具之间缺乏互操作性,这使得共享模型变得困难。
7.️4+1视图模型
4+1是一个视图模型,用于使用多个并发视图来描述大型系统,每个视图都来自不同的利益相关者。它最早是由加拿大软件工程师Philippe Kruchten于1995年提出的。它定义的5个视图分别是逻辑视图、流程视图、开发视图和场景。
👍 优点
- 该方法允许利益相关者轻松地使用模型中对他们最重要的区域。
- 4+1非常适合组织和提供图表和系统信息的结构。
- 如果视图对模型没有贡献,则可以忽略这些视图。
👎 缺点
- 4+1没有强制执行正式的表示法或标准,这可能会导致模型应用方式的不一致。
- 可能无法为设计决策的某些领域提供足够的细节,例如安全性、性能或可扩展性。
- 不适用于非常小的系统或具有非常特定焦点的系统。

🏁 结束
我确信还有其他视觉建模语言我们没有时间在本文中介绍。如果你还有其他最喜欢的,以及你在使用它时喜欢或不喜欢什么,请在评论中告诉我们。
- 152 次浏览
【软件架构】软件架构的7种建模语言
视频号
微信公众号
知识星球
比较用于设计和建模软件系统的7种流行语言

🚀
我们开始吧
由于软件的复杂性,一直需要以图形方式可视化软件体系结构,并与其他软件体系结构进行通信。通过对这些系统及其抽象进行建模和绘图,我们可以分析和改进设计,从而在构建它们时实现更高质量的实现。
在本文中,我们将比较七种流行的视觉建模语言。
1️⃣ Unified Modeling Language (UML)
统一建模语言是由一群软件工程师和研究人员在20世纪90年代创建的,现在由对象管理小组(OMG)维护。UML是一种图形语言,它为软件系统建模提供了一组标准的符号和表示法。UML2.5包括14种不同的图表类型,用于对软件开发生命周期的各个部分进行建模。
👍 优点
- UML提供了强大而广泛的标准化表示法,可以改善大型组织中的通信。
- 在需要时只使用符号的特定部分的灵活性。
- 该工具通常支持代码生成,这可以加快开发速度。
👎 缺点
- 对于初学者来说,复杂的记法是一条陡峭的学习曲线,以便有效地学习和使用。
- UML可能过于复杂和耗时,尤其是对于小型和简单的软件系统。
- 工具通常很昂贵,难以使用,并且需要培训。
2️⃣ C4 Model
C4模型是一种为特定受众可视化软件体系结构的轻量级结构化方法。它是由一位名叫Simon Brown的软件架构师和作者于2011年创建的。C4模型本质上只是两件事,一组常见抽象的层次结构和四种标准图类型。C4型号是独立于符号的,这意味着没有规定标准的形状、颜色或风格。
👍 优点
- 分层结构允许为需要它的受众放大更多的技术细节。
- 简单易学,便于工程师、利益相关者和非技术团队成员理解。
- C4模型具有灵活性和适应性,因此可以用于各种工具和符号。
👎 缺点
- 对于需要广泛图表类型(如用例图、活动图和类图)的大型组织来说,一组有限的功能可能是一种限制。
- C4模型仍然越来越受欢迎,与UML等标准相比并没有被广泛采用。
- 有一些C4模型工具,但与更成熟的建模语言相比,仍然有一组相对有限的工具。
3️⃣ ArchiMate
ArchiMate 是一种用于企业体系结构的开放且独立的建模语言。它是由开放集团于2011年开发的,该集团是一个开发和维护多个开放标准的行业联盟。它提供了三层抽象(业务、应用程序和技术)、标准建模元素(包括业务参与者、业务流程和应用程序组件)以及它们之间的关系。
👍 优点
- ArchiMate提供了一个全面的框架,具有广泛的抽象和符号来描述和交流架构。
- 包括用于区分架构组件类型的颜色编码方案。
- 设计为与其他企业架构标准(如TOGAF和BPMN)兼容。
👎 缺点
- 尽管在欧洲被广泛使用,但世界部分地区的采纳仍然有限。
- ArchiMate是一种复杂的建模语言,可能需要时间来学习如何有效地使用它,这可能会成为一些人进入的障碍。
- 通常与特定的软件工具一起使用,这有时会限制ArchiMate模型的可移植性。
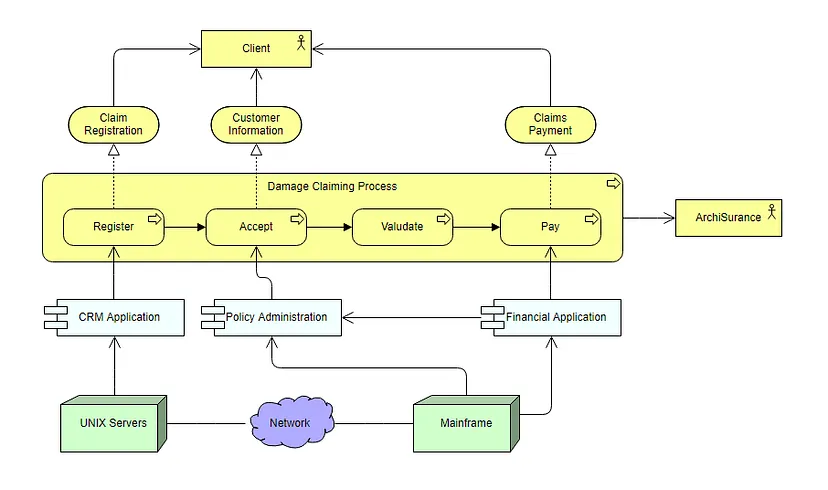
4️⃣ The Open Group Architecture Framework (TOGAF)
The Open Group Architecture Framework TOGAF是一个企业架构框架,分为4个关键领域:业务、应用程序、数据和技术。它最初由开放集团创建于1995年,该集团还负责维护ArchiMate。TOGAF提供了一种全面而系统的方法,包括企业架构的开发和实现的逐步过程。
👍 优点
- 提供了一种全面且适应性强的语言,这意味着组织可以随着时间的推移根据其特定需求进行调整。
- 与供应商无关,这意味着它可以与任何技术或供应商解决方案一起使用,为组织提供灵活性。
- TOGAF是一个被世界各地的组织广泛认可和使用的行业标准,它可以为利益相关者提供保证和可信度。
👎 缺点
- 对于那些不熟悉该框架的人来说,TOGAF和ADM过程可能特别难以学习,并且可能需要大量时间来实现。
- TOGAF对标准和治理的重视有助于保持一致性,但也有变得过于僵化和不灵活的风险。
- 认证和培训可能很昂贵,这可能会成为一些想要使用该框架的组织的障碍。
5️⃣ Business Process Model and Notation (BPMN)
是一种图形建模语言,为业务流程、活动、事件、网关、流和工件提供标准表示法。它是分析和改进业务流的强大工具。BPMN最初由一群组织创建于2004年,令人反感,此后一直由对象管理小组(OMG)维护。
👍 优点
- BPMN的设计便于技术和非技术利益相关者理解,因此非常适合广泛的受众。
- 提供易于理解的标准表示法,并为设计和实现业务流程弥合沟通差距。
- 子模型以一种查看者可以轻松发现最适用于它们的区域的方式来划分图表。
👎 缺点
- 符号是全面的,可能很难从头到尾学习,这意味着对于那些生产模型的人来说,可能会有一个陡峭的学习曲线。
- 一些供应商实现和执行BPMN图的方式略有不同,尽管有明确的标准。
6️⃣ Systems Modeling Language (SysML)
SysML 是一种扩展UML的开源建模语言,旨在分析复杂系统。它最初创建于2001年,后来被对象管理小组(OMG)采用。系统工程师使用SysML来通信和分析各种系统,例如:软件、硬件、信息、流程和人员。
👍 优点
- 删除了UML的软件特定限制,允许对更广泛的系统(如物理和人员)进行建模。
- SysML删除了UML的一些特性,使其更简单、更容易学习。
- 为UML中有限的模型、视图和视点提供广泛的支持。
👎 缺点
- 由于SysML是基于UML的,它继承了UML的许多困难和缺点。
- 关于图的完整程度的模糊规则可能会导致错误。
- 各种SysML工具之间缺乏互操作性,使得共享模型变得困难。
7️⃣ 4+1 View Model
The 4+1 is a view model 用于使用多个并发视图来描述大型系统,每个视图都来自不同的利益相关者。它最早是由加拿大软件工程师Philippe Kruchten于1995年提出的。它定义的5个视图分别是逻辑视图、流程视图、开发视图和场景。
👍 优点
- 该方法允许利益相关者轻松地使用模型中对他们最重要的区域。
- 4+1非常适合组织和提供图表和系统信息的结构。
- 如果视图对模型没有贡献,则可以省略视图。
👎 缺点
- 4+1没有强制使用正式的表示法或标准,这可能会导致模型应用方式的不一致。
- 可能无法为设计决策的某些领域提供足够的细节,例如安全性、性能或可扩展性。
- 不适用于非常小的系统或具有非常特定焦点的系统。
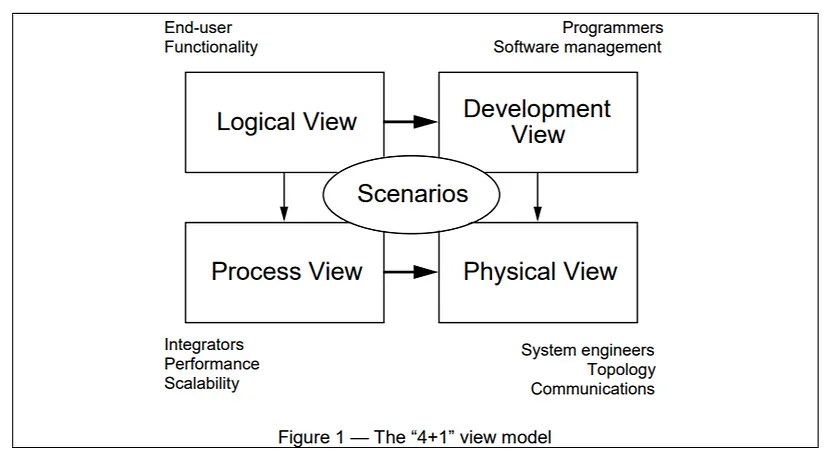
🏁 To wrap up
我相信还有其他视觉建模语言我们没有时间在本文中介绍。如果你还有其他最喜欢的,以及你在使用它时喜欢或不喜欢什么,请在评论中告诉我们。
保持冷静🧊
- 212 次浏览
【软件架构】软件架构资料
与 800 位挚友一起做架构:谈 Comcast 架构协议的演变
https://www.infoq.cn/article/dYCKYXZORi_JE4MCtwz5
Segment 放弃了微服务
https://www.infoq.cn/article/v3VjP*BYtY3qhD3438ay
微服务架构体系的深度治理
https://www.infoq.cn/article/q65dDiRTdSbF*E6Ki2P4
Qarkus Java 框架答疑
https://www.infoq.cn/article/j3XQTfHg*3gdbLZme7ls
- 149 次浏览