人工智能治理
视频号

微信公众号

知识星球

- 59 次浏览
【AI治理】AI道德与治理
视频号
微信公众号
知识星球
设计和部署符合道德、透明和值得信赖的负责任的人工智能解决方案。
责任AI:自信地衡量AI
AI给企业带来了前所未有的机遇,同时也带来了难以置信的责任。它对人们生活的直接影响引起了AI伦理、数据治理、信任和合法性等方面的大量问题。事实上,埃森哲2022年技术愿景研究发现,只有35%的全球消费者相信组织如何实施人工智能。77%的人认为组织必须为他们滥用人工智能负责。
压力就在眼前。随着组织开始扩大其AI的使用以获取业务利益,他们需要注意新的和未决的法规,以及他们必须采取的步骤,以确保其组织是合规的。这就是负责任的人工智能。
那么,什么是负责任的人工智能?
负责任人工智能是一种设计、开发和部署人工智能的实践,其目的是赋予员工和企业权力,公平地影响客户和社会,使公司能够产生信任并自信地扩展人工智能。
责任AI的好处
有了负责任的AI,您可以制定关键目标并制定治理策略,创建使AI和业务蓬勃发展的系统。
最小化意外偏差
在AI中构建责任,以确保算法和基础数据尽可能公正和具有代表性。
确保AI透明度
为了在员工和客户之间建立信任,开发跨流程和功能透明的可解释AI。
为员工创造机会
授权您企业中的个人对AI系统提出疑问或担忧,并有效地管理技术,而不会扼杀创新。
保护数据的隐私和安全
利用隐私和安全第一的方法,确保个人和/或敏感数据不会被不道德地使用。
使客户和市场受益
通过为人工智能创建道德基础,您可以降低风险并建立有利于股东、员工和整个社会的系统。
启用可信赖的AI
原则和治理
定义并阐明负责任的人工智能任务和原则,同时在整个组织中建立透明的治理结构,以建立对人工智能技术的信心和信任。
风险、政策和控制
加强对现行法律法规的遵守,同时监测未来的法律法规,制定减轻风险的政策,并通过定期报告和监测的风险管理框架实施这些政策。
技术和促成因素
开发工具和技术以支持公平性、可解释性、鲁棒性、可追溯性和隐私等原则,并将其构建到所使用的AI系统和平台中。
文化与培训
授权领导层将负责任的人工智能提升为一项关键业务,并要求进行培训,以使所有员工清楚地了解负责任的人工智能原则和成功标准。
在规模化之前识别AI偏差
算法评估是一种技术评估,有助于识别和解决整个业务中人工智能系统的潜在风险和意外后果,以产生信任并围绕人工智能决策建立支持系统。
首先对用例进行优先级排序,以确保您正在评估和补救那些具有最高风险和影响的用例。
一旦确定了优先级,它们将通过算法评估进行评估,包括一系列定性和定量检查,以支持AI开发的各个阶段。评估包括四个关键步骤:
- 考虑到不同的最终用户,围绕系统的公平性目标设定目标。
- 测量并发现不同用户或群体之间潜在结果和偏见来源的差异。
- 使用建议的补救策略减轻任何意外后果。
- 监视和控制系统,其流程标记和解决AI系统发展过程中的未来差异。
- 54 次浏览
【人工智能】MS致力于推进安全、可靠和值得信赖的人工智能
视频号
微信公众号
知识星球
今天,微软宣布支持拜登-哈里斯政府制定的新的自愿承诺,以帮助确保先进的人工智能系统安全可靠。通过支持拜登总统提出的所有自愿承诺,并独立致力于支持这些关键目标的其他几项承诺,微软正在与其他行业领导者合作,扩大其安全和负责任的人工智能实践。
通过迅速行动,白宫的承诺为确保人工智能的前景领先于其风险奠定了基础。我们欢迎总统领导科技行业共同制定具体措施,帮助人工智能更安全、更安全,对公众更有利。
在安全、保障和信任的持久原则的指导下,自愿承诺解决了先进人工智能模型带来的风险,并促进采用具体做法,如红队测试和发布透明度报告,这将推动整个生态系统向前发展。这些承诺建立在美国政府已有的强有力的工作基础上(如NIST人工智能风险管理框架和人工智能权利法案蓝图),是对欧洲和其他地方为高风险应用制定的措施的自然补充。我们期待着它们被行业广泛采用,并被纳入正在进行的关于有效国际行为准则可能是什么样子的全球讨论。
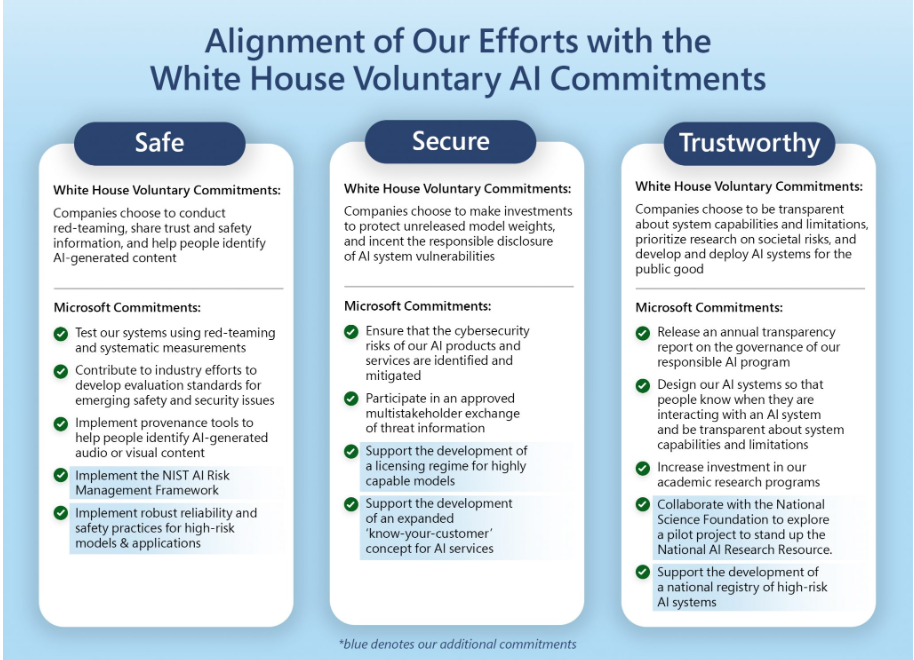
微软的额外承诺集中在我们将如何进一步加强生态系统并实施安全、保障和信任原则上。从支持国家人工智能研究资源的试点到倡导建立高风险人工智能系统的国家登记册,我们相信这些措施将有助于提高透明度和问责制。我们还致力于大规模实施NIST人工智能风险管理框架,并采用适应独特人工智能风险的网络安全实践。我们知道,这将带来更值得信赖的人工智能系统,不仅使我们的客户受益,也使整个社会受益。
您可以在此处查看Microsoft做出的详细承诺。
需要一个村庄来制定这样的承诺,并将其在微软付诸实践。我想借此机会感谢微软首席技术官Kevin Scott,我与他共同赞助了我们负责任的人工智能项目,以及Natasha Crampton、Sarah Bird、Eric Horvitz、Hanna Wallach和Ece Kamar,他们在我们负责任人工智能生态系统中发挥了关键领导作用。
正如白宫的自愿承诺所反映的那样,人们必须继续处于我们人工智能工作的中心,我很感激微软的强大领导,帮助我们履行承诺,继续发展我们在过去七年中一直在建设的项目。在这项新兴技术开发的早期制定行为准则不仅有助于确保安全、保障和可信度,还将使我们能够更好地释放人工智能对美国和世界各地社区的积极影响。
- 35 次浏览
【人工智能】普华永道负责任的人工智能
视频号
微信公众号
知识星球
人工智能为推动我们作为一个社会向前发展带来了无限的潜力,但巨大的潜力也带来了巨大的风险。
当你使用人工智能来支持基于敏感数据的关键业务决策时,你需要确保你了解人工智能在做什么,以及为什么。它是否做出了准确、有偏见的决定?这侵犯了任何人的隐私吗?你能管理和监控这项强大的技术吗?在全球范围内,各组织认识到对负责任人工智能的需求,但正处于不同的发展阶段。
负责任的人工智能(RAI)是减轻人工智能风险的唯一途径。现在是时候评估你现有的做法或创建新的做法,以负责任和合乎道德的方式构建技术和使用数据,并为未来的监管做好准备了。未来的收益将给早期采用者带来竞争对手可能永远无法超越的优势。
普华永道的RAI诊断调查可以帮助您评估组织相对于行业同行的绩效。该调查需要5-10分钟才能完成,并将生成一个分数,根据需要考虑的行动对您的组织进行排名。
潜在的人工智能风险
多种因素可以影响人工智能风险,随着时间的推移而变化,包括利益相关者、部门、用例和技术。以下是人工智能技术应用的六大风险类别。
性能
将真实世界的数据和偏好作为输入的人工智能算法可能存在学习和模仿可能的偏见和偏见的风险。
性能风险包括:
- 错误风险
- 存在偏见和歧视的风险
- 不透明和缺乏可解释性的风险
- 性能不稳定的风险
安全
自从自动化系统存在以来,人类就一直试图绕过它们。这与人工智能没有什么不同。
安全风险包括:
- 对抗性攻击
- 网络入侵和隐私风险
- 开源软件风险
控制
与任何其他技术类似,人工智能应该在全组织范围内进行监督,明确识别风险和控制措施。
控制风险包括:
- 缺乏人的能动性
- 检测流氓人工智能和意外后果
- 缺乏明确的问责制
经济的
自动化在经济各个领域的广泛应用可能会影响就业,并将需求转移到不同的技能上。
经济风险包括:
- 工作调动风险
- 加剧不平等
- 一个或几个公司内的权力集中风险
社会的
复杂和自主人工智能系统的广泛采用可能导致机器之间产生“回声室”,并对人机交互产生更广泛的影响。
社会风险包括:
- 错误信息和操纵风险
- 情报分歧的风险
- 监视和战争风险
企业
人工智能解决方案的设计考虑了特定的目标,这些目标可能会与它们运作的总体组织和社会价值观相竞争。长期以来,社区往往非正式地同意一套核心价值观,供社会反对。有一个运动,以确定一套价值观,从而道德,以帮助推动人工智能系统,但仍有分歧,这些伦理可能意味着在实践中,以及如何管理他们。因此,上述风险类别也是固有的道德风险。
企业风险包括:
- 声誉风险
- 财务业绩风险
- 法律和合规风险
- 歧视风险
- 价值不一致的风险
普华永道责任AI工具包
您的利益相关者,包括董事会成员、客户和监管机构,将对您的组织如何使用AI和数据(从如何开发到如何管理)提出许多问题。您不仅需要准备好提供答案,还必须展示持续的治理和法规遵从性。
我们的负责任AI工具包是一套可定制的框架、工具和流程,旨在帮助您以合乎道德和负责任的方式利用AI的力量——从战略到执行。借助负责任的AI工具包,我们将定制解决方案,以满足您组织的独特业务需求和AI成熟度。
我们的负责任AI工具包解决负责任AI的三个维度
谁对您的AI系统负责?负责任人工智能的基础是一个端到端的企业治理框架,重点关注组织从上到下的人工智能过程中的风险和控制。普华永道开发了可根据您的组织量身定制的稳健治理模型。该框架使监督具有明确的角色和职责、跨越三道防线的明确要求以及可追溯性和持续评估机制。

在普华永道,信任是我们宗旨的核心。
我们拥有一个合适的团队,负责在内部和为客户构建人工智能,并在人工智能采用的各个阶段将大想法付诸实践。
- AI、数据和数据使用治理
- 人工智能与数据伦理
- 人工智能专业知识:机器学习、模型操作和数据科学
- 隐私权
- 网络安全
- 风险管理
- 变更管理
- 合规与法律
- 可持续性与气候变化
- 多样性和包容性
普华永道自豪地与世界经济论坛合作,为跨行业使用的人工智能开发制定前瞻性思维和实用指南。在此处了解更多信息。
我们支持RAI旅程的所有阶段
- 评估:对模型和过程进行技术和定性评估,以确定差距
- 构建:根据特定需求和机会开发和设计新模型和流程
- 验证+规模:技术模型验证和部署服务;治理与伦理变革管理
- 评估+监控:AI准备就绪,包括确认控制框架设计、内部审计培训
- 53 次浏览
【人工智能合规】Github Copilot影响分析
视频号
微信公众号
知识星球
GitHub Copilot引入了人工智能系统常见的几种风险,包括模型偏差风险、隐私问题、合规问题和环境影响。应对某些风险的一些缓解措施。其中包括阻止攻击性语言和个人识别信息的内容过滤器,购买碳抵消以实现碳中和,以及评估可访问性的内部测试。然而,该工具缺乏如何生成建议的可解释性、如何使用的可见性以及控件的可配置性。个人资料上次更新时间:2023年7月13日
产品描述
GitHub Copilot是一款人工智能驱动的配对程序员,旨在帮助开发人员更快、更轻松地编写代码。它使用注释和代码中的上下文来即时建议单个行和整个函数。GitHub Copilot由OpenAI Codex提供支持,这是一个由OpenAI创建的生成性预训练语言模型。它可以作为几种流行的集成开发环境(IDE)的扩展[1]。
GitHub Copilot的Codex模型是根据自然语言文本和来自公开来源的源代码进行训练的,包括GitHub上公共存储库中的代码。它的设计目的是在给定其可以访问的上下文的情况下生成尽可能好的代码,但它不会测试它建议的代码,因此代码可能并不总是有效,甚至没有意义。建议开发人员在将代码推向生产之前仔细测试、审查和审查代码[1]。截至2023年2月,GitHub开始依赖更新的“Codex”模型[12]。最初的法典模式和目前使用的模式之间的差异尚不清楚。
提供GitHub Copilot的公司GitHub是一个使用Git进行软件开发和版本控制的成熟平台。GitHub成立于2008年,2018年被微软收购,现已发展成为世界上最大的代码存储库之一,拥有数百万用户和存储库。该公司提供各种支持选项,包括文档、社区论坛和对企业客户的直接支持[1]。
个人资料上次更新时间:2023年7月13日
预期使用案例
GitHub Copilot旨在成为一名人工智能配对程序员,帮助开发人员更高效、更轻松地编写代码。它旨在在客户的组织中使用,以提高开发人员的生产力、满意度和整体代码质量[1]。
GitHub Copilot根据开发人员当前工作的上下文提供代码建议,包括注释和代码。它可以建议单独的代码行或整个函数,帮助开发人员浏览不熟悉的库或框架。开发人员可以节省时间,减少脑力劳动,并专注于更有意义的任务。GitHub Copilot并不是为了取代开发人员,而是为了增强他们的能力,使他们更有效率[1]。
风险和缓解总结
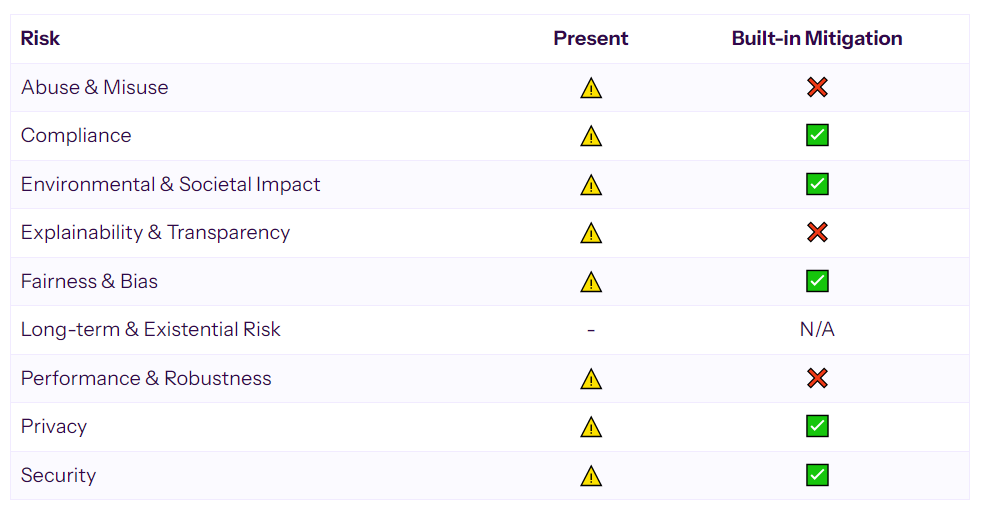
下表简要总结了GitHub Copilot产品中存在哪些常见的genAI驱动的风险,以及哪些风险已通过该工具提供的蓄意缓解措施得到解决(但不一定消除)。
有关每种风险的定义,请参阅下文。
滥用和误用
与人工智能系统被恶意或不负责任地使用的可能性有关,包括用于创建深度伪造、自动网络攻击或入侵监控系统。滥用特别指故意将人工智能用于有害目的。
任意代码生成
- 由于GitHub Copilot能够生成任意代码,因此它可以用于生成网络攻击中使用的代码。例如,恶意用户可以使用Copilot生成用于编排机器人网络的代码。成功的网络攻击可能需要额外的黑客专业知识;单凭GitHub Copilot不太可能让恶意行为者实施网络攻击,但它可以降低不那么老练的黑客的门槛。
合规
涉及人工智能系统违反法律、法规和道德准则的风险(包括版权风险)。不合规可能导致法律处罚、声誉损害和用户信任的丧失。
侵犯版权
- GitHub Copilot是根据公开的代码[1]进行培训的。GitHub的文档没有披露这些培训数据的组成。Copilot可能会根据用户提示提供(即复制)此代码,并且复制的代码可能不会被批准用于所有用途。例如,使用“copyleft”许可证发布的代码可能会出现在Copilot的培训数据中,GitHub不保证,如果Copilot工具复制了代码,它会包括适当的归因。使用复制代码的合法性受到正在进行的诉讼的制约[2]。
法规遵从性
- 由于GitHub Copilot能够生成任意代码,因此它可能被用于构建违反法律法规的系统。例如,Copilot可用于生成软件应用程序,这些应用程序以违反应用程序部署所在司法管辖区法规的方式跟踪使用情况和用户参与度。这种风险通常取决于GitHub Copilot用户提示工具提供特定功能的代码。尽管如此,无意中生成具有非法功能的代码并非不可能。
- GitHub不存储发送到Codex模型和从Codex模型返回的提示或模型响应。尽管如此,某些使用可能违反数据安全法。例如,Copilot的使用可能不符合需要政府安全许可的项目,即使与产品交换的内容是无害的。
GitHub Copilot采用了一种内容过滤器,旨在解决版权输入的风险。有关更多详细信息,请参阅下面的缓解部分。
环境和社会影响
人们担心人工智能可能会在社会中引发更广泛的变化,如劳动力转移、心理健康影响,或deepfakes等操纵技术的影响。它还包括人工智能对环境的影响,特别是训练复杂的人工智能模型对自然资源和碳排放造成的压力,与人工智能帮助缓解环境问题的潜力相平衡。
碳足迹
- 根据基于Github Copilot的Codex模型的开发者OpenAI的说法,Codex是GPT-3模型120亿参数变体的微调版本。它是在2020年末或2021年初训练的。直接估计训练计算和碳足迹是不可能的[3]。作为参考,Meta的LLaMa-13B类似模型在2022年末或2023年初使用了约59兆瓦时的能源[4]进行了训练,大致相当于5个美国家庭的年消耗量[8]。由于元模型的训练得益于更高效的硬件(2年的硬件进步)、更高效的训练机制(由于在该领域获得了2年的专业知识,需要更少的实验),并且没有经过微调,Credo AI认为,Meta模型的指标应被视为Codex模型训练的排放和能量消耗的下限。
- 使用Meta的LLaMA-13B模型作为参考,与Codex模型类似大小的模型可以在推断时在英伟达V100 GPU[4]上运行,每个实例的最大功率为300W[6]。无法对GitHub Copilot的持续碳足迹进行可靠的第三方评估。这样做需要任何给定时间的平均用户数数据和Microsoft Azure配置信息(即单个模型实例可以服务的用户数)。
软件开发人员中断
- 对开发者的影响尚不确定。GitHub的研究[7]以及社交媒体上分享的轶事证据表明,Copilot在提高开发人员生产力方面是有效的。这可能会降低市场对熟练程序员的需求——如果现有程序员能够100%满足市场对编程任务的需求,任何效率的提高都会减少市场所需的程序员数量。或者,它可能会增加对编程的需求——随着效率的提高,更多的任务变得可行,从而导致对熟练程序员的需求净增加。
- 该工具(以及类似的工具)有可能创建一个双层环境。如果GitHub[7]吹嘘的效率提升是真实的,那么市场对不使用和不熟练使用Copilot的程序员的需求可能会减少。
- 使用GitHub Copilot可能会导致对该工具的依赖。GitHub Copilot的用户可能会发展“即时工程”技能,以获得更有用的模型输出,而不太强调练习某些与Copilot辅助工作流程无关的编程技能。
GitHub的母公司微软声称通过购买碳信用实现净零排放。有关更多详细信息,请参阅下面的缓解部分。
可解释性和透明度
指的是理解和解释人工智能系统的决策和行动的能力,以及对所使用的数据、所使用的算法和所做决策的开放性。缺乏这些要素可能会造成滥用、误解和缺乏问责制的风险。
模型输出
GitHub Copilot没有解释它是如何在用户提示下获得输出的。
培训和评估数据
关于用于训练Codex模型的数据的信息是有限的。数据来自“托管在GitHub上的5400万个公共软件存储库”,并根据文件大小进行过滤[3]。有关训练集中代码的许可证或质量的信息是有限的。
设计决策
Codex模型是在原始GPT-3模型[3]的基础上进行微调的。描述Codex模型的学术论文[3]详细描述了训练方法,并给出了理由。
公平与偏见
源于人工智能系统做出系统性地对某些群体或个人不利的决策的潜力。偏见可能源于训练数据、算法设计或部署实践,导致不公平的结果和可能的法律后果。
语言
- “鉴于公共来源主要是英语,GitHub Copilot在开发者提供的自然语言提示不是英语和/或语法不正确的情况下可能效果不佳。因此,非英语使用者可能会体验到较低的服务质量。”[1]
可访问性
- 在撰写本文时,GitHub Copilot没有任何旨在提高广大用户可访问性的广告功能。
冒犯性输出或有偏见的语言
- GitHub Copilot的输出是其训练数据的函数。由于它是在数百万个公共GitHub存储库上训练的,没有(公开的)攻击性语言过滤,因此Copilot可能会以生成的代码注释或变量名的形式输出攻击性语言。
GitHub在Copilot产品文档中宣传,他们正在与残疾开发者合作,以确保无障碍。有关更多详细信息,请参阅下面的缓解部分。
GitHub Copilot采用了一种内容过滤器,旨在解决输出攻击性语言的风险。有关更多详细信息,请参阅下面的缓解部分。
长期和存在风险
考虑未来先进的人工智能系统对人类文明构成的推测性风险,无论是由于滥用,还是由于其目标与人类价值观相一致的挑战。不适用
性能和稳健性
与人工智能准确实现其预期目的的能力以及对扰动、异常输入或不利情况的弹性有关。性能故障是人工智能系统执行其功能的基础。稳健性的失败可能会导致严重后果,尤其是在关键应用程序中。
- GitHub Copilot可能会输出包含错误或安全漏洞的代码[1]。GitHub的文档没有评估该模型在常见编程任务上的性能,也没有评估其对各种提示策略的稳健性。GitHub对用户体验进行了研究,发现大约46%的模型建议完成被开发人员接受[12]。有关更多详细信息,请参阅[正式评估](#正式评估)部分。
- OpenAI独立于GitHub评估了Codex模型。他们报告了28.81%pass@k在现实编程问题基准HumanEval上,k=1的性能。pass@k性能任务模型响应于用户提示生成k个独立输出,并评估k个输出中的任何一个是否通过了与问题相关联的预定义单元测试。如果用户只提示模型一次(无论结果如何,都选择接受或拒绝建议并继续前进),这28.81%的成功率可能足以代表现实世界的性能[3]。这些评估可能无法反映截至2023年2月的最新法典模型[12]。
隐私
指人工智能通过个人收集的数据、处理数据的方式或得出的结论侵犯个人隐私权的风险。
- GitHub Copilot可能会从其培训数据中输出姓名、联系信息或其他个人身份信息[1]。例如,训练数据中编码在代码注释中的识别信息可以由模型再现。这种现象的频率尚不清楚——GitHub将其描述为“非常罕见”。
- GitHub Copilot for Business不记录用户提示或模型输出。敏感数据通过与产品的直接交互“泄露”到GitHub或其模型提供商OpenAI的风险有限。
GitHub Copilot采用了一种内容过滤器,旨在解决输出PII的风险。有关更多详细信息,请参阅下面的缓解部分。
安全
包含人工智能系统中可能危及其完整性、可用性或机密性的潜在漏洞。安全漏洞可能导致重大伤害,从错误的决策到侵犯隐私。
易受攻击的代码生成
- GitHub Copilot可能输出包含漏洞的代码。GitHub没有提供这种情况发生频率的估计,并将验证代码安全的责任交给了用户[1]。
其他安全
- 由于GitHub Copilot for Business既不存储用户提示,也不模拟输出,因此使用该服务的风险与使用非人工智能互联网连接应用程序不相上下。Copilot的源代码(包括旨在与第三方IDE接口的扩展)可能包含漏洞,这可能会导致用户的安全暴露。
**截至2023年2月Copilot[12]的更新,该产品使用基于LLM的漏洞扫描仪来识别生成代码中的一些安全漏洞。我们将在[缓解措施](#缓解措施)一节中进一步讨论这一缓解措施**
缓解措施
在本节中,我们将讨论产品内置的缓解措施(无论是否默认启用)。我们还评论了由采购组织管理其员工使用该工具的可行性。
内容过滤
内容过滤器GitHub Copilot有一个内容过滤器来解决genAI系统的几个常见风险。该过滤器在GitHub Copilot常见问题解答页面[1]中进行了描述。其功能如下:
- 它“屏蔽了提示中的冒犯性语言,避免在敏感上下文中综合建议”。没有提供有关此功能的有效性、性能或稳健性的详细信息。该功能在默认情况下似乎已启用,并且从可用文档中看,该功能不可配置[1]。
- 它“根据GitHub上的公共代码,检查代码建议及其周围约150个字符的代码。如果匹配或接近匹配,建议将不会显示给[用户]。”GitHub没有提供有关该功能的有效性、性能或稳健性的详细信息。此功能可为组织客户配置。没有记录该功能是否在组织帐户中默认启用[9]。
- 它“在以标准格式显示时阻止电子邮件”。根据GitHub的说法,“如果你足够努力,仍然有可能让模型建议这类内容。”没有提供有关该功能的有效性、性能或稳健性的详细信息。该功能在默认情况下似乎已启用,并且从可用文档中看,该功能不可配置[1]。
碳中和
碳中和微软,GitHub的母公司,声称是碳中和的[10]。他们通过购买碳信用和抵消来实现这一目标。他们公开承诺到2030年实现净零排放。由于GitHub作为微软子公司的地位,很可能所有与GitHub Copilot相关的系统(包括Codex模型)都部署在微软的Azure云平台上,从而被纳入微软更广泛的碳核算。
无障碍
无障碍测试GitHub正在“对GitHub Copilot的残疾开发者易用性进行内部测试”[1]。该公司鼓励发现可用性问题的用户联系专门的电子邮件地址。没有提供有关这些测试状态的详细信息。
漏洞过滤
漏洞过滤器截至2023年2月Copilot更新,该服务包括一个“漏洞预防系统”,该系统使用大型语言模型来分析生成的代码,目的是识别和阻止常见的安全漏洞,如SQL注入、路径注入和硬编码凭据[12]。Credo AI无法找到有关这一缓解措施的性能或有效性的详细信息。漏洞过滤器不太可能识别和阻止所有可能的安全漏洞。
治理能力
对于一个组织来说,管理其人工智能系统的开发或使用,有两个功能是关键:组织观察员工使用模式的能力,以及组织实施和配置控制措施以降低风险的能力。Credo AI在这两个维度上评估系统。
GitHub Copilot不为其Copilot for Business客户提供使用可见性。企业没有机制来观察基本法典模型的投入或产出,也不能查看使用情况的统计摘要。
GitHub Copilot提供了有限的控件可配置性(见上文)。GitHub Copilot不允许企业实施和配置自己(或第三方)的技术控制来管理风险。
正式评估和认证
评估
GitHub Copilot和Codex模型的开发人员各自进行了研究,以评估使用该工具的性能和功效[7,3]。
GitHub的研究重点是开发人员使用该工具的体验。主要结果来自一项发给参加GitHub技术预览的开发者的调查。该调查有大约2000名受访者(11.7%的回答率),可能存在显著的回答偏差。调查发现,“60-75%”的用户对自己的工作感到更满足,在一项针对95名开发人员的对照研究中,发现Copilot将执行特定任务的速度提高了55%[7]。
最近,更新后的Codex模型使Copilot生成的开发人员代码文件的比例增加了19个百分点:从27%增加到46%。目前尚不清楚该统计数据是指完全由Copilot生成的文件,还是仅指包含Copilot产生代码的文件[12]。2023年2月的更新还引入了一种独立于Codex的新模型,以预测用户是否会接受特定建议。GitHub声称,该模型将不需要的建议率提高了4.5%[12]。
OpenAI的研究提出了一个新的基准HumanEval,它由164个新的编程问题组成,专门针对可能出现在其训练数据中的问题来测试模型,因为这些问题存在于互联网上。编程问题伴随着单元测试,以实现自动、客观的评估,而不是人工判断。当为每个问题生成单个输出时,该模型实现了28.8%的通过率。当允许每个问题生成100个输出,并且如果任何一个输出是正确的,则该模型被视为“正确的”时,该模型的通过率为72.3%。OpenAI认为这是写测试调试过程的代表,但他们主张使用输出排名来选择单个最佳输出——根据这一指标,该模型的通过率为44.5%[3]。
已经进行了几项独立研究来评估GitHub Copilot的性能和疗效。其中,Credo AI评估的构成高质量学术研究的相对较少。一篇论文[11]试图严格评估Copilot在基本编程问题(排序、搜索等)上的正确性,并将Copilot解决方案与编程任务的人工解决方案的基准数据集进行比较。作者发现,基于人类对正确性的判断,Copilot产生了正确的解决方案,从一些排序和图形算法的0%的时间(在提示样本中)到其他一些搜索算法的100%的时间。他们发现,随着时间的推移,该模型不一致,在30天的窗口期内重复试验,但这可能是由于基础法典模型的温度设置造成的。作者没有报告基本算法任务的总体正确率。基准测试解决方案数据集包含几个编程问题的正确解决方案和错误解决方案。作者报告了一个正确率,即基准测试中给定任务的正确解决方案的比例,并将其与Copilot的性能进行比较。Copilot在3/5任务上优于基准,基于pass@1精确作者建议,Copilot最好由“专家开发人员”使用,可能不适合新手,因为他们可能无法检测到有缺陷或非最佳解决方案。
所获证书
Credo AI已确定以下与我们客户的隐私、安全和合规要求相关的法规和标准。GitHub公布的合规性详细信息如下。有关更多详细信息,请参阅https://github.com/security

结论
GitHub Copilot是一款基于人工智能的工具,旨在帮助软件开发人员编写代码。它由OpenAI的Codex模型提供动力,这是一个在数百万行开源代码上训练的预训练语言模型。Copilot根据开发人员当前正在编写的代码的上下文提供代码建议和完成。它旨在提高开发人员的生产力、满意度和代码质量。然而,它也引入了人工智能系统常见的几种风险,包括模型偏差风险、隐私问题、合规问题和环境影响。
GitHub和OpenAI已经实施了一些缓解措施来应对某些风险。其中包括阻止攻击性语言和个人识别信息的内容过滤器,购买碳抵消以实现碳中和,以及评估可访问性的内部测试。然而,该工具缺乏如何生成建议的可解释性、如何使用的可见性以及控件的可配置性。对该工具的正式评估发现,它可以提高开发人员的速度和满意度,但它很难处理一些复杂的编程任务,从而在评估中获得广泛的正确性结果。
尽管GitHub Copilot是一个有用的生产力工具,但它引入了需要治理来解决的风险。缺乏可见性和可配置性给旨在管理工具风险并确保合规和合乎道德使用的组织带来了挑战。对该工具的能力、局限性和最佳监督实践进行进一步研究,将有利于用户和利益相关者。有了适当的治理,Copilot可以成为一种资产,但如果没有它,它就有可能成为一种负债。
参考
-
[1] GitHub Copilot FAQs - https://github.com/features/copilot
-
[2] GitHub Copilot Class Action Lawsuit -
-
[3] Evaluating Large Language Models Trained on Code -
-
[4] LLaMA: Open and Efficient Foundation Language Models -
-
[6] NVidia V100 - https://www.nvidia.com/en-us/data-center/v100/
-
[11] GitHub Copilot AI pair programmer: Asset or Liability? - https://www.sciencedirect.com/science/article/pii/S0164121223001292
-
[12] GitHub Copilot now has a better AI model and new capabilities -
笔记
斜体表示Credo AI对关键概念的定义。
人工智能披露:“产品描述”、“预期用例”和“结论”部分是在聊天调整的大型语言模型的帮助下生成的。对于前两个部分,Credo AI将官方产品文档提供给OpenAI的ChatGPT,并提示模型生成包含相关信息的文本。对于后一部分,Credo AI提供了该风险简介的其余部分作为背景参考信息,并促使Anthropic的Claude聊天机器人总结信息。对最终文本的准确性和适用性进行了审查,并由Credo AI进行了人工编辑。
- 255 次浏览
【人工智能合规】NIST值得信赖和负责任的人工智能:受众
视频号
微信公众号
知识星球
识别和管理人工智能风险和潜在影响——包括积极影响和消极影响——需要在人工智能生命周期中有一套广泛的视角和参与者。理想情况下,人工智能参与者将代表不同的经验、专业知识和背景,并包括人口统计学和学科上不同的团队。人工智能RMF旨在供人工智能参与者在整个人工智能生命周期和维度中使用。
经合组织制定了一个框架,根据五个关键的社会技术维度对人工智能生命周期活动进行分类,每个维度都具有与人工智能政策和治理相关的属性,包括风险管理【经合组织(2022)经合组织人工智能系统分类框架|经合组织数字经济论文】。图2显示了这些维度,NIST对此框架进行了轻微修改。NIST的修改强调了测试、评估、验证和确认(TEVV)过程在整个人工智能生命周期中的重要性,并概括了人工智能系统的操作环境。
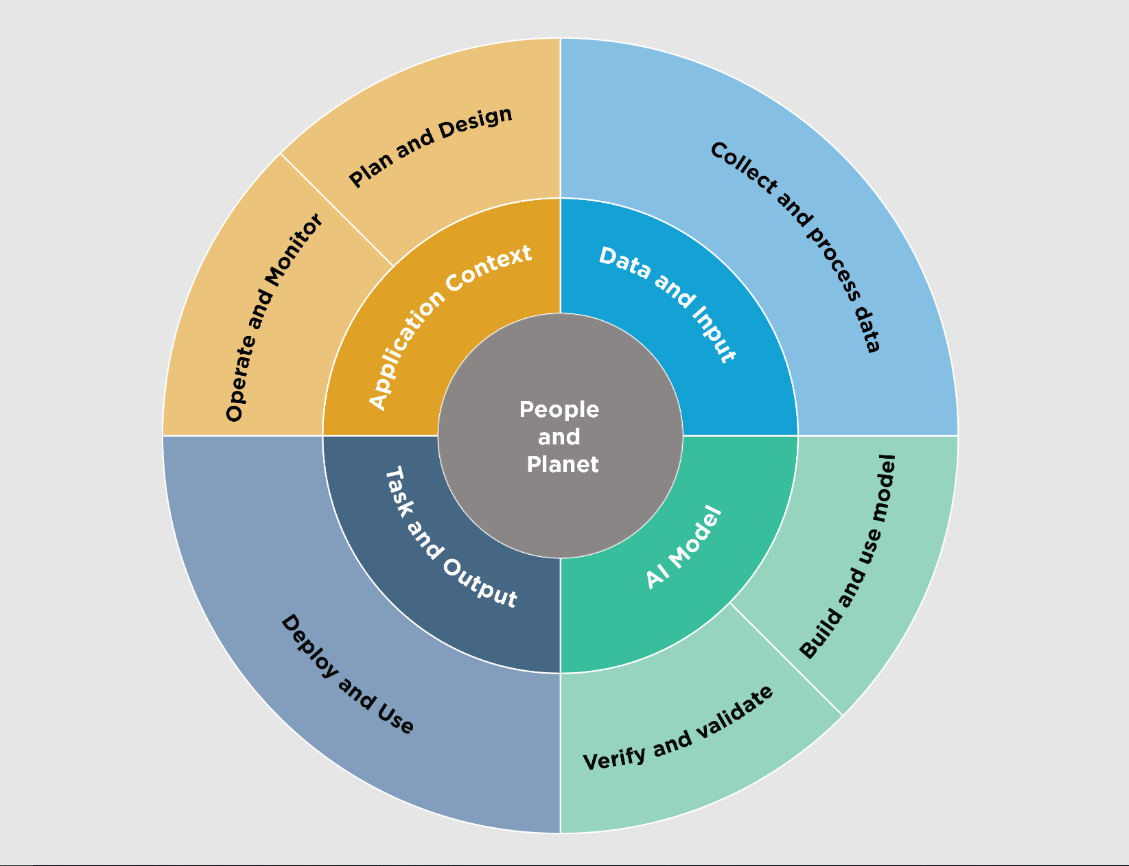
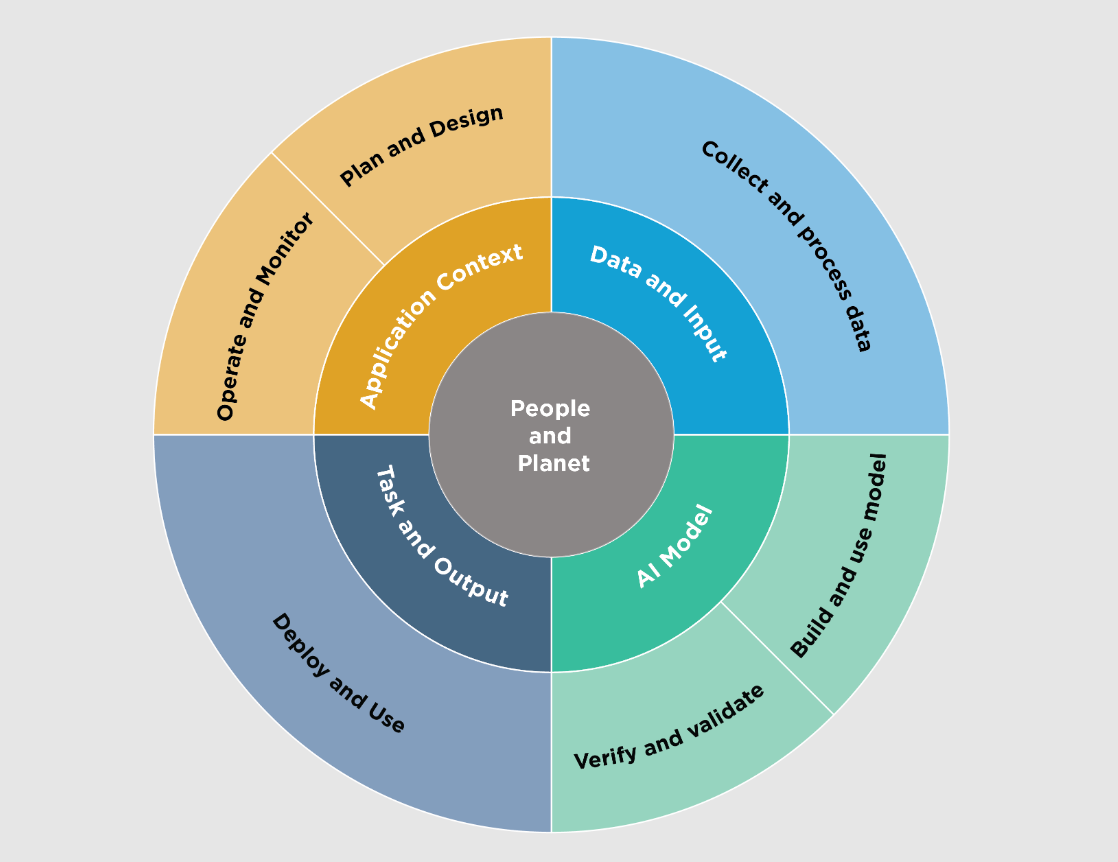
人工智能系统的生命周期和关键维度。
图2:人工智能系统的生命周期和关键维度。修改自经合组织(2022)《经合组织人工智能系统分类框架》|经合组织数字经济论文。两个内圈显示人工智能系统的关键维度,外圈显示人工智能生命周期阶段。理想情况下,风险管理工作从应用程序环境中的计划和设计功能开始,并在整个人工智能系统生命周期中执行。具有代表性的人工智能参与者见图3。
人工智能参与者

图3:人工智能生命周期各阶段的人工智能参与者。有关人工智能参与者任务的详细描述,包括测试、评估、验证和验证任务的详细信息,请参见附录A。请注意,人工智能模型维度(图2)中的人工智能参与者作为最佳实践是分开的,构建和使用模型的参与者与验证和验证模型的参与者是分开的。
图2中显示的AI维度是应用程序上下文、数据和输入、AI模型以及任务和输出。参与这些维度的人工智能参与者是人工智能RMF的主要受众,他们执行或管理人工智能系统的设计、开发、部署、评估和使用,并推动人工智能风险管理工作。
图3列出了整个生命周期维度的代表性人工智能参与者,并在附录A中进行了详细描述。在人工智能RMF中,所有人工智能参与者共同努力管理风险,实现值得信赖和负责任的人工智能的目标。具有TEVV特定专业知识的人工智能参与者在整个人工智能生命周期中都是集成的,特别有可能从该框架中受益。定期执行,TEVV任务可以提供与技术、社会、法律和道德标准或规范相关的见解,并有助于预测影响、评估和跟踪紧急风险。作为人工智能生命周期内的常规流程,TEVV允许进行中期补救和事后风险管理。
图2中心的人与地球维度代表了人权以及社会和地球的更广泛福祉。这个维度中的人工智能参与者包括一个单独的人工智能RMF受众,该受众向主要受众提供信息。这些人工智能参与者可能包括行业协会、标准制定组织、研究人员、倡导团体、环境团体、民间社会组织、最终用户以及可能受到影响的个人和社区。这些参与者可以:
- 协助提供背景,了解潜在和实际影响;
- 成为人工智能风险管理的正式或准正式规范和指导的来源;
- 指定人工智能操作的界限(技术、社会、法律和道德);和
- 促进讨论平衡与公民自由和权利、公平、环境和地球以及经济相关的社会价值观和优先事项所需的权衡。
成功的风险管理取决于人工智能参与者的集体责任感,如图3所示。第5节中描述的AI RMF功能需要不同的视角、学科、专业和经验。多样化的团队有助于更公开地分享关于技术目的和功能的想法和假设,使这些隐含的方面更加明确。这种更广泛的集体视角为揭示问题和识别现有和紧急风险创造了机会。
- 34 次浏览
【人工智能治理】NIST 人工智能风险管理框架
视频号
微信公众号
知识星球
人工智能风险管理框架(AI RMF)旨在自愿使用,并提高将可信度(trustworthiness )考虑纳入人工智能产品、服务和系统的设计、开发、使用和评估的能力。
作为一种共识资源,人工智能RMF是在18个月的时间里以公开、透明、多学科和多利益相关者的方式开发的,并与来自私营企业、学术界、民间社会和政府的240多个贡献组织合作。在人工智能RMF开发过程中收到的反馈可在NIST网站上公开获取。
框架风险
框架风险包括以下信息:
- 了解和应对风险、影响和危害
- 人工智能风险管理面临的挑战
观众
识别和管理人工智能风险和潜在影响需要在人工智能生命周期中有一套广泛的视角和参与者。受众部分描述了人工智能参与者和人工智能生命周期。
人工智能风险与可信度
为了让人工智能系统值得信赖,它们通常需要对对对相关方有价值的多种标准做出反应。提高人工智能可信度的方法可以降低人工智能的负面风险。人工智能风险和可信度部分阐述了值得信赖的人工智能的特点,并为解决这些问题提供了指导。
AI RMF的有效性
“效果”一节介绍了该框架用户的预期收益。
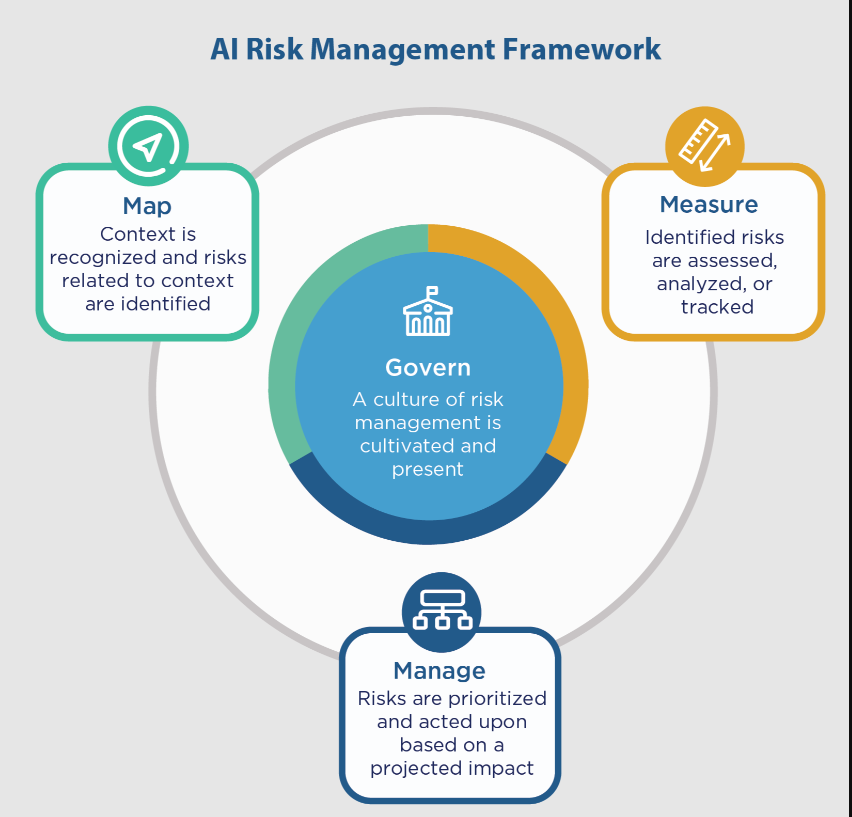
AI RMF核心
人工智能RMF核心提供的结果和行动能够实现对话、理解和活动,以管理人工智能风险和责任,开发值得信赖的人工智能系统。这是通过四个功能来操作的:管理、映射、测量和管理。
AI RMF画象文件
用例简介是基于框架用户的需求、风险承受能力和资源,针对特定设置或应用程序的AI RMF功能、类别和子类别的实现。
- Appendix A: Descriptions of AI Actor Tasks
- Appendix B: How AI Risks Differ from Traditional Software Risks
- Appendix C: AI Risk Management and Human-AI Interaction
- Appendix D: Attributes of the AI RMF
- 300 次浏览
【人工智能治理】NIST值得信赖和负责任的人工智能:人工智能RMF核心
视频号
微信公众号
知识星球
人工智能RMF核心提供结果和行动,使对话、理解和活动能够管理人工智能风险,并负责任地开发值得信赖的人工智能系统。如图5所示,Core由四个功能组成:治理、映射、测量和管理。这些高级功能中的每一个都被细分为类别和子类别。类别和子类别被细分为具体的行动和结果。行动不构成检查表,也不一定是一套有序的步骤。
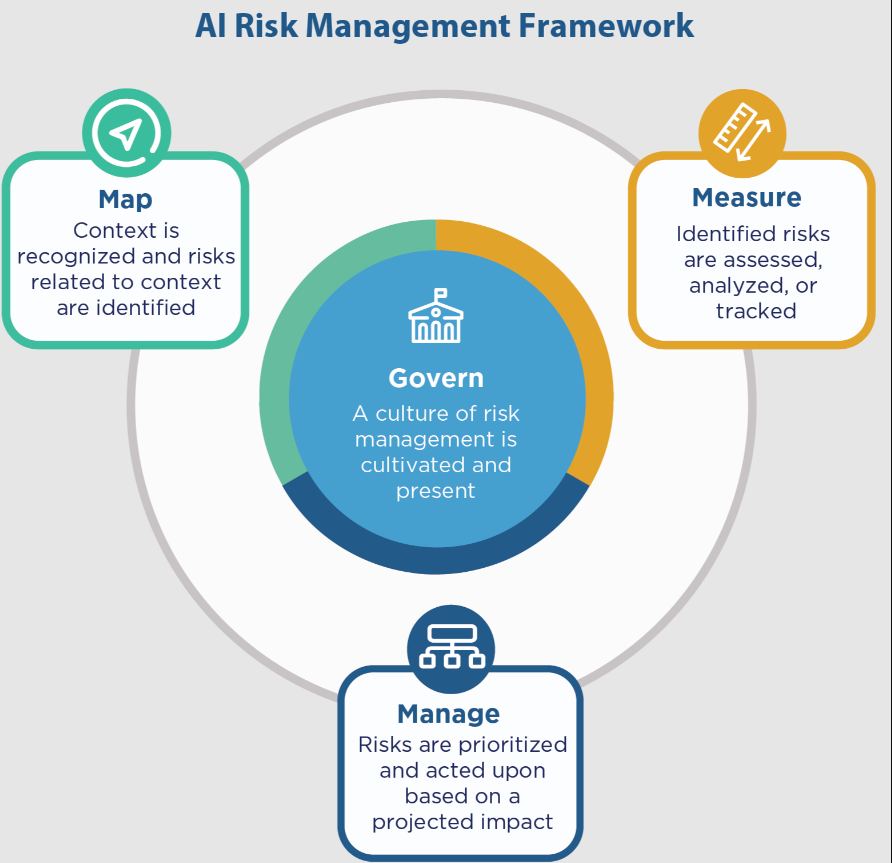
Figure 5: Functions organize AI risk management activities at their highest level to govern, map, measure, and manage AI risks. Governance is designed to be a cross-cutting function to inform and be infused throughout the other three functions.
风险管理应该是连续的、及时的,并在整个人工智能系统生命周期维度上执行。人工智能RMF核心功能的执行方式应反映多样性和多学科的观点,可能包括组织外人工智能参与者的观点。拥有一个多元化的团队有助于更开放地分享关于正在设计、开发、部署或评估的技术的目的和功能的想法和假设,这可以为发现问题和识别现有和紧急风险创造机会。
人工智能RMF的在线配套资源,即NIST人工智能RMF-行动手册,可用于帮助组织导航人工智能RMF.并通过建议的战术行动实现其成果,这些行动可以在自己的环境中应用。与AI RMF一样,行动手册是自愿的,组织可以根据自己的需求和兴趣使用建议。行动手册用户可以从建议的材料中选择量身定制的指南供自己使用,并提出建议与更广泛的社区分享。与人工智能RMF一起,行动手册也是NIST值得信赖和负责任的人工智能资源中心的一部分。
框架用户可以根据其资源和能力,应用最适合其管理人工智能风险需求的这些功能。一些组织可能会选择从类别和子类别中进行选择;其他人可以选择并有能力应用所有类别和子类别。假设治理结构到位,在人工智能生命周期中,功能可以按任何顺序执行,因为框架的用户认为这会增加价值。在治理中建立结果后,人工智能RMF的大多数用户将从地图功能开始,并继续测量或管理。无论用户如何集成功能,该过程都应该是迭代的,必要时在功能之间进行交叉引用。同样,也有一些类别和子类别的元素适用于多个功能,或者在逻辑上应该在某些子类别决策之前发生。
5.1治理
管理功能:
- 在设计、开发、部署、评估或获取人工智能系统的组织内培养和实施风险管理文化;
- 概述了预测、识别和管理系统可能构成的风险(包括对用户和社会其他人的风险)的流程、文件和组织方案,以及实现这些结果的程序;
- 纳入评估潜在影响的过程;
- 提供了一个结构,通过该结构,人工智能风险管理功能可以与组织原则、政策和战略优先事项保持一致;
- 将人工智能系统设计和开发的技术方面与组织价值观和原则联系起来,并为参与获取、培训、部署和监控此类系统的个人提供组织实践和能力;和
- 解决整个产品生命周期和相关流程,包括与使用第三方软件或硬件系统和数据有关的法律和其他问题。
governance是一个贯穿整个人工智能风险管理的功能,并实现流程的其他功能。治理的各个方面,特别是与遵约或评价有关的方面,应纳入每一项其他职能。对治理的关注是在人工智能系统的寿命和组织的层次结构中进行有效人工智能风险管理的持续和内在要求。
强有力的治理可以推动和加强内部实践和规范,以促进组织风险文化。管理当局可以确定指导组织使命、目标、价值观、文化和风险承受能力的总体政策。高级领导层为组织内的风险管理以及组织文化定下基调。管理层将人工智能风险管理的技术方面与政策和运营相结合。文档可以提高透明度,改进人工审核流程,并加强人工智能系统团队的问责制。
在建立起治理职能中描述的结构、系统、流程和团队后,组织应受益于专注于风险理解和管理的目标驱动文化。随着知识、文化以及人工智能参与者的需求或期望随着时间的推移而演变,框架用户有责任继续执行治理功能。
NIST人工智能RMF行动手册中描述了与管理人工智能风险相关的实践。表1列出了管理功能的类别和子类别。
表1:政府职能的类别和子类别。
| Categories | Subcategories |
|---|---|
| Govern 1: 整个组织中与人工智能风险的映射、测量和管理相关的政策、流程、程序和实践已经到位、透明并得到有效实施。 | Govern 1.1: 1.1:理解、管理和记录涉及人工智能的法律和监管要求。 |
| Govern 1.2: 值得信赖的人工智能的特征被整合到组织政策、流程、程序和实践中。 | |
| Govern 1.3: 流程、程序和实践已到位,可根据组织的风险承受能力确定所需的风险管理活动水平。 | |
| Govern 1.4: 风险管理过程及其结果是通过透明的政策、程序和基于组织风险优先级的其他控制建立的。 | |
| Govern 1.5: 计划对风险管理过程及其结果进行持续监测和定期审查,明确界定组织角色和责任,包括确定定期审查的频率。 | |
| Govern 1.6: 建立了人工智能系统库存机制,并根据组织风险优先级提供资源。 | |
| Govern 1.7: 已经制定了安全退役和逐步淘汰人工智能系统的流程和程序,且不会增加风险或降低组织的可信度。 | |
| Govern 2: 责任制结构已经到位,因此适当的团队和个人被授权、负责并接受了映射、测量和管理AI风险的培训。 | Govern 2.1: 与映射、测量和管理人工智能风险相关的角色、责任和沟通渠道都有文件记录,整个组织的个人和团队都清楚。 |
| Govern 2.2: 该组织的人员和合作伙伴接受人工智能风险管理培训,使他们能够根据相关政策、程序和协议履行职责。 | |
| Govern 2.3: 组织的执行领导层负责与人工智能系统开发和部署相关的风险决策。 | |
| Govern 3: 劳动力多样性、公平性、包容性和可访问性过程在整个生命周期的人工智能风险映射、测量和管理中被优先考虑。 | Govern 3.1: 在整个生命周期中,与绘制、测量和管理人工智能风险相关的决策由不同的团队提供信息(例如,人口统计、学科、经验、专业知识和背景的多样性)。 |
| Govern 3.2: 制定了政策和程序,以定义和区分人工智能配置和人工智能系统监督的角色和责任。 | |
| Govern 4: 组织团队致力于考虑和沟通AI风险的文化。 | Govern 4.1: 制定了组织政策和实践,在人工智能系统的设计、开发、部署和使用中培养批判性思维和安全第一的心态,以最大限度地减少潜在的负面影响。 |
| Govern 4.2: 组织团队记录他们设计、开发、部署、评估和使用的人工智能技术的风险和潜在影响,并更广泛地交流影响。 | |
| Govern 4.3: 组织实践已经到位,可以实现人工智能测试、事件识别和信息共享。 | |
| Govern 5: 制定了与相关AI参与者进行有力互动的流程。 | Govern 5.1: 组织政策和实践已经到位,可以收集、考虑、优先考虑和整合开发或部署人工智能系统的团队外部人员对人工智能风险相关的潜在个人和社会影响的反馈。 |
| Govern 5.2: 建立机制,使开发或部署人工智能系统的团队能够定期将相关人工智能参与者的裁决反馈纳入系统设计和实施。 | |
| Govern 6: 制定了政策和程序,以解决由第三方软件和数据以及其他供应链问题引起的人工智能风险和收益。 | Govern 6.1: 制定了解决与第三方实体相关的人工智能风险的政策和程序,包括侵犯第三方知识产权或其他权利的风险。 |
| Govern 6.2: 应急流程用于处理被认为是高风险的第三方数据或人工智能系统中的故障或事件。 |
5.2映射
映射功能建立了与人工智能系统相关的风险框架。人工智能的生命周期包括许多相互依存的活动,涉及不同的参与者(见图3)。在实践中,负责流程某一部分的人工智能参与者往往无法完全了解或控制其他部分及其相关上下文。这些活动之间以及相关人工智能参与者之间的相互依赖性可能会使人们难以可靠地预测人工智能系统的影响。例如,识别人工智能系统目的和目标的早期决策可能会改变其行为和能力,部署设置的动态(如最终用户或受影响的个人)可能会影响人工智能系统决策。因此,人工智能生命周期的一个维度内的最佳意图可能会通过与其他后续活动中的决策和条件的交互而受到破坏。这种复杂性和不同程度的可见性可能会给风险管理实践带来不确定性。预测、评估和以其他方式解决负面风险的潜在来源可以减轻这种不确定性,并增强决策过程的完整性。
在执行映射功能时收集的信息能够实现负面风险预防,并为模型管理等流程的决策提供信息,以及关于人工智能解决方案的适当性或需求的初步决策。地图功能的结果是衡量和管理功能的基础。如果没有上下文知识和对所确定的上下文中的风险的认识,风险管理就很难执行。地图功能旨在增强组织识别风险和更广泛的促成因素的能力。
通过整合来自不同内部团队的观点以及与开发或部署人工智能系统的团队外部人员的接触,这一功能的实施得到了加强。根据特定人工智能系统的风险水平、内部团队的组成和组织政策,与外部合作者、最终用户、潜在受影响的社区和其他人的接触可能会有所不同。收集如此广泛的视角可以帮助组织主动预防负面风险,并通过以下方式开发更值得信赖的人工智能系统:
- 提高他们理解环境的能力;
- 检查他们对使用环境的假设;
- 能够识别系统何时在其预期上下文内或外不起作用;
- 确定其现有人工智能系统的积极和有益用途;
- 提高对人工智能和ML过程局限性的理解;
- 识别现实世界应用程序中可能导致负面影响的约束条件;
- 识别与人工智能系统的预期使用相关的已知和可预见的负面影响;和
- 预期使用人工智能系统超出预期用途的风险。
在完成地图功能后,框架用户应该有足够的关于人工智能系统影响的上下文知识,以告知是否设计、开发或部署人工智能系统的初步决定。如果决定继续进行,组织应利用衡量和管理职能以及管理职能中制定的政策和程序,协助人工智能风险管理工作。随着环境、能力、风险、收益和潜在影响的演变,框架用户有责任继续将地图功能应用于人工智能系统。
NIST人工智能RMF行动手册中描述了与绘制人工智能风险图相关的实践。表2列出了地图功能的类别和子类别。
表2:MAP函数的类别和子类别。
| Categories | Subcategories |
|---|---|
| Map 1: 建立并理解上下文。 | Map 1.1: 理解并记录人工智能系统部署的预期目的、潜在有益用途、特定背景的法律、规范和期望以及预期设置。考虑因素包括:用户的特定集合或类型及其期望;系统使用对个人、社区、组织、社会和地球的潜在积极和消极影响;在整个开发或产品AI生命周期中,关于AI系统目的、用途和风险的假设和相关限制;以及相关的TEVV和系统指标。 |
| Map 1.2: 跨学科人工智能参与者,能力,技能和建立背景的能力反映了人口多样性以及广泛的领域和用户体验专业知识,并记录了他们的参与情况。优先考虑跨学科合作的机会。 | |
| Map 1.3: 组织的使命和人工智能技术的相关目标得到了理解和记录。 | |
| Map 1.4: 业务价值或业务使用背景已经明确定义,或者在评估现有AI系统的情况下,重新评估。 | |
| Map 1.5: 确定并记录组织风险容忍度。 | |
| Map 1.6: 系统要求(例如,“系统应尊重其用户的隐私”)来自相关AI参与者并被其理解。设计决策考虑了社会技术影响,以解决人工智能风险。 | |
| Map 2: 对AI系统进行分类。 | Map 2.1: 定义了用于实现AI系统将支持的任务的特定任务和方法(例如,分类器,生成模型,推荐者)。 |
| Map 2.2:记录了有关人工智能系统的知识限制以及人类如何利用和监督系统输出的信息。文档提供了足够的信息,以帮助相关AI参与者做出决策并采取后续行动。 | |
| Map 2.3: 确定并记录科学完整性和TEVV考虑因素,包括与实验设计,数据收集和选择(例如可用性,代表性,适用性),系统可信度和构建验证相关的因素。 | |
| Map 3: 了解人工智能功能、目标使用、目标以及与适当基准相比的预期收益和成本。 | Map 3.1:检查并记录预期AI系统功能和性能的潜在好处。 |
| Map 3.2: 检查并记录由预期或实现的人工智能错误或系统功能和可信度(与组织风险承受能力相关)产生的潜在成本,包括非货币成本。 | |
| Map 3.3: 根据系统的能力、已建立的上下文和AI系统分类,指定并记录目标应用范围。 | |
| Map 3.4: 定义、评估和记录了操作员和从业者熟练掌握人工智能系统性能和可信度的流程,以及相关的技术标准和认证。 | |
| Map 3.5: 根据治理职能部门的组织政策,定义、评估和记录人力监督流程。 | |
| Map 4: AI系统的所有组件(包括第三方软件和数据)都映射了风险和收益。 | Map 4.1: 绘制人工智能技术及其组件的法律风险(包括使用第三方数据或软件)的方法已经到位、遵循并记录,侵犯第三方知识产权或其他权利的风险也是如此。 |
| Map 4.2: 识别并记录人工智能系统组件(包括第三方人工智能技术)的内部风险控制。 | |
| Map 5: 对个人、团体、社区、组织和社会的影响具有特征。 | Map 5.1: 根据预期用途、人工智能系统在类似情况下的过去使用情况、公共事件报告、开发或部署人工智能系统的团队外部的反馈或其他数据,确定并记录每个确定影响(潜在有益和有害)的可能性和程度。 |
| Map 5.2: 制定并记录了支持与相关人工智能参与者定期接触的实践和人员,并整合了关于正面、负面和意外影响的反馈。 |
5.3措施
衡量功能采用定量、定性或混合方法工具、技术和方法来分析、评估、基准测试和监测人工智能风险和相关影响。它使用与地图功能中识别的人工智能风险相关的知识,并通知管理功能。人工智能系统应在部署前进行测试,并在运行中定期进行测试。人工智能风险测量包括记录系统功能和可信度的各个方面。
衡量人工智能风险包括跟踪值得信赖的特征、社会影响和人类人工智能配置的指标。衡量职能部门制定或采用的流程应包括严格的软件测试和绩效评估方法,以及相关的不确定性衡量标准、与绩效基准的比较,以及正式的结果报告和文件记录。独立审查程序可以提高测试的有效性,并可以减轻内部偏见和潜在的利益冲突。
当值得信赖的特征之间出现权衡时,测量提供了一个可追溯的基础,为管理决策提供信息。选项可能包括重新校准、减轻影响或将系统从设计、开发、生产或使用中移除,以及一系列补偿、检测、威慑、指令和恢复控制。
在完成测量功能后,目标、可重复或可扩展的测试、评估、验证和确认(TEVV)过程,包括指标、方法和方法,都已到位、遵循并记录在案。计量和测量方法应遵守科学、法律和道德规范,并在公开透明的过程中进行。可能需要开发新的定性和定量测量方法。应考虑每种测量类型为人工智能风险评估提供独特和有意义信息的程度。框架用户将增强其全面评估系统可信度、识别和跟踪现有和紧急风险以及验证指标有效性的能力。衡量结果将用于管理职能,以协助风险监测和应对工作。随着知识、方法、风险和影响的演变,框架用户有责任继续将测量功能应用于人工智能系统。
NIST人工智能RMF行动手册中描述了与测量人工智能风险相关的实践。表3列出了度量函数的类别和子类别。
表3:MEASURE函数的类别和子类别
| Categories | Subcategories |
|---|---|
| Measure 1: Appropriate methods and metrics are identified and applied. | Measure 1.1: Approaches and metrics for measurement of AI risks enumerated during the map function are selected for implementation starting with the most significant AI risks. The risks or trustworthiness characteristics that will not – or cannot – be measured are properly documented. |
| Measure 1.2: Appropriateness of AI metrics and effectiveness of existing controls are regularly assessed and updated, including reports of errors and potential impacts on affected communities. | |
| Measure 1.3: Internal experts who did not serve as front-line developers for the system and/or independent assessors are involved in regular assessments and updates. Domain experts, users, AI actors external to the team that developed or deployed the AI system, and affected communities are consulted in support of assessments as necessary per organizational risk tolerance. | |
| Measure 2: AI systems are evaluated for trustworthy characteristics. | Measure 2.1: Test sets, metrics, and details about the tools used during TEVV are documented. |
| Measure 2.2: Evaluations involving human subjects meet applicable requirements (including human subject protection) and are representative of the relevant population. | |
| Measure 2.3: AI system performance or assurance criteria are measured qualitatively or quantitatively and demonstrated for conditions similar to deployment setting(s). Measures are documented. | |
| Measure 2.4: The functionality and behavior of the AI system and its components – as identified in the map function – are monitored when in production. | |
| Measure 2.5: The AI system to be deployed is demonstrated to be valid and reliable. Limitations of the generalizability beyond the conditions under which the technology was developed are documented. | |
| Measure 2.6: The AI system is evaluated regularly for safety risks – as identified in the map function. The AI system to be deployed is demonstrated to be safe, its residual negative risk does not exceed the risk tolerance, and it can fail safely, particularly if made to operate beyond its knowledge limits. Safety metrics reflect system reliability and robustness, real-time monitoring, and response times for AI system failures. | |
| Measure 2.7: AI system security and resilience – as identified in the map function – are evaluated and documented. | |
| Measure 2.8: Risks associated with transparency and accountability – as identified in the map function – are examined and documented. | |
| Measure 2.9: The AI model is explained, validated, and documented, and AI system output is interpreted within its context – as identified in the map function – to inform responsible use and governance. | |
| Measure 2.10: Privacy risk of the AI system – as identified in the map function – is examined and documented. | |
| Measure 2.11: Fairness and bias – as identified in the map function – are evaluated and results are documented. | |
| Measure 2.12: Environmental impact and sustainability of AI model training and management activities – as identified in the map function – are assessed and documented. | |
| Measure 2.13: Effectiveness of the employed TEVV metrics and processes in the measure function are evaluated and documented. | |
| Measure 3: Mechanisms for tracking identified AI risks over time are in place. | Measure 3.1: Approaches, personnel, and documentation are in place to regularly identify and track existing, unanticipated, and emergent AI risks based on factors such as intended and actual performance in deployed contexts. |
| Measure 3.2: Risk tracking approaches are considered for settings where AI risks are difficult to assess using currently available measurement techniques or where metrics are not yet available. | |
| Measure 3.3: Feedback processes for end users and impacted communities to report problems and appeal system outcomes are established and integrated into AI system evaluation metrics. | |
| Measure 4: Feedback about efficacy of measurement is gathered and assessed. | Measure 4.1: Measurement approaches for identifying AI risks are connected to deployment context(s) and informed through consultation with domain experts and other end users. Approaches are documented. |
| Measure 4.2: Measurement results regarding AI system trustworthiness in deployment context(s) and across the AI lifecycle are informed by input from domain experts and relevant AI actors to validate whether the system is performing consistently as intended. Results are documented. | |
| Measure 4.3: Measurable performance improvements or declines based on consultations with relevant AI actors, including affected communities, and field data about context-relevant risks and trustworthiness characteristics are identified and documented. |
5.4管理
管理职能要求按照管理职能的规定,定期将风险资源分配给映射和测量的风险。风险处理包括对事件或事件作出反应、恢复和沟通的计划。
从专家咨询中收集的背景信息和相关人工智能参与者的输入——在治理中建立并在地图中执行——被用于该功能,以降低系统故障和负面影响的可能性。在治理中建立并在地图和测量中使用的系统文档实践支持人工智能风险管理工作,并提高透明度和问责制。评估紧急风险的流程以及持续改进的机制已经到位。
在完成管理职能后,将制定优先考虑风险以及定期监测和改进的计划。框架用户将增强管理已部署人工智能系统风险的能力,并根据评估和优先排序的风险分配风险管理资源。随着方法、环境、风险以及相关人工智能参与者的需求或期望随着时间的推移而演变,框架用户有责任继续将管理功能应用于部署的人工智能系统。
NIST人工智能RMF行动手册中描述了与人工智能风险管理相关的实践。表4列出了管理功能的类别和子类别。
表4:MANAGE功能的类别和子类别。
| Categories | Subcategories |
|---|---|
| Manage 1: AI risks based on assessments and other analytical output from the MAP and MEASURE functions are prioritized, responded to, and managed | Manage 1.1: A determination is made as to whether the AI system achieves its intended purposes and stated objectives and whether its development or deployment should proceed. |
| Manage 1.2: Treatment of documented AI risks is prioritized based on impact, likelihood, and available resources or methods. | |
| Manage 1.3: Responses to the AI risks deemed high priority, as identified by the map function, are developed, planned, and documented. Risk response options can include mitigating, transferring, avoiding, or accepting. | |
| Manage 1.4: Negative residual risks (defined as the sum of all unmitigated risks) to both downstream acquirers of AI systems and end users are documented. | |
| Manage 2: Strategies to maximize AI benefits and minimize negative impacts are planned, prepared, implemented, documented, and informed by input from relevant AI actors. | Manage 2.1: Resources required to manage AI risks are taken into account – along with viable non-AI alternative systems, approaches, or methods – to reduce the magnitude or likelihood of potential impacts. |
| Manage 2.2: Mechanisms are in place and applied to sustain the value of deployed AI systems. | |
| Manage 2.3: Procedures are followed to respond to and recover from a previously unknown risk when it is identified. | |
| Manage 2.4: Mechanisms are in place and applied, and responsibilities are assigned and understood, to supersede, disengage, or deactivate AI systems that demonstrate performance or outcomes inconsistent with intended use. | |
| Manage 3: AI risks and benefits from third-party entities are managed. | Manage 3.1: AI risks and benefits from third-party resources are regularly monitored, and risk controls are applied and documented. |
| Manage 3.2: Pre-trained models which are used for development are monitored as part of AI system regular monitoring and maintenance. | |
| Manage 4: Risk treatments, including response and recovery, and communication plans for the identified and measured AI risks are documented and monitored regularly. | Manage 4.1: Post-deployment AI system monitoring plans are implemented, including mechanisms for capturing and evaluating input from users and other relevant AI actors, appeal and override, decommissioning, incident response, recovery, and change management. |
| Manage 4.2: Measurable activities for continual improvements are integrated into AI system updates and include regular engagement with interested parties, including relevant AI actors. | |
| Manage 4.3: Incidents and errors are communicated to relevant AI actors, including affected communities. Processes for tracking, responding to, and recovering from incidents and errors are followed and documented. |
- 56 次浏览
【人工智能治理】NIST值得信赖和负责任的人工智能:人工智能RMF画象
视频号
微信公众号
知识星球
AI RMF用例简介是基于框架用户的要求、风险承受能力和资源,对特定环境或应用程序的AI RMF功能、类别和子类别的实现:例如,AI RMF招聘简介或AI RMF公平住房简介。简介可以说明并深入了解如何在人工智能生命周期的各个阶段或特定行业、技术或最终用途应用中管理风险。人工智能RMF档案有助于组织决定如何最好地管理与其目标相一致的人工智能风险,考虑法律/监管要求和最佳实践,并反映风险管理的优先事项。
人工智能RMF时间概况是对给定部门、行业、组织或应用环境中特定人工智能风险管理活动的当前状态或期望的目标状态的描述。人工智能RMF当前概况表明了人工智能目前的管理方式以及当前结果的相关风险。目标简介表示实现所需或目标人工智能风险管理目标所需的结果。
比较当前和目标概况可能会发现需要解决的差距,以实现人工智能风险管理目标。可以制定行动计划来解决这些差距,以实现特定类别或子类别的成果。差距缓解的优先顺序是由用户的需求和风险管理流程决定的。这种基于风险的方法还使框架用户能够将其方法与其他方法进行比较,并衡量所需资源(如人员配置、资金),以成本效益高、优先的方式实现人工智能风险管理目标。
AI RMF跨部门简介涵盖了可以跨用例或部门使用的模型或应用程序的风险。跨部门简介还可以涵盖如何管理、绘制、测量和管理跨部门常见的活动或业务流程的风险,如使用大型语言模型、基于云的服务或收购。
该框架没有规定配置文件模板,允许在实施中具有灵活性。
- 115 次浏览
【人工智能治理】NIST值得信赖和负责任的人工智能:人工智能RMF的有效性
视频号
微信公众号
知识星球
对人工智能RMF有效性的评估——包括衡量人工智能系统可信度底线改善的方法——将与人工智能社区一起成为NIST未来活动的一部分。
鼓励各组织和该框架的其他用户定期评估人工智能RMF是否提高了其管理人工智能风险的能力,包括但不限于其政策、流程、实践、实施计划、指标、测量和预期结果。NIST打算与其他机构合作,制定评估人工智能RMF有效性的指标、方法和目标,并广泛共享结果和支持信息。框架用户有望受益于:
- 加强人工智能风险的治理、绘图、测量和管理流程,并明确记录结果;
- 提高了对可信度特征、社会技术方法和人工智能风险之间的关系和权衡的认识;
- 制定允许/不允许系统调试和部署决策的明确流程;
- 为改进与人工智能系统风险相关的组织问责工作而制定的政策、流程、实践和程序;
- 加强组织文化,优先识别和管理人工智能系统风险以及对个人、社区、组织和社会的潜在影响;
- 更好地在组织内部和组织之间共享有关风险、决策过程、责任、常见陷阱、TEVV实践和持续改进方法的信息;
- 更多的背景知识,提高对下游风险的认识;
- 加强与有关各方和人工智能相关行为者的接触;和
- 增强了人工智能系统的TEVV能力和相关风险。
- 41 次浏览
【人工智能治理】NIST值得信赖和负责任的人工智能:人工智能风险和可信度
视频号
微信公众号
知识星球
为了让人工智能系统值得信赖,它们通常需要对对对相关方有价值的多种标准做出反应。提高人工智能可信度的方法可以降低人工智能的负面风险。该框架阐明了值得信赖的人工智能的以下特征,并为解决这些特征提供了指导。值得信赖的人工智能系统的特征包括:有效可靠、安全、有保障和弹性、负责透明、可解释和可解释、增强隐私、公平并管理有害偏见。创造值得信赖的人工智能需要根据人工智能系统的使用环境来平衡这些特征中的每一个。虽然所有特征都是社会技术系统属性,但问责制和透明度也与人工智能系统内部及其外部环境的流程和活动有关。忽视这些特征会增加负面后果的可能性和程度。

Figure 4: Characteristics of trustworthy AI systems. Valid & Reliable is a necessary condition of trustworthiness and is shown as the base for other trustworthiness characteristics. Accountable & Transparent is shown as a vertical box because it relates to all other characteristics.
可信度特征(如上图4所示)与社会和组织行为、人工智能系统使用的数据集、人工智能模型和算法的选择以及构建者所做的决策,以及与提供此类系统洞察力和监督的人类的互动密不可分。在决定与人工智能可信度特征相关的具体指标以及这些指标的精确阈值时,应采用人工判断。
单独处理人工智能可信度特征并不能确保人工智能系统的可信度;通常会涉及权衡,很少所有特征都适用于每个环境,有些特征在任何特定情况下或多或少都很重要。归根结底,可信度是一个社会概念,它涵盖了各个领域,只有其最弱的特征才是强大的。
在管理人工智能风险时,组织在平衡这些特征时可能会面临艰难的决策。例如,在某些情况下,在优化可解释性和实现隐私之间可能会出现权衡。在其他情况下,组织可能面临预测准确性和可解释性之间的权衡。或者,在数据稀疏等特定条件下,隐私增强技术可能会导致准确性损失,影响某些领域中关于公平性和其他价值观的决策。处理权衡需要考虑决策背景。这些分析可以强调不同措施之间权衡的存在和程度,但它们并没有回答如何进行权衡的问题。这些问题取决于相关背景下的价值观,应以透明和合理的方式加以解决。
在人工智能生命周期中,有多种方法可以增强上下文意识。例如,主题专家可以协助评估TEVV发现,并与产品和部署团队合作,使TEVV参数与需求和部署条件相一致。如果资源充足,在整个人工智能生命周期中增加相关方和相关人工智能参与者的投入的广度和多样性,可以增加为上下文敏感的评估提供信息的机会,并确定人工智能系统的好处和积极影响。这些做法可以增加在社会环境中出现的风险得到适当管理的可能性。
对可信度特征的理解和处理取决于人工智能参与者在人工智能生命周期中的特定角色。对于任何给定的人工智能系统,人工智能设计者或开发人员对特性的感知可能与部署者不同。
本文件中解释的可信度特征相互影响。高度安全但不公平的系统,准确但不透明且无法解释的系统,以及不准确但安全、隐私增强且透明的系统都是不可取的。风险管理的综合方法要求在可信度特征之间进行权衡。所有人工智能参与者共同负责确定人工智能技术对于特定的背景或目的是否是合适或必要的工具,以及如何负责任地使用它。委托或部署人工智能系统的决定应基于对可信度特征和相对风险、影响、成本和收益的上下文评估,并由广泛的利益相关方提供信息。
3.1有效可靠
验证是“通过提供客观证据,确认特定预期用途或应用的要求已得到满足”(来源:iso 9000:2015)。人工智能系统的部署不准确、不可靠,或对其训练之外的数据和设置概括不力,会产生并增加人工智能的负面风险,降低可信度。
可靠性在同一标准中被定义为“项目在给定条件下,在给定时间间隔内按要求执行而不发生故障的能力”(来源:iso/iec ts 5723:2022)。可靠性是人工智能系统在预期使用条件下和给定时间段(包括系统的整个寿命)内运行的总体正确性的目标。
准确性和稳健性有助于人工智能系统的有效性和可信度,并且在人工智能系统中可能相互紧张。
iso/iec ts 5723:2022将准确度定义为“观测、计算或估计结果与真实值或被接受为真实值的接近度”。准确度的测量应考虑以计算为中心的测量(如假阳性率和假阴性率)、人工智能团队,并证明外部有效性(可在训练条件之外推广)。准确度测量应始终与明确定义和现实的测试集(代表预期使用条件)以及测试方法的细节相结合;这些应包含在相关文档中。精度测量可能包括对不同数据段的结果进行分解。
稳健性或可推广性被定义为“系统在各种情况下保持其性能水平的能力”(来源:iso/iec ts 5723:2022)。鲁棒性是在广泛的条件和情况下实现适当系统功能的目标,包括最初未预期的人工智能系统的使用。鲁棒性不仅要求系统在预期用途下的性能与预期性能完全一致,而且还要求系统在意外环境中运行时,其性能应最大限度地减少对人员的潜在危害。
部署的人工智能系统的有效性和可靠性通常通过持续的测试或监测来评估,以确认系统是否按预期运行。有效性、准确性、稳健性和可靠性的测量有助于提高可信度,并应考虑到某些类型的故障可能造成更大的危害。人工智能风险管理工作应优先考虑将潜在的负面影响降至最低,并可能需要在人工智能系统无法检测或纠正错误的情况下包括人工干预。
3.2安全(safety)
人工智能系统不应“在特定条件下导致人类生命、健康、财产或环境受到威胁”(来源:iso/iec ts 5723:2022)。人工智能系统的安全运行通过以下方式得到改善:
- 负责任的设计、开发和部署实践;
- 向部署人员提供关于负责任地使用该系统的明确信息;
- 部署人员和最终用户负责任的决策;和
- 基于事件经验证据的风险解释和文件记录。
不同类型的安全风险可能需要根据背景和潜在风险的严重程度量身定制的人工智能风险管理方法。构成严重伤害或死亡潜在风险的安全风险需要最紧迫的优先顺序和最彻底的风险管理流程。
在生命周期中采用安全考虑因素,并尽早开始规划和设计,可以防止可能导致系统危险的故障或情况。人工智能安全的其他实用方法通常涉及严格的模拟和领域内测试、实时监控,以及关闭、修改或让人工干预偏离预期或预期功能的系统的能力。
人工智能安全风险管理方法应借鉴交通和医疗保健等领域的安全努力和指南,并与现有的行业或应用特定的指南或标准保持一致。
3.3安全且有弹性
如果人工智能系统及其部署的生态系统能够承受环境或使用中的意外不利事件或意外变化,或者在面对内部和外部变化时能够保持其功能和结构,并在必要时安全优雅地退化,则可以说它们是有弹性的(改编自:iso/iec ts 5723:2022)。常见的安全问题涉及对抗性示例、数据中毒以及通过人工智能系统端点过滤模型、训练数据或其他知识产权。人工智能系统可以通过防止未经授权的访问和使用的保护机制来保持机密性、完整性和可用性,可以说是安全的。NIST网络安全框架和风险管理框架中的指南在此适用。
安全性和复原力是相关但不同的特征。虽然弹性是指在发生意外不良事件后恢复正常功能的能力,但安全性包括弹性,但也包括避免、保护、响应或从攻击中恢复的协议。弹性与稳健性有关,并超越了数据的来源,涵盖了对模型或数据的意外或对抗性使用(或滥用或误用)。
3.4负责且透明
值得信赖的人工智能依赖于问责制。问责制以透明度为前提。透明度反映了与人工智能系统交互的个人可以在多大程度上获得有关人工智能系统及其输出的信息,无论他们是否意识到自己在这样做。有意义的透明度提供了基于人工智能生命周期阶段的适当级别的信息访问,并根据人工智能参与者或与人工智能系统交互或使用人工智能系统的个人的角色或知识进行定制。通过促进更高水平的理解,透明度增加了人们对人工智能系统的信心。
该特性的范围从设计决策和训练数据到模型训练、模型的结构、其预期用例,以及部署、部署后或最终用户决策的方式和时间以及由谁做出。对于与人工智能系统输出不正确或以其他方式导致负面影响有关的可采取行动的补救措施,透明度往往是必要的。透明度应考虑人类与人工智能的互动:例如,当检测到人工智能系统造成的潜在或实际不利结果时,如何通知人类操作员或用户。透明的系统不一定是准确的、增强隐私的、安全的或公平的系统。然而,很难确定不透明的系统是否具有这些特征,也很难随着复杂系统的发展而确定。
在寻求对人工智能系统的结果负责时,应考虑人工智能参与者的作用。与人工智能和技术系统相关的风险和问责制之间的关系在文化、法律、部门和社会背景下有着更广泛的差异。当后果严重时,例如当生命和自由受到威胁时,人工智能开发人员和部署人员应考虑按比例主动调整其透明度和问责制做法。维护减少伤害的组织实践和治理结构,如风险管理,有助于建立更负责任的系统。
加强透明度和问责制的措施还应考虑到这些努力对执行实体的影响,包括必要的资源水平和保护专有信息的必要性。
维护训练数据的来源并支持将人工智能系统的决策归因于训练数据的子集,有助于提高透明度和问责制。培训数据也可能受到版权保护,并应遵守适用的知识产权法。
随着人工智能系统的透明度工具和相关文档的不断发展,鼓励人工智能系统开发人员与人工智能部署人员合作测试不同类型的透明度工具,以确保人工智能系统按预期使用。
3.5可解释(Explainable)和可解释(Interpretable)
可解释性是指人工智能系统运行的基本机制的表示,而可解释性则是指在其设计的功能目的的背景下人工智能系统输出的含义。可解释性和可解释性共同帮助操作或监督人工智能系统的人员以及人工智能系统用户更深入地了解系统的功能和可信度,包括其输出。潜在的假设是,对负面风险的感知源于缺乏适当理解或情境化系统输出的能力。可解释和可解释的人工智能系统提供的信息将帮助最终用户了解人工智能系统的目的和潜在影响。
缺乏可解释性的风险可以通过描述人工智能系统的功能来管理,并根据用户的角色、知识和技能水平等个人差异进行描述。可以更容易地调试和监控可解释的系统,并且它们有助于更彻底的文档、审计和治理。
可解释性的风险通常可以通过传达人工智能系统为什么做出特定预测或建议的描述来解决。(请参阅此处的“可解释人工智能的四个原则”和“人工智能中可解释性和可解释性的心理基础”。)
透明性、可解释性和可解释性是相互支持的不同特征。透明度可以回答系统中“发生了什么”的问题。可解释性可以回答系统中“如何”做出决策的问题。可解释性可以回答系统做出决定的“原因”及其对用户的意义或上下文的问题。
3.6隐私增强
隐私通常是指有助于维护人类自主性、身份和尊严的规范和做法。这些规范和做法通常涉及免于入侵、限制观察或个人同意披露或控制其身份各方面(如身体、数据、声誉)的自由。NIST隐私框架:通过企业风险管理改善隐私的工具
匿名、保密和控制等隐私价值观通常应指导人工智能系统设计、开发和部署的选择。与隐私相关的风险可能会影响安全性、偏见和透明度,并与这些其他特征进行权衡。与安全和安保一样,人工智能系统的特定技术特征可能会促进或减少隐私。人工智能系统还可以通过允许推断来识别个人或以前关于个人的私人信息,从而给隐私带来新的风险。
人工智能的隐私增强技术(“PET”),以及某些模型输出的去识别和聚合等数据最小化方法,可以支持隐私增强人工智能系统的设计。在某些条件下,如数据稀疏性,隐私增强技术可能会导致准确性的损失,影响某些领域中关于公平性和其他价值的决策。
3.7公平——管理有害偏见
人工智能中的公平包括通过解决有害的偏见和歧视等问题来关注平等和公平。公平的标准可能很复杂,很难定义,因为不同文化对公平的看法不同,而且可能会根据应用而变化。各组织的风险管理工作将通过认识和考虑这些差异而得到加强。减少有害偏见的制度不一定是公平的。例如,残疾人或受数字鸿沟影响的人可能仍然无法使用预测在不同人口群体中有所平衡的系统,或者可能加剧现有的差异或系统性偏见。
偏见比人口平衡和数据代表性更广泛。NIST确定了需要考虑和管理的三大类人工智能偏见:系统性、计算和统计性以及人类认知性。每一种情况都可能发生在没有偏见、偏袒或歧视意图的情况下。系统偏见可能存在于人工智能数据集、整个人工智能生命周期的组织规范、实践和流程,以及使用人工智能系统的更广泛社会中。计算和统计偏差可能存在于人工智能数据集和算法过程中,通常源于非代表性样本造成的系统误差。人类的认知偏见与个人或群体如何感知人工智能系统信息以做出决定或填写缺失信息有关,也与人类如何思考人工智能系统的目的和功能有关。人类的认知偏见在人工智能生命周期和系统使用的决策过程中无处不在,包括人工智能的设计、实施、运营和维护。
偏见以多种形式存在,并可能在帮助我们做出生活决策的自动化系统中根深蒂固。虽然偏见并不总是一种负面现象,但人工智能系统可能会增加偏见的速度和规模,并使对个人、团体、社区、组织和社会的伤害永久化和扩大。偏见与社会中的透明度和公平性概念密切相关。(有关偏见的更多信息,包括三类,请参阅NIST特别出版物1270,《建立人工智能中识别和管理偏见的标准》。)
- 90 次浏览
【人工智能治理】NIST值得信赖和负责任的人工智能:框架风险
视频号
微信公众号
知识星球
1框架风险
人工智能风险管理提供了一条途径,可以最大限度地减少人工智能系统的潜在负面影响,如对公民自由和权利的威胁,同时也提供了最大限度地扩大积极影响的机会。有效地解决、记录和管理人工智能风险和潜在的负面影响可以带来更值得信赖的人工智能系统。
1.1了解和应对风险、影响和危害
在AI RMF的背景下,风险是指事件发生概率和相应事件后果的大小或程度的综合衡量标准。人工智能系统的影响或后果可能是积极的、消极的,也可能是两者兼而有之,并可能导致机会或威胁(改编自:iso 31000:2018)。当考虑潜在事件的负面影响时,风险是1)如果情况或事件发生,将产生的负面影响或伤害程度和2)发生的可能性的函数(改编自:omb通告a-130:2016)。个人、团体、社区、组织、社会、环境和地球都可能受到负面影响或伤害。
“风险管理是指在风险方面指导和控制组织的协调活动”(来源:iso 31000:2018)。
虽然风险管理流程通常解决负面影响,但该框架提供了将人工智能系统的预期负面影响降至最低的方法,并确定了最大限度地发挥积极影响的机会。有效管理潜在危害的风险可以带来更值得信赖的人工智能系统,并为人们(个人、社区和社会)、组织和系统/生态系统带来潜在利益。风险管理可以使人工智能开发人员和用户了解其模型和系统的影响,并解释其固有的局限性和不确定性,这反过来可以提高系统的整体性能和可信度,以及人工智能技术以有益的方式使用的可能性。
AI RMF旨在应对出现的新风险。在影响不易预见且应用程序不断发展的情况下,这种灵活性尤为重要。虽然人工智能的一些风险和好处是众所周知的,但评估负面影响和危害程度可能很有挑战性。图1提供了与人工智能系统相关的潜在危害示例。
人工智能风险管理工作应考虑到,人类可能会认为人工智能系统在所有环境中都能正常工作。例如,无论是否正确,人工智能系统通常被认为比人类更客观,或者比通用软件提供更大的功能。
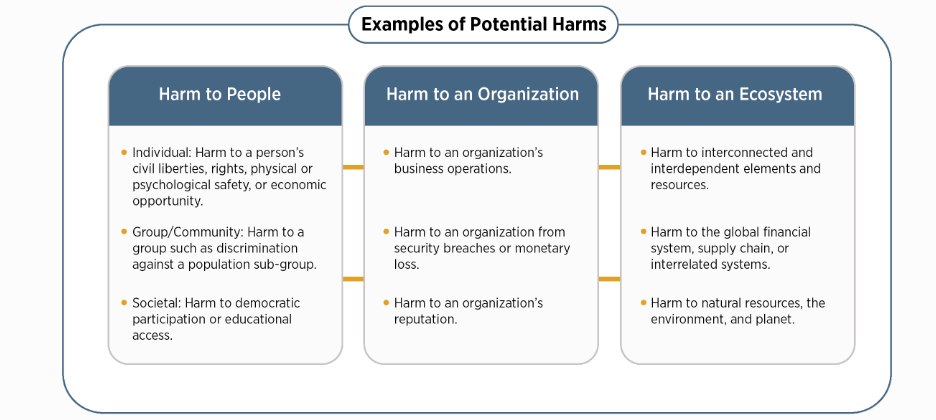
图1:与人工智能系统相关的潜在危害示例。值得信赖的人工智能系统及其负责任的使用可以减轻负面风险,为人们、组织和生态系统带来好处。
1.2人工智能风险管理面临的挑战
以下介绍了几个挑战。在管理风险以追求人工智能可信度时,应将其考虑在内。
1.1.1风险度量
人工智能的风险或失败没有明确定义或充分理解,很难定量或定性地衡量。无法适当衡量人工智能风险并不意味着人工智能系统必然会带来高风险或低风险。一些风险衡量挑战包括:
- 与第三方软件、硬件和数据相关的风险:第三方数据或系统可以加速研发并促进技术转型。它们也可能使风险衡量复杂化。风险既可能来自第三方数据、软件或硬件本身,也可能来自其使用方式。开发人工智能系统的组织所使用的风险度量或方法可能与部署或运行该系统的组织使用的风险指标或方法不一致。此外,开发人工智能系统的组织可能对其使用的风险指标或方法不透明。客户如何使用或将第三方数据或系统集成到人工智能产品或服务中,尤其是在没有足够的内部治理结构和技术保障的情况下,风险测量和管理可能会变得复杂。无论如何,各方和人工智能参与者都应该管理他们开发、部署或用作独立或集成组件的人工智能系统中的风险。
- 跟踪突发风险:将通过识别和跟踪突发风险并考虑测量技术来加强组织的风险管理工作。人工智能系统影响评估方法可以帮助人工智能参与者了解特定背景下的潜在影响或危害。
- 可靠指标的可用性:目前对风险和可信度的稳健和可验证的测量方法以及对不同人工智能用例的适用性缺乏共识,这是人工智能风险测量的挑战。在寻求衡量负面风险或危害时,潜在的陷阱包括这样一个现实,即指标的制定通常是一项机构努力,可能会无意中反映出与潜在影响无关的因素。此外,测量方法可能过于简单化、游戏化、缺乏关键的细微差别、以意想不到的方式被依赖,或者无法解释受影响群体和环境的差异。
如果认识到环境很重要,伤害可能会对不同的群体或子群体产生不同的影响,并且可能受到伤害的社区或其他子群体并不总是系统的直接用户,那么衡量对人群影响的方法效果最好。
- 人工智能生命周期不同阶段的风险:在人工智能生命生命周期的早期阶段测量风险可能会产生与在后期测量风险不同的结果;一些风险可能在给定的时间点是潜在的,并且可能随着人工智能系统的适应和发展而增加。此外,人工智能生命周期中不同的人工智能参与者可能有不同的风险视角。例如,提供人工智能软件(如预训练模型)的人工智能开发人员可能与负责在特定用例中部署预训练模型的人工智能参与者有不同的风险视角。这些部署人员可能没有意识到,他们的特定用途可能会带来与最初开发人员所感知的风险不同的风险。所有相关的人工智能参与者都有责任设计、开发和部署一个符合目的的值得信赖的人工智能系统。
- 现实世界环境中的风险:虽然在实验室或受控环境中测量人工智能风险可能会在部署前产生重要见解,但这些测量可能与实际操作环境中出现的风险不同。
- 不可破解性:不可破解的人工智能系统会使风险衡量复杂化。不可破解性可能是由于人工智能系统的不透明性(可解释性或可解释性有限)、人工智能系统开发或部署缺乏透明度或文档,或人工智能系统固有的不确定性。
- 人类基线:旨在增强或取代人类活动的人工智能系统的风险管理,例如决策,需要某种形式的基线指标进行比较。这很难系统化,因为人工智能系统执行的任务与人类不同,执行的任务也不同
1.1.2风险承受能力
虽然AI RMF可用于优先考虑风险,但它并未规定风险承受能力。风险承受能力是指组织或人工智能参与者(见附录A)为实现其目标而承担风险的意愿。风险承受能力可能受到法律或监管要求的影响(改编自:iso指南73)。风险承受能力和组织或社会可接受的风险水平是高度相关的,并且是特定于应用程序和用例的。风险承受能力可能受到人工智能系统所有者、组织、行业、社区或政策制定者制定的政策和规范的影响。随着人工智能系统、政策和规范的发展,风险承受能力可能会随着时间的推移而变化。不同的组织由于其特定的组织优先级和资源考虑因素,可能具有不同的风险承受能力。
企业、政府、学术界和民间社会将继续发展和讨论新出现的知识和方法,以更好地了解危害/成本效益权衡。在指定人工智能风险承受能力的挑战仍未解决的情况下,可能存在风险管理框架尚不适用于减轻人工智能负面风险的情况。
该框架旨在具有灵活性,并加强现有的风险实践,这些实践应符合适用的法律、法规和规范。组织应遵循组织、领域、学科、部门或专业要求制定的风险标准、容忍度和应对措施的现有法规和指南。一些部门或行业可能已经确定了危害的定义,或制定了文件、报告和披露要求。在部门内,风险管理可能取决于特定应用程序和用例设置的现有指南。在没有既定指导方针的情况下,组织应定义合理的风险承受能力。一旦定义了容差,该AI RMF就可以用于管理风险和记录风险管理流程。
1.1.3风险优先级
试图完全消除负面风险在实践中可能会适得其反,因为并非所有的事件和失败都能消除。对风险的不切实际的期望可能导致组织以一种使风险分类低效或不切实际或浪费稀缺资源的方式分配资源。风险管理文化可以帮助组织认识到,并非所有的人工智能风险都是相同的,资源可以有目的地分配。可采取行动的风险管理工作为评估组织开发或部署的每个人工智能系统的可信度制定了明确的指导方针。应根据评估的风险水平和人工智能系统的潜在影响,优先考虑政策和资源。人工智能系统可以在多大程度上根据人工智能部署者使用的特定环境进行定制或定制,这可能是一个促成因素。
在应用人工智能RMF时,组织确定在给定使用环境下人工智能系统的风险最高,需要最紧急的优先级排序和最彻底的风险管理流程。如果人工智能系统呈现出不可接受的负面风险水平,例如重大负面影响迫在眉睫、严重危害实际发生或存在灾难性风险,则应以安全的方式停止开发和部署,直到风险得到充分管理。如果人工智能系统的开发、部署和用例在特定情况下被发现是低风险的,这可能意味着优先级可能会降低。
与非人工智能系统相比,设计或部署用于与人类直接交互的人工智能系统之间的风险优先级可能有所不同。在人工智能系统在由敏感或受保护数据(如个人身份信息)组成的大型数据集上进行训练的环境中,或者人工智能系统的输出对人类有直接或间接影响的环境中可能需要更高的初始优先级。人工智能系统设计为仅与计算系统交互,并在非敏感数据集(例如,从物理环境中收集的数据)上进行训练,可能需要较低的初始优先级。尽管如此,基于上下文定期评估和优先考虑风险仍然很重要,因为面向非人类的人工智能系统可能会产生下游安全或社会影响。
剩余风险——定义为风险处理后的剩余风险(来源:iso指南73)——直接影响最终用户或受影响的个人和社区。记录剩余风险将要求系统提供商充分考虑部署人工智能产品的风险,并告知最终用户与系统交互的潜在负面影响。
1.1.4组织整合与风险管理
人工智能风险不应单独考虑。不同的人工智能参与者有不同的责任和意识,这取决于他们在生命周期中的角色。例如,开发人工智能系统的组织通常没有关于如何使用该系统的信息。人工智能风险管理应整合并纳入更广泛的企业风险管理战略和流程。将人工智能风险与其他关键风险(如网络安全和隐私)一起处理,将产生更综合的结果和组织效率。
人工智能RMF可与相关指南和框架一起用于管理人工智能系统风险或更广泛的企业风险。与人工智能系统相关的一些风险在其他类型的软件开发和部署中很常见。重叠风险的例子包括:与使用基础数据训练人工智能系统有关的隐私问题;与资源密集型计算需求相关的能源和环境影响;与系统及其培训和输出数据的机密性、完整性和可用性相关的安全问题;以及人工智能系统底层软件和硬件的一般安全性。
各组织需要建立和维护适当的问责机制、作用和责任、文化和激励结构,以使风险管理有效。单独使用AI RMF不会导致这些变化或提供适当的激励措施。有效的风险管理是通过高层的组织承诺实现的,可能需要组织或行业内的文化变革。此外,管理人工智能风险或实施人工智能RMF的中小型组织可能面临与大型组织不同的挑战,这取决于它们的能力和资源。
- 41 次浏览
【人工智能治理】我们如何最好地管理人工智能?
视频号
微信公众号
知识星球

这篇文章是Brad Smith为微软的报告《治理人工智能:未来蓝图》撰写的前言。报告的第一部分详细介绍了政府应考虑人工智能相关政策、法律和法规的五种方式。第二部分重点介绍了微软对道德人工智能的内部承诺,展示了该公司如何运作和建立负责任的人工智能文化。
“不要问计算机能做什么,要问它们应该做什么。”
这是我在2019年合著的一本书中关于人工智能和伦理的章节的标题。当时,我们写道,“这可能是我们这一代人的决定性问题之一。”四年后,这个问题不仅在世界各国首都,而且在许多餐桌上占据了中心位置。
当人们使用或听说OpenAI的GPT-4基础模型的力量时,他们经常感到惊讶甚至震惊。许多人都很兴奋。有些人感到担忧甚至害怕。几乎所有人都清楚的是,我们在四年前就注意到了这一点——我们是人类历史上第一代创造出能够做出以前只能由人做出的决定的机器。
世界各国都在提出共同的问题。我们如何利用这项新技术来解决我们的问题?我们如何避免或管理它可能产生的新问题?我们如何控制如此强大的技术?
这些问题不仅需要广泛和深思熟虑的对话,而且需要果断和有效的行动。本文提供了我们作为一家公司的一些想法和建议。
这些建议建立在我们多年来所做工作的基础上。微软首席执行官萨蒂亚·纳德拉在2016年写道,“也许我们能进行的最富有成效的辩论不是善与恶的辩论:辩论应该是关于创造这项技术的人和机构所灌输的价值观。”
从那时起,我们就定义、发布并实施了指导我们工作的伦理原则。我们建立了不断改进的工程和治理系统,将这些原则付诸实践。如今,我们有近350人在微软从事负责任的人工智能工作,帮助我们实施最佳实践,构建安全、可靠和透明的人工智能系统,造福社会。
改善人类状况的新机遇
我们的方法由此取得的进步使我们有能力和信心看到人工智能改善人们生活的不断扩大的方式。我们已经看到人工智能帮助拯救个人视力,在癌症新疗法方面取得进展,对蛋白质产生新的见解,并提供预测,保护人们免受危险天气的影响。其他创新是抵御网络攻击,帮助保护基本人权,即使在遭受外国入侵或内战的国家也是如此。
日常活动也会受益。通过在人们的生活中充当副驾驶,GPT-4等基础模型的力量正在将搜索变成一种更强大的研究工具,并提高人们的工作效率。而且,对于那些很难记住如何帮助13岁的孩子完成代数作业的家长来说,基于人工智能的帮助是一个很有帮助的导师。
在很多方面,人工智能为人类的利益提供的潜力可能比之前的任何发明都要大。自14世纪发明活字印刷机以来,人类的繁荣一直在加速增长。蒸汽机、电力、汽车、飞机、计算机和互联网等发明为现代文明提供了许多基石。而且,就像印刷机本身一样,人工智能提供了一种新的工具来真正帮助推进人类的学习和思考。

未来的护栏(Guardrails )
另一个结论同样重要:仅仅关注利用人工智能改善人们生活的许多机会是不够的。这也许是从社交媒体的作用中得到的最重要的教训之一。十多年前,技术专家和政治评论员都对社交媒体在阿拉伯之春期间传播民主的作用赞不绝口。然而,五年后,我们了解到,社交媒体和之前的许多其他技术一样,将成为一种武器和工具——在这种情况下,其目标是民主本身。
今天,我们老了10岁,更聪明了,我们需要把这种智慧发挥作用。我们需要尽早、清醒地思考未来可能出现的问题。随着技术的发展,确保对人工智能的适当控制与追求其利益同样重要。作为一家公司,我们致力于并决心以安全和负责任的方式开发和部署人工智能。然而,我们也认识到,人工智能所需的护栏需要广泛的责任感,不应该只留给科技公司。
当我们微软在2018年通过人工智能的六项道德原则时,我们注意到其中一项原则是其他一切的基石——问责制。这是根本的需要:确保机器仍然受到人们的有效监督,设计和操作机器的人仍然对其他人负责。简而言之,我们必须始终确保人工智能处于人类的控制之下。这必须是科技公司和政府的首要任务。
这与另一个基本概念直接相关。在民主社会中,我们的一个基本原则是,任何人都不能凌驾于法律之上。任何政府都不能凌驾于法律之上。任何公司都不能凌驾于法律之上,任何产品或技术都不应凌驾于法律之外。这导致了一个关键的结论:设计和操作人工智能系统的人不能承担责任,除非他们的决定和行动受到法治的约束。
在许多方面,这是正在展开的人工智能政策和监管辩论的核心。政府如何最好地确保人工智能服从法治?简而言之,新的法律、法规和政策应该采取什么形式?
人工智能公共治理的五点蓝图
本文的第一节提供了一个五点蓝图,通过公共政策、法律和监管来解决当前和新兴的人工智能问题。我们提出这一点是认识到,这一蓝图的每一部分都将受益于更广泛的讨论,并需要更深入的发展。但我们希望这能对今后的工作作出建设性贡献。
首先,实施和建立新的政府主导的人工智能安全框架。
成功的最好方法往往是建立在他人的成功和良好想法的基础上。尤其是当一个人想快速行动的时候。在这种情况下,有一个重要的机会在美国国家标准与技术研究所(NIST)四个月前刚刚完成的工作的基础上再接再厉。作为商务部的一部分,NIST已经完成并推出了一个新的人工智能风险管理框架。
我们提供了四个具体的建议来实施和建立这一框架,包括微软在白宫最近与领先的人工智能公司举行的会议上做出的承诺。我们还相信,政府和其他政府可以通过基于这一框架的采购规则来加快势头。

其次,需要为控制关键基础设施的人工智能系统提供有效的安全刹车(safety brakes)。
在某些方面,有思想的人越来越多地问,随着人工智能变得越来越强大,我们是否能令人满意地控制它。有时会对电网、供水系统和城市交通流等关键基础设施的人工智能控制提出担忧。
现在正是讨论这个问题的恰当时机。这一蓝图提出了新的安全要求,实际上,这将为控制指定关键基础设施运行的人工智能系统创造安全刹车。这些故障安全系统将是系统安全综合方法的一部分,该方法将把有效的人类监督、弹性和稳健性放在首位。在精神上,它们将类似于工程师长期以来在电梯、校车和高速列车等其他技术中构建的制动系统,不仅可以安全地管理日常场景,还可以安全地处理紧急情况。
在这种方法中,政府将定义控制关键基础设施的高风险人工智能系统类别,并保证采取此类安全措施,作为系统管理综合方法的一部分。新的法律将要求这些系统的操作员通过设计将安全制动器构建到高风险的人工智能系统中。然后,政府将确保运营商定期测试高风险系统,以确保系统安全措施有效。控制指定关键基础设施运行的人工智能系统将仅部署在获得许可的人工智能数据中心,这些数据中心将通过应用这些安全制动器的能力确保第二层保护,从而确保有效的人工控制。
第三,基于人工智能的技术架构,制定一个广泛的法律和监管框架。
我们认为,需要有一个反映人工智能本身技术架构的人工智能法律和监管架构。简言之,法律需要根据不同参与者在管理人工智能技术不同方面的作用,将各种监管责任赋予他们。
因此,这份蓝图包括了关于构建和使用新的生成人工智能模型的一些关键部分的信息。以此为背景,它建议不同的法律将特定的监管责任赋予在技术堆栈的三层行使某些责任的组织:应用程序层、模型层和基础设施层。
这应该首先将应用层的现有法律保护应用于人工智能的使用。这是人们的安全和权利将受到最大影响的一层,特别是因为人工智能的影响在不同的技术场景中可能会明显不同。在许多领域,我们不需要新的法律法规。相反,我们需要应用和执行现有的法律法规,帮助机构和法院发展适应新的人工智能场景所需的专业知识。
然后,将需要为高能力的人工智能基础模型制定新的法律和法规,最好由新的政府机构实施。这将影响技术堆栈的两层。第一个要求对这些车型本身进行新的法规和许可。第二个将涉及开发和部署这些模型的人工智能基础设施运营商的义务。下面的蓝图为每一层提供了建议的目标和方法。
在这样做的过程中,这一蓝图在一定程度上建立在近几十年来银行业制定的一项原则之上,该原则旨在防止洗钱和金融服务的犯罪或恐怖主义使用。“了解你的客户”(KYC)原则要求金融机构核实客户身份,建立风险档案,并监控交易,以帮助发现可疑活动。采取这一原则并应用KY3C方法是有意义的,该方法在人工智能环境中创造了了解自己的云、客户和内容的某些义务。

首先,指定的强大人工智能模型的开发者首先“了解”他们的模型开发和部署的云。
此外,例如对于涉及敏感用途的场景,与客户有直接关系的公司——无论是模型开发人员、应用程序提供商还是运行该模型的云运营商——都应该“了解访问该模型的客户”。
此外,当视频或音频文件等内容是由人工智能模型而非人类制作的时,公众应该有权通过使用标签或其他标记来“了解”人工智能正在创建的内容。这一标签义务还应保护公众免受原始内容的更改和“深度造假”的影响。这将需要制定新的法律,还有许多重要的问题和细节需要解决。但民主的健康和公民话语的未来将受益于阻止使用新技术欺骗或欺骗公众的深思熟虑的措施。
第四,提高透明度,确保学术和非营利组织获得人工智能。
我们认为,一个关键的公共目标是提高透明度,扩大获得人工智能资源的机会。虽然透明度和安全需求之间存在一些重要的紧张关系,但仍有许多机会以负责任的方式使人工智能系统更加透明。这就是为什么微软承诺发布年度人工智能透明度报告和其他措施,以扩大我们人工智能服务的透明度。
我们还认为,扩大学术研究和非营利社区对人工智能资源的获取至关重要。自20世纪40年代以来,基础研究,尤其是大学基础研究,对美国的经济和战略成功至关重要。但是,除非学术研究人员能够获得更多的计算资源,否则科学和技术研究将面临真正的风险,包括与人工智能本身有关的风险。我们的蓝图要求采取新的步骤,包括我们将在整个微软采取的步骤,以解决这些优先事项。
第五,寻求新的公私合作伙伴关系,将人工智能作为一种有效工具,以应对新技术带来的不可避免的社会挑战。
近年来的一个教训是,当民主社会利用技术的力量,将公共和私营部门团结在一起时,它们可以取得什么成就。这是我们需要吸取的教训,以应对人工智能对社会的影响。
我们所有人都将受益于坚定的乐观态度。人工智能是一种非凡的工具。但是,与其他技术一样,它也可以成为一种强大的武器,世界各地也会有一些人寻求以这种方式使用它。但我们应该从网络战线和乌克兰战争的最后一年半中振作起来。我们发现,当公共和私营部门合作,当志同道合的盟友走到一起,当我们开发技术并将其用作盾牌时,它比地球上任何一把剑都更强大。
现在需要开展重要工作,利用人工智能保护民主和基本权利,提供广泛的人工智能技能,促进包容性增长,并利用人工智能的力量促进地球的可持续性需求。也许最重要的是,一波新的人工智能技术为大胆思考和行动提供了机会。在每一个领域,成功的关键将是制定具体的举措,并将政府、受人尊敬的公司和充满活力的非政府组织聚集在一起推动这些举措。我们在这份报告中提出了一些初步想法,我们期待着在未来的几个月和几年里做得更多。
管理微软内部的人工智能
最终,每个创建或使用先进人工智能系统的组织都需要开发和实施自己的治理系统。本文的第二节描述了微软内部的人工智能治理系统——我们从哪里开始,我们今天在哪里,以及我们如何走向未来。
正如本节所认识到的,为新技术开发新的治理体系本身就是一段旅程。十年前,这个领域还几乎不存在。如今,微软有近350名员工专门从事it工作,我们正在下一财年进行投资,以进一步发展这一业务。
如本节所述,在过去的六年里,我们在微软建立了一个更全面的人工智能治理结构和系统。我们并不是从头开始,而是借鉴了保护网络安全、隐私和数字安全的最佳实践。这都是公司全面企业风险管理(ERM)系统的一部分,该系统已成为当今世界企业和许多其他组织管理的关键部分。
谈到人工智能,我们首先制定了伦理原则,然后必须将其转化为更具体的企业政策。我们现在使用的是公司标准的第2版,它体现了这些原则,并为我们的工程团队定义了更精确的实践。我们通过不断快速成熟的培训、工具和测试系统实施了该标准。这得到了其他治理过程的支持,这些过程包括监控、审计和法规遵从性措施。
就像生活中的一切一样,一个人从经验中学习。谈到人工智能治理,我们最重要的一些学习来自于审查特定敏感人工智能用例所需的详细工作。2019年,我们建立了一个敏感用途审查计划,对我们最敏感和最新颖的人工智能用例进行严格、专业的审查,从而提供量身定制的指导。从那时起,我们已经完成了大约600个敏感的用例评审。这项活动的步伐已经加快,与人工智能的进步步伐相匹配,在11个月内进行了近150次此类审查。
所有这些都建立在我们已经做的工作的基础上,并将继续通过公司文化推动负责任的人工智能。这意味着雇佣新的多样化人才来发展我们负责任的人工智能生态系统,并投资于我们在微软已经拥有的人才,以发展技能,并使他们能够广泛思考人工智能系统对个人和社会的潜在影响。这也意味着,与过去相比,技术前沿更需要一种多学科的方法,将优秀的工程师与来自文科的才华横溢的专业人士相结合。
本文提供的所有这些都是本着我们正在为人工智能打造一个负责任的未来的集体旅程的精神。我们都可以互相学习。无论我们今天认为事情有多好,我们都需要不断变得更好。
随着技术变革的加速,负责任地管理人工智能的工作必须跟上步伐。只要做出正确的承诺和投资,我们相信它可以做到。
- 45 次浏览
【人工智能治理】推进欧洲和国际人工智能治理
视频号
微信公众号
知识星球
编者按:这篇文章是微软副主席兼总裁Brad Smith为微软的报告《人工智能在欧洲:迎接整个欧盟的机遇》撰写的一章。2023年6月29日,他在布鲁塞尔举行的“欧洲数字化转型——拥抱人工智能机遇”活动上发表了主题演讲,阐述了这里表达的想法。
你可以在这里阅读全球人工智能治理报告:未来蓝图。
利用人工智能的力量为欧洲的增长和价值做出贡献有着巨大的机会。但另一个层面同样清晰。仅仅关注利用人工智能改善人们生活的许多机会是不够的。我们需要以同样的决心关注人工智能可能带来的挑战和风险,我们需要有效地管理它们。
这也许是从社交媒体的作用中得到的最重要的教训之一。十多年前,技术专家和政治评论员都对社交媒体在阿拉伯之春期间传播民主的作用赞不绝口。然而,五年后,我们了解到,社交媒体和之前的许多其他技术一样,将成为一种武器和工具——在这种情况下,其目标是民主本身。
今天,我们老了10岁,更聪明了,我们需要把这种智慧发挥作用。我们需要尽早、清醒地思考未来可能出现的问题。随着技术的发展,确保对人工智能的适当控制与追求其利益同样重要。作为一家公司,我们致力于并决心以安全和负责任的方式开发和部署人工智能。然而,我们也认识到,人工智能所需的护栏需要广泛的责任感,不应该只留给科技公司。简言之,科技公司需要加快步伐,政府也需要加快步伐。
当我们微软在2018年通过人工智能的六项道德原则时,我们注意到其中一项原则是其他一切的基石——问责制。这是确保机器仍然受到人们有效监督的根本需要,并且设计和操作机器的人仍然对其他人负责。简而言之,我们必须始终确保人工智能处于人类的控制之下。这必须是科技公司和政府的首要任务。
这与另一个基本概念直接相关。在民主社会中,我们的一个基本原则是,任何人都不能凌驾于法律之上。任何政府都不能凌驾于法律之上。任何公司都不能凌驾于法律之上,任何产品或技术都不应凌驾于法律之外。这导致了一个关键的结论:设计和操作人工智能系统的人不能承担责任,除非他们的决定和行动受到法治的约束。
5月,微软发布了一份白皮书《治理人工智能:未来蓝图》,试图解决我们如何最好地治理人工智能的问题,并制定了微软的五点蓝图。

该蓝图建立在多年工作、投资和投入的经验教训之上。在这里,我们将其中的一些想法与欧洲、欧洲在人工智能监管方面的领导地位以及在国际上推进人工智能治理的可行途径结合起来。
随着欧洲议会最近对《欧盟人工智能法案》的投票和正在进行的三语讨论,欧洲现在处于建立指导和监管人工智能技术模式的前沿。
从一开始,我们就支持欧洲的监管制度,该制度有效地解决安全问题,维护基本权利,同时继续推动创新,确保欧洲保持全球竞争力。我们的意图是提供建设性的贡献,帮助为今后的工作提供信息。与欧洲和世界各地的领导人和政策制定者的合作既重要又重要。
本着这种精神,我们希望在这里扩展我们的五点蓝图,强调它如何与欧盟人工智能法案的讨论相一致,并就在这一监管基础上发展的机会提供一些想法。
首先,实施和建立新的政府主导的人工智能安全框架
加快政府行动的最有效方法之一是在现有或新兴政府框架的基础上推进人工智能安全。
确保更安全地使用这项技术的一个关键因素是基于风险的方法,围绕风险识别和缓解以及部署前的测试系统制定了明确的流程。《人工智能法案》规定了这样一个框架,这将是未来的一个重要基准。在世界其他地区,其他机构也推进了类似的工作,如美国国家标准与技术研究所(NIST)开发的人工智能风险管理框架,以及预计将于2023年秋季发布的关于人工智能管理系统的新国际标准ISO/IEC 42001。
微软已承诺实施NIST人工智能风险管理框架,我们将实施未来的相关国际标准,包括《人工智能法案》之后出现的标准。在国际上调整这些框架的机会应继续成为正在进行的欧盟与美国对话的重要组成部分。
随着欧盟最终确定《人工智能法案》,欧盟可以考虑使用采购规则来促进相关值得信赖的人工智能框架的使用。例如,在采购高风险人工智能系统时,欧盟采购当局可以要求供应商通过第三方审计证明其符合相关国际标准。
我们认识到,人工智能的发展步伐提出了与安全保障相关的新问题,我们致力于与其他人合作,制定可操作的标准,以帮助评估和解决这些重要问题。这包括与高性能基础模型相关的新标准和附加标准。
其次,控制关键基础设施的人工智能系统需要有效的安全刹车
随着人工智能越来越强大,公众越来越多地围绕其控制权展开辩论。同样,对电网、供水系统和城市交通流等关键基础设施的人工智能控制也存在担忧。现在是讨论这些问题的时候了——这场辩论已经在欧洲进行,高风险人工智能系统的开发者将负责保证必要的安全措施到位。
我们的蓝图提出了新的安全要求,实际上,这些要求将为控制指定关键基础设施运行的人工智能系统创造安全刹车。这些故障安全系统将是系统安全综合方法的一部分,该方法将把有效的人类监督、弹性和稳健性放在首位。它们类似于工程师长期以来在电梯、校车和高速列车等其他技术中构建的制动系统,不仅可以安全地管理日常场景,还可以安全地处理紧急情况。
在这种方法中,政府将定义控制关键基础设施的高风险人工智能系统类别,并保证采取此类安全措施,作为系统管理综合方法的一部分。新的法律将要求这些系统的操作员通过设计将安全制动器构建到高风险的人工智能系统中。然后,政府将要求运营商定期测试高风险系统。这些系统将仅部署在获得许可的人工智能数据中心,这些数据中心将提供第二层保护并确保安全。
第三,基于人工智能的技术架构,制定广泛的法律和监管框架
在过去的一年里,我们在这项新技术的前沿对人工智能模型进行了研究,得出的结论是,为人工智能开发一个反映其技术架构的法律和监管架构至关重要。
监管责任需要根据不同参与者在管理人工智能技术不同方面的作用而定。那些最接近设计、部署和使用相关决策的人最适合遵守相应的责任并减轻各自的风险,因为他们最了解具体的上下文和用例。这听起来很简单,但正如欧盟的讨论所表明的那样,这并不总是容易的。
《人工智能法案》承认,通过其基于风险的方法来制定高风险系统的要求,监管复杂架构面临挑战。在应用层,这意味着应用和执行现有法规,同时负责任何新的人工智能特定部署或使用考虑事项。
同样重要的是,要确保将义务附加到强大的人工智能模型上,重点关注一类定义的高能力基础模型,并根据模型级别的风险进行校准。这将影响技术堆栈的两层。第一个要求对这些模型本身进行新的规定。第二个将涉及开发和部署这些模型的人工智能基础设施运营商的义务。我们制定的蓝图为每一层提供了建议的目标和方法。

不同的作用和责任需要联合支持。我们致力于通过我们最近宣布的人工智能保障计划,帮助我们的客户应用“了解你的客户”(KYC)原则。金融机构利用这一框架来核实客户身份、建立风险档案和监控交易,以帮助发现可疑活动。正如Antony Cook所详述的,我们相信这种方法可以应用于我们所称的“KY3C”中的人工智能:了解自己的云、客户和内容。《人工智能法案》没有明确包括KYC要求,但我们认为,这种方法将是满足该法案精神和义务的关键。
《人工智能法案》要求高风险系统的开发人员建立风险管理系统,以确保系统经过测试,尽可能降低风险,包括通过负责任的设计和开发,并参与上市后监测。我们完全支持这一点。人工智能法案尚未最终确定,这一事实不应阻止我们今天应用其中的一些做法。即使在《人工智能法案》实施之前,我们也会在发布之前测试我们所有的人工智能系统,并对高风险系统进行红队测试。
第四,提高透明度,确保学术和非营利组织获得人工智能
提高人工智能系统的透明度和扩大对人工智能资源的访问也至关重要。虽然透明度和安全需求之间存在一些固有的紧张关系,但仍有许多机会使人工智能系统更加透明。这就是为什么微软承诺发布年度人工智能透明度报告,并采取其他措施扩大我们人工智能服务的透明度。
《人工智能法案》将要求人工智能提供商向用户明确表示,他们正在与人工智能系统进行交互。同样,无论何时使用人工智能系统来创建人工生成的内容,都应该很容易识别。我们完全支持这一点。人工智能生成的欺骗性内容或“深度伪造”——尤其是模仿政治人物的视听内容——对社会和民主进程的潜在危害尤其令人担忧。
在解决这个问题时,我们可以从已经存在的构建块开始。其中之一是内容来源真实性联盟(C2PA),这是一个全球标准机构,拥有60多个成员,包括Adobe、英国广播公司、英特尔、微软、Publicis Groupe、索尼和Truepic。该组织致力于增强在线信息的信任和透明度,包括在2022年发布世界上第一个数字内容认证技术规范,其中现在包括对Generative AI的支持。正如微软首席科学官Eric Horvitz去年所说,“我相信,内容来源将在提高透明度和加强对我们在网上看到和听到的内容的信任方面发挥重要作用。”
未来几个月将有机会在大西洋两岸和全球共同采取重要步骤,推进这些目标。微软将很快部署新的最先进的出处工具,帮助公众识别人工智能生成的视听内容并了解其来源。在我们的年度开发者大会Build 2023上,我们宣布了一项新媒体出处服务的开发。该服务实现了C2PA规范,将用有关其来源的元数据标记和签署人工智能生成的视频和图像,使用户能够验证一段内容是人工智能生成。微软最初将支持主要的图像和视频格式,并发布该服务,供微软的两款新人工智能产品——微软设计器和必应图像创建者使用。《人工智能法案》中的透明度要求,以及可能与该法案相关的几个待制定标准,为利用此类行业举措实现共同目标提供了机会。
我们还认为,扩大学术研究和非营利社区对人工智能资源的获取至关重要。除非学术研究人员能够获得更多的计算资源,否则科学和技术研究将面临真正的风险,包括与人工智能本身有关的风险。我们的蓝图要求采取新的措施,包括我们将在整个微软采取的措施,以解决这些优先事项。
第五,寻求新的公私合作伙伴关系,将人工智能作为一种有效工具,以应对新技术带来的不可避免的社会挑战
近年来的一个教训是,当民主社会利用技术的力量,将公共和私营部门团结在一起时,它们往往能够取得最大成就。这是我们需要吸取的教训,以应对人工智能对社会的影响。
人工智能是一种非凡的工具。但是,与其他技术一样,它也可以成为一种强大的武器,世界各地也会有一些人寻求以这种方式使用它。我们需要共同努力,开发防御性的人工智能技术,创造一个能够抵御和击败地球上任何不良行为者行为的盾牌。
现在需要开展重要工作,利用人工智能保护民主和基本权利,提供广泛的人工智能技能,促进包容性增长,并利用人工智能的力量促进地球的可持续性需求。也许最重要的是,一波新的人工智能技术为大胆思考和行动提供了机会。在每个领域,成功的关键将是制定具体的举措,并将政府、公司和非政府组织聚集在一起推动这些举措。微软将在每一个领域尽自己的一份力量。
推进人工智能治理的国际伙伴关系
欧洲早期开始对人工智能进行监管,为建立一个以法治为基础的有效法律框架提供了机会。但除了民族国家层面的立法框架之外,还需要多边公私伙伴关系,以确保人工智能治理能够在今天产生影响,而不仅仅是几年后,而且在国际层面。
在《人工智能法案》等法规生效之前,这是一个重要的临时解决方案,但也许更重要的是,它将帮助我们朝着一套共同的原则努力,这套原则可以指导民族国家和公司。
在欧盟关注《人工智能法案》的同时,欧盟、美国、七国集团其他成员国以及印度和印度尼西亚也有机会在一系列共同的价值观和原则上共同前进。如果我们能在自愿的基础上与他人合作,那么我们都会更快地行动,更加小心和专注。这不仅对科技界来说是个好消息,对整个世界来说也是个好消息。
认识到人工智能和许多技术一样,现在和将来都会跨境开发和使用,努力实现全球一致的方法很重要。它将使每个人都能在适当的控制下,获得满足其需求的最佳工具和解决方案。
我们对最近的国际措施感到非常鼓舞,包括欧盟-美国贸易和技术理事会(TTC)在5月底宣布了一项新的倡议,以制定一项自愿的人工智能行为准则。这可以将私人和公共合作伙伴聚集在一起,为开发人工智能系统的公司实施关于人工智能透明度、风险管理和其他技术要求的不具约束力的国际标准。同样,在2023年5月于广岛举行的七国集团年度峰会上,各国领导人承诺“根据我们共同的民主价值观,推进关于包容性人工智能治理和互操作性的国际讨论,以实现我们值得信赖的人工智能的共同愿景和目标”。微软完全支持并赞同国际社会为制定这样一个自愿准则所作的努力。技术发展和公共利益将受益于原则级护栏的创建,即使最初它们是不具有约束力的。
为了使人工智能治理的许多不同方面在国际层面上发挥作用,我们需要一个多边框架,将各种国家规则连接起来,并确保在一个司法管辖区被认证为安全的人工智能系统在另一个司法辖区也能被认定为安全的。这方面有许多有效的先例,例如国际民用航空组织制定的共同安全标准,这意味着飞机从布鲁塞尔到纽约的飞行途中不需要改装。
我们认为,国际准则应当:
- 在经合组织已经完成的工作的基础上,制定值得信赖的人工智能原则
- 为受监管的人工智能开发人员提供一种手段,以证明这些系统的安全性符合国际商定的标准
- 通过提供跨境合规和安全相互承认的手段,促进创新和准入
在《人工智能法案》和其他正式法规生效之前,我们今天必须采取措施,为控制关键基础设施的人工智能系统实施安全刹车。安全刹车的概念,以及高性能基础模型的许可和人工智能基础设施义务,应该是签署国同意纳入其国家系统的自愿、国际协调的七国集团准则的关键要素。例如,与关键基础设施(如运输、电网、供水系统)或可能导致严重侵犯基本权利或其他重大伤害的系统有关的高风险人工智能系统可能需要更多的国际监管机构,以国际民用航空组织的模式为基础。
《人工智能法》为欧盟高风险系统数据库制定了一项规定。我们认为这是一种重要的方法,应该成为国际准则的一个考虑因素。开发一种连贯、联合、全球的方法对所有参与开发、使用和监管人工智能的人来说都具有不可估量的意义。
最后,我们必须确保学术研究人员能够深入研究人工智能系统。围绕人工智能系统有一些重要的开放研究问题,包括如何在负责任的人工智能维度上正确评估它们,如何最好地使它们具有可解释性,以及它们如何与人类价值观最佳一致。经合组织在人工智能系统评估方面的工作取得了良好进展。但通过促进国际研究合作,并通过参与这一过程来推动学术界的努力,我们有机会走得更远、更快。欧盟与美国合作,在这方面处于领先地位。
人工智能治理是一段旅程,而不是目的地。没有人知道所有的答案,我们倾听、学习和合作很重要。科技行业、政府、企业、学术界和民间社会组织之间强有力、健康的对话对于确保治理跟上人工智能的发展速度至关重要。我们可以一起帮助实现人工智能的潜力,成为一股向善的积极力量。
- 52 次浏览
【版权】微软宣布为客户提供新的Copilot版权承诺
视频号
微信公众号
知识星球
01.05.2024更新:2023年11月15日,微软宣布扩大Copilot版权承诺,现在称为客户版权承诺,将使用Azure OpenAI服务的商业客户包括在内。 通过将承诺范围扩大到Azure OpenAI服务的输出,微软正在扩大我们的承诺,为这些客户辩护,并在他们因使用Azure OpenAI Service输出而被起诉侵犯版权时支付任何不利判决的费用。我们扩大版权承诺的目的是进一步解决客户对使用微软Copilots和Azure OpenAI服务的输出可能导致的潜在知识产权侵权责任的担忧。我们的客户必须已经实施了我们提供的必要护栏和缓解措施,才有资格享受客户版权承诺提供的福利。对于我们的Azure OpenAI服务,我们提供支持负责任地使用人工智能并降低侵犯版权内容风险的文档和工具。
微软的人工智能Copilots 正在改变我们的工作方式,使客户更高效,同时释放出新的创造力。虽然这些变革性工具为新的可能性打开了大门,但它们也提出了新的问题。一些客户担心,如果他们使用生成人工智能产生的输出,会有知识产权侵权索赔的风险。考虑到作者和艺术家最近公开询问他们自己的作品如何与人工智能模型和服务结合使用,这是可以理解的。
为了解决客户的这一问题,微软宣布了我们新的Copilot版权承诺。当客户询问他们是否可以使用微软的Copilot服务及其生成的输出而不必担心版权索赔时,我们提供了一个直截了当的答案:是的,你可以,如果你因版权原因受到质疑,我们将承担潜在的法律风险。
这一新承诺将我们现有的知识产权赔偿支持扩展到商业Copilot服务,并建立在我们之前的人工智能客户承诺的基础上。具体而言,如果第三方起诉商业客户使用微软的Copilots或其生成的输出侵犯版权,我们将为客户辩护,并支付诉讼产生的任何不利判决或和解金额,只要客户使用了我们在产品中内置的护栏和内容过滤器。
您将在下面找到更多详细信息。让我从我们提供此计划的原因开始:
当客户使用我们的产品时,我们相信要支持他们。
我们正在向商业客户收取Copilot的费用,如果使用Copilot会产生法律问题,我们应该将其作为我们的问题,而不是客户的问题。这一理念并不新鲜:大约20年来,我们一直在为客户辩护,使其免受与我们产品有关的专利索赔,随着时间的推移,我们稳步扩大了这一覆盖范围。将我们的辩护义务扩大到涵盖针对我们的复制品的版权索赔是沿着这些路线迈出的另一步。
我们对作者的担忧很敏感,我们认为微软而不是我们的客户应该承担起解决这些问题的责任。
即使在现有版权法明确的地方,生成性人工智能也提出了新的公共政策问题,并为多个公共目标带来了光明。我们认为,世界需要人工智能来推动知识的传播,并帮助解决重大的社会挑战。然而,对于作者来说,根据版权法保留对其权利的控制权并从其创作中获得健康的回报是至关重要的。我们应该确保训练和构建人工智能模型所需的内容不会以扼杀竞争和创新的方式被一家或几家公司掌握。我们致力于采取创造性和建设性步骤来推进所有这些目标所需的艰苦和持续的努力。
我们在复制品中建立了重要的护栏,以帮助尊重作者的版权。
我们引入了过滤器和其他技术,旨在降低Copilots返回侵权内容的可能性。这些基于分类器、元提示、内容过滤、操作监控和滥用检测等广泛的护栏,包括可能侵犯第三方内容的护栏,建立并补充了我们保护数字安全、安保和隐私的工作。我们新的Copilot版权承诺要求客户使用这些技术,从而激励每个人更好地尊重版权问题。
关于我们Copilot版权承诺的更多详细信息
Copilot版权承诺将微软现有的知识产权赔偿范围扩展到与使用我们的人工智能Copilot相关的版权索赔,包括它们产生的输出,特别是针对微软商业Copilot服务和必应聊天企业的付费版本。这包括Microsoft 365 Copilot,它为Word、Excel、PowerPoint等带来了生成性人工智能,使用户能够对自己的数据进行推理或将文档转化为演示文稿。它还包括GitHub Copilot,它使开发人员能够在死记硬背的编码上花费更少的时间,而在创建全新的变革性输出上花费更多的时间。
这个项目有一些重要的条件,认识到我们的技术可能会被故意滥用以产生有害内容。为了防止这种情况发生,客户必须使用产品中内置的内容过滤器和其他安全系统,不得试图生成侵权材料,包括不向客户无权使用的Copilot服务提供输入。
这一新福利并没有改变微软的立场,即其Copilot服务的输出不主张任何知识产权。
我们已经为客户发布了更多关于Copilot版权承诺的详细信息,并欢迎有机会随着Copilot的普及进行进一步的对话。
我们共享的人工智能之旅
今天的宣布是第一步。与所有新技术一样,人工智能提出了法律问题,我们的行业需要与广泛的利益相关者合作解决。这一步骤代表着对我们的客户的承诺,即我们产品的版权责任是我们的,而不是他们的。
微软看好人工智能的好处,但与任何强大的技术一样,我们清楚地看到了与之相关的挑战和风险,包括保护创意作品。我们有责任通过倾听科技部门的其他人、作家和艺术家及其代表、政府官员、学术界和民间社会的意见并与他们合作,帮助管理这些风险。我们期待着在这些公告的基础上,推出新的举措,帮助确保人工智能在保护创作者的权利和需求的同时,促进知识的传播。
- 68 次浏览
【负责的AI】PIAR工具和平台
视频号
微信公众号
知识星球
我们构建开源工具和平台,使ML模型更易于理解、可信和公平。
您也可以在Github上查看我们的更多代码。
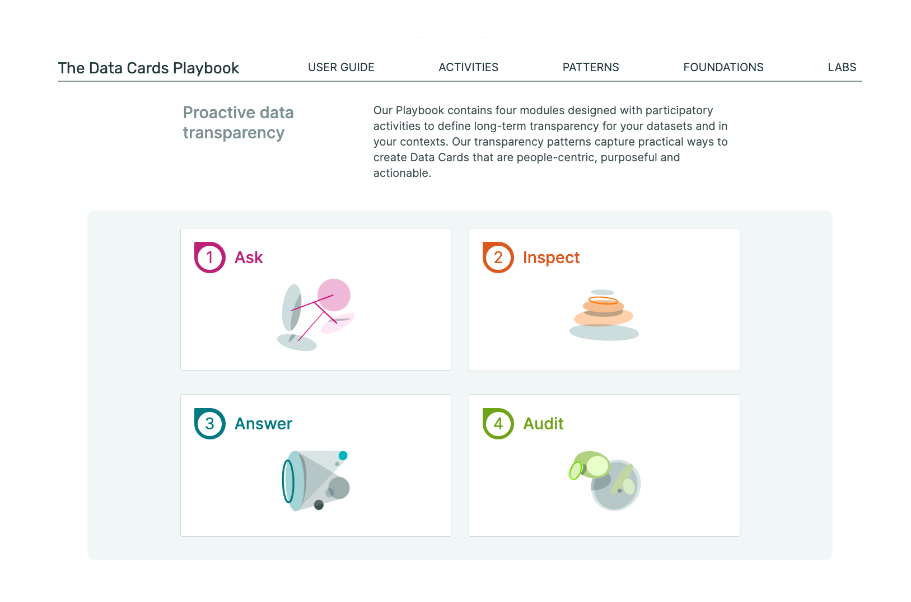
The Data Cards Playbook
一个由参与性活动、框架和指导组成的工具包,旨在提高数据集的透明度
![]() Explore the Data Cards Playbook
Explore the Data Cards Playbook
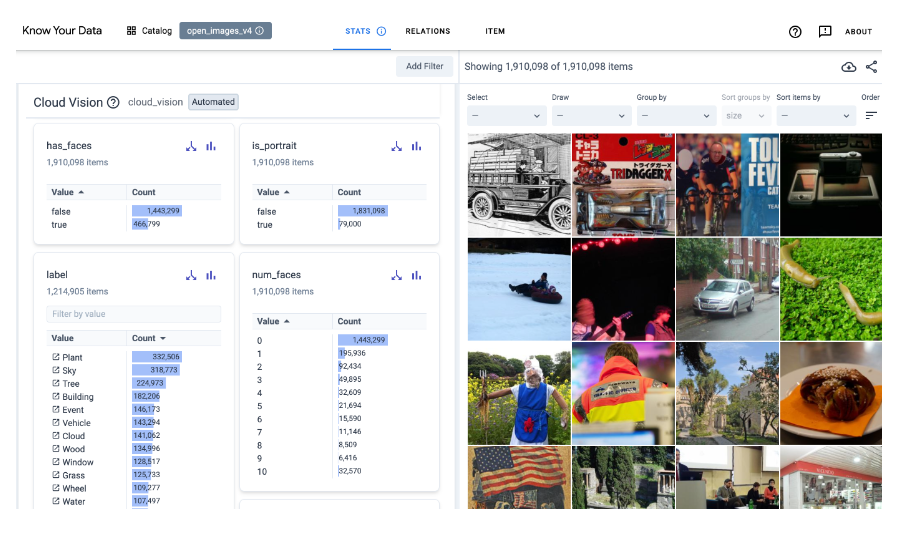
Know Your Data - Beta
交互式调查数据集,以提高数据质量,缓解公平性和偏见问题。
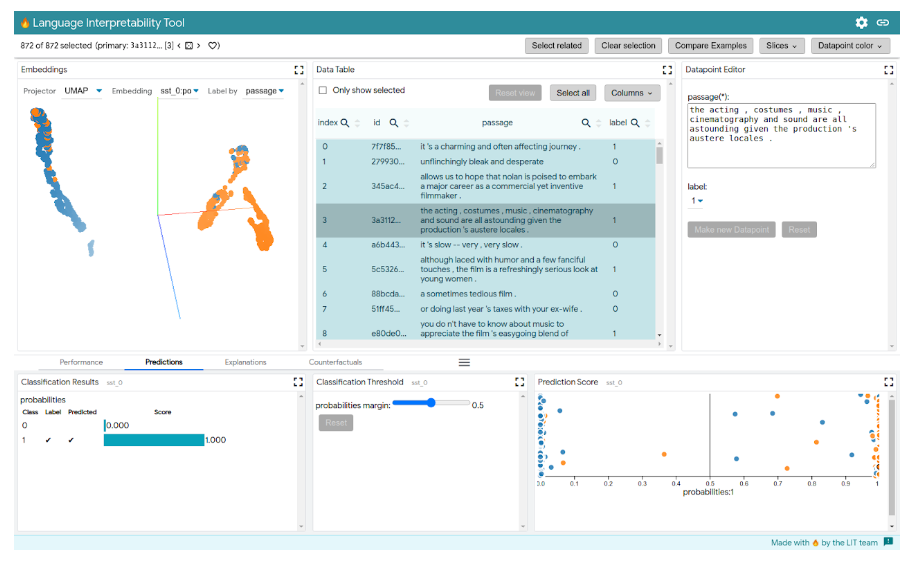
LIT
一个用于多种ML模型的可视化、交互式可解释性和调试工具。
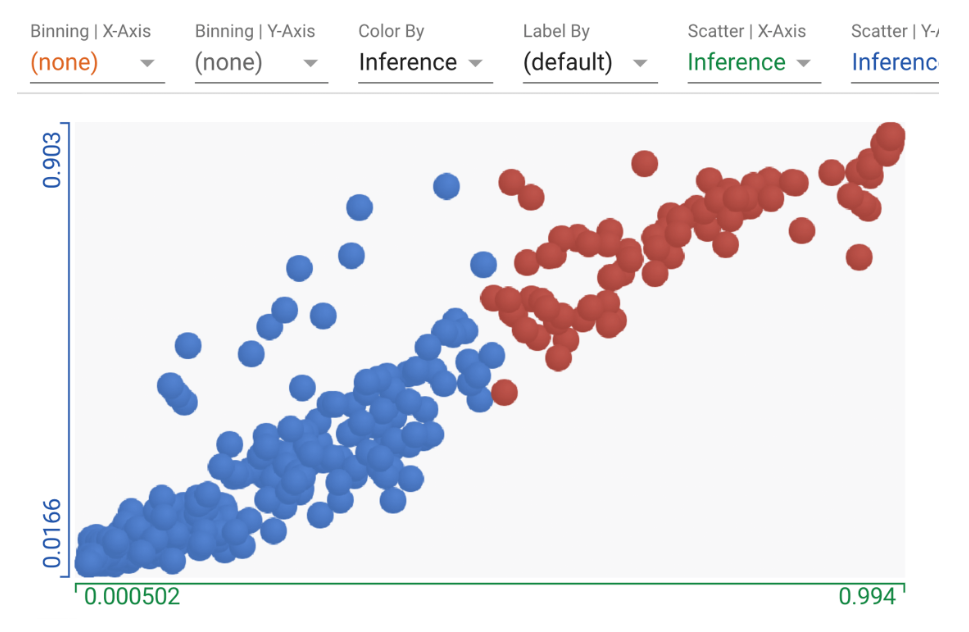
What-If Tool
用最少的编码直观地探测经过训练的模型的行为。
Facets
用于探索、理解和分析大型机器学习数据集的可视化库。

Tensorflow.js
用Javascript开发ML模型,并在浏览器或Node.js中使用它们。
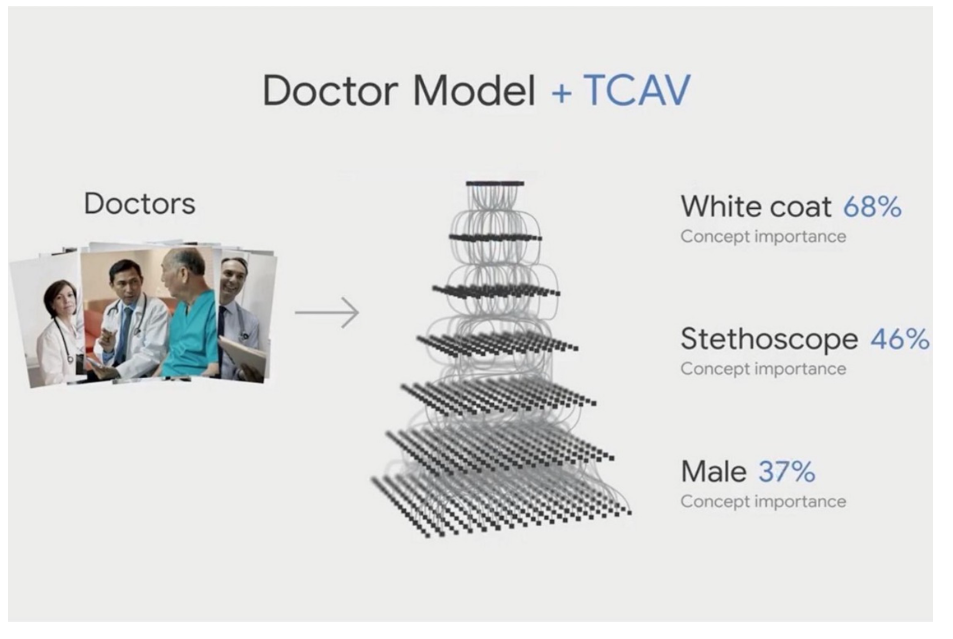
TCAV
超越特征归因的可解释性:概念激活向量的定量测试。
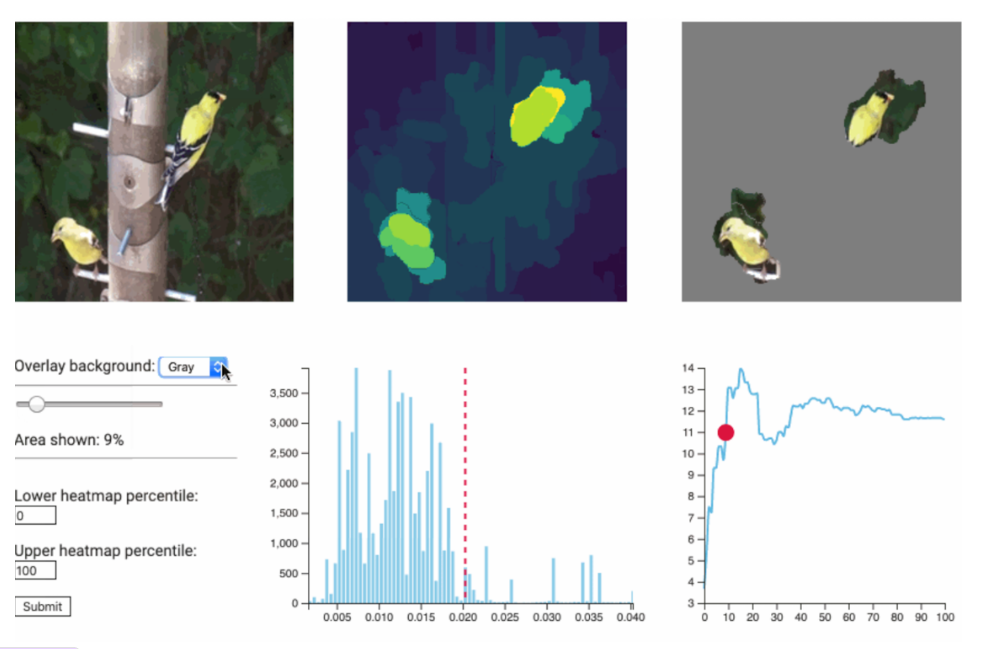
XRAI
通过区域更好地归因的工具。
Embedding Projector
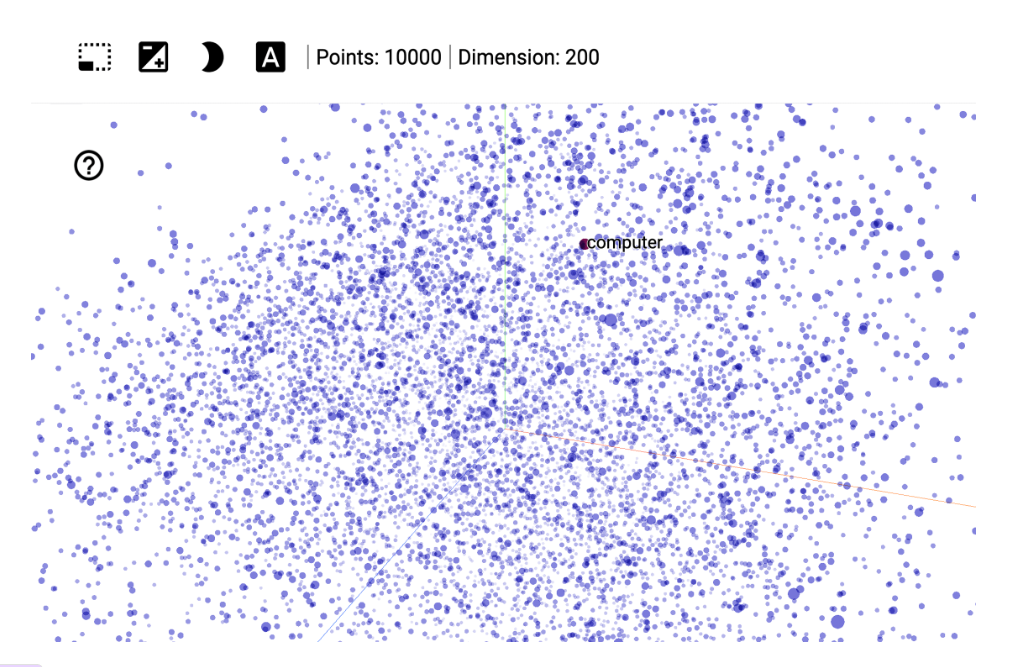
以各种嵌入方式交互可视化高维数据。
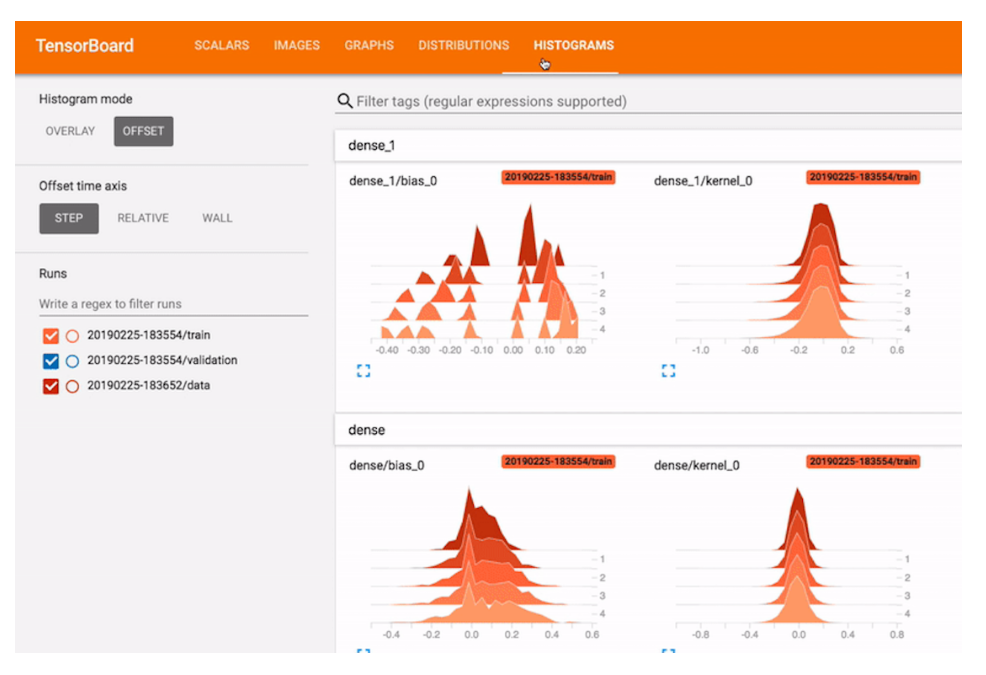
Tensorboard
机器学习实验的可视化和工具。
- 99 次浏览
【负责的AI】机器学习中的公平
视频号
微信公众号
知识星球
人工智能系统的公平性
由于各种原因,人工智能系统可能会表现得不公平。有时,这是因为在这些系统的开发和部署过程中,训练数据和决策中反映了社会偏见。在其他情况下,人工智能系统的不公平行为不是因为社会偏见,而是因为数据的特征(例如,关于某一群人的数据点太少)或系统本身的特征。很难区分这些原因,特别是因为它们并不相互排斥,而且往往会加剧彼此。因此,我们从人工智能系统对人的影响(即伤害)来定义其行为是否不公平,而不是从具体原因(如社会偏见)或意图(如偏见prejudice)来定义。
单词bias的用法。由于我们根据伤害而不是具体原因(如社会偏见)来定义公平,因此在描述公平学习的功能时,我们避免使用偏见(bias )或去偏见(debiasing )这两个词。
危害类型
有许多类型的危害(例如,参见K.Crawford在NeurIPS 2017上的主题演讲)。其中一些是:
- Allocation harms :当人工智能系统扩展或保留机会、资源或信息时,可能会发生分配危害。一些关键的申请是在招聘、入学和贷款方面。
- Quality-of-service :当一个系统对一个人的工作不如对另一个人的好时,即使没有机会、资源或信息被扩展或扣留,也可能会对服务质量造成损害。例如,人脸识别、文档搜索或产品推荐的准确性各不相同。
- Stereotyping harms:当一个系统建议完成使刻板印象永久化时,刻板印象的危害可能会发生。当搜索引擎建议完成部分类型的查询时,经常会出现这种情况。关于这一问题的深入研究,见“团结贵族”项目[1]。请注意,即使是名义上积极的刻板印象也是有问题的,因为它们仍然基于外在特征产生期望,而不是将人视为个体。
- Erasure harms :当系统表现得好像组(或其作品)不存在时,可能会发生擦除危害。例如,提示“19世纪的女科学家”的文本生成器可能不会产生结果。当被问及密苏里州圣路易斯附近的历史遗迹时,搜索引擎可能不会提到卡霍基亚。关于南部非洲的类似问题可能会忽视大津巴布韦,而集中在殖民时代的遗址上。更微妙的是,艾伦·图灵的一本简短传记可能没有提到他的性取向。
这份清单并不是详尽无遗的,重要的是要记住,伤害并不是相互排斥的。一个系统可以以不同的方式伤害多个群体,也可以访问单个群体的多个伤害。公平学习方案最适用于分配和服务质量危害,因为这些危害最容易衡量。
概念词汇表
本术语表中概述的概念与社会技术背景相关。
构造有效性
在许多情况下,与公平相关的危害可以追溯到将现实世界的问题转化为机器学习任务的方式。我们打算预测哪个目标变量?将包括哪些功能?我们考虑哪些(公平)约束?其中许多决定可以归结为社会科学家所说的测量:我们测量(抽象)现象的方式。
本术语表中概述的概念介绍了测量建模语言,如Jacobs和Wallach[2]所述。这个框架可以成为一个有用的工具来测试问题公式的(隐含的)假设的有效性。通过这种方式,它可以帮助减轻由于公式和应用程序的真实环境之间的不匹配而可能产生的与公平相关的危害。
关键术语
- 社会技术背景——围绕技术系统的背景,包括社会方面(如人、机构、社区)和技术方面(如算法、技术过程)。一个系统的社会技术背景决定了谁可能受益或受到人工智能系统的伤害。
- 不可观测的理论结构——一种不可观测且不能直接测量的想法或概念,但必须通过测量模型中定义的可观测测量来推断。
- 测量模型——用于测量不可观测理论结构的方法和方法。
- 结构可靠性——这可以被认为是在不同的时间点测量时,不可观测的理论结构的测量值保持不变的程度。结构可靠性的缺乏可能是由于对不可观测的理论结构的理解与用于测量该结构的方法之间的不一致,也可能是由于结构本身的变化。构念有效性与构念可靠性是相辅相成的。
- 构念有效性——这可以被认为是测量模型以有意义和有用的方式测量预期构念的程度。
关键术语示例-不可观测的理论结构和测量模型
- Fairness :公平是一个不可观测的理论结构的例子。有几种衡量公平的衡量模型,包括人口均等。这些测量可以结合在一起形成一个测量模型,在该模型中,几个测量被组合以最终测量公平性。有关衡量公平性的衡量模型的更多示例,请参阅fairlearn.metrics。
- 教师效能是一个不可观察的理论建构的例子。常见的测量模型包括学生在标准化考试中的表现和教师对学生的定性反馈。
- 社会经济地位是一个不可观察的理论结构的例子。一个常见的衡量模型包括家庭年收入。
- 患者利益是一个不可观察的理论结构的例子。一个常见的衡量模型涉及患者护理成本。有关相关示例,请参见[3]。
注:为了解释上述关键术语,我们引用了几个不可观测的理论结构和测量模型的例子。有关更详细的示例,请参考Jacobs和Wallach[2]。
什么是结构有效性?
尽管Jacobs和Wallach[2]同时探讨了结构可靠性和结构有效性,但我们下面将重点探讨结构有效性。我们注意到,两者在理解社会技术背景下的公平方面都发挥着重要作用。话虽如此,Jacobs和Wallach[2]提出了一种以公平为导向的结构有效性概念,这有助于在社会技术背景下思考公平。我们在七个关键部分中捕捉到了这一观点,即当结合起来时,可以作为分析人工智能任务和试图建立结构有效性的框架:
- 表面有效性——从表面上看,测量模型产生的测量结果看起来有多可信?
- 内容有效性–这有三个子组成部分:
- 争议性——对不可观测的理论结构有单一的理解吗?或者这种理解是有争议的(因此取决于上下文)。
- 实质有效性——我们能否证明测量模型包含与感兴趣的结构相关的可观察属性和其他不可观察的理论结构(并且仅包含这些)?
- 结构有效性-测量模型是否适当地捕捉了感兴趣的结构与测量的可观察特性和其他不可观察的理论结构之间的关系?
- 收敛有效性-所获得的测量值是否与已建立结构有效性的测量模型中的其他测量值(存在)相关?
- 判别有效性——感兴趣结构的测量值是否与相关结构相关?
- 预测有效性——从测量模型中获得的测量值是否可以预测任何相关可观测特性或其他不可观测理论结构的测量值?
- 假设有效性——这描述了测量模型产生的测量中可能出现的假设的性质,以及这些假设是否“实质上有趣”。
- 结果有效性——识别和评估使用测量模型获得的测量结果的后果和社会影响。以问题为框架:使用测量来塑造世界是如何的,我们希望生活在什么世界?
注:以上部分的探索顺序和使用方式可能因具体的社会技术背景而异。这只是为了解释可以在分析任务的框架中使用的关键概念。
公平性评估和不公平缓解
在Fairlearn中,我们提供了评估分类和回归预测因子公平性的工具。我们还提供了减轻分类和回归中不公平现象的工具。在评估和缓解场景中,公平性都是使用差异度量进行量化的,如下所述。
群体公平,敏感特征
公平概念化有多种方法。在公平学习中,我们遵循被称为群体公平的方法,该方法问道:哪些群体的个人面临遭受伤害的风险?
相关组(也称为子群)是使用敏感特征(或敏感属性)定义的,这些特征作为向量或矩阵(称为sensitive_features)(即使它只是一个特征)传递给Fairlearn估计器。该术语表明,系统设计者在评估群体公平性时应对这些特征保持敏感。尽管这些功能有时可能会对隐私产生影响(例如,性别或年龄),但在其他情况下可能不会(例如,无论某人是否以特定语言为母语)。此外,“敏感”一词并不意味着这些特征不应用于预测——事实上,在某些情况下,将其包括在内可能会更好。
公平文献也使用术语“受保护属性”作为敏感特征。该术语基于反歧视法,该法定义了特定的受保护阶层。由于我们寻求在更广泛的环境中应用群体公平,我们避免使用这个术语。
均等约束
组公平性通常由一组对预测器行为的约束形式化,称为奇偶性约束(也称为标准)。奇偶性约束要求预测器行为的某些方面(或多个方面)在由敏感特征定义的组之间具有可比性。
允许
表示用于预测的特征向量,
是单个敏感特征(如年龄或种族),以及
成为真正的标签。平价约束是根据对分配的期望来表述的
例如,在Fairlearn中,我们考虑以下类型的奇偶性约束。
二进制分类:
-
Demographic parity (also known as statistical parity): A classifier satisfies demographic parity under a distribution over if its prediction is statistically independent of the sensitive feature . This is equivalent to . [4]
-
Equalized odds: A classifier satisfies equalized odds under a distribution over if its prediction is conditionally independent of the sensitive feature given the label . This is equivalent to . [4]
-
Equal opportunity: a relaxed version of equalized odds that only considers conditional expectations with respect to positive labels, i.e., . [5]
回归:
-
Demographic parity: A predictor satisfies demographic parity under a distribution over if is independent of the sensitive feature . This is equivalent to . [6]
-
Bounded group loss: A predictor satisfies bounded group loss at level under a distribution over if . [6]
如上所述,人口均等旨在减轻分配危害,而有限群体损失主要旨在减轻服务质量危害。均等机会和均等机会可用于诊断分配危害和服务质量危害。
差异度量、组度量
视差度量评估给定预测器与满足奇偶性约束的距离。他们可以根据比率或差异来比较不同群体的行为。例如,对于二进制分类:
-
Demographic parity difference is defined as .
-
Demographic parity ratio is defined as .
Fairlearn包提供了将scikit学习中的常见准确性和错误度量转换为组度量的功能,即对整个数据集以及每个组单独评估的度量。此外,组度量产生最小和最大度量值,以及对哪些组观察到这些值,以及最大值和最小值之间的差异和比率。有关更多信息,请参阅子包fairlearn.metrics。
在建模一个社会问题时,我们会陷入什么陷阱?
现实世界中使用的机器学习系统本质上是社会技术系统,包括技术和社会参与者。机器学习系统的设计者通常通过抽象将真实世界的上下文转化为机器学习模型:只关注上下文的“相关”方面,这些方面通常由输入、输出及其之间的关系来描述。然而,通过抽象社会背景,他们有陷入“抽象陷阱”的风险:没有考虑社会背景和技术是如何相互关联的。
在本节中,我们将解释这些陷阱是什么,并就如何避免它们提出一些建议。
在“社会技术系统中的公平与抽象”一书中,Selbst等人[7]确定了建模时抽象掉社会背景可能产生的故障模式。他们将其识别为:
- 解决方案主义陷阱
- 波纹效应陷阱
- 形式主义陷阱
- 便携性陷阱
- 框架陷阱
我们提供了这些陷阱的一些定义和示例,以帮助Fairlearn用户思考他们在工作中所做的选择如何导致或避免这些常见的陷阱。
解决方案主义陷阱
当我们假设问题的最佳解决方案可能涉及技术,而没有识别出该领域之外的其他可能解决方案时,就会出现这种陷阱。在公平的定义可能会随着时间的推移而变化的情况下,解决方案主义的方法也可能不合适(见下文的“形式主义陷阱”)。
例如:考虑农村社区的互联网连接问题。解决方案主义陷阱的一个例子是假设使用数据科学来测量给定地区的网速可以帮助改善互联网连接。然而,如果一个社区内存在额外的社会经济挑战,例如教育、基础设施、信息技术或医疗服务,那么纯粹关注网速的算法解决方案可能无法有意义地满足社区的需求。
波纹效应陷阱
当我们不考虑将技术引入现有社会体系的意外后果时,就会出现这种陷阱。这些后果包括行为、结果、个人经历的变化,或给定社会系统的潜在社会价值观和激励的变化;例如通过增加可量化度量相对于不可量化度量的感知值。
例如:考虑银行决定是否应批准个人贷款的问题。在使用机器学习算法计算“分数”之前,银行可能会依靠贷款官员与客户进行对话,根据客户的独特情况推荐计划,并与其他团队成员讨论以获得反馈。通过引入算法,贷款官员可能会限制他们与团队成员和客户的对话,假设算法的建议足够好,而没有这些额外的信息来源。
为了避免这个陷阱,我们必须意识到,一旦一项技术被纳入社会环境,新的群体可能会对其进行不同的解释。我们应该采用“假设”情景来设想引入模型后社会环境可能会发生怎样的变化,包括它可能会如何改变现有群体在该背景下的权力动态,或者参与者可能会如何通过改变他们的行为来与模型博弈。
形式主义陷阱
数据科学家的许多任务都涉及某种形式的形式化:从将真实世界的现象作为数据进行测量,到将业务关键绩效指标(KPI)和约束转化为度量、损失函数或参数。当我们不能充分理解公平等社会概念的含义时,我们就会陷入形式主义陷阱。
公平是一个有争议的复杂结构:在特定的情况下,不同的人可能对什么是公平有不同的想法。虽然数学公平性度量可以捕捉公平性的某些方面,但它们无法捕捉所有相关方面。例如,群体公平性指标没有考虑到个人经历的差异,也没有考虑到程序公正性。
在某些情况下,不能同时满足公平性指标,如人口均等和均等几率。乍一看,这可能是一个数学问题。然而,这种冲突实际上是基于对公平的不同理解。因此,没有数学方法来解决这种冲突。相反,我们需要决定哪些指标可能适合当前的情况,同时牢记数学形式化的局限性。在某些情况下,可能没有合适的度量标准。
我们陷入这个陷阱的一些原因是,公平取决于环境,因为它可以被不同的人群争论,也因为法律世界(即程序性的公平)和公平的ML群体(即基于结果的公平)之间对公平的思考方式存在差异。
数学抽象遇到限制的地方是在获取有关上下文的信息时(不同的社区可能对什么是“不公平”的结果有不同的定义;例如,雇佣一个母语为英语的申请人来担任英语职位,而不是雇佣一个唯一口语不是英语的申请人,这不公平吗?);可争议性(歧视和不公平的定义在政治上存在争议,并随着时间的推移而变化,这可能会对其数学表达提出根本挑战);和程序性(例如,法官和警察如何确定保释、咨询、缓刑或监禁是否合适);
便携性陷阱
当我们无法理解为一个特定的社会背景设计的模型或算法的重用不一定适用于不同的社会背景时,就会出现这种陷阱。重复使用算法解决方案,而不考虑相关社会环境中的差异,可能会导致误导性结果和潜在的有害后果。
例如,将用于筛选护理行业工作申请的机器学习算法重新用于筛选信息技术部门工作申请的系统,可能会陷入可移植性陷阱。两种情况之间的一个重要区别是在两个行业取得成功所需的技能不同。这些背景之间的另一个关键差异涉及每个行业员工的人口统计学差异(就性别而言),这可能是由于招聘信息中的措辞、关于性别和社会角色的社会结构,以及每个领域每个(性别)群体成功申请者的百分比。
框架陷阱
当我们在抽象一个社会问题时没有考虑到特定社会背景的全貌时,就会出现这种陷阱。所涉及的要素包括但不限于:所选现象所处的社会环境、所选情况下个人或环境的特征、所涉及的第三方及其环境,以及正在制定的抽象任务(即计算风险分数、在候选人库中进行选择、选择适当的治疗方法等)。
为了帮助我们避免在问题范围内划定狭窄的界限,我们可以考虑围绕问题范围使用更宽的“框架”,从算法框架转移到社会技术框架。
例如,采用社会技术框架(而不是以数据为中心或算法框架)可以让我们认识到,机器学习模型是人与技术之间社会和技术互动的一部分,因此,给定社会背景的社会组成部分应作为问题制定和建模方法的一部分(包括地方决策过程、激励结构、制度过程等)。
例如,我们可能会陷入这种陷阱,因为我们评估了被指控犯罪的个人再次参与犯罪行为的风险,而没有考虑刑事司法系统中种族偏见的遗留问题、社会经济地位和心理健康与犯罪社会结构的关系,以及法官、警察或其他社会行为者在围绕刑事司法算法的更大社会技术框架中的现有社会偏见等因素。
在社会技术框架内,该模型不仅包含了关于案件历史的更细微的数据,还包含了判断和推荐结果的社会背景。该框架可能包括与犯罪报告相关的过程、犯罪审判流程,以及对各种社会参与者和算法之间的关系如何影响给定模型的预期结果的认识。
工具书类
- 154 次浏览
【负责的AI】衡量公平性
视频号
微信公众号
知识星球
衡量公平性
你如何确保一个模型同样适用于不同的人群?事实证明,在许多情况下,这比你想象的要困难。
问题是,有不同的方法来衡量模型的准确性,而且通常在数学上不可能在各组之间都相等。
我们将通过创建一个(假)医学模型来对这些人进行疾病筛查,从而说明这种情况是如何发生的。
基本事实
这些人中大约有一半实际上患有甲型肝炎;其中一半没有。

模型预测
在一个完美的世界里,只有病人的检测结果呈阳性,只有健康人的检测结果为阴性。
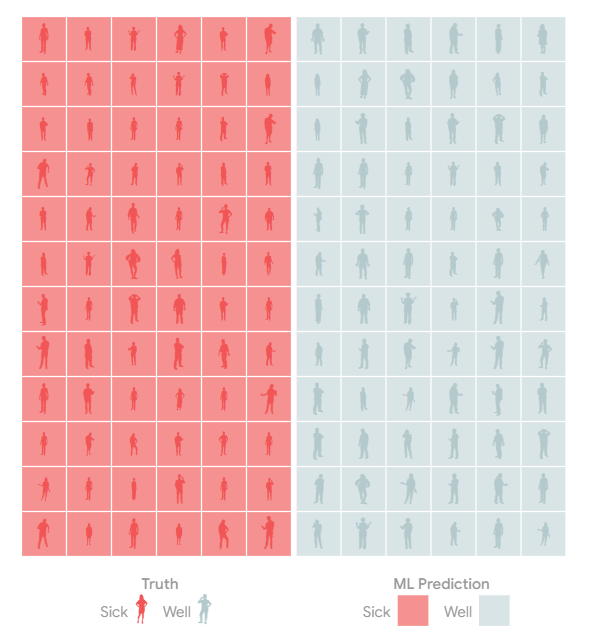
模型错误
但模型和测试并不完美。
该模型可能会犯错误,将生病的人标记为健康的c。
或者相反:将一个健康的人标记为生病的f。
千万不要错过疾病。。。
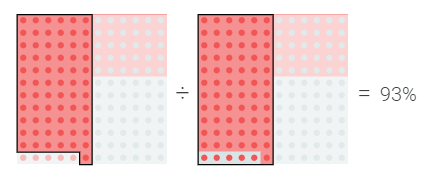
如果有一个简单的后续测试,我们可以让该模型积极地称为密切病例,这样它就很少错过这种疾病。
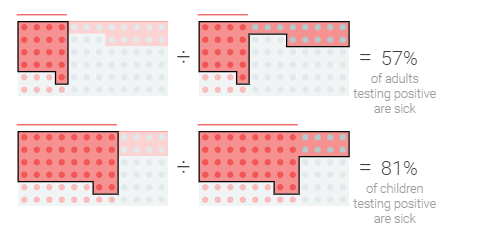
我们可以通过测量检测呈阳性的病人的百分比来量化这一点
…还是避免过度拥挤?
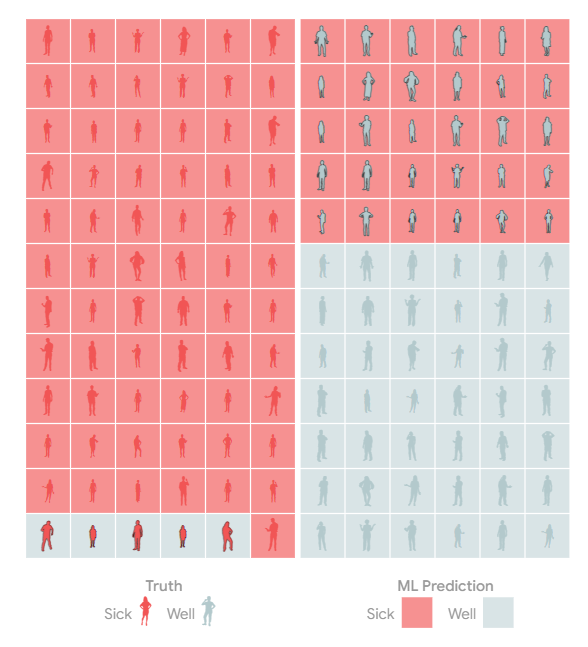
另一方面,如果没有二次检测,或者治疗使用的药物供应有限,我们可能更关心检测呈阳性的人中实际患病的百分比。
模型优化中的这些问题和权衡并不是什么新鲜事,但当我们有能力精确调整疾病诊断的积极性时,它们就会成为焦点。

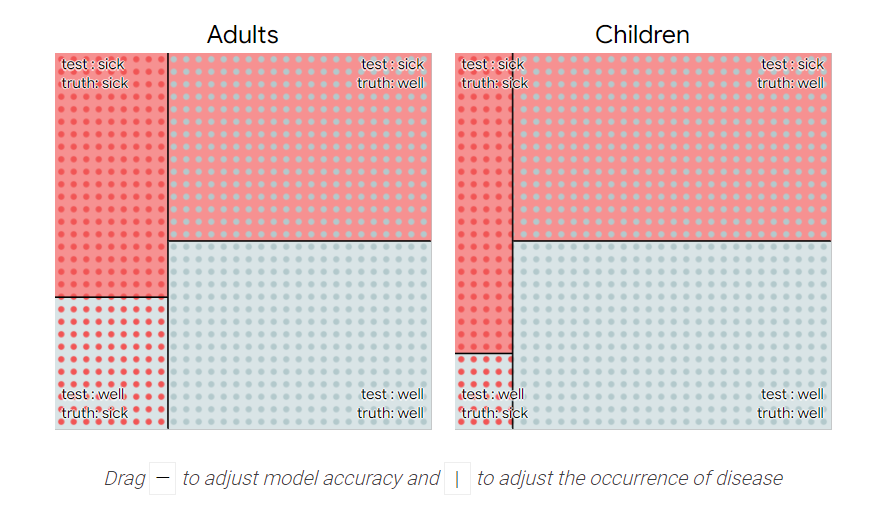
试着调整模型在诊断疾病方面的积极性
分组分析
当我们检查模型是否公平对待不同的群体时,事情变得更加复杂。¹
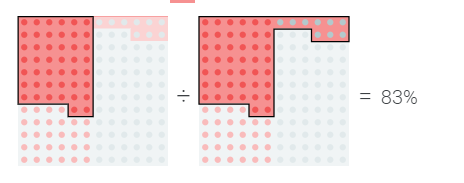
无论我们在这些指标之间的权衡方面做出什么决定,我们都可能希望它们在不同的人群中大致持平。
如果我们试图平均分配资源,那么让该模型遗漏的儿童病例比成年人多就不好了!
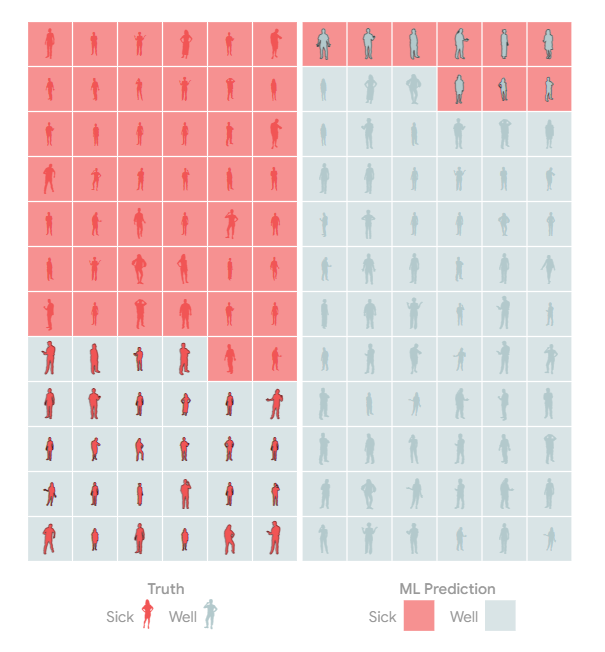
基本发病率
如果你仔细观察,你会发现这种疾病在儿童中更为普遍。也就是说,不同群体的疾病“基本发病率”不同。
基本利率的不同使情况变得异常棘手。首先,尽管该检测检测到的患病成年人和患病儿童的比例相同,但检测呈阳性的成年人感染该疾病的可能性低于检测呈阳性儿童。
不平衡指标
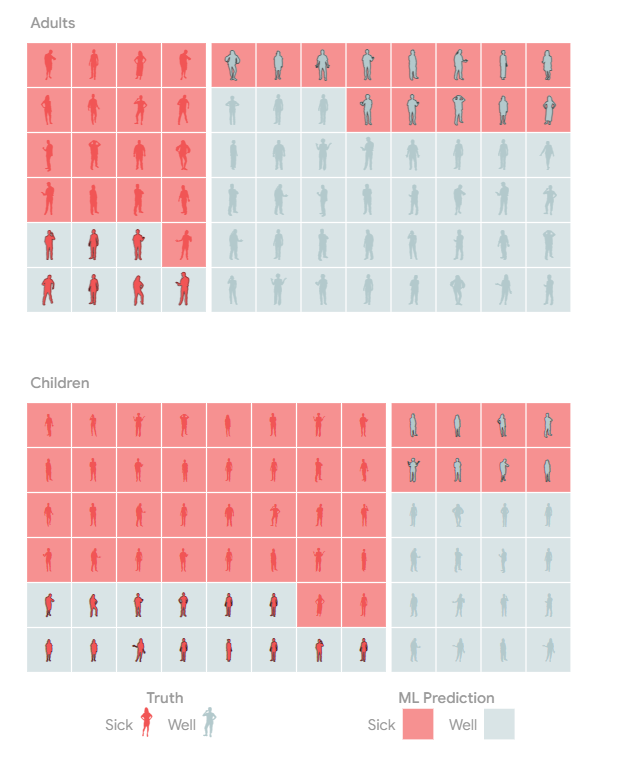
为什么儿童和成人在诊断方面存在差异?健康成年人的比例更高,因此测试中的错误会导致更多健康成年人被标记为“阳性”,而不是健康儿童(同样,错误的阴性)。
为了解决这个问题,我们可以让模型将年龄考虑在内。

试着调整滑块,使模型级成人的攻击性低于儿童。

结论
值得庆幸的是,你选择满足的公平概念将取决于你的模型的上下文,所以虽然不可能满足公平的每一个定义,但你可以专注于对你的用例有意义的公平概念。
即使不可能在各个方面都做到公平,我们也不应该停止检查偏见。隐藏的偏见探索概述了人类偏见可以输入ML模型的不同方式。
更多阅读
在某些情况下,为不同人群设定不同的阈值可能是不可接受的。你能让人工智能比法官更公平吗?探索了一种可以把人送进监狱的算法。
有很多不同的指标可以用来确定算法是否公平。用更智能的机器学习来攻击歧视,这表明了其中一些是如何工作的。将公平指标与假设工具和其他公平工具结合使用,您可以根据常用的公平指标测试自己的模型。
机器学习从业者使用“回忆”等词来描述检测呈阳性的病人的百分比。查看PAIR指南手册词汇表,了解如何与构建模型的人员交谈。
附录
这篇文章使用了非常学术的、数学的公平标准,并没有涵盖我们在口语中可能包含的公平的所有内容。这里对算法的技术描述与它们所部署的社会环境之间存在差距。
²有时我们可能更关心不同人群中的不同错误模式。如果儿童的治疗风险更大,我们可能希望该模型在诊断方面不那么激进。
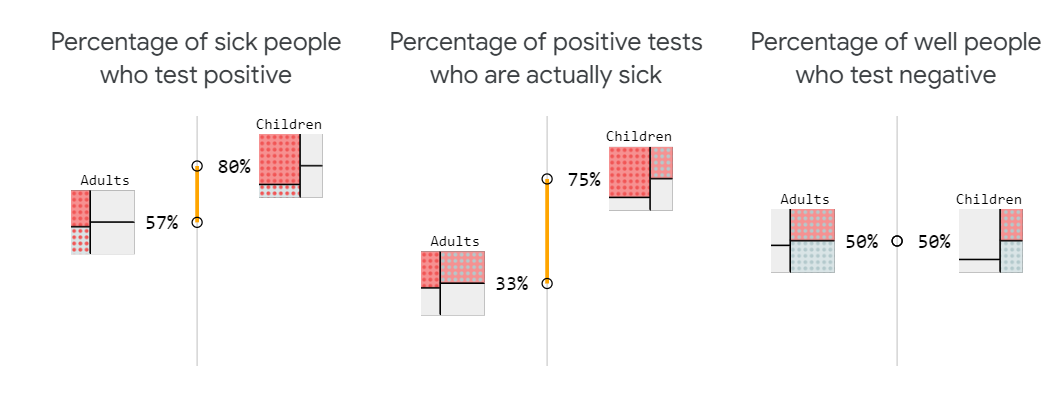
³上面的例子假设模型根据人们生病的可能性对他们进行分类和评分。通过完全控制模型在两组中诊断不足和过度的确切比率,实际上有可能将我们迄今为止讨论的两个指标保持一致。试着调整下面的模型,使两者对齐。
再加上第三个指标,即e检测呈阴性的健康人的百分比,就不可能实现完美的公平。你能明白为什么除非两个人群的基本发病率相同,否则这三个指标都不会一致吗?
信用
Adam Pearce//2020年5月
感谢Carey Radebaugh、Dan Nanas、David Weinberger、Emily Denton、Emily Reif、Fernanda Viégas、Hal Abelson、James Wexler、Kristen Olson、Lucas Dixon、Mahima Pushkarna、Martin Wattenberg、Michael Terry、Rebecca Salois、Timnit Gebru、Tulsee Doshi、Yannick Assogba、Yoni Halpern、Zan Armstrong和我在谷歌的其他同事对这篇文章的帮助。
- 59 次浏览
人工智能治理
视频号
微信公众号
知识星球
- 31 次浏览