深度学习
【ANN】ANN Benchmarks是一个用于近似最近邻算法搜索的基准测试环境
视频号

微信公众号

知识星球

信息
ANN Benchmarks是一个用于近似最近邻算法搜索的基准测试环境。本网站包含当前的基准测试结果。请访问http://github.com/erikbern/ann-benchmarks/以获得对评估的数据集和算法的概述。在Github上发出pull请求,为基准测试系统添加您自己的代码或改进。
基准测试结果
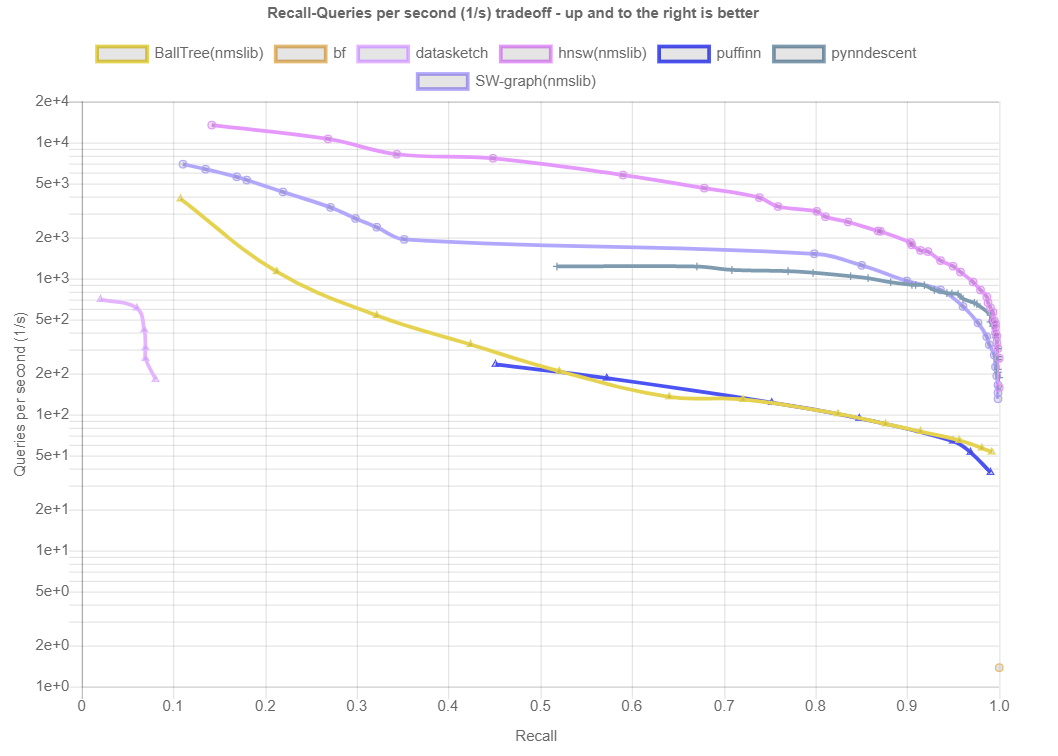
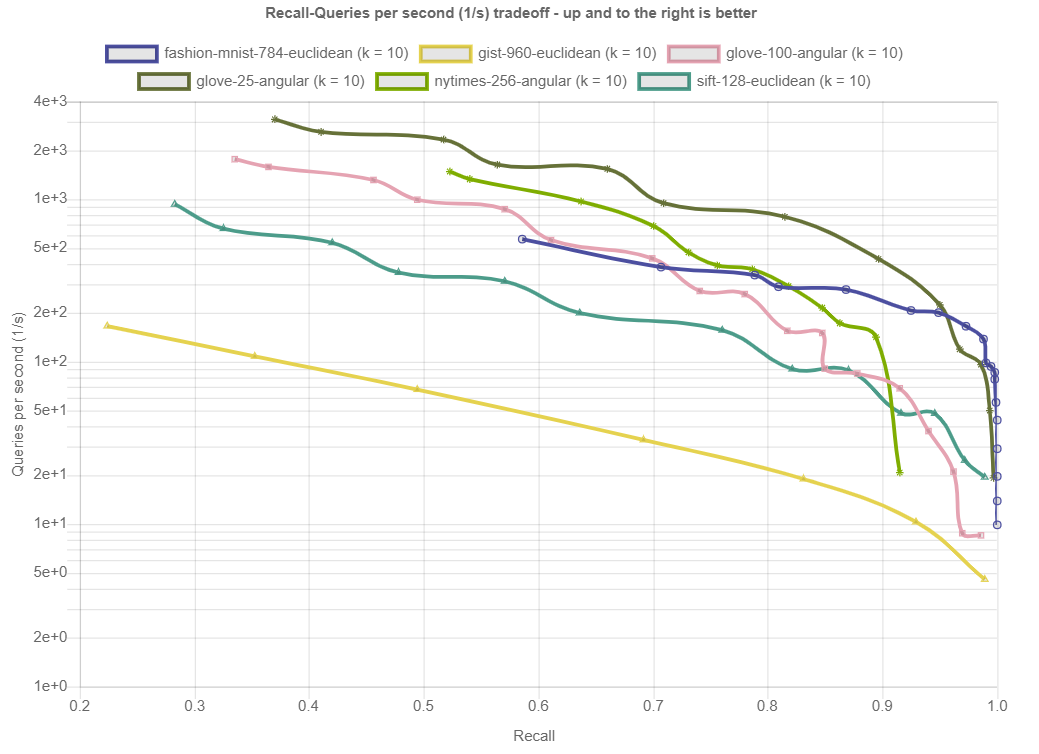
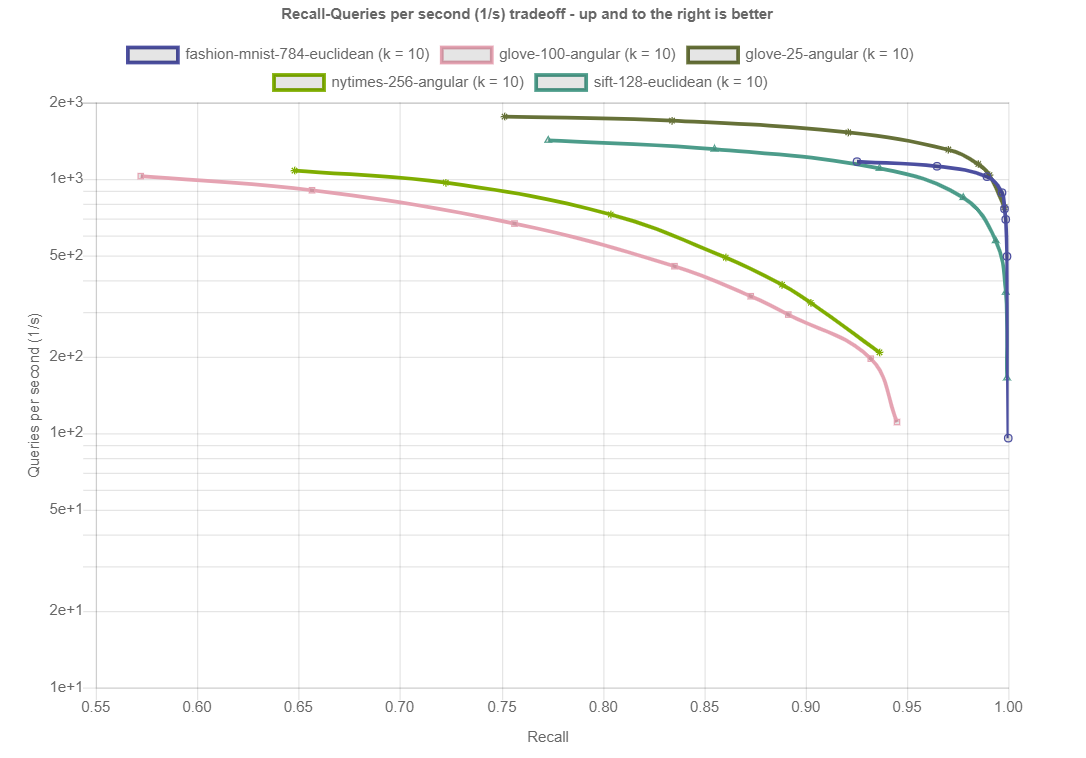
结果按距离测量和数据集划分。在底部,您可以找到算法在所有数据集上的性能概述。每个数据集由(k=…)表示,即算法应该返回的最近邻居的数量。所示的图描绘了每秒针对查询的Recall(在所有查询中平均找到的真正最近邻居的分数)。点击绘图会显示详细的交互式绘图,包括大致召回、索引大小和构建时间。
单个查询的基准
按数据集列出的结果
距离:角度
glove-100-angular_10_angular.
https://ann-benchmarks.com/fashion-mnist-784-euclidean_10_euclidean.html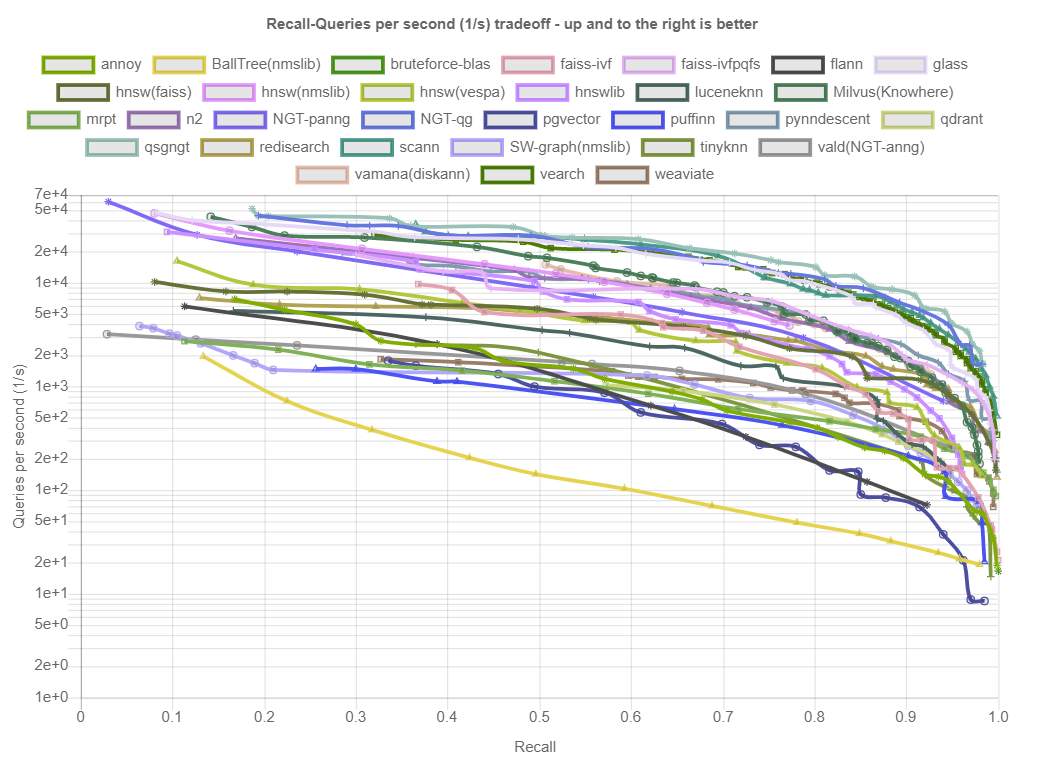
https://ann-benchmarks.com/glove-100-angular_10_angular.html
Distance: Euclidean

https://ann-benchmarks.com/fashion-mnist-784-euclidean_10_euclidean.html
Distance: Jaccard
 https://ann-benchmarks.com/kosarak-jaccard_10_jaccard.html
https://ann-benchmarks.com/kosarak-jaccard_10_jaccard.html
Results by Algorithm
- Algorithms:
- pgvector
- annoy
- glass
- hnswlib
- BallTree(nmslib)
- vald(NGT-anng)
- hnsw(faiss)
- NGT-qg
- qdrant
- n2
- Milvus(Knowhere)
- qsgngt
- faiss-ivfpqfs
- mrpt
- redisearch
- SW-graph(nmslib)
- NGT-panng
- pynndescent
- vearch
- hnsw(vespa)
- vamana(diskann)
- flann
- luceneknn
- weaviate
- puffinn
- hnsw(nmslib)
- bruteforce-blas
- tinyknn
- NGT-onng
- elastiknn-l2lsh
- sptag
- ckdtree
- kd
- opensearchknn
- datasketch
- bf
Plots for pgvector
https://ann-benchmarks.com/pgvector.html
Plots for qdrant
https://ann-benchmarks.com/qdrant.html
Plots for Milvus(Knowhere)
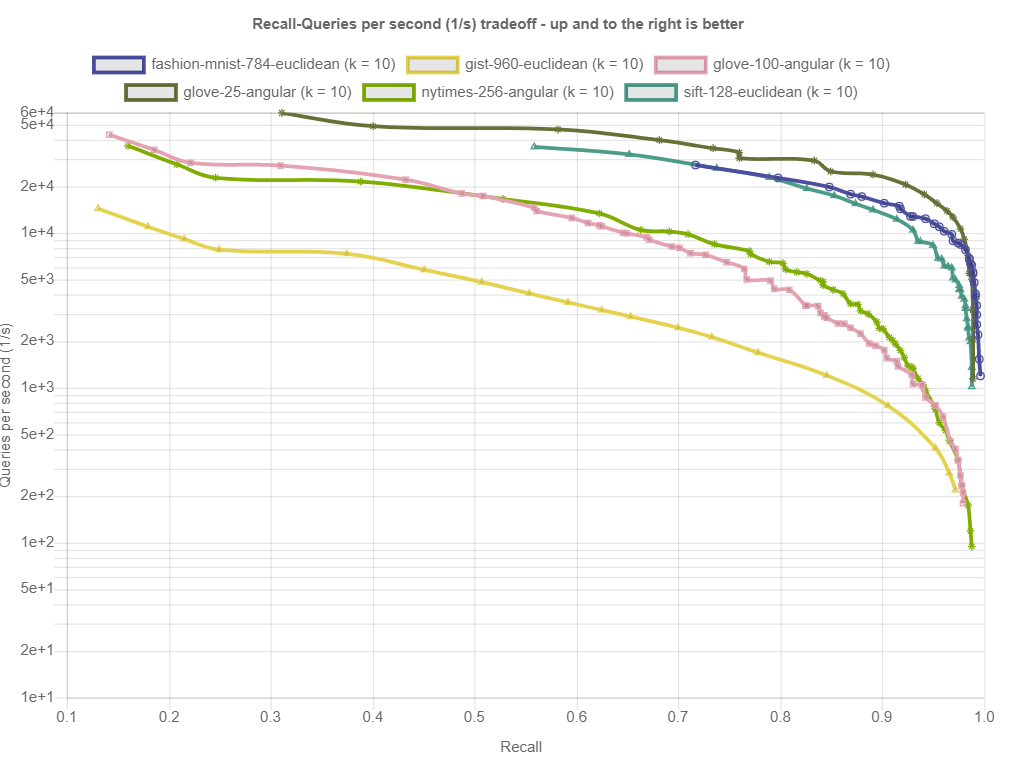
https://ann-benchmarks.com/Milvus(Knowhere).html
Plots for weaviate
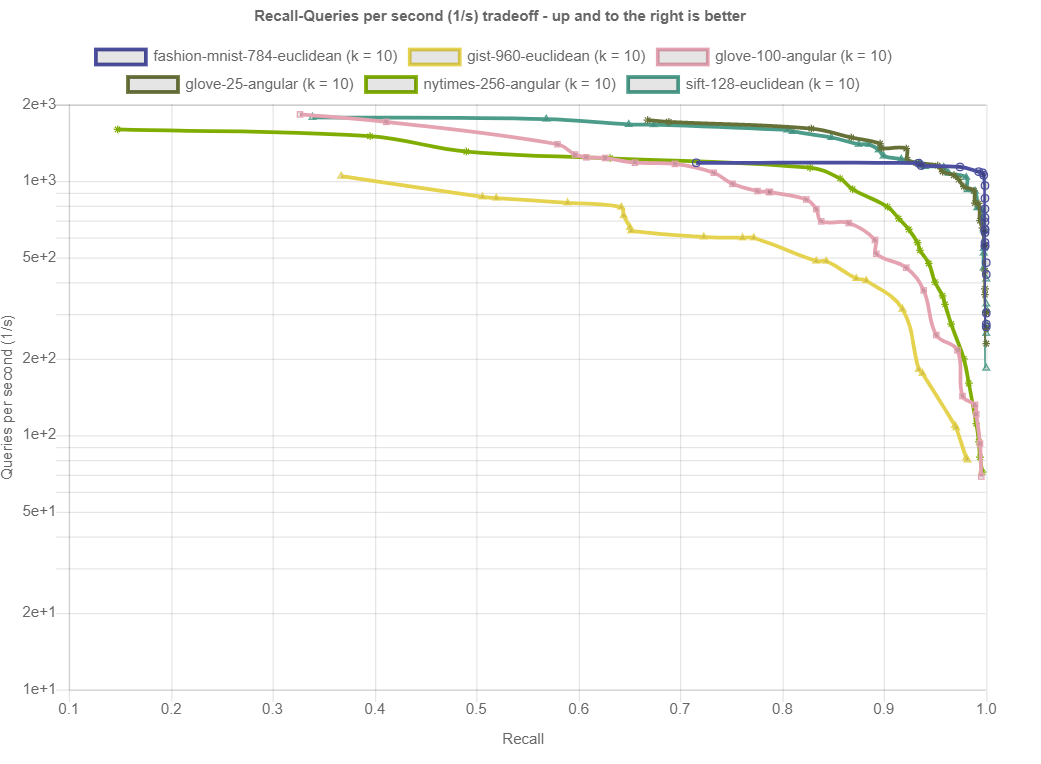
https://ann-benchmarks.com/weaviate.html
- 310 次浏览
【GAN架构】GAN与transformer模型:比较架构和用途
视频号
微信公众号
知识星球
发现生成对抗性网络和transformer之间的差异,以及这两种技术在未来如何结合,为用户提供更好的结果。
生成对抗性网络在生成图像、声音以及药物分子等媒体方面具有相当大的前景。在几年前变形金刚问世之前,它们也是最流行的生成人工智能技术之一。
transformer是支撑大型语言模型许多进步的基础技术,例如生成预训练transformer(GPT)。他们现在正在扩展到多模式人工智能应用,能够比GANs等技术更有效地将文本、图像、音频和机器人指令等多种内容关联到多种媒体类型。
让我们来探索每种技术的起源、它们的用例,以及研究人员现在如何将这两种技术组合成各种transformerGAN组合。
GAN架构说明
GANs由Ian Goodfellow及其同事于2014年推出,用于生成逼真的数字和人脸。它们结合了以下两种神经网络:
- 生成器,通常是基于文本或图像提示创建内容的卷积神经网络(CNN)。
- 鉴别器,通常是一个反进化神经网络,用于识别真实图像和伪造图像。
人工智能增强民主研究所的创始人Adrian Zidaritz说,在GANs之前,计算机视觉主要是用CNN来捕捉图像的较低层次特征,如边缘和颜色,以及代表整个物体的较高层次特征。GAN架构的新颖性源于它的对抗性方法,其中一个神经网络提出生成的图像,而另一个则否决它们,如果它们不能接近给定数据集中的真实图像。
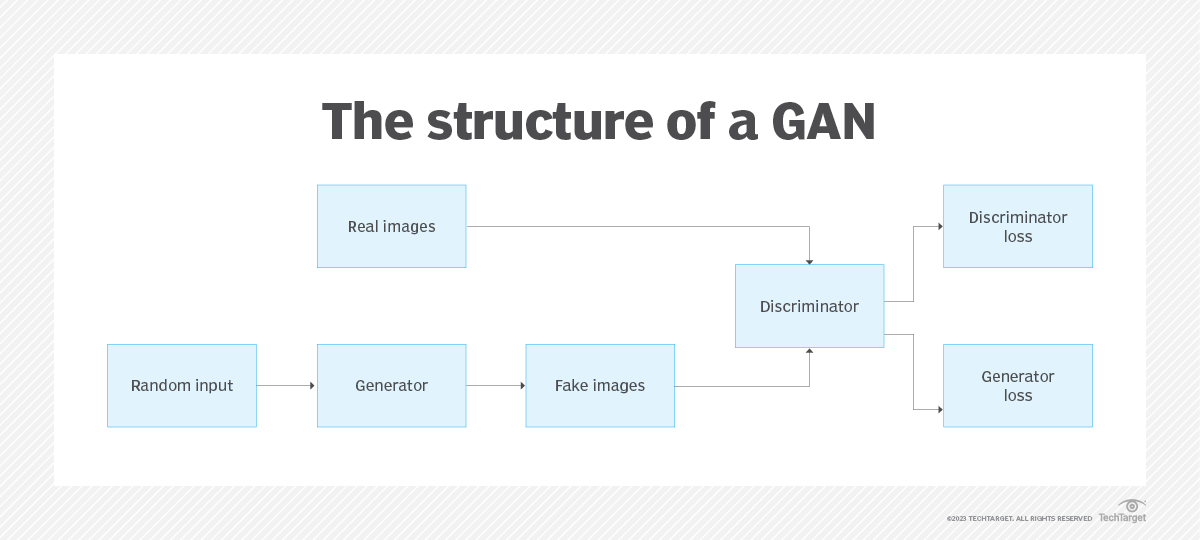
Diagram of a generative adversarial network
如今,研究人员正在探索使用其他神经网络模型的方法,包括transformer。
transformer架构说明
2017年,谷歌的一个研究团队推出了transformer,他们希望打造一个更高效的翻译器。在一篇题为《注意力就是你所需要的一切》的论文中,研究人员提出了一种新的技术,根据单词在短语、句子和文章中对其他单词的描述来辨别单词的含义。
先前解释文本的工具经常使用一个神经网络使用先前构建的字典将单词翻译成向量,而另一个神经网则处理文本序列,例如递归神经网络(RNN)。相反,transformer本质上是通过处理大量未标记的文本来直接理解单词的含义。同样的方法也可以用于识别其他类型数据中的模式,如蛋白质序列、化学结构、计算机代码和物联网数据流。这使得研究人员能够扩展大型语言模型,从而推动该领域的最新进展和宣传。transformer还可以找到相距甚远的单词之间的关系,这在RNN中是不切实际的。

Zidaritz说,图像的小片段也可以由它们出现的整个图像的上下文来定义。自然语言处理中的自注意思想在计算机视觉中变成了自相似。
GAN与transformer:每种模型的最佳用例
数据安全平台Fortanix负责机密计算的副总裁Richard Searle表示,GANs在其潜在的应用范围内更加灵活。在不平衡的数据(例如与阴性病例数量相比,阳性病例数量较少)可能导致大量假阳性分类的情况下,它们也很有用。因此,对抗性学习在歧视任务的训练数据有限的用例中,或者在欺诈检测中,与更常见的交易相比,只有少量交易可能代表欺诈,都显示出了希望。例如,在欺诈场景中,黑客不断引入新的输入来欺骗欺诈检测算法。GANs往往更善于适应和抵御这些技术。
Searle说,transformer通常用于必须推导顺序输入输出关系的地方,并且可能的特征组合的数量需要集中注意力来提供局部上下文。出于这个原因,transformer在NLP应用程序中已经确立了卓越地位,因为它们可以处理任何长度的内容,例如短语或整个文档。变形金刚还善于在游戏等应用中提出下一步行动,在游戏中,必须根据输入的条件序列来评估一组潜在的响应。
还积极研究将GANs和transformer组合成所谓的GANsformers。这个想法是使用transformer来提供注意力参考,这样生成器就可以增加上下文的使用来增强内容。
Searle解释道:“GANsformers背后的直觉是,除了潜在的全球特征外,人类的注意力还基于感兴趣对象的特定局部特征。”。由此产生的改进的表示更有可能模拟人类在真实样本中可能感知到的全局和局部特征,例如真实的人脸或与人声的音调和节奏一致的计算机生成的音频。
基于transformer的网络是否比GANs更强?
由于transformer在ChatGPT等流行工具中的作用以及对多模式人工智能的支持,transformer的知名度正在提高。但transformer不一定会取代所有应用程序的GANs。
Searle希望看到更多的集成,以创建具有增强真实感的文本、语音和图像数据。他说:“这可能是可取的,因为在人机交互或数字内容中提高上下文真实性或流畅性会增强用户体验。”。例如,当面对人类用户和训练有素的机器评估者时,GANsformers可能能够生成合成数据来通过图灵测试。在文本响应的情况下,例如GPT系统提供的文本响应,包含特殊错误或风格特征可能会掩盖人工智能衍生输出的真实来源。
相反,用于发动网络攻击、损害品牌或传播假新闻的deepfakes可能会提高真实感。在这些情况下,GANsformers可以提供更好的过滤器来检测深度伪造。
Searle说:“对抗性训练和上下文评估的使用可以产生人工智能系统,该系统能够使用生成僵尸网络提供增强的安全性、改进的内容过滤和防御错误信息攻击。”。
但Zidaritz认为,transformer在许多用例中都有可能淘汰Gan,因为它们可以更容易地应用于文本和图像。他说:“新的GAN将继续开发,但其应用将比GPT更有限。”。“我们也可能会看到更多类似GAN的transformer和类似transformer的GAN,其中具有自我关注或自我相似机制的transformer将是核心。”
- 1430 次浏览
【机器学习】10个数据库支持数据库机器学习
尽管方法和功能有所不同,但所有这些数据库都允许您在数据所在的地方构建机器学习模型。
在我2022年10月的文章《如何选择云机器学习平台》中,我选择平台的第一条准则是“靠近数据”。保持代码靠近数据是保持低延迟的必要条件,因为光速限制了传输速度。毕竟,机器学习——尤其是深度学习——往往会多次浏览所有数据(每次浏览都被称为一个时代)。
对于非常大的数据集,理想的情况是在数据已经存在的地方构建模型,这样就不需要大量数据传输。几个数据库在有限程度上支持这一点。下一个自然的问题是,哪些数据库支持内部机器学习,它们是如何做到的?我将按字母顺序讨论这些数据库。
Amazon Redshift
AmazonRedshift是一种受管理的PB级数据仓库服务,旨在使使用现有商业智能工具分析所有数据变得简单且经济高效。它针对从几百GB到1 PB或更多的数据集进行了优化,每年每TB的成本不到1000美元。
AmazonRedshiftML旨在让SQL用户使用SQL命令轻松创建、训练和部署机器学习模型。Redshift SQL中的CREATE MODEL命令定义了用于训练的数据和目标列,然后通过同一区域中加密的Amazon S3存储桶将数据传递给Amazon SageMaker Autopilot进行训练。
在AutoML训练之后,Redshift ML编译最佳模型,并将其注册为Redshift集群中的预测SQL函数。然后,可以通过调用SELECT语句内的预测函数来调用模型进行推理。
总结:Redshift ML使用SageMaker Autopilot根据您通过SQL语句指定的数据自动创建预测模型,并将其提取到S3存储桶中。找到的最佳预测函数注册在Redshift聚类中。
BlazingSQL
BlazingSQL是一个基于RAPID生态系统的GPU加速SQL引擎;它是一个开源项目和付费服务。RAPID是一套开源软件库和API,由Nvidia开发,使用CUDA,基于Apache Arrow柱状内存格式。CuDF是RAPID的一部分,是一个类似Pandas的GPU DataFrame库,用于加载、连接、聚合、过滤和以其他方式处理数据。
[参加11月8日的虚拟峰会-首席信息官云峰会的未来:掌握复杂性和数字创新–立即注册!]
Dask是一个开源工具,可以将Python包扩展到多台机器。Dask可以在同一系统或多节点集群中的多个GPU上分发数据和计算。Dask与RAPID cuDF、XGBoost和RAPID cuML集成,用于GPU加速数据分析和机器学习。
总结:BlazingSQL可以在AmazonS3中的数据湖上运行GPU加速查询,将生成的DataFrames传递给cuDF进行数据处理,最后使用RAPID XGBoost和cuML进行机器学习,并使用PyTorch和TensorFlow进行深度学习。
Brytlyt
Brytlyt是一个以浏览器为主导的平台,支持具有深度学习能力的数据库内AI。Brytlyt将PostgreSQL数据库、PyTorch、Jupyter笔记本、Scikit learn、NumPy、Pandas和MLflow组合成一个无服务器平台,作为三种GPU加速产品:数据库、数据可视化工具和使用笔记本的数据科学工具。
Brytlyt可以连接任何具有PostgreSQL连接器的产品,包括Tableau和Python等BI工具。它支持从外部数据文件(如CSV)和PostgreSQL外部数据包装器(FDW)支持的外部SQL数据源加载和接收数据。后者包括Snowflake、Microsoft SQL Server、Google Cloud BigQuery、Databricks、Amazon Redshift和Amazon Athena等。
作为一个具有并行连接处理的GPU数据库,Brytlyt可以在几秒内处理数十亿行数据。Brytlyt在电信、零售、石油和天然气、金融、物流、DNA和基因组学方面有应用。
小结:通过PyTorch和Scikit学习集成,Brytlyt可以支持深度学习和简单的机器学习模型,这些模型在内部根据其数据运行。GPU支持和并行处理意味着所有操作都相对较快,尽管针对数十亿行训练复杂的深度学习模型当然需要一些时间。
谷歌云BigQuery
BigQuery是谷歌云管理的PB级数据仓库,可让您对大量数据进行近乎实时的分析。BigQueryML允许您使用SQL查询在BigQuery中创建和执行机器学习模型。
BigQueryML支持预测的线性回归;用于分类的二元和多类逻辑回归;用于数据分割的K-means聚类;用于创建产品推荐系统的矩阵分解;执行时间序列预测的时间序列,包括异常、季节性和假日;XGBoost分类和回归模型;用于分类和回归模型的基于TensorFlow的深度神经网络;AutoML表格;和TensorFlow模型导入。您可以使用具有来自多个BigQuery数据集的数据的模型进行训练和预测。BigQueryML不会从数据仓库中提取数据。通过在CREATEMODEL语句中使用TRANSFORM子句,可以使用BigQueryML执行特性工程。
总结:BigQueryML将Google Cloud Machine Learning的大部分功能与SQL语法结合到BigQuery数据仓库中,而无需从数据仓库中提取数据。
IBM Db2仓库
IBM Db2 Warehouse on Cloud是一个托管的公共云服务。您还可以使用自己的硬件或在私有云中在本地设置IBM Db2 Warehouse。作为数据仓库,它包括内存数据处理和用于在线分析处理的列表等功能。其Netezza技术提供了一组强大的分析,旨在有效地将查询带到数据中。一系列库和函数帮助您获得所需的精确见解。
Db2Warehouse支持Python、R和SQL中的数据库内机器学习。IDAX模块包含分析存储过程,包括方差分析、关联规则、数据转换、决策树、诊断度量、离散化和矩、K均值聚类、K近邻、线性回归、元数据管理、朴素贝叶斯分类、主成分分析、概率分布、随机抽样、回归树、,顺序模式和规则以及参数和非参数统计。
概要:IBM Db2 Warehouse包括一组广泛的数据库内SQL分析,其中包括一些基本的机器学习功能,以及对R和Python的数据库内支持。
Kinetica
Kinetica流式数据仓库将历史和流式数据分析与位置智能和AI结合在一个平台上,所有这些都可以通过API和SQL访问。Kinetica是一个非常快速、分布式、列式、内存优先、GPU加速的数据库,具有过滤、可视化和聚合功能。
Kinetica将机器学习模型和算法与您的数据相集成,用于大规模实时预测分析。它允许您简化数据管道和分析、机器学习模型和数据工程的生命周期,并使用流计算功能。Kinetica为GPU加速的机器学习提供了全生命周期解决方案:托管Jupyter笔记本电脑、通过RAPID进行模型训练,以及Kinetica平台中的自动模型部署和推理。
小结:Kinetica为GPU加速的机器学习提供了一个完整的数据库生命周期解决方案,可以从流数据中计算特征。
Microsoft SQL Server
Microsoft SQL Server Machine Learning Services支持SQL Server RDBMS中的R、Python、Java、PREDICT T-SQL命令和rxPredict存储过程,以及SQL Server大数据集群中的SparkML。在R语言和Python语言中,Microsoft包括几个用于机器学习的包和库。您可以将经过训练的模型存储在数据库中或外部。Azure SQL托管实例支持Python和R的机器学习服务作为预览。
Microsoft R具有扩展功能,允许它处理磁盘和内存中的数据。SQL Server提供了一个扩展框架,以便R、Python和Java代码可以使用SQL Server数据和函数。SQL Server大数据集群在Kubernetes中运行SQL Server、Spark和HDFS。当SQL Server调用Python代码时,它可以反过来调用Azure Machine Learning,并将生成的模型保存在数据库中以用于预测。
摘要:当前版本的SQL Server可以用多种编程语言训练和推断机器学习模型。
Oracle数据库
Oracle云基础设施(OCI)数据科学是一个可管理的无服务器平台,供数据科学团队使用Oracle云基础架构(包括Oracle自治数据库和Oracle自治数据仓库)构建、培训和管理机器学习模型。它包括开放源码社区开发的以Python为中心的工具、库和包,以及支持预测模型端到端生命周期的Oracle加速数据科学(ADS)库:
- 数据采集、分析、准备和可视化
- 功能工程
- 模型培训(包括Oracle AutoML)
- 模型评估、解释和解释(包括Oracle MLX)
- Oracle功能的模型部署
OCI数据科学与Oracle云基础架构堆栈的其他部分集成,包括功能、数据流、自主数据仓库和对象存储。
当前支持的型号包括:
- Oracle AutoML
- Keras
- Scikit-learn
- XGBoost
- ADSTuner (hyperparameter tuning)
总结:Oracle云基础架构可以托管与其数据仓库、对象存储和功能集成的数据科学资源,从而实现完整的模型开发生命周期。
Vertica公司
Vertica Analytics Platform是一个可扩展的柱状存储数据仓库。它以两种模式运行:Enterprise和EON,前者将数据本地存储在组成数据库的节点的文件系统中,后者为所有计算节点共同存储数据。
Vertica使用大规模并行处理来处理数PB的数据,并使用数据并行性进行内部机器学习。它有八个内置的数据准备算法,三个回归算法,四个分类算法,两个聚类算法,几个模型管理功能,以及导入TensorFlow和PMML模型的能力。拟合或导入模型后,可以将其用于预测。Vertica还允许使用C++、Java、Python或R编程的用户定义扩展。您可以使用SQL语法进行训练和推理。
总结:Vertica内置了一套不错的机器学习算法,可以导入TensorFlow和PMML模型。它可以从导入的模型以及自己的模型进行预测。
MindsDB
如果您的数据库还不支持内部机器学习,那么很可能可以使用MindsDB添加该功能,MindsDB集成了六个数据库和五个BI工具。支持的数据库包括MariaDB、MySQL、PostgreSQL、ClickHouse、Microsoft SQL Server和Snowflake,目前正在进行MongoDB集成,并将于2021晚些时候与流媒体数据库集成。目前支持的BI工具包括SAS、Qlik Sense、Microsoft Power BI、Looker和Domo。
MindsDB具有AutoML、AI表和可解释AI(XAI)。您可以从MindsDB Studio、SQL INSERT语句或Python API调用调用AutoML培训。培训可以选择使用GPU,也可以选择创建时间序列模型。
您可以将模型保存为数据库表,并通过针对保存的模型的SQL SELECT语句、MindsDB Studio或Python API调用来调用它。您可以从MindsDB Studio评估、解释和可视化模型质量。
您还可以将MindsDB Studio和Python API连接到本地和远程数据源。MindsDB还提供了一个简化的深度学习框架Lightwood,该框架在PyTorch上运行。
小结:MindsDB为一些缺乏机器学习内置支持的数据库带来了有用的机器学习功能。
越来越多的数据库支持在内部进行机器学习。确切的机制各不相同,有些人比其他人更有能力。然而,如果您有太多的数据,否则可能需要在采样子集上拟合模型,那么上面列出的八个数据库中的任何一个以及MindsDB帮助下的其他数据库都可以帮助您从完整的数据集构建模型,而不会导致数据导出的严重开销。
- 279 次浏览
【机器学习】DVC:面向机器学习项目的开源版本控制系统
DVC跟踪ML模型和数据集
DVC的建立是为了使ML模型具有可共享性和可复制性。它设计用于处理大型文件、数据集、机器学习模型、度量以及代码。
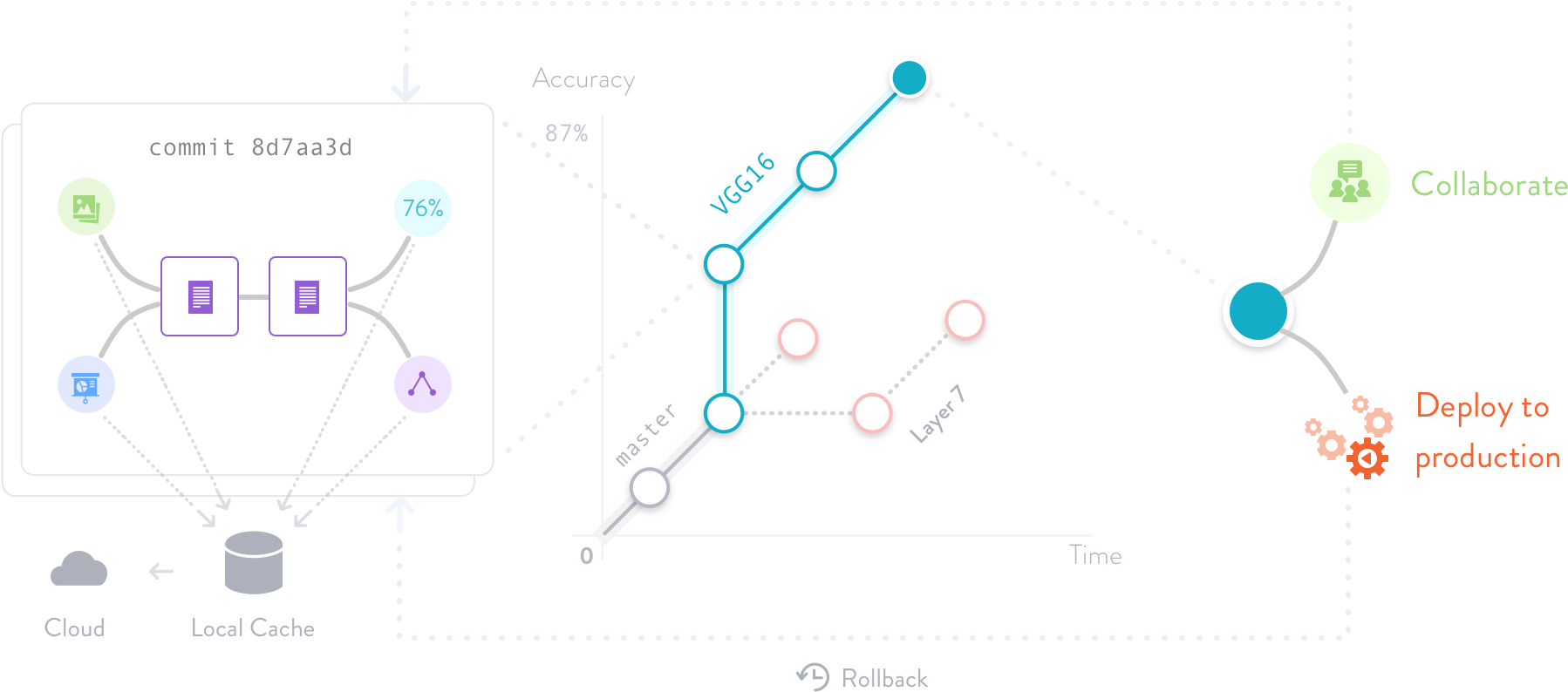
ML项目版本控制
版本控制机器学习模型,数据集和中间文件。DVC通过代码将它们连接起来,并使用Amazon S3、Microsoft Azure Blob存储、Google Drive、Google云存储、Aliyun OSS、SSH/SFTP、HDFS、HTTP、网络连接存储或光盘来存储文件内容。
完整的代码和数据来源有助于跟踪每个ML模型的完整演化。这保证了再现性,并使其易于在实验之间来回切换。
ML实验管理
利用Git分支的全部功能尝试不同的想法,而不是代码中草率的文件后缀和注释。使用自动度量跟踪来导航,而不是使用纸张和铅笔。
DVC被设计成保持分支像Git一样简单和快速-无论数据文件大小如何。除了一流的市民指标和ML管道,这意味着一个项目有更干净的结构。比较想法和挑选最好的很容易。中间工件缓存可以加快迭代速度。
部署与协作
使用push/pull命令将一致的ML模型、数据和代码包移动到生产、远程机器或同事的计算机中,而不是临时脚本。
DVC在Git中引入了轻量级管道作为一级公民机制。它们与语言无关,并将多个步骤连接到一个DAG中。这些管道用于消除代码进入生产过程中的摩擦。
特性:
Git兼容
DVC运行在任何Git存储库之上,并与任何标准Git服务器或提供者(GitHub、GitLab等)兼容。数据文件内容可以由网络可访问存储或任何支持的云解决方案共享。DVC提供了分布式版本控制系统的所有优点—无锁、本地分支和版本控制。
存储不可知
使用Amazon S3、Microsoft Azure Blob存储、Google Drive、Google云存储、Aliyun OSS、SSH/SFTP、HDFS、HTTP、网络连接存储或光盘存储数据。支持的远程存储列表在不断扩展。
再现性
可复制的
单个“dvc repro”命令端到端地再现实验。DVC通过始终如一地维护输入数据、配置和最初用于运行实验的代码的组合来保证再现性。
低摩擦分支
DVC完全支持即时Git分支,即使是大文件也是如此。分支漂亮地反映了ML过程的非线性结构和高度迭代的性质。数据是不重复的-一个文件版本可以属于几十个实验。创建尽可能多的实验,瞬间来回切换,并保存所有尝试的历史记录。
度量跟踪
指标是DVC的一等公民。DVC包含一个命令,用于列出所有分支以及度量值,以跟踪进度或选择最佳版本。
ML管道框架
DVC有一种内置的方式,可以将ML步骤连接到DAG中,并端到端地运行整个管道。DVC处理中间结果的缓存,如果输入数据或代码相同,则不会再次运行步骤。
语言与框架不可知论
不可知语言框架
无论使用哪种编程语言或库,或者代码是如何构造的,可再现性和管道都基于输入和输出文件或目录。Python、R、Julia、Scala Spark、custom binary、Notebooks、flatfiles/TensorFlow、PyTorch等都支持。
HDFS、Hive和Apache Spark
HDFS、Hive和Apache Spark
在DVC数据版本控制周期中包括Spark和Hive作业以及本地ML建模步骤,或者使用DVC端到端管理Spark和Hive作业。通过将繁重的集群作业分解为更小的DVC管道步骤,可以大大减少反馈循环。独立于依赖项迭代这些步骤。
故障跟踪
追踪故障
坏主意有时比成功的主意能在同事间激发更多的想法。保留失败尝试的知识可以节省将来的时间。DVC是建立在一个可复制和易于访问的方式跟踪一切。
用例
保存并复制你的实验
在任何时候,获取你或你的同事所做实验的全部内容。DVC保证所有的文件和度量都是一致的,并且在正确的位置复制实验或者将其用作新迭代的基线。
版本控制模型和数据
DVC将元文件保存在Git中,而不是Google文档中,用于描述和控制数据集和模型的版本。DVC支持多种外部存储类型,作为大型文件的远程缓存。
为部署和协作建立工作流
DVC定义了作为一个团队高效一致地工作的规则和流程。它用作协作、共享结果以及在生产环境中获取和运行完成的模型的协议。
本文:
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】或者QQ群【11107777】
- 238 次浏览
【深度学习】45测试深度学习基础知识的数据科学家的问题(以及解决方案)
视频号
微信公众号
知识星球
介绍
早在2009年,深度学习只是一个新兴领域。 只有少数人认为它是一个富有成果的研究领域。 今天,它被用于开发一些被认为是难以做到的事情的应用程序。
语音识别,图像识别,数据集中的查找模式,照片中的对象分类,字符文本生成,自驾车等等只是几个例子。 因此,熟悉深度学习及其概念很重要。
在这次技能测试中,我们测试了我们的社区关于深度学习的基本概念。 共有1070人参加了这项技能测试。
如果你错过了考试,你可以看看这些问题并检查你的技能水平。
总体成绩
以下是分数的分布,这将有助于您评估您的表现:

您可以在这里访问您的演出。 超过200人参加了技能测试,最高分为35.以下是关于分配的一些统计数据。
Overall distribution
- Mean Score: 16.45
- Median Score: 20
- Mode Score: 0
看起来很多人很晚就开始了比赛,也没有超出几个问题。 我不完全确定为什么,但可能是因为这个问题是为了很多观众而进步的。
有用的资源
深入学习的基础 - 从人工神经网络开始:
https://www.analyticsvidhya.com/blog/2016/03/introduction-deep-learning…
在Python中实现神经网络的实用指南(使用Theano):
https://www.analyticsvidhya.com/blog/2016/04/neural-networks-python-the…
Python深入学习入门的完整指南:
https://www.analyticsvidhya.com/blog/2016/08/deep-learning-path/
教程:使用Keras优化神经网络(使用图像识别案例研究):
https://www.analyticsvidhya.com/blog/2016/10/tutorial-optimizing-neural…
使用TensorFlow实现神经网络的介绍:
https://www.analyticsvidhya.com/blog/2016/10/an-introduction-to-impleme…
问题与解答
Q1. A neural network model is said to be inspired from the human brain.
The neural network consists of many neurons, each neuron takes an input, processes it and gives an output. Here’s a diagrammatic representation of a real neuron.
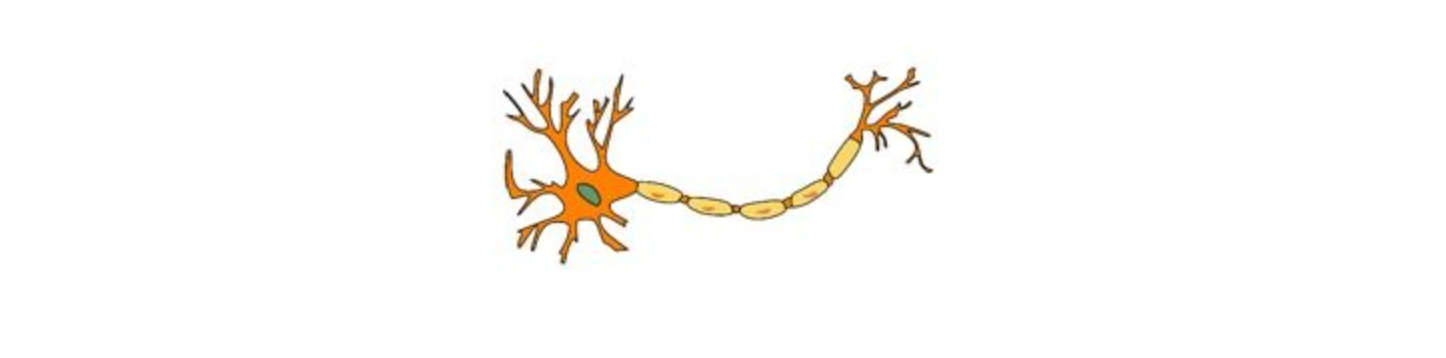
Which of the following statement(s) correctly represents a real neuron?
A. A neuron has a single input and a single output only
B. A neuron has multiple inputs but a single output only
C. A neuron has a single input but multiple outputs
D. A neuron has multiple inputs and multiple outputs
E. All of the above statements are valid
Solution: (E)
A neuron can have a single Input / Output or multiple Inputs / Outputs.
Q2. Below is a mathematical representation of a neuron.
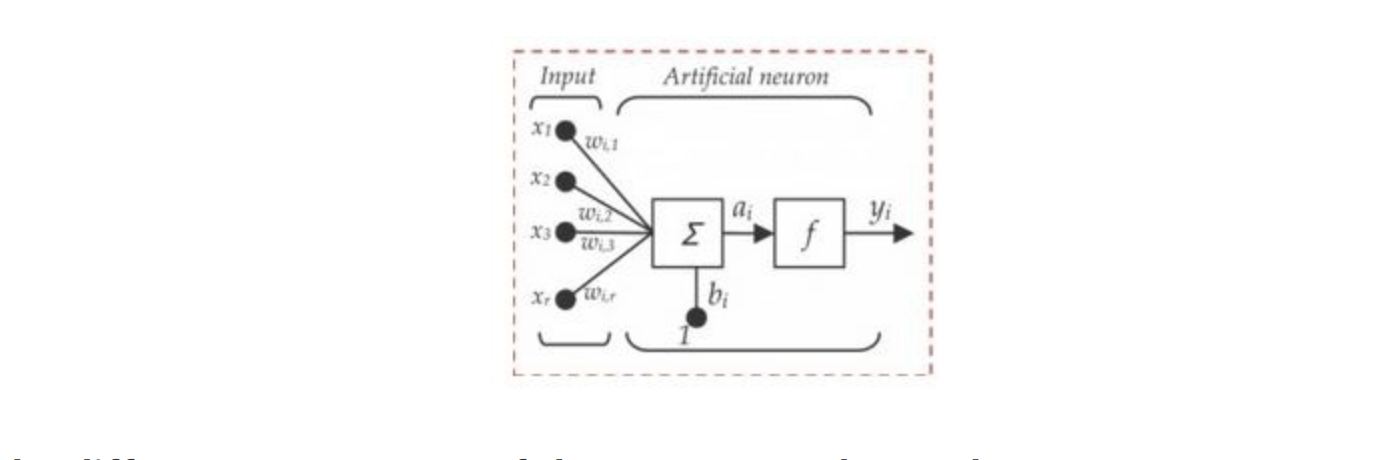
The different components of the neuron are denoted as:
- x1, x2,…, xN: These are inputs to the neuron. These can either be the actual observations from input layer or an intermediate value from one of the hidden layers.
- w1, w2,…,wN: The Weight of each input.
- bi: Is termed as Bias units. These are constant values added to the input of the activation function corresponding to each weight. It works similar to an intercept term.
- a: Is termed as the activation of the neuron which can be represented as
- and y: is the output of the neuron
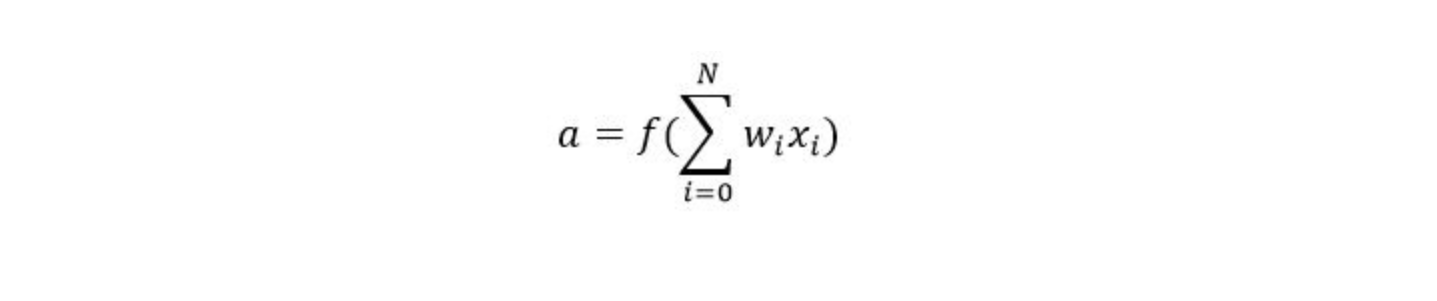
Considering the above notations, will a line equation (y = mx + c) fall into the category of a neuron?
A. Yes
B. No
Solution: (A)
A single neuron with no non-linearity can be considered as a linear regression function.
Q3. Let us assume we implement an AND function to a single neuron. Below is a tabular representation of an AND function:
| X1 | X2 | X1 AND X2 |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
The activation function of our neuron is denoted as:
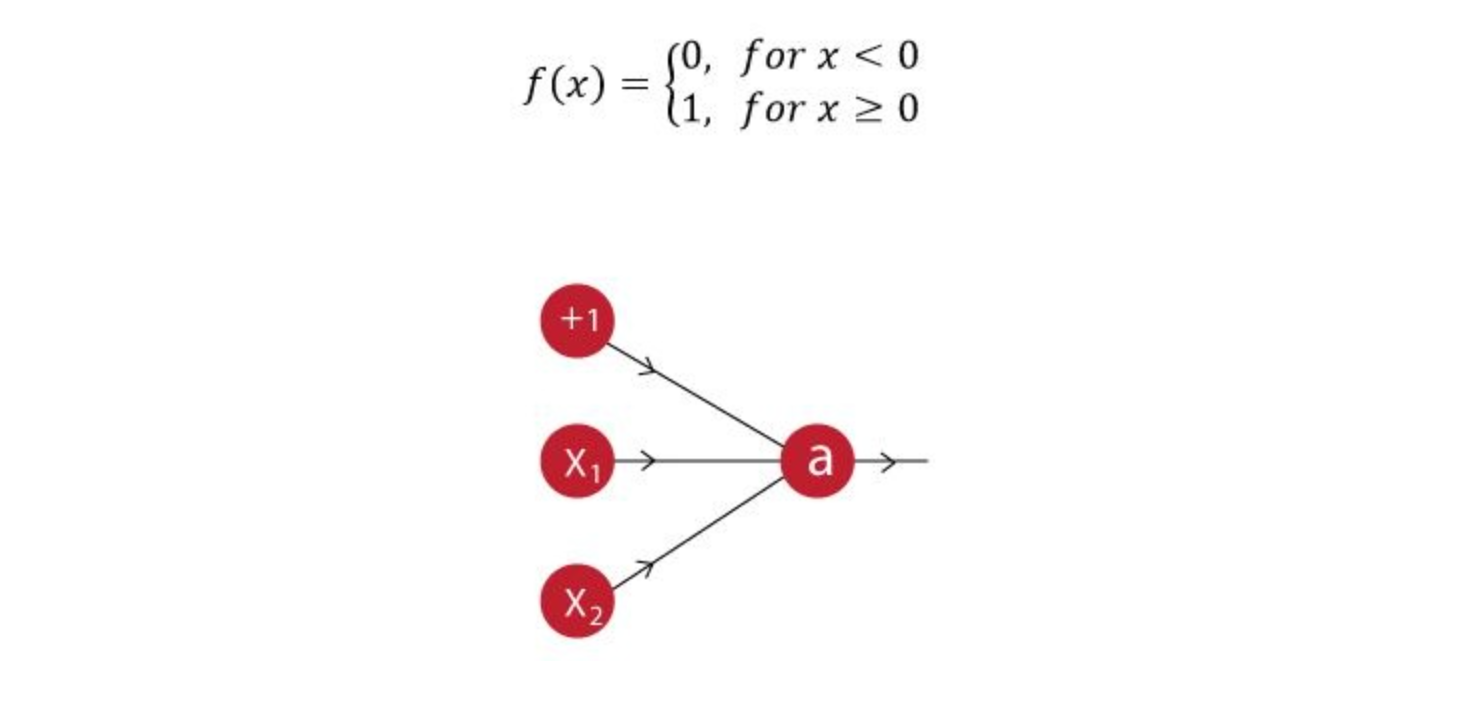
What would be the weights and bias?
(Hint: For which values of w1, w2 and b does our neuron implement an AND function?)
A. Bias = -1.5, w1 = 1, w2 = 1
B. Bias = 1.5, w1 = 2, w2 = 2
C. Bias = 1, w1 = 1.5, w2 = 1.5
D. None of these
Solution: (A)
A.
- f(-1.5*1 + 1*0 + 1*0) = f(-1.5) = 0
- f(-1.5*1 + 1*0 + 1*1) = f(-0.5) = 0
- f(-1.5*1 + 1*1 + 1*0) = f(-0.5) = 0
- f(-1.5*1 + 1*1+ 1*1) = f(0.5) = 1
Therefore option A is correct
Q4. A network is created when we multiple neurons stack together. Let us take an example of a neural network simulating an XNOR function.
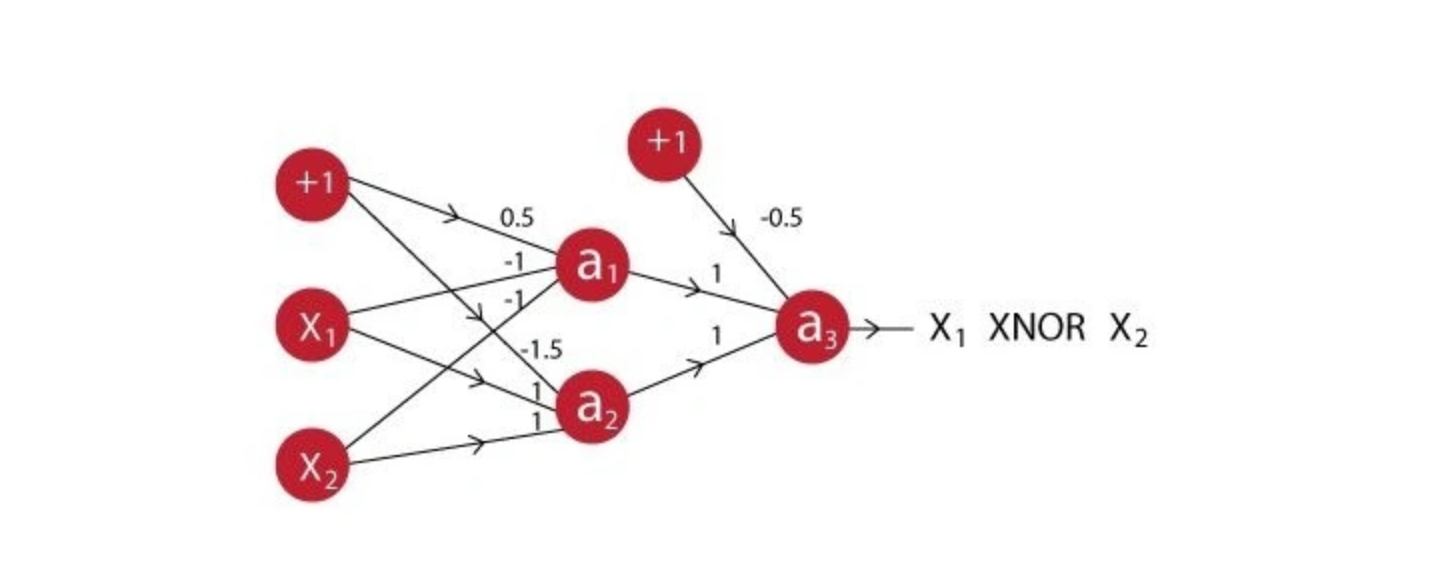
You can see that the last neuron takes input from two neurons before it. The activation function for all the neurons is given by:
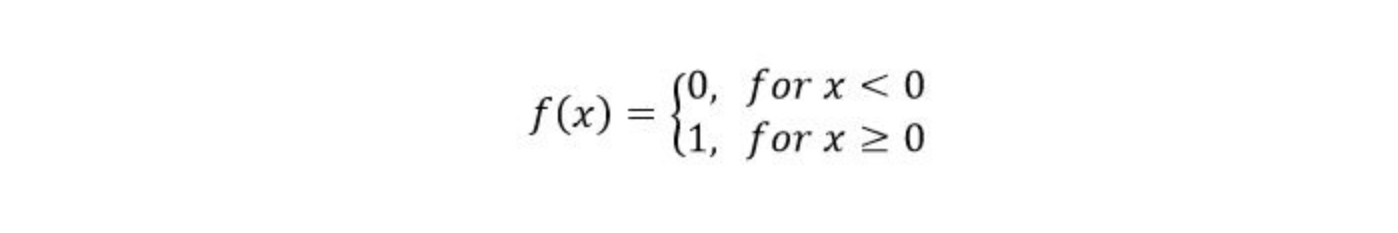
Suppose X1 is 0 and X2 is 1, what will be the output for the above neural network?
A. 0
B. 1
Solution: (A)
Output of a1: f(0.5*1 + -1*0 + -1*1) = f(-0.5) = 0
Output of a2: f(-1.5*1 + 1*0 + 1*1) = f(-0.5) = 0
Output of a3: f(-0.5*1 + 1*0 + 1*0) = f(-0.5) = 0
So the correct answer is A
Q5. In a neural network, knowing the weight and bias of each neuron is the most important step. If you can somehow get the correct value of weight and bias for each neuron, you can approximate any function. What would be the best way to approach this?
A. Assign random values and pray to God they are correct
B. Search every possible combination of weights and biases till you get the best value
C. Iteratively check that after assigning a value how far you are from the best values, and slightly change the assigned values values to make them better
D. None of these
Solution: (C)
Option C is the description of gradient descent.
Q6. What are the steps for using a gradient descent algorithm?
- Calculate error between the actual value and the predicted value
- Reiterate until you find the best weights of network
- Pass an input through the network and get values from output layer
- Initialize random weight and bias
- Go to each neurons which contributes to the error and change its respective values to reduce the error
A. 1, 2, 3, 4, 5
B. 5, 4, 3, 2, 1
C. 3, 2, 1, 5, 4
D. 4, 3, 1, 5, 2
Solution: (D)
Option D is correct
Q7. Suppose you have inputs as x, y, and z with values -2, 5, and -4 respectively. You have a neuron ‘q’ and neuron ‘f’ with functions:
q = x + y
f = q * z
Graphical representation of the functions is as follows:

What is the gradient of F with respect to x, y, and z?
(HINT: To calculate gradient, you must find (df/dx), (df/dy) and (df/dz))
A. (-3,4,4)
B. (4,4,3)
C. (-4,-4,3)
D. (3,-4,-4)
Solution: (C)
Option C is correct.
Q8. Now let’s revise the previous slides. We have learned that:
- A neural network is a (crude) mathematical representation of a brain, which consists of smaller components called neurons.
- Each neuron has an input, a processing function, and an output.
- These neurons are stacked together to form a network, which can be used to approximate any function.
- To get the best possible neural network, we can use techniques like gradient descent to update our neural network model.
Given above is a description of a neural network. When does a neural network model become a deep learning model?
A. When you add more hidden layers and increase depth of neural network
B. When there is higher dimensionality of data
C. When the problem is an image recognition problem
D. None of these
Solution: (A)
More depth means the network is deeper. There is no strict rule of how many layers are necessary to make a model deep, but still if there are more than 2 hidden layers, the model is said to be deep.
Q9. A neural network can be considered as multiple simple equations stacked together. Suppose we want to replicate the function for the below mentioned decision boundary.
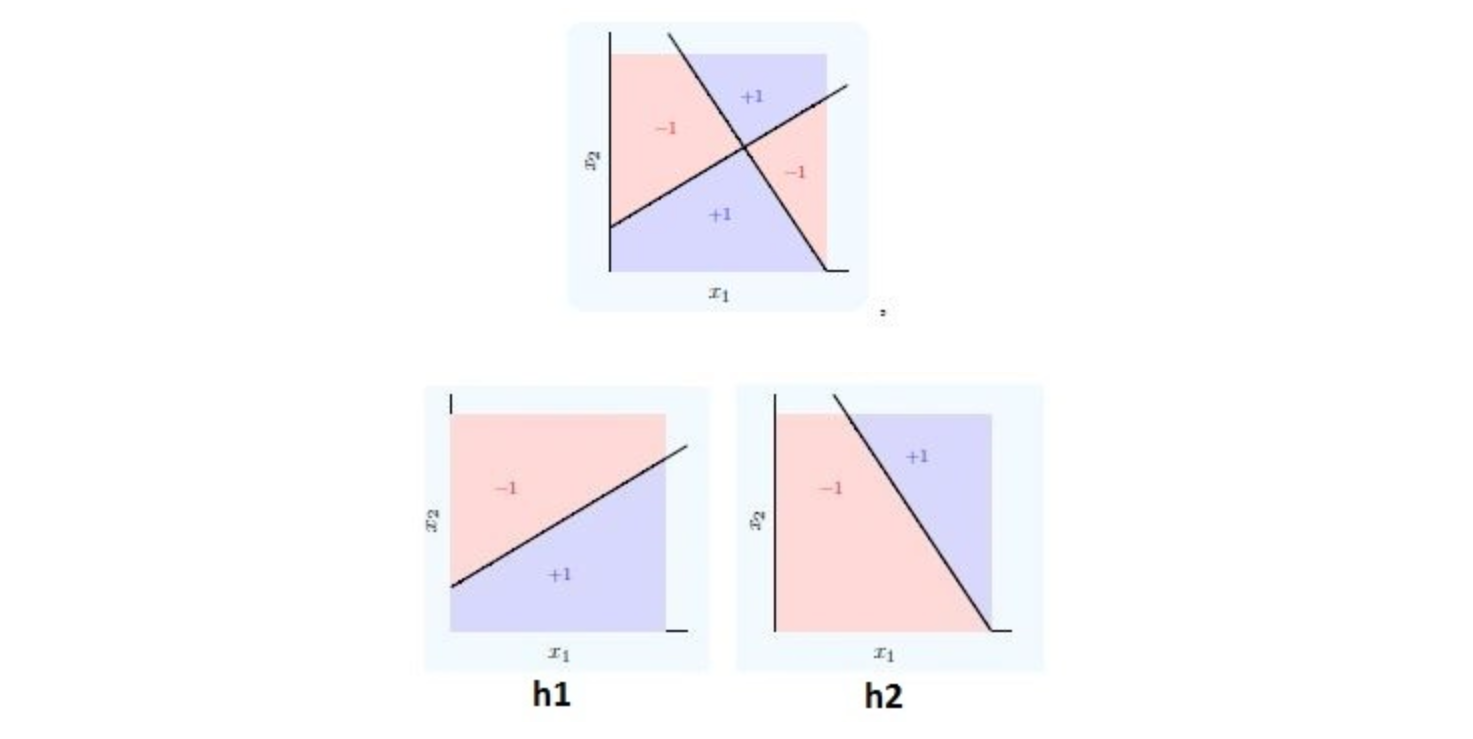
Using two simple inputs h1 and h2
What will be the final equation?
A. (h1 AND NOT h2) OR (NOT h1 AND h2)
B. (h1 OR NOT h2) AND (NOT h1 OR h2)
C. (h1 AND h2) OR (h1 OR h2)
D. None of these
Solution: (A)
As you can see, combining h1 and h2 in an intelligent way can get you a complex equation easily. Refer Chapter 9 of this book
Q10. “Convolutional Neural Networks can perform various types of transformation (rotations or scaling) in an input”. Is the statement correct True or False?
A. True
B. False
Solution: (B)
Data Preprocessing steps (viz rotation, scaling) is necessary before you give the data to neural network because neural network cannot do it itself.
Q11. Which of the following techniques perform similar operations as dropout in a neural network?
A. Bagging
B. Boosting
C. Stacking
D. None of these
Solution: (A)
Dropout can be seen as an extreme form of bagging in which each model is trained on a single case and each parameter of the model is very strongly regularized by sharing it with the corresponding parameter in all the other models. Refer here
Q 12. Which of the following gives non-linearity to a neural network?
A. Stochastic Gradient Descent
B. Rectified Linear Unit
C. Convolution function
D. None of the above
Solution: (B)
Rectified Linear unit is a non-linear activation function.
Q13. In training a neural network, you notice that the loss does not decrease in the few starting epochs.
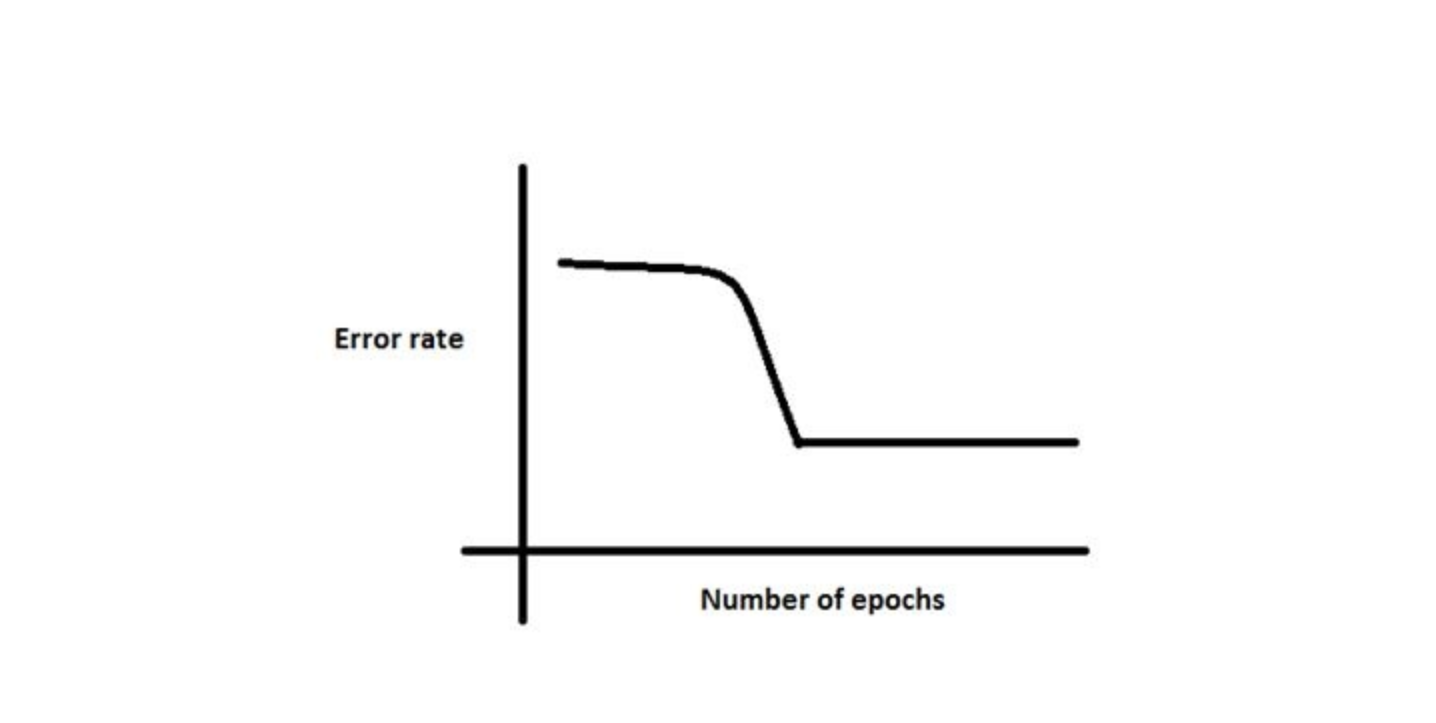
The reasons for this could be:
- The learning is rate is low
- Regularization parameter is high
- Stuck at local minima
What according to you are the probable reasons?
A. 1 and 2
B. 2 and 3
C. 1 and 3
D. Any of these
Solution: (D)
The problem can occur due to any of the reasons mentioned.
Q14. Which of the following is true about model capacity (where model capacity means the ability of neural network to approximate complex functions) ?
A. As number of hidden layers increase, model capacity increases
B. As dropout ratio increases, model capacity increases
C. As learning rate increases, model capacity increases
D. None of these
Solution: (A)
Only option A is correct.
Q15. If you increase the number of hidden layers in a Multi Layer Perceptron, the classification error of test data always decreases. True or False?
A. True
B. False
Solution: (B)
This is not always true. Overfitting may cause the error to increase.
Q16. You are building a neural network where it gets input from the previous layer as well as from itself.
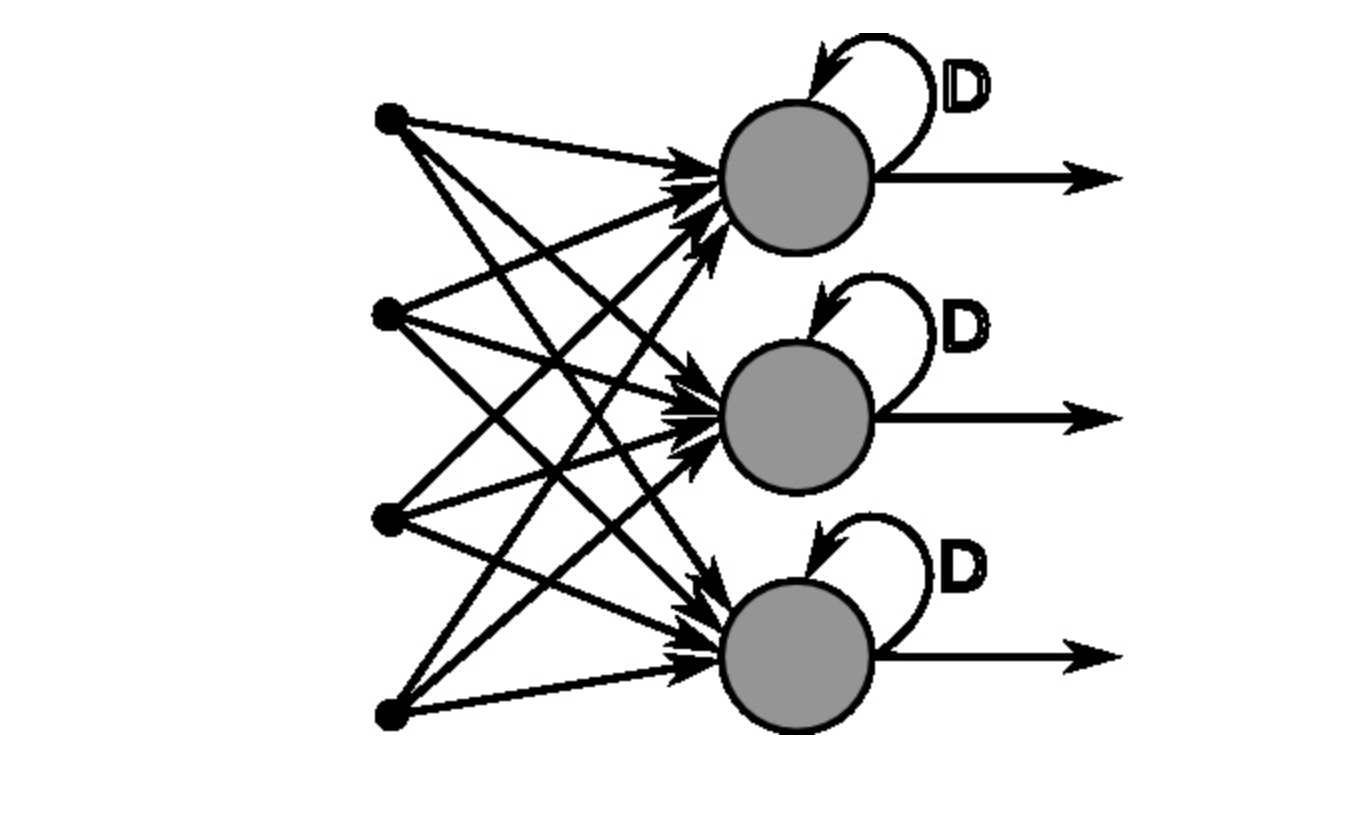
Which of the following architecture has feedback connections?
A. Recurrent Neural network
B. Convolutional Neural Network
C. Restricted Boltzmann Machine
D. None of these
Solution: (A)
Option A is correct.
Q17. What is the sequence of the following tasks in a perceptron?
- Initialize weights of perceptron randomly
- Go to the next batch of dataset
- If the prediction does not match the output, change the weights
- For a sample input, compute an output
A. 1, 2, 3, 4
B. 4, 3, 2, 1
C. 3, 1, 2, 4
D. 1, 4, 3, 2
Solution: (D)
Sequence D is correct.
Q18. Suppose that you have to minimize the cost function by changing the parameters. Which of the following technique could be used for this?
A. Exhaustive Search
B. Random Search
C. Bayesian Optimization
D. Any of these
Solution: (D)
Any of the above mentioned technique can be used to change parameters.
Q19. First Order Gradient descent would not work correctly (i.e. may get stuck) in which of the following graphs?
A.
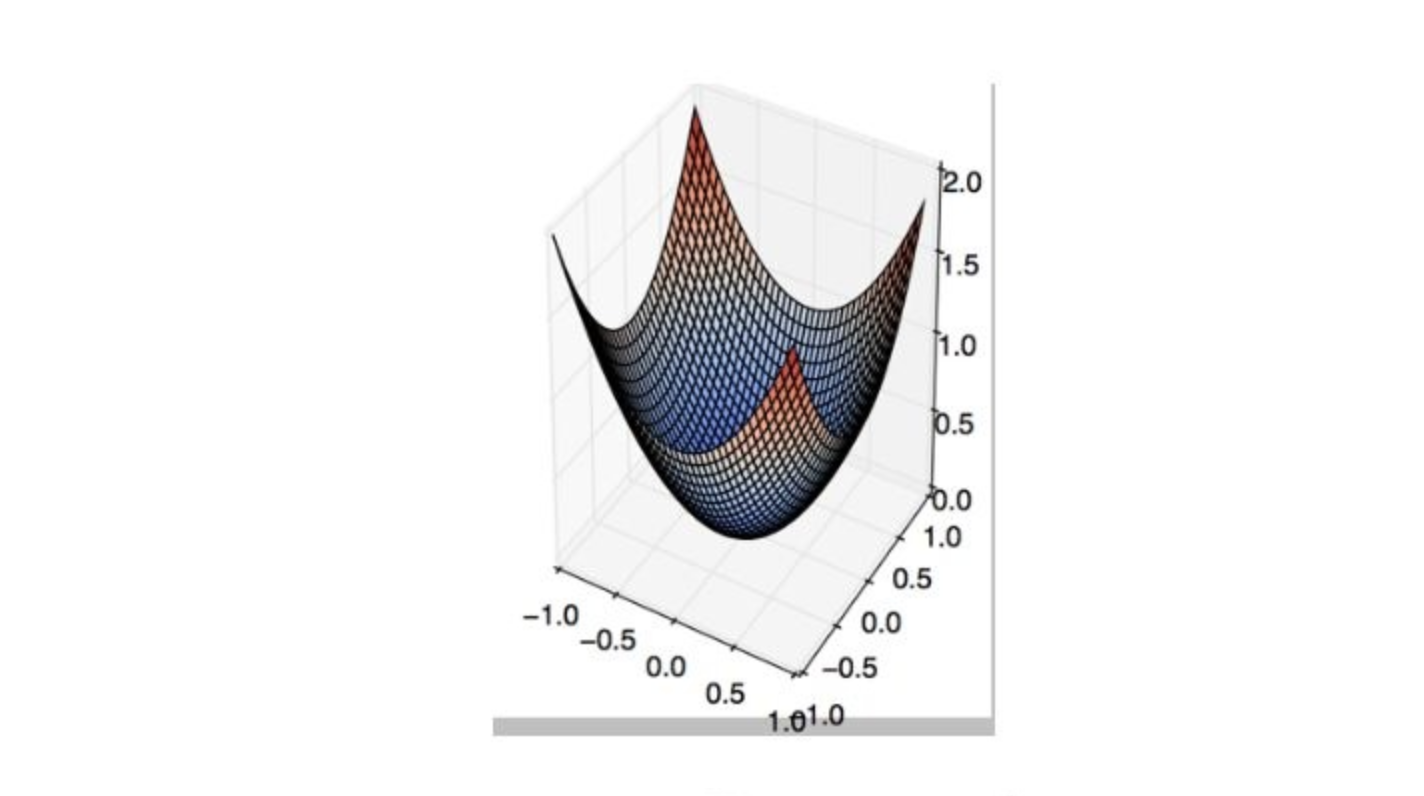
B.

C.
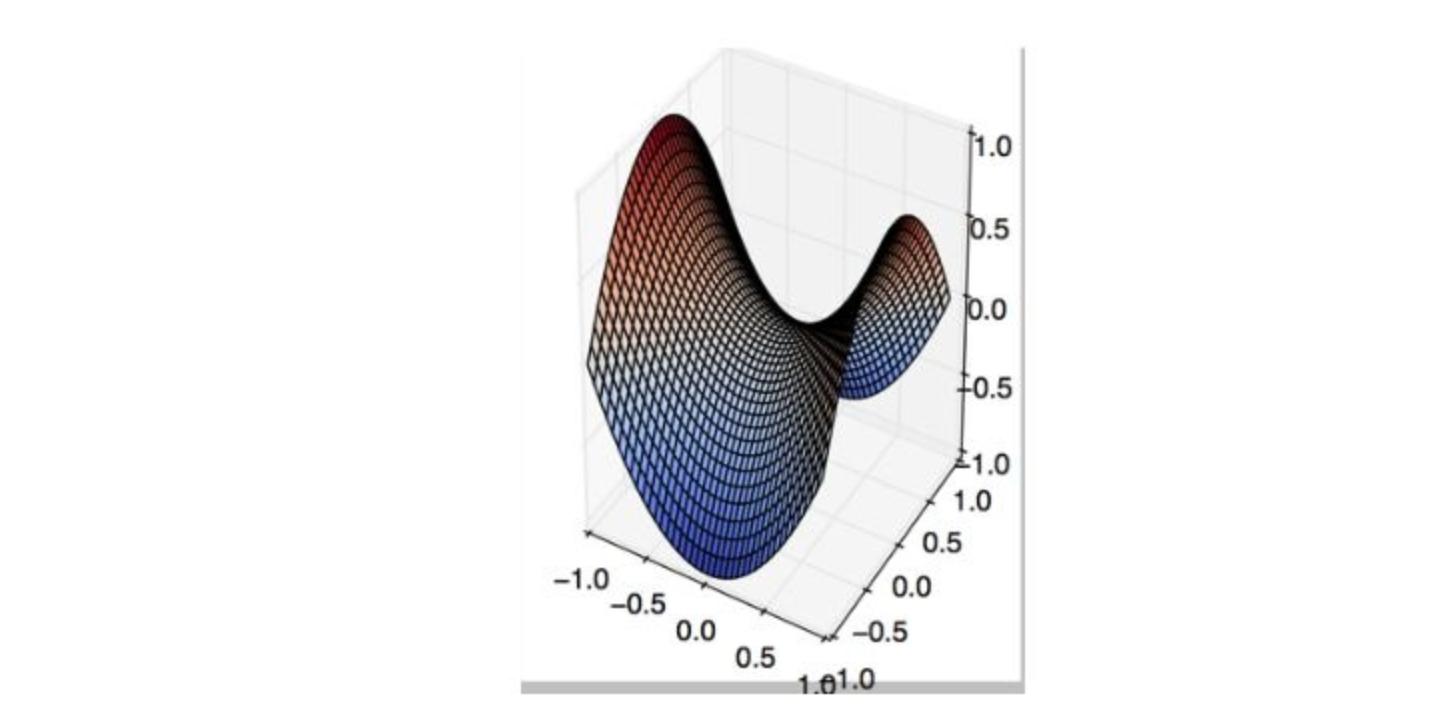
D. None of these
Solution: (B)
This is a classic example of saddle point problem of gradient descent.
Q20. The below graph shows the accuracy of a trained 3-layer convolutional neural network vs the number of parameters (i.e. number of feature kernels).

The trend suggests that as you increase the width of a neural network, the accuracy increases till a certain threshold value, and then starts decreasing.
What could be the possible reason for this decrease?
A. Even if number of kernels increase, only few of them are used for prediction
B. As the number of kernels increase, the predictive power of neural network decrease
C. As the number of kernels increase, they start to correlate with each other which in turn helps overfitting
D. None of these
Solution: (C)
As mentioned in option C, the possible reason could be kernel correlation.
Q21. Suppose we have one hidden layer neural network as shown above. The hidden layer in this network works as a dimensionality reductor. Now instead of using this hidden layer, we replace it with a dimensionality reduction technique such as PCA.
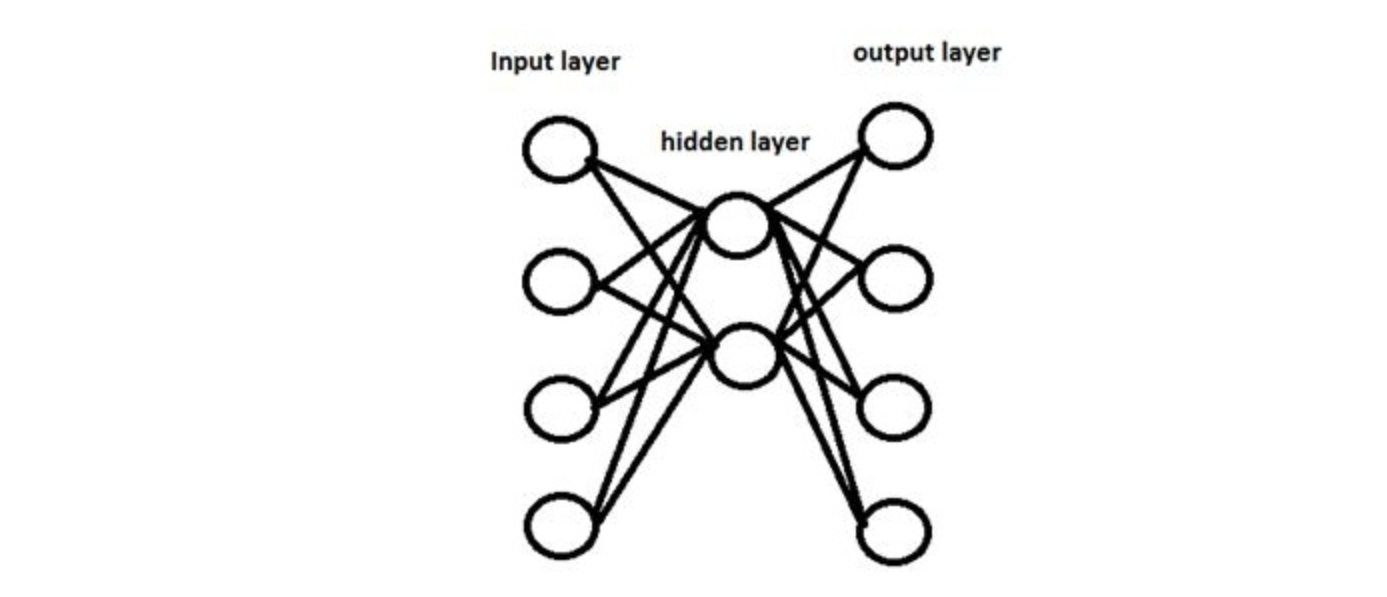
Would the network that uses a dimensionality reduction technique always give same output as network with hidden layer?
A. Yes
B. No
Solution: (B)
Because PCA works on correlated features, whereas hidden layers work on predictive capacity of features.
Q22. Can a neural network model the function (y=1/x)?
A. Yes
B. No
Solution: (A)
Option A is true, because activation function can be reciprocal function.
Q23. In which neural net architecture, does weight sharing occur?
A. Convolutional neural Network
B. Recurrent Neural Network
C. Fully Connected Neural Network
D. Both A and B
Solution: (D)
Option D is correct.
Q24. Batch Normalization is helpful because
A. It normalizes (changes) all the input before sending it to the next layer
B. It returns back the normalized mean and standard deviation of weights
C. It is a very efficient backpropagation technique
D. None of these
Solution: (A)
To read more about batch normalization, see refer this video
Q25. Instead of trying to achieve absolute zero error, we set a metric called bayes error which is the error we hope to achieve. What could be the reason for using bayes error?
A. Input variables may not contain complete information about the output variable
B. System (that creates input-output mapping) may be stochastic
C. Limited training data
D. All the above
Solution: (D)
In reality achieving accurate prediction is a myth. So we should hope to achieve an “achievable result”.
Q26. The number of neurons in the output layer should match the number of classes (Where the number of classes is greater than 2) in a supervised learning task. True or False?
A. True
B. False
Solution: (B)
It depends on output encoding. If it is one-hot encoding, then its true. But you can have two outputs for four classes, and take the binary values as four classes(00,01,10,11).
Q27. In a neural network, which of the following techniques is used to deal with overfitting?
A. Dropout
B. Regularization
C. Batch Normalization
D. All of these
Solution: (D)
All of the techniques can be used to deal with overfitting.
Q28. Y = ax^2 + bx + c (polynomial equation of degree 2)
Can this equation be represented by a neural network of single hidden layer with linear threshold?
A. Yes
B. No
Solution: (B)
The answer is no because having a linear threshold restricts your neural network and in simple terms, makes it a consequential linear transformation function.
Q29. What is a dead unit in a neural network?
A. A unit which doesn’t update during training by any of its neighbour
B. A unit which does not respond completely to any of the training patterns
C. The unit which produces the biggest sum-squared error
D. None of these
Solution: (A)
Option A is correct.
Q30. Which of the following statement is the best description of early stopping?
A. Train the network until a local minimum in the error function is reached
B. Simulate the network on a test dataset after every epoch of training. Stop training when the generalization error starts to increase
C. Add a momentum term to the weight update in the Generalized Delta Rule, so that training converges more quickly
D. A faster version of backpropagation, such as the `Quickprop’ algorithm
Solution: (B)
Option B is correct.
Q31. What if we use a learning rate that’s too large?
A. Network will converge
B. Network will not converge
C. Can’t Say
Solution: B
Option B is correct because the error rate would become erratic and explode.
Q32. The network shown in Figure 1 is trained to recognize the characters H and T as shown below:
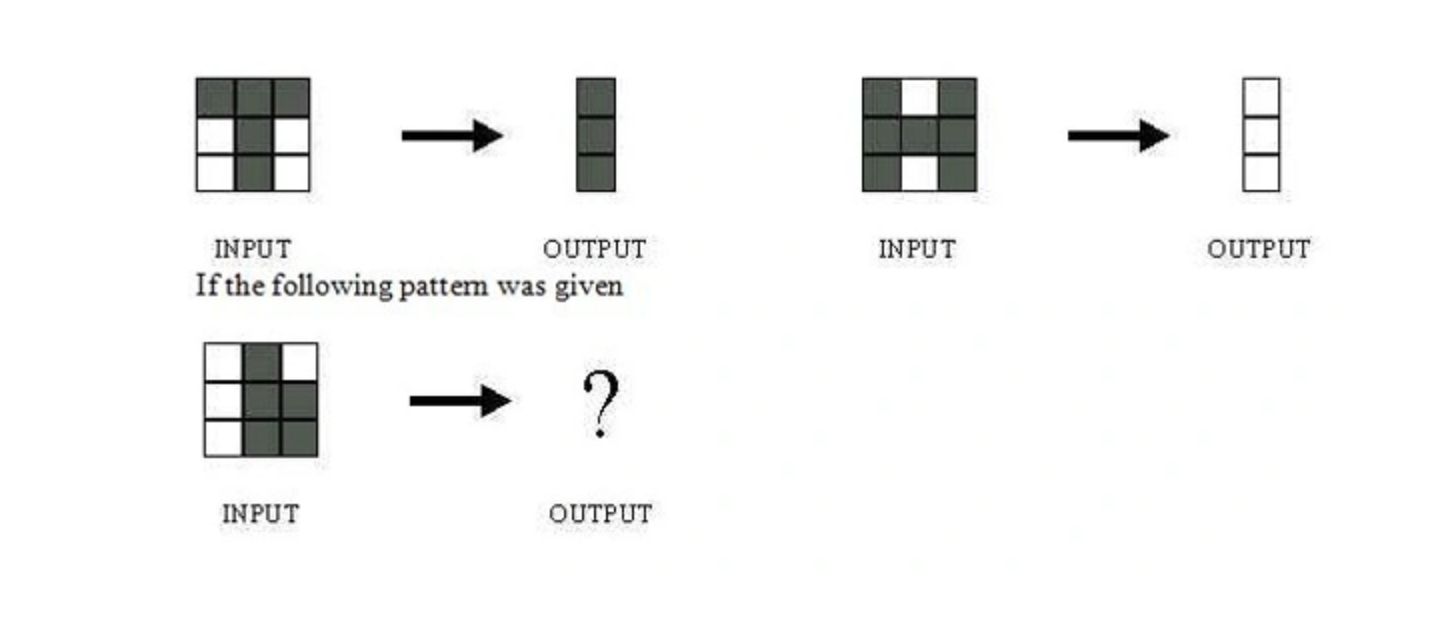
What would be the output of the network?
A

B

C

D: Could be A or B depending on the weights of neural network
Solution: (D)
Without knowing what are the weights and biases of a neural network, we cannot comment on what output it would give.
Q33. Suppose a convolutional neural network is trained on ImageNet dataset (Object recognition dataset). This trained model is then given a completely white image as an input.The output probabilities for this input would be equal for all classes. True or False?
A. True
B. False
Solution: (B)
There would be some neurons which are do not activate for white pixels as input. So the classes wont be equal.
Q34. When pooling layer is added in a convolutional neural network, translation in-variance is preserved. True or False?
A. True
B. False
Solution: (A)
Translation invariance is induced when you use pooling.
Q35. Which gradient technique is more advantageous when the data is too big to handle in RAM simultaneously?
A. Full Batch Gradient Descent
B. Stochastic Gradient Descent
Solution: (B)
Option B is correct.
Q36. The graph represents gradient flow of a four-hidden layer neural network which is trained using sigmoid activation function per epoch of training. The neural network suffers with the vanishing gradient problem.
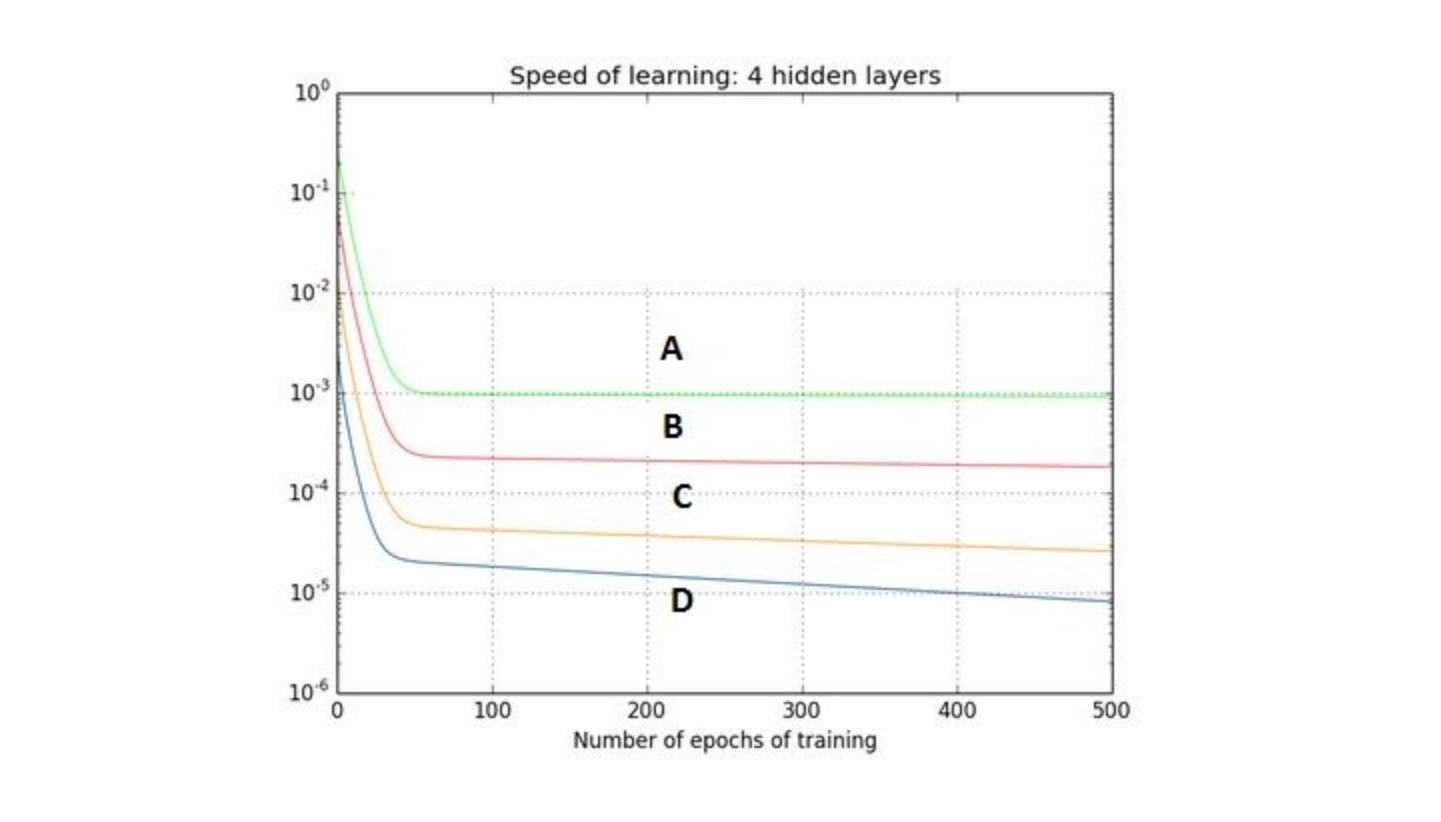
Which of the following statements is true?
A. Hidden layer 1 corresponds to D, Hidden layer 2 corresponds to C, Hidden layer 3 corresponds to B and Hidden layer 4 corresponds to A
B. Hidden layer 1 corresponds to A, Hidden layer 2 corresponds to B, Hidden layer 3 corresponds to C and Hidden layer 4 corresponds to D
Solution: (A)
This is a description of a vanishing gradient problem. As the backprop algorithm goes to starting layers, learning decreases.
Q37. For a classification task, instead of random weight initializations in a neural network, we set all the weights to zero. Which of the following statements is true?
A. There will not be any problem and the neural network will train properly
B. The neural network will train but all the neurons will end up recognizing the same thing
C. The neural network will not train as there is no net gradient change
D. None of these
Solution: (B)
Option B is correct.
Q38. There is a plateau at the start. This is happening because the neural network gets stuck at local minima before going on to global minima.
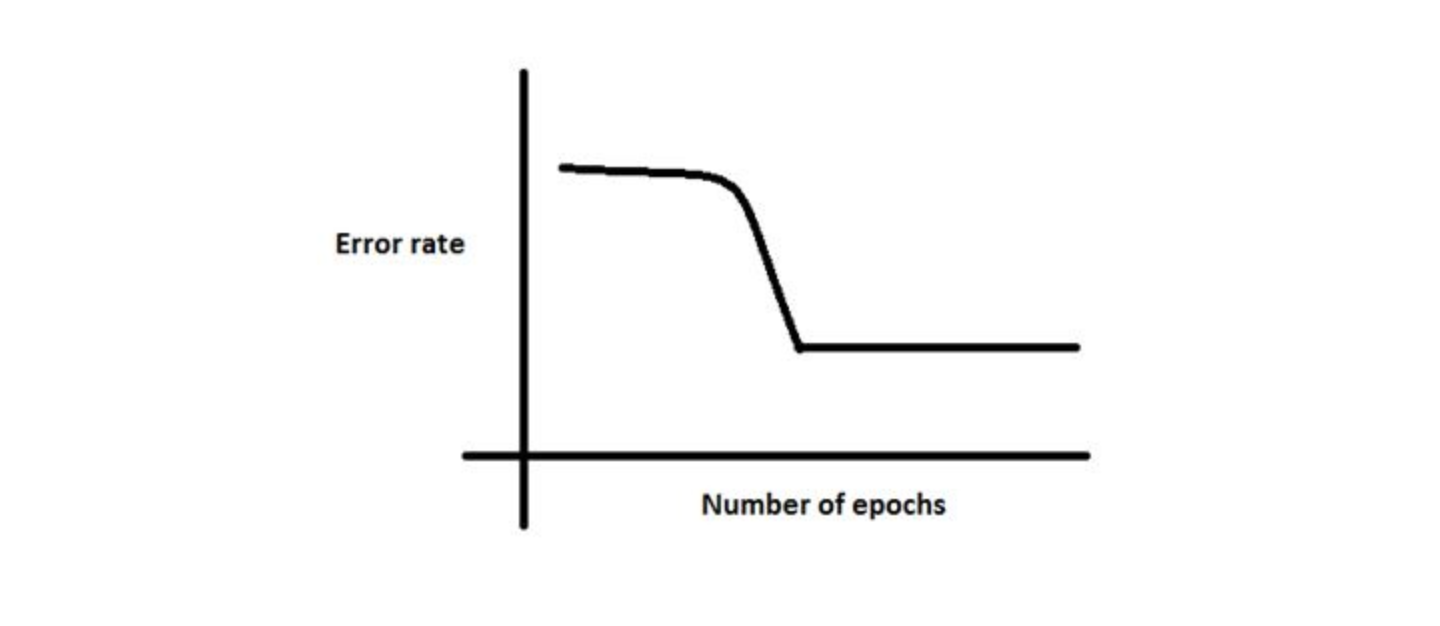
To avoid this, which of the following strategy should work?
A. Increase the number of parameters, as the network would not get stuck at local minima
B. Decrease the learning rate by 10 times at the start and then use momentum
C. Jitter the learning rate, i.e. change the learning rate for a few epochs
D. None of these
Solution: (C)
Option C can be used to take a neural network out of local minima in which it is stuck.
Q39. For an image recognition problem (recognizing a cat in a photo), which architecture of neural network would be better suited to solve the problem?
A. Multi Layer Perceptron
B. Convolutional Neural Network
C. Recurrent Neural network
D. Perceptron
Solution: (B)
Convolutional Neural Network would be better suited for image related problems because of its inherent nature for taking into account changes in nearby locations of an image
Q40. Suppose while training, you encounter this issue. The error suddenly increases after a couple of iterations.

You determine that there must a problem with the data. You plot the data and find the insight that, original data is somewhat skewed and that may be causing the problem.

What will you do to deal with this challenge?
A. Normalize
B. Apply PCA and then Normalize
C. Take Log Transform of the data
D. None of these
Solution: (B)
First you would remove the correlations of the data and then zero center it.
Q41. Which of the following is a decision boundary of Neural Network?
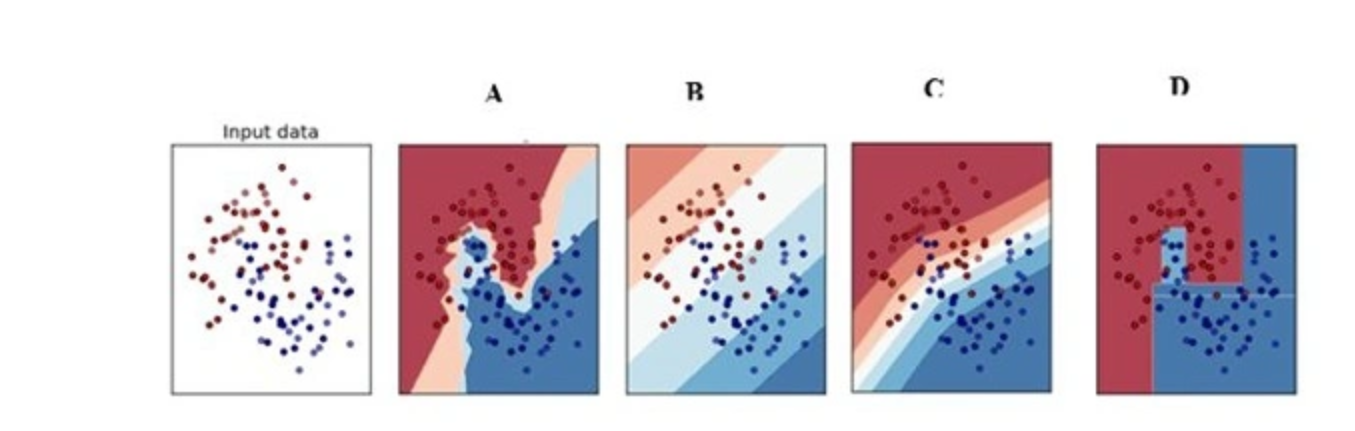
A) B
B) A
C) D
D) C
E) All of these
Solution: (E)
A neural network is said to be a universal function approximator, so it can theoretically represent any decision boundary.
Q42. In the graph below, we observe that the error has many “ups and downs”
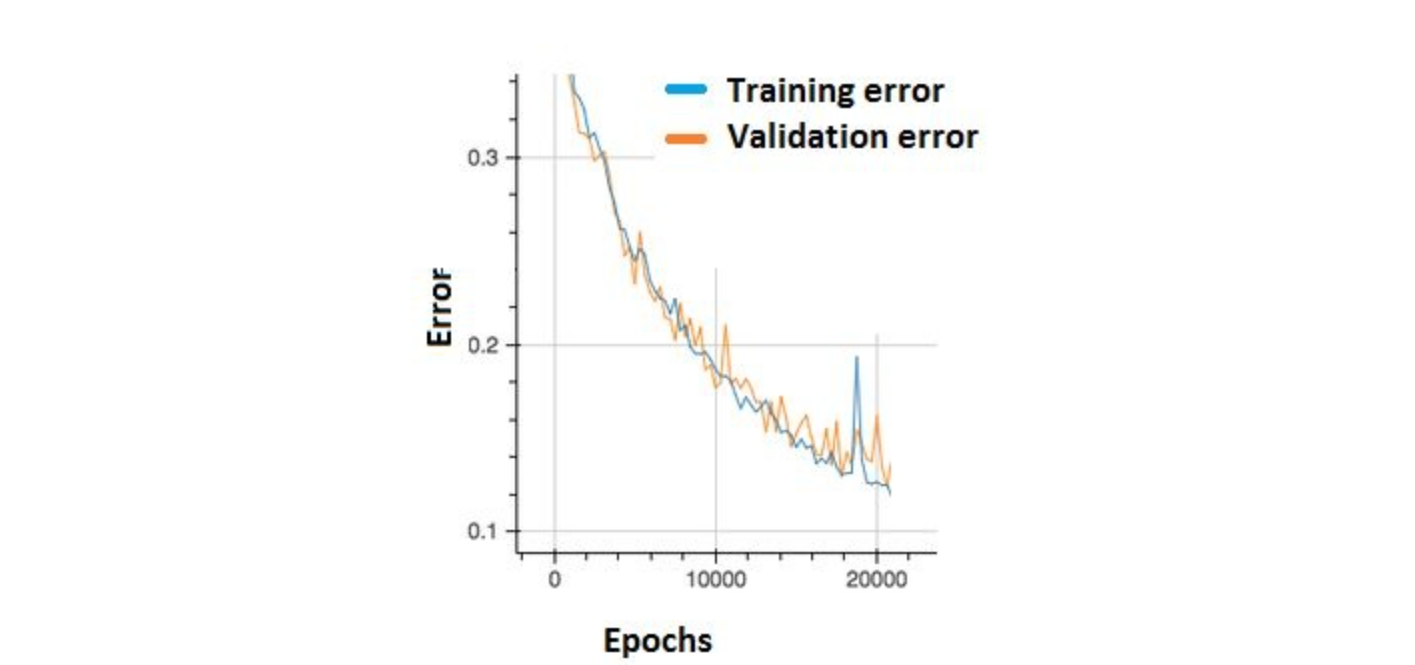
Should we be worried?
A. Yes, because this means there is a problem with the learning rate of neural network.
B. No, as long as there is a cumulative decrease in both training and validation error, we don’t need to worry.
Solution: (B)
Option B is correct. In order to decrease these “ups and downs” try to increase the batch size.
Q43. What are the factors to select the depth of neural network?
- Type of neural network (eg. MLP, CNN etc)
- Input data
- Computation power, i.e. Hardware capabilities and software capabilities
- Learning Rate
- The output function to map
A. 1, 2, 4, 5
B. 2, 3, 4, 5
C. 1, 3, 4, 5
D. All of these
Solution: (D)
All of the above factors are important to select the depth of neural network
Q44. Consider the scenario. The problem you are trying to solve has a small amount of data. Fortunately, you have a pre-trained neural network that was trained on a similar problem. Which of the following methodologies would you choose to make use of this pre-trained network?
A. Re-train the model for the new dataset
B. Assess on every layer how the model performs and only select a few of them
C. Fine tune the last couple of layers only
D. Freeze all the layers except the last, re-train the last layer
Solution: (D)
If the dataset is mostly similar, the best method would be to train only the last layer, as previous all layers work as feature extractors.
Q45. Increase in size of a convolutional kernel would necessarily increase the performance of a convolutional network.
A. True
B. False
Solution: (B)
Increasing kernel size would not necessarily increase performance. This depends heavily on the dataset.
结束笔记
我希望你喜欢参加测试,你发现解决方案有帮助。测试集中在深度学习的概念知识。
我们试图通过这篇文章清除所有的疑问,但如果我们错过了一些事情,那么让我在下面的评论中知道。如果您有任何建议或改进,您认为我们应该在下一个技能测试中,通过在评论部分放弃您的反馈来告知我们。
- 4201 次浏览
【深度学习】CNN与RNN:它们有什么不同?
视频号
微信公众号
知识星球
卷积神经网络和递归神经网络是许多推动商业价值的人工智能应用的基础。在本初级读本中了解细胞神经网络与RNN。
为了在不错过机会的情况下设定对人工智能的现实期望,了解算法的能力和局限性很重要。
在本文中,我们探讨了推动人工智能领域向前发展的两种算法——卷积神经网络(CNNs)和递归神经网络(RNNs)。我们将介绍它们是什么,它们是如何工作的,它们的局限性是什么,以及它们在哪里相辅相成。
但首先,简要总结CNN和RNN之间的主要区别。
- CNNs 通常用于解决与空间数据(如图像)相关的问题。RNN更适合分析时间序列数据,如文本或视频。
- CNN与RNN具有不同的体系结构。细胞神经网络是使用滤波器和池化层的“前馈神经网络”,而RNN将结果反馈到网络中(下面将详细介绍这一点)。
- 在CNNs 中,输入和输出的大小是固定的。也就是说,CNN接收固定大小的图像,并将它们连同其预测的置信水平一起输出到适当的水平。在RNN中,输入和结果输出的大小可能会变化。
- CNNs 的使用案例包括面部识别、医学分析和分类。RNN的用例包括文本翻译、自然语言处理、情感分析和语音分析。
ANNs,CNNs,RNNs:什么是神经网络?
神经网络在其发明时被广泛认为是该领域的一项重大突破。根据我们大脑中神经元的工作方式,神经网络架构引入了一种算法,使计算机能够微调其决策——换句话说,就是学习。
人工神经网络由许多感知器组成。在最简单的形式中,感知器由一个函数组成,该函数接受两个输入,将它们乘以两个随机权重,将它们与偏差值相加,通过激活函数传递结果并打印结果。权重和偏差值是可调整的,并且它们定义了感知器的结果,给定两个特定的输入值。
这种架构非常天才:将感知器组合在一起,生成了几乎可以承担任何任务的可调整变量层。然而,问题是,为了进行正确的计算,应该为权重和偏差值选择什么数字。
人工神经元中的偏差
在人工和生物网络中,当神经元处理他们接收到的输入时,他们决定输出是否应该作为输入传递到下一层。是否发送信息的决定被称为偏差,它由系统中内置的激活函数决定。例如,只有当人工神经元的输入(实际上是电压)之和超过某个特定阈值时,人工神经元才能将输出信号传递到下一层。
--琳达·图奇
这是通过一种称为反向传播的机制来解决的。向人工神经网络提供输入,并将结果与预期输出进行比较。期望输出和实际输出之间的差异通过数学计算返回到神经网络中,该数学计算确定了应该如何调整每个感知器以达到期望的结果。
这个训练人工智能的过程被重复,直到达到令人满意的精度水平。
像这样的神经网络非常适合简单的统计预测,比如根据一个人的年龄、性别和地理位置来预测他最喜欢的足球队。但人工智能如何用于图像识别等更困难的任务?答案引出了一个问题,即我们首先如何将数据输入网络。

This chart outlines the chief differences between a convolutional neural network and a recurrent neural network.
卷积神经网络
我们在计算机中看到的图像实际上是一组颜色值,分布在一定的宽度和高度上。我们所看到的形状和物体在机器上显示为一组数字。卷积神经网络通过一种称为滤波器的机制,然后汇集层来理解这些数据。
Ajay Divakaran解释道:“滤波器是一个随机数字矩阵。在CNN中,滤波器与图像部分的矩阵表示相乘,有效地逐像素扫描图像,获得所有相邻像素的平均值,从而检测最重要的特征。”,SRI国际视觉技术中心视觉与学习实验室的高级技术总监,该中心是一家非营利性科学研究机构。
他补充道:“这些信息通过池化层传递,池化层将获取的特征图浓缩为最基本的信息。”。最后一步大大减少了数据的大小,并使神经网络更快。然后将得到的信息输入到神经网络中。
CNN由几层感知器组成,滤波器有效地构建了一个网络,通过每一层都能理解越来越多的图像。第一层理解轮廓和边界,第二层开始理解形状,第三层理解物体。这个模型的强大之处在于它能够识别物体,无论它们出现在图片中的什么位置或旋转。
细胞神经网络非常擅长识别物体、动物和人,但如果我们想了解图片中发生了什么呢?
例如,考虑一张球在空中的照片。我们怎么知道球是扔上去的还是掉下来的?回答这个问题需要比一张图片更多的信息——我们需要一段视频。图片的顺序将决定球是向上还是向下。但是,我们如何让神经网络记住他们之前处理过的信息,并将其用于计算?
递归神经网络
记忆的问题不仅仅局限于视频——事实上,许多自然语言理解算法(通常只处理文本)需要某种记忆,比如讨论的主题或句子中的前一个单词。
递归神经网络正是为了解决这个问题而设计的。该算法将结果反馈给自己,使其成为最终答案的一部分。
为了说明这一点,假设我们想翻译以下句子:“它是什么日期?”该算法将每个单词分别输入神经网络,当它到达单词“it”时,其输出已经受到单词“What”的影响
不过,RNN确实存在问题。在前面的例子中,最后输入网络的单词对结果的影响更大(在我们的例子中是单词“是吗?”)。这两个词并没有让我们对整句话有太多的理解——算法正在遭受“记忆丧失”。这个问题并没有被忽视,长短期记忆(LSTM)等新算法解决了这个问题。
下图来自Wikimedia Commons,显示了一个单单元递归神经网络。
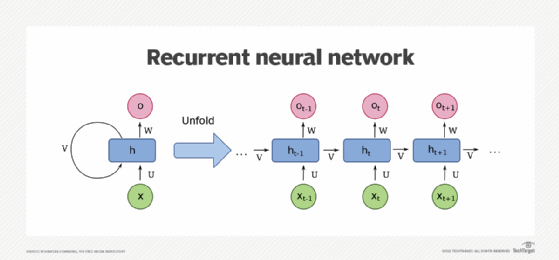
This diagram, courtesy of Wikimedia Commons, depicts a one-unit RNN. From bottom to top: input state, hidden state, output state. U, V, W are the weights of the network. Compressed diagram on the left and the unfold version of it on the right.
CNNs与RNN:优势与劣势
在了解了每个网络是如何设计的之后,我们现在可以指出每个网络的优势和劣势。
聊天机器人开发公司Kore.ai的首席技术官Prasanna Arikala解释道:“在解释视觉数据、稀疏数据或非序列数据时,细胞神经网络是首选。”。另一方面,递归神经网络被设计用于识别顺序或时间数据。当数据与前一个或下一个数据节点相关时,考虑到数据的顺序或序列,它们可以做出更好的预测
Arikala说,细胞神经网络特别有用的应用包括人脸检测、医学分析、药物发现和图像分析。RNN可用于语言翻译、实体提取、会话智能、情感分析和语音分析。
因为RNN依赖于以前的状态来预测未来的状态,所以它们“对股市来说是有意义的,因为预测股票的走势在很大程度上取决于它之前的走势,”他说。
然而,正如我们之前所了解到的,当扫描图片时,CNN的过滤器在工作时会考虑相邻的像素。它能不对相邻单词使用相同的机制吗?
迪瓦卡兰解释说:“这并不是说这样的方法根本不起作用。”。“(但)这是一种不必要的迂回方法。”迪瓦卡兰表示,试图利用CNN的空间建模能力来捕捉基本上是一种时间现象,从定义上来说是次优的,需要更多的精力和记忆才能完成同样的任务。
卷积神经网络与递归神经网络:互补模型
但在某些情况下,这两种模式是相辅相成的。阿里卡拉分享了一个有趣的案例。
他说:“对于一些亚洲语言,如汉语、日语和韩语,其中的字符就像特殊的图像,我们使用CNN和RNN组合构建的深度神经网络进行意图检测和情绪分析。”。
在这些所谓的语标语言中,一些字符可以翻译成一个或几个英语单词,而另一些字符只有在后缀为其他字符时才有意义,从而改变了原始字符的含义。
Arikala解释道:“神经网络的组合之所以在这里起作用,是因为与在其他语言中[使用]树库/WordNet标记化相比,我们在语标语言中进行字符标记化。”。“CNN和LSTM的结合比纯RNN效果要好得多。”
帮助零售商设定最优价格的人工智能公司Competera的数据科学负责人Fred Navruzov同意,这些模型可以合作,而不是相互竞争。
他说:“如今,CNN和RNN使用之间的界限有些模糊,因为你可以将这些架构组合到CRNN中,以提高解决视频标记或手势识别等特定任务的效率。”。例如,在视频帧序列的分析中,RNN可用于捕获时间信息,而CNN可用于从单个帧中提取空间特征。
深入挖掘不断扩大的神经网络领域
值得注意的是,CNN和RNN只是最流行的两类神经网络架构。有几十种其他方法可以组织神经元连接在一起的方式,其中一些几年前还不清楚的方法如今正在显著增长。
新的神经网络的例子包括:
- Transformers,它正在帮助解决RNN在处理大量文本、音频或视频流以及构建大型语言模型(如Google BERT)方面的许多局限性。
- 生成对抗性网络,它结合了多个相互竞争的神经网络,使设计药物、生成数字赝品或改进媒体制作成为可能。
- 自动编码器正在成为降维、图像压缩和数据编码的首选工具。
此外,人工智能服务正在寻找方法,使用神经架构搜索在飞行中自动创建新的高度优化的神经网络。这些技术为特定问题创建了一个启动架构,并交互分析结果以微调更好的架构。
目前自动机器学习的实现包括谷歌的AutoML、IBM Watson的AutoAI和开源的AutoKeras。研究人员还在探索使用集成学习技术将相同或不同架构的多个神经网络模型组合在一起的更好方法。
用于比较神经网络架构的性能和准确性的更好技术也可以发挥作用,使研究人员更容易筛选特定人工智能任务的许多选项。研究人员开始寻找创造性的方法来应用传统的统计技术来比较不同神经网络架构的相对性能。
- 1188 次浏览
【深度学习】Transformers 的工作原理
视频号
微信公众号
知识星球
如果你喜欢这篇文章,想了解机器学习算法是如何工作的,它们是如何产生的,以及它们将走向何方,我推荐以下内容:
Transformers 是一种越来越受欢迎的神经网络架构。OpenAI最近在其语言模型中使用了Transformers ,DeepMind最近也在AlphaStar中使用了它,AlphaStar是他们击败顶级职业星际玩家的程序。
Transformers 是为了解决序列转换或神经机器翻译的问题而开发的。这意味着任何将输入序列转换为输出序列的任务。这包括语音识别、文本到语音的转换等。。

Sequence transduction. The input is represented in green, the model is represented in blue, and the output is represented in purple. GIF from 3
对于进行序列转导的模型来说,有某种记忆是必要的。例如,假设我们正在将以下句子翻译成另一种语言(法语):
“Transformers”是一个日本[[硬核朋克]乐队。这支乐队成立于1968年,当时正值日本音乐史的鼎盛时期
在这个例子中,第二句中的“乐队”一词指的是第一句中介绍的乐队“变形金刚”。当你在第二句中读到这个乐队时,你知道它指的是“变形金刚”乐队。这可能对翻译很重要。有很多例子,有些句子中的单词指的是前一句中的单词。
对于翻译这样的句子,模型需要找出这些依赖关系和连接。递归神经网络(RNNs)和卷积神经网络(CNNs)因其特性而被用于处理这一问题。让我们回顾一下这两种体系结构及其缺点。
循环神经网络
递归神经网络中有循环,允许信息持久存在。
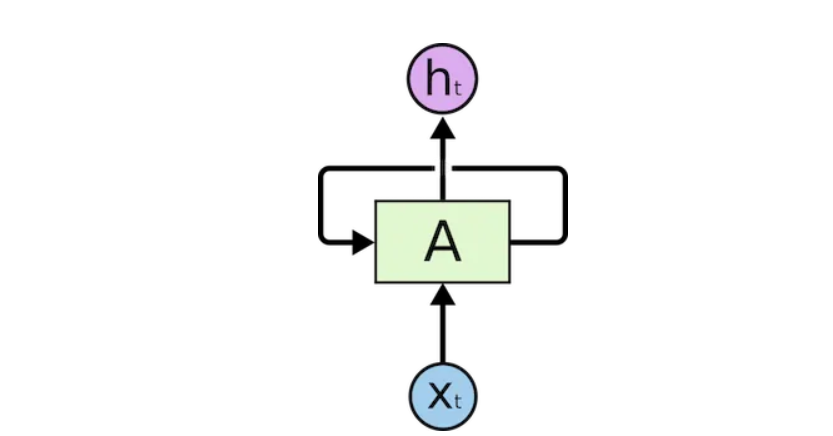
The input is represented as x_t
在上图中,我们看到神经网络的一部分A处理一些输入x_t和输出h_t。循环允许信息从一个步骤传递到下一个步骤。
这些循环可以用不同的方式来思考。递归神经网络可以被认为是同一网络A的多个副本,每个网络都将消息传递给后续网络。考虑一下如果我们展开循环会发生什么:
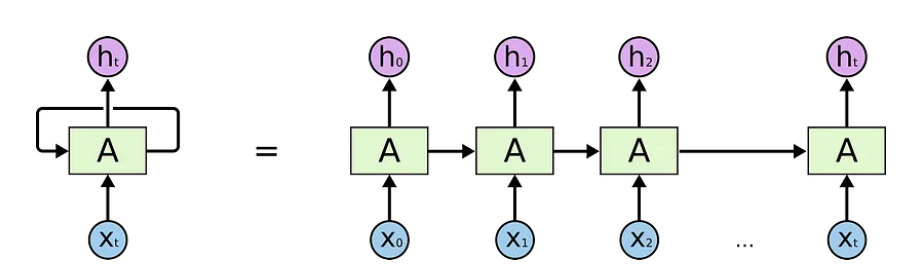
一个展开的递归神经网络
这种链式性质表明,递归神经网络显然与序列和列表有关。这样,如果我们想翻译一些文本,我们可以将每个输入设置为该文本中的单词。递归神经网络将前一个单词的信息传递给下一个可以使用和处理该信息的网络。
下图显示了序列到序列模型通常如何使用递归神经网络工作。每个单词都被单独处理,通过将隐藏状态传递给解码阶段来生成结果句子,然后解码阶段生成输出。
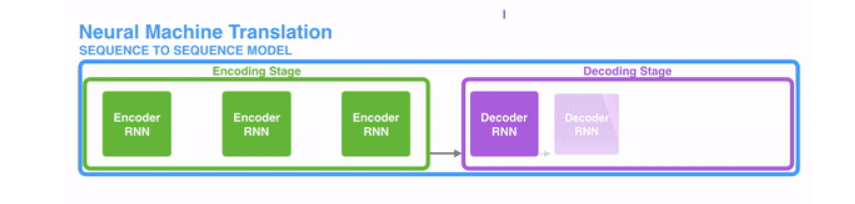
GIF from 3
长期依赖性问题
考虑一个语言模型,它试图根据前一个单词来预测下一个单词。如果我们试图预测“天空中的云”这句话的下一个单词,我们不需要进一步的上下文。很明显,下一个词将是天空。
在这种情况下,相关信息和所需地点之间的差异很小,RNN可以学会使用过去的信息,并找出这句话的下一个单词是什么。

Image from 6
但在某些情况下,我们需要更多的背景。例如,假设您正在尝试预测文本的最后一个单词:“我在法国长大……我说得很流利……”。最近的信息表明,下一个单词可能是一种语言,但如果我们想缩小哪种语言的范围,我们需要法国的上下文,那就在文本的后面。
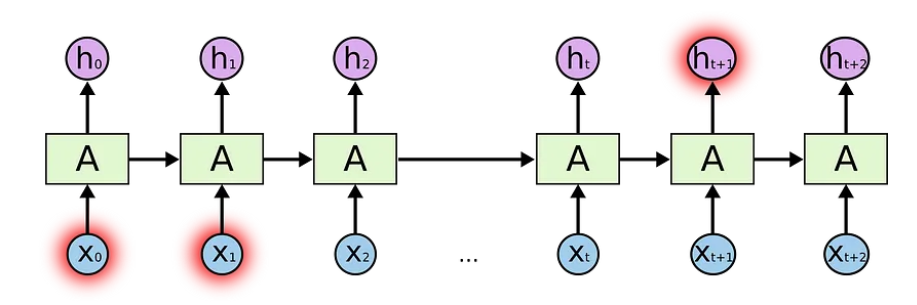
Image from 6
当相关信息和所需信息之间的差距变得非常大时,RNN就会变得非常无效。这是因为信息在每一步都会传递,而且链越长,信息在链上丢失的可能性就越大。
理论上,RNN可以学习这种长期依赖关系。在实践中,他们似乎没有学会它们。LSTM是一种特殊类型的RNN,试图解决这类问题。
长短期记忆:Long-Short Term Memory (LSTM)
在安排一天的日历时,我们会优先安排约会。如果有什么重要的事情,我们可以取消一些会议,并安排重要的事情。
RNN不会这么做。每当它添加新信息时,就会通过应用一个函数来完全转换现有信息。整个信息都被修改了,没有考虑什么是重要的,什么不是。
LSTM通过乘法和加法对信息进行小的修改。使用LSTM,信息通过一种称为细胞状态的机制流动。通过这种方式,LSTM可以选择性地记住或忘记重要和不那么重要的事情。
在内部,LSTM看起来如下:
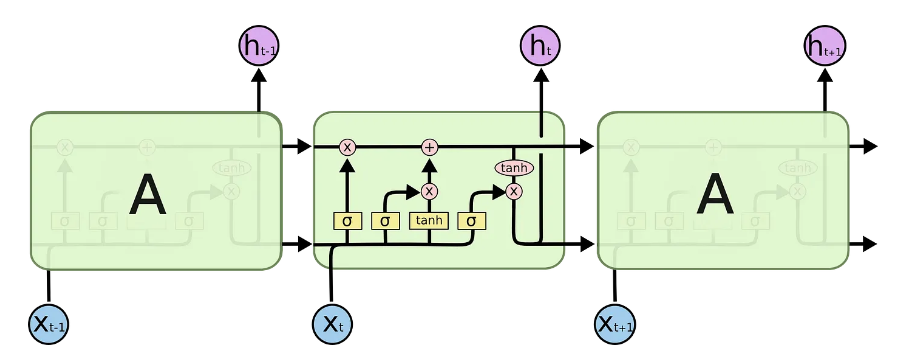
来自6的图像
每个单元格将x_t(在句子到句子翻译的情况下为单词)、前一单元格状态和前一单元格的输出作为输入。它操纵这些输入,并基于它们生成新的细胞状态和输出。我不会详细介绍每个单元的力学原理。如果你想了解每个细胞是如何工作的,我推荐Christopher的博客文章:
对于细胞状态,在翻译时,句子中对翻译单词很重要的信息可能会从一个单词传递到另一个单词。
LSTM的问题
RNN通常也会遇到同样的问题,即当句子太长时,LSTM仍然做得不太好。其原因是,与正在处理的当前单词相距较远的单词保持上下文的概率随着与该单词的距离呈指数级下降。
这意味着,当句子很长时,模型往往会忘记序列中远处位置的内容。RNN和LSTM的另一个问题是,很难并行处理句子,因为你必须逐字处理。不仅如此,还没有长期和短期依赖关系的模型。总之,LSTM和RNN存在3个问题:
- 顺序计算抑制并行化
- 没有对长期和短期依赖关系进行显式建模
- 位置之间的“距离”是线性的
注意
为了解决其中的一些问题,研究人员创造了一种关注特定单词的技术。
翻译一个句子时,我会特别注意我正在翻译的单词。当我转录一段录音时,我会仔细地听我主动写下的片段。如果你让我描述一下我坐的房间,我会一边描述一边环顾四周。
神经网络可以使用注意力来实现同样的行为,将注意力集中在它们所提供的信息的子集的一部分上。例如,一个RNN可以参与另一个RN网络的输出。在每一个时间步长,它都关注另一个RNN中的不同位置。
为了解决这些问题,注意力是一种用于神经网络的技术。对于RNN,不是只在隐藏状态下编码整个句子,而是每个单词都有一个相应的隐藏状态,并一直传递到解码阶段。然后,在RNN的每个步骤中使用隐藏状态进行解码。下面的gif图显示了这种情况是如何发生的。

The green step is called the encoding stage and the purple step is the decoding stage. GIF from 3
其背后的想法是,一个句子中的每个单词都可能包含相关信息。因此,为了使解码准确,它需要考虑输入的每个单词,使用注意力。
为了引起对RNNs在序列转导中的注意,我们将编码和解码分为两个主要步骤。一个步骤用绿色表示,另一个用紫色表示。绿色步骤称为编码阶段,紫色步骤称为解码阶段。
GIF from 3
绿色步骤负责根据输入创建隐藏状态。我们没有像使用注意力之前那样只将一个隐藏状态传递给解码器,而是将句子中每个“单词”产生的所有隐藏状态传递到解码阶段。每个隐藏状态都被用于解码阶段,以找出网络应该注意的地方。
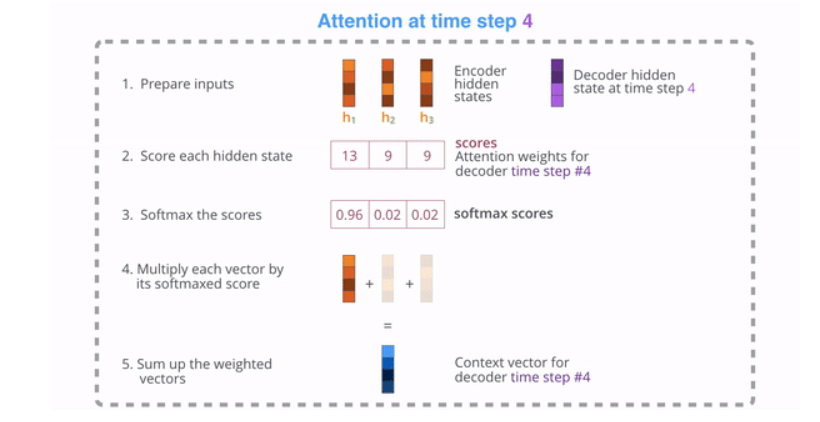
例如,当将句子“Je suisétudant”翻译成英语时,要求解码步骤在翻译时考虑不同的单词。
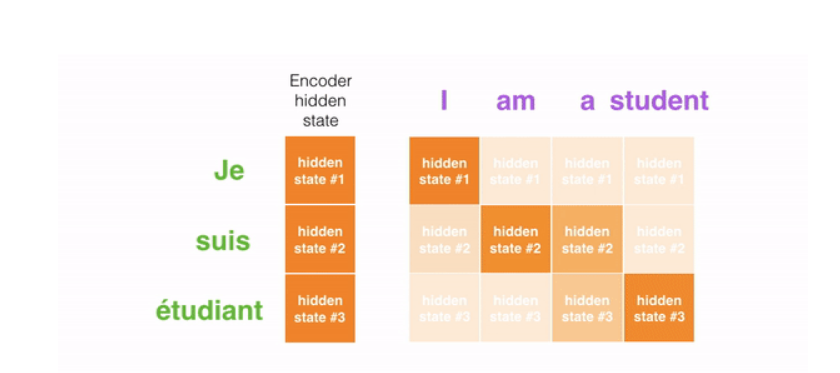
This gif shows how the weight that is given to each hidden state when translating the sentence “Je suis étudiant” to English. The darker the color is, the more weight is associated to each word. GIF from 3
例如,当你把“1992年欧洲经济区协议”这句话从法语翻译成英语时,以及它对每一个输入的关注程度。

Translating the sentence “L’accord sur la zone économique européenne a été signé en août 1992.” to English. Image from 3
但是,我们讨论的一些问题仍然没有通过使用注意力的RNN来解决。例如,并行处理输入(单词)是不可能的。对于大量的文本语料库,这增加了翻译文本所花费的时间。
卷积神经网络
卷积神经网络有助于解决这些问题。有了他们,我们可以
- 并行化的琐碎(每层)
- 利用本地依赖关系
- 位置之间的距离是对数的
用于序列转导的一些最流行的神经网络,Wavenet和Bytente,是卷积神经网络。

Wavenet, model is a Convolutional Neural Network (CNN). Image from 10
卷积神经网络之所以可以并行工作,是因为输入的每个单词都可以同时处理,而不一定取决于要翻译的前一个单词。不仅如此,CNN的输出词和任何输入之间的“距离”都是log(N)的顺序——也就是从输出到输入生成的树的高度的大小(你可以在上面的GIF上看到它。这比RNN的输出和输入之间的距离要好得多,后者的顺序是N。
问题是卷积神经网络不一定有助于解决翻译句子时的依赖性问题。这就是为什么变形金刚诞生的原因,它们是两个备受关注的细胞神经网络的结合。
Transformers
为了解决并行化问题,Transformers试图通过使用编码器和解码器以及注意力模型来解决这个问题。注意力提高了模型从一个序列转换到另一个序列的速度。
让我们来看看Transformer是如何工作的。Transformer是一种利用注意力来提高速度的模型。更具体地说,它使用自我关注。

The Transformer. Image from 4
在内部,Transformer具有与上述先前模型类似的体系结构。但是Transformer由六个编码器和六个解码器组成。

来自4的图像
每个编码器彼此非常相似。所有编码器都具有相同的架构。解码器具有相同的特性,即它们彼此也非常相似。每个编码器由两层组成:自注意和前馈神经网络。
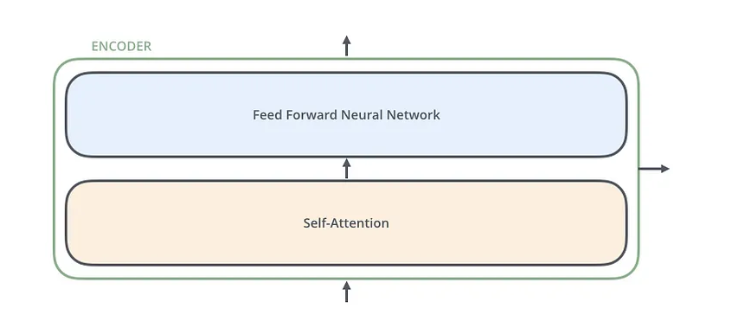
来自4的图像
编码器的输入首先流经自关注层。它有助于编码器在对特定单词进行编码时查看输入句子中的其他单词。解码器具有这两个层,但在它们之间是一个注意力层,帮助解码器专注于输入句子的相关部分。
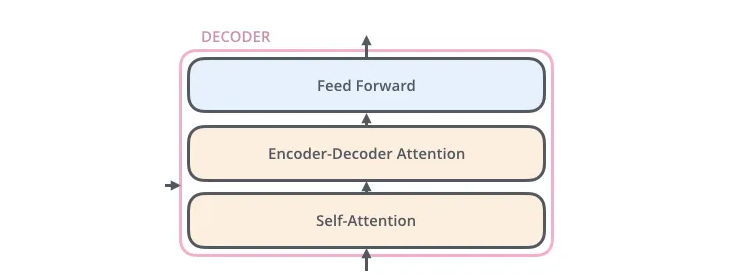
来自4的图像
自我关注
注:此部分来自Jay Allamar的博客文章
让我们开始看看各种向量/张量,以及它们如何在这些组件之间流动,将训练模型的输入转化为输出。与一般NLP应用程序的情况一样,我们首先使用嵌入算法将每个输入单词转换为向量。

图片取自4
每个单词被嵌入到大小为512的向量中。我们将用这些简单的方框来表示这些向量。
嵌入只发生在最底层的编码器中。所有编码器共同的抽象是它们接收每个大小为512的矢量的列表。
在底部编码器中,这将是单词嵌入,但在其他编码器中,它将是直接在下面的编码器的输出。在我们的输入序列中嵌入单词后,每个单词都会流经编码器的两层中的每一层。

来自4的图像
在这里,我们开始看到Transformer的一个关键特性,即每个位置的单词在编码器中流经其自己的路径。在自我关注层中,这些路径之间存在依赖关系。然而,前馈层不具有这些依赖性,因此各种路径可以在流过前馈层时并行执行。
接下来,我们将把这个例子切换到一个较短的句子,我们将看看编码器的每个子层中发生了什么。
自我关注
让我们先来看看如何使用向量计算自我关注,然后再看看它是如何实际实现的——使用矩阵。
Figuring out relation of words within a sentence and giving the right attention to it. Image from 8
计算自我注意的第一步是根据编码器的每个输入向量创建三个向量(在这种情况下,是每个单词的嵌入)。因此,我们为每个单词创建一个Query向量、一个Key向量和一个Value向量。这些向量是通过将嵌入乘以我们在训练过程中训练的三个矩阵来创建的。
请注意,这些新矢量的尺寸小于嵌入矢量的尺寸。它们的维度是64,而嵌入和编码器输入/输出向量的维度是512。它们不必更小,这是一种架构选择,可以使多头注意力的计算(大部分)保持不变。

图片取自4
将x1乘以WQ权重矩阵得到q1,即与该单词相关联的“查询”向量。我们最终为输入句子中的每个单词创建一个“查询”、一个“键”和一个“值”投影。
什么是“查询”、“键”和“值”矢量?
它们是对计算和思考注意力很有用的抽象概念。一旦你开始阅读下面是如何计算注意力的,你就会知道这些向量所扮演的角色。
计算自我注意力的第二步是计算分数。假设我们正在计算本例中第一个单词“思考”的自我注意力。我们需要根据输入句子中的每个单词来打分。分数决定了当我们在某个位置编码一个单词时,对输入句子的其他部分的关注程度。
分数是通过查询向量与我们评分的单词的关键向量的点积来计算的。因此,如果我们处理位置#1的单词的自我关注,第一个分数将是q1和k1的点积。第二个分数将是q1和k2的点积。

来自4的图像
第三步和第四步是将分数除以8(论文中使用的关键向量的维数的平方根-64。这导致具有更稳定的梯度。这里可能有其他可能的值,但这是默认值),然后通过softmax操作传递结果。Softmax将分数标准化,使其全部为正,加起来为1。

来自4的图像
这个softmax分数决定了每个单词在这个位置上的表达量。显然,这个位置的单词将具有最高的softmax分数,但有时关注与当前单词相关的另一个单词是有用的。
第五步是将每个值向量乘以softmax分数(准备将它们相加)。这里的直觉是保持我们想要关注的单词的值不变,并淹没不相关的单词(例如,将它们乘以0.001等微小数字)。
第六步是对加权值向量进行求和。这就在这个位置产生了自注意层的输出(对于第一个单词)。
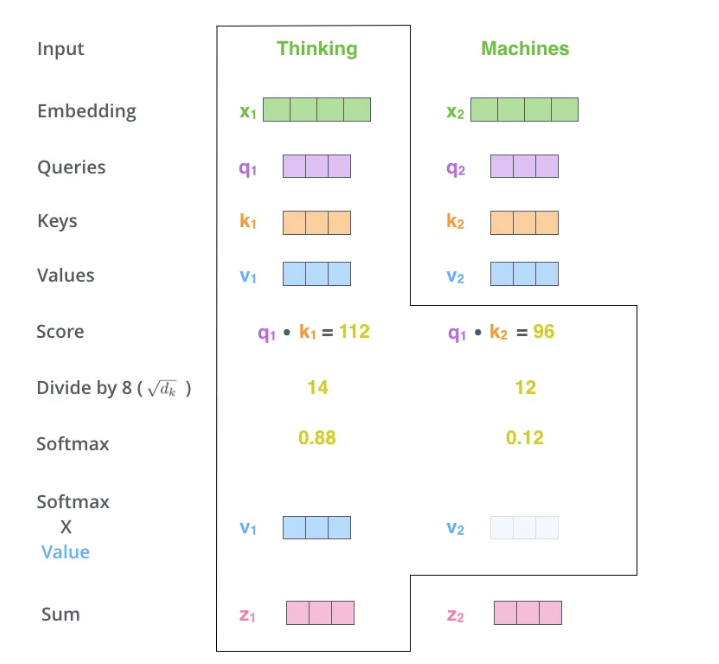
来自4的图像
自我关注计算到此结束。得到的矢量是我们可以发送到前馈神经网络的矢量。然而,在实际实现中,为了更快地处理,这种计算是以矩阵形式进行的。现在我们来看一下,我们已经看到了单词水平上计算的直觉。
多头注意力
变形金刚基本上就是这样工作的。还有一些其他细节可以使它们更好地工作。例如,变形金刚使用了多头注意力的概念,而不是只在一个维度上相互关注。
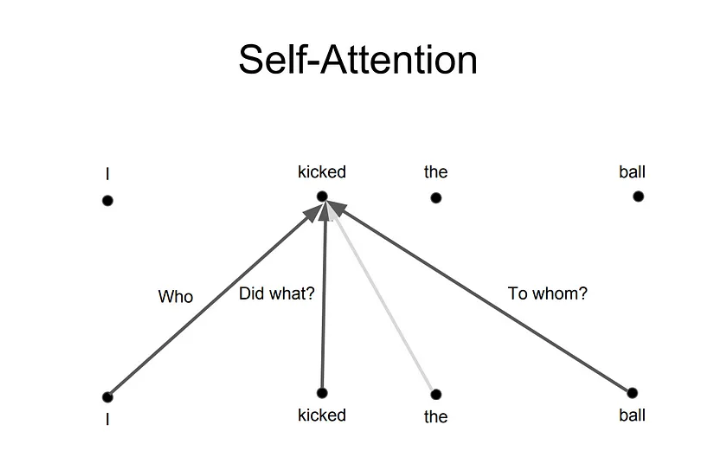
其背后的想法是,每当你翻译一个单词时,你可能会根据所问问题的类型对每个单词给予不同的关注。下面的图片显示了这意味着什么。例如,每当你翻译“我踢了球”这句话中的“踢”时,你可能会问“谁踢的”。根据答案的不同,将单词翻译成另一种语言可能会发生变化。或者问其他问题,比如“做了什么?”等等…
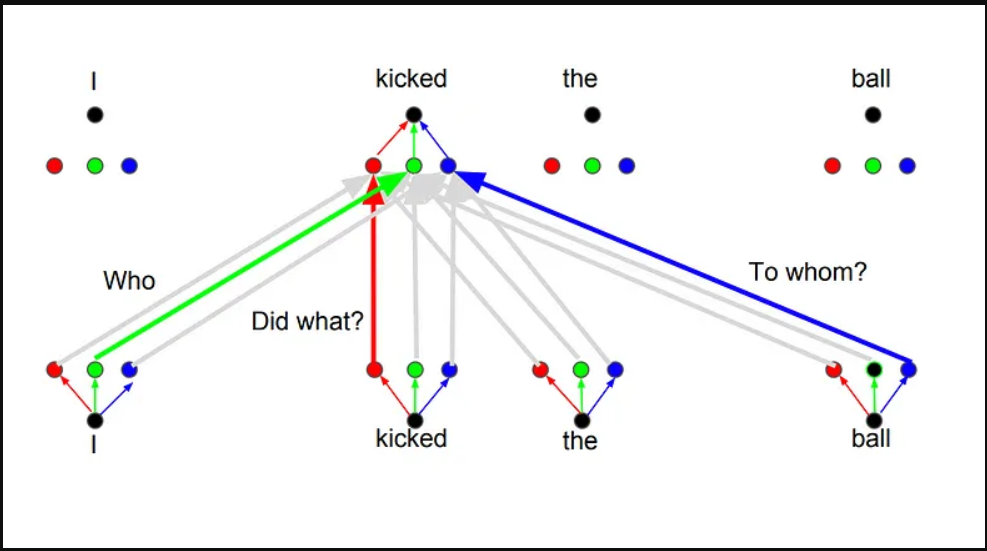
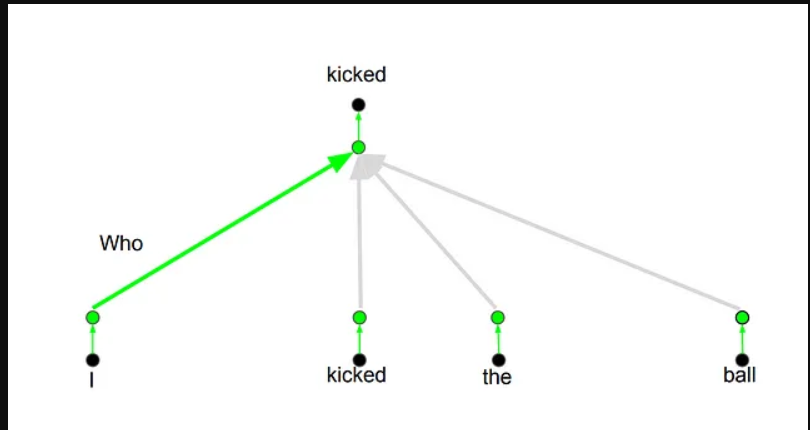

来自8的图像
位置编码
Transformer上的另一个重要步骤是在对每个单词进行编码时添加位置编码。对每个单词的位置进行编码是相关的,因为每个词的位置都与翻译相关。
概述
我概述了变压器是如何工作的,以及为什么这是用于序列转导的技术。如果你想深入了解该模型的工作原理及其所有细微差别,我推荐以下帖子、文章和视频,作为总结该技术的基础
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Understanding LSTM Networks
- Visualizing A Neural Machine Translation Model
- The Illustrated Transformer
- The Transformer — Attention is all you need
- The Annotated Transformer
- Attention is all you need attentional neural network models
- Self-Attention For Generative Models
- OpenAI GPT-2: Understanding Language Generation through Visualization
- WaveNet: A Generative Model for Raw Audio
- 88 次浏览
【深度学习】使用 TensorFlow 构建 RNN 推荐引擎
推荐引擎是使浏览内容更容易的强大工具。此外,一个出色的推荐系统可以帮助用户找到他们自己不会想到要寻找的东西。由于这些原因,推荐工具可以极大地提高电子商务的营业额。在这里,我们展示了我们如何 - 在法国迪卡侬 - 实现了一个 RNN(循环神经网络)推荐系统,该系统在精度指标(离线)上比我们之前的模型(ALS,交替最小二乘法)高出 20% 以上。
如果您正在寻找有关推荐系统的更全面介绍,我们建议您阅读我们加拿大同事的精彩文章。
业务问题
迪卡侬在线目录非常大,我们在我们的在线平台上销售数万种不同的商品。对于寻找引人注目的新内容的用户来说,如此广泛的选择可能是一个障碍。当然,客户可以使用搜索来访问内容。在这方面,推荐引擎可以派上用场,因为它可以显示用户可能不会自己搜索的项目,从而极大地提高客户体验和转化率。
为了改进我们之前的解决方案 (ALS),我们开发了一个新的推荐引擎(基于深度学习),为每个确定的客户个性化 www.decathlon.fr 的主页。因此,每个识别出的用户都会看到不同的个性化推荐。
数据科学解决方案
我们之前的推荐系统是使用 spark.ml 库实现的协同过滤。 spark.ml 包使用交替最小二乘 (ALS) 算法来学习用户-项目关联矩阵的潜在因素。
协同过滤通常用于推荐系统。然而,事实证明它是一个严格的框架,阻止使用任何其他有用的元数据。此外,它假设用户和项目仅线性相关。最近的工作(Netflix、YouTube、Spotify)表明,由于使用了更丰富的输入数据非线性变换以及添加了有用的元数据,深度学习框架的性能优于经典分解方法。
我们的深度学习方法受到最近的文本生成技术的启发,这些技术使用能够从给定短语(单词序列)生成后续单词的 RNN 模型。对于我们的推荐问题,我们用项目序列替换了词序列并应用了相同的方法(下图描述了 NLP 和推荐的类比)。
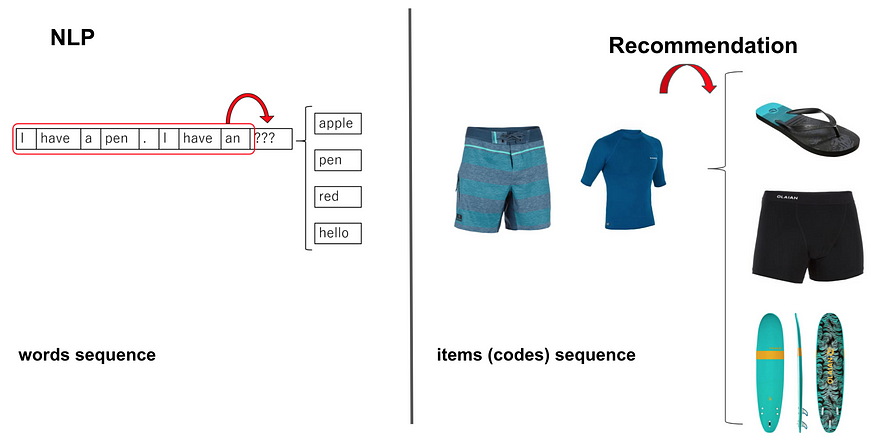
NLP and Recommandation analogy to predict the next more likely word and item respectively
输入数据
用于开发我们的推荐引擎的数据包括每个已识别客户的购买商品的时间排序序列和(购买商品的)新近度序列。 这是我们输入数据的示例:

在哪里:
- customer_id :是客户唯一标识符;
- item_id :包含每个客户购买的商品 ID 序列的字符串;
- nb_days:包含从物品购买和上次培训日期(每件购买物品的购买新近度)经过的天数序列的字符串。
注意:item_id 和 nb_days 序列是按时间顺序排列的。
特征变换
特征 item_id 和 nb_days 在将它们提供给模型之前需要适当地转换。即,item_id 将被标记和编码,而 nb_days 将被分桶。
item_id 的标记化和编码
为了为 RNN 模型准备输入数据,每个购买的商品序列都被标记化,并且序列中的每个商品都被整数编码。
这是通过使用 tensorflow.keras.preprocessing.text 中的 Tokenizer 类实现的,该类允许向量化文本语料库,通过将每个文本转换为整数序列(查看文档了解更多详细信息)。比如上面的item序列的字符串变成了下面的数组(numpy):
"15431,164271,300287,300358"->[74, 276, 362, 119]"1733,11687,15623,103080,1733,310789"->[1, 2, 33, 289, 1, 27].
nb_days 的分桶
nb_days 特征包含从 365 到 1 的整数值的可变长度序列。这是因为我们提取了一年的交易历史,因此 365 表示购买商品的最旧时间(以天表示的一年),1 表示最近一次。
我们决定将 nb_days 分成 100 个 bins(如果需要,这个值可以改变),用 1 到 100 的离散值表示。例如,上面的新近序列字符串变成以下数组(numpy):
'354,354,327,327'->[96, 96, 89, 89]'116,116,116,8,8,1'->[32, 32, 32, 2, 2, 1].
这种转换可以通过 tensorflow.feature_column.bucketized_column 轻松实现。
创建输入和目标特征张量
为了训练模型,我们需要创建一个包含输入和目标特征的张量。
值得注意的是,输入特征是 item_id 和 nb_days 的转换版本,没有最后一个元素,而目标特征是 item_id 的转换版本(没有第一个元素)。
这是因为我们想让 RNN 模型学习在给定先前输入特征的情况下预测目标序列的下一项。
例如,如果 item_id、nb_days 的变换特征分别为 [74, 276, 362, 119] 和 [96, 96, 89, 89],则特征张量将为:
{
'item_id': [74, 276, 362],
'nb_days': [96, 96, 89],
'target': [276, 362, 119]
}
填充
为了使所有序列的长度相同,然后通过 tensorflow.keras.preprocessing.sequence 中的 pad_sequences() 函数填充输入和目标特征。为了我们的目的,我们发现将每个序列的最大长度固定为 20(max_len,程序配置的一部分)工作正常。该值对应于序列长度的第 80 个百分位,即 80% 的 item_id 序列由最多 20 个项目组成。
例如,当 max_len = 5 时,上例的特征张量将变为:
{
'item_id': [0, 0, 74, 276, 362],
'nb_days': [0, 0, 96, 96, 89],
'target': [0, 0, 276, 362, 119]
}
特征数据
最终的特征数据是一个字典,其键是 item_id、nb_days、target,值是 N x max_length numpy 数组,其中 N 表示用于训练的序列数(最多为用户数),max_length 是用于填充的最大长度.
train_dict = {
'item_id': [[0, 0,...,0, 74, 276, 362], ...]
'nb_days': [[0, 0,...,0, 96, 96, 89], ...]
'target': [[0, 0,...0, 276, 362, 119], ...]
}
最终,我们使用 tf.data.Dataset.from_tensor_slices 函数创建了一个用于模型训练的训练数据集(见下面的代码)。
import tensorflow as tf
def create_train_tfdata(train_feat_dict, train_target_tensor,
batch_size, buffer_size=None):
"""
Create train tf dataset for model train input
:param train_feat_dict: dict, containing the features tensors for train data
:param train_target_tensor: np.array(), the training TARGET tensor
:param batch_size: (int) size of the batch to work with
:param buffer_size: (int) Optional. Default is None. Size of the buffer
:return: (tuple) 1st element is the training dataset,
2nd is the number of steps per epoch (based on batch size)
"""
if buffer_size is None:
buffer_size = batch_size*50
train_steps_per_epoch = len(train_target_tensor) // batch_size
train_dataset = tf.data.Dataset.from_tensor_slices((train_feat_dict,
train_target_tensor)).cache()
train_dataset = train_dataset.shuffle(buffer_size).batch(batch_size)
train_dataset = train_dataset.repeat().prefetch(tf.data.experimental.AUTOTUNE)
return train_dataset, train_steps_per_epoch
train_feat_dict = {'item_id': train_dict['item_id'],
'nb_days': train_dict['nb_days']}
train_target_tensor = train_dict['target']
train_dataset, train_steps_per_epoch = create_train_tfdata(train_feat_dict,
train_target_tensor,
batch_size=512)
模型
此处实施的建模策略包括根据之前购买的商品的顺序(item_id 功能)和购买新近度(nb_days 功能)为每个用户预测下一个最有可能购买的产品。
nb_days 功能在显着提高模型性能方面发挥了关键作用。 事实上,此功能有助于模型更好地跟踪购买的季节性行为,从而跨时间推荐更适合的产品。
最后,我们还添加了一个自我注意层,它已被确定为序列到序列模型架构的性能助推器,就像我们的例子一样。
因此,这里实现的模型是一个 RNN 模型,加上一个具有以下架构的自注意力层:

Recommendation Engine model architecture
模型的超参数为:
- emb_item_id_units:每个项目(item_id)将被编码(嵌入)在一个形状为(1,emb_item_id_units)的密集向量中
- emb_nb_days_units:每个分桶的新近值 (nb_days) 将被编码(嵌入)在一个形状为 (1, emb_nb_days_units) 的密集向量中
- recurrent_dropout:LSTM 层的 drop-out 值
- rnn_units:LSTM 层的单元(“神经元”)数量
- learning_rate: 训练模型的学习率
而(不可调整的)参数是:
- max_length:每个item序列的最大长度,见数据预处理部分
- item_id_vocab_size:唯一项的数量 + 1(考虑到零填充)
- batch_size:同时提供给模型进行训练的样本(序列)数量
在这里你可以找到上述推荐架构的 TensorFlow 实现:
def build_model(hp, max_len, item_vocab_size):
"""
Build a model given the hyper-parameters with item and nb_days input features
:param hp: (kt.HyperParameters) hyper-parameters to use when building this model
:return: built and compiled tensorflow model
"""
inputs = {}
inputs['item_id'] = tf.keras.Input(batch_input_shape=[None, max_len],
name='item_id', dtype=tf.int32)
# create encoding padding mask
encoding_padding_mask = tf.math.logical_not(tf.math.equal(inputs['item_id'], 0))
# nb_days bucketized
inputs['nb_days'] = tf.keras.Input(batch_input_shape=[None, max_len],
name='nb_days', dtype=tf.int32)
# Pass categorical input through embedding layer
# with size equals to tokenizer vocabulary size
# Remember that vocab_size is len of item tokenizer + 1
# (for the padding '0' value)
embedding_item = tf.keras.layers.Embedding(input_dim=item_vocab_size,
output_dim=hp.get('embedding_item'),
name='embedding_item'
)(inputs['item_id'])
# nbins=100, +1 for zero padding
embedding_nb_days = tf.keras.layers.Embedding(input_dim=100 + 1,
output_dim=hp.get('embedding_nb_days'),
name='embedding_nb_days'
)(inputs['nb_days'])
# Concatenate embedding layers
concat_embedding_input = tf.keras.layers.Concatenate(
name='concat_embedding_input')([embedding_item, embedding_nb_days])
concat_embedding_input = tf.keras.layers.BatchNormalization(
name='batchnorm_inputs')(concat_embedding_input)
# LSTM layer
rnn = tf.keras.layers.LSTM(units=hp.get('rnn_units_cat'),
return_sequences=True,
stateful=False,
recurrent_initializer='glorot_normal',
name='LSTM_cat'
)(concat_embedding_input)
rnn = tf.keras.layers.BatchNormalization(name='batchnorm_lstm')(rnn)
# Self attention so key=value in inputs
att = tf.keras.layers.Attention(use_scale=False, causal=True,
name='attention')(inputs=[rnn, rnn],
mask=[encoding_padding_mask,
encoding_padding_mask])
# Last layer is a fully connected one
output = tf.keras.layers.Dense(item_vocab_size, name='output')(att)
model = tf.keras.Model(inputs, output)
model.compile(
optimizer=tf.keras.optimizers.Adam(hp.get('learning_rate')),
loss=loss_function,
metrics=['sparse_categorical_accuracy'])
return modelTensorFlow implementation of the RNN recommendation engine
作为损失函数,我们使用了 tf.keras.losses.sparse_categorical_crossentropy 的修改版本,其中我们跳过了零填充元素的损失计算:
def loss_function(real, pred):
"""
We redefine our own loss function in order to get rid of the '0' value
which is the one used for padding. This to avoid that the model optimize itself
by predicting this value because it is the padding one.
:param real: the truth
:param pred: predictions
:return: a masked loss where '0' in real (due to padding)
are not taken into account for the evaluation
"""
# to check that pred is numric and not nan
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_object_ = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction='none')
loss_ = loss_object_(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
TensorFlow implementation of custom loss function
超参数优化
模型超参数已经使用在 keras-tuner 库中实现的 Hyperband 优化算法进行了调整,这使得人们可以用几行代码为 TensorFlow 模型进行可分发的超参数优化
值得注意的是,超参数优化是使用验证数据集进行的,该数据集由训练数据中随机选择的样本的 10% 组成。 此外,我们使用 sparse_categorical_accuracy 作为衡量优化试验排名的指标。
我们为batch_size 参数尝试了几个值,最终使用batch_size=512。
训练
最终模型在所有可用数据上进行训练,并使用在前一个优化阶段结束时获得的最佳超参数进行训练。
def fit_model(model, train_dataset, steps_per_epoch, epochs):
"""
Fit the Keras model on the training dataset for a number of given epochs
:param model: tf model to be trained
:param train_dataset: (tf.data.Dataset object) the training dataset
used to fit the model
:param steps_per_epoch: (int) Total number of steps (batches of samples) before
declaring one epoch finished and starting the next epoch.
:param epochs: (int) the number of epochs for the fitting phase
:return: tuple (mirrored_model, history) with trained model and model history
"""
# mirrored_strategy allows to use multi GPUs when available
mirrored_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy(
tf.distribute.experimental.CollectiveCommunication.AUTO)
with mirrored_strategy.scope():
mirrored_model = model
history = mirrored_model.fit(train_dataset,
steps_per_epoch=steps_per_epoch,
epochs=epochs, verbose=2)
return mirrored_model, history
TensorFlow implementation of the fitting method
结果
在使用我们的新推荐系统之前,我们采用了回测策略来评估模型预测性能。 事实上,回溯测试通过发现模型如何使用历史数据进行回顾来评估模型的可行性。
其基本理论是,任何过去运行良好的模型将来都可能运行良好,反之,任何过去运行不佳的模型在未来都可能运行不佳。
为此,我们使用了一年的历史交易作为训练数据,并在接下来的一个月测试了模型性能(见下图)。

Backtesting strategy representation
下表显示了几个模型在回测期间的基准性能。 我们使用经典指标对推荐模型的结果进行排名,即精度、召回率、MRR、MAP 和覆盖率,所有这些指标都是根据每个用户最好的五个推荐项目计算的。

Benchmark of backtesting results (orange-production, green-challenger, gray-baseline)
橙色线代表实际生产模型 (ALS) 性能,这是我们旨在改进的性能。我们开发了多个版本的 RNN 推荐系统(挑战者、绿线),其复杂程度不断提高。
最简单的 RNN,仅包含 item_id 作为特征,接近 ALS 性能,但在几乎所有指标上都较差。
最大的改进提升是由于添加了 nb_days 功能。这种时间特征允许基于 RNN 的推荐系统在所有给定指标上明显超越 ALS 模型。最后,注意力层的加入最终提高了 RNN 的整体性能。
为了可比性,我们还计算了一些(简单的)基线(表中的灰色线),它们清楚地显示了与更复杂模型(ALS 和 RNN 版本)的性能差距。
在线 A/B 测试正在进行中,初步结果证实了 RNN 推荐引擎的卓越性能。
结论
我们已经描述了我们用于在迪卡侬网站上推荐项目的新深度神经网络架构,并展示了如何使用 TensorFlow 实现它。该模型 - 受最近的文本再生技术启发 - 使用循环神经网络 (RNN) 架构,其输入是与购买新近序列(nb_days 功能)相关联的已购买商品序列。由于深度学习模型需要输入特征的特殊表示,我们还描述了如何在将这些输入序列(item_id 和 nb_days)馈送到模型之前正确转换它们。
最后,通过回测策略,我们展示了 nb_days 特征的使用如何在超越我们基于矩阵分解方法 (ALS) 的历史生产模型方面发挥关键作用。
这种新的深度学习架构为我们提供了添加新功能(与用户和项目相关)的可能性,从而可以进一步提高模型性能和用户体验,从而开辟了新的视角。
你呢? 您在深度学习和推荐系统方面有经验吗? 请在下面的评论中告诉我们!
原文:https://medium.com/decathlontechnology/building-a-rnn-recommendation-en…
- 88 次浏览
【深度学习】使用TensorFlow实现神经网络的介绍
介绍
如果您一直在追踪数据科学/机器学习,您将不会错过深度学习和神经网络周围的动态。组织正在寻找具有深度学习技能的人,无论他们在哪里。从竞争开始到开放采购项目和大额奖金,人们正在尝试一切可能的事情来利用这个有限的人才。自主驾驶的工程师正在被汽车行业的大型枪支所猎杀,因为该行业处于近几十年来面临的最大破坏的边缘!
如果您对深度学习所提供的潜在客户感到兴奋,但还没有开始您的旅程 - 我在这里启用它。从这篇文章开始,我将撰写一系列深入学习的文章,涵盖深受欢迎的深度学习图书馆及其实践实践。
在本文中,我将向您介绍TensorFlow。阅读本文后,您将能够了解神经网络的应用,并使用TensorFlow来解决现实生活中的问题。本文将要求您了解神经网络的基础知识,并熟悉编程。虽然这篇文章中的代码在python中,但我已经将重点放在了概念上,并且尽可能地保持与语言无关。
让我们开始吧!
TensorFlow
目录
-
何时应用神经网?
-
一般解决神经网络问题的方法
-
了解图像数据和流行图书馆来解决它
-
什么是TensorFlow?
-
TensorFlow的典型“流”
-
在TensorFlow中实施MLP
-
TensorFlow的限制
-
TensorFlow与其他库
-
从哪里去?
何时应用神经网络?
现在,神经网络已经成为焦点。有关神经网络和深度学习的更详细的解释,请阅读这里。其“更深层次”的版本在图像识别,语音和自然语言处理等诸多领域取得了巨大的突破。
出现的主要问题是什么时候和何时不应用神经网络?这个领域现在就像一个金矿,每天都有很多发现。而要成为这个“淘金热”的一部分,你必须注意几点:
首先,神经网络需要清晰和翔实的数据(主要是大数据)进行训练。尝试想象神经网络作为一个孩子。它首先观察父母的行为。然后,它试图自己行走,并且每一步,孩子学习如何执行一个特定的任务。它可能会下降几次,但经过几次不成功的尝试,它会学习如何走路。如果你不让它走路,它可能不会学习如何走路。您可以向孩子提供的曝光次数越多越好。
对于像图像处理这样的复杂问题,使用神经网络是谨慎的。神经网络属于称为表示学习算法的一类算法。这些算法将复杂问题分解成更简单的形式,使其变得可理解(或“可表示”)。想想它在你吞咽之前咀嚼食物。对于传统(非表示学习)算法,这将更加困难。
当您有适当类型的神经网络来解决问题。每个问题都有自己的扭曲。所以数据决定了你解决问题的方式。例如,如果问题是序列生成,则循环神经网络更适合。而如果是图像相关的问题,那么你可能会更好地采用卷积神经网络进行改变。
最后但并非最不重要的是,硬件要求对于运行深层神经网络模型至关重要。神经网络很久以前就被“发现”了,但近年来,由于计算资源越来越强大,主要原因在于神经网络。如果你想解决这些网络的现实生活中的问题,准备购买一些高端的硬件!
一般解决神经网络问题的方法
神经网络是一种特殊类型的机器学习(ML)算法。因此,作为每个ML算法,它遵循数据预处理,模型构建和模型评估的通常的ML工作流程。为了简洁起见,我列出了如何处理神经网络问题的DO DO列表。
检查是否是神经网络给您提升传统算法的问题(参见上一节中的清单)
做一个关于哪个神经网络架构最适合所需问题的调查
定义您选择的任何语言/图书馆的神经网络架构。
将数据转换为正确的格式,并将其分批
根据您的需要预处理数据
增加数据以增加尺寸并制作更好的训练模型
饲料批次到神经网络
训练和监测培训和验证数据集中的变化
测试您的模型,并保存以备将来使用
对于这篇文章,我将专注于图像数据。所以让我们明白,首先我们深入了解TensorFlow。
了解图像数据和流行库来解决它
图像大部分排列为3-D阵列,其尺寸为高度,宽度和颜色通道。例如,如果您在此时拍摄个人电脑的屏幕截图,那么首先将其转换为3-D数组,然后压缩它的“.jpeg”或“.png”文件格式。
虽然这些图像对于人来说很容易理解,但计算机很难理解它们。这种现象被称为“语义差距”。我们的大脑可以在几秒钟内观看图像并了解完整的图像。另一方面,计算机将图像视为数字数组。那么问题是我们如何将这个图像解释给机器?
在早期的时候,人们试图将这个图像分解为“可理解”的格式,像“模板”一样。例如,脸部总是具有特定的结构,每个人都有一些保护,例如眼睛,鼻子或脸部的形状。但是这种方法将是乏味的,因为当要识别的对象的数量会增加时,“模板”将不成立。
快速到2012年,深层神经网络架构赢得了ImageNet的挑战,这是一个从自然场景识别物体的巨大挑战。它继续在所有即将到来的ImageNet挑战中统治其主权,从而证明了解决图像问题的有用性。
那么人们通常使用哪些图书馆/语言来解决图像识别问题?最近的一项调查显示,大多数流行的深层学习库都有Python接口,其次是Lua,Java和Matlab。最受欢迎的图书馆,仅举几例:
-
Caffe
-
DeepLearning4j
-
TensorFlow
-
Theano
-
Torch
现在,您了解图像的存储方式以及使用的常用库,我们来看看TensorFlow提供的功能。
什么是TensorFlow?
让我们从官方的定义开始,
“TensorFlow是一个使用数据流图进行数值计算的开源软件库。图中的节点表示数学运算,而图形边缘表示在它们之间传递的多维数据阵列(又称张量)。灵活的架构允许您将计算部署到具有单个API的桌面,服务器或移动设备中的一个或多个CPU或GPU。
如果这听起来有点可怕 - 别担心。这是我简单的定义 - 看看TensorFlow只是一个麻烦的扭曲。如果你以前一直在努力,理解TensorFlow将是一块蛋糕! numpy和TensorFlow之间的一个主要区别在于TensorFlow遵循一个懒惰的编程范例。它首先构建要完成的所有操作的图形,然后当调用“会话”时,它会“运行”图形。它是通过将内部数据表示更改为张量(也称为多维数组)来实现的。构建计算图可以被认为是TensorFlow的主要成分。要了解更多关于计算图的数学结构,请阅读本文。
将TensorFlow分类为神经网络库很容易,但不仅仅是这样。是的,它被设计成一个强大的神经网络库。但它有权力做得比这更多。您可以在其上构建其他机器学习算法,如决策树或k-最近的邻居。你可以从字面上做一切你通常会做的麻烦!它恰当地称为“类固醇类”
使用TensorFlow的优点是:
-
它具有直观的结构,因为顾名思义,它具有“张量的流动”。您可以轻松地显示图形的每个部分。
-
轻松地在cpu / gpu上进行分布式计算
-
平台灵活性您可以随时随地运行模型,无论是在移动设备,服务器还是PC上。
TensorFlow的典型“流”
每个图书馆都有自己的“实现细节”,即一种写在其编码范例之后的方式。 例如,在实现scikit-learning时,首先创建所需算法的对象,然后在列车上建立一个模型,并在测试集上得到预测,如下所示:
# define hyperparamters of ML algorithm
正如我刚才所说,TensorFlow遵循一种懒惰的方法。 在TensorFlow中运行程序的通常工作流程如下:
-
构建计算图,这可以是TensorFlow支持的任何数学运算。
-
初始化变量,编译前面定义的变量
-
创建会话,这是魔法开始的地方!
-
在会话中运行图形,将编译的图形传递给会话,该会话开始执行。
-
关闭会话,关闭会话。
一些在TensoFlow中使用的术语
-
placeholder: A way to feed data into the graphs
-
feed_dict: A dictionary to pass numeric values to computational graph
placeholder: 一种将数据提供给图表的方式
feed_dict:将数值传递到计算图的字典
让我们写一个小程序来添加两个数字!
# import tensorflow
在TensorFlow中实现神经网络
注意:我们可以使用不同的神经网络架构来解决这个问题,但为了简单起见,我们深入实施了前馈多层感知器。
让我们先记住我们对神经网络的了解。
神经网络的典型实现如下:
-
定义神经网络架构进行编译
-
将数据传输到您的模型
-
在引擎盖下,数据首先分为批次,以便可以摄取。批次首先进行预处理,增强,然后进入神经网络进行培训
-
然后模型逐步训练
-
显示特定数量的时间步长的准确性
-
训练后保存模型供日后使用
-
在新数据上测试模型并检查它的执行情况
在这里我们解决我们深刻的学习实践问题 - 识别数字。我们来看看我们的问题陈述。
我们的问题是图像识别,用于识别给定28×28图像中的数字。我们有一个子集的图像训练和其余的测试我们的模型。首先下载火车和测试文件。数据集包含数据集中所有图像的压缩文件,train.csv和test.csv都具有对应的列车和测试图像的名称。数据集中没有提供任何其他功能,只是原始图像以“.png”格式提供。
如您所知,我们将使用TensorFlow制作神经网络模型。所以你应该首先在系统中安装TensorFlow。根据您的系统规格,请参阅官方安装指南进行安装。
我们将按照上述模板。用python 2.7内核创建Jupyter笔记本,并按照以下步骤操作。
-
我们导入所有必需的模块
%pylab inline
-
我们设置种子值,以便我们可以控制我们的模型随机性
# To stop potential randomness
-
第一步是设置目录路径,保护!
root_dir = os.path.abspath('../..')-
现在让我们看看我们的数据集。 这些是.csv格式,并具有一个文件名以及适当的标签
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
| filename | label | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
让我们看看我们的数据看起来如何! 我们读取我们的图像并显示它。
img_name = rng.choice(train.filename)
上面的图像被表示为numpy数组,如下所示
-
为了方便数据操作,我们将所有图像存储为数字数组
temp = []
由于这是一个典型的ML问题,为了测试我们模型的正常运行,我们创建一个验证集。 我们采取70:30的分组大小,用于训练集和验证集
split_size = int(train_x.shape[0]*0.7)
-
现在我们在我们的程序中定义了一些我们以后使用的帮助函数
def dense_to_one_hot(labels_dense, num_classes=10):
现在是主要部分! 让我们来定义我们的神经网络架构。 我们定义一个具有3层的神经网络; 输入,隐藏和输出。 输入和输出中的神经元数量是固定的,因为输入是我们的28×28图像,输出是表示该类的10×1矢量。 我们在隐藏层中采集500个神经元。 这个数字可以根据你的需要而变化。 我们还为其余变量分配值。 阅读关于神经网络基础知识的文章,深入了解它的工作原理。
### set all variables
-
现在创建我们的神经网络计算图
hidden_layer = tf.add(tf.matmul(x, weights['hidden']), biases['hidden'])
-
另外,我们需要定义神经网络的成本
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output_layer, y))
-
并设置优化器,即我们的反向推算算法。 这里我们使用Adam,它是Gradient Descent算法的有效变体。 在张量流中还有一些其他优化器(请参阅这里)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
-
在定义了我们的神经网络架构之后,让我们初始化所有的变量
init = tf.initialize_all_variables()
-
现在让我们创建一个会话,并在会话中运行我们的神经网络。 我们还验证我们的模型在我们创建的验证集上的准确性
with tf.Session() as sess:
这将是上述代码的输出
Epoch: 1 cost = 8.93566
-
用自己的眼睛来测试我们的模型,让我们来看看它的预测
img_name = rng.choice(test.filename)
Prediction is: 8
-
我们看到我们的模特表现相当不错! 现在我们来创建一个提交
sample_submission.filename = test.filename
并做了! 我们刚刚创建了自己训练有素的神经网络!
TensorFlow的限制
尽管TensorFlow功能强大,但它仍然是一个低级别的图书馆。例如,它可以被认为是机器级语言。但是,对于大多数目的,您需要模块化和高级接口,如keras
-
它还在发展,这么多的awesomeness来了!
-
这取决于你的硬件规格,越多越好
-
仍然不是许多语言的API。
-
还有很多事情尚未被包括在TensorFlow中,比如OpenCL支持。
上面提到的大多数都在TensorFlow开发人员的视野中。他们为制定未来图书馆的发展方向制定了路线图。
TensorFlow与其他库
TensorFlow建立在与使用数学计算图的Theano和Torch类似的原理。但是,随着分布式计算的额外支持,TensorFlow可以更好地解决复杂的问题。已经支持部署TensorFlow模型,这使得它更容易用于工业目的,打击了Deeplearning4j,H2O和Turi等商业图书馆。 TensorFlow有Python,C ++和Matlab的API。最近还有一些支持其他语言(如Ruby和R)的激增。因此,TensorFlow正在努力拥有通用语言支持。
到哪里去
所以你看到如何用TensorFlow构建一个简单的神经网络。这段代码是为了让人们了解如何开始实施TensorFlow,所以请拿一些盐。记住,为了解决更复杂的现实生活中的问题,你必须稍微调整一下代码。
可以抽象出许多上述功能,以提供无缝的端到端工作流程。如果您已经使用scikit学习,您可能会知道一个高级别的图书馆如何抽象出“底层”的实现方式,为终端用户提供了一个更简单的界面。虽然TensorFlow的大部分实现都已经被抽象出来了,但高级库正在出现,如TF-slim和TFlearn。
有用的资源
-
TensorFlow官方存储库
-
Rajat Monga(TensorFlow技术主管)“TensorFlow for everyone”视频
-
专门的资源列表
- 65 次浏览
【深度学习】全栈深度学习第二讲:开发基础设施和工具
视频号
微信公众号
知识星球
https://youtu.be/BPYOsDCZbno?list=PL1T8fO7ArWleMMI8KPJ_5D5XSlovTW_Ur
1-简介
ML开发的梦想是,给定一个项目规范和一些样本数据,您可以得到一个不断改进的大规模部署的预测系统。
现实情况截然不同:
- 您必须对数据进行收集、聚合、处理、清理、标记和版本设置。
- 您必须找到模型体系结构及其预先训练的权重,然后编写和调试模型代码。
- 您运行训练实验并审查结果,这些结果将反馈到尝试新架构和调试更多代码的过程中。
- 现在可以部署模型了。
- 在模型部署之后,您必须监视模型预测并关闭数据飞轮循环。基本上,您的用户会为您生成新的数据,这些数据需要添加到训练集中。

这个现实大约有三个组成部分:数据、开发和部署。对他们来说,工具基础设施的前景是巨大的,所以我们将有三场讲座来涵盖这一切。本次讲座的重点是开发部分。
2-软件工程

语言
对于编程语言的选择,Python是科学和数据计算领域的明显赢家,因为已经开发了所有的库。有一些竞争者,比如Julia和C/C++,但Python确实赢了。
编辑
要编写Python代码,您需要一个编辑器。您有许多选项,如Vim、Emacs、Jupyter Notebook/Lab、VS Code、PyCharm等。
- 我们推荐VS Code,因为它有一些不错的功能,比如内置的git版本控制、文档窥视、远程项目打开、linters和类型提示来捕捉bug等等。
- 许多从业者使用Jupyter笔记本进行开发,这是数据科学项目的“初稿”。在开始编码并看到即时输出之前,您必须稍微考虑一下。然而,笔记本电脑有各种各样的问题:原始编辑器、无序的执行工件,以及对它们进行版本和测试的挑战。与这些问题相对应的是nbdev包,它允许您在一个笔记本环境中编写和测试所有代码。
- 我们建议您使用对笔记本电脑具有内置支持的VS Code,您可以在导入笔记本电脑的模块中编写代码。它还可以进行出色的调试。
如果你想构建更具互动性的东西,Streamlight是一个很好的选择。它可以装饰Python代码,获得交互式小程序,并将它们发布在网络上与世界共享。

对于设置Python环境,我们建议您看看我们是如何在实验室中完成的。
3-深度学习框架

深度学习并不是像Numpy那样使用矩阵数学库的大量代码。但是,当你必须将代码部署到CUDA上进行GPU驱动的深度学习时,你需要考虑深度学习框架,因为你可能正在编写奇怪的层类型、优化器、数据接口等。
框架
有各种各样的框架,如PyTorch、TensorFlow和Jax。它们都很相似,首先通过运行Python代码来定义模型,然后收集不同部署模式(CPU、GPU、TPU、移动)的优化执行图。
- 我们更喜欢PyTorch,因为它在模型数量、论文数量和竞赛获胜者数量等方面绝对占主导地位。例如,在2021年ML竞赛的获胜者中,约77%使用PyTorch。
- 使用TensorFlow,您可以使用TensorFlow.js(可以在浏览器中运行深度学习模型)和Keras(为轻松的模型开发提供无与伦比的开发体验)。
- Jax是一个用于深度学习的元框架。
PyTorch拥有出色的开发经验,并且已经做好了生产准备,使用TorchScript的速度甚至更快。有一个很棒的分布式培训生态系统。有用于视觉、音频等的库。还有移动部署目标。
PyTorch Lightning为组织训练代码、优化器代码、评估代码、数据加载器等提供了一个很好的结构。有了这个结构,您可以在任何硬件上运行代码。有一些不错的功能,如性能和瓶颈探查器、模型检查点、16位精度和分布式训练库。
另一种可能性是FastAI软件,它是与fast.ai课程一起开发的。它提供了许多高级技巧,如数据增强、更好的初始化、学习速率调度器等。它具有模块化结构,具有低级API、中级API、高级API和特定应用程序。FastAI的主要问题是它的代码风格与主流Python截然不同。
在FSDL,我们更喜欢PyTorch,因为它有强大的生态系统,但TensorFlow仍然非常好。如果你有特定的理由更喜欢它,你仍然会玩得很开心。
Jax是谷歌最近的一个项目,并不是专门针对深度学习的。它提供通用的矢量化、自动区分和GPU/TPU代码的编译。对于深度学习,有单独的框架,如Flax和Haiku。您应该只针对特定需要使用Jax。
元框架和模型Zoos
大多数时候,您将至少从某人开发或发布的模型体系结构开始。您将在模型中枢上使用特定的体系结构(使用预先训练的权重对特定数据进行训练)。
- ONNX是一个用于保存深度学习模型的开放标准,允许您从一种类型的格式转换到另一种类型。它可以很好地工作,但也可能遇到一些边缘情况。
- HuggingFace已经成为一个绝对一流的模型库。它从NLP任务开始,但后来扩展到各种任务(音频分类、图像分类、对象检测等)。所有这些任务都有60000个预先训练的模型。有一个Transformers库,可以与PyTorch、TensorFlow和Jax一起使用。人们上传了7500个数据集。它还有一个社区方面,有一个问答论坛。
- TIMM是最先进的计算机视觉模型和相关代码的集合,看起来很酷。
4-分布式培训

假设我们有多台由上面的小方块表示的机器(每台机器中有多个GPU)。您正在发送要由带有参数的模型处理的数据批。数据批处理可以适合单个GPU,也可以不适合。模型参数可以适合单个GPU,也可以不适合。
最好的情况是,您的数据批处理和模型参数都适用于单个GPU。这就是所谓的琐碎并行。您可以在其他GPU/机器上启动更多独立的实验,也可以增加批量大小,直到它不再适合一个GPU。
数据并行性
如果你的模型仍然适合一个GPU,但你的数据不再适合,你必须尝试数据并行性——这可以让你在GPU之间分布一批数据,并在GPU之间分配模型计算的平均梯度。很多模型开发工作都是跨GPU的,所以您需要确保GPU具有快速的互连。
如果你使用的是服务器卡,那么在训练时间上要有线性的加速。如果您使用的是消费卡,请期待次线性加速。
数据并行是在PyTorch中使用强大的DistributedDataParallel库实现的。Horovod是另一个第三方图书馆选项。PyTorch Lightning使使用这两个库中的任何一个都变得非常简单——其中的加速似乎是相同的。
一个更高级的场景是,你甚至不能在一个GPU上安装你的模型。您必须将模型分布在多个GPU上。对此有三种解决方案。
碎片数据并行性
碎片数据并行性从一个问题开始:究竟是什么占用了GPU内存?
- 模型参数包括组成模型层的浮动。
- 需要梯度来进行反向传播。
- 优化器状态包括有关梯度的统计信息
- 最后,您必须发送一批用于模型开发的数据。
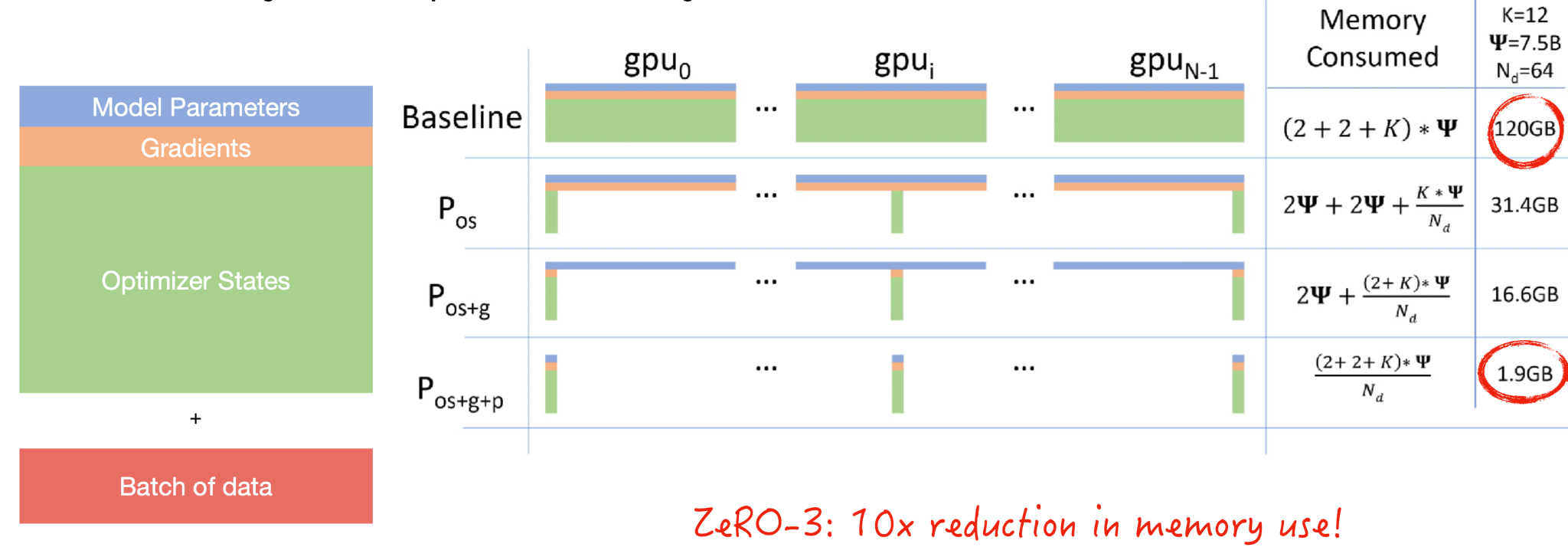
共享是一个来自数据库的概念,如果你有一个数据源,你实际上可以将其分解为分布在分布式系统中的数据碎片。微软实现了一种称为ZeRO的方法,该方法对优化器状态、梯度和模型参数进行分片。这导致内存使用量减少了一个疯狂的数量级,这意味着你的批量大小可能会大10倍。您应该观看本文中的视频,了解随着计算的进行,模型参数是如何在GPU之间传递的。
共享数据并行由微软的DeepSpeed库和脸书的FairScale库实现,也由PyTorch原生实现。在PyTorch中,它被称为完全共享的DataParallel。使用PyTorch Lightning,您可以尝试在不更改模型代码的情况下大幅减少内存。
同样的ZeRO原理也可以应用于单个GPU。您可以在单个V100(32GB)GPU上训练13B参数模型。Fairscale实现了这一点(称为CPU卸载)。
流水线模型并行性
模型并行性意味着您可以将模型的每一层放在每个GPU上。本机实现很简单,但一次只能有一个GPU处于活动状态。像DeepSpeed和FairScale这样的库通过流水线计算使其更好,从而充分利用GPU。您需要将批量大小上的流水线数量调整到如何在GPU上拆分模型的确切程度。
张量平行度
张量并行是另一种方法,它观察到矩阵乘法没有什么特别之处,它需要整个矩阵在一个GPU上。您可以将矩阵分布在多个GPU上。NVIDIA发布了威震天LM回购,该回购针对Transformer型号进行。
如果你真的想扩展一个巨大的模型(比如GPT-3大小的语言模型),你实际上可以使用上面提到的所有三种技术。阅读这篇关于BLOOM培训背后的技术的文章,感受一下。
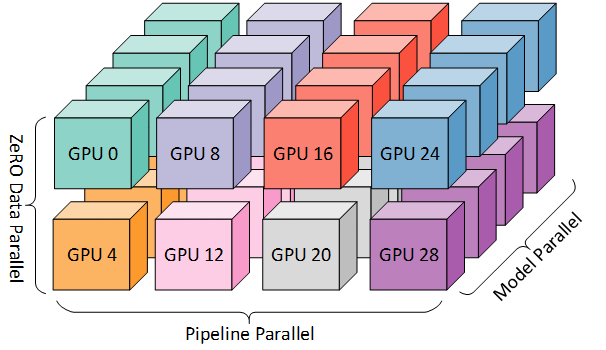
总结:
- 如果你的模型和数据适合一个GPU,那就太棒了。
- 如果他们没有,并且您想加快培训速度,请尝试DistributedDataParallel。
- 如果模型仍然不适合,请尝试ZeRO-3或Full Sharded Data Parallel。
- 有关加快模型训练的更多资源,请查看DeepSpeed、MosaicML和FFCV编制的列表。
5-计算

计算是开发机器学习模型和产品的下一个重要组成部分。
正如OpenAI和HuggingFace的下图所示,在过去十年中,模型的计算强度急剧增长。

最近的发展,包括GPT-3等模型,加速了这一趋势。这些模型非常大,需要大量的PB级运算才能进行训练。
GPU
为了有效地训练深度学习模型,需要GPU。NVIDIA一直是GPU供应商的首选,尽管谷歌推出了TPU(张量处理单元),这些TPU是有效的,但只能通过谷歌云提供。选择GPU时有三个主要考虑因素:
- GPU能容纳多少数据?
- GPU处理数据的速度有多快?要评估这一点,您的数据是16位还是32位?后者的资源更加密集。
- CPU和GPU之间以及GPU之间的通信速度有多快?
看看最近的NVIDIA GPU,很明显每隔几年就会推出一种新的高性能架构。这些芯片之间有区别,它们被许可用于个人用途,而不是公司用途;企业应该只使用服务器卡。
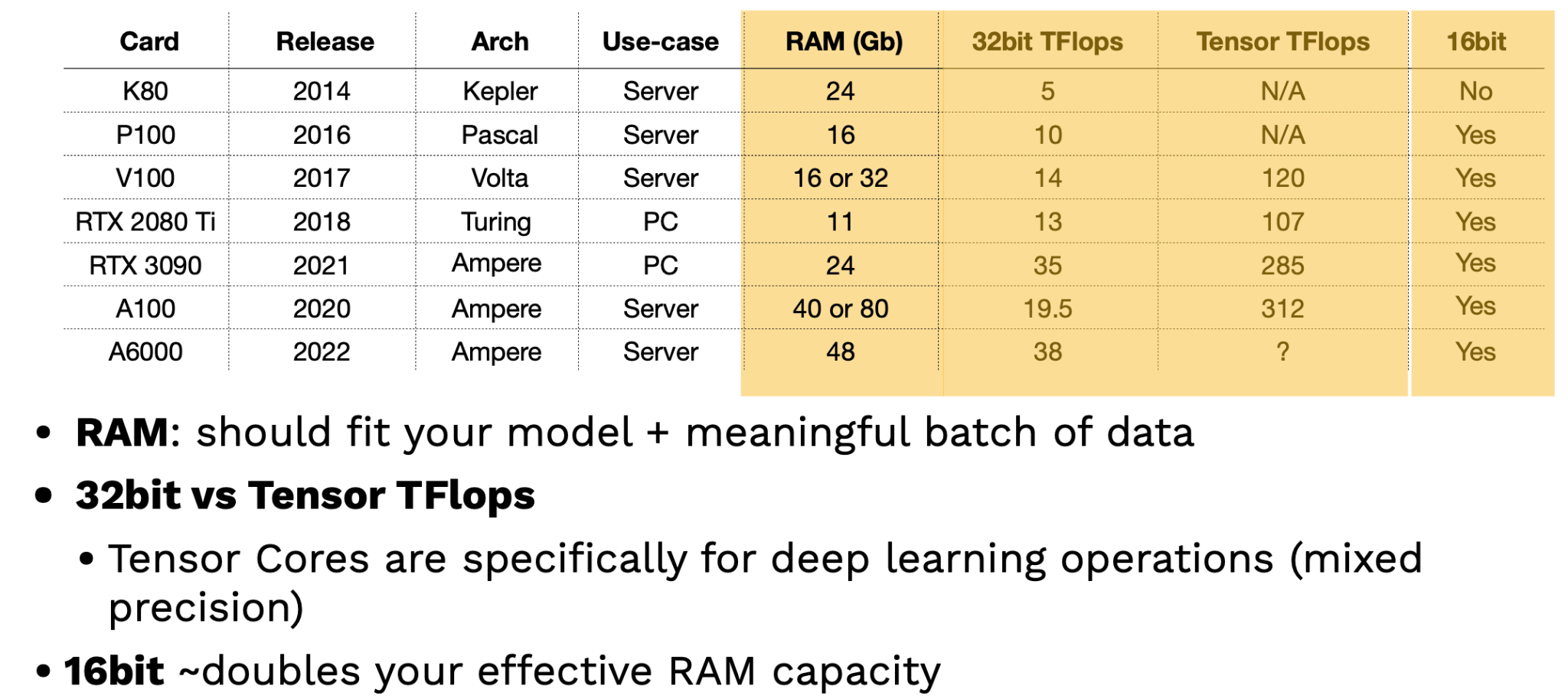
评估GPU的两个关键因素是RAM和张量TFlops。RAM越多,GPU包含的大型模型和数据集就越好。张量TFlops是NVIDIA专门为深度学习操作提供的特殊张量核心,可以处理更密集的混合精度操作。提示:利用16位训练可以有效地使您的RAM容量翻倍!
虽然这些理论基准很有用,但GPU在实际中是如何执行的?Lambda实验室在这里提供了最好的基准测试。他们的研究结果表明,最新的服务器级NVIDIA GPU(A100)比经典的V100 GPU快2.5倍以上。RTX芯片的性能也优于V100。AIME也是GPU基准测试的另一个来源。
微软Azure、谷歌云平台和亚马逊网络服务等云服务是购买GPU访问权限的默认场所。Paperspace、CoreWeave和Lambda Labs等初创云提供商也提供此类服务。
TPU
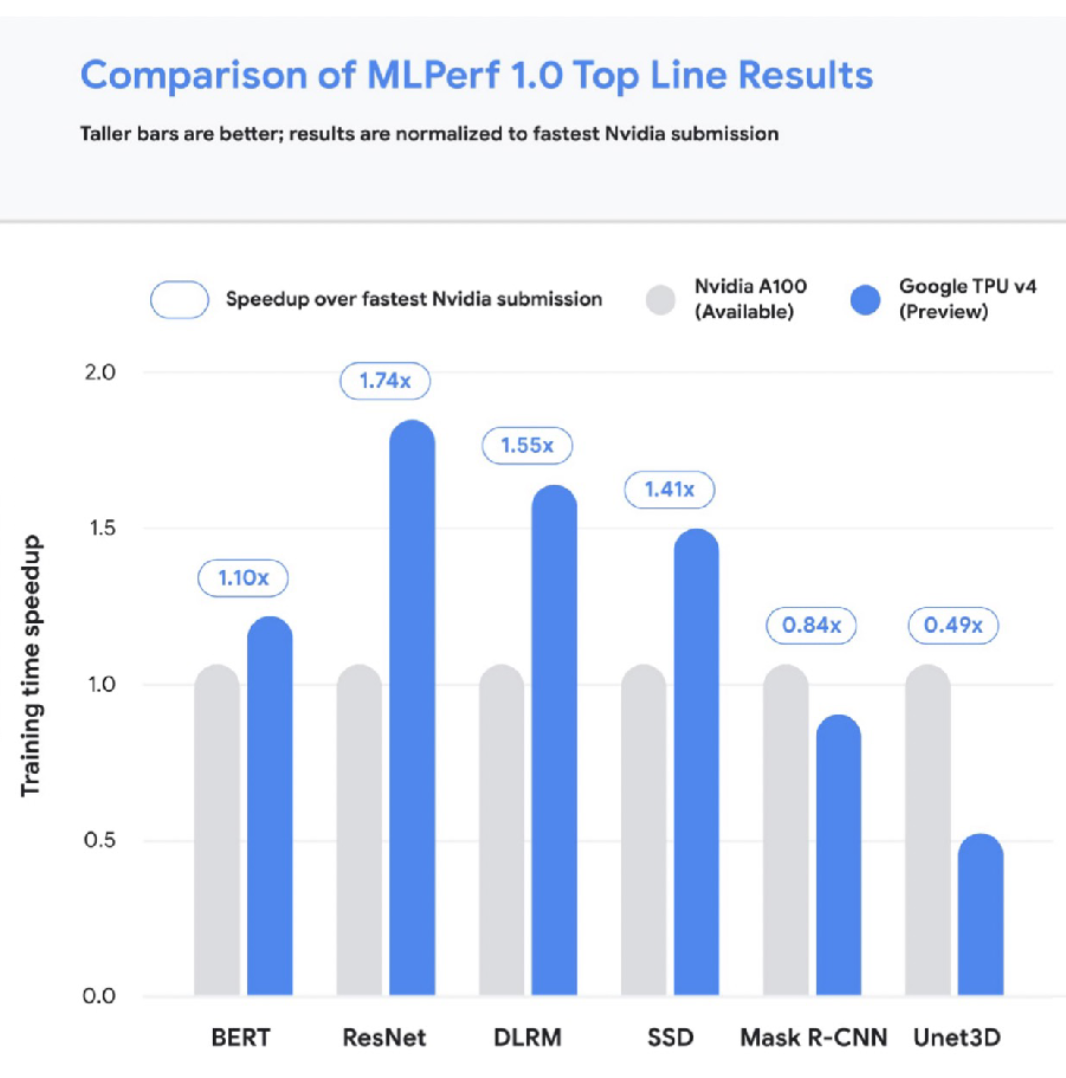
让我们简单讨论一下TPU。有四代TPU,最新的v4是深度学习最快的加速器。V4 TPU目前还不普遍,但TPU通常擅长扩展到更大的尺寸和模型尺寸。下图将TPU与速度最快的A100 NVIDIA芯片进行了比较。
将云访问的成本与GPU进行比较可能会让人不知所措,所以我们制作了一个解决这个问题的工具!请随时为我们的云GPU成本指标库做出贡献。该工具具有各种漂亮的功能,如仅为最新的芯片型号启用过滤器等。
如果我们将成本指标与性能指标相结合,我们会发现每小时最昂贵的芯片并不是每次实验最昂贵的!举个例子:在4个V100上运行相同的变形金刚实验在72小时内花费1750美元,而在4个A100上运行同样的实验仅在8小时内花费250美元。根据你试图训练的模型仔细考虑成本和性能。
这里有一些有用的启发式方法:
- 在最便宜的云中使用每小时最昂贵的GPU。
- 初创企业(例如Paperspace)往往比主要的云提供商更便宜。
On-Prem与Cloud
对于预构建用例,您可以很容易地构建自己的计算机,也可以选择NVIDIA等公司的预构建计算机。你可以花大约7000美元打造一台拥有128 GB RAM和2个RTX 3909的安静PC,并在一天内完成安装。超越这一点可能会变得更加昂贵和复杂。Lambda Labs提供一台售价60000美元的机器,配有8个A100(超级快!)。Tim Dettmers提供了一个关于在这里建造机器的很好的(稍微过时的)视角。
关于prem与云使用的一些提示:
- 拥有自己的GPU机器可以将您的心态从最小化成本转变为最大化效用,这可能很有用。
- 要想真正扩大实验规模,你可能只需要在最便宜的云中使用最昂贵的机器。
- 考虑到TPU的性能,它值得在大规模训练中进行试验。
- Lambda Labs是赞助商,我们非常鼓励on-prem和云GPU上使用它们!
6-资源管理

既然我们已经讨论了原始计算,那么让我们讨论一下如何管理计算资源的选项。假设我们想要管理一组实验。从广义上讲,我们需要GPU形式的硬件、软件需求(例如PyTorch版本)和数据来进行训练。
解决
利用指定依赖关系的最佳实践(例如Poetry、conda、pip工具),可以在一台机器上快速轻松地进行此类实验。
然而,如果您有一组机器可以在上面运行实验,那么SLURM是一种行之有效的工作负载管理解决方案,目前仍在广泛使用。
为了更具可移植性,Docker是一种将整个依赖堆栈打包为轻量级虚拟机包的方法。Kubernetes是在集群上运行许多Docker容器的最流行方式。OSS Kubeflow项目帮助管理依赖Kubernetes的ML项目。
这些项目很有用,但可能不是最简单或最好的选择。如果您已经建立并运行了集群,那么它们就很好了,但您实际上是如何建立集群或计算平台的呢?
在继续之前,FSDL更喜欢开源和/或价格透明的产品。我们讨论的是属于这些类别的工具,而不是定价不透明的SaaS。
工具
对于AWS的从业者来说,AWS Sagemaker为构建机器学习模型提供了一个方便的端到端解决方案,从标记数据到部署模型。Sagemaker有大量特定于AWS的配置,这可能会让人反感,但它带来了许多易于使用的老式算法进行训练,并允许您使用BYO算法。他们也在增加对PyTorch的支持,尽管PyTorch价格上涨了15-20%。
Anyscale是一家由伯克利OSS项目Ray的制造商创建的公司。Anyscale最近推出了Ray Train,他们声称它比具有类似价值主张的Sagemaker更快。Anyscale使提供计算集群变得非常容易,但它比其他选择要昂贵得多。
Grid.ai是由PyTorch Lightning的创建者创建的。网格允许您通过“网格运行”指定要轻松使用的计算参数,然后指定所需的计算类型和选项。您可以在后台使用它们的实例或AWS。电网的未来并不确定,因为其未来与Lightning的兼容性(考虑到其品牌重塑)尚未明确。
还有几个非ML选项可用于启动计算!编写自己的脚本,使用各种库,甚至Kubernetes都是可以选择的。这条路线比较难。
Determined.AI是一个用于管理预处理和云集群的OSS解决方案。它们提供集群管理、分布式培训等。它非常易于使用,并且正在积极开发中。
尽管如此,在许多云提供商上启动培训的易用性仍有提高的空间。
7-实验和模型管理
与计算相比,实验管理几乎要解决了。实验管理是指帮助我们跟踪在模型开发生命周期中迭代的代码、模型参数和数据集的工具和过程。这些工具对于有效的模型开发至关重要。这里有几种解决方案:
- TensorBoard:一个非独占的谷歌解决方案,可有效进行一次性实验跟踪。管理许多实验是困难的。
- MLflow:一个非排他性的Databricks项目,除了实验管理之外,还包括模型封装等。它必须是自托管的。
- Weights and Biases::一个易于使用的解决方案,对个人和学术项目免费!日志记录只需简单地从一个“实验配置”命令开始。
- 其他选项包括 Neptune AI, Comet ML, and Determined AI,,所有这些都有可靠的实验跟踪选项。
其中许多平台还提供智能超参数优化,这使我们能够控制为模型搜索正确参数的成本。例如,Weights and Biases有一个名为Sweep的产品,可以帮助进行超参数优化。最好将其作为常规ML培训工具的一部分;不需要专用工具。
8-“一体化”
有机器学习基础设施解决方案可以提供一切——培训、实验跟踪、扩展、部署等。这些“一体式”平台简化了事情,但价格不便宜!示例包括 Gradient by Paperspace, Domino Data Lab, AWS Sagemaker,等。
- 247 次浏览
【深度学习】深度学习工具集-概述
作者:Timon Ruban, Luminovo的联合创始人
每一个值得解决的问题都需要强大的工具来支持。深度学习也不例外。如果说有什么不同的话,那就是在这个领域中,好的工具将在未来几年变得越来越重要。我们仍处于深度学习超新星的相对早期阶段,许多深度学习工程师和狂热者以自己的方式进入高效的过程。然而,我们也注意到越来越多的优秀工具有助于促进复杂的深度学习过程,使其更容易获得和更有效。深入学习是不断传播工作的研究人员和学者到更广泛的领域的DL爱好者想要进入这个领域(可访问性),和越来越多的工程团队希望简化他们的流程和降低复杂性(效率),我们有最好的DL工具的概述。
深入了解深度学习的生命周期
为了更好地评估能够促进深度学习的可访问性和效率的工具,让我们首先看看这个过程到底是什么样的。
一个典型的(有监督的)深度学习应用程序的生命周期由不同的步骤组成,从原始数据开始,到最终的预测。

A typical deep learning lifecycle © 2018 Luminovo
数据寻源
任何深度学习应用的第一步都是寻找正确的数据。有时你很幸运,有现成的历史数据。有时您需要搜索开源数据集、在web上搜索、购买原始数据或使用模拟数据集。由于此步骤通常是非常特定于手头的应用程序的,所以我们没有将其包含在我们的工具环境中。请注意,然而,有网站像谷歌的数据集搜索或Fast。ai数据集,可以缓解寻找正确数据的问题。
数据标签
大多数受监督的深度学习应用程序处理图像、视频、文本或音频,在训练模型之前,您需要用ground-truth标签注释这些原始数据。这可能是一个成本密集和耗时的任务。在理想的设置中,这个过程与模型培训和部署交织在一起,并尽可能利用训练过的深度学习模型(即使它们的性能还不完美)。
数据版本控制
随着时间的推移,数据发展得越多(假设你建立了一个智能标记过程,并随着数据集的增长不断对模型进行再训练),更新数据集的版本就变得越重要(就像你应该总是更新你的代码和训练过的模型一样)。
扩展硬件
这个步骤与模型培训和部署都相关:访问正确的硬件。当在模型训练期间从本地开发转移到大规模实验时,您的硬件需要适当地扩展。在部署模型时,根据用户需求进行扩展也是如此。
模型架构
要开始训练你的模型,你需要选择你的神经网络的模型架构。
注意:如果你有一个标准的问题(如识别猫在互联网文化基因),这通常意味着不超过复制粘贴最新最先进的模型从一个开源GitHub库,但是偶尔你会想弄脏你的手和调整模型的体系结构来提高性能。随着神经体系结构搜索(NAS)等新方法的出现,选择正确的模型体系结构越来越多地包含在模型训练阶段,但截至2018年,对于大多数应用程序来说,NAS性能的边际增长并不值得增加计算成本。
这一步是人们在编写深度学习应用程序时经常想到的,但正如你所看到的,它只是众多步骤之一,通常不是最重要的。
模型训练
在模型训练你喂带安全标签的数据时神经网络模型和迭代更新重量最小化训练集上的损失。一旦你选择一个指标(见模型评价)你可以训练你的模型与许多不同的hyperparameters(如组合学习速率的模型结构和设置预处理步骤的选择)的过程称为hyperparameter调优。
模型评价
如果你不能区分好模型和坏模型,那么训练神经网络就没有意义了。在模型评估期间,您通常会选择一个要优化的指标(同时可能会观察到许多其他指标)。对于这个指标,您要尝试找到从训练数据到验证数据的最佳性能模型。这包括跟踪不同的实验(可能有不同的超参数、架构和数据集)及其性能指标,可视化训练模型的输出,并将实验相互比较。如果没有正确的工具,这可能很快变得令人费解和困惑,特别是当与多个工程师在同一深度学习管道合作时。
模型版本控制
在最终的模型评估和模型部署之间的一小步(但仍然值得一提):用不同的版本标记您的模型。当您发现最新的模型版本没有达到您的期望时,这允许您轻松地回滚到工作良好的模型版本。
模型部署
如果您有一个乐意投入生产的模型版本,那么您需要以一种用户(可以是人或其他应用程序)可以与您的模型对话的方式来部署它:发送带有数据的请求并返回模型的预测。理想情况下,您用于模型部署的工具支持在不同模型版本之间逐步切换,这样您就可以预测在生产环境中使用新模型的影响。
监测预测
一旦您的模型部署好了,您就需要密切关注它在现实世界中做出的预测,并在用户上门投诉您的服务之前警惕数据分布的变化和性能下降。
注意:流程图已经暗示了典型的深度学习工作流的循环性质。事实上,在您的深度学习工作流中,将已部署模型和新标签(通常称为human-in-the-loop)之间的反馈回路视为头等公民,可能是许多应用程序最重要的成功因素之一。在现实生活中的深度学习工作中,事情往往比流程图显示的要复杂得多。你会发现自己跳过步骤(例如,当你正在与一个pre-labeled数据集),回到几个步骤(模型性能不够准确,需要更多的数据来源)或在疯狂来回循环(架构= >培训= >评价= > = = > >评估架构)。

我们最喜欢的深度学习工具
在Luminovo,我们努力创造工具,让我们的工程师更有效率,同时也利用了那些优秀的深度学习人员创造的强大工具。优秀的代码应该是共享的,所以下图展示了目前市场上最有前途的深度学习工具的概述。DL工程师为DL工程师和所有渴望了解更多关于创建令人敬畏的深度学习应用程序的人。

PDF版本的请私信。
讨论:请加入知识星球【首席架构师智库】或者小号【ca_cea】或者QQ群【11107777】
- 102 次浏览
【深度学习】深度学习架构的设计模式:介绍
读者须知
在这里引入这个材料可能有些突兀,但理解思想过程的一种方法是遵循直觉机器博客。
深度学习架构概述
深度学习架构可以被描述为建立机器学习系统的新方法或风格。深度学习更有可能推动更先进的人工智能形式,其巨大突破已经持续了十多年。在当前乐观的氛围中,我们正处于新一轮的 AI 发展浪潮。然而,当前的深度学习方法仍然具有“炼金术”色彩。每位研究者似乎都有自己独特的“黑魔法”来设计架构。因此,该领域需要向前迈进,类似于从炼金术到化学的转变,甚至建立深度学习的“周期表”。
虽然深度学习仍处于发展初期,但本书尝试在深度学习实践中形成一些统一的思想框架,并利用称为“模式语言”的描述方法。
什么是模式语言?
模式语言是一种从模式(Pattern)衍生出的表达方式,用于解决复杂问题。每个模式描述一个问题,并提供可替代的解决方案。通过模式语言,我们能够更系统地表达从经验中总结出的复杂解决方案,使从业者更容易理解和交流解决方案。
在计算机科学领域,“设计模式”是更常见的术语。然而,我们选择使用“模式语言”是为了反映深度学习领域的快速发展和不成熟性。我们所描述的模式可能并非最终的模式,而是当前的研究基础,未来仍需进一步探索和澄清。
模式语言的历史
模式语言最初由克里斯托弗·亚历山大(Christopher Alexander)提出,用于描述建筑和城市规划。后来,这些概念被面向对象编程(OOP)领域的从业者采用,用于描述软件设计模式。GoF(Gang of Four)在其经典著作《设计模式》中证明了这种方法的有效性。此后,模式语言扩展到用户界面设计、交互设计、企业架构、SOA 和可扩展性设计等多个领域。
深度学习的模式语言
在机器学习(ML)领域,深度学习(DL)是一种新的实践方式。DL 并非单一算法,而是一类表现出类似特征的算法集合。例如,DL 系统通常由多层神经网络(如多层感知机)构成。这一概念自 20 世纪 60 年代首次提出以来,随着计算能力(GPU)和数据量的增长,DL 研究逐渐兴起,并在 2011 年后取得了显著成果。
然而,DL 领域存在术语混乱的问题。例如,前馈网络(Feedforward Network)又被称为全连接网络(FCN),而卷积网络(ConvNet)、循环神经网络(RNN)以及限制玻尔兹曼机(RBM)等都属于 DL 网络。它们的共同点在于层次结构,而模式语言可以帮助总结这些特征。
数学基础与模式语言
许多人希望深度学习建立在严密的数学基础之上。然而,许多深度学习研究涉及高阶数学,如路径积分、张量计算、希尔伯特空间和测度论等。然而,数学的便利性并不一定代表它是描述现实世界的最佳方式。例如,高斯分布的普遍性更多源于数学的便利性,而非现实本身的特性。
模式语言在多个非数学领域中都有应用。例如,用户界面、软件过程和可用性等领域都成功使用了模式语言,而这些领域并没有严格的数学基础。因此,我们可以借鉴模式语言的思维方式来更好地描述深度学习体系。
深度学习模式语言的框架
1. 理论基础
本章介绍理解深度学习框架所需的数学基础,并提供一些术语和符号,以便在后续章节中使用。
2. 模式语言概述
介绍模式语言的基本概念,并定义深度学习模式的分类结构。
3. 方法论
借鉴敏捷开发和精益方法,并将其应用于深度学习领域。由于深度学习系统具备自我进化能力,因此需要建立适应性的实践方法。
4. 规范模式(Canonical Patterns)
本章介绍深度学习中的基本模式,并构建其他模式的基础。
5. 模型模式(Model Patterns)
介绍深度学习实践中的各种模型架构模式。
6. 复合模型模式(Composite Model Patterns)
探讨如何组合多个模型来构建更复杂的深度学习系统。
7. 记忆模式(Memory Patterns)
介绍如何集成记忆机制,以提升深度学习模型的性能。
8. 特征模式(Feature Patterns)
探讨输入数据的表示方法及其对模型性能的影响。
9. 学习模式(Learning Patterns)
介绍深度学习的各种训练方法及优化策略。
10. 集体学习模式(Collective Learning Patterns)
介绍多个神经网络协作以解决更复杂任务的模式。
11. 解释模式(Interpretability Patterns)
探讨如何提升深度学习模型的可解释性。
12. 服务模式(Service Patterns)
介绍在生产环境中部署深度学习模型的最佳实践。
深度学习应用与未来发展
深度学习数据集
介绍常用的数据集,并讨论数据质量对模型性能的影响。
常见问题解答(FAQ)
解答在深度学习模式语言实践中常见的问题。
未来研究方向
探讨深度学习模式语言的发展趋势,以及如何进一步提升深度学习模型的可扩展性和可解释性。
目标读者与适用范围
本书适用于有人工神经网络(ANN)基础的读者。它不会涵盖 ANN 的基础介绍或大学水平的数学知识。如果需要基础入门,建议阅读 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 的《深度学习》。本书的目标是提供深度学习实践中的模式框架,而非涵盖所有理论细节。
此外,我们不会涉及生物学可信性的问题。神经网络与生物神经元之间的关系已被讨论数十年,但其相关性较低。本书重点关注深度学习架构的实践方法,而非历史回顾。
结论
本书采用逻辑推理的方法,最小化假设。我们认为深度学习系统可以被视为动态系统,目标是通过最小化相对熵来优化模型表现。通过模式语言的方式,我们希望为深度学习提供更清晰的架构设计方法,帮助实践者更有效地构建和部署深度学习系统。
注意:这是一个进步的工作。像 https://www.facebook.com/deeplearningpatterns
一样接收更新。或者,按照媒体:https://medium.com/intuitionmachine
- 461 次浏览
【深度学习】神经网络计算爆炸
深度挖掘的公司开始为特定应用定制这种方法,并花费大量资金来获得初创公司。
具有先进并行处理的神经网络已经开始扎根于预测地震和飓风到解析MRI图像数据的许多市场,以便识别和分类肿瘤。
由于这种方法在更多的地方得到实施,所以它是以许多专家从未设想的方式进行定制和解析的。它正在推动对这些计算架构如何应用的新研究。
荷兰Asimov研究所的深度学习研究员Fjodor van Veen已经确定了27种不同的神经网络结构类型。 (参见下面的图1)。差异主要是应用程序特定的。
神经网络
图。 1:神经网络架构。资料来源:阿西莫夫研究所
神经网络是基于阈值逻辑算法的概念,这是1943年由神经生理学家Warren McCulloch和逻辑学家Walter Pitts首次提出的。研究在接下来的70年里一直徘徊,但是它真的开始飙升。
Nvidia的加速计算集团产品团队负责人Roy Kim表示:“2012-2013年的大爆炸事件发生在两个里程碑式的出版物上。其中一篇论文是由Geoffrey Hinton和他的团队从多伦多大学(现在也是谷歌的半时间)撰写,题为“ImageNet Classification with Deep Convolutional Neural Networks”。然后在2013年,Stanford的Andrew Ng(现在也是百度首席科学家),他的团队发表了“与COTS HPC系统深度学习”。
Nvidia早期认识到,深层神经网络是人工智能革命的基础,并开始投资于将GPU引入这个世界。 Kim指出卷积神经网络,复发神经网络和长时间内存(LSTM)网络,其中每个网络都设计用于解决特定问题,如图像识别,语音或语言翻译。他指出,Nvidia正在所有这些领域招聘硬件和软件工程师。
6月份,Google大幅增加新闻,Google在神经网络手臂竞赛的半导体领域处于领先地位。 Google卓越的硬件工程师Norm Jouppi公布了公司几年努力的细节,Tensor处理器单元(TPU)是实现硅芯片神经网络组件的ASIC,而不是使用原始硅计算电源和内存库和软件,这也是谷歌也做的。
TPU针对TensorFlow进行了优化,TensorFlow是Google使用数据流图进行数值计算的软件库。它已经在Google数据中心运行了一年多。
不过,这不仅仅是一些正在争夺这一市场的玩家。创业公司Knupath和Nervana进入这个战争,寻求设计具有神经网络的晶体管领域。英特尔上个月向Nervana报了4.08亿美元。
Nervana开发的硅“引擎”是在2017年的某个时候。Nervana暗示了前进的内存缓存,因为它具有8 Tb /秒的内存访问速度。但事实上,Nervana在2014年以种子资本开始投入60万美元,并在两年之后卖出近680倍的投资,这证明了行业和金融家们正在占据的空间 - 以及这个市场有多热。
市场驱动
汽车是该技术的核心应用,特别适用于ADAS。 Arteris董事长兼首席执行官Charlie Janac说:“关键是您必须决定图像是什么,并将其转化为卷积神经网络算法。 “有两种方法。一个是GPU。另一种是ASIC,其最终获胜并且使用较少的电力。但一个非常好的实现是紧密耦合的硬件和软件系统。
然而,到紧密耦合系统的这一点,取决于对什么问题需要解决的深刻理解。
Leti首席执行官Marie Semeria说:“我们必须开发不同的技术选择。 “这是全新的。首先,我们必须考虑使用。这是一种完全不同的驾驶技术方式。这是一个神经性的技术推动。你需要什么?然后,您将根据此开发解决方案。“
该解决方案也可以非常快。 Cadence顾问Chris Rowen表示,其中一些系统每秒可以运行数万亿次操作。但并不是所有这些操作都是完全准确的,而且这个操作也必须被构建到系统中。
Rowen说:“你必须采取一种统计手段来管理正确性。 “你正在使用更高的并行架构。”
最有效的
比较这些系统并不容易。在讨论Google TPU时,Jouppi强调了世界各地的研究人员和工程师团队的基本工作方法,以及他们正在使用的硬件和软件的性能:ImageNet。 ImageNet是大学研究人员独立维护的1400万张图像的集合,它允许工程团队将他们的系统找到对象和分类(通常是其子集)的时间缩短。
本月晚些时候,ImageNet大型视觉识别挑战赛(ILSVRC)的结果将于2016年发布,作为在阿姆斯特丹举行的欧洲计算机视觉会议(ECCV)的一部分。
所有在这里讨论的玩家将在那里,包括Nvidia,百度,谷歌和英特尔。高通也将在那里,因为它开始关键的软件库,就像Nvidia一样。 Nvidia将展示其DGX-1深度学习用具和Jetson嵌入式平台,适用于视频分析和机器学习。
ECCV 2016的总裁Arnold Smeulders和Theo Gevers告诉“半导体工程”,ECCV的许多与会者都在半导体技术领域工作(而不是硅片上运行的软件),从而实现计算机视觉。
“最近,半导体技术强国已经开始对计算机视觉感兴趣,”他们通过电子邮件说。 “现在,电脑可以了解图像中存在哪些类型的场景和类型的场景。这需要从注释示例中描述与机器学习匹配的特征中的图像。在过去五年中,这些算法的力量使用深层学习架构大大增加。由于它们是计算密集型产品,包括高通,英特尔,华为和三星在内的芯片制造商,以及苹果,谷歌,亚马逊等大型企业以及许多高科技创业公司也将进入计算机视觉阶段。
Smeulders和Gevers表示,兴趣已经增长到这样的高度,会议场地在一个月前达到最大容量,注册预计将会结束。
以前的ECCV版本长期以来每年大约有100名与会者长大,在苏黎世的上一版本以1,200的成绩结束。 “今年,我们在会议前一个月已经有1500位与会者。在这一点上,我们不得不关闭注册,因为我们雇用的建筑,荷兰皇家剧院,不能更舒适地拥有,“他们写道。
随着行业的复杂和变化,工程经理寻找必要的技能是很困难的。它还引发了电气工程和计算机科学学生关于他们的课程是否会过时的问题,然后才能将它们应用于市场。那么一个学生对电子学有兴趣,特别是半导体在计算机视觉中的作用呢,可以在现场找到工作吗?
Semulders和Gevers表示:“由于图像[识别]是每1/30秒的大量数据,所以半导体行业受到重视是很自然的事情。” “由于大量的数据,直到最近,注意力仅限于处理图像以产生另一个图像(更可见,更清晰的图像中的突出显示元素)或减少图像(目标区域或压缩版本)。这是图像处理领域:图像输入,图像输出。但最近,计算机视觉领域 - 即对图像中可见的解释 - 已经经历了一个非常有成效的时期。他们写道:要了解图像的本质,正在形成的方式和深入网络分析的方式,是现代计算机视觉的关键组成部分。
随机信号处理,机器学习和计算机视觉将是学习和培训的领域。
ECCV的亚洲对手是亚洲CCV。在这几年,国际CCV举行。 Smeulders和Gevers指出,每年夏天在美国举行的计算机视觉和模式识别会议是对CCVs的补充,但是重点略有不同。 Google认为它是所有审查学科的前100名研究来源之一,这是列表中唯一的会议。论文将于11月15日在檀香山举行的7月份e会议上公布。
Nvidia的Kim和其他人认为2012年至2013年将成为在这些神经网络应用中用于计算机视觉等任务的GPU的“大爆炸”。那么下一个大爆炸又是什么?
“自2004年以来,对图像内容进行分类的比赛重新开始,几个算法步骤已经铺平了道路,”Smeulders和Gevers写道。 “一个是SIFT特征[Scale Invariant Feature Transform]。另一种是一些单词和其他编码方案,以及特征定位算法,以及大量图像数据的特征学习。然后,GPU为深入学习网络铺平了道路,进一步提高了性能,因为它们加速了数据集的学习。这意味着需要几周的任务现在可以在一夜之间运行。下一个大爆炸将再次在算法方面。
鉴于投入这笔市场的金额很大,毫无疑问,大事情将会前进。还有多大的待观察,但鉴于这种方法的活动量以及投资的数量,预期是非常高的。
- 64 次浏览
【深度学习架构】CNN与RNN与ANN——分析深度学习中的3种神经网络
视频号
微信公众号
知识星球
介绍
本文将向您介绍深度学习中的3种不同类型的神经网络,并教您何时使用哪种类型的神经网来解决深度学习问题。它还将以易于阅读的表格格式向您展示这些不同类型的神经网络之间的比较!
目录
- 介绍
- 为什么选择深度学习?
- 深度学习中不同类型的神经网络
- 什么是人工神经网络?我们为什么要使用它?
- 什么是递归神经网络(RNN)?我们为什么要使用它?
- 什么是卷积神经网络(CNN)?我们为什么要使用它?
为什么选择深度学习?
这是一个中肯的问题。机器学习算法并不短缺,那么为什么数据科学家应该倾向于深度学习算法呢?神经网络提供了传统机器学习算法所没有的什么?
我看到的另一个常见问题是——神经网络需要大量的计算能力,那么使用它们真的值得吗?虽然这个问题有细微差别,但这里有一个简短的答案——是的!
深度学习中不同类型的神经网络,如卷积神经网络(CNN)、递归神经网络(RNN)、人工神经网络(ANN)等,正在改变我们与世界互动的方式。这些不同类型的神经网络是深度学习革命的核心,为无人机、自动驾驶汽车、语音识别等应用提供动力。
人们很自然地会想,难道机器学习算法就不能做到这一点吗?研究人员和专家倾向于选择深度学习而不是机器学习的两个关键原因是:
- 决策边界
- 特性工程
好奇的很好——让我解释一下。
1.机器学习与深度学习:决策边界
每个机器学习算法都学习从输入到输出的映射。在参数模型的情况下,算法学习具有几组权重的函数:
Input -> f(w1,w2…..wn) -> Output
在分类问题的情况下,算法学习分离两个类的函数——这被称为决策边界。决策边界有助于我们确定给定的数据点属于正类还是负类。
例如,在逻辑回归的情况下,学习函数是一个Sigmoid函数,它试图分离两个类:

逻辑回归的决策边界
正如您在这里看到的,逻辑回归算法学习线性决策边界。它无法学习像这样的非线性数据的决策边界:

非线性数据
类似地,每种机器学习算法都不能学习所有的函数。这限制了这些算法可以解决的涉及复杂关系的问题。
2.机器学习与深度学习:特征工程
特征工程是模型构建过程中的关键一步。这是一个分两步进行的过程:
- 特征提取
- 特征选择
在特征提取中,我们提取问题陈述所需的所有特征,在特征选择中,我们选择提高机器学习或深度学习模型性能的重要特征。
考虑一个图像分类问题。从图像中手动提取特征需要对主题和领域有很强的了解。这是一个极其耗时的过程。得益于深度学习,我们可以自动化特征工程的过程!

Comparison between Machine Learning & Deep Learning
既然我们理解了深度学习的重要性,以及为什么它超越了传统的机器学习算法,让我们进入本文的核心。我们将讨论用于解决深度学习问题的不同类型的神经网络。
如果您刚刚开始学习机器学习和深度学习,这里有一门课程可以帮助您完成旅程:
深度学习中不同类型的神经网络
本文关注三种重要类型的神经网络,它们构成了深度学习中大多数预训练模型的基础:
- 人工神经网络 (ANN)
- 卷积神经网络(CNN)
- 递归神经网络 (RNN)
让我们详细讨论每个神经网络。
什么是人工神经网络?我们为什么要使用它?
单个感知器(或神经元)可以想象为逻辑回归。人工神经网络(Artificial Neural Network,简称ANN)是一组位于每一层的多个感知器/神经元。ANN也被称为前馈神经网络,因为输入仅在正向方向上进行处理:

正如你在这里看到的,人工神经网络由3层组成——输入、隐藏和输出。输入层接受输入,隐藏层处理输入,输出层产生结果。从本质上讲,每一层都试图学习某些权重。
如果你想了解更多关于人工神经网络如何工作的信息,我建议你阅读以下文章:
人工神经网络可用于解决与以下方面相关的问题:
- 表格数据
- 图像数据
- 文本数据
人工神经网络的优点
人工神经网络能够学习任何非线性函数。因此,这些网络通常被称为通用函数逼近器。神经网络有能力学习将任何输入映射到输出的权重。
普遍近似背后的主要原因之一是激活函数。激活函数为网络引入了非线性特性。这有助于网络学习输入和输出之间的任何复杂关系。
 Perceptron
Perceptron
正如你在这里看到的,每个神经元的输出是输入的加权和的激活。但是等等——如果没有激活功能会发生什么?网络只学习线性函数,永远无法学习复杂的关系。这就是为什么:
激活函数是人工神经网络的强大动力!
人工神经网络面临的挑战
当使用ANN解决图像分类问题时,第一步是在训练模型之前将二维图像转换为一维向量。这有两个缺点:
- 可训练参数的数量随着图像大小的增加而急剧增加

ANN: Image classification
在上述场景中,如果图像的大小是224*224,那么在仅有4个神经元的第一隐藏层处的可训练参数的数量是602112。太棒了!
- 人工神经网络失去了图像的空间特征。空间特征是指图像中像素的排列。我将在以下章节中详细介绍这一点

Backward Propagation
因此,在非常深的神经网络(具有大量隐藏层的网络)的情况下,梯度在向后传播时消失或爆炸,这导致梯度消失和爆炸。
- 人工神经网络不能捕获输入数据中处理序列数据所需的序列信息
现在,让我们看看如何使用两种不同的架构来克服MLP的局限性——递归神经网络(RNN)和卷积神经网络(CNN)。
什么是递归神经网络(RNN)?我们为什么要使用它?
让我们首先从架构的角度来理解RNN和ANN之间的区别:
神经网络隐藏层上的循环约束转化为RNN。
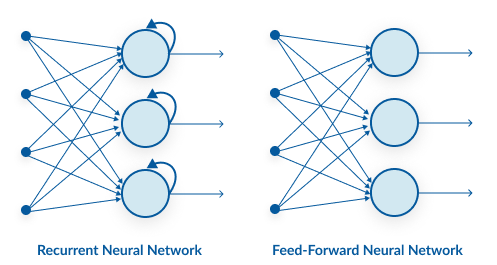
正如您在这里看到的,RNN在隐藏状态上有一个循环连接。这种循环约束确保在输入数据中捕获顺序信息。
您应该通过以下教程来了解更多关于RNN如何在后台工作的信息(以及如何在Python中构建RNN):
我们可以使用递归神经网络来解决与以下相关的问题:
- 时间序列数据
- 文本数据
- 音频数据
递归神经网络(RNN)的优点
RNN捕获输入数据中存在的顺序信息,即在进行预测时文本中单词之间的相关性:

正如您在这里看到的,每个时间步长的输出(o1,o2,o3,o4)不仅取决于当前单词,还取决于前一个单词。
- RNN在不同的时间步长上共享参数。这通常被称为参数共享。这导致需要训练的参数更少,并降低了计算成本
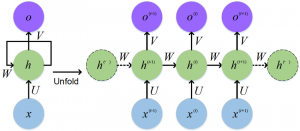
Unrolled RNN
如上图所示,3个权重矩阵——U、W、V,是所有时间步长共享的权重矩阵。
递归神经网络(RNN)面临的挑战
深度RNN(具有大量时间步长的RNN)也存在消失和爆炸梯度问题,这是所有不同类型的神经网络中常见的问题。
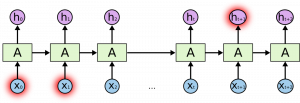
正如你在这里看到的,在最后一个时间步长计算的梯度在到达初始时间步长时消失。
什么是卷积神经网络(CNN)?我们为什么要使用它?
卷积神经网络(CNN)目前在深度学习社区风靡一时。这些CNN模型被用于不同的应用程序和领域,在图像和视频处理项目中尤为普遍。
细胞神经网络的构建块是过滤器,也就是内核。核用于使用卷积运算从输入中提取相关特征。让我们试着了解使用图像作为输入数据的过滤器的重要性。使用过滤器对图像进行卷积会生成特征图:

卷积的输出
想了解更多关于卷积神经网络的信息吗?我建议您完成以下教程:
你也可以报名参加美国有线电视新闻网的免费课程,了解更多关于它们的信息:从头开始的卷积神经网络
尽管卷积神经网络被引入来解决与图像数据相关的问题,但它们在顺序输入上的表现也令人印象深刻。
卷积神经网络(CNN)的优点
- CNN在没有明确提及的情况下自动学习过滤器。这些过滤器有助于从输入数据中提取正确的相关特征

CNN–图像分类
- CNN从图像中捕捉到空间特征。空间特征是指图像中像素的排列及其之间的关系。它们帮助我们准确地识别物体、物体的位置以及它与图像中其他物体的关系

在上面的图像中,我们可以通过观察眼睛、鼻子、嘴巴等特定特征很容易地识别出这是人脸。我们还可以看到这些特定特征是如何排列在图像中的。这正是细胞神经网络能够捕捉到的。
- CNN也遵循参数共享的概念。单个过滤器应用于输入的不同部分,以生成特征图:
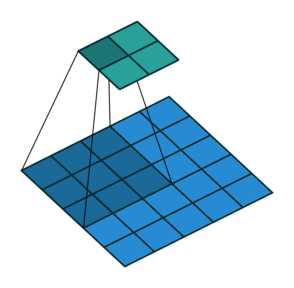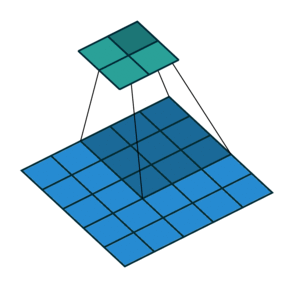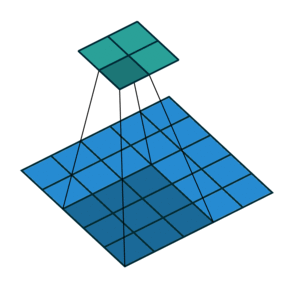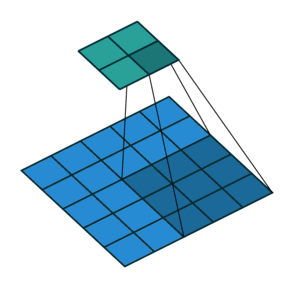
Convolving image with a filter
请注意,2*2特征图是通过在图像的不同部分上滑动相同的3*3滤波器来生成的。
比较不同类型的神经网络(MLP(ANN)与RNN与CNN)
在这里,我总结了不同类型的神经网络之间的一些差异:

结论
在这篇文章中,我讨论了深度学习的重要性以及不同类型神经网络之间的差异。我坚信知识共享是学习的终极形式。我期待着听到更多的不同!
常见问题
Q1.有多少种类型的神经网络?
A.有几种类型的神经网络,每种都是为特定的任务和应用而设计的。一些常见类型的神经网络是人工神经网络(ANN)、卷积神经网络(CNN)和递归神经网络(RNN)。
Q2.神经网络中的三种学习类型是什么?
A.神经网络中的三种主要学习类型是监督学习、无监督学习和强化学习。
- 453 次浏览