数据安全
- 532 次浏览
「数据安全」介绍ACRA-开源数据库安全套件
如果您担心数据安全性,这意味着要面对需要警惕和防御各种攻击的威胁形势。 攻击的主要目标之一仍然是存储在后端数据库存储中的敏感数据。 从简单发现不安全的数据库,到经典的SQL注入技术,再到允许批量复制数据库内容的受损基础架构,攻击更加注重数据资产的精确度。
来自哥萨克实验室的Acra提供了一系列新颖且成熟的技术,旨在保护存储在后端数据库系统中的敏感数据。 Acra将这些作为一套易于使用,部署和自动化的数据库保护工具提供。
Acra提供三个主要功能,使您能够:
- 使用强大的,经过验证的加密方案有选择地保护敏感记录。
- 监视请求流到数据库以防止恶意请求。
- 将这些安全功能部署在一个隔离良好的基础架构中,在这个基础架构中,已知并理解风险和攻击面。
Acra可以部署在传统的数据库前端Web服务和大型,微服务丰富的基础架构中。与许多其他数据库加密工具不同,Acra与您现有的基础架构集成,无需重建组件即可添加安全层。此外,Acra的选择性加密功能不仅可以与您的应用程序集成,还可以集成迁移脚本,归档数据转储以及任何涉及数据库请求的过程。
Acra使用GoLang构建,目前支持PostgreSQL数据库以及Ruby,Python,PHP,Node.js或GoLang应用程序开发环境。 Acra被授权为Apache 2开源软件。
Acra如何运作?
Acra使前端应用程序代码能够使用一组仅加密密钥有选择地加密数据。 然后将加密数据(通过AcraProxy服务)传输到数据库。 访问数据的请求通过AcraServer路由 - 一个包含解密密钥的网络服务,解密数据并通过安全连接将响应转发给应用程序。 此外,可以将AcraServer配置为检测意外请求并采取适当的操作。
- 213 次浏览
【MongoDB】MongoDB可查询加密简介
MongoDB 6.0引入了一个预览功能,它实现了一个近乎神奇的功能,即允许将加密数据用作搜索目标,而无需将密钥传输到数据库。
出于可以理解的原因,可查询加密是MongoDB World 2022的主要吸引力。它引入了一种独特的功能,可在多种使用情况下减少机密数据的攻击面。特别是,数据在插入、存储和查询时保持加密。查询和它们的响应都通过导线加密,并随机化以进行频率分析。
其结果是,应用程序可以支持需要搜索分类数据的用例,而不会在数据存储基础设施中以明文形式公开。出于显而易见的原因,持有私人信息的数据存储是黑客的主要目标。MongoDB的加密字段意味着该信息在数据库中始终是加密安全的,但仍可用于搜索。事实上,数据库根本不保存用于解密数据的密钥。这意味着,即使完全破坏数据库服务器也不会导致私人信息的丢失。
消除了几个突出和复杂的攻击向量。例如:
- 不道德或被黑客入侵的数据库管理员帐户。
- 访问磁盘文件。
- 访问内存数据。
这有点像散列密码。出于同样的原因,我们在数据库中散列密码,因此黑客甚至数据库管理员都无法查看密码。当然,最大的区别在于,散列密码是单向的。您可以验证密码是否正确,但仅此而已。无法查询这样的字段,也无法恢复明文。可查询加密保留了处理字段的能力。
该系统另一个有趣的特点是,字段以随机方式加密,因此相同的值将在不同的运行中输出不同的密文。这意味着系统也能抵抗频率分析攻击。该系统通过控制哪些客户端有权访问密钥,允许严格区分对搜索结果具有查看权限的客户端和没有查看权限的客户。
例如,应用程序可能存储机密信息,如信用卡号,以及不太敏感的信息,如用户名。非特权客户端可以通过不为客户端提供加密密钥,以严格的方式查看用户名,而不是信用卡。有权访问密钥的客户端可以在搜索中查看和使用信用卡,同时在发送、搜索、存储和检索信用卡的步骤中对卡号进行加密。
可查询加密的权衡
当然,所有这些都是有代价的。具体而言,对于涉及加密字段的查询,存在空间和时间要求的成本。(MongoDB指南对加密数据的额外存储要求约为2-3倍,但预计未来会下降)。
查询加密数据是由MongoDB处理的,它将元数据合并到加密集合本身,以及带有其他元数据的单独集合中。这说明了使用这些数据集以及实际加密和解密工作时存储和时间需求的增加。
此外,还存在必须以密钥管理服务(KMS)的形式支持的体系结构复杂性,以及使用它的编码开销以及加密和解密工作本身。
可查询加密的工作原理
在最高级别,它类似于图1。
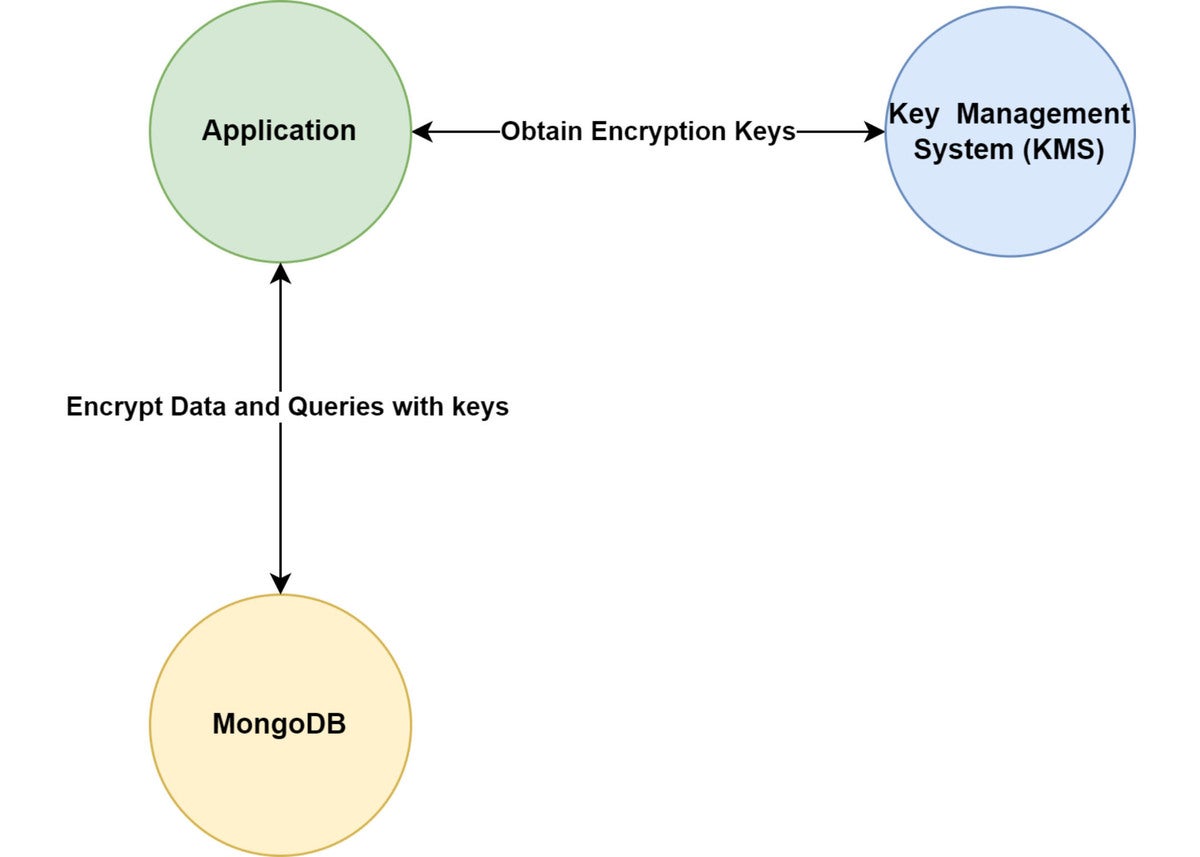
Figure 1. High-level architecture of queryable encryption
图1说明了系统添加了一个架构组件:KMS。典型事件流的另一个变化是,数据和查询通过MongoDB驱动程序进行加密和解密。KMS提供了该过程的密钥。
自动和手动加密
可查询加密有两种基本模式:自动和手动。在自动模式下,MongoDB驱动程序本身处理加密和解密。在手动中,应用程序开发人员使用KMS中的密钥进行更多的实践工作。
密钥类型:客户主密钥(CMK)和数据加密密钥(DEK)
在可查询加密系统中,有两种类型的密钥:客户主密钥(CMK)和数据加密密钥(DEK)。DEK是用于加密数据的实际工作密钥。CMK用于加密DEK。这提供了额外的安全性。客户端应用程序本身可以仅通过首先使用CMK对DEK进行解密来使用DEK(以及用它加密的数据)。
因此,即使DEK以其加密形式公开,如果攻击者无法访问CMK,它也是无用的。该架构可以被安排为使得客户端应用程序从不持有CMK本身,如下面使用密钥管理服务所述。底线是,双密钥安排是私钥的额外安全层。
数据加密密钥(DEK)存储在额外密钥库集合中,如下所述。
钥匙保管库
数据使用对称密钥加密。这些密钥属于应用程序开发人员,永远不会发送到MongoDB。它们存储在钥匙库中。管理密钥有三种基本场景,按安全性升序如下所述。
本地文件密钥提供程序。
- 仅适用于开发。
- 密钥与应用程序一起存储在本地系统中
KMIP(密钥管理互操作性协议)提供程序。
- 适用于生产,但安全性不如使用KMS提供商。
- 客户主密钥(CMK)被传输到客户端应用程序
完整的KMS(密钥管理服务)提供者。适合生产
- 支持的云KM包括:AWS、Azure和GCP
- 支持本地HSM(硬件安全模块)和KMS
- 只有数据加密密钥传输到客户端应用程序
用于开发的本地密钥提供者
在开发时,应用程序开发人员可以生成密钥(例如,使用OpenSSL)并将其存储在本地。然后,这些密钥用于加密和解密发送到MongoDB实例的信息。这仅用于开发,因为它在密钥中引入了一个主要漏洞,从而降低了可查询加密的许多优势。
KMIP提供商
有许多KMIP实现(包括开源)和商业服务。在这种情况下,CMK存储在KMIP提供程序中,并在需要加密或解密DEK以供使用时传输到客户端应用程序。如果密钥库集合被破坏,数据将保持安全。这种布置如图2所示。
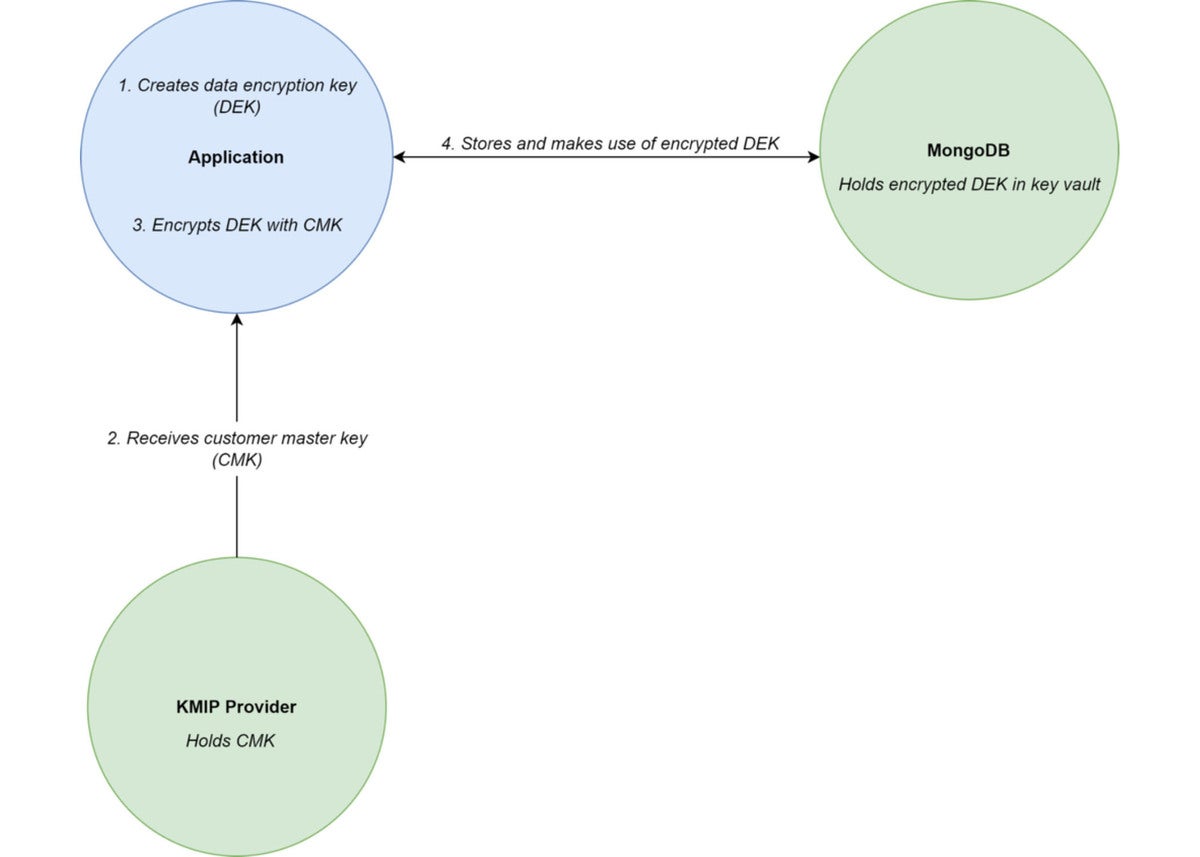
Figure 2. KMIP architecture outline
KMS提供商
通过使用KMS提供商(如AWS、Azure或GCP),客户主密钥永远不会暴露给网络或客户端应用程序。相反,KMS提供加密DEK的服务。DEK本身被发送到KMS,加密后作为密码文本返回,然后存储在MongoDB中的一个特殊密钥库集合中。
然后可以以类似的方式用KMS检索和解密存储的DEK,再次防止CMK本身的暴露。与KMIP一样,如果密钥库集合被破坏,数据将保持安全。
您可以在图3中看到这个布局。
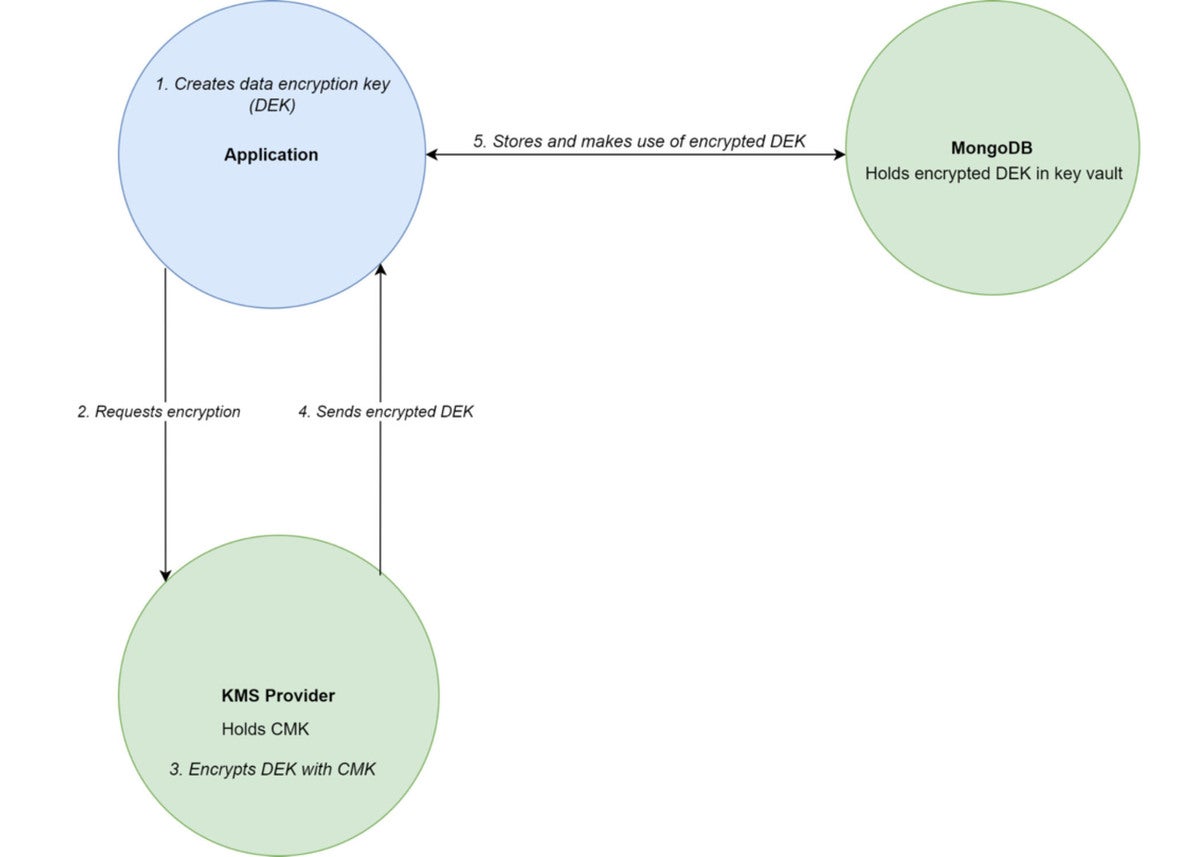
Figure 3. KMS Architecture outline
结论
可查询加密是一种预览功能,目前仅支持相等查询。路线图上还有更多的查询类型,如范围。
尽管它需要额外的设置,可查询加密为需要搜索机密数据的用例提供了一个关键功能,而这是以任何其他方式都无法实现的。这是一种引人注目的独特能力。
有关加密的更多信息:
- 4 hot areas for encryption innovation
- 5 myths about data encryption
- The race for quantum-proof cryptography
Next read this
- The 10 most powerful cybersecurity companies
- 7 hot cybersecurity trends (and 2 going cold)
- The Apache Log4j vulnerabilities: A timeline
- Using the NIST Cybersecurity Framework to address organizational risk
- 11 penetration testing tools the pros use
本文:
- 223 次浏览
【信息安全】什么是PGP加密?它是如何工作的?
Pretty Good Privacy(PGP)是一种加密系统,用于发送加密电子邮件和加密敏感文件。自1991年发明以来,PGP已成为电子邮件安全的事实标准。
PGP的流行基于两个因素。首先,该系统最初是作为免费软件提供的,因此在那些希望为其电子邮件提供额外安全级别的用户中迅速传播。第二,由于PGP同时使用对称加密和公钥加密,它允许从未见过面的用户在不交换私钥的情况下互相发送加密消息。
如果您想提高电子邮件的安全性,PGP提供了一种相对简单且经济高效的方法。在本指南中,我们将向您展示如何。
- PGP加密使用
- 利弊
- PGP解决方案
- PGP常见问题
PGP加密是如何工作的?
PGP与您可能听说过的其他加密系统共享一些功能,例如Kerberos加密(用于验证网络用户)和SSL加密(用于保护网站)。
在基本级别上,PGP加密使用两种加密形式的组合:对称密钥加密和公钥加密。
为了了解PGP是如何工作的,请看一个图表:

加密背后的数学可能会变得相当复杂(不过,如果你愿意,你可以看看数学),所以这里我们将坚持基本概念。在最高级别,PGP加密的工作原理如下:
- 首先,PGP使用两种(主)算法中的一种生成随机会话密钥。这个密钥是一个无法猜测的巨大数字,并且只能使用一次。
- 接下来,对会话密钥进行加密。这是使用消息的预期收件人的公钥完成的。公钥与特定人的身份有关,任何人都可以使用它向他们发送消息。
- 发送方将加密的PGP会话密钥发送给接收方,并且他们可以使用私钥对其进行解密。使用此会话密钥,收件人现在可以解密实际消息。
这似乎是一种奇怪的做事方式。为什么要加密密钥本身?
答案很简单。公钥加密比对称加密慢得多(发送方和接收方都有相同的密钥)。但是,使用对称加密要求发送方以明文形式与接收方共享加密密钥,这是不安全的。因此,通过使用(非对称)公钥系统对对称密钥进行加密,PGP将对称加密的效率与公钥密码的安全性结合起来。
PGP加密实例
实际上,发送用PGP加密的消息比上面的解释听起来更简单。让我们看看ProtonMail——作为一个例子。
ProtonMail本机支持PGP,加密电子邮件所需做的就是选择Sign Mail。你会在他们邮件的主题行看到一个挂锁图标。电子邮件将如下所示(出于隐私原因,电子邮件地址已变得模糊):

ProtonMail与大多数提供PGP的电子邮件客户端一样,隐藏了消息加密和解密的所有复杂性。如果您与ProtonMail之外的用户通信,则需要首先向他们发送公钥。

因此,尽管消息是安全地发送的,但是接收者不必担心这样做的复杂性。
PGP加密使用

基本上,PGP有三个主要用途:
- 发送和接收加密电子邮件。
- 正在验证向您发送此邮件的人的身份。
- 加密存储在设备或云中的文件。
在这三种用途中,第一种——发送安全电子邮件——是目前PGP的主要应用。但让我们简单地看一下这三个
加密电子邮件
在上面的例子中,大多数人使用PGP发送加密的电子邮件。在PGP的早期,它主要被活动家、记者和其他处理敏感信息的人使用。事实上,PGP系统最初是由一位名叫paulzimmerman的和平与政治活动家设计的,他最近加入了最受欢迎的私人搜索引擎Startpage。
如今,PGP的普及率已经显著提高。随着越来越多的用户意识到公司和政府正在收集多少信息,现在有大量的人使用这个标准来保护他们的私人信息。
数字签名验证
PGP的一个相关用途是它可以用于电子邮件验证。例如,如果记者不确定向其发送消息的人的身份,他们可以使用PGP旁边的数字签名来验证这一点。
数字签名的工作原理是使用一种算法将发送者的密钥与他们发送的数据相结合。这将生成一个“哈希函数”,这是另一种可以将消息转换为固定大小的数据块的算法。然后使用发送方的私钥对其进行加密。
然后,消息的接收者可以使用发送者的公钥解密这些数据。即使邮件中有一个字符在传输过程中发生了变化,收件人也会知道。这可能表明发送者不是他们所说的人,他们试图伪造数字签名,或者消息被篡改。
加密文件
PGP的第三个用途是加密文件。由于PGP使用的算法(通常是RSA算法)本质上是不可破解的,因此PGP提供了一种高度安全的静态文件加密方法,尤其是与威胁检测和响应解决方案一起使用时。事实上,这种算法是如此安全,它甚至被用于高知名度的恶意软件,如CryptoLocker恶意软件。
早在2010年,赛门铁克就收购了PGP公司,后者持有PGP系统的使用权。此后,赛门铁克通过赛门铁克加密桌面和赛门铁克加密桌面存储等产品成为PGP文件加密软件的主要供应商。该软件为您的所有文件提供PGP加密,同时还隐藏了加密和解密过程的复杂性。
我需要很好的隐私加密吗?

是否需要使用PGP加密将取决于您希望通信(或文件)的安全程度。与任何隐私或安全软件一样,使用PGP需要在发送和接收消息时多做一些工作,但也可以显著提高系统的抗攻击能力。
让我们仔细看看。
PGP加密的优点
PGP加密的主要优点是它本质上是不可破解的。这就是为什么它仍然被记者和活动家使用,以及为什么它常常被视为改善云安全的最佳方式。简而言之,任何人——无论是黑客还是国家安全局——根本不可能破解PGP加密。
尽管有一些新闻指出PGP的一些实现存在安全缺陷,例如Efail漏洞,但必须认识到PGP本身仍然非常安全。
PGP加密的缺点
PGP加密最大的缺点是它没有那么好用。这一点正在发生变化——感谢我们即将推出的现成解决方案——但使用PGP可以为您的日常日程安排增加大量额外的工作和时间。此外,那些使用该系统的人需要知道它是如何工作的,以防他们不正确地使用它而引入安全漏洞。这意味着,考虑转向PGP的企业将需要提供培训。
出于这个原因,许多企业可能想考虑替代方案。例如,像Signal这样的加密信息应用程序提供了更简单易用的加密。在存储数据方面,匿名化可以是加密的一个很好的替代方法,并且可以更有效地利用资源。
最后,您应该知道PGP加密您的消息,但它不会使您匿名。与使用代理服务器或通过VPN隐藏真实位置的匿名浏览器不同,通过PGP发送的电子邮件可以追踪到发件人和收件人。他们的主题行也没有加密,所以你不应该把任何敏感信息放在那里。
如何设置PGP加密?
在绝大多数情况下,设置PGP加密需要下载电子邮件程序的附加组件,然后按照安装说明进行操作。Thunderbird、Outlook和Apple Mail都有类似的附加组件,我们将在下面介绍这些。近年来,我们也看到了一些默认包含PGP的在线电子邮件系统的出现(最著名的是ProtonMail)。
对于那些希望使用PGP加密文件的人,有许多大型软件解决方案可用。例如,Symantec提供基于PGP的产品,例如用于加密通过网络共享的文件的Symantec File Share Encryption和用于在台式机、移动设备和可移动存储上进行全磁盘加密的Symantec Endpoint Encryption。
PGP加密软件
如果您希望开始使用PGP加密,这通常需要下载一个软件来自动进行加密和解密。有许多不同的产品可以做到这一点,但你应该知道什么寻找。
如何选择PGP软件
- 使用PGP的主要原因是为了确保消息的安全性。因此,在寻找PGP软件时,安全性应该是您首先考虑的问题。尽管PGP本身是牢不可破的,但也有一些特定的实现遭到破坏的情况。除非您是一个有经验的程序员,否则发现这些漏洞基本上是不可能的,因此最好的解决方案是检查您正在考虑的软件中报告的任何漏洞。
- 除此之外,选择PGP软件还取决于您的个人(或业务)需求。例如,你不太可能需要加密你发送的每封电子邮件,因此为你的日常电子邮件客户端下载一个附加组件可能会有点过头。相反,考虑使用一个在线PGP服务发送重要电子邮件。
- 最后,通过客户支持团队或用户社区,选择一个同时提供专门支持的软件提供商。学习使用PGP通常会在您第一次浏览系统时遇到挫折,在这个阶段您可能需要帮助。
不同的PGP解决方案
根据使用PGP的原因以及需要使用PGP的频率,有几种不同的设置方法。在本节中,我们将重点介绍大多数用户需要从PGP(安全电子邮件)获得什么,而不是加密文件存储,这是一个更复杂的问题。下面是在家庭或商业网络上实现PGP的五种解决方案。
1.gpg4o展望
Gpg4o是最受Windows用户欢迎的PGP解决方案之一,旨在与Outlook 2010–2016无缝集成。
- 优点:Gpg4o提供了简单的电子邮件处理,并与Outlook很好地集成。对于大多数Windows用户来说,它提供了最简单、最友好的PGP插件。
- 缺点:尽管Gpg4o是围绕OpenPGP标准构建的,OpenPGP标准是开源的,并且可以进行详细检查,但是附加组件本身是专有的。此外,附加组件的营业执照目前相对昂贵€56.36,尽管如此,您还可以获得专门的支持。
2.使用GPGTools的Apple Mail
为Mac用户提供PGP加密的标准实现是GPGTools,它是一套软件,为Mac系统的所有区域提供加密。
- 优点:GPGTools与applemail集成良好,如上面的示例所示。它还提供了一个密钥管理器、一个允许您在几乎任何应用程序中使用PGP的软件,以及一个允许您使用命令行执行最常见的密钥管理任务的工具。
- 缺点:尽管GPGTools为Mac用户提供了开始使用PGP加密的最简单方法,但是对主电子邮件使用这种加密会降低Apple邮件的性能。
3.神秘的雷鸟(Thunderbird With Enigmail)
与上面的工具一样,Enigmail被设计成与一个特定的电子邮件客户端(在本例中是Thunderbird)集成。
- 优点:Enigmail有几个关键的优点。第一个是,与Thunderbird一样,该插件与平台无关。其次,这个附加组件是完全开源的,是免费提供的。它也会定期更新,开发团队能够快速响应已识别的恶意软件实例。
- 缺点:与大多数开源软件一样,Enigmail不提供专门的支持。另一方面,用户社区又大又活跃,已经汇编了大量的参考资料来帮助你入门。
4.协议邮件(ProtonMail)
ProtonMail是最早的安全电子邮件提供商之一,也是最受欢迎的电子邮件提供商之一。与上述解决方案不同,ProtonMail通过一个web门户进行操作,这意味着它很容易与您的日常收件箱分离。
- 优点:ProtonMail会自动对其服务的两个用户之间发送的消息使用PGP加密,这减少了设置和使用PGP的大部分复杂性。像这样的服务——Hushmail和Mailfence是类似的——是一种发送偶尔加密的电子邮件的简单方法,而无需重新设置整个系统。
- 缺点:因为ProtonMail通过嵌入在网站中的JavaScript实现PGP,所以有些人并不认为它是完全安全的。也就是说,ProtonMail非常重视他们系统的安全性,并且在改进系统方面非常积极。
5.Android和FairEmail
最后是FairEmail,它将PGP加密扩展到Android手机。这是一个独立的电子邮件应用程序,可以免费使用。
- 优点:对于想在Android手机上使用PGP加密的用户来说,FairEmail是最简单的解决方案。它为您提供了加密消息的选项,而不是默认情况下这样做,因此您可以选择要加密的内容。
- 缺点:由于通过Android使用PGP的情况仍然很少见,FairEmail的用户群体非常小。
很好的隐私常见问题
即使经过以上的解释,你可能仍然有一些问题。以下是关于PGP最常见问题的答案。
问:PGP加密安全吗?
A:是的。虽然PGP已经有20多年的历史了,但是在系统的基本实现中还没有发现漏洞。这就是说,加密你的电子邮件是不够的总安全,你应该始终使用PGP结合一个完整的网络安全套件,包括威胁检测软件。
问:PGP加密是如何工作的?
答:PGP结合了对称加密和公钥加密,为用户提供了一种安全的方式来互相发送消息。
问:什么是最好的PGP软件?
A:“最好的”PGP软件将取决于您的需要。大多数人不需要加密他们所有的电子邮件,因此对大多数人来说,基于网络的PGP电子邮件提供商将是最好的解决方案。也就是说,如果你经常发送需要加密的电子邮件,你可以考虑为你的标准电子邮件客户端下载PGP插件。
问:我需要加密软件吗?
A:要看情况。如果您正在存储客户信息,答案是肯定的。加密你的个人文件不是必要的,但可以大大提高你对网络攻击的防御能力。基于PGP的加密软件通常是最容易使用的,并且是加密文件的好地方。
PGP加密是保护您的数据、隐私和安全的强大工具。它为您提供了一种相对简单、完全安全的发送电子邮件的方法,还允许您验证与您通信的人的身份。由于PGP附加组件也可用于大多数主要电子邮件客户端,因此这种加密形式通常很容易实现。
尽管如此,安全电子邮件只是网络安全的一个方面。您应该确保,除了PGP之外,您还可以使用健壮的数据安全平台和数据丢失预防软件。使用尽可能广泛的工具是确保您的隐私和安全的最佳方式。
原文:https://www.varonis.com/blog/pgp-encryption/
本文:http://jiagoushi.pro/node/1510
讨论:请加小号【chief_engr】
- 964 次浏览
【加密库】Milagro简介
视频号

微信公众号

知识星球

Apache Milagro是一套专门为去中心化网络和分布式系统构建的核心安全基础设施和加密库,同时也为需要互联网规模的以云连接应用程序为中心的软件和物联网设备提供价值。
Milagro的目的是为集中式和专有的单一信任提供商(如商业证书颁发机构和依赖它们的证书支持的密码系统)提供一种安全、积极的开源替代方案。
配对密码学
在过去的十年里,椭圆曲线上的配对一直是密码学中一个非常活跃的研究领域,特别是在去中心化网络和分布式系统中。
配对是在椭圆曲线上定义的一种双线性映射。例子包括威尔配对、泰特配对、最优泰特配对等等。
配对将椭圆曲线上的点对映射到有限域的乘法群中。它们独特的特性使许多以前不可行的新密码协议成为可能。
基于配对的密码学(PBC)正在成为一种复杂问题的解决方案,这些问题被证明是公钥密码学的标准数学所难以解决的,例如基于身份的加密(IBE),由此客户端的身份可以用作其公钥。
在某些用例中,这消除了对PKI基础设施的需求,因为颁发证书的主要原因是将公钥/私钥对绑定到身份,而使用IBE时不需要此功能。
消除证书管理负担使身份管理和密钥生命周期能够在去中心化密码系统本身中进行。
因此,Milagro的去中心化密码系统设计目标是提供比传统PKI更易于扩展和管理的产品,消除根密钥“单一折衷点”的弱点,并无缝适应当今的去中心网络和分布式系统。
配对成为主流
配对是Apache Milagro加密库和产品中的关键构建块。例如,BLS签名在Milagro去中心化信托机构(D-TA)中占有突出地位,而M-Pin协议则用于Milagro ZKP-MFA客户端和服务器。
BLS签名因其签名聚合能力而在加密货币领域得到广泛认可。BLS签名现在正在通过IETF提交审查第一标准化过程。
M-Pin protocolsecond是一种建立在零知识证明基础上的多因素身份验证协议,由英国政府广泛部署在云基础设施和面向公众的部署中。
Zcash实现了他们自己的零知识证明算法zk-SNARKs(零知识简洁非交互式知识论证)第四。zk-SNARKs用于保护Zcash交易的隐私。配对是构建zk-SNARKS的关键因素。
Cloudflare引入了Geo Key Managerfifth,以限制将客户的私钥分发到其数据中心的子集。为了实现这一功能,使用了基于属性的加密,配对再次成为关键的构建块。
可信计算组(TCG)在可信平台模块的规范中指定了ECDAA(椭圆曲线直接匿名认证)。ECDAA是一种用于向验证器证明由可信平台模块(TPM)持有的证明而不暴露由该TPM持有的证明的协议。配对密码学用于构造ECDAA。FIDO Allianceseventh和W3Ceighth也发布了类似于TCG的ECDAA算法。
2015年,NIST(“后NSA”NIST)在其出版物《基于配对的密码学报告》中建议对基于配对的加密进行标准化。
“基于这项研究,该报告提出了一种将基于配对的密码方案纳入NIST密码工具包的方法。正如我们所看到的,基于配对的加密有很多可供选择的。基于配对的方案,如IBE,提供了传统PKI无法直接提供的特殊特性ice添加到NIST的加密工具包中。我们特别关注IBE。IBE简化了基于证书的公钥基础设施的密钥管理程序。IBE还提供了有趣的功能,这些功能源于将附加信息编码到用户身份中的可能性。自从第一个IBE计划提出以来,已经有十年的时间了。这些方案已经得到了密码社区的足够关注,并且没有发现任何弱点。“
---NIST,基于配对的密码学报告
迈向后量子时代
目前使用的几乎所有公钥密码系统的安全性都依赖于计算假设,如整数分解(IF)和离散对数(DL)问题,作为其安全性的基础。这些都是当今经典计算机无法解决的问题。1994年,Shorninth证明,基于量子物理定律,IF和DL问题在量子计算机上都很容易解决。因此,如果量子计算机成为现实,几乎所有目前部署的公钥密码系统都将变得完全不安全。
根据NIST在其关于后量子密码学的报告中,“要确保从目前广泛使用的密码系统平稳、安全地迁移到抗量子计算的密码系统,需要付出巨大努力。因此,无论我们能否估计量子计算时代到来的确切时间,我们都必须从现在开始准备我们的信息安全系统,使其能够抵御量子计算。”
大多数专家都有一系列强大的量子计算,足以破解当今即将出现的密码系统,时间从五年到二十年不等。还应该指出的是,量子计算只会将强力密钥搜索速度提高平方根的一倍,因此任何对称算法都可以通过将密钥长度加倍(即,将AES从128位提高到256位)来确保对量子计算机的安全。
Milagro已经开始在其代码库中实现后量子算法,从超奇异的Isogeny密钥封装Leventh协议开始。为什么?
显然,瞬态且不能保持长期价值的数据不需要对后量子对手提供一定程度的保护。当数据被长期保留时,这就成了一个问题。如果数据被收集和存储,并且即使在几十年后仍保持价值,那么它应该受到后量子程度的保护。简言之,当一台工作的量子计算机上线时,你正在保护数据。
希望Apache Milagro将成为对配对协议感兴趣的密码学家的一个安全、无知识产权的创新之岛,为去中心化网络和分布式系统的发展提供急需的核心安全基础设施。
我们希望你能加入我们,成为这段旅程的一部分。
- IETF BLS Signature Internet Draft↩
- IETF M-Pin Informational Draft↩
- UK Government selects M-Pin protocol based authentication provider↩
- Lindemann, R., "What are zk-SNARKs?", July 2018↩
- Geo Key Manager: How It Works↩
- TPM 2.0 Library Specification", September 2016↩
- FIDO ECDAA Algorithm - FIDO Alliance Review Draft 02↩
- Web Authentication: An API for accessing Public Key Credentials Level 1 - W3C Candidate Recommendation↩
- Algorithms for quantum computation: discrete logarithms and factoring↩
- Report on post-quantum cryptography↩
- SIKE↩
- 153 次浏览
【加密解密】使用Mozilla SOPS解密
视频号
微信公众号
知识星球
将机密存储在存储库中,并使用Mozilla SOPS对其进行解密
先决条件
- Codefresh帐户
- 公共和私有GnuGP密钥对
- 凭据yaml,使用Mozilla SOPS加密,并存储在您的存储库中
Java应用程序示例
你可以在GitHub上找到这个示例项目。
示例应用程序从管道中检索系统变量“password”,并使用它对Redis数据库进行身份验证,但您可以自由使用任何类型的数据库。
String password = System.getenv("password");
String host = System.getProperty("server.host");
RedisClient redisClient = new RedisClient(
RedisURI.create("redis://" + password + "@" + host + ":6379"));
RedisConnection<String, String> connection = redisClient.connect();示例应用程序中还有一个简单的单元测试,确保我们能够读取数据并将数据写入数据库。
加密的凭据文件存储在存储库中(以及公钥):
credentials.yaml
password: ENC[AES256_GCM,data:Jsth2tY8GhLgj6Jct27l,iv:3vcKVoD5ms29R5SWHiFhDhSAvvJTRzjn9lA6woroUQ8=,tag:OjkLvcHxE4m5RSCV7ej+FA==,type:str]
sops:
kms: []
gcp_kms: []
azure_kv: []
lastmodified: '2020-03-30T19:12:49Z'
mac: ENC[AES256_GCM,data:jGMTkFhXjgGMdWBpaSWjGZP6fta3UuYjEsnqziNELQZ2cLScT9v+GKg/c8iJYv1Gfiz3aw4ivYYrWzwmZehIbPHaw3/XBv/VRCQhzRWYKaf6pPFUXIS7XALSf9L9VbGOXL/CGPRae3t3HpaOor+knd6iQk2WR3K9kSeib4RBSCE=,iv:WSP8hBwaBv3ymTGltBOaVVC1sT08IG4hwqESlG8rN9w=,tag:3hZvCuql+ASWe/Mm5Bl7xg==,type:str]
pgp:
- created_at: '2020-03-30T19:12:49Z'
enc: |
-----BEGIN PGP MESSAGE-----
hQGMA9TqgBq6RQVRAQv/UouNaHfxkJ5PwXLvda97Fgj/2ew2VXPAlAnLvoGvTsb2
U4GXcaE7c4mYf7wSKF9k/F0FZTUEnd3CRji/OqjrNyvj5zI/9KGRABCKvzjsx+ZG
JolVnDifHl78Mor1CUPQ4JXasHKbVSlNLMGgDHIsvpeC7f7pIi8YDUDIa3/zXhFK
jcKzz4nlrW1Ph8zukmQk49Xvv6+DFj2NTptOB3U6mh79RCdnyCSRHxA3f0X00Pi5
g0p5x46S5E04uC2wXrZv8i/gyQbLHxwjmdbLq+P1Peu4/i9eSZZOpx0mc1KJ2mjr
oKRvgnUFz3xuYrSNzjC1vM01UbuSytlwx+S3J7VVLPSZRso1sbgv2+ylUOAHS+gZ
64uL0j/BZrF4wZI8y8zr0nJ6cZLiiF3LeXhfcuWJJ7+5p1OBEvfO+sWorLahIZTw
pogYPDpz4rGnrJRKBkNsVlYuUG8aNerIfhEBr6n//VJtt7QXTEXraLCTt4a6z/Fl
R6YSeNCKWQlURrTfm4Kv0lwBzMTLUb+Fg3HO8ShhiE9/2dKTSJkRJMVXRDp22Fm1
vO/wMFUjg6Dkrj1LVqQ9zcXc5QElgc4mF/V7SazacbQ7/g67tVtUrTit9LXgR9A0
k7wU5iT5oWLJtWwpkA==
=Il2p
-----END PGP MESSAGE-----
fp: C70833A85193F72C2D72CB9DBC109AFC69E0185D
encrypted_regex: password
version: 3.5.0您无法在本地运行应用程序,因为它需要在管道中运行才能使用我们的环境变量进行连接。
创建管道
该管道包含四个阶段:
- 克隆阶段
- 导入私钥/公钥对的阶段
- 解密凭证文件的阶段
- 打包 jar 并运行单元测试的阶段
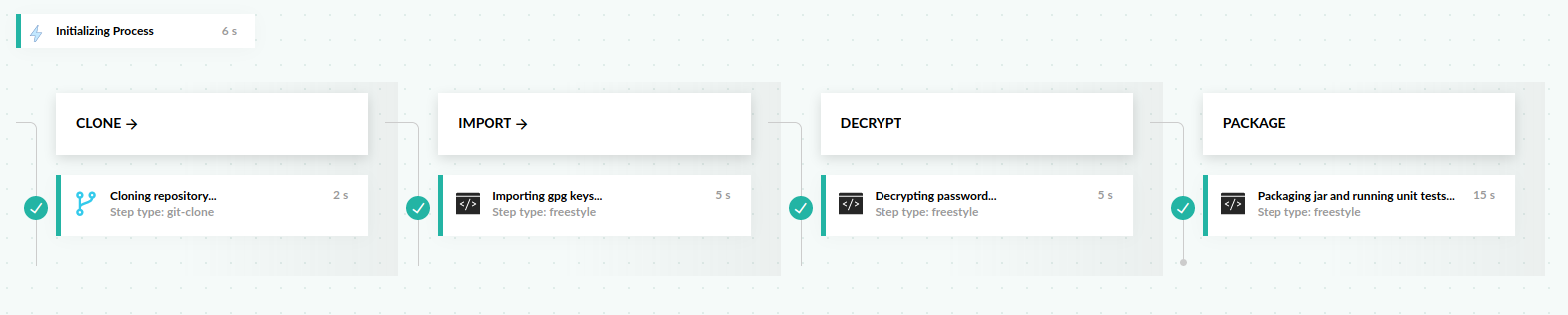
Codefresh UI管道视图
首先,您需要为私钥添加一个管道变量PRIV_KEY。您可以在UI中导航到内嵌的YAML编辑器,然后在右侧找到Variables选项卡:
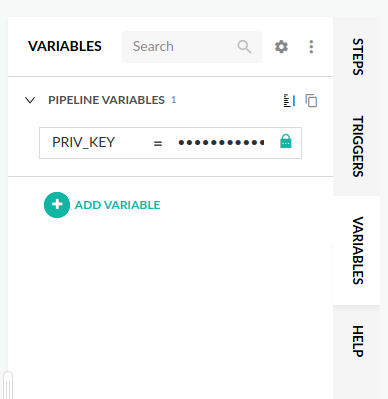
Pipeline Variables
这是整个管道:
codefresh.yaml
# More examples of Codefresh YAML can be found at
# https://codefresh.io/docs/docs/example-catalog/ci-examples/
version: "1.0"
# Stages can help you organize your steps in stages
stages:
- "clone"
- "import"
- "decrypt"
- "package"
steps:
clone:
title: "Cloning repository..."
type: "git-clone"
stage: "clone"
arguments:
repo: "codefresh-contrib/mozilla-sops-app"
revision: "master"
import_keys:
title: "Importing gpg keys..."
type: "freestyle"
stage: "import"
working_directory: '${{clone}}'
arguments:
image: "vladgh/gpg"
commands:
- gpg --import public.key
- echo -e "${{PRIV_KEY}}" > private.key
- gpg --allow-secret-key-import --import private.key
decrypt_password:
title: "Decrypting password..."
type: "freestyle"
working_directory: "${{clone}}"
stage: "decrypt"
arguments:
image: "mozilla/sops"
commands:
- cp -r /codefresh/volume/.gnupg /root/.gnupg
- cf_export password=$(sops --decrypt --extract '["password"]' credentials.yaml)
package_jar:
title: "Packaging jar and running unit tests..."
working_directory: ${{clone}}
stage: "package"
arguments:
image: "maven:3.5.2-jdk-8-alpine"
commands:
- mvn -Dmaven.repo.local=/codefresh/volume/m2_repository -Dserver.host=my-redis-db-host clean package
services:
composition:
my-redis-db-host:
image: 'redis:4-alpine'
command: 'redis-server --requirepass $password'
ports:
- 6379此管道执行以下操作:
- 通过git克隆步骤克隆主存储库。
- 使用GPG映像并通过自由式步骤导入公钥和私钥对。
- 通过不同的自由式步骤解密凭据文件。在这一步中,SOPS在/root下查找.gnupg目录(存储密钥环的目录)。我们需要从Codefresh Volume中复制它,因为/root不保存在容器之间。
- 最后一步,package_jar,做了一些特别的事情需要注意:
- 在6379端口上启动一个运行Redis的Service Container,并使用导出的环境变量设置数据库的密码
- 设置maven.report.local将maven依赖项缓存到本地codefresh卷中,以加快构建速度
- 运行单元测试并打包jar。请注意,当我们设置server.host时,如何直接引用服务容器的名称(我的redis-db-host)
- 74 次浏览
【微服务安全】与 Spring Boot、Kafka、Vault 和 Kubernetes 通信——第 2 部分:设置 Kubernetes 和 Kafka
链接
- 第 1 部分:简介和架构
- 第 2 部分:设置 Kubernetes 和 Kafka <--本文
- 第 3 部分:设置保险柜
- 第 4 部分:构建微服务
- 第 5 部分:部署和测试
要求
目录结构
我们将使用的目录结构如下:
- $PROJECTS
- —|—DepositAccount
- —|—GatewayKafka
- —|—Transaction
- —|—Registry
- —|—k8s
- —|—kafkatools
软件
这些是入门所需的软件
- Java
- OpenSSL
设置 Kubernetes 和 Helm
- 在本教程中,我们将使用 Docker Desktop 及其 Kubernetes 引擎。
- 按照本教程 [安装 Docker 桌面] 中的步骤操作:https://github.com/azrulhasni/Ebanking-JHipster-Keycloak-Nginx-K8#insta…
- 同时安装 Helm https://github.com/azrulhasni/Ebanking-JHipster-Keycloak-Nginx-K8#insta…
设置Kafka
- 我们将在 Kubernetes 集群中运行 Kafka。我们将为此使用 Helm。
使用 Helm 安装 Kafka
- 首先,运行下面的两个命令行。这将使用 Helm 将 Kafka 安装到您的 Kubernetes 集群
> helm repo add bitnami https://charts.bitnami.com/bitnami > helm install kafka bitnami/kafka
- 完成后,您将收到以下消息:
NAME: kafka LAST DEPLOYED: Mon Sep 14 09:08:13 2020 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: ** Please be patient while the chart is being deployed ** Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster: kafka.default.svc.cluster.local Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster: kafka-0.kafka-headless.default.svc.cluster.local:9092 To create a pod that you can use as a Kafka client run the following commands: kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.6.0-debian-10-r18 --namespace default --command -- sleep infinity kubectl exec --tty -i kafka-client --namespace default -- bash PRODUCER: kafka-console-producer.sh \ --broker-list kafka-0.kafka-headless.default.svc.cluster.local:9092 \ --topic test CONSUMER: kafka-console-consumer.sh \ --bootstrap-server kafka.default.svc.cluster.local:9092 \ --topic test \ --from-beginning
- 要仔细检查,请运行:
> kubectl get pods
- 你应该得到下面的结果。我们应该看到处于运行状态的 Kafka 和 ZooKeeper pod

在 Kubernetes 中暴露 Kafka 供我们管理
- Kafka 现在已成功运行。为了让我们管理它(例如创建新主题),我们需要将它暂时暴露给外界
- 运行以下命令。这会将 Kafka 暴露给 localhost 的 9092 端口。
> kubectl port-forward kafka-0 9092:9092
安装 Kafdrop
- Kafdrop 是 Kafka 的管理工具。我们可以用它来管理我们的 Kafka 集群
- 从 https://github.com/obsidiandynamics/kafdrop/releases 下载 jar 文件并将其放在 $PROJECTS/KafkaTools 文件夹中
- 运行以下命令。确保将 <version> 替换为您下载的 Kafdrop 版本号。请注意,属性 —kafka.brokerConnect 指向我们在上一段中公开的端口 (localhost:9092):
> java -jar kafdrop-<version>.jar --kafka.brokerConnect=localhost:9092
- 然后将浏览器指向 http://localhost:9000 。您应该看到以下页面:

- 导航到页面底部并找到主题部分。单击 (+) 按钮

- 您将获得下面的页面,您可以在其中创建主题。

- 创建 2 个主题:deposit-debit-response 和 deposit-debit-request

- 返回运行 port-forward 命令的命令行控制台,在其中按 Ctrl+C 以关闭该外部连接。或者,您可以关闭命令行控制台窗口。
- 恭喜!我们已经成功运行 Kafka 并在其中创建了 2 个主题。
- 79 次浏览
【微服务安全】使用 Spring Boot、Kafka、Vault 和 Kubernetes 保护微服务间通信——第 1 部分:简介和架构
链接
- 第 1 部分:简介和架构 <--本文
- 第 2 部分:设置 Kubernetes 和 Kafka
- 第 3 部分:设置保险柜
- 第 4 部分:构建微服务
- 第 5 部分:部署和测试
介绍
微服务是一种设计模式,其中大型单体应用程序被分离成更小、更易于管理的组件。这些组件可以协同工作来解决特定的业务问题。
为此,组件需要相互通信。组件之间的通信可以通过多种方式实现:RESTful Web 服务、SOAP Web 服务、RPC、消息传递等。消息传递(发布/订阅)的一种流行实现是 Kafka。
与大多数消息传递系统相比,Kafka 具有更好的吞吐量、内置的分区、复制和容错能力,这使其成为大规模消息处理应用程序的良好解决方案。
https://kafka.apache.org/
发布订阅
Kafka 遵循发布订阅模式。这种模式就像一个公告板。例如,如果爱丽丝在公告板上发布公告。鲍勃和查尔斯都能读懂它们。他们可以同时阅读,也可以一个接一个地阅读。 Bob 今天可以阅读黑板,Charles 可以在明天阅读。爱丽丝的公告将保留在公告板上,直到它的到期日期过去为止。
在消息传递系统中,我们会有发布者(Alice)和订阅者(Bob 和 Charles)。公告板称为主题,公告称为事件或消息。
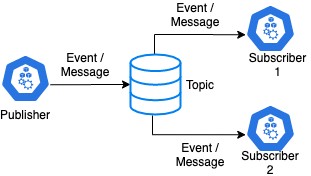
如您所见,主题需要在规定的时间段内保留数据。因此,需要保护主题中的数据。不幸的是,Kafka(在撰写本文时)不处理端到端的数据加密。
这就是 Vault 的用武之地。
保险库
Vault 为我们提供加密服务。这使我们能够为我们的消息拥有和端到端的加密方案。
但为什么是保险柜?我们真的需要它吗?现在,当然,我们需要加密从发布者到订阅者的消息是私钥/公钥基础设施。创建这些密钥并将它们嵌入到发布者和订阅者服务中非常容易,如下所示:
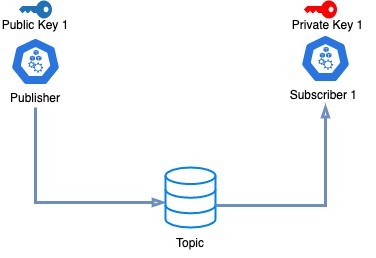
问题是当我们有多个订阅者时,每个订阅者都有自己的一组私钥/公钥。当我们需要管理密钥的生命周期时,问题就会出现。例如,在到期时,两个密钥都需要更换。如果密钥是嵌入的,则可能需要重新部署。
另一个问题是何时需要临时撤销和替换密钥。使用嵌入式键没有简单的方法来做到这一点。
在不同服务具有不同密钥集的微服务环境中,这个问题变得更加夸张——例如下面的服务网格:
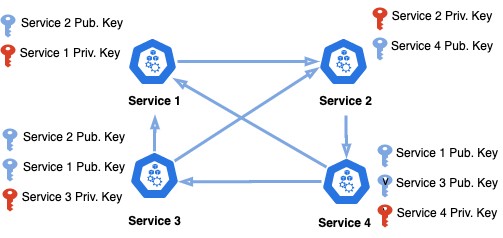
试图在仅有 4 个服务网格中管理或撤销密钥几乎是不可能的。
Vault 允许我们集中管理所有这些密钥:

此外,Vault 允许我们动态分配哪个服务可以访问哪个密钥。如果某项服务遭到破坏,一旦系统再次受到保护,密钥就很容易被撤销和恢复。
架构
我们的应用程序的架构如下所示。它支持使用 Vault 和 Kafka 的安全端到端通信(消息传递):
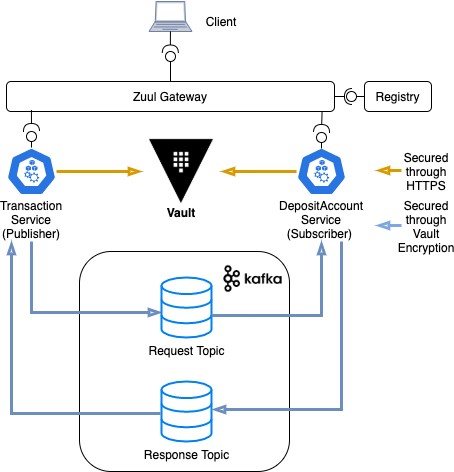
申请流程:
- 交易服务将启动从一个存款账户到另一个存款账户的资金转移。
- Transaction Message 由 Transaction 微服务创建并由 Vault 加密。
- 将加密的交易消息传递给请求主题
- 订阅者将消费消息并执行交易——将资金从一个账户转移到另一个账户。
- 然后,订阅者将通过响应主题将结果余额回复给事务服务
- 93 次浏览
【微服务安全】使用 Spring Boot、Kafka、Vault 和 Kubernetes 保护微服务间通信——第 3 部分:设置 Vault
- 第 1 部分:简介和架构
- 第 2 部分:设置 Kubernetes 和 Kafka
- 第 3 部分:设置 Vault <--本文
- 第 4 部分:构建微服务
- 第 5 部分:部署和测试
设置Vault
- 如果我们回想一下我们的架构,我们说过我们将提供端到端加密。虽然 Vault 将保护我们的信息,但谁在保护 Vault? - 为此,我们将使用经典的 TLS 连接 (HTTPS) 来保护我们与 Vault 的通信。我们将为此创建一个自签名证书。
使用 TLS 安装
- 以下步骤主要取自以下教程:https://www.vaultproject.io/docs/platform/k8s/helm/examples/standalone-…
- 在开始之前,让我们验证您是否拥有 OpenSSL。启动命令行控制台并运行以下命令
> openssl version
- 如果你有 openssl,你应该得到下面的响应(或类似的)。如果您没有 OpenSSL,请从此处 [https://www.openssl.org/] 下载并安装
LibreSSL 2.6.5
- 接下来,运行以下命令为我们的设置设置环境变量
> SERVICE=vault > NAMESPACE=default > SECRET_NAME=vault-server-tls > TMPDIR=/tmp
SERVICE:包含 Vault 的服务名称
NAMESPACE:运行 Vault 的 Kubernetes 命名空间
SECRET_NAME:包含 TLS 证书的 Kubernetes 密钥
TMPDIR:临时工作目录
- 然后,创建一个用于签名的密钥
> openssl genrsa -out ${TMPDIR}/vault.key 2048
- 我们现在将创建一个证书签名请求 (CSR)。首先,让我们创建一个 CSR 配置文件:
> cat <<EOF >${TMPDIR}/csr.conf
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[ v3_req ]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
[alt_names]
DNS.1 = ${SERVICE}
DNS.2 = ${SERVICE}.${NAMESPACE}
DNS.3 = ${SERVICE}.${NAMESPACE}.svc
DNS.4 = ${SERVICE}.${NAMESPACE}.svc.cluster.local
IP.1 = 127.0.0.1
EOF
- 然后,我们将创建 CSR 文件本身
> openssl req -new -key ${TMPDIR}/vault.key -subj "/CN=${SERVICE}.${NAMESPACE}.svc" -out ${TMPDIR}/server.csr -config ${TMPDIR}/csr.conf
- 现在,我们将创建实际的证书。从命令行运行
> export CSR_NAME=vault-csr
- 然后我们将创建一个 csr.yaml 文件
> cat <<EOF >${TMPDIR}/csr.yaml
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
name: ${CSR_NAME}
spec:
groups:
- system:authenticated
request: $(cat ${TMPDIR}/server.csr | base64 | tr -d '\n')
usages:
- digital signature
- key encipherment
- server auth
EOF
- 然后我们将在 Kubernetes 中创建一个证书签名请求
> kubectl create -f ${TMPDIR}/csr.yaml
- 要验证是否创建了证书签名请求,请运行以下命令。
> kubectl get csr ${CSR_NAME}
- 然后,批准 CSR。通过此命令,您已签署 CSR
> kubectl certificate approve ${CSR_NAME}
- 之后,将证书导出到名为 vault.crt 的文件中
> serverCert=$(kubectl get csr ${CSR_NAME} -o jsonpath='{.status.certificate}')
> echo "${serverCert}" | openssl base64 -d -A -out ${TMPDIR}/vault.crt
- 同时导出 Kubernetes CA
> kubectl config view --raw --minify --flatten -o jsonpath='{.clusters[].cluster.certificate-authority-data}' | base64 -d > ${TMPDIR}/vault.ca
- 创建一个秘密存储上面创建的所有文件
> kubectl create secret generic ${SECRET_NAME} --namespace ${NAMESPACE} --from-file=vault.key=${TMPDIR}/vault.key --from-file=vault.crt=${TMPDIR}/vault.crt --from-file=vault.ca=${TMPDIR}/vault.ca
- 接下来,我们将在 $PROJECTS/k8s 文件夹中创建一个名为 custom-values.yaml 的文件。该文件的内容应为:
global:
enabled: true
tlsDisable: false
server:
extraEnvironmentVars:
VAULT_CACERT: /vault/userconfig/vault-server-tls/vault.ca
extraVolumes:
- type: secret
name: vault-server-tls
standalone:
enabled: true
config: |
listener "tcp" {
address = "[::]:8200"
cluster_address = "[::]:8201"
tls_cert_file = "/vault/userconfig/vault-server-tls/vault.crt"
tls_key_file = "/vault/userconfig/vault-server-tls/vault.key"
tls_client_ca_file = "/vault/userconfig/vault-server-tls/vault.ca"
}
storage "file" {
path = "/vault/data"
}- 然后,我们将使用 Helm 安装通过我们的自签名 SSL 保护的独立 Vault。将命令行控制台指向文件夹 $PROJECTS/k8s 并运行:
> helm repo add hashicorp https://helm.releases.hashicorp.com > helm install vault -f custom-values.yaml hashicorp/vault
- 要验证 Vault 是否正在运行,请运行以下命令:
> kubectl get pods
- 您应该在 pod 列表中看到 vault

保险库 Kubernetes 服务
- 运行以下命令以获取服务列表
> kubectl get svc
- 您应该看到下面的列表。Vault服务的名称是“Vault”。由于 Vault 在默认集群中运行,因此 Vault 服务(在 Kubernetes 内)的完全限定域名应该是 vault.default.svc。

初始化Vault
- 要初始化 Vault,我们需要运行以下命令:
> kubectl exec -ti vault-0 -- vault operator init -format=json > cluster-keys.json
- 这将创建一个包含 5 个键的 json 文件。 json 文件的内容可能如下所示:
{
"keys": [
"dea...94",
"0c0...10",
"800...29",
"88e...1e",
"5by...8z"
],
"keys_base64": [
"...",
"...",
"...",
"...",
"..."
],
"root_token": "s.Tyu...d"
}
开封保险库
- 初始化 Vault 时,它以密封模式运行。我们需要解封它才能使 Vault 有用。
- 您还需要在每次重新启动时解封 Vault
- 在上面的步骤(Initialize Vault)中,我们创建了一个包含 5 个密钥的子文件。我们需要提供 3 个密钥来解封 Vault。要解封,请运行以下命令:
> kubectl exec -ti vault-0 -- vault operator unseal
- 此命令将提示输入密钥。键入其中一个键并按回车键。
- 您将得到以下结果:
Key Value --- ----- Seal Type shamir Initialized true Sealed false Total Shares 5 Threshold 3 Version 1.5.2 Cluster Name vault-cluster-e4b6a573 Cluster ID 80...b HA Enabled false
- 每次使用不同的键重新运行以上命令 2 次
- 祝贺。你有开封Vault。
暴露 Vault web ui
- 接下来,我们将使用他之前在 Kafka 中使用的 port-forward 命令将 Vault 暴露给 Kubernetes 之外的世界。请注意,使用 Vault,我们通过端口转发而不是 pod 公开服务。
> kubectl port-forward service/vault 8200:8200
创建中转(transit )引擎
- Vault Transit 引擎是 Vault 提供的一种加密即服务工具。我们将使用它来加密我们的消息。
- 将浏览器指向地址 https://localhost:8200(注意它是 https)。您可能会看到一个对话框,您需要在其中接受自签名证书。单击确定。

- 然后您将看到下面的页面。在 Token 字段中,键入刚才在初始化期间创建的 cluster-key.json 文件中的 root_token 值。

- 然后,点击启用新引擎

- 选择过境,然后点击下一步

- 然后,在 Path 字段中输入“transit”,然后单击 Enable Engine

- 您将获得您的秘密中列出的运输引擎

- 在中转页面上,单击“创建加密密钥”

- 在“创建加密密钥”页面中,在名称字段中输入 my-encryption-key,然后单击创建加密密钥

- 您将看到已创建加密密钥

- 祝贺。您创建了一个 Transit 引擎
管理访问权限和策略
- 单击菜单策略。然后单击“创建 ACL 策略”

- 在名称中,输入 my-encrypt-policy。在策略中放入下面的代码。这将允许此策略仅加密以下数据。完成后,单击“创建策略”:
path "transit/decrypt/my-encryption-key" {
capabilities = [ "update" ]
}

- 再次单击策略 > 创建 ACL 策略。在 Name 中输入“my-encrypy-policy”,在 Policy 中输入下面的代码。然后点击“创建策略”
path "transit/encrypt/my-encryption-key" {
capabilities = [ "update" ]
}

- 您现在应该设置 2 个策略:

- 然后启动你的命令行控制台并运行下面的 curl 命令。请注意,下面的值 s.Tyu…d 是从上面的文件 cluster-keys.json 获得的根令牌的值。我们创建的策略 my-encrypt-policy 的值也在下面指定。 (我们在 curl 命令上使用选项 -k 因为我们使用的证书是自签名的。没有 -k,curl 命令将抱怨我们的证书)
> curl --header "X-Vault-Token: s.Tyu...d" --request POST --data '{"policies": ["my-encrypt-policy"]}' -k https://localhost:8200/v1/auth/token/create
- 你应该得到下面的回应。请注意客户端令牌的 values.O1...k。让我们称之为加密令牌
{
"request_id":"d5b47829-53f0-a35e-4b7c-0e9d8f4f3cbc",
"lease_id":"",
"renewable":false,
"lease_duration":0,
"data":null,
"wrap_info":null,
"warnings":null,
"auth":{
"client_token":"s.O1sI3QhVvSmbG1lyfKSMXXFk",
"accessor":"T...8",
"policies":[
"default",
"my-encrypt-policy"
],
"token_policies":[
"default",
"my-encrypt-policy"
],
"metadata":null,
"lease_duration":2764800,
"renewable":true,
"entity_id":"",
"token_type":"service",
"orphan":false
}
}
- 让我们重复相同的 curl 命令,这一次,我们将使用 my-decrypt-policy 策略
curl --header "X-Vault-Token: s.WuTNTDpBqsspinc6dlDN0cbz" --request POST --data '{"policies": ["my-decrypt-policy"]}' -k https://localhost:8200/v1/auth/token/create
- 我们应该看到下面的结果。注意客户端令牌(s.7x…Xv)。我们将此令牌称为解密器令牌
{
"request_id":"d5b47829-53f0-a35e-4b7c-0e9d8f4f3cbc",
"lease_id":"",
"renewable":false,
"lease_duration":0,
"data":null,
"wrap_info":null,
"warnings":null,
"auth":{
"client_token":"s.7xdIhRPcJXFw2B1s6fKasHXv",
"accessor":"TSNoAMVNwFEUzlmx8tjRh9w8",
"policies":[
"default",
"my-encrypt-policy"
],
"token_policies":[
"default",
"my-encrypt-policy"
],
"metadata":null,
"lease_duration":2764800,
"renewable":true,
"entity_id":"",
"token_type":"service",
"orphan":false
}
测试 Vault 的加密即服务
- 因此,让我们测试一下我们的设置。首先,我们需要一个 base-64 字符串。打开命令行控制台并运行以下命令。这会将字符串编码为 base-64。当然,您可以使用“Hello world”以外的其他语言。
> echo -n 'Hello world'|openssl base64
- 你会得到
SGVsbG8gd29ybGQ=
- 让我们使用加密器令牌加密该字符串。
> curl --header "X-Vault-Token: s.O1sI3QhVvSmbG1lyfKSMXXFk" --request POST --data '{"plaintext": "SGVsbG8gd29ybGQ="}' -k https://127.0.0.1:8200/v1/transit/encrypt/my-encryption-key
- 您将收到以下回复。加密数据在字段密文中。
{
"request_id":"c345db50-2517-90de-cc8c-f66812b27d6b",
"lease_id":"",
"renewable":false,
"lease_duration":0,
"data":{
"ciphertext":"vault:v1:+VZG+5sZA0AQworFh5+o/kTyri6I+ooKWjfwbVOtB+lY/AWRurhO",
"key_version":1
},
"wrap_info":null,
"warnings":null,
}
- 现在,让我们尝试使用解密器令牌进行解密。请注意,字段密文包含上面的加密数据
curl --header "X-Vault-Token: s.7xdIhRPcJXFw2B1s6fKasHXv" --request POST --data '{"ciphertext":"vault:v1:+VZG+5sZA0AQworFh5+o/kTyri6I+ooKWjfwbVOtB+lY/AWRurhO"}' -k https://127.0.0.1:8200/v1/transit/decrypt/my-encryption-key
- 然后你会得到下面的回复。请注意,我们取回了我们之前加密的 base 64 字符串。
{
"request_id":"7d00a316-90ff-9c94-3e6f-d8e60b0560e3",
"lease_id":"",
"renewable":false,
"lease_duration":0,
"data":{
"plaintext":"SGVsbG8gd29ybGQ="
},
"wrap_info":null,
"warnings":null,
"auth":null
}
- 现在,让我们尝试一个否定的测试用例。让我们尝试加密数据,但改用解密器令牌
> curl --header "X-Vault-Token: s.7xdIhRPcJXFw2B1s6fKasHXv" --request POST --data '{"plaintext": "SGVsbG8gd29ybGQ="}' -k https://127.0.0.1:8200/v1/transit/encrypt/my-encryption-key
- 您最终会遇到错误
{"errors":["1 error occurred:\n\t* permission denied\n\n"]}
- 您可以尝试相反,尝试使用加密令牌进行解密
> curl --header "X-Vault-Token: s.O1sI3QhVvSmbG1lyfKSMXXFk" --request POST --data '{"ciphertext":"vault:v1:+VZG+5sZA0AQworFh5+o/kTyri6I+ooKWjfwbVOtB+lY/AWRurhO"}' -k https://127.0.0.1:8200/v1/transit/decrypt/my-encryption-key
您最终将遇到与上述相同的错误
{"errors":["1 error occurred:\n\t* permission denied\n\n"]}
为加密和解密创建令牌
- 回想一下我们的架构,其中 Transaction Services 和 DepositAccount Service 都需要消费和发送消息。这意味着他们需要加密和解密功能。要创建具有这两个功能的令牌,只需指定两个策略:
curl --header "X-Vault-Token: s.WuTNTDpBqsspinc6dlDN0cbz" --request POST --data '{"policies": ["my-decrypt-policy", "my-encrypt-policy"]}' -k https://localhost:8200/v1/auth/token/create
- 您将收到以下回复。您可以使用“client_token”安全地登录到 Vault 以获得加密和解密功能:
{
"request_id": "a1f0fc87-5c27-94e3-b043-29adc5c87557",
"lease_id": "",
"renewable": false,
"lease_duration": 0,
"data": null,
"wrap_info": null,
"warnings": null,
"auth": {
"client_token": "s.WuTNTDpBqsspinc6dlDN0cbz",
"accessor": "Qc...dU",
"policies": [
"default",
"my-decrypt-policy",
"my-encrypt-policy"
],
"token_policies": [
"default",
"my-decrypt-policy",
"my-encrypt-policy"
],
"metadata": null,
"lease_duration": 2764800,
"renewable": true,
"entity_id": "",
"token_type": "service",
"orphan": false
}
}
Vault的结论
我们终于在我们的 Kubernetes 集群中安装和设置了 Vault(独立设置)。我们已经激活了加密即服务引擎,并创建了两个具有两种不同功能的不同令牌。加密器令牌用于加密数据,解密器令牌用于解密数据。我们还使用令牌测试了引擎的 API,我们看到正面和负面的测试用例都通过了。最后,我们创建了一个用于加密和解密功能的令牌。
- 137 次浏览
【微服务安全】使用 Spring Boot、Kafka、Vault 和 Kubernetes 保护微服务间通信——第 4 部分:构建微服务
- 第 1 部分:简介和架构
- 第 2 部分:设置 Kubernetes 和 Kafka
- 第 3 部分:设置保险柜
- Part 4: 构建微服务 <--本文
- 第 5 部分:部署和测试
创建微服务
- 我们将创建 2 个微服务:Transaction 和 DepositAccount。我们将为此使用 JHipster。
- 首先,我们需要安装 JHipster。请按照此处的教程安装 JHipster [https://www.jhipster.tech/installation/]
准备信任库(truststore)
- 如果您从 Java 程序调用自签名受保护端点(例如本教程中的 Vault),则需要首先信任自签名证书
- 通常这是通过将自签名证书注册到 JVM 的信任库中来完成的。
- 我们将面临的问题是:当我们创建 docker 镜像并在其中运行我们的微服务时,我们不会使用我们机器的 JVM。我们将改为使用图像的 JVM。我们如何将我们的证书注册到镜像的 JVM 信任库中?
- 当我们进入本教程的部署部分时,我们将解决这个问题。同时,让我们将 Vault 的根证书注册到信任库中。请记住证书 TMPDIR/vault.crt。我们将使用此证书。
- 我们需要找到 JVM cacerts 在哪里。在 Mac 机器上,它位于文件夹中的某个位置:$(/usr/libexec/java_home)/lib/security.你可以参考这个关于堆栈溢出的讨论:https://stackoverflow.com/questions/11936685/how-to-obtain-the-location…
- 运行以下命令。当提示输入密码时,请指定插入符号密码。默认情况下是 changeit
> sudo keytool -import -file "/tmp/vault.crt" -keystore "$(/usr/libexec/java_home)/lib/security/cacerts" -alias "vault certificate"
- 您可能需要更改生产环境的 cacerts 密码
- 我们现在已经将 Vault 的证书注册为可信证书。
设置 JHipster 注册表
- 将 JHipster Registry https://www.jhipster.tech/jhipster-registry/ 下载为 jar 文件并放入 $PROJECTS/Registry 文件夹
- 创建另一个文件夹:$PROJECTS/Registry/central-config。在 central-config 中,创建一个名为 application.yml 的文件并在下面插入内容。请确保将 my-secret-key-which-should-be-changed-in-production-and-be-base64-encoded 替换为您自己的生产机密:
# ===================================================================
# JHipster Sample Spring Cloud Config.
# ===================================================================
# Property used on app startup to check the config server status
configserver:
name: JHipster Registry config server
status: Connected to the JHipster Registry config server!
# Default JWT secret token (to be changed in production!)
jhipster:
security:
authentication:
jwt:
# It is recommended to encrypt the secret key in Base64, using the `base64-secret` property.
# For compabitibily issues with applications generated with older JHipster releases,
# we use the non Base64-encoded `secret` property here.
secret: my-secret-key-which-should-be-changed-in-production-and-be-base64-encoded
# The `base64-secret` property is recommended if you use JHipster v5.3.0+
# (you can type `echo 'secret-key'|base64` on your command line)
# base64-secret: bXktc2VjcmV0LWtleS13aGljaC1zaG91bGQtYmUtY2hhbmdlZC1pbi1wcm9kdWN0aW9uLWFuZC1iZS1iYXNlNjQtZW5jb2RlZAo=
# Enable /management/logfile endpoint for all apps
logging:
path: /tmp
file: ${spring.application.name}.log
- 您已成功设置 JHipster Registry
设置 API 网关
启动命令行控制台并将其指向 $PROJECTS/GatewayKafka 文件夹。跑:
> jhipster
将提出一系列问题。回答他们如下。请注意,当被问及您还想使用哪些其他技术?不要选择 Kafka。我们将单独处理 Kafka,而不是通过 JHipster:
? Which *type* of application would you like to create? Microservice gateway ? [Beta] Do you want to make it reactive with Spring WebFlux? No ? What is the base name of your application? GatewayKafka ? As you are running in a microservice architecture, on which port would like yo ur server to run? It should be unique to avoid port conflicts. 8080 ? What is your default Java package name? com.azrul.ebanking.gatewaykafka ? Which service discovery server do you want to use? JHipster Registry (uses Eur eka, provides Spring Cloud Config support and monitoring dashboards) ? Which *type* of authentication would you like to use? JWT authentication (stat eless, with a token) ? Which *type* of database would you like to use? SQL (H2, MySQL, MariaDB, Postg reSQL, Oracle, MSSQL) ? Which *production* database would you like to use? PostgreSQL ? Which *development* database would you like to use? H2 with disk-based persist ence ? Do you want to use the Spring cache abstraction? No - Warning, when using an S QL database, this will disable the Hibernate 2nd level cache! ? Do you want to use Hibernate 2nd level cache? No ? Would you like to use Maven or Gradle for building the backend? Maven ? Which other technologies would you like to use? ? Which *Framework* would you like to use for the client? Angular ? Would you like to use a Bootswatch theme (https://bootswatch.com/)? Default JH ipster ? Would you like to enable internationalization support? No ? Besides JUnit and Jest, which testing frameworks would you like to use? ? Would you like to install other generators from the JHipster Marketplace? (y/N ) No
- 您现在已成功设置 API 网关
设置交易微服务
启动命令行控制台并将其指向 $PROJECTS/Transaction 文件夹。跑:
> jhipster
将提出一系列问题。回答他们如下。请注意,当被问及您还想使用哪些其他技术时?不要选择卡夫卡。我们将单独处理 Kafka,而不是通过 JHipster:
? Which *type* of application would you like to create? Microservice application ? [Beta] Do you want to make it reactive with Spring WebFlux? No ? What is the base name of your application? Transaction ? As you are running in a microservice architecture, on which port would like yo ur server to run? It should be unique to avoid port conflicts. 8081 ? What is your default Java package name? com.azrul.ebanking.transaction ? Which service discovery server do you want to use? JHipster Registry (uses Eur eka, provides Spring Cloud Config support and monitoring dashboards) ? Which *type* of authentication would you like to use? JWT authentication (stat eless, with a token) ? Which *type* of database would you like to use? SQL (H2, MySQL, MariaDB, Postg reSQL, Oracle, MSSQL) ? Which *production* database would you like to use? PostgreSQL ? Which *development* database would you like to use? H2 with disk-based persist ence ? Do you want to use the Spring cache abstraction? No - Warning, when using an S QL database, this will disable the Hibernate 2nd level cache! ? Would you like to use Maven or Gradle for building the backend? Maven ? Which other technologies would you like to use? ? Would you like to enable internationalization support? No ? Besides JUnit and Jest, which testing frameworks would you like to use? ? Would you like to install other generators from the JHipster Marketplace? No
指定对 Kafka 和 Vault 的依赖关系
- 首先,让我们处理依赖关系。在文件 $PROJECTS/Transaction/pom.xml 中,在 <dependencies> </dependencies> 标记中添加以下依赖项。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-vault-config</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
- 在同一个 pom.xml 文件下,我们还需要在 <dependencyManagement><dependencies> ... </dependencies></dependencyManagement> 下添加一个条目
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
需要 spring-cloud-starter-vault-config 和 spring-cloud-dependencies 以允许 Vault 集成
编写事务微服务
- 让我们创建一种将数据从发布者传输到消费者并再次返回的方法。为此,我们在名为 com.azrul.ebanking.common.dto 的包中创建了一个“数据传输对象”(DTO)。这将是生产者和消费者的通用包。在那里,让我们按照下面的方式创建一个 Transaction 类。请注意,为了使 Transaction 类可序列化,它必须实现 Serializable 接口,必须有一个默认构造函数,toString 和 equals 方法:

- [完整来源:https://raw.githubusercontent.com/azrulhasni/Ebanking-JHipster-Kafka-Va…]
- 在 com.azrul.ebanking.transaction.config 包下创建一个名为 KafkaConfig 的配置类

- [完整来源:https://raw.githubusercontent.com/azrulhasni/Ebanking-JHipster-Kafka-Va…]
- Kafka配置
- Spring 使用 spring-kafka 库对 Kafka 提供了广泛的支持。这包括序列化器和反序列化器 - 这将使消息传递类型安全。另一方面,我们不会使用这些序列化器/反序列化器,因为我们将在消息到达我们自己的 Kafka 之前对其进行加密。我们将选择一个基本的字符串序列化器/反序列化器。
- 这是我们将用来连接到 Kafka 的 KafkaTemplate。请注意,我们使用的是一种特殊的 KafkaTemplate,称为 ReplyingKafkaTemplate。这个类将允许我们发送请求并获得响应,而无需我们自己做太多的管道
- 我们还需要一个配置文件。在 $PROJECTS/Transaction/src/main/resources/config 文件夹下,在 application.yml 文件中添加:
kafka:
bootstrap-servers: kafka-headless.default.svc.cluster.local:9092
deposit-debit-request-topic: deposit-debit-request
deposit-debit-response-topic: deposit-debit-response
consumer:
group.id: transaction
auto.offset.reset: earliest
producer:
- 在 $PROJECTS/Transaction/src/main/resources/config 文件夹下,在文件 bootstrap.yml 中,在 spring.cloud 下添加以下属性。
- 在方案中,确保我们把 https
- 在主机中,确保我们放置自己的 Vault Kubernetes 服务的完全限定域名。回想上面的 Vault Kubernetes Service 段落
- 在连接超时和读取超时中,设置一个合理的超时时间。我们放了一个大的进行测试。放一个小的(比如几秒钟)用于生产
- 在认证中,输入TOKEN,表示我们将通过安全令牌登录
- 在令牌中,确保您在之前的“为加密和解密创建令牌”段落中输入了 client_token 值。
vault:
scheme: https
host: vault.default.svc
port: 8200
connection-timeout: 3600000
read-timeout: 3600000
authentication: TOKEN
token: s.WuTNTDpBqsspinc6dlDN0cbz
kv:
enabled=true:
- 接下来,在 com.azrul.ebanking.transaction.web.rest 包中,创建一个名为 TransactionKafkaResource 的控制器

- [完整来源:https://raw.githubusercontent.com/azrulhasni/Ebanking-JHipster-Kafka-Va…]
- 让我们分解这段代码:
- 首先,我们需要获取请求和响应主题。回想一下我们的架构。另外,我们还在我们的KafkaTemplate中进行了wire,方便我们调用Kafka
- 我们还在 VaultTemplate 中进行接线以方便我们调用 Vault
- 这是我们将收到一个宁静的电话的地方。我们将加密该调用中的数据,创建 ProducerRecord 并将消息发送到 deposit-debit-request 主题。然后,我们将等待来自 deposit-debit-response 主题的回复。回复将包含我们得到的余额。一旦我们有了这些数据,我们就会解密它并返回给调用者。
- 这是我们加密数据的地方。最初,我们的数据是对象(Transaction 类型)的形式。然后我们将其转换为一系列字节。然后将一系列字节转换为 Base64 字符串。接下来,我们使用 Vault Transit 引擎加密 Base64 字符串。
- 这是我们解密数据的地方。最初,我们会得到一个加密的 Base64 字符串。我们需要使用 Vault Transit 引擎解密这个字符串。这将产生一个解密的 Base64 字符串。接下来,我们将 Base64 解密后的字符串解码为一系列字节。最后,我们将一系列字节转换回一个对象。
使用 Transaction 微服务的自签名证书处理 SSL
- 请回想一下我们关于从微服务调用自签名保护端点的困难的讨论(准备信任库段落)。我们将利用 Jib 来帮助我们解决这个问题并部署到 Kubernetes。
- 如果您注意到,JHipster 创建的文件夹之一称为 Jib ($PROJECTS/Transaction/src/main/jib)。此文件夹中的任何内容都将复制到根级别的 Docker 映像。
- 例如。如果我们有 $PROJECTS/Transaction/src/main/jib/myfolder/myfile.txt,当我们创建 Docker 镜像时,Jib 会将 myfolder 和 myfile.txt 复制到 Docker 镜像中。这会在图像中创建 /myfolder/myfile.txt
- 我们将创建一个名为 truststore 的文件夹,并在其中复制我们的主机/本地信任库(cacerts)。这会将 cacerts 复制到 /truststore/cacerts 的映像中。回想一下,我们可以找到信任库作为 JDK 的一部分。请在此处查看堆栈溢出讨论:https://stackoverflow.com/questions/11936685/how-to-obtain-the-location…

- 接下来,我们需要告诉 Java 使用 /truststore/cacerts 中的 cacerts。在我们的 TransactionApp.java 文件的 main 方法中,添加以下行。确保我们使用正确的 cacerts 密码(默认为 changeit):
System.setProperty("javax.net.ssl.trustStore","/truststore/cacerts");
System.setProperty("javax.net.ssl.trustStorePassword","changeit");

设置 DepositAccount 微服务
启动命令行控制台并将其指向 $PROJECTS/DepositAccount 文件夹。跑:
> jhipster
将提出一系列问题。回答他们如下。请注意,当被问及您还想使用哪些其他技术时?不要选择卡夫卡。我们将单独处理 Kafka,而不是通过 JHipster:
? Which *type* of application would you like to create? Microservice application ? [Beta] Do you want to make it reactive with Spring WebFlux? No ? What is the base name of your application? DepositAccount ? As you are running in a microservice architecture, on which port would like yo ur server to run? It should be unique to avoid port conflicts. 8082 ? What is your default Java package name? com.azrul.ebanking.depositaccount ? Which service discovery server do you want to use? JHipster Registry (uses Eur eka, provides Spring Cloud Config support and monitoring dashboards) ? Which *type* of authentication would you like to use? JWT authentication (stat eless, with a token) ? Which *type* of database would you like to use? SQL (H2, MySQL, MariaDB, Postg reSQL, Oracle, MSSQL) ? Which *production* database would you like to use? PostgreSQL ? Which *development* database would you like to use? H2 with disk-based persist ence ? Do you want to use the Spring cache abstraction? No - Warning, when using an S QL database, this will disable the Hibernate 2nd level cache! ? Would you like to use Maven or Gradle for building the backend? Maven ? Which other technologies would you like to use? ? Would you like to enable internationalization support? No ? Besides JUnit and Jest, which testing frameworks would you like to use? ? Would you like to install other generators from the JHipster Marketplace? (y/N ) No
指定对 Kafka 和 Vault 的依赖关系
- DepositAccount 微服务的依赖与 Transaction 微服务相同。无论如何,我们将在这里重复以完成目的
- 首先,让我们处理依赖关系。在文件 $PROJECTS/DepositAccount/pom.xml 中,在 <dependencies> </dependencies> 标记中添加以下依赖项。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-vault-config</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
- 在同一个 pom.xml 文件下,我们还需要在 <dependencyManagement><dependencies> ... </dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
- 需要 spring-cloud-starter-vault-config 和 spring-cloud-dependencies 以允许 Vault 集成
为 DespositAccount 创建数据模型和存储库
- 我们现在将为 DepositAccount 创建一个数据模型。
- 在文件夹 $PROJECTS/DepositAccount/ 中创建一个名为 banking.jh 的文件。在那里,将数据模型放在下面
entity DepositAccount{
accountNumber String,
productId String,
openingDate ZonedDateTime,
status Integer,
balance BigDecimal
}
// Set service options to all except few
service all with serviceClass- // 将服务选项设置为除少数之外的所有选项
使用 serviceClass 服务所有
然后,启动命令行控制台并将其指向文件夹 $PROJECTS/DepositAccount。 运行以下命令:
> jhipster import-jdl ./banking.jh
这将创建诸如 DepositAccountService 等可用于查询和保存存款账户数据的类。
编码 DespositAccount 微服务
- 首先,我们需要与事务微服务相同的 DTO
- 创建名为 com.azrul.ebanking.common.dto 的包,并在其中创建一个名为 Transaction 的类。回想一下,Transaction 类需要实现 Serialisable 接口,需要有一个默认构造函数,并且需要有 equals、hashCode 和 toString 方法:

- [完整源代码:https://raw.githubusercontent.com/azrulhasni/Ebanking-JHipster-Kafka-Va…]
- 然后我们将处理配置。 DepositAccount 微服务的配置与 Transaction 微服务相同。 无论如何,为了完成目的,我们将在这里重复一遍。 下面是 KafkaConfig 类

- 卡夫卡配置
- Spring 使用 spring-kafka 库对 Kafka 提供了广泛的支持。这包括序列化器和反序列化器 - 这将使消息传递类型安全。另一方面,我们不会使用这些序列化器/反序列化器,因为我们将在消息到达我们自己的 Kafka 之前对其进行加密。我们将选择一个基本的字符串序列化器/反序列化器。
- 这是我们将用来连接到 Kafka 的 KafkaTemplate。请注意,我们使用的是一种特殊的 KafkaTemplate,称为 ReplyingKafkaTemplate。这个类将允许我们发送请求并获得响应,而无需我们自己做太多的管道
- 我们还需要一个配置文件。在 $PROJECTS/DepositAccount/src/main/resources/config 文件夹下,在 application.yml 文件中添加:
kafka:
bootstrap-servers: kafka-headless.default.svc.cluster.local:9092
deposit-debit-request-topic: deposit-debit-request
deposit-debit-response-topic: deposit-debit-response
consumer:
group.id: transaction
auto.offset.reset: earliest
producer:
- 在 $PROJECTS/DepositAccount/src/main/resources/config 文件夹下,在文件 bootstrap.yml 中,在 spring.cloud 下添加以下属性。
- 在方案中,确保我们把 https
- 在主机中,确保我们放置自己的 Vault Kubernetes 服务的完全限定域名。回想上面的 Vault Kubernetes Service 段落
- 在连接超时和读取超时中,设置一个合理的超时时间。我们放了一个大的进行测试。放一个小的(比如几秒钟)用于生产
- 在认证中,输入TOKEN,表示我们将通过安全令牌登录
- 在令牌中,确保您在之前的“为加密和解密创建令牌”段落中输入了 client_token 值。
vault:
scheme: https
host: vault.default.svc
port: 8200
connection-timeout: 3600000
read-timeout: 3600000
authentication: TOKEN
token: s.WuTNTDpBqsspinc6dlDN0cbz
kv:
enabled=true:
- 接下来我们将创建一个监听器。在 com.azrul.ebanking.depositaccount.service 包中,创建一个名为 Transfer 的类,如下所示:

- [完整源代码:https://github.com/azrulhasni/Ebanking-JHipster-Kafka-Vault/blob/master…]
- 注入 VaultTemplate 允许我们解密进来的数据并加密返回的数据。
- 注入 DespositAccountService 让我们可以查询和保存存款账户数据
- 这是真正的听众。我们将通过输入参数从请求主题中获取我们的加密数据。我们十继续将这些数据解密到 Transaction 对象中。该对象将告诉我们要借记的源账户、要贷记的目标账户和金额。我们将继续执行该交易并计算借方和贷方账户中的结果余额。然后,我们将借记帐户余额放回消息中,并使用此编辑对象回复发布者。
- 该方法与 Transaction 微服务中的方法相同,用于加密和对象
- 该方法与 Transaction 微服务中的方法相同,用于解密和对象
使用 DepositAccount 微服务的自签名证书处理 SSL
- 就像事务微服务一样,我们需要在这里做同样的事情
- 我们将复制 cacerts(回想一下关于 stackoverflow 上关于 cacerts 在您的系统堆栈溢出中可用位置的讨论:https://stackoverflow.com/questions/11936685/how-to-obtain-the-location…- the-default-java-installation) 到 $PROJECTS/DepositAccounts/src/main/jib/truststore
- 然后,我们需要通过添加以下代码来修改 main 方法(在文件 $PROJECTS/DepositAccounts/src/main/java/com/azrul/ebanking/depositaccount/DepositAccountApp.java 中):
System.setProperty("javax.net.ssl.trustStore","/truststore/cacerts");
System.setProperty("javax.net.ssl.trustStorePassword","changeit");
- [完整源代码:https://raw.githubusercontent.com/azrulhasni/Ebanking-JHipster-Kafka-Va…]
- 在下一部分中,我们将看到如何部署所有这些。
- 87 次浏览
【微服务安全】使用 Spring Boot、Kafka、Vault 和 Kubernetes 保护微服务间通信——第 5 部分:部署和测试
- 第 1 部分:简介和架构
- 第 2 部分:设置 Kubernetes 和 Kafka
- 第 3 部分:设置保险柜
- 第 4 部分:构建微服务
- 第 5 部分:部署和测试 <--本文
部署微服务
- 我们将使用 Jib 进行部署。在这里回忆一下部署到 Kubernetes 的概念 [https://github.com/azrulhasni/Ebanking-JHipster-Keycloak-Nginx-K8#deplo…]
-
我们将首先将我们的图像推送到 Docker Hub (hub.docker.com) 并将它们拉回我们的 Kubernetes 集群。为此,我们需要一个 Docker Hub 帐户。您可以免费注册一个。
构建镜像并部署到 Kubernetes
- 将命令行控制台指向 $PROJECTS/k8s 文件夹。运行命令
> jhipster kubernetes
- 提出的选择是:
- which * type *- 选择微服务应用
- 输入根目录 - 在我们的例子中,我们使用 (../)
- 当被问及您想要包含哪个应用程序时 - 选择 GatewayKafka、Transaction 和 DepositAccount
- 确保输入注册表管理员密码
- 对于 Kubernetes 命名空间 - 选择默认值
- 对于基础 Docker 存储库 - 使用您的 Docker Hub 用户名
- 推送 docker 镜像 - 选择 docker push
- 对于 istio - 设置为否
- 对于边缘服务的 Kubernetes 服务类型 - 选择 LoadBalancer
- 对于动态存储配置 - 是
- 对于存储类,使用默认存储类 - 将答案留空
- 成功后,您将看到以下屏幕
Kubernetes configuration successfully generated! WARNING! You will need to push your image to a registry. If you have not done so, use the following commands to tag and push the images: docker image tag depositaccount azrulhasni/depositaccount docker push azrulhasni/depositaccount docker image tag gatewaykafka azrulhasni/gatewaykafka docker push azrulhasni/gatewaykafka docker image tag transaction azrulhasni/transaction docker push azrulhasni/transaction INFO! Alternatively, you can use Jib to build and push image directly to a remote registry: ./mvnw -ntp -Pprod verify jib:build -Djib.to.image=azrulhasni/depositaccount in /Users/azrul/Documents/GitHub/Ebanking-JHipster-Kafka-Vault/DepositAccount ./mvnw -ntp -Pprod verify jib:build -Djib.to.image=azrulhasni/gatewaykafka in /Users/azrul/Documents/GitHub/Ebanking-JHipster-Kafka-Vault/GatewayKafka ./mvnw -ntp -Pprod verify jib:build -Djib.to.image=azrulhasni/transaction in /Users/azrul/Documents/GitHub/Ebanking-JHipster-Kafka-Vault/Transaction You can deploy all your apps by running the following kubectl command: bash kubectl-apply.sh -f [OR] If you want to use kustomize configuration, then run the following command: bash kubectl-apply.sh -k Use these commands to find your application's IP addresses: kubectl get svc gatewaykafka INFO! Congratulations, JHipster execution is complete!
- 我们将使用 Jib 版本。将命令行控制台指向 $PROJECTS/DepositAccount
- 运行以下命令。这会将 DepositAccount 推送到 Docker Hub。
>./mvnw -ntp -Pprod verify jib:build -Djib.to.image=azrulhasni/depositaccount
- 然后,转到 $PROJECTS/GatewayKafka 并运行以下命令。这会将 GatewayKafka 推送到 Docker Hub。
> ./mvnw -ntp -Pprod verify jib:build -Djib.to.image=azrulhasni/gatewaykafka
- 最后,转到 $PROJECTS/Transaction 并运行以下命令。这会将事务推送到 Docker Hub。
>./mvnw -ntp -Pprod verify jib:build -Djib.to.image=azrulhasni/transaction
- 然后,返回 $PROJECTS/k8s 并运行以下命令。这会将上面的所有三个图像拉到我们的 Kubernetes 集群中。
> bash kubectl-apply.sh -f
- 要验证微服务是否已正确部署并运行,请运行以下命令:
>kubectl get pods
- 您将在下面看到结果。请注意,我们部署了每个微服务、其对应的数据库以及 JHipster 注册表。

测试微服务
- 首先,我们需要安装 JQ。 JQ 是一个允许我们 grep json 数据的工具。 JQ 分布可以在这里找到 https://stedolan.github.io/jq/download/
- 回想一下我们的架构。为了让我们调用事务微服务,我们必须通过我们的网关。还记得我们在创建网关时选择了 JWT 身份验证。运行以下命令为此类访问创建令牌。令牌将被导出到一个名为 TOKEN 的变量中。请注意,我们使用的是默认管理员用户和密码。我们应该为生产创建合适的用户。
> export TOKEN=`curl -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' -d '{ "password": "admin", "rememberMe": true, "username": "admin" }' 'http://localhost:8080/api/authenticate' | jq -r .id_token`
- 要验证令牌,请运行:
> echo $TOKEN
- 您应该得到如下响应
> echo $TOKEN eyJhbGciOiJIUzUxMiJ9...AE2w
- 首先,我们可能想要创建 2 个存款账户,我们也可以从中借记和贷记。使用下面的 curl 命令。我们将创建一个帐号为 1111 的帐户,余额为 10000。
> curl -X POST "http://localhost:8080/services/depositaccount/api/deposit-accounts" -H "accept: */*" -H "Content-Type: application/json" -H "Authorization: Bearer $TOKEN" -d "{ \"accountNumber\": \"1111\", \"balance\": 10000, \"openingDate\": \"2020-10-17T11:55:02.749Z\", \"productId\": \"DEPOSIT\", \"status\": 0}"
{"id":1001,"accountNumber":"1111","productId":"DEPOSIT","openingDate":"2020-10-17T11:55:02.749Z","status":0,"balance":10000}- 然后创建第二个帐户。账号为2222,余额为0
> curl -X POST "http://localhost:8080/services/depositaccount/api/deposit-accounts" -H "accept: */*" -H "Content-Type: application/json" -H "Authorization: Bearer $TOKEN" -d "{ \"accountNumber\": \"2222\", \"balance\": 0, \"openingDate\": \"2020-10-17T11:55:02.749Z\", \"productId\": \"DEPOSIT\", \"status\": 0}"
{"id":1002,"accountNumber":"2222","productId":"DEPOSIT","openingDate":"2020-10-17T11:55:02.749Z","status":0,"balance":0}- 现在是关键时刻。让我们将 10 从账户 1111 转移到账户 2222
> curl -X POST "http://localhost:8080/services/transaction/api/transaction-kafka/transfer" -H "accept: */*" -H "Content-Type: application/json" -H "Authorization: Bearer $TOKEN" -d "{ \"amount\": \"10\", \"finalBalance\": \"\", \"fromAccountNumber\": \"1111\", \"toAccountNumber\": \"2222\"}"
{"fromAccountNumber":"1111","toAccountNumber":"2222","amount":"10","finalBalance":"9990.00"}- 请注意,finalBalance 字段现在是 9990。
- 您还可以运行下面的 curl 命令来查看两个帐户的当前余额:
> curl -X GET "http://localhost:8080/services/depositaccount/api/deposit-accounts" -H "accept: */*" -H "Authorization: Bearer $TOKEN"
您将收到以下回复:
[
{
"id": 1001,
"accountNumber": "1111",
"productId": "DEPOSIT",
"openingDate": "2020-10-17T12:22:57.494Z",
"status": 0,
"balance": 9990
},
{
"id": 1002,
"accountNumber": "2222",
"productId": "DEPOSIT",
"openingDate": "2020-10-17T12:22:57.494Z",
"status": 0,
"balance": 10
}
]
结论
我们从一个简单的架构开始,我们希望从一个微服务向另一个微服务发送加密消息(并接收响应)。
我们探索了 Kafka,也安装了 Kubernetes。我们还探索了 Vault 并尝试了它的功能。
最后,我们创建了 2 个微服务,并将加密消息从一个发送到另一个并接收回复。我们的教程到此结束
完整的应用程序可以在这里访问:https://github.com/azrulhasni/Ebanking-JHipster-Kafka-Vault
- 72 次浏览
【数据安全】5最糟糕的大数据隐私风险(以及如何防范)
大数据分析有巨大的收益,但也有巨大的潜在风险,可能会导致任何从尴尬到彻底歧视的事情。 这里有什么要注意的 - 以及如何保护自己和员工
正如其支持者近十年来一直在说的那样,大数据可以带来巨大的收益:广告专注于你实际想买的东西,智能型汽车可以帮助您避免碰撞,或者如果碰巧进入救援车,请联系救护车无论如何,可穿戴或可植入的设备,可以监控您的健康,并通知您的医生,如果出现问题。
它也可能导致大的隐私问题。到目前为止,显而易见的是,当人们每天都会产生数千个数据点时,他们去哪里,他们沟通,他们读写什么,他们买什么,吃什么,他们看什么,他们锻炼多少,锻炼多少他们很多睡觉和更多 - 他们容易受到一代以前难以想象的暴露。
同样显而易见的是,在营销人员,金融机构,雇主和政府手中的这些详细信息可以影响从关系到获得工作的一切,以及从符合资格获得贷款甚至上飞机的资格。虽然隐私权倡导者和政府多次表达了关注,但在线,永远相互联系的世界中,改善隐私保护的行动一直很少。
五年多前,奥巴马政府在2012年2月发布了一项名为“消费者权益保障法案”(CPBR)的蓝图。该文件宣称:“美国的消费者隐私数据框架实际上是强大的...(但它)缺少两个要素:适用于商业世界的基本隐私原则的明确声明,以及所有利益相关者持续承诺解决消费者数据隐私问题,因为技术和商业模式的进步。
三年后,2015年2月,该蓝图成为同名提名的立法,但是立即遭到行业团体的攻击,业界人士表示会强加“繁重”的规定,以及隐私权倡导者,他们说这是被充斥漏洞。它从来没有让它投票。
事实上,美国国家安全局(NSA)承包商爱德华·斯诺登(NSA)承诺商爱德华·斯诺登(Edward Snowden)的启示之前,“美国的消费者隐私数据框架实际上是强大的”CPBR声明表明美国政府实际上是对其公民进行监视。
除此之外,政府还未能就其他隐私举措达成一致。联邦通信委员会(FCC)在2016年选举之前发布的所谓宽带隐私规则,这些规则将受到互联网服务提供商(ISP)数据收集有限的限制,已于3月份废除,之后才能生效。
美国消费者联合会(CFA)消费者保护和隐私总监苏珊·格兰特(Susan Grant)称之为“一个可怕的挫折”,并表示允许互联网服务提供商“谍客户并未经许可出售其数据”然而,有人认为,对ISP的限制仍然会让其他像谷歌这样的在线巨头免费收集和销售他们收集的数据,消费者也会看到很少的利益。
鉴于这一点,专家认为隐私风险更加激烈,保护隐私的挑战变得更加复杂,这并不奇怪。像CFA,电子隐私信息中心(EPIC)和民主与科技中心(CDT)等组织,以及隐私教授首席执行官Rebecca Herold等个人倡导者已经列举了大量数据分析和结果自动化的多种方式决策,可以侵犯个人的个人隐私。他们包括:
1.歧视
EPIC在三年多前宣布,在向美国科学技术政策局发表的意见中指出:“现在可以由政府和公司使用公共和私营部门的预测分析来确定我们的能力飞行,获得工作,清关或信用卡。使用我们的协会在预测分析中做出对个人产生负面影响的决定直接抑制结社自由。“
隐私倡导者说,此后事情变得更糟。虽然歧视是非法的,但自动决策使得更难证明。全球共同领导人爱德华·麦克尼科拉斯(Edward McNicholas)说:“大数据算法在过去几年中已经显着成熟,随着新兴事物互联网数据的泛滥,以及使用人工智能变体分析这些数据的能力。 “Sidley Austin律师事务所的隐私,数据安全和信息法实践”,但尽管技术发展有限,法律保护也没有实质性进展。
CDT的政策顾问约瑟夫·杰罗姆(Joseph Jerome)说:“我认为围绕大数据进行的讨论已经超出了对歧视的指责,而对自动化决策的关注越来越大。”CDT的政策顾问Joseph Jerome说:“已被使用,”直接拨打电话中心,评估和消除教师,甚至预测再犯。“
Herold多年来一直在说大数据分析可以使歧视本质上“自动化”,因此更难以检测或证明。她表示,“今天以”比以往更多的方式“是真实的。她说:“大数据分析加上事物互联网(IoT)数据将会 - 并已经能够识别那些个人甚至不认识自己的个人的健康问题和遗传细节。”
McNicholas认为,“最重大的风险是它被用来掩盖基于非法标准的歧视,并证明决定对脆弱人群的不同影响是合理的。”
2.尴尬的违规行为
到目前为止,在像Target和Home Depot这样的多个零售商遇到灾难性的数据泄露之后,像P.F. Chang的在线市场,如eBay,人事管理联邦办公室,暴露了2200万当前和前联邦雇员,大学和在线服务巨头如雅虎的个人信息,公众对信用卡欺诈和身份盗用的认识可能是全部时间高。
不幸的是,风险仍然很高,特别是考虑到数十亿个物联网设备在家用电器到汽车的一切设备仍然是绝对不安全的现实,作为加密和安全大师,IBM首席技术官Bruce Schneier
3.再见匿名
Herold说,在现代生活中做的很多事情越来越难,“没有你的身份与之相关联”。她说甚至取消了数据并不一定会消除隐私风险。 “即使在一两年前使用的标准已经不够了。想要将数据匿名化然后将其用于其他目的的组织将会越来越难。她说:“数据的有效匿名化将很快变得几乎是不可能的,因为相关的个人不能被重新识别。”
除了容易受到破坏之外,IoT设备是用户最多的个人信息的大量数据收集引擎。 Jerome说:“个人正在为智能设备支付费用,制造商可以立刻改变其隐私条款。” “告诉用户停止使用Web服务是一回事;告诉他们拔掉他们的智能电视或断开他们连接的汽车。
4.政府豁免
根据EPIC,“美国人比以往更多的政府数据库”,包括联邦调查局收集个人身份信息(PII)的名单,任何别名,种族,性别,出生日期和地点,社会保险号码,护照驾驶执照号码,地址,电话号码,照片,指纹,银行账户等财务信息,就业和业务信息。
然而,“令人难以置信的是,该机构已经免除了联邦调查局只保留”准确,相关,及时和完整的个人记录“的1974年”隐私法“要求,以及”隐私法“所要求的其他信息保护措施, EPIC说。美国国家安全局还在2014年在犹他州的布拉夫代尔开设了一个存储设施,据报道能够存储12个千兆字节的数据 - 单个zettabyte是将需要7,500亿张DVD存储的信息量。
虽然有来自前总统奥巴马的保证,那个政府是“不听你的电话或是看你的电子邮件”,这显然是说政府是否存储这个问题。
5.你的数据被代理
许多公司收集和销售用于个人资料的消费者数据,没有太多的控制或限制。由于自动化决策,有一些着名的公司开始向孕妇推销产品,之后才告诉家里的其他人。像性取向或像癌症这样的疾病也是如此。
“自2014年以来,数据经纪人一直在为销售他们可以从互联网上找到的所有数据进行销售。而且有几个 - 我没有明确的知道 - 涉及个人的法律保护,“Herold说。 “这种做法会增加,不受约束,直到限制这种用途的隐私法被颁布为止。还有很少甚至没有责任,甚至保证信息是准确的。
我们该怎么办?
那些不是唯一的风险,没有办法消除它们。但是有办法限制它们。根据杰罗姆的说法,一个是使用大数据分析来解决问题。他说:“在许多方面,大数据正在帮助我们做出更好,更公正的决策,”他指出,“这是一个强大的工具,可以帮助用户和反对歧视。可以使用更多的数据来以歧视的方式显示某些事情的完成。传统上,发现歧视的最大问题之一是缺乏数据,“他说。
倡导者普遍认为,国会需要通过CPBR版本,呼吁消费者权利包括:
-
个人控制个人数据公司收集他们以及如何使用它们。
-
透明度或易于理解和可访问的有关隐私和安全措施的信息。
-
以与消费者提供数据的上下文相一致的方式收集,使用和披露个人数据。
-
个人资料的安全和负责任的处理。
-
以可用格式访问他们的个人数据,并纠正错误。
-
公司收集和保留的个人资料的合理限制。
麦克尼科拉斯说,“透明度”应该包括对“隐私政策”的大修,这些“隐私政策”如此密集,充满了几乎没有人读过的法定人士。他说:“告诉消费者阅读隐私政策和选择退出权利似乎是一个更适合上个世纪的解决方案。”消费者隐私必须转向以消费者为中心,消费者对其信息的真正控制。
杰罗姆同意“我当然不认为我们可以期望消费者阅读隐私政策。这是疯狂。我们应该期待的是更好和更多的控制。用户可以查看和删除他们的回音记录是件好事。他说,Twitter允许用户切换所有种类的个性化,并看看谁针对他们,这是非常好的。 “但是最终,如果个人没有提供更多的收集和分享选择,我们将会对我们的个人自主权有严重的问题。”
鉴于国会有争议的气氛,很少有机会像CPBR那样快速通过。那并不意味着消费者手无寸铁。他们能做什么?
即使用户没有阅读完整的政策,Jerome也表示,他们应该“点击”确定“之前还要花一点时间来考虑为什么和他们分享他们的信息。最近的一项研究表明,个人会放弃自己的敏感信息来换取自制饼干。“
Herold提供了其他几种措施来降低您的隐私风险:
-
在社交媒体上退出分享。她说:“如果您只有几个人想要查看照片或视频,请直接发送给他们,而不是发布许多人可以访问的人。”
-
不要为与您开展业务的目的不必要的企业或其他组织提供信息。除非他们真的需要你的地址和电话号码,否则不要给他们。
-
使用匿名浏览器,如Hotspot Shield或Tor(洋葱路由器)访问网站时,可能会产生可能导致人们对您的不准确结论的信息。
-
在不知情的情况下,请别人不要在线分享有关您的信息。 “这可能会感到尴尬,但是你需要做到这一点,”她说,并补充说,艰难的事实是,消费者需要保护自己,因为没有人会为他们做这件事。
关于立法方面,她说她没有听说过CPBR在作品中的其他草稿,“我坦白地说,不要指望在未来四年内会有任何改善消费者隐私的东西;事实上,我预计政府的保护会恶化。 “我希望我错了,”她说。
- 138 次浏览
【数据安全】Age vs GPG
视频号
微信公众号
知识星球
GnuPG和Age之间的主要区别是简单性(或者复杂性,如果你愿意的话):
- 在Age中使用的文件格式比GnuPG(即OpenPGP)使用的格式简单得多,后者相当复杂,因为它必须支持许多用例和许多遗留问题;参见RFC 4880,与age v1相比;
- 密码学套件在Age中非常“固执己见”(每个目的只有一个算法,主要是ChaCha20和Curve25519,两者都由Daniel J.Bernstein开发),而GnuPG(因为它必须实现OpenPGP)支持相当广泛的算法(其中一些不是很“现代”,可能有弱点);因此,当使用GnuPG时,尤其是对于敏感数据,必须知道使用了什么实际算法;
- (与前一点有点关系)可用的加密参数(算法、强度、轮次、密钥大小等)由Age开发人员根据常见的最佳实践进行选择,同时在GnuPG中(由于OpenPGP的支持),人们可以选择(因此很可能是因为不知道削弱加密的含义),默认值更“保守”;
- 然而Age是比GnuPG年轻得多的设计和实现,这既有优势(更干净的代码、当前的最佳实践、当前的密码学等),也有劣势(可能发现潜在问题的审查和审计较少;)(例如,GnuPG试图通过Linux上的mlock使用内存锁定来确保加密材料(即密钥字节)不会泄露给交换;搜索Age的问题和代码以查找mlock或安全内存或内存锁定不会产生任何结果;)
- GnuPG的一个主要优势(这让我个人陷入困境)是存在缓存密钥材料的gpg代理,因此我可以执行多次加密/解密,而无需多次提供密码(或使用无密码身份文件);
- 显然,Age只支持加密/解密,但GnuPG也支持签名;(对于这个用例,可以使用以类似于Age的方式构建的minisign;)
关于您关于Age密码套件安全性的问题,正如Age所说(基于规范):
- ChaCha20-Poly1305(RFC 7539)(由D.J.Bernstein开发)——用于加密实际数据(基于密码和私钥/公钥模式);
- X25519(RFC 7748)(由D.J.Bernstein开发)——用于私钥/公钥加密;
- scrypt(RFC 7914)——用于密码推导;
- HKDF-SHA-256(RFC 5869)——用于各种密钥派生(而非密码);
因此,所有的算法都是基于RFC的(因此,至少听起来符合目的),并且所有算法都是“现代的”,因为社区不建议从它们转向更好的替代方案。(唯一的小例外可能是向Argon2推进的scrypt。)
另一个重要的观察结果是,ChaCha20-Poly1305和X25519都是由D.J.Berstein开发的,这两个似乎都是当前许多开源项目“最喜欢”的密码套件。(尽管密码学不是一场流行竞赛。):)
我是否从GnuPG切换到Age?
目前我一直和GnuPG呆在一起。对于一个单一的用例,我已经使用了Age,如果不是因为#256问题(即无法从文件描述符中读取密码),我会将更多的用例迁移到Age(包括在我的个人笔记本电脑上解密磁盘加密的密钥)。
目前,Age缺少一些用户体验关键功能(至少对我来说):
- 它没有代理来缓存密钥材料;(因此,我只能重复输入密码或使用无密码的身份文件;)
- 它不支持从文件描述符中读取密码;(密码仍然提供了一些,但在早期Linux启动的情况下,必须通过systemd询问密码;)
此外,我仍在观望Age如何进一步发展。Age在GnuPG上的最初特点(至少对我来说)是简单:一个二进制文件可以完成它所支持的所有功能,没有配置文件,没有$HOME强制要求;最近几个月,我在Age的讨论中看到了很多提到的“插件”,因此我担心GnuPG的复杂性会通过这些“可选插件”重新出现。(事实上,文件描述符中的密码被暗示为“插件”,对于早期的系统引导用例来说,这似乎太复杂了。)
- 204 次浏览
【数据安全】HashiCorp Vault被高估,Mozilla与KMS和Git的SOPS被严重低估
视频号
微信公众号
知识星球
当我开始使用Kubernetes和Infrastructure as Code时,我很快发现我需要一个秘密管理解决方案,但当我在谷歌上搜索时,似乎没有就可以普遍应用于所有情况的最佳实践方法达成坚实的共识。因此,今年早些时候,我为自己设定了一个目标,即发现存在哪些应用程序和基础设施秘密管理解决方案,找出我认为最好的解决方案,并掌握它。在追求这个目标的同时,我得出的结论是,HashiCorp Vault被夸大了,而Mozilla与KMS和Git的SOPS被严重低估了。我认为SOPS被低估的主要原因有两个:
- 大多数人对云KMS是什么或做什么没有从技术到外行的理解。
- 这些人没有意识到,尽管过去没有安全的方式在Git中存储加密的秘密,但密码学从那时起就发生了变化,现在由于AWS KMS、Azure KeyVault或GCP KMS等云提供商KMS解决方案,在Git上安全存储加密的密钥成为可能。
Vault的大部分宣传都是有道理的,因为几十年来一直没有好的秘密管理解决方案,然后是Terraform制造商的Vault,它具有内置的秘密轮换功能,随着时间的推移得到了积极维护,拥有出色的文档、支持和社区,Vault是唯一一个满足我对理想的秘密管理方案的要求的解决方案。我说Vault被夸大了,因为我经常认为它被推荐为黄金标准,应该应用于所有机密管理场景。
理想的秘密管理解决方案要求
- 通用(任何云和on-prem)
- 通过REST API或独立于平台的CLI二进制文件与任何技术堆栈很好地集成。(如果它与Terraform、Ansible、Kubernetes和CICD Pipelines顺利集成,则会获得额外奖励)
- 经得起未来考验
- 开源/免费(没有服务消失或价格上涨的风险)
- 大型社区或长期维护的历史(不要放弃软件,除非它可能是永恒的/功能完整的放弃软件,如Unix实用程序)
- 扩展良好并提供高可用性
- 真正安全(我应该能够说服任何安全负责人,它足够防弹,可以通过安全审计。)
- 静止时的加密
- 传输中的加密
- 访问权限应可撤销
- 应预先研究漏洞,并采取应对措施。
- 支持细粒度ACL+开发人员秘密创建自助服务选项
- 开发人员应该能够管理开发秘密,但不能管理产品秘密。
- 运维人员应该能够管理开发和生产机密。
- 项目级隔离:项目A的运作,不应该看到项目B的产品秘密。
- 版本化机密(可以帮助转移和自动化、部署、回滚,以及支持机密和配置在配置文件和数据库连接字符串中交织在一起的技术债务场景。)
*注意:Mozilla SOPS也符合我的要求,但当时我没有意识到,因为我最初认为没有安全的方法来加密git机密。
在git repo中存储机密的安全挑战
- 许多工具都将解密密钥存储在用户的主目录或密钥环(keyring)中,这会导致加密数据和密钥位于同一台机器上。
- 在这种情况下,解密密钥受损在统计上是不可避免的(Vulnerabilities multiplied by clones of the repo multiplied by time)
- 撤销泄露的解密密钥是不可能的。如果你担心解密密钥可能已经被泄露,但泄露的可能性很低,那么由于git的分布式历史,撤销密钥不是一种选择。即使您可以清除git服务器的历史记录,并用新的加密密钥重新加密所有机密,仍然存在可以用旧密钥解密的repo的历史克隆。
- 如果怀疑有妥协,唯一可行的对策是轮换所有证书,这是一项昂贵的操作,管理层通常不愿意凭直觉放弃。
- 一些git加密工具是脚踏板解决方案:运行命令解密机密,然后在将其推送到repo之前忘记加密。
每当我发现一个秘密管理解决方案时,我注意到我可以将其分为4大类:
- 特定于单个云提供商(我出于原因1和3驳回了这些请求)
- 特定于单个技术堆栈(Ansible、Chef、Puppet、Salt、Jenkins)(我出于原因2和5驳回了这些)
- 加密的Git Repo(我驳回了这些原因4和5)
- 推出自己的秘密管理服务(有几个潜在的可行选项,但每个选项都有自己的复杂性,所以专注于其中一个是有意义的。Hashicorp的Vault是明显的赢家,因为它有很多功能、文档、大型社区以及长期支持和开发的记录。)
分析完成后,我花了一个月的业余时间在Vault服务器上工作,用于存储静态机密,以帮助我掌握Vault,我希望它安全、易于维护和易于使用。为了实现这一点,我尽了最大努力,启用TLS,将Vault配置、角色、策略和Kubernetes基础设施作为高可用的Vault/Culus群集的代码添加到git repo中,使用KMS自动解封,编写良好的自述文档,启用版本化的键值存储、LDAP身份验证、web GUI和Adobe称为Cryptr的第三方桌面GUI。在学习Vault时,我注意到它的使用有很多缺点:
- 保险库仍然需要一个地方来存储它的秘密。(Vault将其基础结构作为代码机密存储在何处?KMS Auto Unsecal的HTTPS证书和IAM密码)
- 保险库在很多方面都非常昂贵。(你必须为基础设施和存储付费。你可以从头开始设置它,写一个自述文件,并在一个小时内培训几个人如何使用它,这还不够简单,使用基础设施作为代码和git repo中的预制自述文件会有所帮助,但即使这样,仍有很多东西需要学习。运营人员需要花时间通过备份、升级和监控来维护它o花时间编写自定义包装脚本来验证和提取所需的数据。)
- Vault让那些需要存储秘密的人的生活更加艰难,所以他们会避免使用它,这损害了它作为中央秘密库的目标。(开发人员需要学习几个新命令才能与Vault交互,或者依赖于速度较慢的Vault GUI。大多数现有的工具都是为与文件系统上的文件交互而设计的。因此,使用vimdiff等工具现在需要额外的步骤,包括登录、获取机密、将其转换为文件,以及在完成后删除文件。)
- 默认实现有一个安全漏洞,该漏洞的安全代价很高。(如果有人获得了对Vault服务器的root访问权限,他们可以通过内存转储来获得主解密密钥。在Kubernetes或Cloud VM上托管Vault会带来更多获得root访问权限的机会。为了完全降低root访问的风险,您需要为计算机配备Intel Software Guard Extensions,并在SCONE Security Enclaves中的计算机上运行Vault服务器(在加密RAM中运行的容器)。增加这些将增加更多的基础设施和研究成本。Twistlock、Aqua或SysDig是部分缓解这种风险的替代选项。)
考虑到这些缺点,我决定更深入地研究,这项研究让我找到了Soluto的Kamus,在那里我被介绍了两个很酷的概念:GitOps和零信任秘密加密。这让我一跃成为加密技术的拉比。在旅程的最后,我想出了以下的心理图式。
密码学的简编进化
1.)对称加密密钥:
- 长密码用于加密和解密。
2.)非对称加密公私密钥对:
- 公钥加密数据,私钥解密用公钥加密的数据。
3.)HSM(硬件安全模块):
- 确保私钥不会泄露。
- HSM很贵。
- HSM对用户或自动化都不友好。
4.)云KMS(密钥管理服务):
- KMS是一种受信任的服务,代表客户对数据进行加密和解密,它基本上允许用户或机器使用其身份(identity )而不是加密/解密密钥对数据进行解密。(客户端根据KMS进行身份验证,KMS根据ACL检查其身份,如果客户端具有解密权限,则客户端可以在请求中向KMS发送加密数据,然后KMS将代表客户端解密数据,并通过安全TLS隧道将解密后的数据发送回客户端。)
- KMS很便宜。
- KMS是通过REST API公开的,这使得它们对用户和自动化都很友好。
- KMS是非常安全的,它们使它可以在十年内不泄露解密密钥。
- KMS加密技术的发明引入了3个杀手级功能:
- 在应对已知漏洞时:在KMS之前解密密钥泄露:你不能撤销解密密钥,这意味着你需要轮换几个解密密钥,用新密钥重新加密所有数据,并尽最大努力清除旧的加密数据。在完成所有这些工作的同时,您需要与管理层进行斗争,以获得批准,从而导致多个生产系统停机,最大限度地减少所述停机时间,即使您做得很好,您也可能无法完全清除旧的加密数据,如git历史记录和备份。KMS之后,身份凭据会被泄露:身份凭据可以被吊销,当它们被吊销时,它们就毫无价值了。重新加密数据和清除旧的加密数据的噩梦消失了。您仍然需要轮换机密(身份凭据与解密密钥),但轮换行为变得足够便宜,可以作为预防措施进行自动化和调度。
- 加密数据的管理从涉及分布式解密密钥的不可能的任务转变为管理集中式ACL的琐碎任务。现在可以轻松地撤销、编辑和分配对加密数据的细粒度访问;另外,由于云KMS、IAM和SSO身份联合会集成在一起,您可以利用预先存在的用户身份。
- 加密锚定(Crypto Anchoring )技术成为可能:
- 可以将网络ACL应用于KMS,使其能够在您的环境中解密数据。
- 可以监测KMS解密速率的基线,当发生异常速率时,可以触发警报和速率限制。
- KMS的解密密钥可以通过HSM进行保护。
- 解密密钥被泄露的机会几乎为零,因为客户端不直接与解密密钥交互。
- 云提供商可以雇佣最优秀的安全专业人员,并实施昂贵的操作流程,这些流程是保持后端系统尽可能安全所必需的,因此后端密钥泄漏的机会也几乎为零。
我对高级加密技术的新理解使我意识到KMS可以用来防止解密密钥泄露。再加上无需对加密文件进行任何更改即可撤销解密权限的能力,使Git中真正安全的加密文件成为现实。我重新审视了一些我之前拒绝的基于Git的加密解决方案,发现Mozilla SOPS满足了我理想的秘密管理解决方案的所有标准。它还与CICD管道工具很好地集成:有一个SOPS Terraform Provider,Helm Secrets只是SOPS的包装器,您总是可以回退到:
Bash# sops --decrypt mysecret.yaml | kubectl apply -f -
(其中kubectl可以是任何接受标准输入的CLI实用程序(-))SOPS没有其他基于Git的加密解决方案的缺点:其他基于Gits的加密方案的一个亮点是,有人可能会意外地将解密的秘密推送到Git repo。使用SOPS,当你想编辑一个文件时,文件会在磁盘上加密,在RAM中解密,在那里你可以用vim编辑它,当你保存编辑后的文件时,它会在写入磁盘之前重新加密。同时,它确实提供了快速解密一些文件的灵活性,因此您可以使用vimdiff这样的工具。SOPS没有Vault的缺点:它不需要基础设施,而且和KMS一样便宜。你可以很容易地设置它,培训几个人,并在一小时内编写一个自述文件,下面是一个设置和使用的简单示例:
Bash# aws kms create-key --description "Mozilla SOPS” | grep Arn
"Arn": "arn:aws:kms:us-east-1:020522090443:key/4882a19d-5a98-40ae-a1ad-a60423afbddb",
Bash# cd $repo
Bash# vim .sops.yaml
(创建一个名为.sops.yaml的文件,其中包含以下2行文本)
creation_rules: - kms: 'arn:aws:kms:us-east-1:020522090443:key/4882a19d-5a98-40ae-a1ad-a60423afbddb'
Bash# sops mysecret.yaml
这将打开vim编辑器,以便您可以键入要存储在秘密中的内容。这个简单的命令用于创建和编辑文件。
Bash# cat mysecret.yaml
会给你看一个加密的yaml
Bash# sops --decrypt mysecret.yaml
将向您显示解密的yaml SOPS将使用存储在 ~/.aws 中的AWS凭据对KMS进行身份验证,这样您就可以在没有密码的情况下进行加密和解密。SOPS还会递归地查找.SOPS.yaml文件,这样它就会自动发现关于应该如何加密和解密东西的元数据,这有两个重要的后果:
- 首先,用户不必学习大量的命令或标志。
- 其次,可以将一个额外的.sops.yaml文件添加到表示生产环境或不同项目的子文件夹中,该.sops.yaml文件可以具有不同的加密/解密密钥。
您可以为不同的Cloud IAM用户授予每个KMS密钥不同的权限,以实现细粒度的访问控制。如果你担心有人删除你的AWS KMS密钥,你可以配置SOPS,这样数据就可以由AWS、GCP或Azure KMS解决方案加密或解密,这样你就可以保留一个很少有人能访问的辅助备份KMS。
SOPS鼓励工作流程模式,让生活更轻松。
- Devs可以将加密后的秘密存储在使用它的代码版本旁边并与之同步。秘密管理突然获得了git的所有好处:可审核的更改管理、通过拉取请求进行的同行评审、对秘密的编辑差异都很有意义,因为只有编辑后的值才会在编辑时更新,而整个文件都会重新加密,这也降低了合并冲突的可能性。
- 一致性和标准化总是让自动化和CICD管道开发变得更容易,这让运营人员感到高兴。SOPS允许将代码、配置和机密存储在一致的位置,这使得GitOps工作流更容易实现。
- Hashicorp Vault将很难实现其成为组织集中秘密存储库的目标,因为用户会发现它很难使用,devops会发现维护起来很麻烦,管理层可能会发现它成本高昂。
- 另一方面,SOPS使用起来很轻松,易于学习,维护成本低廉,并支持使生活更轻松的工作流程模式!这些因素加在一起意味着,只要有人能向组织推销,就不会有采用的障碍,这意味着整个组织更有可能加强安全态势。
这就是为什么KMS和Git的SOPS被严重低估的原因。我想澄清一下,这篇文章的目的并不是说Vault不好,你应该使用SOPS和KMS。我写这篇文章有三个原因:一,我喜欢教书。第二,我想指出Vault的一些缺点。第三,KMS和SOPS是一个被严重低估的惊人组合:似乎没有人知道它,我在研究过程中从未遇到过对这两者的正确解释,根据谷歌趋势,与Vault相比,对SOPS的搜索并不多。
我想在这篇文章的结尾说,我衷心建议大家学习SOPS、KMS和Vault。如果Vault很难,为什么要学习它,而使用KMS的SOPS可以轻松地完成同样的事情?真正的原因有两个:一,Vault在PKI和机密轮换方面是同类中最好的,这两项都是满足许多政府和银行安全合规标准所必需的。第二,Vault每年都变得更容易使用:社区已经将其视为一个明显的赢家,并将Vault支持添加到了几个产品中:Jenkins、证书管理器和Kubernetes。尤其是Kubernetes,它与Vault配合得很好,许多痛点都被抽象化和自动化,使它们能够顺利地结合在一起。Vault团队也有着良好的记录,致力于通过改进文档、提供一些IaC和响应社区的需求,使Vault随着时间的推移更易于使用:在社区制作了自动解封解决方案、后端存储迁移解决方案和第三方web GUI之后;Vault的开发人员决定将这些功能移植到开源版本中。有鉴于此,如果将来Vault的Transit Secrets Engine(Vault的KMS解决方案)能够与Mozilla SOPS顺利集成,我也不会感到惊讶。
- 238 次浏览
【数据安全】OAuth 2.0 释疑
需要使用令牌保护应用程序?您正在寻找OAuth 2.0安全框架。它具有Web,移动和IoT客户端的流程,以及用于管理令牌生命周期的有用API。最初作为授予第三方访问社交个人资料的简单有效的解决方案,已经发展到支持各种领域的应用程序,甚至是最严格的安全要求。
1.使用OAuth 2.0进行基于令牌的安全性
令牌已成为保护互联网上应用程序的流行模式。开发人员喜欢它的概念简单性,架构师能够设计具有良好分离的安全角色的应用程序。然而,看似容易将基于令牌的安全潜伏陷阱陷入困境。
为了建立一个处理令牌的坚实框架,具有明显平衡的安全性和易用性,同时借鉴早期成功点击(特别是最初的OAuth)的经验教训,来自互联网社区的工程师设计了OAuth 2.0并将其作为RFC 6749发布于2012。
OAuth 2.0框架中的关键方面是故意保持开放和可扩展的。基本RFC 6749指定了四种安全角色,并引入了四种方法,称为授权授权,以便客户端获取访问令牌。其余的,例如令牌内的内容,留给实施者或未来的扩展填写。
2. OAuth中的四个角色
OAuth定义了四个角色,清晰地分离了他们的顾虑。这与将安全相关的复杂性转移到专用授权服务器相结合,可以快速推出具有一致安全属性的受OAuth 2.0保护的应用程序和服务。
资源所有者
通常意味着最终用户。 该术语反映了OAuth的初始目的,代表用户提供第三方软件访问,但框架的使用已经超出了这一范围。
资源服务器
受保护资产,通常是Web API,需要令牌才能访问。 令牌验证逻辑可以保持非常小,也可以是无状态的。
客户
应用程序 - 基于Web,移动,桌面或基于设备的应用程序,需要获取令牌才能访问资源服务器。 由于复杂性转移到授权服务器,因此客户端OAuth逻辑很简单。
授权服务器
在成功验证最终用户并确保所请求的访问权限可以通过最终用户的同意,应用策略或其他方式后,向客户端发出访问令牌的专用服务器。
3.客户如何获得令牌?
为了获得访问令牌,客户端需要向授权服务器提供有效的授权(凭证)。
如果有一件事经常让OAuth 2.0的新人望而却步,那就是为他们的应用选择合适的补助金。 如果您知道您拥有的客户端类型(网络,移动设备等),那么选择就会变得很明显。
这是一个粗略的指南:
| Grant type | Client type / Use case |
|---|---|
| Authorisation code | Intended for traditional web applications with a backend as well as native (mobile or desktop) applications to take advantage of single sign-on via the system browser. |
| Implicit | Intended for browser-based (JavaScript) applications without a backend. |
| Password | For trusted native clients where the application and the authorisation server belong to the same provider. |
| Client credentials | For clients, such as web services, acting on their own behalf. |
| Refresh token | A special grant to let clients refresh their access token without having to go through the steps of a code orpassword grant again. |
| SAML 2.0 bearer | Lets a client in possession of a SAML 2.0 assertion (sign-in token) exchange it for an OAuth 2.0 access token. |
| JWT bearer | Lets a client in possession of a JSON Web Token (JWT) assertion from one security domain exchange it for an OAuth 2.0 access token in another domain. |
| Device code | For devices without a browser or with constrained input, such as a smart TV, media console, printer, etc. |
| Token exchange | Lets applications and services obtain an access token in delegation and impersonation scenarios. |
3.1授权代码流程示例
现在,我们将通过一个客户端的示例,使用授权代码授权从OAuth 2.0授权服务器获取访问令牌。 此授权主要用于Web应用程序。
客户端需要执行两个步骤来获取令牌,第一个涉及浏览器,第二个步骤是反向通道请求。 这就是为什么这一系列步骤也称为代码流。
| Step 1 | Step 2 | |
|---|---|---|
| Purpose | 1. Authenticate the user 2. Authorise the client |
1. Authenticate client (optional) 2. Exchange code for token(s) |
| Via | Front-channel request (browser redirection) |
Back-channel request (app to web server) |
| To | Authorisation endpoint | Token endpoint |
| Result on success | Authorisation code (step 2 input) |
Access token Refresh token (optional) |
代码流程:第1步
客户端通过授权请求将浏览器重定向到授权服务器来启动代码流。
示例重定向到授权服务器:
HTTP/1.1 302 Found
Location: https://authz.c2id.com/login?
response_type=code &
scope=myapi-read%20myapi-write &
client_id=s6BhdRkqt3 &state=af0ifjsldkj &
redirect_uri=https%3A%2F%2Fclient.example.org%2Fcb
授权请求参数在URI查询中编码:
- response_type:设置为code以指示授权代码流。
- scope:指定请求的令牌的范围。如果省略,授权服务器可能会采用某个默认范围。
- client_id:授权服务器上的客户端的标识符。当客户端通过客户端注册API,开发人员控制台或其他方法向授权服务器注册时,将分配此标识符。
- state:客户端设置的可选opaque值,用于维护请求和回调之间的状态。
- redirect_uri:授权响应的客户端回调URI。如果省略,授权服务器将采用客户端的默认注册重定向URI。
在授权服务器处,通常通过检查用户是否具有有效会话(由浏览器cookie建立)来验证用户,并且如果没有,则通过提示用户登录来验证用户。之后,服务器将通过询问用户的同意,应用规则或策略,或通过其他方式来确定客户端是否被授权。
然后,授权服务器将使用授权代码(成功时)或错误代码调用客户端redirect_uri(如果访问被拒绝,或者发生了一些其他错误,则检测到这样的格式错误的请求)。
HTTP/1.1 302 Found
Location: https://client.example.org/cb?
code=SplxlOBeZQQYbYS6WxSbIA &
state=af0ifjsldkj
客户端必须验证状态参数,并使用代码继续下一步 - 交换访问令牌的代码。
代码流程:第2步
授权代码是一个中间凭证,它对在步骤1中获得的授权进行编码。因此,它对客户端是不透明的,只对授权服务器有意义。要检索访问令牌,客户端必须将代码提交给授权服务器,但这次使用直接反向通道请求。这样做有两个原因:
在显示令牌之前,使用授权服务器对机密客户端进行身份验证;
将令牌直接传递给客户端,从而避免将其暴露给浏览器。
令牌代码交换发生在授权服务器的令牌端点:
POST /token HTTP/1.1
Host: openid.c2id.com
Content-Type: application/x-www-form-urlencoded
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
grant_type=authorization_code &
code=SplxlOBeZQQYbYS6WxSbIA &
redirect_uri=https%3A%2F%2Fclient.example.org%2Fcb
客户端ID和密钥通过Authorization标头传递。除了HTTP基本身份验证之外,OAuth 2.0还支持使用JWT进行身份验证,JWT不会使用令牌请求公开客户端凭据,因此已过期,因此可提供更强的安全性。
令牌请求参数是表单编码的:
- grant_type设置为authorization_code。
- 代码从步骤1获得的代码。
- redirect_uri重复步骤1中的回调URI。
成功时,授权服务器将返回具有已颁发访问令牌的JSON对象:
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: no-store
Pragma: no-cache
{ "access_token" : "SlAV32hkKG",
"token_type" : "Bearer",
"expires_in" : 3600,
"scope" : "myapi-read myapi-write"
}
expires_in参数通知客户端访问令牌有效的秒数。范围参数是令牌实际具有的功能,因为某些最初请求的范围值可能已被拒绝,或者其他未明确请求的范围值被授予。
JSON对象可以包含可选的刷新令牌,该令牌允许客户端从授权服务器获取新的访问令牌,而无需重复代码流。
4.客户端如何使用令牌访问受保护资源?
使用令牌访问资源服务器(例如Web API)非常简单。 OAuth 2.0中的访问令牌通常是类型承载,这意味着客户端只需要为每个请求传递令牌。 HTTP Authorization标头是推荐的方法。
GET /resource/v1 HTTP/1.1
Host: api.example.com
Authorization: Bearer oab3thieWohyai0eoxibaequ0Owae9oh
如果资源服务器确定令牌有效且未过期,则它将继续为请求提供服务。
否则,它将在HTTP WWW-Authenticate响应头中返回适当的错误。
无效或过期令牌的示例错误:
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Bearer realm="api.example.com",
error="invalid_token",
error_description="The access token is invalid or expired"
如果客户端收到过去工作的访问令牌的invalid_token错误,则表明它必须从授权服务器请求新的错误。
承载令牌(bearer tokens)的使用在RFC 6750中指定。
请记住,令牌的承载性质意味着拥有它的任何人都可以访问资源服务器。因此,必须保护承载令牌 - 首先,通过将它们保存在安全的客户端存储中,然后在传输中,通过TLS提交它们。发行短期令牌可以减少令牌泄漏的潜在风险。
5.如何使用令牌保护资源服务器?
要清除提交的请求,资源服务器需要验证令牌。验证确保以下内容:
- 访问令牌已由授权服务器发出。
- 令牌尚未过期。
- 其范围涵盖了请求。
如何完成取决于访问令牌的特定实现,该实现由授权服务器确定。更多内容将在下一章中介绍。
所需的令牌验证逻辑可以很容易地从底层资源中抽象出来,或者改装到现有资源上。可以使用反向HTTP代理或API网关来实现该目的。
最受欢迎的Web服务器和框架(例如Apache httpd和Spring)提供某种模块来验证使用承载访问令牌保护的传入请求。在成功验证后,可以向底层资源提供所选的有用令牌属性,例如最终用户的身份。这又是一个实施问题。
6.访问令牌
OAuth 2.0框架没有规定访问令牌的特定实施例。 这个决定留给实现者的理由很充分:对于客户端,令牌只是一个不透明的字符串; 它们的验证是授权服务器和资源服务器之间的问题,并且由于它们通常属于同一个提供者,因此没有足够的需求来指定标准令牌格式。
从根本上说,有两种类型的持票人令牌:
| Identifier-based | Self-contained |
|---|---|
| The token represents a hard-to-guess string which is a key to a record in the authorisation server's database. A resource server validates such a token by making a call to the authorisation server's introspection endpoint. | The token encodes the entire authorisation in itself and is cryptographically protected against tampering. JSON Web Token (JWT) has become the defacto standard for self-contained tokens. |
|
Pros / cons of identifier-based tokens:
|
Pros / cons of self-contained tokens:
|
7.授权服务器
授权服务器负责为其域中的受保护资源发出访问令牌。
OAuth使服务器实施者可以自由地确定最终用户的身份验证方式以及实际授权的执行方式。 Connect2id服务器充分利用了这一点,并提供了一个灵活的Web API,用于插入任何类型的身份验证因素以及逻辑,以确定已发布的访问令牌的范围。
7.1最终用户认证
授权服务器可以例如实现密码和基于风险的认证的组合,其中当客户端请求高价值资源或交易的访问令牌时,需要诸如U2F的第二因素。
用户的认证也可以委托给外部提供者,例如通过给用户选择流行的社交登录。也可以利用自发的身份。
成功进行身份验证后,通常会建立一个会话,以便为用户提供单点登录(对于涉及浏览器的OAuth授权或流量)的好处。
可以要求用户重新认证他们的浏览器的IP地址是否改变,或者如果令牌范围要求更大确定合法用户存在。这再次受制于具体的服务器策略。
7.2授权
与最终用户身份验证一样,授权过程和确定发布的令牌接收的范围是特定于实现的。
发布用于访问最终用户数据和其他资源的令牌的授权服务器通常呈现同意表,其中最终用户可以决定授予哪些范围以及哪些范围不授予请求应用程序。
公司中的授权服务器将查阅策略,该策略考虑员工的状态和角色以确定令牌范围,跳过任何与同意相关的交互。客户的信任级别,例如内部应用程序与外部应用程序,也可能是一个因素。
7.3客户端认证
OAuth定义了两种类型的客户端,具体取决于它们使用授权服务器进行安全身份验证的能力:
机密 - 可以将其凭据与最终用户和其他实体保密的客户端。在Web服务器上执行的Web应用程序可以是此类客户端。
公共 - 在用户的设备上,用户的浏览器或类似环境中执行的客户端,可以相对轻松地提取客户端中存储的任何凭据。
无论其类型如何,所有客户端都会获得授权服务器分配的唯一client_id。
到目前为止,已指定了六种不同的客户端身份验证方法,授权服务器可以实现其中任何一种:
| Method | Description |
|---|---|
| client_secret_basic | Essentially HTTP basic authentication with a shared secret. The most widely implemented because of its simplicity, but also with the weakest security properties. |
| client_secret_post | A variant of basic authentication where the credentials are passed as form parameters instead of in the Authorization header. |
| client_secret_jwt | The client authenticates with a JSON Web Token (JWT) secured with an HMAC using the client secret as key. Prevents leakage of the secret and limits the time-window for replay if the request is accidentally sent over unsecured HTTP. |
| private_key_jwt | Another JWT-based authentication method, but using a private key, such as RSA or EC, which public part is registered with the authorisation server. Private key authentication limits the proliferation of secrets and also provides a non-repudiation property. |
| tls_client_auth | The client authenticates with a client X.509 certificateissued from a CA authority trusted by the authorisation server. |
| self_signed_tls_client_auth | The client authenticates with a self-signed client X.509 certificate. Has similar properties as the private key JWT method. |
7.4。 授权服务器端点
| Core endpoints | Optional endpoints |
|---|---|
7.4.1授权端点
这是服务器端点,其中对最终用户进行身份验证,并在授权代码中授予请求客户端授权和隐式流(授权)。剩余的OAuth 2.0授权不涉及此端点,而是令牌令牌。
这也是通过前端通道(浏览器)和用户与服务器交互的唯一标准端点。
7.4.2令牌端点
令牌端点允许客户端为访问令牌交换有效授权,例如从授权端点获得的代码。
还可以发布刷新令牌,以允许客户端在其到期时获得新的访问令牌,而不必重新提交原始授权授权的新实例,例如代码或资源所有者密码凭证。这样做的目的是最小化最终用户与授权服务器的交互量,从而更好地体验整体体验。
如果客户端是机密的,则需要在令牌端点进行身份验证。
7.4.3可选端点
授权服务器可以具有以下附加端点:
服务器元数据 - 列出服务器端点URL及其支持的OAuth 2.0功能的JSON文档。客户端可以使用此信息配置对服务器的请求。
服务器JWK集 - 带有服务器公钥(通常为RSA或EC)的JSON文档,采用JSON Web Key(JWK)格式。这些密钥可用于保护发布的JWT编码的访问令牌和其他对象。
客户端注册 - 用于向授权服务器注册客户端的RESTful Web API。注册可能受到保护(需要预先授权)或开放(公共)。
令牌内省 - 用于让资源服务器验证基于标识符的访问令牌。也可用于验证自包含访问令牌。
令牌撤销 - 用于让客户端通知授权服务器不再需要先前获得的刷新或访问令牌。请注意,此端点不用于撤消对最终用户或客户端的访问;这将需要一个自定义API。
8.常见问题
8.1 OpenID Connect如何与OAuth 2.0相关?
OpenID Connect是用于验证最终用户的具体协议,在OAuth 2.0框架之上设计。因此,OpenID Connect通常也称为OAuth 2.0的配置文件。
OpenID Connect引入了一个新令牌,称为ID令牌,用于编码最终用户的身份。 ID令牌通过现有的标准OAuth 2.0流程提供。
仍然使用访问令牌。它有助于从OpenID提供程序的UserInfo端点检索同意的配置文件详细信息(称为声明或属性)。
8.2还存在哪些其他OAuth 2.0配置文件?
社区正在开发除OpenID Connect之外的其他具体配置文件,由专家仔细审查,为特定行业或应用程序域提供基于令牌的安全性:
- FAPI - 用于开放式银行和PSD2实施的金融级应用程序的高安全性配置文件。
- HEART - 允许个人控制对其健康相关数据的访问的配置文件。
- MODRNA - 适用于向依赖方提供身份服务的移动网络运营商。
- EAP - 集成令牌绑定和FIDO的安全和隐私配置文件。
- iGOV - 用于在全球范围内通过公共部门服务对同意数据进行身份验证和共享。
原文:https://connect2id.com/learn/oauth-2
本文:http://pub.intelligentx.net/node/467
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 81 次浏览
【数据安全】OpenID Connect 释疑
OpenID Connect已成为互联网上单点登录和身份提供的领先标准。 它的成功公式:简单的基于JSON的身份令牌(JWT),通过OAuth 2.0流程提供,专为基于Web,基于浏览器和本机/移动应用程序而设计。
1.本地用户身份验证与身份提供商
应用程序通常需要识别其用户。简单的方法是为用户的帐户和凭证创建本地数据库。如果有足够的技术保养,这可以使其运作良好。但是,本地身份验证可能对业务不利:
- 人们发现注册和帐户创建繁琐,这是正确的。消费者网站和应用程序可能因此而遭受废弃的购物车,这意味着业务和销售的损失。
- 对于拥有许多应用程序的企业而言,维护单独的用户数据库很容易成为管理和安全的噩梦。您可能希望更好地使用IT资源。
这些问题的既定解决方案是将用户身份验证和配置委派给专用的专用服务,称为身份提供商(IdP)。
谷歌,Facebook和Twitter,互联网上的许多人都注册,为他们的用户提供这样的IdP服务。通过将登录与这些IdP集成,消费者网站可以极大地简化用户入职。
在企业中,理想情况下,这将是一个内部IdP服务,供员工和承包商登录内部应用程序。集中化具有相当大的好处,例如更轻松的管理以及新应用程序可能更快的开发周期。你可能会问:这不会造成单点故障吗?不,不是在为冗余构建IdP服务时。
2.进入OpenID Connect
OpenID Connect于2014年发布,不是IdP的第一个标准,但在可用性和简单性方面绝对是最好的,从SAML和OpenID 1.0和2.0等过去的工作中汲取了教训。
OpenID Connect成功的公式是什么?
- 易于使用的身份令牌:客户端接收以安全的JSON Web令牌(JWT)编码的用户身份,称为ID令牌。 JWT的优雅和便携性以及对各种签名和加密算法的支持非常受欢迎。这一切使得JWT在ID令牌工作中表现突出。
- 基于OAuth 2.0协议:ID令牌通过标准OAuth 2.0流程获得,支持Web应用程序以及本机/移动应用程序。 OAuth 2.0还意味着拥有一个用于身份验证和授权的协议(获取访问令牌)。
- 简单性:OpenID Connect非常简单,可以与基本应用程序集成,但它还具有满足苛刻的企业要求的功能和安全选项。
3.身份令牌
ID令牌类似于标识JWT格式的身份证的概念,由OpenID提供商(OP)签名。要获得一个身份令牌,客户端需要通过身份验证请求将用户发送到他们的OP。
ID令牌的功能:
- 断言用户的身份,在OpenID(sub)中称为subject。
- 指定颁发机构(iss)。
- 是为特定受众生成的,即客户(aud)。
- 可能包含一个nonce(nonce)。
- 可以指定何时(auth_time)以及如何在强度(acr)方面对用户进行身份验证。
- 有发放(iat)和到期时间(exp)。
- 可能包含有关主题的其他请求详细信息,例如姓名和电子邮件地址。
- 是经过数字签名的,因此可以由目标收件人进行验证。
- 可以选择加密以保密。
ID令牌语句或声明包装在一个简单的JSON对象中:
{
“sub”:“爱丽丝”,
“iss”:“https://openid.c2id.com”,
“aud”:“client-12345”,
“nonce”:“n-0S6_WzA2Mj”,
“auth_time”:1311280969,
“acr”:“c2id.loa.hisec”,
“iat”:1311280970,
“exp”:1311281970
}
ID令牌头,声称JSON和签名被编码为基本64位URL安全字符串,以便于传递 arround,例如作为URL参数。
eyJhbGciOiJSUzI1NiIsImtpZCI6IjFlOWdkazcifQ.ewogImlzcyI6ICJodHRw
Oi8vc2VydmVyLmV4YW1wbGUuY29tIiwKICJzdWIiOiAiMjQ4Mjg5NzYxMDAxIiw
KICJhdWQiOiAiczZCaGRSa3F0MyIsCiAibm9uY2UiOiAibi0wUzZfV3pBMk1qIi
wKICJleHAiOiAxMzExMjgxOTcwLAogImlhdCI6IDEzMTEyODA5NzAKfQ.ggW8hZ
1EuVLuxNuuIJKX_V8a_OMXzR0EHR9R6jgdqrOOF4daGU96Sr_P6qJp6IcmD3HP9
9Obi1PRs-cwh3LO-p146waJ8IhehcwL7F09JdijmBqkvPeB2T9CJNqeGpe-gccM
g4vfKjkM8FcGvnzZUN4_KSP0aAp1tOJ1zZwgjxqGByKHiOtX7TpdQyHE5lcMiKP
XfEIQILVq0pc_E2DzL7emopWoaoZTF_m0_N0YzFC6g6EJbOEoRoSK5hoDalrcvR
YLSrQAZZKflyuVCyixEoV9GfNQC3_osjzw2PAithfubEEBLuVVk4XUVrWOLrLl0
nx7RkKU8NXNHq-rvKMzqg
您可以在RFC 7519中阅读有关JWT数据结构及其编码的更多信息。
4.如何申请ID令牌
既然我们知道ID令牌是什么,那么OpenID Connect中称为依赖方(RP)的客户端如何请求?
身份验证必须在身份提供者处进行,身份提供者将检查用户的会话或凭据。为此,需要受信任的代理,此角色通常由Web浏览器执行。
浏览器弹出窗口是Web应用程序将用户重定向到IdP的首选方式。 Android或iOS等平台上的移动应用程序应为此目的启动系统浏览器。嵌入式Web视图不受信任,因为没有什么可以阻止应用程序窥探用户密码。用户身份验证必须始终发生在与应用程序(例如浏览器)分开的可信上下文中。
请注意,OpenID Connect未指定用户应如何进行实际身份验证,这由提供商决定。
通过OAuth 2.0协议请求ID令牌,该协议本身取得了巨大成功。 OAuth最初被设计为一种简单的授权机制,方便应用程序获取Web API或其他受保护资源的访问令牌。它具有针对所有应用程序类型设计的流程:传统的基于服务器的Web应用程序,仅浏览器(JavaScript)应用程序以及本机/移动应用程序。
那么获取ID令牌的流程或路径是什么?
- 授权代码流 - 最常用的流程,适用于传统的Web应用程序以及本机/移动应用程序。涉及到/来自OP的初始浏览器重定向以进行用户认证和同意,然后是第二个反向通道请求以检索ID令牌。此流程提供最佳安全性,因为令牌不会泄露给浏览器,客户端也可以进行身份验证。
- 隐式流 - 适用于没有后端的基于浏览器(JavaScript)的应用程序。使用来自OP的重定向响应直接接收ID令牌。此处不需要反向频道请求。
- 混合流 - 很少使用,允许应用程序前端和后端彼此分开接收令牌。本质上是代码和隐式流的组合。
OpenID Connect规范提供了三种流程的良好比较,这里以简化形式再现。
| Flow property | Code | Implicit | Hybrid |
|---|---|---|---|
| Browser redirection step | ✔ | ✔ | ✔ |
| Backend request step | ✔ | ✕ | ✔ |
| Tokens revealed to browser | ✕ | ✔ | ✔ |
| Client can be authenticated | ✔ | ✕ | ✔ |
5.ID令牌使用
除了基本登录之外,还可以使用ID令牌:
- 无状态会话 - 将ID令牌放入浏览器cookie可以实现轻量级无状态会话。这消除了在服务器端(在内存或磁盘上)存储会话的需要,这可能是管理和扩展的负担。通过验证ID令牌来检查会话。当令牌达到其发布时间戳(iat)之后的某个预定义年龄时,应用程序可以通过silent prompt = none请求简单地向OP请求新的时间戳。
- 将身份传递给第三方 - 当需要了解用户身份时,ID令牌可以传递给其他应用程序组件或后端服务,例如记录审计跟踪。
- 令牌交换 - 可以在OAuth 2.0授权服务器(draft-ietf-oauth-token-exchange-12)的令牌端点处交换ID令牌以获取访问令牌。当需要身份证件来获取访问权限时,有真实世界的场景,例如当您在酒店办理登机手续以获取房间钥匙时。令牌交换用于分布式和企业应用程序。
6.示例OpenID身份验证
现在,我们将使用授权代码流,通过一个最小的示例来说明如何从OP获取用户的ID令牌。这是传统Web应用程序最常用的流程。可以在OpenID Connect规范中找到隐式和混合流的示例。
代码流有两个步骤:
| Step 1 | Step 2 | |
|---|---|---|
| Purpose | 1. Authenticate user 2. Receive user consent |
1. Authenticate client (optional) 2. Exchange code for token(s) |
| Via | Front-channel request (browser redirection) |
Back-channel request (app to web server) |
| To | Authorisation endpoint | Token endpoint |
| Result on success | Authorisation code (step 2 input) |
ID token (+ OAuth 2.0 access token) |
代码流程:第1步
RP通过将浏览器重定向到OpenID提供程序的OAuth 2.0授权端点来启动用户身份验证。 OpenID身份验证请求本质上是一个OAuth 2.0授权请求,用于访问用户的身份,由scope参数中的openid值指示。
验证重定向到OP的示例:
HTTP/1.1 302
Found Location: https://openid.c2id.com/login?
response_type=code &
scope=openid &
client_id=s6BhdRkqt3 &state=af0ifjsldkj &
redirect_uri=https%3A%2F%2Fclient.example.org%2Fcb
请求参数在URI查询中编码:
- response_type:设置为
code以指示授权代码流。 - scope:用于在OAuth中指定所请求授权的范围。范围值openid表示对OpenID身份验证和ID令牌的请求。
- client_id :OP上RP的客户端标识符。通过客户端注册API,开发人员控制台或其他方法向RP注册RP时,将分配此标识符。
- state :RP设置的不透明值,用于维护请求和回调之间的状态。
- redirect_uri:身份验证响应的RP回调URI。
在OP,通常通过检查用户是否具有有效会话(由浏览器cookie建立)来验证用户,并且如果没有,则通过提示用户登录来验证用户。之后,通常会询问用户是否同意登录RP。
然后,OP将使用授权代码(成功时)或错误代码调用客户端redirect_uri(如果访问被拒绝,或者发生了一些其他错误,则检测到这样的格式错误的请求)。
HTTP/1.1 302 Found
Location: https://client.example.org/cb?
code=SplxlOBeZQQYbYS6WxSbIA &
state=af0ifjsldkj
RP必须验证state 参数,并使用code继续下一步 - 交换ID令牌的代码。
代码流程:第2步
授权代码(authorisation code )是一个中间凭证,它对在步骤1中获得的授权进行编码。因此,它对RP不透明,只对OP服务器有意义。要检索ID令牌,RP必须将code提交给OP,但这次使用直接反向通道请求。这样做有两个原因:
在揭示令牌之前使用OP对机密客户端进行身份验证;
将令牌直接传递给RP,从而避免将它们暴露给浏览器。
代码交换发生在OP的令牌端点:
POST /token HTTP/1.1
Host: openid.c2id.com
Content-Type: application/x-www-form-urlencoded
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
grant_type=authorization_code &
code=SplxlOBeZQQYbYS6WxSbIA &
redirect_uri=https%3A%2F%2Fclient.example.org%2Fcb
客户端ID和密钥通过Authorization标头传递。除了HTTP基本身份验证之外,OpenID Connect还支持使用JWT进行身份验证,JWT不会使用令牌请求公开客户端凭据,并且已过期,因此可提供更强的安全性。
令牌请求参数是表单编码的:
- grant_type:设置为authorization_code。
- code :从步骤1获得的代码。
- redirect_uri 重复步骤1中的回调URI。
成功后,OP将返回一个带有ID令牌,访问令牌和可选刷新令牌的JSON对象:
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: no-store
Pragma: no-cache
{ "id_token": "eyJhbGciOiJSUzI1NiIsImtpZCI6IjFlOWdkazcifQ.ewogImlzc yI6ICJodHRwOi8vc2VydmVyLmV4YW1wbGUuY29tIiwKICJzdWIiOiAiMjQ4Mjg5 NzYxMDAxIiwKICJhdWQiOiAiczZCaGRSa3F0MyIsCiAibm9uY2UiOiAibi0wUzZ fV3pBMk1qIiwKICJleHAiOiAxMzExMjgxOTcwLAogImlhdCI6IDEzMTEyODA5Nz AKfQ.ggW8hZ1EuVLuxNuuIJKX_V8a_OMXzR0EHR9R6jgdqrOOF4daGU96Sr_P6q Jp6IcmD3HP99Obi1PRs-cwh3LO-p146waJ8IhehcwL7F09JdijmBqkvPeB2T9CJ NqeGpe-gccMg4vfKjkM8FcGvnzZUN4_KSP0aAp1tOJ1zZwgjxqGByKHiOtX7Tpd QyHE5lcMiKPXfEIQILVq0pc_E2DzL7emopWoaoZTF_m0_N0YzFC6g6EJbOEoRoS K5hoDalrcvRYLSrQAZZKflyuVCyixEoV9GfNQC3_osjzw2PAithfubEEBLuVVk4 XUVrWOLrLl0nx7RkKU8NXNHq-rvKMzqg"
"access_token": "SlAV32hkKG",
"token_type": "Bearer",
"expires_in": 3600,
}
ID令牌是JWT,在被接受之前必须由RP正确验证。
请注意,还包括 bearer access token。这是为了确保令牌响应符合OAuth 2.0规范。对于仅请求ID令牌的基本OpenID身份验证请求,此访问令牌是名义上的,可以安全地忽略。然而,访问令牌在请求访问UserInfo端点处的用户配置文件数据时也起作用。更多相关内容将在下一章中介绍。
7.索赔Claims(用户信息)
OpenID Connect指定一组标准声明或用户属性。 它们旨在根据请求向客户提供同意的用户详细信息,如电子邮件,姓名和图片。 语言标签支持本地化。
| cope value | Associated claims |
|---|---|
| email, email_verified | |
| phone | phone_number, phone_number_verified |
| profile | name, family_name, given_name, middle_name, nickname, preferred_username, profile, picture, website, gender, birthdate, zoneinfo, locale, updated_at |
| address | address |
客户可以通过两种方式申请索赔:
- 整个声明类别按其作用域值(请参阅上表中的声明映射的作用域值)
- 单独使用可选的声明请求参数。
通过简单地将范围设置为openid email来访问用户身份(ID令牌)和电子邮件的示例请求:
HTTP/1.1 302 Found
Location: https://openid.c2id.com/login?
response_type=code &
scope=openid%20email &
client_id=s6BhdRkqt3 &state=af0ifjsldkj &
redirect_uri=https%3A%2F%2Fclient.example.org%2Fcb
如果您是应用程序开发人员,请尊重用户的隐私,并将所请求的声明保持在最重要的位置。这将增加您转换用户的机会,并确保遵守最近的隐私法律。
请注意,即使用户允许应用程序访问其身份,他们也可能选择拒绝发布某些声明。应用程序应该能够优雅地处理这些决定。
声明格式为JSON:
{ "sub" : "alice",
"email" : "alice@wonderland.net",
"email_verified" : true,
"name" : "Alice Adams",
"given_name" : "Alice",
"family_name" : "Adams",
"phone_number" : "+359 (99) 100200305",
"profile" : "https://c2id.com/users/alice",
"https://c2id.com/groups" : [ "audit", "admin" ]
}
OpenID提供程序可以扩展标准JSON声明模式以包含其他属性。例如,企业可以定义诸如员工角色,经理和部门之类的声明。任何其他声明的名称都应以URL为前缀,以便为它们创建安全的命名空间并防止冲突。
8. OpenID Connect提供程序端点
| Core endpoints | Optional endpoints |
|---|---|
8.1授权端点
这是OP服务器端点,其中要求用户进行身份验证并授予客户端对用户身份(ID令牌)的访问权限以及可能的其他请求详细信息,例如电子邮件和名称(称为UserInfo声明)。
这是用户通过用户代理与OP交互的唯一标准端点,该角色通常由Web浏览器承担。
8.2令牌端点
令牌端点允许客户端appf交换从授权端点接收的代码以获取ID令牌和访问令牌。如果客户端是机密的,则需要在令牌端点进行身份验证。
令牌端点它还可以接受其他OAuth 2.0授权类型来发出令牌,例如:
- JWT断言
- SAML 2.0断言
8.3 UserInfo端点
UserInfo端点将先前同意的用户配置文件信息返回给客户端。为此需要有效的访问令牌。
GET /userinfo HTTP/1.1
Host: openid.c2id.com
Authorization: Bearer SlAV32hkKG
UserInfo是JSON编码的,可以选择打包为签名或加密的JWT。
HTTP/1.1 200 OK
Content-Type: application/json
{
"sub" : "alice",
"email" : "alice@wonderland.net",
"email_verified" : true,
"name" : "Alice Adams",
"picture" : "https://c2id.com/users/alice.jpg"
}
8.4可选端点
OpenID Connect提供商可以拥有以下额外端点:
- WebFinger - 根据用户的电子邮件地址或其他详细信息,为给定用户启用OpenID Connect提供程序的动态发现。
- 提供程序元数据 - 列出OP端点URL和它支持的OpenID Connect / OAuth 2.0功能的JSON文档。客户端可以使用此信息来配置对OP的请求。
- Provider JWK set - 包含JSON Web Key(JWK)格式的提供者公钥(通常为RSA)的JSON文档。这些密钥用于保护已颁发的ID令牌和其他工件。
- 客户端注册 - 用于使用OP注册客户端应用程序的RESTful Web API。注册可能受到保护(需要预先授权)或开放(公共)。
- 会话管理 - 使客户端应用程序能够检查登录用户是否仍与OpenID Connect提供程序进行活动会话。也方便退出。
9.规格在哪里?
该标准由OpenID基金会的一个工作组制作,包含一组文件,可在http://openid.net/connect/上进行探讨。
10.常见问题
10.1 OpenID Connect如何与OAuth 2.0相关?
OAuth 2.0是一个用于获取受保护资源(如Web API)的访问令牌的框架。 OpenID Connect利用OAuth 2.0语义和流程允许客户端(依赖方)访问用户身份,该身份使用名为ID令牌的JSON Web令牌(JWT)进行编码。访问令牌有助于从OpenID提供者的UserInfo端点检索同意的配置文件详细信息(称为声明或属性)。
10.2 OpenID提供商如何对用户进行身份验证?
OpenID Connect完全取决于特定的IdP。实现者可以使用任何方法来验证用户,或者将两种方法结合起来以提高安全性(2FA)。
- 用户名密码
- 硬件令牌
- 短信确认
- 生物识别技术
- 等等。
IdP可以在ID令牌中设置可选的acr和amr声明,以通知客户端用户如何被认证。
客户端也可以控制身份验证:
- 可选的prompt = login参数将导致用户(重新)进行身份验证,即使他们具有IdP的有效会话(cookie)。
- 通过支持各种身份验证强度的IdP,应用程序可以使用可选的acr_values参数请求更强的身份验证。
10.3什么是承载访问令牌(bearer access token)?
访问令牌类似于物理令牌或票证的概念。它允许持有者访问特定的HTTP资源或Web服务,该服务通常受范围限制并具有到期时间。
承载访问令牌易于使用 - 任何拥有一个令牌的人都可以调用受保护的资源。因此,必须始终通过安全通道(TLS / HTTPS)传递并安全存储。
OpenID Connect使用OAuth 2.0访问令牌,允许客户端应用程序从UserInfo端点检索同意的用户信息。
OpenID提供程序可以将访问令牌范围扩展到其他受保护资源和Web API。
原文:https://connect2id.com/learn/openid-connect
本文:http://pub.intelligentx.net/node/466
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 250 次浏览
【数据安全】PostgreSQL的DataSunrise数据库防火墙
DataSunrise的PostgreSQL防火墙可确保数据库安全,防范外部和内部威胁。 它检查每个传入的SQL查询并阻止那些被定义为禁止查询的查询。 访问权限根据安全策略进行控制。
技术信息
DataSunrise的PostgreSQL防火墙是一个功能强大的工具,用于保护PostgreSQL--世界上最先进的开源数据库。 它不间断地监视数据库流量并处理传入的查询和数据库响应,持续分析数据库活动并准确捕获与管理员定义的安全策略相矛盾的行为。
防火墙部署为代理。 它提供更高级别的保护,深度数据包过滤和详细日志记录。 防火墙驻留在数据库和客户端之间,审核并控制拦截带有恶意代码的数据包的流量。
深度流量检查可确保更高级别的安全性,防止各种类型的入侵。特殊的智能算法可持续监控数据库活动和SQL注入预防。 DataSunrise阻止了基本的SQL注入技术,包括基于联合的利用,基于布尔的利用,带外利用等。
最初部署防火墙后,将激活学习模式。 DataSunrise分析传入的SQL流量,并形成在给定环境中通常遇到的查询列表。假设典型查询是安全的,因此是允许的。其他一切都被阻止了。
支持Kerberos协议DataSunrise Database Firewall可以用作身份验证代理。配置用户映射,防火墙将注意只有Active Directory域中包含的用户才能访问具有敏感性的数据库。
DataSunrise的PostgreSQL防火墙支持最新的PostgreSQL数据库版本(版本7.4-9.5.2),可在Windows和Linux上运行。
原文:https://www.datasunrise.com/firewall/postgresql/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 191 次浏览
【数据安全】SOPS综合指南:像一个有远见的人而不是一个在职人员一样管理你的秘密
视频号
微信公众号
知识星球
你听说过SOP吗?如果你已经处于需要与队友分享敏感信息的情况,这是为你准备的。
1.SOP简介
1.1什么是SOP?
首先,让我们切入正题,直接进入房间里的大象:什么是SOP?
SOPS,Secrets OPerationS的缩写,是一个开源的文本文件编辑器,可以自动加密/解密文件。
强调文本编辑器、加密和自动化。
通常,当您想要加密文本文件时,您可以执行以下操作:
- 使用您喜爱的编辑器编写、编辑和操作文本数据,并将其另存为文件。
- 使用加密/解密工具对整个文件进行加密。
当您需要读取加密文件时:
- 首先,您需要使用加密/解密工具对文件进行解密。
- 使用您选择的文本编辑器打开解密的文件(现在它是一个常规文本文件)。
这种“正常”过程的缺点是显而易见的:一个作业需要两个工具(一个编辑器和一个加密/解密工具)。
进入SOPS。
安装SOPS最简单的方法是通过brew:
brew install sops对于其他操作系统用户,请参阅official GitHub repo of SOPS.
💡
注意:你绝对可以使用其他具有SOPS的文本编辑器。对于VSCode,您甚至有一个名为VSCode sop的扩展,它将使您能够使用简单的基于项目的配置自动解密/加密VSCode中的文件。请记住,此扩展仍处于早期开发阶段,可能包含错误。
即使你不想安装扩展,你仍然可以使用VSCode来编辑文件:将$EDITOR环境变量设置为code–wait(在你的~/.bashrc或~/.zshrc中),VSCode将在调用sops my-file.yaml时打开文件。
1.2它是如何工作的?
简言之,SOPS在一个包中提供加密/解密和文本编辑,工作流程完全自动化。这就是它的闪光点:
- 当您写入文件时,SOPS首先使用您选择的指定加密方法对文件进行加密,然后再将其保存到磁盘。这是自动完成的,不需要任何人工干预。当然,如果你用SOPS以外的另一个文本编辑器打开文件,你就无法读取内容,因为它是加密的。
- 当你用SOPS读取加密的文件时,它首先解密文件,打开它,并向你显示它。虽然这听起来像是两步走的工作,但SOPS会自动完成,所以对最终用户来说,这看起来只是一步。
1.3亮点:灵活性
SOPS支持各种加密方法,如:
- GPG(如果你不知道它是什么,请继续阅读)
- AWS KMS
- GCP KMS
- HashiCorp Vault
- 等等
这使得管理和编辑敏感文件变得简单而灵活。
如果我想使用本地GPG键编辑文本文件,没有问题;如果我想编辑一个ENV文件,并希望它由HashiCorp Vault加密,SOPS也为我提供了帮助。我不必对您的所有文件使用单一的加密方法,因为SOPS是高度可定制的。
好吧,说得够多了;让我们试一试,亲身体验一下吧。
2. SOPS with PGP Keys
2.1 PGP与GPG
PGP,GPG,令人困惑。。。我知道,对吧?
简而言之,GPG是一个实现PGP的CLI工具:
- PGP(Pretty Good Privacy)是一个加密程序,为数据通信提供加密隐私和身份验证。它可以用于对文本、电子邮件、文件、目录和整个磁盘分区进行签名、加密和解密,并提高电子邮件通信的安全性。
- 另一方面,GPG代表GnuPG,它是OpenPGP标准RFC4880的免费实现(命令行工具)。GPG允许您对数据和通信进行加密和签名;它具有通用的密钥管理系统和用于各种公钥目录的访问模块。
现在我们已经解决了令人困惑的命名法,让我们使用GPG CLI工具创建一个PGP密钥;然后,我们可以测试SOPS是如何工作的。
2.2使用GPG创建PGP密钥
安装GnuPG最简单的方法是通过brew,macOS的软件包管理器:
brew install gnupg如果您正在使用另一个操作系统,例如Linux,则可以使用相应的软件包管理器。最有可能的是,这将起作用:
sudo apt-get install gnupg使用GnuPG,创建密钥非常简单,如下所示(请记住将您的名称作为key_name的值):
export KEY_NAME="Tiexin Guo"
export KEY_COMMENT="test key for sops"
gpg --batch --full-generate-key <<EOF
%no-protection
Key-Type: 1
Key-Length: 4096
Subkey-Type: 1
Subkey-Length: 4096
Expire-Date: 0
Name-Comment: ${KEY_COMMENT}
Name-Real: ${KEY_NAME}
EOF现在,如果您运行gpg --list-keys,您将看到生成的密钥:
$ gpg --list-keys
gpg: checking the trustdb
gpg: marginals needed: 3 completes needed: 1 trust model: pgp
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
/Users/tiexin/.gnupg/pubring.kbx
--------------------------------
pub rsa4096 2022-09-15 [SCEA]
A2B73FB4DA0891B38EECD35B47991CD146C9C4BC
uid [ultimate] Tiexin Guo (test key for sops)
sub rsa4096 2022-09-15 [SEA]在输出的“pub”部分,您可以获得GPG密钥指纹。或者,您可以运行 gpg --list-secret-keys "${KEY_NAME}" 来获取它。
存储密钥指纹以备将来参考。
2.3 SOPS配置
我们需要一个简单的配置,让SOPS知道我们将使用之前生成的PGP密钥进行加密/解密。为此,请在$HOME目录下创建一个名为.sops.yaml的文件,其中包含以下内容:
creation_rules:
- pgp: >-
A2B73FB4DA0891B38EECD35B47991CD146C9C4BC请记住替换在上一步中生成的密钥指纹。
好了,现在我们结束了。
2.4带文本文件的SOPS
运行以下命令创建一个名为a-text-file.txt的新文件:
cd
sops a-text-file.txt开始编辑内容(例如,我输入“hello world”),然后保存。
现在,如果我们尝试对文件进行cat操作,我们将无法获取内容:
$ cat a-text-file.txt
{
"data": "ENC[AES256_GCM,data:U1j0eOC7URJZsNb+Iqs=,iv:4F3Bw1YOIE2xxdag+PbrMLGcqAjG48qVDeiu+xTfnro=,tag:2tX0jUssBYeI0IF7Lxmy+A==,type:str]",
"sops": {
"kms": null,
"gcp_kms": null,
"azure_kv": null,
"hc_vault": null,
"age": null,
"lastmodified": "2022-09-15T04:38:19Z",
"mac": "ENC[AES256_GCM,data:w1HJ/A7t0DxD1KObLeLQVzSWVrobIAF/lUg/8DRH9khba8/cDGVjhrkheki09uWDfHo4vb+odrPsBBW6vtRemqd4Y+HTAH37l8e9IltbH1eUzgoKyOh0uNULLnxbpDTnxykTOCychgiHmPS0ggpetagHLxi0jOLGFe4FxOfbCdY=,iv:qMOCu7AtT7HnnQn22L3VsJ7JY/Wb5C0RLEfdl8g5OG4=,tag:PAb7sKHQZB65TBPts71s2g==,type:str]",
"pgp": [
{
"created_at": "2022-09-15T04:38:09Z",
"enc": "-----BEGIN PGP MESSAGE-----\n\nhQIMAxuQA5jWgsG6AQ/9HE0Xk8zM/oLJOqx4SaxKFKNmncYvRWSdADlXC341qYUG\n353VeMIbfl1u8Mg3iZxoUvD4SrkAEl63DOunhATWTtY2phtjoVxpoFhxOnu170zw\nKawewc9qzzjcAG5Oq/EqZeo0ip81VdZdfk9h05rSvH7y1vJ8YLgt6/3t6ZYlLdKA\nOF5jkjEqSyY9iaSZiFxVarT2PLygaIeG3zp9+mWcUjIaR9dzGILXDfwhNooFYlMN\no8GoEoMZUQVLLb4oFmWvnP/dG92ksimxp9ba4L0YWcd+HUJNGIxx8a1w5njGduqI\nDI67rVH8t94CwD30WGJq6d4yeo99JkN/gx88GdgLzuNzdclrMVbtR2f+ifqW0+KX\nza0e/AMCaCFHOUVZ8OGPJPZbBAB11hS/cRb9+JA/+OVolB9eGu6YkGhhAPS2xYVD\n4WC6vaNBgRwbu0YUxEiMWng2KM2QVeZlnFDJzUN/WNDwnmP9vY3keOqLJAAkkNtp\nyGCzA2PG2LvrMEPxoFj1uEtR8vxVcs56vp9Q6JdtA1wh+w61Mt1mnFbY6/6fsFQK\nC40L0UpukNNGsl1rl6jvlJEUoyjqxG9eWPMX3VKyXIrwEFYcEQ2pvEnsTHLx9pZa\nfxN4oiEW7leMPYzS5bEbx2pUxSrp94Om6T1fVRtBhWBGb2QaWPZCYR2p2cQRW1zU\naAEJAhAV9CcPDhhrHpYn06QbJf4kvM1SNXT5vRkeeC/fxS7HkqM3ukNzHkgrUijz\nj5k9vB7prn+2fGkpNxYSLOOW0Zgn0INpEkaBoRpdcfvFeE+kVv+rmUL9jsPWJpOA\nygzUZnejMwOn\n=v3OP\n-----END PGP MESSAGE-----\n",
"fp": "A2B73FB4DA0891B38EECD35B47991CD146C9C4BC"
}
],
"unencrypted_suffix": "_unencrypted",
"version": "3.7.3"
}
}但根据产出,我们可以得出结论:
- 整个文件都是加密的(请参阅上面输出的数据部分)。
- 加密方法(GPG,密钥指纹)作为文件的一部分存储在同一个文件中。
要读取文件,请执行以下操作:
sops a-text-file.txt我们找回了原来的内容!
请注意,在读取文件时,我们不需要指定使用哪种加密/解密方法来读取加密文件,因为当我们首先创建该文件时,加密/解密方式已经通过SOPS作为文件的一部分存储。
2.5结构化数据的SOPS
自动加密文本文件的全部内容是SOPS的一个显著优势,但如果文件包含结构化数据,例如:
- YAML
- JSON
- *.ini
- ENV
SOPS可以做得更好!
让我们试试:
sops a-yaml-file.yaml我放了以下内容:
username: tiexin
password: test如果我们用常规文本编辑器打开文件,比如说,我们将其编辑为cat:
$cat a-yaml-file.yaml
$ cat a-yaml-file.yaml
username: ENC[AES256_GCM,data:h/BVd2tf,iv:IjzYAQQErVeWhwIIuMMfq/pjFr9YJVDNSl6ceRPv+6Q=,tag:2+xJOR89rsOMIQMWHNSEqw==,type:str]
password: ENC[AES256_GCM,data:zaz1Jw==,iv:VZ81YN4FRQf14g4olKwb6A8W00BIFT/OgWSEqkrO29s=,tag:tRJHVU7ANvGSw0tOjqGKiQ==,type:str]
...(omitted)似乎只有“值”是加密的,而不是“密钥”!
这是一个巨大的优势,因为如果我们用常规文本编辑器打开这个文件,我们仍然可以获得数据的结构,只是我们无法读取加密的内容。
我想你知道我为什么对这个功能感到兴奋,因为我刚刚想到了一个很棒的应用程序:加密Kubernetes机密YAML文件!加密后,我们仍然可以清楚地看到内容和密钥,但不能看到值,从而可以安全地将文件存储在某个地方并与他人共享。
值得一提的是,对于YAML文件,SOPS还加密注释,这是另一个很好的功能:敏感值字段可能在注释部分也有一些敏感的描述。
到目前为止,我们已经用标准文本文件和结构化文件演示了SOPS的基本功能。但是,我们已经使用PGP密钥完成了所有操作,它可能不太常见,不适合在生产环境中使用。接下来,让我们使用HashiCorp Vault和AWS KMS这两个最著名的秘密/密钥管理器来尝试SOPS。
3个带HashiCorp Vault的SOP
3.1 Vault简介
如果你不了解HashiCorp Vault,它的核心是一个秘密管理器,但它可以做更多的事情,包括加密管理。典型的用例包括机密管理、加密服务、密钥管理等。这是一个开源项目,您可以在自己的基础设施中运行;HashiCorp还提供基于云的服务。
3.2建立本地保险库进行测试
对于SOPS教程,我们将设置一个本地Vault服务进行测试,最快的方法是使用Docker:
docker run -d -p8200:8200 vault:1.2.0 server -dev -dev-root-token-id=toor请注意,这只是为了设置本地开发Vault服务器;不要在生产环境中执行此操作。关于生产用途,请查看官方文档。
在Docker容器中本地运行Vault后,运行以下命令进行验证:
$ export VAULT_ADDR=http://127.0.0.1:8200
$ export VAULT_TOKEN=toor
$ vault status
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed false
Total Shares 1
Threshold 1
Version 1.2.0
Cluster Name vault-cluster-618cc902
Cluster ID e532e461-e8f0-1352-8a41-fc7c11096908
HA Enabled falseVault启动并运行后,让我们创建一个供SOPS使用的密钥:
$ # enable a transit engine if not already done
$ # It is suggested to create a transit engine specifically for SOPS
$ vault secrets enable -path=sops transit
Success! Enabled the transit secrets engine at: sops/
$ # create a key
$ vault write sops/keys/firstkey type=rsa-4096
Success! Data written to: sops/keys/firstkey3.3使用带SOPS的保险箱钥匙
接下来,让我们使用在Vault中创建的密钥编辑文件:
sops --hc-vault-transit $VAULT_ADDR/v1/sops/keys/firstkey another-yaml-file.yaml以YAML格式编写一些键/值对,然后保存。
如果我们用另一个文本编辑器(例如vim)打开文件,我们可以看到Vault相关信息也作为文件的一部分保存。因此,当我们需要阅读它时,我们只需运行:
sops another-yaml-file.yaml就是这样:这个过程与使用PGP密钥完全相同。
SOPS在其配置文件中支持精细范围的规则,因此它知道根据这些用户定义的规则对每个文件使用什么加密方法和哪个密钥。
4带AWS KMS的SOP
4.1 KMS简介
AWS KMS(密钥管理服务)是一种基于云的服务,可帮助创建和控制加密密钥。与HashiCorp Vault类似,它可以创建、存储和使用加密密钥;不同的是,HashiCorp Vault也是一个机密管理器,而AWS有一个单独的服务(AWS机密管理器)用于轮换、管理和提供机密。
4.2创建AWS KMS密钥
对于这一部分,我们将使用AWS CLI。
如果你还没有安装,请按照这里的官方文档操作。安装完成后,我们需要在使用之前对其进行正确配置。
在这里,我们假设您的AWS CLI已经可以正常工作,并且具有访问AWS KMS所需的权限。
使用AWS CLI在AWS KMS中创建密钥非常简单:
aws kms create-key \
--tags TagKey=Purpose,TagValue=Test \
--description "Test key"从输出中复制ARN,我们可以将其保存为ENV变量(用您自己的值替换ARN):
export ARN=arn:aws:kms:ap-southeast-1:858104165444:key/620abad4-8043-4166-8712-2b4684378d3a4.3将AWS KMS的密钥与SOPS一起使用
同样简单明了:
sops --kms $ARN aws-kms-encryption-example.yaml类似地,加密方法信息作为文件的一部分保存,使用SOPS读取文件不需要指定解密方法,就像使用GPG或Vault一样。
SOPS支持更多加密方法,如GCP KMS、Azure密钥库等。从SOPS的回购中了解更多!
5总结
5.1为什么需要SOP
在完成了整个教程并自己执行了许多命令之后,您一定有点累了。现在是放松的故事时间了:
几年前,我正在做一个与fin-tech相关的大型项目,整个基础设施的中心是一个OpenShift集群(可以把它想象成一个定制的Kubernetes)。
在集群中,我们使用名称空间来分隔不同的环境;我们使用OpenShift集群作为机密管理的唯一真相来源。
例如:如果我们需要更新机密的值,我们可以在OpenShift控制台中进行更新。如果我们需要在Jenkins中使用秘密,我们会在OpenShift中添加一个秘密,它会自动同步为Jenkins秘密。一切似乎都很好。
然而,如果我们想与另一个团队成员共享一个秘密,或者将该秘密迁移到另一个集群/环境中,这会很棘手:我们必须将秘密导出为K8s秘密YAML文件,然后共享该文件。
这既是一个安全问题,也是一个生产力问题:如果YAML被一个本不应该访问该秘密的人共享怎么办?如果OpenShift集群中的秘密发生了变化,但我们不知道,因为我们手头的YAML文件不可能自动与集群同步,该怎么办?
一般来说,使用K8s原生秘密作为唯一的真相来源并不是一种最佳实践,但从K8s环境之外的地方消费秘密并不简单。即使秘密只在集群中使用,您仍然需要创建硬编码的YAML副本:您将tho保存在哪里
5.2某些用例的替代方案
有两种类似的工具功能要差得多,但根据您的具体用例,它们可能同样有价值:
- Git crypt实现了Git repo中文件的自动加密和解密。您选择保护的文件在提交时加密,在签出时解密。gitcrypt允许您自由共享包含公共和私有内容的混合存储库。如果你想在团队中分享秘密,这是一个很好的工具,但它只支持PGP密钥加密;你必须自己生成和管理那些PGP密钥。而且,如果你只想在不使用git的情况下自动进行一些加密/解密,那就没有意义了。
- Ansible Vault对变量和文件进行加密,以保护密码或密钥等敏感内容,而不是将其作为明文显示在Ansible剧本或角色中。它的工作原理与SOPS类似,但显然,它只能在Ansible上下文中使用。当然,您也可以将SOPS与Ansible一起使用。
SOPS仍然是通用的王,尤其是如果你想对不同的文件使用不同的加密方法。
5.3 SOPS不是什么
需要明确的是:SOPS不是一个秘密管理者。是的,您可以将其作为一种快速而廉价的解决方案,将敏感数据存储在加密文件中。但是,随着用例的扩展,您很可能会碰壁。仅以文件格式保存机密有其局限性。例如,在某个时刻,您可能需要API访问您的秘密。SOPS并不是为这个而设计的,在它之上构建一个定制的解决方案充其量也只是笨拙的。
这正是秘密管理器(secrets managers )的用途:允许您灵活地处理所有秘密的格式、策略和访问方法(如文件、K8s本地YAML、应用程序、实际用户等)。现代秘密管理器与CLI、CI/CD系统、编排平台等有许多集成,因此很有可能在不加密文件的情况下满足您的所有需求。
最近,我在区块上发现并测试了一个新的孩子:Doppler,它可以自动将机密同步到K8s集群,从而无需将K8s机密存储在YAML文件中。它甚至可以在相关机密更新时重新启动pod。如果感兴趣,请在此处阅读更多信息。
- 186 次浏览
【数据安全】Vault参考架构
本文档的目标是推荐HashiCorp Vault部署实践。 该参考架构传达了一种通用架构,应该进行调整以适应每种实现的特定需求。
本指南中涉及以下主题:
- 一个数据中心内的部署拓扑
- 网络连接
- 部署系统要求
- 硬件考虑因素
- 负载均衡
- 高可用性
- 多个数据中心的部署拓扑
- Vault复制
- 其他参考文献
本文档假定Vault使用Consul作为存储后端,因为这是生产部署的推荐存储后端。
一个数据中心内的部署拓扑
本节介绍如何在一个数据中心中部署Vault开源群集。 Vault Enterprise中通过群集复制包含对多个数据中心的支持。
参考图
带有Consul存储后端的八个节点

设计摘要
此设计是生产环境的推荐架构,因为它提供了灵活性和弹性。 Consul服务器与Vault服务器分开,因此软件升级更容易执行。此外,单独的Consul和Vault服务器允许为每个服务器单独调整大小。 Vault to Consul后端连接是通过HTTP进行的,应使用TLS和Consul令牌进行保护,以提供所有流量的加密。
有关以加密模式运行Consul的详细信息,请参阅联机文档。
容忍失败
云环境中的典型分布是将Consul / Vault节点分散到高带宽,低延迟网络(例如AWS区域)内的单独可用区(AZ)中。下图显示了在AZ之间传播的Vault和Consul,其中Consul服务器采用冗余区域配置,每个AZ提升单个投票成员,同时提供区域和节点级别的故障保护。
请参阅在线文档以了解有关领事领导者选举流程的更多信息。

网络连接详细信息

部署系统要求
下表提供了服务器大小调整的准则。 特别值得注意的是强烈建议避免使用非固定性能CPU或AWS术语中的“Burstable CPU”,例如T系列实例。

硬件考虑因素
小尺寸类别适用于大多数初始生产部署或开发/测试环境。
大尺寸适用于工作负载一致的生产环境。这可能是大量的交易,大量的秘密,或两者的结合。
通常,处理要求将取决于加密工作负载和消息传递工作负载(每秒操作数和操作类型)。内存要求将取决于存储在内存中的机密/密钥的总大小,并应根据该数据进行调整大小(硬盘驱动器存储也应如此)。 Vault本身具有最小的存储要求,但底层存储后端应具有相对高性能的硬盘子系统。如果频繁生成/旋转许多机密,则此信息需要经常刷新到磁盘,如果使用较慢的硬盘驱动器,可能会影响性能。
此部署中的Consul服务器功能用作Vault的存储后端。这意味着存储为Vault中持久性的所有内容都由Vault加密,并在静态时写入存储后端。此数据将写入Consul服务目录的键值存储部分,该部分需要在每个Consul服务器上完整存储在内存中。这意味着当更多客户端向Vault进行身份验证时,内存可能成为扩展中的约束,更多秘密会持久存储在Vault中,并且会从Vault中租用更多临时密钥。如果需要额外的空间,这还需要在Consul服务器的内存上进行垂直缩放,因为整个服务目录存储在每个Consul服务器的内存中。
此外,网络吞吐量是Vault和Consul服务器的共同考虑因素。由于两个系统都是HTTPS API驱动的,所有传入请求,Vault和Consul之间的通信,Consul集群成员之间的基础八卦通信,与外部系统的通信(每个auth或秘密引擎配置,以及一些审计日志记录配置)和响应都会消耗网络带宽。
由于Consul群集操作中的网络性能注意事项,应通过性能或DR复制来实现跨网络边界的Vault数据集的复制,而不是跨越网络和物理边界传播Consul群集。如果单个consul集群分布在远程或跨区域的网段上,则可能导致集群内的同步问题或某些云提供商的额外数据传输费用。
其他考虑因素
Vault生产强化建议提供了有关Vault的生产强化部署的最佳实践的指导。
使用Consul接口进行负载均衡
Consul可以提供负载平衡功能,但它要求任何Vault客户端都是Consul。 这意味着客户端可以使用Consul DNS或API接口来解析活动的Vault节点。 客户端可以通过以下URL访问Vault:http://active.vault.service.consul:8200
这依赖于操作系统DNS解析系统,并且可以将请求转发给Consul以获得实际的IP地址响应。 该操作对于遗留应用程序可以是完全透明的,并且可以像典型的DNS解析操作一样操作。
使用外部负载均衡器进行负载均衡

还支持外部负载平衡器,它们将放置在Vault群集的前面,并将轮询特定的Vault URL以检测活动节点并相应地路由流量。
具有以下URL的活动节点的HTTP请求将以200状态响应:http:// <Vault Node URL>:8200 / v1 / sys / health
以下是来自HAProxy的示例配置块,用于说明:
listen vault bind 0.0.0.0:80 balance roundrobin option httpchk GET /v1/sys/health server vault1 192.168.33.10:8200 check server vault2 192.168.33.11:8200 check server vault3 192.168.33.12:8200 check
注意,当使用软件负载平衡器时,Consul(带有consul-template)可以生成上述块。 当负载均衡器是Nginx,HAProxy或Apache等软件时,可能会出现这种情况。
上述HAProxy块的示例Consul模板:
listen vault bind 0.0.0.0:8200 balance roundrobin option httpchk GET /v1/sys/health{{range service "vault"}} server {{.Node}} {{.Address}}:{{.Port}} check{{end}}
客户端IP地址处理
有两种支持的方法用于处理代理或负载均衡器后面的客户端IP寻址; X-Forwarded-For Headers和PROXY v1。 两者都需要受信任的负载均衡器,并且需要IP地址白名单以遵守安全最佳实践。
高可用性
Vault群集是一个数据中心内高度可用的部署单元。 推荐的方法是三个带有Consul存储后端的Vault服务器。 使用此配置,在Vault服务器中断期间,无需人工干预即可立即处理故障转移。
要了解有关在HA模式下设置Vault服务器的更多信息,请阅读带有Consul指南的Vault HA。
具有性能备用节点的高可用性和跨数据中心的数据位置需要Vault Enterprise。
多个数据中心的部署拓扑

Vault复制
仅限企业:Vault复制功能是Vault Enterprise的一部分。
HashiCorp Vault Enterprise提供两种复制模式,性能和灾难恢复。 Vault文档提供了有关Vault Enterprise中复制功能的更多详细信息。

性能复制
Vault性能复制允许跨多个站点进行秘密管理。 秘密,身份验证方法,授权策略和其他详细信息将被复制为活动且可在多个位置使用。
有关过滤掉跨区域复制的秘密引擎的信息,请参阅Vault Mount过滤器指南。
灾难恢复复制
Vault灾难恢复复制可确保备用Vault群集与活动的Vault群集保持同步。 这种复制模式包括诸如临时认证令牌,基于时间的令牌信息以及令牌使用数据之类的数据。 这为在防止短暂运行数据丢失引起最大关注的环境中提供了积极的恢复点目标。
跨区域灾难恢复
如果您的灾难恢复策略是计划丢失整个数据中心,则下图说明了可能的复制方案。

在这种情况下,如果区域A中的Vault群集出现故障并且您将区域B中的DR群集提升为新的主群集,则您的应用程序将需要从区域B中的Vault群集读取和写入机密。这可能会也可能不会引发 您的应用程序的问题,但您需要在规划期间考虑到这一点。
区域内灾难恢复
如果您的灾难恢复策略是计划丢失群集而不是整个数据中心,则下图说明了可能的复制方案。

有关其他信息,请参阅Vault灾难恢复设置指南。
腐败或破坏性灾难恢复
防止在云环境中更普遍的另一种常见方案是提供非常高水平的内在弹性,可能是数据和配置的有目的或意外损坏,或者是云帐户控制的丢失。 Vault的DR Replication旨在复制实时数据,这会传播故意或意外的数据损坏或删除。为了防止这些可能性,您应该备份Vault的存储后端。这通过Consul Snapshot功能得到支持,该功能可以自动进行常规归档备份。可以从Consul快照重新补充冷站点或新基础架构。
有关Consul快照的详细信息,请参阅联机文档。
复制说明
复制集中的群集数量没有设置限制。目前最大的部署在30多个集群范围内。
Performance复制集中的任何群集都可以充当灾难恢复主群集。
Performance复制集中的集群还可以复制到多个Disaster Recovery辅助集群。
虽然Vault群集可以拥有复制角色(或多个角色),但在基础架构方面不需要特殊考虑,并且群集可以承担(或被提升)到另一个角色。与安装过滤器和HSM使用相关的特殊情况可能会限制角色的交换,但这些基于特定的组织配置。
与Unseal proxy_protocol_behavior相关的注意事项
使用与HSM设备集成的Vault集群进行复制以实现自动开封操作具有一些在规划阶段应该理解的细节。
如果性能主群集使用HSM,则该复制集中的所有其他群集也必须使用HSM。
如果性能主群集不使用HSM(使用Shamir机密共享方法),则可以混合该复制集内的群集,以便某些群集可以使用HSM,其他群集可以使用Shamir。
为了便于讨论,云自动开封功能被视为HSM。
其他参考文献
Vault体系结构文档介绍了每个Vault组件
要将Vault与现有LDAP服务器集成,请参阅LDAP验证方法文档
请参阅AppRole Pull Authentication指南,以编程方式为计算机或应用程序生成令牌
无论位于何处,Consul都是运行弹性Vault群集的重要组成部分。有关详细信息,请参阅在线Consul文档。
下一步
阅读生产强化,了解Vault的生产强化部署的最佳实践。
阅读部署指南,了解安装和配置单个HashiCorp Vault群集所需的步骤。
原文:https://sethbergman.tech/vault-reference-architecture/
本文:https://pub.intelligentx.net/vault-reference-architecture
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 337 次浏览
【数据安全】业务连续性计划(BCP)
视频号
微信公众号
知识星球
您的灾难恢复计划应该是组织业务连续性计划(BCP)的一个子集,而不应该是一个独立的文档。如果由于灾难对除工作负载之外的业务要素的影响而无法实现工作负载的业务目标,那么维护用于恢复工作负载的积极灾难恢复目标是没有意义的。例如,地震可能会阻止您运输在电子商务应用程序上购买的产品–即使有效的灾难恢复使您的工作负载正常运行,您的BCP也需要满足运输需求。您的灾难恢复战略应基于业务需求、优先级和环境。
业务影响分析和风险评估
业务影响分析应量化工作负载中断的业务影响。它应该确定无法使用您的工作负载对内部和外部客户的影响以及对业务的影响。分析应有助于确定工作负载需要多长时间可用,以及可以容忍多少数据丢失。然而,重要的是要注意,不应孤立地制定恢复目标;中断概率和恢复成本是有助于为工作负载提供灾难恢复的业务价值的关键因素。
业务影响可能取决于时间。您可能需要考虑将其纳入灾难恢复计划中。例如,在每个人都拿到工资之前,工资系统的中断可能会对业务产生非常大的影响,但在每个人已经拿到工资之后,可能会产生很小的影响。
对灾害类型和地理影响的风险评估,以及工作负载的技术实施概述,将确定每种灾害发生中断的概率。
对于高度关键的工作负载,您可以考虑在多个区域部署基础架构,并在适当的位置进行数据复制和连续备份,以将业务影响降至最低。对于不太关键的工作负载,一个有效的策略可能是根本不进行任何灾难恢复。对于某些灾难场景,根据灾难发生的概率低,不制定任何灾难恢复策略作为明智的决策也是有效的。请记住,AWS区域内的可用性区域已经设计好了它们之间的距离,并仔细规划了位置,这样,最常见的灾难应该只影响一个区域,而不会影响其他区域。因此,AWS区域内的多AZ架构可能已经满足了您的许多风险缓解需求。
应评估灾难恢复选项的成本,以确保灾难恢复策略在考虑到业务影响和风险的情况下提供正确的业务价值水平。
利用所有这些信息,您可以记录不同灾难场景和相关恢复选项的威胁、风险、影响和成本。这些信息应用于确定每个工作负载的恢复目标。
恢复目标(RTO和RPO)
在创建灾难恢复(DR)战略时,组织通常会规划恢复时间目标(RTO)和恢复点目标(RPO)。
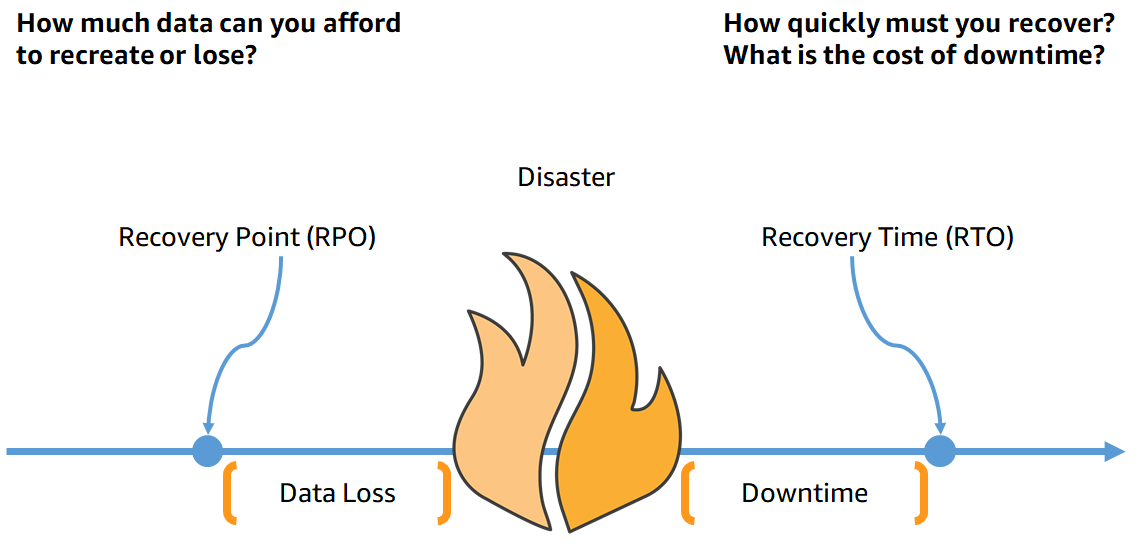
图3-恢复目标
恢复时间目标(RTO)是服务中断和恢复服务之间的最大可接受延迟。该目标确定了服务不可用时的可接受时间窗口,并由组织定义。
本文大致讨论了四种灾难恢复策略:备份和恢复、引导灯( pilot light)、热备用(warm standby)和多站点活动/活动(multi-site active/active)(请参阅云中的灾难恢复选项)。在下图中,业务部门已经确定了其最大允许RTO以及在服务恢复策略上可以花费的金额限制。考虑到业务目标,灾难恢复策略Pilot Light或Warm Standby将同时满足RTO和成本标准。
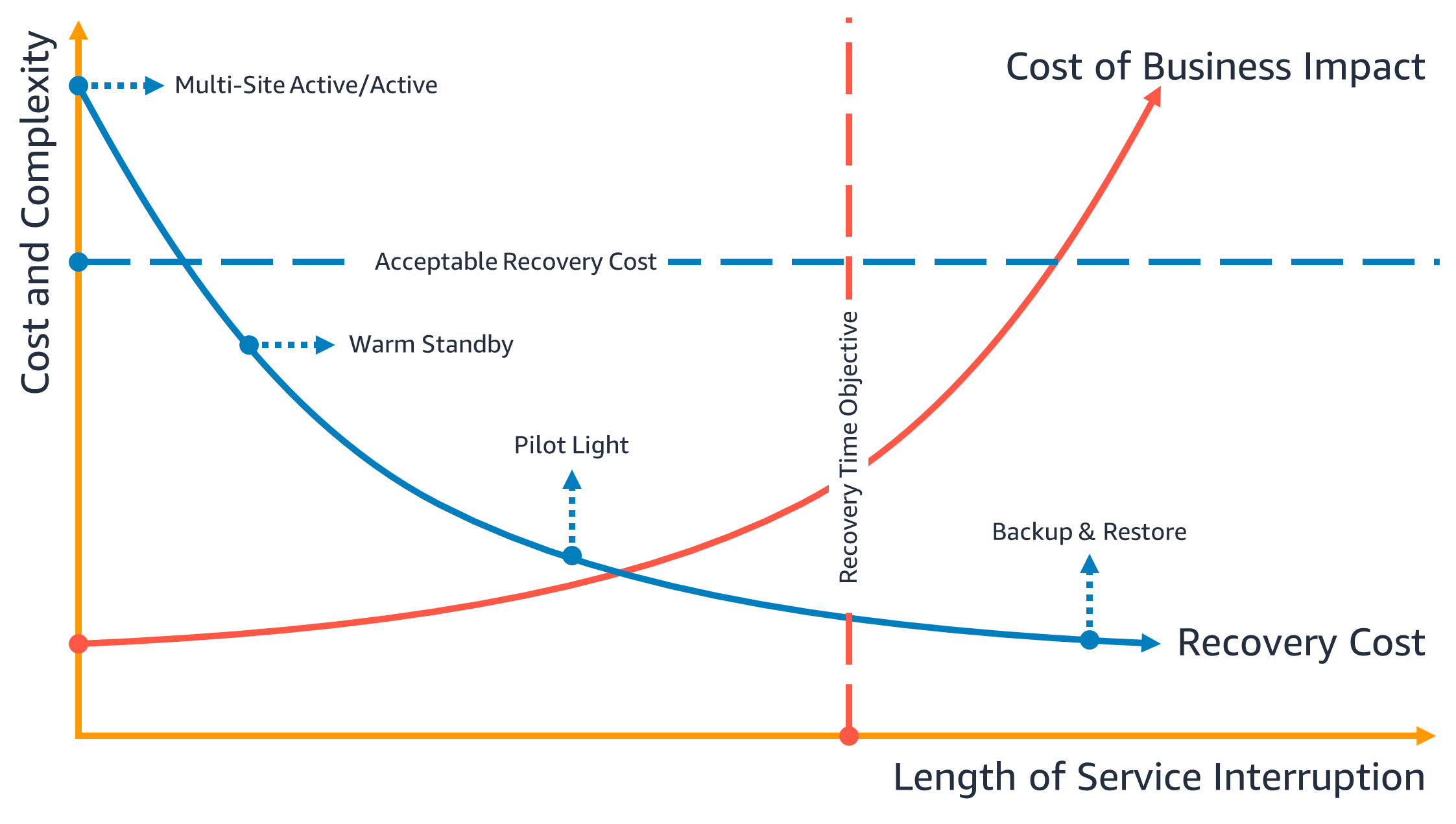
图4-恢复时间目标
恢复点目标(RPO)是自上一个数据恢复点以来可接受的最长时间。该目标确定了在最后一个恢复点和服务中断之间的数据可接受损失,并由组织定义。
在下图中,业务部门确定了其允许的最大RPO,以及他们在数据恢复策略上可以花费的资金限制。在这四种灾难恢复策略中,“引燃光”或“热备用”灾难恢复策略都符合RPO和成本标准。
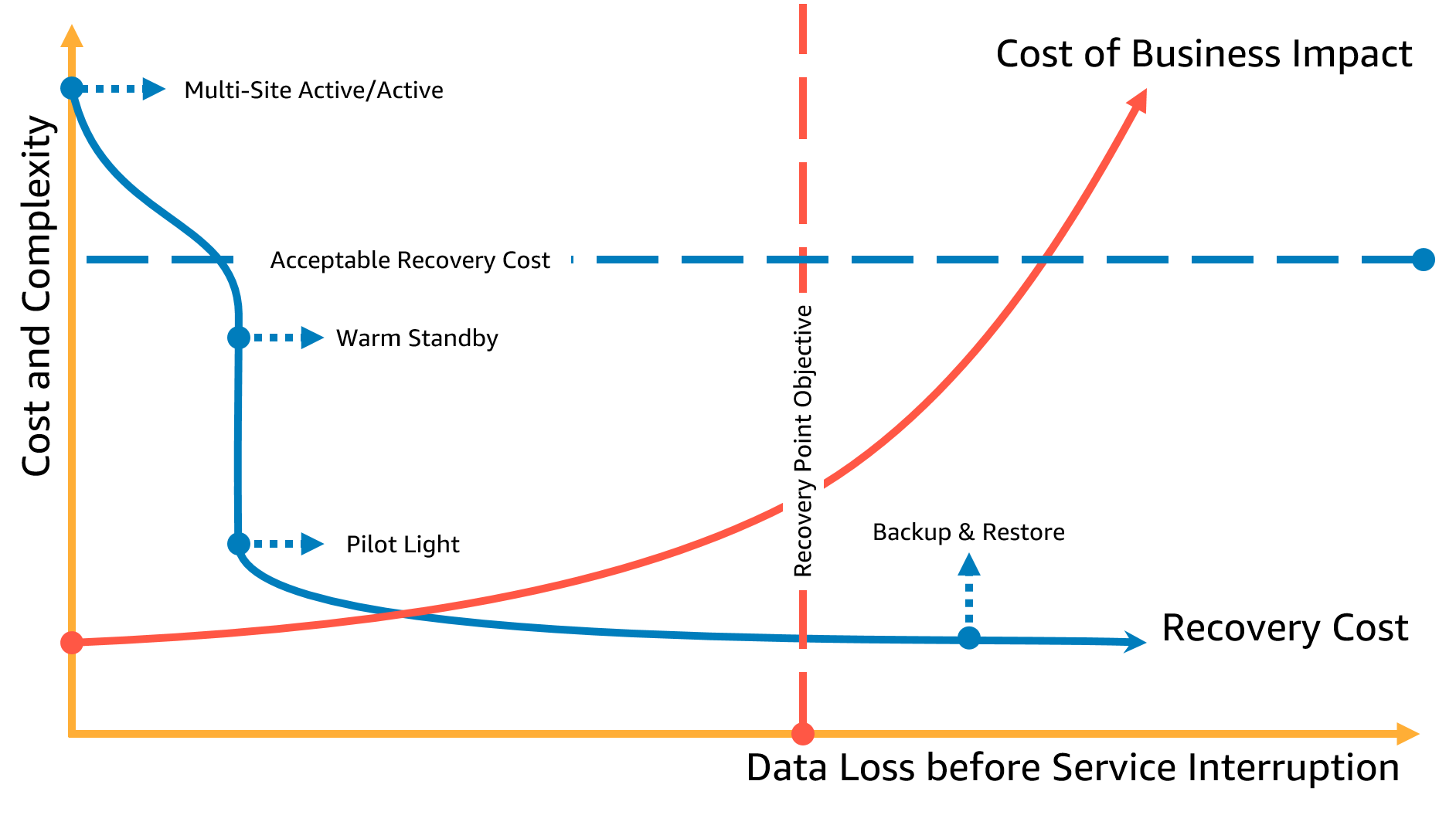
图5-恢复点目标
笔记
如果恢复策略的成本高于故障或损失的成本,则除非存在第二驱动因素(如监管要求),否则不应实施恢复选项。在进行评估时,考虑不同成本的恢复策略。
- 276 次浏览
【数据安全】五个SQL Server 最佳实践
你一直在电视新闻,印刷杂志和在线文章中听到它......一个新的漏洞,一个新的攻击,一个新的威胁,一个新的漏洞。
但是,您是否知道超过97%的数据泄露是由于SQL注入的帮助或完成的?
这意味着您的数据的最大漏洞不是来自新的和未知的,而是来自于未能遵循数据库安全性中经过验证的最佳实践。
那么,什么是SQL以及为什么它容易受到攻击?
简而言之,SQL Server是一种关系数据库管理系统(RDBMS),它依赖结构化查询语言(SQL)与应用程序交换数据。最大的SQL提供商是微软,它目前提供六个版本,这是今年的最新版本。 SQL Server的主要功能是在应用程序之间存储,接收和共享数据。这些应用程序可以通过云虚拟连接到服务器,也可以通过内部共享计算机网络连接。
2013年,Target直接了解到,当一个巨大的漏洞影响了超过4000万的客户及其借记卡和信用卡信息时,有害的SQL Server做法是多么糟糕。可悲的是,Target只是数百个每年遭受破坏的数据库之一。
为了使您和您的公司免受同样代价高昂的破坏,您应立即实施以下五种最佳实践:(1)在SQL本身之外进行身份验证,(2)删除不必要的用户,(3)限制权限,(4)监视失败登录尝试; (5)禁用未使用的功能或浏览器服务。我们来看看每一个。
1.在SQL本身之外进行身份验证
SQL Server的本机身份验证(称为“混合模式”)会带来巨大的安全风险,尤其是其对暴力攻击的脆弱性。今天,黑客暴力通过帐户强制执行可以每秒生成数百万个密码。不幸的是,SQL Server本身没有配备登录限制;因此,黑客可以在不被锁定的情况下尝试数百万个密码。而且,当SQL Server处理身份验证凭据(用户名和密码)时,不存在识别攻击的方法。因此,第一个最佳实践是在混合模式下避免SQL Server身份验证,并使用Windows身份验证连接到SQL Server。
Windows身份验证提供了以下主要优势:与SQL Server身份验证(Microsoft不提供支持)相比,Microsoft直接支持它,它可以防止和识别强力尝试,并将组织的帐户管理集中到Active Directory中。
2.删除不必要的用户
在数据库中,不应该同等地向所有用户授予访问权限,而是将其限制为与其工作相关的必要用户。将此视为“需要知道”的公式。数据库备份文件夹也是如此,其中应该向需要访问权限的用户授予权限。在用户级采用宽松,一刀切的访问规则会导致数据处理不当,删除关键文件以及滥用敏感信息。此外,删除离开公司的用户,对于消除心怀不满的员工的恶意活动至关重要。
3.限制权限
安装或运行SQL Server时,您将在三个系统定义的帐户之间进行默认选择:本地系统,网络服务和本地服务。这些帐户定义了您要运行的服务的权限(即权限)。而不是选择这三个系统定义的帐户之一,创建一个具有最小权限的本地域帐户。识别权限可能很困难,因此您应该根据员工需求再次限制权限,而不是为每个帐户做出假设。由于某些服务需要某些权限,因此您可能需要为每个服务创建单独的帐户。此外,只应为SQL Server帐户管理员提供数据,备份目录和读/写活动的完全授权。
4.监控登录失败
与我们的第一个最佳实践密切相关 - 在SQL本身之外进行身份验证 - 这个最佳实践也是关于防止暴力攻击。为此,您必须能够通过在Windows SQL Server身份验证中启用登录监控来审核失败的登录。启用后,失败并成功登录将记录在SQL Server错误日志中。有了这些信息,您可以根据正常的数据库行为创建更准确的用户和权限规则。通过扩展,您还可以识别异常行为并在威胁发生时对其进行响应。
5.禁用浏览器服务和未使用的功能
我们的最后一个最佳做法是使用SQL Server配置管理器禁用未使用的服务,或者如果您使用的是2008或更高版本的SQL Server,则通过基于策略的管理功能。应禁用XP_CMDSHELL,OLE AUTOMATION,OPENROWSET和OPENDATASET等功能,以减少表面区域攻击。
此外,SQL Server支持四种类型的协议:共享内存,命名管道,TCP / IP和VIA。为了进一步降低安全风险和损害,您应该只使用这些协议中的最低限度。与用户和权限一样,这意味着禁用未使用的所有功能或服务以及将协议保持在最低限度。
超越基本SQL最佳实践
刚才提到的五个实践将为您提供保护SQL Server安全的途径。除了基础知识之外,还需要其他最佳实践。
- 其中一种额外做法是禁用SA帐户以防止攻击者使用默认管理员帐户。
- 您可能想要选择的另一种做法是强制执行复杂的密码和密码更改策略;
- 实施密码短语而不是密码会使您不那么容易受到攻击,实际上员工可以更容易地跟踪。
- 最后,请始终记住使用Windows身份验证模式并避免创建SQL Server登录;
- 相反,使用Active Directory来控制对组的访问权限。
但是,您是否知道超过97%的数据泄露是由于SQL注入的帮助或完成的?虽然数据库安全性无法处理所有形式的SQL注入,但应该考虑使用最先进的Web应用程序防火墙(WAF)来防止SQL注入。
原文:https://www.imperva.com/blog/five-sql-best-practices/
本文:http://pub.intelligentx.net/five-sql-server-best-practices
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 321 次浏览
【数据安全】什么是安全飞地(Secure Enclave)?
安全飞地:默认情况下确保数据安全的强大方法
安全飞地:默认情况下确保数据安全的强大方法
执行摘要
企业IT的一个主要威胁已经存在于组织内部:内部人员。虽然大多数企业已经采取措施保护系统不受最终用户的影响,但有资格的内部人员可以不受限制地访问更为危险,这不仅限于员工。第三方,包括云提供商的员工,往往是内部违规的罪魁祸首。民族国家和其他不好的行为体也可以提供让他们看起来像内部人的凭证。
当前防止IT内部威胁的方法和技术具有严重的局限性。现在,几乎每个主要硬件和云供应商都在实施一种新方法。安全飞地提供了一个全面、更安全的解决方案,保护数据、应用程序和存储免受内部人员和第三方的影响,无论是在私有云还是公共云中。
什么是安全飞地?
安全的enclave在每台服务器上提供CPU硬件级隔离和内存加密,将应用程序代码和数据与任何具有特权的人隔离,并加密其内存。通过附加软件,安全飞地可以实现存储和网络数据的加密,从而实现简单的全栈安全。英特尔和AMD的所有新CPU都内置了安全enclave硬件支持。
内部人士:没有人愿意谈论的威胁
到目前为止,大多数网络安全工作都集中在控制外部人员或最终用户的网络访问。然而,最大的危害可能来自内部人员系统管理员、网络架构师、系统分析师、开发人员和站点可靠性工程师,他们通常有权访问数据、网络和应用程序。他们可能滥用或滥用其访问权限,窃取或损坏敏感数据。由于安全协议不严格,也可能无意中发生违规。据估计,所有违规行为中有43%是由内部人员意外或故意造成的。1
可能最臭名昭著的故意内幕违规案例之一是爱德华·斯诺登(Edward Snowden),他是博思艾伦公司(Booz Allen)的承包商,与国家安全局合作。2013年,斯诺登窃取了近200万份情报文件,这被认为是美国历史上最大的盗窃案之一。作为系统管理员和架构师,斯诺登可以无限制地访问NSA系统,他还可以访问其他网站的文件,包括其他国家的文件。2入侵继续发生。2019年,两名推特员工被指控通过访问使用推特平台的沙特阿拉伯持不同政见者的信息为沙特阿拉伯进行间谍活动。3
即使组织在内部保护自己的系统,第三方入侵的威胁仍然存在。访问您的IT数据和网络的第三方越多,违规风险越高。其中一个更为广为人知的早期违规行为涉及利用一家经批准的暖通空调供应商的登录对目标公司的销售点系统进行黑客攻击,导致4000万张借记卡和信用卡数据被盗。
坏演员提供的证书使他们看起来像是局内人。万豪酒店透露,未经授权的黑客攻击已经暴露了3.83亿名客人的个人信息,而且黑客攻击已经发生了近五年未被发现。该公司指责中国黑客造成了这一漏洞。在高风险地区,政府机构也可能会越界。敌对国家行为体可能正在使用硬件攻击,而这些攻击在被盗信息被使用数月或数年后才能被检测到。
向基于云计算的转移只会加剧问题,因为IT云平台提供商对能够访问您的文件的人员的责任和控制有限。2019年初,Capital One的数据泄露暴露了超过1亿银行客户和申请人的个人数据,包括社会保障号码、信用评分、出生日期和关联银行账号。肇事者是一名前云员工,她在网上吹嘘自己的所作所为。
这些威胁的代价是巨大的。除了数百万美元的直接财务损失和对股票价格的负面影响外,披露商业秘密可能会产生长期影响。由于客户对公司保护个人信息的能力失去信心,商业信誉受到打击。如果不遵守隐私法规,如欧洲的GDPR或加州消费者隐私法案(CCPA),或某些行业存在重大监管影响,可能会被罚款。万豪酒店被处以1.23亿美元的GDPR罚款。英国航空公司因披露50万名客户的付款和个人信息而被罚款,数额更大:2.3亿美元。
目前的努力不起作用
在网络安全上投入了这么多的注意力和资金,为什么这仍然是一个严重的问题?
迄今为止,网络安全解决方案一直专注于检测黑客和入侵。虽然检测技术不断改进,但问题是检测是在事后进行的。违规行为可能在数月或数年后才会被发现(就像万豪酒店的情况一样,多年来,入侵行为一直未被发现)。到那时,损害很可能已经发生了。
检测通常是不完整的。攻击者仍然可以利用零日漏洞获取访问权限并规避软件防御。基础设施内部人员具有如此高的访问级别,他们可以删除检测日志并绕过任何软件安全机制。可以访问主机内存的系统管理员或程序可以删除日志、绕过安全审计并访问静态数据(Capital One攻击似乎就是这样)。
静态数据的加密也不是答案。应用程序和数据仍然必须解密才能进行运行时处理。此外,IT内部人员可以访问加密密钥;智能系统管理员可以删除审核日志。容器或虚拟机中的安全性不足会导致额外的风险。
我们需要的是一种在不限制IT内部人员充分履行职责的情况下,使安全自动化的方法。应该有一种方法,通过将IT职责与企业数据和网络的访问分离,实现安全的生产力。
最近的选项尚未准备就绪
在过去几年中,保护供应商提供了许多新选项。其中大多数都是点式解决方案,它们既不是端到端的,也不是准备好在企业范围内部署的。加密数据和程序是零碎和复杂的。因此,这些产品的实施往往很复杂,或者需要对正常的IT运营造成严重的中断。
还有另一个重要的限制。单点产品仅保护静态数据或网络上未使用的数据。在内存中运行应用程序以明文形式公开数据、主密钥、加密密钥和其他机密。特权访问管理(PAM)仅保护凭据。任何拥有授权凭据的人仍然可以查看数据和应用程序。
所有这些选项都需要额外的不必要的软件复杂性层,从而降低了生产率。挑战在于如何在安全性和隐私性与可用性和易实现性之间取得平衡。
预防而不是检测
在当今的环境中,企业永远无法确保及时检测和处理所有威胁。转向预防将重点从追踪已经发生的恶意行为转向维护安全资源和网络。
为确保企业安全,仅保护数据和应用程序是不够的。内存和网络也需要保护。这种保护不仅应包括本地应用程序和数据,还应包括在私有和公共云中运行的操作。虽然今天的方法保护静止和传输中的数据,但使用中的数据尚未得到适当处理,因为它是最复杂和最难保护的状态。
机密计算联盟成立于2019年,由Linux基金会赞助,旨在解决这一问题。该联盟的目标是定义和促进保密计算的采用,特别是保护系统内存中的敏感数据。20多位行业领袖加入了该集团,包括阿里巴巴、安居纳、ARM、百度、Facebook、谷歌云、IBM、英特尔、微软、甲骨文、红帽、腾讯和VMware。5
安全飞地提供高级别硬件安全
安全飞地(也称为可信执行环境或TEE)是机密计算的核心。安全飞地是嵌入新CPU中的一组安全相关指令代码。它们保护使用中的数据,因为enclave仅在CPU内实时解密,然后仅对enclave本身内运行的代码和数据进行解密。
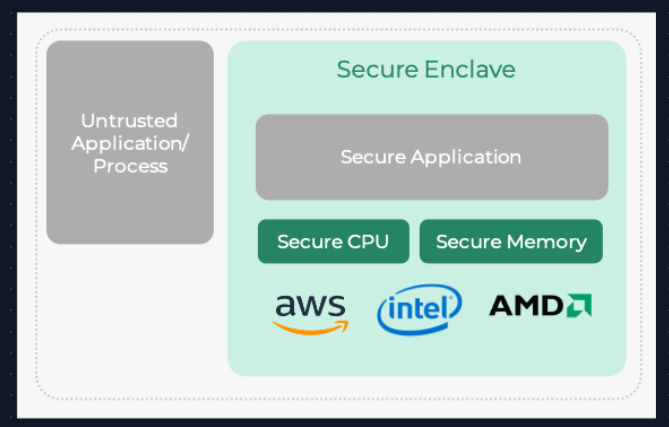
Intel推出的Software Guard Extensions(SGX)6安全外壳基于硬件级加密内存隔离。AMD现在通过内置于Epyc中的SEV技术提供类似的功能。到2020年底,几乎所有服务器和云平台都将支持安全的飞地,包括Intel、AMD、Amazon AWS(及其新的Nitro enclaves)7、Microsoft Azure8、VMware、Google、Docker和Red Hat。9
在安全的飞地中,应用程序在与主机隔离的环境中运行。内存与机器上的任何其他东西(包括操作系统)完全隔离。私钥在硬件级别进行硬编码。一个称为认证的过程允许飞盘对其内部运行的硬件进行认证,并向远程方证明飞盘内存的完整性。安全的飞地可以简单有效地在本地、跨网络和云中保护应用程序、数据和存储。
在安全的飞地内运行时,任何其他实体都无法访问应用程序代码和数据。对系统具有root或物理访问权限的内部人员无权访问内存。甚至来宾操作系统、虚拟机监控程序或主机操作系统上的特权用户也会被阻止。整合安全堆栈可以降低复杂性,从而降低成本。
企业安全的新水平
安全的飞地为企业IT操作提供了更高级别的安全性。有了安全的飞地,IT内部人员就无法采取恶意行动,但仍能做好自己的工作。该过程对IT用户完全透明。
有了安全的飞地,企业也可以免受零日攻击。目前,“已知未知”允许攻击者在执行客户端任务时渗透操作系统。然而,即使操作系统、虚拟机监控程序或容器软件遭到破坏,在安全飞地内运行的应用程序也会在任何级别的权限上与主机操作系统隔离。这允许真正的数据分离和隔离。
访问数据和系统的第三方越多,风险越高。私有托管的云和数据中心为恶意内部人员提供了复制敏感数据或窃取驱动器的可能性。在云中,敏感数据在被基于云的软件应用程序使用时不受保护。安全的飞地解决了这些关键的操作问题,而不需要严格的安全区域,这会导致服务器基础架构配置过度或利用不足。优化服务器利用率有助于降低基础架构和运营成本。
领先的数据中心公司Equinix表示,网络安全威胁的增加是影响数字信息基础设施的一个关键问题。2020年,Equinix预测:
“新的数据处理能力,如多方安全计算、完全同态加密(在加密数据上操作)和安全飞地(即使云运营商也无法窥视云消费者执行的代码),将走向主流,并将允许企业以安全的方式运行其计算。”10
安全封装防止关键威胁
作为一名CISO,您的企业面临多种威胁——从被盗数据到系统管理员或SRE的未经授权访问。安全封地可以通过一种整合的、易于实施的方法帮助您防止各种威胁。
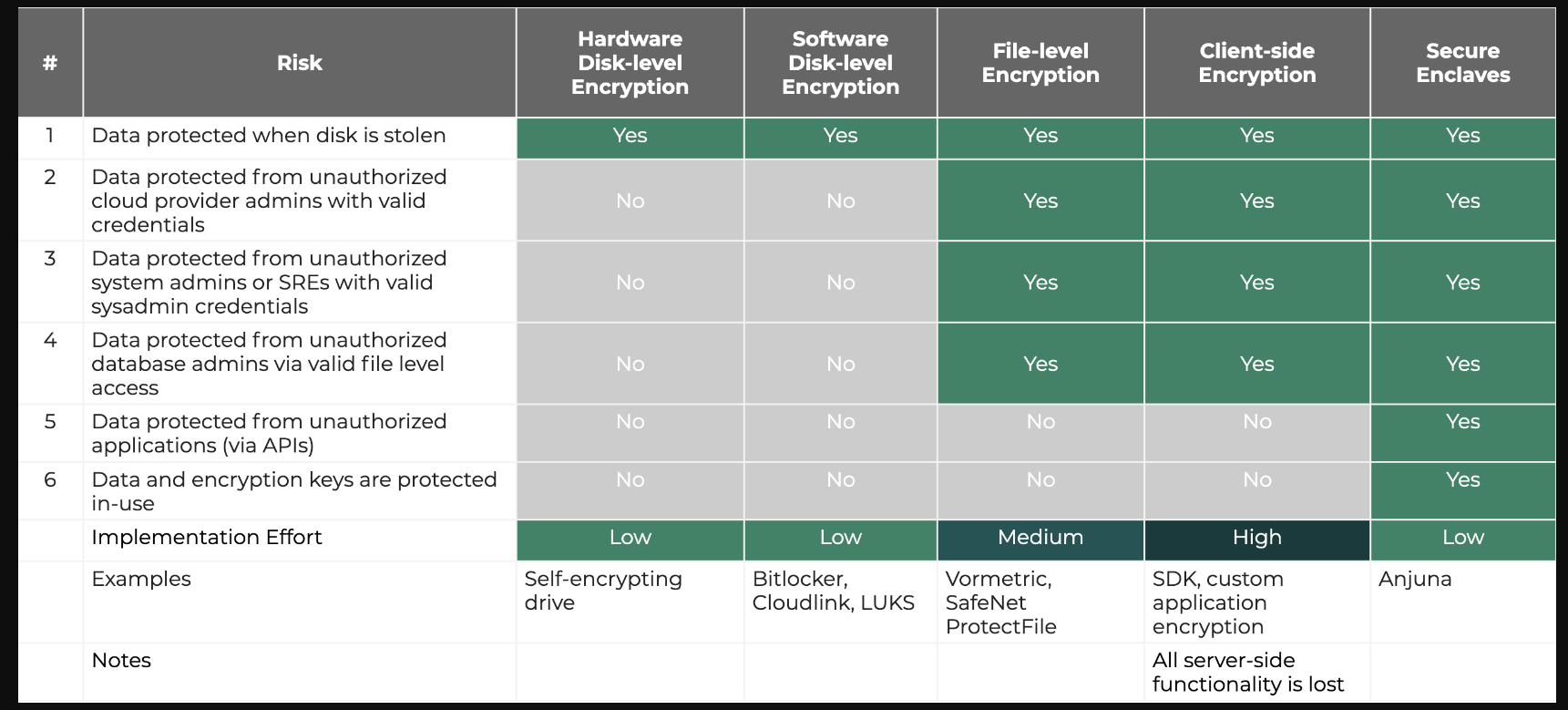
采纳障碍
到目前为止,实施安全飞地既复杂又昂贵。必须对应用程序进行大量重写才能使用安全的enclave,并且经常需要对IT流程进行更改。此外,每个芯片供应商都有自己的软件开发工具包(SDK)。这意味着实现需要大量的设计、开发和测试资源,这使得过程既昂贵又耗时。
在这个领域有几种开源替代方案,包括Asylo、open Enclaves和Intel的SGX。然而,这些也需要重新编译每个应用程序并使用SDK。此外,这些产品目前不提供企业级所需的支持或部署功能,如灾难恢复、高可用性和云环境中的扩展。
解决这些问题的新解决方案消除了软件重写或实施新流程的需要。有关更多详细信息,请参阅安朱纳白皮书:为什么安朱纳:防止内部威胁。
下一步:立即准备
保护飞地的行动势头越来越大。在未来几年内,安全飞地将成为企业的标准安全技术。随着多个计算环境(从本地数据中心到公共云到边缘)的使用越来越多,现在是准备为您的操作实施这一级别的保护的时候了。
向您的团队提出以下问题:
- 如何保护公共云中的敏感应用程序?
- 您的云提供商正在采取哪些措施来应对这一持续的内部威胁?
- 您有第三方风险敞口吗?如何在不受信任的地区保护您的应用程序和数据?
- 您是否担心政府传票可能要求访问客户数据?
- 您是否准备重新编写应用程序以利用安全飞地?
- 拥有一个能够自动将应用程序移动到安全环境中的解决方案有多重要?
要了解Anjuna如何在不需要重写软件的情况下简单直接地部署安全飞地,请参阅白皮书《防止内部威胁》。
参考资料
- 1https://www.infosecurity-magazine.com/news/insider-threats-reponsible-for-43/
- 2https://www.bloomberg.com/news/articles/2014-01-09/pentagon-finds-snowden-took-1-7-million-files-rogers-says
- 3https://www.washingtonpost.com/national-security/former-twitter-employees-charged-with-spying-for-saudi-arabia-by-digging-into-the-accounts-of-kingdom-critics/2019/11/06/2e9593da-00a0-11ea-8bab-0fc209e065a8_story.html
- 4https://www.gartner.com/smarterwithgartner/gartner-top-7-security-and-risk-trends-for-2019/
- 5https://confidentialcomputing.io
- 6https://software.intel.com/en-us/sgx
- 7https://aws.amazon.com/ec2/nitro/
- 8https://azure.microsoft.com/en-us/solutions/confidential-compute/
- 9https://www.ibm.com/cloud/blog/data-use-protection-ibm-cloud-using-intel-sgx?mhsrc=ibmsearch_a&mhq=secure%20enclaves
- 10https://www.equinix.com/newsroom/press-releases/pr/123853/Top--Technology-Trends-to-Impact-the-Digital-Infrastructure-Landscape-in-/
- 1059 次浏览
【数据安全】什么是数据标记化?市场规模、用例和公司
数据正在推动全球经济。从初创企业到企业,整个工业部门的组织都希望完善其数据管理模型,标记化是他们的一个重要关注领域。在接下来的研究讨论中,我们将阐述数据标记化的范围和意义,它在现代企业中的作用,以及最终在行业中处于领先地位的关键公司。
标记化定义
标记化是指将高度敏感数据转换为非敏感替代值(称为标记)的过程。令牌不是一个真实的、可利用的值,而只是一个引用,一旦放入令牌化系统进行解码,它就可以连接回机密、敏感数据。
什么是数据标记化(Tokenization)和数据去标记化?
标记化是一种用非关键数据交换关键数据的特定技术。该非敏感数据(称为令牌)没有可解释的值,仅是连接回敏感信息的标识符,因此用户无法访问信息。
标记化的主要目的是保护原始数据不被暴露,并保护其价值。标记化的过程与加密完全不同,在加密中,易受影响的数据被更改和保存,并且在任何情况下都不允许将其用于组织目的。
数据标记化有助于加密数据,从而保持数据安全。例如,客户使用信用卡或借记卡,并打算在网上购物。这个“东西”可以是公司提供的产品或服务。在这里,即使是管理层人员也无法获得信用卡信息,因为信用卡信息以加密代码提供。此外,实时信息和加密信息之间不存在连接。
理解去标记化(De-Tokenization)
这与所谓的标记化正好相反。它需要令牌化发生的原始系统,因为不可能在任何其他桌面或系统上获得确切的数字或令牌。如果要执行一次性在线交易,则无需为未来交易存储数据。相反,如果交易要进行多次,则必须进行加密,以便任何人都无法访问信息。
标记化与加密的比较
符号化
- 使用替代的随机值
- 以随机形式在数据库中保存映射
- 这种方法是不能推翻的
- 它保护高优先级数据,如卡号等。它保护互联网上的信息。对于卡现付款( card-present payment)至关重要。
加密
- 将明文转换为密文
- 扰乱信息,以便政权稍后使用
- 这种方法是可以推翻的
- 用于在线和离线商店的存档卡(card on file )和定期付款(recurring payment)方式。
加密改变了整个信息的模式,因此将其更改回来将是一项艰巨的任务,但这也可以在需要时完成。的确,这是一项艰巨的任务,但并非不可能。简单易懂的算法永远无法实现加密,因此需要复杂的算法。
当我们说加密可以在那里逆转时,一个事实是标记化永远不会被推翻。在这种情况下,即使黑客试图入侵信息,他们也永远无法访问信息。这些信息不是以算法的形式,而是将数据转换为无意义的占位符,这些占位符永远无法更改。
如果我们必须强调标记化和加密之间的一些差异,那么我们需要标记以下几点:-
- 标记化将数据转换为一些随机代码,不可能反转,而加密可以由专家反转。
- 卡号、安全号等是令牌化的实例。另一方面,文件和电子邮件被加密。
- 通过电话支付(Payments over the phone)或亲自进行的交易是加密数据的示例,如果我们看到令牌化的用例,则它们是文件卡支付、定期支付和在不同位置存储客户数据。
- 令牌化中的安全数据保留在锁和加密中,关键数据进入加密算法。对于高安全性,数据标记化是最好的,但如果可能出现任何解密的可能性,则可以使用加密,这里要提到的是,即使加密破坏也不是一个简单的过程。
企业家的PCI范围可以减少PCI PA DSS的业务范围。如果我们讨论一个公共元素,那么这两个元素都消除了供应商的PCI PA DSS范围。
令牌化情况下的数据可以很容易地使用,保存在“令牌库”中,并进行加密,该库被锁定,必要时可以解密。在易于猜测实际值的情况下,标记化可能是一个糟糕的选择,这就是为什么需要使用这两种方法的专家知识。从而可以容易地作出审慎的决定。
市场规模、增长和趋势
标记化统计
- 统计 值
- 当前市场规模(2022年): 25亿美元
- 2026年的市场规模(预计):56亿美元
- 数据泄露的平均成本: 424万美元
- 年增长率 : 19%
- 2030年(预计)市场规模:92亿美元+
数据符号化与市场统计
根据《市场与市场报告》,全球市场已从2021的23亿美元飙升至2026年的56亿美元,复合年增长率为19%。
有几个因素将以猖獗的速度提高代币化的效果和传播,如下所示:
因素1:成本效益高的云的兴起
基于云的令牌化是一种将敏感数据交换为称为令牌的不可逆、非敏感占位符,并将原始敏感数据安全存储在组织内部系统之外的方法。
它可以比传统的本地令牌化更便宜,更易于集成。它还通过从数据环境中删除敏感数据,进一步降低了组织的风险和合规范围。
此外,通过使用格式和/或长度保留标记作为原始敏感数据的占位符,企业可以在不牺牲其实用性或当前业务流程灵活性的情况下保护数据。
因素2:非接触式支付的兴起
关键因素是现在需要非接触式支付。由于新冠疫情,人们希望交换流动性货币而不是货币。
该方法还消除了对实际存储过程的要求。不需要保存信用卡和借记卡信息,这种流动资金可以帮助很多。
需要非接触式支付,以拯救人类免受新冠肺炎等流行病的传播。
有趣的事实:根据研究与市场,BFSI拥有巨大的市场份额,未来几年甚至会如此。在垂直交易中,有各种各样的交易,它们引诱网络罪犯。BFSI交易对于罪犯来说是一个迷人的地方。根据预测,基于API的段有助于生成不可逆的代码。它揭示了对标记化的日益增长的需求。
因素3:数据泄露的增加
犯罪分子以接受信用卡和借记卡的企业为目标,因为支付信息中有丰富的情报。标记化有助于保护企业免受数据盗窃的负面财务影响。即使在发生漏洞的情况下,有价值的个人数据也根本无法窃取。
信用卡代币化有助于在线企业提高数据安全性,从数据捕获到存储,因为它消除了POS机和内部系统中信用卡号的实际存储。
欺诈活动和数据泄露正在吸引每个组织的注意。将数据暴露给黑客的风险与日俱增,因此需要采用适当的防止数据的方法进行检查。增加数据泄露的风险可以促进代币化市场。
IBM最近的一份报告发现,在同一时间段内,数据泄露的平均成本上升了10%,从386万美元上升到424万美元。有趣的是,远程工作和疫情带来的数字化转型使数据泄露的总成本平均增加了107万美元。
使用数据产品实现标记化
以前,数据标记化解决方案将业务合作伙伴数据存储在集中数据库中。这样一个共同的失败点是一个巨大的风险。正如已经详细讨论的,Web 3.0,分散数据存储时代确保了数据产品计划的更大范围,该计划将加密和标记化数据集分发到数百万个微数据库中。领先的数据管理结构K2View已成功实施了该方法。Fabric为每个业务合作伙伴专用一个微数据库,从而降低违规风险,同时确保合规性。
此外,K2View数据产品为多个操作用例实时标记数据。这也适用于批量分析工作负载。不容错过的是,它们保留了格式,并在整个数据环境中保持了数据的完整性。实时
用例和限制
4数据标记化用例
如上所述,在标记化系统之外,标记化不能逆转为其原始形式。这确保了数据机密性的端到端保护,从而跨流程驱动多个用例。最常见的用例是支付代币化,它推动了web 3.0各种应用程序的数字资产交易,例如与区块链相关的应用程序。其他包括:
1) 历史数据的符号化
在许多公司中,数据是存储的,这些数据没有用处,但可能会被误用。历史数据,如姓氏、信用卡信息和与个人医疗保健相关的价值等,因此如果要进行分析,那么也可以在没有此类信息的情况下进行分析。算法可以用来表示特定的数据,这是最简单和最安全的方法。
2) 开发和QA环境中的标记化
标记化是一种为软件开发人员和测试人员提供数据格式和连续性所需信息的方法。有趣的是,实际数据并没有公开,因为它是以隐藏形式提供的。
真实值永远不可见,因为它们在被传输到系统之前被代币替代,并且关联也得到了很好的维护。而在加密中,数据的维度保持原样。
通过这种软件开发和质量保证数据,您消除了这些系统的损坏风险,并消除了数据丢失和质量保证团队对数据丢失的怀疑。
标记化有助于分析增长和质量保证环境的一致数据。风险在于披露客户相关数据,因为公司无法显示实际价值。IT部门可以开发一种方法来象征性地显示数据,以保持机密性。
3) BI的标记化
商业智能和查询,即BI,是在很大程度上使用标记化的重要场所。IT部门提供一些隐藏的报告,并为用户的利益创建这些报告,用户可以根据这些报告分析当前的趋势,如果以简单的形式给出,则可以增加责任和任务,从而使IT部门更负责任,只是数据不能直接公开,只有获得相关信息。
总体而言,代币化的好处是不可估量的,并将在多个组织中谨慎和广泛地使用,以保护用户的隐私,这些用户显示了对商业组织的信任,毫无疑问,未来是绿色的。
4) 简化数据仓库和湖泊的法规遵从性
在传统方法中,集中式数据仓库(如仓库和湖泊)接收和存储来自多个源的数据,这些数据可以是结构化和非结构化格式。这使得按照法规遵从性规范实施数据保护变得复杂。标记化解决了这个问题。它使您能够将原始PII与湖泊和仓库分开。这有助于降低违反任何合规准则的风险。
数据标记化限制
作为一种安全协议,它使数据管理基础设施复杂化。此外,它仍然只有数量有限的支付处理程序支持,因此您可能不得不使用可能不是您首选的支付处理工具。
使用标记化的数据需要从远程服务中对其进行去标记和检索。这会给流程带来事务时间的少量增加,在大多数情况下可以忽略不计。
此外,采用标记化并不意味着支付网关完全没有风险,特别是当第三方必须访问信息时。
在这种情况下,组织必须监控第三方在其端部具有完全安全的系统。使用标记化信息需要对其进行去标记化并从远程服务中恢复。事务时间延迟并产生问题。
简而言之,
- 可能无法处理大型组织使用的所有数据;
- 可能不适用于应用程序和处理技术。
因此,您必须权衡您的选择,并与正确的数据产品平台协作。此时,您应该围绕关键空白构建清晰性,以填充数据景观。
顶级标记化平台
顶级数据标记化产品公司
鉴于对高级数据标记化的需求快速增长,服务提供商数量大幅增加。除IBM等高端IT巨头外,我们发现以下三家公司正在通过其创新方法增加价值。它们中的每一个都填补了现有数据架构中的空白。还有更多。
1) K2View
K2VIEW因其独特的数据结构和标记化架构而广受欢迎。结构首次成功实现了微数据库的概念。在这里,基础设施将业务合作伙伴数据存储在一个小型数据库中。这些微数据库中的每一个都只保存特定业务合作伙伴的数据,而fabric维护着数百万个数据。
数据管理产品提供了广泛的其他服务,如网格、数据编排、集成等。该公司采用数据产品方法,提供最安全、可扩展和运营效率最高的数据标记化解决方案。该系统工作在一个中央机制上,用于操作和分析工作负载的标记化和去标记化。
2) TokenEx
ToeknEX为客户提供企业级令牌化服务,并在访问、存储和保护数据的方式上提供无限的数字灵活性。他们的团队与各种数据处理渠道和最新技术无缝协作,帮助您提供资产标记化服务。它致力于将代币化标准化,作为监管和行业合规的一种手段。它们因服务于BFSI行业而受欢迎,尤其是在支付网关/集成模块上工作的产品。
3) Imperva
Imperva是一家数据管理咨询公司,提供一系列用于屏蔽原始数据的加密技术的产品/服务。该公司的代币化服务非常专注于跨本地系统、云系统或混合环境的端到端数据安全。Imperva以其网络安全服务而闻名,使各组织能够透明地查看其通过垂直渠道访问、持有、使用和传输的数据。
本文:
- 165 次浏览
【数据安全】使用 SOPS 保护您的服务器凭据
视频号
微信公众号
知识星球

在我们的团队中,有多个人处理Kubernets中的生产环境。对于每项服务,我们都会维护一个单独的Kubernets秘密文件。问题是,每当一个秘密值发生变化时,就很难在维护人员之间进行分配,也很难跟踪变化。我们可以维护git-reo来解决这个问题,但将DB凭据存储到普通文件中是有风险的。这里有一个方便的SOPS,Mozilla广泛使用它来保守他们的秘密。SOPS的基本概念非常简单,通过使用SOPS,您可以使用所有维护者的公共加密密钥来加密您的秘密文件。然后将加密的文件存储在git存储库中。每当你或你的团队成员需要实际的文件时,只需使用SOPS解密文件。SOPS最好的部分是它可以识别文件类型,只加密值而不是密钥。由于它只对值进行加密,git历史记录可以指出哪些密钥值被更改了。SOPS支持多种加密机制,但在本文中,我只关注gpg密钥。
GnuPG安装
正如我提到的,我将只关注gpg密钥加密,你需要在你的系统中安装GnuPG来生成gpg密钥。你可以使用二进制安装程序安装GnuPG,我更喜欢使用Homebrew,
>>> brew install gnupg2
现在您要生成您的gpg密钥,在运行以下命令后,您将被要求输入您的姓名和电子邮件地址。如果您的所有信息都可以,请按“O”并点击回车键,控制台会要求您设置一个可选的密码,如果您不想设置密码,请按OK。
>>> gpg --generate-key gpg (GnuPG) 2.2.15; Copyright (C) 2019 Free Software Foundation, Inc. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law.Note: Use "gpg --full-generate-key" for a full featured key generation dialog.GnuPG needs to construct a user ID to identify your key.Real name: Mr. x Email address: mr.x@email.com You selected this USER-ID: "Mr. x <mr.x@email.com>"Change (N)ame, (E)mail, or (O)kay/(Q)uit? O We need to generate a lot of random bytes. It is a good idea to perform some other action (type on the keyboard, move the mouse, utilize the disks) during the prime generation; this gives the random number generator a better chance to gain enough entropy. We need to generate a lot of random bytes. It is a good idea to perform some other action (type on the keyboard, move the mouse, utilize the disks) during the prime generation; this gives the random number generator a better chance to gain enough entropy. gpg: key 411F71D23B22E116 marked as ultimately trusted gpg: revocation certificate stored as '/Users/rana/.gnupg/openpgp-revocs.d/0AB19F525F991CC847F744CA411F71D23B22E116.rev' public and secret key created and signed.pub rsa2048 2019-05-17 [SC] [expires: 2021-05-16] 0AB19F525F991CC847F744CA411F71D23B22E116 uid Mr. x <mr.x@email.com> sub rsa2048 2019-05-17 [E] [expires: 2021-05-16]
您已经生成了密钥和指纹(0AB19F525F991CC847F744CA411F71D23B22E116),现在将您的公钥注册到公钥服务器,例如http://keyserver.ubuntu.com/。 为此,只需导出您的公钥并将其粘贴到密钥服务器的大盒子中,然后按提交即可。 要导出您的公钥,请运行以下命令
>>> gpg --armor --export mr.x@email.com -----BEGIN PGP PUBLIC KEY BLOCK-----mQENBFzeQjABCACpKlgNWMQJolFZhs5gqeyWevYJ7QtPsF4LpX3AHxJSRBcYCZk9 pYaMCxCcU8tDRxgYpVace90DcP6MnyddKq0L+948fWpjZUqSlE/BByitkdhY834z 8noXyky+GLJ+5YJgEBwGK7mF32B1yFga057wK7p+8ziGsQ3Ib4nDCiVfbD5suiGa FpwWMxU/15Tx+2i+6TZKmwtCR3bIPuYa0x0P0nQphAKD1LrSMjUu3BEgv4abrl1x W9iFEKtk3jcfwWYCvFOHB0BuwFnTqqkmm+YJP+J6Qf6PTl/Z0N0YLFMDyWv347W+ l2UwIvxYpUSvrPhegzLUzhXfBubZ/bCXzuodABEBAAG0Fk1yLiB4IDxtci54QGVt YWlsLmNvbT6JAVQEEwEIAD4WIQQKsZ9SX5kcyEf3RMpBH3HSOyLhFgUCXN5CMAIb AwUJA8JnAAULCQgHAgYVCgkICwIEFgIDAQIeAQIXgAAKCRBBH3HSOyLhFrJRCACg rwsNYYvgrr4LRntxXdYrP32Hg23G4w6mWCngk0kHH7djCSzSeVRcPPPG+rkUN+xt QAIKuCnrAx4wH+lgINJ1BGf8CeAFPVRwNMxyB0OfU1ersTlOoPd0JubFWx647nuq RBh6cpjyPP4T/JUGmqzYlHTJU3UlKu7zWdvrqnh0DInqkB7n/TmJrULLIJOXJxXD fKCHC6nOQ52A7NhZMjn8jTFdtwEAvoih2H5jwrJ+/6srDnTZ8Hv5FunHxgeNS5LH /JjDSk2Z5FF1+BwSdN6BQdiRLC6607qRGnnYY2QDaiixwDyZF73xbbeeVgA+HP7F 9+Fsc/y+VjCVAVcp1gFbuQENBFzeQjABCADDeHfFyYQkILPk12Vf/PXF753uBup5 z1IYjGAf9TjwwdGq/VeS+4pTIYjTVU51+SEF2ezv7o+ml8kSQwU3ZoysPFE0pi6O huG/mo4oB7vv9wKZXf5OUjaKJXCVL05/GjHaRnFr/uJC9Rv7p6Nbyafr8ZBFzimu X08Df+HuFuLpENcctfDW9GKmxMwE9pTYMciAGcg0a5F29CISJEQdaX4hCYxF10RD 7BadXxf+l2GF8P1rLL8Cps2vM5QL4IhXlkvSX9gi+Hyg/DgL56RwAA18kYaQTMop HrxawWxYmCv//2N4xZuvUKNghoh52gmDuPUbbBvFXBfsgs9a9fd1DGJTABEBAAGJ ATwEGAEIACYWIQQKsZ9SX5kcyEf3RMpBH3HSOyLhFgUCXN5CMAIbDAUJA8JnAAAK CRBBH3HSOyLhFhzuB/0aB5IRnFMN6DZjLZbU+SeviI++AwsS3pBSZcCGAG4wm00H 0GbXv6ag8EGnACEpiRQ+bjMw5iySYAZZ1CJlRGT2xdupy9KWQIUp8p0tHpjHnwRv jxkk+6omW/SA/Apg/WJHVOYm9Csv2wyAtGw1ykV62gzbEcg5396Xlgqtb26tFTfP tJx7HRBntl8cL7BKqONox1rIs9SIlZ3yjb2nDmFk1X2W8uP+VnRsqX5v/6FcPHZL LtY+6/Yc133q3YuBo2NzrOttCIvxcw8EgApmxcTcM5bZsyNI12vdksOYN9zwxomW buccuqGEXERbq+Op1NU7/c5nSM9fR6Efq7K5UZLl =PYP/ -----END PGP PUBLIC KEY BLOCK-----
SOPS安装
对于sop的安装,Golang是先决条件。请确保您已经安装了Golang。所以就跑吧
>>>go get-u go.mozilla.org/sops/cmd/sops
如果Golang bin路径没有安装您的路径变量,您将无法全局访问sops二进制文件。要全局访问sops二进制文件,您可以使用路径变量装载Golang bin路径,或者只需将sop二进制文件复制到系统bin文件夹中。现在您必须设置一些环境变量。打开您的shell配置文件(在我的例子中是.zshrc)并导出以下变量
export SOPS_GPG_EXEC=“GPG” export SOPS_PGP_FP=“15EAB6D9F4D4C305B78E3388FDCAF78DECEB84EB” export SOPS_GPG_KEYSERVER=“KEYSERVER.ubuntu.com”
SOPS_GPG_EXEC是GPG二进制文件。SOPS_PGP_FP是一个以逗号分隔的方式列出的指纹列表,为您添加所有团队成员的指纹,以便您访问您的机密。SOPS_GPG_KEYSERVER用于指向您和您的团队成员已注册公钥的密钥服务器。
使用SOPS
假设我们有一个“secrets-dec.yaml”文件,其中包含非常重要的密钥foo和超机密值栏
要加密,请运行以下命令
>>> sops -e secrets-dec.yaml > secrets-enc.yaml
>>> cat secrets-enc.yaml
foo: ENC[AES256_GCM,data:lLNm,iv:quQDpvEezvAv7vu8D8KOzXl2pbTLbhtCG5E6UwJwXk4=,tag:q0kuoGQraWWYxhVkbnwU6g==,type:str]
sops:
kms: []
gcp_kms: []
azure_kv: []
lastmodified: '2019-05-17T05:56:21Z'
mac: ENC[AES256_GCM,data:Jku7XHp9qM6SiY0QmqzjG+n285nLWcaceEmLA3B2A7OcnMqTpT8Vz7U8ibrzVBfHKsaZGvbKgA+S7bYI27aUfOGJP0n5FcQrWmMi09dUxVElXefjp57O7zmS2IqcRQfOHn9EdUM3QUN0dr35fYAE+7NlaXe4WQ3o2OjpfMSsLN0=,iv:vcwVusEkNAx+UHqbYJ3LdKcqGDvfWNaCH49jbcwcXbg=,tag:bVlxYilnU+NCNKeBF/QLbQ==,type:str]
pgp:
- created_at: '2019-05-17T05:55:16Z'
enc: |
-----BEGIN PGP MESSAGE-----hQEMA5Z1h+jahM/SAQf8CnoK+jJ4kfGA7BiP0XftoRnTZgzGh0haChY/nI2J3yAd
o5P4BmQBlm9xgxHg4QOUVSmwBRZ87lK/cgrrm+nXCMUZRtdxY/WBY3ELKNIy5A6M
Pw4V4l5R+o6Z6up7JwLqbrDXjO1Ll48NdQBLGGb6cnXB5OskHbbHKKEtligBaPHE
harHh1vlp4z7L6RPv5+IqZK8waX8ENG1RSODyK6Hj04qyUOT3pq8qZ71PSw+q7Rv
ciPeV5SwXfAZ8QTGYa8m3T/pdYOxlwEjT5Xr7Dqy2wzzp9w3IES4XYhMPxbFS1rQ
6Zp+YBQUrKyU+efzxcVcBUL4+nsqWqn2dk5SKfrX2NJeAf3GO2UHagi3f2aix5xQ
OVD2aDe0z9f29/imx6EqlgbU3mQrqL0AgZcHiJRRGr4VOpeG5KBRs8wtNEJYHh2v
NpUbuUfq1cace+7nRcXKzf7VTfSpPDR8Apa/fWGeYA==
=1Z6N
-----END PGP MESSAGE-----
fp: 15EAB6D9F4D4C305B78E3388FDCAF78DECEB84EB
unencrypted_suffix: _unencrypted
version: 3.3.0sop最棒的地方是,它只会加密你的价值观。因此,如果您更改任何值,git-diff可以向您显示更改的键。每当您需要解密文件时,只需运行以下命令
>>> sops -d secrets-enc.yaml > secrets-dec.yaml >>> cat secrets-dec.yaml foo: bar
所以这是基本的sops去扔。sop有一些很棒的功能,要了解更多关于sop的信息,请阅读他们的完整文档。
小贴士
您可以维护一个约定,即每个未加密的文件都将以“-dec”结尾
加密后的文件将以“-enc”结尾,然后将以下模式添加到.gitignore文件中
*-dec.{your file extension}
- 55 次浏览
【数据安全】使用Mozilla SOPS管理Kubernetes机密
视频号
微信公众号
知识星球
为了将机密安全存储在公共或私人Git存储库中,您可以使用Mozilla的SOPS CLI通过OpenPGP、AWS KMS、GCP KMS和Azure Key Vault加密Kubernetes机密。
先决条件
要遵循本指南,您需要一个安装了GitOps工具包控制器的Kubernetes集群。请参阅入门指南或安装指南。
安装gnupg和SOPS:
brew install gnupg sops
生成GPG密钥
生成不带密码短语的GPG/OpenPGP密钥(%no-protection):
export KEY_NAME="cluster0.yourdomain.com"
export KEY_COMMENT="flux secrets"
gpg --batch --full-generate-key <<EOF
%no-protection
Key-Type: 1
Key-Length: 4096
Subkey-Type: 1
Subkey-Length: 4096
Expire-Date: 0
Name-Comment: ${KEY_COMMENT}
Name-Real: ${KEY_NAME}
EOF
上面的配置创建了一个不会过期的rsa4096密钥。有关要为您的环境考虑的选项的完整列表, see Unattended GPG key generation.
检索GPG密钥指纹(sec列的第二行):
gpg --list-secret-keys "${KEY_NAME}"
sec rsa4096 2020-09-06 [SC]
1F3D1CED2F865F5E59CA564553241F147E7C5FA4
将密钥指纹存储为环境变量:
export KEY_FP=1F3D1CED2F865F5E59CA564553241F147E7C5FA4
Export the public and private keypair from your local GPG keyring and create a Kubernetes secret named sops-gpg in the flux-system namespace:
gpg --export-secret-keys --armor "${KEY_FP}" |
kubectl create secret generic sops-gpg \
--namespace=flux-system \
--from-file=sops.asc=/dev/stdin
最好使用密码管理器或离线存储来备份此密钥/K8s secret。还要考虑从您的计算机中删除机密解密密钥:
gpg --delete-secret-keys "${KEY_FP}"
配置群集中机密解密
在集群上注册Git存储库:
flux create source git my-secrets \
--url=https://github.com/my-org/my-secrets \
--branch=main
创建一个kustomization来协调集群上的机密:
flux create kustomization my-secrets \
--source=my-secrets \
--path=./clusters/cluster0 \
--prune=true \
--interval=10m \
--decryption-provider=sops \
--decryption-secret=sops-gpg
Note that the sops-gpg can contain more than one key, SOPS will try to decrypt the secrets by iterating over all the private keys until it finds one that works.
Optional: Export the public key into the Git directory
Commit the public key to the repository so that team members who clone the repo can encrypt new files:
gpg --export --armor "${KEY_FP}" > ./clusters/cluster0/.sops.pub.asc
Check the file contents to ensure it’s the public key before adding it to the repo and committing.
git add ./clusters/cluster0/.sops.pub.asc
git commit -am 'Share GPG public key for secrets generation'
Team members can then import this key when they pull the Git repository:
gpg --import ./clusters/cluster0/.sops.pub.asc
The public key is sufficient for creating brand new files. The secret key is required for decrypting and editing existing files because SOPS computes a MAC on all values. When using solely the public key to add or remove a field, the whole file should be deleted and recreated.
Configure the Git directory for encryption
Write a SOPS config file to the specific cluster or namespace directory used to store encrypted objects with this particular GPG key’s fingerprint.
cat <<EOF > ./clusters/cluster0/.sops.yaml
creation_rules:
- path_regex: .*.yaml
encrypted_regex: ^(data|stringData)$
pgp: ${KEY_FP}
EOF
This config applies recursively to all sub-directories. Multiple directories can use separate SOPS configs. Contributors using the sops CLI to create and encrypt files won’t have to worry about specifying the proper key for the target cluster or namespace.
encrypted_regex helps encrypt the data and stringData fields for Secrets. You may wish to add other fields if you are encrypting other types of Objects.
Hint
Note that you should encrypt only the data or stringData section. Encrypting the Kubernetes secret metadata, kind or apiVersion is not supported by kustomize-controller.
Encrypting secrets using OpenPGP
Generate a Kubernetes secret manifest with kubectl:
kubectl -n default create secret generic basic-auth \
--from-literal=user=admin \
--from-literal=password=change-me \
--dry-run=client \
-o yaml > basic-auth.yaml
Encrypt the secret with SOPS using your GPG key:
sops --encrypt --in-place basic-auth.yaml
You can now commit the encrypted secret to your Git repository.
Hint
Note that you shouldn’t apply the encrypted secrets onto the cluster with kubectl. SOPS encrypted secrets are designed to be consumed by kustomize-controller.
Encrypting secrets using age
age is a simple, modern alternative to OpenPGP. It’s recommended to use age over OpenPGP, if possible.
Encrypting with age follows the same workflow than PGP.
Generate an age key with age using age-keygen:
$ age-keygen -o age.agekey
Public key: age1helqcqsh9464r8chnwc2fzj8uv7vr5ntnsft0tn45v2xtz0hpfwq98cmsg
Create a secret with the age private key, the key name must end with .agekey to be detected as an age key:
cat age.agekey |
kubectl create secret generic sops-age \
--namespace=flux-system \
--from-file=age.agekey=/dev/stdin
Use sops and the age public key to encrypt a Kubernetes secret:
sops --age=age1helqcqsh9464r8chnwc2fzj8uv7vr5ntnsft0tn45v2xtz0hpfwq98cmsg \
--encrypt --encrypted-regex '^(data|stringData)$' --in-place basic-auth.yaml
And finally set the decryption secret in the Flux Kustomization to sops-age.
Encrypting secrets using HashiCorp Vault
HashiCorp Vault is an identity-based secrets and encryption management system.
Encrypting with HashiCorp Vault follows the same workflow as PGP & Age.
Export the VAULT_ADDR and VAULT_TOKEN environment variables to your shell, then use sops to encrypt a Kubernetes Secret (see HashiCorp Vault for more details on enabling the transit backend and sops).
Then use sops to encrypt a Kubernetes Secret:
export VAULT_ADDR=https://vault.example.com:8200
export VAULT_TOKEN=my-token
sops --hc-vault-transit $VAULT_ADDR/v1/sops/keys/my-encryption-key --encrypt \
--encrypted-regex '^(data|stringData)$' --in-place basic-auth.yaml
Create a secret the vault token, the key name must be sops.vault-token to be detected as a vault token:
echo $VAULT_TOKEN |
kubectl create secret generic sops-hcvault \
--namespace=flux-system \
--from-file=sops.vault-token=/dev/stdin
And finally set the decryption secret in the Flux Kustomization to sops-hcvault.
Encrypting secrets using various cloud providers
When using AWS/GCP KMS, you don’t have to include the gpg secretRef under spec.provider (you can skip the --decryption-secret flag when running flux create kustomization), instead you’ll have to bind an IAM Role with access to the KMS keys to the kustomize-controller service account of the flux-system namespace for kustomize-controller to be able to fetch keys from KMS.
AWS
Enabled the IAM OIDC provider on your EKS cluster:
eksctl utils associate-iam-oidc-provider --cluster=<clusterName>
Create an IAM Role with access to AWS KMS e.g.:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"kms:Decrypt",
"kms:DescribeKey"
],
"Effect": "Allow",
"Resource": "arn:aws:kms:eu-west-1:XXXXX209540:key/4f581f5b-7f78-45e9-a543-83a7022e8105"
}
]
}
Hint
The above policy represents the minimal permissions needed for the controller to be able to decrypt secrets. Policies for users/clients who are meant to be encrypting and managing secrets will additionally require the kms:Encrypt, kms:ReEncrypt* and kms:GenerateDataKey* actions.
Bind the IAM role to the kustomize-controller service account:
eksctl create iamserviceaccount \
--role-only \
--name=kustomize-controller \
--namespace=flux-system \
--attach-policy-arn=<policyARN> \
--cluster=<clusterName>
Annotate the kustomize-controller service account with the role ARN:
kubectl -n flux-system annotate serviceaccount kustomize-controller \
--field-manager=flux-client-side-apply \
eks.amazonaws.com/role-arn='arn:aws:iam::<ACCOUNT_ID>:role/<KMS-ROLE-NAME>'
Restart kustomize-controller for the binding to take effect:
kubectl -n flux-system rollout restart deployment/kustomize-controller
Bootstrap
Note that when using flux bootstrap you can set the annotation to take effect at install time.
Azure
When using Azure Key Vault you need to authenticate kustomize-controller either with aad-pod-identity or by passing Service Principal credentials as environment variables.
Create the Azure Key-Vault:
export VAULT_NAME="fluxcd-$(uuidgen | tr -d - | head -c 16)"
export KEY_NAME="sops-cluster0"
export RESOURCE_GROUP=<AKS-RESOURCE-GROUP>
az keyvault create --name "${VAULT_NAME}" -g ${RESOURCE_GROUP}
az keyvault key create --name "${KEY_NAME}" \
--vault-name "${VAULT_NAME}" \
--protection software \
--ops encrypt decrypt
az keyvault key show --name "${KEY_NAME}" \
--vault-name "${VAULT_NAME}" \
--query key.kid
If using AAD Pod-Identity, Create an identity within Azure that has permission to access Key Vault:
export IDENTITY_NAME="sops-akv-decryptor"
# Create an identity in Azure and assign it a role to access Key Vault (note: the identity's resourceGroup should match the desired Key Vault):
az identity create -n ${IDENTITY_NAME} -g ${RESOURCE_GROUP}
az role assignment create --role "Key Vault Crypto User" --assignee-object-id "$(az identity show -n ${IDENTITY_NAME} -o tsv --query principalId -g ${RESOURCE_GROUP})"
# Fetch the clientID and resourceID to configure the AzureIdentity spec below:
export IDENTITY_CLIENT_ID="$(az identity show -n ${IDENTITY_NAME} -g ${RESOURCE_GROUP} -otsv --query clientId)"
export IDENTITY_RESOURCE_ID="$(az identity show -n ${IDENTITY_NAME} -g ${RESOURCE_GROUP} -otsv --query id)"
Create a Keyvault access policy so that the identity can perform operations on Key Vault keys/
export IDENTITY_ID="$(az identity show -g ${RESOURCE_GROUP} -n ${IDENTITY_NAME} -otsv --query principalId)"
az keyvault set-policy --name ${VAULT_NAME} --object-id ${IDENTITY_ID} --key-permissions decrypt
Create an AzureIdentity object that references the identity created above:
---
apiVersion: aadpodidentity.k8s.io/v1
kind: AzureIdentity
metadata:
name: ${IDENTITY_NAME} # kustomize-controller label will match this name
namespace: flux-system
spec:
clientID: ${IDENTITY_CLIENT_ID}
resourceID: ${IDENTITY_RESOURCE_ID}
type: 0 # user-managed identity
Create an AzureIdentityBinding object that binds pods with a specific selector with the AzureIdentity created above.
apiVersion: "aadpodidentity.k8s.io/v1"
kind: AzureIdentityBinding
metadata:
name: ${IDENTITY_NAME}-binding
namespace: flux-system
spec:
azureIdentity: ${IDENTITY_NAME}
selector: ${IDENTITY_NAME}
Customize your Flux Manifests so that kustomize-controller has the proper credentials. Patch the kustomize-controller Pod template so that the label matches the AzureIdentity selector. Additionally, the SOPS specific environment variable AZURE_AUTH_METHOD=msi to activate the proper auth method within kustomize-controller.
apiVersion: apps/v1
kind: Deployment
metadata:
name: kustomize-controller
namespace: flux-system
spec:
template:
metadata:
labels:
aadpodidbinding: ${IDENTITY_NAME} # match the AzureIdentity name
spec:
containers:
- name: manager
env:
- name: AZURE_AUTH_METHOD
value: msi
Alternatively, if using a Service Principal stored in a K8s Secret, patch the Pod’s envFrom to reference the AZURE_TENANT_ID/AZURE_CLIENT_ID/AZURE_CLIENT_SECRET fields from your Secret.
apiVersion: apps/v1
kind: Deployment
metadata:
name: kustomize-controller
namespace: flux-system
spec:
template:
spec:
containers:
- name: manager
envFrom:
- secretRef:
name: sops-akv-decryptor-service-principal
At this point, kustomize-controller is now authorized to decrypt values in SOPS encrypted files from your Sources via the related Key Vault.
See Mozilla’s guide to Encrypting Using Azure Key Vault to get started committing encrypted files to your Git Repository or other Sources.
Google Cloud
Workload Identity has to be enabled on the cluster and on the node pools.
Terraform
If you like to use terraform instead of gcloud, you will need the following resources from the hashicorp/google provider:
- create GCP service account: “google_service_account”
- add role KMS encrypter/decrypter: “google_project_iam_member”
- bind GCP SA to Flux kustomize-controller SA: “google_service_account_iam_binding”
- Create a GCP service account with the role Cloud KMS CryptoKey Encrypter/Decrypter.
gcloud iam service-accounts create <SERVICE_ACCOUNT_ID> \
--description="DESCRIPTION" \
--display-name="DISPLAY_NAME"
gcloud projects add-iam-policy-binding <PROJECT_ID> \
--member="serviceAccount:<SERVICE_ACCOUNT_ID>@<PROJECT_ID>.iam.gserviceaccount.com" \
--role="roles/cloudkms.cryptoKeyEncrypterDecrypter"
- Create an IAM policy binding between the GCP service account and the kustomize-controller Kubernetes service account of the flux-system.
gcloud iam service-accounts add-iam-policy-binding \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:<PROJECT_ID>.svc.id.goog[<K8S_NAMESPACE>/<KSA_NAME>]" \
SERVICE_ACCOUNT_ID@PROJECT_ID.iam.gserviceaccount.com
For a GCP project named total-mayhem-123456 with a configured GCP service account flux-gcp and assuming that Flux runs in the (default) namespace flux-system, this would translate to the following:
gcloud iam service-accounts add-iam-policy-binding \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:total-mayhem-123456.svc.id.goog[flux-system/kustomize-controller]" \
flux-gcp@total-mayhem-123456.iam.gserviceaccount.com
- Customize your Flux Manifests and patch the kustomize-controller service account with the proper annotation so that Workload Identity knows the relationship between the gcp service account and the k8s service account.
### add this patch to annotate service account if you are using Workload identity
patchesStrategicMerge:
- |-
apiVersion: v1
kind: ServiceAccount
metadata:
name: kustomize-controller
namespace: flux-system
annotations:
iam.gke.io/gcp-service-account: <SERVICE_ACCOUNT_ID>@<PROJECT_ID>.iam.gserviceaccount.com
If you didn’t bootstap Flux, you can use this instead
kubectl annotate serviceaccount kustomize-controller \
--field-manager=flux-client-side-apply \
--namespace flux-system \
iam.gke.io/gcp-service-account=<SERVICE_ACCOUNT_ID>@<PROJECT_ID>.iam.gserviceaccount.com
Bootstrap
Note that when using flux bootstrap you can set the annotation to take effect at install time.
GitOps workflow
A cluster admin should create the Kubernetes secret with the PGP keys on each cluster and add the GitRepository/Kustomization manifests to the fleet repository.
Git repository manifest:
apiVersion: source.toolkit.fluxcd.io/v1
kind: GitRepository
metadata:
name: my-secrets
namespace: flux-system
spec:
interval: 1m
url: https://github.com/my-org/my-secrets
Kustomization manifest:
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: my-secrets
namespace: flux-system
spec:
interval: 10m0s
sourceRef:
kind: GitRepository
name: my-secrets
path: ./
prune: true
decryption:
provider: sops
secretRef:
name: sops-gpg
Hint
You can generate the above manifests using flux create <kind> --export > manifest.yaml.
Assuming a team member wants to deploy an application that needs to connect to a database using a username and password, they’ll be doing the following:
- create a Kubernetes Secret manifest locally with the db credentials e.g.
db-auth.yaml - encrypt the secret
datafield with sops - create a Kubernetes Deployment manifest for the app e.g.
app-deployment.yaml - add the Secret to the Deployment manifest as a volume mount or env var
- commit the manifests
db-auth.yamlandapp-deployment.yamlto a Git repository that’s being synced by the GitOps toolkit controllers
Once the manifests have been pushed to the Git repository, the following happens:
- source-controller pulls the changes from Git
- kustomize-controller loads the GPG keys from the
sops-pgpsecret - kustomize-controller decrypts the Kubernetes secrets with SOPS and applies them on the cluster
- kubelet creates the pods and mounts the secret as a volume or env variable inside the app container
- 48 次浏览
【数据安全】使用SOPS管理Git中的秘密-常见操作
视频号
微信公众号
知识星球
用SOPS管理Git中的秘密(5部分系列)
- 使用SOPS在Git中管理您的秘密
- 使用SOPS管理Git中的秘密-常见操作
- 使用SOPS和GitLab CI在Git中管理您的秘密🦊
- 使用Kubernetes的SOPS在Git中管理您的秘密☸️
- 使用Kuectl&Kustomize的SOPS在Git中管理您的秘密🔧
我们在上一篇文章中看到了如何使用SOPS在Git中存储我们的秘密。在这里,我们将看到使用SOPS时需要的一些常见操作。
编辑机密
Alice想更改dev_asecret中的值。为此,她可以使用sops dev_a.encrypted.env命令打开$EDITOR并允许就地更改。
place changes.
After the edition, the secret is encrypted back, and she can commit the file in Git.
向其他人添加秘密访问权限
Alice would like to let Bobby read the dev_a secret. To do that, she will use sops --rotate --in-place --add-pgp <bobby-key-id> dev_a.encrypted.env command.
After this modification, Bobby can fetch modifications. He is now able to read (and modify) the secret.
删除对其他人的秘密访问
Alice now wants to remove Bobby access to dev_a secret. She is able to do this by using the sops --rotate --in-place --rm-pgp <bobby-key-id> dev_a.encrypted.env.
After this, Bobby is unable to decrypt the secret anymore.
配置自动钥匙选择
Like we saw before, sops commands often requires references to key-id of people concerned by the modification... and this is error prone and hard to manage if you share access with a lot of people.
To simplify this, the team can create a file, named .sops.yaml and placed it in the root of our Git repository.
creation_rules:
# Specific to `dev_a` env
- path_regex: dev_a\.encrypted\.env$
# Here, only the `Alice` key-id
pgp: >-
5844C613B763F4374BAB2D2FC735658AB38BF93A
# Specific to `int` env
- path_regex: int\.encrypted\.env$
# Here, we have :
# * `Alice` key-id: 5844C613B763F4374BAB2D2FC735658AB38BF93A
# * `Bobby` key-id: AE0D6FD0242FF896BE1E376B62E1E77388753B8E
# * `Devon` key-id: 57E6DA39E907744429FB07871141FE9F63986243
pgp: >-
5844C613B763F4374BAB2D2FC735658AB38BF93A,
AE0D6FD0242FF896BE1E376B62E1E77388753B8E,
57E6DA39E907744429FB07871141FE9F63986243
# Specific for new env `dev_a_and_b`
- path_regex: dev_a_and_b\.encrypted.env$
# Here, we have only `Alice` and `Bobby` :
# * `Alice` key-id: 5844C613B763F4374BAB2D2FC735658AB38BF93A
# * `Bobby` key-id: AE0D6FD0242FF896BE1E376B62E1E77388753B8E
pgp: >-
5844C613B763F4374BAB2D2FC735658AB38BF93A,
AE0D6FD0242FF896BE1E376B62E1E77388753B8E
Here, Bobby will create a new secret for dev_a_and_b env just with the command sops dev_a_and_b.encrypted.env. No more --pgp <key-id>, sops automatically selects the closest .sops.yaml file from the CWD (see this).
Keys are selected by matching a regex againt the path of the file, so possibilities are wide and this is simpler than using parameters in command line !
添加或删除访问权限 .sops.yaml
If a .sops.yaml file is used, Alice can simplify the add-pgp or rm-pgp command previously seen. She just need to change the .sops.yaml and use the command sops updatekeys dev_a.encrypted.env to update who can decrypt the file.
结论
Those are the most common operations required to use sops in your project. This is simple and still helps you to keep your secrets in sync with your code !
You can find the source code of this article, files, and scripts in this GitLab repository.
- 59 次浏览
【数据安全】保护数据隐私 - 解决方案架构师的义务
数据隐私失败
过去几年出现了一个转折点,即人们越来越意识到组织如何使用他们的数据以及掌握个人数据所带来的责任。

最近的例子
在公司保护数据隐私的一些重大缺陷之后:
- Equifax Data Breach One Year Later
- Marriott Breach Exposes More Than Data
- Cathay Pacific faces probe over massive data breach
这些违规行为导致公众对个人数据的重要性和价值的认识不断提高。各国政府也注意到个人数据泄露事件的影响越来越大,并且已经引入了诸如GDPR和强制性数据泄露通知法等立法。
政府和公民都在越来越多地质疑公司如何收集,使用(和滥用)人们的数据。
设计数据隐私
适当的隐私和安全控制的义务也扩展到解决方案架构师和设计师。收集或消费个人数据的解决方案需要考虑并包含适当的保护措施以保护个人隐私。
在设计解决方案时,我们遵循功能性和非功能性要求,技术前景和组织路线图。数据隐私不应该被方便地划分,省略或作为非功能性要求的事后考虑。解决方案架构师需要将数据隐私的影响视为解决方案设计的关键基础。 MVP解决方案仍然需要提供足够的安全控制,因为维护数据隐私应始终位于MVP范围内。
解决方案架构师可以发挥作用,确保解决方案所有者了解并考虑投资保护用户数据隐私的解决方案的必要性。采用安全的设计方法越来越重要。
基础
从解决方案的角度来看,大多数解决方案都会关注传统的控制方法:
- 对用户进行身份验证,希望使用比用户名,密码更强大的功能,即多因素,密码强度检查
- 验证集成端点和集成安全策略的应用
- 保护飞行和休息时的数据
- 记录用户事件和数据更改。
但是,虽然这些类型的控制解决了访问和身份的情况,但还有其他需要考虑的方案。并非所有危害数据隐私的安全威胁都来自外部来源。我们必须承认,没有万无一失的解决方案。我们需要考虑如果违反解决方案安全机制或通过忽视或错误暴露数据会发生什么。如果组织的安全性失败或被接管,会发生什么?是否会维护数据控制?如果通过疏忽暴露用户数据会发生什么?
最近的历史有许多大小公司的例子,这些公司可能成为不能充分保护其客户数据的受害者。看到
- List of data breaches in Australia 2018-2019
- Saudi caller ID app exposes 5 million users
- 21 biggest data breaches if 2018
在设计时考虑到数据安全性
从这些示例中学习应该考虑到您的解决方案设计以及操作安全控制。采用“安全设计”原则是加强保护客户数据整体能力的重要方面:
- 仅存储对业务流程至关重要的个人数据。您真的想通过收获和存储您实际不需要的数据来扩大用户影响的风险吗?
- 实现控制和计划,以便在不再需要时销毁数据
- 在不需要用户身份时去识别数据,例如,分析,
- 主动监控日志中的可疑活动(内部和外部)
- 确保生产数据不会用于测试数据。
- 数据存储的分区和分区,因此可以使用不同的密钥或算法分别加密每个数据存储,并减轻单个数据存储违规的影响。
- 定期更新加密密钥和重新加密数据的机制。
- 您真的需要拥有或存储可识别个人身份的数据吗?可以使用代理数据对用户进行分类而不是识别它们吗?
- 解决方案所有者是否了解其在澳大利亚隐私原则下的义务?
当今出现的解决方案越来越多地利用云平台的灵活性和经济性来运行更大的数据集。连接的物联网设备的增长将数据提供给解决方案,再加上机器学习的潜在用途,可以关联不同的数据集,这进一步强化了积极考虑解决方案如何保护用户数据隐私的需求。
人们正在意识到数据隐私的重要性和价值。全面的T&C协议复选框不是忽略解决方案设计隐私或接受不考虑数据隐私的要求的借口。

让真正的数据所有者负责
最终,个人应该是他们私人数据的唯一所有者,并且该所有权可以控制谁拥有他们的数据以及如何使用它们。我们需要解决方案来考虑如何让用户控制他们的数据。随着GDPR,CDR以及数据泄露和信任违规的影响等立法继续在主流渠道中具有很高的知名度,这将成为客户的强制要求。
想象一下,个人维护自己的私有数据平台的解决方案。用户必须具有易于使用的控件,以便为选定的个人和组织生成有限的数据访问密钥,并且可以根据需要或在指定的时间段内撤销数据访问密钥。
这听起来很像OAuth OpenID Connect方法,用户拥有容纳其私有数据的数据平台。根据您对信任的看法,这可能是像Facebook这样的公共平台,但我怀疑有一种易于使用,面向消费者的私有数据平台服务的可能性,使个人能够控制他们的数据共享和访问。
一旦您授予组织访问权限(即使有限),就没有技术手段阻止他们在未经您许可的情况下存储和重新分发您的数据。仍然需要对数据滥用进行适当的政府控制和处罚。
较低的技术门槛不会降低义务
云平台提供丰富的功能,同时降低了进入小型组织的成本。这使得具有高级数据匹配和处理功能的大型数据集可以进入小型公司的业务范围,这些公司的人员数量很少,而且不包括具有不同风险和合规角色的人员。这并没有消除他们保护数据隐私的义务,并且解决方案架构师放大了确保隐私作为解决方案设计的固有元素得到解决的需求。
结论
使用云平台服务构建的解决方案的支持能力以及越来越容易跨数字渠道的集成使我们能够以比传统的内部部署解决方案更低的成本构建功能丰富的解决方案。这减少了进入障碍,但也增加了架构师在设计过程中认真和主动地考虑数据隐私控制和安全性的重要性。
- 75 次浏览
【数据安全】加密切碎
加密粉碎是通过故意删除或覆盖加密密钥来“删除”数据的做法。[1]这要求数据已加密。数据来自以下三种状态:静态数据,传输中的数据和使用中的数据。在CIA保密性,完整性和可用性三元组中,所有三个州都必须得到充分保护。
当信息的机密性受到关注时,像旧备份磁带一样摆脱静态数据,存储在云中的数据,计算机,电话和多功能打印机可能具有挑战性;当加密到位时,它可以平滑地处理数据。机密性和隐私是加密的重要驱动因素。
动机
删除数据的动机可能是:缺陷产品,旧产品,不再使用数据,没有合法权利保留数据等等。法律义务可能来自以下规则:被遗忘的权利,通用数据保护法规等
使用
在某些情况下,所有内容都是加密的(例如硬盘,计算机文件,数据库等),但在其他情况下只有特定数据(例如护照号码,社会安全号码,银行帐号,人名,数据库中的记录等)是加密。此外,一个系统中的相同特定数据可以用另一个系统中的另一个密钥加密。每个数据片段的加密程度越高(使用不同的键),可以将更具体的数据切碎。
示例:iOS设备在激活“擦除所有内容和设置”时通过丢弃“可擦除存储”中的所有密钥来使用加密粉碎。这会使设备上的所有用户数据无法访问。[2]
最佳做法
- 安全地存储加密密钥对于切碎有效非常重要。加密密钥在已被泄露(复制)后被粉碎时无效。可信平台模块解决了这个问题。硬件安全模块是使用和存储加密密钥的最安全方法之一。
- 自带加密是指云计算安全模型,以帮助云服务客户使用自己的加密软件并管理自己的加密密钥。
- Salt:Hashing可能不足以保密,因为哈希总是相同的。例如:特定社会安全号码的哈希值可以通过彩虹表格进行逆向设计。 Salt解决了这个问题。
安全考虑
- 当计算机变得更快或发现缺陷时,加密强度会随着时间的推移而变弱。
- 暴力攻击:如果数据没有充分加密,仍然可以通过强力解密信息。量子计算有可能在未来加速蛮力攻击。[3]然而,量子计算对抗对称加密的效率低于公钥加密。假设使用对称加密,最快的攻击是Grover的算法,可以通过使用更大的密钥来减轻这种影响。[4]
- 正在使用的数据。例如:临时在RAM中使用的(明文)加密密钥可能受到冷启动攻击,硬件高级持续威胁,rootkit / bootkits,计算机硬件供应链攻击以及来自内部人员(员工)的计算机的物理威胁的威胁。
- 数据剩磁:例如:当硬盘上的数据在存储后加密时,硬盘上仍有可能存在未加密的数据。加密数据并不意味着它将覆盖未加密数据的完全相同位置。此外,坏扇区也无法加密。在存储数据之前最好加密。
- 休眠对使用加密密钥构成威胁。当加密密钥加载到RAM中并且机器在此时休眠时,所有内存(包括加密密钥)都存储在硬盘上(加密密钥的安全存储位置之外)。
上述安全问题并非特定于加密粉碎,而是一般适用于加密。除了加密粉碎,数据擦除,消磁和物理粉碎物理设备(磁盘)可以进一步降低风险。
See also
参考
- Crypto-shredding in 'The Official ISC2 Guide to the SSCP CBK' ISBN 1119278651
- ^ Crypto-shredding using effaceable storage in iOS on stanford.edu
- ^ Factsheet post quantum cryptography on ncsc.nl
- ^ Post Quantum-Crypto for dummies on wiley-vch.de
原文:https://en.wikipedia.org/wiki/Crypto-shredding
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 129 次浏览
【数据安全】加密破碎:它如何解决现代数据保留挑战
对于需要高级别密钥安全性保证的场景,密钥可以由中间服务加载,该中间服务代表应用程序加密和解密数据。 这意味着业务应用程序永远不会收到密钥,因此可以更好地保证密钥没有泄露或泄露。 像这样的解决方案的影响是每个受保护数据的序列化,传输和反序列化所涉及的计算和网络开销。 这种方法不适用于除了琐碎的系统之外的所有系统。
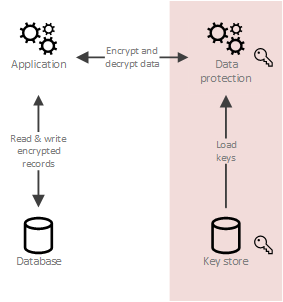
图06:一个简单的应用程序,它提取关键操作以提高密钥的安全性。
数据和密钥具有同等重要的价值
解密数据和解密密钥都表示相等的值。泄露的解密数据的影响通常会传达财务,声誉和法律风险。如果泄露了解密密钥,则无法自信地应用加密破碎。如果密钥存在于某处,则加密的个人数据是可恢复的,因此不符合被遗忘权的要求。
个人数据和解密密钥都非常有价值,需要加以保护。因此,将解密密钥与减轻前一示例中的计算和网络负载的应用程序共享是切实可行的。
但是,密钥遍历的范围不应超过内部处理。在与第三方交互时,应共享解密数据,因为客户密钥不应离开组织。第三方可以使用自己的密钥库实现自己的加密碎化实现。如果GDPR适用,它负责确保第三方遵守GDPR要求的组织。
图07:组织是密钥和加密数据的边界。第三方应该接收解密数据 - 它们也可能实现密钥粉碎,但它应该使用自己的密钥。
数据保护服务是可选的,但在较大的应用程序中,它的作用是对关键用途的抽象和审计。
查询数据
由于每个记录都使用自己的密钥进行单独加密 - 持久层无法访问 - 因此查询数据集变得极其困难且性能也很差。为了找到1980年代出生的所有客户,有必要解密每条记录的出生日期字段以识别匹配的客户。这将需要相当于数据库中记录数量的许多密钥。
加密粉碎的目的是让我们有效地擦除个人数据而不必改变历史档案。它不是试图保护静止或传输中的数据 - 还有其他技术可以实现这一目标。
如果数据未持久保存到任何形式的长期备份或存档,则以未加密的形式维护数据是合理的。因此,我们可以将未加密形式的数据复制到系统的缓存层。可以针对此缓存层执行查询。缓存层可以是或可以不是主存储器下面的相同存储技术。
图08:客户数据的解密副本。 这不应该长期存储。
缓存层和主存储库之间的主要区别是可变性和持久性。 应用程序不应直接写入缓存。 只有在数据以加密形式成功写入主存储时,才应更新缓存。 这可确保可以从主存储重建缓存,因此不需要长期持久性。 如果缓存失败,则可以重建它而不会丢失任何数据。 出于可用性目的,应该使用与主存储相同的高可用性要求来处理缓存层。
实现缓存可能看起来像最终的一致性架构。 构建缓存将需要访问密钥来解密数据。
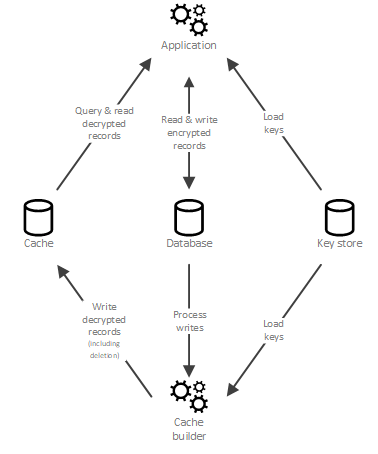
图09:包含用于查询操作的解密数据存储的体系结构中的组件之间的数据流。
对于对最终一致性具有较低容忍度的应用程序,可能需要在大多数时间从主存储中读取。仍然需要对缓存层执行查询,但可以从主存储加载结果。
如果对最终一致性没有容忍度,则应用程序可以在单个分布式事务中写入主存储和缓存。这为应用程序层增加了相当大的存储和事务复杂性。现代系统应该旨在避免这种情况。
分析处理
大多数组织都需要对个人数据进行分析处理。在这些情况下,需要解密数据以构建数据仓库。要实现被遗忘的权利,数据仓库填充过程应检测并删除已删除的个人数据。由于数据仓库将存储解密的个人数据,因此应遵循与密钥存储类似的保留做法。数据仓库应避免存储无法从主存储重建的任何数据。
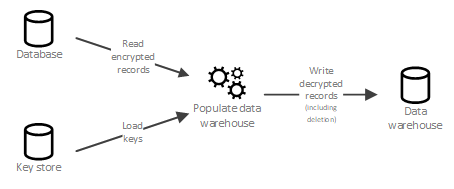
图10:使用解密的客户数据填充数据仓库的过程。
对于事务处理,可以使用高速缓存来促进数据的查询。 这需要一个完全填充的缓存。 然后,这个相同的缓存将用于重建数据仓库 - 而不是还需要加载密钥和解密记录的ETL。 这将减少处理时间以及密钥库上的耦合。
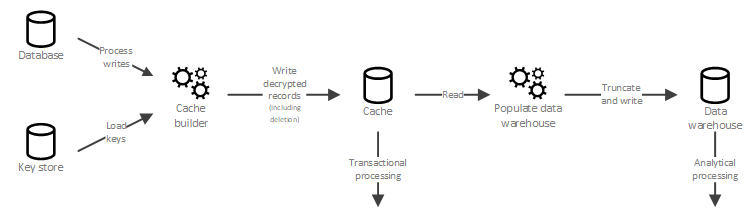
图11:使用缓存填充数据仓库,减少处理。
其他处理注意事项
法律保留和限制处理
可能存在有效擦除个人数据不可行的情况。这种情况可能涉及法律诉讼,其中法律要求组织保留个人数据,而不管被遗忘的权利如何。在某些情况下,可能有必要在不删除数据的情况下阻止对个人数据的任何进一步处理。
GDPR承认可能无法行使被遗忘权的少数案件,例如:
......不适用于必要的处理范围
(b)遵守法律义务......
(e)设立,行使或辩护法律索偿。
GDPR:第三章,第17条,第3点
GDPR规定客户可以请求暂停数据处理,但数据可能不会被删除。
数据主体有权从控制器获得处理限制......
GDPR:第三章,第18条,第1点
为了解决这些情况,可以修改密钥存储以跟踪被遗忘的权利是否被搁置,或者处理是否受到限制。
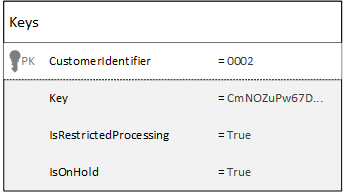
图12:用于跟踪受限处理和数据保留保留的示例数据结构。
在此实现中,受限制处理意味着不应使用密钥来解密客户数据以进行正常的日常处理。 它应该只用于解决限制。 保持意味着无法从密钥库中删除密钥。 相反,这也意味着不应从主要商店中删除客户数据。 限制处理和保持可以独立运行 - 也就是说,一个不会强制执行另一个。
图13:处理和保留的限制。
恢复已删除的数据
虽然被遗忘的权利强制个人从组织中删除其数据的权利,但GDPR还对组织提出了保护数据完整性的要求。
“个人数据应采用以下方式处理:使用适当的技术或组织措施(”完整性和机密性“),确保个人数据的适当安全性,包括防止未经授权或非法处理以及意外丢失,破坏或损坏。 “
GDPR:第二章,第5条,第1f点
可以实现被遗忘的权利,同时还使用户能够恢复其数据。这可能适用于客户帐户遭到入侵,提交恶意删除请求或仅仅为客户提供改变主意的时间窗口的情况。
当收到被遗忘的请求权时,组织必须有效地删除数据而不会有不适当的延迟。组织可以通过使用仅为用户知道的短语加密客户密钥来实现此目的。随着时间的推移,组织可以删除加密的密钥,从而消除数据的任何可恢复性。
删除请求后,密钥库可能如下所示:
图14:用于跟踪可恢复删除请求的数据结构示例。
密钥已被删除,并标记为删除。密钥以加密形式存储,其中只有用户知道解密短语。为了防止恶意删除请求,应该生成该短语并通过现有的可信信道(例如,经过验证的电子邮件地址)发送给用户。要恢复用户的数据,将对解密和恢复加密密钥,允许应用程序再次读取客户数据。如果删除日期未恢复密钥,则应删除密钥以及客户的数据。
在原始删除请求的每一点上,组织都有效地擦除了客户的数据 - 因为它无法处理数据。虽然逻辑控制可以实现类似的结果,但它不符合GDPR的要求,它强制执行删除处理而没有不适当的延迟。
真实世界的加密切碎
加密粉碎是一个相对较新的概念,由不断变化的技术和政治环境驱动。数据保留的加密粉碎解决方案解决了GDPR的几个技术上困难的要求。它还为应用程序如何使用和分发个人信息带来了广泛的挑战。每种技术解决方案都有其自身的优点,并将以不同方式满足法规遵从性。加密粉碎应该在法律要求和技术能力之间取得平衡,因为它带来了显着的技术复杂性。随着实施开始存在和发展,加密粉碎和类似解决方案可能会变得司空见惯,就像前几年密码散列和信用卡数据加密一样。加密粉碎是另一种保护现代系统和社会数据的技术。
免责声明:您应该检查您的法律义务以及您的技术实施如何与法律专业人士保持一致。本文不是关于如何实现GDPR合规性的法律建议。
本文:http://pub.intelligentx.net/node/559
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 126 次浏览
【数据安全】可信执行环境:Open Enclave SDK
构建基于可信执行环境的应用程序,通过开源SDK帮助保护使用中的数据,该SDK跨飞地技术以及从云到边缘的所有平台提供一致的API界面。
什么是Open Enclave SDK?
机密计算是一项持续不断的工作,旨在保护数据在其整个生命周期中的静止、传输和使用。通过使用“信任执行环境”,客户可以构建在使用过程中保护数据免受外部访问的应用程序。Open Enclave SDK是一个开源SDK,旨在为开发人员创建一个统一的加密抽象,以构建基于可信执行环境(TEE)的应用程序。随着TEE技术的成熟和不同实现的出现,Open Enclave SDK致力于支持一个API集,该API集允许开发人员一次构建并部署在多个技术平台、从云到混合到边缘的不同环境以及Linux和Windows。
基于可信执行环境(TEE)的应用程序开发
飞地应用程序将自己划分为两个组件(1)不受信任的组件(称为主机)和(2)受信任的部件(称为飞地)。主机组件在不受信任的操作系统上未经修改地运行,而受信任的组件则在TEE实现提供的受保护容器内运行。这些保护措施允许飞地执行安全计算,并保证不会泄露机密。
核心原则
普遍的
- 推广飞地应用程序模型,以最小化硬件/软件特定概念
可插拔的
- 组件化以支持所需的运行时和加密库
标准化
- 删除硬件供应商特定的签名和验证要求
多平台
- 考虑到多个软件平台(Windows和Linux)的设计
可共用的
- 更容易启用可重新分发的应用程序
开放
- 开源和基于安全领域的应用程序开发标准
支持的SDK功能
✔飞地创建和管理
函数调用以管理应用程序中飞地的生命周期
✔飞地测量和识别
飞地测量和身份的表达
✔表达
定义呼入和呼出以及与之相关的数据编组的机制
✔系统原语
飞地运行时公开的系统原语,如线程和内存管理
✔密封
支持秘密持久性的功能
✔证明
支持身份验证的功能
✔运行时和加密库
可插入的库,在一个飞地内提供必要的语言和密码支持
- 224 次浏览
【数据安全】如何为您的应用程序选择JOSE / JWT加密算法
JavaScript Object Signing and Encryption(JOSE)采用了一系列标准加密算法,包括新的Edwards曲线算法(2017年增加)。 那么您应该使用哪种算法来保护您的应用程序中的JSON Web令牌(JWT)或其他对象? 本指南将为您提供做出明智选择的基本标准。 但是,也要咨询该领域的文章,文献和专家,仔细检查您的假设,并确保没有错过任何关键。
常见的数据安全问题
我们保护数据(如令牌)的需求通常源于一个或多个问题:
|
完整 关注:该数据未被篡改 |
关注:可以验证数据的来源 |
|
|
|




{kind=link}
了解我们所追求的安全方面是选择合适的JOSE算法的第一步。
可用的JOSE算法类
JOSE提供三种不同类型的加密算法,以满足四个安全问题,具有部分重叠的属性:
| Integrity | Authentication | Non-repudiation | Confidentiality | |
|---|---|---|---|---|
| HMAC |
✔ | ✔ | ||
| Digital signatures | ✔ | ✔ | ✔ | |
| Authenticated encryption | ✔ | ✔ | ✔ |
- HMAC算法:一种特殊的超高效散列(HMAC),用于确保数据的完整性和真实性。 为了计算HMAC,您需要一个密钥。
- 数字签名:提供HMAC的属性,以及加密的不可否认性(允许除签名者之外的其他人检查签名的有效性)。 数字签名基于公钥/私钥加密。 需要公钥/私钥对(RSA类型,椭圆曲线(EC)或Edwards曲线八位字节密钥对(OKP))。
- 经过身份验证的加密:加密数据,同时确保其完整性和真实性(如HMAC)。 JOSE使用公钥/私钥,秘密(共享)密钥和密码提供加密。
1.基于哈希的消息认证码(HMAC)
| Provide | Integrity, Authentication |
|---|---|
| JOSE format | JSON Web Signature (JWS) |
| Key type | Secret key |
| Algorithms | HMAC with SHA-2:
|
| Use cases |
|
| Notes |
|
HMAC算法(具有JOSE alg标识符HS256,HS384和HS512)是保护令牌和其他需要发送或存储在外部的信息的理想选择,以便最终由发布应用程序使用。这里的关键问题是确保1)数据恢复时的完整性,2)数据实际上是由我们生成的。
一个很好的例子是使用HMAC安全的JWT来生成无状态会话cookie。 JWT可以包括有关登录用户的ID和其他信息。当Web应用程序收到cookie时,重新计算HMAC并与JWT进行比较。如果两个HMAC不匹配,我们可以假设cookie已被篡改,或者不是我们的。
示例JWT声明了无状态会话cookie:
{
“sub”:“user-12345”,
“email”:“alice@wonderland.net”,
“login_ip”:“172.16.254.1”,
“exp”:1471102267
}
一种常见的误解是消息认证码符合数字签名的要求。他们没有!这是因为验证需要访问用于计算HMAC的原始密钥,并且就其性质而言,您无法与其他人共享该密钥,也无法让他们生成自己的HMAC。如果您想要不可否认性,请使用RSA,EC或EdDSA签名。
2.数字签名
| Provide | Integrity, Authentication, Non-repudiation |
|---|---|
| JOSE format | JSON Web Signature (JWS) |
| Key type | Public / private key pair:
|
| Algorithms | RSA signature with PKCS #1 and SHA-2:
Edwards-curve DSA signature with SHA-2:
|
| Use cases |
|
| Notes |
|
数字签名适用于发布令牌,声明,断言和文档,其完整性和真实性必须由其他方验证。
示例用途:
- 由OpenID提供商发布的身份令牌,依赖方需要验证该签名才能登录用户。
- OAuth 2.0服务器发出的访问令牌,资源服务器/ Web API必须在提供请求之前验证。
数字签名仅适用于公钥/私钥:
- 发行者需要在签署JWT或其他对象之前生成公钥/私钥对。
- 签名是使用私钥计算的,私钥必须始终保持安全,否则存在冒充的风险。
- 使用公钥验证JWT或JWS对象的签名。接收者可以发现和下载公钥的方法是特定于应用程序的。例如,OpenID Connect服务器以JWK格式在URL上公布其公钥。
选择哪种数字签名算法?
- 如果您正在寻求广泛的支持,请选择RS256。该算法基于RSA PKCS#1,它仍然是最广泛使用的公钥/私钥加密标准。任何体面的JWT库都应该支持它。 RSxxx签名也需要很少的CPU时间来验证(有利于确保在资源服务器上快速处理访问令牌)。建议的RSA密钥长度为2048位。
- ESxxx签名算法使用椭圆曲线(EC)密码术。它们需要更短的键并产生更小的签名(相当于RSA强度)。 EC签名有一个缺点:他们的验证速度明显较慢。
- 新的Edxxx算法提供了最佳的符号/验证性能组合。特别是签名在2048位RSA上提升62倍,在EC DSA上用P-265曲线提升14倍。
我们有RSA,EC和EdDSA签署的JWT的示例。
3.认证加密
| Provide | Confidentiality, Integrity, Authentication |
|---|---|
| JOSE format | JSON Web Encryption (JWE) |
| Key type |
|
| Algorithms | Public / private key encryption:
Secret (shared) key encryption:
Password based encryption:
|
| Use cases |
|
| Notes |
|
JOSE提供以下加密:
- 一个密钥( secret key)。如果你想为自己加密数据。 如果密钥与其他方共享(by some out-of-band mean),它们也可以用它加密数据/解密密文。 请查看上表,了解可用的密钥加密算法。
- 收件人提供的公钥(RSA,EC或OKP)。例如,OpenID Connect提供程序以可发现的URL以JWK格式发布其公钥。然后,收件人可以使用其匹配的私钥解密JWT / JOSE对象。公共/私有密钥加密是在无法或不可行地传送带外密钥的情况下的理想选择(Public / private key cryptography is ideal in situations where communicating a secret key out-of-band is not possible or feasible)。
- 如果要使用您能记住的某些短语加密数据,请使用密码。
JOSE中的加密始终是经过身份验证的,这意味着密文的完整性可以防止被篡改。因此,经过身份验证的加密使得在JSON Web加密(JWE)冗余中嵌套HMAC JWT;仅使用JWE加密。
JWE加密是一个“两步”过程:
- 数据或内容始终使用AES密钥(称为内容加密密钥或CEK)进行加密,并且每个JWT / JWE对象使用不同的CEK。 Nimbus库将自动为您生成此AES密钥,其长度将取决于enc(加密方法)标头参数(例如,“enc”:“A128GCM”将导致生成128位AES密钥)。除了三种AES密钥长度(128,198和256)的选择外,JOSE还支持两种内容加密模式:AxxxCBC-HSxxx和AxxxGCM。 AxxxCBC-HSxxx模式通常得到更广泛的支持。
- 第二步是使用输入密钥(即您提供的密钥,公钥或密码)加密(也称为包装)生成的AES CEK。这由alg JWE头参数指定。如果您想跳过第二步,并直接提供AES CEK,请选择直接加密并指定“alg”:“dir”JWE标头参数。
示例JWE标头,其中内容在GCM模式下使用128位AES加密,而AES CEK本身使用公共RSA密钥加密(使用RSA OAEP加密):
{
“alg”:“RSA-OAEP”,
“enc”:“A128GCM”
}
您可以查看使用RSA公钥加密JWT的示例。
嵌套签名和加密
可以对签名的JWT / JWS对象进行额外加密,从而为数据提供完整性,真实性,不可否认性和机密性。
这是通过简单的嵌套实现的(参见示例):
- JWT使用私有RSA,EC或OKP密钥签名。
- 然后,签名的JWT成为JWE对象的有效载荷(明文),该对象用接收者的公钥(RSA,EC,OKP)加密,或者用双方共享的密钥加密。
处理嵌套的JWT可以向后工作:
- 使用适当的密钥(RSA,EC或OKP的私钥或已建立的密钥)解密JWE对象。
- 然后将提取的有效负载(纯文本)解析为签名的JWT,并使用颁发者的公钥(RSA,EC或OKP)进行验证。
Nimbus JOSE + JWT库提供了一个处理嵌套JWT的完整框架。
OpenID Connect中的算法选择
在给定客户注册的情况下,以下规则可以让您了解哪些ID令牌算法是可行的:
- 具有client_secret的客户端可以接收使用HMAC(其中client_secret用作HMAC密钥)或使用签名(RSA,EC或EdDSA)保护的ID令牌。为了验证RSA,EC或EdDSA签名ID令牌,客户端只需要检索OpenID提供程序的匹配公钥(来自其JWK集URL)。
- 具有client_secret的客户端也可以接收加密的ID令牌,其中client_secret用于从中获取秘密的AES密钥。
- 如果使用HMAC,则发布的client_secrets必须足够长以适合所需的密钥长度。例如,256位client_secret允许HMAC与HS256。
- 为了使客户端能够接收RSA或ECDH加密的ID令牌,它必须具有向OpenID提供者注册的公共RSA,EC或OKP密钥。
- OpenID Connect还允许没有client_secret的客户端。此类客户端需要向OpenID提供程序注册公共RSA,EC或OKP密钥,并使用该密钥在令牌端点进行身份验证(通过JWT)。如上所述,ID令牌可以被加密到该公钥。
原文:https://connect2id.com/products/nimbus-jose-jwt/algorithm-selection-guide
本文:http://pub.intelligentx.net/node/465
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 209 次浏览
【数据安全】如何使用 Vault 在 Spring Boot 中隔离数据库凭证
如今,数据隐私和安全变得至关重要。 因此,我们需要隔离数据库凭证并使其对我们的应用程序/服务透明。
概述
在我的旧帖子中,我写了关于使用 Jasypt 加密数据库凭证的内容。但是我们仍然在属性文件中保留加密值。这意味着,在某些时候,开发人员可以解密该值并读取这些凭据。
但..
从应用程序的角度让它真正透明怎么样?我所说的透明的意思是;该应用程序对凭据一无所知。因此,在这篇博文中,我想从应用程序的角度分享如何保护您的数据库凭据。
我将使用 Hashicorp Vault 作为秘密管理工具。所有数据库凭据都将存储在 Vault 中,我将在引导应用程序时检索这些凭据。
用例
在此用例中,我将创建一个服务并将其命名为 pg_service_1。服务本身将连接到 postgres 数据库,就像任何普通服务一样。但是,不同的是,我不会在属性文件中放置任何数据库凭据配置。相反,它们将保存在 Vault 中。
pg_service_1 会将具有一定有效期的初始令牌传递给 Vault。接下来,通过使用 AppRole 身份验证模式,该服务将在应用程序启动期间使用提取秘密 ID 模式检索数据库凭据。然后虚拟服务将连接到数据库并继续准备好为请求提供服务。
For this purpose, I will have two personas, which are admin and app (pg_service_1).
Admin
第 1 步:启用 AppRole 身份验证并创建 Vault 策略、
# enable approle
vault auth enable approle
# create secret path
vault secrets enable -path=database kv-v2
# database-policy.hcl
# Read-only permission on 'database/*' path
tee database-policy.hcl <<"EOF"
path "database/*" {
capabilities = [ "read" ]
}
EOF
vault policy write database database-policy.hcl
# database-init-token.hcl
# policy for initial token
tee database-init-token.hcl <<"EOF"
path "auth/approle/*" {
capabilities = [ "create", "read", "update" ]
}
EOF
vault policy write database-init-token database-init-token.hclStep 2: Write AppRole for pg_service_1
# write approle for pg_service_1 with policy:database and ttl:1h vault write auth/approle/role/pg_service_1 policies="database" token_ttl=1h
Step 3: Store KV Data
# Store kv data
tee postgres.txt <<"EOF"
{
"url": "jdbc:postgresql://10.10.10.10:5432/db",
"username": "user",
"password": "password"
}
EOF
vault kv put database/postgres/service_1 @postgres.txt
Step 4: Generate Init Token and Pass It to App
# Generate init token for APP, valid for 3 days vault token create -policy=database-init-token -ttl=72h # Result: s.rMdwZh8udP9HVYmu1SmrSO3F
App
For App, I will use Spring Boot as our pg_service_1.
Step 1: Add vault dependencies in pom.xml
<!-- snippet code -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.vault</groupId>
<artifactId>spring-vault-core</artifactId>
</dependency>Step 2: application.yml
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: org.postgresql.Driver
hikari:
poolName: Hikari
maximum-pool-size: 5
auto-commit: false
connection-test-query: SELECT 1
jpa:
database: POSTGRESQL
hibernate:
ddl-auto: update
properties:
hibernate.jdbc.lob.non_contextual_creation: true
hibernate.connection.provider_disables_autocommit: true
vault:
appconfig:
token: ${TOKEN:default}Please note I exclude url, username and password under spring.datasouce key.
Step 3: Configure Spring Vault
@Configuration
@ConfigurationProperties(prefix = "vault.appconfig")
public class AppConfig extends AbstractVaultConfiguration {
private String token;
public String getToken() {
return this.token;
}
public void setToken(final String token) {
this.token = token;
}
@Override
public ClientAuthentication clientAuthentication() {
final VaultToken initialToken = VaultToken.of(token);
final AppRoleAuthenticationOptions options = AppRoleAuthenticationOptions
.builder()
.appRole("pg_service_1")
.roleId(RoleId.pull(initialToken))
.secretId(SecretId.pull(initialToken))
.build();
return new AppRoleAuthentication(options, this.restOperations());
}
@Override
public VaultEndpoint vaultEndpoint() {
final VaultEndpoint vaultEndpoint = VaultEndpoint.create("localhost", 8200);
vaultEndpoint.setScheme("http");
return vaultEndpoint;
}
}AppRole authentication with PULL mechanism.
Step 4: Reconfigure Datasource Configuration
@Primary
@Configuration
@ConfigurationProperties(prefix = "spring.datasource")
public class DataSourceConfig extends DataSourceProperties {
@Autowired
private AppConfig appConfig;
@Override
public void afterPropertiesSet() throws Exception {
final VaultToken login = this.appConfig.clientAuthentication().login();
final VaultTemplate vaultTemplate = new VaultTemplate(this.appConfig.vaultEndpoint(),
new TokenAuthentication(login.getToken()));
final VaultKeyValueOperations operations = vaultTemplate.opsForKeyValue("database",
KeyValueBackend.versioned());
final Map<String, Object> data = operations.get("postgres/service_1").getData();
this.setUsername((String) data.get("username"));
this.setUrl((String) data.get("url"));
this.setPassword((String) data.get("password"));
super.afterPropertiesSet();
}
}Note: set as @Primary bean, extends DataSourceProperties class and override afterPropertiesSet method.
Step 5: Start Application Using Init Token from Admin-Step 4
# pass init-token using -DTOKEN # init-token: s.rMdwZh8udP9HVYmu1SmrSO3F mvn spring-boot:run -DTOKEN=s.rMdwZh8udP9HVYmu1SmrSO3F
The service should be up and running; with connection to postgres database.
结论
通过使用这种数据库凭证隔离,我们可以确保只有某些人有权访问凭证。 这种方法将使您的 IT 生态系统更加安全、可审核和可控相关用户对生产数据库的访问
- 328 次浏览
【数据安全】如何使用 sops 加密配置文件中的机密
视频号
知识星球
相当长一段时间以来,我一直在寻找一种简单的解决方案来加密配置文件中的密码/秘密(即 Web 应用程序的配置文件中的 mySQL 密码)。 当这些文件分散在工作站文件系统或(希望是私有的)git 存储库中时,这将大大提高实际安全性,其中通常仅以加密形式存在这些秘密就足够了。 完全解密的配置文件通常仅在部署应用程序的服务器上需要。
当然,有许多解决方案可以通过外部服务器或服务(Hashicorp Vault、AWS secrets Manager等)和特定于平台/工具的解决方案(Ansible、Kubernetes、gitlab、Docker(Swarm)等中的机密管理)来正确处理机密。但它们要么增加了依赖外部服务器/服务的复杂性,要么过于特定于域。
我最近偶然发现了Mozilla的sops工具。
“sops 是加密文件的编辑器,支持 YAML、JSON、ENV、INI 和 BINARY 格式,并使用 AWS KMS、GCP KMS、Azure Key Vault 和 PGP 进行加密.”
(sops on github)
所以它的目的是加密/解密配置文件中的敏感值。 虽然它似乎主要是为了与主要云提供商的密钥管理服务集成,但它也可以使用本地安装的 PGP 来完全运行。 因此,本地安装的 sops(这是一个用 Go 编写的独立命令行工具,编译为“只是”单个二进制文件)和 GnuPG 的组合确实可以实现使任何配置文件的行为有点像密码的密码容器的愿景 像keepass这样的管理器:你必须解锁它们才能以明文形式揭示其中包含的秘密。
使用sop的简单工作流程
让我们用sop设置一个最简单的工作流程,对配置文件中的特定机密值进行加密。
Here we have a yaml file with two sensitive keys in clear text: password and pin.
$ cat test.yaml username: jonathan.archer password: StarfleetAcademy2184 pin: 1234 description: my login to LCARS
Let’s try to encrypt/decrypt these fields with sops.
- install gnupg (installers/packages for all relevant platforms are here)
- install the sops command line tool (it’s a single binary file, we can download it from the project’s github releases page and copy it to a
PATHlocation, i.e./usr/local/binorc:\windows\system32). - generate a pgp key pair (for this example with no passphrase and no expiration date):
$ gpg --batch --generate-key <<EOF %no-protection Key-Type: default Subkey-Type: default Name-Real: MyApp Config 1 Name-Email: myapp-config-1@mydomain.local Expire-Date: 0 EOF
3. find the public fingerprint for the newly generated key:
$ gpg --list-keys "myapp-config-1@mydomain.local" | grep pub -A 1 | grep -v pub68BC5F69E1F773157BA324C7ECF51418A7705AC9
4. now let’s use sops to encrypt the sensitive fields in the yaml file:
$ sops --encrypt --in-place --encrypted-regex 'password|pin' --pgp 68BC5F69E1F773157BA324C7ECF51418A7705AC9 test.yaml
or alternatively in a bit more lazy way (without having to copy and paste the fingerprint):
$ sops --encrypt --in-place --encrypted-regex 'password|pin' --pgp `gpg --fingerprint "myapp-config-1@mydomain.local" | grep pub -A 1 | grep -v pub | sed s/\ //g` test.yaml
note: if we would leave out --encrypted-regex(it’s optional), the values of all keys in the yaml file would get encrypted.
The yaml file now looks like:
$ cat test.yaml username: jonathan.archer password: ENC[AES256_GCM,data:PFzX2Q8mBsBfEDNJlgbTePYQcFM=,iv:FFls0uZktGsD4ueL1FFxXn6PnbqUpyJ5IkKn0FBtwbM=,tag:vIxYtwh/Vf09Omg0yOGRlA==,type:str] pin: ENC[AES256_GCM,data:LfljTQ==,iv:AtEKzJwO2SpZO4xA9KXEAmVuSOCkteSU5knc50SK7Uw=,tag:p9dZ7MMi+FyR72HQqmUKgg==,type:int] description: my login to LCARS sops: ...
To decrypt it to STDOUT (cat-like) on the same machine/as the same user, we could run:
$ sops --decrypt test.yaml username: jonathan.archer password: StarfleetAcademy2184 pin: 1234 description: my login
As the private key is stored in the user’s keystore (in $HOME/.gnupg) and doesn’t require a passphrase the decryption happens fully unattended. The decryption could therefore get incorporated in scripts (i.e. in an install script for our app).
5. Now what if we would need to be able to decrypt the secrets in the yaml file on another machine (i.e. to decrypt it on an app server as part of our app’s installation/upgrade procedure or on a CI runner for running tests)?
For this we could export the pgp private key from our current machine to the other machine.
On the current machine (workstation):
$ gpg --export -a "myapp-config-1@mydomain.local" > public.key $ gpg --export-secret-key -a "myapp-config-1@mydomain.local" > private.key
And on the new machine (server), under the relevant user:
gpg --import public.key gpg --allow-secret-key-import --import private.key
Now it should be possible to run sops --decrypt test.yaml unattended on our server machine as well.
一个小小的免责声明
这个工作流程(我相信)使用和入门相对简单(因此很实用),同时比在配置文件中使用纯文本密码有了很大的改进。 但它可能存在某些缺陷。 因此,它可能适合也可能不适合特定用例的安全要求,并且可能有更好的选择(即使使用 sops,它具有更强大的功能)。 正如圣堂武士所说:你必须选择,但要明智地选择。
- 290 次浏览
【数据安全】密钥库和密钥管理解决方案
视频号
微信公众号
知识星球
https://github.com/Infisical/infisical
Infisical is the open-source secret management platform: Sync secrets across your team/infrastructure and prevent secret leaks.
https://github.com/bitwarden/sdk
Secrets Manager SDK
https://github.com/tellerops/teller
Cloud native secrets management for developers - never leave your command line for secrets.
https://github.com/eth0izzle/shhgit
Ah shhgit! Find secrets in your code. Secrets detection for your GitHub, GitLab and Bitbucket repositories.
https://github.com/bitwarden/server
The core infrastructure backend (API, database, Docker, etc).
https://github.com/square/keywhiz
A system for distributing and managing secrets
https://github.com/sniptt-official/ots
Share end-to-end encrypted secrets with others via a one-time URL
https://github.com/manifoldco/torus-cli
A secure, shared workspace for secrets
https://github.com/deepfence/SecretScanner
Find secrets and passwords in container images and file systems
https://github.com/GoogleCloudPlatform/berglas
A tool for managing secrets on Google Cloud
the Crypto Undertaker
https://github.com/jkroepke/helm-secrets
A helm plugin that help manage secrets with Git workflow and store them anywhere
https://github.com/freeipa/freeipa
Mirror of FreeIPA, an integrated security information management solution
https://github.com/stakater/Reloader
A Kubernetes controller to watch changes in ConfigMap and Secrets and do rolling upgrades on Pods with their associated Deployment, StatefulSet, DaemonSet and DeploymentConfig – [✩Star] if you're using it!
https://github.com/trufflesecurity/trufflehog
Find and verify credentials
https://github.com/tink-crypto/tink-java
https://github.com/tink-crypto
A multi-language, cross-platform library that provides cryptographic APIs that are secure, easy to use correctly, and hard(er) to misuse. See also: https://developers.google.com/tink.
The Tink Cryptography Library is split into multiple repositories.
| Tink implementation | Repository |
|---|---|
| Tink Java | tink-crypto/tink-java |
| Tink C++ | tink-crypto/tink-cc |
| Tink Go | tink-crypto/tink-go |
| Tink Python | tink-crypto/tink-py |
| Tink Obj-C | tink-crypto/tink-objc |
We provide a command line interface for key management, named Tinkey
We also provide integrations with various key management systems (KMS) and other systems.
| Tink extension | Repository |
|---|---|
| Tink Java AWS KMS extension | tink-crypto/tink-java-awskms |
| Tink Java Google Cloud KMS extension | tink-crypto/tink-java-gcpkms |
| Tink Java apps extension | tink-crypto/tink-java-apps |
| Tink C++ AWS KMS extension | tink-crypto/tink-cc-awskms |
| Tink C++ Google Cloud KMS extension | tink-crypto/tink-cc-gcpkms |
| Tink Go AWS KMS extension | tink-crypto/tink-go-awskms |
| Tink Go Google Cloud KMS extension | tink-crypto/tink-go-gcpkms |
| Tink Go HashiCorp Vault KMS extension | tink-crypto/tink-go-hcvault |
https://github.com/pac4j/pac4j
https://github.com/cryptomator/cryptomator
Multi-platform transparent client-side encryption of your files in the cloud
https://medium.com/@cyberlands.io/best-secrets-management-solution-hash…
Best Secrets Management Solution: Hashicorp vs KeyWhiz
Encrypting Confidential Data at Rest
https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
https://kubernetes.io/docs/concepts/configuration/secret/
https://external-secrets.io/main/introduction/overview/
The External Secrets Operator extends Kubernetes with Custom Resources, which define where secrets live and how to synchronize them. The controller fetches secrets from an external API and creates Kubernetes secrets. If the secret from the external API changes, the controller will reconcile the state in the cluster and update the secrets accordingly.
https://cloud.yandex.com/en/services/lockbox
A service for creating and storing secrets in the Yandex Cloud infrastructure.
Create secrets in the management console or using the API.
https://walkingtree.tech/secrets-management-using-mozilla-sops/
As automation is taking place at a rapid pace, the areas where human intervention is involved are appearing as huge speed breakers. One such task is keeping the secret information with humans and providing necessary approvals as and when needed. This task does not involve a lot of logical thinking but the important aspect is keeping trustworthy information and using it for regular activity.
Keeping the secrets in a file and allowing access to information to a wider set of people will be a serious challenge. One way to solve this problem is to keep the secrets in a file but in an encrypted format and ensure only the target environment can decrypt. This way we can still allow the automation to happen and keep the environments secured.
In this blog, I will be touching upon the basics of securing secrets, introduce you to SOPS, explain to you how SOPS works and its effective use in building cloud-agnostic applications.
Manage Your Secrets with Mozilla SOPS and GitOps Toolkit (Flux CD v2)
https://medium.com/picus-security-engineering/manage-your-secrets-with-…
"Sealed Secrets" for Kubernetes
https://github.com/bitnami-labs/sealed-secrets
Safe storage of Kubernetes Secrets with Mozilla SOPS and IaC
https://softwaremill.com/safe-storage-of-kubernetes-secrets-with-mozill…
SOPS (Secrets OPerationS – Kubernetes Operator): Secure your sensitive data, while maintaining ease of use
https://deyan7.de/en/sops-secrets-operations-kubernetes-operator-secure…
Simplify and Secure Your Kubernetes Deployments with Mozilla SOPS
https://systemweakness.com/simplify-and-secure-your-aks-deployments-wit…
How to commit encrypted files to Git with Mozilla SOPS
https://blog.thenets.org/how-to-commit-encrypted-files-to-git-with-mozi…
Encrypt your Kubernetes Secrets with Mozilla SOPS
https://www.thorsten-hans.com/encrypt-your-kubernetes-secrets-with-mozi…
- 69 次浏览
【数据安全】教程:使用 Azure Key Vault 证书保护 Spring Boot 应用程序
本教程向你展示如何使用 Azure Key Vault 和 Azure 资源的托管标识通过 TLS/SSL 证书保护你的 Spring Boot(包括 Azure Spring 应用程序)应用程序。
生产级 Spring Boot 应用程序,无论是在云端还是在本地,都需要使用标准 TLS 协议对网络流量进行端到端加密。您遇到的大多数 TLS/SSL 证书都可以从公共根证书颁发机构 (CA) 中发现。然而,有时候,这种发现是不可能的。当证书不可发现时,应用程序必须有某种方式来加载此类证书,将它们呈现给入站网络连接,并从出站网络连接中接受它们。
Spring Boot 应用程序通常通过安装证书来启用 TLS。证书安装到运行 Spring Boot 应用程序的 JVM 的本地密钥库中。使用 Azure 上的 Spring,不会在本地安装证书。相反,Microsoft Azure 的 Spring 集成提供了一种安全且无摩擦的方式来借助 Azure Key Vault 和 Azure 资源的托管身份来启用 TLS。

在本教程中,您将学习如何:
- 使用系统分配的托管标识创建 GNU/Linux VM
- 创建 Azure Key Vault
- 创建自签名 TLS/SSL 证书
- 将自签名 TLS/SSL 证书存储在 Azure Key Vault 中
- 运行 Spring Boot 应用程序,其中入站连接的 TLS/SSL 证书来自 Azure Key Vault
- 运行 Spring Boot 应用程序,其中用于出站连接的 TLS/SSL 证书来自 Azure Key Vault
重要的
目前,Spring Cloud Azure Certificate starter 4.x 版本不支持 TLS/mTLS,它们仅自动配置 Key Vault 证书客户端。因此,如果要使用 TLS/mTLS,则无法迁移到版本 4.x。
先决条件
- 如果您没有 Azure 订阅,请在开始之前创建一个免费帐户。
- curl命令。大多数类 UNIX 操作系统都预装了此命令。特定于操作系统的客户端可在官方 curl 网站上获得。
- jq 命令。大多数类 UNIX 操作系统都预装了此命令。官方 jq 网站上提供了特定于操作系统的客户端。
- Azure CLI,版本 2.38 或更高版本
- 受支持的 Java 开发工具包 (JDK),版本 8。有关详细信息,请参阅 Azure 和 Azure Stack 上的 Java 支持。
- Apache Maven,版本 3.0。
重要的
完成本文中的步骤需要 Spring Boot 2.5 或更高版本。
使用系统分配的托管标识创建 GNU/Linux VM
使用以下步骤创建具有系统分配的托管标识的 Azure VM,并准备运行 Spring Boot 应用程序。有关 Azure 资源的托管标识的概述,请参阅什么是 Azure 资源的托管标识?。
- 打开 Bash 外壳。
- 注销并删除一些身份验证文件以删除任何挥之不去的凭据。
az logout rm ~/.azure/accessTokens.json rm ~/.azure/azureProfile.json
- 登录到 Azure CLI。
az login
- 设置订阅 ID。请务必将占位符替换为适当的值。
az account set -s <your subscription ID>
- 创建 Azure 资源组。记下资源组名称以备后用。
az group create \
--name <your resource group name> \
--location <your resource group region>
- 设置默认资源组。
az configure --defaults group=<your resource group name>
- 使用 UbuntuServer 提供的映像 UbuntuLTS 创建启用了系统分配的托管标识的 VM 实例。
az vm create \
--name <your VM name> \
--debug \
--generate-ssh-keys \
--assign-identity \
--role contributor \
--scope /subscriptions/<your subscription> \
--image UbuntuLTS \
--admin-username azureuser
在 JSON 输出中,记下 publicIpAddress 和 systemAssignedIdentity 属性的值。您将在本教程的后面部分使用这些值。
笔记
UbuntuLTS 这个名字是统一资源名称 (URN) 的别名,它是为像 UbuntuLTS 这样的流行图像创建的缩写版本。运行以下命令以表格格式显示缓存的流行图像列表:
az vm image list --output table
- 安装微软 OpenJDK。有关 OpenJDK 的完整信息,请参阅 Microsoft Build of OpenJDK。
ssh azureuser@<your VM public IP address>
- 添加存储库。替换以下命令中的版本占位符并执行:
wget https://packages.microsoft.com/config/ubuntu/{version}/packages-microsoft-prod.deb -O packages-microsoft-prod.deb
sudo dpkg -i packages-microsoft-prod.deb
通过运行以下命令安装 Microsoft Build of OpenJDK:
sudo apt install apt-transport-https sudo apt update sudo apt install msopenjdk-11
创建和配置 Azure Key Vault
使用以下步骤创建 Azure Key Vault,并授予 VM 的系统分配托管标识访问 Key Vault 以获取证书的权限。
在资源组中创建 Azure Key Vault。
az keyvault create \
--name <your Key Vault name> \
--location <your resource group region>
export KEY_VAULT_URI=$(az keyvault show --name <your Key Vault name>
| jq -r '.properties.vaultUri')
记下 KEY_VAULT_URI 值。你稍后会用到它。
- 授予 VM 使用证书密钥保管库的权限。
az keyvault set-policy \ --name <your Key Vault name> \ --object-id <your system-assigned identity> \ --secret-permissions get list \ --certificate-permissions get list import
创建并存储自签名 TLS/SSL 证书
本教程中的步骤适用于直接存储在 Azure Key Vault 中的任何 TLS/SSL 证书(包括自签名)。自签名证书不适合在生产中使用,但对开发和测试应用程序很有用。本教程使用自签名证书。要创建证书,请使用以下命令。
az keyvault certificate create \
--vault-name <your Key Vault name> \
--name mycert \
--policy "$(az keyvault certificate get-default-policy)"
使用安全入站连接运行 Spring Boot 应用程序
在本部分中,你将创建一个 Spring Boot 入门应用程序,其中用于入站连接的 TLS/SSL 证书来自 Azure Key Vault。
要创建应用程序,请使用以下步骤:
- 浏览到 https://start.spring.io/。
- 选择此列表后面的图片中显示的选项。
Project: Maven Project Language: Java Spring Boot: 2.7.4 Group: com.contoso (You can put any valid Java package name here.) Artifact: ssltest (You can put any valid Java class name here.) Packaging: Jar Java: 11
- 选择添加依赖项....
- 在文本字段中,键入 Spring Web 并按 Ctrl+Enter。
- 在文本字段中键入 Azure Support,然后按 Enter。您的屏幕应如下所示。
- 带有基本选项的 Spring Initializr 的屏幕截图。
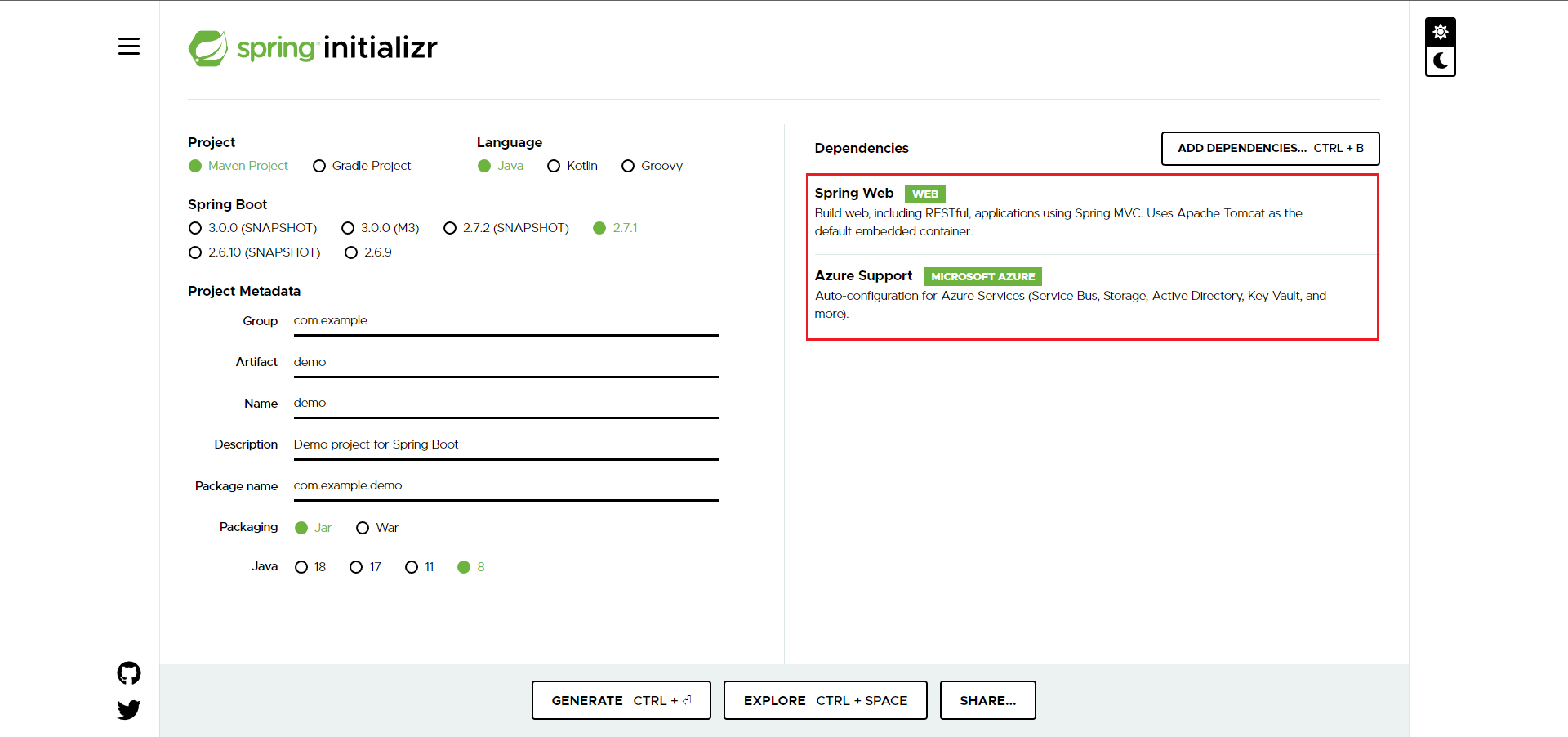
- 在页面底部,选择“生成”。
- 出现提示时,将项目下载到本地计算机上的某个路径。本教程使用当前用户主目录中的 ssltest 目录。上面的值将为您提供该目录中的 ssltest.zip 文件。
启用 Spring Boot 应用程序以加载 TLS/SSL 证书
要使应用程序能够加载证书,请使用以下步骤:
- 解压缩 ssltest.zip 文件。
- 删除测试目录及其子目录。本教程忽略测试,因此您可以放心删除该目录。
- 将 src/main/resources 中的 application.properties 重命名为 application.yml。
- 文件布局如下所示。
├── HELP.md
├── mvnw
├── mvnw.cmd
├── pom.xml
└── src
└── main
├── java
│ └── com
│ └── contoso
│ └── ssltest
│ └── SsltestApplication.java
└── resources
├── application.yml
├── static
└── templates
- 修改 POM 以添加对 azure-spring-boot-starter-keyvault-certificates 的依赖。将以下代码添加到 pom.xml 文件的 <dependencies> 部分。
<dependency> <groupId>com.azure.spring</groupId> <artifactId>azure-spring-boot-starter-keyvault-certificates</artifactId> </dependency>
- 编辑 src/main/resources/application.yml 文件,使其具有以下内容。
server:
ssl:
key-alias: <the name of the certificate in Azure Key Vault to use>
key-store-type: AzureKeyVault
trust-store-type: AzureKeyVault
port: 8443
azure:
keyvault:
uri: <the URI of the Azure Key Vault to use>- 这些值使 Spring Boot 应用程序能够执行 TLS/SSL 证书的加载操作,如本教程开头所述。下表描述了属性值。
| Property Name | Explanation |
|---|---|
| server.port | The local TCP port on which to listen for HTTPS connections. |
| server.ssl.key-alias | The value of the --name argument you passed to az keyvault certificate create. |
| server.ssl.key-store-type | Must be AzureKeyVault. |
| server.ssl.trust-store-type | Must be AzureKeyVault. |
| azure.keyvault.uri | The vaultUri property in the return JSON from az keyvault create. You saved this value in an environment variable. |
唯一特定于 Key Vault 的属性是 azure.keyvault.uri。该应用在其系统分配的托管标识已被授予访问 Key Vault 的 VM 上运行。因此,该应用程序也已被授予访问权限。
这些更改使 Spring Boot 应用程序能够加载 TLS/SSL 证书。在下一节中,您将允许应用程序执行 TLS/SSL 证书的接受操作,如本教程开头所述。
创建一个 Spring Boot REST 控制器
要创建 REST 控制器,请使用以下步骤:
- 编辑 src/main/java/com/contoso/ssltest/SsltestApplication.java 文件,使其具有以下内容。
package com.contoso.ssltest;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class SsltestApplication {
public static void main(String[] args) {
SpringApplication.run(SsltestApplication.class, args);
}
@GetMapping(value = "/ssl-test")
public String inbound(){
return "Inbound TLS is working!!";
}
@GetMapping(value = "/exit")
public void exit() {
System.exit(0);
}
}- 从未经身份验证的 REST GET 调用中调用 System.exit(0) 仅用于演示目的。不要在实际应用程序中使用 System.exit(0)。
此代码说明了本教程开头提到的当前操作。以下列表突出显示了有关此代码的一些详细信息:
- 现在在 Spring Initializr 生成的 SsltestApplication 类上有一个 @RestController 注释。
- 有一个用@GetMapping 注释的方法,其中包含您将进行的HTTP 调用的值。
- 当浏览器向 /ssl-test 路径发出 HTTPS 请求时,入站方法只返回一条问候语。 inbound 方法说明了服务器如何向浏览器提供 TLS/SSL 证书。
- exit 方法将导致 JVM 在被调用时退出。此方法有助于使示例易于在本教程的上下文中运行。
- 打开一个新的 Bash shell 并导航到 ssltest 目录。运行以下命令。
mvn clean package
- Maven 编译代码并将其打包成可执行的 JAR 文件
验证在 <您的资源组名称> 中创建的网络安全组是否允许来自您的 IP 地址的端口 22 和 8443 上的入站流量。要了解如何配置网络安全组规则以允许入站流量,请参阅创建、更改或删除网络安全组的使用安全规则部分。
- 将可执行 JAR 文件放在 VM 上。
cd target sftp azureuser@<your VM public IP address> put *.jar
在服务器上运行应用程序
现在您已经构建了 Spring Boot 应用程序并将其上传到 VM,请使用以下步骤在 VM 上运行它并使用 curl 调用 REST 端点。
- 使用 SSH 连接到 VM,然后运行可执行 jar。
set -o noglob ssh azureuser@<your VM public IP address> "java -jar *.jar"
- 打开一个新的 Bash shell 并执行以下命令以验证服务器是否提供 TLS/SSL 证书。
curl --insecure https://<your VM public IP address>:8443/ssl-test
- 调用退出路径以终止服务器并关闭网络套接字。
curl --insecure https://<your VM public IP address>:8443/exit
现在您已经看到使用自签名 TLS/SSL 证书加载和呈现操作,您将对应用程序进行一些微不足道的更改以查看接受操作。
使用安全出站连接运行 Spring Boot 应用程序
在本节中,你将修改上一节中的代码,以便出站连接的 TLS/SSL 证书来自 Azure Key Vault。因此,从 Azure Key Vault 中可以满足加载、呈现和接受操作。
修改 SsltestApplication 以说明出站 TLS 连接
使用以下步骤修改应用程序:
- 通过将以下代码添加到 pom.xml 文件的 <dependencies> 部分来添加对 Apache HTTP 客户端的依赖。
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.13</version> </dependency>
- 添加一个名为 ssl-test-outbound 的新 rest 端点。此端点为自身打开一个 TLS 套接字,并验证 TLS 连接是否接受 TLS/SSL 证书。
用以下代码替换 SsltestApplication.java 的内容。
package com.contoso.ssltest;
import java.security.KeyStore;
import javax.net.ssl.HostnameVerifier;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSession;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import com.azure.security.keyvault.jca.KeyVaultLoadStoreParameter;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.http.client.HttpComponentsClientHttpRequestFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import org.apache.http.conn.ssl.SSLConnectionSocketFactory;
import org.apache.http.conn.ssl.TrustSelfSignedStrategy;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.ssl.SSLContexts;
@SpringBootApplication
@RestController
public class SsltestApplication {
public static void main(String[] args) {
SpringApplication.run(SsltestApplication.class, args);
}
@GetMapping(value = "/ssl-test")
public String inbound(){
return "Inbound TLS is working!!";
}
@GetMapping(value = "/ssl-test-outbound")
public String outbound() throws Exception {
KeyStore azureKeyVaultKeyStore = KeyStore.getInstance("AzureKeyVault");
KeyVaultLoadStoreParameter parameter = new KeyVaultLoadStoreParameter(
System.getProperty("azure.keyvault.uri"));
azureKeyVaultKeyStore.load(parameter);
SSLContext sslContext = SSLContexts.custom()
.loadTrustMaterial(azureKeyVaultKeyStore, null)
.build();
HostnameVerifier allowAll = (String hostName, SSLSession session) -> true;
SSLConnectionSocketFactory csf = new SSLConnectionSocketFactory(sslContext, allowAll);
CloseableHttpClient httpClient = HttpClients.custom()
.setSSLSocketFactory(csf)
.build();
HttpComponentsClientHttpRequestFactory requestFactory =
new HttpComponentsClientHttpRequestFactory();
requestFactory.setHttpClient(httpClient);
RestTemplate restTemplate = new RestTemplate(requestFactory);
String sslTest = "https://localhost:8443/ssl-test";
ResponseEntity<String> response
= restTemplate.getForEntity(sslTest, String.class);
return "Outbound TLS " +
(response.getStatusCode() == HttpStatus.OK ? "is" : "is not") + " Working!!";
}
@GetMapping(value = "/exit")
public void exit() {
System.exit(0);
}
}- 构建应用程序。
cd ssltest mvn clean package
- 使用本文前面的相同 sftp 命令再次上传应用程序。
cd target sftp <your VM public IP address> put *.jar
- 在 VM 上运行应用程序。
set -o noglob ssh azureuser@<your VM public IP address> "java -jar *.jar"
- 服务器运行后,验证服务器是否接受 TLS/SSL 证书。在发出上一个 curl 命令的同一个 Bash shell 中,运行以下命令。
curl --insecure https://<your VM public IP address>:8443/ssl-test-outbound
您应该会看到消息出站 TLS 正在工作!!。
- 调用退出路径以终止服务器并关闭网络套接字。
curl --insecure https://<your VM public IP address>:8443/exit
你现在已经看到了一个简单的说明,说明了使用存储在 Azure Key Vault 中的自签名 TLS/SSL 证书进行加载、呈现和接受操作。
清理资源
使用完本教程中创建的 Azure 资源后,可以使用以下命令删除它们:
az group delete --name <your resource group name>
- 120 次浏览
【数据安全】用SOPS和GPG在2分钟内从零到保密
视频号
微信公众号
知识星球
You probably heard about mozilla/sops, but even if the readme is amazingly detailed, a from-scratch example is always nice to have.
sops, in a nutshell, bridges the gap between various key management services (PGP, AWS KMS, GCP KMS, Azure Key Vault) and you. This post will attempt to get you on your feet as fast as possible, in 3 simple steps: from “I have no idea what to do with my hands” to “No way it’s that easy!”.
Install the dependencies:
$ brew install sops gnupg
And run these 3-ish commands to convince yourself:
# Clone the example repository
$ git clone https://github.com/ervinb/sops-gpg-example.git
$ cd sops-gpg-example
# Import the encryption key
$ gpg --import <(curl -L https://gist.githubusercontent.com/ervinb/288c44a45cf2614a0684bea333b3aa36/raw/sops-gpg-example.asc)
# Decrypt and open the file
$ sops secrets/mysecrets.dev.enc.yaml
Your day-to-day interaction with this would be only the last line.
gpg --import has to be executed only once, after which the key will be part of the local keychain (persists reboots as well). That’s literally all there is to it, after following the below steps.
Do it yourself
Start the stopwatch - we have 2 minutes.
- Generate a PGP key
$ gpg --batch --generate-key <<EOF %no-protection Key-Type: default Subkey-Type: default Name-Real: Foo Bar Expire-Date: 0 EOFThe key is created without a passphrase because of the
%no-protectionoption. Otherwise aPassphrase: <pass>would be required. - Create a sops configuration file with the key’s fingeprint. This is the ✨ magic ✨ ingredient, which makes the onboarding so frictionless.
$ gpg --list-keys pub rsa2048 2020-12-06 [SC] 7E6DC556C66C43D928A95EA3715A56B718EAF0B6 uid [ultimate] Foo Bar sub rsa2048 2020-12-06 [E] $ cat .sops.yaml creation_rules: - path_regex: secrets/.*\.dev\.enc\.yaml$ pgp: 7E6DC556C66C43D928A95EA3715A56B718EAF0B6This is also perfect if you want more control over the secrets, like using different keys for different environments. For example
secrets/*.dev.enc.yamlcould use one key, andsecrets/*.prod.enc.yamlanother one. More details on this here. - Use
sopsto edit and create new secrets
$ sops secrets/mysecrets.dev.enc.yamlThen it just a question of distributing the keys to the right people and/or environment. Which brings us to Keybase.
Note for Linux users
I’ve found that both on Fedora and Ubuntu, for whatever reason, creating a new file with sops throws the following cryptic error:
$ sops secrets/new.dev.enc.yaml
<save the file in the editor>
File has not changed, exiting.
The solution is to create the file first and encrypt it in-place afterwards:
$ vi secrets/new.dev.enc.yaml
$ sops -i -e secrets/new.dev.enc.yaml
Distributing the key to firends and family
To extract the PGP key from your local keychain, use:
$ gpg --list-keys
-------------------------------
pub rsa2048 2020-12-06 [SC]
7E6DC556C66C43D928A95EA3715A56B718EAF0B6
uid [ultimate] Foo Bar
sub rsa2048 2020-12-06 [E]
$ gpg --armor --export-secret-keys 7E6DC556C66C43D928A95EA3715A56B718EAF0B6 > key.asc
--armor makes it so that the output is ASCII (.asc) formatted, and not in binary (default).
One of the most seamless ways to distribute keys and other sensitive files is Keybase. It has a low barrier of entry, and you can control the granularity of access with “teams”. It also integrates nicely with the filesystem.
- Install Keybase
$ brew install keybase - Create an account
- Create a new team and store the secret key under the team’s folder
After that, you grab the universal path and import the key to anywhere with gpg installed. Your peers can also grab the key after they join your team.
The command below imports the same PGP key we used at the beginning of the post. The sopsgpg team is open, so you can join if you want to test it out.
## The path is Keybase specific and it will work on any platform - no need to use your local filesystem path.
## Join the 'sopsgpg' team in Keybase first.
$ gpg --import <(keybase fs read /keybase/team/sopsgpg/pgp/key.asc)
Use it in your applications
To use the decrypted values in your application, you can just add a line to your setup scripts to run
sops -d secrets/mysecret.dev.enc.yaml > configuration.yaml
(make sure to add the decrypted files to .gitignore)
For Terraform projects use terraform-sops, and if you’re into Terragrunt, it has a built-in sops_decrypt_file function.
You will be running sops only to create or edit secrets, otherwise, it will be invisible (and incredible).
- 71 次浏览
【数据安全】采用HashiCorp Vault :第N天
存储密钥轮换
存储密钥对存储在Vault中的每个秘密进行加密,并且仅在内存中未加密。 只需向正确的API端点或CLI发送呼叫,即可在线轮换此密钥:
$ vault operator rotate Key Term 3 Install Time 01 May 17 10:30 UTC
这需要在策略上设置的权限。从旋转密钥的时间点开始,每个新密钥都用新密钥加密。这是一个相当简单的过程,大多数组织每六个月进行一次,除非有妥协。
主钥匙旋转
主密钥包装存储密钥,并且只在内存中未加密。使用自动开封时,主密钥将由密封密钥加密,并且将为某些操作提供恢复密钥。此过程也是在线的,不会造成任何中断,但需要密钥持有者输入其当前的分片或恢复密钥以验证过程,并且它的时间限制。该程序的执行方式如下:
- 密钥持有者将其GPG公钥发送给运营商。
- 操作员将启动重新键入过程,提供密钥持有者GPG公钥,并从Vault中检索随机数。
- 该随机数被移交给主要官员以验证该操作。法定人数的主要官员继续提交他们的钥匙。
- 运营商(一旦达到法定人数的关键人员),可以检索使用GPG加密的新密钥,并将其交给关键人员。
- 主要官员可以着手验证他们的新共享。
只要钥匙扣长时间不再可用,就应执行此程序。传统上,在组织中与人力资源部门进行一定程度的协作,或者这些程序已经存在于使用HSM的组织,并且可以用于Vault。
该程序的说明可以在下面找到。
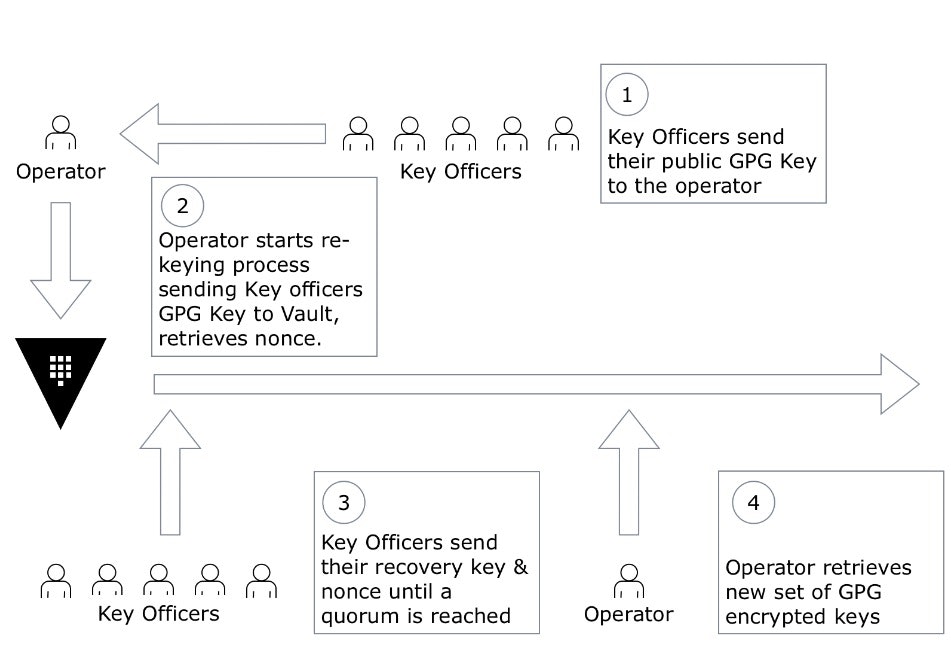
除非有妥协,否则此程序通常由组织每年执行。
密封钥匙旋转
这个程序因密封而异。
对于PKCS#11密封,传统上操作员只需更改key_label和hmac_key_label参数。 在检测到标签已更改且与用于加密主密钥的标签不匹配时,Vault将仅重新包装它:
2018-09-05T11:56:22.892Z [DEBUG] cluster listener addresses synthesized: cluster_addresses=[127.0.0.1:8201] 2018-09-05T11:56:22.892Z [INFO ] core: stored unseal keys supported, attempting fetch 2018-09-05T11:56:22.892Z [DEBUG] sealwrap: unwrapping entry: key=core/hsm/barrier-unseal-keys 2018-09-05T11:56:22.893Z [DEBUG] sealwrap: unwrapping entry: key=core/keyring 2018-09-05T11:56:22.895Z [INFO ] core: vault is unsealed 2018-09-05T11:56:22.895Z [INFO ] core: post-unseal setup starting 2018-09-05T11:56:22.895Z [DEBUG] core: clearing forwarding clients 2018-09-05T11:56:22.895Z [DEBUG] core: done clearing forwarding clients 2018-09-05T11:56:22.895Z [DEBUG] sealwrap: checking upgrades 2018-09-05T11:56:22.895Z [DEBUG] sealwrap: unwrapping entry: key=core/hsm/barrier-unseal-keys 2018-09-05T11:56:22.896Z [TRACE] sealwrap: wrapping entry: key=core/hsm/barrier-unseal-keys 2018-09-05T11:56:22.898Z [DEBUG] sealwrap: unwrapping entry: key=core/keyring 2018-09-05T11:56:22.899Z [TRACE] sealwrap: wrapping entry: key=core/keyring 2018-09-05T11:56:22.900Z [DEBUG] sealwrap: upgrade completed successfully 2018-09-05T11:56:22.900Z [DEBUG] sealwrap: unwrapping entry: key=core/wrapping/jwtkey 2018-09-05T11:56:22.902Z [TRACE] sealwrap: wrapping entry: key=core/wrapping/jwtkey
可以使用HSM工具或pkcs11-list命令验证密钥的存在:
$ pkcs11-list Enter Pin: object[0]: handle 2 class 4 label[11] 'vault_key_2' id[10] 0x3130323636303831... object[2]: handle 4 class 4 label[16] 'vault_hmac_key_1' id[9] 0x3635313134313231... object[3]: handle 5 class 4 label[11] 'vault_key_1' id[10] 0x3139303538303233...
DR推广
将执行DR促销程序以在灾难性故障时继续服务,这将使主集群无法使用。如果主群集正在使用中,则不应执行此过程,因为它可能会产生意外后果。
触发DR促销的可能原因包括但不限于:
- 主数据中心故障
- 主群集上的数据损坏
- 密封键丢失
- 密封密钥篡改
此程序包括保险柜操作员和主要官员,类似于启封或关键轮换,因为法定人数需要通过提交其关键份额来批准操作。
- 运营商提交将辅助群集提升为主要群组的请求。这是DR群集可用的唯一端点之一,在正常参数下无法运行。它将检索操作的nonce。
- 主要官员将继续提交他们的关键碎片。
- 一旦达到法定人数的关键人员,操作员就可以检索操作密钥。
- 该操作键是一次性使用,操作员将使用它来开始促销过程。
该过程如下图所示。
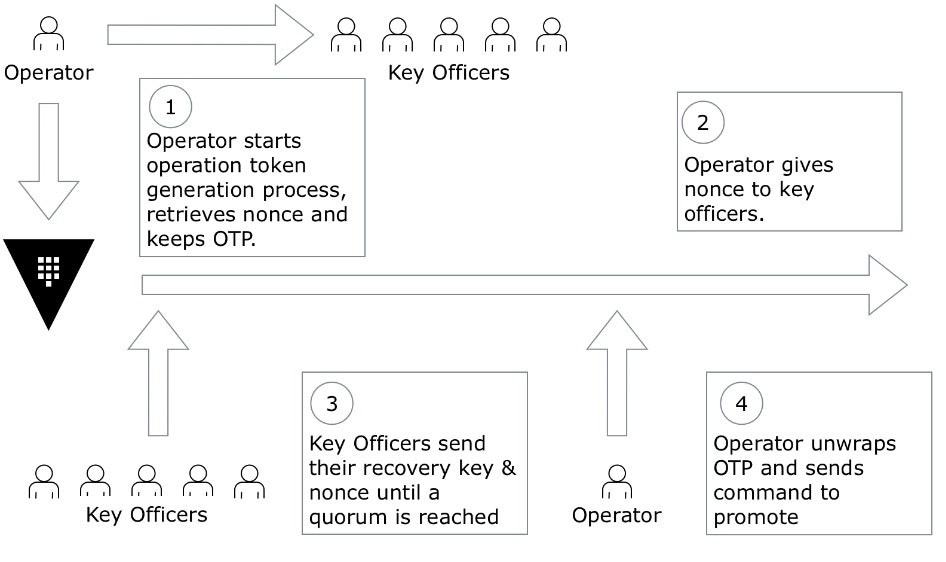
政策维护模式
当集中管理策略时,实现管道以维护Vault中的策略添加是非常常见的,以便启用合并批准系统,潜在的消费者可以请求访问,并且运营商和中央安全性都可以允许合并。 Terraform可用于读取策略文件并确保代码和策略之间的符合性。
策略模板还可用作减少维护策略数量的方法,基于来自属性的插值或来自实体的键值对。
例如,从包含“应用程序”键的实体,带有“APMA”值:
$ vault read identity/entity/id/670577b3-0acb-2f5c-6e14-0222d3478ce3 Key Value --- ----- aliases [map[canonical_id:670577b3-0acb-2f5c-6e14-0222d3478ce3 creation_time:2018-11-13T13:15:04.400343Z mount_path:auth/userpass/ mount_type:userpass name:nico id:14129432-cf46-d6a6-3bdf-dcad71a51f4a last_update_time:2018-11-13T13:15:04.400343Z merged_from_canonical_ids:<nil> metadata:<nil> mount_accessor:auth_userpass_31a3c976]] creation_time 2018-11-13T13:14:57.741079Z direct_group_ids [] disabled false group_ids [] id 670577b3-0acb-2f5c-6e14-0222d3478ce3 inherited_group_ids [] last_update_time 2018-11-13T13:20:53.648665Z merged_entity_ids <nil> metadata map[application:APMA] name nico policies [default test]
可以存在一个策略来访问与已定义键的值匹配的静态秘密装载:
path "{{identity.entity.metadata.application}}/*" { capabilities = ["read","create","update","delete"] }
可以通过Sentinel引入治理导向策略,作为角色或端点管理策略。
应用上线
将新秘密添加到Vault并使新应用程序能够使用它们是Vault中最常规的操作。
每个组织在秘密生成,消费和移交点方面都有自己的指导方针,但一般来说,提前商定以下几个方面:
- 什么是消费者参与这个过程。消费者将负责通过Vault进行身份验证,保护令牌,然后获取机密,或者期望存在一定程度的自动化以保证令牌前进。切换点需要事先商定。
- 是否有一个团队处理运行时,因此,开发人员没有参与,应用程序外部的工具将用于消耗秘密。
- 消费者是命名空间的一部分,因此应该为新应用程序创建角色。
- 如果使用静态机密,消费者是否希望将密钥手动存储到Vault中,或者是否会由进程自动刷新。
最常见的是,如前所述,组织首先审核已存储在多个源中的静态密码,并将其存储到Vault中以使其受到管理。从那里,应用程序可以使用上述模式来使用它,并且可以引入过程来管理它们的生命周期,或者有效地将生命周期管理转移到秘密引擎。
否则,入门应用程序的步骤非常通用:
- 使用Vault设置身份验证,或者只是创建一个映射到策略的角色(除非使用上面提到的技术之一)
- 定义将存储秘密的位置
- 设置应用程序以使用它
其他资源
- What is the crawl, walk, run journey for using Vault?
- How do security teams keep up with DevOps and deploy security at scale?
- How long does it take to roll out Vault?
- What does Dev, Ops, and Security do in a Vault rollout?
- What are the Dev, Ops, and Security journeys for secrets management?
- How should Dev, Ops, and Security collaborate on secrets management?
- What application should I secure with Vault first?
原文:https://www.hashicorp.com/resources/adopting-hashicorp-vault#day-n
本文:https://pub.intelligentx.net/adopting-hashicorp-vault-day-n
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 124 次浏览
【数据安全】采用HashiCorp Vault :第一天
第一天
部署模式
推荐体系结构的首选部署模式是执行HashiCorp Vault和Consul的不可变构建,并执行蓝/绿部署。因此,建议使用HashiCorp Packer等工具为不同平台构建不可变图像,HashiCorp提供了许多关于如何通过现有CI / CD编排构建这些元素的示例。
HashiCorp认识到有些组织没有采用这些模式,因此有许多配置管理模式可供安装,升级和配置Vault,可在不同的存储库中使用:
- 在Ansible Galaxy中,Brian Shumate的Vault角色
- 在Ansible Galaxy,Brian Shumate的领事角色
- 在Puppet Forge中,Vault模块
- 在Chef Supermarket,hashicorp-vault cookbook
建议您限制对Vault服务器的SSH访问,因为系统上的易失性存储器中存储了许多敏感项。
Vault发布周期
HashiCorp按季度发布Vault的主要版本,以及根据需要发布的次要版本,但至少每月发布一次,因此在组织中更新Vault的过程应该相当简化并且高度自动化。
监控
Vault会侦听单个端口(服务和管理)上的请求,如前所述,这是一个HTTP REST端点。默认情况下,这是TCP端口8200,并且有一个不受保护的状态端点,可用于监视群集的状态,如下所示:
curl -sS http://localhost:8200/v1/sys/health | jq { "initialized": true, "sealed": false, "standby": false, "performance_standby": false, "replication_performance_mode": "disabled", "replication_dr_mode": "disabled", "server_time_utc": 1545132958, "version": "1.0.0-beta1", "cluster_name": "vault-cluster-fc75786e", "cluster_id": "bb14f30a-6585-d225-ca12-0b2011de4b23" }
还可以查询节点的单个密封状态,如下所示:
curl -sS http://localhost:8200/v1/sys/seal-status | jq { "type": "shamir", "initialized": true, "sealed": false, "t": 1, "n": 1, "progress": 0, "nonce": "", "version": "1.0.0-beta1", "migration": false, "cluster_name": "vault-cluster-fc75786e", "cluster_id": "bb14f30a-6585-d225-ca12-0b2011de4b23", "recovery_seal": false }
在最佳实践设置中,HashiCorp Consul将监控Vault的状态,并可以通过DNS提供Service Discovery,或自动配置许多流行的开源负载均衡器,如官方参考体系结构指南中所述。 HashiCorp Learn Vault轨道中还提供了详细的分步指南。
遥测
在大规模运行Vault时,建议使用Vault的遥测输出结合遥测分析解决方案(如StatsD,Circonus或Datadog)来分析系统的性能。
审计
从Vault的角度来看,使用SIEM系统是跟踪访问代理的必要条件。 Vault通过Syslog,File或Unix套接字提供输出。大多数组织通过Splunk或使用ELK Stack中的工具来解析和评估此信息。审计输出是JSON数据,使组织能够轻松地解析和分析信息。
备份还原
解决方案的备份是通过Consul Snapshot Agent完成的,Consul Snapshot Agent可以将加密的备份自动上传到S3存储桶,也可以将备份保留在文件系统上,以便传统的企业备份解决方案将其运出。
失败场景
- 如果单个节点发生故障或最多两个节点发生故障,解决方案将继续运行而无需操作员干预。
- 如果Vault群集出现故障,则可以使用相同的Storage Backend配置重新设置它。
- 如果Consul集群失去法定人数,则可以选择重新获得服务可用性,尽管从RTO / RPO角度推荐的方法是故障转移到DR群集或提升性能副本。
- 如果要删除或不可用密封密钥,则唯一支持的方案是故障转移到DR群集或性能副本。
初始化仪式
虽然Vault中的每个操作都可以由API驱动,并且因此自动化,但初始化过程可确保Vault中的加密信任。持有Unseal Keys或最常见的恢复密钥的密钥持有者是Vault信托的监护人。对于任何Vault安装,此过程只会执行一次。
初始化过程完成后,Vault最容易受到攻击,因为存在根令牌。此根令牌会覆盖策略系统,并且仅在初始阶段用于配置生产身份验证方法和基本策略,或者在主身份验证方法不可用的情况下,在这种情况下需要重新生成根令牌。
建议在单个房间进行初始化仪式,在整个过程中将有操作员和保险柜密钥持有人在场,具体如下:
- 操作员启动Vault守护程序和初始化过程,如文档中所述,提供来自密钥持有者的公共GPG密钥,以及操作员拥有根令牌的公共GPG密钥。
- Vault将返回GPG加密恢复密钥,这些密钥应在密钥持有者之间分配。
- 操作员使用根令牌加载初始策略并配置第一个身份验证后端,传统上是Active Directory或LDAP,以及审计后端。
- 操作员验证他们可以使用其目录帐户登录Vault,并可以添加更多策略。
- 运算符撤消根令牌。密钥持有人现在可以离开房间,保证没有人拥有对Vault的完全和未经审计的访问权限。

初始化
尽管应考虑以下参数,但脚注中引用的Vault文档中描述了完整的初始化选项集:
- -root-token-pgp-key:将用于加密根令牌的Operator Public PGP密钥
- -recovery-shares / threshold:要提供的密钥数量(基于密钥持有者的数量),以及执行恢复操作所需的密钥持有者的法定人数(通常是一半的密钥持有者加一个)
- -recovery-pgp-keys:与上面的参数类似,来自密钥持有者的公共PGP密钥列表,以便提供密钥共享的加密输出
基本配置
为了在不需要使用根令牌的情况下继续进行进一步配置,必须配置备用身份验证方法。传统上,这是通过LDAP身份验证后端配置Active Directory / LDAP集成,或最近通过OIDC或Okta支持完成的。
组或声明定义为向Vault提供某些管理属性。
此外,策略定义为Vault中的管理操作(如添加挂载,策略,配置进一步的身份验证,审计等...),加密操作(如启动密钥轮换操作),以及最终消费模式,通常定义在以后根据要求。示例管理策略可以定义如下:
## Operations # List audit backends path "/sys/audit" { capabilities = ["read","list"] } # Create an audit backend. Operators are not allowed to remove them. path "/sys/audit/*" { capabilities = ["create","read","list","sudo"] } # List Authentication Backends path "/sys/auth" { capabilities = ["read","list"] } # CRUD operations on Authentication Backends path "/sys/auth/*" { capabilities = ["read","list","update","sudo"] } # CORS configuration path "/sys/config/cors" { capabilities = ["read", "list", "create", "update", "sudo"] } # Start root token generation path "/sys/generate-root/attempt" { capabilities = ["read", "list", "create", "update", "delete"] } # Configure License path "/sys/license" { capabilities = ["read", "list", "create", "update", "delete"] } # Get Storage Key Status path "/sys/key-status" { capabilities = ["read"] } # Initialize Vault path "/sys/init" { capabilities = ["read", "update", "create"] } #Get Cluster Leader path "/sys/leader" { capabilities = ["read"] } # Manage policies path "/sys/policies*" { capabilities = ["read", "list", "create", "update", "delete"] } # Manage Mounts path "/sys/mounts*" { capabilities = ["read", "list", "create", "update", "delete"] }
Auditor策略的示例可以定义如下:
## Audit # Remove audit devices path "/sys/audit/*" { capabilities = ["delete"] } # Hash values to compare with audit logs path "/sys/audit-hash/*" { capabilities = ["create"] } # Read HMAC configuration for redacting headers path "/sys/config/auditing/request-headers" { capabilities = ["read", "sudo"] } # Configure HMAC for redacting headers path "/sys/config/auditing/request-headers/*" { capabilities = ["read", "list", "create", "update", "sudo"] } # Get Storage Key Status path "/sys/key-status" { capabilities = ["read"] }An example Key Officer policy could be defined as follows:
## Key Officers path "/sys/generate-root/update" { capabilities = ["create", "update"] } # Get Storage Key Status path "/sys/key-status" { capabilities = ["read"] } # Submit Key for Re-keying purposes path "/sys/rekey-recovery-key/update" { capabilities = ["create", "update"] } # Rotate Storage Key path "/sys/rotate" { capabilities = ["update", "sudo"] } # Verify update path "/sys/rekey-recovery-key/verify" { capabilities = ["create", "update"] }
这些策略并非详尽无遗,虽然定义了三个配置文件,但在大多数组织中,角色隔离的运行范围更深。
值得注意的是,由于某些端点的敏感性,大多数组织选择使用控制组以便为某些配置更改要求批准工作流,例如,在添加或修改策略时,如下例所示:
# Create a Control Group for approvals for CRUD operations on policies path "/sys/policies*" { capabilities = ["create", "update"] control_group = { ttl = "4h" factor "tech leads" { identity { group_names = ["managers", "leads"] approvals = 2 } } factor "CISO" { identity { group_names = ["infosec"] approvals = 1 } } } }
通过这种方式,策略更改将需要来自“管理者”或“潜在客户”组的两个批准者,以及来自“信息安全”组的一个批准者。
根令牌撤销
如前面指南中所述,根令牌只应用于初始化和紧急“中断玻璃”操作。配置Vault后,应撤消根令牌,并应使用常规身份验证方法来引入更改。
运营商和法定数量的密钥持有者可以在紧急情况下重新生成根令牌。
组织角色
在大规模部署Vault的大多数组织中,不需要额外的人员配置或招聘。在部署和运行解决方案方面。 Vault没有预定义的角色和配置文件,因为策略系统允许对不同团队的职责进行非常精细的定义,但一般来说,这些已在大多数组织中定义如下:
- 消费者:需要能够使用机密或需要命名空间保险库功能的个人或团队。
- 运营商:登录消费者的个人或团队,以及秘密引擎功能,策略,命名空间和身份验证方法。
- 加密:管理关键轮换和审计策略的个人或团队。
- 审核:审核和审核使用情况的个人或团队。
原文:https://www.hashicorp.com/resources/adopting-hashicorp-vault#day-one
本文:https://pub.intelligentx.net/adopting-hashicorp-vault-day-one
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 381 次浏览
【数据安全】采用HashiCorp Vault :第二天
第二天
命名空间
Vault Enterprise允许组织对Vault安装进行逻辑分段。
传统上,在Vault作为中心功能运行的组织中,需要维护大量策略的某些团队将获得自己的命名空间。这也可以是分段的,例如,与一组Kubernetes命名空间对齐。
在顶部名称空间处获得的标记可以被分段以遍历多个名称空间。
对于某些运行Vault的专用团队的组织而言,名称空间可能不会增加显着优势,并可能增加复杂性。
命名空间通常以自动方式配置,与团队或项目入职一致,例如在配置新的Kubernetes命名空间或AWS账户时。
安全介绍
在能够使用机密之前,用户或应用程序必须登录Vault,并获得一个短期令牌。用于应用程序的方法通常基于运行应用程序的平台(AWS,GCE,Azure,Kubernetes,OIDC)或用于部署它的工作流程(带有CI工具的AppRole,如Jenkins或Circle CI) 。
令牌必须维护在客户端,并且在到期时可以简单地续订。对于短期工作流,传统的令牌将被创建,其生命周期与平均部署时间相匹配,并且可以使其过期,从而确保每个部署的新令牌。
认证方法通常由操作员在初始配置时配置。
最常见的是,系统会自动执行身份验证过程,但是当多个团队负责配置系统或部署应用程序时,执行流程的责任通常被认为是切换的一部分。
基于现有属性(如LDAP组,OIDC声明,IAM角色,Google Project ID等),角色在不同的身份验证后端中创建,后端映射到策略(最终授予对机密的访问权限)。
每种身份验证方法都会详细记录安全介绍过程,并提供了许多可用的分析文档。
存储和检索秘密
Vault将存储或动态生成可以以编程方式或以交互方式访问的机密。
最常见的采用模式,首先是在Vault中存储传统上分散在文件中的秘密,桌面密码管理工具,版本控制系统和配置管理,并利用下面描述的一些消费模式作为获取秘密的手段。消费它的应用程序。
向前移动大多数组织开始采用秘密引擎作为减少开销的方法,例如使用PKI作为中间CA并自动生成短期证书,或短期数据库凭证。
API
如前所述,Vault提供了一个HTTP Restful API,允许应用程序以编程方式使用机密。有大量的客户端库和语言内抽象,可以实现更简单的编程。
传统上,这是从Vault检索机密的最安全模式,因为它们通常作为变量存储在内存中,并在应用程序不使用它们时进行清理。
此模式具有很强的侵入性,因为它需要修改应用程序以从Vault检索机密(通常在初始化时或使用外部服务)。
非侵入性模式
HashiCorp提供了两个应用程序,通过配置文件或环境变量,使用最常见的秘密消费模式,提供工作流来使用凭证而无需修改应用程序。
这些应用程序要么渲染配置文件模板内插机密,要么使用从Vault获取的值传递环境变量。
响应包装
在第三方软件通常提供凭证的情况下,该系统可以请求包装的响应,其中秘密最终在消耗该秘密的系统中展开,而不需要向配置该应用的自动化系统公开凭证。
加密即服务
Vault提供加密服务,消费者可以通过API调用简单地加密/解密信息,密钥生命周期和管理通常由外部团队管理(通常由自动化协助)。
生成的每个密钥都有单独的API路径用于管理,以及每个服务操作(加密/解密/签名/验证),允许在非常精细的级别设置策略,与组织中现有的角色保持一致。例如,虽然安全部门可能对特定的传输装载具有以下权限:
## Crypto officers # Create key material, non deletable, non exportable in unencrypted fashion, only aes-256 or rsa-4096 path "/transit/keys/*" { capabilities = ["create", "update"] allowed_parameters = { "allow_plaintext_backup" = ["false"] "type" = ["aes256-gcm96", "rsa-4096"] "convergent_encryption" = [] "derived" = [] } } # List keys path "/transit/keys" { capabilities = ["list"] } # Rotate Key path "/transit/keys/*/rotate" { capabilities = ["create"] }
而消费者只能访问该服务:
## Consumers # Encrypt information path "/transit/encrypt/keyname" { capabilities = ["create"] } # Decrypt information path "/transit/decrypt/keyname" { capabilities = ["create"] } # Rewrap information path "/transit/rewrap/keyname" { capabilities = ["create"] }
原文:https://www.hashicorp.com/resources/adopting-hashicorp-vault#day-two
本文:https://pub.intelligentx.net/adopting-hashicorp-vault-day-two
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 155 次浏览
【数据安全】采用HashiCorp Vault :第零天
部署,采用和超越
与每个HashiCorp产品一样,采用Vault时,有一种“爬行,行走,跑步”的方法。因此,本文档旨在根据软件最佳实践和大型组织中大规模部署Vault的经验,就HashiCorp Vault部署和采用的每个阶段所需的步骤提供一些可预测性。本文档不是深入介绍Vault的文档,而是提供旅程的概述,适当时引用文档,并关注操作方面。
本文档的部分内容旨在成为组织Runbook的基础,描述通常在Vault中运行的某些过程。
第零天
Vault内部和密钥加密原理
HashiCorp Vault是一种秘密管理解决方案,通过程序化访问,可以通过系统访问人和机器。可以存储,动态生成秘密,并且在加密的情况下,可以将密钥作为服务使用,而无需公开底层密钥材料。
可以使用下图汇总秘密消费方面的工作流程:
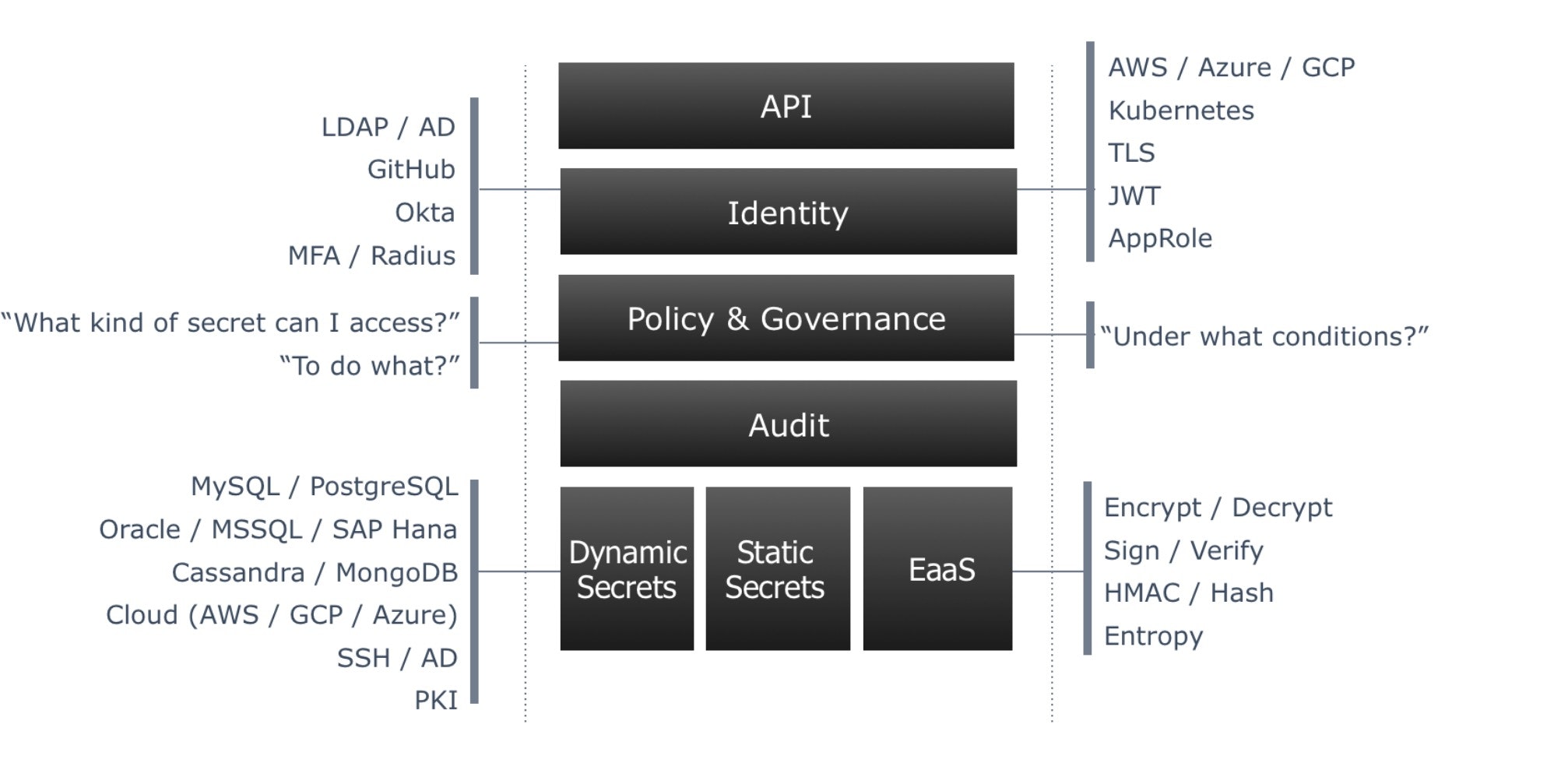
- Vault的主要界面是通过HTTP Restful API。 CLI和Web GUI都通过相同的API与Vault连接。开发人员将使用此API进行编程访问。除了通过此API之外,没有其他方法可以在Vault中公开功能。
- 为了消费秘密,客户(用户或应用程序)需要建立自己的身份。虽然Vault支持用户的通用身份验证平台,例如LDAP或Active Directory,但它还添加了基于平台信任以编程方式建立应用程序身份的不同方法,利用AWS IAM,Google IAM,Azure应用程序组,TLS证书和Kubernetes命名空间等等。在身份验证后,并且基于某些身份属性(如组成员身份或项目名称),Vault将授予与特定策略集对齐的短期令牌。
- Vault中的策略与身份分离,并定义特定身份可以访问的秘密集。它们被定义为HashiCorp配置语言(HCL)中的代码。可以使用Sentinel规则定义丰富的策略,该规则旨在回答实体可以访问秘密的“在什么条件下”,而不是传统的“谁访问”常规ACL中定义的秘密。
- Vault通过Syslog,File或Socket将审计信息发送到SIEM系统或记录后端。如果Vault无法正确提供审核信息,则不会响应。
- 最终,Vault可以动态存储或生成秘密。凭借“安装”发动机:
- 可以使用KV / 2引擎存储和版本化静态机密。
- 可以使用不同的引擎动态生成不同类型的秘密,包括数据库,SSH / AD访问,PKI(X.509证书)等
- 密钥材料可以通过提供加密/解密/签名/验证/ HMAC功能的特定端点来使用,而无需离开Vault。
可以使用下图汇总Vault内部体系结构:
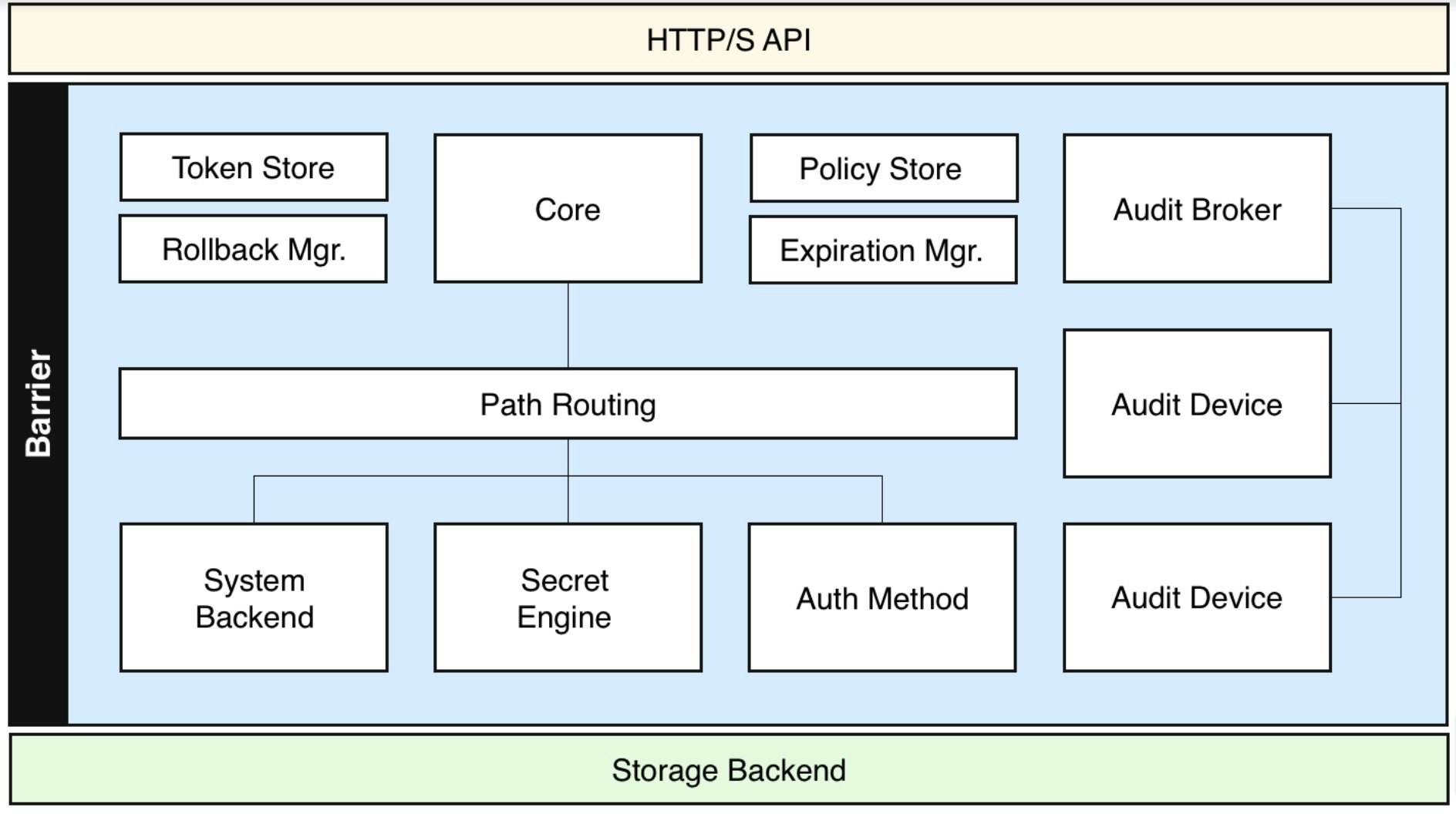
从数据组织的角度来看,Vault具有伪分层API路径,其中可以安装顶级引擎来存储或生成某些机密,提供任意路径(即/ secret / sales / password)或预定义路径动态秘密(例如/ pki / issue / internal)。
没有秘密以未加密的形式离开加密屏障(仅存在于Vault主机上的易失性存储器中)。该屏障由一组键保护。通过HTTP API提供的信息使用TLS加密。存储后端中存储的信息使用存储密钥加密,存储密钥由主密钥加密,主密钥可选地由外部密封加密以便于操作,并自动执行开封过程,如下图所示。 (有关详细信息,请参阅Vault体系结构)相同的密封也可用于加密机密。例如,对于需要以符合FIPS的方式加密的机密,Vault的“Seal Wrap”与HSM一起可用于实现此功能。
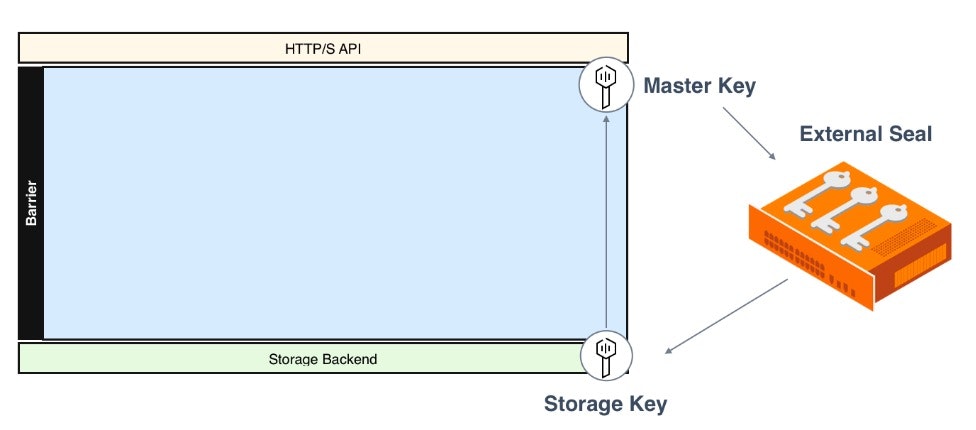
Vault HSM工作流程
Vault解决方案架构
HashiCorp Vault使用分布式系统概念和范例设计。因此,在部署方面有很多可能性,但只有少数可能由HashiCorp进行全面测试和支持。在单站点或多站点弹性和扩展要求方面,有不同的策略。出于本文档和任何架构决策的目的,您应将站点视为往返时间不超过8毫秒的地理区域。
单一网站
对于单个站点,Vault的生产部署是一个集群单元,通常由三个节点组成。在其开源变体中,一个节点自动被指定为“活动”,而其余两个节点处于“待机”模式(不主动提供服务)。当使用HashiCorp Consul时,这些“待机”节点将在“主动节点”(在这种情况下立即进行故障转移)有序关闭时自动执行“活动”角色,或者故障(在不干净的关闭下故障转移需要45秒) ,推荐的存储后端。使用Vault Enterprise Premium时,可以将备用节点设置为“性能备用”,这样可以通过直接回答某些查询来使它们水平扩展群集,同时透明地将其他节点转发到主动节点。簇。如前所述,Active和Standby节点之间的延迟存在严格限制。
Vault可以使用许多不同的存储后端。但是,HashiCorp仅使用Consul作为真正可扩展的生产级解决方案,为Vault集群提供支持。通常,Consul后端部署为5节点群集,以支持3节点Vault群集。
HashiCorp Consul必须始终保持法定人数以提供服务(N + 1个节点/投票),并且法定人数损失不是可接受的操作方案;因此,产品中有许多策略和自动驾驶仪功能可确保服务连续性和扩展,例如非投票成员,冗余区域和更新迁移。
最常见的单站点Vault部署如下所示:
上图中的Consul集群图标由下图中所示的组件组成(在这种情况下,Consul客户端将是Vault服务器):
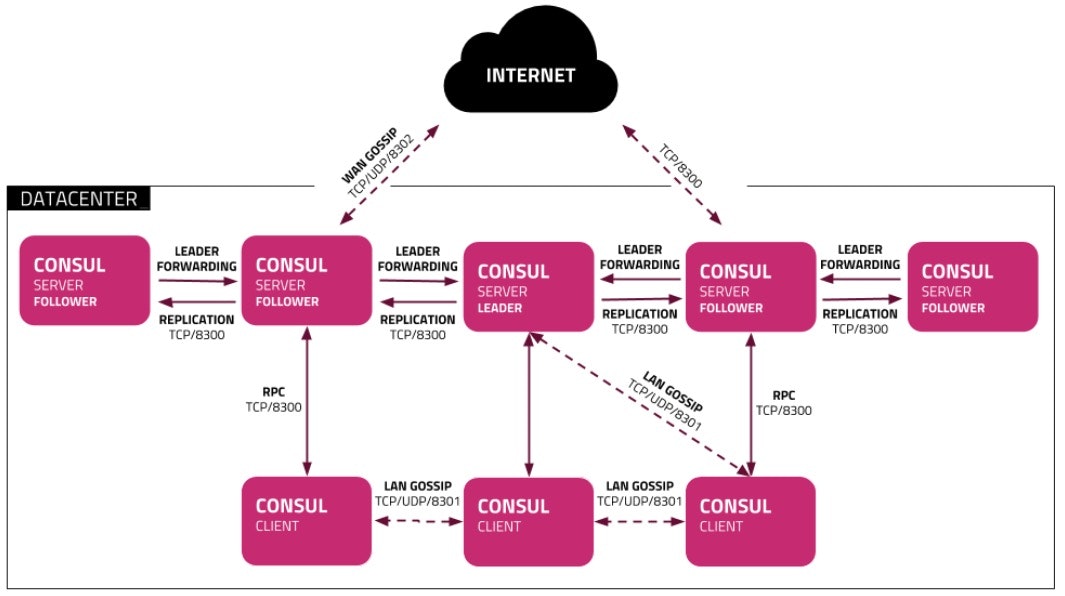
该架构旨在满足以下原则:
- 每个服务最多两个节点可能会失败而不会导致中断,但如果使用“性能备用”可能会导致性能下降,直到重新配置其他服务器。
- 系统分布在奇数个网络区域或可用区域,以适应最多整个区域的故障。
- 每个区域都有一个数据源(存储后端)和一个加密密封。
多个站点
HashiCorp Vault提供两种复制模式,其中主群集将有选择地将日志发送到辅助群集。
从弹性角度来看,最低要求是配置灾难恢复(DR)副本,它是一个热备份并拥有所有内容的完整副本。 DR副本在升级之前无法应答请求。从运营角度来看,DR副本将在以下情况下提供服务连续性:
- 数据篡改:意外或故意操纵存储后端,存储后端保存二进制加密数据。通过备份/恢复技术可以在一定程度上缓解这一方面,对DR副本不受RMP副本影响的RPO和RTO产生相当大的影响。
- 密封篡改:密钥是加密保证的组成部分,不可恢复。如果要删除或篡改加密密钥,则Vault将无法恢复。 DR副本具有单独的密封,应该对其进行隔离。
- 基础架构故障:如果主集群从网络或计算角度变得不可用,则可以升级DR副本以提供服务连续性而不会产生任何影响。
更常见的是,存在于多个地理位置的组织将创建一组性能副本,在地理上传播。虽然此设置可以在位置内提供秘密和配置的复制,但最重要的是它可以跨位置统一单个密钥环(主密钥和存储密钥),这对于在大规模使用Vault时减少操作开销至关重要。
在“性能复制”模式下,所选路径将复制到不同的群集,并且在辅助群集中执行尽可能多的操作以最大程度地减少延迟。两种复制模式可以组合在一起,这将允许广泛的操作效率和弹性,如附图所示。
原文:https://www.hashicorp.com/resources/adopting-hashicorp-vault#day-zero
本文:https://pub.intelligentx.net/node/737
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 626 次浏览
【机密计算】关于机密计算的五大须知
在Linux基金会下成立的保密计算联盟可能会彻底改变公司共享数据的方式。Tom Merritt列出了关于机密计算的五件事。
你可以在静态时保护数据——你可以加密它。你可以保护传输中的数据——这有点棘手,但你也可以加密它。你用的时候呢?你需要解密数据才能使用它,对吗?如果邮件是加密的,当你试图查看它时,你很难阅读它。这是一个问题,因为您使用的数据在内存中,可以被转储,然后恶意的人就会得到您未加密的数据。有些人认为您可以保护正在使用的数据。关于机密计算,这里有五件事要知道。
- 机密计算是由机密计算联盟开发的。这个联盟是在Linux基金会下成立的,包括红帽、微软、英特尔、甲骨文、谷歌、阿里巴巴、Arm、VMware、Facebook、腾讯、瑞士通信、AMD等公司的人士。
- 将机密数据隔离在计算机上。特别是可信执行环境(TEE)。数据在内存中加密,TEE使用云提供商无法访问的嵌入式硬件密钥。TEE只允许授权代码访问数据,使其远离操作系统。如果代码被更改,TEE将拒绝访问。
- 机密计算可以使一些云计算应用成为可能。Fortanix的sethknox是该财团的外联主席,他说公司可以合并数据集而不必访问彼此的数据。一个例子是零售商和信用卡公司在不暴露用户数据的情况下检查交易数据是否存在欺诈。
- 机密计算不仅关乎安全。TEE还可以用于其他事情,比如图像处理或用主CPU划分任务。
- 算法可以在TEE中生存。你可以用它们来处理你的数据。你可以在不知道它是什么的情况下访问算法,算法可以在不共享数据的情况下处理数据。
在一个共享数据不仅不受欢迎而且风险很大的世界里,机密计算可以让公司在云端进行协作,而不必将数据或代码暴露给彼此。
原文:https://www.techrepublic.com/article/top-5-things-to-know-about-confidential-computing/
本文:
讨论:请加入知识星球【数据和计算以及智能】或者小号【it_strategy】或者QQ群【1033354921】
- 172 次浏览
【灾难恢复】高可用性不是灾难恢复
视频号
微信公众号
知识星球
可用性和灾难恢复都依赖于一些相同的最佳做法,例如监控故障、部署到多个位置以及自动故障切换。然而,可用性侧重于工作负载的组件,而灾难恢复侧重于整个工作负载的离散副本。灾难恢复具有不同于可用性的目标,即在发生符合灾难条件的大规模事件后测量恢复时间。您应该首先确保工作负载满足可用性目标,因为高可用性架构将使您能够在发生影响可用性的事件时满足客户的需求。您的灾难恢复策略需要不同于可用性的方法,重点是将分散的系统部署到多个位置,以便您可以在必要时对整个工作负载进行故障切换。
您必须在灾难恢复规划中考虑工作负载的可用性,因为这会影响您采取的方法。在一个可用性区域中的单个AmazonEC2实例上运行的工作负载不具有高可用性。如果本地洪泛问题影响该可用区域,则此场景需要故障切换到另一个AZ以满足灾难恢复目标。将此场景与部署在多站点活动/活动的高可用工作负载进行比较,其中工作负载部署在多个活动区域中,所有区域都在为生产流量提供服务。在这种情况下,即使在不太可能发生大规模灾难导致某个区域无法使用的情况下,灾难恢复策略也可以通过将所有流量路由到剩余区域来实现。
在可用性和灾难恢复之间,您处理数据的方式也有所不同。考虑一个连续复制到另一个站点以实现高可用性的存储解决方案(例如多站点、活动/活动工作负载)。如果主存储设备上的一个或多个文件被删除或损坏,则可以将这些破坏性更改复制到辅助存储设备。在这种情况下,尽管具有高可用性,但数据删除或损坏时的故障切换能力将受到影响。相反,作为灾难恢复战略的一部分,还需要时间点备份。
- 80 次浏览
【网络安全】SQL注入攻击:如此陈旧,但仍然如此相关。 这是为什么
我们生活在数据的黄金时代。有些公司将其分析为更好的自己,有些公司为了获利而进行交易,没有一家公司因其价值而自由放弃 - 对于他们的业务和犯罪分子。
SQL(结构化查询语言)是一种非常流行的与数据库通信的方式。虽然许多新数据库使用非SQL语法,但大多数仍然与SQL兼容。这使得SQL成为任何想要访问数据的人的便利工具,无论他们的动机如何。
SQL注入(或SQLi)攻击已经存在了近20年。他们永远不会停止使用Imperva的Web应用程序防火墙(WAF)。所以我们有丰富的数据和经验可供分享。在这篇文章中,我们将分享Imperva保护下数千个网站的最新统计数据和图表,以及攻击示例以及保护网站的方法。
基于SQL的应用程序的常见攻击
SQL Injection是一种用于攻击应用程序的代码注入技术。攻击者可以使用工具,脚本甚至浏览器将SQL语句插入应用程序字段。然后由数据库引擎执行这些语句。此类攻击通常用于:
- 欺骗身份
- 篡改现有数据
- 窃取数据
- 销毁数据
- 更改数据库权限
应用程序背后的数据通常是关键任务,这就是SQL注入攻击被认为非常严重的原因。
来自Imperva WAF的统计数据
Imperva的WAF每天都会在我们保护的网站上减少数百万次SQL注入攻击。我们保护的网站中至少有80%每个月都会受到攻击。我们的数百个网站每天都会面临SQLi攻击。
您可以在下面找到我们监控的攻击中使用的国家,行业和工具的统计数据。
图1:网站行业分布 - 由于BakerHostetler的2018年网络安全报告指出它是数据泄露最严重的行业,因此受攻击程度最高的行业是健康行业,这一点非常有意思,但并不奇怪。
没有图示的是受攻击最多的数据库(按递减顺序):Oracle,PostgreSQL,MySQL和MongoDB。 同时,受攻击最多的平台是WordPress,Drupal,Joomla和Quest。
图2:受攻击网站的国家/地区与攻击来源 - 看到黑客倾向于攻击自己国家/地区内的网站并不奇怪。 当然,这有可能恰恰相反 - 这些结果可能反映了黑客使用在他们攻击的国家/地区拥有端点的VPN /代理,以逃避地理阻塞。
每天大量使用SQLi公共漏洞。 例如:CVE-2017-8917和CVE-2015-7858都是Joomla SQLi公共漏洞,这些漏洞在我们监控的66,000个事件中使用。
图3:顶级漏洞扫描程序 - 由于我们计算事件而非请求,每个扫描程序生成的有效负载数量都没有影响。 尽管SQLi Dumper取得了成功,但Joomla扫描仪并不落后。
我们每月监控数万个攻击性IP,并使用攻击分析来查找恶意IP并防范它们。 我们通过分析过去几个月的攻击IP收集了一些有趣的统计数据:
图4:日复一日尝试SQLi攻击的IP。 蓝色:在当天和当天尝试SQLi攻击的IP的百分比,在当天尝试SQLi攻击的IP中。 橙色:包含由这些攻击IP发送的SQLi尝试的请求的百分比,包含SQLi尝试的总请求数。
令人好奇的是,即使平均每天不到三分之一的IP攻击(蓝线),他们的请求构成了超过80%的SQLi请求(橙色线)。 这可能是由于各种漏洞扫描程序正在进行扫描。 这些工具倾向于轰炸目标以寻找漏洞,这解释了高IP到请求比率。
图5:顶级攻击工具 - 非常通用且广泛使用,因此cURL占据如此重要的位置并不奇怪。 但是,深入分析显示,与cURL一起发送的大多数可疑请求实际上是攻击后检查,即被阻止的黑客,然后使用cURL来测试他们是否仍然可以访问该网站。 cURL紧随其后的是Python - 黑客的首选武器,以及Ruby - 用于编写Metasploit的语言代码。
攻击示例
以下是我们最近一个月跟踪的一些流行攻击:
| Vector | Incidents | Description |
| 1 and 1=2 union select password from qianbo_admin | 634,566 | Trying to query passwords |
| 1’A=0 | 125,365 | Probing |
| N;O=D and 1=1
nessus= or 1=1– CONCAT(‘whs(‘,’)SQLi’) |
76,155 | Probing by vulnerability scanners:
Veracode, Nessus and WhiteHat Security, respectively |
| ‘ union select unhex(hex(version())) — | 848,096 | Attempting to discover database version |
| ;WAITFOR DELAY ’00:00:28′; | 1,226,955 | Blind probing — testing for delay in response |
表1:SQL注入攻击的示例
如何保护您的应用程序免受SQL注入
有许多方法可以保护您的应用程序免受SQL注入攻击。有些应该在应用程序开发期间使用,其他应该在部署应用程序后使用。
开发阶段:
使用预准备语句 - 一种“模板化”SQL以使其适应SQL注入的方法。只有某些输入值可以发送到数据库,因此无法运行模板化语句以外的语句。稍后使用不同协议传输的值不像语句模板那样编译。因此不能发生SQL注入。
这里有两个Python代码示例,包含和不包含预准备语句。该代码基于MySQL连接器驱动程序(https://dev.mysql.com/doc/connector-python/en/):
def add_employee(id: int, email: str):
sql = “””INSERT INTO employees (id, email)
VALUES (%s, %s)”””
cursor = connection.cursor(prepared=True)
cursor.execute(sql, (id, email))
cnx.commit()
cursor.close()
句的Python代码示例。这些值将发送到与SQL文本分开的“执行方法”。
def add_employee(id: int, email: str):
sql = f”””INSERT INTO employees (id, email)
VALUES ({id}, {email})”””
cursor = connection.cursor()
cursor.execute(sql)
上面是没有预准备语句的Python代码示例。电子邮件可能包含可由数据库引擎执行的SQL注入语句。
除了预处理语句之外,还有其他方法可以在开发和部署应用程序期间阻止SQL注入:
- 消毒 - 摆脱任何可能是恶意的特殊字符,单词或短语。例如,删除保留字SELECT或CONTACT,或删除短语WAIT FOR DELAY或DROP TABLE。这不是最佳实践,但在某些情况下它可能很有用。
- 转义 - 转义在SQL中具有特殊含义的字符。例如,用两个单引号替换双引号。这是一种简单但易于出错的方式。
- 转义和模式检查 - 可以验证数字和布尔参数数据类型,而字符串参数可以限制为模式。
- 数据库权限限制 - 将应用程序用户的权限限制为仅需要的权限,因为它可能有助于降低攻击的有效性。
后开发 - 应用程序安全性:
- 漏洞扫描程序 - 这些可以检测应用程序中的SQL注入漏洞,以后可以由开发团队修复。请记住,应用程序会不断变化 - 因此您应定期运行扫描程序。
- Web应用程序防火墙 - WAF还可以检测和阻止对您的应用程序的攻击。
总结
保护产品免受SQL注入是必不可少的,以确保其正常运行并防止数据泄露。
当您编写访问数据库的代码时,考虑从一开始就防止SQL注入是一种很好的做法。这是防止这些漏洞发生的最佳时机,而不是以后修补它们。开发过程应包括针对SQL注入的测试,然后是外部扫描程序。
最后,WAF是您产品保护的重要补充。它可以保护您免受错过的漏洞,同时让您有时间尽可能地修补它们。
原文:https://www.imperva.com/blog/sql-injection-attacks-so-old-but-still-so-relevant-heres-why-charts/
本文:http://pub.intelligentx.net/sql-injection-attacks-so-old-still-so-relevant-heres-why-charts
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 92 次浏览
【零信任】如何开始应用谷歌的“零信任”模式
![]()
关于谷歌采用“零信任”网络架构来保障安全性的问题越来越多,虽然它并不新鲜,但它现在正在获得思想共享,即使更多组织认为仅靠外围防御无法保护其数字资产。
作为一种理念,Zero Trust简单地要求内部网络在与互联网相同的级别上受到信任 - 换句话说,根本不是。采用这种理念将安全责任的轨迹从外围推向应用。这将焦点转移到应用程序及其数据以及如何访问它们,而不是建立更大的城墙来保护内部网络。
谷歌已经覆盖了很多实施第一个企业级零信托网络的基础,并在BeyondCorp的保护下分享了它的学习,供其他人采用。参考体系结构显示了任何Zero Trust实现必须提供的核心功能,包括身份提供者,访问代理和访问策略提供者,以及综合资产数据库。
完美的起点是团队会议,所有利益相关者都同意他们的零信托的定义,然后根据政策定义目标。然后,制定路线图以实现这些目标。这并不意味着丢弃目前部署的保护周边的技术。相反,它引发了方法的组织变革,以及我们如何考虑保护核心资产。
技术决策是最后的,这是有道理的。你不能出去“购买”Zero Trust。这是跨界关注的组合,使其发挥作用 - 这就是为什么它不容易。高层领导的真正承诺和理解将是关键。值得注意的是,谷歌通往零信任的道路是从2013年开始的为期四年的旅程。因此,这不是一夜之间发生的项目。
关键是要了解谁想要访问的上下文,请求来自哪个设备,然后将其映射到每个应用程序的访问策略。这相当于仅授予访问权限的白名单方法。
要完全实现与Zero Trust一致的应用程序,必须对应用程序的每次访问进行身份验证,授权和加密。每项服务必须确保每次通话都进行了这些检查。这超出了作为身份验证和授权的简单API密钥;它需要真正了解服务请求者与访问策略相结合的上下文。
这是一个很高的订单,促使有足够的初创公司承诺完全实现零信任网络解决方案 - 但这是不可能的。重要的是要记住Zero Trust不仅仅是一个建筑指南;这是一个思考过程和方法,促使企业重新思考如何创建组织的网络安全态势。实际上,使Zero Trust成功的艰难之处在于创建和维护数据策略,以及授权访问读取和写入数据的应用程序,这是一项枯燥乏味的工作。保持对政策和访问控制的更新并证明合规性对于零信任方法的长期有用性至关重要。
没有灵丹妙药,每个安全团队都有独特的挑战。对于许多组织而言,定义数据访问策略需要相当长的时间并且是一项复杂的挑对于其他人来说,它是识别访问关键数据的所有应用程序,或者实现和管理统一授权和访问控制系统。由于他们非常了解业务的驱动因素和核心资产,因此内部团队将面临沉重的负担。
简而言之,SecOps是否会使用Zero Trust网络?不,因为它无法解决技术娴熟的安全分析师的巨大缺失。但它确实重新定义了受监控,分类和响应的内容 - 而现在,这是领先一步。
原文:https://thenewstack.io/how-to-start-applying-googles-zero-trust-model/
本文:https://pub.intelligentx.net/how-start-applying-googles-zero-trust-model
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 120 次浏览