企业技术架构
视频号

微信公众号

知识星球

- 697 次浏览
「可扩展性」可扩展性最佳实践:来自eBay的经验教训
在eBay,我们每天都在争论的主要架构力量之一是可扩展性。它为我们制定的每一个架构和设计决策着色和推动。全球有数亿用户,每天超过20亿的页面浏览量,以及我们系统中的数PB数据,这不是一个选择 - 它是必需的。
在可扩展的体系结构中,资源使用应该随负载线性增加(或更好),其中可以在用户流量,数据量等中测量负载。在性能与单个工作单元相关的资源使用情况下,可伸缩性是关于如何随着工作单元数量或大小的增加,资源使用情况发生变化。换句话说,可伸缩性是价格 - 性能曲线的形状,而不是其在该曲线中的一点处的值。
可伸缩性有许多方面 - 事务性,操作性,开发性工作。在本文中,我将概述我们随着时间的推移学习的几个关键最佳实践,以扩展基于Web的系统的事务吞吐量。大多数这些最佳实践对您来说都很熟悉。有些人可能没有。所有这些都来自开发和运营eBay网站的人们的集体经验。
最佳实践#1:按功能划分
无论您将其称为SOA,功能分解还是简单的良好工程,相关的功能都属于一体,而不相关的功能则属于不同。此外,不相关的功能可以解耦得越多,就越需要彼此独立地扩展它们。
在代码级别,我们都会一直这样做。 JAR文件,包,包等都是我们用来隔离和抽象一组功能的机制。
在应用层,eBay将不同的功能划分为单独的应用程序池。销售功能由一组应用程序服务器提供,竞标功能由另一组应用程序服务器提供,另一组应用程序服务器进行搜索。总的来说,我们将大约16,000个应用服务器组织到220个不同的池中。这允许我们根据其功能的需求和资源消耗,彼此独立地扩展每个池。它进一步允许我们隔离和合理化资源依赖性 - 例如,销售池只需要与相对较小的后端资源子集进行通信。
在数据库层,我们遵循相同的方法。 eBay上没有单一的整体数据库。相反,有一组用于用户数据的数据库主机,一个用于项目数据的集合,一个用于购买数据的集合等。 - 在400个物理主机上共有1000个逻辑数据库。同样,这种方法允许我们为每种类型的数据独立地扩展数据库基础结构。
最佳实践#2:水平分割
虽然功能分区使我们成为一种方式,但对于完全可扩展的架构而言,它本身并不足够。由于一个功能可能与另一个功能分离,因此单个功能区域的需求可能并且将随着时间的推移而超过任何单个系统。或者,正如我们想提醒自己的那样,“如果你不能拆分它,你就无法扩展它。”因此,在特定的功能区域内,我们需要能够将工作量分解为可管理的单元,其中每个单元保持良好的性价比。这是水平分割的来源。
在应用层,eBay的交互是设计无状态的,水平分割是微不足道的。使用标准负载平衡器来路由传入流量。因为所有应用程序服务器都是相同的,并且没有保留任何事务状态,所以它们中的任何一个都可以。如果我们需要更多处理能力,我们只需添加更多应用服务器。
数据库层出现了更具挑战性的问题,因为根据定义数据是有状态的。在这里,我们沿着主要访问路径水平分割(或“分片”)数据。例如,用户数据当前分为20个主机,每个主机包含1/20的用户。随着用户数量的增长,以及我们为每个用户存储的数据增长,我们会添加更多主机,并进一步细分用户。同样,我们对项目,购买,帐户等使用相同的方法。不同的用例使用不同的方案来划分数据:一些基于密钥的简单模数(以1结尾的项目ID转到一个主机,以2结尾的那些等等,其中一些在一系列ID(0-1M,1-2M等)上,一些在查找表上,一些在这些策略的组合上。然而,无论分区方案的细节如何,一般的想法是支持数据分区和重新分区的基础设施将比不支持分区和重新分区的基础设施更具可扩展性。
最佳实践#3:避免分布式事务
此时,您可能想知道如何通过事务保证在功能和水平方面对数据进行分区。毕竟,几乎任何有趣的操作都会更新多种类型的实体 - 用户和物品会立即浮现在脑海中。正统的答案是众所周知且易于理解的 - 使用两阶段提交在各种资源之间创建分布式事务,以保证所有资源的所有更新都发生或不发生。不幸的是,这种悲观的方法带来了巨大的成本。协调成本会对扩展,性能和延迟产生负面影响,随着您增加依赖资源和传入客户端的数量,协调成本会恶化。可用性同样受限于所有相关资源可用的要求。务实的答案是放宽不相关系统的交易保证。
事实证明,你不能拥有一切。特别是,通常既不需要也不可能保证跨多个系统或分区的立即一致性。大约10年前由Inktomi的Eric Brewer提出的CAP定理指出,分布式系统的三个非常理想的特性 - 一致性(C),可用性(A)和分区容差(P) - 你只能选择两个一度。对于高流量网站,我们必须选择分区容差,因为它是扩展的基础。对于24x7网站,我们通常会选择可用性。因此,即时一致性必须让位。
在eBay,我们绝对不允许任何类型的客户端或分布式事务 - 没有两阶段提交。在某些明确定义的情况下,我们将单个数据库上的多个语句组合成单个事务操作。但是,在大多数情况下,单个语句是自动提交的。虽然这种对正统ACID属性的有意放松并不能保证在任何地方都能立即保持一致,但实际情况是大多数系统在绝大多数情况下都是可用的。当然,我们采用各种技术来帮助系统达到最终的一致性:仔细排序数据库操作,异步恢复事件以及协调或结算批次。我们根据特定用例的一致性要求选择技术。
对于架构师和系统设计师来说,关键的一点是,不应将一致性视为一个全有或全无的命题。大多数真实世界的用例根本不需要立即一致性。正如可用性不是全部或全部,我们经常将其与成本和其他力量进行权衡,同样我们的工作也会根据特定操作的要求定制适当的一致性保证。
最佳实践#4:异步解耦功能
扩展的下一个关键要素是积极使用异步。如果组件A同步调用组件B,则A和B紧密耦合,并且该耦合系统具有单一的可伸缩性特征 - 为了扩展A,您还必须扩展B.同样有问题的是它对可用性的影响。回到逻辑101,if A implies B, then not-B implies not-A。换句话说,如果B下降则A下降。相反,如果A和B异步集成,无论是通过队列,多播消息传递,批处理过程还是其他方式,每个都可以独立于另一个进行缩放。此外,A和B现在具有独立的可用性特征 - 即使B关闭或受困,A仍可继续前进。
这个原则可以而且应该在基础设施上下应用。诸如SEDA(分阶段事件驱动架构)之类的技术可用于在单个组件内部进行异步,同时保留易于理解的编程模型。在组件之间,原理是相同的 - 尽可能避免同步耦合。通常情况下,这两个组件在任何情况下都没有业务直接对话。在每个级别,将处理分解为阶段或阶段,并将它们异步连接,对于扩展至关重要。
最佳实践#5:将处理转移到异步流程
现在您已异步解耦,请将尽可能多的处理移动到异步端。在快速回复请求的系统中,这可以大大减少请求者所经历的延迟。在web站点或交易系统中,用数据或执行延迟(我们完成所有工作的速度有多快)换取用户延迟(用户得到响应的速度有多快)是值得的。活动跟踪,计费,结算和报告是属于后台的处理的明显示例。但是,处理主要用例的重要步骤通常可以分解为异步运行。任何可以等待的东西都应该等待。
同样重要但同样重要的是异步可以大大降低基础设施成本。同步执行操作会迫使您根据峰值负载扩展基础架构 - 它需要在最后一秒处理最糟糕的第二天。但是,将昂贵的处理转移到异步流可以让您根据平均负载而不是峰值来扩展基础架构。队列不是需要立即处理所有请求,而是随着时间的推移扩展处理,从而抑制峰值。系统负载越尖锐或变化越大,这种优势就越大。
最佳实践#6:在所有级别进行虚拟化
虚拟化和抽象无处不在,遵循旧的计算机科学格言,即每个问题的解决方案都是另一个层次的间接。操作系统抽象硬件。许多现代语言中的虚拟机抽象了操作系统。对象关系映射层抽象数据库。负载平衡器和虚拟IP抽象网络端点。当我们通过功能和数据划分来扩展我们的基础架构时,这些分区的额外虚拟化水平变得至关重要。
例如,在eBay,我们虚拟化数据库。应用程序与数据库的逻辑表示交互,然后通过配置将其映射到特定的物理机器和实例。应用程序类似地从拆分路由逻辑中抽象出来,拆分路由逻辑将特定记录(例如,用户XYZ的记录)分配给特定分区。这两种抽象都是在我们自己开发的O / R层实现的。这允许操作团队在物理主机之间重新平衡逻辑主机,通过分离它们,合并它们或移动它们 - 所有这些都不需要触及应用程序代码。
我们同样虚拟化搜索引擎。为了检索搜索结果,聚合器组件在多个分区上并行化查询,并使高度分区的搜索网格作为一个逻辑索引显示给客户端。
这里的动机不仅是程序员的便利性,还有操作灵活性。硬件和软件系统发生故障,需要重新路由请求。添加,移动和删除组件,计算机和分区。通过明智地使用虚拟化,您的基础架构的更高级别可以幸免于未发现这些变化,因此您可以自由地制作它们。虚拟化使得扩展基础架构成为可能,因为它使得扩展可管理。
最佳实践#7:正确缓存
扩展的最后一个组成部分是明智地使用缓存。这里的具体建议不太普遍,因为它们往往高度依赖于用例的细节。在一天结束时,高效缓存系统的目标是在存储限制内最大化缓存命中率,满足可用性要求以及对陈旧性的容忍度。事实证明,这种平衡可能非常难以实现。一旦受到打击,我们的经验表明,它也很可能随着时间而改变。
例如,最明显的缓存机会来自缓慢变化的读取主要数据 - 元数据,配置和静态数据。在eBay,我们积极地缓存这类数据,并使用拉动和推送方法的组合,以使系统在面对更新时合理地保持同步。减少对相同数据的重复请求可以而且确实产生重大影响。更具挑战性的是快速变化的读写数据。在大多数情况下,我们故意在eBay上回避这些挑战。我们传统上没有在请求之间进行任何临时会话数据的缓存。我们同样不会在应用程序层中缓存共享业务对象,如项目或用户数据。我们明确地根据可用性和正确性来缓存这些数据的潜在好处。应该注意的是,其他网站确实采取不同的方法,做出不同的权衡,并且也是成功的。
毫不奇怪,很可能有太多好事。为缓存分配的内存越多,可用于为单个请求提供服务的可用性就越少。在通常受内存限制的应用层中,这是一个非常真实的权衡。但更重要的是,一旦你开始依赖缓存,并采取了极其诱人的步骤来缩小主要系统以处理缓存未命中,那么没有它,你的基础设施可能无法生存。一旦您的主系统无法再直接处理负载,您的站点的可用性现在取决于缓存的100%正常运行时间 - 这是一种潜在的危险情况。即使像重新平衡,移动或冷启动缓存这样的常规操作也会成为问题。
如果操作正确,一个好的缓存系统可以将您的缩放曲线弯曲到线性以下 - 后续请求从缓存中便宜地检索数据,而不是相对更昂贵的主存储。另一方面,缓存不佳会带来大量额外的开销和可用性挑战。我还没有看到一个没有重要缓存机会的系统。但关键是要确保您的缓存策略适合您的情况。
总结
可伸缩性有时被称为“非功能性需求”,暗示它与功能无关,并强烈暗示它不那么重要。没有东西会离事实很远。相反,我想说,可扩展性是功能的先决条件 - 一个“优先级为0”的要求,如果有的话。
我希望您发现这些最佳实践的描述很有用,并且它们可以帮助您以新的方式思考您自己的系统,无论其规模如何。
参考
- eBay's Architectural Principles (video)
- Werner Vogels on scalability
- Dan Pritchett on You Scaled Your What?
- The Coming of the Shard
- Trading Consistency for Availability in Distributed Architectures
- Eric Brewer on the CAP Theorem
- SEDA: An Architecture for Well-Conditioned, Scalable Internet Services
- 200 次浏览
「技术架构」CDC (捕获数据变化) Debezium 介绍
Debezium是什么?
Debezium是一个分布式平台,它将您现有的数据库转换为事件流,因此应用程序可以看到数据库中的每一个行级更改并立即做出响应。Debezium构建在Apache Kafka之上,并提供Kafka连接兼容的连接器来监视特定的数据库管理系统。Debezium在Kafka日志中记录数据更改的历史,您的应用程序将从这里使用它们。这使您的应用程序能够轻松、正确、完整地使用所有事件。即使您的应用程序停止(或崩溃),在重新启动时,它将开始消耗它停止的事件,因此它不会错过任何东西。
Debezium架构
最常见的是,Debezium是通过Apache Kafka连接部署的。Kafka Connect是一个用于实现和操作的框架和运行时
- 源连接器,如Debezium,它将数据摄取到Kafka和
- 接收连接器,它将数据从Kafka主题传播到其他系统。
下图显示了一个基于Debezium的CDC管道的架构:
除了Kafka代理本身之外,Kafka Connect是作为一个单独的服务来操作的。部署了用于MySQL和Postgres的Debezium连接器来捕获这两个数据库的更改。为此,两个连接器使用客户端库建立到两个源数据库的连接,在使用MySQL时访问binlog,在使用Postgres时从逻辑复制流读取数据。
默认情况下,来自一个捕获表的更改被写入一个对应的Kafka主题。如果需要,可以在Debezium的主题路由SMT的帮助下调整主题名称,例如,使用与捕获的表名不同的主题名称,或者将多个表的更改转换为单个主题。
一旦更改事件位于Apache Kafka中,来自Kafka Connect生态系统的不同连接器就可以将更改流到其他系统和数据库,如Elasticsearch、数据仓库和分析系统或Infinispan等缓存。根据所选的接收连接器,可能需要应用Debezium的新记录状态提取SMT,它只会将“after”结构从Debezium的事件信封传播到接收连接器。
嵌入式引擎
使用Debezium连接器的另一种方法是嵌入式引擎。在这种情况下,Debezium不会通过Kafka Connect运行,而是作为一个嵌入到定制Java应用程序中的库运行。这对于在应用程序内部使用更改事件非常有用,而不需要部署完整的Kafka和Kafka连接集群,或者将更改流到其他消息传递代理(如Amazon Kinesis)。您可以在示例库中找到后者的示例。
Debezium特性
Debezium是Apache Kafka Connect的一组源连接器,使用change data capture (CDC)从不同的数据库中获取更改。与其他方法如轮询或双写不同,基于日志的CDC由Debezium实现:
- 确保捕获所有数据更改
- 以非常低的延迟(例如,MySQL或Postgres的ms范围)生成更改事件,同时避免增加频繁轮询的CPU使用量
- 不需要更改数据模型(如“最后更新”列)
- 可以捕获删除
- 可以捕获旧记录状态和其他元数据,如事务id和引发查询(取决于数据库的功能和配置)
要了解更多关于基于日志的CDC的优点,请参阅本文。
Debezium的实际变化数据捕获特性被修改了一系列相关的功能和选项:
- 快照:可选的,一个初始数据库的当前状态的快照可以采取如果连接器被启动并不是所有日志仍然存在(通常在数据库已经运行了一段时间和丢弃任何事务日志不再需要事务恢复或复制);快照有不同的模式,请参考特定连接器的文档以了解更多信息
- 过滤器:可以通过白名单/黑名单过滤器配置捕获的模式、表和列集
- 屏蔽:可以屏蔽特定列中的值,例如敏感数据
- 监视:大多数连接器都可以使用JMX进行监视
- 不同的即时消息转换:例如,用于消息路由、提取新记录状态(关系连接器、MongoDB)和从事务性发件箱表中路由事件
有关所有受支持的数据库的列表,以及关于每个连接器的功能和配置选项的详细信息,请参阅连接器文档。
原文:https://debezium.io/documentation/reference/0.10/features.html
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 547 次浏览
【IT技术架构】IT的弹性(弹力)VS. 灾难恢复:有什么不同?
技术世界充满了流行语。因此,有时这种行业术语变得更加混乱而不是有用。一些流行语可能会使问题变得复杂,而不是澄清问题,使人们不太可能理解所谈论的内容。因此,有时需要停下来确保技术语言保持在我们能够理解的范围内。
这种术语的一个很好的例子是“灾难恢复”和“IT弹性(弹力)”。今天,寻找行业参与者可互换使用这两个短语的情况并不少见。但对于那些寻求理解的人来说,以这种方式使用它们往往会造成混乱。因为下次您访问IT灾难恢复服务提供商时,这些短语可能会在您的对话中出现,让我们花一些时间来解释每个短语的含义以及每个对商业企业的影响。
什么是灾难恢复?
灾难恢复是指企业为每次中断发生时恢复对其关键系统以及数据的访问而设置的协议。这些协议通常包括要遵循的程序以及用于使企业恢复正常运营的策略。
灾难恢复的重点是创建简化的流程,而不是简化和快速恢复数据,从而减少业务的停机时间。
通过制定灾难恢复计划,企业可以确信,当灾难发生时,他们将足够快地恢复正常的业务流程,以避免造成巨大损失并破坏其品牌。在创建灾难恢复计划时,企业通常会确保其拥有适当的工具,程序和策略,以便在速度(恢复时间目标)和恢复点(恢复点目标)方面满足其恢复目标。
在大多数人的心目中,灾难恢复只有在发生地震或海啸等重大灾难后才有必要。但是,对于企业而言,每次企业都无法访问其文件或系统时,都需要进行灾难恢复。这是因为,短时间内被锁定在他们的业务系统中可能导致数千美元的业务在空气中消失。
灾难思路的问题只是洪水,火灾和地震等重大事件,你可能会想要制定一个灾难恢复计划。毕竟,这种大灾难并不常见。但是,当您将灾难视为可能发生业务损失数据或访问其文件的事件时,您可以采取必要的协议来保护您的业务。
什么是它的弹性?
IT弹性是指企业维护对其数据和系统的访问的整体协议,无论发生的事件如何,包括灾难发生时。这意味着IT灾难是IT弹性的一部分。 IT弹性是指确保企业的关键流程无论如何都不会中断的过程,而不是企业为减轻可能的威胁所做的投资。
企业的目标是每天每分钟都能持续访问其数据。对于大多数企业领导者来说,超过四小时的停机时间是不可接受的,因此任何可行的计划必须允许在四小时之前完全恢复。实现这一目标的唯一方法是在IT弹性而非灾难恢复方面实现恢复。
虽然灾难恢复侧重于从灾难中恢复,但IT恢复能力侧重于企业可以采取的主动措施,即使在最糟糕的情况发生时也能保持运行。 IT恢复能力可以避免灾难,灾难恢复可以在灾难破坏业务系统或锁定其用户访问任务关键型文件和进程时找到备份方法。
- 129 次浏览
【企业技术架构】企业自动化是下一代架构吗?
设置舞台
自动化是所有 IT 领导者“待办事项”清单上的一项举措。但所有领导者对自动化的定义并不一致。定义中的许多歧义与范围有关。企业自动化有意从业务角度看待自动化。另一方面,IT 自动化更侧重于消除人类重复性任务。
可以将企业自动化视为整个企业中许多 IT 自动化项目的整合。但是,从自动化中实现真正价值的唯一方法是协调和整合这些战术项目以实现战略目标。否则,这些 IT 自动化项目只是独立的计划,可能会也可能不会在关键的交叉点协同工作。
将自动化视为一项战略举措并不是我看到很多组织真正考虑的事情。
考虑到一些自动化计划可能专注于组织的混合云基础架构,而同一企业内的另一项计划可能正在推动自动化安全修复。其他项目的目标可能是确保系统始终符合安全标准。
这些计划中的每一个都可能需要接触基础设施组件,例如网络和服务器,以及对应用程序 API 提供的更改做出反应。仔细考虑这一点,可以看出企业自动化计划的内在复杂性。
我在这篇文章中的目标是确定组织在实施企业自动化战略时应考虑的要点。
自动化的价值是什么?
在考虑下一代架构时,组织应从企业/战略角度考虑自动化。为此,IT 领导者需要能够就此类计划的价值提出业务案例。但是如何定义自动化的价值呢?与产品成本相比,成本节约是否足够衡量?如果一个组织只关注短期战术项目,那么关注成本可能是一种有效的方法。但是,如果不将其作为更广泛战略的一部分加以解决,实施短期战术自动化项目可能会产生长期的技术债务。
企业自动化是一个战略性的业务级项目,从长远来看,战略价值超过成本。
战略性企业自动化战略必须着眼于组织可以实现的业务价值。质量的提高是一个巨大的战略价值,敏捷性和执行速度也是如此。如何提高效率,让员工专注于增长计划?合规性是另一个对许多组织来说成本高昂的因素。组织还拥有必须利用的现有资产。使用自动化来简化这些流程也是应该考虑的事情。
所有这些因素在企业范围自动化的商业案例中都占有一席之地,但这种方法真正需要的是组织将自动化视为一项战略举措,而不仅仅是一项技术举措。
企业框架是关键
如何在企业级别实现自动化战略?当今的企业是高度复杂、相互依存的生态系统。它们由跨越本地、公共云和越来越多的公共云的基础设施组成。这些基础设施的自动化需求涵盖供应、修补和事件响应。基础设施即代码是满足这些需求的一种很有前途的技术,但是如何解决网络组件和应用程序以及计算和存储组件?
安全足迹通常由事件生成软件的组合组成,这些软件必须关联,通常是手动的。在较大的组织中,这些流程可能因负责该部分安全性的团队而异。当发生可疑事件并且需要进行更深入的调查以防止违规时会发生什么?
机密管理是企业内部复杂性的另一个例子。应用程序、基础设施和数据库可能合法地需要提升的权限。创建一个标准的编码流程,允许从机密管理存储库中提取这些凭证并在多个自动化运行中安全使用,这是一个非常需要的集成点。
大多数成熟的自动化流程都是在代码中实现的。考虑如何管理自动化代码存储库是另一个重要的考虑因素。应考虑结构、访问和代码质量等因素。
创建一个解决人员、流程和技术的框架,从本质上控制自动化,这是发展组织架构的关键步骤。一旦组织了解需要企业自动化框架,就应该寻找合适的工具来实现其目标。
进入 Ansible 自动化平台
Ansible 自动化平台是企业自动化框架的技术部分,该平台可以轻松与跨基础架构(公共和本地、网络、计算和存储)的其他以产品为中心的工具集成,能够通过它们的应用程序与应用程序交互API,协调安全事件响应,支持秘密管理等功能。
虽然有其他工具组合可以支持这个企业框架,但红帽的 Ansible 自动化平台 2 是一个单一的统一平台,应该在任何 IT 领导者短名单中,以帮助组织实现这一目标。
作为 API 优先平台,其所有功能都通过其 REST API 公开。这为平台提供了与其他应用程序 API 集成的能力,以启用该应用程序中的某些功能或接受来自该应用程序的调用并执行某些编码活动。
作为新兴的 IT 自动化事实语言,Ansible 集合、角色和剧本在互联网上激增。其中许多可通过诸如galaxy.ansible.com 等社区网站获得。但是这些社区开发的剧本管理得如何?是否有一些不良行为者可能会毒害一个集合,从而可能损害一个人的企业自动化战略或更糟?作为一个在社区中茁壮成长的组织,红帽了解如何保护软件供应链。
我们在如何以认证内容集合的形式将开源项目产品化为 Ansible 内容方面运用了我们的专业知识。在红帽自动化中心(可作为服务或本地使用)内,我们已对 56 个合作伙伴的 114 个集合进行了认证,包括 AWS、微软、思科、Cyberark 和 ServiceNOW。
Red Hat 在考虑组织委派的情况下接触了 AAP 的基于角色的访问控制。我们有一个组织和团队结构,允许主题专家 (SME) 获得他们需要的访问权限,以便在 Ansible 剧本中编写他们的流程,并将它们作为工作模板分发给企业。这些模板使用安全方法分发,允许在执行 playbook 运行期间使用提升的凭据,但绝不会暴露给任何人。这种方法可以让中小企业腾出时间从事更高价值的工作,同时为需要这些流程的团队提供更有效地完成工作的机会。
然后,自动化架构师能够在 Ansible 工作流中使用来自不同团队的 SME 提供的作业模板来创建一个整体的编码服务,然后可以向自动化消费者公开和使用该服务。该服务的构建方式可以包括任何适当的批准,并在您组织帐户下的红帽混合云上发布,或者基于红帽提供的私有服务(技术预览)发布。
自动化指标
通过这篇博客的大部分内容,我谈到了自动化中难以量化的部分,例如通过编纂流程来确保质量,以及提高效率,让员工腾出时间并致力于增长计划。然而,虽然质量、增长和合规性应该是任何企业自动化战略的关键部分,但显然仍必须考虑成本。
Ansible 自动化平台的一个经常被忽视的特性是 Red Hat Insights for Ansible。该服务为客户提供了一些功能:1) 使用 Saving Planner 预测自动化成本节省和 2) 使用自动化计算器确定从实施的自动化中实现的节省。
我们提供这些服务以帮助组织计算 Ansible 自动化平台投资的潜在成本节约。
结束
我在这篇文章中的一个目标是解决自动化应该被视为一项战略举措这一点。此外,随着企业架构师为企业自动化构建业务案例,它应该包括其他因素,例如提高质量、提供增长机会、保持合规性以及在成本之外最大限度地利用现有资产。企业自动化战略的任何解决方案都应包括创建一个框架,该框架将允许适当的工具集成并协同工作。集成点和多样化的生态系统对于这种规模的项目的成功至关重要。
最后,我想说明 Ansible 自动化平台 2 应该出现在任何 IT 领导者的产品短名单中,以评估此类计划。
企业自动化是下一代架构吗?是否应考虑成本以外的因素? Ansible 自动化平台 2 是企业自动化计划的可行解决方案吗?
你怎么看?我阅读并回复所有评论。
原文:https://briandumont.medium.com/is-enterprise-automation-next-generation…
本文:https://jiagoushi.pro/enterprise-automation-next-generation-architecture
- 57 次浏览
【应用架构】使用新的群集,API管理和服务网格功能更新NGINX应用程序平台
世界以惊人的速度走向数字化。 技术是我们日常生活的前沿和中心。 从娱乐到银行,再到我们与朋友的沟通方式,技术改变了我们与世界互动的方式。 各种规模和各行各业的企业都在推出引人注目的数字化功能,以吸引,留住和丰富客户。 每家公司现在都是一家科技公司。
在此过程中的公司需要掌握数字化转型,许多公司转向NGINX来创建现代应用程序堆栈。 超过4亿个网站依赖我们的开源软件。 我们的技术可帮助企业消除数字交付带来的摩擦,优化数字供应链,并更快地推出数字服务。 NGINX应用程序平台是一套整合的工具,可提高应用程序性能,自动化应用程序交付,并降低资本和运营成本。
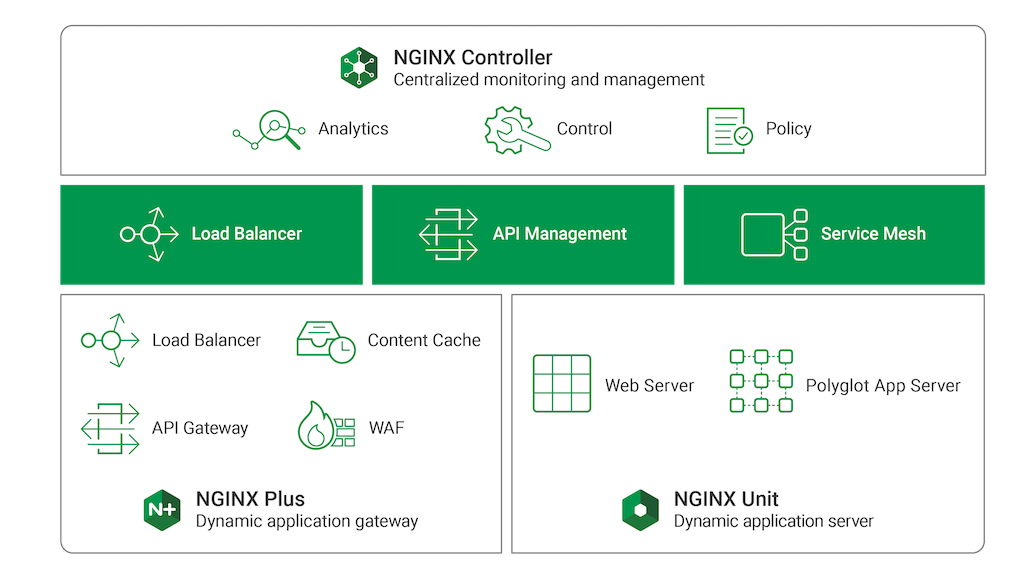
NGINX应用平台产品套件包括NGINX控制器,NGINX Plus,NGINX WAF和NGINX单元
今天,我们发布了最初宣布的NGINX应用平台最重要的更新。这些更新利用NGINX Controller的模块化架构,使企业能够为在数据平面中管理NGINX Plus的合适团队提供合适的工作流程。这些功能通过将应用交付,API管理和服务网格管理整合到一个解决方案中,扩展了NGINX进一步简化应用基础架构的能力。
以下是所有三个产品版本的快速摘要(有关详细信息,请参见下文):
- NGINX Controller 2.0增强了模块化架构 - 您现在可以通过NGINX Controller的插件模块管理API。新的API管理模块通过直观的UI为其定义API端点和策略。 NGINX Controller 2.0还更新现有的负载均衡器模块,以改善配置管理。最后,我们宣布开发服务网格解决方案。面向控制器的服务网格模块将简化组织从容器的常见Ingress模式转变为更复杂的服务网格体系结构的方式,这些体系结构旨在优化数十,数百或数千个微服务的管理。
- NGINX Plus R16推出新的动态集群 - 最新版本的NGINX Plus包括在NGINX Plus实例的分布式集群中共享状态和键值存储的功能。这提供了独特的动态功能,如API网关的全局速率限制和DDoS缓解。 NGINX Plus R16还为Kubernetes Ingress控制和微服务用例引入了新的负载平衡算法;增强的UDP支持,适用于OpenVPN,IP语音(VoIP)和虚拟桌面基础设施(VDI)等环境;以及与AWS PrivateLink的新集成,以帮助组织加速混合云部署。
- NGINX Unit 1.4提高了安全性和语言支持 - NGINX Unit是一个开源的Web和应用服务器,于2018年4月全面上市.NGINX Unit 1.4增加了TLS功能,可以“随处加密”。 NGINX Unit支持通过API进行动态重新配置,这意味着零停机配置随着无缝证书更新而变化。准备好新证书后,只需激活API即可激活它,而无需终止或重新启动应用程序进程。 NGINX Unit 1.4还增加了对Node.js的JavaScript实验支持,扩展了对Go,Perl,PHP,Python和Ruby的当前语言支持。完全支持JavaScript和Java即将推出。
要了解有关NGINX应用平台最新变化的更多信息,请观看NGINX Conf 2018现场直播或点播的主题演讲。
详细更新
NGINX控制器2.0
NGINX Controller为NGINX Plus提供集中监控和管理。 NGINX Controller 2.0引入了一种新的模块化架构,类似于NGINX本身。有了这个新的模块化架构,我们的计划是创建增强核心NGINX控制器功能的新模块。 NGINX Controller 1.0中引入的负载平衡功能本身就是一个模块。我们在NGINX Controller 2.0中发布的第一个新模块是API管理模块,将于2018年第四季度推出。我们还将宣布一个新的服务网格模块,计划于明年上半年发布。
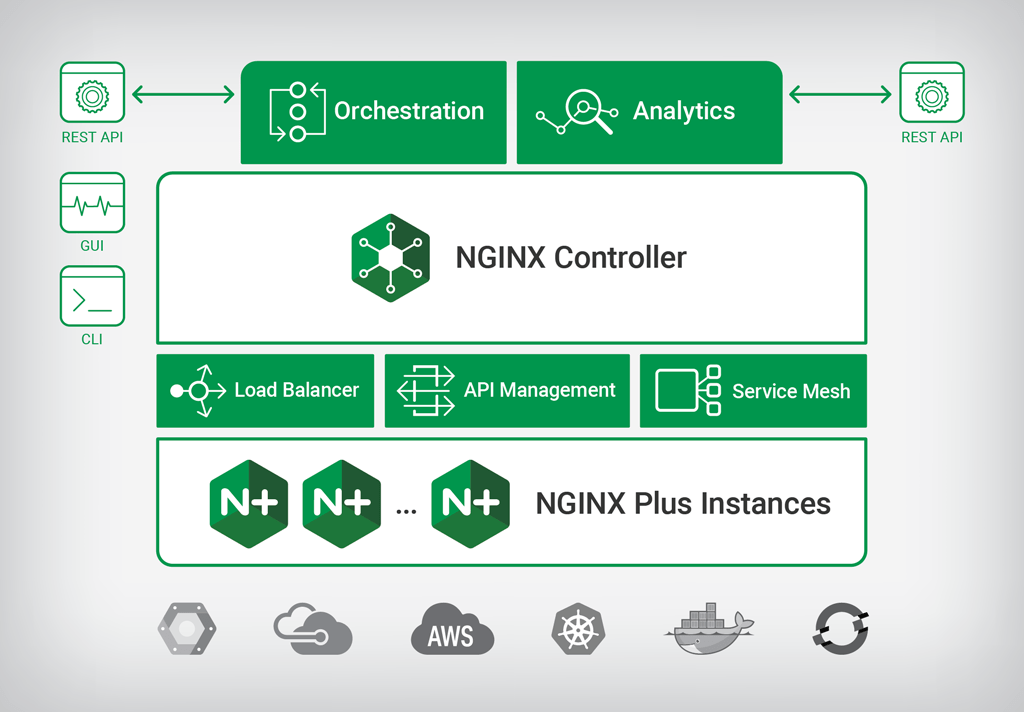
NGINX Controller通过Load Balancer,API Management和Service Mesh Modules提供NGINX Plus的集中监控和管理
新的API管理模块
NGINX正在为NGINX Controller发布一个新模块,该模块扩展了其作为API网关管理NGINX Plus的能力。 通过该模块,NGINX Controller提供API定义,监控和网关配置管理。 与Apigee和Axway等传统API管理解决方案相比,这种更轻量级,更简单的解决方案为管理企业API流量提供了更好的选择。
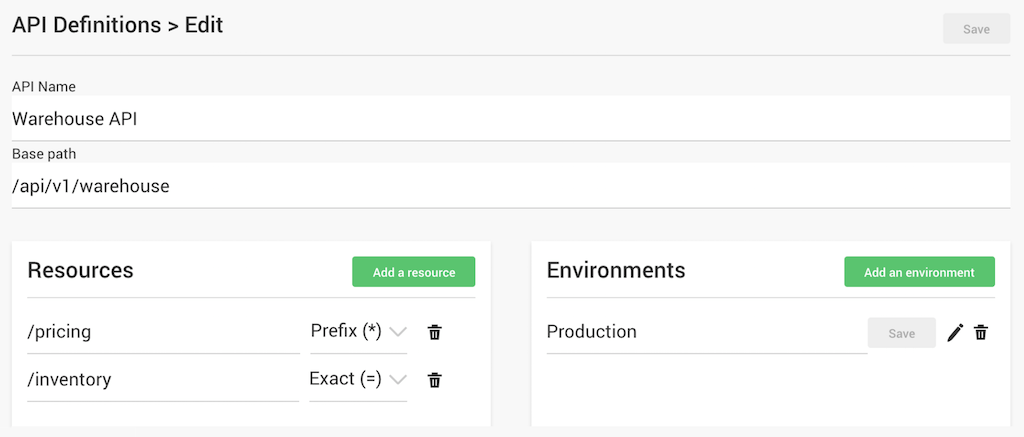
NGINX Controller提供了一种简单,直观的API定义方法
使用NGINX Controller API管理模块,API是一流的公民。您可以定义API的基本路径,其基础服务(上面示例中的/ pricing和/ inventory)以及支持这些服务的服务器。您还可以定义策略,例如每个API的身份验证和速率限制。
有关NGINX Controller API管理模块及其与NGINX Plus如何协作的更多详细信息,请参阅我们的配套博客文章。
增强型负载平衡器模块
NGINX Controller 1.0于2018年6月推出,使您能够从一个位置管理和监控大型NGINX Plus集群。在NGINX Controller 2.0中,我们将此功能打包在负载平衡器模块中并添加更多功能。新功能包括高级配置管理 - 为版本控制,差异和恢复的NGINX Plus实例启用配置优先方法 - 以及ServiceNow webhook集成。
即将推出的服务网格模块
服务网状体系结构正在成为一种在微服务环境中管理网络的方式。他们寻求解决影响组织部署大量微服务时的治理,安全和控制问题。 NGINX控制器服务网格模块建立在两年前推出的NGINX微服务参考架构的Fabric模型之上。这个新模块使NGINX Controller能够管理和监控服务网格部署,应用流量管理策略,并简化复杂的服务到服务工作流程。
服务网格模块的推出计划于2019年上半年推出。
NGINX Plus R16
NGINX Plus是一体化负载均衡器,内容缓存,Web服务器和API网关。它在NGINX开源软件之上具有企业级功能。 NGINX Plus R16包括新的群集功能,增强的UDP负载平衡和DDoS缓解,使其成为昂贵的F5 BIG-IP硬件和其他负载平衡基础架构的更完整替代品。
NGINX Plus R16的新功能包括:
- 群集感知速率限制 - 您现在可以指定在NGINX Plus群集中应用的全局速率限制。全局速率限制是API网关的一个重要特性,是NGINX Plus非常流行的用例。
- 支持群集的键值存储 - NGINX Plus键值存储现在可以跨群集同步,并包含新的超时参数。键值存储现在可用于提供动态DDoS缓解,分发经过身份验证的会话令牌以及构建分布式内容缓存(CDN)。
- Random with Two Choices负载均衡算法 - 使用这种新算法,随机选择两个后端服务器,然后将请求发送到两者中负载较小的服务器。 Random with Two Choices对集群非常有效,并且将成为下一版NGINSX Ingress Controller for Kubernetes的默认设置。
- 增强的UDP负载平衡 - NGINX Plus R16可以处理来自客户端的多个UDP数据包,使我们能够支持更复杂的UDP协议,如OpenVPN,VoIP和VDI。
- AWS PrivateLink支持 - PrivateLink是亚马逊用于创建安全VPN隧道到虚拟私有云的技术。通过此版本,您现在可以对PrivateLink数据中心内的流量进行身份验证,路由,负载平衡和优化。
要了解有关NGINX Plus R16的更多信息,请阅读我们的公告博客。
NGINX Unit 1.4
NGINX Unit是由NGINX Open Source的原作者Igor Sysoev创建的动态Web和应用程序服务器。使用NGINX Unit,您可以在同一台服务器上运行用Go,Perl,PHP,Python和Ruby编写的应用程序。它采用REST API驱动的JSON配置语法,是完全动态的。所有配置更改都发生在内存中,因此没有服务重新启动或重新加载。
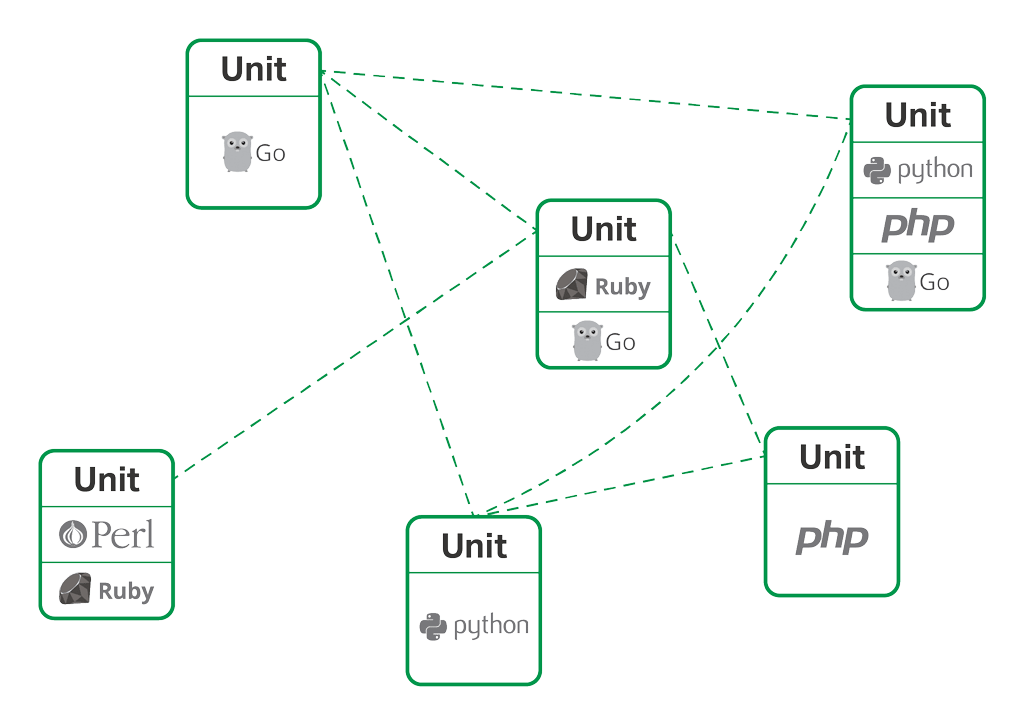
NGINX Unit在同一台服务器上同时运行多种语言
NGINX Unit 1.4中的新功能是支持使用证书存储API进行SSL加密,该API提供有关证书链的详细信息,包括常用名称和备用名称以及到期日期。
此外,我们正在发布初步的Node.JS支持。我们还致力于完整的Java支持,WebSocket,灵活的请求路由和静态内容的提供。
NGINX Unit是开源的;今天试试吧。
NGINX作为动态应用程序开发和交付堆栈
凭借这些新功能,NGINX现在是唯一一家帮助基础架构团队构建动态入口和出口层以优化南北交通的供应商,以及一个动态后端,可帮助应用团队开发和扩展单片和微服务的东西向流量应用。
此动态应用程序开发和交付堆栈可以部署为:
- 动态应用程序网关 - NGINX应用程序平台是业界唯一的解决方案,它将反向代理,缓存,负载均衡器,API网关和WAF功能组合到一个用于南北应用程序和API流量的单一动态应用程序网关中。 R16中的新集群和状态共享功能与NGINX Controller中的新负载平衡和API管理功能相结合,提供了一种能够实时适应不断变化的应用,安全性和性能需求的解决方案。传统的应用程序交付控制器(ADC)不提供API网关功能,并且缺乏作为单个分布式入口和出口层的灵活性,该层可以跨任何云计算任何应用程序。
- 动态应用程序基础架构 - NGINX是用于高性能站点和应用程序的最流行的Web服务器。但随着组织从单块体到微服务的过程,它们需要额外的基础架构。 NGINX通过补充其业界领先的Kubernetes Ingress控制器以及NGINX Controller作为轻量级服务网的即将到来的增强功能来解决这个问题。结合这些功能与NGINX Unit执行单片和微服务应用程序代码的能力,我们现在提供业界唯一的动态应用程序基础架构,为网络和应用程序服务器提供优化的东西向流量,适用于任何微服务成熟阶段的公司。
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 145 次浏览
【技术架构】10个10倍应用程序性能提升的技巧
提高web应用程序性能比以往任何时候都更加重要。在线经济活动的份额正在增长;超过5%的发达国家的经济现在是在互联网上的(参见参考资料中的互联网统计数据)。而我们这个始终在线、高度连接的现代世界意味着用户的期望比以往任何时候都要高。如果您的站点没有立即响应,或者您的应用程序不能立即工作,用户将很快转向您的竞争对手。
例如,亚马逊近10年前的一项研究证明,即使在那时,页面加载时间每减少100毫秒,收入也会增加1%。最近的另一项研究强调了这样一个事实:超过一半的受访网站所有者表示,由于应用程序性能不佳,他们失去了收入或客户。
一个网站需要多快?每加载一个页面一秒钟,大约有4%的用户会放弃它。顶级电子商务网站提供从1秒到3秒的首次互动时间,这提供了最高的转化率。很明显,web应用程序性能的风险很高,而且可能还会增加。
想要提高性能很容易,但实际看到结果却很难。为了帮助你的旅程,这篇博客文章为你提供了10个技巧,帮助你将网站性能提高10倍。这是一个系列文章的第一部分,详细介绍了如何在一些经过良好测试的优化技术的帮助下,并在NGINX的支持下,提高应用程序的性能。本系列还概述了在此过程中可能获得的安全性改进。
技巧1 -使用反向代理服务器加速并保护应用程序
如果您的web应用程序在一台机器上运行,那么性能问题的解决方案可能很明显:使用一台更快的机器,拥有更多处理器、更多RAM、更快的磁盘阵列,等等。然后,新机器可以运行您的WordPress服务器,Node.js应用程序,Java应用程序等,比以前更快。(如果您的应用程序访问数据库服务器,解决方案可能看起来仍然很简单:获得两台更快的机器,以及它们之间更快的连接。)
问题是,机器的速度可能不是问题所在。Web应用程序通常运行缓慢,因为计算机在不同类型的任务之间切换:在数千个连接上与用户交互、从磁盘访问文件、运行应用程序代码等等。应用程序服务器可能会崩溃——耗尽内存、将内存块交换到磁盘,并让许多请求等待磁盘I/O等单个任务。
您可以采用完全不同的方法,而不是升级硬件:添加反向代理服务器来卸载这些任务。反向代理服务器位于运行应用程序的机器前面,处理Internet流量。只有反向代理服务器直接连接到Internet;与应用服务器的通信是通过一个快速的内部网络进行的。
使用反向代理服务器可以让应用服务器从等待用户与web应用程序交互的过程中解放出来,并让它集中精力构建页面,以便反向代理服务器通过Internet发送。不再需要等待客户机响应的应用程序服务器可以以接近优化基准测试的速度运行。
添加反向代理服务器还可以增加web服务器设置的灵活性。例如,如果一个给定类型的服务器被重载,可以很容易地添加另一个相同类型的服务器;如果服务器宕机,可以很容易地替换它。
由于它提供的灵活性,反向代理服务器也是许多其他性能提升功能的先决条件,比如:
- 负载平衡(参见技巧2)——负载平衡器运行在反向代理服务器上,以便在多个应用服务器之间均匀地共享流量。有了负载平衡器,您就可以添加应用程序服务器,而不需要更改您的应用程序。
- 缓存静态文件(参见技巧3)——直接请求的文件,如图像文件或代码文件,可以存储在反向代理服务器上,并直接发送到客户机,这样可以更快地为资产提供服务,并卸载应用程序服务器,从而使应用程序运行得更快。
- 保护您的站点——反向代理服务器可以配置为高安全性,并进行监视,以便快速识别和响应攻击,保护应用程序服务器。
NGINX软件是专门为用作反向代理服务器而设计的,具有上面描述的附加功能。NGINX使用事件驱动的处理方法,这比传统服务器更有效。NGINX Plus添加了更高级的反向代理特性,比如应用程序健康检查、特殊的请求路由、高级缓存和支持。
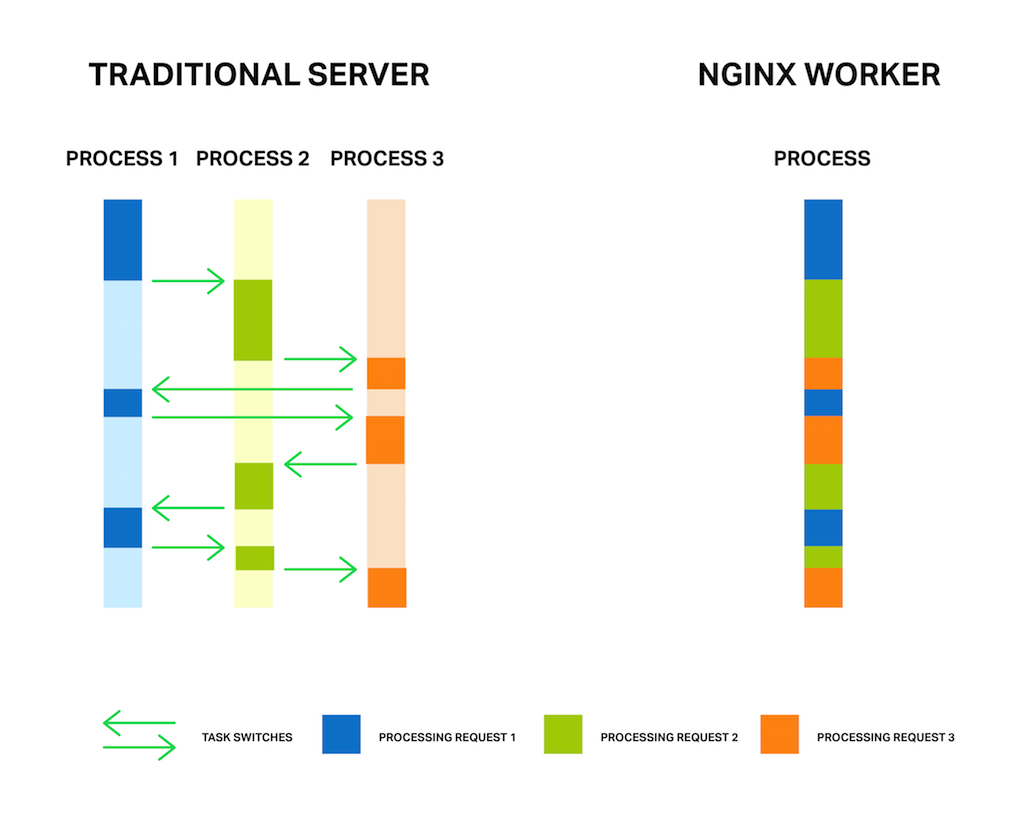
技巧2 -添加一个负载平衡器
添加负载平衡器是一个相对容易的更改,它可以显著提高站点的性能和安全性。不需要使核心web服务器更大更强大,而是使用负载平衡器在多个服务器之间分配流量。即使应用程序编写得很差,或者存在伸缩性问题,负载平衡器也可以在不进行任何其他更改的情况下改善用户体验。
首先,负载均衡器是一个反向代理服务器(请参阅技巧1)——它接收Internet流量并将请求转发到另一台服务器。诀窍在于负载均衡器支持两个或多个应用程序服务器,使用多种算法在服务器之间分割请求。最简单的负载平衡方法是轮询,将每个新请求发送到列表上的下一个服务器。其他方法包括向活动连接最少的服务器发送请求。NGINX Plus具有在同一服务器上继续给定用户会话的功能,这称为会话持久性。
负载平衡器可以极大地提高性能,因为当其他服务器等待流量时,它们可以防止一个服务器过载。它们还可以方便地扩展web服务器的容量,因为您可以添加成本相对较低的服务器,并确保它们将得到充分利用。
可以负载平衡的协议包括HTTP、HTTPS、SPDY、HTTP/2、WebSocket、FastCGI、SCGI、uwsgi、memcached,以及其他几种应用程序类型,包括基于TCP的应用程序和其他第4层协议。分析您的web应用程序,以确定您使用的是哪种应用程序,以及在哪些地方性能比较差。
用于负载平衡的同一或多个服务器还可以处理其他几个任务,比如SSL终止、对HTTP/1的支持。客户端使用x和HTTP/2,并缓存静态文件。
NGINX通常用于负载平衡。要了解更多,请下载我们的电子书,选择软件负载平衡器的五个理由。您可以使用NGINX和NGINX Plus获得负载平衡的基本配置说明,第1部分以及NGINX Plus管理指南中的完整文档。NGINX Plus是我们的商业产品,支持更专业的负载平衡特性,比如基于服务器响应时间的负载路由,以及基于微软NTLM协议的负载平衡能力。
技巧3 -缓存静态和动态内容
通过更快地将内容交付给客户机,缓存提高了web应用程序的性能。缓存可以包括几种策略:在需要时对内容进行预处理以实现快速交付、将内容存储在更快的设备上、将内容存储在离客户机更近的地方,或者组合使用。
有两种不同类型的缓存需要考虑:
- 静态内容缓存——不经常更改的文件,如图像文件(JPEG、PNG)和代码文件(CSS、JavaScript),可以存储在边缘服务器上,以便从内存或磁盘快速检索。
- 缓存动态内容——许多Web应用程序为每个页面请求生成新的HTML。通过在短时间内缓存生成的HTML的一个副本,您可以显著减少必须生成的页面总数,同时仍然交付足够新鲜的内容来满足您的需求。
例如,如果一个页面每秒有10个视图,而您将其缓存1秒,那么对该页面的90%的请求将来自缓存。如果单独缓存静态内容,即使是新生成的页面版本也可能主要由缓存的内容组成。
缓存web应用程序生成的内容有三种主要技术:
- 将内容移动到离用户更近的地方——将内容的副本保持在离用户更近的地方,可以减少其传输时间。
- 将内容移动到更快的机器上——内容可以保存在更快的机器上,以便更快地检索。
- 将内容从过度使用的机器上移开——机器有时在特定任务上的运行速度比基准测试慢得多,因为它们忙于其他任务。在不同的机器上进行缓存可以提高缓存资源的性能,也可以提高非缓存资源的性能,因为主机的过载更少。
web应用程序的缓存可以从内部(web应用程序服务器)到外部实现。首先,缓存用于动态内容,以减少应用服务器上的负载。然后,缓存用于静态内容(包括动态内容的临时副本),进一步卸载应用服务器。然后缓存将从应用服务器转移到速度更快和/或更接近用户的机器上,从而减轻应用服务器的负担,减少检索和传输时间。
改进的缓存可以极大地加快应用程序的速度。对于许多web页面,静态数据(如大型图像文件)占内容的一半以上。在没有缓存的情况下,检索和传输这样的数据可能需要几秒钟,但是如果数据是本地缓存的,那么只需要几秒钟。
作为在实践中如何使用缓存的示例,NGINX和NGINX Plus使用两个指令来设置缓存:proxy_cache_path和proxy_cache。您可以指定缓存位置和大小、缓存中保存的最大时间文件以及其他参数。使用第三个(也是非常流行的)指令proxy_cache_use_陈腐,您甚至可以在提供新鲜内容的服务器繁忙或宕机时直接使用缓存来提供陈旧的内容,从而为客户机提供一些内容,而不是什么也没有。从用户的角度来看,这可能会极大地提高站点或应用程序的正常运行时间。
NGINX Plus具有高级缓存功能,包括支持缓存清除和在仪表板上显示缓存状态,以便实时监控活动。
有关NGINX缓存的更多信息,请参阅参考文档和NGINX Plus管理指南。
注意:缓存跨越了开发应用程序的人员、进行资本投资决策的人员和实时运行网络的人员之间的组织界线。复杂的缓存策略(如这里提到的那些)是DevOps透视图价值的一个很好的例子,在DevOps透视图中,应用程序开发人员、体系结构和操作透视图被合并,以帮助满足站点功能、响应时间、安全性和业务结果(如完成的事务或销售)的目标。
技巧4 -压缩数据
压缩是一个巨大的潜在性能加速器。对于照片(JPEG和PNG)、视频(MPEG - 4)和音乐(MP3)等,都有精心设计和高效的压缩标准。这些标准中的每一个都将文件大小减少一个数量级或更多。
文本数据——包括HTML(包括纯文本和HTML标记)、CSS和JavaScript等代码——通常是未压缩传输的。压缩这些数据可能会对web应用程序的性能产生不成比例的影响,特别是对于移动连接缓慢或受限的客户端。
这是因为文本数据通常足以让用户与页面交互,而在页面中,多媒体数据可能更具支持性或装饰性。智能内容压缩可以减少HTML、Javascript、CSS和其他基于文本的内容的带宽需求,通常可以减少30%或更多,并相应地减少加载时间。
如果使用SSL,压缩会减少必须经过SSL编码的数据量,从而抵消了压缩数据所需的一些CPU时间。
压缩文本数据的方法各不相同。例如,请参阅技巧6了解SPDY和HTTP/2中的一个新的文本压缩方案,该方案专门针对头数据进行了调整。作为文本压缩的另一个例子,您可以在NGINX中打开GZIP压缩。在预压缩服务上的文本数据之后,可以使用gzip_static指令直接提供压缩后的.gz文件。
技巧5 -优化SSL/TLS
安全套接字层(SSL)协议及其后续协议传输层安全(TLS)协议正在越来越多的网站上使用。SSL/TLS对从源服务器传输到用户的数据进行加密,以帮助提高站点安全性。影响这一趋势的部分原因是,谷歌现在使用SSL/TLS作为对搜索引擎排名的积极影响。
尽管越来越受欢迎,但SSL/TLS涉及的性能问题仍然是许多站点的症结所在。SSL/TLS降低网站性能有两个原因:
- 每当打开新连接时,建立加密密钥所需的初始握手。浏览器使用HTTP/1的方式。为每台服务器建立多个连接。
- 在服务器上加密数据和在客户机上解密数据的持续开销。
为了鼓励使用SSL/TLS, HTTP/2和SPDY(在下一篇技巧文章中描述)的作者设计了这些协议,使浏览器在每个浏览器会话中只需要一个连接。这大大减少了SSL开销的两个主要来源之一。然而,现在可以做更多的工作来改进通过SSL/TLS交付的应用程序的性能。
优化SSL/TLS的机制因web服务器而异。例如,NGINX使用OpenSSL在标准的商用硬件上运行,以提供类似于专用硬件解决方案的性能。NGINX SSL性能有良好的文档记录,并将执行SSL/TLS加密和解密的时间和CPU消耗降到最低。
此外,有关如何提高SSL/TLS性能的详细信息,请参阅本文。简而言之,这些技术是:
- 会话缓存——使用ssl_session_cache指令缓存使用SSL/TLS保护每个新连接时使用的参数。
- 会话票证或ID——这些信息存储在票证或ID中关于特定SSL/TLS会话的信息,这样就可以顺利地重用连接,而不需要新的握手。
- 通过缓存SSL/TLS证书信息,减少握手时间。
NGINX和NGINX Plus可用于SSL/TLS终止——处理客户机流量的加密和解密,同时与其他服务器进行明文通信。要设置NGINX或NGINX Plus来处理SSL/TLS终止,请参阅HTTPS连接和加密TCP连接的说明。
技巧6 -实现HTTP/2或SPDY
对于已经使用SSL/TLS、HTTP/2和SPDY的站点,很可能会提高性能,因为单个连接只需要一次握手。对于还没有使用SSL/TLS的站点,HTTP/2和SPDY将迁移到SSL/TLS(这通常会降低性能),从响应性的角度来看,这是一种洗刷。
谷歌在2012年引入SPDY,作为在HTTP/1.x之上实现更快性能的一种方式。HTTP/2是最近批准的基于SPDY的IETF标准。SPDY得到了广泛的支持,但是很快就会被弃用,取而代之的是HTTP/2。
SPDY和HTTP/2的关键特性是使用单个连接,而不是多个连接。单个连接是多路复用的,因此它可以同时携带多个请求和响应。
通过充分利用一个连接,这些协议避免了设置和管理多个连接的开销,这是浏览器实现HTTP/1.x的方式所要求的。使用单个连接对SSL特别有帮助,因为它将SSL/TLS设置安全连接所需的握手时间降到最低。
SPDY协议要求使用SSL/TLS;HTTP/2并没有正式要求它,但是到目前为止,所有支持HTTP/2的浏览器都只在启用SSL/TLS时才使用它。也就是说,支持HTTP/2的浏览器只有在网站使用SSL且服务器接受HTTP/2流量时才使用它。否则,浏览器通过HTTP/1.x进行通信。
当您实现SPDY或HTTP/2时,您不再需要典型的HTTP性能优化,例如域分片、资源合并和图像spriting。这些更改使您的代码和部署更简单、更容易管理。要了解更多关于HTTP/2带来的变化,请阅读我们的白皮书《Web应用程序开发人员的HTTP/2》。
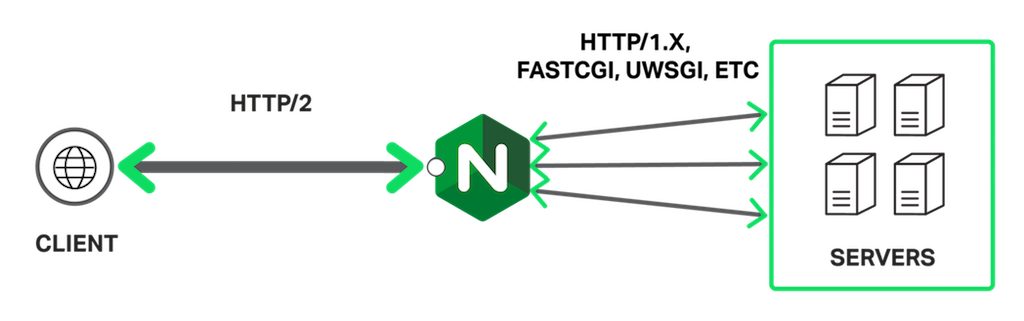
作为支持这些协议的一个例子,NGINX从一开始就支持SPDY,现在大多数使用SPDY的站点都运行在NGINX上。NGINX也是HTTP/2支持的先驱,截至2015年9月,NGINX开源和NGINX Plus都支持HTTP/2。
随着时间的推移,我们NGINX希望大多数站点能够完全启用SSL并迁移到HTTP/2。这将导致安全性的提高,并且,随着新的优化的发现和实现,更简单的代码执行得更好。
技巧7 -更新软件版本
提高应用程序性能的一个简单方法是根据组件的稳定性和性能为软件堆栈选择组件。此外,由于高质量组件的开发人员可能会追求性能增强并随着时间的推移修复bug,因此使用最新的稳定版本的软件是值得的。新版本得到了开发人员和用户社区的更多关注。更新的构建还利用了新的编译器优化,包括针对新硬件的调优。
稳定的新版本通常比旧版本更兼容,性能更高。当您关注软件更新时,更容易掌握调优优化、bug修复和安全警报。
使用旧的软件也会阻止您利用新功能。例如,上面描述的HTTP/2目前需要OpenSSL 1.0.1。从2016年年中开始,HTTP/2将需要于2015年1月发布的OpenSSL 1.0.2。
NGINX用户可以从移动到最新版本的NGINX或NGINX Plus开始;它们包括新的功能,如套接字分片和线程池(请参阅技巧9),并且都在不断地进行性能调优。然后深入了解您的堆栈中的软件,并尽可能地使用最新的版本。
技巧8 -调优Linux的性能
Linux是当今大多数web服务器实现的底层操作系统,作为基础设施的基础,Linux代表着提高性能的重要机会。默认情况下,许多Linux系统都进行了保守的调优,以使用很少的资源并匹配典型的桌面工作负载。这意味着web应用程序用例至少需要一定程度的调优才能获得最大的性能。
Linux优化是特定于web服务器的。以NGINX为例,下面是一些你可以考虑的加速Linux的变化:
- 积压队列——如果您的连接似乎正在停滞,请考虑增加net.core。可以排队等待NGINX注意的最大连接数。如果现有连接限制太小,您将看到错误消息,您可以逐渐增加此参数,直到错误消息停止。
- 文件描述符- NGINX为每个连接使用最多两个文件描述符。如果您的系统正在提供大量连接,您可能需要增加sys.fs。file_max是文件描述符的系统范围限制,nofile是用户文件描述符的限制,以支持增加的负载。
- 临时端口——当用作代理时,NGINX为每个上游服务器创建临时(“临时”)端口。您可以增加由net.ipv4设置的端口值范围。ip_local_port_range,以增加可用端口的数量。您还可以在网络.ipv4重用非活动端口之前减少超时。tcp_fin_timeout设置,允许更快的周转。
对于NGINX,请查看NGINX性能调优指南,了解如何优化您的Linux系统,使其能够轻松处理大量网络流量!
技巧9 -调优Web服务器的性能
无论使用什么web服务器,都需要根据web应用程序性能对其进行调优。下面的建议通常适用于任何web服务器,但是为NGINX提供了特定的设置。主要包括:优化
访问日志—您可以缓冲内存中的条目,并将它们作为一个组写入磁盘,而不是立即为每个请求写入一个日志条目。对于NGINX,将buffer=size参数添加到access_log指令中,以便在内存缓冲区满时将日志条目写入磁盘。如果添加flush=time参数,缓冲区内容也会在指定的时间之后写入磁盘。
缓冲—缓冲将响应的一部分保存在内存中,直到缓冲区填满为止,这可以提高与客户机的通信效率。不适合内存的响应被写入磁盘,这会降低性能。当NGINX缓冲打开时,使用proxy_buffer_size和proxy_buffers指令来管理它。
- 客户机keepalives—Keepalive连接可以减少开销,特别是在使用SSL/TLS时。对于NGINX,您可以增加客户机在给定连接上可以发出的keepalive_requests的最大数量(默认值为100),您还可以增加keepalive_timeout以允许keepalive连接保持更长时间的打开状态,从而加快后续请求的速度。
- 上游保持连接—上游连接—到应用程序服务器、数据库服务器等的连接—也可以从保持连接中获益。对于上游连接,您可以增加keepalive,即为每个工作进程保持打开状态的空闲keepalive连接的数量。这允许增加连接重用,减少了打开全新连接的需要。有关更多信息,请参考我们的博客文章、HTTP Keepalive连接和Web性能。
- 限制——限制客户端使用的资源可以提高性能和安全性。对于NGINX, limit_conn和limit_conn_zone指令限制来自给定源的连接数量,而limit_rate限制带宽。这些设置可以阻止合法用户“占用”资源,还有助于防止攻击。limit_req和limit_req_zone指令限制客户机请求。对于到上游服务器的连接,使用max_conns参数到上游配置块中的服务器指令。这将限制到上游服务器的连接,防止过载。关联的queue指令创建一个队列,该队列在达到max_conns限制之后,在指定的时间长度内保存指定数量的请求。
- 工作进程——工作进程负责处理请求。NGINX使用基于事件的模型和依赖于操作系统的机制来有效地在工作进程之间分发请求。建议将worker_processes的值设置为每个CPU一个。如果需要,可以在大多数系统上安全地启动worker_connections的最大数量(默认为512);尝试找出最适合您的系统的值。
- 套接字分片——通常,一个套接字侦听器将新连接分配给所有工作进程。套接字分片为每个工作进程创建套接字侦听器,内核在套接字侦听器可用时将连接分配给它们。这可以减少锁争用,提高多核系统的性能。要启用套接字分片,请在listen指令上包含reuseport参数。
- 线程池——任何计算机进程都可以通过一个缓慢的操作来阻塞。对于web服务器软件,磁盘访问可以支持许多更快的操作,比如在内存中计算或复制信息。当使用线程池时,慢操作被分配给一组单独的任务,而主处理循环继续运行更快的操作。当磁盘操作完成时,结果返回到主处理循环。在NGINX中,两个操作——read()系统调用和sendfile()——被卸载到线程池。

小费。当更改任何操作系统或支持服务的设置时,每次更改一个设置,然后测试性能。如果更改导致问题,或者没有使站点运行得更快,请将其更改回来。
有关优化NGINX web服务器的更多信息,请参阅我们的博客文章“优化NGINX以获得性能”。
技巧10 -监控活动以解决问题和瓶颈
应用程序开发和交付的高性能方法的关键是密切和实时地观察应用程序的实际性能。您必须能够监视特定设备内和跨web基础设施的活动。
监控站点活动主要是被动的——它告诉您发生了什么,然后让您发现问题并修复它们。
监视可以捕获几种不同类型的问题。它们包括:
- 服务器宕机。
- 服务器正在中断连接。
- 服务器的缓存丢失率很高。
- 服务器没有发送正确的内容。
像New Relic或Dynatrace这样的全局应用程序性能监视工具可以帮助您从远程位置监视页面加载时间,而NGINX可以帮助您监视应用程序交付端。应用程序性能数据告诉您,什么时候您的优化对用户产生了真正的影响,以及什么时候您需要考虑向基础设施添加容量来维持流量。
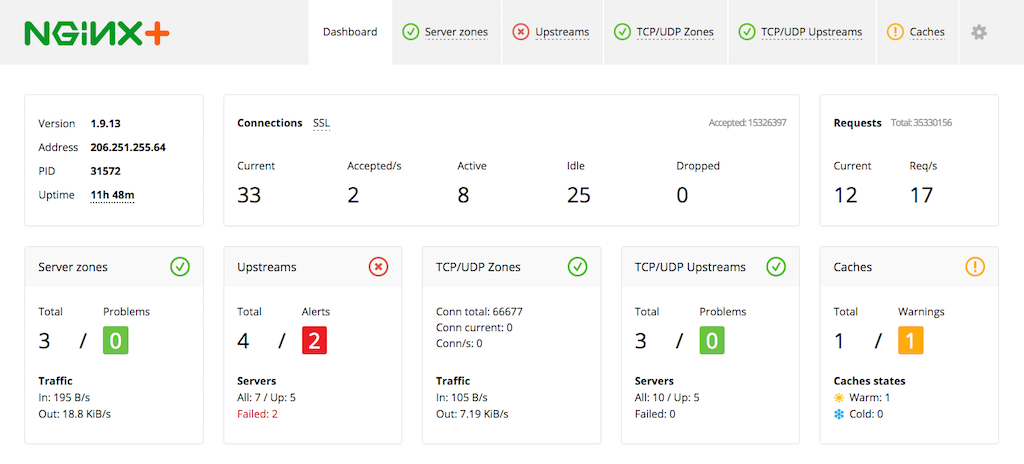
为了帮助快速识别和解决问题,NGINX Plus添加了应用程序感知的健康检查——经常重复的合成事务,用于提醒您注意问题。NGINX Plus还具有会话耗尽功能,在现有任务完成时停止新连接,启动速度较慢,允许恢复的服务器在负载平衡的组中加快速度。当有效使用时,健康检查允许您在问题严重影响用户体验之前识别问题,而会话耗尽和启动缓慢允许您替换服务器,并确保流程不会对感知的性能或正常运行时间产生负面影响。图中显示了内建的NGINX Plus活动监视仪表板,用于具有服务器、TCP连接和缓存的web基础设施。
结论-性能提高10倍
任何一个web应用程序的性能改进都有很大的不同,实际的收益取决于您的预算、您可以投入的时间和现有实现中的差距。那么,如何为自己的应用程序实现10倍的性能改进呢?
为了帮助您了解每种优化的潜在影响,这里有一些关于上述每种技巧可能带来的改进的提示,尽管您的经验几乎肯定会有所不同:
- 反向代理服务器和负载平衡——没有负载平衡,或者负载平衡不好,可能会导致性能非常差的情况。添加反向代理服务器(如NGINX)可以防止web应用程序在内存和磁盘之间发生抖动。负载平衡可以将处理从过载的服务器转移到可用的服务器,并使扩展变得容易。这些变化可以带来显著的性能改进,与当前实现中最糟糕的时刻相比,可以轻松实现10倍的性能改进,总体性能方面的成就虽小,但却很可观。
- 缓存动态和静态内容——如果您的web服务器负担过重,并且其性能是应用服务器的两倍,那么仅通过缓存动态内容就可以在峰值时间内提高10倍。静态文件的缓存也可以提高性能的个位数倍数。
- 压缩数据——使用媒体文件压缩,如照片的JPEG、图形的PNG、电影的MPEG - 4和音乐文件的MP3,可以大大提高性能。一旦这些都被使用,那么压缩文本数据(代码和HTML)可以将初始页面加载时间提高两倍。
- 优化SSL/TLS——安全握手对性能有很大的影响,因此优化握手可以使初始响应能力提高2倍,特别是对于文本较多的站点。在SSL/TLS下优化媒体文件传输可能只会带来很小的性能改进。
- 实现HTTP/2和SPDY——当与SSL/TLS一起使用时,这些协议可能会导致站点整体性能的增量改进。
- 调优Linux和web服务器软件(如NGINX)——诸如优化缓冲、使用keepalive连接和将耗费大量时间的任务卸载到单独的线程池等修复可以显著提高性能;例如,线程池可以将磁盘密集型任务的速度提高近一个数量级。
我们希望您亲自尝试这些技巧。我们希望听到您能够实现的应用程序性能改进。在下面的评论中分享你的结果,或者用#NGINX和#webperf的散列标签发布你的故事!
互联网统计资料
Resources for Internet Statistics
- Statista.com – Share of the internet economy in the gross domestic product in G‑20 countries in 2016
- Kissmetrics – How Loading Time Affects Your Bottom Line (infographic)
- Econsultancy – Site speed: case studies, tips and tools for improving your conversion rate
原文:https://www.nginx.com/blog/10-tips-for-10x-application-performance/
本文:https://pub.intelligentx.net/node/761
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 117 次浏览
【技术架构】AMQP, MQTT或STOMP

在本文中,我想写一些关于面向消息的协议,这些协议用于服务器、设备之间的通信,反之亦然。有许多面向消息的协议,每个协议都有自己的优缺点。其中最受欢迎的有AMQP, MQTT和STOMP。流行的消息代理如ActiveMQ、RabbitMQ和Kafka都支持它们,您可以调整您的消息代理(或无代理)并更改其配置,以告诉它们应该使用什么协议工作、通信、发送和接收消息。有些人说一个协议比另一个好,但我不同意这个判断,因为根据你的项目,它的规模和其他不同的因素,如安全性,互操作性,甚至带宽,你应该决定哪个协议最适合你。例如,MQTT是一种遥测协议,主要用于物联网和没有足够带宽的项目(如拨号和带宽较慢)中。我知道facebook使用它,所以它很好。AMQP也是一种很好的协议,它具有许多安全的、可互操作的特性和功能,被广泛使用。例如,NASA和摩根大通使用AMQP每天处理数十亿条消息。另一个需要注意的是MQTT是由IBM和AMQP由摩根大通设计的。
STOMP协议很简单,并且是基于文本的,在内部很像HTTP,您甚至可以使用Telnet连接到STOMP代理。
在这里,我建议您参考Raphael Cohn (StormMQ的首席架构师)撰写的一篇很好的文章,这篇文章很好地比较了AMQP和MQTT。
https://lists.oasis-open.org/archives/amqp/201202/msg00086/StormMQ_WhitePaper_-_A_Comparison_of_AMQP_and_MQTT.pdf
要了解更多信息,您可以浏览stackoverflow讨论,了解来自全球各地的开发人员对这些协议有什么样的体验。
关于哪种message broker是最好的还有一个很长的故事,以及不同系统中的许多不同基准测试。其中一个X更好,另一个基准Y更好的硬件和平台。我对这些判断完全中立,因为例如,一些开发人员比较代理的消息中间件和无代理的消息中间件,这是一个荒谬的比较。例如ActiveMQ、RabbitMQ和KAFKA都是代理消息传递中间件,而ZeroMQ和NanoMsg则是无代理消息传递系统。顺便说一句,我可能会写和文章关于比较一些他们和基准。我有使用ActiveMQ, RabbitMQ和KAFKA的经验,所有这些都很好。ActiveMQ对于事务性不高的项目来说足够快,而且非常稳定,支持JMS主题、队列和许多协议,如AMQP、MQTT、STOMP和OpenWire。此外,RabbitMQ是一个非常好的选择,它具有很好的消息分派策略,如循环调度和公平分派(很好的策略)。另外Kafka是非常快,使用Zookeeper,但配置是一个麻烦在***。ZeroMQ是非常快的,但是考虑到它是没有经纪的,所以你错过了经纪功能。
请随时与我联系,并在这里留下您使用消息代理和无代理的经验(它们的特性、性能、稳定性、互操作性和安全性)。
感谢阅读这篇文章的朋友,保重,祝你有个愉快的一天。
本文:http://jiagoushi.pro/node/1123
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 453 次浏览
【技术架构】EA874:技术架构的原则和标准
企业技术架构中EA原则的应用
原则经常是正式EA工作的一部分。它们在个人决策和广泛适用且独立于具体决策的基本业务目标之间提供了更强的联系。原则是组织为激发最佳行为而选择的准则或最佳实践。它们很可能(在最高级别)被追溯到基本的业务需求和策略。如果使用得当,给定解决方案中的关键选择或决策应该可以追溯到解决方案的目标,特别是在创建过程中应用的原则,这些原则代表了IT组织(ITO)或IT中的特定参与者甚至业务的所有IT项目或解决方案的更一般的目标作为一个整体。这使得ITO能够提醒业务部门为什么要这样做,特别是在建议某个特定项目之外的问题应该影响该单个项目的预算时。毕竟,通过批准EA原则,企业表明这一原则是重要的;ITO只是在某一特定领域根据这一建议或愿望行事。
因此,对于企业技术架构或基础设施规划,在完成设计或模型(如技术模式和技术服务)之前,定义关键的ETA设计架构原则(DAPs)并就其达成一致也是很有用的。将ETA与整个EA(或IT)和业务原则联系起来有助于简化采用,并且坦率地说,有助于促进行为的真正变化

图1
原则(或其含义)应继承自更高层次的原则,并针对这些更具体和更实用的技术模型和/或基础设施设计进行专门化(或形成新的一般原则)。原则随后成为最高级别EA指导和更详细的ETA建模或基础设施设计工作之间的主要联系。直观显示连杆的矩阵是分析基于原理的分析或设计的连通性和完整性的常用工具。
优先原则
由于有许多原则可以帮助定义使用原则来管理或评估解决方案的规则,因此需要对原则进行一些优先级排序。在某些情况下,原则(或者至少是单独原则的含义)可能存在直接冲突。例如,组织可能有一个“低成本”原则,但也有一个“高可用性”原则-显然,在特定情况下,其中一个设计目标必须大于另一个。因此,必须对哪些原则应优于其他原则的某些预设决定进行定义。但是,对于任何给定的项目,所有原则都可以被项目目标覆盖。在这一点上,应该简单地指出,具体的项目要求或更一般的、先前商定的原则正在被具体拒绝,并指出这一决定可能产生的后果。至少这些原则没有被完全忽视。
使技术标准发挥作用
在许多组织中,技术标准被忽略。这在业务人员很少或根本不参与体系结构的企业中尤其常见。企业架构师总是在努力改变这种行为。
缺少的一个关键元素是架构和业务好处之间的链接。特别是,企业架构必须从业务策略中驱动。此链接为架构提供了适当的上下文,并允许在架构标准的好处和向项目授予标准豁免之间进行权衡。然而,架构仍然有许多障碍需要协商才能使这种连接有效。其中包括:
- ·寻找商业战略
- ·商业战略分析
- ·获得架构的业务支持
- ·制定适当的治理安排
获得企业架构的执行支持有一个重要的文化因素。另一个可能遇到的障碍是来自IT人员的阻力,他们经常对自己设计选择的限制感到不满。
为了克服这种阻力,建筑师可以做以下工作
1] 创建架构恐慌图-
架构恐慌图可以生动地传达降低IT产品组合复杂性的需要。下面是一个架构恐慌图的例子。

图2
2] 机会主义地选择项目——
寻找涉及多个业务部门变更的项目。这样的项目优化了跨多个业务单元运行的端到端业务流程,或者它可能正在构建一个通用的、企业范围的客户或产品视图。架构师必须警惕这些项目带来的机会,并主动提出一个解决方案,使他们能够推进自己的事业。在这一点上,建筑师必须务实。
3] 在企业中交朋友-
在项目中与企业建立良好的关系。尝试理解业务问题,并帮助提出解决方案,该解决方案也可能有助于为体系结构创建下一个迭代。
4] 在技术标准的制定中包括关键的利益相关者——
利益相关者为支持标准设置的评估和意见带来了有价值的视角。参与技术标准决策的制定必然会获得更高水平的支持,这意味着更愿意在实践中应用标准。
5] 积极主动地与项目合作-
架构师应该在项目.If架构师是项目高级设计团队的一部分,与项目中的所有利益相关者和人员建立了更健康的关系。
6] 使技术标准易于项目查找和使用-
这些标准必须易于通过企业内部网访问并清楚地记录在案。然后,将技术标准聚合到可重用的技术模式中,以解决特定的用途,例如大容量在线事务处理或友好和安全的客户Web访问。
本文:http://jiagoushi.pro/node/1061
讨论:请加入知识星球【首席架构师圈】或者小编小号【jiagiushi_pro】
- 168 次浏览
【技术架构】EA874:技术架构的战略规划与管理
在经济困难的情况下,早期采用新兴技术可以使他们的公司具有竞争优势。在采用新技术时,如果公司在采用“根据需要”的被动方法,则有可能做出代价高昂、个性驱动的选择,而不是与其更大的公司战略和目标相一致的战术决策。
本战略分析报告介绍了与战略技术规划有关的建议活动和最佳做法。这些建议适用于企业是否拥有正式的先进技术集团(ATG)或结构较低的战略技术规划职能。
战略技术规划过程
使用共同的一组步骤——范围(scope)、跟踪(Track)、排名(rank)、评估(evaluate)、传播/布道(evangelize )和转移(transfer )(STREET)——构成典型的战略技术规划过程。
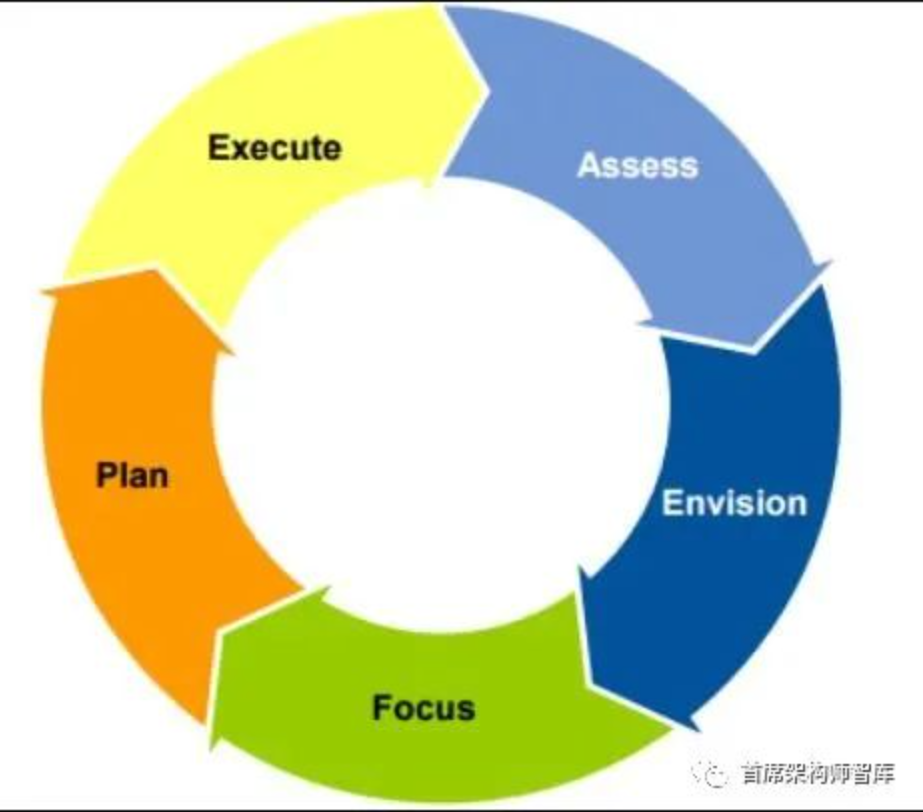
图1
- 范围:通过了解公司目标、行业方向和业务流程瓶颈,为技术投资提供重点和范围。
- 跟踪:扫描新的技术机会,并以适合进一步决策的格式捕获结果。
- 排名:选择最有可能给企业带来重大利益的技术、计划和项目想法的子集。排名涉及在两组活动之间和内部平衡资源:支持业务部门和管理层的请求,主动识别和推动战略技术,例如在业务部门请求之前。
- 评估:调查对技术或其影响了解不足,无法最终确定是否将技术投入运营的领域。
- 布道:影响那些有能力将技术投入生产的人。营销、教育、网络和激励他人是ATG活动的核心部分,并贯穿整个生命周期,但其重要性在评估阶段之后最为明显,因为ATG通常无权要求采纳其建议。
- 转移:将知识和责任转移给将开发操作系统的人员。包括知识丰富的员工和需要学习技能的员工。
在企业技术架构中采用新技术
企业架构(EA)团队应该采用结构化的方法来计划将新技术和产品引入其企业IT环境。许多新技术和新产品将继续推动ETA产品组合的变化。EA团队必须对这种影响进行建模,捕获初始或更改的用途,并帮助企业在合理的生命周期中实际有效地开发技术。企业将从深思熟虑的新技术和新产品战略中获益,而不是草率采用。应制定有计划的程序和框架,以确保成功采用技术。该计划还应更清楚地说明创新何时适当,何时不适当。
企业技术架构框架
1] 新模型还是对现有模型的更改?-
最关键的区别是新技术或新产品是否是你已经拥有的或真正新的东西的替代品。它需要一个新的模型还是仅仅成为现有模型中的一个替代模型?添加全新的组件或其他模型通常会产生更广泛和更长期的影响,并且需要更严格的规划、更正式的变更批准才能采用新的模型案例,而不是向现有模型添加更多的数据或选项。
2] 定义一个新的技术组件标准-
许多新技术被恰当地定义为ETA中定义的技术组件或块的实例。EA应推动计划和建模活动,记录ETA标准和指南的变化,以反映新技术或产品。
采用组件技术选择后,应评估并选择特定产品作为组件标准的一部分。在这样做时,规划者还应该考虑哪些相关的支持产品或技术应该从“生产”状态列表中删除。
以下是技术和产品采用的“生命周期”视图
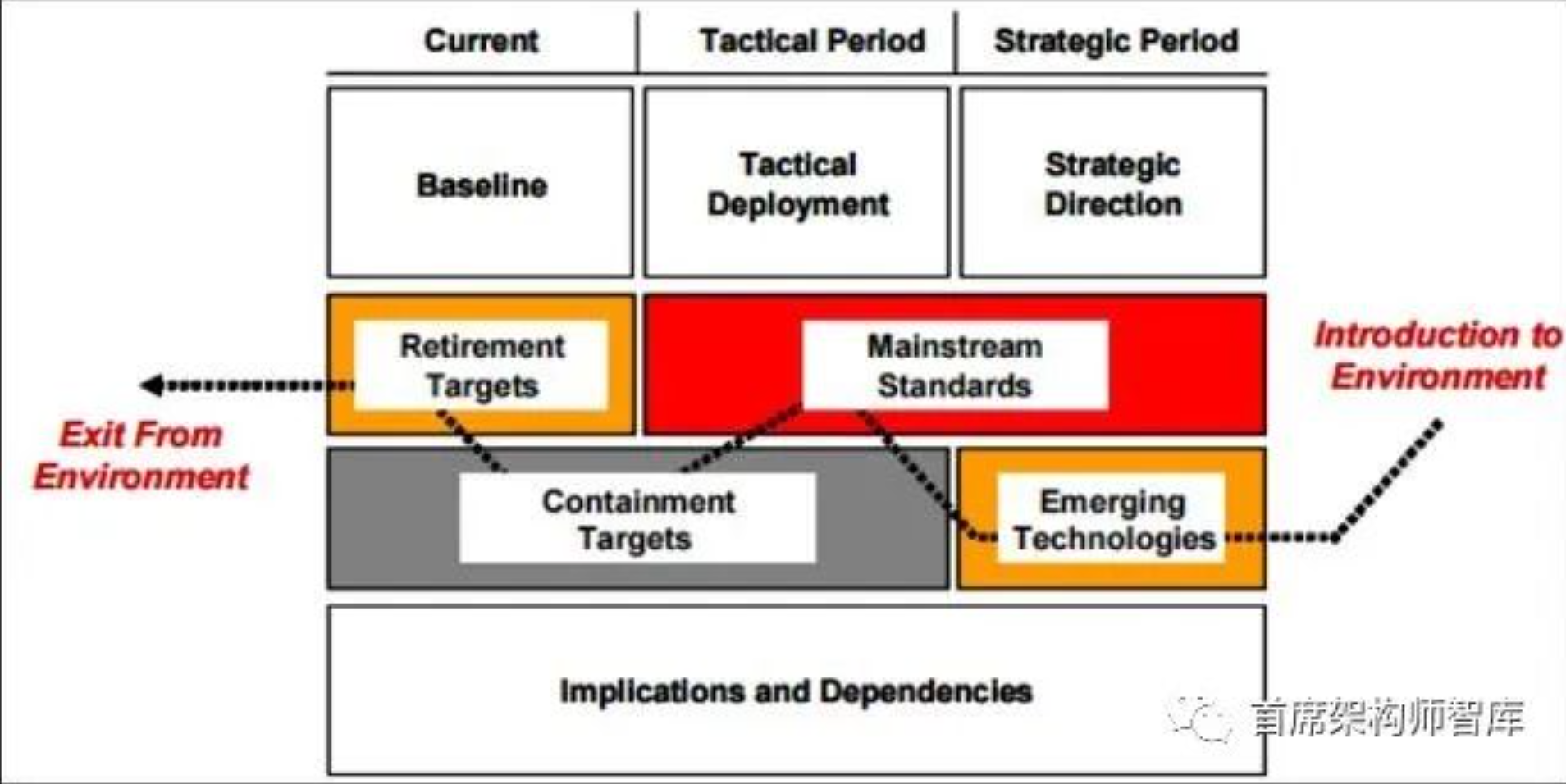
图2
3] 技术领域层面的影响-
技术领域层面是从组件决策到自上而下或业务驱动的EA原则和通用需求愿景的第一点。像“使用标准”和“首选商品解决方案”这样的EA原则应该在技术组件或砖块级别通知和匹配中小企业驱动的工作。
4] 对技术模式标准的影响——
采用一项主要的新技术应该放在为应用程序提供正确的基础设施或技术设计的背景下。这就是ETA中的基础设施或技术模式模型应该定义的内容。应根据需要检查和更新每个模式,以利用新技术。不是所有的模式都应该马上添加新技术。即使模式应该用新技术更新,也不是该模式中的所有领域都需要添加该技术。
5] 对技术服务标准的影响——
采用新技术可能会引起技术服务方面的考虑,也应加以审查。
6] 为营销(推广)标准指导和项目定义制定新的技术战略-
对于所有ETA地区,组织应定义一个战略和路线图,说明何时应在今年和明年的项目中启用每个指导选项,包括基础设施和应用程序。规划者必须检查所需的人力资源,以规划新的技术战略。他们还应考虑进行利益相关者分析,并制定沟通计划,使利益相关者了解战略的最新情况。如果组织收到许多与新技术相关的问题或新项目请求,它们将知道需要采取这一步骤。
讨论:请加入知识星球【首席架构师圈】或者小编小号【ca_cea】
- 154 次浏览
【技术架构】EA874:技术组件和技术领域
技术架构角度
技术架构(architecture)视点或企业技术架构(ETA)定义了技术和产品使用的可重用标准和指南,并描述了它们如何互操作以及如何支持其他视点(业务和信息)。
企业技术体系结构不仅应定义部件级建议,还应定义这些技术组件的哪些组合或配置应在单独的实现(技术模式)中重复,以及哪些组合应作为共享基础结构(技术服务)实际重用。
启动企业技术架构开发工作
任何一个EA观点都应该从定义未来状态开始——在这里,需求被识别,EA原则被建立,未来状态模型被创建。然后定义当前状态体系结构,执行差距分析并创建迁移路线图。
在开始任何建模工作之前,请认识到所有模型都是从企业架构(EA)流程生成的。EA实践者和相关角色必须通过遵循流程来生成模型。
企业技术架构组织概念
技术领域:传统的技术架构方法将组件组织到基于技术或组织相似性的技术领域中。几个相关的组件可以这样分组;公共域包括网络和数据库。

图1
尽管技术领域模型是必要和有用的,但它们本身并不足够。技术规划需要一个整体的、端到端的视图。特别是,设计人员(架构师或工程师)必须清楚地表达模型,这些模型能够更有效地表达应用程序和共享服务交付的目标。这种类型的技术领域方法的一个典型结果是,对单个技术组件集进行了优化,但没有对这些组件的集体优化直接映射到应用程序需求。需要来自每个域的组件来定义完整的端到端应用程序
技术模式:模式有助于从业务需求到技术(基础设施)设计的映射。设计或蓝图代表了一些需要重复的东西——技术模式具体地包含了整个类或一组应用程序成功所需的所有组件。

技术服务:服务是作为单个单元(包括流程和人员)实现和重用的组件,但不必对任何一个应用程序都是必需的。它们通常由来自多个域的组件组成,但并不总是如此。通用技术服务包括广域网、大型机、分析集成(数据仓库)和事务集成(EAI、IEI)。技术服务也可以直接支持应用服务。其他合理的组件集合模型也存在,包括框架,比如Java EE;如果有用的话,将它们考虑进来。
下面是一个3/N层的事务模式-

本文:http://jiagoushi.pro/node/1060
讨论:请加入知识星球【首席架构师圈】或者小编小号【jiagoushi_pro】
- 171 次浏览
【技术架构】TOGAF建模:处理图
处理图着重于可部署的代码/配置单元,以及如何将它们部署到技术平台上。部署单元表示业务功能、服务或应用程序组件的分组。处理图解决了以下问题:
- 需要将哪一组应用程序组件分组以形成部署单元?
- 一个部署单元如何与另一个(局域网、广域网和适用的协议)连接/交互?
- 应用程序配置和使用模式如何产生不同技术组件的负载或容量需求?
参见网络计算硬件图。为了呈现部署单元,处理图将以一种更通用的方式使用部署。部署单元可以作为部署应用程序组件的组件实例,或者作为将宿主部署的应用程序组件的物理实用程序组件(例如,应用程序服务器)。
这些部署单元之间的关联将表示连接(例如,一个网络),而信息流将表示正在交换的信息的性质。
在这些图表中,提供了容量需求的指示。
UML/BPMN EAP Profile

![]() Entity application component: An entity component is frequently derived from business entities, and is responsible for managing the access to the entity, and its integrity.
Entity application component: An entity component is frequently derived from business entities, and is responsible for managing the access to the entity, and its integrity.
![]() Process application component: A process application component is responsible for a business process execution. It orchestrates the tasks of the process.
Process application component: A process application component is responsible for a business process execution. It orchestrates the tasks of the process.
![]() Utility component: Represents an application component that is frequently reused, and most of the cases bought off the shelf.
Utility component: Represents an application component that is frequently reused, and most of the cases bought off the shelf.
![]() Information flow: Defines the flow of any kind of information (business entity, event, product, informal, etc) between active entities of the enterprise.
Information flow: Defines the flow of any kind of information (business entity, event, product, informal, etc) between active entities of the enterprise.
![]() Association between two classes: An association has a name, and for each extremity provides the role name and cardinalities (possible number of occurrences) of related elements.
Association between two classes: An association has a name, and for each extremity provides the role name and cardinalities (possible number of occurrences) of related elements.
Archimate

此处理图显示了如何在不同类型的应用程序服务器下部署应用程序组件。
上面的部署配置仍然独立于未来在物理服务器上的部署。
原文:https://www.togaf-modeling.org/models/technology-architecture/processing-diagrams.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 140 次浏览
【技术架构】TOGAF建模:环境和位置图
环境和位置图描述了哪些位置承载哪些应用程序,确定了哪些位置使用了哪些技术和/或应用程序,最后确定了业务用户通常与应用程序交互的位置。该图还应该显示不同部署环境的存在和位置,包括非生产环境,例如开发和预生产环境。
UML/BPMN EAP Profile

![]() Headquarter location: defines geographically where the elements of the enterprise are deployed (organization units, hardware devices, actors, etc.)
Headquarter location: defines geographically where the elements of the enterprise are deployed (organization units, hardware devices, actors, etc.)
![]() Site location: defines geographically where the elements of the enterprise are deployed (organization units, hardware devices, actors, etc.). Generally, an enterprise has one headquarter and several sites.
Site location: defines geographically where the elements of the enterprise are deployed (organization units, hardware devices, actors, etc.). Generally, an enterprise has one headquarter and several sites.
![]() Server device: Represents a hardware platform, that can be connected to other devices, and on which are deployed application components.
Server device: Represents a hardware platform, that can be connected to other devices, and on which are deployed application components.
![]() Workstation: Workstation are connected via network links to the IS. Application components can be deployed there.
Workstation: Workstation are connected via network links to the IS. Application components can be deployed there.
![]() Application: This Application component corresponds to legacy applications, off the shelf products, or can be an assembly of application components.
Application: This Application component corresponds to legacy applications, off the shelf products, or can be an assembly of application components.
![]() Interaction application component: Represents the top level components that manage the interaction with the external of the IS. In most cases, it is a GUI component, such as here a web interface.
Interaction application component: Represents the top level components that manage the interaction with the external of the IS. In most cases, it is a GUI component, such as here a web interface.
![]() Association between two classes: An association has a name, and provide at each end the role name, and the cardinalities (possible number of occurrences) of related elements.
Association between two classes: An association has a name, and provide at each end the role name, and the cardinalities (possible number of occurrences) of related elements.
Archimate

主要的应用和设备位于巴黎
在这个图中,设备(服务器、工作站)被嵌入到(已部署的)位置。应用程序组件还被嵌入到设备中。
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 128 次浏览
【技术架构】TOGAF建模:网络计算硬件图
从从大型机到客户机-服务器系统的转换开始,后来随着电子商务和J2EE的出现,大型企业主要迁移到高度基于网络的分布式网络计算环境中,该环境具有防火墙和非军事区。目前,大多数应用程序都有web前端,看看这些应用程序的部署架构,在网络环境中通常会发现三个不同的层:web表示层、业务逻辑或应用程序层和后端数据存储层。在共享的公共基础设施环境中部署和承载应用程序是一种常见的做法。因此,记录在开发和生产环境中支持应用程序的逻辑应用程序和技术组件(例如,服务器)之间的映射变得非常关键。网络计算硬件图的目的是显示分布式网络计算环境中逻辑应用程序组件的部署逻辑视图。
UML/BPMN EAP Profile

![]() Server device: Represents a hardware platform, that can be connected to other devices, and on which application components are deployed.
Server device: Represents a hardware platform, that can be connected to other devices, and on which application components are deployed.
![]() Workstation: Workstations are connected via network links to the IS. Application components can be deployed there.
Workstation: Workstations are connected via network links to the IS. Application components can be deployed there.
![]() Process application component: A process application component is responsible for a business process execution. It orchestrates the tasks of the process.
Process application component: A process application component is responsible for a business process execution. It orchestrates the tasks of the process.
![]() Entity application component: An entity component is frequently derived from business entities, and is responsible for managing the access to the entity, and its integrity.
Entity application component: An entity component is frequently derived from business entities, and is responsible for managing the access to the entity, and its integrity.
![]() Utility component: Represents an application component that is frequently reused, and most of the cases bought off the shelf.
Utility component: Represents an application component that is frequently reused, and most of the cases bought off the shelf.
![]() Interaction application component: Represents the top level components that manage the interaction with elements outside the IS. In most cases, it is a GUI component, such as here a web interface.
Interaction application component: Represents the top level components that manage the interaction with elements outside the IS. In most cases, it is a GUI component, such as here a web interface.
![]() Database application component: This represents a repository. In pure SOA architecture, these elements should not appear. However, for legacy analysis or technology architecture, modeling repositories or repository deployment can be useful.
Database application component: This represents a repository. In pure SOA architecture, these elements should not appear. However, for legacy analysis or technology architecture, modeling repositories or repository deployment can be useful.
![]() Application: This application component corresponds to legacy applications, off the shelf products, or can be an assembly of application components.
Application: This application component corresponds to legacy applications, off the shelf products, or can be an assembly of application components.
![]() Internal actor: An actor that belongs to the enterprise
Internal actor: An actor that belongs to the enterprise
![]() Association between two classes: An association has a name, and for each extremity provides the role name and cardinalities (possible number of occurrences) of related elements.
Association between two classes: An association has a name, and for each extremity provides the role name and cardinalities (possible number of occurrences) of related elements.
Archimate

此图显示了应用程序组件部署的位置、计算机如何联网,等等。
此图展示了通过网络互连的硬件(服务器、工作站),以及部署在此硬件上的技术和应用程序组件。
技术、体系结构组件(如web服务器)被添加到应用程序体系结构中标识的逻辑组件中。
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 136 次浏览
【技术架构】为本地应用程序选择最佳高可用性和灾难恢复拓扑
如果您的本地应用程序失败,您可能会对业务连续性产生重大影响。要获得成功,您必须实施包含高可用性(HA)和灾难恢复(DR)解决方案的业务连续性计划。但是,如何为您的解决方案选择最佳的HADR拓扑?
高可用性与灾难恢复
术语高可用性和灾难恢复通常可以互换使用。但是,它们是两个截然不同的概念:
- 高可用性(HA)描述了应用程序抵御所有计划内和计划外中断的能力(计划中断可能正在执行系统升级)并为业务关键型应用程序提供连续处理。
- 灾难恢复(DR)涉及一系列策略,工具和过程,用于在灾难性中断后将系统,应用程序或整个数据中心返回到完全运行状态。它包括将已安装系统的基本数据复制和存储在安全位置,以及恢复该数据以恢复操作正常的过程。
高可用性是关于避免单点故障并确保应用程序将继续处理请求。灾难恢复是指在系统或应用程序遭受灾难性故障或整个数据中心可用性丧失后将系统或应用程序恢复到正常运行状态的策略和过程。
开发您的HADR解决方案
要为您的本地应用程序指导高可用性灾难恢复(HADR)解决方案的开发,您应该考虑业务挑战,功能要求和架构原则。
您的HADR解决方案面临的业务挑战
您的HADR解决方案应该解决这些挑战:
- 对于业务连续性,应用程序及其支持的业务流程应保持可用且无任何中断,尽管存在人为或自然灾害。它应无缝地服务于其预期的功能。
- 为了实现持续可用性,精心设计的HA解决方案可通过快速的系统响应时间和实时交易执行来保持最佳的客户体验。
- 该架构必须能够处理因业务交易激增而产生的额外工作量,并降低收入机会损失的风险。
- 为了提高操作灵活性,您应该拥有一个设计良好的HA拓扑,在辅助站点中复制代码和数据,并以足够的地理距离隔开。应用程序可以在另一个位置重新构建和/或激活,在主站点发生意外灾难性故障后处理工作。
HADR解决方案的功能要求
您应该考虑HADR解决方案的以下功能要求:
- 最大限度地减少应用程序正常操作的中断。如果任何应用程序组件存在可用性问题,请确保将应用程序组件平稳快速地恢复到正常操作。
- 恢复任何应用程序组件的服务必须完全自动化,或者必须由人员通过单一操作激活。
- 监视应用程序的每个应用程序组件的可用性。在服务级别问题的情况下发出警报,例如响应时间慢或任何应用程序组件没有响应。通过自动化或由负责应用程序高可用性的人工专家执行的单个操作激活快速恢复。
影响HADR解决方案的架构原则
可能导致软件应用程序无法处理用户或其他系统请求的事件可分为三类。每种方法都需要不同的技术来缓解。
- 涉及系统中仅一个组件意外故障的事件,例如操作系统进程,物理机器或连接系统成员的网络链接。
- 涉及系统许多组件同时发生意外故障的事件。这些事件可能由自然灾害,人为错误或两者的组合触发。
- 由人为错误引起的事件,涉及通过将不正确或不连贯的内容持久保存到主数据存储区的逻辑损坏。
示例:本地B2B订单应用程序
在此示例中,组织开发内部部署应用程序以处理来自其B2B客户的在线订单。 B2B订单应用程序使用多个组件提供特定服务,例如用户界面,产品目录,订单创建,工作流,决策和集成服务以及分析。 ERP应用程序存储产品数据,例如价格和库存以及订单。目录应用程序管理与产品相关的非结构化数据,例如图像。在线订单应用程序使用NoSQL数据库存储其产品目录和传统的RDBMS用于其分析和ERP后端应用程序。
这是内部部署订单应用程序中涉及的组件的高级说明。

HADR的数据中心拓扑选项
要实现高可用性,您可以从两个部署拓扑选项中选择 - 两个数据中心体系结构和三个数据中心体系结构。您可以在主数据中心和辅助数据中心的高可用性群集配置中以相同的方式设置B2B订单应用程序。
两个数据中心拓扑
您可以在活动 - 备用模式或主动 - 主动模式下配置两个数据中心拓扑。最简单的配置是活动 - 备用拓扑,其中辅助数据中心中的B2B订单应用程序处于冷备用模式。在主动 - 主动拓扑中,应用程序及其使用的服务在两个数据中心都处于活动状态。
三个数据中心拓扑
三个数据中心的配置有两种变体,主动 - 主动 - 主动和主动 - 主动 - 备用。在主动 - 主动 - 备用配置中,应用程序和服务在主数据中心和辅助数据中心处于活动模式,而应用程序在第三个数据中心处于待机模式。
灾难恢复方案
当灾难发生时,您所做的拓扑和配置选择将决定您的应用程序如何恢复。您需要了解与每个相关的成本和收益,以确定满足您需求的最佳成本和收益。
使用两个数据中心拓扑进行灾难恢复
主动 - 主动或主动 - 备用是此方案的两种可能配置。在这两种情况下,您必须在两个数据中心之间连续复制数据。
主动 - 主动配置

与主用 - 备用配置相比,此配置提供了更高的可用性,最少的人为参与。 两个数据中心都提供请求。 您应该使用适当的超时配置边缘服务(负载平衡器)并重试逻辑,以便在第一个数据中心环境中发生故障时自动将请求路由到第二个数据中心。
此配置的好处是减少恢复时间目标(RTO)和恢复点目标(RPO)。 对于RPO要求,两个活动数据中心之间的数据同步必须非常及时,以允许无缝请求流。
主动 - 备用配置

请求从活动站点提供。在发生中断或应用程序故障的情况下,执行预应用程序工作以使备用数据中心准备好为请求提供服务。从活动数据中心切换到备用数据中心是一项耗时的操作。与主动 - 主动配置相比,恢复时间目标(RTO)和恢复点目标(RPO)都更高。
备用数据中心可以是热备用环境,也可以是冷备用环境。在热备用选项中,订单应用程序和相关服务部署到两个数据中心,但负载均衡器仅将流量定向到活动数据中心中的应用程序。此配置的好处是,当活动数据中心遇到灾难时,可以激活热备用数据中心。 DR过程仅需要重新配置负载平衡器以将流量重定向到新激活的数据中心。热备用的缺点是第二个数据中心保持活动状态,应用程序保持最新,但不用于处理客户请求。软件许可证适用于两个数据中心,但只有一个正在使用中。
在冷备用选项中,订单应用程序和相关服务部署到两个数据中心,但不在备用数据中心中启动。如果活动数据中心遇到灾难,则DR过程包括启动应用程序和服务,以及重新配置负载平衡器以重定向流量。就软件许可证成本和数据中心运营成本(包括人员)而言,此选项具有成本效益。但是,应用程序可用性可能会受到影响,具体取决于冷备用数据中心和订单应用程序启动和激活以处理请求的速度。
在中断后恢复主数据中心中的应用程序时,您可以修改边缘服务DNS以将用户请求路由到主数据中心中的现在活动的应用程序。辅助数据中心中的应用程序可以切换回待机模式。
使用三个数据中心拓扑进行灾难恢复
在这个Always On服务时代,对停机时间零容忍,客户希望每个商业服务都能在世界任何地方随时随地访问。对企业而言,一种经济高效的策略包括构建基础架构以实现持续可用性,而不是构建灾难恢复基础架构。
三个数据中心拓扑比两个数据中心提供更高的弹性和可用性。它可以通过在数据中心内更均匀地分布负载来提供更好的性能。如果企业只有两个数据中心,则可以在一个数据中心部署两个应用程序,在第二个数据中心部署第三个应用程序。或者,您可以在3活动拓扑中部署业务逻辑和表示层,并在2活动拓扑中部署数据层。
此方案考虑了两种可能的配置,即主动 - 主动 - 主动(3主动)和主动 - 主动 - 备用配置。在这两种情况下,数据中心之间都需要连续复制数据。
主动 - 主动 - 主动(3主动)配置

请求由在三个活动数据中心中的任何一个中运行的应用程序提供。 IBM.com网站上的一个案例研究表明,3-active只需要每个群集50%的计算,内存和网络容量,但2-active需要每个群集100%。 数据层是成本差异突出的地方。 有关更多详细信息,请阅读“始终开启:评估,设计,实施和管理连续可用性”。
主动 - 主动 - 备用配置

在这种情况下,当主数据中心和辅助数据中心中的两个活动应用程序中的任何一个遭受中断时,第三个数据中心中的备用应用程序将被激活。遵循两个数据中心场景中描述的DR过程来恢复正常以处理客户请求。第三个数据中心的备用应用程序可以设置为热备用或冷备用配置。
跨数据中心的数据复制
在三个数据中心的数据库之间连续复制数据的过程和技术应遵循供应商建议的标准,既定实践和客户现有的企业IT标准和程序。
利用数据库管理工具(如IBMDb2®HADR功能和Oracle Data Guard)将数据库内容复制到远程站点。
- 使用特定于供应商的数据镜像技术复制SQL数据库,以将分析数据从主站点镜像到辅助站点。
- 复制NoSQL数据库,以便将数据从主数据中心站点复制到辅助数据中心站点。
- 使用特定于供应商的数据镜像技术复制ERP数据库,以便将订单数据从主站点镜像到辅助站点。
为您的HADR解决方案选择最佳拓扑
如何实施HADR解决方案是一项重要的体系结构决策,会影响内部部署应用程序提供的服务的持续可用性。虽然主动 - 主动 - 主动配置提供最大的弹性,但它是最昂贵的拓扑。主动 - 备用配置是最具成本效益的,但可以降低应用程序可用性。您应该选择最能满足业务连续性和操作灵活性需求的拓扑。
有关本文中讨论的拓扑,请参阅以下解决方案体系结构:
-
On-premises high availability disaster recovery: Active-active-standby topology
-
On-premises high availability disaster recovery: Active-active topology
-
On-premises high availability disaster recovery: Active-standby topology
原文:https://www.ibm.com/cloud/garage/architectures/resilience/hadr-on-premises-app
本文:http://pub.intelligentx.net/node/534
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 111 次浏览
【技术架构】使用NGINX部署Spring Boot
介绍
Spring / Spring引导应用程序的部署总是与Apache Tomcat相关联,而且由于框架本身运行在嵌入式Tomcat web服务器之上,所以它似乎是默认的解决方案。我一直认为这是一个问题,因为我对Apache的解决方案不是很熟悉,而且它处理配置和设置的方式对我来说似乎有些过火。我决定抛弃它,支持NGINX,到目前为止,这个解决方案没有任何缺陷。要在ssl安全的NGINX下部署Spring Boot JAR(或WAR)工件,您必须这样做。
准备Spring引导应用程序
除了通过适当的servlet参数设置资源/应用程序的上下文路径外,在应用程序本身中实际上没有什么可做的。属性文件:
服务器:
server:
servlet:
contextPath= /myapplication
上下文路径定义了我们应用程序的入口点,并且为我们创建的每个应用程序设置不同的路径是一种总体的好习惯。 指定此参数后,应用程序将在127.0.0.1:8080/myapplication上可用,而不是默认的127.0.0.1:8080/,并且对于NGINX而言,此单路径更改将非常方便。
更新应用程序配置后,我们可以生成一个准备部署的JAR或WAR文件,并使用FTP或SSH将其上传到我们的服务器,以便稍后我们可以在远程计算机上运行它。
准备服务器环境
在我的项目中,我使用了运行Debian 9的虚拟机,并进行了库存设置和配置。 为了使一切正常运行,我们需要安装:
- Java,运行应用程序
- UFW,以保护我们的服务器端口
- NGINX,处理Web请求
对于Java,我们可以安装开源OpenJDK:
- sudo apt update
- sudo apt install java
或Oracle提供的专有Java JDK:
# Required to add PPA's
sudo apt install software-properties-common
# Adding a PPA providing Oracle's JDK
sudo apt-add-repository ppa:webupd8team/java
sudo apt update
# Replace '8' with desired java version
sudo apt install oracle-java8-installer
对于其他软件,在Debian(可能还有其他基于Debian的系统)上,这些命令应该可以完成以下工作:
sudo apt update
sudo apt install ufw nginx
安装完所有组件后,我们可以启用UFW,以阻止除NGINX处理的所有传入连接之外的所有传入连接:
sudo systemctl start ufw
sudo systemctl enable ufw
# 'Full' can be replaced with 'HTTP' or 'HTTPS' to allow only selected protocol s
udo ufw allow 'Nginx Full'
现在我们可以启用并启动NGINX:
sudo systemctl start nginx
sudo systemctl enable nginx
将Spring Boot应用程序作为后台服务运行
在NGINX准备提供数据时,我们需要运行我们的应用程序。 我们当然可以通过一个简单的java -jar myapplication.jar命令来执行此操作,但是此解决方案无法使我们的应用程序保持活动状态并提供各种启动功能,因此最好创建一个后台服务,以使我们的应用程序永远在其中运行。 的背景。 为此,我们需要创建一个服务文件。 Debian正在运行systemd管理器,因此我们的文件将是/etc/systemd/system/myapplication.service。 对于其他Linux发行版,系统服务路径可能不同。 我们的文件如下所示:
[Unit]
Description= # Place a descriptive application name here
After=syslog.target
After=network.target[Service]
User= # Define a user account that will own our app
Type=simple[Service]
ExecStart=/usr/bin/java -jar # Provide /path/to/file/myapplication.jar
Restart=always
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier= # A short identifier for system journal, f. e. 'myapplication'[Install]
WantedBy=multi-user.target
保存文件后,可以使用默认的systemd服务管理器启动服务:
# This will start service from file we created earlier
sudo systemctl start myapplication.service# To see if it's running we can check system journal
journalctl -u myapplication -b
如果一切正常,我们的应用程序现在应在后台运行,所有日志应写入系统日志。
配置NGINX代理请求
如果我们的应用程序启动,我们现在可以将NGINX配置为反向代理请求。 我们已经安装了所有内容,因此现在我们需要创建一个配置文件,这将使我们的NGINX实例服务器请求正确的方式。 为此,我们需要创建一个文件/etc/nginx/sites-available/myserver.com,在其中可以将myserver.com替换为服务器名,应用程序名或其他用于标识配置的文件。 创建的文件应如下所示:
server {
# NGINX will listen on port 80 for both IP V4 and V6
listen 80;
listen [::]:80;# Here we should specify the name of server
server_name myserver.com;# Requests to given location will be redirected
location /myapplication {
# NGINX will pass all requests to specified location here
proxy_pass http://localhost:8080/;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
}
}
创建我们的配置后,我们可以使用NGINX内置的测试工具,通过调用以下命令来检查它是否可以正确应用:
sudo nginx -t
如果测试没有返回任何错误,我们可以安全地重新启动NGINX服务:
sudo systemctl restart nginx
测试反向代理
现在,为了测试我们的设置,我们可以将示例请求发送到http:// <server> / myapplication / <endpoint>。 NGINX将收到请求,然后将/ myapplication / <endpoint>重定向到我们的Spring Boot应用程序,该应用程序在端口8080上本地运行。Spring的上下文路径设置为/ myapplication,因此我们的应用程序将仅接收/ <endpoint>部分, 调用指定的URL。
为HTTPS连接启用SSL
使用NGINX,我们可以将所有HTTP连接重定向到安全HTTP。 如果我们的服务器没有SSL证书,最简单的方法是让我们加密CertBot(https://certbot.eff.org/),该证书可以从apt安装在Debian上,并自动配置NGINX来提供HTTPS服务 ,并使用一些简单的命令重定向所有HTTP通信:
sudo apt-get install certbot python-certbot-nginx -t stretch-backports
sudo certbot --nginx certonly
sudo certbot renew --dry-run
如果我们已经有了生成的SSL证书,则无需运行Certbot并获取一个新的证书。 相反,我们可以更改NGINX配置以使用已经存在的证书。 在线上有很多教程可以指导这一过程。
摘要
在NGINX代理后面运行Spring Boot应用程序是使我们的应用程序运行的一种相当不错的方法,它解决了Tomcat产生的许多问题。 传递启动参数可以轻松得多,可以将日志写入系统日志,可以在单个配置文件中完成SSL设置,并且我们的应用程序可以作为标准系统服务运行。 此设置也比Tomcat部署轻得多。
原文:https://ikurek.pl/deploying-spring-boot-with-nginx/
本文:https://pub.intelligentx.net/deploying-spring-boot-nginx
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 260 次浏览
【技术架构】可靠性不够 - 利用容器式微服务构建弹性应用
当我们谈论应用程序及其在生产中的部署时,我们经常将可靠性视为非功能性需求。当我们说“可靠”时,我们真正想要的应用程序及其部署是什么?
通常,我们的意思是我们希望应用程序执行预期的操作并在没有故障和中断的情况下运行。对于许多人来说,这意味着它必须是稳定的(对代码的要求)和可用的(部署要求)。因此,您可以进行大量测试和QA以获得稳定的“无错误”应用程序。然后,您可以从具有高SLA的云或其他基础架构提供商那里获得服务器,例如“五个9”。但是应用程序现在真的可靠吗?实际上可靠吗?这是在2015年构建和部署高度复杂和可扩展的应用程序的正确方法吗?

也许......如果不是墨菲定律(“如果有什么事情可以出错,它会”)。一方面,只要我们受到共同的时间和预算限制,我们就有一个很难“无bug”的应用程序。总有一些你没有预见到的东西,你没有测试过。现在常见的分布式系统和基于技术的创新必须快速发展,这一点变得更加糟糕。另一方面,我们有服务器(硬件和软件加网络和存储),永远无法保证100%的可用性。当然,我们可以尝试在问题上投入更多资金,但我们永远不会达到100%,那么为什么不采取不同的路线呢?为什么不构建弹性部署的弹性应用程序?
弹性定义
首先,什么是弹性?根据您的要求以及使用的背景,有几种定义。让我们来看看它们中的一些并了解它对我们意味着什么:
弹性(elasticity)
弯曲,压缩或拉伸后返回原始形状,位置等的能力或能力;。
韧性 (toughness)
(http://dictionary.reference.com/browse/resilience)从困难中迅速恢复的能力;。
(https://www.google.de/webhp?q=resilience%20definition)[系统]应对变化的能力。 (http://en.wikipedia.org/wiki/Resilience)
第一个定义告诉我们这个术语的一般背景。以下文学描述非常合适:
“橡树在风中挣扎而且被打破了,柳树在它必须的时候弯曲并幸免于难。” - 罗伯特乔丹
因此,弹性系统应该能够弹性地应对问题并且不能防止失效,这在某些程度上是不够的并且导致破裂。
第二个是更明确地说明系统(或者如果在心理环境中使用的人)的快速恢复。如上所述,您可以随时减少故障,但永远不会100%无故障。因此,你需要在从失败中恢复过程中尽可能好,这与我们的第一个定义中的弹性图像相辅相成。
第三个定义来自供应链背景,更多的是关于保持系统运行。适应更一般的背景,系统应该能够应对变化以及轻微或重大的中断。
应用程序开发和部署的弹性
现在让我们将这些概念带入应用程序开发和部署领域,看看哪些模式和工具可以帮助我们实现目标。 (注意:我们不会在安全上下文中使用弹性软件,这本身就是一个完全不同的主题)。回顾我们的背景,一方面我们有一个复杂的应用程序,必须根据市场的动态变化进行迭代和调整。为了保持竞争力,必须通过测试和快速投入生产 - 最好甚至连续。另一方面,我们已经部署了所述应用程序,其中必须将其部署到生产环境(以及之前的测试/暂存)环境,通过动态的用户/使用量大量增加和扩展,并保持高可用性在众多场景中。
使用微服务进行弹性应用程序开发
在应用程序方面,工程师和组织正在寻求微服务架构更灵活,并构建更好的应用程序。在微服务架构中,应用程序分为高度分离的,简单的分布式服务,这些服务通过轻量级通信机制(如消息队列和HTTP API)相互通信。
微服务是高度分离的,并且是为失败而构建的(注意:这并不意味着您不应该进行备份),因此它们能够应对故障和中断。这种简单的小型服务的隔离使它们彼此独立,因此当一个失败时,其他人不会停止工作。它们是明确构建的,以期望失败(在服务本身以及其他服务中的失败)。
通过这种分离,我们实际上可以在我们的应用程序中获得很大的弹性。他们有能力应对变化和破坏。所有这一切,同时保持开发过程中的敏捷性和速度。然而,弹性和恢复部分的弹性仍然需要不仅仅是移动到开发中的微服务架构来实现。
在群集基础结构上使用容器进行弹性部署
弹性和恢复虽然部分必须内置到服务中,但更多的是部署,管理和扩展所述微服务系统的工作 - 并且不要忘记保持高可用性。这就是容器和集群基础架构发挥作用的地方。
通过容器化,我们获得了一种简单的技术,可将我们的微服务打包成持久可部署的单元。由于这些容器可以在各种环境中运行,因此开发人员不必处理开发,升级和生产方面的差异。
但是,现在遇到了困难的部分:这些容器需要在生产中进行部署,管理和扩展。请记住,我们希望具有弹性,即弹性和恢复能力。理想情况下,我们不希望出现任何单点故障。理想情况下,我们希望在集群基础架构上运行,从而抽象出底层硬件并为我们带来冗余。此外,我们必须在服务之间使用负载平衡器和断路器,以使我们能够水平地上下弹性扩展。
扩展和冗余有助于我们在发生故障时不会完全中断。但是,要真正具有弹性,我们需要能够应对故障并恢复到应用程序的预期/原始状态。此外,当应用程序的某些部分出现故障时,它们必须再次出现。但是,其余服务必须知道如何才能达到新服务。这可以通过从容器中取出配置并仅在运行时注入它来解决。此过程导致容器被配置服务(理想情况下也在容器中运行)包围,这有助于它们在相应的环境中运行并找到它们的对等体。当这些容器连在一起使得它们没有完全断裂,而是下降并且优雅地一起上升时,我们得到一种弹性意义上的弹性部署。它确保服务从外部返回到看起来像原始状态的状态(即使例如底层服务器已更改)。
现实生活中的复原力很难
获得应用程序的弹性是可能的,像Netflix,Twitter,Facebook和其他公司正在展示自己的方式。他们与公众共享的一些发展,其中一些甚至专门针对工程弹性。他们用例如工具严格测试他们自己的系统。 Simian军甚至可以关闭整个数据中心以测试弹性。然而,即使这些具有高级弹性架构的公司也无法完全防止停机。
即使拥有所有这些工具,如果您是一家开发人员少于100人的公司,也不容易构建弹性系统。两者,开始使用微服务架构以及所述微服务的弹性部署都很困难。在Giant Swarm,我们尝试用两者来帮助我们的用户。首先,我们尝试为他们提供构建他们自己的微服务架构所需的工具,同时确保如果他们想要使用他们认为更好的其他工具,我们给他们自由使用他们喜欢的任何东西。其次,我们为用户提供微服务基础架构,使其易于部署和管理应用程序。到底
弹性就是能够克服意外情况。可持续性就是生存。恢复力的目标是茁壮成长。 - Jamais Cascio
弹性应用程序为您提供的不仅仅是可靠性,它们可以帮助您构建持续的创新流程,从而快速实现目标并保持领先地位。它们可以帮助你茁壮成长。
- 58 次浏览
【技术架构】在5分钟把前端应用程序安装到NGINX
Nginx是一个流行的web服务器,用于提供web应用程序的静态资源(客户端源)。我将解释如何将Nginx设置为静态内容资源web服务器,以及如何将它配置为Linux系统上的反向代理(连接客户机和后端)。基本上如何设置前端+后端与Nginx在Linux上。如果你:
- 希望将您的Angular/React/Vue或任何其他基于前端的框架应用程序放在Nginx上;
- 希望将Nginx上的客户端与后端连接(如Node.js或Java app);
- 要将域调用委托给内部web服务器,例如在其他端口(代理)上工作;
在Nginx上的前端应用
如果您使用任何框架(如Vue、Angular或React)开发前端应用程序,那么您最终将生成一个产品包——准备部署在web服务器上的文件(html、js、css)。在大多数框架中,运行生产构建将类似于npm构建,或者例如在Vue: Quasar构建中使用Quasar。您的生产文件应该在项目文件夹中生成的dest文件夹中。
在destfolder中生成的文件(前端应用程序)可以放在web服务器上,比如Apache或Nginx。
我假设您已经在目标机器上安装了Nginx(就像您的服务器机器一样)。
Nginx前端应用配置
Nginx配置可以在/etc/ Nginx下找到主配置文件名为nginx.conf。取决于你的系统配置可以有一点不同:
- nginx.conf文件中的整个配置(例如Arch linux)
- nginx中的主配置。conf,每个域分割域配置(就像在Ubuntu中,域配置可以在insitesavailable文件夹中找到)
假设您的域名是domain.com。您希望在http://domain.com(默认80端口)下设置前端应用程序。
nginx的配置如下:
- server {
- server_name domain.com;
- location / {
- root /usr/share/nginx/html/domain;
- try_files $uri $uri/ /index.html;
- }
- }
如果您的配置基于nginx.conf (例如Arch linux):
在nginx.conf的http部分粘贴上面的配置
如果你使用Ubuntu:
- 在/etc/nginx/sites-available中创建文件domain.com(touch domain.com)
- 将上面的配置粘贴到文件中
- 转到/etc/nginx/sites-enabled并调用:sudo ln -s /etc/nginx/sites-available/domain.com /etc/nginx/sites-enabled/
下一步是向nginx resources文件夹提供前端应用程序内容。首先构建前端应用程序(例如,npm构建取决于您的设置)。然后将前端应用程序dist文件夹中创建的每个文件/文件夹移动到/usr/share/nginx/html/domain(必须在/usr/share/nginx/html下创建域文件夹)。
最后一步:sudo systemctl restart nginx.service
现在访问http://domain.com应该呈现前端应用程序。
连接后端
使用Angular/Vue/React,你可能正在开发服务器上工作,它会在更改后重新加载你的代码,并将你的请求代理到后端。现在,Nginx配置中必须提供类似的代理配置。
让我们假设所有从客户端到后端执行的请求都有/api前缀,例如get('/api/myWallet')正在对本地主机8888/api/myWallet后端服务器执行请求。您的配置可能不同,但通常情况下是这样工作的。
现在我们要做的就是将nginx设置为代理每个domain.com/api/*请求到本地主机:8888。这是配置:
- location /api {
- proxy_pass http://localhost:8888/api;
- }
将此配置粘贴到server{}部分(您在上面定义的)。
最后它应该是这样的:
- server {
- server_name domain.com;
- location / {
- root /usr/share/nginx/html/domain;
- try_files $uri $uri/ /index.html;
- }
- location /api {
- proxy_pass http://localhost:8888/api;
- }
- }
最后 :sudo systemctl restart nginx.service
总结
Nginx是一个功能强大的工具,在简单的场景中可以处理前端web应用程序的静态资源,并有可能将请求代理到后端服务器——这就是我们所需要的。实际上,我们在服务器上得到了类似于facade的东西,可以设置它来过滤甚至平衡流量。
原文:https://pthomann.pl/setup-frontend-application-on-nginx-in-5-minutes/
本文:https://pub.intelligentx.net/setup-frontend-application-nginx-5-minutes
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 88 次浏览
【技术架构】如果一切都进入云,谁需要架构师?
云计算的炒作使得预期上升。 IT部门的作用一般是什么?特别是建筑师的角色?最近在BiZZdesign的荷兰阿默斯福特办公室举办了一场非常成功的医疗保健企业架构研讨会。我们与与会者讨论了这个主题,并在本博文中介绍了结论。
架构保持相关性
架构要留下来并且与世界相关的原因有几个,其中支持业务的大多数功能都来自云。
- 您的所有问题都没有云解决方案。云中不提供定制功能。
- 业务变化将始终对流程,信息流和信息需求产生影响。有人必须分析影响并指导变化。
- 该组织将对提供给客户的产品和服务负责。因此,(细)线业务架构保持其相关性。即使您最终将所有内容外包出去,质量也将成为建筑师可以做出贡献的主题。
- 你总是需要一些基础设施。连接和屏幕是每个组织将来保持的最低预期。
所以,我们确实希望架构保持相关的纪律......但绝对会改变!
不同类型的架构师师
我们预计,在云计算是商品的未来世界中,三种类型的架构师将占据自己的位置。
首先,建造导向的架构师。
这些“超级设计师”了解其背景下的系统,并了解应用程序如何与技术相互依赖。这些架构师可能在当今的终端用户组织中受雇较少,而对于技术(云)提供商则更多。

第二,面向集成的架构师。
这些将用于系统集成商和大型最终用户组织。 选择并与组织一起使用的所有-AAS(PAAS,SAAS,CAAS等)解决方案的集成是关键。 整个连接服务链的安全性,业务连续性和数据管理(例如报告)成为“云化”世界中日益增长的挑战。

第三,面向业务的架构师。
他们将在定义业务需求方面发挥更突出的作用,转化云应用为业务带来的新可能性。 了解业务模型,业务目标和业务流程将是最终用户组织所采用的业务架构师面临的主要挑战。
这三种类型的架构师涵盖了您的组织使用云解决方案取得成功的所有相关方面。
原文:https://bizzdesign.com/blog/who-needs-an-architect-if-everything-goes-to-the-cloud/
本文:http://pub.intelligentx.net/who-needs-architect-if-everything-goes-cloud
讨论:请加入知识星球【首席架构师圈】
- 102 次浏览
【技术架构】弹性参考架构
构建弹性应用程序是成功的关键因素。 无论您是在本地部署还是在云上部署应用程序,您的用户都希望您的应用程序随时可用。 您必须确保它具有高可用性,可以从数据中心或可用区域丢失中恢复,在灾难情况下已准备好计划,并且您具有运行应用程序所需的所有内容的备份和恢复过程。 这就是您使应用程序具有弹性的方法。
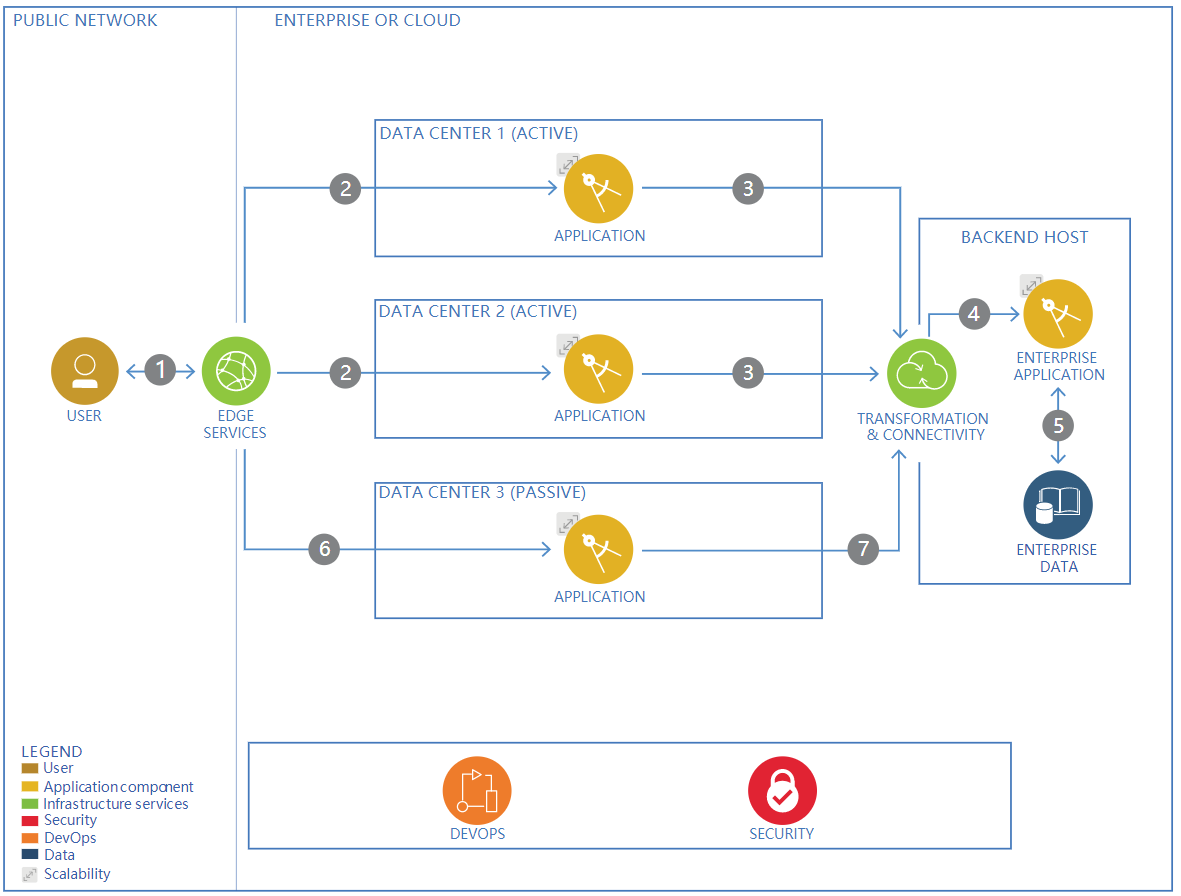
组件
User
Someone who accesses the application.
Edge services
Improves application availability and scalability. Provides firewall, load balancing, and reverse proxy. Ensures continuous availability during disaster recovery.
Products (use any)
- IBM HTTP Server
- Nginx HTTP Server
- Akamai
- Dyn
Application
Provides the business logic for the order processing application.
Products
- Example: IBM WebSphere® Liberty
Transformation and connectivity
Connect securely between applications running in the data centers and applications running on the back-end host.
Products
- Enterprise-specific
Enterprise application
Applications that accomplish business goals and objectives and that may interact with cloud services.
Products
- Enterprise-specific, for example SAP
Enterprise data
Systems of record and metadata about the data for enterprise applications.
Products
- Enterprise-specific, for example IBM Db2® or MySQL
DevOps
Provides DevOps services
Products
- Enterprise-specific, for example IBM DevOps offerings
Security
Provides identity and access management, data security, network protection, security intelligence and operation, and more.
Products
- Enterprise-specific, for example IBM Security offerings
流程
应用程序部署到多个数据中心。 数据中心1和数据中心2上的活动实例提供高可用性。 数据中心3上的被动实例提供灾难恢复。
步骤1
用户向边缘服务发送请求(例如HTTP请求)。
第2步
作为负载均衡器的边缘服务将请求发送到应用程序的活动实例。
第3步
应用程序向后端主机发送请求以从ERP系统检索数据。
第4步
后端区域前面的转换和连接组件可确保请求来自有效源并将请求发送到企业应用程序。
第5步
企业应用程序从企业数据库中检索数据。 (未显示:企业应用程序构建响应并将其发送回应用程序。然后,应用程序将响应发送回用户。)
第6步
当数据中心运行状况检查指示灾难时,边缘服务会检测到灾难,激活数据中心3上的应用程序的被动实例,并将请求路由到该数据。从而应用程序从灾难中恢复,应用程序的高可用性继续。
第7步
数据中心3上的应用程序通过转换和连接组件向后端主机发送请求,以从ERP系统检索数据。 (未显示:企业应用程序构建响应并将其发送回应用程序。然后,应用程序将响应发送回用户。这样,应用程序将从灾难中恢复,并且应用程序的高可用性将继续。)
原文:https://www.ibm.com/cloud/garage/architectures/resilience/reference-architecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 151 次浏览
【技术架构】我阅读了ThoughtWorks Technology Radar Vol.18,所以你不需要
仅供参考:新版本可在此处找到。请享用!

现在我们可以开始了。

对于那些不知道的人,ThoughtWorks是咨询公司 - 在他们的团队中有Martin Fowler和Rebecca Parson。由于他们的业务类型,他们有机会与来自不同行业,不同问题的不同客户合作。各种用例允许他们评估不同的技术,平台,工具,框架和语言,提出真正值得考虑的内容,以及从长远来看哪些内容过于夸张和有问题。
因此,他们能够创建技术雷达。这是他们的季度报告,对于数字业务中发生的事情持高度看法。从我的角度来看,他们是我们行业的时代精神 - 在你不值得的时间和每个人之间的甜蜜点 - 已经厌倦了主题的外观。不幸的是,虽然充满了知识,但由于它的结构,它也有点压倒性。区块链,云和移动开发混合在一起,因此很难检索特定于我们感兴趣的类别的知识。
这就是为什么我决定对当前版本进行分析并向您展示从中产生的结论。我也允许自己在其上添加一些我自己的分析。我希望对于那些已经完整阅读过的人以及那些从未听过它的人来说,这将是一次有趣的讲座。
玩的很开心。
区块链和分布式分类帐
我认为在技术雷达中真正有价值的事实是它不是炒作驱动的 - 编辑们相当克制自己的每一个新的闪亮的东西,通过黑客新闻的头条新闻。这就是为什么他们在将Distributed Ledgers添加到报告之前犹豫不决的原因。即使ICO在世界各地蓬勃发展,仍然只有少量提及区块链。现在,当尘埃落定并且我们生活在“后革命”世界时,可以在雷达中找到经过实战检验的技术。通过浏览,我们可以轻松区分市场上的两个主要参与者。
First是Hyperledger,一个“许可的”分布式分类帐。
它特别针对企业,并由IBM和英特尔等大公司提供支持。 Hyperledger从评估阶段毕业到试用阶段,这意味着只要适用的商业案例失败,它就可以被视为正确的工具。它主要是由于Composer,这个框架为平台带来了非常愉快的开发者体验。

第二个是以太坊平台。
它在Solidity(以太坊使用的智能合约语言),Truffle(应用程序开发框架)和Open Zeppeline(用于编写安全智能合约的Solidity层)中得到了充分体现。这两个平台正成为任何想要将Distributed Ledgers集成到公司流程中的人的主要参与者。
ThoughtWorks的编辑也看到了区块链之间互操作性的重要性,展示了Ripple已经使用过的Interledger协议。我们还可以提到Corda分类帐,区块链的分布式替代品,专门用于商业用途。虽然这种相当年轻的技术的稳定性问题仍然是一个问题,但各种可能的用法使该技术在竞争之间处于有趣的位置。
时代精神:区块链不再是一种黑客工具,目前许多工具正在成为主流。为了“销售”给企业,他们让开发人员在提供各种涵盖的业务场景时体验得更加愉快。对Hyperledger和Corda等典型区块链的许可替代品越来越受到关注。然而,以太坊仍然是分散用例的王者,并且随着生态系统的丰富,它将很难被废除。
移动
除了移动市场肯定成熟的一系列证据外,该部分并没有太多新颖之处。
谷歌正处于Android开发标准化的过程中,使其更加愉快和高效。 Flutter(类似于React Native的基于Dart的框架)和Android Architectural Components等项目尝试定义应如何在Google平台上创建应用程序。前者特别有趣,可以将应用程序与Android本身分离,这可能很有价值,因为谷歌正在投资Chrome OS或Fushia等项目。与此同时,优步的Ribs是后者的反对者,提出了一种不同的移动架构方法。他们的目标是iOS和Android应用程序,他们获得了很多社区支持。观察这场比赛的结果会很有趣。
尽管Android开发人员长期以来一直在使用Reactive Programming,但在iOS上它最近越来越受欢迎。在新的雷达版本中引入SwiftNIO就反映了这一点。与Netty类似,基于Event Loop的框架正在获得牵引力,而作为Apple本身的一个项目肯定有助于那里。虽然SwiftNIO本身不具有反应性,但它已经成为新兴工具集的重要组成部分。
更重要的是,我们还可以找到解决问题的有趣工具,这些问题会吓到当前的移动市场 - 用户正在下载更少的应用程序,从而强制将更多功能打包到现有应用程序中。为了在使用那些糟糕的单片代码库时不会疯狂,我们可以使用像Atlas和Beehive这样的工具,它们分别是针对Android和iOS的阿里巴巴问题的实用解决方案。
最后,新报告试图帮助您测试移动应用程序 - 包括低级别,推广可嵌入式模拟技术,将您的应用程序与外部依赖关系分离,以及提供像Appium这样的强大平台,允许在多个设备上进行分布式自动化测试。
聊天机器人
在这里看不多。这也是一个有趣的信息。
我们在这个版本中可以看到的最值得注意的事情是,没有提到像DialogFlow或亚马逊Alexa Stack这样的锁定平台了。在他们的位置,ThoughtWorks专家推广Rasa - 开源替代方案,允许您创建自己的会话API而无需与外部供应商共享您的数据。即使目前所有关于它们的嗡嗡声,它清楚地表明现实中没有太多真实的商业用例可以证明投资在激动人心的(从技术爱好者的角度来看)技术。也许谷歌双工将改变这一点。

虽然聊天机器人和VA似乎在西方市场处于中断状态,但当我们看看东方市场时,有一个明显不同的故事。微信正在成为事实上的主要平台,可以被视为中国的“另一个互联网”。在进入该市场的过程中,您绝对不能错过与它的集成。虽然许多不同的平台试图复制这种成功(我指的是你,Facebook Messenger和Slack),但要实现这样的市场渗透水平,还有很长的路要走。
前端
很高兴看到Angular vs React不再是有趣的话题。社区已经分裂,没有必要讨论使用其中一个主要玩家。提到的唯一“框架”(但仅在评估阶段)是炒作,主要是由于它的简约方法和不断增长的社区。我们可能会考虑暂时关闭JavaScript框架的主题,至少从ThoughtWorks的角度来看。
这并不意味着前端没有任何有趣的事情发生。微服务也渗透到了这种环境中,并且微行业正在成为多个团队维护的产品的可行解决方案。更重要的是,工具正在发展 - 使用替代的打包管理器(如yarn to nom),替代构建工具(Parcel to Webpack)和静态分析工具(如Flow to TypeScript)。这样可以快速测试新的想法(就像Yarn和NPM一样)强迫已经建立的工具更快地发展 - 这些东西总能为生态系统带来价值。

GraphQL并没有失去它的速度 - Apollo被提及作为一个至少应该尝试的工具,并且建议也使用GraphQL进行后端聚合,我们可能会开始认真考虑GraphQL不是时尚,而是技术和我们在一起呆更长的时间。
WebAssembly是一个未来 - 它仍然需要大量的抛光才能被认为是生产准备好的,但是如果有人想加入它的潮流,那是最好的时刻 - 也许今年还没有,但很快我们肯定会听到有趣的用途这场巨大革命的案例即将上映。
最后但同样重要的是,CSS世界也在不断发展 - 像CSS Grid和CSS Modules这样的新标准/方法证明了社区开始聚集如何解决可能是前端堆栈最混乱部分的问题。关于时间。
后端
我记得当.NET Core发布时,它被视为.NET技术的“结束”,即微软堆栈的天鹅之歌。现在,我们可以将其视为市场上最重要的平台之一,在多个云平台(不仅仅是Azure)和不断扩展的生态系统(如同提到的Swashbuckle)中获得普及。我们行业的未来主义者经常错过他们的预测。

对于JVM平台,Kotlin受到了很多人的欢迎,并使之前的Poster Childs黯然失色,比如Scala,Groovy或Clojure。后者仍然在报告中作为一种支持Clara规则的语言进行了讨论 - 在Clojure中提供了很好的DSL规则引擎。同时,提到Reactor正在巩固这样一个事实:使用Reactive Stream,添加到JVM平台,反应系统成为编写Java应用程序的越来越自然的方式。
安全
安全始终是,而且永远是开发人员工作的关键部分 - 尤其是在公司实体中,这些公司实体是最大的通信公司客户。这就是为什么报告的每个版本都包含许多工具,可用于保存宝贵的公司机密和客户数据。
从技术开始,我们有Sidecar用于端点安全性。 Sidecars是一种很有前途的架构模式,有助于保持应用程序的核心逻辑清洁,同时将必要的复杂性(如安全性)委托给外部代理进程。它似乎是其他建筑趋势的一个很好的补充。
报告中还可以找到不同的安全审核工具 - AWS的Scout2和cfn_nag,节点应用程序的nsp。更重要的是,基础设施配置扫描仪本身可以找到超出值得评估的技术。当我们添加dependabot(自动检查依赖项的新鲜度)时,我们正在接收强大的保护层组合。
但并非每个攻击向量都可以预先预测。这就是为什么Security Chaos Engineering是一种强大的技术,可以让您随时通过不断自我攻击系统做好准备。虽然难以正确实施,但由于其潜力巨大,因此不容易被解雇。
报告编辑器中还有一个特殊的位置,它存储可帮助您验证用户的工具。托管身份即服务是一种非常有前景的技术,而Keycloak是一个有趣的开源平台,可以帮助您在微服务世界中进行授权和身份验证。
如果凭据未得到正确保护,则系统不安全。 GoPass是一个帮助以安全方式分发凭证的工具示例。但是,我们需要记住,当您没有良好的公司密码处理文化时,没有任何工具可以帮助您。如果您的基础架构正确自动化,那么实施三R企业安全(旋转,修复,重新保存)是使攻击层非常薄的好方法。
谈到安全问题,我们不能忘记它不能使你的组织瘫痪。连接所有开发人员有一件事 - 每个人都讨厌VPN。这就是为什么在报告中我们可以找到由Google创建的BeyondCorp--研究论文,描述良好实践,实施后允许员工通过开放网络连接安全服务,无需代理或VPN。我绝对希望生活在每个公司都实施这些技术的世界里。
测试和监控
这一类别肯定是技术雷达的重要组成部分。
在标准测试框架(如Enzyme for React和AssertJ for Java)和众所周知的技术(如混沌工程)之间,推出了许多不同寻常但有趣的解决方案。很容易发现它是本版本创作过程中的重要主题。

有一个负载测试工具(Flood.io),读者可以使用Jupyter Notebook来测试自动化。我们也能看到原始的想法,比如......建筑的单元测试。另外,我们有WireMock,这是一个很棒的工具,可以用作模拟服务器,允许您在测试工具下替换您的依赖项。每个人都应该为自己找到一些东西。
此外,绝对是国王在E2E测试套装中应对UI。多种工具令人惊讶。我们有Chrome和Firefox的Headless版本,我们还发现BackstopJS,它们用于执行回归测试。更重要的是,如果您想在CI环境下在这样的测试套件下完全注册应用程序的行为,您可以使用赛普拉斯生成这样的截屏视频。最后但并非最不重要的是,对于移动开发人员,有Appium Test Distribution,它允许您同时在多个设备上执行测试。 UI回归始终是测试套件中最难和最昂贵的部分,因此很高兴看到很多工具正在出现,以帮助您抵御这类错误。
监控

尽管很少关注监测工具,但我们在报告中可以找到的这些项目令人印象深刻。来自监控世界的人肯定喜欢做缩写,而对于广泛使用的ELK(弹性搜索,Logstash,Kibana)堆栈,我们现在可以添加TICK堆栈 - Telegraf,InfluxDB,Chronograph和Kapacitor。 Influx在社区中有很多积极的嗡嗡声,所以很高兴看到围绕它的生态系统建设正在增长。
我们在Radar中可以找到另一个有趣的工具是Sentry。在经常发现JavaScript错误的世界中,Sentry允许开发人员快速做出反应,提供出色的客户满意度。
在不是ReallyBigThing(tm)的情况下,每个请求的日志级别是一种技术,应该由开发人员使用,并且由日志工具支持。可能任何曾经用大量噪音挖掘不必要的大型生产日志的人都会同意我的观点。
容器

好的,Kubernetes是胜利者。我们可以转到下一节。
没有人正在讨论Docker Swarm或Docker Enterprise Edition(它本身支持Kubernetes开箱即用)作为可行的替代方案。每个重要的云播放器都拥有自己的Kubernetes工具(Google Kubernetes Engine,由远程容器服务提供支持的AWS Fargate(以及近期的EKS),Azure Kubernetes服务支持的Azure Service Fabric)以及围绕此技术的工具生态系统正在以前所未有的速度出现 - Technology Radar不仅提到由Kubernetes团队自己创建的Package Manager(Helm)和操作工具箱(kops),还提供监控(Sonobuoy)和服务网格实现(Conduit),这些工具是由想要在Kubernetes上货币化的外部企业创建的。人气。
玩家投入技术的人越多,留下来的机会就越大。拥有所有大型云提供商和外部公司组合是Kubernetes Stack进一步整合的标志。他们正在迅速走上反叛道路。
名誉提到有Windows容器 - 微软在该技术上投入了大量资金,目前他们可以准备好生产。借助“原生”Docker对MacO的支持,不再将容器视为Linux域。
有趣的是,Docker在本报告中的报道很少。对于开创集装箱化趋势的公司来说,这不是一个好景象。我们可能会在不久的将来看到他们是否仍有任何好主意将他们的行业突破技术货币化。
机器学习

在描述Contenerization趋势时,我写道Kubernetes是一个明显的赢家。我们与机器学习有类似的情况。突出显示PyTorch易于掌握和使用舒适不会改变全球范围:TensorFlow是那些对深度学习感兴趣的人的主要平台,它的优势每天都在增长,整个生态系统都在不断增长。
这就是为什么我要关注不太明显的趋势和工具。其中第一个是Jupyter笔记本 - 我看到很多人对这个开源的,更为hackish的替代老好的Mathematica(来自可爱的大学时代的美好记忆)以及它开始出现的各种用法(分析,测试)的热情对于任何对数据科学感兴趣的人来说,它都是一个多功能工具。我最近自己测试了,我肯定将来会更多地使用它。
很高兴看到,在一个花哨的框架世界中,来自Whileworks的人们不会忘记旧的,好的数学,这是所有计算机科学的基础,他们突出了CVXPY。很高兴看到以优雅的方式解决数学问题的图书馆仍然能够引起社区和咨询公司的注意。
云
如果我需要展示我最喜欢的,最有影响力的建议,从当前的技术雷达中茁壮成长,我会选择ThoughtWorks撰写的有关云在商业中使用的内容。
他们促进不同云的使用,总是选择最适合工作的工具。更有趣的是,他们强烈反对仅使用来自云提供商的通用解决方案,并认为仅通过裸机或存储,我们就会失去其最有价值的锁定解决方案所带来的竞争优势。这一直是一个艰难的决定,但我们不能忘记,可怕的供应商锁定只是一种风险,应该加权我们可以使用云提供商工具链的高度专业化元素实现的收益。
在一个甚至市场领导者背后都有竞争的市场中,为大型云播放器雇佣的大型开发团队已经解决的问题创建自制解决方案始终是时间,控制和成本之间的平衡。在特定的提供商上依赖你的业务肯定会让你在后面开枪,历史告诉我们什么(解析,我们会记住!),但有时这是值得冒的风险,特别是如果云能力只是目标的意思,不是你的战略优势。
数据库

高可用性是连接此类别中所有产品的主题。
专有的全球分布式数据库备受瞩目。微软的Cosmos DB和Google Cloud Spanner都是同类中最好的,在不同方面解决问题,仍然解决了非常重要的客户问题 - 以分布式,一致且高可用的方式存储数据的能力。更重要的是,它们是能够为您提供钱包可以处理的吞吐量的解决方案。虽然供应商锁定是一个可能存在的问题,但ThoughtWorks认为它们是解决各种挑战的有趣方式。
但是,如果你仍然希望建立自己的高可用数据库,那么第三个位置 - Zalando的Patroni - 应该引起你的兴趣。它是创建自己的HA PostgreSQL的模板,包括电池(监控,编排)。它被描述为一个经过实战考验的解决方案,可以解决许多不同的边缘情况,特别是那些在开始实现自己的数据库集群之前甚至都没想过的情况。更重要的是,他们的支持Kubernetes(该文章中有很多Kubernetes)。
架构
当前的架构趋势总是在ThoughtWorks Technology Radar中得到很好的体现。
首先,与之前的版本一样,推广使用轻量级建筑记录。我最近有机会加入一个执行该技术超过一年的团队,我个人看到了加入你组织的新人有多好。
建筑健身功能是一个在2017年引起很大关注的概念,由两个响亮的(虽然不是普遍赞赏的)书籍代表:鲍勃叔叔的“清洁建筑”和“建筑进化建筑”,由同一作者共同撰写Rebecca Parson,ThoughtWorks的首席技术官。虽然现在说这个理论概念是否会起飞还为时尚早,但我会观察它未来对行业的影响。
Service Mesh也在报告中表示,既作为技术本身,也作为名为Conduit的Kubernetes实现。在微服务不再“时髦”的世界里,Service Mesh成为一种建筑潮流,将成为未来几年会议发言人的主题。
报告中涉及跨服务通信的技术也很受关注。我们有几个与事件相关的概念:在真正的基于事件的系统中我们应该依赖它们多么强大(EventSourcing作为事实的来源),或者消费者应该如何推动他们的设计(Domain Scoped Events)。
而且,服务之间的GraphQL使用建议,不仅对于前端应用程序肯定吸引了眼球。我也非常高兴看到明确指出您的事件队列(以及Kafka专门)不应该像旧的Enterprise Service Bus一样使用。我已经看到了朝着这个方向发展的趋势,所以现在是时候对这个想法有多糟糕了。我们不能让历史圆满结束。
无服务器
无服务器平台肯定成为主流。它们是如此主流,现在我们的行业开始提出难题 - 关于许多小功能的编排,不会让我们的团队疯狂。其中一个可能的解决方案是使用API网关将许多较小的功能组合在一起。 ThoughtWorks不愿意这样做 - 一方面,他们将Kong API Gateway作为一个有趣的想法推广,同时警告过度使用API网关会让开发人员生活变得悲惨。在每种情况下都需要中庸之道。

从工具方面来说,代替前面提到的无服务器框架,在这个版本中,我们可以发现它是最大的竞争对手Apex。虽然不是市场上最灵活的(仅支持AWS Lambda,而无服务器框架也适用于Google云功能,Azure功能和IBM的开放式高手),但Apex不那么复杂,为那些不需要的人提供了更好的开发人员体验。同时支持许多平台。特别是因为通用云使用已被提及为我们行业的问题。
CI / CD
有趣的是,与先前版本相比,Continous Integration / Deployment的覆盖范围有限。我们只收到两个工具(现代,与他们自己的CI / CD系统非常相似)和一种使用Pipelines来处理我们的“基础设施作为代码”的技术。
虽然IaaC和持续部署的协同作用似乎是一个非常令人兴奋的想法,但CI / CD的代表性不足表明我们应该开始考虑解决问题,特别是与几年前的情况相比。看到我们的行业在这方面成熟,我们可以专注于其他更加紧迫的问题,这真是太棒了。
文化
为了更好地理解这一部分,我们需要记住谁是ButWorks的主要客户 - 大公司。这些组织拥有完善的内部结构和许多稳定(有时称为传统)产品。这带来了很多问题 - 我想大多数人都在阅读这些公司,所以你可以想象。
有一本名为“创新者的困境”的邪教经典着作以令人信服(并且令人恐惧)的方式描述了禁止在这样一个组织中改变(和创新)的所有力量。 Domain Driven Design为架构级别的旧服务同居问题提供了解决方案 - 反腐败层。在新技术雷达中,它从技术层面升级到团队层面。无论我们称之为自主泡泡模式(我开始在一个地方使用的一个美妙的名字)或内部创业,我很高兴ThoughtWorks尝试编写这样的方法,因为当你有一个吸引人的名字,你可以开始提到它的会议的必要性:)
如果我们想要使用第二种推广技术 - 将产品管理应用于内部平台,从我的角度来看,自主泡泡模式是必需的。我想每个人都在过去就内部产品工作,一个没有概念和想法的开发,被客户推动。如果您将内部服务视为产品,那么您就会获得力量 - 选择开发工作方向的能力。你对自己的成功负责 - 很难找到更具激励性的东西。
物联网

在物联网领域,LoRaWan是社区的话题 - 低功耗设备之间的下一代无线通信层。虽然尚未成为非常受欢迎的标准 - 目前正在评估广泛测试的过程并且可能的潜力。
对于那些对机器人项目感兴趣的人来说,当前版雷达的两个位置将会很有趣。首先,我们有流行的Cylon.js的兄弟GoBot。 Go是发现IoT社区人们非常感兴趣的语言,特别是由于它很容易掌握并发模型(我仍然看到很多投资到Rust,所以我们将看到谁将成为这场战斗的赢家) 。
由于Arduino仍然是霍比特人机器人构造函数的主要参与者,Moongose OS主要关注商业实现 - Arduino太高级别的用例,而Native SDK太低级别。 Google云平台和AWS IoT的支持无疑是该平台的一大优势。
从我的角度来看,报告中最重要的是对WebBluetooth标准的支持越来越多。对智能设备的主要协议蓝牙缺乏支持,这是Web和本机应用程序之间的巨大差距。很高兴看到这种裂痕每年都变得越来越小。
其他
“平台”类别中也很少有东西不符合我的任何部分。
Godot是Unity的竞赛,专为VR体验而设。 Contentful是面向开发人员的API-First CMS,如果您需要更简单的工具,Netlify似乎是非常快速部署静态页面的好方法。
尽管如此,我从该部分中选择的(虽然从我自己的角度来看可能是最不实用的)是语言服务器协议 - Microsoft在其Visual Studio代码编辑器中使用的工具,用于智能语法建议。很高兴看到像开源这样的东西。
结论
呃,那很长。如果你到了那里,谢谢你。我希望我的“反向索引”技术雷达有一点评论让它更容易掌握。我感谢所有的反馈 - 我希望每个季度,我都能够生产出更好更好的包装:)
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 142 次浏览
【技术架构】技术路线图概述
技术路线图是支持战略和长期规划的灵活规划技术,通过将短期和长期目标与特定的技术解决方案相匹配。[1][2]这是一种适用于新产品或新工艺的计划,可能包括使用技术预测或技术侦察来确定合适的新兴技术。[3]这是一种已知的技术,有助于管理创新的模糊前端。[4]这也是预计路线图技术可能有助于公司在动荡的环境中生存[1]并帮助他们以更全面的方式进行规划,包括非财务目标,并推动实现更可持续的发展。[5]在这里,路线图可以与其他公司的前瞻性方法相结合,以促进系统性变革。[6]
制定路线图有三个主要用途。[7]它有助于就一系列需求和满足这些需求所需的技术达成共识,它提供了一种帮助预测技术发展的机制,它提供了一个帮助规划和协调技术发展的框架。[8]它还可以用作分析工具来映射新兴产业的发展与崛起。
流程
技术路线图过程可以分为三个阶段:初步活动、路线图开发和后续活动阶段。因为流程对于一个模型来说太大,所以阶段是分开建模的。在模型中没有不同的角色;这是因为所有的事情都是由参与者作为一个组来完成的。[9]
第一阶段:初步阶段
图2。初步阶段的过程数据模型。
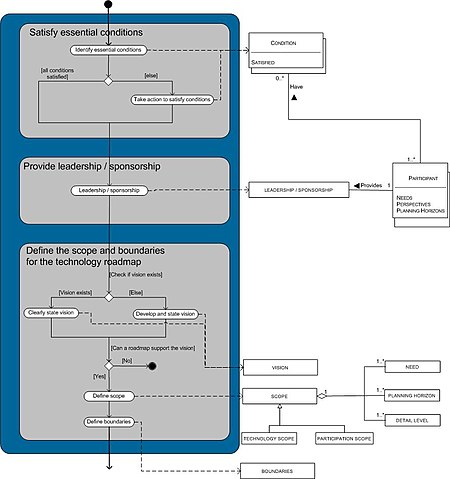
第一阶段即初步阶段
(见图2),包括3个步骤:
- 满足基本条件,
- 提供领导/赞助,以及
- 定义技术路线图的范围和边界。
在此阶段,关键决策者必须确定他们有问题,并且技术路线图可以帮助他们解决问题。
满足基本条件
在这一步中,必须弄清楚条件是什么(必须确定),如果不满足,谁采取行动来满足这些条件。这些条件包括,例如:
- 对技术路线图的需求
- 来自组织不同部门(如市场营销、研发、战略业务部门)的不同规划视野和观点的投入和参与。
应满足所有条件(或商定的一方采取必要行动)以继续下一步。参与者可以有自己的零个或多个条件。它适用于所有具有要满足或不满足的属性的条件。
提供领导/赞助
由于创建技术路线图所需的时间和精力,需要有坚定的领导力。此外,领导应该来自一个参与者,其中一个提供领导和赞助。这意味着生产线组织必须驱动流程,并使用路线图来制定资源分配决策。[10]
界定范围和界限
在此步骤中,将指定路线图的上下文。在公司里应该有一个愿景,而且必须清楚的是,路线图能够支持这个愿景。如果愿景不存在,则应制定并明确说明。完成后,应该指定路线图的边界和范围。此外,应设定规划范围和详细程度。范围可进一步分为技术范围和参与范围。
在表1中可以看到初步活动阶段的所有不同子活动。所有子活动都有作为最终产品的概念(用粗体标记)。这些概念是实际的元数据模型,它是一个经过调整的类图
表1。初步活动阶段活动表
| 活动 | 子活动 | 说明 |
|---|---|---|
| 满足基本条件 | 确定基本条件 | 当所有参与者聚集在一起时,可以确定基本条件(例如,应该涉及哪些组、哪些是关键客户、哪些是关键供应商)。 |
| 采取行动去满足条件 | 要使技术路线图成功,必须满足参与者的条件。 | |
| 提供领导/赞助 | 领导/赞助的部分应由直线组织承担;他们必须推动路线图制定过程,并使用路线图做出资源分配决策。 | |
| 定义技术路线图的范围和边界 | 清晰地陈述愿景 | 已经存在的愿景必须是明确的。 |
| 发展愿景 | 这一愿景得到了明确的发展和阐述。 | |
| 定义范围 | 项目范围可以进一步定义需求集、规划范围和详细程度。范围可进一步分为技术范围和参与范围。 | |
| 定义边界 | 边界也应该包括在内。 |
第2阶段:开发阶段
图3。开发阶段的过程数据模型。
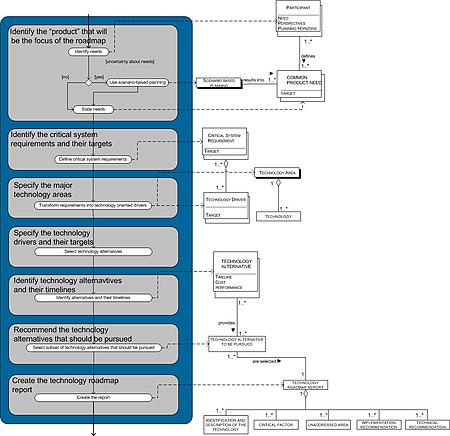
第二阶段,技术路线图阶段的开发(见图3),包括7个步骤:
- 确定“产品”是路线图的重点,
- 确定关键系统需求及其目标,
- 明确主要技术领域,
- 指定技术驱动因素及其目标,
- 确定技术替代方案及其时间表,
- 建议应采用的技术替代方案,以及
- 创建技术路线图报告。
- 国防后勤局,[12]
确定路线图的产品重点
在这一步中,共同的产品需求被确定,并得到所有参与者的同意。这对于让所有小组接受这个过程很重要。在产品需求不确定的情况下,可以使用基于场景的规划来确定共同的产品需求。在图3中,参与者和可能的基于场景的规划提供了共同的产品需求。
确定关键系统需求及其目标
一旦确定了必须制定的路线图,就可以确定关键的系统需求;它们为技术路线图提供了总体框架。需求可以有目标(如图3中的属性),如可靠性和成本。
明确主要技术领域
这些是帮助实现关键系统需求的领域。对于每个技术领域,都可以找到一些技术。示例技术领域有:市场评估、横切技术、组件开发和系统开发。
指定技术驱动因素及其目标
在这一步中,第二步的关键系统需求转化为特定技术领域的技术驱动因素(带目标)。这些驱动因素是选择技术替代方案的关键变量。驱动因素取决于技术领域,但它们与技术如何满足关键系统需求有关。
确定技术替代方案及其时间表
此时,应指定技术驱动因素及其目标,并应指定能够满足这些目标的技术备选方案。对于每一种备选方案,都应估计其相对于技术驱动目标成熟程度的时间表。
时间因子可以适应特定的情况。电子商务和软件相关部门的时间跨度通常很短。其他的区别可以在尺度和间隔上做出。
推荐应采用的技术替代方案
由于备选方案可能在成本、时间表等方面有所不同,因此必须对备选方案进行选择。这些是图3所示的备选方案。在这一步中,必须在不同目标的不同替代方案之间做出许多权衡:例如,性能高于成本,甚至目标高于目标。
创建报表
至此,技术路线图已经完成。在图3中,可以看到技术路线图报告由5部分组成:
- 每个技术领域的识别和描述,
- 路线图中的关键因素,
- 未处理的区域,
- 执行建议,以及
- 技术建议。
报告还可以包括其他信息。在表2中可以看到开发阶段的所有不同子活动。
开发阶段活动表
| 活动 | 子活动 | 说明 |
|---|---|---|
| 确定路线图关注的“产品” | 确定需求 | 这一关键步骤是让参与者确定并同意共同的产品需求。这对他们的接受很重要。 |
| 使用基于场景的规划 | 如果共同产品需求存在重大不确定性,则可以使用基于场景的规划。每个方案必须合理,内部一致,并与其他方案可比。 | |
| 陈述需求 | 这些是产品的需求。 | |
| 确定关键系统需求及其目标 | 定义关键系统需求 | 关键系统需求为路线图提供了总体框架,是技术相关的高级维度。这些包括可靠性和成本。 |
| 定义目标 | 必须为每个系统需求定义目标。 | |
| 明确主要技术领域 | 将需求转换为面向技术的驱动者 | 应规定主要技术领域,以帮助实现产品的关键系统要求。然后,关键系统需求转化为特定技术领域的技术驱动因素。 |
| 指定技术驱动因素及其目标 | 根据目标选择技术方案 | 技术驱动因素及其目标是基于关键系统需求目标设定的。它规定了在某一特定日期前必须如何执行可行的技术替代方案。必须从现有的技术选择中作出选择。 |
| 确定技术替代方案及其时间表 | 确定备选方案及其时间表 | 必须确定能够满足目标的技术替代方案。接下来,必须确定每个备选方案的时间线。 |
| 推荐应采用的技术替代方案 | 必须选择技术替代方案的子集 | 确定采用哪种技术以及何时转向另一种技术。整合最好的信息,并形成许多专家的共识。 |
| 创建技术路线图报告 | 创建报表 | 这里创建了实际的技术路线图报告。本报告包括:确定和说明技术、关键因素、未解决的领域、执行建议和技术建议。 |
第3阶段:后续活动阶段
在这个时刻,路线图必须被参与任何实现的团队批判、验证并希望被接受。这需要使用技术路线图制定计划。下一步,必须有一个定期的回顾和更新点,因为参与者的需求和技术的发展。
快速启动路线图方法
考虑到路线图创建的潜在复杂性和组织惯性,剑桥大学的研究人员[13]专注于开发路线图快速启动方法。[14]这种方法称为T-Plan,创建于20世纪90年代末,主要是帮助组织以最小的成本迈出路线图制定的第一步资源和时间承诺。它在传播和吸收国际路线图方面具有影响力,包括将T-Plan工作簿[15]翻译成中文(传统和现代)、德语、日语和西班牙语。该方法(以及与之对应的创新和战略路线图,S计划)是灵活和可扩展的,因此,快速和精益的方法对于中小型企业来说尤为重要,并且已经被证明能够为中小型企业的集群提供指导
规划和业务发展背景
5。方案规划实例。
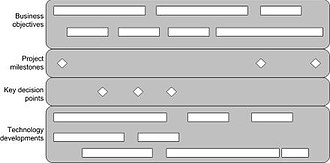
6 酒吧的例子。
7号。图表示例。
技术路线图制定过程符合企业战略、企业战略规划、技术规划和业务发展环境。三个关键要素应该联系起来:需求、产品和技术。
所需知识和技能
有技能的顾问
创建技术路线图需要一定的知识和技能。一些参与者必须知道技术路线图的目的。其次是小组讨论和人际交往技巧,因为这个过程包括很多讨论和找出共同的需要是什么。如果参与人数真的很大,可能需要一名顾问或促进者。
目的
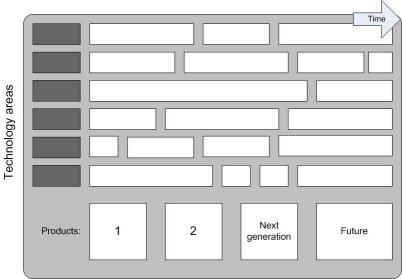
路线图中的产品规划
这是最常见的技术路线图类型:将技术插入到产品中。
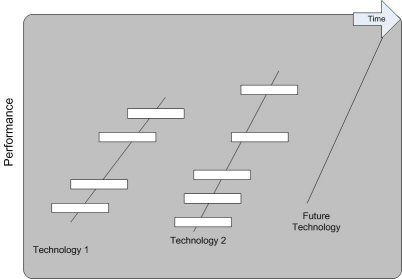
方案规划
这种类型更多的是针对战略的实施和相关的项目规划。图5显示了技术开发阶段、计划阶段和里程碑之间的关系。
格式
- 条形图:几乎所有的路线图(部分)都用条形图表示。这使得路线图非常简单和统一,从而使通信和集成更加容易。
- 图:技术路线图也可以表示为图,通常每个子层一个。(例如,IMEC使用第二种方法)。
原文:https://en.wikipedia.org/wiki/Technology_roadmap
本文:https://jiagoushi.pro/node/952
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 1582 次浏览
【技术架构】技术风险管理
技术风险是任何潜在的技术失败,以中断您的业务,如信息安全事件或服务中断
- 介绍
- 关于技术风险你需要知道的
- 技术风险评估的好处
- 如何进行技术风险评估
- 深挖:临终管理
- 深挖:合规
- 深挖:复杂性
- 结论
技术风险管理导论
让我以一个令人震惊的例子开始,它说明了一个失控的IT风险事件是如何造成灾难性的影响的,就像发生在达美航空子公司Comair的事情一样。在一个繁忙的12月,科梅尔的机组调度系统出现了故障,因为它每个月只能处理一定数量的变化。该系统突然停止运行,导致近20万名乘客在圣诞节前夕滞留在美国各地。这一事件直接造成的收入损失估计为2 000万美元。最新的EA目录为您提供有关所有应用程序的信息,包括应用程序所基于的技术。这可以帮助您评估哪些应用程序可能处于风险之中,因为底层的IT组件不再受到支持,并且可以让您跟踪自己的技术标准。由于不支持的技术部件而发生的事故平均将花费公司约60万欧元。
在这个权威指南中,你将学习如何避免这种情况。
关于技术风险你需要知道的
大多数公司更擅长引进新技术,而不是淘汰它们。运行不受支持的技术的成本可能很高。IT中断和数据泄露的成本高达数百万美元。在技术的生命周期结束时,IT管理必须处理诸如集成问题、有限的功能、低服务水平、可用技能的缺乏以及缺少供应商的支持等挑战。
仅20家最大的技术供应商就提供了超过100万种不同的技术产品。相关的信息,比如生命周期,每天都在变化。
大多数公司更擅长引进新技术,而不是淘汰新技术。67%的CIO表示他们的技术风险管理是无效的。
如果您正在研究如何进行技术风CIO险评估,那么这个故事对您来说可能已经很熟悉了。这就是为什么我们创建了一个明确的技术风险评估指南。
技术过时-受益于技术百科生命周期目录以避免风险[白皮书]:学习如何管理技术风险,从生命周期到业务影响。»
技术风险格局正在迅速变化,这主要是由于区块链等新兴技术或微服务等新方法。如果不进行相应的处理,就会导致IT风险的增加,从而增加整个企业的风险。
根据毕马威的技术风险管理调查,技术风险管理需要发展,以准备这个新的、快节奏和颠覆性的世界。许多组织在数字运作时代不认为技术风险是一个价值中心,仍然停留在传统的、以合规性为中心的技术风险方法中,这些方法不能提供对技术资产、过程和人员的最佳控制——包括静态的定性度量、反应性风险决策和缺乏创新。
你知道吗? 72%的组织在技术风险问题已经出现时,会将技术风险团队带进项目,47%的组织甚至在没有进行风险评估的情况下就采用了移动应用程序和设备等技术。
技术风险评估的好处
这样做有很多好处。其中有:
降低成本
通过评估每个IT组件的功能适合度和业务临界性,找出最佳技术。这让您可以跨区域或办公室选择标准,从而减少冗余的应用程序和/或技术。例如,我们为什么要使用Oracle和MySQL?
当其中一项可能适合整个组织时,我们将支付两项费用。你可以在这里了解更多。
降低了风险
如果我们还没有把软件升级到最新版本会发生什么?或者更糟的是,为什么我们要使用五个不同的版本?这可能是由于底层技术。依赖于底层应用程序的其他应用程序可能最终导致整个组织内错误的滚雪球效应。识别和理解存在哪些底层技术、它们的生命周期和任何软件依赖关系是至关重要的。
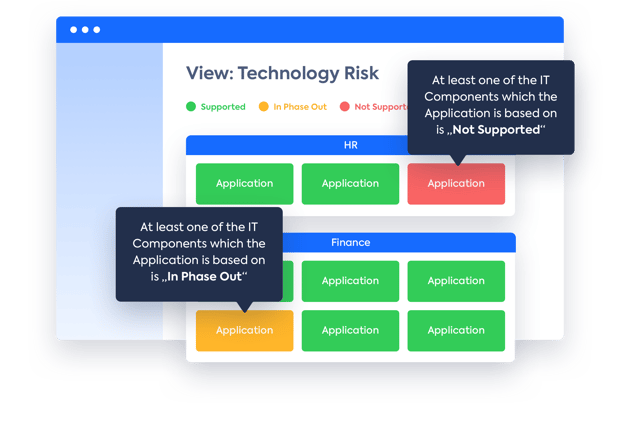
图1:IT组件矩阵显示了IT组件关于其提供者和技术栈的生命周期。
提高敏捷性
大多数公司都在努力解决的一个问题是标准化。当我们没有明确的标准定义时,事情很快就会变得混乱。一旦定义了这些标准,我们还必须确保它们得到遵守。理想情况下,人们不应该挨家挨户地评估,例如,涉众遵守IT安全标准的程度。为了承认这一点,我们建议使用调查。你可以使用工具,比如Surveymonkey,或者使用LeanIX调查功能,它会自动将所有答案导入到工具中,准备好进行评估。
Image 2: LeanIX´ Survey showing how to efficiently do an IT-security assessment.
如何进行技术风险评估
现在我们已经确定了优点,您可能想知道创建全面技术评估的步骤。
我们的建议如下:
获取您使用的应用程序的完整列表
希望您在过去的一年里已经为您的应用程序编写了文档。如果没有,我建议先阅读应用程序合理化的9条规则和指导原则。
如果没有当前应用程序的概况,那么开始技术评估就没有意义。你不会在没有配料清单的情况下开始烤蛋糕,对吧?作为第一步,您需要收集当前在企业中使用的所有应用程序的列表。
评估正在使用的软件版本
下一步是找出正在使用的软件版本。
作为最佳实践,我们建议使用技术堆栈对软件进行分组。您还可以标记您的软件(手动或使用开箱即用的LeanIX标记),以便将来引用它们。在下面的截图示例中,您可以看到我们通过Candidate、Leading、Exception、Sunset模型对它们进行了标记。
评估正在使用的服务器和数据中心
下一步与前面的步骤相似。我们再次建议为每个服务器和数据中心分配一个技术栈。
在这个步骤中,您还应该验证数据。例如,您可以使用IT组件位置报告来检查服务器的位置。

Image 3: Report showing where IT-components are located.
将软件和服务器连接到应用程序
在前面的步骤中收集并验证了所有数据之后,现在创建软件、服务器和应用程序之间的链接非常重要。这使您以后能够理解这些对象之间的依赖关系,从而避免前面描述的情况。

Image 4: Free draw report showing dependencies between an application and its IT-components and technical stacks.
找出技术是如何影响你的业务的
你做到了最后一步。现在是时候找出技术风险对你的企业到底意味着什么了。现在是时候把这些片段放在一起了,例如,我们现在可以找出使用某些软件版本的应用程序的托管位置。
深挖:临终管理
技术风险管理中最重要的因素之一是寿命结束管理。
这是什么意思?与那些密切关注IT领域中元素生命周期的公司相比,那些不注意已部署的技术即将过时的公司将面临更多的安全风险和漏洞。此外,继续使用不再被支持的硬件或软件会使网络犯罪分子更容易访问系统和数据。
这个关键的话题经常被忽视,甚至政府机构也不能幸免。美国政府审计人员在2015年抨击美国国税局(IRS)未能在截止日期前升级Windows XP pc和运行Windows Server 2003的数据中心服务器,这两款服务器都已被微软淘汰。在Windows XP从微软的支持名单上跌落9个月后,该机构仍然无法计算1300台电脑的数量,约占其总数的1%,因此无法说明这些电脑是否已经被清除了这一古老的操作系统。国税局还必须支付微软的退休后支持合同,以提供关键的安全更新。
Figure 5 - Business impact of technology obsolescence.
深挖:合规
企业需要遵守从HIPAA到PCI和FISMA的许多规定。虽然遵从性确实需要花钱,而且就技术而言,需要对应用程序和技术有准确的看法,但不遵从性的成本通常较高。根据经验,专家表示,不遵守规定的成本比遵守规定的成本高2.5倍。
一个最新的EA库存不仅为您提供可靠的数据,您可以使用它来记录您遵守法规的情况。LeanIX调查插件还可以帮助您为适当的人员创建特别的或定期的调查,以维护有关应用程序使用敏感数据的准确信息。
当前用例是例如GDPR;我们可以评估我们的数据,以确定其隐私敏感性的级别,将其分类为公开/非机密、敏感、受限或机密。如果你使用的是专业的企业架构管理工具,比如LeanIX,你可以使用标签来添加更多的属性(例如。“GDPR限制”)一个数据对象或应用程序。这通常已经是您的内部安全流程的一部分,您在其中为数据分配机密性、完整性或可用性等属性。
您可以在这里了解关于如何建模的更多信息。
深挖:复杂性
复杂性是安全的敌人。当谈到老技术的退役时,CIO们必须小心地平衡这两个方面。一方面,他们需要“保持灯火通明”。首先,他们需要确保IT操作顺利运行。有句古老的谚语说:“如果没有坏,就不要修理它。”但这句CIO谚语写的时候并没有想到数字化转型。当然,这句话有一定的道理,因为更新技术的升级通常伴随着某种中断,但保持现状是以增加复杂性为代价的。

Figure 6: LeanIX dashboard illustrates which applications are at risk as the underlying IT components are out of the lifecycle.
过时和硬件维护,以及安全,是当今组织所面临的一些最紧迫的信息技术问题。到目前为止,不为技术的未来做计划是许多企业所犯的代价最大的IT错误之一。
结论:
大多数公司更擅长引进新技术,而不是淘汰它们。运行不受支持的技术的成本可能很高。IT中断和数据泄露的成本高达数百万美元。
技术风险管理是一个广泛而复杂的主题,无论您的团队多么优秀,都无法通过手工数据维护来解决。在LeanIX软件的帮助下,企业架构师可以快速获取最新的技术产品信息。在评估应用程序环境的风险,以及以智能的方式计划、管理和退役技术组件时,这些信息是必不可少的。
原文:https://www.leanix.net/en/technology-risk-management
本文:http://jiagoushi.pro/node/1224
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 182 次浏览
【技术架构】本地高可用性灾难恢复:主动 - 主动 - 备用拓扑
要提高数据中心中运行的系统的可用性和灾难恢复功能,可以跨三个数据中心实施主动 - 主动 - 备用或主动 - 主动 - 主动拓扑。与两个数据中心的主动 - 主动拓扑相比,这两种拓扑都具有非常高的弹性。该架构描述了一种主动 - 主动 - 备用拓扑,其弹性比两个数据中心拓扑具有更好的弹性,但弹性低于三个数据中心的主动 - 主动 - 主动拓扑。
业务挑战
适用于主动 - 主动 - 备用架构实施的一些重大挑战包括:
- 业务连续性:尽管存在人为或自然灾害,应用程序及其支持的业务流程仍可保持可用且无任何中断,并可无缝地提供其预期功能。
- 持续可用性:精心设计的HA解决方案可通过快速的系统响应时间保持最佳的客户体验。它能够处理因业务交易激增而导致的额外工作量,并降低收入机会损失的风险。
- 操作灵活性:这意味着具有设计良好的DR拓扑,在辅助站点中复制代码和数据,并以足够的地理距离隔开。它允许在另一个位置重新构建和/或激活应用程序,并在主站点发生意外灾难性故障后处理工作。
流程
主要的分销公司需要提高在其数据中心运行的B2B订单系统的可用性和灾难恢复能力。它将系统部署在三个数据中心的主动 - 主动 - 备用拓扑中,与主动 - 主动拓扑相比,它提供了非常高的弹性。根据建议的该组件的最佳实践,B2B订单系统中的每个单独组件都可以水平或垂直聚类。
步骤1
B2B客户从Web浏览器访问本地应用程序。
第2步
边缘服务是一组服务,用于处理请求并将其发送到数据中心应用程序区域中的正确目标应用程序。它确定数据中心1或数据中心2中的UI应用程序是否可以更快地响应用户请求并相应地路由请求。
第3步
UI应用程序将请求转发到分析应用程序,该应用程序返回要在用户的Web浏览器中显示的产品列表。接下来,它向订单应用程序转发请求,以获取用户所选产品的价格信息和交付日期可用性。它向用户显示响应数据。 UI应用程序将请求转发给订单应用程序,以便为用户选择的产品下订单。它显示从用户浏览器中的企业应用程序接收的订单信息。
第4步
目录应用程序接收转发的请求,从NoSQL数据库中检索符合条件的产品信息,并将其返回给UI应用程序。
第5步
订单应用程序从UI应用程序接收由企业应用程序管理的产品可用性和价格信息的请求。订单应用程序将其转发到集成服务组件。它稍后向集成服务发送请求,以便在ERP中为用户选择的产品下订单。
第6步
企业集成服务处理接收到的请求,并根据需要转换数据和协议,以供企业应用程序处理。此过程是针对产品价格的第一次请求完成的,随后是为了在用户所选产品的ERP中创建订单而完成的。
第7步
数据中心1中的负载均衡器确定数据中心1或数据中心2中的企业应用程序是否能够更好地服务于来自数据中心1中的企业集成服务的请求,并相应地路由该请求。数据中心2中的负载平衡器以相同的方式起作用。结果是一种高度可用的解决方案,可以更快地响应用户的请求。
第8步
企业应用程序处理产品价格和可用性请求,并通过企业集成服务向订单应用程序返回响应。稍后,企业应用程序会收到为客户选择的产品创建订单并返回订单数据的请求。
第9步
决策服务应用程序从订单应用程序接收请求并对其进行处理以确定合格的价格折扣百分比或促销。此外,它还确定是否需要批准以及合格的审批者角色或人员。它返回信息以响应订单应用程序的请求。
第10步
订单应用程序向工作流应用程序发送请求以创建人工审批任务。工作流程批准完成后会发送响应。
功能要求
- 最大限度地减少应用程序正常操作的中断。 如果任何应用程序组件存在可用性问题,请确保将应用程序组件平稳快速地恢复到正常操作。
- 恢复任何应用程序组件的服务必须完全自动化,或者必须由人员通过单一操作激活。
- 监控每个应用程序组件的可用性 在服务级别问题的情况下发出警报,例如响应时间慢或任何应用程序组件没有响应。 通过自动化或由负责应用程序高可用性的人工专家的单一操作激活应用程序组件的快速恢复。
讨论:请加入知识星球【首席架构师圈】
- 175 次浏览
【技术架构】连续架构:从内到外转变数据库以改进转型决策
在当今的商业环境中,有效的转型对于企业保持竞争力至关重要。根据定义,转换会随着时间推移而发
企业(或其某些子部分)具有需要变得更好的当前状态。这种变化 - 无论大小 - 都会导致不同的未来状态。随着敏捷工作实践和基于DevOps的持续交付的广泛采用,这些变化可能非常小且非常频繁。
-Nick Reed和Bart Molenkamp
随着市场的不断变化和企业变得更具适应性的必要性,期望的未来状态也会更频繁地发生变化。换句话说,一旦您开始从当前状态A行驶到期望的未来状态B,B已经改变到新的期望未来状态C.
最重要的是,A,B和C也可能不是企业范围的。这意味着在不同的细节和范围内存在多个未来状态,这些状态都在不断地并行发展。这些未来国家之间也存在相互依存关系。
为了增加复杂性,企业的数字化允许实时运营数据和KPI为建筑决策提供信息。例如,服务事件的数量,API的容量以及技术组件的漏洞都可能有助于架构决策。
创建和管理有状态架构
把所有这些放在一起,不难看出为什么传统的架构方法不再足够。 “沸腾海洋”(为整个企业建模以期回答任何问题)的日子早已不复存在。对所有当前和未来状态以及路线图进行建模,并手动将所有这些状态与所有小的,频繁的更改保持同步只是过多的开销。如果您需要让不同的利益相关者群体及时了解他们感兴趣的位置,那么尤其如此。
因此,现代架构面临的挑战是如何管理“有状态”架构,在这种架构中,您可以可靠地跟踪架构的当前和未来状态,并在多个并行流中进行所有这些更改。
精简的架构方法 - 通常被描述为“足够,及时” - 对于最大限度地缩短价值实现时间以及为EA提供频繁,迭代的投资回报至关重要。
传统上,架构框架侧重于利益相关者集合以及他们在不同详细程度上所需的观点,涵盖所有(传统)架构领域。采用更现代化的精益建筑方法,我们不希望涵盖整个组织的所有领域(“沸腾海洋”),而是采取一种自适应方法,使特定利益相关者能够实时获得他们所需的特定视图。这些组织还需要一个足够灵活的架构解决方案,以便在需要时容纳新的利益相关者和新视图。
幸运的是,社交媒体世界在一段时间内一直在努力应对类似的挑战,并且已经提出了一些非常酷的技术来应对它。

分拆架构
LinkedIn需要处理大量传入的用户更新(“写入”)以及大量用户消费他们关注的连接和主题的更新(“读取”)。保持所有对每个人都有效的数据的当前状态的问题迫使LinkedIn对如何使事物保持同步有不同的看法。
他们提出了两项关键创新,解决了他们的问题,并为系统架构提供了全新的方法:
- 将数据中的所有更改记录为不随时间变化的“事实”流。换句话说,所有更改都记录为“不可变事件流”。此方法的最大优点是它保留了所有数据的历史记录。有一个独特的时间概念(一个实体随着时间的推移有多个值),而不是数据库,您通常只有最新的值。当您需要查询数据(或者更可能是数据的特定子集)时,您可以通过处理截至当前时刻发生的所有更改从数据集中派生“视图”(或者您可以类似地派生仅通过处理某个特定时刻的更改来查看历史快照。我们将这些数据称为“物化视图”。通常,这些物化视图是持久的,并且通过逐步应用写入流的新事实,它们很容易保持同步。
- 使用事件流日志作为系统之间的缓冲区。生产者可以在不知道谁使用数据的情况下编写数据。这可以是一个消费者,没有消费者,也可以是多个消费者。生产者不知道那些系统,它只知道日志。它在时间和空间上分离系统。如果消费者系统崩溃或运行缓慢,则不会影响生产者。
在将焦点从数据集的当前状态改变为关注数据集中所有不可变的变化时,变化的概念变得成为系统的核心。
您可以根据需要为任意目的构建任意数量的视图,使用最适合目的的任何技术,例如面向文档的搜索数据库,用于网络分析的图形数据库,或者用于旧的关系数据库。报告和数据透视表分析。可以将其视为分拆数据库,或者以EA的形式将分解结构拆分。
这就是为什么我们采用一种全新的架构管理架构方法。
这对BiZZdesign平台意味着什么
在BiZZdesign,我们围绕事件流构建了新一代产品,以实现比传统系统更快适应的自适应,灵活和强大的平台。
这种方法基于现代尖端技术,使我们能够从内到外地改变数据库,并将新功能的创新速度提高了几个数量级。事件流的概念具有广泛的适用性,从与外部数据源的集成到新闻源的个性化。范式转换是从请求 - 响应到订阅 - 通知。这是一种思维转变,并彻底改变了我们的应用程序开发方法。
这为我们的客户带来了许多好处,包括:
- 我们平台的“向前兼容性”:我们可以使用事件流的任何子集在将来添加新的物化视图。我们将来添加的物化视图将考虑所有历史数据。
- 完整的审计跟踪数据,可用于多种用途。
- 在新用例出现时灵活使用新技术:我们已经在使用一系列数据库技术来支持不同的用例,例如搜索,商业智能报告和我们的API,还有更多用例。
- 一种现代而灵活的集成方法:BiZZdesign消耗来自外部数据源的事件流,并提供外部系统消耗的事件流,从而灵活地在IT生态系统中生成和使用数据。
这就是为什么您将继续以不断增长的速度看到添加到BiZZdesign平台的新功能。敬请关注…
参考文献:
https://www.confluent.io/blog/leveraging-power-database-unbundled/
https://www.confluent.io/blog/turning-the-database-inside-out-with-apac…
https://www.confluent.io/blog/stream-data-platform-1/
原文:https://bizzdesign.com/blog/continuous-architecture-turning-the-database-inside/
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 76 次浏览
【技术规划】描绘未来第 4 部分:技术路线图
我关于路线图的最后一部分以技术路线图结束。第 1 部分侧重于路线图的类型及其关系。第 2 部分侧重于能力路线图,第 3 部分侧重于产品路线图。所以现在我们用最复杂的路线图来总结它。
技术路线图是信息技术 (IT) 组织正在实施的技术的拟议未来。技术是当今每家公司的重要方面。该技术路线图旨在通过结构分析帮助规划未来。它很复杂,因为它有很多输入,可能包括大量技术。
技术路线图的输入包括我们之前讨论过的两个路线图(能力和产品)、战略、以前的技术路线图(如果存在)和当前的架构状态。技术路线图是所有其他路线图和战略的下游,但它也是其他路线图的反馈提供者。为了使技术执行与业务规划保持一致,必须考虑给予和接受。这就是技术路线图如此重要的原因:它采用想法并验证它们的可行性。
这种给予和接受取决于两个限制条件:预算和可用资源。预算规划可能很困难。总是需要控制成本,但同时,你需要投资于未来。这就是战略和能力路线图很重要的地方。它们提供了一个可以执行预算决策的镜头。预算限制了可以做的事情。实施哪些能力最重要?真正需要哪些技术来支持这些功能?投资回报率是多少?
后一个问题可能很难回答。传统上,投资回报率是基于每个项目进行分析的。但是当我们谈论技术和能力时,一个单独的项目可能会跨越能力,或者一个能力可能需要几个依赖项目才能实现投资回报率。这不是一对一的受益支出,这使得分析变得更加困难。这是一个复杂的杂耍行为,帮助杂耍的工具并不容易获得(除了人脑)。
如上所述,另一个依赖项是资源。对于技术项目,这通常是人力资源——您是否拥有完成工作的内部专业知识?您的市场上是否有可供您雇佣的资源(永久或作为承包商)?即便如此,他们是否有足够的管理带宽或成熟度来承担该项目。在讨论承担新的技术项目时,组织问题很重要——这也不仅仅与 IT 组织有关。可能需要对业务人员进行教育或增强以支持该技术。至少,可能需要延长项目时间表(特别是如果需要定制开发),以便资源能够满足需求。
与所有其他路线图一样,技术路线图定义了随着时间的推移要实施的技术。对于技术路线图应该提前多远,我将给出相同的答案:这取决于您的业务需求。一些企业需要比其他企业更长的规划周期,在很长一段时间内需要大量的资本支出。其他人有更温和的要求,不需要如此长的规划范围。不管那个时间框架是什么,在最初的几年里它会更容易预测,然后随着时间线的延长变得更加模糊。
综上所述,我们如何实际制定路线图?这并不容易,也不是一门精确的科学。这 10 个步骤包括:
- 从能力路线图中,确定支持能力所需的技术。最初这只是一个列表——我们稍后会详细介绍。
- 让我们对产品路线图做同样的事情。确定需要实施的技术。同样,只是一个列表。
- 按主题和史诗对您的技术列表进行分类。主题是一种概括的策略,而史诗是策略中更详细的部分。这一步在某种程度上是可选的,只要技术可以与战略相关。它可能很复杂,因为一项技术可能是两个不同史诗或主题的一部分。
- 如果您没有以前的技术路线图,那么您将需要确定所有当前的技术和工作,预测未来的维护、许可、支持和开发成本以及资源需求。希望您将有一个先前的路线图可以继续,但也许需要一些工作来获取数据。
- 从技术列表中,确定具体技术。您使用的是 Microsoft Azure Synapse 或 AWS Redshift 还是 Snowflake?这是技术选择阶段。它不一定是完美的,尤其是在未来需要实施产品时。这项工作的一部分应该包括你是构建、购买还是租用(SaaS、云计算或外包开发或服务)的问题。
- 开始构建新技术的细节。您将需要了解何时需要交付它们(从能力或产品路线图获得)、实施需要多长时间(这定义了开始日期)、与它们相关的成本以及所需的资源实施和维护它们。请注意,它不需要是完美的。一个粗略的数量级适用于定价,并且可能将时间范围设置为最接近的季度或最好的一个月。
- 有了上面的数据,您应该可以列出粗略的时间表。您还应该对每月或每季度的成本和资源需求有一个很好的估计。如果您像大多数 IT 商店一样,当您看到巨大的价格标签或需要实施的军队时,就会出现恐慌。不要恐慌 。 . .然而。
- 所以,让我们开始减法。通过添加所有这些技术,您现有的一些技术将会消失。确定它何时会消失并减少支持这些技术所需的成本和资源。记住要保持一些重叠——切换很少意味着被替换的技术会立即关闭。
- 那么,数字是否仍然太大?现在是艰苦的工作。摇晃。有很多方法可以让事情变得合适。首先是向钱包管理员要更多的钱。我们都知道它是如何运作的——但如果你能讲述一个引人入胜的故事(并且一切都与策略相关,你有数据来讲述一个引人入胜的故事),你可能会有一些运气。但在你提出这个问题之前,请验证你的号码。费用是否正确?资源计划是否正确?是否有更便宜但不是最佳但足够的解决方案?是否有更便宜的临时解决方案可行?一旦一切都正确并经过验证,您有几个选择:a.) 在时间线上将技术项目移到更远的位置。这意味着其他相关的项目也可能被推出。 b.) 拉伸项目——不能对所有项目都这样做;主要是定制软件开发工作。 c.) 从路线图中删除项目。这样做时,可能还需要删除其他技术。这三个选项中的任何一个都可能需要调整能力或产品路线图。
- 完成这一切之后,需要根据需要调整路线图。数据不断涌入。项目滑倒,项目提前完成,颠覆性或新技术发挥作用,事件导致战略变化。对保持路线图的持续关注使企业能够保持更敏捷并更快地做出反应,从而制定战略,对需要战略变革的事件的延迟更短。
过程并不完美。一个特别的问题是在敏捷过程中。公司需要敏捷性,并且已经加入了敏捷的行列。路线图,顾名思义,是在制定一个计划——这不是敏捷的。那么,这是如何调和的呢?简而言之,它不是,至少据我所知。但如果我发现了,我会告诉你的。我知道的一件事是,可以做出高水平的估计,以及接受变化和随波逐流的态度。
本文:https://jiagoushi.pro/mapping-future-part-4-technical-roadmaps
- 200 次浏览
【演进架构】架构在实施之前是抽象的。
这是一个思想实验。拿一台计算机,在其上安装主流操作系统,以及各种软件(数据库,应用程序服务器,Web服务器等)。一切正常后,拔下电脑并将其放入壁橱中一年。在这一年过去之后,从它的避风港取回它,将其插入电源和互联网,并启动它。什么是第一件事(或者说,第一套事情)会发生什么? 47软件更新可用!新病毒定义!! Office需要关闭所有浏览器才能自行更新!即使壁橱内没有任何改变,整个宇宙仍然继续其无情的步伐。软件世界中没有任何东西是静态的。
软件架构师有责任通过创建具有不同程度排序的图表来阐明系统如何组合在一起的决策。图表周围有一种模糊的确定性,一种飘荡的数学香气。因此,架构师经常陷入将软件架构设想为他们必须解决的等式的陷阱。销售给软件架构师的大部分商业工具都强化了数字化的确定性,用盒子,线条和箭头图表不会说谎!虽然有用,但这些图提供了一个二维视图,一个理想世界的快照,但我们生活在一个四维世界。要充实2D图,您必须具体说明它。 2D图上的ORM标签变为Hibernate v4.2.17,演变为世界的三维视图。如果您有计划如何将其投入生产并在六个月内升级到不可避免的Hibernate v4.3.0.1,那么您已经毕业于四维世界。太多的建筑师没有意识到architetcure的静态图片的保质期很短。软件世界存在于不断变化的状态,它是动态的而不是静态的。架构不是一个等式,而是一个正在进行的过程的快照。
持续交付和DevOps运动说明了忽略实施架构并保持最新状态所需工作的缺陷。建模体系结构和捕获这些工作没有任何问题,但实现只是第一步。架构在实施之前是抽象的。换句话说,除非你不仅实现了它,而且还要升级它,否则你无法真正判断任何架构的长期可行性。甚至可能使它能够承受不寻常的事件。
这是一个基于真实客户体验的具体示例。航空公司的架构师使用规范的客户服务创建了基于服务的架构,封装了所有关于客户的知识。这是软件设计的自然本能,DRY(不要重复自己)原则,单一真理来源和其他好(但抽象)的想法。然后,冰岛爆发了一座火山,大大扰乱了航空旅行。该航空公司的客户通过电话向支持中心充斥,询问灾难是否会影响他们的航班。在世界上未受影响的地区持票的人无法登机(因为当然,票务查询涉及到客户)。虽然这种架构具有逻辑意义,但在特殊情况下它却失败了。虽然它可能看起来很浪费甚至可能导致重复(喘气!),但拥有多个客户服务(一个处理客户问题,一个处理登机)将更好地为业务服务。只有考虑架构的操作方面,才能构建更强大的系统,这是微服务架构的目标之一。
微服务架构是DevOps后的第一次革命架构,突出了架构和DevOps必须融合的认识,使运营问题成为建筑设计中的一流公民。传统上,变更是软件架构最令人担忧的事情。 Martin Fowler撰写了一篇名为“谁需要建筑师?突出了几个建筑的历史定义,其中一些人说“建筑是必须在项目早期制定的一系列设计决策”。因为架构元素呈现其他一切必须依赖的脚手架,所以对架构的改变通常是耗时且困难的。这种困难的一部分是由于忽视了架构的操作方面。微服务架构假设不断演变,即使在特殊情况下也会降低成本并且容易出错。设计稳健性的一个很好的例子来自参考微服务架构之一NetFlix。许多运营团体将其部署视为脆弱,微妙的事物。 Netflix试图通过像Simian Army这样的工具破坏他们的生态系统,旨在以富有想象力的方式强调他们的架构。
您不必一直走到异国情调的微服务架构,看看这种观点转变带来的好处。良好的操作控制对架构的赋权效果的一个很好的例子是将部署与发布分离的持续交付实践。 Going Live是传统巨石最可怕的事件之一,因为你必须让所有变化同时发挥作用:数据库,代码,配置,集成等。如果你已经习惯了这个大爆炸世界,那么像连续部署一样的练习疯了:你怎么能一直管理所有变化?秘诀是将部署与功能发布分开。功能切换是一种常见的持续交付实践,允许在基于主干的开发中进行飞行中的功能定义。像Togglz这样的切换库允许您通过过滤器servlet在运行时控制功能展示。因此,您可以将一个组件部署到您的生态系统中,其中包括切换代码,这样您就可以确保(通过监控)已部署的组件对生态系统没有任何不良影响。在选定的时间,您可以启用该功能,继续监控以确保没有任何错误。如果出现问题,请在确定修复时关闭该功能。通过将部署与发布分离,我们将操作问题与开发人员和用户分开。
微服务恰好是第一个完全接受DevOps的架构,但它不会是最后一个架构。架构的操作问题将继续影响我们的设计和决策,我认为这是软件架构成熟过程的一部分。
原文:http://nealford.com/memeagora/2015/03/30/architecture_is_abstract_until_operationalized.html
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 188 次浏览