微服务测试
- 203 次浏览
【API测试】API测试自动化教程:循序渐进指南
贵公司是否为其软件编写API? 如果答案是肯定的,那么你绝对需要对它进行测试 - 幸运的是,本教程逐步解释了如何使用Postman,Newman,Jenkins和qTest Manager等工具进行自动API测试。
但首先,让我们来看看这块土地。事实证明,您的软件API实际上是您可以测试的应用程序中最重要的部分,因为它具有最高的安全风险。
您的软件API实际上是您可以测试的应用程序中最重要的部分,因为它具有最高的安全风险
例如,容纳客户端软件的浏览器或应用程序可以防止很多糟糕的用户体验,例如发送100个字符的用户名或允许奇怪的编码字符输入,但您的API是否也会阻止这些事情?如果有人开始猜测其他用户的“独特”令牌,软件是否会回复真实数据?它是否有Apache错误消息,其中包含正在运行的服务版本?如果这些问题的答案都是肯定的,那么就存在一个相当大的安全漏洞。或者,如果有人要破解API怎么办?他们可以得到生产数据,他们可以比特币赎回服务器,或者他们可以隐藏在机器上,直到有趣的事情发生。最重要的是,使用API时的风险远高于应用程序用户界面中的错误 - 您的数据可能存在风险,并且通过代理可能会影响您的所有用户数据。
幸运的是,API测试不仅是对您的应用程序进行的最重要的测试,而且它也是最简单,最快速的执行。这意味着没有理由你不应该有一个广泛的API测试套件(并相信我,有一个将帮助你在晚上睡得更好)。使用持续集成的API测试套件,您可以轻松地:
- 无论托管在何处,从AWS Lambda到本地计算机,都要测试所有端点
- 快速确保所有服务按预期运行
- 确认您的所有端点都受到未经授权和未经身份验证的用户的保护
- 观察您的测试执行“神奇地”填充在您的测试管理工具中
那么你如何将所有这些付诸行动呢?你来对地方了。继续阅读有关如何设置Postman和Newman的逐步API测试教程,如何从Jenkins执行测试,以及如何将所有这些测试结果集成到qTest Manager等测试管理工具中。
让我们开始吧!
Set Up Postman
1)第一件事是第一件事:你需要下载Postman。
它是免费的,很有趣,适用于Mac,Windows和Linux机器。注意:如果您拥有更大的团队并经常更新服务和测试,您可能需要考虑Postman Pro(但您可以随时决定升级)。
![]()
2)确保您的应用程序的API文档很方便。
对于本演示,我将使用qTest Manager API,因为它简单明了。如果你想逐字尝试这些演示,你可以在这里免费试用qTest Manager。您还可以使用大量可在线使用的API(如果您正在寻找其他地方,我建议您从AnyAPI开始)。
3)接下来,提取您正在使用的API的登录调用文档(您可以在下面找到qTest Manager的文档)。该文件应包括:
- Method (POST/PUT/GET/DELETE/etc)
- URI (/oauth/token which will follow the URL for the instance of qTest you’re using)
- Headers
- Body
在此示例中,登录调用需要x-www-form-urlencoded内容类型标头。您只需在Postman中选择它,它就会自动添加相应的标题。选择此选项后,Postman将允许您为授权类型,用户名和密码输入名称/值对。注意:每次拨打电话时,请确保您的网络协议是HTTPS,否则您通过互联网传递的所有数据都是明文,没有人想要这样。
![]()
4)如果您正在使用qTest Manager,请继续构建测试并写出您想要在测试用例中测试的内容。完成后,我们将通过映射测试用例ID将测试用例链接到自动API测试。通常,在测试用例管理工具中首先写出测试应该做的事情是编写自动化测试用例的一个很好的过程。
5)构建测试并编写您希望测试用例的内容后,将该工作链接到您的完全可跟踪性要求,然后将自动测试执行挂钩到该测试用例。如果您使用的链接到JIRA的qTest Manager等工具,您将在JIRA中看到所有匹配要求的文本执行。很酷,嗯?
6)现在让我们第一次调用登录端点,以便我们可以获得一个令牌(我们稍后会将令牌传递给后续调用,以便API知道我们已经登录)。查看登录文档,我看到这是一个POST请求。如果是GET,您将通过URL传递您的用户名和密码。为确保一切顺利进行,请确保您具有以下设置:
- Method: Post
- URL: your http://your.qTestURL/oauth/token
- Click on the Body tab and set the request body to x-www-form-urlencoded (these are just different standard ways to pass data in the body of your HTTP request) – and clicking the radio button just sets an HTTP header field Content-Type to be application/x-www-form-urlencoded.
- Now set 3 name/value in the Body:
- grant_type : password
- username : your qTest username
- password : your qTest password
请注意API文档中有关未填写密码的命令,在Postman提供的字段中的名称/密码区域中。
![]()
![]()
![]()
7)你的设置是否匹配?大!现在您有一个有效的API调用。我们将它保存到邮递员集合中,以便我们以后可以重复使用它。要创建新的Postman Collection,只需点击左侧面板中加号的文件夹图标即可。
创建集合后,您可以通过单击屏幕右上角的“保存”按钮来保存呼叫(标准操作系统快捷方式也可以)。我使用qTest中的测试用例ID命名了我的API调用。这将允许我映射我的测试用例,以便每次运行此API调用以及其余测试时都可以跟踪。
8)在我们实际编写测试之前再多一步,因为我们需要对HTTP响应做一些事情:
- Verify the status code is 200 (OK)
- Verify that you get back a non-empty access token
- Verify that your scope is accurate
请注意,我们并不关心其他字段 - 它们对您测试您已登录并不重要。
9)现在是时候编写第一个测试了!小心不要让你的测试变得脆弱 - 要清楚你正在测试的是什么以及为什么要测试它。
10)接下来,让我们编写另一个测试,将测试用例添加到现有项目中。首先,我们需要登录并存储我们的令牌。我们将创建一个环境变量并将其命名为“access_token”:
![]()
![]()
存储此访问令牌的好处是您现在可以在后续调用中使用它。 这意味着您可以自动执行测试,而无需每次都手动获取登录令牌。 优秀! 在下一个调用中,您将看到使用双花括号{{access_token}}的令牌。
11)让我们看一下添加测试用例的文档,您可以在这里找到:
![]()
然后继续为您的新测试用例创建一个位置:
![]()
12)现在让我们创建一个新的POST请求来添加一个测试用例。 URL(路径)中有一个名为{project}的变量。 要填写此变量,我们需要在qTest中获取项目的ID,我们可以从qTest URL获取该ID。 在这种情况下,你可以看到它是45625:
![]()
我们还需要在字段中填写这些字符串:
- name: Testing Create Test Case
- description: This test case was created by the API test
- parent_id: 2656708
请注意,parent_id是我们刚刚为这些测试转储的文件夹/模块的ID。该ID可以在该测试模块页面的URL中找到。
13)接下来,我们必须将注意力转向我们拥有的两个数组属性。对于test_steps,这将是一个JSON数组,它是两个方括号之间的逗号分隔的JSON对象列表。每个对象都是一个步骤,数组字符串中的每个JSON对象都应该在引号内。注意不要从Microsoft Word文档或其他来源复制“漂亮的引号”,以进一步美化您的文本。
Test_steps:
“test_steps” : [{
“description”: “Step 1 – open login page”,
“expected”: “login page opens, obviously”,
“attachments”: []
},
{
“description”: “Step 2 – log in with happy path”,
“expected”: “user is redirected to the home screen”,
“attachments”: []
},
{
“description”: “Step 3 – click hamburger bar “,
“expected”: “side menu shows up”,
“attachments”: []
}]
14)最终请求标头使用第一次调用的令牌。如前所述,我们可以使用带有双括号表示法{{}}的已保存变量:
![]()
和请求身体:
![]()
- 然后进行一些测试:
![]()
要验证响应,请进入测试选项卡,确保返回正确的数据。
15)现在,您可以使用“Runner”立即运行整个测试套件或仅运行子文件夹。
![]()
这些通常都是快乐的路径,但是这些调用可能会出现很多问题,而且你可以做几十或几百个测试,包括很多安全测试。如果项目属于另一个客户怎么办?如果模块ID不存在怎么办?如果你上传一个庞大的文件怎么办?写一次,每次测试!
我们没有涉及的一个重要项目是存储不同的环境。如果要对开发,QA,登台或生产环境进行测试,则可能需要为每个环境使用不同的测试数据或登录。您可以设置它并在通过GUI运行测试时选择环境(如我们所见)或从Newman的命令行中选择。我们接下来就这样做。
Set Up Newman
既然您有一个要执行的集合,并且可能是相应的环境配置,那么您将需要从命令行运行它。您必须能够执行此操作才能从Jenkins或任何其他持续集成调度程序运行它。为此,我推荐Newman,它是一个可执行程序,用于运行Postman集合,这些集合是用Javascript编写的,可以与节点包管理器(NPM)一起安装。只需几个小步骤:
1)打开您选择的终端/命令行应用程序:https://www.davidbaumgold.com/tutorials/command-line/
2)安装npm:https://www.npmjs.com/get-npm
3)在您的机器上全局安装Newman:https://www.npmjs.com/package/newman/tutorial
![]()
4)从Postman导出您的收藏(只需右键单击要在左窗格中导出的测试)并从Postman导出您的环境(转到“管理环境”并点击下载按钮)。 将这些保存在您在终端中导航的计算机上。
5)一旦你进入你的终端,除了运行你的测试之外别无选择! 在这种情况下,您不需要任何选项或环境变量,因此命令应该只说:
`newman run path / to / my / exported / json / postman / collection.json`
![]()
看起来很漂亮吧?漂亮很棒,但是当你使用Jenkins时却不是!让我们使用Jenkins可以理解的更典型的JUnit输出。就像是:
`newman run -reporters junit,json path / to / my / exported / json / postman / collection.json
此命令实际上产生两种类型的输出:标准的,描述性较低的JUnit以及高度描述性的.json文件。看看两者 - 它们应该在你工作目录中名为“Newman”的文件夹下创建(也就是运行Newman命令的目录)。
我们很快就会编写一个脚本来将测试结果上传到qTest,并且使用JUnit输出将允许Jenkins显示内置图形并帮助系统在没有任何其他帮助的情况下通过或失败构建。
虽然您也可以使用JUnit结果和自动化内容将结果直接上传到qTest Manager,但使用API可以更灵活地确定测试结果在工具中的显示方式和位置。
现在我们已经从命令行运行了测试,现在是时候将它放入我们的Jenkins作业中,这样它就可以作为持续集成的一部分。我建议每次开发人员推送到工作分支时,都要针对您的开发环境运行此操作。
从Jenkins执行你的测试
我不会进入Jenkins的设置,只是作业的配置,但如果你想在本地试用,这里是下载页面。
如果您不想直接在计算机上安装Jenkins,可以使用Docker进行安装。如果您确实想使用Docker,可以先下载事实上的Jenkins Docker实例,然后使用Docker / Jenkins存储库中的以下节点安装代码将Dockerfile更改为包含节点:
#安装节点
运行curl -sL https://deb.nodesource.com/setup_4.x |庆典
运行apt-get -y安装nodejs
运行节点-v
运行npm -v
运行npm install -g newman
从这里开始,您需要重建Docker镜像,然后使用与此GitHub自述文件相同的说明启动容器。
您现在应该在本地安装一个完全正常工作的Jenkins实例。大!现在回到使用新安装的Jenkins实例的任务:
1)在Jenkins中创建一个新的“Freestyle”类型的工作。
在这种情况下,我们将其设置为允许您将集合作为参数上载。当您使用自己的项目执行此操作时,您应该将Postman集合提交到您正在使用的任何存储库中,并通过选择“此项目已参数化”然后选择“添加参数”并使用“文件参数”直接从该存储库中进行构建“。
![]()
2)选择两个文件上传 - 一个用于集合,一个用于环境。
![]()
3)使用“执行Shell”添加后构建步骤(如果Jenkins在Windows机器上运行,则执行“执行Windows批处理命令”)。 您将使用之前用于从您自己的命令行运行它的相同命令(假设您使用相同的操作系统),除了您的路径现在应该只是collection.js,因为您将其命名为`newman run collection.json` 在文件参数名称字段中。
4)现在测试它并运行构建。 我刚刚上传了collection.json,因为我还没有使用环境文件,但你可以将它添加到命令行:
`newman run collection.json -e environment.json`
![]()
![]()
为确保一切正常,请检查测试的内容 - 应该在项目中添加一些新的测试用例。
此外,如果要使用内置的JUnit Jenkins查看器,可以存档XML测试结果并将测试指向它。 以下是如何归档和使用JUnit测试结果的示例。 如果您正在使用qTest Manager,也可以在此处下载Jenkins qTest Manager插件。
![]()
通过API将结果上传到qTest
此时,我们已成功编写了与CI作业一起运行的测试。如果测试失败,我们可能会失败这里的构建(API测试的好主意!),但我认为我们还应该将测试结果上传到qTest,以证明这些测试通过或失败。为此,我们可以使用我编写的脚本,您可以在此处找到该脚本。
1)要使用此脚本,我们将使用纽曼的.json记者。
在该文件夹中,您应该找到您的样本Newman测试结果。如果您想在不在Postman中设置测试的情况下尝试此节点脚本,您可以,但是您需要修改.json测试结果文件以使数据与您自己的项目相匹配。在下面的示例中,您将需要更改测试用例ID以匹配您自己项目中的测试用例ID。
2)现在我们将使用该命令运行脚本
node uploadNewmanToQTest.js -f newman-json-result.json -c creds.json -i true -r“([0-9] +)\ - *?”
-r选项之后的部分有点可怕。它是一个JavaScript正则表达式,告诉脚本在哪里查找测试用例ID(如果存在-i false,则为名称)。这将获得第一个数字并将它们用作测试用例ID。默认情况下,如果未提供正则表达式,则将使用结果中的整个测试用例名称。例如,如果测试用例名称为“Verify Successful Login”和-i false(使用测试用例名称而不是ID),那么它将查找名为“Verify Successful Login”的相应测试用例。当然,如果此名称出现两次,它将更新两个测试用例的相关测试运行。此脚本有很多选项,并非所有选项都已完成。如果您有什么想看的,请不要犹豫,评论或删除QASymphony。
就是这样,因为你应该得到一个成功的输出!
当然,这只是众多API测试的一个例子。您还可以查看这篇Postman教程和Postman&Jenkins的介绍,了解更多精彩信息。
如果您有任何具体要求,请在下面评论,我会尽力回复。否则,快乐测试!
- 92 次浏览
【API测试】使用Dredd测试您的API
通常,在开发应用程序时,前端和后端开发人员在实现路径上采用两条不同的路径。前端开发人员更多地是设计驱动的,而后端开发人员则更注重数据。这通常会导致潜在的整合差距,其中一个团队在提供的数据,响应的结构等方面具有某些期望,而另一个团队实现完全不同的东西。
介绍
在本文中,我们将展示一个技术堆栈,旨在弥合前端和后端开发人员之间的差距,使我们能够记录API并在实现后不断测试它。
本文中介绍的堆栈包含以下内容:
- Dredd - 使用API Blueprint和Swagger API描述格式的API测试工具
- API Blueprint - 规范语言,允许我们以类似Markdown的语法记录我们的API
- Drakov - 可以使用我们API的API蓝图描述并设置模拟服务器来托管端点的工具
本文中的示例将使用简单的Node.js API和Express中间件显示。
安装和设置
Dredd基于Node.js,因此在安装之前,请确保在您的计算机上安装了Node.js和npm。 它可以使用以下命令安装为npm包:
> npm install -g dredd
安装完成后,您可以通过运行来检查它是否正确安装:
> dredd --version
API Blueprint描述文件的简单示例
假设我们有一个带端点的API来创建新用户:
POST /api/users
它接受包含电子邮件和密码值的JSON请求正文:
{
"email": "testing@email.com",
"password": "pa55w0rd"
}
用于测试以下端点的API Blueprint规范如下所示:
FORMAT: 1A
# Dredd example
## Users [/api/users]
### Create User [POST]
+ Request (application/json)
{
"email": "test@email.com",
"password": "pa55w0rd"
}
+ Response 200 (application/json; charset=utf-8)
+ Headers
jwt-token: (string, required)
+ Body
{
"id": 1,
"email": "test@mail.com",
"password": "pa55w0rd",
"provider": "local",
"role": "user"
}
我们可以通过两种方式根据Blueprint文件验证API实现。
手动运行
Dredd使我们能够通过指定API蓝图文件的名称和API的URL来运行临时测试:
> dredd api-description.apib http://localhost:9090
上面的命令假设API Blueprint文件名为api-description.apib,并且您的API在端口9090上的本地计算机上运行。根据您的设置,值可能会有所不同。
配置运行
还有一种更简单的方法来设置Dredd,即运行> dredd init命令,该命令运行配置向导以帮助您在项目根目录中创建dredd.yml文件。 从交互式向导回答几个问题后,只需输入以下命令即可运行测试:> dredd。 如果配置正确,Dredd将使用您向向导提供的命令启动后端服务器进程并开始测试。
在这两种情况下,输出都与此类似:
> dredd info: Configuration './dredd.yml' found, ignoring other arguments. warn: Apiary API Key or API Project Subdomain were not provided. Configure Dredd to be able to save test reports alongside your Apiary API project: https://dredd.readthedocs.io/en/latest/how-to-guides/#using-apiary-reporter-and-apiary-tests info: Starting backend server process with command: npm run start info: Waiting 3 seconds for backend server process to start > dredd-example@0.0.1 start /Users/code/dredd-example > node server/app.js Express server listening on 9000, in development mode info: Beginning Dredd testing... pass: POST (200) /api/users duration: 55ms complete: 1 passing, 0 failing, 0 errors, 0 skipped, 1 total complete: Tests took 901ms POST /api/users 200 4.167 ms - 151 complete: See results in Apiary at: https://app.apiary.io/public/tests/run/f1642892-a4eb-4970-8423-5db5c986a509 info: Backend server process exited
由于我们没有指定任何API密钥,Dredd警告我们测试运行不会保存到我们的Apiary帐户。 在这种情况下,它们被保存为公共运行并保存24小时,这对于本文来说已经足够了。 让我们使用输出中的URL打开我们的测试运行(注意 - 您的URL会有所不同):https://app.apiary.io/public/tests/run/f1642892-a4eb-4970-8423-5db5c986a509
在Test Run Viewer中,我们可以检查测试运行中的每个请求,返回的响应,差异和结果。
使用挂钩进行设置和拆卸
与许多其他测试框架一样,Dredd还支持添加挂钩以运行设置和拆卸代码,编写自定义期望,处理授权以及在测试之间共享数据。 钩子可以用许多支持的语言编写,在本文中,我们将看到如何在本机支持的Node.js中添加钩子。
我们首先在项目中添加一个钩子文件(在我们的例子中,我们可以将它添加到项目根目录并命名为dredd-hooks.js)。
有两种方法可以让Dredd使用钩子文件。 一种是手动添加命令参数和我们的钩子文件的路径:
> dredd --hookfiles=dredd-hooks.js
另一种方法是编辑我们的dredd.yml文件并通过设置hookfiles属性来更新配置。
dry-run: null
hookfiles: dredd-hooks.js
language: nodejs
sandbox: false
server: npm run start
server-wait: 3
init: false
custom: {}
names: false
only: []
reporter: apiary
output: []
header: []
sorted: false
user: null
inline-errors: false
details: false
method: []
color: true
level: info
timestamp: false
silent: false
path: []
hooks-worker-timeout: 5000
hooks-worker-connect-timeout: 1500
hooks-worker-connect-retry: 500
hooks-worker-after-connect-wait: 100
hooks-worker-term-timeout: 5000
hooks-worker-term-retry: 500
hooks-worker-handler-host: 127.0.0.1
hooks-worker-handler-port: 61321
config: ./dredd.yml
blueprint: api-description.apib
endpoint: 'http://localhost:9000'
现在我们有了文件,我们可以开始围绕每个事务编写代码。 Dredd在API蓝图描述文件(.apib)中按名称标识事务。 要在测试运行期间列出事务名称,可以添加--names命令参数:> dredd --names。
在我们的示例中,我们有一个名为Users> Create User的事务,我们将在代码中引用它。
当我们的API中有很多端点时,挂钩尤其重要,我们不希望依赖于它们执行的任何特定顺序。 例如,如果我们有一个删除用户的端点,为了单独测试它(不依赖于首先运行的Create User端点),我们必须在执行测试之前创建一个测试用户。 这是钩子文件的样子:
var hooks = require('hooks');
var User = require('../dredd-example/server/api/user/user.service');
var testStash = {
newUserId: null
};
hooks.before('Users > Delete User', function(transaction) {
hooks.log('Executing hook "before" transaction "Users > Delete User"');
User.save({
email: 'user@test.com',
password: '12345'
}, function(err, newUser) {
if (!err) {
hooks.log('New user created');
testStash.newUserId = newUser.id;
} else {
transaction.fail = 'Unable to create new user';
}
})
});
hooks.after('Users > Delete User', function(transaction) {
hooks.log('Executing hook "after" transaction "Users > Delete User"');
// In case the actual test failed, we want to clean up the data
if (testStash.newUserId != null) {
User.delete(testStash.newUserId);
}
});
上面的代码中有几点需要考虑:
我们声明了一个名为testStash的新变量,我们用它来保存跨多个测试钩子的新创建用户的ID。
在before hook中,如果我们无法创建用户,我们可以通过使用失败消息设置fail属性来手动测试失败。
在挂钩后,我们从存储中获取用户的ID,并在测试后通过删除用户来清理它。
设置模拟服务器
使用API Blueprint格式记录的API时,另一个很酷的功能是我们也可以使用相同的文件来启动模拟服务器来托管我们的端点。这对前端开发人员特别有用,因为他们不必等待API完成和部署。相反,他们可以使用.apib文件来启动模拟服务器,将客户端应用程序与它集成,并确保真正的API也符合相同的规范。
该工作的工具称为Drakov,它也可以通过运行以下命令安装为npm包:
> npm install -g drakov
安装完成后,我们只需键入以下内容即可将Drakov指向我们的API Blueprint文件:
> drakov -f api-description.apib
此命令将使用默认参数运行Drakov并显示以下输出:
> drakov -f api-description.apib [INFO] No configuration files found [INFO] Loading configuration from CLI DRAKOV STARTED [LOG] Setup Route: GET / Get Message [LOG] Setup Route: POST /api/users Create User [LOG] Setup Route: GET /api/users/:id Get User Info [LOG] Setup Route: DELETE /api/users/:id Delete User Drakov 1.0.4 Listening on port 3000
现在,我们可以对模拟的API执行任何HTTP操作,并开始获取文档中定义的HTTP响应。
最后的话
今天提供的工具既简单又直接,但也非常强大。 它们涵盖了许多任务,包括记录API,测试实现以及运行模拟服务器以方便使用。
Dredd有很多选项,可以配置各种类型的请求。 它还可以与所有主要的CI工具集成,以便重复测试,为开发人员提供了一个很好的安全网。
API Blueprint是一种非常富有表现力的降价格式,可用于描述请求和响应的几乎所有细节。
Drakov非常简单,可以通过运行一个简单的命令来开箱即用。
所有这些只需要几个小时来准备和配置,之后您将能够告别未记录的API。
- 168 次浏览
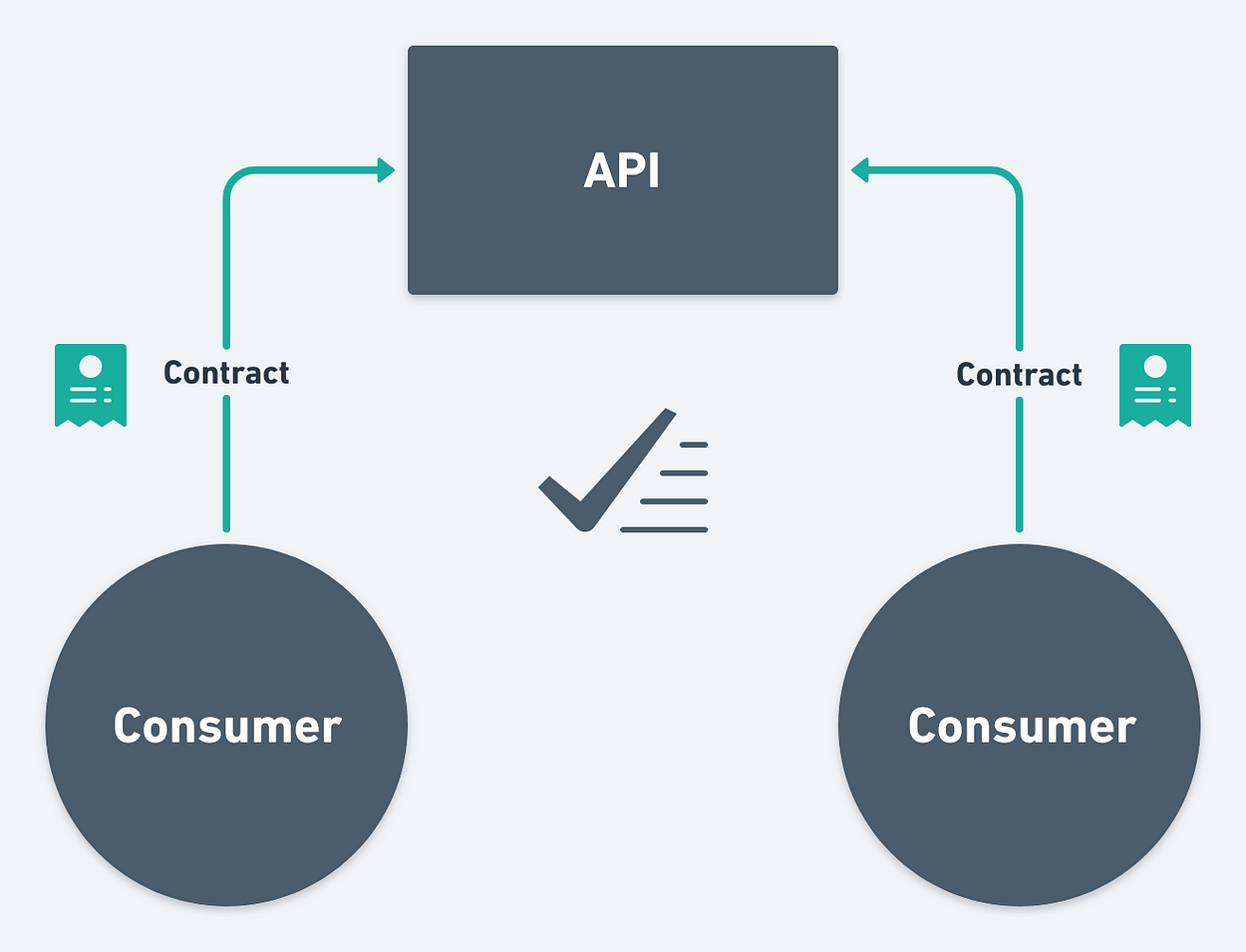
【合约测试】Pact 101 - 契约和消费者驱动的合同测试入门
所以你听说过Pact并希望开始。本指南应该有助于您朝着正确的方向前进。
什么是Pact?
Pact系列测试框架(Pact-JVM,Pact Ruby,Pact .NET,Pact Go,Pact.js,Pact Swift等)为依赖系统之间的消费者驱动合同测试提供支持,其中集成基于HTTP(或消息)某些实现的队列)。它们对于μ服务特别有用,在这些服务中可能存在大量相互依赖的服务,并且集成测试很快变得不可行。
在我们深入了解Pact之前,您需要了解消费者驱动的合同。
什么是消费者驱动的合同?
消费者驱动的合同是一种模式或方法,其中相互依赖的服务之间的合同是从服务消费者的角度设计的。它的主要文章是消费者驱动的合同:服务进化模式,但它在技术方面有点过时(它谈论了很多关于XML和模式)。但是文章中表达的概念与我们今天构建的计算机系统有关。
我发现很多时候构建μ服务或内部API的团队都遵循与外部或公共API相同的思路。服务提供商或API团队会考虑其服务的任何消费者需要的所有内容(在此过程中做出许多假设),然后提供服务以及如何使用它的文档。他们建立它并希望消费者来。
当他们稍后需要更改它时,他们会进行更改,然后将其与所有消费者需要遵循的说明一起发布以使用更新的API。它们可能包含多个版本的服务,以保护消费者免受重大变化的影响。

我目睹了第一手开发和使用API的两个团队。 在构建消费者和提供者之后,他们花了很多天才在集成测试环境中进行交互,因为消费者团队认为API将基于发布JSON文档(它是从Web浏览器调用),而 提供程序团队实现了application / x-www-form-urlencoded POST API。
但具有讽刺意味的是,对于内部API和服务而言,要弄清楚服务的所有消费者是谁以及他们的要求是什么并不难。 大多数时候,他们都在同一个组织工作。
消费者驱动的合同扭转了这一切。 交互合同由服务的消费者开发。

这种方法的好处是,您知道您的服务的所有消费者是谁,您将知道何时进行重大更改,以便更容易进行更改,合同也是一种文档形式。 其次,您将确切地知道需要提供哪些功能,以便您可以实现消费者所需的正确服务,并遵循YAGNI原则。
交互的发展始于消费者方面,希望通过测试。 消费者团队定义交互合同并根据合同实现服务使用者。

然后将此合同提供给提供者团队(在某些情况下,它是同一个团队),并且实施提供者服务以履行合同。

开始时我需要做什么?
大多数信息可以在Github页面上找到,用于各种Pact实现。 Ruby Pact在wiki中有很多信息。
- Ruby Pact: https://github.com/realestate-com-au/pact
- JVM Pact: https://github.com/DiUS/pact-jvm
- .Net Pact: https://github.com/SEEK-Jobs/pact-net
- Pact Go: https://github.com/pact-foundation/pact-go
- Pact.js: https://github.com/pact-foundation/pact-js
- Pact Swift: https://github.com/DiUS/pact-consumer-swift
- Pact Python: https://github.com/pact-foundation/pact-python
特别是,要了解Pact的工作原理,请阅读:https://github.com/realestate-com-au/pact#how-does-it-work。
从消费者测试开始
这完全是关于消费者的,所以从那里开始。支持许多测试框架,因此根据您使用的测试工具,请阅读相关文档。
对于Ruby和RSpec,请阅读使用pacts简化微服务测试的示例。
对于基于JVM的测试框架(JUnit,Groovy等),请查看https://github.com/DiUS/pact-jvm#service-consumers。 JUnit似乎是最受欢迎的。有很多示例测试。
一旦运行了消费者测试,就应该生成pact文件。这些是消费者驱动合同意义上的合同。您可以通过多种方式发布这些文件。常见的方法是将它们提交到源存储库,将它们上载到文件服务器,将它们存储为CI构建中的工件或将它们上载到Pact Broker。
验证您的提供者
该方法的后半部分是验证您的提供商实际上是否符合消费者的期望。对于已实现消费者测试的每个消费者,您应该在某处发布pact文件。通常,您希望在其CI构建中验证您的提供商,以便您知道更改何时破坏了与消费者的交互,并且您还将知道您受影响的消费者。
给定一组已发布的pact文件,有两种主要方法可以验证您的提供程序是否遵守pact文件中封装的合同。
使用构建插件来验证协议
第一种方法是使用构建插件,该插件可以在pact文件中针对您的提供者执行请求。在某些情况下(如Ruby Rake任务),提供程序从测试工具(Rack Test for ruby)中启动,重放请求,然后将响应与pact文件的预期响应进行比较。在其他情况下(如Maven和Gradle插件),实际的提供程序需要运行,构建插件会向正在运行的提供程序发出实际请求。
有关为Ruby提供程序使用Ruby Rake任务的示例,请阅读使用pacts简化微服务测试的“提供程序”部分。
JVM构建插件(Maven,Gradle,Leiningen和SBT)的自述文件包含有关如何使用这些工具的更多信息。在大多数情况下,您需要能够事先启动您的提供程序并在之后停止它,并且有办法提供协议所需的测试数据。有关更多信息,请参阅Pact-JVM自述文件的“服务提供程序”部分。
Pact具有状态更改机制,用于在验证测试运行期间控制提供程序的状态。本质上,这是一个可以在每个请求之前调用的钩子,其中描述了提供者为了能够成功处理请求而需要的预期状态。例如“用户Andy应该存在”或“订单表应该为空”。 Ruby实现允许定义设置和拆除块,而JVM构建插件允许定义状态更改URL,该URL将在实际请求发出之前接收具有状态描述的POST请求。
使用测试框架来验证契约
使用某些构建插件的最大缺点是,您需要让您的提供程序运行,并且您需要能够设置测试数据。这涉及预先加载所有契约所需的夹具数据,或者使用状态更改机制来动态更改提供者的状态。这两种方法都需要相当多的编排,尤其是在CI环境中。
由于社区贡献,Pact JUnit提供程序运行程序可供使用基于JVM的提供程序的人员使用。它允许您仅处理提供者处理请求的部分提供者代码,并且您可以使用JUnit设置和拆除机制以及状态注释标记来设置协议所需的数据。您也可以使用标准的模拟框架来存根依赖关系,尽管我会添加一个警告,以确保您不会影响您的模拟和存根的行为。自述文件包含更多信息。
原文:https://dius.com.au/2016/02/03/microservices-pact/
讨论:加入知识星球【首席架构师圈】
- 220 次浏览
【合约测试】Pact Broker是一个用于共享消费者驱动的合同和验证结果的应用程序。
启用您的消费者驱动的合同工作流程http://pactflow.io
Pact Broker是一个用于共享消费者驱动的合同和验证结果的应用程序。它被优化用于“pacts”(由Pact框架创建的契约),但可以用于任何类型的可以序列化为JSON的契约。
我为什么需要一个?
合同测试是传统集成测试的另一种方法,它为您提供更快速执行的测试,并且可以更大规模地维护。该方法的一个缺点是在集成测试套件执行结束时可以在一个地方获得的重要信息(即,一起测试的所有应用程序的版本号,以及测试是否通过或失败的)现在分散在许多不同的版本中。 Pact Broker是一个工具,可以将所有这些信息重新组合在一起,并允许您安全地部署。
它:
- 通过独立部署服务并避免集成测试的瓶颈,您可以快速,自信地发布客户价值
- 解决了如何在消费者和提供者项目之间共享合同和验证结果的问题
- 告诉您可以安全地一起部署哪些版本的应用程序
- 自动修改合同
- 允许您确保多个消费者和提供者版本之间的向后兼容性(例如,在移动或多租户环境中)
- 提供您的应用程序的API文档,保证是最新的
- 向您展示服务如何交互的真实示例
- 允许您可视化服务之间的关系
特征:
- 用于发布和检索协议的RESTful API。
- 用于导航API的嵌入式API浏览器。
- 每个协议的自动生成文档。
- 动态生成的网络图,以便您可以可视化您的微服务网络。
- 显示提供程序验证结果,以便您知道是否可以安全部署。
- 提供兼容的消费者和提供商版本的“矩阵”,以便您了解哪些版本可以安全地一起部署。
- 提供徽章以在README中显示协议验证状态。
- 允许标记应用程序版本(即“prod”,“feat / customer-preferences”)以允许类似于存储库的工作流程。
- 提供webhook以在pacts更改时触发操作,例如。运行提供程序构建,通知Slack通道。
- 查看Pact版本之间的差异,以便了解哪些期望已发生变化。
- Docker Pact Broker
- 用于将Pact工作流程加载到持续集成过程的CLI。
我如何使用Pact Broker?
步骤1.消费者CI构建
- 使用者项目使用Pact库运行其测试以提供模拟服务。
- 测试运行时,模拟服务将请求和预期响应写入JSON“pact”文件 - 这是消费者合同。
- 然后将生成的协议发布到Pact Broker。大多数Pact库都会为您提供一个可以轻松完成此任务的任务,但是,最简单的是,它是指定消费者名称和应用程序版本以及提供者名称的资源的PUT。例如:http://my-pact-broker/pacts/provider/Animal%20Service/consumer/Zoo%20App/version/1.0.0(请注意,您在URL中指定了消费者应用程序版本,而不是协议版本。当内容发生变化时,代理将负责在幕后对该协议进行版本控制。预计消费者应用程序版本将随着每个CI构建而增加。)
- 发布协议时,如果协议内容自上一版本以来发生更改,则Pact Broker中的webhook将启动提供程序项目的构建。
步骤2.提供者CI构建
- 提供程序具有验证任务,该任务使用URL进行配置,以检索自身与使用者之间的最新协议。例如http:// my-pact-broker / pacts / provider / Animal%20Service / consumer / Zoo%20App / latest。
- 提供者构建运行pact验证任务,该任务从Pact Broker检索pact,对提供者重放每个请求,并检查响应是否与预期响应匹配。
- 如果协议验证失败,则构建失败。 Pact Broker CI Nerf Gun神奇地确定是谁导致验证失败,然后射击它们。
- 验证结果由契约验证工具发布回Pact Broker,因此消费者团队将知道他们编写的代码是否可以在现实生活中使用。
如果您没有Pact Broker CI Nerf Gun,那么当消费者和提供者由不同的团队编写时,您可能想要阅读有关使用pact的信息。
步骤3.返回Consumer CI构建
以下功能是测试版。您的反馈意见将不胜感激。
- 消费者CI通过运行pact-broker can-i-deploy --pacticipant CONSUMER_NAME --version CONSUMER_VERSION ...来确定协议是否已经过验证(请参阅此处的文档)
- 如果已验证协议,则可以继续部署。
在Wiki页面的概述中阅读有关如何使用Pact Broker的更多信息。
文档
有关Pact Broker的文档,请参阅Wiki。请首先阅读概述页面,以了解代理中的HTTP资源以及它们之间的相互关系。
截图
Index
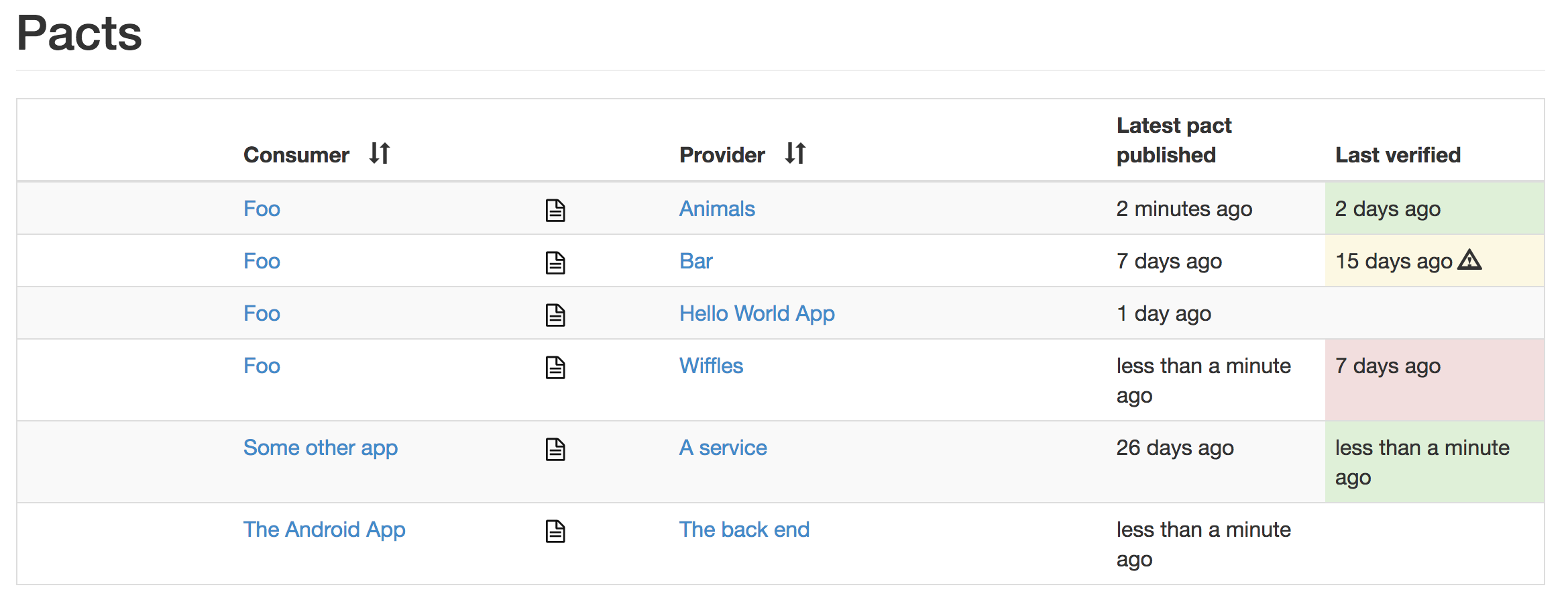
自动生成的文档
将pact URL粘贴到浏览器中以查看该协议的HTML版本。
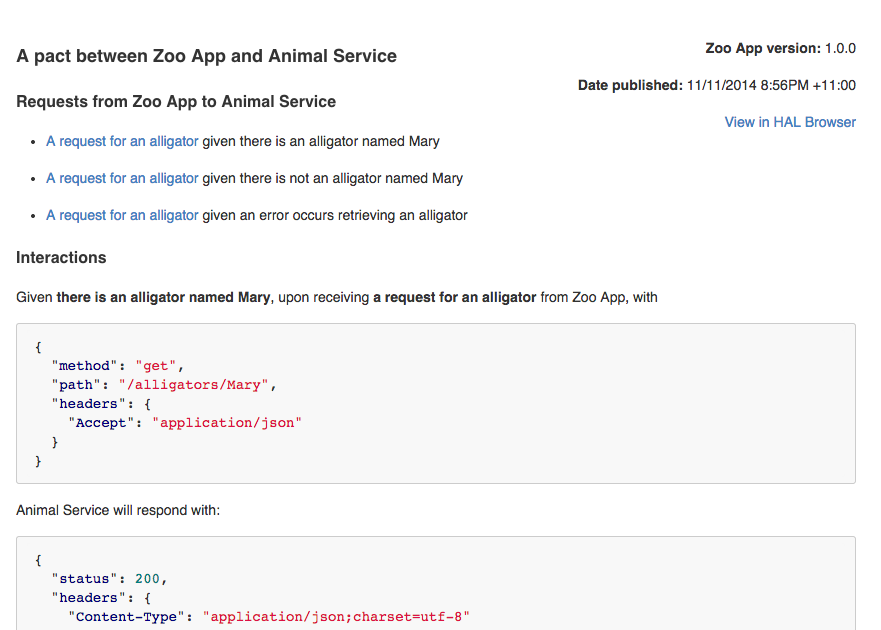
Network diagram
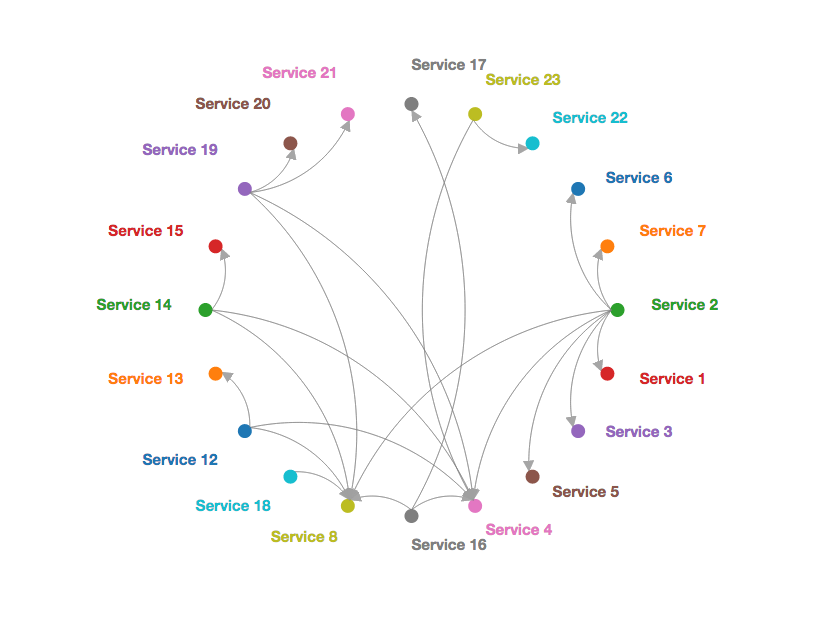
HAL浏览器
使用嵌入式HAL浏览器导航API。
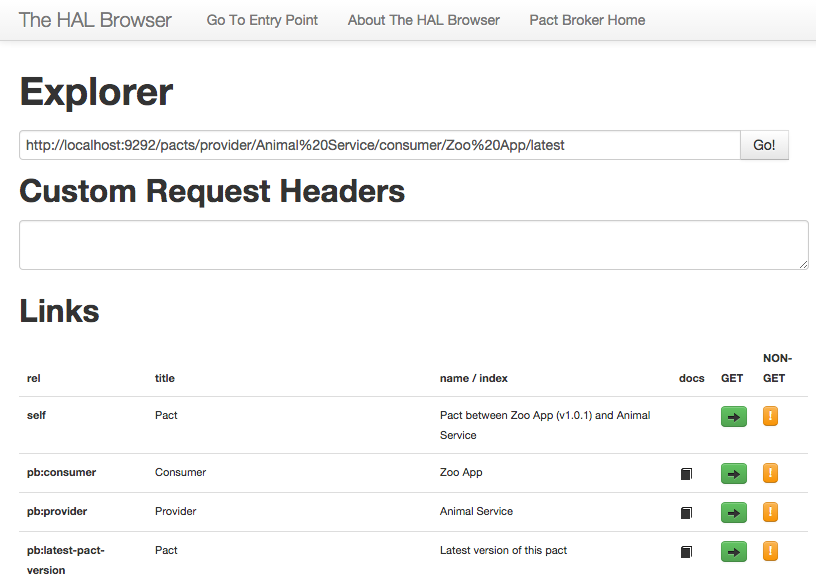
HAL文档
在浏览时使用HAL浏览器查看文档。

用法
在本地计算机上玩游戏
- Install ruby 2.2.0 or later and bundler >= 1.12.0
- Windows users: get a Rails/Ruby installer from RailsInstaller and run it
- unix users just use your package manager
- Run
git clone git@github.com:pact-foundation/pact_broker.git && cd pact_broker/example - Run
bundle install - Run
bundle exec rackup -p 8080(this will use a Sqlite database. If you want to try it out with a Postgres database, see the README in the example directory.) - Open http://localhost:8080 and you should see a list containing the pact between the Zoo App and the Animal Service.
- Click on the arrow to see the generated HTML documentation.
- Click on either service to see an autogenerated network diagram.
- Click on the HAL Browser link to have a poke around the API.
- Click on the book icon under "docs" to view documentation related to a given relation.
真的
Hosted
In a hurry? Hate having to run your own infrastructure? Check out the Hosted Pact Broker - it's fast, it's secure and it's free!
Container solutions
You can use the Pact Broker Docker image or Terraform on AWS. See the wiki for instructions on using a reverse proxy with SSL.
Rolling your own
- Are you sure you don't just want to use the Pact Broker Docker image? No Docker at your company yet? Ah well, keep reading.
- Create a PostgreSQL (recommended) or MySQL (not as recommended because of @bethesque's personal prejudices, but still fully supported) database.
- To ensure you're on a supported version of the database that you choose, check the travis.yml file to see which versions we're currently running our tests against.
- If you're using PostgreSQL (did we mention this was recommended!) you'll find the database creation script in the example/config.ru.
- Install ruby 2.4 or later and the latest version of bundler (if you've come this far, I'm assuming you know how to do both of these. Did I mention there was a Docker image?)
- Copy the pact_broker directory from the Pact Broker Docker project. This will have the recommended settings for database connections, logging, basic auth etc. Note that the Docker image uses Phusion Passenger as the web application server in front of the Pact Broker Ruby application, which is the recommended set up.
- Modify the config.ru and Gemfile as desired (eg. choose database driver gem, set your database credentials. Use the "pg" gem if using Postgres and the "mysql2" gem if using MySQL)
- example Sequel configuration for postgres
{adapter: "postgres", database: "pact_broker", username: 'pact_broker', password: 'pact_broker', :encoding => 'utf8'} - example Sequel configuration for mysql
{adapter: "mysql2", database: "pact_broker", username: 'pact_broker', password: 'pact_broker', :encoding => 'utf8'}`
- example Sequel configuration for postgres
- Please ensure you use
encoding: 'utf8'in your Sequel options to avoid encoding issues. - For production usage, use a web application server like Phusion Passenger or Nginx to serve the Pact Broker application. You'll need to read up on the documentation for these yourself as it is beyond the scope of this documentation. See the wiki for instructions on using a reverse proxy with SSL.
- Ensure the environment variable
RACK_ENVis set toproduction. - Deploy to your location of choice.
升级
Please read the UPGRADING.md documentation before upgrading your Pact Broker, for information on the supported upgrade paths.
原文 :https://github.com/pact-foundation/pact_broker
讨论: 知识星球【数字化和智能转型】
- 341 次浏览
【合约测试】使用Postman进行消费者驱动的合同测试
实施消费者驱动的合同测试是维护不断增长的微服务堆栈的好方法。 它使团队在定期完成时不会因API差异而受阻。 这是Postman如何帮助您做得更好。
API行为通常在文档页面中描述,该页面列出了可用的端点,请求数据结构和预期的响应数据结构,以及示例查询和响应。然后,构建使用这些API的系统的人员将使用这些文档。
但是,单独编写的文档不会保护API的使用者免受API的更改。 API生产者可能需要更改响应数据结构或完全重命名端点以满足业务需求。
然后,合并这些更改的责任落在那些必须不断检查文档以进行任何更改的API的消费者身上。该模型不能很好地扩展。消费者经常会遇到意想不到的错误,因为他们期待的反应已经发生了变化。
这是让消费者对API合同断言变得有用的地方。这些API的消费者可以通过让生产者知道他们想要从API获得哪些数据来设置期望,而不是让API生成者自己构建规范。

然后,API设计将转变为消费者需要的内容与提供商可以提供的内容之间的协商。
使API合约显式且可执行
Postman在今年早些时候进行了一项调查,结果显示大多数业务API都是内部的。这些是在组织内构建服务的团队,这些团队聚集在一起构建面向用户的更大产品。在这种情况下,确保消费者的期望与API提供的数据之间没有差异,这成为组织工作流程的重要组成部分。拥有明确,可共享和可执行的合同可以防止这种混乱和挫折。
生产者可以通过使用市场上任何流行的工具(如RAML,API Blueprint,OpenAPI,Pact或Postman Collections)为其API创建规范,而不是在静态页面中记录API行为。最后两个,Pact和Postman让您实现消费者驱动的合同作为一流的概念。 Pact进一步专注于合同测试,而Postman生态系统除此之外还包含更多功能。
所有这些格式都允许您指定有关API行为的详细信息。它们允许您通过端点名称,描述,数据类型以及请求和响应的数据结构来传达API的意图。他们还支持向每个端点添加示例。
一旦获得这些格式的规范,就可以运行生成测试代码的工具,或使用规范中描述的端点结构直接将请求发送到给定服务。您获得的灵活程度因您使用的工具集而异。
这些规范构成了服务合同的来源 - 生产者提供的内容与消费者期望的内容之间的协议。每个工具集的基本价值在于,它们使您的API结构对于协作构建服务以及服务的使用者而言是明确的。
针对多个消费者测试合同
如果您是消费者,拥有这样的规范便可让您确切地知道要从API中获取哪些数据。您可以编写测试来设置期望并断言您的服务将使用的数据。这种方法有两个主要好处:
- 只要规范发生变化,您就可以运行测试套件,并主动响应API规范中的更改,并且,
- 您可以作为消费者参与API的设计过程,并在合同正式化之前让您的需求得到了解。
在消费者驱动的合同测试中,合同由消费者明确编写和管理。如果生产者需要对其服务进行一些更改,例如实施新功能,生产者只需查看哪些消费者的合同测试失败就可以了解他们打破了哪些消费者。这使得API提供商不必担心每次他们对服务进行一些更改时都会意外破坏消费者应用或服务。
独立服务测试
这减少了执行端到端服务测试的需要。如果所有合同测试都通过,API生产商可以合理地确定他们的服务在与其他服务集成时按预期执行。对于在微服务环境中进行端到端测试的复杂性而言,这是一个巨大的缓解。
对于API的每次更改,端到端测试都是昂贵且繁琐的。生产者和消费者可以按照自己的步调移动,拥有自己的路线图并不断部署他们的变化。消费者团队只有在合同测试失败时才需要担心。将此与从规范自动生成的更新文档相结合,可以快速检测故障,而无需构建运行端到端测试所需的复杂设置。
将Postman用于消费者驱动的合同
Postman拥有您开始在组织中实施合同测试所需的所有工具。 Postman Collections是API的可执行规范。您可以使用Postman应用程序在本地计算机上运行集合,在命令行上使用newman运行CI系统,使用监视器在云中运行集合。在任何一种情况下,集合中的请求都是按顺序执行的。
此外,您可以使用预请求脚本为请求添加动态行为,并通过测试对响应进行断言。有关在Postman中从手动过渡到自动API测试的文章将向您介绍这些步骤的详细信息。
将所有这些与Postman中的Workspace相结合,您就可以为整个团队准备好可执行,共享和协作的合同集合。您无需与团队成员手动共享这些详细信息。
让我向您介绍一个示例用例,了解这些用例如何实现以消费者为导向的合同。
示例用例:简单日志检索服务
假设我们需要构建一个假设的服务,该服务返回来自某个集中式日志存储的日志条目列表。此服务仅公开一个端点(为简单起见),它返回最新的5个日志条目,其中包含创建条目的服务的名称,条目的时间戳以及描述该条目的描述字符串。
端点位于/ api / v1 / logs。向此端点发送GET请求应该返回此结构中的JSON数据:
{
"count": Number,
"entries": Array[Object]
}
entries数组将包含每个日志条目的对象。他们的数据结构如下所示:
{
"serviceName": String,
"timestamp": Number,
"description": String
}蓝图
首先,我们创建一个蓝图集合。蓝图集合规定了API结构。这是由服务的生产者创建的。
您可以在此处访问此示例的蓝图集合。
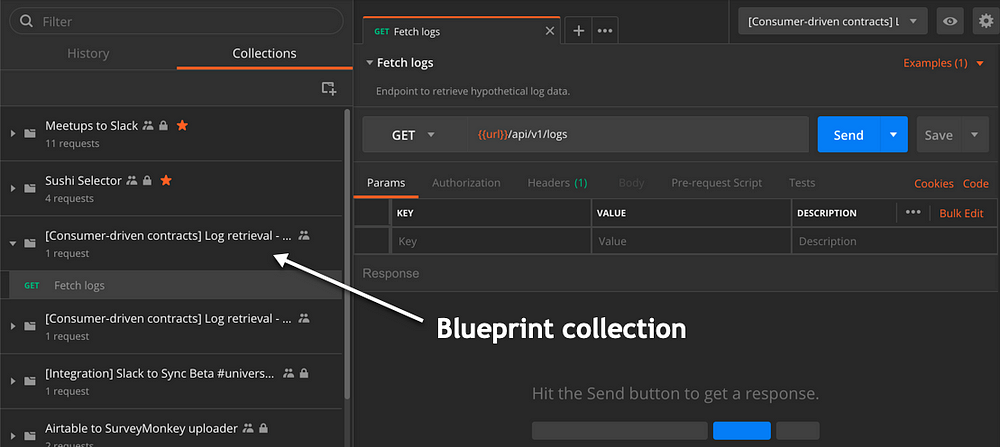
示例蓝图集合
然后,我们为请求添加示例。我已经添加了一个例子。示例允许此类蓝图集合描述响应数据。它们出现在Postman生成的文档中。以下是此服务的默认输出的响应数据示例:
{
"count": 5,
"entries": [
{
"serviceName": "foo",
"timestamp": 1540206226229,
"description": "Received foo request from user 100"
},
{
"serviceName": "bar",
"timestamp": 1540206226121,
"description": "Sent email to user 99"
},
{
"serviceName": "foo",
"timestamp": 154020622502,
"description": "Received foo request from user 10"
},
{
"serviceName": "baz",
"timestamp": 1540206223230,
"description": "Activated user 101"
},
{
"serviceName": "bar",
"timestamp": 1540206222126,
"description": "Error sending email to user 10"
}
]
}
每个示例都有一个名称和特定的请求路径。这就是它在Postman应用程序中的外观:
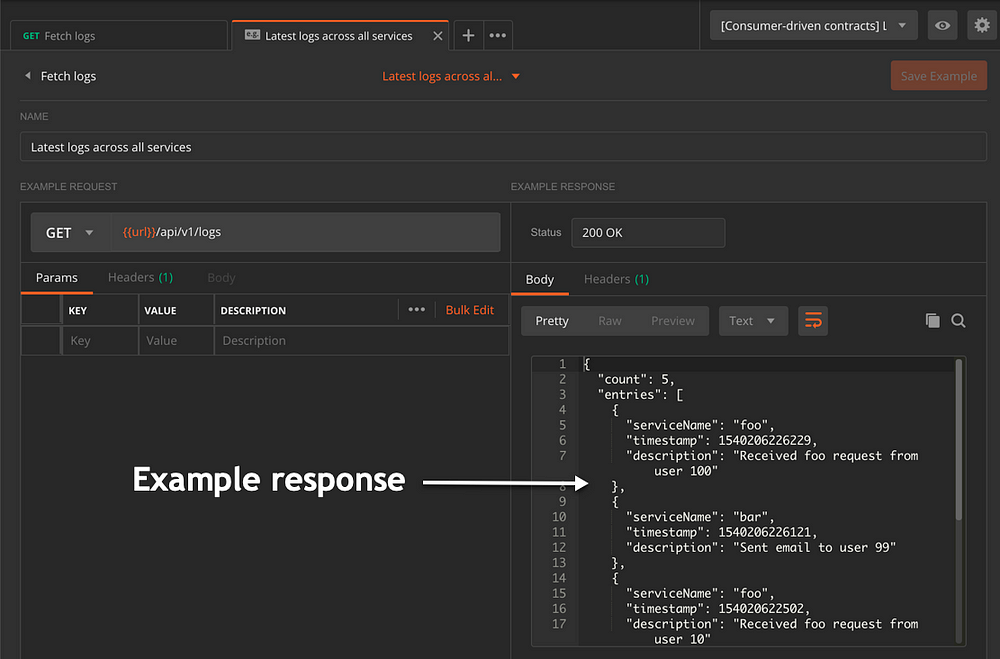
添加示例以示例蓝图集合的请求
有了这些,Postman会自动为蓝图生成基于Web的文档。以下是已发布文档的截图。
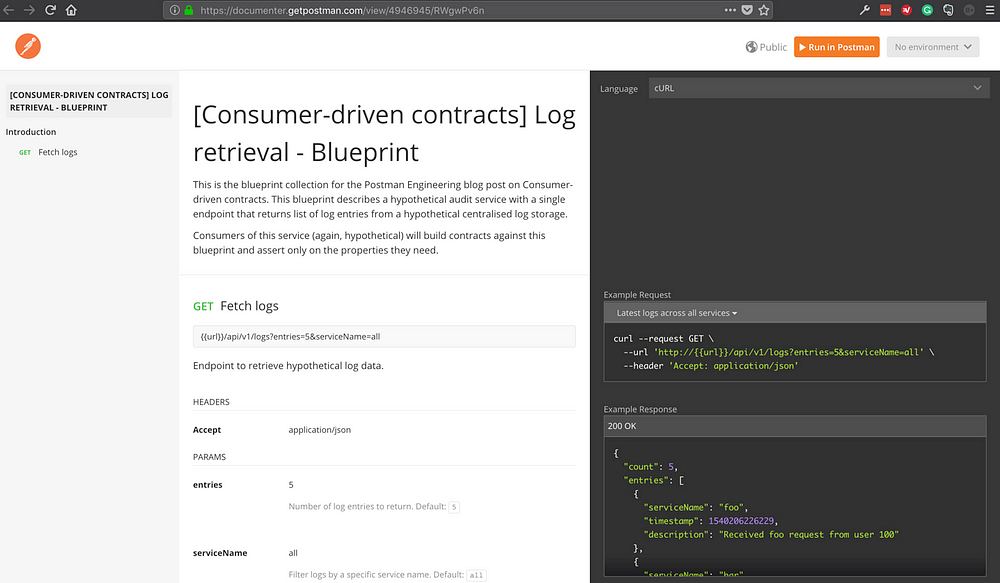
由Postman从示例蓝图集合生成的已发布文档
作为创建此集合的工作空间的所有成员可以查看文档并访问集合,使其成为与其他成员协作的绝佳方式。然后,服务所有者可以基于此集合在Postman中创建模拟服务器。请求中添加的示例将作为模拟服务器响应的一部分发送。
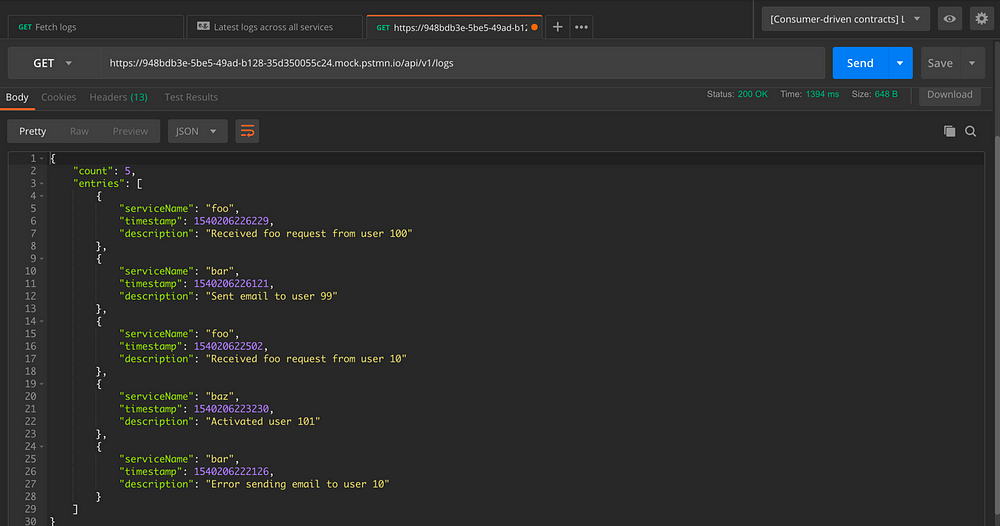
在Postman中创建模拟服务器后,您可以在Postman为您生成的模拟服务器URL之后使用相同的端点向模拟服务发出请求。因此,向https:// <mock-server-id> .pstmn.io / api / v1 / logs发出请求将返回以下响应:
从样本集合创建的模拟服务器返回响应
写合同集合
服务的消费者可以根据蓝图和模拟来构建合同集合。 Postman测试允许您在响应的每个方面断言 - 包括响应标头,正文和响应时间。 因此,合同可以利用所有这些并构建可靠的测试。
对于此示例,我们假设此服务只有一个使用者。 为了简单起见,我们的契约集合示例也将有一个请求,它将仅在响应数据结构上断言。 现实世界的合同将断言数据结构以及响应中收到的数据。
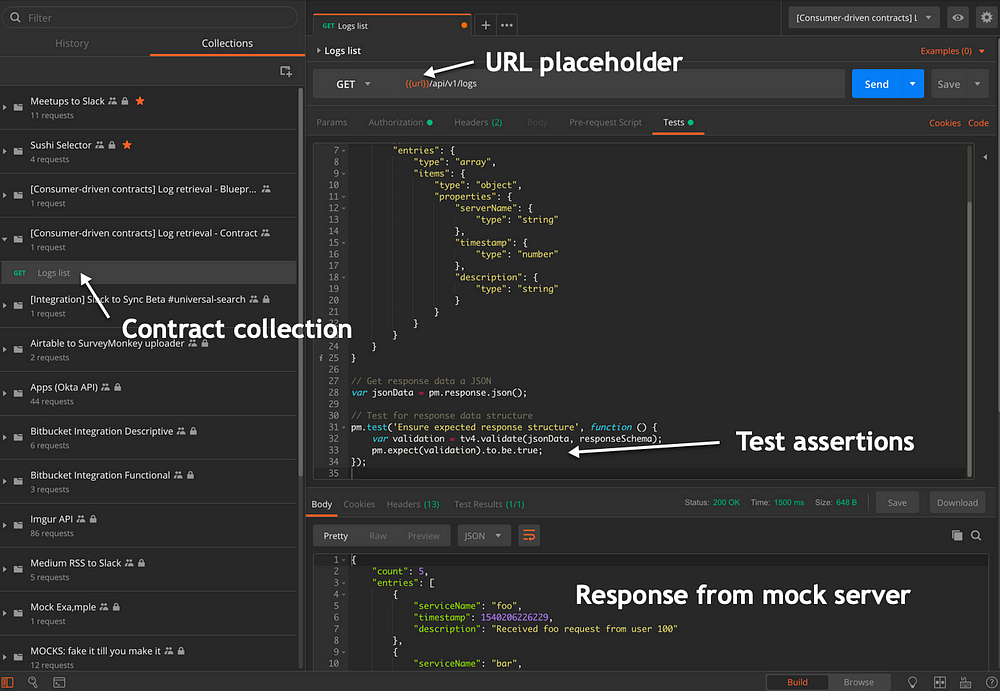
以下是合同集合可用于测试上述数据结构的测试脚本。 它使用tv4库,它作为Postman Sandbox的一部分提供:
// Define the schema expected in response var responseSchema = { "type": "object", "properties": { "count": { "type": "number" }, "entries": { "type": "array", "items": { "type": "object", "properties": { "serverName": { "type": "string" }, "timestamp": { "type": "number" }, "description": { "type": "string" } } } } } }// Get response data as JSON var jsonData = pm.response.json();// Test for response data structure pm.test('Ensure expected response structure', function () { var validation = tv4.validate(jsonData, responseSchema); pm.expect(validation).to.be.true; });
合同集合在此发布。您可以使用该页面上的“Run in Postman”按钮在Postman应用程序中加载该集合,并浏览与该请求相关的测试。
请注意在合同集合中使用{{url}}变量占位符。当服务处于早期阶段时,消费者可以使用模拟服务器URL来发出请求。构建服务后,可以将环境变量切换为指向服务的托管实例。这样,消费者应用程序或服务的开发可以并行发生,而不会被阻止以构建上游服务。
持续测试
合同需要不断测试,以确保它们随着时间的推移有效。有两种方法可以实现。
如果您有一个现有的持续集成系统:您可以从Postman导出集合文件和环境,并使用newman从命令行运行它们。有关为Jenkins和Travis CI设置连续构建的步骤,请参阅newman的文档。每当规范或新版本的上游服务发生更改时,都可以触发构建管道。
除此之外,您还可以使用Postman Monitors运行合同集合。监视器可以定期运行,使其成为一个很好的工具,可以长期了解合同中断情况。
阅读有关使用Postman持续测试API的更多信息。
组织合同测试
真实世界的测试有设置和拆卸阶段。合同测试也不例外。合同测试的一个常见用例是使用某些数据填充正在测试的系统,然后对其执行操作,最后删除这些测试数据。
在Postman中模拟这种模式的一种巧妙模式是将Setup文件夹作为集合中的第一个文件夹,将Teardown文件夹作为集合的最后一个文件夹。然后,所有合同测试都将作为Setup和Teardown文件夹之间的文件夹。这将确保Postman始终在集合运行开始时在Setup文件夹中运行请求,然后运行执行实际测试的请求,并以运行Teardown文件夹中的所有请求结束。
在编写内部合同时,我们会大量使用这种模式。
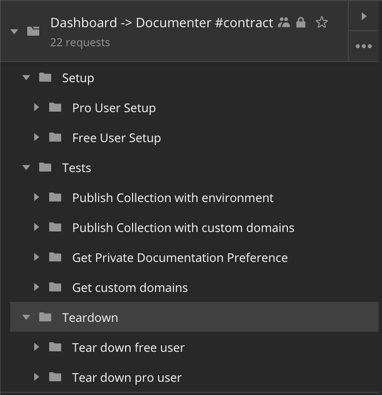
这有助于通过抽象出第一个和最后一个文件夹中的重复任务来巧妙地分组和组织测试。 理想情况下,API生产者应提供包含Setup和Teardown请求的集合。 消费者可以创建该集合的副本并添加他们的合同测试。
合同测试的复杂性取决于您的业务案例。 编写消费者驱动的合同测试的一个额外好处是,通过查看服务所拥有的消费者合同集合的数量,您可以轻松发现服务变得太大或具有太多依赖性。
总体而言,消费者驱动的合同有助于保持表面区域以测试微服务并将变更协商到可控大小。
快乐的测试!
参考
- Consumer-Driven Contracts: A Service Evolution Pattern by Ian Robinson
- Building Microservices: Designing fine-grained systems by Sam Newman
- Microservices From Day One by Cloves Carneiro Jr., Tim Schmelmer
- How to be Confident That Your Microservices Can Still Communicate in Production with Pact and Docker by Harry Winser
原文:https://medium.com/better-practices/consumer-driven-contract-testing-using-postman-f3580dba5370
讨论: 加入知识星球【首席架构师圈】
- 170 次浏览
【微服务测试】合同测试与功能测试
合同测试和功能测试之间的差异似乎是一个经常出现在那些开始认真投资于合同测试的团队的辩论。挑战在于它不是黑白相间的情况,而是更多的东西开始在合同测试的深度上爬行。
它可以是常见的一个地方是验证规则和被拒绝的请求。例如,我们可能有一个简单的用户服务,允许消费者注册新用户,通常使用POST请求,其中包含正文中创建的用户的详细信息。
这种交互的简单快乐路径场景可能如下所示:
Given "there is no user called Mary"
When "creating a user with username Mary"
POST /users { "username": "mary", email: "...", ... }
Then
Expected Response is 200 OK
坚持幸福路径存在丢失不同响应代码的风险,并且可能让消费者误解提供者的行为方式。那么,让我们来看一个失败的场景:
Given "there is already a user called Mary"
When "creating a user with username Mary"
POST /users { "username": "mary", email: "...", ... }
Then
Expected Response is 409 Conflict
到目前为止,我们正在使用不同的响应代码覆盖新行为。
现在我们一直在与管理用户服务的团队交谈,他们告诉我们用户名的最大长度为20个字符,他们只允许用户名中的字母和空白用户名显然无效。也许这是我们应该在合同中添加的内容?
这就是我们进入滑坡的地方......现在为我们的合同添加3个场景非常诱人,例如:
When "creating a user with a blank username"
POST /users { "username": "", email: "...", ... }
Then
Expected Response is 400 Bad Request
Expected Response body is { "error": "username cannot be blank" }
When "creating a user with a username with 21 characters"
POST /users { "username": "thisisalooongusername", email: "...", ... }
Then
Expected Response is 400 Bad Request
Expected Response body is { "error": "username cannot be more than 20 characters" }
When "creating a user with a username containing numbers"
POST /users { "username": "us3rn4me", email: "...", ... }
Then
Expected Response is 400 Bad Request
Expected Response body is { "error": "username can only contain letters" }
我们已经过了合同测试,我们实际上正在测试用户服务是否正确地实现了验证规则:这是功能测试,它应该由用户服务在其自己的代码库中涵盖。
这有什么害处...更多的测试是好的,对吧?这里的问题是这些场景太过分了,并且创建了一个不必要的紧密合同 - 如果用户服务团队确定实际上20个字符对用户名的限制太多并且将其增加到50个字符会怎么样?如果用户名中允许现在的号码怎么办?任何消费者都不应受任何这些变化的影响,遗憾的是,用户服务只会通过放松验证规则来破坏我们的契约。这些不是重大变化,但通过过度指定我们的方案,我们正在阻止用户服务团队实施它们。
让我们回到我们的场景,而只选择一个简单的例子来测试用户服务对错误输入的反应方式:
When "creating a user with an invalid username"
POST /users { "username": "bad_username_that_breaks_some_rule_that_you_are_fairly_confident_will_not_change", ... }
Then
Response is 400 Bad Request
Response body is { "error": "<any string>" }
微妙,但更灵活!现在,用户服务团队可以更改(大多数)他们的验证规则而不破坏我们给他们的契约...我们并不真正关心每个单独的业务规则,我们只关心如果我们发错了,那么我们理解用户服务响应我们的方式。
在为交互编写测试时,请问自己要覆盖的内容。合同应该是关于捕捉:
- 消费者中的错误
- 消费者对终点或有效负载的误解
- 中断提供者对端点或有效负载的更改
简而言之,您的Pact场景不应该深入了解提供商的业务逻辑,而应该坚持验证消费者和提供商是否对请求和响应有共同的理解。在我们的验证示例中,编写有关验证失败的方案,而不是验证失败的原因。
- 46 次浏览
【微服务测试】微服务测试策略
过去 10 年是分布式架构快速普及的时期。这种新架构背后的承诺是提高企业的敏捷性。频繁发布新功能使我们能够测试有关客户需求的假设。成功的关键因素之一是每次部署的信心。每次新软件版本即将投入生产时,运行一组测试所获得的信心。与测试范围由整个系统的复杂性定义的单体系统相比,在微服务中可以限制测试范围以节省时间,但仍不影响信心。这种新的架构方法需要审查我们所知道的测试结构。今天,我们将介绍对微服务系统的体面质量保证有用的自动化测试类型。
在本文中,您将学习
- 在微服务系统中测试什么
- 每个微服务部分需要哪些测试类型
- 如何有效地实施它们
- 如何平衡您的测试以实现成本和时间效率
本文中的所有代码示例都是用 Java 编写的,但所介绍的方法和模式也适用于其他语言。所有提到的工具都可以与不同的语言和框架一起使用,例如卡夫卡,WireMock。
微服务系统中的测试类型
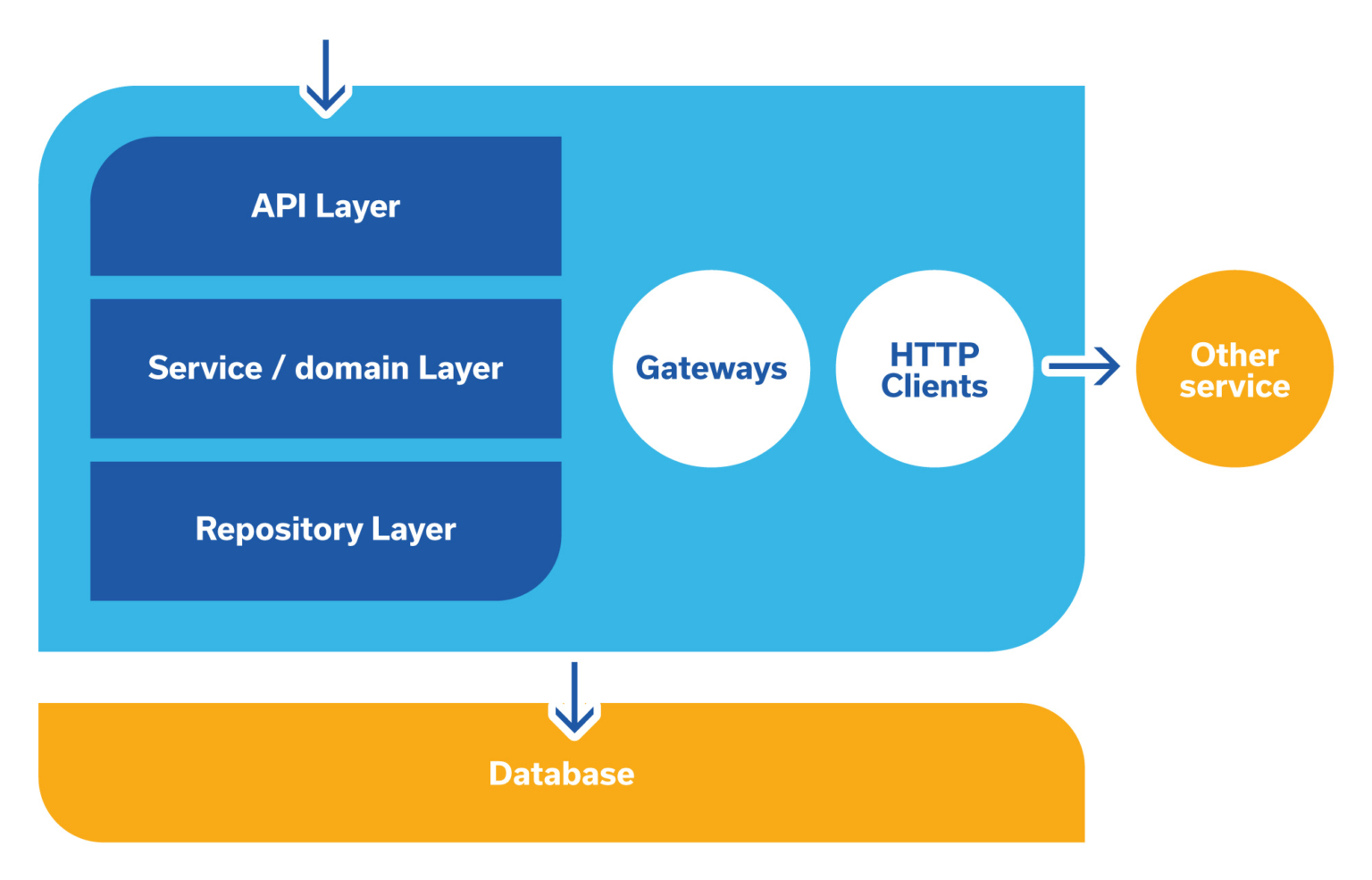
当您查看典型应用程序的成分时,识别测试微服务所需的测试类型会更容易。通常它是一个被集成和协调代码包围的到达域。然后,系统的每个部分都由具有单一职责的较小单元组成,如果可能的话。
让我们尝试根据主题的标准来识别测试类型,测试应该检查。
单元测试
最小的软件片段通过单元测试进行测试。此类测试的目标是检查每个软件单元在与其他单元隔离的情况下是否正确运行。大多数专业开发人员每天都会编写它。测试的单元隔离是通过模拟所有依赖项来构建的。
单元测试的特点是:
- 速度——单个测试的平均执行时间低于 1 毫秒
- 可重复性——单元测试不依赖于环境
- 简单性——在狭窄的代码段上调用测试,因此很容易识别失败原因
集成测试
查看上图,您可以注意到微服务应用程序需要连接和协作的外部系统:
- 数据库,例如PostgreSQL
- 消息代理,例如阿帕奇卡夫卡
- 其他可通过 REST 或 SOAP 访问的服务
通常,在代码级别,开发人员会提取负责与外部系统通信的专用代码片段,并为域层和集成系统之间的通信提供方便的接口。
- 对于数据库集成,我们可以使用 ORM 和 Spring Data
- 对于消息代理集成,我们可以使用 Spring Cloud Streams 来创建消息网关
- 对于不提供 SDK 的 REST 服务,我们可以使用纯 Java 11 HTTP 客户端
集成测试的主题是那些提供与外部系统通信的类/功能。任何集成代码的单元测试几乎没有什么好处,因为它假定所有依赖项都被模拟。在集成测试中,即使使用集成系统的测试实例,也应该使用真实的网络协议访问所有依赖项。
与单元测试相比,集成测试需要更多的时间来执行并且不验证业务逻辑的实现。
相反,集成测试的目的是检查:
- 是否建立了与数据库的连接并且请求的查询是否正确执行
- 消息网关是否广播包含正确数据的消息
- HTTP 客户端是否正确理解服务器的响应
组件测试
让所有部分独立正常工作并确保所有外部依赖项都可以访问并不能保证整个微服务的行为符合预期。为了验证它,测试包含在单个组件中的完整用例或流程。外部依赖可以用进程内模拟来代替,以加快执行速度。每个测试都以通过公开接口的业务功能请求开始,并使用公共接口或通过检查模拟模式使用情况来验证预期结果。
除了检查微服务本身是否正常工作之外,组件测试还验证:
- 微服务配置
- 微服务是否与其依赖项/协作者正确通信
端到端测试
层次结构类型中最高的测试是 E2E 测试。在这种测试中,整个微服务系统都在运行,通常与生产环境的设置完全相同。成功的端到端测试结果意味着用户的旅程已经完成。端到端测试是最通用的测试类型,但这种通用性的代价是复杂性和脆弱性。
组件测试的目的是检查:
- 整个微服务系统是否正常工作
- 系统配置是否有效
- 微服务之间是否正确通信
- 整个业务流程能否顺利完成
测试类型分布
一旦我们确定使用不同类型的测试来确保代码在不同级别上“工作”,就该开始考虑实际问题了。
经验表明,与单元测试和集成测试相比,编写和维护组件测试的难度要高得多。
经验还表明,与组件测试相比,编写和维护 E2E 测试的难度要高得多。
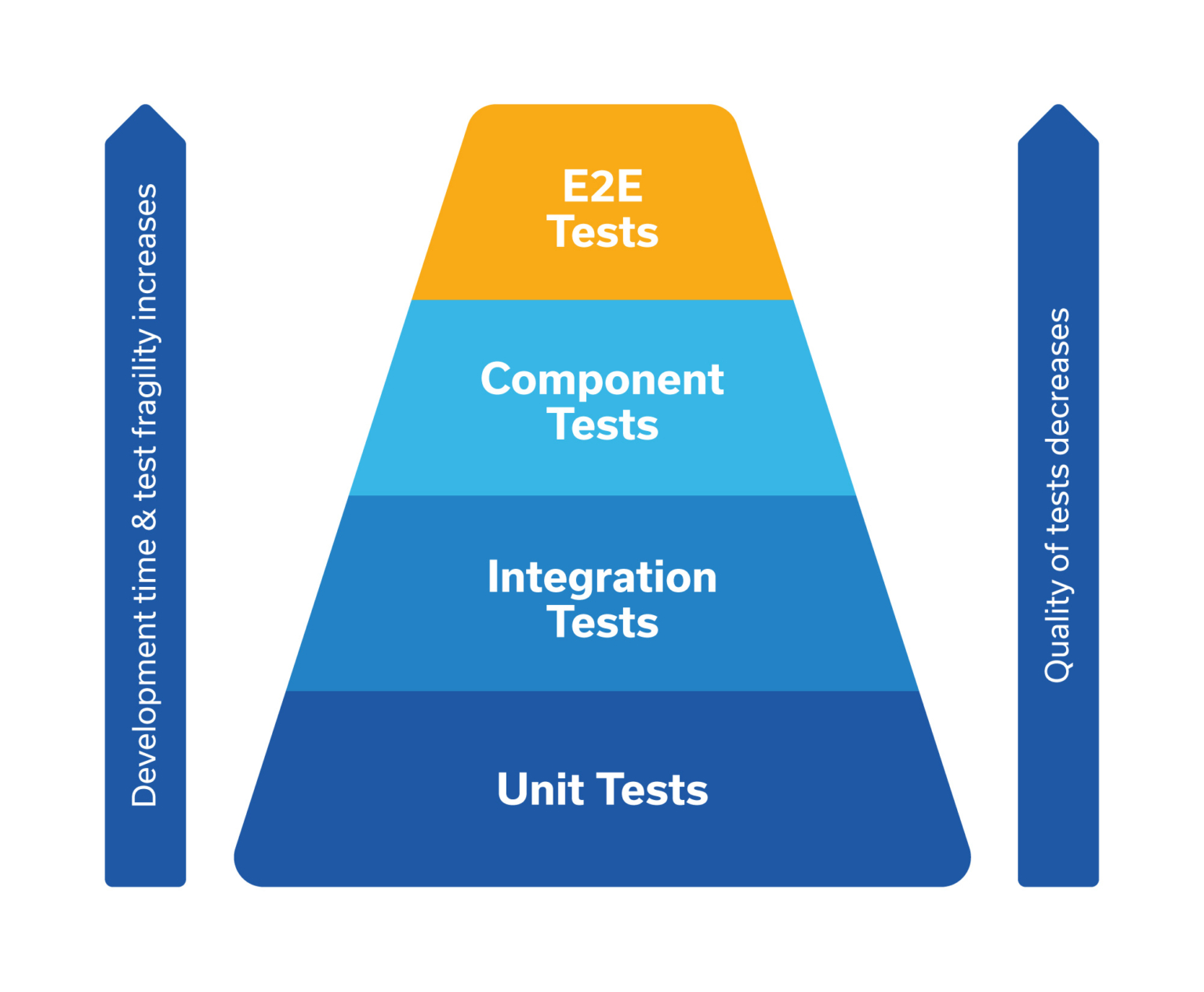
知道了这一点,我们必须采取一些方法来跨测试类型分布我们的测试覆盖率。一般原则可以表述为“尝试用你能写的最简单的测试来测试实现的行为”。尽可能在单元测试级别测试您的功能。这些很便宜,因此您可以负担得起测试所有可能的情况。
如前所述,组件测试更难编写和维护,因此您希望将它们的数量保持在相当低的水平。与其测试每一个可能的案例,不如尝试限制自己从业务角度测试主要案例——例如一条“幸福的道路”和一条“悲伤的道路”。
另一方面,E2E 测试是完全不同的野兽。 E2E 测试失败的原因有很多,而且很难识别。请记住,组件和集成测试都不会捕获由以下原因引起的错误:
- 发生 HTTP 超时
- 系统配置错误
- 使用不兼容版本的合作服务
这意味着为了可维护性,E2E 测试应仅限于关键的业务流程和用户旅程。
测试系统概述
在本文的下一段中,我们将介绍已识别测试类型的实现。 为此,让我们回顾一下测试系统的高级快照。
出于本文的目的,让我们考虑一个系统“Piko”,它使用户能够管理和发布他们的旅游景点。
Piko 系统由三个部分组成:
piko-admin –> piko-locations <– piko-maps
从创建位置到发布的用户旅程包括以下步骤:
| # | Description | Component |
| 1 | The user creates the location | piko-locations |
| 2 | The user marks the location as awaiting the publication | piko-locations |
| 3 | The administrator accepts the location | piko-admin |
| 4 | The published location is sent to the application that serves public traffic | piko-maps |
应用程序之间的大部分通信由 Kafka 消息代理处理。
对于用户身份验证,Piko 使用 AWS Cognito 服务颁发的 JWT 令牌。
您可以使用以下命令签出代码:
git 克隆 https://github.com/bluesoftcom/piko.git
实施单元测试
很可能,您已经在编写单元测试了。 该主题非常受欢迎,并且已经在大量其他材料中涵盖。 然而,让我们快速浏览一下可以使您的单元测试变得更好的一组实践。
让我们考虑以下测试用例:
@Test
void testChangeLocationStatusToAwaitingForPublication() {// given:
final LoggedUser loggedUser = someLoggedUser().build(); final Location location = someLocation().build(); when(locationsRepository.find(any())).thenReturn(location);
// when:
final DetailedJsonLocation updatedLocation =
locationsService.updateLocationStatus(
location.getId(),
LocationStatus.AWAITING_PUBLICATION,
loggedUser
);
// then:
assertThat(updatedLocation.getStatus()).isEqualTo(LocationStatus.AWAITING_PUBLICATION); verify(locationsGateway).sendPublicationRequestIssued(location.getId()); }
这个单一的测试已经包含许多技巧/方法,确实使该测试清晰且可维护。
使用 given-when-then 结构保持您的测试井井有条
每个测试应包括三个部分:
- given——这代表了测试前关于世界状态的所有假设
- when - 这指定了测试的行为
- then——这描述了期望的结果
这种结构可以更广泛地应用,而不仅仅是单元测试。它适用于我们编写的所有自动化测试。此外,它也是用户故事接受标准的一种高度合格的形式。尝试清楚地识别测试的每个部分,尤其是给出的时间和时间。请记住,当部分仅包含经过测试的调用时是理想的。
使用夹具(fixtures )使您的测试设置清晰易读
测试设置通常是最复杂和最长的部分。随着给定部分的增长和可读性的降低,您应该立即做出反应。缺乏快速轻松设置测试的方法会促使开发人员进行不受控制的代码重复。
提供干净和灵活的测试设置方法的最佳方法之一是“夹具”模式。它只需要提取一个类,该类将包含准备好在测试中使用的预配置构建器的工厂方法。提到的测试使用 someLocation() 方法来创建 Location 对象。
public class LocationFixtures {
public static Location.LocationBuilder someLocation() {
return Location.builder()
.status(LocationStatus.DRAFT)
.id(“e3c2e50c-7cb3-11ea-bc55-0242ac130003”)
.lat(51)
.lng(21)
.createdAt(Instant.parse(“2012-12-12T00:00:00Z”))
.owner(“trevornooah”)
.name(“Corn Flower Museum”);
}
}然后,可以自定义返回的构建器,以帮助您构建所需的任何测试用例。
使用描述性断言库
那些使用 JUnit 4 的读者仍然记得内置的断言库有多么有限。 在 JUnit 5 中它明显好转,但 AssertJ 库在这方面遥遥领先。
考虑以下测试和故障报告示例:
JUnit
@Test
void testJunit() {
final List<String> input = List.of("John", "Brad", "Trevor");
final List<String> expected = List.of("John", "Trevor");
assertIterableEquals(expected, input);
}
produces
iterable contents differ at index [1], expected: <Trevor> but was: <Brad>
AssertJ
@Test
void testAssertj() {
final List<String> input = List.of("John", "Brad", "Trevor");
assertThat(input).containsExactly("John", "Trevor");
}
produces
Expecting:
<["John", "Brad", "Trevor"]>
to contain exactly (and in same order):
<["John", "Trevor"]>
but some elements were not expected:
<["Brad"]>防止你的测试断言不同的东西
该原则跨越了单个单元测试的边界,但随着代码库的增长变得至关重要。 它是所需测试套件特性的实际实现——“对于一个错误,一个单元测试应该失败”。
考虑以下方法:
public DetailedJsonLocation updateLocation(String locationId,
JsonLocation jsonLocation, LoggedUser user) {
log.info(“Updating location: {} by user: {} with data: {}”,
locationId, user, jsonLocation);
final Location location = locationsRepository.find(locationId);
checkUserIsLocationOwner(location, user);
final LocationStatus previousStatus = location.getStatus();
final Location updatedLocation = transactionOperations.execute(status ->
{
final Location foundLocation = locationsRepository.find(locationId);
// … mapping code
return foundLocation;
});
if (previousStatus == AWAITING_PUBLICATION) {
locationsGateway.sendPublicationRequestWithdrawn(updatedLocation.getId());
}
return toDetailedJsonLocation(updatedLocation);
}此方法包含四个测试:
| Test method | Asserted scope |
testUpdateLocationAwaitingForPublication |
Behavior unique to updating location that awaits for publication |
testUpdateDraftLocation |
Behavior unique to updating location that is a draft |
testUpdateLocation |
Behavior common to all location updates |
testUpdateLocationOwnerByOtherUser |
Behavior unique to update of the location owner by somebody else |
使用这种方法,如果位置更新过程中存在错误,我最终将只有一个失败的测试而不是四个。这简化了根本原因的分析。
实施集成测试
如上一节所述,集成测试旨在测试用作外部系统适配器的类的行为。确保您对所有集成都有准确的测试覆盖率。在本节中,我们将回顾一种测试微服务中实现的最常见集成的方法。
测试数据库集成
数据库肯定是最容易测试的集成,尤其是当您使用 Spring-Data 时,它为您提供了开箱即用的生成存储库实现。由于最近 Docker 的流行度增长,开发人员可以使用真实数据库进行测试,而不是像 H2 这样的内存数据库。该方法在 piko 中实现,您可以在 docker-compose.yml 和 application.yml 中找到数据库配置。
当您的应用程序调用一些复杂的查询,或者特别是动态查询时,您应该为该存储库编写集成测试。例如 piko-locations 调用使用参数和排序的查询 LocationsRepository#findByOwner。
通过重用我之前为单元测试创建的固定装置,我可以很容易地测试该查询(以及排序)。
@Test
void testFindByOwner() {
// given: final String owner = "owner:" + UUID.randomUUID().toString();
final Location location1 = locationsRepository.save(
someLocation()
.id(UUID.randomUUID().toString())
.createdAt(Instant.parse("2020-03-03T12:00:00Z"))
.owner(owner)
.build()
);
final Location location2 = locationsRepository.save(
someLocation()
.id(UUID.randomUUID().toString())
.createdAt(Instant.parse("2020-03-03T13:00:00Z"))
.owner(owner)
.build()
);
final Location location3 = locationsRepository.save(
someLocation()
.id(UUID.randomUUID().toString())
.owner("other-user")
.build()
);
// when: final List<Location> locations =
locationsRepository.findByOwner(owner, Sort.by("createdAt"));
// then:
assertThat(locations).containsExactly(location1, location2); }
有用的注释:如果你的测试是@Transactional,你应该在测试调用之前和之后调用EntityManager.flush()。 Hibernate 不保证所有数据库指令都立即发送到数据库,而是在事务刷新期间发送。
这种行为有时会导致误报结果,其中测试通过只是因为 Hibernate 没有执行数据库语句,而是将它们缓存在内存中。
测试 HTTP 客户端和模拟服务器
使用 HTTP 协议通过网络进行通信是微服务集成的重要组成部分。毫不奇怪,为了进行彻底的测试,开发人员需要强大的工具来模拟外部服务。为此目的,最受欢迎的工具是 WireMock 库,它使存根服务器变得非常容易。
虽然 WireMock 用例的可能性令人印象深刻,但在“Piko”中,我们将自己限制为存根一个 AWS Cognito 端点以获取用户详细信息。
考虑到实现,准备一个专门的类来管理 WireMock 服务器和存根是非常方便的。在 piko-admin 应用程序中,您可以找到为此目的编写的 CognitoApi 类。
@Component
@Slf4j
public class CognitoApi implements Closeable {
private final WireMockServer server;
private final CognitoProperties cognitoProperties;
@SneakyThrows
public void mockSuccessfulAdminGetUser(String username) {
final String json = “{…}”;
server.stubFor(
post(urlPathEqualTo(cognitoProperties.getEndpoint().getPath()))
.andMatching(request ->
request.header(“X-Amz-Target”).firstValue()
.equals(“AWSCognitoIdentityProviderService.AdminGetUser”)
? MatchResult.exactMatch()
: MatchResult.noMatch()
)
.willReturn(
aResponse()
.withStatus(200)
.withBody(json)
)
);
}
}
以这种方式准备的存根可以很容易地用于集成测试,只需一行代码:
@Test
void testSendLocationPublishedNotification() throws Exception {
// given: final String username = "johndoe-" + UUID.randomUUID().toString();
final String recipient = String.format("<%s@email.test>", username);
cognitoApi.mockSuccessfulAdminGetUser(username);
// ... }测试与 SMTP 服务器的集成
交易电子邮件发送是应用程序中常见的业务需求之一。 虽然开发人员使用 Papercut 等本地 SMTP 服务器已经有很长时间了,但在自动化测试中使用类似概念仍然不常见。
在 Docker Hub 上有许多本地 SMTP 服务器,它们公开 API 以供编程使用。 其中之一是 schickling/mailcatcher。 在测试中发送电子邮件后,您需要做的就是调用 MailCatcher API 并进行断言。
@Test void testSendLocationPublishedNotification()
throws
Exception {
// given: final String username = "johndoe-" + UUID.randomUUID().toString();
final String recipient = String.format("<%s@email.test>", username);
cognitoApi.mockSuccessfulAdminGetUser(username);
final DetailedJsonLocation location =…
;
// when:
adminLocationsNotifications.sendLocationPublishedEmail(location);
// then:
final List<MessageSummary> messages = mailCatcherClient.listMessages();
final MessageSummary foundMessage = findByRecipient(messages, recipient);
assertThat(foundMessage).isNotNull();
final MailcatcherMessage message =
mailCatcherClient.fetchMessage(foundMessage.getId());
assertThat(message.getRecipients()).contains(recipient);
assertThat(message.getSender()).isEqualTo(String.format(“<%s>”,
notificationsProperties.getFromAddress()));
assertThat(message.getSubject()).isEqualTo(“Your location Corn Flower Museum was published”);
assertThat(message.getSource())
.contains(username)
.contains(location.getLocation().getName());
}
使用 MailcatcherClient 获取捕获的消息后,我可以检查电子邮件是否发送到正确的地址或从正确的地址发送,以及检查电子邮件内容是否包含所需的信息。
测试消息代理集成
微服务集成的第二种常见方式是使用一些消息代理。 如果使用 Spring Cloud Streams 向 Apache Kafka 发送和接收 Piko 异步消息。 除了简化消息生产者和消费者实现之外,它还公开了一个方便的 API 来测试消息传递。
在单元测试部分,您可能已经注意到调用负责将消息发送到 Kafka 主题的 LocationsGateway 的断言。
让我们考虑一个验证 LocationsGateway 发送正确消息的测试:
@BeforeEach
void setUp() {
locationEventsMessageCollector.dumpMessages();
}
@Test
void testSendPublicationRequestWithdrawn() {
// given:
final Location location = locationsRepository.save(
someLocation()
.id(UUID.randomUUID().toString())
.build()
);
// when:
locationsGateway.sendPublicationRequestWithdrawn(location.getId());
// then:
final LocationMessage message =
locationEventsMessageCollector.captureLastLocationMessage();
assertThat(message).isEqualTo(
LocationMessage.builder()
.id(location.getId())
.status(location.getStatus())
.event(LocationEventType.PUBLICATION_REQUEST_WITHDRAWN)
.lat(location.getLat())
.lng(location.getLng())
.createdAt(location.getCreatedAt())
.owner(location.getOwner())
.name(location.getName())
.build()
);
}该测试使用 LocationEventsMessageCollector,它是一个非常薄的类,可以更方便地处理消息。 它使用 Spring Cloud Streams
public LocationMessage captureLastLocationMessage() {
final Message<String> lastMessage = (Message<String>) messageCollector
.forChannel(locationEventsBindings.outboundChannel())
.poll();
Objects.requireNonNull(lastMessage, “Could not capture last message for: “
+ locationEventsBindings.OUT + ” binding”);
return objectMapper.readValue(lastMessage.getPayload(),
LocationMessage.class);
}实施组件测试
组件测试是您将在特定微服务代码中找到的最后一种测试类型。 它们的范围是最大的,它们确保整个业务流程在应用程序内部正确执行。
在编写组件测试时,应特别注意编写准确的断言。 虽然组件测试的范围很广,但您应该尽量保持您的断言肤浅,只断言整个操作成功并且调用了必要的函数。 无需检查每个功能和集成的行为,因为它已通过单元和集成测试进行验证。
使用 HTTP 调用的测试流程
我们的大部分业务流程都是通过调用 REST 端点触发的,因此 Spring Framework 有一个方便的工具来测试 HTTP 端点——MockMvc 也就不足为奇了。 让我们看看它是如何用于 Piko 系统中最重要的组件测试 - 验证位置发布过程的。
@Test
void testPublishLocation() throws Exception {
// given:
final LoggedUser loggedUser = someLoggedUser("user-" + UUID.randomUUID().toString())
.build();
final Location location = locationsRepository.save(
someLocation()
.id(UUID.randomUUID().toString())
.owner(loggedUser.getUsername())
.build()
);
cognitoApi.mockSuccessfulAdminGetUser(loggedUser.getUsername());
// when & then:
mvc.perform(put("/locations/{locationId}/status", location.getId())
.contentType(MediaType.APPLICATION_JSON)
.content("{ \"status\": \"PUBLISHED\" }")
.with(authenticatedUser(loggedUser)))
.andDo(print())
.andExpect(status().isOk())
.andExpect(jsonPath("$.status").value(LocationStatus.PUBLISHED.name()));
// and: final Location foundLocation =
locationsRepository.tryFind(location.getId());
assertThat(foundLocation).isNull();
final LocationMessage locationMessage =
locationEventsMessageCollector.captureLastLocationMessage();
assertThat(locationMessage.getId()).isEqualTo(location.getId());
assertThat(locationMessage.getEvent()).isEqualTo(LocationEventType.LOCATION_PUBLISHED);
final String expectedRecipient = String.format("<%s>",
loggedUser.getEmail());
final List<MailCatcherClient.MessageSummary> capturedEmails =
mailCatcherClient.listMessages();
assertThat(capturedEmails).anySatisfy(capturedEmail ->
assertThat(capturedEmail.getRecipients()).contains(expectedRecipient)
);
}即使测试的“then”部分很长,你仍然可以注意到上面提到的“浅断言”原则。 通过观察业务流程结果来测试组件行为。 预期结果是:
- REST API 响应操作成功
- 位置已从 piko-admin 数据库中删除
- 应用程序已广播 LOCATION_PUBLISHED 事件
- 有一封电子邮件发送给用户
这种方法使该测试不受我们不需要在此处检查的可能的小而频繁的更改的影响。 所有这些都包含在不同的测试中。
| Change example | Verification point |
| Change in the endpoint response format | Unit test and another component test |
| Change in the Kafka message format | Integration tests |
| Change in the email logic | Integration test |
使用消息代理调用的测试流程
这可能不是特别直观,但是对传入消息做出反应的侦听器通常会调用业务流程,并且是组件测试的完美测试对象。 就像在 HTTP 端点测试中一样,我们想要测试整个接口层、业务逻辑和集成。
与 HTTP 端点的 MockMvc 类似,Spring Cloud Streams 公开了方便的 API 以将消息放入通道并路由到我们的应用程序。 让我们看一下在 piko-locations 中检查位置发布过程阶段的测试。
@Test
void testLocationPublishedEvent() throws Exception {
// given: final Location location = locationsRepository.save(
someLocation()
.id(UUID.randomUUID().toString())
.status(LocationStatus.AWAITING_PUBLICATION)
.lastPublishedAt(null)
.build()
);
final LocationMessage message = toLocationMessage(location,
LocationEventType.LOCATION_PUBLISHED);
// when:
locationEventsBindings.inboundChannel().send(
new
GenericMessage<>( objectMapper.writeValueAsString(message) ) );
// then:
final Location publishedLocation =
locationsRepository.find(location.getId());
assertThat(publishedLocation.getStatus()).isEqualTo(LocationStatus.PUBLISHED);
assertThat(publishedLocation.getLastPublishedAt()).isNotNull();
}
该测试用例更简单,但您也可以发现浅断言方法。使用 inboundChannel().send(...) 将消息发送到通道是完全同步的,因此我们的测试环境是安全且可重复的。
在 Maven 中组织测试执行
Apache Maven 使用两个生命周期阶段来执行测试:测试和验证。它们之间的区别在于默认为该阶段执行的插件。
在阶段测试中,执行插件 maven-surefire-plugin,它运行具有 Test 后缀的测试用例。
在验证阶段,执行插件 maven-failsafe-plugin,运行具有 IT 后缀的测试用例。
Maven FAQ 中介绍了它们之间的技术差异。
对于项目构建组织,基于“IoC 容器要求”标准区分测试而不是为每种测试类型设计不同的执行是实用的,因为它只会使您的构建更长。
最简单和最方便的设置是为您的单元测试添加后缀 Test 和 IT 的集成和组件测试。然后,默认配置将使 maven-surefire-plugin 立即进行单元测试,并使 maven-failsafe-plugin 进行集成和组件测试。
概括
在本文中,我们介绍了有助于确保开发的应用程序正常工作的测试类型。对于每种类型的测试,我们都回顾了有用的技术、模式、原则和工具来实现它们。
在高级别的组件测试中,您可以注意到我们所采取的措施相互配合得多么好,允许在测试中重用测试逻辑。
| Used tool or pattern | Unit tests | Integration tests | Component tests |
| Fixtures | yes | yes | yes |
| Server stubs | no | yes | yes |
| Message collectors | no | yes | yes |
所有类型的审查测试相互重叠一点,让我们在一个应用程序中完成代码验证过程。
- 136 次浏览
【自动化测试】微服务自动化测试简介

什么是微服务?
微服务 - 也称为微服务架构 - 是一种构建方式,它将应用程序构建为松散耦合服务的集合,具有完整的业务功能。微服务架构允许连续交付/部署大型复杂应用程序。本文将概述自动微服务测试工具和最佳实践。
它还使组织能够发展其技术堆栈。微服务逐渐用于创建更大,更复杂的应用程序,这些应用程序作为较小服务的组合得到更好的开发和管理,这些服务可以协同工作以实现更重要的应用程序范围的功能。
大而复杂的应用程序由更直接和独立的程序组成,这些程序可由它们自己执行。这些小程序聚集在一起,提供了大型单片应用程序的所有功能。
什么是微服务测试?
所采用的任何测试策略都应旨在覆盖每层和服务层之间,同时保持轻量级。 MicroServices测试需要替代方法 - 测试团队应该制定策略,以便在设计阶段开始测试微服务。测试团队最初参与设计/架构小组,以了解功能,使用情况和未覆盖的界面,这些都将对您有所帮助。除上述内容外,测试人员还应确保所有接口都是通用的,以便其他系统/服务可以毫无障碍地使用。
由于需要自动化所有内容,因此请使用Micro Services测试自动化工具。这些工具有助于验证每个独立服务单元的功能,并通过组合多个这些微服务来执行集成测试。
微服务的自动化测试级别
- 单元测试 - 这是测试单个微服务测试单元的内部工作。这些可以使用自动单元测试框架在每个编程级别自动化。
- 合同测试 - 这是为了测试每个微服务单元是否遵守所建立的合同中提供的给定功能。这里每个服务组件都单独作为黑盒测试。在合同测试中,即使服务发生变化,服务也应该为相同的给定输入提供相同的结果。 MicroService Architecture中的每项服务都可以在更长的时间内稳健运行。它保证在不影响现有使用者的情况下为每项服务添加新功能。
- 集成测试 - 检查多个服务是否相互通信,并提供服务功能级别文档中给出的所需结果。这可以是整体微服务架构集成测试,也可以只占用架构和测试的子区域。
- UI功能测试 - 在此,与UI集成的服务和通过UI完成的测试,其中通过UI提供MicroServices所需的输入,并通过UI测试所需的输出。
对于所有这些类型的测试,可以执行自动测试。
对于单元测试,使用基于NUnit或JUnit的单元测试框架,以较少的QA参与自动化测试。
对于合同测试,QA测试自动化工程师参与。此测试在每个服务单元中执行,通过隔离它并命中服务的单个URI。合同中给出的函数将使用测试自动化框架内的自动化脚本集进行测试。
集成测试通过合同测试中使用的相同工具集自动化。这里唯一的区别是将考虑不止一个服务单元,并且自动化脚本触发功能以在这些处理器内提供通信,其中验证了所需的输出。这里的自动化测试还将验证通信消息格式以及处理器之间链接的任何数据库。
UI功能测试使用自动化测试工具自动化,如UFT,Selenium或任何其他基于UI的自动化工具。
在进行Micro Service Automated测试时,可以集成多个工具或框架。将API自动化测试工具框架和基于UI的自动化测试工具框架集成在一起也是一种很好的做法。这是测试自动化的未来。大多数组织使用全局混合测试自动化框架,而不是维护单独的框架。
如何自动化测试工作?
单独测试每项服务
测试自动化是测试离散微服务的工具。很容易创建一个简单的测试工具,重复调用服务并将一组已知输入与预期输出进行比较。无论如何,所有这一切,都不会在测试中变得异常。它将释放测试团队专注于更复杂的测试。
测试应用程序的不同功能部分
在认识到应用程序中的关键功能元素后,应该尝试以传统方式进行集成测试的方式对其进行测试。这里测试自动化的优势很明显。每次其中一个微服务刷新时,都会快速构建测试脚本。将新代码的输出与先前的输出进行比较,快速确定是否有任何变化。
不要在小型设置中进行测试
一些管理人员有能力保留测试组的资源。但是,对于基于微服务的应用程序,这会适得其反。与尝试制作小型本地登台环境以测试代码相反,应该考虑利用基于云的测试。这里动态分配资源作为测试需要它们,在测试完成后释放它们。因此,测试自动化在这里不会直接提供帮助。
尝试跨不同的设置进行测试
建议使用多个环境来测试代码,类似于Web应用程序的跨浏览器测试。我们的想法是将代码暴露给库类型,底层硬件等可能在部署到生产时影响它的任何微小变化。实现此目的的一种方法可能是在运行中制作登台环境。利用Kubernetes,可以想象创建一个测试环境,使用来自已知源的数据填充它,加载代码然后运行测试。卓越之处在于每次重新创建环境时都会自动暴露于可能存在的任何差异。当然,另一方面是诊断任何错误的根本原因变得更加困难。
尽可能使用Canary测试
金丝雀测试是一种方法,其中一小部分用户呈现代码中的变化,并将他们的经验与仍然运行旧代码的用户的体验进行对比。该方法对于测试微服务特别有用。它使用监控来调查变更的影响。它可以通过采用一次一个服务实例更新的策略来快速判断错误率,服务负载,响应能力和类似指标,从而判断新代码是否会产生负面影响。自动做金丝雀测试。
金丝雀测试是一种方法,在这种方法中,客户稍微安排一下代码的变化,对比体验以及那些运行旧代码的客户的遭遇。这种方法对测试微服务特别有用。它利用检查来调查变化的影响。它查看了错误率,利益负担,响应性和比较测量,以揭示新代码是否具有不利影响。通过采用一个程序,当一个管理案例同时令人耳目一新时,可以毫不费力地进行,从而进行金丝雀测试。
人工智能测试
AI或人工智能用于完全自动化微服务应用程序的Canary测试。深度学习等AI方法可识别新代码激活的更改和问题。很少有用户转移到新框架,AI将经验与现有用户的体验进行了比较。由于这可以自动实现,因此它会取代循环中的人。
可调试代码
编写可调试代码包括稍后进行查询的能力,这反过来涉及 -
正确的代码检测。
了解所选择的可观察性安排(无论是指标还是日志或独特的案例追踪器或痕迹或这些的混合)及其优缺点。
根据给定服务的要求,依赖性的操作怪癖和良好的工程直觉,选择最佳可观察性的能力。
微服务自动化测试的好处
测试微服务有以下好处 -
- 激励更好地隔离服务和设计更好的系统。
- 它对程序员施加了一定的设计压力,以便以易于使用的方式构建API。
- 测试充当应用程序公开的API的精彩文档。
- 单独测试每项服务。
- 测试应用程序的不同功能部分。
- 监控以评估变更的影响。
- 监控应用程序的持续性能。
为什么微服务的自动测试很重要?
由于以下原因,微服务测试很重要 -
解耦
每个功能都松散耦合,以帮助SaaS / SOA架构。 MicroServices通过网络分散在各个平台上,并通过REST over HTTP进行集成。
可维护性
每项服务都是独立维护,升级和测试的,这是SaaS架构的基本要求。这使得微服务成为持续交付的必要推动者,支持频繁发布,同时提供高系统可用性和稳定性。
可扩展性
每个微服务根据用途自动缩放。每个服务都根据资源需求部署在自治硬件上,这在传统的单片设计方法中是不可能的。
可用性
每个微服务都可以自主设计和部署,以实现故障转移和容错。例如,内存和CPU使用等问题在本地传递,而不同的服务通常继续工作。
如何对微服务进行自动化测试?
有五种策略用于成功测试微服务。
文档优先策略
遵循文档第一种方法,大多数文档都是Git中的markdown。 API文档保持开源,所以它都是公开的。此时,在任何人编写任何API更改或不同的API之前,首先刷新文档,调查该更改,以确保它使用完全记录的API约定和标准进行调整,并确保不存在重大更改。确保它符合命名约定等等。
完整的堆栈内置策略
整个堆栈一体化策略需要在本地复制云环境并在一个流浪者实例中测试所有内容(“$ vagrant up”)。
AWS测试策略
第三种方法涉及启动Amazon Web Services(AWS)框架以部署和运行测试。对于完整堆栈盒内策略,这是一种更具适应性的方法。有些人将此称为个人部署[策略],每个人都拥有自己的AWS账户。在大约十分钟内将工作站上的代码推送到AWS,然后像真实系统一样运行它。
共享测试实例策略
第四种策略是完整堆栈内置和AWS测试之间的交叉品种。这是因为它涉及在自己的本地站工作,同时利用微服务的不同共享实例在测试期间指向本地环境。有些运行微服务的不同实例仅用于测试本地构建。但是,本地构建器将指向在Google基础结构中运行的测试映像解析器。
存根服务策略
微服务的标记或“存根”表现得像正确的服务,并在服务发现中作为真实服务进行宣传,但却是虚拟模仿。例如,测试服务可能要求服务意识到用户执行一组任务。使用存根服务,假设用户任务已经发生,而没有随之而来的典型复杂性。与在整体上运行服务相比,这种方法更轻量级。
自动化微服务测试的最佳实践
隔离测试
微服务很难测试,因为有许多独立服务以许多(通常是未预料到的)方式与其他独立服务进行通信。开始测试自动化工作的一个好地方是直接测试特定微服务的功能。通常,通过使用REST API与服务进行通信以及一些模拟来快速完成,以便单独测试服务,而无需与其他服务进行任何集成。
签订合同
几乎不可能知道消费者使用服务的所有方式。通过消费者驱动的交易,消费者必须提供一套测试,以确定所需的交互类型和格式。然后服务将同意合同并确保合同没有被破坏。这规定了其他服务的条件。此方法还可以验证交易是否在构建时完成。像Pact这样的工具可以更好地理解如何实现这种类型的功能来开发和测试微服务。一旦有了消费者驱动的合同流程,测试微服务的下一步就是转移到以前被禁止的生产世界。
转右 (Shift-Right )- 投入生产
在DevOps,微服务领域,生产测试成为整体质量计划的必要条件。通过基于微服务架构的流动,移动关系,如何确定许多服务将扩展的方式?如何提前了解服务的行为?如何测试此漏洞?答案是开始在生产中进行测试。
监控和警报
建立密钥检查和警报系统,并在生产中进行跟踪至关重要。如果其中一项服务出现故障或无响应,请立即显示。通过在监控的帮助下识别生产过程中的问题,在用户甚至知道存在问题之前,通常可以轻松地返回到上一个已知的优质服务版本。
最佳自动化微服务测试工具
- Hoverfly - 模拟API延迟和故障。
- Vagrant - 构建和维护可移植的虚拟软件开发环境。
- 录像机 - 一种单元测试工具。
- 契约 - 框架由消费者驱动的合同测试。
- Apiary - API文档工具。
- API蓝图 - 设计和原型API。
- Swagger - 设计和原型API。
原文:https://www.xenonstack.com/insights/what-is-automated-testing-for-microservices/
本文:http://pub.intelligentx.net/introduction-automated-testing-microservices
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 157 次浏览
【软件测试】Pact最佳实践:消费者--->使用Pact进行合同测试,而不是生产者的功能测试
- 功能测试是关于确保提供者通过请求做正确的事情。这些测试属于提供程序代码库,而编写它们并不是消费者团队的工作。
- 合同测试旨在确保您的消费者团队和提供者团队对每种可能方案中的请求和响应有共同的理解。
- 契约测试应该关注
暴露消费者如何创建请求或处理响应的错误
暴露了对提供者如何回应的误解
- 契约测试不应该关注
暴露提供程序中的错误(尽管这可能是副产品)
您可以在此处阅读有关合同和功能测试之间差异的更多信息。
计算出测试或不测试内容的经验法则是 - 如果我不包括这种情况,那么消费者中的哪些错误或者对提供者如何响应的误解可能会被遗漏。如果答案是否定的,请不要包括它。
使用Pact进行隔离(单元)测试
- 作为模拟(在测试后验证对模拟的调用)不是存根(对存根的调用未经验证)。使用Pact作为存根会破坏使用Pacts的目的。
- 对于负责从Consumer应用程序到Provider应用程序进行HTTP调用的类的隔离测试(即单元测试),而不是整个消费者代码库的集成测试。
- 仔细地,在您的消费者代码库中进行任何类型的功能或集成测试。
为什么?
如果您使用完全匹配的Pact进行集成测试,那么您将会疯狂。由于Pact会检查每个传出路径,JSON节点,查询参数和标头,因此您将进行非常脆弱的Consumer测试。您最终还会遇到需要在提供商方面进行验证的笛卡尔互动。这将增加您花费在提交者测试通过上的时间,而不会有用地增加测试覆盖率。
仔细考虑如何将它用于非隔离测试(功能,集成测试)
保持孤立,完全匹配测试。这些将确保您将域对象中的正确数据映射到请求中。
对于集成测试,为请求使用松散的,基于类型的匹配以避免脆弱,并将设置拉出到可以在测试之间共享的方法,这样您就不会有一百万次交互来验证(这将有所帮助,因为“契约”中的交互集合就像一个集合,并丢弃完全重复的内容。
如果您不关心验证您的交互,可以使用Webmock之类的东西进行集成测试,并使用共享fixture来处理这些测试和Pact测试之间的请求/响应,以确保您进行某种程度的验证。
通过URL向提供商提供最新协议
请参阅在Consumer和Provider之间共享pacts以获取实现此目的的选项。
确保对提供程序的所有调用都通过已使用Pact测试的类
不要直接在您的Consumer应用程序中手动创建任何HTTP请求。通过客户端类(一个独立负责处理与提供者的HTTP交互的类)进行测试,可以更加确保您的消费者应用程序将创建您认为应该的HTTP请求。
确保您在其他测试中使用的模型实际上可以从您期望的响应中创建
当然,您已经检查过您的客户端将HTTP响应反序列化到您期望的Alligator中,但是您需要确保在另一个测试中创建Alligator时,使用有效属性创建它(例如,Alligator的last_login_time a时间还是日期时间?)。一种方法是使用工厂或夹具为所有测试创建模型。有关更详细的说明,请参阅此要点。
小心垃圾输入,垃圾输出PUT / POST / PATCH
每个交互都是隔离测试的,这意味着您不能执行PUT / POST / PATCH,然后使用GET跟踪它以确保您发送的值实际上由提供者成功读取。例如,如果您有一个可选的姓氏字段,并且您发送了lastname,那么提供者很可能会忽略错误名称字段,并返回200,无法提醒您,您的姓氏已经转到了大/ dev /在天空中无效。
为了确保您没有Garbage In Garbage Out情况,期望响应主体包含新更新的资源值,并且一切都会很好。
如果出于性能原因,您不希望在响应中包含更新的资源,另一种避免GIGO的方法是在GET响应主体和PUT / POST请求主体之间使用共享夹具。这样,您就知道您正在PUTing或POSTing的字段与您将要获取的字段相同。
使用can-i-deploy
使用Pact Broker CLI的can-i-deploy功能。如果您正在部署的消费者版本与其所有提供商兼容,它将为您提供明确的答案。
- 66 次浏览