安全运营
【安全运营】是时候信任你的软件了!
JFrog Xray - 不仅仅是另一个安全漏洞扫描程序。
我们刚刚正式推出了JFrog Xray,客户已经问过为什么我们认为应该使用JFrog Xray而不是$ YOUR_FAVORITE_SECURITY_SCANNING_TOOL。 Xray喜欢黑鸭吗? 也许它就像Docker Security Scanning? 也许它类似于Sonatype Nexus组件智能?
![]()
在进入差异列表之前,有一个巨大的概念转变。 Xray不仅仅是另一个带有普通扫描器的安全数据库。它是通用二元影响分析产品。递归分析的能力使Xray成为独一无二的,并且它是开放且通用的,可以连接到您的安全和许可证数据库或任何其他元数据。不确定我的意思?继续阅读,这篇文章的结尾都有意义。
现在,在我们成功确定Xray与传统安全漏洞扫描程序(如Sonatype Nexus组件智能或Docker Security Scanner)不同的类别之后,让我们将苹果与橙子进行比较,以更好地理解为什么Xray会大大改变您对二进制影响的思考方式分析:
1.这不仅仅是安全漏洞。影响分析应该是普遍的。
确实恐慌是卖(问一些政治家),但正如Roy Schestowitz博士所说,我们不卖FUD。您希望了解许多不同的度量标准,并提醒您有关组件的许可 - 许可证合规性,运行时性能问题,错误,体系结构决策,过时的组件,甚至还有完全特殊的规则要应用,例如检测组件你的竞争对手的IP。是的,安全漏洞也是如此。
Xray使用内部元数据源与其连接的外部元数据源相结合,为您提供真正的通用影响分析。
2.那容器怎么样?!并非所有的软件都是Java(或NuGet或npm)。影响分析应该是普遍的。
Java主导软件世界(或多或少),但今天,很难找到只做Java的组织。 Polyglot编程是新的“正常”,然后有DevOps将其他类型的软件带到开发人员的板块 - Docker,RPM,YUM,Vagrant。一个只能扫描Java组件的工具是...... 2005年?
目前,Xray能够扫描Java JAR和WAR,Nuget包,Python egg,npm包,RPM和Debian包,当然还有Docker镜像。很快,Xray将支持世界上最全面的工件库中支持的所有包类型 - JFrog Artifactory。
![]()
3.一个数据库无法全部了解,但影响分析应具有普遍性。
世界上没有数据库可以包含全面影响分析所需的所有元数据 - 所有不同类型组件的所有安全漏洞,所有许可证,所有版本,当然世界上没有数据库可以包含您的专有决策制作元数据。此外,有不同的影响分析方法可能适合其他组织,但不适合您的(例如,您是否可以将依赖关系的指纹发送到云?)。
Xray为您提供了选择的自由 - 您可以使用Xray的内部安全漏洞,许可证和组件版本数据库来实现零配置体验。由于我们设计Xray是通用的,我们的合作伙伴已经构建了集成,因此您可以连接任意数量的外部工具,如Black Duck,WhiteSource和Aqua(如果它们更适合您的需求,请继续关注更多)。 JFrog还将继续添加更多元数据提供程序以与Xray集成。但是自定义元数据怎么样?通过一个开放的REST API,Xray为您提供了一种将任何决策机制挂钩到Xray的简单方法,并了解它如何影响您的应用程序。
4.组件不是扁平的。影响分析应该是普遍的。
因此,例如,Nexus Component Intelligence能够扫描Java组件。或者,让我们来看看Docker Security Scanner。它只能扫描Docker镜像。但是,在Docker镜像,RPMor Debian软件包或gzip压缩文件中,Java组件呢?不。在Nexus Component Intelligence的世界中,组件只能以独立的扁平结构存在。
现实世界是不同的。组件像俄罗斯娃娃一样包含在内; WAR中的JAR,Debian软件包内,Docker镜像内,Vagrant框内的JAR。 Xray作为一个通用工具,知道如何打开这些包,发现内部的内容,并递归地索引这些组件。
5.您需要在全公司范围内进行影响分析,这应该是普遍的。
想象一下,如果Xray在组织内某个项目的一个生产环境中的Docker容器内运行的其中一个Nuget包中发现了运行时错误(现在你知道它可以)。如果你的其他项目的同事也知道受这个bug影响的所有组件,那不是很梦幻吗?
您可以使用Nexus组件智能或类似工具无法完成Xray的其他工作 - 全公司范围的影响分析。一旦Xray连接到公司内不同项目和组织中运行的所有Artifactory实例,它就构建了一个真正的通用组件图,并且可以对公司内可能受所讨论的单个组件影响的所有组件运行影响分析。
好吧,我相信你现在已经有了这个想法。你需要你的影响分析是普遍的,你只能用JFrog Xray来实现。
为了完善整个故事,JFrog Artifactory 4.11与JFrog Xray共同发布,这两款产品紧密相互补充。 Artifactory,唯一真正的通用工件存储库,提供所有二进制工件及其随附的元数据,JFrog Xray是唯一可以连接到任意数量的外部源并真正提供通用影响分析的产品,为您提供完整的图片所有问题和漏洞都会影响整个组织中任何格式的二进制工件。
原文:https://jfrog.com/blog/it-is-time-to-trust-your-software/
本文:http://pub.intelligentx.net/it-time-trust-your-software
讨论:请加入知识星球【首席架构师圈】
- 66 次浏览
【安全战略】跨AWS帐户架构安全性和治理第2部分:AWS上的事件响应。

这是“跨AWS帐户架构安全性和治理”的第二部分。”系列。在这一部分中,我们将在AWS cloud上浏览事件响应规划的窄巷;我们还将使用云托管实现有趣的自动事件响应活动。
“建立声誉需要20年的时间,而几分钟的网络事件就能毁掉它。——史蒂芬·纳波
NIST,安全事件”的发生实际上或潜在危害的保密性,完整性或可用性的信息系统或信息系统流程、商店、传送或构成违反或违反安全策略的迫在眉睫的威胁,安全程序,或可接受的使用政策”。
好吧,满嘴都是,我们化简一下。意外事件是对您的IT服务的意外降级。
在本部分中,我们将介绍您轻松应对安全漏洞的过程、AWS服务和策略。
有很多事件响应框架,它们详细地解释了您需要实现哪些内容,以便围绕流程实现有效的事件响应团队、剧本和自动化。
让我们从讨论事件响应阶段和AWS上的攻击面开始,然后尝试招募AWS Lambda到我们的事件响应团队中,在出现问题时提供帮助;我希望我们能负担得起Lambda的薪水:)
云中的事件响应阶段(NIST)

参考文献:NIST SP 800-53,修订版4
当涉及到对安全事件的响应时,与传统数据中心相比,云中的阶段并没有发生太大的变化,但是技术实现确实发生了巨大的变化,变得更好。让我们来探索这些阶段。
高效运行手册的七个事件响应阶段

1-准备阶段:

准备阶段
你猜对了,这个阶段就是准备阶段。我们需要做好准备,完成威胁建模,缩小攻击面,并采取任何必要的主动措施,从一开始就防止安全事件的发生。我们需要启用日志记录、监控、加密和限制爆炸半径。
采取积极措施做好准备:
- 数据分类:识别数据敏感性级别、所有者和安全需求。
- 所有权:所有资源都应该被标记,很高兴知道谁拥有一组受损的资源,至少所有者可以提供关于资源或配置中数据存储的敏感性级别的信息,这可能会导致折衷。提示:我们应该始终标记我们的资源!
- 风险管理:识别威胁、风险和漏洞,确定您的风险偏好,然后根据您愿意容忍的风险级别管理您的风险和漏洞。
- 弹性:架构师高度可用,容错基础设施。提示:使用AWS well architect工具并阅读well-architect白皮书。
- 最小特权原则:使用AWS IAM和资源策略,只授予需要访问数据或操作环境的人有限的访问权限。
- 测试(比赛日):测试您的事件响应计划。我相信在真正的安全事件发生之前,您会发现可以解决的缺点。
准备好一切:
没有理由不在所有帐户和区域上启用CloudTrail和其他日志服务。你将没有法医学来告诉你的资产发生了什么事,在事件的违反。
当您启用CloudTrail时,您接触的任何AWS服务都将在CloudTrail中记录对它们采取的操作,CloudTrail还可以与CloudWatch和日志集成,并将存储在一个集中的s3存储桶中。
CloudWatch事件可以被AWS Lambda用于实时修复,也可以被SNS用于实时通知。无论您使用的是SDK、控制台还是AWS CLI,所有操作都将被记录下来。你对AWS资源采取的任何行动都可能被用来对付你:)我知道这是坏的,我保证不再这样做。最后一点,请不要忘记启用ClouTrail日志文件验证。

CloudTrail工作流
通过限制爆炸半径来准备

爆炸半径
使用AWS组织和VPC、子网NACLs、EC2安全组等,根据业务单元、产品等隔离AWS帐户和资源,限制爆炸半径。
这种方法与深度防御等原则相结合,可以提供更大的保护,抵御威胁。
准备加密一切:
数据隐私专家会告诉你,“对待你的数据就像每个人都在看它一样,因为他们可能一直在看。”
加密是使用加密算法和加密密钥屏蔽数据的过程。如果使用了健壮的加密算法,如果坏人能够在传输过程中拦截数据或在静止时访问数据,他们就无法将数据读取为明文。
AWS提供了加密数据的选项,包括但不限于KMS。
AWS KMS和其他直接加密数据的服务使用一种称为信封加密的方法来提供性能和安全性之间的平衡。见下文:

服务器端加密
2-鉴定阶段:

识别阶段
折衷的指标有很多,比如AWS GuardDuty high severity alert,它说明您的EC2实例正在向与比特币挖掘相关的域发出出站调用,或者最好不是正在下降的生产服务。
识别阶段是我们发现事件正在实现的阶段。实现标识阶段的最佳方法是确保为所有您认为重要的安全发现(如AWS root帐户登录)设置警报。
以下是当你意识到某个事件已经发生时,你需要回答的一些问题:
- 原因:了解攻击背后的意图可以帮助您确定产品和资源的范围和攻击的性质。
- 内容:识别丢失的数据和损坏的资源,以及您需要清理、隔离和减轻哪些工作和资源。
- 如何:找出他们利用的弱点,以获得未经授权的访问您的系统。
- When:确保你记录下所有的事件
- 谁:谁是坏演员。
在识别安全问题时,依赖于人类是一种不好的做法,因为我们在关联异常值和异常方面不如机器。使用AWS服务的自动事件响应是解决之道,您还可以通过应用机器学习和安全分析来解决这一问题。
3-围堵阶段:

控制阶段:
你已经经历了所有繁琐的识别步骤现在怎么办?这一阶段涉及的是消除安全威胁。
我们应该有一个Cloudformation或Terraform模板,它拥有构建用于取证调查的隔离环境所需的所有资源。我们需要采取的一些行动是:
- 将您的AWS帐户移动到一个组织单元,该组织单元具有非常严格的AWS组织服务控制策略。
- 拒绝访问s3桶
- 限制安全小组,所以他们只允许指定的港口进行调查。
- 全球拒绝* IAM政策应附加到所有实体,不涉及此阶段
应该部署自动化来停止受损害的资源、快照卷、禁用KMS加密密钥和更改的Route53记录集。
4-调查阶段:

调查阶段
调查阶段包括包含阶段之后的活动,包括但不限于取证和一般日志分析。调查阶段应披露事件发生的时间,以及不法分子为进入我们的系统采取了什么行动,这次入侵的副作用是什么,以及根据目前收集到的证据,这次入侵再次发生的可能性。如前所述,调查应在一个孤立的环境中进行。
你可以使用的服务:
- VPC Flow Logs.
- CloudTrail.
- CloudWatch.
- Athena for analyzing logs.
5-根除阶段:

根除阶段
这个阶段涉及到对受影响资源的仔细处理。如果有必要,我们会删除资源,并将健康和清洁资源转移到更安全的环境中。
加密的数据应该是无法被攻击者破译的,这意味着我们可以执行以下一些操作:
- 禁用或删除KMS密钥
- 从EBS卷中删除溢出的文件,并将干净的数据转移到新的加密的EBS卷
- 删除s3服务器端加密的加密s3对象
- 删除使用KMS或客户密钥加密的s3对象和s3对象的加密CMKs
如果数据没有加密,您唯一的选择是将存储资源从最后一个已知的良好状态恢复到您可以保证它没有被篡改的状态。
6-恢复阶段:
经济复苏阶段
现在我们已经做了一切来确定发生了什么,并且已经尽我们最大的能力进行了数据清理,我们需要将操作恢复到正常状态。
我们可以在这个舞台上表演的一些动作:
- 恢复资源。
- 恢复网络连接。
- 使用新的和改进的访问控制策略和加密密钥。
- 监控你的环境是否有任何不寻常的行为。
7-后续阶段:

后续阶段
后续阶段,也就是事后分析,是关于吸取的教训和需要采取的后续行动,以避免发生新的安全事件,并改进我们的事件运行记录。
自动化
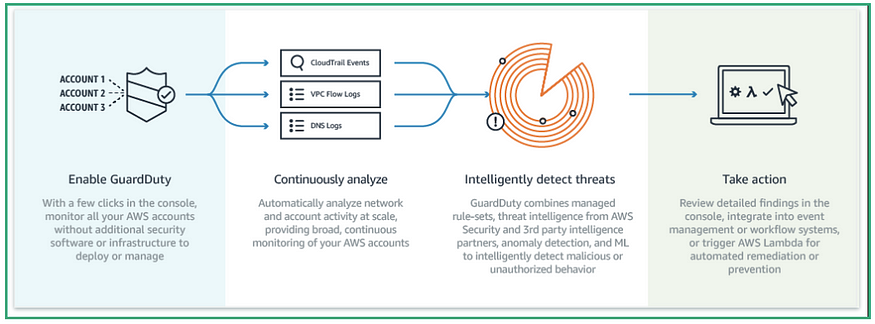
AWS警卫自动化工作流程
如果你已经做到了,谢谢你!让我们动手看看一个用例,这个用例应该能够使我们到目前为止所讨论的思想深入人心。最后,如果你不付诸行动,只有一个可靠的计划是不够的。
为此,我们需要:
- 孤立的AWS环境。请不要使用您的生产环境,因为此活动可能会占用资源。
- 在孤立的AWS环境中,必须启用AWS GuardDuty,以便生成将由CloudWatch事件和AWS Lambda使用的结果。
- EC2实例(t2.micro),为了生成一些安全结果,我们可以打开所有端口或类似的东西。
- 我们将设置Cloud保管器,以便它部署此活动所需的无服务器组件。
注意:您需要将云托管部署到您启用GuardDuty的同一区域。
当我们的云托管策略检测到AWS GuardDuty生成的中/高严重性发现时,它应该对范围内的资源采取行动,这个解决方案非常简单。
托管方将对受影响的EC2实例采取什么行动:
- 删除附加到EC2实例的IAM角色。
- 停止EC2实例。
- 取证调查卷快照。
让我们从安装云托管开始,并编写我们的第一个策略。在你的终端机运行以下命令安装抄送:

安装云托管
然后,创建一个名为custodian.yml,内容如下:
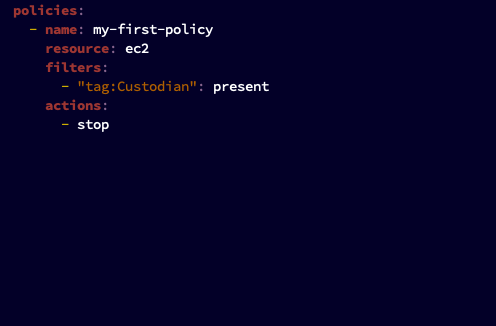
你的第一个政策

这个策略所做的就是,停止任何具有标记键“托管人”的EC2实例。
执行您的第一个策略:
我假设你使用概要文件访问通过CLI AWS帐户,如果不是你可以查找如何验证使用API密钥托管,或托管人承担角色的命令,如果你正在使用一个配置文件,下面是如何使用AWS CLI概要文件在本地运行政策,意味着这一政策不会运行基于CloudTrail所产生的一个事件或一个预定义的时间表。
如果成功,您应该在命令行上看到类似于下面的输出:

现在您是一个云托管专家,可以在AWS上实现安全自动化,让我们拿出真正的策略!

真正的交易
遵循您的第一份保单提供的步骤;编写策略,保存策略,并将其部署到一个独立的AWS环境中,然后观察其神奇之处。如果GuardDuty生成结果,策略Lambda将使用生成的事件,并通过执行我们在上面解释的操作进行响应。
好吧!这就是事件响应部分!

本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 67 次浏览
【安全架构】20个CIS 控制和资源
基本CIS控件
- 硬件资产的库存和控制
- 软件资产的库存和控制
- 持续漏洞管理
- 管理特权的使用
- 移动设备、笔记本电脑、工作站和服务器上的硬件和软件的安全配置
- 审计日志的维护、监控和分析
基础CIS控制
- 电子邮件和Web浏览器保护
- 恶意软件防御
- 网络端口、协议和服务的限制和控制
- 数据恢复功能
- 网络设备(如防火墙、路由器和交换机)的安全配置
- 边界防御
- 数据保护
- 基于知情需要的受控访问
- 无线接入控制
- 账户监控
组织CIS控制
- 实施安全意识和培训计划
- 应用软件安全
- 事件响应和管理
- 渗透测试和红队演习
原文:https://www.cisecurity.org/controls/cis-controls-list/
本文:
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】
- 217 次浏览
【安全运营】2019年要知道的开源安全风险和漏洞
组织正在利用许多开源产品,包括代码库,操作系统,软件和各种用例的应用程序。开源在灵活性,成本效益和速度方面可能是有利的,但是它提出了一些独特的安全挑战。高达96%的商业应用程序可能包含开源组件,因此面临的挑战是确保您的软件安全。
什么是开源漏洞?
开源中的漏洞就像是专有产品中出现的漏洞。这些是代码作者意外编写的代码,黑客可以从中受益,或者允许攻击者以代码作者未规划的方式进行资本化的功能。在某些情况下,这可能导致诸如拒绝服务(DoS)和使服务脱机等问题,而在严重违规时,黑客可以获得对组织系统的远程访问。
但是,专有和开源之间的相似之处在此结束。虽然内部代码是由一组坚持组织集中指导的开发人员编写的,但开源是在编写,修复和保持项目运动的社区成员之间分配的。
这种集中式与分布式系统通常被称为大教堂和市集。在集中式系统中,有一个独特的组织,它有一个处理修复和新增功能的标准系统。组织可能会发现开源代码更难以处理,因为它遵循一套不同的,通常更为模糊的规则。
在这种非结构化环境中工作对于组织来说可能很难处理,并且黑客通常会利用这种缺乏集中管理的能力。很多时候,开发人员将从站点上的存储库中获取开源代码,并且无法查看该组件是否具有任何已知漏洞。更可怕的是,没有多少组织建立了跟踪其产品或库存中的开源的解决方案。
Equifax Breach
新发布的2018年OSSRA报告研究了来自500多个组织的1,000多个商业代码库的审计结果。扫描确定的中心数据点是,平均而言,发现漏洞需要更长的时间。平均而言,审计中发现的漏洞在六年前与2017年记录的四年相比有所揭示。这些调查结果表明,负责补救的人可能需要更长的时间来重新调解,或者没有重新调解所有。它还表明这些人正在让开源漏洞在他们的代码库中积累。
一个例子是导致Equifax漏洞的Apache Struts漏洞。这一漏洞影响了超过1.48亿美国客户,接近7,00,000英国居民和19,000多名加拿大消费者的数据。 2017年3月,Struts漏洞被公布,并发布了一个补丁。 2017年9月,由未修补的Struts版本推动的Equifax漏洞被公布。随后的宣传将使参与应用程序安全的任何人都难以忽略修补任何易受攻击的Struts版本的需要。
然而,似乎组织没有被提示采取行动,并且Equifax新闻几乎没有影响。据发现,8%的审计代码库包含Apache Struts,其中33%仍有Struts漏洞导致Equifax漏洞。
4开源安全风险和漏洞需要注意
1.攻击的公共性质
在开源项目中,代码可供任何人使用。这有其优势,因为开源社区中的人可以标记他们在代码中识别的潜在漏洞,这使得开源团队领导者有时间在公开发布漏洞信息之前修复问题。但是,所有漏洞都会及时成为国家漏洞数据库(NVD)的公共信息。黑客可以访问这些信息,并追踪那些对依赖于具有漏洞的开源项目的应用程序进行修补的速度慢的组织。
2.潜在的侵权风险
开源组件可能会产生知识产权侵权风险,因为这些项目没有标准的商业控制。因此,专有代码可以进入开源项目。
3.运营问题
使用开源组件的企业面临的一个关键风险领域是组织的运营效率低下。从操作的角度来看,严重关注的是组织未能跟踪开源组件并更新这些组件,与新版本保持一致。
4.开发人员的医疗事故
开发人员的不法行为,包括从开源库复制和粘贴代码。复制和粘贴是有问题的,因为开发人员在复制时会复制项目代码中可能存在的任何漏洞。此外,一旦开发人员将代码片段添加到组织的代码库中,就无法更新或跟踪代码片段。这使得组织的应用程序容易出现将来可能发生的漏洞。可能发生的另一个不法行为是通过电子邮件手动转移开源组件。
结论
未来一年,开源安全可能会变得更加紧迫。你问为什么?随着开放在Web应用程序开发中变得越来越普遍,它将成为攻击者更大,更具吸引力的目标。攻击者可能会找到一个开源库或组件的漏洞,并且可能同时影响多个应用程序。由于这些库和组件是开放的,攻击者可以更容易地找到这些漏洞。
那么我们从这一切中得到什么呢?在2019年保持最新的开源安全风险和漏洞是值得的,并且您解决这些潜在风险的速度越快,您的组织可能承受的损害就越小。
原文:https://blog.bitsrc.io/open-source-security-risks-and-vulnerabilities-to-know-in-2019-8354058f6ad3
本文:http://pub.intelligentx.net/open-source-security-risks-and-vulnerabilities-know-2019
讨论: 加入知识星球【首席架构师圈】
- 55 次浏览
【安全运营】Frogs and Ducks,,你的开源安全哨兵

Black Duck Software创建产品以保护和管理应用程序和容器中的开源,消除与开源安全漏洞和许可证合规性相关的痛苦。他们在2016年进行的第十届开源调查年度未来,提供了证明我们已经知道的许多关于开源的事情的数字。
首先,“每个人”都在使用开源,或者作为调查结果状态......
“无处不在的全球开源软件开发是常规。”
该调查还显示,使用开源的主要驱动力是免于供应商锁定。这也是JFrog的主要驱动因素之一,也是我们创造的一切都是通用的原因:
Artifactory,通用工件存储库管理器
Bintray,通用软件分发平台,
Xray,用于通用工件分析,
Mission Control,通用仓库管理。
大多数组织盲目使用开源
但调查还显示,大多数组织缺乏对开源软件的可见性和控制力。开源通过许多已知和未知的来源(包括开发人员,供应商和外部承包商)在组织的应用程序代码中输入和传播。 Black Duck On-Demand服务进行的开源审计发现,平均而言,公司使用的开源数量是之前所知的两倍,而67%的应用程序包含已知的开源漏洞。
你需要一个过程才能看到光明
为了解除开源使用的“迷雾”,组织需要一些自动化且可重复的过程,在大多数情况下,这些过程不存在。这些包括:
- 在进入代码流时检测和批准新的开源
- 盘点并跟踪其代码库和Docker容器中开源软件的使用情况
- 识别或监控与他们使用的开源软件相关的已知开源漏洞(如Heartbleed,ShellShock等)
- 随着时间的推移,协调或跟踪风险补救工作
- 评估使用具有不兼容许可条款的开源软件可能产生的诉讼和知识产权(IP)风险。
- 审核和实施开源安全策略和许可证合规性。
所有这些过程现在都更容易实现,Black Duck Hub集成到JFrog Xray和Black Duck的二进制存储库集成插件中,用于JFrog Artifactory
Xray通过Black Duck Hub点亮前进的道路
Xray的深度递归扫描会将Artifactory存储库中的包和深入到最深层次,以识别您正在使用的所有开源依赖项。 Xray通过其漏洞的全局数据库交叉引用这些依赖关系,这些漏洞汇集自不同的来源。
Black Duck Hub在整个软件开发生命周期(SDLC)中为组织提供开源风险管理 - 包括IDE,SCM,构建,CI,二进制存储库和Docker容器。
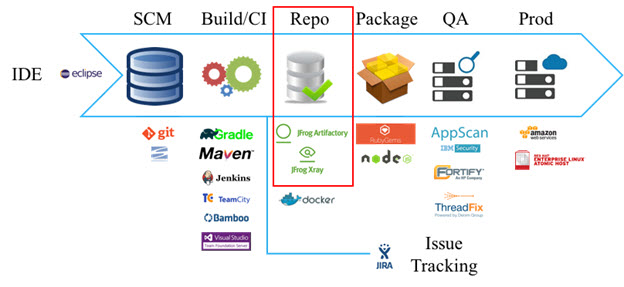
通过Xray与Black Duck Hub的集成,您可以大大扩展漏洞数据库,包括Black Duck全面的KnowledgeBase(™),包括2,000,000多个开源项目和150,000个漏洞。 您需要做的就是在Xray的集成模块中输入您的Black Duck凭证。

Black Duck与JFrog Artifactory和Xray的集成允许组织在SDLC中的不同级别管理构建输出扫描和存储库检查。在使用Artifactory Pro的存储库级别或在Xray的正式SDLC过程之外。例如,构建输出扫描程序插件可以在开发过程中更早地监视构建并提供风险信息,例如,当需要监视开发人员构建时。当企业拥有多个不同的SDLC工具集并且无法在所有工具集中进行统一集成时,存储库检查器插件提供了监视工件的功能。将Black Duck Hub集成到Xray中也可以通过Xray提供类似的功能。 Xray根据您定义的Watches扫描存储库中的构建和工件,使用其全局数据库与Black Duck KnowledgeBase交叉引用这些工件以识别问题和漏洞,然后它可以生成相应的警报以进行补救。
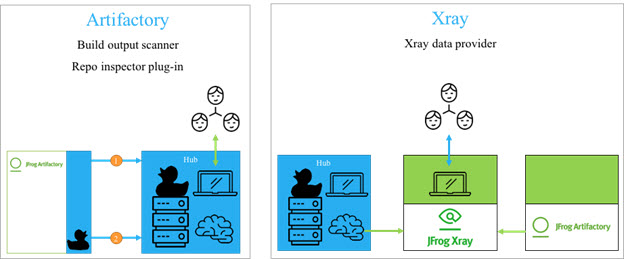
将JFrog Xray和JFrog Artifactory的强大功能与Black Duck Hub相结合,使组织能够消除开源安全漏洞,满足许可证合规性义务并限制操作风险。
识别组件和开源安全风险
Xray会自动跟踪Artifactory存储库中组件和Docker镜像使用的开源。它将这些组件映射到其全局数据库和Black Duck的KnowledgeBase中报告的已知开源安全漏洞的组件,并监视许可证和组件质量风险。
自动化补救和政策执行
使用Watches中定义的许可过滤器轻松实施开源许可策略,并通过在构建中检测到漏洞的早期干预自动CI过程来简化实施。
持续监控新漏洞的应用程序
Xray的全球数据库和Black Duck的KnowledgeBase都聚合了多个漏洞数据源,因此您可以获得生产应用中检测到的新漏洞的当天警报。通知可以通过Xray UI,通过电子邮件或调用webhooks发布
随着Xray和Black Duck守卫你的大门,你对开源软件的使用受到了关注。您完全了解组织使用的所有开源组件,可以在SDLC的早期检测和修复漏洞,当检测到生产系统中可能潜伏的新漏洞并使用开源时,您会立即收到通知不仅无处不在,而且也是安全的。
原文:https://jfrog.com/blog/frogs-and-ducks-your-sentinels-for-open-source-security/
本文:http://pub.intelligentx.net/node/426
讨论:加入知识星球【首席架构师圈】
- 72 次浏览
【安全运营】为什么现有的安全SDLC方法失败
规模,自动化和不断增长的成本越来越多地促使组织采用安全的软件开发生命周期(SDLC)方法。虽然静态代码分析和漏洞扫描等工具在提高应用程序安全性方面取得了成功,但组织已经开始认识到SDLC内安全审查早期集成的价值 - 最显着的是它降低了管理和修复成本的能力与安全相关的错误。
但是,许多用于执行此操作的方法(如OpenSAMM,BSIMM和Microsoft的SDL)采用的方法类似于低效,自上而下的瀑布式方法。这些保护SDLC的方法在业界很多都失败了,需要采用新的方法。
流行的安全SDLC方法
正如许多专家建议的那样,软件组织通常采用自上而下的方法来实施安全的SDLC方法。虽然这种方法的好处是可以确保安全软件开发过程所需的组件,但它并不能保证安全的产品。
以下是目前帮助组织在其SDLC中集成安全性的流行方法的简短列表。
- OpenSAMM:软件保障成熟度模型(SAMM)是一个OWASP项目,用于指导SDLC中的安全性集成。所描述的12项活动分为四类:治理,建设,验证和部署。
- BSIMM:由Cigital开发的建筑安全成熟度模型(BSIMM)由12个实践组成,分为4个领域:治理,智能,安全软件开发生命周期(S-SDLC)接触点和部署。
- SDL:Microsoft安全开发生命周期旨在创建符合法规标准的安全软件,同时降低开发成本。微软开始推广这种方法,强调分别在2001年和2002年遵循CodeRed和Nimda蠕虫的安全编码实践的重要性。
安全SDLC方法已经为软件开发人员做出了许多承诺,特别是SDLC中早期安全集成带来的成本节约,这有助于避免代价高昂的设计缺陷并提高软件项目的长期可行性。
但是,这些方法并非没有缺点。
瀑布SDLC方法在敏捷环境中受阻
流行的方法通常将组织划分为业务单元或业务功能,并且仅在其他活动完成后才依赖于启动某些活动。这种组织结构假设业务活动以特定的线性顺序发生,这是敏捷框架难以协调的主张。
例如,Microsoft SDL定义了一种称为“建立安全和隐私要求”的做法,该做法建议尽早开发安全和隐私目标,以便最大限度地减少调度冲突,但这也会产生创建敏捷环境中通常不存在的严格时间线的效果。
在敏捷框架下,他们强调持续集成和持续部署,很少有软件开发团队创建详细记录长期计划的文档。这使得敏捷团队难以实现这种以瀑布为中心的安全SDLC。
实施成本很高
与实施SDLC相关的成本可能过高。根据OpenSAMM自己的估计,当使用下表第二列中描述的估计小时费用时,实施其12项活动中的每项活动将花费大约90,000美元。

尽管为确保整个组织的开发过程提供90,000美元看起来似乎很划算,但应该提到三个警告。
90,000美元的估算仅包括实施OpenSAMM第一级到期水平的成本,不包括第二级或第三级的成本,这无疑会大大提高最终成本。
90,000美元的估计是保守的。 OpenSAMM每年为第一个成熟度级别所需的代码审查活动分配五到九天。因此,这可能是一个非常小的组织,或者估计是不完整的,可能只考虑设置成本而不是持续的运营费用。我组织并参与了无数的代码审查,我可以证明它们是一项耗时的活动,在大多数情况下很容易超过90,000美元的估算。
最后,方法所推荐的实施活动的价值往往在这个过程中丢失,而这些活动的实施完全是因为它们作为必须满足的清单上的要求而存在才能继续前进。例如,实施漏洞扫描并不能保证甚至可以查看扫描,更不用说采取行动了。如果要从其实施中获得价值,则必须了解活动的背景及其相关指标的相互作用。
自下而上的安全SDLC
也许SDLC方法不应该从上到下,而是从下到上来处理和实施。您可以先确定目标,然后确定并采用最有效地帮助您实现这些目标的活动,而不是实施满足检查表要求的活动。
对于这种方法,有必要首先确定对您的组织成功至关重要的指标。在我看来,有两个重要指标:漏洞总数及其平均补救时间。
- 漏洞总数:任何方法的唯一目的是帮助组织系统地,始终如一地生成更安全的代码。查找并减少代码中的漏洞数量意味着您已经创建了一个更安全的最终项目。
- 平均修复时间:由于两个重要原因,修复后期制作中的错误比在预生产中修复它们要成本高得多。首先,存在的错误越长,攻击者就越需要利用它们。其次,随着开发人员转向不同的项目,或者在某些情况下,其他公司,组织解决安全问题的能力会降低,从而增加与修复这些问题相关的成本。
确定关键指标后,首先要实施可以帮助您尽快达到指标目标的活动。所选指标将指导您识别和实施可帮助您实现目标的活动。安全的用户故事,安全代码审查,渗透测试和环境强化只是一些可能有用的活动。
分析后的行动项目
在最初的活动实施后,您的重点应转向持续的投资和改进。例如,如果安全代码审查的实现揭示了过多的错误,那么投资培训以改进安全编码技术可能是有利的。或者,如果需要时间进行补救,那么投资漏洞管理系统可以帮助开发人员更好地管理漏洞并缩短补救时间。
敏捷,度量驱动的方法
当前的技术前景要求公司认真对待软件安全以获得成功,并且越来越多的人已经做到这一点,向左转并采用安全的SDLC方法。
虽然大多数组织依赖于敏捷软件开发框架(如Scrum),但许多安全的SDLC方法都是针对瀑布式方法而设计的。遗憾的是,DevOps对速度和自动化的关注意味着这些方法落后,需要大量的手动工作才能跟上快速发展的发展前景。
如果开发人员要保持领先于他们日常面临的日益增长的安全挑战,那么在当今敏捷,以开发为导向的世界中,对更轻,敏捷和度量驱动的方法的需求已成为必需。
原文:https://techbeacon.com/security/why-existing-secure-sdlc-methodologies-are-failing
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 104 次浏览
【安全运营】什么定义了已知的开源漏洞?
介绍
开源软件 - 其代码可供公众查阅,通常可免费使用 - 非常棒。作为消费者,它使我们无需重新发明轮子,让我们专注于我们的核心功能并大幅提高我们的生产力。作为作者,它让我们分享我们的工作,获得社区的爱,建立声誉,并且有时对软件的工作方式产生实际影响。
因为它太神奇了,开源使用率飙升。实际上,从妈妈和流行商店到银行和政府的每个组织都依靠开源来运营他们的技术堆栈 - 以及他们的业务。工具和最佳实践已经发展到使这种消费变得越来越容易,通过单个代码或终端线来降低大量功能。
不幸的是,使用开源也存在很大的风险。我们依靠这些由陌生人编写的众包代码来运行任务关键型系统。通常情况下,我们很少或根本没有仔细检查,几乎没有意识到我们正在使用什么,完全不知道它的血统。
您使用的每个库都存在多个潜在的陷阱。该库是否存在攻击者可以利用的软件漏洞?它是否使用病毒许可证使我们的知识产权面临风险?恶意贡献者是否在良好的代码中隐藏了恶意软件?
与商业软件不同,免费开源软件(FOSS)很少提供任何担保或保证。作为开源软件的消费者,您有责任了解并减轻这些风险。
2017年9月宣布的Equifax数据泄露事件使这一风险完全成为现实。由于开源Apache Struts库存在严重漏洞,该漏洞暴露了1.43亿人的极端个人信息。 2017年3月披露了此漏洞,只有在发现漏洞后,有问题的Equifax系统才会在7月底之前修补。 Equifax完全有能力更早识别和解决这个问题,防止大规模泄漏,许多人声称不这样做是公司的疏忽。 Equifax漏洞肯定会成为保护数据和负责任地使用开源的重要性的典型代表。
书籍目的和目标受众
本书将帮助您解决易受攻击的开源库的风险,这是绊倒Equifax的原因。正如我将在本书中讨论的那样,这些易受攻击的依赖项最有可能被攻击者利用,并且您需要良好的实践和工具来大规模保护您的应用程序。
由于在开发(包括DevOps)和应用程序安全性之间共享应用程序及其库的安全责任,因此本书面向这两个部门的架构师和从业者。
考虑到这一点,接下来的几节将进一步解释本书的内容和范围。其余主题有望在未来更广泛的书中介绍。
工具与库
开源项目有多种形式和形式。对它们进行分类的一种有些过于简单的方法是将它们分成工具和库。
工具是独立的实体,无需编写自己的应用程序即可使用或运行。工具可以大小,从小型Linux实用程序(如cat和cURL)到完整和复杂的平台(如CloudFoundry或Hadoop)。
库具有旨在在应用程序内部使用的功能。示例包括Node.js的Express Web服务器,Java的OkHttp HTTP客户端或本机OpenSSL TLS库。与项目一样,库的大小,复杂性和广度也有很大差异。
本书专注于库。虽然一些开源项目可以作为工具和库使用,但本书仅考虑库方面。
应用程序与操作系统依赖关系
开源软件(OSS)项目可以直接从他们的网站或GitHub存储库下载,但主要通过注册表来使用,注册表包含打包和版本化的项目快照。
一类注册表包含操作系统依赖性。例如,Debian和Ubuntu系统使用apt注册表来下载实用程序,Fedora和RedHat用户利用yum,许多Mac用户使用HomeBrew在他们的机器上安装工具。这些通常被称为服务器依赖项,更新它们通常称为“修补服务器”。
另一种类型的注册表包含主要用于应用程序的软件库。这些注册表主要是语言特定的 - 例如,pip包含Python库,npm包含Node.js和前端JavaScript代码,Maven服务于Java和相邻社区。
保护服务器依赖性主要归结为通过经常运行诸如apt-get upgrade之类的命令来更新依赖关系。虽然现实问题从未如此简单,但保护服务器依赖性比保护应用程序依赖性要好得多。因此,虽然它的大部分逻辑适用于所有类型的库,但本书仅专注于应用程序依赖性。
要了解有关保护服务器(包括其依赖关系)的更多信息,请查看Lee Brotherston和Amanda Berlin的防御安全手册(O'Reilly,2017)。
已知的漏洞与其他风险
消费开源库存在多种类型的风险,包括对库许可的法律问题,陈旧或管理不善的项目中的可靠性问题,以及具有恶意或妥协贡献者的库。
但是,在我看来,最直接的安全风险在于开源库中的已知漏洞。正如我将在下一章解释的那样,这些已知的漏洞是攻击者利用的最简单的途径,并且大多数组织都很难理解和处理。
本书侧重于不断发现,修复和预防开源库中的已知漏洞。其目的是帮助您了解这种风险以及您需要采取的措施。
比较工具
有助于解决易受攻击库的工具通常称为软件组合分析(SCA)工具。这个首字母缩略词并不代表整个风险范围(特别是,它没有捕获分析后的补救措施),但由于这是分析师使用的术语,我将在本书中使用它。
由于工具环境正在迅速发展,我将主要避免引用特定工具的功能,除非工具与相关功能紧密相关。在命名工具时,我将专注于免费或免费增值工具,允许您在使用前对其进行审核。第6章从更高层次的角度对评估工具进行了评估,从而在选择解决方案时提供了更加明确的视角,了解哪些方面最重要。
书大纲
既然您已经理解了本书的主题,那么让我们快速回顾一下这个流程:
- 开源软件包中的已知漏洞定义并讨论了已知的漏洞以及为什么跟上它们的重要性。
- 第2章到第5章解释了解决开源库中已知漏洞的四个逻辑步骤:查找漏洞,修复漏洞,防止添加新的易受攻击的库,以及响应新披露的漏洞。
- 如前所述,第6章从解释SCA工具之间的差异,突出我认为最重要的属性重点。
- 最后,第7章总结了我们所学到的内容,并简要介绍了未详细介绍的主题。
本书假定您已熟悉使用开源注册表(如npm,Maven或RubyGems)的基础知识。如果你不是,那么在开始阅读本书之前,有必要阅读一两个这样的生态系统,以充分利用它。
开源软件包中的已知漏洞
“已知漏洞”听起来像是一个非常不言自明的术语。顾名思义,这是一个公开报道的安全漏洞。然而,由于这些缺陷的数量和重要性,围绕这种风险形成了一个完整的生态系统,包括广泛使用的标准以及商业和政府参与者。
本章试图更好地定义已知漏洞的含义,并解释在建立解决方法时需要理解的关键行业术语。
可重用产品中的漏洞
已知漏洞仅适用于具有多个部署的可重用产品,也称为第三方组件。这些产品可以是软件或硬件,免费或商业,但它们总是部署多个实例。如果一个漏洞仅存在于一个系统中,则对其进行清点并让其他人了解它(除了攻击者之外)是没有价值的。
因此,当我们谈到已知的漏洞时,我们只提到可重用的产品。由于大多数已知漏洞处理商业产品(开源已知漏洞的世界有点新生),负责产品的实体通常被称为供应商。在本书中,因为它涉及开源软件包而不是商业软件,所以我将该实体称为软件包的所有者或作者。
漏洞数据库
在最基本的层面上,一旦漏洞被公开发布在一个相当容易找到的位置,就会被认为是漏洞。一旦漏洞被广泛披露,维护者就可以了解它并保护他们的应用程序,但攻击者 - 包括自动化或不太复杂的攻击者 - 也有机会轻松找到并利用它。
也就是说,互联网是一个很大的地方,并拥有大量的软件。新的漏洞会定期披露,有时甚至会在一天内泄漏数十个漏洞。为了使防御者能够跟上,这些漏洞需要存储在一个易于查找的中心位置。为此目的,已经创建了许多结构化数据库,包括商业和开放数据库,以编译这些漏洞和有关它们的信息,允许个人和工具查询测试他们的系统以防止他们持有的漏洞。
此外,有几个数据库专注于开源软件包中的漏洞,例如Snyk的DB,Node Security Project,Rubysec和Victims DB。但是,在深入研究之前,让我们回顾一下已知漏洞数据库世界的更广泛和更标准化的基础:CVE,CWE,CPE和CVSS。
技巧
已知的漏洞与零日
漏洞也可以为某些方所知,但不能公开发布。例如,糟糕的演员经常在流行的库中发现漏洞并在黑市上出售(通常称为“黑暗网络”)。这些漏洞通常被称为零日漏洞,这意味着自披露以来零日已过去。
Common Vulnerabilities and Exposures
常见漏洞与暴露(CVE)
最常见的漏洞信息是常见漏洞和披露(CVE)。 CVE是一个免费的漏洞词典,由美国政府创建和赞助,由MITRE非营利组织维护。在美国政府的支持下,CVE在全球范围内被用作分类系统。
当披露新的漏洞时,可以向MITRE(或其他CVE编号机构之一)报告,该漏洞可以确认问题是真实的并为其分配CVE编号。从那时起,CVE编号可以用作此缺陷的跨系统标识符,从而可以轻松地在安全工具之间进行关联。实际上,即使在为给定漏洞维护自己的ID时,大多数漏洞数据库也会保留并共享CVE。
值得注意的是,CVE本身不是一个数据库,而是一个ID字典。为了帮助自动化系统访问所有CVE,美国政府还支持国家漏洞数据库(NVD)。 NVD是一个数据库,通过标准化的安全内容自动化协议(SCAP)公开漏洞信息。
CVE是一个非常混乱的漏洞列表,因为它适用于各种各样的系统。为了使其与消费者保持一致和可用,MITRE围绕内容和分类制定了各种指导方针和政策。至少对于OSS库世界而言,三个最值得注意的是CPE,CWE和CVSS。
Common Platform Enumeration
通用平台枚举(CPE)
除了它们所代表的大量漏洞之外,CVE还表明了极其不同的产品存在缺陷。为了使您更容易发现给定的CVE是否适用于您的产品,NVD可以使用一个或多个Common Product Enumeration(CPE)字段修改每个CVE。 CPE是一种相对宽松的数据结构,它描述了此CVE适用的产品名称和版本范围(以及可能还有其他数据)。请注意,CPE不是CVE的一部分,而是NVD的一部分。这意味着一个已知的漏洞不会有产品信息,除非它进入NVD,这并不总是会发生(稍后会详细介绍)。
CPE是一个强大的想法,可以实现漏洞的自动发现。但是,以通用方式定义产品非常困难,并且缺乏许多CVE的内容质量。因此,在实践中,CPE通常是不准确的,部分的,或者根本不是自动化友好的,足以实用。严重依赖CPE的产品,如OWASP依赖检查器,需要使用模糊逻辑来理解CPE,并在缺少内容时失败,从而导致大量误报和漏报。
为了解决这一差距,OSS库空间中的大多数商业漏洞扫描程序和数据库仅使用CPE作为起点,但是将CVE的映射保持为相关产品。
Common Weakness Enumeration
常见弱点枚举(CWE)
虽然每个漏洞都是它自己独特的雪花,但在一天结束时,大多数漏洞都属于更有限的漏洞类型列表。 MITER将这些类型分类为Common Weakness Enumeration(CWE)列表,并提供有关每种弱点类型的信息。虽然CWE项目可以非常具体(例如,CWE-608表示在Struts的ActionForm类中使用非私有字段),但其更广泛的类别被更广泛地使用。例如,CWE-285描述了不正当授权,而CWE-20代表了不正确输入验证的许多变体。 CWE也是分层的,允许更广泛的范围CWE包含多个更窄范围的CWE。
较少数量的CWE使得为每个项目提供丰富的详细信息和补救建议更为可行,或者根据漏洞类型定义策略。每个CVE都使用一个或多个CWE进行分类,帮助其消费者专注于他们最感兴趣的CWE,并且无需为每个相关的CVE重复CWE级信息。
常见漏洞评分系统(CVSS)
漏洞定期披露,并以相当惊人的速度披露,但并非所有漏洞都需要放弃所有内容并采取行动。例如,向攻击者泄露信息并不像允许他们远程执行服务器上的命令那么糟糕。此外,如果可以通过简单的HTTP请求利用漏洞,则修复比要求攻击者修改后端文件的漏洞更紧急。
也就是说,对漏洞进行分类并不容易,因为有很多参数,很难判断每个参数的重量。访问DB的程度是否比远程命令执行更严重?如果此执行是作为低权限用户完成的,那么与以root身份执行的漏洞利用相比,应该降低其严重性分数的程度是多少?如何判断需要长序列请求的漏洞,但是可以使用从Web下载的工具来完成?
除此之外,问题的严重性还取决于它所在的系统。例如,银行网站上的信息泄露漏洞比静态新闻网站上的漏洞更严重,需要物理机访问的漏洞对设备而言比对云服务更重要。
为了帮助解决所有这些问题,MITRE创建了一个通用漏洞评分系统(CVSS)。该系统目前处于第三次迭代,因此您可能会看到对CVSSv3的引用,这是此处讨论的版本。 CVSSv3将得分分为三个不同的分数,每个分数分成几个较小的分数:
基础(Base)
有关漏洞的不可变细节,包括攻击媒介,利用复杂性以及它可能产生的影响。
暂时的 (Temporal)
时间敏感信息,例如漏洞利用工具的成熟度或易于修复。
环境的 (Environmental)
易受攻击的系统的上下文信息,例如它的敏感程度或可访问性。
图1-1显示了样本漏洞的CVSSv3评分的变量和计算(计算是使用FIRST.org的在线工具生成的)。
虽然所有三个分数都很重要,但公共数据库通常仅显示基于Base组件的CVSS分数。时间分数的不断变化使维护成本高昂,根据定义,环境分数是每个漏洞实例特有的。尽管如此,这些数据库的用户仍然可以填写这两个分数,根据需要调整权重,并获得最终分数。
![]()
CVE和NVD之外的已知漏洞
拥有CVE很有帮助,但这也很麻烦。收到CVE号码要求作者或记者首先了解它,然后进行一定量的文书工作和备案工作。最后,CVE需要得到特定CVE编号机构(CNA)的批准,这需要时间。因此,尽管CVE是某些类型系统(例如,网络设备)中的漏洞的标准,但它们在其他世界中并不常见。
当涉及OSS包中的已知漏洞时,CVE的形状尤其糟糕。截至2017年10月,基于Snyk的数据库,只有67%的Ruby gem漏洞分配了CVE,而11%的npm软件包漏洞只有这样的ID。
造成这种差距的一个原因是,开发人员(而非安全研究人员)报告了许多库漏洞,并将其作为漏洞进行通信。这些问题通常很快得到解决,但一旦修复,作者和记者很少会通过CVE流程。即使他们这样做,CVE的任务也远远落后,而攻击者可能正在利用现在已知的漏洞。
在CVE的分配和将其发布到NVD之间又发生了另一个滞后,提供了更多的细节,也许还有CPE。当新漏洞在经过负责任的披露过程中保留一定数量时,预计会出现此类延迟,但这种延迟通常在漏洞已知后发生。
在查看易受攻击的Maven软件包时,这种滞后非常明显:37%的具有CVE的Maven软件包漏洞在被添加到NVD之前是公开的,其中20%在被添加之前已经公开了40周或更长时间。
NVD上没有的已知漏洞仍然存在,但难以检测。库漏洞可能要么没有CVE,要么没有在NVD上列出(因此没有咨询或CPE),或者质量差的CPE。其中每一项都会阻止它们通过专门依赖这些公共数据源的工具进行检测,尤其是OWASP依赖检查器。
技巧
在没有CVE的情况下使用CWE和CVSS
虽然CVE,CWE和CVSS都是MITRE标准,但它们可以彼此独立使用。 CWE和CVSS通常用于没有CVE的漏洞,即使没有行业范围的ID,也提供标准化的分类和严重性。
未知与已知漏洞
每个已知的漏洞在某些时候都是未知的。这似乎是显而易见的,但这是一个重要的理解点 - 一个新的已知漏洞不是一个新的漏洞,而是一个新披露的漏洞。在发现和报告之前,漏洞本身已存在。然而,虽然披露漏洞并不能创建它,但它确实改变了它应该如何处理,以及它应该如何紧急修复。
对于攻击者来说,查找和利用未知漏洞很难。存在无穷无尽的潜在攻击变体,需要在避免检测的同时快速调用。确定攻击是否成功并不总是容易的,这意味着提交的有效载荷可能已经成功通过,而攻击者仍然不是更聪明。
一旦泄露漏洞,利用它就变得容易多了。攻击者可以详细了解漏洞及其调用方式,只需要识别正在运行的软件(称为指纹识别的过程)并获取恶意负载。通过自动漏洞利用工具可以更轻松地完成此过程,该工具可以列举已知的漏洞及其漏洞。这种自动化还降低了进入障碍,允许不太复杂的攻击者尝试渗透。
已知的漏洞在很大程度上被认为是野外成功攻击的主要原因。引用两个样本来源,Verizon表示“大多数攻击都利用已知的漏洞,这些漏洞从未修补过,尽管有几个月,甚至几年可用的补丁”,赛门铁克预测“到2020年,99%的漏洞利用将继续是已知的漏洞由安全和IT专业人员至少一年“。在应用方面,Gartner和RedMonk等分析公司一再声明处理开源库中已知漏洞的重要性。
因此,应该紧急处理已知的漏洞。即使它是相同的漏洞,它的披露使攻击者更有可能使用它来访问您的系统。漏洞的披露引发了一场竞赛,看看一名防守者是否可以在攻击者通过它之前封堵洞。图1-2显示了攻击者对前面提到的严重Struts2漏洞披露的反应,在几天内从零攻击逐渐增加到每天观察到的超过一千次攻击。
![]()
好消息是已知漏洞比未知漏洞更容易防御。通常,已知的漏洞也具有已知的解决方案,通常以软件升级或补丁的形式。即使不存在软件解决方案,您至少应该更好地了解如何检测攻击并防止它们通过安全控制。正如我将在第5章中讨论的那样,重要的是投资系统,让您快速了解此类披露,并比不良行为者更快地采取行动。
负责任的披露
到目前为止,我谈到了披露作为一个单一的时间点,实际上它不应该是二元的。披露漏洞的正确方式,被称为负责任的披露,涉及几个步骤,旨在让维权者在上述竞选中领先一步。
理解负责任的披露对于开源消费者来说并不重要,但对于开源作者来说这一点非常重要。要了解有关负责任披露的更多信息,您可以阅读Tim Kadlec的优秀博客文章,或者查看Snyk负责任的披露模板。
摘要
已知的漏洞并不像最初出现的那么简单。已知的内容的定义和漏洞元数据的管理很难做得很好。
CVE和NVD适用于策划商业产品中的漏洞,但不能扩展到开源项目的卷和所有权模型。随着时间的推移,这些标准可能会发展以满足这种需求,但是现在它们的覆盖范围和细节水平还不足以保护您的库。
原文:https://www.oreilly.com/ideas/what-defines-a-known-open-source-vulnerability
本文:http://pub.intelligentx.net/node/422
讨论: 加入知识星球【首席架构师圈】
- 121 次浏览
【安全运营】什么是CI / CD管道中的代码静态分析?
借助DevOps实践,企业IT更快,更灵活。自动构建,测试和发布形式的自动化在实现这些优势方面发挥着重要作用,并为持续集成/持续部署(CI / CD)管道奠定了基础。但是,是否可以在不降低流程速度的情况下将安全性集成到混合中? IT团队可以将安全性集成到DevOps管道中的一种方法是确保发布的代码从一开始就是安全的。将安全性作为一流公民集成到DevOps流程中的概念称为DevSecOps,是安全敏感型企业的最佳实践。
Cloud Academy最近发布了一套新的DevOps实验室,重点介绍了CI / CD管道自动化的一些最佳实践。在这篇文章中,我将向您展示如何在CI / CD管道中使用静态分析来提高代码质量,从而减少现在和将来的问题。
什么是静态分析?
静态分析是一种在推送到生产之前分析缺陷,错误或安全问题的代码的方法。静态分析工具通常被称为“linters”,可以从代码中删除不必要的毛茸茸,并执行一些自动检查以提高代码质量。静态分析工具可以检查:
- 代码风格约定和标准不一致。它可以像执行一致的缩进和变量名一样简单,也可以像强制执行MISRA或CERT安全编码标准那样复杂
- 资源泄漏,例如无法释放已分配的内存,最终可能导致程序崩溃或无法关闭文件
- 应用程序编程接口(API)的使用不正确
- 常见的安全漏洞,例如Open Web Application Security Project(OWASP)或Common Weakness Enumeration(CWE)所识别的漏洞
有哪些静态分析工具?
可用的静态分析工具可以根据它们支持的功能进行分类,包括:
- 编程语言:工具可能支持单语言或多语言。如果你的代码库涵盖多种语言,像Coverity这样支持14种语言(包括JavaScript,.NET,Java和Python)的单一工具可能是发现跨语言错误的最全面的选择。
- 实时工具:瞬时分析工具非常适合在编写开发环境时检查代码。在这里,权衡是对更彻底,耗时的检查的速度。其中许多是开源的,可以更容易地采用和定制。
- 深度分析工具:另一方面,深度分析工具可能需要更长的时间,并且可能会识别实时工具可能遗漏的问题。该领域的企业级工具通常需要很高的许可费用,并且它们可能会带来更多的问题,而不是您要解决的带宽问题。其中许多工具可能配置为仅报告最重要的问题。
- 编译器:虽然不是专用的静态分析工具,但编译器也可用于提高代码质量。您可以使用配置标志来调整它们执行的检查数。
在CI / CD中集成静态分析
在使用静态分析工具的众多好处中,对组织最有益的是能够在错误发布之前发现错误(以及修复成本较低的时候)。在CI / CD的DevOps实践中,静态分析工具提供了额外的好处。
在开发过程中,需要花费很长时间才能运行的工具会被忽略。即使静态分析并不总是一个漫长的过程,它仍然不是开发人员时间的最佳用途。在CI / CD中集成分析工具可确保一致且自动地使用它们,同时提供额外级别的分析,以确保无法通过任何内容。
如何在您的环境中集成静态分析工具有不同的选项。一种方法是在管道的早期运行它以及其他自动化测试。此时,您将能够在同行代码审查之前解决任何问题,并加快整个过程。反过来,开发人员花在审查上的时间更少,并且有更多时间来开发新代码。
如果您拥有大量代码库,则在每次提交时运行深入分析可能会花费太多时间。相反,您可以在开发分支上使用不太全面的分析配置,并按计划执行更昂贵的扫描,或者在集成到上游分支时执行。我们的目标是尽可能早地发现错误,您可以选择最适合您团队的系统。像Klocwork这样的工具完全采用了CI / CD工作流程,并且可以逐步分析每次提交时的代码更改。
高端静态分析工具还可以随时跟踪错误。这可以帮助您选择在当前发布周期中处理哪些问题,因为源代码不断被集成。在长期遗留的代码中报告的问题没有引起问题,可能不值得花时间投资来解决它们。相反,使用宝贵的开发人员时间来关注更近期的问题。
另一个实际约束是可用于静态分析的预算。不是为每个开发人员获取许可证,而是在一定数量的构建计算机(如果可能的话,单个计算机)上运行分析工具。
通过在Cloud Academy上的CI / CD管道实验室中完成静态代码分析,您可以体验静态分析在CI / CD中的工作原理。这个新的动手实验室使用以AWS为中心的连续部署管道来部署Node.js应用程序。该应用程序最初发布到生产中而不执行静态分析。您将学习如何对已部署的应用程序执行注入攻击,然后使用静态分析来识别安全问题。最后,将静态分析集成到管道中的AWS CodeBuild构建阶段,以防止在实施修复之前部署易受攻击的代码。这是最终的环境:

CI / CD中基础设施静态分析代码
作为代码的基础设施(IaC)为开发人员提供了许多好处,包括没有配置偏差,易于重现的环境以及简化的版本控制协作。您是否知道静态分析还可用于实施代码标准并识别基础架构的安全漏洞?通过对基础架构代码使用静态分析,与需要实际部署基础架构的基础架构测试相比,您可以自动化流程并接收早期反馈,这可能是一项耗时的操作。
对于您可能正在使用的大多数IaC框架,通常都会内置某种形式的静态分析。可能有命令检查语法,确保使用有效的参数值,并自动设置代码样式。您还可以执行干运行部署,以检查环境中发生的更改,或在实际部署任何基础结构更改之前检测错误。
您可以使用自己的自定义分析代码补充这些命令,以检查您需要验证的任何内容,例如确保某些端口不对公共互联网开放。幸运的是,通常有开源静态分析工具已经提供了常见的检查。例如,cfn_nag可用于检查AWS CloudFormation模板(AWS的本机IaC框架)中的安全问题。 cfn_nag检查的其他示例包括:
- 确保IAM策略不会过于宽松
- 确保在提供加密的服务上启用加密
- 确保安全组不会过于宽松
如果开源IaC静态分析工具不提供您想要的检查,则可能更容易将其添加到现有代码库而不是从头开始。
您可以亲身体验如何在云学院动手实验室的CI / CD管道中进行IaC静态分析:静态分析和基础设施警报作为代码。该实验室使用Terraform作为IaC框架,使用Jenkins作为其持续集成管道。您将了解Terraform中内置的静态分析功能以及两个改进Terraform本机功能的开源静态分析工具。通过推送到Git存储库,可以持续集成新的基础架构代码。您还将学习如何根据静态分析的结果配置Amazon SNS通知。这是实验室的最终环境:

补充静态分析
虽然静态分析工具在不断改进,但它们并不是满足您所有代码质量和安全需求的灵丹妙药。 相反,将它们视为更全面的解决方案的一部分,以提高应用程序和基础架构代码的质量和安全性。 有时,您仍然需要使用传统的应用程序单元和集成测试,甚至是基础架构测试。 您将能够在我们的动手实验室,使用Serverspec进行基础架构测试中自行测试Serverspec基础架构测试框架。

安全性是另一个重要的自动化测试框架类别。 在此动手实验中学习如何使用Gauntlt保护您的代码免受攻击。 使用Gauntlt,您可以为几种流行的安全分析工具编写自动化测试,并且可以轻松扩展到其他工具。

确保安全的应用程序是安全性的一个重要方面。 传输层安全性(TLS)/安全套接字层(SSL)协议是保护Web上通信的标准。 了解部署SSL / TLS的最佳实践以及在此Cloud Academy实验室中测试SSL / TLS部署的工具。

原文:https://cloudacademy.com/blog/what-is-static-analysis-within-ci-cd-pipelines/
本文:http://pub.intelligentx.net/what-static-analysis-within-cicd-pipelines
讨论:请加入知识星球【首席架构师圈】
- 95 次浏览
【安全运营】什么是运行时应用程序自我保护(RASP)?
应用程序已成为希望渗透企业的Web掠夺者的成熟目标。这是有充分理由的。 Black Hats知道如果他们能够在应用程序中找到并利用漏洞,他们就有三分之一的机会成功解决数据泄露问题。更重要的是,在应用中发现漏洞的可能性也很大。 Contrast Security表示,90%的应用程序在开发和质量保证阶段都没有针对漏洞进行测试,甚至更多的应用程序在生产过程中没有受到保护。
由于企业中存在如此多的易受攻击的应用程序,网络防御者面临的挑战是如何保护这些应用程序免受攻击。一种方法是让应用程序通过实时识别和阻止攻击来保护自己。这就是运行时应用程序自我保护(RASP)所做的技术。
什么是RASP?
RASP是一种在服务器上运行并在应用程序运行时启动的技术。它旨在实时检测对应用程序的攻击。当应用程序开始运行时,RASP可以通过分析应用程序的行为和该行为的上下文来保护它免受恶意输入或行为的影响。通过使用应用程序持续监控自己的行为,可以立即识别和缓解攻击,无需人为干预。
RASP将安全性整合到正在运行的应用程序中,无论它位于服务器上。它拦截从应用程序到系统的所有调用,确保它们是安全的,并直接在应用程序内验证数据请求。 Web和非Web应用程序都可以通过RASP进行保护。该技术不会影响应用程序的设计,因为RASP的检测和保护功能在应用程序运行的服务器上运行。
RASP如何运作
当应用程序中发生安全事件时,RASP会控制应用程序并解决问题。在诊断模式下,RASP只会发出警告,表示出现问题。在保护模式下,它会尝试阻止它。例如,它可以停止执行似乎是SQL注入攻击的数据库的指令。
RASP可以采取的其他操作包括终止用户会话,停止应用程序执行或警告用户或安全人员。
开发人员可以通过几种方式实现RASP。他们可以通过应用程序源代码中包含的函数调用来访问该技术,或者他们可以将完整的应用程序放入一个包装器中,该应用程序只需按一下按钮即可保护应用程序。第一种方法更精确,因为开发人员可以在应用程序中做出有关他们想要保护的内容的具体决策,例如登录,数据库查询和管理功能。
无论哪种方法与RASP一起使用,最终结果就像将Web应用程序防火墙与应用程序的运行时上下文捆绑在一起。与应用程序的紧密连接意味着RASP可以更好地适应应用程序的安全需求。
超越外围以获得更好的应用安全性
RASP与传统防火墙具有一些共同特征。例如,它查看流量和内容,并可以终止会话。但是,防火墙是一种外围技术,无法看到周边内部发生的情况。他们不知道应用程序内部发生了什么。此外,随着云计算的兴起和移动设备的激增,外围变得更加多孔化。这降低了通用防火墙和Web应用防火墙(WAF)的有效性。
“安全顾问与WAF有着爱恨交织的关系,因为他们通常在服务的那一天最有效,并且在接下来的几个月里逐渐变得不那么有效,”Rendition InfoSec的首席顾问杰克·威廉姆斯在一篇论文中写道SANS研究所题为“内部保护:应用安全方法比较”。
“有效性下降的原因是,在组织执行成本分析并决定WAF部署比修复应用程序的源代码更便宜之后,WAF部署通常是针对某些渗透测试或安全事件而发生的。”
自我保护应用程序成为现实
RASP的一个优点是,一旦攻击者穿透了外围防御,它就可以保护系统。它深入了解应用程序逻辑,配置和数据事件流。这意味着RASP可以高精度地阻止攻击。它可以区分实际攻击和合法的信息请求,从而减少误报,并允许网络防御者花费更多的时间来解决实际问题,减少追逐数字安全死角的时间。
此外,它自我保护应用程序数据的能力意味着保护随着数据从出生到破坏而传播。这对于需要满足合规性要求的组织尤其有用,因为自我保护的数据对于数据窃贼来说是无用的。在某些情况下,如果被盗数据的形式使其在被盗时不可读,则监管机构不要求报告数据泄露事件。
与WAF一样,RASP也不会修复应用程序的源代码。但是,Williams解释说它确实与应用程序的底层代码库集成,并在源代码级别保护应用程序的易受攻击区域。
“当客户端进行包含可能对Web应用程序造成损害的参数的函数调用时.RASP在运行时拦截调用,记录或阻止调用,具体取决于配置。这种保护Web应用程序的方法与WAF基本不同。 “
为BYOD提供更好的技术,但需要付出代价?
RASP还可以使移动环境受益。根据移动操作系统的不同,保护应用程序免受攻击对组织来说是一个可疑的主张。使用RASP保护它们可以使BYOD成为IT部门的安全挑战。
不利的一面是,在部署RASP时,应用程序性能可能会受到打击,尽管受到多大关注是该技术的批评者和支持者之间争论的焦点。自我保护过程可以减慢应用程序的速度,RASP的动态特性也是如此。如果这种延迟对用户来说变得明显,那么它肯定会在组织中产生焦虑。但是,在更多应用程序开始将RASP合并到其功能中之前,性能问题的严重程度将不明确。
记住RASP是盾牌也很重要。如果某个应用程序存在缺陷,即使受到RASP保护,它也会保持不变。此外,RASP无法抵御所有类型的漏洞。因此,尽管它将为应用程序提供大量保护,但它并不能使应用程序像从开始到结束时安装到应用程序中的安全性一样安全。出于这些原因,一些安全专家建议将该技术与其他方法一起使用以保护应用程序。
在安全方面建设更好,但在那之前......
由于RASP还处于青春期,它相信它将能够克服其缺陷并成为应用程序安全的未来。正如Veracode首席创新官约瑟夫·费曼(Joseph Feiman)在担任Gartner研究副总裁期间所说:
“现代安全无法测试和保护所有应用程序。因此,应用程序必须能够进行安全自检,自我诊断和自我保护。它应该是CISO的首要任务。”
另一方面,如果安全性开始在开发时间线中更深入地传播,那么RASP旨在阻止的许多攻击将被内置到应用程序的源代码中。这将减少对RASP的需求,但保护旧版应用程序仍然很方便。
原文:https://techbeacon.com/security/what-runtime-application-self-protection-rasp
本文:http://pub.intelligentx.net/node/470
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 162 次浏览
【安全运营】使用Artifactory和Xray阻止下载
没有人想生病,所以我们会在天气变冷的时候穿夹克,服用维生素C,避免在湿雪的雪地里外出。我们都做了不同的事情,以避免讨厌令人讨厌的病毒和细菌,因为我们知道生产力的损失和我们必须努力使我们的身体系统再次恢复良好的负担远远超过我们一直采取的这些预防措施。
检测安全漏洞,以便您的系统不会“感冒”
您的软件系统也是如此。如果具有已知问题或漏洞的工件进入您的生态系统,则需要花费您去除它。当然,既然您拥有JFrog Xray,您就可以检测到安全漏洞,性能问题甚至是您定义的自定义问题,但如果您只是在使用它们时才检测到这些问题,那么您将需要做一些工作。您的组件已经经历了X开发和QA循环,您可能已准备好发布到生产中,然后有人记得Xray在几周前暴露了其中一个依赖项中的安全漏洞。哎呀,停止开发,找到替代组件,重构代码,开发-QA-repeat-X-times,花费数周的时间让你的代码再次运行良好。如果你可以避免这种情况,那不是很好吗?好吧,现在你可以!
预防胜于治疗
到目前为止,这些东西都是手动处理的。将工件下载到远程存储库缓存时,会触发Xray运行扫描,如果检测到任何问题,则会通知DevSec工作人员。然后你必须决定是否发布工件以供下载,并手动管理。 JFrog Artifactory的最新版本允许您将DevSec带出循环。您现在可以自动阻止Xray检测到安全漏洞的工件下载。
有两个级别的保护。首先,您可以指定引入Artifactory的工件(无论它们是否已缓存在远程存储库中,还是上载到本地存储库),在Xray对其进行索引和扫描之前,无法下载这些工件。这类似于信用卡公司在授予您信用卡之前进行的背景调查。同样,在对它们运行背景检查(X射线扫描)之前,您不希望为工件提供任何信用。
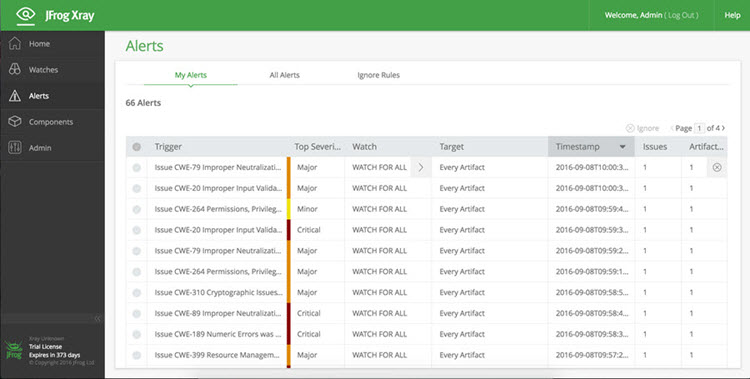
第二级保护可以更好地控制应该阻止哪些工件(如果有的话)。 工件中发现的问题按严重性级别进行评级:次要,主要或严重。 并非每一个小问题都必须成为您的交易障碍。 这是你控制的东西。 当问题暴露时,您会收到通知,但在您有机会进一步调查问题之前,您可能不想立即停止开发。 相反,你很有可能想要阻止任何有关键问题的工件,而你的开发人员只需要寻找其他东西。 因此,如果Xray检测到问题,您可以指定要在哪个严重性级别阻止工件。
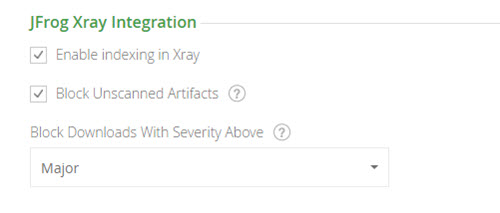
无论您选择使用哪种设置,只要设置它们,Xray就会被触发扫描整个存储库,因此任何未通过信用检查的组件都会立即被阻止。
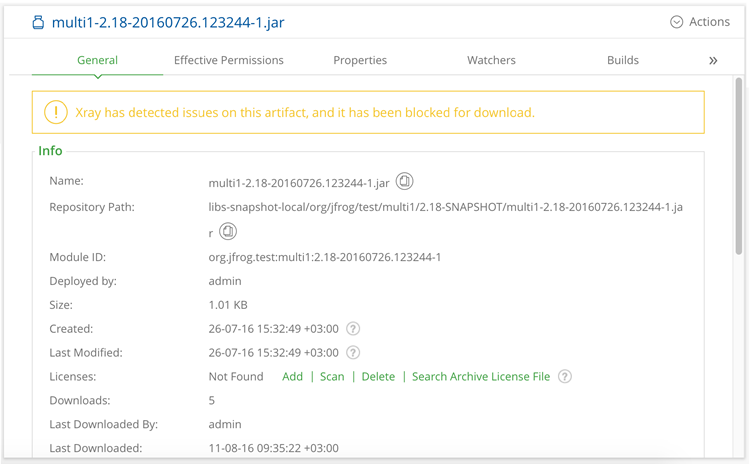
为避免让开发人员误解他们为什么空手而归,Artifactory会在树形浏览器中显示有关被阻止工件的通知,并为REST API调用提供信息性错误消息,因为工件已被阻止而失败。
所以Xray和Artifactory一起是你的软件系统夹克,羊毛帽子或膳食补充剂。 他们是不知疲倦的哨兵,防止任何未经检查,可疑和可能有害的文物进入您珍贵的生产系统附近。 通过下载阻止,您的系统可以接种神器疾病,因此您可以信任它们以最佳状态执行并执行他们应该执行的操作。 这一切都是自动发生在背景中而不必抬起手指。
原文:https://jfrog.com/blog/blocking-downloads-with-artifactory-and-xray/
本文:
讨论:请加入知识星球【首席架构师圈】
- 80 次浏览
【安全运营】使用Serverspec进行基础设施测试
描述
实验室概述
DevOps中的一个重要原则是测试您的基础架构。测试应作为持续交付管道的一部分运行,为您提供基础架构变更的灵活性和信心。 Serverspec是基础架构测试框架的一个示例。 Serverspec可用于通过SSH或WinRM连接来测试本地和远程目标计算机。
本实验说明了如何使用Serverspec执行基础结构测试。您将编写Serverspec测试以指定在反向代理,负载平衡层和示例应用程序的应用程序层中运行的计算机的预期行为。测试说明了如何描述服务器和Docker容器的预期行为。您将在命令行和Docker容器中使用Serverspec运行测试。
实验室目标
完成本实验后,您将能够:
- 了解自动化基础架构测试适合DevOps的位置
- 初始化Serverspec基础结构测试套件
- 编写Serverspec测试各种Serverspec资源,包括包,服务,端口和Docker基础结构
- 从命令行和Docker容器中运行Serverspec
实验室先决条件
你应该熟悉:
- 一种编程语言。 Ruby熟悉是最有益的,但不是必需的。
- 基本的Docker概念,例如图像和容器
- 基本的Linux概念,例如命令行,进程,包和服务
实验室环境
在完成实验室说明之前,环境将如下所示:

完成实验室说明后,环境应类似于:

讨论:请加入知识星球【首席架构师圈】
- 74 次浏览
【安全运营】大规模的威胁模型:如何从策略转向执行
每个组织都希望具备网络弹性。大多数团队使用横向软件开发生命周期(SDLC)思维模式(如安全要求,威胁建模,代码扫描程序等)自下而上地解决问题。不幸的是,尽管这些方法很有用,但它们并不能很好地扩展。
利益相关者不知道围绕安全要求要求什么,威胁建模是不一致的 - 取决于建模和代码扫描程序错过50%或更多安全问题的团队。但是有更好的方法。
专注于您的垂直管道 - 从标准和知名行业框架生成的安全策略到SDLC启动的过程。策略提供了一个指导SDLC的护栏,以便您建立安全性。
由于管道本质上是垂直的,因此在SDLC中完成的任何工作都会自动汇总到更高级别,从而使您可以近乎实时地了解应用程序组合的安全状况。
以下是如何以独立于平台的方式创建策略到执行管道。
解决政策与执行之间的差距
在一个专注于安全性的典型企业中,您通常会看到三组人:
- 安全团队,专注于应用程序和操作安全性,供应商风险管理,威胁监控和培训
- 风险和合规团队,专注于处理隐私,审计和策略创建的合规生命周期
- IT团队(包括开发和运营)专注于与敏捷,DevOps和混合基础架构管理相关的活动

图1.安全性与创建策略的风险和合规性团队以及必须执行这些策略的IT团队之间经常存在策略到程序的差距。
安全性以及风险和合规性团队根据ISO-27001等标准制定策略,并将这些策略交给IT团队,假设IT可以针对他们执行。
但大多数IT团队并不了解如何解释这种高级抽象政策。它们习惯于处理与缓存,身份和访问管理相关的过程。
因此,根本的挑战是将抽象的高级策略转换为IT团队可以执行的事项。这是政策与执行之间的差距。
使用集成流程实现策略到执行
每个团队都有自己的流程和工作流程。安全团队有自己的流程专注于持续的安全管理。同样,风险和合规团队拥有持续的风险和合规性管理工作流程,技术团队拥有DevOps管道。

图2.安全性与风险和合规性团队(左)和技术团队(右)创建的流程之间经常存在脱节。

图3.在安全性,风险和合规性团队以及技术团队之间架起不同的流程需要创建对所有方面都有意义的通用标准。
面临的挑战是将每个不同的流程整合到对风险管理有意义的业务中。实现这一目标的方法是从生成安全标准的安全团队开始。
在安全标准中,您有几个子句。这些条款然后进入另外两个工作流程:
- 技术团队,其中安全控制由标准中的条款生成
- 风险和合规团队,根据风险来衡量这些条款,以确定哪些条款具有更高的优先级
当技术团队执行日常活动时,他们的工作结果就是确认政策是否得到满足。您可以通过将安全控件映射到预定义的应用程序体系结构来实现此证明。映射到体系结构而不是单个应用程序的原因是为了减少为每个应用程序复制一组接受的控件的开销。
集成工具
这一切都始于对业务风险的评估。通过该评估,您可以确定安全业务需求,从而进入使用建模工具捕获的体系结构或服务定义。
然后,此体系结构将进行威胁建模活动,其结果将进入与DevOps管道集成的业务安全需求存储库。在管道中,您将集成应用程序生命周期管理(ALM)工具,构建工具和静态/动态分析测试工具。构建成功后,工件将移动到包含配置文件,代码文件和脚本的存储库中。
在构建存储库中,您将部署执行到测试环境中,该测试环境使用功能和非功能测试工具来解决质量问题。如果发现错误,它将被推回到您的ALM,DevOps管道再次启动。如果一切都过去了,管道的下一个阶段将返回到存储库并部署到您的预生产和生产环境中,您可以在其中进行真正的用户测试。
但是如果有任何错误,它会在测试环境中重新测试。最后,如果在测试中确认了失败,则必须在DevOps管道开始时返回并启动它。
构建生产后,SecOps工具会监视生产环境。如果发现任何漏洞,它们将再次返回到您的DevOps管道中,并根据需要修改安全策略。这创建了一个完整的循环,从业务风险管理一直到您的DevOps管道,并带有持续改进的反馈循环。
[另请参阅:为什么以及如何使用Jenkins将管道实现为代码]
关注相关指标
考虑对业务最有意义的领域。在Info-Tech Research Group的研究中,我们发现了三个:
- 弹性:哪些指标会显示您可以在发生违规时快速恢复的业务?
- 风险和合规性:哪些指标会显示您符合标准或法规?
- 速度:哪些指标会显示您在保持安全的同时不会妨碍业务?
以下是一些需要考虑的指标:
- 是时候修补漏洞了
- 大多数代码区域已更改
- 部署频率
- 改变失败率
- 应用性能
一步一步
总之,您需要了解三件事。 首先,高层政策与执行之间存在根本差距。 其次,解决这一差距需要整合安全性,风险和技术工作流程。 第三,不要试图一次性完成这一切。 从最容易注入安全性的地方开始,然后从那里开始构建。
最终,您的目标是建立一种价值安全的文化,因为它降低了业务风险,并且不会妨碍其需求。 正如需要通过DevOps集成开发和运营活动一样,您现在需要集成安全和风险团队。
想知道更多? 来参加我的SecureGuild在线安全测试会议,我将从威胁建模的角度详细介绍如何创建垂直管道。 会议从5月20日到21日举行。不能成功吗? 活动结束后,注册人可以完全访问所有演示文稿。
原文:https://techbeacon.com/security/threat-model-scale-how-go-policy-execution
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 92 次浏览
【安全运营】开源软件安全风险和最佳实践
开源软件的本质意味着,虽然它由多个开发人员审查,但应采取额外步骤以确保其安全性。
企业正在利用各种开源产品,包括操作系统,代码库,软件和应用程序,用于各种业务用例。虽然使用开源具有成本,灵活性和速度优势,但它也可能带来一些独特的安全挑战。鉴于开源组件可能存在于高达96%的商业应用程序中,您如何确保您的软件是安全的?
我们询问了Cloud Academy内容团队的两名成员 - 我们的DevOps专家Logan Rakai和我们的所有安全专家Stuart Scott - 分享他们帮助保持开源组件安全的技巧。
是什么让开源组件容易受到安全风险的影响?
一些开源项目的短暂发布周期可能难以跟上。
从好的方面来说,新功能和补丁很快就会被部署。但是,审核每个版本可能是某人的全职工作,当您在一个版本中管理所有问题时,另一个版本已准备就绪。本周风味的开源框架是一个安全的噩梦,虽然拥有一个扫描最新更新的自动化系统将有所帮助,但它不是一个可以识别所有问题的故障保护。
有了这么广泛的用户群来测试软件,发现潜在的漏洞安全漏洞,开源软件(OSS)通常被认为更安全。但是,在捕获和修复安全问题时,仅仅关注问题是不够的。安全问题需要安全专业知识,并非所有开发人员都是安全专他们可能已经足够了解并尝试实施某些修复,但这可能会产生错误的风险缓解感。例如,加密等更高级的主题可以进一步缩小那些可以检查代码是否存在此类安全漏洞的人。
开源项目中的依赖性允许一些漏洞在雷达下飞行。
从包管理器中提取的包含未知第三方库的项目可能会传递不易看到的漏洞。许多开发人员确定版本范围,以确保未来的补丁可用。但是,删除多个项目的依赖项可能首先更难以注意到,并且更有可能是可以被利用的攻击向量。
开发人员和DevOps团队可以做些什么来更好地保护开源组件?
将所有内容视为代码,包括合规性。这样做有助于确保遵循已知的法规,包括支付卡行业(PCI)或医疗保健(HIPAA)信息隐私。这也可以更容易地确保普遍应用补丁。
拥抱自动化。
及时了解在线源(例如国家漏洞数据库)中记录的漏洞或在项目主页上发布的漏洞,这也是非常耗时的。放置一些前线工具以帮助捕获明显的事物(有一些很棒的商业和开源动态应用程序安全测试(DAST)解决方案可用)并使用监控工具来跟上实时发生的事情。 SumoLogic等工具非常棒,可作为安全信息和事件管理(SIEM)的现代替代品。静态代码分析至少必须是CI / CD过程的一部分,它可以自动,及早地检测安全问题,以补充同行评审。
将开发人员和安全性结合。
在一起请您的安全团队培训开发人员,以全面了解安全性和最新趋势。与安全团队合作举办的初步安全编码研讨会是开展工作的好方法。邀请他们设计评论,并在进行高风险变更时将其纳入会议。
建立安全第一的文化。
您的组织必须关注的不仅仅是将开发人员和安全性结合在一起,还要确保将有效的安全实践内置到您执行的所有操作中。世界上最好的解决方案和最好的警报机制无法解决不良的安全措施。例如,Equifax漏洞归因于开源软件Adobe Struts的易受攻击版本,就是一个很好的例子。自2017年广为人知的违规行为以来,尽管有补丁可用,公司仍在下载易受攻击的软件包版本。 (补丁也在Equifax漏洞发布前两个月发布,并且自那时起多次发布。)在DevOps文化中,安全性讨论必须尽早发生,并且通常在整个软件开发生命周期内及之后发生。如果您使用的是开源组件,那么您有责任了解更新并实际应用它们。
幸运的是,有一些工具可以帮助您评估并提供有关您在应用程序中使用的开源软件的安全性的信心。 Black Duck和Sonatype Nexus提供两种工具,为管理开源风险提供企业级端到端解决方案。请注意,这些解决方案不是一夜之间的解决方案,需要时间进行集成。
还有免费工具可用于评估开源软件和容器中的风险。许多开源软件包使用免费的静态分析扫描仪,结果可供所有人检查。
Coverity Scan提供对开源软件的免费深度扫描,其中包括Common Weakness Enumeration(CWE / SANS)Top 25漏洞。许多项目都信任Coverity Scan,包括Linux内核和Apache项目,如Hadoop。您可以在项目页面上找到它们。
如果您对所识别的风险不满意,可以考虑使用备用软件或版本。同样,如果您在DevOps实践中使用Docker容器,则可以利用Docker托管的官方映像的Docker Security Scanning结果,并使用相同的技术扫描您自己的私有存储库映像。
原文:https://dzone.com/articles/open-source-software-security-risks-and-best-pract
本文:http://pub.intelligentx.net/open-source-software-security-risks-and-best-practices
讨论:请加入知识星球【首席架构师】
- 99 次浏览
【安全运营】当你拥有自己的工具攻击时:前5名
今年早些时候,一群网络犯罪分子开始使用大杂烩技术攻击公司,留下电影“黑客帝国”的参考资料,并使用勒索软件加密关键企业系统。
这一被反病毒软件供应商Sophos称为“MegaCortex”的攻击似乎来自受攻击的域控制器,攻击者可能使用窃取的管理员凭据访问了这些域控制器。一旦进入内部,攻击者就会使用常用技术来使用已经受到攻击的系统上的工具 - 称为“在陆地上生活” - 以避免被发现。
例如,该组使用PowerShell中的命令行界面,可在所有Microsoft Windows系统上使用。使用PowerShell,他们解码并运行一个模糊的脚本,在系统中设置后门,然后使用Windows Management Instrumentation(WMI)软件自动感染网络上的其他计算机。
Sophos高级安全顾问John Shier表示,这些技术正变得越来越普遍,并且不乏可以为攻击者目的而增加的工具。
“有超过100种不同的工具可供攻击者自动攻击使用。他们正在使用Windows系统自己的工具来对抗它。”
-John Shier
以下是攻击者针对您的企业系统的主要工具。
1. PowerShell
当Windows系统成为攻击的目标时,PowerShell通常是攻击者的常驻工具。与Linux系统上的Bash shell一样,PowerShell允许攻击者创建可以自动执行危害系统任务的脚本。
2010年,两位安全专业人士--Dave Kennedy和Josh Kelly在DEFCON 18的演讲中强调了PowerShell作为后期开发技术的实用性。2011年,另一位安全专业人士Matt Graeber写了一篇关于他自己涉足帖子的描述-exploitation PowerShell编码,在他博客的帖子中有一个例子。
Palo Alto Networks威胁情报副总裁Ryan Olson表示,Graeber开发的脚本已经进入许多公共工具,用于将代码加载到内存中以避免将代码写入磁盘。
“自Windows 7以来,PowerShell内置于所有Windows系统中,这意味着总有一个强大的脚本引擎可以访问他们可以访问的任何Windows主机上的资源。”
-Ryan Olson
2. Docker
对于许多开发人员和运营专业人员而言,Docker是一种工具,可以让容器快速旋转,以便在自定义应用程序环境中工作。它还可以在软件转移到生产之前测试正在开发的应用程序。
但是,如果开发人员不关心他们使用哪些图像作为其容器的基础,则攻击者可以使用恶意Docker容器在公司网络内运行代码。虽然Docker容器的安全功能是他们无法在没有明确许可的情况下访问本地软件,但他们可以扫描网络以寻找其他系统来感染或执行其他任务,Crowdstrike威胁情报副总裁Adam Meyers表示,安全服务公司。
“这是一个很棒的工具,但是如果镜像不安全或者镜像上的东西不必存在,或者它们有漏洞,那么攻击者可能会利用它。”
-Adam Meyers
3. WMI
这种基于Windows的应用程序界面允许访问管理信息,并且作为攻击者获取有关网络上系统的其他信息并自动进一步攻击的管道非常有用。
Meyers说,WMI已被犯罪分子和民族国家的对手使用。
“对手可以访问的任何东西,以及可以发出命令并让它执行动作的东西,对他们来说都具有潜在的价值。”
-Adam Meyers
4. VBScript
Microsoft系统管理员使用Visual Basic Scripting(VBScript)语言使用类似Visual Basic的语言自动管理计算机。但是VBScript也是攻击者自动感染系统的常用方法,特别是如果它们将其作为Office文档的一部分包含在内。
Palo Alto Networks的Olson表示,使用VBScript和其他工具防范攻击需要安全管理员权衡工具的好处和风险。
“对于很多像PowerShell和VBScript这样的工具,限制它们的使用和实用性非常重要。为这些工具创建白名单和黑名单。你可以将它们仅限于某些系统或某些功能。”
-Ryan Olson
5.压缩工具
任何攻击者的一个关键步骤是从目标系统中获取数据,因此他们通常会在系统上使用压缩工具,这不仅可以缩小数据的大小,还可以对信息进行模糊处理。他们可以共同选择各种常用工具来帮助他们。
“对于数据泄露,攻击者通常需要在将文件发送到另一个位置之前对其进行归档,”Olson说。 “他们可以使用Windows中的内置压缩功能实现这一目标,或者寻找其他已安装的工具,如7-Zip或WinRAR。”
这些常用工具并不是攻击者从受感染系统扩展妥协的唯一方法。开发人员必须提防知识渊博的攻击者,他们将代码插入到他们的开发路径中,例如最近针对游戏公司的攻击。
Sophos的Shier表示,在这些情况下,攻击者采取编译器和陷阱陷阱,以便当开发人员编写代码时,它会在那里放一些特殊的酱 - 一个后门。
“仅仅因为它不是PowerShell或WMI并不意味着具有足够技能的攻击者无法进入您的环境并在您的路径中添加DLL,最终会为您的代码添加后门。”
-John Shier
关闭你的系统
虽然适用于网络安全的“生活在陆地上”这一术语有点新,但技术却并非如此。 1986年,正如“咕咕蛋”中记载的那样,来自西德的攻击者闯入劳伦斯利弗莫尔国家实验室的计算机,攻击了其他各种政府和军用计算机,主要使用系统上已有的工具。
然而,当前技术使用的增加标志着十年前趋势的逆转,当时攻击者使用自定义恶意软件。 Crowdstrike的Meyers表示,随着越来越多的公司使用可以检测恶意定制软件的防御系统,攻击者会专注于以恶意方式使用现有工具。
“从威胁演员的角度来看,他们希望在检测之前增加时间,以便他们可以离开那个系统。通过在陆地上生活并使用已经在系统上的工具,他们可以避免大量的传统的防病毒类解决方案。“
-Adam Meyers
原文:https://techbeacon.com/security/when-your-own-tools-attack-top-5-offenders
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 57 次浏览
【安全运营】您应该了解的Web应用程序防火墙测试
如果您已经拥有端到端测试,UI测试或其他与真实最终用户相似的测试,请考虑在开发生命周期的早期阶段向这些测试添加Web应用程序防火墙(WAF)。它不会花费太多时间,您将获得许多额外的安全性和其他好处。
理想情况下,您已经对Web应用程序进行了测试。如果没有,请创建它们。然后使用相同的测试来确定您是否仍然在应用程序前面使用WAF具有完整的应用程序功能。您的测试仍应成功,并且您的ModSecurity日志应为空 - 这意味着您的测试不会触发WAF规则。
作为WAF ModSecurity的OWASP核心规则集(CRS)的共同开发者,我觉得分享如何将WAF引入DevOps非常重要。我希望通过自动化WAF测试来减少对WAF的恐惧。
以下是如何确保您的团队使用WAF顺利进行。
什么是WAF?
传统防火墙在TCP或IP网络层工作,而WAF在应用层阻止攻击。它有助于保护您免受Web应用程序攻击,并在您的应用程序前创建一个安全网。你需要它,因为你永远不能相信你的代码100%。
不幸的是,WAF也可能阻止合法流量,导致误报和生产问题。只有当所有组件都是DevOps /测试/自动化管道的一部分时,DevOps,测试和自动化才有意义。让一切都完全自动化并经过测试是没有意义的,然后在生产中将WAF放在您的应用程序前面。使WAF成为您测试的一部分。
如果您在开发周期的早期开始使用Web应用程序测试WAF,则可以确保Web应用程序正常运行。 WAF可以帮助防止Web应用程序攻击,例如SQL注入,跨站点脚本,对HTTP协议的攻击以及其他威胁。 WAF不会阻止所有攻击,但它使攻击者更难以利用漏洞。
以下是您的测试工具所需的工具。
ModSecurity WAF
ModSecurity是一种流行的WAF,可用作NGINX,Apache或IIS模块。 ModSecurity是引擎,它需要规则来检查每个HTTP请求和响应。
这就是CRS的用武之地。它主要由正则表达式组成,它为每个请求决定它是合法的,攻击还是信息泄漏。 ModSecurity和CRS都是免费提供的开源软件,并且拥有出色的社区支持。
OWASP DevSlop的Pixi
OWASP DevSlop代表“草率的DevOps”。该项目的目标是使用几个示例管道,博客文章,YouTube频道等展示DevSecOps。
DevSlop由不同的模块和管道组成。有些可以作为DevSecOps如何完成的一个例子。它的一些应用程序或模块可以作为试验Web应用程序攻击或使用ModSecurity和CRS的游乐场。
Pixi是DevSlop项目中许多计划应用程序中的第一个。您可以使用这个故意易受攻击的Web应用程序来试验Web应用程序攻击。当Pixi受CRS(另一个DevSlop模块)保护时,示例Web应用程序攻击不再成功。
TestCafe
您可以使用TestCafe的开源版本来测试Web应用程序,同时模拟用户的使用方式,您也可以使用相同的测试来测试您的WAF。
具体来说,您可以测试在应用程序前是否仍具有WAF的完整应用程序功能,以及ModSecurity日志是否仍为空。
设置管道
手动测试WAF是一个枯燥且容易出错的过程。相反,使用自动端到端测试在前面测试带有WAF的Pixi应用程序。您不必再关心测试了:每次将Web应用程序代码提交到存储库时,一切都会自动启动并运行。
获取您的WAF
使用正确的工具和软件,您可以在其前面使用WAF测试任何Web应用程序,并自动执行此操作。
这不仅适用于WAF专家。只要你测试它,WAF就是每个人的朋友。这是您抵御网络攻击的第一层防线。它是开源的,免费的,并创建了其他可能性,如虚拟补丁,扩展日志记录和监控。你绝对应该在测试和生产中使用WAF。
讨论:请加入知识星球【首席架构师圈】
- 118 次浏览
【安全运营】漏洞管理:100%的代码和漏洞覆盖是否切合实际?
在应用程序安全性测试领域,经常使用术语“代码覆盖率”和“漏洞覆盖率”。但他们真正的意思是什么?代码覆盖率是扫描的代码量,用于识别软件应用程序中的潜在漏洞。漏洞覆盖率是指软件代码中可能存在潜在威胁的特定缺陷或系统错误配置的数量。
您的AppSec团队应该实现100%的代码和漏洞覆盖吗?这是现实的吗?真正的答案是,“这取决于。”让我们看看各种考虑因素以及如何尽可能获得最佳覆盖率。
代码和漏洞覆盖范围:SAST,DAST等
软件开发人员和渗透测试人员使用复杂的软件保障测试工具来查找其软件中的漏洞。挑战在于没有一种工具(或工具类型)能够为整个目标应用提供足够的覆盖。当今市场上的应用程序安全测试工具在应用程序中发现了特定的弱点。尽管他们在识别特定漏洞方面可能非常出色,但没有一种解决方案可以做到这一切。
每个工具都专注于不同的语言和不同的弱点类(例如,缓冲区处理,文件处理,初始化和关闭以及数字处理)。虽然您可能对识别某些类型的弱点的测试结果感到欣喜若狂,但如果您只测试一小部分代码,则结果不能提供真实的表示。
静态应用程序安全性测试(SAST)工具(也称为白盒测试工具)在软件开发过程的早期阶段用于从内到外测试应用程序。它们逐行进行测试源代码,字节代码或二进制文件。
使用SAST工具,可以实现100%的代码覆盖率,因为它们可以访问应用程序的内部。
但是,即使可以访问所有代码的静态分析工具也无法提供完整的漏洞覆盖。事实上,专家表示,普通工具只能覆盖代码中14%的漏洞。因此,利用多种工具和相互补充的工具类型是行业最佳实践。
黑盒测试工具,也称为动态应用程序安全测试(DAST)工具,通常具有有限的代码覆盖率,基于他们能够识别的攻击面的多少以及它们在应用程序中模糊的输入以导致不同类型的漏洞。 DAST工具从外部进行测试。他们在应用程序运行时对其进行测试,尝试渗透它以发现潜在的漏洞,包括代码之外和第三方界面中的漏洞。
如果您想要实现全面的代码和漏洞覆盖,其他类型的工具(如交互式应用程序安全测试(IAST)工具,威胁建模工具,甚至手动测试)也是AppSec难题中的重要部分。即便如此,我们建议您更进一步,使用可帮助您理解这些AppSec工具的工具,并真正了解您的代码覆盖率是多么完整。
超越AppSec工具:使用代码覆盖工具提高可见性
虽然使用多个应用程序安全测试工具有许多优点,但也有一些障碍需要克服。使用每个额外的工具需要额外的成本,更多的时间来实现和运行它,以及比较不同结果集(例如,命名约定和严重性评级)的挑战。这是代码覆盖工具(如应用程序漏洞管理器和可视化工具)提供无与伦比的优势的地方。
应用程序漏洞管理工具将商业和开源工具的结果进行关联和规范化。它提供了一组统一的结果,可以更好地覆盖源代码中的潜在漏洞,并更好地评估组织的整体企业风险。
这一工具可处理重复数据删除,补救管理,报告和合规性检查。工作流集成选项允许您的开发人员在解决应用程序漏洞问题的同时保留其首选环境 - Eclipse,Jira,Jenkins和其他环境。
Code Dx应用程序漏洞管理工具还提供应用程序漏洞关联(AVC),通常称为混合分析。这是指SAST结果(识别潜在漏洞)与DAST结果(确定哪些威胁实际可利用)的组合。这使您可以确定代码中存在哪些威胁,并且可以被外部攻击者利用,因此您可以先解决这些威胁。
Code Dx团队还开发了一个免费的OWASP解决方案,称为Code Pulse。这种开源渗透测试可视化工具提供了对实时代码覆盖率分析测试的深入了解。它可以帮助您的测试团队评估用于应用程序安全性测试的每个工具的性能和覆盖范围。
它通过对应用程序攻击面的可视化说明以及渗透测试如何与之交互来实现。因为它在您的应用程序处于活动状态时实时运行,所以您可以准确地确定渗透测试涵盖了代码的哪些部分,以及哪些部分不是。
Code Pulse还会显示每个工具涵盖应用程序的哪些部分,因此您可以看到存在重叠的位置 - 更重要的是,哪里有间隙。这有助于您评估代码和漏洞覆盖率,并确定是否需要在测试过程中添加不同的工具。您可以快速比较所有工具的覆盖范围,查看尚未测试的任何代码,并立即查看扫描设置调整的结果。
总之,SAST工具可以提供100%的代码覆盖率(与DAST工具不同),但它们不能提供100%的漏洞覆盖率。为了尽可能接近100%的漏洞覆盖率,我们建议结合使用SAST,DAST和其他AppSec测试工具来获得全面的覆盖率。虽然这似乎是一项艰巨的任务,但应用程序漏洞管理器可帮助您了解这些工具的结果。像Code Pulse这样的可视化工具可以让您轻松查看覆盖的位置以及放大保护所需的位置。
原文:https://codedx.com/100-code-vulnerability-coverage-realistic/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 49 次浏览
【网络安全】如何调整您的WAF安装以减少误报
使用调整的ModSecurity / Core规则集安装优化您的NGINX设置。
站点管理员使用Web应用程序防火墙(WAF)来阻止恶意或危险的Web流量,但也存在阻止某些有效流量的风险。误报是您的WAF阻止有效请求的实例。
误报是每次WAF安装的天敌。每个误报都意味着两件坏事:你的WAF工作太辛苦,消耗计算资源以便做一些不应该做的事情,并且不允许合法的流量通过。产生太多误报的WAF造成的伤害可能与成功攻击造成的伤害一样糟糕 - 并且可能导致您在挫折中放弃使用您的WAF。
调整您的WAF安装以减少误报是一个繁琐的过程。本文将帮助您减少NGINX上的误报,让您进行干净安装,允许合法请求通过并立即阻止攻击。
WAF引擎ModSecurity最常用于与OWASP ModSecurity核心规则集(CRS)协调。这为Web应用程序攻击创建了第一道防线,例如OWASP Top Ten项目所描述的攻击。
CRS是用于对传入请求中的异常进行评分的规则集。它使用通用黑名单技术在攻击应用程序之前检测攻击。 CRS还允许您通过更改配置文件crs-setup.conf中的Paranoia Level来调整规则集的激进程度。
误报与真实攻击相互混合
由于使用CRS导致的误报导致阻止合法用户的恐惧是真实的。如果您有大量用户或具有可疑流量的Web应用程序,则警报的数量可能会令人生畏。
开箱即用的CRS配置已经过调整,可以积极地减少误报的数量。但是,如果您对默认安装的检测功能不满意,则需要更改偏执等级以改善覆盖范围。在配置文件中提高偏执等级会激活默认关闭的规则。它们不是Paranoia Level 1默认安装的一部分,因为它们有产生误报的倾向。妄想症等级设置越高,实施的规则就越多。因此,规则集变得越激进,产生的误报就越多。
考虑到这一点,您需要一种减轻误报的策略。如果允许它们与真实攻击的痕迹混合,它们会破坏规则集的价值。所以,你需要摆脱误报,以便最终得到一个干净的安装,让合法的请求通过并阻止攻击者。
问题很简单:
- 如何识别误报
- 如何处理个人误报
- 实用的方法是什么样的? (或者:你如何扩展这个?)
当十几个误报出现时,很难识别它们。对应用程序的深入了解有助于从恶意的请求中获取良性但可疑的请求。但是,如果您不想逐个查看它们,则需要过滤警报并确保最终只得到包含误报的数据集。因为如果你不这样做,你可能最终会调出指向发生攻击的真实警报。
您可以使用IP地址来识别已知用户,已知本地网络等。或者,您可以假设成功通过身份验证的用户不是攻击者(可能是天真的,具体取决于您的业务规模)。或者您可以使用其他一些识别方法。确切的方法实际上取决于您的设置和您的测试过程。
当您确定个体误报时,有多种方法可以避免将来重复误报。使用CRS,您不会编辑规则集,因为它意味着作为一个不可编辑且连贯的整体运行。相反,您可以通过ModSecurity指令重新配置规则集的使用方式。这使您可以将相同的更改应用于CRS的未来版本,而无需重新创建编辑。
通常有四种处理误报的方法:
- 您可以完全禁用规则
- 您可以通过规则从检查中删除参数
- 您可以在运行时禁用给定请求的规则(通常基于请求的URI)
- 您可以在运行时从规则检查中删除给定请求的参数
很明显,禁用某些规则会影响规则集的检测率。实际上,您希望对规则集进行最小的更改,以允许良性但可疑的请求通过,从而避免误报。在各种情况下做出最佳选择需要一些经验。
我在cheatsheet上总结了四个一般变体,你可以从netnea.com下载。
缩放调整过程
掌握这个调整过程需要一些练习。当你对这个新手时,看起来并不像它会扩展。事实上,许多新人只是接近警报并尝试通过它 - 通常没有太大的成功。
鉴于ModSecurity警报的可读性较低,人们采用这种方法的事实并不令人意外。以下是真实攻击的一个例子(真正的正面):
2018/01/15 18:52:34 [info] 7962#7962: *1 ModSecurity: Warning. Matched "Operator `PmFromFile' with parameter `lfi-os-files.data' against variable `ARGS:test' (Value: `/etc/passwd' ) [file "/home/dune73/data/git/nginx-crs/rules/REQUEST-930-APPLICATION-ATTACK-LFI.conf"] [line "71"] [id "930120"] [rev "4"] [msg "OS File Access Attempt"] [data "Matched Data: etc/passwd found within ARGS:test: /etc/passwd"] [severity "2"] [ver "OWASP_CRS/3.0.0"] [maturity "0"] [accuracy "0"] [tag "application-multi"] [tag "language-multi"] [tag "platform-multi"] [tag "attack-lfi"] [tag "OWASP_CRS/WEB_ATTACK/FILE_INJECTION"] [tag "WASCTC/WASC-33"] [tag "OWASP_TOP_10/A4"] [tag "PCI/6.5.4"] [hostname "127.0.0.1"] [uri "/index.html"] [unique_id "151603875418.798396"] [ref "o1,10v21,11t:utf8toUnicode,t:urlDecodeUni,t:normalizePathWin,t:lowercase"], client: 127.0.0.1, server: localhost, request: "GET /index.html?test=/etc/passwd HTTP/1.1", host: "localhost"
如果您有数千个这样的日志条目,警报疲劳是正常的反应。你需要工具来找到自己的方式。最简单的工具是一组shell别名,它们以更易读的方式提取信息并显示它 - 我开发了一组执行此任务的shell别名。您也可以从netnea下载这些。
以下是此文件中的一个示例,它提供了警报消息的摘要:
alias melidmsg='grep -o "\[id [^]]*\].*\[msg [^]]*\]" | sed -e "s/\].*\[/] [/" -e "s/\[msg //" | cut -d\ -f2- | tr -d "\]\"" | sed -e "s/(Total .*/(Total ...) .../"'
以上面的示例消息为例,并应用此别名:
$> cat sample-alert.log | melidmsg 930120 OS File Access Attempt
这样做要好得多:ID为930120的规则是由请求触发的,指向操作系统文件访问尝试。可疑请求试图访问/ etc / passwd-服务器的本地密码文件,Web服务器永远不应该访问该文件。这是真正攻击的明显迹象。
现在让我们列出一个在Paranoia Level 3上使用CRS安装的典型非调整站点上发现的误报列表。我应用了melidmsg别名并按规则对它们求和(sort | uniq -c | sort -n):
8 932160 Remote Command Execution: Unix Shell Code Found
30 921180 HTTP Parameter Pollution (ARGS_NAMES:op)
75 942130 SQL Injection Attack: SQL Tautology Detected.
275 942200 Detects MySQL comment-/space-obfuscated injections and backtick
termination
308 942270 Looking for basic sql injection. Common attack string for mysql,
oracle and others.
402 942260 Detects basic SQL authentication bypass attempts 2/3
445 942410 SQL Injection Attack
448 921180 HTTP Parameter Pollution (ARGS_NAMES:fields[])
483 942431 Restricted SQL Character Anomaly Detection (args): # of special
characters exceeded (6)
541 941170 NoScript XSS InjectionChecker: Attribute Injection
8188 942450 SQL Hex Encoding Identified
给出的第一个数字是误报的数量。第二个数字是触发的规则的ID。后面的字符串是规则的文本描述。
这是分布在11个不同规则上的数千个错误警报。这不仅仅是我们可以一口咬下来的,而只是从第一个警报开始就不会让我们到任何地方。至少我们获得了定量信息。好像最大的问题似乎是看起来是十六进制编码的信息,CRS认为它可能是一个混淆的攻击。通常,这是一个会话ID,如果它在cookie中。
然而,即使以最大数量的误报开始也会给我们带来即时的满足感,但这并不是最好的方法。当我们点击XSS规则时,由此规则产生的541警报(编号941170)很可能会转换为数十种不同的形式和参数。这将使得在单个块中正确处理它们变得非常困难。
所以,我们不要急于求成。让我们想出一个更好的方法。
为调整过程带来意义和理由
我们需要开发更好的方法是一个不同的视角。我们不应该再看不同的规则了。我们应该查看触发规则的请求。因此,我们将查看成千上万的请求,并将误报放在一边,而不是几千个警报。
为此,我们需要知道服务器上所有请求的异常分数。不仅是那些得分,还有那些没有引起任何警报的人。该分数显然为零,但必须知道此类别中的请求数量,以便更好地了解误报的数量。
当我以前在Apache上工作时,让ModSecurity在服务器的访问日志中报告每个请求的异常分数是相当容易的。使用NGINX并不容易。因此,我们需要采用不同的技术:我们添加一条规则,在请求完成后报告异常分数(在ModSecurity的日志记录阶段5)。我们分配此规则ID 980145。
SecAction \
"id:980145,\
phase:5,\
pass,\
t:none,\
log,\
noauditlog,\
msg:\'Incoming Anomaly Score: %{TX.ANOMALY_SCORE}\'"
当我们grep这个规则ID时,我们得到每个请求的分数。
重新格式化输出,我们可以有效地提取异常分数:
$> cat error-2.log | grep 980145 | egrep -o "Incoming Anomaly Score: [0-9]+" | cut -b25- 0 0 0 5 0 0 10 0 3 0 0 0 ...
这些价值如何分配?
$> cat error-2.log | grep 980145 | egrep -o "Incoming Anomaly Score: [0-9]+" | cut -b25- | modsec-positive-stats.rb --incoming INCOMING Num of req. | % of req. | Sum of % | Missing % Number of incoming req. (total) | 897096 | 100.0000% | 100.0000% | 0.0000% Empty or miss. incoming score | 0 | 0.0000% | 0.0000% | 100.0000% Reqs with incoming score of 0 | 888984 | 99.0957% | 99.0957% | 0.9043% Reqs with incoming score of 1 | 0 | 0.0000% | 99.0957% | 0.9043% Reqs with incoming score of 2 | 3 | 0.0003% | 99.0960% | 0.9040% Reqs with incoming score of 3 | 1392 | 0.1551% | 99.2512% | 0.7488% Reqs with incoming score of 4 | 0 | 0.0000% | 99.2512% | 0.7488% Reqs with incoming score of 5 | 616 | 0.0686% | 99.3199% | 0.6801% Reqs with incoming score of 6 | 1 | 0.0001% | 99.3200% | 0.6800% Reqs with incoming score of 7 | 0 | 0.0000% | 99.3200% | 0.6800% Reqs with incoming score of 8 | 10 | 0.0011% | 99.3211% | 0.6789% Reqs with incoming score of 9 | 0 | 0.0000% | 99.3211% | 0.6789% Reqs with incoming score of 10 | 5856 | 0.6527% | 99.9739% | 0.0261% Reqs with incoming score of 11 | 0 | 0.0000% | 99.9739% | 0.0261% Reqs with incoming score of 12 | 0 | 0.0000% | 99.9739% | 0.0261% Reqs with incoming score of 13 | 12 | 0.0013% | 99.9752% | 0.0248% Reqs with incoming score of 14 | 0 | 0.0000% | 99.9752% | 0.0248% Reqs with incoming score of 15 | 82 | 0.0091% | 99.9843% | 0.0157% Reqs with incoming score of 16 | 0 | 0.0000% | 99.9843% | 0.0157% Reqs with incoming score of 17 | 0 | 0.0000% | 99.9843% | 0.0157% Reqs with incoming score of 18 | 5 | 0.0005% | 99.9849% | 0.0151% Reqs with incoming score of 19 | 0 | 0.0000% | 99.9849% | 0.0151% Reqs with incoming score of 20 | 5 | 0.0005% | 99.9855% | 0.0145% Reqs with incoming score of 21 | 0 | 0.0000% | 99.9855% | 0.0145% ... Reqs with incoming score of 29 | 0 | 0.0000% | 99.9855% | 0.0145% Reqs with incoming score of 30 | 126 | 0.0140% | 99.9995% | 0.0005% Reqs with incoming score of 31 | 0 | 0.0000% | 99.9995% | 0.0005% ... Reqs with incoming score of 60 | 4 | 0.0001% | 99.9999% | 0.0001% Incoming average: 0.0796 Median 0.0000 Standard deviation 0.9168
在这里,我使用了一个名为modsec-positive-stats.rb的脚本,我也在netnea网站上发布了这个脚本。它需要STDIN的异常分数并对它们运行几个统计数据。您可以获得各种百分比,平均分数,中位数甚至标准差。
让我们现在专注于第二列:它给出了传入异常分数的分布。现在我们有了数字,我们可以想象它们:
fixme图形分布

图1.传入请求的异常分数的分布。 Y轴上每个分数的请求数,以对数标度表示。资料来源:O'Reilly。
我们得到一条非常崎岖不平的曲线,在长尾中向右延伸。最高请求数的异常得分为0.这是所有通过规则集而没有任何警报的请求被记录的地方。在此位置右侧是触发一个或多个警报的请求。
我们越靠右,分数越高。你可以说这些是最可疑的请求。左侧更多,分数较低,我们看到仅触发一个或两个规则的请求。也许这些甚至都不是关键规则,但那些具有更多信息的弯曲 - 就像缺少Accept标题等。
如您所知,核心规则集是一种异常评分规则集。请求首先通过所有规则,并计算异常分数。然后,我们将累积的异常分数与异常阈值进行比较。默认阈值为5,这意味着单个关键规则警报将导致阻止请求。这就是我们希望它在安全设置中的方式。
实际上,如果我们愿意,我们可以更改此限制。在整合过程中,这实际上很有意义。如果我们将限制设置为10,000(是的,我在生产系统中看到了10,000分),我们可以确定核心规则集不会阻止任何合法请求。这样,我们可以使用真实数据检查规则集和我们的服务,并开始调整误报。
目标是将异常评分阈值降低到5,但我们不要试图一步完成。最好从10,000到100,然后到50,到20,到10,再到5。
如果我们采取这条道路,那么采取第一步并将异常限制设定为较低值的方法是什么?再看一下图1中的图表。如果我们在该图表中将异常阈值设置为50,我们将以60的分数阻止请求。因此,如果我们想要降低限制,我们会更好地处理这些请求以及所有其他要求得分更高的请求超过目标限制。
我们不需要立即查看大量剩余的误报 - 通常是令人生畏的景象。相反,我们专注于少量具有最高异常分数的请求作为开始。如果我们确定了这些,我们可以过滤导致这些高分的警报。我们可以借助作为ModSecurity警报消息一部分的唯一标识来完成此操作。
$> grep 980145 error.log | grep "Incoming Anomaly Score: 60\"" | melunique_id > ids
然后使用这些唯一ID来过滤那些导致上述得分的警报:
$> grep -F -f ids error.log | melidmsg | sort | uniq -c | sort -n 8 941140 XSS Filter - Category 4: Javascript URI Vector 12 932130 Remote Command Execution: Unix Shell Expression Found 12 941210 IE XSS Filters - Attack Detected. 16 941170 NoScript XSS InjectionChecker: Attribute Injection
然后我们可以调整这些误报并使我们能够降低异常阈值,同时高度保证不会阻止合法客户。如果您对此不熟悉,不要急于求成。调整一些误报,然后让调整后的规则集运行几天。
随着时间的推移,您已准备好进行下一次迭代:调整误报,阻止您进一步降低限制。当你看到这些请求时,你会发现一个惊人的发现。第一次调整迭代还减少了您在第二轮中必须检查的请求数。
如果你想一下这一点,那就很有意义了。导致得分最高的许多规则是导致中等分数的相同规则。因此,如果我们处理导致得分最高的第一批规则,则第二次调整迭代只需处理那些在得分最高的请求中不存在的误报。
这整个方法允许您构建规则集的调整以消除误报。看起来像是一个不可逾越的山峰,已经变成了一系列较低的,可行的山丘。您可以逐个使用它们,通常在给定的迭代中解决5到10个误报。 (如果更多,请采取更小的步骤。)
选择正确的误报来处理不再是猜谜游戏,您将能够快速降低异常分数阈值。因此,从降低异常限制的那一刻起,您就可以提高站点的安全性。 (根据我的经验,实质性保护只从20或更低的阈值开始)。
简而言之,调整过程
让我总结一下这种处理误报的方法。我们总是在阻止模式下工作。我们最初将异常阈值设置为一个非常高的数字,并进行多次迭代:
- 查看具有最高异常分数的请求并处理其误报
- 将异常分数阈值降低到下一步
- 冲洗并重复,直到异常评分阈值为5
我通常称之为误报调整的迭代方法。有些人称之为Folini方法,因为我似乎是唯一一个以这种方式使用ModSecurity和CRS教授课程的人。
许多人已经在Apache上以非常成功的方式使用了这种技术多年。我强烈建议您试试NGINX ModSecurity / CRS设置。
Links:
- OWASP ModSecurity Core Rule Set (CRS)
- BIG Cheatsheet Download
- Apache / ModSecurity Tutorials
- NGINX Plus Admin Guide and Tutorial
This post is a collaboration between O'Reilly and NGINX.
See our statement of editorial independence.
原文:https://www.oreilly.com/ideas/how-to-tune-your-waf-installation-to-reduce-false-positives
本文:http://pub.intelligentx.net/how-tune-your-waf-installation-reduce-false-positives
讨论:请加入知识星球【首席架构师圈】
- 327 次浏览