【人工智能】超越ChatGPT的炒作
视频号

微信公众号

知识星球

想象一下,在一个公司会议室里,一个高管领导团队聚集在董事会的桌子旁——有些是面对面,有些是在屏幕上。在通常的闲聊中,有一个议程项目神秘地命名为“聊天GPT”。
这位首席执行官率先指出,主要竞争对手再次获得了他们的支持,他们发布了新闻稿,宣布在客户服务、软件开发、营销、法律咨询和销售方面采用了新的基于人工智能的聊天机器人,这意味着他们正在大幅节省成本。市场分析师对这一消息表示欢迎,他们全面上调了股票评级。
这位首席技术官将她的笔记本电脑插入屏幕,并以米奇·拉特克利夫1992年在《技术评论》中的一句名言开始了她的演讲:“除了手枪和龙舌兰酒,电脑可以让你比任何其他发明更快地犯更多的错误。”
董事会的桌子周围有几个困惑和失望的面孔…
___
OpenAI的ChatGPT自2022年11月推出以来,受到了极大的关注。人们的反应各不相同。许多人对它能够快速完成耗时的任务感到惊讶,比如撰写专业散文、学术论文,甚至产品策略。另一方面,随着利益集团和专业人士对ChatGPT进行集体压力测试,其局限性变得显而易见。从制作中间立场、编造东西、编写错误率很高的代码,甚至制作不道德的内容,对于每一个关于ChatGPT能力的热情故事,都有同样多的人强调需要克制和谨慎。
在这个由两部分组成的系列中,我们借鉴了Thoughtworks在提供人工智能系统方面的经验,以揭开ChatGPT背后的技术神秘面纱。我们将介绍它可能的应用、它的局限性以及对那些正在考虑围绕生成语言模型构建业务能力的组织的必然影响。但首先,让我们仔细看看它是如何实际工作的。
ChatGPT的工作原理
ChatGPT是一种大型语言模型(简称LLM,有时也称为生成语言模型)。在讨论LLM的优势和局限性之前,简要描述一下它们是如何工作的,这很有帮助。
LLM令人眼花缭乱的大部分内容都归结为下一个“象征性”(即单词)预测。LLM是在大量文本数据(通常称为“语料库”)上进行训练的。通过这个训练过程,该模型建立了单词或“嵌入”的内部数字表示,这样它就可以预测任何给定单词或短语的下一个最可能的单词。
例如,如果我们给一个经过训练的语言模型一个提示,“Mary had a”,并让它完成句子,我们本质上是在问它:哪些单词最有可能遵循“Mary had a…”的顺序?任何对童谣稍有熟悉的人都会知道答案是“小羊羔”。
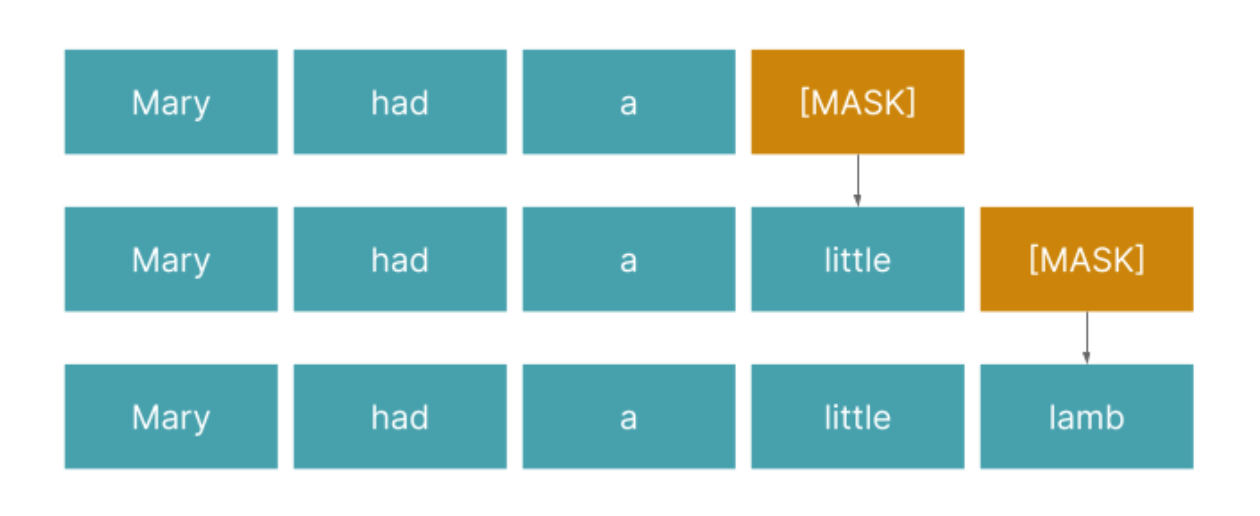
Figure 1: LLMs are able to generate sentences and whole essays through its ability to predict the next highest-probability candidate word for any given word or phrase. It learns to do so through techniques such as masked language modeling.
ChatGPT与早期的LLM(如GPT-2)不同之处在于,它引入了一种额外的机制——从人类反馈中强化学习(RLHF)。这意味着人类注释器进一步训练LLM,以减轻其训练数据中存在的偏差。
这列火车不是每站都停:大型语言模型的局限性
ChatGPT不可思议的文本生成能力无疑激发了许多人的想象力:我如何利用或重新创建像ChatGPT这样的工具来为我的业务创造价值?然而,谷歌Bard和微软的ChatGPT Bing最近的失误凸显了LLM的局限性;当我们在生成性人工智能项目上投入资金和时间时,需要正确理解这些,以设定预期并避免失望。考虑到这一点,让我们看看LLM的三个关键限制。
1.它们是复杂但具有概率的自动完成机( auto-complete machines)
LLM本质上是一种“自动完成”机器,使用复杂的模式识别方法进行操作。它模仿并重建了它训练过的散文,但它这样做是有可能的;这就是为什么它经常会犯错误,甚至编造“事实”或编造参考文献。这些所谓的“幻觉”并不是一种失常——它是任何生成系统固有的行为。
正如我们的同事David Johnston在LinkedIn上解释的那样,它不能也不应该完成需要逻辑推理的任务。你会用一个不会数学的工具来提供财务建议吗?
2.他们的文本生成能力不适合容错率低的环境
第一个限制的必然结果是,LLM的文本生成功能不太适合“容错率”较低的任务。例如,法律写作和税务建议的容错率较低,是需要专业知识、责任感和信任的高度具体的用例,而不仅仅是页面上的文字。此外,这样的场景通常保证了事实上的准确性,而不是概率上的写作。
另一方面,创造性写作等任务在某些情况下可能具有很高的容错性,LLM的高方差实际上可能是一个特征,而不是一个缺陷,因为它可以帮助生成人类以前没有考虑过的创造性和有价值的选项。即便如此,人类的节制也是绝对必要的,以避免你的客户接触到无拘无束的、可能产生幻觉的聊天机器人反应。
话虽如此,LLM除了ChatGPT众所周知的自由格式、基于提示的文本生成功能之外,还有其他有用的功能。其中包括分类、情感分析、摘要、问答、翻译等。自2018年以来,BERT和GPT-2等LLM已经可以在这些自然语言处理(NLP)任务上取得最先进的成果。这些功能范围更窄,更易于测试,可以应用于解决业务问题,如知识管理、文档分类和客户支持等。
3.数据安全和隐私风险
您的组织和客户的数据的移动和存储可能会受到法律和法规的限制。ChatGPT在知识工作者中的广泛使用带来了将机密数据暴露给第三方系统的严重风险。这些数据将用于训练未来发布的OpenAI模型,这意味着它可能会被重新灌输给公众。
那么,这会给我们留下什么呢?
ChatGPT的局限性并不意味着我们应该抹杀生成人工智能在解决重要问题方面的潜力。然而,通过意识到这些局限性,我们可以确保我们对它实际能提供什么有现实的期望。在考虑使用生成语言模型来解决业务问题时,以下是一些高级指南:
-
从具有高容错性的业务用例开始
- 在特定领域的数据上微调预先训练的LLM(也称为迁移学习)。使用安全的云基础设施或经批准的PaaS或MLaaS技术以及必要的数据安全和隐私控制来创建与您的业务领域相关的模型
- 确保LLM始终由能够验证和调节其内容的人员进行监控(尽管似乎不是每个人都会记得这样做)
即使牢记这些准则,重要的是要记住,培训高质量的生成语言模型在计算、测试、部署和治理方面成本高昂且具有挑战性。因此,我们应该小心,不要落入技术至上的陷阱——我们有一把闪亮的锤子,我们能用它打什么?相反,组织需要缩小规模,(i)从寻找值得解决的高价值问题开始,(ii)找到安全、轻量级、经济高效的方法来迭代解决这些问题。
根据我们的经验,人工智能解决方案的交付必须以敏捷工程、精益交付和产品思维的基础实践为基础,以便快速、可靠和负责任地交付价值。如果没有这些元素,组织很可能会陷入乏味的人工智能开发和交付风险中,甚至发布用户不想要或不需要的产品。结果是沮丧、失望和拙劣的投资。
我们将在本博客的第二部分探讨这一点,在这里我们分享了五条建议,这些建议是我们从为行业领先的客户提供人工智能解决方案的经验中提炼出来的。
- 59 次浏览