数据工程
视频号

微信公众号

知识星球

- 212 次浏览
【数据格式】Kafka与AVRO vs Kafka和Protobuf vs Kafka与JSON Schema
视频号
微信公众号
知识星球
Kafka串行化方案——在Confluent Streaming Platform中播放AVRO、Protobuf、JSON Schema。这些示例的代码可在https://github.com/saubury/kafka-serialization
Apache Avro在很长一段时间内一直是默认的Kafka串行化机制。Confluent刚刚更新了他们的Kafka流媒体平台,增加了对使用协议缓冲区(或protobuf)和JSON模式串行化串行化数据的支持。

Kafka与AVRO vs.,Kafka和Protobuf vs.,Kafka与JSON Schema
Protobuf特别酷,提供了一些巧妙的机会,超出了Avro的可能。Protobuf和JSON模式的包含适用于生产者和消费者库、模式注册表、Kafka连接、ksqlDB以及控制中心。花几分钟时间熟悉流媒体应用程序的串行化策略可能带来的新机会是值得的。
我关心结构化数据的序列化吗?
那么,为什么要对结构化数据进行串行化呢?让我们从一个示例数据字符串开始…“cookie,50,null”这个数据是什么意思?cookie是一个名字、一个地方还是一种吃的东西?50岁左右呢?这是年龄、温度还是其他原因?
如果您使用数据库(如Postgres或Oracle)来存储数据,您将创建一个表定义(具有命名良好的列和适当的数据类型)。流媒体平台也是如此——你真的应该选择数据格式来串行化结构化数据。在您的数据平台上保持一致的奖励积分!
直到最近,您在Kafka中串行化结构化数据的选择还是有限的。您有“糟糕”的选择(如自由文本或CSV),或者使用ApacheAvro是“更好”的选择。Avro是一个开源的数据序列化系统,它将您的数据(以及它的适当模式)封送为高效的二进制格式。Avro的核心功能之一是能够为我们的数据定义模式。因此,我们的数据cookie 50,null将与这样的小吃Avro模式相关联
{
"type": "record",
"name": "snacks",
"fields": [
{"name": "name", "type": "string" }
, {"name": "calories", "type": "float" }
, {"name": "colour", "type": "string", "default": null}
]
}在这里我们可以看到我们的数据cookie,50,null是零食数据(最重要的数据类型)。我们可以看到饼干是一个字符串,代表小吃的名称。我们的模式为我们提供了很大的灵活性(我们的模式可以随着时间的推移而发展),并确保了数据的完整性(例如,确保卡路里是整数)。
尽管大多数ApacheKafka用户都使用ApacheAvro来定义消息的契约,但这始终有点像“Java的东西”。ApacheAvro编译器自动生成的类有利于JVM开发人员。你当然可以在几乎任何语言中使用AVRO,然而,谷歌协议缓冲区(protobuf)在其他语言(Python、Rust、Ruby、Go)中非常流行,用于串行化、去串行化和验证数据。
AVRO、Protobuf、JSON Schema与Kafka一起使用
这不是一个关于“最佳”连载策略的博客。然而,让我们熟悉如何使用新的选择来序列化结构化数据
我们将浏览几个例子。请记住,我们保存在snacks.txt文件中的最初一组美味数据如下所示
{"name": "cookie", "calories": 500, "colour": "brown"}
{"name": "cake", "calories": 260, "colour": "white"}
{"name": "timtam", "calories": 80, "colour": "chocolate"}
AVRO串行化
让我们提醒自己如何使用AVRO串行化对我们的零食进行编码。我们将使用include命令行工具kafka-avro控制台生产者作为kafka生产者,它可以执行串行化(提供模式作为命令行参数)。生产者是将数据写入卡夫卡经纪人的东西。
kafka-avro-console-producer --broker-list localhost:9092 --topic SNACKS_AVRO --property value.schema='
{
"type": "record",
"name": "myrecord",
"fields": [
{"name": "name", "type": "string" }
, {"name": "calories", "type": "float" }
, {"name": "colour", "type": "string" }
]
}' < snacks.txt
为了读取数据,我们可以使用kafka avro控制台consumer命令行应用程序作为kafka consumer来读取和串行化我们的avro数据
kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic SNACKS_AVRO --from-beginning {"name":"cookie","calories":500.0,"colour":"brown"}
{"name":"cake","calories":260.0,"colour":"white"}
{"name":"timtam","calories":80.0,"colour":"chocolate"}
Protocol Buffers (Protobuf) serialization
这一次,我们将使用protobuf系列化与新的kafkaprotobuf控制台生产商kafka生产商。这个概念与我们在AVRO中采用的方法相似,但这一次我们的卡夫卡制作人将可以执行protobuf系列化。请注意,protobuf模式是作为命令行参数提供的。
kafka-protobuf-console-producer --broker-list localhost:9092 --topic SNACKS_PROTO --property value.schema='
message Snack {
required string name = 1;
required int64 calories = 2;
optional string colour = 3;
}' < snacks.txt
为了读取数据,我们可以使用kafka protobuf控制台consumerkafka consumer对我们的protobuf数据进行去串行化
kafka-protobuf-console-consumer --bootstrap-server localhost:9092 --topic SNACKS_PROTO --from-beginning {"name":"cookie","calories":"500","colour":"brown"}
{"name":"cake","calories":"260","colour":"white"}
{"name":"timtam","calories":"80","colour":"chocolate"}
JSON Schema serialization
最后,我们将使用JSON模式串行化与新的kafkajson模式控制台生成器kafka-productor。请注意,json模式模式是作为命令行参数提供的。
kafka-json-schema-console-producer --broker-list localhost:9092 --topic SNACKS_JSONSCHEMA --property value.schema='
{
"definitions" : {
"record:myrecord" : {
"type" : "object",
"required" : [ "name", "calories" ],
"additionalProperties" : false,
"properties" : {
"name" : {"type" : "string"},
"calories" : {"type" : "number"},
"colour" : {"type" : "string"}
}
}
},
"$ref" : "#/definitions/record:myrecord"
}' < snacks.txt
为了读取数据,我们可以使用kafkajson模式控制台consumerkafkaconsumer来解串行化我们的json模式数据
kafka-json-schema-console-consumer --bootstrap-server localhost:9092 --topic SNACKS_JSONSCHEMA --from-beginning {"name":"cookie","calories":"500","colour":"brown"}
{"name":"cake","calories":"260","colour":"white"}
{"name":"timtam","calories":"80","colour":"chocolate"}
What you can do with Protobuf and can’t do with Avro?
让我们看一个更复杂的建模示例,以说明Protobuf模式的一些可能性。想象一下,我们想为一顿饭建模,并描述饭中的成分。我们可以使用protobuf模式来描述一顿饭,比如由牛肉馅和奶酪浇头组成的玉米卷。
我们的玉米卷和炸鱼薯条的数据可能是这样的
{
"name": "tacos",
"item": [
{
"item_name": "beef",
"type": "FILLING"
},
{
"item_name": "cheese",
"type": "TOPPING"
}
]
}, {
"name": "fish and chips",
"alternate_name": "fish-n chips",
"item": []
}
一个代表我们膳食的protobuf模式示例如下
message Meal {
required string name = 1;
optional string alternate_name = 2; enum FoodType {
INGREDIENT = 0;
FILLING = 1;
TOPPING = 2;
} message MealItems {
required string item_name = 1;
optional FoodType type = 2 [default = INGREDIENT];
} repeated MealItems item = 4;
}
To try this modelling with protobuf in Kafka
kafka-protobuf-console-producer --broker-list localhost:9092 --topic MEALS_PROTO --property value.schema='
message Meal {
required string name = 1;
optional string alternate_name = 2; enum FoodType {
INGREDIENT = 0;
FILLING = 1;
TOPPING = 2;
} message MealItems {
required string item_name = 1;
optional FoodType type = 2 [default = INGREDIENT];
} repeated MealItems item = 4;
}' < meals.txt
这让您了解了在Kafka中使用protobuf可以如何灵活地表示数据。但是,如果我们需要对这些模式进行更改,会发生什么呢?
具有Confluent Schema注册表的Protobuf
您可能想知道上面的例子中的模式到底去了哪里?Confluent Schema Registry一直在努力存储这些模式(当使用kafka-blah控制台生成器时,作为序列化过程的一部分)。也就是说,模式名称(例如SNACKS_PROTO-value)、模式内容、版本和样式(protobuf、Avro)都已存储。我们可以使用curl在存储的模式上达到峰值。例如,为了探索我们的零食最近使用的protobuf模式
curl -s -X GET http://localhost:8081/subjects/SNACKS_PROTO-value/versions/1
Which responds the this snack schema (yummy)
{
"subject": "SNACKS_PROTO-value",
"version": 1,
"id": 6,
"schemaType": "PROTOBUF",
"schema": "\nmessage Snack {\n required string name = 1;\n required int64 calories = 2;\n required string colour = 3;\n}\n"
}
Protobuf的模式进化
俗话说,唯一不变的就是变化。任何好的数据平台都需要适应变化——比如对模式的添加或更改。支持模式进化是流媒体平台的基本要求,因此我们的序列化机制也需要支持模式更改(或进化)。Protobuf和Avro都提供了在不破坏下游消费者的情况下更新模式的机制——下游消费者可能仍然使用以前的模式版本。
在我们的膳食中添加饮料
墨西哥玉米饼和披萨听起来很棒——但让我们在用餐时喝点什么吧!现在,我们可以向我们的模式添加一些额外的属性,以包括膳食。这有时被称为模式进化。请注意,我们将继续使用现有的MEALS_PROTO主题。
新的数据有效载荷(包括啤酒)
{
"name": "pizza",
"drink": [
{
"drink_name": "beer",
"type": "ALCOHOLIC"
}
]
}
So to encode the command looks like
kafka-protobuf-console-producer --broker-list localhost:9092 --topic MEALS_PROTO --property value.schema='
message Meal {
required string name = 1;
optional string alternate_name = 2; enum FoodType {
INGREDIENT = 0;
FILLING = 1;
TOPPING = 2;
} enum DrinkType {
BUBBLY = 0;
ALCOHOLIC = 1;
} message MealItems {
required string item_name = 1;
optional FoodType type = 2 [default = INGREDIENT];
} message DrinkItems {
required string drink_name = 1;
optional DrinkType type = 2 ;
} repeated MealItems item = 4;
repeated DrinkItems drink = 5;
}' < meals-2.txt
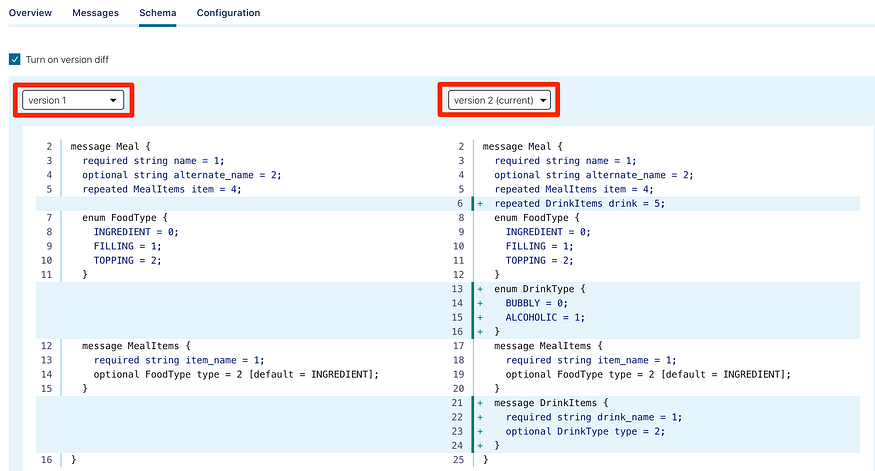
Visualising schema difference with Confluent Control Center
One nice inclusion with the Confluent Control Center (the Web GUI included in the Confluent platform) is the ability to look at schemas, and the differences between schemas. For example, we can see version 1 and version 2 of the MEALS_PROTO-value schema
Application Binding — Protobuf classes with Python
Let us now build an application demonstrating protobuf classes. To generate protobuf classes you must first install the protobuf compiler protoc. See the protocol buffer docs for instructions on installing and using protoc.
We can compile our Python schema like this. This will take our schema (from meal.proto) and will create the meal_pb2.py Python class file.
protoc -I=. --python_out=. ./meal.protoExcellent, with the meal_pb2.py Python class file you can now build protobuf classes and produce into Kafka with code like this
import meal_pb2
mybeer = Meal.DrinkItems(drink_name="beer")
mywine = Meal.DrinkItems(drink_name="wine")
meal = Meal(name='pizza', drink=[mybeer,mywine])producer.produce(topic='MEAL_PROTO', value=meal)
看看producer-protobuf.py,了解Python中protobuf-Kafka生产者的完整示例。
结论
Kafka的功能不断增长,在Confluent平台中使用AVRO、Protobuf和JSON Schema的选项为构建酷炫的流媒体应用程序提供了更多机会
这些示例的代码可在
- 133 次浏览
【数据转换】2023年7款最佳数据转换工具(优点、缺点、最佳)
视频号
微信公众号
知识星球
数据转换过程通过以下方式将数据从原始的混乱转变为业务金矿:
- 删除不必要的数据(重复数据、异常值、过滤)
- 重塑数据(对数据模型、数据透视表、聚合度量值施加模式约束)
- 标准化数据格式(正确拼写,一个热编码变量)
- 构建自己的度量和维度(平均值、偏差、总和、计数和其他聚合)
- 丰富数据
- …以及更多操作(请查看此处的转换列表)。
使用数据转换工具可以简化整个过程,并为您节省时间和精力来完成这些有价值但乏味的任务。
在本文中,我们将探讨市场上7种最佳的数据转换工具。每种工具都将与优缺点进行评估,并明确决定该工具最适合谁。
你赶时间吗?不用担心,这里是TL;DR最好的工具以及它们最适合哪些人:
- Keboola:整体最佳。涵盖了所有转换用例,从业务专家的无代码到工程师的低代码(在SQL、Python、R和Julia中),以及所有dbt转换。
- dbt:分析工程师,喜欢在数据仓库中使用SQL驱动的转换中的开发人员实践。
- Matillion:中小型组织的IT用户,他们希望使用一个简单但强大的工具来运行ETL过程。
- Trifacta:希望使用类似于Excell(但比Excell更强大)的解决方案转换数据的企业用户。
- Informatica:一个大型企业的数据工程师团队,他们希望在所有数据操作中完全采用Informatica的整个产品生态系统。
- Datameer:希望改进Snowflake中分析工作负载的非编码数据分析师。
- Hevo Data:希望通过直观的拖放界面创建数据管道和转换的业务专家。
想深入了解细节以使您的决策更好吗?以下是最佳数据转换工具的完整分类。
7种最佳数据转换工具
1.Keboola

Keboola是一个数据平台即服务,可帮助您自动化所有数据操作。
Keboola提供了多种工具来简化转换,但它还自动化了围绕ETL、ELT和反向ETL数据管道的数据操作。
每个公民都可以使用Keboola将原始数据转化为商业机会:
- 业务用户可以利用无代码转换,并使用拖放功能构建自己的数据管道(请检查Visual Flow Builder)。
- 工程师和数据科学家可以在SQL、Python、R和Julia中使用低代码转换。除此之外,您还可以获得监控、版本控制、数据访问控制、转换共享和可扩展后端以及并行化,以加快作业速度。
- 使用dbt的组织可以将dbt转换合并到其整个工作流中。使用Keboola还可以在ELT、ETL和反向ETL数据流中运行提取和加载。
优点:
- 为每个人提供自助服务。使用无代码、低代码或dbt转换的选项使每个用户都能够以最适合自己的模式转换自己的数据。
- 广泛涵盖转型运营。低代码和dbt转换涵盖了任何可以想象的数据操作。无代码转换涵盖了可点击的预构建解决方案的绝大多数用例:过滤、数据删除、数据标准化、重新编码值、构建(聚合)度量和维度等…
- 端到端自动化。您可以通过按计划设置转换或指定触发器来运行转换作业,从而实现转换的自动化。
- 完全监控和可审计。每个转换运行都会被监视以执行,并会触发警报,通知您数据质量问题或故障。您可以检查转换日志,以审核每个转换的参与者,并通过版本控制验证转换是如何更改的。
- 可共享且可重复使用。转换可以与传入和传出数据集一起共享。转换的重用可以加快您的开发时间,并使您的团队能够使用相同的过程。
- 设计可扩展性。您可以通过缩放运行转换的后端来调整分配给作业的资源。
- 超越转换的功能。Keboola不仅仅为ELT和ETL过程提供功能和工具。解决方案丰富的平台可帮助您通过数据目录等简化机器学习、数据管理、安全、共享和记录数据等方面的数据操作。
缺点:
- 运行时间过长的转换作业将自动中断,以防止未完成作业中出现错误或高资源消耗。要无限制地运行完全在线和连续的转换引擎,您必须调整默认的转换后端。
最适合:
- 由数据科学家、数据工程师、数据分析师和/或数据驱动的业务专家组成的团队,他们希望用自己喜欢的工具(无代码、低代码或dbt)将数据从原始的混乱转变为商机的金矿。
2.dbt

dbt是一个流行的开源转换引擎,它在您的数据平台(数据仓库、湖泊、数据库或查询引擎)中运行SQL转换。它提供了多种功能来简化围绕转换的数据操作,如调度、版本控制、组织、CI/CD等。
赞成:
- dbt转换非常直观,因为它们是用SQL编写的。
- dbt简化了转换,因此在编写SQL转换时避免了通常的样板和DDL代码。
- 因为转换是由数据仓库执行的,所以它们几乎实时运行。
- 优秀的支持将单个转换(称为“模型”)组织到项目中并记录转换。
- 围绕转换的操作特性(CI/CD、版本控制、协作)是精简和健壮的。
缺点:
- 不面向非技术用户。你需要了解SQL。
- dbt仅以转换为中心。要运行完整的数据操作,您需要额外的工具来从数据源提取数据、将数据加载或发送到不同的目的地、管理数据、控制访问等。
- 允许您在自己的仓库中运行dbt的数据仓库适配器是有限的。当然,dbt涵盖了主要嫌疑(Snowflake、BigQuery、Databricks、AWS Redshift、Postgres),但列表中缺少了几个数据湖、关系数据库和数据仓库。
最适合:
- 喜欢在数据仓库中使用SQL驱动转换中的开发人员最佳实践的分析工程师。
3.Matillion

Matillion是一个开源ETL工具,可以通过简单的无代码/低代码拖放用户界面构建数据管道。
Matillion通过将不同的组件拖到数据流中来创建转换。例如,首先使用“过滤器”组件删除行,然后应用“SQL”组件创建新的度量。
赞成:
- 即使对于非技术用户,拖放式用户界面也是用户友好和直观的
- 以及数据操作中根深蒂固的变更数据捕获和批处理。
- Matillion可以帮助您覆盖其他数据操作,而不仅仅是转换。它完全支持ETL、ELT和反向ETL。Matillion涵盖的预建连接器的数量和类型非常广泛,足以涵盖绝大多数数据分析用例。
缺点:
- 无代码ETL功能以更高的价格解锁,并且不是免费产品的一部分。
- 基于代码的转换仅限于SQL(数据科学家没有Python、R或Julia)。
- Matillion有时会在扩展硬件基础设施方面遇到问题,特别是对于更需要资源的转换的EC2实例。
- 定价是复杂的-您为Matillion及其用于在云上执行数据操作的计算资源付费。
- 用户经常报告文档可能过时,Matillion的新版本很少向后兼容(因此在更新软件时需要进行大量维护),并且对版本控制(git)的支持很差。
最适合:
- 中小型组织的IT用户,他们希望使用简单但强大的工具来运行ETL过程。
4.Trifacta

Trifacta的Designer Cloud是一个与您自己的云提供商(AWS、Azure、Google Cloud platform、Databricks)集成的云平台,运行低代码或无代码的ELT或ETL管道。
在Designer Cloud中,转换的执行方式类似于在Excel中执行转换的方式。您可以使用Trifacta的“Wrangle语言”(一种类似Excel的数据争用语言)编写所需的转换。例如,您可以写“pivot by X column”。然后,Trifacta Wrangler将在类似Excel的表格上执行命令,并围绕表格旋转。
赞成:
- 可以很好地扩展大型数据集。
- 通过示例推断转换。用户提供了所需结果的示例,Trifacta自动推断出转换背后的规则。
- 通过分析元数据和数据集的完整性、准确性和有效性,自动进行数据质量检查和数据分析。
- Trifacta通过智能采样算法加快作业执行速度。
缺点:
- 这些转换需要大量繁忙的工作,而且不便于用户使用,也不总是直观的。
- 没有免费增值模式,最便宜(而且功能有限)的价格是每月80美元。
最适合:
- 希望使用类似于Excel(但比Excel更强大)的解决方案转换数据的企业用户。
5.Informatica

Informatica为企业数据用户提供了两种主要的ETL产品(提取、转换、加载或经典数据管道):
- Informatica PowerCenter,大型企业的ETL平台,以及
- Informatica云数据集成(ICDI),一种更实惠的集成平台即服务(IPaaS)。
- 安装Informatica Developer(开发人员工具)时,用户可以使用这两个工具进行转换。
- 一旦配置了转换引擎和体系结构,就可以在可单击的用户界面中构建转换。
赞成:
- 这是一款经过高度打磨且具有弹性的产品,可与大数据需求无缝扩展。
- 处理大型企业中常见的多种类型的数据格式,如复杂的XML文件、特定于行业的企业数据格式(SWIFT、HL7…)以及COBOL复制本等传统数据格式。
- Informatica提供特定行业垂直领域(医疗保健、金融、银行等)中使用的大多数转换的预构建库。
缺点:
- 供应商锁定度高。要使用该工具,您需要根据解决方案的设计调整数据基础结构和体系结构,并学习其专有的建模语言。例如,Informatica对转换数据的数据存储选项非常有限。您只能使用Amazon Redshift进行数据仓库或Microsoft Azure SQL data Lake作为数据湖。
- 定价不透明,没有自助服务业务模式。你必须与销售人员交谈,并通过合同来演示产品。基本的数据集成云服务起价为每月2000美元。
- 该工具功能强大但复杂。在释放平台的全部潜力之前,准备好数据团队(多个),以承受陡峭的学习曲线。
- 转换主要围绕XML数据格式构建。无论传入的数据流格式是什么,都必须先将其转换为XML,然后才能对其进行操作。
最适合:
- 一个大型企业的数据工程师团队,他们将投资并专注于Informatica的定制平台,以收获强大机器的果实。
6.Datameer

Datameer帮助您充分利用Snowflake数据仓库。它通过提供SQL和无代码转换(作为拖放组件)扩展了Snowflake的转换能力,因此技术和非技术同事都可以自助处理自己的数据需求。
赞成:
- 用于运行Snowflake变换的更好的变换工具。
- 该工具有大量文档记录,并为常见的分析用例提供了许多视频演示。
- 通过查看显示转换依赖性的可视化图表,复杂和多阶段转换变得更加直观。
缺点:
- Datameer是市场上的一个新手,尽管它显示出了前景,但可以缺少无代码转换的开箱即用特性,而且某些转换在其库中更难执行。
- Datameer仅限于Snowflake。
最适合:
- 希望改进Snowflake中分析工作负载的非编码数据分析师。
7.Hevo数据

Hevo Data是一个无代码数据集成平台,可简化ETL、ELT和反向ETL数据管道。
数据转换可以通过在Hevo Data仪表板中拖放预先构建的转换块来构建,也可以通过编写Python脚本来执行转换。
赞成:
- 包括无代码(针对不编码的业务专家)和完全编码的Python转换。
- 失败工作流的警报。
- 非常适合涉及复制的ETL过程—利用CDC加快数据复制。
缺点:
- 没有基于SQL的转换(只有Python)用于编写完全自定义的转换。
- Python转换通常限于简单的函数调用。复杂的转换更难编写和维护。
- 作为ETL/ELT工具,它为外部数据源提供了有限的预构建连接器。
最适合:
- 希望通过直观的拖放界面创建数据管道和转换的业务专家。
那么,在7种最佳的数据转换工具中,您如何做出最终选择?
如何为您的组织选择正确的数据转换工具?
在选择首选的数据转换工具时,请记住以下三个标准:
- 目标受众。没有代码工具最适合于那些不知道如何编码的业务用户。低代码工具简化了工程团队的工作。选择一个适合这两个受众的工具(如果您想增强整个组织的能力,则选择两者)。
- 定价。开源解决方案通常比供应商提供的数据平台和工具更便宜(无需支付费用、无需许可证、无需在“不公平”消费阈值下节流,以及其他供应商技巧)。但对于开源解决方案(维护、调试、运行自己的DataOps以提供开源工具所需的服务器和实例等),总体拥有成本通常更高。在评估您选择的工具时,请记住所有可能的费用和隐藏费用。
- 支持和文档。当出现问题时,是否有强大的支持系统,如供应商保证的支持SLA?或者如果该工具是开源的,是否有强大的用户群体可以回答您的问题?您是否可以依赖大量的文档?
数据工程师的专业提示
在比较工具时,性能很重要。检查转换工具如何:
- 可根据工作负载资源和传入数据的速度和数量进行扩展。
- 通过并行化加速转换。
- 提供补充功能,如转换版本控制、日志检查、监视和警报。
来源:
- dbt: https://www.getdbt.com/product/what-is-dbt/
- Matillion: https://documentation.matillion.com/docs/2694747
- Trifacta: https://docs.trifacta.com/display/SS/Transform+Basics
- Informatica: https://docs.informatica.com/data-integration/data-services/10-2/web-se…
- Datameer: https://www.g2.com/products/datameer/reviews
- Hevo: https://docs.hevodata.com/pipelines/transformations/
- 992 次浏览