技术



SAP技术
【SAP ChaRM】SAP ChaRM解决方案完整指南
视频号
微信公众号
知识星球
SAP ChaRM(更改请求管理)是一个用于管理和跟踪对SAP系统所做更改的模块。它是一种帮助组织以结构化和高效的方式处理和控制SAP系统更改的工具。
ChaRM模块允许用户创建和跟踪更改请求,即对SAP系统进行的更改。这些更改请求可能与自定义或配置更改、开发更改或紧急更改有关。
目录
- ChaRM简介
- 什么是魅力
- ChaRM的范围
- ChaRM的好处是什么?
- 谁使用ChaRM
- SAP ChaRM循序渐进
- SAP Charm配置
- 结论
ChaRM力简介
在过去几年中,越来越多的项目(通常被称为SAP ChaRM)正与变更请求经理一起使用。更改请求管理器功能。我们将在本博客中讨论SAP CHARM。本文旨在为您提供有关什么是Charm、Charm的范围、可用于满足业务需求的优点和配置的信息。
SAP ChaRM是一个由SAP Solution Manager集成的工具,用于处理从设计到测试的过渡过程中发生的任务,直到最终引入生产。它允许您在整个业务解决方案中跟踪更改、传输请求和更改。
要充分了解和利用SAP目前提供的新功能,了解SAP变更管理的背景和历史至关重要。作为软件物流工具,它有助于维护生产环境的安全性;ChaRM让项目受益于SAP运输管理系统(TMS)中经过良好测试的功能,这是最初的意图。
什么是ChaRM
SAP ChaRM是一款SAP Solution Manager工具,用于管理从概念到测试直至最终广告和生产的过渡过程。我们可以在整个业务系统中跟踪变更和传输变更管理系统的请求。
SAP ChaRM使用基于工作流的运输管理审批,以及经过审核的环境变化功能记录。ChaRM以前的自动化手动程序:
- 变更和运输电子表格
- 将文档与更改紧密结合
- 将更改状态与TMS状态同步

使用该项目和ChaRM,我们可以扩展TMS功能,确保所有运输活动一起进入QA,进行整体集成和回归测试,并共同导入生产。
不再需要电子表格,因为SAP Solution Manager项目将跟踪哪些运输请求与哪些项目相关联,以及它们的导入顺序。
ChaRM的范围
- 分发ABAP和非ABAP(CTS+)软件更改
- 全面的、工作流驱动的管理
- 维护管理模板,实施和升级项目
- Charm回答了这样的问题:谁要求更改,谁测试更改,还有哪些更改仍在开发中?正在接受测试?正在等待生产部署
ChaRM的好处是什么?
ChaRM模块提供了许多好处,包括:
- 提高了透明度:ChaRM模块允许用户查看更改请求的状态,并在更改过程的不同阶段跟踪更改的进度。
- 增强的控制:ChaRM模块帮助组织实施其变更管理政策和程序,确保变更得到控制和一致性。
- 提高了效率:ChaRM模块为更改请求提供了一个中央存储库,并自动化了管理更改的许多步骤,从而简化了更改管理流程。
- SAP ChaRM使组织能够有效地监控和管理SAP系统内的更改。
- 它确保对SAP系统的任何修改都遵循既定的程序和流程,其中包括强制性控制和文件化程序。
- 对变更的跟踪和审计能力
- 降低纠正或项目失败的风险
- 减少对业务的干扰。
- 提高维护和项目效率
- 降低纠正和项目失败的风险
- 最小化项目管理和IT成本
在变更实施过程中,SAP Solution Manager会提供文档和工作流信息。SAP ChaRM报告中提供了以下详细信息。SAP ChaRM报告可以提供以下详细信息。
- 更改请求:按状态、步骤、类型。
- 更改请求持续时间每个用户,按组织类型,步骤
- 更改请求和运输请求
- 运输系统的现状
- 变更请求期间触发的事件以以下方式:组织、SAP组件
谁使用ChaRM
- 变更经理/发布经理:跟踪变更、支出流程、控制维护周期
- 潜在客户/解决方案架构师:为请求和确认的更改创建更改文档(CD)
- 开发人员/功能顾问:对指定的测试人员进行可移植的更改和发布
- 开发人员可以创建运输请求
- 开发人员将能够发布传输请求任务
- 开发人员将能够创建一个新的传输请求任务
- 开发人员将能够创建TOC
- 开发者将能够发布原始TR
- 测试人员:在质量体系中进行测试并确认测试成功
- 基础/技术相关:自动化质量导入,手动执行生产导入
- BASIS将能够将TR导入生产
- BASIS将能够导入TOC
- BASIS将能够将原始TR导入QA

SAP ChaRM循序渐进
登录到ChaRM Solution Manager工作中心,然后单击“更改和发布管理”。平铺提供适当的筛选器以查找现有的更改周期,然后单击搜索按钮
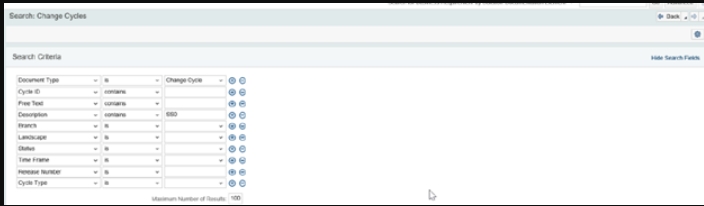
选择适当的周期阶段以“范围”并创建任务列表,
将阶段设置为“范围”单击操作->

出现一个弹出窗口,单击是创建任务列表,然后单击下一步提供详细信息。如果在检查先决条件中发现任何问题/错误,请纠正所有红绿灯,然后只发布更改
SAP Charm配置
Charm配置的前提条件
- 景观系统的正确配置。
- 解决方案管理和卫星系统之间的RFC通信。
- STMS配置。
- 在系统范围内定义系统之间的运输路线。
- TMS中传输的主动扩展控制
- 禁用质量保证审批流程,然后仅启用单一运输策略。
解决问题的更多帮助

结论
总的来说,ChaRM模块对于需要以结构化和高效的方式管理和跟踪SAP系统更改的SAP用户来说是一个非常有价值的工具。在商业的这个关键时刻,一个包罗万象的魅力解决方案可以提高运营效率,提升客户体验,并使公司在竞争中占据优势。通过集成CRM SCM、ERP和CRM系统,公司可以简化流程,根据基于数据的洞察力做出决策,并实现长期增长。为了在您的领域保持竞争力,确定最适合您业务需求的解决方案,然后找到最适合提供此类魅力解决方案的公司;实施与目标相一致的个人计划,使您的公司比以前更高充分利用魅力解决方案,让您的公司更上一层楼!
- 244 次浏览
【SAP Fiori】SAP Fiori:改变业务运营的未来
视频号
微信公众号
知识星球
我们将在本博客中了解SAP Fiori应用程序。SAP Fiori是一个应用程序集合,对SAP用户来说是一种全新的体验。SAP Fiori应用程序以一致的方式设计,并使用通用的技术基础设施。它们提供了一致的端到端用户体验,可以在所有类型的设备上使用,而无需额外努力。
SAP S/4HANA、SAP Customer Experience、SAP Fieldglass、SAP Concur、SAP Ariba和SAP SuccessFactors只是Fiori应用程序旨在采用的SAP产品中的一小部分。
目录
- 什么是Fiori应用程序
- 为什么使用Fiori应用程序
- 菲奥里是什么意思?
- SAP Fiori设计原则
- 基于角色
- 自适应
- 易于理解的
- 连贯的
- 使人快乐的
- SAP Fiori Launchpad
- SAP Fiori应用程序的类型
- 事务性应用程序
- 分析应用程序
- 概况应用程序
- SAP Fiori–分析应用程序
- SMART业务
- 虚拟数据模型
- KPI建模器
- 什么是HTML5
- 什么是SAP UI5框架?
- Odata是什么
什么是Fiori应用程序
SAP Fiori是SAP S/4HANA用户体验(UX)应用程序。SAP Fiori是一款基于角色的应用程序,旨在跨多台设备轻松使用。SAP Fiori应用程序基于SAP GUI用户可能熟悉的事务功能。这些应用程序在SAP Fiori中经常更新,以包含新功能,如向下搜索功能和过滤器。这些应用程序可以与SAP S/4HANA或SAP ERP 6.0中的任何数据库结合使用。
为什么使用Fiori应用程序
SAP客户之前曾抱怨标准屏幕的外观和感觉过时,以及大多数事务只能通过其桌面GUI访问SAP的事实。根据来自世界各地的客户反馈,并推出了一套基于HTML5的应用程序,其中包括最广泛和最频繁使用的SAP事务:PO审批、销售订单创建。采购订单审批、销售订单创建、自助服务任务等等。这些HTML5应用程序在台式机、平板电脑和智能手机上使用起来很简单。
所有用户界面都是使用HTML5和移动SAP UI5等先进技术构建的。您可以使用Fiori应用程序通过OData服务访问数据的最新后端版本。您可以指定用户可以通过以前定义的角色和授权访问哪些应用程序和哪些数据。
菲奥里(Fiori)是什么意思?
SAP Fiori是以意大利语中“花”的意思命名的。我们都知道花看起来很漂亮,是由大自然的智能设计形成的。受花名“Fiori”的启发,我们推出了这款花。
SAP Fiori设计原则
SAP Fiori的五个基本设计元素如下:
基于角色
基于角色的原则侧重于向最终用户提供所有必要的信息。换句话说,它是根据用户的需求和操作风格为他们制作的。Fiori应用程序将复杂的应用程序降级为基于任务的体验,每个用户都有一个中心入口点。
自适应
用户可以从各种设备和形状因素访问业务应用程序,如移动设备、平板电脑、台式机或大型台式机,这得益于适应性和响应性的理念。
易于理解的
简单的想法是,完成手头活动所需的信息应该是可用的规则。
连贯的
这种连贯的方法在许多平台和解决方案中提供了可比较、可理解和一致的用户体验。
使人快乐的
应用程序和用户可以连接,这得益于愉快原则丰富的用户体验。
SAP Fiori Launchpad
简单地说,SAP Fiori启动板是一个基于SAPUI5的应用程序,用作应用程序容器(也称为外壳),用于托管许多SAP Fioris应用程序(例如,SAPUI5组件、Web Dynpro ABAP组件、用于运行SAP GUI事务的HTML的SAP GUI、Web客户端UI和任意URL)。通过适应性强的设计方法,它可以作为所有这些应用程序类型和相关分析见解的起点,这些应用程序可以在许多设备上查看或访问。
SAP Fiori启动板是Fiori中所有应用程序的中心入口,用户可以通过tile访问这些应用程序。按用户角色组织。启动板具有导航、自定义、个人注册和搜索服务。靴垫和瓷砖具有灵活性和适应性,可满足您的需求。SAP Fiori启动板搜索可用于对关键SAP Business Suite应用程序进行跨实体搜索。搜索使用SAP NetWeaver在SAP HANA数据库上的嵌入式搜索技术。为SAP HANA提供了核心业务对象的新搜索模型。
SAP Fiori应用程序的类型
通常,存在三种不同类型的SAP Fiori应用程序:
事务性应用程序
SAP GUI中可用的传统ABAP事务与这些程序类似。SAP ERP 6.0和SAP S/4HANA都支持任何数据库上的这些应用程序。Change Sales Orders应用程序是一个以销售为重点的交易应用程序的示例。
分析应用程序
这些应用程序包含利用SAP HANA数据库容量的集成分析。分析应用程序试图通过使用复杂的算法快速提供商业见解。对于SAP HANA上的SAP S/4HANA和SAP Business Suite,可以访问这些应用程序。销售订单履行应用程序是一个分析应用程序。
概况应用程序(情况说明书)
为了在特定情况下提供搜索结果,这些应用程序利用了SAP HANA数据库的企业级搜索功能。对于SAP HANA上的SAP S/4HANA和SAP Business Suite,可以访问这些应用程序。
SAP Fiori–分析应用程序
Fiori应用程序非常熟悉其丰富的分析。分析应用程序越来越多地被用于提供基于角色的实时业务运营数据。分析应用程序将SAP HANA的强大功能与SAP的业务套件集成在一起。它在前端web浏览器中提供来自大量数据的实时信息。
我们将使用Fiori应用程序密切跟踪关键绩效指标KPI。我们可以对您的业务活动进行复杂的汇总和分析,并对市场状况的变化做出快速反应。
SAP Fiori Analytical应用程序在SAP HANA数据库中运行,并使用虚拟数据模型。
分析应用程序有两种类型——
- SMART业务
- 虚拟数据模型
SMART业务
SAP Fiori智能业务应用程序用于实时监控您最重要的KPI,并根据市场状况立即做出更改。
注−这个保护伞下大约有84个分析应用程序,其中69个是智能商业应用程序,15个是分析应用程序。
分析应用程序只能在SAP HANA数据库上运行,而事务应用程序则可以在任何数据库上运行。SAP Fiori通过使用虚拟数据模型利用XS引擎,XS引擎内有2个组件
- 适用于各个业务套件的HANA Live Apps内容
- SMART业务内容
SAP HANA Live允许通过数据模型以行业标准访问SAP数据,从而为所有企业套件提供卓越的分析功能。数据模型用于使用HANA数据库中的视图进行分析。视图是一个虚拟数据模型,客户和合作伙伴可以重用它。
虚拟数据模型
虚拟数据模型提供了一种处理HANA数据库中大量数据质量的方法。这些视图可以由富UI客户端使用,而无需使用任何其他软件。有三种类型的视图-
- 私有视图:私有视图是SAP视图,不能修改。
- 重用视图重用视图是SAP HANA模型的核心,在结构上是公开的,旨在供其他视图重用
- 查询视图-查询视图是层次结构中的顶部视图,供分析应用程序直接使用,不能更改。
KPI建模器
它是一个用于建模KPI和报告瓦片的工具,用于使用Fiori Launchpad监控业务数据。我们可以定义KPI和报告,您可以对其应用不同的计算,并允许您根据不断变化的市场条件进行调整。
我们可以配置深入视图以了解更多内部信息。
什么是HTML5
HTML5是超文本标记语言编程语言的缩写
什么是SAP UI5框架?
SAP UI5是一个与web应用程序兼容的框架。响应能力与性能无关,但它是一个能够适应每一台设备的应用程序。它在所有平台(不同的设备/浏览器)上提供一致的用户体验。该框架是一个库集合,类包括每个库和每个类的方法
Odata是什么
开放数据协议(OData)是一种基于web的数据访问协议,基于HTTP等核心协议和REST等广泛接受的方法。OData接口是任何应用程序和程序都可以使用的开放标准。
- 167 次浏览
【SAP GUI】什么是SAP GUI(图形用户界面)以及如何使用它
视频号
微信公众号
知识星球
SAP GUI(图形用户界面)是前端软件,允许用户访问SAP系统并执行各种任务,如创建和运行报告、输入和处理事务以及管理数据。
这些教程的目的是了解什么是SAP GUI,它的基本特征以及它们如何与SAP系统和各种类型的GUI交互。SAP GUI代表系统应用程序接口。它是一个有助于应用程序开发和维护的图形用户界面。这是一个有助于SAP配置和管理的系统。它被开发用于商业企业。这种更容易管理SAP的方式是SAP生态系统的关键组成部分。
目录
- 什么是SAP GUI
- 什么是SAP GUI系列?
- 有哪些类型的SAP GUI?
- 适用于Windows的SAP GUI
- SAP GUI for Java
- 用于HTML的SAP GUI
- 带有Windows终端服务器的SAP GUI
- SAP GUI如何工作
- SAP GUI使用什么协议
- 链接
- SAP路由器
- 安全网络通信(SNC)
- SAP GUI使用什么协议
- 什么是SAP GUI版本?
- 如何查找我的SAP GUI版本?
- 什么是SAP GUI脚本
- 如何下载适用于Windows/Mac的SAP GUI(前端)
- 如何安装SAP GUI
- 如何自定义SAP GUI选项| SAP GUI配置
什么是SAP GUI
SAP GUI,通常被称为SAP图形用户界面,是一种前端软件,允许用户轻松地与众多SAP应用程序交互。它提供了简化的用户体验,简化了开发人员、管理员和所有年龄段用户的复杂操作,从而成为最终用户和SAP系统之间的桥梁。无论您在公司中的职位如何,或者您只是最终用户,此SAP图形用户界面对于加快业务流程至关重要。
SAP图形用户界面(SAPGUI)的用户界面在各种操作平台上运行,如Windows 3.1/95/98/NT、Motif、OS/2演示管理器和Macintosh。
在SAP ERP、SAP Business Suite(SAP CRM、SAP SCM和SAP PLM)、SAP Business Intelligence等SAP应用程序中,SAP Interface是SAP访问SAP功能的通用客户端。SAP界面的工作方式与浏览器类似。SAP系统的体系结构由三层组成(称为三层模型),如下所示
- 表示层
- 应用程序层
- 数据库层
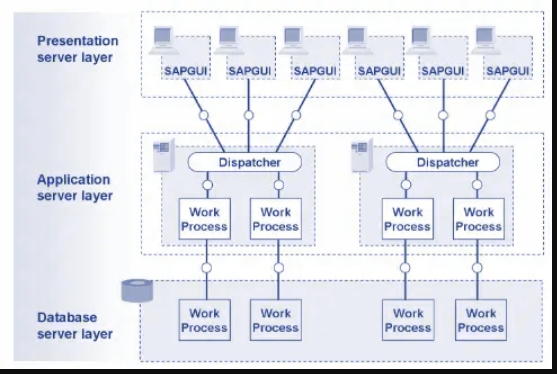
SAP GUI表示SAP系统的客户端-服务器体系结构中的表示层。它显示了应用程序的屏幕以及用户与系统的交互。SAP GUI是一个图形化的、基于窗口的程序,您可以使用键盘和鼠标进行控制。为了确保向最终用户可靠、安全地交付应用程序,您必须提供最佳的支持基础架构。它从SAP服务器获取信息,如在SAP服务器窗口中显示内容的内容、位置、时间和方式。
不管运行它们的操作系统是什么,所有SAPGUI看起来都是一样的。此界面因您使用的SAP或SAPGUI版本而异,但明显的差异很小。屏幕和工具的显示是可配置的。
什么是SAP GUI家族?
所有SAP GUI系列成员都具有特定的特性,这些特性使它们特别适合各种用户环境。以下三种不同的风格来自SAP GUI:
有哪些类型的SAP GUI?
SAP GUI客户有三种类型:
- 适用于Windows的SAP GUI
- SAP GUI for Java
- 用于HTML的SAP GUI
适用于Windows的SAP GUI
SAP GUI被称为mySAP&R/3的前端,是Windows的SAP界面。它适用于所有运行Microsoft Windows 32位的平台。SAP GUI for Windows具有独特的功能集优势。SAP GUI for Windows是一种Windows操作系统实现,提供类似Windows的用户体验,并与其他基于OLE接口或ActiveX控件的软件集成。
SAP GUI for Java
SAP Interface for Java看起来与Windows SAP GUI完全相同。在大多数公认的平台上,SAP Interface for Java运行,并且具有与SAP GUI for Windows几乎相同的功能。用于多个平台的单一SAP前端是用于Java环境的SAP接口。它基于一个独立于平台和Java实现的体系结构。作为一个主要优势,它提供了对基于控制功能的SAP应用程序的访问,因此过去是为Windows用户保留的。请注意,Java SAP接口在Windows上也可用。
用于HTML的SAP GUI
为了显示应用程序及其详细信息,SAP Interface for HTML使用预安装的Web浏览器。不需要特殊的客户端安装,但SAP Internet Transaction Server仍然是一个附加的中间件组件(ITS)。SAP Interface for HTML使用SAP Internet Transaction Server中提供的HTML Business功能,自动将SAP事务中的屏幕元素映射到HTML。SAP GUI for HTML使用HTML业务功能自动将SAP事务中的屏幕元素映射到HTML。
带有Windows终端服务器的SAP GUI
在Windows终端服务器上,我们还可以运行SAP GUI(WTS)。任何类型的SAP接口都在WTS上运行。但是,使用SAP GUI for Windows是公平的,但也有一些例外。SAP Framework RDBMS Windows终端服务器Windows终端客户端SAP界面图3窗口终端服务SAP GUI在WTS上使用SAP GUI,用户工作站只执行输入和输出操作。如果您想在多个用户在WAN连接上操作的分布式场景中使用SAP Interface,或者如果您使用带有WTSS的瘦客户端,这将非常有用。
SAP GUI如何工作
SAP GUI的技术体系结构大致分为以下几类。
SAP GUI使用什么协议
Connection
Windows/Java SAP GUI仅使用TCP/IP协议连接到SAP系统。所有连接都是从前端进行的,而不是从SAP服务器进行的。如果我们使用消息服务器进行负载平衡,SAP GUI将开始与消息服务器建立TCP连接,以确定最合适的应用程序服务器。SAP GUI现在建立了与应用程序服务器上调度程序的TCP连接。相同的TCP连接用于会话期间打开的所有模式。
SAP路由器
该连接还可以与一个或多个SAP路由器发生;在这种情况下,TCP连接只连接到SAP路由器,后者又连接到下一个通信伙伴。SAP路由器充当反向代理(没有任何缓存机制),使SAP GUI客户端能够连接到无法访问的网段(如防火墙)中的SAP系统。您可以连续使用几个SAP路由器。通过SAP路由器连接SAP系统,客户端使用所谓的“路由字符串”来寻址所使用的SAP路由器和目标系统。看见http://service.sap.com/saprouter有关此路由字符串的详细信息。
安全网络通信(SNC)
SNC(安全网络通信)是SAP体系结构中的一个接口,允许您使用外部加密产品来保护SAP通信。SAP不在自己的软件中实施任何加密方法,而是允许用户选择第三方加密程序和基础设施。SAP未直接提供的其他安全功能,如智能卡或生物识别技术,也可由安全产品使用。多种产品已通过SAP使用认证。SNC保护应用层上的数据。这确保了SAP通信节点之间(例如,SAPgui和SAP应用程序服务器之间)的安全连接,而与com无关。
什么是SAP GUI版本?
SAP软件GUI的第一个版本没有随着时间的推移添加到新功能中的图形元素,如复选框、单选按钮和图标。目前,7.5是Windows市场上可用的最新版本。另一个新版本(7.60)已定于2022年4月12日发布。介绍了伯利兹主题,使GUI的视觉设计与Fiori SAP应用程序的其余部分保持一致。它删除了“享受”/“流线”/“贸易展”/“系统相关”主题。
如何查找我的SAP GUI版本?
只需打开已安装在计算机上的SAP GUI登录板。单击左侧角的三行,然后单击关于SAP登录。
弹出窗口将显示发布详细信息
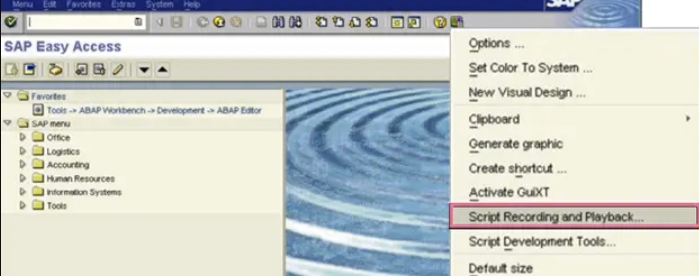
什么是SAP GUI脚本
SAP GUI Scripting是一个自动化界面,可增强Windows和Java的SAP GUI功能。使用此界面可以通过录制和运行类似宏的脚本来自动执行重复任务。它有助于实现日常工作的自动化
如何下载适用于Windows/Mac的SAP GUI(前端)
- Step 1: We need to go to the SAP Marketplace to download SAP GUI for Windows, Mac, or any other operating system. The landed page will appear as below, On the right-hand corner, software download.
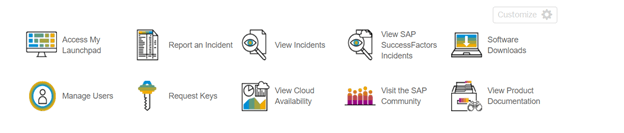 Download SAP GUI
Download SAP GUI
- Step 2: Once we select the Software Download Option, it will redirect to the SAP One Support Launchpad login. Here you need to enter your S-user and password as provided by SAP.
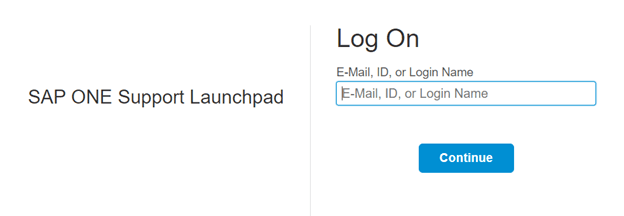 SAP One Support Launchpad login
SAP One Support Launchpad login
- Step 3 : Then we need to choose SAP Frontend components category installation & upgrade >> By Category
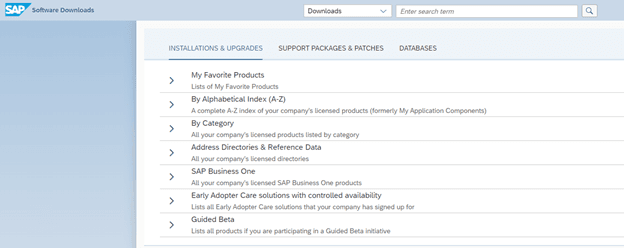 SAP Gui By Category
SAP Gui By Category
- Step 4 : Choose the SAP GUI component for your OS system requirements.
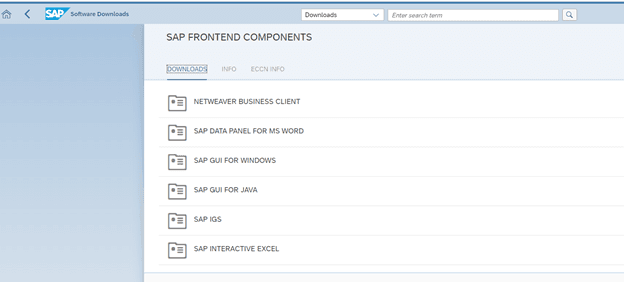 SAP Frontend Component
SAP Frontend Component
- Steps 5: Choose SAP GUI 7.30/ 7.5 Core which is the latest one.Choose Add to download Basket
 Download SAP GUI
Download SAP GUI
Choose the Download Basket,Choose Your download and it will begin shortly
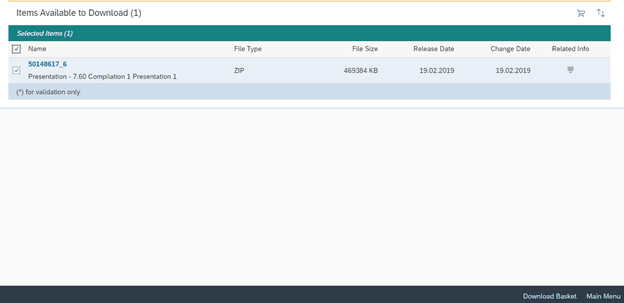
How to install SAP GUI
Please follow below procedure for Installation of SAP GU.
Click on Start NWSAPSetup.exe or File which has been downloaded .The SAP Setup installation wizard will appear
选择下一个。安装向导可能会提示您输入或更改信息以自定义所选产品的安装,例如安装文件夹。将显示产品功能列表。已安装的产品是预先选择的。
安装向导可能会提示您输入或更改信息以自定义所选产品的安装,例如安装文件夹。如有必要,请更改此信息,然后选择“下一步”开始安装。
从要删除的产品中选择要安装或禁用的产品或SAP前端组件。
选择后,选择“下一步”安装开始并显示进度屏幕。
如何自定义SAP GUI选项| SAP GUI配置
SAP GUI允许您更改默认颜色和文本大小。您可以自定义SAP系统的布局和设置,以根据个性化SAP外观修改文本和颜色。您可以自定义不同的主题
 How to customize SAP GUI options
How to customize SAP GUI options
Hope this article helps you to SAP GUI .Here are a couple of other articles that you check
- 1308 次浏览
【SAP HANA】SAP HANA Vora是如何成为最佳的?
视频号
微信公众号
知识星球
SAP HANA Vora是最新推出的SAP解决方案,用于在Hadoop平台上分析内存中的大数据,Hadoop平台运行在内存计算引擎上。SAP HANA Vora是SAP的一个交互式大数据分析引擎,它连接到Apache Spark和Hadoop系统,以提高Hadoop大数据的可访问性和可用性。归根结底,公司可以使用数据分析、KPI、服务来提高业绩。
目录
- 什么是SAP HANA Vora?
- SAP HANA Vora简介
- 什么是大数据
- 什么是HADOOP
- 什么是Apache Spark
- HANA VORA是什么
- 为什么HANA VORA
- SAP Vora引擎体系结构
- SAP HANA Vora:使用案例研究
- 实时供应链优化
- 客户洞察和定制
- SAP Leonardo的用途
- 什么是HDFS
- 什么是MLlib
什么是SAP HANA Vora?
SAP HANA Vora是一个强大的内存计算平台,旨在轻松地与Apache Hadoop和Apache Spark交互,并通过实时分析处理大量结构化和非结构化数据来扩展SAP HANA平台的功能。企业可以通过采用该软件来充分利用大数据分析的力量,从而实现更精确、更及时的决策。
SAP HANA Vora简介
数据科学家和分析师使用数据分析工具,公司在决策中也使用这些工具。数据分析将有助于企业更好地了解客户的业务和改进领域,评估其广告活动,个性化营销内容,制定内容战略,以及开发新产品。因此,大数据分析展示了一些增长的见解,并为其竞争对手提供了优势。
SAP Vora支持广泛的数据类型,包括图形数据、关系数据和JSON,以及时间序列。一个专门的引擎通过内部数据结构和算法管理每种类型的数据,这些结构和算法可以原生地支持并高效地处理数据。
我们可以将关系信息加载到主内存中,然后使用查询处理快速访问代码。有各种各样的引擎处理剩余的数据以进行后续分析。
- 关系磁盘引擎处理无法放入主存的大型数据集。
- 时间序列引擎可以使用不同的压缩技术来压缩时间序列数据。它还为压缩数据提供诸如互相关或直方图计算之类的算法。
- 图形引擎允许您对图形数据执行常见操作。它特别适用于大型图上的复杂只读查询。文档存储支持JSON数据的丰富查询处理
在我们开始深入了解HANA Vora之前,我们需要了解大数据、HADOOP和Apache Spark的概念
什么是大数据
移动传感、空气(遥感)、相机、麦克风、RFID读取器和无线传感器网络、社交媒体和存档数据。企业数据通常存储在昂贵的硬件中,而大型数据存储在价格较低的分布式商品硬件中。
什么是HADOOP
分布式计算开源软件。当您希望在分布式环境中保存大量数据时,HADOOP会执行以下操作。HADOOP支持您通过多种景观系统的组合来创建分布式环境。HADOOP有助于将数据和负载处理分发到各种场景。HADOOP只能在操作系统之上的一层使用HADOOP分布式文件系统。分布式计算(HDFS)。H
因此,HADOOP处理数据的文件。在大多数情况下,当数据以非结构化文件格式存储时,数据无法轻松处理。因此,为了构建数据结构,我们需要一些软件。在我们的传统系统中,我们总是使用MySQL、ORACLE、DB2等软件来组织数据文件。同样,我们需要一些软件来构建HDFS文件,
HANA VORA有助于解决这两个问题,并弥合企业大数据差距。公司数据是当前业务交易的数据,如销售订单、采购订单等。
什么是Apache Spark
用外行的语言来说,它是内存中的数据处理,它具有非常快速的数据处理能力。它支持Scala、Python和Java等多编程语言,支持ApacheSpark和Vora系统。Apache Spark中使用的Scala语言是目前最常见的。Vora将通过提供额外的业务功能和与SAP HANA的最佳集成来扩展Apache Spark,使用组织的实时企业数据实现跨消耗报告和高级分析。
Spark为与Spark流和机器学习(MLlib)相关的机器学习算法提供了进一步的高级可行性。
数据分析方面的挑战。
- 一旦我们必须掌握大数据,我们就面临着重大挑战
- 分布式数据存储在复杂的分析环境中,每次查询结果都不好
- 由于两种数据的环境不同,因此对需要业务和大数据相结合的报告的要求将非常高。
HANA VORA是什么
HANA-Vora使用可以实时处理的HANA内存数据库,然后在分析中添加一层来处理Hadoop数据。这允许Vora收集Hadoop中存储的大量数据,以便开发人员和数据分析师能够立即访问聚合数据并做出上下文感知决策。
为了处理数字企业的特定业务场景,SAP从SAP HANA开发了SAP Vora。2015年9月,SAP HANA Vora在本地和云中发布。Hadoop为大量数据提供了成本较低的存储,但公司最初接受度滞后,因为数据湖中的数据是非结构化的,难以处理。
为了通过Apache Spark结构化查询语言(SQL)接口对组合数据进行OLAP式内存分析,SAP HANA Vora为Hadoop数据集构建结构化数据层次结构,并将其与HANA数据集成。
为什么HANA VORA
例如,通过快速检测交易和客户历史异常,金融机构可以通过更好地分析网络流量模式来减少风险和欺诈,以防止瓶颈并提高服务质量(QoS),或者金融机构可以被允许减轻欺诈;通过分析物料清单、制造数据和传感器数据,制造商可以改进其产品召回过程。
SAP HANA Vora是一个内存查询引擎,它连接到Apache Spark的执行框架,以提供增强的Hadoop交互分析。
SAP Vora引擎体系结构
SAP Vora支持各种数据类型,包括关系数据、图形数据、JSON文档集合和时间序列。专门的引擎通过定制的内部数据和算法来管理每种数据类型,以本地高效地支持这种数据类型。
HANA-Vora允许将关系数据加载到主存储器中,以便通过查询处理和使用不同压缩技术的代码生成快速访问,同时在压缩数据上提供互相关或直方图等算法。对数据的图形化操作,特别适合处理复杂只读分析查询的超大图表
SAP Vora可以从外部分布式商店加载数据,如SAP BW、ERP和非SAP来源,如物联网、社交媒体、日志和遥感器。数据要么存储在内存中,要么编制索引并存储在硬盘上。允许批量数据处理,分析和转换复杂逻辑在执行查询之前准备数据并以可视化格式表示
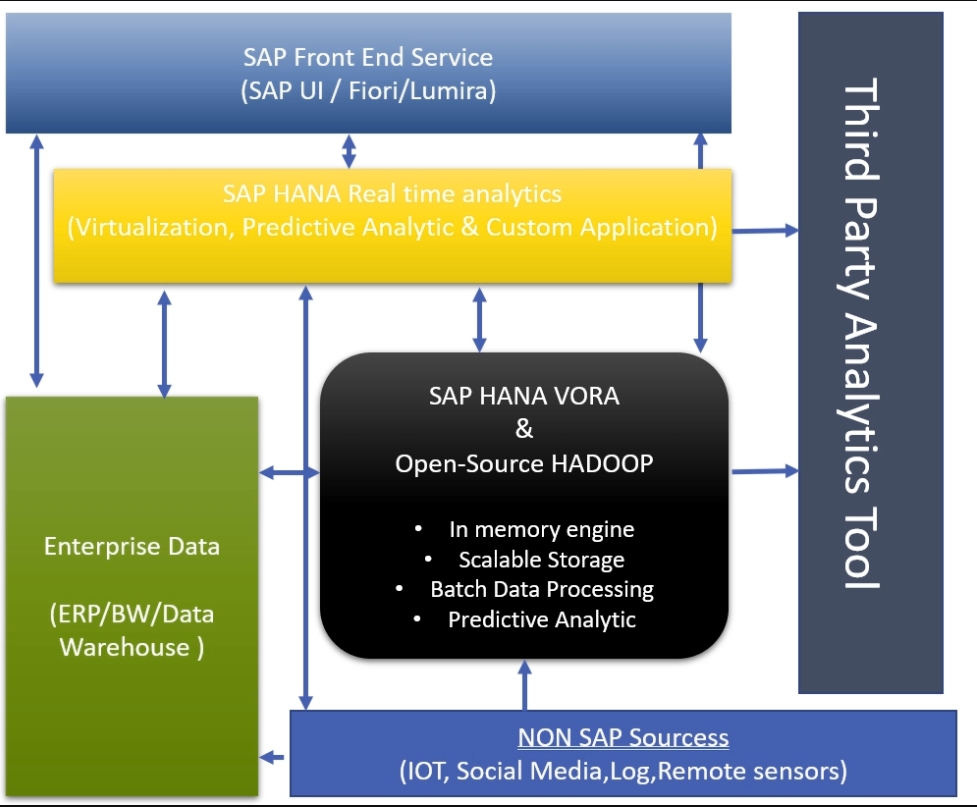
SAP HANA Vora:使用案例研究
实时供应链优化
改善供应链对于在当今竞争激烈的企业环境中保持领先至关重要。SAP HANA Vora的实时分析功能使企业能够实时监控和分析供应链数据。企业可以利用这种改进的数据处理能力来快速发现问题、优化运营并做出明智的决策,以提高供应链的效率和性能。
客户洞察和定制
识别客户的偏好和行为对于创造个性化体验和建立长期关系至关重要。SAP HANA Vora使组织能够实时分析大量客户数据,从而产生见解,推动营销策略、个性化推荐和整体更好的客户体验。这些先进的分析为公司提供了竞争优势,同时也提高了客户忠诚度。
关于文章中术语使用的常见问题解答
SAP Leonardo的用途
SAP Leonardo使企业能够自动化部分分析过程和业务决策,从而使用机器学习等智能技术获得动态见解
什么是HDFS
HDFS是指Hadoop分布式文件系统
什么是MLlib
MLlib指的是机器学习库(MLlib),内容有用的Spark机器学习算法
SAP HANA VORA入门
这里还有几篇文章可以帮助你提高知识。
- 82 次浏览
【SAP IDOC】SAP IDOC配置
视频号
微信公众号
知识星球
我们今天将尝试解释sap中的Idoc配置。这个博客用简单的步骤解释了Idoc的入站和出站配置。EDI消息可以很容易地与SAPIDoc和BAPI集成。将EDI集成到SAP中只需要几个步骤。下面是对sapedi配置的逐步描述。
Sap EDI IDOC分步指南,包含sapIDOC事务代码,可帮助您为新项目需求的任何新自定义开发设置快速EDI配置。在开始深入驱动IDOC配置之前,我们必须了解与IDOC相关的术语。本文的第一部分将讨论与基本idoc相关的术语以及如何使用它们。
目录
- 什么是IDOC?
- IDOC的结构
- IDOC类型是什么
- 什么是细分市场?
- 什么是消息类型
- 什么是流程代码
- 什么是Port
- 扩展IDOC类型是什么?
- 父细分市场和子细分市场:
- 合作伙伴:
- SAP EDI/IDOC逐步设置
- 创建IDoc类型(WE30)
- 创建IDoc类型
- IDoc细分市场的创建(WE31)
- 创建IDoc消息类型(WE81)
- 将IDoc类型分配给IDoc消息类型(WE82)
- 将FM(功能模块)分配给IDoc类型和消息类型(WE57)
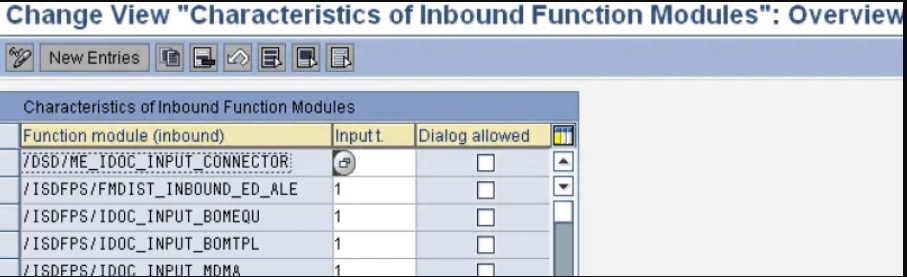
- 定义入站FM特征(BD51)
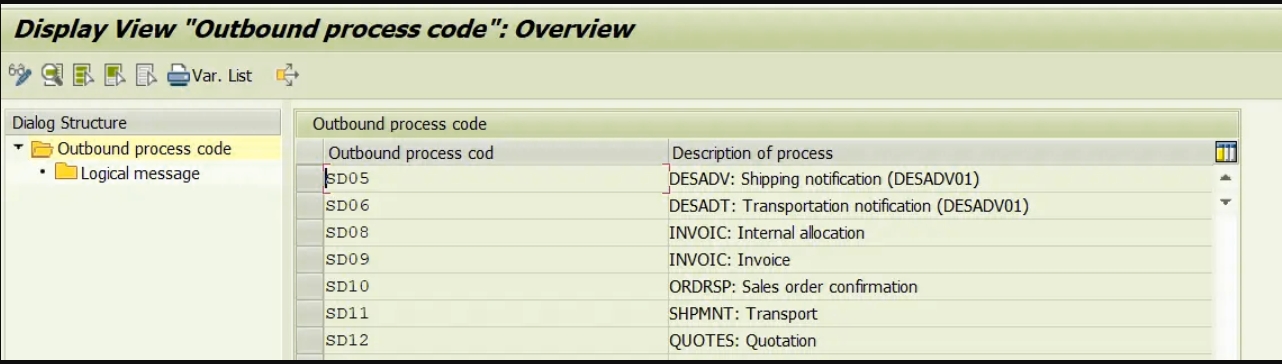
- 创建出站流程代码(WE41)
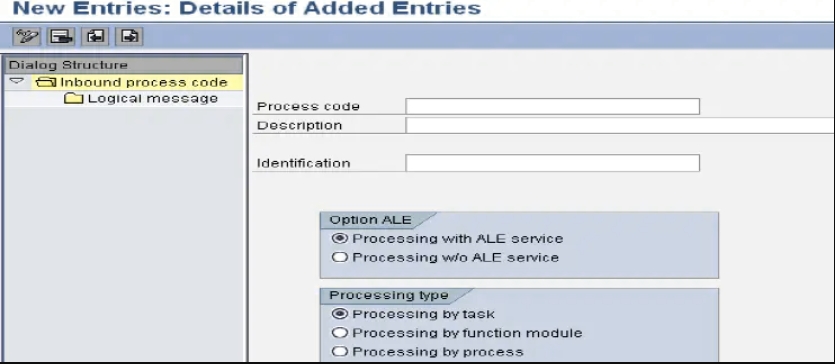
- 创建入站流程代码(WE42)
- 有用的IDOC计划
什么是IDOC?
IDocs是指sap中的中间文档。IDoc可以被描述为一个中间文档,用于在SAP与非SAP系统之间以及通过ALE或EDI技术从SAP与非SAPSAP系统之间传输信息。换句话说,IDoc就像一个盒子或数据容器,您可以在里面放置任何类型的信息或数据,然后SAP会将盒子发送到另一个系统,该系统可能是SAP或非SAP。
IDOC的结构
Idocs结构有以下几种:
- 控制记录(单个)
- 数据记录的记录(多个)
- 状态记录(多个)
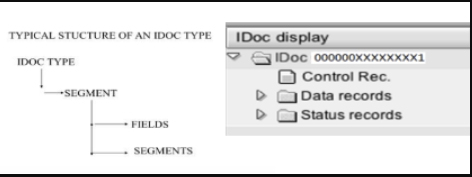
数据存储在SAP的透明表中。确实如此。EDIDC,EDID4,EDIDS。
IDOC类型是什么
IDoc类型基于SAP提供的EDI标准。它以EDIFACT标准为基础。基本类型(或IDoc类型)定义IDoc的结构。每个基本类型定义基本IDoc段、数据字段的格式和大小。基本类型也进行了定义。扩展由客户端确定,并与基本类型配对以创建一个全新的IDoc类型。示例,对于物料主数据-MATMAS,客户主数据-DEMAS
什么是细分市场?
IDoc段是发送给合作伙伴或由合作伙伴接收的真实信息。它们包含作为IDoc传输的一部分发送的确切数据。IDoc段是包含从合作伙伴接收或发送的真实信息的IDoc段。这些段包含作为传输的一部分在iDocs中传输的确切值。
什么是消息类型
IDoc处理需要将文档作为消息发送或接收,每个消息对应于SAP记录。这些单据包括订单、发货确认书、提前发货通知、良好收据或发票。与合作伙伴交换的数据或文档的类型由连接到基本IDoc类型(基本类型)的消息类型决定。
什么是流程代码
过程代码是关于IDoc过程中使用的功能模块的信息。消息的类型可以直接链接到过程代码。
什么是Port
IDoc端口包含有关如何在目标系统和源系统之间传输数据的信息。端口类型定义了端口中包含的数据。对于端口类型,“Internet”端口将包含目标系统的IP地址。当端口类型为“文件”时,会保留文件的目录或名称信息。“tRFC”端口包含有关如何到达目标系统的RFC位置的信息。为了支持IDoc传输,使用ALE“tRFC”端口。
扩展IDOC类型是什么?
基本类型具有进行业务交易所需的所有字段。如果需要向合作伙伴提供其他信息,那么我们可以使用IDoc Extension。IDoc扩展功能。IDoc扩展是对基本类型的扩展,包括自定义的IDoc段以及标准类型中不包括的字段。
IDOC是一种可分为两种类型的文档:IDOC可分为以下两种类型
IDOC有两种类型:
- 基本的
- 扩大
IDoc段是传递给合作伙伴或从合作伙伴处获得的实际信息的来源。这些段包含实际数据,这些数据是IDoc传输的一部分。IDoc传输。
父细分市场和子细分市场:
如果iDoc段包含自己的段,则将其称为父段。这些从属分段称为子分段
合作伙伴:
业务合作伙伴将使用IDoc进行数据交换。它可以是供应商或客户,也可以是其他类型的系统。根据传输信息的方向,它可以发挥“发送伙伴”或“接收伙伴”的功能
SAP EDI/IDOC逐步设置
- 创建逻辑系统并将其分配给客户端
- 激活SAP工作流
- 激活事件接收器链接
- 设置IDoc管理员
- 定义端口
- 定义用户特定参数
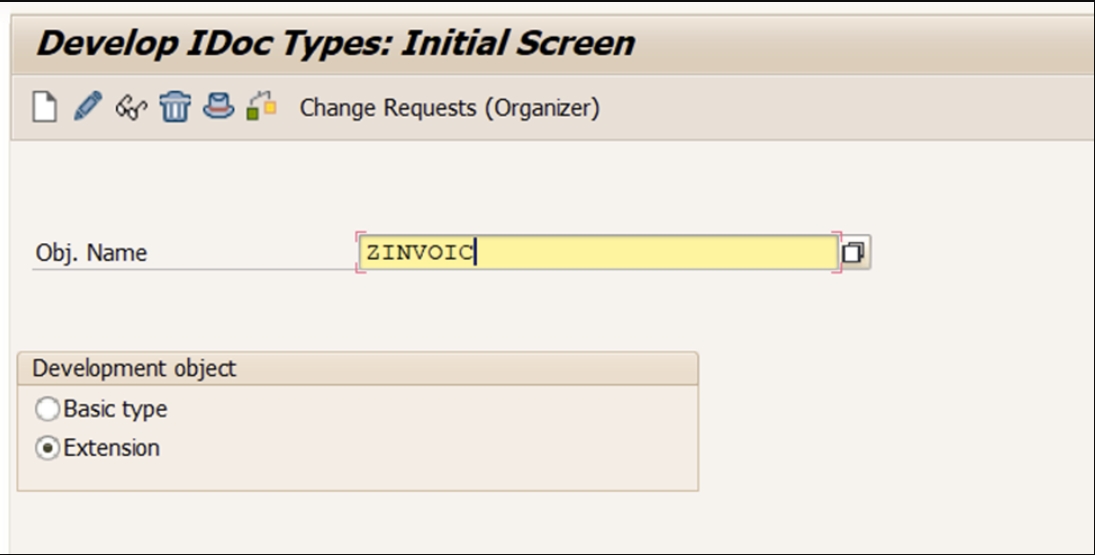
创建IDoc类型(WE30)
为e,g INVOIC02创建新的IDoc类型,代表需要以电子方式发送给客户的发票。根据SAP的建议,任何自定义开发都应该从Z开始,因此我们将创建新的ID OC类型ZINVOICE。您可以自己命名。
创建IDoc类型我们需要遵循以下步骤
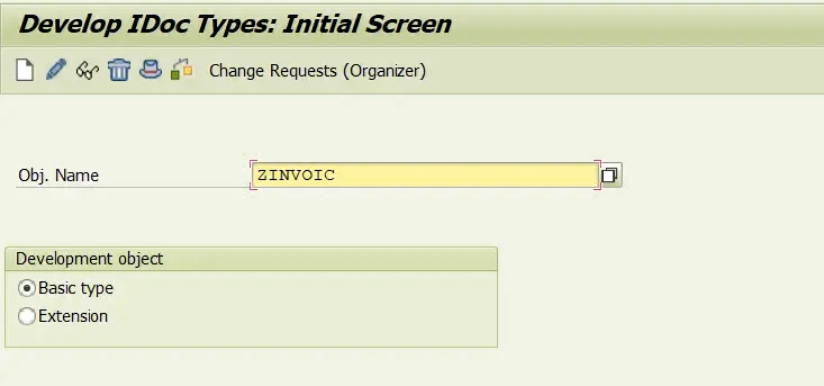
创建IDoc类型
- 转到交易代码WE30
- 输入对象的名称,选择“基本类型”,然后单击“创建”图标
- 选择一个新选项来创建并输入基本IDoc类型的描述,然后按enter键。
- 选择IDoc的名称,然后按创建图标
- 系统会提示您输入线束段的类型及其属性。
- 选择所需的值,然后按Enter键
- 系统将把段类型的名称传输到IDoc编辑器。
- 按照以下步骤向父关系或父子关系添加更多分段。
- 保存并返回
- 转到编辑->设置发布
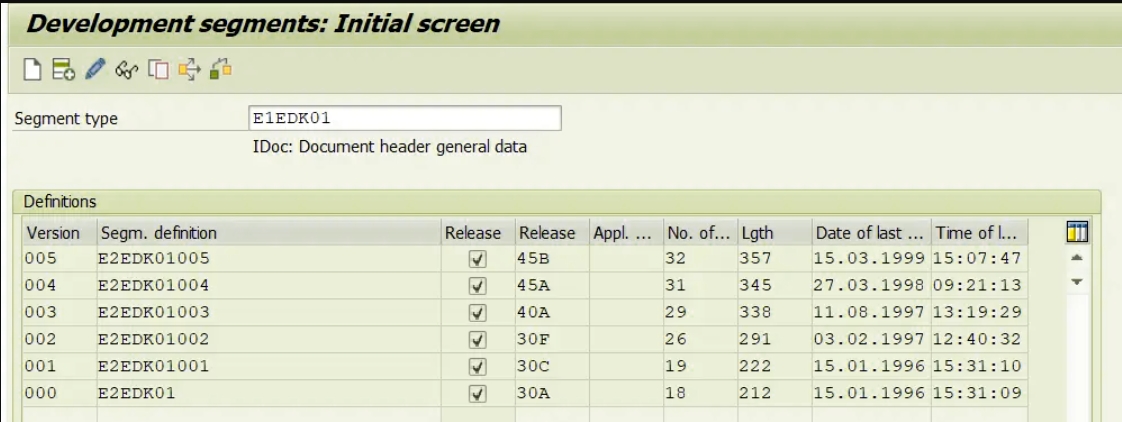
IDoc细分市场的创建(WE31)
创建IDOC段类型我们需要遵循以下步骤
- 转到WE31交易代码
- 输入分段类型的名称,然后单击“创建”图标
- 键入短文本
- 输入变量和数据元素的名称
- 保存它,然后回到那里。
- 转到编辑->设置发布
- 按照相同的步骤创建更多线段
创建IDoc消息类型(WE81)
创建IDOC消息类型我们需要遵循以下步骤
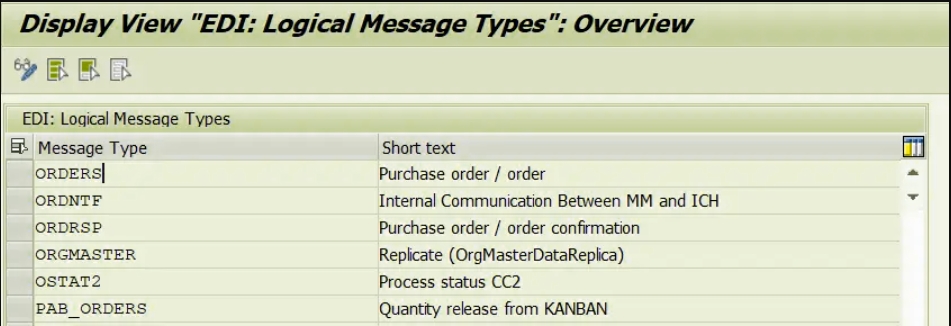
- 创建消息类型
- 转到WE81交易代码
- 将“显示模式”中的详细信息更改为“更改模式”
- 选择后,系统将发送此消息,“表格是跨客户端的(有关详细信息,请参阅帮助)。”Enter Press
- 单击“新建条目”创建新类型的消息
- 填写详细信息
- 保存它,然后回到那里。
将IDoc类型分配给IDoc消息类型(WE82)
现在我们需要用IDOC消息类型分配IDOC类型,这里我们需要用基本消息类型分配IDOC类型
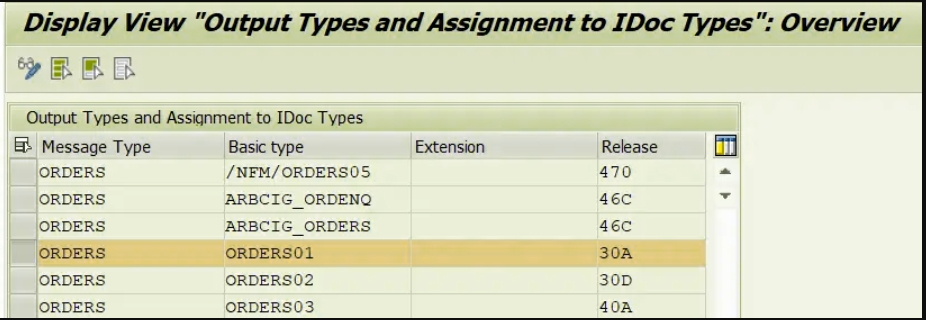
将FM(功能模块)分配给IDoc类型和消息类型(WE57)
按照以下步骤进行分配:
- 转到WE57交易代码
- 将“显示模式”中的详细信息更改为“更改模式”
- 选择后,系统将发送此消息,“表格是跨客户端的(有关详细信息,请参阅帮助)。”Enter Press
- 单击“新建条目”创建新类型的消息
- 填写详细信息
- 保存它,然后回到那里。
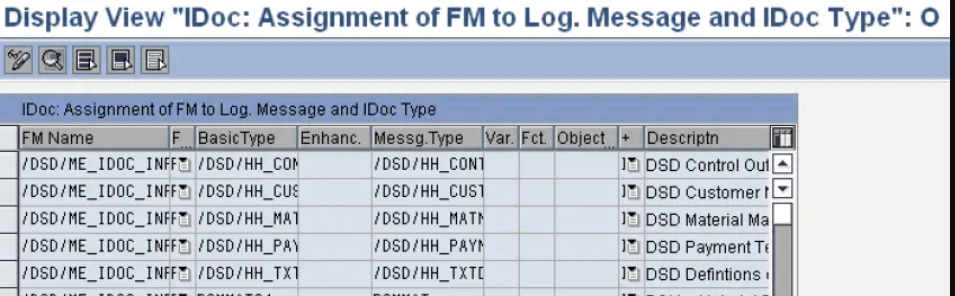
定义入站FM特征(BD51)
- 取交易代码BD51
- 将“显示模式”中的详细信息更改为“更改模式”
- 选择后,系统将发送此消息,“表格是跨客户端的(有关详细信息,请参阅帮助)。”Enter Press
- 单击“新建条目”创建新类型的消息
- 填写详细信息
- 保存它,然后回到那里。
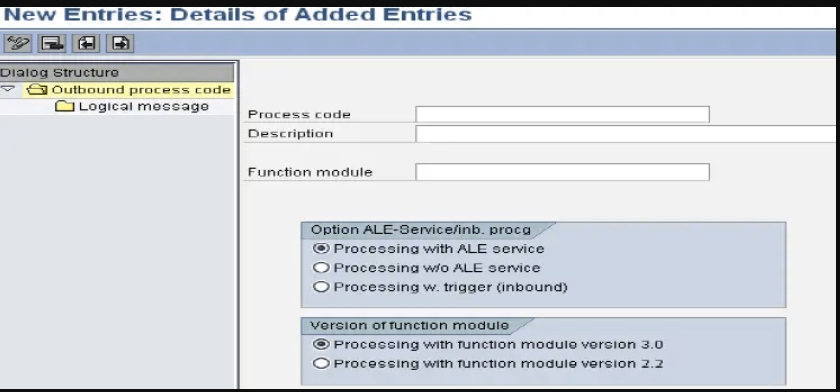
创建出站流程代码(WE41)
流程代码包含用于IDoc处理的功能模块的详细信息。我们可以将消息类型链接到流程代码。
请执行以下步骤:
- 转到WE41交易代码
- 将“显示模式”中的详细信息更改为“更改模式”
- 选择后,系统将发送以下消息:“该表是跨客户端的(有关详细信息,请参阅帮助)。”请按Enter键。
- 单击“新建条目”按钮以创建新的出站流程代码。
- 填写详细信息
- 保存它,然后回到那里。
创建入站流程代码(WE42)

请执行以下步骤:
- 转到WE42交易代码
- 将“显示模式”中的详细信息更改为“更改模式”
- 选择后,系统将发送以下消息:“该表是跨客户端的(有关详细信息,请参阅帮助)。”请按Enter键。
- 单击“新建条目”按钮以创建新的入站流程代码。
- 填写详细信息
- 保存它,然后回到那里。
现在,您的配置已准备好进行测试。触发新创建的消息以进行进一步测试
有用的IDOC计划
- RBDAPP01申请文件的传入IDoc
- ALE输入错误后IDocs的RBDAGAI2再处理
- RBDAGAIE编辑的IDocs的再处理
- RBDMANIN未发布IDocs的错误处理
- 按文件对RSEINB00 IDoc的入站处理
- RSEUT00处理出站IDoc
希望这篇文章能帮助你了解edi的配置
- 210 次浏览
【SAP S4HANA】SAP S4HANA完整入门指南
视频号
微信公众号
知识星球
SAP S4HANA是由SAP开发的尖端企业资源规划(ERP)解决方案,SAP是商业软件解决方案的市场领导者。凭借其革命性的架构和复杂的功能,S4HANA已迅速成为ERP系统中的游戏规则改变者。在这篇文章中,我们将更深入地了解S4HANA,研究它的功能、好处,以及它如何彻底改变了公司在全球的运营。
本博客的重点将是了解SAP S4HANA的概述——什么是S/4HANA,客户正在投资的S/4HAN中有什么有趣的地方,它提供了什么好处,以及SAP计划如何使其与自己的ERP不同?让我们开始深潜来理解这个概念。
目录
- 什么是S4HANA?
- S4 Hana做什么?
- SAP HANA概述
- 内存数据:
- 内存中数据的优化:
- 数据存储模型:
- 数据压缩:
- 增量存储:
- 数据老化:
- SAP HANA Live
- 联机分析处理
- OLTP:(在线跨国处理)
- S4 HANA中的简化
- 业务合作伙伴方法:
- 材料主数据的更改:
- 对外贸易:
- 删除状态表:
- 数据模型更改:
- 高级ATP:
- 信贷管理:
- 需求驱动的补货:
- 结算管理(返利处理):
- SAP ERP和S4HANA之间有什么区别?
什么是S4HANA?
SAP S/4HANA是由SAP AG开发的企业资源规划(ERP)系统。它于2001年首次推出,已用于许多不同的行业,包括零售和物流、制造、医疗保健、运输和教育。SAP S/4HANA是新一代软件,可帮助公司实现事半功倍。它能够分析和预测业务需求,识别机会,并为业务创造价值。
S4 Hana做什么?
SAP S/4HANA(SAP Business Suite 4 SAP HANA)是由SAP开发的实时企业资源规划(ERP)软件。它旨在为组织提供一个数字核心,可以支持各个行业的端到端业务流程。
SAP S/4HANA包括一系列模块和功能,可支持各种业务功能,包括财务、采购、供应链管理、制造和人力资源。它基于SAP HANA内存数据库,允许实时处理大量数据,并使组织能够做出更快、更明智的决策。
让我们在文章中探讨更多细节…
SAP S/4HANA是基于本机SAP HANA的改进,是当前SAP ERP的精简解决方案。SAP S/4HANA的财务方面在最初的SAP ECC框架中完全稳定。但重复和弱点依然存在。SAP努力消除这些障碍。因此,SAP S/4HANA软件的设计考虑到了频繁的客户反馈以及系统中的重大变化和创造性。这个故事始于2015年,当时推出了一款名为“简单金融”的产品,一些项目是在SAP致力于改进的情况下启动的。然而,产品并没有预期的那么好。相反,它被重新设计为最终名称SAP S/4HANA,并以1503、1610和1709(YYYM)等发布号作为后缀。在创新和功能方面,到目前为止还没有完成任何产品版本。为了让消费者更轻松、更实用,SAP还将改进集成到软件中。经过很长一段时间,SAP进行了这一大规模创新。
SAP S/4HANA被设计为仅在SAP HANA数据库上运行,它已经具备了SAP强大的内存设计的所有功能。它可以根据需要在本地、云上或混合云上部署,而且非常灵活。SAP S/4HANA业务模式已得到简化。这导致删除了几个表格。这在很大程度上减少了数据占用,也简化了系统的设计、可用性和可扩展性。这有助于简化和加快财务管理。使用Fiori,最终用户可以提供具有特定数据级别的定制信息,从而了解交易行项目的详细信息。数据分析是一个组织上多样化的过程。
SAP S/4HANA不是一个单一的产品;它有许多应用。客户将开始使用基本组件,根据更多应用程序的需要,这些组件可以连接到购物篮上。SAP S/4HANA企业管理的理想起点是。它是简化的核心,被认为是SAP ERP的替代品。它为所有核心业务流程提供支持。SAP S/4HANA企业管理可以轻松地与SAP S/4HANA业务线(LoB)解决方案集成。这些选项可以随时添加,并提供一流的业务线解决方案和与SAP业务网络的连接。客户可以选择对其业务最有用的业务线解决方案。
- SAP SuccessFactors ,SAP S/4HANA和SAP SuccessFactors员工中央工资快速部署系统的集成(涵盖已完成活动、COBL检查和正在进行的成本中心副本的web服务功能模块尚未开始)
- SAP Ariba:Ariba发票管理(买方)和付款建议和取消付款建议Ariba折扣管理(买方方)和PayMeNow
- Concur:使用Concur实施SAP S/4HANA,并重复使用SAP ERP插件(由Concur产品交付)
- SAP Fieldglass:SAP S/4HANA集成计划在与SAP Fieldglas、LOB PROC和SAP主数据治理的联合项目中进行(FIN负责成本中心和内部订单的复制)。
- SAP CEC:SAP CEC允许在SAP CEC工具集中高效规划客户旅程,其中商业、订单管理、产品数据管理和SAP客户和Hybris营销云相结合。
- SAP hybris:SAP hybris Marketing是一款基于HANA的应用程序,可集中访问营销功能。
SAP S/4 HANA是基于高性能内存内HANA平台的最新SAP产品,使用FIORI软件可丰富用户体验。新方法在过渡过程中进行了重大改进和实质性简化。将FIORI应用程序用于新用户界面上的底层数据结构。
SAP HANA概述
SAP HANA是一个基于内存的数据库管理系统(DBMS)。在SAP HANA中,内存在一定程度上是可用的,数据存储不是限制。这使得它不同于其他有内存限制的数据库,尽管它们在硬件方面有潜力。SAP HANA优化了缓存和主/主内存之间的内存访问。在当今时代,数据量对所有组织,特别是金融组织来说都是一个重大挑战,因为由于审计要求,它们必须将数据存储更长的时间,当然还有规划和预测目的。
SAP HANA的基本概念包括以下几个方面:
- 内存中的数据
- 内存中数据的优化
- 增量存储
- 数据压缩
- 增量存储
- 数据老化
内存数据:
内存中数据库使用一种技术,其中所有数据都是从源系统中整理的,而不是存储在RAM存储器中笨重的硬盘中。在SAP HANA中,内存数据库技术用于存储大型数据库,因此CPU可以在分析或信息处理需要时在纳秒内访问数据。
内存中数据的优化:
SAP HANA以柱状格式存储数据,从而有效压缩和减小数据的总体大小。它还解决了主内存和缓存之间的数据流问题
数据存储模型:
通常,存储在数据库中的数据是表格格式的。表是对信息进行组织的数据结构。它可以在行和列中存储数据,并用于以结构化格式显示数据。数据库通常由几个表组成,每个表都有特定的用途。使用柱状模型可以提高性能,因为它通过只访问适当的列来实现高效投影,从而减少了内存访问次数。此外,它还允许进行有效的压缩,尤其是在进行列排序时
数据压缩:
用于减少数据位数的技术被定义为存储器的数据压缩。在这种技术中减少了总内存,因此降低了成本,并且所有数据读取都是在压缩集上完成的。许多压缩方法(如行程编码)在基于行的布局中不可用。这是一个真正的技术问题,因此我们在此不做过多的详细介绍,但目前了解存储场景和压缩上下文非常重要。
增量存储:
将数据集成到压缩数据中通常非常缓慢。SAP HANA解决了这个问题,因为它带来了增量存储的概念。在这个系统中,列表存储包含了增量的中央存储和存储。任何写操作,如插入、更新或删除,都是在增量存储中完成的,增量存储也是列式存储,任何添加都会附加到结构的末尾。
数据老化:
HANA,老化与归档的不同之处在于,冷数据仍然保存在SAP HANA数据库中,并且可以通过SQL在与热数据相同的表中访问。每天定期查询热数据,而冷数据通常是分区的。配置必须在设置阶段定义一次,使用此解决方案,数据可以通过后台任务进行重组,并在需要时自动从内存中推出。
SAP HANA Live
SAP S/4HANA由SAP HANA提供支持,它结合了OLTP和OLAP的处理。事务数据不需要移动到另一个系统进行分析,它们在同一个表中运行,这提高了效率并避免了冗余。SAP HANA Live是一个预先配置、开箱即用且可扩展的数据模型。它是一种体系结构,可在SAP HANA数据库中用于分析报告。这有助于企业基于语义数据模型构建分析包,丰富SAP ERP的底层结构。
为了在任何竞争中获得市场价值和优势,组织拥有自己的数据分析是很重要的。每一个决策都是由数据驱动的,但如果数据分析尽可能准确,决策可能会更高效。随着技术的出现,决策的数据模型发生了变化。新的实时数据已经取代了旧数据,可以多次访问单一的真相来源。复杂的系统和数据,如OLAP和OLTP系统,可能具有多层结构。让我们了解以下概念:
OLAP:联机分析处理
这是许多商业智能应用程序背后的技术。OLAP是一种通用的数据发现工具,具有不受限制的报告功能、查看、复杂的分析计算和预测性的“假设”场景(预算、预测)规划。
OLTP:联机交易处理
以大量快速在线交易为特征(INSERT、Edit、DELETE)。OLTP系统的主要关注点是快速查询处理、在多址环境中保持数据完整性以及通过每秒事务数来衡量效率。
传统数据库中的事务处理与分析处理完全不同。其中的关键元素是数据库的两个框架的体系结构。然而,它导致了复杂和冗余的数据处理。现在处理交易,一天后也可以进行分析,这会延迟财务部门的工作,尤其是在交易结束时。
此数据模型具有以下属性:
- 针对运营报告进行了优化
- 消除了重复数据
- 准备消费
- 可扩展
- 易于使用,具有真正的类似业务的语义
S4 HANA中的简化
现在让我们了解SD领域中的数据模型简化。以下是主要的简化点:
业务合作伙伴方法:
在SAP S/4HANA中,业务伙伴是维护业务伙伴、客户和供应商(以前称为供应商)主数据的主要对象和单一入口点。这确保了上述主数据保持简单,并实现了它们之间的协调。与传统的ERP交易相比,通过业务伙伴维护客户和供应商主数据有几个优势。其他如下
- 业务合作伙伴允许维护具有相应地址用途的多个地址。
- 在经典交易中,一个客户只能与一个帐户组关联。但在业务伙伴中,同一业务伙伴可以关联多个角色。
- 最大限度的数据共享和数据重用使数据整合更加容易。
- 常规数据可用于所有不同的业务伙伴角色,并为每个角色存储特定数据。
- 维护与同一业务伙伴的多个关系。
- 维护不同子实体角色、地址、关系、银行数据等的时间相关性。
过时的事务:FD06、FK06、MK06、MK12、MK18、MK19、VD06、XD06、XD0、V+21、V+22、V+23、MAP21、FD0
重定向到事务BP的事务:FD01、FD02、FD03、FK01、FK02、FK03、MAP2、MAP3、MK01、MK02、MK03、V-03、V-04、V-05、V-06、V-07、V-08、V-09、V-11、VAP1、VAP2、VAP3、VD01、VD02、VD03、XD01、XK06、XK07、XK02、XK03
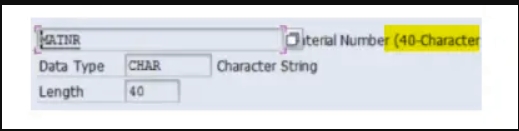
材料主数据的更改:
物料主基本事务代码仍然与ECC中的相同:MM01创建MM02,将MM03更改为显示。但是,物料编号的长度随着一些字段级别的更改而更改。添加了新字段,并删除了一些字段。最大的变化是“材质”编号字段的长度。这是客户的高需求,因为不同的行业要求有大量的材料。它在SAP ECC中是18个字符,现在在s/4HANA中是40个字符。让我们看看两个系统中的一个示例,看看“材质”编号是什么样子的
SAP S/4HANA物料编号视图如下:然而,默认的SAP S/4ANA系统只有18个字符,需要根据客户要求进行扩展。
然而,默认的SAP S/4HANA系统只有18个字符,需要根据客户需求进行扩展。
以下是激活此项的路径:SPRO–IMG–跨应用程序组件–通用应用程序功能–字段长度扩展–激活扩展字段
对外贸易:
材料大师的另一大动作是外贸数据。这现在是SAP GTS的一部分,在S/4HANA中不可用。添加了新的SERV型材料。顾名思义,它旨在用于服务。以下是物料类型的可用视图:基础数据销售视图采购视图会计
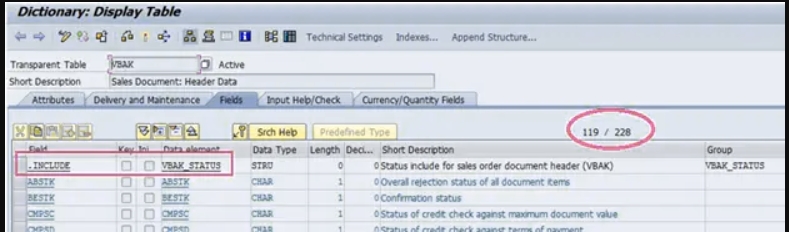
删除状态表:
S4 Hana不再需要状态表VBUK和VBUP。现在可用于状态表字段的“销售订单标题”和“项目”位于表VBAK和VBAP中。
- VBFA主键更改
- SD文档类别VBTYP:字段长度扩展
- 删除扩展SD文档类别VBTYPEXT_V、VBTYPEXT_N
- 删除1709年添加的S/4HANA 1511/1610中的STUFE列
- 删除S/4HANA 1511中的CMETH列,1610年添加
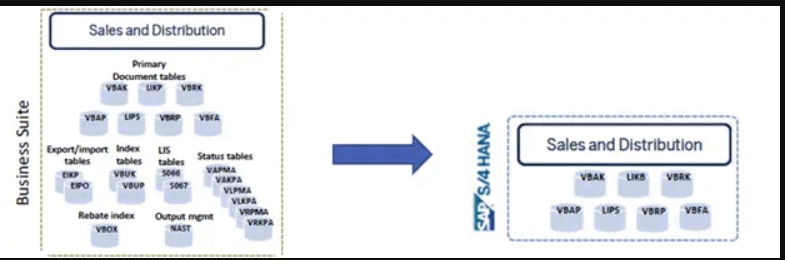
数据模型更改:
随着SAP S/4HANA的推出,SAP SD定价中引入了一些更改:价格存储在KONV中,但现在将存储在PRCD_ELEMENTS状态表中:删除的索引表VBUK和VBUP:VAKPA、VAPMA、VLKPA、VLPMA和VRKPA表:VBOX、S066和S067。
将KONV表替换为新的PRCD ELEMENTS表,作为定价影响的数据持久性。KONV仍然可以用于声明数据。它还确定应用程序代码中的定价结果结构
所有条件头表,包括KONH(定价)、NACH(输出确定)、KOND3(活动确定)、KONDN(免费商品确定)、KONHM(投资组合确定)、J3GPRLHD(CEM价目表确定)和WIND(文档索引),都从条件表的级联可变键字段VAKEY中删除。级联变量数据字段VADAT也已删除
对条件技术进行了以下DDIC更改和接口更改:
- 对于内部处理,引入了长度为CHAR255的长数据元素VAKEY_long和VADAT_KO_long。
- 新的长VAKEY和VADAT的内容可以在运行时使用服务类CL_COND_VAKEY_SRV的方法来确定
多个字段的字段长度增加,从而在定价和条件技术方面具有更大的灵活性
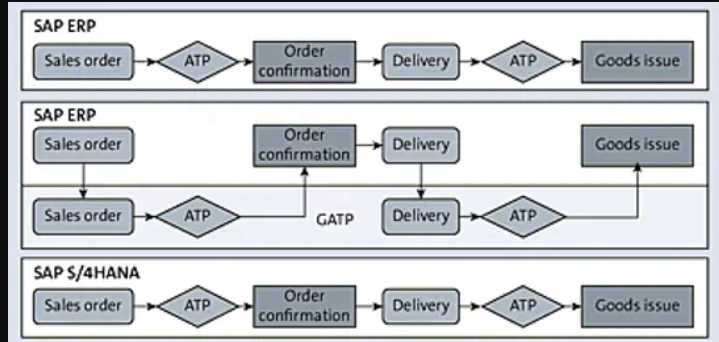
高级ATP:
SAP S/4HANA中的AATP嵌入到SAP S/4ANA核心产品分配(PAL)中。这是一种管理秩序的方法,以防止“先到先得”的问题。
延期订单处理(BOP):这是一个重新ATP过程(即在初始订单创建后执行ATP),以确认高优先级订单和未确认的低优先级订单
- 已删除销售订单要求的汇总表VBBS。
- VBBE,其中明确存储了每个ATP相关要求。
- 包括基于特征的ATP的新时尚解决方案不可用。
- 基本ATP的概念
ATP数量=库存+计划收货-计划出库
信贷管理:
S/4 HANA已停止信贷管理,推荐的解决方案是FSCM。因此,不再允许F.28、F.31、F.32和F.33等交易。以下是这些领域的新交易:新交易旧交易目的UKM_BP FD32信用额度维护UKM_MY_DCDS VKM1到期冻结销售订单的释放

需求驱动的补货:
需求驱动补货的概念包括以下核心组成部分(以及其他部分),
- 关注真实的客户需求(即不根据预测进行计划)
- 在选定的解耦点(DP)进行战略缓冲定位的概念
- 基于真实数据分析/反馈循环的连续缓冲区(重新)大小调整,以根据不断变化的现实调整缓冲区
- 需求驱动补货有助于,
- 通过将库存保持在供应链中的正确位置和正确数量,实现改善和顺畅的物料流,减少例外。
- 获得对真实客户需求做出反应的响应能力,以需求驱动的方式进行覆盖(从而避免不必要的生产)。
- 通过基于真实数据分析的反馈实现的适应性,通过这种适应性,解决方案的设置/参数得到了改进,并根据“真实生活”进行了修改。
结算管理(返利处理):
- 继S/4HANA中的结算管理之后,1709条件合同是取代回扣管理的新解决方案。
- 条件合同结算能够集中管理各种后续结算相关业务流程的主数据和结算相关数据。
- 条件合同结算应用程序是根据合同条款创建、编辑和结算条件的单一入口点。
- 表VBOX(回扣指数)现在在S/4 HANA中消失了,因为由于HANA的力量,回扣条件立即适用。
- 这大大减少了数据占用空间和内存

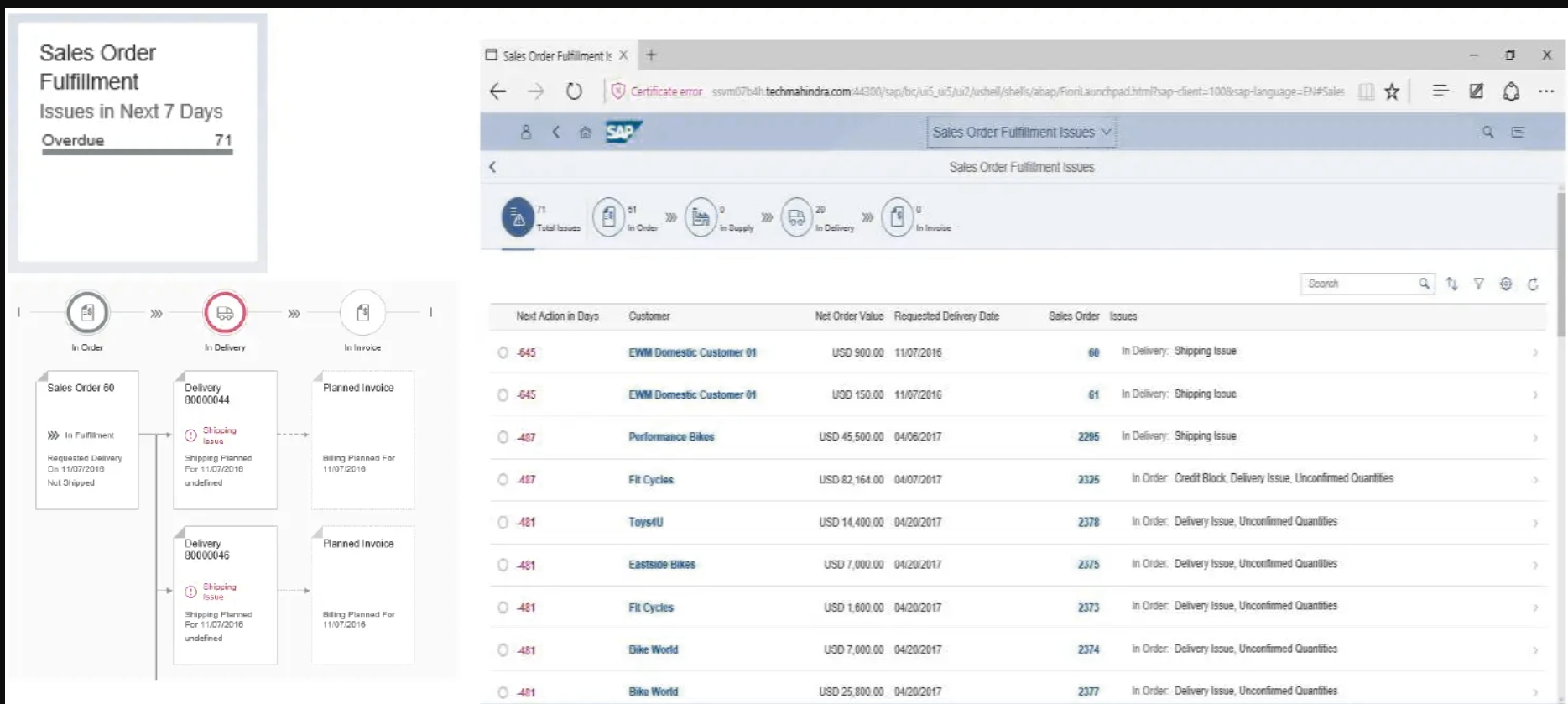
面向销售客户的Fiori应用程序–360°视图:
- 通过回顾过去和现在的汇总销售数据对一个特定客户进行概述
- 连接的流程步骤链和相应业务文档(文档流)的图形概述。
- 使用文档ID、客户参考或创建文档的用户的用户ID的特定销售文档
- 显示此客户的履行问题列表或导航到问题详细信息
SAP S/4 HANA简化列表更新如下
- SAP S/4HANA 1909的简化列表
- SAP S/4HANA 1809的简化列表
- SAP S/4HANA 1709的简化列表
SAP ERP和S4HANA之间有什么区别?
SAP ERP是S4HANA的前身,使用传统的基于行的数据库。另一方面,S4HANA使用SAP HANA内存数据库来实现更快的数据处理、更好的分析能力、简化的数据模型、改进的用户体验以及与SAP ERP不同的智能自动化功能。
- 1098 次浏览
【SAP】如何在5分钟内在sap中创建拒绝理由
视频号
微信公众号
知识星球
在本博客中,我们将了解如何在SAP SD中配置拒绝原因。在SAP中,拒绝原因是一个指标,可以让我们了解被拒绝的项目及其原因。SAP是领先的业务应用软件解决方案。它是一个用于管理业务运营的企业资源规划(ERP)软件。因此,企业使用SAP来实时管理业务事务。然而,企业资源规划系统并不完善,可能需要不时更新。在这种情况下,用户可能需要提供拒绝其请求的理由。此博客提供了SAP拒绝的原因。
目录
- sap中拒绝原因介绍
- SAP中拒绝原因的配置。
- 拒绝统计值的原因是什么
- 销售订单中拒绝更新的程序原因
- 拒绝理由的强化。
sap中拒绝原因介绍
在业务场景中,组织或最终用户不想继续流程,因为项目太贵、交货日期太晚、存在信用问题等。在这种场景中,需要维护拒绝,这将显示在处理过程中拒绝原因的下拉列表中。根据每个拒绝原因的配置方式,系统的行为会有所不同。今天我们将详细了解它的配置部分。
SAP中拒绝原因的配置。
此配置指定了拒绝的原因。这些可以在销售文档中用于指示可能的拒绝原因。这些因素也会影响商品被拒绝时的情况。
首先,我们需要打开SPRO配置并遵循以下路径
IMG → Sales and Distribution → Sales → Sales Documents → Sales Document Item → Define Reasons or reasons for rejection transaction Code – OVAG
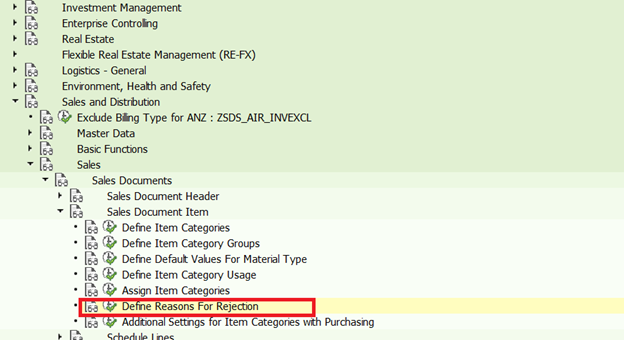
单击新条目以创建新的拒绝代码。转到新条目,并用Z作为前缀定义自己的条目。一个两位数的代码,表示拒绝的原因E,g我们创建了01–交货日期太晚。
有三个复选框将控制您的销售订单中拒绝的总体原因。
- NRP:这是否与打印有关
- BIC:计费相关性
- Stat:统计值
拒绝统计值的原因是什么
指示系统在计算文档总值时是否考虑项目的值。Stat.(统计值)列位于此处。与销售订单中所述的原因相反,不应保留空白,而应保留X或Y。
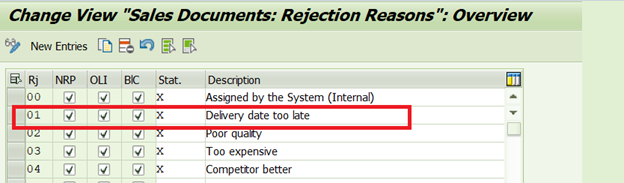
- X–无累积–值不能用于统计(该值不会添加到销售订单总价值中,但可以在LIS/SIS中使用)。
- Y–无累积–数值可用于统计(数值不会相加。
这样可以确保拒绝项目的值不会添加到销售订单的总值中。
销售订单中拒绝更新的程序原因
我们可以选择拒绝整个销售文档或个别项目。一旦有更改,拒绝的原因现在可以在销售文档中使用。我们可以输入一个或多个项目的拒绝原因。唯一的要求是我们处于销售文档的更改模式。
拒绝所有内容:
- 如果要拒绝所有项目,请在销售文档的更改模式中选择“拒绝文档”。系统会自动选择所有项目,您可以在下面的对话框中输入拒绝的原因。
- 输入相应的拒绝原因,然后选择“复制”。系统会以相同的原因拒绝所有选定的项目。个别项目应被拒绝:
拒绝项目:
- 如果您只想拒绝少数项目,请在项目概述屏幕中选择它们,然后单击编辑。快速更改…拒绝的原因因为01交货日期太晚。此时会出现一个对话框,您可以在其中指定拒绝的原因。
- 输入相应的拒绝原因,然后选择“复制”。系统会为所有选定项目提供相同的拒绝原因
拒绝具有不同拒绝原因的单个项目:更改销售文档时,从概览屏幕中选择拒绝原因选项卡页面,以输入项目的不同拒绝原因。在拒绝原因字段中,您可以为每个项目输入不同的拒绝原因。
Sap拒绝原因表为VBAP,字段为ABGRU
拒绝理由的强化。
创建特定的销售订单类型时,业务部门希望阻止该订单进行进一步处理,并且必须指定拒绝原因。通过一点SPRO配置,我们可以使用以下配置自动将Delivery/Billing Blocks设置为Sales Document Type。
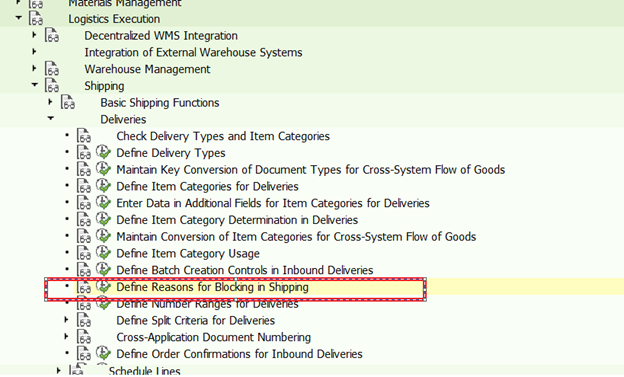
这样可以确保交付/计费块在创建后立即分配给销售订单,并且只能由授权用户删除。在删除该块之前,以下事务将被拒绝。
或者,我们选择ABAPer或技术顾问的Custom Development,以包含一个代码来检查销售文档类型,并在User Exit–USEREXIT FIELD MODIFICATION字段中写入拒绝原因。
我们希望你发现这篇文章对学习拒绝的原因很有用。这里有一些你应该阅读的文章的链接。
- 72 次浏览
【SAP】如何在sap中查找用户出口
视频号
微信公众号
知识星球
为了增强SAP的功能并实现平稳的定制,SAP认识到用户在SAP中退出的价值。为了确保您完全了解这些强大的工具如何改善您的SAP环境,本文深入探讨了它们的定义、优点和最佳实践。
目录
- 了解用户出口
- 什么是用户出口
- 调整SAP系统的不同方式
- 用户出口的优势
- 如何在sap中编写用户出口
- 如何在SAP ABAP中实现用户退出
- sap tcode中的用户出口
- Sap SD中的用户出口
- 销售订单处理(模块池–SAPMV45A)
- 价格确定:模块池SAPLV60A,包括RV60AFZZ:
- 计费:模块池SAPLV60A,包括RV60AFZZ:
- 通用计费接口:
- 自行计费:
- 计费计划:
- 转入会计:
- Sap MM中的用户出口
- Sap FICO中的用户退出
- 如何在SAP中查找用户出口
了解用户出口
用户出口是SAP系统的关键组件,因为它们允许用户在不修改源代码的情况下向现有SAP系统添加自定义功能。这些出口充当占位符或挂钩,您可以在其中插入自己的代码,允许用户调整和改进系统以满足其特定的业务需求。
什么是用户出口
这个博客是基于用户在sap中的出口。User Exits是SAP最早提供的在标准SAP控制流中执行自定义代码的工具之一。增强原则可帮助您将自己的功能应用于SAP的现有业务应用程序,而无需更改原始应用程序。我们可以根据客户要求使用增强系统来更改标准SAP操作。
SAP软件在全球拥有超过65000个安装。这一成功的原因有很多。但一个关键原因是将系统塑造成关键业务流程的灵活性和能力。SAP允许您使用ABAP代码为开发环境创建自定义代码增强功能。例程、用户退出和客户退出(在某些方面)给客户留下了合理的责任,但开发人员需要在开始任何客户端定义的例程或用户退出之前探索替代方案。
SAP提供了多种方法或技术来定制和改进标准功能。今天,我们将专注于使用ABAP代码增强现有的销售和分销(SD)/材料管理(MM)/财务会计(FI)功能。
调整SAP系统的不同方式
有四种不同的方法可以调整SAP系统以满足您的需求:
- 自定义:在系统实施过程中,需要通过特殊界面配置系统参数,预先规划可能的更改,并进行有组织的自定义。
- 修改:以自定义修改的形式更改SAP存储库对象。当发生SAP更改时,必须手动协调客户版本。
- 客户更改SAP存储库对象而不进行修改。
- 自定义开发:在客户名称范围内创建自定义对象。

用户出口的优势
您应该使用出口而不是自己修改SAP软件,主要有两个原因。附加到出口的附加组件具有以下优点:
- 它们不会影响标准SAP源代码。
- 它们不会影响软件更新。
- 可以通过Exits实现增强功能。
如何在sap中编写用户出口
用户出口是标准编码中预先计划好的出口例程,这意味着SAP有意在标准代码中将其留空。用户的输出只能在组件中找到。从历史上看,从技术角度来看,用户需要进行修改。然而,随着增强系统的引入,情况发生了变化。用户出口有时被称为表单出口,因为它们是子例程。
User Exit是在常规SAP控制流之间执行自定义代码的首批SAP机制之一。这是作为子程序调用(PERFORM xxx)完成的。User Exit的经典示例是MV45AFZZ包含在SAP R/3的订单处理模块中。尽管这包括一个不属于客户端命名空间的对象,但在升级过程中不会覆盖该对象。

如何在SAP ABAP中实现用户退出
SAP中的增强点
- 如果需要将增强直接纳入ABAP源代码,则应提供该技术。该技术的实现也称为源代码插件。对源代码有两种类型的增强是可能的。
- 隐式增强选项
- 显式增强选项
- 您需要处于“更改增强模式”(编辑器中提供的螺旋图标)才能实现这些源代码增强。从技术上讲,源代码插件实现存储在一个单独的include程序中,而不是作为原始源程序的一部分。
隐式增强选项:增强选项在整个ABAP系统的某些预定义位置自动可用。一些隐含选项如下:
- 在所有程序(包括、报告、函数池、模块池等)的末尾,在最后一句语句之后
- 在所有FORM子程序的开头和结尾
- 在所有功能模块的末尾
- 在本地级别的所有可见性区域(公共、受保护和私有)的末尾
要查看源代码中可用的所有隐式选项,请从编辑器中选择“编辑->增强操作->显示隐式增强选项”。
显式增强选项:有两种类型的显式增强可用。另一个可以在特定位置给出的是增强阶段,另一个可用于替换称为增强页面的语句集合。我们现在有两个新的ABAP语句,即。
- 增强点
- 增强截面
一旦应用了增强部分,就只执行增强,而不执行初始代码。从执行中删除任何常规SAP代码是一种现代策略,以前在任何旧的改进形式中都不存在这种策略。因此,加强科只能有一次成功实施。相反,可能存在增强点的几个活动实现,在这种情况下,所有实现都将在执行顺序上没有任何确定性的情况下实现。
SAP tcode中的用户出口
CMOD:此事务通过定义事务的增强来帮助您创建PROJECT。您需要在评估作为项目一部分的所有升级后启用项目。您还需要对用户出口进行编码;因此,您可能需要等到该阶段完成后才能启用PROJECT。
SMOD:该交易通过定义您的组件来促进项目中包含的增强功能的开发。如果SAP已经为其预定义的用户出口创建了增强,则无需使用SMOD事务;相反,您只能使用CMOD事务。
SAP SD中的用户出口
以下SAP增强功能可用于SD
销售订单处理(模块池–SAPMV45A)
包括:MV45AFZZ
- USEREXIT_DELETE_DOCUMENT-(MV45AF0B_BELEG_LOESCHEN)
- USEREXIT_FIELD_MODIFICATION-(MV45AFFE_FELDAUSWAHL_old)
- USEREXIT_MOVE_FIELD_TO_VBAK-(FV45KFAK_VBAK_FUELLEN)
- USEREXIT_MOVE_FIELD_TO_VBAP-(FV45KFAK_VBAP_FUELLEN)
- USEREXIT_MOVE_FIELD_TO_VBEP-(FV45KFAK_VBEP_FUELLEN)
- USEREXIT_MOVE_FIELD_TO_VBKD(业务数据)-(FV45KFKD_VBKD_FUELLEN_TEIL_2)
- USEREXIT_NUMBER_RANGE-(MV45AF0B_BELEG_SICHERN)
使用此用户出口可以定义将内部文档编号分配给所需字段的编号范围。例如,如果要根据销售代理(VKORG)和销售业务(VKBUR)设置范围,则使用此用户出口。
- USEREXIT_PRICING_REPREPARE_TKOMK(定价的Hdr Strctr)–FV45PF0P_PREISFINDUNG_VORBEREI
- USEREXIT_PRICING_REPREPARE_TKOMP(定价的Itm Strctr)–FV45PF0P_PREISFINDUNG_VORBEREI
- USEREXIT_SAVE_DOCUMENTß(MV45AF0B_BELEG_SICHERN)
包括:MV45AFZA
- USEREXIT_MOVE_FIELD_TO_KOMKD(收割台材料确定)
- USEREXIT_MOVE_FIELD_TO_KOMPD(物料材料确定)
- USEREXIT_MOVE_FIELD_TO_KOMKG(表头材料清单)
- USEREXIT_MOVE_FIELD_TO_KOMPG(物料清单)
- USEREXIT_REFRESH_DOCUMENT
包括:MV45AFZB
- USEREXIT_CHECK_XVBEP_FOR_DELET
- USEREXIT_CHECK_VBAP(未完成检查)
- USEREXIT_CHECK_VBKD(未完成检查业务数据)
- USEREXIT_CHECK_VBEP(未完成检查,BOM分解明细表行)
- USEREXIT_CHECK_VBSN(不完整检查序列号)
- USEREXIT_CHECK_XVBSN_FOR_DELET
- USEREXIT_FILL_fbap_FROM_HVBAP
- USEREXIT_MOVE_FIELD_TO_TVCOM_H(标题文本的文本确定)
- USEREXIT_MOVE_FIELD_TO_TVCOM_I(项目文本的文本确定)
- USEREXIT CUST MATERIAL READ(在客户的物料数据记录中放入另一个客户编号(例如公司层次结构)
- USEREXIT_NEW_PRICING_VBAP(用于输入再次执行定价的先决条件的选项(例如,对某个项目字段所做的更改可以用作再次进行定价的先条件)
- USEREXIT_NEW_PRICING_VBKD
- USEREXIT_SOURCE_DETERMINATION(用于确定将使用哪个工厂进行交付。在标准系统中,交付工厂是从客户主数据或客户材料信息记录中复制的。如果要使用不同的规则,则必须在此用户出口中输入)
包括:MV45AFZ4
- USEREXIT_MOVE_FIELD_TO_KOMK(标题自由商品确定)
- USEREXIT_MOVE_FIELD_TO_KOMP(无项目商品确定)
包括:MV45AFZF
- USEREXIT_AVAIL_CHECK_CREDIT(此用户出口允许您确定系统是否应该在被阻止的文档发布后或在新的信用检查后执行可用性检查)
包括:FV45EFZ1
USEREXIT_CHANGE_SALES_ORDER(在标准SAP R/3系统中,如果发出采购请求并更新销售记录(如金额、日期),则销售合同计划行的数量和确认日期会自动更新。如果您想在标准系统中更改此配置,可以定义某些要求以保护您的销售订单不被自动更改。为此原因使用此使用者的出口。在此阶段决定是否要更改时间表)
价格确定:模块池SAPLV60A,包括RV60AFZZ:
- USEREXIT_PRICING_REPREPARE_TKOMK(复制TKOMK通信结构中用于定价的附加字段(标题字段),这些字段在标准SAP系统中尚未提供)
- USEREXIT_PRICING_REPREPARE_TKOMP(复制TKOMP通信结构中定价的其他字段(项目字段)
- 模块池SAPMV61A,包括MV61AFZA:USEREXIT_FIELD_MODIFICATION、USEREXIT_PRICING_CHECK和USEREXIT_CHANGE_PRICING_RULE
- 模块池SAPLV61A,包括RV61AFZA:USEREXIT_PRICING_RULE和USEREXIT_PRECING_COPY
计费:模块池SAPLV60A,包括RV60AFZZ:
- USEREXIT_NUMBER_RANGE、USEREXIT_ACCOUNT_PREP_KOMKCV和USEREXIT_ACCOUNT_PREP_KOMPCV
- 模块池SAPLV60A,包括RV60AFZC:USEREXIT_NUMBER_RANGE_INV_DATE&USEREXIT_FILL_VRK_VBRP
- 模块池SAPLV61A,包括RV61AFZB:USEREXIT_PRINT_ITEM和USEREXIT_PRENT_HEAD
- 包括RV60AFZD:USEREXIT_RELI_XVBPAK_AVBPAK、USEREXIT_NEWROLE_XVBPAK-AVBPAK和USEREXIT_NEWROLE_XVBPAP_AVBPAK
通用计费接口:
- 包括RV60AFZA、RV60AFZB和RV60AFZC
自行计费:
- EXIT_SAPLVED4_001至EXIT_SAPLVED4_006
计费计划:
- 包括RV60FUS1:BILLING_SCHEDULE_DELTA、USEREXIT_MOVE_FIELD_TO_FPLT和USEREXIT_MOVE_FIELD_TO_FPLA
- 包括RV60FUS2:USEREXIT_PRICING_REPREPARE_TKOMX
- 包括RV60FUS3:USEREXIT_DATE_PROPOSAL,计费计划SDFPLA02的修改报告,添加到计费计划–SDVAX001&更改计费计划日期–用户退出V60F0001
转入会计:
- 模块池SAPLV60B:EXIT_SAPLV60B_001到EXIT_SAPLV 60B_011
Sap MM中的用户出口
以下SAP增强功能可用于MM:
- AMPL0001附加AMPL数据的用户子屏幕(制造商部件号)
- LMELA002在产品交付时接受装运通知中的批号
- LMELA010进货通知:收到IDoc元素数据
- LMEQR001用于源标识的用户出口M06BB0001用于需求发布的角色标识
- M06BB0001请求发布协调系统的变更
- M06BB0003区域编号和文件编号
- M06B0004编号范围和文件编号
- M06BB0005采购申请最终发布的联系系统中的更改
- M06E0004采购文件发布联系人系统的变更
- me06e005
- MELAB001生成预计交付时间表:通过生产概况实施
- MEQUERY1文本摘要的增强ME21N/ME51N
- MEVME001最大GR量和超/低交付公差的计算
- MM06E001用于入站EDI通信和出站采购文档的用户出口
- MM06E003区域编号和记录编号
- MM06E004采购订单导入数据屏幕的控制
- MM06E005用于购买文档的客户区域
- MEREQ001采购订单的客户自有数据
- MM06E007转换为采购订单时更改请购单
- MM06E008监控发布订单的合同目标值
- MM06E009“exi文本”的相关文本
- MMAL0002 ALE源列表的分发:入站处理
- MMAL0003-ALE采购数据分发记录:出库处理
- MMAL0004-ALE采购数据分发记录:入库交货
- MMDA0001交货地址的默认值
- MMFAB001发布生成的用户出口
- MRFLB001释放过程中的控制对象
- LWBON001通过扩展MCKONA联系系统增强LIS更新(业务量和回扣收入)
- LWBON003在生成结算单之前更改期末退款结算的结算明细
- LWSUS001零售业客户特定来源的确定
- LMEXF001购买单据的条件
Sap FICO中的用户退出
以下SAP增强功能可用于FI
- F050S001 FIDCMT、FIDCC1、FIDCC2:编辑用户定义的IDoc部分
- F0500S002 FIDCC1:更新IDoc/不提交
- F0500S003 FIDCC2:切换IDoc/不提交
- F0500S004 FIDCMT、FIDCC1、FIDCC2:更改出站IDoc/不发送。
- F0500S005 FIDCMT、FIDCC1、FIDCC2入站IDoc:修改FI单据
- F0500S006 FI传出IDoc:重置FI文档中的清除
- F0500S007 FIDCCH出站:IDoc对记录切换的影响
- F1800A001资产负债表调整
- FARC0002 MM供应商主数据的增强存档测试
- RFAVIS01用户退出以更改支付辅助段文本
- RFEPOS00线路视图项目:检查选择条件
- RFKORIEX的自动通信
- SAPLF051 FI工作流程(预捕获、发布)
- 您也可以参阅SAP Note 381348,“使用SD中的用户出口、客户出口和VOFM。”
如何在SAP中查找用户出口
查找用户出口的第一步是确定要更改的SAP过程或事务。它可以是任何东西,从销售订单、采购请求或主客户数据记录。了解要更改的特定流程将使您能够定位与该用户相关的用户出口。
利用您的SAP事务编号SE19查找用户退出:SAP事务代码SE19用于查找SAP内用户的条目。要使用SE19,请在命令字段中输入交易编号,然后按enter键。将显示用户退出初始屏幕。
在初始屏幕上填写适当的信息。您必须输入所有相关的详细信息才能搜索用户的出口。这是程序的名称、客户出口的名称以及包含该名称的名称。程序的名称是SAP程序的名称,其中包含您希望更改的流程或事务。
输入所需信息后输入信息后,单击“执行”,然后单击“执行“开始搜索。SAP将查看用户的出口,以确定他们是否符合您指定的标准,然后显示结果列表。
- 183 次浏览
【SAP技术】2023年掌握RICEFW的快速提示
视频号
微信公众号
知识星球
我们经常遇到如果您在SAP中遇到RICEFW和WRICEF术语,但不知道这些术语,那么SAP Worlds中会有一些新术语。我们将在本文中介绍RICEFW的各个方面。本博客关注RICEFW及其在SAP项目中的用途。RICEFW指的是报表界面、转换、增强功能表单、工作流和报表
目录
- 了解SAP RICEFW
- 什么是WRICEF?
- 什么是RICEFW?RICEF到底是什么意思?
- RICEFW的用途是什么?
- R–报告
- I–接口
- C–转换
- E–增强功能
- F–表格
- W-工作流
- 实施SAP RICEFW
- 需求评估:
- 自定义
- 测试
- 用户培训
- 上线
- 结论
- 什么是SAP功能规范?
- 如何在SAP中检查RICEF
了解SAP RICEFW
什么是WRICEF?
为了实现各种业务目标,典型的SAP设置包括多种类型的自定义解决方案。SAP实施项目中的自定义开发可以分为六种主要的开发类型:工作流、报告、界面、转换升级和称为WRICEF的表单。
什么是RICEFW?RICEF到底是什么意思?
报告、接口、增强、转换、表单和工作流(Reports, Interfaces, Enhancements, Conversions, Forms, and Workflow )是RICEFW的缩写。技术和职能顾问在实施阶段的整个SAP项目生命周期中都参与RICEFW。当使用传统SAP功能或标准配置无法满足业务需求时。我们需要RICEFW对象。每个对象都是根据任何推出、实现、升级或迁移项目中使用的RICEFW分类定义的。
RICEFW的用途是什么?
如果在项目实施阶段,标准配置无法满足业务需求,我们将需要开发一个自定义对象来满足业务需求。这些项目将单独制定。另一个团队正在开发RICEFW。我们需要为影响其各自业务流程的RICEF技术对象创建功能规范。让我们了解不同发展的步骤。
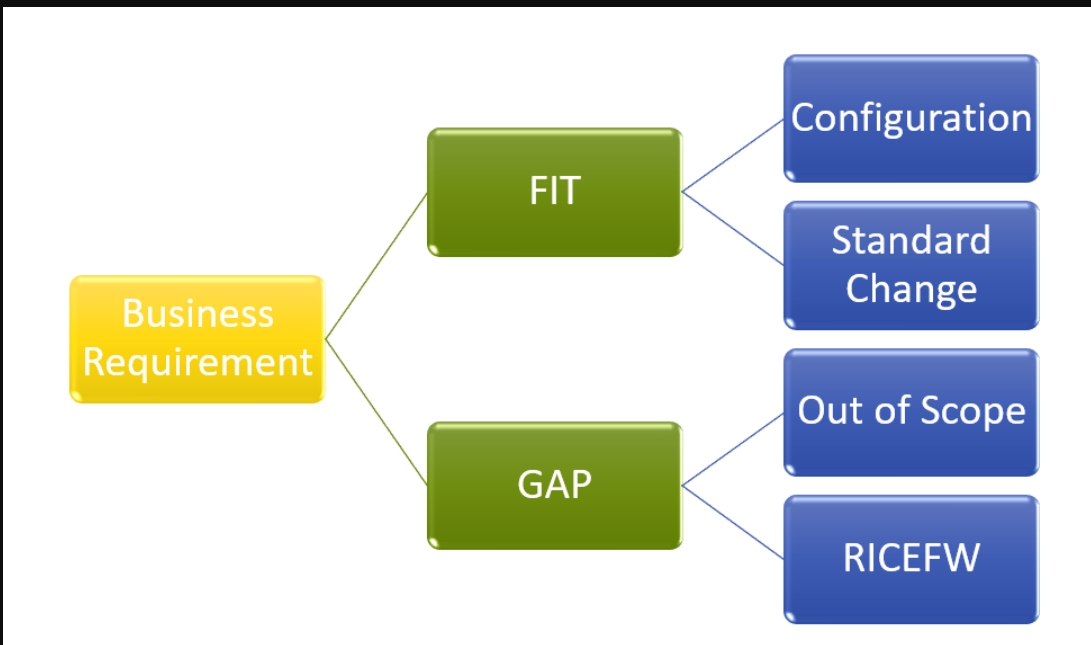
通常,它被称为“RICEFW”一词来描述它。
- R–报告这包括经典报告和交互式报告
- I-与其他SAP和第三方工具的接口——本文是关于ALE/IDoc的
- C–转换包括使用的BDC和LSMW。
- E–增强–这就是我们所说的BADI和用户出口。
- F–表格(输出)表格(输出(Output))包括智能表格
- W-工作流程
让我们仔细看看这些组件中的每一个。
R–报告
R是对报表编程的引用。当然,第一种是传统的报表编程,WRITE语句。之后,它表示您正在使用ALV和ABAP对象的函数进行编程。
如果标准报告不包括满足客户需求的必要功能,项目团队将创建自定义报告。要做到这一点,重要的是要了解全部需求,然后完成选择屏幕、关键字段以及报告完成后将产生的输出格式。然后,该报告被视为RICEFW对象
SAP数据库。报告可以描述为ABAP程序,通常从SAP数据库中以列表形式生成数据(报告)。报告通常在线显示并通过显示器显示。它们也被下载并作为电子邮件的附件发送(通常是电子表格或电子表格),或者直接发送到存储假脱机(甚至可以打印)。性能繁重的报告(包含大量数据或需要很长时间才能完成)和定期报告通常以批处理模式执行
SAP中的报表是使用一个或多个从数据库中检索必要信息的应用程序构建的自定义操作。它根据在屏幕中输入的用于选择用户输入的交易的输入标准,在报告执行后创建或显示输出。它是基于特定选项所需格式的数据的可视化显示。以下是报告类型:
- 标准报告在SAP中可用,并且仅由标准SAP提供。
- 项目工作人员使用标准SAP报告作为参考依据制作的自定义设计报告。
- 查询使用常规SAP表创建我们的报告。
ABAP工作台附带一个ABAP编辑器(se38),用于生成报告。ABAP列表查看器ALV(ABAP函数)在ABAP程序中被广泛用于生成报告。SAP Query是另一个用于创建报告的工具。某些SAP模块配备了专门的报告工具,如Report Painter。它也被称为QuickViewer,它可以是一种不同的工具,用于根据需求实时创建系统内开发的自定义报告。
报告的示例包括未结销售订单报告、批量销售订单报告等。
I–接口
接口是ABAP函数、程序和其他组件,允许在多个系统之间交换和传输信息和数据。大多数情况下,接口直接从原始系统检索信息,然后将数据发送到目标系统(出站)或使用发起数据的系统接收的数据升级目标系统(入站),而无需用户干预。
接口是ALE和IDOC的进步。这不仅仅是开发,而是ABAP程序员根据业务需求定制ALE/IDOC。在大多数企业中,销售、采购、财务和物流等部门都有许多流程。它们都通过外部第三方系统进行管理,这些系统是非SAP系统。例如,他们利用第三方物流系统来选择和包装货物,并在运输过程中交付货物。为此,SAP交付详细信息被发送到不是SAP的外部系统,然后通过中间件从SAP系统接收包装、提货和发货详细信息。这些EDI消息通过接口和IDocs发送。传输数据。
SAP提供具有不同部分和字段的标准EDI结构。然而,我们仍然需要设计自定义的分段和字段,因为我们需要的分段不具有默认值。为此,职能顾问需要向ABAP团队提供需要接收、传输的数据的细节,以及字段、分段等。然后可以将其视为一个附加的RICEFW对象。
接口可以设计为支持RFC的RFC函数(用于远程调用)、IDOC处理功能模块以及可以创建或处理文件或执行RFC调用的ABAP程序。IDOC正在生成ABAP函数或程序、可以执行BDC和其他功能的ABAP程序或函数。
C–转换
大多数转换是用于批输入的BDC编程函数、BDC编程模块BDC数据排列或CALL TRANSACTION。也许转换是指传统的程序员被转换为批量输入。可能是LSMW。
转换可以使用ABAP程序创建,使用CATT脚本、LSMW(信息非常少)、BDC、BAPI函数或生成IDocs。
一旦SAP系统成功实施,预计该公司将终止其旧系统。因此,将数据上传到SAP系统中,如Materials Master、Customer Master、Inventory Master等。这意味着他们的实时数据需要上传到SAP。数据必须根据系统的要求从一种格式转换为另一种格式。这被称为转换。
SAP应用程序。业务团队从他们以前的遗留系统中提取数据。然后,项目团队希望将详细信息导入SAP系统,使用SAP工具进行数据迁移,如BDC、LSMW、LTMC等。功能顾问与客户和技术小组成员合作开发程序,从这些文件中获取数据,然后将其加载到SAP中。这将导致RICEFW列表中出现新对象。
转换是一种有助于传输数据的程序——新系统是从以前的系统发展而来的。作为源(包含数据)的系统可以在转换后退役,甚至共存。转换通常被称为“迁移”或“数据迁移”。转换过程可能需要对数据进行大量手动或编程调整和修改,以使其适应当前系统。如果原始系统在转换时还没有退役,那么可能会构造一个接口而不是转换。在这种情况下,当系统使用接口“切换”时,将加载所需的全部数据。
转换对象完全取决于正在实现的模块。转换的示例包括客户主账簿(SD)和供应商主账簿(MM)总账(FI)等。
E–增强功能
如果标准SAP功能无法满足业务需求,负责项目的团队将通过修改SAP的SAP标准来开发定制功能。这些被称为增强功能
增强功能可以包括用户退出、BADI业务事务事件(BTE)和事务对话框的实现,或使用BAPI调用、函数调用、BDC、函数、IDoc、表单退出、字段退出任务、工作流对象和模板等的可执行ABAP应用程序。
增强功能是控制、修改或生成通过传统SAP系统生成的数据的对象和程序。当标准SAP系统提供的配置不足以满足系统或系统的要求时,需要进行增强。
增强功能可以是验证、来自用户捕获数据的额外输入、在原始工作流之外创建的数据、数据的额外更新或警报。增强是应用程序或项目过程中最多的ABAP对象类型。
增强是由使用BADI或增强框架的ABAP技术顾问和用户出口创建的。这些是新的RICEFW对象,项目的职能团队与业务团队一起收集需求,然后与技术专家团队合作,更改或使用SAP的SAP标准,并根据业务需求开发定制解决方案。
F–表格
表单包括SAPscript表单、SAPscript打印程序和智能表单。SAP提供ABAP工作台工具,如SAP脚本、智能表单、Adobe交互式表单、OLE等。开发“表格”。
表单是SAP应用程序在保存事务信息后生成的打印输出。示例包括采购订单打印材料文档打印、采购订单打印交货记录和提货单实物库存单标签打印。标准SAP为所有这些表格提供了既定的格式和模板;但是,这些预定义的表单可能不符合业务要求,因为它们可能希望在文档中包含公司徽标或合法打印内容。职能团队必须使用ABAP,并根据业务需求设计自定义表单。
表单是ABAP应用程序和对象,可以生成易于阅读、可打印和格式化的输出,通常与合作伙伴(客户、银行、供应商、员工、福利公司、政府机构等)共享,或者通过电子邮件附件(pdf和文档,pdf)发送,或者简单地显示在屏幕上(用户可以决定打印、通过传真发送或通过电子邮件发送)。
一些表格的例子包括客户发票、供应商发票、付款通知单等。
W-工作流
工作流是促进多步骤过程的对象和程序。它们可以与工作流对象一起创建,也可以作为单步任务创建。它们也可以通过自定义编程进行创建。它们可以是简单的通知,涉及用户选择或用户操作、审查或包括更新的后台程序。
为了简化,工作流被归类为增强功能。尽管它可能是多步骤的,但大多数工作流都具有与增强功能相同的特性。它们也可以是交互式的,源和目标与它们所在的系统相同,并更新系统中的信息。
总之,RICEFW指的是以下列出的对象。这就结束了本主题
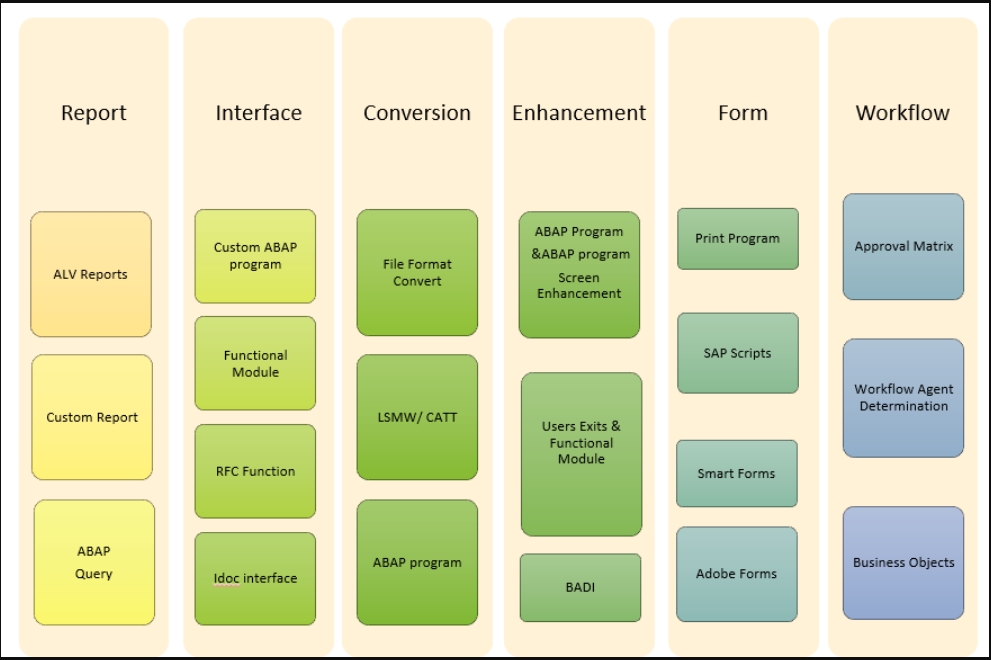
实施SAP RICEFW
遵循这些程序,在项目开发中有效集成SAP RICEFW组件
需求评估:
确定组织的特殊要求。确定SAP RICEFW组件是最关键的业务流程。
自定义
与SAP顾问合作,根据个人需求定制RICEFW组件。这一步骤对于确保SAP完全集成到业务流程中至关重要。
测试
在实施SAP RICEFW以确定任何潜在问题之前,必须进行彻底的测试。这一阶段对平稳过渡至关重要。
用户培训
应培训最终用户如何有效利用SAP RICEFW。共享知识对于充分发挥这一系统的潜力至关重要。
上线
一切都安排好之后,是时候上线了。SAP RICEFW应与现有SAP实施结合使用。
结论
为了识别与SAP集成的外部系统,在SAP Activate方法的Explore阶段构建SAP RICEFW对象。在转换过程中,RICEFW模板生成了一个根据客户需求量身定制的解决方案,该解决方案满足预先确定的业务需求,并允许业务在迁移过程中继续按预期运行,SAP项目经理和架构师必须定义必要的规范。设置和报告有很多好处
什么是SAP功能规范?
功能规范是一个全面的文档,是根据业务需求文档创建的。功能规范是描述特定对象的功能、技术细节和功能的文件
如何在SAP中检查RICEF
SAP的自定义开发很容易找到。TADIR(存储库对象目录)表存储SAP中的所有对象。因此,我们可以使用命名约定Z*来查找TADIR或TRDIR表。本节包含已在系统中创建的自定义对象的列表。
- 124 次浏览
【SAP技术】SAP ABAP初学者学习SAP表单
视频号
微信公众号
知识星球
在本文中,我们将了解SAP Forms工具。SmartForms技术允许设计打印表单。通过用电子表格取代纸质文档,可以减少潜在的错误,并使整个系统的流程更加透明和可跟踪(表格与SAP相连,但工作人员没有)。
- SAP智能表单简介
- 什么是SAP表单
- SAP脚本
- 交互式表单
- Adobe表单
- SmartForms
- 智能表单的进步
- 在SAP中,如何制作SmartForms?
- 表单生成器
- 控制流程和条件:
- 输出格式
- 结论
SAP智能表单简介
SAP智能表单是一种复杂的SAP系统功能,使您能够生成和管理文档。由于其用户友好的界面和广泛的功能,该应用程序使企业能够轻松地设计、打印和格式化文档,包括发票、采购订单、发票和送货单。我们将介绍此产品的主要功能和优点,以及SAP Smart Forms如何帮助您简化文档处理流程。作为一个文档管理工具开发的,这个东西。
什么是SAP表单
它广泛用于打印和发送SAP文档,如发票、订单确认和交付通知等。Smart Form允许开发人员使用此程序创建在线表单、PDF文件、电子邮件和纸张。该实用程序提供了一个界面,用于创建和维护窗体的布局和逻辑。SAP还提供各种形式的业务运营,如客户、供应商的发票、已经满足销售和分销(SD)、材料管理(MM)和财务会计(FI)需求的付款建议。
该工具允许您使用基本的图形工具来更改表单,而不是使用编程工具。这有助于没有编程技能的业务用户,他们可以很容易地用业务流程的信息填写这些表格
SAP eg. SmartForms、SAP脚本、Adobe表单、Interactive表单中有许多可用的表单。让我们深入了解细节
SAP脚本
SAP脚本是一种文本处理系统,在范围和形式上可与世界顶级文本处理系统相媲美。SAP脚本使用预先格式化的表单打印预先格式化的文本。这是非常老式的。SAP脚本具有以下功能:
- 编辑器:这是一个允许您插入和编辑文本行的程序。
- Sap脚本布局和样式设置用于打印特定表单的布局,并为任何业务表单创建单独的文本
- Composer用于为表单生成输出
- 编程接口用于控制页面布局设置的显示方式。
- 数据库:SAP脚本利用了许多数据库表,这些表可能存储大量文本、集合和样式。

交互式表单
表单可以是交互式的,也可以只是一个没有可编辑元素的打印输出。交互式表单可以在线填写(使用SAP集成),也可以离线填写(不使用SAP集成的)。该表格可以通过电子邮件发送、保存到本地光盘、离线完成并返回。该表单建立在SAP NetWeaver Portal上,也可以使用Web Dynpro技术发布。
在SAP环境中工作的开发人员可以使用各种技术来创建交互式表单。交互式表单可以通过SAP NetWeaver Studio或使用SE80生成。这两种设置都与用于开发表单的工具Adobe LiveCycle Designer集成。
Adobe表单
输入的数据和布局信息使用XML格式存储在Adobe表单中。由于这一标准,SAP系统和最终用户之间的信息传输程序已经标准化。PDF格式允许支持任何类型的表单,并且它看起来与打印的表单几乎相同。因此,习惯于硬拷贝表格布局的用户会发现切换到电子版本相对简单。
SmartForms
在4.6C版本中,Smart Form技术取代了SAPscript技术,而Adobe的Interactive Forms自6.40版本以来取代了Smart Forms。提供了用于不同中央业务操作的智能表单(从BBP开始;SD、MM、HR 4.6C)。支持SAP脚本表单的迁移
基于生成的XML输出的交互式Web表单(XSF,Basis Release 4.6C;HTML+XSF,SAP Web AS 6.10)。

ABAP程序必须“调用”它们才能生成假脱机并准备打印。。当智能窗体处于活动状态时,将创建一个必须由ABAP程序调用的函数模块。您永远不应该将此功能模块的名称视为面值,因为在每个系统中导入后,它可能会发生变化。
数据是从智能窗体中的静态和动态表中检索的。表标题和小计由触发的事件指定,然后在最终输出之前对数据进行排序。它包括智能表单中的视觉效果,可以作为表单的一部分或背景显示。如有必要,您还可以在打印表单时关闭背景图形。
数据是从智能表单中的静态和动态表中检索的。触发的事件定义表标题和小计,然后在生成数据之前对数据进行排序。您可以在智能表单中包含视觉效果,该视觉效果可以作为表单的一部分或背景显示。如有必要,您还可以在打印表单时关闭背景图形。
智能表单的进步
- 文本、照片、表格和条形码都可以嵌入。
- 必须定义导入参数,ABAP程序才能提交要打印的数据。
- 当智能窗体处于活动状态时,将创建一个必须由ABAP程序调用的函数模块。您永远不应该将此功能模块的名称视为面值,因为在每个系统中导入后,它可能会发生变化。
- 文本、照片、表格和条形码都可以嵌入。
- 由于完全图形化的用户界面,它们有助于在不需要编程经验的情况下调整表格。
- 当智能表单被激活时,系统会在运行时自动构建功能模块。
- 我们必须使用拖放、剪切和粘贴来进行任何修改。这些行为不包括创建代码行或使用脚本语言。
- 我们能够插入静态表和动态表。个别表格单元格中的换行、触发表格标题和小计的事件以及在输出前对数据进行排序都是这些方面的例子。
- 用户可以包括智能表单中的图形,这些图形可以作为表单的一部分或作为背景图像显示。在打印过程中,用户可以根据需要关闭或关闭背景图形。
- 生成的XML输出可用于web发布。
- 在设计页面上,窗口是输出区域。
- 各种各样的窗户
在SAP中,如何制作SmartForms?
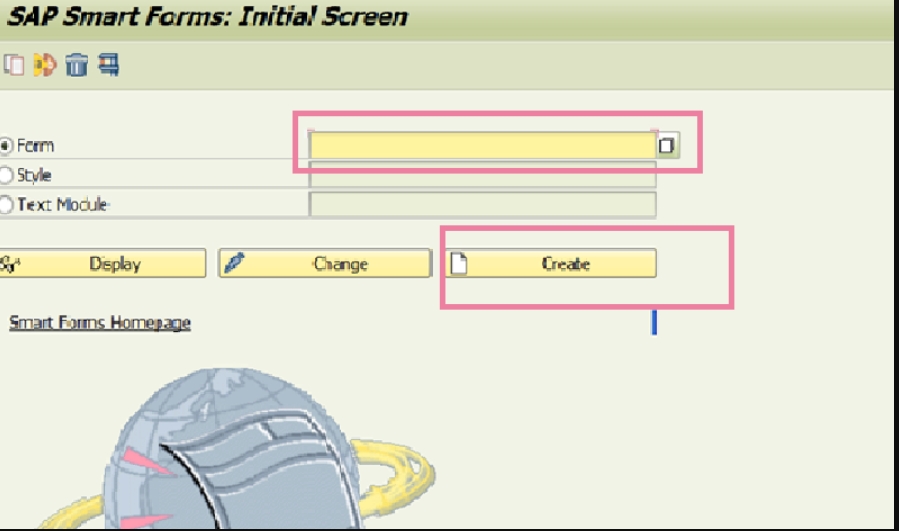
表单生成器
Form Builder将出现在屏幕中。表单生成器有三个基本选项卡来控制智能表单
- 导航树
- 属性
- 表单打印机

控制流程和条件:
在SAP智能表单中,调节导航窗格中定义的树层次结构的流处理。双击带有条件的节点,我们可以在条件选项卡中检查带有两个操作数的特定逻辑或条件。

输出格式
您可以以“输出文本”格式打印智能表单,也可以出于各种目的打印各种其他输出格式,例如用于智能表单的XML和用于在web浏览器中显示表单的HTML。下面列出了一些最常用的输出格式。
- 输出文本格式这是一种标准输出文本格式,在SAP系统中广泛用于打印表单。您也可以将其转换为其他格式,例如PDF。
- XSF输出这是一个智能表单的XML格式。它显示已处理表单的表单内容,但不显示布局信息。
- HTML格式:表单也可以在Web浏览器中显示。它是XSF输出和HTML格式的混合体,其中内容在没有任何布局信息的情况下进行处理,数据以表单格式显示给web浏览器。

我们希望您发现这篇文章有助于初学者理解SAP表单。这里有几篇你应该读的文章。
结论
借助SAP智能表单这一有效的解决方案,公司可以成功地开发、更改和管理表单。该软件为企业提供了一个强大的文档管理工具,可以提高生产力、提高准确性并节省资金。它还提供了跨表单的定制灵活性,以提高使用灵活性。它拥有用户友好的功能以及与SAP系统的无缝连接。采用它可以帮助你的公司完全接受数字化转型。
- 79 次浏览
【SAP技术】SAP Afaria如何简化移动设备上的信息技术(IT)。
视频号
微信公众号
知识星球
今天,我们将进一步了解SAP Afaria。SAP Afaria是一款适用于移动设备的设备管理应用程序。它帮助大型组织将手机和平板电脑等移动设备连接到工作场所网络,同时简化信息技术(It)内容页
本文的指南将利用SAP Afaria,这是一个企业移动设备管理平台,旨在让企业控制其移动设备和应用程序。作为市场领导者,我们的使命是让您了解SAP Afaria的潜力及其优势和最佳实践。我们将帮助您优化移动设备管理,并在当今快速变化的工作环境中保持领先地位。
目录
- 什么是SAP Afaria
- SAP Afaria的功能是什么
- Afaria架构
- Afaria成分
- 结论
什么是SAP Afaria
Afaria是一种用于管理移动设备(MDM)的解决方案,它允许移动应用程序得到保护和管理。Afaria允许您远程连接到启用Afaria的移动设备,以便配置设备并安装必要的软件。Afaria是SAP Mobile Secure软件包的一部分,该软件包还包括Mobile Docs和Mobile Afaria。
Afaria可以为公司和员工管理设备。Afaria支持Android、iOS、Windows、Windows CE、Windows Mobile、Windows Phone和带有MDM客户端(Windows DM)设备的Windows。
SAP Afaria的功能是什么
数据和设备必须保持安全。Afaria包括各种安全机制和技术来保护注册的设备。例如,利用网络现有的安全基础设施,如Active Directory和LDAP,以确保只有网络已知的用户才能访问它。Afaria还使用证书来保护Afaria和其他设备之间的连接。
- Afaria可以利用设备的安全功能(如密码强制执行或加密)来保护关键的公司数据。Afaria还可以用于远程锁定丢失或被盗的设备,甚至从中“删除”业务数据。
- 它还根据公司策略配置设备。Afaria使您能够配置和管理设备属性和设置,以确保为网络正确配置移动设备。连接和同步参数等ActiveSync设置可以由Afaria管理。
- Afaria还可以用于配置连接设置,如网络服务数据、服务器地址和从远程位置登录。选项用于同步电子邮件、日历和联系人信息的配置可以集中指定,并在客户端设备上强制执行。
- 可以控制移动应用程序。Afaria可用于确保所有设备运行所有相关软件的最新版本。Afaria简化了移动应用程序的分发、安装和维护,这些应用程序既可以在内部生成,也可以在苹果应用商店或谷歌Play等应用商店上公开提供。
- 由于Afaria可以安装程序文件、替换丢失或损坏的文件以及删除或回滚应用程序,因此所有用户都将始终拥有最新的版本、更新和设置。它还管理公司资产并生成移动设备使用数据。Afaria允许我们查看设备清单,其中包括谁在使用设备、安装了什么软件以及预配置了什么设置。
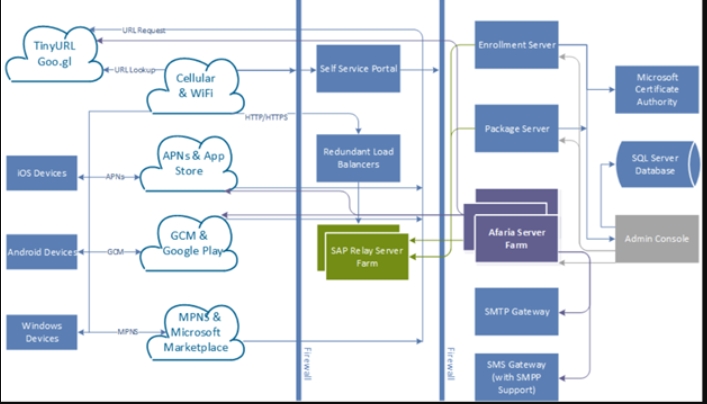
Afaria架构
Afaria是一个软件即服务的分布式移动设备管理解决方案。关键组件是Afaria服务器、Afaria管理控制台、注册服务器、包服务器和Afaria数据库。
Afaria与Microsoft SQL Server和SAP SQL或任何位置的数据库都兼容。数据库服务器软件不包含在Afaria中。有关更多信息,请参阅Afaria组件。
Afaria技术具有很强的可扩展性。Afaria可以安装在单个服务器上(“独立”)进行小型部署,也可以分布在多个服务器上进行大型设置。在该系统中,Afaria可以在可能位于不同位置的分布式服务器之间同步数据。客户端与之通信的任何服务器都具有相同的功能。
对于大型部署,可以在服务器场设置中安装许多Afaria服务器。在这种情况下,您安装的第一个Afaria服务器是“主”服务器;随后的Afaria服务器被称为场服务器。主服务器可以与许多场服务器通信,以执行负载平衡,并支持与托管设备的数十万远程连接。Afaria客户端可以连接到服务器场上的任何服务器,并使用分配给它们的通道。大量客户端同时加入,这可以用作负载平衡解决方案。
分布式服务器环境由一组服务器组成,这些服务器在不同的物理位置独立运行,其操作完全或部分由单个主服务器控制。分布式Afaria服务器场提供了一个隔离的Afaria数据库的本地使用,该数据库仅包含其支持的服务器的日志记录、清单和警报数据。
在分布式Afaria服务器设置中,源服务器(或主服务器)是创建、更新和维护所有管理任务的服务器。这些策略被复制到目标服务器,客户端可以连接到服务器场中的任何服务器以执行指定的策略。
如果您有大量分散在多个地区的客户端,这将提供一个负载平衡选项。成组的客户端可以连接到本地服务器,避免WAN的通信和拥塞延迟。
Afaria服务器场提供了对集中式Afaria数据库的共享使用,该数据库包含服务器场上所有Afaria Server的日志记录、库存和警报数据。服务器场中动态选择的计算机运行警报规则引擎和警报通知,以及所有服务器的资源清册更改检测。
Afaria组件
- Afaria服务器:与MDM管理的设备通信,应用配置策略并收集库存数据。
- Afaria管理控制台:一个基于web的Afaria用户界面,允许您配置Afaria、管理设备以及报告TEM和库存。
- 注册服务器:管理Afaria设备注册,并为iOS设备提供管理有效负载。注册服务器和Afaria主机应安装在同一台服务器上。
- 捆绑服务器:为设备提供Afaria应用程序捆绑包,同时为使用它的第三方应用程序维护证书和设备配置数据。网关服务器不向设备提供商业软件。
- 自助服务门户:允许最终用户在Afaria管理中注册他们的设备,获取设备信息,以及执行密码重置等命令。门户中的注册是可选的,它允许用户在包服务器的帮助下安装应用程序策略。自助服务门户旨在部署在企业防火墙内,在DMZ中使用面向Internet的Microsoft Forefront Threat Management Gateway案例,该案例配置为接受设备连接并将流量转发到内部门户。
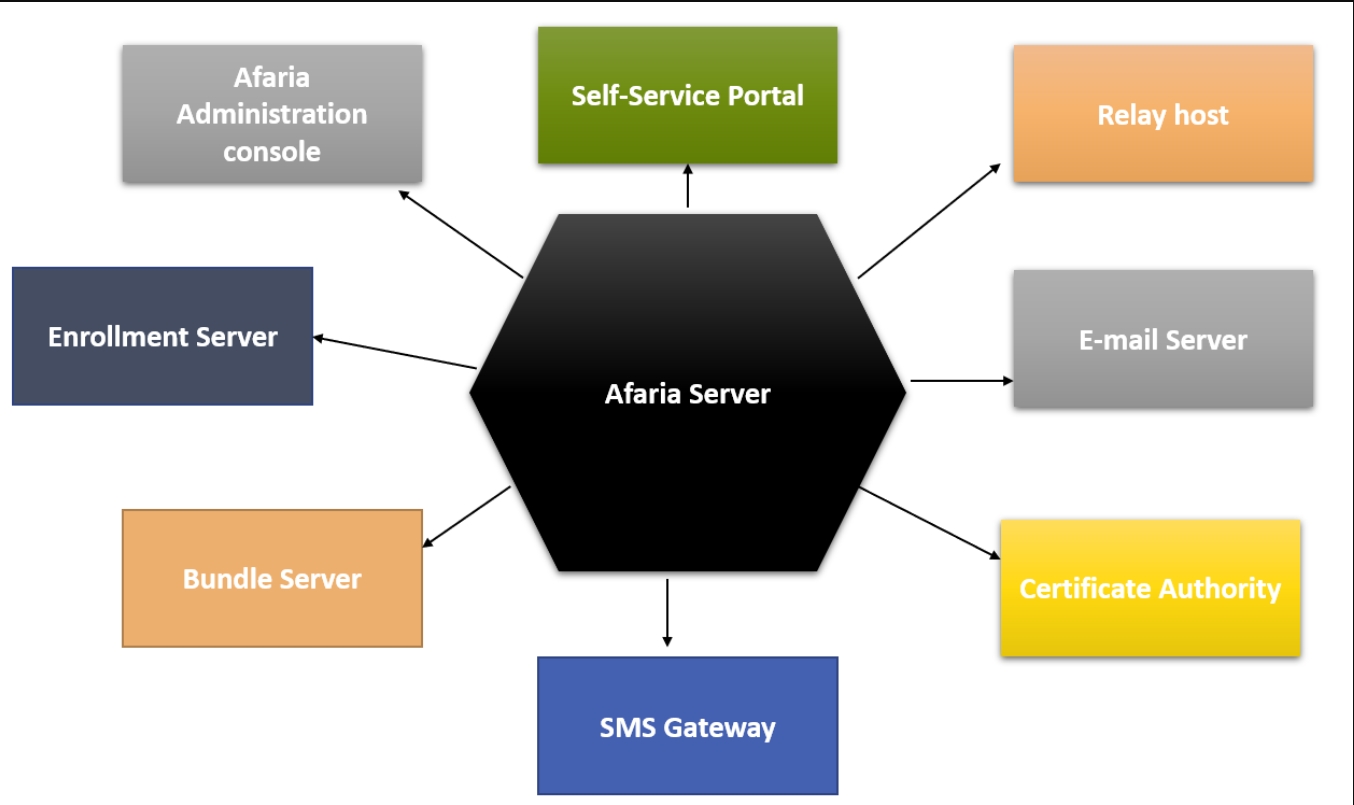
- SMS网关:处理SMS消息,如出站通知和远程擦除请求。SMS网关使用Cygwin商品库和Cygnus Solutions的工具,以及其他开源资源。Afaria不需要SMS网关即可正常工作。Afaria使用SMS网关发送出站警报、远程擦除控制、开放移动联盟(OMA)配置和主机通知消息,以及为SMS路由配置的任何其他Afaria通信。
- 中继主机:Internet HTTP和HTTPS连接到部分服务器的中介,如Afaria服务器或注册服务器。中继是可选的,尽管强烈建议使用它来提高业务网络安全性。
- 证书颁发机构:将证书颁发机构定义分配给注册和捆绑服务器,以支持设备注册或简化应用程序登录的证书设置。
- 电子邮件服务器:对于公司电子邮件的访问控制(可选属性),服务器托管访问控制PowerShell服务,该服务研究Afaria服务器以获得当前的访问控制策略,并将该数据提供给DMZ中的电子邮件代理。对于托管电子邮件的访问控制,电子邮件托管在Internet上,不包括企业中的电子邮件服务器。
结论
SAP Afaria是一项卓越的移动设备管理技术,它使企业能够简化移动程序,同时保持最高级别的安全性和法规遵从性。公司可以通过利用平台最重要的功能和遵循最优秀的技术,在不断变化的数字世界中提高生产力、削减开支并获得优势。立即切换到SAP Afaria,将您公司的移动设备管理提升到性能和效率的新高度。
我们希望您发现这篇文章有助于理解sap移动设备管理。这里有几篇你应该读的文章。
- 22 次浏览
【SAP技术】SAP快捷键在SAP中有什么用途?
视频号
微信公众号
知识星球
SAP快捷键可以代替图标按钮使用。这需要用户将光标拖动到光标上,这对于键盘用户来说是一项乏味的任务。快捷键是用户无需鼠标即可访问SAP中图标按钮功能的组合键。
在这个博客中,我们将看到当我们在屏幕之间调用事务时如何节省时间。我们可以使用sap快捷键命令。
但是,在计算机或笔记本电脑上,当鼠标悬停在图标上时,会显示图标名称以及键盘快捷键。SAP的这些键盘快捷键可以用于相同的图标,具体取决于它们显示的屏幕。这些快捷键适用于Microsoft和Mac电脑。
有两种方法可以进入交易屏幕。您可以使用交易代码

或者sap菜单的路径。为了使用sap菜单路径,我们应该始终转到sap菜单路径和sap IMG菜单。
SAP可以使用它在屏幕之间转移所有这些问题,而无需返回菜单屏幕。您有一个交易代码,可以在交易屏幕上的命令栏中为SAP中的每个交易直接输入。以下是与交易代码一起使用的快捷代码列表
Standard SAP Shortcut keys :
| Shortcut | Action |
| F1 | Help |
| F3 | Back |
| F4 | List of Possible entries or Match code |
| F8 | Execute |
| F5 | Refresh the window content |
| F3 | Go back one step |
| F10 | positions the cursor on the menu bar |
| /n | End the current transaction |
| /nXXXX | Move you from anywhere into transaction & terminate the current tcode |
| /nVA00 | Move you from anywhere into the sales screen |
| /nVS00 | Move you from anywhere into the sales Master data |
| /nVC00 | Move you from anywhere into the sales support |
| /nVL00 | Move you from anywhere into the Shipping |
| /nVT00 | Move you from anywhere into the Transportation |
| /nVF00 | Move you from anywhere into the Billing |
| /nVX00 | Move you from anywhere into the Foreign trade |
| /i | Deleted the current session |
| /nend | log off from the system |
| /nex | log off from the system without confirmation |
| /o | Generates a session list |
| /oXXXX | Open transaction XXXX in a new session |
| Ctrl +S | Save the transaction |
| Ctrl +F | Ctrl F |
| Ctrl +G | Find Next |
| Ctrl+Shift+ P | Capture hard copy of the screen which contain status text and pop-up as well |
| Alt+F12 | Customizing of local layout screen |
| Ctrl +F10 | display User Menu |
| Ctrl +F11 | To display SAP Menu |
| ALT | Jump to menu |
| ALT + SPACE | Jump to the system menu |
| TAB | Navigate to the next element |
| SHIFT + TAB | Navigate to the previous element |
| ALT + CTRL + ARROW right | Navigate to the read-only element |
| CTRL + + | Open a new SAP GUI window |
| CTRL + TAB | Navigate to the next group |
| SHIFT + CTRL + TAB | Navigate to the previous group |
| ESCAPE | Cancel actions, step-by-step |
| CTRL + + | Open a new SAP GUI window |
| ALT + SPACE, then M | Move window |
| ALT + SPACE+ S | Resize window |
| ALT + SPACE+ N | Minimize the GUI window |
| ALT + SPACE +X | Maximize the GUI window |
| ALT + SPACE+R | Restore the GUI window |
| Ctrl+P | |
| Ctrl+G | Continue search |
| Ctrl+N | Open a new session in sap |
| Ctrl+F10 | User menu display |
| Ctrl+F11 | SAP Menu |
| Ctrl+shft+F6 | Add a transaction code to your favorite list |
SAP中的功能键是什么?
使用功能键可以快速访问常用功能。功能键(F键)是允许触发无菜单功能的特殊键。
在sap中的任何时候,您都可以使用F1。按光标上的字段,然后单击F1。将显示供您参考的SAP辅助菜单。这是学习功能的最佳方式
如果要执行事务,只需填写所需的整个字段,然后按屏幕执行按钮或按F8执行即可。
以下是一些有助于您了解SAP解决方案的文章
- 76 次浏览
【SAP技术】什么是SAP ALE、EDI和IDOC
视频号
微信公众号
知识星球
我们经常在各种项目中遇到ALE、EDI和IDOC等术语。本教程将介绍电子数据交换(EDI)、应用程序链接启用(ALE)和中间文档(IDOC)的一些基本概念。如今,ALE、EDI IDoc在大多数SAP应用程序中被用于将消息(信息)从SAP系统传输到其他系统,反之亦然。
目录
- 什么是ALE?
- 什么是EDI
- 什么是EDI标准
- 它是如何工作的?
- 数据发送:
- 数据接收:
- 什么是SAP中的IDOC?
- EDI的优点是什么
- SAP中的IDOC类型是什么?
- SAP中的Outbound IDOC是什么
- SAP中的入站IDOC是什么?
- SAP中的IDOC状态是什么?
- 如何在SAP中触发IDOC?
- 什么是SAP IDOC接口?
- 如何在SAP中处理IDOC?
- 如何查找IDOCtype文档?
什么是ALE?
ALE代表应用程序链接启用,是一种用于远程连接的技术,通过链接去中心化的系统来实现业务流程的去中心化。
使用ALE同步几个SAP结构非常简单,这样它们就可以随时包含相同的数据对象。主数据(客户、供应商、总账账户、成本中心等)或交易数据(FI文档、采购订单等)可能是这些对象。ALE支持系统之间的大规模数据传输,以及在上次传输后修改的对象的选择性数据传输,以允许同步。
什么是EDI
EDI代表电子数据交换,是指根据计算机系统之间商定的消息标准,通过电子方式交换结构化数据。结构化数据类似于显示文档数据材料的简单明了的方式,无论是发票、采购订单还是任何其他形式的文档
可以由计算机以标准格式处理的商业记录的电子计算机到计算机的交换。电子数据交换(EDI)是指与您的贸易伙伴进行电子商务和交易。EDI包括大多数通常使用纸质信件完成的项目,如下订单和与供应商进行财务交易。
电子数据交换(EDI)是一种标准化格式,允许一家公司以电子方式而非纸质方式向另一家公司发送信息,以进行商业信息的电子交换。贸易伙伴被称为以电子方式开展业务的商业组织。
EDI的基本原理是将数据从一种格式转换为另一种格式。使用了许多标准,其中最常用的是ANSI X12(美国标准)和EDIFACT(欧洲标准)。大多数转换工作都是用EDI软件完成的。包可用于将平面文件格式转换为常规EDI文件,该文件删除所有空格,并使用标准代码和限定符分隔字段值。
指定了计算机系统确保正确解释信息的方法。自R/3 Release 2.2x以来,SAP一直为EDI提供支持,并继续开发其解决方案,尽早意识到EDI作为关键业务推动者的重要性。
SAP中的电子数据交换组件由一个中间文档(IDoc)组成
什么是EDI标准
EDI是业务合作伙伴的计算机系统之间通过通信网络使用通用格式进行的电子商务文档交换。对于电子数据交换,两个常用的标准是用于电子传输信息的ANSI ASC X12和EDIFACT。ANSI ASC X12是一个由主要组织、政府机构和EDI软件公司成员组成的委员会,负责确定EDI知识共享要求和指南。
UN/EDIFACT代表联合国政府、商业和运输电子数据交换,于1985年使用ANSI X12和UNTDI作为基本标准(联合国交换数据交换)开发。
ANSI X12将商业单据识别为交易,每个交易由三位数字定义,例如880采购订单、885采购订单识别。
它是如何工作的?
从高层角度来看,该方法简单明了:发送方系统选择需要传输的数据,将其打包为标准格式,并将其发送到一个或多个接收系统。当接收设备获取数据时,它会打开标准格式的包装并记录数据。
实际上,在这个过程中,涉及到三个层次:
- 一种选择并记录R/3数据的应用层。
- 过滤和转换信息的分布层。
- 一种通信层,确保以标准格式生成的记录进行实际通信。
由于有了一个所谓的分配模型来确定传输规则(谁向谁发送什么?),发送者和接收者就被决定了。所有涉及的系统(无论是作为发送方还是接收方)都必须熟悉分布模型的概念,因此必须存在于所有这些系统中。

数据发送:
- 计算机系统起着数据存储库的作用。
- EDI从当前的计算机程序中收集知识。
- 传输无纸化、计算机可读的电话线路文件。
数据接收:
- 它被直接输入计算机系统。
- 自动处理并与内部软件接口。
- 时间处理
- 在几分钟内完成。
- 没有任何重新键入。
- 没有文件的混乱。
- 编写和分发手册文件不收取任何附带费用。
什么是SAP中的IDOC?
IDocs代表中间文档。IDoc本质上是一个数据容器,用于在任何两个能够理解数据语法和语义的进程之间共享数据。
在大多数SAP应用程序中,IDoc通常用于将消息信息从SAP系统传输到其他系统,反之亦然。虽然IDocs上有很多可用的文件,但由于其技术性质,实用的顾问很难理解这些文件。尽管实际顾问不应完全理解IDoc原则,但已尝试收集处理IDoc上的项目/支持问题所需的最低限度的知识。。
IDoc是一个SAP实体,它以电子消息的形式将业务交易数据从一个设备带到另一个设备。IDoc是Document Intermediate的缩写。IDoc旨在将SAP数据或信息传输到其他系统,反之亦然。从SAP到非SAP系统的转换通过EDI(电子数据交换)的子系统进行,而ALE用于两个SAP系统之间的传输。
在SAP系统或EDI子系统中,可以激活IDoc。这取决于IDoc的发送方式,因此被称为Inbound IDoc和Outbound IDoc。IDoc在SAP中通过文档消息控制在出站流的情况下触发,对于入站流,EDI转换合作伙伴数据,并在SAP中创建IDoc。成功发布IDoc后,将向SAP发布/创建应用程序文档。
EDI的优点是什么
- 减少手动处理过程中的数据输入错误
- 减少了周期处理时间,实时分发,
- 电子格式数据的可用性
- 降低的文书工作
- 降低了成本
- 减少库存和更好的准备
- 标准通信方式
- 更好的公司方法
- 竞争性收益
SAP中的IDOC类型是什么?
SAP中有两种类型的Idocs类型
SAP中的Outbound IDOC是什么
出站Idoc消息-通过电子数据交换(EDI)向第三方系统发送订单确认等消息。用于发送EDI消息的出站消息。在出站处理中,文档数据被写入IDocs并发送到接收系统。以下出站EDI消息在“销售和分销”中可用:
- 发送报价信息
- 发送订单确认
- 订单变更请求
- 交付创建
- 装运通知处理
- 向第三方发送发票信息等。
SAP中的入站IDOC是什么?
入站IDOC消息–入站IDOC消息用于通过EDI接收来自第三方公司的销售订单请求。在入站Idoc处理中,Idoc被传输到Idoc接口并存储在SAP系统中。文件中的数据在第二阶段生成。在Sales and Distribution中,可以使用以下入站EDI消息类型:
- 接收客户咨询
- 接收销售订单请求
- 接收销售订单变更请求
- 接收预测交货时间表
- 收到的贷项通知单
- 接收来自外部代理供应商等的交货创建通知

SAP中的IDOC状态是什么?
IDOC有许多状态列表,Outbound IDOC状态从01到42开始。在所有出站状态代码列表下方。
| IDoc status | Direction | Processing level | Description |
| 01 | Outbound | IDoc Interface (SAP) | IDoc generated |
| 02 | Outbound | IDoc Interface (SAP) | Error passing data to port |
| 03 | Outbound | IDoc Interface (SAP) | Data passed to port OK |
| 04 | Outbound | External system/EDI subsystem | Error within control information of EDI subsystem |
| 05 | Outbound | External system/EDI subsystem | Error During Translation |
| 06 | Outbound | External system/EDI subsystem | Translation OK |
| 07 | Outbound | External system/EDI subsystem | Error during syntax check |
| 08 | Outbound | External system/EDI subsystem | Syntax check OK |
| 09 | Outbound | External system/EDI subsystem | Error during interchange handling |
| 10 | Outbound | External system/EDI subsystem | Interchange handling OK |
| 11 | Outbound | External system/EDI subsystem | Error during dispatch |
| 12 | Outbound | External system/EDI subsystem | Dispatch OK |
| 13 | Outbound | External system/EDI subsystem | Retransmission OK |
| 14 | Outbound | External system/EDI subsystem | Interchange Acknowledgement positive |
| 15 | Outbound | External system/EDI subsystem | Interchange Acknowledgement negative |
| 16 | Outbound | External system/EDI subsystem | Functional Acknowledgement positive |
| 17 | Outbound | External system/EDI subsystem | Functional Acknowledgement negative |
| 18 | Outbound | IDoc Interface (SAP) | Triggering EDI subsystem OK |
| 19 | Outbound | IDoc Interface (SAP) | Data transfer for test OK |
| 20 | Outbound | IDoc Interface (SAP) | Error triggering EDI subsystem |
| 21 | Outbound | IDoc Interface (SAP) | Error passing data for test |
| 22 | Outbound | External system/EDI subsystem | Dispatch OK, acknowledgement still due |
| 23 | Outbound | External system/EDI subsystem | Error during retransmission |
| 24 | Outbound | External system/EDI subsystem | Control information of EDI subsystem OK |
| 25 | Outbound | IDoc Interface (SAP) | Processing despite syntax error (outbound) |
| 26 | Outbound | IDoc Interface (SAP) | Error during syntax check of IDoc (outbound) |
| 27 | Outbound | IDoc Interface (SAP) | Error in dispatch level (ALE service) |
| 28 | Outbound | IDoc Interface (SAP) | IDoc sent to ALE distribution unit retroactively |
| 29 | Outbound | IDoc Interface (SAP) | Error in ALE service |
| 30 | Outbound | IDoc Interface (SAP) | IDoc ready for dispatch (ALE service) |
| 31 | Outbound | IDoc Interface (SAP) | Error – no further processing |
| 32 | Outbound | IDoc Interface (SAP) | IDoc was edited |
| 33 | Outbound | IDoc Interface (SAP) | Original of an IDoc which was edited |
| 34 | Outbound | IDoc Interface (SAP) | Error in control record of IDoc |
| 35 | Outbound | IDoc Interface (SAP) | IDoc reloaded from archive |
| 36 | Outbound | External system/EDI subsystem | Electronic signature not performed (timeout) |
| 37 | Outbound | IDoc Interface (SAP) | IDoc added incorrectly |
| 38 | Outbound | IDoc Interface (SAP) | IDoc archived |
| 39 | Outbound | IDoc Interface (SAP) | IDoc is in the target system (ALE service) |
| 40 | Outbound | IDoc Interface (SAP) | Application document not created in target system |
| 41 | Outbound | IDoc Interface (SAP) | Application document created in target system |
| 42 | Outbound | IDoc Interface (SAP) | IDoc was created by test transaction |
Similarly, inbound IDOC status starting with 50 to 75 status.Below list of all inbound status codes.
| IDoc status | Direction | Processing level | Description |
| 50 | Inbound | IDoc Interface (SAP) | IDoc added |
| 51 | Inbound | SAP application | Application document not posted |
| 52 | Inbound | SAP application | Application document not fully posted |
| 53 | Inbound | SAP application | Application document posted |
| 54 | Inbound | SAP application | Error during formal application check |
| 55 | Inbound | SAP application | Formal application check OK |
| 56 | Inbound | IDoc Interface (SAP) | IDoc with errors added |
| 57 | Inbound | SAP application | Test IDoc: Error during application check |
| 58 | Inbound | IDoc Interface (SAP) | IDoc copy from R/2 connection |
| 59 | Inbound | IDoc Interface (SAP) | Not used |
| 60 | Inbound | IDoc Interface (SAP) | Error during syntax check of IDoc (inbound) |
| 61 | Inbound | IDoc Interface (SAP) | Processing despite syntax error (inbound) |
| 62 | Inbound | IDoc Interface (SAP) | IDoc passed to application |
| 63 | Inbound | IDoc Interface (SAP) | Error passing IDoc to application |
| 64 | Inbound | IDoc Interface (SAP) | IDoc ready to be transferred to application |
| 65 | Inbound | IDoc Interface (SAP) | Error in ALE service |
| 66 | Inbound | IDoc Interface (SAP) | IDoc is waiting for predecessor IDoc (serialization) |
| 67 | Inbound | IDoc Interface (SAP) | Not used |
| 68 | Inbound | IDoc Interface (SAP) | Error – no further processing |
| 69 | Inbound | IDoc Interface (SAP) | IDoc was edited |
| 70 | Inbound | IDoc Interface (SAP) | Original of an IDoc which was edited |
| 71 | Inbound | IDoc Interface (SAP) | IDoc reloaded from archive |
| 72 | Inbound | IDoc Interface (SAP) | Not used, only R/2 |
| 73 | Inbound | IDoc Interface (SAP) | IDoc archived |
| 74 | Inbound | IDoc Interface (SAP) | IDoc was created by test transaction |
| 75 | Inbound | IDoc Interface (SAP) | IDoc is in inbound queue |
Inbound IDOC Status
如何在SAP中触发IDOC?
IDOC可以使用功能模块或使用程序来触发。如果它是典型的Outbound IDOC,则FM IDOC OUTPUT ORDERS可能会生成它。
可以有一个自定义程序,可以使用FM MASTER IDOC DISTRIBUTE来生成标准以及自定义出站IDOC。如果在FM上放置断点并尝试生成IDOC,则可以使用调用堆栈跟踪程序。
什么是SAP IDOC接口?
标准SAP接口提供了将外部系统连接到SAP的选项,我们称之为接口。SAP接口允许与任何其他应用程序和其他解决方案的SAP系统进行数据交换。
如何在SAP中处理IDOC?
通常,在标准SAP中有各种IDOCS处理程序可用。根据管理员定义的处理状态和时间安排为后台作业。如果需要,我们可以使用交易代码BD87手动处理文档
如何查找IDOCtype文档?
我们可以使用交易代码WE60获取SAP IDOC文档。例如,对于发票,我们想知道强制和可选分段、最小和最大分段数量等信息。

希望这篇文章能帮助你理解EDI、ALE和IDOC的基本概念。我们将在下一篇文章中介绍IDOC配置。。这是你检查的其他几篇文章
- 491 次浏览
【SAP技术】关于SAP MDG和SAP MDM的所有信息
视频号
微信公众号
知识星球
许多人仍然对SAP MDG和SAP MDM数据处理的差异感到困惑。本文将解释SAP产品中MDG(SAP主数据治理)和MDM之间的差异。MDM和MDG工具的共同目标是管理本组织的主数据。然而,它们的数据分布不同。让我们来了解它们的作用以及如何使用它们
组织在全球扩张,社交媒体是商业环境的主要组成部分,由于复杂性和数量的增加,数字营销给主数据管理带来了更大的风险。为了管理、组织、管理、治理和优化主数据管理,必须有一个坚实的结构

目录
- 什么是主数据
- 什么是SAP MDM(主数据管理)?
- 什么是SAP MDG(主数据治理)?
- SAP MDM(主数据管理)有哪些好处
- SAP MDG(SAP主数据治理)有哪些好处
什么是主数据
Master,数据可以在所有系统和应用程序中使用。它用于维护数据的完整性,降低成本,并为所有业务功能(如SD、MM、FI等)提供单一的真相来源。集中的主数据库将使组织能够做出明智的决策并确保透明度。SAP提供主数据管理(MDM)和主数据治理(MDG)。这些解决方案使公司能够管理所有主数据,同时在所有业务运营中提供一致、全面和相关的数据。
SAP为MDM和SAP MDG提供了两种方法,这两种方法与嵌入式治理框架相集成,帮助企业定义业务规则,通过角色分配将责任分配给主数据人员,并确保可以通过工作流监控主数据管理周期。
SAP MDG是SAP ECC预装解决方案。此解决方案继承了本机SAP ECC业务规则和角色。它允许围绕此过程创建工作流。审计跟踪、验证和检查都是信息管理过程的一部分。主数据用于将数据复制到所有ERP和目标系统
什么是SAP MDM(主数据管理)?
SAP MDM,也称为主数据管理,是SAP MDM中的一个元素,是SAP软件套件的一部分,专注于协调和集成整个组织的主数据。主数据是指各种企业及其系统使用和共享的基本数据元素,如客户、产品和供应商信息。SAP MDM旨在建立统一一致的主数据,以确保整个公司的数据完整性及其准确性。
它具有在不同系统和应用程序之间开发、更新和共享主数据的工具和程序,从而消除冗余或不一致的数据。SAP MDM提供数据治理、数据质量管理和数据同步等功能。数据治理涉及创建如何创建和维护主数据的指导方针、标准和程序。它确保数据是可靠的,并符合业务规则和法规。
SAP MDM用于确保主数据的真实性。SAP MDM解决方案使用面向服务的设计向SAP和非SAP系统提供数据。MDM解决方案通过流程集成(PI)将主数据直接分发到ERP系统。主数据更新仅从MDM进行。然后可以在ERP系统中对它们进行更新。
什么是SAP MDG(主数据治理)?
SAP MDG管理组织数据。它为大数据管理奠定了基础,并可操作您的数据以优化业务效益。SAP MDG自动化并加速维护和业务运营。它也是所有信息的仓库。其中数据在电路内循环。企业资源规划系统提供数据,并对其进行调整和整合,以实现千年发展目标。在这里进行数据添加和更改,数据仍然通过流程集成(PI)进行分发。

现在让我们比较一下SAP主数据管理(SAP Master Data Governance)和SAP Master Data Management(SAP Master数据管理)。
SAP MDM(主数据管理)有哪些好处
- 流程集成使主数据能够立即提供给ERP系统(PI)。
- ERP系统从MDM工具更新主数据。
- MDM是一种数据分发和集成工具,可以与SAP和其他平台一起使用。
- MDM需要第三方中间件来连接其他系统。
- MDM允许将所有主数据对象存储在SAP环境中,而不管其来源如何。
- 中央存储库存储主数据以及与其连接的丰富内容。
- 作为数据导入过程的一部分,对数据进行重组、清理和合理化。
SAP MDG(SAP主数据治理)有哪些好处
- 主数据在MDG中添加或更改,并分发给PI。
- 数据在MDG系统内的电路中移动。数据来自ERP。然后根据千年发展目标对其进行调整和巩固。
- MDG可以是SAP的附加组件。它可以共享SAP-ERP服务器并提供集中的数据。它与非SAP系统不兼容。
- MDG可以与SAP集成,以发送和接收来自ERP、CRM和SRM等所有系统的数据。
- MDG只能在SAP和ERP配置中访问。。它允许动态同步和存储主数据对象。
- SAP MDG有助于在本地和云中混合位置管理大数据。
- 保护、管理并确保向适当的职能部门和人员报告数据更改。
- 它提供了可靠的数据,降低了总体拥有成本,并且高度安全
我们希望这篇文章能帮助您了解SAP主数据管理和SAP主数据治理之间的区别……您应该在这里阅读一些文章。
- 322 次浏览
【SAP技术】关于SAP S_ALR事务的须知
视频号
微信公众号
知识星球
我们正在寻找将交付给用户或客户用于内部报告和报告目的的相关报告,但我们找不到达到标准报告的正确导航路径。因此,本文将帮助新来者了解SAP S_ALR标准报告和导航路径。
SAP创建了大量标准报告,以解决客户的基本优势,避免定制改进。甚至我们也经常收到客户的请求,要求制作基本SAP报告的记录。
SAP S_ALR tcode/reports在SAP中的含义
SAP S_ALR是任何人都可以用于报告目的的标准报告。这些报告涵盖了广泛的应用领域,包括SD、MM和FI。这些报告现在可以从命令行启动,保存到收藏夹列表中,并单独授权。
R/3版本中有数千个SAP S_ALR报告,这些报告可以以ALV报告格式获取数据,对管理信息系统(MIS)非常有用,但SAP S_ALR报告存在某些限制,因为它是基于标准表构建的。
S ALR tcode生成序列号,当SAP将旧的报告树移动到区域菜单并添加新的报告功能时,这些序列号将被使用。
现在,如果您有特定于客户的需求,复制现有报告并对其进行更改以满足业务需求总是一个好主意。
SAP提供了一个自定义事务,以确定每个模块可访问的标准报告列表。让我们探讨一下如何确定标准报告的列表;每个模块都有可用的标准报告列表。
导航到SAP1事务代码,如下所示:

对于本例,我们选择了Sales and Distribution模块。深入研究会将其分为子模块和标准SAP中提供的一组典型报告。选择“在桌面上创建快捷方式”或添加到“收藏夹”以便于导航
同样,现在我们想找出用于G/L账户报告目的的SAP S_ALR报告或交易代码的标准列表。转到TSTCT表并输入S_ALR*&*G/L*,如下所示,它将为您提供交易代码/报告列表。

按下execute,以下SAP S ALR事务将显示如下

如果要下载文件,请单击下载。我们希望这篇文章对您的SAP S_ALR报告有所帮助。下面是你应该读的几篇有趣的文章。
- 206 次浏览
【SAP解决方案】以下SAP行业解决方案中的哪一个是SAP产品。
视频号
微信公众号
知识星球
SAP行业解决方案是一种策略和战略,旨在解决特定行业中组织遇到的独特需求和问题。具有丰富行业知识的专家开发专门针对该行业的解决方案,为组织提供改进的运营、提高的效率和竞争优势。
目录
- 什么是SAP行业解决方案?
- sap提供了多少特定于行业的解决方案?
- 离散行业:
- 能源和自然资源:
- 金融服务:
- 公共服务:
- 服务业:
- 消费行业
- 结论
什么是SAP行业解决方案?
SAP为不同行业提供SAP行业解决方案。这是一个既定的事实。这篇文章将深入了解SAP内不同产品线的这些解决方案的开发情况。
SAP为ERP选项提供了超过25个SAP行业解决方案。SAP行业解决方案提供了一个特定于行业的系统,可以让您的公司全面了解特定于您行业的业务流程。与合作伙伴和SAP开发团队合作,创建了行业解决方案图,以帮助确定特定行业部门的需求。
当需要SAP Business One解决方案来满足某个行业垂直领域的需求时,客户必须购买该垂直领域的附加组件。此插件通常由SAP开发合作伙伴开发,该合作伙伴一直在为客户提供SAP咨询服务。合作伙伴开发附加组件并将其发送给SAP AG以供批准。经过测试后,该解决方案将成为该特定垂直行业的真正SAP附加组件。
特定垂直领域的需求也预先配置到SAP All-in-One解决方案中。这是针对高端的中型企业。这是由适当的渠道或开发合作伙伴预先配置给SAP AG的。SAP AG颁发了一份证书,证明预配置的解决方案符合行业垂直的要求。
R/3是行业解决方案可以与标准SAP组件无缝集成的地方。然后考虑客户的要求。客户在购买SAP时将购买相应的SAP行业解决方案套件。
R/3应用程序可分为三个核心功能类别:财务、后勤和人力。资源这三个功能领域可以进一步细分为应用程序模块。在这些应用程序中,SAP还开发了特定于行业的解决方案。
顾名思义,这些产品是为特定行业定制的。以下是几个例子
- IS-OIL是SAP行业为石油公司提供的解决方案
- IS Telecom SAP行业电信解决方案
- IS Bank为银行设计的SAP行业解决方案
- IS-零售是SAP行业的零售解决方案
这些行业解决方案目前有19个,可以与标准的交叉应用程序相结合。有许多组件,包括SAP业务工作流。
独特的应用程序或模块,可在整个系统中使用,以集成和自动化R/3流程。以下是一些最重要功能的快速概述和描述。
sap提供了多少特定于行业的解决方案?
SAP提供适用于各个行业的软件包。该产业集群为制造成品的行业提供解决方案
SAP目前提供以下行业套件:
离散行业(Discrete Industries):
- SAP for Automotive
- 用于航空航天和国防的SAP
- 工业用零部件和机械
- 高科技工程、施工和运营
能源和自然资源:
生产运输或电信服务等无形商品的行业。该行业集群中的解决方案
- SAP for Oil&Gas
- SAP for Chemicals,Pharmaceuticals
- 面向消费者的SAP产品
- SAP for Products&Mining
- SAP for Chemicals
金融服务:
该集群提供银行和保险解决方案
- SAP for Banking
- SAP for Insurance
公共服务:
在政府服务和高等教育领域,这个产业集群提供了解决方案。
- SAP for Defense&Security
- SAP用于酒店服务、医疗保健和其他服务
- SAP for Research and higher education
- 公共部门SAP
服务业:
为运输或电信服务等生产非物质商品的行业提供解决方案。这个产业集群提供了解决方案
- SAP for Engineering,Construction and Operations
- SAP for Media
- SAP for Professional Services
- SAP for Sports&Entertainment
- SAP for Telecommunications
- SAP for Transportation
- SAP for Travel
消费行业
这一公司集群为个人和家庭而非公司和公司收购的产品提供解决方案
- 消费类产品SAP
- SAP for Fashion(SAP AFS-服装和鞋类解决方案)
- SAP for Life Sciences
- SAP for Retail
- SAP for Wholesale
- SAP for Distribution
结论
对于希望在当今竞争激烈的环境中蓬勃发展的企业来说,SAP行业解决方案可能是极其重要的工具。组织可以通过实施专门的方法和技术来简化运营,提高效率,并获得竞争优势,从而简化运营,同时提高生产力,从而在其部门取得长期成功。采用行业解决方案带来了深远的好处,不仅可以节省成本:它支持长期增长,从而在各个方面取得成功。
我们希望这有助于理解“什么是SAP行业解决方案?”?SAP提供了哪些解决方案?我们将在下一篇博客中介绍IS的特定功能。以下是您需要查看的一些项目。
- 32 次浏览
【SAP配置】SAP变体配置,让您的生活更美好。
视频号
微信公众号
知识星球
目录
- 介绍
- 变体配置的使用
- 什么是变体配置?
- 可配置材料
- 特点
- 依赖项
- 配置配置文件
- 可变条件
- 如何创建变体条件
- 如何实现变体条件
- 可变条件下的定价因素
- 变体配置中的步骤
- 创建可配置的材质类型。
- 为材料创建特征
- 为材质创建类
- 为类指定特征
- 为材料创建配置文件
- 创建特性的依赖项
- 定价程序中的可变条件。
- 维护定价条件记录
- 使用VA01创建销售订单
介绍
欢迎收看教程,今天我们将仔细了解变量配置。当制造商对同一产品有不同的规格时,它是一种简化复杂制造过程的工具。比如,汽车。汽车价格从标准设备开始,如果想购买任何特定功能,价格将高于汽车的基本价格。SAP Variant Configuration使我们能够在没有任何增强的情况下满足这样的要求。
很多时候,只要对现有产品进行简单的更改,我们就能满足客户的期望。只是为现有产品添加新的属性。变体配置是我们为材料创建属性并配置材料以满足客户期望的一种响应。
变体配置的使用
- 通过引入新型号或对现有产品进行改进,利用消费者的不同配置期望。
- 通过以更高的价格销售新商品来增加公司的利润。
- 在创建新产品时,变体配置显著降低了研发成本。
- 立即配置新产品的功能,并调整制造成本,系统会自动考虑新产品的价格
什么是变体配置?
变体的配置是为了开发复杂的商品。制造商必须始终销售新产品或现有产品的版本。对现有产品设计的修改也会产生新产品。最重要的是快速响应客户的需求和市场需求。
消费者决定产品的特性。例如,购买自行车的客户可以选择自行车的功能,并根据需要组合这些功能。模型设计增强了销售、工程和制造之间的知识共享。变体配置允许客户或销售人员编制产品需求,以确保产品可以根据这些需求制造。它还确保生产成本不会超过预先设定的水平。
变体的配置包含以下基线配置
- 可配置内容
- 特征包含用于描述对象的值。
- 依赖关系用于限制特征值的混合。
- 配置配置文件:-在销售订单中用于监控物料的配置。
- 变更条件用于描述各种费率或附加费。
可配置材料
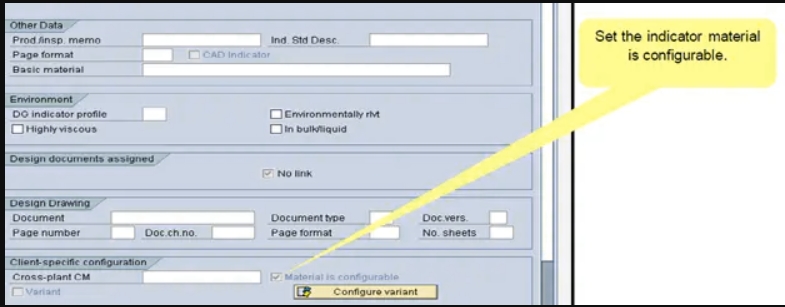
材料主记录必须具有在我们可以构建可配置的内容之前,在其基本数据中选择“材料可配置指标”。我们可以使用自定义中指定的材料形式来构建材料,该材料形式具有可配置的指标。这意味着所有使用这种材料形式制成的材料都是可配置的。为此,在标准系统中指定了材料类型KMAT。我们可以描述e其他材料类型的单个材料的可配置性。为此,请在物料主记录的“基本数据”中设置“可配置物料”指示器。
特点
我们使用属性来描述可配置材料的特性。为了允许我们使用属性来配置材质,我们将材质分配给类型为300的类。例如,正如消费者所预期的那样,自行车的类型、颜色和发动机都是可能的特征。对于客户可以在不同选项之间进行选择的特征(值)
依赖项
依赖性适用于由于技术或市场原因而不可能实现的功能组合示例:我们不能将所有类型的自行车发动机与所有类型的变速器组合,因为某些类型的发动机型号仅适用于更昂贵的型号
我们在变体配置中使用依赖项来管理变体组合。这避免了不允许的替代方案的组合。依赖项通常会精确地选择正确的BOM表组件和操作来生成版本。
配置配置文件
可配置对象必须具有配置配置文件。物料配置配置文件控制销售订单配置过程。
维护可以配置为指定核心对象设置的对象的配置配置文件。我们可以为具有不同配置的对象创建多个配置配置文件。如果一个对象有多个配置配置文件,则在配置过程中必须选择一个配置文件。我们只能使用您用于首先配置对象的配置文件进行配置调整
在配置配置文件中,我们定义了与其他可配置工件不同的材质设置。我们使用配置配置文件为可配置对象分配一组或多组变体。这将对象连接到配置类属性。
请注意,可配置对象然后被分配给类,而不是配置文件。该配置文件可帮助您仅进入分类。
我们可以在值分配屏幕上定义影响显示选项和特性范围的设置。对于每个对象,都可以指定特定的设置,并且这些设置会在使用对象的任何位置引用对象。但是,配置编辑器可以为用户覆盖这些设置。
我们可以使用界面设计将特征分组在一起,并在屏幕上识别一个系列进行赋值。我们必须为接口设计指定一个名称,以便在配置模拟中进行更多维护。
我们可以使用配置文件为可配置对象分配依赖项。只有依赖关系网可以分配给配置配置文件。如果您将配置配置文件委托给活动和过程,我们可以更容易地处理它们,因为它们都在一个位置。
可变条件
我们可以根据特征值来制定变体的价格。对于变体,我们可以使用变体条件来描述过载和折扣。对于材料变体,我们可以创建用于销售订单的变体条件。
根据分配的特征值,我们可能会使用不同的条件来影响可配置项目的价格。我们对变体有两个条件:
- 这种类型的条件表示一个绝对数。
- 这种类型的条件表示附加费/折扣的百分比。
变量条件包括一个关键变量和一个由关键变量定义的量。我们可以在销售和分销中使用可变条件来确定可配置产品的附加费和折扣,具体取决于您分配的特征值。
E、 g:如果任何客户想要一辆带盘式制动器的摩托车,3500卢比的价格会增加净价。对于商品/材料、分销渠道和销售组织的特定关系,我们在销售定价中建立了不同的条件。
如何创建变体条件
我们必须构造一个引用表SDCOM字段VKOND的属性。该字符被分配给可配置内容的变体类。与SDCOM字段VKOND表相关的特征对象是多值的,因为可以加入几个可变条件。
我们维护一个关于产品或材料的分销渠道和销售组织的变体条件。当我们配置材料时,我们访问为材料生成的变体条件。键定义了不断变化的条件。
比方说,我们有两个条件形式VA01和VA02来构建具有不同条件的可配置材料。
VA01用于构造变量的值状态。如果一辆摩托车的颜色是黄色(通常不销售),并且价格不同,那么我们就确定它的条件值。
另一个是VA02,用于构建具有变体附加条件的版本例如,如果订购带有ABS的盘式制动器的摩托车,价格将上涨4000卢比。可配置摩托车材料具有“盘式”制动器重量和ABS特性
如何实现变体条件
- 我们需要创建可变条件VA00,如ABS制动器,总金额为4000卢比。
- 我们需要参考现有的结构SDCOM和字段VKOND来创建一个新的特性VARCOND。
- 最后,我们需要创建一个依赖项,以便必须使用表引用和变量键作为值来输入字符,如$SELF.VARCOND=ABS
请注意,变体密钥适用于个别情况(区分大小写)。在对象依赖项中,变量键的输入方式必须与条件表中的输入方式相同。如果大写字母和小写字母的组合不适合表格,则不会处理变体的状态。
可变条件下的定价因素
比方说,附加费或折扣部分取决于特定的特征值,部分取决于其他因素,如长度。这种定价方法也可以用依赖关系来表示。要执行此操作,请输入要提高或降低附加费或折扣的因素,以及版本的条件。定价因素只能在特征级别上保持,而不能在销售屏幕的顺序中保持。价格因素语法如下:
- $SET_PRICING_FACTOR($SELF,<characteristic>,<variantkey>,<FACTOR>)
- $SET_PRICING_FACTOR($SELF,<characteristic>,<variantkey>,<FACTOR>)
- 该特性指的是SDCOM结构,其中为变体指定了条件。
- 变量的键用于将特征值连接到状态。
- 增加附加费的因子。我们可以将元素作为常量、数值属性或数值表达式联接。
变体配置中的步骤
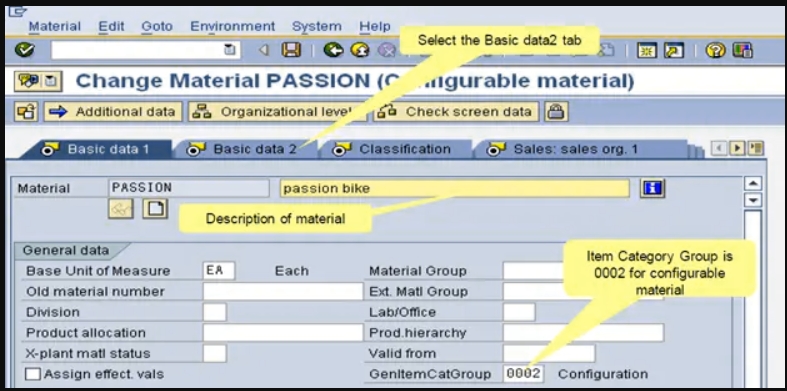
创建可配置的材质类型。
在我们开始配置之前。我们需要在下面创建一个可配置的物料类型:物料类别为(002)的KMAT物料类型。

一旦完成更改,我们将能够创建新的可配置材料。比方说,我们正在将一辆摩托车配置为Passion Bike
为材料创建特征
在这些步骤中,我们需要定义特征。交易代码CT04,屏幕下方出现一个,我们正在创建新的特性作为立方容量。我们经常发现摩托车的定价是基于立方容量的。

一旦我们创建了新的特性,请确保以下设置

在附加数据选项卡中,维护表SDCOM和字段VKOND。我们还可以通过提及摩托车的颜色和摩托车的其他功能来指定值。

为材质创建类
现在我们需要为变体创建一个类。课程将包含特色和细节。

为类指定特征
在这些步骤中,我们必须添加定义材料的任何特性。e、 g我们定义了一个特性,即颜色、体积、价格
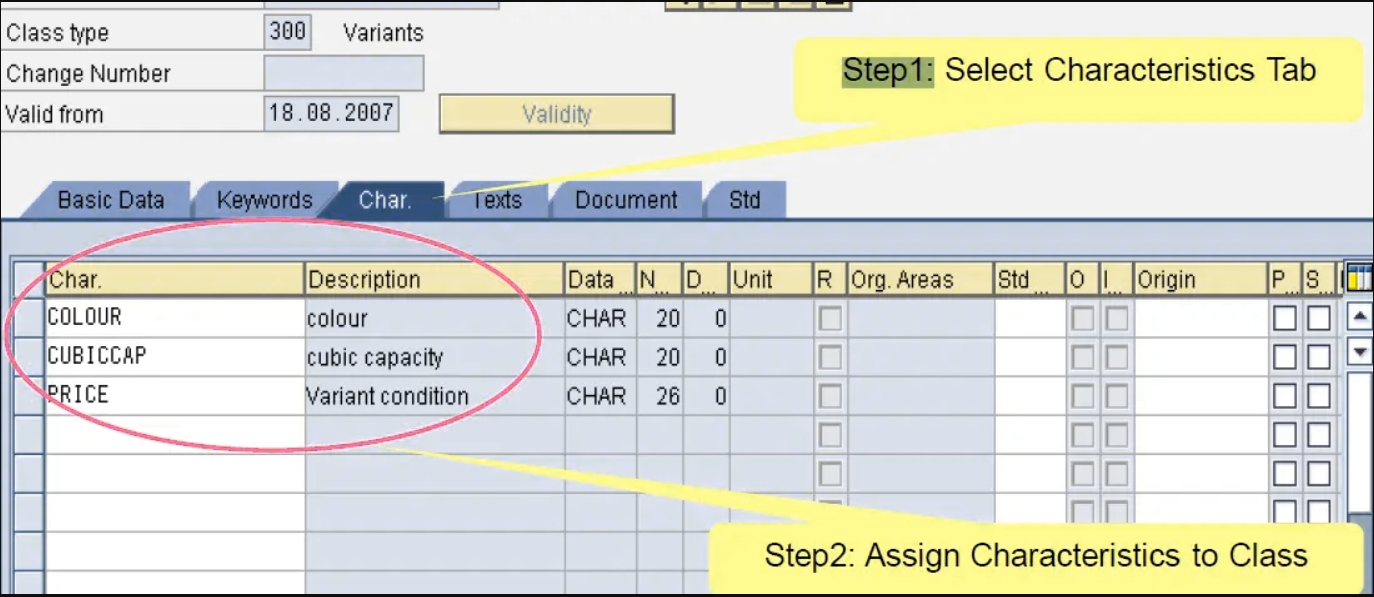
为材料创建配置文件
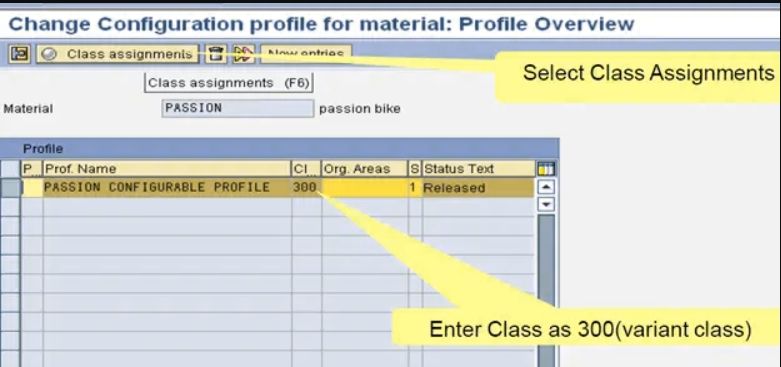
现在,我们需要通过CU41配置配置文件,选择材料并输入描述,然后单击课堂作业
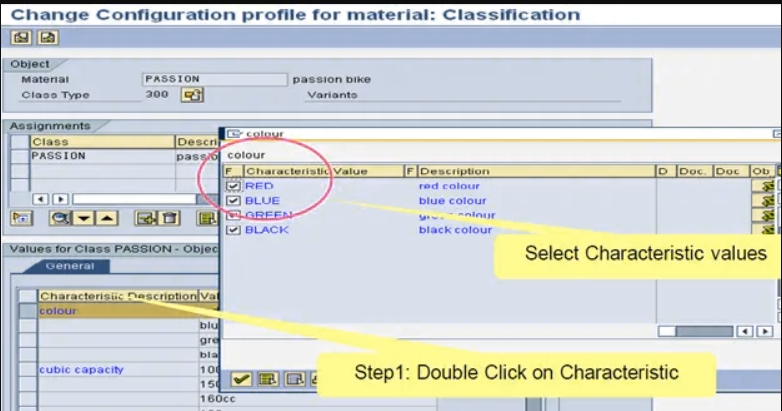
创建特性的依赖项
现在返回CU41并指定要为其创建依赖项的选择字符。依赖项将为–$self。ZPrice=“Red”并保存。对其他值重复该过程。

定价程序中的可变条件。
要对销售订单中的字符值进行流动定价,我们必须在定价过程T中包括可变条件类型。代码V/08如下

维护定价条件记录
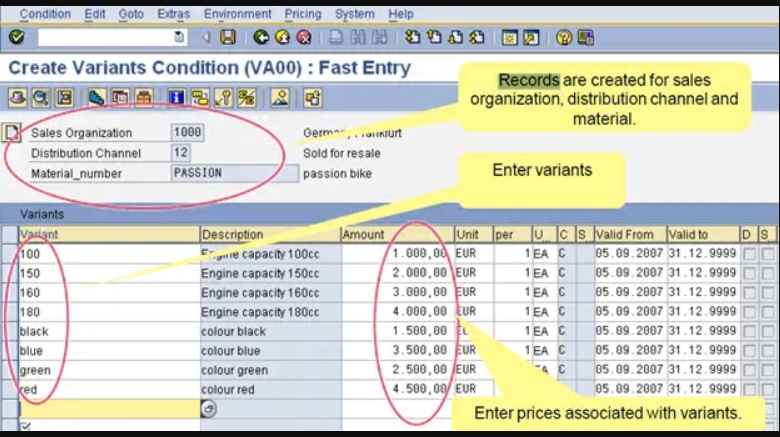
现在我们需要为定价创建条件记录。T.code VK11-输入VA00(条件)-输入变体红色和蓝色,给出相应的价格并创建销售订单
使用VA01创建销售订单
现在我们已经准备好创建销售订单,请确保输入特征值,以便系统可以在销售中分配特征值,并执行正确的定价。
- 122 次浏览
【应用现代化】SAP应用程序现代化的最佳实践和方法
「应用现代化」SAP应用程序现代化的最佳实践和方法"
应用程序现代化是对传统软件编程的重新利用,以使其与当前业务需求更紧密地协调一致。这是企业保持竞争力的关键。虽然存在许多挑战,但通过这一过程获得的效率有助于公司保持相关性,从而使其成为绝对必要。他们需要转换他们的遗留应用程序,从而保持核心业务功能的完整性。
有时,应用程序现代化意味着转换应用程序本身或维护方式。但是,业务改变技术有各种考虑因素。第三方通常管理PaaS产品。如果公司选择使用容器作为其遗留软件现代化的手段,则需要容器协调器或容器管理软件来实现其目标。
根据业务需求,应用程序现代化服务在很大程度上有助于实现数字化转型。在本文中,您将了解适合您业务的最佳现代化方法。
但首先,让我们讨论应用程序现代化采用的最佳实践。
评估应用程序
在此步骤中,您需要确定将哪个遗留系统现代化为高效的SaaS(软件即服务)应用程序。评估操作系统和服务器以运行SaaS系统。请务必考虑要合并的移动设备类型以访问应用程序并相应地自定义您的计划。
评估遗留数据迁移的意义
现代化过程的另一个核心部分包括发现数据处理,移动和存储的重要性。优先考虑数据从高到中到低的重要性,以帮助您的团队轻松了解每个数据类别的重要性。
应用程序安全威胁评估
在此步骤中,您需要通过列出潜在的弱点和敏感性来找到数据丢失的威胁。完成此步骤后,您可以确定缺陷的优先级并部署安全措施以消除它们。
进行软件风险评估
在对遗留系统进行现代化改造时,每个企业都需要考虑被黑客攻击的风险。因此,有必要评估与您的应用程序相关的漏洞。
通过此过程,您可以对高风险区域以及承认业务安全性的影响进行分类。风险越大,安全漏洞可能产生的负面影响就越大。在软件风险评估期间,风险越接近1的值,敏感性的可能性就越大。
数据丢失保护
应用数据丢失保护可以帮助您降低风险和信息丢失量。确保在选择正确的工具之前进行成本效益分析并确定投资回报率。此后,选择合适的安全措施,例如包括更强的密码和数据加密。
应用现代化的不同方法
现在,您已经了解了选择应用程序现代化时要遵循的最佳实践。现在是时候寻找适合您业务的应用程序现代化的最佳方法。
完全转型
应用程序现代化的方法包括重建新技术,同时将旧系统基础化。一切都从头开始,使用标准平台,或使用第三方包作为基础层构建。
该方法适用于当前旧系统不支持市场所需的创新变更或供应商不再支持底层技术平台的情况。
如果竞争对手转向更便宜的堆栈而供应商不再支持当前的技术,则最好采用完全转型。此外,如果公司想要构建具有统一功能的新应用程序,则完全转型是正确的方法。
这种方法风险很大,整个过程都处于危险之中,这可能会影响业务运营。而且,如果该过程在中途失败,则成本难以承受。
如果做得好,它被认为是最好的方法,因为它可以帮助您保持领先于竞争对手。但是,它仅适用于具有所需IT能力和成熟度的公司。
逐步更换
在这种应用程序现代化方法中,IT系统的组件与新技术交换,并作为分离的应用程序转移到生产。该方法比前一种方法风险更小,因为它需要通过一次移动一个整体来转换整个系统。
与完全转换相比,它不需要高昂的成本。此外,功能一次移动一个,成本和故障的影响要低得多。渐进式替换方法比完全转换需要更少的工作,它消耗更少的管理带宽。
该方法允许公司为以后的组件选择不同的技术或更新的版本。在遵循这种方法的同时,它有助于探索为未来应用构建生态组件或其他对象的方法。
如果管理不当,逐步替换的缺点是不同应用程序之间的合并问题。此外,如果架构规划不当,可能会导致太多的集成和组件。它还可能导致一组不相交的应用程序不能作为一个单元工作。
无论风险与逐步替代相关,成功率都高于其他任何方法。
管道胶带方法
通过新技术整合本地小规模变更,以解决应用中的特定问题。但是,核心架构和技术保持不变。该方法非常适合专注于当前问题的公司,例如改进KPI。对于那些年中面临困难的公司 在预算紧张的情况下,管道方法也是一个理想的选择.
应用程序现代化的胶带方法非常适合小规模变更,具有更高的回报。它不需要大量投资,可以通过临时预算获得支持。与较大的转换相比,该方法风险较小,并且不需要管理层的太多关注。
管道胶带方法与许多风险相关联,例如应用程序中的多个更改的成本。此外,该方法可能会导致拼凑的应用程序和糟糕的设计。虽然这种方法的预算很少,但管理层往往忽视了这一过程而没有经过彻底的审查。
尽管存在许多风险,但管道胶带方法是最常见和成功的方法,投资相对较低。
结论
尽管您采用了哪种方法,但应用程序现代化是一个复杂,风险和劳动密集型的过程,但结果非常值得。依赖相同的过时应用程序可能会在未来冒险。技术采用越快,结果就越好。您可能无法通过不采用技术创新来应对损失。
- 89 次浏览
技术趋势
视频号
微信公众号
知识星球
- 177 次浏览
【CIO】2021 年 12 月全球技术政策简报会
节日快乐,欢迎回到 Citizen Tech,InformationWeek 的月度政策综述。在这份 2021 年的最终报告中,我们将着眼于拜登政府的胜利、失败和承诺,以及美国和国外的网络安全、欧洲的数字工作条件等。
- “重建得更好”障碍的影响
- 大科技可能是一个威胁...
- ...但也是打击网络攻击的合作伙伴
- NSA 和 CISA 发布新的 5G 网络安全指南
- 欧洲将劳工权利扩展到数字工作
- “像在家一样漫游”计划获得延期
“重建得更好”碰壁
上周,拜登总统吹嘘的“重建更好的基础设施”法案未能在参议院获得通过,当时乔曼钦 (D-WV) 宣布他不会投票支持该法案。
该计划具有(或者,如果您认为修订版最终会得到曼钦参议员的批准)具有许多重要的技术和数字含义。例如,根据白宫的说法,联邦政府承诺到 2050 年实现净零碳排放,这是一个雄心勃勃的项目,取决于获得许多开发技术,如零排放汽车和 14 兆瓦太阳能设施。情况说明书。
不过,有一点问题。到 2050 年净零的公告以行政命令的形式发布,但 12 月 8 日,也就是 Build Back Better 前 11 天的行政命令失败了。
“一起,”声明中写道,“总统的……重建更好法案将为各机构提供实现行政命令目标所需的资金。”
哎呀。
大科技可能是一种威胁……
正如 POLITICO 报道的那样,“重建更好计划”对科技行业也有更微妙的影响,特别是它打算使美国与国际最低公司税率保持一致。像亚马逊和微软这样的大型美国科技公司对他们认为对他们的底线构成威胁而咆哮:代表大型科技巨头的信息技术工业委员会的一位发言人告诉 POLITICO,公司税提案将“阻碍全球参与的美国雇主的整体竞争力。”
国会民主党人已站在总统一边,本月在众议院和参议院举行听证会,讨论加强对互联网和 Facebook 等大公司的监管。 12 月 9 日,国会议员弗兰克·帕隆 (D-NJ) 告诉能源和商业委员会,“公司显然不会自行改变”以确保透明度、保护举报人、防止儿童接触有害内容并详细说明他们与中国。
“国会必须采取行动 [……] 针对社交媒体生态系统的不同部分,使平台对用户更安全。”
...但也是合作伙伴
另一方面,国土安全部 (DHS) 部长 Alejandro Mayorkas、国家网络总监 Chris Inglis、网络安全和基础设施安全局 (CISA) 总监 Jen Easterly 等人于 12 月 7 日前往旧金山会见 AT&T 的高级代表,思科、谷歌、微软、VMware 和其他科技巨头。使命:面对日益增多的网络攻击,讨论公私合作。
“网络安全威胁影响各种规模的个人、社区和组织。提高全国网络安全弹性是国土安全部和拜登-哈里斯政府的首要任务,”马约卡斯说。 “我们正在采取积极措施,将我们与私营部门的运营合作提升到新的高度,优先考虑我们捍卫安全数字未来的共同目标。”
会议建议或建立了新的合作途径以及成功的衡量标准。总体而言,拜登政府与其他领域科技公司的争论似乎是乐观的背离。
NSA、CISA 发布新的 5G 网络安全指南
与此同时,CISA 和国家安全局 (NSA) 于 12 月 2 日对其 5G 网络安全指南进行了第二次修订。
根据 CISA 的声明,“通过 5G 网络连接的设备和服务传输、使用和存储的数据量呈指数级增长。由四部分组成的 5G 云基础设施安全指南系列的第三部分解释了如何保护敏感数据免遭未经授权的访问。”
新指南遵循零信任原则,反映了白宫对国家网络安全的持续关注。
(其他政府正在跟上步伐,这是有充分理由的:据半岛电视台报道,本月 6 日,加拿大通信安全机构指出,2021 年全球勒索软件攻击比 2020 年激增 151%,其中 235 起此类攻击针对加拿大关键基础设施。 )
欧洲将劳工权利扩展到数字工作
12 月 9 日,欧盟委员会提出了一套新措施,以确保在数字平台上工作的人们的劳动权利。该提案将侧重于透明度、执法、可追溯性和它所谓的“数字劳动力平台”的算法管理。 (这是指 100% 的在线工作,特别不包括拼车、护理工作和类似行业。)
为数字平台工作的欧盟公民人数自 2016 年以来增长了 500%,达到 2800 万,到 2025 年可能会达到 4300 万。在目前的 2800 万中,59% 与其他国家的客户或同事一起工作。该部门价值约140亿欧元。
该提案背后的真正问题是一个熟悉的问题:谁算作员工,谁算作独立承包商?该提案提出了一个框架,因此标准尚不明确。但它确实要求“关于透明度、知情权、试用期、平行就业、工作的最低可预测性和按需合同措施的规则”,以及工作时间、工作与生活的平衡(例如产假)、职业安全和临时工作。
该提案还包括关于人工智能 (AI) 的语言,特别是人工智能系统对工人的不负责任和歧视的风险。
适合数字时代的欧洲执行副总裁玛格丽特·维斯塔格 (Margrethe Vestager) 说:“我们的指令提案将帮助为平台工作的虚假自雇人士正确确定他们的就业状况,并享受随之而来的所有社会权利。平台上真正的个体经营者将通过增强其地位的法律确定性得到保护,并且将有新的保护措施来防止算法管理的陷阱。这是迈向更具社会性的数字经济的重要一步。”
再漫游大陆10年
从布鲁塞尔搬到斯特拉斯堡,欧洲议会于 12 月 9 日宣布,终止欧盟境内移动电话漫游附加费的 2017 年“像在家一样漫游”计划将再延长 10 年。
正如 EP 新闻稿所解释的那样,漫游费用和欧盟内部费用不同。欧洲议会议员未能成功终止欧盟内部电话的收费,尽管他们将该费用限制在每分钟 19 美分,并禁止阻止消费者漫游的做法(例如将他们切换到 4G 到 3G 连接)。
服务提供商之间支付的批发漫游费上限为每 GB 2 欧元,到 2027 年将降至 1 欧元。
原文:https://www.informationweek.com/government/december-2021-global-tech-po…
本文:
- 50 次浏览
【CIO】技术简报:CIO 入门关键新兴技术
企业 IT 领导者通常跨越两个学科。一方面是技术,另一方面是业务。您所处的角色需要了解一些最新技术和新兴技术趋势的优势和功能。但与此同时,您不必了解每种编程语言或如何配置每个基础架构。
但是您必须能够用其他 C 级高管会理解的语言来解释这些新兴技术。在某些情况下,您可能会建议不要在这个特定时间点使用对您的业务或行业没有意义的新技术,并且您需要解释原因。在其他情况下,您可能需要考虑特定技术中的某些用例是否对您的企业有意义。
如果一项技术确实对您的组织有意义,也许您需要向执行级别的同事解释它,以便他们对业务的好处有一个扎实的认识。
无论如何,总会有新技术出现,作为技术专家,您需要及时了解它们是什么以及它们可以为您的企业做什么。考虑到这一点,我们收集了以下系列技术简报,内容涉及过去一年中发展势头强劲的各种技术。使用这些技术简报来了解可能塑造您企业未来的技术的最新信息。
- 向 CEO 解释数据结构:如何以及为什么
- 为了在未来竞争,企业需要快速的答案和向所有人共享统一信息的能力。这就是 IT 领导者现在必须获得对数据结构的支持的原因。
- https://www.informationweek.com/big-data/explaining-data-fabrics-to-the…
- 为什么需要数据结构,而不仅仅是 IT 架构
- 数据结构提供了跟踪、监控和利用数据的机会,而 IT 架构则跟踪、监控和维护 IT 资产。两者都是长期数字化战略所必需的。
- https://www.informationweek.com/big-data/why-you-need-a-data-fabric-not…
- 什么是客户身份和访问管理 (CIAM)?
- 需要强大的网络安全性、低电子商务摩擦和更轻松的身份管理? CIAM 承诺跨越 B2C 和 B2B 环境,提高安全性和隐私性,并改善消费者体验。
- https://www.informationweek.com/security-and-risk-strategy/ciam-101-wha…-
- 一位 CIO 对 Metaverse 的介绍
- 元界来了。以下是 CIO 需要了解的内容——从业务用例到风险,再到来自 Microsoft、Nvidia 和 Facebook 等公司的供应商产品。
- https://www.informationweek.com/strategic-cio/a-cio-s-introduction-to-t…
- 如何避免主要的云迁移错误
- 将操作迁移到云中不一定是一场漂浮的噩梦。避免五个常见的迁移错误将有助于确保平稳快速的过渡。
- https://www.informationweek.com/cloud/how-to-avoid-the-leading-cloud-mi…
- 首席信息官可以在混合劳动力中实现创新的 3 种方式
- 保持创新活动的动力并产生新的活动是许多 CIO 在混合工作场所中需要解决的难题。
- https://www.informationweek.com/strategic-cio/3-ways-cios-can-enable-in…
- 每个人都应该知道的机器学习基础知识
- 人工智能、机器学习、深度学习、神经网络。 ML 术语通常作为同义词使用,但理解它们的差异很重要。
- https://www.informationweek.com/big-data/ai-machine-learning/machine-le…
- CIO 需要了解的有关图数据库技术的信息
- 下面来看看图数据库技术如何与人工智能一起,在数据不断增长的时代帮助企业解决复杂的问题。
- https://www.informationweek.com/big-data/big-data-analytics/what-cios-n…
- 持续交付:为什么需要它以及如何开始
- 随着 IT 寻求更快、更一致地交付新功能和修复缺陷,持续交付获得了动力。
- https://www.informationweek.com/devops/continuous-delivery-why-you-need…
原文:https://www.informationweek.com/strategic-cio/tech-briefing-a-cio-prime…
本文:
- 98 次浏览
【MAD】2023年MAD(机器学习、人工智能和数据)前景
视频号
微信公众号
知识星球

距离我们发表上一篇MAD景观还不到18个月,它充满了戏剧性。
当我们离开时,随着Snowflake的大规模IPO,数据世界正在蓬勃发展,整个创业生态系统都围绕着它组织起来
当然,从那以后,公开市场崩溃,经济衰退,风险投资资金枯竭。整整一代数据/人工智能初创公司都不得不适应新的现实。
与此同时,在过去的几个月里,Generative AI出现了明显的指数级加速,可以说形成了一个新的迷你泡沫。除了技术进步之外,人工智能已经成为主流,世界各地广泛的非技术人员现在可以亲身体验它的力量。
数据、机器学习和人工智能的兴起是我们这一代人最基本的趋势之一。它的重要性远远超出了纯粹的技术层面,对社会、政治、地缘政治和道德产生了深刻影响。
然而,这是一个复杂、技术性强、快速发展的世界,即使对太空从业者来说也常常令人困惑。缩写词、技术、产品和公司琳琅满目,难以追踪,更不用说掌握了:
一年一度的MAD(机器学习、人工智能和数据)景观是我们试图理解这个充满活力的空间。它的总体理念,就像我们的活动系列《数据驱动的纽约》一样,一直是开源工作,我们无论如何都会做,并与社区展开对话。
所以,在2023年,我们又来了。这是我们的第九个年度景观,也是数据和人工智能生态系统的“联盟状态”。以下是之前的版本:2012年、2014年、2016年、2017年、2018年、2019年(第一部分和第二部分)、2020年和2021年
这一年度国情咨文职位分为四个部分:
- 第一部分:景观(此处为PDF,此处为互动版)
- 第二部分:市场趋势:融资、并购和首次公开募股(或缺乏)
- 第三部分:数据基础设施的趋势
- 第四部分:ML/AI的发展趋势
疯狂2023,第一部分:风景
经过大量的研究和努力,我们很自豪能够展示2023年版的MAD景观。当我说“我们”时,我指的是一小群人,在未来的几个月里,他们的夜晚将被在PDF上的拥挤小盒子里进进出出的微小标志的记忆所困扰:凯蒂·米尔斯、凯文·张和保罗·坎波斯。非常感谢他们。是的,当我一开始就告诉他们“哦,这是一个轻松的项目,也许一两天,会很有趣,请在这里签名”时,我是认真的。
所以,就在这里(鼓卷、烟雾机中的提示)。今年MAD有两种消费模式:
PDF(静态)版本:
点击此处查看PDF版本>>>>>>
(是的,它的分辨率都很高,你可以很容易地在桌面和手机上缩放)
<新增!>交互式版本:
此外,今年,我们第一次从头开始进入年轻人所说的“万维网”,提供了一个完全互动的MAD景观版本,这应该会让探索各种类别变得有趣
点击此处查看互动版本>>>>>>
交互式版本说明:
- 每个徽标都是可点击的——当你点击时,右下角会出现一个弹出窗口
- 这里有“风景”和“卡片”视图(见右上角)……还有夜间模式!
- 这是第一个版本,我们将尽快添加更多功能(搜索、过滤等)
- 对于这个互动版本,我们与Gotta Go Fast合作开发应用程序,并与CB Insights合作开发卡片中的数据。非常感谢他们的合作
对于所有问题和意见,请发送电子邮件至MAD2023@firstmarkcap.com
一般方法
首先,我们今年再次做出决定,让数据基础设施和ML/AI保持一致。有人可能会说,这两个世界越来越不同。然而,我们仍然认为,这些领域之间存在着至关重要的共生关系。数据馈送ML/AI模型。数据工程师和机器学习工程师之间的区别通常是不稳定的。在适当利用ML/AI之前,企业需要有一个坚实的数据基础设施。
自2012年我们的第一个版本以来,景观或多或少与每年的景观都建立在相同的结构上。松散的逻辑是从左到右遵循数据流——从存储和处理到分析,再到提供ML/AI模型,并构建面向用户、人工智能驱动或数据驱动的应用程序。
今年,我们又保留了一个单独的“开源”部分。这一直是一个有点尴尬的组织,因为我们有效地将商业公司与他们通常是主要赞助商的开源项目分开。但同样,我们想捕捉这样一个现实,即对于一个开源项目(例如Kafka),你有许多商业公司和/或发行版(例如Kavka–Confluent、Amazon、Aiven等)。此外,一些出现在盒子里的开源项目还不是完全商业化的公司。
出现在MAD领域的绝大多数组织都是独特的公司,有大量由风险投资支持的初创公司。其他一些是产品(如云供应商提供的产品)或开源项目。
公司选择
今年,我们共有1416个标志出现在景观上。相比之下,2012年我们的第一个版本中有139个。
每年我们都说,我们不可能让更多的公司进入市场,而每年,不知何故,我们都需要这样做。这是因为我们要覆盖最具爆炸性的技术领域之一。
然而,特别是今年,我们不得不采取一种更具编辑性、更有主见的方法来决定哪些公司能够进入这一领域。尽管这一类别的公司数量激增,但我们已经远远超过了几乎适合所有人的阶段,所以我们不得不做出选择。
在前几年,我们倾向于根据融资阶段(通常是B-C系列或更晚)和ARR(如果可用),以及所有大型现有公司,为成长阶段的公司提供不成比例的代表权。然而,今年,特别是考虑到像Generative AI这样的全新领域的爆发,大多数公司都只有1到2年的历史,我们做出了编辑决定,将更多非常年轻的初创公司纳入其中。
几个免责声明:
我们是风险投资公司,所以我们对初创公司有偏见,尽管希望我们在大型公司、云供应商产品、开源和偶尔启动的公司方面做得很好
我们总部设在美国,所以我们可能过于强调美国的初创公司。我们确实在MAD领域拥有强大的欧洲和以色列初创公司代表。然而,尽管我们有几家中国公司,但我们可能低估了亚洲市场以及拉丁美洲和非洲市场(BioNTech以6.5亿美元收购了突尼斯出生的Instadeep,这两家公司刚刚在数据/人工智能创业方面取得了令人印象深刻的成功)
分类
这个过程中最困难的部分之一是分类——尤其是当一家公司的产品横跨两个或多个领域时该怎么办。随着许多初创公司逐渐扩大其产品范围,这一趋势每年都会变得更加突出,我们在“第三部分——数据基础设施”中对此进行了讨论。
同样,在这个已经人满为患的环境中,把每一家初创公司都放在多个盒子里是站不住脚的。
因此,我们的一般方法是根据公司的核心产品或其最知名的产品对公司进行分类。因此,初创公司通常只出现在一个盒子里,即使他们做的不仅仅是一件事。
我们对云超大型机(各种盒子中的许多AWS、Azure和GCP产品),以及一些上市公司(例如Datadog)或非常大的私营公司(例如,Databricks)例外。
今年有什么新鲜事
“基础设施”的主要变化:
- 我们(最终)杀死了Hadoop盒子,以反映OG大数据技术的逐渐消失——一个时代的结束!我们决定在MAD 2021景观中保留最后一次,以反映现有的足迹。Hadoop实际上并没有消亡,Hadoop生态系统的一部分仍在积极使用(例如,Hive)——请参阅Hadoop对话是关于下一步的。但它已经下降到足以让我们决定将支持Hadoop的各种供应商和产品合并到数据湖中(并将Hadoop和其他相关项目保留在我们的开源类别中)。
- 说到数据湖,我们将该框重新命名为“数据湖/湖屋”,以反映湖屋趋势(我们在2021年MAD景观中讨论过这一点)
- 在不断发展的数据库世界中,我们创建了三个新的子类别:
- “GPU加速数据库”(用于流式数据和实时机器学习)
- “矢量数据库”(用于为人工智能应用提供动力的非结构化数据,请参阅什么是矢量数据库?)
- “数据库抽象”,这是一个有点无定形的术语,旨在捕捉一组新的无服务器数据库的出现,这些数据库抽象掉了管理和配置数据库所涉及的许多复杂性。更多信息,这里有一个很好的概述:2023 Serverless&Edge数据库的现状(提到了许多供应商,超出了我们的能力范围)
- 我们曾考虑添加一个“嵌入式数据库”类别,其中DuckDB用于OLAP,KuzuDB用于Graph,SQLite用于RDBMS,Chroma用于搜索,但考虑到房地产有限,我们不得不做出艰难的选择——也许是明年。
- 我们添加了一个“数据编排”框,以反映几个商业供应商在该领域的崛起(我们在MAD 2021的“开源”中已经有了一个”数据编排“框)
- 我们将“数据可观察性”和“数据质量”这两个子类别合并到一个框中,以反映该领域的公司虽然有时来自不同的角度,但越来越重叠的事实——这表明该类别可能已经成熟,可以合并。
- 我们创建了一个新的“完全管理”数据基础设施子类别。这反映了初创公司的出现,它们抽象了将数据产品链拼接在一起的复杂性(请参阅第三部分中我们对现代数据堆栈的看法),不仅在技术方面,而且在合同谈判、支付等方面为客户节省了时间。
“分析”的主要变化:
- 目前,我们取消了在2021年MAD领域创建的“度量商店”子类别。当时的想法是,现代数据堆栈中缺少一块。当然,对该功能的需求仍然存在,但尚不清楚是否有足够的空间用于单独的子类别。该领域的早期进入者迅速发展:Supergrain转向,Trace*在其指标存储之上建立了一整层分析,Transform最近被dbt Labs收购
- 我们创建了一个“客户数据平台”框,因为这个子类别已经酝酿了很长时间,而且一直在升温。
- 冒着“非常2022”的风险,我们创建了一个“加密/web3分析”框——我们仍然相信有机会在这个领域建立重要的公司。
“机器学习/人工智能”的主要变化:
- 在我们2021年的MAD布局中,我们将“MLOps”分解为多个子类别——“模型构建”、“功能商店”和“部署和生产”。在今年的MAD中,我们将所有内容重新合并到一个大型MLOps盒子中。这反映了这样一个现实,即该领域的许多供应商的产品现在明显重叠——这是另一个整合时机成熟的类别。
- 我们几乎在MLOps旁边创建了一个新的“LLMOps”类别,以反映一批新的初创公司的出现,他们专注于大型语言模型的特定基础设施需求。但那里的公司数量(至少我们知道)仍然太少,而这些公司实际上才刚刚起步
- 我们将“横向AI”更名为“横向AI/AGI”,以反映一组全新的研究型机构的出现,其中许多机构公开将人工通用智能作为其最终目标。
- 我们创建了一个“封闭源代码模型”框,以反映去年新模型的爆发,特别是在Generative AI领域。我们还在“开源”中添加了一个新框,以捕捉开源模型。
- 我们增加了一个“边缘人工智能”类别——这不是一个新话题,但这一领域似乎正在加速
“应用程序”的主要变化:
- 我们创建了一个新的“应用程序/水平”类别,包括代码、文本、图像、视频等子类别。新框捕捉了过去几个月新一代人工智能初创公司的激增。当然,这些公司中的许多都是GPT之上的薄层,在未来几年可能会出现,也可能不会出现,但我们认为这是一个全新的重要类别,并希望将其反映在2023年的MAD格局中。请注意,“应用程序/企业”中也提到了一些Generative AI初创公司。
- 为了给这个新类别腾出空间:
- 我们删除了“应用程序/企业”中的“安全”框。我们做出这一编辑决定是因为,在这一点上,数千家安全初创公司中几乎每一家都使用ML/AI,我们可以为它们投入整个领域。
- 我们精简了“应用程序/行业”框。特别是,由于金融、健康或工业等领域的许多大公司已经在其产品中建立了一定水平的ML/AI,我们做出了编辑决定,主要关注这些领域的“人工智能优先”公司。
其他值得注意的变化:
- 我们在底部的“数据源和API”中添加了一个新的ESG数据子类别,以反映其日益增长的(有时甚至有争议的)重要性。
我们大幅扩大了“数据服务”类别,并将其更名为“数据与人工智能咨询”,以反映咨询服务在帮助面临复杂生态系统的客户方面日益重要,以及一些纯粹的咨询店开始达到早期规模的事实。
READ NEXT: MAD 2023, PART II: FINANCINGS, M&A AND IPOs
- 82 次浏览
【MAD】MAD 2023,第三部分:数据基础设施的趋势
视频号
微信公众号
知识星球
(注:这是2023 MAD景观的第三部分。景观PDF在这里,交互式版本在这里)
在2019-2021年的超泡沫环境中,数据基础设施(nee Big data)是创始人和风投最热门的领域之一。
这让人眼花缭乱,同时也很有趣,看到市场对最终技术性很强的产品和公司如此热情,也许有点奇怪。
无论如何,随着市场降温,那一刻已经结束。尽管在任何市场周期中都会继续创建好公司,“热门”细分市场也会不断涌现,但对于任何新的数据基础设施初创公司来说,要想从潜在客户和投资者那里获得真正的兴趣,在差异化和质量方面的门槛肯定已经大幅提升。
以下是我们对2023年数据基础设施市场的一些关键趋势的看法。
第一对水平更高,每个人都应该感兴趣,其他的则更为复杂:
- 应对冲击:捆绑和整合
- 压力下的现代数据堆栈
- ETL的终结?
- 反向ETL与CDP
- 数据网格、产品、合同:处理组织复杂性
- 总体而言:趋同的总体趋势
- 额外收获:人工智能将对数据和分析产生什么影响?
应对冲击:捆绑和整合
如果说MAD的前景年复一年地显而易见的话,那就是数据/人工智能市场非常拥挤。
近年来,数据基础设施市场在很大程度上处于“百花齐放”的模式。
Snowflake首次公开募股(有史以来最大的软件首次公开募股)是整个生态系统的催化剂。创始人创办了数百家公司,风投们在几个月内(一次又一次)愉快地为它们提供了资金。新的类别(例如反向ETL、度量存储、数据可观察性)出现了,并立即挤满了许多有希望的人。
在客户方面,有眼光的技术买家,通常在规模扩大或上市科技公司中找到,愿意在几乎没有首席财务官办公室监督的情况下试验和尝试新事物。这导致许多工具同时被试用和购买。
现在,音乐已经停止了。
在客户方面,技术购买者面临着越来越大的预算压力和首席财务官的控制。尽管即使在经济衰退时期,数据/人工智能仍将是许多人的优先事项,但他们有太多的工具,而且他们被要求用更少的资源做更多的事情。他们也没有那么多资源来设计、定制或缝合任何东西。它们不太可能是实验性的,也不太可能与不成熟的工具和未经证实的初创公司合作。他们更有可能选择那些提供紧密集成的产品套件的老牌供应商,这些产品“刚刚好用”
这使得市场上有太多的早期数据基础设施公司在做太多重叠的事情。
特别是,有一大堆“单一功能”数据基础设施(或MLOps)初创公司(这个词可能太苛刻了,因为它们还处于早期阶段)将难以满足这一新标准。这些公司通常都很年轻(存在1-4年),由于在地球上的时间有限,他们的产品在很大程度上仍然是一个单一的功能,尽管每家公司都希望发展成为一个平台;他们有一些好客户,但目前还没有一个响亮的产品市场;他们的ARR很低,通常低于500万美元;它们是由风险投资支持的,在过去几年中通常以50x-200倍的ARR筹集资金;他们与一群由聪明的创始人领导的其他风投支持的初创公司竞争,这些创始人或多或少处于同一阶段;它们没有盈利,现金周转期从6个月到3年不等。
这类公司面临着一场艰苦的战斗——在买家将感到疲惫、风险投资现金稀缺的背景下,还有大量的增长要做。
期待达尔文时代的开始。这些公司中最好的(或最幸运的,或资金最充足的)将找到一种发展的方式,从单一功能扩展到平台(例如,从数据质量扩展到完整的数据可观察性平台),并加深他们的客户关系。
其他公司将成为不可避免的整合浪潮的一部分,要么是对更大平台的收购,要么是初创企业对初创企业的私人合并。这些交易规模较小,不太可能产生创始人和投资者所希望的回报。(我们不排除在未来12-18个月内达成数十亿美元交易的可能性,尤其是与人工智能有关的交易,但这些交易可能很少,至少在潜在的公开收购方看到衰退市场的曙光之前)。
尽管如此,小型收购和初创企业合并将比简单地倒闭要好。破产是创业世界不可避免的一部分,将比过去几年更加普遍,因为公司无法筹集下一轮资金或找到房子。由于许多初创公司仍在依靠过去一两年筹集的现金,这股浪潮甚至还没有真正开始。
在市场的顶端,规模较大的公司已经进入了全产品扩张模式。一直以来,云超规模运营商的战略都是不断向其平台添加产品。现在,Snowflake和Databricks这两个竞争对手也在做同样的事情,它们正遭受巨大的冲击,成为所有数据和人工智能的默认平台(见2021年MAD形势)。
Databricks似乎肩负着在MAD领域几乎每一个领域发布产品的使命。它提供了数据湖(仓库)、流功能、数据目录(Unity catalog,现在有沿袭)、查询引擎(Photon)、一系列数据工程工具、数据市场、数据共享功能以及数据科学和企业ML平台。这一产品扩张几乎完全是有机的,在这一过程中进行了极少数的收购——2022年的Datajoy和Cortex Labs。
Snowflake也在快速发布功能。它也变得更加贪婪。在2023年的前几个月,该公司已经宣布了三项收购:LeapYear、SnowConvert和Myst AI。当它以8亿美元收购Streamset时,它进行了第一次大规模收购。
Confluent是一家建立在开源流项目Kafka之上的上市公司,它也在采取有趣的举措,将业务扩展到非常受欢迎的流媒体处理引擎Flink。它刚刚收购了Immerok。这是一次快速收购,因为Immerok由Flink委员会和PMC成员组成的团队于2022年5月成立,于10月获得1700万美元的资金,并于2023年1月被收购。
资金充足的独角兽型初创公司也开始积极扩张,开始侵占他人的领地,试图发展成为一个更广泛的平台。
例如,转型领导者dbt实验室于2022年10月首次宣布将产品扩展到相邻的语义层区域。然后,它在2023年2月收购了该领域的一个新兴参与者Transform(dbt的博客文章对语义层和度量存储概念进行了很好的概述)。要了解更多关于dbt的信息,请参阅我与数据驱动纽约dbt实验室首席执行官Tristan Handy的对话
数据基础架构中的某些类别对于某种整合来说尤其成熟——MAD环境为这一点提供了很好的视觉帮助,因为整合的潜力与最完整的框非常接近:
“ETL”和“反向ETL”:在过去的三四年里,市场资助了大量的ETL初创公司(将数据转移到仓库中),以及一组单独的反向ETL初创公司。目前尚不清楚在这两个类别中,市场能维持多少初创公司。反向ETL公司面临着来自不同角度的压力(见下文),这两个类别最终可能合并。ETL公司Airbyte收购了反向ETL初创公司Grouparoo。像Hevo Data这样的几家公司将其定位为端到端管道,提供ETL和反向ETL(也有一些转换),数据同步专家Segment也是如此。ETL市场领导者FIvetran能否收购或(不太可能)与Census或Hightouch等反向ETL合作伙伴合并?
“数据质量和可观测性”:市场上出现了大量公司,它们都想成为“数据狗”。Datadog为软件所做的(确保可靠性并最大限度地减少应用程序停机时间),正是这些公司希望为数据所做的——检测、分析和解决与数据管道有关的所有问题。这些公司从不同的角度来解决这个问题——有些公司做数据质量(声明式或通过机器学习),有些公司做的是数据沿袭,另一些公司做的则是数据可靠性。数据编排公司也参与其中。其中许多公司都有优秀的创始人,有一流的风投支持,并生产出高质量的产品。然而,在对数据可观察性的需求仍然相对较低的情况下,它们都朝着同一方向趋同。要了解更多关于该领域公司的信息:请参阅Datafold首席执行官Gleb Mezhanskiy的这场数据驱动的纽约谈话,或我与蒙特卡洛首席执行官Barr Moses的数据驱动纽约谈话。
“数据目录”:随着数据在企业中变得越来越复杂和广泛,需要对所有数据资产进行有组织的库存。输入数据目录,理想情况下还提供搜索、发现和数据管理功能。虽然人们显然需要这一功能,但这一类别中也有许多参与者,他们都有聪明的创始人和强大的风险投资支持,在这里,目前还不清楚这个市场能维持多少。从长远来看,数据目录是否可以是更广泛的数据治理平台之外的独立实体也不清楚。想要了解有趣的数据目录公司,请参阅我与Stemma首席执行官Mark Grover的数据驱动纽约对话,以及Select Star首席执行官Shinji Kim的这场精彩的数据驱动的纽约演讲。此外,有关数据治理的更广泛概述,请参阅我与Collibra首席执行官Felix Van de Maele的数据驱动纽约对话。
“MLOps”:虽然MLOps位于MAD领域的ML/AI部分,但它也是基础设施,可能会经历与上述相同的情况。与其他类别一样,MLOps在整个堆栈中发挥着至关重要的作用,这是由ML/AI在企业中日益重要的作用推动的。然而,这一类别中有大量的公司,其中大多数资金充足,但在收入方面处于早期。它们从不同的地方开始(模型构建、功能存储、部署、透明度等),但当它们试图从单一功能发展到更广泛的平台时,它们正处于相互冲突的过程中。此外,目前许多MLOps公司主要专注于向规模扩大和科技公司销售。随着他们进入高端市场,他们可能会开始接触企业人工智能平台,这些平台已经向Global 2000公司销售了一段时间,如Dataiku、Datarobot、H2O,以及云超大型机。要想了解MLOps的有趣之处,尤其是在信任和可解释性方面,请参阅我与Fiddler首席执行官Krishna Gade的数据驱动纽约对话。
压力下的现代数据堆栈
过去几年的一个标志是“现代数据堆栈”(MDS)的兴起。MDS是一系列现代的、基于云的工具,用于收集、存储、转换和分析数据,部分是架构,部分是供应商之间事实上的营销联盟。它的中心是云数据仓库(Snowflake等)。在数据仓库之前,有各种工具(Fivetran、Matillion、Airbyte、Meltano等)可以从原始源中提取数据并将其转储到数据仓库中。在仓库级别,还有其他转换数据的工具,即过去被称为ETL(提取转换负载)的“T”,现在已被逆转为ELT(这里dbt实验室在很大程度上占据主导地位)。在数据仓库之后,还有其他工具可以分析数据(这就是BI的世界,用于商业智能),或者提取转换后的数据并将其插入SaaS应用程序(这一过程被称为“反向ETL”)。
换句话说,一个真正的装配链,有许多工具处理过程的不同阶段:
直到最近,MDS还是一个不断发展、非常合作的世界。随着Snowflake的财富不断增加,它周围的整个生态系统也会不断增加。
现在,世界已经改变了。随着成本控制变得至关重要,一些人可能会质疑自Hadoop时代以来一直是现代数据管理方法核心的理念——保留所有数据,将其全部转储到某个地方(数据湖、湖边小屋或仓库),并想好以后该怎么办。这种方法导致了数据仓库的兴起,数据仓库是MDS的核心,但事实证明它很昂贵,而且并不总是那么有用(阅读这篇好文章:“大数据已经死了”)。像DucksDB这样的新技术能够实现嵌入式交互式分析,为OLAP(分析)提供了一种可能的新方法。
MDS现在面临压力。在一个预算紧张、合理化的世界里,这几乎是一个过于明显的目标。这很复杂(因为客户需要将所有东西缝合在一起,并与多个供应商打交道)。这很昂贵(大量复制和移动数据;链中的每个供应商都希望获得收入和利润;客户通常需要一个内部数据工程师团队来实现这一切,等等)。可以说,它是精英主义的(因为这些是最前沿、最好的工具,通过更先进的用例满足更复杂用户的需求)。
随着压力的增加,当MDS公司不再友好,开始为较小的客户预算相互竞争时,会发生什么?
顺便说一句,MDS的复杂性催生了一类新的供应商,他们将各种产品“打包”在一个完全管理的平台下(如上所述,我们在2023年的MAD中创建了一个新的盒子,其中包括Y42或Mozart Data等公司)。底层供应商是MDS中的一些常见嫌疑人,这些平台的好处是,它们既抽象了单独管理这些供应商的业务复杂性,又抽象了将各种解决方案拼接在一起的技术复杂性。值得注意的是,一些完全管理的平台自己构建了整个功能套件,并且不打包第三方供应商。
ETL的终结?
作为上述内容的一个转折点,数据界也在平行讨论ETL是否应该成为未来数据基础设施的一部分。ETL,即使使用现代工具,也是数据工程中一个痛苦、昂贵且耗时的部分。
在去年11月的Re:Invent会议上,亚马逊问道:“如果我们能完全消除ETL怎么办?那将是一个我们都会热爱的世界。这是我们的愿景,我们称之为零ETL的未来。在这个未来,数据集成不再是手动的工作”,并宣布支持将亚马逊Aurora与亚马逊Redshift紧密集成的“零ETL”解决方案。在这种集成下,在事务数据写入Aurora的几秒钟内,数据就可以在Amazon Redshift中使用。
这样的集成的好处是显而易见的——无需构建和维护复杂的数据管道,无需重复的数据存储(这可能很昂贵),而且始终是最新的。
现在,两个亚马逊数据库之间的集成本身不足以导致ETL的终结,有理由怀疑零ETL的未来是否会很快实现。
但话说回来,Salesforce和Snowflake还宣布了一项合作伙伴关系,在不移动或复制数据的情况下跨系统实时共享客户数据,这属于相同的一般逻辑。在此之前,Stripe推出了一个数据管道,帮助用户与Redshift和Snowflake同步支付数据。
变化数据捕获的概念并不新鲜,但它正在不断发展。谷歌已经支持在BigQuery中捕获更改数据。Azure Synapse通过预集成Azure数据工厂来实现同样的功能。像Estuary*和Upsolver这样的初创公司正在崛起。
我们的感觉是,ETL作为一个类别的消失还有很长的路要走,但这一趋势值得注意。
反向ETL与CDP
另一个有点混乱但有趣的地方是反向ETL(同样是从仓库中取出数据并将其放回SaaS和其他应用程序的过程)和客户数据平台(聚合来自多个来源的客户数据,像细分一样对其进行分析,并支持营销活动等行动的产品)之间的紧张关系。
在过去一年左右的时间里,这两个类别开始融合在一起。
反向ETL公司大概了解到,“仅仅”作为数据仓库之上的一个管道(不是一项简单的技术壮举)并不能从客户那里获得足够的钱包份额,他们需要在围绕客户数据提供价值方面走得更远。许多反向ETL供应商现在从市场营销的角度将自己定位为CDP。
与此同时,CDP供应商了解到,作为另一个客户需要复制大量数据的存储库,这与数据仓库(或lake或lakehouse)周围数据集中化的总体趋势不一致。因此,CDP供应商开始提供与主要数据仓库和lakehouse提供商的集成。例如,请参阅ActionIQ*启动HybridCompute、mParticle启动Warehouse Sync或Segment引入反向ETL功能。随着CDP公司加强自己的反向ETL功能,除了他们的历史买家(CMO)之外,他们现在开始向更多的技术受众(CIO和分析团队)销售产品。
这给反向ETL公司带来了什么?它们可以发展的一种方式是与ETL提供商进行更深入的集成,我们在上面已经讨论过了。另一种方法是通过添加分析和编排模块,进一步发展成为CDP。
数据网格、产品、合同:处理组织复杂性
正如任何数据从业者都知道的那样:数据的成功当然是技术和产品的努力,但它也在很大程度上围绕着流程和组织问题。
在许多组织中,数据堆栈看起来像是MAD环境的迷你版本。你最终会遇到各种各样的团队在开发各种各样的产品。那么,这一切是如何协同工作的呢?谁负责什么?
关于如何最好地做到这一点,数据界一直在激烈争论。有很多细微差别,也有很多与聪明人的讨论,对其中的任何部分都持不同意见——但这里有一个快速的概述。
我们强调了数据网格是2021年MAD领域的一个新兴趋势。从那以后,它的吸引力才越来越大。数据网格是一种分布式、去中心化(不是加密意义上的)方法,用于管理数据工具和团队。请参阅我们的数据驱动的纽约炉边聊天:Zhamak Dehghani,这一概念的创始人(现任NextData首席执行官)。
请注意它与数据结构的不同之处——这是一个更具技术性的概念,基本上是一个连接企业内所有数据源的单一框架,无论数据源位于何处。
数据网格导致了数据产品的概念——可以是任何东西,从管理数据集到应用程序或API。基本思想是,创建数据产品的每个团队都要对其负全部责任(包括质量、正常运行时间等)。然后,企业内的业务单元在自助服务的基础上使用数据产品。
一个相关的想法是数据合同——“拥有服务的软件工程师和数据消费者之间的类似API的协议,了解业务如何工作,以生成模型良好、高质量、可信的实时数据”(读作:“数据合同的兴起”)。关于这个概念,人们进行了各种有趣的辩论(观看:“数据合同大战皇家队w/Chad Sanderson vs Ethan Aaron”)。讨论的本质是,数据合同是否只在非常大、非常分散的组织中才有意义,而不是在90%的小公司中。
总体而言:趋同的总体趋势
在本节中,我们围绕着同一主题展开了讨论——为了客户的最终利益,数据基础架构总体上需要简化。
一些简化将由公司驱动——公司为其产品线添加更多的功能和特性。
其中一部分将由市场驱动——公司通过收购、合并进行整合,或者不幸的是,公司倒闭。
最后,有些已经并将继续由技术驱动。流式处理和批处理的融合是一个常青树,也是一个重要的主题。事务性(OLTP)和分析性(OLAP)工作负载的融合也是如此。谷歌的AlloyDB是该领域的最新加入者,声称在分析查询方面比标准PostgreSQL快100倍。Snowflake推出了Unistore,提供轻量级(目前)事务处理功能,这是打破事务数据和分析数据之间孤岛的又一步。
额外收获:人工智能将如何影响数据基础设施?
随着人工智能目前的爆炸性进展,这里有一个有趣的问题:数据基础设施肯定一直在为人工智能提供动力,但人工智能现在会反过来影响数据基础设施吗?
可以肯定的是,一些数据基础设施提供商已经使用人工智能一段时间了——例如,参见Anomalo利用ML来识别数据仓库中的数据质量问题。许多数据库供应商现在都嵌入了自动ML功能。
但随着大型语言模型的兴起,出现了一个新的有趣的角度。正如LLM可以创建传统编程代码一样,它们也可以生成数据分析师的语言SQL。让非技术用户能够搜索分析系统的想法并不新鲜,各种提供商已经支持它的变体,请参阅ThoughtSpot、Power BI或Tableau。以下是一些关于这个主题的好文章:dbt实验室的Tristan Handy的LLM对分析(和分析师!)的影响,以及Mode的Benn Stancil的the Rapture and the Reckoning。
READ NEXT: MAD 2023, PART IV: TRENDS IN ML/AI
- 48 次浏览
【MAD】MAD 2023,第二部分:融资、并购和首次公开募股
视频号
微信公众号
知识星球

“这太疯狂了。风险投资以前所未有的速度部署,在全球同比飙升157%[…]。越来越高的估值导致了136家新成立的独角兽[…],IPO窗口已经敞开,公开融资增长了+687%。”
那是…去年。或者更准确地说,15个月前,在2021年9月的MAD 2021帖子中,这篇文章几乎是在市场顶端写的。
当然,从那时起,在地缘政治冲击和通货膨胀上升的推动下,人们期待已久的市场衰退确实发生了。各国央行开始加息,这吸走了整个过度膨胀的资产世界的空气,从投机的加密货币到科技股。公开市场暴跌,首次公开募股窗口关闭,一点一点地,不适情绪蔓延到私人市场——首先是在增长阶段,然后逐渐蔓延到风险投资和种子市场。
我们将按以下顺序讨论2023年的新现实:
- MAD公司面临新的衰退时代
- 冻结的融资市场
- 新生代人工智能,一个新的融资泡沫?
- 并购
MAD公司面临新的衰退时代
这对所有人来说都很艰难,数据/人工智能公司当然也未能幸免。
资本已经从丰富和廉价变成了稀缺和昂贵。在MAD领域,各种规模的公司都不得不将重点从不惜一切代价的增长转移到严格控制开支上。
裁员公告已经成为我们日常生活中令人悲伤的一部分。看看流行的追踪工具Layoffs.fyi,许多出现在2023 MAD版图上的公司都不得不裁员,包括最近的几个例子:Snowplow、Splunk、MariaDB、Confluent、Prisma、Mapbox、Informatica、Pecan AI、Scale AI、Astronomer*、Elastic、UIPath、InfluxData、Domino Data Lab、Collibra、Fivetran、Graphcore、Mode、DataRobot,以及更多(要查看完整列表,请使用“数据”按行业筛选)。
在2022年的一段时间里,我们处于一个暂停的现实时刻——公开市场正在暴跌,但公司的基本业绩保持强劲,许多公司继续快速增长,并超出了他们的计划。
然而,在过去的几个月里,软件产品的整体市场需求已经开始适应新的现实。到目前为止,经济衰退的环境一直是由企业主导的,消费者需求保持着惊人的强劲。这对MAD公司没有太大帮助,因为绝大多数公司都是B2B供应商。首先削减支出的是规模扩大和其他科技公司,这导致了针对这些客户的MAD初创公司在第三季度和第四季度的许多销售失误。现在,Global 2000的客户也调整了2023年的预算。
我们现在正处于一种新的常态,其词汇将与过去的衰退相呼应,并将成为年轻人的一块全新肌肉:负责任的增长、成本控制、首席财务官监督、长销售周期、试点、投资回报率。
这也是公司治理的巨大回报:
随着潮流的消退,许多被隐藏或被剥夺优先权的问题突然全面出现。每个人都被迫多加注意。董事会中的风险投资家不那么忙于追逐下一个闪亮的目标,而是更专注于保护他们现有的投资组合。首席执行官们不再不断受到谄媚的潜在下一轮投资者的追捧,而是发现,当下一轮估值高得多的资本并不是每6到12个月神奇地出现一次时,经营一家初创公司就非常困难。
MAD世界当然也不能免受牛市的过度影响。例如,DataRobot丑闻曝光后,五名高管被允许作为借调人员出售3200万美元的股票,迫使首席执行官辞职(该公司也因歧视被起诉)。
MAD初创公司的一线希望是,在数据、ML和人工智能方面的支出仍然是首席信息官的首要任务。麦肯锡2022年12月的这项研究表明,63%的受访者表示,他们预计未来三年组织对人工智能的投资会增加。
冻结的融资市场
2022年,公共和私人市场实际上都关闭了,2023年看起来将是艰难的一年。市场将把具有持续增长和有利现金流动态的强大、持久的数据/人工智能公司与那些主要受到资本支持、渴望在更投机的环境中获得回报的公司区分开来。
公开市场
作为一个“热门”软件类别,上市MAD公司受到的影响尤其严重。
我们早就应该更新我们的MAD上市公司指数了,但总体而言,公共数据和基础设施公司(最接近我们MAD公司的代理)下跌了51%,而标准普尔500指数在2022年下跌了19%。这些公司中的许多在2021年的低息环境中以大幅溢价进行交易。按照目前的价格,它们很可能被超卖。
- 在我们上一次MAD时,Snowflake是一家市值896.7亿美元的公司,并在2021年11月达到1229.4亿美元的高点。在撰写本文时,该公司目前的市值为495.5亿美元。
- 在我们上一次MAD时,Palantir是一家市值为494.9亿美元的公司,但在2021年1月达到峰值时的交易价格为69.89美元。在撰写本文时,该公司目前的市值为191亿美元。
- 在我们上一次MAD时,Datadog是一家市值4260亿美元的公司,并在2021年11月达到613.3亿美元的高点。在撰写本文时,该公司目前的市值为254.0亿美元。
- 在我们上一次MAD时,MongoDB是一家306.8亿美元的市场公司,并在2021年11月达到390.3亿美元的高点。在撰写本文时,该公司目前的市值为147.7亿美元。
2020年末和2021年的IPO群体表现更糟:
- UiPath(2021年首次公开募股)在2021年5月达到405.3亿美元的峰值,在撰写本文时,目前的交易价格为90.4亿美元。
- Confluent(2021年首次公开募股)在2021年11月达到243.7亿美元的峰值,在撰写本文时,目前的交易价格为79.4亿美元。
- C3 AI(2021年首次公开募股)在2021年2月达到140.5亿美元的峰值,在撰写本文时,目前的交易价格为27.6亿美元。这包括最近的一次大幅上涨:作为罕见的人工智能纯上市公司之一,它受益于过去几个月对人工智能兴趣的爆发,其股票在2023年不到两个月的时间里飙升了150%以上。
- Couchbase(2021年首次公开募股)在2021年5月达到21.8亿美元的峰值,在撰写本文时,目前的交易价格为74亿美元。
至于我们2021年MAD领域中上市的一小群“深度科技”公司,它简直被摧毁了。例如,在自动驾驶卡车运输领域,TuSimple(进行了传统的首次公开募股)、Embark Technologies(SPAC)和Aurora Innovation(SPAC。
鉴于市场状况,首次公开募股窗口已经关闭,何时可能重新开启几乎不可见。IPO总收益较2021年下降了94%,而2022年IPO数量下降了78%。
有趣的是,2022年极为罕见的两次IPO都是MAD公司:
- Databricks无疑是广阔科技市场的一个候选产品,对MAD类别的影响力将更大。与许多私营公司一样,Databricks的估值也很高,最近一次是在2021年8月的H系列中,估值为380亿美元——考虑到目前的倍数,这是一个很高的门槛,尽管其ARR现在远超10亿美元。据报道,尽管该公司在潜在上市前正在加强其系统和流程,但首席执行官Ali Ghodsi在许多场合表示,上市并不特别紧迫。有关Databricks故事和产品的概述,请参阅我与Databricks首席执行官Ali Ghodsi的对话。
我们新兴MAD指数中其他有抱负的IPO候选人(也将进行更新,但方向仍然正确)可能不得不等待轮到他们。
私人市场
在私人市场,今年是风险投资大撤退的一年。
资金大幅放缓。2022年,初创公司共筹集了约2380亿美元,与2021年相比下降了31%。尤其是增长型市场,实际上已经消亡。
私人二级经纪人经历了一系列活动,因为许多股东试图退出他们在被认为估值过高的初创公司中的地位,包括许多MAD领域的公司(ThoughtSpot、Databricks、Sourcegraph、Airtable、D2iQ、Chainalysis、H20.AI、Scale AI、Dataminr等):
风险投资的撤出伴随着一系列市场变化,这些变化可能会使公司在最需要支持的时候成为孤儿。交叉基金对数据/人工智能初创公司有着特别强烈的兴趣,它们基本上已经退出了私人市场,专注于公共市场上更便宜的购买机会。在风险投资公司内部,许多全科医生已经或将要离开,一些独立的全科医生可能无法(或愿意)再筹集一只基金。
在撰写本文时,风险投资市场仍处于停滞状态
在过去几年的火爆市场中,许多数据/人工智能初创公司的估值都很高,甚至可能比同行更高。对于创始人强大的数据基础设施初创公司来说,以8000万至1亿美元的税前估值筹集2000万美元的a轮融资是很常见的,这通常意味着明年ARR的倍数为100倍或更多
当然,问题是,Snowflake、Cloudflare或Datadog等最好的上市公司的交易收入是明年收入的12倍至18倍(这些数字的上升反映了在撰写本文时最近的反弹)
因此,初创企业要想接近最近的估值,或者面临重大的下跌(或者更糟的是,根本没有下跌),还有大量的增长要做。不幸的是,这种增长需要在客户需求放缓的背景下进行
许多初创公司现在坐拥大量现金,现在还不必回到融资市场来面对他们的清算时刻,但除非他们的现金流为正,否则这一时刻将不可避免地发生
值得注意的融资(不包括Generative AI):
2022年上半年有大量的融资公告,因为这些公告往往比实际交易的完成晚几个月。2022年下半年,融资公告放缓到涓涓细流。
- 时间序列数据库InfluxDB于2023年2月在E系列中筹集了5100万美元;
- 机器人和人工智能防御承包商Anduril在2022年12月以85亿美元的估值筹集了15亿美元;
- 领先的企业人工智能平台Dataiku*在2022年12月以37亿美元的估值在F系列中筹集了2亿美元;
- 端到端数据平台Alation以17亿美元的估值筹集了1.23亿美元的E系列;
- 自动驾驶汽车计算平台供应商地平线机器人公司于2022年10月获得了10亿美元的融资;
- RPA平台Automation Anywhere在2022年10月的最新融资中筹集了2亿美元;
- 提供内存数据库的SingleStore在2022年10月的F-2系列扩展中额外筹集了3000万美元,公司估值超过10亿美元;
- 2022年8月,一家流程采矿公司Celonis以130亿美元的估值筹集了4亿美元;
- 可扩展计算平台Anyscale在2022年8月为其C系列额外筹集了9900万美元;
- 2022年7月,托管ML功能平台Tecton以8.5亿美元的估值筹集了1亿美元的C系列;
- NoSQL数据库DataStax在2022年6月以16亿美元的估值在其F-II系列中筹集了1.15亿美元;
- 2022年5月,观察性初创公司Cribl在其D系列中以25亿美元的估值筹集了1.5亿美元;
- 2022年5月,数据可观测性平台蒙特卡洛在其D系列中以16亿美元的估值筹集了1.35亿美元;
- 研究生即服务提供商Suabase于2022年5月筹集了8000万美元的B轮融资;
- 2022年4月,观察性平台供应商Grafana Labs筹集了2.4亿美元的D系列资金;
- Astronomer*是一个基于Apache Airflow的数据编排平台,于2022年3月筹集了2.13亿美元的C系列;
- 2022年3月,智能客户服务平台Cresta以16亿美元的估值筹集了8000万美元的C系列融资;
- 开源数据转换平台dbt Labs于2022年2月以42亿美元的估值收购了2.22亿美元的D系列;
- Voltron Data建立在开源Apache Arrow的基础上,于2022年2月在其A系列中筹集了8800万美元;
- 时间序列数据库供应商Timescale在2022年2月以10亿美元的估值在其C系列中筹集了1.1亿美元
- Starburst是一家建立在Trino之上的分析公司,于2022年2月以335亿美元的估值筹集了2.5亿美元的D系列;
- Dremio是一个基于湖屋建筑的分析平台,在2022年1月以20亿美元的估值筹集了1.6亿美元的E系列。
新生代人工智能,一个新的融资泡沫?
生成型人工智能(见第四部分)是市场普遍低迷的一个非常明显的例外——不仅在数据/人工智能世界,而且在整个技术领域都是一盏明灯。
特别是随着web3/加密货币的命运开始转向,人工智能再次成为热门的新事物——这不是这两个领域第一次在炒作周期中交换位置:
由于Generative AI被认为是科技行业潜在的“15年一遇”的平台转型,风险投资公司开始积极向这一领域投入资金,特别是向OpenAI、Deepmind、谷歌大脑和Facebook AI research等研究实验室的创始人投入资金,几家AGI类型的公司在首轮融资中筹集了1亿美元以上
世代人工智能已经显示出一些小泡沫的迹象。相对于投资者的兴趣,市场上可供使用的“资产”相对较少,因此在赢得交易时,估值往往不是问题。然而,随着无数世代人工智能初创公司突然成立,市场正显示出迅速调整供需的迹象。
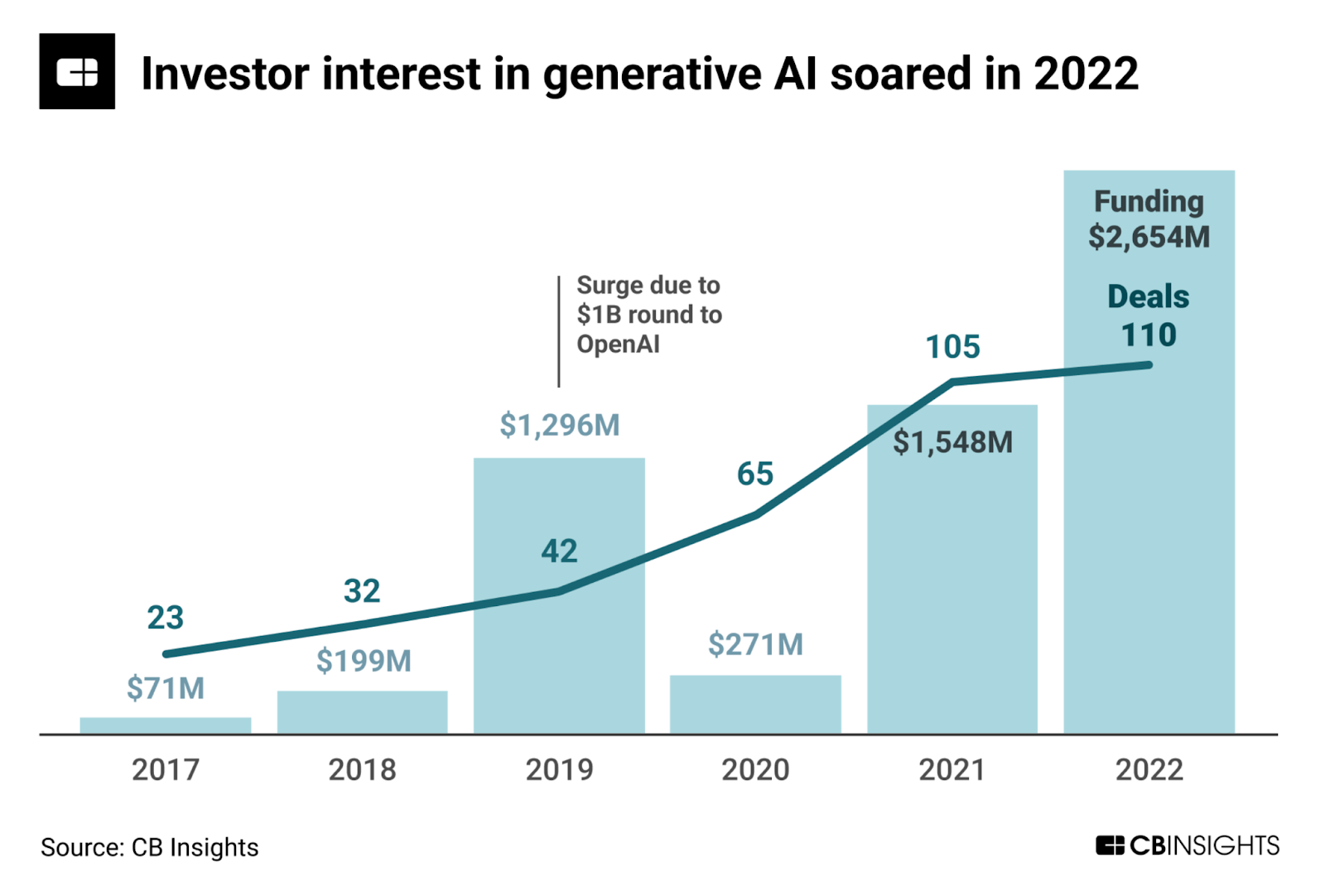
Noteworthy financings in Generative AI:
- 2023年1月,OpenAI获得了微软100亿美元的投资;
- 2022年12月,人工智能视频编辑平台Runway ML以5亿美元的估值筹集了5000万美元的C系列;
- ImagenAI是一家人工智能驱动的照片编辑和后期制作自动化初创公司,于2022年12月筹集了3000万美元;
- Descriptt和人工智能媒体编辑应用程序在2022年11月的C系列中筹集了5000万美元;
- 人工智能笔记应用Mem在2022年11月的A轮融资中筹集了2350万美元;
- 人工智能文案Jasper AI在2022年10月以15亿美元的估值筹集了1.25亿美元;
- Stable Diffusion背后的生成型人工智能公司Stability AI在2022年10月以10亿美元的估值筹集了1.01亿美元;
- 人工智能搜索引擎You在A轮融资中筹集了2500万美元;
- 2022年5月,开源机器学习模型库Hugging Face在其C系列中以10亿美元的估值筹集了1亿美元
- AGI初创公司Infection AI在2022年5月的第一轮股权融资中筹集了2.25亿美元;
- 人工智能研究公司Anthropic在2022年4月的B轮融资中筹集了5.8亿美元(投资者包括SBF和Caroline Ellison!);
- NLP平台Cohere在2022年2月的B轮融资中筹集了1.25亿美元。
预计还会有更多。据报道,Cohere正在谈判在一轮融资中筹集数亿美元,这家初创公司的估值可能超过60亿美元
并购
2022年对收购来说是艰难的一年,其间英伟达以400亿美元收购ARM失败(这将影响数据中心从移动到人工智能的所有领域的竞争格局)。与2021年相比,公开市场,尤其是科技股的下跌,使得任何股票成分的收购都更加昂贵。另一方面,拥有强大资产负债表的后期初创公司通常倾向于减少消耗,而不是进行引人注目的收购。总体而言,初创企业的退出价值同比下降了90%以上,从2021年的7.532亿美元降至714亿美元。
也就是说,有几次大型收购:
- Grail,一家利用机器学习进行癌症检测的癌症检测公司,被Illumina以71亿美元收购;
- Streamlit是一个帮助将数据脚本转化为可共享网络应用程序的平台,被Snowflake以8亿美元收购;
- 人工智能决策平台InstaDeep于2023年初被BioNTech以约6.82亿美元收购;
- Alteryx以4亿美元收购了Trifacta;
- 上市公司的数据供应商Canalyst被Tegus以3亿美元以上的价格收购。
- Apache Flink供应商Immerok被Confluent以1亿美元收购。
- 微软生态系统中的流程映射公司Process Analytics Factory被Celonis收购(我们在过去几年中报道了这家公司,报道了1亿美元),被Snowflake以未披露的金额收购
肯定会有一些(可能)小规模的收购,这预示着2023年会发生一些事情,因为我们预计未来一年会有更多这样的收购。例如:
- HPE收购了Pachyderm;Snowflake收购了Myst;
- IBM收购了Databand;
- Airbyte收购Grouparoo;
- Reddit收购了Spell;
- Alphabet/DeepMind收购了Vicarious
私募股权公司在这种新环境下可能会发挥巨大作用,无论是在买入还是卖出方面
Qlik刚刚宣布有意收购Talend。这一点值得注意,因为这两家公司都由Thoma Bravo所有,他可能是婚姻经纪人
Progress还刚刚完成了对NoSQL数据库提供商MarkLogic的3.55亿美元收购。据传收入“约1亿美元”的MarkLogic由私募股权公司Vector Capital Management所有。
2023年会发生什么?我们主要在第三部分中讨论整合,因为数据基础设施感觉最适合整合——过去几年,该领域疯狂的公司创建和融资导致了非常拥挤的类别,充满了仍处于早期阶段的初创公司。
在不久的将来,任何合并都可能主要采取较小交易的形式,包括初创公司合并作为生存手段,至少在上市公司更好地了解其股价何时可能回升之前。
至少从市场趋势来看,目前数十亿美元的大规模收购似乎不太可能。然而,考虑到最大的科技公司重新将人工智能作为首要战略机遇,这当然不是不可能的。可以想象,FAANG公司花费数十亿美元收购人工智能公司,这些公司的收入可能不高,但资产价值很高,无论是专注于AGI的研究实验室还是像拥抱脸一样的水平平台。另一种情况是,世界上的Snowflakes或Databricks收购企业人工智能平台,以增强其作为所有数据和人工智能的一站式商店的能力。
READ NEXT: MAD 2023, PART III: TRENDS IN DATA INFRASTRUCTURE
- 116 次浏览
【MAD】MAD 2023,第四部分:ML/AI趋势
视频号
微信公众号
知识星球
(note: this is part IV of the 2023 MAD Landscape. The landscape PDF is here, and the interactive version is here)
激动人心!戏剧!行动!
突然间,每个人都在屏息地谈论人工智能。OpenAI获得了100亿美元的投资。谷歌进入红色代码。谢尔盖又开始编码了。比尔·盖茨表示,人工智能在过去12个月里发生的事情“与个人电脑或互联网一样重要”(此处)。全新的初创公司如雨后春笋般涌现(20家Generative AI公司刚刚进入23 YC冬季)。风险投资公司又开始追逐估值数十亿的营收前初创公司。
那么这一切意味着什么呢?这是每隔几十年才会发生的突破性时刻吗?还是仅仅是多年来一直在进行的工作的逻辑延续?我们是否处于真正的指数加速的早期?还是在炒作周期和小型融资泡沫的早期,科技界的许多人都迫切希望在社交和移动以及加密货币假人头之后进行下一次大型平台转型?
所有这些问题的答案是…是的。
我们将按照以下顺序进行挖掘:
- 人工智能成为主流
- Generative AI的指数加速
- 不可避免的反弹
- Generative AI的业务:大型科技公司领先初创公司
人工智能成为主流
整个2022年,这是人工智能世界的一次疯狂之旅,但真正让事情达到狂热的是,当然,Open的人工智能对话机器人ChatGPT于2022年11月30日公开发布。ChatGPT是一款聊天机器人,具有模仿人类健谈者的神奇能力,很快成为有史以来增长最快的产品。
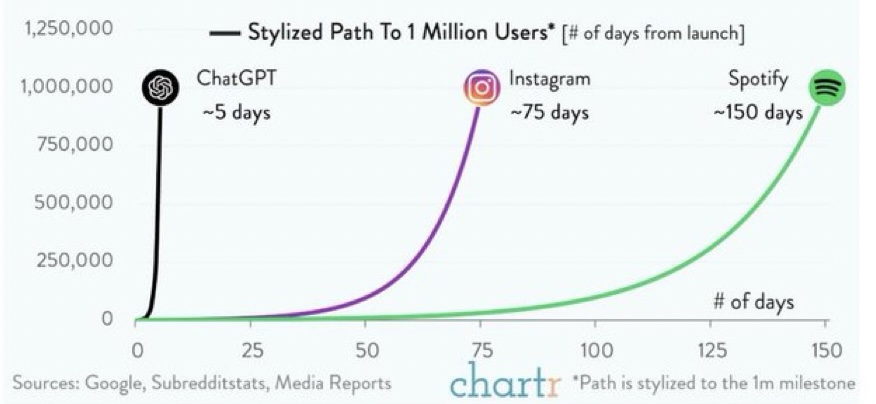
对于当时在场的人来说,第一次与ChatGPT互动的经历让人想起了90年代末他们第一次与谷歌互动的情景。等等,真的那么好吗?那么快?这怎么可能呢?或者刚问世时的iPhone。基本上,这是对指数级未来的第一次一瞥
在硅谷、华尔街和世界各地,ChatGPT立即接管了每一次商务会议、谈话、晚宴,最重要的是,接管了社交媒体的每一点。ChatGPT聪明、有趣、偶尔出错的回复截图在推特上随处可见。
截至1月,ChatGPT的用户已达1亿。
社交媒体上出现了一个由一夜之间的专家组成的整个行业,解释者的帖子和雄心勃勃的TikToker不断轰炸,向我们传授即时工程的方法,这意味着提供能引起ChatGPT最佳反应的输入:
ChatGPT继续积累成就。它通过了律师资格考试。它通过美国医学执照考试。
ChatGPT不是凭空产生的。自2020年6月GPT-3发布以来,人工智能界一直对其议论纷纷,对其高质量的文本输出赞不绝口,以至于很难确定它是否由人类编写。但GPT-3是作为一个面向开发人员而非广大公众的API提供的
ChatGPT(基于GPT 3.5)的发布感觉就像是人工智能真正成为集体意识主流的时刻
在我们的日常生活中,我们都经常通过语音助手、照片自动分类、使用人脸解锁手机,或者在人工智能系统检测到可能的财务欺诈后接听银行的电话,来接触人工智能的强大功能。但是,除了大多数人没有意识到人工智能能提供所有这些功能之外,可以说,这些感觉就像一匹耍把戏的小马
有了ChatGPT,你突然有了与某种感觉像是包罗万象的通用智能交互的体验。
围绕ChatGPT的炒作不仅仅是说说而已。它在很多方面都非常重要,包括因为它迫使行业中的每个人都对此做出积极反应,引发了一场史诗般的互联网搜索之战。
生成型人工智能的指数加速
但是,当然,这不仅仅是ChatGPT。对于任何关注的人来说,在过去的几个月里,似乎每天都有一系列令人眼花缭乱的突破性公告。有了人工智能,你现在可以创建音频、代码、图像、文本和视频
在某种程度上,所谓的合成媒体(2021年MAD景观中的一个类别)被广泛称为生成人工智能——这个术语仍然很新,以至于在撰写本文时,它在维基百科中没有条目
世代人工智能的兴起已经酝酿了好几年。根据你对它的看法,它可以追溯到深度学习(已经有几十年的历史,但在2012年之后急剧加速)和2014年由Ian Goodfellow领导的生成对抗网络(GAN)的出现,在他的教授和图灵奖获得者Yoshua Bengio的监督下
然而,它的开创性时刻发生在不到五年前,谷歌于2017年发布了Transformer(GPT中的“T”)架构——参见谷歌研究的帖子,以及现在著名的论文“注意力就是你所需要的。”
再加上数据基础设施的快速进步、强大的硬件和从根本上协作的开源研究方法,Transformer架构引发了大型语言模型(LLM)现象。
语言模型本身的概念并不新鲜。语言模型的核心功能是预测句子中的下一个单词。
然而,Transformers为语言模型带来了多模态维度。过去有单独的计算机视觉、文本和音频架构。有了变形金刚,一个通用架构现在可以吞噬各种数据,从而实现人工智能的全面融合
此外,最大的变化是能够大规模扩展这些模型
OpenAI的GPT模型是它从2018年开始在互联网上训练的变形金刚的味道。GPT-3是他们的第三代LLM,是目前最强大的型号之一。它可以针对各种任务进行微调——语言翻译、文本摘要等等。GPT-4预计将于2024年某个时候发布,据传将更加令人震惊。(聊天GPT基于GPT 3.5,GPT-3的变体)。
OpenAI在人工智能图像生成中也发挥了推动作用。2021年初,它发布了CLIP,这是一个开源、多模式、零样本模型。给定图像和文本描述,模型可以预测该图像最相关的文本描述,而无需针对特定任务进行优化。
OpenAI与DALL-E合作,DALL-E是一个人工智能系统,可以根据自然语言的描述创建逼真的图像和艺术。特别令人印象深刻的第二个版本DALL-E 2于2022年9月底广泛向公众发布。
已经有多个竞争者在争夺最佳文本到图像模型。Midtravel于2022年7月进入公测版(目前只能通过他们的Discord*访问)。另一个令人印象深刻的模型Stable Diffusion于2022年8月发布。它起源于几个实体的合作,特别是Stability AI、CompVis LMU和Runway ML。它提供了开源的特点,而DALL-E 2和Midtravel则不是。
但是,这些甚至还没有接近2022年年中以来人工智能发布的指数级加速
2022年9月,OpenAI发布了Whisper,这是一种自动语音识别(ASR)系统,可以用多种语言进行转录,并将这些语言翻译成英语。
同样在2022年9月,MetaAI发布了Make-A-Video,这是一个从文本中生成视频的人工智能系统。
2022年10月,CSM(常识机器)发布了CommonSim-1,这是一个创建3D世界的模型。
2022年11月,MetaAI发布了CICERO,这是第一款在人类层面上玩战略游戏《外交》的人工智能,被描述为“人类与人工智能互动的一步,可以使用战略推理和自然语言在游戏中与人互动和竞争。”
2023年1月,谷歌研究公司宣布了MusicLM,“这是一个从文本描述中生成高保真音乐的模型,例如“由扭曲的吉他即兴段支撑的平静的小提琴旋律”
Generative AI的另一个特别丰富的领域是代码的创建。
2021年,OpenAI发布了Codex,这是一个将自然语言翻译成代码的模型。你可以使用codex来完成诸如“将注释转化为代码,为提高效率而重写代码,或在上下文中完成下一行”之类的任务。codex基于GPT-3,也在5400万个GitHub存储库上接受过培训。反过来,Github联合试点使用Codex从编辑器中直接建议代码。
反过来,谷歌的DeepMind于2022年2月发布了Alphacode,Salesforce于2022年3月发布了CodeGen。华为于2022年7月推出了PanGu编码器
文本、图像、代码…生成型人工智能还可以生成令人难以置信的化身(此处,使用Synthesia创建*):
不可避免的反弹
在过去的几个月里,人工智能的发展呈指数级加速,这让大多数人感到惊讶。这是一个明显的例子,在社会、政治、法律框架和道德方面,技术远远领先于我们人类。尽管令人兴奋,但一些人对此感到恐惧,而我们正处于研究如何应对这场大规模创新爆发及其后果的早期阶段。
ChatGPT几乎立即被一些学校、人工智能会议(讽刺!)和程序员网站禁止。稳定扩散被滥用来创建NSFW色情生成器不稳定扩散,后来在Kickstarter上关闭。有指控称,参与数据标注过程的肯尼亚工人受到剥削。微软/Github在培训CoPilot时因侵犯知识产权而被起诉,CoPilot被指控杀害开源社区。Stability AI因侵犯版权被盖蒂起诉。Midtravel可能是下一个(Meta正在与Shutterstock合作以避免这个问题)。当人工智能创作的作品《空间歌剧院》在科罗拉多州博览会上获得数字类第一名时,世界各地的艺术家都群情激奋。
人工智能和工作
当人们面对Generative AI的力量时,很多人的反应是它会扼杀工作。过去几年的普遍观点是,人工智能会逐渐使最无聊和重复的工作自动化。人工智能会最后扼杀创造性工作,因为创造力是人类最典型的特征。但我们到了,Generative AI正在直接追求创造性的追求。
艺术家们正在学习与人工智能共同创作(与Karen K Chang的播客)。许多人意识到这其中涉及到一种不同的技能。空间歌剧院(Théâtre d‘Opéra Spatial)的创作者杰森·艾伦(Jason Allen)解释说,他花了80个小时创作了900幅图像,然后才得到完美的组合。
同样,编码人员正在研究如何与Co-Pilot一起工作。人工智能领导者Andrej Karpathy表示,Co-Pilot已经编写了80%的代码。早期的研究似乎表明开发人员的生产力和幸福感有了显著的提高。
我们似乎正在朝着一种协同工作的模式发展,在这种模式下,人工智能模型作为“配对程序员”或“配对艺术家”与人类一起工作
也许人工智能将创造新的就业机会。已经有了一个销售高质量文本提示的市场——Promptbase。
AI偏差
对Generative AI的一个严重打击是,它有偏见,而且可能有毒。考虑到人工智能反映了其训练数据集,并且考虑到GPT和其他人是在高度偏见和有毒的互联网上训练的,这种情况的发生并不奇怪。
早期研究发现,像稳定扩散和DALL-E这样的图像生成模型不仅延续,而且放大了人口刻板印象。
在撰写本文时,保守派圈子里有一个争议,即ChatGPT被痛苦地唤醒了。
人工智能虚假信息
另一个不可避免的问题是,使用如此强大的新工具可以做的所有邪恶的事情。
新的研究表明,人工智能能够模拟特定人类群体的反应,这可能会在信息战中释放出另一个层次。
Gary Marcus警告我们人工智能的侏罗纪公园时刻——虚假信息网络将如何利用ChatGPT,“以前所未有的规模攻击社交媒体和制作虚假网站。”
人工智能平台正在迅速采取行动,帮助反击,特别是通过检测人类写的东西与人工智能写的东西。OpenAI刚刚推出了一种新的分类器来做到这一点,它在检测人工智能生成的文本方面击败了最新技术。
人工智能内容只是…无聊吗?
对Generative AI的另一个打击是,它可能大多表现平平。
一些评论家担心,大量无趣、公式化的内容旨在帮助SEO或展示肤浅的专业知识,这与内容农场(一种需求媒体)过去所做的并不不同(新的人工智能聊天机器人是干什么的?没什么好的)。
Jack Clark在他的OpenAI时事通讯中撅着嘴:“我们建立这些模型是为了丰富我们自己的体验,还是这些模型最终会被用来分割和分割人类的创造力,并将其重新包装和商品化?这些模型最终是否会强化一种文化同质性,成为永远停留在过去的锚定物?或者这些模型是否会在一种新的音乐采样和混音文化中发挥自己的作用?”
AI幻觉
最后,也许对Generative AI最大的打击是,它往往是错误的。
ChatGPT尤其以“幻觉”而闻名,意思是编造事实,同时对其答案充满自信地传达事实。
人工智能领域的领导者对此非常明确,比如OpenAI首席执行官Sam Altman:

大型科技公司已经充分意识到了风险。
MetaAI于2022年11月推出了Galactica,这是一款旨在帮助科学家的模型,但三天后就取消了。该模型产生了令人信服的科学内容和令人信服的(偶尔还有种族主义的)废话。
也许是由于2018年Duplex的强烈反对,谷歌将其在2021年推出的强大对话模式LaMBDA保持在非常私人的状态,通过实验应用AI Test Kitchen只对一小群人开放。点击此处了解Jeff Dean的声誉风险
微软作为外包研究机构与OpenAI合作的天才之处在于,作为一家初创公司,OpenAI可以承担微软无法承担的风险。人们可以假设,微软仍在遭受2016年泰氏灾难的影响。
然而,微软迫于竞争(或者可能无法抗拒诱惑),打开潘多拉的盒子,在其必应搜索引擎中公开添加GPT。
这并没有达到预期效果,Bing威胁用户或向他们表达爱意。
在OpenAI和微软的压力下,谷歌也匆忙推出了自己的ChatGPT竞争对手,名字有趣的巴德。
这也不太顺利,在巴德在其第一个演示中犯了事实错误后,谷歌市值损失了1000亿美元(在撰写本文时,巴德仍然只对一小群测试版用户开放)。
人工智能业务:大型科技公司领先初创公司
风险投资和创业圈子里每个人心中的问题是:什么是商机?在最近的技术史上,在过去的几十年里,每15年左右就会有一次重大的平台转变:大型机、个人电脑、互联网、移动设备。许多人认为加密货币和区块链架构是下一个重大转变,但至少目前还没有定论。Generative AI是一个15年一次的世代机会,即将掀起新一轮的创业浪潮(以及风投的融资机会)吗?让我们来探讨一些关键问题。
现任者会拥有市场吗?
硅谷传说中的成功故事是这样的:大人物拥有一个巨大的市场,但却有资格和懒惰;一家小型初创公司拿出了10倍更好的技术;尽管困难重重,但通过出色的执行力(当然还有董事会风险投资的明智之举),小初创公司实现了超增长,成为了大公司,并超越了大公司。
人工智能的问题是,小型初创公司面临着一种非常特殊的在职者——世界上最大的科技公司,包括Alphabet/Google、微软、Meta/Facebook和Amazon/AWS。
这些现任者不仅不“懒惰”,而且在许多方面他们一直在领导人工智能的创新。谷歌从一开始就认为自己是一家人工智能公司(拉里·佩奇在2000年说:“人工智能将是谷歌的终极版本……这基本上就是我们的工作”)。该公司在人工智能领域进行了许多关键创新,包括前面提到的变压器、Tensorflow和Tensor处理单元(TPU)。Meta/Facebook我们谈到了变形金刚是如何来自谷歌的,但这只是该公司多年来发布的众多创新之一。Meta/Facebook创建了PyTorch,这是最重要和最常用的机器学习框架之一。亚马逊、苹果、微软、奈飞都制作了开创性的作品。
在职人员还拥有一些最好的研究实验室、经验丰富的机器学习工程师、大量数据、巨大的处理能力、巨大的分销和品牌影响力。
最后,人工智能很可能会成为当务之急,因为它正在成为一个主要的战场。
如上所述,谷歌和微软现在正在进行一场史诗般的搜索大战,微软将GPT视为给必应注入新生命的机会,谷歌则认为这可能危及生命。
Meta/Facebook在一个非常不同的领域下了巨大的赌注——元宇宙。这一赌注仍被证明是非常有争议的。与此同时,它依靠的是世界上一些最优秀的人工智能人才和技术。它要多久才能逆转方向,开始在人工智能上加倍或三倍?
多年来,Amazon/AWS在ML/AI领域无疑非常活跃,拥有一套横跨MAD领域许多类别的工具。然而,由于其业务主要针对开发者,在过去几个月的Generative AI辩论中,它没有那么直接出现。我们预计该公司将继续在这一领域采取行动,就像刚刚宣布的与拥抱脸的合作一样。
人工智能只是一个功能吗?
除了必应,微软还在团队中迅速推出了GPT。Notion推出了NotionAI,一款新的GPT-3驱动的写作助手。Canva推出了自己的人工智能工具。Quora推出了Poe,这是它自己的人工智能聊天机器人。客户服务领导者Intercom和Ada*宣布了GPT支持的功能。
公司推出人工智能功能的速度有多快,似乎有多容易,这似乎表明人工智能很快就会无处不在。
在之前的平台转型中,故事的很大一部分是,每一家公司都采用了新的平台——企业实现了互联网,每个人都建立了移动应用程序,等等。
我们预计这里不会发生任何不同的事情。长期以来,我们在之前的帖子中一直认为,数据和人工智能技术的成功在于它们最终将变得无处不在,并消失在后台。它是使技术变得隐形的成功的赎金。
创业公司有哪些机会?
然而,正如历史一再表明的那样,不要低估初创公司。给他们一个技术突破,企业家就会找到建立伟大公司的方法。
是的,当移动设备出现时,所有公司都启用了移动设备。然而,创始人建立了伟大的初创公司,如果没有移动平台的转变,这些公司就不可能存在——优步就是最明显的例子。
谁将成为Generative AI的优步?
新一代人工智能实验室可能正在构建Generative AI的AWS,而不是优步。OpenAI、Anthropic、Stability AI、Adept、Midtravel等正在构建广泛的横向平台,许多应用程序已经在其上创建。这是一项昂贵的业务,因为构建大型语言模型需要耗费大量资源——尽管成本可能会迅速下降(从头开始训练稳定扩散成本<16万美元(Mosaic博客))。这些平台的商业模式仍在制定中。OpenAI推出了ChatGPT Plus,这是ChatGPT的付费高级版本。Stability AI计划通过对客户特定版本收费来实现平台货币化。
利用GPT的新创业公司激增,尤其是用于各种生成任务,从创建代码到营销拷贝再到视频。许多被嘲笑为GPT之上的“薄层”。这是有一定道理的,他们的辩护能力也不清楚。但也许这是一个错误的问题。也许这些公司只是下一代软件公司,而不是人工智能公司。随着他们在核心人工智能引擎的基础上围绕工作流和协作等功能构建更多的功能,他们的防御能力不会比一般的SaaS公司多,但也不会少。
我们相信,有很多机会可以建立伟大的公司:
- 特定于垂直领域或特定于任务的公司,它们将智能地利用Generative AI做它擅长的事情。
- 人工智能第一的公司将为本质上没有生成性的任务开发自己的模型。
- LLM运营公司将提供必要的基础设施。
还有更多。下一波浪潮才刚刚开始,我们迫不及待地想看看会发生什么。
- 53 次浏览
【Web架构】36种网络发展趋势将改变2023年创建网站的方式之一
视频号
微信公众号
知识星球
如今,用户与网站的互动方式与五年前有所不同。准确地说,他们现在使用语音命令进行搜索,这表明新的网络发展趋势正在出现。
Web开发趋势是创建和改进Web应用程序的最新实践。这些趋势随着新兴技术和用户偏好的变化而不断发展。然而,他们非常重视响应能力和可访问性,为用户提供最佳体验。
2023年,许多新的网络开发趋势凸显出来,彻底改变了网站的开发方式。你可能已经注意到,用户现在比以往任何时候都更需要便利、个性化体验和定制。因此,语音搜索正在实现,虚拟现实正在整合,人工智能正在发挥作用。
在本博客中,我们将逐一探讨2023年的最新网络发展趋势。我们将解释它们是什么,它们是如何工作的,等等。
2023年36大网络发展趋势
- 区块链技术
- 渐进式Web应用程序(PWA)
- 物联网
- 加速移动页面(AMP)
- 语音搜索优化
- API优先开发
- 人工智能聊天机器人
- 推送通知
- 利用机器学习实现内容个性化
- 运动UI
- 数据安全
- 多重体验
- 网络安全
- 微型前端
- 虚拟现实
- 无服务器体系结构
- 云计算
- 单页应用程序(SPA)
- JavaScript框架
- 自动化测试
- 响应式网站
- 黑暗模式
- WebAssembly
- 无代码/低代码开发
- 增强现实
- 移动友好型Web开发
- 核心网络简历
- WordPress开发
- 元框架
- 数据库复兴
- Monoretos
- 静态站点生成器
- 数据合规性
- 三维元素
- 无头CMS架构
- 服务器端渲染
1.区块链技术

区块链是一种加密的数据库存储系统。与传统系统不同,它将信息存储在块中,然后将块连接为链。它提供了无数的好处,其中之一是它使交易更加安全和无错误。这是一种分布式账本技术,允许透明和防篡改的交易。这项技术是数字货币比特币的基础。由于主要支付系统决定接受比特币,加密货币的使用在过去十年中大幅增加。截至2022年,钱包用户已超过8000万。
区块链技术使参与者能够在没有第三方干扰的情况下通过互联网进行交易。这项技术有可能通过降低网络犯罪的风险,彻底改变不同的商业部门。区块链技术允许网络开发人员在项目中使用开源系统,这使得开发过程更加容易。
区块链在Web开发中的优势
让我们来看看区块链在网络开发中的主要优势:
- 区块链基于共识算法,这使得它几乎不可能进入。
- 交易由节点网络进行验证,确保交易不可篡改。
- 数据存储在网络上,用户可以很容易地获得数据,也很难隐藏欺诈活动。
- 区块链系统是去中心化的,因此不太容易出错。
- 数据可以在网络上传输,而无需中介机构。
- 区块链可以通过自动化交易和减少对中介机构的需求来提高效率。
早期采用者:
- 巴克莱银行
- Visa
- 沃尔玛
服务提供商:
- 亚马逊网络服务
- Microsoft Azure区块链服务
2.渐进式Web应用程序(PWA)
渐进式web应用程序(PWA)是一种使用HTML和JavaScript等常见web技术构建的应用软件。PWA适用于任何具有普通浏览器的设备。该技术因其提供高质量用户体验的潜力而广受欢迎。
PWA之所以被广泛青睐,还有许多其他原因,包括它有可能取代原生移动应用程序。即使用户离线或在不可靠的网络上,PWA也能提供快速的体验。全球许多网页设计公司已经开始为客户提供PWA解决方案。除了令人惊叹的用户体验外,PWA还具有其他功能,如推送通知和离线访问缓存内容。
PWA在Web开发中的优势
- 该技术使网络开发人员能够将网站和移动应用程序的功能结合起来:
- 通过提供更快、更可靠的服务,创造身临其境的用户体验。
- 通过提供更像本地应用程序的体验和转化率来提高用户参与度。
- 此外,渐进式Web应用程序:
- 开发成本相对较低。
- 可以在不依赖Appstore或Play Store等应用分发服务的情况下使用。
- 提供快速安装和自动更新功能。
用户示例
- 星巴克
- Spotify
平台示例
- Flutter
3.物联网

物联网可以定义为一个由互联网设备组成的网络,数据传输不需要人工参与。它是当前网络发展趋势中最有前途的一个。物体与网络连接的未来不仅仅是2023年的想象。据预测,到2025年,将有大约300亿台互联网设备在运行。
物联网已经被证明是最强大的网络发展趋势之一,因为它促进了不断的数据传输。物联网系统处理从传感器收集并处理的大量数据,以通过云网络传输。它帮助公司以快速的方式与客户互动,创造个性化的体验。此外,物联网可以用于在不同的运营模式和网站布局之间创建高级通信。该技术还具有广泛的应用,如摄像头、传感器、信号设备等,有助于更有效地解决客户需求。
物联网在Web开发中的优势
- 这种智能生态系统的广泛好处可以被网站和移动应用程序中的企业所利用。该技术还可以用于web开发:
- 物联网提供准确的结果,在数据传输方面没有延迟或错误。
- 它可以自动化任务和流程,从而提高效率并降低成本。
- 支持强大的安全技术,保护业务和用户数据。
- 帮助开发人员获得更多见解,分析客户行为,改善整体用户体验。
示例:
- 可穿戴设备
- 互联汽车
- 生物识别网络安全
4.加速移动页面(AMP)
加速移动页面是2023年热门网站发展趋势。这是一个诞生于谷歌和推特合作的项目,旨在创建更快的移动页面。AMP优化的网页加载容易,因此排名优于其他移动网页。与可能需要长达22秒的非AMP页面相比,AMP页面在大约2秒内加载。
随着互联网越来越以用户为导向,AMP是一项开发者正在接受的技术。它可以增加你网站的流量,因为AMP页面在谷歌搜索结果中得到了提升。此外,实施AMP可以让公司节省用户体验成本,并以低网速吸引用户。这项技术旨在鼓励小企业建立能够在移动设备上顺利运行的网站。
AMP在Web开发中的优势
AMP为web开发人员提供了许多好处,如:
- 易于优化搜索引擎。
- 反弹率低。
- 可根据任何浏览器进行调整。
- 无需创建网站地图以供搜索引擎识别。
- 比传统网页开发成本低。
用户示例(早期采用者):
- CNBC
- 《华盛顿邮报》
5.语音搜索优化

语音搜索优化可以简单地定义为优化网页以出现在语音搜索中的过程。由于语音助手和物联网,使用语音识别的设备正在迅速普及。这项技术发展如此之快,到明年,这些设备将能够识别不同人群的声音,并提供基于人工智能的个性化体验。在网络开发领域,最新的创新是声控自立设备,以及应用程序和网站的语音优化。
有了更多支持人工智能的设备,语音识别可以节省我们的时间,帮助我们处理多任务。据估计,到2023年,将有80亿数字语音助理在使用。巨大的增长将影响语音搜索优化在最新网络开发技术列表中的不可避免性。
语音搜索优化在Web开发中的优势
语音搜索优化通过以下方式帮助web开发人员:
- 使本地SEO活动更加有效。
- 一种在从事其他任务的同时与网络进行交互的更方便的方法。
- 可以快速回答客户的查询。
- 培养更多的信任和客户忠诚度。
示例(早期采用者):
- Alexa(亚马逊)
- 谷歌助手
6.API优先开发
顾名思义,在API第一次开发中,API受到高度重视。随着新技术的出现,有必要在它们之间建立连接,API为这些连接提供了便利。原料药已经存在近20年了。但是,早些时候,开发人员往往首先关注产品开发,而与软件和设备建立联系的必要性是事后才想到的。
然而,API-first开发有很大的好处——最重要的是它以用户为中心。该方法允许开发人员并行工作,减少了开发时间和成本。Web应用程序的设计、开发和安全性都可以在API-first模型的帮助下得到增强。此外,它还降低了项目失败的风险,确保所有API都是可靠和一致的。因此,API-first开发正成为当今web开发的一个主要趋势。
API优先模型在Web开发中的优势
- 除了对开发人员友好之外,API-first开发还具有以下巨大优势:
- 由于提供了有据可查且一致的API,减少了开发人员的学习曲线。
- 它可以带来更具适应性的应用程序。
- 它可以优先考虑前端的需求,以创建更高效的API。
- 它更高效,因为它可以减少开发时间。
- API可靠且一致,从而降低了系统故障的风险。它们也可以很容易地在前端进行独立测试。
- 更好的安全性,更容易控制访问API。
- 利益相关者可以在编写任何代码之前就API的设计提供反馈。
早期采用者:
- Netflix
- Etsy
- 566 次浏览
【Web架构】36种网络发展趋势将改变2023年创建网站的方式之三
视频号
微信公众号
知识星球
15.虚拟现实

虚拟现实(VR)是使用电子设备创建的三维图像或环境的模拟体验。2023年,虚拟现实的采用率将大幅上升,我们预计会看到更多这项技术被用于网络开发。
除了上述行业,虚拟现实的另一个应用涉及虚拟会议,这将增强远程工作。最终,这一切都是为了为用户创造最佳体验,因此VR成为最重要的网络发展趋势之一。
虚拟现实在网络开发中的应用
- 为用户提供更引人入胜、更难忘的体验,并增加沉浸感。
- 交互式环境,可以吸引用户并对其进行教育。
- 这是网络开发人员表达创造力和开发创新体验的一种新方式。
- 虚拟现实被用于网站,帮助用户可视化他们将要购买的产品。
- Oculus Rift或Google Cardboard等VR设备有望彻底改变旅游、建筑和零售等行业。
早期采用者:
- 沃尔沃(试驾)
- 麦当劳(快乐护目镜)
16.无服务器架构
无服务器架构,也称为无服务器计算,是一种软件开发模型,其中应用程序由第三方托管,因此您不需要处理服务器软件或硬件。该技术可帮助您避免系统过载、数据丢失并降低开发成本。无服务器架构是一种最新的web开发技术,得到了亚马逊web服务等主要供应商的支持。
该模型允许您用云取代常规服务器,以管理机器资源消耗。除了上述好处之外,无服务器架构还有助于保持互联网的可持续性。预计在未来几年,该技术将广泛用于需要复杂后端请求的物联网应用程序和产品。
无服务器体系结构在Web开发中的优势
以下是该技术对web开发的好处:
- 需要更少的计算能力和人力资源。
- 通过根据需求分配和管理服务器容量提高了可扩展性。
- 它可以通过根据需求自动扩展服务器数量来防止暴行。
- 开发人员有更多的时间关注用户体验。
- IT团队不需要担心服务器管理问题。
示例:
- 谷歌云功能,
- 亚马逊网络服务Lambda,
- Microsoft Azure功能
17.云计算
云计算意味着使用基于云的资源,如存储、网络、软件、分析和智能,以实现灵活性和便利性。这些服务在多个数据中心之间进行备份和复制,因此更加可靠。这样可以确保web应用程序始终可用并运行。随着越来越多的组织转向远程工作,这成为疫情期间的一个重要趋势。
2023年,我们可以期待该领域的新进展。据预测,今年云基础设施市场将增长35%。该技术除了提供降低开发成本、灵活性和强健的体系结构等多项好处外,还有助于避免数据丢失和数据过载。
云计算在Web开发中的优势
以下是云计算如何改变web开发的一些方法:
- 最重要的是,开发人员不必担心存储空间。
- 开发人员可以在不同的位置协同工作。
- 提供各种安全功能,如加密和访问控制。
- 通过灵活部署新功能,帮助保持竞争优势。
- 它可以在全球范围内接触到更广泛的受众。
- 不断进行创新,使网络开发人员能够轻松获得新技术。
- 云计算具有成本效益,便于所有团队成员轻松访问。
用户:
- Netflix(2016年迁移到Cloud)
最常见的提供商:
- 亚马逊网络服务
- 谷歌硬盘
18.单页应用程序(SPA)
单页应用程序可以定义为一种在浏览器中工作时不需要重新加载自己的应用程序。用户可以享受自然的体验和无缝的使用。我们每天使用的应用程序,如Facebook、Gmail和Twitter,都是垃圾邮件。这是2023年最热门的网络发展趋势之一,预计未来大多数功能性网站将以SPAs的形式构建。
单页应用程序有更多的能力来吸引用户的注意力,因为它们似乎运行得很快。与常规网站不同,用户需要等待页面加载才能获得即时反馈。
SPAs在Web开发中的优势
- 更好的SEO优化功能。
- 更快的加载速度,使页面感觉更灵敏。
- 轻松导航可确保更好的用户体验。
- 节省时间和金钱的简单方法。
- 实现和调试不那么复杂。
- 更好的可重用性和缓存。
示例:
- Netflix
- Google Maps
- Paypal
19.JavaScript框架

JavaScript框架是一组代码库,开发人员可以从中访问用于常规编程任务的预先编写的代码。JavaScript并不新鲜,即使在2023年,它也无处不在。它被认为是世界上使用最多的编程语言,未来几年网站的新趋势将见证JavaScript框架的进一步发展。
JavaScript框架预计将涉及UI/UX、测试和产品管理方面。JavaScript的优点,如即时反馈、高效和编码简单,将在未来发挥最大潜力。经过多年的发展,JavaScript已经成为最受欢迎的编程语言,并将继续成为最受青睐的编程语言。
JavaScript框架在Web开发中的优势
以下是JavaScript框架在web开发中的一些值得注意的好处:
- 通过为开发过程提供现有的基础来节省时间和金钱。
- 创建标准化流程,使开发人员更容易使用框架。
- 可重用组件,减少了需要编写的代码量。
- 提供了许多安全功能。
- 它帮助开发人员编写代码模块,而不用担心遗留的浏览器不兼容。
- 提供内置的HTML模板,使标记中的数据易于阅读。
- 提供基于组件的设计,从而实现内容重用。
流行的JS框架:
- Vue.js
- Angular
20.自动化测试
自动化测试可以定义为在很少或没有人机交互的情况下执行软件测试,以实现更高的效率。测试是web开发的重要组成部分,尤其是在交付前保证产品的质量。虽然手动测试是标准流程,但这并不是2023年的最佳方法。开发阶段的自动化使开发人员能够用一个小团队完成复杂的项目。它可以并行运行,不像手动测试必须一次运行一个。同样,测试自动化有助于他们检查产品是否准备好部署,从而提高测试覆盖率和透明度。
自动化测试可以帮助开发团队收集测试用例,从中学习,并减少开发时间和成本(高达20%)。那么,为什么自动化测试是一个重要的web发展趋势呢?仅仅是因为数字环境的竞争越来越激烈,所以更快、更优质的产品将帮助您发挥领导作用。
自动化测试在Web开发中的好处
自动化测试使开发过程变得更加容易。以下是一些好处:
- 代码可重用性——代码是模块化的,因此可以在需要时再次使用。
- 自动化测试可以全天候进行,无需监控。
- 软件测试人员可以专注于更复杂的事情。
- 降低与测试相关的成本。
- 在开发阶段早期检测错误。
工具:
- Selenium
- Eggplant
21.响应式网站

响应式网页设计是一种网页开发方法,用于创建可根据不同屏幕大小进行调整的动态网站。在列出2023年最热门的网络发展趋势时,不能不提到响应型网站。每秒钟都有来自移动设备的搜索请求在互联网上发出,这意味着公司应该投资于响应式网络设计,以创建自动适应任何设备的网站。
这项技术有助于解决很多问题,比如改善用户体验,增加用户在网站上花费的时间。此外,谷歌已经宣布,移动友好性将成为其搜索引擎算法的一个排名因素。
响应式Web设计在Web开发中的优势
以下是web开发人员如何从响应式web设计中获益的一些方法:
- 它比创建一个独立的移动站点花费更少的时间。
- 监控分析数据很容易。
- 响应式网页设计更易于维护;各设备的设计将保持不变。
用户示例:
- Wired
- Dropbox
- 26 次浏览
【Web架构】36种网络发展趋势将改变2023年创建网站的方式之二
视频号
微信公众号
知识星球
如今,用户与网站的互动方式与五年前有所不同。准确地说,他们现在使用语音命令进行搜索,这表明新的网络发展趋势正在出现。
Web开发趋势是创建和改进Web应用程序的最新实践。这些趋势随着新兴技术和用户偏好的变化而不断发展。然而,他们非常重视响应能力和可访问性,为用户提供最佳体验。
2023年,许多新的网络开发趋势凸显出来,彻底改变了网站的开发方式。你可能已经注意到,用户现在比以往任何时候都更需要便利、个性化体验和定制。因此,语音搜索正在实现,虚拟现实正在整合,人工智能正在发挥作用。
在本博客中,我们将逐一探讨2023年的最新网络发展趋势。我们将解释它们是什么,它们是如何工作的,等等。
2023年36大网络发展趋势
- 区块链技术
- 渐进式Web应用程序(PWA)
- 物联网
- 加速移动页面(AMP)
- 语音搜索优化
- API首次开发
- 人工智能聊天机器人
- 推送通知
- 利用机器学习实现内容个性化
- 运动UI
- 数据安全
- 多重体验
- 网络安全
- 微型前端
- 虚拟现实
- 无服务器体系结构
- 云计算
- 单页应用程序(SPA)
- JavaScript框架
- 自动化测试
- 响应式网站
- 黑暗模式
- WebAssembly
- 无代码/低代码开发
- 增强现实
- 移动友好型Web开发
- 核心网络简历
- WordPress开发
- 元框架
- 数据库复兴
- Monoretos
- 静态站点生成器
- 数据合规性
- 三维元素
- 无头CMS架构
- 服务器端渲染
7. AI-Powered Chatbots

人工智能聊天机器人是普通聊天机器人的智能版本。该技术使用自然语言处理(NLP)和机器学习(ML)来更好地理解用户意图,并提供类似人类的体验。基于人工智能的机器人具有高级功能,如24×7解决问题的技能和行为分析能力。根据专家的说法,自学机器人是未来的趋势,公司可以通过更换支持经理来降低成本。人工智能聊天机器人可以很容易地集成到常规/专业网站和PWA中。
从长远来看,人工智能聊天机器人是一种值得投资的趋势。他们可以回答常见问题,将用户与合适的人工助理联系起来,甚至可以接受订单。聊天机器人通常在紧急情况下提供快速答案,并能快速解决投诉。
人工智能聊天机器人在网络开发中的优势
随着客户需要更多功能丰富的可交付成果,人工智能聊天机器人等技术可以通过以下方式让开发者受益:
- 通过替换导航网站元素来简化开发。
- 提供全天候客户支持,提高客户满意度。
- 提供卓越的用户体验。
- 随着聊天机器人与信使的集成,开发的应用程序越来越少。
示例:
- Nestle’s NINA
- HDFC Bank’s EVA
8.推送通知
推送通知是可点击的弹出窗口,出现在用户浏览时。这项技术被用作一个快速渠道,公司可以通过它传递报价和信息等信息。它可以在任何设备上实现——笔记本电脑、智能手机或平板电脑。
正如我们所看到的,推送通知是渐进式Web应用程序最受欢迎的功能之一。它是一个强大的工具,有助于获得用户的关注并提高保留率。像脸书和谷歌这样的互联网巨头已经在他们的网络应用程序中实现了这项技术。
2021年,我们看到这项技术被许多企业采用。此外,这些即时通知可能会取代电子邮件等常见的沟通渠道。推送通知可以很容易地集成到在线购物网站、现有博客和其他网站中。因此,推送通知将在2023年变得更加明显。
推送通知在Web开发中的优势
- 推送通知通过以下方式帮助web开发:
- 增强了用户体验,从而提高了参与度。
- 提高品牌知名度。
- 推动访客和点击率。
- 向客户承诺更多的投资回报率。
早期采用者:
- 亚马逊
- Buzzfeed新闻
9.机器学习的内容个性化

机器学习的内容个性化,也称为预测性内容个性化,是一种先进的人工智能驱动方法,可以向每个用户动态显示最相关的内容。
机器学习(ML)用于网络开发,为用户提供改进的体验。开发人员使用ML使软件能够分析传入数据、检测模式和个性化内容。许多领先的公司都使用这项技术来增强用户体验。例如,Airbnb和Netflix使用ML为用户定制搜索结果。
ML可以帮助您在不针对整个用户群体的情况下对内容进行个性化设置。您可以特别识别每个用户,并满足他们的兴趣。算法基于用户意图提供定制的内容。ML的内容个性化是一种惊人的趋势,它允许您通过分析访问者行为来调整内容。
ML在Web开发中的内容个性化优势
- 除了使用ML的高级功能对内容进行个性化之外,开发人员还可以利用这项技术:
- 分析网站导航路径、查看持续时间等。
- 获得比传统A/B测试更多的见解。
- 优化网页变得容易多了。
用户示例:
- Yelp
10.Motion UI
Motion UI是一个前端框架,用于构建完全响应的网页设计。该技术使开发人员能够在本机应用程序设置中创建动作。它带有预定义的运动,可用于任何设计项目。
网站不仅应该提供用户想要的信息,而且必须具有吸引力。漂亮的网站有更多的机会被你的目标受众注意到。运动UI是一种新的设计方法,它使数字产品更加直观和用户友好。
该方法涉及自定义动画集成和CSS转换,这些转换源于具有动画元素阵列的SASS库。Motion UI有助于创建一个简单的界面,引导用户提供愉快的体验。这是web应用程序开发中最重要的趋势之一,因为它使UI设计更快、更简单。
Motion UI在Web开发中的优势
这项技术带来了惊人的好处,将改变网络开发。以下是其中的一些:
- 易于实现–开发人员不需要是JavaScript或jQuery库方面的专家。
- 通过帮助用户找到他们想要的确切信息,使网页设计更加有效。
- 以更快的速度实现动画元素的原型制作。
- 通过使网站或应用程序具有互动性和吸引力,提高参与度并提高可用性。
11.数据安全

顾名思义,数据安全意味着保护您的数字数据免受不必要的数据泄露或网络攻击。网络攻击会对您的业务和声誉造成巨大打击。因此,数据安全是2023年web开发的趋势技术之一。无论你计划推出什么网络应用程序,数据安全都已成为首要问题。
在未来几年,我们可以期待人工智能在数据安全方面变得更有帮助。我们看到的最新创新是人工智能生物识别登录,用于扫描指纹和视网膜。此外,使用人工智能软件更容易检测威胁。
Web开发中数据安全的好处
- 数据安全方面的进步可以通过以下方式帮助web开发人员:
- 使用安全的内容管理系统、插件和扩展。
- 选择安全的主机和服务器。
- 利用好的防火墙应用程序。
- 提高客户信任。
数据安全提供商:
- Cisco
- Symantec
- IBM
12.多体验
多体验可以定义为跨不同数字接触点(如网站、应用程序、聊天机器人、可穿戴设备等)使用单个应用程序的整个用户体验。该技术的目的是促进无缝一致的用户旅程。
多体验是2023年不可避免的网站发展趋势。如今,智能手机、平板电脑和笔记本电脑并不是潜在客户使用的唯一智能设备。还有其他小工具,如智能手表、AR/VR模块、语音助手和其他物联网设备。
除了创建一个适应常见设备的动态网站外,你还应该追求多体验,在那里你可以通过客户可能使用的所有设备与他们交流。2023年专注于创建一个多体验应用程序可以增加你成为利基市场中最好的企业的几率。
多体验可以通过以下方式改进web开发:
- 该技术实现了跨设备的快速和可扩展的开发。
- 开发人员将能够访问一系列前端工具和后端服务,这些工具和服务将有助于满足所有需求。
- 它建立在低代码框架上,让开发人员对部署有更多的控制权。
多体验开发平台:
- Oracle
- Appian
- Salesforce
- Microsoft
示例:
- Google Home
- Alexa
- Slack
13. Cybersecurity

网络安全的定义是保护计算机系统和网络免受信息泄露、盗窃、损坏或破坏。它在2023年变得更加重要,因为在我们实现更多流程自动化的同时,我们的数据被盗的风险也在增加。你可以与流行的网络安全公司合作,了解该领域的最新技术,包括保护用户免受网络钓鱼攻击的算法开发。另一个有趣的趋势是物联网交互保护和移动安全。
欧洲GDPR(《通用数据保护条例》)等隐私政策的制定也是网络安全领域的最新发展之一。这些新的网络安全创新可帮助您简化信息安全并优化业务连续性管理。
网络安全在Web开发中的作用
网络安全在以下方面帮助网络开发人员:
- 他们可以使用Django或RubyonRails等web框架来避免跨站点脚本(XSS)等重大威胁。
- 可以通过使用强大的加密技术来保护敏感数据,从而采取预防措施。
- 通过监控可疑活动分析可能的攻击。
热门提供商:
- 思科
- 国际商用机器公司
- UpGuard
14.微型前端
Micro Frontends是最近的一种网络发展趋势,它将前端整体拆分成更小、更易于管理的部分。微服务体系结构在过去几年里一直很受欢迎,因为它帮助开发人员构建灵活的后端,而不是老式的后端。然而,前端仍然存在复杂性,其中使用单片代码库来构建接口。幸运的是,Micro Frontends可以避免这种头痛。
该技术帮助开发人员在单独测试和部署之前,将单片前端切割成简单的单元。此外,多个团队可以处理不同的前端组件,然后将它们放在一起创建一个令人惊叹的web应用程序。这也使应用程序升级更容易,并有助于整体开发流程。
微前端在Web开发中的优势
看看Micro Frontends如何帮助web开发人员:
- 它可以简化大型工作流系统,使创建和更新更容易。
- 代码库更小,因此更易于管理。
- 对应用程序的不同部分进行独立开发可以提高灵活性。
- 与传统的单片应用程序相比,每个前端都可以独立缩放。
- 提高可重用性—在创建新工作流的同时节省时间和精力。
- 49 次浏览
【Web架构】36种网络发展趋势将改变2023年创建网站的方式之五
视频号
微信公众号
知识星球
如今,用户与网站的互动方式与五年前有所不同。准确地说,他们现在使用语音命令进行搜索,这表明新的网络发展趋势正在出现。
Web开发趋势是创建和改进Web应用程序的最新实践。这些趋势随着新兴技术和用户偏好的变化而不断发展。然而,他们非常重视响应能力和可访问性,为用户提供最佳体验。
2023年,许多新的网络开发趋势凸显出来,彻底改变了网站的开发方式。你可能已经注意到,用户现在比以往任何时候都更需要便利、个性化体验和定制。因此,语音搜索正在实现,虚拟现实正在整合,人工智能正在发挥作用。
在本博客中,我们将逐一探讨2023年的最新网络发展趋势。我们将解释它们是什么,它们是如何工作的,等等。
2023年36大网络发展趋势
- 区块链技术
- 渐进式Web应用程序(PWA)
- 物联网
- 加速移动页面(AMP)
- 语音搜索优化
- API首次开发
- 人工智能聊天机器人
- 推送通知
- 利用机器学习实现内容个性化
- 运动UI
- 数据安全
- 多重体验
- 网络安全
- 微型前端
- 虚拟现实
- 无服务器体系结构
- 云计算
- 单页应用程序(SPA)
- JavaScript框架
- 自动化测试
- 响应式网站
- 黑暗模式
- WebAssembly
- 无代码/低代码开发
- 增强现实
- 移动友好型Web开发
- 核心网络简历
- WordPress开发
- 元框架
- 数据库复兴
- Monoretos
- 静态站点生成器
- 数据合规性
- 三维元素
- 无头CMS架构
- 服务器端渲染
29.元框架
元框架的出现为使用多个框架提供了统一的界面,从而影响了web开发。虽然单页应用程序(SPAs)和服务器端渲染(SSR)仍然是广泛使用的方法,但元框架可以同时使用这两种方法,并提供了更快的开发时间、更容易的代码维护和更好的性能等优势。
使用最广泛的元框架之一是Next.js,它与React.js有着密切的联系。这种集成实际上是Next.jsp在开发者中流行的原因之一。然而,Remix是另一个采用不同方法与React.js集成的元框架,它优先考虑web标准。
其他需要考虑的替代元框架包括SvelteKit,它建立在Svelte.js上,并得到Vercel的支持,以及SolidStart,它建立于Solid.js之上,与React.js相比,提供了更好的开发体验(DX)。
元框架的好处
- 预构建框架:元框架确实可以为开发人员提供一个预构建框架和一套工具,可以简化开发过程,减少所需的样板代码量。
- 提高性能:元框架还可以通过使用服务器端渲染(SSR)而不是客户端渲染(CSR)来提高web应用程序的性能和加载时间。
- 灵活性:元框架可以为开发人员提供更大的灵活性,允许他们使用多种库和技术来构建应用程序。
- 改进的SEO:依赖SSR的元框架可以促进更好的搜索引擎优化(SEO),因为搜索引擎可以轻松地抓取和索引内容。
- 生态系统:许多元框架都有活跃的社区、广泛的文档以及一系列插件和扩展,这些插件和扩展可以让开发人员更容易地找到信息和支持。
示例
- Next.js
- Remix
- SvelteKit
- SolidStart
30.数据库复兴
“数据库复兴”一词描述了在少数大公司经历了一段缓慢的创新和霸权之后,人们对数据库技术的兴趣和创新最近的复苏。这种复兴是由大数据的增长、云计算的出现以及新应用程序架构和编程语言的采用等因素推动的。因此,出现了新的技术、工具和数据库,满足了当代应用程序和数据管理的需求。
例如,已经为微服务和无服务器应用程序架构设计了新的数据库和数据管理工具。无服务器数据库领域的一些热门竞争者包括PlanetScale(MySQL)、Neon(PostgreSQL)和Xata(PostgreQL),它们提供了数据库分支、模式区分、强大的搜索、分析和见解等功能。向云的转移也使部署和管理数据库变得更容易、更实惠,从而开发了新的云原生数据库和服务。这些服务通常提供边缘缓存或分布式只读数据库,以使数据更接近用户并最大限度地减少延迟。”
31.Monoretos
单存储库,也称为单一存储库,是一种源代码存储库,通常使用Git将应用程序或微服务的所有代码保存在一个位置。通过具有统一和自动化的构建和部署过程的monorepo,可以缓解许多开发问题。如今,monorespo已经不局限于大规模应用,即使是较小的公司和开源项目也可以从中受益。
例如,一家公司可以在一个单仓库中拥有多个包,包括共享的UI组件、共享的设计系统(例如,可重复使用的公司设计)以及各自领域的常用实用程序功能。尽管有其优势,monoretos还是可以发展到巨大的规模。例如,据传谷歌拥有有史以来最大的代码库,每天有数以万计的提交,大小超过80 TB。
Monorespo的好处
- monorepo中的可见性特性允许改进协作和跨团队贡献,因为每个人都可以查看彼此的代码。
- 由于共享依赖关系非常简单,因此monoreo中的依赖关系管理变得更简单。
- 在单一的事实来源中拥有单一的真实性来源可以确保不存在版本控制冲突或依赖性问题。
- 由于所有代码都在一个地方,并且可以保持一致性,因此在monoreo中执行代码质量标准和统一风格更容易。
- monoreto中的共享时间线会立即暴露API或共享库中的突破性变化,促进不同团队之间的沟通和团队合作。
- 由于所有代码已经统一在一个地方,从而导致了隐式CI过程,因此在单回购中保证了连续集成。
- 统一的CI/CD部署过程可以用于monoreo中的每个项目。
- 共享构建过程可以用于monoreo中的每个应用程序,从而形成统一的构建过程。
用户示例
- Uber
- Shopify
32.静态网站生成器
由于其能够提供更快的加载时间、改进的可扩展性、增强的安全性和用户友好的简单性,静态站点生成器(SSG)正在成为2023年web开发的流行趋势。SSG是从模板和内容中生成静态HTML、CSS和JavaScript文件的web开发框架。与动态网站相比,静态网站速度更快,因为它们不需要每次用户访问都进行服务器渲染。它们在构建过程中预先生成所有HTML页面和资产,允许直接从CDN或web服务器提供服务。
此外,静态网站更安全,因为它们缺少服务器端代码,因此不易受到安全攻击。SSG以其简单性而闻名,使其易于开发和部署,而无需复杂的服务器设置。总体而言,SSG为传统动态网站提供了一种更快、更安全、更简单的替代方案。
静态网站生成器的好处
- Quicker load times.
- Improved scalability and handling of increased traffic.
- Enhanced security
- User-friendly and simple to use.
服务提供商
- Jekyll
- Hugo
- Gatsby
33.数据合规性
随着企业在不断升级的网络安全挑战中优先考虑用户数据保护和法规遵从性,数据合规成为今年网络开发的一个突出趋势。对于组织来说,遵守数据管理法规并承担保护客户信息的责任至关重要。随着网络攻击的增加,战略事件管理规划和团队培训对于防止数据泄露是必要的。
不同的国家有自己的数据合规标准,例如针对欧盟受众的GDPR和针对加利福尼亚州企业的CCPA。不遵守规定可能导致罚款。为了避免长期问题,组织必须遵守当地和全球数据保护法,这使得数据合规成为2023年网络开发的一个组成部分。
34.3D元素
随着网络开发人员寻求创造更具沉浸感和吸引力的用户体验,3D元素的使用成为一种突出且即将到来的趋势。随着2K和4K等高分辨率显示器的日益普及,3D设计已成为最近的趋势。这些元素可以创造身临其境的交互式用户体验,增强网站的整体设计。
结合3D模型、动画和互动元素可以让用户体验更加引人入胜。此外,3D元素能够以更直观的方式有效地传达复杂信息,使其对教育网站和产品演示非常有用。此外,使用3D元素可以增强网站的视觉吸引力,使其更令人难忘,并有助于品牌知名度和客户吸引力。所有这些都使得3D成为动态网页设计世界中的主流趋势。
三维元素的优点
- 沉浸式用户体验
- 3D元素的使用增强了网站的视觉吸引力。
- 增加参与度
- 难忘的品牌体验
- 与高分辨率显示器的兼容性
35.无头CMS架构
随着企业在网络开发中寻求更大的灵活性、无缝内容交付和增强的安全性,Headless CMS架构将成为2023年的一个突出趋势。无头CMS体系结构是一个将内容管理系统(CMS)与前端显示层分离的概念。作为一名开发人员,它可以让你对网站布局的创建和设计有更多的控制权。在无头CMS中,内容被单独存储在中央存储库中,允许在任何设备或应用程序上访问和显示。
这种内容和演示的解耦使企业能够在不同的平台和设备之间无缝地交付内容,而无需修改内容本身。此外,无头CMS体系结构提供了可扩展性和增强的安全性,因为它们不在服务器上存储任何表示逻辑,从而将安全漏洞的风险降至最低。
无头CMS体系结构的优点
- 有了无头CMS,开发人员可以在不影响内容的情况下自由选择和切换前端技术和框架。
- 内容可以在多个平台和设备上重复使用。
- 将内容管理系统与前端分离可以进行独立的更新和修改。
- 使企业能够通过跨多个渠道和平台提供内容来建立全渠道的影响力。
36.服务器端渲染
服务器端渲染是2023年web开发的一个流行趋势。这是一种网络开发技术,在将网页发送到浏览器之前,在服务器上呈现网页的初始HTML。这意味着浏览器不必自己进行渲染,从而加快初始页面加载时间并提高性能。SSR对于包含大量内容或复杂JavaScript的网页特别有用,因为它显著加快了加载过程。
此外,SSR还具有SEO优势,因为搜索引擎可以对渲染的HTML进行索引,而它们可能难以处理JavaScript渲染的页面。通过减少浏览器的工作负载,SSR提高了网页的整体性能,使其响应能力更强,尤其是在处理动态内容时。服务器端渲染有可能彻底改变网络性能和用户体验,预计它将越来越受欢迎,并成为未来几年网络开发的主要技术。
服务器端渲染的好处
- 更快的页面加载
- 改进的SEO
- 增强了互联网速度较慢或设备处理能力有限的用户的可访问性
- 非常适合具有动态内容的复杂web应用程序
- 确保用户及时收到格式完整的页面
- 使用Next.js和Nuxt.js等框架
Web开发的未来是什么?
2023年将见证网络开发领域的许多进步。在这个博客中,我们了解了未来最重要的趋势。区块链技术、PWA、AMP、AI、VR、微前端等将成为未来网络发展趋势的各种技术之一。这些技术将统治未来几年,不断调整以适应公众的需求。
自2001年以来,GMI一直处于数字革命的前沿。我们为中东和印度的客户提供世界级的网络开发服务。我们的网络开发专家团队始终紧跟潮流,提供一流的服务。如果你正在考虑如何在你的网站开发工作中采用这些趋势,今天就和我们的专家谈谈。
- 39 次浏览
【Web架构】36种网络发展趋势将改变2023年创建网站的方式之四
视频号
微信公众号
知识星球
如今,用户与网站的互动方式与五年前有所不同。准确地说,他们现在使用语音命令进行搜索,这表明新的网络发展趋势正在出现。
Web开发趋势是创建和改进Web应用程序的最新实践。这些趋势随着新兴技术和用户偏好的变化而不断发展。然而,他们非常重视响应能力和可访问性,为用户提供最佳体验。
2023年,许多新的网络开发趋势凸显出来,彻底改变了网站的开发方式。你可能已经注意到,用户现在比以往任何时候都更需要便利、个性化体验和定制。因此,语音搜索正在实现,虚拟现实正在整合,人工智能正在发挥作用。
在本博客中,我们将逐一探讨2023年的最新网络发展趋势。我们将解释它们是什么,它们是如何工作的,等等。
2023年36大网络发展趋势
- 区块链技术
- 渐进式Web应用程序(PWA)
- 物联网
- 加速移动页面(AMP)
- 语音搜索优化
- API优先开发
- 人工智能聊天机器人
- 推送通知
- 利用机器学习实现内容个性化
- 运动UI
- 数据安全
- 多重体验
- 网络安全
- 微型前端
- 虚拟现实
- 无服务器体系结构
- 云计算
- 单页应用程序(SPA)
- JavaScript框架
- 自动化测试
- 响应式网站
- 黑暗模式
- WebAssembly
- 无代码/低代码开发
- 增强现实
- 移动友好型Web开发
- 核心网络简历
- WordPress开发
- 元框架
- 数据库复兴
- Monoretos
- 静态站点生成器
- 数据合规性
- 三维元素
- 无头CMS架构
- 服务器端渲染
22.黑暗模式
黑暗模式几年前首次引入,但从2020年到2021年,它成为了网络开发的主流趋势。基本上,暗模式与所使用的配色方案相关联。也就是说,网站使用较暗的背景,在其上以浅色显示文本和其他UI元素。
黑暗模式是当今每一项发展的主要考虑因素。调查显示,大多数人更喜欢黑暗模式而不是光明模式。一些解决方案将其提供为一种选项,其中用户可以根据自己的偏好在设置中的暗模式或亮模式之间切换。其他一些解决方案将暗模式作为其唯一的配色方案。无论以何种方式实现,毫无疑问,暗模式将是2023年不可避免的网络发展趋势
暗模式在Web开发中的好处
深色模式之所以受欢迎,不仅是因为它时尚美观,还因为它有几个实际好处,例如:
- 它可以减少眼睛疲劳,尤其是在光线不足的情况下。
- 当使用暗模式而不是相同亮度的亮模式时,它消耗的电池更少。
- 它被发现对有视觉障碍或光敏性的人有帮助
- 激活暗模式时,蓝光发射较少。
早期采用者
- 苹果
- 谷歌
- YouTube
23. WebAssembly

WebAssembly是一项功能强大的技术,旨在解决web应用程序的性能相关问题。这是一种可以在浏览器中与JavaScript一起运行的新语言。WebAssembly是作为一种高级语言编写的,无论其编程语言如何,都可以以更快的性能执行任何代码。它被编译为本地机器代码,由浏览器的CPU直接执行,确保执行速度比JavaScript代码快得多。
WebAssembly不能替代JavaScript;相反,开发它是为了解决由于JavaScript计算而出现的缓慢性能问题。WebAssembly具有二进制代码格式,因此它非常强大和快速。它也用于无服务器计算。
WebAssembly在Web开发中的优势
WebAssembly在网络游戏、在线编辑器、交互式应用程序等的开发中有很多应用。它的好处是:
- 由于用户不必编写代码,因此可以节省时间。
- 提供了可以自动执行数据输入和验证等任务的功能。
- 允许多个用户在同一应用程序上工作,从而改进了协作。
- 它可以在任何网络浏览器上运行,因此可以从任何地方访问。
- 可能以接近本机速度运行代码。
- 它支持多种编程语言。
- 它是一个被浏览器沙盒化的安全平台。
- 在内存和CPU使用方面高效运行复杂的应用程序。
早期采用者
- Autocad
- Figma
24.无代码/低代码开发
如果你正在寻找一种易于使用的技术,可以帮助创建软件解决方案,而不必编写代码,那么这两种技术都适合你。它们通常提供一个拖放界面,用户可以在其中创建用户界面、链接数据源并向应用程序添加功能。开发人员可能对传统编程语言知之甚少,可以轻松地使用这些技术。这是因为它们为应用程序开发提供了一种可视化的方法。然而,它们的相似之处到此为止。它们的区别如下:
目标
Ninetex和Outsystems等低代码平台允许您创建可自由访问的高需求应用程序。另一方面,没有代码更适合满足企业的特定需求。市场上流行的无代码平台有Webflow、Scapic和Mailchimp。
精通
没有任何代码允许没有经验的程序员创建解决方案。然而,只有经验丰富的程序员才能有效地使用低代码平台。
构建逻辑
无代码的基本设计使用简单的拖放逻辑,而低代码的构建逻辑与高代码的解决方案相同。
25.增强现实

如果不提及AR或增强现实,一篇关于技术趋势的文章将是不完整的。这一趋势已经渗透到教育、医疗保健、游戏等各个可能的领域。有了AR,用户可以通过引人入胜、个性化和有趣的设计在自己的环境中体验事物。AR应用的一些值得注意的例子包括:
-
Nintendo’s Pokemon Go App
-
Google Pixels Star Wars Sticker
-
Weather Channel Studio Effects
如今,宜家、亚马逊等许多电子商务网站也在使用AR,通过创建虚拟展厅来增强用户体验。AR提供的娱乐价值得到了所有用户的充分享受。在短短的一个世纪里,AR从梦想变成了现实,所以用不了多久,AR就会与日常生活相结合,提高生产力和效率。
26.移动友好型Web开发
移动友好型网络开发意味着通过修剪或重新格式化网站的主要元素,并删除效果,使其在较小的屏幕上工作,来浓缩网站。
自从谷歌宣布移动优先索引以来,建立考虑到移动用户的网站已经变得很常见。这一趋势今年也将继续下去。2022年第二季度,全球58.99%的网站流量来自智能手机。因此,任何企业都不能忽视拥有一个移动网站的重要性。
有三种方式可以为移动网站用户提供服务。
1) 移动优化网站:主要为智能手机用户创建网站。
2) 响应式网页设计:创建一个灵活的界面,可以响应所有屏幕大小。
3) 移动友好型网络开发:精简网站元素,使其适合较小的屏幕。
还有一个叫做Accelerated Mobile Pages,这是一个纯粹为移动用户创建的框架。
移动友好型Web开发的好处
一个移动友好型网站有很多优点,其中一些最重要的优点如下:
- 为用户提供无缝的网络体验,无论他们使用什么设备
- 增加网络流量,从而提高转化率
- 成本效益高,因为没有创建新的网站或应用程序;相反,现有的网站正在精简,其方向正在调整以适应移动屏幕
27.Core Web Vitals
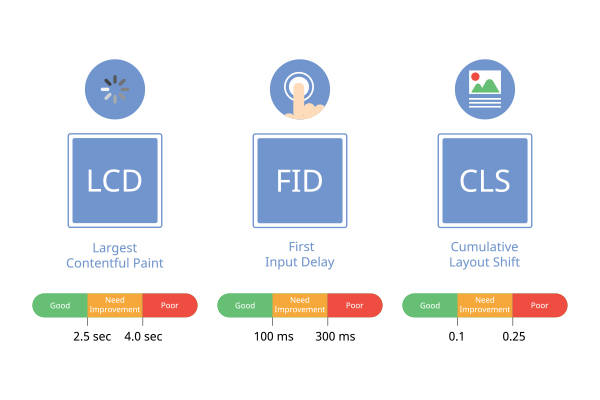
核心网络活力是2023年的另一个网络发展趋势,将持续很长一段时间。谷歌于2020年推出的Core Web Vitals是一系列因素(目前有三个),如果进行适当优化,可以改善网站的整体用户体验。根据谷歌的说法,这些指标在未来可能会根据用户认为的卓越页面体验而改变。
- 最大内容绘制(LCP)–它显示最重要的内容加载速度;它可以是文本、图像或视频。基准分数:2.5秒或更短。
- 首次输入延迟(FID)–它显示页面的交互性。换句话说,用户点击网页上的链接或视频“播放”按钮后,你的网站做出响应所需的时间。基准分数:100毫秒或更短。
- 累积布局偏移(CLS)–它显示页面是否稳定。如果你的页面在视觉上不稳定,也就是说,如果页面上的元素在加载时移动,你的用户会有不好的体验。基准分数:0.1或更低。
核心网络活力的重要性
尽管内容相关性仍然是搜索引擎排名的主要因素,但Core Web Vitals本身就很重要。如果两个或两个以上的网站都有相关内容,谷歌会优先选择为核心网络简历优化的网站。
衡量核心网络活力的工具
有许多工具可用于检查您网站的Core Web Vitals评分并进行必要的调整:
-
PageSpeed Insights
-
Google search console
-
Lighthouse
28.WordPress开发
由于其可扩展性和易用性,WordPress网站开发不仅在2023年,而且在未来几年都可能成为一种趋势。此外,它的最新版本6.0在几个月前发布。
随着一切都变得快节奏,如今的企业正在寻找简单、现成的解决方案,这些解决方案可以帮助他们节省时间,并在没有专业知识的情况下管理一切。在WordPress上建立和运行一个网站是轻而易举的事,因为它是一个CMS,社区已经完成了很多艰苦的工作。通过WooCommerce插件,该平台还提供了建立电子商务商店的解决方案。
根据W3techs的数据,截至2023年1月,63.6%的网站使用WordPress,市场份额为43.20%。
WordPress Web开发的好处
- 具有无限数量的主题和插件以及顶级安全性的开源CMS
- 活跃的在线社区和支持论坛为几乎任何问题提供帮助。
- 初学者友好平台
- 提供电子商务解决方案
使用WordPress的热门网站
-
TechCrunch
-
Yelp
-
PlayStation
- 49 次浏览
【战略趋势】Gartner对2024年及以后的顶级战略预测
视频号
微信公众号
知识星球
- 2023年,生成型人工智能释放了巨大的创造力和生产力潜力。
- 我们对2024年的最高预测显示,每一次战略对话都需要包括GenAI。
全局
了解今年的预测如何影响你的思维和战略规划
我们的年度顶级战略预测列表使IT内外精明、前瞻性思维的高管能够审视人工智能从工具转变为合作者和创造者意味着什么。像规划假设一样考虑这些预测:确定每个预测的时间范围,并评估近期标志,以确定预测实现的可能性是越来越大还是越来越小。
Gartner对2024年的预测分为三类,涵盖了技术和业务发展的最关键领域,我们预计您的组织将在未来三到五年内面临这些预测。

第一类:GenAI让人们在个人和职业上变得更好、更强大
个人可以使用GenAI创建更好的简历、报告、工作产品以及与他人的互动。到2026年,30%的员工将利用数字“魅力过滤器”,让你看起来比实际情况更好,在他们的职业生涯中实现以前无法实现的进步。
因为GenAI可以提高整个劳动力的产出,拥有大量廉价劳动力的国家将不会有那么明显的优势。到2027年,人工智能的生产力价值将被公认为国家实力的主要经济指标,这主要是由于劳动力生产力的普遍提高。
GenAI可以帮助创建一个更加多样化的劳动力队伍,包括来自不同教育和种族背景的不同年龄组以及神经分化的人。到2027年,25%的财富500强公司将积极招聘神经多样性人才,以提高业务绩效。
立即观看:Gartner对2024年的预测:行业网络研讨会系列
第二类:企业会更好地克服最糟糕的特质
为计算机供电的电力需求迅速增长。GenAI提高了能源成本和可用性。到2026年,一半的G20成员国将经历每月限电,将能源意识运营转变为竞争优势或重大故障风险。
GenAI可以提供现代化计划、重构计划、测试和验证以及其他功能,以加快现代化工作。到2027年,GenAI工具将用于解释遗留业务应用程序并创建适当的替代品,从而将现代化成本降低70%。
用机器人补充劳动力可以帮助企业发展,但这将暴露出改变企业运营的必要性。到2028年,由于劳动力短缺,智能机器人的数量将超过制造业、零售业和物流业的一线工人。
机器工人和客户的崛起促使人们重新思考关键业务运营。到2026年,30%的大公司将拥有专门的业务部门或销售渠道,以进入快速增长的机器客户市场。
第3类:新的威胁产生新的责任和社区
虽然GenAI带来了大量的机会,但虚假信息是一种新的威胁载体。到2028年,企业用于对抗它的支出将超过300亿美元,蚕食10%的营销和网络安全预算。
首席执行官必须授权一位负责任的高管,如CISO,来应对整个组织中虚假信息的挑战。到2027年,由于监管压力的增加和攻击面的扩大,45%的CISO的职责将扩展到网络安全之外。
工会历来向组织和政府施压,要求他们在公司之前保护员工。到2028年,在采用生成人工智能的推动下,知识工作者的工会化将增加1000%。
- 55 次浏览
【技术趋势】2022 年 5 大战略技术趋势
了解来年商业技术战略的发展趋势。 汤姆梅里特告诉我们要注意哪些。
了解趋势很有用。一方面,当有人使用最新的流行语时,它们可以帮助您不显得古怪。您不想回应说您的数据结构是棉质的,是吗?
Gartner 最近在增长、变革和信任类别中提出了 2022 年的 12 大战略技术趋势。
让我们找出一些您可能想要密切关注的内容。以下是 2022 年的五个战略技术趋势。
总体体验或TX。
这结合了所有的 X。您的客户体验、员工体验和最终用户体验都融合在一起。在 Total Experience 中,每个体验的领导者都对客户和员工的综合需求负有同等责任。其理念是提高客户和员工的信心、满意度、忠诚度和拥护度。
生成式人工智能或 GAN
使用机器学习来找出有关内容或对象的新见解,而无需教授模型。它可以创建代码、定位营销、识别新产品等等。
超自动化。
这意味着找到可以自动化的事情并尽快完成。让您的员工能够处理更重要的问题或您从未想过可以解决的问题。 Gartner 表示,超自动化团队应该专注于质量、速度和增强决策。
数据织物
这是对跨平台和业务用户集成数据的描述。这样做的目的是使您可以轻松使用您拥有的数据并减少数据管理工作。
网络安全网格。
没有边界了,伙计们。您的数据无处不在。网络安全网格架构(CSMA)认识到这一点,并致力于保护数据,无论数据在哪里。
这只是我想指出的五个,但还有更多,例如可组合应用程序和分布式企业。想知道它们的意思吗? Gartner 分析师 Esther Shein 在文章中将它们全部分解:12 项技术可在 2022 年加速增长、建立信任并塑造变革。
原文:https://www.techrepublic.com/article/top-5-strategic-tech-trends-for-20…
本文:
- 112 次浏览
【技术趋势】2022 年 5 大技术趋势
2022 年即将到来,科技界并未坐以待毙。当我每天为 Daily Tech News Show 报道科技新闻时,随着趋势的到来、加速和消失,我坐在前排。
以下是我对 2022 年要寻找的前五项技术趋势的看法。
1. 中央银行数字货币或 CBDC。
您已经看到有关在中国或实施这些试验的小国进行的有限试验的报道。我的意思是像巴哈马这样的实际政府数字货币没有像萨尔瓦多那样采用比特币。今年,更多主要政府将参与创建由政府发行的数字货币的游戏,以试图避免加密货币浪潮的潜在威胁。
2. 电池技术。
我不打算预测电池技术的重大突破——那是 5 到 10 年之后。但是太阳能和风能将继续变得更好,更具创新性,这将为我们可以用现有的电池技术做些什么亮灯。想象一下您所看到的智能手机电池发生在工业化电力存储中的情况。
3.芯片短缺。
可悲的是,我认为它不会在今年结束,但到 2022 年底,我们将看到隧道尽头、航道尽头或您喜欢的任何后勤比喻的曙光。事实上,随着晶圆厂迎头赶上,所有正在建造的新工厂都需要证明其合理性,因此请准备好接受有关容量管理的故事。
4.元宇宙。
你会经常听到元节这个词。尽管如此,就像现在一样,它在很大程度上将毫无意义。 2022 年将不会有真正的元宇宙,尽管有几家公司声称他们已经做到了。 Web3 是真实的——元节还不是......
5.人工智能反弹。
我猜对人工智能的强烈反对会越来越大。人们越来越关注机器学习算法中的偏见,这将继续成为主流意识。由于对人工智能的影响有些毫无根据的恐惧,这将导致抵制,并呼吁加强监管。期待数据隐私发生的事情开始转向人工智能。
抱歉,我知道所有这些都不是晴天,但它们是我在我面前看到的趋势。明年再来看看我是对还是错。
原文:https://www.techrepublic.com/article/top-5-tech-trends-for-2022/
- 67 次浏览
【技术趋势】2022 年以后将影响企业的 5 种技术趋势
很难理解技术对企业和整个社会的影响。今年的年度 Thoughtworks 窥镜报告试图将广泛的技术纳入视野,以便企业领导者了解技术将它们带向何方。
该报告采用整体方法来分析 100 种当前和新兴技术的影响。该报告分为称为镜头的部分,“为行业领导者提供了如何最好地竞争并成为颠覆者的建议。”
“我们使用窥镜中的镜头来帮助理解所有个人趋势,这些镜头类似于我们认为重要的大‘故事情节’,”Thoughtworks 全球技术主管迈克尔梅森说。 “有趣的是还要考虑组合镜头。如果我们将人机体验的演变与人工智能的爆炸性相结合,那么这将对特定行业或组织产生什么影响?虽然我们在报告,这个练习对读者来说也是一个很好的用来激发他们思考的练习。”
与人工智能合作
第一个镜头,与 AI 合作,着眼于企业如何从机器学习和 AI 的快速采用中获得最大收益。要做到这一点,企业必须了解该技术在哪些方面表现良好,在哪些方面表现不佳。例如,需要创造力或直觉的问题并不是人工智能的最佳用例。在这些情况下应用人工智能应该是为了帮助人类决策,而不是取代它。
在其他领域,例如部署聊天机器人来回答基本查询或将客户请求上报给人类客户服务代表,人工智能的效果非常好。受益于人工智能驱动的自动化的领域包括动态定价、推荐系统、异常检测和供应链优化。
在这个领域值得关注的一些趋势包括:尊重隐私的计算、AutoML、联邦学习,以及在最遥远的未来,量子机器学习。
不断发展的人机体验
下一个镜头侧重于人机体验。众所周知,这是一个需要改进的领域。本节重点介绍虚拟世界的新兴概念,这是现实世界和数字世界重叠的现实领域。扩展现实应用——VR、AR 和混合现实——在这个领域占据主导地位。
该报告的作者预计,随着 VR 和 AR 设备制造商和初创公司试图从中获利,该领域将得到更多关注。根据 Emergen Research 报告中引用的研究,元界市场将呈爆炸式增长,同比增长 40% 至 800B 美元到 2028 年。
值得关注的技术包括:脑机接口、视网膜投影、情感计算,以及在更遥远的未来,元宇宙。
发挥平台的潜力
第三个镜头侧重于将平台建设作为核心业务战略。报告称,这是一个“充满歧义”的领域,因为即使是“平台”或“平台方法”的概念也很难定义。
“成功的平台方法取决于明确定义,”报告称。 “平台可以推动利益相关者之间的各种价值和误解或错位,这将导致低于标准或浪费的努力。”
为避免这些问题,报告建议首先定义您想要实现的目标、您想要的结果,并确保所有利益相关者都理解并分享相同的目标。
“平台是加速器或催化剂,拥有平台可以让你更快地做某事,”梅森说。
根据 Mason 的说法,目前使用的平台分为三种类型:
- 以开发人员为中心的基础架构平台,通过一种通用的、经过验证的安全性和合规性方法来加快上市时间并降低风险。
- 业务能力平台通过提供一组 API 来加速新产品的开发,这些 API 封装了现有的业务能力,并使使用现有资源构建新服务变得更加容易。
- 通过促进消费者、同行和服务提供商之间的互动来创造价值的平台商业模式。
在这个领域值得关注的一些技术包括:雾计算、信任生态系统、机器对机器协作,以及在更遥远的未来,私有物联网 PaaS 平台。
扩大敌对技术的影响
通过这个镜头,报告的作者探索了即使是好的技术也可能被用于坏目的的想法。
“根据我们的定义,‘敌对’技术不仅包括恶意软件和黑客工具等犯罪技术,还包括广告和客户定位等用例,”报告称。 “一个例子是算法或机器学习系统中的偏见。这些可能表现出对某些客户群体的‘敌对’倾向,而没有受到损害或故意以这种方式设计,因为它们的构建或开发方式出现了计划外和未被注意的扭曲。”
即使是合法的活动,例如在人们上网时跟踪他们,也可能被一些人视为敌对,而其他人则自由地放弃他们的隐私以换取目标广告等感知利益。
为了避免疏远客户并提高信任度,该报告的作者建议尊重客户的意愿,避免侵入性定位和根除偏见人工智能。
在这个领域值得关注的一些趋势包括:尊重隐私的计算、隐私感知通信、差分隐私,以及在更遥远的未来,量子机器学习和元宇宙。
加速实现可持续发展
第五个也是最后一个镜头着眼于技术推动的增长和消费的大局和长期可行性。报告称,消费者、政府和投资者都要求企业对环境承担更大的责任,因为“走向绿色已经从可有可无变成了企业的当务之急”。
“技术是气候变化的主要贡献者,大多数科技公司都在试图解决这个问题……”报告称,但它“也可以帮助我们的日常生活更加可持续,例如支持优化交通的智能城市减少污染。向可持续世界的转变正在加速,这一趋势具有广泛的商业影响。
其中一些影响包括要求能源效率和可持续性的政府政策和立法;投资者更喜欢具有强大环境、社会和治理标准的公司;以及利用绿色举措吸引新客户并留住现有客户的公司。
“有两个关键趋势需要注意,”梅森说。 “首先,消费者越来越意识到可持续实践的必要性,并担心环境影响和气候变化,他们确实会根据公司对可持续发展的看法改变他们的购买行为。这与购买的依据不同然而,决定了实际的 ESG 评级。”
在这个领域值得关注的一些技术包括:循环经济技术、可持续性区块链、绿色软件工程,以及在更遥远的未来,元宇宙和 DNA 数据存储。
原文:https://www.techrepublic.com/article/5-tech-trends-that-will-impact-bus…
- 65 次浏览
【技术趋势】2023年Gartner的10项技术趋势
从新进入者到现有者,每项技术都有一点是正确的:定制是关键。
 商业技术有两个主要目标:通过效率降低成本,帮助企业增加收入。这是每个供应商的标准宣传的一部分。
商业技术有两个主要目标:通过效率降低成本,帮助企业增加收入。这是每个供应商的标准宣传的一部分。
在Gartner 2023年的顶级战略趋势中,出现了一种新的、选择自己的冒险方法来应对技术的关键转变,该方法展示了企业如何使用特定的战略和产品来反映总体目标。
一些企业热衷于明年削减成本,而另一些企业则预计增长水平会飙升。高德纳(Gartner)杰出副总裁分析师弗朗西丝·卡拉穆齐斯(Frances Karamouzis)表示,第三组人只是在重塑自己。
卡拉穆齐斯说:“实现这一目标的三种方式是优化、扩展和开拓。”。
该报告于周一在佛罗里达州奥兰多举行的Gartner IT研讨会/Xpo 2022上发表,展示了过去一年技术类别的演变。它还显示了企业可以推进技术研究,并在适当情况下进行投资,以抵御潜在竞争对手的潜力。
但定制是关键。
Karamouzis告诉首席信息官Dive:“其中很多都有多种底层技术,需要将它们结合在一起并进行架构设计,以便客户能够真正实现这些技术。”。“我们不期望一个客户会出去做所有的10件事。”
以下是Gartner 2023年的顶级战略技术趋势:
持续性
可持续性,或更具体地说,可持续技术,是战略趋势中的一个首要主题,因为环境和社会变化在行政议程中日益重要。
她说:“这真的是在谈论所有的基础技术,这些技术将帮助客户关注环境因素、治理和社会。”。
可追溯性、分析、可再生能源和人工智能是该小组的工具组成部分。
元宇宙
作为2022年最热门词汇的竞争者,“元宇宙”对不同的人来说可能意味着不同的东西。
Gartner在其趋势中将其定义为一个集体虚拟3D共享空间,“由虚拟增强的物理和数字现实融合而成”。尽管Facebook母公司Meta大力推动市场营销,但该分析公司预计,这一空间不会由一家供应商拥有。
Gartner预测,在未来五年中,五分之二的大型组织将结合Web3、AR云和数字孪生,推出基于元宇宙的项目,以增加收入。
这是该技术首次被列入年度趋势清单。
超级应用程序
根据Gartner的数据,预计到2027年,全球一半的人口将成为多个超级应用程序的每日活跃用户。但什么是超级应用程序?
卡拉穆齐斯说:“超级应用程序将应用程序平台和生态系统的功能融为一体。”。“它有自己的一套功能,但它也是第三方开发和发布自己的迷你应用程序的平台。”
换句话说,超级应用程序可以为客户或员工整合和替换多个应用程序。
卡拉穆齐斯说:“就终端用户可用的内容而言,这是一个游戏规则的改变者,但就品牌而言,这也是一个游戏改变者。”。
自适应AI
当前的人工智能系统必须根据过去的数据进行训练,以确保准确性,这在条件快速变化时成为一个挑战。
但Gartner建议,自适应人工智能将能够使用实时反馈,并动态改变其学习内容,根据需要调整目标。
数字免疫系统
安全性是技术高管的首要任务,无论他们的垂直行业。
在数字免疫系统中,数据驱动的洞察力有助于改进操作、自动化事件解决并提高系统的稳定性。
Karamouzis表示:“这意味着要将可观测性、增强测试、混沌工程、自动修复、站点可靠性等概念纳入到所有开发人员的预配置元素中,从而优化他们推出的应用程序平台的弹性。”。
应用可观测性
这一策略使公司能够获取可观察到的工件(日志、跟踪或API调用),并采取综合方法来加速决策。
Karamouzis在趋势公告中表示:“当进行战略规划并成功实施时,应用可观测性是数据驱动决策的最有力来源。”。
AI信任、风险和安全管理
该框架适用于所有人工智能算法以及在人工智能下运行的模型,本质上通过将这些控件集成到模型中来处理可能危及人工智能模型或数据的问题。
正如Gartner所说的,TRiSM将信任、风险和安全管理纳入模型中,“因此它是对环境中新事物的自我测试”,Karamouzis说道。
行业云平台
SaaS、PaaS和IaaS的组合将为公司提供行业特定的模块化功能集,以支持特定行业业务所需的用例。
多年来,从微软到AWS,供应商一直在寻求满足特定行业的需求。
这些平台的使用将加快,Gartner预测到2027年,一半的企业将使用行业云平台。
平台工程
报告称,平台工程允许公司构建和运营用于软件交付和生命周期管理的自助开发平台。
该公司预测,到2026年,五分之四的公司将建立平台团队。该方法将使公司能够优化开发人员体验,加快客户价值交付。
无线价值实现
5G技术的支持者称其为潜在的企业技术颠覆者。虽然特定领域的应用程序已经显示出价值,但Gartner预计,没有哪种技术能够主导所需的无线解决方案。
Karamouzis表示,这一趋势“主要是如何围绕所有不同的无线技术扩展网络和端点”。“因此,这是一系列适用于许多不同环境的无线解决方案”和纯连接。
他们将使用内置分析提供洞察力,低功耗系统将直接从网络获取能量。这意味着网络将成为直接商业价值的来源。
- 188 次浏览
【技术趋势】Gartner 2024年十大战略技术趋势
视频号
微信公众号
知识星球
- 这些创新可以推动你更快地实现商业目标,尤其是在人工智能快速发展的时代。
- 有目的地集成精选的几个,以帮助建立和保护您的数字组织,同时创造价值。
全局
这些战略性技术趋势将在未来三年内纳入业务和技术决策
Gartner敦促您评估每一种技术趋势的影响和好处,以确定哪种创新或战略组合将对您的组织的成功产生最重大的影响。
下载电子书:Gartner 2024年十大战略技术趋势的详细指南
- 人工智能信任、风险和安全管理(AI TRiSM)
- 持续威胁暴露管理
- 可持续技术
- 平台工程
- 人工智能增强开发
- 行业云平台
- 智能应用程序
- 民主化的世代人工智能
- 增强的互联员工队伍
- 机器客户
每一种趋势都与一个或多个关键的业务主题有关:保护和保存过去和未来的投资,在正确的时间为正确的利益相关者构建正确的解决方案,并为不断变化的内部和外部客户环境提供价值。

主题1:保护您的投资
为了确保技术投资的持续影响,请:
- 故意的。停止所有方向不足的不受控制的实验。努力应该是有意的,并产生良好的日常使用效果。
- 现实的。通过从一开始就考虑必要的保护措施来计算项目的投资回报率。
- 前瞻性。在确保您的权利(即知识产权和创作所有权)和未来的持久地位的同时,量身定制创新并考虑到重复使用。
属于这一类别的IT趋势是:
- 人工智能信任、风险和安全管理(AI TRiSM)
- 持续威胁暴露管理
- 行业云平台
- 可持续技术
- 民主化的生成式人工智能
到2026年,生成人工智能将显著改变70%的新网络应用程序和移动应用程序的设计和开发工作。
来源:Gartner
主题2:建设者的崛起
通过以下方式释放构建应用程序和解决方案的无数社区的创造力:
- 使用适合您所在行业、特定组织需求和专业员工的技术。
- 开发您的路线图,使非专业人员能够创建。
- 与业务利益相关者密切合作,以确定软件交付和产品组合生命周期管理。
属于这一主题的IT趋势是:
- 平台工程
- 人工智能增强开发
- 行业云平台
- 智能应用程序
- 可持续技术
- 民主化的生成式人工智能
到2027年,80%的首席信息官将拥有与IT组织可持续性相关的绩效指标。
来源:Gartner
主题3:传递价值
通过以下方式优化和加快您改善利益相关者体验的方式,并扩大您推动收入的选择:
- 不断适应不断变化的内部和外部客户需求,创造价值确定和交付的良性循环。
- 包括针对基于算法的客户的方法,这些客户的影响力正在迅速增长。
- 促进对快速发展的数字工具的受控访问,无论这些工具与生成性人工智能、劳动力技能和迁移有关,还是与其他增强和自动化的机会有关。
属于这一主题的IT趋势是:
- 机器客户
- 增强的互联员工队伍
- 智能应用程序
- 可持续技术
- 民主化的生成式人工智能

如何使用这些技术实现首席执行官和首席信息官2024年及以后的目标
- 根据组织的具体情况,检查趋势的潜力,将其纳入未来几年的战略规划,并适当调整您的商业模式和运营。
- 这些趋势是相辅相成的,而不是孤立的。将技术结合起来,以符合您的战略、转型意图和利益。
- 积极成果包括增强韧性、最大限度地实现数据价值、吸引和留住人才、实现ESG目标、推动增长和加快数字业务。
研究背后的故事
来自Gartner副总裁兼分析师Bart Willemsen的办公桌
“技术中断和社会经济不确定性需要有大胆行动和战略性增强抵御能力的意愿,而不是依赖临时应对措施。IT领导者必须确保经过计算的风险,并进行可靠和持久的投资,以可持续地实现内部和外部价值创造。”
- 146 次浏览
【技术趋势】企业技术 2022:IT 的未来
在过去的两年里,预测未来变得更加困难。大流行病、供应链危机、这些事件的经济影响以及政治动荡的世界已经使世界天翻地覆,使得根据最近的历史预测未来变得更加困难。
在过去的两年里,我们看到远程工作的加速,人们离开工作或职业的“伟大辞职”,从实体购物到在线购物的更大转变,以及企业 IT 组织需要优先考虑云和自动化。
已经发生了很多变化。 COVID-19 病毒的 omicron 变体的到来,以及我们对这次新爆发的反应,也是图中的一个新因素。一些科技巨头已经取消了他们在大型科技会议 CES 上的亲自参与。
尽管如此,有迹象表明组织可以监控以了解未来可能发生的事情,然后制定计划以利用即将到来的机会。我们要去哪里,你需要采取什么行动?我们只收集了过去几个月的几篇文章,为塑造 2022 年及以后的力量提供了展望。
以下是您对 2022 年的预测指南:
- Gartner:2022 年及以后 IT 组织和用户的顶级预测
- 老板会被淘汰吗?非洲会成为新的印度吗?企业会不会停止尝试收集如此多的消费者信息?
- https://www.informationweek.com/executive-insights-and-innovation/gartn…
- CIO 议程:未来的云、网络安全和人工智能投资
- Gartner 表示,在大流行造成的波动期间,采用“业务可组合性”的企业更有可能取得成功。这种波动性将持续存在,所以现在是准备的时候了
- https://www.informationweek.com/executive-insights-and-innovation/cio-a…
- 云可能会看到更多的人工智能,面临地缘政治摩擦加剧
- Gartner 和 Forrester 的分析师分别认为,未来几年会更广泛地使用自动化并提高政府对云领域的参与度。
- https://www.informationweek.com/cloud/cloud-may-see-more-ai-face-increa…
- IT 领导者可能在 2022 年花费预算的地方
- 数字化、数据利用、IT 上市速度和严密的安全性将成为 2022 年的业务和 IT 重点——以及对人才永无止境的追求。
- https://www.informationweek.com/strategic-cio/where-it-leaders-are-like…
- 更多的技术支出从 IT 中转移出去
- 企业技术支出正在增加,但 CIO 和 IT 领导者的预算将减少。业务单位本身是
- https://www.informationweek.com/strategic-cio/enterprise-tech-2022-what…
原文:https://www.informationweek.com/strategic-cio/enterprise-tech-2022-what…
本文:
- 82 次浏览
技术选型
- 382 次浏览
【大数据架构】Apache Flink和Apache Spark—比较指南
1. 目标
在本教程中,我们将讨论Apache Spark和Apache Flink之间的比较。Apache spark和Apache Flink都是用于大规模批处理和流处理的开源平台,为分布式计算提供容错和数据分布。本指南提供了Apache Flink和Apache Spark这两种蓬勃发展的大数据技术在特性方面的明智比较。

2. Apache Flink vs Apache Spark
| Features | Apache Flink | Apache Spark |
|---|---|---|
| Computation Model | Flink基于基于操作器的计算模型。 | Spark是基于微批处理模式的。 |
| Streaming engine | Apache Flink为所有工作负载使用流:流、SQL、微批处理和批处理。批处理是流数据的有限集。 | Apache Spark对所有工作负载使用微批。但对于需要处理大量实时数据流并实时提供结果的用例来说,这是不够的。 |
| Iterative processing | Flink API提供了两个专用的迭代操作Iterate和Delta Iterate。 | Spark基于非本地迭代,在系统外部实现为规则的for - loop。 |
| Optimization | Apache Flink附带了一个独立于实际编程接口的优化器。 | 在Apache中,Spark作业必须手动优化。 |
| Latency | 通过最小的配置努力,Apache Flink的数据流运行时实现了低延迟和高吞吐量。 | 与Apache Flink相比,Apache Spark具有较高的延迟。 |
| Performance | 与其他数据处理系统相比,Apache Flink的总体性能非常出色。Apache Flink使用本地闭环迭代操作符,这使得机器学习和图形处理更快。 | 尽管Apache Spark拥有优秀的社区背景,现在它被认为是最成熟的社区。但是它的流处理效率并不比Apache Flink高,因为它使用微批处理。 |
| Fault tolerance | Apache Flink遵循的容错机制是基于Chandy-Lamport分布式快照的。该机制是轻量级的,从而在保持高吞吐率的同时提供了强大的一致性保证。 | Spark 流恢复丢失的工作,并提供精确的一次性语义开箱即用,没有额外的代码或配置。(请参阅火花容错特征指南) |
| Duplicate elimination | Apache Flink一次处理每条记录,因此消除了重复。 | Spark还精确地处理每条记录一次,因此消除了重复。 |
| Window Criteria | Flink具有基于记录或任何自定义用户定义的窗口条件。 | Spark有一个基于时间的窗口条件 |
| Memory -Management | Flink提供自动内存管理。 | Spark提供可配置的内存管理。Spark 1.6, Spark也已经转向自动化内存管理。 |
| Speed | Flink以闪电般的速度处理数据 | Spark的处理模型比Flink慢 |
3.结论
Apache Spark和Flink都是吸引业界关注的下一代大数据工具。两者都提供与Hadoop和NoSQL数据库的本地连接,并且可以处理HDFS数据。两者都是几个大数据问题的好解决方案。但由于其底层架构,Flink比Spark更快。Apache Spark是Apache存储库中最活跃的组件。Spark拥有非常强大的社区支持和大量的贡献者。Spark已经部署在生产环境中。但就流功能而言,Flink要比Spark好得多(因为Spark以微批的形式处理流),并且对流有本地支持。Spark被认为是大数据的3G,而Flink被认为是大数据的4G。
原文:https://data-flair.training/blogs/comparison-apache-flink-vs-apache-spark/
本文:http://jiagoushi.pro/node/1121
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 439 次浏览
【技术选型】AMQP vs MQTT
视频号
微信公众号
知识星球

AMQP和MQTT之间的差异
在过去的几十年中,用于消息异步排队的开源协议是AMQP与MQTT。最近,它已经适应了新的更新。AMQP打算成为国际标准组织或国际电化学委员会的一部分,并由OASIS选择,MQTT已采用Eclipse。AMQP使用wire执行其消息队列。因此,它是有线协议,在网络上被转换成大量的字节值。MQTT是为带宽最小的有限设备开发的。它是一个轻量级的广播系统,用户可以像客户端一样传输和接收消息。
AMQP和MQTT之间的正面比较
以下是AMQP与MQTT之间的14个最大差异:

AMQP和MQTT之间的关键区别
AMQP和MQTT都用于物联网。但是,让我们讨论一下主要的区别:
- MQTT具有客户机/代理体系结构,而AMQP具有客户机或代理以及客户机或服务器体系结构。
- MQTT遵循发布和订阅的抽象,而AMQP遵循响应或请求以及发布或订阅方法。
- AMQP的头大小为8bytes,MQTT的头大小为2bytes。MQTT的消息大小很小且已定义,而AMQP具有可协商的和未定义的。
- MQTT的方法是connected、publish、close、subscribe和disconnect。AMQP遵循Consume, deliver, publish, get, select, acknowledge, delete, recover, reject, open, and close.
- MQTT部分支持缓存和代理,而AMQP则提供完全支持。
- AMQP和MQTT都遵循TCP协议、二进制标准和开源队列系统。
- AMQP提供的安全性是IPSec、SASL、TLS或SSL,而MQTT只提供TLS或SSL安全标准。AMQP和TCP一起使用SCTP进行传输。OASIS同时支持AMQP和MQTT。
-
MQTT提供的服务质量是fire和forget,如果QoS为0。如果QoS为1,则至少有一个,如果QoS为2,则正好有一个。AMQP提供的服务质量是与MQTT类似的结算和取消结算格式。
AMPQ与MQTT比较表
以下是AMQP与MQTT之间的比较:
| 比较的基础 | AMQP | MQTT |
| 定义 | AMQP被扩展为高级消息队列协议。AMQP提供了更丰富的消息传递环境。 | MQTT定义为消息队列遥测传输。它提供了一种简单的消息队列服务方式,主要在嵌入式系统中实现. |
| 背景
|
AMQP是由金融集团开发的一个开源的、客户驱动的队列。在没有任何定制的情况下,它在市场上一天天地在进步。 | MQTT主要由供应商驱动并由IBM开发,实现成本很高。 |
| 设计协议
|
AMQP使用TCP进行消息的异步传输,而不管选择什么操作系统、硬件或编程语言。它提供了具有完全生命力的消息传递服务。AMQP在网络用户和基础设施资源的不同控制下运行。 | 与AMQP类似,MQTT在异步方法中使用TCP共享消息,而不依赖于任何属性。它是专门为在网络的最小带宽上运行的小型设备设计的。MQTT将复杂的各方视为由附近的私有基础设施管理的。 |
| 框架的优化
|
它在数据帧的连线上进行了高级优化,有一种提高服务器性能的缓冲方法。 | 它还基于线(Wire)框架,它使用类似流的方法来执行帧的最小内存设备。它不允许批量传输消息。 |
| 消息服务 | AMQP应用于5个不同的属性中,比如不影响生存期的发布者-订阅者,只要它需要,它就保持在队列中,如果没有人使用队列,它就保持不变。它支持各种消息传递循环、经典或传统消息队列、组合以及保存和转发。它执行元数据消息来帮助幂等消息和消息分组。 | 基于内容的发布和订阅消息传递,并且是高度瞬变的。它主要用于主动路由因此链接的订阅者和发布者。它在传统的延长生命周期消息队列中应用有限。 |
| 消息的事务 | 它支持不同的确认、事务、用例以及整个消息队列。它支持分解各种事务代码,并且在有延迟时确认过期以调整性能。 | MQTT不支持任何类型的事务。它只支持一般承认。 |
| 连接的安全 | AMQP与TLS和SASL是统一的,并且使用特殊的特性来使用连接。它能够消除SASL和TLS策略,并通过不断的更新来提高性能。 | MQTT不会处理任何连接中的安全问题。 |
| 用户的安全 | AMQP利用SASL方法来选择安全性,而不需要改变协议。它为相同网络中的组件提供不同的名称。因此,这个特性使我们能够使用嵌套的防火墙和看门人。在广播任何消息之前,它将与用户进行身份验证。 | MQTT需要较小的用户名和最低密码,并且在这个趋势期间不设置任何预防措施。 |
| Last value queues | 它不支持队列中的最后一个值。 | 它提供Retain命令并支持队列中的最后一个值。 |
| 消息可靠性 | 它只启用触发和遗忘策略。一旦接收到,就无法检索。 | 它类似于AMQP,数据传递太可靠了。 |
|
消息的 命名空间 |
它允许以多种方式查找节点和队列等消息。 | 它在消息的分层传输中使用“名称空间”。 |
| 附加的属性 | AMQP支持对等连接,并允许整个网络的负载平衡,它是多路复用的。它可以使用容器,主题是双对称的。 | MQTT为DNS服务器提供了基本要求。MQTT是不对称的,不支持任何高级特性。 |
| 实现 | AMQP是在小于64kb RAM的组件中实现的。 | 它是开源库中的一个较小的协议,在RAM小于64kb的设备中实现 |
| 可扩展性 | 它的结构点允许在特定的供应商中进行扩展,并同意即将采用的不兼容扩展的方式。它允许通过隔离在层中进行更改。 | MQTT需要一个完整的协议草案。 |
结论
虽然AMQP和MQTT在体系结构和协议上有很多不同,但它们在物联网等各种应用中得到了广泛的应用。作为开源协议,AMQP和MQTT都可以根据客户机需求和可用带宽应用于所有应用程序。
本文:http://jiagoushi.pro/node/1126
讨论:请加入知识星球【首席架构师圈】或者小号【ca_cea】
- 3022 次浏览
【技术选型】AWS 和 AZURE的全面比较
视频号
微信公众号
知识星球

AWS和AZURE之间的区别
亚马逊网络服务(AWS)是亚马逊的一个云服务平台,提供不同领域的服务,如计算、存储、交付和其他功能,帮助业务规模和增长。我们可以以服务的形式利用这些域,这些服务可用于在云平台中创建和部署不同类型的应用程序。微软Azure是微软的一个云服务平台,它在不同的领域提供服务,如计算、存储、数据库、网络、开发工具和其他功能,帮助组织扩大和增长他们的业务。Azure服务被广泛地分为平台即服务(PaaS)、软件即服务(SaaS)和基础设施即服务(IaaS),这些服务可被开发人员和软件员工通过云来创建、部署和管理服务和应用程序。
AWS是什么?
AWS服务被设计成可以相互协作并产生可伸缩且高效的结果的方式。AWS提供的服务分为三类,如基础设施即服务(IaaS)、软件即服务(SaaS)和平台即服务(PaaS)。AWS于2006年推出,成为目前可用的云平台中最好的云平台。云平台提供了各种优势,比如降低管理开销、最小化成本等等。
AZURE是什么?
微软Azure于2010年推出,成为最大的商业云服务提供商之一。它提供了广泛的集成云服务和功能,如分析、计算、网络、数据库、存储、移动和web应用程序,它们与您的环境无缝集成,以实现效率和可伸缩性。
AWS和AZURE的正面比较(信息图)
下面是AWS和AZURE之间的6大比较
AWS和Azure的主要区别
两者都是市场上的热门选择;让我们来讨论一下主要的区别:
- AWS EC2用户可以配置他们自己的虚拟机或预配置的映像,而Azure用户需要选择虚拟硬盘来创建由第三方预配置的虚拟机,并需要指定所需的核数和内存。
- AWS提供在实例启动时分配的临时存储,在实例终止时分配的临时存储,S3提供对象存储。而Azure通过页blob为VM提供块存储,通过块存储为对象存储提供临时存储。
- AWS提供虚拟私有云,这样用户就可以在云中创建隔离的网络,而Azure提供虚拟网络,通过它我们可以创建隔离的网络、子网、路由表、私有IP地址范围,就像AWS一样。
- Azure对混合云系统开放,而AWS对私有或第三方云提供商不那么开放。
- AWS是按小时计费的,而Azure是按分钟计费的,它提供了比AWS更精确的定价模式。
- AWS有更多的特性和配置,它提供了大量的灵活性、功能和定制,并支持许多第三方工具的集成。然而,如果我们熟悉windows, Azure会很容易使用,因为它是一个windows平台,很容易集成本地windows服务器和云实例来创建一个混合环境。
AWS vs AZURE对照表
以下是要点列表,描述比较:
| 比较点 | AWS | AZURE |
| 计算 | 我们有计算机来进行数据的计算、处理和计算,我们可以根据我们的需求在云服务提供商的帮助下扩展到数千个处理节点。AWS使用弹性计算云(EC2)作为可伸缩计算和管理Docker或Kubernetes软件容器的主要解决方案,它使用ECS (EC2容器服务)和EC2容器注册。 | Azure在计算方面使用虚拟机,在很大程度上使用虚拟机规模集,在软件管理方面,在Docker container中使用container Service (AKS),在Docker container Registry中使用container Registry。 |
| 存储 | 存储位于云提供商的主要服务旁边。AWS使用S3(简单存储服务),它比Azure运行时间长,并且提供了大量的文档和教程。它提供冰川存档存储、数据存档和S3不频繁访问(IA)。 | Azure使用存储块blob进行存储,存储由块组成,可以高效地上传大的blob。它使用存储冷却和存储归档来归档数据。 |
| 网络 | 云提供商提供不同的合作伙伴和网络,这些合作伙伴和网络将与使用不同产品的数据中心相互连接。AWS使用虚拟私有云进行网络连接,并使用API网关进行跨场所连接。AWS使用弹性负载平衡来实现联网期间的负载平衡。 | Azure使用虚拟网络进行联网或内容交付,并使用VPN网关进行跨场所连接。为了实现内容传递过程中的负载均衡,它使用负载均衡器和应用程序网关进行管理 |
| 部署应用 | AWS也提供了类似的解决方案,包括弹性的Beanstalk、批处理、Lambda、容器服务等。但它在应用托管端没有很多功能。 | 云提供商的优势之一是部署应用程序的过程很简单。作为一名开发人员,我们希望通过使用PaaS特性虚拟地将我们的应用程序部署到多个服务器上。Azure拥有云服务、容器服务、功能、批处理、app服务等多种应用部署工具。 |
| 数据库 | 几乎所有的云提供商都提供了在SQL和NoSQL解决方案中实现数据库的能力。AWS通过使用RDS使用关系数据库作为服务,对于NoSQL,它使用Dynamo DB,缓存使用弹性缓存。 | Azure使用SQL数据库,MySQL和PostgreSQL作为关系数据库,使用Cosmos DB作为NoSQL解决方案,使用Redis Cache作为缓存目的。 |
| 开源开发 | AWS非常适合开放源码开发人员,因为它欢迎Linux用户,并为不同的开放源码应用程序提供了几种集成。 | Azure为企业用户提供了这个工具,这样他们就可以使用当前的active directory帐户在Azure云平台上签名,并在Windows、Linux和MacOS上运行。net框架。 |
结论
最后,概述AWS和AZURE云提供商之间的差异。我希望您能更好地了解AWS和AZURE提供商提供的服务,并根据您的需求选择云提供商。如果您正在寻找作为服务的基础设施或广泛的服务和工具,那么您可以选择AWS。如果您正在寻找windows集成或良好的平台服务(PaaS)云提供商,那么您可以选择Azure。
本文:https://jiagoushi.pro/node/1133
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 2385 次浏览
【技术选型】Cloudflare vs CloudFront
Cloudflare和CloudFront的区别
作为世界上最大的网络之一,Cloudflare提供的服务增加了网站和应用程序的安全和性能问题。在早期,当使用Internet并试图访问网站或web信息时,最初需要从系统向服务器发送请求,这将根据需要反映所需的输出。但有时会出现系统崩溃的情况,或者当大量请求同时到达承载数据的服务器时,系统变得无响应。为了克服这些困难,使他们的网站和应用程序安全可靠,他们使用了Cloudflare服务。Cloudflare通过保护互联网属性不受恶意攻击、恶意程序等的攻击来提供安全保障。
然而,云前端是一个内容分发网络(CDN),它提供了一个全球分布的代理服务器网络,这些代理服务器缓存内容,从而提高了下载内容的速度性能。Cloud Front的工作模式是“按使用付费”。
Cloudflare与CloudFront的正面比较(信息图表)
以下是Cloudflare和CloudFront之间的十大区别:
Cloudflare与CloudFront的主要区别
以下是Cloudflare与CloudFront的主要区别:
Cloudflare
Cloudflare采用反向代理的方式工作,我们用Cloudflare建立了一个站点;它把名字服务器给了Cloudflare。这使得Cloudflare能够控制您的站点,并将所有流量驱动到您的站点。Cloudflare也提供了许多CDN之外的其他功能。
当任何人访问您的网站时,Cloudflare将获取静态内容并将数据存储在世界各地的各种Cloudflare网络上,以便从他们需要的位置访问。
Cloudflare的设置包括以下步骤:
- 注册Cloudflare账户。
- 启动“添加站点”向导。
- 更改您的域名服务器(由于反向代理方法
- 一旦完成,我们就可以从仪表板上访问和管理Cloudflare设置。
Cloudflare提供的其他服务包括:
- 免费SSL证书(但它的共享版本)
- DDoS保护
- Web应用程序防火墙
- 图像优化
- 移动优化
CloudFront
CloudFront是一种CDN,它通过一个称为边缘位置的网络来传递数据,从而在用户提前请求数据时能够快速访问数据、低延迟、低网络流量。
在这里,我们不需要更改Cloudflare这样的名称服务器。云锋采用推拉方式。CloudFront自动从原始位置提取您的数据,并将其放到全球各个服务器网络上。Cloudflare与CloudFront的主要区别如下:
就像Cloudflare控制名称服务器一样,CloudFront没有这样做,因为它不能自动为任何站点提供来自任何边缘位置的内容。这就需要一个单独的URL来发挥作用,即cdn.yoursite.com(最近的CloudFront Edge服务器),在这里,yoursite.com被Cloudflare称为。
对CloudFront和Cloudflare的偏好
- Cloudflare的设置过程比CloudFront简单。
- Cloudflare的边缘网络略大于CloudFront。
- WordPress火箭提供了一个专门的Cloudflare集成。
CloudFront提供了一些WordPress不太需要的特性,比如:
- 它提供了对HTTP报头和缓存无效的控制。
- CloudFront使用实时流媒体。
Cloudflare与CloudFront的对比表
让我们来讨论一下Cloudflare和CloudFront之间的顶级比较:
|
Cloudflare |
CloudFront |
| Cloudflare提供了一个具有快速性能和安全特性的全球CDN。 | CloudFront是亚马逊的CDN,也是世界上最大的云服务提供商。 |
| Cloudflare的设置非常简单 | CloudFront的设置包括两种方式:推和拉 |
| Cloudflare不支持流媒体视频直播 | CloudFront提供实时流媒体视频 |
| Cloudflare用于图像优化 | CloudFront不支持图像优化。 |
| Cloudflare拥有比CloudFront更广泛的边缘网络。 | CloudFront的数据略低于Cloudflare。 |
| Cloudflare提供免费的SSL服务 | CloudFront的付费模式是按需付费 |
| 与Cloudflare集成的工具有Buddy、Cloudcraft、Mixmax。 | 与CloudFront集成的工具有:谷歌Analytics、Terraform |
| 它最适合管理服务器负载和站点速度。 | 当静态和动态web内容需要速度时,就会使用CloudFront |
| 完全支持SPDY协议 | 不支持SPDY协议 |
|
不支持原始推送
No of Pops (入网点): 71 |
原始推送被部分支持
No of Pops: 41 |
除了以上这些比较之外,Cloudflare的界面要比CloudFront好得多。Cloudflare提供24/7的电话和电子邮件支持,而CloudFront也提供同样的支持,但包含了额外的费用。Cloudflare并不是一个真正的CDN,而是一个接收总体流量的反向代理,CloudFront是一种既适合静态内容又适合动态内容的高级CDN。Cloudflare主要由FounderLY、Stack Overflow和Code Guard使用。CloudFront没有公布网络容量,因为它的规模很大,而Cloudflare的网络容量为15Tbps。
结论
Cloudflare和CloudFront提供CDN服务,可以加速您的网站页面的性能,降低服务器的负载。大多数WordPress用户都使用Cloudflare简单的设置过程,而CloudFront则不使用。与两者相比,Cloudflare在提供服务和安全方面提供了比CloudFront更好的选择。
CloudFront作为一种更快的内容交付服务,为最终用户提供了内容的可靠性和可用性,而Cloudflare在其发布的高峰期提供了不安全的互联网协议的安全版本,并通过安全HTTPS服务(通用SSL)免费提供这些协议。因此,Cloudflare为所有终端用户提供了一个可靠、快速和安全的互联网。因此CloudFront和Cloudflare都适合用户,并根据用户的需要和要求进行应用。因此,Cloudflare比CloudFront更加灵活可靠。
原文:https://www.educba.com/cloudflare-vs-cloudfront
本文:http://jiagoushi.pro/node/1132
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 2075 次浏览
【技术选型】Elasticsearch vs. Solr -选择开源搜索引擎
我们为什么在这里?我存在的目的是什么?我应该锻炼还是休息以节省精力?早起上班还是开始工作到很晚?我吃薯条要加蕃茄酱还是蛋黄酱?
这些都是古老的问题,可能有也可能没有答案。其中一些非常难,或者非常主观。但我还是要花点时间来回答其中一个问题:我应该用Elasticsearch还是Solr?
这是一个场景。您的组织希望实现您的第一个搜索引擎,切换到另一个搜索引擎-呼叫所有谷歌搜索设备(GSA)用户寻找替代品!——或者尝试通过开源来节省资金。您,作为一个熟练和有能力的开发人员,被要求解决一个难题。您的问题有许多业务需求,但其核心是一个“大数据和搜索”问题。
您需要从多个数据源提取大量内容,并从这些数据中获得洞察力,以帮助您的公司增长并实现今年的目标。
管中窥豹
这里有很多利害关系。你不会错过的,你只有一次机会。您需要合适的搜索引擎,您考虑的是开源,您有两个流行的选择:Elasticsearch或Solr,根据db - engine的说法,这两个搜索引擎在开源和商业搜索引擎中稳居前两名。

你会选择哪个开源搜索引擎?
这不是掷硬币或简单的选择。这两个搜索引擎都很棒,但没有一个“正确”的选择。这完全取决于你的需求。
因此,第一步是理解必须构建的应用程序。然后,下一步是看看每个搜索引擎都能提供什么。顺便说一句,如果你还处在开源和商业解决方案的交叉点,请阅读我们的免费电子书,深入了解在选择搜索引擎时要考虑的10个关键标准。
功能纲要
几年前,我们写了一个关于Elasticsearch与Solr的高级概览博客,其中讨论了总体趋势和非技术见解。现在,随着Elasticsearch和已发展成为开源搜索引擎市场的主导玩家,让我们重新审视一下它们,看看它将带给我们什么。
年龄和成熟
在这种情况下,我们可以说Solr有更长的历史,因为它是由CNET Networks的Yonik Seely在2004年创建的,然后在2006年将其贡献给Apache。2007年,它最终成为一个顶级项目。另一方面,我们有Elasticsearch,它是在2010年正式创建的,虽然它实际上是在2001年由其创始人Shay Bannon以Compass的名义创建的。从那时起,Kibana、Logstash和Beats的创建者加入了Elasticsearch,创建了Elastic Stack产品家族,成为搜索和日志分析领域的强大玩家。也就是说,Solr的优势在于能够更早地出现在市场中。
社区和开源
两者都有非常活跃的社区。如果你查看Github,你会发现它们是非常流行的开源项目,发布了很多版本。

一个非常重要的细节是,虽然两者都是在Apache许可下发布的,而且都是开源的,但它们的工作方式略有不同。Solr确实是开源的——任何人都可以提供帮助和贡献。有了Elasticsearch,虽然人们仍然可以提供他们的贡献,但只有Elastic的员工(创建Elasticsearch和Elastic Stack的公司)可以接受这些贡献。
这是好事还是坏事?这取决于你怎么看它。这意味着,如果您需要一种特性并将其贡献给社区,并且具有足够的质量,那么Solr可以接受它。在Elasticsearch中,由Elastic决定某个贡献是否被接受。所以Solr上可能有更多的特性选项。另一方面,对于Elasticsearch的贡献,通过更多级别的质量检查,可以提供更高的一致性和质量。
文档
Elasticsearch和Solr都有非常完善的参考指南。Elasticsearch运行在Github之上,Solr使用Atlassian Confluence。你可以通过下面的链接找到它们。
核心技术
让我们更专业一点。Elasticsearch和Solr是两种不同的搜索引擎。但在底层,它们都使用Lucene,这意味着它们都构建在“巨人的肩膀上”。
对于那些想知道为什么我认为Lucene是一个“巨人”的人,它实际上是许多搜索引擎背后的信息检索软件库。它非常快,稳定,可能没有比这更好的了。Lucene是由Hadoop的创始人之一Doug Cutting在1999年创建的。所以,Lucene是用于搜索引擎核心的完美选择。
Java API和REST
Elasticsearch有一个更“Web 2.0”的REST API,但是Solr有一个更好的Java API,使用SolrJ——或者使用Microsoft技术的SolrNet。Elasticsearch有Nest和Elasticsearch.Net。Solr的REST API可能感觉不太灵活,但它对于您所需要的:索引和查询非常有效。Elasticsearch使用的是JSON,所以如果您使用JSON,那么它是一个很好的选择。Solr也支持JSON,但它是在后期添加的,最初是为XML设计的。
内容处理
因为它们都公开API,所以很容易从自定义应用程序或现有的可配置应用程序索引内容。例如,我们的Aspire内容处理框架能够连接到多个数据源并post到Elasticsearch或Solr。
Solr还有一个特性,可以使用Apache Tika从二进制文件中提取文本。因此,您可以通过ExtractRequestHandler上传PDF文件,Solr将知道如何处理它。
另一方面,Elasticsearch与Logstash合作得很好,它可以处理来自任何来源的数据并为其建立索引。
可伸缩性
伸缩性是一个关键的考虑因素。在这种情况下,当Solr仍然被限制为主从关系时,Elasticsearch将赢得比赛。然而,SolrCloud最近加入了这个游戏。在Zookeeper的帮助下,现在可以以更简单、更快的方式扩展Solr集群—这是对旧版本的Solr的增强,它具有主从功能。它仍然需要大量的改进,但是从Solr中可摄取和搜索的数据集的大小来看,它的前景是光明的。
供应商支持
有几家公司已经到了必须决定哪种产品最适合自己的地步。例如,Cloudera选择Solr作为他们的搜索引擎,将其集成到开源的CDH(包括Hadoop的Cloudera发行版)中。另一方面,也有其他厂商选择Elasticsearch作为其解决方案的搜索引擎。我们在搜索技术帮助咨询,部署和支持这两个搜索引擎。
远景与生态系统
Solr更倾向于文本搜索。Elasticsearch迅速开拓了自己的小众市场,通过创建Elastic堆栈(以前称为ELK堆栈)来实现日志分析,Elastic Stack代表Elasticsearch、Logstash、Kibana和Beats。双方都有清晰的愿景,正在朝着各自的方向大步前进。
值得重申的一点是,这两个搜索引擎如何被用作许多领先的搜索和大数据平台的基础。例如,Elasticsearch是微软Azure搜索的一部分,而Solr已经集成到Cloudera搜索中。
性能
说到性能,根据我从许多开发人员那里听到的经验,我们可以说这两个引擎的性能都很好。因此,对于大多数用例,无论是内部的还是外部的搜索应用程序,如果开发人员正确地设计和配置它们,性能将不是什么大问题。
网络管理
Solr捆绑了web管理,而Elasticsearch有多个用于安全性、警报和监视的高级插件。这个列表展示了Elastic的整个产品系列。
可视化
在Elasticsearch和Solr中有许多可视化数据的方法——您可以构建自定义可视化仪表板,或者使用搜索引擎的标准可视化特性,可能需要做一些调整。但有一个区别值得一提。
Solr主要关注文本搜索。它在这方面做得很好,成为了搜索应用程序的标准。但是Elasticsearch已经向不同的方向发展,它已经超越了搜索,使用Elastic堆栈处理日志分析和可视化。下面是一些你可以用Kibana 5实现的可视化。

这并不意味着一个比另一个好。它只是表明,每个搜索引擎在不同的用例和需求中都有自己的优势,而您的选择将在很大程度上取决于您的组织想要实现什么。
长话短说,Elasticsearch和Solr都是优秀的开源选择,它们将帮助您从数据中获得更多信息。这完全取决于您的需求、预算、时间安排和项目的复杂性。
原文:https://www.searchtechnologies.com/blog/solr-vs-elasticsearch-top-open-source-search
本文:http://jiagoushi.pro/node/1152
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】
- 61 次浏览
【技术选型】Keras、TensorFlow和PyTorch的区别
视频号
微信公众号
知识星球
数据科学家在深度学习中选择的最顶尖的三个开源库框架是PyTorch、TensorFlow和Keras。Keras是一个用python脚本编写的神经网络库,可以在TensorFlow的顶层执行。它是专门为深度神经网络的鲁棒执行而设计的。TensorFlow是一种在数据流编程和机器学习应用中用于执行多个任务的工具。PyTorch是一个用于自然语言处理的机器学习库。
Keras、TensorFlow和PyTorch的头对头比较(Infographics)
以下是Keras与TensorFlow和Pytorch之间的十大区别:

Keras与TensorFlow与PyTorch的关键区别
下面列出了Keras、TensorFlow和PyTorch的体系结构、函数、编程和各种属性等主要区别。
- API级别:Keras是一种高级的API,可以运行在Theano、CNTK和TensorFlow的顶层,后者因其快速开发和语法简单而受到关注。TensorFlow可以在API的低级别和高级别上工作,而PyTorch只能在API的低级别上工作。
- 框架的架构和性能:Keras的架构简单、简洁、易读,性能低下。TensorFlow是刚性使用,但支持Keras更好的表现。与Keras相比,PyTorch的架构复杂且难以解释。但TensorFlow 和PyTorch 的性能是健壮的,这提供了最大的性能,也提供了在更大的数据集高效率。由于Keras的性能较低,它只适用于较小的数据集。
- 调试过程:一个简单网络的调试是由Keras提供的,这是经常需要的。但是在TensorFlow中,调试是一个非常复杂的过程,而与Keras和TensorFlow相比,PyTorch提供了灵活的调试功能。PyTorch在神经网络中的操作描述了PyCharm、ipdb、PDB等调试工具的有效计算时间。但是当涉及到TensorFlow时,有一个叫做tfdbg的高级选项,它可以通过浏览所有的张量在特定的运行时在会话范围内操作。由于它是用python代码内建的,所以不需要单独使用PDB。TensorFlow在模式上比PyTorch先进,具有比PyTorch和Keras更广泛的群体。
- 框架的适用性。: Keras在小数据集中是首选,它提供了快速原型和扩展的大量后端支持,而TensorFlow在对象检测方面提供了高性能和功能,可以在大数据集中实现。PyTorch具有较强的灵活性和调试能力,可以在最短的数据集训练时间内适应。
- 神经网络框架的性能:PyTorch具有开发递归网络的多层和细胞级类。层的对象管理输入数据和一个单位单元中的一个时间步长,也表示具有双向属性的RNN。因此,由于没有进一步优化的必要,网络的众多层为单元提供了一个合适的包装。TensorFlow由dropout包装器、多个RNN单元和单元级类组成,用于实现深度神经网络。Keras由全连接层、GRU和用于创建递归神经网络的LSTM组成。
Keras与TensorFlow与PyTorch的对比表
以下是TensorFlow和Spark之间的十大区别:
| 行为参数 | Keras | TensorFlow | PyTorch |
| 定义 | 神经网络库是开源的。 | TensorFlow是一个开源和免费的软件库 | 这是一个开放源码的机器学习库。 |
| 编程语言 | 它可以作为编码来使用。所有代码都脚本化在一行中。 | 这个库与C、c++、Java和其他编码语言很紧凑。用小的代码对其进行编程,可以提高其准确性。 | 它仅使用python编写脚本。PyTorch的密码有更大的脚本。 |
| 应用 | 它被设计用于在神经网络中进行鲁棒性实验。 | 它被用来教机器多种计算技术 | 它被用于构建自然语言处理和神经网络。 |
| API的层级 | 它可以在Theano和CNTK上执行,因为它有高级API | 它包括低级和高级API | PyTorch只关注数组表达式,因为它的API很低。 |
| 架构 | 它有一个可理解的语法,可以很容易地解释。 | 它以其在各种平台上的快速计算能力而不具有难以解释的复杂体系结构而受到广泛欢迎 | 初学者觉得PyTorch的架构很复杂,但他们对它的深度学习应用程序很感兴趣,也用于各种学术目的。 |
| 速度 | 它仅以最低速度运行 | 它工作在最大速度,轮流提供高性能 | PyTorch的性能和速度与TensorFlow相似。 |
| 数据集 | 由于执行速度较慢,因此在较小的数据集中可以有效地运行。 | 它具有管理大型数据集的高度能力,因为它具有最大的执行速度 | 它可以在更高维度数据集中管理高性能任务。 |
| 调试 | 管理员不需要任何频繁的调试过程 | 执行调试是一项挑战。 | 它的调试能力比Keras和TensorFlow要好 |
| 流行度 | 它广泛应用于神经网络中,支持卷积层和效用层。 | 它以其自动图像捕捉软件和内部使用的谷歌而闻名。 | 它在深度学习网络上的自动分化,支持高功率GPU应用,包括神经网络模块、优化模块和autograd模块。 |
| 判决 | 它提供了多种后端支持和健壮的原型。 | 在大数据集上的高性能和功能的目标检测。 | 灵活性。培训的时间很短。具有多种调试功能。 |
结论
PyTorch简单且用户友好,而TensorFlow由于API不全面而被采用。Keras和TensorFlow有一个坚固的砖墙,但剩下的小孔用于通信,而PyTorch与Python紧密绑定,适用于许多应用程序。
推荐的文章
这是Keras vs TensorFlow vs PyTorch的指南。本文讨论了Keras、TensorFlow和PyTorch之间的区别,以及与信息图和比较表的头对头比较。你也可以通过我们的其他相关文章了解更多-
- Python与Groovy
- TensorFlow vs Spark
- Kafka和 Spark
- Apache Kafka vs Flume
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 4310 次浏览
【技术选型】OLTP vs OLAP
OLTP和OLAP的区别
OLTP被扩展为在线事务处理,OLAP被扩展为在线分析处理。顾名思义,OLTP是管理和更新数据库中的事务的过程,而OLAP是从数据库中检索所需数据以便将其用于分析操作的过程。OLTP通常很简单,在系统中可以轻松查询,而OLAP是一个复杂的系统,具有更大的数据量,因此需要复杂的查询。
联机事务处理(OLTP)
为了让大型/中型公司执行他们的行政/业务或销售任务,必须有OLTP系统,以处理每天发生的大量交易。
例子
OLTP系统的一个例子是大型杂货店。例如,一个人买了15件商品,到柜台结账。现在是OLTP系统来处理将要发生的事务。让我们计算一下可能发生的事务的数量。
- 第一个应该是将要生成并存储在DB中的账单的发票
- 第二个事务可能是针对发票在数据库中插入产品信息。
- 如果客户有任何会员卡,如果他使用它,交易将发生从他的卡扣除积分,并将更新他的卡的新积分。
- 另一种交易是根据客户购买的产品数量来减少产品的总数。例如,如果超市有3489包凝乳包,而客户购买了其中的2包,将发生一个交易,该交易将把总数更新为3489减2,即3487。类似的交易也会发生在其他产品上。
OLTP系统的几个例子是:
- 自动取款机
- 银行
- 购物中心
- 在线预订火车和航班
- 电子商务
联机分析处理(OLAP)
在OLAP级别上发生的事务非常少,它们有助于企业做出更好的决策。OLAP系统允许用户分析来自多个数据库的数据,ETL被强制作为来自不同数据库的数据的原因是不同的格式。因此,在将它们存储到数据仓库之前,需要使用ETL。
例子
电子商务公司想要比较2月和3月的销售数据,也想看到销售区域明智,然后是州明智,时间明智,最后是国家明智。
为了实现这一点,应该有一个系统可以将来自不同OLTP数据库的数据插入数据仓库并应用ETL过程。然后OLAP开发人员将从OLAP系统中获取数据,并根据业务需求创建不同类型的报告和图表。OLAP软件的例子有:SAP BI/BO/BOBJ,微软的Power BI, Tableau, Spotify, SAS, Python和R, Excel, Apache Spark, Splunk,谷歌Analytics。
OLTP和OLAP(信息图)的比较
下面是OLTP和OLAP的前12个比较:

OLTP和OLAP的优缺点:
以下是OLTP和OLAP的优缺点:
OLTP
以下是OLTP的优缺点
优势
- 通过提供健壮的机制来处理和存储事务性数据,它极大地简化了组织的事务性事件。
- OLTP系统非常快速和即时。
- 它们通过简化单个流程来增加组织的客户数量
缺点
- 对数据分析几乎没有洞察力。
- 在服务器失败的情况下,事务可能会导致延迟,在某些情况下可能会导致数据丢失。
- 更容易被黑客攻击。
OLAP
以下是OLAP的优缺点
优势
- 对来自不同来源的数据进行分析的单一平台。
- 来自不同来源的数据存储在一个集中的位置,因此能够更容易地访问大型信息。
- 精确和快速的计算。
- 高级安全。
缺点
- 由于软件的许可和价格较高,实现OLAP的成本很高。
- OLAP系统的全端到端监控、实现和升级依赖于该领域的IT专家。
- 由于从OLTP到OLAP系统的数据插入可能涉及多个数据库,因此要与所有的DB团队保持一致可能会带来挑战。
OLTP和OLAP系统的比较表
| Basis of Comparison | OLTP (联机事务处理系统) | OLAP (在线交易分析系统) |
| Process | 它用于管理每天发生的事务和更新数据库。 | 它用于从OLTP系统检索数据并对数据进行分析。 |
| Data Source | 在这里,OLTP系统本身就是数据源。 | OLAP的数据来自不同的OLTP数据库。 |
| Need | 无缝地运营业务。 | 对业务进行分析和预测,找出业务中存在的不足和发展的领域,并采取相应的行动。 |
| Insert and Update | 快速和短的插入和更新用户数据。 | 通常,长时间运行的批处理作业负责数据插入。 |
| Queries | 负责数据处理的小而简单的查询 | 相对较大和复杂的查询 |
| Method | 它利用了传统的DBMS系统 | 它利用了数据仓库 |
| Response Time | OLTP系统的响应时间以毫秒为单位。 | OLAP系统的响应时间更大,可能在秒、分钟甚至小时之间变化。 |
| Database Table Normalization | OLTP表是高度规范化的 | OLAP系统通常是反规范化的 |
| Access | 允许读和写两种访问 | 大多数情况下允许读访问,很少允许写访问。 |
| Integrity | OLTP系统需要维护数据完整性。 | 由于OLAP系统不会经常修改,因此数据完整性不是强制性的 |
| Backup and Recovery | 由于数据可用性在OLTP系统中非常关键,所以需要对所有数据库进行完整的备份 | OLAP系统的备份是及时的,而不是定期的。 |
| Target audience | 主要是为了市场洞察力。 | 这是为了客户洞察。 |
结论
在本文中,我们通过实际示例了解了OLTP和OLAP系统的定义,了解了这两个系统之间的区别以及它们在何处被使用和实现。现在您就可以区分OLTP和OLAP软件及其功能了。
推荐的文章
这是OLTP与OLAP之间最大区别的指南。这里我们还讨论了OLTP和OLAP与信息图和对照表的关键区别。你也可以看看下面的文章来学习更多-
- 数据仓库vs数据集市
- OLAP是什么?
- OLTP是什么?
- OLAP的类型
- 什么是数据集市?|类型,数据集市的特性
原文:https://www.educba.com/oltp-vs-olap
本文:http://jiagoushi.pro/node/1127
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 649 次浏览
【技术选型】Power BI vs Tableau vs Qlik的区别

Power BI vs Tableau vs Qlik的区别
Power Bi是一个商业智能工具,我们可以在整个公司上传和发布数据。业务智能响应任何查询并改进决策制定。为业务添加强大的功能,以实现良好的数据可视化。Power BI的另一个特性是Quick Insights,我们可以在数据集中搜索有趣的模式,并提供一个图表列表来更好地理解数据。利用人工智能和数据挖掘技术对数据进行分析。Qlik也是一个商业智能和数据可视化工具。
这是一个端到端ETL解决方案产生良好的客户服务。使用qlik,我们可以创建一个灵活的终端用户界面,根据数据进行良好的演示,创建动态图形图表和表格,执行统计分析,构建自己的专家系统。Qlik可以与虚拟数据库一起使用。它是一个基于窗口的工具,需要以下组件:Qlik服务器,Qlik发布器。
它们是最普遍使用的商业智能工具,用于在任何时候为用户创建、显示和共享交互式报告。它们是独立于平台的,需要较少数量的技术专家一起工作。它们采用客户机-服务器架构,以实现快速部署。它们非常适合需要优秀BI的高层管理人员。Tableau具有访问速度快、交互式可视化、性价比高、维护良好的安全性等优点。
Power BI的特点
- 从复杂的BI数据中获得丰富的图形可视化。
- 专门报告
- 好的导航窗格
- 包括具有可自定义仪表板的数据集。
Qlik的特点
- 通过使用混合方法,用户可以将存储在内存数据集中的Qlik视图中的大数据源中的数据关联起来。
- 在直接发现的帮助下,它们允许用户执行业务发现和可视化分析。
- 可移动就绪、角色和权限
- 与动态应用程序,仪表板交互。
Tableau 特性表
- 他们有一个很好的拖放。
- 为了数据共享,他们使用Tableau Public。
- 它们在web上实现交互式数据可视化。
- 它们的性能强大、可靠,运行于巨大的数据之上。
- 它们对移动设备友好,并支持完整的在线版本。
Power BI与Tableau与Qlik(Infographics)的正面比较
以下是Power BI、Tableau和Qlik之间的9大差异
Power BI和Tableau以及Qlik的主要区别
这些都是市场上的热门选择;让我们来讨论一下主要的区别:
- Qlik可以被多个用户立即访问。Qlik比Tableau快。Power bI连接到任何不需要ETL的数据源。
- 文件存储。我们可以通过Qlik Views专有通信协议访问这些文档并存储在Windows OS中,所有的事件都在Qlik服务器中获取,他们负责客户端-服务器.Power BI有三种类型的文件excel(.xls), Power BI desktop(.pbix), (.csv)。Tableau解压文件可以有(.tde)文件扩展名。
- Qlik支持用于外部数据源的OLEDB接口。Power BI从OLEDB加载数据并在BI服务器中发布。目前它们只支持实时连接。
- Qlik结构管理不善,而Tableau结构管理良好的用户指南。
- Qlik是一种独立的技术。将数据发布到外部世界是由QlikView发布者管理的。Power BI只在SAAS模型上可用,而Tableau有云和本地选项。Power BI桌面版是免费的。
- 使用PowerBI可以增加数据建模功能。在Qlik中,数据洞察力是快速产生的。
- Tableau和Power BI是用户友好的。Qlik有很高的可定制模式。
- Qlik 和tableau 支持统计分析。Power BI没有这个功能。
Power BI vs Tableau vs Qlik对照表
下面是9个最重要的比较
| 比较点 | Power BI | Tableau | Qlik |
| 性能 | 它在数据可视化方面落后。 | 他们是更友好的,因为非技术用户可以使用这个工具。他们使用立方技术 | Qlik需要一个开发人员来处理报告和指示板。他们使用所有类型的数据集。 它们有很好的可视化效果。 |
| UI | 当具有良好的用户界面来发布报表时,仪表板是PowerBI的关键特性。 | 用户界面更好 | 与Tableau相比,用户界面是相当差。 |
| 轻松学习 | 用户友好-有Excel的知识就足够了 | 它们不需要任何技术或编程技能。 | 有数据科学背景易于学习 |
| 支持的需求 | Power BI有Power BI桌面、网关 | 他们使用前端工具,如R。 | Qlik包括前端(Qlik开发人员)和后端(Qlik发布人员) |
| 版本 | 桌面版是免费的,Power BI Pro是按月付费的。 | Tableau Reader是一个免费版本。Tableau服务器是一个许可服务器。 | Qlik个人版是Qlik的免费版本,运行时无需许可证密钥。 |
|
成本-效果 |
更便宜。 | 它节省了金钱、时间和精力。加载数据仓库时非常昂贵。 | Qlik网站有两个版本。个人版免费,企业版可与团队联系使用。 |
| 在线分析 | 它们通过SQL服务器连接到OLAP多维数据集进行多维分析。 | Tableau可以连接到OLAP,在最深层取出立方体的措施。 | 对OLAP的访问提供了封装的数据视图。 |
| 速度 | 他们有聪明的恢复 | 速度取决于RAM和数据集。 | 它们有更好的速度,因为它们将数据存储在服务器RAM(内存存储)中。 |
| 优势 | Power BI成本低廉,并且对于大型项目具有可伸缩性。 | 他们在智能可视化方面排名第一。 | 他们提供广泛的深度分析,他们有良好的客户满意度评级。 |
结论
决定哪一个是最好的需求分析。拖放功能以及安全的数据连接使tableau成为市场的领跑者。Qlik的优势包括可视化模式的内存引擎功能。通过Power BI创建的报告可以在团队之间共享,并且可以在任何设备上访问。总体来说,Power BI是三种工具中竞争对手的工具。它是高级的Microsoft应用程序和平台,并对云平台提供了高级支持。Tableau是目前市场上商业分析的首选。
推荐的文章
这是Power BI、Tableau和Qlik之间最大的区别。这里我们还讨论了与信息图和对照表的关键区别。你也可以看看下面的文章来了解更多。
- Power BI vs SSRS - 差异
- Looker和Tableau之间的有用比较
- QlikView和QlikSense——哪个更好
- 如何在Power BI桌面中使用图标?
- 如何在Power BI中使用日历DAX功能?
- 谷歌Data Studio与Tableau 的差异
原文:https://www.educba.com/power-bi-vs-tableau-vs-qlik
本文:http://jiagoushi.pro/node/1131
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 543 次浏览
【技术选型】Solr vs Elasticsearch:选择开源搜索引擎
云、分析和认知搜索时代的开源搜索引擎
Solr与Elasticsearch在我们的客户项目和企业搜索社区中经常讨论。但是随着传统的企业搜索已经发展成为Gartner所说的“洞察引擎”,我们重新讨论了这个主题,提供了结合云、分析和认知搜索能力的最新观察结果,以帮助您评估Solr和Elasticsearch。
Solr是什么?
Solr是Apache软件基金会Lucene项目的一个领先的开源搜索引擎。由于其灵活性、可伸缩性和成本效益,Solr被大型和小型企业广泛使用。
Elasticsearch是什么?
同样基于Lucene的Elasticsearch是另一个领先的开源搜索引擎,支持强大的企业应用程序。Elastic是一家开发Elasticsearch和Elastic Stack的公司,它为搜索、日志分析和其他高级分析用例提供企业解决方案。
选择您的开源搜索引擎
通常,当我们帮助客户执行有关在其企业解决方案中使用开源搜索引擎的评估时,会有人问:“Solr和Elasticsearch哪个更好?”虽然可能会有一种先入为主的观念,认为一个人天生就比另一个人好,但如果用“哪个对我更好?”这样的说法来表述,这个问题就更相关了。
有各种搜索引擎技术可用,但最流行的开源变体是那些依赖于Apache Lucene底层核心功能的技术,从本质上说,这是使搜索引擎工作的部分。Solr和Elasticsearch是搜索库之上的组件,它们为一个完整的搜索产品提供自己的实现和特性。Lucene的核心功能为Solr和Elasticsearch的基本搜索功能提供了相同的体验,但它们围绕Lucene的实现方法创造了不同之处。
搜索引擎的作用已经不仅仅是有效地查找信息,而是在内容分析、预测建模以及与认知/智能搜索功能(如自然语言处理(NLP)、机器学习(ML)和相关性评分)的集成方面发挥关键作用。我们已经在我们的客户工作中探索并实现了这些智能功能——在这里了解更多信息。
Solr和Elasticsearch:哪个对我的组织更好?
这得视情况而定。
围绕一种技术而不是另一种技术的采用有许多用例。但是当被问到这个问题时,我通常会从操作管理的角度用一个类比来回答:“Solr就像Linux。Elasticsearch就像窗户。您可以对Solr进行大量的定制和定制,以满足您的需求,但是与Elasticsearch相比,管理和部署更加复杂,也更加耗费资源。Elasticsearch非常容易部署、管理和监控(使用X-Pack),具有设计良好的用户界面(Kibana),允许数据探索和创建分析可视化,但定制其功能有限,使用插件框架更加困难。
Elasticsearch可以为你,如果你想:
- 运行迅速与很少开销得得到你的搜索引擎,
- 尽快开始探索你的数据;和
- 将分析和可视化作为用例的核心组件。
Solr可能适合你,如果你:
- 需要对大量数据进行索引和再处理;
- 有可用的资源来投资管理Solr和用于交互的工具;和
- 拥有一个与Solr一起工作的现有企业框架(像其他Apache产品,如Hadoop,或企业框架,如构建在Hadoop上的Cloudera、Hortonworks或HDInsights)。
这并不是说一个Hadoop平台不能使用Elasticsearch(我们客户提出了这种情况),但一些平台,Cloudera尤其是Hortonworks,提供额外的工具和方法和管理中的Solr索引数据的生态系统(这是一个特殊的例子Cloudera即将发布的CDH 6支持Solr 7)。
Solr与Elasticsearch:特性比较
从经验来看,评估可以为客户定义战略和实施路线图提供巨大的价值。在我们的评估过程中,我们执行一个搜索引擎比较矩阵,它根据特定客户的需求和用例评估搜索引擎的适用性,并使用基于某些特性的优先级的加权评分机制。基于此分析,在对搜索引擎进行总体推荐时,有一些公共特性和用例可以作为感兴趣的点。
下面的图表展示了一些关于Solr和Elasticsearch的观察结果:
| SOLR | ELASTICSEARCH | |
|---|---|---|
| 用例 |
|
|
|
可视化 工具 |
|
|
|
云和 大数据 |
|
|
|
认知 搜索 能力和 整合 |
|
|
|
管理和 运营 |
|
|
|
开发 架构 |
|
|
|
集群 状态 管理 |
|
|
| 安全 |
|
|
|
批量 索引 工具 |
|
|
|
近实时(NRT) 索引 |
|
|
| 分析 |
|
|
|
嵌套的 数据 结构 |
|
|
|
查询 操作 |
|
|
| API 交互 |
|
|
选择Solr和Elasticsearch?考虑这些
决定哪个搜索引擎最适合您的特定用例和需求,不应该是基于“非此即彼”的假设做出的决定。Solr中某个特定功能的总体重要性可能超过Elasticsearch的操作优势,例如:
在一个客户端案例中,与Solr部署相关的开销和不得不使用过时的SolrNET客户端(当时)被Solr的可插拔特性所抵消。需要定制加密更新和请求处理程序来使用旋转数据加密键对索引内容应用加密,因此必须使用Solr而不是Elasticsearch。索引加密过程所需要的功能并不能在Elasticsearch中有效地实现。
相反,在不考虑大数据或分析的情况下,为通用搜索用例评估搜索引擎选项时,Elasticsearch成为了一个更受欢迎的选择,因为它减少了维护和部署开销,以及完全托管和管理环境的选项。
在一些基于什么对客户最重要的情况下,它不是立即清楚哪个搜索引擎(包括商业引擎)将最好地满足客户的需求,尽管应用了评分规则。在这种情况下,可以使用示例数据集执行“烘烤”,面向客户评估每个引擎对于特定用例集的执行情况。
归根结底,Solr和Elasticsearch都是功能强大、灵活、可扩展且极其强大的开源搜索引擎。总体用例和业务需求,以及您所需的特性、操作考虑,以及与新的认知搜索和分析功能的集成,将最终驱动您决定是选择Solr还是Elasticsearch。
本文:http://jiagoushi.pro/node/1145
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 100 次浏览
【技术选型】Solr与Elasticsearch:谁是领先的开源搜索引擎?
搜索是任何应用程序的组成部分。当速度、性能和高可用性是核心需求时,对tb和pb级的数据执行搜索可能具有挑战性。这篇博客文章将讨论Solr和Elasticsearch这两个最受欢迎的开源搜索引擎,它们在过去几年的发展方向不同。
它们都构建在Apache Lucene之上,所以它们支持的特性非常相似。但是,它们在部署、可伸缩性、查询语言和许多其他功能方面存在显著差异。
关于Apache Solr
Apache Solr是构建在Lucene之上的开源搜索服务器,它通过HTTP请求提供Lucene的所有搜索功能。它已经存在了将近15年,是一个拥有广泛用户社区的成熟产品。
Solr提供强大的特性,如分布式全文搜索、面、近实时索引、高可用性、NoSQL特性、与Hadoop等大数据工具的集成,以及处理Word和PDF等富文本文档的能力。
关于Elasticsearch
Elasticsearch也是建立在Apache Lucene之上的开源搜索引擎,ELK的其余部分,也叫Elastic,包括Logstash和Kibana。它使用RESTful api扩展了Lucene强大的索引和搜索功能,并使用索引和碎片概念将分布的数据归档到多个服务器上。Elasticsearch完全基于JSON,适用于时间序列和NoSQL数据。
这个工具比Solr年轻得多,但由于其功能丰富的用例而获得了广泛的欢迎。它的一些主要特性包括分布式全文分布式搜索、高可用性、强大的查询DSL、多租户、Geo搜索和水平伸缩。
相对受欢迎程度
db - engine根据数据库管理系统和搜索引擎的受欢迎程度对它们进行排名,根据db - engine, Elasticsearch排名第一,Solr排名第三。
Solr在其诞生的前10年就已经很受欢迎,但Elasticsearch自2016年以来一直是最受欢迎的搜索引擎。
图1:db - engine排序elasticsearch与Solr流行度(来源:db - engine)
安装和配置
Java是安装这两个引擎的主要先决条件,但是默认的Elasticsearch配置需要1GB的堆内存。这可以在jvm中更改。配置目录中的选项文件。
默认情况下,Solr至少需要512MB堆内存来分配给实例。该设置可以在solr脚本文件或solr.in中更改。cmd文件。这两个文件都位于Solr安装的bin目录中。
Elasticsearch易于安装和配置,但它比Solr要重一些。Elasticsearch的最新版本(7.7.1版本,于2020年6月发布)的压缩大小为314.5MB,而Solr(8.5.2版本,于2020年5月发布)的压缩大小为191.7MB。
在Elasticsearch中的配置文件以YML格式编写。Solr支持基于xml的配置文件。
索引和搜索
Solr和Elasticsearch都在Lucene写索引。但是,由于分片和复制(以及其他特性)存在差异,因此它们的文件和架构也存在差异。此外,Elasticsearch具有原生DSL支持,而Solr具有与Lucene语法一致的健壮标准查询解析器。
数据源
这两种工具都支持广泛的数据源。
Solr使用请求处理程序从XML文件、CSV文件、数据库、Microsoft Word文档和pdf中摄取数据。通过对Apache Tika库的本机支持,它支持从一千多种文件类型中提取和索引。Solr附带一个简单的命令行post。例如,要在名为testcollection的集合中摄取基于csv的数据,您只需使用以下命令:
bin/post -c testcollection *.csv
另一方面,Elasticsearch完全是基于jsf的。它支持使用Beats系列(弹性堆栈中可用的轻量级数据传输程序)和Logstash从多个源摄取数据。
用例
虽然这两个产品都是面向文档的搜索引擎,但Solr一直更侧重于使用高级信息检索(IR)进行面向企业的文本搜索。因此,它更适合使用大量静态数据的搜索应用程序。Solr更适合已经实现大数据生态系统工具(如Hadoop和Spark)的企业应用程序。此外,Solr在处理富文本格式(RTF)文档方面非常出色。为了与Elasticsearch竞争,最近的Solr版本提供了一些新特性,比如并行SQL接口和流表达式。
Elasticsearch更侧重于缩放、数据分析和处理时间序列数据,以获得有意义的见解和模式。它的大规模日志分析性能使它非常受欢迎。Elasticsearch更适合以JSON格式输入和输出数据的现代web应用程序。Elasticsearch也投入了大量的开发工作,使其工具更具弹性。这将它转换为主数据存储。
搜索
Solr和Elasticsearch都支持NRT(接近实时)搜索,并充分利用了Lucene的所有搜索功能。由于它们都支持基于json的查询DSL,因此它们都具有附加的与搜索相关的特性集,如下所述。
早期的Solr版本必须依赖于它的标准查询解析器,但是Solr现在还支持基于jsf的查询DSL。虽然Solr的标准查询解析器允许用户创建各种结构化查询,但在编写这些查询时出现语法错误的几率要高得多。然而,您可以在Solr中编写在Elasticsearch中不可用的非常复杂的搜索查询。Solr包括一个名为Velocity search的示例搜索UI,它提供了强大的特性,如搜索、显示、突出显示、自动完成和地理搜索。
Elasticsearch的DSL是原生的。Elasticsearch中的聚合框架功能强大,api中的聚合查询具有更好的缓存。该工具的最新版本提供了更好的内存占用管理。
索引
因为Elasticsearch是无模式的,所以很容易索引非结构化数据和动态字段,而无需预先定义索引的模式。早期的Solr版本在索引数据之前需要一个已定义的模式。但是,Solr现在支持无模式模式。
这两个搜索引擎都支持自定义分析程序、基于同义词的索引、词根分析和各种记号化选项。
可伸缩性和分布式
搜索引擎必须快速处理大量的数据和对数以亿计的记录集的复杂查询。有时候,这些查询可能非常耗费资源,以至于可能会导致整个系统崩溃——尤其是在您没有提前计划负载并且无法快速伸缩的情况下。因此,搜索引擎本质上必须具有可伸缩性和容错能力。
集群、分片和再平衡
Elasticsearch和SolrCloud都提供对分片的支持。但是,由于Elasticsearch的设计考虑了水平伸缩,因此它对伸缩和集群管理提供了更好的支持。它的缺点是,尽管您可以使用收缩API来减少索引的切分,但切分一旦创建,就不能增加。SolrCloud支持进一步拆分现有的切分,但不支持收缩切分。
Elasticsearch内置的zen discovery模块处理集群协调。SolrCloud需要Apache Zookeeper,这是一个额外的服务。
在出现切分或节点故障时,Elasticsearch会自行进行集群再平衡,很少需要手动干预。在SolrCloud中,再平衡是复杂而难以管理的。
社区
Solr拥有一个广泛的开源社区。任何人都可以为Solr做出贡献,新的Solr开发人员或代码提交者是根据能力选出的。Elasticsearch技术上是开源的,但并不完全开放。所有贡献者都可以访问源代码,用户可以进行更改并贡献它们。但最终的变更会得到Elastic(运行Elasticsearch和其他软件的公司)员工的确认。因此,Elasticsearch更多的是由单个公司驱动,而不是整个社区。这还不包括Elasticsearch提供的非开放的高级特性(以及Elastic/ELK栈))。
回到2010年代中期,Solr贡献者和提交者跨越多个组织,而Elasticsearch提交者仅来自弹性组织。Solr强大的社区拥有健康的项目管道和许多知名公司的参与。这些成员还在整个开发和工程过程中对平台进行投资。
在过去的五年里,这种情况发生了巨大的变化。Elasticsearch的贡献者社区和用户基础得到了极大的发展。到目前为止,它是本世纪20年代初DevOps中最流行的开源时间序列数据库和搜索引擎。
从历史上看,两者都拥有强大的用户基础和丰富的开发人员社区,但Elasticsearch已经超过了Solr。Solr已经存在了很长一段时间,但是它的生态系统已经停滞不前,即使在拥有了良好的开发和更大的用户基础之后。
文档
在这一点上,Elasticsearch文档胜出。Elasticsearch的官方网站不仅提供了条理清晰、高质量的文档和清晰的示例,而且由于该工具的普及,互联网上充斥着书籍和指南。在过去的四年里,Elasticsearch加强了文档的编制,使其超越了组织。此外,它还提供了很好的示例和清晰的配置说明。
相比之下,Solr文档是缺乏的。Solr api的总体覆盖范围很小,很难找到好的技术示例和教程。以前是相反的:Solr是一个文档非常完善的产品,具有清晰的API用例示例和上下文。然而,它的文档维护已经落后,许多用户注意到差距。
概要:Solr vs Elasticsearch
要在这两种技术中选择一个明显的赢家,需要完全理解它们所支持的用例、它们的特性集、它们提供的伸缩选项以及它们的易于维护。
下面是每个工具属性的总结:
| Solr | Elasticsearch | |
| 安装和配置 | 易于启动和运行和非常支持的文档 | 易于启动和运行与非常支持的文档。有几个包可用于各种平台。 |
| 搜索和索引 | 适合文本搜索和接近大数据生态系统的企业应用 | 作为文本搜索和分析引擎都很有用,因为它有强大的聚合模块 |
| 可伸缩性和集群 | 支持从Solr云和Apache Zookeeper依赖集群协调 | 更好的固有的可伸缩性;为云部署设计最佳方案 |
| 社区 | 历史上的大生态系统 | 一个蓬勃发展的自由/开源软件版本Elasticsearch和ELK堆栈的生态系统 |
| 文档 | 不完整的,过时的 | Well-documented |
这两种技术都很容易开始使用。Solr在信息检索领域提供了很好的功能,但是Elasticsearch更容易投入生产和扩展。在选择工具时,请确保查看您的需求,并为您的特定用例做出最佳选择。
原文:https://logz.io/blog/solr-vs-elasticsearch/
本文:http://jiagoushi.pro/node/1151
讨论:请加入知识星球【首席架构师圈】或者小号【jiaoushi_pro】
- 172 次浏览
【技术选型】Spark SQL vs Presto
Spark SQL与Presto之间的区别
简单来说 Presto 就是“SQL查询引擎”,最初是为Apache Hadoop开发的。它是一个开源的分布式SQL查询引擎,用于对各种大小的数据集运行交互式分析查询。
Spark SQL是一个分布式内存中计算引擎,在结构化和半结构化数据集之上有一个SQL层。由于它是在内存中处理的,所以在Spark SQL中处理速度会很快。
Spark SQL和Presto (Infographics)的头对头比较
下面是Spark SQL和Presto之间的前7个比较:

Spark SQL和Presto之间的关键区别
下面是关于Presto和Spark SQL之间的关键区别的列表:
- Apache Spark引入了一个用于处理结构化数据的编程模块,称为Spark SQL。Spark SQL包含一个称为数据帧的编码抽象,它可以作为分布式SQL查询引擎。
- Presto创立的初衷是为了实现交互式分析和商业数据仓库的速度,使组织规模能够与Facebook相匹配。
- Spark SQL是Spark Core上的一个组件,它引入了名为SchemaRDD(弹性分布式数据集)的新数据抽象,它提供了对结构化/半结构化数据的支持。
- Presto被设计为使用MapReduce作业(如Hive或Pig)查询HDFS数据的工具的替代品,但Presto并不仅限于HDFS。
- Spark SQL遵循内存中处理,这提高了处理速度。Spark被设计用于处理广泛的工作负载,如批处理查询、迭代算法、交互式查询、流媒体等。
- Presto能够执行联邦查询。下面是快速联邦查询的示例
让我们假设任何RDMS 表sample1与HIVE表sample2 ,
' Testdb '是hive和MYSQL中的数据库。使用Presto,我们可以评估数据使用在一个单一的查询一旦他们的连接器配置正确,如下所示-
presto> <Function (select/Group by ..etc)> hive.Testdb.sample2
- Spark SQL架构由Spark SQL, Schema RDD, and Data Frame组成
- 数据帧是数据的集合;数据被组织成指定的列。从技术上讲,它与关系数据库表相同。
- 模式RDD: Spark Core包含称为RDD的特殊数据结构。Spark SQL适用于模式、表和记录。因此,用户可以使用模式RDD作为临时表。这样用户就可以把这个模式称为数据框架
- Data Frame 能力:数据框架在单个节点集群上处理从千字节到千兆字节的数据,
- Data Frame支持不同的数据格式(CSV, elasticsearch, Cassandra等)和存储系统(HDFS, HIVE表,MySQL等),它可以集成与所有大数据工具/框架通过Spark-Core,并提供API的语言,如Python, Java, Scala,和R编程。
- Presto是一个分布式引擎,可以在集群设置中工作。Presto体系结构易于理解和扩展。Presto客户端(CLI)将SQL语句提交给管理处理的主守护进程协调器。
- 使用Presto的公司:Facebook、Netflix、Airbnd、Dropbox等。
- Apache Spark用例可以在金融、零售、医疗保健和旅游等行业中找到。许多电子商务网站,如eBay、阿里巴巴、Pinterest都在其电子商务平台上使用Spark SQL来分析数百PB的数据。
比较Spark SQL和Presto表
下面是SQL和Presto之间最顶层的比较。
|
比较的基础 |
Presto | Spark SQL |
|
生态系统/平台 |
Hadoop、大数据处理等 | Spark框架、大数据处理等 |
| 目的 |
Presto是为在大数据(巨大的工作负载)上运行SQL查询而设计的。 它是由Facebook设计来处理他们巨大的工作量。 |
Spark SQL是Apache Spark Core的组件之一。 Spark Core是Spark平台的基本执行引擎 |
| 安装 |
|
|
|
功能/特性 |
Presto允许对许多数据源进行数据查询;例如,数据可能驻留在数据存储中:Hive、Cassandra、RDBMS和其他一些专有数据存储中。 | Spark SQL提供了使用数据框架和JDBC连接器与其他数据源集成的灵活性。 |
|
连接器 支持 |
Presto支持可插拔连接器。这些连接器为查询提供数据集。 下面是presto中可用的几个预先存在的连接器,同时presto还提供了与定制连接器连接的能力。 下面是it支持的一些连接器
|
数据框架接口允许不同的数据源在Spark SQL上工作。 Spark SQL包括一个具有行业标准JDBC和ODBC连接的服务器模式。 |
|
联邦查询 |
Presto支持联邦查询。Presto可以配置连接到不同的DBs,一旦配置;它的CLI可以用来启动“联邦查询”。 在一个Presto查询中,用户可以组合来自多个数据源的数据并运行查询。 |
Spark SQL带有一个使用JDBC连接其他数据库的内建特性,即“JDBC到其他数据库”,它有助于联邦特性。 Spark利用scala/python API使用JDBC:数据库特性创建数据框架,但它也可以直接与Spark SQL Thrift server一起工作,并允许用户像其他hive/ Spark表一样毫不费力地查询外部JDBC表。 |
|
谁在使用 |
数据分析师、数据工程师、数据科学家等等 | 数据分析师、数据工程师、数据科学家、Spark开发人员等等 |
结论
Spark SQL和Presto都是市场上可用的SQL分布式引擎。
Presto在处理双类型查询时非常有用,而Spark SQL在大型分析查询中的性能领先。与配置相比,Presto的设置比Spark SQL简单。Spark SQL和Presto在市场上的地位是平等的,它们解决的是不同类型的业务问题。
推荐的文章
这是Spark SQL与Presto的一个指南。在这里,我们讨论了Spark SQL与即时头对头比较、关键区别以及信息图和比较表。你也可以看看下面的文章来了解更多-
- Apache Spark vs Apache Flink -你需要知道的8件有用的事情
- Apache Hive vs Apache Spark SQL - 13惊人的差异
- Hadoop和SQL之间的最佳6个比较
- Hadoop与Teradata——有价值的区别
原文:https://www.educba.com/spark-sql-vs-presto
本文:http://jiagoushi.pro/node/1129
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 1507 次浏览
【技术选型】比较MongoDB和PostgreSQL
在我们开始之前:MongoDB和Postgres都是很好的数据库管理系统。这篇文章的目的是让你快速了解每个数据库的个性,以及每个数据库最适合的用例类型。
MongoDB和PostgreSQL:一个简单的比较
MongoDB是主要的文档数据库。它构建在分布式、向外扩展的架构上,并已成为一个用于管理和向应用程序交付数据的综合云平台。MongoDB可以大规模地处理事务、操作和分析工作负载。如果您关心的是上市时间、开发人员的生产力、支持DevOps和敏捷方法,以及构建无需操作操作就可伸缩的东西,那么MongoDB就是最好的选择。
PostgreSQL是一个坚如磐石的、开放源码的企业级SQL数据库,30年来一直在扩展它的功能。你想从关系数据库中得到的所有东西都可以在PostgreSQL中找到,它依赖于一个扩展的架构。如果您关心的是兼容性,从数百个表中提供数千个查询,利用现有的SQL技能,并将SQL推到极限,PostgreSQL将会做得非常出色。
这两个数据库都很棒,但是您需要什么呢?
作为一个精明的读者应该已经知道,真正的问题不是MongoDB和Postgres,而是最好的文档数据库和最好的关系数据库。两个数据库都很棒。
如果您正在为处理快速变化、多结构数据的现代事务和分析应用程序寻找分布式数据库,那么MongoDB就是最佳选择。
如果SQL数据库符合您的需要,那么Postgres是一个很好的选择。
你需要的正确答案当然是基于你正在尝试做的事情。在本文中,我们的目标是帮助解释每个数据库的个性和特征,以便您更好地了解它是否满足您的需要。
但是通常在开发项目的开始阶段,项目负责人通常很好地掌握了用例,但是对于他们的业务和用户将需要的具体应用程序特性并不是很清楚。他们不得不打赌谁最适合。本文的其余部分旨在提供有助于进行安全打赌的信息。
Postgresql vs MongoDB概述
但是,对于那些想要马上了解故事的人,这里是我们的一般指导的一个总结:
- 如果你在一个开发项目的开始阶段,试图通过敏捷的开发过程找出你的需求和数据模型,MongoDB将会大出风头,因为开发人员可以在他们需要的时候,自己重塑数据。MongoDB允许您管理任何结构的数据,而不仅仅是预先定义的表格结构。
- 如果你支持一个应用程序,你知道它需要扩展流量或数据大小(或两者都需要),并且需要跨区域分布数据本地或数据主权,MongoDB的扩展架构将自动满足这些需求。
- 如果你想要一个在每个公共云上都以相同方式工作的多云数据库,可以在特定的地理区域存储客户数据,并支持最新的无服务器和移动开发范例,MongoDB Atlas是正确的选择。
- 如果你是一个SQL商店,引入一个新的范例所花费的成本比上面提到的任何好处都要高,那么PostgreSQL是一个很可能满足你所有需求的选择。
- 如果你想要一个关系数据库,运行复杂的SQL查询,并与许多现有的基于表格、关系数据模型的应用程序一起工作,PostgreSQL可以完成这项工作。
- 如果你是一个创造性的SQL开发人员和想把SQL索引限制通过使用先进的技术,存储和搜索大量的结构化数据类型,创建用户定义的函数在不同的语言中,和调优数据库第n个学位,你可能能够更进一步,比任何其他RDBMS PostgreSQL。
所以,现在不耐心的人已经得到了满足,患者可以深入到MongoDB,然后是PostgreSQL,然后进行比较。
MongoDB:可伸缩的文档数据库,已成为一个数据平台
文档模型的美丽之处
MongoDB的文档数据模型自然地映射到应用程序代码中的对象,使得开发人员可以很容易地学习和使用它。文档使您能够表示层次关系,从而方便地存储数组和其他更复杂的结构。JSON文档可以将数据存储在字段中,作为数组,甚至作为嵌套的子文档。这样就可以将相关信息存储在一起,通过丰富而富有表现力的MongoDB查询语言进行快速查询访问。
MongoDB以名为BSON(二进制JSON)的二进制表示形式将数据存储为文档。字段可以因文档而异;不需要向系统声明文档的结构—文档是自描述的。如果需要将新字段添加到文档中,那么可以在不影响集合中的所有其他文档的情况下创建该字段,不需要更新中央系统目录、更新ORM,也不需要使系统脱机。可选地,模式验证可用于对每个集合实施数据治理控制。
这种灵活性在合并来自不同来源的信息或适应随时间变化的文档时非常有用,特别是在不断部署新的应用程序功能时。
PostgreSQL和MongoDB的术语和概念
MongoDB的文档模型中使用的许多术语和概念与PostgreSQL的表格模型相同或相似:
| PostgreSQL | MongoDB |
|---|---|
| ACID Transactions | ACID Transactions |
| Table | Collection |
| Row | Document |
| Column | Field |
| Secondary Index | Secondary Index |
| JOINs, UNIONs | Embedded documents, $lookup & $graphLookup, $unionWith |
| Materialized Views | On-demand Materialized Views |
| GROUP_BY | Aggregation Pipeline |
文档模型的增强
MongoDB允许您以几乎任何结构存储数据,并且每个字段——甚至是那些嵌套在子文档和数组中的字段——都可以建立索引并有效地搜索。
MongoDB向文档模型和查询引擎添加元素,以处理数据的地理空间和时间序列标记。这扩展了可以在数据库上执行的查询和分析类型。
BSON包含了JSON数据中没有的数据类型(例如,datetime、int、long、date、浮点数、decimal128和字节数组),提供了对多种数字类型的严格类型处理,而不是通用的“数字”类型。
模式验证允许您对模式应用治理和数据质量控制。
用于对许多文档进行更改的ACID事务
ACID事务是关系数据库中使编写应用程序更加容易的最强大的特性之一。关于如何定义和实现ACID事务的细节充斥着许多计算机科学教科书。计算机科学领域的许多讨论都是关于数据库事务中的隔离级别的)。PostgreSQL默认为read committed隔离级别,并允许用户将其调优到serializable隔离级别。
需要记住的重要事情是,事务允许在组中对数据库进行许多更改或在组中回滚。
在关系数据库中,所涉及的数据将在表模式中跨独立的父-子表建模。这意味着一次更新所有记录将需要一个事务。
从某种意义上说,文档数据库更容易实现事务,因为它们将数据聚集在文档中,而写和读文档是原子操作,因此不需要多文档事务。可以在单个操作中写入一个或多个字段,包括对多个子文档和数组元素的更新。MongoDB保证了文档更新时的完全隔离。任何错误都将触发更新操作回滚,恢复更改并确保客户端接收到文档的一致视图。
MongoDB还支持跨多个文档的数据库事务,因此相关的大块更改可以作为一个组提交或回滚。凭借其多文档事务功能,MongoDB是少数几个将传统关系数据库的ACID保证与文档模型的速度、灵活性和强大功能结合起来的数据库之一。
从程序员的角度来看,MongoDB中的事务就像开发人员在PostgreSQL中已经熟悉的事务一样。MongoDB中的事务是多语句的,具有与快照隔离类似的语法(例如starttransaction和committransaction),因此对于任何有事务经验的人来说都很容易添加到任何应用程序中。
比较MongoDB查询语言和SQL
PostgreSQL使用的关系数据库模型依赖于将数据存储在表中,然后使用结构化查询语言(SQL)进行数据库访问。
要做到这一点,在PostgreSQL和所有其他SQL数据库中,必须在填充数据之前创建数据库模式和建立数据关系。相关信息可以存储在不同的表中,但是通过使用外键和连接进行关联。模式中的大多数更改都需要迁移过程,迁移过程可能会使数据库离线或降低应用程序在运行时的性能。
SQL的强大之处在于它的强大且广为人知的查询语言,以及大量的工具。
使用关系数据库的挑战是需要预先定义其结构。加载数据后更改结构通常非常困难,需要跨开发、DBA和Ops的多个团队紧密地协调更改。
现在在MongoDB的文档数据库世界中,数据的结构不需要预先在数据库中规划,而且更改起来更容易。开发人员可以决定应用程序中需要什么,并相应地在数据库中更改它。
MongoDB默认不使用SQL。相反,为了处理MongoDB中的文档并提取数据,MongoDB提供了自己的查询语言(MQL),它提供了与SQL相同的大部分功能和灵活性。例如,与SQL一样,MQL允许您引用来自多个表的数据,转换和聚合这些数据,并筛选所需的特定结果。与SQL不同,MQL的工作方式对于每种编程语言都是惯用的。
MongoDB中的查询性能可以通过在文档和子文档的字段上创建索引来提高。MongoDB允许文档的任何字段,包括那些深深嵌套在数组和子文档中的字段,被建立索引并有效地查询。
下面的图表比较了SQL和MongoDB查询数据的方法,并展示了一些SQL语句的例子以及它们如何映射到MongoDB:
查询语言映射
PostgreSQL和MongoDB都有丰富的查询语言。下面是一些SQL语句的示例以及它们如何映射到MongoDB。在MongoDB文档中可以找到更全面的语句列表。
| SQL | MongoDB |
|---|---|
|
Not Required |
|
|
|
|
|
|
|
|
查看这些资源来进行更多的比较:
敏捷性和协作
文档模型还具有突出的特性,使开发和协作更容易、更快。
从开发人员个人的角度来看,MongoDB使数据更像代码。开发人员可以定义JSON或BSON文档的结构、进行一些开发、查看如何进行、随时添加新字段并随意修改数据,这就是文档模型的美妙之处。这种灵活性避免了要求DBA重新构造数据定义语言语句,然后重新创建和加载关系数据库,或者让开发人员做这些工作所带来的延迟和瓶颈。
在文档数据库中,开发人员或团队可以拥有文档或文档的一部分,并根据需要对其进行改进,而不需要在不同的团队之间使用中介和复杂的依赖链。
可伸缩性、弹性和安全性
MongoDB是为向外扩展而构建的。因此,需要超级快速查询和大量数据(或者两者都需要)的用例可以通过由小型机器组成更大的集群来处理。
MongoDB基于分布式架构,允许用户跨多个实例向外扩展,并被证明可以支持大型应用程序,无论是通过用户还是数据大小来衡量。向外扩展策略依赖于使用大量较小且通常廉价的机器。这种策略可以扩展到数百台机器。
在PostgreSQL中,扩展的方法取决于你说的是写数据还是读数据。对于写,它是基于一个扩展的架构,在这个架构中,运行PostgreSQL的单个主机器必须尽可能强大才能扩展。对于读取,可以通过创建副本扩展PostgreSQL,但是每个副本必须包含数据库的完整副本。
MongoDB可伸缩的基础是集群中跨实例智能分区(分片)数据的思想。MongoDB不分解文档;文档是独立的单元,这使得它更容易分布在多个服务器上,同时保持数据的局部性。
在完全管理的全球MongoDB地图集云服务中,跨地区分发数据很容易。某些文档可以被标记,因此它们将总是物理地存储在特定的国家或地理区域。这样的位置感知可以:
- 通过将数据存储在目标用户附近来减少延迟
- 帮助遵守有关数据可能被合法存储的地方的法律
每个MongoDB碎片都作为一个副本集运行:一个由三个或多个独立服务器组成的同步集群,在它们之间不断复制数据,提供冗余,并在面临系统故障或计划维护时防止停机。还可以跨数据中心安装副本,从而提供针对区域中断的弹性。在MongoDB Atlas中,创建和配置这样的集群变得更加容易和快速。
MongoDB已经实现了一套现代化的网络安全控制和集成,包括内部版本和云版本。这包括强大的安全范例,如客户端字段级加密,它允许在数据通过网络发送到数据库之前对其进行加密。
PostgreSQL有完整的安全特性,包括许多类型的加密。所有主要的云服务提供商都提供了PostgreSQL。虽然数据库是相同的,但操作和开发人员工具因云供应商的不同而不同,这使得不同云之间的迁移更加复杂。MongoDB Atlas以相同的方式运行在所有三大云提供商之间,简化了迁移和多云部署。
成熟的平台生态系统
随着数据库等基础技术的发展,它将得到由服务、集成、合作伙伴和相关产品组成的平台生态系统的支持。MongoDB平台生态系统的中心是数据库,但它有许多层,提供附加价值和解决问题。
MongoDB已经被大量采用,并且是最流行的现代数据库,根据Stackoverflow开发人员调查,它是开发人员最想使用的数据库。多亏了MongoDB工程和社区的努力,我们已经建立了一个完整的平台来满足开发者的需求。
PostgreSQL可以作为一个安装的、自管理的版本,或者作为一个数据库即服务在所有领先的云服务提供商上运行。每一个实现都按照创建它们的云提供商所希望的方式工作。要获得对PostgreSQL的支持,你必须使用云版本或者第三方提供的专门服务
MongoDB有以下几种形式:
- MongoDB Atlas是一个数据库即服务的产品,运行在所有主要的云平台上(AWS、微软Azure和谷歌云平台)。
- MongoDB Community edition是一个开放的免费数据库,可以安装在Linux、Windows或Mac OS上。
- MongoDB企业版基于MongoDB社区版,附加的功能只能通过MongoDB企业高级订阅获得。Enterprise Advanced包括对MongoDB部署的全面支持。它还添加了面向企业的特性,如LDAP和Kerberos支持、磁盘加密、审计和操作工具。MongoDB Enterprise可以安装在Linux、Windows或Mac OS上。
此外,MongoDB支持多种编程语言。为十多种语言提供了本地的惯用驱动程序——社区还构建了更多的驱动程序——支持特别查询、实时聚合和富索引,以提供强大的编程方法来访问和分析任何结构的数据。
MongoDB有一个强大的开发者社区,它代表了从爱好者到最具创新性的初创企业到最大的企业和政府机构的每个人,包括众多的系统集成商和顾问,他们提供广泛的商业服务。
MongoDB Atlas也通过MongoDB Realm进行了扩展,以简化应用程序开发,通过Lucene提供的Atlas搜索,以及支持在云对象存储上构建的数据湖的特性。
PostgreSQL和MongoDB都有强大的开发人员和顾问社区,他们随时准备提供帮助。
MongoDB的适合目的
在开发的这个阶段,MongoDB提供了业界领先的可伸缩性、弹性、安全性和性能:但它的最佳位置在哪里呢?
MongoDB擅长处理现代应用程序和api生成的数据结构,理想的定位是支持敏捷、快速变化的当今开发实践的开发周期。
真正的问题是你的数据最终会是什么样子。如果数据与应用程序代码中的对象一致,那么就可以很容易地用文档表示它。MongoDB在开发和生产中都是一个很好的选择,特别是当你需要扩展的时候。
但是,如果您有许多基于关系数据模型的现有应用程序,并且团队只熟悉SQL,那么像MongoDB这样的文档数据库可能不太合适。
文档数据库可以进行连接,但是它们与多页SQL语句不同,多页SQL语句有时是必需的,通常由BI工具自动生成。也就是说,MongoDB确实有一个ODBC连接器,允许SQL访问,主要来自BI工具。
Posrgresql:一个现代的SQL数据库
和Linux一样,PostgreSQL是一个管理良好的开源项目的例子。作为采用最广泛的关系数据库之一,PostgreSQL起源于1986年加州大学伯克利分校的POSTGRES项目,并随着时代的发展而发展。
PostgreSQL是一个对象关系数据库
PostgreSQL自称是一个开源的对象关系数据库系统。
它是一个SQL数据库,它有一些处理索引、增加并发性和实现优化和性能增强的策略,包括高级索引、表分区和其他机制。
PostgreSQL的对象部分与许多扩展相关,这些扩展使它能够包含其他数据类型,如JSON数据对象、键/值存储和XML。
核心SQL支持
PostgreSQL的设计原则强调SQL和关系表,并允许扩展性。
PostgreSQL提供了许多方法来提高数据库的效率,但在其核心上它使用了一种扩展策略。
像MySQL和其他开放源码关系数据库一样,PostgreSQL已经在许多行业中被证明是具有高要求用例的坩埚。
在我们进行比较的主要问题之前,让我们先介绍一下PostgreSQL的一些优势:什么时候表格、关系模型和sql最适合应用程序?
PostgreSQL采取了一种实用的、工程思维的方法来处理几乎所有的事情。例如,考虑以下关于符合最新SQL标准的声明:
“PostgreSQL试图遵循SQL标准,这样的一致性不会与传统特性相冲突,也不会导致糟糕的架构决策。”
对他们有利。正如他们正确指出的那样:
“在撰写本文时,没有任何关系数据库完全符合本标准。”
在SQL的世界中,有很好的SQL引擎,可以很好地处理一组简单的查询,也有更健壮的SQL引擎,带有查询优化器,可以处理复杂的查询,并且总是能够得到正确的结果。PostgreSQL是一个健壮的SQL引擎。
这种稳健性来自于长期的稳定发展。一个应该给SQL迷留下深刻印象的细节是,它支持“SQL标准中定义的所有事务隔离级别,包括serializable”。“这是一个工程水平,大多数长期使用的商业数据库都不会为此烦恼,因为它很难以足够的性能实现。”
性能、安全性和可靠性
因为PostgreSQL依赖于一个扩展策略来扩展写入或数据量,所以它必须充分利用可用的计算资源。PostgreSQL通过各种索引和并发策略来实现这一点。
PostgreSQL提供了各种强大的索引类型来最佳匹配给定的查询工作负载。索引策略包括b -树、多列、表达式和部分,以及高级索引技术,如GiST、SP-Gist、KNN GiST、GIN、BRIN、覆盖索引和bloom过滤器。
除了一个成熟的查询规划器和优化器,PostgreSQL还提供了性能优化,包括并行化读取查询、表分区和即时(JIT)表达式编译。
该数据库遵守广泛的安全标准,并具有许多特性来支持可靠性、备份和灾难恢复(通常通过第三方工具)。
可扩展性
PostgreSQL支持多种方式的可扩展性,包括存储函数和过程,从过程性语言(如PL/PGSQL、Perl、Python等)访问,SQL/JSON路径表达式,以及使用标准SQL接口连接到其他数据库或流的外部数据包装器。
许多扩展提供了额外的功能,包括PostGIS,一个用于地理空间分析的模块。
领导和标准化
因为PostgreSQL被广泛使用,所以可以肯定的是,大多数开发工具和其他系统都已经用它进行过测试,并且是兼容的。
PostgreSQL所采取的将语言的api连接到它的数据库的方法已经被许多其他数据库模仿,使得运行在PostgreSQL上的程序更容易移动到另一个SQL数据库上,反之亦然。
PostgreSQL是符合目的的
正如我们在开始所说的,问题不是“MongoDB vs PostgreSQL?”而是“什么时候使用文档数据库vs关系数据库有意义?”因为每个数据库都是其特定数据库格式的最佳版本。
SQL的优点包括为使用SQL数据库而构建的工具、集成和编程语言的庞大生态系统。您可以很容易地找到帮助,使您的SQL数据库项目在一般情况下和PostgreSQL项目在特定情况下工作。PostgreSQL还有很多部署选项。
MongoDB还是PostgreSQL?
放弃SQL意味着离开已经使用SQL的大型技术生态系统。如果您正在开发一个新的应用程序,或者计划对现有的应用程序进行现代化,那么这样做会更容易。
许多数据管理和BI工具都依赖于SQL,并以编程的方式生成复杂的SQL语句,以便从数据库中获得正确的数据集合。PostgreSQL在这种情况下做得很好,因为它是一个健壮的、企业级的实现,被许多开发人员理解。
此外,如果您有一个扁平的、表格式的数据模型,它不会经常更改,也不需要向外扩展,那么关系数据库和SQL可能是一个强大的选择。
但是,必须考虑SQL的预期好处带来的成本。
与MongoDB相比,PostgreSQL的缺点是它依赖于关系数据模型,而这种模型对开发人员在代码中使用的数据结构不友好,而且必须提前定义,因此每当需求发生变化时,开发进度就会变慢。
MongoDB之所以能够很好地支持快速、迭代的开发周期,是因为文档数据库在开发人员的控制下将数据转换为代码。这种速度被关系数据库中使用的严格的表格数据模型的性质所破坏,数据库管理员通常必须通过一个中间过程对其进行重塑,从而降低了整个开发过程。这样的瓶颈会阻碍创新。
当一个应用程序上线时,PostgreSQL用户必须准备好与可伸缩性进行斗争。PostgreSQL使用了一种扩展策略。这意味着在某些情况下,对于高性能用例来说,您可能会遇到瓶颈,或者不得不转移资源,通过缓存或反规范化数据或使用其他策略来寻找其他扩展方法。
在MongoDB中,这类技术通常是不需要的,因为通过本地分片内置了可伸缩性,支持水平向外扩展的方法。在正确分片集群之后,您总是可以添加更多实例并继续向外扩展。MongoDB Atlas拥有广阔的多云、全球感知的平台随时待命,一切为您全面管理。
PostgreSQL可以支持复制,但自动故障转移等更高级的功能必须由独立于数据库开发的第三方产品支持。这种方法比MongoDB内置的自修复功能更复杂,运行速度更慢,无缝性也更差。
您的数据模型将走向何处?
您的数据和目标用例的性质也非常重要。那些拥有大量SQL技能和工具的生态系统以及大量现有应用程序的用户可以选择继续使用关系数据模型。
但是MongoDB已经成功了,尤其是在企业中,因为它打开了通向开发人员生产力新水平的大门,而静态关系表常常带来障碍。如果您有需要大规模交付的数据,那么可以从开发人员对模式的控制中获益,或者满足您一开始并不能完全理解的需求,那么像MongoDB这样的文档数据库就很适合。
MongoDB和PostgreSQL都是优秀的数据库。我们希望这次讨论能给您一些新的启发,使您能更好地满足您的需要。
原文:https://www.mongodb.com/compare/mongodb-postgresql
本文:http://jiagoushi.pro/node/1138
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 199 次浏览
【数据库架构】构建具有更好性能的强一致性的Cassandra:YugaByte
在之前关于数据库一致性的博客中,我们详细讨论了应用程序在处理最终一致的NoSQL数据库时所面临的风险和挑战。我们也打破了一致星展银行最终比强烈一致星展银行表现更好的神话。在这篇博客中,我们将更深入地研究YugaByte数据库是如何在提供强一致性的同时优于Apache Cassandra这样的最终一致性数据库的。注意,YugaByte DB保留了与Cassandra Query Language (CQL) API的drop-in兼容性。
YugaByte DB vs Apache Cassandra性能
雅虎云服务基准测试(YCSB)是一个广为人知的NoSQL数据库基准测试。我们对YugaByte DB和Apache Cassandra运行了YCSB测试,并且兴奋地发现YugaByte DB在吞吐量和百分之99 (p99)延迟上都比Apache Cassandra要好。

YCSB—读写吞吐量(越多越好)
YCSB -读取和写入P99延迟(越少越好)
不仅YugaByte的DB性能更好,而且随着数据密度(更多的键)的增加,边际也会扩大。对详细的性能数字和测试配置感兴趣的读者可以在这里查看我们的文章。
为什么YugaByte DB优于Apache Cassandra?
YugaByte DB优于Apache Cassandra有6个重要的架构上的原因。
1. 较高的读取吞吐量和较低的延迟
为了使用仲裁读取在最终一致的DB中实现强一致性(到某一点),读操作需要从仲裁中的所有副本中读取数据,以返回大多数仲裁同意的结果。因此,读取的次数乘以复制因子(3x或更多)。同样的复制因子放大了系统负载,从而对系统的吞吐量产生了负面影响。
不仅负载放大了,而且由于从副本读取所需的额外网络往返,响应时间也增加了一倍以上。当网络被额外的流量堵塞时,情况会变得更糟。另外,在读取的关键路径上放置3台服务器会对p99延迟产生不利影响。由于这些架构上的约束,Apache Cassandra的吞吐量较低,延迟较高。
1x vs 3x读取YugaByte vs Apache Cassandra
让我们将其与在读取操作期间执行的YugaByte进行比较。由于使用了RAFT consensus协议,quorum leader持有的数据保证是一致的。所以读操作只需要从前导器读取一次(1x)。因此,如下表所示,YugaByte可以提供更好的性能,因为它既没有读取放大也没有到其他副本的往返。
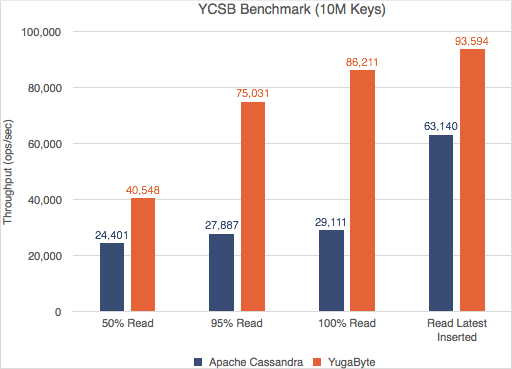
YCSB – Read Throughput (More is Better)
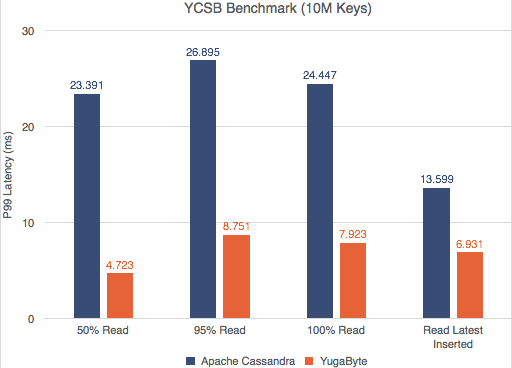
YCSB -读取P99延迟(越少越好)
2. 较高的读-修改-写吞吐量和较低的延迟
非原子的读-修改-写:在上面的读-修改-写工作负载中,YCSB使用两个独立的不带原子性的读和写数据库语句对读-修改-写操作建模。因此,我们已经看到YugaByte DB比Apache Cassandra更好。
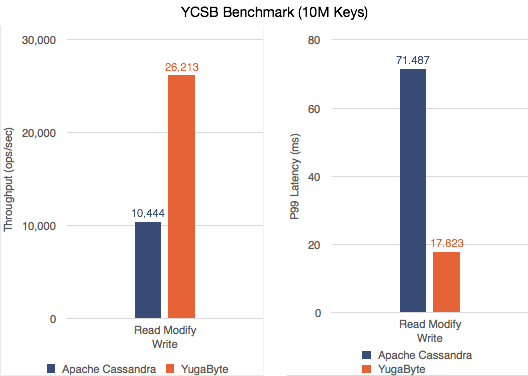
YCSB—读写吞吐量(越多越好)和P99延迟(越少越好)
原子的读-修改-写:为了实现原子性,读-修改-写操作可以作为一个轻量级事务(LWT)执行。在Apache Cassandra中,LWT从leader到副本总共需要4次往返,以准备、读取、提议和提交事务。许多往返会导致严重的延迟和LWT性能差,对用户应用程序产生负面影响。
在ygabyte DB中,因为quorum leader总是保存一致的并且是最新的数据副本,所以LWT只需要一次(1x)往返到副本来更新数据。这种更好的一致性设计使YugaByte执行LWT比Apache Cassandra更快。
3.压缩期间的可预测性能
Apache Cassandra中另一个导致速度变慢的主要原因是后台压缩。当运行主要的压缩时,用户经常抱怨他们的应用层有较高的前台延迟。
这是因为长时间运行或主要压缩会“饿死”较小但关键的压缩作业。这种饥饿会导致读取延迟的增加。完成较大的压缩之后,就可以运行较小的压缩,延迟也会降低。这使得延迟在应用程序端不可预测。高级技术用户通常会在非高峰时间在后台安排自己的压缩,但这既困难又不总是可能的。
在YugaByte DB中,我们将压缩分为主压缩和小压缩,并将它们安排在不同的队列中,并具有不同的优先级。这保证了较小的关键压缩具有一定的服务质量,将后台压缩对用户应用程序的影响降到最低。
4. 没有读取/反熵修复
在像Apache Cassandra这样最终一致的数据库中,任何副本中都可能存在不一致的数据。有两种处理方法。
读修复:一个读操作需要从所有副本读取以确定一致的结果。每当在任何副本中检测到不一致的数据时,该副本将需要立即进行前台读修复。
反熵维护:此外,最终一致的数据库还需要定期的后台反熵维护,对所有副本中的数据进行比较,并修复任何不一致的数据。
上面的操作开销很大,需要大量的CPU和网络带宽来将数据的副本发送给副本并进行比较。对于最终用户应用程序,这表现为更高的/不可预测的延迟,以及系统无法有效地支持更大的数据集。
在YugaByte DB的情况下,由于筏协议保证了强一致性,既不需要读修复,也不需要反熵维护。这将导致较低且可预测的p99延迟。我们使用Netflix数据存储基准(NDBench)进行了7天的基准测试,很高兴地看到p99的延迟低于6毫秒,甚至p995的延迟低于7毫秒。
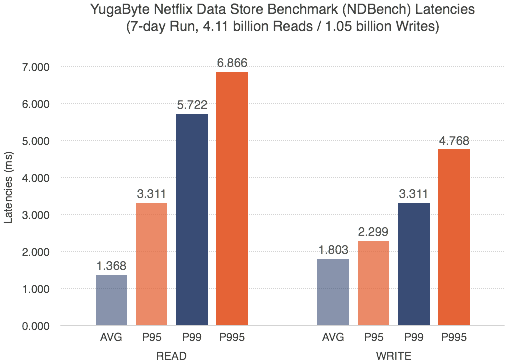
NDBench - YugaByte DB vs Cassandra Latency
5. 没有垃圾收集暂停
在基于java的NoSQL数据库(如Apache Cassandra)中,长时间的垃圾收集(GC)暂停是生产环境中的一个众所周知的问题。当垃圾收集器暂停应用程序、标记和移动正在使用的对象以及丢弃未使用的对象以回收内存时,就会发生这种情况。在一个长时间运行的数据库中,这种GC暂停通常会导致周期性的系统不可用和长响应时间(“长尾”问题)。虽然最先进的垃圾优先(Garbage First, G1) GC可以通过限制暂停时间在一定程度上缓解这个问题,但不幸的是,它是以降低吞吐量为代价的。最后,用户将不得不牺牲应用程序吞吐量或延迟。
因为YugaByte DB是用c++实现的,不需要垃圾收集,所以我们的用户可以毫无妥协地拥有最大的吞吐量和可预测的响应时间。
6. 利用更大的内存来获得更好的性能
除了GC调优,Java内存调优是Apache Cassandra用户面临的另一个典型挑战。它需要非常了解JVM堆大小应该是什么,哪些数据存储在堆外缓冲区中。而且,将更多内存分配给Java堆可能会损害性能,因为GC暂停时间更长。所有这些都增加了用户需要克服的操作复杂性。
另一方面,YugaByte DB可以在大内存机器上高效运行,有效利用可用内存,而不需要手动调整和调优。
总结
在这篇博客中,我们深入探讨了YugaByte DB如何通过更好的设计和实现来提供强大的一致性和卓越的性能。
原文:https://blog.yugabyte.com/building-a-strongly-consistent-cassandra-with-better-performance/
本文:http://jiagoushi.pro/node/1140
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 73 次浏览