数据保护
数据保护 intelligentx- 241 次浏览
【数据备份】3种数据备份方式是什么?
最佳备份策略因每个组织的需求而异。 本主题将介绍备份方法的主要类型(完整、增量和差异)以及它们的优缺点,以帮助您选择最适合您和您的业务的方法。
例如,小型企业可能会选择每天备份所有内容,但大型企业可能会选择增量或差异备份策略。
完全备份
完整备份是制作所有文件和文件夹的完整副本。 这是所有执行方法中最耗时的备份,如果在网络上进行备份,可能会给您的网络带来压力。
但它也是最快的恢复方式,因为您需要的所有文件都包含在同一个备份集中。
定期进行完整备份需要每种方法中最多的存储空间。
好处
- 快速恢复时间
缺点
- 需要最多的存储空间
- 占用大量网络带宽
- 如果您不加密备份,可能会被盗
因为小型企业可能没有太多数据要备份,所以完全备份可能是最好的选择。维护和恢复它们很容易。
但是,如果您计划使用完整备份,则应考虑对备份进行加密。如果未经授权的用户可以访问您的备份,他们可以访问未加密的所有内容。但是,如果您的备份是加密的,他们可能会窃取您的整个备份驱动器,并且在没有您的加密密钥的情况下仍然一无所有。

增量备份
此方法需要至少进行一次完整备份,然后仅重新备份自上次完整备份以来发生更改的数据。
与差异备份和完整备份相比,增量备份占用的空间和时间最少,但在所有恢复完整系统的方法中,它是最耗时的。
您首先必须恢复最新的完整备份集,然后按顺序恢复每个增量备份集。如果其中一个备份集丢失或损坏,则无法进行完全恢复。
好处
- 占用最少的空间
- 使用相对较少的网络带宽
缺点
- 耗时的恢复
- 如果其中一个增量备份丢失或损坏,则无法完全恢复
使用增量备份比单独使用完整备份更好地为处理大量数据的企业提供服务,因为增量备份在三种主要方法中占用的空间最少。但是,如果您在失去业务或利润之前无法长时间不访问您的数据,并且您的恢复时间目标 (RTO) 非常小,请考虑改用差异备份。

差异备份
差异备份是执行定期完整备份和定期增量备份之间的折衷。
增量备份需要进行一次完整备份。 之后,仅备份自上次完整备份以来更改的文件。 这意味着要恢复,您只需要最新的完整备份集和最新的差异备份集。
不需要恢复超过这两个备份集,这比从增量备份恢复节省更多时间,但仍然比从完整备份恢复需要更长的时间。 它还比增量备份占用更少的空间,但比完整备份占用更多空间。
好处
- 比完整备份占用更少的空间
- 比增量备份更快的恢复
缺点
- 使用比增量备份更多的网络带宽,但比完整备份少、
既然您了解了三种主要类型的备份方法,您还应该考虑基于这些的许多其他类型的备份方法。
其中一些包括虚拟完整备份、近乎连续的数据保护、反向增量备份和永久增量备份。 其中之一可能是您的组织的理想选择。
原文:https://iosafe.com/data-protection-topics/3-types-of-backup/
- 149 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 -- 介绍
视频号

微信公众号

知识星球

2021 10月,福布斯技术委员会发表了一篇题为《为什么灾难恢复不再是当今企业的可选方案》的文章。文章引用了美国联邦紧急事务管理局(FEMA)的一项研究,该研究指出,美国40%的中小企业在灾难后倒闭。此外,25%的重新开业的企业在一年内再次关闭。鉴于这一问题的严重性,一个精心准备的业务连续性计划(包括IT资产的灾难恢复(DR)战略)对于确保业务的长期增长和成功至关重要。云计算通过降低进入壁垒,使灾难恢复即使对中小型企业也可行。鉴于在发生灾难时缺乏适当的解决方案所带来的风险,作为业务领导者,包含灾难恢复战略的业务连续性计划应该是您的首要任务。
如果您的工作负载运行在AWS上,那么毫无疑问,您的大部分数据都驻留在AWS数据库中。无论是存储在关系数据库系统(RDBMS)(如Amazon Aurora MySQL Compatible Edition)中的数据,还是存储在NoSQL数据库(如Amazon DynamoDB)中,这些数据对您的业务都很有价值。制定针对AWS上数据库的灾难恢复策略有助于您了解AWS在数据库灾难恢复方面提供了什么,以及如何在AWS云灾难恢复计划中利用这些信息。
以下泳道图显示了与定义和实施灾难恢复策略相关的高级任务。这两列显示了执行管理团队拥有的任务以及应用程序所有者和架构师拥有的任务。执行管理团队拥有决策权。该团队定义了组织要遵循的灾难恢复策略,推动了整个组织的灾难恢复采用,决定是否需要自动化来实现灾难恢复目标,并定义了灾难恢复测试计划。
灾难恢复战略实施后,执行管理团队将与应用程序所有者和架构师合作,以选择符合灾难恢复战略所带来的恢复时间目标(RTO)和恢复点目标(RPO)期望的正确数据库。当执行管理团队推动采用灾难恢复战略时,应用程序所有者和架构师会评估其应用程序中使用的数据库,如果当前的数据库不能达到应用程序的RTO和RPO设置,则会迁移到正确的数据库。应用程序所有者和架构师还可以根据需要构建自动化,并参与灾难恢复测试,以优化和改进应用程序级灾难恢复。
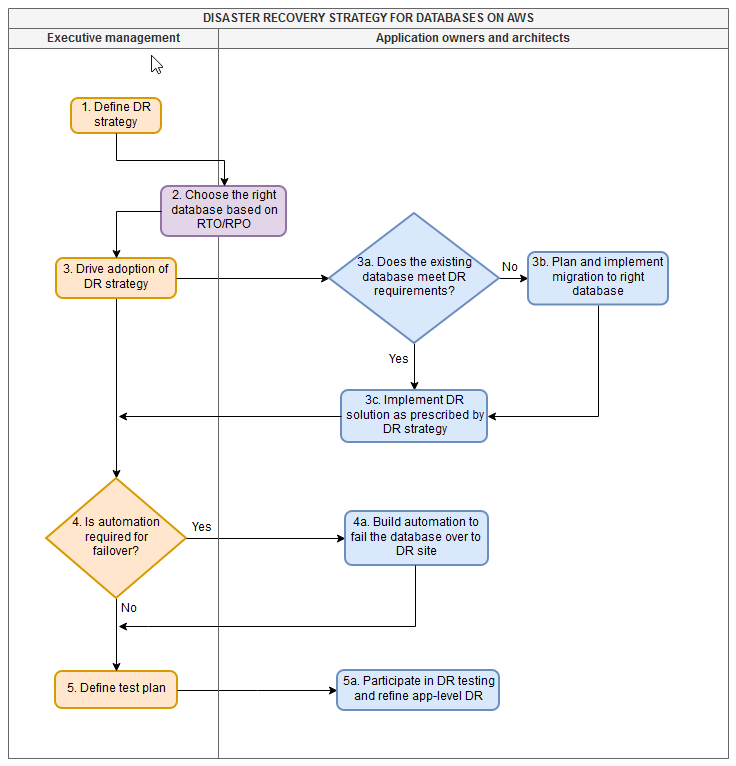
本文为希望制定跨区域灾难恢复战略以帮助实现其业务目标的企业领导者和决策者提供了高层次的这些步骤。本文假设具备一些技术知识并熟悉灾难恢复术语,但没有AWS专业知识。
- 68 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 --定义灾难恢复战略
视频号
微信公众号
知识星球
根据组织中的应用程序对业务的重要性,您可以为所有应用程序制定统一的策略,或根据每个应用程序的重要性制定更复杂的灾难恢复策略。在灾难恢复站点中启动所有应用程序之前,您的组织可能会容忍几个小时的停机时间。在这种情况下,您可以选择基于所有数据库的备份和恢复的经济高效的灾难恢复策略。另一方面,您公司的业务可能取决于某些关键服务或应用程序的快速可用性,具有更严格的RPO和RTO要求,而其他应用程序可能容忍不那么严格的RPO或RTO要求。在这种情况下,您需要为每一层应用程序和数据库分配正确的灾难恢复策略。
下表描述了AWS云中运行的工作负载的四个灾难恢复选项,以帮助您确定和定义组织的灾难恢复策略。本表中记录的RPO和RTO适用于包括应用程序和数据库组件的完整堆栈。有关更多信息,请参阅AWS良好架构框架文档中的云灾难恢复选项。下一节将介绍特定于数据库的RPO和RTO选项。
| Recovery option | RPO | RTO | Infrastructure tasks in DR Region | Cost |
|---|---|---|---|---|
| 备份和恢复 | 小时 | 少于24小时 |
在DR区域中调配所有必需的应用程序资源,并从复制的快照恢复数据库。 |
低的 |
| 指示灯 | 几十分钟 | 几十分钟 |
提供应用程序基础结构的副本并关闭应用程序堆栈中的资源。 将数据从一个区域复制到另一个区域。保持数据库始终打开并与主数据库同步。在故障切换和测试事件期间按需调配资源。 您还需要同时将基础架构更改和应用程序更改部署到两个地区。您可以通过构建自动化管道来简化这一过程,该管道可以同步主区域和灾难恢复区域中的代码和基础设施。 |
中等的 |
| 热备用 | Minutes | 分钟 |
在灾难恢复区域中调配整个应用程序基础架构的副本,但与主区域相比,保持该副本的规模缩小。DR区域将能够以比主要区域更小的流量接受流量。 |
高的 |
| 多站点或活动/活动 | Near zero | 零或接近零 |
将基础架构的完整副本调配到灾难恢复区域。灾难恢复地区的所有资源将与主要地区的资源相等,并能够以与主要地区相同的规模服务交通。由于流量没有中断,因此此选项不需要将故障切换任务作为灾难恢复计划的一部分。 |
较高的 |
- 37 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 --接下来的步骤和资源
视频号
微信公众号
知识星球
有关AWS上灾难恢复的更多信息,请阅读白皮书《AWS上工作负载的灾难恢复:云中恢复》。
审查AWS良好架构框架中的可靠性支柱。
探索AWS弹性中心,以跟踪和验证AWS工作负载的弹性。
查看以下其他资源:
-
Using failover in an Amazon Aurora global database (Aurora documentation)
-
Replication across AWS Regions using global datastores (ElastiCache for Redis documentation)
-
Disaster Recovery and Amazon DocumentDB Global Clusters (Amazon DocumentDB documentation)
-
Prepare for faster disaster recovery: Deploy an Amazon Aurora global database with Terraform (Part 1) (AWS blog post)
-
Amazon DynamoDB global tables (AWS website)
-
Disaster Recovery on AWS, Cross-Region Replication (Amazon RDS lab)
-
Cross-Region disaster recovery of Amazon RDS for SQL Server (AWS blog post)
-
Managed disaster recovery with Amazon RDS for Oracle cross-Region automated backups – Part 1 (AWS blog post)
- 51 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 --推动灾难恢复战略的采用
视频号
微信公众号
知识星球
当您的灾难恢复战略到位后,您可以推动整个组织采用该战略。当您的策略达到100%采用率时,所有应用程序及其数据库都将能够处理不利的灾难恢复事件,并可以通过测试追求灾难恢复的成熟度。
您可以与应用程序所有者和架构师合作,通过在整个组织中传达灾难恢复策略并要求员工评估其应用程序中使用的当前AWS数据库来推动采用。这确保了当前使用的所有数据库都能满足灾难恢复战略中设定的期望。如果应用程序所有者和架构师确定他们为其应用程序选择的数据库不能满足灾难恢复战略的要求,则他们必须计划迁移到能够实现所选RTO和RPO预期的适当AWS数据库。例如,如果您的业务中的一个关键应用程序需要几秒钟的RPO和几分钟的RTO,而该应用程序当前使用的是Amazon RDS For Oracle DB实例,那么Amazon RDS将无法满足这些期望。在这种情况下,您可以考虑将工作负载迁移到AmazonAuroraPostgreSQLCompatible,并使用全局数据库来满足DR策略设定的期望。
- 103 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 --测试以获得信心
视频号
微信公众号
知识星球
数据库的最佳灾难恢复解决方案是经过频繁测试并通过以下检查的解决方案:
- 适当的数据恢复,满足每个数据库的RPO期望
- 在预期的RTO时间框架内完全恢复正常运行的数据库,这允许应用程序连接到数据库并恢复全部功能
灾难恢复测试应该是您的业务战略的一部分,以便备份在最需要时工作。灾难恢复测试还应解决以下情况:
- 数据库的规模大幅增长,您当前的灾难恢复战略不再符合业务的服务级别协议(SLA)。
- 备份文件已损坏,这可能会在恢复过程中导致问题。
测试灾难恢复战略时应考虑什么
- 在RPO和RTO方面有明确的业务连续性目标,并确保测试结果符合您的目标。
- 创建详细的灾难恢复测试计划,将测试的财务和人力资源需求考虑在内。
- 分配资源记录潜在问题和经验教训。
- 根据经验更新您的灾难恢复战略,找到支持最佳流程和自动化的解决方案,为您的组织工作。
DR解决方案的测试频率
- 除非法规明确规定,否则DR测试周期没有设定建议。例如,支付卡行业数据安全标准(PCI DSS)合规性审计要求组织每年至少测试一次灾难恢复计划。(请参阅PCI DSS要求网站上的PCI DSS灾难恢复要求。)
- 当应用程序或基础架构发生变化时,应用程序团队还可以对其单个灾难恢复解决方案进行连续测试。
漂移检测
DR解决方案还应管理漂移检测。这将确保主区域和DR区域处于正确的同步级别,并确保测试过程中的顺利进行。AWS Config提供基础架构中配置的配置管理和历史跟踪,可以帮助您有效地管理漂移。
可观察性
提高可观测性会对测试准备产生积极影响。所有灾难恢复解决方案都将数据从主区域移动到辅助(DR)区域。您可以为复制延迟和备份设置警报,或者设置一个流程来执行日常检查,以确保您的数据成功复制到DR区域。
- 48 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 --自动化灾难恢复战略
视频号
微信公众号
知识星球
您可以选择实施完全或部分自动化,以更好地控制灾难恢复。如果您使用的是备份和恢复DR选项,则可以使用AWS backup自动化备份,该选项支持所有Amazon RDS数据库以及DynamoDB、Amazon DocumentDB和Amazon Neptune表。
灾难事件检测
为了缩短恢复时间,您可以考虑自动检测区域范围的事件,然后可以启动到灾难恢复区域的故障切换。为了实现自动化检测以实现积极的RTO,您可以构建一个基于健康检查的解决方案。这些健康检查不会停止于心跳(检查网络中的控制平面和数据平面模块是否可以彼此通信),而是更深入地评估应用程序组件的相互关联性,以实现准确的预测。然而,自动化解决方案可能会带来错误警报的风险,从而导致不必要的故障切换。在这种情况下,您应该谨慎,因为不必要的故障切换会给您的业务带来可用性问题。您还可以在工作流中构建手动覆盖,以确认已执行故障切换。您可以订阅Service Health Dashboard RSS提要,随时了解服务级别中断的情况。此外,您可以在您的主要地区和帐户中使用AWS Health Dashboard(需要AWS帐户),以了解可能影响您帐户的事件。这些可以帮助您在发生区域性事件时做出明智的失败决策。
故障转移
无论您选择哪种灾难恢复策略,您都可以构建自定义灾难恢复自动化解决方案,以执行到灾难恢复区域的故障切换。这种自动化可以最大限度地减少手动干预的需要,并在测试DR解决方案时提供更好的控制。您可以从AWS服务API中进行选择,AWS根据组织的偏好提供多种语言,如JavaScript、Python、PHP、.NET、Ruby、Java、Go、Node.js和C++。要构建使用这些AWS服务API的自动化,您应该首先将重点放在将数据库基础设施转换为AWS CloudFormation或Terraform模板形式的代码上。这些模板可以帮助您自动化多个数据库的故障切换,并维护应用程序和数据库组件在DR区域中的备份顺序。
出于灾难恢复目的,我们建议您关注以下两个目标:
- 现有的CloudFormation堆栈应该导出有关数据库的相关信息,包括实例名称和端点。您的自动化流程可以参考区域内的这些导出值,并执行有助于DR操作的操作。
- 如果您有生产中的资源,但没有关联的CloudFormation堆栈,那么应该专注于为这些资源创建堆栈。还要确保这些堆栈包含正确的导出值,如前一点所述。
当您达到这两个目标后,您可以使用组织选择的语言构建自动化解决方案,以利用CloudFormation导出,并在发生灾难时自动执行所需的切换操作。例如,如果您有作为CloudFormation模板部署的ElastiCache For Redis全局数据存储,则自动化代码可以访问CloudFormation导出,该导出提供有关全局数据存储的详细信息。在发生灾难时,代码可以使用ElastiCache for Redis服务API自动将辅助数据存储升级到主数据存储,而无需任何手动干预。
在一个典型的场景中,自动化应该可以扩展到组织中的多个数据库。您可以使用AWS Step Functions或AWS Batch来扩展多个数据库的自动化解决方案。
- 35 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 --选择适合您的RTO和RPO要求的数据库
视频号
微信公众号
知识星球
当您根据上一节中的表定义了组织的灾难恢复战略后,请选择最适合您的RPO和RTO要求的数据库。默认情况下,所有AWS数据库服务都提供备份和恢复功能。使用下表了解AWS数据库服务提供的更高级灾难恢复功能,并将其与您的灾难恢复需求相匹配。
| AWS数据库服务 | 到灾难恢复区域的复制方法 | 可能的备用分类 | RTO | RPO |
|---|---|---|---|---|
| Amazon RDS for MySQL | Cross-Region read replica |
|
Usually minutes. Automation can minimize delays. | Typically under 1 second |
| Amazon RDS for PostgreSQL | Cross-Region read replica |
|
Usually minutes. Automation can minimize delays. | Typically under 1 second |
| Amazon RDS for MariaDB | Cross-Region read replica |
|
Usually minutes. Automation can minimize delays. | Typically under 1 second |
| Amazon Aurora MySQL-Compatible Edition | Global database has secondary cluster(s) in a different Region |
|
Typically under 1 minute. | Typically under 1 second |
| Amazon Aurora PostgreSQL-Compatible Edition | Global database has secondary cluster(s) in a different Region |
|
Typically under 1 minute. | Typically under 1 second |
| Amazon DocumentDB (with MongoDB compatibility) | Global cluster has secondary cluster(s) in a different Region |
|
Usually minutes. Automation can minimize delays. | Typically in seconds |
| Amazon ElastiCache for Redis | Global datastore has a secondary cluster in a different Region |
|
Usually minutes. Automation can minimize delays. | Typically under 1 second |
| Amazon DynamoDB | DynamoDB global tables | Active/active configuration accepts write operations in secondary Region | Zero or near zero. | Sub-second |
| Amazon RDS for Oracle | Read replica promotion across Regions (Oracle Enterprise Edition and Active Data Guard) |
|
Usually minutes. | Usually minutes |
| Amazon RDS for Oracle (alternative) | Mounted read replica promotion across Regions (Oracle Enterprise Edition) |
|
Usually minutes. | Usually minutes |
| Amazon RDS for SQL Server | AWS Database Migration Service (AWS DMS) requires change data capture (CDC), which incurs a SQL Server license cost for the target instance | Continuous replication | Depends on redo log volume (usually minutes). | Near zero |
- 60 次浏览