【数据目录】Apache Atlas:起源、架构、功能、安装、替代方案和比较
视频号

微信公众号

知识星球

Apache Atlas是一个开源元数据和大数据治理框架,可帮助数据科学家、工程师和分析师对其数据资产进行编目、分类、治理和协作。
什么是Apache Atlas?
通过将元数据表示为类型和实体,Apache Atlas为组织在Hadoop集群上构建、分类和管理其数据资产提供了元数据管理和治理功能。
这些“实体”是元数据类型的实例,存储有关元数据对象及其互连的详细信息。
您对Apache Atlas作为元数据管理框架感兴趣吗?然后您应该熟悉活动元数据。活动元数据越来越受欢迎,因为它可以帮助数据团队节省时间和金钱。以下是这个概念的基本介绍,以及如何开始使用它。
“在Atlas中,Type是元数据对象的定义,Entity是元数据对象实例,”~IBM Developer
Apache提供了最先进的“图谱建模”服务,可以帮助您概述数据的来源,以及所有的转换和工件。该服务通过利用标签和分类向实体添加元数据,省去了管理元数据的麻烦。尽管任何人都可以创建标签并将其分配给实体,但分类通过Atlas策略由系统管理员控制
 Atlas Labels and Classifications
Atlas Labels and Classifications
Apache Atlas起源
Apache Atlas最初由Hortonworks于2014年孵化,作为数据治理倡议(DGI)。这一举措旨在为企业实施全面的数据治理实践。
五个月后,这项工作作为一个开源项目正式移交给了Apache基金会,之后它不断证明自己是一个顶级项目,直到2017年年中毕业。
自2015年以来,该项目一直由社区为社区维护,目前2.2版本正在运行。
 From DGI to Apache Atlas
From DGI to Apache Atlas
Apache Atlas的用途是什么?
Apache Atlas用于:
- 在整个数据生态系统中对数据进行控制
- 通过元数据映射沿袭关系
- 提供元数据“桥梁”
- 创建和维护业务本体
- 数据屏蔽
对数据进行完全控制
Apache Atlas为企业提供的数据图表功能有助于蓝筹股和初创公司导航其数据生态系统。它有助于映射和组织元数据表示,使您能够适应操作和分析数据的使用。
“Apache Atlas旨在与Hadoop堆栈内外的其他工具和流程交换元数据,从而实现与平台无关的治理控制,有效地满足法规遵从性要求。”~ Hortonworks数据平台:数据治理

通过元数据映射沿袭关系
通过分配业务元数据,Atlas促进了实体的产生,这些实体可以帮助您设计业务词汇表来跟踪您的数据资产。更重要的是,一旦接收到查询信息,就会自动生成谱系图。查询本身会被注意到,它的输入和输出用于可视化数据转换是如何以及何时发生的。因此,您可以跟踪变化并设想影响。
提供元数据“桥梁”
Atlas还使元数据的收集能够通过使用“桥梁”实现自动化,通过使用API可以从给定来源的不同数据资产导入这些信息。
创建和维护业务本体
通过管理分类和标签,Apache Atlas可以帮助您增强元数据的功能。它的仪表板有助于注释标记的实体,从而创建特定于用例和业务本体的基础设施。分类本身按层次结构排列,添加单个术语会生成与查询相关联的所有实体的报告。
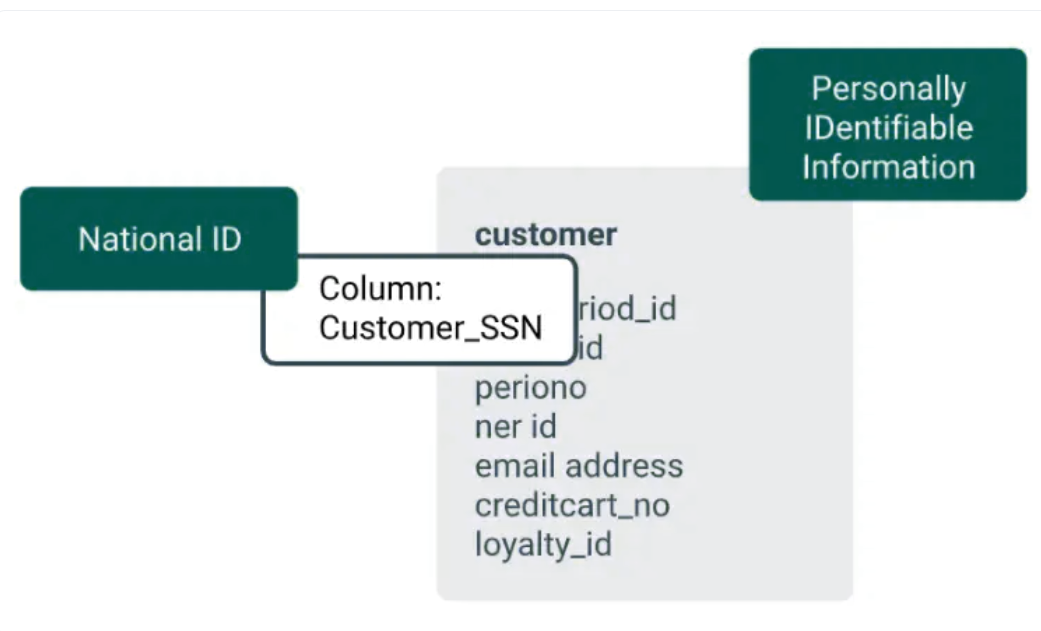
数据屏蔽
一旦数据被组织到一个清单中,就形成了一个数据目录。基于作为任何给定数据目录骨干的分类,Apache Atlas在与Apache Ranger集成后帮助屏蔽数据访问。此功能对于确保对操作和实体实例的访问安全至关重要。
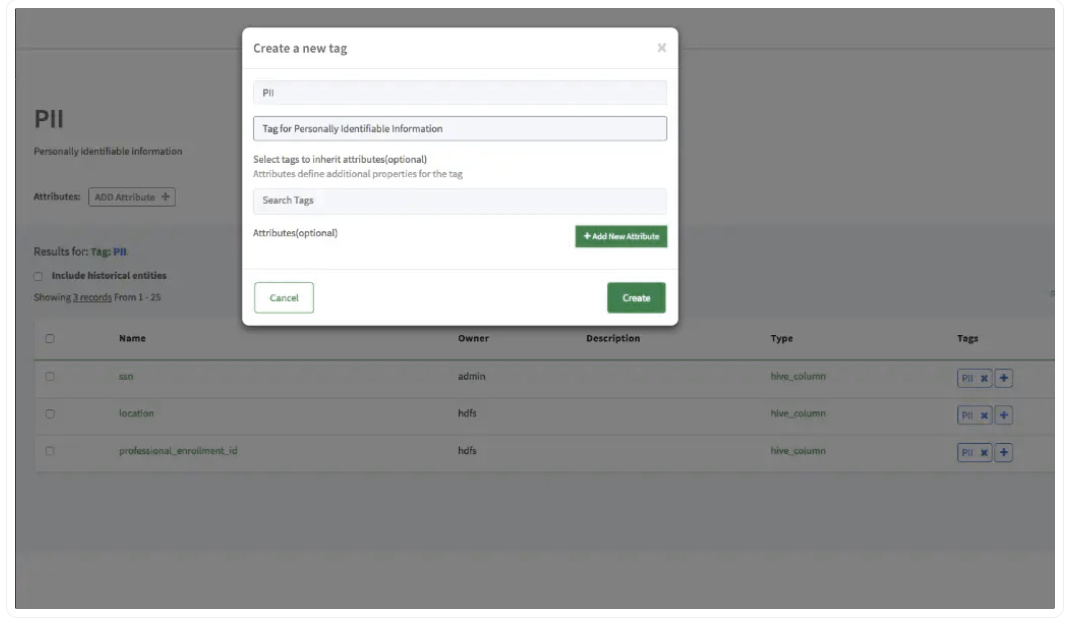 Creation of a Personally Identifiable Information tag
Creation of a Personally Identifiable Information tag
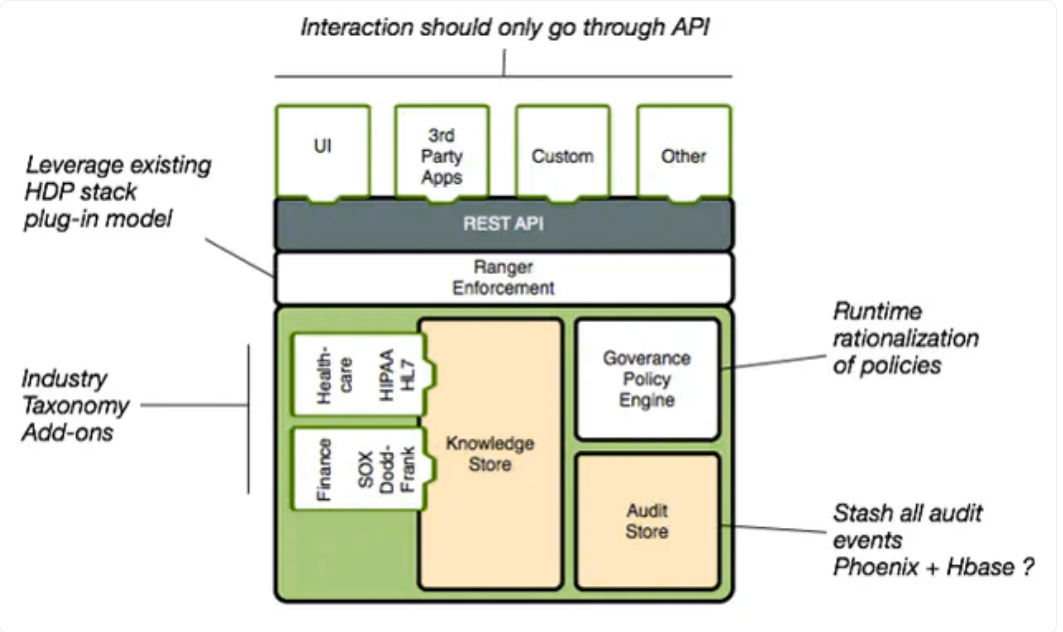
Apache Atlas体系结构
Apache Atlas的体系结构分为4个主要部分,这是其受欢迎程度和功能背后的原因。其中包括:
- 元数据源和集成:Apache Kafka中用于组织消息的类别,称为Kafka消息主题[集成],通常通过Atlas插件[元数据源]接收元数据。
- 核心:因此,Atlas必须读取每条消息,这些消息随后存储在JanusGraph[核心]中。反过来,JanusGraph用于可视化实体之间的关系,在这种情况下使用的数据存储是HBase。Solr名称的搜索索引也被用来获得其搜索功能的好处。
- 应用程序:所有这些组件都允许Atlas管理元数据,这些元数据最终被各种面向治理的用例[应用程序]使用。

Apache Atlas的功能
作为元数据和治理的框架,Apache Atlas的体系结构包含以下功能:
- 通过类型和实体系统定义元数据
- 通过Graph存储库存储元数据(JanusGraph)
- Apache Solr搜索能力
- Apache Kafka通知服务
- 通过API查询和填充元数据(Rest API)
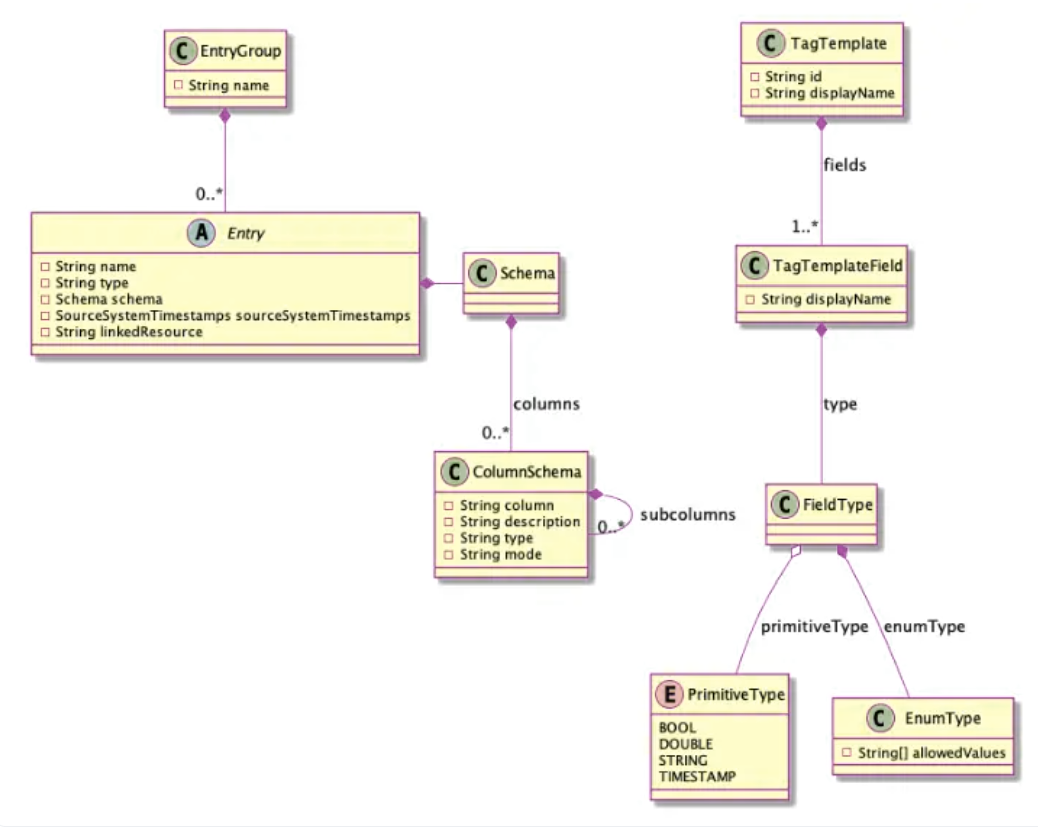
1.通过类型和实体系统定义元数据
该工具的主要模块之一是类型系统,其操作灵感来自OOP(面向对象编程)如何使用实例(即实体)和类(即类型)。在Apache Atlas的形式中,我们获得了一个简单直观的工具,可以对各种“类型”进行建模,然后将有关它们的信息存储为“实体”(实例)。这种系统化允许用户通过数据目录的分类和使用来解决当今与数据治理相关的许多挑战。
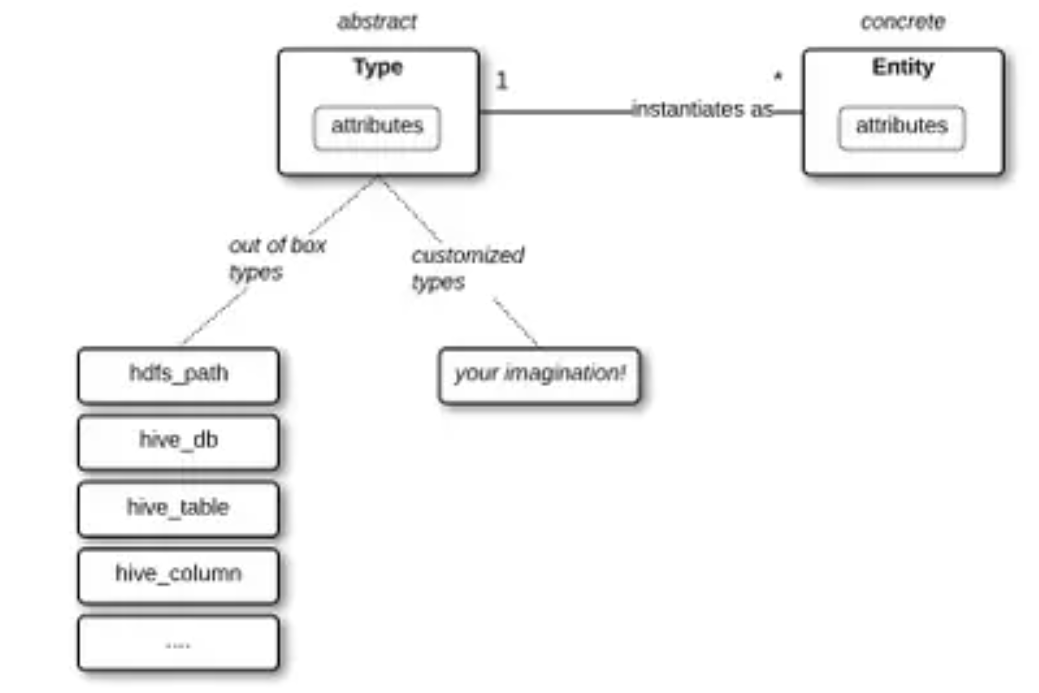 Apache Atlas Types and Entities
Apache Atlas Types and Entities
2.通过Graph存储库存储元数据(JanusGraph)
Atlas的获取和导出系统提取数据后,通过图形引擎模块发现并索引信息。该模块由名为Janus的开源图形数据库提供支持,使Apache Atlas不仅可以突出数据目录中各种实体之间的相互联系,还可以根据信息源定位实体的元信息,这些信息将存储在名为HBase的面向列的数据库中。因此,ApacheAtlas可以轻松而有弹性地处理大量具有稀疏数据的非常大的表。
 Vertex (Types) and Edges (Relationships) in a JanusGraph
Vertex (Types) and Edges (Relationships) in a JanusGraph
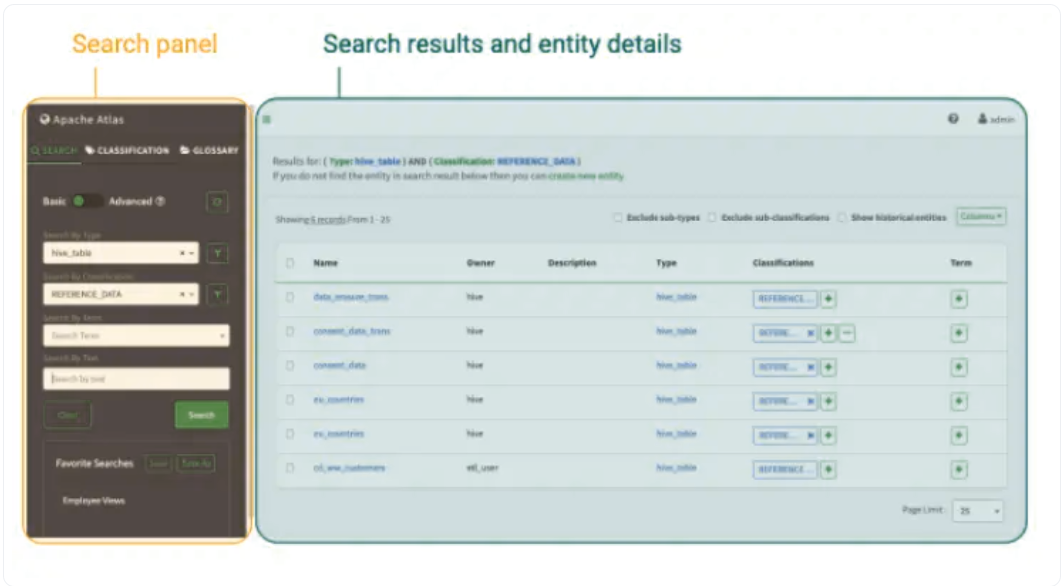
3.Apache Solr搜索能力
Atlas使用Solr索引技术(即面向索引的数据库)来提高搜索能力,因为它有助于发现动作。借助三个集合(即全文索引、边缘索引和顶点索引),用户可以在Atlas UI上高效地搜索数据。它是一个用户友好且灵活的全文搜索引擎。
4.Apache Kafka通知服务
Apache Atlas的另一个显著功能是如何通过Kafka将实时数据导入和导出与各种目录集成。Apache Kafka通知服务允许将消息作为单个Kafka主题推送,从而实现与其他数据治理工具的集成和权限读取,以及实时更改通知。

5.通过API查询和填充元数据(Rest API)
HTTP Rest API是与Apache Atlas集成的主要方法。除了四个主要的存储功能(即创建、读取、更新和删除)外,Apache还提供高级探索和查询,因为它公开了大量REST端点来处理类型、实体、沿袭和数据发现。
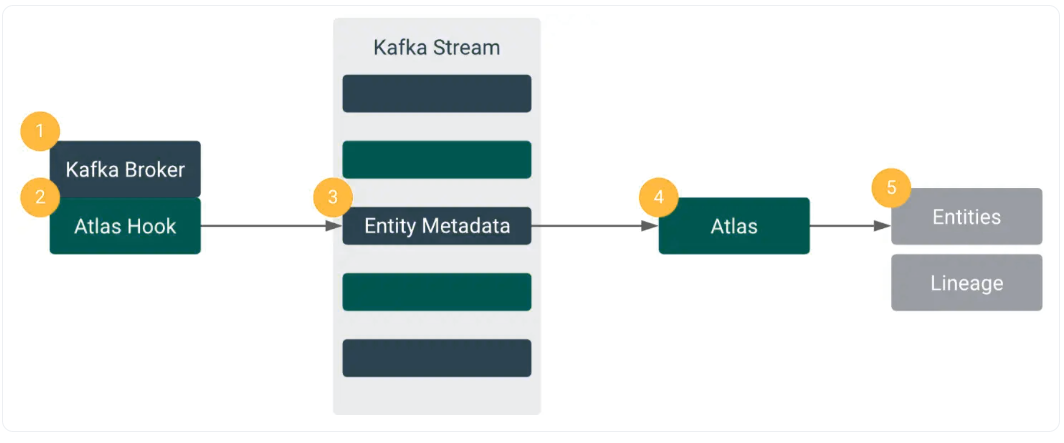
Kafka - Atlas Populating Metadata across Multiple Clusters. Source
如何安装Apache Atlas?
建立Apache Atlas的整个过程可以分为五个简单的步骤。
步骤1:了解先决条件
需要运行Docker和Docker Compose的云虚拟机、相关的GitHub存储库、Docker映像和Maven才能成功启动安装序列。
步骤2:克隆存储库
访问克隆存储库的根目录后,使用docker compose up命令开始设置过程。
步骤3:执行Docker Compose
只有在从Hive、Hadoop和Kafka中提取Docker映像后,Docker Compose才会触发Atlas的Maven构建。然后,安装Apache Atlas服务器。
步骤4:加载元数据
登录Atlas的管理UI后,在成功进行状态验证后,将填充元数据。
步骤5:导航UI
元数据的加载允许您访问实体、制定分类,并确定用于数据上下文化的特定于业务的词汇表。
Apache Atlas替代方案
尽管Atlas是一款受欢迎的数据编目软件,得到了活跃的开源社区的支持,但一些值得注意的竞争对手,如Lyft的Amundsen、LinkedIn的DataHub和Netflix的Metacat,值得一提。
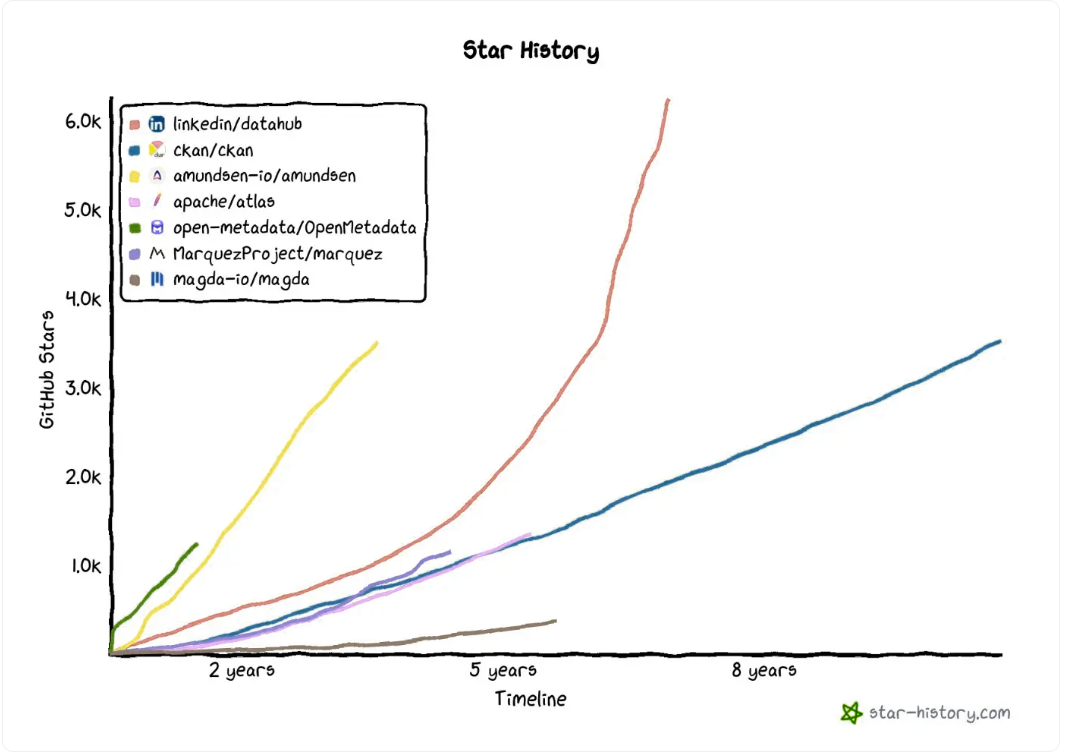
- Lyft的Amundsen:与Atlas类似,Amundsen也因其简单的文本搜索、方便的上下文共享和数据使用设施而广受欢迎。
- 领英的DataHub:DataHub始于2016年,是领英第二次尝试通过上下文理解、自动元数据获取和简化数据资产浏览来解决其编目问题。
- Netflix的Metacat:Metacat通过更改通知、定义的元数据存储以及对来自不同来源的数据的无缝聚合和评估,确保了Netflix的互操作性和数据发现。
Apache Atlas vs Amundsen
人们经常问Amundsen与Apache Atlas相关的能力。
借此机会,我们想强调的是,Amundsen专注于支持多个后端环境,确保易用性,并提供复杂的预览,以更好地实现数据上下文。
而Atlas优先考虑赋予用户对其数据的更大控制权,同时使他们能够使用词汇表来添加特定于业务的上下文信息。
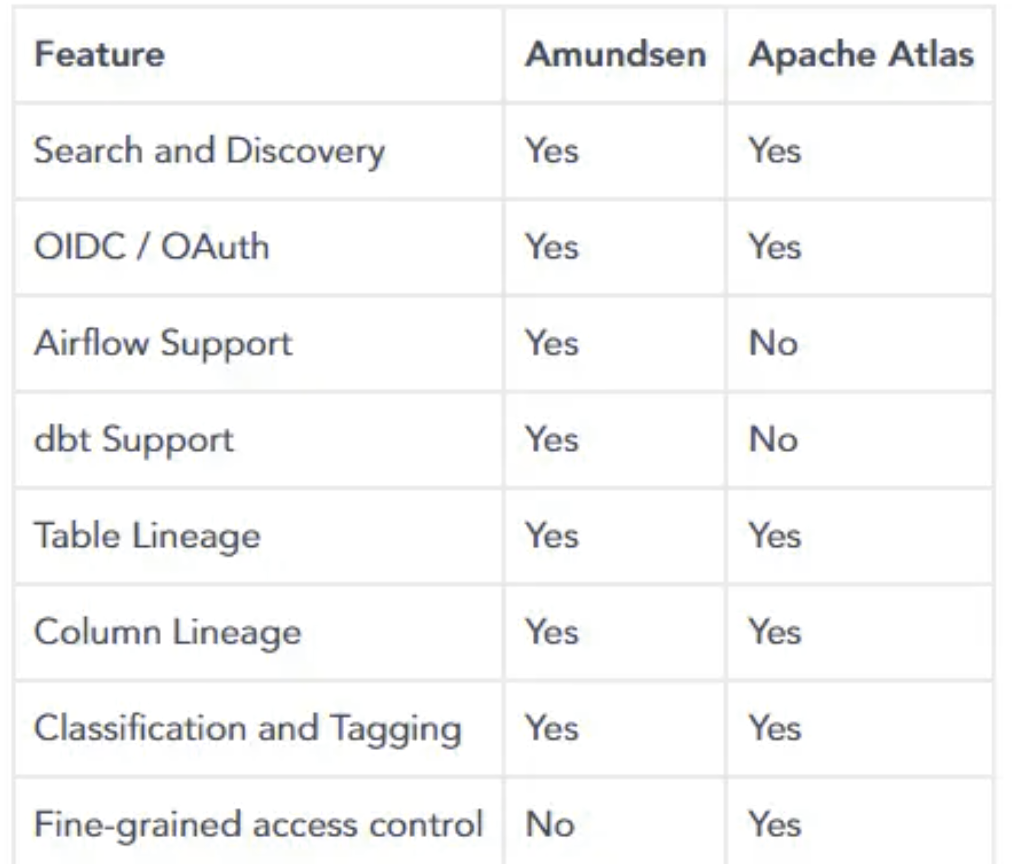
Click here for a comprehensive comparison between Amundsen and Atlas.
结论
一家公司对其数据的控制越大,其数据治理就越好。Apache Atlas旨在满足这一需求,并集中精力和架构来制定一种工具,使数据从业者能够做到这一点。
尽管如此,部署这样的解决方案是一个耗费精力和技能的过程。一旦有一支久经沙场、值得信赖的工程师团队在你身边,就要做好全力以赴的准备。
如果你正处于构建与购买的思维框架中,那么值得一看像Atlan这样的现成替代品。你将从一开始就得到一个现成的工具,它是为充分利用Apache Atlas等开源系统而构建的。
Apache Atlas: Related Resources
- A comprehensive guide to help install and set up Apache Atlas.
- Popular open source data catalog platforms to consider in 2023
- Apache Atlas Alternatives: Amundsen, DataHub, Metacat, and Databook
- Amundsen Vs Atlas: A deep dive into how both the open source data discovery tools compare and contrast.
- Understanding AWS Glue data catalog: Use cases, benefits, and more
- How do you evaluate a data catalog for a modern data stack: 5 key considerations and an evaluation guide to help you out.
- 298 次浏览