数据网格架构



【分布式数据网格】如何超越单片数据湖迁移到分布式数据网格
许多企业正在投资他们的下一代数据湖,希望大规模普及数据以提供业务洞察力并最终做出自动化的智能决策。 基于数据湖架构的数据平台具有常见的故障模式,导致无法实现大规模的承诺。 为了解决这些故障模式,我们需要从湖的集中式范式或其前身数据仓库转变。 我们需要转向借鉴现代分布式架构的范式:将域视为首要关注点,应用平台思维创建自助式数据基础设施,并将数据视为产品。
内容
- 当前企业数据平台架构
- 架构失效模式
- 集中式和单体式
- 耦合流水线分解
- 孤立和超专业的所有权
- 下一代企业数据平台架构
- 数据和分布式域驱动架构融合
- 面向领域的数据分解和所有权
- 面向源的领域数据
- 面向消费者和共享域数据
- 分布式管道作为域内部实现
- 数据和分布式域驱动架构融合
- 数据与产品思维的融合
- 领域数据作为产品
- 可发现的
- 可寻址
- 值得信赖和真实
- 自描述语义和句法
- 可互操作并受全球标准监管
- 受全球访问控制的保护和管理
- 领域数据跨职能团队
- 领域数据作为产品
- 数据与自助平台设计融合
- 向数据网格的范式转变
成为一个数据驱动的组织仍然是与我合作的许多公司的首要战略目标之一。我的客户很清楚获得智能授权的好处:基于数据和超个性化提供最佳客户体验;通过数据驱动的优化降低运营成本和时间;并通过趋势分析和商业智能赋予员工超能力。他们一直在大力投资构建数据和智能平台等推动因素。尽管在构建此类支持平台方面付出了越来越多的努力和投资,但组织发现结果中等。
我同意组织在转型为数据驱动方面面临着多方面的复杂性;从数十年的遗留系统迁移,遗留文化对依赖数据的抵制,以及不断竞争的业务优先事项。然而,我想与您分享的是支撑许多数据平台计划失败的架构观点。我展示了我们如何将过去十年在构建分布式架构方面的知识应用到数据领域;我将介绍一种新的企业数据架构,我称之为数据网格。
在继续阅读之前,我的要求是暂时搁置当前传统数据平台架构范式所建立的深层假设和偏见;对超越单一和集中式数据湖向有意分布式数据网格架构的可能性持开放态度;拥抱数据永远存在、无处不在和分布式的现实。
当前企业数据平台架构
它是集中的、单一的、与领域无关的,也就是数据湖。
几乎每个与我合作的客户都在计划或构建他们的第三代数据和智能平台,同时承认过去几代人的失败:
- 第一代:专有的企业数据仓库和商业智能平台;具有高价格标签的解决方案给公司留下了同样大量的技术债务;数以千计的无法维护的 ETL 作业、表格和报告中的技术债务,只有一小部分专业人士才能理解,从而导致对业务的积极影响未被充分实现。
- 第二代:以数据湖为银弹的大数据生态系统;由超专业数据工程师组成的中央团队运营的复杂大数据生态系统和长期运行的批处理作业创造了数据湖怪物,充其量只能进行研发分析;过度承诺和实现不足。
- 第三代和当前的数据平台或多或少与上一代相似,具有现代化的转变:(a) 使用 Kappa 等架构实现实时数据可用性的流式传输,(b) 统一批处理和流式处理以进行数据转换使用 Apache Beam 等框架,以及 (c) 完全采用基于云的存储托管服务、数据管道执行引擎和机器学习平台。很明显,第三代数据平台正在解决前几代的一些差距,例如实时数据分析,以及降低管理大数据基础设施的成本。然而,它受到许多导致前几代人失败的潜在特征的影响。
架构失效模式
为了解开所有代数据平台所具有的潜在限制,让我们来看看它们的架构和特性。在这篇文章中,我以 Spotify、SoundCloud、Apple iTunes 等互联网媒体流业务领域为例来阐明一些概念。
集中式和单体式
在 30,000 英尺处,数据平台架构如下图 1 所示;一个集中式架构,其目标是:
- 从企业的各个角落摄取数据,包括运行业务的运营和事务系统和域,或增强企业知识的外部数据提供者。例如,在流媒体业务中,数据平台负责摄取大量数据:“媒体播放器性能”、“用户如何与播放器互动”、“他们播放的歌曲”、“他们关注的艺术家”等作为企业已加入的“标签和艺术家”,与艺术家的“财务交易”以及外部市场研究数据,例如“客户人口统计”信息。
- 清理、丰富源数据并将其转换为可满足不同消费者需求的可信赖数据。在我们的示例中,其中一种转换将用户交互的点击流转换为富含用户详细信息的有意义的会话。这试图将用户的旅程和行为重建为聚合视图。
- 将数据集提供给具有不同需求的各种消费者。这包括从分析消费到探索数据以寻找洞察力、基于机器学习的决策制定,再到总结业务绩效的商业智能报告。在我们的媒体流示例中,该平台可以通过 Kafka 等分布式日志接口提供有关全球媒体播放器的近乎实时的错误和质量信息,或者提供正在播放的特定艺术家记录的静态聚合视图,以推动财务支付计算给艺术家和唱片公司。
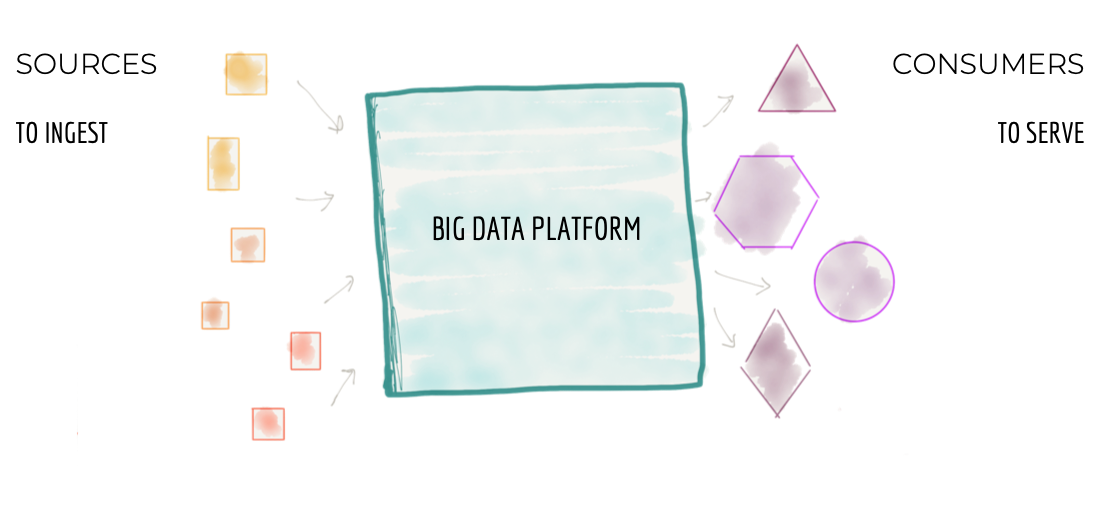
Figure 1: The 30,000 ft view of the monolithic data platform
单一数据平台托管和拥有逻辑上属于不同域的数据是一个公认的约定,例如 “播放事件”、“销售 KPI”、“艺术家”、“专辑”、“唱片公司”、“音频”、“播客”、“音乐事件”等; 来自大量不同领域的数据。
虽然在过去十年中,我们已经成功地将领域驱动设计和有界上下文应用到我们的操作系统中,但我们在很大程度上忽略了数据平台中的领域概念。 我们已经从面向领域的数据所有权转变为集中的与领域无关的数据所有权。 我们以创建其中最大的单体——大数据平台而自豪。
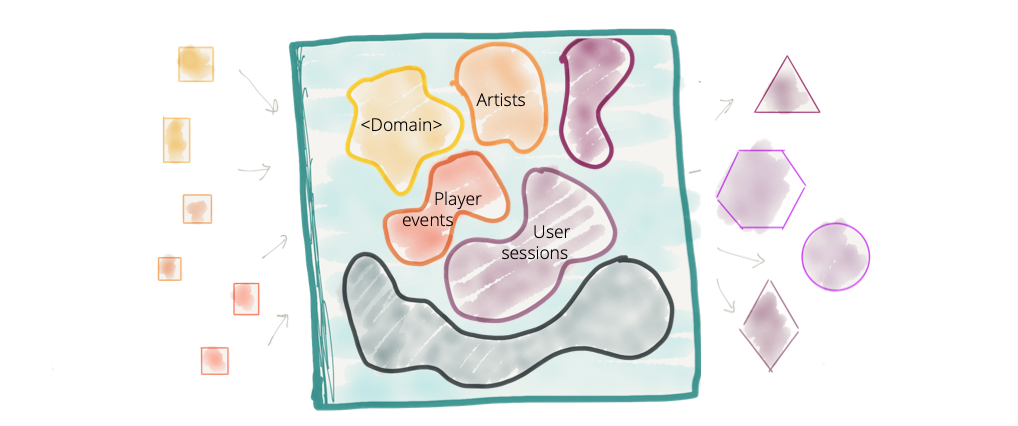
Figure 2: Centralized data platform with no clear data domain boundaries and ownership of domain oriented data
虽然这种集中式模型适用于具有更简单领域和较少不同消费案例的组织,但不适用于具有丰富领域、大量来源和多样化消费者集的企业。
中心化数据平台的架构和组织结构有两个压力点,往往导致其失败:
- 无处不在的数据和源扩散:随着越来越多的数据变得无处不在,在一个平台的控制下在一个地方消费和协调它的能力正在减弱。想象一下,仅在“客户信息”领域,就有越来越多的资源在组织边界内外提供有关现有和潜在客户的信息。我们需要在一个地方摄取和存储数据以从不同来源获取价值的假设将限制我们对数据源激增做出响应的能力。我认识到数据科学家和分析师等数据用户需要以低开销处理各种数据集,并且需要将操作系统数据使用与用于分析目的的数据分开。但我认为现有的集中式解决方案对于拥有丰富领域和不断增加新资源的大型企业来说并不是最佳答案。
- 组织的创新议程和消费者激增:组织对快速实验的需求引入了大量使用平台数据的用例。这意味着对数据进行越来越多的转换——聚合、预测和切片,可以满足创新的测试和学习周期。满足数据消费者需求的较长响应时间在历史上一直是组织摩擦的一个点,并且在现代数据平台架构中仍然如此。
- 虽然我现在还不想透露我的解决方案,但我需要澄清一下,我并不是在提倡分散的、孤立的、面向领域的数据,这些数据通常隐藏在操作系统的内部。难以发现、理解和消费的孤立领域数据。我并不是在提倡多个分散的数据仓库,这些数据仓库是多年积累的技术债务的结果。这是行业领导者表达的担忧。但我认为,对这些意外的无法访问数据孤岛的反应不是创建一个集中的数据平台,并拥有一个拥有和管理来自所有域的数据的集中团队。正如我们在上面学习和展示的那样,它在组织上没有规模。
耦合流水线分解
传统数据平台架构的第二种失效模式与我们如何分解架构有关。在 10,000 英尺处放大集中式数据平台,我们发现围绕摄取、清理、聚合、服务等机械功能的架构分解。组织中的架构师和技术领导者分解架构以响应平台的增长。如上一节所述,加入新资源或响应新消费者的需求需要平台发展。架构师需要找到一种方法,通过将系统分解为其架构量来扩展系统。如构建进化架构中所述,架构量子是具有高功能凝聚力的独立可部署组件,其中包括系统正常运行所需的所有结构元素。将系统分解为其架构量子背后的动机是创建独立的团队,每个团队都可以构建和操作架构量子。跨这些团队并行工作,以实现更高的运营可扩展性和速度。
鉴于前几代数据平台架构的影响,架构师将数据平台分解为数据处理阶段的管道。一个在非常高的水平上围绕处理数据的技术实现实现功能凝聚的管道;即摄取、准备、聚合、服务等的能力。
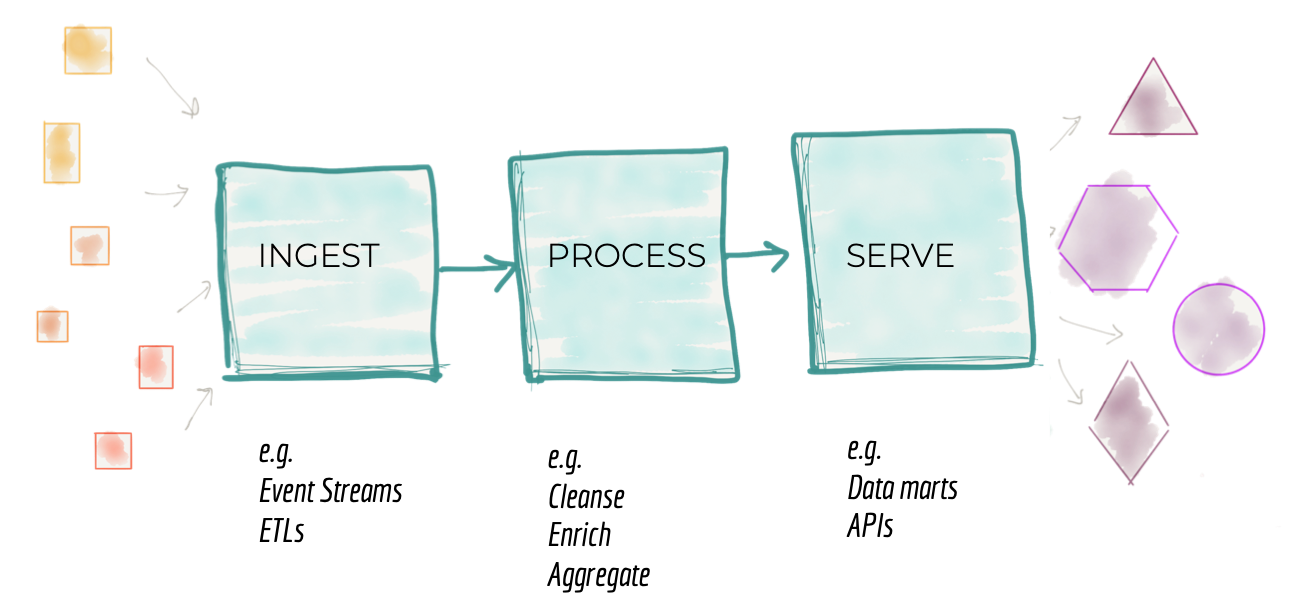
Figure 3: Architectural decomposition of data platform
尽管此模型提供了一定程度的规模,但通过将团队分配到管道的不同阶段,它有一个固有的限制,会减慢功能的交付。它在管道的各个阶段之间具有高度耦合,以提供独立的功能或价值。它与变化轴正交分解。
让我们看看我们的媒体流示例。互联网媒体流媒体平台围绕其提供的媒体类型具有强大的域结构。他们通常以“歌曲”和“专辑”开始他们的服务,然后扩展到“音乐活动”、“播客”、“广播节目”、“电影”等。播客播放率”,需要更改管道的所有组件。团队必须引入新的摄取服务、新的清理和准备以及用于查看播客播放率的聚合。这需要跨团队实现不同组件的同步和发布管理。许多数据平台提供通用和基于配置的摄取服务,可以应对扩展,例如轻松添加新源或修改现有源以最小化引入新源的开销。然而,这并没有消除从消费者的角度引入新数据集的端到端依赖管理。尽管在纸面上,管道架构看起来好像我们已经实现了管道阶段的架构量子,但实际上整个管道(即整体平台)是必须更改以适应新功能的最小单元:解锁新数据集并使其可用于新的或现有的消费。这限制了我们在响应新的消费者或数据源时实现更高速度和规模的能力。
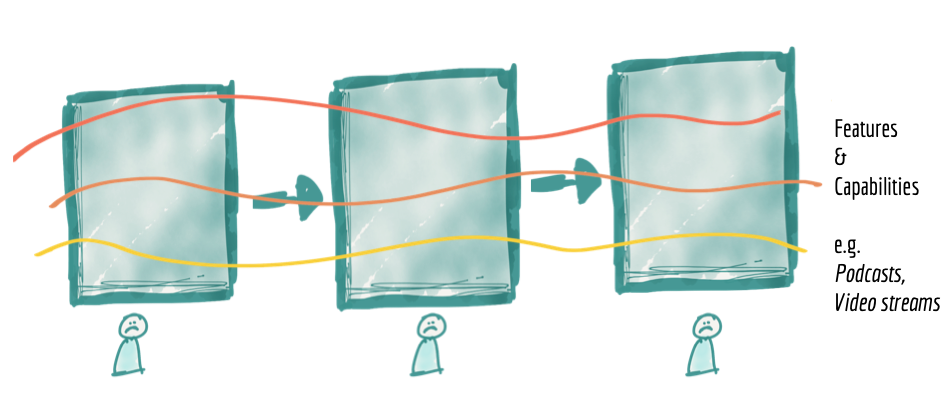
Figure 4: Architecture decomposition is orthogonal to the axis of change when introducing or enhancing features, leading to coupling and slower delivery
孤立和超专业的所有权
当今数据平台的第三种失效模式与我们如何构建构建和拥有平台的团队有关。 当我们放大到足够近来观察构建和运营数据平台的人们的生活时,我们会发现一群超专业的数据工程师与组织的运营部门隔离开来; 数据的来源或使用地点以及用于行动和决策的地点。 数据平台工程师不仅在组织上是孤立的,而且根据他们在大数据工具方面的技术专长,往往缺乏业务和领域知识。
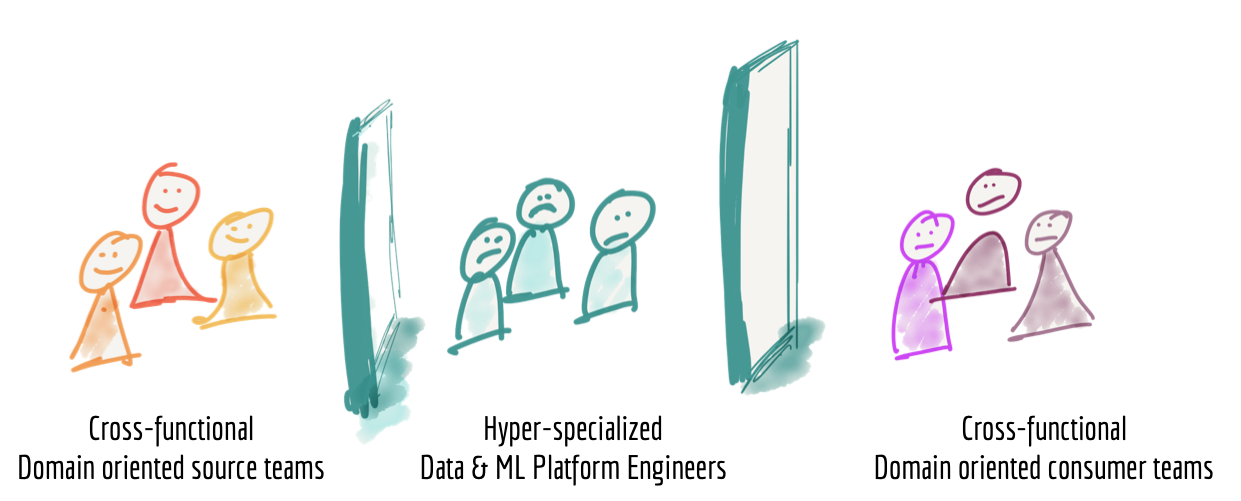
Figure 5: Siloed hyper-specialized data platform team
我个人并不羡慕数据平台工程师的生活。他们需要使用来自没有动力提供有意义、真实和正确数据的团队的数据。他们对生成数据的源领域知之甚少,并且缺乏团队中的领域专业知识。他们需要为各种需求(操作或分析)提供数据,而无需清楚地了解数据的应用和访问消费领域的专家。
例如,在媒体流领域,在源端,我们有跨职能的“媒体播放器”团队,它们提供有关用户如何与他们提供的特定功能交互的信号,例如。 “播放歌曲事件”、“购买事件”、“播放音频质量”等;而另一端则是消费者跨职能团队,例如“歌曲推荐”团队、“销售团队”报告销售 KPI、“艺术家支付团队”,他们根据播放事件计算和支付艺术家费用,等等。可悲的是,中间是数据平台团队,他们通过努力为所有来源和消费提供合适的数据。
实际上,我们发现源团队脱节、沮丧的消费者在数据平台团队积压工作中争夺一席之地,以及数据平台团队过度紧张。
我们创建的架构和组织结构无法扩展,也无法实现创建数据驱动组织的承诺价值。
下一代企业数据平台架构
它通过分布式数据网格包含无处不在的数据。
那么我们上面讨论的故障模式和特征的答案是什么?在我看来,范式转变是必要的。有助于大规模构建现代分布式架构的技术交汇处的范式转变;整个科技行业已加速采用并创造了成功成果的技术。
我建议下一个企业数据平台架构是分布式域驱动架构、自助服务平台设计和数据产品思维的融合。

Figure 6: Convergence: the paradigm shift for building the next data platforms
尽管这听起来像是一句话中的很多流行语,但这些技术中的每一种都对操作系统技术基础的现代化产生了特定且令人难以置信的积极影响。让我们深入探讨如何将这些学科中的每一个应用于数据世界,以摆脱从多年遗留数据仓库架构中继承下来的当前范式。
数据和分布式域驱动架构融合
面向领域的数据分解和所有权
Eric Evans 的《领域驱动设计》一书深刻影响了现代建筑思维,进而影响了组织建模。它通过将系统分解为围绕业务领域功能构建的分布式服务来影响微服务架构。它从根本上改变了团队的形成方式,使团队可以独立自主地拥有领域能力。
尽管我们在实现运营能力时采用了面向领域的分解和所有权,但奇怪的是,我们在数据方面忽略了业务领域的概念。 DDD 在数据平台架构中最接近的应用是让源操作系统发出其业务领域事件,并让单体数据平台摄取它们。然而,在摄取点之外,域的概念和不同团队对域数据的所有权丢失了。
Domain Bounded Context 是一个非常强大的工具来设计数据集的所有权。 Ben Stopford 的 Data Dichotomy 文章揭示了通过流共享域数据集的概念。
为了分散单体数据平台,我们需要扭转我们对数据的看法,即数据的位置和所有权。域需要以易于使用的方式托管和服务其域数据集,而不是将域中的数据流入中央拥有的数据湖或平台。
在我们的示例中,与其想象数据从媒体播放器流入某种集中的地方以供中央团队接收,不如想象一个播放器域拥有并提供其数据集以供任何团队出于任何下游目的访问。数据集实际驻留的物理位置以及它们的流动方式是“玩家域”的技术实现。物理存储当然可以是集中式基础设施,例如 Amazon S3 存储桶,但播放器数据集的内容和所有权仍然属于生成它们的域。同样在我们的示例中,“推荐”域以适合其应用程序的格式创建数据集,例如图形数据库,同时使用玩家数据集。如果有其他领域(例如“新艺术家发现领域”)发现“推荐领域”图形数据集有用,他们可以选择提取并访问该数据集。
这意味着我们可能会在不同域中复制数据,因为我们将它们转换为适合该特定域的形状,例如相关艺术家图表的时间序列播放事件。
这需要将我们的思维从传统上通过 ETL 以及最近通过事件流的推送和摄取转变为跨所有领域的服务和拉取模型。
面向领域的数据平台中的架构量子是一个领域,而不是管道阶段。
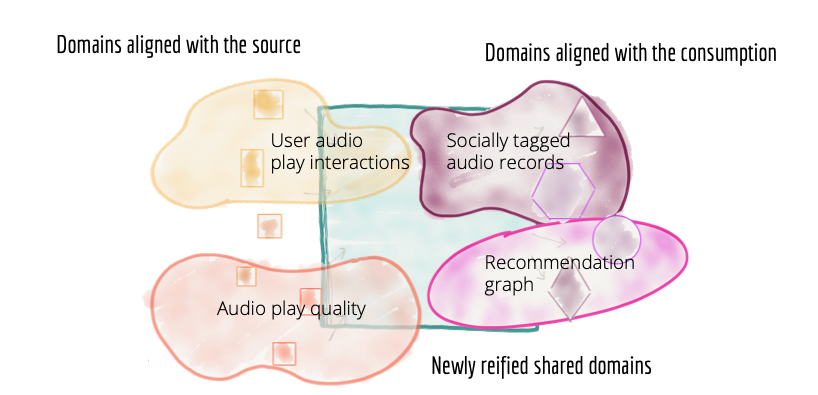
Figure 7: Decomposing the architecture and teams owning the data based on domains - source, consumer, and newly created shared domains
面向源的领域数据
一些域自然地与数据来源一致。源域数据集代表业务的事实和现实。源域数据集捕获的数据与其起源的操作系统、现实系统生成的内容非常接近。在我们的示例中,诸如“用户如何与服务交互”或“入职标签的过程”等业务事实导致创建域数据集,例如“用户点击流”、“音频播放质量流”和“板载标签”。这些事实最为人所知,并由位于起源点的操作系统生成。例如,媒体播放器系统最了解“用户点击流”。
在成熟和理想的情况下,一个操作系统及其团队或组织单元不仅负责提供业务能力,还负责提供其业务领域的真相作为源域数据集。在企业规模上,域概念和源系统之间从来没有一对一的映射。通常有许多系统可以为属于某个域的部分数据提供服务,有些是遗留的,有些是易于更改的。因此,可能有许多源对齐数据集,即现实数据集,最终需要聚合到一个有凝聚力的域对齐数据集。
业务事实最好以业务领域事件的形式呈现,可以存储并作为时间戳事件的分布式日志提供给任何授权消费者访问。
除了定时事件,源数据域还应该提供源域数据集的易于使用的历史快照,这些快照在一个时间间隔内聚合,密切反映其域的变化间隔。例如,在“加入标签”源域中,它显示为流媒体业务提供音乐的艺术家的标签,除了通过流程生成的事件之外,每月汇总加入标签是一个合理的视图。入职标签。
请注意,源对齐的域数据集必须与内部源系统的数据集分开。域数据集的性质与操作系统用于完成其工作的内部数据非常不同。它们的体积要大得多,代表不可变的定时事实,并且比它们的系统更改的频率低。出于这个原因,实际的底层存储必须适合大数据,并与现有的操作数据库分开。数据和自助平台设计融合部分描述了如何创建大数据存储和服务基础设施。
源域数据集是最基本的数据集,并且变化较少,因为业务事实不会经常变化。这些域数据集预计将被永久捕获并提供,以便随着组织发展其数据驱动和智能服务,它们始终可以回到业务事实,并创建新的聚合或预测。
请注意,源域数据集非常接近创建时的原始数据,并且没有为特定消费者拟合或建模。
面向消费者和共享域数据
一些领域与消费密切相关。消费者领域数据集和拥有它们的团队旨在满足一组密切相关的用例。例如,专注于根据用户彼此的社交联系提供推荐的“社交推荐域”,创建适合此特定需求的域数据集;也许通过“用户社交网络的图形表示”。虽然此图形数据集对推荐用例很有用,但它也可能对“听众通知”域有用,该域提供有关发送给听众的不同类型通知的数据,包括他们社交网络中的人正在收听的内容。因此,“用户社交网络”有可能成为一个共享且新近具体化的域数据集,供多个消费者使用。 “用户社交网络”域团队专注于提供“用户社交网络”的始终精选和最新视图。
与源域数据集相比,消费者对齐的域数据集具有不同的性质。它们在结构上经历了更多的变化,它们将源域事件转换为适合特定访问模型的聚合视图和结构,例如我们上面看到的图形示例。面向领域的数据平台应该能够轻松地从源头重新生成这些消费者数据集。
分布式管道作为域内部实现
虽然数据集所有权从中央平台委托给域,但仍然需要清理、准备、聚合和提供数据,数据管道的使用也是如此。在此架构中,数据管道只是数据域的内部复杂性和实现,并在域内部进行处理。结果,我们将看到数据管道阶段在每个域中的分布。
例如,源域需要包括对其域事件的清理、去重、丰富,以便它们可以被其他域使用,而无需复制清理。每个域数据集必须为其提供的数据质量建立一个服务级别目标:及时性、错误率等。例如,我们提供音频“播放点击流”的媒体播放器域可以包括在其域中清理和标准化数据管道,提供符合组织编码事件标准的近乎实时的“播放音频点击事件”的重复数据流。
同样,我们将看到集中式管道的聚合阶段进入消费域的实现细节。
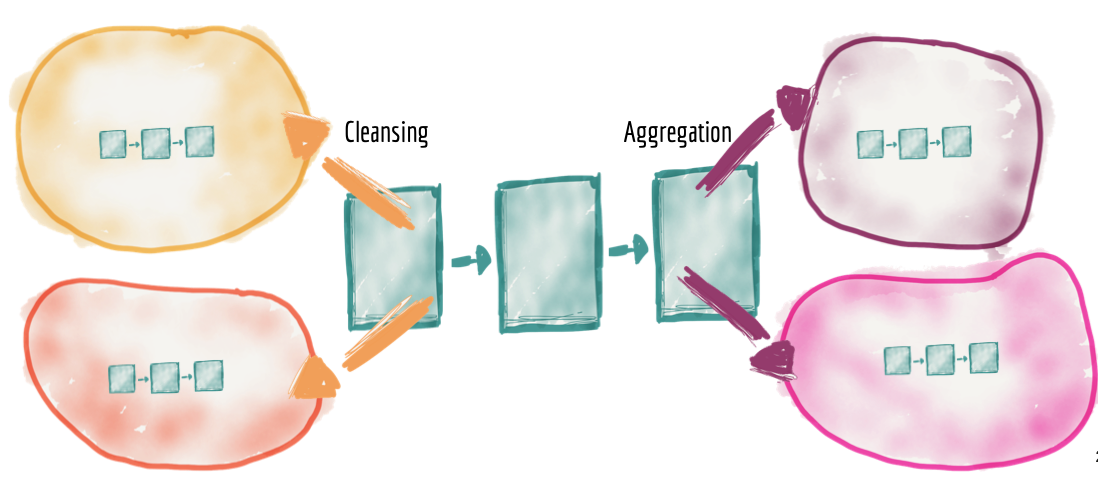
Figure 8: Distribute the pipelines into the domains as a second class concern and the domain's internal implementation detail
有人可能会争辩说,这种模型可能会导致每个领域重复努力来创建自己的数据处理管道实现、技术堆栈和工具。当我们讨论数据和平台思维与自助共享数据基础设施作为平台的融合时,我将很快解决这个问题。
数据与产品思维的融合
将数据所有权和数据管道实施分配到业务领域的手中引起了对分布式数据集的可访问性、可用性和协调性的重要关注。这就是应用产品思维和数据资产所有权的学习派上用场的地方。
领域数据作为产品
在过去的十年中,运营领域已经将产品思维构建到了它们提供给组织其他部分的能力中。领域团队将这些功能作为 API 提供给组织中的其他开发人员,作为创建更高阶价值和功能的构建块。团队努力为他们的领域 API 创造最佳的开发者体验;包括可发现和可理解的 API 文档、API 测试沙箱以及密切跟踪的质量和采用 KPI。
要使分布式数据平台取得成功,领域数据团队必须以类似严谨的方式将产品思维应用于他们提供的数据集;将他们的数据资产视为他们的产品,将组织的其他数据科学家、ML 和数据工程师视为他们的客户。
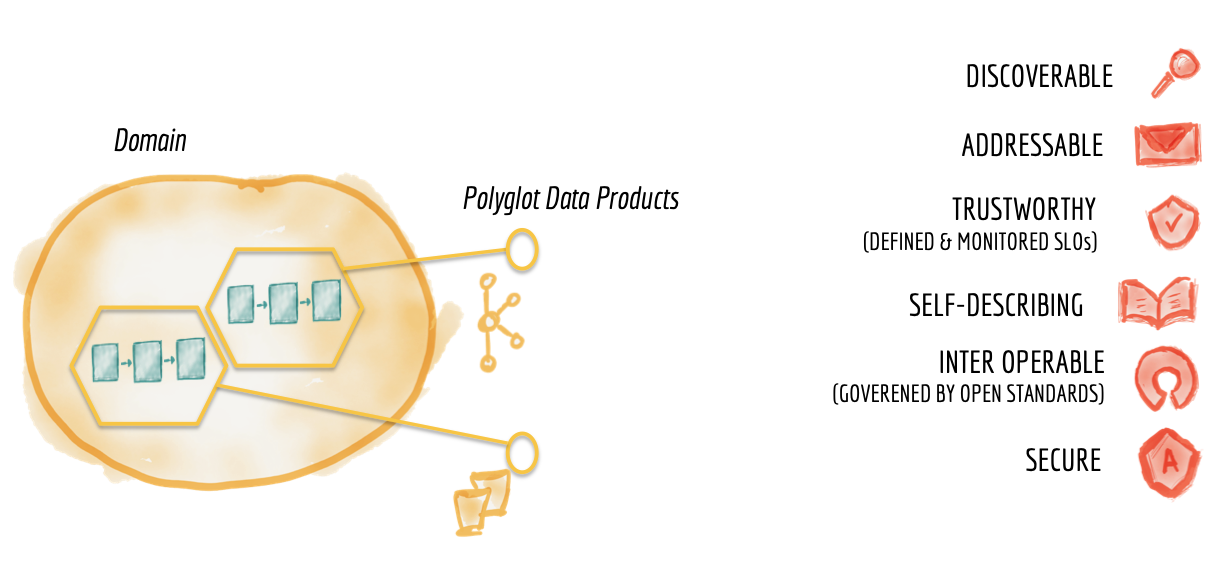
Figure 9: Characteristics of domain datasets as product
考虑我们的示例,互联网媒体流业务。它的关键领域之一是“播放事件”,即谁在何时何地播放了哪些歌曲。这个关键域在组织中有不同的消费者;例如,对用户体验和可能的错误感兴趣的近实时消费者,以便在客户体验下降或客户支持呼叫的情况下可以快速响应以恢复错误。还有一些消费者更喜欢每日或每月歌曲播放事件汇总的历史快照。
在这种情况下,我们的“播放歌曲”域向组织的其他部分提供了两个不同的数据集作为其产品;在事件流上公开的实时播放事件,以及在对象存储上作为序列化文件公开的聚合播放事件。
任何技术产品(在这种情况下为领域数据产品)的一个重要品质是取悦消费者;在这种情况下,数据工程师、机器学习工程师或数据科学家。为消费者提供最佳的用户体验,领域数据产品需要具备以下基本素质:
可发现的
数据产品必须易于发现。一个常见的实现是为所有可用的数据产品建立一个注册表、一个数据目录,以及它们的元信息,例如它们的所有者、来源、血统、样本数据集等。这种集中的可发现性服务允许数据消费者、工程师和科学家在一个组织,轻松找到他们感兴趣的数据集。每个域数据产品都必须在这个集中的数据目录中注册,以便于发现。
请注意,这里的观点转变是从提取和拥有数据以供其使用的单个平台,到每个域以可发现的方式将其数据作为产品提供。
可寻址
数据产品一旦被发现,应该有一个遵循全球约定的唯一地址,以帮助其用户以编程方式访问它。组织可能对其数据采用不同的命名约定,具体取决于数据的底层存储和格式。考虑到易用性作为目标,在去中心化架构中,有必要制定通用约定。不同的域可能以不同的格式存储和提供其数据集,事件可能通过流(例如 Kafka 主题)存储和访问,柱状数据集可能使用 CSV 文件或序列化 Parquet 文件的 AWS S3 存储桶。多语言环境中数据集可寻址性的标准消除了查找和访问信息时的摩擦。
值得信赖和真实
没有人会使用他们无法信任的产品。在传统的数据平台中,提取和载入有错误、不能反映业务真实性且根本不可信的数据是可以接受的。这是集中数据管道的大部分工作集中的地方,在摄取后清理数据。
根本性转变要求数据产品的所有者围绕数据的真实性提供可接受的服务水平目标,以及它在多大程度上反映了已发生事件的真实性或已获得洞察力的真实性的高概率。生成。在创建数据产品时应用数据清理和自动化数据完整性测试是用于提供可接受的质量水平的一些技术。提供数据出处和数据沿袭作为与每个数据产品相关的元数据有助于消费者对数据产品及其对他们特定需求的适用性获得进一步的信心。
数据完整性(质量)指标的目标值或范围因域数据产品而异。例如,“播放事件”域可以提供两种不同的数据产品,一种是具有较低准确度级别的近实时数据产品,包括丢失或重复的事件,另一种具有较长延迟和较高级别的事件准确度。每个数据产品定义并确保其作为一组 SLO 的完整性和真实性的目标水平。
自描述语义和句法
优质产品无需消费者手持:它们可以被独立发现、理解和消费。将数据集构建为数据工程师和数据科学家使用的摩擦最小的产品,需要对数据的语义和语法进行良好描述,最好以样本数据集作为示例。数据模式是提供自助数据资产的起点。
可互操作并受全球标准监管
分布式域数据架构的主要关注点之一是跨域关联数据并以奇妙、有见地的方式将它们拼接在一起的能力;加入、过滤、聚合等。跨域数据有效关联的关键是遵循某些标准和协调规则。这种标准化应该属于全球治理,以实现多语言域数据集之间的互操作性。这种标准化工作的共同关注点是字段类型格式化、跨不同领域识别多义词、数据集地址约定、通用元数据字段、事件格式(如 CloudEvents)等。
例如,在流媒体业务中,“艺术家”可能出现在不同的域中,并且在每个域中具有不同的属性和标识符。 'play eventstream' 域对艺术家的识别可能与处理发票和付款的'artists payment' 域不同。然而,为了能够跨不同领域数据产品关联关于艺术家的数据,我们需要就如何将艺术家识别为多义词达成一致。一种方法是考虑具有联合实体的“艺术家”和“艺术家”的唯一全局联合实体标识符,类似于如何管理联合身份。
全球管理的通信互操作性和标准化是构建分布式系统的基础支柱之一。
受全球访问控制的保护和管理
无论架构是否集中,都必须安全地访问产品数据集。在分散的面向领域的数据产品的世界中,访问控制以更精细的粒度应用于每个领域数据产品。与操作域类似,访问控制策略可以集中定义,但在访问每个单独的数据集产品时应用。使用企业身份管理系统 (SSO) 和基于角色的访问控制策略定义是实施产品数据集访问控制的便捷方式。
数据和自助服务平台设计融合部分描述了共享基础架构,该基础架构可以轻松自动地为每个数据产品启用上述功能。
领域数据跨职能团队
将数据作为产品提供的域;需要增加新的技能:(a) 数据产品所有者和 (b) 数据工程师。
数据产品所有者围绕数据产品的愿景和路线图做出决策,关注消费者的满意度,并不断衡量和改进其领域拥有和生产的数据的质量和丰富性。她负责域数据集的生命周期,何时更改、修订和停用数据和模式。她在域数据消费者的竞争需求之间取得了平衡。
数据产品所有者必须为其数据产品定义成功标准和与业务一致的关键绩效指标 (KPI)。例如,数据产品的消费者成功发现和使用数据产品的前置时间是可衡量的成功标准。
为了构建和操作域的内部数据管道,团队必须包括数据工程师。这种跨职能团队的一个奇妙的副作用是不同技能的异花授粉。我目前的行业观察是,一些数据工程师虽然擅长使用他们的行业工具,但在构建数据资产时缺乏软件工程标准实践,例如持续交付和自动化测试。同样,构建操作系统的软件工程师通常没有使用数据工程工具集的经验。消除技能集孤岛将导致创建组织可用的更大更深的数据工程技能集。我们已经观察到 DevOps 运动的交叉技能授粉,以及 SRE 等新型工程师的诞生。
数据必须被视为任何软件生态系统的基础部分,因此软件工程师和软件通才必须将数据产品开发的经验和知识添加到他们的工具带中。同样,基础架构工程师需要增加管理数据基础架构的知识和经验。组织必须提供从通才到数据工程师的职业发展途径。数据工程技能的缺乏导致形成集中式数据工程团队的本地优化,如孤立和超专业所有权部分所述。

Figure 10: Cross functional domain data teams with explicit data product ownership
数据与自助平台设计融合
将数据所有权分配给域的主要问题之一是在每个域中操作数据管道技术堆栈和基础设施所需的重复工作和技能。 幸运的是,将通用基础设施构建为平台是一个很好理解和解决的问题。 尽管不可否认,工具和技术在数据生态系统中并不成熟。
将与领域无关的基础设施功能收集并提取到数据基础设施平台中,解决了重复设置数据管道引擎、存储和流式基础设施的工作的需要。 数据基础架构团队可以拥有并提供域需要捕获、处理、存储和服务其数据产品的必要技术。
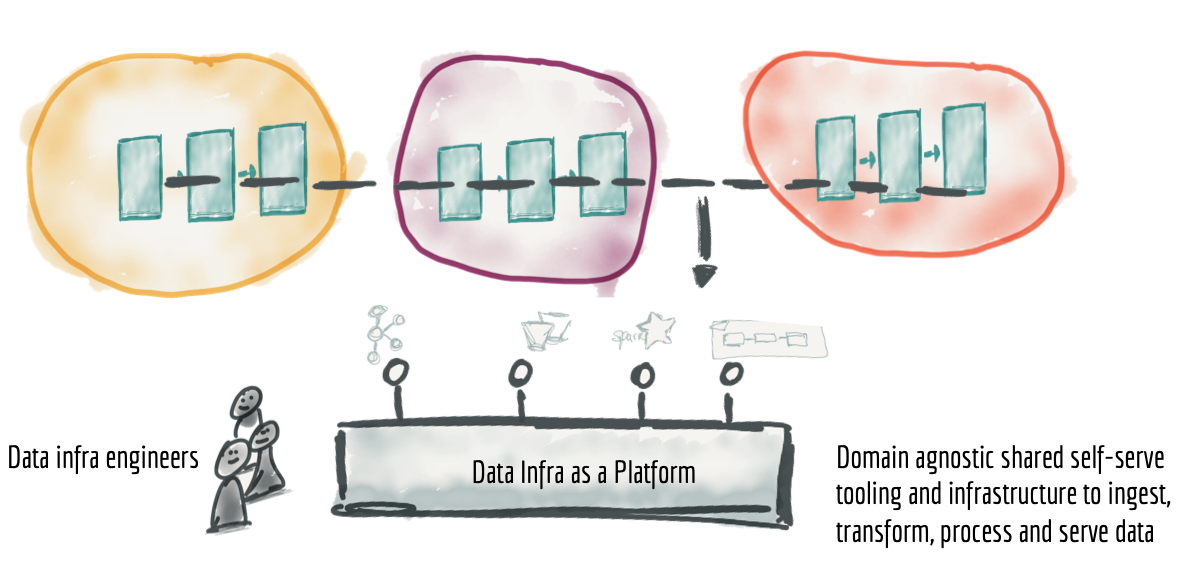
Figure 11: Extracting and harvesting domain agnostic data pipeline infrastructure and tooling into a separate data infrastructure as a platform
将数据基础架构构建为平台的关键是 (a) 不包含任何特定领域的概念或业务逻辑,使其与领域无关,以及 (b) 确保平台隐藏所有底层复杂性并提供数据基础架构组件一种自助方式。自助式数据基础设施作为平台提供给其用户(域的数据工程师)的功能有很长的列表。这里有几个:
- 可扩展的多语言大数据存储
- 静态和动态数据加密
- 数据产品版本控制
- 数据产品架构
- 数据产品去标识化
- 统一的数据访问控制和日志记录
- 数据管道实现和编排
- 数据产品发现、目录注册和发布
- 数据治理和标准化
- 数据产品谱系
- 数据产品监控/告警/日志
- 数据产品质量指标(收集和共享)
- 内存数据缓存
- 联合身份管理
- 计算和数据局部性
自助数据基础架构的成功标准是降低基础架构上的“创建新数据产品的准备时间”。这导致了自动化,这是实现“数据产品”功能所必需的,如“域数据作为产品”部分所述。例如,通过配置和脚本自动获取数据、创建数据产品脚本以放置脚手架、在目录中自动注册数据产品等。
使用云基础设施作为基础降低了提供对数据基础设施的按需访问所需的运营成本和工作量,但它并没有完全消除需要在业务环境中实施的更高抽象层。无论是哪家云提供商,数据基础设施团队都可以使用丰富且不断增长的数据基础设施服务。
向数据网格的范式转变
读了很久。让我们把它放在一起。我们研究了当前数据平台的一些基本特征:集中式、单体式、具有高度耦合的管道架构,由超专业数据工程师的孤岛操作。我们介绍了作为平台的无处不在的数据网格的构建块;面向领域的分布式数据产品,由独立的跨职能团队拥有,这些团队拥有嵌入式数据工程师和数据产品所有者,使用通用数据基础设施作为平台来托管、准备和服务他们的数据资产。
数据网格平台是一种有意设计的分布式数据架构,在集中治理和互操作性标准化下,由共享和协调的自助数据基础设施支持。我希望很清楚,它远离无法访问数据的碎片孤岛。
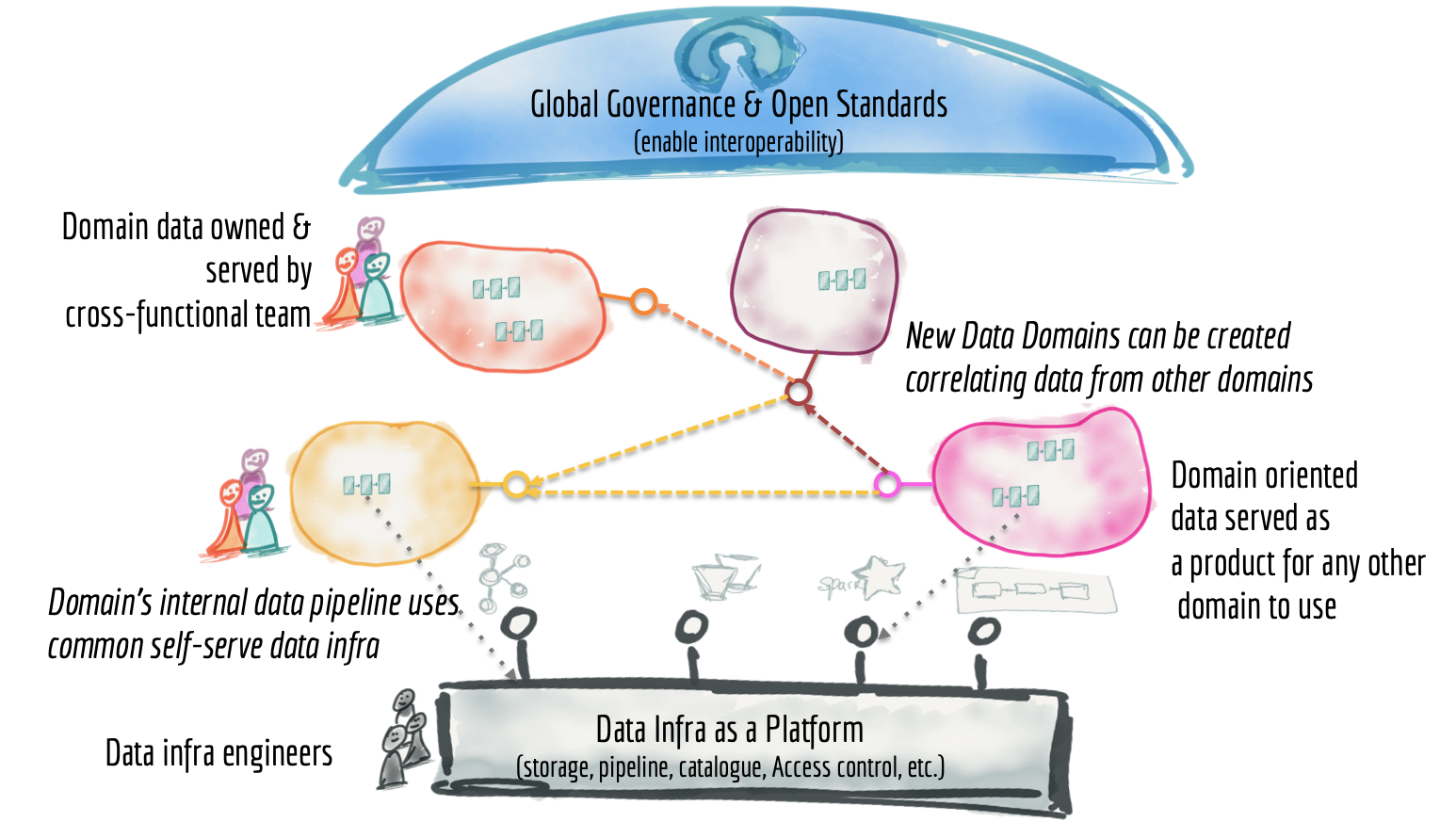
Figure 12: Data mesh architecture from 30,000 foot view
您可能会问,数据湖或数据仓库在这个架构中的位置是什么?它们只是网格上的节点。我们很可能不需要数据湖,因为保存原始数据的分布式日志和存储可用于从不同的可寻址不可变数据集作为产品进行探索。但是,如果我们确实需要对数据的原始格式进行更改以进行进一步探索,例如标记,具有这种需求的域可能会创建自己的湖或数据中心。
因此,数据湖不再是整个架构的核心。我们将继续将数据湖的一些原则应用到面向源的领域数据产品中,例如使不可变数据可用于探索和分析使用。我们将继续使用数据湖工具,但无论是用于数据产品的内部实施还是作为共享数据基础设施的一部分。
事实上,这让我们回到了一切开始的地方:James Dixon 在 2010 年打算将数据湖用于单个域,而多个数据域将形成一个“水上花园”。
主要的转变是将域数据产品视为第一类关注点,将数据湖工具和管道视为第二类关注点——实现细节。这将当前的心智模型从集中式数据湖转变为可以很好地协同工作的数据产品生态系统,即数据网格。
同样的原则也适用于用于业务报告和可视化的数据仓库。它只是网格上的一个节点,并且可能位于网格的面向消费者的边缘上。
我承认,尽管我看到数据网格实践被应用在我的客户的口袋里,但企业规模的采用仍有很长的路要走。我不认为技术是这里的限制,我们今天使用的所有工具都可以适应多个团队的分发和所有权。特别是向批处理和流的统一以及 Apache Beam 或 Google Cloud Dataflow 等工具的转变,可以轻松地处理可寻址的多语言数据集。
谷歌云数据目录等数据目录平台提供分布式域数据集的集中发现、访问控制和治理。多种云数据存储选项使域数据产品能够选择适合用途的多语言存储。
需求是真实的,工具已经准备好。组织中的工程师和领导者应该意识到,现有的大数据范式和一个真正的大数据平台或数据湖,只会重复过去的失败,只是使用新的基于云的工具。
这种范式转变需要一套新的管理原则和一种新的语言:
- 服务超过摄取
- 发现和使用过度提取和加载
- 通过集中式管道将事件发布为流过流动数据的流
- 中心化数据平台上的数据产品生态系统
让我们将大数据单体分解为一个协调、协作和分布式的数据网格生态系统。
原文:https://martinfowler.com/articles/data-monolith-to-mesh.html
- 135 次浏览
【数据架构】数据网格解释
“我想指出,所提供的链接都不是附属的,我从本文中提到的公司中没有任何收获。我做这一切是因为直到最近我才听说过数据网格,我很期待这次活动,并希望在此之前深入了解一下。我还认为这可能会让其他人感兴趣,并付出了额外的努力以清晰简洁的方式分享我的笔记。 ”
本文/报告的目的是根据 Zhamak Dehghani 在即将举行的 Datanova — 数据网格峰会之前关于 Martin Fowler 的前两篇文章,分享和解释我对数据网格的理解。许多句子直接取自扎马克的文章。
Dahghani 女士最近出版了一本关于该主题的书。我还没有读过它,但我毫不怀疑它会澄清这篇文章的一些内容。
作为图表的忠实粉丝,我尝试制作一些图表来解释一些概念。
在接下来的文章中,我首先简要介绍 Zhamak Dehghani。我继续解释什么是数据网格以及为什么它很重要。我简要总结一下它是如何工作的。最后,分享几个我自己的问题。
在本文末尾,您将找到数据网格技术术语表和本文使用的或您可能感兴趣的资源列表。
扎马克·德加尼是谁?

Zhamak Dehghani — source ThoughtWorks
Zhamak 拥有计算机科学专业的工程学士学位和信息技术管理硕士学位。她做了几年软件工程师。今天,她是 ThoughtWorks 的新兴技术总监,过去 10 年她一直在该公司工作。
“她在 2018 年创立了 Data Mesh 的概念,这是大数据管理向数据去中心化的范式转变,此后一直在向更广泛的行业宣传这一概念。
Zhamak 是 ThoughtWorks 技术顾问委员会的成员,并为创建 ThoughtWorks 技术雷达做出了贡献。她作为技术专家工作了 20 多年,并为分布式计算通信以及嵌入式设备技术方面的多项专利做出了贡献。” — 思想工场
什么是数据网格,为什么它很重要?
尽管我们仍然在通过科学方法发现或重新发现早已超越直觉的智慧,但在许多领域,人类已经对自己感兴趣的主题产生了透彻的理解:意识、生活、冲突、教与学等。 , 21 世纪的特点是两个尚未彻底分析的概念:敏捷方法和数据的力量。
数据和敏捷性可能早在我们开始创造特定术语来描述它们之前就已经存在,但只是“最近”,这要归功于我们新发现的计算能力,我们才真正了解它们的重要性。
数据网格是敏捷思维和对数据的透彻理解的结果。数据网格最简单的形式是处理数据的敏捷框架。
目前,数据湖是大型刚性结构。数据从这些刚性结构中提取、处理并作为一个单一的超级强大的数据平台提供服务。然而,数据湖存在一些“可扩展性”缺陷:
- 由于数据在一个地方全部处理,因此它们通常不利于轻松添加新的数据源,这在数据是黄金且高效处理是关键的世界中至关重要。
- 他们冒着负责摄取、处理或提供数据的专业团队之间沟通问题的风险。与中国耳语游戏类似,最终用户的需求很容易被那些摄取和处理数据的人误解。
- 它们不利于可互换的用例和实验。

(Simplified diagram of a data lake)
上图可能显示了添加新数据源将如何需要更新整个数据湖,这涉及各种流程和多个独立团队。每个新客户或新来源都意味着修改复杂性不断增加的结构。
刚性总比没有好,因此数据湖曾经是必要的。然而,敏捷总是比刚性好,数据网格是刚性数据湖的敏捷改进。
数据网格如何工作?
[ 重要的! ] 这可能只是我遇到的一个问题。我认为数据产品是核心功能基于数据的产品。
数据产品是“通过使用数据促进最终目标的产品”——DJ Patil,Data Jujitsu。
汽车不是数据产品,但 GPS 是。在线流媒体服务是一种数据产品,但视频商店不是。但是,对于 Zhamak Dehghani 来说,由于产品就是数据本身,因此术语数据产品用于将特定数据域定义为产品。重要的是要理解,在这种情况下,数据产品是一个有据可查、高质量的特定领域数据集,数据消费者(数据科学家、分析师等)可以通过 API 使用它。数据网格的目标是为公司的最终数据产品(它向消费者提供的产品)提供服务。我将通过将 Dehghani 女士的“数据产品”称为“领域数据产品”来尝试澄清这一点。
数据网格是一个框架。虽然只有某些技术可能允许其实施,但并不限于特定技术。因此,Zhamak Dehghani 仅提供原理和逻辑架构来解释如何实现它。
数据网格基于四个原则:
面向领域的去中心化数据所有权和架构
数据网格是特定领域数据产品的网络。它比数据湖具有更好的扩展性,因为新的数据源或新的数据消费者只意味着添加一个新的域(数据产品),而不是重新访问整个数据湖。
数据作为产品
每个域都像消费者一样为数据工程师服务,并具有以下属性。
- 可发现:所有可用数据域的注册表(或市场)。
- 可寻址:允许数据消费者以编程方式访问的唯一地址。
- 值得信赖:域“所有者”提供数据的质量保险以及数据出处和数据沿袭作为与域数据产品相关的元数据。
- 自我描述的语义和语法:域元数据应该足够清晰,任何人都可以自己开始使用数据。
- 可互操作并受全球标准监管:得益于全球质量和识别标准,数据可以跨域处理。
- 安全并受全球标准监管:使用企业身份管理系统 (SSO) 和基于角色的访问控制。
- 领域数据跨职能团队:领域特定的产品所有者和数据工程师,能够处理从源到数据消费者的整个领域数据。
作为平台的自助数据基础设施
每个域的数据集都需要可供任何希望使用它们的人使用。访问数据集的数据消费者需要通过上一个原理中的属性描述找到一个完善的数据产品。
联合计算治理
数据湖的优势在于,如果不遵循数据湖标准,则没有任何效果。因此,保证整个数据网格的功能至少与数据湖一样的唯一方法是实施全局治理。全局治理意味着两套标准:全球标准和领域特定标准。其中包括与数据产品属性相关的标准,例如数据质量、数据集之间的交叉引用、命名约定、元数据语法等。
数据网格可以很容易地与 Python 进行比较。 Python 的强大之处不仅在于它是一种简单的编码语言,还在于任何遵循全球库标准的开发人员都可以构建一个新的 Python 库(一种代码产品)并使其在官方 Python 库的全球市场上可用。 每个开发人员还可以自由设置自己的附加库标准。
在她的文章中,Zhamak 将数据产品显示为属于域,但没有没有数据产品的域,所以在我的情况下,它们是相同的。
单个数据域(数据产品)可以表示如下:
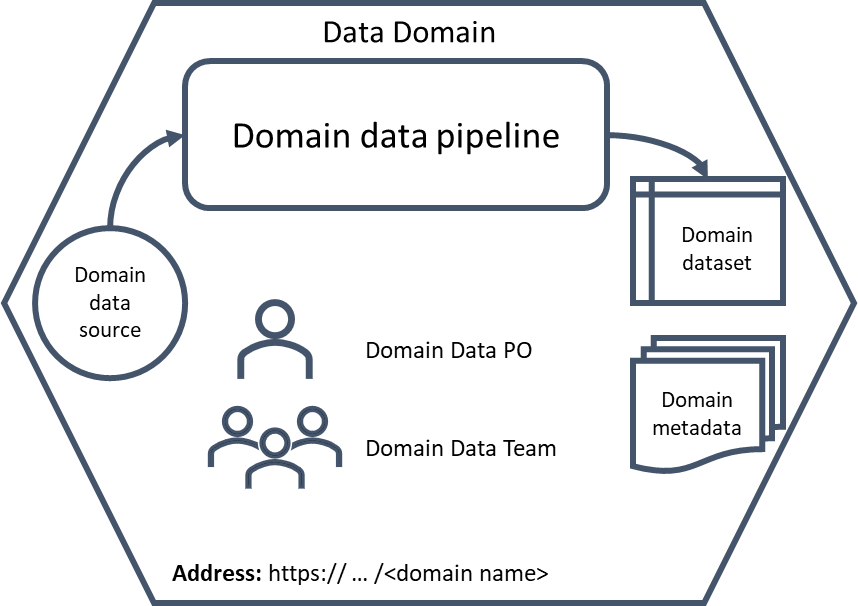
(A single data domain and its components)
使用六边形表示单个数据域,我们可以像这样表示数据网格:

(A simple data mesh diagram with five data domains)
域 4 和域 5 使用来自其他域的数据,但它们也可能从自己的来源获取自己的数据。
Zhamak 还谈到了多平面数据平台。 (请参阅数据网格原理和逻辑架构)老实说,虽然她将平面定义为“代表一个存在层次——既集成又分离”,但我不确定平面是什么意思。 😅
我的理解是,数据网格需要多个接口,以便使用它的任何人都可以轻松访问其不同的组件。 例如,数据消费者需要访问数据产品(数据集和相关元数据)的完整注册表。 其他用户可能需要访问治理标准,并且能够轻松了解它们是全局的还是特定于某些域的。 其他用户可能需要访问数据网格本身的可视化表示、访问其基础架构等。
下图试图在单个图像中解释数据网格:
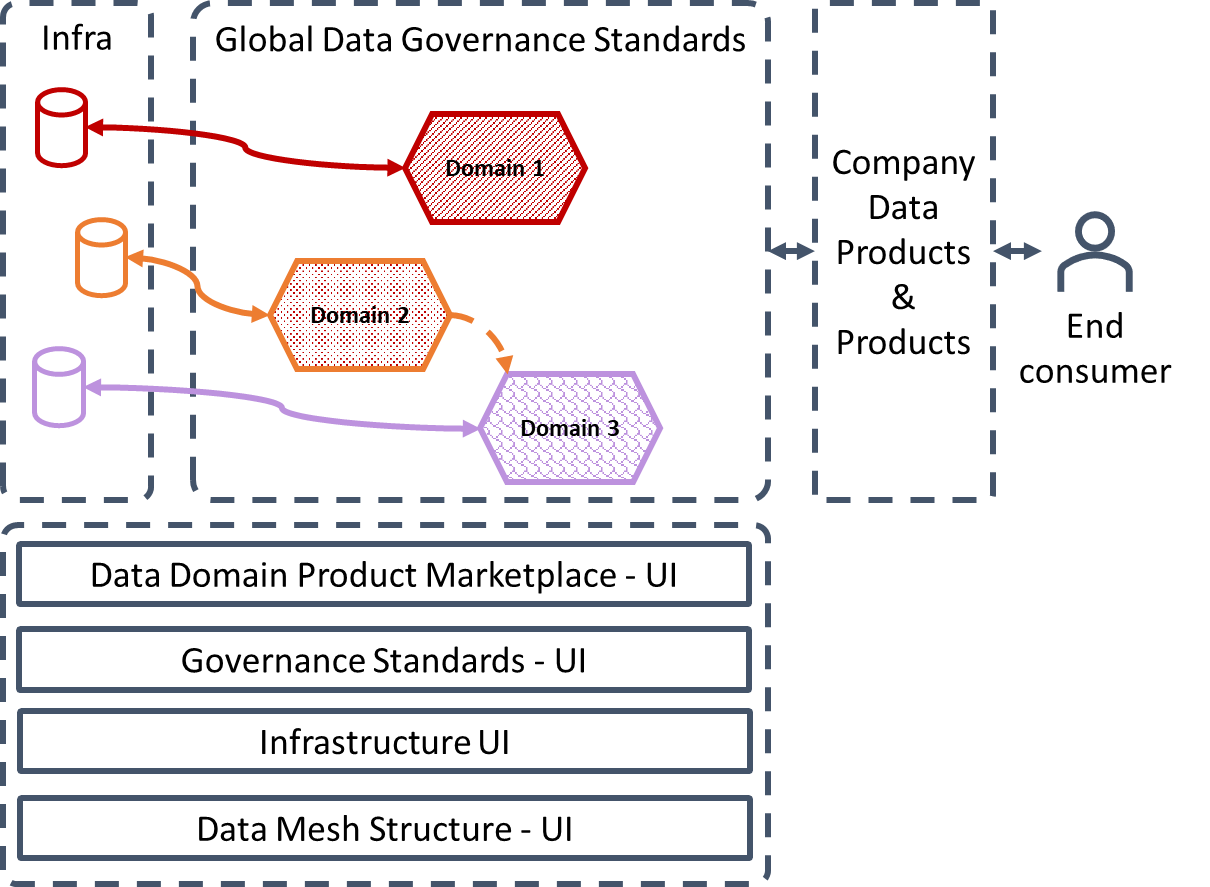
(The full data mesh as I understand it)
作为去中心化领域特定数据产品的网络,对于需要管理许多数据源和数据消费者的企业而言,数据网格有可能成为一个非常强大的解决方案,但对于数据网格的构建和工作方式没有清晰的界面在公司内部,扩展和维护结果可能比数据湖更加混乱和耗时。
结论和问题
我很高兴发现了数据网格,并期待了解更多信息并澄清一些混乱的元素。我期待着这次会议,阅读这本书,如果可能的话,我会更新这篇文章或写另一篇文章。
每个数据域都应该由一个独立的团队管理。这是否意味着公司需要为每个新领域雇佣一个全新的团队?这不违背域的可扩展性吗?
每个数据域的管道都必须遵循全局数据治理规则,那么治理规则的变化不会导致每个管道的变化吗?
除了上一个问题,每个域的域数据管道是否应该在一个公共基础设施中注册并独立地为每个域提供服务,类似于开源 Python 库?下图可以阐明我的意思:
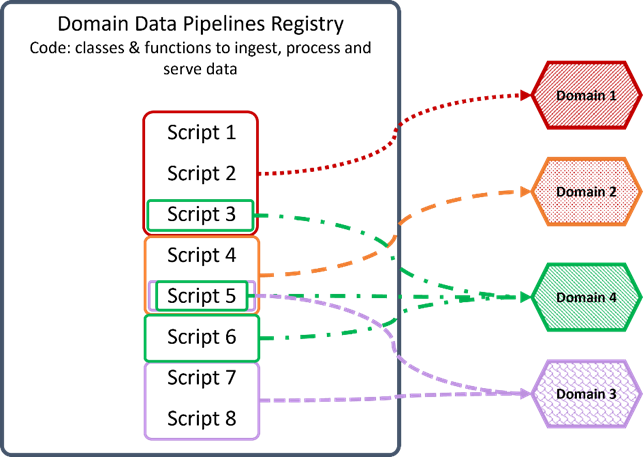
(Data mesh code Registry concept)
这引发了其他问题,例如数据团队之间的脚本所有权。此外,如果修改脚本 5 以适应仅适用于域 2 的修改而不是新脚本,则需要为域 3 和 4 创建旧脚本 5 的副本。(域拥有自己的域似乎更简单代码,也许我正在将这种敏捷性推到很远。😆)
今天可能没有任何现有的特定数据网格技术,但在我看来,作为域管道功能、域数据集和访问全球治理标准的注册表的单一平台将是这样一项技术。现有的任何其他东西都可以作为更完整解决方案的 MVP 方法。
数据网格词汇表
- 数据网格:专注于去中心化数据管理的数据框架。
- 数据产品:将数据用作其核心功能的一部分的产品。
- 数据即产品:当数据是最终产品时。消费者是数据消费者:业务分析师、数据科学家、数据分析师、数据工程师等等。他们将“购买”数据并在自己的数据产品中使用。
- 领域:计算机程序的目标主题领域。在这种情况下,数据的目标主体。如果数据用于分析“用户配置文件”,则域为“用户配置文件”,如果用于分析“歌曲”,则域为“歌曲”。
- 域数据产品:特定于数据网格中唯一域的数据产品。
- 源域数据集:一个数据集,它紧密地代表创建时的原始数据,并且没有为特定消费者拟合或建模。
- 消费者对齐的域数据集:经过面向消费者的转换的源域数据集。
- 域数据团队:负责专门管理数据网格内的数据域的数据团队。
- 领域数据产品所有者:A P.O.负责将数据作为产品交付。
- 领域驱动设计:将系统分解为围绕业务领域能力构建的分布式服务。
- 架构量子:可以独立部署且具有高功能凝聚力的最小建筑单元,包括其功能所需的所有结构元素。
- 联合计算治理:由域数据产品所有者和数据平台产品所有者联合领导的决策模型,具有自治和域本地决策权,同时创建并遵守一组全局规则——规则适用于所有数据产品及其接口——以确保一个健康且可互操作的生态系统。
Ressources
Zhamak Deghani’s original articles on data mesh:
- https://martinfowler.com/articles/data-monolith-to-mesh.html
- https://martinfowler.com/articles/data-mesh-principles.html
原文:https://medium.com/@david.c.dupuis/data-mesh-explained-a95b6ae50878
- 98 次浏览
【数据网格】什么是数据网格——以及如何不将其网格化
视频号
微信公众号
知识星球
实施最新行业趋势的初学者指南:数据网格。
Image Courtesy of Ronan Furuta on Unsplash.
询问数据行业的任何人这些天最热门的是什么,“数据网格”很有可能会上升到列表的顶部。但是什么是数据网格,为什么要构建一个?求知者想知道。
在自助式商业智能时代,几乎每家公司都认为自己是一家数据优先的公司,但并不是每家公司都以应有的民主化和可扩展性水平来对待他们的数据架构。
例如,贵公司将数据视为创新的驱动力。你的老板是业内最早看到 Snowflake 和 Looker 潜力的人之一。或者,您的 CDO 带头开展了一项跨职能计划,对团队进行数据管理最佳实践教育,而您的 CTO 投资了一个数据工程团队。然而,最重要的是,您的整个数据团队希望有一种更简单的方法来管理组织不断增长的需求,从处理永无止境的临时查询流到通过中央 ETL 管道处理不同的数据源。
支持这种民主化和可扩展性的愿望是意识到您当前的数据架构(在许多情况下,孤立的数据仓库或具有一些有限实时流功能的数据湖)可能无法满足您的需求。
幸运的是,寻求新的数据租约的团队只需要查看数据网格,这是一种席卷整个行业的架构范式。
什么是数据网格?
就像软件工程团队从单体应用程序过渡到微服务架构一样,数据网格在很多方面都是微服务的数据平台版本。
正如 ThoughtWorks 顾问和该术语的原始架构师 Zhamak Dehghani 首次定义的那样,数据网格是一种数据平台架构,它通过利用面向领域的自助式设计来包含企业中无处不在的数据。借用 Eric Evans 的领域驱动设计理论,一种将代码的结构和语言与其相应的业务领域相匹配的范式,数据网格被广泛认为是数据的下一个重大架构转变。
与在一个中央数据湖中处理数据消耗、存储、转换和输出的传统单片数据基础设施不同,数据网格支持分布式、特定于领域的数据消费者,并将数据视为产品,每个领域处理自己的数据管道。连接这些域及其相关数据资产的组织是一个通用互操作性层,它应用相同的语法和数据标准。
我们将把数据网格的定义归结为几个关键概念,并重点介绍它与传统数据架构的区别,而不是重新发明Zhamak经过深思熟虑构建的轮子。
(不过,如果你还没有读过她的开创性文章,我强烈建议你读一读《如何从一个单一的数据湖转移到一个分布式的数据网格》,或者看看马克斯·舒尔特(Max Schulte)关于Zalando为什么要过渡到数据网格的技术演讲。你不会后悔的)。
At a high level, a data mesh is composed of three separate components: data sources, data infrastructure, and domain-oriented data pipelines managed by functional owners. Underlying the data mesh architecture is a layer of universal interoperability, reflecting domain-agnostic standards, as well as observability and governance. (Image courtesy of Monte Carlo Data.)
面向领域的数据所有者和管道
数据网格联合了域数据所有者之间的数据所有权,域数据所有者负责将其数据作为产品提供,同时也促进了跨不同位置的分布式数据之间的通信。
虽然数据基础架构负责为每个域提供处理数据的解决方案,但域的任务是管理数据的摄取、清理和聚合,以生成可供商业智能应用程序使用的资产。每个域负责拥有自己的ETL管道,但一组应用于所有域的功能,用于存储、编目和维护对原始数据的访问控制。一旦数据被提供给给定域并由其转换,域所有者就可以利用这些数据满足其分析或运营需求。
自助服务功能
数据网格利用面向领域的设计原则来提供自助式数据平台,允许用户抽象技术复杂性并专注于各自的数据用例。
正如Zhamak所概述的,面向领域设计的一个主要问题是维护每个领域中的数据管道和基础设施所需的工作和技能的重复。为了解决这个问题,data mesh收集和提取与领域无关的数据基础设施功能,并将其整合到一个中央平台中,该平台处理数据管道引擎、存储和流式基础设施。同时,每个域负责利用这些组件来运行定制的ETL管道,为它们提供必要的支持,以方便地为其数据提供服务,并提供真正拥有流程所需的自主权。
通信的互操作性和标准化
每个域的基础都是一套通用的数据标准,在必要时帮助促进域之间的协作,而且通常是这样。不可避免的是,一些数据(包括原始数据源和经过清理、转换和服务的数据集)将对多个领域有价值。为了实现跨域协作,数据网格必须在格式、治理、可发现性和元数据字段等数据功能上实现标准化。此外,就像单个微服务一样,每个数据域都必须定义并商定SLA和质量度量,以“保证”其消费者。
为什么要使用数据网格?
直到最近,许多公司还利用连接到无数商业智能平台的单一数据仓库。这些解决方案由一小群专家维护,并经常背负着沉重的技术债务。
2020年,du jour体系结构是一个具有实时数据可用性和流处理的数据湖,其目标是从集中式数据平台获取、丰富、转换和服务数据。对于许多组织来说,这种体系结构在以下几个方面存在不足:
中央ETL管道减少了团队对不断增加的数据量的控制
随着每家公司成为一家数据公司,不同的数据用例需要不同类型的转换,这给中央平台带来了沉重的负担
这样的数据湖会导致断开连接的数据生产者、不耐烦的数据消费者,更糟糕的是,积压的数据团队难以跟上业务需求的步伐。相反,面向领域的数据架构(如数据网格)为团队提供了两全其美的优势:一个集中的数据库(或分布式数据湖),其中的域(或业务区域)负责处理自己的管道。正如Zhamak所说,数据架构可以通过分解成更小的、面向领域的组件来最容易地扩展。
数据网格通过为数据所有者提供更大的自主权和灵活性,促进更大的数据实验和创新,同时减轻数据团队通过单个管道满足每个数据消费者的需求的负担,为数据湖的缺点提供了解决方案。
同时,数据网格的自助式基础设施即平台为数据团队提供了一种通用的、与领域无关且通常自动化的方法来实现数据标准化、数据产品沿袭、数据产品监控、警报、日志记录和数据产品质量指标(换句话说,数据收集和共享)。总而言之,与传统数据架构相比,这些优势提供了竞争优势,传统数据架构通常因摄取者和消费者之间缺乏数据标准化而受阻。
网格化还是不网格化:这是个问题
处理大量数据源并需要对数据进行试验(换句话说,快速转换数据)的团队考虑利用数据网格是明智的。
我们进行了一个简单的计算,以确定您的组织投资数据网格是否有意义。请用一个数字回答下面的每个问题,然后将它们加在一起得出总分,换句话说,就是您的数据网格分数。
- 数据源的数量。贵公司有多少数据源?
- 您的数据团队的规模。您的数据团队中有多少数据分析师、数据工程师和产品经理(如果有)?
- 数据域的数量。有多少职能团队(营销、销售、运营等)依赖您的数据源来推动决策制定,您的公司有多少产品,以及正在构建多少数据驱动的功能?加总。
- 数据工程瓶颈。数据工程团队多久会成为实施新数据产品的瓶颈,从 1 到 10,1 表示“从不”,10 表示“总是”?
- 数据治理。从 1 到 10,1 表示“我可以不在乎”,10 表示“它让我彻夜难眠”,您的组织的数据治理有多少优先级?
数据网格得分
通常,您的分数越高,您公司的数据基础架构要求就越复杂和苛刻,反过来,您的组织就越有可能从数据网格中受益。如果您的得分高于 10,那么实施一些数据网格最佳实践可能对您的公司有意义。如果您的得分高于 30,那么您的组织处于数据网格的最佳位置,您将明智地加入数据革命。
以下是如何分解你的分数:
- 1-15:鉴于数据生态系统的规模和单维性,您可能不需要数据网格。
- 15-30:您的组织正在迅速成熟,甚至可能正处于真正能够依靠数据的十字路口。我们强烈建议结合一些数据网格最佳实践和概念,以便以后的迁移可能更容易。
- 30 或以上:您的数据组织是您公司的创新驱动力,数据网格将支持任何正在进行或未来的计划,以使数据大众化并在整个企业内提供自助分析。
随着数据变得越来越普遍以及数据消费者的需求不断多样化,我们预计数据网格对于拥有 300 多名员工的基于云的公司将变得越来越普遍。
Image Courtesy of Meme Generator.net.
不要忘记可观察性
对于数据行业的许多人来说,使用数据网格架构的巨大潜力既令人兴奋又令人生畏。事实上,我们的一些客户担心数据网格不可预见的自治和民主化会带来与数据发现和健康以及数据管理相关的新风险。
鉴于围绕数据网格的相对新颖性,这是一个相当值得关注的问题,但我鼓励有好奇心的人阅读细则。数据网格实际上并没有引入这些风险,而是要求您的数据具有可扩展的、自助式的可观察性。
事实上,如果没有可观察性,域就无法真正拥有自己的数据。根据 Zhamak 的说法,任何好的数据网格所固有的这种自助服务能力包括:
- 静态和动态数据加密
- 数据产品版本控制
- 数据产品架构
- 数据产品发现、目录注册和发布
- 数据治理和标准化
- 数据生产沿袭
- 数据产品监控、警报和日志记录
- 数据产品质量指标
当打包在一起时,这些功能和标准化提供了一个强大的可观察性层。数据网格范式还为各个域规定了一种标准化的、可扩展的方式来处理这些不同的可观察性租户,从而允许团队回答这些问题等等:
- 我的数据是新鲜的吗?
- 我的数据是否损坏?
- 如何跟踪架构更改?
- 我的管道的上游和下游依赖项是什么?
如果你能回答这些问题,你就可以放心,你的数据是完全可观察的——并且是可信的。
有兴趣了解有关数据网格的更多信息吗?除了 Zhamak 和 Max 的资源之外,请查看我们最喜欢的一些关于这位数据工程新星的文章:
- 应用数据网格 — Sven Balnojan
- 数据网格:重新思考数据集成 — Kevin Petrie
- 您的应用程序是否应该考虑数据网格连接? — 乔·格林瑟
- 您的公司是否正在构建数据网格?向 Barr Moses 和 Lior Gavish 提出您的经验、技巧和痛点。我们很乐意听取您的意见!
- 本文由 Monte Carlo 首席执行官 Barr Moses 和 Monte Carlo 首席技术官 Lior Gavish 撰写。
- 131 次浏览
【数据网格】如何选择数据网格技术
视频号
微信公众号
知识星球
目前有一个特别的问题经常出现:数据网格应该使用什么技术?人们经常问Databricks是否是一个不错的选择,或者他们是否应该使用AWS、Snowflake或开源选项。然而,正如微服务没有合适的技术一样,数据网格也没有合适的科技。这意味着,虽然这篇博客文章不会为您提供技术的购物清单,但它会为您提供一些帮助,帮助您了解现有的技术,以及您应该如何为网格实现评估它。
数据网格是一种范式,而不是一种解决方案架构
不同的组织将有不同的数据网格实现,由不同的架构支持。简而言之,数据网格是一种风格,而不是单一的架构。这意味着在AWS、Azure或谷歌上构建网格的方法不止一种。Mesh的一个很好的基本情况是“类似于微服务,但适用于分析数据”。
这意味着没有一个简单的技术列表可以让你开始做数据网格。正如我们将看到的,有一些有用的工具,但与其直接深入研究这些工具,不如考虑数据网格的特性或功能,这将帮助我们了解需要什么类型的工具以及用于什么目的。
要做到这一点,最简单的方法是从数据网格的核心原则开始,并从技术角度考虑这些原则的含义:
领域所有权
这需要根据明确的价值流而不是技术边界来划分数据产品。同样重要的是,每个单独的数据产品团队都要能够管理自己的管道和策略,以及数据存储和输出端口(如API)。
数据作为产品
数据的消费者希望数据的形式适合他们。团队需要能够以取悦数据消费者的方式转换和分发数据。正是出于这个原因,数据作为产品的原则需要一个灵活适应数据产品需求的多语言生态系统。这需要灵活性,并可能限制您的技术选择——尽管固执己见的现成解决方案可能看起来很棒,但可能会受到限制。
自助数据平台
在基础设施方面,团队不应该不断地重新发明轮子——这会浪费他们的时间和精力,使他们无法专注于构建出色的数据产品。自助式平台赋予开发人员权力并为其提供支持,以便处理资源调配等任务。
联合计算治理
数据网格产品应该具有一定程度的互操作性——这意味着我们需要确保分布式所有权与标准化相平衡。这有两个关键原因:第一是为了使数据产品在组织内部更容易被发现,第二是为了保证和保持一定的质量、互操作性和安全标准。
将原理映射到功能和技术
现在我们已经概述了数据网格的核心原理,我们可以开始将这些原理映射到许多特性和功能中。(为了简单起见,我将域所有权和数据作为一种产品合并为“数据产品”。)
对于每一个,我都包含了一些可能使用的工具。
平台
- 提供共享功能(API、UI、连接器代码)
- 基础设施作为代码工具,如Terraform、Ansible或CloudFormation等;非现成数据平台API;持续集成工具,如Jenkins。
- 流功能
- Kafka、MQ、Flink、Kinesis等工具。
- 开发人员门户网站(完全集成)
- 内部构建或使用类似Spotify后台的东西。
治理
- 目录(文档和元数据索引;可发现的爬网程序)
- Wiki工具,如confluence (用于基本目录);商业目录,如collibra或开源选项-amundsen、DataHub。
- 数据和API标准
- 数据治理工具、wiki、swagger、开放数据协议
- 访问策略
- wiki、目录元数据、可能在数据产品中实现的单个策略、自定义http API或集成工具的OPA或类似功能、Hadoop的ranger
- 监控和自动化法规遵从性
- 数据治理工具;数据可观察性工具和库,如Great Expecteds.io、内部仪表板
- 数据沿袭
- 数据沿袭工具或具有集成沿袭的数据治理工具也可以在ETL(例如,pachyderm)或存储(例如,delta lake)中
- IDM集成
- 数据存储工具中的自定义代码或连接器。
数据产品
- 数据存储
- 数据库:SQL、NoSQL、Graph、Search。
- 输入和输出端口
- 自定义API、ETL工具、连接器(例如流输入或BI或报告输出的插件)
- 跨产品集成
- 数据虚拟化工具、starburst.io、云提供商或现成的数据平台工具
关于所有这些类型的工具,我在GitHub中的概述提供了更多详细信息。
数据所有权如何?
数据所有权并不能转化为功能,更多的是组织实践和流程的问题。然而,这并不意味着在数据网格实现的背景下没有一些重要的事情需要考虑:域驱动设计、事件风暴、团队拓扑、用例和发现研讨会等方法在数据网格中都特别有用。
从轻量级解决方案到成熟的开发人员体验门户
需要注意的是,您可能需要一系列可能的功能。在最复杂和“成熟”的一端,您可能有一个数据产品开发人员体验门户,其中所有内容都是自动提供的。这将从本质上为开发人员提供一个向导,可以从中创建新的数据产品,从而非常容易地选择他们想要的数据存储技术,以及输入、输出端口和连接器等技术。这本质上就是Zhamak Dehghani所说的“体验飞机”(你可以在网络研讨会“数据网格中的沟渠教训”中看到更多体验飞机的样子。)
构建开发人员体验门户很困难。你当然不应该觉得这很重要。在更轻量级的一端,你可以只使用模板来为数据产品提供自举基础设施,并使用wiki来创建数据目录;这仍然可能非常有效。Zhamak Dehghani建议(在上述网络研讨会的52:00)尽早建立平台API,即使它们最初并没有完成你希望它们做的一切。你可以从较轻的一端开始,并根据需要逐渐向平台添加更多。
我可以使用现成的解决方案吗?
有现成的云和数据平台解决方案可用于数据网格实现。在这里,我指的不仅仅是特定的工具,而是将自己定位为端到端平台的解决方案。这些都有价值,但应该注意的是,在撰写本文时,它们通常是通用的。如果你正在寻找开发人员体验平台提供的定制级别,你必须自己开发。
如果你有兴趣使用现成的解决方案,你可以在GitHub上找到我对一些领先供应商的功能的概述。
如果你正在考虑现成的方法,你需要记住一些注意事项:
- 现成的数据平台基于服务/功能,而不是数据产品。因此,无法说你想构建一个数据产品,它应该有一定的存储和输出端口等。因此,现成的数据平台无法提供真正的网格体验平面。
- 现成的数据平台没有自定义数据API的概念。可能有通用数据API,但如果开发人员想编写代码来公开数据或机器学习模型的自定义API,则可能需要走出数据平台。
- 他们的ETL理念不是多语言的——他们通常固执己见(针对平台的本地存储和元数据进行集成)。
- 他们提供了一种通用的体验,而没有任何选择来策划开发人员从中选择什么工具。
- 基于帐户的租赁模型可能具有非常严格的限制性。如果你试图在一个云帐户中做很多事情,那么你很可能会达到极限(如“数据网格中战壕的教训”中所述)。
尽管有这些注意事项,但现成的平台对网格实现无疑是有价值的。重要的是要记住,它们不是数据网格平台;none(在撰写本文时)是成功实现数据网格的灵丹妙药。
那么,我该如何为数据网格选择技术呢?
希望您现在能更清楚地了解技术选项是什么,以及您可能需要在网格实现中使用哪些元素。但你可能仍然有一些高水平的工具选择问题,你不确定。你知道你的用例和环境,所以你需要根据你的目标和公司的技术战略来决定如何选择工具。我能提供的是一些关于关键主题的一般性建议:
- 您应该使用现成的数据平台还是组装自己的数据平台?要决定这一点,您需要考虑成本、具体用例以及您希望平台体验的定制程度等因素。
- 你需要一个数据平台UI吗?或者你可以用一个API,甚至只是一些指导和模板吗?尽早构建平台是件好事,但您最初几个用例的初始平台可能与最终使用的平台不同。让一个平台尽早启动第一批数据产品与在平台上投入大量资金之间存在权衡。
- 您是否需要扩展到策略和监控的治理?这可能取决于您的数据的敏感性,您对其潜在质量和互操作性的关注程度,以及质量或数据安全问题对您的用例的影响。
- 最重要的建议是尽早确定关键的用例。如果你试图在不清楚用例的情况下评估工具,那么你就不知道自己要解决什么问题。您不想被吸引去寻找现有的“最佳”工具或“理想”网格实现,因为这些都是兔子洞。你想清楚自己想要实现什么,这样你才能找到最适合你的工具。
- 57 次浏览
【数据网格】应用数据网格
逐步从单一数据湖转移到分散的 21 世纪数据网格。
(另请查看后续文章:三种数据网格)
Left: data lakes with central access, on the right: user accessing data from teams domain teams providing a great data product. (all images by the author)
21 世纪的数据格局如何? ThoughtWorks 的 Zhamak Deghani 给出了一个漂亮的、对我来说令人惊讶的答案:它是去中心化的,与我们目前在几乎所有公司中看到的都非常不同。答案被称为“数据网格”。
如果您像我一样感受到公司当前数据架构的痛苦,那么您想迁移到数据网格。但是怎么做?这就是我在本文中探索的内容。
但首先,简要回顾一下数据网格。
Twitter 数据网格总结
现代软件开发需要一种分散的数据方法。数据必须被其生成团队视为产品;他们需要为它服务;分析团队和软件团队需要改变!
更长的总结
DDD、微服务和 DevOps 在过去十年改变了我们开发软件的方式。然而,分析部门的数据并没有赶上这一点。为了在采用现代开发方法的公司中加快基于数据的决策,分析和软件团队需要改变。
- (1) 软件团队必须将数据视为他们服务于其他所有人(包括分析团队)的产品
- (2) 分析团队必须以此为基础,停止囤积数据,而是按需提取数据
- (3) 分析团队必须开始将他们的数据湖/数据仓库也视为数据产品。
如果简短的摘要对您有吸引力,让我带您了解如何从您当前的起点实际进入数据网格。我们将通过一个示例,在途中经过遗留的单体、数据湖和数据仓库。我们一步一步地从我们的“旧”系统转移到这个新系统。
旁注:将数据湖称为“旧”对您来说可能看起来很奇怪,对我来说也是如此。时任 Pentaho 的首席技术官/创始人的 James Dixon 仅在 10 年前就设想了数据湖的概念。然而,围绕数据湖的核心转变,即软件、DevOps、DDD、微服务也是在过去十年才出现的。因此,我们确实需要迎头赶上,因为在这些趋势完全改变我们开发软件的方式之前,中央全能数据湖是一个老问题的答案。此外,一个全能的数据湖并不是 Dixon 最初想象的那样。
我们从一个典型的电子商务业务微服务架构示例开始。
- 我们展示了这个示例在数据湖/数据仓库架构中的样子(A 点),
- 然后与数据网格架构进行比较(C 点)
- 然后举这个例子,但是添加一个“数据湖作为数据节点”(B),因为这实际上是我们从 A 到 C 的方式。
- 我们考虑应该启动我们从 A 到 C 的转变的痛点。
- 我们从 A -> B -> C 一步一步来。
- 我们会考虑首先移动哪些部件的细节。
- 我们考虑可能的问题以及如何处理它们。
- 我们考虑另一种解决问题的方法。
具有数据网格架构的电子商务微服务架构

E-commerce business modeled with three operational microservices.
这是一个基本的微服务体系结构,有两个域,一个“客户域”和一个客户API,一个CRM系统,“订单域”和一个订单API。这些服务是运营服务,它们运营着电子商务网站。这些API允许您在order API中创建订单,在CRM系统中的customer API中创建客户,检查信用额度等等。它们可能是REST API,再加上一些事件流、一些发布子系统,具体的实现并不重要。
旁注:对我们来说,订单和客户是不同的领域。这意味着这些领域的语言可能会有所不同。从团队2,即订单团队中看到的“客户”只有一个意思,即通过客户id识别的人,他们刚刚在网站上买了东西。在团队1中,含义可能有所不同。他们可能会考虑客户从CRM系统中的实体,它可以将状态从仅仅“领先”改变为“购买”客户,只有第二个在团队2方知道。
团队1拥有客户域。他们对这个领域了如指掌。他们知道什么是潜在客户,从潜在客户到实际客户的过渡状态如何等等。另一方面,团队2知道关于订单域的一切。他们知道被取消的订单是否可以恢复,网站上的订单漏斗是什么样子,等等。团队可能对另一个领域略知一二,但不是所有的细节。它们不是自己的。
这两个域都会生成大量数据作为副产品。组织中的很多人都需要这些数据。让我们看看其中的一些:
- 数据工程师:需要订单和客户数据进行转换,以生成OLAP多维数据集基础数据、模块化数据;在开始进行转换之前,他还需要数据来测试和理解它。
- 营销人员:需要按商品类别对订单进行概述,以便每天动态地扩展他们的活动。
- 数据科学家:正在构建推荐系统,因此需要所有订单数据始终保持最新,以训练他的系统。
- 管理层:希望对整体增长进行总体概述。
针对这些需求的数据湖/数据仓库解决方案将以类似的形式出现。
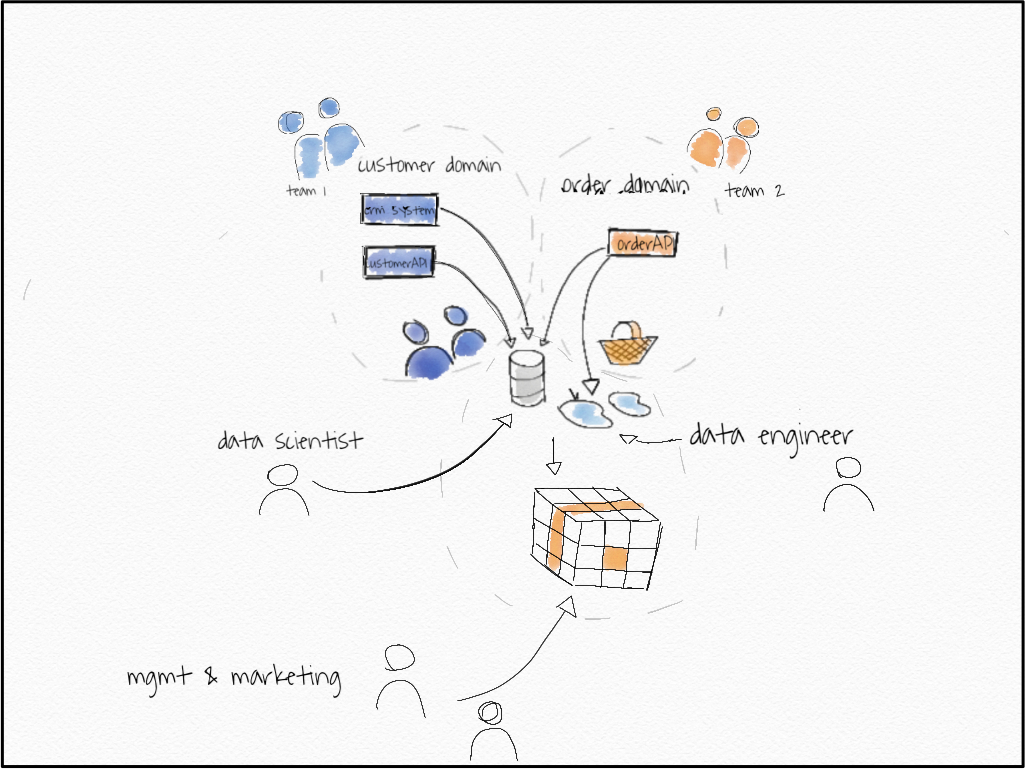
一个由数据工程师组成的中央团队很可能会通过 ETL 工具或流解决方案提供所有数据。 他们将拥有一个中央数据湖或数据仓库,以及一个用于营销和管理的 BI 前端。
数据科学家可能会直接从数据湖中获取数据,这可能是他们访问数据的最简单方式。
我们看到这种架构有哪些可能的问题?
- 这种架构在数据工程团队中造成了中心瓶颈
- 它可能会导致领域知识在通过其中心枢纽的途中丢失,
- 并对所有这些不同的、异构的需求进行优先排序。
到目前为止这么好。 那么数据网格方法呢?
这是具有数据网格架构的同一个电子商务网站。

Green: new data-APIs. Bottom: Mgmt with straight BI tool access, marketing with data form data-API, left: data scientist with data from data-API
发生了什么变化?首先,数据科学家和营销人员可以访问源域中的数据!但还有更多。
旁注:数据网格架构的关键是获取数据 DATSIS。可发现的、可寻址的、可信赖的、自描述的、可互操作的和安全的。
我会提到以下几点。
让我们逐步了解要点
- 客户域:客户域有两个新的只读“数据 API”。对于示例而言,可能只有一个或两个 API 并不重要。在这两种情况下,客户域都将确保将 CRM 系统和客户 API 中的“客户”概念联系起来。
- 订单域:订单域获得了一个新的数据API,即订单数据API。
- 客户数据 API 数据示例:客户数据 API 可能有多个端点:
allCustomers/:每行为一个“客户”提供数据。
stats/ :使用诸如“Num customers: 1,000, Num Lead: 4,000;客户电话:1,500,中小企业客户联系:500,中小企业客户:600”
更多端点。
- order-data-API 数据示例: order-data-API 可能有多个端点:
allOrderItems/:每行提供一个订单行项目。
allBuckets/:每行提供一个存储桶,它是订单项的集合。
stats/:提供数据,如“订单:1,000,000,2019 年订单:600,000 平均桶容量:30 美元”; stats 端点可能采用日期范围、年份等参数。
- 数据 API 是只读的。其他人不是。 * Data API 将 DATA 作为他们的产品,非常完美。您可以将 SLA 固定到它们,检查它们的使用情况。 API 被建模为它们自己的 API,我们不会滥用 Order API 作为数据 API。因此,我们可以分别关注不同的用户。
- *-data-APIs 可以以任何合理的形式实现,例如:
- 作为位于 AWS S3 存储桶中的 CSV/parquet 文件(端点由子文件夹分隔,API 由顶级文件夹分隔)(可寻址)
- 作为通过 JSON/JSON 行的 REST API
- 通过中央数据库和模式。(是的,我知道“中央”不是“去中心化”)
- Schemata 位于数据旁边。 (自我描述)。
- CRM 系统可以同时被视为操作 API 和数据 API,但您确实希望将其包装为符合您设置的标准。否则,您将失去数据网格架构的任何好处。
- 所有数据 API 应具有相同的格式。这让消费变得非常容易! (可互操作且安全)
- 数据 API 可以通过 Confluence 页面或任何更高级的表单或数据目录发现,我们知道哪个团队拥有该数据并可以在下游使用它。 (可发现)
- 有一个新域。数据工程师刚刚获得了自己的商业智能建模数据域。他知道他正在为一个利益相关者服务。该域被包装为服务,仅服务于一个利益相关者。通过这种方式,数据工程师可以将管理需求集中在建模数据上并适当地确定其优先级。
- 营销团队可以直接从源头访问他们的“按类别订购数据”,因为它是特定领域的。
- BI 系统来自数据库,我们将其包装为数据服务。为什么?因为我们只为管理提供服务,他们只想要我们无法从 API 获得的建模和连接数据,这很好。整体增长听起来像是一个与某个领域无关但跨领域的实体。
让我们来看看数据用户的需求以及发生了什么变化
- 数据工程师:数据工程师已经从数据 API 接收到大部分建模数据。这意味着,不会丢失任何领域知识。他有 SLA 可以查看并确切知道他得到了什么。他可以轻松地使用用于两种 data-* API 的一种标准 API 以任何方式组合数据并将其放入他自己的数据服务中。他确切地知道向谁索取特定数据,并且所有数据都记录在同一个地方。
- 营销人员:可以直接从订单源中提取他们需要的数据,即使数据工程师数据服务(还没有?)提供该信息。因此,如果他们想要更改该数据,他们可以直接去找具有领域知识的人。如果他们想合并“漏斗数据”,他们可以询问真正知道那是什么的团队!
- 数据科学家:可以直接使用经过测试并具有 SLA 的 order-data-API,以应对他将一直进行的大量阅读。数据在一秒钟内就在那里,不需要破解数据库,这是我见过的不止一次。它已经投入生产,可以立即纳入推荐系统。数据科学家很容易实现他们的 CD4ML 版本。
- 管理层:仍然通过他们的商业智能系统获得他们的总体观点。但是,根据领域的不同,可能的更改可以在三个地方实现,而不仅仅是一个。中央数据团队不再是瓶颈。
数据团队仍然在那里,但可能的负载被适当地分配给分散的参与者,无论如何这些参与者更适合这项工作。但是,数据团队也有自己的服务。怎么可能看起来完全一样?让我们看看数据湖如何仍然适合数据网格以及可能的痛点。如果你从一个开始,就会有一个重要的过渡状态。
我们的数据湖,只是另一个节点
在三种情况下,现在不一定是中央数据湖或仓库仍然有意义:
如果我们想结合两个数据域来建模中间的东西,这不能发生在一个域中,而应该发生在一个新的域中。
如果我们想整合市场数据等外部数据。外部数据通常不符合我们的标准,因此我们需要以某种方式包装它们。
如果我们从 A -> C 点过渡,我们不仅会丢弃我们的数据湖,还会降低它的复杂性。
痛点
什么时候应该考虑迁移到数据网格?首先,如果您对自己的结构感到满意,如果您对公司使用数据做出决策的方式感到满意,那么不要这样做。但是,如果您感到以下任何痛苦,则解决方案是数据网格。
- 如果您将域复杂性与微服务/域驱动设计相结合,您可能会觉得事情过于“复杂”,以至于中央团队无法立即正确地提供数据。
- 如果确实如此,您认为将数据导入数据仓库的成本很高,因此您忽略了要导入的对个人用户有价值的数据源。这些应该单独提供服务,并且是“作为数据网格节点剥离”的完美候选者。
- 你还没有关闭数据 -> 信息 -> 洞察力 -> 决策 -> 行动回到数据的循环。
- 您是数据 -> 连续智能周期中的数据速度以周和月为单位,而不是几天或几小时。
- 您已经在“将数据转换尽可能靠近数据用户”;这是我们目前正在做的事情,通常这是数据 -> 信息 -> 洞察力 -> 决策 -> 行动 -> 数据管道中出现瓶颈的迹象。这可以被认为是一个中间阶段,有关更多信息,请参见最后一段。
从单一数据湖到数据网格
让我们面对现实吧。数据仓库或数据湖,以及负责导入和建模数据的中央分析团队。这是一个遗留的整体,团队从中导入数据时没有API,可能有直接的数据库访问和大量的ETL作业、表格等。也许我们在新的领域中获得了一些新的微服务……让我们保持简单但通用的方式。
旁注:我喜欢Michael Feathers对遗留代码的定义:没有测试的代码。这就是我的意思,大的,丑陋的,不快乐的代码,没有人喜欢使用。
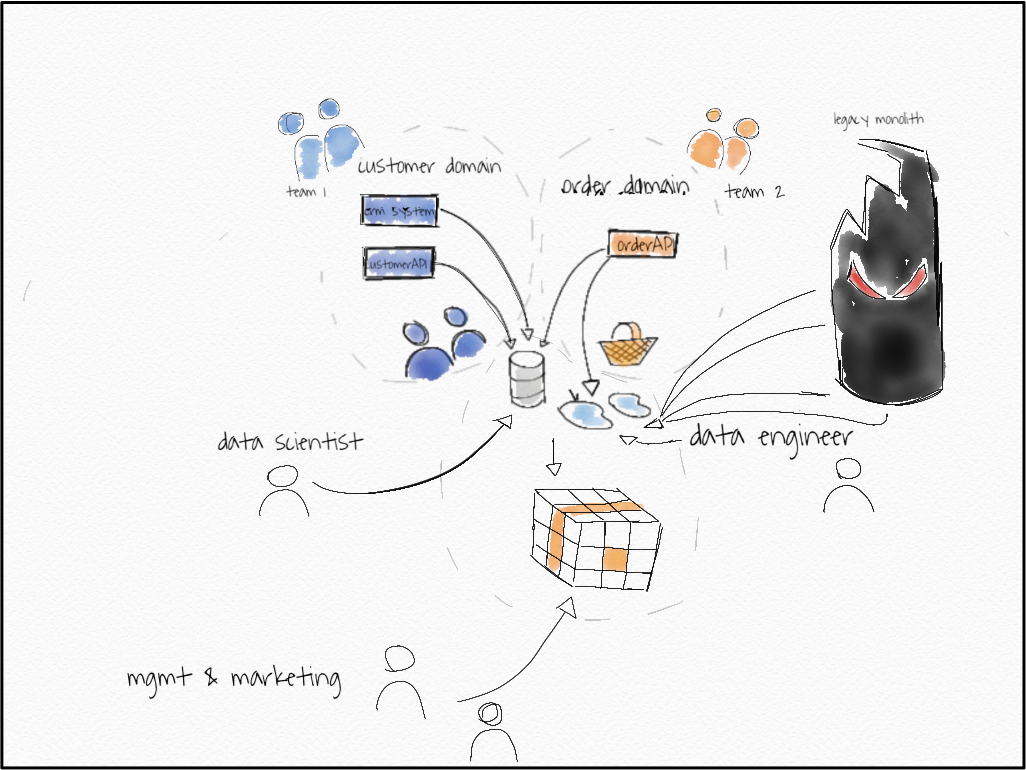
请记住,目标是逐步获取所有数据 DATSIS。
- 第 1 步:(可寻址数据)重新路由数据湖数据并更改 BI 工具访问权限。
所有数据当前都通过数据湖消费和服务。如果我们想改变这一点,我们首先需要在那里打开大开关,同时为未来的迁移修复可寻址性的标准化。
为此,让我们尝试使用 S3 存储桶。因此,我们将标准化固定为:
示例:可以通过以下方式访问 {name}-data-service:
- - s3://samethinghere/data-services/{name}
详细地说,所有服务都至少有一个端点,即默认数据端点。其他端点是子文件夹,例如:
- s3://samethinghere/data-services/{name}/default
- s3://samethinghere/data-services/{name}/{endpoint1}
- s3://samethinghere/data-services/{name}/{endpoint2}
架构版本位于:
- s3://samethinghere/data-services/{name}/schemata/v1.1.1.datetoS.???
我们使用格式为“vX.Y.Z”的语义版本,日期为秒。
数据文件以“vX.Y.Z.datapart01.???”的形式表示,每个文件限制为 1000 行,以便于使用。
我们将数据湖重新路由到它的新“地址”并更改 BI 工具访问权限。
s3://samethinghere/data-services/data-lake/default
s3://samethinghere/data-services/data-lake/growthdata
s3://samethinghere/data-services/data-lake/modelleddata
???
这对组织的其他人来说还没有改变,我们需要给他们访问权限。
- 第 2 步:(可发现性)创建一个空间来查找我们的新 data-* 源。
我们可以通过在我们的知识管理系统中创建一个页面来实现最简单的可发现性形式(即 confluence/您的内部 wiki,...)。
好的,所以现在除了当前使用数据湖的人之外的新人可以找到数据。现在我们可以开始将节点添加到我们的数据网格中,我们可以采取任何一种方式,通过打破一个闪亮的新微服务或打破那些令人讨厌的旧旧片段之一。
让我们首先考虑微服务案例。
- 第 3 步:开发一个新的微服务。
拆分服务的重点是将所有权交给创建数据的领域团队,例如,您可以让分析团队中的某个人加入负责的领域团队。现在,让我们以“订单团队”为例。
我们创建新的订单数据 API。修复一组基本的 SLA,并确保遵守您为数据湖设置的标准。我们现在有两个数据服务:
s3://samethinghere/data-services/data-lake/default
s3://samethinghere/data-services/data-lake/growthdata
s3://samethinghere/data-services/data-lake/modelleddata
s3://samethinghere/data-services/order-data/default
s3://samethinghere/data-services/order-data/allorderitems
s3://samethinghere/data-services/order-data/stats
将新服务放入可发现性工具中。
第二种选择是让中央分析团队创建这个数据服务,在这种情况下,所有权仍然存在。但至少我们分离了服务。
- 第 4 步:打破传统作品。
遗留系统通常不像闪亮的新微服务那样好用。通常,您将拥有某种数据库表,您甚至不知道从其中获取数据,从某些服务器或任何其他形式的遗留数据中获取一些 CSV,没有良好记录和标准化的接口。
没关系。你现在可以保持这种状态。您已经有了某种方式将该数据导入您的数据仓库或数据湖,因此将其拆分出来并将其表示为数据服务。
例如,您可以从:
源数据库 — ETL 工具 → 数据湖中的原始数据 → 数据湖中的转换数据
围绕前两个阶段进行总结,并使用标准化:
(源数据库 - ETL 工具 → 数据湖中的原始数据 → S3 存储桶)= 新数据服务
(新数据服务的S3 Bucket)——ETL工具→将数据导入数据湖→数据湖转换数据
这样,当你转移服务时,域团队只需要切换主干,依赖用户就可以切换到新的数据消费方式,甚至在域团队获得所有权之前。
- 第 5 步:(可发现性)切换可发现性和 BI 工具源。
现在开始将您的数据服务推送给普通受众以获得快速反馈,让营销团队找到您已经突破的来源。然后将 BI 工具切换到现在的两个数据服务,而不仅仅是一个。
然后,您可以考虑关闭对数据湖服务中订单数据的支持。
- 第 6 步:迁移所有权。
如果你在这里,恭喜,你已经打破了中央数据湖的第一部分,现在你需要确保在这些服务的新功能请求流入之前,所有权也已经转移。你可以这样做:
- 通过迁移一些人,连同服务到域团队
- 也许通过为新服务创建一个新团队
- 只需将服务迁移到域团队
- 第 7 步:继续。
包装,包装,包装,打破越来越多的服务。优雅地推出旧部分并用新的 API 替换它们。开始收集分布式服务的新功能请求。
到目前为止,您的中央数据湖将变得非常小,仅包含已连接和建模的数据,如果您开始转移人员,您的数据团队也会如此。
- 第 8 步:(TSIS)使其值得信赖、自我描述、可互操作且安全。
构建通用数据平台。这可能意味着每个人都可以使用库将文件放置在正确的位置或任何其他更复杂的工具集中。无论团队中有什么重复,您都可以将大部分内容掌握在中央手中。例如,如果您很快注意到营销和销售人员不容易访问 AWS S3 文件,您可能会决定从 S3 切换到可通过 EXCEL 访问的中央数据库等。
在这种情况下,您需要一个库来通过简单的升级进行切换,而不会给团队带来太多麻烦。例如,在 AWS 设置中,您可以使用通用的“data-service-shipper”创建一个 lambda 函数,该函数负责:
- 获取版本化模式并将它们映射到中央数据库中的数据库模式。
- 将数据传送到数据库中的适当模式中。
这样,域团队除了升级他们的“库”之外几乎没有任何努力。其他选项可能包括创建一个通用 REST API,您可以用它发出数据及其位置的信号,并让 API 处理其余部分,例如将 CSV、parquet 等转换为单一格式。
我首先选择哪部分数据进行突破?
因此,与微服务一样,从单体应用开始的最佳方法是在您感到某种“痛苦”时分解部分。但是我们先突破哪一部分呢?这是基于三个考虑的判断电话:
- 成本:分解数据有多难?
- 好处:数据多久更改一次?
- 好处:数据对您的业务有多重要?
这些好处间接表明,您将能够收集多少真实数据服务的用例,因为不断变化的数据意味着数据服务的变化,而数据的重要性意味着许多人希望从该数据服务中获得洞察力.
如果你权衡这些事情,你可能会得出不同的结论。例如,在我们的示例中,客户域可能是一个很好的起点,因为此类数据很可能经常更改。但是,有时它不如订单数据重要,另一方面,订单数据可能难以突破,这取决于您已经在其上放置了多少 1000 个 ETL 作业。
如果您有一个起点,那么您的道路上仍有垫脚石。
垫脚石
目前,作为副产品提供数据的团队没有适当关注该数据的动机,主要是因为该数据的潜在“利益相关者/消费者”没有直接反馈。
这是必须改变的,你必须把它作为一个核心部分来处理。这可能就是为什么Zhamak Deghani建议您使用特定的用例,识别用户,并组建一个新团队,只关心特定的用户。一、 另一方面,我不明白为什么当前的订单团队不能担任这个角色。诚然,这种转变有点困难,但公司必须花费的资源要容易得多,而且可能更容易销售。
如果你无法让数据生成团队跳上这列火车,你有两个选择:
- 创建一个新团队并接受一个用例
- 利用现有的中心团队担任该角色,并收集数据。检查数据服务的需求及其创造的价值,然后决定将其推广到哪里。
最后,让我们探讨一下这种体系结构的可能替代方案。
还有其他选择吗?
我试图想出一个替代方案,但意识到这更像是一个由不同实现组成的矩阵。
数据网格的关键概念是分散所有权,我们可以这样说,因为域团队通常认为他们的数据是他们真正拥有的副产品。因此,数据湖是原始数据的集中所有权。
如果我们现在区分原始数据和转换数据,我们可以看到四种不同的数据架构。我们还可以看到从数据湖到数据网格的2-3种不同方式。
Ownership of raw & transformed data can both be central or decentralized. This produces four quadrants with a variety of solutions.
如果从“数据湖”移动到“B 点”,然后再到完整的数据网格,我们在上面所描述的内容。
然而,第二种选择是首先实现去中心化的“转换数据所有权”,然后可能考虑转向完整的数据网格。
去中心化转换后的数据所有权如何?
- 数据湖仍然可以导入所有“原始数据”
- 然后,靠近决策者的数据知识丰富的用户可以访问原始数据,并在本地桌面 ETL 解决方案中进行转换。
- 原始数据也可以被推送到分散的数据仓库中,在那里,离用户更近的“某人”可以对该数据进行基本的 ETL。
- 当然,每个部门都可以有自己的小型数据团队为该部门做 ETL。
区别在哪里?在这种情况下,您可以收集大量需求,并锐化部门对数据的确切用例。像市场营销这样的部门通常更接近领域,然后是中间数据团队,所以你会在“领域语言”问题上获得一些优势,但不是全部。您仍然会在原始数据消耗方面保持中心瓶颈,而不是将“数据作为产品”推入领域团队。我认为这两者在未来的某个地方都是必要的。
结束
我试图写一篇比 Zhamak Deghani 更短的文章,但这似乎行不通。以下是我能找到有关数据网格架构信息的仅有的四个地方:
- Zhamak Deghanis 文章位于 Martin Fowlers 网站
- Zhamak 出现在 ThoughtWorks 播客第 30 集中,他们还提到了“将转型推向最终用户”的概念
- 数据工程播客第 90 集以数据网格为特色
- 以数据网格为特色的软件工程周刊播客
原文:https://towardsdatascience.com/data-mesh-applied-21bed87876f2
本文:
- 95 次浏览
【数据网格】数据网格 101:入门所需的一切

您的公司想要构建数据网格。伟大的!怎么办?这是一个快速入门指南,可帮助您入门 - 并防止您的数据基础设施变成热网格。
自 2010 年代初以来,微服务架构已被广泛的公司采用(想想:Uber、Netflix 和 Airbnb 等)作为当前的软件范例,引发了工程团队关于面向领域设计的利弊的讨论.
现在,在 2021 年,您将很难找到一位数据工程师,他的团队正在讨论是否要从单体架构迁移到分散的数据网格。
由 Thoughtworks 的 Zhamak Dehghani 开发的数据网格是一种数据平台架构,它通过利用领域驱动的自助式设计来拥抱企业中无处不在的数据。
随着公司越来越受数据驱动,数据网格非常适合现代数据组织的三个关键要素:
- 越来越多的数据被整个公司的利益相关者吸收和利用,而不是一个单独的“数据管理员”团队
- 随着团队寻求用他们的数据做越来越多的智能事情,数据管道的复杂性越来越高
- 标准化数据可观察性和可发现性层的兴起,以了解数据资产在其生命周期中的健康状况
数据网格的潜力既令人兴奋又令人生畏,就像之前的微服务架构一样,它激发了很多关于如何大规模操作数据的讨论。

与在一个中央数据湖中处理 ETL 的传统单体数据基础架构不同,数据网格支持分布式的、特定于域的数据消费者并查看“数据即产品”,每个域都处理自己的数据管道。数据网格的基础是可观察性和治理的标准化层,可确保数据始终可靠且值得信赖。图片由蒙特卡洛提供。
为了指导您的数据网格之旅,我们汇总了基本数据网格阅读清单:
基础
- 如何超越单片数据湖进入分布式数据网格——Zhamak Deghani 的原创作品是所有数据网格内容的圣杯。将本文视为您进入数据网格规范其余部分的门户,激发您对未来在实践中实施设计时围绕机遇、挑战和关键考虑因素进行讨论的兴趣。她的架构图对于理解数据网格如何针对集中式架构形成新的姿势至关重要。
- 数据网格原理和逻辑架构——Zhamak 第一篇文章的后续,本文详细介绍了如何实际大规模实施数据网格,并后退一步解释联邦治理如何以及为何对架构的关键成功。任何对数据网格的具体细节感兴趣的人都必须阅读。
- 数据网格应用——Mercateo Gruppe 数据分析和数据科学主管 Sven Balnojan 向读者介绍了数据团队如何通过从单一数据仓库迁移将 DevOps、“数据即产品”思维方式应用到他们的数据架构中和湖泊到数据网格。他还谈到了普通企业(在本例中为电子商务公司)如何进行这种迁移,以及如何适当地实现数据所有权和访问权的民主化。
补充阅读
- 什么是数据网格——以及如何不将其网格化——在 2020 年,一些客户向我和我的联合创始人提出了关于如何大规模实施数据网格架构以及数据网格是否有意义的问题为他们的团队。在本初学者指南中,我们将介绍一些关键注意事项,尤其是与设置网格以实现数据可观察性和可发现性的成功有关。
- 数据网格适合您的组织吗? – 在 Hyperight 关于该主题的最新消息中,他们采访了各种数据领导者和顾问,了解为什么(或为什么不)实施数据网格架构。 TL;DR:如果您的团队已经在采用面向领域的数据所有权方法并在数据管理方面苦苦挣扎,那么数据网格可能是让您的组织更上一层楼的正确架构。一个关键点:倾向于自动化和 DataOps 的公司更有可能为没有成功的公司设立。
- 数据网格简介:分析数据管理中的范式转变(第 1 部分和第 2 部分)——将这两个视频视为 Zhamak 早期关于数据网格的写作的额外背景。在 Starburst Data 的 SuperNova 会议的这两次演讲中,Zhamak 更详细地介绍了她设计这种新范式的动机,以及一流的数据团队如何已经大规模应用数据网格(自动化)以提供更可靠、更可行的数据洞察他们的公司。
主要资源
- 实践中的数据网格:欧洲领先的时尚在线平台如何超越数据湖——Zalando 的数据工程师 Max Shultze 和 ThoughtWorks 顾问 Arif Wider 讨论时尚电子商务公司如何将他们的“数据沼泽”变成通过利用数据网格原则的领域驱动的、可操作的数据湖。对于那些认真考虑去中心化他们的数据架构和消除数据工程瓶颈(无论你是否要使用全网格)的人来说,这是必须关注的。
- Intuit 的数据网格战略 – Intuit 数据平台的首席架构师 Tristan Baker 讨论了 Intuit 决定实施数据网格架构的原因和方式,正如他所说,“减少混乱并提高生产力,以恢复让客户满意的业务。”根据 Tristan 的说法,关键挑战包括数据可发现性、数据可理解性和数据信任。通过将代码和数据组织为“数据产品”,Intuit 能够设定明确的数据责任、服务所有权和目标结果。
- Netflix 数据网格:可组合数据处理 - 在 Flink Forward 2020 的这段视频中,Netflix 数据架构总监 Justin Cunningham 讨论了他的团队如何构建数据网格架构来专门处理可组合数据处理。与其他演讲和文章不同,本次演讲深入探讨了他们如何应用数据网格框架来处理数据转换过程的一个元素——在 Netflix 系统之间移动数据。
- 此列表绝不是详尽无遗的,但它应该可以帮助您开始数据网格之旅。对于那些对构建数据网格或希望分享最佳实践感到好奇的人,可以考虑加入 Data Mesh Learning Slack 小组。
直到下一次——祝你数据网格魔法!
原文:https://www.montecarlodata.com/blog-data-mesh-101-everything-you-need-t…
- 191 次浏览
【数据网格】数据网格原理和逻辑架构
我们希望通过数据来增强和改善业务和生活的各个方面,这要求我们大规模管理数据的方式发生范式转变。 虽然过去十年的技术进步已经解决了数据量和数据处理计算的规模,但它们未能解决其他方面的规模问题:数据格局的变化、数据源的扩散、数据用例和用户的多样性 ,以及对变化的响应速度。 数据网格解决了这些维度,建立在四个原则上:面向领域的去中心化数据所有权和架构、数据作为产品、自助数据基础设施作为平台以及联合计算治理。 每个原则都推动了技术架构和组织结构的新逻辑视图。
内容
- 数据的巨大鸿沟
- 数据网格的核心原理和逻辑架构
- 领域所有权
- 逻辑架构:面向领域的数据和计算
- 数据作为产品
- 逻辑架构:数据产品架构量子
- 自助数据平台
- 逻辑架构:多平面数据平台
- 联合计算治理
- 逻辑架构:嵌入在网格中的计算策略
- 原理总结和高层逻辑架构
最初的文章,如何从单一数据湖转移到分布式数据网格——我鼓励你在回到这里之前阅读它——理解当今架构和组织挑战的痛点,以便成为数据驱动的,使用数据竞争,或使用大规模数据来推动价值。它提供了另一种视角,此后引起了许多组织的关注,并为不同的未来带来了希望。虽然最初的文章描述了这种方法,但它留下了许多设计和实现的细节。我无意在本文中过于规范,扼杀围绕数据网格实现的想象力和创造力。然而,我认为它只负责澄清数据网格的架构方面,作为推动范式向前发展的垫脚石。
这篇文章是为了跟进而写的。它通过列举其基础原则以及这些原则驱动的高级逻辑架构来总结数据网格方法。在我在以后的文章中深入研究数据网格核心组件的详细架构之前,建立高级逻辑模型是必要的基础。因此,如果您正在寻找有关数据网格的确切工具和配方的处方,本文可能会让您失望。如果您正在寻找一种建立通用语言的简单且与技术无关的模型,那就来吧。
数据的巨大鸿沟
数据的真正含义是什么?答案取决于你问谁。当今的格局分为运营数据和分析数据。操作数据位于微服务提供的业务功能背后的数据库中,具有事务性,保持当前状态并满足运行业务的应用程序的需求。分析数据是业务事实随时间推移的时间和汇总视图,通常被建模以提供回顾性或未来视角的见解;它训练 ML 模型或提供分析报告。
技术、架构和组织设计的当前状态反映了这两个数据平面的分歧——两个存在层次,集成但分离。这种分歧导致了脆弱的架构。不断失败的 ETL(提取、转换、加载)作业和日益复杂的数据管道迷宫对于许多试图连接这两个平面、将数据从操作数据平面流向分析平面并返回到操作平面。
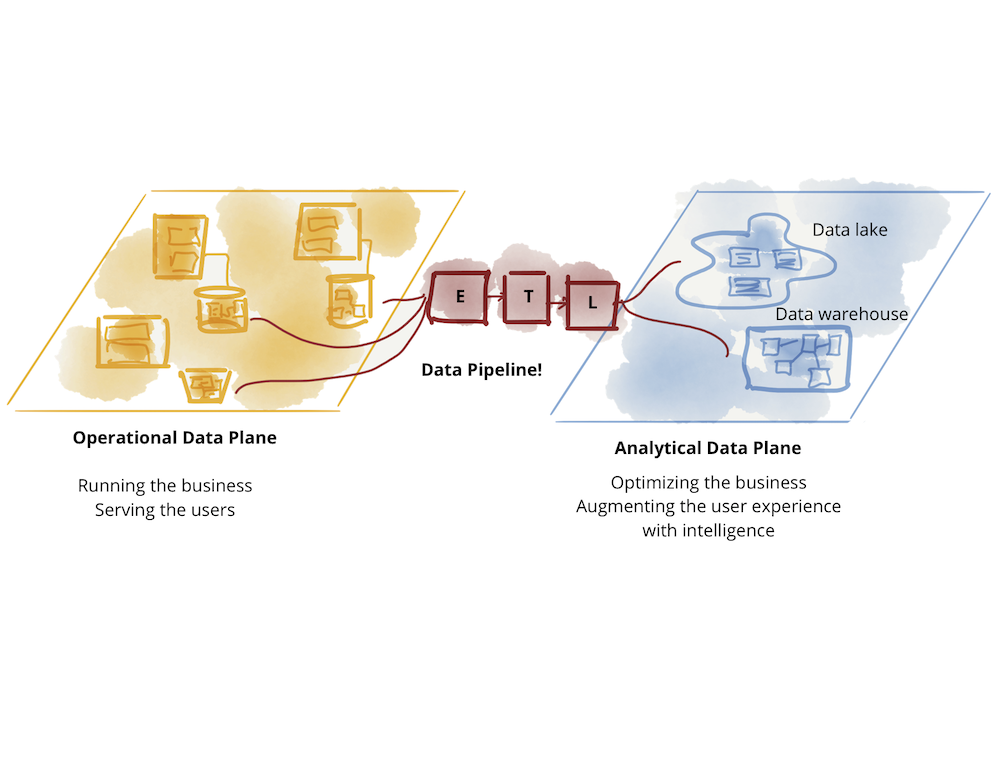
Figure 1: The great divide of data
分析数据平面本身已经分化为两个主要的架构和技术栈:数据湖和数据仓库; 数据湖支持数据科学访问模式,数据仓库支持分析和商业智能报告访问模式。 在这次对话中,我将两个技术堆栈之间的关系放在一边:数据仓库试图加入数据科学工作流,数据湖试图为数据分析师和商业智能提供服务。 最初关于数据网格的文章探讨了现有分析数据平面架构的挑战。
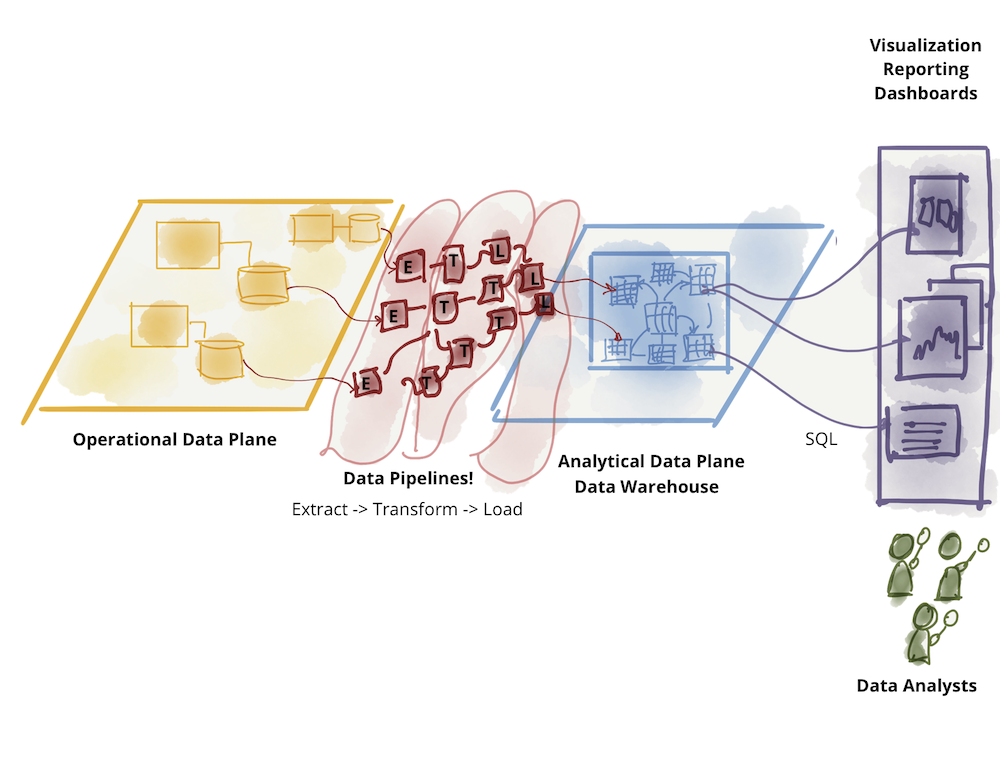
Figure 2: Further divide of analytical data - warehouse
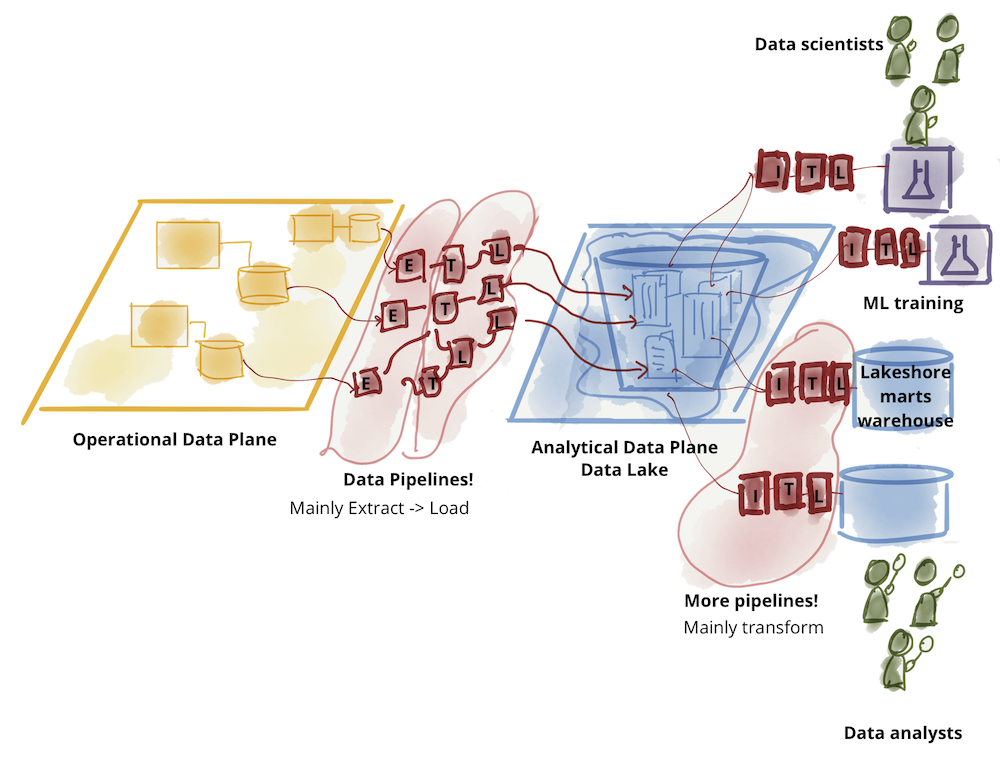
Figure 3: Further divide of analytical data - lake
数据网格承认并尊重这两个层面之间的差异:数据的性质和拓扑、不同的用例、数据消费者的个人角色,以及最终的不同访问模式。然而,它试图在不同的结构下连接这两个平面 - 基于域而不是技术堆栈的倒置模型和拓扑 - 重点放在分析数据平面上。当今管理这两种数据原型的可用技术的差异不应导致组织、团队和工作人员的分离。在我看来,操作和事务数据的技术和拓扑是比较成熟的,主要是由微服务架构驱动的;数据隐藏在每个微服务的内部,通过微服务的 API 进行控制和访问。是的,真正实现多云原生操作数据库解决方案仍有创新空间,但从架构的角度来看,它满足了业务的需求。然而,分析数据的管理和访问仍然是一个大规模的摩擦点。这是数据网格关注的地方。
我确实相信,在未来的某个时候,我们的技术会不断发展,让这两个飞机更加靠近,但就目前而言,我建议我们将它们的关注点分开。
数据网格的核心原理和逻辑架构
数据网格的目标是为从大规模分析数据和历史事实中获取价值奠定基础——大规模应用于数据环境的不断变化、数据源和消费者的扩散、用例所需的转换和处理的多样性、速度对变化的反应。为了实现这一目标,我建议任何数据网格实现都包含四个基本原则,以实现规模化承诺,同时提供使数据可用所需的质量和完整性保证:1)面向领域的分散数据所有权和架构,2 ) 作为产品的数据,3) 作为平台的自助数据基础设施,以及 4) 联合计算治理。
虽然我预计这些原则的实践、技术和实现会随着时间的推移而变化和成熟,但这些原则保持不变。
我打算让这四项原则共同成为必要和充分的;实现弹性扩展,同时解决不兼容数据孤岛或运营成本增加的问题。让我们深入研究每个原则,然后设计支持它的概念架构。
领域所有权
数据网格的核心是分散和将责任分配给最接近数据的人,以支持持续的变化和可扩展性。问题是,我们如何分解和分散数据生态系统的组成部分及其所有权。这里的组件由分析数据、其元数据以及为它提供服务所需的计算组成。
数据网格遵循组织单元的接缝作为分解轴。我们今天的组织是根据其业务领域进行分解的。这种分解将持续变化和进化的影响——在大多数情况下——本地化到域的有界上下文中。因此,使业务领域的有界上下文成为数据所有权分配的良好候选者。
在本文中,我将继续使用与原始文章“一家数字媒体公司”相同的用例。可以想象,媒体公司根据“播客”、管理播客发布的团队和系统及其主机等领域来划分其运营,因此支持运营的系统和团队; “艺术家”、管理入职和付费艺术家的团队和系统等。数据网格认为分析数据的所有权和服务应该尊重这些领域。例如,管理“播客”的团队在提供用于发布播客的 API 的同时,还应负责提供代表“已发布播客”随时间推移的历史数据以及其他事实,例如随时间推移的“收听率”。要更深入地了解这一原则,请参阅面向领域的数据分解和所有权。
逻辑架构:面向领域的数据和计算
为了促进这种分解,我们需要建模一个按域排列分析数据的架构。在此架构中,域与组织其他部分的接口不仅包括操作能力,还包括对域所服务的分析数据的访问。例如,“播客”域提供了操作 API 来“创建新的播客剧集”,还提供了一个分析数据端点,用于检索“过去 <n> 个月内的所有播客剧集数据”。这意味着架构必须消除任何摩擦或耦合,以让域提供其分析数据并发布计算数据的代码,独立于其他域。为了扩展,架构必须支持领域团队在发布和部署其操作或分析数据系统方面的自主权。
以下示例演示了面向领域的数据所有权原则。这些图只是逻辑表示和示例性的。它们并不打算完整。
每个域可以公开一个或多个操作 API,以及一个或多个分析数据端点
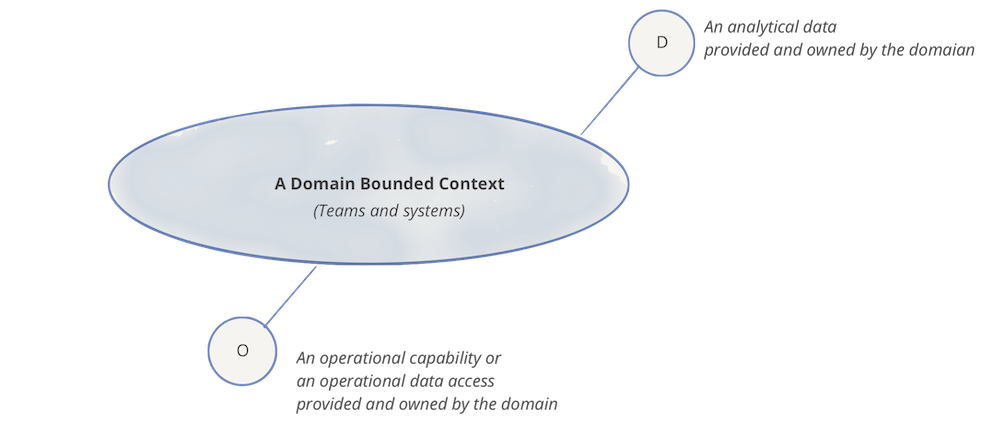
Figure 4: Notation: domain, its analytical data and operational capabilities
自然地,每个域都可以依赖于其他域的操作和分析数据端点。 在以下示例中,“播客”域使用来自“用户”域的“用户更新”分析数据,因此它可以通过其“播客听众人口统计”数据集提供播客听众的人口统计图。
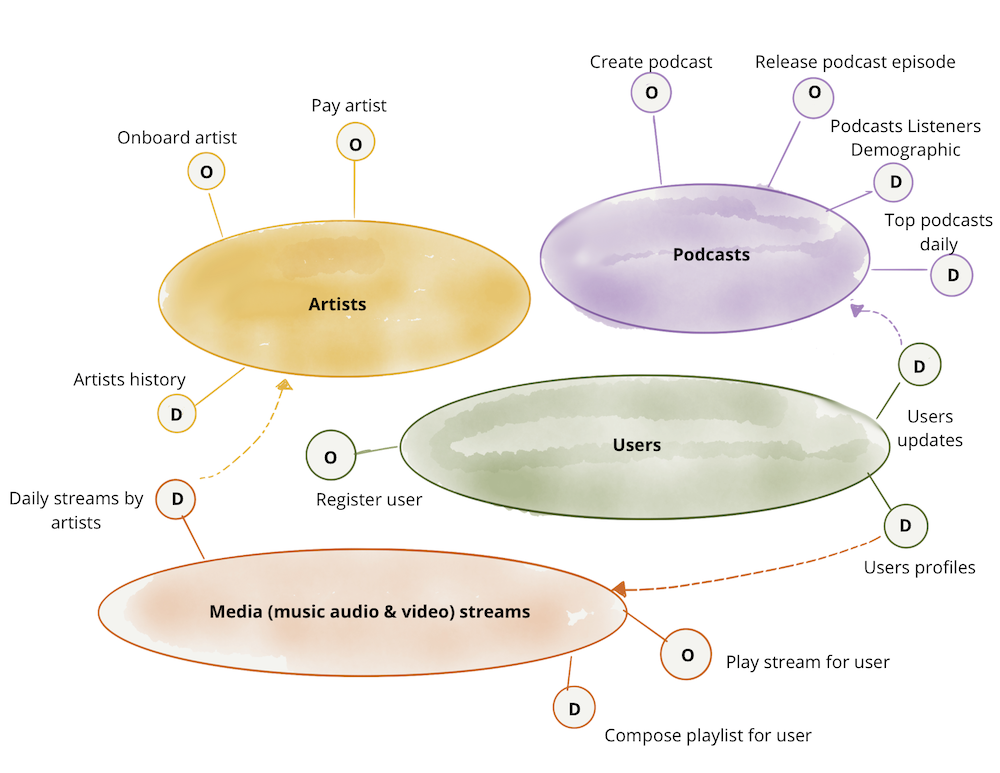
Figure 5: Example: domain oriented ownership of analytical data in addition to operational capabilities
注意:在示例中,我使用了一种命令式语言来访问操作数据或功能,例如“付费艺术家”。这只是为了强调访问操作数据与分析数据的意图之间的区别。我确实认识到,实际上操作 API 是通过更具声明性的接口实现的,例如访问 RESTful 资源或 GraphQL 查询。
数据作为产品
现有分析数据架构的挑战之一是发现、理解、信任和最终使用高质量数据的高摩擦和成本。如果不解决,这个问题只会随着数据网格的增加而加剧,因为提供数据(域)的地方和团队的数量会增加。这将是我们第一个去中心化原则的结果。数据即产品原则旨在解决数据质量和古老的数据孤岛问题;或者正如 Gartner 所说的暗数据——“组织在日常业务活动中收集、处理和存储的信息资产,但通常无法用于其他目的”。域提供的分析数据必须被视为一种产品,而该数据的消费者应该被视为客户——快乐和高兴的客户。
原始文章列举了一系列能力,包括可发现性、安全性、可探索性、可理解性、可信赖性等,数据网格实现应支持将域数据视为产品。它还详细介绍了组织必须引入的领域数据产品所有者等角色,负责确保数据作为产品交付的客观措施。这些措施包括数据质量、减少数据消耗的前置时间,以及通过净推荐值获得的总体数据用户满意度。领域数据产品所有者必须深入了解数据用户是谁,他们如何使用数据,以及他们习惯于使用数据的原生方法是什么。这种对数据用户的深入了解导致设计出满足他们需求的数据产品界面。实际上,对于网格上的大多数数据产品,都有一些具有独特工具和期望的传统角色、数据分析师和数据科学家。所有数据产品都可以开发标准化的接口来支持它们。数据用户与产品所有者之间的对话是建立数据产品接口的必要环节。
每个域将包括数据产品开发人员角色,负责构建、维护和服务域的数据产品。数据产品开发人员将与该领域的其他开发人员一起工作。每个领域团队可以提供一个或多个数据产品。也可以组建新的团队来提供不适合现有运营领域的数据产品。
注意:与过去的范例相比,这是一种倒置的责任模型。数据质量的责任在尽可能靠近数据源的地方向上游转移。
逻辑架构:数据产生架构量子
在架构上,为了支持数据作为域可以自主服务或消费的产品,数据网格引入了数据产品的概念作为其架构量子。进化架构定义的架构量子是可以独立部署且具有高功能凝聚力的最小架构单元,并包含其功能所需的所有结构元素。
数据产品是网格上的节点,它封装了其功能所需的三个结构组件,作为产品提供对域分析数据的访问。
- 代码:它包括 (a) 负责消费、转换和服务上游数据的数据管道代码——从域的操作系统或上游数据产品接收的数据; (b) 提供对数据、语义和语法模式、可观察性指标和其他元数据的访问的 API 代码; (c) 用于执行特征的代码,例如访问控制策略、合规性、出处等。
- 数据和元数据:这就是我们在这里的全部目的,多语言形式的基础分析和历史数据。根据领域数据的性质及其消费模型,数据可以作为事件、批处理文件、关系表、图形等,同时保持相同的语义。为了使数据可用,有一组相关的元数据,包括数据计算文档、语义和语法声明、质量指标等;数据固有的元数据,例如它的语义定义,以及传达计算治理使用的特征以实现预期行为的元数据,例如访问控制策略。
- 基础设施:基础设施组件支持构建、部署和运行数据产品的代码,以及存储和访问大数据和元数据。
Figure 6: Data product components as one architectural quantum
以下示例建立在上一节的基础上,将数据产品演示为架构量子。 该图仅包含示例内容,并不旨在完整或包含所有设计和实施细节。 虽然这仍然是一个逻辑表示,但它越来越接近物理实现。
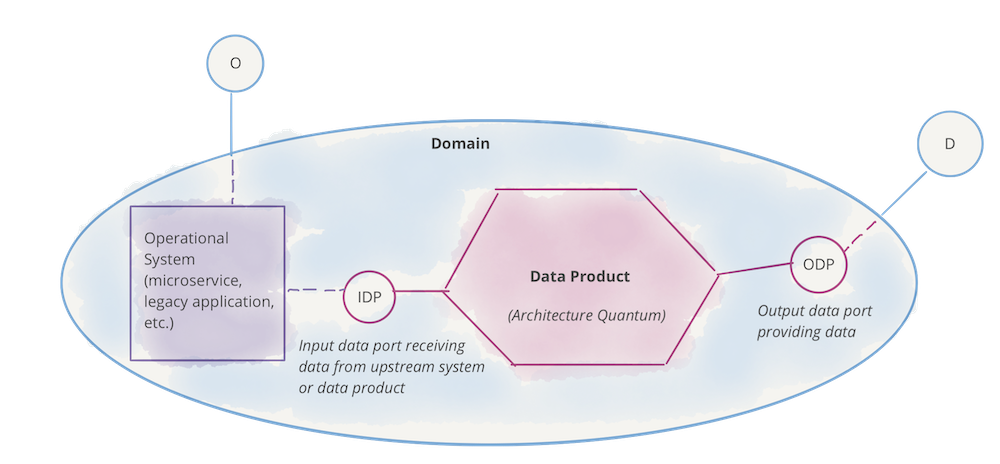
Figure 7: Notation: domain, its (analytical) data product and operational system
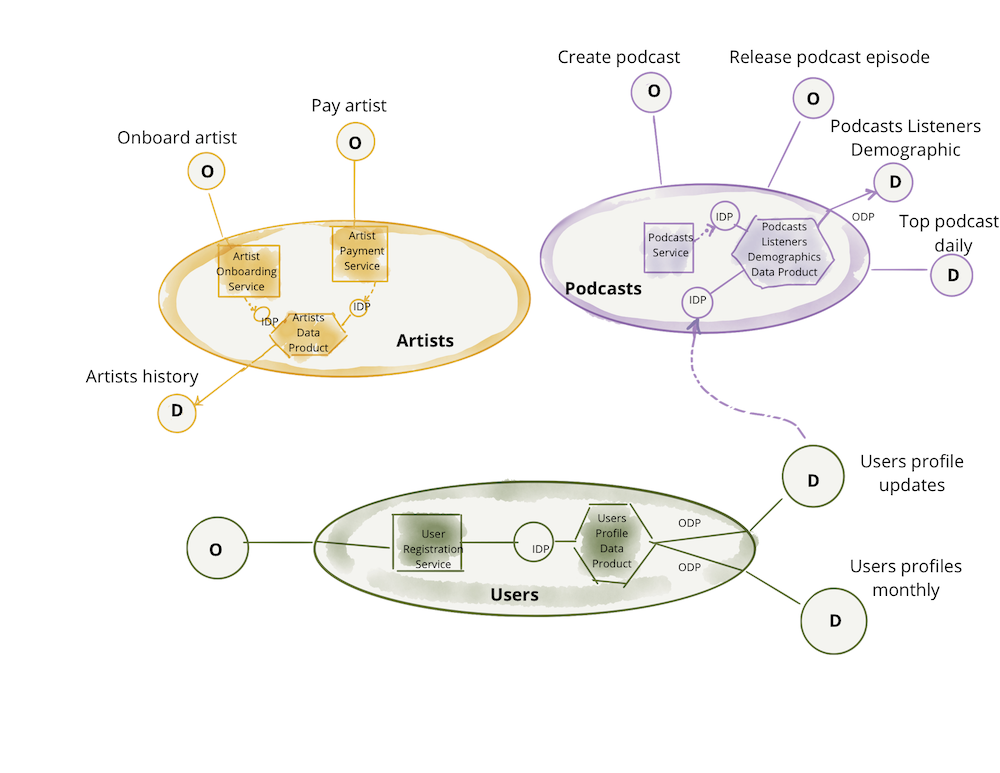
Figure 8: Data products serving the domain-oriented analytical data
注意:数据网格模型不同于过去将管道(代码)作为与其产生的数据的独立组件进行管理的范例;通常基础设施,如仓库或湖泊存储帐户的实例,在许多数据集之间共享。数据产品是所有组件(代码、数据和基础设施)的组合,以域的有界上下文为粒度。
自助数据平台
正如您可以想象的那样,要构建、部署、执行、监控和访问一个不起眼的六边形——一种数据产品——需要配置和运行相当多的基础设施;提供这种基础设施所需的技能是专门的,很难在每个领域中复制。最重要的是,团队可以自主拥有他们的数据产品的唯一方法是访问高级抽象的基础设施,从而消除配置和管理数据产品生命周期的复杂性和摩擦。这需要一个新的原则,将自助数据基础设施作为实现域自治的平台。
数据平台可以被认为是已经存在的用于运行和监控服务的交付平台的扩展。然而,如今操作数据产品的底层技术堆栈与服务交付平台看起来非常不同。这仅仅是由于大数据技术堆栈与操作平台的差异。例如,领域团队可能将他们的服务部署为 Docker 容器,而交付平台使用 Kubernetes 进行编排;但是,相邻的数据产品可能会在 Databricks 集群上将其管道代码作为 Spark 作业运行。这需要配置和连接两组非常不同的基础设施,在数据网格之前不需要这种级别的互操作性和互连性。我个人的希望是,我们开始看到运营和数据基础设施在有意义的地方融合。例如,也许在同一个编排系统上运行 Spark,例如Kubernetes。
实际上,为了使通才开发人员能够访问分析数据产品开发,对于现有的域开发人员配置文件,自助服务平台除了简化配置之外还需要提供一种新的工具和接口。自助数据平台必须创建工具,以支持域数据产品开发人员创建、维护和运行数据产品的工作流程,而现有技术所假定的专业知识较少;自助式基础设施必须具备降低当前成本和构建数据产品所需的专业化能力。最初的文章包括自助数据平台提供的一系列功能,包括访问可扩展的多语言数据存储、数据产品模式、数据管道声明和编排、数据产品沿袭、计算和数据局部性等。
逻辑架构:多平面数据平台
自助平台功能分为模型中所称的多个类别或平面。注意:一个位面代表了一个存在层次——既整合又分离。类似于物理和意识平面,或网络中的控制和数据平面。平面既不是层,也不意味着强大的分层访问模型。
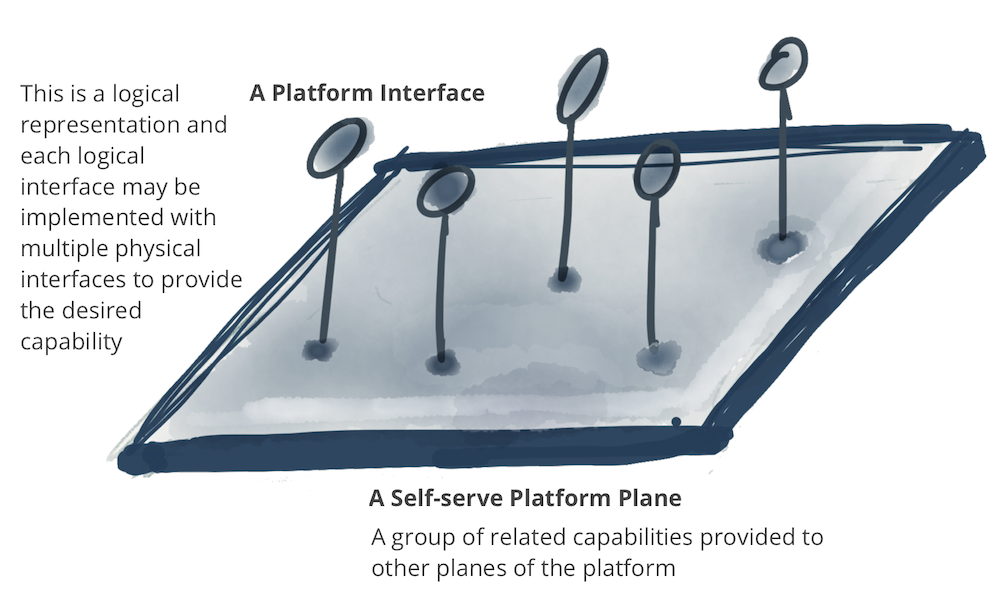
Figure 9: Notation: A platform plane that provides a number of related capabilities through self-serve interfaces
自助服务平台可以有多个平面,每个平面服务于不同的用户档案。在以下示例中,列出了三个不同的数据平台平面:
- 数据基础设施供应平面:支持运行数据产品组件和产品网格所需的底层基础设施供应。这包括提供分布式文件存储、存储帐户、访问控制管理系统、运行数据产品内部代码的编排、在数据产品图上提供分布式查询引擎等。我希望其他数据平台平面或者只有高级数据产品开发人员直接使用此接口。这是一个相当低级的数据基础设施生命周期管理平面。
- 数据产品开发者体验平面:这是典型的数据产品开发者使用的主要界面。该接口抽象了支持数据产品开发人员工作流所需的许多复杂性。它提供了比“供应平面”更高级别的抽象。它使用简单的声明式接口来管理数据产品的生命周期。它自动实现被定义为一组标准和全局约定的横切关注点,适用于所有数据产品及其接口。
- 数据网格监督平面:有一组最好在网格级别提供的功能 - 连接数据产品的图形 - 全局。虽然这些接口中的每一个的实现都可能依赖于单独的数据产品功能,但在网格级别提供这些功能会更方便。例如,发现特定用例的数据产品的能力最好通过搜索或浏览数据产品的网格来提供;或关联多个数据产品以创建更高阶的洞察力,最好通过执行可以跨网格上的多个数据产品操作的数据语义查询来提供。
以下模型仅是示例性的,并不打算完整。虽然平面的层次结构是可取的,但下面没有暗示严格的分层。
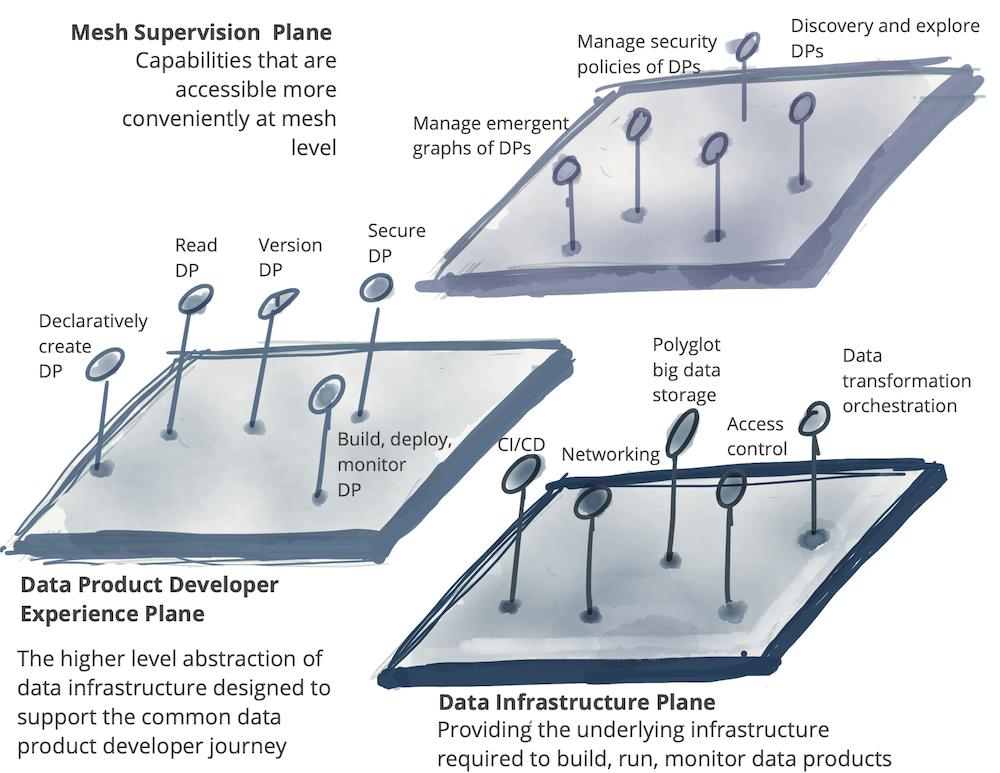
Figure 10: Multiple planes of self-serve data platform *DP stands for a data product
联合计算治理
如您所见,数据网格遵循分布式系统架构;一组具有独立生命周期的独立数据产品,由可能的独立团队构建和部署。然而,对于大多数用例而言,为了以高阶数据集、洞察力或机器智能的形式获得价值,这些独立的数据产品需要互操作;能够关联它们、创建联合、查找交点或执行其他图形或对它们进行大规模设置操作。为了使任何这些操作成为可能,数据网格实现需要一个治理模型,该模型包含去中心化和域自主权、通过全球标准化的互操作性、动态拓扑以及最重要的是平台自动执行决策。我称之为联合计算治理。由域数据产品所有者和数据平台产品所有者联合领导的决策模型,具有自治和域本地决策权,同时创建并遵守一组全局规则——适用于所有数据产品及其接口的规则——以确保健康和可互操作的生态系统。该集团有一项艰巨的工作:保持集中和分散之间的平衡;哪些决策需要本地化到每个域,哪些决策应该针对所有域全局进行。最终,全球决策只有一个目的,即通过数据产品的发现和组合创造互操作性和复合网络效应。
数据网格中治理的优先级不同于分析数据管理系统的传统治理。虽然他们最终都开始从数据中获取价值,但传统的数据治理试图通过集中决策来实现这一目标,并在对变更的支持最少的情况下建立数据的全球规范表示。相比之下,数据网格的联合计算治理包含变化和多种解释上下文。
将系统置于恒定的紧身衣中可能会导致脆弱性演变。
——C.S. Holling,生态学家
逻辑架构:嵌入在网格中的计算策略
支持性的组织结构、激励模型和架构对于联邦治理模型的运作是必要的:达成互操作性的全球决策和标准,同时尊重本地域的自主权,并有效地实施全球政策。
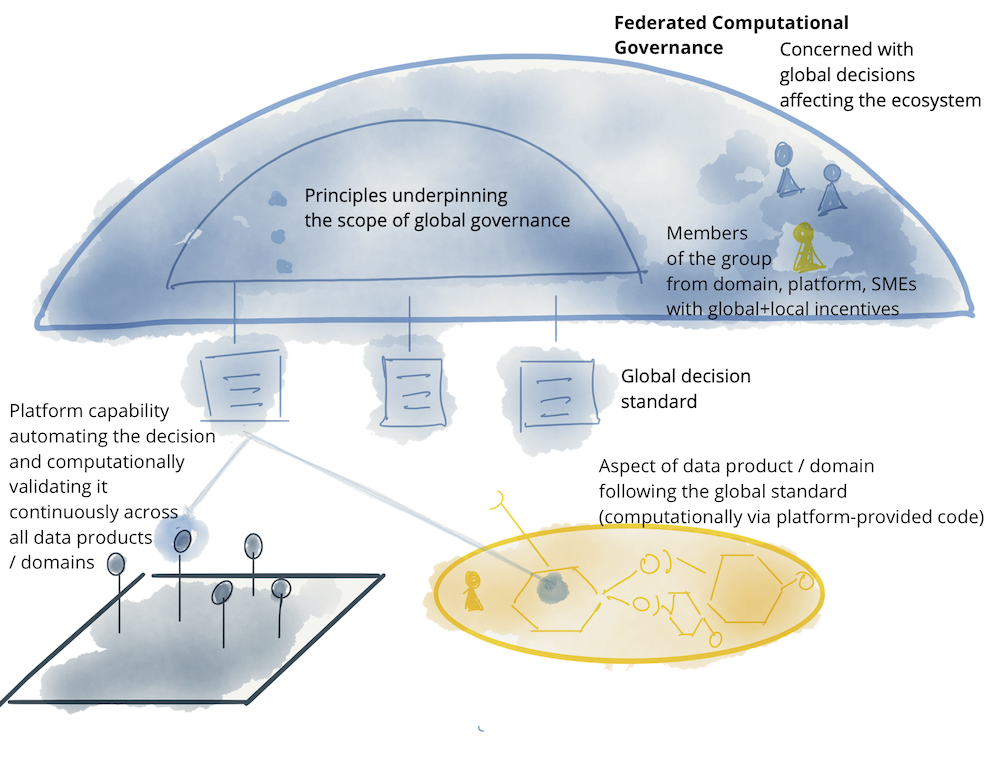
Figure 11: Notation: federated computational governance model
如前所述,在全球标准化、平台对所有领域及其数据产品实施和强制执行的内容与由领域决定的内容之间取得平衡,是一门艺术。例如,域数据模型是一个应该本地化到最熟悉它的域的关注点。例如,“播客受众”数据模型的语义和语法如何定义必须留给“播客领域”团队。然而相比之下,关于如何识别“播客听众”的决定是一个全球关注的问题。播客听众是“用户”群体的成员——它的上游有界上下文——他们可以跨越域的边界并在其他域中找到,例如“用户播放流”。统一标识允许关联关于既是“播客听众”又是“蒸汽听众”的“用户”的信息。
以下是数据网格治理模型中涉及的元素示例。这不是一个全面的例子,只是说明了全球层面的相关问题。
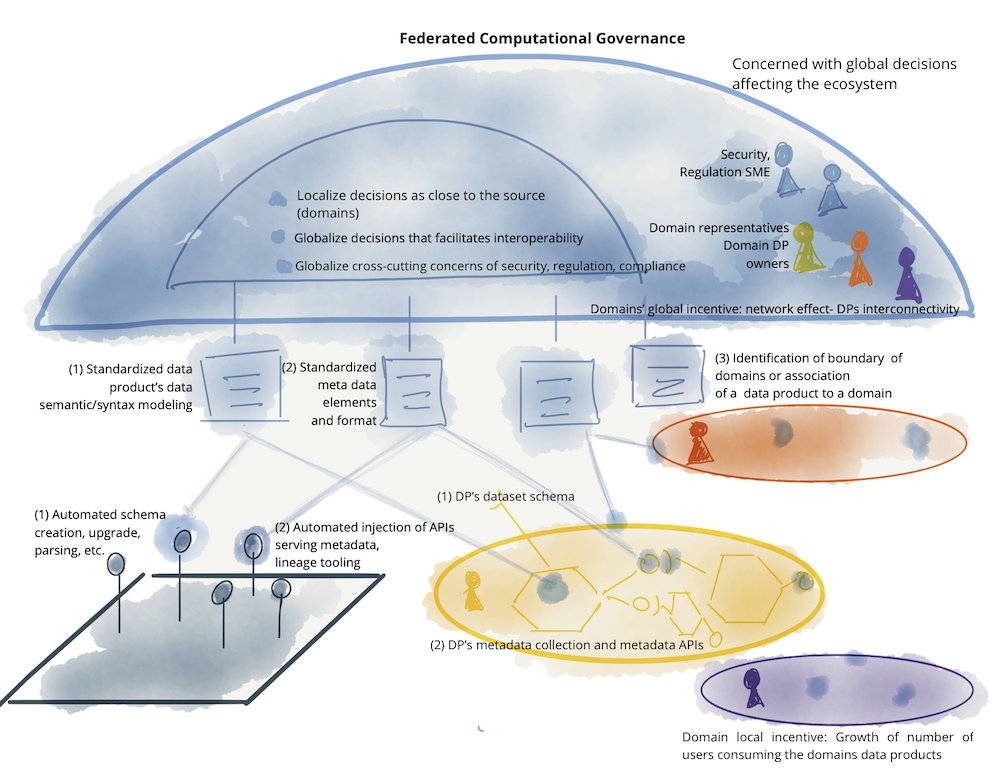
Figure 12: : Example of elements of a federated computational governance: teams, incentives, automated implementation, and globally standardized aspects of data mesh
数据网格前治理的许多实践,作为一个集中的功能,不再适用于数据网格范式。例如,过去强调黄金数据集的认证——经过集中质量控制和认证并被标记为可信赖的数据集——作为治理的核心功能不再相关。这源于这样一个事实,即在以前的数据管理范例中,无论质量和格式如何,数据都从运营域的数据库中提取并集中存储在仓库或湖泊中,现在需要一个集中的团队进行清理、协调及其加密过程;通常在集中治理组的监管下。数据网格完全分散了这种担忧。域数据集只有在域内,根据预期的数据产品质量指标和全球标准化规则,经过质量保证过程后,才成为数据产品。领域数据产品所有者最适合决定如何衡量其领域的数据质量,因为他们首先要了解产生数据的领域操作的细节。尽管有这样的本地化决策和自主权,但他们需要遵守基于全球标准的 SLO 质量和规范建模,由全球联合治理团队定义,并由平台自动化。
下表显示了数据治理的集中式(数据湖、数据仓库)模型与数据网格之间的对比。
| 预数据网格治理方面 | 数据网格治理方面 |
|---|---|
| 中心化团队 | 联合团队 |
| 负责数据质量 | 负责定义如何对构成质量的内容进行建模 |
| 负责数据安全 | 负责定义数据安全的各个方面,即平台自动构建和监控的数据敏感度级别 |
| 负责遵守法规 | 负责定义平台自动构建和监控的法规要求 |
| 数据集中保管 | 按域对数据进行联合托管 |
| 负责全球规范数据建模 | 负责建模多义词 - 跨越多个领域边界的数据元素 |
| 团队独立于域 | 团队由领域代表组成 |
| 以定义明确的静态数据结构为目标 | 旨在实现有效的网格操作,包括网格的连续变化和动态拓扑 |
| 单体湖/仓库使用的集中技术 | 每个域使用的自助平台技术 |
| 根据管理数据(表格)的数量或数量衡量成功 | 基于网络效应衡量成功 - 表示网格上数据消耗的连接 |
| 人工干预的手动流程 | 平台实现的自动化流程 |
| 防止错误 | 通过平台的自动处理检测错误并进行恢复 |
原理总结和高层逻辑架构
让我们把它们放在一起,我们讨论了支撑数据网格的四个原则:
| 面向领域的去中心化数据所有权和架构 | 因此,随着数据源数量、用例数量和数据访问模型多样性的增加,创建和使用数据的生态系统可以扩展; 只需增加网格上的自治节点。 |
| 数据作为产品 | 让数据用户可以轻松地发现、理解和安全地使用高质量的数据并获得愉快的体验; 分布在多个域中的数据。 |
| 作为平台的自助数据基础设施 | 因此,领域团队可以使用平台抽象自主创建和使用数据产品,从而隐藏构建、执行和维护安全且可互操作的数据产品的复杂性。 |
| 联合计算治理 | 因此,数据用户可以从独立数据产品的聚合和关联中获得价值——网格表现为遵循全球互操作性标准的生态系统; 以计算方式融入平台的标准。 |
这些原则推动了一个逻辑架构模型,该模型在将分析数据和操作数据在同一域下更紧密地结合在一起的同时,尊重它们的基础技术差异。 这些差异包括分析数据的托管位置、用于处理操作服务与分析服务的不同计算技术、查询和访问数据的不同方式等。
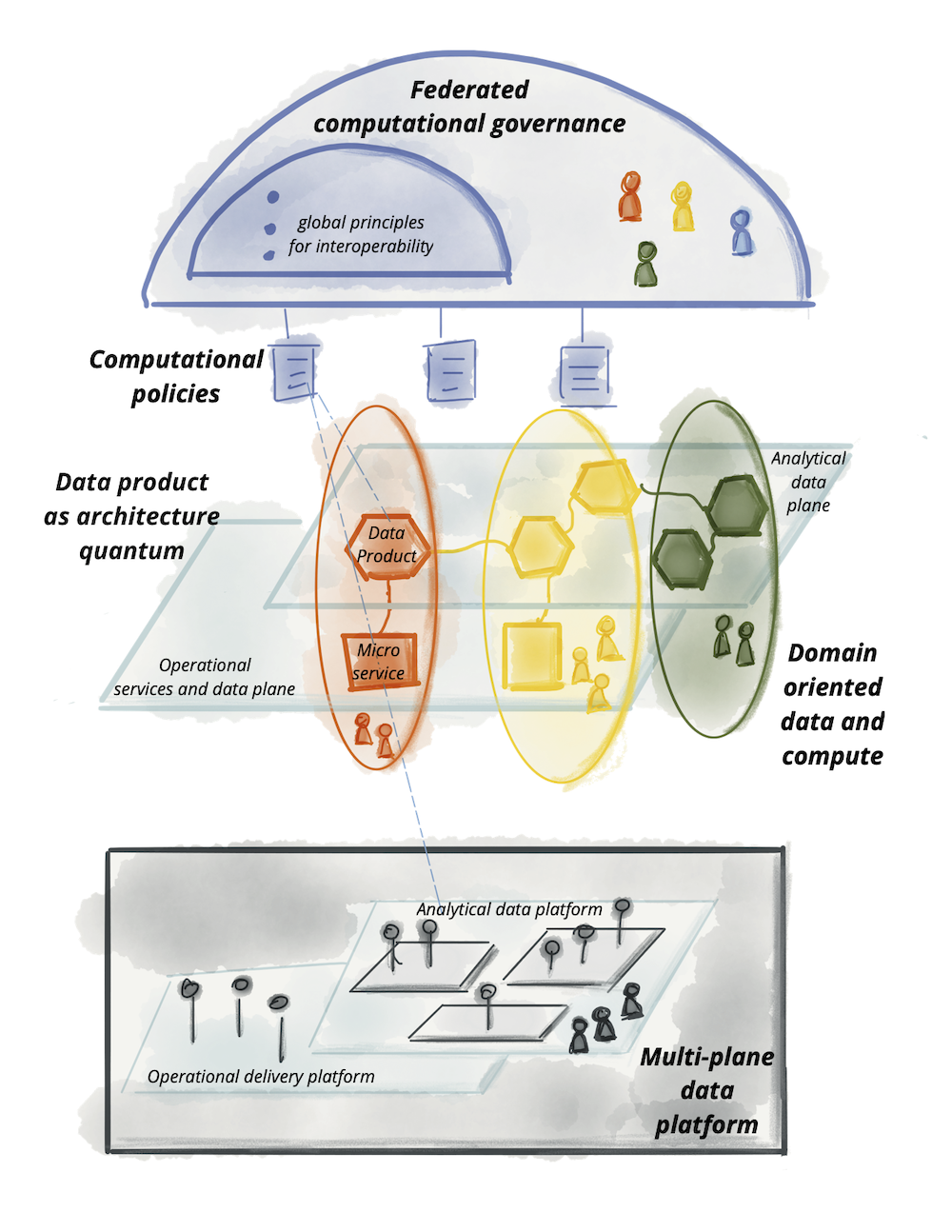
Figure 13: Logical architecture of data mesh approach
我希望到此为止,我们现在已经建立了一种通用语言和一种逻辑思维模型,我们可以共同推进网格组件的详细蓝图,例如数据产品、平台和所需的标准化。
原文:https://martinfowler.com/articles/data-mesh-principles.html
- 182 次浏览
【数据网格】数据网格架构的优势和挑战
视频号
微信公众号
知识星球
ThoughtWorks 顾问 Zhamak Dehghani 创建了数据网格的概念,作为一种自助式、面向领域的设计,后来演变成一种数据即产品设计。 通过同时集成和分析来自断开连接的系统的数据,数据网格架构无需从多个系统中提取数据并对其进行预处理,从而使组织受益。
在数据仓库或数据湖等传统数据架构中,数据在单个位置收集、存储、清理和处理以供进一步分析。 然而,在数据网格中,数据保留在各自的领域中,领域团队使用他们的领域数据来开发满足自己需求的数据产品,并将这些产品出售给其他消费者。
在这种情况下,领域团队完全拥有他们的数据基础设施、数据管道和数据产品。 各个域团队在数据网格内完成他们的数据处理任务——在控制每个域的后端存储和计算的集中单元中。
数据网格促进跨域的分布式数据、非 IT 人员的自助操作以及以域为中心的数据控制。 数据网格的操作原则包括以域为中心的数据控制、自助式数据访问、数据即产品 (DaaP) 以及数据网格框架内的标准化治理。
此外,根据作者 Cameron Turner 的说法,DaaP 方法使域所有者能够摆脱“集中式数据湖”,并将其域数据直接出售给其他域,从而为创收创造新的途径。
组织何时应使用数据网格架构?
如果企业有突然的扩展需求,必须在短时间内执行,那么数据网格就可以派上用场。 随着数据源和数据消费者的不断增长,单一、集中的数据管理方法可能会导致难以管理的扩展问题。
在许多情况下,企业数据的集中控制会造成不良瓶颈。 在数据优先的业务生态系统中,企业现在需要考虑有机地支持扩展的数据平台。
数据网格促进了分布式数据管理,这自然与整个组织的分布式数据创建模式保持一致。 一般来说,如果您的公司对云迁移、领域驱动开发或微服务感兴趣,现在是考虑实施数据网格架构的好时机。
使用数据网格架构的好处
数据网格架构可以帮助企业找到日常问题的快速解决方案,发现管理资源的更好方法,并开发更敏捷的业务模型。 以下是对数据网格架构优势的快速回顾:
- 数据网格架构是适应性强的,因为它可以适应公司规模、变化和成长的变化。
- 数据网格支持同时收集、集成和分析来自不同系统的数据,从而无需在一个中央位置从不同系统提取数据以进行进一步处理。
- 在数据网格中,各个域成为一个小型企业,并获得自我管理和服务于其数据科学和数据处理项目的各个方面的能力。
- 数据网格架构允许公司通过消除单个管道中的数据流来提高效率,同时通过集中监控基础架构保护系统。
- 领域团队可以设计和开发他们的特定需求、分析和操作用例,同时保持对其所有数据产品和服务的完全控制。
- 数据网格架构通过明智地跨域分配 IT 团队,独立控制所有与数据相关的活动,从而在不牺牲规模的情况下帮助解决数据治理瓶颈。
- 数据网格通过使领域团队遵守所有标准、政策和法规,同时通过快速访问数据、快速周转时间和量身定制的数据解决方案来奖励他们,从而维护集中式治理标准。
- 数据网格使用数据目录使领域驱动的数据产品和服务可被发现。
- 数据网格中的基础设施即平台 (IaaP) 提供了一种自动化的数据标准化和数据产品生命周期监控方法。
数据网格架构挑战
本节仅涉及围绕数据网格的一些技术和实施挑战,这些挑战需要进一步探索:
- 数据网格的采用迫使用户可能会抵制许多更改,因此实施需要大量组织支持。 数据工程师必须了解情况,这样他们才不会违背数据网格的利益。
- 不同数据系统之间的互操作性是数据网格工作的先决条件。
- 在维护数据管道的特定领域控制的同时,领域仍然必须遵守所有标准化的数据治理协议。
- 在数据网格中,数据访问围绕适当的权限进行,因此如果没有足够的权限,数据访问可能会被拒绝。
- 数据目录必须保持更新,以使数据产品保持可发现性。
- 在数据网格中,确保采用一致的方法来配置云基础设施、为数据产品制定明确的标准以及遵守标准化的治理协议尤为重要。
- 从单体数据仓库和数据湖迁移到数据网格需要的不仅仅是技术和后勤准备——文化和思维方式的改变,以及对业务领域建模采用更多跨职能方法的承诺。
- 域之间的最小共享治理可能会带来自己的挑战。
尾注
数据网格架构在提供对域的直接数据访问的同时,保留了在需要时将数据仓库或数据湖纳入其框架的灵活性。 在数据网格环境中,IT 和业务团队协作构建数据产品或为整个组织中的其他数据消费者提供 DaaP 服务。
数据网格的最大受益者是拥有许多域和断开连接的系统的组织。 领域团队生成并拥有特定于领域的数据以满足他们的日常需求,但他们也有能力构建自己的数据产品并将它们出售 (DaaP) 给其他领域或其他外部消费者。
数据网格架构不是依赖一个中央数据工程团队和一名数据科学家来完成整个数据管理操作,而是将 IT(数据)团队均匀分布在组织单位中。 尽管存在潜在挑战,但分散的领域团队和 IT 团队获得了密切合作以提供增值产品和服务的绝佳机会。
- 114 次浏览
【数据网格】没有可信核心数据,Data Mesh就是Data Meh
视频号
微信公众号
知识星球
为应对不断增长的数据挑战而寻求快速响应和可持续解决方案的组织越来越依赖数据网格等架构方法来快速高效地提供信息。 数据网格和其他虚拟数据方法连接、统一信息,并使其在众多数据孤岛和仓库中可用,以将其有效地交到分析师和其他用户手中,从而做出更好的决策、增加数据集的所有权和分布式协作 ,以及其他积极成果。
然而,高质量、可信的数据是许多数据网格架构中经常被忽视的组成部分。 简单地将数据移动到云端并使其更易于访问并不能解决数据质量问题。 不准确、重复或过时的数据——无论是来自仓库还是通过数据网格虚拟化交付——加剧了现有问题并使问题变得更糟。 将基于云的主数据管理 (MDM) 解决方案添加到数据网格或任何虚拟数据架构有助于解决数据质量难题,并可以促进任何云转型。
虚拟数据有多种形式
数据虚拟化使应用程序能够访问和集成来自多个不相关数据源的数据,就好像它们是一个统一的数据源一样。 数据虚拟化可以实时访问数据库、文件系统和基于云的数据存储等来源,并创建一个可供应用程序和其他系统访问的虚拟数据层。 这可以在不物理移动或复制数据的情况下完成,从而节省时间和资源。
不同的数据虚拟化方法不断涌现,包括数据网格和数据结构。 虚拟化数据的力量在于创建数据产品,这些产品是特定业务领域可以使用的一组特定的有组织和可重用的信息,并且明确由最接近该数据的团队拥有。 数据产品可以为数据分析师节省时间,他们可以花更多的时间分析数据,而花更少的时间查找和修复数据。
数据网格和数据结构相似,但在关键方面有所不同:
- 数据网格是一种分散式数据架构,为存储和管理大量数据提供灵活且可扩展的基础设施。 这种方法可以提高数据的可访问性,增加协作,并支持创建高质量、可靠和可重用的数据产品。 数据网格是一个概念,它将信息从集中的湖泊和仓库中转移出来,并将其交到领域和主题专家的手中。 在此构造中,数据被视为产品并由领域专家拥有。 Fabric 可以帮助领域专家和分析师确定可以在何处使用数据
- 数据结构是互连数据存储和处理资源的网络,使组织能够更有效地访问和使用其数据。 Data Fabric 提供了一个统一的平台来管理、存储和访问数据,无论数据位于何处或如何构建。 数据结构通常包括一系列技术和工具,例如分布式存储系统、数据湖和数据管道,它们协同工作使组织能够大规模收集、处理和分析数据。 数据结构类似于元数据; 它是一个目录系统,用于识别可用的信息及其所在位置。
虽然这些架构因其解决数据访问问题的潜力而受到追捧,但也存在潜在的局限性,包括无法提供可信、准确的信息。 除非同时解决质量问题,否则仅将数据移动到云端或使其更及时和更易于访问无法改变业务
MDM:现代数据架构的统一基础
基于云的 MDM 使组织能够管理和维护组织关键核心数据的一致且准确的视图,例如有关客户、供应商、位置、资产和供应商的信息等。 这是每个组织运行所依赖的重要数据。 核心数据可能驻留在许多孤岛中,这给大多数组织带来了挑战。 核心数据通常不准确、过时或在其他地方重复。 解决这些问题既费时又费钱,因此越来越多的组织转向基于云的解决方案来掌握核心数据。
通过创建关键业务数据的单一、准确视图,MDM 可以确保虚拟化架构中的数据一致、准确和更新。 这可以提高数据质量,并大大提升数据对业务用户的价值。
换句话说,“核心数据作为产品”和 MDM 的概念有着密切的内在联系。
基于云的 MDM 通过提供用于管理数据定义、关系和规则的集中式系统,简化了虚拟化架构中的数据管理。 这使得数据管理员和其他数据管理专业人员更容易理解和管理数据,从而大大提高了虚拟架构的整体有效性。
基于云的 MDM 为组织提供了更大的可扩展性和灵活性,并帮助他们提高数据质量和一致性。 由于数据受到管理和治理,组织可以轻松执行数据标准并确保信息准确和最新。 由于云可以无缝扩展或收缩以满足不断变化的需求,因此组织可以快速添加或删除数据源和用户,而无需投资额外的硬件或软件。 这有助于避免代价高昂的错误并提高数据驱动决策的可靠性。
改善业务成果依赖于及时准确的数据
每家公司都越来越迫切地转向数字优先方向以提高效率、增长和风险管理,尤其是在考虑客户体验时。 消费者、供应商和员工期望在几乎任何情况下都能获得“按需”或全渠道体验。 他们希望能够利用数字技术实现 24/7 全天候自助服务(任何设备、任何地点、任何时间),并辅以呼叫中心等其他渠道。 犯了这个错误——或者让您的客户因不一致或糟糕的体验而感到沮丧,会将他们送到他们的竞争对手那里。 这就是为什么尽管最近面临经济挑战,但仍有如此多的人继续投资于云迁移和数字化转型。 现代数据架构方法是朝着这个方向迈出的重要的第一步。 然而,如果没有准确、可信和实时的核心数据作为基础,这些举措可能会适得其反。 投资基于云的现代 MDM 解决方案作为数据网格或任何虚拟数据架构的基础,可以提供准确、实时的核心数据统一视图,组织可以使用该视图来实现这些业务目标,同时提供切实的投资回报率。
- 53 次浏览