数据目录
视频号

微信公众号

知识星球

- 165 次浏览
【数据目录】2023年前五大开源数据目录
视频号
微信公众号
知识星球
Apache Atlas、Lyft Amundsen、Linkedin Datahub、Netflix Metacat、OpenMetadata
世界正日益受到数据的驱动。随着数据的涌入,企业拥有一个全面的开源数据目录来组织、存储和理解其数据生态系统是至关重要的。本文深入探讨了2023年排名前五的开源数据目录,以最好地满足您的业务需求。我们将讨论每个数据目录的功能、优点和缺点,以便您可以为您的组织选择合适的数据目录。
什么是数据目录?
数据目录是一种数字存储库,旨在对组织的数据资产进行编目、存储和组织。数据目录有助于用户快速访问不同类型的可用数据,并构成全面数据治理战略的基础。它使用户能够快速了解已知数据集的位置、数据代表什么、谁拥有它,以及应该如何使用或可以使用它。
为什么我们应该使用数据目录?
数据目录对于数据治理、安全性和访问至关重要。它为查找和理解组织中的数据集提供了一个单一的参考点。数据目录使快速定位符合特定标准的可靠数据变得更加容易,加快了数据获取过程,同时通过控制谁可以访问哪些信息来确保组织的安全。此外,数据目录作为集中的可搜索存储库,使用户能够轻松查找和理解存储在整个组织中的各种类型的数据,管理不同数据集之间的关系,并提供相关的上下文背景。总而言之,一个好的数据目录使组织数据资产能够被发现,并减少管理同一底层信息的多个来源的冗余工作,从而能够有效利用这些资产。
Apache Atlas
Apache Atlas-Hadoop的数据治理和元数据框架
Apache Atlas是一个开源的数据治理和元数据框架。它提供了管理和审核数据的全面功能。Apache Atlas使用户能够跟踪企业中使用的所有分布式数据资产的数据资产,如数据集、沿袭、标记、访问控制策略、元数据定义和分类。
优点
- 这是一个开源元数据管理解决方案,提供了一种统一的方式来定义和存储企业数据资产,以及管理和管理其访问。
- 高级版本控制功能使跟踪更改变得容易,并确保符合内部策略。
- Apache Atlas还提供了审计日志记录功能,有助于了解数据资产是如何随着时间的推移而被访问、使用和/或修改的。它简化了审核访问请求或在检测到可疑活动时向管理员发出警报的能力。
- 由于其灵活的体系结构和功能,易于与其他应用程序集成。
缺点
- 它需要Java 8或更高版本作为其底层技术,因此用户可能需要额外的资源来支持安装、配置和更新。
- 对于不熟悉Apache Hadoop(Hadoop分布式文件系统(HDFS))或HiveQuery语言(HQL)的新系统开发人员来说,这是一条陡峭的学习曲线。
Lyft Amundsen
Lyft Amundsen是一个开源的、受欢迎的元数据驱动的导航系统,它配有仪表板,用于深入了解组织的数据湖。它用于发现数据并提供对Tableau和Superset等第三方工具的访问。该平台使用户能够与其他团队成员协作,快速从元数据中获得答案,从而提高查询性能或做出更好的产品决策。
优点
- Amundsen为开发人员提供了一种简单的方法来探索和访问公司数据仓库中的数据。
- Amundsen使用元数据标记,使开发人员不需要完全理解底层数据库结构。
- 它有助于简化数据发现,因为它提供了数据集的快速可视化,使快速查找信息变得更容易。
- 编辑器可以创建复杂查询的图形表示,使开发人员能够更快、更轻松地探索数据集。
- 它更适合那些在组织内构建和管理全面元数据层方面已经有经验的公司。
- 对于需求不大的企业来说,这可能不是最合适的选择,因为高级定制可能需要额外的外部援助。
缺点
- 阿蒙森有一条陡峭的学习曲线,这比简单地使用不需要任何高级知识的应用程序更具挑战性。
- 目前,它与一些应用程序的集成相对有限,限制了它用于某些任务的能力,如查询某些类型的数据库或度量跟踪和报告。
- 它更适合那些在组织内构建和管理全面元数据层方面已经有经验的公司。
- 对于需求不大的企业来说,这可能不是最合适的选择,因为高级定制可能需要额外的外部援助。
领英 DataHub
领英数据中心是一个用于管理数据仓库的开源平台,有助于组织实现自助分析,以提高整个组织的个人和团队的决策能力。它的设计重点是可扩展性、健壮性和通用性,可扩展性内置于多个级别的体系结构中,如节点、实例、集群等。
优点
- 易于设置和使用,学习曲线低
- 灵活性,因为它是开源的,所以用户可以根据需要轻松地自定义设置或添加功能
- 通过协作和开源共享扩展数据目录。
- 加密、身份验证和授权等安全控制可用于保护存储的数据。
缺点
- 由于依赖LinkedIn未提供的外部工具,安装过程复杂
- 难以集成到可能与开源架构不兼容的现有系统中
- 对第三方数据源和实时流媒体的有限支持可能需要额外的开发工作。
网飞Metacat
Netflix Metacat是由Netflix开发的一种开源分布式编目工具,允许用户在单个平台内访问和创建所有元数据相关摄取的可搜索记录。Metacat加速了亚马逊网络服务(AWS)新客户进入Netflix流媒体平台侧车服务的速度,并在其视频流媒体库生态系统中添加了新的芯片组,这进一步减少了由于拥有管理复杂元数据需求的集中解决方案而带来的延迟问题。
优点
- 可扩展性:Metacat为用户提供了一套全面的功能,以实现可扩展性。它可以支持大规模的数据收集,并提供强大的功能,如搜索、索引、元数据标记、表格见解、查询生成器等。
- 灵活:Metacat允许用户轻松访问各种格式的数据,如CSV、JSON、XML等。这使得用户很容易使用数据,即使他们不熟悉格式。
- 集成:Metacat还集成了流行的商业智能工具,如Power BI、Tableau和Looker。这使企业更容易将其数据资产与这些平台快速连接起来,并从中了解其整体业务绩效。
- 快速数据访问:Metacat易于在云平台上安装和部署。这确保了用户无论在什么平台上都能以无与伦比的速度访问其数据资产。
缺点
- 有限的安全性:Metacat的开源性质意味着提供的安全措施有限,如第三方产品或服务将使用的加密和其他安全协议。
- 有限的工具集:虽然Metacat提供了广泛的功能,但与提供更多选项(如访问控制协议或自定义元数据管理系统)的企业目录解决方案相比,这些功能可能有些有限。
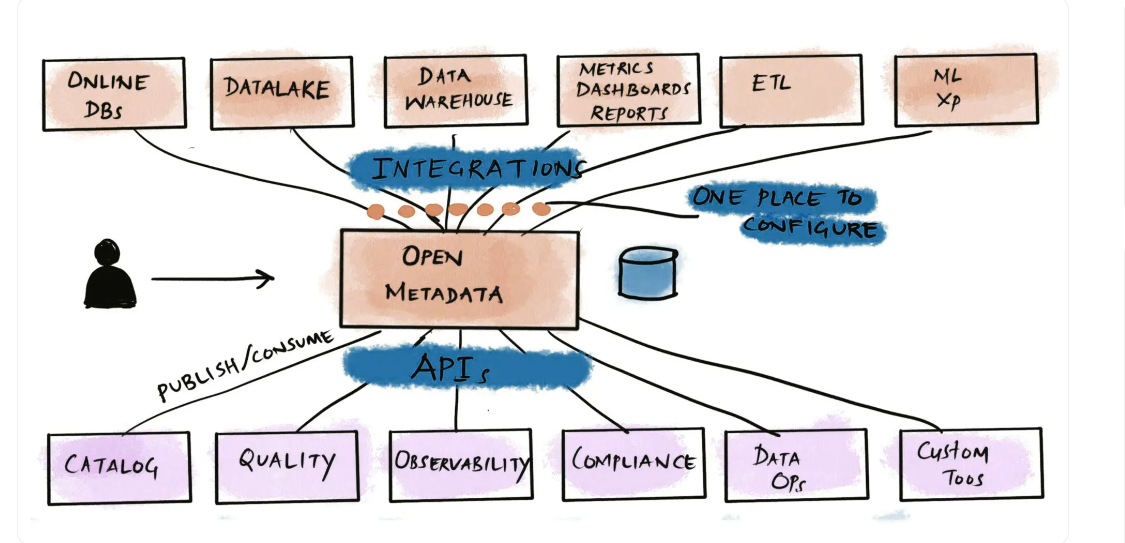
OpenMetadata
OpenMetadata是一个元数据管理平台,使企业能够定位、理解和管理其数据资产。它提供了一个集中的存储库,用于收集和维护各种数据源的信息,使用户可以轻松地搜索和查找组织内部的数据资产。OpenMetadata支持广泛的数据源,包括数据库、数据仓库和数据湖,并提供跨数据资产的数据沿袭和连接的统一视图。
它基于JSON模式,并提供用于编程访问的REST API。OpenMetadata还包括一个简单的web界面,允许非技术人员在不知道如何使用API的情况下与系统交互。该项目是开源的,有一个充满活力的社区为其发展和维护做出贡献。
优点
- 灵活性:OpenMetadata的设计具有高度的灵活性和可定制性。它可以很容易地与各种数据工具和平台集成,使组织能够构建满足其特定需求的定制数据目录。
- 基于API的架构:OpenMetadata的基于API架构使其能够与数据生态系统中的各种工具和服务集成,从而提供灵活性和可扩展性。
- 协作:OpenMetadata支持协作和数据治理,允许多个用户一起管理和维护数据目录。它还支持基于角色的访问控制,确保只有授权用户才能访问敏感数据。
- 提供数据沿袭和治理:OpenMetadata提供数据沿袭,跟踪数据从来源到最终目的地,以及治理,确保数据质量和安全。
OpenMetadata 1.0版本
OpenMetadata 1.0版本提供了各种更改和新功能,以帮助用户进行元数据管理和数据发现。稳定和增强的API和模式,从源中提取元数据时的性能改进,从云存储中提取元数据的新服务,以及更好的SQL查询和词汇表UI都包含在本版本中。此外,OpenMetadata现在支持多语言本地化,并实现了标记PII数据的自动化方式。为了增强保护,已经启用了SAML支持,并且Chrome浏览器插件现在可以在浏览Looker、Superset和其他应用程序时访问元数据。
总体而言,OpenMetadata为元数据管理系统提供了一种简单且适应性强的产品方法,用户可以通过较少的已验证依赖关系来实现该方法。该体系结构针对用户角色和用例进行了优化,为元数据消费提供了全面的API,并为需要它的人提供了与Kafka的简单集成。
总结
本文概述了组织在管理和组织数据资产时使用的最佳开源数据目录。它强调了数据目录在最大限度地利用公司数据资产、使其可被发现以及消除在维护相同信息的不同来源方面的重复工作方面的重要性。本文讨论了前五大数据目录,包括Apache Atlas、Lyft Amundsen、LinkedIn Datahub、Netflix Metacat和OpenMetadata,以及每个目录的优点和缺点。本文还讨论了采用数据目录的优势,如数据治理、安全性和访问,以及它作为全面数据治理计划基础的功能。
- 704 次浏览
【数据目录】Amundsen 与 DataHub:你应该选择哪种数据发现工具?
视频号
微信公众号
知识星球
我们生活在这样一个时代,从每天一次的数据仓库和数据湖加载到5分钟的微批量和近乎实时的流媒体。因此,构建下一代产品的公司需要更快、大规模的分析和实时数据发现。
这就是 Amundsen和DataHub这两个最受欢迎的元数据架构工具的诞生。有了阿蒙森,Lyft将其数据团队的生产力提高了20%。同样,DataHub帮助领英实现了数据民主化——每周有1500名员工访问DataHub,搜索、发现和使用数据来完成工作。
如果你想弄清楚,“阿蒙森vs数据中心——它们有什么相似之处?有区别吗?”那么你来对地方了。
Amundsen vs Amundsen :比较的关键参数
底层架构相比如何?
- Amundsen和Amundsen 中的元数据摄取是如何工作的?
- 评估内置的目录、沿袭和治理功能。
- 在部署、身份验证和授权方面有什么区别?
- 他们的美国专利有什么不同?阿蒙森和DataHub未来的产品路线图看起来如何?
Amundsen vs DataHub:比较底层架构
Amundsen和DataHub是使用类似组件构建的元数据搜索和发现工具。两者都使用 neo4j 作为数据库元数据,并使用Elasticsearch来促进元数据搜索。他们还使用REST API支持通信。
相似之处到此为止。当涉及到元数据摄取时,这些工具采用不同的方法。
元数据摄取在Amundsen是如何工作的?
Amundsen从Apache Goblin中汲取灵感,建立了ETL框架和编排引擎。它还支持与Airflow的无缝集成。
Databuilder数据摄取库由提取器、转换器和加载器组成。Amundsen的Databuilder支持Python、Cassandra、Hive、Snowflake、Postgres等各种提取器。这是因为Amundsen支持各种各样的数据库来存储元数据。您还可以使用Apache Atlas来处理Amundsen的部分后端和存储。
如果你没有找到你要找的提取器,你可以从通用提取器中得到一些提示,建立自己的generic extractor。同样的概念也适用于变压器(transformers )和装载机(loaders )。

DataHub中的元数据摄取与阿蒙森有何不同?
DataHub有一个基于Python的元数据接收包,由DataHub的商业部门Acryl Data维护。
对于任何源或接收器,您必须安装相关的插件。您可以使用Python包通过Kafka事件或REST API调用摄取元数据。此软件包与DataHub的CLI工具集成。或者,您可以在定制的Python库中使用acryl datahub包。对于复杂或计划的工作流,您可以将此软件包与Airflow无缝集成。
除了REST API,DataHub还支持GraphQL和基于AVRO的API over Kafka,用于跨其架构的各个元素进行通信。
以下是我们迄今为止讨论的所有内容的快速摘要:
| Tool | Database | Search | Ingestion | Service Communication |
|---|---|---|---|---|
| Amundsen | neo4j | Elasticsearch | Databuilder | REST API |
| DataHub | neo4j / MySQL | Elasticsearch | source-specific plugins | REST API, GraphQL, Kafka |
接下来,让我们看看它们的功能是如何不同的。
Amundsen vs DataHub:数据目录、谱系和治理
Amundsen和DataHub都支持以下用例:
- 搜索和发现 : 元数据搜索和发现是通过一个与各种来源集成的中央平台进行的。
- 世系 : 您可以跟踪数据的来源、移动和演变,以实现法规遵从性和业务上下文。
- 法规遵从性:您可以定义细粒度的策略来控制信息访问。此外,数据分类法基于各种内部业务规则和全球监管标准(GDPR、CCPA)。
- 质量 : 您可以使用外部工具配置定义数据质量的业务规则,并设置质量合规集成、报告和仪表板。
除了这些用例之外,这两个工具还支持几个摄取源和仪表板连接器。
例如,Amundsen有20多个数据库连接器用于接收,还有几个仪表板连接器。有了像AWS Glue这样的通用连接器和Superset这样的仪表板的支持,Amundsen在不编写连接器的情况下实现了巨大的可扩展性。
同样,DataHub具有广泛的接收源、仪表板连接器、ML集成、管道以及其他元数据搜索和发现功能。
Amundsen vs DataHub:关键差异和USPs
Amundsen易于理解、安装、修改和部署。关键USP包括:
- 后端支持:阿蒙森被认为在后端支持方面处于领先地位。除了neo4j(阿蒙森的默认后端)之外,它还支持AWS Neptune和Apache Atlas作为后端环境。
- 预览:此功能非常独特。使用预览,您可以将元数据目录与实时数据库连接,并预览数据样本以获取更多上下文。
以下是Amundsen的联合创始人在将该工具与DataHub进行比较时要说的话。
同时,DataHub的优势在于其数据治理能力。其中包括:
- 更精细的访问控制:DataHub支持列级和数据集级分类、PII标记、自动数据删除(以帮助遵守GDPR)等。
- 数据沿袭:在其路线图中,DataHub承诺列级沿袭映射,并与Great Experiences、dbt测试和deequ等测试框架集成。
虽然DataHub不像Amundsen那样支持多个后端环境,但DataHub的路线图将此功能列为优先事项。
以下是DataHub的创始人之一如何将其与Amundsen区分开来。
| Feature | Amundsen | DataHub |
|---|---|---|
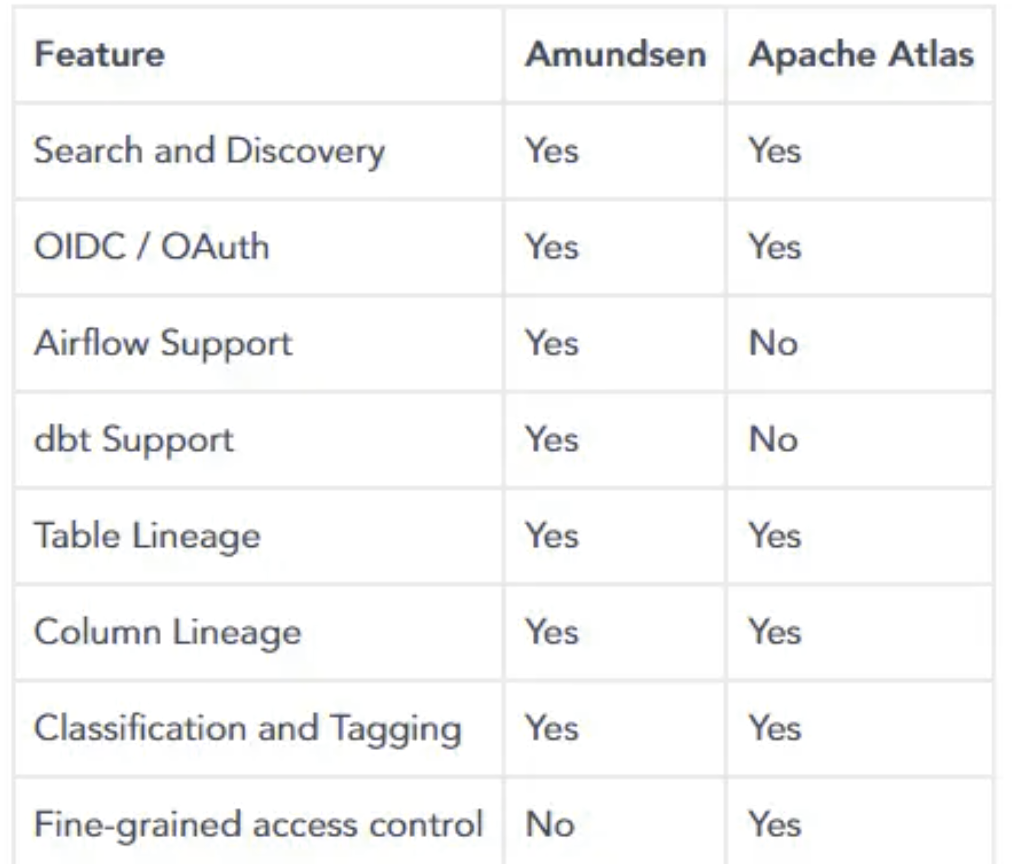
| Search and discovery | Yes | Yes |
| OIDC/OAuth | Yes | Yes |
| Airflow support | Yes | Yes |
| dbt support | Yes | Yes |
| Multiple backend support | Yes | No |
| Table lineage | Yes | Yes |
| Column lineage | Yes | No |
| Classification and tagging | Yes | Yes |
| Fine-grained access control | No | Yes |
Amundsen vs DataHub:部署、身份验证和授权
这两种工具都可以使用二进制文件轻松构建和部署。然而,如果你想快速轻松地开始,你可以在Docker上运行它们。
唯一的先决条件是,您需要Docker和Docker Compose以及Python或Node.js版本。如果您需要更多帮助来部署这些工具,下面是一些分步设置指南:
Amundsen vs DataHub:路线图、更新和社区
这两个项目都有一个公共路线图和广泛的社区支持,您可以遵循。
Amundsen为路线图维护了一个摘要页面,以及一个GitHub问题页面,在那里你可以确切地看到正在进行的工作。此外,你可以通过以下方式参与:
- 通过收集标记为“良好的第一期”的问题,为GitHub上的项目做出贡献
- 在Medium上订阅阿蒙森的月度更新
- 关注Stemma的博客
和Amundsen一样,DataHub也维护产品路线图,并在Medium上频繁更新。
Amundsen vs DataHub:什么对你最有利?
虽然有很多元数据搜索和发现工具,但很难找到完美的解决方案。最好的工具是能够满足您的业务需求,同时与您的技术堆栈无缝集成。
为了总结一切,我们制作了一个功能矩阵,突出显示了这两种工具的功能。
| Tool | Amundsen | DataHub |
|---|---|---|
| Developed by | Lyft | |
| Architecture | ETL-based metadata ingestion | Plugin-based metadata ingestion |
| Features | 1. Easy to set up, modify and deploy 2. Search and discovery 3. Multiple backend support 4. Data lineage (table and column) 5. Data classification and tagging |
1. Search and discovery 2. Integrates with the stream ecosystem using Kafka and supports GraphQL 3. Data lineage (column-based lineage is in the roadmap) 4. Fine-grained access control 5. Data classification and tagging |
| Deployment | 1. Kubernetes 2. AWS ECS 3. Standalone docker |
1. Kubernetes 2. Google Cloud GKE (Google Kubernetes Engine) 3. Standalone docker |
| Authentication | OAuth OIDC (OpenID Connect) | 1. OAuth OIDC 2. JaaS (Java Authentication and Authorization Service) |
| Authorization | In the roadmap | Platform and metadata policies |
| Roadmap and updates | 1. Amundsen roadmap 2. Updates on Medium and Stemma 3. GitHub (also lets you contribute) |
1. DataHub roadmap 2. Updates on Medium |
Amundsen vs DataHub:相关资源
- Amundsen vs. Atlas: What are the differences and similarities? Which one is better for you?
- A quick introduction to Amundsen, Lyft’s open source data discovery platform
- A quick start guide to Linkedin’s Datahub, an open source metadata management tool
- Get access to Amundsen demo and DataHub demo: Sandbox demo sites pre-populated with sample data.
- Understanding AWS Glue Data Catalog: Architecture, components, and crawlers.
- 311 次浏览
【数据目录】Apache Atlas:起源、架构、功能、安装、替代方案和比较
视频号
微信公众号
知识星球
Apache Atlas是一个开源元数据和大数据治理框架,可帮助数据科学家、工程师和分析师对其数据资产进行编目、分类、治理和协作。
什么是Apache Atlas?
通过将元数据表示为类型和实体,Apache Atlas为组织在Hadoop集群上构建、分类和管理其数据资产提供了元数据管理和治理功能。
这些“实体”是元数据类型的实例,存储有关元数据对象及其互连的详细信息。
您对Apache Atlas作为元数据管理框架感兴趣吗?然后您应该熟悉活动元数据。活动元数据越来越受欢迎,因为它可以帮助数据团队节省时间和金钱。以下是这个概念的基本介绍,以及如何开始使用它。
“在Atlas中,Type是元数据对象的定义,Entity是元数据对象实例,”~IBM Developer
Apache提供了最先进的“图谱建模”服务,可以帮助您概述数据的来源,以及所有的转换和工件。该服务通过利用标签和分类向实体添加元数据,省去了管理元数据的麻烦。尽管任何人都可以创建标签并将其分配给实体,但分类通过Atlas策略由系统管理员控制
 Atlas Labels and Classifications
Atlas Labels and Classifications
Apache Atlas起源
Apache Atlas最初由Hortonworks于2014年孵化,作为数据治理倡议(DGI)。这一举措旨在为企业实施全面的数据治理实践。
五个月后,这项工作作为一个开源项目正式移交给了Apache基金会,之后它不断证明自己是一个顶级项目,直到2017年年中毕业。
自2015年以来,该项目一直由社区为社区维护,目前2.2版本正在运行。
 From DGI to Apache Atlas
From DGI to Apache Atlas
Apache Atlas的用途是什么?
Apache Atlas用于:
- 在整个数据生态系统中对数据进行控制
- 通过元数据映射沿袭关系
- 提供元数据“桥梁”
- 创建和维护业务本体
- 数据屏蔽
对数据进行完全控制
Apache Atlas为企业提供的数据图表功能有助于蓝筹股和初创公司导航其数据生态系统。它有助于映射和组织元数据表示,使您能够适应操作和分析数据的使用。
“Apache Atlas旨在与Hadoop堆栈内外的其他工具和流程交换元数据,从而实现与平台无关的治理控制,有效地满足法规遵从性要求。”~ Hortonworks数据平台:数据治理

通过元数据映射沿袭关系
通过分配业务元数据,Atlas促进了实体的产生,这些实体可以帮助您设计业务词汇表来跟踪您的数据资产。更重要的是,一旦接收到查询信息,就会自动生成谱系图。查询本身会被注意到,它的输入和输出用于可视化数据转换是如何以及何时发生的。因此,您可以跟踪变化并设想影响。
提供元数据“桥梁”
Atlas还使元数据的收集能够通过使用“桥梁”实现自动化,通过使用API可以从给定来源的不同数据资产导入这些信息。
创建和维护业务本体
通过管理分类和标签,Apache Atlas可以帮助您增强元数据的功能。它的仪表板有助于注释标记的实体,从而创建特定于用例和业务本体的基础设施。分类本身按层次结构排列,添加单个术语会生成与查询相关联的所有实体的报告。
数据屏蔽
一旦数据被组织到一个清单中,就形成了一个数据目录。基于作为任何给定数据目录骨干的分类,Apache Atlas在与Apache Ranger集成后帮助屏蔽数据访问。此功能对于确保对操作和实体实例的访问安全至关重要。
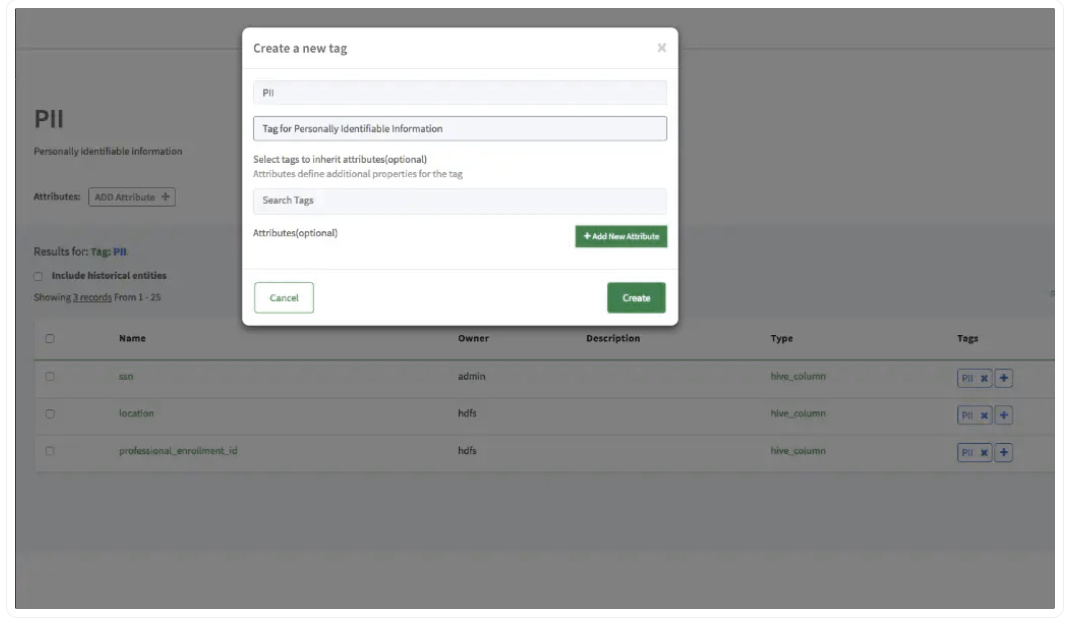 Creation of a Personally Identifiable Information tag
Creation of a Personally Identifiable Information tag
Apache Atlas体系结构
Apache Atlas的体系结构分为4个主要部分,这是其受欢迎程度和功能背后的原因。其中包括:
- 元数据源和集成:Apache Kafka中用于组织消息的类别,称为Kafka消息主题[集成],通常通过Atlas插件[元数据源]接收元数据。
- 核心:因此,Atlas必须读取每条消息,这些消息随后存储在JanusGraph[核心]中。反过来,JanusGraph用于可视化实体之间的关系,在这种情况下使用的数据存储是HBase。Solr名称的搜索索引也被用来获得其搜索功能的好处。
- 应用程序:所有这些组件都允许Atlas管理元数据,这些元数据最终被各种面向治理的用例[应用程序]使用。

Apache Atlas的功能
作为元数据和治理的框架,Apache Atlas的体系结构包含以下功能:
- 通过类型和实体系统定义元数据
- 通过Graph存储库存储元数据(JanusGraph)
- Apache Solr搜索能力
- Apache Kafka通知服务
- 通过API查询和填充元数据(Rest API)
1.通过类型和实体系统定义元数据
该工具的主要模块之一是类型系统,其操作灵感来自OOP(面向对象编程)如何使用实例(即实体)和类(即类型)。在Apache Atlas的形式中,我们获得了一个简单直观的工具,可以对各种“类型”进行建模,然后将有关它们的信息存储为“实体”(实例)。这种系统化允许用户通过数据目录的分类和使用来解决当今与数据治理相关的许多挑战。
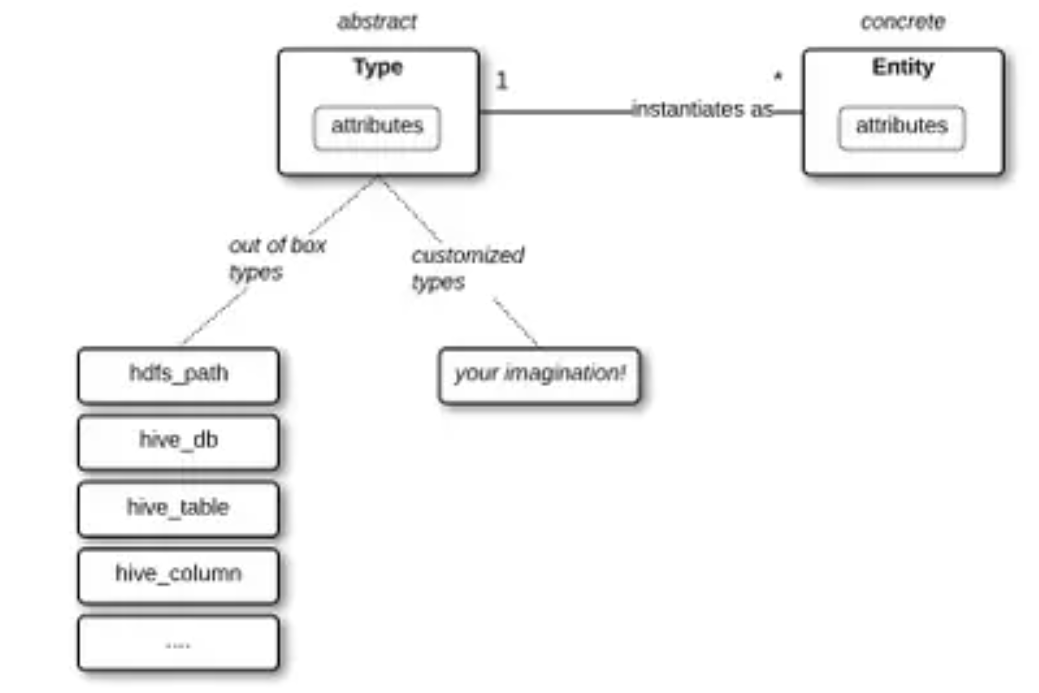 Apache Atlas Types and Entities
Apache Atlas Types and Entities
2.通过Graph存储库存储元数据(JanusGraph)
Atlas的获取和导出系统提取数据后,通过图形引擎模块发现并索引信息。该模块由名为Janus的开源图形数据库提供支持,使Apache Atlas不仅可以突出数据目录中各种实体之间的相互联系,还可以根据信息源定位实体的元信息,这些信息将存储在名为HBase的面向列的数据库中。因此,ApacheAtlas可以轻松而有弹性地处理大量具有稀疏数据的非常大的表。
 Vertex (Types) and Edges (Relationships) in a JanusGraph
Vertex (Types) and Edges (Relationships) in a JanusGraph
3.Apache Solr搜索能力
Atlas使用Solr索引技术(即面向索引的数据库)来提高搜索能力,因为它有助于发现动作。借助三个集合(即全文索引、边缘索引和顶点索引),用户可以在Atlas UI上高效地搜索数据。它是一个用户友好且灵活的全文搜索引擎。
4.Apache Kafka通知服务
Apache Atlas的另一个显著功能是如何通过Kafka将实时数据导入和导出与各种目录集成。Apache Kafka通知服务允许将消息作为单个Kafka主题推送,从而实现与其他数据治理工具的集成和权限读取,以及实时更改通知。

5.通过API查询和填充元数据(Rest API)
HTTP Rest API是与Apache Atlas集成的主要方法。除了四个主要的存储功能(即创建、读取、更新和删除)外,Apache还提供高级探索和查询,因为它公开了大量REST端点来处理类型、实体、沿袭和数据发现。
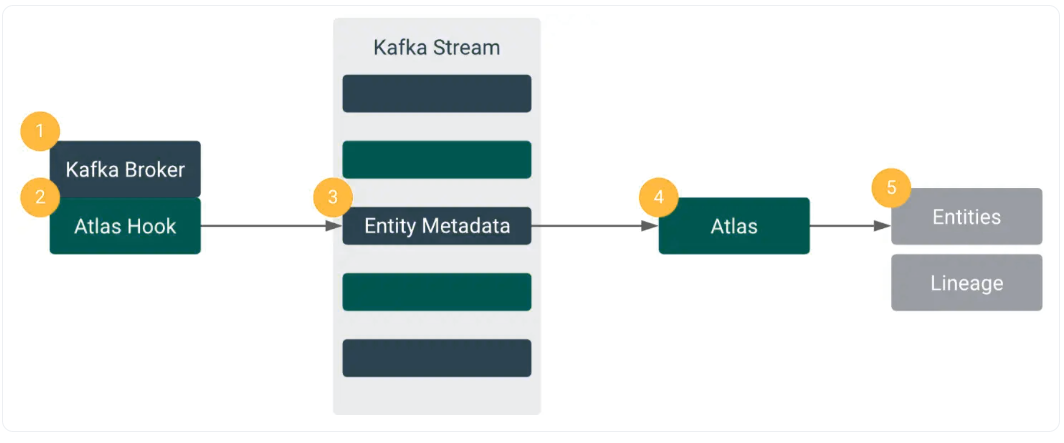
Kafka - Atlas Populating Metadata across Multiple Clusters. Source
如何安装Apache Atlas?
建立Apache Atlas的整个过程可以分为五个简单的步骤。
步骤1:了解先决条件
需要运行Docker和Docker Compose的云虚拟机、相关的GitHub存储库、Docker映像和Maven才能成功启动安装序列。
步骤2:克隆存储库
访问克隆存储库的根目录后,使用docker compose up命令开始设置过程。
步骤3:执行Docker Compose
只有在从Hive、Hadoop和Kafka中提取Docker映像后,Docker Compose才会触发Atlas的Maven构建。然后,安装Apache Atlas服务器。
步骤4:加载元数据
登录Atlas的管理UI后,在成功进行状态验证后,将填充元数据。
步骤5:导航UI
元数据的加载允许您访问实体、制定分类,并确定用于数据上下文化的特定于业务的词汇表。
Apache Atlas替代方案
尽管Atlas是一款受欢迎的数据编目软件,得到了活跃的开源社区的支持,但一些值得注意的竞争对手,如Lyft的Amundsen、LinkedIn的DataHub和Netflix的Metacat,值得一提。
- Lyft的Amundsen:与Atlas类似,Amundsen也因其简单的文本搜索、方便的上下文共享和数据使用设施而广受欢迎。
- 领英的DataHub:DataHub始于2016年,是领英第二次尝试通过上下文理解、自动元数据获取和简化数据资产浏览来解决其编目问题。
- Netflix的Metacat:Metacat通过更改通知、定义的元数据存储以及对来自不同来源的数据的无缝聚合和评估,确保了Netflix的互操作性和数据发现。
Apache Atlas vs Amundsen
人们经常问Amundsen与Apache Atlas相关的能力。
借此机会,我们想强调的是,Amundsen专注于支持多个后端环境,确保易用性,并提供复杂的预览,以更好地实现数据上下文。
而Atlas优先考虑赋予用户对其数据的更大控制权,同时使他们能够使用词汇表来添加特定于业务的上下文信息。
Click here for a comprehensive comparison between Amundsen and Atlas.
结论
一家公司对其数据的控制越大,其数据治理就越好。Apache Atlas旨在满足这一需求,并集中精力和架构来制定一种工具,使数据从业者能够做到这一点。
尽管如此,部署这样的解决方案是一个耗费精力和技能的过程。一旦有一支久经沙场、值得信赖的工程师团队在你身边,就要做好全力以赴的准备。
如果你正处于构建与购买的思维框架中,那么值得一看像Atlan这样的现成替代品。你将从一开始就得到一个现成的工具,它是为充分利用Apache Atlas等开源系统而构建的。
Apache Atlas: Related Resources
- A comprehensive guide to help install and set up Apache Atlas.
- Popular open source data catalog platforms to consider in 2023
- Apache Atlas Alternatives: Amundsen, DataHub, Metacat, and Databook
- Amundsen Vs Atlas: A deep dive into how both the open source data discovery tools compare and contrast.
- Understanding AWS Glue data catalog: Use cases, benefits, and more
- How do you evaluate a data catalog for a modern data stack: 5 key considerations and an evaluation guide to help you out.
- 286 次浏览
【数据目录】DataHub:领英的数据发现、目录和元数据管理开源工具
视频号
微信公众号
知识星球
什么是DataHub?
DataHub由LinkedIn构建,是一个元数据驱动的平台,可帮助您为业务实现数据编目、发现、可观察性和治理。它为您提供了所有技术和逻辑元数据的360º视图,使您能够查找和使用您所掌握的所有数据。
领英为什么要建立DataHub?
领英在构建、扩展和开源工具和技术方面有着良好的记录,如Kafka, Pinot, Rest.li, Gobblin,以及最近的 Venice等。
在DataHub之前的几年,LinkedIn open-sourced WhereHows,这是他们“大数据生态系统的数据发现和谱系平台”。在大规模构建和使用WhereHows的过程中,领英决定创建DataHub。
随着资源和数据资产的增加,可能会出现更大程度的混乱,尤其是当您有复杂的数据管道和作业时。为了防止这种混乱,并确保他们的所有数据都是可搜索、可发现和可理解的,领英需要有一个具有新架构的全面数据目录
- 具有模块化、面向服务的设计
- 支持元数据接收的推送和拉取选项
- 能够与现代数据堆栈中的工具进行深度集成
- 能够通过全文搜索支持搜索和发现
- 集成了端到端细粒度数据谱系
- 具有数据隐私和安全方面的数据治理能力
DataHub的一些功能是什么?
DataHub主要是LinkedIn的数据目录,用于搜索和发现用例。除了核心数据编目功能外,DataHub还提供了细粒度数据沿袭、联邦数据治理等功能。让我们来谈谈领英的数据编目工具DataHub的一些功能。
- 搜索和发现
- 端到端数据沿袭
- 数据治理
搜索和发现
DataHub的搜索和发现功能由全文搜索引擎支持,该引擎对从基本技术元数据到逻辑元数据(如标签和分类)的所有内容进行索引。
该搜索引擎由Elasticsearch支持,它将所有数据存储在文档中,然后将这些文档作为反向索引进行索引,以实现超快的搜索体验。对于编程访问,DataHub还通过GraphQL提供对全文搜索、跨实体搜索和跨沿袭搜索的访问。
DataHub中的搜索功能可通过直观的UI访问,您可以使用该UI搜索DataHub的所有数据资产,包括资产名称、描述、所有权信息、细粒度属性等。
想要更结构化的搜索和发现方法的用户可以使用筛选器和高级(自定义)筛选器来细化全文搜索的结果。为了获得更高级的搜索查询体验,您可以混合使用模式匹配、逻辑表达式和筛选。
端到端数据沿袭
DataHub使用基于 file-based lineage来存储和接收来自各种平台、数据集、管道、图表和仪表板的数据沿袭信息。您需要以规定的基于YAML的沿袭文件格式存储沿袭信息。
下面是一个沿袭YAML文件的示例,该文件包含多个数据资产的沿袭信息。DataHub允许像dbt和Superset这样的集成自动将沿袭数据摄取到系统中。您还可以使用Airflow的沿袭API来摄取DataHub中的沿袭数据。
当对代码进行更改时,了解数据沿袭是非常关键的,这些更改可能会破坏上游或下游的脚本、作业、DAG等。DataHub社区多次投票支持的一个功能是列级数据沿袭,这对于业务用户了解数据在进入消费层的过程中是如何变化和转换的非常重要。
随着其最新版本的发布,DataHub已开始支持列级数据沿袭。有关更多信息,请参阅细粒度沿袭的文档。
数据治理
领英已经考虑了一些关于模式保存、进化和注释的关键问题。领英使用PDL(飞马定义语言)和Avro的组合,这两种语言可以用于它们之间的无损转换,也可以用于存储和流媒体目的。
许多其他数据定义语言,如基于SQL的DDL、Thrift和Protobuf,也可以进行修改,以支持高级注释和无损转换。尽管如此,领英之所以选择这两个项目,可能是因为之前在Rest.li、Avro2TF和Kafka等其他项目上的经验。
这种选择不仅有助于更好地进行数据编目,而且有助于提高数据沿袭和治理能力,具有以下功能:
- 基于角色的访问控制
- 标签、词汇表术语和域
- 行动框架
基于角色的访问控制
DataHub允许一种相对细粒度的方法,使用RBAC和存储在DataHub系统中的元数据的组合来控制对数据资产的访问。
对于身份验证和授权,DataHub支持基于角色的访问控制机制(已经实现了初始RFC的部分内容)。您可以强制执行不同类型的策略,以便对不同的资源类型提供不同的权限集。您可以将这些策略附加到用户或组。
标签、词汇表术语和域
在数据治理的业务方面,DataHub允许您将资产分配给所有者并使用特定于业务的元数据,如标签、词汇表术语和域,从而实现更好的数据治理。
行动框架
DataHub的Actions Framework使您能够出于可观察性的目的触发外部工作流,从而增强您的数据治理体验。
了解DataHub体系结构
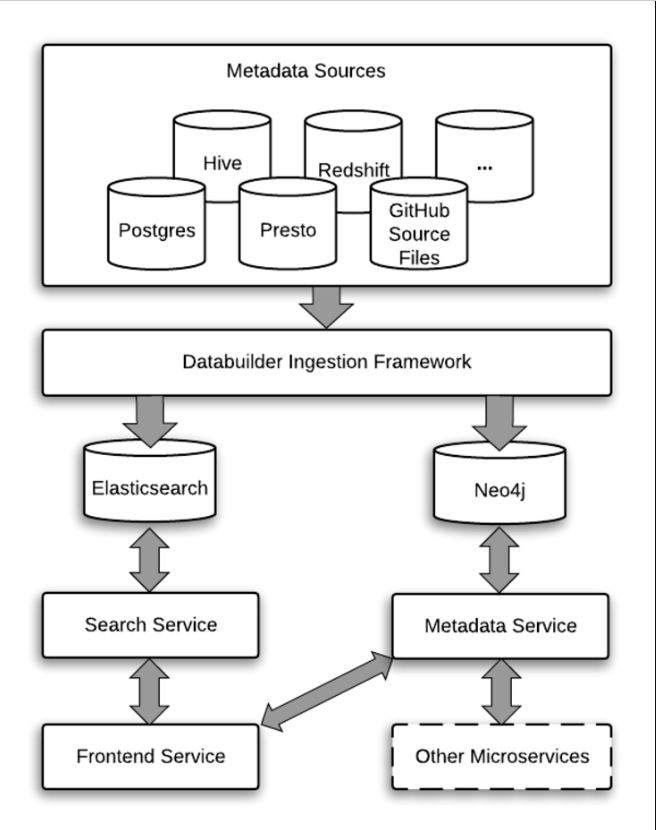
领英工程博客上的一篇博客文章解释了三代元数据应用程序。它解释了WhereHows如何来自第一代元数据应用程序架构,以及DataHub如何成为由细粒度微服务定义的第三代架构的少数实现之一,其中事件和日志为元数据的获取和消费提供了动力。
三代元数据平台架构
以下是领英定义的三代元数据平台的摘要:
- 第一代架构-基于爬网的元数据系统,平台中的所有内容都由一个包含前端、后端、搜索、关系等的整体提供服务。例如Amundsen和Airbnb Data Portal。
- 第二代体系结构——SOA(面向服务的体系结构),具有一个基于推送的元数据服务层,与其他内容分开,但可以通过API访问。例如马尔克斯。
- 第三代架构-更细粒度的服务设计,元数据来源于数据源的事件和日志,并支持流式传输和基于推送的API。示例包括DataHub, Apache Atlas, and Egeria.
现在让我们更详细地了解一下DataHub的体系结构。
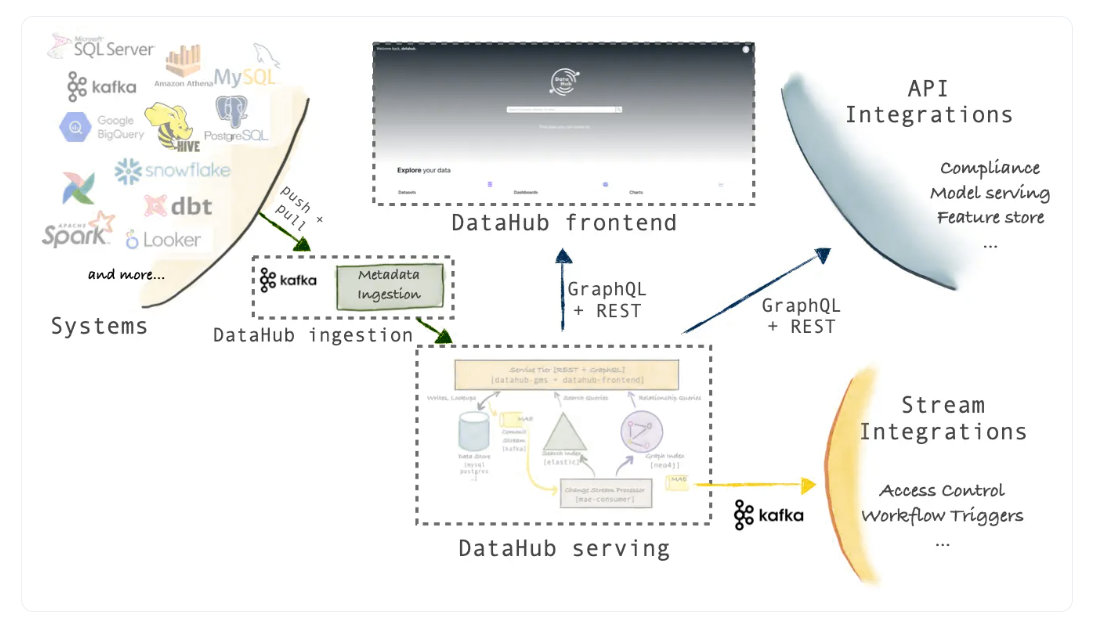
DataHub体系结构概述
根据第三代元数据平台架构规范的规定,DataHub使用不同的服务来获取和服务元数据。
所有服务都集成了GraphQL、RESTAPI和Kafka等技术。为了服务于搜索、发现和治理等不同的用例,DataHub需要在内部支持不同的数据访问模式,而这反过来又需要专门构建的数据库,如MySQL、Elasticsearch和neo4j。
这三个数据源构成DataHub的服务层,并满足来自前端、API集成和其他下游应用程序的所有请求。
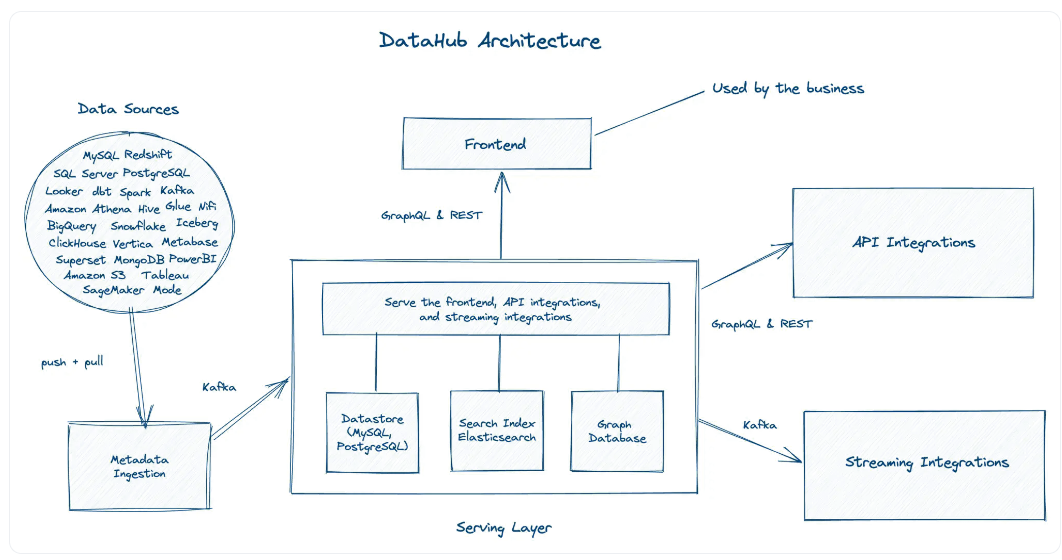
High level understanding of DataHub architecture. Image source: Atlan
在上图中,您可以看到DataHub有三个范围广泛的层,即来源层、服务层和消费层。源层从一个或多个数据源中获取数据。
来自这些源的数据被提取并推送到元数据接收,然后由Kafka提取,以便与服务层中专门构建的数据存储共享。该层将请求引导到正确类型的数据存储,以确保最快的响应时间。
消费层包括业务、通过前端应用程序消费元数据,以及使用GraphQL、REST API和Kafka消费数据的其他系统集成。
如何安装DataHub
安装DataHub进行尝试非常简单。您可以从官方Docker镜像安装DataHub,并在几分钟内启动并运行。如果你想在生产中部署DataHub,你可以在任何云平台上部署它,比如AWS或带有Docker和Kubernetes的谷歌云。以下是关于如何开始使用DataHub的详细教程:
Docker上的DataHub入门
DataHub替代方案
DataHub还有其他几种开源替代方案。有些人采取了非常不同的方法来解决相同的搜索、发现和治理问题。 Lyft’s Amundsen和优步的Databook启发的OpenMetadata 就是这样两种开源数据编目工具。我们花了一些时间对这些工具进行了全面的比较。查看以下文章:
Linkedin DataHub: Related reads
- Explore LinkedIn DataHub: A hosted demo environment with pre-populated sample data
- DataHub tutorial: We will guide you through the steps required to configure and install LinkedIn DataHub.
- Amundsen vs DataHub: What is the difference? Which data discovery tool should you choose?
- Open-source data catalog software: 5 popular tools to consider in 2023
- Enterprise metadata management and its importance in the modern data stack
- 536 次浏览
【数据目录】Databook:优步内部元数据目录为可扩展数据发现提供动力
视频号
微信公众号
知识星球
什么是Databook?
Databook是优步的内部元数据管理平台,可大规模实现数据发现和探索的民主化。Databook之于优步,Amundsen之于Lyft,DataHub之于LinkedIn,Metacat之于Netflix。
2010年,优步彻底改变了交通行业,目前在全球拥有数百万用户的10000多个城市运营。自成立以来,优步在很大程度上实现了业务多元化。它将乘客与司机、美食家与餐馆、承运人与托运人等联系起来。该组织处理针对用户乘车请求、付款、餐厅订单、运输详细信息等产生的大量每日实时数据。Databook跟踪所有这些不同的数据源,并维护数据目录。
为什么要建立Databook?
Databook旨在对与优步数据集、仪表盘、位置数据、分析和营销指标相关的元数据进行编目。优步旨在帮助员工利用数据目录中的上下文信息,探索并最终将数PB的实时运营数据转换为智能。
Databook的演变(2016-2020)
优步于2016年推出了第一个Databook,当时整体数据基础设施简单,分布相对较少。在此之前,优步使用静态HTML页面对其数据集和表进行编目,并手动维护和更新。随着公司的发展,优步Databook 取代了静态HTML页面,这种页面在一段时间内运行得相当好。
优步随后建立了新的业务链来扩大其合资企业,包括优步美食、优步电梯、优步货运和自行车。这种扩展导致了指数级的数据增长,并认为有必要开发更先进的数据目录软件。
优步的员工开始对数据进行更详细的分类。他们收集了有关数据集、其所有者、如何生成数据、从数据集派生出哪些业务指标、构建了哪些仪表板、有关数据存储管道的信息以及各种表列的描述的详细信息。
2017年,优步从头开始重新设计了Databook(Databook2.0),以适应这些变化,因为它称赞了决策过程,并帮助推导出有意义的商业见解。更新后的Databook具有响应式用户界面,并针对新的数据需求改进了功能。
优步在Databook中添加了更多关于其数据收集策略的信息。他们引入了Querybuilder,一种搜索和发现优步数据库的前端功能,以及Dashbuilder,这是一种高级元数据可视化工具,可以帮助用户学习和更好地理解数据关系。
优步Databook架构
最初的Databook架构专注于搜索数据集、呈现描述和所有者的基本系统,当他们的数据格局开始在数量和复杂性上蓬勃发展时,这远远不够。
本节讨论了帮助重新设计、重新评估和重建Databook体系结构的原则。基于这些原则,我们将讨论Databook2.0的各种体系结构组件。
Databook体系结构原理
Databook设计原则是重要的指导方针,有助于为重组战略奠定坚实的基础。其中包括:
- 元数据的意义很重要
- 真正可扩展的数据模型
- 集中式元数据系统与去中心化元数据系统
- 关注用户体验
- 数据实体之间关系的重要性
元数据的意义很重要
随着数据实体和元数据来源的增加,数据文档变得不一致。为了更好地管理元数据,开发了一种名为Dragon的模式生成工具,该工具有助于构建和维护一致的元数据词汇表。
真正可扩展的数据模型
第一个Databook将元数据限制在特定的数据集,而忽略了仪表板和业务指标等非数据集源。在一个模型中添加不同的数据条目会损害其清晰度和可理解性。优步建立了一个灵活且可扩展的数据模型,以插入具有不同元数据的数据实体,而不是将它们拟合到预定义的数据模型中。
集中式元数据系统与去中心化元数据系统
随着元数据源的增加,复制具有类似用例的元数据系统是不利的。优步开发了一个用于处理所有元数据源和数据实体的集中式系统。
关注用户体验
优步鼓励其开发人员、分析师和数据本最终用户就改进数据本功能提供反馈。基于用户体验,优步精简了元数据接收管道,并改进了Databook UI,以实现更好的元数据发现。
数据实体之间关系的重要性
优步应用程序中的数据从Kafka到Hive等不同路线流入。向系统中添加更多的数据实体增加了这些路由的复杂性。优步使用Graph数据结构来准确地表示这些复杂数据实体之间的关系。
优步Databook功能
根据上面讨论的五个原则,Databook 2.0体系结构衍生出以下功能:
- 元数据关联的标准词汇
- 可扩展的数据模型,以适应不同的元数据及其各自的关系
- 通过Databook UI和API改善用户体验
优步Databook的组成部分
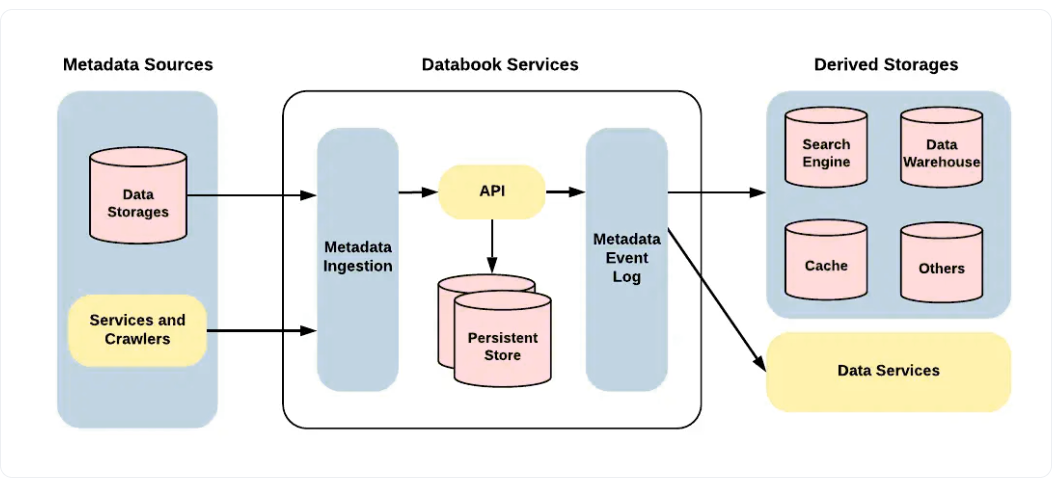
优步接收来自各种输入源的数据,这些数据经过处理并存储在多个数据存储库中。Databook 2.0添加了各种元数据源、存储单元、摄取机制和事件日志,以管理大量传入数据,并为优步的进一步数据服务提供燃料。以下是组成部分:
- 元数据源
- 元数据摄入
- 永久存储
- 元数据事件日志
- 派生存储器
每个Databook组件的详细描述如下:
元数据源
优步使用存储在各种存储单元中的数据实体进行操作,如Hive、Cassandra、MySQL、Vertica等。Databook有一个灵活的框架来支持许多用例,以调整数据存储系统或提供输入的网络爬虫中的数据实体。Databook使用统一的输入过程和标准化的API来确保可扩展性。
元数据摄入
不同的团队成员需要通过访问元数据源来执行各种任务。元数据接收过程有助于组织成员的数据,并使用更改的所有详细信息和历史记录更新事件日志。
永久存储
MySQL用于保存数据的整个轨迹和相关的关系。它为Databook体系结构提供了灵活性、可访问性和可扩展性。ElasticSearch还用于改进索引和加快元数据搜索。
元数据事件日志
在获取元数据之后,转换的详细信息会列在Kafka的事件日志中。这些数据有助于审核、重建存储库和触发各种任务。事件日志跟踪数据本活动并实时更新更改。
派生存储器
派生存储使用元数据事件日志来帮助各种用例和需求。优步捕获了由不同存储单元维护的基本元数据,因为单个存储库无法管理不同的模式和数据需求。
Databook用例
通过重新设计的架构,优步改进并启用了Databook的以下用例:
发现
优步用户经常在Databook上搜索与其工作场所相关的数据实体或该组织的其他流行数据条目。优步引入了有组织的数据实体表示,以改进Databook接口。在跟踪用户的活动和偏好后,优步增加了一项功能,可以推荐他们感兴趣的实体。搜索引擎经过优化,可以智能地解释关键词并产生相关结果。
理解
在引导用户进行搜索后,优步团队希望继续前进,帮助他们了解有关数据的复杂细节。通过添加更多关于数据实体的信号,如使用分析、数据质量和隐私指标,重新设计了Databook架构。
Databook web UI使用红绿灯指示器表示来显示资产的数据质量或状态。红绿灯信号颜色有助于通知用户资产的可用性或异常的存在。
管理
用不同的数据实体和元数据源扩展数据模型使系统过载。优步希望简化沟通渠道,直接联系数据提供商,询问问题并提供反馈。
优步建立了一个界面,在一个页面上处理所有数据实体,用户可以在其中发布问题并报告问题。为数据手册用户提供了基于知识的表示,而不是基于wiki的模型来管理数据实体。该接口在后端跟踪问题,并将查询路由到可用的成员。
优步Databook是开源的吗?
优步Databook不是一个开源的元数据编目工具。Databook是优步的内部平台,其代码库不会在GitHub上公开共享。
然而,Databook架构设计及其完整的重组过程细节是公开的。它为有兴趣构建开放数据目录软件的组织提供了指南。
结论
本文讨论了Databook,这是优步为满足其不断增长的数据发现、探索和管理需求而构建的元数据目录。我们已经介绍了Databook的组件、设计原则和基本功能,这些功能可以让您深入了解Databook的工作原理。
有兴趣了解其他大型科技公司是如何管理其不断发展的数据需求的?深入研究这个顶级开源数据目录软件列表。
此外,如果你想为自己的团队部署数据目录,你可能想看看Atlan,这是一个第三代数据目录,它是对传统软件的飞跃,建立在最好的开源基础上。
- 121 次浏览
【数据目录】IBM数据目录介绍
视频号
微信公众号
知识星球
数据目录利用元数据和数据管理工具在组织内创建数据资产清单,使用户能够快速方便地查找和访问信息。
数据目录
数据目录是组织中所有数据资产的详细清单,旨在帮助数据专业人员快速找到最适合任何分析或业务目的的数据。
什么是数据目录?
数据目录使用描述或汇总数据的元数据数据来创建组织中所有数据资产的信息丰富且可搜索的清单。这些资产可以包括(但不限于)以下内容:
- 结构化(表格)数据
- 非结构化数据,包括文档、网页、电子邮件、社交媒体内容、移动数据、图像、音频和视频
- 报告和查询结果
- 数据可视化和仪表板
- 机器学习模型
- 数据库之间的连接
该清单使数据公民、数据分析师、数据科学家、数据管理员和其他有权访问公司数据的数据专业人员能够搜索组织的所有可用数据资产,并帮助自己获得最适合其分析或业务目的的数据。
数据目录通常包括收集和不断丰富或管理与每个数据资产相关联的元数据的能力,以便使每个资产更容易识别、评估和正确使用。该目录还提供了使用户能够执行以下操作的工具:
- 搜索目录
- 自动发现他们没有专门搜索的潜在相关数据
- 按照行业或政府法规管理数据的使用
什么是元数据?
在上述简要定义的基础上,元数据是描述数据资产或提供有关资产的信息的数据,使其更容易定位、评估和理解。
元数据的经典或最常用的例子是图书馆的卡片目录或在线目录。在这些卡片或清单中,每个卡片或清单都包含有关书籍或出版物的信息(例如,标题、作者、主题、出版日期、版本、图书馆内的位置以及摘要或简介),这些信息使读者更容易找到和评估出版物。例如:它是最新的还是过时的?它有我要找的信息吗?作者是我信任的人还是我喜欢他的作品?
元数据有很多类,但数据目录主要处理三类:技术元数据、流程元数据和业务元数据。
技术元数据
技术元数据(也称为结构元数据)通过描述数据对象(如表、列、行、索引和连接)的结构来描述如何组织数据并向用户显示数据。技术元数据告诉数据专业人员他们需要如何处理数据,例如,他们是否可以按原样处理数据,或者是否需要转换数据以进行分析或集成。
流程元数据
流程元数据(也称为管理元数据)描述了数据资产创建的情况,以及何时、如何以及由谁访问、使用、更新或更改数据资产。它还应该描述谁有权访问和使用这些数据。
流程元数据提供了有关资产历史和谱系的信息,可以帮助分析师确定资产是否足够新,是否来自可靠的来源,是否由值得信赖的个人更新,等等。流程元数据还可以用于解决查询问题。而且,越来越多的流程元数据被挖掘,以获取有关软件用户或客户的信息,例如他们正在使用什么软件以及他们正在体验的服务级别。
业务元数据
业务元数据(有时称为外部元数据)描述了数据资产的业务方面、它对组织的业务价值、它对特定目的或各种目的的适用性、有关法规遵从性的信息等等。业务元数据是数据专业人员和业务线用户对数据资产使用相同语言的地方。
数据目录至少应该使您能够轻松查找(或获取)和组织与组织中任何数据资产相关的所有现有元数据。它还应该提供工具,使数据专家能够通过标签、关联、评级、注释以及任何其他信息和上下文来策划和丰富元数据,帮助用户更快地找到数据并放心地使用它。
数据目录工具---寻找什么
数据目录需要在软件和数据公民的时间和精力上进行大量投资——大多数组织只想进行一次投资。在评估数据目录解决方案时,请查找以下功能(除了上述元数据管理功能外):
- 出色的数据“购物”体验,包括数据发现:数据目录的目标是让所有数据公民都能为自己提供所需的数据。你应该期待与Netflix、亚马逊或其他流行的商业在线体验相同的搜索体验,任何人都可以根据搜索的元数据快速找到结果,还可以根据其他用户的评分和评论收到相关的推荐和/或警告。
- 简化了合规性:保持数据合规几乎是人类不可能做到的;在撰写本文时,仅保护个人数据隐私一项,就有107个国家颁布了相关法规。数据目录应通过分析数据资产,推断其与特定法规的相关性,并自动对其进行分类和标记以供将来参考,从而简化法规遵从性。机器学习功能在这里是强大的工作保护程序。
- 与各种数据源的连接:为了作为企业范围的数据资产清单,数据目录需要连接到企业中的所有资产。寻找与你现在拥有的所有类型资产的联系,并致力于建立未来的联系。此外,还要寻找一个目录,您可以将其部署到数据驻留在本地或公共、私有、混合或混合多云环境中的任何位置。
- 支持确保数据可信的质量和治理:数据目录应与您现有的任何质量和治理程序和工具无缝集成,包括数据质量规则、业务术语表和工作流。
- 支持“可解释的人工智能”:数据治理越来越多地负责管理人工智能(AI)模型,不仅要了解所使用的数据,还要了解不同的输入如何影响决策和结果。确保您选择的任何数据目录都有助于标记和准备数据资产,以便在您的人工智能模型中实现最佳使用和透明度。
数据目录优势
当数据专业人员可以在没有IT干预的情况下帮助自己获得所需的数据,而不必依赖于寻找专家或同事的建议,不必将自己局限于他们所知道的资产,也不必担心治理和法规遵从性时,整个组织都会受益。
- 通过改进上下文更好地理解数据:分析师可以找到数据的详细描述,包括其他数据公民的评论,并更好地了解数据与业务的相关性。
- 提高了运营效率:数据目录在用户和IT数据之间创造了最佳分工。公民可以更快地访问和分析数据,IT员工可以花更多时间专注于高优先级任务。
- 降低风险:分析师更有信心使用他们被授权用于特定目的的数据,遵守行业和数据隐私法规。他们还可以快速查看注释和元数据,以发现可能影响分析的空字段或错误值。
- 数据管理计划取得更大成功:数据分析师越难发现、访问、准备和信任数据,商业智能(BI)计划和大数据项目就越不可能成功。
- 更好的数据和更好的分析,更快地获得竞争优势:数据专业人员可以根据组织内所有最合适的上下文数据,通过分析和回答,快速应对问题、挑战和机遇。
数据目录还可以帮助您的组织满足特定的技术和业务挑战以及目标。通过为分析师提供单一、全面的客户视图,数据目录可以帮助发现交叉销售、追加销售、定向促销等新机会。通过促进、简化或自动化治理,数据目录可以帮助您实施数据湖治理,防止数据沼泽,并为设计、部署和监控人工智能模型提供政策框架,重点关注公平性、问责制、安全性和透明度。
数据目录和IBM云
IBM Watson知识目录是一个开放和智能的数据目录,用于企业数据和人工智能模型治理、质量和协作。它可以帮助数据公民快速发现、整理、分类和共享数据资产、数据集、分析模型,以及他们与组织其他成员的关系。
Watson Knowledge Catalog为IBM Cloud Pak for Data提供支持,为数据工程师、数据管理员、数据科学家和业务分析师提供了一个单一的真相来源,让他们能够自助访问他们可以信任的数据。它还提供数据治理、数据质量和主动策略管理,以帮助您的组织保护和管理敏感数据、跟踪数据谱系、管理数据湖,并为您的人工智能之旅做好准备。
- 83 次浏览
【数据目录】Lyft Amundsen数据目录:开源数据发现工具
视频号
微信公众号
知识星球
什么是Amundsen数据目录?
Amundsen是Lyft开发的一个数据发现平台和元数据引擎,旨在解决数据科学家、工程师和研究人员在典型工作流程中面临的常见痛点。
阿蒙森由Lyft工程团队土生土长,以挪威探险家罗尔德·阿蒙森的名字命名,他因领导第一次成功的南极探险而闻名。
阿蒙森将Lyft的数据科学家、分析师和研究人员的生产力提高了约20%
Lyft为什么要建造Amundsen?
Lyft报告称,2021年第一季度的活跃骑手基数为1349万。现在,想象一下,这个数字反过来会产生大量的数据来存储、处理和分析,还有大量的人可能每天都在使用这些数据来做出明智的决定。
在Lyft这样一家基本上现代的数据驱动公司,每一次互动都是由数据驱动的,如果数据团队没有能力高效地使用这些数据,就不可能可持续地扩展。
Lyft认识到了这一挑战,并开发了Amundsen,他们于2019年4月推出了该产品,以解决数据发现难题。
Lyft创造了阿蒙森,使其能够
- 从所有不同的数据源捕获元数据
- 生成数据在其生命周期中如何演变的可见性(通过元数据)
- 通过前端与用户共享此元数据,使他们能够发现、信任和使用数据。
Amundsen数据目录是开源的吗?
Amundsen于2019年10月开源,一年前在Lyft投入生产,并根据Apache许可证2.0版获得许可。许可证的副本可以在这里找到。以下是管理许可证的权限、限制和条件的汇总。
Amundsen was donated to Linux Foundation AI in July 2020.
Amundsen据目录是如何工作的?
阿蒙森数据目录主要致力于让用户能够发现、信任和理解他们的数据。阿蒙森的各种特征共同作用,实现了同样的目的。以下是阿蒙森的主要能力:
- 轻松发现可信数据
- 自动化和精心策划的元数据
- 能够与同事共享上下文
- 从数据使用中学习和理解
轻松发现可信数据
阿蒙森通过简单的文本搜索帮助查找组织内的数据。搜索结果在一定程度上显示了内联元数据,其中包括数据的描述以及数据更新的最后日期。受页面排名启发的算法返回受欢迎程度排名和推荐——查询量高的表会被提升到更高的位置以供考虑,而使用量最小的表会在稍后的结果中填充。

自动化和精心策划的元数据
当点击数据资产时,会向用户显示其详细描述和行为。详细描述包括用户手动整理的信息。有关数据行为的信息是通过浏览审计日志生成的。通过设计,鼓励用户使用基于受欢迎程度的列级数据。用户还可以看到受欢迎的用户和数据的一般概况。
能够与同事共享上下文
人们可以更新对数据资产的描述,从而减少在特定数据资产中寻找更多上下文的同事之间的来回交流——例如,用描述更新表和列可以为数据用户提供关于哪个表最适合特定查询以及该表中哪个特定查询特别感兴趣的必要信息。
从数据使用中学习和理解
用户可以查看哪些数据资产被频繁使用、拥有或添加书签。通过查看在给定表上构建的仪表板,甚至可以理解表的最常见查询。这被归类为行为元数据,并且是自动策划的。
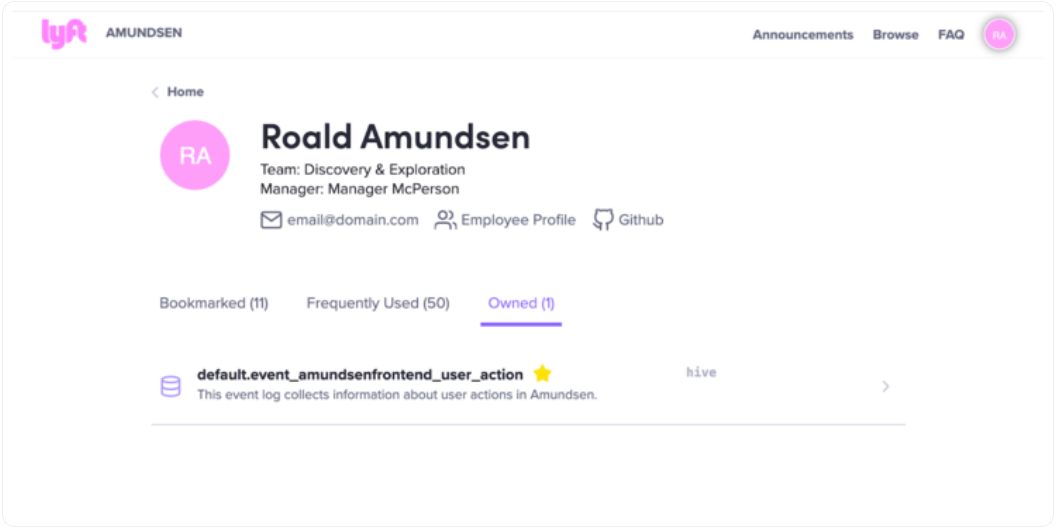
Lyft Amundsen架构
Lyft的Amundsen由五个主要组件组成,并遵循微服务架构:
- 元数据服务:能够处理来自前端服务和微服务的请求
- 搜索服务:支持弹性搜索
- 前端服务:承载web应用程序
- 数据构建器:从各种来源提取元数据的摄入框架
- 公共组件:保存微服务之间公共代码的库存储库
元数据服务
能够处理来自前端服务和微服务的请求。从本质上讲,元数据通过前端服务公开给最终用户,也用于Lyft的其他服务。值得注意的是,元数据实体目前在阿蒙森上建模为图形,这使得在生成更多实体时更容易扩展模型。
搜索服务
由Elastic搜索支持-搜索服务提供API,将资源索引到搜索引擎中,并通过前端服务为最终用户的搜索查询提供服务。目前,阿蒙森支持以下类型的搜索:
- 普通搜索:指定特定术语和资源术语的搜索
- 类别搜索:过滤的资源如果搜索词与元数据类别匹配,则在提供结果时会考虑相关性
- 通配符搜索:用户可以对不同的资源进行通配符搜索
前端服务
承载web应用程序。它由两个不同的部分组成:
- 用于编写用户界面的React应用程序
- 充当元数据或搜索服务请求中介的Flask服务器
数据生成器
ETL Ingestion框架从各种来源提取元数据。据说它受到了阿帕奇哥布林的高度启发。数据生成器的每个组件都是高度模块化的。组件包括:
- Extractor
- Transformer
- Loader
- Publisher (optional)
通用组件
Amundsen微服务的公共代码库
Lyft的数据发现民主化
Lyft有750名数据用户使用Amundsen。
数据团队多种多样。数据工程师、数据科学家、分析师、产品经理和高管都在寻找数据来处理和做出明智的决策。当每个寻找数据资源的人都确切地知道系统中有哪些可用数据以及如何使用这些数据时,真正的民主化是可能的,但这也可能对数据隐私和安全带来挑战。阿蒙森试图通过将元数据分为两组来平衡民主化和安全:
基本元数据
基本元数据,如表和字段的名称和描述、所有者、上次更新等,对所有人都可见。这使用户能够发现它的存在,并了解它是否适合他们的查询。
更丰富的元数据
更丰富的元数据,如列统计数据、预览等,仅对有数据访问权限的用户可用。如果人们确信更丰富的元数据适合他们,他们也可以请求访问这些元数据。
Lyft Amundsen关键链接
- Lyft Amundsen Website
- Lyft Amundsen GitHub
- Experience Amundsen hands-on: Access a sandbox environment loaded with sample data
Mail Lists:
让您开始使用Amundsen的资源:
- Amundsen demo: Take a test drive and get a feel for how the Amundsen data catalog works. Get access to a sandbox instance populated with sample data.
- Amundsen setup: We will guide you through the steps required to configure and install Amundsen.
- A step-by-step walk-through of setting up Amundsen data lineage with dbt
区别是什么:比较开源数据发现工具
- Learn more about how Amundsen compares with other open source data catalog and metadata tools:
- Lyft Amundsen Vs. Linkedin DataHub: A deep dive into how Amundsen and DataHub compare in terms of architecture, metadata ingestion, ease of deployment, and core data discovery features.
- Lyft Amundsen Vs. Apache Atlas: Read more about how Amundsen and Apache Atlas compare and contrast in data discovery, data catalog, and data lineage features.
- Understanding AWS Glue data catalog: Architecture, components, and crawlers
了解有关数据目录的详细信息:
- Evaluating a data catalog? Here are the 5 essential features to look for in a modern data catalog
- Data Catalog: The Must-Have Tool for Data Leaders in 2023
- What are the benefits of a data catalog? 5 key reasons why you need one
- Data catalogs are going through a paradigm shift! Here is everything you need to know about the Third-Generation Data Catalog.
- Learn more about Atlan: The pioneering third-generation data catalog for modern data teams.
Amundsen在Lyft中被广泛采用,并拥有一个由扩展和使用它的个人和组织组成的有凝聚力的社区。然而,与任何其他开源工具一样,它是由工程师和工程师制作的,因此设置起来相当技术化。
- 292 次浏览
【数据目录】Netflix的Metacat:用于数据发现的开源联邦元数据服务
视频号
微信公众号
知识星球
Metacat作为Netflix支持的所有数据存储的真实性和元数据访问层的单一来源。
什么是Metacat?
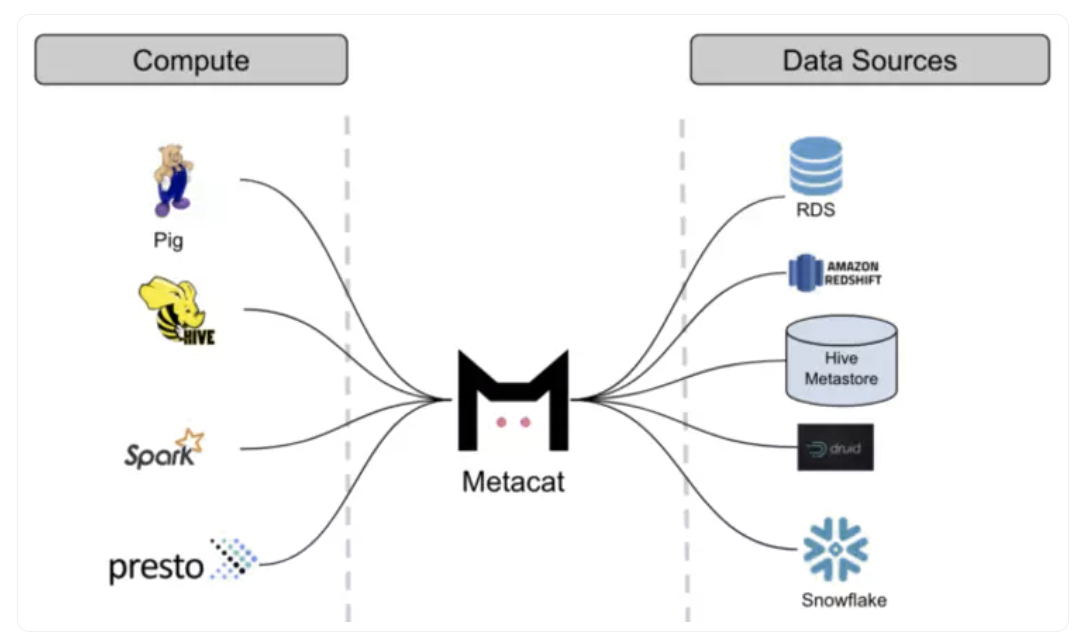
Metacat是一个在Netflix上构建的联邦服务,提供了一个统一的REST/Trift接口来访问其各种数据存储的元数据。它试图使数据易于发现、处理和管理。
Metacat有三个主要目标:
- 所有元数据系统的联合视图
- 统一的API可从各种来源访问元数据
- 针对数据集的任意业务和用户元数据存储的解决方案
 A centralized service that all compute engines could use to access the different data sets. Image source:
A centralized service that all compute engines could use to access the different data sets. Image source:
Netflix为什么要建立Metacat?
数据,而不是元数据,可能是Netflix作为一家公司最有价值的战略资产,它为他们所做的一切提供动力。从手表推荐到根据用户口味变化的缩略图,无所不包。因此,在一段时间后,处理如此庞大的大数据成为一项挑战,这是很自然的。
Netflix运营的庞大数据池分布在多个平台上,如Amazon S3、Druid、Redshift和MySql等。Netflix构建了Metacat,以保持所有平台的无缝互操作性。
Joris Evers在2013年表示,Netflix大约有3300万个不同版本,当时全球有3300万订户。2021年初,他们拥有超过2.03亿付费用户!
Metacat在Netflix的数据基础设施中的地位如何?
Metacat填补了Netflix数据堆栈中的一个重要空白,介于他们的PIG ETL系统和Hive之间。它提供了一个统一的API来发现和访问Netflix生态系统中各种数据源(如Amazon S3、Druid、Redshift和MySql)的元数据。
Netflix的数据架构有三个主要服务:执行服务、元数据服务(Metacat)和事件服务。
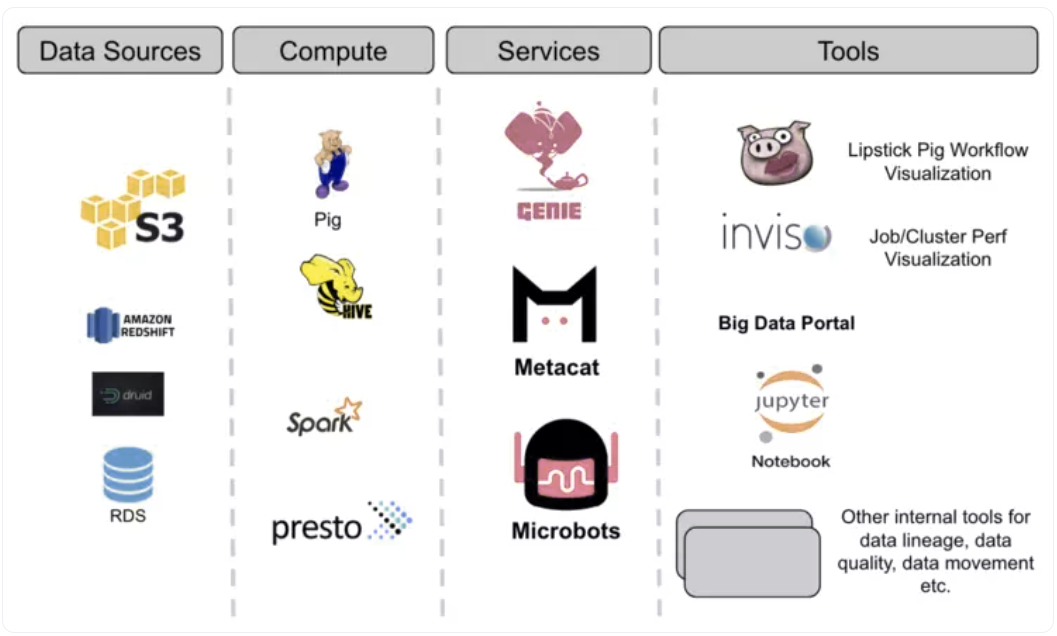
Metacat的功能是什么?
Metacat功能可以简单地分类如下:
- 数据抽象和互操作性
- 业务和用户定义的元数据存储
- 数据发现
- 数据更改审核和通知
数据抽象和互操作性
Metacat表现为一个通用的抽象层,因此可以通过Netflix使用的多个查询引擎(Pig、Spark、Presto和Hive)访问数据集。
业务和用户定义的元数据存储
Metacat有助于记录有关数据资产的业务和用户定义的元数据。从而确保为数据用户提供数据资产中的更多信息,以及如何处理这些信息的标准规则。
数据发现
Metacat通过Elastic Search返回模式元数据和业务/用户定义元数据,这有助于通过文本搜索进行查询。还启用了自动完成、自动建议和标签,以便更快地识别感兴趣的数据。
数据更改审核和通知
任何元数据更改或更新都由Metacat捕获。对于可能需要数据管理员、生产者和消费者注意的此类事件,将启用推送通知。

Metacat是您的数据堆栈中缺失的部分吗?
Metacat是开源的,并且正在不断增强,但它可以高度定制Netflix的数据堆栈和管道,并且没有任何可用的公共文档。其他第三方使用Metacat构建自己的元数据引擎和数据发现平台的信息也不多。
如果你也在考虑是否为你的团队构建或购买数据目录和发现平台,你可能想尝试像Atlan这样的现成工具,它们具有Metacat、Atlas或Amundsen等开源工具的所有功能和复杂性,但所有数据用户都可以轻松使用,而不仅仅是工程师。
Netflix Metacat:相关阅读
- Evaluating a data catalog? Here are the 5 essential features to look for in a modern data catalog
- Open-source data catalog software: 5 popular tools to consider in 2023
- 5 popular open-source data lineage tools in 2023
- Data catalogs are going through a paradigm shift! Here is everything you need to know about the Third-Generation Data Catalog.
- Learn more about Atlan: The pioneering third-generation data catalog for modern data teams.
- 405 次浏览
【数据目录】OpenMetadata与DataHub:比较架构、功能、集成等
视频号
微信公众号
知识星球
OpenMetadata和DataHub是目前最流行的两种开源数据编目工具。这两种工具在功能上有很大的重叠,但它们也有一些区别。在这里,我们将根据这两种工具的架构、接收方法、功能、可用集成等对其进行比较。
什么是OpenMetadata?
OpenMetadata是创建Databook以解决优步数据编目问题的团队学习的结果。OpenMetadata查看了现有的数据编目系统,发现难题中缺少的部分是统一的元数据模型。
除此之外,他们还增加了元数据的灵活性和可扩展性。尽管如此,因为它在市场上的新颖性;其可靠的数据治理引擎,以及强大的搜索引擎的支持,OpenMetadata引起了人们的极大关注。
点击此处阅读更多关于OpenMetadata的信息。
什么是DataHub?
DataHub是领英解决数据发现和编目问题的第二次尝试;他们早些时候开源了另一个工具,名为WhereHows。
在第二次迭代中,领英通过创建作为DataHub骨干的通用元数据服务,解决了拥有多种数据系统、查询语言和访问机制的问题。
点击此处了解更多关于DataHub的信息。
OpenMetadata和DataHub之间有什么区别?
让我们根据以下标准比较OpenMetadata和DataHub:
- 架构和技术堆栈
- 元数据建模和接收
- 数据治理能力
- 数据沿袭
- 数据质量和数据分析
- 上游和下游集成
我们策划了上述标准,以在这些工具之间进行比较,了解了解哪些是至关重要的,尤其是如果您要选择其中一个作为元数据管理平台,为您的组织提供特定的用例。
让我们详细考虑这些因素中的每一个,并澄清我们对它们的理解。
OpenMetadata与DataHub:架构和技术堆栈
DataHub使用Kafka介导的摄取引擎将数据存储在三个独立的层中——MySQL、Elasticsearch和neo4j,使用 Kafka stream。
这些层中的数据通过API服务层提供。除了标准REST API之外,DataHub还支持Kafka和GraphQL用于下游消费。DataHub使用带有自定义注释的Pegasus定义语言(PDL)来存储模型元数据。

High level understanding of DataHub architecture. Image source: LinkedIn Engineering
OpenMetadata使用MySQL作为数据库,将所有元数据存储在统一的元数据模型中。元数据是完全可搜索的,因为它由Elasticsearch提供支持,与DataHub相同。OpenMetadata不使用专用的图形数据库,但它使用JSON模式来存储实体关系。
使用OpenMetadata的系统和人员可以直接或通过UI调用REST API。要了解有关数据模型的更多信息,请参阅解释OpenMetadata高级设计的文档页面。
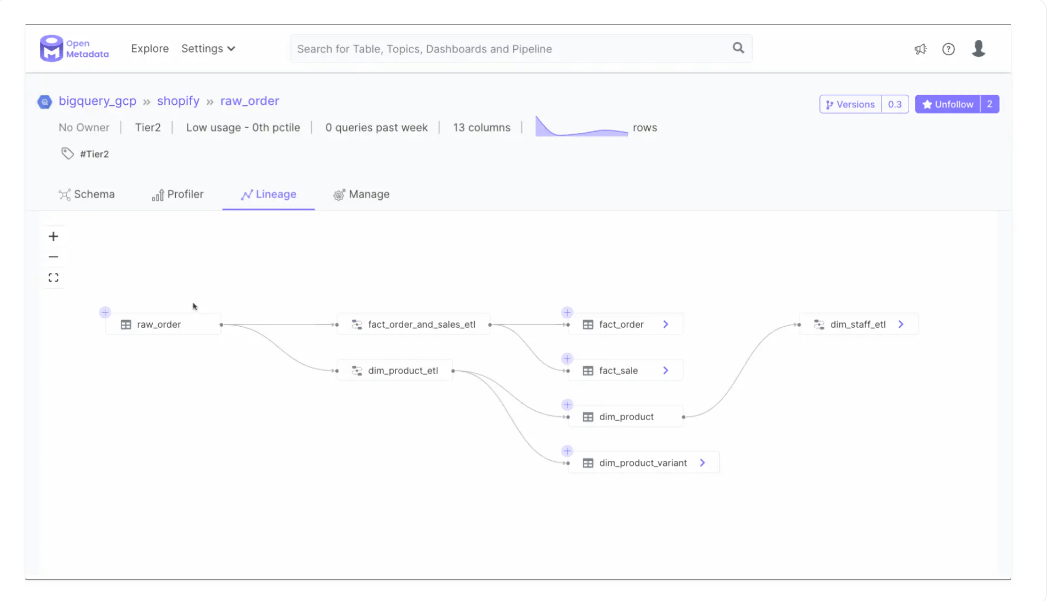
OpenMetadata与DataHub:元数据建模和接收
这两种工具的主要区别之一是,DataHub专注于基于拉和推的数据提取,而OpenMetadata显然是为基于拉的数据提取机制而设计的。
默认情况下,DataHub和OpenMetadata主要使用基于推送的提取,尽管不同之处在于DataHub使用Kafka,而OpenMetadata使用Airflow来提取数据。
DataHub中的不同服务可以从Kafka中过滤数据并提取所需内容,而OpenMetadata的Airflow将数据推送到下游应用程序的API服务器DropWizard。
这两种工具在存储元数据的方式上也有所不同。如前一节所述,DataHub使用带注释的PDL,而OpenMetadata使用带注释基于JSON模式的文档。
OpenMetadata与DataHub:数据治理功能
在今年早些时候的一次发布中,DataHub集成了他们所称的行动框架,为数据治理引擎供电。Action Framework是一个基于事件的系统,允许您出于可观察性的目的触发外部工作流。数据治理引擎会自动注释新的和已更改的实体。
OpenMetadata和DataHub都内置了基于角色的访问控制,用于管理访问和所有权。
OpenMetadata引入了一些其他概念,如重要性,以通过附加上下文提供更好的搜索和发现体验。DataHub使用一种称为Domains的结构作为常用标签和术语表术语之上的高级标签,为您提供更好的搜索体验。
OpenMetadata与DataHub:数据沿袭
随着DataHub的最新发布,它现在能够支持列级数据沿袭。OpenMetadata预计将于2022年11月中旬发布,它还承诺增强列级沿袭。
OpenMetadata的Python SDK for Lineage允许您使用用于存储沿袭数据的entityLineage架构规范从数据源实体获取自定义沿袭数据。
除了自动沿袭捕获之外,DataHub还提供了从名为“基于文件的沿袭”的数据源将沿袭数据作为文件摄取的功能。DataHub使用此处指定的基于YAML的沿袭文件格式。
OpenMetadata与DataHub:数据质量和数据分析
尽管DataHub不久前就有一些与数据质量相关的功能的路线图项目,但它们还没有实现。然而,DataHub确实提供了与 Great Expectations和 dbt等工具的集成。您可以使用这些工具来获取元数据及其测试和验证结果。
看看这个在DataHub上运行的Great Expectations演示。
OpenMetadata对质量有不同的看法。他们已经将数据质量和分析集成到该工具中。由于有许多用于检查数据质量的开源工具,因此有许多方法可以定义测试,但OpenMetadata选择在定义测试的元数据标准方面支持Great Experiences。
如果Great Experiences已经与您的其他工作流集成,并且您更希望将其作为您的中央数据质量工具,那么您可以通过OpenMetadata的Great Experences集成实现这一点。
OpenMetadata与DataHub:上游和下游集成
DataHub和OpenMetadata都有一个基于插件的元数据摄取架构。这使它们能够与数据堆栈中的一系列工具顺利集成。
DataHub提供了一个GraphQL API、一个Open API和几个SDK,供您的应用程序或工具开发和与DataHub交互。此外,您可以使用CLI来安装所需的插件。这些与DataHub交互的各种方法允许您将数据摄入DataHub,并将数据从DataHub中取出以供进一步消费。
OpenMetadata支持50多个连接器来获取元数据,从数据库到BI工具,从消息队列到数据管道,包括其他元数据编目工具,如Apache Atlas和Amundsen。OpenMetadata目前提供两种集成-Great Experiences和Prefect。
OpenMetadata与DataHub:比较摘要
DataHub和OpenMetadata都试图解决数据编目、搜索、发现、治理和质量方面的相同问题。这两种工具都是为拥有大量数据源、团队和用例支持的大型组织解决这些问题而产生的。
尽管这些工具在发布历史和成熟度方面有点不同,但它们的功能有很大的重叠。以下是其中一些功能的快速摘要:
| Feature | OpenMetadata | DataHub |
|---|---|---|
| Search & discovery | Elasticsearch | Elasticsearch |
| Metadata backend | MySQL | MySQL |
| Metadata model specification | JSON Schema | Pegasus Definition Language (PDL) |
| Metadata extraction | Pull and push | Pull |
| Metadata ingestion | Pull | Pull |
| Data governance | RBAC, glossary, tags, importance, owners, and the capability to extend entity metadata | RBAC, tags, glossary terms, domains, and the Action Framework |
| Data lineage | Column-level (soon) | Column-level |
| Data profiling | Built-in with the possibility of using external tools | Via third-party integrations, such as dbt and Great Expectations |
| Data quality | Built-in with the possibility of using external tools like Great Expectations | Via third-party integrations, such as dbt and Great Expectations |
如果你是数据消费者或生产者,并且希望为自己的团队部署数据编目和元数据管理,同时权衡构建与购买选项,你可能想看看Atlan,这是一个为现代数据堆栈构建的第三代数据目录。
OpenMetadata与DataHub:相关资源
- Evaluating a data catalog? Here are the 5 essential features to look for in a modern data catalog
- What are the benefits of a data catalog? 5 key reasons why you need one
- Data catalogs are going through a paradigm shift! Here is everything you need to know about the Third-Generation Data Catalog.
- Learn more about Atlan: The pioneering third-generation data catalog for modern data teams.
- 1941 次浏览
【数据目录】dbt数据目录:讨论本机功能以及与Atlan加强协作和治理的潜力
视频号
微信公众号
知识星球
dbt是一种流行的工具,可以帮助分析师和工程师更有效地转换仓库中的数据。dbt的数据目录可以帮助您在dbt模型上收集足够的元数据和信任信号。
这可以帮助下游消费者发现、信任和理解为他们准备的数据资产。
活动数据目录更进一步,甚至可以让dbt用户放心地处理dbt模型。它们提供了任何更改如何影响下游表或仪表板的完整可见性。
在本文中,我们将讨论dbt的原生数据编目功能,并概述您应该考虑将其引入堆栈以实现dbt资产的全面编目和治理的其他功能。
首先,让我们认识到拥有dbt数据目录的重要性
目录
- 编目dbt资产的重要性
- dbt数据目录的本机功能
- 部署dbt数据目录时要考虑的功能
- Atlan+dbt:弥合分析工程师和业务用户之间的差距
- dbt数据目录的底线
- Atlan+dbt实现:相关资源
编目dbt资产的重要性
与现代数据堆栈中的许多其他工具一样,dbt诞生于通过更好的组织和模板化来标准化大规模转换工作负载的模型实现的需要。然而,要充分利用dbt的潜力,对资产进行编目是关键。
为什么dbt的数据编目是不可谈判的一些原因:
- 高效的文档:对于更小、分布式和自主的团队,需要在整个组织中明确业务定义,以确保无缝协作。在这种情况下,高效的文档是至关重要的。
- 可访问和可发现的文档:在数据世界中,高效的文档不仅仅是简单的旧文本;它必须是交互式的。数据用户应该能够探索数据源、实体、关系、模型、约束、谱系等,这些都可以通过数据目录进行搜索和发现。
- 血统的自动捕获:dbt的数据目录解决方案可以自动捕获数据血统,这可以帮助分析师和工程师了解任何变化的影响,并确保下游消费者能够信任和理解为他们准备的数据资产。这有助于防止错误和不一致,提高效率,并最终提高所生成数据的质量。
dbt在其鼓励和支持的工作负载下,需要这样一个数据目录。那么,我们从哪里开始呢?让我们首先来看一下dbt的本机目录功能。
dbt数据目录的本机功能
dbt为您提供了一种自动生成数据模型文档的方法。默认情况下,dbt将此文档发布在静态网站上。您可以使用一个简单的dbs-docs-serve命令启动并运行静态文档。
本文档为您提供了以下功能:
- 搜索和发现dbt项目中的所有数据模型
- 不同实体和数据模型之间的关系
- 有关列、列类型、允许值等的详细信息。
- 任何给定实体或数据模型的SQL脚本
- dbt项目中所有数据模型的表级沿袭
让我们详细了解其中的一些功能:
数据模型中的列级详细信息
使用dbt数据目录,您可以获得所有数据库对象列的描述性表格表示,其中包含详细信息,如列描述、数据类型、列级测试、允许的值等。
例如,这里是jaffle_shop项目中订单表的Columns部分。
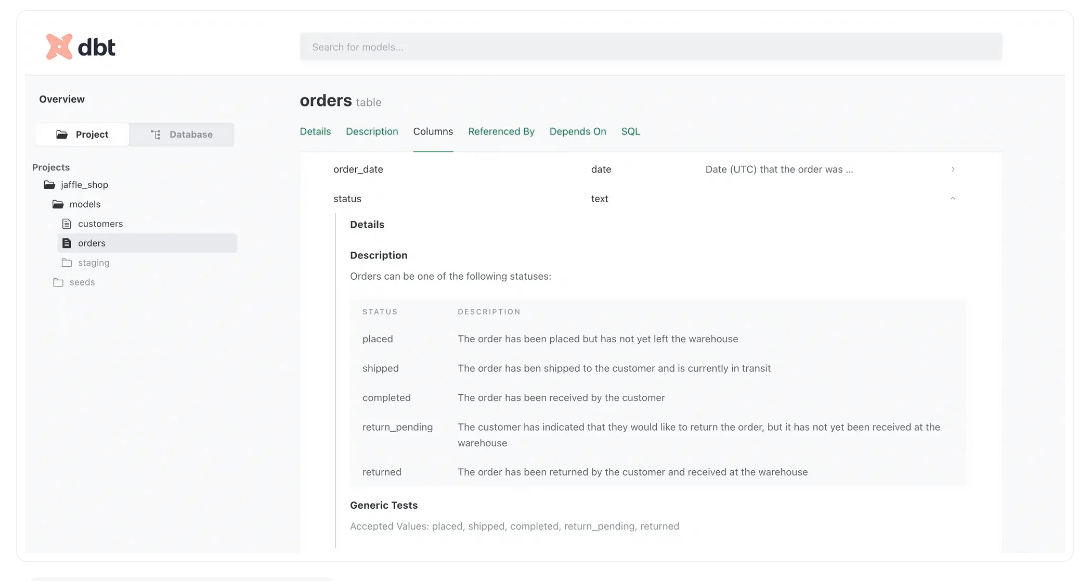
查看允许的值是如何通过描述来丰富的,这样任何阅读文档的人都可以清楚地理解该列的用途。
搜索和发现
基于菜单的导航很方便,但它仍然为许多用例留下了空间,在这些用例中,不知道数据库模式或项目结构的业务用户发现搜索他们想要的内容很有挑战性。
幸运的是,dbt允许您使用位于页面顶部的搜索栏对目录中的所有内容执行全文搜索,如下图所示:
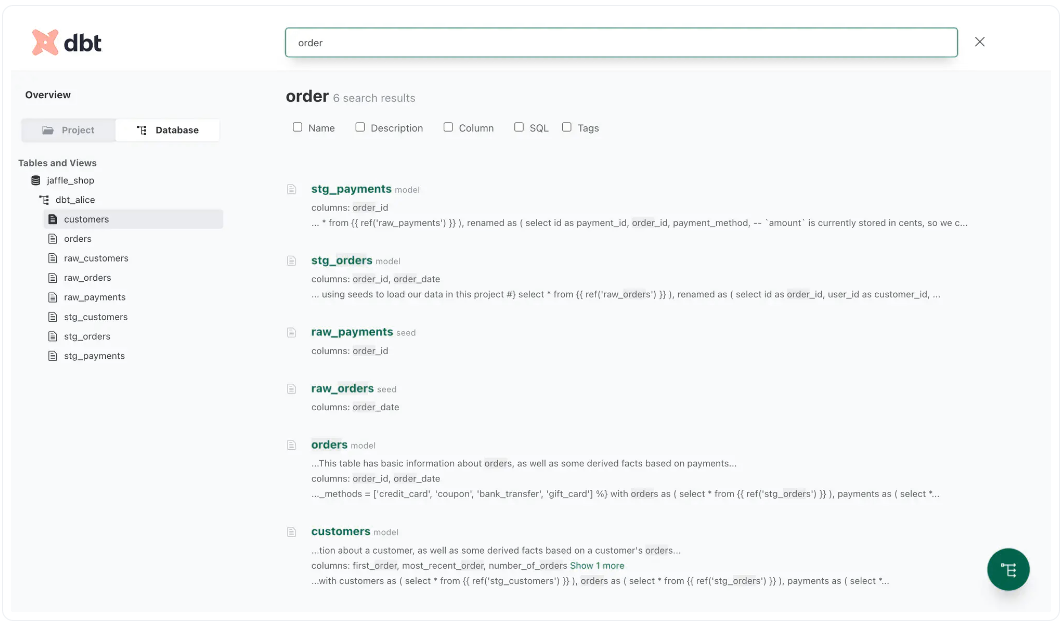
dbt提供本地搜索以发现数据资产。
搜索功能还允许您搜索特定的信息子集,如名称、描述和标记。
表级数据沿袭
最后,沿袭图是dbt数据目录的另一个重要功能。您将在文档页面的右下角看到一个圆形的绿色图标。
按下此图标后,将打开一个全尺寸弹出窗口,其中包含一个描述数据转换过程的沿袭图,如下图所示。
Understand how the data flows with dbt's table-level data lineage
数据沿袭可视化建立在依赖字段和由字段引用的基础上,dbt为基于转换工作流的每个数据模型维护这些字段。您可以通过选择要用于计算沿袭的资源来自定义沿袭图;如下图所示。
dbt的数据目录涵盖了相当多的领域,使其对开发人员和一些数据团队,尤其是dbt开发人员来说是有价值的。然而,业务团队可能需要更多关于他们正在使用的数据的信息。
在下一节中,让我们探索一些更好的编目机会,这些机会在dbt数据目录中是不可能的。
部署dbt数据目录时要考虑的功能
dbt的原生数据目录提供了一些必要的功能,如搜索和发现、表级沿袭和元数据管理。
然而,它没有涉及到关键领域,例如数据治理,这就是为什么尽管它是dbt的一个很好的补充,但它保证需要一个全面的数据编目解决方案。
在为您的dbt资产部署编目解决方案时,您必须寻找一些其他功能:
- 数据治理功能,尤其是分类、标记和关键性
- 更精细的数据沿袭功能,例如具有自定义元数据的列级沿袭
- 自动化数据编目人工智能支持的工作流、个性化和元数据管理
- 能够跨数据堆栈进行集成-从源层到消费层
- dbt数据目录和dbt工作流中其他首选工具之间的双向元数据流
- 直观的UI/UX,鼓励技术和非技术数据从业者采用
其中一些缺失的功能对于数据编目解决方案至关重要,以推动业务关键型成果的实现。
Atlan+dbt:弥合分析工程师和业务用户之间的差距
除了对dbt在数据编目方面提供的显著改进外,Atlan还通过添加最先进的数据治理、数据沿袭、搜索和发现功能来提供价值。这有助于您全面获得数据的360°视图。
一些受用户欢迎的功能包括:
- 主动数据治理
- 端到端列级沿袭
- dbt度量作为一种资产,具有自己的配置文件
- GitHub中的嵌入式影响分析
- 直接从dbt构建文档标准
- 向整个团队公开dbt文档
- 将dbt上下文引入其他工具
- 在数据消费者和生产者中实现自助服务
让我们更详细地了解Atlan的一些功能。
主动数据治理
Atlan强大的数据治理引擎不仅涵盖了dbt数据目录中缺少的所有内容。广泛的所有权和分类功能有助于整个组织的团队更高效地处理数据,同时考虑到所有的法规遵从性和管理问题。统一的权限模型允许您将dbt与其他数据源无缝集成。

端到端列级沿袭
为了获得完整的上下文和数据的360°视图,您需要了解数据是如何端到端地从一个系统流到下一个系统的。虽然dbt提供了表级数据沿袭,但这对大多数业务团队来说是不够的。
Atlan全面的列级数据沿袭功能允许您在尽可能多的上下文中以最佳级别跟踪沿袭。通过流畅的交互式用户界面,您可以在整个组织的任何系统中轻松找到绕过数据的方法。
GitHub中的嵌入式影响分析
Atlan与GitHub的集成解决了数据工程师面临的协作挑战,他们对数据资产的下游使用缺乏可见性,并急于解释每一个变化。
这种集成通过帮助数据工程师了解dbt模型中的变化如何影响上游资产,使数据治理能够更接近数据创建过程。
通过Atlan和GitHub,数据工程师可以识别资产所有者并与之合作,影响高价值资产的变更可以由利益相关者批准或不批准。Atlan为GitHub带来了沿袭,使人们很容易看到对重要数据管道所做更改的影响。每当有人打开一个更改dbt模型的拉取请求时,Atlan GitHub操作会自动创建一个将受到影响的所有下游资产的列表。
作为Atlan上的一流公民的dbt指标
Atlan与dbt语义层的集成将dbt丰富的度量引入到数据堆栈的其余部分。通过这种集成,公司指标现在是列级沿袭的一部分,从数据源和数据存储到转换和BI工具。
详细了解联合用户如何从这种集成中获益。
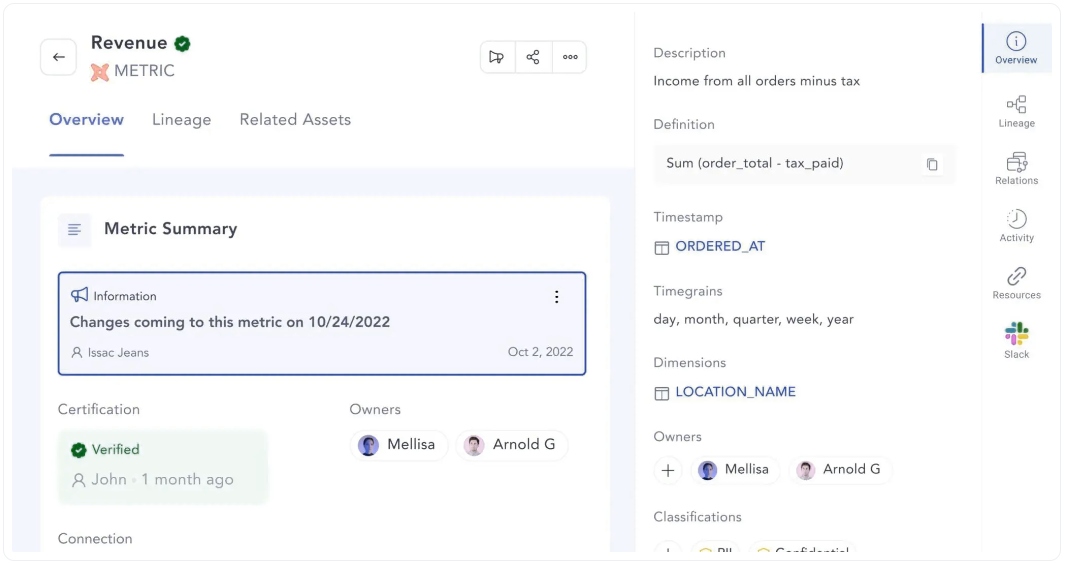
直接从dbt构建文档标准
Atlan与dbt的深度集成使您能够在dbt模型中创建可重复的元数据属性——表所有者和已验证的标记。它通过为开发人员标准化文档,为整个组织共享知识提供了基础。
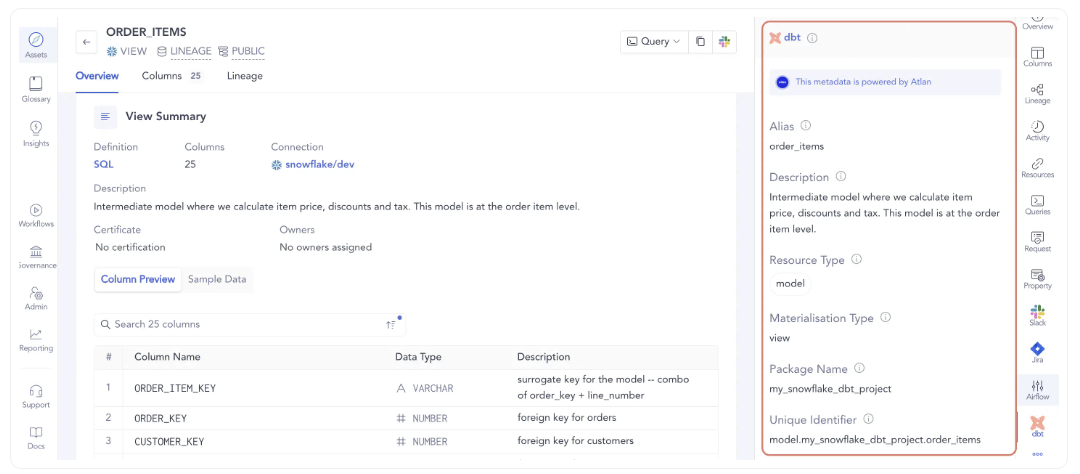
 Business glossary and data dictionary
Business glossary and data dictionary
向整个团队公开dbt文档
凭借认证、新鲜度、相关性和受欢迎程度等功能,以及类似谷歌搜索的搜索界面,Atlan增强了您的数据发现体验,为您节省了宝贵的时间来整理文档,并在电子邮件和聊天中查找信息。
 Search and discover assets through your entire data ecosystem
Search and discover assets through your entire data ecosystem
将dbt上下文带到工具中(反向元数据)
Atlan的Chrome扩展为您的工作带来了dbt元数据。如果您在BI仪表板中,则不必在dbt中搜索上下文。
在数据消费者和生产者中实现自助服务
Atlan使整个业务团队能够通过自助服务来满足他们的数据需求,这是现代数据堆栈及其迄今发展的核心功能。智能自动化、个性化和自定义元数据等功能使Atlan对每个团队来说都更加直观、灵活和有价值。
Self-service data discovery for everyone who wants to understand their business better
dbt数据目录的底线
仅仅创建数据仓库或数据湖这样的数据资产是不够的。您必须确保业务和技术团队能够看到、发现和理解数据。数据目录在实现这一目标方面发挥着重要作用。
dbt数据目录对于dbt用户来说是一个很好的内置工具,无需额外的成本或开发工作,但如果您想要一个全面的解决方案,为您提供数据治理、数据沿袭以及高级搜索和发现功能,您绝对应该试试Atlan。
Atlan+dbt实现:相关资源
- How to crawl dbt?
- What does Atlan crawl from dbt Core?
- What does Atlan crawl from dbt Cloud?
- How to add impact analysis in GitHub?
- How can I reuse my documentation from dbt?
- Data Catalog: The Must-Have Tool for Data Leaders in 2023
- Best Alation Alternative: 5 Reasons Why Customers Choose Atlan
- AI Data Catalog: Exploring the Possibilities That Artificial Intelligence Brings to Your Metadata Applications & Data Interactions
- Best Collibra Alternative — 8 Reasons Why Future-Focused Data Teams Are Choosing Atlan
- 195 次浏览
【数据目录】techtarget 数据目录介绍
视频号
微信公众号
知识星球
什么是数据目录?
数据目录是一种软件应用程序,用于创建组织数据资产清单,以帮助数据专业人员和业务用户找到相关数据用于分析。它还通过整合治理策略和控制、数据质量规则、带有通用术语的业务术语表和其他信息来帮助数据治理,以确保数据得到正确使用。
数据目录由元数据驱动,元数据是关于用于创建数据清单的数据的描述性数据。底层元数据还提供了有关数据资产的上下文信息,以帮助编目用户了解IT系统中可用的数据,并决定它是否符合他们的需求。
随着组织越来越依赖数据分析来推动业务战略和运营,数据目录的使用正在增长。目录现在是许多数据管理环境的核心组成部分,市场研究公司IDC预测,从2020年到2025年,全球数据目录软件的收入将以16.8%的复合年增长率增长。
数据目录是如何工作的?
数据目录从不同的源系统以及支持商业智能(BI)、分析和数据科学应用的数据仓库和数据湖收集元数据。内置的元数据管理功能可组织和丰富元数据,使其对最终用户有用。例如,标签可以应用于数据条目,以添加有关它们的更多信息,例如数据分类设置、数据质量分数和使用度量。越来越多的人工智能(AI)和机器学习算法被用于自动获取、编目、分类和标记元数据。
目录中的数据清单是可搜索的;通常,用户可以根据商业术语、技术名称、标签和其他关键字进行搜索,也可以通过自然语言查询进行搜索。数据目录还提供自动搜索推荐,就像常规搜索引擎一样。或者,用户可以浏览目录以查找满足其应用程序需求的数据。总的来说,目录的设计是为了唤起“数据购物”的体验。
为了帮助用户理解数据,目录包括数据沿袭的详细信息,例如数据是在哪里创建的,以及数据如何在it系统中流动并转换为不同的用途。他们还提供数据管理功能,使数据管理和分析专业人员能够为自己的应用程序或其他用户访问组织数据集。在数据条目中添加评论、评论和评级的功能通常也被嵌入,聊天功能和其他协作工具也是如此。
数据目录中收集的元数据类型
不同类型的元数据被拉入数据目录,以提供关于其中列出的数据资产的广泛信息。以下是数据目录中使用的三种主要元数据类型。
- 技术元数据。有时也称为结构元数据,它提供有关数据技术结构的信息。例如,技术元数据描述数据库和数据仓库中的模式、表、列、索引、文件名和其他对象。它还确定了数据在It系统中的位置,并记录了数据类型、数据模型和自动化数据转换脚本等内容。
- 操作元数据。这描述了如何创建、更新、更改和使用数据资产,以及何时处理或修改数据,以及谁更新或转换了数据。元数据还可以包括数据所有者和数据管理员的姓名、数据使用统计数据以及数据访问权限和限制的详细信息。它有时被称为过程元数据,尽管它也被视为专注于数据处理、管理和分析所涉及的步骤的操作元数据的子集。
- 业务元数据。这将业务上下文和意义应用于数据资产,以帮助目录用户理解它们。例如,它包括内部数据定义和相关的业务术语,例如业务词汇表中列出的术语。也可以添加其他业务关键字。数据分类、业务规则和关于创建数据的业务域的信息及其对特定用途的适用性也是业务元数据的示例。
数据目录用户和用例
数据目录由组织中的不同人员使用。在最终用户方面,包括数据科学家、其他数据分析师、数据工程师和BI团队成员,以及希望分析数据的业务分析师、高管和经理。数据管理员和数据治理团队的其他成员也使用数据目录作为管理治理过程的一部分。此外,监管合规和风险管理官员使用它们来跟踪数据资产的管理和使用情况。
以下是数据目录的一些常见用例。
- 数据发现。如上所述,数据目录的主要目的是帮助分析用户找到他们需要的数据。如果没有数据发现,数据发现可能是一个费力、耗时的过程,这也是数据科学家80%的时间都在寻找和准备数据,而只有20%的时间在分析数据这一格言的原因之一。更糟糕的是,他们可能不知道一些相关数据,这可能会降低分析的准确性。数据目录旨在简化数据发现并使其更加有效。
- 自助分析和BI。数据发现是分析过程的一个切入点。有了数据目录的帮助,数据科学家和分析师可以更容易地进行机器学习、预测建模和其他高级分析应用程序,而不需要it和数据管理团队的任何帮助。同样,业务用户能够更好地访问和分析自助BI应用程序的数据集。
- 数据治理和管理。数据目录可以帮助数据治理经理和数据管理员确保用户遵守治理策略和过程。例如,他们可以在目录中定义策略,自动化数据管理工作流,并跟踪对数据集和用户访问控制的更改。业务术语表还有助于推动有效的数据治理,内置的质量评估和监控功能可以促进相关的数据质量改进计划。
- 数据管理。通过使用数据目录来整理用于分析的数据集,数据管理器可以进一步简化分析过程,并确保包括应用程序所需的所有数据。这对重复运行的分析应用程序特别有帮助;此外,经过策划的数据集还可以用于其他目的。数据管理员是一些组织中的正式角色。在其他情况下,管理可能由各种数据专业人员处理,包括BI团队和数据科学家、分析师和工程师。
数据目录提供的好处
大多数组织都会构建一个企业数据目录来清点其所有数据资产。有些组织,尤其是大型组织,可能有多个单独部门和业务单元的数据目录。在这两种情况下,数据目录都可以提供以下好处:
- 更准确的分析。通过让用户更容易找到分析应用程序的所有适用数据,数据目录有助于提高结果的准确性。
- 更好的商业决策。改进的分析结果推动企业高管做出更明智的决策,理想情况下会导致更强有力的商业战略和运营决策。
- 生产力的提高。数据目录减少了用户查找数据的时间,使他们能够进行更多的分析工作。它还可以消除不同分析师重复的数据转换和准备任务。
- 更高质量、更可靠的数据。嵌入式数据治理、数据质量和数据安全功能有助于为分析用户创建可信的数据集。
- 改进了法规遵从性。内置的数据分类设置、访问控制和治理策略有助于提高对数据隐私法和其他法规的遵守程度。
- 提高了分析能力和业务灵活性。数据目录还使数据科学家和其他分析师能够更快地响应不断变化的业务对分析信息的需求。
数据目录的主要功能
虽然数据目录首先是数据资产的清单,但它为最终用户、数据管理和治理团队提供了一系列广泛的功能。以下项目是一些常见的数据目录功能:
- 连接到各种数据源的连接器。这些使数据目录能够从操作系统、数据仓库、数据湖和其他存储库中获取元数据。
- 元数据管理工具。数据管理团队和其他目录用户可以在元数据被纳入目录后使用这些工具来组织、分类和丰富元数据。
- 人工智能和机器学习算法。元数据收集、编目和标记现在通常通过使用内置的人工智能和机器学习技术实现自动化。
- 业务术语表。它包含业务术语和概念的内部定义,例如客户的构成,用于将它们映射到目录中列出的数据资产。
- 数据沿袭函数。它们使用目录中的元数据来记录并提供数据流、数据转换和其他有关数据的历史细节的可视化视图。
- 搜索功能。为了帮助数据发现,用户可以通过关键字或自然语言查询来搜索数据目录的内容,并获得有关相关数据的推荐。
- 协作工具。目录用户可以相互聊天和共享信息,共同处理数据工作流,并对数据资产进行评论、审查和评级。
- 集成数据治理。嵌入式工具支持数据治理过程中的各个步骤,包括数据管理、数据质量管理和数据安全。
数据目录工具和供应商
许多软件供应商提供数据目录工具,这些工具可以自动化构建和管理数据目录的过程,其中包括上述功能。以下是一些著名的供应商:
- 主要的IT供应商和云提供商,如AWS、谷歌云、IBM、微软和甲骨文;
- 拥有广泛产品组合的软件供应商,包括数据管理和治理工具,如日立Vantara和Quest software;
- 专注于数据管理和治理的供应商,如Atacama、Boomi、Collibra、Informatica和Talend;
- 数据目录和元数据管理专家,如Alation、Alex Solutions、Atlan、data.world、OvalEdge和Zeenea;和
- BI和分析软件供应商提供配套的数据目录工具,如Alteryx、Qlik、Tableau和Tibco。
咨询公司Gartner在2022年7月发布的一份关于新兴数据管理技术的报告中表示,人工智能驱动的数据目录工具——或现在所称的增强数据目录和元数据管理解决方案——正处于成熟的“早期主流”阶段。Gartner补充道,它们可能在未来两到五年内不会完全成熟。但它对这些工具对用户组织的潜在好处给予了“高”评级。
或者,组织可以使用各种开源数据目录工具。例子包括Amundsen、Apache Atlas、DataHub和Metacat。
继续阅读关于数据目录
- 为什么要考虑增强数据目录?
- 数据治理对企业的最大好处
- 成功的数据治理计划的7个最佳实践
- 数据目录提高了效率,加快了洞察速度
- 数据驱动世界中的数据目录:原因和内容
- 54 次浏览
【数据目录】人工智能数据目录:探索人工智能为您的元数据应用程序和数据交互带来的可能性
视频号
微信公众号
知识星球
人工智能数据目录在您的数据庄园中搜索元数据,然后对其进行处理,以自动化数据工作流程,并提供智能建议,丰富数据发现、探索、文档和治理。
有了人工智能数据目录,你可以在几秒钟内获得所需的所有数据和上下文,这样你就可以做出更好、更有洞察力的决策。让我们了解人工智能在数据编目中的可能性,然后探索人工智能数据编目的商业影响。
什么是人工智能数据目录?
人工智能数据目录是一种现代数据目录,它使用自动化和智能推荐来抓取、收集和处理元数据,优化数据文档、搜索、发现和探索。它能够从资产的元数据中提取上下文,帮助数据从业者多思考、少工作、提高效率。
根据Gartner的说法,人工智能数据目录“自动化了数据编目中涉及的各种繁琐任务,包括元数据发现、摄入、翻译、丰富,以及元数据之间语义关系的创建。”
对于被视为人工智能数据目录的数据目录,它应该:
- 为数据文档提供自动建议-业务词汇表、数据资产描述、自述文件
- 建议您可以询问的有关数据的问题
- 自动完成和编写SQL查询,增强现有查询脚本并修复错误,以便每个人都可以探索数据集
- 支持整个数据庄园的自然语言搜索
- 搜索数据时推荐类似资产
- 自动建议和更新数据标签,以便您可以轻松地对数据进行大规模分类
- 运行自动质量检查,并在资产或管道出现问题时提醒合适的人员
人工智能的世界在不断发展,创新方面的突破每天都在取得。例如,微软最近在OpenAI上投资了100亿美元,GitHub推出了一款名为Copilot的配对编程AI,文本和图像处理聊天机器人GPT-4现在也可以使用了。人工智能的这些令人难以置信的进步开辟了新的可能性,并显示了人工智能在改变和革命各种工作流程方法方面的潜力。
因此,人工智能如何改变你的数据编目体验的可能性也是无穷无尽的。
为什么你需要关心你的数据目录是否具有人工智能功能?
人工智能数据目录可以帮助数据从业者在日常工作中提高生产力和效率。
Gartner表示,“人工智能可以协助数据准备、洞察生成和洞察解释。它通过自动化数据科学、机器学习以及人工智能模型开发、管理和部署的许多方面,为专家和公民数据科学家提供支持。”
以下是《福布斯》如何强调人工智能在编目中的可能性。有了人工智能数据目录,首席营销官可以问这样的问题:“在过去的18个月里,我们最新产品线的印刷和数字广告支出的回报是多少?”
如果没有人工智能数据目录,即使是确定回答这些问题所需的数据点,也需要IT部门的参与,而IT部门由于其他优先事项的积压,可能会在几周内得到答案。有了人工智能支持的现代数据目录,用户可以在几分钟内自己寻找并找到这些问题的答案。
阅读更多关于人工智能如何为数据目录工作流程提供动力的信息——可以节省时间,提高效率,并大规模从数据中提取价值。
人工智能数据目录对业务的影响是什么?
人工智能已经在改变我们的工作方式,很容易想象它给我们的数据交互和体验带来的可能性。当我们感到兴奋时,让我们考虑如何使用人工智能数据目录来推动业务成果。
- 通过更快、更高效的数据发现节省成本
- 大规模发掘新机会,推动收入增长
- 使用自动化和智能数据文档建议,减少工作量
- 通过确保所有应用程序的数据一致性来减少数据混乱
- 无需代码数据探索即可缩短洞察时间
- 改进数据安全、隐私和法规遵从性,以避免昂贵的罚款并建立信任
让我们看看如何。
1.通过更快、更高效的数据发现节省成本
人工智能数据目录可以在您的整个数据庄园中搜索元数据,以提高数据搜索和发现工作的准确性和相关性。
数据从业者可能会花费数小时搜索他们想要的数据——平均每位员工每天花费3.6小时搜索信息。IT团队花半天时间(4.2小时)寻找相关信息以支持业务用户请求。
有了人工智能数据目录,数据从业者可以减少寻找正确数据所需的工作量。他们可以使用类似谷歌的搜索界面询问有关数据的问题,并获得闪电般的搜索结果。
这意味着每天至少可以节省3个小时,从而显著节省时间和成本。
2.大规模发现新机会,推动收入增长
数据从业者可以大规模发现新的机会,因为人工智能数据目录可以分析和解释整个数据产业的元数据。
因此,每当你寻找某种资产时,人工智能也会为类似的数据资产提供建议,这样你就可以更好地理解数据资产关系。按照谷歌搜索中的“人们也会问”和“与…相关的搜索”部分来思考。
如果没有人工智能,建立这样的连接可能需要几天时间。在某些情况下,你可能会完全错过它们——“未知的未知”,即你甚至不知道的事情。
HBR通过本案例研究解释了“未知的未知因素”:
“GNS Healthcare应用机器学习软件来发现患者健康记录和其他地方的数据之间被忽视的关系。在确定了一种关系后,该软件大量提出了许多假设来解释它,然后提出了其中哪些最有可能。因此,GNS发现了隐藏在非结构化患者笔记中的一种新的药物相互作用。”
人工智能数据目录如何帮助做类似的事情?
人工智能数据目录可以研究客户行为的元数据,以建立联系并提供见解。因此,例如,如果你搜索某个客户的购买历史,人工智能数据目录可能会建议查看同一客户的服务请求或反馈数据。
3.数据文档的自动化和智能化建议减少了工作量
人工智能数据目录可以研究相关资产的元数据,为数据描述、词汇表、自述文件等提供自动建议。然后,数据从业者可以选择接受、修改或拒绝这些建议。
这一过程可能需要数小时,并导致不一致。例如,不同的团队可以用不同的方式解释“收入”:
- 销售团队可能认为收入是从客户那里收到的金额
- 营销团队可以将收入解释为营销活动产生的资金
- 财务团队的解释可能是扣除取消或退款后的金额
- 高管可以将收入解释为其组织的整体财务健康状况
将这些术语标准化并确保所有团队保持一致对于确保每个人都站在同一立场至关重要。
人工智能可以从类似的数据资产中抓取元数据,以自动填充数据描述和定义,从而完全避免此类难题。因此,数据从业者花费更少的时间和精力手动记录数据,并依靠智能建议进行大规模记录。
4.通过确保所有应用程序的数据一致性来减少数据混乱
人工智能数据目录,尤其是由活动元数据提供支持的数据目录,也实现了元数据的双向流动。如前所述,人工智能可以通过智能建议加快数据文档的编写速度。
数据从业者还可以在所有应用程序中对数据描述、证书、所有者、分类、状态和其他此类元数据执行批量更新。因此,您的整个数据产业是同步的,每个人都可以访问一致且新鲜的数据。
5.减少洞察时间,无需代码数据探索
人工智能数据目录可以帮助业务用户编写SQL查询,并通过英语提示理解现有脚本。人工智能还可以审查代码,发现错误,并提供修复建议,这样你就不必依赖IT来查询数据了。
在没有人工智能的情况下,这一过程包括向IT或工程部门提交请求。他们可能需要几个小时甚至几天才能回来。
即使他们回来了,结果也可能不是你所需要的,因为业务和IT团队用不同的视角查询数据。虽然业务用户试图将数据中的见解与直接影响整体业务的项目指标联系起来,但IT可能没有这种背景。
《福布斯》就业务和IT团队如何看待数据的问题进行了总结:
“高管们通过战略、销售增长、目标市场、竞争威胁、客户体验和公司使命来处理业务问题。IT专业人士从一个截然不同的角度看待世界。”
人工智能使业务用户能够自己探索数据,这也腾出了IT或中央数据团队用于支持业务请求的时间,以便他们能够专注于数据质量、安全性和可用性。
6.改善数据安全、隐私和法规遵从性,以避免昂贵的罚款并建立信任
人工智能数据目录可以帮助您根据类似数据资产的标签自动标记数据并通过沿袭传播数据。因此,如果你已经将患者记录识别为PII,那么人工智能数据目录会编译相关资产,并建议将其标记为PII。
该目录还将通过跟踪资产在各种工作流中的行程,确保将正确的数据加密、屏蔽和匿名化策略应用于PII资产。这有助于您避免法规遵从性问题,并确保数据隐私和完整性。
就像分类和加密一样,人工智能数据目录也可以通过沿袭传播访问控制策略。此外,它还可以通过研究类似资产的元数据,为拥有或修改数据资产的人提供建议。这有助于监控数据访问和安全性。
使用人工智能数据目录,您可以降低与数据错误、合规问题和低效工作流程相关的成本。
此外,由于数据在整个生命周期中都得到了正确的分类、标记和跟踪,因此您可以知道数据来自何处,如何处理,以及谁可以访问数据。这可以建立对数据可靠性和质量的信任。
以下是人工智能数据目录的功能
总结
人工智能在数据编目方面与电信行业的iPhone时代相似。从数据发现到探索,人工智能可以为许多用例提供动力,自动化重复任务,并使数据团队离100%自助分析更近一步。
将人工智能数据目录视为一个始终开启的智能工作空间,它充当数据庄园的上下文、控制、协作和行动平面。
人工智能数据目录可以让数据从业者花更少的时间做繁重的工作,花更多的时间解决可以推动收入增长、发现商机和提高效率的问题。
准备好获取人工智能数据目录了吗?注册加入候补名单。
AI数据目录:相关阅读
- What Is a Data Catalog? & Do You Need One?
- 8 Ways AI-Powered Data Catalogs Save Time Spent on Documentation, Tagging, Querying & More
- 15 Essential Data Catalog Features to Look For in 2023
- What is Active Metadata? — Definition, Characteristics, Example & Use Cases
- Data catalog benefits: 5 key reasons why you need one
- Open Source Data Catalog Software: 5 Popular Tools to Consider in 2023
- Data Catalog Platform: The Key To Future-Proofing Your Data Stack
- Top Data Catalog Use Cases Intrinsic to Data-Led Enterprises
- Business Data Catalog: Users, Differentiating Features, Evolution & More
- 185 次浏览
【数据目录】什么是数据目录?定义、示例和最佳实践
视频号
微信公众号
知识星球
数据目录是组织中有组织的数据资产清单。单击此处了解2021年数据目录的定义、示例和最佳实践。
数据目录被定义为组织中所有数据资产的库存。它可以帮助数据专业人员为任何分析或业务目的找到最相关的数据。数据目录使用元数据创建组织中所有数据资产的信息丰富且可搜索的清单。本文讨论了数据目录的定义、构建过程,以及2021年数据目录的10大最佳实践。
目录
- 什么是数据目录?
- 数据目录过程:关键步骤及示例
- 2021年数据目录十大最佳实践
什么是数据目录?
数据目录是组织中所有数据资产的清单,可帮助数据专业人员为任何分析或业务目的找到最相关的数据。它是一个数据清单,并提供必要的信息来评估数据是否适合预期用途。它还帮助分析师和其他数据用户找到他们为特定目的所需的目标数据。
让我们考虑一下图书馆的类比。
当你想知道图书馆里是否有特定的书时,你通常会使用图书馆目录。除了它的可用性,目录还告诉你这本书的版本和位置。简而言之,目录为您提供了书籍的各种详细信息,以决定您是否需要它。如果需要,它会告诉您如何找到它。这是当今许多对象存储、数据库和数据仓库的基本功能。
现在,让我们扩大图书馆目录的影响力,使其覆盖全国的每一个图书馆。想象一下,你只有一个用户界面,你可以在这个国家的每一个图书馆找到你想要的书的副本。你也可以在这个用户界面上找到你想要了解的每一本书的所有细节。
这正是数据目录对所有组织数据所做的工作。它为您提供了一个单一而全面的视图,可以查看所有数据,而不是一次只查看一个数据存储。
Aberdeen Strategy&research最近进行的研究表明,数据编目赋予用户分析能力,进而推动业务绩效。拥有数据目录的用户不仅报告了总客户群的增加,而且现有客户的满意度也有所提高。
数据目录元数据主题
数据目录元数据主题
在当今大数据和自助分析时代,数据目录已成为元数据管理的关键。现代的元数据比商业智能(BI)时代的元数据要广泛得多。
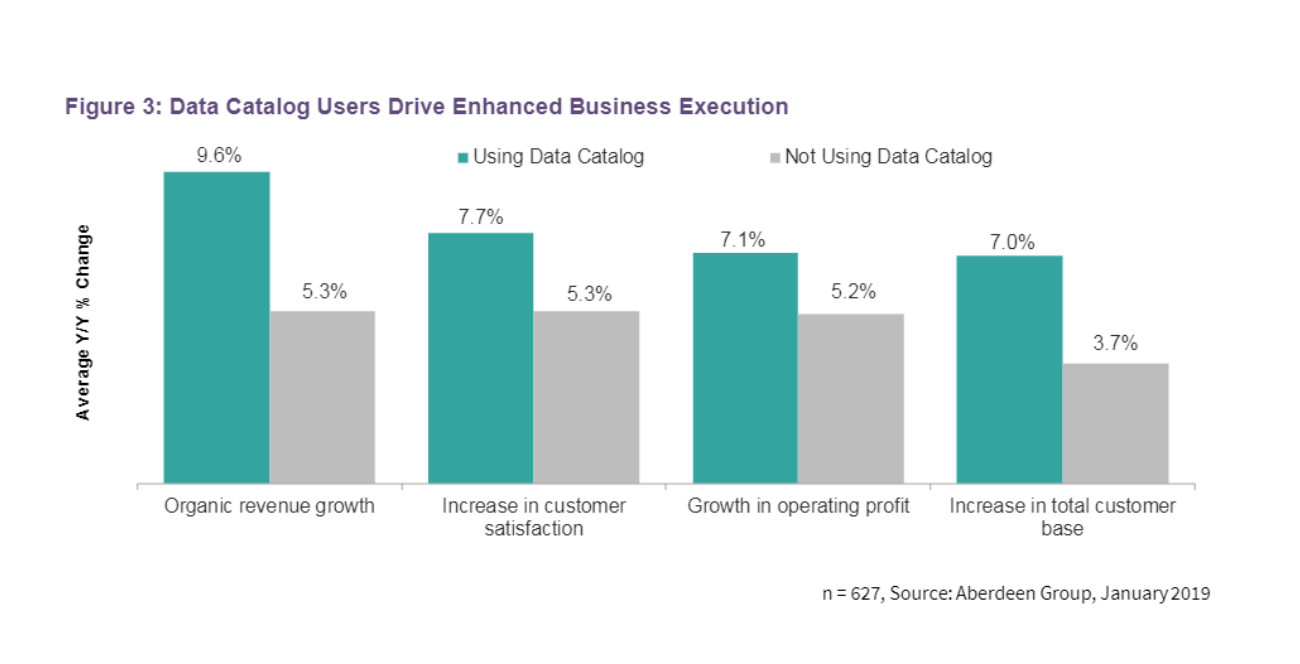
数据目录用户推动增强的业务执行
资料来源:Aberdeen Strategy&Research开启新窗口
根据Aberdeen的研究,如今的公司所处理的数据环境同比增长超过30%,有些甚至远高于此。数据目录工具通过在一个集中的平台上组织来自多个来源的数据,使数据团队能够更有效地定位、理解和利用数据。
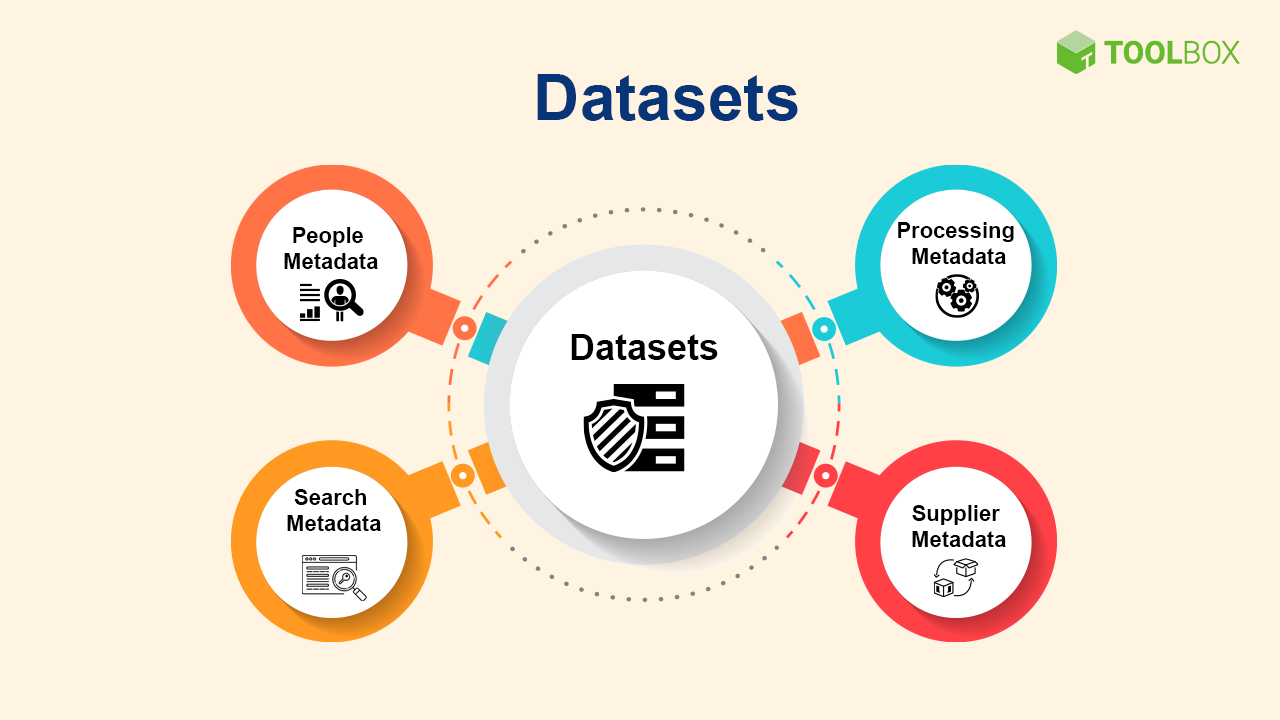
数据目录主要关注数据集(即可用数据的库存),然后将这些数据集与丰富的信息联系起来,让相关人员了解管理数据的信息。数据目录的核心是以下元数据主题:
让我们详细了解每个元数据主题:
1.数据集
数据集是组织人员访问的文件和表格。这些可以位于数据湖、仓库、主数据存储库或任何其他共享数据资源中。
2.人员元数据
这描述了处理数据的人员,包括消费者、策展人(curators)、管理人员(stewards)、主题专家等。
3.搜索元数据
此元数据支持标记和关键字,以帮助人们查找数据。
4.处理元数据
这一类别详细阐述了在数据的整个生命周期中进行管理时应用的各种转换和派生。
5.供应商元数据
供应商元数据包括从外部来源获取的数据,因为它通知来源以及与数据相关联的订阅或许可限制。
另请阅读:什么是数据治理?定义、重要性和最佳实践
数据目录过程:关键步骤及示例
构建有效的数据目录有五个步骤。让我们详细了解每一步:
1.捕获数据
构建数据目录需要捕获所有数据。为了确保收集正确的数据,需要回答两个问题:捕获哪些元数据以及如何捕获?
让我们一次解决每一个问题。
要捕获哪些元数据?
使用数据的形状、结构和语义填充数据目录是构建数据目录的第一步。大多数数据用户,如数据科学家、数据工程师、业务分析师和其他人,都是根据数据所在的模式或表来引用数据的。以以下问题和答案为例:
- 在哪里可以找到至少购买了一件商品的客户?
- 检查“客户_采购”表
- 发票是如何生成的?
- 发票中有一个或多个订单。请查看“发票”和“订单”表中的数据。如果发票已经付款,您可以在“付款”表中找到付款。
如今,流式数据和非表格数据(如JSON、Parquet structs)随处可见,它们的数量明显在以不断增长的速度增长。即使您现在不使用这些技术,也要寻找一个支持嵌套数据结构并允许您在未来集成流技术的数据目录。
最后,一个有效的数据目录必须能够捕获数据沿袭。数据沿袭使用户能够看到数据的来源和数据的轨迹。这对于提供用户在使用数据时经常需要的上下文至关重要。,
如何获取元数据?
一旦建立了数据目录,您将需要一个可以方便地代表您填充目录的工具。这节省了大量时间,因为它避免了手动更新数据生态系统中的每个数据库、表和字段。所有主要的数据库和数据存储(例如,AWS S3)都有可用的API,允许您提取表示数据形状和语义的元数据。因此,在构建数据目录时,您应该考虑自动填充元数据的能力。
在某些情况下,您可能无法直接连接到数据库。例如,考虑您不想公开敏感数据,或者您使用的是不公开的托管数据库。在这种情况下,您应该能够使用示例文件和数据存储中的提取,作为直接连接到数据库的替代方案。
在最坏的情况下,当一切都失败时,您应该能够在没有自动化的情况下自行快速捕获数据。考虑到不同数据库的所有客户端库的更改频率,不能保证有一个完美的过程或工具。因此,拥有一个自己修复问题的选项对于构建一个健壮的数据目录至关重要。
另请阅读:2021年十大数据治理工具
2.指定联络点
在构建数据目录之后,确定每个数据资产的重要人员是谁是很重要的。因此,将数据用户(如所有者)分配给数据资产非常重要。这允许有其他问题或查询的用户联系合适的个人。
不同数据用户的问题可以分为两类:
- 此数据资产的业务上下文
- Null对此字段意味着什么?
- 数据资产的技术属性
- 谁可以将此新字段添加到架构中?
数据目录可能有许多类型的所有者(例如,数据管理员【data steward】、技术所有者、企业所有者、高管所有者等)。然而,数据管理员和技术所有者发挥着重要作用。数据管家使您的用户能够知道向谁查询所有与业务相关的信息。同时,技术所有者可以回答数据用户可能存在的技术导向问题。
创建数据目录时,可以将任务分配给所有者。这些任务旨在确保您的数据目录有良好的文档记录,并对其他队友有用。
3.记录每次互动
当你开始在数据目录中记录你的数据时,你想要捕获的大量信息一开始可能看起来势不可挡。假设您有两个数据库,每个数据库都有几十个表。每个表还有一些字段。此时此刻,您似乎已经看到了几千个数据资产。
因此,您可以先选择一种方法,然后随着时间的推移慢慢添加文档。这将确保您在几个月内达到一定的覆盖率,可能达到90%或更低。一些常见的方法包括:
- 无论何时了解,都要记录下来
当每个人学习到尚未记录的新内容时,都应该负责更新数据目录。
- 当代码发生更改时,请更改文档
随着团队发布新功能,相关团队成员应更新数据文档。
- 为团队成员留出时间
让你的每个团队成员每周花一个小时,或者每天早上花15分钟在数据目录上。这将允许他们为他们熟悉的数据资产添加新的文档,或者研究他们不知道的数据资产。
所有数据资产都应该在数据目录中有丰富的文本文档,以便用户能够突出显示关键点。数据目录还应为用户提供将资产分组到公共集合中的能力。这可以通过标记数据来实现。例如,如果您希望能够看到关于您所有个人身份信息(PII)的报告,您可以用“PII”标记包含此类数据的所有表和字段。
此外,当你的数据目录允许你的用户与你的数据进行对话时,你就释放了文档的力量。当用户有一个关于数据的问题,并且该数据最终得到了回答时,那么这个问题、答案以及导致答案的对话都应该记录在目录中。
这使得下一个有类似问题的数据用户能够查看之前的对话,并理解答案的上下文。这节省了时间,因为重复同一组问题和答案的无数对话都会被记录下来。例如:
- 人员A:我如何从电脑连接到数据库?
- 人员B:您只需要登录VPN,就可以直接指向数据库主机。(记录在案)
在本例中,人员A可以参考人员B对所需解决方案的书面回答。
另请阅读:什么是企业数据管理(EDM)?定义、重要性和最佳实践
4.确保数据目录是最新的
组织面临的主要挑战之一是保持数据目录的新鲜性。开发人员通常会偶尔更改数据库的结构,并经常创建新的管道。数据科学家和业务分析师通常会创建数据立方体或在分析环境之间移动数据,以同样频繁地创建新的仪表板。引用这些模式,您的数据目录应该在可能的情况下自动识别这些更改,并相应地更新自己。
为了确保数据目录是新鲜的,一些用户交互来仔细检查信息的质量和陈旧性是很重要的。当用户认为基础文档可能陈旧或过时时,您的数据目录可以使用治理操作来促使他们采取行动。
5.根据需要进行优化
每个公司都根据自己的要求和需要使用数据目录。因此,您需要为组织使用数据目录的方式设置标准和规范。这里需要注意的是,您的团队计划使用数据目录的方式将极大地影响您捕获文档的方式。因此,如果你不知道你的团队将如何使用数据目录,那么你花在记录数据上的时间很可能会导致结果不充分。
您的团队可以采取一些常见做法来优化与数据目录的交互:
- 设置标准化的文档格式,并跨数据库、模式、字段和数据沿袭使用。
- 确定关键的学习模块,并用一个共同的主题标记每个学习模块中包含的资产。
- 强调团队对数据目录使用的规范。这将在团队成员中深入嵌入数据文化。
2021年数据目录十大最佳实践
数据目录可以是强大的数据管理平台。然而,如果没有适当的数据编目方法,数据编目的力量和功能可能会付诸东流。考虑到这一点,以下是2021年数据编目的10大最佳实践

1.将所有内容添加到您的库存中
数据无处不在——文本文件、电子表格等等。尽管数据可能分散,但在清点完所有数据之前,您甚至无法开始解决数据问题。团队中的每个人都应该接受培训,思考他们的数据可能所在的所有地方。然后确保对这些离散数据的每一部分进行编目。
2.管理数据流
数据沿袭和来源工具是很好的,但它们大多绘制出已知域或一组域内的数据流。一个好的数据目录,一个有数据流发现支持的目录,通常会识别不同数据集之间的流。这样的安排可以帮助您发现组织内可能不为人所知的数据移动。然后可以检查这些流的有效性。因此,管理数据流是构建有效数据目录的良好实践。
3.优先考虑敏感数据
有效数据目录的主要目的之一是帮助识别敏感数据的位置。在多个地方发现相同敏感数据的情况下,它可以帮助识别冗余数据。因此,通过管理敏感和冗余数据,您可以最大限度地减少漏洞的表面区域,并建立强大的数据保护,以抵御任何外部攻击。
4.考虑非结构化数据
非结构化数据(文档、网页、电子邮件、社交媒体内容、移动数据、图像、音频和视频)是指不符合数据模型且没有易于识别的结构的数据。它不太适合主流关系数据库。也就是说,您的数据目录可以帮助使隐式数据结构显式。这可以通过基于团队或组织需求重新设计整体数据结构来实现。因此,考虑“非结构化”数据对任何数据目录都至关重要。
5.指定可发现的名称和描述
一个好的名称和详细的描述将使相关团队成员更容易发现您的数据。描述可以指示同一对象的备用名称,并有助于构建全面的数据本体。
6.区别对待数据湖表
在关系数据库中,数据可能分布在多个表中。然而,数据湖往往会将大量数据聚集到单个文件中。在商业智能领域,单个数据集可以将度量和维度存储在一起,而不是单独存储。即使对于将数据表示为数据库中的表的系统也是如此。这可能会降低数据的可发现性,但数据目录直接解决了这个问题。
7.提供透明的评级
数据目录中的众包评级、背书和负面评级可以帮助用户更快地获得相关和可靠的信息。但这需要严格的标准。除非数据达到非常高的标准基准,否则不应该获得五星评级。同样,好的数据不应该被评为差。用户需要对评分有信心,否则他们不会信任他们。因此,一个组织应该确保标准是统一和精确的。
8.把它变成一个湖泊,而不是沼泽
对数据湖中的所有内容进行编目可以使您对其进行组织并使其可用。一旦你的湖泊被编目,你就可以在其中建立区域,让它成为商业用户获取数据的首选场所,而不仅仅是他们倾倒数据的地方。
9.采用数据验证规则
数据目录中的英文描述很重要,因为它们有助于记录所谓的过时知识,并将其传播给各种业务用户。这需要技术人员的参与,因为严格的数据验证规则可以帮助验证数据是否与目录定义匹配。这样的过程确保了数据质量,并起到了检查更多定性星级的作用。因此,在数据目录中使用简化的验证规则可以在数据用户之间灌输信任。
10.利用机器学习技术
由于数据量的增加,手工编目在今天是一项不可能完成的任务。编目永远不会完成,甚至不会随着新数据的到来而跟上步伐。然而,机器学习(ML)是一种很有前途的工具,可以用来控制音量问题。
ML模型可以识别数据类型和关系。这有助于在更多的数据集上构建您的目录。它还可以比手动目录更快地在更多对象之间传播数据标记。因此,如果你的数据目录没有在实际数据中利用ML,你可能会在数据驱动的旅程中面临巨大的阻力。
总之,数据目录是您的数据指南,其组织方式对您、您的团队和您的业务都有意义。通过精简的方法,您将能够最大限度地管理、管理和利用您的数据。上面的最佳实践应该会让您在数据目录路径上有一个良好的开端。
另请阅读:2021年八大大数据安全最佳实践
收获
数据目录在组织实现数据智能的过程中发挥着至关重要的作用。它是推动收入、优化运营效率、促进创新和增长的重要因素。既然您已经意识到数据目录的重要性,我们希望您部署一个最适合您业务需求的数据目录
阿伯丁战略的更多内容&研究
- 1099 次浏览
【数据目录】什么是数据目录?数据目录功能和优点
视频号
微信公众号
知识星球
数据目录: 一个在企业中查找、理解和管理数据的地方
数据目录已迅速成为现代数据管理的核心组成部分。成功实现数据目录的组织在数据分析的速度和质量以及需要执行数据分析的人员的参与度和热情方面都发生了显著变化。相比之下,没有数据目录的组织通常会有以下问题:什么是数据目录?为什么我们需要一个数据目录?数据目录的作用是什么?这些都是很好的问题,也是开始数据编目之旅的一个合乎逻辑的地方。
什么是数据目录?
数据目录是一个元数据集合,与数据管理和搜索工具相结合,帮助分析师和其他数据用户找到他们需要的数据,作为可用数据的库存,并提供信息来评估数据是否适合预期用途。
这个简短的定义提出了关于数据目录、数据管理、搜索、数据库存和数据评估的几点,但所有这些都取决于提供元数据集合的中心能力。
数据目录已经成为大数据时代和自助式商业智能时代元数据管理的标准。我们今天需要的元数据比BI时代的元数据更为广泛。数据目录首先关注数据集(可用数据的清单),并将这些数据集与丰富的信息联系起来,为使用数据的人提供信息。图1展示了数据目录中包含的典型元数据主题。
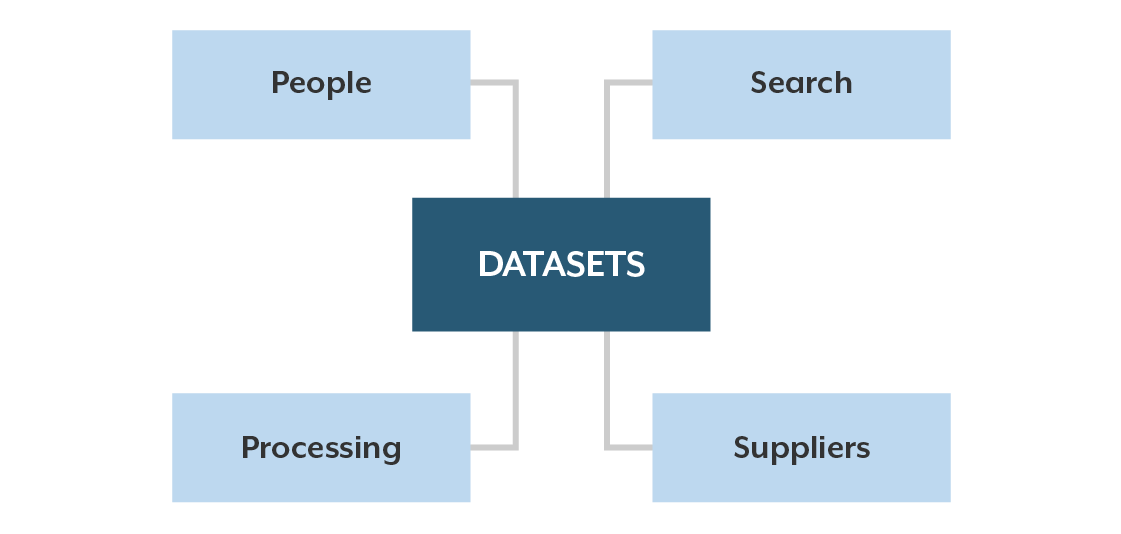
数据集是数据工作者需要查找和访问的文件和表。它们可以位于数据湖、仓库、主数据存储库或任何其他共享数据资源中。人员元数据描述那些与数据消费者、策展人、管理员、主题专家等合作的人员。搜索元数据支持标记和关键字,以帮助人们查找数据。处理元数据描述了在数据的整个生命周期中进行管理时应用的转换和派生。供应商元数据对于从外部来源获取的数据尤其重要,这些数据提供了有关来源和订阅或许可限制的信息。我将在即将发布的博客中深入研究目录元数据。
数据目录的作用是什么?
现代数据目录包括许多特性和功能,这些特性和功能都取决于对数据进行编目的核心能力——收集识别和描述可共享数据库存的元数据。尝试将编目作为一种手动工作是不切实际的。数据集的自动发现对于初始目录构建和新数据集的持续发现都至关重要。将人工智能和机器学习用于元数据收集、语义推理和标记,对于从自动化中获得最大价值和最大限度地减少手动工作非常重要。
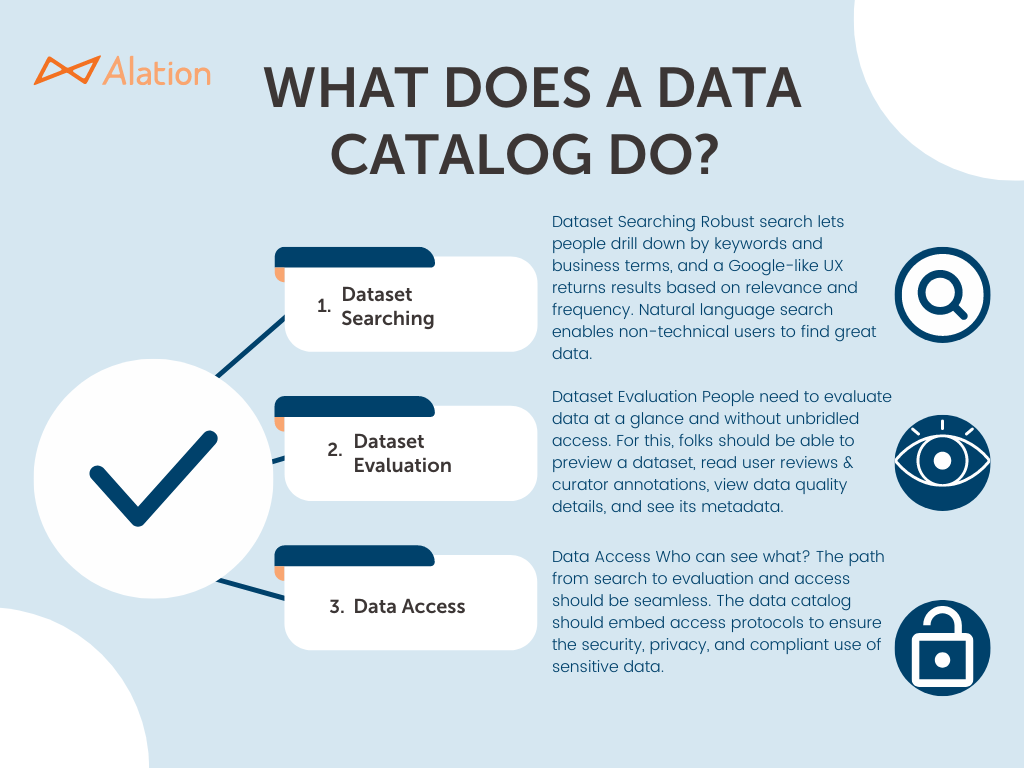
以健壮的元数据作为数据目录的核心,支持许多其他特性和功能,其中最重要的包括:
数据集搜索.
强大的搜索功能包括按方面、关键字和商业术语进行搜索。自然语言搜索功能对于非技术用户来说尤其有价值。根据相关性和使用频率对搜索结果进行排名是特别有用和有益的功能。
数据集评估
选择正确的数据集取决于评估其适用于分析用例的能力,而无需首先下载或获取数据。重要的评估功能包括预览数据集、查看所有相关元数据、查看用户评分、阅读用户评论和策展人注释以及查看数据质量信息的功能。
数据访问
从搜索到评估,再到数据访问的路径应该是无缝的用户体验,使用目录知道的访问协议,并直接提供访问或与访问技术互操作。数据访问功能包括对安全、隐私和法规遵从性敏感数据的访问保护。
一个强大的数据目录软件应该提供许多其他功能,包括支持数据管理和协作数据管理、数据使用跟踪、智能数据集推荐和各种数据治理功能。
数据目录的好处
- 提高了数据效率
- 改进的数据上下文
- 降低错误风险
- 改进的数据分析
通过反思元数据的价值和使用综合元数据创建的功能,数据目录的数据管理优势变得显而易见。然而,最大的价值往往体现在对分析活动的影响上。我们工作在一个自助分析的时代。IT组织无法提供不断增加的数据分析人员所需的所有数据。但今天的业务和数据分析师往往是盲目工作的,无法了解现有的数据集、这些数据集的内容以及每个数据集的质量和有用性。他们花了太多时间寻找和理解数据,经常重新创建已经存在的数据集。他们经常使用不充分的数据集,导致不充分和不正确的分析。图2说明了当分析师使用数据目录时,分析过程是如何变化的。
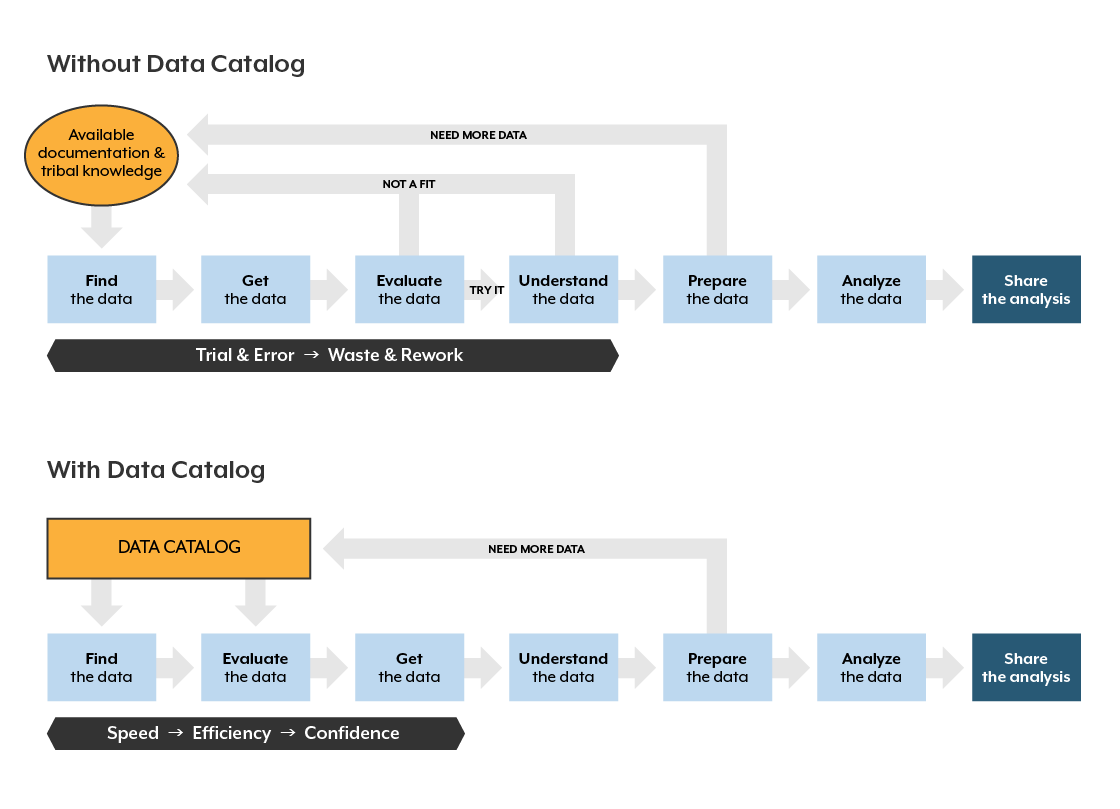
figure 2 – Process With and Without a Data Catalog
在没有目录的情况下,分析师通过整理文档、与同事交谈、依靠部落知识或简单地使用熟悉的数据集来寻找数据,因为他们知道这些数据集。这个过程充满了试错、浪费和返工,以及重复的数据集搜索,随着时间的流逝,这些搜索往往会导致使用“足够接近”的数据。通过数据目录,分析师能够快速搜索和查找数据,查看所有可用的数据集,评估并做出明智的选择,使用哪些数据,并高效而自信地进行数据准备和分析。通常情况下,80%的时间用于查找数据,仅20%用于分析,而20%用于查找和准备数据,80%用于分析。在不增加更多分析师的情况下,大大提高了分析质量,提高了组织分析能力。
结论
在大数据、数据湖和自助服务时代管理数据具有挑战性。数据目录有助于应对这些挑战。主动数据管理是数据目录成功的核心要素,也是现代数据管理的关键实践。在我的下一篇博客中,我将回答这个问题:什么是数据整理?
- 342 次浏览
【数据目录】开源数据目录-2023年需要考虑的6种流行工具列表
视频号
微信公众号
知识星球
数据目录有助于用户查找、理解、信任数据,并在数据上协同工作。部署数据目录工具标志着一个组织正在采取措施打破数据孤岛,实现数据民主化。在评估数据目录工具的市场时,组织通常会考虑开源和企业选项。
几年前,最大的科技公司建立了自己的数据发现和编目解决方案,以解决其独特的工作流程和用例。他们也自然而然地致力于创新和解决数据团队的普遍挑战——发现、信任和理解他们的数据。这些公司中的大多数最终都开放了数据目录软件,供外部团队在其基础上进行构建。

流行的开源数据目录工具
2023年最受欢迎的6种开源数据目录工具列表。

1. Apache Atlas
Apache Atlas是一个开源元数据管理工具和治理平台,由Hortonworks在数据治理倡议的保护伞下孵化。
它后来于2015年加入了Apache基金会孵化器,并于2017年发展成为一个顶级项目。Apache Atlas被广泛认为是现代数据平台的构建块之一,因为它早期设想使用元数据来解决数据编目、分类、发现、治理和协作方面的挑战。
Apache Atlas的主要功能是什么?
- 元数据分类:Apache Atlas使您能够自动对PII、敏感数据和其他敏感数据进行分类。数据资产可以与多个分类相关联。策略还通过沿袭进行传播,从而确保派生数据继承相同的分类和安全控制。
- 元数据类型和实例:根据Apache文档,“类型”是指如何在Atlas中存储和访问特定类型的元数据对象的定义。这使数据管理员能够定义技术元数据和业务元数据。
- 搜索和谱系:Apache Atlas中的直观用户界面允许用户按类型、分类、属性值或自由文本对数据类型进行预定义和特别的探索。它还维护了数据源或显式数据是如何构建的,以及它是如何随着时间的推移而演变的历史。
- 安全和数据屏蔽:Apache Atlas主要是一种数据治理工具。它允许细粒度的元数据访问安全性,允许设置对实体实例访问的控制,还可以设置添加/更新/删除分类等操作。
2. Amundsen Lyft
Amundsen是一个开源数据目录平台,最初由Lyft的工程团队构建。它于2019年10月开源,一年后推出供内部使用。
Amundsen有一个由贡献者和用户组成的有凝聚力的社区。它也被其他组织广泛采用,这些组织建立在这个开源数据目录工具的基础上,以推动其数据民主化、治理和元数据服务计划。
阿蒙森的主要能力是什么?
- 轻松发现可信数据:阿蒙森通过简单的文本搜索帮助找到各种来源的数据。搜索结果甚至显示了内联元数据。
- 自动化和策划的元数据:当点击数据资产时,用户会看到其详细描述和行为,分别是手动策划和自动生成的。
- 与同事共享上下文的能力:可以更新数据资产的描述,从而减少同事之间在特定数据资产中寻找更多上下文的来回。
- 从数据使用中学习和理解:用户可以看到哪些数据资产经常被使用、拥有或添加书签。通过查看在给定表上构建的仪表板,甚至可以理解与表相关的最常见查询。
3. LinkedIn DataHub
DataHub是一个开源元数据管理平台,由领英工程团队开发。
事实上,这是领英解决数据编目、发现、可观察性和谱系挑战的第二次尝试。在DataHub之前,他们早在2016年就构建了一个名为WhereHows的开源数据目录工具。DataHub于2019年发布,并于2020年开源。领英维护了两个不同版本的DataHub,一个供内部使用,另一个开源供其他人使用。
DataHub的主要功能是什么?
- 自动化元数据摄入:在LinkedIn中,DataHub元数据通过API或Kafka流推送从不同来源摄入。
- 轻松的数据发现:对于最终用户,在最高级别上,DataHub前端支持三种类型的交互:搜索、浏览和查看/编辑元数据。
- 通过上下文理解数据:DataHub上的每个数据实体都有一个配置文件页面,显示与该数据实体相关的所有元数据,从而为用户开发有关该数据的上下文提供必要的信息。
4. Netflix Metacat
Metacat是一项联邦元数据管理服务,由Netflix构建,于2018年6月开源。Metacat旨在简化数据的编目、发现、处理和管理。
它主要构成了从Netflix的不同来源访问所有数据资产的单一来源。尽管Metacat是一个开源数据目录,但似乎缺乏对其他人有效使用其架构和扩展的重要公共知识。
Metacat的主要功能是什么?
- 数据抽象和互操作性:Metacat形成了一个通用的抽象层,可以通过Netflix的多个查询引擎访问数据集。
- 业务和用户定义的元数据存储:Metacat有助于记录有关数据资产的业务和用户自定义元数据,确保为数据用户提供更多关于数据资产的信息,以及如何处理这些信息的标准规则。
- 数据发现:Metacat通过ElasticSearch提供带有模式元数据和业务/用户定义元数据的数据,这有助于通过文本搜索进行查询。
- 数据更改审核和通知:捕获任何元数据更改或更新-为可能需要用户注意的事件启用推送通知。
5. OpenMetadata
OpenMetadata是一个开源的端到端元数据管理解决方案,它定义了规范,以使用模式优先的方法来标准化元数据。
它主要选择解决被动元数据锁定在竖井中、元数据重复和元数据不可互操作的问题。
它于2021年8月发布,以Apache许可证2.0版发布
OpenMetadata的主要功能包括:
- 发现:通过关键字搜索、关联和高级搜索实现数据发现
- 活动提要:数据活动视图,显示数据更改事件的摘要
- 描述性元数据:能够在数据资产上添加部落知识作为描述
- RBAC:用于元数据操作的基于角色的访问控制(RBAC)
- 沿袭:可编辑的无代码数据沿袭
- 集成:能够连接到数据堆栈中流行的连接器
6. Open Data Discovery
开放数据发现(ODD)是一个开源平台,致力于数据资产的发现、编目和管理。
Silicon Valley人工智能咨询公司Provectus于2021年8月宣布发布开放数据发现。
开放数据发现的主要功能:
这是开源数据目录工具列表中的一个非常新的添加,他们的网站提供了以下功能:
- 数据发现:ODD对来自多个来源的数据进行爬网和索引,提供搜索功能,使用户能够找到相关的数据集。
- 数据编目:ODD为每个数据集提供元数据和模式信息,允许用户理解数据的结构、格式和上下文。
- 数据质量:ODD根据用户定义的规则和机器学习算法对数据集的质量进行评估和评分,确保用户能够信任他们正在使用的数据。
- 数据沿袭:ODD跟踪数据的来源和转换,帮助用户跟踪数据沿袭并了解更改对其数据资产的影响。
- 数据治理:ODD通过提供一个集中的平台来执行数据策略、管理访问控制并确保遵守法规,从而支持数据治理。
- 协作:ODD通过提供注释、共享和版本控制等功能来促进协作,使用户能够在数据项目上协同工作。
正在评估开源数据目录工具
每个组织都有自己的数据目录工具评估标准框架,这取决于他们想要解决的核心挑战和主要用例。通常,要找到一个能够解决数据团队面临的所有挑战的单一开源数据目录工具是很有挑战性的。
我们开发了一个指南,帮助您创建一个定制的评估标准框架,并以循序渐进的方式从POC(概念验证)中获得最大价值。
同样重要的是要记住,这些开源数据目录工具大多是由工程师为工程师制作的,他们需要大量的时间和资源投资,才能为您的组织构建一个有效的数据目录工具。当您处于评估过程中时,您可能还想查看像Atlan这样的现成解决方案,它是对传统企业数据目录软件解决方案的飞跃,建立在最好的开源基础上。
- 528 次浏览
【数据目录】数据目录与元数据管理:差异,以及它们如何协同工作?
视频号
微信公众号
知识星球
数据目录与元数据管理:主要区别
元数据管理和数据目录之间的主要区别在于,元数据管理是一种处理数据的策略或方法。相比之下,数据目录是一种工具,是支持元数据管理的一种手段。
下面是一个表,总结了数据目录和元数据管理之间的区别。
| 方面 | 数据目录 | 元数据管理 |
|---|---|---|
| 释义 | 数据目录是所有数据资产的有组织的列表,这些资产赋予了整个公司的数据团队权力。 | 元数据管理帮助组织决定如何收集、分析和维护上下文信息——元数据。 |
| 范围 | 它是所有数据源的有组织的数据清单。它能够在正确的上下文中进行数据搜索和发现数据资产。 | 它确保元数据按照数据管理策略使用。 |
| 关键差异 | 它是一种实现元数据管理以及数据发现、分析、质量和治理等功能的工具。 | 这是一种管理元数据的收集、存储和使用的方法。 |
目录
- 数据目录与元数据管理:主要区别
- 什么是数据目录?
- 什么是元数据管理?
- 元数据与主数据与参考数据
- 数据目录是否包含元数据?
- 通过强大的数据目录实现高效的元数据管理
- 数据目录与元数据管理:相关阅读
数据目录与元数据管理有区别吗?这些概念在数据生态系统中经常可以互换使用。
虽然这两个术语之间有一些区别,但这里有一个简短的解释——数据目录是实现元数据管理的工具。因此,与其争论非此即彼,不如探讨如何建立一个支持有效元数据管理的目录。
与其考虑数据编目与元数据管理,不如考虑数据编目+元数据管理,以实现更好的数据管理。
本文分析了编目和元数据管理的概念,以及它们的协同作用和差异。
首先,让我们从数据编目开始。
什么是数据目录?
数据目录是一种帮助建立组织数据资产综合列表的工具。数据目录使数据工程师和业务分析师更容易找到和使用正确的数据。
集中式数据目录可以有效地分解数据竖井,从而在整个组织中实现更好的数据可访问性。
此外,为现代数据堆栈构建的数据目录可以跟踪沿袭,并帮助设置细粒度的访问策略和权限。这样可以实现更好的数据安全性,并遵守各种数据保护法规和隐私法。
有兴趣了解更多有关数据目录的信息吗?查看我们的深入指南,了解数据目录的价值、好处和功能。
在我们讨论元数据之前需要注意的另一件事是,数据目录与数据字典不同。原因如下。
数据目录与数据字典
正如我们已经提到的,数据编目是组织或清点数据资产的过程。
现代数据目录可以包括元数据存储库、上下文业务词汇表、类似谷歌的搜索以实现数据可发现性,以及确保良好治理的能力。范围因组织的需要而异。
同时,数据字典描述数据库、数据模型或数据源中包括的数据类型和数据结构。
过去,IT团队用来维护组织的数据字典来处理元数据管理。然而,随着越来越多的数据消费者和业务用户,数据字典已经成为更全面的数据目录的构建块之一。
要了解更多关于数据字典及其优点的信息,这里有一篇文章可能会对您有所帮助。
在数据目录中集成数据字典、业务词汇表以及搜索和发现功能的最大优势是数据民主化。
了解更多:数据目录与数据字典-差异、示例和用例
数据目录在数据民主化中的作用
《实践中的大数据》畅销书作者Bernard Marr表示:
“数据民主化意味着每个人都可以访问数据,或者没有在网关或数据入口点造成瓶颈的看门人。”
数据民主化使组织中的每个人都能在需要时访问他们想要的数据。因此,每个人都可以快速找到、理解并使用正确的数据进行战略决策。
强大的数据目录平台通过赋予数据团队各种功能,实现数据民主化,而不会损害数据安全或隐私,例如:
- 数据搜索和发现
- 业务术语表和数据字典
- 自动数据分析和自动词汇表建议
- API与现代数据堆栈其余部分的集成
- 在线聊天、注释和一键数据共享,实现无缝协作
- 数据沿袭和影响分析
现在让我们来看看元数据管理。
什么是元数据,什么是元数据管理?
元数据是描述数据的数据。
例如,图像的元数据包括图像名称、描述、格式、大小、作者、创建日期和修改日期。
同样,包含员工记录的excel表也有大量的元数据信息。excel工作表中每列的元数据包括名称、说明、数据类型等。
在现代数据堆栈中,业务利益相关者经常混淆元数据,并将其与主数据和参考数据互换使用。让我们来理解这些概念。
元数据与主数据与参考数据
元数据、主数据和参考数据之间的主要区别在于,元数据是关于数据的描述性信息,有助于组织理解其数据。主数据是交易所需的重要业务信息。示例包括对客户、产品、供应商零件的描述,以及来自交易数据的其他此类信息。最后,参考数据是主数据的一个子集。它是组织业务流程中各种系统所引用的数据。
元数据是关于数据的描述性信息,有助于组织理解其数据。
例如,客户记录数据库的元数据将包括列名、列数据类型、描述和格式等信息。
要了解更多关于元数据的信息,请查看我们关于元数据的详细指南,并使用它解锁数据资产的价值。
接下来是主数据。
主数据是交易所需的重要业务信息。示例包括对客户、产品、供应商零件的描述,以及来自交易数据的其他此类信息。
Gartner将主数据定义为:
主数据是一组一致和统一的标识符和扩展属性,用于描述企业的核心实体,包括客户、潜在客户、公民、供应商、站点、层次结构和会计科目表。
您需要元数据来管理主数据。Forrester表示,这就是为什么主数据管理和元数据就像一枚硬币的两面:
MDM通常涉及一些以业务为中心的声明,即实现客户、产品或其他一些关键数据的单一可信视图,而IT通常着眼于元数据,通过对公司的“关于数据的数据”有一个单一的真实版本来降低复杂性,提高生产力、重用和协作
最后,参考数据是主数据的一个子集。它是组织业务流程中各种系统所引用的数据。
一些参考数据是根据ISO等管理机构的规范进行标准化的。示例包括国家代码、邮政代码和货币代码。
其他的,如客户状态或产品类别,是在组织内定义的。
回到元数据,有效地管理所有这些信息可以构建数据的完整画面,并使其更易于理解和有意义。
元数据管理是一组管理元数据存储和使用的策略和过程。
如果做得好,元数据管理可以帮助组织遵守数据法,同时增强组织内部的数据民主化能力。
传统上,您可以使用excel表和结构化数据库来处理元数据管理。然而,随着大数据和云计算的兴起,元数据管理变得具有挑战性。
这就是数据目录可以提供帮助的地方。
数据目录是否包含元数据?
如前所述,数据目录是将元数据整合到单个存储库中的工具,可以提供组织内所有数据资产的完整情况。所以,是的,它们包括元数据。
现代数据目录通过提供单个存储库中所有元数据的概述来实现元数据管理,从而为元数据建立一个单一的真相来源。
让我们看看如何。
数据目录与元数据管理:数据目录在哪里适合元数据管理?
首先,元数据管理是一种处理数据的策略或方法。相比之下,数据目录是一种工具,是支持元数据管理的一种手段。
接下来,选择元数据管理工具将只处理元数据,这可能会也可能不会提供足够的上下文,并使发现更容易。
然而,组织可以通过数据目录以集中、协作和用户友好的方式管理大量数据,其功能包括:
- 为元数据编制索引
- 启用搜索和发现
- 简化治理
下面是一个表,总结了数据目录和元数据管理之间的区别。
| 方面 | 数据目录 | 元数据管理 |
|---|---|---|
| 释义 | 数据目录是所有数据资产的有组织的列表,这些资产赋予了整个公司的数据团队权力。 | 元数据管理帮助组织决定如何收集、分析和维护上下文信息——元数据。 |
| 范围 | 它是所有数据源的有组织的数据清单。它能够在正确的上下文中进行数据搜索和发现数据资产。 | 它确保元数据按照数据管理策略使用。 |
| 关键差异 | 它是一种实现元数据管理以及数据发现、分析、质量和治理等功能的工具。 | 这是一种管理元数据的收集、存储和使用的方法。 |
| Aspect | Data Catalog | Metadata Management |
|---|---|---|
| Definition | A data catalog is an organized list of all the data assets which empower data teams throughout the company. | Metadata management helps organizations decide how to collect, analyze, and maintain contextual information — metadata. |
| Scope | It serves as an organized data inventory for all data sources. It enables data search and discovery of data assets, with the right context. | It ensures that the metadata is used as per the data governance policies. |
| Key difference | It is a tool that enables metadata management, among other things such as data discovery, profiling, quality, and governance. | It is an approach to manage the collection, storage, and use of metadata. |
通过强大的数据目录实现高效的元数据管理
一个强大的数据目录有助于元数据管理等,以帮助组织有效地管理和使用其数据。这就是为什么争论不应该是数据目录与元数据管理,而是数据目录+元数据管理。
如果你想知道“健壮”是什么样子,可以考虑使用Atlan的现代数据目录进行试驾。
数据目录与元数据管理:相关阅读
- Metadata management: Definition, benefits, best practices, and tools
- Data catalog vs. Data dictionary — Differences, examples, and use cases
- What Is a Data Catalog? & Do You Need One?
- Data catalog benefits: 5 key reasons why you need one
- Open source data catalog software: 5 popular tools to consider in 2023
- Data Catalog vs. Data Dictionary: Definitions, Differences, Benefits & Why Do You Need Them?
- Data Inventory vs. Data Catalog: Definitions, Differences, and Examples
- Data Dictionary vs. Business Glossary: Definitions, Examples & Why Do They Matter?
- Modern Data Catalog: 5 Essential Features and Tool Evaluation Guide
- Data Catalog vs. Data Warehouse: Differences, and How They Work Together?
- 680 次浏览
【数据目录】数据目录:2023年数据领导者必备工具
视频号
微信公众号
知识星球
数据目录终于成熟了。它正在发展到一个超越自己名字的程度。
数据从业者期望从数据目录中驱动的用例在过去几年中发生了显著变化。虽然这一变化并不突然,但我们似乎正处于一个转折点,组织被迫从其数据目录中要求更多。
什么是数据目录?它是如何成熟的?在为您的组织评估数据目录解决方案时,您应该考虑哪些表利害关系?本文探讨了这些问题以及更多内容。
目录
- 什么是数据目录?
- 数据目录通常是如何定义的?
- 数据目录和寒武纪大爆发(2021-2025)
- 2023年的数据目录:定义能力
- 您应该能够从数据目录中获得什么值?
- 数据目录用例
- 数据目录:深潜资源
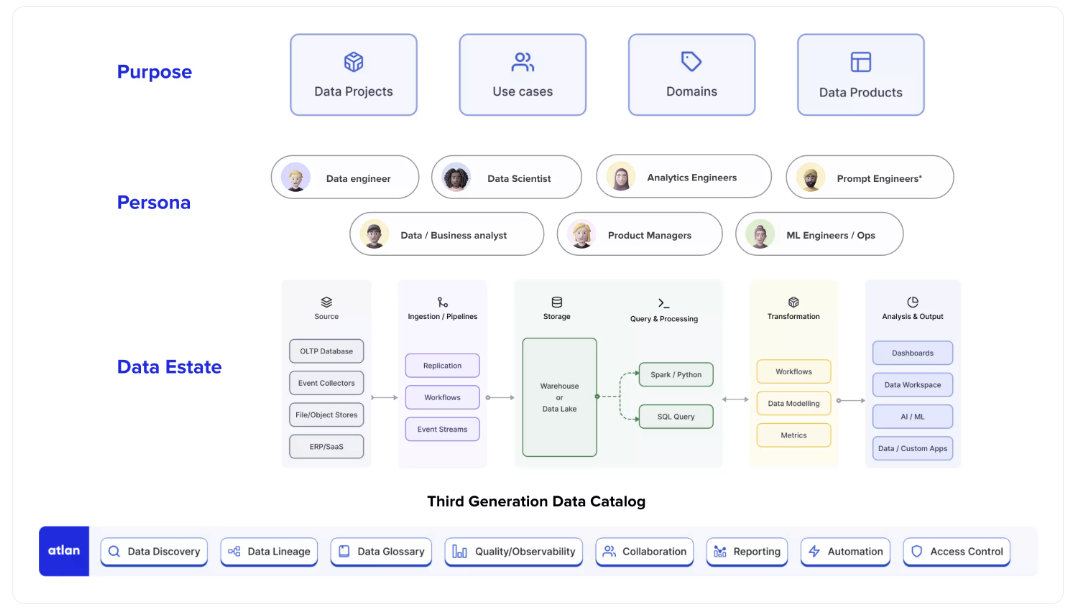
什么是数据目录?
数据目录是一个工作空间,用作上下文、控制、协作和操作平面,集成您的整个数据庄园、不同的数据用户和不同的数据用例。
数据目录通常是如何定义的?
如果你问ChatGPT什么是数据目录,它会这样定义它:

虽然这一定义并不错误,但需要改变观点。首先,将数据目录限定为仅仅是数据的存储库或库存是有限制的。
Forrester列出了以下定义最佳数据目录工具的必备属性
引用一下,他们建议企业数据目录客户应该寻找以下提供商:
- 处理数据和元数据的多样性、粒度和动态特性
- 对数据流和交付的性质和路径产生深刻的透明度
- 提供增强现代DataOps和工程最佳实践的UI/UX
资料来源:Forrester Wave™: 2022年第二季度DataOps企业数据目录
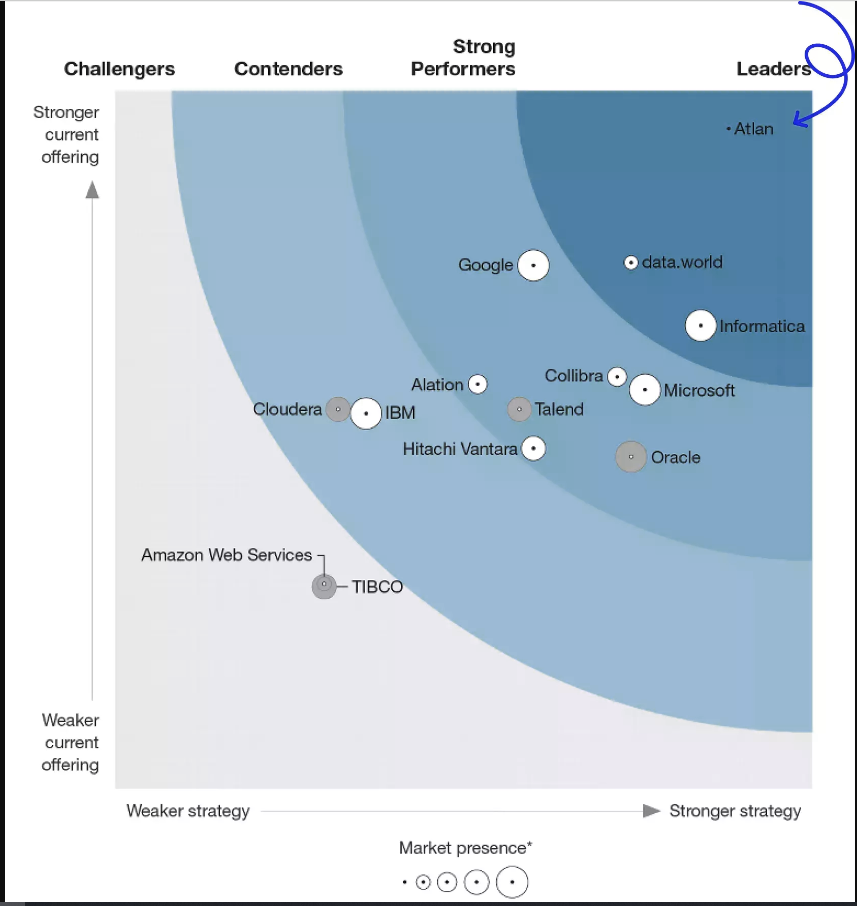
Gartner也宣称传统的元数据做法不足
值得注意的是,生态系统一段时间以来一直呼吁对元数据采取修订方法。Gartner此前已将其元数据管理幻方图替换为活动元数据市场指南。报告的开头几行足以促使人们采取行动。
对协调现有系统和新系统的需求增加,使得传统的元数据做法不足。组织需要“主动元数据”来确保增强数据管理能力。来源:Gartner,《主动元数据管理市场指南》
不仅是行业顾问,数据从业者也在口头上对数据目录无法满足他们的需求感到不安
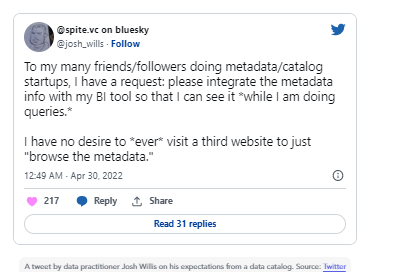
数据目录和寒武纪(Cambrian )大爆发(2021-2025)
2020年12月,dbt实验室创始人兼首席执行官特里斯坦·汉迪写了一篇博客文章,表达了他对现代数据堆栈的愿景。
在帖子中,他思考了最好的工具是否达到了一定的成熟/停滞水平,并写道,他急切地等待着下一次寒武纪大爆发,那时拿到一个工具就像被授予了超能力。
那么,理想的数据目录在2023年应该是什么样子?数据目录中的哪些功能会让你觉得自己拥有超能力?让我们从我们最初的定义中得出
数据目录是一个工作空间,用作上下文、控制、协作和操作平面,集成您的整个数据庄园、不同的数据用户和不同的数据用例。
从本质上讲,在实现数据目录时,考虑数据的“为什么”、“谁”和“如何”是很重要的

2023年的数据目录:定义能力
2023年数据目录的所有功能都以以下四种基本和转型能力为指导:
- 您整个数据产业的端到端可视性
- 嵌入式协作,统一不同数据用户的工作流程
- 可编程机器人,可根据不同的使用情况进行培训
- 默认情况下基本开放的体系结构
1.整个数据产业的端到端可视性
用户希望完全了解其数据资产,包括所有权、源和允许的使用情况,而无需在各种数据质量、沿袭、目录和治理工具之间切换。数据目录可以在一次无缝体验中实现这一点。这体现在几个功能上:
- 列级沿袭
- 360度数据资产配置文件
- 从ETL工具、编排工具等引入上下文的自定义元数据
- 可视化数据预览和相关查询
- 以及更多
2.嵌入式协作,统一不同数据用户的工作流程
嵌入式协作就是让工作在你所在的地方进行,尽可能减少摩擦。数据目录识别数据用户的多样性及其不同的工具偏好,并确保与团队的日常工作流程无缝集成。
这可以采取多种形式,包括:
- 通过链接请求和访问数据资产。
- 使用您首选的协作工具批准或拒绝访问请求。
- 在Slack上配置数据质量警报,允许您的团队询问有关数据资产的问题,并直接在Slack中接收上下文。
- 在Jira上触发支持请求,而无需离开正在调查数据资产的屏幕。
3.可编程机器人,可根据不同的用例进行训练
没有任何一种算法能够神奇地为每个行业、公司和用例创建上下文、识别异常并实现智能数据管理的梦想。
这就是为什么第三代工具依赖于可编程机器人的原因——这是一个允许团队创建自己算法的框架。例如,对其数据集有特定命名约定的公司可以创建机器人,使用预设规则自动组织、分类和标记其数据生态系统。
4.默认情况下基本开放的体系结构
元数据将是解锁未来几个操作用例的关键,例如自动调优数据管道和CI/CD管道。它甚至可以作为数据编织和数据网格等现代概念的基础。为了实现这一点,基本元数据存储需要有一个可公开访问的API层,允许团队在此基础上进行构建。
您应该能够从数据目录中获得什么值?
数据目录可能是2023年作为数据领导者所能做出的最佳投资之一。以下是使用数据目录生成值的各种方法:
- 降低成本
- 最大限度地提高生产力
- 缓解风险
- 实现收入最大化
- 改善客户体验
#1-降低成本
例如,数据目录可以用于折旧昂贵和未使用的数据资产,或者减少不必要的数据处理并提高资源利用率。
阅读有关数据目录可以降低成本的更多方法
#2-最大限度地提高生产力
众所周知,数据目录可以将新员工的入职时间从几周缩短到几天。数据目录还使非技术用户能够自助服务数据请求,从而大大提高了数据消费者的生产效率
了解一家价值35亿美元的初创公司如何突破“数据即服务”陷阱,通过可重复使用的数据产品实现自助服务
#3-缓解风险
使用数据目录可以很容易地遵守全球和本地法规—这些策略的部署可以在数小时内完成,而不是几天
了解一家拥有近50万小企业客户的英国数字银行如何通过使用数据目录自动化手动流程来提高对GDPR“擦除权”的合规性
#4-实现收入最大化
安全和可访问的数据、提高的数据质量和信任,以及自信地对数据采取行动的能力,都是为企业利用数据中发现的见解进行创新奠定基础的重要因素。
了解一家价值200亿美元的全球保险公司如何使用数据目录通过更好的数据提供更好的保险解决方案
#5-改善客户体验
例如,为了提高客户满意度,对下游数据的使用进行影响分析。该分析确定了数据收集后的使用方式,以及下游流程中的任何潜在问题如何影响客户体验。
以下是纳斯达克如何通过增强现代数据堆栈(包括部署数据目录工具)来加速关键业务用户访问数据的能力
数据目录用例
以下是数据目录可以支持的一些典型用例:
每个用例都链接到了相关的功能预览,以便您探索和理解这些抽象概念是如何在第三代数据目录工具中体现的。
阅读Brainly如何实施数据目录并优先考虑其采用,以提高整个公司的数据发现能力和治理能力
你什么时候需要购买数据目录工具?

正如Austin Kronz在其关于如何启动数据治理计划的博客中所解释的那样,随着团队的成长,价值实现时间的任何持续增长(例如,季度比季度)都表明你需要投资于数据目录。
引用同一资源:
认识到数据和分析角色增长的拐点以及对价值实现时间的影响,是时候正式化数据治理工作并获取现代数据目录了。如果没有这一点,组织将不得不在招聘上投入过多的资金来手动管理新的数据产品——这在2023年面临的经济条件下是不可能的。
数据目录:深潜资源
我们整理了一些资源,将帮助您找到有关数据目录的更多问题的答案。这些将定期更新。
什么
- 数据目录和数据字典之间的区别是什么?
- 数据目录中的数据沿袭是什么?
- 数据目录的一些用例是什么?
- 什么是企业数据目录?
- 什么是开源数据目录工具?
- Gartner如何看待数据目录?
- What is the difference between a data catalog and a data dictionary?
- What is data lineage in data catalogs?
- What are some use cases of a data catalog?
- What is an enterprise data catalog?
- What are some open-source data catalog tools?
- What does Gartner think about data catalogs?
怎样
- 如何评估数据目录?
- Forrester如何定义企业数据目录?
- 数据目录和仓库是如何协同工作的?
- How to evaluate a data catalog?
- How does Forrester define enterprise data catalogs?
- How do a data catalog and warehouse work together?
为什么?
- 为什么数据目录很重要?
- 为什么传统的数据目录会出现采用问题?
- Why is a data catalog important?
- Why do traditional data catalogs suffer from an adoption problem?
- 42 次浏览
【数据目录】数据目录:您的企业真的需要吗?
视频号
微信公众号
知识星球
数据目录是现代数据管理的支柱,使组织能够有效地查找、理解、信任和使用其数据。继续阅读,了解更多关于什么是数据目录以及为什么在2023年需要数据目录的信息。
目录
- 什么是数据目录
- 什么是数据目录
- 现代数据目录的组成部分
- 数据目录的类型
- 你需要数据目录吗?
- 接下来是什么
- 什么是数据目录:相关阅读
什么是数据目录?
现代数据目录有助于人们查找、理解、信任和使用数据。
例如,假设你在政府卫生部门担任分析师。数据目录可以帮助您:
- 查找相关数据。数据目录可以告诉你需要哪些数据集来分析流感病例。
- 跟踪、跟踪和信任数据。如果你想知道是谁编辑了一个数据集,它有多旧,或者它来自哪里,数据目录会告诉你这一点。
- 合作。如果你需要与另一个部门的人合作来理解和策划你的数据集,该怎么办?这就是协作功能的用武之地,比如共享工作区。
- 共享您的数据。通过发布您的数据和相关元数据,让其他部门可以轻松获得您的发现。
- 实施治理策略和访问控制。强制谁有权访问哪些数据和文件,以遵守《通用数据保护条例》(GDPR)等法规。
一些最常见的数据目录用例包括:
- 高效的数据管理:数据目录通过将不同来源的数据汇集在一起,使众包数据管理变得更容易,因此您可以组织和维护它们。
- 提高数据团队的生产力:数据从业者花费更多的时间来寻找正确的数据,而不是实际使用数据。数据目录通过减少数据搜索和发现所需的时间,大大提高了生产力。
- 统一所有数据上下文:数据目录统一了生态系统中所有数据的上下文,并作为业务的可信语义层。
- 简化员工入职:通过数据目录,让新员工加入组织,让团队成员加入新项目,这是非常高效的,可以让他们轻松、快速、安全地访问有上下文的可信数据。
- 加快根本原因分析:数据目录中的Lineage功能意味着在数据产品出现故障时可以更快地进行故障排除和根本原因分析。
- 简化安全和法规遵从性:数据目录可能是在整个组织中简化数据安全和法规遵循性的唯一也是最简单的方法。

数据目录不是什么
- 数据清单。与数据目录不同,数据清单通常是一种静态资产,没有搜索等功能。
- 数据仓库。数据目录并不像数据仓库那样被设计成持久性和访问层。
- 业务术语表。业务术语表有助于为数据存储中使用的术语定义通用语言,并与数据目录一起使用。
- 数据字典。与数据词汇表一样,字典帮助用户理解数据的语义,但不提供编目功能。
- 一个数据湖。数据湖和数据仓库一样,都是持久层。它们不一定会组织或帮助用户使用它们所包含的数据。
数据目录的组件
- 数据搜索和发现:一种与搜索信息或在线购买物品一样直观的搜索体验。具有推荐、信任信号和过滤功能的Replete
- 业务术语表:业务术语表,包括关键数据元素,如定义、类别、用法、所有者详细信息,以及为数据资产添加上下文的其他信息
- 数据沿袭:自动可视化沿袭,以跟踪数据流及其在整个生命周期中所经历的转换
- 协作:一个无缝融入数据团队日常工作流程的工作空间,简化了数据共享和访问请求监控
- 数据治理:能够为细粒度控制设置工作流,以根据角色、资产类型、分类等限制访问
- 集成:与数据堆栈中所有关键组件和工具的本机或API驱动集成
1.数据发现和搜索
多亏了谷歌、亚马逊、奈飞、优步和其他公司,我们的搜索体验发生了根本性的变化。如果你在网上买一件t恤,如果你的搜索结果随机返回34亿,你会大笑起来。
你期望最相关的结果对你来说是顶尖的。你也知道,与你相关的事情可能与你儿子无关——你的需求和经历会有所不同。
同样,当考虑购买东西时,你需要背景。你想阅读其他人的评论,看看他们在不同天气下穿着t恤的照片,等等。
这是2023年,您的团队在搜索要使用的数据资产时,希望您的数据目录也能如此。他们期望:
- 像谷歌一样快速返回搜索结果
- 一个数据目录,可以知道他们何时拼写错误
- 使用业务上下文进行筛选
- 对数据的信心
- 了解数据资产的使用行为、沿袭可见性和验证状态
了解更多信息→ 检查数据发现和搜索在数据目录中的实际效果。

2.术语表
业务术语表有助于定义、标准化和上下文化数据资产,以便每个人都说相同的语言。
因此,您可以停止提问,例如:
- “这个数据资产意味着什么?”
- “这份报告中的Y代表什么?”
- “Y和X有什么不同?”
早在2017年,爱彼迎的Chris Williams和John Bodley就曾著名地谈到部落知识(tribal knowledge)扼杀了数据团队的生产力。没有上下文的数据是无用的。
想想你团队中试图理解“salesfigureNA_f.”的新成员,或者你在另一个大陆的团队成员,他一直在阅读英制数字,而你所有的计算都是公制的。两者都需要一个词汇表才能达到相同的目的。
Business glossary: A centralized knowledge bank that explains key business terms and concepts. Source: Atlan.
3.数据沿袭
数据目录中的数据沿袭功能提供了对数据起源及其生命周期演变的可见性。
最好的数据目录工具可确保:
了解更多信息→ 数据沿袭的重要性、用例和好处。
 Data lineage helps you understand the journey of data from its source to dashboards
Data lineage helps you understand the journey of data from its source to dashboards
4.协作
数据目录将所有东西汇集在一起——来自不同来源的数据、数据的智能(机器+人类)、生产和消费数据的人以及他们所使用的工具。协作使这种融合成为可能。
现代数据目录允许用户在日常工作流程中直观地行动(协作):
- 标记团队成员,要求他们向数据资产添加更多上下文
- 将有关数据资产的Slack对话引入目录本身
- 提出JIRA票证以解决管道破裂问题
了解更多信息→ 体验嵌入式协作如何在数据生态系统中带来重要的“流量”。

5.数据治理
正确且维护良好的数据资产清单(传统目录)可能是治理的良好起点。然而,考虑到现代企业中数据的速度、数量和复杂性,这是不够的。
我们需要将治理政策嵌入日常工作流程的数据目录,而不是事后思考。现代数据目录明白,数据治理需要从底层开始。它必须由从业者主导,而不是自上而下地处理。
对于部署数据目录工具来说,实现一个健壮的数据治理程序是一个巨大的业务案例。这就是为什么企业会寻找能够让他们通过设计进行管理的数据目录。
这是如何表现的?以下是一些例子:
- 灵活反映团队工作方式
- 能够实现基于域、基于角色和基于目的的访问策略
- 敏感数据的自动识别
- 通过沿袭自动传播自定义分类
了解更多信息→ 数据目录如何启用和自动化主动数据治理。
 A data catalog helps automate the propagation of PII classifications through data lineage
A data catalog helps automate the propagation of PII classifications through data lineage
6.集成
我们前面提到过,但值得重复:数据目录必须与现代数据堆栈中的所有关键数据源和工具集成,才能使用元数据。
数据目录通常与以下内容集成:
- 数据源-数据仓库(如Snowflake)、关系数据库(如MySQL)和lakehouses(如Databricks等)。
- 转换引擎-dbt云,dbt核心。
- 商业智能工具-Looker、Power BI、Tableau。
默认情况下,现代数据目录也是打开的。它们具有可扩展性和可定制性。除了支持本机集成外,它们还使数据工程师能够使用开放API从其他来源引入元数据。
了解更多信息→ 了解开放API和机器人程序如何帮助自动化数据文档。
数据目录的类型
目前主要有两种类型的数据目录工具可用:
- 企业数据目录软件
- 开源数据目录工具
企业数据目录软件是现成的解决方案,从一开始就提供无缝的用户体验。他们还通过入职培训和研讨会提供支持,以推进您的数据启用计划。
Forrester最近发布了DataOps报告的企业数据目录,以帮助数据领导者评估和确定适合其数据生态系统的最佳数据目录软件。他们认为,客户应该寻找以下企业数据目录软件:
- 处理数据和元数据的多样性、粒度和动态特性。
- 对数据流和交付的性质和路径产生深刻的透明度。
- 提供增强现代数据操作和工程最佳实践的用户界面/用户体验。
该报告还根据26项评估标准对14个最突出的企业数据目录进行了评估。
该报告强调了企业数据目录解决DataOps用例的重要性:
企业数据目录创建了数据透明度,使数据工程师能够实施DataOps活动,开发、协调和编排数据策略和控制的供应,并管理数据和分析产品组合。
了解更多信息→ 企业数据目录:发现、协作、数据操作和治理
开源数据目录工具通常是由大型科技公司构建的,作为他们自己的数据发现和目录解决方案,后来为外部团队开源。
示例包括:
如何评估数据目录工具?
评估数据目录可能会带来很多问题。我们已经确定了一个5步框架,以帮助简化您的数据目录评估。
- 确定您的组织需求和预算
- 创建评估标准
- 了解市场上的供应商和产品
- 入围并演示潜在的解决方案
- 执行概念验证(POC)
你需要数据目录吗?
许多组织将从数据目录中受益。但您可能需要的一些具体迹象包括数据团队:
- 是否花费大量时间来确定要使用哪些数据集,或使用不同的数据集
- 跨多个源管理数据,如数据湖、数据库和仓库
- 对于哪些数据集是正确使用的存在分歧
- 将受益于记录有关其数据集的机构知识
- 对数据治理有安全或法规要求
- 正在考虑为企业主提供数据民主化和自助服务
 The bottom of this curve is the ideal time to buy a data catalog.
The bottom of this curve is the ideal time to buy a data catalog.
接下来是什么
部署数据目录将启动组织中数据民主化和数据启用的种子进程。它表明您的组织非常重视数据价值的最大化。它还认识到,当我们为组织中不同的数据用户创造一个公平的竞争环境时,我们可以从数据中提取更多。数据目录是这一包容性举措的起点。
你正在为你的组织寻找数据目录吗?你可能想看看Atlan。
原因如下:
- 最新的Forrester报告将Atlan评为DataOps企业数据目录的领导者,在17项评估标准中给予了最高的分数,包括产品愿景、市场方法、创新路线图、性能、连接性、互操作性和可移植性。
- Atlan与现代数据堆栈中最好的解决方案进行深度集成并建立合作伙伴关系。在这里查看我们的合作伙伴。
- Atlan已经得到了世界上一些最好的数据团队的喜爱和信心,包括WeWork、Postman、Monster、Plaid和Ralph Lauren等。在这里查看我们的客户对我们的评价。
什么是数据目录:相关阅读
- Enterprise data catalog: Definition, Importance & benefits
- Data catalog benefits: 5 key reasons why you need one
- Open Source Data Catalog Software: 5 Popular Tools to Consider in 2023
- Data Catalog Platform: The Key To Future-Proofing Your Data Stack
- Top Data Catalog Use Cases Intrinsic to Data-Led Enterprises
- AWS Glue Data Catalog: Architecture, Components, and Crawlers
- Airbnb Data Catalog — Democratizing Data With Dataportal
- Lexikon: Spotify’s Efficient Solution For Data Discovery And What You Can Learn From It
- Google Cloud Data Catalog Guide - Everything You Need to Know
- 73 次浏览
【数据目录】用383行Python构建数据目录
视频号
微信公众号
知识星球
数据分析师、数据科学家、工程师甚至业务用户经常需要深入了解其组织数据的细节。该领域的供应商让数据目录听起来真的很花哨——例如,Atlan说“数据目录是一个协作工作空间,供不同的数据用户在企业的数据生态系统中导航。”什么?更简单地说,数据目录是我的数据集列表和其中内容的描述。
以下是数据目录可以帮助人们的一些方法-
- 查找正确的表和列(数据发现)
- 调试数据质量问题
- 编写SQL查询
已经有许多数据目录可用——既有开源的(Amundsen, DataHub),也有商业的(Atlan, Alation, Collibra)。但它们通常非常重,不可能或很难为您自己的组织进行定制。其中一些每年的成本高达10万美元!
相反,如果您可以使用不到400行纯Python的全功能(尽管有点基础)数据目录,并为您的组织定制它,会怎么样?让我们深入了解一下。
Links: Live App | Github | Youtube | Pycob | Google Slides
<yt视频>
应用程序演示
对于我们的演示,我们将使用Northwind数据库。根据链接的Github-
Northwind示例数据库由Microsoft Access提供,作为管理小企业客户、订单、库存、采购、供应商、运输和员工的教程模式。Northwind是小型企业ERP的优秀教程模式,包括客户、订单、库存、采购、供应商、运输、员工和单项会计。
表和关系如下所示。

对于我们的数据目录应用程序,我们在数据目录中有两个主页面——一个显示表列表,另一个显示每个表的内容。
第一页是表格列表,以及一些基本信息,如表格描述、行数、表格上次更新的时间等。它还有一个链接,可以查看有关表格的详细信息。

如果我们点击订单表,它会将我们带到表格详细信息页面。我们可以看到一些基本信息,比如行数(830)。
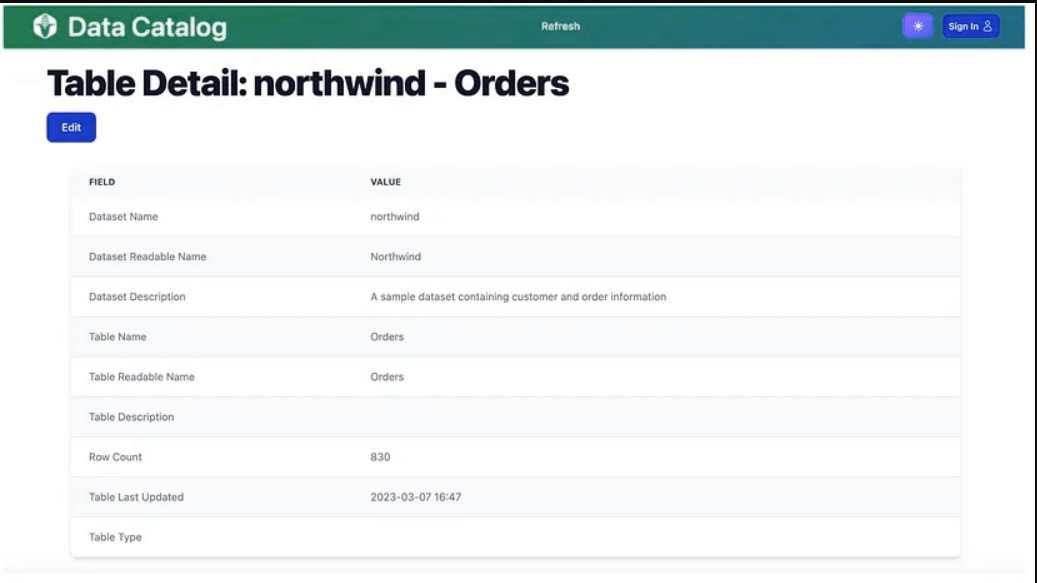
在下面,我们看到了该表中的列列表,以及一些有用的列元数据,如名称、数据类型、最小值、最大值、空值数量等。

最后,我们有几行示例数据。这让用户能够了解表中的内容。

最后,底部有一个指向“编辑表元数据”的链接。编辑页面的第一部分允许用户编辑表级信息-

第二部分允许用户在单个屏幕中编辑每个列。这对于数据分析员希望同时添加多个列的信息的工作流非常有用。

最后,注意顶部的“刷新”按钮。此按钮将通过重新读取数据库并更新表、列和统计信息来刷新数据目录中的信息。

架构
让我们从技术角度来看看这一切是如何结合在一起的。

我们有四种主要的数据结构-数据集、数据集、表、列
此外,我们还有五个页面——tables、refresh、edit、table_detail和update。
代码
接下来我们将逐步了解一些重要的代码。
首先,让我们看看数据集的数据类。我们有四个字段,包括表列表。我们还有两个函数,一个如下所示,它将表转换为DataFrame。
@dataclass
class Dataset:
name: str
readable_name: str
description: str
tables: list[Table]
def to_dataframe(self) -> pd.DataFrame:
records = []
for table in self.tables:
row = {}
row['dataset_name'] = self.name
row['dataset_readable_name'] = self.readable_name
row['dataset_description'] = self.description
row['table_name'] = table.name
row['table_readable_name'] = table.readable_name
row['table_description'] = table.description
row['row_count'] = table.row_count
row['table_last_updated'] = table.last_updated.strftime("%Y-%m-%d %H:%M")
row['table_type'] = table.type
records.append(row)
return pd.DataFrame(records)然后,我们获取我们的云泡菜,利用Pycob功能,使我们能够轻松地保存和读取云泡菜-
# PyCob has a built-in cloud pickle feature that allows you to save and load objects to the cloud.
dsets: Datasets
try:
print("Loading from cloud pickle")
dsets = app.from_cloud_pickle("northwind.pkl")让我们来看看一些刷新代码的内核。我们使用一些SQL命令(SQLite)来获取有关表和列的信息。
for table_name in tables['name']:
# Get table metadata
# Get columns
columns = pd.read_sql_query(f"PRAGMA table_info('{table_name}')", conn)
# Remove the "Picture" or "Photo" column from the sample data
columns = columns[columns['name'] != 'Picture']
columns = columns[columns['name'] != 'Photo']
page.add_pandastable(columns)
sample = pd.read_sql_query(f"SELECT * FROM \"{table_name}\" LIMIT 10", conn)既然我们已经将数据存储在云pickle中,并且已经读取了该pickle,那么让我们显示这些表。add_datagrid做了一些肮脏的工作,并在应用程序上呈现了一个漂亮的表小部件。
def tables(server_request: cob.Request) -> cob.Page:
page = cob.Page("Tables")
page.add_header("Tables")
if dsets is None:
page.add_alert("Refresh required", "Error", "red")
return page
action_buttons = [
cob.Rowaction(label="View", url="/table_detail?dataset_name={dataset_name}&table_name={table_name}", open_in_new_window=False),
]
page.add_datagrid(dsets.to_dataframe(), action_buttons=action_buttons)
return page接下来,让我们看看table_detail页面的内容。在这里,我们对add_pandastable进行了三次调用,并在页面上呈现了表元数据、列列表和示例数据。
table_df = dset.to_dataframe().iloc[table_index,:].reset_index()
table = dset.tables[table_index]
table_df.columns = ["Field", "Value"]
# Make the field names more readable
table_df['Field'] = table_df['Field'].map(lambda x: x.replace("_", " ").title())
page.add_pandastable(table_df)
page.add_header("Columns", size=2)
page.add_pandastable(table.to_dataframe())
page.add_header("Sample Data", size=2)
page.add_pandastable(table.sample)
page.add_link("Edit Table Metadata", f"/edit?dataset_name={dset.name}&table_name={table_name}")最后是编辑页面。在这里,我们有特定于表的值以及一个循环来获取所有列可编辑字段。
with page.add_card() as card:
card.add_header(f"Edit")
card.add_header(f"{dset.readable_name} - {table.readable_name}", size=2)
with card.add_form(action="/update") as form:
form.add_formhidden("dataset_name", value=dataset_name)
form.add_formhidden("table_name", value=table_name)
form.add_formtext("Dataset Readable Name", "dataset_readable_name", value=dset.readable_name)
form.add_formtext("Table Readable Name", "table_readable_name", value=table.readable_name)
table = dset.tables[table_index]
form.add_formselect("Table Type", "table_type", options=["Fact", "Dimension"], value=table.type)
form.add_formtextarea("Table Description", "table_description", placeholder="Table Description", value=table.description)
for column in table.columns:
form.add_text(f"Column <code>{column.name}</code>")
with form.add_container(grid_columns=2) as container:
container.add_formtext(f"Readable Name", f"column_{column.name}_readable_name", value=column.readable_name)
container.add_formtextarea(f"Description", f"column_{column.name}_description", value=column.description, placeholder="Column Description")
form.add_formsubmit("Save")部署
现在我们已经在本地机器上运行了该应用程序,让我们将其部署到Pycob的云主机上,以便我们组织中的其他人可以访问它。部署非常简单,只要有了API密钥,只需一步。你所需要做的就是-
python3 -m pycob.deploy
等待大约5分钟,应用程序就可以在服务器上运行了!
在您的组织中使用数据目录应用程序
为了使其适合您的组织,您可能需要进行许多修改和增强。整个应用程序是100%免费和开源的,可以在您的环境中本地运行,也可以通过Pycob外部托管。您可能需要进行一些更改-
- 自定义连接字符串。这是强制性的-你不想要Northwind的数据:)。
- 向列和表中添加更多计算。
- 安排更新自动运行。
- 100 次浏览
【数据目录】语义数据目录:释放本体论和向量搜索的力量来导航数据网格
视频号
微信公众号
知识星球
关键词:埃森哲实验室,语义搜索,数据目录,矢量搜索,数据网格
随着数据越来越成为组织运营的基础,数据目录对于管理和利用数据资产变得至关重要。数据目录允许用户根据各种标准搜索和发现相关数据,例如数据资产的名称、元数据和相关的业务术语。现有的数据目录通常依赖于简单的字符串匹配技术,这可能会限制它们理解目录中概念的含义和关系的能力。这可能导致在搜索目录时丢失可能有用的数据资产。
为了增加复杂性,管理数据的新范式,如数据网格范式,要求公司构建按域组织并由不同组织单位管理的数据产品。这些数据重组在搜索数据时带来了新的挑战,因为不同领域专家创建的数据产品可能会导致相似的概念以不同的方式表达。
语义数据目录为上述挑战提供了解决方案,因为它为组织管理分布式数据产品提供了一个框架,可以使用语义搜索引擎从集中式公共目录中有效地搜索分布式数据产品。
在本博客中,我们介绍了语义数据目录框架,该框架利用本体、本体嵌入和向量搜索的力量,使用语义搜索来改进数据发现和管理。
使用语义数据目录的潜在好处包括:
- 提高了搜索的准确性和相关性:通过理解概念的含义及其之间的关系,语义数据目录可以提供更准确、更相关的搜索结果。
- 增强的数据发现:语义数据目录可以帮助用户找到他们可能不知道的数据资产,或者使用传统技术可能不容易发现的数据资产。
- 更好的数据组织和分类:通过利用本体作为语义数据目录的关键部分,它可以帮助数据资产的组织和分类,从而形成更结构化和一致的数据环境。
- 增强的数据治理:通过提供对数据概念的含义和关系的清晰理解,语义数据目录可以帮助组织更好地管理和利用其数据。
- 更高的效率和生产力:通过让用户更容易找到和访问相关数据,语义数据目录可以帮助提高数据驱动任务的效率和生产率。
下面,我们介绍了构建简单语义数据目录的一般方法,并提供了示例代码。由于在构建目录方面存在许多挑战,本博客不会解决所有问题,但会尝试突出需要解决的问题。
构建语义数据目录。
我们从构建语义数据目录的步骤的高级概述开始。首先,我们创建一个本体目录,它为每个数据资产保存一个本体。本体表示数据资产内和数据资产之间的概念和关系。其次,我们在目录上训练本体嵌入模型,以生成数字向量,或捕捉概念的含义和关系的“嵌入”。第三,我们将嵌入加载到向量搜索引擎中,该引擎允许用户使用文本搜索查询来搜索目录中的数据资产。最后,给定用户(无论是数据工程师、数据科学家还是业务用户)的查询,我们使用模型嵌入查询,并使用向量搜索引擎检索到大多数相关概念。下图展示了语义数据目录的高级架构。
与基于字符串匹配和预定义搜索标准搜索目录的传统方法不同,语义数据目录可以使用本体嵌入技术提供更准确和相关的搜索结果。
嵌入可以随着时间的推移进行调整,以适应目录中的变化,或者进一步改进搜索结果,并允许组织更好地利用其现有的数据资产。
在这个博客中,我们描述了实现语义数据目录所需的主要步骤。正在运行的示例是为了说明目的,而不是作为一个完整目录的实现。
第一步:创建本体目录
数据目录通常包含各种类型的数据资产,从结构化数据集(例如,csv表)到高度规范化的数据集(如,第三范式),到半结构化(例如,json模式),再到非结构化数据集中(例如,blob存储上的文档)。
为了能够有效地在各种各样的数据资产中进行搜索,我们为每个数据资产创建了一个本体。本体是一个领域内一组概念和关系的形式表示,通常使用形式语言来表达。在我们的上下文中,我们创建本体来建模数据资产中的概念和关系,并在不同数据资产中连接概念。这些本体将作为我们数据资产之上的语义层。
为数据资产创建本体需要数据建模师和了解数据资产的专家共同工作,直到获得合适的概念本体。虽然这一过程可能需要大量人力,但通过利用自动化本体创建过程的工具(例如,Anzo、Stardog有一些产品),以及从公共本体库(例如,FIBO、D3FEND)借用概念,可以大大加快这一过程。
运行示例。在我们的运行示例中,我们将使用一个虚构的公司,它有三个数据资产,由三个公共本体描述:Edas(学术领域)、GoodRelations(商业领域)和Pizza(食品领域)。
A high-level view of the D3FEND Ontology in prote’ge’
评论虽然存在几种用于指定本体的语言,但W3C(万维网联盟)的OWL(网络本体语言)因其简单、可用的编辑器(例如prote'ge')以及数据管理平台(Anzo、Stardog、Neo4j、TopBraid等)的支持而脱颖而出。在我们的上下文中,最重要的是,一些最先进的本体嵌入技术要求本体用OWL编写。正如我们在下一节中所展示的那样,这一点至关重要。
第二步:在目录上训练本体嵌入模型
创建本体目录后,我们可以为本体中定义的每个概念(类、数据属性、对象属性等)创建嵌入。为此,我们可以使用预先训练的大型语言模型(Word2Vec、BERT)或本体嵌入技术(OWL2VEC*、EL嵌入和量子嵌入)。
在这个博客中,我们将使用牛津大学的开源库OWL2VEC*。OWL2VEC*获取一个本体目录,并构建一个嵌入本体的模型。关于如何做到这一点的详细信息以及对代码的访问可以在这里找到。
我们将目录中的本体放在一个目录中,并在本体上训练模型。训练完成后,嵌入模型被存储到一个文件中。
运行示例。我们克隆了OWL2VEC*项目,并将我们的示例本体放入/克隆项目中的ontologies目录。我们将该工具配置为使用预先训练的语言模型Word2Vec,并运行以下命令根据我们的本体对模型进行微调。
# Clone the OWL2Vec* project, follow the installation instructions # git clone https://github.com/KRR-Oxford/OWL2Vec-Star.git # 1. Create dir 'OWL2Vec-Star/ontologies' and place the ontologies. # 2. Create an empty directory 'OWL2Vec-Star/output' # 3. In 'OWL2Vec-Star/default_multi.cfg': # a. Uncomment the line starting with "pre_train_model =" and set the path of the local file of a pre-trained WORD2VEC model (inlude all extracted files in the same directory) # b. Comment the line starting with "cache_dir = " # c. change the training parameters: embed_size = 200; epoch = 200 # The following line will use OWL2VEC* to fine-tune the word2vec model on all ontologies in ./ontologies, and saves the trained model in ./output/multi_word2vec !python OWL2Vec_Standalone_Multi.py --ontology_dir ./ontologies --embedding_dir ./output/multi_word2vec --URI_Doc --Lit_Doc --Mix_Doc # This may take a few minutes # Install faiss, a vector search library by facebook # !pip install --upgrade pip # !pip install faiss-cpu
生成的模型存储在中/输出/multi-word2vec。
评论。
- 默认情况下,OWL2VEC*被训练来创建用于本体论概念(继承和类成员关系)之间的链接预测的嵌入。尽管如此,我们还是发现它的嵌入对搜索非常有效。这可能是由于它使用的底层语言模型(Word2VEC),该模型是在整个维基百科上训练的。
- OWL2VEC*生成的嵌入在很大程度上受到语言模型和本体嵌入配置参数的影响。因此,建议进行实验,直到产生适当的嵌入。
- 为了测试嵌入,您可以创建一个查询和匹配概念的小测试集。为了测量嵌入的准确性,您可以使用搜索引擎的常用度量,如平均倒数排名和命中率。
步骤三:将本体嵌入加载到向量搜索引擎
在为我们的本体创建嵌入之后,我们准备将模型和本体加载到向量搜索引擎中。为此,我们可以使用像FAISS这样的矢量搜索包,也可以使用像Pinecone这样的成熟矢量数据库。在矢量搜索引擎中,我们创建可搜索的索引。每个索引存储一组可以有效搜索的向量。
为了填充我们的索引,我们对本体的实体进行迭代,并使用模型生成添加到索引中的嵌入。
运行示例。在下面的代码片段中,我们创建了一个索引,其中包括所有本体的类,以及每个本体的单独索引。
首先,我们定义了一些辅助函数来规范化和嵌入文本。
from typing import List, Tuple, Dict, Union
import numpy as np
from gensim.models.word2vec import Word2Vec
# split string in camel notation to a list of words, and convert it to lower case as words in our model aer lower-cased
def parse_camel_plus(string: str) -> List[str]:
matches = re.finditer('.+?(?:(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])|$)', string)
words = [m.group(0) for m in matches]
return [word.lower() for word in words]
# function to produce an embedding for a sentence by averaging the word embeddings
def embed_text(sentence:Union[str,List[str]], model:Word2Vec) -> np.ndarray:
# make sure sentence is a list of words
if isinstance(sentence, str):
sentence = sentence.split()
# init a vector of zeros to sum word embeddings, and defined known_words counter
emb_sum = np.zeros(model.vector_size, dtype=np.float32)
known_words = 0
# sum up embeddings of words known by the model
for word in sentence:
if word in model.wv.index_to_key:
emb_sum += model.wv.get_vector(word)
known_words += 1
# if there was at least one known word, return average embedding of all words
if known_words:
return emb_sum / known_words
else:
raise ValueError("no words recognized in the given sentence")然后,我们准备嵌入。我们加载模型和本体。我们使用owlready2从本体中解析和提取类,并使用模型嵌入类。我们为每个类创建两个嵌入,一个基于IRI的编码,另一个基于其标签。
import re
import gensim
import owlready2
# use the environment in which OWL2VEC* is installed and load model and ontologies
model = gensim.models.Word2Vec.load('./output/multi_word2vec')
ontologies:List[owlready2.Ontology] = [owlready2.get_ontology('./ontologies/'+onto_path).load() for onto_path in os.listdir('./ontologies')]
# Create an embedding dictionary per ontology.
# Map each ontology to a list of mappings for its classes, from class identifiers (IRI) to vector embeddings.
# Create two embedding per class based on the IRI and its label.
onto_iri2embeds:Dict[str,List[Tuple[str,np.ndarray]]] = dict()
for onto in ontologies:
onto_iri2embeds[onto.base_iri] = list()
for cls in onto.classes():
onto_iri2embeds[onto.base_iri].append((cls.iri, model.wv.get_vector(cls.iri)))
try:
cls_name = ' '.join(parse_camel_plus(cls.name))
onto_iri2embeds[onto.base_iri].append((cls.iri, embed_text(cls_name, model)))
except ValueError:
pass最后,我们创建了几个搜索索引,以支持按标准进行文本搜索。每个索引都是使用FAISS创建的。
import faiss
from faiss.swigfaiss import IndexFlatIP
from itertools import chain
# Create a faiss index out of a list of embedding mappings
def create_index(embeddings: List[Tuple[str,np.ndarray]], model: Word2Vec) -> IndexFlatIP:
# make 2D array of all embeddings
embeddings = [embedding[1] for embedding in embeddings]
embeddings_2d = np.stack(embeddings, axis=0)
# create a faiss search index, and add give embeddings to it
search_index = faiss.IndexFlatIP(model.vector_size)
search_index.add(embeddings_2d)
return search_index
# Create a dictionary of Faiss indices.
# Creat an index for all classes, and index per ontology
name2faiss_index:Dict[str, IndexFlatIP] = dict()
all_embeddings = list(chain.from_iterable(onto_iri2embeds.values()))
name2faiss_index['All'] = create_index(all_embeddings, model)
for ontology_iri in onto_iri2embeds:
name2faiss_index[ontology_iri] = create_index(onto_iri2embeds[ontology_iri], model)评论。
- 为了支持过滤搜索,我们定义了多个索引。Pinecone提供了一个支持过滤搜索的矢量数据库。这消除了创建专用过滤器的需要。
- 要包括其他本体论实体(如个人、数据属性或对象属性),只需扩展索引即可。
第四步:围绕搜索引擎索引构建包装并运行查询
为了激活我们的搜索引擎,我们可以实现一个带有查询挂钩的API或一个CLI,它可以触发系统根据文本查询生成顶级匹配的本体实体。
给定搜索查询和搜索条件,我们从匹配索引中检索最相关的实体。我们将使用我们的模型嵌入查询,并使用搜索引擎返回最匹配的实体。
运行示例。下面是一个简单的代码片段,它使用我们的训练模型和相关索引来运行文本查询。
首先,我们使用helper函数并嵌入查询。然后,我们使用相关的FAISS索引(在我们的示例中为“All”)来获得最匹配的实体。
以下是对所有目录本体的示例查询:
# query = 'onion' over entire catalog
query = 'spicy'
query_emb = embed_text(query, model).reshape(1,-1) # reshape because that's how faiss expect to receive it
scores, indexes = name2faiss_index['All'].search(query_emb, 5) # faiss returns similarity scores and indexes of the closest vectors
results = [all_embeddings[ind][0] for ind in indexes[0]] # get entity IRIs of the closest vectos
for result in results:
print(result)http://www.co-ode.org/ontologies/pizza/pizza.owl#SpicyTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#SpicyPizza
http://www.co-ode.org/ontologies/pizza/pizza.owl#SauceTopping
http://edas#MealMenu
http://www.co-ode.org/ontologies/pizza/pizza.owl#Food
可以看出,我们从pizza本体获得了四个点击,从edas本体获得了一个点击。
这是相同的查询,但仅在披萨本体上搜索。
# 'onion' query over the pizza ontology
query = 'onion'
query_emb = embed_text(query, model).reshape(1,-1) # reshape because that's how faiss expect to receive it
scores, indexes = name2faiss_index['http://www.co-ode.org/ontologies/pizza/'].search(query_emb, 5) # faiss returns similarity scores and indexes of the closest vectors
ontology_embeddings = onto_iri2embeds['http://www.co-ode.org/ontologies/pizza/']
results = [ontology_embeddings[ind][0] for ind in indexes[0]] # get entity IRIs of the closest vectos
for result in results:
print(result)
name2faiss_index.keys()
http://www.co-ode.org/ontologies/pizza/pizza.owl#OnionTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#RedOnionTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#GarlicTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#ChickenTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#Soho
挑战
在本博客中,我们介绍了构建语义数据目录的主要步骤,并提供了一个运行示例进行说明。我们在不同步骤中添加了一些考虑因素。尽管如此,重要的是要注意到,还有更多的考虑因素和挑战需要解决。首先,训练高质量的本体嵌入模型并在添加新的数据资产时保持其准确性需要时间和计算资源。此外,评估嵌入的有效性并随着目录的发展更新搜索索引是确保检索到相关结果的关键。应对这些挑战可能需要作出重大努力。我们希望,随着矢量搜索数据库成为更成熟的技术,其中一些挑战将随着时间的推移得到解决。尽管如此,为了充分发挥语义数据目录的潜力,必须考虑和解决这些挑战。
- 结束语。在这个博客中,我们描述了语义数据目录,它提供了一种强大而有效的方法来管理和发现数据网格中的数据。使用本体有助于数据资产的组织和分类,并改善数据治理,而基于本体的向量搜索可以提供更准确和相关的搜索结果,以提高数据利用率。语义数据目录也带来了一些新的挑战,我们在本博客中列出了其中的一些挑战。如果您希望改进数据管理策略,请考虑实现语义数据目录,以最大限度地发挥数据资产的全部潜力。无论您是数据工程师、数据科学家还是业务用户,语义数据目录都可以提供丰富的好处,帮助您更好地利用数据来推动更多见解和成功。
- 147 次浏览